
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- README.md +53 -0
- benchmark.ipynb +0 -0
- requirements.txt +299 -0
- results/layout-benchmark-results-images-1.jpg +0 -0
- results/layout-benchmark-results-images-10.jpg +0 -0
- results/layout-benchmark-results-images-2.jpg +0 -0
- results/layout-benchmark-results-images-3.jpg +0 -0
- results/layout-benchmark-results-images-4.jpg +0 -0
- results/layout-benchmark-results-images-5.jpg +0 -0
- results/layout-benchmark-results-images-6.jpg +0 -0
- results/layout-benchmark-results-images-7.jpg +0 -0
- results/layout-benchmark-results-images-8.jpg +0 -0
- results/layout-benchmark-results-images-9.jpg +0 -0
- surya/__pycache__/detection.cpython-310.pyc +0 -0
- surya/__pycache__/layout.cpython-310.pyc +0 -0
- surya/__pycache__/ocr.cpython-310.pyc +0 -0
- surya/__pycache__/recognition.cpython-310.pyc +0 -0
- surya/__pycache__/schema.cpython-310.pyc +0 -0
- surya/__pycache__/settings.cpython-310.pyc +0 -0
- surya/benchmark/bbox.py +22 -0
- surya/benchmark/metrics.py +139 -0
- surya/benchmark/tesseract.py +179 -0
- surya/benchmark/util.py +31 -0
- surya/detection.py +139 -0
- surya/input/__pycache__/processing.cpython-310.pyc +0 -0
- surya/input/langs.py +19 -0
- surya/input/load.py +74 -0
- surya/input/processing.py +116 -0
- surya/languages.py +101 -0
- surya/layout.py +204 -0
- surya/model/detection/__pycache__/processor.cpython-310.pyc +0 -0
- surya/model/detection/__pycache__/segformer.cpython-310.pyc +0 -0
- surya/model/detection/processor.py +284 -0
- surya/model/detection/segformer.py +468 -0
- surya/model/ordering/config.py +8 -0
- surya/model/ordering/decoder.py +557 -0
- surya/model/ordering/encoder.py +83 -0
- surya/model/ordering/encoderdecoder.py +90 -0
- surya/model/ordering/model.py +34 -0
- surya/model/ordering/processor.py +156 -0
- surya/model/recognition/__pycache__/config.cpython-310.pyc +0 -0
- surya/model/recognition/__pycache__/decoder.cpython-310.pyc +0 -0
- surya/model/recognition/__pycache__/encoder.cpython-310.pyc +0 -0
- surya/model/recognition/__pycache__/model.cpython-310.pyc +0 -0
- surya/model/recognition/__pycache__/processor.cpython-310.pyc +0 -0
- surya/model/recognition/__pycache__/tokenizer.cpython-310.pyc +0 -0
- surya/model/recognition/config.py +111 -0
- surya/model/recognition/decoder.py +511 -0
- surya/model/recognition/encoder.py +469 -0
- surya/model/recognition/model.py +64 -0
README.md
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
---
|
| 4 |
+
|
| 5 |
+
# Suryolo : Layout Model For Arabic Documents
|
| 6 |
+
|
| 7 |
+
Suryolo is combination of Surya layout Model form SuryaOCR(based on Segformer) and YoloV10 objection detection.
|
| 8 |
+
|
| 9 |
+
## Setup Instructions
|
| 10 |
+
|
| 11 |
+
### Clone the Surya OCR GitHub Repository
|
| 12 |
+
|
| 13 |
+
```bash
|
| 14 |
+
git clone https://github.com/vikp/surya.git
|
| 15 |
+
cd surya
|
| 16 |
+
```
|
| 17 |
+
|
| 18 |
+
### Switch to v0.4.14
|
| 19 |
+
|
| 20 |
+
```bash
|
| 21 |
+
git checkout f7c6c04
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
### Install Dependencies
|
| 25 |
+
|
| 26 |
+
You can install the required dependencies using the following command:
|
| 27 |
+
|
| 28 |
+
```bash
|
| 29 |
+
pip install -r requirements.txt
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
```bash
|
| 33 |
+
pip install ultralytics
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
```bash
|
| 37 |
+
pip install supervision
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
### Suryolo Pipeline
|
| 41 |
+
|
| 42 |
+
Download `surya_yolo_pipeline.py` file from the Repository.
|
| 43 |
+
|
| 44 |
+
```python
|
| 45 |
+
from surya_yolo_pipeline import suryolo
|
| 46 |
+
from surya.postprocessing.heatmap import draw_bboxes_on_image
|
| 47 |
+
|
| 48 |
+
image_path = "sample.jpg"
|
| 49 |
+
image = Image.open(image_path)
|
| 50 |
+
bboxes = suryolo(image_path)
|
| 51 |
+
plotted_image = draw_bboxes_on_image(bboxes,image)
|
| 52 |
+
```
|
| 53 |
+
#### Refer to `benchmark.ipynb` for comparison between Traditional Surya Layout Model and Suryolo Layout Model.
|
benchmark.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
absl-py==2.1.0
|
| 2 |
+
accelerate==0.34.2
|
| 3 |
+
addict==2.4.0
|
| 4 |
+
aiofiles==23.2.1
|
| 5 |
+
aiohappyeyeballs==2.4.0
|
| 6 |
+
aiohttp==3.10.5
|
| 7 |
+
aiosignal==1.3.1
|
| 8 |
+
albucore==0.0.17
|
| 9 |
+
albumentations==1.4.18
|
| 10 |
+
altair==5.4.1
|
| 11 |
+
annotated-types==0.7.0
|
| 12 |
+
antlr4-python3-runtime==4.8
|
| 13 |
+
anyio==4.6.0
|
| 14 |
+
appdirs==1.4.4
|
| 15 |
+
astor==0.8.1
|
| 16 |
+
asttokens @ file:///home/conda/feedstock_root/build_artifacts/asttokens_1698341106958/work
|
| 17 |
+
async-timeout==4.0.3
|
| 18 |
+
attrs==24.2.0
|
| 19 |
+
av==13.1.0
|
| 20 |
+
babel==2.16.0
|
| 21 |
+
bce-python-sdk==0.9.23
|
| 22 |
+
bcrypt==4.2.0
|
| 23 |
+
beartype==0.19.0
|
| 24 |
+
beautifulsoup4==4.12.3
|
| 25 |
+
bitsandbytes==0.44.1
|
| 26 |
+
blinker==1.8.2
|
| 27 |
+
boto3==1.35.34
|
| 28 |
+
botocore==1.35.34
|
| 29 |
+
braceexpand==0.1.7
|
| 30 |
+
Brotli @ file:///croot/brotli-split_1714483155106/work
|
| 31 |
+
cachetools==5.5.0
|
| 32 |
+
certifi @ file:///croot/certifi_1725551672989/work/certifi
|
| 33 |
+
cffi==1.17.1
|
| 34 |
+
cfgv==3.4.0
|
| 35 |
+
charset-normalizer @ file:///croot/charset-normalizer_1721748349566/work
|
| 36 |
+
click==8.1.7
|
| 37 |
+
colossalai==0.4.0
|
| 38 |
+
comm @ file:///home/conda/feedstock_root/build_artifacts/comm_1710320294760/work
|
| 39 |
+
contexttimer==0.3.3
|
| 40 |
+
contourpy==1.3.0
|
| 41 |
+
cpm-kernels==1.0.11
|
| 42 |
+
cryptography==43.0.1
|
| 43 |
+
cycler==0.12.1
|
| 44 |
+
Cython==3.0.11
|
| 45 |
+
datasets==3.0.0
|
| 46 |
+
debugpy @ file:///croot/debugpy_1690905042057/work
|
| 47 |
+
decorator==4.4.2
|
| 48 |
+
decord==0.6.0
|
| 49 |
+
deepspeed==0.15.1
|
| 50 |
+
defusedxml==0.7.1
|
| 51 |
+
Deprecated==1.2.14
|
| 52 |
+
diffusers==0.30.3
|
| 53 |
+
dill==0.3.8
|
| 54 |
+
distlib==0.3.8
|
| 55 |
+
distro==1.9.0
|
| 56 |
+
docker-pycreds==0.4.0
|
| 57 |
+
doclayout_yolo==0.0.2
|
| 58 |
+
easydict==1.13
|
| 59 |
+
einops==0.7.0
|
| 60 |
+
entrypoints @ file:///home/conda/feedstock_root/build_artifacts/entrypoints_1643888246732/work
|
| 61 |
+
eval_type_backport==0.2.0
|
| 62 |
+
exceptiongroup @ file:///home/conda/feedstock_root/build_artifacts/exceptiongroup_1720869315914/work
|
| 63 |
+
executing @ file:///home/conda/feedstock_root/build_artifacts/executing_1725214404607/work
|
| 64 |
+
fabric==3.2.2
|
| 65 |
+
faiss-cpu==1.8.0.post1
|
| 66 |
+
fastapi==0.110.0
|
| 67 |
+
ffmpy==0.4.0
|
| 68 |
+
filelock @ file:///croot/filelock_1700591183607/work
|
| 69 |
+
fire==0.6.0
|
| 70 |
+
flash-attn==2.6.3
|
| 71 |
+
Flask==3.0.3
|
| 72 |
+
flask-babel==4.0.0
|
| 73 |
+
fonttools==4.54.1
|
| 74 |
+
frozenlist==1.4.1
|
| 75 |
+
fsspec==2024.6.1
|
| 76 |
+
ftfy==6.2.3
|
| 77 |
+
future==1.0.0
|
| 78 |
+
fvcore==0.1.5.post20221221
|
| 79 |
+
galore-torch==1.0
|
| 80 |
+
gast==0.3.3
|
| 81 |
+
gdown==5.1.0
|
| 82 |
+
gitdb==4.0.11
|
| 83 |
+
GitPython==3.1.43
|
| 84 |
+
gmpy2 @ file:///tmp/build/80754af9/gmpy2_1645455533097/work
|
| 85 |
+
google==3.0.0
|
| 86 |
+
google-auth==2.35.0
|
| 87 |
+
google-auth-oauthlib==1.0.0
|
| 88 |
+
gradio==4.44.1
|
| 89 |
+
gradio_client==1.3.0
|
| 90 |
+
grpcio==1.66.1
|
| 91 |
+
h11==0.14.0
|
| 92 |
+
h5py==3.10.0
|
| 93 |
+
hjson==3.1.0
|
| 94 |
+
httpcore==1.0.5
|
| 95 |
+
httpx==0.27.2
|
| 96 |
+
huggingface-hub==0.25.0
|
| 97 |
+
identify==2.6.1
|
| 98 |
+
idna==3.6
|
| 99 |
+
imageio==2.35.1
|
| 100 |
+
imageio-ffmpeg==0.5.1
|
| 101 |
+
imgaug==0.4.0
|
| 102 |
+
importlib_metadata==8.5.0
|
| 103 |
+
importlib_resources==6.4.5
|
| 104 |
+
invoke==2.2.0
|
| 105 |
+
iopath==0.1.10
|
| 106 |
+
ipykernel @ file:///home/conda/feedstock_root/build_artifacts/ipykernel_1719845459717/work
|
| 107 |
+
ipython @ file:///home/conda/feedstock_root/build_artifacts/ipython_1725050136642/work
|
| 108 |
+
ipywidgets==8.1.5
|
| 109 |
+
itsdangerous==2.2.0
|
| 110 |
+
jedi @ file:///home/conda/feedstock_root/build_artifacts/jedi_1696326070614/work
|
| 111 |
+
Jinja2 @ file:///croot/jinja2_1716993405101/work
|
| 112 |
+
jiter==0.5.0
|
| 113 |
+
jmespath==1.0.1
|
| 114 |
+
joblib==1.4.2
|
| 115 |
+
jsonschema==4.23.0
|
| 116 |
+
jsonschema-specifications==2023.12.1
|
| 117 |
+
jupyter-client @ file:///home/conda/feedstock_root/build_artifacts/jupyter_client_1654730843242/work
|
| 118 |
+
jupyter_core @ file:///home/conda/feedstock_root/build_artifacts/jupyter_core_1727163409502/work
|
| 119 |
+
jupyterlab_widgets==3.0.13
|
| 120 |
+
kiwisolver==1.4.7
|
| 121 |
+
lazy_loader==0.4
|
| 122 |
+
lightning-utilities==0.11.7
|
| 123 |
+
lmdb==1.5.1
|
| 124 |
+
lxml==5.3.0
|
| 125 |
+
Markdown==3.7
|
| 126 |
+
markdown-it-py==3.0.0
|
| 127 |
+
MarkupSafe @ file:///croot/markupsafe_1704205993651/work
|
| 128 |
+
matplotlib==3.7.5
|
| 129 |
+
matplotlib-inline @ file:///home/conda/feedstock_root/build_artifacts/matplotlib-inline_1713250518406/work
|
| 130 |
+
mdurl==0.1.2
|
| 131 |
+
mkl-service==2.4.0
|
| 132 |
+
mkl_fft @ file:///croot/mkl_fft_1725370245198/work
|
| 133 |
+
mkl_random @ file:///croot/mkl_random_1725370241878/work
|
| 134 |
+
mmengine==0.10.5
|
| 135 |
+
moviepy==1.0.3
|
| 136 |
+
mpmath @ file:///croot/mpmath_1690848262763/work
|
| 137 |
+
msgpack==1.1.0
|
| 138 |
+
multidict==6.1.0
|
| 139 |
+
multiprocess==0.70.16
|
| 140 |
+
narwhals==1.9.1
|
| 141 |
+
nest_asyncio @ file:///home/conda/feedstock_root/build_artifacts/nest-asyncio_1705850609492/work
|
| 142 |
+
networkx @ file:///croot/networkx_1717597493534/work
|
| 143 |
+
ninja==1.11.1.1
|
| 144 |
+
nodeenv==1.9.1
|
| 145 |
+
numpy==1.26.0
|
| 146 |
+
nvidia-cublas-cu12==12.1.3.1
|
| 147 |
+
nvidia-cuda-cupti-cu12==12.1.105
|
| 148 |
+
nvidia-cuda-nvrtc-cu12==12.1.105
|
| 149 |
+
nvidia-cuda-runtime-cu12==12.1.105
|
| 150 |
+
nvidia-cudnn-cu12==9.1.0.70
|
| 151 |
+
nvidia-cufft-cu12==11.0.2.54
|
| 152 |
+
nvidia-curand-cu12==10.3.2.106
|
| 153 |
+
nvidia-cusolver-cu12==11.4.5.107
|
| 154 |
+
nvidia-cusparse-cu12==12.1.0.106
|
| 155 |
+
nvidia-ml-py==12.560.30
|
| 156 |
+
nvidia-nccl-cu12==2.20.5
|
| 157 |
+
nvidia-nvjitlink-cu12==12.6.77
|
| 158 |
+
nvidia-nvtx-cu12==12.1.105
|
| 159 |
+
oauthlib==3.2.2
|
| 160 |
+
omegaconf==2.1.1
|
| 161 |
+
openai==1.51.0
|
| 162 |
+
opencv-contrib-python==4.10.0.84
|
| 163 |
+
opencv-python==4.9.0.80
|
| 164 |
+
opencv-python-headless==4.9.0.80
|
| 165 |
+
opensora @ file:///share/data/drive_3/ketan/t2v/Open-Sora
|
| 166 |
+
opt-einsum==3.3.0
|
| 167 |
+
orjson==3.10.7
|
| 168 |
+
packaging @ file:///home/conda/feedstock_root/build_artifacts/packaging_1718189413536/work
|
| 169 |
+
paddleclas==2.5.2
|
| 170 |
+
paddleocr==2.8.1
|
| 171 |
+
paddlepaddle==2.6.2
|
| 172 |
+
pandarallel==1.6.5
|
| 173 |
+
pandas==2.0.3
|
| 174 |
+
parameterized==0.9.0
|
| 175 |
+
paramiko==3.5.0
|
| 176 |
+
parso @ file:///home/conda/feedstock_root/build_artifacts/parso_1712320355065/work
|
| 177 |
+
peft==0.13.0
|
| 178 |
+
pexpect @ file:///home/conda/feedstock_root/build_artifacts/pexpect_1706113125309/work
|
| 179 |
+
pickleshare @ file:///home/conda/feedstock_root/build_artifacts/pickleshare_1602536217715/work
|
| 180 |
+
Pillow==9.5.0
|
| 181 |
+
platformdirs @ file:///home/conda/feedstock_root/build_artifacts/platformdirs_1726613481435/work
|
| 182 |
+
plumbum==1.9.0
|
| 183 |
+
portalocker==2.10.1
|
| 184 |
+
pre_commit==4.0.0
|
| 185 |
+
prettytable==3.11.0
|
| 186 |
+
proglog==0.1.10
|
| 187 |
+
prompt_toolkit @ file:///home/conda/feedstock_root/build_artifacts/prompt-toolkit_1718047967974/work
|
| 188 |
+
protobuf==4.25.5
|
| 189 |
+
psutil @ file:///opt/conda/conda-bld/psutil_1656431268089/work
|
| 190 |
+
ptyprocess @ file:///home/conda/feedstock_root/build_artifacts/ptyprocess_1609419310487/work/dist/ptyprocess-0.7.0-py2.py3-none-any.whl
|
| 191 |
+
pure_eval @ file:///home/conda/feedstock_root/build_artifacts/pure_eval_1721585709575/work
|
| 192 |
+
py-cpuinfo==9.0.0
|
| 193 |
+
pyarrow==17.0.0
|
| 194 |
+
pyasn1==0.6.1
|
| 195 |
+
pyasn1_modules==0.4.1
|
| 196 |
+
pyclipper==1.3.0.post5
|
| 197 |
+
pycparser==2.22
|
| 198 |
+
pycryptodome==3.20.0
|
| 199 |
+
pydantic==2.9.2
|
| 200 |
+
pydantic-settings==2.5.2
|
| 201 |
+
pydantic_core==2.23.4
|
| 202 |
+
pydub==0.25.1
|
| 203 |
+
Pygments @ file:///home/conda/feedstock_root/build_artifacts/pygments_1714846767233/work
|
| 204 |
+
PyNaCl==1.5.0
|
| 205 |
+
pyparsing==3.1.4
|
| 206 |
+
pypdfium2==4.30.0
|
| 207 |
+
PySocks @ file:///home/builder/ci_310/pysocks_1640793678128/work
|
| 208 |
+
python-dateutil @ file:///home/conda/feedstock_root/build_artifacts/python-dateutil_1709299778482/work
|
| 209 |
+
python-docx==1.1.2
|
| 210 |
+
python-dotenv==1.0.1
|
| 211 |
+
python-multipart==0.0.12
|
| 212 |
+
pytorch-lightning==2.2.1
|
| 213 |
+
pytorchvideo==0.1.5
|
| 214 |
+
pytz==2024.2
|
| 215 |
+
PyYAML @ file:///croot/pyyaml_1698096049011/work
|
| 216 |
+
pyzmq @ file:///croot/pyzmq_1705605076900/work
|
| 217 |
+
qudida==0.0.4
|
| 218 |
+
RapidFuzz==3.10.0
|
| 219 |
+
rarfile==4.2
|
| 220 |
+
ray==2.37.0
|
| 221 |
+
referencing==0.35.1
|
| 222 |
+
regex==2023.12.25
|
| 223 |
+
requests==2.32.3
|
| 224 |
+
requests-oauthlib==2.0.0
|
| 225 |
+
rich==13.9.2
|
| 226 |
+
rotary-embedding-torch==0.5.3
|
| 227 |
+
rpds-py==0.20.0
|
| 228 |
+
rpyc==6.0.0
|
| 229 |
+
rsa==4.9
|
| 230 |
+
ruff==0.6.9
|
| 231 |
+
s3transfer==0.10.2
|
| 232 |
+
safetensors==0.4.5
|
| 233 |
+
scikit-image==0.24.0
|
| 234 |
+
scikit-learn==1.3.2
|
| 235 |
+
scikit-video==1.1.11
|
| 236 |
+
scipy==1.10.1
|
| 237 |
+
seaborn==0.13.2
|
| 238 |
+
semantic-version==2.10.0
|
| 239 |
+
sentencepiece==0.2.0
|
| 240 |
+
sentry-sdk==2.15.0
|
| 241 |
+
setproctitle==1.3.3
|
| 242 |
+
shapely==2.0.6
|
| 243 |
+
shellingham==1.5.4
|
| 244 |
+
six @ file:///home/conda/feedstock_root/build_artifacts/six_1620240208055/work
|
| 245 |
+
smmap==5.0.1
|
| 246 |
+
sniffio==1.3.1
|
| 247 |
+
soupsieve==2.6
|
| 248 |
+
spaces==0.30.3
|
| 249 |
+
stack-data @ file:///home/conda/feedstock_root/build_artifacts/stack_data_1669632077133/work
|
| 250 |
+
starlette==0.36.3
|
| 251 |
+
supervision==0.23.0
|
| 252 |
+
SwissArmyTransformer==0.4.12
|
| 253 |
+
sympy @ file:///croot/sympy_1724938189289/work
|
| 254 |
+
tabulate==0.9.0
|
| 255 |
+
tensorboard==2.14.0
|
| 256 |
+
tensorboard-data-server==0.7.2
|
| 257 |
+
tensorboardX==2.6.2.2
|
| 258 |
+
termcolor==2.4.0
|
| 259 |
+
test_tube==0.7.5
|
| 260 |
+
thop==0.1.1.post2209072238
|
| 261 |
+
threadpoolctl==3.5.0
|
| 262 |
+
tifffile==2024.9.20
|
| 263 |
+
timm==0.9.16
|
| 264 |
+
tokenizers==0.20.0
|
| 265 |
+
tomli==2.0.2
|
| 266 |
+
tomlkit==0.12.0
|
| 267 |
+
torch==2.4.1
|
| 268 |
+
torch-lr-finder==0.2.2
|
| 269 |
+
torchaudio==2.4.1
|
| 270 |
+
torchdiffeq==0.2.3
|
| 271 |
+
torchmetrics==1.3.2
|
| 272 |
+
torchvision==0.19.1
|
| 273 |
+
tornado @ file:///home/conda/feedstock_root/build_artifacts/tornado_1648827254365/work
|
| 274 |
+
tqdm==4.66.5
|
| 275 |
+
traitlets @ file:///home/conda/feedstock_root/build_artifacts/traitlets_1713535121073/work
|
| 276 |
+
transformers==4.45.1
|
| 277 |
+
triton==3.0.0
|
| 278 |
+
typer==0.12.5
|
| 279 |
+
typing_extensions @ file:///croot/typing_extensions_1715268824938/work
|
| 280 |
+
tzdata==2024.1
|
| 281 |
+
ujson==5.10.0
|
| 282 |
+
ultralytics==8.3.1
|
| 283 |
+
ultralytics-thop==2.0.8
|
| 284 |
+
urllib3==2.2.1
|
| 285 |
+
uvicorn==0.29.0
|
| 286 |
+
virtualenv==20.26.6
|
| 287 |
+
visualdl==2.5.3
|
| 288 |
+
wandb==0.18.3
|
| 289 |
+
wcwidth @ file:///home/conda/feedstock_root/build_artifacts/wcwidth_1704731205417/work
|
| 290 |
+
webdataset==0.2.100
|
| 291 |
+
websockets==11.0.3
|
| 292 |
+
Werkzeug==3.0.4
|
| 293 |
+
widgetsnbextension==4.0.13
|
| 294 |
+
wrapt==1.16.0
|
| 295 |
+
xxhash==3.5.0
|
| 296 |
+
yacs==0.1.8
|
| 297 |
+
yapf==0.40.2
|
| 298 |
+
yarl==1.11.1
|
| 299 |
+
zipp==3.20.2
|
results/layout-benchmark-results-images-1.jpg
ADDED

|
results/layout-benchmark-results-images-10.jpg
ADDED

|
results/layout-benchmark-results-images-2.jpg
ADDED
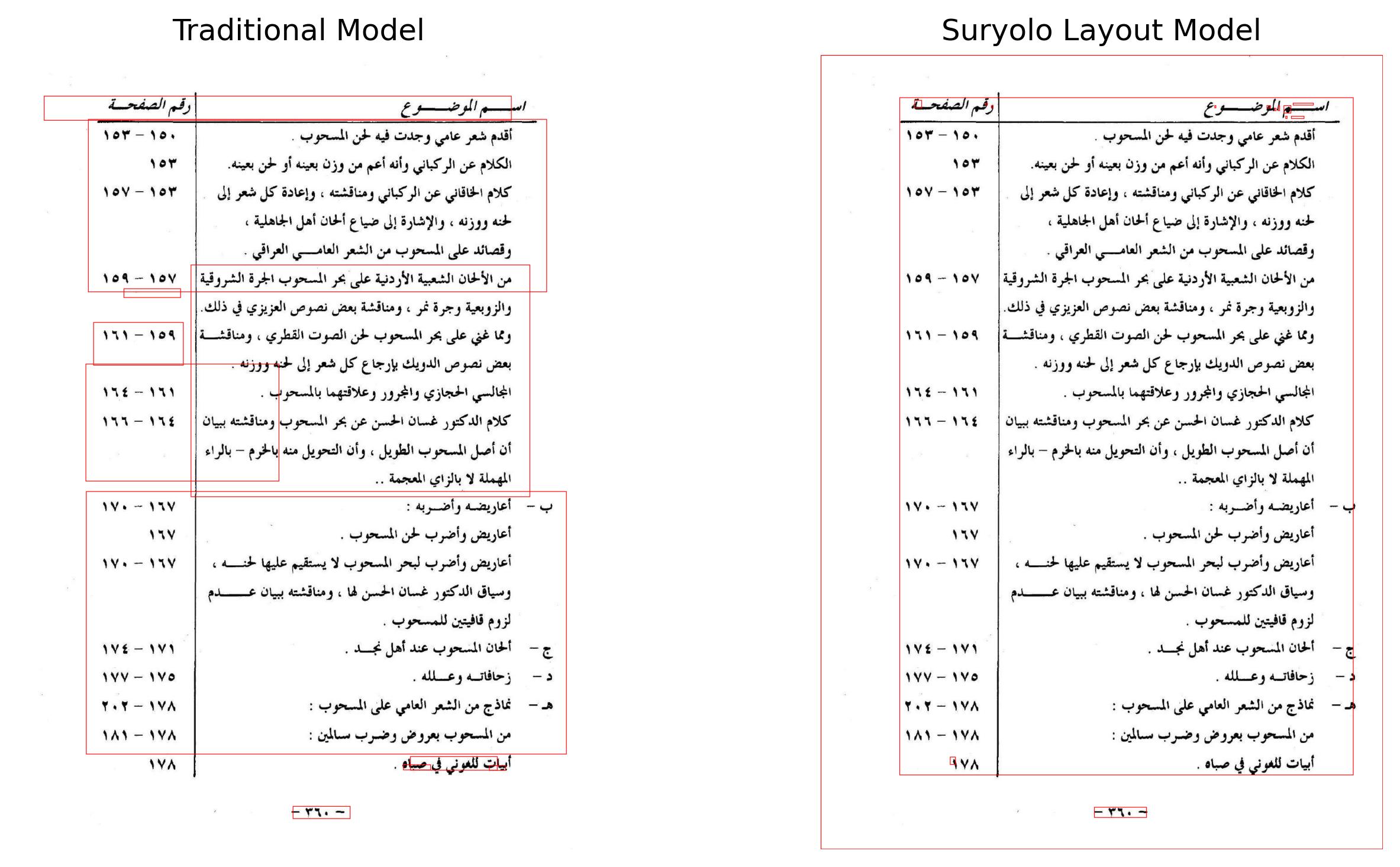
|
results/layout-benchmark-results-images-3.jpg
ADDED

|
results/layout-benchmark-results-images-4.jpg
ADDED

|
results/layout-benchmark-results-images-5.jpg
ADDED

|
results/layout-benchmark-results-images-6.jpg
ADDED

|
results/layout-benchmark-results-images-7.jpg
ADDED

|
results/layout-benchmark-results-images-8.jpg
ADDED
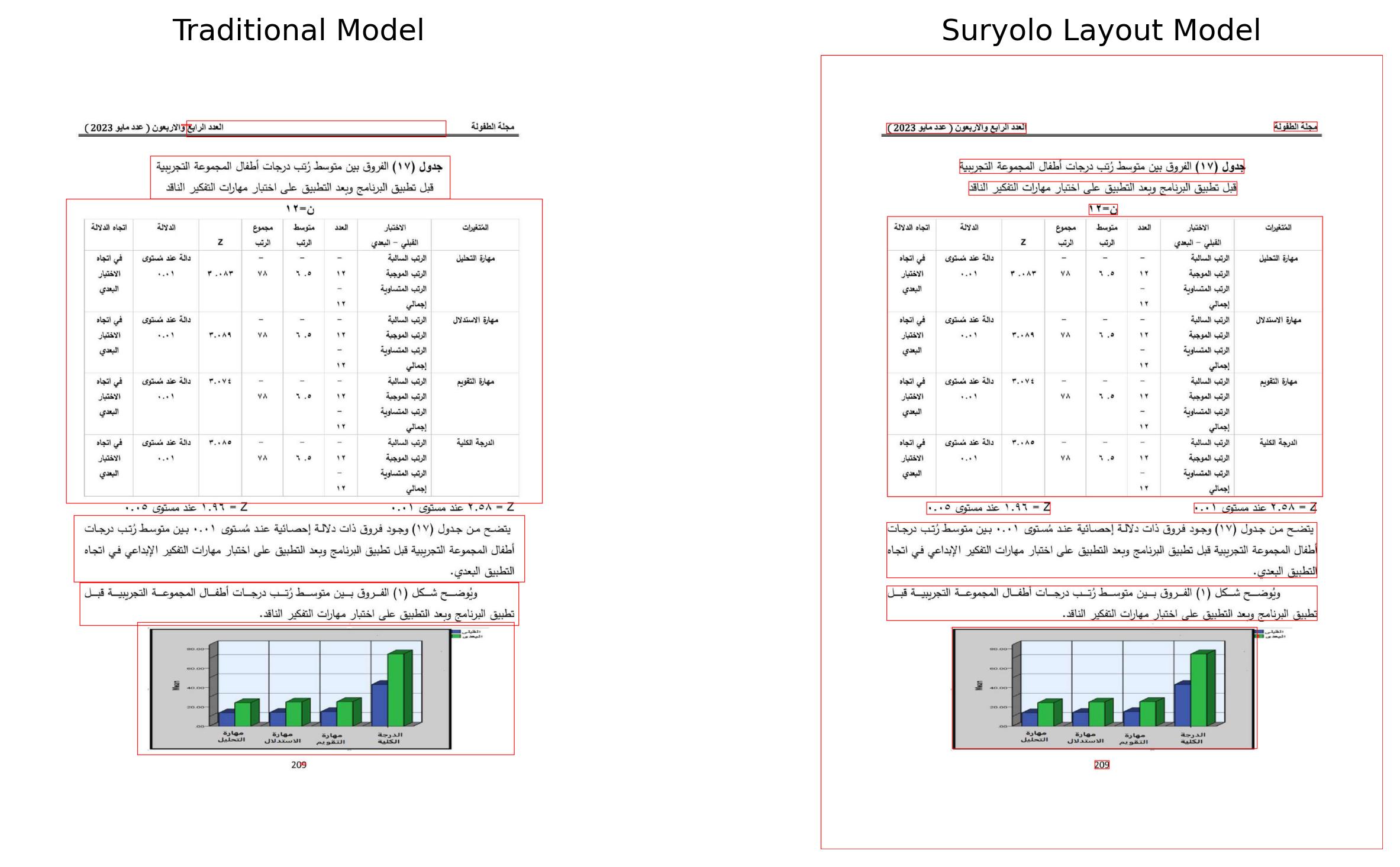
|
results/layout-benchmark-results-images-9.jpg
ADDED

|
surya/__pycache__/detection.cpython-310.pyc
ADDED
|
Binary file (5.06 kB). View file
|
|
|
surya/__pycache__/layout.cpython-310.pyc
ADDED
|
Binary file (6.35 kB). View file
|
|
|
surya/__pycache__/ocr.cpython-310.pyc
ADDED
|
Binary file (2.79 kB). View file
|
|
|
surya/__pycache__/recognition.cpython-310.pyc
ADDED
|
Binary file (5.86 kB). View file
|
|
|
surya/__pycache__/schema.cpython-310.pyc
ADDED
|
Binary file (6.41 kB). View file
|
|
|
surya/__pycache__/settings.cpython-310.pyc
ADDED
|
Binary file (3.77 kB). View file
|
|
|
surya/benchmark/bbox.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import fitz as pymupdf
|
| 2 |
+
from surya.postprocessing.util import rescale_bbox
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def get_pdf_lines(pdf_path, img_sizes):
|
| 6 |
+
doc = pymupdf.open(pdf_path)
|
| 7 |
+
page_lines = []
|
| 8 |
+
for idx, img_size in enumerate(img_sizes):
|
| 9 |
+
page = doc[idx]
|
| 10 |
+
blocks = page.get_text("dict", sort=True, flags=pymupdf.TEXTFLAGS_DICT & ~pymupdf.TEXT_PRESERVE_LIGATURES & ~pymupdf.TEXT_PRESERVE_IMAGES)["blocks"]
|
| 11 |
+
|
| 12 |
+
line_boxes = []
|
| 13 |
+
for block_idx, block in enumerate(blocks):
|
| 14 |
+
for l in block["lines"]:
|
| 15 |
+
line_boxes.append(list(l["bbox"]))
|
| 16 |
+
|
| 17 |
+
page_box = page.bound()
|
| 18 |
+
pwidth, pheight = page_box[2] - page_box[0], page_box[3] - page_box[1]
|
| 19 |
+
line_boxes = [rescale_bbox(bbox, (pwidth, pheight), img_size) for bbox in line_boxes]
|
| 20 |
+
page_lines.append(line_boxes)
|
| 21 |
+
|
| 22 |
+
return page_lines
|
surya/benchmark/metrics.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
from itertools import repeat
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
from concurrent.futures import ProcessPoolExecutor
|
| 6 |
+
|
| 7 |
+
def intersection_area(box1, box2):
|
| 8 |
+
x_left = max(box1[0], box2[0])
|
| 9 |
+
y_top = max(box1[1], box2[1])
|
| 10 |
+
x_right = min(box1[2], box2[2])
|
| 11 |
+
y_bottom = min(box1[3], box2[3])
|
| 12 |
+
|
| 13 |
+
if x_right < x_left or y_bottom < y_top:
|
| 14 |
+
return 0.0
|
| 15 |
+
|
| 16 |
+
return (x_right - x_left) * (y_bottom - y_top)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def intersection_pixels(box1, box2):
|
| 20 |
+
x_left = max(box1[0], box2[0])
|
| 21 |
+
y_top = max(box1[1], box2[1])
|
| 22 |
+
x_right = min(box1[2], box2[2])
|
| 23 |
+
y_bottom = min(box1[3], box2[3])
|
| 24 |
+
|
| 25 |
+
if x_right < x_left or y_bottom < y_top:
|
| 26 |
+
return set()
|
| 27 |
+
|
| 28 |
+
x_left, x_right = int(x_left), int(x_right)
|
| 29 |
+
y_top, y_bottom = int(y_top), int(y_bottom)
|
| 30 |
+
|
| 31 |
+
coords = np.meshgrid(np.arange(x_left, x_right), np.arange(y_top, y_bottom))
|
| 32 |
+
pixels = set(zip(coords[0].flat, coords[1].flat))
|
| 33 |
+
|
| 34 |
+
return pixels
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def calculate_coverage(box, other_boxes, penalize_double=False):
|
| 38 |
+
box_area = (box[2] - box[0]) * (box[3] - box[1])
|
| 39 |
+
if box_area == 0:
|
| 40 |
+
return 0
|
| 41 |
+
|
| 42 |
+
# find total coverage of the box
|
| 43 |
+
covered_pixels = set()
|
| 44 |
+
double_coverage = list()
|
| 45 |
+
for other_box in other_boxes:
|
| 46 |
+
ia = intersection_pixels(box, other_box)
|
| 47 |
+
double_coverage.append(list(covered_pixels.intersection(ia)))
|
| 48 |
+
covered_pixels = covered_pixels.union(ia)
|
| 49 |
+
|
| 50 |
+
# Penalize double coverage - having multiple bboxes overlapping the same pixels
|
| 51 |
+
double_coverage_penalty = len(double_coverage)
|
| 52 |
+
if not penalize_double:
|
| 53 |
+
double_coverage_penalty = 0
|
| 54 |
+
covered_pixels_count = max(0, len(covered_pixels) - double_coverage_penalty)
|
| 55 |
+
return covered_pixels_count / box_area
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def calculate_coverage_fast(box, other_boxes, penalize_double=False):
|
| 59 |
+
box_area = (box[2] - box[0]) * (box[3] - box[1])
|
| 60 |
+
if box_area == 0:
|
| 61 |
+
return 0
|
| 62 |
+
|
| 63 |
+
total_intersect = 0
|
| 64 |
+
for other_box in other_boxes:
|
| 65 |
+
total_intersect += intersection_area(box, other_box)
|
| 66 |
+
|
| 67 |
+
return min(1, total_intersect / box_area)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def precision_recall(preds, references, threshold=.5, workers=8, penalize_double=True):
|
| 71 |
+
if len(references) == 0:
|
| 72 |
+
return {
|
| 73 |
+
"precision": 1,
|
| 74 |
+
"recall": 1,
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
if len(preds) == 0:
|
| 78 |
+
return {
|
| 79 |
+
"precision": 0,
|
| 80 |
+
"recall": 0,
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
# If we're not penalizing double coverage, we can use a faster calculation
|
| 84 |
+
coverage_func = calculate_coverage_fast
|
| 85 |
+
if penalize_double:
|
| 86 |
+
coverage_func = calculate_coverage
|
| 87 |
+
|
| 88 |
+
with ProcessPoolExecutor(max_workers=workers) as executor:
|
| 89 |
+
precision_func = partial(coverage_func, penalize_double=penalize_double)
|
| 90 |
+
precision_iou = executor.map(precision_func, preds, repeat(references))
|
| 91 |
+
reference_iou = executor.map(coverage_func, references, repeat(preds))
|
| 92 |
+
|
| 93 |
+
precision_classes = [1 if i > threshold else 0 for i in precision_iou]
|
| 94 |
+
precision = sum(precision_classes) / len(precision_classes)
|
| 95 |
+
|
| 96 |
+
recall_classes = [1 if i > threshold else 0 for i in reference_iou]
|
| 97 |
+
recall = sum(recall_classes) / len(recall_classes)
|
| 98 |
+
|
| 99 |
+
return {
|
| 100 |
+
"precision": precision,
|
| 101 |
+
"recall": recall,
|
| 102 |
+
}
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def mean_coverage(preds, references):
|
| 106 |
+
coverages = []
|
| 107 |
+
|
| 108 |
+
for box1 in references:
|
| 109 |
+
coverage = calculate_coverage(box1, preds)
|
| 110 |
+
coverages.append(coverage)
|
| 111 |
+
|
| 112 |
+
for box2 in preds:
|
| 113 |
+
coverage = calculate_coverage(box2, references)
|
| 114 |
+
coverages.append(coverage)
|
| 115 |
+
|
| 116 |
+
# Calculate the average coverage over all comparisons
|
| 117 |
+
if len(coverages) == 0:
|
| 118 |
+
return 0
|
| 119 |
+
coverage = sum(coverages) / len(coverages)
|
| 120 |
+
return {"coverage": coverage}
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def rank_accuracy(preds, references):
|
| 124 |
+
# Preds and references need to be aligned so each position refers to the same bbox
|
| 125 |
+
pairs = []
|
| 126 |
+
for i, pred in enumerate(preds):
|
| 127 |
+
for j, pred2 in enumerate(preds):
|
| 128 |
+
if i == j:
|
| 129 |
+
continue
|
| 130 |
+
pairs.append((i, j, pred > pred2))
|
| 131 |
+
|
| 132 |
+
# Find how many of the prediction rankings are correct
|
| 133 |
+
correct = 0
|
| 134 |
+
for i, ref in enumerate(references):
|
| 135 |
+
for j, ref2 in enumerate(references):
|
| 136 |
+
if (i, j, ref > ref2) in pairs:
|
| 137 |
+
correct += 1
|
| 138 |
+
|
| 139 |
+
return correct / len(pairs)
|
surya/benchmark/tesseract.py
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import pytesseract
|
| 5 |
+
from pytesseract import Output
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
|
| 8 |
+
from surya.input.processing import slice_bboxes_from_image
|
| 9 |
+
from surya.settings import settings
|
| 10 |
+
import os
|
| 11 |
+
from concurrent.futures import ProcessPoolExecutor
|
| 12 |
+
from surya.detection import get_batch_size as get_det_batch_size
|
| 13 |
+
from surya.recognition import get_batch_size as get_rec_batch_size
|
| 14 |
+
from surya.languages import CODE_TO_LANGUAGE
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def surya_lang_to_tesseract(code: str) -> Optional[str]:
|
| 18 |
+
lang_str = CODE_TO_LANGUAGE[code]
|
| 19 |
+
try:
|
| 20 |
+
tess_lang = TESS_LANGUAGE_TO_CODE[lang_str]
|
| 21 |
+
except KeyError:
|
| 22 |
+
return None
|
| 23 |
+
return tess_lang
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def tesseract_ocr(img, bboxes, lang: str):
|
| 27 |
+
line_imgs = slice_bboxes_from_image(img, bboxes)
|
| 28 |
+
config = f'--tessdata-dir "{settings.TESSDATA_PREFIX}"'
|
| 29 |
+
lines = []
|
| 30 |
+
for line_img in line_imgs:
|
| 31 |
+
line = pytesseract.image_to_string(line_img, lang=lang, config=config)
|
| 32 |
+
lines.append(line)
|
| 33 |
+
return lines
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def tesseract_ocr_parallel(imgs, bboxes, langs: List[str], cpus=None):
|
| 37 |
+
tess_parallel_cores = min(len(imgs), get_rec_batch_size())
|
| 38 |
+
if not cpus:
|
| 39 |
+
cpus = os.cpu_count()
|
| 40 |
+
tess_parallel_cores = min(tess_parallel_cores, cpus)
|
| 41 |
+
|
| 42 |
+
# Tesseract uses up to 4 processes per instance
|
| 43 |
+
# Divide by 2 because tesseract doesn't seem to saturate all 4 cores with these small images
|
| 44 |
+
tess_parallel = max(tess_parallel_cores // 2, 1)
|
| 45 |
+
|
| 46 |
+
with ProcessPoolExecutor(max_workers=tess_parallel) as executor:
|
| 47 |
+
tess_text = tqdm(executor.map(tesseract_ocr, imgs, bboxes, langs), total=len(imgs), desc="Running tesseract OCR")
|
| 48 |
+
tess_text = list(tess_text)
|
| 49 |
+
return tess_text
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def tesseract_bboxes(img):
|
| 53 |
+
arr_img = np.asarray(img, dtype=np.uint8)
|
| 54 |
+
ocr = pytesseract.image_to_data(arr_img, output_type=Output.DICT)
|
| 55 |
+
|
| 56 |
+
bboxes = []
|
| 57 |
+
n_boxes = len(ocr['level'])
|
| 58 |
+
for i in range(n_boxes):
|
| 59 |
+
# It is possible to merge by line here with line number, but it gives bad results.
|
| 60 |
+
_, x, y, w, h = ocr['text'][i], ocr['left'][i], ocr['top'][i], ocr['width'][i], ocr['height'][i]
|
| 61 |
+
bbox = (x, y, x + w, y + h)
|
| 62 |
+
bboxes.append(bbox)
|
| 63 |
+
|
| 64 |
+
return bboxes
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def tesseract_parallel(imgs):
|
| 68 |
+
# Tesseract uses 4 threads per instance
|
| 69 |
+
tess_parallel_cores = min(len(imgs), get_det_batch_size())
|
| 70 |
+
cpus = os.cpu_count()
|
| 71 |
+
tess_parallel_cores = min(tess_parallel_cores, cpus)
|
| 72 |
+
|
| 73 |
+
# Tesseract uses 4 threads per instance
|
| 74 |
+
tess_parallel = max(tess_parallel_cores // 4, 1)
|
| 75 |
+
|
| 76 |
+
with ProcessPoolExecutor(max_workers=tess_parallel) as executor:
|
| 77 |
+
tess_bboxes = tqdm(executor.map(tesseract_bboxes, imgs), total=len(imgs), desc="Running tesseract bbox detection")
|
| 78 |
+
tess_bboxes = list(tess_bboxes)
|
| 79 |
+
return tess_bboxes
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
TESS_CODE_TO_LANGUAGE = {
|
| 83 |
+
"afr": "Afrikaans",
|
| 84 |
+
"amh": "Amharic",
|
| 85 |
+
"ara": "Arabic",
|
| 86 |
+
"asm": "Assamese",
|
| 87 |
+
"aze": "Azerbaijani",
|
| 88 |
+
"bel": "Belarusian",
|
| 89 |
+
"ben": "Bengali",
|
| 90 |
+
"bod": "Tibetan",
|
| 91 |
+
"bos": "Bosnian",
|
| 92 |
+
"bre": "Breton",
|
| 93 |
+
"bul": "Bulgarian",
|
| 94 |
+
"cat": "Catalan",
|
| 95 |
+
"ceb": "Cebuano",
|
| 96 |
+
"ces": "Czech",
|
| 97 |
+
"chi_sim": "Chinese",
|
| 98 |
+
"chr": "Cherokee",
|
| 99 |
+
"cym": "Welsh",
|
| 100 |
+
"dan": "Danish",
|
| 101 |
+
"deu": "German",
|
| 102 |
+
"dzo": "Dzongkha",
|
| 103 |
+
"ell": "Greek",
|
| 104 |
+
"eng": "English",
|
| 105 |
+
"epo": "Esperanto",
|
| 106 |
+
"est": "Estonian",
|
| 107 |
+
"eus": "Basque",
|
| 108 |
+
"fas": "Persian",
|
| 109 |
+
"fin": "Finnish",
|
| 110 |
+
"fra": "French",
|
| 111 |
+
"fry": "Western Frisian",
|
| 112 |
+
"guj": "Gujarati",
|
| 113 |
+
"gla": "Scottish Gaelic",
|
| 114 |
+
"gle": "Irish",
|
| 115 |
+
"glg": "Galician",
|
| 116 |
+
"heb": "Hebrew",
|
| 117 |
+
"hin": "Hindi",
|
| 118 |
+
"hrv": "Croatian",
|
| 119 |
+
"hun": "Hungarian",
|
| 120 |
+
"hye": "Armenian",
|
| 121 |
+
"iku": "Inuktitut",
|
| 122 |
+
"ind": "Indonesian",
|
| 123 |
+
"isl": "Icelandic",
|
| 124 |
+
"ita": "Italian",
|
| 125 |
+
"jav": "Javanese",
|
| 126 |
+
"jpn": "Japanese",
|
| 127 |
+
"kan": "Kannada",
|
| 128 |
+
"kat": "Georgian",
|
| 129 |
+
"kaz": "Kazakh",
|
| 130 |
+
"khm": "Khmer",
|
| 131 |
+
"kir": "Kyrgyz",
|
| 132 |
+
"kor": "Korean",
|
| 133 |
+
"lao": "Lao",
|
| 134 |
+
"lat": "Latin",
|
| 135 |
+
"lav": "Latvian",
|
| 136 |
+
"lit": "Lithuanian",
|
| 137 |
+
"mal": "Malayalam",
|
| 138 |
+
"mar": "Marathi",
|
| 139 |
+
"mkd": "Macedonian",
|
| 140 |
+
"mlt": "Maltese",
|
| 141 |
+
"mon": "Mongolian",
|
| 142 |
+
"msa": "Malay",
|
| 143 |
+
"mya": "Burmese",
|
| 144 |
+
"nep": "Nepali",
|
| 145 |
+
"nld": "Dutch",
|
| 146 |
+
"nor": "Norwegian",
|
| 147 |
+
"ori": "Oriya",
|
| 148 |
+
"pan": "Punjabi",
|
| 149 |
+
"pol": "Polish",
|
| 150 |
+
"por": "Portuguese",
|
| 151 |
+
"pus": "Pashto",
|
| 152 |
+
"ron": "Romanian",
|
| 153 |
+
"rus": "Russian",
|
| 154 |
+
"san": "Sanskrit",
|
| 155 |
+
"sin": "Sinhala",
|
| 156 |
+
"slk": "Slovak",
|
| 157 |
+
"slv": "Slovenian",
|
| 158 |
+
"snd": "Sindhi",
|
| 159 |
+
"spa": "Spanish",
|
| 160 |
+
"sqi": "Albanian",
|
| 161 |
+
"srp": "Serbian",
|
| 162 |
+
"swa": "Swahili",
|
| 163 |
+
"swe": "Swedish",
|
| 164 |
+
"syr": "Syriac",
|
| 165 |
+
"tam": "Tamil",
|
| 166 |
+
"tel": "Telugu",
|
| 167 |
+
"tgk": "Tajik",
|
| 168 |
+
"tha": "Thai",
|
| 169 |
+
"tir": "Tigrinya",
|
| 170 |
+
"tur": "Turkish",
|
| 171 |
+
"uig": "Uyghur",
|
| 172 |
+
"ukr": "Ukrainian",
|
| 173 |
+
"urd": "Urdu",
|
| 174 |
+
"uzb": "Uzbek",
|
| 175 |
+
"vie": "Vietnamese",
|
| 176 |
+
"yid": "Yiddish"
|
| 177 |
+
}
|
| 178 |
+
|
| 179 |
+
TESS_LANGUAGE_TO_CODE = {v:k for k,v in TESS_CODE_TO_LANGUAGE.items()}
|
surya/benchmark/util.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def merge_boxes(box1, box2):
|
| 2 |
+
return (min(box1[0], box2[0]), min(box1[1], box2[1]), max(box1[2], box2[2]), max(box1[3], box2[3]))
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def join_lines(bboxes, max_gap=5):
|
| 6 |
+
to_merge = {}
|
| 7 |
+
for i, box1 in bboxes:
|
| 8 |
+
for z, box2 in bboxes[i + 1:]:
|
| 9 |
+
j = i + z + 1
|
| 10 |
+
if box1 == box2:
|
| 11 |
+
continue
|
| 12 |
+
|
| 13 |
+
if box1[0] <= box2[0] and box1[2] >= box2[2]:
|
| 14 |
+
if abs(box1[1] - box2[3]) <= max_gap:
|
| 15 |
+
if i not in to_merge:
|
| 16 |
+
to_merge[i] = []
|
| 17 |
+
to_merge[i].append(j)
|
| 18 |
+
|
| 19 |
+
merged_boxes = set()
|
| 20 |
+
merged = []
|
| 21 |
+
for i, box in bboxes:
|
| 22 |
+
if i in merged_boxes:
|
| 23 |
+
continue
|
| 24 |
+
|
| 25 |
+
if i in to_merge:
|
| 26 |
+
for j in to_merge[i]:
|
| 27 |
+
box = merge_boxes(box, bboxes[j][1])
|
| 28 |
+
merged_boxes.add(j)
|
| 29 |
+
|
| 30 |
+
merged.append(box)
|
| 31 |
+
return merged
|
surya/detection.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Tuple
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
from PIL import Image
|
| 6 |
+
|
| 7 |
+
from surya.model.detection.segformer import SegformerForRegressionMask
|
| 8 |
+
from surya.postprocessing.heatmap import get_and_clean_boxes
|
| 9 |
+
from surya.postprocessing.affinity import get_vertical_lines
|
| 10 |
+
from surya.input.processing import prepare_image_detection, split_image, get_total_splits, convert_if_not_rgb
|
| 11 |
+
from surya.schema import TextDetectionResult
|
| 12 |
+
from surya.settings import settings
|
| 13 |
+
from tqdm import tqdm
|
| 14 |
+
from concurrent.futures import ProcessPoolExecutor
|
| 15 |
+
import torch.nn.functional as F
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def get_batch_size():
|
| 19 |
+
batch_size = settings.DETECTOR_BATCH_SIZE
|
| 20 |
+
if batch_size is None:
|
| 21 |
+
batch_size = 6
|
| 22 |
+
if settings.TORCH_DEVICE_MODEL == "cuda":
|
| 23 |
+
batch_size = 24
|
| 24 |
+
return batch_size
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def batch_detection(images: List, model: SegformerForRegressionMask, processor, batch_size=None) -> Tuple[List[List[np.ndarray]], List[Tuple[int, int]]]:
|
| 28 |
+
assert all([isinstance(image, Image.Image) for image in images])
|
| 29 |
+
if batch_size is None:
|
| 30 |
+
batch_size = get_batch_size()
|
| 31 |
+
heatmap_count = model.config.num_labels
|
| 32 |
+
|
| 33 |
+
images = [image.convert("RGB") for image in images] # also copies the images
|
| 34 |
+
|
| 35 |
+
orig_sizes = [image.size for image in images]
|
| 36 |
+
splits_per_image = [get_total_splits(size, processor) for size in orig_sizes]
|
| 37 |
+
|
| 38 |
+
batches = []
|
| 39 |
+
current_batch_size = 0
|
| 40 |
+
current_batch = []
|
| 41 |
+
for i in range(len(images)):
|
| 42 |
+
if current_batch_size + splits_per_image[i] > batch_size:
|
| 43 |
+
if len(current_batch) > 0:
|
| 44 |
+
batches.append(current_batch)
|
| 45 |
+
current_batch = []
|
| 46 |
+
current_batch_size = 0
|
| 47 |
+
current_batch.append(i)
|
| 48 |
+
current_batch_size += splits_per_image[i]
|
| 49 |
+
|
| 50 |
+
if len(current_batch) > 0:
|
| 51 |
+
batches.append(current_batch)
|
| 52 |
+
|
| 53 |
+
all_preds = []
|
| 54 |
+
for batch_idx in tqdm(range(len(batches)), desc="Detecting bboxes"):
|
| 55 |
+
batch_image_idxs = batches[batch_idx]
|
| 56 |
+
batch_images = convert_if_not_rgb([images[j] for j in batch_image_idxs])
|
| 57 |
+
|
| 58 |
+
split_index = []
|
| 59 |
+
split_heights = []
|
| 60 |
+
image_splits = []
|
| 61 |
+
for image_idx, image in enumerate(batch_images):
|
| 62 |
+
image_parts, split_height = split_image(image, processor)
|
| 63 |
+
image_splits.extend(image_parts)
|
| 64 |
+
split_index.extend([image_idx] * len(image_parts))
|
| 65 |
+
split_heights.extend(split_height)
|
| 66 |
+
|
| 67 |
+
image_splits = [prepare_image_detection(image, processor) for image in image_splits]
|
| 68 |
+
# Batch images in dim 0
|
| 69 |
+
batch = torch.stack(image_splits, dim=0).to(model.dtype).to(model.device)
|
| 70 |
+
|
| 71 |
+
with torch.inference_mode():
|
| 72 |
+
pred = model(pixel_values=batch)
|
| 73 |
+
|
| 74 |
+
logits = pred.logits
|
| 75 |
+
correct_shape = [processor.size["height"], processor.size["width"]]
|
| 76 |
+
current_shape = list(logits.shape[2:])
|
| 77 |
+
if current_shape != correct_shape:
|
| 78 |
+
logits = F.interpolate(logits, size=correct_shape, mode='bilinear', align_corners=False)
|
| 79 |
+
|
| 80 |
+
logits = logits.cpu().detach().numpy().astype(np.float32)
|
| 81 |
+
preds = []
|
| 82 |
+
for i, (idx, height) in enumerate(zip(split_index, split_heights)):
|
| 83 |
+
# If our current prediction length is below the image idx, that means we have a new image
|
| 84 |
+
# Otherwise, we need to add to the current image
|
| 85 |
+
if len(preds) <= idx:
|
| 86 |
+
preds.append([logits[i][k] for k in range(heatmap_count)])
|
| 87 |
+
else:
|
| 88 |
+
heatmaps = preds[idx]
|
| 89 |
+
pred_heatmaps = [logits[i][k] for k in range(heatmap_count)]
|
| 90 |
+
|
| 91 |
+
if height < processor.size["height"]:
|
| 92 |
+
# Cut off padding to get original height
|
| 93 |
+
pred_heatmaps = [pred_heatmap[:height, :] for pred_heatmap in pred_heatmaps]
|
| 94 |
+
|
| 95 |
+
for k in range(heatmap_count):
|
| 96 |
+
heatmaps[k] = np.vstack([heatmaps[k], pred_heatmaps[k]])
|
| 97 |
+
preds[idx] = heatmaps
|
| 98 |
+
|
| 99 |
+
all_preds.extend(preds)
|
| 100 |
+
|
| 101 |
+
assert len(all_preds) == len(images)
|
| 102 |
+
assert all([len(pred) == heatmap_count for pred in all_preds])
|
| 103 |
+
return all_preds, orig_sizes
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def parallel_get_lines(preds, orig_sizes):
|
| 107 |
+
heatmap, affinity_map = preds
|
| 108 |
+
heat_img = Image.fromarray((heatmap * 255).astype(np.uint8))
|
| 109 |
+
aff_img = Image.fromarray((affinity_map * 255).astype(np.uint8))
|
| 110 |
+
affinity_size = list(reversed(affinity_map.shape))
|
| 111 |
+
heatmap_size = list(reversed(heatmap.shape))
|
| 112 |
+
bboxes = get_and_clean_boxes(heatmap, heatmap_size, orig_sizes)
|
| 113 |
+
vertical_lines = get_vertical_lines(affinity_map, affinity_size, orig_sizes)
|
| 114 |
+
|
| 115 |
+
result = TextDetectionResult(
|
| 116 |
+
bboxes=bboxes,
|
| 117 |
+
vertical_lines=vertical_lines,
|
| 118 |
+
heatmap=heat_img,
|
| 119 |
+
affinity_map=aff_img,
|
| 120 |
+
image_bbox=[0, 0, orig_sizes[0], orig_sizes[1]]
|
| 121 |
+
)
|
| 122 |
+
return result
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def batch_text_detection(images: List, model, processor, batch_size=None) -> List[TextDetectionResult]:
|
| 126 |
+
preds, orig_sizes = batch_detection(images, model, processor, batch_size=batch_size)
|
| 127 |
+
results = []
|
| 128 |
+
if settings.IN_STREAMLIT or len(images) < settings.DETECTOR_MIN_PARALLEL_THRESH: # Ensures we don't parallelize with streamlit, or with very few images
|
| 129 |
+
for i in range(len(images)):
|
| 130 |
+
result = parallel_get_lines(preds[i], orig_sizes[i])
|
| 131 |
+
results.append(result)
|
| 132 |
+
else:
|
| 133 |
+
max_workers = min(settings.DETECTOR_POSTPROCESSING_CPU_WORKERS, len(images))
|
| 134 |
+
with ProcessPoolExecutor(max_workers=max_workers) as executor:
|
| 135 |
+
results = list(executor.map(parallel_get_lines, preds, orig_sizes))
|
| 136 |
+
|
| 137 |
+
return results
|
| 138 |
+
|
| 139 |
+
|
surya/input/__pycache__/processing.cpython-310.pyc
ADDED
|
Binary file (4.05 kB). View file
|
|
|
surya/input/langs.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
from surya.languages import LANGUAGE_TO_CODE, CODE_TO_LANGUAGE
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def replace_lang_with_code(langs: List[str]):
|
| 6 |
+
for i in range(len(langs)):
|
| 7 |
+
if langs[i].title() in LANGUAGE_TO_CODE:
|
| 8 |
+
langs[i] = LANGUAGE_TO_CODE[langs[i].title()]
|
| 9 |
+
if langs[i] not in CODE_TO_LANGUAGE:
|
| 10 |
+
raise ValueError(f"Language code {langs[i]} not found.")
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def get_unique_langs(langs: List[List[str]]):
|
| 14 |
+
uniques = []
|
| 15 |
+
for lang_list in langs:
|
| 16 |
+
for lang in lang_list:
|
| 17 |
+
if lang not in uniques:
|
| 18 |
+
uniques.append(lang)
|
| 19 |
+
return uniques
|
surya/input/load.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import PIL
|
| 2 |
+
|
| 3 |
+
from surya.input.processing import open_pdf, get_page_images
|
| 4 |
+
import os
|
| 5 |
+
import filetype
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import json
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def get_name_from_path(path):
|
| 11 |
+
return os.path.basename(path).split(".")[0]
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def load_pdf(pdf_path, max_pages=None, start_page=None):
|
| 15 |
+
doc = open_pdf(pdf_path)
|
| 16 |
+
last_page = len(doc)
|
| 17 |
+
|
| 18 |
+
if start_page:
|
| 19 |
+
assert start_page < last_page and start_page >= 0, f"Start page must be between 0 and {last_page}"
|
| 20 |
+
else:
|
| 21 |
+
start_page = 0
|
| 22 |
+
|
| 23 |
+
if max_pages:
|
| 24 |
+
assert max_pages >= 0, f"Max pages must be greater than 0"
|
| 25 |
+
last_page = min(start_page + max_pages, last_page)
|
| 26 |
+
|
| 27 |
+
page_indices = list(range(start_page, last_page))
|
| 28 |
+
images = get_page_images(doc, page_indices)
|
| 29 |
+
doc.close()
|
| 30 |
+
names = [get_name_from_path(pdf_path) for _ in page_indices]
|
| 31 |
+
return images, names
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def load_image(image_path):
|
| 35 |
+
image = Image.open(image_path).convert("RGB")
|
| 36 |
+
name = get_name_from_path(image_path)
|
| 37 |
+
return [image], [name]
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def load_from_file(input_path, max_pages=None, start_page=None):
|
| 41 |
+
input_type = filetype.guess(input_path)
|
| 42 |
+
if input_type.extension == "pdf":
|
| 43 |
+
return load_pdf(input_path, max_pages, start_page)
|
| 44 |
+
else:
|
| 45 |
+
return load_image(input_path)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def load_from_folder(folder_path, max_pages=None, start_page=None):
|
| 49 |
+
image_paths = [os.path.join(folder_path, image_name) for image_name in os.listdir(folder_path) if not image_name.startswith(".")]
|
| 50 |
+
image_paths = [ip for ip in image_paths if not os.path.isdir(ip)]
|
| 51 |
+
|
| 52 |
+
images = []
|
| 53 |
+
names = []
|
| 54 |
+
for path in image_paths:
|
| 55 |
+
extension = filetype.guess(path)
|
| 56 |
+
if extension and extension.extension == "pdf":
|
| 57 |
+
image, name = load_pdf(path, max_pages, start_page)
|
| 58 |
+
images.extend(image)
|
| 59 |
+
names.extend(name)
|
| 60 |
+
else:
|
| 61 |
+
try:
|
| 62 |
+
image, name = load_image(path)
|
| 63 |
+
images.extend(image)
|
| 64 |
+
names.extend(name)
|
| 65 |
+
except PIL.UnidentifiedImageError:
|
| 66 |
+
print(f"Could not load image {path}")
|
| 67 |
+
continue
|
| 68 |
+
return images, names
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def load_lang_file(lang_path, names):
|
| 72 |
+
with open(lang_path, "r") as f:
|
| 73 |
+
lang_dict = json.load(f)
|
| 74 |
+
return [lang_dict[name].copy() for name in names]
|
surya/input/processing.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
import cv2
|
| 4 |
+
import numpy as np
|
| 5 |
+
import math
|
| 6 |
+
import pypdfium2
|
| 7 |
+
from PIL import Image, ImageOps, ImageDraw
|
| 8 |
+
import torch
|
| 9 |
+
from surya.settings import settings
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def convert_if_not_rgb(images: List[Image.Image]) -> List[Image.Image]:
|
| 13 |
+
new_images = []
|
| 14 |
+
for image in images:
|
| 15 |
+
if image.mode != "RGB":
|
| 16 |
+
image = image.convert("RGB")
|
| 17 |
+
new_images.append(image)
|
| 18 |
+
return new_images
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def get_total_splits(image_size, processor):
|
| 22 |
+
img_height = list(image_size)[1]
|
| 23 |
+
max_height = settings.DETECTOR_IMAGE_CHUNK_HEIGHT
|
| 24 |
+
processor_height = processor.size["height"]
|
| 25 |
+
if img_height > max_height:
|
| 26 |
+
num_splits = math.ceil(img_height / processor_height)
|
| 27 |
+
return num_splits
|
| 28 |
+
return 1
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def split_image(img, processor):
|
| 32 |
+
# This will not modify/return the original image - it will either crop, or copy the image
|
| 33 |
+
img_height = list(img.size)[1]
|
| 34 |
+
max_height = settings.DETECTOR_IMAGE_CHUNK_HEIGHT
|
| 35 |
+
processor_height = processor.size["height"]
|
| 36 |
+
if img_height > max_height:
|
| 37 |
+
num_splits = math.ceil(img_height / processor_height)
|
| 38 |
+
splits = []
|
| 39 |
+
split_heights = []
|
| 40 |
+
for i in range(num_splits):
|
| 41 |
+
top = i * processor_height
|
| 42 |
+
bottom = (i + 1) * processor_height
|
| 43 |
+
if bottom > img_height:
|
| 44 |
+
bottom = img_height
|
| 45 |
+
cropped = img.crop((0, top, img.size[0], bottom))
|
| 46 |
+
height = bottom - top
|
| 47 |
+
if height < processor_height:
|
| 48 |
+
cropped = ImageOps.pad(cropped, (img.size[0], processor_height), color=255, centering=(0, 0))
|
| 49 |
+
splits.append(cropped)
|
| 50 |
+
split_heights.append(height)
|
| 51 |
+
return splits, split_heights
|
| 52 |
+
return [img.copy()], [img_height]
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def prepare_image_detection(img, processor):
|
| 56 |
+
new_size = (processor.size["width"], processor.size["height"])
|
| 57 |
+
|
| 58 |
+
# This double resize actually necessary for downstream accuracy
|
| 59 |
+
img.thumbnail(new_size, Image.Resampling.LANCZOS)
|
| 60 |
+
img = img.resize(new_size, Image.Resampling.LANCZOS) # Stretch smaller dimension to fit new size
|
| 61 |
+
|
| 62 |
+
img = np.asarray(img, dtype=np.uint8)
|
| 63 |
+
img = processor(img)["pixel_values"][0]
|
| 64 |
+
img = torch.from_numpy(img)
|
| 65 |
+
return img
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def open_pdf(pdf_filepath):
|
| 69 |
+
return pypdfium2.PdfDocument(pdf_filepath)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def get_page_images(doc, indices: List, dpi=settings.IMAGE_DPI):
|
| 73 |
+
renderer = doc.render(
|
| 74 |
+
pypdfium2.PdfBitmap.to_pil,
|
| 75 |
+
page_indices=indices,
|
| 76 |
+
scale=dpi / 72,
|
| 77 |
+
)
|
| 78 |
+
images = list(renderer)
|
| 79 |
+
images = [image.convert("RGB") for image in images]
|
| 80 |
+
return images
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def slice_bboxes_from_image(image: Image.Image, bboxes):
|
| 84 |
+
lines = []
|
| 85 |
+
for bbox in bboxes:
|
| 86 |
+
line = image.crop((bbox[0], bbox[1], bbox[2], bbox[3]))
|
| 87 |
+
lines.append(line)
|
| 88 |
+
return lines
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def slice_polys_from_image(image: Image.Image, polys):
|
| 92 |
+
image_array = np.array(image, dtype=np.uint8)
|
| 93 |
+
lines = []
|
| 94 |
+
for idx, poly in enumerate(polys):
|
| 95 |
+
lines.append(slice_and_pad_poly(image_array, poly))
|
| 96 |
+
return lines
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def slice_and_pad_poly(image_array: np.array, coordinates):
|
| 100 |
+
# Draw polygon onto mask
|
| 101 |
+
coordinates = [(corner[0], corner[1]) for corner in coordinates]
|
| 102 |
+
bbox = [min([x[0] for x in coordinates]), min([x[1] for x in coordinates]), max([x[0] for x in coordinates]), max([x[1] for x in coordinates])]
|
| 103 |
+
|
| 104 |
+
# We mask out anything not in the polygon
|
| 105 |
+
cropped_polygon = image_array[bbox[1]:bbox[3], bbox[0]:bbox[2]].copy()
|
| 106 |
+
coordinates = [(x - bbox[0], y - bbox[1]) for x, y in coordinates]
|
| 107 |
+
|
| 108 |
+
# Pad the area outside the polygon with the pad value
|
| 109 |
+
mask = np.zeros(cropped_polygon.shape[:2], dtype=np.uint8)
|
| 110 |
+
cv2.fillPoly(mask, [np.int32(coordinates)], 1)
|
| 111 |
+
mask = np.stack([mask] * 3, axis=-1)
|
| 112 |
+
|
| 113 |
+
cropped_polygon[mask == 0] = settings.RECOGNITION_PAD_VALUE
|
| 114 |
+
rectangle_image = Image.fromarray(cropped_polygon)
|
| 115 |
+
|
| 116 |
+
return rectangle_image
|
surya/languages.py
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
CODE_TO_LANGUAGE = {
|
| 2 |
+
'af': 'Afrikaans',
|
| 3 |
+
'am': 'Amharic',
|
| 4 |
+
'ar': 'Arabic',
|
| 5 |
+
'as': 'Assamese',
|
| 6 |
+
'az': 'Azerbaijani',
|
| 7 |
+
'be': 'Belarusian',
|
| 8 |
+
'bg': 'Bulgarian',
|
| 9 |
+
'bn': 'Bengali',
|
| 10 |
+
'br': 'Breton',
|
| 11 |
+
'bs': 'Bosnian',
|
| 12 |
+
'ca': 'Catalan',
|
| 13 |
+
'cs': 'Czech',
|
| 14 |
+
'cy': 'Welsh',
|
| 15 |
+
'da': 'Danish',
|
| 16 |
+
'de': 'German',
|
| 17 |
+
'el': 'Greek',
|
| 18 |
+
'en': 'English',
|
| 19 |
+
'eo': 'Esperanto',
|
| 20 |
+
'es': 'Spanish',
|
| 21 |
+
'et': 'Estonian',
|
| 22 |
+
'eu': 'Basque',
|
| 23 |
+
'fa': 'Persian',
|
| 24 |
+
'fi': 'Finnish',
|
| 25 |
+
'fr': 'French',
|
| 26 |
+
'fy': 'Western Frisian',
|
| 27 |
+
'ga': 'Irish',
|
| 28 |
+
'gd': 'Scottish Gaelic',
|
| 29 |
+
'gl': 'Galician',
|
| 30 |
+
'gu': 'Gujarati',
|
| 31 |
+
'ha': 'Hausa',
|
| 32 |
+
'he': 'Hebrew',
|
| 33 |
+
'hi': 'Hindi',
|
| 34 |
+
'hr': 'Croatian',
|
| 35 |
+
'hu': 'Hungarian',
|
| 36 |
+
'hy': 'Armenian',
|
| 37 |
+
'id': 'Indonesian',
|
| 38 |
+
'is': 'Icelandic',
|
| 39 |
+
'it': 'Italian',
|
| 40 |
+
'ja': 'Japanese',
|
| 41 |
+
'jv': 'Javanese',
|
| 42 |
+
'ka': 'Georgian',
|
| 43 |
+
'kk': 'Kazakh',
|
| 44 |
+
'km': 'Khmer',
|
| 45 |
+
'kn': 'Kannada',
|
| 46 |
+
'ko': 'Korean',
|
| 47 |
+
'ku': 'Kurdish',
|
| 48 |
+
'ky': 'Kyrgyz',
|
| 49 |
+
'la': 'Latin',
|
| 50 |
+
'lo': 'Lao',
|
| 51 |
+
'lt': 'Lithuanian',
|
| 52 |
+
'lv': 'Latvian',
|
| 53 |
+
'mg': 'Malagasy',
|
| 54 |
+
'mk': 'Macedonian',
|
| 55 |
+
'ml': 'Malayalam',
|
| 56 |
+
'mn': 'Mongolian',
|
| 57 |
+
'mr': 'Marathi',
|
| 58 |
+
'ms': 'Malay',
|
| 59 |
+
'my': 'Burmese',
|
| 60 |
+
'ne': 'Nepali',
|
| 61 |
+
'nl': 'Dutch',
|
| 62 |
+
'no': 'Norwegian',
|
| 63 |
+
'om': 'Oromo',
|
| 64 |
+
'or': 'Oriya',
|
| 65 |
+
'pa': 'Punjabi',
|
| 66 |
+
'pl': 'Polish',
|
| 67 |
+
'ps': 'Pashto',
|
| 68 |
+
'pt': 'Portuguese',
|
| 69 |
+
'ro': 'Romanian',
|
| 70 |
+
'ru': 'Russian',
|
| 71 |
+
'sa': 'Sanskrit',
|
| 72 |
+
'sd': 'Sindhi',
|
| 73 |
+
'si': 'Sinhala',
|
| 74 |
+
'sk': 'Slovak',
|
| 75 |
+
'sl': 'Slovenian',
|
| 76 |
+
'so': 'Somali',
|
| 77 |
+
'sq': 'Albanian',
|
| 78 |
+
'sr': 'Serbian',
|
| 79 |
+
'su': 'Sundanese',
|
| 80 |
+
'sv': 'Swedish',
|
| 81 |
+
'sw': 'Swahili',
|
| 82 |
+
'ta': 'Tamil',
|
| 83 |
+
'te': 'Telugu',
|
| 84 |
+
'th': 'Thai',
|
| 85 |
+
'tl': 'Tagalog',
|
| 86 |
+
'tr': 'Turkish',
|
| 87 |
+
'ug': 'Uyghur',
|
| 88 |
+
'uk': 'Ukrainian',
|
| 89 |
+
'ur': 'Urdu',
|
| 90 |
+
'uz': 'Uzbek',
|
| 91 |
+
'vi': 'Vietnamese',
|
| 92 |
+
'xh': 'Xhosa',
|
| 93 |
+
'yi': 'Yiddish',
|
| 94 |
+
'zh': 'Chinese',
|
| 95 |
+
}
|
| 96 |
+
|
| 97 |
+
LANGUAGE_TO_CODE = {v: k for k, v in CODE_TO_LANGUAGE.items()}
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def is_arabic(lang_code):
|
| 101 |
+
return lang_code in ["ar", "fa", "ps", "ug", "ur"]
|
surya/layout.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import defaultdict
|
| 2 |
+
from concurrent.futures import ProcessPoolExecutor
|
| 3 |
+
from typing import List, Optional
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
from surya.detection import batch_detection
|
| 8 |
+
from surya.postprocessing.heatmap import keep_largest_boxes, get_and_clean_boxes, get_detected_boxes
|
| 9 |
+
from surya.schema import LayoutResult, LayoutBox, TextDetectionResult
|
| 10 |
+
from surya.settings import settings
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def get_regions_from_detection_result(detection_result: TextDetectionResult, heatmaps: List[np.ndarray], orig_size, id2label, segment_assignment, vertical_line_width=20) -> List[LayoutBox]:
|
| 14 |
+
logits = np.stack(heatmaps, axis=0)
|
| 15 |
+
vertical_line_bboxes = [line for line in detection_result.vertical_lines]
|
| 16 |
+
line_bboxes = detection_result.bboxes
|
| 17 |
+
|
| 18 |
+
# Scale back to processor size
|
| 19 |
+
for line in vertical_line_bboxes:
|
| 20 |
+
line.rescale_bbox(orig_size, list(reversed(heatmaps[0].shape)))
|
| 21 |
+
|
| 22 |
+
for line in line_bboxes:
|
| 23 |
+
line.rescale(orig_size, list(reversed(heatmaps[0].shape)))
|
| 24 |
+
|
| 25 |
+
for bbox in vertical_line_bboxes:
|
| 26 |
+
# Give some width to the vertical lines
|
| 27 |
+
vert_bbox = list(bbox.bbox)
|
| 28 |
+
vert_bbox[2] = min(heatmaps[0].shape[0], vert_bbox[2] + vertical_line_width)
|
| 29 |
+
|
| 30 |
+
logits[:, vert_bbox[1]:vert_bbox[3], vert_bbox[0]:vert_bbox[2]] = 0 # zero out where the column lines are
|
| 31 |
+
|
| 32 |
+
logits[:, logits[0] >= .5] = 0 # zero out where blanks are
|
| 33 |
+
|
| 34 |
+
# Zero out where other segments are
|
| 35 |
+
for i in range(logits.shape[0]):
|
| 36 |
+
logits[i, segment_assignment != i] = 0
|
| 37 |
+
|
| 38 |
+
detected_boxes = []
|
| 39 |
+
for heatmap_idx in range(1, len(id2label)): # Skip the blank class
|
| 40 |
+
heatmap = logits[heatmap_idx]
|
| 41 |
+
bboxes = get_detected_boxes(heatmap)
|
| 42 |
+
bboxes = [bbox for bbox in bboxes if bbox.area > 25]
|
| 43 |
+
for bb in bboxes:
|
| 44 |
+
bb.fit_to_bounds([0, 0, heatmap.shape[1] - 1, heatmap.shape[0] - 1])
|
| 45 |
+
|
| 46 |
+
for bbox in bboxes:
|
| 47 |
+
detected_boxes.append(LayoutBox(polygon=bbox.polygon, label=id2label[heatmap_idx], confidence=1))
|
| 48 |
+
|
| 49 |
+
detected_boxes = sorted(detected_boxes, key=lambda x: x.confidence, reverse=True)
|
| 50 |
+
# Expand bbox to cover intersecting lines
|
| 51 |
+
box_lines = defaultdict(list)
|
| 52 |
+
used_lines = set()
|
| 53 |
+
|
| 54 |
+
# We try 2 rounds of identifying the correct lines to snap to
|
| 55 |
+
# First round is majority intersection, second lowers the threshold
|
| 56 |
+
for thresh in [.5, .4]:
|
| 57 |
+
for bbox_idx, bbox in enumerate(detected_boxes):
|
| 58 |
+
for line_idx, line_bbox in enumerate(line_bboxes):
|
| 59 |
+
if line_bbox.intersection_pct(bbox) > thresh and line_idx not in used_lines:
|
| 60 |
+
box_lines[bbox_idx].append(line_bbox.bbox)
|
| 61 |
+
used_lines.add(line_idx)
|
| 62 |
+
|
| 63 |
+
new_boxes = []
|
| 64 |
+
for bbox_idx, bbox in enumerate(detected_boxes):
|
| 65 |
+
if bbox.label == "Picture" and bbox.area < 200: # Remove very small figures
|
| 66 |
+
continue
|
| 67 |
+
|
| 68 |
+
# Skip if we didn't find any lines to snap to, except for Pictures and Formulas
|
| 69 |
+
if bbox_idx not in box_lines and bbox.label not in ["Picture", "Formula"]:
|
| 70 |
+
continue
|
| 71 |
+
|
| 72 |
+
covered_lines = box_lines[bbox_idx]
|
| 73 |
+
# Snap non-picture layout boxes to correct text boundaries
|
| 74 |
+
if len(covered_lines) > 0 and bbox.label not in ["Picture"]:
|
| 75 |
+
min_x = min([line[0] for line in covered_lines])
|
| 76 |
+
min_y = min([line[1] for line in covered_lines])
|
| 77 |
+
max_x = max([line[2] for line in covered_lines])
|
| 78 |
+
max_y = max([line[3] for line in covered_lines])
|
| 79 |
+
|
| 80 |
+
# Tables and formulas can contain text, but text isn't the whole area
|
| 81 |
+
if bbox.label in ["Table", "Formula"]:
|
| 82 |
+
min_x_box = min([b[0] for b in bbox.polygon])
|
| 83 |
+
min_y_box = min([b[1] for b in bbox.polygon])
|
| 84 |
+
max_x_box = max([b[0] for b in bbox.polygon])
|
| 85 |
+
max_y_box = max([b[1] for b in bbox.polygon])
|
| 86 |
+
|
| 87 |
+
min_x = min(min_x, min_x_box)
|
| 88 |
+
min_y = min(min_y, min_y_box)
|
| 89 |
+
max_x = max(max_x, max_x_box)
|
| 90 |
+
max_y = max(max_y, max_y_box)
|
| 91 |
+
|
| 92 |
+
bbox.polygon[0][0] = min_x
|
| 93 |
+
bbox.polygon[0][1] = min_y
|
| 94 |
+
bbox.polygon[1][0] = max_x
|
| 95 |
+
bbox.polygon[1][1] = min_y
|
| 96 |
+
bbox.polygon[2][0] = max_x
|
| 97 |
+
bbox.polygon[2][1] = max_y
|
| 98 |
+
bbox.polygon[3][0] = min_x
|
| 99 |
+
bbox.polygon[3][1] = max_y
|
| 100 |
+
|
| 101 |
+
if bbox_idx in box_lines and bbox.label in ["Picture"]:
|
| 102 |
+
bbox.label = "Figure"
|
| 103 |
+
|
| 104 |
+
new_boxes.append(bbox)
|
| 105 |
+
|
| 106 |
+
# Merge tables together (sometimes one column is detected as a separate table)
|
| 107 |
+
for i in range(5): # Up to 5 rounds of merging
|
| 108 |
+
to_remove = set()
|
| 109 |
+
for bbox_idx, bbox in enumerate(new_boxes):
|
| 110 |
+
if bbox.label != "Table" or bbox_idx in to_remove:
|
| 111 |
+
continue
|
| 112 |
+
|
| 113 |
+
for bbox_idx2, bbox2 in enumerate(new_boxes):
|
| 114 |
+
if bbox2.label != "Table" or bbox_idx2 in to_remove or bbox_idx == bbox_idx2:
|
| 115 |
+
continue
|
| 116 |
+
|
| 117 |
+
if bbox.intersection_pct(bbox2) > 0:
|
| 118 |
+
bbox.merge(bbox2)
|
| 119 |
+
to_remove.add(bbox_idx2)
|
| 120 |
+
|
| 121 |
+
new_boxes = [bbox for idx, bbox in enumerate(new_boxes) if idx not in to_remove]
|
| 122 |
+
|
| 123 |
+
# Ensure we account for all text lines in the layout
|
| 124 |
+
unused_lines = [line for idx, line in enumerate(line_bboxes) if idx not in used_lines]
|
| 125 |
+
for bbox in unused_lines:
|
| 126 |
+
new_boxes.append(LayoutBox(polygon=bbox.polygon, label="Text", confidence=.5))
|
| 127 |
+
|
| 128 |
+
for bbox in new_boxes:
|
| 129 |
+
bbox.rescale(list(reversed(heatmaps[0].shape)), orig_size)
|
| 130 |
+
|
| 131 |
+
detected_boxes = [bbox for bbox in new_boxes if bbox.area > 16]
|
| 132 |
+
|
| 133 |
+
# Remove bboxes contained inside others, unless they're captions
|
| 134 |
+
contained_bbox = []
|
| 135 |
+
for i, bbox in enumerate(detected_boxes):
|
| 136 |
+
for j, bbox2 in enumerate(detected_boxes):
|
| 137 |
+
if i == j:
|
| 138 |
+
continue
|
| 139 |
+
|
| 140 |
+
if bbox2.intersection_pct(bbox) >= .95 and bbox2.label not in ["Caption"]:
|
| 141 |
+
contained_bbox.append(j)
|
| 142 |
+
|
| 143 |
+
detected_boxes = [bbox for idx, bbox in enumerate(detected_boxes) if idx not in contained_bbox]
|
| 144 |
+
|
| 145 |
+
return detected_boxes
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def get_regions(heatmaps: List[np.ndarray], orig_size, id2label, segment_assignment) -> List[LayoutBox]:
|
| 149 |
+
bboxes = []
|
| 150 |
+
for i in range(1, len(id2label)): # Skip the blank class
|
| 151 |
+
heatmap = heatmaps[i]
|
| 152 |
+
assert heatmap.shape == segment_assignment.shape
|
| 153 |
+
heatmap[segment_assignment != i] = 0 # zero out where another segment is
|
| 154 |
+
bbox = get_and_clean_boxes(heatmap, list(reversed(heatmap.shape)), orig_size)
|
| 155 |
+
for bb in bbox:
|
| 156 |
+
bboxes.append(LayoutBox(polygon=bb.polygon, label=id2label[i]))
|
| 157 |
+
heatmaps.append(heatmap)
|
| 158 |
+
|
| 159 |
+
bboxes = keep_largest_boxes(bboxes)
|
| 160 |
+
return bboxes
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def parallel_get_regions(heatmaps: List[np.ndarray], orig_size, id2label, detection_results=None) -> LayoutResult:
|
| 164 |
+
logits = np.stack(heatmaps, axis=0)
|
| 165 |
+
segment_assignment = logits.argmax(axis=0)
|
| 166 |
+
if detection_results is not None:
|
| 167 |
+
bboxes = get_regions_from_detection_result(detection_results, heatmaps, orig_size, id2label,
|
| 168 |
+
segment_assignment)
|
| 169 |
+
else:
|
| 170 |
+
bboxes = get_regions(heatmaps, orig_size, id2label, segment_assignment)
|
| 171 |
+
|
| 172 |
+
segmentation_img = Image.fromarray(segment_assignment.astype(np.uint8))
|
| 173 |
+
|
| 174 |
+
result = LayoutResult(
|
| 175 |
+
bboxes=bboxes,
|
| 176 |
+
segmentation_map=segmentation_img,
|
| 177 |
+
heatmaps=heatmaps,
|
| 178 |
+
image_bbox=[0, 0, orig_size[0], orig_size[1]]
|
| 179 |
+
)
|
| 180 |
+
|
| 181 |
+
return result
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
def batch_layout_detection(images: List, model, processor, detection_results: Optional[List[TextDetectionResult]] = None, batch_size=None) -> List[LayoutResult]:
|
| 185 |
+
preds, orig_sizes = batch_detection(images, model, processor, batch_size=batch_size)
|
| 186 |
+
id2label = model.config.id2label
|
| 187 |
+
|
| 188 |
+
results = []
|
| 189 |
+
if settings.IN_STREAMLIT or len(images) < settings.DETECTOR_MIN_PARALLEL_THRESH: # Ensures we don't parallelize with streamlit or too few images
|
| 190 |
+
for i in range(len(images)):
|
| 191 |
+
result = parallel_get_regions(preds[i], orig_sizes[i], id2label, detection_results[i] if detection_results else None)
|
| 192 |
+
results.append(result)
|
| 193 |
+
else:
|
| 194 |
+
futures = []
|
| 195 |
+
max_workers = min(settings.DETECTOR_POSTPROCESSING_CPU_WORKERS, len(images))
|
| 196 |
+
with ProcessPoolExecutor(max_workers=max_workers) as executor:
|
| 197 |
+
for i in range(len(images)):
|
| 198 |
+
future = executor.submit(parallel_get_regions, preds[i], orig_sizes[i], id2label, detection_results[i] if detection_results else None)
|
| 199 |
+
futures.append(future)
|
| 200 |
+
|
| 201 |
+
for future in futures:
|
| 202 |
+
results.append(future.result())
|
| 203 |
+
|
| 204 |
+
return results
|
surya/model/detection/__pycache__/processor.cpython-310.pyc
ADDED
|
Binary file (11.6 kB). View file
|
|
|
surya/model/detection/__pycache__/segformer.cpython-310.pyc
ADDED
|
Binary file (14.5 kB). View file
|
|
|
surya/model/detection/processor.py
ADDED
|
@@ -0,0 +1,284 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
from typing import Any, Dict, List, Optional, Union
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
from transformers.image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
|
| 7 |
+
from transformers.image_transforms import to_channel_dimension_format
|
| 8 |
+
from transformers.image_utils import (
|
| 9 |
+
IMAGENET_DEFAULT_MEAN,
|
| 10 |
+
IMAGENET_DEFAULT_STD,
|
| 11 |
+
ChannelDimension,
|
| 12 |
+
ImageInput,
|
| 13 |
+
PILImageResampling,
|
| 14 |
+
infer_channel_dimension_format,
|
| 15 |
+
make_list_of_images,
|
| 16 |
+
)
|
| 17 |
+
from transformers.utils import TensorType
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
import PIL.Image
|
| 21 |
+
import torch
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class SegformerImageProcessor(BaseImageProcessor):
|
| 25 |
+
r"""
|
| 26 |
+
Constructs a Segformer image processor.
|
| 27 |
+
|
| 28 |
+
Args:
|
| 29 |
+
do_resize (`bool`, *optional*, defaults to `True`):
|
| 30 |
+
Whether to resize the image's (height, width) dimensions to the specified `(size["height"],
|
| 31 |
+
size["width"])`. Can be overridden by the `do_resize` parameter in the `preprocess` method.
|
| 32 |
+
size (`Dict[str, int]` *optional*, defaults to `{"height": 512, "width": 512}`):
|
| 33 |
+
Size of the output image after resizing. Can be overridden by the `size` parameter in the `preprocess`
|
| 34 |
+
method.
|
| 35 |
+
resample (`PILImageResampling`, *optional*, defaults to `Resampling.BILINEAR`):
|
| 36 |
+
Resampling filter to use if resizing the image. Can be overridden by the `resample` parameter in the
|
| 37 |
+
`preprocess` method.
|
| 38 |
+
do_rescale (`bool`, *optional*, defaults to `True`):
|
| 39 |
+
Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the `do_rescale`
|
| 40 |
+
parameter in the `preprocess` method.
|
| 41 |
+
rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
|
| 42 |
+
Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
|
| 43 |
+
method.
|
| 44 |
+
do_normalize (`bool`, *optional*, defaults to `True`):
|
| 45 |
+
Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
|
| 46 |
+
method.
|
| 47 |
+
image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_MEAN`):
|
| 48 |
+
Mean to use if normalizing the image. This is a float or list of floats the length of the number of
|
| 49 |
+
channels in the image. Can be overridden by the `image_mean` parameter in the `preprocess` method.
|
| 50 |
+
image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_STD`):
|
| 51 |
+
Standard deviation to use if normalizing the image. This is a float or list of floats the length of the
|
| 52 |
+
number of channels in the image. Can be overridden by the `image_std` parameter in the `preprocess` method.
|
| 53 |
+
do_reduce_labels (`bool`, *optional*, defaults to `False`):
|
| 54 |
+
Whether or not to reduce all label values of segmentation maps by 1. Usually used for datasets where 0 is
|
| 55 |
+
used for background, and background itself is not included in all classes of a dataset (e.g. ADE20k). The
|
| 56 |
+
background label will be replaced by 255. Can be overridden by the `do_reduce_labels` parameter in the
|
| 57 |
+
`preprocess` method.
|
| 58 |
+
"""
|
| 59 |
+
|
| 60 |
+
model_input_names = ["pixel_values"]
|
| 61 |
+
|
| 62 |
+
def __init__(
|
| 63 |
+
self,
|
| 64 |
+
do_resize: bool = True,
|
| 65 |
+
size: Dict[str, int] = None,
|
| 66 |
+
resample: PILImageResampling = PILImageResampling.BILINEAR,
|
| 67 |
+
do_rescale: bool = True,
|
| 68 |
+
rescale_factor: Union[int, float] = 1 / 255,
|
| 69 |
+
do_normalize: bool = True,
|
| 70 |
+
image_mean: Optional[Union[float, List[float]]] = None,
|
| 71 |
+
image_std: Optional[Union[float, List[float]]] = None,
|
| 72 |
+
do_reduce_labels: bool = False,
|
| 73 |
+
**kwargs,
|
| 74 |
+
) -> None:
|
| 75 |
+
if "reduce_labels" in kwargs:
|
| 76 |
+
warnings.warn(
|
| 77 |
+
"The `reduce_labels` parameter is deprecated and will be removed in a future version. Please use "
|
| 78 |
+
"`do_reduce_labels` instead.",
|
| 79 |
+
FutureWarning,
|
| 80 |
+
)
|
| 81 |
+
do_reduce_labels = kwargs.pop("reduce_labels")
|
| 82 |
+
|
| 83 |
+
super().__init__(**kwargs)
|
| 84 |
+
size = size if size is not None else {"height": 512, "width": 512}
|
| 85 |
+
size = get_size_dict(size)
|
| 86 |
+
self.do_resize = do_resize
|
| 87 |
+
self.size = size
|
| 88 |
+
self.resample = resample
|
| 89 |
+
self.do_rescale = do_rescale
|
| 90 |
+
self.rescale_factor = rescale_factor
|
| 91 |
+
self.do_normalize = do_normalize
|
| 92 |
+
self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
|
| 93 |
+
self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
|
| 94 |
+
self.do_reduce_labels = do_reduce_labels
|
| 95 |
+
self._valid_processor_keys = [
|
| 96 |
+
"images",
|
| 97 |
+
"segmentation_maps",
|
| 98 |
+
"do_resize",
|
| 99 |
+
"size",
|
| 100 |
+
"resample",
|
| 101 |
+
"do_rescale",
|
| 102 |
+
"rescale_factor",
|
| 103 |
+
"do_normalize",
|
| 104 |
+
"image_mean",
|
| 105 |
+
"image_std",
|
| 106 |
+
"do_reduce_labels",
|
| 107 |
+
"return_tensors",
|
| 108 |
+
"data_format",
|
| 109 |
+
"input_data_format",
|
| 110 |
+
]
|
| 111 |
+
|
| 112 |
+
@classmethod
|
| 113 |
+
def from_dict(cls, image_processor_dict: Dict[str, Any], **kwargs):
|
| 114 |
+
"""
|
| 115 |
+
Overrides the `from_dict` method from the base class to make sure `do_reduce_labels` is updated if image
|
| 116 |
+
processor is created using from_dict and kwargs e.g. `SegformerImageProcessor.from_pretrained(checkpoint,
|
| 117 |
+
reduce_labels=True)`
|
| 118 |
+
"""
|
| 119 |
+
image_processor_dict = image_processor_dict.copy()
|
| 120 |
+
if "reduce_labels" in kwargs:
|
| 121 |
+
image_processor_dict["reduce_labels"] = kwargs.pop("reduce_labels")
|
| 122 |
+
return super().from_dict(image_processor_dict, **kwargs)
|
| 123 |
+
|
| 124 |
+
def _preprocess(
|
| 125 |
+
self,
|
| 126 |
+
image: ImageInput,
|
| 127 |
+
do_resize: bool,
|
| 128 |
+
do_rescale: bool,
|
| 129 |
+
do_normalize: bool,
|
| 130 |
+
size: Optional[Dict[str, int]] = None,
|
| 131 |
+
resample: PILImageResampling = None,
|
| 132 |
+
rescale_factor: Optional[float] = None,
|
| 133 |
+
image_mean: Optional[Union[float, List[float]]] = None,
|
| 134 |
+
image_std: Optional[Union[float, List[float]]] = None,
|
| 135 |
+
input_data_format: Optional[Union[str, ChannelDimension]] = None,
|
| 136 |
+
):
|
| 137 |
+
|
| 138 |
+
if do_rescale:
|
| 139 |
+
image = self.rescale(image=image, scale=rescale_factor, input_data_format=input_data_format)
|
| 140 |
+
|
| 141 |
+
if do_normalize:
|
| 142 |
+
image = self.normalize(image=image, mean=image_mean, std=image_std, input_data_format=input_data_format)
|
| 143 |
+
|
| 144 |
+
return image
|
| 145 |
+
|
| 146 |
+
def _preprocess_image(
|
| 147 |
+
self,
|
| 148 |
+
image: ImageInput,
|
| 149 |
+
do_resize: bool = None,
|
| 150 |
+
size: Dict[str, int] = None,
|
| 151 |
+
resample: PILImageResampling = None,
|
| 152 |
+
do_rescale: bool = None,
|
| 153 |
+
rescale_factor: float = None,
|
| 154 |
+
do_normalize: bool = None,
|
| 155 |
+
image_mean: Optional[Union[float, List[float]]] = None,
|
| 156 |
+
image_std: Optional[Union[float, List[float]]] = None,
|
| 157 |
+
data_format: Optional[Union[str, ChannelDimension]] = None,
|
| 158 |
+
input_data_format: Optional[Union[str, ChannelDimension]] = None,
|
| 159 |
+
) -> np.ndarray:
|
| 160 |
+
"""Preprocesses a single image."""
|
| 161 |
+
# All transformations expect numpy arrays.
|
| 162 |
+
if input_data_format is None:
|
| 163 |
+
input_data_format = infer_channel_dimension_format(image)
|
| 164 |
+
|
| 165 |
+
image = self._preprocess(
|
| 166 |
+
image=image,
|
| 167 |
+
do_resize=do_resize,
|
| 168 |
+
size=size,
|
| 169 |
+
resample=resample,
|
| 170 |
+
do_rescale=do_rescale,
|
| 171 |
+
rescale_factor=rescale_factor,
|
| 172 |
+
do_normalize=do_normalize,
|
| 173 |
+
image_mean=image_mean,
|
| 174 |
+
image_std=image_std,
|
| 175 |
+
input_data_format=input_data_format,
|
| 176 |
+
)
|
| 177 |
+
if data_format is not None:
|
| 178 |
+
image = to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format)
|
| 179 |
+
return image
|
| 180 |
+
|
| 181 |
+
def __call__(self, images, segmentation_maps=None, **kwargs):
|
| 182 |
+
"""
|
| 183 |
+
Preprocesses a batch of images and optionally segmentation maps.
|
| 184 |
+
|
| 185 |
+
Overrides the `__call__` method of the `Preprocessor` class so that both images and segmentation maps can be
|
| 186 |
+
passed in as positional arguments.
|
| 187 |
+
"""
|
| 188 |
+
return super().__call__(images, segmentation_maps=segmentation_maps, **kwargs)
|
| 189 |
+
|
| 190 |
+
def preprocess(
|
| 191 |
+
self,
|
| 192 |
+
images: ImageInput,
|
| 193 |
+
segmentation_maps: Optional[ImageInput] = None,
|
| 194 |
+
do_resize: Optional[bool] = None,
|
| 195 |
+
size: Optional[Dict[str, int]] = None,
|
| 196 |
+
resample: PILImageResampling = None,
|
| 197 |
+
do_rescale: Optional[bool] = None,
|
| 198 |
+
rescale_factor: Optional[float] = None,
|
| 199 |
+
do_normalize: Optional[bool] = None,
|
| 200 |
+
image_mean: Optional[Union[float, List[float]]] = None,
|
| 201 |
+
image_std: Optional[Union[float, List[float]]] = None,
|
| 202 |
+
do_reduce_labels: Optional[bool] = None,
|
| 203 |
+
return_tensors: Optional[Union[str, TensorType]] = None,
|
| 204 |
+
data_format: ChannelDimension = ChannelDimension.FIRST,
|
| 205 |
+
input_data_format: Optional[Union[str, ChannelDimension]] = None,
|
| 206 |
+
**kwargs,
|
| 207 |
+
) -> PIL.Image.Image:
|
| 208 |
+
"""
|
| 209 |
+
Preprocess an image or batch of images.
|
| 210 |
+
|
| 211 |
+
Args:
|
| 212 |
+
images (`ImageInput`):
|
| 213 |
+
Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
|
| 214 |
+
passing in images with pixel values between 0 and 1, set `do_rescale=False`.
|
| 215 |
+
segmentation_maps (`ImageInput`, *optional*):
|
| 216 |
+
Segmentation map to preprocess.
|
| 217 |
+
do_resize (`bool`, *optional*, defaults to `self.do_resize`):
|
| 218 |
+
Whether to resize the image.
|
| 219 |
+
size (`Dict[str, int]`, *optional*, defaults to `self.size`):
|
| 220 |
+
Size of the image after `resize` is applied.
|
| 221 |
+
resample (`int`, *optional*, defaults to `self.resample`):
|
| 222 |
+
Resampling filter to use if resizing the image. This can be one of the enum `PILImageResampling`, Only
|
| 223 |
+
has an effect if `do_resize` is set to `True`.
|
| 224 |
+
do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
|
| 225 |
+
Whether to rescale the image values between [0 - 1].
|
| 226 |
+
rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
|
| 227 |
+
Rescale factor to rescale the image by if `do_rescale` is set to `True`.
|
| 228 |
+
do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
|
| 229 |
+
Whether to normalize the image.
|
| 230 |
+
image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
|
| 231 |
+
Image mean.
|
| 232 |
+
image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
|
| 233 |
+
Image standard deviation.
|
| 234 |
+
do_reduce_labels (`bool`, *optional*, defaults to `self.do_reduce_labels`):
|
| 235 |
+
Whether or not to reduce all label values of segmentation maps by 1. Usually used for datasets where 0
|
| 236 |
+
is used for background, and background itself is not included in all classes of a dataset (e.g.
|
| 237 |
+
ADE20k). The background label will be replaced by 255.
|
| 238 |
+
return_tensors (`str` or `TensorType`, *optional*):
|
| 239 |
+
The type of tensors to return. Can be one of:
|
| 240 |
+
- Unset: Return a list of `np.ndarray`.
|
| 241 |
+
- `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
|
| 242 |
+
- `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
|
| 243 |
+
- `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
|
| 244 |
+
- `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
|
| 245 |
+
data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
|
| 246 |
+
The channel dimension format for the output image. Can be one of:
|
| 247 |
+
- `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
|
| 248 |
+
- `ChannelDimension.LAST`: image in (height, width, num_channels) format.
|
| 249 |
+
input_data_format (`ChannelDimension` or `str`, *optional*):
|
| 250 |
+
The channel dimension format for the input image. If unset, the channel dimension format is inferred
|
| 251 |
+
from the input image. Can be one of:
|
| 252 |
+
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
|
| 253 |
+
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
|
| 254 |
+
- `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
|
| 255 |
+
"""
|
| 256 |
+
do_resize = do_resize if do_resize is not None else self.do_resize
|
| 257 |
+
do_rescale = do_rescale if do_rescale is not None else self.do_rescale
|
| 258 |
+
do_normalize = do_normalize if do_normalize is not None else self.do_normalize
|
| 259 |
+
resample = resample if resample is not None else self.resample
|
| 260 |
+
size = size if size is not None else self.size
|
| 261 |
+
rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
|
| 262 |
+
image_mean = image_mean if image_mean is not None else self.image_mean
|
| 263 |
+
image_std = image_std if image_std is not None else self.image_std
|
| 264 |
+
|
| 265 |
+
images = make_list_of_images(images)
|
| 266 |
+
images = [
|
| 267 |
+
self._preprocess_image(
|
| 268 |
+
image=img,
|
| 269 |
+
do_resize=do_resize,
|
| 270 |
+
resample=resample,
|
| 271 |
+
size=size,
|
| 272 |
+
do_rescale=do_rescale,
|
| 273 |
+
rescale_factor=rescale_factor,
|
| 274 |
+
do_normalize=do_normalize,
|
| 275 |
+
image_mean=image_mean,
|
| 276 |
+
image_std=image_std,
|
| 277 |
+
data_format=data_format,
|
| 278 |
+
input_data_format=input_data_format,
|
| 279 |
+
)
|
| 280 |
+
for img in images
|
| 281 |
+
]
|
| 282 |
+
|
| 283 |
+
data = {"pixel_values": images}
|
| 284 |
+
return BatchFeature(data=data, tensor_type=return_tensors)
|
surya/model/detection/segformer.py
ADDED
|
@@ -0,0 +1,468 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gc
|
| 2 |
+
import warnings
|
| 3 |
+
|
| 4 |
+
from transformers.activations import ACT2FN
|
| 5 |
+
from transformers.pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
|
| 6 |
+
|
| 7 |
+
warnings.filterwarnings("ignore", message="torch.utils._pytree._register_pytree_node is deprecated")
|
| 8 |
+
|
| 9 |
+
import math
|
| 10 |
+
from typing import Optional, Tuple, Union
|
| 11 |
+
|
| 12 |
+
from transformers import SegformerConfig, SegformerForSemanticSegmentation, SegformerDecodeHead, \
|
| 13 |
+
SegformerPreTrainedModel
|
| 14 |
+
from surya.model.detection.processor import SegformerImageProcessor
|
| 15 |
+
import torch
|
| 16 |
+
from torch import nn
|
| 17 |
+
|
| 18 |
+
from transformers.modeling_outputs import SemanticSegmenterOutput, BaseModelOutput
|
| 19 |
+
from surya.settings import settings
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def load_model(checkpoint=settings.DETECTOR_MODEL_CHECKPOINT, device=settings.TORCH_DEVICE_DETECTION, dtype=settings.MODEL_DTYPE_DETECTION):
|
| 23 |
+
config = SegformerConfig.from_pretrained(checkpoint)
|
| 24 |
+
model = SegformerForRegressionMask.from_pretrained(checkpoint, torch_dtype=dtype, config=config)
|
| 25 |
+
if "mps" in device:
|
| 26 |
+
print("Warning: MPS may have poor results. This is a bug with MPS, see here - https://github.com/pytorch/pytorch/issues/84936")
|
| 27 |
+
model = model.to(device)
|
| 28 |
+
model = model.eval()
|
| 29 |
+
print(f"Loaded detection model {checkpoint} on device {device} with dtype {dtype}")
|
| 30 |
+
return model
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def load_processor(checkpoint=settings.DETECTOR_MODEL_CHECKPOINT):
|
| 34 |
+
processor = SegformerImageProcessor.from_pretrained(checkpoint)
|
| 35 |
+
return processor
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class SegformerForMaskMLP(nn.Module):
|
| 39 |
+
def __init__(self, config: SegformerConfig, input_dim, output_dim):
|
| 40 |
+
super().__init__()
|
| 41 |
+
self.proj = nn.Linear(input_dim, output_dim)
|
| 42 |
+
|
| 43 |
+
def forward(self, hidden_states: torch.Tensor):
|
| 44 |
+
hidden_states = hidden_states.flatten(2).transpose(1, 2)
|
| 45 |
+
hidden_states = self.proj(hidden_states)
|
| 46 |
+
return hidden_states
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class SegformerForMaskDecodeHead(SegformerDecodeHead):
|
| 50 |
+
def __init__(self, config):
|
| 51 |
+
super().__init__(config)
|
| 52 |
+
decoder_layer_hidden_size = getattr(config, "decoder_layer_hidden_size", config.decoder_hidden_size)
|
| 53 |
+
|
| 54 |
+
# linear layers which will unify the channel dimension of each of the encoder blocks to the same config.decoder_hidden_size
|
| 55 |
+
mlps = []
|
| 56 |
+
for i in range(config.num_encoder_blocks):
|
| 57 |
+
mlp = SegformerForMaskMLP(config, input_dim=config.hidden_sizes[i], output_dim=decoder_layer_hidden_size)
|
| 58 |
+
mlps.append(mlp)
|
| 59 |
+
self.linear_c = nn.ModuleList(mlps)
|
| 60 |
+
|
| 61 |
+
# the following 3 layers implement the ConvModule of the original implementation
|
| 62 |
+
self.linear_fuse = nn.Conv2d(
|
| 63 |
+
in_channels=decoder_layer_hidden_size * config.num_encoder_blocks,
|
| 64 |
+
out_channels=config.decoder_hidden_size,
|
| 65 |
+
kernel_size=1,
|
| 66 |
+
bias=False,
|
| 67 |
+
)
|
| 68 |
+
self.batch_norm = nn.BatchNorm2d(config.decoder_hidden_size)
|
| 69 |
+
self.activation = nn.ReLU()
|
| 70 |
+
|
| 71 |
+
self.classifier = nn.Conv2d(config.decoder_hidden_size, config.num_labels, kernel_size=1)
|
| 72 |
+
|
| 73 |
+
self.config = config
|
| 74 |
+
|
| 75 |
+
def forward(self, encoder_hidden_states: torch.FloatTensor) -> torch.Tensor:
|
| 76 |
+
batch_size = encoder_hidden_states[-1].shape[0]
|
| 77 |
+
|
| 78 |
+
all_hidden_states = ()
|
| 79 |
+
for encoder_hidden_state, mlp in zip(encoder_hidden_states, self.linear_c):
|
| 80 |
+
if self.config.reshape_last_stage is False and encoder_hidden_state.ndim == 3:
|
| 81 |
+
height = width = int(math.sqrt(encoder_hidden_state.shape[-1]))
|
| 82 |
+
encoder_hidden_state = (
|
| 83 |
+
encoder_hidden_state.reshape(batch_size, height, width, -1).permute(0, 3, 1, 2).contiguous()
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
# unify channel dimension
|
| 87 |
+
height, width = encoder_hidden_state.shape[2], encoder_hidden_state.shape[3]
|
| 88 |
+
encoder_hidden_state = mlp(encoder_hidden_state)
|
| 89 |
+
encoder_hidden_state = encoder_hidden_state.permute(0, 2, 1)
|
| 90 |
+
encoder_hidden_state = encoder_hidden_state.reshape(batch_size, -1, height, width)
|
| 91 |
+
# upsample
|
| 92 |
+
encoder_hidden_state = encoder_hidden_state.contiguous()
|
| 93 |
+
encoder_hidden_state = nn.functional.interpolate(
|
| 94 |
+
encoder_hidden_state, size=encoder_hidden_states[0].size()[2:], mode="bilinear", align_corners=False
|
| 95 |
+
)
|
| 96 |
+
all_hidden_states += (encoder_hidden_state,)
|
| 97 |
+
|
| 98 |
+
hidden_states = self.linear_fuse(torch.cat(all_hidden_states[::-1], dim=1))
|
| 99 |
+
hidden_states = self.batch_norm(hidden_states)
|
| 100 |
+
hidden_states = self.activation(hidden_states)
|
| 101 |
+
|
| 102 |
+
# logits are of shape (batch_size, num_labels, height/4, width/4)
|
| 103 |
+
logits = self.classifier(hidden_states)
|
| 104 |
+
|
| 105 |
+
return logits
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
class SegformerOverlapPatchEmbeddings(nn.Module):
|
| 109 |
+
"""Construct the overlapping patch embeddings."""
|
| 110 |
+
|
| 111 |
+
def __init__(self, patch_size, stride, num_channels, hidden_size):
|
| 112 |
+
super().__init__()
|
| 113 |
+
self.proj = nn.Conv2d(
|
| 114 |
+
num_channels,
|
| 115 |
+
hidden_size,
|
| 116 |
+
kernel_size=patch_size,
|
| 117 |
+
stride=stride,
|
| 118 |
+
padding=patch_size // 2,
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
self.layer_norm = nn.LayerNorm(hidden_size)
|
| 122 |
+
|
| 123 |
+
def forward(self, pixel_values):
|
| 124 |
+
embeddings = self.proj(pixel_values)
|
| 125 |
+
_, _, height, width = embeddings.shape
|
| 126 |
+
# (batch_size, num_channels, height, width) -> (batch_size, num_channels, height*width) -> (batch_size, height*width, num_channels)
|
| 127 |
+
# this can be fed to a Transformer layer
|
| 128 |
+
embeddings = embeddings.flatten(2).transpose(1, 2)
|
| 129 |
+
embeddings = self.layer_norm(embeddings)
|
| 130 |
+
return embeddings, height, width
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class SegformerEfficientSelfAttention(nn.Module):
|
| 134 |
+
"""SegFormer's efficient self-attention mechanism. Employs the sequence reduction process introduced in the [PvT
|
| 135 |
+
paper](https://arxiv.org/abs/2102.12122)."""
|
| 136 |
+
|
| 137 |
+
def __init__(self, config, hidden_size, num_attention_heads, sequence_reduction_ratio):
|
| 138 |
+
super().__init__()
|
| 139 |
+
self.hidden_size = hidden_size
|
| 140 |
+
self.num_attention_heads = num_attention_heads
|
| 141 |
+
|
| 142 |
+
if self.hidden_size % self.num_attention_heads != 0:
|
| 143 |
+
raise ValueError(
|
| 144 |
+
f"The hidden size ({self.hidden_size}) is not a multiple of the number of attention "
|
| 145 |
+
f"heads ({self.num_attention_heads})"
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
self.attention_head_size = int(self.hidden_size / self.num_attention_heads)
|
| 149 |
+
self.all_head_size = self.num_attention_heads * self.attention_head_size
|
| 150 |
+
|
| 151 |
+
self.query = nn.Linear(self.hidden_size, self.all_head_size)
|
| 152 |
+
self.key = nn.Linear(self.hidden_size, self.all_head_size)
|
| 153 |
+
self.value = nn.Linear(self.hidden_size, self.all_head_size)
|
| 154 |
+
|
| 155 |
+
self.sr_ratio = sequence_reduction_ratio
|
| 156 |
+
if sequence_reduction_ratio > 1:
|
| 157 |
+
self.sr = nn.Conv2d(
|
| 158 |
+
hidden_size, hidden_size, kernel_size=sequence_reduction_ratio, stride=sequence_reduction_ratio
|
| 159 |
+
)
|
| 160 |
+
self.layer_norm = nn.LayerNorm(hidden_size)
|
| 161 |
+
|
| 162 |
+
def transpose_for_scores(self, hidden_states):
|
| 163 |
+
new_shape = hidden_states.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
|
| 164 |
+
hidden_states = hidden_states.view(new_shape)
|
| 165 |
+
return hidden_states.permute(0, 2, 1, 3)
|
| 166 |
+
|
| 167 |
+
def forward(
|
| 168 |
+
self,
|
| 169 |
+
hidden_states,
|
| 170 |
+
height,
|
| 171 |
+
width,
|
| 172 |
+
output_attentions=False,
|
| 173 |
+
):
|
| 174 |
+
query_layer = self.transpose_for_scores(self.query(hidden_states))
|
| 175 |
+
|
| 176 |
+
if self.sr_ratio > 1:
|
| 177 |
+
batch_size, seq_len, num_channels = hidden_states.shape
|
| 178 |
+
# Reshape to (batch_size, num_channels, height, width)
|
| 179 |
+
hidden_states = hidden_states.permute(0, 2, 1).reshape(batch_size, num_channels, height, width)
|
| 180 |
+
# Apply sequence reduction
|
| 181 |
+
hidden_states = self.sr(hidden_states)
|
| 182 |
+
# Reshape back to (batch_size, seq_len, num_channels)
|
| 183 |
+
hidden_states = hidden_states.reshape(batch_size, num_channels, -1).permute(0, 2, 1)
|
| 184 |
+
hidden_states = self.layer_norm(hidden_states)
|
| 185 |
+
|
| 186 |
+
key_layer = self.transpose_for_scores(self.key(hidden_states))
|
| 187 |
+
value_layer = self.transpose_for_scores(self.value(hidden_states))
|
| 188 |
+
|
| 189 |
+
# Take the dot product between "query" and "key" to get the raw attention scores.
|
| 190 |
+
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
|
| 191 |
+
|
| 192 |
+
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
|
| 193 |
+
|
| 194 |
+
# Normalize the attention scores to probabilities.
|
| 195 |
+
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
|
| 196 |
+
|
| 197 |
+
context_layer = torch.matmul(attention_probs, value_layer)
|
| 198 |
+
|
| 199 |
+
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
|
| 200 |
+
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
|
| 201 |
+
context_layer = context_layer.view(new_context_layer_shape)
|
| 202 |
+
|
| 203 |
+
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
|
| 204 |
+
|
| 205 |
+
return outputs
|
| 206 |
+
|
| 207 |
+
class SegformerEncoder(nn.Module):
|
| 208 |
+
def __init__(self, config):
|
| 209 |
+
super().__init__()
|
| 210 |
+
self.config = config
|
| 211 |
+
|
| 212 |
+
# patch embeddings
|
| 213 |
+
embeddings = []
|
| 214 |
+
for i in range(config.num_encoder_blocks):
|
| 215 |
+
embeddings.append(
|
| 216 |
+
SegformerOverlapPatchEmbeddings(
|
| 217 |
+
patch_size=config.patch_sizes[i],
|
| 218 |
+
stride=config.strides[i],
|
| 219 |
+
num_channels=config.num_channels if i == 0 else config.hidden_sizes[i - 1],
|
| 220 |
+
hidden_size=config.hidden_sizes[i],
|
| 221 |
+
)
|
| 222 |
+
)
|
| 223 |
+
self.patch_embeddings = nn.ModuleList(embeddings)
|
| 224 |
+
|
| 225 |
+
# Transformer blocks
|
| 226 |
+
blocks = []
|
| 227 |
+
cur = 0
|
| 228 |
+
for i in range(config.num_encoder_blocks):
|
| 229 |
+
# each block consists of layers
|
| 230 |
+
layers = []
|
| 231 |
+
if i != 0:
|
| 232 |
+
cur += config.depths[i - 1]
|
| 233 |
+
for j in range(config.depths[i]):
|
| 234 |
+
layers.append(
|
| 235 |
+
SegformerLayer(
|
| 236 |
+
config,
|
| 237 |
+
hidden_size=config.hidden_sizes[i],
|
| 238 |
+
num_attention_heads=config.num_attention_heads[i],
|
| 239 |
+
sequence_reduction_ratio=config.sr_ratios[i],
|
| 240 |
+
mlp_ratio=config.mlp_ratios[i],
|
| 241 |
+
)
|
| 242 |
+
)
|
| 243 |
+
blocks.append(nn.ModuleList(layers))
|
| 244 |
+
|
| 245 |
+
self.block = nn.ModuleList(blocks)
|
| 246 |
+
|
| 247 |
+
# Layer norms
|
| 248 |
+
self.layer_norm = nn.ModuleList(
|
| 249 |
+
[nn.LayerNorm(config.hidden_sizes[i]) for i in range(config.num_encoder_blocks)]
|
| 250 |
+
)
|
| 251 |
+
|
| 252 |
+
def forward(
|
| 253 |
+
self,
|
| 254 |
+
pixel_values: torch.FloatTensor,
|
| 255 |
+
output_attentions: Optional[bool] = False,
|
| 256 |
+
output_hidden_states: Optional[bool] = False,
|
| 257 |
+
return_dict: Optional[bool] = True,
|
| 258 |
+
) -> Union[Tuple, BaseModelOutput]:
|
| 259 |
+
all_hidden_states = () if output_hidden_states else None
|
| 260 |
+
|
| 261 |
+
batch_size = pixel_values.shape[0]
|
| 262 |
+
|
| 263 |
+
hidden_states = pixel_values
|
| 264 |
+
for idx, x in enumerate(zip(self.patch_embeddings, self.block, self.layer_norm)):
|
| 265 |
+
embedding_layer, block_layer, norm_layer = x
|
| 266 |
+
# first, obtain patch embeddings
|
| 267 |
+
hidden_states, height, width = embedding_layer(hidden_states)
|
| 268 |
+
# second, send embeddings through blocks
|
| 269 |
+
for i, blk in enumerate(block_layer):
|
| 270 |
+
layer_outputs = blk(hidden_states, height, width, output_attentions)
|
| 271 |
+
hidden_states = layer_outputs[0]
|
| 272 |
+
# third, apply layer norm
|
| 273 |
+
hidden_states = norm_layer(hidden_states)
|
| 274 |
+
# fourth, optionally reshape back to (batch_size, num_channels, height, width)
|
| 275 |
+
if idx != len(self.patch_embeddings) - 1 or (
|
| 276 |
+
idx == len(self.patch_embeddings) - 1 and self.config.reshape_last_stage
|
| 277 |
+
):
|
| 278 |
+
hidden_states = hidden_states.reshape(batch_size, height, width, -1).permute(0, 3, 1, 2).contiguous()
|
| 279 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 280 |
+
|
| 281 |
+
return all_hidden_states
|
| 282 |
+
|
| 283 |
+
class SegformerSelfOutput(nn.Module):
|
| 284 |
+
def __init__(self, config, hidden_size):
|
| 285 |
+
super().__init__()
|
| 286 |
+
self.dense = nn.Linear(hidden_size, hidden_size)
|
| 287 |
+
|
| 288 |
+
def forward(self, hidden_states, input_tensor):
|
| 289 |
+
hidden_states = self.dense(hidden_states)
|
| 290 |
+
return hidden_states
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
class SegformerAttention(nn.Module):
|
| 294 |
+
def __init__(self, config, hidden_size, num_attention_heads, sequence_reduction_ratio):
|
| 295 |
+
super().__init__()
|
| 296 |
+
self.self = SegformerEfficientSelfAttention(
|
| 297 |
+
config=config,
|
| 298 |
+
hidden_size=hidden_size,
|
| 299 |
+
num_attention_heads=num_attention_heads,
|
| 300 |
+
sequence_reduction_ratio=sequence_reduction_ratio,
|
| 301 |
+
)
|
| 302 |
+
self.output = SegformerSelfOutput(config, hidden_size=hidden_size)
|
| 303 |
+
self.pruned_heads = set()
|
| 304 |
+
|
| 305 |
+
def prune_heads(self, heads):
|
| 306 |
+
if len(heads) == 0:
|
| 307 |
+
return
|
| 308 |
+
heads, index = find_pruneable_heads_and_indices(
|
| 309 |
+
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
# Prune linear layers
|
| 313 |
+
self.self.query = prune_linear_layer(self.self.query, index)
|
| 314 |
+
self.self.key = prune_linear_layer(self.self.key, index)
|
| 315 |
+
self.self.value = prune_linear_layer(self.self.value, index)
|
| 316 |
+
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
|
| 317 |
+
|
| 318 |
+
# Update hyper params and store pruned heads
|
| 319 |
+
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
|
| 320 |
+
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
|
| 321 |
+
self.pruned_heads = self.pruned_heads.union(heads)
|
| 322 |
+
|
| 323 |
+
def forward(self, hidden_states, height, width, output_attentions=False):
|
| 324 |
+
self_outputs = self.self(hidden_states, height, width, output_attentions)
|
| 325 |
+
|
| 326 |
+
attention_output = self.output(self_outputs[0], hidden_states)
|
| 327 |
+
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
|
| 328 |
+
return outputs
|
| 329 |
+
|
| 330 |
+
class SegformerDWConv(nn.Module):
|
| 331 |
+
def __init__(self, dim=768):
|
| 332 |
+
super().__init__()
|
| 333 |
+
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
|
| 334 |
+
|
| 335 |
+
def forward(self, hidden_states, height, width):
|
| 336 |
+
batch_size, seq_len, num_channels = hidden_states.shape
|
| 337 |
+
hidden_states = hidden_states.transpose(1, 2).view(batch_size, num_channels, height, width)
|
| 338 |
+
hidden_states = self.dwconv(hidden_states)
|
| 339 |
+
hidden_states = hidden_states.flatten(2).transpose(1, 2)
|
| 340 |
+
|
| 341 |
+
return hidden_states
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
class SegformerMixFFN(nn.Module):
|
| 345 |
+
def __init__(self, config, in_features, hidden_features=None, out_features=None):
|
| 346 |
+
super().__init__()
|
| 347 |
+
out_features = out_features or in_features
|
| 348 |
+
self.dense1 = nn.Linear(in_features, hidden_features)
|
| 349 |
+
self.dwconv = SegformerDWConv(hidden_features)
|
| 350 |
+
if isinstance(config.hidden_act, str):
|
| 351 |
+
self.intermediate_act_fn = ACT2FN[config.hidden_act]
|
| 352 |
+
else:
|
| 353 |
+
self.intermediate_act_fn = config.hidden_act
|
| 354 |
+
self.dense2 = nn.Linear(hidden_features, out_features)
|
| 355 |
+
|
| 356 |
+
def forward(self, hidden_states, height, width):
|
| 357 |
+
hidden_states = self.dense1(hidden_states)
|
| 358 |
+
hidden_states = self.dwconv(hidden_states, height, width)
|
| 359 |
+
hidden_states = self.intermediate_act_fn(hidden_states)
|
| 360 |
+
hidden_states = self.dense2(hidden_states)
|
| 361 |
+
return hidden_states
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
class SegformerLayer(nn.Module):
|
| 365 |
+
"""This corresponds to the Block class in the original implementation."""
|
| 366 |
+
|
| 367 |
+
def __init__(self, config, hidden_size, num_attention_heads, sequence_reduction_ratio, mlp_ratio):
|
| 368 |
+
super().__init__()
|
| 369 |
+
self.layer_norm_1 = nn.LayerNorm(hidden_size)
|
| 370 |
+
self.attention = SegformerAttention(
|
| 371 |
+
config,
|
| 372 |
+
hidden_size=hidden_size,
|
| 373 |
+
num_attention_heads=num_attention_heads,
|
| 374 |
+
sequence_reduction_ratio=sequence_reduction_ratio,
|
| 375 |
+
)
|
| 376 |
+
self.layer_norm_2 = nn.LayerNorm(hidden_size)
|
| 377 |
+
mlp_hidden_size = int(hidden_size * mlp_ratio)
|
| 378 |
+
self.mlp = SegformerMixFFN(config, in_features=hidden_size, hidden_features=mlp_hidden_size)
|
| 379 |
+
|
| 380 |
+
def forward(self, hidden_states, height, width, output_attentions=False):
|
| 381 |
+
self_attention_outputs = self.attention(
|
| 382 |
+
self.layer_norm_1(hidden_states), # in Segformer, layernorm is applied before self-attention
|
| 383 |
+
height,
|
| 384 |
+
width,
|
| 385 |
+
output_attentions=output_attentions,
|
| 386 |
+
)
|
| 387 |
+
|
| 388 |
+
attention_output = self_attention_outputs[0]
|
| 389 |
+
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
|
| 390 |
+
|
| 391 |
+
# first residual connection (with stochastic depth)
|
| 392 |
+
hidden_states = attention_output + hidden_states
|
| 393 |
+
|
| 394 |
+
mlp_output = self.mlp(self.layer_norm_2(hidden_states), height, width)
|
| 395 |
+
|
| 396 |
+
# second residual connection (with stochastic depth)
|
| 397 |
+
layer_output = mlp_output + hidden_states
|
| 398 |
+
|
| 399 |
+
outputs = (layer_output,) + outputs
|
| 400 |
+
|
| 401 |
+
return outputs
|
| 402 |
+
|
| 403 |
+
class SegformerModel(SegformerPreTrainedModel):
|
| 404 |
+
def __init__(self, config):
|
| 405 |
+
super().__init__(config)
|
| 406 |
+
self.config = config
|
| 407 |
+
|
| 408 |
+
# hierarchical Transformer encoder
|
| 409 |
+
self.encoder = SegformerEncoder(config)
|
| 410 |
+
|
| 411 |
+
# Initialize weights and apply final processing
|
| 412 |
+
self.post_init()
|
| 413 |
+
|
| 414 |
+
def _prune_heads(self, heads_to_prune):
|
| 415 |
+
"""
|
| 416 |
+
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
|
| 417 |
+
class PreTrainedModel
|
| 418 |
+
"""
|
| 419 |
+
for layer, heads in heads_to_prune.items():
|
| 420 |
+
self.encoder.layer[layer].attention.prune_heads(heads)
|
| 421 |
+
|
| 422 |
+
def forward(
|
| 423 |
+
self,
|
| 424 |
+
pixel_values: torch.FloatTensor,
|
| 425 |
+
output_attentions: Optional[bool] = None,
|
| 426 |
+
output_hidden_states: Optional[bool] = None,
|
| 427 |
+
return_dict: Optional[bool] = None,
|
| 428 |
+
) -> Union[Tuple, BaseModelOutput]:
|
| 429 |
+
encoder_outputs = self.encoder(
|
| 430 |
+
pixel_values,
|
| 431 |
+
output_attentions=output_attentions,
|
| 432 |
+
output_hidden_states=output_hidden_states,
|
| 433 |
+
return_dict=return_dict,
|
| 434 |
+
)
|
| 435 |
+
return encoder_outputs
|
| 436 |
+
|
| 437 |
+
class SegformerForRegressionMask(SegformerForSemanticSegmentation):
|
| 438 |
+
def __init__(self, config, **kwargs):
|
| 439 |
+
super().__init__(config)
|
| 440 |
+
self.segformer = SegformerModel(config)
|
| 441 |
+
self.decode_head = SegformerForMaskDecodeHead(config)
|
| 442 |
+
|
| 443 |
+
# Initialize weights and apply final processing
|
| 444 |
+
self.post_init()
|
| 445 |
+
|
| 446 |
+
def forward(
|
| 447 |
+
self,
|
| 448 |
+
pixel_values: torch.FloatTensor,
|
| 449 |
+
**kwargs
|
| 450 |
+
) -> Union[Tuple, SemanticSegmenterOutput]:
|
| 451 |
+
|
| 452 |
+
encoder_hidden_states = self.segformer(
|
| 453 |
+
pixel_values,
|
| 454 |
+
output_attentions=False,
|
| 455 |
+
output_hidden_states=True, # we need the intermediate hidden states
|
| 456 |
+
return_dict=False,
|
| 457 |
+
)
|
| 458 |
+
|
| 459 |
+
logits = self.decode_head(encoder_hidden_states)
|
| 460 |
+
# Apply sigmoid to get 0-1 output
|
| 461 |
+
sigmoid_logits = torch.special.expit(logits)
|
| 462 |
+
|
| 463 |
+
return SemanticSegmenterOutput(
|
| 464 |
+
loss=None,
|
| 465 |
+
logits=sigmoid_logits,
|
| 466 |
+
hidden_states=None,
|
| 467 |
+
attentions=None,
|
| 468 |
+
)
|
surya/model/ordering/config.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import MBartConfig, DonutSwinConfig
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class MBartOrderConfig(MBartConfig):
|
| 5 |
+
pass
|
| 6 |
+
|
| 7 |
+
class VariableDonutSwinConfig(DonutSwinConfig):
|
| 8 |
+
pass
|
surya/model/ordering/decoder.py
ADDED
|
@@ -0,0 +1,557 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
from typing import Optional, List, Union, Tuple
|
| 3 |
+
|
| 4 |
+
from transformers import MBartForCausalLM, MBartConfig
|
| 5 |
+
from torch import nn
|
| 6 |
+
from transformers.activations import ACT2FN
|
| 7 |
+
from transformers.modeling_attn_mask_utils import _prepare_4d_causal_attention_mask, _prepare_4d_attention_mask
|
| 8 |
+
from transformers.modeling_outputs import CausalLMOutputWithCrossAttentions, BaseModelOutputWithPastAndCrossAttentions
|
| 9 |
+
from transformers.models.mbart.modeling_mbart import MBartPreTrainedModel, MBartDecoder, MBartLearnedPositionalEmbedding, MBartDecoderLayer
|
| 10 |
+
from surya.model.ordering.config import MBartOrderConfig
|
| 11 |
+
import torch
|
| 12 |
+
import math
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 16 |
+
"""
|
| 17 |
+
From llama
|
| 18 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 19 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 20 |
+
"""
|
| 21 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 22 |
+
if n_rep == 1:
|
| 23 |
+
return hidden_states
|
| 24 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
| 25 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class MBartGQAttention(nn.Module):
|
| 29 |
+
def __init__(
|
| 30 |
+
self,
|
| 31 |
+
embed_dim: int,
|
| 32 |
+
num_heads: int,
|
| 33 |
+
num_kv_heads: int,
|
| 34 |
+
dropout: float = 0.0,
|
| 35 |
+
is_decoder: bool = False,
|
| 36 |
+
bias: bool = True,
|
| 37 |
+
is_causal: bool = False,
|
| 38 |
+
config: Optional[MBartConfig] = None,
|
| 39 |
+
):
|
| 40 |
+
super().__init__()
|
| 41 |
+
self.embed_dim = embed_dim
|
| 42 |
+
self.num_heads = num_heads
|
| 43 |
+
self.num_kv_heads = num_kv_heads
|
| 44 |
+
self.num_kv_groups = self.num_heads // self.num_kv_heads
|
| 45 |
+
|
| 46 |
+
assert self.num_heads % self.num_kv_heads == 0, f"num_heads ({self.num_heads}) must be divisible by num_kv_heads ({self.num_kv_heads})"
|
| 47 |
+
assert embed_dim % self.num_kv_heads == 0, f"embed_dim ({self.embed_dim}) must be divisible by num_kv_heads ({self.num_kv_heads})"
|
| 48 |
+
|
| 49 |
+
self.dropout = dropout
|
| 50 |
+
self.head_dim = embed_dim // num_heads
|
| 51 |
+
self.config = config
|
| 52 |
+
|
| 53 |
+
if (self.head_dim * num_heads) != self.embed_dim:
|
| 54 |
+
raise ValueError(
|
| 55 |
+
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim}"
|
| 56 |
+
f" and `num_heads`: {num_heads})."
|
| 57 |
+
)
|
| 58 |
+
self.scaling = self.head_dim**-0.5
|
| 59 |
+
self.is_decoder = is_decoder
|
| 60 |
+
self.is_causal = is_causal
|
| 61 |
+
|
| 62 |
+
self.k_proj = nn.Linear(embed_dim, self.num_kv_heads * self.head_dim, bias=bias)
|
| 63 |
+
self.v_proj = nn.Linear(embed_dim, self.num_kv_heads * self.head_dim, bias=bias)
|
| 64 |
+
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
|
| 65 |
+
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
|
| 66 |
+
|
| 67 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 68 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 69 |
+
|
| 70 |
+
def _shape_key_value(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 71 |
+
return tensor.view(bsz, seq_len, self.num_kv_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 72 |
+
|
| 73 |
+
def forward(
|
| 74 |
+
self,
|
| 75 |
+
hidden_states: torch.Tensor,
|
| 76 |
+
key_value_states: Optional[torch.Tensor] = None,
|
| 77 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 78 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 79 |
+
layer_head_mask: Optional[torch.Tensor] = None,
|
| 80 |
+
output_attentions: bool = False,
|
| 81 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 82 |
+
"""Input shape: Batch x Time x Channel"""
|
| 83 |
+
|
| 84 |
+
# if key_value_states are provided this layer is used as a cross-attention layer
|
| 85 |
+
# for the decoder
|
| 86 |
+
is_cross_attention = key_value_states is not None
|
| 87 |
+
|
| 88 |
+
bsz, tgt_len, _ = hidden_states.size()
|
| 89 |
+
|
| 90 |
+
# get query proj
|
| 91 |
+
query_states = self.q_proj(hidden_states) * self.scaling
|
| 92 |
+
# get key, value proj
|
| 93 |
+
# `past_key_value[0].shape[2] == key_value_states.shape[1]`
|
| 94 |
+
# is checking that the `sequence_length` of the `past_key_value` is the same as
|
| 95 |
+
# the provided `key_value_states` to support prefix tuning
|
| 96 |
+
if (
|
| 97 |
+
is_cross_attention
|
| 98 |
+
and past_key_value is not None
|
| 99 |
+
and past_key_value[0].shape[2] == key_value_states.shape[1]
|
| 100 |
+
):
|
| 101 |
+
# reuse k,v, cross_attentions
|
| 102 |
+
key_states = past_key_value[0]
|
| 103 |
+
value_states = past_key_value[1]
|
| 104 |
+
elif is_cross_attention:
|
| 105 |
+
# cross_attentions
|
| 106 |
+
key_states = self._shape_key_value(self.k_proj(key_value_states), -1, bsz)
|
| 107 |
+
value_states = self._shape_key_value(self.v_proj(key_value_states), -1, bsz)
|
| 108 |
+
elif past_key_value is not None:
|
| 109 |
+
# reuse k, v, self_attention
|
| 110 |
+
key_states = self._shape_key_value(self.k_proj(hidden_states), -1, bsz)
|
| 111 |
+
value_states = self._shape_key_value(self.v_proj(hidden_states), -1, bsz)
|
| 112 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 113 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 114 |
+
else:
|
| 115 |
+
# self_attention
|
| 116 |
+
key_states = self._shape_key_value(self.k_proj(hidden_states), -1, bsz)
|
| 117 |
+
value_states = self._shape_key_value(self.v_proj(hidden_states), -1, bsz)
|
| 118 |
+
|
| 119 |
+
if self.is_decoder:
|
| 120 |
+
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
|
| 121 |
+
# Further calls to cross_attention layer can then reuse all cross-attention
|
| 122 |
+
# key/value_states (first "if" case)
|
| 123 |
+
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
|
| 124 |
+
# all previous decoder key/value_states. Further calls to uni-directional self-attention
|
| 125 |
+
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
|
| 126 |
+
# if encoder bi-directional self-attention `past_key_value` is always `None`
|
| 127 |
+
past_key_value = (key_states, value_states)
|
| 128 |
+
|
| 129 |
+
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
|
| 130 |
+
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
|
| 131 |
+
|
| 132 |
+
# Expand kv heads, then match query shape
|
| 133 |
+
key_states = repeat_kv(key_states, self.num_kv_groups)
|
| 134 |
+
value_states = repeat_kv(value_states, self.num_kv_groups)
|
| 135 |
+
key_states = key_states.reshape(*proj_shape)
|
| 136 |
+
value_states = value_states.reshape(*proj_shape)
|
| 137 |
+
|
| 138 |
+
src_len = key_states.size(1)
|
| 139 |
+
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
|
| 140 |
+
|
| 141 |
+
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
|
| 142 |
+
raise ValueError(
|
| 143 |
+
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
|
| 144 |
+
f" {attn_weights.size()}"
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
if attention_mask is not None:
|
| 148 |
+
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
|
| 149 |
+
raise ValueError(
|
| 150 |
+
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
|
| 151 |
+
)
|
| 152 |
+
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
|
| 153 |
+
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
|
| 154 |
+
|
| 155 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 156 |
+
|
| 157 |
+
if layer_head_mask is not None:
|
| 158 |
+
if layer_head_mask.size() != (self.num_heads,):
|
| 159 |
+
raise ValueError(
|
| 160 |
+
f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
|
| 161 |
+
f" {layer_head_mask.size()}"
|
| 162 |
+
)
|
| 163 |
+
attn_weights = layer_head_mask.view(1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
|
| 164 |
+
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
|
| 165 |
+
|
| 166 |
+
if output_attentions:
|
| 167 |
+
# this operation is a bit awkward, but it's required to
|
| 168 |
+
# make sure that attn_weights keeps its gradient.
|
| 169 |
+
# In order to do so, attn_weights have to be reshaped
|
| 170 |
+
# twice and have to be reused in the following
|
| 171 |
+
attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
|
| 172 |
+
attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
|
| 173 |
+
else:
|
| 174 |
+
attn_weights_reshaped = None
|
| 175 |
+
|
| 176 |
+
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
|
| 177 |
+
|
| 178 |
+
attn_output = torch.bmm(attn_probs, value_states)
|
| 179 |
+
|
| 180 |
+
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
|
| 181 |
+
raise ValueError(
|
| 182 |
+
f"`attn_output` should be of size {(bsz * self.num_heads, tgt_len, self.head_dim)}, but is"
|
| 183 |
+
f" {attn_output.size()}"
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
|
| 187 |
+
attn_output = attn_output.transpose(1, 2)
|
| 188 |
+
|
| 189 |
+
# Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
|
| 190 |
+
# partitioned across GPUs when using tensor-parallelism.
|
| 191 |
+
attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
|
| 192 |
+
|
| 193 |
+
attn_output = self.out_proj(attn_output)
|
| 194 |
+
|
| 195 |
+
return attn_output, attn_weights_reshaped, past_key_value
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
MBART_ATTENTION_CLASSES = {
|
| 199 |
+
"eager": MBartGQAttention,
|
| 200 |
+
"flash_attention_2": None
|
| 201 |
+
}
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
class MBartOrderDecoderLayer(MBartDecoderLayer):
|
| 205 |
+
def __init__(self, config: MBartConfig):
|
| 206 |
+
nn.Module.__init__(self)
|
| 207 |
+
self.embed_dim = config.d_model
|
| 208 |
+
|
| 209 |
+
self.self_attn = MBART_ATTENTION_CLASSES[config._attn_implementation](
|
| 210 |
+
embed_dim=self.embed_dim,
|
| 211 |
+
num_heads=config.decoder_attention_heads,
|
| 212 |
+
num_kv_heads=config.kv_heads,
|
| 213 |
+
dropout=config.attention_dropout,
|
| 214 |
+
is_decoder=True,
|
| 215 |
+
is_causal=True,
|
| 216 |
+
config=config,
|
| 217 |
+
)
|
| 218 |
+
self.dropout = config.dropout
|
| 219 |
+
self.activation_fn = ACT2FN[config.activation_function]
|
| 220 |
+
self.activation_dropout = config.activation_dropout
|
| 221 |
+
|
| 222 |
+
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
|
| 223 |
+
self.encoder_attn = MBART_ATTENTION_CLASSES[config._attn_implementation](
|
| 224 |
+
self.embed_dim,
|
| 225 |
+
config.decoder_attention_heads,
|
| 226 |
+
num_kv_heads=config.kv_heads,
|
| 227 |
+
dropout=config.attention_dropout,
|
| 228 |
+
is_decoder=True,
|
| 229 |
+
config=config,
|
| 230 |
+
)
|
| 231 |
+
self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim)
|
| 232 |
+
self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
|
| 233 |
+
self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
|
| 234 |
+
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
class BboxEmbedding(nn.Module):
|
| 238 |
+
def __init__(self, config):
|
| 239 |
+
super().__init__()
|
| 240 |
+
self.x1_embed = nn.Embedding(config.max_width, config.d_model)
|
| 241 |
+
self.y1_embed = nn.Embedding(config.max_height, config.d_model)
|
| 242 |
+
self.x2_embed = nn.Embedding(config.max_width, config.d_model)
|
| 243 |
+
self.y2_embed = nn.Embedding(config.max_height, config.d_model)
|
| 244 |
+
self.w_embed = nn.Embedding(config.max_width, config.d_model)
|
| 245 |
+
self.h_embed = nn.Embedding(config.max_height, config.d_model)
|
| 246 |
+
self.cx_embed = nn.Embedding(config.max_width, config.d_model)
|
| 247 |
+
self.cy_embed = nn.Embedding(config.max_height, config.d_model)
|
| 248 |
+
self.box_pos_embed = nn.Embedding(config.max_position_embeddings, config.d_model)
|
| 249 |
+
|
| 250 |
+
def forward(self, boxes: torch.LongTensor, input_box_counts: torch.LongTensor, past_key_values_length: int):
|
| 251 |
+
x1, y1, x2, y2 = boxes.unbind(dim=-1)
|
| 252 |
+
# Shape is (batch_size, num_boxes/seq len, d_model)
|
| 253 |
+
w = x2 - x1
|
| 254 |
+
h = y2 - y1
|
| 255 |
+
# Center x and y in torch long tensors
|
| 256 |
+
cx = (x1 + x2) / 2
|
| 257 |
+
cy = (y1 + y2) / 2
|
| 258 |
+
cx = cx.long()
|
| 259 |
+
cy = cy.long()
|
| 260 |
+
|
| 261 |
+
coord_embeds = self.x1_embed(x1) + self.y1_embed(y1) + self.x2_embed(x2) + self.y2_embed(y2)
|
| 262 |
+
embedded = coord_embeds + self.w_embed(w) + self.h_embed(h) + self.cx_embed(cx) + self.cy_embed(cy)
|
| 263 |
+
|
| 264 |
+
# Add in positional embeddings for the boxes
|
| 265 |
+
if past_key_values_length == 0:
|
| 266 |
+
for j in range(embedded.shape[0]):
|
| 267 |
+
box_start = input_box_counts[j, 0]
|
| 268 |
+
box_end = input_box_counts[j, 1] - 1 # Skip the sep token
|
| 269 |
+
box_count = box_end - box_start
|
| 270 |
+
embedded[j, box_start:box_end] = embedded[j, box_start:box_end] + self.box_pos_embed.weight[:box_count]
|
| 271 |
+
|
| 272 |
+
return embedded
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
class MBartOrderDecoder(MBartDecoder):
|
| 276 |
+
def __init__(self, config: MBartConfig, embed_tokens: Optional[nn.Embedding] = None):
|
| 277 |
+
MBartPreTrainedModel.__init__(self, config)
|
| 278 |
+
self.dropout = config.dropout
|
| 279 |
+
self.layerdrop = config.decoder_layerdrop
|
| 280 |
+
self.padding_idx = config.pad_token_id
|
| 281 |
+
self.max_target_positions = config.max_position_embeddings
|
| 282 |
+
self.embed_scale = math.sqrt(config.d_model) if config.scale_embedding else 1.0
|
| 283 |
+
|
| 284 |
+
self.embed_tokens = BboxEmbedding(config) if embed_tokens is None else embed_tokens
|
| 285 |
+
|
| 286 |
+
if embed_tokens is not None:
|
| 287 |
+
self.embed_tokens.weight = embed_tokens.weight
|
| 288 |
+
|
| 289 |
+
self.embed_positions = MBartLearnedPositionalEmbedding(
|
| 290 |
+
config.max_position_embeddings,
|
| 291 |
+
config.d_model,
|
| 292 |
+
)
|
| 293 |
+
# Language-specific MoE goes at second and second-to-last layer
|
| 294 |
+
self.layers = nn.ModuleList([MBartOrderDecoderLayer(config) for _ in range(config.decoder_layers)])
|
| 295 |
+
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
|
| 296 |
+
self.layernorm_embedding = nn.LayerNorm(config.d_model)
|
| 297 |
+
self.layer_norm = nn.LayerNorm(config.d_model)
|
| 298 |
+
|
| 299 |
+
self.gradient_checkpointing = False
|
| 300 |
+
# Initialize weights and apply final processing
|
| 301 |
+
self.post_init()
|
| 302 |
+
|
| 303 |
+
def forward(
|
| 304 |
+
self,
|
| 305 |
+
input_boxes: torch.LongTensor = None,
|
| 306 |
+
input_boxes_mask: Optional[torch.Tensor] = None,
|
| 307 |
+
input_boxes_counts: Optional[torch.Tensor] = None,
|
| 308 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 309 |
+
encoder_attention_mask: Optional[torch.LongTensor] = None,
|
| 310 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 311 |
+
cross_attn_head_mask: Optional[torch.Tensor] = None,
|
| 312 |
+
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
|
| 313 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 314 |
+
use_cache: Optional[bool] = None,
|
| 315 |
+
output_attentions: Optional[bool] = None,
|
| 316 |
+
output_hidden_states: Optional[bool] = None,
|
| 317 |
+
return_dict: Optional[bool] = None,
|
| 318 |
+
) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]:
|
| 319 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 320 |
+
output_hidden_states = (
|
| 321 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 322 |
+
)
|
| 323 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 324 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 325 |
+
|
| 326 |
+
# retrieve input_ids and inputs_embeds
|
| 327 |
+
if input_boxes is not None and inputs_embeds is not None:
|
| 328 |
+
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
|
| 329 |
+
elif input_boxes is not None:
|
| 330 |
+
input = input_boxes
|
| 331 |
+
input_shape = input_boxes.size()[:-1] # Shape (batch_size, num_boxes)
|
| 332 |
+
elif inputs_embeds is not None:
|
| 333 |
+
input_shape = inputs_embeds.size()[:-1]
|
| 334 |
+
input = inputs_embeds[:, :, -1]
|
| 335 |
+
else:
|
| 336 |
+
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
|
| 337 |
+
|
| 338 |
+
# past_key_values_length
|
| 339 |
+
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
|
| 340 |
+
|
| 341 |
+
if inputs_embeds is None:
|
| 342 |
+
inputs_embeds = self.embed_tokens(input_boxes, input_boxes_counts, past_key_values_length) * self.embed_scale
|
| 343 |
+
|
| 344 |
+
if self._use_flash_attention_2:
|
| 345 |
+
# 2d mask is passed through the layers
|
| 346 |
+
attention_mask = input_boxes_mask if (input_boxes_mask is not None and 0 in input_boxes_mask) else None
|
| 347 |
+
else:
|
| 348 |
+
# 4d mask is passed through the layers
|
| 349 |
+
attention_mask = _prepare_4d_causal_attention_mask(
|
| 350 |
+
input_boxes_mask, input_shape, inputs_embeds, past_key_values_length
|
| 351 |
+
)
|
| 352 |
+
|
| 353 |
+
if past_key_values_length == 0:
|
| 354 |
+
box_ends = input_boxes_counts[:, 1]
|
| 355 |
+
box_starts = input_boxes_counts[:, 0]
|
| 356 |
+
input_shape_arranged = torch.arange(input_shape[1], device=attention_mask.device)[None, :]
|
| 357 |
+
# Enable all boxes to attend to each other (before the sep token)
|
| 358 |
+
# Ensure that the boxes are not attending to the padding tokens
|
| 359 |
+
boxes_end_mask = input_shape_arranged < box_ends[:, None]
|
| 360 |
+
boxes_start_mask = input_shape_arranged >= box_starts[:, None]
|
| 361 |
+
boxes_mask = boxes_end_mask & boxes_start_mask
|
| 362 |
+
boxes_mask = boxes_mask.unsqueeze(1).unsqueeze(1) # Enable proper broadcasting
|
| 363 |
+
attention_mask = attention_mask.masked_fill(boxes_mask, 0)
|
| 364 |
+
|
| 365 |
+
# expand encoder attention mask
|
| 366 |
+
if encoder_hidden_states is not None and encoder_attention_mask is not None:
|
| 367 |
+
if self._use_flash_attention_2:
|
| 368 |
+
encoder_attention_mask = encoder_attention_mask if 0 in encoder_attention_mask else None
|
| 369 |
+
else:
|
| 370 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 371 |
+
encoder_attention_mask = _prepare_4d_attention_mask(
|
| 372 |
+
encoder_attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
|
| 373 |
+
)
|
| 374 |
+
|
| 375 |
+
# embed positions
|
| 376 |
+
positions = self.embed_positions(input, past_key_values_length)
|
| 377 |
+
|
| 378 |
+
hidden_states = inputs_embeds + positions.to(inputs_embeds.device)
|
| 379 |
+
hidden_states = self.layernorm_embedding(hidden_states)
|
| 380 |
+
|
| 381 |
+
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
|
| 382 |
+
|
| 383 |
+
if self.gradient_checkpointing and self.training:
|
| 384 |
+
if use_cache:
|
| 385 |
+
use_cache = False
|
| 386 |
+
|
| 387 |
+
# decoder layers
|
| 388 |
+
all_hidden_states = () if output_hidden_states else None
|
| 389 |
+
all_self_attns = () if output_attentions else None
|
| 390 |
+
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
|
| 391 |
+
next_decoder_cache = () if use_cache else None
|
| 392 |
+
|
| 393 |
+
# check if head_mask/cross_attn_head_mask has a correct number of layers specified if desired
|
| 394 |
+
for attn_mask, mask_name in zip([head_mask, cross_attn_head_mask], ["head_mask", "cross_attn_head_mask"]):
|
| 395 |
+
if attn_mask is not None:
|
| 396 |
+
if attn_mask.size()[0] != len(self.layers):
|
| 397 |
+
raise ValueError(
|
| 398 |
+
f"The `{mask_name}` should be specified for {len(self.layers)} layers, but it is for"
|
| 399 |
+
f" {attn_mask.size()[0]}."
|
| 400 |
+
)
|
| 401 |
+
for idx, decoder_layer in enumerate(self.layers):
|
| 402 |
+
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
|
| 403 |
+
if output_hidden_states:
|
| 404 |
+
all_hidden_states += (hidden_states,)
|
| 405 |
+
if self.training:
|
| 406 |
+
dropout_probability = torch.rand([])
|
| 407 |
+
if dropout_probability < self.layerdrop:
|
| 408 |
+
continue
|
| 409 |
+
|
| 410 |
+
past_key_value = past_key_values[idx] if past_key_values is not None else None
|
| 411 |
+
|
| 412 |
+
if self.gradient_checkpointing and self.training:
|
| 413 |
+
layer_outputs = self._gradient_checkpointing_func(
|
| 414 |
+
decoder_layer.__call__,
|
| 415 |
+
hidden_states,
|
| 416 |
+
attention_mask,
|
| 417 |
+
encoder_hidden_states,
|
| 418 |
+
encoder_attention_mask,
|
| 419 |
+
head_mask[idx] if head_mask is not None else None,
|
| 420 |
+
cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None,
|
| 421 |
+
None,
|
| 422 |
+
output_attentions,
|
| 423 |
+
use_cache,
|
| 424 |
+
)
|
| 425 |
+
else:
|
| 426 |
+
layer_outputs = decoder_layer(
|
| 427 |
+
hidden_states,
|
| 428 |
+
attention_mask=attention_mask,
|
| 429 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 430 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 431 |
+
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
|
| 432 |
+
cross_attn_layer_head_mask=(
|
| 433 |
+
cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None
|
| 434 |
+
),
|
| 435 |
+
past_key_value=past_key_value,
|
| 436 |
+
output_attentions=output_attentions,
|
| 437 |
+
use_cache=use_cache,
|
| 438 |
+
)
|
| 439 |
+
hidden_states = layer_outputs[0]
|
| 440 |
+
|
| 441 |
+
if use_cache:
|
| 442 |
+
next_decoder_cache += (layer_outputs[3 if output_attentions else 1],)
|
| 443 |
+
|
| 444 |
+
if output_attentions:
|
| 445 |
+
all_self_attns += (layer_outputs[1],)
|
| 446 |
+
|
| 447 |
+
if encoder_hidden_states is not None:
|
| 448 |
+
all_cross_attentions += (layer_outputs[2],)
|
| 449 |
+
|
| 450 |
+
hidden_states = self.layer_norm(hidden_states)
|
| 451 |
+
|
| 452 |
+
# add hidden states from the last decoder layer
|
| 453 |
+
if output_hidden_states:
|
| 454 |
+
all_hidden_states += (hidden_states,)
|
| 455 |
+
|
| 456 |
+
next_cache = next_decoder_cache if use_cache else None
|
| 457 |
+
if not return_dict:
|
| 458 |
+
return tuple(
|
| 459 |
+
v
|
| 460 |
+
for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_cross_attentions]
|
| 461 |
+
if v is not None
|
| 462 |
+
)
|
| 463 |
+
return BaseModelOutputWithPastAndCrossAttentions(
|
| 464 |
+
last_hidden_state=hidden_states,
|
| 465 |
+
past_key_values=next_cache,
|
| 466 |
+
hidden_states=all_hidden_states,
|
| 467 |
+
attentions=all_self_attns,
|
| 468 |
+
cross_attentions=all_cross_attentions,
|
| 469 |
+
)
|
| 470 |
+
|
| 471 |
+
|
| 472 |
+
class MBartOrderDecoderWrapper(MBartPreTrainedModel):
|
| 473 |
+
"""
|
| 474 |
+
This wrapper class is a helper class to correctly load pretrained checkpoints when the causal language model is
|
| 475 |
+
used in combination with the [`EncoderDecoderModel`] framework.
|
| 476 |
+
"""
|
| 477 |
+
|
| 478 |
+
def __init__(self, config):
|
| 479 |
+
super().__init__(config)
|
| 480 |
+
self.decoder = MBartOrderDecoder(config)
|
| 481 |
+
|
| 482 |
+
def forward(self, *args, **kwargs):
|
| 483 |
+
return self.decoder(*args, **kwargs)
|
| 484 |
+
|
| 485 |
+
|
| 486 |
+
class MBartOrder(MBartForCausalLM):
|
| 487 |
+
config_class = MBartOrderConfig
|
| 488 |
+
_tied_weights_keys = []
|
| 489 |
+
|
| 490 |
+
def __init__(self, config, **kwargs):
|
| 491 |
+
config = copy.deepcopy(config)
|
| 492 |
+
config.is_decoder = True
|
| 493 |
+
config.is_encoder_decoder = False
|
| 494 |
+
MBartPreTrainedModel.__init__(self, config)
|
| 495 |
+
self.model = MBartOrderDecoderWrapper(config)
|
| 496 |
+
|
| 497 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 498 |
+
|
| 499 |
+
# Initialize weights and apply final processing
|
| 500 |
+
self.post_init()
|
| 501 |
+
|
| 502 |
+
def forward(
|
| 503 |
+
self,
|
| 504 |
+
input_boxes: torch.LongTensor = None,
|
| 505 |
+
input_boxes_mask: Optional[torch.Tensor] = None,
|
| 506 |
+
input_boxes_counts: Optional[torch.Tensor] = None,
|
| 507 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 508 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 509 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 510 |
+
cross_attn_head_mask: Optional[torch.Tensor] = None,
|
| 511 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 512 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 513 |
+
labels: Optional[torch.LongTensor] = None,
|
| 514 |
+
use_cache: Optional[bool] = None,
|
| 515 |
+
output_attentions: Optional[bool] = None,
|
| 516 |
+
output_hidden_states: Optional[bool] = None,
|
| 517 |
+
return_dict: Optional[bool] = None,
|
| 518 |
+
**kwargs
|
| 519 |
+
) -> Union[Tuple, CausalLMOutputWithCrossAttentions]:
|
| 520 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 521 |
+
output_hidden_states = (
|
| 522 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 523 |
+
)
|
| 524 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 525 |
+
|
| 526 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 527 |
+
outputs = self.model.decoder(
|
| 528 |
+
input_boxes=input_boxes,
|
| 529 |
+
input_boxes_mask=input_boxes_mask,
|
| 530 |
+
input_boxes_counts=input_boxes_counts,
|
| 531 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 532 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 533 |
+
head_mask=head_mask,
|
| 534 |
+
cross_attn_head_mask=cross_attn_head_mask,
|
| 535 |
+
past_key_values=past_key_values,
|
| 536 |
+
inputs_embeds=inputs_embeds,
|
| 537 |
+
use_cache=use_cache,
|
| 538 |
+
output_attentions=output_attentions,
|
| 539 |
+
output_hidden_states=output_hidden_states,
|
| 540 |
+
return_dict=return_dict,
|
| 541 |
+
)
|
| 542 |
+
|
| 543 |
+
logits = self.lm_head(outputs[0])
|
| 544 |
+
|
| 545 |
+
loss = None
|
| 546 |
+
if not return_dict:
|
| 547 |
+
output = (logits,) + outputs[1:]
|
| 548 |
+
return (loss,) + output if loss is not None else output
|
| 549 |
+
|
| 550 |
+
return CausalLMOutputWithCrossAttentions(
|
| 551 |
+
loss=loss,
|
| 552 |
+
logits=logits,
|
| 553 |
+
past_key_values=outputs.past_key_values,
|
| 554 |
+
hidden_states=outputs.hidden_states,
|
| 555 |
+
attentions=outputs.attentions,
|
| 556 |
+
cross_attentions=outputs.cross_attentions,
|
| 557 |
+
)
|
surya/model/ordering/encoder.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn
|
| 2 |
+
import torch
|
| 3 |
+
from typing import Optional, Tuple, Union
|
| 4 |
+
import collections
|
| 5 |
+
import math
|
| 6 |
+
|
| 7 |
+
from transformers import DonutSwinPreTrainedModel
|
| 8 |
+
from transformers.models.donut.modeling_donut_swin import DonutSwinPatchEmbeddings, DonutSwinEmbeddings, DonutSwinModel, \
|
| 9 |
+
DonutSwinEncoder
|
| 10 |
+
|
| 11 |
+
from surya.model.ordering.config import VariableDonutSwinConfig
|
| 12 |
+
|
| 13 |
+
class VariableDonutSwinEmbeddings(DonutSwinEmbeddings):
|
| 14 |
+
"""
|
| 15 |
+
Construct the patch and position embeddings. Optionally, also the mask token.
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
def __init__(self, config, use_mask_token=False, **kwargs):
|
| 19 |
+
super().__init__(config, use_mask_token)
|
| 20 |
+
|
| 21 |
+
self.patch_embeddings = DonutSwinPatchEmbeddings(config)
|
| 22 |
+
num_patches = self.patch_embeddings.num_patches
|
| 23 |
+
self.patch_grid = self.patch_embeddings.grid_size
|
| 24 |
+
self.mask_token = nn.Parameter(torch.zeros(1, 1, config.embed_dim)) if use_mask_token else None
|
| 25 |
+
self.position_embeddings = None
|
| 26 |
+
|
| 27 |
+
if config.use_absolute_embeddings:
|
| 28 |
+
self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 1, config.embed_dim))
|
| 29 |
+
|
| 30 |
+
self.row_embeddings = None
|
| 31 |
+
self.column_embeddings = None
|
| 32 |
+
if config.use_2d_embeddings:
|
| 33 |
+
self.row_embeddings = nn.Parameter(torch.zeros(1, self.patch_grid[0] + 1, config.embed_dim))
|
| 34 |
+
self.column_embeddings = nn.Parameter(torch.zeros(1, self.patch_grid[1] + 1, config.embed_dim))
|
| 35 |
+
|
| 36 |
+
self.norm = nn.LayerNorm(config.embed_dim)
|
| 37 |
+
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
| 38 |
+
|
| 39 |
+
def forward(
|
| 40 |
+
self, pixel_values: Optional[torch.FloatTensor], bool_masked_pos: Optional[torch.BoolTensor] = None, **kwargs
|
| 41 |
+
) -> Tuple[torch.Tensor]:
|
| 42 |
+
|
| 43 |
+
embeddings, output_dimensions = self.patch_embeddings(pixel_values)
|
| 44 |
+
# Layernorm across the last dimension (each patch is a single row)
|
| 45 |
+
embeddings = self.norm(embeddings)
|
| 46 |
+
batch_size, seq_len, embed_dim = embeddings.size()
|
| 47 |
+
|
| 48 |
+
if bool_masked_pos is not None:
|
| 49 |
+
mask_tokens = self.mask_token.expand(batch_size, seq_len, -1)
|
| 50 |
+
# replace the masked visual tokens by mask_tokens
|
| 51 |
+
mask = bool_masked_pos.unsqueeze(-1).type_as(mask_tokens)
|
| 52 |
+
embeddings = embeddings * (1.0 - mask) + mask_tokens * mask
|
| 53 |
+
|
| 54 |
+
if self.position_embeddings is not None:
|
| 55 |
+
embeddings = embeddings + self.position_embeddings[:, :seq_len, :]
|
| 56 |
+
|
| 57 |
+
if self.row_embeddings is not None and self.column_embeddings is not None:
|
| 58 |
+
# Repeat the x position embeddings across the y axis like 0, 1, 2, 3, 0, 1, 2, 3, ...
|
| 59 |
+
row_embeddings = self.row_embeddings[:, :output_dimensions[0], :].repeat_interleave(output_dimensions[1], dim=1)
|
| 60 |
+
column_embeddings = self.column_embeddings[:, :output_dimensions[1], :].repeat(1, output_dimensions[0], 1)
|
| 61 |
+
|
| 62 |
+
embeddings = embeddings + row_embeddings + column_embeddings
|
| 63 |
+
|
| 64 |
+
embeddings = self.dropout(embeddings)
|
| 65 |
+
|
| 66 |
+
return embeddings, output_dimensions
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class VariableDonutSwinModel(DonutSwinModel):
|
| 70 |
+
config_class = VariableDonutSwinConfig
|
| 71 |
+
def __init__(self, config, add_pooling_layer=True, use_mask_token=False, **kwargs):
|
| 72 |
+
super().__init__(config)
|
| 73 |
+
self.config = config
|
| 74 |
+
self.num_layers = len(config.depths)
|
| 75 |
+
self.num_features = int(config.embed_dim * 2 ** (self.num_layers - 1))
|
| 76 |
+
|
| 77 |
+
self.embeddings = VariableDonutSwinEmbeddings(config, use_mask_token=use_mask_token)
|
| 78 |
+
self.encoder = DonutSwinEncoder(config, self.embeddings.patch_grid)
|
| 79 |
+
|
| 80 |
+
self.pooler = nn.AdaptiveAvgPool1d(1) if add_pooling_layer else None
|
| 81 |
+
|
| 82 |
+
# Initialize weights and apply final processing
|
| 83 |
+
self.post_init()
|
surya/model/ordering/encoderdecoder.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional, Union, Tuple, List
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from transformers import VisionEncoderDecoderModel
|
| 5 |
+
from transformers.modeling_outputs import Seq2SeqLMOutput, BaseModelOutput
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class OrderVisionEncoderDecoderModel(VisionEncoderDecoderModel):
|
| 9 |
+
def forward(
|
| 10 |
+
self,
|
| 11 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 12 |
+
decoder_input_boxes: torch.LongTensor = None,
|
| 13 |
+
# Shape (batch_size, num_boxes, 4), all coords scaled 0 - 1000, with 1001 as padding
|
| 14 |
+
decoder_input_boxes_mask: torch.LongTensor = None, # Shape (batch_size, num_boxes), 0 if padding, 1 otherwise
|
| 15 |
+
decoder_input_boxes_counts: torch.LongTensor = None, # Shape (batch_size), number of boxes in each image
|
| 16 |
+
encoder_outputs: Optional[Tuple[torch.FloatTensor]] = None,
|
| 17 |
+
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
|
| 18 |
+
decoder_inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 19 |
+
labels: Optional[List[List[int]]] = None,
|
| 20 |
+
use_cache: Optional[bool] = None,
|
| 21 |
+
output_attentions: Optional[bool] = None,
|
| 22 |
+
output_hidden_states: Optional[bool] = None,
|
| 23 |
+
return_dict: Optional[bool] = None,
|
| 24 |
+
**kwargs,
|
| 25 |
+
) -> Union[Tuple[torch.FloatTensor], Seq2SeqLMOutput]:
|
| 26 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 27 |
+
|
| 28 |
+
kwargs_encoder = {argument: value for argument, value in kwargs.items() if not argument.startswith("decoder_")}
|
| 29 |
+
|
| 30 |
+
kwargs_decoder = {
|
| 31 |
+
argument[len("decoder_") :]: value for argument, value in kwargs.items() if argument.startswith("decoder_")
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
if encoder_outputs is None:
|
| 35 |
+
if pixel_values is None:
|
| 36 |
+
raise ValueError("You have to specify pixel_values")
|
| 37 |
+
|
| 38 |
+
encoder_outputs = self.encoder(
|
| 39 |
+
pixel_values=pixel_values,
|
| 40 |
+
output_attentions=output_attentions,
|
| 41 |
+
output_hidden_states=output_hidden_states,
|
| 42 |
+
return_dict=return_dict,
|
| 43 |
+
**kwargs_encoder,
|
| 44 |
+
)
|
| 45 |
+
elif isinstance(encoder_outputs, tuple):
|
| 46 |
+
encoder_outputs = BaseModelOutput(*encoder_outputs)
|
| 47 |
+
|
| 48 |
+
encoder_hidden_states = encoder_outputs[0]
|
| 49 |
+
|
| 50 |
+
# optionally project encoder_hidden_states
|
| 51 |
+
if (
|
| 52 |
+
self.encoder.config.hidden_size != self.decoder.config.hidden_size
|
| 53 |
+
and self.decoder.config.cross_attention_hidden_size is None
|
| 54 |
+
):
|
| 55 |
+
encoder_hidden_states = self.enc_to_dec_proj(encoder_hidden_states)
|
| 56 |
+
|
| 57 |
+
# else:
|
| 58 |
+
encoder_attention_mask = None
|
| 59 |
+
|
| 60 |
+
# Decode
|
| 61 |
+
decoder_outputs = self.decoder(
|
| 62 |
+
input_boxes=decoder_input_boxes,
|
| 63 |
+
input_boxes_mask=decoder_input_boxes_mask,
|
| 64 |
+
input_boxes_counts=decoder_input_boxes_counts,
|
| 65 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 66 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 67 |
+
inputs_embeds=decoder_inputs_embeds,
|
| 68 |
+
output_attentions=output_attentions,
|
| 69 |
+
output_hidden_states=output_hidden_states,
|
| 70 |
+
use_cache=use_cache,
|
| 71 |
+
past_key_values=past_key_values,
|
| 72 |
+
return_dict=return_dict,
|
| 73 |
+
labels=labels,
|
| 74 |
+
**kwargs_decoder,
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
if not return_dict:
|
| 78 |
+
return decoder_outputs + encoder_outputs
|
| 79 |
+
|
| 80 |
+
return Seq2SeqLMOutput(
|
| 81 |
+
loss=decoder_outputs.loss,
|
| 82 |
+
logits=decoder_outputs.logits,
|
| 83 |
+
past_key_values=decoder_outputs.past_key_values,
|
| 84 |
+
decoder_hidden_states=decoder_outputs.hidden_states,
|
| 85 |
+
decoder_attentions=decoder_outputs.attentions,
|
| 86 |
+
cross_attentions=decoder_outputs.cross_attentions,
|
| 87 |
+
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
|
| 88 |
+
encoder_hidden_states=encoder_outputs.hidden_states,
|
| 89 |
+
encoder_attentions=encoder_outputs.attentions,
|
| 90 |
+
)
|
surya/model/ordering/model.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import DetrConfig, BeitConfig, DetrImageProcessor, VisionEncoderDecoderConfig, AutoModelForCausalLM, \
|
| 2 |
+
AutoModel
|
| 3 |
+
from surya.model.ordering.config import MBartOrderConfig, VariableDonutSwinConfig
|
| 4 |
+
from surya.model.ordering.decoder import MBartOrder
|
| 5 |
+
from surya.model.ordering.encoder import VariableDonutSwinModel
|
| 6 |
+
from surya.model.ordering.encoderdecoder import OrderVisionEncoderDecoderModel
|
| 7 |
+
from surya.model.ordering.processor import OrderImageProcessor
|
| 8 |
+
from surya.settings import settings
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def load_model(checkpoint=settings.ORDER_MODEL_CHECKPOINT, device=settings.TORCH_DEVICE_MODEL, dtype=settings.MODEL_DTYPE):
|
| 12 |
+
config = VisionEncoderDecoderConfig.from_pretrained(checkpoint)
|
| 13 |
+
|
| 14 |
+
decoder_config = vars(config.decoder)
|
| 15 |
+
decoder = MBartOrderConfig(**decoder_config)
|
| 16 |
+
config.decoder = decoder
|
| 17 |
+
|
| 18 |
+
encoder_config = vars(config.encoder)
|
| 19 |
+
encoder = VariableDonutSwinConfig(**encoder_config)
|
| 20 |
+
config.encoder = encoder
|
| 21 |
+
|
| 22 |
+
# Get transformers to load custom model
|
| 23 |
+
AutoModel.register(MBartOrderConfig, MBartOrder)
|
| 24 |
+
AutoModelForCausalLM.register(MBartOrderConfig, MBartOrder)
|
| 25 |
+
AutoModel.register(VariableDonutSwinConfig, VariableDonutSwinModel)
|
| 26 |
+
|
| 27 |
+
model = OrderVisionEncoderDecoderModel.from_pretrained(checkpoint, config=config, torch_dtype=dtype)
|
| 28 |
+
assert isinstance(model.decoder, MBartOrder)
|
| 29 |
+
assert isinstance(model.encoder, VariableDonutSwinModel)
|
| 30 |
+
|
| 31 |
+
model = model.to(device)
|
| 32 |
+
model = model.eval()
|
| 33 |
+
print(f"Loaded reading order model {checkpoint} on device {device} with dtype {dtype}")
|
| 34 |
+
return model
|
surya/model/ordering/processor.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from copy import deepcopy
|
| 2 |
+
from typing import Dict, Union, Optional, List, Tuple
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import TensorType
|
| 6 |
+
from transformers import DonutImageProcessor, DonutProcessor
|
| 7 |
+
from transformers.image_processing_utils import BatchFeature
|
| 8 |
+
from transformers.image_utils import PILImageResampling, ImageInput, ChannelDimension, make_list_of_images, \
|
| 9 |
+
valid_images, to_numpy_array
|
| 10 |
+
import numpy as np
|
| 11 |
+
from PIL import Image
|
| 12 |
+
import PIL
|
| 13 |
+
from surya.settings import settings
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def load_processor(checkpoint=settings.ORDER_MODEL_CHECKPOINT):
|
| 17 |
+
processor = OrderImageProcessor.from_pretrained(checkpoint)
|
| 18 |
+
processor.size = settings.ORDER_IMAGE_SIZE
|
| 19 |
+
box_size = 1024
|
| 20 |
+
max_tokens = 256
|
| 21 |
+
processor.token_sep_id = max_tokens + box_size + 1
|
| 22 |
+
processor.token_pad_id = max_tokens + box_size + 2
|
| 23 |
+
processor.max_boxes = settings.ORDER_MAX_BOXES - 1
|
| 24 |
+
processor.box_size = {"height": box_size, "width": box_size}
|
| 25 |
+
return processor
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class OrderImageProcessor(DonutImageProcessor):
|
| 29 |
+
def __init__(self, *args, **kwargs):
|
| 30 |
+
super().__init__(*args, **kwargs)
|
| 31 |
+
|
| 32 |
+
self.patch_size = kwargs.get("patch_size", (4, 4))
|
| 33 |
+
|
| 34 |
+
def process_inner(self, images: List[np.ndarray]):
|
| 35 |
+
images = [img.transpose(2, 0, 1) for img in images] # convert to CHW format
|
| 36 |
+
|
| 37 |
+
assert images[0].shape[0] == 3 # RGB input images, channel dim last
|
| 38 |
+
|
| 39 |
+
# Convert to float32 for rescale/normalize
|
| 40 |
+
images = [img.astype(np.float32) for img in images]
|
| 41 |
+
|
| 42 |
+
# Rescale and normalize
|
| 43 |
+
images = [
|
| 44 |
+
self.rescale(img, scale=self.rescale_factor, input_data_format=ChannelDimension.FIRST)
|
| 45 |
+
for img in images
|
| 46 |
+
]
|
| 47 |
+
images = [
|
| 48 |
+
self.normalize(img, mean=self.image_mean, std=self.image_std, input_data_format=ChannelDimension.FIRST)
|
| 49 |
+
for img in images
|
| 50 |
+
]
|
| 51 |
+
|
| 52 |
+
return images
|
| 53 |
+
|
| 54 |
+
def process_boxes(self, boxes):
|
| 55 |
+
padded_boxes = []
|
| 56 |
+
box_masks = []
|
| 57 |
+
box_counts = []
|
| 58 |
+
for b in boxes:
|
| 59 |
+
# Left pad for generation
|
| 60 |
+
padded_b = deepcopy(b)
|
| 61 |
+
padded_b.append([self.token_sep_id] * 4) # Sep token to indicate start of label predictions
|
| 62 |
+
padded_boxes.append(padded_b)
|
| 63 |
+
|
| 64 |
+
max_boxes = max(len(b) for b in padded_boxes)
|
| 65 |
+
for i in range(len(padded_boxes)):
|
| 66 |
+
pad_len = max_boxes - len(padded_boxes[i])
|
| 67 |
+
box_len = len(padded_boxes[i])
|
| 68 |
+
box_mask = [0] * pad_len + [1] * box_len
|
| 69 |
+
padded_box = [[self.token_pad_id] * 4] * pad_len + padded_boxes[i]
|
| 70 |
+
padded_boxes[i] = padded_box
|
| 71 |
+
box_masks.append(box_mask)
|
| 72 |
+
box_counts.append([pad_len, max_boxes])
|
| 73 |
+
|
| 74 |
+
return padded_boxes, box_masks, box_counts
|
| 75 |
+
|
| 76 |
+
def resize_img_and_boxes(self, img, boxes):
|
| 77 |
+
orig_dim = img.size
|
| 78 |
+
new_size = (self.size["width"], self.size["height"])
|
| 79 |
+
img.thumbnail(new_size, Image.Resampling.LANCZOS) # Shrink largest dimension to fit new size
|
| 80 |
+
img = img.resize(new_size, Image.Resampling.LANCZOS) # Stretch smaller dimension to fit new size
|
| 81 |
+
|
| 82 |
+
img = np.asarray(img, dtype=np.uint8)
|
| 83 |
+
|
| 84 |
+
width, height = orig_dim
|
| 85 |
+
box_width, box_height = self.box_size["width"], self.box_size["height"]
|
| 86 |
+
for box in boxes:
|
| 87 |
+
# Rescale to 0-1024
|
| 88 |
+
box[0] = box[0] / width * box_width
|
| 89 |
+
box[1] = box[1] / height * box_height
|
| 90 |
+
box[2] = box[2] / width * box_width
|
| 91 |
+
box[3] = box[3] / height * box_height
|
| 92 |
+
|
| 93 |
+
if box[0] < 0:
|
| 94 |
+
box[0] = 0
|
| 95 |
+
if box[1] < 0:
|
| 96 |
+
box[1] = 0
|
| 97 |
+
if box[2] > box_width:
|
| 98 |
+
box[2] = box_width
|
| 99 |
+
if box[3] > box_height:
|
| 100 |
+
box[3] = box_height
|
| 101 |
+
|
| 102 |
+
return img, boxes
|
| 103 |
+
|
| 104 |
+
def preprocess(
|
| 105 |
+
self,
|
| 106 |
+
images: ImageInput,
|
| 107 |
+
boxes: List[List[int]],
|
| 108 |
+
do_resize: bool = None,
|
| 109 |
+
size: Dict[str, int] = None,
|
| 110 |
+
resample: PILImageResampling = None,
|
| 111 |
+
do_thumbnail: bool = None,
|
| 112 |
+
do_align_long_axis: bool = None,
|
| 113 |
+
do_pad: bool = None,
|
| 114 |
+
random_padding: bool = False,
|
| 115 |
+
do_rescale: bool = None,
|
| 116 |
+
rescale_factor: float = None,
|
| 117 |
+
do_normalize: bool = None,
|
| 118 |
+
image_mean: Optional[Union[float, List[float]]] = None,
|
| 119 |
+
image_std: Optional[Union[float, List[float]]] = None,
|
| 120 |
+
return_tensors: Optional[Union[str, TensorType]] = None,
|
| 121 |
+
data_format: Optional[ChannelDimension] = ChannelDimension.FIRST,
|
| 122 |
+
input_data_format: Optional[Union[str, ChannelDimension]] = None,
|
| 123 |
+
**kwargs,
|
| 124 |
+
) -> PIL.Image.Image:
|
| 125 |
+
images = make_list_of_images(images)
|
| 126 |
+
|
| 127 |
+
if not valid_images(images):
|
| 128 |
+
raise ValueError(
|
| 129 |
+
"Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
|
| 130 |
+
"torch.Tensor, tf.Tensor or jax.ndarray."
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
new_images = []
|
| 134 |
+
new_boxes = []
|
| 135 |
+
for img, box in zip(images, boxes):
|
| 136 |
+
if len(box) > self.max_boxes:
|
| 137 |
+
raise ValueError(f"Too many boxes, max is {self.max_boxes}")
|
| 138 |
+
img, box = self.resize_img_and_boxes(img, box)
|
| 139 |
+
new_images.append(img)
|
| 140 |
+
new_boxes.append(box)
|
| 141 |
+
|
| 142 |
+
images = new_images
|
| 143 |
+
boxes = new_boxes
|
| 144 |
+
|
| 145 |
+
# Convert to numpy for later processing steps
|
| 146 |
+
images = [np.array(image) for image in images]
|
| 147 |
+
|
| 148 |
+
images = self.process_inner(images)
|
| 149 |
+
boxes, box_mask, box_counts = self.process_boxes(boxes)
|
| 150 |
+
data = {
|
| 151 |
+
"pixel_values": images,
|
| 152 |
+
"input_boxes": boxes,
|
| 153 |
+
"input_boxes_mask": box_mask,
|
| 154 |
+
"input_boxes_counts": box_counts,
|
| 155 |
+
}
|
| 156 |
+
return BatchFeature(data=data, tensor_type=return_tensors)
|
surya/model/recognition/__pycache__/config.cpython-310.pyc
ADDED
|
Binary file (2.41 kB). View file
|
|
|
surya/model/recognition/__pycache__/decoder.cpython-310.pyc
ADDED
|
Binary file (14.2 kB). View file
|
|
|
surya/model/recognition/__pycache__/encoder.cpython-310.pyc
ADDED
|
Binary file (13.2 kB). View file
|
|
|
surya/model/recognition/__pycache__/model.cpython-310.pyc
ADDED
|
Binary file (2.56 kB). View file
|
|
|
surya/model/recognition/__pycache__/processor.cpython-310.pyc
ADDED
|
Binary file (7.14 kB). View file
|
|
|
surya/model/recognition/__pycache__/tokenizer.cpython-310.pyc
ADDED
|
Binary file (3.5 kB). View file
|
|
|
surya/model/recognition/config.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import T5Config, MBartConfig, DonutSwinConfig
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class MBartMoEConfig(MBartConfig):
|
| 5 |
+
pass
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class VariableDonutSwinConfig(DonutSwinConfig):
|
| 9 |
+
pass
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# Config specific to the model, needed for the tokenizer
|
| 13 |
+
TOTAL_TOKENS = 65536
|
| 14 |
+
TOKEN_OFFSET = 3 # Pad, eos, bos
|
| 15 |
+
SPECIAL_TOKENS = 253
|
| 16 |
+
TOTAL_VOCAB_SIZE = TOTAL_TOKENS + TOKEN_OFFSET + SPECIAL_TOKENS
|
| 17 |
+
LANGUAGE_MAP = {
|
| 18 |
+
'af': 0,
|
| 19 |
+
'am': 1,
|
| 20 |
+
'ar': 2,
|
| 21 |
+
'as': 3,
|
| 22 |
+
'az': 4,
|
| 23 |
+
'be': 5,
|
| 24 |
+
'bg': 6,
|
| 25 |
+
'bn': 7,
|
| 26 |
+
'br': 8,
|
| 27 |
+
'bs': 9,
|
| 28 |
+
'ca': 10,
|
| 29 |
+
'cs': 11,
|
| 30 |
+
'cy': 12,
|
| 31 |
+
'da': 13,
|
| 32 |
+
'de': 14,
|
| 33 |
+
'el': 15,
|
| 34 |
+
'en': 16,
|
| 35 |
+
'eo': 17,
|
| 36 |
+
'es': 18,
|
| 37 |
+
'et': 19,
|
| 38 |
+
'eu': 20,
|
| 39 |
+
'fa': 21,
|
| 40 |
+
'fi': 22,
|
| 41 |
+
'fr': 23,
|
| 42 |
+
'fy': 24,
|
| 43 |
+
'ga': 25,
|
| 44 |
+
'gd': 26,
|
| 45 |
+
'gl': 27,
|
| 46 |
+
'gu': 28,
|
| 47 |
+
'ha': 29,
|
| 48 |
+
'he': 30,
|
| 49 |
+
'hi': 31,
|
| 50 |
+
'hr': 32,
|
| 51 |
+
'hu': 33,
|
| 52 |
+
'hy': 34,
|
| 53 |
+
'id': 35,
|
| 54 |
+
'is': 36,
|
| 55 |
+
'it': 37,
|
| 56 |
+
'ja': 38,
|
| 57 |
+
'jv': 39,
|
| 58 |
+
'ka': 40,
|
| 59 |
+
'kk': 41,
|
| 60 |
+
'km': 42,
|
| 61 |
+
'kn': 43,
|
| 62 |
+
'ko': 44,
|
| 63 |
+
'ku': 45,
|
| 64 |
+
'ky': 46,
|
| 65 |
+
'la': 47,
|
| 66 |
+
'lo': 48,
|
| 67 |
+
'lt': 49,
|
| 68 |
+
'lv': 50,
|
| 69 |
+
'mg': 51,
|
| 70 |
+
'mk': 52,
|
| 71 |
+
'ml': 53,
|
| 72 |
+
'mn': 54,
|
| 73 |
+
'mr': 55,
|
| 74 |
+
'ms': 56,
|
| 75 |
+
'my': 57,
|
| 76 |
+
'ne': 58,
|
| 77 |
+
'nl': 59,
|
| 78 |
+
'no': 60,
|
| 79 |
+
'om': 61,
|
| 80 |
+
'or': 62,
|
| 81 |
+
'pa': 63,
|
| 82 |
+
'pl': 64,
|
| 83 |
+
'ps': 65,
|
| 84 |
+
'pt': 66,
|
| 85 |
+
'ro': 67,
|
| 86 |
+
'ru': 68,
|
| 87 |
+
'sa': 69,
|
| 88 |
+
'sd': 70,
|
| 89 |
+
'si': 71,
|
| 90 |
+
'sk': 72,
|
| 91 |
+
'sl': 73,
|
| 92 |
+
'so': 74,
|
| 93 |
+
'sq': 75,
|
| 94 |
+
'sr': 76,
|
| 95 |
+
'su': 77,
|
| 96 |
+
'sv': 78,
|
| 97 |
+
'sw': 79,
|
| 98 |
+
'ta': 80,
|
| 99 |
+
'te': 81,
|
| 100 |
+
'th': 82,
|
| 101 |
+
'tl': 83,
|
| 102 |
+
'tr': 84,
|
| 103 |
+
'ug': 85,
|
| 104 |
+
'uk': 86,
|
| 105 |
+
'ur': 87,
|
| 106 |
+
'uz': 88,
|
| 107 |
+
'vi': 89,
|
| 108 |
+
'xh': 90,
|
| 109 |
+
'yi': 91,
|
| 110 |
+
'zh': 92
|
| 111 |
+
}
|
surya/model/recognition/decoder.py
ADDED
|
@@ -0,0 +1,511 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
from typing import Optional, List, Union, Tuple
|
| 3 |
+
|
| 4 |
+
from transformers import MBartForCausalLM, MBartConfig
|
| 5 |
+
from torch import nn
|
| 6 |
+
from transformers.activations import ACT2FN
|
| 7 |
+
from transformers.modeling_outputs import CausalLMOutputWithCrossAttentions, BaseModelOutputWithPastAndCrossAttentions
|
| 8 |
+
from transformers.models.mbart.modeling_mbart import MBartPreTrainedModel, MBartDecoder
|
| 9 |
+
from .config import MBartMoEConfig
|
| 10 |
+
import torch
|
| 11 |
+
import math
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class MBartLearnedPositionalEmbedding(nn.Embedding):
|
| 15 |
+
"""
|
| 16 |
+
This module learns positional embeddings up to a fixed maximum size.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
def __init__(self, num_embeddings: int, embedding_dim: int):
|
| 20 |
+
# MBart is set up so that if padding_idx is specified then offset the embedding ids by 2
|
| 21 |
+
# and adjust num_embeddings appropriately. Other models don't have this hack
|
| 22 |
+
self.offset = 2
|
| 23 |
+
super().__init__(num_embeddings + self.offset, embedding_dim)
|
| 24 |
+
|
| 25 |
+
def forward(self, input_ids: torch.Tensor, past_key_values_length: int = 0):
|
| 26 |
+
"""`input_ids' shape is expected to be [bsz x seqlen]."""
|
| 27 |
+
|
| 28 |
+
bsz, seq_len = input_ids.shape[:2]
|
| 29 |
+
positions = torch.arange(
|
| 30 |
+
past_key_values_length, past_key_values_length + seq_len, dtype=torch.long, device=self.weight.device
|
| 31 |
+
).expand(bsz, -1)
|
| 32 |
+
|
| 33 |
+
return super().forward(positions + self.offset)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class MBartExpertMLP(nn.Module):
|
| 37 |
+
def __init__(self, config: MBartConfig, is_lg=False, is_xl=False):
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.ffn_dim = config.d_expert
|
| 40 |
+
if is_lg:
|
| 41 |
+
self.ffn_dim = config.d_expert_lg
|
| 42 |
+
if is_xl:
|
| 43 |
+
self.ffn_dim = config.d_expert_xl
|
| 44 |
+
self.hidden_dim = config.d_model
|
| 45 |
+
|
| 46 |
+
self.w1 = nn.Linear(self.hidden_dim, self.ffn_dim, bias=False)
|
| 47 |
+
self.w2 = nn.Linear(self.ffn_dim, self.hidden_dim, bias=False)
|
| 48 |
+
self.w3 = nn.Linear(self.hidden_dim, self.ffn_dim, bias=False)
|
| 49 |
+
self.dropout = nn.Dropout(config.activation_dropout)
|
| 50 |
+
|
| 51 |
+
self.act_fn = ACT2FN[config.activation_function]
|
| 52 |
+
|
| 53 |
+
def forward(self, hidden_states):
|
| 54 |
+
current_hidden_states = self.act_fn(self.w1(hidden_states)) * self.w3(hidden_states)
|
| 55 |
+
current_hidden_states = self.w2(current_hidden_states)
|
| 56 |
+
return current_hidden_states
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
class MBartExpertLayer(nn.Module):
|
| 60 |
+
# From mixtral, with modifications
|
| 61 |
+
def __init__(self, config):
|
| 62 |
+
super().__init__()
|
| 63 |
+
self.dropout = nn.Dropout(config.activation_dropout)
|
| 64 |
+
|
| 65 |
+
self.hidden_dim = config.d_model
|
| 66 |
+
|
| 67 |
+
self.lg_lang_codes = sorted(config.lg_langs.values()) if hasattr(config, "lg_langs") else []
|
| 68 |
+
self.xl_lang_codes = sorted(config.xl_langs.values()) if hasattr(config, "xl_langs") else []
|
| 69 |
+
|
| 70 |
+
self.lang_codes = sorted(config.langs.values())
|
| 71 |
+
self.num_experts = len(self.lang_codes)
|
| 72 |
+
|
| 73 |
+
self.experts = nn.ModuleDict({str(lang): MBartExpertMLP(config, is_lg=(lang in self.lg_lang_codes), is_xl=(lang in self.xl_lang_codes)) for lang in self.lang_codes})
|
| 74 |
+
|
| 75 |
+
def forward(self, hidden_states: torch.Tensor, langs: torch.LongTensor) -> torch.Tensor:
|
| 76 |
+
batch_size, sequence_length, hidden_dim = hidden_states.shape
|
| 77 |
+
|
| 78 |
+
final_hidden_states = torch.zeros(
|
| 79 |
+
(batch_size, sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
# Weight experts based on how many languages in the input
|
| 83 |
+
routing_weights = 1 / ((langs > 3).sum(axis=-1))
|
| 84 |
+
# Set weights to 1 if zero experts activated
|
| 85 |
+
routing_weights[torch.isinf(routing_weights)] = 1
|
| 86 |
+
|
| 87 |
+
unique_langs = langs.unique(dim=None, sorted=True)
|
| 88 |
+
unique_langs = unique_langs[unique_langs > 3] # Remove start token
|
| 89 |
+
|
| 90 |
+
# Loop over all available experts in the model and perform the computation on each expert
|
| 91 |
+
for expert_lang in unique_langs:
|
| 92 |
+
# Check which samples match with this expert
|
| 93 |
+
lang_match = (langs == expert_lang).any(dim=-1)
|
| 94 |
+
idx = torch.nonzero(lang_match, as_tuple=True)[0]
|
| 95 |
+
|
| 96 |
+
if idx.shape[0] == 0:
|
| 97 |
+
continue
|
| 98 |
+
|
| 99 |
+
expert_layer = self.experts[str(expert_lang.item())]
|
| 100 |
+
|
| 101 |
+
current_state = hidden_states[idx]
|
| 102 |
+
current_hidden_states = expert_layer(current_state.view(-1, hidden_dim))
|
| 103 |
+
current_hidden_states = current_hidden_states.view(-1, sequence_length, hidden_dim)
|
| 104 |
+
|
| 105 |
+
# Weight by number of languages in the input
|
| 106 |
+
selected_routing_weights = routing_weights[idx].view(-1, 1, 1)
|
| 107 |
+
current_hidden_states *= selected_routing_weights
|
| 108 |
+
|
| 109 |
+
final_hidden_states.index_add_(0, idx, current_hidden_states)
|
| 110 |
+
|
| 111 |
+
return final_hidden_states
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
class MBartGQAttention(nn.Module):
|
| 115 |
+
def __init__(
|
| 116 |
+
self,
|
| 117 |
+
embed_dim: int,
|
| 118 |
+
num_heads: int,
|
| 119 |
+
num_kv_heads: int,
|
| 120 |
+
dropout: float = 0.0,
|
| 121 |
+
is_decoder: bool = False,
|
| 122 |
+
bias: bool = True,
|
| 123 |
+
is_causal: bool = False,
|
| 124 |
+
config: Optional[MBartConfig] = None,
|
| 125 |
+
):
|
| 126 |
+
super().__init__()
|
| 127 |
+
self.embed_dim = embed_dim
|
| 128 |
+
self.num_heads = num_heads
|
| 129 |
+
self.num_kv_heads = num_kv_heads
|
| 130 |
+
self.num_kv_groups = self.num_heads // self.num_kv_heads
|
| 131 |
+
|
| 132 |
+
self.dropout = dropout
|
| 133 |
+
self.head_dim = embed_dim // num_heads
|
| 134 |
+
self.config = config
|
| 135 |
+
self.scaling = self.head_dim**-0.5
|
| 136 |
+
self.is_decoder = is_decoder
|
| 137 |
+
self.is_causal = is_causal
|
| 138 |
+
|
| 139 |
+
self.k_proj = nn.Linear(embed_dim, self.num_kv_heads * self.head_dim, bias=bias)
|
| 140 |
+
self.v_proj = nn.Linear(embed_dim, self.num_kv_heads * self.head_dim, bias=bias)
|
| 141 |
+
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
|
| 142 |
+
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
|
| 143 |
+
|
| 144 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 145 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 146 |
+
|
| 147 |
+
def _shape_key_value(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 148 |
+
return tensor.view(bsz, seq_len, self.num_kv_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 149 |
+
|
| 150 |
+
def forward(
|
| 151 |
+
self,
|
| 152 |
+
hidden_states: torch.Tensor,
|
| 153 |
+
key_value_states: Optional[torch.Tensor] = None,
|
| 154 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 155 |
+
is_prefill: Optional[bool] = False,
|
| 156 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 157 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 158 |
+
"""Input shape: Batch x Time x Channel"""
|
| 159 |
+
|
| 160 |
+
# if key_value_states are provided this layer is used as a cross-attention layer
|
| 161 |
+
# for the decoder
|
| 162 |
+
is_cross_attention = key_value_states is not None
|
| 163 |
+
|
| 164 |
+
bsz, tgt_len, _ = hidden_states.size()
|
| 165 |
+
|
| 166 |
+
# get query proj
|
| 167 |
+
query_states = self.q_proj(hidden_states) * self.scaling
|
| 168 |
+
# get key, value proj
|
| 169 |
+
# `past_key_value[0].shape[2] == key_value_states.shape[1]`
|
| 170 |
+
# is checking that the `sequence_length` of the `past_key_value` is the same as
|
| 171 |
+
# the provided `key_value_states` to support prefix tuning
|
| 172 |
+
if is_cross_attention:
|
| 173 |
+
if is_prefill:
|
| 174 |
+
# cross_attentions
|
| 175 |
+
key_states = self._shape_key_value(self.k_proj(key_value_states), -1, bsz)
|
| 176 |
+
value_states = self._shape_key_value(self.v_proj(key_value_states), -1, bsz)
|
| 177 |
+
past_key_value = torch.cat([key_states.unsqueeze(0), value_states.unsqueeze(0)], dim=0)
|
| 178 |
+
else:
|
| 179 |
+
# reuse k,v, cross_attentions
|
| 180 |
+
key_states = past_key_value[0]
|
| 181 |
+
value_states = past_key_value[1]
|
| 182 |
+
past_key_value = None
|
| 183 |
+
# Self-attention
|
| 184 |
+
else:
|
| 185 |
+
if is_prefill:
|
| 186 |
+
# initial prompt
|
| 187 |
+
key_states = self._shape_key_value(self.k_proj(hidden_states), -1, bsz)
|
| 188 |
+
value_states = self._shape_key_value(self.v_proj(hidden_states), -1, bsz)
|
| 189 |
+
past_key_value = torch.cat([key_states[:, :, -tgt_len:].unsqueeze(0), value_states[:, :, -tgt_len:].unsqueeze(0)], dim=0)
|
| 190 |
+
else:
|
| 191 |
+
# reuse k, v, self_attention
|
| 192 |
+
key_states = self._shape_key_value(self.k_proj(hidden_states), -1, bsz)
|
| 193 |
+
value_states = self._shape_key_value(self.v_proj(hidden_states), -1, bsz)
|
| 194 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 195 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 196 |
+
past_key_value = torch.cat([key_states[:, :, -tgt_len:].unsqueeze(0), value_states[:, :, -tgt_len:].unsqueeze(0)], dim=0)
|
| 197 |
+
|
| 198 |
+
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
|
| 199 |
+
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
|
| 200 |
+
|
| 201 |
+
# Expand kv heads, then match query shape
|
| 202 |
+
key_states = key_states.repeat_interleave(self.num_kv_groups, dim=1).reshape(*proj_shape)
|
| 203 |
+
value_states = value_states.repeat_interleave(self.num_kv_groups, dim=1).reshape(*proj_shape)
|
| 204 |
+
|
| 205 |
+
src_len = key_states.size(1)
|
| 206 |
+
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
|
| 207 |
+
|
| 208 |
+
if not is_cross_attention:
|
| 209 |
+
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
|
| 210 |
+
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
|
| 211 |
+
|
| 212 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 213 |
+
|
| 214 |
+
attn_output = torch.bmm(attn_weights, value_states).view(bsz, self.num_heads, tgt_len, self.head_dim).transpose(1,2)
|
| 215 |
+
|
| 216 |
+
# Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
|
| 217 |
+
# partitioned across GPUs when using tensor-parallelism.
|
| 218 |
+
attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
|
| 219 |
+
attn_output = self.out_proj(attn_output)
|
| 220 |
+
|
| 221 |
+
return attn_output, past_key_value
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
class MBartMoEDecoderLayer(nn.Module):
|
| 225 |
+
def __init__(self, config: MBartConfig, has_moe=False):
|
| 226 |
+
super().__init__()
|
| 227 |
+
self.embed_dim = config.d_model
|
| 228 |
+
|
| 229 |
+
self.self_attn = MBartGQAttention(
|
| 230 |
+
embed_dim=self.embed_dim,
|
| 231 |
+
num_heads=config.decoder_attention_heads,
|
| 232 |
+
num_kv_heads=config.kv_heads,
|
| 233 |
+
dropout=config.attention_dropout,
|
| 234 |
+
is_decoder=True,
|
| 235 |
+
is_causal=True,
|
| 236 |
+
config=config,
|
| 237 |
+
)
|
| 238 |
+
self.dropout = config.dropout
|
| 239 |
+
self.activation_fn = ACT2FN[config.activation_function]
|
| 240 |
+
self.activation_dropout = config.activation_dropout
|
| 241 |
+
|
| 242 |
+
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
|
| 243 |
+
self.encoder_attn = MBartGQAttention(
|
| 244 |
+
self.embed_dim,
|
| 245 |
+
config.decoder_attention_heads,
|
| 246 |
+
num_kv_heads=config.kv_heads,
|
| 247 |
+
dropout=config.attention_dropout,
|
| 248 |
+
is_decoder=True,
|
| 249 |
+
config=config,
|
| 250 |
+
)
|
| 251 |
+
self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim)
|
| 252 |
+
self.has_moe = has_moe
|
| 253 |
+
if has_moe:
|
| 254 |
+
self.moe = MBartExpertLayer(config)
|
| 255 |
+
else:
|
| 256 |
+
self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
|
| 257 |
+
self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
|
| 258 |
+
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
|
| 259 |
+
|
| 260 |
+
def forward(
|
| 261 |
+
self,
|
| 262 |
+
hidden_states: torch.Tensor,
|
| 263 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 264 |
+
langs: Optional[torch.LongTensor] = None,
|
| 265 |
+
self_kv_cache: Optional[torch.Tensor] = None,
|
| 266 |
+
cross_kv_cache: Optional[torch.Tensor] = None,
|
| 267 |
+
is_prefill: Optional[bool] = False,
|
| 268 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 269 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 270 |
+
use_cache: Optional[bool] = True,
|
| 271 |
+
) -> torch.Tensor:
|
| 272 |
+
residual = hidden_states
|
| 273 |
+
hidden_states = self.self_attn_layer_norm(hidden_states)
|
| 274 |
+
|
| 275 |
+
# Self Attention
|
| 276 |
+
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
|
| 277 |
+
# add present self-attn cache to positions 1,2 of present_key_value tuple
|
| 278 |
+
hidden_states, present_key_value = self.self_attn(
|
| 279 |
+
hidden_states=hidden_states,
|
| 280 |
+
past_key_value=self_kv_cache,
|
| 281 |
+
is_prefill=is_prefill,
|
| 282 |
+
attention_mask=attention_mask,
|
| 283 |
+
)
|
| 284 |
+
hidden_states = residual + hidden_states
|
| 285 |
+
|
| 286 |
+
# Cross-Attention Block
|
| 287 |
+
if encoder_hidden_states is not None:
|
| 288 |
+
residual = hidden_states
|
| 289 |
+
hidden_states = self.encoder_attn_layer_norm(hidden_states)
|
| 290 |
+
|
| 291 |
+
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
|
| 292 |
+
hidden_states, cross_attn_present_key_value = self.encoder_attn(
|
| 293 |
+
hidden_states=hidden_states,
|
| 294 |
+
key_value_states=encoder_hidden_states,
|
| 295 |
+
is_prefill=is_prefill,
|
| 296 |
+
attention_mask=encoder_attention_mask,
|
| 297 |
+
past_key_value=cross_kv_cache,
|
| 298 |
+
)
|
| 299 |
+
hidden_states = residual + hidden_states
|
| 300 |
+
|
| 301 |
+
# add cross-attn to positions 3,4 of present_key_value tuple
|
| 302 |
+
present_key_value = (present_key_value, cross_attn_present_key_value)
|
| 303 |
+
|
| 304 |
+
# Fully Connected
|
| 305 |
+
residual = hidden_states
|
| 306 |
+
hidden_states = self.final_layer_norm(hidden_states)
|
| 307 |
+
if self.has_moe:
|
| 308 |
+
hidden_states = self.moe(hidden_states, langs)
|
| 309 |
+
else:
|
| 310 |
+
hidden_states = self.activation_fn(self.fc1(hidden_states))
|
| 311 |
+
hidden_states = self.fc2(hidden_states)
|
| 312 |
+
|
| 313 |
+
hidden_states = residual + hidden_states
|
| 314 |
+
|
| 315 |
+
outputs = (hidden_states,)
|
| 316 |
+
|
| 317 |
+
if use_cache:
|
| 318 |
+
outputs += (present_key_value,)
|
| 319 |
+
|
| 320 |
+
return outputs
|
| 321 |
+
|
| 322 |
+
|
| 323 |
+
class MBartMoEDecoder(MBartDecoder):
|
| 324 |
+
def __init__(self, config: MBartConfig, embed_tokens: Optional[nn.Embedding] = None):
|
| 325 |
+
MBartPreTrainedModel.__init__(self, config)
|
| 326 |
+
self.dropout = config.dropout
|
| 327 |
+
self.layerdrop = config.decoder_layerdrop
|
| 328 |
+
self.padding_idx = config.pad_token_id
|
| 329 |
+
self.max_target_positions = config.max_position_embeddings
|
| 330 |
+
self.embed_scale = math.sqrt(config.d_model) if config.scale_embedding else 1.0
|
| 331 |
+
|
| 332 |
+
self.embed_tokens = nn.Embedding(config.vocab_size, config.d_model, self.padding_idx)
|
| 333 |
+
|
| 334 |
+
if embed_tokens is not None:
|
| 335 |
+
self.embed_tokens.weight = embed_tokens.weight
|
| 336 |
+
|
| 337 |
+
self.embed_positions = MBartLearnedPositionalEmbedding(
|
| 338 |
+
config.max_position_embeddings,
|
| 339 |
+
config.d_model,
|
| 340 |
+
)
|
| 341 |
+
# Language-specific MoE goes at second and second-to-last layer
|
| 342 |
+
self.layers = nn.ModuleList([MBartMoEDecoderLayer(config, has_moe=(i in config.moe_layers) and config.use_moe) for i in range(config.decoder_layers)])
|
| 343 |
+
self.layernorm_embedding = nn.LayerNorm(config.d_model)
|
| 344 |
+
self.layer_norm = nn.LayerNorm(config.d_model)
|
| 345 |
+
|
| 346 |
+
self.gradient_checkpointing = False
|
| 347 |
+
# Initialize weights and apply final processing
|
| 348 |
+
self.post_init()
|
| 349 |
+
|
| 350 |
+
def forward(
|
| 351 |
+
self,
|
| 352 |
+
input_ids: torch.LongTensor = None,
|
| 353 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 354 |
+
self_kv_cache: Optional[torch.Tensor] = None,
|
| 355 |
+
cross_kv_cache: Optional[torch.Tensor] = None,
|
| 356 |
+
past_token_count: Optional[int] = None,
|
| 357 |
+
langs: Optional[torch.LongTensor] = None,
|
| 358 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 359 |
+
) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]:
|
| 360 |
+
use_cache = True
|
| 361 |
+
return_dict = True
|
| 362 |
+
|
| 363 |
+
input = input_ids
|
| 364 |
+
input_shape = input.size()
|
| 365 |
+
input_ids = input_ids.view(-1, input_shape[-1])
|
| 366 |
+
|
| 367 |
+
# past_key_values_length
|
| 368 |
+
past_key_values_length = past_token_count if self_kv_cache is not None else 0
|
| 369 |
+
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
|
| 370 |
+
|
| 371 |
+
# embed positions
|
| 372 |
+
positions = self.embed_positions(input, past_key_values_length)
|
| 373 |
+
|
| 374 |
+
hidden_states = inputs_embeds + positions
|
| 375 |
+
hidden_states = self.layernorm_embedding(hidden_states)
|
| 376 |
+
|
| 377 |
+
# decoder layers
|
| 378 |
+
all_hidden_states = None
|
| 379 |
+
all_self_attns = None
|
| 380 |
+
all_cross_attentions = None
|
| 381 |
+
next_decoder_cache = () if use_cache else None
|
| 382 |
+
|
| 383 |
+
for idx, decoder_layer in enumerate(self.layers):
|
| 384 |
+
is_prefill = past_token_count == 0
|
| 385 |
+
layer_self_kv_cache = self_kv_cache[idx] if self_kv_cache is not None else None
|
| 386 |
+
layer_cross_kv_cache = cross_kv_cache[idx] if cross_kv_cache is not None else None
|
| 387 |
+
layer_outputs = decoder_layer(
|
| 388 |
+
hidden_states,
|
| 389 |
+
attention_mask=attention_mask,
|
| 390 |
+
langs=langs,
|
| 391 |
+
self_kv_cache=layer_self_kv_cache,
|
| 392 |
+
cross_kv_cache=layer_cross_kv_cache,
|
| 393 |
+
is_prefill=is_prefill,
|
| 394 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 395 |
+
encoder_attention_mask=None,
|
| 396 |
+
use_cache=use_cache,
|
| 397 |
+
)
|
| 398 |
+
hidden_states = layer_outputs[0]
|
| 399 |
+
|
| 400 |
+
if use_cache:
|
| 401 |
+
next_decoder_cache += (layer_outputs[1],)
|
| 402 |
+
|
| 403 |
+
hidden_states = self.layer_norm(hidden_states)
|
| 404 |
+
|
| 405 |
+
next_cache = next_decoder_cache if use_cache else None
|
| 406 |
+
if not return_dict:
|
| 407 |
+
return tuple(
|
| 408 |
+
v
|
| 409 |
+
for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_cross_attentions]
|
| 410 |
+
if v is not None
|
| 411 |
+
)
|
| 412 |
+
return BaseModelOutputWithPastAndCrossAttentions(
|
| 413 |
+
last_hidden_state=hidden_states,
|
| 414 |
+
past_key_values=next_cache,
|
| 415 |
+
hidden_states=all_hidden_states,
|
| 416 |
+
attentions=all_self_attns,
|
| 417 |
+
cross_attentions=all_cross_attentions,
|
| 418 |
+
)
|
| 419 |
+
|
| 420 |
+
|
| 421 |
+
class MBartMoEDecoderWrapper(MBartPreTrainedModel):
|
| 422 |
+
"""
|
| 423 |
+
This wrapper class is a helper class to correctly load pretrained checkpoints when the causal language model is
|
| 424 |
+
used in combination with the [`EncoderDecoderModel`] framework.
|
| 425 |
+
"""
|
| 426 |
+
|
| 427 |
+
def __init__(self, config):
|
| 428 |
+
super().__init__(config)
|
| 429 |
+
self.decoder = MBartMoEDecoder(config)
|
| 430 |
+
|
| 431 |
+
def forward(self, *args, **kwargs):
|
| 432 |
+
return self.decoder(*args, **kwargs)
|
| 433 |
+
|
| 434 |
+
|
| 435 |
+
class MBartMoE(MBartForCausalLM):
|
| 436 |
+
config_class = MBartMoEConfig
|
| 437 |
+
_tied_weights_keys = ["lm_head.weight"]
|
| 438 |
+
|
| 439 |
+
def __init__(self, config, **kwargs):
|
| 440 |
+
config = copy.deepcopy(config)
|
| 441 |
+
config.is_decoder = True
|
| 442 |
+
config.is_encoder_decoder = False
|
| 443 |
+
MBartPreTrainedModel.__init__(self, config)
|
| 444 |
+
self.model = MBartMoEDecoderWrapper(config)
|
| 445 |
+
|
| 446 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 447 |
+
|
| 448 |
+
# Initialize weights and apply final processing
|
| 449 |
+
self.post_init()
|
| 450 |
+
|
| 451 |
+
def forward(
|
| 452 |
+
self,
|
| 453 |
+
input_ids: torch.LongTensor = None,
|
| 454 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 455 |
+
self_kv_cache: Optional[torch.FloatTensor] = None,
|
| 456 |
+
cross_kv_cache: Optional[torch.FloatTensor] = None,
|
| 457 |
+
past_token_count: Optional[int] = None,
|
| 458 |
+
langs: Optional[torch.LongTensor] = None,
|
| 459 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 460 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 461 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 462 |
+
cross_attn_head_mask: Optional[torch.Tensor] = None,
|
| 463 |
+
past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
|
| 464 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 465 |
+
labels: Optional[torch.LongTensor] = None,
|
| 466 |
+
use_cache: Optional[bool] = None,
|
| 467 |
+
output_attentions: Optional[bool] = None,
|
| 468 |
+
output_hidden_states: Optional[bool] = None,
|
| 469 |
+
return_dict: Optional[bool] = None,
|
| 470 |
+
**kwargs
|
| 471 |
+
) -> Union[Tuple, CausalLMOutputWithCrossAttentions]:
|
| 472 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 473 |
+
|
| 474 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 475 |
+
outputs = self.model.decoder(
|
| 476 |
+
input_ids=input_ids,
|
| 477 |
+
attention_mask=attention_mask,
|
| 478 |
+
self_kv_cache=self_kv_cache,
|
| 479 |
+
cross_kv_cache=cross_kv_cache,
|
| 480 |
+
past_token_count=past_token_count,
|
| 481 |
+
langs=langs,
|
| 482 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 483 |
+
)
|
| 484 |
+
|
| 485 |
+
logits = self.lm_head(outputs[0])
|
| 486 |
+
|
| 487 |
+
if not return_dict:
|
| 488 |
+
output = (logits,) + outputs[1:]
|
| 489 |
+
return output
|
| 490 |
+
|
| 491 |
+
return CausalLMOutputWithCrossAttentions(
|
| 492 |
+
loss=None,
|
| 493 |
+
logits=logits,
|
| 494 |
+
past_key_values=outputs.past_key_values,
|
| 495 |
+
hidden_states=outputs.hidden_states,
|
| 496 |
+
attentions=outputs.attentions,
|
| 497 |
+
cross_attentions=outputs.cross_attentions,
|
| 498 |
+
)
|
| 499 |
+
|
| 500 |
+
def prune_moe_experts(self, keep_keys: List[int]):
|
| 501 |
+
# Remove experts not specified in keep_keys
|
| 502 |
+
str_keep_keys = [str(key) for key in keep_keys]
|
| 503 |
+
for layer in self.model.decoder.layers:
|
| 504 |
+
if not layer.has_moe:
|
| 505 |
+
continue
|
| 506 |
+
|
| 507 |
+
lang_keys = list(layer.moe.experts.keys())
|
| 508 |
+
for lang in lang_keys:
|
| 509 |
+
if lang not in str_keep_keys:
|
| 510 |
+
layer.moe.experts.pop(lang)
|
| 511 |
+
layer.lang_codes = keep_keys
|
surya/model/recognition/encoder.py
ADDED
|
@@ -0,0 +1,469 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn
|
| 2 |
+
import torch
|
| 3 |
+
from typing import Optional, Tuple, Union
|
| 4 |
+
|
| 5 |
+
from transformers.models.donut.modeling_donut_swin import DonutSwinPatchEmbeddings, DonutSwinEmbeddings, DonutSwinModel, \
|
| 6 |
+
DonutSwinEncoder, DonutSwinModelOutput, DonutSwinEncoderOutput, DonutSwinAttention, DonutSwinDropPath, \
|
| 7 |
+
DonutSwinIntermediate, DonutSwinOutput, window_partition, window_reverse
|
| 8 |
+
|
| 9 |
+
# from config import VariableDonutSwinConfig
|
| 10 |
+
|
| 11 |
+
from .config import VariableDonutSwinConfig
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class VariableDonutSwinEmbeddings(DonutSwinEmbeddings):
|
| 15 |
+
"""
|
| 16 |
+
Construct the patch and position embeddings. Optionally, also the mask token.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
def __init__(self, config, use_mask_token=False):
|
| 20 |
+
super().__init__(config, use_mask_token)
|
| 21 |
+
|
| 22 |
+
self.patch_embeddings = DonutSwinPatchEmbeddings(config)
|
| 23 |
+
num_patches = self.patch_embeddings.num_patches
|
| 24 |
+
self.patch_grid = self.patch_embeddings.grid_size
|
| 25 |
+
self.mask_token = nn.Parameter(torch.zeros(1, 1, config.embed_dim)) if use_mask_token else None
|
| 26 |
+
self.position_embeddings = None
|
| 27 |
+
|
| 28 |
+
if config.use_absolute_embeddings:
|
| 29 |
+
self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 1, config.embed_dim))
|
| 30 |
+
|
| 31 |
+
self.norm = nn.LayerNorm(config.embed_dim)
|
| 32 |
+
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
| 33 |
+
|
| 34 |
+
def forward(
|
| 35 |
+
self, pixel_values: Optional[torch.FloatTensor], bool_masked_pos: Optional[torch.BoolTensor] = None
|
| 36 |
+
) -> Tuple[torch.Tensor]:
|
| 37 |
+
|
| 38 |
+
embeddings, output_dimensions = self.patch_embeddings(pixel_values)
|
| 39 |
+
# Layernorm across the last dimension (each patch is a single row)
|
| 40 |
+
embeddings = self.norm(embeddings)
|
| 41 |
+
batch_size, seq_len, embed_dim = embeddings.size()
|
| 42 |
+
|
| 43 |
+
if bool_masked_pos is not None:
|
| 44 |
+
mask_tokens = self.mask_token.expand(batch_size, seq_len, -1)
|
| 45 |
+
# replace the masked visual tokens by mask_tokens
|
| 46 |
+
mask = bool_masked_pos.unsqueeze(-1).type_as(mask_tokens)
|
| 47 |
+
embeddings = embeddings * (1.0 - mask) + mask_tokens * mask
|
| 48 |
+
|
| 49 |
+
if self.position_embeddings is not None:
|
| 50 |
+
embeddings = embeddings + self.position_embeddings[:, :seq_len, :]
|
| 51 |
+
|
| 52 |
+
embeddings = self.dropout(embeddings)
|
| 53 |
+
|
| 54 |
+
return embeddings, output_dimensions
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class VariableDonutSwinPatchMerging(nn.Module):
|
| 58 |
+
"""
|
| 59 |
+
Patch Merging Layer.
|
| 60 |
+
|
| 61 |
+
Args:
|
| 62 |
+
input_resolution (`Tuple[int]`):
|
| 63 |
+
Resolution of input feature.
|
| 64 |
+
dim (`int`):
|
| 65 |
+
Number of input channels.
|
| 66 |
+
norm_layer (`nn.Module`, *optional*, defaults to `nn.LayerNorm`):
|
| 67 |
+
Normalization layer class.
|
| 68 |
+
"""
|
| 69 |
+
|
| 70 |
+
def __init__(self, input_resolution: Tuple[int], dim: int, norm_layer: nn.Module = nn.LayerNorm) -> None:
|
| 71 |
+
super().__init__()
|
| 72 |
+
self.input_resolution = input_resolution
|
| 73 |
+
self.dim = dim
|
| 74 |
+
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
|
| 75 |
+
self.norm = norm_layer(4 * dim)
|
| 76 |
+
|
| 77 |
+
def maybe_pad(self, input_feature, height, width):
|
| 78 |
+
should_pad = (height % 2 == 1) or (width % 2 == 1)
|
| 79 |
+
if should_pad:
|
| 80 |
+
pad_values = (0, 0, 0, width % 2, 0, height % 2)
|
| 81 |
+
input_feature = nn.functional.pad(input_feature, pad_values)
|
| 82 |
+
|
| 83 |
+
return input_feature
|
| 84 |
+
|
| 85 |
+
def forward(self, input_feature: torch.Tensor, input_dimensions: Tuple[int, int]) -> torch.Tensor:
|
| 86 |
+
height, width = input_dimensions
|
| 87 |
+
# `dim` is height * width
|
| 88 |
+
batch_size, dim, num_channels = input_feature.shape
|
| 89 |
+
|
| 90 |
+
input_feature = input_feature.view(batch_size, height, width, num_channels)
|
| 91 |
+
# pad input to be disible by width and height, if needed
|
| 92 |
+
input_feature = self.maybe_pad(input_feature, height, width)
|
| 93 |
+
# [batch_size, height/2, width/2, num_channels]
|
| 94 |
+
input_feature_0 = input_feature[:, 0::2, 0::2, :]
|
| 95 |
+
# [batch_size, height/2, width/2, num_channels]
|
| 96 |
+
input_feature_1 = input_feature[:, 1::2, 0::2, :]
|
| 97 |
+
# [batch_size, height/2, width/2, num_channels]
|
| 98 |
+
input_feature_2 = input_feature[:, 0::2, 1::2, :]
|
| 99 |
+
# [batch_size, height/2, width/2, num_channels]
|
| 100 |
+
input_feature_3 = input_feature[:, 1::2, 1::2, :]
|
| 101 |
+
# batch_size height/2 width/2 4*num_channels
|
| 102 |
+
input_feature = torch.cat([input_feature_0, input_feature_1, input_feature_2, input_feature_3], -1)
|
| 103 |
+
input_feature = input_feature.view(batch_size, -1, 4 * num_channels) # batch_size height/2*width/2 4*C
|
| 104 |
+
|
| 105 |
+
input_feature = self.norm(input_feature)
|
| 106 |
+
input_feature = self.reduction(input_feature)
|
| 107 |
+
|
| 108 |
+
return input_feature
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
class VariableDonutSwinLayer(nn.Module):
|
| 112 |
+
def __init__(self, config, dim, input_resolution, num_heads, shift_size=0):
|
| 113 |
+
super().__init__()
|
| 114 |
+
self.chunk_size_feed_forward = config.chunk_size_feed_forward
|
| 115 |
+
self.shift_size = shift_size
|
| 116 |
+
self.window_size = config.window_size
|
| 117 |
+
self.input_resolution = input_resolution
|
| 118 |
+
self.layernorm_before = nn.LayerNorm(dim, eps=config.layer_norm_eps)
|
| 119 |
+
self.attention = DonutSwinAttention(config, dim, num_heads, window_size=self.window_size)
|
| 120 |
+
self.drop_path = DonutSwinDropPath(config.drop_path_rate) if config.drop_path_rate > 0.0 else nn.Identity()
|
| 121 |
+
self.layernorm_after = nn.LayerNorm(dim, eps=config.layer_norm_eps)
|
| 122 |
+
self.intermediate = DonutSwinIntermediate(config, dim)
|
| 123 |
+
self.output = DonutSwinOutput(config, dim)
|
| 124 |
+
|
| 125 |
+
def set_shift_and_window_size(self, input_resolution):
|
| 126 |
+
if min(input_resolution) <= self.window_size:
|
| 127 |
+
# if window size is larger than input resolution, we don't partition windows
|
| 128 |
+
self.shift_size = 0
|
| 129 |
+
self.window_size = min(input_resolution)
|
| 130 |
+
|
| 131 |
+
def get_attn_mask(self, height, width, dtype):
|
| 132 |
+
if self.shift_size > 0:
|
| 133 |
+
# calculate attention mask for SW-MSA
|
| 134 |
+
img_mask = torch.zeros((1, height, width, 1), dtype=dtype)
|
| 135 |
+
height_slices = (
|
| 136 |
+
slice(0, -self.window_size),
|
| 137 |
+
slice(-self.window_size, -self.shift_size),
|
| 138 |
+
slice(-self.shift_size, None),
|
| 139 |
+
)
|
| 140 |
+
width_slices = (
|
| 141 |
+
slice(0, -self.window_size),
|
| 142 |
+
slice(-self.window_size, -self.shift_size),
|
| 143 |
+
slice(-self.shift_size, None),
|
| 144 |
+
)
|
| 145 |
+
count = 0
|
| 146 |
+
for height_slice in height_slices:
|
| 147 |
+
for width_slice in width_slices:
|
| 148 |
+
img_mask[:, height_slice, width_slice, :] = count
|
| 149 |
+
count += 1
|
| 150 |
+
|
| 151 |
+
mask_windows = window_partition(img_mask, self.window_size)
|
| 152 |
+
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
|
| 153 |
+
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
|
| 154 |
+
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
|
| 155 |
+
else:
|
| 156 |
+
attn_mask = None
|
| 157 |
+
return attn_mask
|
| 158 |
+
|
| 159 |
+
def maybe_pad(self, hidden_states, height, width):
|
| 160 |
+
pad_right = (self.window_size - width % self.window_size) % self.window_size
|
| 161 |
+
pad_bottom = (self.window_size - height % self.window_size) % self.window_size
|
| 162 |
+
pad_values = (0, 0, 0, pad_right, 0, pad_bottom)
|
| 163 |
+
hidden_states = nn.functional.pad(hidden_states, pad_values)
|
| 164 |
+
return hidden_states, pad_values
|
| 165 |
+
|
| 166 |
+
def forward(
|
| 167 |
+
self,
|
| 168 |
+
hidden_states: torch.Tensor,
|
| 169 |
+
input_dimensions: Tuple[int, int],
|
| 170 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 171 |
+
output_attentions: Optional[bool] = False,
|
| 172 |
+
always_partition: Optional[bool] = False,
|
| 173 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 174 |
+
if not always_partition:
|
| 175 |
+
self.set_shift_and_window_size(input_dimensions)
|
| 176 |
+
else:
|
| 177 |
+
pass
|
| 178 |
+
height, width = input_dimensions
|
| 179 |
+
batch_size, _, channels = hidden_states.size()
|
| 180 |
+
shortcut = hidden_states
|
| 181 |
+
|
| 182 |
+
hidden_states = self.layernorm_before(hidden_states)
|
| 183 |
+
|
| 184 |
+
hidden_states = hidden_states.view(batch_size, height, width, channels)
|
| 185 |
+
|
| 186 |
+
# pad hidden_states to multiples of window size
|
| 187 |
+
hidden_states, pad_values = self.maybe_pad(hidden_states, height, width)
|
| 188 |
+
|
| 189 |
+
_, height_pad, width_pad, _ = hidden_states.shape
|
| 190 |
+
# cyclic shift
|
| 191 |
+
if self.shift_size > 0:
|
| 192 |
+
shifted_hidden_states = torch.roll(hidden_states, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
|
| 193 |
+
else:
|
| 194 |
+
shifted_hidden_states = hidden_states
|
| 195 |
+
|
| 196 |
+
# partition windows
|
| 197 |
+
hidden_states_windows = window_partition(shifted_hidden_states, self.window_size)
|
| 198 |
+
hidden_states_windows = hidden_states_windows.view(-1, self.window_size * self.window_size, channels)
|
| 199 |
+
attn_mask = self.get_attn_mask(height_pad, width_pad, dtype=hidden_states.dtype)
|
| 200 |
+
if attn_mask is not None:
|
| 201 |
+
attn_mask = attn_mask.to(hidden_states_windows.device)
|
| 202 |
+
|
| 203 |
+
attention_outputs = self.attention(
|
| 204 |
+
hidden_states_windows, attn_mask, head_mask, output_attentions=output_attentions
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
attention_output = attention_outputs[0]
|
| 208 |
+
|
| 209 |
+
attention_windows = attention_output.view(-1, self.window_size, self.window_size, channels)
|
| 210 |
+
shifted_windows = window_reverse(attention_windows, self.window_size, height_pad, width_pad)
|
| 211 |
+
|
| 212 |
+
# reverse cyclic shift
|
| 213 |
+
if self.shift_size > 0:
|
| 214 |
+
attention_windows = torch.roll(shifted_windows, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
|
| 215 |
+
else:
|
| 216 |
+
attention_windows = shifted_windows
|
| 217 |
+
|
| 218 |
+
was_padded = pad_values[3] > 0 or pad_values[5] > 0
|
| 219 |
+
if was_padded:
|
| 220 |
+
attention_windows = attention_windows[:, :height, :width, :].contiguous()
|
| 221 |
+
|
| 222 |
+
attention_windows = attention_windows.view(batch_size, height * width, channels)
|
| 223 |
+
|
| 224 |
+
hidden_states = shortcut + self.drop_path(attention_windows)
|
| 225 |
+
|
| 226 |
+
layer_output = self.layernorm_after(hidden_states)
|
| 227 |
+
layer_output = self.intermediate(layer_output)
|
| 228 |
+
layer_output = hidden_states + self.output(layer_output)
|
| 229 |
+
|
| 230 |
+
layer_outputs = (layer_output, attention_outputs[1]) if output_attentions else (layer_output,)
|
| 231 |
+
return layer_outputs
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
class VariableDonutSwinStage(nn.Module):
|
| 235 |
+
def __init__(self, config, dim, input_resolution, depth, num_heads, drop_path, downsample):
|
| 236 |
+
super().__init__()
|
| 237 |
+
self.config = config
|
| 238 |
+
self.dim = dim
|
| 239 |
+
self.blocks = nn.ModuleList(
|
| 240 |
+
[
|
| 241 |
+
VariableDonutSwinLayer(
|
| 242 |
+
config=config,
|
| 243 |
+
dim=dim,
|
| 244 |
+
input_resolution=input_resolution,
|
| 245 |
+
num_heads=num_heads,
|
| 246 |
+
shift_size=0 if (i % 2 == 0) else int(config.window_size // 2),
|
| 247 |
+
)
|
| 248 |
+
for i in range(depth)
|
| 249 |
+
]
|
| 250 |
+
)
|
| 251 |
+
|
| 252 |
+
# patch merging layer
|
| 253 |
+
if downsample is not None:
|
| 254 |
+
self.downsample = downsample(input_resolution, dim=dim, norm_layer=nn.LayerNorm)
|
| 255 |
+
else:
|
| 256 |
+
self.downsample = None
|
| 257 |
+
|
| 258 |
+
self.pointing = False
|
| 259 |
+
|
| 260 |
+
def forward(
|
| 261 |
+
self,
|
| 262 |
+
hidden_states: torch.Tensor,
|
| 263 |
+
input_dimensions: Tuple[int, int],
|
| 264 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 265 |
+
output_attentions: Optional[bool] = False,
|
| 266 |
+
always_partition: Optional[bool] = False,
|
| 267 |
+
) -> Tuple[torch.Tensor]:
|
| 268 |
+
height, width = input_dimensions
|
| 269 |
+
for i, layer_module in enumerate(self.blocks):
|
| 270 |
+
layer_head_mask = head_mask[i] if head_mask is not None else None
|
| 271 |
+
|
| 272 |
+
layer_outputs = layer_module(
|
| 273 |
+
hidden_states, input_dimensions, layer_head_mask, output_attentions, always_partition
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
hidden_states = layer_outputs[0]
|
| 277 |
+
|
| 278 |
+
hidden_states_before_downsampling = hidden_states
|
| 279 |
+
if self.downsample is not None:
|
| 280 |
+
height_downsampled, width_downsampled = (height + 1) // 2, (width + 1) // 2
|
| 281 |
+
output_dimensions = (height, width, height_downsampled, width_downsampled)
|
| 282 |
+
hidden_states = self.downsample(hidden_states_before_downsampling, input_dimensions)
|
| 283 |
+
else:
|
| 284 |
+
output_dimensions = (height, width, height, width)
|
| 285 |
+
|
| 286 |
+
stage_outputs = (hidden_states, hidden_states_before_downsampling, output_dimensions)
|
| 287 |
+
|
| 288 |
+
if output_attentions:
|
| 289 |
+
stage_outputs += layer_outputs[1:]
|
| 290 |
+
return stage_outputs
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
class VariableDonutSwinEncoder(nn.Module):
|
| 294 |
+
def __init__(self, config, grid_size):
|
| 295 |
+
super().__init__()
|
| 296 |
+
self.num_layers = len(config.depths)
|
| 297 |
+
self.config = config
|
| 298 |
+
dpr = [x.item() for x in torch.linspace(0, config.drop_path_rate, sum(config.depths))]
|
| 299 |
+
self.layers = nn.ModuleList(
|
| 300 |
+
[
|
| 301 |
+
VariableDonutSwinStage(
|
| 302 |
+
config=config,
|
| 303 |
+
dim=int(config.embed_dim * 2**i_layer),
|
| 304 |
+
input_resolution=(grid_size[0] // (2**i_layer), grid_size[1] // (2**i_layer)),
|
| 305 |
+
depth=config.depths[i_layer],
|
| 306 |
+
num_heads=config.num_heads[i_layer],
|
| 307 |
+
drop_path=dpr[sum(config.depths[:i_layer]) : sum(config.depths[: i_layer + 1])],
|
| 308 |
+
downsample=VariableDonutSwinPatchMerging if (i_layer < self.num_layers - 1) else None,
|
| 309 |
+
)
|
| 310 |
+
for i_layer in range(self.num_layers)
|
| 311 |
+
]
|
| 312 |
+
)
|
| 313 |
+
|
| 314 |
+
self.gradient_checkpointing = False
|
| 315 |
+
|
| 316 |
+
def forward(
|
| 317 |
+
self,
|
| 318 |
+
hidden_states: torch.Tensor,
|
| 319 |
+
input_dimensions: Tuple[int, int],
|
| 320 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 321 |
+
output_attentions: Optional[bool] = False,
|
| 322 |
+
output_hidden_states: Optional[bool] = False,
|
| 323 |
+
output_hidden_states_before_downsampling: Optional[bool] = False,
|
| 324 |
+
always_partition: Optional[bool] = False,
|
| 325 |
+
return_dict: Optional[bool] = True,
|
| 326 |
+
) -> Union[Tuple, DonutSwinEncoderOutput]:
|
| 327 |
+
all_hidden_states = () if output_hidden_states else None
|
| 328 |
+
all_reshaped_hidden_states = () if output_hidden_states else None
|
| 329 |
+
all_self_attentions = () if output_attentions else None
|
| 330 |
+
|
| 331 |
+
if output_hidden_states:
|
| 332 |
+
batch_size, _, hidden_size = hidden_states.shape
|
| 333 |
+
# rearrange b (h w) c -> b c h w
|
| 334 |
+
reshaped_hidden_state = hidden_states.view(batch_size, *input_dimensions, hidden_size)
|
| 335 |
+
reshaped_hidden_state = reshaped_hidden_state.permute(0, 3, 1, 2)
|
| 336 |
+
all_hidden_states += (hidden_states,)
|
| 337 |
+
all_reshaped_hidden_states += (reshaped_hidden_state,)
|
| 338 |
+
|
| 339 |
+
for i, layer_module in enumerate(self.layers):
|
| 340 |
+
layer_head_mask = head_mask[i] if head_mask is not None else None
|
| 341 |
+
|
| 342 |
+
if self.gradient_checkpointing and self.training:
|
| 343 |
+
layer_outputs = self._gradient_checkpointing_func(
|
| 344 |
+
layer_module.__call__,
|
| 345 |
+
hidden_states,
|
| 346 |
+
input_dimensions,
|
| 347 |
+
layer_head_mask,
|
| 348 |
+
output_attentions,
|
| 349 |
+
always_partition,
|
| 350 |
+
)
|
| 351 |
+
else:
|
| 352 |
+
layer_outputs = layer_module(
|
| 353 |
+
hidden_states, input_dimensions, layer_head_mask, output_attentions, always_partition
|
| 354 |
+
)
|
| 355 |
+
|
| 356 |
+
hidden_states = layer_outputs[0]
|
| 357 |
+
hidden_states_before_downsampling = layer_outputs[1]
|
| 358 |
+
output_dimensions = layer_outputs[2]
|
| 359 |
+
|
| 360 |
+
input_dimensions = (output_dimensions[-2], output_dimensions[-1])
|
| 361 |
+
|
| 362 |
+
if output_hidden_states and output_hidden_states_before_downsampling:
|
| 363 |
+
batch_size, _, hidden_size = hidden_states_before_downsampling.shape
|
| 364 |
+
# rearrange b (h w) c -> b c h w
|
| 365 |
+
# here we use the original (not downsampled) height and width
|
| 366 |
+
reshaped_hidden_state = hidden_states_before_downsampling.view(
|
| 367 |
+
batch_size, *(output_dimensions[0], output_dimensions[1]), hidden_size
|
| 368 |
+
)
|
| 369 |
+
reshaped_hidden_state = reshaped_hidden_state.permute(0, 3, 1, 2)
|
| 370 |
+
all_hidden_states += (hidden_states_before_downsampling,)
|
| 371 |
+
all_reshaped_hidden_states += (reshaped_hidden_state,)
|
| 372 |
+
elif output_hidden_states and not output_hidden_states_before_downsampling:
|
| 373 |
+
batch_size, _, hidden_size = hidden_states.shape
|
| 374 |
+
# rearrange b (h w) c -> b c h w
|
| 375 |
+
reshaped_hidden_state = hidden_states.view(batch_size, *input_dimensions, hidden_size)
|
| 376 |
+
reshaped_hidden_state = reshaped_hidden_state.permute(0, 3, 1, 2)
|
| 377 |
+
all_hidden_states += (hidden_states,)
|
| 378 |
+
all_reshaped_hidden_states += (reshaped_hidden_state,)
|
| 379 |
+
|
| 380 |
+
if output_attentions:
|
| 381 |
+
all_self_attentions += layer_outputs[3:]
|
| 382 |
+
|
| 383 |
+
if not return_dict:
|
| 384 |
+
return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
|
| 385 |
+
|
| 386 |
+
return DonutSwinEncoderOutput(
|
| 387 |
+
last_hidden_state=hidden_states,
|
| 388 |
+
hidden_states=all_hidden_states,
|
| 389 |
+
attentions=all_self_attentions,
|
| 390 |
+
reshaped_hidden_states=all_reshaped_hidden_states,
|
| 391 |
+
)
|
| 392 |
+
|
| 393 |
+
|
| 394 |
+
class VariableDonutSwinModel(DonutSwinModel):
|
| 395 |
+
config_class = VariableDonutSwinConfig
|
| 396 |
+
def __init__(self, config, add_pooling_layer=True, use_mask_token=False, **kwargs):
|
| 397 |
+
super().__init__(config)
|
| 398 |
+
self.config = config
|
| 399 |
+
self.num_layers = len(config.depths)
|
| 400 |
+
self.num_features = int(config.embed_dim * 2 ** (self.num_layers - 1))
|
| 401 |
+
|
| 402 |
+
self.embeddings = VariableDonutSwinEmbeddings(config, use_mask_token=use_mask_token)
|
| 403 |
+
self.encoder = VariableDonutSwinEncoder(config, self.embeddings.patch_grid)
|
| 404 |
+
|
| 405 |
+
self.pooler = nn.AdaptiveAvgPool1d(1) if add_pooling_layer else None
|
| 406 |
+
|
| 407 |
+
# Initialize weights and apply final processing
|
| 408 |
+
self.post_init()
|
| 409 |
+
|
| 410 |
+
def forward(
|
| 411 |
+
self,
|
| 412 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 413 |
+
bool_masked_pos: Optional[torch.BoolTensor] = None,
|
| 414 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 415 |
+
output_attentions: Optional[bool] = None,
|
| 416 |
+
output_hidden_states: Optional[bool] = None,
|
| 417 |
+
return_dict: Optional[bool] = None,
|
| 418 |
+
**kwargs
|
| 419 |
+
) -> Union[Tuple, DonutSwinModelOutput]:
|
| 420 |
+
r"""
|
| 421 |
+
bool_masked_pos (`torch.BoolTensor` of shape `(batch_size, num_patches)`):
|
| 422 |
+
Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
|
| 423 |
+
"""
|
| 424 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 425 |
+
output_hidden_states = (
|
| 426 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 427 |
+
)
|
| 428 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 429 |
+
|
| 430 |
+
if pixel_values is None:
|
| 431 |
+
raise ValueError("You have to specify pixel_values")
|
| 432 |
+
|
| 433 |
+
# Prepare head mask if needed
|
| 434 |
+
# 1.0 in head_mask indicate we keep the head
|
| 435 |
+
# attention_probs has shape bsz x n_heads x N x N
|
| 436 |
+
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
|
| 437 |
+
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
|
| 438 |
+
head_mask = self.get_head_mask(head_mask, len(self.config.depths))
|
| 439 |
+
|
| 440 |
+
embedding_output, input_dimensions = self.embeddings(pixel_values, bool_masked_pos=bool_masked_pos)
|
| 441 |
+
|
| 442 |
+
encoder_outputs = self.encoder(
|
| 443 |
+
embedding_output,
|
| 444 |
+
input_dimensions,
|
| 445 |
+
head_mask=head_mask,
|
| 446 |
+
output_attentions=output_attentions,
|
| 447 |
+
output_hidden_states=output_hidden_states,
|
| 448 |
+
return_dict=return_dict,
|
| 449 |
+
)
|
| 450 |
+
|
| 451 |
+
sequence_output = encoder_outputs[0]
|
| 452 |
+
|
| 453 |
+
pooled_output = None
|
| 454 |
+
if self.pooler is not None:
|
| 455 |
+
pooled_output = self.pooler(sequence_output.transpose(1, 2))
|
| 456 |
+
pooled_output = torch.flatten(pooled_output, 1)
|
| 457 |
+
|
| 458 |
+
if not return_dict:
|
| 459 |
+
output = (sequence_output, pooled_output) + encoder_outputs[1:]
|
| 460 |
+
|
| 461 |
+
return output
|
| 462 |
+
|
| 463 |
+
return DonutSwinModelOutput(
|
| 464 |
+
last_hidden_state=sequence_output,
|
| 465 |
+
pooler_output=pooled_output,
|
| 466 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 467 |
+
attentions=encoder_outputs.attentions,
|
| 468 |
+
reshaped_hidden_states=encoder_outputs.reshaped_hidden_states,
|
| 469 |
+
)
|
surya/model/recognition/model.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
warnings.filterwarnings("ignore", message="torch.utils._pytree._register_pytree_node is deprecated")
|
| 6 |
+
|
| 7 |
+
import logging
|
| 8 |
+
logging.getLogger("transformers.modeling_utils").setLevel(logging.ERROR)
|
| 9 |
+
|
| 10 |
+
from typing import List, Optional, Tuple
|
| 11 |
+
from transformers import VisionEncoderDecoderModel, VisionEncoderDecoderConfig, AutoModel, AutoModelForCausalLM
|
| 12 |
+
from surya.model.recognition.config import MBartMoEConfig, VariableDonutSwinConfig
|
| 13 |
+
from surya.model.recognition.encoder import VariableDonutSwinModel
|
| 14 |
+
from surya.model.recognition.decoder import MBartMoE
|
| 15 |
+
from surya.settings import settings
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def load_model(checkpoint=settings.RECOGNITION_MODEL_CHECKPOINT, device=settings.TORCH_DEVICE_MODEL, dtype=settings.MODEL_DTYPE, langs: Optional[List[int]] = None):
|
| 19 |
+
config = VisionEncoderDecoderConfig.from_pretrained(checkpoint)
|
| 20 |
+
|
| 21 |
+
# Prune moe experts that are not needed before loading the model
|
| 22 |
+
if langs is not None:
|
| 23 |
+
config.decoder.langs = {lang_iso : lang_int for lang_iso, lang_int in config.decoder.langs.items() if lang_int in langs}
|
| 24 |
+
|
| 25 |
+
decoder_config = vars(config.decoder)
|
| 26 |
+
decoder = MBartMoEConfig(**decoder_config)
|
| 27 |
+
config.decoder = decoder
|
| 28 |
+
|
| 29 |
+
encoder_config = vars(config.encoder)
|
| 30 |
+
encoder = VariableDonutSwinConfig(**encoder_config)
|
| 31 |
+
config.encoder = encoder
|
| 32 |
+
|
| 33 |
+
# Get transformers to load custom encoder/decoder
|
| 34 |
+
AutoModel.register(MBartMoEConfig, MBartMoE)
|
| 35 |
+
AutoModelForCausalLM.register(MBartMoEConfig, MBartMoE)
|
| 36 |
+
AutoModel.register(VariableDonutSwinConfig, VariableDonutSwinModel)
|
| 37 |
+
|
| 38 |
+
model = LangVisionEncoderDecoderModel.from_pretrained(checkpoint, config=config, torch_dtype=dtype)
|
| 39 |
+
assert isinstance(model.decoder, MBartMoE)
|
| 40 |
+
assert isinstance(model.encoder, VariableDonutSwinModel)
|
| 41 |
+
|
| 42 |
+
model = model.to(device)
|
| 43 |
+
model = model.eval()
|
| 44 |
+
print(f"Loaded recognition model {checkpoint} on device {device} with dtype {dtype}")
|
| 45 |
+
return model
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class LangVisionEncoderDecoderModel(VisionEncoderDecoderModel):
|
| 49 |
+
def prepare_inputs_for_generation(
|
| 50 |
+
self, input_ids, decoder_langs=None, past_key_values=None, attention_mask=None, use_cache=None, encoder_outputs=None, **kwargs
|
| 51 |
+
):
|
| 52 |
+
decoder_inputs = self.decoder.prepare_inputs_for_generation(input_ids, langs=decoder_langs, past_key_values=past_key_values)
|
| 53 |
+
decoder_attention_mask = decoder_inputs["attention_mask"] if "attention_mask" in decoder_inputs else None
|
| 54 |
+
input_dict = {
|
| 55 |
+
"attention_mask": attention_mask,
|
| 56 |
+
"decoder_attention_mask": decoder_attention_mask,
|
| 57 |
+
"decoder_input_ids": decoder_inputs["input_ids"],
|
| 58 |
+
"encoder_outputs": encoder_outputs,
|
| 59 |
+
"past_key_values": decoder_inputs["past_key_values"],
|
| 60 |
+
"use_cache": use_cache,
|
| 61 |
+
"decoder_langs": decoder_inputs["langs"],
|
| 62 |
+
}
|
| 63 |
+
return input_dict
|
| 64 |
+
|