
Update README.md
Browse files
README.md
CHANGED
|
@@ -7,8 +7,8 @@ tags:
|
|
| 7 |
- not-for-all-audiences
|
| 8 |
---
|
| 9 |
|
| 10 |
-
# Limamono-7B (Mistral) v0.
|
| 11 |
-
This is an **early version** (
|
| 12 |
_extremely limited_ amounts of almost entirely synthetic data of hopefully higher quality than typical
|
| 13 |
human conversations. The intended target audience is straight men and lesbians.
|
| 14 |
|
|
@@ -154,7 +154,7 @@ in the repository.
|
|
| 154 |
## Text generation settings
|
| 155 |
For testing I use these settings:
|
| 156 |
- Temperature: 1.0
|
| 157 |
-
- Tail-Free Sampling: 0.85
|
| 158 |
- Repetition Penalty: 1.11
|
| 159 |
- Repetition Penalty range: 2048
|
| 160 |
- Top-p: 1 (disabled), Top-k: 0 (disabled)
|
|
@@ -163,7 +163,7 @@ For testing I use these settings:
|
|
| 163 |
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training
|
| 164 |
on one NVidia RTX3090.
|
| 165 |
|
| 166 |
-
The training data consisted of **
|
| 167 |
of roughly 4k tokens length. The learning rate is the one that about minimizes the
|
| 168 |
eval loss on one epoch with a constant learning schedule. For the following two epochs
|
| 169 |
what would be normally considered overfitting occurs, but at the same time output
|
|
@@ -182,7 +182,7 @@ quality also improves.
|
|
| 182 |
- micro_batch_size: 1
|
| 183 |
- num_epochs: 3
|
| 184 |
- optimizer: adamw_torch
|
| 185 |
-
- lr_scheduler:
|
| 186 |
- learning_rate: 0.0002
|
| 187 |
- weight_decay: 0.1
|
| 188 |
- train_on_inputs: false
|
|
@@ -192,8 +192,4 @@ quality also improves.
|
|
| 192 |
- tf32: true
|
| 193 |
|
| 194 |
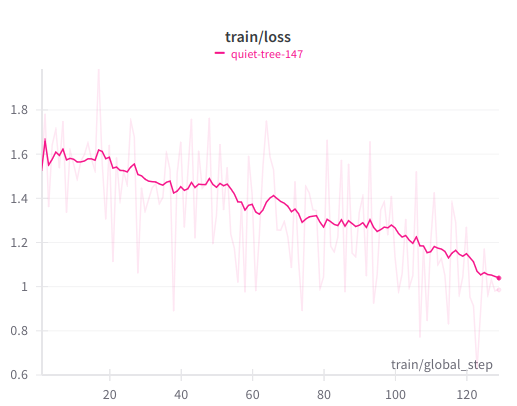
### Train loss graph
|
| 195 |
-
|
| 196 |
-
with similar end results but a smoother graph without sudden jumps compared to finetuning
|
| 197 |
-
unique data for 3 epochs.
|
| 198 |
-
|
| 199 |
-
|
|
|
|
| 7 |
- not-for-all-audiences
|
| 8 |
---
|
| 9 |
|
| 10 |
+
# Limamono-7B (Mistral) v0.50
|
| 11 |
+
This is an **early version** (50% completed) of a strongly NSFW roleplaying model trained with
|
| 12 |
_extremely limited_ amounts of almost entirely synthetic data of hopefully higher quality than typical
|
| 13 |
human conversations. The intended target audience is straight men and lesbians.
|
| 14 |
|
|
|
|
| 154 |
## Text generation settings
|
| 155 |
For testing I use these settings:
|
| 156 |
- Temperature: 1.0
|
| 157 |
+
- Tail-Free Sampling: 0.85
|
| 158 |
- Repetition Penalty: 1.11
|
| 159 |
- Repetition Penalty range: 2048
|
| 160 |
- Top-p: 1 (disabled), Top-k: 0 (disabled)
|
|
|
|
| 163 |
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training
|
| 164 |
on one NVidia RTX3090.
|
| 165 |
|
| 166 |
+
The training data consisted of **50** conversations (199k tokens / 1117 messages)
|
| 167 |
of roughly 4k tokens length. The learning rate is the one that about minimizes the
|
| 168 |
eval loss on one epoch with a constant learning schedule. For the following two epochs
|
| 169 |
what would be normally considered overfitting occurs, but at the same time output
|
|
|
|
| 182 |
- micro_batch_size: 1
|
| 183 |
- num_epochs: 3
|
| 184 |
- optimizer: adamw_torch
|
| 185 |
+
- lr_scheduler: cosine
|
| 186 |
- learning_rate: 0.0002
|
| 187 |
- weight_decay: 0.1
|
| 188 |
- train_on_inputs: false
|
|
|
|
| 192 |
- tf32: true
|
| 193 |
|
| 194 |
### Train loss graph
|
| 195 |
+

|
|
|
|
|
|
|
|
|
|
|
|