
Update README.md
Browse files
README.md
CHANGED
|
@@ -4,8 +4,6 @@ license: mit
|
|
| 4 |
#### Overview
|
| 5 |
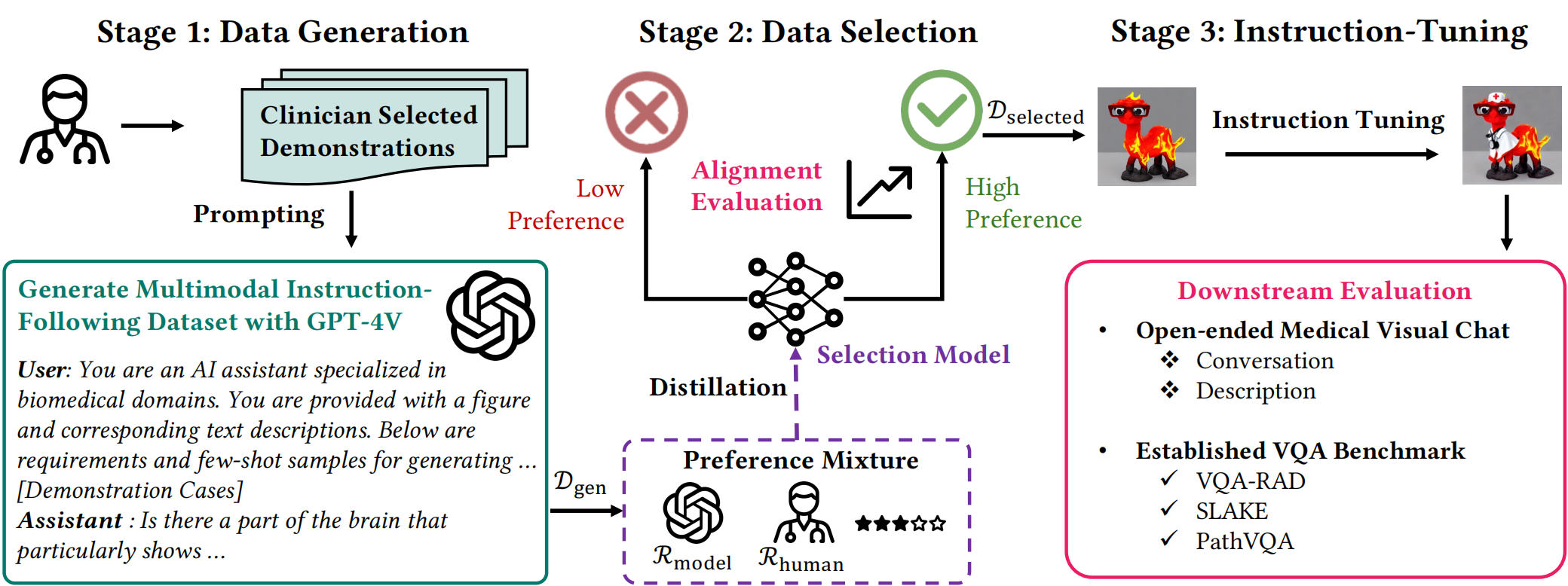
BioMed-VITAL is a multimodal foundation model specifically tuned for biomedical applications. It leverages visual and textual data to improve understanding and reasoning within the biomedical domain.
|
| 6 |
|
| 7 |
-
|
| 8 |
-
|
| 9 |
#### Model Training
|
| 10 |
The training of BioMed-VITAL involved two key stages, both incorporating clinician preferences to ensure the relevance and quality of the training data:
|
| 11 |
|
|
@@ -17,14 +15,4 @@ The training of BioMed-VITAL involved two key stages, both incorporating clinici
|
|
| 17 |
The effectiveness of BioMed-VITAL was demonstrated through significant improvements in two key areas:
|
| 18 |
|
| 19 |
- **Open Visual Chat:** The model showed a relative improvement of 18.5%, indicating enhanced capabilities in engaging in visual dialogues pertinent to biomedical contexts.
|
| 20 |
-
- **Medical Visual Question Answering (VQA):** BioMed-VITAL achieved a win rate of up to 81.73% in this domain, showcasing its superior performance in interpreting and responding to complex medical imagery and queries.
|
| 21 |
-
|
| 22 |
-
## Case Study
|
| 23 |
-
### Biomedical Visual Instruction-Following Example
|
| 24 |
-

|
| 25 |
-
### Biomedical VQA Benchmark
|
| 26 |
-

|
| 27 |
-
### Clinician Annotation Examples
|
| 28 |
-

|
| 29 |
-
|
| 30 |
-
For more information, access to the dataset, and to contribute, please visit our [GitHub repository](https://github.com/yourrepo/biomed-vital).
|
|
|
|
| 4 |
#### Overview
|
| 5 |
BioMed-VITAL is a multimodal foundation model specifically tuned for biomedical applications. It leverages visual and textual data to improve understanding and reasoning within the biomedical domain.
|
| 6 |
|
|
|
|
|
|
|
| 7 |
#### Model Training
|
| 8 |
The training of BioMed-VITAL involved two key stages, both incorporating clinician preferences to ensure the relevance and quality of the training data:
|
| 9 |
|
|
|
|
| 15 |
The effectiveness of BioMed-VITAL was demonstrated through significant improvements in two key areas:
|
| 16 |
|
| 17 |
- **Open Visual Chat:** The model showed a relative improvement of 18.5%, indicating enhanced capabilities in engaging in visual dialogues pertinent to biomedical contexts.
|
| 18 |
+
- **Medical Visual Question Answering (VQA):** BioMed-VITAL achieved a win rate of up to 81.73% in this domain, showcasing its superior performance in interpreting and responding to complex medical imagery and queries.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|