
End of training
Browse files- README.md +5 -5
- all_results.json +9 -9
- egy_training_log.txt +2 -0
- eval_results.json +4 -4
- train_results.json +6 -6
- train_vs_val_loss.png +0 -0
- trainer_state.json +105 -10
README.md
CHANGED
|
@@ -18,11 +18,11 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [riotu-lab/ArabianGPT-01B](https://huggingface.co/riotu-lab/ArabianGPT-01B) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
-
- Loss: 0.
|
| 22 |
-
- Bleu: 0.
|
| 23 |
-
- Rouge1: 0.
|
| 24 |
-
- Rouge2: 0.
|
| 25 |
-
- Rougel: 0.
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
|
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [riotu-lab/ArabianGPT-01B](https://huggingface.co/riotu-lab/ArabianGPT-01B) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.4183
|
| 22 |
+
- Bleu: 0.2374
|
| 23 |
+
- Rouge1: 0.6213
|
| 24 |
+
- Rouge2: 0.3630
|
| 25 |
+
- Rougel: 0.6195
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
all_results.json
CHANGED
|
@@ -1,19 +1,19 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
"eval_bleu": 0.23736106874390867,
|
| 4 |
"eval_loss": 0.4183219075202942,
|
| 5 |
"eval_rouge1": 0.6213217050496613,
|
| 6 |
"eval_rouge2": 0.3629928034660268,
|
| 7 |
"eval_rougeL": 0.6194945230812778,
|
| 8 |
-
"eval_runtime":
|
| 9 |
"eval_samples": 1675,
|
| 10 |
-
"eval_samples_per_second":
|
| 11 |
-
"eval_steps_per_second":
|
| 12 |
"perplexity": 1.5194097050971664,
|
| 13 |
-
"total_flos":
|
| 14 |
-
"train_loss": 0.
|
| 15 |
-
"train_runtime":
|
| 16 |
"train_samples": 6700,
|
| 17 |
-
"train_samples_per_second":
|
| 18 |
-
"train_steps_per_second":
|
| 19 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 14.0,
|
| 3 |
"eval_bleu": 0.23736106874390867,
|
| 4 |
"eval_loss": 0.4183219075202942,
|
| 5 |
"eval_rouge1": 0.6213217050496613,
|
| 6 |
"eval_rouge2": 0.3629928034660268,
|
| 7 |
"eval_rougeL": 0.6194945230812778,
|
| 8 |
+
"eval_runtime": 6.133,
|
| 9 |
"eval_samples": 1675,
|
| 10 |
+
"eval_samples_per_second": 273.111,
|
| 11 |
+
"eval_steps_per_second": 34.241,
|
| 12 |
"perplexity": 1.5194097050971664,
|
| 13 |
+
"total_flos": 6127298150400000.0,
|
| 14 |
+
"train_loss": 0.03383859399638808,
|
| 15 |
+
"train_runtime": 1080.9024,
|
| 16 |
"train_samples": 6700,
|
| 17 |
+
"train_samples_per_second": 123.97,
|
| 18 |
+
"train_steps_per_second": 15.506
|
| 19 |
}
|
egy_training_log.txt
CHANGED
|
@@ -317,3 +317,5 @@ INFO:root:Epoch 13.0: Train Loss = 0.0936, Eval Loss = 0.470233678817749
|
|
| 317 |
INFO:absl:Using default tokenizer.
|
| 318 |
INFO:root:Epoch 14.0: Train Loss = 0.0899, Eval Loss = 0.47367072105407715
|
| 319 |
INFO:absl:Using default tokenizer.
|
|
|
|
|
|
|
|
|
| 317 |
INFO:absl:Using default tokenizer.
|
| 318 |
INFO:root:Epoch 14.0: Train Loss = 0.0899, Eval Loss = 0.47367072105407715
|
| 319 |
INFO:absl:Using default tokenizer.
|
| 320 |
+
INFO:__main__:*** Evaluate ***
|
| 321 |
+
INFO:absl:Using default tokenizer.
|
eval_results.json
CHANGED
|
@@ -1,13 +1,13 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
"eval_bleu": 0.23736106874390867,
|
| 4 |
"eval_loss": 0.4183219075202942,
|
| 5 |
"eval_rouge1": 0.6213217050496613,
|
| 6 |
"eval_rouge2": 0.3629928034660268,
|
| 7 |
"eval_rougeL": 0.6194945230812778,
|
| 8 |
-
"eval_runtime":
|
| 9 |
"eval_samples": 1675,
|
| 10 |
-
"eval_samples_per_second":
|
| 11 |
-
"eval_steps_per_second":
|
| 12 |
"perplexity": 1.5194097050971664
|
| 13 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 14.0,
|
| 3 |
"eval_bleu": 0.23736106874390867,
|
| 4 |
"eval_loss": 0.4183219075202942,
|
| 5 |
"eval_rouge1": 0.6213217050496613,
|
| 6 |
"eval_rouge2": 0.3629928034660268,
|
| 7 |
"eval_rougeL": 0.6194945230812778,
|
| 8 |
+
"eval_runtime": 6.133,
|
| 9 |
"eval_samples": 1675,
|
| 10 |
+
"eval_samples_per_second": 273.111,
|
| 11 |
+
"eval_steps_per_second": 34.241,
|
| 12 |
"perplexity": 1.5194097050971664
|
| 13 |
}
|
train_results.json
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"total_flos":
|
| 4 |
-
"train_loss": 0.
|
| 5 |
-
"train_runtime":
|
| 6 |
"train_samples": 6700,
|
| 7 |
-
"train_samples_per_second":
|
| 8 |
-
"train_steps_per_second":
|
| 9 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 14.0,
|
| 3 |
+
"total_flos": 6127298150400000.0,
|
| 4 |
+
"train_loss": 0.03383859399638808,
|
| 5 |
+
"train_runtime": 1080.9024,
|
| 6 |
"train_samples": 6700,
|
| 7 |
+
"train_samples_per_second": 123.97,
|
| 8 |
+
"train_steps_per_second": 15.506
|
| 9 |
}
|
train_vs_val_loss.png
CHANGED
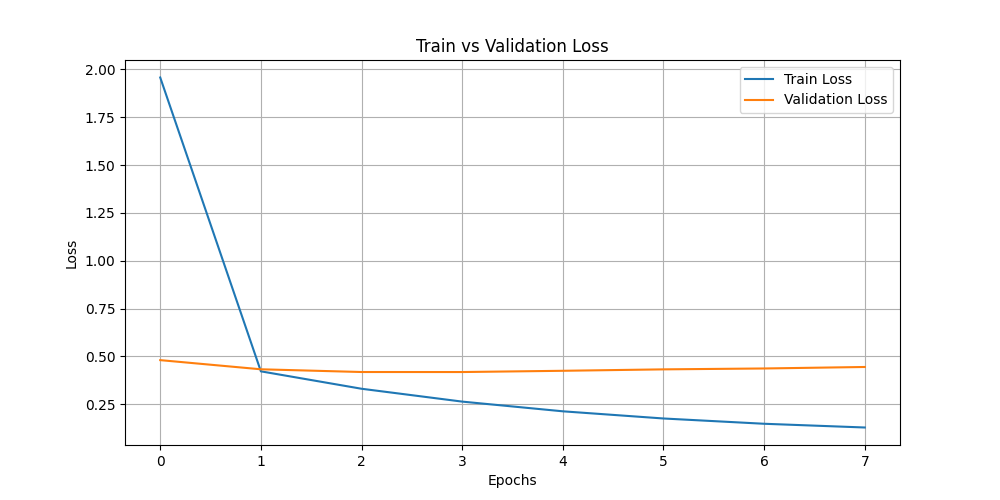
|
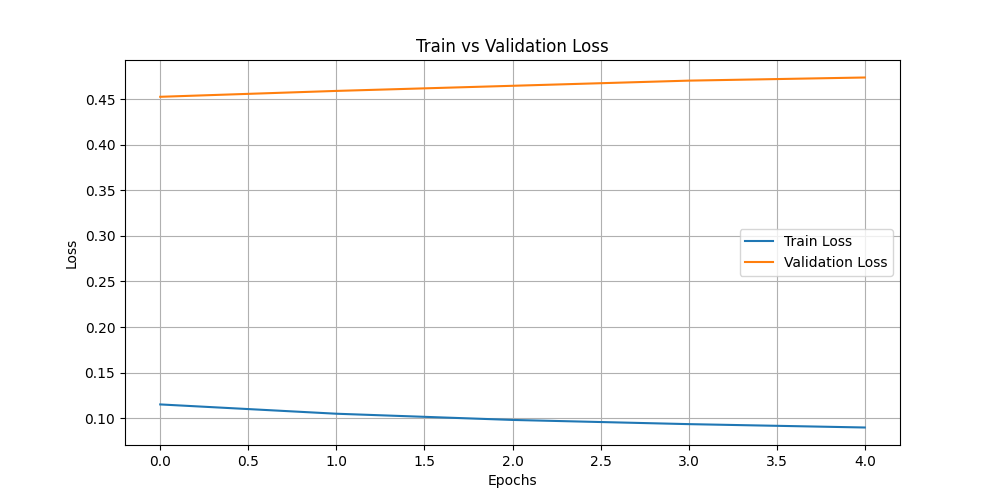
|
trainer_state.json
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
{
|
| 2 |
"best_metric": 0.4183219075202942,
|
| 3 |
"best_model_checkpoint": "/home/iais_marenpielka/Bouthaina/res_nw_gulf/checkpoint-3352",
|
| 4 |
-
"epoch":
|
| 5 |
"eval_steps": 500,
|
| 6 |
-
"global_step":
|
| 7 |
"is_hyper_param_search": false,
|
| 8 |
"is_local_process_zero": true,
|
| 9 |
"is_world_process_zero": true,
|
|
@@ -180,13 +180,108 @@
|
|
| 180 |
"step": 7542
|
| 181 |
},
|
| 182 |
{
|
| 183 |
-
"epoch":
|
| 184 |
-
"
|
| 185 |
-
"
|
| 186 |
-
"
|
| 187 |
-
"
|
| 188 |
-
|
| 189 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 190 |
}
|
| 191 |
],
|
| 192 |
"logging_steps": 500,
|
|
@@ -215,7 +310,7 @@
|
|
| 215 |
"attributes": {}
|
| 216 |
}
|
| 217 |
},
|
| 218 |
-
"total_flos":
|
| 219 |
"train_batch_size": 8,
|
| 220 |
"trial_name": null,
|
| 221 |
"trial_params": null
|
|
|
|
| 1 |
{
|
| 2 |
"best_metric": 0.4183219075202942,
|
| 3 |
"best_model_checkpoint": "/home/iais_marenpielka/Bouthaina/res_nw_gulf/checkpoint-3352",
|
| 4 |
+
"epoch": 14.0,
|
| 5 |
"eval_steps": 500,
|
| 6 |
+
"global_step": 11732,
|
| 7 |
"is_hyper_param_search": false,
|
| 8 |
"is_local_process_zero": true,
|
| 9 |
"is_world_process_zero": true,
|
|
|
|
| 180 |
"step": 7542
|
| 181 |
},
|
| 182 |
{
|
| 183 |
+
"epoch": 10.0,
|
| 184 |
+
"grad_norm": 1.159719705581665,
|
| 185 |
+
"learning_rate": 2.5768757687576876e-05,
|
| 186 |
+
"loss": 0.105,
|
| 187 |
+
"step": 8380
|
| 188 |
+
},
|
| 189 |
+
{
|
| 190 |
+
"epoch": 10.0,
|
| 191 |
+
"eval_bleu": 0.2555335148067654,
|
| 192 |
+
"eval_loss": 0.45896273851394653,
|
| 193 |
+
"eval_rouge1": 0.6440840106866277,
|
| 194 |
+
"eval_rouge2": 0.3998364161836553,
|
| 195 |
+
"eval_rougeL": 0.6425824451349154,
|
| 196 |
+
"eval_runtime": 5.4849,
|
| 197 |
+
"eval_samples_per_second": 305.385,
|
| 198 |
+
"eval_steps_per_second": 38.287,
|
| 199 |
+
"step": 8380
|
| 200 |
+
},
|
| 201 |
+
{
|
| 202 |
+
"epoch": 11.0,
|
| 203 |
+
"grad_norm": 0.923600435256958,
|
| 204 |
+
"learning_rate": 2.3191881918819188e-05,
|
| 205 |
+
"loss": 0.0982,
|
| 206 |
+
"step": 9218
|
| 207 |
+
},
|
| 208 |
+
{
|
| 209 |
+
"epoch": 11.0,
|
| 210 |
+
"eval_bleu": 0.25802091175426106,
|
| 211 |
+
"eval_loss": 0.46457362174987793,
|
| 212 |
+
"eval_rouge1": 0.6455262594531862,
|
| 213 |
+
"eval_rouge2": 0.40187791063551404,
|
| 214 |
+
"eval_rougeL": 0.6445205006389869,
|
| 215 |
+
"eval_runtime": 6.4432,
|
| 216 |
+
"eval_samples_per_second": 259.965,
|
| 217 |
+
"eval_steps_per_second": 32.593,
|
| 218 |
+
"step": 9218
|
| 219 |
+
},
|
| 220 |
+
{
|
| 221 |
+
"epoch": 12.0,
|
| 222 |
+
"grad_norm": 0.9120431542396545,
|
| 223 |
+
"learning_rate": 2.0615006150061504e-05,
|
| 224 |
+
"loss": 0.0936,
|
| 225 |
+
"step": 10056
|
| 226 |
+
},
|
| 227 |
+
{
|
| 228 |
+
"epoch": 12.0,
|
| 229 |
+
"eval_bleu": 0.257202175451904,
|
| 230 |
+
"eval_loss": 0.470233678817749,
|
| 231 |
+
"eval_rouge1": 0.6456936789584837,
|
| 232 |
+
"eval_rouge2": 0.4045772651416589,
|
| 233 |
+
"eval_rougeL": 0.6445820832270409,
|
| 234 |
+
"eval_runtime": 13.7399,
|
| 235 |
+
"eval_samples_per_second": 121.907,
|
| 236 |
+
"eval_steps_per_second": 15.284,
|
| 237 |
+
"step": 10056
|
| 238 |
+
},
|
| 239 |
+
{
|
| 240 |
+
"epoch": 13.0,
|
| 241 |
+
"grad_norm": 0.6435267329216003,
|
| 242 |
+
"learning_rate": 1.8038130381303812e-05,
|
| 243 |
+
"loss": 0.0899,
|
| 244 |
+
"step": 10894
|
| 245 |
+
},
|
| 246 |
+
{
|
| 247 |
+
"epoch": 13.0,
|
| 248 |
+
"eval_bleu": 0.25765634141938715,
|
| 249 |
+
"eval_loss": 0.47367072105407715,
|
| 250 |
+
"eval_rouge1": 0.6488279078084271,
|
| 251 |
+
"eval_rouge2": 0.40534740561340493,
|
| 252 |
+
"eval_rougeL": 0.6478436883847489,
|
| 253 |
+
"eval_runtime": 17.2761,
|
| 254 |
+
"eval_samples_per_second": 96.955,
|
| 255 |
+
"eval_steps_per_second": 12.156,
|
| 256 |
+
"step": 10894
|
| 257 |
+
},
|
| 258 |
+
{
|
| 259 |
+
"epoch": 14.0,
|
| 260 |
+
"grad_norm": 0.7371336221694946,
|
| 261 |
+
"learning_rate": 1.5461254612546124e-05,
|
| 262 |
+
"loss": 0.0871,
|
| 263 |
+
"step": 11732
|
| 264 |
+
},
|
| 265 |
+
{
|
| 266 |
+
"epoch": 14.0,
|
| 267 |
+
"eval_bleu": 0.2606034683461693,
|
| 268 |
+
"eval_loss": 0.4779162108898163,
|
| 269 |
+
"eval_rouge1": 0.6491650390141908,
|
| 270 |
+
"eval_rouge2": 0.40618585329089035,
|
| 271 |
+
"eval_rougeL": 0.6482221321240169,
|
| 272 |
+
"eval_runtime": 5.371,
|
| 273 |
+
"eval_samples_per_second": 311.859,
|
| 274 |
+
"eval_steps_per_second": 39.099,
|
| 275 |
+
"step": 11732
|
| 276 |
+
},
|
| 277 |
+
{
|
| 278 |
+
"epoch": 14.0,
|
| 279 |
+
"step": 11732,
|
| 280 |
+
"total_flos": 6127298150400000.0,
|
| 281 |
+
"train_loss": 0.03383859399638808,
|
| 282 |
+
"train_runtime": 1080.9024,
|
| 283 |
+
"train_samples_per_second": 123.97,
|
| 284 |
+
"train_steps_per_second": 15.506
|
| 285 |
}
|
| 286 |
],
|
| 287 |
"logging_steps": 500,
|
|
|
|
| 310 |
"attributes": {}
|
| 311 |
}
|
| 312 |
},
|
| 313 |
+
"total_flos": 6127298150400000.0,
|
| 314 |
"train_batch_size": 8,
|
| 315 |
"trial_name": null,
|
| 316 |
"trial_params": null
|