---
license: cc-by-4.0
language:
- en
library_name: NeMo
tags:
- Self-supervised Learning
- Conformer
- NeMo
- speech
- audio
---
# NVIDIA NEST XLarge En
[](#model-architecture)
| [](#model-architecture)
The NEST framework is designed for speech self-supervised learning, which can be used as a frozen speech feature extractor or as weight initialization for downstream speech processing tasks. The NEST-XL model has about 600M parameters and is trained on an English dataset of roughly 100K hours.
This model is ready for commercial/non-commercial use.
### License
License to use this model is covered by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/). By downloading the public and release version of the model, you accept the terms and conditions of the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) license.
## Reference
[1] [NEST: Self-supervised Fast Conformer as All-purpose Seasoning to Speech Processing Tasks](https://arxiv.org/abs/2408.13106)
[2] [NVIDIA NeMo Framework](https://github.com/NVIDIA/NeMo)
[3] [Stateful Conformer with Cache-based Inference for Streaming Automatic Speech Recognition](https://arxiv.org/abs/2312.17279)
[4] [Less is More: Accurate Speech Recognition & Translation without Web-Scale Data](https://arxiv.org/abs/2406.19674)
[5] [Sortformer: Seamless Integration of Speaker Diarization and ASR by Bridging Timestamps and Tokens](https://arxiv.org/abs/2409.06656)
[6] [Leveraging Pretrained ASR Encoders for Effective and Efficient End-to-End Speech Intent Classification and Slot Filling](https://arxiv.org/abs/2307.07057)
## Model Architecture
The [NEST](https://arxiv.org/abs/2408.13106) framework comprises several building blocks, as illustrated in the left part of the following figure. Once trained, the NEST encoder can be used as weight initialization or feature extractor for downstream speech processing tasks.
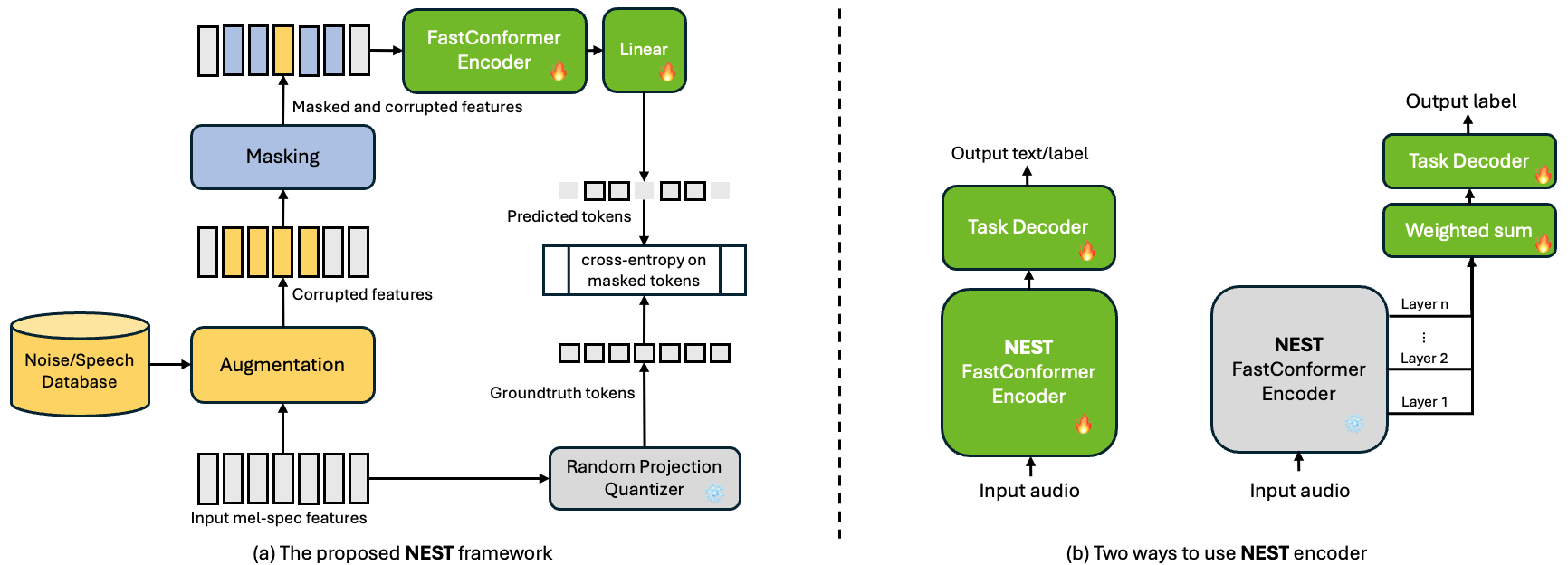
**Network Architecture:**
- Encoder: FastConformer (24 layers)
- Decoder: Linear classifier
- Masking: Random block masking
- Augmentor: Speaker/noise augmentation
- Loss: Cross-entropy on masked positions
### Input
**Input Type(s):** Audio
**Input Format(s):** wav files
**Input Parameters:** One-Dimensional (1D)
**Other Properties Related to Input:** 16000 Hz Mono-channel Audio
### Output:
**Output Type(s):** Audio features
**Output Format:** Audio embeddings
**Output Parameters:** Feature sequence (2D)
**Other Properties Related to Output:** Audio feature sequence of shape [D,T]
## Model Version(s)
`ssl_en_nest_xlarge_v1.0`
## How to Use the Model
The model is available for use in the NVIDIA NeMo Framework [2], and can be used as weight initialization for downstream tasks or as a frozen feature extractor.
### Automatically Instantiate the Model
```python
from nemo.collections.asr.models import EncDecDenoiseMaskedTokenPredModel
nest_model = EncDecDenoiseMaskedTokenPredModel.from_pretrained(model_name="nvidia/ssl_en_nest_xlarge_v1.0")
```
### Using NEST as Weight Initialization for Downstream Tasks
```bash
# use ASR as example:
python /examples/asr/asr_ctc/speech_to_text_ctc_bpe.py \
# (Optional: --config-path= --config-name=) \
++init_from_pretrained.name="nvidia/ssl_en_nest_xlarge_v1.0" \
++init_from_pretrained.include=["encoder"] \
model.train_ds.manifest_filepath= \
model.validation_ds.manifest_filepath= \
model.tokenizer.dir= \
model.tokenizer.type= \
trainer.devices=-1 \
trainer.accelerator="gpu" \
trainer.strategy="ddp" \
trainer.max_epochs=100 \
model.optim.name="adamw" \
model.optim.lr=0.001 \
model.optim.betas=[0.9,0.999] \
model.optim.weight_decay=0.0001 \
model.optim.sched.warmup_steps=2000
exp_manager.create_wandb_logger=True \
exp_manager.wandb_logger_kwargs.name="" \
exp_manager.wandb_logger_kwargs.project=""
```
More details can be found at [maybe_init_from_pretrained_checkpoint()](https://github.com/NVIDIA/NeMo/blob/main/nemo/core/classes/modelPT.py#L1236).
### Using NEST as Frozen Feature Extractor
NEST can also be used as a frozen feature extractor for downstream tasks. For example, in the case of speaker verification, embeddings can be extracted from different layers of the NEST model, and a learned weighted combination of those embeddings can be used as input to the speaker verification model.
Please refer to this example [script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/speech_pretraining/downstream/speech_classification_mfa_train.py) and [config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/ssl/nest/multi_layer_feat/nest_titanet_small.yaml) for details.
### Extracting and Saving Audio Features from NEST
NEST supports extracting audio features from multiple layers of its encoder:
```bash
python /scripts/ssl/extract_features.py \
--model_path="nvidia/ssl_en_nest_xlarge_v1.0" \
--input= \
--output=