
End of training
Browse files- README.md +9 -14
- all_results.json +13 -13
- eval_results.json +7 -7
- f1_scores.png +0 -0
- losses.png +0 -0
- model.safetensors +1 -1
- test_results.json +6 -6
README.md
CHANGED
|
@@ -19,10 +19,10 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 19 |
|
| 20 |
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on an unknown dataset.
|
| 21 |
It achieves the following results on the evaluation set:
|
| 22 |
-
- Loss: 0.
|
| 23 |
-
- Precision: 0.
|
| 24 |
- Recall: 1.0
|
| 25 |
-
- F1: 0.
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
|
@@ -54,17 +54,12 @@ The following hyperparameters were used during training:
|
|
| 54 |
|
| 55 |
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 |
|
| 56 |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|
|
| 57 |
-
| 0.
|
| 58 |
-
| 0.
|
| 59 |
-
| 0.
|
| 60 |
-
| 0.
|
| 61 |
-
| 0.
|
| 62 |
-
| 0.
|
| 63 |
-
| 0.5672 | 7.0 | 1351 | 0.5718 | 0.7404 | 1.0 | 0.8509 |
|
| 64 |
-
| 0.5639 | 8.0 | 1544 | 0.5715 | 0.7415 | 0.9956 | 0.8500 |
|
| 65 |
-
| 0.5624 | 9.0 | 1737 | 0.5725 | 0.7416 | 0.9912 | 0.8485 |
|
| 66 |
-
| 0.5619 | 10.0 | 1930 | 0.5715 | 0.7431 | 0.9860 | 0.8475 |
|
| 67 |
-
| 0.5613 | 11.0 | 2123 | 0.5720 | 0.7422 | 0.9842 | 0.8463 |
|
| 68 |
|
| 69 |
|
| 70 |
### Framework versions
|
|
|
|
| 19 |
|
| 20 |
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on an unknown dataset.
|
| 21 |
It achieves the following results on the evaluation set:
|
| 22 |
+
- Loss: 0.5881
|
| 23 |
+
- Precision: 0.7395
|
| 24 |
- Recall: 1.0
|
| 25 |
+
- F1: 0.8502
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
|
|
|
| 54 |
|
| 55 |
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 |
|
| 56 |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|
|
| 57 |
+
| 0.5965 | 1.0 | 193 | 0.5881 | 0.7395 | 1.0 | 0.8502 |
|
| 58 |
+
| 0.5885 | 2.0 | 386 | 0.5808 | 0.7395 | 1.0 | 0.8502 |
|
| 59 |
+
| 0.5791 | 3.0 | 579 | 0.5772 | 0.7395 | 1.0 | 0.8502 |
|
| 60 |
+
| 0.5751 | 4.0 | 772 | 0.5768 | 0.7395 | 1.0 | 0.8502 |
|
| 61 |
+
| 0.5712 | 5.0 | 965 | 0.5726 | 0.7396 | 0.9982 | 0.8497 |
|
| 62 |
+
| 0.5707 | 6.0 | 1158 | 0.5718 | 0.7398 | 0.9965 | 0.8491 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 63 |
|
| 64 |
|
| 65 |
### Framework versions
|
all_results.json
CHANGED
|
@@ -1,17 +1,17 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"eval_f1": 0.
|
| 4 |
-
"eval_loss": 0.
|
| 5 |
-
"eval_precision": 0.
|
| 6 |
"eval_recall": 1.0,
|
| 7 |
-
"eval_runtime": 8.
|
| 8 |
-
"eval_samples_per_second":
|
| 9 |
-
"eval_steps_per_second":
|
| 10 |
-
"test_f1": 0.
|
| 11 |
-
"test_loss": 0.
|
| 12 |
-
"test_precision": 0.
|
| 13 |
"test_recall": 1.0,
|
| 14 |
-
"test_runtime": 8.
|
| 15 |
-
"test_samples_per_second":
|
| 16 |
-
"test_steps_per_second":
|
| 17 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 6.0,
|
| 3 |
+
"eval_f1": 0.8502235469448585,
|
| 4 |
+
"eval_loss": 0.5881040692329407,
|
| 5 |
+
"eval_precision": 0.7394685677252106,
|
| 6 |
"eval_recall": 1.0,
|
| 7 |
+
"eval_runtime": 8.5024,
|
| 8 |
+
"eval_samples_per_second": 181.479,
|
| 9 |
+
"eval_steps_per_second": 2.94,
|
| 10 |
+
"test_f1": 0.8412757973733583,
|
| 11 |
+
"test_loss": 0.5977824926376343,
|
| 12 |
+
"test_precision": 0.7260362694300518,
|
| 13 |
"test_recall": 1.0,
|
| 14 |
+
"test_runtime": 8.6861,
|
| 15 |
+
"test_samples_per_second": 177.756,
|
| 16 |
+
"test_steps_per_second": 2.878
|
| 17 |
}
|
eval_results.json
CHANGED
|
@@ -1,10 +1,10 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"eval_f1": 0.
|
| 4 |
-
"eval_loss": 0.
|
| 5 |
-
"eval_precision": 0.
|
| 6 |
"eval_recall": 1.0,
|
| 7 |
-
"eval_runtime": 8.
|
| 8 |
-
"eval_samples_per_second":
|
| 9 |
-
"eval_steps_per_second":
|
| 10 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 6.0,
|
| 3 |
+
"eval_f1": 0.8502235469448585,
|
| 4 |
+
"eval_loss": 0.5881040692329407,
|
| 5 |
+
"eval_precision": 0.7394685677252106,
|
| 6 |
"eval_recall": 1.0,
|
| 7 |
+
"eval_runtime": 8.5024,
|
| 8 |
+
"eval_samples_per_second": 181.479,
|
| 9 |
+
"eval_steps_per_second": 2.94
|
| 10 |
}
|
f1_scores.png
CHANGED

|

|
losses.png
CHANGED
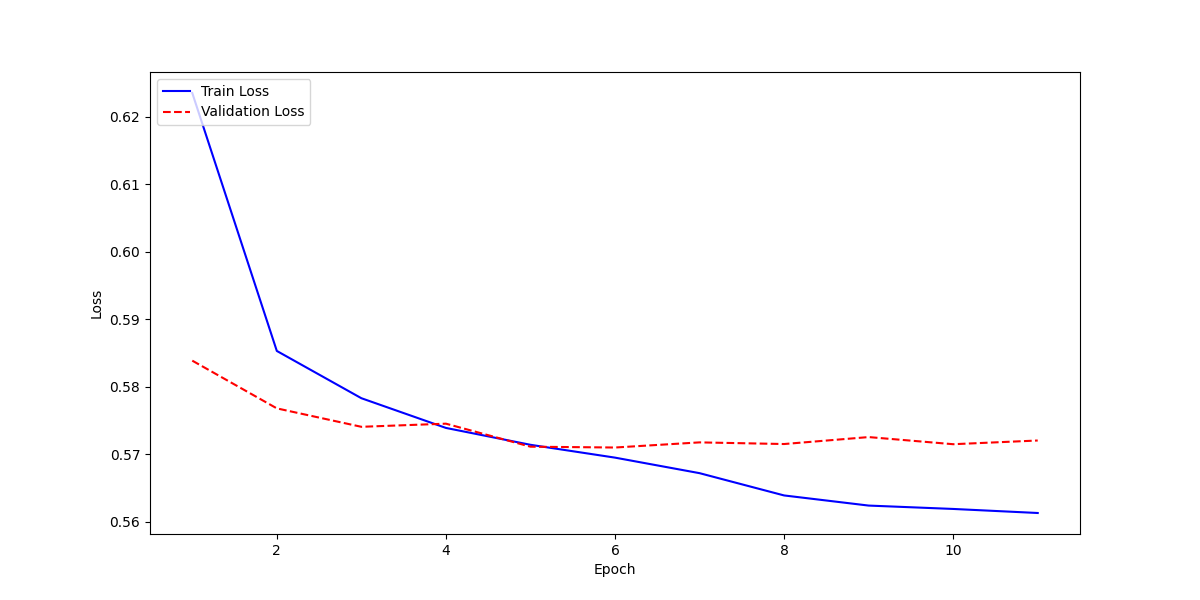
|
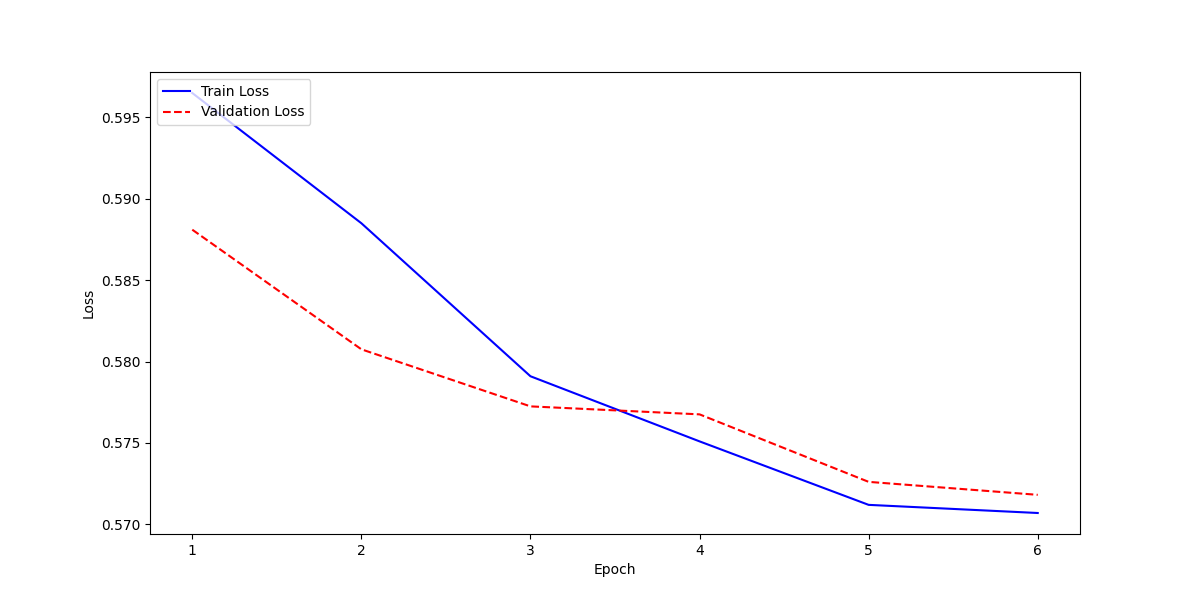
|
model.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 243126200
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f53be861a33b6a9ca04b1baf6eb7acb0ab0f8b9bc03b9e033136354e5b6af32a
|
| 3 |
size 243126200
|
test_results.json
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
{
|
| 2 |
-
"test_f1": 0.
|
| 3 |
-
"test_loss": 0.
|
| 4 |
-
"test_precision": 0.
|
| 5 |
"test_recall": 1.0,
|
| 6 |
-
"test_runtime": 8.
|
| 7 |
-
"test_samples_per_second":
|
| 8 |
-
"test_steps_per_second":
|
| 9 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"test_f1": 0.8412757973733583,
|
| 3 |
+
"test_loss": 0.5977824926376343,
|
| 4 |
+
"test_precision": 0.7260362694300518,
|
| 5 |
"test_recall": 1.0,
|
| 6 |
+
"test_runtime": 8.6861,
|
| 7 |
+
"test_samples_per_second": 177.756,
|
| 8 |
+
"test_steps_per_second": 2.878
|
| 9 |
}
|