
End of training
Browse files- README.md +7 -7
- all_results.json +8 -8
- eval_results.json +4 -4
- f1_scores.png +0 -0
- losses.png +0 -0
- model.safetensors +1 -1
- test_results.json +4 -4
README.md
CHANGED
|
@@ -19,7 +19,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 19 |
|
| 20 |
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on an unknown dataset.
|
| 21 |
It achieves the following results on the evaluation set:
|
| 22 |
-
- Loss: 0.
|
| 23 |
- Precision: 0.6500
|
| 24 |
- Recall: 1.0
|
| 25 |
- F1: 0.7879
|
|
@@ -54,12 +54,12 @@ The following hyperparameters were used during training:
|
|
| 54 |
|
| 55 |
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 |
|
| 56 |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|
|
| 57 |
-
| 0.
|
| 58 |
-
| 0.
|
| 59 |
-
| 0.
|
| 60 |
-
| 0.
|
| 61 |
-
| 0.
|
| 62 |
-
| 0.
|
| 63 |
|
| 64 |
|
| 65 |
### Framework versions
|
|
|
|
| 19 |
|
| 20 |
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on an unknown dataset.
|
| 21 |
It achieves the following results on the evaluation set:
|
| 22 |
+
- Loss: 0.6502
|
| 23 |
- Precision: 0.6500
|
| 24 |
- Recall: 1.0
|
| 25 |
- F1: 0.7879
|
|
|
|
| 54 |
|
| 55 |
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 |
|
| 56 |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|
|
| 57 |
+
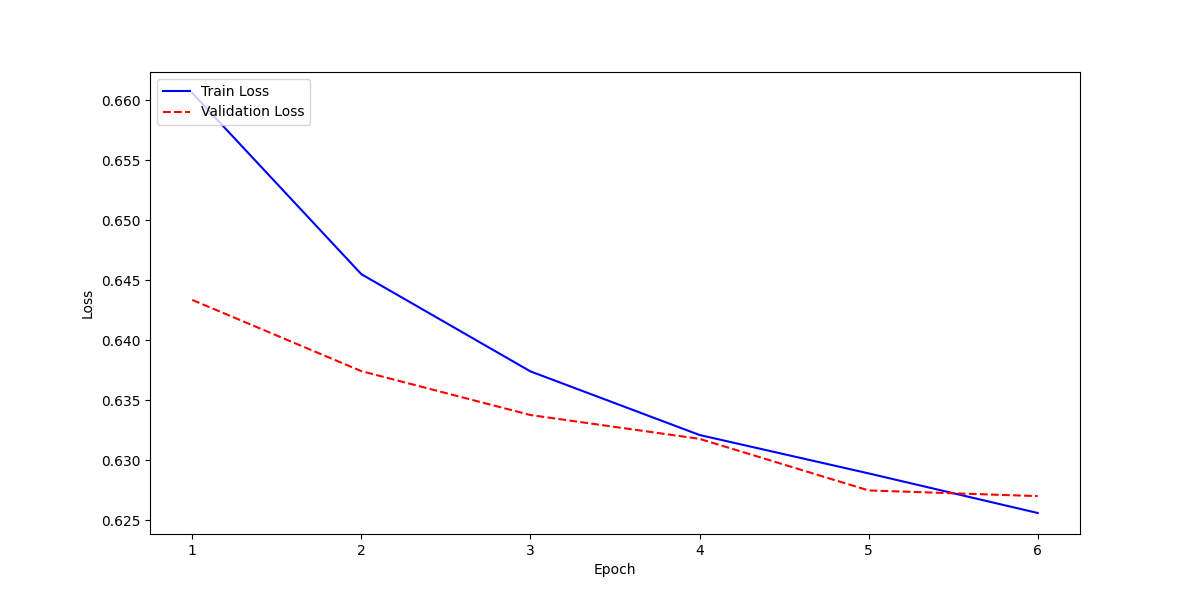
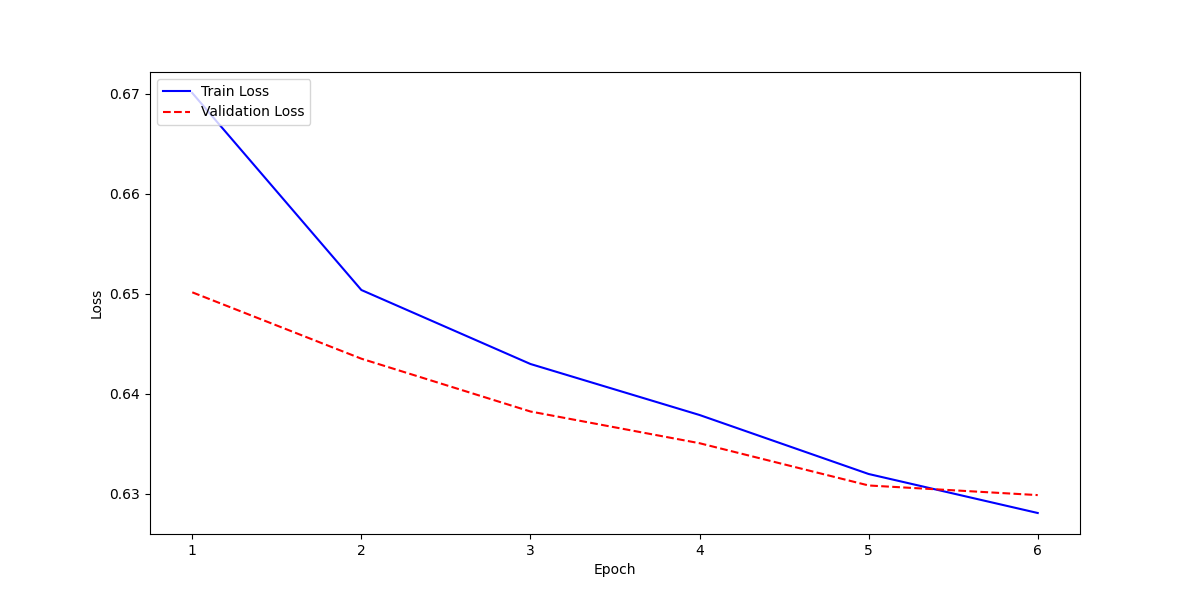
| 0.6701 | 1.0 | 193 | 0.6502 | 0.6500 | 1.0 | 0.7879 |
|
| 58 |
+
| 0.6504 | 2.0 | 386 | 0.6435 | 0.6500 | 1.0 | 0.7879 |
|
| 59 |
+
| 0.643 | 3.0 | 579 | 0.6382 | 0.6494 | 0.9970 | 0.7865 |
|
| 60 |
+
| 0.6379 | 4.0 | 772 | 0.6351 | 0.6504 | 0.9831 | 0.7829 |
|
| 61 |
+
| 0.632 | 5.0 | 965 | 0.6309 | 0.6653 | 0.9511 | 0.7829 |
|
| 62 |
+
| 0.6281 | 6.0 | 1158 | 0.6299 | 0.6695 | 0.9472 | 0.7845 |
|
| 63 |
|
| 64 |
|
| 65 |
### Framework versions
|
all_results.json
CHANGED
|
@@ -1,17 +1,17 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 6.0,
|
| 3 |
"eval_f1": 0.7879025923016496,
|
| 4 |
-
"eval_loss": 0.
|
| 5 |
"eval_precision": 0.6500324044069994,
|
| 6 |
"eval_recall": 1.0,
|
| 7 |
-
"eval_runtime": 8.
|
| 8 |
-
"eval_samples_per_second":
|
| 9 |
-
"eval_steps_per_second":
|
| 10 |
"test_f1": 0.7823343848580442,
|
| 11 |
-
"test_loss": 0.
|
| 12 |
"test_precision": 0.6424870466321243,
|
| 13 |
"test_recall": 1.0,
|
| 14 |
-
"test_runtime": 8.
|
| 15 |
-
"test_samples_per_second":
|
| 16 |
-
"test_steps_per_second":
|
| 17 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 6.0,
|
| 3 |
"eval_f1": 0.7879025923016496,
|
| 4 |
+
"eval_loss": 0.65016770362854,
|
| 5 |
"eval_precision": 0.6500324044069994,
|
| 6 |
"eval_recall": 1.0,
|
| 7 |
+
"eval_runtime": 8.4133,
|
| 8 |
+
"eval_samples_per_second": 183.401,
|
| 9 |
+
"eval_steps_per_second": 2.971,
|
| 10 |
"test_f1": 0.7823343848580442,
|
| 11 |
+
"test_loss": 0.6548706293106079,
|
| 12 |
"test_precision": 0.6424870466321243,
|
| 13 |
"test_recall": 1.0,
|
| 14 |
+
"test_runtime": 8.4053,
|
| 15 |
+
"test_samples_per_second": 183.694,
|
| 16 |
+
"test_steps_per_second": 2.974
|
| 17 |
}
|
eval_results.json
CHANGED
|
@@ -1,10 +1,10 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 6.0,
|
| 3 |
"eval_f1": 0.7879025923016496,
|
| 4 |
-
"eval_loss": 0.
|
| 5 |
"eval_precision": 0.6500324044069994,
|
| 6 |
"eval_recall": 1.0,
|
| 7 |
-
"eval_runtime": 8.
|
| 8 |
-
"eval_samples_per_second":
|
| 9 |
-
"eval_steps_per_second":
|
| 10 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 6.0,
|
| 3 |
"eval_f1": 0.7879025923016496,
|
| 4 |
+
"eval_loss": 0.65016770362854,
|
| 5 |
"eval_precision": 0.6500324044069994,
|
| 6 |
"eval_recall": 1.0,
|
| 7 |
+
"eval_runtime": 8.4133,
|
| 8 |
+
"eval_samples_per_second": 183.401,
|
| 9 |
+
"eval_steps_per_second": 2.971
|
| 10 |
}
|
f1_scores.png
CHANGED

|

|
losses.png
CHANGED
|
|
model.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 243126200
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:93808603de3853a585d6628d5dec2d3b7514affc0bf65feb4513b5b057b41f4a
|
| 3 |
size 243126200
|
test_results.json
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
{
|
| 2 |
"test_f1": 0.7823343848580442,
|
| 3 |
-
"test_loss": 0.
|
| 4 |
"test_precision": 0.6424870466321243,
|
| 5 |
"test_recall": 1.0,
|
| 6 |
-
"test_runtime": 8.
|
| 7 |
-
"test_samples_per_second":
|
| 8 |
-
"test_steps_per_second":
|
| 9 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"test_f1": 0.7823343848580442,
|
| 3 |
+
"test_loss": 0.6548706293106079,
|
| 4 |
"test_precision": 0.6424870466321243,
|
| 5 |
"test_recall": 1.0,
|
| 6 |
+
"test_runtime": 8.4053,
|
| 7 |
+
"test_samples_per_second": 183.694,
|
| 8 |
+
"test_steps_per_second": 2.974
|
| 9 |
}
|