Data-Juicer Sandbox: A Comprehensive Suite for Multimodal Data-Model Co-development
 yxdyc
yxdyc


Abstract
The emergence of large-scale multi-modal generative models has drastically advanced artificial intelligence, introducing unprecedented levels of performance and functionality. However, optimizing these models remains challenging due to historically isolated paths of model-centric and data-centric developments, leading to suboptimal outcomes and inefficient resource utilization. In response, we present a novel sandbox suite tailored for integrated data-model co-development. This sandbox provides a comprehensive experimental platform, enabling rapid iteration and insight-driven refinement of both data and models. Our proposed "Probe-Analyze-Refine" workflow, validated through applications on state-of-the-art LLaVA-like and DiT based models, yields significant performance boosts, such as topping the VBench leaderboard. We also uncover fruitful insights gleaned from exhaustive benchmarks, shedding light on the critical interplay between data quality, diversity, and model behavior. With the hope of fostering deeper understanding and future progress in multi-modal data and generative modeling, our codes, datasets, and models are maintained and accessible at https://github.com/modelscope/data-juicer/blob/main/docs/Sandbox.md.
Community
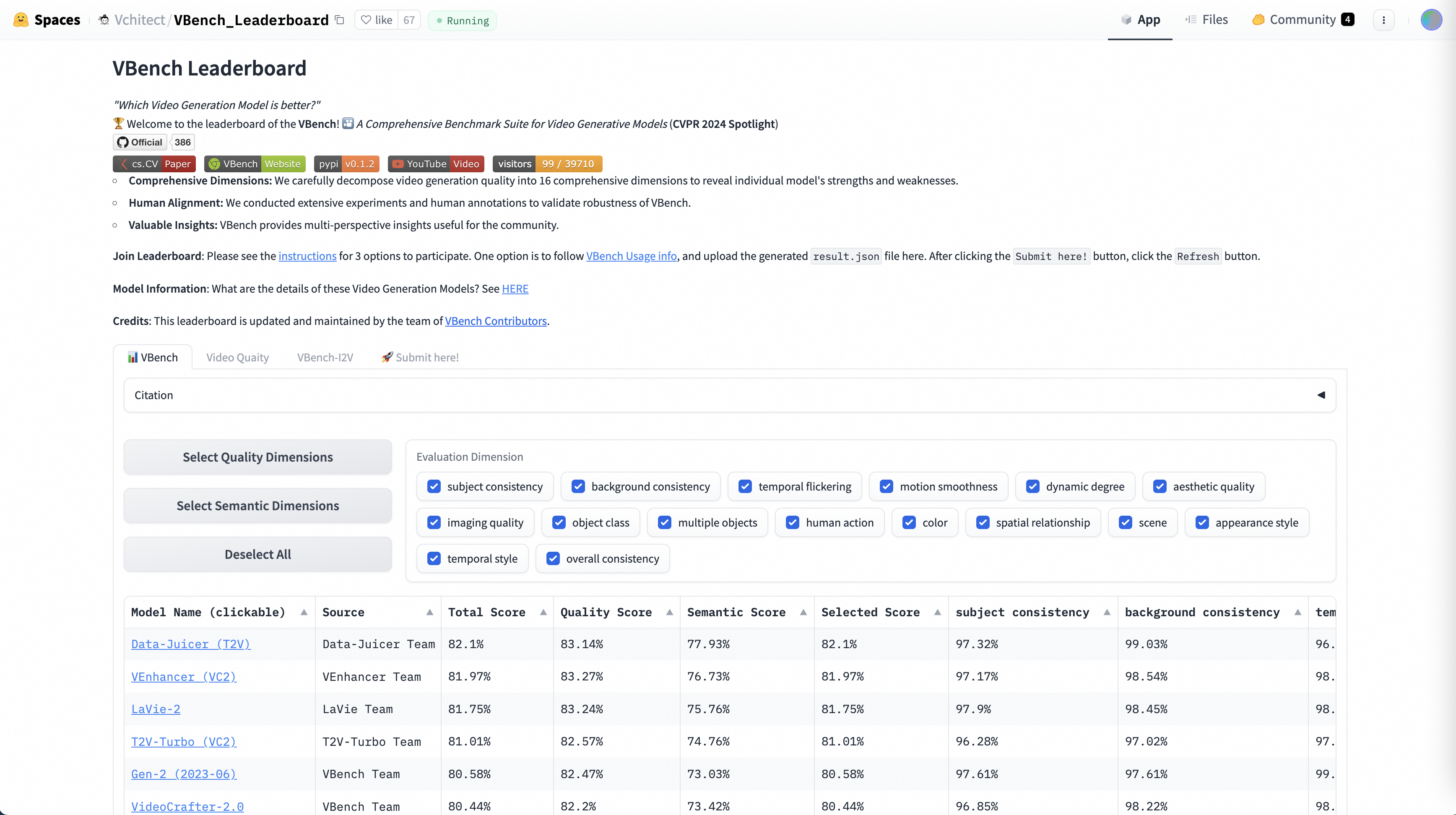
New top1 performance on V-Bench leaderboard.
Continuously maintained and accessible at data-juicer sandbox page.


This is an automated message from the Librarian Bot. I found the following papers similar to this paper.
The following papers were recommended by the Semantic Scholar API
- The Synergy between Data and Multi-Modal Large Language Models: A Survey from Co-Development Perspective (2024)
- On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey (2024)
- PAS: Data-Efficient Plug-and-Play Prompt Augmentation System (2024)
- Fennec: Fine-grained Language Model Evaluation and Correction Extended through Branching and Bridging (2024)
- UniGen: A Unified Framework for Textual Dataset Generation Using Large Language Models (2024)
Please give a thumbs up to this comment if you found it helpful!
If you want recommendations for any Paper on Hugging Face checkout this Space
You can directly ask Librarian Bot for paper recommendations by tagging it in a comment:
@librarian-bot
recommend
Models citing this paper 0
No model linking this paper
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper