
robbiemu merge
Browse files- .gitattributes +14 -0
- .gitignore +189 -0
- IQ2_M_log.txt +341 -0
- IQ2_S_log.txt +341 -0
- IQ3_M_log.txt +341 -0
- IQ4_NL_log.txt +268 -0
- IQ4_XS_log.txt +341 -0
- Q3_K_L_log.txt +341 -0
- Q3_K_M_log.txt +341 -0
- Q4_K_M_log.txt +341 -0
- Q4_K_S_log.txt +341 -0
- Q5_K_M_log.txt +341 -0
- Q5_K_S_log.txt +341 -0
- Q6_K_log.txt +341 -0
- Q8_0_log.txt +268 -0
- README.md +48 -1
- images/comparison_of_quantization.png +0 -0
- imatrix_dataset.ipynb +0 -0
- imatrix_log.txt +148 -0
- on_perplexity.md +30 -0
- on_quantization.md +100 -0
- perplexity_IQ2_M.txt +146 -0
- perplexity_IQ2_S.txt +146 -0
- perplexity_IQ3_M.txt +147 -0
- perplexity_IQ4_NL.txt +144 -0
- perplexity_IQ4_XS.txt +145 -0
- perplexity_Q3_K_L.txt +146 -0
- perplexity_Q3_K_M.txt +148 -0
- perplexity_Q4_K_M.txt +147 -0
- perplexity_Q4_K_S.txt +147 -0
- perplexity_Q5_K_M.txt +147 -0
- perplexity_Q5_K_S.txt +145 -0
- perplexity_Q6_K.txt +145 -0
- perplexity_Q8_0.txt +144 -0
- perplexity_bf16.txt +139 -0
- ppl_test_data.txt +0 -0
- quanization_results.md +23 -0
- quantizations.yaml +137 -0
- quantize.ipynb +599 -0
.gitattributes
CHANGED
|
@@ -34,3 +34,17 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
images/salamandra_header.png filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
images/salamandra_header.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
salamandra-2b-instruct_bf16.gguf filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
salamandra-2b-instruct_IQ2_M.gguf filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
salamandra-2b-instruct_IQ3_M.gguf filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
salamandra-2b-instruct_Q3_K_L.gguf filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
salamandra-2b-instruct_Q5_K_S.gguf filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
salamandra-2b-instruct_IQ2_S.gguf filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
salamandra-2b-instruct_Q4_K_S.gguf filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
salamandra-2b-instruct_Q6_K.gguf filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
salamandra-2b-instruct_IQ4_NL.gguf filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
salamandra-2b-instruct_Q3_K_M.gguf filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
salamandra-2b-instruct_Q4_K_M.gguf filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
salamandra-2b-instruct_Q8_0.gguf filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
salamandra-2b-instruct_IQ4_XS.gguf filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
salamandra-2b-instruct_Q5_K_M.gguf filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/latest/usage/project/#working-with-version-control
|
| 110 |
+
.pdm.toml
|
| 111 |
+
.pdm-python
|
| 112 |
+
.pdm-build/
|
| 113 |
+
|
| 114 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 115 |
+
__pypackages__/
|
| 116 |
+
|
| 117 |
+
# Celery stuff
|
| 118 |
+
celerybeat-schedule
|
| 119 |
+
celerybeat.pid
|
| 120 |
+
|
| 121 |
+
# SageMath parsed files
|
| 122 |
+
*.sage.py
|
| 123 |
+
|
| 124 |
+
# Environments
|
| 125 |
+
.env
|
| 126 |
+
.venv
|
| 127 |
+
env/
|
| 128 |
+
venv/
|
| 129 |
+
ENV/
|
| 130 |
+
env.bak/
|
| 131 |
+
venv.bak/
|
| 132 |
+
|
| 133 |
+
# Spyder project settings
|
| 134 |
+
.spyderproject
|
| 135 |
+
.spyproject
|
| 136 |
+
|
| 137 |
+
# Rope project settings
|
| 138 |
+
.ropeproject
|
| 139 |
+
|
| 140 |
+
# mkdocs documentation
|
| 141 |
+
/site
|
| 142 |
+
|
| 143 |
+
# mypy
|
| 144 |
+
.mypy_cache/
|
| 145 |
+
.dmypy.json
|
| 146 |
+
dmypy.json
|
| 147 |
+
|
| 148 |
+
# Pyre type checker
|
| 149 |
+
.pyre/
|
| 150 |
+
|
| 151 |
+
# pytype static type analyzer
|
| 152 |
+
.pytype/
|
| 153 |
+
|
| 154 |
+
# Cython debug symbols
|
| 155 |
+
cython_debug/
|
| 156 |
+
|
| 157 |
+
# PyCharm
|
| 158 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 159 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 160 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 161 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 162 |
+
#.idea/
|
| 163 |
+
|
| 164 |
+
# General
|
| 165 |
+
.DS_Store
|
| 166 |
+
.AppleDouble
|
| 167 |
+
.LSOverride
|
| 168 |
+
|
| 169 |
+
# Icon must end with two \r
|
| 170 |
+
Icon
|
| 171 |
+
|
| 172 |
+
# Thumbnails
|
| 173 |
+
._*
|
| 174 |
+
|
| 175 |
+
# Files that might appear in the root of a volume
|
| 176 |
+
.DocumentRevisions-V100
|
| 177 |
+
.fseventsd
|
| 178 |
+
.Spotlight-V100
|
| 179 |
+
.TemporaryItems
|
| 180 |
+
.Trashes
|
| 181 |
+
.VolumeIcon.icns
|
| 182 |
+
.com.apple.timemachine.donotpresent
|
| 183 |
+
|
| 184 |
+
# Directories potentially created on remote AFP share
|
| 185 |
+
.AppleDB
|
| 186 |
+
.AppleDesktop
|
| 187 |
+
Network Trash Folder
|
| 188 |
+
Temporary Items
|
| 189 |
+
.apdisk
|
IQ2_M_log.txt
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_IQ2_M.gguf' as IQ2_M
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to iq3_s .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 214.84 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 49 |
+
|
| 50 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 51 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 52 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 53 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 54 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 55 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 56 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 57 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 58 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 59 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 60 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 61 |
+
|
| 62 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 63 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 64 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 65 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 66 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 67 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 68 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 69 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 70 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 71 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 72 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 73 |
+
|
| 74 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 75 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 76 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 77 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 78 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 80 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 81 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 82 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 83 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 85 |
+
|
| 86 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 87 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 88 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 89 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 90 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 91 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 92 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 93 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 94 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 95 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 96 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 97 |
+
|
| 98 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 99 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 100 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 101 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 102 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 103 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 104 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 105 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 106 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 107 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 108 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 109 |
+
|
| 110 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 111 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 112 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 113 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 114 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 116 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 117 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 118 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 119 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 121 |
+
|
| 122 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 123 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 124 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 125 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 126 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 127 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 128 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 129 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 130 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 131 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 132 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 133 |
+
|
| 134 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 135 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 136 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 137 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 138 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 139 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 140 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 141 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 142 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 143 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 144 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 145 |
+
|
| 146 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 147 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 148 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 149 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 150 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 152 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 153 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 154 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 155 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 157 |
+
|
| 158 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 159 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 160 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 161 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 162 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 163 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 164 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 165 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 166 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 167 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 168 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 169 |
+
|
| 170 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 171 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 172 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 173 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 174 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 175 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 176 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 177 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 178 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 179 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 180 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 181 |
+
|
| 182 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 183 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 184 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 185 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 186 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 188 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 189 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 190 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 191 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 193 |
+
|
| 194 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 195 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 196 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 197 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 198 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 199 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 200 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 201 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 202 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 203 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 204 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 205 |
+
|
| 206 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 207 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 208 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 209 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 210 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 211 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 212 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 213 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 214 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 215 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 216 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 217 |
+
|
| 218 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 219 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 220 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 221 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 222 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 224 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 225 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 226 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 227 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 229 |
+
|
| 230 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 231 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 232 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 233 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 234 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 235 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 236 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 237 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 238 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 239 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 240 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 241 |
+
|
| 242 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 243 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 244 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 245 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 246 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 247 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 248 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 249 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 250 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 251 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 252 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 253 |
+
|
| 254 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 255 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 256 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 257 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 258 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 260 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 261 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 262 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 263 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 265 |
+
|
| 266 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 267 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 268 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 269 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 270 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 271 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 272 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 273 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 274 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 275 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 276 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 277 |
+
|
| 278 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 279 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 280 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 281 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 282 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 283 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 284 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 285 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 286 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 287 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 288 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 289 |
+
|
| 290 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 291 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 292 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 293 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 294 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 295 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 296 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 297 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 298 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 299 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 300 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 301 |
+
|
| 302 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 303 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 304 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 305 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 306 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 307 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 308 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 309 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 310 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 311 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 312 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 313 |
+
|
| 314 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 315 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 316 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 317 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 318 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 319 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 320 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 321 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 322 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 323 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 324 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 325 |
+
|
| 326 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_s - using fallback quantization iq4_nl
|
| 327 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 328 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 329 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_s .. size = 21.25 MiB -> 3.40 MiB
|
| 330 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 331 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 332 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 333 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_s .. size = 8.00 MiB -> 1.28 MiB
|
| 334 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 335 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 336 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 337 |
+
llama_model_quantize_internal: quant size = 1666.02 MB
|
| 338 |
+
llama_model_quantize_internal: WARNING: 24 of 169 tensor(s) required fallback quantization
|
| 339 |
+
|
| 340 |
+
main: quantize time = 22948.49 ms
|
| 341 |
+
main: total time = 22948.49 ms
|
IQ2_S_log.txt
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_IQ2_S.gguf' as IQ2_S
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to iq3_s .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 214.84 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 49 |
+
|
| 50 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 51 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 52 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 53 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 54 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 55 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 56 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 57 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 58 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 59 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 60 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 61 |
+
|
| 62 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 63 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 64 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 65 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 66 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 67 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 68 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 69 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 70 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 71 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 72 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 73 |
+
|
| 74 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 75 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 76 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 77 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 78 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 80 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 81 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 82 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 83 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 85 |
+
|
| 86 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 87 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 88 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 89 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 90 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 91 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 92 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 93 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 94 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 95 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 96 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 97 |
+
|
| 98 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 99 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 100 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 101 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 102 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 103 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 104 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 105 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 106 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 107 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 108 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 109 |
+
|
| 110 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 111 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 112 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 113 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 114 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 116 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 117 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 118 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 119 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 121 |
+
|
| 122 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 123 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 124 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 125 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 126 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 127 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 128 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 129 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 130 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 131 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 132 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 133 |
+
|
| 134 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 135 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 136 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 137 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 138 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 139 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 140 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 141 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 142 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 143 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 144 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 145 |
+
|
| 146 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 147 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 148 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 149 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 150 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 152 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 153 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 154 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 155 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 157 |
+
|
| 158 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 159 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 160 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 161 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 162 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 163 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 164 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 165 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 166 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 167 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 168 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 169 |
+
|
| 170 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 171 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 172 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 173 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 174 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 175 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 176 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 177 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 178 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 179 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 180 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 181 |
+
|
| 182 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 183 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 184 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 185 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 186 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 188 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 189 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 190 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 191 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 193 |
+
|
| 194 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 195 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 196 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 197 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 198 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 199 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 200 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 201 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 202 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 203 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 204 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 205 |
+
|
| 206 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 207 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 208 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 209 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 210 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 211 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 212 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 213 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 214 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 215 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 216 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 217 |
+
|
| 218 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 219 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 220 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 221 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 222 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 224 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 225 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 226 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 227 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 229 |
+
|
| 230 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 231 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 232 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 233 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 234 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 235 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 236 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 237 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 238 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 239 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 240 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 241 |
+
|
| 242 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 243 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 244 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 245 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 246 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 247 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 248 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 249 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 250 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 251 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 252 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 253 |
+
|
| 254 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 255 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 256 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 257 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 258 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 260 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 261 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 262 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 263 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 265 |
+
|
| 266 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 267 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 268 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 269 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 270 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 271 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 272 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 273 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 274 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 275 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 276 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 277 |
+
|
| 278 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 279 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 280 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 281 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 282 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 283 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 284 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 285 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 286 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 287 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 288 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 289 |
+
|
| 290 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 291 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 292 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 293 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 294 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 295 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 296 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 297 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 298 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 299 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 300 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 301 |
+
|
| 302 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 303 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 304 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 305 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 306 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 307 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 308 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 309 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 310 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 311 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 312 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 313 |
+
|
| 314 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 315 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 316 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 317 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 318 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 319 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 320 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 321 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 322 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 323 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 324 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 325 |
+
|
| 326 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq2_xs - using fallback quantization iq4_nl
|
| 327 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 328 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 329 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq2_xs .. size = 21.25 MiB -> 3.07 MiB
|
| 330 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 331 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 332 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 333 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq2_xs .. size = 8.00 MiB -> 1.16 MiB
|
| 334 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 335 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 336 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 337 |
+
llama_model_quantize_internal: quant size = 1644.09 MB
|
| 338 |
+
llama_model_quantize_internal: WARNING: 24 of 169 tensor(s) required fallback quantization
|
| 339 |
+
|
| 340 |
+
main: quantize time = 36947.58 ms
|
| 341 |
+
main: total time = 36947.58 ms
|
IQ3_M_log.txt
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_IQ3_M.gguf' as IQ3_M
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to iq3_s .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 214.84 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 49 |
+
|
| 50 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 51 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 52 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 53 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 54 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 55 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 56 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 57 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 58 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 59 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 60 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 61 |
+
|
| 62 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 63 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 64 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 65 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 66 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 67 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 68 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 69 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 70 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 71 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 72 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 73 |
+
|
| 74 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 75 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 76 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 77 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 78 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 80 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 81 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 82 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 83 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 85 |
+
|
| 86 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 87 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 88 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 89 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 90 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 91 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 92 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 93 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 94 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 95 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 96 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 97 |
+
|
| 98 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 99 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 100 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 101 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 102 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 103 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 104 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 105 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 106 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 107 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 108 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 109 |
+
|
| 110 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 111 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 112 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 113 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 114 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 116 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 117 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 118 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 119 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 121 |
+
|
| 122 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 123 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 124 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 125 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 126 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 127 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 128 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 129 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 130 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 131 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 132 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 133 |
+
|
| 134 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 135 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 136 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 137 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 138 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 139 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 140 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 141 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 142 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 143 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 144 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 145 |
+
|
| 146 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 147 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 148 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 149 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 150 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 152 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 153 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 154 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 155 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 157 |
+
|
| 158 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 159 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 160 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 161 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 162 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 163 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 164 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 165 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 166 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 167 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 168 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 169 |
+
|
| 170 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 171 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 172 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 173 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 174 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 175 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 176 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 177 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 178 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 179 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 180 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 181 |
+
|
| 182 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 183 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 184 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 185 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 186 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 188 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 189 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 190 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 191 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 193 |
+
|
| 194 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 195 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 196 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 197 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 198 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 199 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 200 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 201 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 202 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 203 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 204 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 205 |
+
|
| 206 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 207 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 208 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 209 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 210 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 211 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 212 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 213 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 214 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 215 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 216 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 217 |
+
|
| 218 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 219 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 220 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 221 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 222 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 224 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 225 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 226 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 227 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 229 |
+
|
| 230 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 231 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 232 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 233 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 234 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 235 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 236 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 237 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 238 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 239 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 240 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 241 |
+
|
| 242 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 243 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 244 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 245 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 246 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 247 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 248 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 249 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 250 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 251 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 252 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 253 |
+
|
| 254 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 255 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 256 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 257 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 258 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 260 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 261 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 262 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 263 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 265 |
+
|
| 266 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 267 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 268 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 269 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 270 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 271 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 272 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 273 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 274 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 275 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 276 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 277 |
+
|
| 278 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 279 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 280 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 281 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 282 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 283 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 284 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 285 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 286 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 287 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 288 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 289 |
+
|
| 290 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 291 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 292 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 293 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 294 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 295 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 296 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 297 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 298 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 299 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 300 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 301 |
+
|
| 302 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 303 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 304 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 305 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 306 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 307 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 308 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 309 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 310 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 311 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 312 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 313 |
+
|
| 314 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 315 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 316 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 317 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 318 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 319 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 320 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 321 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 322 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 323 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 324 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 325 |
+
|
| 326 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq3_s - using fallback quantization iq4_nl
|
| 327 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 328 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 329 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq3_s .. size = 21.25 MiB -> 4.57 MiB
|
| 330 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 331 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 332 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 333 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq3_s .. size = 8.00 MiB -> 1.72 MiB
|
| 334 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 335 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 336 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 337 |
+
llama_model_quantize_internal: quant size = 1772.29 MB
|
| 338 |
+
llama_model_quantize_internal: WARNING: 24 of 169 tensor(s) required fallback quantization
|
| 339 |
+
|
| 340 |
+
main: quantize time = 20033.18 ms
|
| 341 |
+
main: total time = 20033.18 ms
|
IQ4_NL_log.txt
ADDED
|
@@ -0,0 +1,268 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_IQ4_NL.gguf' as IQ4_NL
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to iq4_nl .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 281.25 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 49 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 50 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 51 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 52 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 53 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 54 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 55 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 56 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 57 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 58 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 59 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 60 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 61 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 62 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 63 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 64 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 65 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 66 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 67 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 68 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 69 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 70 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 71 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 72 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 73 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 74 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 75 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 76 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 77 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 78 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 80 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 81 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 82 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 83 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 85 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 86 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 87 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 88 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 89 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 90 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 91 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 92 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 93 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 94 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 95 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 96 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 97 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 98 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 99 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 100 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 101 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 102 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 103 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 104 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 105 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 106 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 107 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 108 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 109 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 110 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 111 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 112 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 113 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 114 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 116 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 117 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 118 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 119 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 121 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 122 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 123 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 124 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 125 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 126 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 127 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 128 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 129 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 130 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 131 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 132 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 133 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 134 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 135 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 136 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 137 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 138 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 139 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 140 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 141 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 142 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 143 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 144 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 145 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 146 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 147 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 148 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 149 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 150 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 152 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 153 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 154 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 155 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 157 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 158 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 159 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 160 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 161 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 162 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 163 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 164 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 165 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 166 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 167 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 168 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 169 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 170 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 171 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 172 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 173 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 174 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 175 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 176 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 177 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 178 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 179 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 180 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 181 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 182 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 183 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 184 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 185 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 186 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 188 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 189 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 190 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 191 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 193 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 194 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 195 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 196 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 197 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 198 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 199 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 200 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 201 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 202 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 203 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 204 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 205 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 206 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 207 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 208 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 209 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 210 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 211 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 212 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 213 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 214 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 215 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 216 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 217 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 218 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 219 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 220 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 221 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 222 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 224 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 225 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 226 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 227 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 229 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 230 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 231 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 232 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 233 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 234 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 235 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 236 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 237 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 238 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 239 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 240 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 241 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 242 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 243 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 244 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 245 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 246 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 247 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 248 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 249 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 250 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 251 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 252 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 253 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 254 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 255 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 256 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 257 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 258 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 260 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 261 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 262 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_nl .. size = 8.00 MiB -> 2.25 MiB
|
| 263 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 265 |
+
llama_model_quantize_internal: quant size = 1927.95 MB
|
| 266 |
+
|
| 267 |
+
main: quantize time = 17815.41 ms
|
| 268 |
+
main: total time = 17815.41 ms
|
IQ4_XS_log.txt
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_IQ4_XS.gguf' as IQ4_XS
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to iq4_xs .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 265.62 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 49 |
+
|
| 50 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 51 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 52 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 53 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 54 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 55 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 56 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 57 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 58 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 59 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 60 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 61 |
+
|
| 62 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 63 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 64 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 65 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 66 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 67 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 68 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 69 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 70 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 71 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 72 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 73 |
+
|
| 74 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 75 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 76 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 77 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 78 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 80 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 81 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 82 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 83 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 85 |
+
|
| 86 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 87 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 88 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 89 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 90 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 91 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 92 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 93 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 94 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 95 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 96 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 97 |
+
|
| 98 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 99 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 100 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 101 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 102 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 103 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 104 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 105 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 106 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 107 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 108 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 109 |
+
|
| 110 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 111 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 112 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 113 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 114 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 116 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 117 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 118 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 119 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 121 |
+
|
| 122 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 123 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 124 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 125 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 126 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 127 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 128 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 129 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 130 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 131 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 132 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 133 |
+
|
| 134 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 135 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 136 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 137 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 138 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 139 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 140 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 141 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 142 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 143 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 144 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 145 |
+
|
| 146 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 147 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 148 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 149 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 150 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 152 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 153 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 154 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 155 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 157 |
+
|
| 158 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 159 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 160 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 161 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 162 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 163 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 164 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 165 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 166 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 167 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 168 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 169 |
+
|
| 170 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 171 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 172 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 173 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 174 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 175 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 176 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 177 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 178 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 179 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 180 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 181 |
+
|
| 182 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 183 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 184 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 185 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 186 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 188 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 189 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 190 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 191 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 193 |
+
|
| 194 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 195 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 196 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 197 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 198 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 199 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 200 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 201 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 202 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 203 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 204 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 205 |
+
|
| 206 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 207 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 208 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 209 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 210 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 211 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 212 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 213 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 214 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 215 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 216 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 217 |
+
|
| 218 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 219 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 220 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 221 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 222 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 224 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 225 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 226 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 227 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 229 |
+
|
| 230 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 231 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 232 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 233 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 234 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 235 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 236 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 237 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 238 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 239 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 240 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 241 |
+
|
| 242 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 243 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 244 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 245 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 246 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 247 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 248 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 249 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 250 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 251 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 252 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 253 |
+
|
| 254 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 255 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 256 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 257 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 258 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 260 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 261 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 262 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 263 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 265 |
+
|
| 266 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 267 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 268 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 269 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 270 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 271 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 272 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 273 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 274 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 275 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 276 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 277 |
+
|
| 278 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 279 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 280 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 281 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 282 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 283 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 284 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 285 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 286 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 287 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 288 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 289 |
+
|
| 290 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 291 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 292 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 293 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 294 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 295 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 296 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 297 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 298 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 299 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 300 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 301 |
+
|
| 302 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 303 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 304 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 305 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 306 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 307 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 308 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 309 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 310 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 311 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 312 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 313 |
+
|
| 314 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 315 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 316 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 317 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 318 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 319 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 320 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 321 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 322 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 323 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 324 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 325 |
+
|
| 326 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for iq4_xs - using fallback quantization iq4_nl
|
| 327 |
+
converting to iq4_nl .. size = 21.25 MiB -> 5.98 MiB
|
| 328 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 329 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to iq4_xs .. size = 21.25 MiB -> 5.64 MiB
|
| 330 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 331 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 332 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 333 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 334 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to iq4_xs .. size = 8.00 MiB -> 2.12 MiB
|
| 335 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 336 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 337 |
+
llama_model_quantize_internal: quant size = 1884.38 MB
|
| 338 |
+
llama_model_quantize_internal: WARNING: 24 of 169 tensor(s) required fallback quantization
|
| 339 |
+
|
| 340 |
+
main: quantize time = 17803.82 ms
|
| 341 |
+
main: total time = 17803.82 ms
|
Q3_K_L_log.txt
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_Q3_K_L.gguf' as Q3_K_L
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to q3_K .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 214.84 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 49 |
+
|
| 50 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 51 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 52 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 53 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 54 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 55 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 56 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 57 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 58 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 59 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 60 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 61 |
+
|
| 62 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 63 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 64 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 65 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 66 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 67 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 68 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 69 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 70 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 71 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 72 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 73 |
+
|
| 74 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 75 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 76 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 77 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 78 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 80 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 81 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 82 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 83 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 85 |
+
|
| 86 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 87 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 88 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 89 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 90 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 91 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 92 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 93 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 94 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 95 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 96 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 97 |
+
|
| 98 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 99 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 100 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 101 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 102 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 103 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 104 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 105 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 106 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 107 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 108 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 109 |
+
|
| 110 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 111 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 112 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 113 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 114 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 116 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 117 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 118 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 119 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 121 |
+
|
| 122 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 123 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 124 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 125 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 126 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 127 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 128 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 129 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 130 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 131 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 132 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 133 |
+
|
| 134 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 135 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 136 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 137 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 138 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 139 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 140 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 141 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 142 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 143 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 144 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 145 |
+
|
| 146 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 147 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 148 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 149 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 150 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 152 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 153 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 154 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 155 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 157 |
+
|
| 158 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 159 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 160 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 161 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 162 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 163 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 164 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 165 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 166 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 167 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 168 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 169 |
+
|
| 170 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 171 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 172 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 173 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 174 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 175 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 176 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 177 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 178 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 179 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 180 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 181 |
+
|
| 182 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 183 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 184 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 185 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 186 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 188 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 189 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 190 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 191 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 193 |
+
|
| 194 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 195 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 196 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 197 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 198 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 199 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 200 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 201 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 202 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 203 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 204 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 205 |
+
|
| 206 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 207 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 208 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 209 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 210 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 211 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 212 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 213 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 214 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 215 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 216 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 217 |
+
|
| 218 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 219 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 220 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 221 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 222 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 224 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 225 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 226 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 227 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 229 |
+
|
| 230 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 231 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 232 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 233 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 234 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 235 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 236 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 237 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 238 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 239 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 240 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 241 |
+
|
| 242 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 243 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 244 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 245 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 246 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 247 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 248 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 249 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 250 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 251 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 252 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 253 |
+
|
| 254 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 255 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 256 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 257 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 258 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 260 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 261 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 262 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 263 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 265 |
+
|
| 266 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 267 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 268 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 269 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 270 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 271 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 272 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 273 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 274 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 275 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 276 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 277 |
+
|
| 278 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 279 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 280 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 281 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 282 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 283 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 284 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 285 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 286 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 287 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 288 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 289 |
+
|
| 290 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 291 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 292 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 293 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 294 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 295 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 296 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 297 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 298 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 299 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 300 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 301 |
+
|
| 302 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 303 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 304 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 305 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 306 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 307 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 308 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 309 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 310 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 311 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 312 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 313 |
+
|
| 314 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 315 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 316 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 317 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 318 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 319 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 320 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 321 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 322 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 323 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 324 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 325 |
+
|
| 326 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 327 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 328 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 329 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 330 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 331 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 332 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 333 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 334 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 335 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 336 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 337 |
+
llama_model_quantize_internal: quant size = 1840.12 MB
|
| 338 |
+
llama_model_quantize_internal: WARNING: 24 of 169 tensor(s) required fallback quantization
|
| 339 |
+
|
| 340 |
+
main: quantize time = 6413.71 ms
|
| 341 |
+
main: total time = 6413.71 ms
|
Q3_K_M_log.txt
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_Q3_K_M.gguf' as Q3_K_M
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to q3_K .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 214.84 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 49 |
+
|
| 50 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 51 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 52 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 53 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 54 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 55 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 56 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 57 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 58 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 59 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 60 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 61 |
+
|
| 62 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 63 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 64 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 65 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 66 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 67 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 68 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 69 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 70 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 71 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 72 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 73 |
+
|
| 74 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 75 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 76 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 77 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 78 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 80 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 81 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 82 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 83 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 85 |
+
|
| 86 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 87 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 88 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 89 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 90 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 91 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 92 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 93 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 94 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 95 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 96 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 97 |
+
|
| 98 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 99 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 100 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 101 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 102 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 103 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 104 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 105 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 106 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 107 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 108 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 109 |
+
|
| 110 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 111 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 112 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 113 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 114 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 116 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 117 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 118 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 119 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 121 |
+
|
| 122 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 123 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 124 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 125 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 126 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 127 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 128 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 129 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 130 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 131 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 132 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 133 |
+
|
| 134 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 135 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 136 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 137 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 138 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 139 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 140 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 141 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 142 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 143 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 144 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 145 |
+
|
| 146 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 147 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 148 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 149 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 150 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 152 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 153 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 154 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 155 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 157 |
+
|
| 158 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 159 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 160 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 161 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 162 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 163 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 164 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 165 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 166 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 167 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 168 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 169 |
+
|
| 170 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 171 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 172 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 173 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 174 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 175 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 176 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 177 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 178 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 179 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 180 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 181 |
+
|
| 182 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 183 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 184 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 185 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 186 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 188 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 189 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 190 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 191 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 193 |
+
|
| 194 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 195 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 196 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 197 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 198 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 199 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 200 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 201 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 202 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 203 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 204 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 205 |
+
|
| 206 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 207 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 208 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 209 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 210 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 211 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 212 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 213 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 214 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 215 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 216 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 217 |
+
|
| 218 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 219 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 220 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 221 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 222 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 224 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 225 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 226 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 227 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 229 |
+
|
| 230 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 231 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 232 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 233 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 234 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 235 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 236 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 237 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 238 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 239 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 240 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 241 |
+
|
| 242 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 243 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 244 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 245 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 246 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 247 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 248 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 249 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 250 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 251 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 252 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 253 |
+
|
| 254 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 255 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 256 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 257 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 258 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 260 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 261 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 262 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 263 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 265 |
+
|
| 266 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 267 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 268 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 269 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 270 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 271 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 272 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 273 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 274 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 275 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 276 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 277 |
+
|
| 278 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 279 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 280 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 281 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 282 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 283 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 284 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 285 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 286 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 287 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 288 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 289 |
+
|
| 290 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 291 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 292 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 293 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 294 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 295 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 296 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 297 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 298 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 299 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 300 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 301 |
+
|
| 302 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 303 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 304 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 305 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 306 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 307 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 308 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 309 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 310 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 311 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 312 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 313 |
+
|
| 314 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 315 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 316 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 317 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 318 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 319 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 320 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 321 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 322 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 323 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 324 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 325 |
+
|
| 326 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 327 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 328 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 329 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q3_K .. size = 21.25 MiB -> 4.57 MiB
|
| 330 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 331 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 332 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 333 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q3_K .. size = 8.00 MiB -> 1.72 MiB
|
| 334 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 335 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 336 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 337 |
+
llama_model_quantize_internal: quant size = 1801.84 MB
|
| 338 |
+
llama_model_quantize_internal: WARNING: 24 of 169 tensor(s) required fallback quantization
|
| 339 |
+
|
| 340 |
+
main: quantize time = 5431.48 ms
|
| 341 |
+
main: total time = 5431.48 ms
|
Q4_K_M_log.txt
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_Q4_K_M.gguf' as Q4_K_M
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to q4_K .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 281.25 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 49 |
+
|
| 50 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 51 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 52 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 53 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 54 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 55 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 56 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 57 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 58 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 59 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 60 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 61 |
+
|
| 62 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 63 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 64 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 65 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 66 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 67 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 68 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 69 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 70 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 71 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 72 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 73 |
+
|
| 74 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 75 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 76 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 77 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 78 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 80 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 81 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 82 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 83 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 85 |
+
|
| 86 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 87 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 88 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 89 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 90 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 91 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 92 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 93 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 94 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 95 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 96 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 97 |
+
|
| 98 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 99 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 100 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 101 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 102 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 103 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 104 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 105 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 106 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 107 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 108 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 109 |
+
|
| 110 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 111 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 112 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 113 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 114 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 116 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 117 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 118 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 119 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 121 |
+
|
| 122 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 123 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 124 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 125 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 126 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 127 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 128 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 129 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 130 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 131 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 132 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 133 |
+
|
| 134 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 135 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 136 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 137 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 138 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 139 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 140 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 141 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 142 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 143 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 144 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 145 |
+
|
| 146 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 147 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 148 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 149 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 150 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 152 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 153 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 154 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 155 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 157 |
+
|
| 158 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 159 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 160 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 161 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 162 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 163 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 164 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 165 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 166 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 167 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 168 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 169 |
+
|
| 170 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 171 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 172 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 173 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 174 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 175 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 176 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 177 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 178 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 179 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 180 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 181 |
+
|
| 182 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 183 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 184 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 185 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 186 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 188 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 189 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 190 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 191 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 193 |
+
|
| 194 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 195 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 196 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 197 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 198 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 199 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 200 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 201 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 202 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 203 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 204 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 205 |
+
|
| 206 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 207 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 208 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 209 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 210 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 211 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 212 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 213 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 214 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 215 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 216 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 217 |
+
|
| 218 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 219 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 220 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 221 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 222 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 224 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 225 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 226 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 227 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 229 |
+
|
| 230 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 231 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 232 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 233 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 234 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 235 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 236 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 237 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 238 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 239 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 240 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 241 |
+
|
| 242 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 243 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 244 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 245 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 246 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 247 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 248 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 249 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 250 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 251 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 252 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 253 |
+
|
| 254 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 255 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 256 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 257 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 258 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 260 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 261 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 262 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 263 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 265 |
+
|
| 266 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 267 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 268 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 269 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 270 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 271 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 272 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 273 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 274 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 275 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 276 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 277 |
+
|
| 278 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 279 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 280 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 281 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 282 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 283 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 284 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 285 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 286 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 287 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 288 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 289 |
+
|
| 290 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 291 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 292 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 293 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 294 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 295 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 296 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 297 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 298 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 299 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 300 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 301 |
+
|
| 302 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 303 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 304 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 305 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 306 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 307 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 308 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 309 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 310 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 311 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 312 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 313 |
+
|
| 314 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 315 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 316 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 317 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 318 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 319 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 320 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 321 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 322 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 323 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 324 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 325 |
+
|
| 326 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 327 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 328 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 329 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 330 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 331 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 332 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 333 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 334 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 335 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 336 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 337 |
+
llama_model_quantize_internal: quant size = 2020.01 MB
|
| 338 |
+
llama_model_quantize_internal: WARNING: 24 of 169 tensor(s) required fallback quantization
|
| 339 |
+
|
| 340 |
+
main: quantize time = 8837.33 ms
|
| 341 |
+
main: total time = 8837.33 ms
|
Q4_K_S_log.txt
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_Q4_K_S.gguf' as Q4_K_S
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to q4_K .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 281.25 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 49 |
+
|
| 50 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 51 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 52 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 53 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 54 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 55 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 56 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 57 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 58 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 59 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 60 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 61 |
+
|
| 62 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 63 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 64 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 65 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 66 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 67 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 68 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 69 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 70 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 71 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 72 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 73 |
+
|
| 74 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 75 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 76 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 77 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 78 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 80 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 81 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 82 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 83 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 85 |
+
|
| 86 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 87 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 88 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 89 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 90 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 91 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 92 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 93 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 94 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 95 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 96 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 97 |
+
|
| 98 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 99 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 100 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 101 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 102 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 103 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 104 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 105 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 106 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 107 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 108 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 109 |
+
|
| 110 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 111 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 112 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 113 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 114 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 116 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 117 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 118 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 119 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 121 |
+
|
| 122 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 123 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 124 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 125 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 126 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 127 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 128 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 129 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 130 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 131 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 132 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 133 |
+
|
| 134 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 135 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 136 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 137 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 138 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 139 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 140 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 141 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 142 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 143 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 144 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 145 |
+
|
| 146 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 147 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 148 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 149 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 150 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 152 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 153 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 154 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 155 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 157 |
+
|
| 158 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 159 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 160 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 161 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 162 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 163 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 164 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 165 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 166 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 167 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 168 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 169 |
+
|
| 170 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 171 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 172 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 173 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 174 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 175 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 176 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 177 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 178 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 179 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 180 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 181 |
+
|
| 182 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 183 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 184 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 185 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 186 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 188 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 189 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 190 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 191 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 193 |
+
|
| 194 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 195 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 196 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 197 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 198 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 199 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 200 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 201 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 202 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 203 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 204 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 205 |
+
|
| 206 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 207 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 208 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 209 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 210 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 211 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 212 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 213 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 214 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 215 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 216 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 217 |
+
|
| 218 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 219 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 220 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 221 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 222 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 224 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 225 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 226 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 227 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 229 |
+
|
| 230 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 231 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 232 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 233 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 234 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 235 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 236 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 237 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 238 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 239 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 240 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 241 |
+
|
| 242 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 243 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 244 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 245 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 246 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 247 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 248 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 249 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 250 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 251 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 252 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 253 |
+
|
| 254 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 255 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 256 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 257 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 258 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 260 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 261 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 262 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 263 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 265 |
+
|
| 266 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 267 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 268 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 269 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 270 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 271 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 272 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 273 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 274 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 275 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 276 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 277 |
+
|
| 278 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 279 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 280 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 281 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 282 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 283 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 284 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 285 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 286 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 287 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 288 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 289 |
+
|
| 290 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 291 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 292 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 293 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 294 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 295 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 296 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 297 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 298 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 299 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 300 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 301 |
+
|
| 302 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 303 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 304 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 305 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 306 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 307 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 308 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 309 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 310 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 311 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 312 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 313 |
+
|
| 314 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 315 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 316 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 317 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 318 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 319 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 320 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 321 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 322 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 323 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 324 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 325 |
+
|
| 326 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q4_K - using fallback quantization q5_0
|
| 327 |
+
converting to q5_0 .. size = 21.25 MiB -> 7.30 MiB
|
| 328 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 329 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q4_K .. size = 21.25 MiB -> 5.98 MiB
|
| 330 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 331 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 332 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 333 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 334 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
|
| 335 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 336 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 337 |
+
llama_model_quantize_internal: quant size = 1963.81 MB
|
| 338 |
+
llama_model_quantize_internal: WARNING: 24 of 169 tensor(s) required fallback quantization
|
| 339 |
+
|
| 340 |
+
main: quantize time = 9251.91 ms
|
| 341 |
+
main: total time = 9251.91 ms
|
Q5_K_M_log.txt
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_Q5_K_M.gguf' as Q5_K_M
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to q5_K .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 343.75 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 49 |
+
|
| 50 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 51 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 52 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 53 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 54 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 55 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 56 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 57 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 58 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 59 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 60 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 61 |
+
|
| 62 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 63 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 64 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 65 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 66 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 67 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 68 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 69 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 70 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 71 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 72 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 73 |
+
|
| 74 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 75 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 76 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 77 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 78 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 80 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 81 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 82 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 83 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 85 |
+
|
| 86 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 87 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 88 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 89 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 90 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 91 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 92 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 93 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 94 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 95 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 96 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 97 |
+
|
| 98 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 99 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 100 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 101 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 102 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 103 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 104 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 105 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 106 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 107 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 108 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 109 |
+
|
| 110 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 111 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 112 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 113 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 114 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 116 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 117 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 118 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 119 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 121 |
+
|
| 122 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 123 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 124 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 125 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 126 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 127 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 128 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 129 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 130 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 131 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 132 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 133 |
+
|
| 134 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 135 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 136 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 137 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 138 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 139 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 140 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 141 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 142 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 143 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 144 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 145 |
+
|
| 146 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 147 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 148 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 149 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 150 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 152 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 153 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 154 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 155 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 157 |
+
|
| 158 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 159 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 160 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 161 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 162 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 163 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 164 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 165 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 166 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 167 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 168 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 169 |
+
|
| 170 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 171 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 172 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 173 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 174 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 175 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 176 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 177 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 178 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 179 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 180 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 181 |
+
|
| 182 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 183 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 184 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 185 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 186 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 188 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 189 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 190 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 191 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 193 |
+
|
| 194 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 195 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 196 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 197 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 198 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 199 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 200 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 201 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 202 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 203 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 204 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 205 |
+
|
| 206 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 207 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 208 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 209 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 210 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 211 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 212 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 213 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 214 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 215 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 216 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 217 |
+
|
| 218 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 219 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 220 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 221 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 222 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 224 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 225 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 226 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 227 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 229 |
+
|
| 230 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 231 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 232 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 233 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 234 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 235 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 236 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 237 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 238 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 239 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 240 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 241 |
+
|
| 242 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 243 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 244 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 245 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 246 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 247 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 248 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 249 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 250 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 251 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 252 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 253 |
+
|
| 254 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 255 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 256 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 257 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 258 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 260 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 261 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 262 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 263 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 265 |
+
|
| 266 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 267 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 268 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 269 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 270 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 271 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 272 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 273 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 274 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 275 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 276 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 277 |
+
|
| 278 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 279 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 280 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 281 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 282 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 283 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 284 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 285 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 286 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 287 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 288 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 289 |
+
|
| 290 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 291 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 292 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 293 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 294 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 295 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 296 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 297 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 298 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 299 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 300 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 301 |
+
|
| 302 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 303 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 304 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 305 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 306 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 307 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 308 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 309 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 310 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 311 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 312 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 313 |
+
|
| 314 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 315 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 316 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 317 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 318 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 319 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 320 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 321 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 322 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 323 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 324 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 325 |
+
|
| 326 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 327 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 328 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 329 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 330 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 331 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 332 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 333 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 334 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 335 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 336 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 337 |
+
llama_model_quantize_internal: quant size = 2196.23 MB
|
| 338 |
+
llama_model_quantize_internal: WARNING: 24 of 169 tensor(s) required fallback quantization
|
| 339 |
+
|
| 340 |
+
main: quantize time = 9470.02 ms
|
| 341 |
+
main: total time = 9470.02 ms
|
Q5_K_S_log.txt
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_Q5_K_S.gguf' as Q5_K_S
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to q5_K .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 343.75 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 49 |
+
|
| 50 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 51 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 52 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 53 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 54 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 55 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 56 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 57 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 58 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 59 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 60 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 61 |
+
|
| 62 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 63 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 64 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 65 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 66 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 67 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 68 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 69 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 70 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 71 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 72 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 73 |
+
|
| 74 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 75 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 76 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 77 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 78 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 80 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 81 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 82 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 83 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 85 |
+
|
| 86 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 87 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 88 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 89 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 90 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 91 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 92 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 93 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 94 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 95 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 96 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 97 |
+
|
| 98 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 99 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 100 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 101 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 102 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 103 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 104 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 105 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 106 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 107 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 108 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 109 |
+
|
| 110 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 111 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 112 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 113 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 114 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 116 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 117 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 118 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 119 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 121 |
+
|
| 122 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 123 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 124 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 125 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 126 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 127 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 128 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 129 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 130 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 131 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 132 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 133 |
+
|
| 134 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 135 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 136 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 137 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 138 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 139 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 140 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 141 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 142 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 143 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 144 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 145 |
+
|
| 146 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 147 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 148 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 149 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 150 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 152 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 153 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 154 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 155 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 157 |
+
|
| 158 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 159 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 160 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 161 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 162 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 163 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 164 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 165 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 166 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 167 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 168 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 169 |
+
|
| 170 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 171 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 172 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 173 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 174 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 175 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 176 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 177 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 178 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 179 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 180 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 181 |
+
|
| 182 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 183 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 184 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 185 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 186 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 188 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 189 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 190 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 191 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 193 |
+
|
| 194 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 195 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 196 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 197 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 198 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 199 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 200 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 201 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 202 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 203 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 204 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 205 |
+
|
| 206 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 207 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 208 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 209 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 210 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 211 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 212 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 213 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 214 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 215 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 216 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 217 |
+
|
| 218 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 219 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 220 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 221 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 222 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 224 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 225 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 226 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 227 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 229 |
+
|
| 230 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 231 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 232 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 233 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 234 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 235 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 236 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 237 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 238 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 239 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 240 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 241 |
+
|
| 242 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 243 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 244 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 245 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 246 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 247 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 248 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 249 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 250 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 251 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 252 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 253 |
+
|
| 254 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 255 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 256 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 257 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 258 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 260 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 261 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 262 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 263 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 265 |
+
|
| 266 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 267 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 268 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 269 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 270 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 271 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 272 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 273 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 274 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 275 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 276 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 277 |
+
|
| 278 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 279 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 280 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 281 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 282 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 283 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 284 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 285 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 286 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 287 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 288 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 289 |
+
|
| 290 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 291 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 292 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 293 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 294 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 295 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 296 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 297 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 298 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 299 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 300 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 301 |
+
|
| 302 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 303 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 304 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 305 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 306 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 307 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 308 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 309 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 310 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 311 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 312 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 313 |
+
|
| 314 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 315 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 316 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 317 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 318 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 319 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 320 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 321 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 322 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 323 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 324 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 325 |
+
|
| 326 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q5_K - using fallback quantization q5_1
|
| 327 |
+
converting to q5_1 .. size = 21.25 MiB -> 7.97 MiB
|
| 328 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 329 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q5_K .. size = 21.25 MiB -> 7.30 MiB
|
| 330 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 331 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 332 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 333 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 334 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q5_K .. size = 8.00 MiB -> 2.75 MiB
|
| 335 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 336 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 337 |
+
llama_model_quantize_internal: quant size = 2150.01 MB
|
| 338 |
+
llama_model_quantize_internal: WARNING: 24 of 169 tensor(s) required fallback quantization
|
| 339 |
+
|
| 340 |
+
main: quantize time = 10218.60 ms
|
| 341 |
+
main: total time = 10218.60 ms
|
Q6_K_log.txt
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_Q6_K.gguf' as Q6_K
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to q6_K .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 410.16 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 49 |
+
|
| 50 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 51 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 52 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 53 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 54 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 55 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 56 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 57 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 58 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 59 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 60 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 61 |
+
|
| 62 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 63 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 64 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 65 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 66 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 67 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 68 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 69 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 70 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 71 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 72 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 73 |
+
|
| 74 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 75 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 76 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 77 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 78 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 80 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 81 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 82 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 83 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 85 |
+
|
| 86 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 87 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 88 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 89 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 90 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 91 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 92 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 93 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 94 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 95 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 96 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 97 |
+
|
| 98 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 99 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 100 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 101 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 102 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 103 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 104 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 105 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 106 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 107 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 108 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 109 |
+
|
| 110 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 111 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 112 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 113 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 114 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 116 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 117 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 118 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 119 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 121 |
+
|
| 122 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 123 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 124 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 125 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 126 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 127 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 128 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 129 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 130 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 131 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 132 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 133 |
+
|
| 134 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 135 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 136 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 137 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 138 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 139 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 140 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 141 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 142 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 143 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 144 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 145 |
+
|
| 146 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 147 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 148 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 149 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 150 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 152 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 153 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 154 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 155 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 157 |
+
|
| 158 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 159 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 160 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 161 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 162 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 163 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 164 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 165 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 166 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 167 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 168 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 169 |
+
|
| 170 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 171 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 172 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 173 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 174 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 175 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 176 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 177 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 178 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 179 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 180 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 181 |
+
|
| 182 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 183 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 184 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 185 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 186 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 188 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 189 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 190 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 191 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 193 |
+
|
| 194 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 195 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 196 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 197 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 198 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 199 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 200 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 201 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 202 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 203 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 204 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 205 |
+
|
| 206 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 207 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 208 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 209 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 210 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 211 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 212 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 213 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 214 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 215 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 216 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 217 |
+
|
| 218 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 219 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 220 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 221 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 222 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 224 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 225 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 226 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 227 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 229 |
+
|
| 230 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 231 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 232 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 233 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 234 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 235 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 236 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 237 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 238 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 239 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 240 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 241 |
+
|
| 242 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 243 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 244 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 245 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 246 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 247 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 248 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 249 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 250 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 251 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 252 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 253 |
+
|
| 254 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 255 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 256 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 257 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 258 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 260 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 261 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 262 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 263 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 265 |
+
|
| 266 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 267 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 268 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 269 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 270 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 271 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 272 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 273 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 274 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 275 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 276 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 277 |
+
|
| 278 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 279 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 280 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 281 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 282 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 283 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 284 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 285 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 286 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 287 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 288 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 289 |
+
|
| 290 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 291 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 292 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 293 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 294 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 295 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 296 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 297 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 298 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 299 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 300 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 301 |
+
|
| 302 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 303 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 304 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 305 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 306 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 307 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 308 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 309 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 310 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 311 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 312 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 313 |
+
|
| 314 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 315 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 316 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 317 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 318 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 319 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 320 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 321 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 322 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 323 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 324 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16,
|
| 325 |
+
|
| 326 |
+
llama_tensor_get_type : tensor cols 5440 x 2048 are not divisible by 256, required for q6_K - using fallback quantization q8_0
|
| 327 |
+
converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 328 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 329 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q6_K .. size = 21.25 MiB -> 8.72 MiB
|
| 330 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 331 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 332 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 333 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 334 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q6_K .. size = 8.00 MiB -> 3.28 MiB
|
| 335 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 336 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 337 |
+
llama_model_quantize_internal: quant size = 2414.84 MB
|
| 338 |
+
llama_model_quantize_internal: WARNING: 24 of 169 tensor(s) required fallback quantization
|
| 339 |
+
|
| 340 |
+
main: quantize time = 4824.77 ms
|
| 341 |
+
main: total time = 4824.77 ms
|
Q8_0_log.txt
ADDED
|
@@ -0,0 +1,268 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
main: build = 3906 (7eee341b)
|
| 2 |
+
main: built with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 3 |
+
main: quantizing 'salamandra-2b-instruct_bf16.gguf' to './salamandra-2b-instruct_Q8_0.gguf' as Q8_0
|
| 4 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 5 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 6 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 7 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 8 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 9 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 10 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 11 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 12 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 13 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 14 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 15 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 16 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 17 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 18 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 19 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 20 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 21 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 22 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 23 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 24 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 25 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 26 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 27 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 28 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 29 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 30 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 31 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 32 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 33 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 34 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 35 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 36 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 37 |
+
llama_model_loader: - type f32: 49 tensors
|
| 38 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 39 |
+
================================ Have weights data with 168 entries
|
| 40 |
+
[ 1/ 219] output.weight - [ 2048, 256000, 1, 1], type = bf16, size = 1000.000 MB
|
| 41 |
+
[ 2/ 219] token_embd.weight - [ 2048, 256000, 1, 1], type = bf16,
|
| 42 |
+
====== llama_model_quantize_internal: did not find weights for token_embd.weight
|
| 43 |
+
converting to q8_0 .. load_imatrix: imatrix dataset='./imatrix/oscar/imatrix-dataset.txt'
|
| 44 |
+
load_imatrix: loaded 168 importance matrix entries from imatrix/oscar/imatrix.dat computed on 44176 chunks
|
| 45 |
+
prepare_imatrix: have 168 importance matrix entries
|
| 46 |
+
size = 1000.00 MiB -> 531.25 MiB
|
| 47 |
+
[ 3/ 219] blk.0.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 48 |
+
[ 4/ 219] blk.0.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 49 |
+
[ 5/ 219] blk.0.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 50 |
+
[ 6/ 219] blk.0.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 51 |
+
[ 7/ 219] blk.0.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 52 |
+
[ 8/ 219] blk.0.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 53 |
+
[ 9/ 219] blk.0.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 54 |
+
[ 10/ 219] blk.0.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 55 |
+
[ 11/ 219] blk.0.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 56 |
+
[ 12/ 219] blk.1.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 57 |
+
[ 13/ 219] blk.1.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 58 |
+
[ 14/ 219] blk.1.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 59 |
+
[ 15/ 219] blk.1.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 60 |
+
[ 16/ 219] blk.1.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 61 |
+
[ 17/ 219] blk.1.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 62 |
+
[ 18/ 219] blk.1.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 63 |
+
[ 19/ 219] blk.1.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 64 |
+
[ 20/ 219] blk.1.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 65 |
+
[ 21/ 219] blk.10.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 66 |
+
[ 22/ 219] blk.10.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 67 |
+
[ 23/ 219] blk.10.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 68 |
+
[ 24/ 219] blk.10.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 69 |
+
[ 25/ 219] blk.10.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 70 |
+
[ 26/ 219] blk.10.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 71 |
+
[ 27/ 219] blk.10.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 72 |
+
[ 28/ 219] blk.10.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 73 |
+
[ 29/ 219] blk.10.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 74 |
+
[ 30/ 219] blk.11.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 75 |
+
[ 31/ 219] blk.11.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 76 |
+
[ 32/ 219] blk.11.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 77 |
+
[ 33/ 219] blk.11.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 78 |
+
[ 34/ 219] blk.11.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 79 |
+
[ 35/ 219] blk.11.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 80 |
+
[ 36/ 219] blk.11.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 81 |
+
[ 37/ 219] blk.11.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 82 |
+
[ 38/ 219] blk.11.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 83 |
+
[ 39/ 219] blk.12.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 84 |
+
[ 40/ 219] blk.12.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 85 |
+
[ 41/ 219] blk.12.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 86 |
+
[ 42/ 219] blk.12.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 87 |
+
[ 43/ 219] blk.12.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 88 |
+
[ 44/ 219] blk.12.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 89 |
+
[ 45/ 219] blk.12.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 90 |
+
[ 46/ 219] blk.12.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 91 |
+
[ 47/ 219] blk.12.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 92 |
+
[ 48/ 219] blk.13.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 93 |
+
[ 49/ 219] blk.13.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 94 |
+
[ 50/ 219] blk.13.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 95 |
+
[ 51/ 219] blk.13.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 96 |
+
[ 52/ 219] blk.13.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 97 |
+
[ 53/ 219] blk.13.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 98 |
+
[ 54/ 219] blk.13.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 99 |
+
[ 55/ 219] blk.13.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 100 |
+
[ 56/ 219] blk.13.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 101 |
+
[ 57/ 219] blk.14.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 102 |
+
[ 58/ 219] blk.14.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 103 |
+
[ 59/ 219] blk.14.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 104 |
+
[ 60/ 219] blk.14.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 105 |
+
[ 61/ 219] blk.14.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 106 |
+
[ 62/ 219] blk.14.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 107 |
+
[ 63/ 219] blk.14.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 108 |
+
[ 64/ 219] blk.14.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 109 |
+
[ 65/ 219] blk.14.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 110 |
+
[ 66/ 219] blk.15.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 111 |
+
[ 67/ 219] blk.15.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 112 |
+
[ 68/ 219] blk.15.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 113 |
+
[ 69/ 219] blk.15.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 114 |
+
[ 70/ 219] blk.15.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 115 |
+
[ 71/ 219] blk.15.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 116 |
+
[ 72/ 219] blk.15.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 117 |
+
[ 73/ 219] blk.15.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 118 |
+
[ 74/ 219] blk.15.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 119 |
+
[ 75/ 219] blk.16.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 120 |
+
[ 76/ 219] blk.16.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 121 |
+
[ 77/ 219] blk.16.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 122 |
+
[ 78/ 219] blk.16.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 123 |
+
[ 79/ 219] blk.16.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 124 |
+
[ 80/ 219] blk.16.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 125 |
+
[ 81/ 219] blk.16.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 126 |
+
[ 82/ 219] blk.16.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 127 |
+
[ 83/ 219] blk.16.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 128 |
+
[ 84/ 219] blk.17.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 129 |
+
[ 85/ 219] blk.17.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 130 |
+
[ 86/ 219] blk.17.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 131 |
+
[ 87/ 219] blk.17.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 132 |
+
[ 88/ 219] blk.17.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 133 |
+
[ 89/ 219] blk.17.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 134 |
+
[ 90/ 219] blk.17.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 135 |
+
[ 91/ 219] blk.17.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 136 |
+
[ 92/ 219] blk.17.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 137 |
+
[ 93/ 219] blk.18.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 138 |
+
[ 94/ 219] blk.18.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 139 |
+
[ 95/ 219] blk.18.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 140 |
+
[ 96/ 219] blk.18.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 141 |
+
[ 97/ 219] blk.18.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 142 |
+
[ 98/ 219] blk.18.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 143 |
+
[ 99/ 219] blk.18.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 144 |
+
[ 100/ 219] blk.18.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 145 |
+
[ 101/ 219] blk.18.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 146 |
+
[ 102/ 219] blk.19.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 147 |
+
[ 103/ 219] blk.19.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 148 |
+
[ 104/ 219] blk.19.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 149 |
+
[ 105/ 219] blk.19.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 150 |
+
[ 106/ 219] blk.19.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 151 |
+
[ 107/ 219] blk.19.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 152 |
+
[ 108/ 219] blk.19.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 153 |
+
[ 109/ 219] blk.19.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 154 |
+
[ 110/ 219] blk.19.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 155 |
+
[ 111/ 219] blk.2.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 156 |
+
[ 112/ 219] blk.2.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 157 |
+
[ 113/ 219] blk.2.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 158 |
+
[ 114/ 219] blk.2.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 159 |
+
[ 115/ 219] blk.2.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 160 |
+
[ 116/ 219] blk.2.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 161 |
+
[ 117/ 219] blk.2.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 162 |
+
[ 118/ 219] blk.2.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 163 |
+
[ 119/ 219] blk.2.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 164 |
+
[ 120/ 219] blk.20.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 165 |
+
[ 121/ 219] blk.20.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 166 |
+
[ 122/ 219] blk.20.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 167 |
+
[ 123/ 219] blk.20.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 168 |
+
[ 124/ 219] blk.20.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 169 |
+
[ 125/ 219] blk.20.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 170 |
+
[ 126/ 219] blk.20.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 171 |
+
[ 127/ 219] blk.20.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 172 |
+
[ 128/ 219] blk.20.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 173 |
+
[ 129/ 219] blk.21.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 174 |
+
[ 130/ 219] blk.21.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 175 |
+
[ 131/ 219] blk.21.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 176 |
+
[ 132/ 219] blk.21.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 177 |
+
[ 133/ 219] blk.21.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 178 |
+
[ 134/ 219] blk.21.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 179 |
+
[ 135/ 219] blk.21.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 180 |
+
[ 136/ 219] blk.21.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 181 |
+
[ 137/ 219] blk.21.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 182 |
+
[ 138/ 219] blk.22.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 183 |
+
[ 139/ 219] blk.22.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 184 |
+
[ 140/ 219] blk.22.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 185 |
+
[ 141/ 219] blk.22.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 186 |
+
[ 142/ 219] blk.22.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 187 |
+
[ 143/ 219] blk.22.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 188 |
+
[ 144/ 219] blk.22.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 189 |
+
[ 145/ 219] blk.22.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 190 |
+
[ 146/ 219] blk.22.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 191 |
+
[ 147/ 219] blk.23.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 192 |
+
[ 148/ 219] blk.23.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 193 |
+
[ 149/ 219] blk.23.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 194 |
+
[ 150/ 219] blk.23.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 195 |
+
[ 151/ 219] blk.23.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 196 |
+
[ 152/ 219] blk.23.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 197 |
+
[ 153/ 219] blk.23.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 198 |
+
[ 154/ 219] blk.23.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 199 |
+
[ 155/ 219] blk.23.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 200 |
+
[ 156/ 219] blk.3.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 201 |
+
[ 157/ 219] blk.3.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 202 |
+
[ 158/ 219] blk.3.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 203 |
+
[ 159/ 219] blk.3.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 204 |
+
[ 160/ 219] blk.3.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 205 |
+
[ 161/ 219] blk.3.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 206 |
+
[ 162/ 219] blk.3.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 207 |
+
[ 163/ 219] blk.3.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 208 |
+
[ 164/ 219] blk.3.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 209 |
+
[ 165/ 219] blk.4.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 210 |
+
[ 166/ 219] blk.4.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 211 |
+
[ 167/ 219] blk.4.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 212 |
+
[ 168/ 219] blk.4.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 213 |
+
[ 169/ 219] blk.4.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 214 |
+
[ 170/ 219] blk.4.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 215 |
+
[ 171/ 219] blk.4.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 216 |
+
[ 172/ 219] blk.4.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 217 |
+
[ 173/ 219] blk.4.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 218 |
+
[ 174/ 219] blk.5.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 219 |
+
[ 175/ 219] blk.5.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 220 |
+
[ 176/ 219] blk.5.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 221 |
+
[ 177/ 219] blk.5.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 222 |
+
[ 178/ 219] blk.5.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 223 |
+
[ 179/ 219] blk.5.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 224 |
+
[ 180/ 219] blk.5.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 225 |
+
[ 181/ 219] blk.5.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 226 |
+
[ 182/ 219] blk.5.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 227 |
+
[ 183/ 219] blk.6.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 228 |
+
[ 184/ 219] blk.6.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 229 |
+
[ 185/ 219] blk.6.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 230 |
+
[ 186/ 219] blk.6.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 231 |
+
[ 187/ 219] blk.6.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 232 |
+
[ 188/ 219] blk.6.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 233 |
+
[ 189/ 219] blk.6.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 234 |
+
[ 190/ 219] blk.6.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 235 |
+
[ 191/ 219] blk.6.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 236 |
+
[ 192/ 219] blk.7.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 237 |
+
[ 193/ 219] blk.7.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 238 |
+
[ 194/ 219] blk.7.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 239 |
+
[ 195/ 219] blk.7.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 240 |
+
[ 196/ 219] blk.7.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 241 |
+
[ 197/ 219] blk.7.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 242 |
+
[ 198/ 219] blk.7.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 243 |
+
[ 199/ 219] blk.7.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 244 |
+
[ 200/ 219] blk.7.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 245 |
+
[ 201/ 219] blk.8.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 246 |
+
[ 202/ 219] blk.8.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 247 |
+
[ 203/ 219] blk.8.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 248 |
+
[ 204/ 219] blk.8.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 249 |
+
[ 205/ 219] blk.8.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 250 |
+
[ 206/ 219] blk.8.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 251 |
+
[ 207/ 219] blk.8.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 252 |
+
[ 208/ 219] blk.8.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 253 |
+
[ 209/ 219] blk.8.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 254 |
+
[ 210/ 219] blk.9.attn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 255 |
+
[ 211/ 219] blk.9.ffn_down.weight - [ 5440, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 256 |
+
[ 212/ 219] blk.9.ffn_gate.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 257 |
+
[ 213/ 219] blk.9.ffn_up.weight - [ 2048, 5440, 1, 1], type = bf16, converting to q8_0 .. size = 21.25 MiB -> 11.29 MiB
|
| 258 |
+
[ 214/ 219] blk.9.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 259 |
+
[ 215/ 219] blk.9.attn_k.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 260 |
+
[ 216/ 219] blk.9.attn_output.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 261 |
+
[ 217/ 219] blk.9.attn_q.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 262 |
+
[ 218/ 219] blk.9.attn_v.weight - [ 2048, 2048, 1, 1], type = bf16, converting to q8_0 .. size = 8.00 MiB -> 4.25 MiB
|
| 263 |
+
[ 219/ 219] output_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MB
|
| 264 |
+
llama_model_quantize_internal: model size = 4298.38 MB
|
| 265 |
+
llama_model_quantize_internal: quant size = 2752.45 MB
|
| 266 |
+
|
| 267 |
+
main: quantize time = 3190.13 ms
|
| 268 |
+
main: total time = 3190.13 ms
|
README.md
CHANGED
|
@@ -27,7 +27,7 @@ language:
|
|
| 27 |
- mt
|
| 28 |
- nl
|
| 29 |
- nn
|
| 30 |
-
- no
|
| 31 |
- oc
|
| 32 |
- pl
|
| 33 |
- pt
|
|
@@ -41,6 +41,53 @@ language:
|
|
| 41 |
- uk
|
| 42 |
---
|
| 43 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 44 |

|
| 45 |
|
| 46 |
# Salamandra Model Card
|
|
|
|
| 27 |
- mt
|
| 28 |
- nl
|
| 29 |
- nn
|
| 30 |
+
- \no
|
| 31 |
- oc
|
| 32 |
- pl
|
| 33 |
- pt
|
|
|
|
| 41 |
- uk
|
| 42 |
---
|
| 43 |
|
| 44 |
+
# Quantization summary
|
| 45 |
+
|
| 46 |
+
| **Quantization Type** | **PPL(Q)** | **Log PPL Difference** | **File Size (G)** | **Notes** |
|
| 47 |
+
|-----------------------|------------|------------------------|-------------------|----------------------------------------------------------------|
|
| 48 |
+
| [**IQ3_M**](salamandra-2b-instruct_IQ3_M.gguf) | 16.774 | 0.086769 | 1.7 | Good size efficiency with acceptable PPL increase |
|
| 49 |
+
| [**Q3_K_L**](salamandra-2b-instruct_Q3_K_L.gguf) | 16.5067 | 0.070705 | 1.8 | Further size reduction with modest PPL increase |
|
| 50 |
+
| [**Q4_K_S**](salamandra-2b-instruct_Q4_K_S.gguf) | 15.9346 | 0.035431 | 1.9 | Good size reduction with minimal PPL impact (**recommended**) |
|
| 51 |
+
| [**Q5_K_M**](salamandra-2b-instruct_Q5_K_M.gguf) | 15.4746 | 0.006139 | 2.2 | Excellent balance of PPL and size (**recommended**) |
|
| 52 |
+
| [**Q6_K**](salamandra-2b-instruct_Q6_K.gguf) | 15.3961 | 0.001053 | 2.4 | Nearly lossless performance with reduced size |
|
| 53 |
+
| [**bf16**](salamandra-2b-instruct_bf16.gguf) | 15.3799 | 0.000000 | 4.2 | Baseline |
|
| 54 |
+
|
| 55 |
+
### **Notes:**
|
| 56 |
+
|
| 57 |
+
- **Recommended Quantizations:**
|
| 58 |
+
- **Q4_K_S:** Although it offers good size reduction with minimal PPL impact, it is superseded by more optimal choices like Q5_K_M and Q6_K.
|
| 59 |
+
- **Q5_K_M:** Offers the best balance between low perplexity and reduced file size above Q4, making it ideal for most applications.
|
| 60 |
+
- **Q6_K:** Delivers nearly lossless performance compared to bf16 with a reduced file size (2.4G vs. 4.2G). Ideal for scenarios requiring maximum accuracy with some size savings.
|
| 61 |
+
- **Non-recommended Quantizations:**
|
| 62 |
+
- **IQ3_M:** Represents the best of the I quantization types below Q4, achieving good size efficiency while maintaining low perplexity.
|
| 63 |
+
- **Q3_K_L:** Provides a slightly larger file size (1.8G) with an acceptable PPL (16.5067). While it meets the log PPL difference criteria, it is not as balanced as the recommended quantizations.
|
| 64 |
+
- An attempt was made to get a model below **IQ3_M** size, but perplexity was unacceptable even with **IQ2_M** (more than the 0.3 selection crteria, see next section).
|
| 65 |
+
|
| 66 |
+
---
|
| 67 |
+
|
| 68 |
+
### **Defending the Selection:**
|
| 69 |
+
|
| 70 |
+
The selection of recommended models is designed to provide a spectrum of options that meet the following criteria:
|
| 71 |
+
|
| 72 |
+
- **Diversity in Quantization Types:**
|
| 73 |
+
- **I Quantization Below Q4:** **IQ3_M** is included to offer an option that uses I quantization below the **Q4** level, balancing size and performance.
|
| 74 |
+
- **K Quantization At and Above Q4:** **Q4_K_S**, **Q4_K_M**, **Q5_K_M**, and **Q6_K** provide K quantization options at and above the **Q4** level, giving users choices based on their specific needs.
|
| 75 |
+
- **Highly Compressed Quantization (Q3 and below):** **IQ3_M** and **Q3_K_L** are included as they meet the selection criteria of log PPL diff <0.3 and are not redundant with other models.
|
| 76 |
+
|
| 77 |
+
- **Selection Criteria:**
|
| 78 |
+
- **Log PPL diff <0.3:** All included models have a log PPL difference under 0.3, ensuring that they maintain acceptable performance even when highly quantized.
|
| 79 |
+
- **No Multiple Models Within 100MB of the Same File Size:** Only one model is included per similar file size range to avoid redundancy. For example, **Q3_K_L** (1.8G) is included while other models like **Q3_K_M** (1.7G) are excluded due to nearly equal file sizes and differing PPL, ensuring a sparse yet comprehensive selection.
|
| 80 |
+
|
| 81 |
+
---
|
| 82 |
+
|
| 83 |
+
# Comparison of salamandra 2b/instruct quantization results
|
| 84 |
+
|
| 85 |
+

|
| 86 |
+
|
| 87 |
+
Between the two runs, sost shared quantization types show consistent behavior across both models, reinforcing the reliability of these quantization schemes irrespective of fine-tuning. The 2b instruct quantizations showed a slight upward shift, indicating marginally higher loss for equivalent quantizations.
|
| 88 |
+
|
| 89 |
+
---
|
| 90 |
+
|
| 91 |

|
| 92 |
|
| 93 |
# Salamandra Model Card
|
images/comparison_of_quantization.png
ADDED
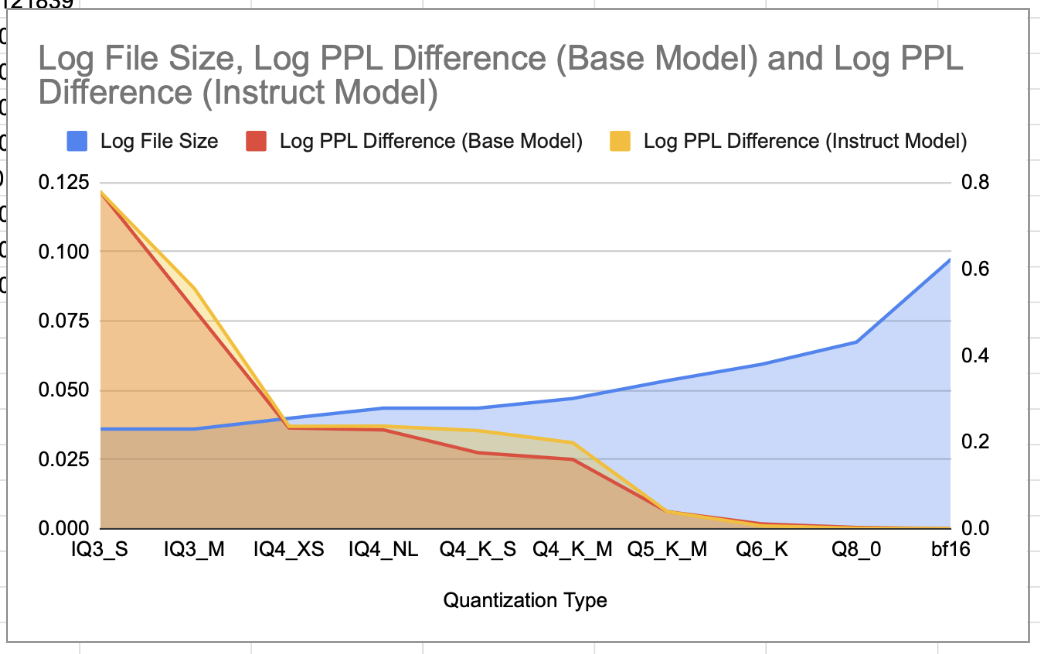
|
imatrix_dataset.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
imatrix_log.txt
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/Users/macdev/Downloads/build/bin/llama-imatrix \
|
| 2 |
+
-m ./salamandra-2b-instruct_bf16.gguf \
|
| 3 |
+
-f ./imatrix/oscar/imatrix-dataset.txt \
|
| 4 |
+
-o ./imatrix/oscar/imatrix.dat \
|
| 5 |
+
--threads 15 \
|
| 6 |
+
--ctx-size 8192 \
|
| 7 |
+
--rope-freq-base 10000.0 \
|
| 8 |
+
--top-p 0.95 \
|
| 9 |
+
--temp 0 \
|
| 10 |
+
--repeat-penalty 1.2
|
| 11 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 12 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from ./salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 13 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 14 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 15 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 16 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 17 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 18 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 19 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 20 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 21 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 22 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 23 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 24 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 25 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 26 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 27 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 28 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 29 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 30 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 31 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 32 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 33 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 34 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 35 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 36 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 37 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 38 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 39 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 40 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 41 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 42 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 43 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 44 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 45 |
+
llama_model_loader: - type f32: 49 tensors
|
| 46 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 47 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 48 |
+
llm_load_vocab: special tokens cache size = 104
|
| 49 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 50 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 51 |
+
llm_load_print_meta: arch = llama
|
| 52 |
+
llm_load_print_meta: vocab type = SPM
|
| 53 |
+
llm_load_print_meta: n_vocab = 256000
|
| 54 |
+
llm_load_print_meta: n_merges = 0
|
| 55 |
+
llm_load_print_meta: vocab_only = 0
|
| 56 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 57 |
+
llm_load_print_meta: n_embd = 2048
|
| 58 |
+
llm_load_print_meta: n_layer = 24
|
| 59 |
+
llm_load_print_meta: n_head = 16
|
| 60 |
+
llm_load_print_meta: n_head_kv = 16
|
| 61 |
+
llm_load_print_meta: n_rot = 128
|
| 62 |
+
llm_load_print_meta: n_swa = 0
|
| 63 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 64 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 65 |
+
llm_load_print_meta: n_gqa = 1
|
| 66 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 67 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 68 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 69 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 70 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 71 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 72 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 73 |
+
llm_load_print_meta: n_ff = 5440
|
| 74 |
+
llm_load_print_meta: n_expert = 0
|
| 75 |
+
llm_load_print_meta: n_expert_used = 0
|
| 76 |
+
llm_load_print_meta: causal attn = 1
|
| 77 |
+
llm_load_print_meta: pooling type = 0
|
| 78 |
+
llm_load_print_meta: rope type = 0
|
| 79 |
+
llm_load_print_meta: rope scaling = linear
|
| 80 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 81 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 82 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 83 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 84 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 85 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 86 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 87 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 88 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 89 |
+
llm_load_print_meta: model type = ?B
|
| 90 |
+
llm_load_print_meta: model ftype = BF16
|
| 91 |
+
llm_load_print_meta: model params = 2.25 B
|
| 92 |
+
llm_load_print_meta: model size = 4.20 GiB (16.00 BPW)
|
| 93 |
+
llm_load_print_meta: general.name = n/a
|
| 94 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 95 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 96 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 97 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 98 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 99 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 100 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 101 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 102 |
+
llm_load_print_meta: max token length = 72
|
| 103 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 104 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 105 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 106 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 107 |
+
llm_load_tensors: Metal buffer size = 4298.39 MiB
|
| 108 |
+
llm_load_tensors: CPU buffer size = 1000.00 MiB
|
| 109 |
+
.......................................................
|
| 110 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 111 |
+
llama_new_context_with_model: n_batch = 2048
|
| 112 |
+
llama_new_context_with_model: n_ubatch = 512
|
| 113 |
+
llama_new_context_with_model: flash_attn = 0
|
| 114 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 115 |
+
llama_new_context_with_model: freq_scale = 1
|
| 116 |
+
ggml_metal_init: allocating
|
| 117 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 118 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 119 |
+
ggml_metal_init: using embedded metal library
|
| 120 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 121 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 122 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 123 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 124 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 125 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 126 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 127 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 128 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 129 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 130 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 131 |
+
llama_new_context_with_model: Metal compute buffer size = 288.00 MiB
|
| 132 |
+
llama_new_context_with_model: CPU compute buffer size = 500.00 MiB
|
| 133 |
+
llama_new_context_with_model: graph nodes = 774
|
| 134 |
+
llama_new_context_with_model: graph splits = 339
|
| 135 |
+
|
| 136 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 137 |
+
compute_imatrix: tokenizing the input ..
|
| 138 |
+
compute_imatrix: tokenization took 49850.6 ms
|
| 139 |
+
compute_imatrix: computing over 2761 chunks with batch_size 2048
|
| 140 |
+
compute_imatrix: 21.89 seconds per pass - ETA 16 hours 47.15 minutes
|
| 141 |
+
[1]9.5013,[2]8.9819,[3]11.9011,[4]12.7153,[5]14.6644,[6]14.1413,[7]13.0545,[8]12.7865,[9]12.6856,[10]12.4469,[11]12.8781,[12]13.0330,[13]13.1550,[14]13.6471,[15]13.2151,[16]13.7717,[17]14.1626,[18]14.6421,[19]14.3569,[20]13.2714,[21]13.2034,[22]13.0614,[23]13.1096,[24]13.1536,[25]12.5522,[26]12.6202,[27]12.6385,[28]12.7061,[29]12.9160,[30]13.1051,[31]12.9912,[32]13.1490,[33]12.7698,[34]12.7757,[35]12.7208,[36]12.6196,[37]12.3513,[38]12.3746,[39]12.3823,[40]12.4091,[41]12.2961,[42]12.3500,[43]12.2301,[44]12.1506,[45]12.1335,[46]12.1013,[47]12.0307,[48]12.1224,[49]12.2420,[50]12.3560,[51]12.4814,[52]12.4640,[53]12.4211,[54]12.5355,[55]12.5829,[56]12.6120,[57]12.7223,[58]12.3899,[59]12.1386,[60]11.7298,[61]11.3254,[62]11.2823,[63]11.3045,[64]11.3086,[65]11.3211,[66]11.3642,[67]11.4704,[68]11.4825,[69]11.3871,[70]11.2217,[71]11.2850,[72]11.2832,[73]11.3711,[74]11.4344,[75]11.4874,[76]11.4223,[77]11.4740,[78]11.5646,[79]11.6103,[80]11.7126,[81]11.9028,[82]11.9351,[83]11.9594,[84]11.6998,[85]11.4874,[86]11.2732,[87]11.0851,[88]10.8654,[89]10.7074,[90]10.6072,[91]10.3987,[92]10.3514,[93]10.3655,[94]10.4841,[95]10.3688,[96]10.4153,[97]10.4250,[98]10.4736,[99]10.5193,[100]10.5617,[101]10.5772,[102]10.6002,[103]10.6418,[104]10.6793,[105]10.7498,[106]10.7743,[107]10.7494,[108]10.7842,[109]10.8352,[110]10.8535,[111]10.8482,[112]10.8848,[113]11.0211,[114]11.0262,[115]10.9986,[116]11.1057,[117]11.1117,[118]11.1211,[119]11.1300,[120]11.1559,[121]11.1875,[122]11.2243,[123]11.2249,[124]11.1641,[125]11.1522,[126]11.1587,[127]11.1700,[128]11.2116,[129]11.2402,[130]11.2678,[131]11.2717,[132]11.2918,[133]11.2277,[134]11.2404,[135]11.3084,[136]11.3322,[137]11.3027,[138]11.3480,[139]11.3910,[140]11.4133,[141]11.4060,[142]11.4164,[143]11.4306,[144]11.4635,[145]11.4672,[146]11.4341,[147]11.4019,[148]11.3954,[149]11.3654,[150]11.3584,[151]11.3320,[152]11.3190,[153]11.2661,[154]11.2901,[155]11.2733,[156]11.2677,[157]11.2611,[158]11.2778,[159]11.2710,[160]11.2894,[161]11.2950,[162]11.2734,[163]11.2402,[164]11.2658,[165]11.3087,[166]11.3204,[167]11.3629,[168]11.3621,[169]11.3818,[170]11.3484,[171]11.3459,[172]11.3319,[173]11.2990,[174]11.2954,[175]11.3011,[176]11.2960,[177]11.3134,[178]11.3298,[179]11.3740,[180]11.3572,[181]11.3844,[182]11.4280,[183]11.4656,[184]11.4963,[185]11.4792,[186]11.4122,[187]11.4182,[188]11.4950,[189]11.5431,[190]11.5263,[191]11.5014,[192]11.4863,[193]11.4442,[194]11.4203,[195]11.3719,[196]11.3324,[197]11.2960,[198]11.3533,[199]11.3776,[200]11.3970,[201]11.4396,[202]11.4640,[203]11.4838,[204]11.4769,[205]11.4690,[206]11.4783,[207]11.5302,[208]11.5653,[209]11.6174,[210]11.6450,[211]11.6782,[212]11.7139,[213]11.7444,[214]11.7722,[215]11.7991,[216]11.8313,[217]11.8288,[218]11.8666,[219]11.8655,[220]11.8907,[221]11.9175,[222]11.9329,[223]11.9511,[224]11.9765,[225]12.0103,[226]12.0359,[227]12.0544,[228]12.0365,[229]12.0627,[230]12.0321,[231]12.0120,[232]12.0348,[233]11.9917,[234]11.9483,[235]11.9279,[236]11.9105,[237]11.9119,[238]11.9349,[239]11.9166,[240]11.9246,[241]11.9522,[242]11.9868,[243]12.0101,[244]12.0340,[245]12.0672,[246]12.0926,[247]12.1097,[248]12.1327,[249]12.1417,[250]12.1622,[251]12.1877,[252]12.2145,[253]12.2328,[254]12.2492,[255]12.2722,[256]12.2965,[257]12.3044,[258]12.3083,[259]12.3126,[260]12.3065,[261]12.3261,[262]12.3085,[263]12.2956,[264]12.2643,[265]12.3003,[266]12.3250,[267]12.3499,[268]12.3265,[269]12.3189,[270]12.2652,[271]12.2213,[272]12.1434,[273]12.1443,[274]12.1442,[275]12.1636,[276]12.1748,[277]12.1989,[278]12.1593,[279]12.1306,[280]12.1396,[281]12.1438,[282]12.1501,[283]12.1425,[284]12.1141,[285]12.0958,[286]12.0766,[287]12.0574,[288]12.0532,[289]12.0503,[290]12.0324,[291]12.0256,[292]12.0512,[293]12.0412,[294]12.0763,[295]12.0863,[296]12.0674,[297]12.0613,[298]12.0444,[299]12.0086,[300]11.9903,[301]11.9801,[302]11.9229,[303]11.8989,[304]11.8846,[305]11.8619,[306]11.8133,[307]11.7972,[308]11.8002,[309]11.7919,[310]11.7858,[311]11.7875,[312]11.7637,[313]11.7869,[314]11.7709,[315]11.7560,[316]11.7998,[317]11.8178,[318]11.8305,[319]11.8572,[320]11.8616,[321]11.8844,[322]11.8902,[323]11.9214,[324]11.9302,[325]11.9520,[326]11.9893,[327]12.0288,[328]12.0494,[329]12.0903,[330]12.1070,[331]12.1445,[332]12.1942,[333]12.2204,[334]12.2560,[335]12.3614,[336]12.4010,[337]12.4221,[338]12.4652,[339]12.4888,[340]12.5400,[341]12.5532,[342]12.5872,[343]12.6067,[344]12.6270,[345]12.6445,[346]12.6591,[347]12.7206,[348]12.7413,[349]12.8833,[350]12.9409,[351]12.9721,[352]12.9868,[353]13.0017,[354]13.0076,[355]13.0192,[356]13.0349,[357]13.1299,[358]13.1529,[359]13.2356,[360]13.3636,[361]13.4324,[362]13.4609,[363]13.5077,[364]13.5348,[365]13.5758,[366]13.6566,[367]13.7284,[368]13.7417,[369]13.7719,[370]13.8147,[371]13.8814,[372]13.9159,[373]13.9173,[374]13.9554,[375]13.9693,[376]13.9922,[377]14.0296,[378]14.0492,[379]14.0522,[380]14.0603,[381]14.0861,[382]14.1127,[383]14.1310,[384]14.1417,[385]14.1564,[386]14.1736,[387]14.1969,[388]14.2045,[389]14.1967,[390]14.1772,[391]14.1956,[392]14.1798,[393]14.2065,[394]14.1998,[395]14.2094,[396]14.2531,[397]14.2660,[398]14.2788,[399]14.3046,[400]14.3244,[401]14.3455,[402]14.3579,[403]14.3676,[404]14.3413,[405]14.2996,[406]14.2519,[407]14.2430,[408]14.2536,[409]14.2597,[410]14.2609,[411]14.2687,[412]14.2645,[413]14.2616,[414]14.2558,[415]14.2378,[416]14.2233,[417]14.2105,[418]14.2053,[419]14.2290,[420]14.2257,[421]14.2265,[422]14.2366,[423]14.2403,[424]14.2466,[425]14.2692,[426]14.2846,[427]14.3007,[428]14.3143,[429]14.3445,[430]14.3567,[431]14.3859,[432]14.4059,[433]14.4204,[434]14.4457,[435]14.4613,[436]14.4651,[437]14.4880,[438]14.5049,[439]14.5236,[440]14.5401,[441]14.5517,[442]14.5680,[443]14.5682,[444]14.5842,[445]14.5679,[446]14.5724,[447]14.5921,[448]14.5986,[449]14.5956,[450]14.5947,[451]14.6032,[452]14.5799,[453]14.5979,[454]14.5842,[455]14.6443,[456]14.6570,[457]14.6684,[458]14.6827,[459]14.6670,[460]14.6162,[461]14.6853,[462]14.6723,[463]14.6706,[464]14.6677,[465]14.6966,[466]14.7157,[467]14.6939,[468]14.7017,[469]14.7015,[470]14.6964,[471]14.7140,[472]14.7065,[473]14.7036,[474]14.7050,[475]14.7125,[476]14.7240,[477]14.6868,[478]14.6947,[479]14.7111,[480]14.7209,[481]14.7017,[482]14.6421,[483]14.6385,[484]14.6412,[485]14.6594,[486]14.6646,[487]14.6691,[488]14.6694,[489]14.6671,[490]14.6625,[491]14.6668,[492]14.6665,[493]14.6635,[494]14.6524,[495]14.6526,[496]14.5771,[497]14.5880,[498]14.5844,[499]14.5905,[500]14.5958,[501]14.5835,[502]14.5874,[503]14.5867,[504]14.5829,[505]14.5815,[506]14.5805,[507]14.5555,[508]14.5598,[509]14.5931,[510]14.6050,[511]14.6260,[512]14.6153,[513]14.6264,[514]14.6091,[515]14.6115,[516]14.5885,[517]14.5186,[518]14.4598,[519]14.4657,[520]14.4574,[521]14.4715,[522]14.4794,[523]14.4694,[524]14.4552,[525]14.4493,[526]14.4338,[527]14.4575,[528]14.4625,[529]14.4957,[530]14.4718,[531]14.4740,[532]14.4672,[533]14.4456,[534]14.4323,[535]14.4260,[536]14.4082,[537]14.3975,[538]14.3947,[539]14.3962,[540]14.3851,[541]14.3900,[542]14.3858,[543]14.3790,[544]14.3547,[545]14.3367,[546]14.3035,[547]14.2733,[548]14.2498,[549]14.2229,[550]14.2240,[551]14.2112,[552]14.1870,[553]14.1610,[554]14.1242,[555]14.1375,[556]14.1410,[557]14.1220,[558]14.1181,[559]14.1090,[560]14.0989,[561]14.0923,[562]14.0908,[563]14.0929,[564]14.0899,[565]14.0927,[566]14.0972,[567]14.1003,[568]14.1032,[569]14.1003,[570]14.1050,[571]14.0970,[572]14.0907,[573]14.0985,[574]14.1019,[575]14.1064,[576]14.0480,[577]14.0376,[578]14.0284,[579]14.0119,[580]13.9976,[581]13.9988,[582]13.9881,[583]13.9816,[584]13.9683,[585]13.9373,[586]13.9361,[587]13.9308,[588]13.9027,[589]13.8894,[590]13.8352,[591]13.7821,[592]13.7312,[593]13.6981,[594]13.6624,[595]13.6605,[596]13.6564,[597]13.6590,[598]13.6378,[599]13.6308,[600]13.6179,[601]13.5890,[602]13.5721,[603]13.5452,[604]13.5301,[605]13.5181,[606]13.5029,[607]13.4880,[608]13.4834,[609]13.4747,[610]13.4565,[611]13.4410,[612]13.4245,[613]13.4079,[614]13.3848,[615]13.3968,[616]13.4224,[617]13.4209,[618]13.4154,[619]13.4172,[620]13.4132,[621]13.4126,[622]13.4240,[623]13.4352,[624]13.4212,[625]13.4095,[626]13.3994,[627]13.3798,[628]13.3846,[629]13.3581,[630]13.3683,[631]13.3753,[632]13.3432,[633]13.3323,[634]13.3309,[635]13.3247,[636]13.3179,[637]13.3141,[638]13.3146,[639]13.3171,[640]13.2895,[641]13.2562,[642]13.2282,[643]13.2212,[644]13.1749,[645]13.1307,[646]13.1321,[647]13.1057,[648]13.0901,[649]13.0771,[650]13.0594,[651]13.0486,[652]13.0559,[653]13.0391,[654]13.0233,[655]13.0115,[656]13.0164,[657]13.0165,[658]13.0249,[659]13.0203,[660]13.0147,[661]13.0041,[662]12.9908,[663]12.9941,[664]12.9920,[665]12.9908,[666]12.9808,[667]12.9807,[668]12.9784,[669]12.9800,[670]12.9804,[671]12.9692,[672]12.9695,[673]12.9740,[674]12.9615,[675]12.9589,[676]12.9651,[677]12.9701,[678]12.9667,[679]12.9642,[680]12.9606,[681]12.9649,[682]12.9462,[683]12.9351,[684]12.9419,[685]12.9388,[686]12.9355,[687]12.9337,[688]12.9249,[689]12.9072,[690]12.8898,[691]12.8838,[692]12.8760,[693]12.8669,[694]12.8476,[695]12.8483,[696]12.8454,[697]12.8369,[698]12.8363,[699]12.8346,[700]12.8305,[701]12.8266,[702]12.8268,[703]12.8261,[704]12.8206,[705]12.8062,[706]12.8054,[707]12.8061,[708]12.8164,[709]12.8169,[710]12.8359,[711]12.8462,[712]12.8602,[713]12.8678,[714]12.8769,[715]12.8873,[716]12.8685,[717]12.8706,[718]12.8818,[719]12.8809,[720]12.8827,[721]12.8886,[722]12.8861,[723]12.8825,[724]12.8749,[725]12.8632,[726]12.8636,[727]12.8691,[728]12.8780,[729]12.8776,[730]12.8943,[731]12.8495,[732]12.8521,[733]12.8426,[734]12.8870,[735]12.8858,[736]12.8884,[737]12.8995,[738]12.8956,[739]12.8932,[740]12.8987,[741]12.8983,[742]12.8974,[743]12.9046,[744]12.9115,[745]12.9043,[746]12.8907,[747]12.8969,[748]12.8952,[749]12.9005,[750]12.9074,[751]12.9160,[752]12.9280,[753]12.9352,[754]12.9423,[755]12.9473,[756]12.9517,[757]12.9581,[758]12.9627,[759]12.9681,[760]12.9729,[761]12.9819,[762]12.9837,[763]12.9897,[764]12.9942,[765]12.9982,[766]13.0043,[767]13.0082,[768]13.0110,[769]13.0145,[770]13.0205,[771]13.0279,[772]13.0343,[773]13.0354,[774]13.0409,[775]13.0453,[776]13.0509,[777]13.0541,[778]13.0514,[779]13.0613,[780]13.0621,[781]13.0587,[782]13.0549,[783]13.0478,[784]13.0445,[785]13.0438,[786]13.0442,[787]13.0721,[788]13.0844,[789]13.0921,[790]13.0942,[791]13.0977,[792]13.0913,[793]13.0782,[794]13.0868,[795]13.0944,[796]13.0898,[797]13.0943,[798]13.0927,[799]13.0834,[800]13.0818,[801]13.0807,[802]13.0876,[803]13.0929,[804]13.0920,[805]13.1008,[806]13.1059,[807]13.1053,[808]13.1044,[809]13.0929,[810]13.0975,[811]13.0972,[812]13.1076,[813]13.1042,[814]13.1030,[815]13.0971,[816]13.0942,[817]13.0905,[818]13.0900,[819]13.0869,[820]13.0785,[821]13.0823,[822]13.0879,[823]13.0864,[824]13.0970,[825]13.1036,[826]13.1189,[827]13.1281,[828]13.1258,[829]13.1520,[830]13.1777,[831]13.1836,[832]13.1794,[833]13.1791,[834]13.1839,[835]13.1860,[836]13.1825,[837]13.1892,[838]13.1958,[839]13.1931,[840]13.1930,[841]13.1898,[842]13.1970,[843]13.2069,[844]13.2392,[845]13.2541,[846]13.2531,[847]13.2528,[848]13.2532,[849]13.2560,[850]13.2598,[851]13.2666,[852]13.2670,[853]13.2749,[854]13.2795,[855]13.2821,[856]13.2820,[857]13.2886,[858]13.2890,[859]13.2772,[860]13.2703,[861]13.2732,[862]13.2723,[863]13.2839,[864]13.2862,[865]13.2836,[866]13.2843,[867]13.2868,[868]13.2862,[869]13.2800,[870]13.2854,[871]13.3065,[872]13.3407,[873]13.3738,[874]13.4093,[875]13.4055,[876]13.3957,[877]13.3923,[878]13.3944,[879]13.3975,[880]13.4036,[881]13.4048,[882]13.4036,[883]13.4037,[884]13.4378,[885]13.4567,[886]13.4511,[887]13.4532,[888]13.4485,[889]13.4466,[890]13.4451,[891]13.4375,[892]13.4383,[893]13.4309,[894]13.4271,[895]13.4269,[896]13.4311,[897]13.4311,[898]13.4335,[899]13.4376,[900]13.4511,[901]13.4717,[902]13.4735,[903]13.4708,[904]13.4737,[905]13.4719,[906]13.4713,[907]13.4783,[908]13.4728,[909]13.4751,[910]13.4911,[911]13.4865,[912]13.4908,[913]13.4903,[914]13.4940,[915]13.4943,[916]13.4932,[917]13.4953,[918]13.4867,[919]13.4874,[920]13.4882,[921]13.4713,[922]13.4633,[923]13.4570,[924]13.4523,[925]13.4430,[926]13.4380,[927]13.4394,[928]13.4393,[929]13.4392,[930]13.4362,[931]13.4401,[932]13.4435,[933]13.4405,[934]13.4454,[935]13.4406,[936]13.4481,[937]13.4576,[938]13.4623,[939]13.4598,[940]13.4612,[941]13.4655,[942]13.4715,[943]13.4743,[944]13.4806,[945]13.4765,[946]13.4802,[947]13.4859,[948]13.4907,[949]13.4936,[950]13.4906,[951]13.4924,[952]13.4914,[953]13.4928,[954]13.4875,[955]13.4905,[956]13.4939,[957]13.4960,[958]13.4904,[959]13.4911,[960]13.4912,[961]13.4896,[962]13.4963,[963]13.4953,[964]13.4939,[965]13.4900,[966]13.4903,[967]13.4897,[968]13.4862,[969]13.4852,[970]13.4885,[971]13.4823,[972]13.4848,[973]13.4826,[974]13.4742,[975]13.4663,[976]13.4597,[977]13.4537,[978]13.4581,[979]13.4714,[980]13.4792,[981]13.4862,[982]13.4853,[983]13.4894,[984]13.4955,[985]13.4987,[986]13.5001,[987]13.4984,[988]13.5065,[989]13.5131,[990]13.5121,[991]13.5252,[992]13.5363,[993]13.5464,[994]13.5556,[995]13.5637,[996]13.5794,[997]13.5925,[998]13.6083,[999]13.6140,[1000]13.6260,[1001]13.6339,[1002]13.6448,[1003]13.6503,[1004]13.6553,[1005]13.6581,[1006]13.6687,[1007]13.6777,[1008]13.6893,[1009]13.6987,[1010]13.7078,[1011]13.7191,[1012]13.7244,[1013]13.7323,[1014]13.7446,[1015]13.7592,[1016]13.7669,[1017]13.7666,[1018]13.7683,[1019]13.7765,[1020]13.7883,[1021]13.7951,[1022]13.8011,[1023]13.8082,[1024]13.8193,[1025]13.8302,[1026]13.8418,[1027]13.8512,[1028]13.8554,[1029]13.8430,[1030]13.8331,[1031]13.8185,[1032]13.8272,[1033]13.8346,[1034]13.8438,[1035]13.8550,[1036]13.8693,[1037]13.8842,[1038]13.8943,[1039]13.9064,[1040]13.9182,[1041]13.9279,[1042]13.9336,[1043]13.9410,[1044]13.9425,[1045]13.9565,[1046]13.9500,[1047]13.9601,[1048]13.9683,[1049]13.9770,[1050]13.9835,[1051]13.9983,[1052]14.0126,[1053]14.0196,[1054]14.0312,[1055]14.0340,[1056]14.0521,[1057]14.0666,[1058]14.0796,[1059]14.0968,[1060]14.1073,[1061]14.1252,[1062]14.1367,[1063]14.1474,[1064]14.1673,[1065]14.1838,[1066]14.2002,[1067]14.2019,[1068]14.2040,[1069]14.2101,[1070]14.2105,[1071]14.2294,[1072]14.2178,[1073]14.2337,[1074]14.2465,[1075]14.2468,[1076]14.2446,[1077]14.2421,[1078]14.2520,[1079]14.2620,[1080]14.2768,[1081]14.2900,[1082]14.2997,[1083]14.2994,[1084]14.3090,[1085]14.3008,[1086]14.2925,[1087]14.2898,[1088]14.2980,[1089]14.3056,[1090]14.3091,[1091]14.3268,[1092]14.3347,[1093]14.3374,[1094]14.3447,[1095]14.3562,[1096]14.3633,[1097]14.3777,[1098]14.3903,[1099]14.3975,[1100]14.4089,[1101]14.4272,[1102]14.4439,[1103]14.4421,[1104]14.4432,[1105]14.4452,[1106]14.4597,[1107]14.4557,[1108]14.4492,[1109]14.4338,[1110]14.4417,[1111]14.4620,[1112]14.4760,[1113]14.4888,[1114]14.5100,[1115]14.5154,[1116]14.5131,[1117]14.5200,[1118]14.5052,[1119]14.4964,[1120]14.4781,[1121]14.4744,[1122]14.4735,[1123]14.4705,[1124]14.4738,[1125]14.4772,[1126]14.4717,[1127]14.4739,[1128]14.4538,[1129]14.4676,[1130]14.4753,[1131]14.4745,[1132]14.4833,[1133]14.4908,[1134]14.4959,[1135]14.4971,[1136]14.5089,[1137]14.5149,[1138]14.5347,[1139]14.5421,[1140]14.5500,[1141]14.5606,[1142]14.5754,[1143]14.5816,[1144]14.5925,[1145]14.6011,[1146]14.6058,[1147]14.6134,[1148]14.6160,[1149]14.6252,[1150]14.6345,[1151]14.6487,[1152]14.6592,[1153]14.6686,[1154]14.6746,[1155]14.6839,[1156]14.6859,[1157]14.6995,[1158]14.7043,[1159]14.7118,[1160]14.7226,[1161]14.7363,[1162]14.7430,[1163]14.7507,[1164]14.7577,[1165]14.7600,[1166]14.7740,[1167]14.7798,[1168]14.7901,[1169]14.7985,[1170]14.8075,[1171]14.8179,[1172]14.8210,[1173]14.8321,[1174]14.8415,[1175]14.8525,[1176]14.8512,[1177]14.8641,[1178]14.8668,[1179]14.8707,[1180]14.8786,[1181]14.8913,[1182]14.9054,[1183]14.9108,[1184]14.9129,[1185]14.9205,[1186]14.9279,[1187]14.9204,[1188]14.9149,[1189]14.9068,[1190]14.9037,[1191]14.9040,[1192]14.9045,[1193]14.9165,[1194]14.9090,[1195]14.9096,[1196]14.9020,[1197]14.9007,[1198]14.8955,[1199]14.8913,[1200]14.8875,[1201]14.8901,[1202]14.8917,[1203]14.8814,[1204]14.8668,[1205]14.8641,[1206]14.8639,[1207]14.8535,[1208]14.8512,[1209]14.8475,[1210]14.8427,[1211]14.8402,[1212]14.8369,[1213]14.8291,[1214]14.8264,[1215]14.8139,[1216]14.8147,[1217]14.8100,[1218]14.8010,[1219]14.8020,[1220]14.8022,[1221]14.7966,[1222]14.7942,[1223]14.7967,[1224]14.7981,[1225]14.7982,[1226]14.7985,[1227]14.7937,[1228]14.7909,[1229]14.7898,[1230]14.7902,[1231]14.7864,[1232]14.7818,[1233]14.7773,[1234]14.7684,[1235]14.7620,[1236]14.7653,[1237]14.7637,[1238]14.7650,[1239]14.7669,[1240]14.7697,[1241]14.7705,[1242]14.7728,[1243]14.7749,[1244]14.7633,[1245]14.7644,[1246]14.7661,[1247]14.7668,[1248]14.7667,[1249]14.7640,[1250]14.7648,[1251]14.7594,[1252]14.7557,[1253]14.7565,[1254]14.7500,[1255]14.7423,[1256]14.7384,[1257]14.7353,[1258]14.7294,[1259]14.7254,[1260]14.7256,[1261]14.7215,[1262]14.7174,[1263]14.7176,[1264]14.7116,[1265]14.7096,[1266]14.7093,[1267]14.7059,[1268]14.7042,[1269]14.6981,[1270]14.6929,[1271]14.6913,[1272]14.6746,[1273]14.6647,[1274]14.6649,[1275]14.6611,[1276]14.6607,[1277]14.6688,[1278]14.6768,[1279]14.6813,[1280]14.6882,[1281]14.6985,[1282]14.7094,[1283]14.7163,[1284]14.7240,[1285]14.7318,[1286]14.7344,[1287]14.7422,[1288]14.7513,[1289]14.7610,[1290]14.7674,[1291]14.7753,[1292]14.7868,[1293]14.7945,[1294]14.8039,[1295]14.8086,[1296]14.8127,[1297]14.8203,[1298]14.8257,[1299]14.8271,[1300]14.8278,[1301]14.8323,[1302]14.8355,[1303]14.8382,[1304]14.8438,[1305]14.8501,[1306]14.8560,[1307]14.8655,[1308]14.8742,[1309]14.8843,[1310]14.8893,[1311]14.8927,[1312]14.8967,[1313]14.9040,[1314]14.9129,[1315]14.9193,[1316]14.9228,[1317]14.9201,[1318]14.9275,[1319]14.9355,[1320]14.9357,[1321]14.9394,[1322]14.9454,[1323]14.9536,[1324]14.9618,[1325]14.9678,[1326]14.9710,[1327]14.9745,[1328]14.9810,[1329]14.9834,[1330]14.9894,[1331]14.9928,[1332]14.9948,[1333]14.9990,[1334]15.0058,[1335]15.0062,[1336]15.0109,[1337]15.0149,[1338]15.0192,[1339]15.0194,[1340]15.0212,[1341]15.0254,[1342]15.0294,[1343]15.0338,[1344]15.0320,[1345]15.0329,[1346]15.0312,[1347]15.0349,[1348]15.0380,[1349]15.0410,[1350]15.0453,[1351]15.0481,[1352]15.0482,[1353]15.0582,[1354]15.0641,[1355]15.0732,[1356]15.0814,[1357]15.0882,[1358]15.0994,[1359]15.1075,[1360]15.1165,[1361]15.1203,[1362]15.1300,[1363]15.1245,[1364]15.1290,[1365]15.1226,[1366]15.1221,[1367]15.1194,[1368]15.1129,[1369]15.1120,[1370]15.1151,[1371]15.1134,[1372]15.1101,[1373]15.1077,[1374]15.1129,[1375]15.1132,[1376]15.1108,[1377]15.1113,[1378]15.1067,[1379]15.1098,[1380]15.1087,[1381]15.1037,[1382]15.1029,[1383]15.1055,[1384]15.1048,[1385]15.1048,[1386]15.1020,[1387]15.1021,[1388]15.0888,[1389]15.0929,[1390]15.0960,[1391]15.0945,[1392]15.0956,[1393]15.0901,[1394]15.0883,[1395]15.0888,[1396]15.0899,[1397]15.0911,[1398]15.0904,[1399]15.0841,[1400]15.0760,[1401]15.0667,[1402]15.0549,[1403]15.0549,[1404]15.0518,[1405]15.0442,[1406]15.0371,[1407]15.0287,[1408]15.0161,[1409]15.0092,[1410]15.0028,[1411]14.9902,[1412]14.9831,[1413]14.9735,[1414]14.9587,[1415]14.9551,[1416]14.9558,[1417]14.9380,[1418]14.9317,[1419]14.9314,[1420]14.9252,[1421]14.9173,[1422]14.9136,[1423]14.9090,[1424]14.9038,[1425]14.8963,[1426]14.8849,[1427]14.8830,[1428]14.8791,[1429]14.8770,[1430]14.8710,[1431]14.8663,[1432]14.8643,[1433]14.8528,[1434]14.8533,[1435]14.8553,[1436]14.8551,[1437]14.8460,[1438]14.8276,[1439]14.8186,[1440]14.8118,[1441]14.7971,[1442]14.7917,[1443]14.7816,[1444]14.7699,[1445]14.7643,[1446]14.7638,[1447]14.7422,[1448]14.7311,[1449]14.7206,[1450]14.7083,[1451]14.7088,[1452]14.7065,[1453]14.6913,[1454]14.6941,[1455]14.7001,[1456]14.6980,[1457]14.6889,[1458]14.6916,[1459]14.6900,[1460]14.6849,[1461]14.6819,[1462]14.6803,[1463]14.6776,[1464]14.6767,[1465]14.6834,[1466]14.6795,[1467]14.6647,[1468]14.6661,[1469]14.6684,[1470]14.6606,[1471]14.6528,[1472]14.6330,[1473]14.6114,[1474]14.6080,[1475]14.6098,[1476]14.6085,[1477]14.6060,[1478]14.6036,[1479]14.6059,[1480]14.6078,[1481]14.6127,[1482]14.6045,[1483]14.6109,[1484]14.6097,[1485]14.6124,[1486]14.6136,[1487]14.6139,[1488]14.6141,[1489]14.6153,[1490]14.6120,[1491]14.6181,[1492]14.6224,[1493]14.6203,[1494]14.6115,[1495]14.6167,[1496]14.6179,[1497]14.6136,[1498]14.6175,[1499]14.6264,[1500]14.6325,[1501]14.6414,[1502]14.6491,[1503]14.6554,[1504]14.6615,[1505]14.6637,[1506]14.6626,[1507]14.6632,[1508]14.6614,[1509]14.6602,[1510]14.6608,[1511]14.6640,[1512]14.6637,[1513]14.6713,[1514]14.6618,[1515]14.6529,[1516]14.6400,[1517]14.6335,[1518]14.6367,[1519]14.6372,[1520]14.6333,[1521]14.6278,[1522]14.6265,[1523]14.6197,[1524]14.6077,[1525]14.6227,[1526]14.6077,[1527]14.5969,[1528]14.5763,[1529]14.5778,[1530]14.5762,[1531]14.5836,[1532]14.5858,[1533]14.5897,[1534]14.5929,[1535]14.5931,[1536]14.5927,[1537]14.5948,[1538]14.5981,[1539]14.6064,[1540]14.6121,[1541]14.6117,[1542]14.5978,[1543]14.5958,[1544]14.5960,[1545]14.6005,[1546]14.6081,[1547]14.6100,[1548]14.6070,[1549]14.6065,[1550]14.6014,[1551]14.6029,[1552]14.6000,[1553]14.5985,[1554]14.5984,[1555]14.5993,[1556]14.5933,[1557]14.5965,[1558]14.5954,[1559]14.5937,[1560]14.5931,[1561]14.5939,[1562]14.5930,[1563]14.6005,[1564]14.5999,[1565]14.6029,[1566]14.6031,[1567]14.6048,[1568]14.6070,[1569]14.6140,[1570]14.6135,[1571]14.6175,[1572]14.6192,[1573]14.6103,[1574]14.6111,[1575]14.6125,[1576]14.6167,[1577]14.6242,[1578]14.6229,[1579]14.6081,[1580]14.6104,[1581]14.6060,[1582]14.6043,[1583]14.6111,[1584]14.6063,[1585]14.6144,[1586]14.6211,[1587]14.6231,[1588]14.6189,[1589]14.6282,[1590]14.6283,[1591]14.6209,[1592]14.6242,[1593]14.6251,[1594]14.6261,[1595]14.6261,[1596]14.6329,[1597]14.6324,[1598]14.6351,[1599]14.6363,[1600]14.6394,[1601]14.6465,[1602]14.6465,[1603]14.6429,[1604]14.6428,[1605]14.6415,[1606]14.6417,[1607]14.6427,[1608]14.6412,[1609]14.6397,[1610]14.6358,[1611]14.6278,[1612]14.6255,[1613]14.6242,[1614]14.6186,[1615]14.6167,[1616]14.6172,[1617]14.6181,[1618]14.6188,[1619]14.6137,[1620]14.6167,[1621]14.6129,[1622]14.6127,[1623]14.6168,[1624]14.6193,[1625]14.6249,[1626]14.6315,[1627]14.6301,[1628]14.6318,[1629]14.6373,[1630]14.6402,[1631]14.6438,[1632]14.6496,[1633]14.6526,[1634]14.6544,[1635]14.6528,[1636]14.6579,[1637]14.6608,[1638]14.6656,[1639]14.6693,[1640]14.6737,[1641]14.6855,[1642]14.6920,[1643]14.7044,[1644]14.7192,[1645]14.7328,[1646]14.7450,[1647]14.7491,[1648]14.7531,[1649]14.7609,[1650]14.7619,[1651]14.7670,[1652]14.7691,[1653]14.7713,[1654]14.7748,[1655]14.7779,[1656]14.7779,[1657]14.7820,[1658]14.7816,[1659]14.7858,[1660]14.7886,[1661]14.7917,[1662]14.7932,[1663]14.7967,[1664]14.7999,[1665]14.7977,[1666]14.7950,[1667]14.7962,[1668]14.7979,[1669]14.8011,[1670]14.8041,[1671]14.8136,[1672]14.8197,[1673]14.8261,[1674]14.8290,[1675]14.8289,[1676]14.8354,[1677]14.8395,[1678]14.8424,[1679]14.8405,[1680]14.8421,[1681]14.8445,[1682]14.8480,[1683]14.8506,[1684]14.8537,[1685]14.8566,[1686]14.8476,[1687]14.8462,[1688]14.8458,[1689]14.8473,[1690]14.8527,[1691]14.8524,[1692]14.8572,[1693]14.8624,[1694]14.8612,[1695]14.8560,[1696]14.8386,[1697]14.8441,[1698]14.8510,[1699]14.8521,[1700]14.8544,[1701]14.8546,[1702]14.8446,[1703]14.8474,[1704]14.8470,[1705]14.8478,[1706]14.8420,[1707]14.8468,[1708]14.8589,[1709]14.8631,[1710]14.8679,[1711]14.8693,[1712]14.8741,[1713]14.8767,[1714]14.8848,[1715]14.8861,[1716]14.8916,[1717]14.8944,[1718]14.9039,[1719]14.9082,[1720]14.9099,[1721]14.9103,[1722]14.9116,[1723]14.9096,[1724]14.9128,[1725]14.9148,[1726]14.9195,[1727]14.9209,[1728]14.9239,[1729]14.9361,[1730]14.9356,[1731]14.9445,[1732]14.9499,[1733]14.9520,[1734]14.9537,[1735]14.9565,[1736]14.9613,[1737]14.9658,[1738]14.9680,[1739]14.9721,[1740]14.9769,[1741]14.9816,[1742]14.9827,[1743]14.9842,[1744]14.9866,[1745]14.9913,[1746]14.9934,[1747]14.9967,[1748]14.9974,[1749]14.9966,[1750]14.9981,[1751]15.0010,[1752]15.0045,[1753]15.0040,[1754]15.0089,[1755]15.0095,[1756]15.0086,[1757]15.0126,[1758]15.0175,[1759]15.0223,[1760]15.0273,[1761]15.0193,[1762]15.0153,[1763]15.0170,[1764]15.0215,[1765]15.0254,[1766]15.0293,[1767]15.0297,[1768]15.0351,[1769]15.0379,[1770]15.0396,[1771]15.0423,[1772]15.0468,[1773]15.0491,[1774]15.0530,[1775]15.0597,[1776]15.0603,[1777]15.0619,[1778]15.0611,[1779]15.0621,[1780]15.0650,[1781]15.0682,[1782]15.0712,[1783]15.0759,[1784]15.0784,[1785]15.0701,[1786]15.0697,[1787]15.0734,[1788]15.0727,[1789]15.0752,[1790]15.0789,[1791]15.0781,[1792]15.0817,[1793]15.0836,[1794]15.0868,[1795]15.0742,[1796]15.0782,[1797]15.0811,[1798]15.0824,[1799]15.0844,[1800]15.0860,[1801]15.0913,[1802]15.0826,[1803]15.0818,[1804]15.0797,[1805]15.0775,[1806]15.0686,[1807]15.0658,[1808]15.0633,[1809]15.0636,[1810]15.0686,[1811]15.0713,[1812]15.0693,[1813]15.0666,[1814]15.0675,[1815]15.0704,[1816]15.0746,[1817]15.0768,[1818]15.0744,[1819]15.0748,[1820]15.0779,[1821]15.0677,[1822]15.0561,[1823]15.0469,[1824]15.0495,[1825]15.0526,[1826]15.0576,[1827]15.0589,[1828]15.0614,[1829]15.0626,[1830]15.0632,[1831]15.0648,[1832]15.0656,[1833]15.0627,[1834]15.0584,[1835]15.0522,[1836]15.0541,[1837]15.0601,[1838]15.0625,[1839]15.0630,[1840]15.0641,[1841]15.0606,[1842]15.0592,[1843]15.0615,[1844]15.0592,[1845]15.0611,[1846]15.0624,[1847]15.0621,[1848]15.0622,[1849]15.0631,[1850]15.0670,[1851]15.0496,[1852]15.0507,[1853]15.0540,[1854]15.0554,[1855]15.0461,[1856]15.0457,[1857]15.0465,[1858]15.0504,[1859]15.0532,[1860]15.0507,[1861]15.0446,[1862]15.0410,[1863]15.0422,[1864]15.0439,[1865]15.0433,[1866]15.0459,[1867]15.0474,[1868]15.0432,[1869]15.0388,[1870]15.0395,[1871]15.0322,[1872]15.0459,[1873]15.0434,[1874]15.0468,[1875]15.0495,[1876]15.0515,[1877]15.0542,[1878]15.0574,[1879]15.0591,[1880]15.0587,[1881]15.0580,[1882]15.0569,[1883]15.0572,[1884]15.0552,[1885]15.0518,[1886]15.0480,[1887]15.0494,[1888]15.0577,[1889]15.0623,[1890]15.0628,[1891]15.0676,[1892]15.0759,[1893]15.0823,[1894]15.0901,[1895]15.0950,[1896]15.1013,[1897]15.1079,[1898]15.1127,[1899]15.1197,[1900]15.1276,[1901]15.1349,[1902]15.1379,[1903]15.1341,[1904]15.1401,[1905]15.1363,[1906]15.1309,[1907]15.1302,[1908]15.1392,[1909]15.1394,[1910]15.1426,[1911]15.1496,[1912]15.1559,[1913]15.1678,[1914]15.1674,[1915]15.1686,[1916]15.1704,[1917]15.1710,[1918]15.1733,[1919]15.1766,[1920]15.1814,[1921]15.1785,[1922]15.1764,[1923]15.1806,[1924]15.1784,[1925]15.1811,[1926]15.1877,[1927]15.1921,[1928]15.1927,[1929]15.1963,[1930]15.1966,[1931]15.1966,[1932]15.1985,[1933]15.2019,[1934]15.2064,[1935]15.2113,[1936]15.2166,[1937]15.2233,[1938]15.2367,[1939]15.2355,[1940]15.2394,[1941]15.2435,[1942]15.2495,[1943]15.2532,[1944]15.2525,[1945]15.2585,[1946]15.2626,[1947]15.2662,[1948]15.2711,[1949]15.2755,[1950]15.2839,[1951]15.2864,[1952]15.2912,[1953]15.2885,[1954]15.2916,[1955]15.2983,[1956]15.3079,[1957]15.3153,[1958]15.3265,[1959]15.3267,[1960]15.3370,[1961]15.3448,[1962]15.3614,[1963]15.3705,[1964]15.3797,[1965]15.3877,[1966]15.3955,[1967]15.3987,[1968]15.4059,[1969]15.4160,[1970]15.4321,[1971]15.4441,[1972]15.4463,[1973]15.4440,[1974]15.4419,[1975]15.4385,[1976]15.4379,[1977]15.4294,[1978]15.4144,[1979]15.4054,[1980]15.3961,[1981]15.3828,[1982]15.3751,[1983]15.3659,[1984]15.3622,[1985]15.3631,[1986]15.3608,[1987]15.3532,[1988]15.3443,[1989]15.3323,[1990]15.3294,[1991]15.3220,[1992]15.3198,[1993]15.3188,[1994]15.3176,[1995]15.3190,[1996]15.3197,[1997]15.3166,[1998]15.3165,[1999]15.3177,[2000]15.3183,[2001]15.3142,[2002]15.3126,[2003]15.3126,[2004]15.3114,[2005]15.3142,[2006]15.3119,[2007]15.3100,[2008]15.3068,[2009]15.3014,[2010]15.2996,[2011]15.2976,[2012]15.2977,[2013]15.2960,[2014]15.3005,[2015]15.2983,[2016]15.2915,[2017]15.2832,[2018]15.2700,[2019]15.2698,[2020]15.2680,[2021]15.2667,[2022]15.2711,[2023]15.2682,[2024]15.2663,[2025]15.2558,[2026]15.2557,[2027]15.2549,[2028]15.2559,[2029]15.2556,[2030]15.2572,[2031]15.2588,[2032]15.2593,[2033]15.2585,[2034]15.2611,[2035]15.2603,[2036]15.2600,[2037]15.2607,[2038]15.2627,[2039]15.2634,[2040]15.2611,[2041]15.2624,[2042]15.2647,[2043]15.2635,[2044]15.2651,[2045]15.2639,[2046]15.2615,[2047]15.2653,[2048]15.2609,[2049]15.2593,[2050]15.2570,[2051]15.2442,[2052]15.2376,[2053]15.2360,[2054]15.2374,[2055]15.2435,[2056]15.2417,[2057]15.2365,[2058]15.2396,[2059]15.2369,[2060]15.2363,[2061]15.2356,[2062]15.2358,[2063]15.2258,[2064]15.2181,[2065]15.2173,[2066]15.2110,[2067]15.2044,[2068]15.2032,[2069]15.2025,[2070]15.2030,[2071]15.2016,[2072]15.2000,[2073]15.1984,[2074]15.1954,[2075]15.1898,[2076]15.1932,[2077]15.1860,[2078]15.1868,[2079]15.1860,[2080]15.1851,[2081]15.1853,[2082]15.1871,[2083]15.1864,[2084]15.1868,[2085]15.1867,[2086]15.1818,[2087]15.1834,[2088]15.1826,[2089]15.1755,[2090]15.1750,[2091]15.1751,[2092]15.1725,[2093]15.1751,[2094]15.1739,[2095]15.1727,[2096]15.1737,[2097]15.1753,[2098]15.1758,[2099]15.1764,[2100]15.1684,[2101]15.1655,[2102]15.1656,[2103]15.1731,[2104]15.1723,[2105]15.1708,[2106]15.1634,[2107]15.1639,[2108]15.1592,[2109]15.1564,[2110]15.1547,[2111]15.1535,[2112]15.1567,[2113]15.1553,[2114]15.1548,[2115]15.1574,[2116]15.1566,[2117]15.1536,[2118]15.1501,[2119]15.1488,[2120]15.1475,[2121]15.1483,[2122]15.1490,[2123]15.1483,[2124]15.1453,[2125]15.1410,[2126]15.1421,[2127]15.1427,[2128]15.1377,[2129]15.1385,[2130]15.1380,[2131]15.1396,[2132]15.1409,[2133]15.1428,[2134]15.1432,[2135]15.1453,[2136]15.1450,[2137]15.1462,[2138]15.1453,[2139]15.1409,[2140]15.1416,[2141]15.1437,[2142]15.1442,[2143]15.1400,[2144]15.1390,[2145]15.1349,[2146]15.1194,[2147]15.1181,[2148]15.1172,[2149]15.1174,[2150]15.1173,[2151]15.1063,[2152]15.0954,[2153]15.0909,[2154]15.0807,[2155]15.0721,[2156]15.0723,[2157]15.0689,[2158]15.0692,[2159]15.0715,[2160]15.0723,[2161]15.0701,[2162]15.0670,[2163]15.0673,[2164]15.0706,[2165]15.0693,[2166]15.0717,[2167]15.0720,[2168]15.0722,[2169]15.0847,[2170]15.1006,[2171]15.1036,[2172]15.1057,[2173]15.1102,[2174]15.1099,[2175]15.1088,[2176]15.1094,[2177]15.1069,[2178]15.1083,[2179]15.1108,[2180]15.1126,[2181]15.1135,[2182]15.1129,[2183]15.1130,[2184]15.1132,[2185]15.1157,[2186]15.1165,[2187]15.1191,[2188]15.1195,[2189]15.1233,[2190]15.1236,[2191]15.1260,[2192]15.1269,[2193]15.1257,[2194]15.1256,[2195]15.1255,[2196]15.1236,[2197]15.1250,[2198]15.1288,[2199]15.1290,[2200]15.1292,[2201]15.1241,[2202]15.1179,[2203]15.1200,[2204]15.1204,[2205]15.1189,[2206]15.1173,[2207]15.1131,[2208]15.1127,[2209]15.1100,[2210]15.1117,[2211]15.1097,[2212]15.1053,[2213]15.1038,[2214]15.1032,[2215]15.1031,[2216]15.1010,[2217]15.0963,[2218]15.0935,[2219]15.0934,[2220]15.0932,[2221]15.0901,[2222]15.0851,[2223]15.0836,[2224]15.0838,[2225]15.0805,[2226]15.0812,[2227]15.0838,[2228]15.0773,[2229]15.0733,[2230]15.0772,[2231]15.0743,[2232]15.0731,[2233]15.0712,[2234]15.0726,[2235]15.0765,[2236]15.0786,[2237]15.0752,[2238]15.0725,[2239]15.0786,[2240]15.0791,[2241]15.0780,[2242]15.0830,[2243]15.0847,[2244]15.0862,[2245]15.0875,[2246]15.0928,[2247]15.1009,[2248]15.0962,[2249]15.0914,[2250]15.0915,[2251]15.0911,[2252]15.0936,[2253]15.0943,[2254]15.0866,[2255]15.0848,[2256]15.0814,[2257]15.0783,[2258]15.0761,[2259]15.0619,[2260]15.0556,[2261]15.0545,[2262]15.0534,[2263]15.0529,[2264]15.0534,[2265]15.0538,[2266]15.0533,[2267]15.0531,[2268]15.0507,[2269]15.0489,[2270]15.0466,[2271]15.0436,[2272]15.0394,[2273]15.0375,[2274]15.0363,[2275]15.0366,[2276]15.0365,[2277]15.0367,[2278]15.0343,[2279]15.0336,[2280]15.0355,[2281]15.0364,[2282]15.0368,[2283]15.0356,[2284]15.0350,[2285]15.0231,[2286]15.0223,[2287]15.0208,[2288]15.0208,[2289]15.0187,[2290]15.0122,[2291]15.0067,[2292]15.0020,[2293]14.9978,[2294]14.9952,[2295]14.9918,[2296]14.9789,[2297]14.9760,[2298]14.9726,[2299]14.9668,[2300]14.9662,[2301]14.9658,[2302]14.9657,[2303]14.9656,[2304]14.9617,[2305]14.9600,[2306]14.9606,[2307]14.9587,[2308]14.9545,[2309]14.9540,[2310]14.9518,[2311]14.9505,[2312]14.9500,[2313]14.9467,[2314]14.9439,[2315]14.9414,[2316]14.9426,[2317]14.9401,[2318]14.9387,[2319]14.9407,[2320]14.9437,[2321]14.9379,[2322]14.9368,[2323]14.9388,[2324]14.9378,[2325]14.9332,[2326]14.9313,[2327]14.9252,[2328]14.9195,[2329]14.9143,[2330]14.9091,[2331]14.9072,[2332]14.9034,[2333]14.9010,[2334]14.9000,[2335]14.8970,[2336]14.8974,[2337]14.8974,[2338]14.8938,[2339]14.8908,[2340]14.8884,[2341]14.8894,[2342]14.8918,[2343]14.8941,[2344]14.8941,[2345]14.8950,[2346]14.8932,[2347]14.8978,[2348]14.8959,[2349]14.8972,[2350]14.8930,[2351]14.8769,[2352]14.8794,[2353]14.8787,[2354]14.8804,[2355]14.8760,[2356]14.8776,[2357]14.8744,[2358]14.8769,[2359]14.8789,[2360]14.8809,[2361]14.8807,[2362]14.8806,[2363]14.8814,[2364]14.8834,[2365]14.8770,[2366]14.8770,[2367]14.8776,[2368]14.8750,[2369]14.8715,[2370]14.8684,[2371]14.8691,[2372]14.8707,[2373]14.8607,[2374]14.8484,[2375]14.8348,[2376]14.8261,[2377]14.8161,[2378]14.8033,[2379]14.7938,[2380]14.7825,[2381]14.7723,[2382]14.7621,[2383]14.7512,[2384]14.7404,[2385]14.7323,[2386]14.7267,[2387]14.7154,[2388]14.7045,[2389]14.6951,[2390]14.6885,[2391]14.6807,[2392]14.6771,[2393]14.6696,[2394]14.6607,[2395]14.6637,[2396]14.6658,[2397]14.6697,[2398]14.6721,[2399]14.6721,[2400]14.6738,[2401]14.6753,[2402]14.6763,[2403]14.6764,[2404]14.6793,[2405]14.6793,[2406]14.6757,[2407]14.6738,[2408]14.6757,[2409]14.6770,[2410]14.6793,[2411]14.6808,[2412]14.6873,[2413]14.6940,[2414]14.6950,[2415]14.6958,[2416]14.6982,[2417]14.6974,[2418]14.6996,[2419]14.6977,[2420]14.6999,[2421]14.6996,[2422]14.6972,[2423]14.6956,[2424]14.6958,[2425]14.6966,[2426]14.6885,[2427]14.6813,[2428]14.6802,[2429]14.6770,[2430]14.6712,[2431]14.6727,[2432]14.6720,[2433]14.6715,[2434]14.6716,[2435]14.6715,[2436]14.6722,[2437]14.6678,[2438]14.6661,[2439]14.6657,[2440]14.6667,[2441]14.6655,[2442]14.6674,[2443]14.6705,[2444]14.6727,[2445]14.6728,[2446]14.6741,[2447]14.6747,[2448]14.6782,[2449]14.6805,[2450]14.6847,[2451]14.6883,[2452]14.6921,[2453]14.6951,[2454]14.6970,[2455]14.7012,[2456]14.7023,[2457]14.7020,[2458]14.7068,[2459]14.7093,[2460]14.7122,[2461]14.7165,[2462]14.7120,[2463]14.7157,[2464]14.7185,[2465]14.7199,[2466]14.7221,[2467]14.7223,[2468]14.7207,[2469]14.7156,[2470]14.7092,[2471]14.7136,[2472]14.7176,[2473]14.7215,[2474]14.7250,[2475]14.7274,[2476]14.7292,[2477]14.7317,[2478]14.7348,[2479]14.7393,[2480]14.7440,[2481]14.7452,[2482]14.7477,[2483]14.7452,[2484]14.7478,[2485]14.7508,[2486]14.7537,[2487]14.7549,[2488]14.7570,[2489]14.7594,[2490]14.7601,[2491]14.7617,[2492]14.7654,[2493]14.7712,[2494]14.7763,[2495]14.7750,[2496]14.7778,[2497]14.7783,[2498]14.7779,[2499]14.7785,[2500]14.7801,[2501]14.7776,[2502]14.7750,[2503]14.7750,[2504]14.7861,[2505]14.7963,[2506]14.8072,[2507]14.8187,[2508]14.8237,[2509]14.8339,[2510]14.8453,[2511]14.8569,[2512]14.8643,[2513]14.8758,[2514]14.8786,[2515]14.8874,[2516]14.8832,[2517]14.8830,[2518]14.8827,[2519]14.8821,[2520]14.8798,[2521]14.8799,[2522]14.8795,[2523]14.8804,[2524]14.8816,[2525]14.8803,[2526]14.8813,[2527]14.8824,[2528]14.8851,[2529]14.8845,[2530]14.8841,[2531]14.8837,[2532]14.8839,[2533]14.8834,[2534]14.8831,[2535]14.8820,[2536]14.8821,[2537]14.8835,[2538]14.8846,[2539]14.8829,[2540]14.8830,[2541]14.8839,[2542]14.8852,[2543]14.8869,[2544]14.8866,[2545]14.8865,[2546]14.8854,[2547]14.8847,[2548]14.8873,[2549]14.8892,[2550]14.8893,[2551]14.8825,[2552]14.8824,[2553]14.8831,[2554]14.8839,[2555]14.8846,[2556]14.8847,[2557]14.8821,[2558]14.8810,[2559]14.8770,[2560]14.8781,[2561]14.8789,[2562]14.8796,[2563]14.8794,[2564]14.8891,[2565]14.8901,[2566]14.8900,[2567]14.8901,[2568]14.8835,[2569]14.8861,[2570]14.8883,[2571]14.8914,[2572]14.8903,[2573]14.8877,[2574]14.8908,[2575]14.9001,[2576]14.9042,[2577]14.9152,[2578]14.9158,[2579]14.9210,[2580]14.9244,[2581]14.9258,[2582]14.9270,[2583]14.9268,[2584]14.9302,[2585]14.9333,[2586]14.9298,[2587]14.9338,[2588]14.9364,[2589]14.9356,[2590]14.9381,[2591]14.9397,[2592]14.9421,[2593]14.9434,[2594]14.9449,[2595]14.9504,[2596]14.9541,[2597]14.9557,[2598]14.9521,[2599]14.9568,[2600]14.9604,[2601]14.9625,[2602]14.9646,[2603]14.9664,[2604]14.9735,[2605]14.9776,[2606]14.9799,[2607]14.9791,[2608]14.9819,[2609]14.9850,[2610]14.9864,[2611]14.9974,[2612]15.0031,[2613]15.0054,[2614]15.0061,[2615]14.9978,[2616]14.9966,[2617]14.9965,[2618]15.0037,[2619]15.0100,[2620]15.0082,[2621]15.0055,[2622]15.0031,[2623]15.0013,[2624]14.9992,[2625]14.9968,[2626]14.9972,[2627]15.0013,[2628]15.0081,[2629]15.0159,[2630]15.0130,[2631]15.0116,[2632]15.0104,[2633]15.0057,[2634]15.0037,[2635]15.0028,[2636]15.0027,[2637]15.0010,[2638]14.9920,[2639]14.9904,[2640]14.9913,[2641]14.9911,[2642]14.9869,[2643]14.9881,[2644]14.9901,[2645]14.9921,[2646]14.9935,[2647]14.9933,[2648]14.9891,[2649]14.9844,[2650]14.9870,[2651]14.9863,[2652]14.9863,[2653]14.9827,[2654]14.9733,[2655]14.9674,[2656]14.9644,[2657]14.9651,[2658]14.9628,[2659]14.9633,[2660]14.9614,[2661]14.9587,[2662]14.9543,[2663]14.9573,[2664]14.9622,[2665]14.9608,[2666]14.9629,[2667]14.9648,[2668]14.9659,[2669]14.9707,[2670]14.9732,[2671]14.9707,[2672]14.9652,[2673]14.9625,[2674]14.9593,[2675]14.9549,[2676]14.9471,[2677]14.9507,[2678]14.9476,[2679]14.9507,[2680]14.9504,[2681]14.9502,[2682]14.9472,[2683]14.9467,[2684]14.9457,[2685]14.9482,[2686]14.9476,[2687]14.9467,[2688]14.9457,[2689]14.9417,[2690]14.9398,[2691]14.9394,[2692]14.9382,[2693]14.9364,[2694]14.9347,[2695]14.9347,[2696]14.9345,[2697]14.9301,[2698]14.9273,[2699]14.9260,[2700]14.9214,[2701]14.9213,[2702]14.9197,[2703]14.9199,[2704]14.9176,[2705]14.9167,[2706]14.9157,[2707]14.9143,[2708]14.9153,[2709]14.9105,[2710]14.9095,[2711]14.9124,[2712]14.9126,[2713]14.9091,[2714]14.9067,[2715]14.9027,[2716]14.9011,[2717]14.9005,[2718]14.9003,[2719]14.8954,[2720]14.8935,[2721]14.8887,[2722]14.8867,[2723]14.8846,[2724]14.8850,[2725]14.8846,[2726]14.8849,[2727]14.8859,[2728]14.8875,[2729]14.8891,[2730]14.8906,[2731]14.8917,[2732]14.8911,[2733]14.8849,[2734]14.8841,[2735]14.8833,[2736]14.8812,[2737]14.8783,[2738]14.8775,[2739]14.8754,[2740]14.8738,[2741]14.8721,[2742]14.8700,[2743]14.8680,[2744]14.8662,[2745]14.8650,[2746]14.8637,[2747]14.8616,[2748]14.8597,[2749]14.8598,[2750]14.8594,[2751]14.8587,[2752]14.8575,[2753]14.8590,[2754]14.8591,[2755]14.8591,[2756]14.8604,[2757]14.8616,[2758]14.8630,[2759]14.8596,[2760]14.8599,[2761]14.8620,
|
| 142 |
+
Final estimate: PPL = 14.8620 +/- 0.01330
|
| 143 |
+
|
| 144 |
+
llama_perf_context_print: load time = 55493.15 ms
|
| 145 |
+
llama_perf_context_print: prompt eval time = 59547279.58 ms / 22618112 tokens ( 2.63 ms per token, 379.83 tokens per second)
|
| 146 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 147 |
+
llama_perf_context_print: total time = 64365038.77 ms / 22618113 tokens
|
| 148 |
+
ggml_metal_free: deallocating
|
on_perplexity.md
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# A concise summary with specific recommendations for selecting PPL sample size in multilingual datasets:
|
| 2 |
+
|
| 3 |
+
When measuring perplexity (PPL) in multilingual models, the number of samples needed per language increases with the diversity and size of the dataset. However, there are diminishing returns as the number of languages grows, particularly when languages share structural or linguistic similarities.
|
| 4 |
+
|
| 5 |
+
Benchmarks like _XTREME_ and _WMT_ suggest that **500-1,000 samples per language** is often sufficient for accurate evaluation. This allows you to capture a representative sample of each language's linguistic features without overwhelming computational resources. As the number of languages increases, it’s common to reduce the sample size for each language proportionally, especially if certain languages dominate the dataset or have significant overlap in characteristics.
|
| 6 |
+
|
| 7 |
+
In the XTREME benchmark, English uses **10,000 samples**, while each of the **40+ other languages** uses **1,000-2,000 samples** to maintain feasibility across multilingual tasks. Similarly, WMT reduces sample sizes for lower-resource languages, scaling from **several thousand for high-resource languages** to **a few hundred or 1,000 per language** when handling many languages. Both examples demonstrate a practical approach to balancing resource usage and linguistic coverage ([XTREME](https://arxiv.org/abs/2003.11080), [WMT Papers](https://www.statmt.org/wmt20/)).
|
| 8 |
+
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
### Recommendations:
|
| 12 |
+
|
| 13 |
+
1. **Start with 500-1,000 samples per language**: This size is commonly used in NLP tasks to balance performance and resource efficiency, ensuring that linguistic coverage is broad enough.
|
| 14 |
+
|
| 15 |
+
2. **Scale based on number of languages**: For datasets with many languages (e.g., 40+), consider reducing the number of samples per language to **50-100**, as is done in benchmarks like XTREME.
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
---
|
| 19 |
+
|
| 20 |
+
### **References**
|
| 21 |
+
|
| 22 |
+
1. **XTREME: A Massively Multilingual Benchmark for Evaluating Cross-lingual Generalization**
|
| 23 |
+
- Authors: Hu et al.
|
| 24 |
+
- Year: 2020
|
| 25 |
+
- Source: [arXiv](https://arxiv.org/abs/2003.11080)
|
| 26 |
+
- Summary: XTREME evaluates models across many languages and scales down sample sizes to maintain feasibility while preserving coverage across languages.
|
| 27 |
+
|
| 28 |
+
2. **WMT: Workshop on Machine Translation Shared Tasks**
|
| 29 |
+
- Source: [WMT Papers](https://www.statmt.org/wmt20/)
|
| 30 |
+
- Summary: WMT tasks often reduce sample sizes per language as the number of target languages grows, demonstrating that smaller samples can still yield accurate model evaluations.
|
on_quantization.md
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# A concise summary with specific recommendations for quantizing your large language models (LLMs):
|
| 2 |
+
|
| 3 |
+
When working with multilingual _quantization_ for _large language models_ (LLMs), the _number of samples needed_ for effective quantization **increases with the number of target languages**. With more linguistic features, the model must learn and adapt across a broader spectrum during the quantization process.
|
| 4 |
+
|
| 5 |
+
Recent work, such as the _Lens_ framework and studies on quantized multilingual LLMs, emphasizes that larger datasets are critical for multilingual models to ensure performance remains consistent across all languages. These models typically perform best when they have **sufficient samples for each language**. This allows them to maintain their accuracy in quantization. In the case of multilingual evaluation tasks, several sources highlight that adding more languages requires **proportional increases** in calibration samples to smooth activations and avoid performance drops. These studies often mention the use of **thousands of samples per language** to preserve accuracy during multilingual post-training quantization ([Lens, 2024](https://ar5iv.org/html/2410.04407), [Quantization for Multilingual LLMs, 2024](https://ar5iv.org/abs/2407.03211)).
|
| 6 |
+
|
| 7 |
+
## Instruction Fine-tuning and Evaluation
|
| 8 |
+
|
| 9 |
+
Instruction fine-tuning has become crucial to enhance language models' ability to follow specific instructions and perform diverse tasks ([Chung et al., 2022](https://ar5iv.org/abs/2210.11416)) and especially chat interations. It typically involves training on datasets consisting of instruction-output pairs, which can be manually curated, transformed from existing datasets, or generated using other models.
|
| 10 |
+
|
| 11 |
+
The evaluation of instruction-tuned models often requires specialized methods ([Honovich et al., 2023](https://ar5iv.org/abs/2308.10792)). These methods focus on assessing the model's ability to follow instructions and generate appropriate responses, rather than relying solely on general metrics like perplexity.
|
| 12 |
+
|
| 13 |
+
Contrary to some assumptions, there is no established requirement or practice of including instruction data in the input matrix (imatrix) used for perplexity testing or other general evaluations ([Wei et al., 2022](https://ar5iv.org/abs/2206.07682)). The evaluation of instruction-tuned models typically involves task-specific metrics and methods that directly measure instruction-following capabilities.
|
| 14 |
+
|
| 15 |
+
----
|
| 16 |
+
|
| 17 |
+
With Salamandra models, the following recommendations can be made:
|
| 18 |
+
|
| 19 |
+
## **1. Use Calibration Data**
|
| 20 |
+
For **post-training quantization (PTQ)**, gather **several thousand calibration samples** per task. This helps smooth activations and adjust weights to avoid performance loss ([SmoothQuant](https://ar5iv.org/pdf/2211.10438v1), [Comprehensive Evaluation](https://aclanthology.org/2024-comprehensive)).
|
| 21 |
+
|
| 22 |
+
## **2. Dataset Size Recommendations**
|
| 23 |
+
- **For 2B models (Base or Instruct)**: Start with **1,000 to 5,000 samples** per language for quantization.
|
| 24 |
+
- **For 7B models (Base or Instruct)**: Start with **5,000 to 20,000 samples** per language.
|
| 25 |
+
- **For 40B models (Base or Instruct)**: Start with **20,000 to 100,000 samples** per language
|
| 26 |
+
|
| 27 |
+
([SmoothQuant](https://ar5iv.org/pdf/2211.10438v1), [QLLM](https://openreview.net/forum?id=QLLLm)).
|
| 28 |
+
|
| 29 |
+
## **3. Balance Languages**
|
| 30 |
+
- For **multilingual models**, ensure you gather **balanced datasets** across languages. If resources are limited, start with a **minimum of 1,000 samples** per language and adjust based on performance ([QLLM](https://openreview.net/forum?id=QLLLm)).
|
| 31 |
+
|
| 32 |
+
## **4. Outlier Handling in Large Models**
|
| 33 |
+
For models over 7B parameters, address outliers in activations using methods like **channel-wise quantization**. Larger models require more robust outlier handling, which can be mitigated by using enough calibration data ([QLLM](https://openreview.net/forum?id=QLLLm), [SmoothQuant](https://ar5iv.org/pdf/2211.10438v1)).
|
| 34 |
+
|
| 35 |
+
<small>note: llama.cpp supports several quantization methods, including row-wise and block-wise quantization schemes but there is no ready support for channel-wise quantization.</small>
|
| 36 |
+
|
| 37 |
+
## **5. Start Small and Scale**
|
| 38 |
+
Begin with smaller datasets, evaluate the quantized model’s performance, and scale up as needed. **Add more samples** if you see significant drops in accuracy or performance after quantization ([Comprehensive Evaluation](https://aclanthology.org/2024-comprehensive), [DataCamp, 2023](https://www.datacamp.com/community/tutorials/quantization-llms)).
|
| 39 |
+
|
| 40 |
+
<small>note: This is beyond the scope of the work in this repo.</small>
|
| 41 |
+
|
| 42 |
+
# This work
|
| 43 |
+
|
| 44 |
+
We have many languages. We could measure the rate of change in PPL for one model each of Q8_0, q4_K_M, and iq3_K starting at, say 10 samples/language to some intermediate (say 200, assuming we sample enough intermediate steps to feel we have the rate of change nailed down), then predict PPL at 1k samples. If the PPL is small than expected, we are reaching diminishing returns and can stop increasing. However, as a first attempt we will only quantize to the minimums in the range.
|
| 45 |
+
|
| 46 |
+
---
|
| 47 |
+
|
| 48 |
+
### **References**
|
| 49 |
+
1. **SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models**
|
| 50 |
+
- Authors: Xiao et al.
|
| 51 |
+
- Year: 2023
|
| 52 |
+
- Source: [arXiv](https://ar5iv.org/pdf/2211.10438v1)
|
| 53 |
+
- Summary: This paper addresses activation outliers in large models and recommends using calibration samples for effective quantization.
|
| 54 |
+
|
| 55 |
+
2. **QLLM: Accurate and Efficient Low-bitwidth Quantization for LLMs**
|
| 56 |
+
- Authors: Liu et al.
|
| 57 |
+
- Year: 2024
|
| 58 |
+
- Source: [ICLR](https://openreview.net/forum?id=QLLLm)
|
| 59 |
+
- Summary: QLLM focuses on outlier handling and low-bitwidth quantization for models like LLaMA, recommending balanced datasets and channel-wise techniques.
|
| 60 |
+
|
| 61 |
+
3. **A Comprehensive Evaluation of Quantization Strategies for Large Language Models**
|
| 62 |
+
- Authors: Jin et al.
|
| 63 |
+
- Year: 2024
|
| 64 |
+
- Source: [ACL Anthology](https://aclanthology.org/2024-comprehensive)
|
| 65 |
+
- Summary: Provides a thorough evaluation of quantization strategies on various LLMs, noting that several thousand samples per task are often needed.
|
| 66 |
+
|
| 67 |
+
4. **Quantization for Large Language Models (LLMs): Reduce AI Model Sizes Efficiently**
|
| 68 |
+
- Year: 2023
|
| 69 |
+
- Source: [DataCamp](https://www.datacamp.com/community/tutorials/quantization-llms)
|
| 70 |
+
- Summary: Introduces practical methods for quantizing models and discusses dataset requirements for ensuring performance.
|
| 71 |
+
|
| 72 |
+
5. **Lens: Rethinking Multilingual Enhancement for Large Language Models**
|
| 73 |
+
- Authors: Zhao, Weixiang, et al.
|
| 74 |
+
- Year: 2024
|
| 75 |
+
- Source: [arXiv](https://ar5iv.org/html/2410.04407)
|
| 76 |
+
- Summary: This study emphasizes that as the number of languages increases, the number of samples required for quantization grows. Multilingual models need larger datasets to maintain performance across all languages. The authors recommend scaling the number of samples per language as the model size and the number of target languages increase.
|
| 77 |
+
|
| 78 |
+
6 **How Does Quantization Affect Multilingual LLMs?**
|
| 79 |
+
- Authors: Ahmadian et al.
|
| 80 |
+
- Year: 2024
|
| 81 |
+
- Source: [arXiv](https://ar5iv.org/abs/2407.03211)
|
| 82 |
+
- Summary: This paper explores the impact of quantization on multilingual LLMs. It highlights the need for larger datasets as the number of target languages increases and suggests using several thousand calibration samples per language to mitigate performance degradation.
|
| 83 |
+
|
| 84 |
+
7 **Emergent Abilities of Large Language Models**
|
| 85 |
+
- Authors: Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., ... & Fedus, W.
|
| 86 |
+
- Year: 2022
|
| 87 |
+
- Source: [arXiv](https://ar5iv.org/abs/2206.07682)
|
| 88 |
+
- Summary: This paper investigates emergent abilities in large language models as they scale in size. The authors demonstrate how model capabilities appear unexpectedly at certain scale thresholds.
|
| 89 |
+
|
| 90 |
+
8 **Scaling Instruction-Finetuned Language Models**
|
| 91 |
+
- Authors: Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., ... & Le, Q. V.
|
| 92 |
+
- Year: 2022
|
| 93 |
+
- Source: [arXiv](https://ar5iv.org/abs/2210.11416)
|
| 94 |
+
- Summary: The authors explore the scaling of instruction-finetuned language models and their impact on downstream task performance, showing how larger models benefit from instruction tuning.
|
| 95 |
+
|
| 96 |
+
9 **Instruction Tuning for Large Language Models: A Survey**
|
| 97 |
+
- Authors: Honovich, O., Shaham, U., Bowman, S. R., & Levy, O.
|
| 98 |
+
- Year: 2023
|
| 99 |
+
- Source: [arXiv](https://ar5iv.org/abs/2308.10792)
|
| 100 |
+
- Summary: This survey paper provides a comprehensive overview of instruction tuning for large language models, summarizing recent advances and challenges in optimizing models for specific instructions.
|
perplexity_IQ2_M.txt
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_IQ2_M.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 29
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type iq4_nl: 24 tensors
|
| 41 |
+
llama_model_loader: - type iq3_s: 49 tensors
|
| 42 |
+
llama_model_loader: - type iq2_s: 96 tensors
|
| 43 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 44 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 45 |
+
llm_load_vocab: special tokens cache size = 104
|
| 46 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 47 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 48 |
+
llm_load_print_meta: arch = llama
|
| 49 |
+
llm_load_print_meta: vocab type = SPM
|
| 50 |
+
llm_load_print_meta: n_vocab = 256000
|
| 51 |
+
llm_load_print_meta: n_merges = 0
|
| 52 |
+
llm_load_print_meta: vocab_only = 0
|
| 53 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 54 |
+
llm_load_print_meta: n_embd = 2048
|
| 55 |
+
llm_load_print_meta: n_layer = 24
|
| 56 |
+
llm_load_print_meta: n_head = 16
|
| 57 |
+
llm_load_print_meta: n_head_kv = 16
|
| 58 |
+
llm_load_print_meta: n_rot = 128
|
| 59 |
+
llm_load_print_meta: n_swa = 0
|
| 60 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 61 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 62 |
+
llm_load_print_meta: n_gqa = 1
|
| 63 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 64 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 65 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 66 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 67 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 68 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 69 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 70 |
+
llm_load_print_meta: n_ff = 5440
|
| 71 |
+
llm_load_print_meta: n_expert = 0
|
| 72 |
+
llm_load_print_meta: n_expert_used = 0
|
| 73 |
+
llm_load_print_meta: causal attn = 1
|
| 74 |
+
llm_load_print_meta: pooling type = 0
|
| 75 |
+
llm_load_print_meta: rope type = 0
|
| 76 |
+
llm_load_print_meta: rope scaling = linear
|
| 77 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 78 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 79 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 80 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 81 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 82 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 83 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 84 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 85 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 86 |
+
llm_load_print_meta: model type = ?B
|
| 87 |
+
llm_load_print_meta: model ftype = IQ2_M - 2.7 bpw
|
| 88 |
+
llm_load_print_meta: model params = 2.25 B
|
| 89 |
+
llm_load_print_meta: model size = 1.63 GiB (6.20 BPW)
|
| 90 |
+
llm_load_print_meta: general.name = n/a
|
| 91 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 92 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 93 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 94 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 95 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 96 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 97 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 98 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 99 |
+
llm_load_print_meta: max token length = 72
|
| 100 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 101 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 102 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 103 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 104 |
+
llm_load_tensors: Metal buffer size = 1666.03 MiB
|
| 105 |
+
llm_load_tensors: CPU buffer size = 214.84 MiB
|
| 106 |
+
.............................
|
| 107 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 108 |
+
llama_new_context_with_model: n_batch = 512
|
| 109 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 110 |
+
llama_new_context_with_model: flash_attn = 0
|
| 111 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 112 |
+
llama_new_context_with_model: freq_scale = 1
|
| 113 |
+
ggml_metal_init: allocating
|
| 114 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 115 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 116 |
+
ggml_metal_init: using embedded metal library
|
| 117 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 118 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 119 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 120 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 121 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 122 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 123 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 124 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 125 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 126 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 127 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 128 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 129 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 130 |
+
llama_new_context_with_model: graph nodes = 774
|
| 131 |
+
llama_new_context_with_model: graph splits = 3
|
| 132 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 133 |
+
|
| 134 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 135 |
+
perplexity: tokenizing the input ..
|
| 136 |
+
perplexity: tokenization took 2958.69 ms
|
| 137 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 138 |
+
perplexity: 9.96 seconds per pass - ETA 22.22 minutes
|
| 139 |
+
[1]24.6873,[2]24.9338,[3]22.0731,[4]21.5617,[5]20.3352,[6]19.5244,[7]20.9527,[8]20.4266,[9]19.9018,[10]18.9376,[11]19.8449,[12]20.0418,[13]21.7210,[14]22.2197,[15]22.1832,[16]22.8980,[17]23.3093,[18]23.1485,[19]23.1590,[20]23.5955,[21]23.5301,[22]21.2644,[23]21.4668,[24]20.8670,[25]20.1188,[26]19.4641,[27]19.1656,[28]18.8924,[29]18.7991,[30]18.4629,[31]18.8051,[32]18.8515,[33]19.4711,[34]19.8213,[35]20.1886,[36]19.7944,[37]19.7345,[38]19.8108,[39]19.5440,[40]19.5595,[41]19.5283,[42]19.2267,[43]19.1196,[44]19.3165,[45]19.5565,[46]19.3342,[47]19.7107,[48]19.9107,[49]20.3577,[50]20.8280,[51]20.8886,[52]21.2299,[53]21.7101,[54]22.1793,[55]22.3834,[56]22.1513,[57]22.0584,[58]21.6444,[59]21.4662,[60]21.1954,[61]21.2462,[62]21.4794,[63]21.7730,[64]21.8675,[65]21.9175,[66]22.2055,[67]22.1659,[68]22.0154,[69]21.8073,[70]21.6691,[71]21.6765,[72]21.6068,[73]21.6309,[74]21.5618,[75]21.5749,[76]21.4933,[77]21.5708,[78]21.5741,[79]21.5906,[80]21.6349,[81]21.1919,[82]21.1488,[83]20.9681,[84]21.0413,[85]21.1279,[86]21.4274,[87]21.4890,[88]21.7182,[89]21.8058,[90]21.9993,[91]22.0906,[92]21.8472,[93]21.9383,[94]21.9085,[95]22.1222,[96]22.3960,[97]22.5114,[98]22.6622,[99]22.9017,[100]22.9584,[101]22.9937,[102]22.9430,[103]22.8901,[104]22.8680,[105]22.8335,[106]22.6443,[107]22.4466,[108]22.5295,[109]22.5529,[110]22.4183,[111]22.3709,[112]22.1711,[113]21.9629,[114]21.9476,[115]21.8984,[116]21.8964,[117]21.7396,[118]21.5493,[119]21.5328,[120]21.6170,[121]21.6406,[122]21.6783,[123]21.7342,[124]21.7686,[125]21.7701,[126]21.8124,[127]21.8536,[128]21.9658,[129]21.9526,[130]21.9195,[131]22.0023,[132]21.9718,[133]21.8911,[134]21.6684,
|
| 140 |
+
Final estimate: PPL = 21.6684 +/- 0.08942
|
| 141 |
+
|
| 142 |
+
llama_perf_context_print: load time = 1070.26 ms
|
| 143 |
+
llama_perf_context_print: prompt eval time = 1307831.03 ms / 1097728 tokens ( 1.19 ms per token, 839.35 tokens per second)
|
| 144 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 145 |
+
llama_perf_context_print: total time = 1348983.83 ms / 1097729 tokens
|
| 146 |
+
ggml_metal_free: deallocating
|
perplexity_IQ2_S.txt
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_IQ2_S.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 28
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type iq2_xs: 96 tensors
|
| 41 |
+
llama_model_loader: - type iq4_nl: 24 tensors
|
| 42 |
+
llama_model_loader: - type iq3_s: 49 tensors
|
| 43 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 44 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 45 |
+
llm_load_vocab: special tokens cache size = 104
|
| 46 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 47 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 48 |
+
llm_load_print_meta: arch = llama
|
| 49 |
+
llm_load_print_meta: vocab type = SPM
|
| 50 |
+
llm_load_print_meta: n_vocab = 256000
|
| 51 |
+
llm_load_print_meta: n_merges = 0
|
| 52 |
+
llm_load_print_meta: vocab_only = 0
|
| 53 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 54 |
+
llm_load_print_meta: n_embd = 2048
|
| 55 |
+
llm_load_print_meta: n_layer = 24
|
| 56 |
+
llm_load_print_meta: n_head = 16
|
| 57 |
+
llm_load_print_meta: n_head_kv = 16
|
| 58 |
+
llm_load_print_meta: n_rot = 128
|
| 59 |
+
llm_load_print_meta: n_swa = 0
|
| 60 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 61 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 62 |
+
llm_load_print_meta: n_gqa = 1
|
| 63 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 64 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 65 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 66 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 67 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 68 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 69 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 70 |
+
llm_load_print_meta: n_ff = 5440
|
| 71 |
+
llm_load_print_meta: n_expert = 0
|
| 72 |
+
llm_load_print_meta: n_expert_used = 0
|
| 73 |
+
llm_load_print_meta: causal attn = 1
|
| 74 |
+
llm_load_print_meta: pooling type = 0
|
| 75 |
+
llm_load_print_meta: rope type = 0
|
| 76 |
+
llm_load_print_meta: rope scaling = linear
|
| 77 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 78 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 79 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 80 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 81 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 82 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 83 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 84 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 85 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 86 |
+
llm_load_print_meta: model type = ?B
|
| 87 |
+
llm_load_print_meta: model ftype = IQ2_S - 2.5 bpw
|
| 88 |
+
llm_load_print_meta: model params = 2.25 B
|
| 89 |
+
llm_load_print_meta: model size = 1.61 GiB (6.12 BPW)
|
| 90 |
+
llm_load_print_meta: general.name = n/a
|
| 91 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 92 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 93 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 94 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 95 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 96 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 97 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 98 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 99 |
+
llm_load_print_meta: max token length = 72
|
| 100 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 101 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 102 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 103 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 104 |
+
llm_load_tensors: Metal buffer size = 1644.10 MiB
|
| 105 |
+
llm_load_tensors: CPU buffer size = 214.84 MiB
|
| 106 |
+
............................
|
| 107 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 108 |
+
llama_new_context_with_model: n_batch = 512
|
| 109 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 110 |
+
llama_new_context_with_model: flash_attn = 0
|
| 111 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 112 |
+
llama_new_context_with_model: freq_scale = 1
|
| 113 |
+
ggml_metal_init: allocating
|
| 114 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 115 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 116 |
+
ggml_metal_init: using embedded metal library
|
| 117 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 118 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 119 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 120 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 121 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 122 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 123 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 124 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 125 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 126 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 127 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 128 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 129 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 130 |
+
llama_new_context_with_model: graph nodes = 774
|
| 131 |
+
llama_new_context_with_model: graph splits = 3
|
| 132 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 133 |
+
|
| 134 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 135 |
+
perplexity: tokenizing the input ..
|
| 136 |
+
perplexity: tokenization took 3608.25 ms
|
| 137 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 138 |
+
perplexity: 13.67 seconds per pass - ETA 30.53 minutes
|
| 139 |
+
[1]29.6010,[2]29.5172,[3]25.7862,[4]25.0898,[5]23.4808,[6]22.3861,[7]24.0240,[8]23.4845,[9]22.8642,[10]21.8118,[11]22.9535,[12]23.1602,[13]25.2016,[14]25.7935,[15]25.7491,[16]26.5747,[17]27.1112,[18]26.9186,[19]26.8906,[20]27.4454,[21]27.3279,[22]24.9212,[23]25.1674,[24]24.4545,[25]23.6118,[26]22.8598,[27]22.5139,[28]22.1881,[29]22.0997,[30]21.6820,[31]22.0830,[32]22.0955,[33]22.8174,[34]23.1896,[35]23.5745,[36]23.0854,[37]22.9720,[38]23.0211,[39]22.6747,[40]22.6684,[41]22.6271,[42]22.2360,[43]22.0886,[44]22.3052,[45]22.5768,[46]22.3153,[47]22.7746,[48]23.0428,[49]23.6171,[50]24.1869,[51]24.2844,[52]24.7079,[53]25.2634,[54]25.8122,[55]26.0916,[56]25.8450,[57]25.7558,[58]25.2386,[59]25.0156,[60]24.6812,[61]24.7264,[62]25.0349,[63]25.4095,[64]25.5203,[65]25.5732,[66]25.9103,[67]25.8713,[68]25.6933,[69]25.4466,[70]25.2968,[71]25.3280,[72]25.2495,[73]25.2949,[74]25.2370,[75]25.2667,[76]25.1723,[77]25.2576,[78]25.2563,[79]25.2661,[80]25.3049,[81]24.7500,[82]24.7057,[83]24.5000,[84]24.5956,[85]24.7109,[86]25.0832,[87]25.1826,[88]25.4442,[89]25.5627,[90]25.7940,[91]25.9148,[92]25.6167,[93]25.7212,[94]25.6776,[95]25.9323,[96]26.2587,[97]26.4019,[98]26.5851,[99]26.8920,[100]26.9814,[101]27.0229,[102]26.9609,[103]26.8877,[104]26.8538,[105]26.7966,[106]26.5723,[107]26.3274,[108]26.4363,[109]26.4825,[110]26.3185,[111]26.2732,[112]26.0267,[113]25.7671,[114]25.7432,[115]25.6708,[116]25.6618,[117]25.4755,[118]25.2418,[119]25.2166,[120]25.3133,[121]25.3392,[122]25.3860,[123]25.4629,[124]25.4971,[125]25.5046,[126]25.5585,[127]25.6160,[128]25.7583,[129]25.7385,[130]25.6987,[131]25.7995,[132]25.7599,[133]25.6648,[134]25.3893,
|
| 140 |
+
Final estimate: PPL = 25.3893 +/- 0.10575
|
| 141 |
+
|
| 142 |
+
llama_perf_context_print: load time = 637.32 ms
|
| 143 |
+
llama_perf_context_print: prompt eval time = 1669379.99 ms / 1097728 tokens ( 1.52 ms per token, 657.57 tokens per second)
|
| 144 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 145 |
+
llama_perf_context_print: total time = 1728537.03 ms / 1097729 tokens
|
| 146 |
+
ggml_metal_free: deallocating
|
perplexity_IQ3_M.txt
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_IQ3_M.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 27
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type q5_0: 3 tensors
|
| 41 |
+
llama_model_loader: - type q4_K: 48 tensors
|
| 42 |
+
llama_model_loader: - type iq4_nl: 21 tensors
|
| 43 |
+
llama_model_loader: - type iq3_s: 97 tensors
|
| 44 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 45 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 46 |
+
llm_load_vocab: special tokens cache size = 104
|
| 47 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 48 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 49 |
+
llm_load_print_meta: arch = llama
|
| 50 |
+
llm_load_print_meta: vocab type = SPM
|
| 51 |
+
llm_load_print_meta: n_vocab = 256000
|
| 52 |
+
llm_load_print_meta: n_merges = 0
|
| 53 |
+
llm_load_print_meta: vocab_only = 0
|
| 54 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 55 |
+
llm_load_print_meta: n_embd = 2048
|
| 56 |
+
llm_load_print_meta: n_layer = 24
|
| 57 |
+
llm_load_print_meta: n_head = 16
|
| 58 |
+
llm_load_print_meta: n_head_kv = 16
|
| 59 |
+
llm_load_print_meta: n_rot = 128
|
| 60 |
+
llm_load_print_meta: n_swa = 0
|
| 61 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 62 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 63 |
+
llm_load_print_meta: n_gqa = 1
|
| 64 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 65 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 66 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 67 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 68 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 69 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 70 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 71 |
+
llm_load_print_meta: n_ff = 5440
|
| 72 |
+
llm_load_print_meta: n_expert = 0
|
| 73 |
+
llm_load_print_meta: n_expert_used = 0
|
| 74 |
+
llm_load_print_meta: causal attn = 1
|
| 75 |
+
llm_load_print_meta: pooling type = 0
|
| 76 |
+
llm_load_print_meta: rope type = 0
|
| 77 |
+
llm_load_print_meta: rope scaling = linear
|
| 78 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 79 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 80 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 81 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 82 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 83 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 84 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 85 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 86 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 87 |
+
llm_load_print_meta: model type = ?B
|
| 88 |
+
llm_load_print_meta: model ftype = IQ3_S mix - 3.66 bpw
|
| 89 |
+
llm_load_print_meta: model params = 2.25 B
|
| 90 |
+
llm_load_print_meta: model size = 1.73 GiB (6.60 BPW)
|
| 91 |
+
llm_load_print_meta: general.name = n/a
|
| 92 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 93 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 94 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 95 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 96 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 97 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 98 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 99 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 100 |
+
llm_load_print_meta: max token length = 72
|
| 101 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 102 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 103 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 104 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 105 |
+
llm_load_tensors: Metal buffer size = 1772.30 MiB
|
| 106 |
+
llm_load_tensors: CPU buffer size = 214.84 MiB
|
| 107 |
+
.................................
|
| 108 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 109 |
+
llama_new_context_with_model: n_batch = 512
|
| 110 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 111 |
+
llama_new_context_with_model: flash_attn = 0
|
| 112 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 113 |
+
llama_new_context_with_model: freq_scale = 1
|
| 114 |
+
ggml_metal_init: allocating
|
| 115 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 116 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 117 |
+
ggml_metal_init: using embedded metal library
|
| 118 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 119 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 120 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 121 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 122 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 123 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 124 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 125 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 126 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 127 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 128 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 129 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 130 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 131 |
+
llama_new_context_with_model: graph nodes = 774
|
| 132 |
+
llama_new_context_with_model: graph splits = 3
|
| 133 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 134 |
+
|
| 135 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 136 |
+
perplexity: tokenizing the input ..
|
| 137 |
+
perplexity: tokenization took 2890.34 ms
|
| 138 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 139 |
+
perplexity: 9.83 seconds per pass - ETA 21.93 minutes
|
| 140 |
+
[1]18.4061,[2]18.7228,[3]16.9636,[4]16.6911,[5]15.9315,[6]15.4477,[7]16.4143,[8]15.9441,[9]15.6135,[10]14.8634,[11]15.5641,[12]15.6470,[13]16.7989,[14]17.1072,[15]17.0945,[16]17.6727,[17]17.9948,[18]17.8842,[19]17.9218,[20]18.2708,[21]18.2889,[22]16.2120,[23]16.4019,[24]15.9924,[25]15.4426,[26]14.9617,[27]14.7509,[28]14.5617,[29]14.5069,[30]14.2784,[31]14.5307,[32]14.6402,[33]15.1358,[34]15.4459,[35]15.7638,[36]15.4968,[37]15.4756,[38]15.5472,[39]15.3758,[40]15.4026,[41]15.3792,[42]15.1704,[43]15.1092,[44]15.2776,[45]15.4926,[46]15.3325,[47]15.5945,[48]15.7287,[49]16.0399,[50]16.3537,[51]16.3955,[52]16.6311,[53]16.9749,[54]17.3215,[55]17.4507,[56]17.2744,[57]17.1832,[58]16.8902,[59]16.7721,[60]16.5675,[61]16.6174,[62]16.7689,[63]16.9712,[64]17.0356,[65]17.0683,[66]17.2709,[67]17.2451,[68]17.1232,[69]16.9706,[70]16.8599,[71]16.8582,[72]16.8005,[73]16.8126,[74]16.7535,[75]16.7409,[76]16.6818,[77]16.7421,[78]16.7394,[79]16.7468,[80]16.7839,[81]16.4756,[82]16.4519,[83]16.3109,[84]16.3508,[85]16.4038,[86]16.6127,[87]16.6455,[88]16.8133,[89]16.8720,[90]17.0075,[91]17.0714,[92]16.8962,[93]16.9663,[94]16.9512,[95]17.0981,[96]17.3049,[97]17.3865,[98]17.4932,[99]17.6478,[100]17.6922,[101]17.7221,[102]17.6839,[103]17.6504,[104]17.6344,[105]17.6155,[106]17.4776,[107]17.3381,[108]17.4053,[109]17.4274,[110]17.3304,[111]17.2922,[112]17.1356,[113]16.9843,[114]16.9750,[115]16.9445,[116]16.9529,[117]16.8367,[118]16.6960,[119]16.6880,[120]16.7538,[121]16.7715,[122]16.7987,[123]16.8405,[124]16.8602,[125]16.8544,[126]16.8818,[127]16.9109,[128]16.9952,[129]16.9866,[130]16.9615,[131]17.0232,[132]16.9991,[133]16.9385,[134]16.7740,
|
| 141 |
+
Final estimate: PPL = 16.7740 +/- 0.06799
|
| 142 |
+
|
| 143 |
+
llama_perf_context_print: load time = 1199.03 ms
|
| 144 |
+
llama_perf_context_print: prompt eval time = 1313152.96 ms / 1097728 tokens ( 1.20 ms per token, 835.95 tokens per second)
|
| 145 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 146 |
+
llama_perf_context_print: total time = 1353111.24 ms / 1097729 tokens
|
| 147 |
+
ggml_metal_free: deallocating
|
perplexity_IQ4_NL.txt
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_IQ4_NL.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 25
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type iq4_nl: 169 tensors
|
| 41 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 42 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 43 |
+
llm_load_vocab: special tokens cache size = 104
|
| 44 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 45 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 46 |
+
llm_load_print_meta: arch = llama
|
| 47 |
+
llm_load_print_meta: vocab type = SPM
|
| 48 |
+
llm_load_print_meta: n_vocab = 256000
|
| 49 |
+
llm_load_print_meta: n_merges = 0
|
| 50 |
+
llm_load_print_meta: vocab_only = 0
|
| 51 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 52 |
+
llm_load_print_meta: n_embd = 2048
|
| 53 |
+
llm_load_print_meta: n_layer = 24
|
| 54 |
+
llm_load_print_meta: n_head = 16
|
| 55 |
+
llm_load_print_meta: n_head_kv = 16
|
| 56 |
+
llm_load_print_meta: n_rot = 128
|
| 57 |
+
llm_load_print_meta: n_swa = 0
|
| 58 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 59 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 60 |
+
llm_load_print_meta: n_gqa = 1
|
| 61 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 62 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 63 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 64 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 65 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 66 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 67 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 68 |
+
llm_load_print_meta: n_ff = 5440
|
| 69 |
+
llm_load_print_meta: n_expert = 0
|
| 70 |
+
llm_load_print_meta: n_expert_used = 0
|
| 71 |
+
llm_load_print_meta: causal attn = 1
|
| 72 |
+
llm_load_print_meta: pooling type = 0
|
| 73 |
+
llm_load_print_meta: rope type = 0
|
| 74 |
+
llm_load_print_meta: rope scaling = linear
|
| 75 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 76 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 77 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 78 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 79 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 80 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 81 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 82 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 83 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 84 |
+
llm_load_print_meta: model type = ?B
|
| 85 |
+
llm_load_print_meta: model ftype = IQ4_NL - 4.5 bpw
|
| 86 |
+
llm_load_print_meta: model params = 2.25 B
|
| 87 |
+
llm_load_print_meta: model size = 1.88 GiB (7.18 BPW)
|
| 88 |
+
llm_load_print_meta: general.name = n/a
|
| 89 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 90 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 91 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 92 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 93 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 94 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 95 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 96 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 97 |
+
llm_load_print_meta: max token length = 72
|
| 98 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 99 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 100 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 101 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 102 |
+
llm_load_tensors: Metal buffer size = 1927.95 MiB
|
| 103 |
+
llm_load_tensors: CPU buffer size = 281.25 MiB
|
| 104 |
+
....................................
|
| 105 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 106 |
+
llama_new_context_with_model: n_batch = 512
|
| 107 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 108 |
+
llama_new_context_with_model: flash_attn = 0
|
| 109 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 110 |
+
llama_new_context_with_model: freq_scale = 1
|
| 111 |
+
ggml_metal_init: allocating
|
| 112 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 113 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 114 |
+
ggml_metal_init: using embedded metal library
|
| 115 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 116 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 117 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 118 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 119 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 120 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 121 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 122 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 123 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 124 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 125 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 126 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 127 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 128 |
+
llama_new_context_with_model: graph nodes = 774
|
| 129 |
+
llama_new_context_with_model: graph splits = 3
|
| 130 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 131 |
+
|
| 132 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 133 |
+
perplexity: tokenizing the input ..
|
| 134 |
+
perplexity: tokenization took 2930.16 ms
|
| 135 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 136 |
+
perplexity: 10.21 seconds per pass - ETA 22.80 minutes
|
| 137 |
+
[1]17.8129,[2]18.1041,[3]16.4180,[4]16.1482,[5]15.4605,[6]14.9659,[7]15.8652,[8]15.3564,[9]15.0572,[10]14.3328,[11]14.9764,[12]15.0290,[13]16.1215,[14]16.4023,[15]16.3759,[16]16.9183,[17]17.2192,[18]17.1140,[19]17.1522,[20]17.4642,[21]17.4981,[22]15.4612,[23]15.6374,[24]15.2560,[25]14.7359,[26]14.2838,[27]14.0927,[28]13.9146,[29]13.8618,[30]13.6526,[31]13.8921,[32]13.9902,[33]14.4671,[34]14.7690,[35]15.0739,[36]14.8319,[37]14.8161,[38]14.8899,[39]14.7338,[40]14.7628,[41]14.7376,[42]14.5433,[43]14.4871,[44]14.6541,[45]14.8603,[46]14.7111,[47]14.9554,[48]15.0698,[49]15.3552,[50]15.6439,[51]15.6804,[52]15.8969,[53]16.2215,[54]16.5492,[55]16.6635,[56]16.4929,[57]16.3979,[58]16.1194,[59]16.0097,[60]15.8135,[61]15.8653,[62]16.0048,[63]16.1949,[64]16.2594,[65]16.2889,[66]16.4813,[67]16.4558,[68]16.3421,[69]16.1984,[70]16.0900,[71]16.0856,[72]16.0296,[73]16.0389,[74]15.9815,[75]15.9688,[76]15.9092,[77]15.9666,[78]15.9660,[79]15.9735,[80]16.0090,[81]15.7020,[82]15.6750,[83]15.5430,[84]15.5791,[85]15.6284,[86]15.8285,[87]15.8571,[88]16.0137,[89]16.0674,[90]16.1958,[91]16.2560,[92]16.0914,[93]16.1578,[94]16.1434,[95]16.2849,[96]16.4783,[97]16.5552,[98]16.6532,[99]16.8006,[100]16.8424,[101]16.8692,[102]16.8301,[103]16.8010,[104]16.7855,[105]16.7688,[106]16.6373,[107]16.5060,[108]16.5673,[109]16.5854,[110]16.4956,[111]16.4596,[112]16.3089,[113]16.1649,[114]16.1582,[115]16.1324,[116]16.1411,[117]16.0320,[118]15.8980,[119]15.8904,[120]15.9506,[121]15.9657,[122]15.9907,[123]16.0273,[124]16.0451,[125]16.0401,[126]16.0667,[127]16.0905,[128]16.1714,[129]16.1614,[130]16.1365,[131]16.1945,[132]16.1701,[133]16.1129,[134]15.9602,
|
| 138 |
+
Final estimate: PPL = 15.9602 +/- 0.06509
|
| 139 |
+
|
| 140 |
+
llama_perf_context_print: load time = 1276.58 ms
|
| 141 |
+
llama_perf_context_print: prompt eval time = 1349267.03 ms / 1097728 tokens ( 1.23 ms per token, 813.57 tokens per second)
|
| 142 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 143 |
+
llama_perf_context_print: total time = 1388038.33 ms / 1097729 tokens
|
| 144 |
+
ggml_metal_free: deallocating
|
perplexity_IQ4_XS.txt
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_IQ4_XS.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 30
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type iq4_nl: 24 tensors
|
| 41 |
+
llama_model_loader: - type iq4_xs: 145 tensors
|
| 42 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 43 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 44 |
+
llm_load_vocab: special tokens cache size = 104
|
| 45 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 46 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 47 |
+
llm_load_print_meta: arch = llama
|
| 48 |
+
llm_load_print_meta: vocab type = SPM
|
| 49 |
+
llm_load_print_meta: n_vocab = 256000
|
| 50 |
+
llm_load_print_meta: n_merges = 0
|
| 51 |
+
llm_load_print_meta: vocab_only = 0
|
| 52 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 53 |
+
llm_load_print_meta: n_embd = 2048
|
| 54 |
+
llm_load_print_meta: n_layer = 24
|
| 55 |
+
llm_load_print_meta: n_head = 16
|
| 56 |
+
llm_load_print_meta: n_head_kv = 16
|
| 57 |
+
llm_load_print_meta: n_rot = 128
|
| 58 |
+
llm_load_print_meta: n_swa = 0
|
| 59 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 60 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 61 |
+
llm_load_print_meta: n_gqa = 1
|
| 62 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 63 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 64 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 65 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 66 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 67 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 68 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 69 |
+
llm_load_print_meta: n_ff = 5440
|
| 70 |
+
llm_load_print_meta: n_expert = 0
|
| 71 |
+
llm_load_print_meta: n_expert_used = 0
|
| 72 |
+
llm_load_print_meta: causal attn = 1
|
| 73 |
+
llm_load_print_meta: pooling type = 0
|
| 74 |
+
llm_load_print_meta: rope type = 0
|
| 75 |
+
llm_load_print_meta: rope scaling = linear
|
| 76 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 77 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 78 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 79 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 80 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 81 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 82 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 83 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 84 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 85 |
+
llm_load_print_meta: model type = ?B
|
| 86 |
+
llm_load_print_meta: model ftype = IQ4_XS - 4.25 bpw
|
| 87 |
+
llm_load_print_meta: model params = 2.25 B
|
| 88 |
+
llm_load_print_meta: model size = 1.84 GiB (7.01 BPW)
|
| 89 |
+
llm_load_print_meta: general.name = n/a
|
| 90 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 91 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 92 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 93 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 94 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 95 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 96 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 97 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 98 |
+
llm_load_print_meta: max token length = 72
|
| 99 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 100 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 101 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 102 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 103 |
+
llm_load_tensors: Metal buffer size = 1884.39 MiB
|
| 104 |
+
llm_load_tensors: CPU buffer size = 265.62 MiB
|
| 105 |
+
..................................
|
| 106 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 107 |
+
llama_new_context_with_model: n_batch = 512
|
| 108 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 109 |
+
llama_new_context_with_model: flash_attn = 0
|
| 110 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 111 |
+
llama_new_context_with_model: freq_scale = 1
|
| 112 |
+
ggml_metal_init: allocating
|
| 113 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 114 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 115 |
+
ggml_metal_init: using embedded metal library
|
| 116 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 117 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 118 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 119 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 120 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 121 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 122 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 123 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 124 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 125 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 126 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 127 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 128 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 129 |
+
llama_new_context_with_model: graph nodes = 774
|
| 130 |
+
llama_new_context_with_model: graph splits = 3
|
| 131 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 132 |
+
|
| 133 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 134 |
+
perplexity: tokenizing the input ..
|
| 135 |
+
perplexity: tokenization took 3099.45 ms
|
| 136 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 137 |
+
perplexity: 10.31 seconds per pass - ETA 23.00 minutes
|
| 138 |
+
[1]17.8167,[2]18.0705,[3]16.3976,[4]16.1215,[5]15.4362,[6]14.9422,[7]15.8537,[8]15.3436,[9]15.0474,[10]14.3227,[11]14.9690,[12]15.0226,[13]16.1201,[14]16.4014,[15]16.3742,[16]16.9158,[17]17.2166,[18]17.1125,[19]17.1527,[20]17.4651,[21]17.5004,[22]15.4609,[23]15.6366,[24]15.2567,[25]14.7378,[26]14.2840,[27]14.0919,[28]13.9120,[29]13.8603,[30]13.6514,[31]13.8921,[32]13.9921,[33]14.4692,[34]14.7709,[35]15.0755,[36]14.8338,[37]14.8171,[38]14.8906,[39]14.7340,[40]14.7632,[41]14.7391,[42]14.5446,[43]14.4886,[44]14.6561,[45]14.8620,[46]14.7118,[47]14.9569,[48]15.0716,[49]15.3563,[50]15.6462,[51]15.6825,[52]15.8983,[53]16.2220,[54]16.5502,[55]16.6636,[56]16.4935,[57]16.3981,[58]16.1197,[59]16.0098,[60]15.8137,[61]15.8656,[62]16.0061,[63]16.1968,[64]16.2610,[65]16.2910,[66]16.4835,[67]16.4573,[68]16.3437,[69]16.2004,[70]16.0920,[71]16.0879,[72]16.0330,[73]16.0426,[74]15.9853,[75]15.9703,[76]15.9103,[77]15.9678,[78]15.9668,[79]15.9740,[80]16.0093,[81]15.7006,[82]15.6736,[83]15.5423,[84]15.5787,[85]15.6275,[86]15.8283,[87]15.8570,[88]16.0134,[89]16.0676,[90]16.1957,[91]16.2561,[92]16.0921,[93]16.1584,[94]16.1444,[95]16.2856,[96]16.4782,[97]16.5562,[98]16.6545,[99]16.8011,[100]16.8430,[101]16.8704,[102]16.8313,[103]16.8018,[104]16.7863,[105]16.7704,[106]16.6389,[107]16.5075,[108]16.5685,[109]16.5863,[110]16.4964,[111]16.4600,[112]16.3090,[113]16.1650,[114]16.1582,[115]16.1318,[116]16.1406,[117]16.0316,[118]15.8973,[119]15.8895,[120]15.9499,[121]15.9650,[122]15.9896,[123]16.0269,[124]16.0444,[125]16.0395,[126]16.0661,[127]16.0901,[128]16.1712,[129]16.1612,[130]16.1360,[131]16.1936,[132]16.1694,[133]16.1121,[134]15.9591,
|
| 139 |
+
Final estimate: PPL = 15.9591 +/- 0.06513
|
| 140 |
+
|
| 141 |
+
llama_perf_context_print: load time = 1240.44 ms
|
| 142 |
+
llama_perf_context_print: prompt eval time = 1316825.15 ms / 1097728 tokens ( 1.20 ms per token, 833.62 tokens per second)
|
| 143 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 144 |
+
llama_perf_context_print: total time = 1357907.16 ms / 1097729 tokens
|
| 145 |
+
ggml_metal_free: deallocating
|
perplexity_Q3_K_L.txt
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_Q3_K_L.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 13
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type q5_1: 24 tensors
|
| 41 |
+
llama_model_loader: - type q3_K: 97 tensors
|
| 42 |
+
llama_model_loader: - type q5_K: 48 tensors
|
| 43 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 44 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 45 |
+
llm_load_vocab: special tokens cache size = 104
|
| 46 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 47 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 48 |
+
llm_load_print_meta: arch = llama
|
| 49 |
+
llm_load_print_meta: vocab type = SPM
|
| 50 |
+
llm_load_print_meta: n_vocab = 256000
|
| 51 |
+
llm_load_print_meta: n_merges = 0
|
| 52 |
+
llm_load_print_meta: vocab_only = 0
|
| 53 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 54 |
+
llm_load_print_meta: n_embd = 2048
|
| 55 |
+
llm_load_print_meta: n_layer = 24
|
| 56 |
+
llm_load_print_meta: n_head = 16
|
| 57 |
+
llm_load_print_meta: n_head_kv = 16
|
| 58 |
+
llm_load_print_meta: n_rot = 128
|
| 59 |
+
llm_load_print_meta: n_swa = 0
|
| 60 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 61 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 62 |
+
llm_load_print_meta: n_gqa = 1
|
| 63 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 64 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 65 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 66 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 67 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 68 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 69 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 70 |
+
llm_load_print_meta: n_ff = 5440
|
| 71 |
+
llm_load_print_meta: n_expert = 0
|
| 72 |
+
llm_load_print_meta: n_expert_used = 0
|
| 73 |
+
llm_load_print_meta: causal attn = 1
|
| 74 |
+
llm_load_print_meta: pooling type = 0
|
| 75 |
+
llm_load_print_meta: rope type = 0
|
| 76 |
+
llm_load_print_meta: rope scaling = linear
|
| 77 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 78 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 79 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 80 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 81 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 82 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 83 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 84 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 85 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 86 |
+
llm_load_print_meta: model type = ?B
|
| 87 |
+
llm_load_print_meta: model ftype = Q3_K - Large
|
| 88 |
+
llm_load_print_meta: model params = 2.25 B
|
| 89 |
+
llm_load_print_meta: model size = 1.80 GiB (6.85 BPW)
|
| 90 |
+
llm_load_print_meta: general.name = n/a
|
| 91 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 92 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 93 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 94 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 95 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 96 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 97 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 98 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 99 |
+
llm_load_print_meta: max token length = 72
|
| 100 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 101 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 102 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 103 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 104 |
+
llm_load_tensors: Metal buffer size = 1840.13 MiB
|
| 105 |
+
llm_load_tensors: CPU buffer size = 214.84 MiB
|
| 106 |
+
....................................
|
| 107 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 108 |
+
llama_new_context_with_model: n_batch = 512
|
| 109 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 110 |
+
llama_new_context_with_model: flash_attn = 0
|
| 111 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 112 |
+
llama_new_context_with_model: freq_scale = 1
|
| 113 |
+
ggml_metal_init: allocating
|
| 114 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 115 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 116 |
+
ggml_metal_init: using embedded metal library
|
| 117 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 118 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 119 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 120 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 121 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 122 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 123 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 124 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 125 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 126 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 127 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 128 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 129 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 130 |
+
llama_new_context_with_model: graph nodes = 774
|
| 131 |
+
llama_new_context_with_model: graph splits = 3
|
| 132 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 133 |
+
|
| 134 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 135 |
+
perplexity: tokenizing the input ..
|
| 136 |
+
perplexity: tokenization took 2741.95 ms
|
| 137 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 138 |
+
perplexity: 10.33 seconds per pass - ETA 23.05 minutes
|
| 139 |
+
[1]18.3751,[2]18.7063,[3]16.8806,[4]16.5903,[5]15.8444,[6]15.3400,[7]16.2943,[8]15.7614,[9]15.4661,[10]14.7455,[11]15.4058,[12]15.4707,[13]16.6022,[14]16.9078,[15]16.8926,[16]17.4456,[17]17.7709,[18]17.6703,[19]17.6898,[20]18.0172,[21]18.0413,[22]15.9789,[23]16.1688,[24]15.7649,[25]15.2233,[26]14.7550,[27]14.5496,[28]14.3645,[29]14.3079,[30]14.0839,[31]14.3321,[32]14.4502,[33]14.9338,[34]15.2396,[35]15.5478,[36]15.2922,[37]15.2753,[38]15.3457,[39]15.1808,[40]15.2087,[41]15.1848,[42]14.9793,[43]14.9167,[44]15.0906,[45]15.3037,[46]15.1467,[47]15.4100,[48]15.5334,[49]15.8348,[50]16.1429,[51]16.1849,[52]16.4173,[53]16.7558,[54]17.0960,[55]17.2191,[56]17.0438,[57]16.9502,[58]16.6601,[59]16.5426,[60]16.3405,[61]16.3897,[62]16.5398,[63]16.7419,[64]16.8083,[65]16.8394,[66]17.0364,[67]17.0094,[68]16.8909,[69]16.7384,[70]16.6228,[71]16.6213,[72]16.5604,[73]16.5666,[74]16.5139,[75]16.5047,[76]16.4420,[77]16.5047,[78]16.5027,[79]16.5087,[80]16.5418,[81]16.2233,[82]16.1985,[83]16.0625,[84]16.0991,[85]16.1511,[86]16.3592,[87]16.3892,[88]16.5549,[89]16.6120,[90]16.7460,[91]16.8066,[92]16.6348,[93]16.7024,[94]16.6877,[95]16.8355,[96]17.0351,[97]17.1187,[98]17.2222,[99]17.3725,[100]17.4156,[101]17.4451,[102]17.4032,[103]17.3732,[104]17.3571,[105]17.3399,[106]17.2031,[107]17.0649,[108]17.1284,[109]17.1473,[110]17.0546,[111]17.0157,[112]16.8633,[113]16.7129,[114]16.7039,[115]16.6748,[116]16.6818,[117]16.5711,[118]16.4363,[119]16.4301,[120]16.4939,[121]16.5105,[122]16.5380,[123]16.5775,[124]16.5954,[125]16.5914,[126]16.6190,[127]16.6449,[128]16.7290,[129]16.7188,[130]16.6922,[131]16.7515,[132]16.7253,[133]16.6661,[134]16.5067,
|
| 140 |
+
Final estimate: PPL = 16.5067 +/- 0.06740
|
| 141 |
+
|
| 142 |
+
llama_perf_context_print: load time = 1256.77 ms
|
| 143 |
+
llama_perf_context_print: prompt eval time = 1373342.06 ms / 1097728 tokens ( 1.25 ms per token, 799.31 tokens per second)
|
| 144 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 145 |
+
llama_perf_context_print: total time = 1414333.17 ms / 1097729 tokens
|
| 146 |
+
ggml_metal_free: deallocating
|
perplexity_Q3_K_M.txt
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_Q3_K_M.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 12
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type q5_0: 23 tensors
|
| 41 |
+
llama_model_loader: - type q5_1: 1 tensors
|
| 42 |
+
llama_model_loader: - type q3_K: 97 tensors
|
| 43 |
+
llama_model_loader: - type q4_K: 46 tensors
|
| 44 |
+
llama_model_loader: - type q5_K: 2 tensors
|
| 45 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 46 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 47 |
+
llm_load_vocab: special tokens cache size = 104
|
| 48 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 49 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 50 |
+
llm_load_print_meta: arch = llama
|
| 51 |
+
llm_load_print_meta: vocab type = SPM
|
| 52 |
+
llm_load_print_meta: n_vocab = 256000
|
| 53 |
+
llm_load_print_meta: n_merges = 0
|
| 54 |
+
llm_load_print_meta: vocab_only = 0
|
| 55 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 56 |
+
llm_load_print_meta: n_embd = 2048
|
| 57 |
+
llm_load_print_meta: n_layer = 24
|
| 58 |
+
llm_load_print_meta: n_head = 16
|
| 59 |
+
llm_load_print_meta: n_head_kv = 16
|
| 60 |
+
llm_load_print_meta: n_rot = 128
|
| 61 |
+
llm_load_print_meta: n_swa = 0
|
| 62 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 63 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 64 |
+
llm_load_print_meta: n_gqa = 1
|
| 65 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 66 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 67 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 68 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 69 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 70 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 71 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 72 |
+
llm_load_print_meta: n_ff = 5440
|
| 73 |
+
llm_load_print_meta: n_expert = 0
|
| 74 |
+
llm_load_print_meta: n_expert_used = 0
|
| 75 |
+
llm_load_print_meta: causal attn = 1
|
| 76 |
+
llm_load_print_meta: pooling type = 0
|
| 77 |
+
llm_load_print_meta: rope type = 0
|
| 78 |
+
llm_load_print_meta: rope scaling = linear
|
| 79 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 80 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 81 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 82 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 83 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 84 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 85 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 86 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 87 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 88 |
+
llm_load_print_meta: model type = ?B
|
| 89 |
+
llm_load_print_meta: model ftype = Q3_K - Medium
|
| 90 |
+
llm_load_print_meta: model params = 2.25 B
|
| 91 |
+
llm_load_print_meta: model size = 1.76 GiB (6.71 BPW)
|
| 92 |
+
llm_load_print_meta: general.name = n/a
|
| 93 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 94 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 95 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 96 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 97 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 98 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 99 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 100 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 101 |
+
llm_load_print_meta: max token length = 72
|
| 102 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 103 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 104 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 105 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 106 |
+
llm_load_tensors: Metal buffer size = 1801.85 MiB
|
| 107 |
+
llm_load_tensors: CPU buffer size = 214.84 MiB
|
| 108 |
+
...................................
|
| 109 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 110 |
+
llama_new_context_with_model: n_batch = 512
|
| 111 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 112 |
+
llama_new_context_with_model: flash_attn = 0
|
| 113 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 114 |
+
llama_new_context_with_model: freq_scale = 1
|
| 115 |
+
ggml_metal_init: allocating
|
| 116 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 117 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 118 |
+
ggml_metal_init: using embedded metal library
|
| 119 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 120 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 121 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 122 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 123 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 124 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 125 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 126 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 127 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 128 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 129 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 130 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 131 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 132 |
+
llama_new_context_with_model: graph nodes = 774
|
| 133 |
+
llama_new_context_with_model: graph splits = 3
|
| 134 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 135 |
+
|
| 136 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 137 |
+
perplexity: tokenizing the input ..
|
| 138 |
+
perplexity: tokenization took 3245.03 ms
|
| 139 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 140 |
+
perplexity: 10.50 seconds per pass - ETA 23.45 minutes
|
| 141 |
+
[1]18.6436,[2]19.1149,[3]17.2307,[4]16.9491,[5]16.1724,[6]15.6363,[7]16.6124,[8]16.0910,[9]15.7972,[10]15.0672,[11]15.7426,[12]15.8047,[13]16.9639,[14]17.2806,[15]17.2621,[16]17.8314,[17]18.1578,[18]18.0537,[19]18.0718,[20]18.4048,[21]18.4235,[22]16.3393,[23]16.5358,[24]16.1249,[25]15.5668,[26]15.0885,[27]14.8773,[28]14.6864,[29]14.6278,[30]14.3999,[31]14.6618,[32]14.7695,[33]15.2614,[34]15.5712,[35]15.8861,[36]15.6201,[37]15.6016,[38]15.6714,[39]15.5003,[40]15.5259,[41]15.5006,[42]15.2864,[43]15.2186,[44]15.3937,[45]15.6112,[46]15.4493,[47]15.7212,[48]15.8468,[49]16.1577,[50]16.4769,[51]16.5221,[52]16.7616,[53]17.1090,[54]17.4590,[55]17.5842,[56]17.4052,[57]17.3113,[58]17.0118,[59]16.8908,[60]16.6834,[61]16.7317,[62]16.8849,[63]17.0935,[64]17.1618,[65]17.1949,[66]17.3988,[67]17.3709,[68]17.2497,[69]17.0926,[70]16.9750,[71]16.9734,[72]16.9132,[73]16.9217,[74]16.8675,[75]16.8623,[76]16.8000,[77]16.8626,[78]16.8608,[79]16.8673,[80]16.9007,[81]16.5635,[82]16.5366,[83]16.3972,[84]16.4370,[85]16.4925,[86]16.7065,[87]16.7367,[88]16.9057,[89]16.9635,[90]17.1000,[91]17.1627,[92]16.9849,[93]17.0537,[94]17.0377,[95]17.1891,[96]17.3957,[97]17.4828,[98]17.5903,[99]17.7496,[100]17.7934,[101]17.8236,[102]17.7789,[103]17.7470,[104]17.7305,[105]17.7120,[106]17.5711,[107]17.4287,[108]17.4930,[109]17.5125,[110]17.4178,[111]17.3773,[112]17.2224,[113]17.0680,[114]17.0578,[115]17.0285,[116]17.0352,[117]16.9202,[118]16.7823,[119]16.7747,[120]16.8409,[121]16.8578,[122]16.8858,[123]16.9270,[124]16.9460,[125]16.9417,[126]16.9712,[127]16.9982,[128]17.0843,[129]17.0735,[130]17.0460,[131]17.1078,[132]17.0812,[133]17.0198,[134]16.8567,
|
| 142 |
+
Final estimate: PPL = 16.8567 +/- 0.06889
|
| 143 |
+
|
| 144 |
+
llama_perf_context_print: load time = 1230.31 ms
|
| 145 |
+
llama_perf_context_print: prompt eval time = 1383629.65 ms / 1097728 tokens ( 1.26 ms per token, 793.37 tokens per second)
|
| 146 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 147 |
+
llama_perf_context_print: total time = 1423701.91 ms / 1097729 tokens
|
| 148 |
+
ggml_metal_free: deallocating
|
perplexity_Q4_K_M.txt
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_Q4_K_M.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 15
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type q5_0: 12 tensors
|
| 41 |
+
llama_model_loader: - type q8_0: 12 tensors
|
| 42 |
+
llama_model_loader: - type q4_K: 133 tensors
|
| 43 |
+
llama_model_loader: - type q6_K: 12 tensors
|
| 44 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 45 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 46 |
+
llm_load_vocab: special tokens cache size = 104
|
| 47 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 48 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 49 |
+
llm_load_print_meta: arch = llama
|
| 50 |
+
llm_load_print_meta: vocab type = SPM
|
| 51 |
+
llm_load_print_meta: n_vocab = 256000
|
| 52 |
+
llm_load_print_meta: n_merges = 0
|
| 53 |
+
llm_load_print_meta: vocab_only = 0
|
| 54 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 55 |
+
llm_load_print_meta: n_embd = 2048
|
| 56 |
+
llm_load_print_meta: n_layer = 24
|
| 57 |
+
llm_load_print_meta: n_head = 16
|
| 58 |
+
llm_load_print_meta: n_head_kv = 16
|
| 59 |
+
llm_load_print_meta: n_rot = 128
|
| 60 |
+
llm_load_print_meta: n_swa = 0
|
| 61 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 62 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 63 |
+
llm_load_print_meta: n_gqa = 1
|
| 64 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 65 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 66 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 67 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 68 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 69 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 70 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 71 |
+
llm_load_print_meta: n_ff = 5440
|
| 72 |
+
llm_load_print_meta: n_expert = 0
|
| 73 |
+
llm_load_print_meta: n_expert_used = 0
|
| 74 |
+
llm_load_print_meta: causal attn = 1
|
| 75 |
+
llm_load_print_meta: pooling type = 0
|
| 76 |
+
llm_load_print_meta: rope type = 0
|
| 77 |
+
llm_load_print_meta: rope scaling = linear
|
| 78 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 79 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 80 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 81 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 82 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 83 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 84 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 85 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 86 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 87 |
+
llm_load_print_meta: model type = ?B
|
| 88 |
+
llm_load_print_meta: model ftype = Q4_K - Medium
|
| 89 |
+
llm_load_print_meta: model params = 2.25 B
|
| 90 |
+
llm_load_print_meta: model size = 1.97 GiB (7.52 BPW)
|
| 91 |
+
llm_load_print_meta: general.name = n/a
|
| 92 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 93 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 94 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 95 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 96 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 97 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 98 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 99 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 100 |
+
llm_load_print_meta: max token length = 72
|
| 101 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 102 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 103 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 104 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 105 |
+
llm_load_tensors: Metal buffer size = 2020.02 MiB
|
| 106 |
+
llm_load_tensors: CPU buffer size = 281.25 MiB
|
| 107 |
+
.......................................
|
| 108 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 109 |
+
llama_new_context_with_model: n_batch = 512
|
| 110 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 111 |
+
llama_new_context_with_model: flash_attn = 0
|
| 112 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 113 |
+
llama_new_context_with_model: freq_scale = 1
|
| 114 |
+
ggml_metal_init: allocating
|
| 115 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 116 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 117 |
+
ggml_metal_init: using embedded metal library
|
| 118 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 119 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 120 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 121 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 122 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 123 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 124 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 125 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 126 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 127 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 128 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 129 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 130 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 131 |
+
llama_new_context_with_model: graph nodes = 774
|
| 132 |
+
llama_new_context_with_model: graph splits = 3
|
| 133 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 134 |
+
|
| 135 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 136 |
+
perplexity: tokenizing the input ..
|
| 137 |
+
perplexity: tokenization took 2927.51 ms
|
| 138 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 139 |
+
perplexity: 9.93 seconds per pass - ETA 22.18 minutes
|
| 140 |
+
[1]17.5089,[2]17.8400,[3]16.1878,[4]15.9924,[5]15.2780,[6]14.8035,[7]15.6954,[8]15.1917,[9]14.9173,[10]14.2094,[11]14.8451,[12]14.9078,[13]15.9738,[14]16.2514,[15]16.2354,[16]16.7807,[17]17.0773,[18]16.9739,[19]17.0181,[20]17.3306,[21]17.3653,[22]15.3341,[23]15.5152,[24]15.1377,[25]14.6189,[26]14.1756,[27]13.9808,[28]13.8060,[29]13.7565,[30]13.5495,[31]13.7882,[32]13.9001,[33]14.3769,[34]14.6790,[35]14.9835,[36]14.7423,[37]14.7272,[38]14.8019,[39]14.6457,[40]14.6778,[41]14.6509,[42]14.4603,[43]14.4040,[44]14.5677,[45]14.7754,[46]14.6276,[47]14.8679,[48]14.9861,[49]15.2696,[50]15.5547,[51]15.5905,[52]15.8069,[53]16.1288,[54]16.4542,[55]16.5662,[56]16.3988,[57]16.3056,[58]16.0291,[59]15.9206,[60]15.7269,[61]15.7765,[62]15.9151,[63]16.1024,[64]16.1644,[65]16.1921,[66]16.3829,[67]16.3565,[68]16.2458,[69]16.1030,[70]15.9968,[71]15.9918,[72]15.9369,[73]15.9483,[74]15.8911,[75]15.8734,[76]15.8125,[77]15.8696,[78]15.8679,[79]15.8773,[80]15.9141,[81]15.6136,[82]15.5899,[83]15.4594,[84]15.4937,[85]15.5439,[86]15.7399,[87]15.7652,[88]15.9203,[89]15.9731,[90]16.0986,[91]16.1577,[92]15.9921,[93]16.0569,[94]16.0429,[95]16.1803,[96]16.3732,[97]16.4507,[98]16.5492,[99]16.6969,[100]16.7378,[101]16.7648,[102]16.7253,[103]16.6971,[104]16.6812,[105]16.6661,[106]16.5354,[107]16.4054,[108]16.4670,[109]16.4850,[110]16.3960,[111]16.3583,[112]16.2095,[113]16.0675,[114]16.0616,[115]16.0352,[116]16.0433,[117]15.9357,[118]15.8047,[119]15.7972,[120]15.8571,[121]15.8720,[122]15.8945,[123]15.9307,[124]15.9490,[125]15.9434,[126]15.9677,[127]15.9922,[128]16.0722,[129]16.0628,[130]16.0396,[131]16.0973,[132]16.0732,[133]16.0167,[134]15.8651,
|
| 141 |
+
Final estimate: PPL = 15.8651 +/- 0.06475
|
| 142 |
+
|
| 143 |
+
llama_perf_context_print: load time = 1296.13 ms
|
| 144 |
+
llama_perf_context_print: prompt eval time = 1297338.40 ms / 1097728 tokens ( 1.18 ms per token, 846.14 tokens per second)
|
| 145 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 146 |
+
llama_perf_context_print: total time = 1338884.29 ms / 1097729 tokens
|
| 147 |
+
ggml_metal_free: deallocating
|
perplexity_Q4_K_S.txt
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_Q4_K_S.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 14
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type q5_0: 21 tensors
|
| 41 |
+
llama_model_loader: - type q5_1: 3 tensors
|
| 42 |
+
llama_model_loader: - type q4_K: 141 tensors
|
| 43 |
+
llama_model_loader: - type q5_K: 4 tensors
|
| 44 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 45 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 46 |
+
llm_load_vocab: special tokens cache size = 104
|
| 47 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 48 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 49 |
+
llm_load_print_meta: arch = llama
|
| 50 |
+
llm_load_print_meta: vocab type = SPM
|
| 51 |
+
llm_load_print_meta: n_vocab = 256000
|
| 52 |
+
llm_load_print_meta: n_merges = 0
|
| 53 |
+
llm_load_print_meta: vocab_only = 0
|
| 54 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 55 |
+
llm_load_print_meta: n_embd = 2048
|
| 56 |
+
llm_load_print_meta: n_layer = 24
|
| 57 |
+
llm_load_print_meta: n_head = 16
|
| 58 |
+
llm_load_print_meta: n_head_kv = 16
|
| 59 |
+
llm_load_print_meta: n_rot = 128
|
| 60 |
+
llm_load_print_meta: n_swa = 0
|
| 61 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 62 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 63 |
+
llm_load_print_meta: n_gqa = 1
|
| 64 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 65 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 66 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 67 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 68 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 69 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 70 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 71 |
+
llm_load_print_meta: n_ff = 5440
|
| 72 |
+
llm_load_print_meta: n_expert = 0
|
| 73 |
+
llm_load_print_meta: n_expert_used = 0
|
| 74 |
+
llm_load_print_meta: causal attn = 1
|
| 75 |
+
llm_load_print_meta: pooling type = 0
|
| 76 |
+
llm_load_print_meta: rope type = 0
|
| 77 |
+
llm_load_print_meta: rope scaling = linear
|
| 78 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 79 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 80 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 81 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 82 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 83 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 84 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 85 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 86 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 87 |
+
llm_load_print_meta: model type = ?B
|
| 88 |
+
llm_load_print_meta: model ftype = Q4_K - Small
|
| 89 |
+
llm_load_print_meta: model params = 2.25 B
|
| 90 |
+
llm_load_print_meta: model size = 1.92 GiB (7.31 BPW)
|
| 91 |
+
llm_load_print_meta: general.name = n/a
|
| 92 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 93 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 94 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 95 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 96 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 97 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 98 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 99 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 100 |
+
llm_load_print_meta: max token length = 72
|
| 101 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 102 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 103 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 104 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 105 |
+
llm_load_tensors: Metal buffer size = 1963.82 MiB
|
| 106 |
+
llm_load_tensors: CPU buffer size = 281.25 MiB
|
| 107 |
+
.....................................
|
| 108 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 109 |
+
llama_new_context_with_model: n_batch = 512
|
| 110 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 111 |
+
llama_new_context_with_model: flash_attn = 0
|
| 112 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 113 |
+
llama_new_context_with_model: freq_scale = 1
|
| 114 |
+
ggml_metal_init: allocating
|
| 115 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 116 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 117 |
+
ggml_metal_init: using embedded metal library
|
| 118 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 119 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 120 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 121 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 122 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 123 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 124 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 125 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 126 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 127 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 128 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 129 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 130 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 131 |
+
llama_new_context_with_model: graph nodes = 774
|
| 132 |
+
llama_new_context_with_model: graph splits = 3
|
| 133 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 134 |
+
|
| 135 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 136 |
+
perplexity: tokenizing the input ..
|
| 137 |
+
perplexity: tokenization took 3213.6 ms
|
| 138 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 139 |
+
perplexity: 10.52 seconds per pass - ETA 23.48 minutes
|
| 140 |
+
[1]17.5477,[2]17.9221,[3]16.2638,[4]16.0589,[5]15.3365,[6]14.8584,[7]15.7493,[8]15.2416,[9]14.9662,[10]14.2574,[11]14.8994,[12]14.9625,[13]16.0414,[14]16.3210,[15]16.3080,[16]16.8530,[17]17.1502,[18]17.0427,[19]17.0853,[20]17.4004,[21]17.4331,[22]15.3983,[23]15.5808,[24]15.2009,[25]14.6792,[26]14.2320,[27]14.0352,[28]13.8592,[29]13.8091,[30]13.6025,[31]13.8428,[32]13.9538,[33]14.4326,[34]14.7368,[35]15.0448,[36]14.8038,[37]14.7882,[38]14.8626,[39]14.7051,[40]14.7370,[41]14.7107,[42]14.5182,[43]14.4627,[44]14.6275,[45]14.8360,[46]14.6871,[47]14.9297,[48]15.0471,[49]15.3325,[50]15.6184,[51]15.6550,[52]15.8727,[53]16.1975,[54]16.5253,[55]16.6375,[56]16.4689,[57]16.3747,[58]16.0970,[59]15.9877,[60]15.7936,[61]15.8436,[62]15.9836,[63]16.1730,[64]16.2348,[65]16.2632,[66]16.4551,[67]16.4280,[68]16.3158,[69]16.1721,[70]16.0645,[71]16.0588,[72]16.0047,[73]16.0157,[74]15.9581,[75]15.9404,[76]15.8797,[77]15.9372,[78]15.9354,[79]15.9450,[80]15.9817,[81]15.6790,[82]15.6550,[83]15.5241,[84]15.5590,[85]15.6100,[86]15.8073,[87]15.8330,[88]15.9890,[89]16.0422,[90]16.1685,[91]16.2271,[92]16.0607,[93]16.1260,[94]16.1120,[95]16.2495,[96]16.4435,[97]16.5212,[98]16.6202,[99]16.7698,[100]16.8107,[101]16.8379,[102]16.7980,[103]16.7689,[104]16.7532,[105]16.7382,[106]16.6067,[107]16.4755,[108]16.5369,[109]16.5549,[110]16.4654,[111]16.4273,[112]16.2783,[113]16.1354,[114]16.1296,[115]16.1034,[116]16.1114,[117]16.0036,[118]15.8722,[119]15.8647,[120]15.9249,[121]15.9399,[122]15.9622,[123]15.9989,[124]16.0173,[125]16.0118,[126]16.0367,[127]16.0617,[128]16.1422,[129]16.1329,[130]16.1099,[131]16.1679,[132]16.1440,[133]16.0872,[134]15.9346,
|
| 141 |
+
Final estimate: PPL = 15.9346 +/- 0.06504
|
| 142 |
+
|
| 143 |
+
llama_perf_context_print: load time = 1326.96 ms
|
| 144 |
+
llama_perf_context_print: prompt eval time = 1377983.72 ms / 1097728 tokens ( 1.26 ms per token, 796.62 tokens per second)
|
| 145 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 146 |
+
llama_perf_context_print: total time = 1417581.05 ms / 1097729 tokens
|
| 147 |
+
ggml_metal_free: deallocating
|
perplexity_Q5_K_M.txt
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_Q5_K_M.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 17
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type q5_1: 12 tensors
|
| 41 |
+
llama_model_loader: - type q8_0: 12 tensors
|
| 42 |
+
llama_model_loader: - type q5_K: 133 tensors
|
| 43 |
+
llama_model_loader: - type q6_K: 12 tensors
|
| 44 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 45 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 46 |
+
llm_load_vocab: special tokens cache size = 104
|
| 47 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 48 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 49 |
+
llm_load_print_meta: arch = llama
|
| 50 |
+
llm_load_print_meta: vocab type = SPM
|
| 51 |
+
llm_load_print_meta: n_vocab = 256000
|
| 52 |
+
llm_load_print_meta: n_merges = 0
|
| 53 |
+
llm_load_print_meta: vocab_only = 0
|
| 54 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 55 |
+
llm_load_print_meta: n_embd = 2048
|
| 56 |
+
llm_load_print_meta: n_layer = 24
|
| 57 |
+
llm_load_print_meta: n_head = 16
|
| 58 |
+
llm_load_print_meta: n_head_kv = 16
|
| 59 |
+
llm_load_print_meta: n_rot = 128
|
| 60 |
+
llm_load_print_meta: n_swa = 0
|
| 61 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 62 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 63 |
+
llm_load_print_meta: n_gqa = 1
|
| 64 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 65 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 66 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 67 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 68 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 69 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 70 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 71 |
+
llm_load_print_meta: n_ff = 5440
|
| 72 |
+
llm_load_print_meta: n_expert = 0
|
| 73 |
+
llm_load_print_meta: n_expert_used = 0
|
| 74 |
+
llm_load_print_meta: causal attn = 1
|
| 75 |
+
llm_load_print_meta: pooling type = 0
|
| 76 |
+
llm_load_print_meta: rope type = 0
|
| 77 |
+
llm_load_print_meta: rope scaling = linear
|
| 78 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 79 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 80 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 81 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 82 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 83 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 84 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 85 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 86 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 87 |
+
llm_load_print_meta: model type = ?B
|
| 88 |
+
llm_load_print_meta: model ftype = Q5_K - Medium
|
| 89 |
+
llm_load_print_meta: model params = 2.25 B
|
| 90 |
+
llm_load_print_meta: model size = 2.14 GiB (8.18 BPW)
|
| 91 |
+
llm_load_print_meta: general.name = n/a
|
| 92 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 93 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 94 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 95 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 96 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 97 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 98 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 99 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 100 |
+
llm_load_print_meta: max token length = 72
|
| 101 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 102 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 103 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 104 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 105 |
+
llm_load_tensors: Metal buffer size = 2196.24 MiB
|
| 106 |
+
llm_load_tensors: CPU buffer size = 343.75 MiB
|
| 107 |
+
.........................................
|
| 108 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 109 |
+
llama_new_context_with_model: n_batch = 512
|
| 110 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 111 |
+
llama_new_context_with_model: flash_attn = 0
|
| 112 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 113 |
+
llama_new_context_with_model: freq_scale = 1
|
| 114 |
+
ggml_metal_init: allocating
|
| 115 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 116 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 117 |
+
ggml_metal_init: using embedded metal library
|
| 118 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 119 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 120 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 121 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 122 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 123 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 124 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 125 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 126 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 127 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 128 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 129 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 130 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 131 |
+
llama_new_context_with_model: graph nodes = 774
|
| 132 |
+
llama_new_context_with_model: graph splits = 3
|
| 133 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 134 |
+
|
| 135 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 136 |
+
perplexity: tokenizing the input ..
|
| 137 |
+
perplexity: tokenization took 2711.28 ms
|
| 138 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 139 |
+
perplexity: 10.39 seconds per pass - ETA 23.20 minutes
|
| 140 |
+
[1]17.2226,[2]17.3542,[3]15.7985,[4]15.6000,[5]14.9544,[6]14.5082,[7]15.3873,[8]14.8841,[9]14.6010,[10]13.8990,[11]14.5178,[12]14.5725,[13]15.6016,[14]15.8676,[15]15.8517,[16]16.3829,[17]16.6752,[18]16.5774,[19]16.6203,[20]16.9249,[21]16.9643,[22]14.9799,[23]15.1548,[24]14.7848,[25]14.2787,[26]13.8419,[27]13.6523,[28]13.4800,[29]13.4302,[30]13.2275,[31]13.4596,[32]13.5639,[33]14.0287,[34]14.3274,[35]14.6264,[36]14.3958,[37]14.3842,[38]14.4594,[39]14.3099,[40]14.3445,[41]14.3211,[42]14.1361,[43]14.0849,[44]14.2477,[45]14.4500,[46]14.3055,[47]14.5382,[48]14.6503,[49]14.9219,[50]15.1939,[51]15.2276,[52]15.4355,[53]15.7492,[54]16.0619,[55]16.1694,[56]16.0056,[57]15.9105,[58]15.6455,[59]15.5409,[60]15.3517,[61]15.4022,[62]15.5348,[63]15.7174,[64]15.7781,[65]15.8056,[66]15.9889,[67]15.9635,[68]15.8533,[69]15.7140,[70]15.6085,[71]15.6036,[72]15.5481,[73]15.5581,[74]15.5016,[75]15.4753,[76]15.4155,[77]15.4734,[78]15.4727,[79]15.4807,[80]15.5167,[81]15.2324,[82]15.2101,[83]15.0829,[84]15.1149,[85]15.1614,[86]15.3514,[87]15.3756,[88]15.5277,[89]15.5809,[90]15.7045,[91]15.7595,[92]15.6003,[93]15.6652,[94]15.6532,[95]15.7871,[96]15.9751,[97]16.0495,[98]16.1437,[99]16.2805,[100]16.3214,[101]16.3474,[102]16.3094,[103]16.2810,[104]16.2648,[105]16.2514,[106]16.1249,[107]15.9989,[108]16.0583,[109]16.0749,[110]15.9885,[111]15.9532,[112]15.8075,[113]15.6698,[114]15.6647,[115]15.6397,[116]15.6484,[117]15.5437,[118]15.4168,[119]15.4099,[120]15.4687,[121]15.4837,[122]15.5060,[123]15.5413,[124]15.5575,[125]15.5520,[126]15.5771,[127]15.6011,[128]15.6786,[129]15.6687,[130]15.6461,[131]15.7018,[132]15.6773,[133]15.6226,[134]15.4746,
|
| 141 |
+
Final estimate: PPL = 15.4746 +/- 0.06294
|
| 142 |
+
|
| 143 |
+
llama_perf_context_print: load time = 1424.89 ms
|
| 144 |
+
llama_perf_context_print: prompt eval time = 1380468.79 ms / 1097728 tokens ( 1.26 ms per token, 795.18 tokens per second)
|
| 145 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 146 |
+
llama_perf_context_print: total time = 1421207.09 ms / 1097729 tokens
|
| 147 |
+
ggml_metal_free: deallocating
|
perplexity_Q5_K_S.txt
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_Q5_K_S.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 16
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type q5_1: 24 tensors
|
| 41 |
+
llama_model_loader: - type q5_K: 145 tensors
|
| 42 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 43 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 44 |
+
llm_load_vocab: special tokens cache size = 104
|
| 45 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 46 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 47 |
+
llm_load_print_meta: arch = llama
|
| 48 |
+
llm_load_print_meta: vocab type = SPM
|
| 49 |
+
llm_load_print_meta: n_vocab = 256000
|
| 50 |
+
llm_load_print_meta: n_merges = 0
|
| 51 |
+
llm_load_print_meta: vocab_only = 0
|
| 52 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 53 |
+
llm_load_print_meta: n_embd = 2048
|
| 54 |
+
llm_load_print_meta: n_layer = 24
|
| 55 |
+
llm_load_print_meta: n_head = 16
|
| 56 |
+
llm_load_print_meta: n_head_kv = 16
|
| 57 |
+
llm_load_print_meta: n_rot = 128
|
| 58 |
+
llm_load_print_meta: n_swa = 0
|
| 59 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 60 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 61 |
+
llm_load_print_meta: n_gqa = 1
|
| 62 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 63 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 64 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 65 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 66 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 67 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 68 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 69 |
+
llm_load_print_meta: n_ff = 5440
|
| 70 |
+
llm_load_print_meta: n_expert = 0
|
| 71 |
+
llm_load_print_meta: n_expert_used = 0
|
| 72 |
+
llm_load_print_meta: causal attn = 1
|
| 73 |
+
llm_load_print_meta: pooling type = 0
|
| 74 |
+
llm_load_print_meta: rope type = 0
|
| 75 |
+
llm_load_print_meta: rope scaling = linear
|
| 76 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 77 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 78 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 79 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 80 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 81 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 82 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 83 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 84 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 85 |
+
llm_load_print_meta: model type = ?B
|
| 86 |
+
llm_load_print_meta: model ftype = Q5_K - Small
|
| 87 |
+
llm_load_print_meta: model params = 2.25 B
|
| 88 |
+
llm_load_print_meta: model size = 2.10 GiB (8.00 BPW)
|
| 89 |
+
llm_load_print_meta: general.name = n/a
|
| 90 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 91 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 92 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 93 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 94 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 95 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 96 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 97 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 98 |
+
llm_load_print_meta: max token length = 72
|
| 99 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 100 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 101 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 102 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 103 |
+
llm_load_tensors: Metal buffer size = 2150.02 MiB
|
| 104 |
+
llm_load_tensors: CPU buffer size = 343.75 MiB
|
| 105 |
+
........................................
|
| 106 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 107 |
+
llama_new_context_with_model: n_batch = 512
|
| 108 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 109 |
+
llama_new_context_with_model: flash_attn = 0
|
| 110 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 111 |
+
llama_new_context_with_model: freq_scale = 1
|
| 112 |
+
ggml_metal_init: allocating
|
| 113 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 114 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 115 |
+
ggml_metal_init: using embedded metal library
|
| 116 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 117 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 118 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 119 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 120 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 121 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 122 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 123 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 124 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 125 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 126 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 127 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 128 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 129 |
+
llama_new_context_with_model: graph nodes = 774
|
| 130 |
+
llama_new_context_with_model: graph splits = 3
|
| 131 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 132 |
+
|
| 133 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 134 |
+
perplexity: tokenizing the input ..
|
| 135 |
+
perplexity: tokenization took 2882.91 ms
|
| 136 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 137 |
+
perplexity: 10.23 seconds per pass - ETA 22.83 minutes
|
| 138 |
+
[1]17.2785,[2]17.3956,[3]15.8182,[4]15.6253,[5]14.9784,[6]14.5289,[7]15.4024,[8]14.8970,[9]14.6110,[10]13.9083,[11]14.5294,[12]14.5847,[13]15.6201,[14]15.8849,[15]15.8689,[16]16.3995,[17]16.6897,[18]16.5927,[19]16.6344,[20]16.9387,[21]16.9762,[22]14.9908,[23]15.1671,[24]14.7960,[25]14.2906,[26]13.8526,[27]13.6621,[28]13.4899,[29]13.4404,[30]13.2374,[31]13.4688,[32]13.5754,[33]14.0416,[34]14.3413,[35]14.6406,[36]14.4104,[37]14.3984,[38]14.4738,[39]14.3237,[40]14.3586,[41]14.3349,[42]14.1493,[43]14.0986,[44]14.2616,[45]14.4640,[46]14.3193,[47]14.5523,[48]14.6647,[49]14.9375,[50]15.2097,[51]15.2433,[52]15.4516,[53]15.7659,[54]16.0790,[55]16.1869,[56]16.0226,[57]15.9270,[58]15.6618,[59]15.5568,[60]15.3672,[61]15.4177,[62]15.5506,[63]15.7337,[64]15.7943,[65]15.8222,[66]16.0057,[67]15.9803,[68]15.8701,[69]15.7304,[70]15.6239,[71]15.6188,[72]15.5632,[73]15.5726,[74]15.5157,[75]15.4888,[76]15.4294,[77]15.4869,[78]15.4861,[79]15.4939,[80]15.5303,[81]15.2465,[82]15.2241,[83]15.0971,[84]15.1296,[85]15.1765,[86]15.3665,[87]15.3904,[88]15.5424,[89]15.5955,[90]15.7196,[91]15.7749,[92]15.6150,[93]15.6800,[94]15.6679,[95]15.8016,[96]15.9901,[97]16.0644,[98]16.1586,[99]16.2961,[100]16.3372,[101]16.3631,[102]16.3251,[103]16.2967,[104]16.2805,[105]16.2670,[106]16.1406,[107]16.0144,[108]16.0742,[109]16.0908,[110]16.0044,[111]15.9691,[112]15.8230,[113]15.6850,[114]15.6798,[115]15.6547,[116]15.6632,[117]15.5585,[118]15.4314,[119]15.4247,[120]15.4835,[121]15.4987,[122]15.5208,[123]15.5565,[124]15.5727,[125]15.5673,[126]15.5925,[127]15.6164,[128]15.6942,[129]15.6844,[130]15.6618,[131]15.7177,[132]15.6932,[133]15.6385,[134]15.4901,
|
| 139 |
+
Final estimate: PPL = 15.4901 +/- 0.06304
|
| 140 |
+
|
| 141 |
+
llama_perf_context_print: load time = 1379.17 ms
|
| 142 |
+
llama_perf_context_print: prompt eval time = 1395400.59 ms / 1097728 tokens ( 1.27 ms per token, 786.68 tokens per second)
|
| 143 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 144 |
+
llama_perf_context_print: total time = 1436395.92 ms / 1097729 tokens
|
| 145 |
+
ggml_metal_free: deallocating
|
perplexity_Q6_K.txt
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_Q6_K.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 18
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type q8_0: 24 tensors
|
| 41 |
+
llama_model_loader: - type q6_K: 145 tensors
|
| 42 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 43 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 44 |
+
llm_load_vocab: special tokens cache size = 104
|
| 45 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 46 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 47 |
+
llm_load_print_meta: arch = llama
|
| 48 |
+
llm_load_print_meta: vocab type = SPM
|
| 49 |
+
llm_load_print_meta: n_vocab = 256000
|
| 50 |
+
llm_load_print_meta: n_merges = 0
|
| 51 |
+
llm_load_print_meta: vocab_only = 0
|
| 52 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 53 |
+
llm_load_print_meta: n_embd = 2048
|
| 54 |
+
llm_load_print_meta: n_layer = 24
|
| 55 |
+
llm_load_print_meta: n_head = 16
|
| 56 |
+
llm_load_print_meta: n_head_kv = 16
|
| 57 |
+
llm_load_print_meta: n_rot = 128
|
| 58 |
+
llm_load_print_meta: n_swa = 0
|
| 59 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 60 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 61 |
+
llm_load_print_meta: n_gqa = 1
|
| 62 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 63 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 64 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 65 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 66 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 67 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 68 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 69 |
+
llm_load_print_meta: n_ff = 5440
|
| 70 |
+
llm_load_print_meta: n_expert = 0
|
| 71 |
+
llm_load_print_meta: n_expert_used = 0
|
| 72 |
+
llm_load_print_meta: causal attn = 1
|
| 73 |
+
llm_load_print_meta: pooling type = 0
|
| 74 |
+
llm_load_print_meta: rope type = 0
|
| 75 |
+
llm_load_print_meta: rope scaling = linear
|
| 76 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 77 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 78 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 79 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 80 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 81 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 82 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 83 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 84 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 85 |
+
llm_load_print_meta: model type = ?B
|
| 86 |
+
llm_load_print_meta: model ftype = Q6_K
|
| 87 |
+
llm_load_print_meta: model params = 2.25 B
|
| 88 |
+
llm_load_print_meta: model size = 2.36 GiB (8.99 BPW)
|
| 89 |
+
llm_load_print_meta: general.name = n/a
|
| 90 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 91 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 92 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 93 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 94 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 95 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 96 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 97 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 98 |
+
llm_load_print_meta: max token length = 72
|
| 99 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 100 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 101 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 102 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 103 |
+
llm_load_tensors: Metal buffer size = 2414.85 MiB
|
| 104 |
+
llm_load_tensors: CPU buffer size = 410.16 MiB
|
| 105 |
+
............................................
|
| 106 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 107 |
+
llama_new_context_with_model: n_batch = 512
|
| 108 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 109 |
+
llama_new_context_with_model: flash_attn = 0
|
| 110 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 111 |
+
llama_new_context_with_model: freq_scale = 1
|
| 112 |
+
ggml_metal_init: allocating
|
| 113 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 114 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 115 |
+
ggml_metal_init: using embedded metal library
|
| 116 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 117 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 118 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 119 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 120 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 121 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 122 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 123 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 124 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 125 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 126 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 127 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 128 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 129 |
+
llama_new_context_with_model: graph nodes = 774
|
| 130 |
+
llama_new_context_with_model: graph splits = 3
|
| 131 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 132 |
+
|
| 133 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 134 |
+
perplexity: tokenizing the input ..
|
| 135 |
+
perplexity: tokenization took 2982.84 ms
|
| 136 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 137 |
+
perplexity: 10.33 seconds per pass - ETA 23.05 minutes
|
| 138 |
+
[1]17.0887,[2]17.2480,[3]15.6987,[4]15.5118,[5]14.8759,[6]14.4395,[7]15.3085,[8]14.7978,[9]14.5196,[10]13.8181,[11]14.4324,[12]14.4902,[13]15.5116,[14]15.7730,[15]15.7587,[16]16.2866,[17]16.5783,[18]16.4829,[19]16.5246,[20]16.8268,[21]16.8668,[22]14.8923,[23]15.0668,[24]14.6984,[25]14.1937,[26]13.7606,[27]13.5739,[28]13.4024,[29]13.3543,[30]13.1542,[31]13.3851,[32]13.4915,[33]13.9573,[34]14.2558,[35]14.5529,[36]14.3232,[37]14.3131,[38]14.3892,[39]14.2419,[40]14.2755,[41]14.2509,[42]14.0670,[43]14.0165,[44]14.1783,[45]14.3806,[46]14.2373,[47]14.4687,[48]14.5800,[49]14.8482,[50]15.1185,[51]15.1519,[52]15.3580,[53]15.6689,[54]15.9795,[55]16.0855,[56]15.9232,[57]15.8291,[58]15.5654,[59]15.4625,[60]15.2742,[61]15.3247,[62]15.4560,[63]15.6365,[64]15.6977,[65]15.7257,[66]15.9087,[67]15.8832,[68]15.7747,[69]15.6368,[70]15.5331,[71]15.5278,[72]15.4735,[73]15.4829,[74]15.4266,[75]15.4001,[76]15.3404,[77]15.3975,[78]15.3973,[79]15.4064,[80]15.4421,[81]15.1622,[82]15.1410,[83]15.0137,[84]15.0454,[85]15.0923,[86]15.2814,[87]15.3044,[88]15.4548,[89]15.5065,[90]15.6281,[91]15.6818,[92]15.5223,[93]15.5863,[94]15.5742,[95]15.7075,[96]15.8941,[97]15.9685,[98]16.0622,[99]16.1972,[100]16.2384,[101]16.2648,[102]16.2268,[103]16.1987,[104]16.1825,[105]16.1692,[106]16.0437,[107]15.9193,[108]15.9790,[109]15.9957,[110]15.9096,[111]15.8740,[112]15.7284,[113]15.5919,[114]15.5862,[115]15.5609,[116]15.5698,[117]15.4663,[118]15.3402,[119]15.3331,[120]15.3912,[121]15.4059,[122]15.4282,[123]15.4624,[124]15.4779,[125]15.4721,[126]15.4969,[127]15.5206,[128]15.5981,[129]15.5883,[130]15.5662,[131]15.6214,[132]15.5974,[133]15.5429,[134]15.3961,
|
| 139 |
+
Final estimate: PPL = 15.3961 +/- 0.06268
|
| 140 |
+
|
| 141 |
+
llama_perf_context_print: load time = 1468.10 ms
|
| 142 |
+
llama_perf_context_print: prompt eval time = 1381353.52 ms / 1097728 tokens ( 1.26 ms per token, 794.68 tokens per second)
|
| 143 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 144 |
+
llama_perf_context_print: total time = 1422214.42 ms / 1097729 tokens
|
| 145 |
+
ggml_metal_free: deallocating
|
perplexity_Q8_0.txt
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 35 key-value pairs and 219 tensors from salamandra-2b-instruct_Q8_0.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 7
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - kv 31: quantize.imatrix.file str = imatrix/oscar/imatrix.dat
|
| 36 |
+
llama_model_loader: - kv 32: quantize.imatrix.dataset str = ./imatrix/oscar/imatrix-dataset.txt
|
| 37 |
+
llama_model_loader: - kv 33: quantize.imatrix.entries_count i32 = 168
|
| 38 |
+
llama_model_loader: - kv 34: quantize.imatrix.chunks_count i32 = 44176
|
| 39 |
+
llama_model_loader: - type f32: 49 tensors
|
| 40 |
+
llama_model_loader: - type q8_0: 169 tensors
|
| 41 |
+
llama_model_loader: - type bf16: 1 tensors
|
| 42 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 43 |
+
llm_load_vocab: special tokens cache size = 104
|
| 44 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 45 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 46 |
+
llm_load_print_meta: arch = llama
|
| 47 |
+
llm_load_print_meta: vocab type = SPM
|
| 48 |
+
llm_load_print_meta: n_vocab = 256000
|
| 49 |
+
llm_load_print_meta: n_merges = 0
|
| 50 |
+
llm_load_print_meta: vocab_only = 0
|
| 51 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 52 |
+
llm_load_print_meta: n_embd = 2048
|
| 53 |
+
llm_load_print_meta: n_layer = 24
|
| 54 |
+
llm_load_print_meta: n_head = 16
|
| 55 |
+
llm_load_print_meta: n_head_kv = 16
|
| 56 |
+
llm_load_print_meta: n_rot = 128
|
| 57 |
+
llm_load_print_meta: n_swa = 0
|
| 58 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 59 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 60 |
+
llm_load_print_meta: n_gqa = 1
|
| 61 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 62 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 63 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 64 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 65 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 66 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 67 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 68 |
+
llm_load_print_meta: n_ff = 5440
|
| 69 |
+
llm_load_print_meta: n_expert = 0
|
| 70 |
+
llm_load_print_meta: n_expert_used = 0
|
| 71 |
+
llm_load_print_meta: causal attn = 1
|
| 72 |
+
llm_load_print_meta: pooling type = 0
|
| 73 |
+
llm_load_print_meta: rope type = 0
|
| 74 |
+
llm_load_print_meta: rope scaling = linear
|
| 75 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 76 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 77 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 78 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 79 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 80 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 81 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 82 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 83 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 84 |
+
llm_load_print_meta: model type = ?B
|
| 85 |
+
llm_load_print_meta: model ftype = Q8_0
|
| 86 |
+
llm_load_print_meta: model params = 2.25 B
|
| 87 |
+
llm_load_print_meta: model size = 2.69 GiB (10.25 BPW)
|
| 88 |
+
llm_load_print_meta: general.name = n/a
|
| 89 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 90 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 91 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 92 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 93 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 94 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 95 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 96 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 97 |
+
llm_load_print_meta: max token length = 72
|
| 98 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 99 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 100 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 101 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 102 |
+
llm_load_tensors: Metal buffer size = 2752.45 MiB
|
| 103 |
+
llm_load_tensors: CPU buffer size = 531.25 MiB
|
| 104 |
+
..............................................
|
| 105 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 106 |
+
llama_new_context_with_model: n_batch = 512
|
| 107 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 108 |
+
llama_new_context_with_model: flash_attn = 0
|
| 109 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 110 |
+
llama_new_context_with_model: freq_scale = 1
|
| 111 |
+
ggml_metal_init: allocating
|
| 112 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 113 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 114 |
+
ggml_metal_init: using embedded metal library
|
| 115 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 116 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 117 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 118 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 119 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 120 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 121 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 122 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 123 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 124 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 125 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 126 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 127 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 128 |
+
llama_new_context_with_model: graph nodes = 774
|
| 129 |
+
llama_new_context_with_model: graph splits = 3
|
| 130 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 131 |
+
|
| 132 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 133 |
+
perplexity: tokenizing the input ..
|
| 134 |
+
perplexity: tokenization took 2890.81 ms
|
| 135 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 136 |
+
perplexity: 9.66 seconds per pass - ETA 21.57 minutes
|
| 137 |
+
[1]17.0900,[2]17.2426,[3]15.6960,[4]15.5004,[5]14.8627,[6]14.4270,[7]15.3004,[8]14.7900,[9]14.5098,[10]13.8086,[11]14.4216,[12]14.4788,[13]15.5017,[14]15.7599,[15]15.7465,[16]16.2741,[17]16.5646,[18]16.4675,[19]16.5092,[20]16.8109,[21]16.8498,[22]14.8777,[23]15.0527,[24]14.6855,[25]14.1820,[26]13.7497,[27]13.5624,[28]13.3915,[29]13.3436,[30]13.1437,[31]13.3746,[32]13.4818,[33]13.9475,[34]14.2460,[35]14.5429,[36]14.3139,[37]14.3042,[38]14.3798,[39]14.2324,[40]14.2660,[41]14.2413,[42]14.0575,[43]14.0072,[44]14.1687,[45]14.3701,[46]14.2268,[47]14.4577,[48]14.5686,[49]14.8366,[50]15.1069,[51]15.1403,[52]15.3456,[53]15.6561,[54]15.9664,[55]16.0721,[56]15.9099,[57]15.8156,[58]15.5525,[59]15.4494,[60]15.2612,[61]15.3116,[62]15.4426,[63]15.6231,[64]15.6839,[65]15.7118,[66]15.8945,[67]15.8694,[68]15.7612,[69]15.6235,[70]15.5194,[71]15.5137,[72]15.4592,[73]15.4688,[74]15.4122,[75]15.3869,[76]15.3275,[77]15.3844,[78]15.3841,[79]15.3929,[80]15.4288,[81]15.1483,[82]15.1268,[83]14.9998,[84]15.0316,[85]15.0785,[86]15.2672,[87]15.2901,[88]15.4407,[89]15.4927,[90]15.6146,[91]15.6685,[92]15.5091,[93]15.5730,[94]15.5610,[95]15.6941,[96]15.8808,[97]15.9547,[98]16.0485,[99]16.1837,[100]16.2244,[101]16.2508,[102]16.2129,[103]16.1850,[104]16.1688,[105]16.1554,[106]16.0302,[107]15.9058,[108]15.9652,[109]15.9820,[110]15.8958,[111]15.8602,[112]15.7149,[113]15.5783,[114]15.5728,[115]15.5477,[116]15.5567,[117]15.4532,[118]15.3271,[119]15.3203,[120]15.3782,[121]15.3928,[122]15.4152,[123]15.4498,[124]15.4654,[125]15.4595,[126]15.4843,[127]15.5078,[128]15.5850,[129]15.5754,[130]15.5533,[131]15.6085,[132]15.5844,[133]15.5300,[134]15.3831,
|
| 138 |
+
Final estimate: PPL = 15.3831 +/- 0.06266
|
| 139 |
+
|
| 140 |
+
llama_perf_context_print: load time = 1576.71 ms
|
| 141 |
+
llama_perf_context_print: prompt eval time = 1364068.65 ms / 1097728 tokens ( 1.24 ms per token, 804.75 tokens per second)
|
| 142 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 143 |
+
llama_perf_context_print: total time = 1400622.10 ms / 1097729 tokens
|
| 144 |
+
ggml_metal_free: deallocating
|
perplexity_bf16.txt
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build: 3906 (7eee341b) with Apple clang version 15.0.0 (clang-1500.3.9.4) for arm64-apple-darwin23.6.0
|
| 2 |
+
llama_model_loader: loaded meta data with 31 key-value pairs and 219 tensors from salamandra-2b-instruct_bf16.gguf (version GGUF V3 (latest))
|
| 3 |
+
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
|
| 4 |
+
llama_model_loader: - kv 0: general.architecture str = llama
|
| 5 |
+
llama_model_loader: - kv 1: general.type str = model
|
| 6 |
+
llama_model_loader: - kv 2: general.size_label str = 2.3B
|
| 7 |
+
llama_model_loader: - kv 3: general.license str = apache-2.0
|
| 8 |
+
llama_model_loader: - kv 4: general.tags arr[str,1] = ["text-generation"]
|
| 9 |
+
llama_model_loader: - kv 5: general.languages arr[str,36] = ["bg", "ca", "code", "cs", "cy", "da"...
|
| 10 |
+
llama_model_loader: - kv 6: llama.block_count u32 = 24
|
| 11 |
+
llama_model_loader: - kv 7: llama.context_length u32 = 8192
|
| 12 |
+
llama_model_loader: - kv 8: llama.embedding_length u32 = 2048
|
| 13 |
+
llama_model_loader: - kv 9: llama.feed_forward_length u32 = 5440
|
| 14 |
+
llama_model_loader: - kv 10: llama.attention.head_count u32 = 16
|
| 15 |
+
llama_model_loader: - kv 11: llama.attention.head_count_kv u32 = 16
|
| 16 |
+
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 10000.000000
|
| 17 |
+
llama_model_loader: - kv 13: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
|
| 18 |
+
llama_model_loader: - kv 14: general.file_type u32 = 32
|
| 19 |
+
llama_model_loader: - kv 15: llama.vocab_size u32 = 256000
|
| 20 |
+
llama_model_loader: - kv 16: llama.rope.dimension_count u32 = 128
|
| 21 |
+
llama_model_loader: - kv 17: tokenizer.ggml.add_space_prefix bool = true
|
| 22 |
+
llama_model_loader: - kv 18: tokenizer.ggml.model str = llama
|
| 23 |
+
llama_model_loader: - kv 19: tokenizer.ggml.pre str = default
|
| 24 |
+
llama_model_loader: - kv 20: tokenizer.ggml.tokens arr[str,256000] = ["<unk>", "<s>", "</s>", "<pad>", "<|...
|
| 25 |
+
llama_model_loader: - kv 21: tokenizer.ggml.scores arr[f32,256000] = [-1000.000000, -1000.000000, -1000.00...
|
| 26 |
+
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,256000] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
|
| 27 |
+
llama_model_loader: - kv 23: tokenizer.ggml.bos_token_id u32 = 1
|
| 28 |
+
llama_model_loader: - kv 24: tokenizer.ggml.eos_token_id u32 = 2
|
| 29 |
+
llama_model_loader: - kv 25: tokenizer.ggml.unknown_token_id u32 = 0
|
| 30 |
+
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 0
|
| 31 |
+
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = true
|
| 32 |
+
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
|
| 33 |
+
llama_model_loader: - kv 29: tokenizer.chat_template str = {%- if not date_string is defined %}{...
|
| 34 |
+
llama_model_loader: - kv 30: general.quantization_version u32 = 2
|
| 35 |
+
llama_model_loader: - type f32: 49 tensors
|
| 36 |
+
llama_model_loader: - type bf16: 170 tensors
|
| 37 |
+
llm_load_vocab: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
|
| 38 |
+
llm_load_vocab: special tokens cache size = 104
|
| 39 |
+
llm_load_vocab: token to piece cache size = 1.8842 MB
|
| 40 |
+
llm_load_print_meta: format = GGUF V3 (latest)
|
| 41 |
+
llm_load_print_meta: arch = llama
|
| 42 |
+
llm_load_print_meta: vocab type = SPM
|
| 43 |
+
llm_load_print_meta: n_vocab = 256000
|
| 44 |
+
llm_load_print_meta: n_merges = 0
|
| 45 |
+
llm_load_print_meta: vocab_only = 0
|
| 46 |
+
llm_load_print_meta: n_ctx_train = 8192
|
| 47 |
+
llm_load_print_meta: n_embd = 2048
|
| 48 |
+
llm_load_print_meta: n_layer = 24
|
| 49 |
+
llm_load_print_meta: n_head = 16
|
| 50 |
+
llm_load_print_meta: n_head_kv = 16
|
| 51 |
+
llm_load_print_meta: n_rot = 128
|
| 52 |
+
llm_load_print_meta: n_swa = 0
|
| 53 |
+
llm_load_print_meta: n_embd_head_k = 128
|
| 54 |
+
llm_load_print_meta: n_embd_head_v = 128
|
| 55 |
+
llm_load_print_meta: n_gqa = 1
|
| 56 |
+
llm_load_print_meta: n_embd_k_gqa = 2048
|
| 57 |
+
llm_load_print_meta: n_embd_v_gqa = 2048
|
| 58 |
+
llm_load_print_meta: f_norm_eps = 0.0e+00
|
| 59 |
+
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
|
| 60 |
+
llm_load_print_meta: f_clamp_kqv = 0.0e+00
|
| 61 |
+
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
|
| 62 |
+
llm_load_print_meta: f_logit_scale = 0.0e+00
|
| 63 |
+
llm_load_print_meta: n_ff = 5440
|
| 64 |
+
llm_load_print_meta: n_expert = 0
|
| 65 |
+
llm_load_print_meta: n_expert_used = 0
|
| 66 |
+
llm_load_print_meta: causal attn = 1
|
| 67 |
+
llm_load_print_meta: pooling type = 0
|
| 68 |
+
llm_load_print_meta: rope type = 0
|
| 69 |
+
llm_load_print_meta: rope scaling = linear
|
| 70 |
+
llm_load_print_meta: freq_base_train = 10000.0
|
| 71 |
+
llm_load_print_meta: freq_scale_train = 1
|
| 72 |
+
llm_load_print_meta: n_ctx_orig_yarn = 8192
|
| 73 |
+
llm_load_print_meta: rope_finetuned = unknown
|
| 74 |
+
llm_load_print_meta: ssm_d_conv = 0
|
| 75 |
+
llm_load_print_meta: ssm_d_inner = 0
|
| 76 |
+
llm_load_print_meta: ssm_d_state = 0
|
| 77 |
+
llm_load_print_meta: ssm_dt_rank = 0
|
| 78 |
+
llm_load_print_meta: ssm_dt_b_c_rms = 0
|
| 79 |
+
llm_load_print_meta: model type = ?B
|
| 80 |
+
llm_load_print_meta: model ftype = BF16
|
| 81 |
+
llm_load_print_meta: model params = 2.25 B
|
| 82 |
+
llm_load_print_meta: model size = 4.20 GiB (16.00 BPW)
|
| 83 |
+
llm_load_print_meta: general.name = n/a
|
| 84 |
+
llm_load_print_meta: BOS token = 1 '<s>'
|
| 85 |
+
llm_load_print_meta: EOS token = 2 '</s>'
|
| 86 |
+
llm_load_print_meta: UNK token = 0 '<unk>'
|
| 87 |
+
llm_load_print_meta: PAD token = 0 '<unk>'
|
| 88 |
+
llm_load_print_meta: LF token = 145 '<0x0A>'
|
| 89 |
+
llm_load_print_meta: EOT token = 5 '<|im_end|>'
|
| 90 |
+
llm_load_print_meta: EOG token = 2 '</s>'
|
| 91 |
+
llm_load_print_meta: EOG token = 5 '<|im_end|>'
|
| 92 |
+
llm_load_print_meta: max token length = 72
|
| 93 |
+
llm_load_tensors: ggml ctx size = 0.20 MiB
|
| 94 |
+
llm_load_tensors: offloading 24 repeating layers to GPU
|
| 95 |
+
llm_load_tensors: offloading non-repeating layers to GPU
|
| 96 |
+
llm_load_tensors: offloaded 25/25 layers to GPU
|
| 97 |
+
llm_load_tensors: Metal buffer size = 4298.39 MiB
|
| 98 |
+
llm_load_tensors: CPU buffer size = 1000.00 MiB
|
| 99 |
+
.......................................................
|
| 100 |
+
llama_new_context_with_model: n_ctx = 8192
|
| 101 |
+
llama_new_context_with_model: n_batch = 512
|
| 102 |
+
llama_new_context_with_model: n_ubatch = 128
|
| 103 |
+
llama_new_context_with_model: flash_attn = 0
|
| 104 |
+
llama_new_context_with_model: freq_base = 10000.0
|
| 105 |
+
llama_new_context_with_model: freq_scale = 1
|
| 106 |
+
ggml_metal_init: allocating
|
| 107 |
+
ggml_metal_init: found device: Apple M3 Max
|
| 108 |
+
ggml_metal_init: picking default device: Apple M3 Max
|
| 109 |
+
ggml_metal_init: using embedded metal library
|
| 110 |
+
ggml_metal_init: GPU name: Apple M3 Max
|
| 111 |
+
ggml_metal_init: GPU family: MTLGPUFamilyApple9 (1009)
|
| 112 |
+
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
|
| 113 |
+
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
|
| 114 |
+
ggml_metal_init: simdgroup reduction support = true
|
| 115 |
+
ggml_metal_init: simdgroup matrix mul. support = true
|
| 116 |
+
ggml_metal_init: hasUnifiedMemory = true
|
| 117 |
+
ggml_metal_init: recommendedMaxWorkingSetSize = 42949.67 MB
|
| 118 |
+
llama_kv_cache_init: Metal KV buffer size = 1536.00 MiB
|
| 119 |
+
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
|
| 120 |
+
llama_new_context_with_model: CPU output buffer size = 0.98 MiB
|
| 121 |
+
llama_new_context_with_model: Metal compute buffer size = 72.00 MiB
|
| 122 |
+
llama_new_context_with_model: CPU compute buffer size = 125.00 MiB
|
| 123 |
+
llama_new_context_with_model: graph nodes = 774
|
| 124 |
+
llama_new_context_with_model: graph splits = 339
|
| 125 |
+
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
|
| 126 |
+
|
| 127 |
+
system_info: n_threads = 15 (n_threads_batch = 15) / 16 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 1 | LLAMAFILE = 1 |
|
| 128 |
+
perplexity: tokenizing the input ..
|
| 129 |
+
perplexity: tokenization took 2392.75 ms
|
| 130 |
+
perplexity: calculating perplexity over 134 chunks, n_ctx=8192, batch_size=512, n_seq=1
|
| 131 |
+
perplexity: 26.29 seconds per pass - ETA 58.72 minutes
|
| 132 |
+
[1]17.0945,[2]17.2430,[3]15.6983,[4]15.5040,[5]14.8664,[6]14.4292,[7]15.3001,[8]14.7921,[9]14.5097,[10]13.8068,[11]14.4200,[12]14.4767,[13]15.5006,[14]15.7598,[15]15.7466,[16]16.2740,[17]16.5636,[18]16.4667,[19]16.5097,[20]16.8117,[21]16.8507,[22]14.8782,[23]15.0531,[24]14.6859,[25]14.1819,[26]13.7495,[27]13.5620,[28]13.3912,[29]13.3431,[30]13.1431,[31]13.3738,[32]13.4801,[33]13.9456,[34]14.2441,[35]14.5410,[36]14.3118,[37]14.3020,[38]14.3775,[39]14.2297,[40]14.2632,[41]14.2385,[42]14.0548,[43]14.0045,[44]14.1658,[45]14.3670,[46]14.2237,[47]14.4546,[48]14.5655,[49]14.8335,[50]15.1038,[51]15.1372,[52]15.3426,[53]15.6530,[54]15.9634,[55]16.0689,[56]15.9065,[57]15.8118,[58]15.5488,[59]15.4459,[60]15.2578,[61]15.3081,[62]15.4391,[63]15.6192,[64]15.6799,[65]15.7079,[66]15.8906,[67]15.8656,[68]15.7574,[69]15.6198,[70]15.5156,[71]15.5100,[72]15.4556,[73]15.4652,[74]15.4087,[75]15.3826,[76]15.3231,[77]15.3801,[78]15.3798,[79]15.3887,[80]15.4246,[81]15.1447,[82]15.1232,[83]14.9963,[84]15.0280,[85]15.0748,[86]15.2635,[87]15.2864,[88]15.4369,[89]15.4888,[90]15.6106,[91]15.6644,[92]15.5051,[93]15.5691,[94]15.5571,[95]15.6902,[96]15.8767,[97]15.9505,[98]16.0444,[99]16.1795,[100]16.2202,[101]16.2466,[102]16.2088,[103]16.1811,[104]16.1649,[105]16.1516,[106]16.0264,[107]15.9021,[108]15.9615,[109]15.9784,[110]15.8923,[111]15.8568,[112]15.7114,[113]15.5749,[114]15.5696,[115]15.5445,[116]15.5536,[117]15.4501,[118]15.3239,[119]15.3171,[120]15.3751,[121]15.3897,[122]15.4121,[123]15.4467,[124]15.4623,[125]15.4566,[126]15.4812,[127]15.5047,[128]15.5819,[129]15.5723,[130]15.5502,[131]15.6053,[132]15.5812,[133]15.5268,[134]15.3799,
|
| 133 |
+
Final estimate: PPL = 15.3799 +/- 0.06263
|
| 134 |
+
|
| 135 |
+
llama_perf_context_print: load time = 757.14 ms
|
| 136 |
+
llama_perf_context_print: prompt eval time = 4094189.23 ms / 1097728 tokens ( 3.73 ms per token, 268.12 tokens per second)
|
| 137 |
+
llama_perf_context_print: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
|
| 138 |
+
llama_perf_context_print: total time = 4170459.06 ms / 1097729 tokens
|
| 139 |
+
ggml_metal_free: deallocating
|
ppl_test_data.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
quanization_results.md
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Full Perplexity Comparison Table for Release Documentation
|
| 2 |
+
|
| 3 |
+
| Quantization Type | PPL(Q) | ln(PPL(Q)/PPL(fp16)) | File Size (G) |
|
| 4 |
+
|-------------------|---------|---------------------|---------------|
|
| 5 |
+
| IQ2_S | 25.3893 | 0.501266 | 1.6 |
|
| 6 |
+
| IQ2_M | 21.6684 | 0.342794 | 1.6 |
|
| 7 |
+
| Q3_K_M | 16.8567 | 0.091687 | 1.8 |
|
| 8 |
+
| IQ3_M | 16.774 | 0.086769 | 1.7 |
|
| 9 |
+
| Q3_K_L | 16.5067 | 0.070705 | 1.8 |
|
| 10 |
+
| IQ4_NL | 15.9602 | 0.037037 | 1.9 |
|
| 11 |
+
| IQ4_XS | 15.9591 | 0.036968 | 1.8 |
|
| 12 |
+
| Q4_K_S | 15.9346 | 0.035431 | 1.9 |
|
| 13 |
+
| Q4_K_M | 15.8651 | 0.031060 | 2.0 |
|
| 14 |
+
| Q5_K_S | 15.4901 | 0.007140 | 2.1 |
|
| 15 |
+
| Q5_K_M | 15.4746 | 0.006139 | 2.2 |
|
| 16 |
+
| Q6_K | 15.3961 | 0.001053 | 2.4 |
|
| 17 |
+
| Q8_0 | 15.3831 | 0.000208 | 2.7 |
|
| 18 |
+
| bf16 | 15.3799 | 0.000000 | 4.2 |
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
---
|
| 22 |
+
|
| 23 |
+
This full table documents all the quantization types tested, showing their respective **Perplexity (PPL)**, **ln(PPL(Q)/PPL(fp16))**, and **file sizes**.
|
quantizations.yaml
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
quantizations:
|
| 2 |
+
- IQ2_S
|
| 3 |
+
- IQ2_M
|
| 4 |
+
- IQ3_M
|
| 5 |
+
- IQ4_NL
|
| 6 |
+
- IQ4_XS
|
| 7 |
+
- Q3_K_L
|
| 8 |
+
- Q3_K_M
|
| 9 |
+
- Q4_K_M
|
| 10 |
+
- Q4_K_S
|
| 11 |
+
- Q5_K_M
|
| 12 |
+
- Q5_K_S
|
| 13 |
+
- Q6_K
|
| 14 |
+
- Q8_0
|
| 15 |
+
|
| 16 |
+
allowed_quantization_types:
|
| 17 |
+
- name: Q4_0
|
| 18 |
+
size: 4.34G
|
| 19 |
+
ppl: +0.4685
|
| 20 |
+
details: Llama-3-8B
|
| 21 |
+
- name: Q4_1
|
| 22 |
+
size: 4.78G
|
| 23 |
+
ppl: +0.4511
|
| 24 |
+
details: Llama-3-8B
|
| 25 |
+
- name: Q5_0
|
| 26 |
+
size: 5.21G
|
| 27 |
+
ppl: +0.1316
|
| 28 |
+
details: Llama-3-8B
|
| 29 |
+
- name: Q5_1
|
| 30 |
+
size: 5.65G
|
| 31 |
+
ppl: +0.1062
|
| 32 |
+
details: Llama-3-8B
|
| 33 |
+
- name: IQ2_XXS
|
| 34 |
+
size: "2.06 bpw"
|
| 35 |
+
type: quantization
|
| 36 |
+
- name: IQ2_XS
|
| 37 |
+
size: "2.31 bpw"
|
| 38 |
+
type: quantization
|
| 39 |
+
- name: IQ2_S
|
| 40 |
+
size: "2.5 bpw"
|
| 41 |
+
type: quantization
|
| 42 |
+
- name: IQ2_M
|
| 43 |
+
size: "2.7 bpw"
|
| 44 |
+
type: quantization
|
| 45 |
+
- name: IQ1_S
|
| 46 |
+
size: "1.56 bpw"
|
| 47 |
+
type: quantization
|
| 48 |
+
- name: IQ1_M
|
| 49 |
+
size: "1.75 bpw"
|
| 50 |
+
type: quantization
|
| 51 |
+
- name: TQ1_0
|
| 52 |
+
size: "1.69 bpw"
|
| 53 |
+
type: ternarization
|
| 54 |
+
- name: TQ2_0
|
| 55 |
+
size: "2.06 bpw"
|
| 56 |
+
type: ternarization
|
| 57 |
+
- name: Q2_K
|
| 58 |
+
size: 2.96G
|
| 59 |
+
ppl: +3.5199
|
| 60 |
+
details: Llama-3-8B
|
| 61 |
+
- name: Q2_K_S
|
| 62 |
+
size: 2.96G
|
| 63 |
+
ppl: +3.1836
|
| 64 |
+
details: Llama-3-8B
|
| 65 |
+
- name: IQ3_XXS
|
| 66 |
+
size: "3.06 bpw"
|
| 67 |
+
type: quantization
|
| 68 |
+
- name: IQ3_S
|
| 69 |
+
size: "3.44 bpw"
|
| 70 |
+
type: quantization
|
| 71 |
+
- name: IQ3_M
|
| 72 |
+
size: "3.66 bpw"
|
| 73 |
+
type: quantization mix
|
| 74 |
+
- name: Q3_K
|
| 75 |
+
alias: Q3_K_M
|
| 76 |
+
- name: IQ3_XS
|
| 77 |
+
size: "3.3 bpw"
|
| 78 |
+
type: quantization
|
| 79 |
+
- name: Q3_K_S
|
| 80 |
+
size: 3.41G
|
| 81 |
+
ppl: +1.6321
|
| 82 |
+
details: Llama-3-8B
|
| 83 |
+
- name: Q3_K_M
|
| 84 |
+
size: 3.74G
|
| 85 |
+
ppl: +0.6569
|
| 86 |
+
details: Llama-3-8B
|
| 87 |
+
- name: Q3_K_L
|
| 88 |
+
size: 4.03G
|
| 89 |
+
ppl: +0.5562
|
| 90 |
+
details: Llama-3-8B
|
| 91 |
+
- name: IQ4_NL
|
| 92 |
+
size: "4.50 bpw"
|
| 93 |
+
type: non-linear quantization
|
| 94 |
+
- name: IQ4_XS
|
| 95 |
+
size: "4.25 bpw"
|
| 96 |
+
type: non-linear quantization
|
| 97 |
+
- name: Q4_K
|
| 98 |
+
alias: Q4_K_M
|
| 99 |
+
- name: Q4_K_S
|
| 100 |
+
size: 4.37G
|
| 101 |
+
ppl: +0.2689
|
| 102 |
+
details: Llama-3-8B
|
| 103 |
+
- name: Q4_K_M
|
| 104 |
+
size: 4.58G
|
| 105 |
+
ppl: +0.1754
|
| 106 |
+
details: Llama-3-8B
|
| 107 |
+
- name: Q5_K
|
| 108 |
+
alias: Q5_K_M
|
| 109 |
+
- name: Q5_K_S
|
| 110 |
+
size: 5.21G
|
| 111 |
+
ppl: +0.1049
|
| 112 |
+
details: Llama-3-8B
|
| 113 |
+
- name: Q5_K_M
|
| 114 |
+
size: 5.33G
|
| 115 |
+
ppl: +0.0569
|
| 116 |
+
details: Llama-3-8B
|
| 117 |
+
- name: Q6_K
|
| 118 |
+
size: 6.14G
|
| 119 |
+
ppl: +0.0217
|
| 120 |
+
details: Llama-3-8B
|
| 121 |
+
- name: Q8_0
|
| 122 |
+
size: 7.96G
|
| 123 |
+
ppl: +0.0026
|
| 124 |
+
details: Llama-3-8B
|
| 125 |
+
- name: F16
|
| 126 |
+
size: 14.00G
|
| 127 |
+
ppl: +0.0020
|
| 128 |
+
details: Mistral-7B
|
| 129 |
+
- name: BF16
|
| 130 |
+
size: 14.00G
|
| 131 |
+
ppl: -0.0050
|
| 132 |
+
details: Mistral-7B
|
| 133 |
+
- name: F32
|
| 134 |
+
size: 26.00G
|
| 135 |
+
details: 7B
|
| 136 |
+
- name: COPY
|
| 137 |
+
description: Only copy tensors, no quantizing
|
quantize.ipynb
ADDED
|
@@ -0,0 +1,599 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 2,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"from collections import defaultdict\n",
|
| 10 |
+
"import math\n",
|
| 11 |
+
"import multiprocessing\n",
|
| 12 |
+
"import json\n",
|
| 13 |
+
"import os\n",
|
| 14 |
+
"import re\n",
|
| 15 |
+
"import subprocess\n",
|
| 16 |
+
"import yaml"
|
| 17 |
+
]
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"cell_type": "code",
|
| 21 |
+
"execution_count": 5,
|
| 22 |
+
"metadata": {},
|
| 23 |
+
"outputs": [],
|
| 24 |
+
"source": [
|
| 25 |
+
"# Define base model name and default values for parameters\n",
|
| 26 |
+
"path_to_llamacpp = '/Users/macdev/Downloads/build/bin'\n",
|
| 27 |
+
"base_model_name = 'salamandra-2b-instruct'\n"
|
| 28 |
+
]
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"cell_type": "code",
|
| 32 |
+
"execution_count": 8,
|
| 33 |
+
"metadata": {},
|
| 34 |
+
"outputs": [],
|
| 35 |
+
"source": [
|
| 36 |
+
"def extract_from_config(config_file):\n",
|
| 37 |
+
" \"\"\"Extract parameters like context size, rope frequency base, and other sampling settings from a config JSON file.\"\"\"\n",
|
| 38 |
+
" with open(config_file, 'r') as file:\n",
|
| 39 |
+
" config_data = json.load(file)\n",
|
| 40 |
+
"\n",
|
| 41 |
+
" # Extract parameters if present\n",
|
| 42 |
+
" params = {}\n",
|
| 43 |
+
" params['ctx_size'] = config_data.get(\"max_position_embeddings\") # Context size\n",
|
| 44 |
+
" params['rope_freq_base'] = config_data.get(\"rope_theta\") # RoPE frequency base\n",
|
| 45 |
+
" params['rope_scaling'] = config_data.get(\"rope_scaling\") # RoPE scaling factor\n",
|
| 46 |
+
" params['rope_scaling_type'] = config_data.get(\"rope_scaling_type\") # RoPE scaling type\n",
|
| 47 |
+
" params['torch_dtype'] = config_data.get(\"torch_dtype\") # Torch data type\n",
|
| 48 |
+
" params['top_p'] = config_data.get(\"sampling.top_p\") # Top-p sampling\n",
|
| 49 |
+
" params['temp'] = config_data.get(\"sampling.temperature\") # Sampling temperature\n",
|
| 50 |
+
" params['repeat_penalty'] = config_data.get(\"sampling.repeat_penalty\") # Repetition penalty\n",
|
| 51 |
+
" params['repeat_last_n'] = config_data.get(\"sampling.repeat_last_n\") # Last N tokens for repetition penalty\n",
|
| 52 |
+
" params['min_p'] = config_data.get(\"sampling.min_p\") # Minimum probability sampling\n",
|
| 53 |
+
" params['top_k'] = config_data.get(\"sampling.top_k\") # Top-k sampling\n",
|
| 54 |
+
" params['presence_penalty'] = config_data.get(\"sampling.presence_penalty\") # Presence penalty for repeat tokens\n",
|
| 55 |
+
" params['frequency_penalty'] = config_data.get(\"sampling.frequency_penalty\") # Frequency penalty for repeat tokens\n",
|
| 56 |
+
" params['mirostat'] = config_data.get(\"sampling.mirostat\") # Mirostat sampling\n",
|
| 57 |
+
" params['mirostat_lr'] = config_data.get(\"sampling.mirostat_lr\") # Mirostat learning rate\n",
|
| 58 |
+
" params['mirostat_ent'] = config_data.get(\"sampling.mirostat_ent\") # Mirostat entropy target\n",
|
| 59 |
+
" params['tfs'] = config_data.get(\"sampling.tfs\") # Tail free sampling\n",
|
| 60 |
+
" params['typical'] = config_data.get(\"sampling.typical\") # Locally typical sampling\n",
|
| 61 |
+
"\n",
|
| 62 |
+
" return params\n"
|
| 63 |
+
]
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"cell_type": "code",
|
| 67 |
+
"execution_count": 7,
|
| 68 |
+
"metadata": {},
|
| 69 |
+
"outputs": [],
|
| 70 |
+
"source": [
|
| 71 |
+
"unquantized = defaultdict(lambda: \"fp16\")\n",
|
| 72 |
+
"unquantized[\"float32\"] = \"fp32\"\n",
|
| 73 |
+
"unquantized[\"float16\"] = \"fp16\"\n",
|
| 74 |
+
"unquantized[\"bfloat16\"] = \"bf16\""
|
| 75 |
+
]
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"cell_type": "code",
|
| 79 |
+
"execution_count": 6,
|
| 80 |
+
"metadata": {},
|
| 81 |
+
"outputs": [],
|
| 82 |
+
"source": [
|
| 83 |
+
"def extract_from_generation_config(generation_config_file):\n",
|
| 84 |
+
" \"\"\"Extract generation-specific parameters relevant to llama-perplexity if available.\"\"\"\n",
|
| 85 |
+
" with open(generation_config_file, 'r') as file:\n",
|
| 86 |
+
" generation_data = json.load(file)\n",
|
| 87 |
+
" \n",
|
| 88 |
+
" # Extract and map only parameters useful for llama-perplexity\n",
|
| 89 |
+
" params = {}\n",
|
| 90 |
+
" params['top_p'] = generation_data.get(\"top_p\") # Top-p sampling\n",
|
| 91 |
+
" params['temp'] = generation_data.get(\"temperature\") # Sampling temperature\n",
|
| 92 |
+
" params['repeat_penalty'] = generation_data.get(\"repetition_penalty\") # Repetition penalty\n",
|
| 93 |
+
" params['repeat_last_n'] = generation_data.get(\"repeat_last_n\") # Last N tokens for repetition penalty\n",
|
| 94 |
+
" params['top_k'] = generation_data.get(\"top_k\") # Top-k sampling (if present)\n",
|
| 95 |
+
" params['presence_penalty'] = generation_data.get(\"presence_penalty\") # Presence penalty\n",
|
| 96 |
+
" params['frequency_penalty'] = generation_data.get(\"frequency_penalty\")# Frequency penalty\n",
|
| 97 |
+
"\n",
|
| 98 |
+
" # Remove None values to avoid overwriting defaults\n",
|
| 99 |
+
" params = {key: value for key, value in params.items() if value is not None}\n",
|
| 100 |
+
"\n",
|
| 101 |
+
" return params\n"
|
| 102 |
+
]
|
| 103 |
+
},
|
| 104 |
+
{
|
| 105 |
+
"cell_type": "code",
|
| 106 |
+
"execution_count": 9,
|
| 107 |
+
"metadata": {},
|
| 108 |
+
"outputs": [],
|
| 109 |
+
"source": [
|
| 110 |
+
"def get_parameters(use_temp=False):\n",
|
| 111 |
+
" \"\"\"Retrieve parameters from the configuration files or use defaults, preferring generation_config if available.\"\"\"\n",
|
| 112 |
+
" # Initialize default parameters\n",
|
| 113 |
+
" config_params = dict()\n",
|
| 114 |
+
"\n",
|
| 115 |
+
" # Extract parameters from config.json, if available\n",
|
| 116 |
+
" try:\n",
|
| 117 |
+
" config_params.update(extract_from_config('config.json'))\n",
|
| 118 |
+
" except FileNotFoundError:\n",
|
| 119 |
+
" print(\"config.json not found. Using default values.\")\n",
|
| 120 |
+
"\n",
|
| 121 |
+
" # Extract parameters from generation_config.json, if available and prefer these values\n",
|
| 122 |
+
" try:\n",
|
| 123 |
+
" gen_params = extract_from_generation_config('generation_config.json')\n",
|
| 124 |
+
" # Update config_params with values from gen_params, if they are not None\n",
|
| 125 |
+
" for key, value in gen_params.items():\n",
|
| 126 |
+
" if value is not None:\n",
|
| 127 |
+
" config_params[key] = value\n",
|
| 128 |
+
" except FileNotFoundError:\n",
|
| 129 |
+
" print(\"generation_config.json not found. Using default generation values.\")\n",
|
| 130 |
+
"\n",
|
| 131 |
+
" # Ensure that temperature ('temp') is never used\n",
|
| 132 |
+
" if 'temp' in config_params and use_temp is False:\n",
|
| 133 |
+
" config_params['temp'] = 0 # Set temperature to 0\n",
|
| 134 |
+
"\n",
|
| 135 |
+
" return config_params\n"
|
| 136 |
+
]
|
| 137 |
+
},
|
| 138 |
+
{
|
| 139 |
+
"cell_type": "code",
|
| 140 |
+
"execution_count": 10,
|
| 141 |
+
"metadata": {},
|
| 142 |
+
"outputs": [
|
| 143 |
+
{
|
| 144 |
+
"name": "stdout",
|
| 145 |
+
"output_type": "stream",
|
| 146 |
+
"text": [
|
| 147 |
+
"{'ctx_size': 8192, 'rope_freq_base': 10000.0, 'rope_scaling': None, 'rope_scaling_type': None, 'torch_dtype': 'bfloat16', 'top_p': None, 'temp': 0, 'repeat_penalty': 1.2, 'repeat_last_n': None, 'min_p': None, 'top_k': None, 'presence_penalty': None, 'frequency_penalty': None, 'mirostat': None, 'mirostat_lr': None, 'mirostat_ent': None, 'tfs': None, 'typical': None}\n"
|
| 148 |
+
]
|
| 149 |
+
}
|
| 150 |
+
],
|
| 151 |
+
"source": [
|
| 152 |
+
"# Extract configuration parameters\n",
|
| 153 |
+
"config_params = get_parameters()\n",
|
| 154 |
+
"print(config_params)\n",
|
| 155 |
+
"\n",
|
| 156 |
+
"base_precision = unquantized[config_params[\"torch_dtype\"]]\n",
|
| 157 |
+
"\n",
|
| 158 |
+
"base_model = f'{base_model_name}_{base_precision}.gguf'\n",
|
| 159 |
+
"base_perplexity_file = f\"perplexity_{base_precision}.txt\"\n",
|
| 160 |
+
"\n",
|
| 161 |
+
"threads = max(multiprocessing.cpu_count() - 1, 1)\n",
|
| 162 |
+
"batch_size = 512\n",
|
| 163 |
+
"ubatch_size = 128\n",
|
| 164 |
+
"dataset_file = \"imatrix/oscar/imatrix-dataset.txt\" \n",
|
| 165 |
+
"ppl_file = \"ppl_test_data.txt\""
|
| 166 |
+
]
|
| 167 |
+
},
|
| 168 |
+
{
|
| 169 |
+
"cell_type": "code",
|
| 170 |
+
"execution_count": 3,
|
| 171 |
+
"metadata": {},
|
| 172 |
+
"outputs": [
|
| 173 |
+
{
|
| 174 |
+
"name": "stdout",
|
| 175 |
+
"output_type": "stream",
|
| 176 |
+
"text": [
|
| 177 |
+
"Quantization types: ['IQ2_S', 'IQ2_M', 'IQ3_M', 'IQ4_NL', 'IQ4_XS', 'Q3_K_L', 'Q3_K_M', 'Q4_K_M', 'Q4_K_S', 'Q5_K_M', 'Q5_K_S', 'Q6_K', 'Q8_0']\n"
|
| 178 |
+
]
|
| 179 |
+
}
|
| 180 |
+
],
|
| 181 |
+
"source": [
|
| 182 |
+
"# Load YAML file and extract quantization types\n",
|
| 183 |
+
"yaml_file = 'quantizations.yaml'\n",
|
| 184 |
+
"with open(yaml_file, 'r') as file:\n",
|
| 185 |
+
" data = yaml.safe_load(file)\n",
|
| 186 |
+
"\n",
|
| 187 |
+
"# Extract the list of quantization types\n",
|
| 188 |
+
"quantization_types = data['quantizations']\n",
|
| 189 |
+
"print(\"Quantization types: \", quantization_types)"
|
| 190 |
+
]
|
| 191 |
+
},
|
| 192 |
+
{
|
| 193 |
+
"cell_type": "code",
|
| 194 |
+
"execution_count": 12,
|
| 195 |
+
"metadata": {},
|
| 196 |
+
"outputs": [],
|
| 197 |
+
"source": [
|
| 198 |
+
"# Quantization parameters\n",
|
| 199 |
+
"use_leave_output_tensor = True # Set to False if you don't want to use --leave-output-tensor\n",
|
| 200 |
+
"\n",
|
| 201 |
+
"# Optional importance matrix path (set to None if you don't want to include --imatrix)\n",
|
| 202 |
+
"imatrix_path = \"imatrix/oscar/imatrix.dat\" "
|
| 203 |
+
]
|
| 204 |
+
},
|
| 205 |
+
{
|
| 206 |
+
"cell_type": "code",
|
| 207 |
+
"execution_count": 13,
|
| 208 |
+
"metadata": {},
|
| 209 |
+
"outputs": [],
|
| 210 |
+
"source": [
|
| 211 |
+
"def quantize_model(\n",
|
| 212 |
+
" quantization_type, \n",
|
| 213 |
+
" base_model, \n",
|
| 214 |
+
" base_model_name, \n",
|
| 215 |
+
" path_to_llamacpp=\"\",\n",
|
| 216 |
+
" imatrix_path=None, \n",
|
| 217 |
+
" use_leave_output_tensor=True,\n",
|
| 218 |
+
" output_dir=\".\"\n",
|
| 219 |
+
"):\n",
|
| 220 |
+
" \"\"\"\n",
|
| 221 |
+
" Quantize the base model into the specified quantization type.\n",
|
| 222 |
+
"\n",
|
| 223 |
+
" Parameters:\n",
|
| 224 |
+
" - quantization_type (str): The type of quantization (e.g., \"Q4_0\", \"Q5_K_M\").\n",
|
| 225 |
+
" - base_model (str): Path to the base model file (e.g., \"salamandra-2b_bf16.gguf\").\n",
|
| 226 |
+
" - base_model_name (str): The base name of the model (e.g., \"salamandra-2b\").\n",
|
| 227 |
+
" - path_to_llamacpp (str): Path to the llama-quantize binary.\n",
|
| 228 |
+
" - imatrix_path (str, optional): Path to the importance matrix file. Default is None.\n",
|
| 229 |
+
" - use_leave_output_tensor (bool): Whether to include the --leave-output-tensor flag. Default is True.\n",
|
| 230 |
+
" - output_dir (str): Directory where the quantized models and logs will be saved. Default is current directory.\n",
|
| 231 |
+
"\n",
|
| 232 |
+
" Returns:\n",
|
| 233 |
+
" - None\n",
|
| 234 |
+
" \"\"\"\n",
|
| 235 |
+
" # Construct the output model path\n",
|
| 236 |
+
" output_model = os.path.join(output_dir, f\"{base_model_name}_{quantization_type}.gguf\")\n",
|
| 237 |
+
"\n",
|
| 238 |
+
" # Check if the quantized model already exists\n",
|
| 239 |
+
" if os.path.exists(output_model):\n",
|
| 240 |
+
" print(f\"Quantized model {output_model} already exists. Skipping quantization.\")\n",
|
| 241 |
+
" return\n",
|
| 242 |
+
"\n",
|
| 243 |
+
" # Build the llama-quantize command\n",
|
| 244 |
+
" command_parts = [\n",
|
| 245 |
+
" os.path.join(path_to_llamacpp, \"llama-quantize\")\n",
|
| 246 |
+
" ]\n",
|
| 247 |
+
"\n",
|
| 248 |
+
" # Conditionally add the --imatrix argument if the path is provided\n",
|
| 249 |
+
" if imatrix_path:\n",
|
| 250 |
+
" command_parts.append(f\"--imatrix {imatrix_path}\")\n",
|
| 251 |
+
"\n",
|
| 252 |
+
" # Conditionally add the --leave-output-tensor argument based on the external boolean\n",
|
| 253 |
+
" if use_leave_output_tensor:\n",
|
| 254 |
+
" command_parts.append(\"--leave-output-tensor\")\n",
|
| 255 |
+
"\n",
|
| 256 |
+
" # Add base model, output model, and quantization type\n",
|
| 257 |
+
" command_parts.extend([\n",
|
| 258 |
+
" f\"{base_model}\",\n",
|
| 259 |
+
" f\"\\\"{output_model}\\\"\",\n",
|
| 260 |
+
" f\"{quantization_type}\"\n",
|
| 261 |
+
" ])\n",
|
| 262 |
+
"\n",
|
| 263 |
+
" # Redirect output to a log file for each quantization type\n",
|
| 264 |
+
" log_file = os.path.join(output_dir, f\"{quantization_type}_log.txt\")\n",
|
| 265 |
+
" command_parts.append(f\"> \\\"{log_file}\\\" 2>&1\")\n",
|
| 266 |
+
"\n",
|
| 267 |
+
" # Join the command parts into a single command string\n",
|
| 268 |
+
" quantize_command = \" \".join(command_parts)\n",
|
| 269 |
+
"\n",
|
| 270 |
+
" # Run the quantization command\n",
|
| 271 |
+
" print(f\"Quantizing model to {quantization_type} format with command: {quantize_command}\")\n",
|
| 272 |
+
" result = subprocess.run(quantize_command, shell=True, text=True)\n",
|
| 273 |
+
" if result.returncode != 0:\n",
|
| 274 |
+
" print(f\"Error during quantization to {quantization_type}. Check {log_file} for details.\")\n",
|
| 275 |
+
" else:\n",
|
| 276 |
+
" print(f\"Successfully quantized model to {quantization_type} and saved as {output_model}.\")\n"
|
| 277 |
+
]
|
| 278 |
+
},
|
| 279 |
+
{
|
| 280 |
+
"cell_type": "code",
|
| 281 |
+
"execution_count": 14,
|
| 282 |
+
"metadata": {},
|
| 283 |
+
"outputs": [],
|
| 284 |
+
"source": [
|
| 285 |
+
"def run_command(command):\n",
|
| 286 |
+
" \"\"\"Function to run a command and capture output\"\"\"\n",
|
| 287 |
+
" print(f\"Running command: {command}\")\n",
|
| 288 |
+
" result = subprocess.run(command, shell=True, capture_output=True, text=True)\n",
|
| 289 |
+
" if result.returncode != 0:\n",
|
| 290 |
+
" print(f\"Error executing command: {result.stderr}\")\n",
|
| 291 |
+
" return result.stdout\n"
|
| 292 |
+
]
|
| 293 |
+
},
|
| 294 |
+
{
|
| 295 |
+
"cell_type": "code",
|
| 296 |
+
"execution_count": 15,
|
| 297 |
+
"metadata": {},
|
| 298 |
+
"outputs": [],
|
| 299 |
+
"source": [
|
| 300 |
+
"def extract_perplexity(output):\n",
|
| 301 |
+
" \"\"\"extract perplexity from the output\"\"\"\n",
|
| 302 |
+
" match = re.search(r\"Final estimate: PPL = ([\\d.]+)\", output)\n",
|
| 303 |
+
" if match:\n",
|
| 304 |
+
" return float(match.group(1))\n",
|
| 305 |
+
" return None\n"
|
| 306 |
+
]
|
| 307 |
+
},
|
| 308 |
+
{
|
| 309 |
+
"cell_type": "code",
|
| 310 |
+
"execution_count": 16,
|
| 311 |
+
"metadata": {},
|
| 312 |
+
"outputs": [],
|
| 313 |
+
"source": [
|
| 314 |
+
"def build_command(model, output_file, ppl_file, config_params, threads=8, batch_size=512, ubatch_size=128):\n",
|
| 315 |
+
" \"\"\"Build the perplexity command based on the provided parameters.\"\"\"\n",
|
| 316 |
+
" command_parts = [\n",
|
| 317 |
+
" \"/Users/macdev/Downloads/build/bin/llama-perplexity\",\n",
|
| 318 |
+
" f\"-m {model}\",\n",
|
| 319 |
+
" f\"-f {ppl_file}\",\n",
|
| 320 |
+
" \"--perplexity\",\n",
|
| 321 |
+
" ]\n",
|
| 322 |
+
"\n",
|
| 323 |
+
" # Add parameters only if they are set in config_params\n",
|
| 324 |
+
" if config_params.get('ctx_size') is not None:\n",
|
| 325 |
+
" command_parts.append(f\"--ctx-size {config_params['ctx_size']}\")\n",
|
| 326 |
+
" if config_params.get('rope_freq_base') is not None:\n",
|
| 327 |
+
" command_parts.append(f\"--rope-freq-base {config_params['rope_freq_base']}\")\n",
|
| 328 |
+
" if config_params.get('rope_freq_scale') is not None:\n",
|
| 329 |
+
" command_parts.append(f\"--rope-freq-scale {config_params['rope_freq_scale']}\")\n",
|
| 330 |
+
" if config_params.get('rope_scaling_type') is not None:\n",
|
| 331 |
+
" command_parts.append(f\"--rope-scaling {config_params['rope_scaling_type']}\")\n",
|
| 332 |
+
"\n",
|
| 333 |
+
" # Add sampling-related parameters if they are set\n",
|
| 334 |
+
" if config_params.get('top_p') is not None:\n",
|
| 335 |
+
" command_parts.append(f\"--top-p {config_params['top_p']}\")\n",
|
| 336 |
+
" if config_params.get('repeat_penalty') is not None:\n",
|
| 337 |
+
" command_parts.append(f\"--repeat-penalty {config_params['repeat_penalty']}\")\n",
|
| 338 |
+
" if config_params.get('repeat_last_n') is not None:\n",
|
| 339 |
+
" command_parts.append(f\"--repeat-last-n {config_params['repeat_last_n']}\")\n",
|
| 340 |
+
"\n",
|
| 341 |
+
" # Do not include `temp` as it's set to 0 in `get_parameters` if `use_temp` is False\n",
|
| 342 |
+
" # Only add if temp is non-zero (if `use_temp` is True in get_parameters)\n",
|
| 343 |
+
" if config_params.get('temp') is not None and config_params['temp'] != 0:\n",
|
| 344 |
+
" command_parts.append(f\"--temp {config_params['temp']}\")\n",
|
| 345 |
+
"\n",
|
| 346 |
+
" # Add fixed parameters for threads and batch sizes\n",
|
| 347 |
+
" command_parts.extend([\n",
|
| 348 |
+
" f\"--threads {threads}\",\n",
|
| 349 |
+
" f\"--batch-size {batch_size}\",\n",
|
| 350 |
+
" f\"--ubatch-size {ubatch_size}\",\n",
|
| 351 |
+
" ])\n",
|
| 352 |
+
"\n",
|
| 353 |
+
" # Redirect output to file\n",
|
| 354 |
+
" command = \" \".join(command_parts) + f\" > {output_file} 2>&1\"\n",
|
| 355 |
+
" return command\n"
|
| 356 |
+
]
|
| 357 |
+
},
|
| 358 |
+
{
|
| 359 |
+
"cell_type": "code",
|
| 360 |
+
"execution_count": 17,
|
| 361 |
+
"metadata": {},
|
| 362 |
+
"outputs": [],
|
| 363 |
+
"source": [
|
| 364 |
+
"# Measure perplexity for the base model\n",
|
| 365 |
+
"if os.path.exists(f'perplexity_{base_precision}.txt'):\n",
|
| 366 |
+
" with open(base_perplexity_file, 'r') as file:\n",
|
| 367 |
+
" base_output = file.read()\n",
|
| 368 |
+
"else:\n",
|
| 369 |
+
" base_command = build_command(base_model, base_perplexity_file, ppl_file, config_params=config_params, threads=threads, batch_size=batch_size, ubatch_size= ubatch_size)\n",
|
| 370 |
+
" base_output = run_command(base_command)\n",
|
| 371 |
+
"base_perplexity = extract_perplexity(base_output)\n",
|
| 372 |
+
"calculated_perplexity_recently = False # This will be set to True later"
|
| 373 |
+
]
|
| 374 |
+
},
|
| 375 |
+
{
|
| 376 |
+
"cell_type": "code",
|
| 377 |
+
"execution_count": 26,
|
| 378 |
+
"metadata": {},
|
| 379 |
+
"outputs": [
|
| 380 |
+
{
|
| 381 |
+
"name": "stdout",
|
| 382 |
+
"output_type": "stream",
|
| 383 |
+
"text": [
|
| 384 |
+
"Quantizing model to IQ2_S format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_IQ2_S.gguf\" IQ2_S > \"./IQ2_S_log.txt\" 2>&1\n",
|
| 385 |
+
"Successfully quantized model to IQ2_S and saved as ./salamandra-2b-instruct_IQ2_S.gguf.\n",
|
| 386 |
+
"Quantizing model to IQ2_M format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_IQ2_M.gguf\" IQ2_M > \"./IQ2_M_log.txt\" 2>&1\n",
|
| 387 |
+
"Successfully quantized model to IQ2_M and saved as ./salamandra-2b-instruct_IQ2_M.gguf.\n",
|
| 388 |
+
"Quantizing model to IQ3_M format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_IQ3_M.gguf\" IQ3_M > \"./IQ3_M_log.txt\" 2>&1\n",
|
| 389 |
+
"Successfully quantized model to IQ3_M and saved as ./salamandra-2b-instruct_IQ3_M.gguf.\n",
|
| 390 |
+
"Quantizing model to IQ4_NL format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_IQ4_NL.gguf\" IQ4_NL > \"./IQ4_NL_log.txt\" 2>&1\n",
|
| 391 |
+
"Successfully quantized model to IQ4_NL and saved as ./salamandra-2b-instruct_IQ4_NL.gguf.\n",
|
| 392 |
+
"Quantizing model to IQ4_XS format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_IQ4_XS.gguf\" IQ4_XS > \"./IQ4_XS_log.txt\" 2>&1\n",
|
| 393 |
+
"Successfully quantized model to IQ4_XS and saved as ./salamandra-2b-instruct_IQ4_XS.gguf.\n",
|
| 394 |
+
"Quantizing model to Q3_K_L format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_Q3_K_L.gguf\" Q3_K_L > \"./Q3_K_L_log.txt\" 2>&1\n",
|
| 395 |
+
"Successfully quantized model to Q3_K_L and saved as ./salamandra-2b-instruct_Q3_K_L.gguf.\n",
|
| 396 |
+
"Quantizing model to Q3_K_M format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_Q3_K_M.gguf\" Q3_K_M > \"./Q3_K_M_log.txt\" 2>&1\n",
|
| 397 |
+
"Successfully quantized model to Q3_K_M and saved as ./salamandra-2b-instruct_Q3_K_M.gguf.\n",
|
| 398 |
+
"Quantizing model to Q4_K_M format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_Q4_K_M.gguf\" Q4_K_M > \"./Q4_K_M_log.txt\" 2>&1\n",
|
| 399 |
+
"Successfully quantized model to Q4_K_M and saved as ./salamandra-2b-instruct_Q4_K_M.gguf.\n",
|
| 400 |
+
"Quantizing model to Q4_K_S format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_Q4_K_S.gguf\" Q4_K_S > \"./Q4_K_S_log.txt\" 2>&1\n",
|
| 401 |
+
"Successfully quantized model to Q4_K_S and saved as ./salamandra-2b-instruct_Q4_K_S.gguf.\n",
|
| 402 |
+
"Quantizing model to Q5_K_M format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_Q5_K_M.gguf\" Q5_K_M > \"./Q5_K_M_log.txt\" 2>&1\n",
|
| 403 |
+
"Successfully quantized model to Q5_K_M and saved as ./salamandra-2b-instruct_Q5_K_M.gguf.\n",
|
| 404 |
+
"Quantizing model to Q5_K_S format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_Q5_K_S.gguf\" Q5_K_S > \"./Q5_K_S_log.txt\" 2>&1\n",
|
| 405 |
+
"Successfully quantized model to Q5_K_S and saved as ./salamandra-2b-instruct_Q5_K_S.gguf.\n",
|
| 406 |
+
"Quantizing model to Q6_K format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_Q6_K.gguf\" Q6_K > \"./Q6_K_log.txt\" 2>&1\n",
|
| 407 |
+
"Successfully quantized model to Q6_K and saved as ./salamandra-2b-instruct_Q6_K.gguf.\n",
|
| 408 |
+
"Quantizing model to Q8_0 format with command: /Users/macdev/Downloads/build/bin/llama-quantize --imatrix imatrix/oscar/imatrix.dat --leave-output-tensor salamandra-2b-instruct_bf16.gguf \"./salamandra-2b-instruct_Q8_0.gguf\" Q8_0 > \"./Q8_0_log.txt\" 2>&1\n",
|
| 409 |
+
"Successfully quantized model to Q8_0 and saved as ./salamandra-2b-instruct_Q8_0.gguf.\n"
|
| 410 |
+
]
|
| 411 |
+
}
|
| 412 |
+
],
|
| 413 |
+
"source": [
|
| 414 |
+
"# Quantize the models\n",
|
| 415 |
+
"for quant in quantization_types:\n",
|
| 416 |
+
" quantize_model(\n",
|
| 417 |
+
" quantization_type=quant,\n",
|
| 418 |
+
" base_model=base_model,\n",
|
| 419 |
+
" base_model_name=base_model_name,\n",
|
| 420 |
+
" path_to_llamacpp=path_to_llamacpp,\n",
|
| 421 |
+
" imatrix_path=imatrix_path,\n",
|
| 422 |
+
" use_leave_output_tensor=use_leave_output_tensor,\n",
|
| 423 |
+
" )"
|
| 424 |
+
]
|
| 425 |
+
},
|
| 426 |
+
{
|
| 427 |
+
"cell_type": "code",
|
| 428 |
+
"execution_count": 16,
|
| 429 |
+
"metadata": {},
|
| 430 |
+
"outputs": [
|
| 431 |
+
{
|
| 432 |
+
"name": "stdout",
|
| 433 |
+
"output_type": "stream",
|
| 434 |
+
"text": [
|
| 435 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_IQ2_M.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_IQ2_M.txt 2>&1\n",
|
| 436 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_IQ3_M.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_IQ3_M.txt 2>&1\n",
|
| 437 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_IQ4_NL.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_IQ4_NL.txt 2>&1\n",
|
| 438 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_IQ4_XS.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_IQ4_XS.txt 2>&1\n",
|
| 439 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_Q3_K_L.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_Q3_K_L.txt 2>&1\n",
|
| 440 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_Q3_K_M.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_Q3_K_M.txt 2>&1\n",
|
| 441 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_Q4_K_M.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_Q4_K_M.txt 2>&1\n",
|
| 442 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_Q4_K_S.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_Q4_K_S.txt 2>&1\n",
|
| 443 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_Q5_K_M.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_Q5_K_M.txt 2>&1\n",
|
| 444 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_Q5_K_S.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_Q5_K_S.txt 2>&1\n",
|
| 445 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_Q6_K.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_Q6_K.txt 2>&1\n",
|
| 446 |
+
"Running command: /Users/macdev/Downloads/build/bin/llama-perplexity -m salamandra-2b-instruct_Q8_0.gguf -f ppl_test_data.txt --perplexity --ctx-size 8192 --rope-freq-base 10000.0 --repeat-penalty 1.2 --threads 15 --batch-size 512 --ubatch-size 128 > perplexity_Q8_0.txt 2>&1\n"
|
| 447 |
+
]
|
| 448 |
+
}
|
| 449 |
+
],
|
| 450 |
+
"source": [
|
| 451 |
+
"# Measure perplexity for each quantized model\n",
|
| 452 |
+
"perplexity_results = dict()\n",
|
| 453 |
+
"perplexity_results[base_precision] = base_perplexity\n",
|
| 454 |
+
"for quant in quantization_types:\n",
|
| 455 |
+
" calculated_perplexity_recently = True\n",
|
| 456 |
+
" \n",
|
| 457 |
+
" model = f\"{base_model_name}_{quant}.gguf\"\n",
|
| 458 |
+
" output_file = f\"perplexity_{quant}.txt\"\n",
|
| 459 |
+
"\n",
|
| 460 |
+
" command = build_command(model, output_file, ppl_file, config_params=config_params, threads=threads, batch_size=batch_size, ubatch_size= ubatch_size)\n",
|
| 461 |
+
" output = run_command(command)\n",
|
| 462 |
+
"\n",
|
| 463 |
+
" perplexity = extract_perplexity(output)\n",
|
| 464 |
+
" perplexity_results[quant] = perplexity"
|
| 465 |
+
]
|
| 466 |
+
},
|
| 467 |
+
{
|
| 468 |
+
"cell_type": "code",
|
| 469 |
+
"execution_count": null,
|
| 470 |
+
"metadata": {},
|
| 471 |
+
"outputs": [],
|
| 472 |
+
"source": [
|
| 473 |
+
"# load previous measurements if we didnt just measure perplexity for each quantized model\n",
|
| 474 |
+
"if not calculated_perplexity_recently:\n",
|
| 475 |
+
" perplexity_results = dict()\n",
|
| 476 |
+
" perplexity_results[base_precision] = base_perplexity\n",
|
| 477 |
+
"\n",
|
| 478 |
+
" for quant in quantization_types:\n",
|
| 479 |
+
" output_file = f\"perplexity_{quant}.txt\"\n",
|
| 480 |
+
" try:\n",
|
| 481 |
+
" with open(output_file, 'r') as file:\n",
|
| 482 |
+
" output = file.read()\n",
|
| 483 |
+
" perplexity = extract_perplexity(output)\n",
|
| 484 |
+
" except FileNotFoundError:\n",
|
| 485 |
+
" print(f\"Output file {output_file} not found.\")\n",
|
| 486 |
+
" perplexity = None\n",
|
| 487 |
+
"\n",
|
| 488 |
+
" perplexity_results[quant] = perplexity\n",
|
| 489 |
+
"\n",
|
| 490 |
+
" # Calculate ln(PPL(Q)/PPL(fp16)) and generate the table\n",
|
| 491 |
+
" print(\"\\nPerplexity Comparison Table:\")\n",
|
| 492 |
+
" print(f\"{'Quantization Type':<20} {'PPL(Q)':<10} {'ln(PPL(Q)/PPL(fp16))':<25}\")\n",
|
| 493 |
+
" print(\"=\" * 55)\n",
|
| 494 |
+
" for quant, ppl in perplexity_results.items():\n",
|
| 495 |
+
" if ppl and base_perplexity:\n",
|
| 496 |
+
" ln_ratio = round(math.log(ppl / base_perplexity), 6)\n",
|
| 497 |
+
" print(f\"{quant:<20} {ppl:<10} {ln_ratio:<25}\")\n",
|
| 498 |
+
"\n",
|
| 499 |
+
" print(perplexity_results)\n"
|
| 500 |
+
]
|
| 501 |
+
},
|
| 502 |
+
{
|
| 503 |
+
"cell_type": "code",
|
| 504 |
+
"execution_count": null,
|
| 505 |
+
"metadata": {},
|
| 506 |
+
"outputs": [],
|
| 507 |
+
"source": [
|
| 508 |
+
"# Calculate ln(PPL(Q)/PPL(fp16)) and generate the table\n",
|
| 509 |
+
"print(\"\\nPerplexity Comparison Table:\")\n",
|
| 510 |
+
"print(f\"{'Quantization Type':<20} {'PPL(Q)':<10} {'ln(PPL(Q)/PPL(fp16))':<25}\")\n",
|
| 511 |
+
"print(\"=\" * 55)\n",
|
| 512 |
+
"for quant, ppl in perplexity_results.items():\n",
|
| 513 |
+
" if ppl and base_perplexity:\n",
|
| 514 |
+
" ln_ratio = round(math.log(ppl / base_perplexity), 6)\n",
|
| 515 |
+
" print(f\"{quant:<20} {ppl:<10} {ln_ratio:<25}\")"
|
| 516 |
+
]
|
| 517 |
+
},
|
| 518 |
+
{
|
| 519 |
+
"cell_type": "code",
|
| 520 |
+
"execution_count": 18,
|
| 521 |
+
"metadata": {},
|
| 522 |
+
"outputs": [
|
| 523 |
+
{
|
| 524 |
+
"name": "stdout",
|
| 525 |
+
"output_type": "stream",
|
| 526 |
+
"text": [
|
| 527 |
+
"\n",
|
| 528 |
+
"Perplexity Comparison Table:\n",
|
| 529 |
+
"Quantization Type PPL(Q) ln(PPL(Q)/PPL(fp16)) \n",
|
| 530 |
+
"=======================================================\n",
|
| 531 |
+
"bf16 15.3799 0.0 \n",
|
| 532 |
+
"IQ2_S 25.3893 0.501266 \n",
|
| 533 |
+
"IQ2_M 21.6684 0.342794 \n",
|
| 534 |
+
"IQ3_M 16.774 0.086769 \n",
|
| 535 |
+
"IQ4_NL 15.9602 0.037037 \n",
|
| 536 |
+
"IQ4_XS 15.9591 0.036968 \n",
|
| 537 |
+
"Q3_K_L 16.5067 0.070705 \n",
|
| 538 |
+
"Q3_K_M 16.8567 0.091687 \n",
|
| 539 |
+
"Q4_K_M 15.8651 0.03106 \n",
|
| 540 |
+
"Q4_K_S 15.9346 0.035431 \n",
|
| 541 |
+
"Q5_K_M 15.4746 0.006139 \n",
|
| 542 |
+
"Q5_K_S 15.4901 0.00714 \n",
|
| 543 |
+
"Q6_K 15.3961 0.001053 \n",
|
| 544 |
+
"Q8_0 15.3831 0.000208 \n",
|
| 545 |
+
"{'bf16': 15.3799, 'IQ2_S': 25.3893, 'IQ2_M': 21.6684, 'IQ3_M': 16.774, 'IQ4_NL': 15.9602, 'IQ4_XS': 15.9591, 'Q3_K_L': 16.5067, 'Q3_K_M': 16.8567, 'Q4_K_M': 15.8651, 'Q4_K_S': 15.9346, 'Q5_K_M': 15.4746, 'Q5_K_S': 15.4901, 'Q6_K': 15.3961, 'Q8_0': 15.3831}\n"
|
| 546 |
+
]
|
| 547 |
+
}
|
| 548 |
+
],
|
| 549 |
+
"source": [
|
| 550 |
+
"perplexity_results = dict()\n",
|
| 551 |
+
"perplexity_results[base_precision] = base_perplexity\n",
|
| 552 |
+
"\n",
|
| 553 |
+
"for quant in quantization_types:\n",
|
| 554 |
+
" output_file = f\"perplexity_{quant}.txt\"\n",
|
| 555 |
+
" try:\n",
|
| 556 |
+
" with open(output_file, 'r') as file:\n",
|
| 557 |
+
" output = file.read()\n",
|
| 558 |
+
" perplexity = extract_perplexity(output)\n",
|
| 559 |
+
" except FileNotFoundError:\n",
|
| 560 |
+
" print(f\"Output file {output_file} not found.\")\n",
|
| 561 |
+
" perplexity = None\n",
|
| 562 |
+
"\n",
|
| 563 |
+
" perplexity_results[quant] = perplexity\n",
|
| 564 |
+
"\n",
|
| 565 |
+
"# Calculate ln(PPL(Q)/PPL(fp16)) and generate the table\n",
|
| 566 |
+
"print(\"\\nPerplexity Comparison Table:\")\n",
|
| 567 |
+
"print(f\"{'Quantization Type':<20} {'PPL(Q)':<10} {'ln(PPL(Q)/PPL(fp16))':<25}\")\n",
|
| 568 |
+
"print(\"=\" * 55)\n",
|
| 569 |
+
"for quant, ppl in perplexity_results.items():\n",
|
| 570 |
+
" if ppl and base_perplexity:\n",
|
| 571 |
+
" ln_ratio = round(math.log(ppl / base_perplexity), 6)\n",
|
| 572 |
+
" print(f\"{quant:<20} {ppl:<10} {ln_ratio:<25}\")\n",
|
| 573 |
+
"\n",
|
| 574 |
+
"print(perplexity_results)\n"
|
| 575 |
+
]
|
| 576 |
+
}
|
| 577 |
+
],
|
| 578 |
+
"metadata": {
|
| 579 |
+
"kernelspec": {
|
| 580 |
+
"display_name": "venv",
|
| 581 |
+
"language": "python",
|
| 582 |
+
"name": "python3"
|
| 583 |
+
},
|
| 584 |
+
"language_info": {
|
| 585 |
+
"codemirror_mode": {
|
| 586 |
+
"name": "ipython",
|
| 587 |
+
"version": 3
|
| 588 |
+
},
|
| 589 |
+
"file_extension": ".py",
|
| 590 |
+
"mimetype": "text/x-python",
|
| 591 |
+
"name": "python",
|
| 592 |
+
"nbconvert_exporter": "python",
|
| 593 |
+
"pygments_lexer": "ipython3",
|
| 594 |
+
"version": "3.12.0"
|
| 595 |
+
}
|
| 596 |
+
},
|
| 597 |
+
"nbformat": 4,
|
| 598 |
+
"nbformat_minor": 2
|
| 599 |
+
}
|