

Update README.md
Browse files
README.md
CHANGED
|
@@ -10,7 +10,7 @@ license: apache-2.0
|
|
| 10 |
Paper to appear at [ACL 2023](https://2023.aclweb.org/). Check out the pre-print on arXiv: [](https://arxiv.org/abs/2211.04928)[](https://github.com/SAP-samples/acl2023-micse/)
|
| 11 |
|
| 12 |
# Brief Model Description
|
| 13 |
-
![Schematic
|
| 14 |
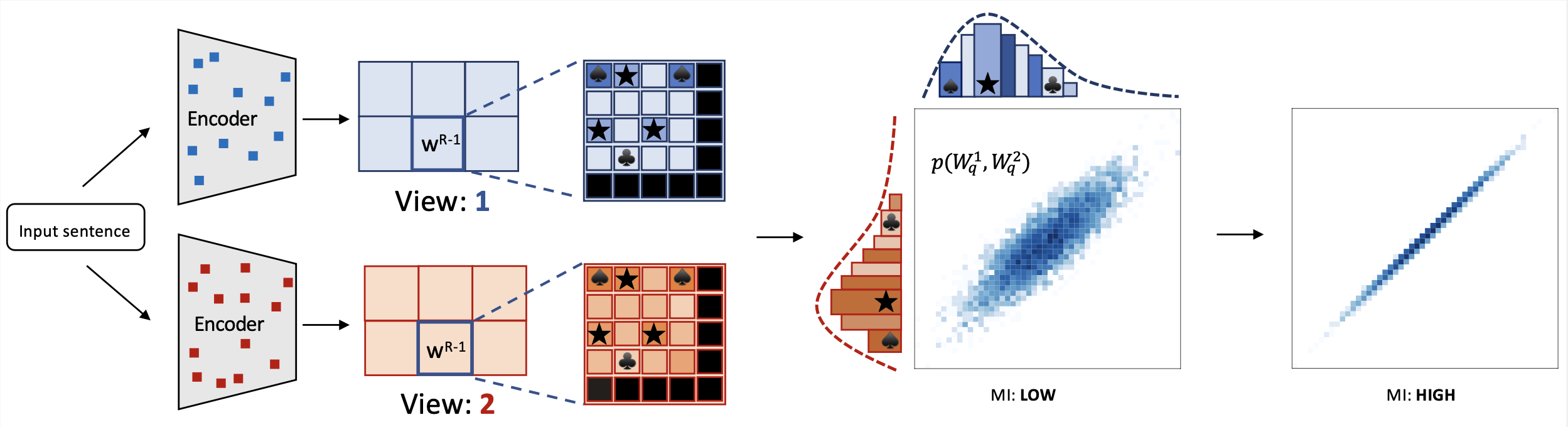
The **miCSE** language model is trained for sentence similarity computation. Training the model imposes alignment between the attention pattern of different views (embeddings of augmentations) during contrastive learning. Intuitively, learning sentence embeddings with miCSE entails enforcing __syntactic consistency across dropout augmented views__. Practically, this is achieved by regularizing the self-attention distribution. By regularizing self-attention during training, representation learning becomes much more sample efficient. Hence, self-supervised learning becomes tractable even when the training set is limited in size. This property makes miCSE particularly interesting for __real-world applications__, where training data is typically limited.
|
| 15 |
# Model Use Cases
|
| 16 |
The model intended to be used for encoding sentences or short paragraphs. Given an input text, the model produces a vector embedding capturing the semantics. Sentence representations correspond to embedding of the _**[CLS]**_ token. The embedding can be used for numerous tasks such as **retrieval**,**sentence similarity** comparison (see example 1) or **clustering** (see example 2).
|
|
|
|
| 10 |
Paper to appear at [ACL 2023](https://2023.aclweb.org/). Check out the pre-print on arXiv: [](https://arxiv.org/abs/2211.04928)[](https://github.com/SAP-samples/acl2023-micse/)
|
| 11 |
|
| 12 |
# Brief Model Description
|
| 13 |
+
|
| 14 |
The **miCSE** language model is trained for sentence similarity computation. Training the model imposes alignment between the attention pattern of different views (embeddings of augmentations) during contrastive learning. Intuitively, learning sentence embeddings with miCSE entails enforcing __syntactic consistency across dropout augmented views__. Practically, this is achieved by regularizing the self-attention distribution. By regularizing self-attention during training, representation learning becomes much more sample efficient. Hence, self-supervised learning becomes tractable even when the training set is limited in size. This property makes miCSE particularly interesting for __real-world applications__, where training data is typically limited.
|
| 15 |
# Model Use Cases
|
| 16 |
The model intended to be used for encoding sentences or short paragraphs. Given an input text, the model produces a vector embedding capturing the semantics. Sentence representations correspond to embedding of the _**[CLS]**_ token. The embedding can be used for numerous tasks such as **retrieval**,**sentence similarity** comparison (see example 1) or **clustering** (see example 2).
|