---
language: en
tags:
- speech-enhancement
- dereverberation
- diffusion-models
- generative-models
- pytorch
- audio-processing
license: mit
datasets:
- VoiceBank-DEMAND
- WSJ0-CHiME3
- WSJ0-REVERB
- EARS-WHAM
- EARS-Reverb
model_name: speech-enhancement-dereverberation-diffusion
model_type: diffusion-based-generative-model
library_name: pytorch
key_files:
- model.py
- train.py
- inference.py
inference: false
pipeline_tag: audio-to-audio
---
# Speech Enhancement and Dereverberation with Diffusion-based Generative Models
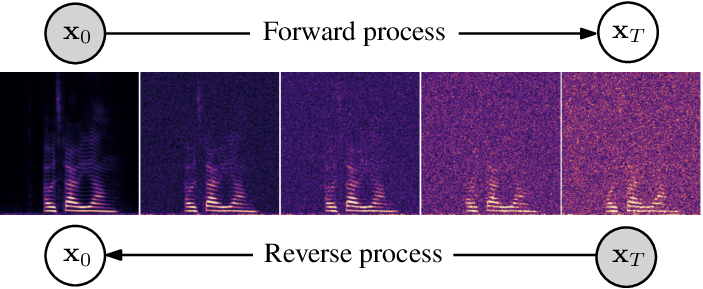 This repository contains the official PyTorch implementations for the papers:
- Simon Welker, Julius Richter, Timo Gerkmann, [*"Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain"*](https://www.isca-speech.org/archive/interspeech_2022/welker22_interspeech.html), ISCA Interspeech, Incheon, Korea, Sept. 2022. [[bibtex]](#citations--references)
- Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay, Timo Gerkmann, [*"Speech Enhancement and Dereverberation with Diffusion-Based Generative Models"*](https://ieeexplore.ieee.org/abstract/document/10149431), IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351-2364, 2023. [[bibtex]](#citations--references)
- Julius Richter, Yi-Chiao Wu, Steven Krenn, Simon Welker, Bunlong Lay, Shinji Watanabe, Alexander Richard, Timo Gerkmann, [*"EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation"*](https://arxiv.org/abs/2406.06185), ISCA Interspecch, Kos, Greece, Sept. 2024. [[bibtex]](#citations--references)
- Julius Richter, Danilo de Oliveira, Timo Gerkmann, [*"Investigating Training Objectives for Generative Speech Enhancement"*](https://arxiv.org/abs/2409.10753) (preprint), 2024. [[bibtex]](#citations--references)
Audio examples and supplementary materials are available on our [SGMSE project page](https://www.inf.uni-hamburg.de/en/inst/ab/sp/publications/sgmse), [EARS project page](https://sp-uhh.github.io/ears_dataset/), and [Investigating training objectives project page](https://sp-uhh.github.io/gen-se/).
## Key Files
The following files are essential for this model:
- `model.py`: Defines the model architecture and training processes.
- `train.py`: Script for training the model.
- `enhancement.py`: Used for evaluating and enhancing audio files.
- `requirements.txt`: Lists the necessary dependencies.
- `calc_metrics.py`: Script for calculating evaluation metrics.
## Follow-up work
Please also check out our follow-up work with code available:
- Jean-Marie Lemercier, Julius Richter, Simon Welker, Timo Gerkmann, [*"StoRM: A Diffusion-based Stochastic Regeneration Model for Speech Enhancement and Dereverberation"*](https://ieeexplore.ieee.org/document/10180108), IEEE/ACM Transactions on Audio, Speech, Language Processing, vol. 31, pp. 2724 -2737, 2023. [[github]](https://github.com/sp-uhh/storm)
- Bunlong Lay, Simon Welker, Julius Richter, Timo Gerkmann, [*"Reducing the Prior Mismatch of Stochastic Differential Equations for Diffusion-based Speech Enhancement"*](https://www.isca-archive.org/interspeech_2023/lay23_interspeech.html), ISCA Interspeech, Dublin, Ireland, Aug. 2023. [[github]](https://github.com/sp-uhh/sgmse-bbed)
## Installation
- Create a new virtual environment with Python 3.11 (we have not tested other Python versions, but they may work).
- Install the package dependencies via `pip install -r requirements.txt`.
- Let pip resolve the dependencies for you. If you encounter any issues, please check `requirements_version.txt` for the exact versions we used.
- If using W&B logging (default):
- Set up a [wandb.ai](https://wandb.ai/) account
- Log in via `wandb login` before running our code.
- If not using W&B logging:
- Pass the option `--nolog` to `train.py`.
- Your logs will be stored as local CSVLogger logs in `lightning_logs/`.
## Pretrained checkpoints
- For the speech enhancement task, we offer pretrained checkpoints for models that have been trained on the VoiceBank-DEMAND and WSJ0-CHiME3 datasets, as described in our journal paper [2]. You can download them [here](https://drive.google.com/drive/folders/1CSnkhUSoiv3RG0xg7WEcVapyLuwDaLbe?usp=sharing).
- SGMSE+ trained on VoiceBank-DEMAND: `gdown 1_H3EXvhcYBhOZ9QNUcD5VZHc6ktrRbwQ`
- SGMSE+ trained on WSJ0-CHiME3: `gdown 16K4DUdpmLhDNC7pJhBBc08pkSIn_yMPi`
- For the dereverberation task, we offer a checkpoint trained on our WSJ0-REVERB dataset. You can download it [here](https://drive.google.com/drive/folders/1082_PSEgrqoVVrNsAkSIcpLF1AAtzGwV?usp=sharing).
- SGMSE+ trained on WSJ0-REVERB: `gdown 1eiOy0VjHh9V9ZUFTxu1Pq2w19izl9ejD`
- Note that this checkpoint works better with sampler settings `--N 50 --snr 0.33`.
- For 48 kHz models [3], we offer pretrained checkpoints for speech enhancement, trained on the EARS-WHAM dataset, and for dereverberation, trained on the EARS-Reverb dataset. You can download them [here](https://drive.google.com/drive/folders/1Tn6pVwjxUAy1DJ8167JCg3enuSi0hiw5?usp=sharing).
- SGMSE+ trained on EARS-WHAM: `gdown 1t_DLLk8iPH6nj8M5wGeOP3jFPaz3i7K5`
- SGMSE+ trained on EARS-Reverb: `gdown 1PunXuLbuyGkknQCn_y-RCV2dTZBhyE3V`
- For the investigating training objectives checkpoints [4], we offer the pretrained checkpoints [here](https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/)
- M1: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m1.ckpt`
- M2: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m2.ckpt`
- M3: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m3.ckpt`
- M4: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m4.ckpt`
- M5: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m5.ckpt`
- M6: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m6.ckpt`
- M7: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m7.ckpt`
- M8: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m8.ckpt`
Usage:
- For resuming training, you can use the `--ckpt` option of `train.py`.
- For evaluating these checkpoints, use the `--ckpt` option of `enhancement.py` (see section **Evaluation** below).
## Training
Training is done by executing `train.py`. A minimal running example with default settings (as in our paper [2]) can be run with
```bash
python train.py --base_dir
```
where `your_base_dir` should be a path to a folder containing subdirectories `train/` and `valid/` (optionally `test/` as well). Each subdirectory must itself have two subdirectories `clean/` and `noisy/`, with the same filenames present in both. We currently only support training with `.wav` files.
To see all available training options, run `python train.py --help`. Note that the available options for the SDE and the backbone network change depending on which SDE and backbone you use. These can be set through the `--sde` and `--backbone` options.
**Note:**
- Our journal [2] uses `--backbone ncsnpp`.
- For the 48 kHz model [3], use `--backbone ncsnpp_48k --n_fft 1534 --hop_length 384 --spec_factor 0.065 --spec_abs_exponent 0.667 --sigma-min 0.1 --sigma-max 1.0 --theta 2.0`
- Our Interspeech paper [1] uses `--backbone dcunet`. You need to pass `--n_fft 512` to make it work.
- Also note that the default parameters for the spectrogram transformation in this repository are slightly different from the ones listed in the first (Interspeech) paper (`--spec_factor 0.15` rather than `--spec_factor 0.333`), but we've found the value in this repository to generally perform better for both models [1] and [2].
- For the investigating training objectives paper [4], we use `--backbone ncsnpp_v2`.
- For the Schrödinger bridge model [4], we use e.g. `--backbone ncsnpp_v2 --sde sbve --loss_type data_prediction --pesq_weight 5e-4`.
## Evaluation
To evaluate on a test set, run
```bash
python enhancement.py --test_dir --enhanced_dir --ckpt
```
to generate the enhanced .wav files, and subsequently run
```bash
python calc_metrics.py --test_dir --enhanced_dir
```
to calculate and output the instrumental metrics.
Both scripts should receive the same `--test_dir` and `--enhanced_dir` parameters. The `--cpkt` parameter of `enhancement.py` should be the path to a trained model checkpoint, as stored by the logger in `logs/`.
## Citations / References
We kindly ask you to cite our papers in your publication when using any of our research or code:
```bib
@inproceedings{welker22speech,
author={Simon Welker and Julius Richter and Timo Gerkmann},
title={Speech Enhancement with Score-Based Generative Models in the Complex {STFT} Domain},
year={2022},
booktitle={Proc. Interspeech 2022},
pages={2928--2932},
doi={10.21437/Interspeech.2022-10653}
}
```
```bib
@article{richter2023speech,
title={Speech Enhancement and Dereverberation with Diffusion-based Generative Models},
author={Richter, Julius and Welker, Simon and Lemercier, Jean-Marie and Lay, Bunlong and Gerkmann, Timo},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
volume={31},
pages={2351-2364},
year={2023},
doi={10.1109/TASLP.2023.3285241}
}
```
```bib
@inproceedings{richter2024ears,
title={{EARS}: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation},
author={Richter, Julius and Wu, Yi-Chiao and Krenn, Steven and Welker, Simon and Lay, Bunlong and Watanabe, Shinjii and Richard, Alexander and Gerkmann, Timo},
booktitle={ISCA Interspeech},
pages={4873--4877},
year={2024}
}
```
```bib
@article{richter2024investigating,
title={Investigating Training Objectives for Generative Speech Enhancement},
author={Richter, Julius and de Oliveira, Danilo and Gerkmann, Timo},
journal={arXiv preprint arXiv:2409.10753},
year={2024}
}
```
>[1] Simon Welker, Julius Richter, Timo Gerkmann. "Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain", ISCA Interspeech, Incheon, Korea, Sep. 2022.
>
>[2] Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay, Timo Gerkmann. "Speech Enhancement and Dereverberation with Diffusion-Based Generative Models", IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351-2364, 2023.
>
>[3] Julius Richter, Yi-Chiao Wu, Steven Krenn, Simon Welker, Bunlong Lay, Shinji Watanabe, Alexander Richard, Timo Gerkmann. "EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation", ISCA Interspeech, Kos, Greece, 2024.
>
>[4] Julius Richter, Danilo de Oliveira, Timo Gerkmann. "Investigating Training Objectives for Generative Speech Enhancement", arXiv preprint arXiv:2409.10753, 2024.
This repository contains the official PyTorch implementations for the papers:
- Simon Welker, Julius Richter, Timo Gerkmann, [*"Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain"*](https://www.isca-speech.org/archive/interspeech_2022/welker22_interspeech.html), ISCA Interspeech, Incheon, Korea, Sept. 2022. [[bibtex]](#citations--references)
- Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay, Timo Gerkmann, [*"Speech Enhancement and Dereverberation with Diffusion-Based Generative Models"*](https://ieeexplore.ieee.org/abstract/document/10149431), IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351-2364, 2023. [[bibtex]](#citations--references)
- Julius Richter, Yi-Chiao Wu, Steven Krenn, Simon Welker, Bunlong Lay, Shinji Watanabe, Alexander Richard, Timo Gerkmann, [*"EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation"*](https://arxiv.org/abs/2406.06185), ISCA Interspecch, Kos, Greece, Sept. 2024. [[bibtex]](#citations--references)
- Julius Richter, Danilo de Oliveira, Timo Gerkmann, [*"Investigating Training Objectives for Generative Speech Enhancement"*](https://arxiv.org/abs/2409.10753) (preprint), 2024. [[bibtex]](#citations--references)
Audio examples and supplementary materials are available on our [SGMSE project page](https://www.inf.uni-hamburg.de/en/inst/ab/sp/publications/sgmse), [EARS project page](https://sp-uhh.github.io/ears_dataset/), and [Investigating training objectives project page](https://sp-uhh.github.io/gen-se/).
## Key Files
The following files are essential for this model:
- `model.py`: Defines the model architecture and training processes.
- `train.py`: Script for training the model.
- `enhancement.py`: Used for evaluating and enhancing audio files.
- `requirements.txt`: Lists the necessary dependencies.
- `calc_metrics.py`: Script for calculating evaluation metrics.
## Follow-up work
Please also check out our follow-up work with code available:
- Jean-Marie Lemercier, Julius Richter, Simon Welker, Timo Gerkmann, [*"StoRM: A Diffusion-based Stochastic Regeneration Model for Speech Enhancement and Dereverberation"*](https://ieeexplore.ieee.org/document/10180108), IEEE/ACM Transactions on Audio, Speech, Language Processing, vol. 31, pp. 2724 -2737, 2023. [[github]](https://github.com/sp-uhh/storm)
- Bunlong Lay, Simon Welker, Julius Richter, Timo Gerkmann, [*"Reducing the Prior Mismatch of Stochastic Differential Equations for Diffusion-based Speech Enhancement"*](https://www.isca-archive.org/interspeech_2023/lay23_interspeech.html), ISCA Interspeech, Dublin, Ireland, Aug. 2023. [[github]](https://github.com/sp-uhh/sgmse-bbed)
## Installation
- Create a new virtual environment with Python 3.11 (we have not tested other Python versions, but they may work).
- Install the package dependencies via `pip install -r requirements.txt`.
- Let pip resolve the dependencies for you. If you encounter any issues, please check `requirements_version.txt` for the exact versions we used.
- If using W&B logging (default):
- Set up a [wandb.ai](https://wandb.ai/) account
- Log in via `wandb login` before running our code.
- If not using W&B logging:
- Pass the option `--nolog` to `train.py`.
- Your logs will be stored as local CSVLogger logs in `lightning_logs/`.
## Pretrained checkpoints
- For the speech enhancement task, we offer pretrained checkpoints for models that have been trained on the VoiceBank-DEMAND and WSJ0-CHiME3 datasets, as described in our journal paper [2]. You can download them [here](https://drive.google.com/drive/folders/1CSnkhUSoiv3RG0xg7WEcVapyLuwDaLbe?usp=sharing).
- SGMSE+ trained on VoiceBank-DEMAND: `gdown 1_H3EXvhcYBhOZ9QNUcD5VZHc6ktrRbwQ`
- SGMSE+ trained on WSJ0-CHiME3: `gdown 16K4DUdpmLhDNC7pJhBBc08pkSIn_yMPi`
- For the dereverberation task, we offer a checkpoint trained on our WSJ0-REVERB dataset. You can download it [here](https://drive.google.com/drive/folders/1082_PSEgrqoVVrNsAkSIcpLF1AAtzGwV?usp=sharing).
- SGMSE+ trained on WSJ0-REVERB: `gdown 1eiOy0VjHh9V9ZUFTxu1Pq2w19izl9ejD`
- Note that this checkpoint works better with sampler settings `--N 50 --snr 0.33`.
- For 48 kHz models [3], we offer pretrained checkpoints for speech enhancement, trained on the EARS-WHAM dataset, and for dereverberation, trained on the EARS-Reverb dataset. You can download them [here](https://drive.google.com/drive/folders/1Tn6pVwjxUAy1DJ8167JCg3enuSi0hiw5?usp=sharing).
- SGMSE+ trained on EARS-WHAM: `gdown 1t_DLLk8iPH6nj8M5wGeOP3jFPaz3i7K5`
- SGMSE+ trained on EARS-Reverb: `gdown 1PunXuLbuyGkknQCn_y-RCV2dTZBhyE3V`
- For the investigating training objectives checkpoints [4], we offer the pretrained checkpoints [here](https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/)
- M1: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m1.ckpt`
- M2: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m2.ckpt`
- M3: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m3.ckpt`
- M4: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m4.ckpt`
- M5: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m5.ckpt`
- M6: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m6.ckpt`
- M7: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m7.ckpt`
- M8: `wget https://www2.informatik.uni-hamburg.de/sp/audio/publications/icassp2025_gense/checkpoints/m8.ckpt`
Usage:
- For resuming training, you can use the `--ckpt` option of `train.py`.
- For evaluating these checkpoints, use the `--ckpt` option of `enhancement.py` (see section **Evaluation** below).
## Training
Training is done by executing `train.py`. A minimal running example with default settings (as in our paper [2]) can be run with
```bash
python train.py --base_dir
```
where `your_base_dir` should be a path to a folder containing subdirectories `train/` and `valid/` (optionally `test/` as well). Each subdirectory must itself have two subdirectories `clean/` and `noisy/`, with the same filenames present in both. We currently only support training with `.wav` files.
To see all available training options, run `python train.py --help`. Note that the available options for the SDE and the backbone network change depending on which SDE and backbone you use. These can be set through the `--sde` and `--backbone` options.
**Note:**
- Our journal [2] uses `--backbone ncsnpp`.
- For the 48 kHz model [3], use `--backbone ncsnpp_48k --n_fft 1534 --hop_length 384 --spec_factor 0.065 --spec_abs_exponent 0.667 --sigma-min 0.1 --sigma-max 1.0 --theta 2.0`
- Our Interspeech paper [1] uses `--backbone dcunet`. You need to pass `--n_fft 512` to make it work.
- Also note that the default parameters for the spectrogram transformation in this repository are slightly different from the ones listed in the first (Interspeech) paper (`--spec_factor 0.15` rather than `--spec_factor 0.333`), but we've found the value in this repository to generally perform better for both models [1] and [2].
- For the investigating training objectives paper [4], we use `--backbone ncsnpp_v2`.
- For the Schrödinger bridge model [4], we use e.g. `--backbone ncsnpp_v2 --sde sbve --loss_type data_prediction --pesq_weight 5e-4`.
## Evaluation
To evaluate on a test set, run
```bash
python enhancement.py --test_dir --enhanced_dir --ckpt
```
to generate the enhanced .wav files, and subsequently run
```bash
python calc_metrics.py --test_dir --enhanced_dir
```
to calculate and output the instrumental metrics.
Both scripts should receive the same `--test_dir` and `--enhanced_dir` parameters. The `--cpkt` parameter of `enhancement.py` should be the path to a trained model checkpoint, as stored by the logger in `logs/`.
## Citations / References
We kindly ask you to cite our papers in your publication when using any of our research or code:
```bib
@inproceedings{welker22speech,
author={Simon Welker and Julius Richter and Timo Gerkmann},
title={Speech Enhancement with Score-Based Generative Models in the Complex {STFT} Domain},
year={2022},
booktitle={Proc. Interspeech 2022},
pages={2928--2932},
doi={10.21437/Interspeech.2022-10653}
}
```
```bib
@article{richter2023speech,
title={Speech Enhancement and Dereverberation with Diffusion-based Generative Models},
author={Richter, Julius and Welker, Simon and Lemercier, Jean-Marie and Lay, Bunlong and Gerkmann, Timo},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
volume={31},
pages={2351-2364},
year={2023},
doi={10.1109/TASLP.2023.3285241}
}
```
```bib
@inproceedings{richter2024ears,
title={{EARS}: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation},
author={Richter, Julius and Wu, Yi-Chiao and Krenn, Steven and Welker, Simon and Lay, Bunlong and Watanabe, Shinjii and Richard, Alexander and Gerkmann, Timo},
booktitle={ISCA Interspeech},
pages={4873--4877},
year={2024}
}
```
```bib
@article{richter2024investigating,
title={Investigating Training Objectives for Generative Speech Enhancement},
author={Richter, Julius and de Oliveira, Danilo and Gerkmann, Timo},
journal={arXiv preprint arXiv:2409.10753},
year={2024}
}
```
>[1] Simon Welker, Julius Richter, Timo Gerkmann. "Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain", ISCA Interspeech, Incheon, Korea, Sep. 2022.
>
>[2] Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay, Timo Gerkmann. "Speech Enhancement and Dereverberation with Diffusion-Based Generative Models", IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351-2364, 2023.
>
>[3] Julius Richter, Yi-Chiao Wu, Steven Krenn, Simon Welker, Bunlong Lay, Shinji Watanabe, Alexander Richard, Timo Gerkmann. "EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation", ISCA Interspeech, Kos, Greece, 2024.
>
>[4] Julius Richter, Danilo de Oliveira, Timo Gerkmann. "Investigating Training Objectives for Generative Speech Enhancement", arXiv preprint arXiv:2409.10753, 2024.