Spaces:
Configuration error

Configuration error
Hisab Cloud
commited on
Commit
•
45e92bd
1
Parent(s):
2aceb76
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +26 -0
- .github/ISSUE_TEMPLATE/bug_report.yaml +89 -0
- .github/ISSUE_TEMPLATE/config.yaml +1 -0
- .github/ISSUE_TEMPLATE/feature_request.yaml +78 -0
- .gitignore +3 -0
- LICENSE +201 -0
- README.md +718 -12
- README_en.md +718 -0
- README_zh.md +731 -0
- assets/MiniCPM-Llama3-V-2.5-peformance.png +0 -0
- assets/Snake_cn_Mushroom_en.gif +3 -0
- assets/Star-History.png +0 -0
- assets/airplane.jpeg +0 -0
- assets/demo_video.mp4 +3 -0
- assets/gif_cases/1-4.gif +3 -0
- assets/gif_cases/Mushroom_en.gif +0 -0
- assets/gif_cases/Mushroom_en_Snake_cn.gif +3 -0
- assets/gif_cases/Snake_en.gif +3 -0
- assets/gif_cases/english_menu.gif +3 -0
- assets/gif_cases/hong_kong_street.gif +3 -0
- assets/gif_cases/london_car.gif +3 -0
- assets/gif_cases/meal_plan.gif +3 -0
- assets/gif_cases/station.gif +3 -0
- assets/gif_cases/ticket.gif +3 -0
- assets/gif_cases/蘑菇_cn.gif +3 -0
- assets/gif_cases/蛇_cn.gif +3 -0
- assets/hk_OCR.jpg +0 -0
- assets/llavabench_compare_3.png +0 -0
- assets/llavabench_compare_phi3.png +0 -0
- assets/minicpm-llama-v-2-5_languages.md +176 -0
- assets/minicpmv-2-peformance.png +0 -0
- assets/minicpmv-llama3-v2.5/case_OCR_en.png +3 -0
- assets/minicpmv-llama3-v2.5/case_complex_reasoning.png +3 -0
- assets/minicpmv-llama3-v2.5/case_information_extraction.png +3 -0
- assets/minicpmv-llama3-v2.5/case_long_img.png +3 -0
- assets/minicpmv-llama3-v2.5/case_markdown.png +3 -0
- assets/minicpmv-llama3-v2.5/cases_all.png +3 -0
- assets/minicpmv-llama3-v2.5/temp +1 -0
- assets/minicpmv-omnilmm.png +0 -0
- assets/minicpmv.png +0 -0
- assets/minicpmv2-cases.png +3 -0
- assets/minicpmv2-cases_1.png +3 -0
- assets/minicpmv2-cases_2.png +3 -0
- assets/modelbest.png +0 -0
- assets/modelscope_logo.png +0 -0
- assets/omnilmm-12b-examples.png +3 -0
- assets/omnilmm-12b-examples_2.pdf +0 -0
- assets/omnilmm-12b-examples_2.png +3 -0
- assets/omnilmm-12b-examples_2_00.jpg +3 -0
- assets/omnilmm-12b-examples_3.png +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,29 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/Snake_cn_Mushroom_en.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/demo_video.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/gif_cases/1-4.gif filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
assets/gif_cases/Mushroom_en_Snake_cn.gif filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
assets/gif_cases/Snake_en.gif filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
assets/gif_cases/english_menu.gif filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
assets/gif_cases/hong_kong_street.gif filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
assets/gif_cases/london_car.gif filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
assets/gif_cases/meal_plan.gif filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
assets/gif_cases/station.gif filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
assets/gif_cases/ticket.gif filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
assets/gif_cases/蘑菇_cn.gif filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
assets/gif_cases/蛇_cn.gif filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
assets/minicpmv-llama3-v2.5/case_OCR_en.png filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
assets/minicpmv-llama3-v2.5/case_complex_reasoning.png filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
assets/minicpmv-llama3-v2.5/case_information_extraction.png filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
assets/minicpmv-llama3-v2.5/case_long_img.png filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
assets/minicpmv-llama3-v2.5/case_markdown.png filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
assets/minicpmv-llama3-v2.5/cases_all.png filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
assets/minicpmv2-cases.png filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
assets/minicpmv2-cases_1.png filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
assets/minicpmv2-cases_2.png filter=lfs diff=lfs merge=lfs -text
|
| 58 |
+
assets/omnilmm-12b-examples.png filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
assets/omnilmm-12b-examples_2.png filter=lfs diff=lfs merge=lfs -text
|
| 60 |
+
assets/omnilmm-12b-examples_2_00.jpg filter=lfs diff=lfs merge=lfs -text
|
| 61 |
+
assets/omnilmm-12b-examples_3.png filter=lfs diff=lfs merge=lfs -text
|
.github/ISSUE_TEMPLATE/bug_report.yaml
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: 🐞 Bug
|
| 2 |
+
description: 提交错误报告 | File a bug/issue
|
| 3 |
+
title: "[BUG] <title>"
|
| 4 |
+
labels: []
|
| 5 |
+
|
| 6 |
+
body:
|
| 7 |
+
- type: checkboxes
|
| 8 |
+
attributes:
|
| 9 |
+
label: 是否已有关于该错误的issue或讨论? | Is there an existing issue / discussion for this?
|
| 10 |
+
description: |
|
| 11 |
+
请先搜索您遇到的错误是否在已有的issues或讨论中提到过。
|
| 12 |
+
Please search to see if an issue / discussion already exists for the bug you encountered.
|
| 13 |
+
[Issues](https://github.com/OpenBMB/MiniCPM-V/issues)
|
| 14 |
+
[Discussions](https://github.com/OpenBMB/MiniCPM-V/discussions)
|
| 15 |
+
options:
|
| 16 |
+
- label: 我已经搜索过已有的issues和讨论 | I have searched the existing issues / discussions
|
| 17 |
+
required: true
|
| 18 |
+
- type: checkboxes
|
| 19 |
+
attributes:
|
| 20 |
+
label: 该问题是否在FAQ中有解答? | Is there an existing answer for this in FAQ?
|
| 21 |
+
description: |
|
| 22 |
+
请先搜索您遇到的错误是否已在FAQ中有相关解答。
|
| 23 |
+
Please search to see if an answer already exists in FAQ for the bug you encountered.
|
| 24 |
+
[FAQ-en](https://github.com/OpenBMB/MiniCPM-V/blob/main/FAQ.md)
|
| 25 |
+
[FAQ-zh](https://github.com/OpenBMB/MiniCPM-V/blob/main/FAQ_zh.md)
|
| 26 |
+
options:
|
| 27 |
+
- label: 我已经搜索过FAQ | I have searched FAQ
|
| 28 |
+
required: true
|
| 29 |
+
- type: textarea
|
| 30 |
+
attributes:
|
| 31 |
+
label: 当前行为 | Current Behavior
|
| 32 |
+
description: |
|
| 33 |
+
准确描述遇到的行为。
|
| 34 |
+
A concise description of what you're experiencing.
|
| 35 |
+
validations:
|
| 36 |
+
required: false
|
| 37 |
+
- type: textarea
|
| 38 |
+
attributes:
|
| 39 |
+
label: 期望行为 | Expected Behavior
|
| 40 |
+
description: |
|
| 41 |
+
准确描述预期的行为。
|
| 42 |
+
A concise description of what you expected to happen.
|
| 43 |
+
validations:
|
| 44 |
+
required: false
|
| 45 |
+
- type: textarea
|
| 46 |
+
attributes:
|
| 47 |
+
label: 复现方法 | Steps To Reproduce
|
| 48 |
+
description: |
|
| 49 |
+
复现当前行为的详细步骤。
|
| 50 |
+
Steps to reproduce the behavior.
|
| 51 |
+
placeholder: |
|
| 52 |
+
1. In this environment...
|
| 53 |
+
2. With this config...
|
| 54 |
+
3. Run '...'
|
| 55 |
+
4. See error...
|
| 56 |
+
validations:
|
| 57 |
+
required: false
|
| 58 |
+
- type: textarea
|
| 59 |
+
attributes:
|
| 60 |
+
label: 运行环境 | Environment
|
| 61 |
+
description: |
|
| 62 |
+
examples:
|
| 63 |
+
- **OS**: Ubuntu 20.04
|
| 64 |
+
- **Python**: 3.8
|
| 65 |
+
- **Transformers**: 4.31.0
|
| 66 |
+
- **PyTorch**: 2.0.1
|
| 67 |
+
- **CUDA**: 11.4
|
| 68 |
+
value: |
|
| 69 |
+
- OS:
|
| 70 |
+
- Python:
|
| 71 |
+
- Transformers:
|
| 72 |
+
- PyTorch:
|
| 73 |
+
- CUDA (`python -c 'import torch; print(torch.version.cuda)'`):
|
| 74 |
+
render: Markdown
|
| 75 |
+
validations:
|
| 76 |
+
required: false
|
| 77 |
+
- type: textarea
|
| 78 |
+
attributes:
|
| 79 |
+
label: 备注 | Anything else?
|
| 80 |
+
description: |
|
| 81 |
+
您可以在这里补充其他关于该问题背景信息的描述、链接或引用等。
|
| 82 |
+
|
| 83 |
+
您可以通过点击高亮此区域然后拖动文件的方式上传图片或日志文件。
|
| 84 |
+
|
| 85 |
+
Links? References? Anything that will give us more context about the issue you are encountering!
|
| 86 |
+
|
| 87 |
+
Tip: You can attach images or log files by clicking this area to highlight it and then dragging files in.
|
| 88 |
+
validations:
|
| 89 |
+
required: false
|
.github/ISSUE_TEMPLATE/config.yaml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
blank_issues_enabled: true
|
.github/ISSUE_TEMPLATE/feature_request.yaml
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "💡 Feature Request"
|
| 2 |
+
description: 创建新功能请求 | Create a new ticket for a new feature request
|
| 3 |
+
title: "💡 [REQUEST] - <title>"
|
| 4 |
+
labels: [
|
| 5 |
+
"question"
|
| 6 |
+
]
|
| 7 |
+
body:
|
| 8 |
+
- type: input
|
| 9 |
+
id: start_date
|
| 10 |
+
attributes:
|
| 11 |
+
label: "起始日期 | Start Date"
|
| 12 |
+
description: |
|
| 13 |
+
起始开发日期
|
| 14 |
+
Start of development
|
| 15 |
+
placeholder: "month/day/year"
|
| 16 |
+
validations:
|
| 17 |
+
required: false
|
| 18 |
+
- type: textarea
|
| 19 |
+
id: implementation_pr
|
| 20 |
+
attributes:
|
| 21 |
+
label: "实现PR | Implementation PR"
|
| 22 |
+
description: |
|
| 23 |
+
实现该功能的Pull request
|
| 24 |
+
Pull request used
|
| 25 |
+
placeholder: "#Pull Request ID"
|
| 26 |
+
validations:
|
| 27 |
+
required: false
|
| 28 |
+
- type: textarea
|
| 29 |
+
id: reference_issues
|
| 30 |
+
attributes:
|
| 31 |
+
label: "相关Issues | Reference Issues"
|
| 32 |
+
description: |
|
| 33 |
+
与该功能相关的issues
|
| 34 |
+
Common issues
|
| 35 |
+
placeholder: "#Issues IDs"
|
| 36 |
+
validations:
|
| 37 |
+
required: false
|
| 38 |
+
- type: textarea
|
| 39 |
+
id: summary
|
| 40 |
+
attributes:
|
| 41 |
+
label: "摘要 | Summary"
|
| 42 |
+
description: |
|
| 43 |
+
简要描述新功能的特点
|
| 44 |
+
Provide a brief explanation of the feature
|
| 45 |
+
placeholder: |
|
| 46 |
+
Describe in a few lines your feature request
|
| 47 |
+
validations:
|
| 48 |
+
required: true
|
| 49 |
+
- type: textarea
|
| 50 |
+
id: basic_example
|
| 51 |
+
attributes:
|
| 52 |
+
label: "基本示例 | Basic Example"
|
| 53 |
+
description: Indicate here some basic examples of your feature.
|
| 54 |
+
placeholder: A few specific words about your feature request.
|
| 55 |
+
validations:
|
| 56 |
+
required: true
|
| 57 |
+
- type: textarea
|
| 58 |
+
id: drawbacks
|
| 59 |
+
attributes:
|
| 60 |
+
label: "缺陷 | Drawbacks"
|
| 61 |
+
description: |
|
| 62 |
+
该新功能有哪些缺陷/可能造成哪些影响?
|
| 63 |
+
What are the drawbacks/impacts of your feature request ?
|
| 64 |
+
placeholder: |
|
| 65 |
+
Identify the drawbacks and impacts while being neutral on your feature request
|
| 66 |
+
validations:
|
| 67 |
+
required: true
|
| 68 |
+
- type: textarea
|
| 69 |
+
id: unresolved_question
|
| 70 |
+
attributes:
|
| 71 |
+
label: "未解决问题 | Unresolved questions"
|
| 72 |
+
description: |
|
| 73 |
+
有哪些尚未解决的问题?
|
| 74 |
+
What questions still remain unresolved ?
|
| 75 |
+
placeholder: |
|
| 76 |
+
Identify any unresolved issues.
|
| 77 |
+
validations:
|
| 78 |
+
required: false
|
.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.bk
|
| 2 |
+
__pycache__
|
| 3 |
+
.DS_Store
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2024 OpenBMB
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,12 +1,718 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
<img src="./assets/minicpmv.png" width="300em" ></img>
|
| 4 |
+
|
| 5 |
+
**A GPT-4V Level Multimodal LLM on Your Phone**
|
| 6 |
+
|
| 7 |
+
<strong>[中文](./README_zh.md) |
|
| 8 |
+
English</strong>
|
| 9 |
+
|
| 10 |
+
<p align="center">
|
| 11 |
+
MiniCPM-Llama3-V 2.5 <a href="https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5/">🤗</a> <a href="https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5">🤖</a> |
|
| 12 |
+
MiniCPM-V 2.0 <a href="https://huggingface.co/openbmb/MiniCPM-V-2/">🤗</a> <a href="https://huggingface.co/spaces/openbmb/MiniCPM-V-2">🤖</a> |
|
| 13 |
+
<a href="https://openbmb.vercel.app/minicpm-v-2-en"> Technical Blog </a>
|
| 14 |
+
</p>
|
| 15 |
+
|
| 16 |
+
</div>
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
**MiniCPM-V** is a series of end-side multimodal LLMs (MLLMs) designed for vision-language understanding. The models take image and text as inputs and provide high-quality text outputs. Since February 2024, we have released 4 versions of the model, aiming to achieve **strong performance and efficient deployment**. The most notable models in this series currently include:
|
| 20 |
+
|
| 21 |
+
- **MiniCPM-Llama3-V 2.5**: 🔥🔥🔥 The latest and most capable model in the MiniCPM-V series. With a total of 8B parameters, the model **surpasses proprietary models such as GPT-4V-1106, Gemini Pro, Qwen-VL-Max and Claude 3** in overall performance. Equipped with the enhanced OCR and instruction-following capability, the model can also support multimodal conversation for **over 30 languages** including English, Chinese, French, Spanish, German etc. With help of quantization, compilation optimizations, and several efficient inference techniques on CPUs and NPUs, MiniCPM-Llama3-V 2.5 can be **efficiently deployed on end-side devices**.
|
| 22 |
+
|
| 23 |
+
- **MiniCPM-V 2.0**: The lightest model in the MiniCPM-V series. With 2B parameters, it surpasses larger models such as Yi-VL 34B, CogVLM-Chat 17B, and Qwen-VL-Chat 10B in overall performance. It can accept image inputs of any aspect ratio and up to 1.8 million pixels (e.g., 1344x1344), achieving comparable performance with Gemini Pro in understanding scene-text and matches GPT-4V in low hallucination rates.
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
## News <!-- omit in toc -->
|
| 27 |
+
|
| 28 |
+
#### 📌 Pinned
|
| 29 |
+
|
| 30 |
+
* [2024.05.28] 🚀🚀🚀 MiniCPM-Llama3-V 2.5 now fully supports its feature in [llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpm-v2.5/examples/minicpmv/README.md) and [ollama](https://github.com/OpenBMB/ollama/tree/minicpm-v2.5)! Please pull the latest code for llama.cpp & ollama. We also release GGUF in various sizes [here](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf/tree/main). FAQ list for ollama usage is comming within a day. Please stay tuned!
|
| 31 |
+
* [2024.05.28] 💫 We now support LoRA fine-tuning for MiniCPM-Llama3-V 2.5, using only 2 V100 GPUs! See more statistics [here](https://github.com/OpenBMB/MiniCPM-V/tree/main/finetune#model-fine-tuning-memory-usage-statistics).
|
| 32 |
+
* [2024.05.23] 🔍 We've released a comprehensive comparison between Phi-3-vision-128k-instruct and MiniCPM-Llama3-V 2.5, including benchmarks evaluations, multilingual capabilities, and inference efficiency 🌟📊🌍🚀. Click [here](./docs/compare_with_phi-3_vision.md) to view more details.
|
| 33 |
+
* [2024.05.23] 🔥🔥🔥 MiniCPM-V tops GitHub Trending and Hugging Face Trending! Our demo, recommended by Hugging Face Gradio’s official account, is available [here](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5). Come and try it out!
|
| 34 |
+
|
| 35 |
+
<br>
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
* [2024.05.25] MiniCPM-Llama3-V 2.5 now supports streaming outputs and customized system prompts. Try it [here](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5#usage)!
|
| 39 |
+
* [2024.05.24] We release the MiniCPM-Llama3-V 2.5 [gguf](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf), which supports [llama.cpp](#inference-with-llamacpp) inference and provides a 6~8 token/s smooth decoding on mobile phones. Try it now!
|
| 40 |
+
* [2024.05.20] We open-soure MiniCPM-Llama3-V 2.5, it has improved OCR capability and supports 30+ languages, representing the first end-side MLLM achieving GPT-4V level performance! We provide [efficient inference](#deployment-on-mobile-phone) and [simple fine-tuning](./finetune/readme.md). Try it now!
|
| 41 |
+
* [2024.04.23] MiniCPM-V-2.0 supports vLLM now! Click [here](#vllm) to view more details.
|
| 42 |
+
* [2024.04.18] We create a HuggingFace Space to host the demo of MiniCPM-V 2.0 at [here](https://huggingface.co/spaces/openbmb/MiniCPM-V-2)!
|
| 43 |
+
* [2024.04.17] MiniCPM-V-2.0 supports deploying [WebUI Demo](#webui-demo) now!
|
| 44 |
+
* [2024.04.15] MiniCPM-V-2.0 now also supports [fine-tuning](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v-2最佳实践.md) with the SWIFT framework!
|
| 45 |
+
* [2024.04.12] We open-source MiniCPM-V 2.0, which achieves comparable performance with Gemini Pro in understanding scene text and outperforms strong Qwen-VL-Chat 9.6B and Yi-VL 34B on <a href="https://rank.opencompass.org.cn/leaderboard-multimodal">OpenCompass</a>, a comprehensive evaluation over 11 popular benchmarks. Click <a href="https://openbmb.vercel.app/minicpm-v-2">here</a> to view the MiniCPM-V 2.0 technical blog.
|
| 46 |
+
* [2024.03.14] MiniCPM-V now supports [fine-tuning](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v最佳实践.md) with the SWIFT framework. Thanks to [Jintao](https://github.com/Jintao-Huang) for the contribution!
|
| 47 |
+
* [2024.03.01] MiniCPM-V now can be deployed on Mac!
|
| 48 |
+
* [2024.02.01] We open-source MiniCPM-V and OmniLMM-12B, which support efficient end-side deployment and powerful multimodal capabilities correspondingly.
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
## Contents <!-- omit in toc -->
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
- [MiniCPM-Llama3-V 2.5](#minicpm-llama3-v-25)
|
| 55 |
+
- [MiniCPM-V 2.0](#minicpm-v-20)
|
| 56 |
+
- [Online Demo](#online-demo)
|
| 57 |
+
- [Install](#install)
|
| 58 |
+
- [Inference](#inference)
|
| 59 |
+
- [Model Zoo](#model-zoo)
|
| 60 |
+
- [Multi-turn Conversation](#multi-turn-conversation)
|
| 61 |
+
- [Inference on Mac](#inference-on-mac)
|
| 62 |
+
- [Deployment on Mobile Phone](#deployment-on-mobile-phone)
|
| 63 |
+
- [WebUI Demo](#webui-demo)
|
| 64 |
+
- [Inference with llama.cpp](#inference-with-llamacpp)
|
| 65 |
+
- [Inference with vLLM](#inference-with-vllm)
|
| 66 |
+
- [Fine-tuning](#fine-tuning)
|
| 67 |
+
- [TODO](#todo)
|
| 68 |
+
- [🌟 Star History](#-star-history)
|
| 69 |
+
- [Citation](#citation)
|
| 70 |
+
|
| 71 |
+
## MiniCPM-Llama3-V 2.5
|
| 72 |
+
|
| 73 |
+
**MiniCPM-Llama3-V 2.5** is the latest model in the MiniCPM-V series. The model is built on SigLip-400M and Llama3-8B-Instruct with a total of 8B parameters. It exhibits a significant performance improvement over MiniCPM-V 2.0. Notable features of MiniCPM-Llama3-V 2.5 include:
|
| 74 |
+
|
| 75 |
+
- 🔥 **Leading Performance.**
|
| 76 |
+
MiniCPM-Llama3-V 2.5 has achieved an average score of 65.1 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks. **With only 8B parameters, it surpasses widely used proprietary models like GPT-4V-1106, Gemini Pro, Claude 3 and Qwen-VL-Max** and greatly outperforms other Llama 3-based MLLMs.
|
| 77 |
+
|
| 78 |
+
- 💪 **Strong OCR Capabilities.**
|
| 79 |
+
MiniCPM-Llama3-V 2.5 can process images with any aspect ratio and up to 1.8 million pixels (e.g., 1344x1344), achieving a **700+ score on OCRBench, surpassing proprietary models such as GPT-4o, GPT-4V-0409, Qwen-VL-Max and Gemini Pro**. Based on recent user feedback, MiniCPM-Llama3-V 2.5 has now enhanced full-text OCR extraction, table-to-markdown conversion, and other high-utility capabilities, and has further strengthened its instruction-following and complex reasoning abilities, enhancing multimodal interaction experiences.
|
| 80 |
+
|
| 81 |
+
- 🏆 **Trustworthy Behavior.**
|
| 82 |
+
Leveraging the latest [RLAIF-V](https://github.com/RLHF-V/RLAIF-V/) method (the newest technique in the [RLHF-V](https://github.com/RLHF-V) [CVPR'24] series), MiniCPM-Llama3-V 2.5 exhibits more trustworthy behavior. It achieves a **10.3%** hallucination rate on Object HalBench, lower than GPT-4V-1106 (13.6%), achieving the best-level performance within the open-source community. [Data released](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset).
|
| 83 |
+
|
| 84 |
+
- 🌏 **Multilingual Support.**
|
| 85 |
+
Thanks to the strong multilingual capabilities of Llama 3 and the cross-lingual generalization technique from [VisCPM](https://github.com/OpenBMB/VisCPM), MiniCPM-Llama3-V 2.5 extends its bilingual (Chinese-English) multimodal capabilities to **over 30 languages including German, French, Spanish, Italian, Korean etc.** [All Supported Languages](./assets/minicpm-llama-v-2-5_languages.md).
|
| 86 |
+
|
| 87 |
+
- 🚀 **Efficient Deployment.**
|
| 88 |
+
MiniCPM-Llama3-V 2.5 systematically employs **model quantization, CPU optimizations, NPU optimizations and compilation optimizations**, achieving high-efficiency deployment on end-side devices. For mobile phones with Qualcomm chips, we have integrated the NPU acceleration framework QNN into llama.cpp for the first time. After systematic optimization, MiniCPM-Llama3-V 2.5 has realized a **150x acceleration in end-side MLLM image encoding** and a **3x speedup in language decoding**.
|
| 89 |
+
|
| 90 |
+
- 💫 **Easy Usage.**
|
| 91 |
+
MiniCPM-Llama3-V 2.5 can be easily used in various ways: (1) [llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpm-v2.5/examples/minicpmv/README.md) and [ollama](https://github.com/OpenBMB/ollama/tree/minicpm-v2.5/examples/minicpm-v2.5) support for efficient CPU inference on local devices, (2) [GGUF](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf) format quantized models in 16 sizes, (3) efficient [LoRA](https://github.com/OpenBMB/MiniCPM-V/tree/main/finetune#lora-finetuning) fine-tuning with only 2 V100 GPUs, (4) [streaming output](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5#usage), (5) quick local WebUI demo setup with [Gradio](https://github.com/OpenBMB/MiniCPM-V/blob/main/web_demo_2.5.py) and [Streamlit](https://github.com/OpenBMB/MiniCPM-V/blob/main/web_demo_streamlit-2_5.py), and (6) interactive demos on [HuggingFace Spaces](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5).
|
| 92 |
+
|
| 93 |
+
### Evaluation <!-- omit in toc -->
|
| 94 |
+
|
| 95 |
+
<div align="center">
|
| 96 |
+
<img src=assets/MiniCPM-Llama3-V-2.5-peformance.png width=66% />
|
| 97 |
+
</div>
|
| 98 |
+
<details>
|
| 99 |
+
<summary>Click to view results on TextVQA, DocVQA, OCRBench, OpenCompass, MME, MMBench, MMMU, MathVista, LLaVA Bench, RealWorld QA, Object HalBench. </summary>
|
| 100 |
+
<div align="center">
|
| 101 |
+
|
| 102 |
+
<table style="margin: 0px auto;">
|
| 103 |
+
<thead>
|
| 104 |
+
<tr>
|
| 105 |
+
<th align="left">Model</th>
|
| 106 |
+
<th>Size</th>
|
| 107 |
+
<th>OCRBench</th>
|
| 108 |
+
<th>TextVQA val</th>
|
| 109 |
+
<th>DocVQA test</th>
|
| 110 |
+
<th>Open-Compass</th>
|
| 111 |
+
<th>MME</th>
|
| 112 |
+
<th>MMB test (en)</th>
|
| 113 |
+
<th>MMB test (cn)</th>
|
| 114 |
+
<th>MMMU val</th>
|
| 115 |
+
<th>Math-Vista</th>
|
| 116 |
+
<th>LLaVA Bench</th>
|
| 117 |
+
<th>RealWorld QA</th>
|
| 118 |
+
<th>Object HalBench</th>
|
| 119 |
+
</tr>
|
| 120 |
+
</thead>
|
| 121 |
+
<tbody align="center">
|
| 122 |
+
<tr>
|
| 123 |
+
<td colspan="14" align="left"><strong>Proprietary</strong></td>
|
| 124 |
+
</tr>
|
| 125 |
+
<tr>
|
| 126 |
+
<td nowrap="nowrap" align="left">Gemini Pro</td>
|
| 127 |
+
<td>-</td>
|
| 128 |
+
<td>680</td>
|
| 129 |
+
<td>74.6</td>
|
| 130 |
+
<td>88.1</td>
|
| 131 |
+
<td>62.9</td>
|
| 132 |
+
<td>2148.9</td>
|
| 133 |
+
<td>73.6</td>
|
| 134 |
+
<td>74.3</td>
|
| 135 |
+
<td>48.9</td>
|
| 136 |
+
<td>45.8</td>
|
| 137 |
+
<td>79.9</td>
|
| 138 |
+
<td>60.4</td>
|
| 139 |
+
<td>-</td>
|
| 140 |
+
</tr>
|
| 141 |
+
<tr>
|
| 142 |
+
<td nowrap="nowrap" align="left">GPT-4V (2023.11.06)</td>
|
| 143 |
+
<td>-</td>
|
| 144 |
+
<td>645</td>
|
| 145 |
+
<td>78.0</td>
|
| 146 |
+
<td>88.4</td>
|
| 147 |
+
<td>63.5</td>
|
| 148 |
+
<td>1771.5</td>
|
| 149 |
+
<td>77.0</td>
|
| 150 |
+
<td>74.4</td>
|
| 151 |
+
<td>53.8</td>
|
| 152 |
+
<td>47.8</td>
|
| 153 |
+
<td>93.1</td>
|
| 154 |
+
<td>63.0</td>
|
| 155 |
+
<td>86.4</td>
|
| 156 |
+
</tr>
|
| 157 |
+
<tr>
|
| 158 |
+
<td colspan="14" align="left"><strong>Open-source</strong></td>
|
| 159 |
+
</tr>
|
| 160 |
+
<tr>
|
| 161 |
+
<td nowrap="nowrap" align="left">Mini-Gemini</td>
|
| 162 |
+
<td>2.2B</td>
|
| 163 |
+
<td>-</td>
|
| 164 |
+
<td>56.2</td>
|
| 165 |
+
<td>34.2*</td>
|
| 166 |
+
<td>-</td>
|
| 167 |
+
<td>1653.0</td>
|
| 168 |
+
<td>-</td>
|
| 169 |
+
<td>-</td>
|
| 170 |
+
<td>31.7</td>
|
| 171 |
+
<td>-</td>
|
| 172 |
+
<td>-</td>
|
| 173 |
+
<td>-</td>
|
| 174 |
+
<td>-</td>
|
| 175 |
+
</tr>
|
| 176 |
+
<tr>
|
| 177 |
+
<td nowrap="nowrap" align="left">Qwen-VL-Chat</td>
|
| 178 |
+
<td>9.6B</td>
|
| 179 |
+
<td>488</td>
|
| 180 |
+
<td>61.5</td>
|
| 181 |
+
<td>62.6</td>
|
| 182 |
+
<td>51.6</td>
|
| 183 |
+
<td>1860.0</td>
|
| 184 |
+
<td>61.8</td>
|
| 185 |
+
<td>56.3</td>
|
| 186 |
+
<td>37.0</td>
|
| 187 |
+
<td>33.8</td>
|
| 188 |
+
<td>67.7</td>
|
| 189 |
+
<td>49.3</td>
|
| 190 |
+
<td>56.2</td>
|
| 191 |
+
</tr>
|
| 192 |
+
<tr>
|
| 193 |
+
<td nowrap="nowrap" align="left">DeepSeek-VL-7B</td>
|
| 194 |
+
<td>7.3B</td>
|
| 195 |
+
<td>435</td>
|
| 196 |
+
<td>64.7*</td>
|
| 197 |
+
<td>47.0*</td>
|
| 198 |
+
<td>54.6</td>
|
| 199 |
+
<td>1765.4</td>
|
| 200 |
+
<td>73.8</td>
|
| 201 |
+
<td>71.4</td>
|
| 202 |
+
<td>38.3</td>
|
| 203 |
+
<td>36.8</td>
|
| 204 |
+
<td>77.8</td>
|
| 205 |
+
<td>54.2</td>
|
| 206 |
+
<td>-</td>
|
| 207 |
+
</tr>
|
| 208 |
+
<tr>
|
| 209 |
+
<td nowrap="nowrap" align="left">Yi-VL-34B</td>
|
| 210 |
+
<td>34B</td>
|
| 211 |
+
<td>290</td>
|
| 212 |
+
<td>43.4*</td>
|
| 213 |
+
<td>16.9*</td>
|
| 214 |
+
<td>52.2</td>
|
| 215 |
+
<td><strong>2050.2</strong></td>
|
| 216 |
+
<td>72.4</td>
|
| 217 |
+
<td>70.7</td>
|
| 218 |
+
<td>45.1</td>
|
| 219 |
+
<td>30.7</td>
|
| 220 |
+
<td>62.3</td>
|
| 221 |
+
<td>54.8</td>
|
| 222 |
+
<td>79.3</td>
|
| 223 |
+
</tr>
|
| 224 |
+
<tr>
|
| 225 |
+
<td nowrap="nowrap" align="left">CogVLM-Chat</td>
|
| 226 |
+
<td>17.4B</td>
|
| 227 |
+
<td>590</td>
|
| 228 |
+
<td>70.4</td>
|
| 229 |
+
<td>33.3*</td>
|
| 230 |
+
<td>54.2</td>
|
| 231 |
+
<td>1736.6</td>
|
| 232 |
+
<td>65.8</td>
|
| 233 |
+
<td>55.9</td>
|
| 234 |
+
<td>37.3</td>
|
| 235 |
+
<td>34.7</td>
|
| 236 |
+
<td>73.9</td>
|
| 237 |
+
<td>60.3</td>
|
| 238 |
+
<td>73.6</td>
|
| 239 |
+
</tr>
|
| 240 |
+
<tr>
|
| 241 |
+
<td nowrap="nowrap" align="left">TextMonkey</td>
|
| 242 |
+
<td>9.7B</td>
|
| 243 |
+
<td>558</td>
|
| 244 |
+
<td>64.3</td>
|
| 245 |
+
<td>66.7</td>
|
| 246 |
+
<td>-</td>
|
| 247 |
+
<td>-</td>
|
| 248 |
+
<td>-</td>
|
| 249 |
+
<td>-</td>
|
| 250 |
+
<td>-</td>
|
| 251 |
+
<td>-</td>
|
| 252 |
+
<td>-</td>
|
| 253 |
+
<td>-</td>
|
| 254 |
+
<td>-</td>
|
| 255 |
+
</tr>
|
| 256 |
+
<tr>
|
| 257 |
+
<td nowrap="nowrap" align="left">Idefics2</td>
|
| 258 |
+
<td>8.0B</td>
|
| 259 |
+
<td>-</td>
|
| 260 |
+
<td>73.0</td>
|
| 261 |
+
<td>74.0</td>
|
| 262 |
+
<td>57.2</td>
|
| 263 |
+
<td>1847.6</td>
|
| 264 |
+
<td>75.7</td>
|
| 265 |
+
<td>68.6</td>
|
| 266 |
+
<td>45.2</td>
|
| 267 |
+
<td>52.2</td>
|
| 268 |
+
<td>49.1</td>
|
| 269 |
+
<td>60.7</td>
|
| 270 |
+
<td>-</td>
|
| 271 |
+
</tr>
|
| 272 |
+
<tr>
|
| 273 |
+
<td nowrap="nowrap" align="left">Bunny-LLama-3-8B</td>
|
| 274 |
+
<td>8.4B</td>
|
| 275 |
+
<td>-</td>
|
| 276 |
+
<td>-</td>
|
| 277 |
+
<td>-</td>
|
| 278 |
+
<td>54.3</td>
|
| 279 |
+
<td>1920.3</td>
|
| 280 |
+
<td>77.0</td>
|
| 281 |
+
<td>73.9</td>
|
| 282 |
+
<td>41.3</td>
|
| 283 |
+
<td>31.5</td>
|
| 284 |
+
<td>61.2</td>
|
| 285 |
+
<td>58.8</td>
|
| 286 |
+
<td>-</td>
|
| 287 |
+
</tr>
|
| 288 |
+
<tr>
|
| 289 |
+
<td nowrap="nowrap" align="left">LLaVA-NeXT Llama-3-8B</td>
|
| 290 |
+
<td>8.4B</td>
|
| 291 |
+
<td>-</td>
|
| 292 |
+
<td>-</td>
|
| 293 |
+
<td>78.2</td>
|
| 294 |
+
<td>-</td>
|
| 295 |
+
<td>1971.5</td>
|
| 296 |
+
<td>-</td>
|
| 297 |
+
<td>-</td>
|
| 298 |
+
<td>41.7</td>
|
| 299 |
+
<td>37.5</td>
|
| 300 |
+
<td>80.1</td>
|
| 301 |
+
<td>60.0</td>
|
| 302 |
+
<td>-</td>
|
| 303 |
+
</tr>
|
| 304 |
+
<tr>
|
| 305 |
+
<td nowrap="nowrap" align="left">Phi-3-vision-128k-instruct</td>
|
| 306 |
+
<td>4.2B</td>
|
| 307 |
+
<td>639*</td>
|
| 308 |
+
<td>70.9</td>
|
| 309 |
+
<td>-</td>
|
| 310 |
+
<td>-</td>
|
| 311 |
+
<td>1537.5*</td>
|
| 312 |
+
<td>-</td>
|
| 313 |
+
<td>-</td>
|
| 314 |
+
<td>40.4</td>
|
| 315 |
+
<td>44.5</td>
|
| 316 |
+
<td>64.2*</td>
|
| 317 |
+
<td>58.8*</td>
|
| 318 |
+
<td>-</td>
|
| 319 |
+
</tr>
|
| 320 |
+
<tr style="background-color: #e6f2ff;">
|
| 321 |
+
<td nowrap="nowrap" align="left">MiniCPM-V 1.0</td>
|
| 322 |
+
<td>2.8B</td>
|
| 323 |
+
<td>366</td>
|
| 324 |
+
<td>60.6</td>
|
| 325 |
+
<td>38.2</td>
|
| 326 |
+
<td>47.5</td>
|
| 327 |
+
<td>1650.2</td>
|
| 328 |
+
<td>64.1</td>
|
| 329 |
+
<td>62.6</td>
|
| 330 |
+
<td>38.3</td>
|
| 331 |
+
<td>28.9</td>
|
| 332 |
+
<td>51.3</td>
|
| 333 |
+
<td>51.2</td>
|
| 334 |
+
<td>78.4</td>
|
| 335 |
+
</tr>
|
| 336 |
+
<tr style="background-color: #e6f2ff;">
|
| 337 |
+
<td nowrap="nowrap" align="left">MiniCPM-V 2.0</td>
|
| 338 |
+
<td>2.8B</td>
|
| 339 |
+
<td>605</td>
|
| 340 |
+
<td>74.1</td>
|
| 341 |
+
<td>71.9</td>
|
| 342 |
+
<td>54.5</td>
|
| 343 |
+
<td>1808.6</td>
|
| 344 |
+
<td>69.1</td>
|
| 345 |
+
<td>66.5</td>
|
| 346 |
+
<td>38.2</td>
|
| 347 |
+
<td>38.7</td>
|
| 348 |
+
<td>69.2</td>
|
| 349 |
+
<td>55.8</td>
|
| 350 |
+
<td>85.5</td>
|
| 351 |
+
</tr>
|
| 352 |
+
<tr style="background-color: #e6f2ff;">
|
| 353 |
+
<td nowrap="nowrap" align="left">MiniCPM-Llama3-V 2.5</td>
|
| 354 |
+
<td>8.5B</td>
|
| 355 |
+
<td><strong>725</strong></td>
|
| 356 |
+
<td><strong>76.6</strong></td>
|
| 357 |
+
<td><strong>84.8</strong></td>
|
| 358 |
+
<td><strong>65.1</strong></td>
|
| 359 |
+
<td>2024.6</td>
|
| 360 |
+
<td><strong>77.2</strong></td>
|
| 361 |
+
<td><strong>74.2</strong></td>
|
| 362 |
+
<td><strong>45.8</strong></td>
|
| 363 |
+
<td><strong>54.3</strong></td>
|
| 364 |
+
<td><strong>86.7</strong></td>
|
| 365 |
+
<td><strong>63.5</strong></td>
|
| 366 |
+
<td><strong>89.7</strong></td>
|
| 367 |
+
</tr>
|
| 368 |
+
</tbody>
|
| 369 |
+
</table>
|
| 370 |
+
|
| 371 |
+
|
| 372 |
+
</div>
|
| 373 |
+
* We evaluate the officially released checkpoint by ourselves.
|
| 374 |
+
|
| 375 |
+
</details>
|
| 376 |
+
|
| 377 |
+
<div align="center">
|
| 378 |
+
<img src="assets/llavabench_compare_3.png" width="100%" />
|
| 379 |
+
<br>
|
| 380 |
+
Evaluation results of multilingual LLaVA Bench
|
| 381 |
+
</div>
|
| 382 |
+
|
| 383 |
+
### Examples <!-- omit in toc -->
|
| 384 |
+
|
| 385 |
+
<table align="center" >
|
| 386 |
+
<p align="center" >
|
| 387 |
+
<img src="assets/minicpmv-llama3-v2.5/cases_all.png" />
|
| 388 |
+
</p>
|
| 389 |
+
</table>
|
| 390 |
+
|
| 391 |
+
We deploy MiniCPM-Llama3-V 2.5 on end devices. The demo video is the raw screen recording on a Xiaomi 14 Pro without edition.
|
| 392 |
+
|
| 393 |
+
<table align="center">
|
| 394 |
+
<p align="center">
|
| 395 |
+
<img src="assets/gif_cases/ticket.gif" width=32%/>
|
| 396 |
+
<img src="assets/gif_cases/meal_plan.gif" width=32%/>
|
| 397 |
+
</p>
|
| 398 |
+
</table>
|
| 399 |
+
|
| 400 |
+
<table align="center">
|
| 401 |
+
<p align="center">
|
| 402 |
+
<img src="assets/gif_cases/1-4.gif" width=64%/>
|
| 403 |
+
</p>
|
| 404 |
+
</table>
|
| 405 |
+
|
| 406 |
+
## MiniCPM-V 2.0
|
| 407 |
+
|
| 408 |
+
<details>
|
| 409 |
+
<summary>Click to view more details of MiniCPM-V 2.0</summary>
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
**MiniCPM-V 2.0** is an efficient version with promising performance for deployment. The model is built based on SigLip-400M and [MiniCPM-2.4B](https://github.com/OpenBMB/MiniCPM/), connected by a perceiver resampler. Our latest version, MiniCPM-V 2.0 has several notable features.
|
| 413 |
+
|
| 414 |
+
- 🔥 **State-of-the-art Performance.**
|
| 415 |
+
|
| 416 |
+
MiniCPM-V 2.0 achieves **state-of-the-art performance** on multiple benchmarks (including OCRBench, TextVQA, MME, MMB, MathVista, etc) among models under 7B parameters. It even **outperforms strong Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on OpenCompass, a comprehensive evaluation over 11 popular benchmarks**. Notably, MiniCPM-V 2.0 shows **strong OCR capability**, achieving **comparable performance to Gemini Pro in scene-text understanding**, and **state-of-the-art performance on OCRBench** among open-source models.
|
| 417 |
+
|
| 418 |
+
- 🏆 **Trustworthy Behavior.**
|
| 419 |
+
|
| 420 |
+
LMMs are known for suffering from hallucination, often generating text not factually grounded in images. MiniCPM-V 2.0 is **the first end-side LMM aligned via multimodal RLHF for trustworthy behavior** (using the recent [RLHF-V](https://rlhf-v.github.io/) [CVPR'24] series technique). This allows the model to **match GPT-4V in preventing hallucinations** on Object HalBench.
|
| 421 |
+
|
| 422 |
+
- 🌟 **High-Resolution Images at Any Aspect Raito.**
|
| 423 |
+
|
| 424 |
+
MiniCPM-V 2.0 can accept **1.8 million pixels (e.g., 1344x1344) images at any aspect ratio**. This enables better perception of fine-grained visual information such as small objects and optical characters, which is achieved via a recent technique from [LLaVA-UHD](https://arxiv.org/pdf/2403.11703.pdf).
|
| 425 |
+
|
| 426 |
+
- ⚡️ **High Efficiency.**
|
| 427 |
+
|
| 428 |
+
MiniCPM-V 2.0 can be **efficiently deployed on most GPU cards and personal computers**, and **even on end devices such as mobile phones**. For visual encoding, we compress the image representations into much fewer tokens via a perceiver resampler. This allows MiniCPM-V 2.0 to operate with **favorable memory cost and speed during inference even when dealing with high-resolution images**.
|
| 429 |
+
|
| 430 |
+
- 🙌 **Bilingual Support.**
|
| 431 |
+
|
| 432 |
+
MiniCPM-V 2.0 **supports strong bilingual multimodal capabilities in both English and Chinese**. This is enabled by generalizing multimodal capabilities across languages, a technique from [VisCPM](https://arxiv.org/abs/2308.12038) [ICLR'24].
|
| 433 |
+
|
| 434 |
+
### Examples <!-- omit in toc -->
|
| 435 |
+
|
| 436 |
+
<table align="center">
|
| 437 |
+
<p align="center">
|
| 438 |
+
<img src="assets/minicpmv2-cases_2.png" width=95%/>
|
| 439 |
+
</p>
|
| 440 |
+
</table>
|
| 441 |
+
|
| 442 |
+
We deploy MiniCPM-V 2.0 on end devices. The demo video is the raw screen recording on a Xiaomi 14 Pro without edition.
|
| 443 |
+
|
| 444 |
+
<table align="center">
|
| 445 |
+
<p align="center">
|
| 446 |
+
<img src="assets/gif_cases/station.gif" width=36%/>
|
| 447 |
+
<img src="assets/gif_cases/london_car.gif" width=36%/>
|
| 448 |
+
</p>
|
| 449 |
+
</table>
|
| 450 |
+
|
| 451 |
+
</details>
|
| 452 |
+
|
| 453 |
+
## Legacy Models <!-- omit in toc -->
|
| 454 |
+
|
| 455 |
+
| Model | Introduction and Guidance |
|
| 456 |
+
|:----------------------|:-------------------:|
|
| 457 |
+
| MiniCPM-V 1.0 | [Document](./minicpm_v1.md) |
|
| 458 |
+
| OmniLMM-12B | [Document](./omnilmm_en.md) |
|
| 459 |
+
|
| 460 |
+
|
| 461 |
+
|
| 462 |
+
## Online Demo
|
| 463 |
+
Click here to try out the Demo of [MiniCPM-Llama3-V 2.5](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5) | [MiniCPM-V 2.0](https://huggingface.co/spaces/openbmb/MiniCPM-V-2).
|
| 464 |
+
|
| 465 |
+
## Install
|
| 466 |
+
|
| 467 |
+
1. Clone this repository and navigate to the source folder
|
| 468 |
+
|
| 469 |
+
```bash
|
| 470 |
+
git clone https://github.com/OpenBMB/MiniCPM-V.git
|
| 471 |
+
cd MiniCPM-V
|
| 472 |
+
```
|
| 473 |
+
|
| 474 |
+
2. Create conda environment
|
| 475 |
+
|
| 476 |
+
```Shell
|
| 477 |
+
conda create -n MiniCPM-V python=3.10 -y
|
| 478 |
+
conda activate MiniCPM-V
|
| 479 |
+
```
|
| 480 |
+
|
| 481 |
+
3. Install dependencies
|
| 482 |
+
|
| 483 |
+
```shell
|
| 484 |
+
pip install -r requirements.txt
|
| 485 |
+
```
|
| 486 |
+
|
| 487 |
+
## Inference
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
### Model Zoo
|
| 491 |
+
|
| 492 |
+
| Model | Device | Memory |          Description | Download |
|
| 493 |
+
|:-----------|:--:|:-----------:|:-------------------|:---------------:|
|
| 494 |
+
| MiniCPM-Llama3-V 2.5 | GPU | 19 GB | The lastest version, achieving state-of-the end-side multimodal performance. | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5/) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5) |
|
| 495 |
+
| MiniCPM-Llama3-V 2.5 gguf | CPU | 5 GB | The gguf version, lower GPU memory and faster inference. | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5-gguf) |
|
| 496 |
+
| MiniCPM-Llama3-V 2.5 int4 | GPU | 8 GB | The int4 quantized version,lower GPU memory usage. | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-int4/) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5-int4) |
|
| 497 |
+
| MiniCPM-V 2.0 | GPU | 8 GB | Light version, balance the performance the computation cost. | [🤗](https://huggingface.co/openbmb/MiniCPM-V-2) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-V-2) |
|
| 498 |
+
| MiniCPM-V 1.0 | GPU | 7 GB | Lightest version, achieving the fastest inference. | [🤗](https://huggingface.co/openbmb/MiniCPM-V) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-V) |
|
| 499 |
+
|
| 500 |
+
### Multi-turn Conversation
|
| 501 |
+
|
| 502 |
+
Please refer to the following codes to run.
|
| 503 |
+
|
| 504 |
+
<div align="center">
|
| 505 |
+
<img src="assets/airplane.jpeg" width="500px">
|
| 506 |
+
</div>
|
| 507 |
+
|
| 508 |
+
|
| 509 |
+
```python
|
| 510 |
+
from chat import MiniCPMVChat, img2base64
|
| 511 |
+
import torch
|
| 512 |
+
import json
|
| 513 |
+
|
| 514 |
+
torch.manual_seed(0)
|
| 515 |
+
|
| 516 |
+
chat_model = MiniCPMVChat('openbmb/MiniCPM-Llama3-V-2_5')
|
| 517 |
+
|
| 518 |
+
im_64 = img2base64('./assets/airplane.jpeg')
|
| 519 |
+
|
| 520 |
+
# First round chat
|
| 521 |
+
msgs = [{"role": "user", "content": "Tell me the model of this aircraft."}]
|
| 522 |
+
|
| 523 |
+
inputs = {"image": im_64, "question": json.dumps(msgs)}
|
| 524 |
+
answer = chat_model.chat(inputs)
|
| 525 |
+
print(answer)
|
| 526 |
+
|
| 527 |
+
# Second round chat
|
| 528 |
+
# pass history context of multi-turn conversation
|
| 529 |
+
msgs.append({"role": "assistant", "content": answer})
|
| 530 |
+
msgs.append({"role": "user", "content": "Introduce something about Airbus A380."})
|
| 531 |
+
|
| 532 |
+
inputs = {"image": im_64, "question": json.dumps(msgs)}
|
| 533 |
+
answer = chat_model.chat(inputs)
|
| 534 |
+
print(answer)
|
| 535 |
+
```
|
| 536 |
+
|
| 537 |
+
You will get the following output:
|
| 538 |
+
|
| 539 |
+
```
|
| 540 |
+
"The aircraft in the image is an Airbus A380, which can be identified by its large size, double-deck structure, and the distinctive shape of its wings and engines. The A380 is a wide-body aircraft known for being the world's largest passenger airliner, designed for long-haul flights. It has four engines, which are characteristic of large commercial aircraft. The registration number on the aircraft can also provide specific information about the model if looked up in an aviation database."
|
| 541 |
+
|
| 542 |
+
"The Airbus A380 is a double-deck, wide-body, four-engine jet airliner made by Airbus. It is the world's largest passenger airliner and is known for its long-haul capabilities. The aircraft was developed to improve efficiency and comfort for passengers traveling over long distances. It has two full-length passenger decks, which can accommodate more passengers than a typical single-aisle airplane. The A380 has been operated by airlines such as Lufthansa, Singapore Airlines, and Emirates, among others. It is widely recognized for its unique design and significant impact on the aviation industry."
|
| 543 |
+
```
|
| 544 |
+
|
| 545 |
+
|
| 546 |
+
|
| 547 |
+
### Inference on Mac
|
| 548 |
+
<details>
|
| 549 |
+
<summary>Click to view an example, to run MiniCPM-Llama3-V 2.5 on 💻 Mac with MPS (Apple silicon or AMD GPUs). </summary>
|
| 550 |
+
|
| 551 |
+
```python
|
| 552 |
+
# test.py Need more than 16GB memory.
|
| 553 |
+
import torch
|
| 554 |
+
from PIL import Image
|
| 555 |
+
from transformers import AutoModel, AutoTokenizer
|
| 556 |
+
|
| 557 |
+
model = AutoModel.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True, low_cpu_mem_usage=True)
|
| 558 |
+
model = model.to(device='mps')
|
| 559 |
+
|
| 560 |
+
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True)
|
| 561 |
+
model.eval()
|
| 562 |
+
|
| 563 |
+
image = Image.open('./assets/hk_OCR.jpg').convert('RGB')
|
| 564 |
+
question = 'Where is this photo taken?'
|
| 565 |
+
msgs = [{'role': 'user', 'content': question}]
|
| 566 |
+
|
| 567 |
+
answer, context, _ = model.chat(
|
| 568 |
+
image=image,
|
| 569 |
+
msgs=msgs,
|
| 570 |
+
context=None,
|
| 571 |
+
tokenizer=tokenizer,
|
| 572 |
+
sampling=True
|
| 573 |
+
)
|
| 574 |
+
print(answer)
|
| 575 |
+
```
|
| 576 |
+
Run with command:
|
| 577 |
+
```shell
|
| 578 |
+
PYTORCH_ENABLE_MPS_FALLBACK=1 python test.py
|
| 579 |
+
```
|
| 580 |
+
</details>
|
| 581 |
+
|
| 582 |
+
### Deployment on Mobile Phone
|
| 583 |
+
MiniCPM-V 2.0 can be deployed on mobile phones with Android operating systems. 🚀 Click [here](https://github.com/OpenBMB/mlc-MiniCPM) to install apk. MiniCPM-Llama3-V 2.5 coming soon.
|
| 584 |
+
|
| 585 |
+
### WebUI Demo
|
| 586 |
+
|
| 587 |
+
<details>
|
| 588 |
+
<summary>Click to see how to deploy WebUI demo on different devices </summary>
|
| 589 |
+
|
| 590 |
+
```shell
|
| 591 |
+
pip install -r requirements.txt
|
| 592 |
+
```
|
| 593 |
+
|
| 594 |
+
```shell
|
| 595 |
+
# For NVIDIA GPUs, run:
|
| 596 |
+
python web_demo_2.5.py --device cuda
|
| 597 |
+
|
| 598 |
+
# For Mac with MPS (Apple silicon or AMD GPUs), run:
|
| 599 |
+
PYTORCH_ENABLE_MPS_FALLBACK=1 python web_demo_2.5.py --device mps
|
| 600 |
+
```
|
| 601 |
+
</details>
|
| 602 |
+
|
| 603 |
+
### Inference with llama.cpp<a id="inference-with-llamacpp"></a>
|
| 604 |
+
MiniCPM-Llama3-V 2.5 can run with llama.cpp now! See our fork of [llama.cpp](https://github.com/OpenBMB/llama.cpp/tree/minicpm-v2.5/examples/minicpmv) for more detail. This implementation supports smooth inference of 6~8 token/s on mobile phones (test environment:Xiaomi 14 pro + Snapdragon 8 Gen 3).
|
| 605 |
+
|
| 606 |
+
### Inference with vLLM<a id="vllm"></a>
|
| 607 |
+
|
| 608 |
+
<details>
|
| 609 |
+
<summary>Click to see how to inference with vLLM </summary>
|
| 610 |
+
Because our pull request to vLLM is still waiting for reviewing, we fork this repository to build and test our vLLM demo. Here are the steps:
|
| 611 |
+
|
| 612 |
+
1. Clone our version of vLLM:
|
| 613 |
+
```shell
|
| 614 |
+
git clone https://github.com/OpenBMB/vllm.git
|
| 615 |
+
```
|
| 616 |
+
2. Install vLLM:
|
| 617 |
+
```shell
|
| 618 |
+
cd vllm
|
| 619 |
+
pip install -e .
|
| 620 |
+
```
|
| 621 |
+
3. Install timm:
|
| 622 |
+
```shell
|
| 623 |
+
pip install timm=0.9.10
|
| 624 |
+
```
|
| 625 |
+
4. Run our demo:
|
| 626 |
+
```shell
|
| 627 |
+
python examples/minicpmv_example.py
|
| 628 |
+
```
|
| 629 |
+
</details>
|
| 630 |
+
|
| 631 |
+
## Fine-tuning
|
| 632 |
+
|
| 633 |
+
### Simple Fine-tuning <!-- omit in toc -->
|
| 634 |
+
|
| 635 |
+
We support simple fine-tuning with Hugging Face for MiniCPM-V 2.0 and MiniCPM-Llama3-V 2.5.
|
| 636 |
+
|
| 637 |
+
[Reference Document](./finetune/readme.md)
|
| 638 |
+
|
| 639 |
+
### With the SWIFT Framework <!-- omit in toc -->
|
| 640 |
+
|
| 641 |
+
We now support MiniCPM-V series fine-tuning with the SWIFT framework. SWIFT supports training, inference, evaluation and deployment of nearly 200 LLMs and MLLMs . It supports the lightweight training solutions provided by PEFT and a complete Adapters Library including techniques such as NEFTune, LoRA+ and LLaMA-PRO.
|
| 642 |
+
|
| 643 |
+
Best Practices:[MiniCPM-V 1.0](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v最佳实践.md), [MiniCPM-V 2.0](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v-2最佳实践.md)
|
| 644 |
+
|
| 645 |
+
|
| 646 |
+
|
| 647 |
+
## TODO
|
| 648 |
+
|
| 649 |
+
- [x] MiniCPM-V fine-tuning support
|
| 650 |
+
- [ ] Code release for real-time interactive assistant
|
| 651 |
+
|
| 652 |
+
## Model License <!-- omit in toc -->
|
| 653 |
+
|
| 654 |
+
The code in this repo is released according to [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE)
|
| 655 |
+
|
| 656 |
+
The usage of MiniCPM-V's and OmniLMM's parameters is subject to "[General Model License Agreement - Source Notes - Publicity Restrictions - Commercial License](https://github.com/OpenBMB/General-Model-License/blob/main/通用模型许可协议-来源说明-宣传限制-商业授权.md)"
|
| 657 |
+
|
| 658 |
+
The parameters are fully open to academic research
|
| 659 |
+
|
| 660 |
+
Please contact cpm@modelbest.cn to obtain written authorization for commercial uses. Free commercial use is also allowed after registration.
|
| 661 |
+
|
| 662 |
+
## Statement <!-- omit in toc -->
|
| 663 |
+
|
| 664 |
+
As LMMs, MiniCPM-V models (including OmniLMM) generate contents by learning a large amount of multimodal corpora, but they cannot comprehend, express personal opinions or make value judgement. Anything generated by MiniCPM-V models does not represent the views and positions of the model developers
|
| 665 |
+
|
| 666 |
+
We will not be liable for any problems arising from the use of MiniCPMV-V models, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination or misuse of the model.
|
| 667 |
+
|
| 668 |
+
|
| 669 |
+
## Institutions <!-- omit in toc -->
|
| 670 |
+
|
| 671 |
+
This project is developed by the following institutions:
|
| 672 |
+
|
| 673 |
+
- <img src="assets/thunlp.png" width="28px"> [THUNLP](https://nlp.csai.tsinghua.edu.cn/)
|
| 674 |
+
- <img src="assets/modelbest.png" width="28px"> [ModelBest](https://modelbest.cn/)
|
| 675 |
+
- <img src="assets/zhihu.webp" width="28px"> [Zhihu](https://www.zhihu.com/ )
|
| 676 |
+
|
| 677 |
+
## Other Multimodal Projects from Our Team <!-- omit in toc -->
|
| 678 |
+
|
| 679 |
+
👏 Welcome to explore other multimodal projects of our team:
|
| 680 |
+
|
| 681 |
+
[VisCPM](https://github.com/OpenBMB/VisCPM/tree/main) | [RLHF-V](https://github.com/RLHF-V/RLHF-V) | [LLaVA-UHD](https://github.com/thunlp/LLaVA-UHD) | [RLAIF-V](https://github.com/RLHF-V/RLAIF-V)
|
| 682 |
+
|
| 683 |
+
## 🌟 Star History
|
| 684 |
+
|
| 685 |
+
<div>
|
| 686 |
+
<img src="./assets/Star-History.png" width="500em" ></img>
|
| 687 |
+
</div>
|
| 688 |
+
|
| 689 |
+
## Citation
|
| 690 |
+
|
| 691 |
+
If you find our model/code/paper helpful, please consider cite our papers 📝 and star us ⭐️!
|
| 692 |
+
|
| 693 |
+
```bib
|
| 694 |
+
@article{yu2023rlhf,
|
| 695 |
+
title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback},
|
| 696 |
+
author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others},
|
| 697 |
+
journal={arXiv preprint arXiv:2312.00849},
|
| 698 |
+
year={2023}
|
| 699 |
+
}
|
| 700 |
+
@article{viscpm,
|
| 701 |
+
title={Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages},
|
| 702 |
+
author={Jinyi Hu and Yuan Yao and Chongyi Wang and Shan Wang and Yinxu Pan and Qianyu Chen and Tianyu Yu and Hanghao Wu and Yue Zhao and Haoye Zhang and Xu Han and Yankai Lin and Jiao Xue and Dahai Li and Zhiyuan Liu and Maosong Sun},
|
| 703 |
+
journal={arXiv preprint arXiv:2308.12038},
|
| 704 |
+
year={2023}
|
| 705 |
+
}
|
| 706 |
+
@article{xu2024llava-uhd,
|
| 707 |
+
title={{LLaVA-UHD}: an LMM Perceiving Any Aspect Ratio and High-Resolution Images},
|
| 708 |
+
author={Xu, Ruyi and Yao, Yuan and Guo, Zonghao and Cui, Junbo and Ni, Zanlin and Ge, Chunjiang and Chua, Tat-Seng and Liu, Zhiyuan and Huang, Gao},
|
| 709 |
+
journal={arXiv preprint arXiv:2403.11703},
|
| 710 |
+
year={2024}
|
| 711 |
+
}
|
| 712 |
+
@article{yu2024rlaifv,
|
| 713 |
+
title={RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness},
|
| 714 |
+
author={Yu, Tianyu and Zhang, Haoye and Yao, Yuan and Dang, Yunkai and Chen, Da and Lu, Xiaoman and Cui, Ganqu and He, Taiwen and Liu, Zhiyuan and Chua, Tat-Seng and Sun, Maosong},
|
| 715 |
+
journal={arXiv preprint arXiv:2405.17220},
|
| 716 |
+
year={2024}
|
| 717 |
+
}
|
| 718 |
+
```
|
README_en.md
ADDED
|
@@ -0,0 +1,718 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
<img src="./assets/minicpmv.png" width="300em" ></img>
|
| 4 |
+
|
| 5 |
+
**A GPT-4V Level Multimodal LLM on Your Phone**
|
| 6 |
+
|
| 7 |
+
<strong>[中文](./README_zh.md) |
|
| 8 |
+
English</strong>
|
| 9 |
+
|
| 10 |
+
<p align="center">
|
| 11 |
+
MiniCPM-Llama3-V 2.5 <a href="https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5/">🤗</a> <a href="https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5">🤖</a> |
|
| 12 |
+
MiniCPM-V 2.0 <a href="https://huggingface.co/openbmb/MiniCPM-V-2/">🤗</a> <a href="https://huggingface.co/spaces/openbmb/MiniCPM-V-2">🤖</a> |
|
| 13 |
+
<a href="https://openbmb.vercel.app/minicpm-v-2-en"> Technical Blog </a>
|
| 14 |
+
</p>
|
| 15 |
+
|
| 16 |
+
</div>
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
**MiniCPM-V** is a series of end-side multimodal LLMs (MLLMs) designed for vision-language understanding. The models take image and text as inputs and provide high-quality text outputs. Since February 2024, we have released 4 versions of the model, aiming to achieve **strong performance and efficient deployment**. The most notable models in this series currently include:
|
| 20 |
+
|
| 21 |
+
- **MiniCPM-Llama3-V 2.5**: 🔥🔥🔥 The latest and most capable model in the MiniCPM-V series. With a total of 8B parameters, the model **surpasses proprietary models such as GPT-4V-1106, Gemini Pro, Qwen-VL-Max and Claude 3** in overall performance. Equipped with the enhanced OCR and instruction-following capability, the model can also support multimodal conversation for **over 30 languages** including English, Chinese, French, Spanish, German etc. With help of quantization, compilation optimizations, and several efficient inference techniques on CPUs and NPUs, MiniCPM-Llama3-V 2.5 can be **efficiently deployed on end-side devices**.
|
| 22 |
+
|
| 23 |
+
- **MiniCPM-V 2.0**: The lightest model in the MiniCPM-V series. With 2B parameters, it surpasses larger models such as Yi-VL 34B, CogVLM-Chat 17B, and Qwen-VL-Chat 10B in overall performance. It can accept image inputs of any aspect ratio and up to 1.8 million pixels (e.g., 1344x1344), achieving comparable performance with Gemini Pro in understanding scene-text and matches GPT-4V in low hallucination rates.
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
## News <!-- omit in toc -->
|
| 27 |
+
|
| 28 |
+
#### 📌 Pinned
|
| 29 |
+
|
| 30 |
+
* [2024.05.28] 🚀🚀🚀 MiniCPM-Llama3-V 2.5 now fully supports its feature in [llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpm-v2.5/examples/minicpmv/README.md) and [ollama](https://github.com/OpenBMB/ollama/tree/minicpm-v2.5)! Please pull the latest code for llama.cpp & ollama. We also release GGUF in various sizes [here](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf/tree/main). FAQ list for ollama usage is comming within a day. Please stay tuned!
|
| 31 |
+
* [2024.05.28] 💫 We now support LoRA fine-tuning for MiniCPM-Llama3-V 2.5, using only 2 V100 GPUs! See more statistics [here](https://github.com/OpenBMB/MiniCPM-V/tree/main/finetune#model-fine-tuning-memory-usage-statistics).
|
| 32 |
+
* [2024.05.23] 🔍 We've released a comprehensive comparison between Phi-3-vision-128k-instruct and MiniCPM-Llama3-V 2.5, including benchmarks evaluations, multilingual capabilities, and inference efficiency 🌟📊🌍🚀. Click [here](./docs/compare_with_phi-3_vision.md) to view more details.
|
| 33 |
+
* [2024.05.23] 🔥🔥🔥 MiniCPM-V tops GitHub Trending and Hugging Face Trending! Our demo, recommended by Hugging Face Gradio’s official account, is available [here](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5). Come and try it out!
|
| 34 |
+
|
| 35 |
+
<br>
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
* [2024.05.25] MiniCPM-Llama3-V 2.5 now supports streaming outputs and customized system prompts. Try it [here](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5#usage)!
|
| 39 |
+
* [2024.05.24] We release the MiniCPM-Llama3-V 2.5 [gguf](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf), which supports [llama.cpp](#inference-with-llamacpp) inference and provides a 6~8 token/s smooth decoding on mobile phones. Try it now!
|
| 40 |
+
* [2024.05.20] We open-soure MiniCPM-Llama3-V 2.5, it has improved OCR capability and supports 30+ languages, representing the first end-side MLLM achieving GPT-4V level performance! We provide [efficient inference](#deployment-on-mobile-phone) and [simple fine-tuning](./finetune/readme.md). Try it now!
|
| 41 |
+
* [2024.04.23] MiniCPM-V-2.0 supports vLLM now! Click [here](#vllm) to view more details.
|
| 42 |
+
* [2024.04.18] We create a HuggingFace Space to host the demo of MiniCPM-V 2.0 at [here](https://huggingface.co/spaces/openbmb/MiniCPM-V-2)!
|
| 43 |
+
* [2024.04.17] MiniCPM-V-2.0 supports deploying [WebUI Demo](#webui-demo) now!
|
| 44 |
+
* [2024.04.15] MiniCPM-V-2.0 now also supports [fine-tuning](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v-2最佳实践.md) with the SWIFT framework!
|
| 45 |
+
* [2024.04.12] We open-source MiniCPM-V 2.0, which achieves comparable performance with Gemini Pro in understanding scene text and outperforms strong Qwen-VL-Chat 9.6B and Yi-VL 34B on <a href="https://rank.opencompass.org.cn/leaderboard-multimodal">OpenCompass</a>, a comprehensive evaluation over 11 popular benchmarks. Click <a href="https://openbmb.vercel.app/minicpm-v-2">here</a> to view the MiniCPM-V 2.0 technical blog.
|
| 46 |
+
* [2024.03.14] MiniCPM-V now supports [fine-tuning](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v最佳实践.md) with the SWIFT framework. Thanks to [Jintao](https://github.com/Jintao-Huang) for the contribution!
|
| 47 |
+
* [2024.03.01] MiniCPM-V now can be deployed on Mac!
|
| 48 |
+
* [2024.02.01] We open-source MiniCPM-V and OmniLMM-12B, which support efficient end-side deployment and powerful multimodal capabilities correspondingly.
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
## Contents <!-- omit in toc -->
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
- [MiniCPM-Llama3-V 2.5](#minicpm-llama3-v-25)
|
| 55 |
+
- [MiniCPM-V 2.0](#minicpm-v-20)
|
| 56 |
+
- [Online Demo](#online-demo)
|
| 57 |
+
- [Install](#install)
|
| 58 |
+
- [Inference](#inference)
|
| 59 |
+
- [Model Zoo](#model-zoo)
|
| 60 |
+
- [Multi-turn Conversation](#multi-turn-conversation)
|
| 61 |
+
- [Inference on Mac](#inference-on-mac)
|
| 62 |
+
- [Deployment on Mobile Phone](#deployment-on-mobile-phone)
|
| 63 |
+
- [WebUI Demo](#webui-demo)
|
| 64 |
+
- [Inference with llama.cpp](#inference-with-llamacpp)
|
| 65 |
+
- [Inference with vLLM](#inference-with-vllm)
|
| 66 |
+
- [Fine-tuning](#fine-tuning)
|
| 67 |
+
- [TODO](#todo)
|
| 68 |
+
- [🌟 Star History](#-star-history)
|
| 69 |
+
- [Citation](#citation)
|
| 70 |
+
|
| 71 |
+
## MiniCPM-Llama3-V 2.5
|
| 72 |
+
|
| 73 |
+
**MiniCPM-Llama3-V 2.5** is the latest model in the MiniCPM-V series. The model is built on SigLip-400M and Llama3-8B-Instruct with a total of 8B parameters. It exhibits a significant performance improvement over MiniCPM-V 2.0. Notable features of MiniCPM-Llama3-V 2.5 include:
|
| 74 |
+
|
| 75 |
+
- 🔥 **Leading Performance.**
|
| 76 |
+
MiniCPM-Llama3-V 2.5 has achieved an average score of 65.1 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks. **With only 8B parameters, it surpasses widely used proprietary models like GPT-4V-1106, Gemini Pro, Claude 3 and Qwen-VL-Max** and greatly outperforms other Llama 3-based MLLMs.
|
| 77 |
+
|
| 78 |
+
- 💪 **Strong OCR Capabilities.**
|
| 79 |
+
MiniCPM-Llama3-V 2.5 can process images with any aspect ratio and up to 1.8 million pixels (e.g., 1344x1344), achieving a **700+ score on OCRBench, surpassing proprietary models such as GPT-4o, GPT-4V-0409, Qwen-VL-Max and Gemini Pro**. Based on recent user feedback, MiniCPM-Llama3-V 2.5 has now enhanced full-text OCR extraction, table-to-markdown conversion, and other high-utility capabilities, and has further strengthened its instruction-following and complex reasoning abilities, enhancing multimodal interaction experiences.
|
| 80 |
+
|
| 81 |
+
- 🏆 **Trustworthy Behavior.**
|
| 82 |
+
Leveraging the latest [RLAIF-V](https://github.com/RLHF-V/RLAIF-V/) method (the newest technique in the [RLHF-V](https://github.com/RLHF-V) [CVPR'24] series), MiniCPM-Llama3-V 2.5 exhibits more trustworthy behavior. It achieves a **10.3%** hallucination rate on Object HalBench, lower than GPT-4V-1106 (13.6%), achieving the best-level performance within the open-source community. [Data released](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset).
|
| 83 |
+
|
| 84 |
+
- 🌏 **Multilingual Support.**
|
| 85 |
+
Thanks to the strong multilingual capabilities of Llama 3 and the cross-lingual generalization technique from [VisCPM](https://github.com/OpenBMB/VisCPM), MiniCPM-Llama3-V 2.5 extends its bilingual (Chinese-English) multimodal capabilities to **over 30 languages including German, French, Spanish, Italian, Korean etc.** [All Supported Languages](./assets/minicpm-llama-v-2-5_languages.md).
|
| 86 |
+
|
| 87 |
+
- 🚀 **Efficient Deployment.**
|
| 88 |
+
MiniCPM-Llama3-V 2.5 systematically employs **model quantization, CPU optimizations, NPU optimizations and compilation optimizations**, achieving high-efficiency deployment on end-side devices. For mobile phones with Qualcomm chips, we have integrated the NPU acceleration framework QNN into llama.cpp for the first time. After systematic optimization, MiniCPM-Llama3-V 2.5 has realized a **150x acceleration in end-side MLLM image encoding** and a **3x speedup in language decoding**.
|
| 89 |
+
|
| 90 |
+
- 💫 **Easy Usage.**
|
| 91 |
+
MiniCPM-Llama3-V 2.5 can be easily used in various ways: (1) [llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpm-v2.5/examples/minicpmv/README.md) and [ollama](https://github.com/OpenBMB/ollama/tree/minicpm-v2.5/examples/minicpm-v2.5) support for efficient CPU inference on local devices, (2) [GGUF](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf) format quantized models in 16 sizes, (3) efficient [LoRA](https://github.com/OpenBMB/MiniCPM-V/tree/main/finetune#lora-finetuning) fine-tuning with only 2 V100 GPUs, (4) [streaming output](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5#usage), (5) quick local WebUI demo setup with [Gradio](https://github.com/OpenBMB/MiniCPM-V/blob/main/web_demo_2.5.py) and [Streamlit](https://github.com/OpenBMB/MiniCPM-V/blob/main/web_demo_streamlit-2_5.py), and (6) interactive demos on [HuggingFace Spaces](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5).
|
| 92 |
+
|
| 93 |
+
### Evaluation <!-- omit in toc -->
|
| 94 |
+
|
| 95 |
+
<div align="center">
|
| 96 |
+
<img src=assets/MiniCPM-Llama3-V-2.5-peformance.png width=66% />
|
| 97 |
+
</div>
|
| 98 |
+
<details>
|
| 99 |
+
<summary>Click to view results on TextVQA, DocVQA, OCRBench, OpenCompass, MME, MMBench, MMMU, MathVista, LLaVA Bench, RealWorld QA, Object HalBench. </summary>
|
| 100 |
+
<div align="center">
|
| 101 |
+
|
| 102 |
+
<table style="margin: 0px auto;">
|
| 103 |
+
<thead>
|
| 104 |
+
<tr>
|
| 105 |
+
<th align="left">Model</th>
|
| 106 |
+
<th>Size</th>
|
| 107 |
+
<th>OCRBench</th>
|
| 108 |
+
<th>TextVQA val</th>
|
| 109 |
+
<th>DocVQA test</th>
|
| 110 |
+
<th>Open-Compass</th>
|
| 111 |
+
<th>MME</th>
|
| 112 |
+
<th>MMB test (en)</th>
|
| 113 |
+
<th>MMB test (cn)</th>
|
| 114 |
+
<th>MMMU val</th>
|
| 115 |
+
<th>Math-Vista</th>
|
| 116 |
+
<th>LLaVA Bench</th>
|
| 117 |
+
<th>RealWorld QA</th>
|
| 118 |
+
<th>Object HalBench</th>
|
| 119 |
+
</tr>
|
| 120 |
+
</thead>
|
| 121 |
+
<tbody align="center">
|
| 122 |
+
<tr>
|
| 123 |
+
<td colspan="14" align="left"><strong>Proprietary</strong></td>
|
| 124 |
+
</tr>
|
| 125 |
+
<tr>
|
| 126 |
+
<td nowrap="nowrap" align="left">Gemini Pro</td>
|
| 127 |
+
<td>-</td>
|
| 128 |
+
<td>680</td>
|
| 129 |
+
<td>74.6</td>
|
| 130 |
+
<td>88.1</td>
|
| 131 |
+
<td>62.9</td>
|
| 132 |
+
<td>2148.9</td>
|
| 133 |
+
<td>73.6</td>
|
| 134 |
+
<td>74.3</td>
|
| 135 |
+
<td>48.9</td>
|
| 136 |
+
<td>45.8</td>
|
| 137 |
+
<td>79.9</td>
|
| 138 |
+
<td>60.4</td>
|
| 139 |
+
<td>-</td>
|
| 140 |
+
</tr>
|
| 141 |
+
<tr>
|
| 142 |
+
<td nowrap="nowrap" align="left">GPT-4V (2023.11.06)</td>
|
| 143 |
+
<td>-</td>
|
| 144 |
+
<td>645</td>
|
| 145 |
+
<td>78.0</td>
|
| 146 |
+
<td>88.4</td>
|
| 147 |
+
<td>63.5</td>
|
| 148 |
+
<td>1771.5</td>
|
| 149 |
+
<td>77.0</td>
|
| 150 |
+
<td>74.4</td>
|
| 151 |
+
<td>53.8</td>
|
| 152 |
+
<td>47.8</td>
|
| 153 |
+
<td>93.1</td>
|
| 154 |
+
<td>63.0</td>
|
| 155 |
+
<td>86.4</td>
|
| 156 |
+
</tr>
|
| 157 |
+
<tr>
|
| 158 |
+
<td colspan="14" align="left"><strong>Open-source</strong></td>
|
| 159 |
+
</tr>
|
| 160 |
+
<tr>
|
| 161 |
+
<td nowrap="nowrap" align="left">Mini-Gemini</td>
|
| 162 |
+
<td>2.2B</td>
|
| 163 |
+
<td>-</td>
|
| 164 |
+
<td>56.2</td>
|
| 165 |
+
<td>34.2*</td>
|
| 166 |
+
<td>-</td>
|
| 167 |
+
<td>1653.0</td>
|
| 168 |
+
<td>-</td>
|
| 169 |
+
<td>-</td>
|
| 170 |
+
<td>31.7</td>
|
| 171 |
+
<td>-</td>
|
| 172 |
+
<td>-</td>
|
| 173 |
+
<td>-</td>
|
| 174 |
+
<td>-</td>
|
| 175 |
+
</tr>
|
| 176 |
+
<tr>
|
| 177 |
+
<td nowrap="nowrap" align="left">Qwen-VL-Chat</td>
|
| 178 |
+
<td>9.6B</td>
|
| 179 |
+
<td>488</td>
|
| 180 |
+
<td>61.5</td>
|
| 181 |
+
<td>62.6</td>
|
| 182 |
+
<td>51.6</td>
|
| 183 |
+
<td>1860.0</td>
|
| 184 |
+
<td>61.8</td>
|
| 185 |
+
<td>56.3</td>
|
| 186 |
+
<td>37.0</td>
|
| 187 |
+
<td>33.8</td>
|
| 188 |
+
<td>67.7</td>
|
| 189 |
+
<td>49.3</td>
|
| 190 |
+
<td>56.2</td>
|
| 191 |
+
</tr>
|
| 192 |
+
<tr>
|
| 193 |
+
<td nowrap="nowrap" align="left">DeepSeek-VL-7B</td>
|
| 194 |
+
<td>7.3B</td>
|
| 195 |
+
<td>435</td>
|
| 196 |
+
<td>64.7*</td>
|
| 197 |
+
<td>47.0*</td>
|
| 198 |
+
<td>54.6</td>
|
| 199 |
+
<td>1765.4</td>
|
| 200 |
+
<td>73.8</td>
|
| 201 |
+
<td>71.4</td>
|
| 202 |
+
<td>38.3</td>
|
| 203 |
+
<td>36.8</td>
|
| 204 |
+
<td>77.8</td>
|
| 205 |
+
<td>54.2</td>
|
| 206 |
+
<td>-</td>
|
| 207 |
+
</tr>
|
| 208 |
+
<tr>
|
| 209 |
+
<td nowrap="nowrap" align="left">Yi-VL-34B</td>
|
| 210 |
+
<td>34B</td>
|
| 211 |
+
<td>290</td>
|
| 212 |
+
<td>43.4*</td>
|
| 213 |
+
<td>16.9*</td>
|
| 214 |
+
<td>52.2</td>
|
| 215 |
+
<td><strong>2050.2</strong></td>
|
| 216 |
+
<td>72.4</td>
|
| 217 |
+
<td>70.7</td>
|
| 218 |
+
<td>45.1</td>
|
| 219 |
+
<td>30.7</td>
|
| 220 |
+
<td>62.3</td>
|
| 221 |
+
<td>54.8</td>
|
| 222 |
+
<td>79.3</td>
|
| 223 |
+
</tr>
|
| 224 |
+
<tr>
|
| 225 |
+
<td nowrap="nowrap" align="left">CogVLM-Chat</td>
|
| 226 |
+
<td>17.4B</td>
|
| 227 |
+
<td>590</td>
|
| 228 |
+
<td>70.4</td>
|
| 229 |
+
<td>33.3*</td>
|
| 230 |
+
<td>54.2</td>
|
| 231 |
+
<td>1736.6</td>
|
| 232 |
+
<td>65.8</td>
|
| 233 |
+
<td>55.9</td>
|
| 234 |
+
<td>37.3</td>
|
| 235 |
+
<td>34.7</td>
|
| 236 |
+
<td>73.9</td>
|
| 237 |
+
<td>60.3</td>
|
| 238 |
+
<td>73.6</td>
|
| 239 |
+
</tr>
|
| 240 |
+
<tr>
|
| 241 |
+
<td nowrap="nowrap" align="left">TextMonkey</td>
|
| 242 |
+
<td>9.7B</td>
|
| 243 |
+
<td>558</td>
|
| 244 |
+
<td>64.3</td>
|
| 245 |
+
<td>66.7</td>
|
| 246 |
+
<td>-</td>
|
| 247 |
+
<td>-</td>
|
| 248 |
+
<td>-</td>
|
| 249 |
+
<td>-</td>
|
| 250 |
+
<td>-</td>
|
| 251 |
+
<td>-</td>
|
| 252 |
+
<td>-</td>
|
| 253 |
+
<td>-</td>
|
| 254 |
+
<td>-</td>
|
| 255 |
+
</tr>
|
| 256 |
+
<tr>
|
| 257 |
+
<td nowrap="nowrap" align="left">Idefics2</td>
|
| 258 |
+
<td>8.0B</td>
|
| 259 |
+
<td>-</td>
|
| 260 |
+
<td>73.0</td>
|
| 261 |
+
<td>74.0</td>
|
| 262 |
+
<td>57.2</td>
|
| 263 |
+
<td>1847.6</td>
|
| 264 |
+
<td>75.7</td>
|
| 265 |
+
<td>68.6</td>
|
| 266 |
+
<td>45.2</td>
|
| 267 |
+
<td>52.2</td>
|
| 268 |
+
<td>49.1</td>
|
| 269 |
+
<td>60.7</td>
|
| 270 |
+
<td>-</td>
|
| 271 |
+
</tr>
|
| 272 |
+
<tr>
|
| 273 |
+
<td nowrap="nowrap" align="left">Bunny-LLama-3-8B</td>
|
| 274 |
+
<td>8.4B</td>
|
| 275 |
+
<td>-</td>
|
| 276 |
+
<td>-</td>
|
| 277 |
+
<td>-</td>
|
| 278 |
+
<td>54.3</td>
|
| 279 |
+
<td>1920.3</td>
|
| 280 |
+
<td>77.0</td>
|
| 281 |
+
<td>73.9</td>
|
| 282 |
+
<td>41.3</td>
|
| 283 |
+
<td>31.5</td>
|
| 284 |
+
<td>61.2</td>
|
| 285 |
+
<td>58.8</td>
|
| 286 |
+
<td>-</td>
|
| 287 |
+
</tr>
|
| 288 |
+
<tr>
|
| 289 |
+
<td nowrap="nowrap" align="left">LLaVA-NeXT Llama-3-8B</td>
|
| 290 |
+
<td>8.4B</td>
|
| 291 |
+
<td>-</td>
|
| 292 |
+
<td>-</td>
|
| 293 |
+
<td>78.2</td>
|
| 294 |
+
<td>-</td>
|
| 295 |
+
<td>1971.5</td>
|
| 296 |
+
<td>-</td>
|
| 297 |
+
<td>-</td>
|
| 298 |
+
<td>41.7</td>
|
| 299 |
+
<td>37.5</td>
|
| 300 |
+
<td>80.1</td>
|
| 301 |
+
<td>60.0</td>
|
| 302 |
+
<td>-</td>
|
| 303 |
+
</tr>
|
| 304 |
+
<tr>
|
| 305 |
+
<td nowrap="nowrap" align="left">Phi-3-vision-128k-instruct</td>
|
| 306 |
+
<td>4.2B</td>
|
| 307 |
+
<td>639*</td>
|
| 308 |
+
<td>70.9</td>
|
| 309 |
+
<td>-</td>
|
| 310 |
+
<td>-</td>
|
| 311 |
+
<td>1537.5*</td>
|
| 312 |
+
<td>-</td>
|
| 313 |
+
<td>-</td>
|
| 314 |
+
<td>40.4</td>
|
| 315 |
+
<td>44.5</td>
|
| 316 |
+
<td>64.2*</td>
|
| 317 |
+
<td>58.8*</td>
|
| 318 |
+
<td>-</td>
|
| 319 |
+
</tr>
|
| 320 |
+
<tr style="background-color: #e6f2ff;">
|
| 321 |
+
<td nowrap="nowrap" align="left">MiniCPM-V 1.0</td>
|
| 322 |
+
<td>2.8B</td>
|
| 323 |
+
<td>366</td>
|
| 324 |
+
<td>60.6</td>
|
| 325 |
+
<td>38.2</td>
|
| 326 |
+
<td>47.5</td>
|
| 327 |
+
<td>1650.2</td>
|
| 328 |
+
<td>64.1</td>
|
| 329 |
+
<td>62.6</td>
|
| 330 |
+
<td>38.3</td>
|
| 331 |
+
<td>28.9</td>
|
| 332 |
+
<td>51.3</td>
|
| 333 |
+
<td>51.2</td>
|
| 334 |
+
<td>78.4</td>
|
| 335 |
+
</tr>
|
| 336 |
+
<tr style="background-color: #e6f2ff;">
|
| 337 |
+
<td nowrap="nowrap" align="left">MiniCPM-V 2.0</td>
|
| 338 |
+
<td>2.8B</td>
|
| 339 |
+
<td>605</td>
|
| 340 |
+
<td>74.1</td>
|
| 341 |
+
<td>71.9</td>
|
| 342 |
+
<td>54.5</td>
|
| 343 |
+
<td>1808.6</td>
|
| 344 |
+
<td>69.1</td>
|
| 345 |
+
<td>66.5</td>
|
| 346 |
+
<td>38.2</td>
|
| 347 |
+
<td>38.7</td>
|
| 348 |
+
<td>69.2</td>
|
| 349 |
+
<td>55.8</td>
|
| 350 |
+
<td>85.5</td>
|
| 351 |
+
</tr>
|
| 352 |
+
<tr style="background-color: #e6f2ff;">
|
| 353 |
+
<td nowrap="nowrap" align="left">MiniCPM-Llama3-V 2.5</td>
|
| 354 |
+
<td>8.5B</td>
|
| 355 |
+
<td><strong>725</strong></td>
|
| 356 |
+
<td><strong>76.6</strong></td>
|
| 357 |
+
<td><strong>84.8</strong></td>
|
| 358 |
+
<td><strong>65.1</strong></td>
|
| 359 |
+
<td>2024.6</td>
|
| 360 |
+
<td><strong>77.2</strong></td>
|
| 361 |
+
<td><strong>74.2</strong></td>
|
| 362 |
+
<td><strong>45.8</strong></td>
|
| 363 |
+
<td><strong>54.3</strong></td>
|
| 364 |
+
<td><strong>86.7</strong></td>
|
| 365 |
+
<td><strong>63.5</strong></td>
|
| 366 |
+
<td><strong>89.7</strong></td>
|
| 367 |
+
</tr>
|
| 368 |
+
</tbody>
|
| 369 |
+
</table>
|
| 370 |
+
|
| 371 |
+
|
| 372 |
+
</div>
|
| 373 |
+
* We evaluate the officially released checkpoint by ourselves.
|
| 374 |
+
|
| 375 |
+
</details>
|
| 376 |
+
|
| 377 |
+
<div align="center">
|
| 378 |
+
<img src="assets/llavabench_compare_3.png" width="100%" />
|
| 379 |
+
<br>
|
| 380 |
+
Evaluation results of multilingual LLaVA Bench
|
| 381 |
+
</div>
|
| 382 |
+
|
| 383 |
+
### Examples <!-- omit in toc -->
|
| 384 |
+
|
| 385 |
+
<table align="center" >
|
| 386 |
+
<p align="center" >
|
| 387 |
+
<img src="assets/minicpmv-llama3-v2.5/cases_all.png" />
|
| 388 |
+
</p>
|
| 389 |
+
</table>
|
| 390 |
+
|
| 391 |
+
We deploy MiniCPM-Llama3-V 2.5 on end devices. The demo video is the raw screen recording on a Xiaomi 14 Pro without edition.
|
| 392 |
+
|
| 393 |
+
<table align="center">
|
| 394 |
+
<p align="center">
|
| 395 |
+
<img src="assets/gif_cases/ticket.gif" width=32%/>
|
| 396 |
+
<img src="assets/gif_cases/meal_plan.gif" width=32%/>
|
| 397 |
+
</p>
|
| 398 |
+
</table>
|
| 399 |
+
|
| 400 |
+
<table align="center">
|
| 401 |
+
<p align="center">
|
| 402 |
+
<img src="assets/gif_cases/1-4.gif" width=64%/>
|
| 403 |
+
</p>
|
| 404 |
+
</table>
|
| 405 |
+
|
| 406 |
+
## MiniCPM-V 2.0
|
| 407 |
+
|
| 408 |
+
<details>
|
| 409 |
+
<summary>Click to view more details of MiniCPM-V 2.0</summary>
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
**MiniCPM-V 2.0** is an efficient version with promising performance for deployment. The model is built based on SigLip-400M and [MiniCPM-2.4B](https://github.com/OpenBMB/MiniCPM/), connected by a perceiver resampler. Our latest version, MiniCPM-V 2.0 has several notable features.
|
| 413 |
+
|
| 414 |
+
- 🔥 **State-of-the-art Performance.**
|
| 415 |
+
|
| 416 |
+
MiniCPM-V 2.0 achieves **state-of-the-art performance** on multiple benchmarks (including OCRBench, TextVQA, MME, MMB, MathVista, etc) among models under 7B parameters. It even **outperforms strong Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on OpenCompass, a comprehensive evaluation over 11 popular benchmarks**. Notably, MiniCPM-V 2.0 shows **strong OCR capability**, achieving **comparable performance to Gemini Pro in scene-text understanding**, and **state-of-the-art performance on OCRBench** among open-source models.
|
| 417 |
+
|
| 418 |
+
- 🏆 **Trustworthy Behavior.**
|
| 419 |
+
|
| 420 |
+
LMMs are known for suffering from hallucination, often generating text not factually grounded in images. MiniCPM-V 2.0 is **the first end-side LMM aligned via multimodal RLHF for trustworthy behavior** (using the recent [RLHF-V](https://rlhf-v.github.io/) [CVPR'24] series technique). This allows the model to **match GPT-4V in preventing hallucinations** on Object HalBench.
|
| 421 |
+
|
| 422 |
+
- 🌟 **High-Resolution Images at Any Aspect Raito.**
|
| 423 |
+
|
| 424 |
+
MiniCPM-V 2.0 can accept **1.8 million pixels (e.g., 1344x1344) images at any aspect ratio**. This enables better perception of fine-grained visual information such as small objects and optical characters, which is achieved via a recent technique from [LLaVA-UHD](https://arxiv.org/pdf/2403.11703.pdf).
|
| 425 |
+
|
| 426 |
+
- ⚡️ **High Efficiency.**
|
| 427 |
+
|
| 428 |
+
MiniCPM-V 2.0 can be **efficiently deployed on most GPU cards and personal computers**, and **even on end devices such as mobile phones**. For visual encoding, we compress the image representations into much fewer tokens via a perceiver resampler. This allows MiniCPM-V 2.0 to operate with **favorable memory cost and speed during inference even when dealing with high-resolution images**.
|
| 429 |
+
|
| 430 |
+
- 🙌 **Bilingual Support.**
|
| 431 |
+
|
| 432 |
+
MiniCPM-V 2.0 **supports strong bilingual multimodal capabilities in both English and Chinese**. This is enabled by generalizing multimodal capabilities across languages, a technique from [VisCPM](https://arxiv.org/abs/2308.12038) [ICLR'24].
|
| 433 |
+
|
| 434 |
+
### Examples <!-- omit in toc -->
|
| 435 |
+
|
| 436 |
+
<table align="center">
|
| 437 |
+
<p align="center">
|
| 438 |
+
<img src="assets/minicpmv2-cases_2.png" width=95%/>
|
| 439 |
+
</p>
|
| 440 |
+
</table>
|
| 441 |
+
|
| 442 |
+
We deploy MiniCPM-V 2.0 on end devices. The demo video is the raw screen recording on a Xiaomi 14 Pro without edition.
|
| 443 |
+
|
| 444 |
+
<table align="center">
|
| 445 |
+
<p align="center">
|
| 446 |
+
<img src="assets/gif_cases/station.gif" width=36%/>
|
| 447 |
+
<img src="assets/gif_cases/london_car.gif" width=36%/>
|
| 448 |
+
</p>
|
| 449 |
+
</table>
|
| 450 |
+
|
| 451 |
+
</details>
|
| 452 |
+
|
| 453 |
+
## Legacy Models <!-- omit in toc -->
|
| 454 |
+
|
| 455 |
+
| Model | Introduction and Guidance |
|
| 456 |
+
|:----------------------|:-------------------:|
|
| 457 |
+
| MiniCPM-V 1.0 | [Document](./minicpm_v1.md) |
|
| 458 |
+
| OmniLMM-12B | [Document](./omnilmm_en.md) |
|
| 459 |
+
|
| 460 |
+
|
| 461 |
+
|
| 462 |
+
## Online Demo
|
| 463 |
+
Click here to try out the Demo of [MiniCPM-Llama3-V 2.5](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5) | [MiniCPM-V 2.0](https://huggingface.co/spaces/openbmb/MiniCPM-V-2).
|
| 464 |
+
|
| 465 |
+
## Install
|
| 466 |
+
|
| 467 |
+
1. Clone this repository and navigate to the source folder
|
| 468 |
+
|
| 469 |
+
```bash
|
| 470 |
+
git clone https://github.com/OpenBMB/MiniCPM-V.git
|
| 471 |
+
cd MiniCPM-V
|
| 472 |
+
```
|
| 473 |
+
|
| 474 |
+
2. Create conda environment
|
| 475 |
+
|
| 476 |
+
```Shell
|
| 477 |
+
conda create -n MiniCPM-V python=3.10 -y
|
| 478 |
+
conda activate MiniCPM-V
|
| 479 |
+
```
|
| 480 |
+
|
| 481 |
+
3. Install dependencies
|
| 482 |
+
|
| 483 |
+
```shell
|
| 484 |
+
pip install -r requirements.txt
|
| 485 |
+
```
|
| 486 |
+
|
| 487 |
+
## Inference
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
### Model Zoo
|
| 491 |
+
|
| 492 |
+
| Model | Device | Memory |          Description | Download |
|
| 493 |
+
|:-----------|:--:|:-----------:|:-------------------|:---------------:|
|
| 494 |
+
| MiniCPM-Llama3-V 2.5 | GPU | 19 GB | The lastest version, achieving state-of-the end-side multimodal performance. | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5/) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5) |
|
| 495 |
+
| MiniCPM-Llama3-V 2.5 gguf | CPU | 5 GB | The gguf version, lower GPU memory and faster inference. | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5-gguf) |
|
| 496 |
+
| MiniCPM-Llama3-V 2.5 int4 | GPU | 8 GB | The int4 quantized version,lower GPU memory usage. | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-int4/) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5-int4) |
|
| 497 |
+
| MiniCPM-V 2.0 | GPU | 8 GB | Light version, balance the performance the computation cost. | [🤗](https://huggingface.co/openbmb/MiniCPM-V-2) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-V-2) |
|
| 498 |
+
| MiniCPM-V 1.0 | GPU | 7 GB | Lightest version, achieving the fastest inference. | [🤗](https://huggingface.co/openbmb/MiniCPM-V) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-V) |
|
| 499 |
+
|
| 500 |
+
### Multi-turn Conversation
|
| 501 |
+
|
| 502 |
+
Please refer to the following codes to run.
|
| 503 |
+
|
| 504 |
+
<div align="center">
|
| 505 |
+
<img src="assets/airplane.jpeg" width="500px">
|
| 506 |
+
</div>
|
| 507 |
+
|
| 508 |
+
|
| 509 |
+
```python
|
| 510 |
+
from chat import MiniCPMVChat, img2base64
|
| 511 |
+
import torch
|
| 512 |
+
import json
|
| 513 |
+
|
| 514 |
+
torch.manual_seed(0)
|
| 515 |
+
|
| 516 |
+
chat_model = MiniCPMVChat('openbmb/MiniCPM-Llama3-V-2_5')
|
| 517 |
+
|
| 518 |
+
im_64 = img2base64('./assets/airplane.jpeg')
|
| 519 |
+
|
| 520 |
+
# First round chat
|
| 521 |
+
msgs = [{"role": "user", "content": "Tell me the model of this aircraft."}]
|
| 522 |
+
|
| 523 |
+
inputs = {"image": im_64, "question": json.dumps(msgs)}
|
| 524 |
+
answer = chat_model.chat(inputs)
|
| 525 |
+
print(answer)
|
| 526 |
+
|
| 527 |
+
# Second round chat
|
| 528 |
+
# pass history context of multi-turn conversation
|
| 529 |
+
msgs.append({"role": "assistant", "content": answer})
|
| 530 |
+
msgs.append({"role": "user", "content": "Introduce something about Airbus A380."})
|
| 531 |
+
|
| 532 |
+
inputs = {"image": im_64, "question": json.dumps(msgs)}
|
| 533 |
+
answer = chat_model.chat(inputs)
|
| 534 |
+
print(answer)
|
| 535 |
+
```
|
| 536 |
+
|
| 537 |
+
You will get the following output:
|
| 538 |
+
|
| 539 |
+
```
|
| 540 |
+
"The aircraft in the image is an Airbus A380, which can be identified by its large size, double-deck structure, and the distinctive shape of its wings and engines. The A380 is a wide-body aircraft known for being the world's largest passenger airliner, designed for long-haul flights. It has four engines, which are characteristic of large commercial aircraft. The registration number on the aircraft can also provide specific information about the model if looked up in an aviation database."
|
| 541 |
+
|
| 542 |
+
"The Airbus A380 is a double-deck, wide-body, four-engine jet airliner made by Airbus. It is the world's largest passenger airliner and is known for its long-haul capabilities. The aircraft was developed to improve efficiency and comfort for passengers traveling over long distances. It has two full-length passenger decks, which can accommodate more passengers than a typical single-aisle airplane. The A380 has been operated by airlines such as Lufthansa, Singapore Airlines, and Emirates, among others. It is widely recognized for its unique design and significant impact on the aviation industry."
|
| 543 |
+
```
|
| 544 |
+
|
| 545 |
+
|
| 546 |
+
|
| 547 |
+
### Inference on Mac
|
| 548 |
+
<details>
|
| 549 |
+
<summary>Click to view an example, to run MiniCPM-Llama3-V 2.5 on 💻 Mac with MPS (Apple silicon or AMD GPUs). </summary>
|
| 550 |
+
|
| 551 |
+
```python
|
| 552 |
+
# test.py Need more than 16GB memory.
|
| 553 |
+
import torch
|
| 554 |
+
from PIL import Image
|
| 555 |
+
from transformers import AutoModel, AutoTokenizer
|
| 556 |
+
|
| 557 |
+
model = AutoModel.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True, low_cpu_mem_usage=True)
|
| 558 |
+
model = model.to(device='mps')
|
| 559 |
+
|
| 560 |
+
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True)
|
| 561 |
+
model.eval()
|
| 562 |
+
|
| 563 |
+
image = Image.open('./assets/hk_OCR.jpg').convert('RGB')
|
| 564 |
+
question = 'Where is this photo taken?'
|
| 565 |
+
msgs = [{'role': 'user', 'content': question}]
|
| 566 |
+
|
| 567 |
+
answer, context, _ = model.chat(
|
| 568 |
+
image=image,
|
| 569 |
+
msgs=msgs,
|
| 570 |
+
context=None,
|
| 571 |
+
tokenizer=tokenizer,
|
| 572 |
+
sampling=True
|
| 573 |
+
)
|
| 574 |
+
print(answer)
|
| 575 |
+
```
|
| 576 |
+
Run with command:
|
| 577 |
+
```shell
|
| 578 |
+
PYTORCH_ENABLE_MPS_FALLBACK=1 python test.py
|
| 579 |
+
```
|
| 580 |
+
</details>
|
| 581 |
+
|
| 582 |
+
### Deployment on Mobile Phone
|
| 583 |
+
MiniCPM-V 2.0 can be deployed on mobile phones with Android operating systems. 🚀 Click [here](https://github.com/OpenBMB/mlc-MiniCPM) to install apk. MiniCPM-Llama3-V 2.5 coming soon.
|
| 584 |
+
|
| 585 |
+
### WebUI Demo
|
| 586 |
+
|
| 587 |
+
<details>
|
| 588 |
+
<summary>Click to see how to deploy WebUI demo on different devices </summary>
|
| 589 |
+
|
| 590 |
+
```shell
|
| 591 |
+
pip install -r requirements.txt
|
| 592 |
+
```
|
| 593 |
+
|
| 594 |
+
```shell
|
| 595 |
+
# For NVIDIA GPUs, run:
|
| 596 |
+
python web_demo_2.5.py --device cuda
|
| 597 |
+
|
| 598 |
+
# For Mac with MPS (Apple silicon or AMD GPUs), run:
|
| 599 |
+
PYTORCH_ENABLE_MPS_FALLBACK=1 python web_demo_2.5.py --device mps
|
| 600 |
+
```
|
| 601 |
+
</details>
|
| 602 |
+
|
| 603 |
+
### Inference with llama.cpp<a id="inference-with-llamacpp"></a>
|
| 604 |
+
MiniCPM-Llama3-V 2.5 can run with llama.cpp now! See our fork of [llama.cpp](https://github.com/OpenBMB/llama.cpp/tree/minicpm-v2.5/examples/minicpmv) for more detail. This implementation supports smooth inference of 6~8 token/s on mobile phones (test environment:Xiaomi 14 pro + Snapdragon 8 Gen 3).
|
| 605 |
+
|
| 606 |
+
### Inference with vLLM<a id="vllm"></a>
|
| 607 |
+
|
| 608 |
+
<details>
|
| 609 |
+
<summary>Click to see how to inference with vLLM </summary>
|
| 610 |
+
Because our pull request to vLLM is still waiting for reviewing, we fork this repository to build and test our vLLM demo. Here are the steps:
|
| 611 |
+
|
| 612 |
+
1. Clone our version of vLLM:
|
| 613 |
+
```shell
|
| 614 |
+
git clone https://github.com/OpenBMB/vllm.git
|
| 615 |
+
```
|
| 616 |
+
2. Install vLLM:
|
| 617 |
+
```shell
|
| 618 |
+
cd vllm
|
| 619 |
+
pip install -e .
|
| 620 |
+
```
|
| 621 |
+
3. Install timm:
|
| 622 |
+
```shell
|
| 623 |
+
pip install timm=0.9.10
|
| 624 |
+
```
|
| 625 |
+
4. Run our demo:
|
| 626 |
+
```shell
|
| 627 |
+
python examples/minicpmv_example.py
|
| 628 |
+
```
|
| 629 |
+
</details>
|
| 630 |
+
|
| 631 |
+
## Fine-tuning
|
| 632 |
+
|
| 633 |
+
### Simple Fine-tuning <!-- omit in toc -->
|
| 634 |
+
|
| 635 |
+
We support simple fine-tuning with Hugging Face for MiniCPM-V 2.0 and MiniCPM-Llama3-V 2.5.
|
| 636 |
+
|
| 637 |
+
[Reference Document](./finetune/readme.md)
|
| 638 |
+
|
| 639 |
+
### With the SWIFT Framework <!-- omit in toc -->
|
| 640 |
+
|
| 641 |
+
We now support MiniCPM-V series fine-tuning with the SWIFT framework. SWIFT supports training, inference, evaluation and deployment of nearly 200 LLMs and MLLMs . It supports the lightweight training solutions provided by PEFT and a complete Adapters Library including techniques such as NEFTune, LoRA+ and LLaMA-PRO.
|
| 642 |
+
|
| 643 |
+
Best Practices:[MiniCPM-V 1.0](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v最佳实践.md), [MiniCPM-V 2.0](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v-2最佳实践.md)
|
| 644 |
+
|
| 645 |
+
|
| 646 |
+
|
| 647 |
+
## TODO
|
| 648 |
+
|
| 649 |
+
- [x] MiniCPM-V fine-tuning support
|
| 650 |
+
- [ ] Code release for real-time interactive assistant
|
| 651 |
+
|
| 652 |
+
## Model License <!-- omit in toc -->
|
| 653 |
+
|
| 654 |
+
The code in this repo is released according to [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE)
|
| 655 |
+
|
| 656 |
+
The usage of MiniCPM-V's and OmniLMM's parameters is subject to "[General Model License Agreement - Source Notes - Publicity Restrictions - Commercial License](https://github.com/OpenBMB/General-Model-License/blob/main/通用模型许可协议-来源说明-宣传限制-商业授权.md)"
|
| 657 |
+
|
| 658 |
+
The parameters are fully open to academic research
|
| 659 |
+
|
| 660 |
+
Please contact cpm@modelbest.cn to obtain written authorization for commercial uses. Free commercial use is also allowed after registration.
|
| 661 |
+
|
| 662 |
+
## Statement <!-- omit in toc -->
|
| 663 |
+
|
| 664 |
+
As LMMs, MiniCPM-V models (including OmniLMM) generate contents by learning a large amount of multimodal corpora, but they cannot comprehend, express personal opinions or make value judgement. Anything generated by MiniCPM-V models does not represent the views and positions of the model developers
|
| 665 |
+
|
| 666 |
+
We will not be liable for any problems arising from the use of MiniCPMV-V models, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination or misuse of the model.
|
| 667 |
+
|
| 668 |
+
|
| 669 |
+
## Institutions <!-- omit in toc -->
|
| 670 |
+
|
| 671 |
+
This project is developed by the following institutions:
|
| 672 |
+
|
| 673 |
+
- <img src="assets/thunlp.png" width="28px"> [THUNLP](https://nlp.csai.tsinghua.edu.cn/)
|
| 674 |
+
- <img src="assets/modelbest.png" width="28px"> [ModelBest](https://modelbest.cn/)
|
| 675 |
+
- <img src="assets/zhihu.webp" width="28px"> [Zhihu](https://www.zhihu.com/ )
|
| 676 |
+
|
| 677 |
+
## Other Multimodal Projects from Our Team <!-- omit in toc -->
|
| 678 |
+
|
| 679 |
+
👏 Welcome to explore other multimodal projects of our team:
|
| 680 |
+
|
| 681 |
+
[VisCPM](https://github.com/OpenBMB/VisCPM/tree/main) | [RLHF-V](https://github.com/RLHF-V/RLHF-V) | [LLaVA-UHD](https://github.com/thunlp/LLaVA-UHD) | [RLAIF-V](https://github.com/RLHF-V/RLAIF-V)
|
| 682 |
+
|
| 683 |
+
## 🌟 Star History
|
| 684 |
+
|
| 685 |
+
<div>
|
| 686 |
+
<img src="./assets/Star-History.png" width="500em" ></img>
|
| 687 |
+
</div>
|
| 688 |
+
|
| 689 |
+
## Citation
|
| 690 |
+
|
| 691 |
+
If you find our model/code/paper helpful, please consider cite our papers 📝 and star us ⭐️!
|
| 692 |
+
|
| 693 |
+
```bib
|
| 694 |
+
@article{yu2023rlhf,
|
| 695 |
+
title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback},
|
| 696 |
+
author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others},
|
| 697 |
+
journal={arXiv preprint arXiv:2312.00849},
|
| 698 |
+
year={2023}
|
| 699 |
+
}
|
| 700 |
+
@article{viscpm,
|
| 701 |
+
title={Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages},
|
| 702 |
+
author={Jinyi Hu and Yuan Yao and Chongyi Wang and Shan Wang and Yinxu Pan and Qianyu Chen and Tianyu Yu and Hanghao Wu and Yue Zhao and Haoye Zhang and Xu Han and Yankai Lin and Jiao Xue and Dahai Li and Zhiyuan Liu and Maosong Sun},
|
| 703 |
+
journal={arXiv preprint arXiv:2308.12038},
|
| 704 |
+
year={2023}
|
| 705 |
+
}
|
| 706 |
+
@article{xu2024llava-uhd,
|
| 707 |
+
title={{LLaVA-UHD}: an LMM Perceiving Any Aspect Ratio and High-Resolution Images},
|
| 708 |
+
author={Xu, Ruyi and Yao, Yuan and Guo, Zonghao and Cui, Junbo and Ni, Zanlin and Ge, Chunjiang and Chua, Tat-Seng and Liu, Zhiyuan and Huang, Gao},
|
| 709 |
+
journal={arXiv preprint arXiv:2403.11703},
|
| 710 |
+
year={2024}
|
| 711 |
+
}
|
| 712 |
+
@article{yu2024rlaifv,
|
| 713 |
+
title={RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness},
|
| 714 |
+
author={Yu, Tianyu and Zhang, Haoye and Yao, Yuan and Dang, Yunkai and Chen, Da and Lu, Xiaoman and Cui, Ganqu and He, Taiwen and Liu, Zhiyuan and Chua, Tat-Seng and Sun, Maosong},
|
| 715 |
+
journal={arXiv preprint arXiv:2405.17220},
|
| 716 |
+
year={2024}
|
| 717 |
+
}
|
| 718 |
+
```
|
README_zh.md
ADDED
|
@@ -0,0 +1,731 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
<!-- <!-- <h1 style="color: #33A6B8; font-family: Helvetica"> OmniLMM </h1> -->
|
| 4 |
+
|
| 5 |
+
<img src="./assets/minicpmv.png" width="300em" ></img>
|
| 6 |
+
|
| 7 |
+
**端侧可用的 GPT-4V 级多模态大模型**
|
| 8 |
+
|
| 9 |
+
<strong>中文 |
|
| 10 |
+
[English](./README_en.md)</strong>
|
| 11 |
+
|
| 12 |
+
<p align="center">
|
| 13 |
+
MiniCPM-Llama3-V 2.5 <a href="https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5/">🤗</a> <a href="https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5">🤖</a> |
|
| 14 |
+
MiniCPM-V 2.0 <a href="https://huggingface.co/openbmb/MiniCPM-V-2/">🤗</a> <a href="https://huggingface.co/spaces/openbmb/MiniCPM-V-2">🤖</a> |
|
| 15 |
+
<a href="https://openbmb.vercel.app/minicpm-v-2">MiniCPM-V 2.0 技术博客</a>
|
| 16 |
+
</p>
|
| 17 |
+
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
**MiniCPM-V**是面向图文理解的端侧多模态大模型系列。该系列模型接受图像和文本输入,并提供高质量的文本输出。自2024年2月以来,我们共发布了4个版本模型,旨在实现**领先的性能和高效的部署**,目前该系列最值得关注的模型包括:
|
| 22 |
+
|
| 23 |
+
- **MiniCPM-Llama3-V 2.5**:🔥🔥🔥 MiniCPM-V系列的最新、性能最佳模型。总参数量8B,多模态综合性能**超越 GPT-4V-1106、Gemini Pro、Claude 3、Qwen-VL-Max 等商用闭源模型**,OCR 能力及指令跟随能力进一步提升,并**支持超过30种语言**的多模态交互。通过系统使用模型量化、CPU、NPU、编译优化等高效推理技术,MiniCPM-Llama3-V 2.5 可以实现**高效的终端设备部署**。
|
| 24 |
+
|
| 25 |
+
- **MiniCPM-V 2.0**:MiniCPM-V系列的最轻量级模型。总参数量2B,多模态综合性能超越 Yi-VL 34B、CogVLM-Chat 17B、Qwen-VL-Chat 10B 等更大参数规模的模型,可接受 180 万像素的任意长宽比图像输入,实现了和 Gemini Pro 相近的场景文字识别能力以及和 GPT-4V 相匹的低幻觉率。
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
## 更新日志 <!-- omit in toc -->
|
| 30 |
+
|
| 31 |
+
#### 📌 置顶
|
| 32 |
+
|
| 33 |
+
* [2024.05.28] 💥 MiniCPM-Llama3-V 2.5 现在在 [llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpm-v2.5/examples/minicpmv/README.md) 和 [ollama](https://github.com/OpenBMB/ollama/tree/minicpm-v2.5/examples/minicpm-v2.5) 中完全支持其功能!请拉取最新的 llama.cpp 和 ollama 代码。我们还发布了各种大小的 GGUF 版本,请点击[这里](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf/tree/main)查看。ollama 使用的 FAQ 将在一天内发布,敬请关注!
|
| 34 |
+
* [2024.05.28] 💫 我们现在支持 MiniCPM-Llama3-V 2.5 的 LoRA 微调,更多内存使用统计信息可以在[这里](https://github.com/OpenBMB/MiniCPM-V/tree/main/finetune#model-fine-tuning-memory-usage-statistics)找到。
|
| 35 |
+
* [2024.05.23] 🔍 我们添加了Phi-3-vision-128k-instruct 与 MiniCPM-Llama3-V 2.5的全面对比,包括基准测试评估、多语言能力和推理效率 🌟📊🌍🚀。点击[这里](./docs/compare_with_phi-3_vision.md)查看详细信息。
|
| 36 |
+
* [2024.05.23] 🔥🔥🔥 MiniCPM-V 在 GitHub Trending 和 Hugging Face Trending 上登顶!MiniCPM-Llama3-V 2.5 Demo 被 Hugging Face 的 Gradio 官方账户推荐,欢迎点击[这里](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5)体验!
|
| 37 |
+
|
| 38 |
+
<br>
|
| 39 |
+
|
| 40 |
+
* [2024.05.25] MiniCPM-Llama3-V 2.5 [支持流式输出和自定义系统提示词](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5#usage)了,欢迎试用!
|
| 41 |
+
* [2024.05.24] 我们开源了 MiniCPM-Llama3-V 2.5 [gguf](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf),支持 [llama.cpp](#llamacpp-部署) 推理!实现端侧 6-8 tokens/s 的流畅解码,欢迎试用!
|
| 42 |
+
* [2024.05.20] 我们开源了 MiniCPM-Llama3-V 2.5,增强了 OCR 能力,支持 30 多种语言,并首次在端侧实现了 GPT-4V 级的多模态能力!我们提供了[高效推理](#手机端部署)和[简易微调](./finetune/readme.md)的支持,欢迎试用!
|
| 43 |
+
* [2024.04.23] 我们增加了对 [vLLM](#vllm) 的支持,欢迎体验!
|
| 44 |
+
* [2024.04.18] 我们在 HuggingFace Space 新增了 MiniCPM-V 2.0 的 [demo](https://huggingface.co/spaces/openbmb/MiniCPM-V-2),欢迎体验!
|
| 45 |
+
* [2024.04.17] MiniCPM-V 2.0 现在支持用户部署本地 [WebUI Demo](#本地webui-demo部署) 了,欢迎试用!
|
| 46 |
+
* [2024.04.15] MiniCPM-V 2.0 现在可以通过 SWIFT 框架 [微调](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v-2最佳实践.md) 了,支持流式输出!
|
| 47 |
+
* [2024.04.12] 我们开源了 MiniCPM-V 2.0,该模型刷新了 OCRBench 开源模型最佳成绩,在场景文字识别能力上比肩 Gemini Pro,同时还在综合了 11 个主流多模态大模型评测基准的 <a href="https://rank.opencompass.org.cn/leaderboard-multimodal">OpenCompass</a> 榜单上超过了 Qwen-VL-Chat 10B、CogVLM-Chat 17B 和 Yi-VL 34B 等更大参数规模的模型!点击<a href="https://openbmb.vercel.app/minicpm-v-2">这里</a>查看 MiniCPM-V 2.0 技术博客。
|
| 48 |
+
* [2024.03.14] MiniCPM-V 现在支持 SWIFT 框架下的[微调](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v最佳实践.md)了,感谢 [Jintao](https://github.com/Jintao-Huang) 的贡献!
|
| 49 |
+
* [2024.03.01] MiniCPM-V 现在支持在 Mac 电脑上进行部署!
|
| 50 |
+
* [2024.02.01] 我们开源了 MiniCPM-V 和 OmniLMM-12B,分别可以支持高效的端侧部署和同规模领先的多模态能力!
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
## 目录 <!-- omit in toc -->
|
| 54 |
+
|
| 55 |
+
- [MiniCPM-Llama3-V 2.5](#minicpm-llama3-v-25)
|
| 56 |
+
- [MiniCPM-V 2.0](#minicpm-v-20)
|
| 57 |
+
- [Online Demo](#online-demo)
|
| 58 |
+
- [安装](#安装)
|
| 59 |
+
- [推理](#推理)
|
| 60 |
+
- [模型库](#模型库)
|
| 61 |
+
- [多轮对话](#多轮对话)
|
| 62 |
+
- [Mac 推理](#mac-推理)
|
| 63 |
+
- [手机端部署](#手机端部署)
|
| 64 |
+
- [本地WebUI Demo部署](#本地webui-demo部署)
|
| 65 |
+
- [llama.cpp 部署](#llamacpp-部署)
|
| 66 |
+
- [vLLM 部署 ](#vllm-部署-)
|
| 67 |
+
- [微调](#微调)
|
| 68 |
+
- [未来计划](#未来计划)
|
| 69 |
+
- [🌟 Star History](#-star-history)
|
| 70 |
+
- [引用](#引用)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
## MiniCPM-Llama3-V 2.5
|
| 74 |
+
**MiniCPM-Llama3-V 2.5** 是 MiniCPM-V 系列的最新版本模型,基于 SigLip-400M 和 Llama3-8B-Instruct 构建,共 8B 参数量,相较于 MiniCPM-V 2.0 性能取得较大幅度提升。MiniCPM-Llama3-V 2.5 值得关注的特点包括:
|
| 75 |
+
|
| 76 |
+
- 🔥 **领先的性能。**
|
| 77 |
+
MiniCPM-Llama3-V 2.5 在综合了 11 个主流多模态大模型评测基准的 OpenCompass 榜单上平均得分 65.1,**以 8B 量级的大小超过了 GPT-4V-1106、Gemini Pro、Claude 3、Qwen-VL-Max 等主流商用闭源多模态大模型**,大幅超越基于Llama 3构建的其他多模态大模型。
|
| 78 |
+
|
| 79 |
+
- 💪 **优秀的 OCR 能力。**
|
| 80 |
+
MiniCPM-Llama3-V 2.5 可接受 180 万像素的任意宽高比图像输入,**OCRBench 得分达到 725,超越 GPT-4o、GPT-4V、Gemini Pro、Qwen-VL-Max 等商用闭源模型**,达到最佳水平。基于近期用户反馈建议,MiniCPM-Llama3-V 2.5 增强了全文 OCR 信息提取、表格图像转 markdown 等高频实用能力,并且进一步加强了指令跟随、复杂推理能力,带来更好的多模态交互体感。
|
| 81 |
+
|
| 82 |
+
- 🏆 **可信行为。**
|
| 83 |
+
借助最新的 [RLAIF-V](https://github.com/RLHF-V/RLAIF-V/) 对齐技术([RLHF-V](https://github.com/RLHF-V/) [CVPR'24]系列的最新技术),MiniCPM-Llama3-V 2.5 具有更加可信的多模态行为,在 Object HalBench 的幻觉率降低到了 **10.3%**,显著低于 GPT-4V-1106 (13.6%),达到开源社区最佳水平。[数据集已发布](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset)。
|
| 84 |
+
|
| 85 |
+
- 🌏 **多语言支持。**
|
| 86 |
+
得益于 Llama 3 强大的多语言能力和 VisCPM 的跨语言泛化技术,MiniCPM-Llama3-V 2.5 在中英双语多模态能力的基础上,仅通过少量翻译的多模态数据的指令微调,高效泛化支持了**德语、法语、西班牙语、意大利语、韩语等 30+ 种语言**的多模态能力,并表现出了良好的多语言多模态对话性能。[查看所有支持语言](./assets/minicpm-llama-v-2-5_languages.md)
|
| 87 |
+
|
| 88 |
+
- 🚀 **高效部署。**
|
| 89 |
+
MiniCPM-Llama3-V 2.5 较为系统地通过**模型量化、CPU、NPU、编译优化**等高效加速技术,实现高效的终端设备部署。对于高通芯片的移动手机,我们首次将 NPU 加速框架 QNN 整合进了 llama.cpp。经过系统优化后,MiniCPM-Llama3-V 2.5 实现了多模态大模型端侧**语言解码速度 3 倍加速**、**图像编码 150 倍加速**的巨大提升。
|
| 90 |
+
|
| 91 |
+
- 💫 **易于使用。**
|
| 92 |
+
MiniCPM-Llama3-V 2.5 可以通过多种方式轻松使用:(1)[llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpm-v2.5/examples/minicpmv/README.md) 和 [ollama](https://github.com/OpenBMB/ollama/tree/minicpm-v2.5/examples/minicpm-v2.5) 支持在本地设备上进行高效的 CPU 推理;(2)提供 16 种尺寸的 [GGUF](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf) 格式量化模型;(3)仅需 2 张 V100 GPU 即可进行高效的 [LoRA](https://github.com/OpenBMB/MiniCPM-V/tree/main/finetune#lora-finetuning) 微调;( 4)支持[流式输出](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5#usage);(5)快速搭建 [Gradio](https://github.com/OpenBMB/MiniCPM-V/blob/main/web_demo_2.5.py) 和 [Streamlit](https://github.com/OpenBMB/MiniCPM-V/blob/main/web_demo_streamlit-2_5.py) 本地 WebUI demo;( 6.)[HuggingFace Spaces](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5) 交互式 demo。
|
| 93 |
+
|
| 94 |
+
### 性能评估 <!-- omit in toc -->
|
| 95 |
+
|
| 96 |
+
<div align="center">
|
| 97 |
+
<img src="assets/MiniCPM-Llama3-V-2.5-peformance.png" width="66%" />
|
| 98 |
+
</div>
|
| 99 |
+
<details>
|
| 100 |
+
<summary>TextVQA, DocVQA, OCRBench, OpenCompass MultiModal Avg Score, MME, MMBench, MMMU, MathVista, LLaVA Bench, RealWorld QA, Object HalBench上的详细评测结果。 </summary>
|
| 101 |
+
<div align="center">
|
| 102 |
+
|
| 103 |
+
<table style="margin: 0px auto;">
|
| 104 |
+
<thead>
|
| 105 |
+
<tr>
|
| 106 |
+
<th align="left">Model</th>
|
| 107 |
+
<th>Size</th>
|
| 108 |
+
<th>OCRBench</th>
|
| 109 |
+
<th>TextVQA val</th>
|
| 110 |
+
<th>DocVQA test</th>
|
| 111 |
+
<th>Open-Compass</th>
|
| 112 |
+
<th>MME</th>
|
| 113 |
+
<th>MMB test (en)</th>
|
| 114 |
+
<th>MMB test (cn)</th>
|
| 115 |
+
<th>MMMU val</th>
|
| 116 |
+
<th>Math-Vista</th>
|
| 117 |
+
<th>LLaVA Bench</th>
|
| 118 |
+
<th>RealWorld QA</th>
|
| 119 |
+
<th>Object HalBench</th>
|
| 120 |
+
</tr>
|
| 121 |
+
</thead>
|
| 122 |
+
<tbody align="center">
|
| 123 |
+
<tr>
|
| 124 |
+
<td colspan="14" align="left"><strong>Proprietary</strong></td>
|
| 125 |
+
</tr>
|
| 126 |
+
<tr>
|
| 127 |
+
<td nowrap="nowrap" align="left">Gemini Pro</td>
|
| 128 |
+
<td>-</td>
|
| 129 |
+
<td>680</td>
|
| 130 |
+
<td>74.6</td>
|
| 131 |
+
<td>88.1</td>
|
| 132 |
+
<td>62.9</td>
|
| 133 |
+
<td>2148.9</td>
|
| 134 |
+
<td>73.6</td>
|
| 135 |
+
<td>74.3</td>
|
| 136 |
+
<td>48.9</td>
|
| 137 |
+
<td>45.8</td>
|
| 138 |
+
<td>79.9</td>
|
| 139 |
+
<td>60.4</td>
|
| 140 |
+
<td>-</td>
|
| 141 |
+
</tr>
|
| 142 |
+
<tr>
|
| 143 |
+
<td nowrap="nowrap" align="left">GPT-4V (2023.11.06)</td>
|
| 144 |
+
<td>-</td>
|
| 145 |
+
<td>645</td>
|
| 146 |
+
<td>78.0</td>
|
| 147 |
+
<td>88.4</td>
|
| 148 |
+
<td>63.5</td>
|
| 149 |
+
<td>1771.5</td>
|
| 150 |
+
<td>77.0</td>
|
| 151 |
+
<td>74.4</td>
|
| 152 |
+
<td>53.8</td>
|
| 153 |
+
<td>47.8</td>
|
| 154 |
+
<td>93.1</td>
|
| 155 |
+
<td>63.0</td>
|
| 156 |
+
<td>86.4</td>
|
| 157 |
+
</tr>
|
| 158 |
+
<tr>
|
| 159 |
+
<td colspan="14" align="left"><strong>Open-source</strong></td>
|
| 160 |
+
</tr>
|
| 161 |
+
<tr>
|
| 162 |
+
<td nowrap="nowrap" align="left">Mini-Gemini</td>
|
| 163 |
+
<td>2.2B</td>
|
| 164 |
+
<td>-</td>
|
| 165 |
+
<td>56.2</td>
|
| 166 |
+
<td>34.2*</td>
|
| 167 |
+
<td>-</td>
|
| 168 |
+
<td>1653.0</td>
|
| 169 |
+
<td>-</td>
|
| 170 |
+
<td>-</td>
|
| 171 |
+
<td>31.7</td>
|
| 172 |
+
<td>-</td>
|
| 173 |
+
<td>-</td>
|
| 174 |
+
<td>-</td>
|
| 175 |
+
<td>-</td>
|
| 176 |
+
</tr>
|
| 177 |
+
<tr>
|
| 178 |
+
<td nowrap="nowrap" align="left">Qwen-VL-Chat</td>
|
| 179 |
+
<td>9.6B</td>
|
| 180 |
+
<td>488</td>
|
| 181 |
+
<td>61.5</td>
|
| 182 |
+
<td>62.6</td>
|
| 183 |
+
<td>51.6</td>
|
| 184 |
+
<td>1860.0</td>
|
| 185 |
+
<td>61.8</td>
|
| 186 |
+
<td>56.3</td>
|
| 187 |
+
<td>37.0</td>
|
| 188 |
+
<td>33.8</td>
|
| 189 |
+
<td>67.7</td>
|
| 190 |
+
<td>49.3</td>
|
| 191 |
+
<td>56.2</td>
|
| 192 |
+
</tr>
|
| 193 |
+
<tr>
|
| 194 |
+
<td nowrap="nowrap" align="left">DeepSeek-VL-7B</td>
|
| 195 |
+
<td>7.3B</td>
|
| 196 |
+
<td>435</td>
|
| 197 |
+
<td>64.7*</td>
|
| 198 |
+
<td>47.0*</td>
|
| 199 |
+
<td>54.6</td>
|
| 200 |
+
<td>1765.4</td>
|
| 201 |
+
<td>73.8</td>
|
| 202 |
+
<td>71.4</td>
|
| 203 |
+
<td>38.3</td>
|
| 204 |
+
<td>36.8</td>
|
| 205 |
+
<td>77.8</td>
|
| 206 |
+
<td>54.2</td>
|
| 207 |
+
<td>-</td>
|
| 208 |
+
</tr>
|
| 209 |
+
<tr>
|
| 210 |
+
<td nowrap="nowrap" align="left">Yi-VL-34B</td>
|
| 211 |
+
<td>34B</td>
|
| 212 |
+
<td>290</td>
|
| 213 |
+
<td>43.4*</td>
|
| 214 |
+
<td>16.9*</td>
|
| 215 |
+
<td>52.2</td>
|
| 216 |
+
<td><strong>2050.2</strong></td>
|
| 217 |
+
<td>72.4</td>
|
| 218 |
+
<td>70.7</td>
|
| 219 |
+
<td>45.1</td>
|
| 220 |
+
<td>30.7</td>
|
| 221 |
+
<td>62.3</td>
|
| 222 |
+
<td>54.8</td>
|
| 223 |
+
<td>79.3</td>
|
| 224 |
+
</tr>
|
| 225 |
+
<tr>
|
| 226 |
+
<td nowrap="nowrap" align="left">CogVLM-Chat</td>
|
| 227 |
+
<td>17.4B</td>
|
| 228 |
+
<td>590</td>
|
| 229 |
+
<td>70.4</td>
|
| 230 |
+
<td>33.3*</td>
|
| 231 |
+
<td>54.2</td>
|
| 232 |
+
<td>1736.6</td>
|
| 233 |
+
<td>65.8</td>
|
| 234 |
+
<td>55.9</td>
|
| 235 |
+
<td>37.3</td>
|
| 236 |
+
<td>34.7</td>
|
| 237 |
+
<td>73.9</td>
|
| 238 |
+
<td>60.3</td>
|
| 239 |
+
<td>73.6</td>
|
| 240 |
+
</tr>
|
| 241 |
+
<tr>
|
| 242 |
+
<td nowrap="nowrap" align="left">TextMonkey</td>
|
| 243 |
+
<td>9.7B</td>
|
| 244 |
+
<td>558</td>
|
| 245 |
+
<td>64.3</td>
|
| 246 |
+
<td>66.7</td>
|
| 247 |
+
<td>-</td>
|
| 248 |
+
<td>-</td>
|
| 249 |
+
<td>-</td>
|
| 250 |
+
<td>-</td>
|
| 251 |
+
<td>-</td>
|
| 252 |
+
<td>-</td>
|
| 253 |
+
<td>-</td>
|
| 254 |
+
<td>-</td>
|
| 255 |
+
<td>-</td>
|
| 256 |
+
</tr>
|
| 257 |
+
<tr>
|
| 258 |
+
<td nowrap="nowrap" align="left">Idefics2</td>
|
| 259 |
+
<td>8.0B</td>
|
| 260 |
+
<td>-</td>
|
| 261 |
+
<td>73.0</td>
|
| 262 |
+
<td>74.0</td>
|
| 263 |
+
<td>57.2</td>
|
| 264 |
+
<td>1847.6</td>
|
| 265 |
+
<td>75.7</td>
|
| 266 |
+
<td>68.6</td>
|
| 267 |
+
<td>45.2</td>
|
| 268 |
+
<td>52.2</td>
|
| 269 |
+
<td>49.1</td>
|
| 270 |
+
<td>60.7</td>
|
| 271 |
+
<td>-</td>
|
| 272 |
+
</tr>
|
| 273 |
+
<tr>
|
| 274 |
+
<td nowrap="nowrap" align="left">Bunny-LLama-3-8B</td>
|
| 275 |
+
<td>8.4B</td>
|
| 276 |
+
<td>-</td>
|
| 277 |
+
<td>-</td>
|
| 278 |
+
<td>-</td>
|
| 279 |
+
<td>54.3</td>
|
| 280 |
+
<td>1920.3</td>
|
| 281 |
+
<td>77.0</td>
|
| 282 |
+
<td>73.9</td>
|
| 283 |
+
<td>41.3</td>
|
| 284 |
+
<td>31.5</td>
|
| 285 |
+
<td>61.2</td>
|
| 286 |
+
<td>58.8</td>
|
| 287 |
+
<td>-</td>
|
| 288 |
+
</tr>
|
| 289 |
+
<tr>
|
| 290 |
+
<td nowrap="nowrap" align="left">LLaVA-NeXT Llama-3-8B</td>
|
| 291 |
+
<td>8.4B</td>
|
| 292 |
+
<td>-</td>
|
| 293 |
+
<td>-</td>
|
| 294 |
+
<td>-</td>
|
| 295 |
+
<td>-</td>
|
| 296 |
+
<td>1971.5</td>
|
| 297 |
+
<td>-</td>
|
| 298 |
+
<td>-</td>
|
| 299 |
+
<td>41.7</td>
|
| 300 |
+
<td>-</td>
|
| 301 |
+
<td>80.1</td>
|
| 302 |
+
<td>60.0</td>
|
| 303 |
+
<td>-</td>
|
| 304 |
+
</tr>
|
| 305 |
+
<tr>
|
| 306 |
+
<td nowrap="nowrap" align="left">Phi-3-vision-128k-instruct</td>
|
| 307 |
+
<td>4.2B</td>
|
| 308 |
+
<td>639*</td>
|
| 309 |
+
<td>70.9</td>
|
| 310 |
+
<td>-</td>
|
| 311 |
+
<td>-</td>
|
| 312 |
+
<td>1537.5*</td>
|
| 313 |
+
<td>-</td>
|
| 314 |
+
<td>-</td>
|
| 315 |
+
<td>40.4</td>
|
| 316 |
+
<td>44.5</td>
|
| 317 |
+
<td>64.2*</td>
|
| 318 |
+
<td>58.8*</td>
|
| 319 |
+
<td>-</td>
|
| 320 |
+
</tr>
|
| 321 |
+
<tr style="background-color: #e6f2ff;">
|
| 322 |
+
<td nowrap="nowrap" align="left">MiniCPM-V 1.0</td>
|
| 323 |
+
<td>2.8B</td>
|
| 324 |
+
<td>366</td>
|
| 325 |
+
<td>60.6</td>
|
| 326 |
+
<td>38.2</td>
|
| 327 |
+
<td>47.5</td>
|
| 328 |
+
<td>1650.2</td>
|
| 329 |
+
<td>64.1</td>
|
| 330 |
+
<td>62.6</td>
|
| 331 |
+
<td>38.3</td>
|
| 332 |
+
<td>28.9</td>
|
| 333 |
+
<td>51.3</td>
|
| 334 |
+
<td>51.2</td>
|
| 335 |
+
<td>78.4</td>
|
| 336 |
+
</tr>
|
| 337 |
+
<tr style="background-color: #e6f2ff;">
|
| 338 |
+
<td nowrap="nowrap" align="left">MiniCPM-V 2.0</td>
|
| 339 |
+
<td>2.8B</td>
|
| 340 |
+
<td>605</td>
|
| 341 |
+
<td>74.1</td>
|
| 342 |
+
<td>71.9</td>
|
| 343 |
+
<td>54.5</td>
|
| 344 |
+
<td>1808.6</td>
|
| 345 |
+
<td>69.1</td>
|
| 346 |
+
<td>66.5</td>
|
| 347 |
+
<td>38.2</td>
|
| 348 |
+
<td>38.7</td>
|
| 349 |
+
<td>69.2</td>
|
| 350 |
+
<td>55.8</td>
|
| 351 |
+
<td>85.5</td>
|
| 352 |
+
</tr>
|
| 353 |
+
<tr style="background-color: #e6f2ff;">
|
| 354 |
+
<td nowrap="nowrap" align="left">MiniCPM-Llama3-V 2.5</td>
|
| 355 |
+
<td>8.5B</td>
|
| 356 |
+
<td><strong>725</strong></td>
|
| 357 |
+
<td><strong>76.6</strong></td>
|
| 358 |
+
<td><strong>84.8</strong></td>
|
| 359 |
+
<td><strong>65.1</strong></td>
|
| 360 |
+
<td>2024.6</td>
|
| 361 |
+
<td><strong>77.2</strong></td>
|
| 362 |
+
<td><strong>74.2</strong></td>
|
| 363 |
+
<td><strong>45.8</strong></td>
|
| 364 |
+
<td><strong>54.3</strong></td>
|
| 365 |
+
<td><strong>86.7</strong></td>
|
| 366 |
+
<td><strong>63.5</strong></td>
|
| 367 |
+
<td><strong>89.7</strong></td>
|
| 368 |
+
</tr>
|
| 369 |
+
</tbody>
|
| 370 |
+
</table>
|
| 371 |
+
|
| 372 |
+
</div>
|
| 373 |
+
* 正式开源模型权重的评测结果。
|
| 374 |
+
</details>
|
| 375 |
+
|
| 376 |
+
<div align="center">
|
| 377 |
+
<img src="assets/llavabench_compare_3.png" width="80%" />
|
| 378 |
+
<br>
|
| 379 |
+
多语言LLaVA Bench评测结果
|
| 380 |
+
</div>
|
| 381 |
+
|
| 382 |
+
|
| 383 |
+
### 典型示例 <!-- omit in toc -->
|
| 384 |
+
<table align="center">
|
| 385 |
+
<p align="center">
|
| 386 |
+
<img src="assets/minicpmv-llama3-v2.5/cases_all.png" width=95%/>
|
| 387 |
+
</p>
|
| 388 |
+
</table>
|
| 389 |
+
|
| 390 |
+
我们将 MiniCPM-Llama3-V 2.5 部署在小米 14 Pro 上,并录制了以下演示视频。
|
| 391 |
+
|
| 392 |
+
<table align="center">
|
| 393 |
+
<p align="center">
|
| 394 |
+
<img src="assets/gif_cases/ticket.gif" width=32%/>
|
| 395 |
+
<img src="assets/gif_cases/meal_plan.gif" width=32%/>
|
| 396 |
+
</p>
|
| 397 |
+
</table>
|
| 398 |
+
|
| 399 |
+
<table align="center">
|
| 400 |
+
<p align="center" width=80%>
|
| 401 |
+
<img src="assets/gif_cases/1-4.gif" width=72%/>
|
| 402 |
+
</p>
|
| 403 |
+
</table>
|
| 404 |
+
|
| 405 |
+
## MiniCPM-V 2.0
|
| 406 |
+
|
| 407 |
+
<details>
|
| 408 |
+
<summary>查看 MiniCPM-V 2.0 的详细信息</summary>
|
| 409 |
+
|
| 410 |
+
**MiniCPM-V 2.0**可以高效部署到终端设备。该模型基于 SigLip-400M 和 [MiniCPM-2.4B](https://github.com/OpenBMB/MiniCPM/)构建,通过perceiver resampler连接。其特点包括:
|
| 411 |
+
|
| 412 |
+
- 🔥 **优秀的性能。**
|
| 413 |
+
|
| 414 |
+
MiniCPM-V 2.0 在多个测试基准(如 OCRBench, TextVQA, MME, MMB, MathVista 等)中实现了 7B 以下模型的**最佳性能**。**在综合了 11 个主流多模态大模型评测基准的 OpenCompass 榜单上超过了 Qwen-VL-Chat 9.6B、CogVLM-Chat 17.4B 和 Yi-VL 34B 等更大参数规模的模型**。MiniCPM-V 2.0 还展现出**领先的 OCR 能力**,在场景文字识别能力上**接近 Gemini Pro**,OCRBench 得分达到**开源模型第一**。
|
| 415 |
+
|
| 416 |
+
|
| 417 |
+
- 🏆 **可信行为。**
|
| 418 |
+
|
| 419 |
+
多模态大模型深受幻觉问题困扰,模型经常生成和图像中的事实不符的文本。MiniCPM-V 2.0 是 **第一个通过多模态 RLHF 对齐的端侧多模态大模型**(借助 [RLHF-V](https://rlhf-v.github.io/) [CVPR'24] 系列技术)。该模型在 [Object HalBench](https://arxiv.org/abs/2312.00849) 达到**和 GPT-4V 相仿**的性能。
|
| 420 |
+
|
| 421 |
+
|
| 422 |
+
- 🌟 **高清图像高效编码。**
|
| 423 |
+
|
| 424 |
+
MiniCPM-V 2.0 可以接受 **180 万像素的任意长宽比图像输入**(基于最新的[LLaVA-UHD](https://arxiv.org/pdf/2403.11703.pdf) 技术),这使得模型可以感知到小物体、密集文字等更加细粒度的视觉信息。
|
| 425 |
+
|
| 426 |
+
|
| 427 |
+
- ⚡️ **高效部署。**
|
| 428 |
+
|
| 429 |
+
MiniCPM-V 2.0 可以**高效部署在大多数消费级显卡和个人电脑上**,包括**移动手机等终端设备**。在视觉编码方面,我们通过perceiver resampler将图像表示压缩为更少的 token。这使得 MiniCPM-V 2.0 即便是**面对高分辨率图像,也能占用较低的存储并展现优秀的推理速度**。
|
| 430 |
+
|
| 431 |
+
- 🙌 **双语支持。**
|
| 432 |
+
|
| 433 |
+
MiniCPM-V 2.0 **提供领先的中英双语多模态能力支持**。
|
| 434 |
+
该能力通过 [VisCPM](https://arxiv.org/abs/2308.12038) [ICLR'24] 论文中提出的多模态能力的跨语言泛化技术实现。
|
| 435 |
+
|
| 436 |
+
### 典型示例 <!-- omit in toc -->
|
| 437 |
+
|
| 438 |
+
|
| 439 |
+
<table align="center">
|
| 440 |
+
<p align="center">
|
| 441 |
+
<img src="assets/minicpmv2-cases_2.png" width=95%/>
|
| 442 |
+
</p>
|
| 443 |
+
</table>
|
| 444 |
+
|
| 445 |
+
我们将 MiniCPM-V 2.0 部署在小米 14 Pro 上,并录制了以下演示视频,未经任何视频剪辑。
|
| 446 |
+
|
| 447 |
+
<table align="center">
|
| 448 |
+
<p align="center">
|
| 449 |
+
<img src="assets/gif_cases/station.gif" width=36%/>
|
| 450 |
+
<img src="assets/gif_cases/london_car.gif" width=36%/>
|
| 451 |
+
</p>
|
| 452 |
+
</table>
|
| 453 |
+
|
| 454 |
+
</details>
|
| 455 |
+
|
| 456 |
+
|
| 457 |
+
<a id='legacy-models'></a>
|
| 458 |
+
|
| 459 |
+
## 历史版本模型 <!-- omit in toc -->
|
| 460 |
+
|
| 461 |
+
|
| 462 |
+
| 模型 | 介绍信息和使用教程 |
|
| 463 |
+
|:----------------------|:-------------------:|
|
| 464 |
+
| MiniCPM-V 1.0 | [文档](./minicpm_v1.md) |
|
| 465 |
+
| OmniLMM-12B | [文档](./omnilmm.md) |
|
| 466 |
+
|
| 467 |
+
|
| 468 |
+
## Online Demo
|
| 469 |
+
|
| 470 |
+
欢迎通过以下链接使用我们的网页端推理服务: [MiniCPM-Llama3-V 2.5](https://huggingface.co/spaces/openbmb/MiniCPM-Llama3-V-2_5) | [MiniCPM-V 2.0](https://huggingface.co/spaces/openbmb/MiniCPM-V-2).
|
| 471 |
+
|
| 472 |
+
## 安装
|
| 473 |
+
|
| 474 |
+
1. 克隆我们的仓库并跳转到相应目录
|
| 475 |
+
|
| 476 |
+
```bash
|
| 477 |
+
git clone https://github.com/OpenBMB/MiniCPM-V.git
|
| 478 |
+
cd MiniCPM-V
|
| 479 |
+
```
|
| 480 |
+
|
| 481 |
+
1. 创建 conda 环境
|
| 482 |
+
|
| 483 |
+
```Shell
|
| 484 |
+
conda create -n MiniCPMV python=3.10 -y
|
| 485 |
+
conda activate MiniCPMV
|
| 486 |
+
```
|
| 487 |
+
|
| 488 |
+
3. 安装依赖
|
| 489 |
+
|
| 490 |
+
```shell
|
| 491 |
+
pip install -r requirements.txt
|
| 492 |
+
```
|
| 493 |
+
|
| 494 |
+
## 推理
|
| 495 |
+
|
| 496 |
+
### 模型库
|
| 497 |
+
|
| 498 |
+
| 模型 | 设备 | 资源 |          简介 | 下载链接 |
|
| 499 |
+
|:--------------|:-:|:----------:|:-------------------|:---------------:|
|
| 500 |
+
| MiniCPM-Llama3-V 2.5| GPU | 19 GB | 最新版本,提供最佳的端侧多模态理解能力。 | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5/) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5) |
|
| 501 |
+
| MiniCPM-Llama3-V 2.5 gguf| CPU | 5 GB | gguf 版本,更低的内存占用和更高的推理效率。 | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-gguf) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5-gguf) |
|
| 502 |
+
| MiniCPM-Llama3-V 2.5 int4 | GPU | 8 GB | int4量化版,更低显存占用。 | [🤗](https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-int4/) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5-int4) |
|
| 503 |
+
| MiniCPM-V 2.0 | GPU | 8 GB | 轻量级版本,平衡计算开销和多模态理解能力。 | [🤗](https://huggingface.co/openbmb/MiniCPM-V-2) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-V-2) |
|
| 504 |
+
| MiniCPM-V 1.0 | GPU | 7 GB | 最轻量版本, 提供最快的推理速度。 | [🤗](https://huggingface.co/openbmb/MiniCPM-V) [<img src="./assets/modelscope_logo.png" width="20px"></img>](https://modelscope.cn/models/OpenBMB/MiniCPM-V) |
|
| 505 |
+
|
| 506 |
+
更多[历史版本模型](#legacy-models)
|
| 507 |
+
|
| 508 |
+
### 多轮对话
|
| 509 |
+
|
| 510 |
+
请参考以下代码进行推理。
|
| 511 |
+
|
| 512 |
+
<div align="center">
|
| 513 |
+
<img src="assets/airplane.jpeg" width="500px">
|
| 514 |
+
</div>
|
| 515 |
+
|
| 516 |
+
|
| 517 |
+
```python
|
| 518 |
+
from chat import MiniCPMVChat, img2base64
|
| 519 |
+
import torch
|
| 520 |
+
import json
|
| 521 |
+
|
| 522 |
+
torch.manual_seed(0)
|
| 523 |
+
|
| 524 |
+
chat_model = MiniCPMVChat('openbmb/MiniCPM-Llama3-V-2_5')
|
| 525 |
+
|
| 526 |
+
im_64 = img2base64('./assets/airplane.jpeg')
|
| 527 |
+
|
| 528 |
+
# First round chat
|
| 529 |
+
msgs = [{"role": "user", "content": "Tell me the model of this aircraft."}]
|
| 530 |
+
|
| 531 |
+
inputs = {"image": im_64, "question": json.dumps(msgs)}
|
| 532 |
+
answer = chat_model.chat(inputs)
|
| 533 |
+
print(answer)
|
| 534 |
+
|
| 535 |
+
# Second round chat
|
| 536 |
+
# pass history context of multi-turn conversation
|
| 537 |
+
msgs.append({"role": "assistant", "content": answer})
|
| 538 |
+
msgs.append({"role": "user", "content": "Introduce something about Airbus A380."})
|
| 539 |
+
|
| 540 |
+
inputs = {"image": im_64, "question": json.dumps(msgs)}
|
| 541 |
+
answer = chat_model.chat(inputs)
|
| 542 |
+
print(answer)
|
| 543 |
+
```
|
| 544 |
+
|
| 545 |
+
可以得到以下输出:
|
| 546 |
+
|
| 547 |
+
```
|
| 548 |
+
"The aircraft in the image is an Airbus A380, which can be identified by its large size, double-deck structure, and the distinctive shape of its wings and engines. The A380 is a wide-body aircraft known for being the world's largest passenger airliner, designed for long-haul flights. It has four engines, which are characteristic of large commercial aircraft. The registration number on the aircraft can also provide specific information about the model if looked up in an aviation database."
|
| 549 |
+
|
| 550 |
+
"The Airbus A380 is a double-deck, wide-body, four-engine jet airliner made by Airbus. It is the world's largest passenger airliner and is known for its long-haul capabilities. The aircraft was developed to improve efficiency and comfort for passengers traveling over long distances. It has two full-length passenger decks, which can accommodate more passengers than a typical single-aisle airplane. The A380 has been operated by airlines such as Lufthansa, Singapore Airlines, and Emirates, among others. It is widely recognized for its unique design and significant impact on the aviation industry."
|
| 551 |
+
```
|
| 552 |
+
|
| 553 |
+
|
| 554 |
+
|
| 555 |
+
|
| 556 |
+
### Mac 推理
|
| 557 |
+
<details>
|
| 558 |
+
<summary>点击查看 MiniCPM-Llama3-V 2.5 / MiniCPM-V 2.0 基于Mac MPS运行 (Apple silicon 或 AMD GPUs)的示例。 </summary>
|
| 559 |
+
|
| 560 |
+
```python
|
| 561 |
+
# test.py Need more than 16GB memory to run.
|
| 562 |
+
import torch
|
| 563 |
+
from PIL import Image
|
| 564 |
+
from transformers import AutoModel, AutoTokenizer
|
| 565 |
+
|
| 566 |
+
model = AutoModel.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True, low_cpu_mem_usage=True)
|
| 567 |
+
model = model.to(device='mps')
|
| 568 |
+
|
| 569 |
+
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True)
|
| 570 |
+
model.eval()
|
| 571 |
+
|
| 572 |
+
image = Image.open('./assets/hk_OCR.jpg').convert('RGB')
|
| 573 |
+
question = 'Where is this photo taken?'
|
| 574 |
+
msgs = [{'role': 'user', 'content': question}]
|
| 575 |
+
|
| 576 |
+
answer, context, _ = model.chat(
|
| 577 |
+
image=image,
|
| 578 |
+
msgs=msgs,
|
| 579 |
+
context=None,
|
| 580 |
+
tokenizer=tokenizer,
|
| 581 |
+
sampling=True
|
| 582 |
+
)
|
| 583 |
+
print(answer)
|
| 584 |
+
```
|
| 585 |
+
运行:
|
| 586 |
+
```shell
|
| 587 |
+
PYTORCH_ENABLE_MPS_FALLBACK=1 python test.py
|
| 588 |
+
```
|
| 589 |
+
</details>
|
| 590 |
+
|
| 591 |
+
|
| 592 |
+
### 手机端部署
|
| 593 |
+
MiniCPM-V 2.0 可运行在Android手机上,点击[2.0](https://github.com/OpenBMB/mlc-MiniCPM)安装apk使用; MiniCPM-Llama3-V 2.5 将很快推出,敬请期待。
|
| 594 |
+
|
| 595 |
+
### 本地WebUI Demo部署
|
| 596 |
+
<details>
|
| 597 |
+
<summary>点击查看本地WebUI demo 在 NVIDIA GPU、Mac等不同设备部署方法 </summary>
|
| 598 |
+
|
| 599 |
+
```shell
|
| 600 |
+
pip install -r requirements.txt
|
| 601 |
+
```
|
| 602 |
+
|
| 603 |
+
```shell
|
| 604 |
+
# For NVIDIA GPUs, run:
|
| 605 |
+
python web_demo_2.5.py --device cuda
|
| 606 |
+
|
| 607 |
+
# For Mac with MPS (Apple silicon or AMD GPUs), run:
|
| 608 |
+
PYTORCH_ENABLE_MPS_FALLBACK=1 python web_demo_2.5.py --device mps
|
| 609 |
+
```
|
| 610 |
+
</details>
|
| 611 |
+
|
| 612 |
+
### llama.cpp 部署<a id="llamacpp-部署"></a>
|
| 613 |
+
MiniCPM-Llama3-V 2.5 现在支持llama.cpp啦! 用法请参考我们的fork [llama.cpp](https://github.com/OpenBMB/llama.cpp/tree/minicpm-v2.5/examples/minicpmv), 在手机上可以支持 6~8 token/s 的流畅推理(测试环境:Xiaomi 14 pro + Snapdragon 8 Gen 3)。
|
| 614 |
+
|
| 615 |
+
### vLLM 部署 <a id='vllm'></a>
|
| 616 |
+
<details>
|
| 617 |
+
<summary>点击查看 vLLM 部署运行的方法</summary>
|
| 618 |
+
由于我们对 vLLM 提交的 PR 还在 review 中,因此目前我们 fork 了一个 vLLM 仓库以供测试使用。
|
| 619 |
+
|
| 620 |
+
1. 首先克隆我们 fork 的 vLLM 库:
|
| 621 |
+
```shell
|
| 622 |
+
git clone https://github.com/OpenBMB/vllm.git
|
| 623 |
+
```
|
| 624 |
+
2. 安装 vLLM 库:
|
| 625 |
+
```shell
|
| 626 |
+
cd vllm
|
| 627 |
+
pip install -e .
|
| 628 |
+
```
|
| 629 |
+
3. 安装 timm 库:
|
| 630 |
+
```shell
|
| 631 |
+
pip install timm=0.9.10
|
| 632 |
+
```
|
| 633 |
+
4. 测试运行示例程序:
|
| 634 |
+
```shell
|
| 635 |
+
python examples/minicpmv_example.py
|
| 636 |
+
```
|
| 637 |
+
|
| 638 |
+
|
| 639 |
+
</details>
|
| 640 |
+
|
| 641 |
+
|
| 642 |
+
## 微调
|
| 643 |
+
|
| 644 |
+
### 简易微调 <!-- omit in toc -->
|
| 645 |
+
|
| 646 |
+
我们支持使用 Huggingface Transformers 库简易地微调 MiniCPM-V 2.0 和 MiniCPM-Llama3-V 2.5 模型。
|
| 647 |
+
|
| 648 |
+
[参考文档](./finetune/readme.md)
|
| 649 |
+
|
| 650 |
+
### 使用 SWIFT 框架 <!-- omit in toc -->
|
| 651 |
+
|
| 652 |
+
我们支持使用 SWIFT 框架微调 MiniCPM-V 系列模型。SWIFT 支持近 200 种大语言模型和多模态大模型的训练、推理、评测和部署。支持 PEFT 提供的轻量训练方案和完整的 Adapters 库支持的最新训练技术如 NEFTune、LoRA+、LLaMA-PRO 等。
|
| 653 |
+
|
| 654 |
+
参考文档:[MiniCPM-V 1.0](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v最佳实践.md),[MiniCPM-V 2.0](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v-2最佳实践.md)
|
| 655 |
+
|
| 656 |
+
## 未来计划
|
| 657 |
+
|
| 658 |
+
- [x] 支持 MiniCPM-V 系列模型微调
|
| 659 |
+
- [ ] 实时多模态交互代码开源
|
| 660 |
+
|
| 661 |
+
|
| 662 |
+
|
| 663 |
+
## 模型协议 <!-- omit in toc -->
|
| 664 |
+
|
| 665 |
+
本仓库中代码依照 Apache-2.0 协议开源
|
| 666 |
+
|
| 667 |
+
本项目中模型权重的使用遵循 “[通用模型许可协议-来源说明-宣传限制-商业授权](https://github.com/OpenBMB/General-Model-License/blob/main/通用模型许可协议-来源说明-宣传限制-商业授权.md)”。
|
| 668 |
+
|
| 669 |
+
本项目中模型权重对学术研究完全开放。
|
| 670 |
+
|
| 671 |
+
如需将模型用于商业用途,请联系 cpm@modelbest.cn 来获取书面授权,登记后可以免费商业使用。
|
| 672 |
+
|
| 673 |
+
|
| 674 |
+
## 声明 <!-- omit in toc -->
|
| 675 |
+
|
| 676 |
+
作为多模态大模型,MiniCPM-V 系列模型(包括 OmniLMM)通过学习大量的多模态数据来生成内容,但它无法理解、表达个人观点或价值判断,它所输出的任何内容都不代表模型开发者的观点和立场。
|
| 677 |
+
|
| 678 |
+
因此用户在使用本项目的系列模型生成的内容时,应自行负责对其进行评估和验证。如果由于使用本项目的系列开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
|
| 679 |
+
|
| 680 |
+
|
| 681 |
+
## 机构 <!-- omit in toc -->
|
| 682 |
+
|
| 683 |
+
本项目由以下机构共同开发:
|
| 684 |
+
|
| 685 |
+
- <img src="assets/thunlp.png" width="28px"> [清华大学自然语言处理实验室](https://nlp.csai.tsinghua.edu.cn/)
|
| 686 |
+
- <img src="assets/modelbest.png" width="28px"> [面壁智能](https://modelbest.cn/)
|
| 687 |
+
- <img src="assets/zhihu.webp" width="28px"> [知乎](https://www.zhihu.com/ )
|
| 688 |
+
|
| 689 |
+
## 其他多模态项目 <!-- omit in toc -->
|
| 690 |
+
|
| 691 |
+
👏 欢迎了解我们更多的多模态项目:
|
| 692 |
+
|
| 693 |
+
[VisCPM](https://github.com/OpenBMB/VisCPM/tree/main) | [RLHF-V](https://github.com/RLHF-V/RLHF-V) | [LLaVA-UHD](https://github.com/thunlp/LLaVA-UHD) | [RLAIF-V](https://github.com/RLHF-V/RLAIF-V)
|
| 694 |
+
|
| 695 |
+
## 🌟 Star History
|
| 696 |
+
|
| 697 |
+
<div>
|
| 698 |
+
<img src="./assets/Star-History.png" width="500em" ></img>
|
| 699 |
+
</div>
|
| 700 |
+
|
| 701 |
+
|
| 702 |
+
## 引用
|
| 703 |
+
|
| 704 |
+
如果您觉得我们模型/代码/论文有帮助,请给我们 ⭐ 和 引用 📝,感谢!
|
| 705 |
+
|
| 706 |
+
```bib
|
| 707 |
+
@article{yu2023rlhf,
|
| 708 |
+
title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback},
|
| 709 |
+
author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others},
|
| 710 |
+
journal={arXiv preprint arXiv:2312.00849},
|
| 711 |
+
year={2023}
|
| 712 |
+
}
|
| 713 |
+
@article{viscpm,
|
| 714 |
+
title={Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages},
|
| 715 |
+
author={Jinyi Hu and Yuan Yao and Chongyi Wang and Shan Wang and Yinxu Pan and Qianyu Chen and Tianyu Yu and Hanghao Wu and Yue Zhao and Haoye Zhang and Xu Han and Yankai Lin and Jiao Xue and Dahai Li and Zhiyuan Liu and Maosong Sun},
|
| 716 |
+
journal={arXiv preprint arXiv:2308.12038},
|
| 717 |
+
year={2023}
|
| 718 |
+
}
|
| 719 |
+
@article{xu2024llava-uhd,
|
| 720 |
+
title={{LLaVA-UHD}: an LMM Perceiving Any Aspect Ratio and High-Resolution Images},
|
| 721 |
+
author={Xu, Ruyi and Yao, Yuan and Guo, Zonghao and Cui, Junbo and Ni, Zanlin and Ge, Chunjiang and Chua, Tat-Seng and Liu, Zhiyuan and Huang, Gao},
|
| 722 |
+
journal={arXiv preprint arXiv:2403.11703},
|
| 723 |
+
year={2024}
|
| 724 |
+
}
|
| 725 |
+
@article{yu2024rlaifv,
|
| 726 |
+
title={RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness},
|
| 727 |
+
author={Yu, Tianyu and Zhang, Haoye and Yao, Yuan and Dang, Yunkai and Chen, Da and Lu, Xiaoman and Cui, Ganqu and He, Taiwen and Liu, Zhiyuan and Chua, Tat-Seng and Sun, Maosong},
|
| 728 |
+
journal={arXiv preprint arXiv:2405.17220},
|
| 729 |
+
year={2024}
|
| 730 |
+
}
|
| 731 |
+
```
|
assets/MiniCPM-Llama3-V-2.5-peformance.png
ADDED

|
assets/Snake_cn_Mushroom_en.gif
ADDED

|
Git LFS Details
|
assets/Star-History.png
ADDED

|
assets/airplane.jpeg
ADDED

|
assets/demo_video.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6bc5bfa395f07b3dfba59e5142a88bba1219b3ff2aa124f8a551ee6867c4c3bb
|
| 3 |
+
size 2704175
|
assets/gif_cases/1-4.gif
ADDED

|
Git LFS Details
|
assets/gif_cases/Mushroom_en.gif
ADDED

|
assets/gif_cases/Mushroom_en_Snake_cn.gif
ADDED

|
Git LFS Details
|
assets/gif_cases/Snake_en.gif
ADDED

|
Git LFS Details
|
assets/gif_cases/english_menu.gif
ADDED

|
Git LFS Details
|
assets/gif_cases/hong_kong_street.gif
ADDED

|
Git LFS Details
|
assets/gif_cases/london_car.gif
ADDED

|
Git LFS Details
|
assets/gif_cases/meal_plan.gif
ADDED

|
Git LFS Details
|
assets/gif_cases/station.gif
ADDED

|
Git LFS Details
|
assets/gif_cases/ticket.gif
ADDED

|
Git LFS Details
|
assets/gif_cases/蘑菇_cn.gif
ADDED

|
Git LFS Details
|
assets/gif_cases/蛇_cn.gif
ADDED

|
Git LFS Details
|
assets/hk_OCR.jpg
ADDED

|
assets/llavabench_compare_3.png
ADDED
|
assets/llavabench_compare_phi3.png
ADDED

|
assets/minicpm-llama-v-2-5_languages.md
ADDED
|
@@ -0,0 +1,176 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- English
|
| 2 |
+
- 中文
|
| 3 |
+
- 한국어
|
| 4 |
+
- 日本語
|
| 5 |
+
- Deutsch
|
| 6 |
+
- Français
|
| 7 |
+
- Português
|
| 8 |
+
- Español
|
| 9 |
+
- မြန်မာဘာသာ
|
| 10 |
+
- ไทย
|
| 11 |
+
- Tiếng Việt
|
| 12 |
+
- Türkçe
|
| 13 |
+
- ܣܘܪܝܝܐ
|
| 14 |
+
- العربية
|
| 15 |
+
- हिन्दी
|
| 16 |
+
- বাংলা
|
| 17 |
+
- नेपाली
|
| 18 |
+
- Türkmençe
|
| 19 |
+
- Тоҷикӣ
|
| 20 |
+
- Кыргызча
|
| 21 |
+
- Русский
|
| 22 |
+
- Українська
|
| 23 |
+
- Беларуская
|
| 24 |
+
- ქართული
|
| 25 |
+
- Azərbaycanca
|
| 26 |
+
- Հայերեն
|
| 27 |
+
- Polski
|
| 28 |
+
- Lietuvių
|
| 29 |
+
- Eesti
|
| 30 |
+
- Latviešu
|
| 31 |
+
- Čeština
|
| 32 |
+
- Slovenčina
|
| 33 |
+
- Magyar
|
| 34 |
+
- Slovenščina
|
| 35 |
+
- Hrvatski
|
| 36 |
+
- Bosanski
|
| 37 |
+
- Crnogorski
|
| 38 |
+
- Српски
|
| 39 |
+
- Shqip
|
| 40 |
+
- Română
|
| 41 |
+
- Български
|
| 42 |
+
- Македонски
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
## 支持语言
|
| 46 |
+
|
| 47 |
+
英语
|
| 48 |
+
|
| 49 |
+
中文
|
| 50 |
+
|
| 51 |
+
韩语
|
| 52 |
+
|
| 53 |
+
日语
|
| 54 |
+
|
| 55 |
+
德语
|
| 56 |
+
|
| 57 |
+
法语
|
| 58 |
+
|
| 59 |
+
葡萄牙语
|
| 60 |
+
|
| 61 |
+
西班牙语
|
| 62 |
+
|
| 63 |
+
缅甸语
|
| 64 |
+
|
| 65 |
+
泰语
|
| 66 |
+
|
| 67 |
+
越南语
|
| 68 |
+
|
| 69 |
+
土耳其语
|
| 70 |
+
|
| 71 |
+
叙利亚语
|
| 72 |
+
|
| 73 |
+
阿拉伯语
|
| 74 |
+
|
| 75 |
+
印地语
|
| 76 |
+
|
| 77 |
+
孟加拉语
|
| 78 |
+
|
| 79 |
+
尼泊尔语
|
| 80 |
+
|
| 81 |
+
土库曼语
|
| 82 |
+
|
| 83 |
+
塔吉克语
|
| 84 |
+
|
| 85 |
+
吉尔吉斯语
|
| 86 |
+
|
| 87 |
+
俄语
|
| 88 |
+
|
| 89 |
+
乌克兰语
|
| 90 |
+
|
| 91 |
+
白俄罗斯语
|
| 92 |
+
|
| 93 |
+
格鲁吉亚语
|
| 94 |
+
|
| 95 |
+
阿塞拜疆语
|
| 96 |
+
|
| 97 |
+
亚美尼亚语
|
| 98 |
+
|
| 99 |
+
波兰语
|
| 100 |
+
|
| 101 |
+
立陶宛语
|
| 102 |
+
|
| 103 |
+
爱沙尼亚语
|
| 104 |
+
|
| 105 |
+
拉脱维亚语
|
| 106 |
+
|
| 107 |
+
捷克语
|
| 108 |
+
|
| 109 |
+
斯洛伐克语
|
| 110 |
+
|
| 111 |
+
匈牙利语
|
| 112 |
+
|
| 113 |
+
斯洛文尼亚语
|
| 114 |
+
|
| 115 |
+
克罗地亚语
|
| 116 |
+
|
| 117 |
+
波斯尼亚语
|
| 118 |
+
|
| 119 |
+
黑山语
|
| 120 |
+
|
| 121 |
+
塞尔维亚语
|
| 122 |
+
|
| 123 |
+
阿尔巴尼亚语
|
| 124 |
+
|
| 125 |
+
罗马尼亚语
|
| 126 |
+
|
| 127 |
+
保加利亚
|
| 128 |
+
|
| 129 |
+
马其顿语
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
## Supported Languages
|
| 134 |
+
|
| 135 |
+
English
|
| 136 |
+
Chinese
|
| 137 |
+
Korean
|
| 138 |
+
Japanese
|
| 139 |
+
German
|
| 140 |
+
French
|
| 141 |
+
Portuguese
|
| 142 |
+
Spanish
|
| 143 |
+
Burmese
|
| 144 |
+
Thai
|
| 145 |
+
Vietnamese
|
| 146 |
+
Turkish
|
| 147 |
+
Syriac
|
| 148 |
+
Arabic
|
| 149 |
+
Hindi
|
| 150 |
+
Bengali
|
| 151 |
+
Nepali
|
| 152 |
+
Turkmen
|
| 153 |
+
Tajik
|
| 154 |
+
Kyrgyz
|
| 155 |
+
Russian
|
| 156 |
+
Ukrainian
|
| 157 |
+
Belarusian
|
| 158 |
+
Georgian
|
| 159 |
+
Azerbaijani
|
| 160 |
+
Armenian
|
| 161 |
+
Polish
|
| 162 |
+
Lithuanian
|
| 163 |
+
Estonian
|
| 164 |
+
Latvian
|
| 165 |
+
Czech
|
| 166 |
+
Slovak
|
| 167 |
+
Hungarian
|
| 168 |
+
Slovenian
|
| 169 |
+
Croatian
|
| 170 |
+
Bosnian
|
| 171 |
+
Montenegrin
|
| 172 |
+
Serbian
|
| 173 |
+
Albanian
|
| 174 |
+
Romanian
|
| 175 |
+
Bulgarian
|
| 176 |
+
Macedonian
|
assets/minicpmv-2-peformance.png
ADDED
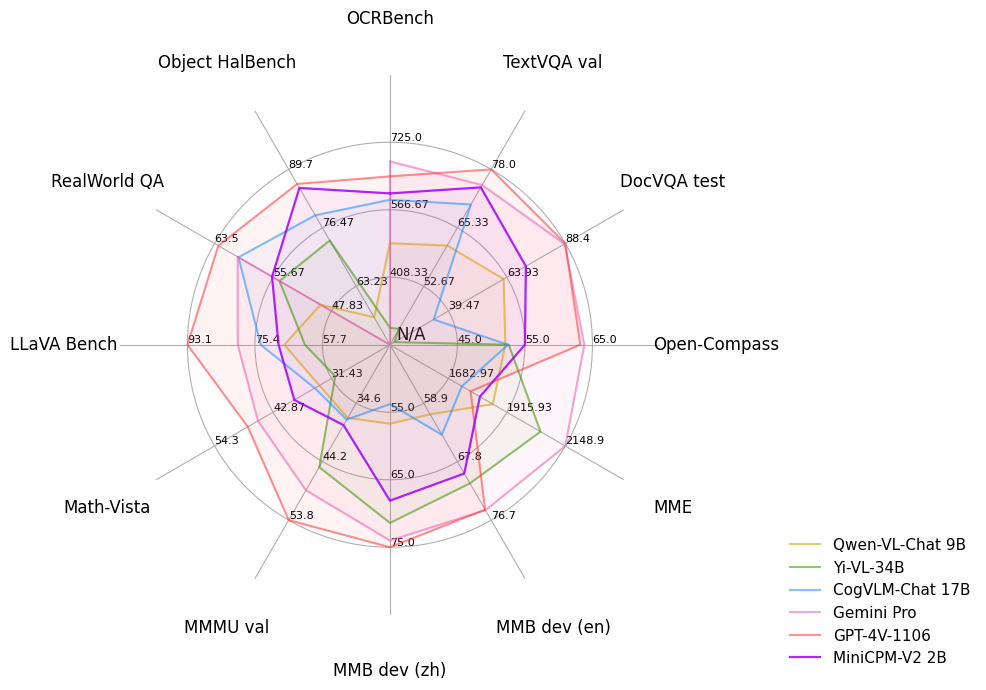
|
assets/minicpmv-llama3-v2.5/case_OCR_en.png
ADDED

|
Git LFS Details
|
assets/minicpmv-llama3-v2.5/case_complex_reasoning.png
ADDED

|
Git LFS Details
|
assets/minicpmv-llama3-v2.5/case_information_extraction.png
ADDED

|
Git LFS Details
|
assets/minicpmv-llama3-v2.5/case_long_img.png
ADDED

|
Git LFS Details
|
assets/minicpmv-llama3-v2.5/case_markdown.png
ADDED

|
Git LFS Details
|
assets/minicpmv-llama3-v2.5/cases_all.png
ADDED

|
Git LFS Details
|
assets/minicpmv-llama3-v2.5/temp
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
assets/minicpmv-omnilmm.png
ADDED

|
assets/minicpmv.png
ADDED

|
assets/minicpmv2-cases.png
ADDED

|
Git LFS Details
|
assets/minicpmv2-cases_1.png
ADDED

|
Git LFS Details
|
assets/minicpmv2-cases_2.png
ADDED

|
Git LFS Details
|
assets/modelbest.png
ADDED

|
assets/modelscope_logo.png
ADDED
|
|
assets/omnilmm-12b-examples.png
ADDED

|
Git LFS Details
|
assets/omnilmm-12b-examples_2.pdf
ADDED
|
Binary file (527 kB). View file
|
|
|
assets/omnilmm-12b-examples_2.png
ADDED

|
Git LFS Details
|
assets/omnilmm-12b-examples_2_00.jpg
ADDED

|
Git LFS Details
|
assets/omnilmm-12b-examples_3.png
ADDED

|
Git LFS Details
|