
Upload 14 files
Browse files- README.md +163 -6
- assets/metrics.png +0 -0
- assets/metrics_small.png +0 -0
- assets/scheme_coco_evaluate.png +0 -0
- detection_metrics.py +203 -0
- detection_metrics/__init__.py +1 -0
- detection_metrics/coco_evaluate.py +225 -0
- detection_metrics/pycocotools/coco.py +491 -0
- detection_metrics/pycocotools/cocoeval.py +631 -0
- detection_metrics/pycocotools/mask.py +103 -0
- detection_metrics/pycocotools/mask_utils.py +76 -0
- detection_metrics/utils.py +156 -0
- requirements.txt +2 -0
- setup.py +42 -0
README.md
CHANGED
|
@@ -1,11 +1,168 @@
|
|
| 1 |
---
|
| 2 |
title: Detection Metrics
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: static
|
| 7 |
-
|
| 8 |
-
|
| 9 |
---
|
| 10 |
|
| 11 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
title: Detection Metrics
|
| 3 |
+
emoji: 📈
|
| 4 |
+
colorFrom: green
|
| 5 |
+
colorTo: indigo
|
| 6 |
sdk: static
|
| 7 |
+
app_file: README.md
|
| 8 |
+
pinned: true
|
| 9 |
---
|
| 10 |
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
This project implements object detection **Average Precision** metrics using COCO style.
|
| 14 |
+
|
| 15 |
+
With `Detection Metrics` you can easily compute all 12 COCO metrics given the bounding boxes output by your object detection model:
|
| 16 |
+
|
| 17 |
+
### Average Precision (AP):
|
| 18 |
+
1. **AP**: AP at IoU=.50:.05:.95
|
| 19 |
+
2. **AP<sup>IoU=.50</sup>**: AP at IoU=.50 (similar to mAP PASCAL VOC metric)
|
| 20 |
+
3. **AP<sup>IoU=.75%</sup>**: AP at IoU=.75 (strict metric)
|
| 21 |
+
|
| 22 |
+
### AP Across Scales:
|
| 23 |
+
4. **AP<sup>small</sup>**: AP for small objects: area < 322
|
| 24 |
+
5. **AP<sup>medium</sup>**: AP for medium objects: 322 < area < 962
|
| 25 |
+
6. **AP<sup>large</sup>**: AP for large objects: area > 962
|
| 26 |
+
|
| 27 |
+
### Average Recall (AR):
|
| 28 |
+
7. **AR<sup>max=1</sup>**: AR given 1 detection per image
|
| 29 |
+
8. **AR<sup>max=10</sup>**: AR given 10 detections per image
|
| 30 |
+
9. **AR<sup>max=100</sup>**: AR given 100 detections per image
|
| 31 |
+
|
| 32 |
+
### AR Across Scales:
|
| 33 |
+
10. **AR<sup>small</sup>**: AR for small objects: area < 322
|
| 34 |
+
11. **AR<sup>medium</sup>**: AR for medium objects: 322 < area < 962
|
| 35 |
+
12. **AR<sup>large</sup>**: AR for large objects: area > 962
|
| 36 |
+
|
| 37 |
+
## How to use detection metrics?
|
| 38 |
+
|
| 39 |
+
Basically, you just need to create your ground-truth data and prepare your evaluation loop to output the boxes, confidences and classes in the required format. Follow these steps:
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
### Step 1: Prepare your ground-truth dataset
|
| 43 |
+
|
| 44 |
+
Convert your ground-truth annotations in JSON following the COCO format.
|
| 45 |
+
COCO ground-truth annotations are represented in a dictionary containing 3 elements: "images", "annotations" and "categories".
|
| 46 |
+
The snippet below shows an example of the dictionary, and you can find [here](https://towardsdatascience.com/how-to-work-with-object-detection-datasets-in-coco-format-9bf4fb5848a4).
|
| 47 |
+
|
| 48 |
+
```
|
| 49 |
+
{
|
| 50 |
+
"images": [
|
| 51 |
+
{
|
| 52 |
+
"id": 212226,
|
| 53 |
+
"width": 500,
|
| 54 |
+
"height": 335
|
| 55 |
+
},
|
| 56 |
+
...
|
| 57 |
+
],
|
| 58 |
+
"annotations": [
|
| 59 |
+
{
|
| 60 |
+
"id": 489885,
|
| 61 |
+
"category_id": 1,
|
| 62 |
+
"iscrowd": 0,
|
| 63 |
+
"image_id": 212226,
|
| 64 |
+
"area": 12836,
|
| 65 |
+
"bbox": [
|
| 66 |
+
235.6300048828125, # x
|
| 67 |
+
84.30999755859375, # y
|
| 68 |
+
158.08999633789062, # w
|
| 69 |
+
185.9499969482422 # h
|
| 70 |
+
]
|
| 71 |
+
},
|
| 72 |
+
....
|
| 73 |
+
],
|
| 74 |
+
"categories": [
|
| 75 |
+
{
|
| 76 |
+
"supercategory": "none",
|
| 77 |
+
"id": 1,
|
| 78 |
+
"name": "person"
|
| 79 |
+
},
|
| 80 |
+
...
|
| 81 |
+
]
|
| 82 |
+
}
|
| 83 |
+
```
|
| 84 |
+
You do not need to save the JSON in disk, you can keep it in memory as a dictionary.
|
| 85 |
+
|
| 86 |
+
### Step 2: Load the object detection evaluator:
|
| 87 |
+
|
| 88 |
+
Install Hugging Face's `Evaluate` module (`pip install evaluate`) to load the evaluator. More instructions [here](https://huggingface.co/docs/evaluate/installation).
|
| 89 |
+
|
| 90 |
+
Load the object detection evaluator passing the JSON created on the previous step through the argument `json_gt`:
|
| 91 |
+
`evaluator = evaluate.load("rafaelpadilla/detection_metrics", json_gt=ground_truth_annotations, iou_type="bbox")`
|
| 92 |
+
|
| 93 |
+
### Step 3: Loop through your dataset samples to obtain the predictions:
|
| 94 |
+
|
| 95 |
+
```python
|
| 96 |
+
# Loop through your dataset
|
| 97 |
+
for batch in dataloader_train:
|
| 98 |
+
|
| 99 |
+
# Get the image(s) from the batch
|
| 100 |
+
images = batch["images"]
|
| 101 |
+
# Get the image ids of the image
|
| 102 |
+
image_ids = batch["image_ids"]
|
| 103 |
+
|
| 104 |
+
# Pass the image(s) to your model to obtain bounding boxes, scores and labels
|
| 105 |
+
predictions = model.predict_boxes(images)
|
| 106 |
+
# Pass the predictions and image id to the evaluator
|
| 107 |
+
evaluator.add(prediction=predictions, reference=image_ids)
|
| 108 |
+
|
| 109 |
+
# Call compute to obtain your results
|
| 110 |
+
results = evaluator.compute()
|
| 111 |
+
print(results)
|
| 112 |
+
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
Regardless your model's architecture, your predictions must be converted to a dictionary containing 3 fields as shown below:
|
| 116 |
+
|
| 117 |
+
```python
|
| 118 |
+
predictions: [
|
| 119 |
+
{
|
| 120 |
+
"scores": [0.55, 0.95, 0.87],
|
| 121 |
+
"labels": [6, 1, 1],
|
| 122 |
+
"boxes": [[100, 30, 40, 28], [40, 32, 50, 28], [128, 44, 23, 69]]
|
| 123 |
+
},
|
| 124 |
+
...
|
| 125 |
+
]
|
| 126 |
+
```
|
| 127 |
+
* `scores`: List or torch tensor containing the confidences of your detections. A confidence is a value between 0 and 1.
|
| 128 |
+
* `labels`: List or torch tensor with the indexes representing the labels of your detections.
|
| 129 |
+
* `boxes`: List or torch tensors with the detected bounding boxes in the format `x,y,w,h`.
|
| 130 |
+
|
| 131 |
+
The `reference` added to the evaluator in each loop is represented by a list of dictionaries containing the image id of the image in that batch.
|
| 132 |
+
|
| 133 |
+
For example, in a batch containing two images, with ids 508101 and 1853, the `reference` argument must receive `image_ids` in the following format:
|
| 134 |
+
|
| 135 |
+
```python
|
| 136 |
+
image_ids = [ {'image_id': [508101]}, {'image_id': [1853]} ]
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
After the loop, you have to call `evaluator.compute()` to obtain your results in the format of a dictionary. The metrics can also be seen in the prompt as:
|
| 140 |
+
|
| 141 |
+
```
|
| 142 |
+
IoU metric: bbox
|
| 143 |
+
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.415
|
| 144 |
+
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.613
|
| 145 |
+
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.436
|
| 146 |
+
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.209
|
| 147 |
+
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.449
|
| 148 |
+
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.601
|
| 149 |
+
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.333
|
| 150 |
+
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.531
|
| 151 |
+
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.572
|
| 152 |
+
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.321
|
| 153 |
+
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.624
|
| 154 |
+
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.794
|
| 155 |
+
```
|
| 156 |
+
|
| 157 |
+
The scheme below illustrates how your `for` loop should look like:
|
| 158 |
+
|
| 159 |
+
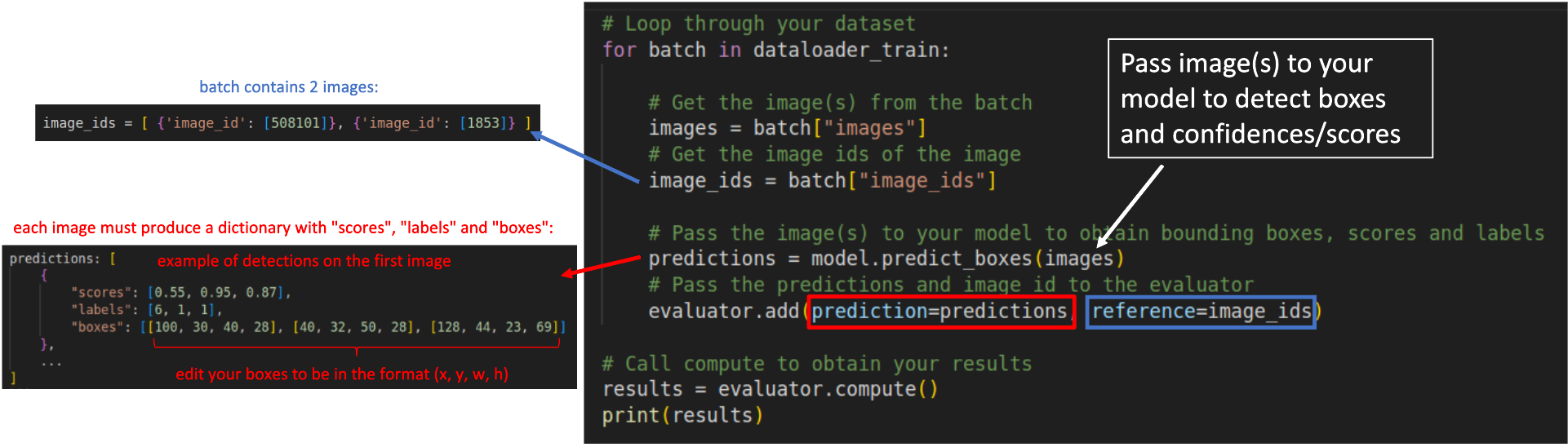
|
| 160 |
+
|
| 161 |
+
-----------------------
|
| 162 |
+
|
| 163 |
+
## References and further readings:
|
| 164 |
+
|
| 165 |
+
1. [COCO Evaluation Metrics](https://cocodataset.org/#detection-eval)
|
| 166 |
+
2. [A Survey on performance metrics for object-detection algorithms](https://www.researchgate.net/profile/Rafael-Padilla/publication/343194514_A_Survey_on_Performance_Metrics_for_Object-Detection_Algorithms/links/5f1b5a5e45851515ef478268/A-Survey-on-Performance-Metrics-for-Object-Detection-Algorithms.pdf)
|
| 167 |
+
3. [A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit](https://www.mdpi.com/2079-9292/10/3/279/pdf)
|
| 168 |
+
4. [COCO ground-truth annotations for your datasets in JSON](https://towardsdatascience.com/how-to-work-with-object-detection-datasets-in-coco-format-9bf4fb5848a4)
|
assets/metrics.png
ADDED

|
assets/metrics_small.png
ADDED

|
assets/scheme_coco_evaluate.png
ADDED

|
detection_metrics.py
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, List, Union
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import datasets
|
| 4 |
+
import torch
|
| 5 |
+
import evaluate
|
| 6 |
+
import json
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
from detection_metrics.pycocotools.coco import COCO
|
| 9 |
+
from detection_metrics.coco_evaluate import COCOEvaluator
|
| 10 |
+
from detection_metrics.utils import _TYPING_PREDICTION, _TYPING_REFERENCE
|
| 11 |
+
|
| 12 |
+
_DESCRIPTION = "This class evaluates object detection models using the COCO dataset \
|
| 13 |
+
and its evaluation metrics."
|
| 14 |
+
_HOMEPAGE = "https://cocodataset.org"
|
| 15 |
+
_CITATION = """
|
| 16 |
+
@misc{lin2015microsoft, \
|
| 17 |
+
title={Microsoft COCO: Common Objects in Context},
|
| 18 |
+
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and \
|
| 19 |
+
Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick \
|
| 20 |
+
and Piotr Dollár},
|
| 21 |
+
year={2015},
|
| 22 |
+
eprint={1405.0312},
|
| 23 |
+
archivePrefix={arXiv},
|
| 24 |
+
primaryClass={cs.CV}
|
| 25 |
+
}
|
| 26 |
+
"""
|
| 27 |
+
_REFERENCE_URLS = [
|
| 28 |
+
"https://ieeexplore.ieee.org/abstract/document/9145130",
|
| 29 |
+
"https://www.mdpi.com/2079-9292/10/3/279",
|
| 30 |
+
"https://cocodataset.org/#detection-eval",
|
| 31 |
+
]
|
| 32 |
+
_KWARGS_DESCRIPTION = """\
|
| 33 |
+
Computes COCO metrics for object detection: AP(mAP) and its variants.
|
| 34 |
+
|
| 35 |
+
Args:
|
| 36 |
+
coco (COCO): COCO Evaluator object for evaluating predictions.
|
| 37 |
+
**kwargs: Additional keyword arguments forwarded to evaluate.Metrics.
|
| 38 |
+
"""
|
| 39 |
+
|
| 40 |
+
class EvaluateObjectDetection(evaluate.Metric):
|
| 41 |
+
"""
|
| 42 |
+
Class for evaluating object detection models.
|
| 43 |
+
"""
|
| 44 |
+
|
| 45 |
+
def __init__(self, json_gt: Union[Path, Dict], iou_type: str = "bbox", **kwargs):
|
| 46 |
+
"""
|
| 47 |
+
Initializes the EvaluateObjectDetection class.
|
| 48 |
+
|
| 49 |
+
Args:
|
| 50 |
+
json_gt: JSON with ground-truth annotations in COCO format.
|
| 51 |
+
# coco_groundtruth (COCO): COCO Evaluator object for evaluating predictions.
|
| 52 |
+
**kwargs: Additional keyword arguments forwarded to evaluate.Metrics.
|
| 53 |
+
"""
|
| 54 |
+
super().__init__(**kwargs)
|
| 55 |
+
|
| 56 |
+
# Create COCO object from ground-truth annotations
|
| 57 |
+
if isinstance(json_gt, Path):
|
| 58 |
+
assert json_gt.exists(), f"Path {json_gt} does not exist."
|
| 59 |
+
with open(json_gt) as f:
|
| 60 |
+
json_data = json.load(f)
|
| 61 |
+
elif isinstance(json_gt, dict):
|
| 62 |
+
json_data = json_gt
|
| 63 |
+
coco = COCO(json_data)
|
| 64 |
+
|
| 65 |
+
self.coco_evaluator = COCOEvaluator(coco, [iou_type])
|
| 66 |
+
|
| 67 |
+
def remove_classes(self, classes_to_remove: List[str]):
|
| 68 |
+
to_remove = [c.upper() for c in classes_to_remove]
|
| 69 |
+
cats = {}
|
| 70 |
+
for id, cat in self.coco_evaluator.coco_eval["bbox"].cocoGt.cats.items():
|
| 71 |
+
if cat["name"].upper() not in to_remove:
|
| 72 |
+
cats[id] = cat
|
| 73 |
+
self.coco_evaluator.coco_eval["bbox"].cocoGt.cats = cats
|
| 74 |
+
self.coco_evaluator.coco_gt.cats = cats
|
| 75 |
+
self.coco_evaluator.coco_gt.dataset["categories"] = list(cats.values())
|
| 76 |
+
self.coco_evaluator.coco_eval["bbox"].params.catIds = [c["id"] for c in cats.values()]
|
| 77 |
+
|
| 78 |
+
def _info(self):
|
| 79 |
+
"""
|
| 80 |
+
Returns the MetricInfo object with information about the module.
|
| 81 |
+
|
| 82 |
+
Returns:
|
| 83 |
+
evaluate.MetricInfo: Metric information object.
|
| 84 |
+
"""
|
| 85 |
+
return evaluate.MetricInfo(
|
| 86 |
+
module_type="metric",
|
| 87 |
+
description=_DESCRIPTION,
|
| 88 |
+
citation=_CITATION,
|
| 89 |
+
inputs_description=_KWARGS_DESCRIPTION,
|
| 90 |
+
# This defines the format of each prediction and reference
|
| 91 |
+
features=datasets.Features(
|
| 92 |
+
{
|
| 93 |
+
"predictions": [
|
| 94 |
+
datasets.Features(
|
| 95 |
+
{
|
| 96 |
+
"scores": datasets.Sequence(datasets.Value("float")),
|
| 97 |
+
"labels": datasets.Sequence(datasets.Value("int64")),
|
| 98 |
+
"boxes": datasets.Sequence(
|
| 99 |
+
datasets.Sequence(datasets.Value("float"))
|
| 100 |
+
),
|
| 101 |
+
}
|
| 102 |
+
)
|
| 103 |
+
],
|
| 104 |
+
"references": [
|
| 105 |
+
datasets.Features(
|
| 106 |
+
{
|
| 107 |
+
"image_id": datasets.Sequence(datasets.Value("int64")),
|
| 108 |
+
}
|
| 109 |
+
)
|
| 110 |
+
],
|
| 111 |
+
}
|
| 112 |
+
),
|
| 113 |
+
# Homepage of the module for documentation
|
| 114 |
+
homepage=_HOMEPAGE,
|
| 115 |
+
# Additional links to the codebase or references
|
| 116 |
+
reference_urls=_REFERENCE_URLS,
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
def _preprocess(
|
| 120 |
+
self, predictions: List[Dict[str, torch.Tensor]]
|
| 121 |
+
) -> List[_TYPING_PREDICTION]:
|
| 122 |
+
"""
|
| 123 |
+
Preprocesses the predictions before computing the scores.
|
| 124 |
+
|
| 125 |
+
Args:
|
| 126 |
+
predictions (List[Dict[str, torch.Tensor]]): A list of prediction dicts.
|
| 127 |
+
|
| 128 |
+
Returns:
|
| 129 |
+
List[_TYPING_PREDICTION]: A list of preprocessed prediction dicts.
|
| 130 |
+
"""
|
| 131 |
+
processed_predictions = []
|
| 132 |
+
for pred in predictions:
|
| 133 |
+
processed_pred: _TYPING_PREDICTION = {}
|
| 134 |
+
for k, val in pred.items():
|
| 135 |
+
if isinstance(val, torch.Tensor):
|
| 136 |
+
val = val.detach().cpu().tolist()
|
| 137 |
+
if k == "labels":
|
| 138 |
+
val = list(map(int, val))
|
| 139 |
+
processed_pred[k] = val
|
| 140 |
+
processed_predictions.append(processed_pred)
|
| 141 |
+
return processed_predictions
|
| 142 |
+
|
| 143 |
+
def _clear_predictions(self, predictions):
|
| 144 |
+
# Remove unnecessary keys from predictions
|
| 145 |
+
required = ["scores", "labels", "boxes"]
|
| 146 |
+
ret = []
|
| 147 |
+
for prediction in predictions:
|
| 148 |
+
ret.append({k: v for k, v in prediction.items() if k in required})
|
| 149 |
+
return ret
|
| 150 |
+
|
| 151 |
+
def _clear_references(self, references):
|
| 152 |
+
required = [""]
|
| 153 |
+
ret = []
|
| 154 |
+
for ref in references:
|
| 155 |
+
ret.append({k: v for k, v in ref.items() if k in required})
|
| 156 |
+
return ret
|
| 157 |
+
|
| 158 |
+
def add(self, *, prediction = None, reference = None, **kwargs):
|
| 159 |
+
"""
|
| 160 |
+
Preprocesses the predictions and references and calls the parent class function.
|
| 161 |
+
|
| 162 |
+
Args:
|
| 163 |
+
prediction: A list of prediction dicts.
|
| 164 |
+
reference: A list of reference dicts.
|
| 165 |
+
**kwargs: Additional keyword arguments.
|
| 166 |
+
"""
|
| 167 |
+
if prediction is not None:
|
| 168 |
+
prediction = self._clear_predictions(prediction)
|
| 169 |
+
prediction = self._preprocess(prediction)
|
| 170 |
+
|
| 171 |
+
res = {} # {image_id} : prediction
|
| 172 |
+
for output, target in zip(prediction, reference):
|
| 173 |
+
res[target["image_id"][0]] = output
|
| 174 |
+
self.coco_evaluator.update(res)
|
| 175 |
+
|
| 176 |
+
super(evaluate.Metric, self).add(prediction=prediction, references=reference, **kwargs)
|
| 177 |
+
|
| 178 |
+
def _compute(
|
| 179 |
+
self,
|
| 180 |
+
predictions: List[List[_TYPING_PREDICTION]],
|
| 181 |
+
references: List[List[_TYPING_REFERENCE]],
|
| 182 |
+
) -> Dict[str, Dict[str, float]]:
|
| 183 |
+
"""
|
| 184 |
+
Returns the evaluation scores.
|
| 185 |
+
|
| 186 |
+
Args:
|
| 187 |
+
predictions (List[List[_TYPING_PREDICTION]]): A list of predictions.
|
| 188 |
+
references (List[List[_TYPING_REFERENCE]]): A list of references.
|
| 189 |
+
|
| 190 |
+
Returns:
|
| 191 |
+
Dict: A dictionary containing evaluation scores.
|
| 192 |
+
"""
|
| 193 |
+
print("Synchronizing processes")
|
| 194 |
+
self.coco_evaluator.synchronize_between_processes()
|
| 195 |
+
|
| 196 |
+
print("Accumulating values")
|
| 197 |
+
self.coco_evaluator.accumulate()
|
| 198 |
+
|
| 199 |
+
print("Summarizing results")
|
| 200 |
+
self.coco_evaluator.summarize()
|
| 201 |
+
|
| 202 |
+
stats = self.coco_evaluator.get_results()
|
| 203 |
+
return stats
|
detection_metrics/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__version__ = "0.0.3"
|
detection_metrics/coco_evaluate.py
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import contextlib
|
| 2 |
+
import copy
|
| 3 |
+
import os
|
| 4 |
+
from typing import Dict, List, Union
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
from detection_metrics.pycocotools.coco import COCO
|
| 10 |
+
from detection_metrics.pycocotools.cocoeval import COCOeval
|
| 11 |
+
from detection_metrics.utils import (_TYPING_BOX, _TYPING_PREDICTIONS, convert_to_xywh,
|
| 12 |
+
create_common_coco_eval)
|
| 13 |
+
|
| 14 |
+
_SUPPORTED_TYPES = ["bbox"]
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class COCOEvaluator(object):
|
| 18 |
+
"""
|
| 19 |
+
Class to perform evaluation for the COCO dataset.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
def __init__(self, coco_gt: COCO, iou_types: List[str] = ["bbox"]):
|
| 23 |
+
"""
|
| 24 |
+
Initializes COCOEvaluator with the ground truth COCO dataset and IoU types.
|
| 25 |
+
|
| 26 |
+
Args:
|
| 27 |
+
coco_gt: The ground truth COCO dataset.
|
| 28 |
+
iou_types: Intersection over Union (IoU) types for evaluation (Supported: "bbox").
|
| 29 |
+
"""
|
| 30 |
+
self.coco_gt = copy.deepcopy(coco_gt)
|
| 31 |
+
|
| 32 |
+
self.coco_eval = {}
|
| 33 |
+
for iou_type in iou_types:
|
| 34 |
+
assert iou_type in _SUPPORTED_TYPES, ValueError(
|
| 35 |
+
f"IoU type not supported {iou_type}"
|
| 36 |
+
)
|
| 37 |
+
self.coco_eval[iou_type] = COCOeval(self.coco_gt, iouType=iou_type)
|
| 38 |
+
|
| 39 |
+
self.iou_types = iou_types
|
| 40 |
+
self.img_ids = []
|
| 41 |
+
self.eval_imgs = {k: [] for k in iou_types}
|
| 42 |
+
|
| 43 |
+
def update(self, predictions: _TYPING_PREDICTIONS) -> None:
|
| 44 |
+
"""
|
| 45 |
+
Update the evaluator with new predictions.
|
| 46 |
+
|
| 47 |
+
Args:
|
| 48 |
+
predictions: The predictions to update.
|
| 49 |
+
"""
|
| 50 |
+
img_ids = list(np.unique(list(predictions.keys())))
|
| 51 |
+
self.img_ids.extend(img_ids)
|
| 52 |
+
|
| 53 |
+
for iou_type in self.iou_types:
|
| 54 |
+
results = self.prepare(predictions, iou_type)
|
| 55 |
+
|
| 56 |
+
# suppress pycocotools prints
|
| 57 |
+
with open(os.devnull, "w") as devnull:
|
| 58 |
+
with contextlib.redirect_stdout(devnull):
|
| 59 |
+
coco_dt = COCO.loadRes(self.coco_gt, results) if results else COCO()
|
| 60 |
+
coco_eval = self.coco_eval[iou_type]
|
| 61 |
+
|
| 62 |
+
coco_eval.cocoDt = coco_dt
|
| 63 |
+
coco_eval.params.imgIds = list(img_ids)
|
| 64 |
+
eval_imgs = coco_eval.evaluate()
|
| 65 |
+
self.eval_imgs[iou_type].append(eval_imgs)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def synchronize_between_processes(self) -> None:
|
| 69 |
+
"""
|
| 70 |
+
Synchronizes evaluation images between processes.
|
| 71 |
+
"""
|
| 72 |
+
for iou_type in self.iou_types:
|
| 73 |
+
self.eval_imgs[iou_type] = np.concatenate(self.eval_imgs[iou_type], 2)
|
| 74 |
+
create_common_coco_eval(
|
| 75 |
+
self.coco_eval[iou_type], self.img_ids, self.eval_imgs[iou_type]
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
def accumulate(self) -> None:
|
| 79 |
+
"""
|
| 80 |
+
Accumulates the evaluation results.
|
| 81 |
+
"""
|
| 82 |
+
for coco_eval in self.coco_eval.values():
|
| 83 |
+
coco_eval.accumulate()
|
| 84 |
+
|
| 85 |
+
def summarize(self) -> None:
|
| 86 |
+
"""
|
| 87 |
+
Prints the IoU metric and summarizes the evaluation results.
|
| 88 |
+
"""
|
| 89 |
+
for iou_type, coco_eval in self.coco_eval.items():
|
| 90 |
+
print("IoU metric: {}".format(iou_type))
|
| 91 |
+
coco_eval.summarize()
|
| 92 |
+
|
| 93 |
+
def prepare(
|
| 94 |
+
self, predictions: _TYPING_PREDICTIONS, iou_type: str
|
| 95 |
+
) -> List[Dict[str, Union[int, _TYPING_BOX, float]]]:
|
| 96 |
+
"""
|
| 97 |
+
Prepares the predictions for COCO detection.
|
| 98 |
+
|
| 99 |
+
Args:
|
| 100 |
+
predictions: The predictions to prepare.
|
| 101 |
+
iou_type: The Intersection over Union (IoU) type for evaluation.
|
| 102 |
+
|
| 103 |
+
Returns:
|
| 104 |
+
A dictionary with the prepared predictions.
|
| 105 |
+
"""
|
| 106 |
+
if iou_type == "bbox":
|
| 107 |
+
return self.prepare_for_coco_detection(predictions)
|
| 108 |
+
else:
|
| 109 |
+
raise ValueError(f"IoU type not supported {iou_type}")
|
| 110 |
+
|
| 111 |
+
def _post_process_stats(
|
| 112 |
+
self, stats, coco_eval_object, iou_type="bbox"
|
| 113 |
+
) -> Dict[str, float]:
|
| 114 |
+
"""
|
| 115 |
+
Prepares the predictions for COCO detection.
|
| 116 |
+
|
| 117 |
+
Args:
|
| 118 |
+
predictions: The predictions to prepare.
|
| 119 |
+
iou_type: The Intersection over Union (IoU) type for evaluation.
|
| 120 |
+
|
| 121 |
+
Returns:
|
| 122 |
+
A dictionary with the prepared predictions.
|
| 123 |
+
"""
|
| 124 |
+
if iou_type not in _SUPPORTED_TYPES:
|
| 125 |
+
raise ValueError(f"iou_type '{iou_type}' not supported")
|
| 126 |
+
|
| 127 |
+
current_max_dets = coco_eval_object.params.maxDets
|
| 128 |
+
|
| 129 |
+
index_to_title = {
|
| 130 |
+
"bbox": {
|
| 131 |
+
0: f"AP-IoU=0.50:0.95-area=all-maxDets={current_max_dets[2]}",
|
| 132 |
+
1: f"AP-IoU=0.50-area=all-maxDets={current_max_dets[2]}",
|
| 133 |
+
2: f"AP-IoU=0.75-area=all-maxDets={current_max_dets[2]}",
|
| 134 |
+
3: f"AP-IoU=0.50:0.95-area=small-maxDets={current_max_dets[2]}",
|
| 135 |
+
4: f"AP-IoU=0.50:0.95-area=medium-maxDets={current_max_dets[2]}",
|
| 136 |
+
5: f"AP-IoU=0.50:0.95-area=large-maxDets={current_max_dets[2]}",
|
| 137 |
+
6: f"AR-IoU=0.50:0.95-area=all-maxDets={current_max_dets[0]}",
|
| 138 |
+
7: f"AR-IoU=0.50:0.95-area=all-maxDets={current_max_dets[1]}",
|
| 139 |
+
8: f"AR-IoU=0.50:0.95-area=all-maxDets={current_max_dets[2]}",
|
| 140 |
+
9: f"AR-IoU=0.50:0.95-area=small-maxDets={current_max_dets[2]}",
|
| 141 |
+
10: f"AR-IoU=0.50:0.95-area=medium-maxDets={current_max_dets[2]}",
|
| 142 |
+
11: f"AR-IoU=0.50:0.95-area=large-maxDets={current_max_dets[2]}",
|
| 143 |
+
},
|
| 144 |
+
"keypoints": {
|
| 145 |
+
0: "AP-IoU=0.50:0.95-area=all-maxDets=20",
|
| 146 |
+
1: "AP-IoU=0.50-area=all-maxDets=20",
|
| 147 |
+
2: "AP-IoU=0.75-area=all-maxDets=20",
|
| 148 |
+
3: "AP-IoU=0.50:0.95-area=medium-maxDets=20",
|
| 149 |
+
4: "AP-IoU=0.50:0.95-area=large-maxDets=20",
|
| 150 |
+
5: "AR-IoU=0.50:0.95-area=all-maxDets=20",
|
| 151 |
+
6: "AR-IoU=0.50-area=all-maxDets=20",
|
| 152 |
+
7: "AR-IoU=0.75-area=all-maxDets=20",
|
| 153 |
+
8: "AR-IoU=0.50:0.95-area=medium-maxDets=20",
|
| 154 |
+
9: "AR-IoU=0.50:0.95-area=large-maxDets=20",
|
| 155 |
+
},
|
| 156 |
+
}
|
| 157 |
+
|
| 158 |
+
output_dict: Dict[str, float] = {}
|
| 159 |
+
for index, stat in enumerate(stats):
|
| 160 |
+
output_dict[index_to_title[iou_type][index]] = stat
|
| 161 |
+
|
| 162 |
+
return output_dict
|
| 163 |
+
|
| 164 |
+
def get_results(self) -> Dict[str, Dict[str, float]]:
|
| 165 |
+
"""
|
| 166 |
+
Gets the results of the COCO evaluation.
|
| 167 |
+
|
| 168 |
+
Returns:
|
| 169 |
+
A dictionary with the results of the COCO evaluation.
|
| 170 |
+
"""
|
| 171 |
+
output_dict = {}
|
| 172 |
+
|
| 173 |
+
for iou_type, coco_eval in self.coco_eval.items():
|
| 174 |
+
if iou_type == "segm":
|
| 175 |
+
iou_type = "bbox"
|
| 176 |
+
output_dict[f"iou_{iou_type}"] = self._post_process_stats(
|
| 177 |
+
coco_eval.stats, coco_eval, iou_type
|
| 178 |
+
)
|
| 179 |
+
return output_dict
|
| 180 |
+
|
| 181 |
+
def prepare_for_coco_detection(
|
| 182 |
+
self, predictions: _TYPING_PREDICTIONS
|
| 183 |
+
) -> List[Dict[str, Union[int, _TYPING_BOX, float]]]:
|
| 184 |
+
"""
|
| 185 |
+
Prepares the predictions for COCO detection.
|
| 186 |
+
|
| 187 |
+
Args:
|
| 188 |
+
predictions: The predictions to prepare.
|
| 189 |
+
|
| 190 |
+
Returns:
|
| 191 |
+
A list of dictionaries with the prepared predictions.
|
| 192 |
+
"""
|
| 193 |
+
coco_results = []
|
| 194 |
+
for original_id, prediction in predictions.items():
|
| 195 |
+
if len(prediction) == 0:
|
| 196 |
+
continue
|
| 197 |
+
|
| 198 |
+
boxes = prediction["boxes"]
|
| 199 |
+
if len(boxes) == 0:
|
| 200 |
+
continue
|
| 201 |
+
|
| 202 |
+
if not isinstance(boxes, torch.Tensor):
|
| 203 |
+
boxes = torch.as_tensor(boxes)
|
| 204 |
+
boxes = boxes.tolist()
|
| 205 |
+
|
| 206 |
+
scores = prediction["scores"]
|
| 207 |
+
if not isinstance(scores, list):
|
| 208 |
+
scores = scores.tolist()
|
| 209 |
+
|
| 210 |
+
labels = prediction["labels"]
|
| 211 |
+
if not isinstance(labels, list):
|
| 212 |
+
labels = prediction["labels"].tolist()
|
| 213 |
+
|
| 214 |
+
coco_results.extend(
|
| 215 |
+
[
|
| 216 |
+
{
|
| 217 |
+
"image_id": original_id,
|
| 218 |
+
"category_id": labels[k],
|
| 219 |
+
"bbox": box,
|
| 220 |
+
"score": scores[k],
|
| 221 |
+
}
|
| 222 |
+
for k, box in enumerate(boxes)
|
| 223 |
+
]
|
| 224 |
+
)
|
| 225 |
+
return coco_results
|
detection_metrics/pycocotools/coco.py
ADDED
|
@@ -0,0 +1,491 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This code is basically a copy and paste from the original cocoapi file:
|
| 2 |
+
# https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocotools/coco.py
|
| 3 |
+
# with the following changes:
|
| 4 |
+
# * Instead of receiving the path to the annotation file, it receives a json object.
|
| 5 |
+
# * Commented out all parts of code that depends on maskUtils, which is not needed
|
| 6 |
+
# for bounding box evaluation.
|
| 7 |
+
|
| 8 |
+
__author__ = "tylin"
|
| 9 |
+
__version__ = "2.0"
|
| 10 |
+
# Interface for accessing the Microsoft COCO dataset.
|
| 11 |
+
|
| 12 |
+
# Microsoft COCO is a large image dataset designed for object detection,
|
| 13 |
+
# segmentation, and caption generation. pycocotools is a Python API that
|
| 14 |
+
# assists in loading, parsing and visualizing the annotations in COCO.
|
| 15 |
+
# Please visit http://mscoco.org/ for more information on COCO, including
|
| 16 |
+
# for the data, paper, and tutorials. The exact format of the annotations
|
| 17 |
+
# is also described on the COCO website. For example usage of the pycocotools
|
| 18 |
+
# please see pycocotools_demo.ipynb. In addition to this API, please download both
|
| 19 |
+
# the COCO images and annotations in order to run the demo.
|
| 20 |
+
|
| 21 |
+
# An alternative to using the API is to load the annotations directly
|
| 22 |
+
# into Python dictionary
|
| 23 |
+
# Using the API provides additional utility functions. Note that this API
|
| 24 |
+
# supports both *instance* and *caption* annotations. In the case of
|
| 25 |
+
# captions not all functions are defined (e.g. categories are undefined).
|
| 26 |
+
|
| 27 |
+
# The following API functions are defined:
|
| 28 |
+
# COCO - COCO api class that loads COCO annotation file and prepare data structures.
|
| 29 |
+
# decodeMask - Decode binary mask M encoded via run-length encoding.
|
| 30 |
+
# encodeMask - Encode binary mask M using run-length encoding.
|
| 31 |
+
# getAnnIds - Get ann ids that satisfy given filter conditions.
|
| 32 |
+
# getCatIds - Get cat ids that satisfy given filter conditions.
|
| 33 |
+
# getImgIds - Get img ids that satisfy given filter conditions.
|
| 34 |
+
# loadAnns - Load anns with the specified ids.
|
| 35 |
+
# loadCats - Load cats with the specified ids.
|
| 36 |
+
# loadImgs - Load imgs with the specified ids.
|
| 37 |
+
# annToMask - Convert segmentation in an annotation to binary mask.
|
| 38 |
+
# showAnns - Display the specified annotations.
|
| 39 |
+
# loadRes - Load algorithm results and create API for accessing them.
|
| 40 |
+
# download - Download COCO images from mscoco.org server.
|
| 41 |
+
# Throughout the API "ann"=annotation, "cat"=category, and "img"=image.
|
| 42 |
+
# Help on each functions can be accessed by: "help COCO>function".
|
| 43 |
+
|
| 44 |
+
# See also COCO>decodeMask,
|
| 45 |
+
# COCO>encodeMask, COCO>getAnnIds, COCO>getCatIds,
|
| 46 |
+
# COCO>getImgIds, COCO>loadAnns, COCO>loadCats,
|
| 47 |
+
# COCO>loadImgs, COCO>annToMask, COCO>showAnns
|
| 48 |
+
|
| 49 |
+
# Microsoft COCO Toolbox. version 2.0
|
| 50 |
+
# Data, paper, and tutorials available at: http://mscoco.org/
|
| 51 |
+
# Code written by Piotr Dollar and Tsung-Yi Lin, 2014.
|
| 52 |
+
# Licensed under the Simplified BSD License [see bsd.txt]
|
| 53 |
+
|
| 54 |
+
import copy
|
| 55 |
+
import itertools
|
| 56 |
+
import json
|
| 57 |
+
# from . import mask as maskUtils
|
| 58 |
+
import os
|
| 59 |
+
import sys
|
| 60 |
+
import time
|
| 61 |
+
from collections import defaultdict
|
| 62 |
+
|
| 63 |
+
import matplotlib.pyplot as plt
|
| 64 |
+
import numpy as np
|
| 65 |
+
from matplotlib.collections import PatchCollection
|
| 66 |
+
from matplotlib.patches import Polygon
|
| 67 |
+
|
| 68 |
+
PYTHON_VERSION = sys.version_info[0]
|
| 69 |
+
if PYTHON_VERSION == 2:
|
| 70 |
+
from urllib import urlretrieve
|
| 71 |
+
elif PYTHON_VERSION == 3:
|
| 72 |
+
from urllib.request import urlretrieve
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def _isArrayLike(obj):
|
| 76 |
+
return hasattr(obj, "__iter__") and hasattr(obj, "__len__")
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class COCO:
|
| 80 |
+
def __init__(self, annotations=None):
|
| 81 |
+
"""
|
| 82 |
+
Constructor of Microsoft COCO helper class for reading and visualizing annotations.
|
| 83 |
+
:param annotation_file (str): location of annotation file
|
| 84 |
+
:param image_folder (str): location to the folder that hosts images.
|
| 85 |
+
:return:
|
| 86 |
+
"""
|
| 87 |
+
# load dataset
|
| 88 |
+
self.dataset, self.anns, self.cats, self.imgs = dict(), dict(), dict(), dict()
|
| 89 |
+
self.imgToAnns, self.catToImgs = defaultdict(list), defaultdict(list)
|
| 90 |
+
# Modified the original code to receive a json object instead of a path to a file
|
| 91 |
+
if annotations:
|
| 92 |
+
assert (
|
| 93 |
+
type(annotations) == dict
|
| 94 |
+
), f"annotation file format {type(annotations)} not supported."
|
| 95 |
+
self.dataset = annotations
|
| 96 |
+
self.createIndex()
|
| 97 |
+
|
| 98 |
+
def createIndex(self):
|
| 99 |
+
# create index
|
| 100 |
+
print("creating index...")
|
| 101 |
+
anns, cats, imgs = {}, {}, {}
|
| 102 |
+
imgToAnns, catToImgs = defaultdict(list), defaultdict(list)
|
| 103 |
+
if "annotations" in self.dataset:
|
| 104 |
+
for ann in self.dataset["annotations"]:
|
| 105 |
+
imgToAnns[ann["image_id"]].append(ann)
|
| 106 |
+
anns[ann["id"]] = ann
|
| 107 |
+
|
| 108 |
+
if "images" in self.dataset:
|
| 109 |
+
for img in self.dataset["images"]:
|
| 110 |
+
imgs[img["id"]] = img
|
| 111 |
+
|
| 112 |
+
if "categories" in self.dataset:
|
| 113 |
+
for cat in self.dataset["categories"]:
|
| 114 |
+
cats[cat["id"]] = cat
|
| 115 |
+
|
| 116 |
+
if "annotations" in self.dataset and "categories" in self.dataset:
|
| 117 |
+
for ann in self.dataset["annotations"]:
|
| 118 |
+
catToImgs[ann["category_id"]].append(ann["image_id"])
|
| 119 |
+
|
| 120 |
+
print("index created!")
|
| 121 |
+
|
| 122 |
+
# create class members
|
| 123 |
+
self.anns = anns
|
| 124 |
+
self.imgToAnns = imgToAnns
|
| 125 |
+
self.catToImgs = catToImgs
|
| 126 |
+
self.imgs = imgs
|
| 127 |
+
self.cats = cats
|
| 128 |
+
|
| 129 |
+
def info(self):
|
| 130 |
+
"""
|
| 131 |
+
Print information about the annotation file.
|
| 132 |
+
:return:
|
| 133 |
+
"""
|
| 134 |
+
for key, value in self.dataset["info"].items():
|
| 135 |
+
print("{}: {}".format(key, value))
|
| 136 |
+
|
| 137 |
+
def getAnnIds(self, imgIds=[], catIds=[], areaRng=[], iscrowd=None):
|
| 138 |
+
"""
|
| 139 |
+
Get ann ids that satisfy given filter conditions. default skips that filter
|
| 140 |
+
:param imgIds (int array) : get anns for given imgs
|
| 141 |
+
catIds (int array) : get anns for given cats
|
| 142 |
+
areaRng (float array) : get anns for given area range (e.g. [0 inf])
|
| 143 |
+
iscrowd (boolean) : get anns for given crowd label (False or True)
|
| 144 |
+
:return: ids (int array) : integer array of ann ids
|
| 145 |
+
"""
|
| 146 |
+
imgIds = imgIds if _isArrayLike(imgIds) else [imgIds]
|
| 147 |
+
catIds = catIds if _isArrayLike(catIds) else [catIds]
|
| 148 |
+
|
| 149 |
+
if len(imgIds) == len(catIds) == len(areaRng) == 0:
|
| 150 |
+
anns = self.dataset["annotations"]
|
| 151 |
+
else:
|
| 152 |
+
if not len(imgIds) == 0:
|
| 153 |
+
lists = [
|
| 154 |
+
self.imgToAnns[imgId] for imgId in imgIds if imgId in self.imgToAnns
|
| 155 |
+
]
|
| 156 |
+
anns = list(itertools.chain.from_iterable(lists))
|
| 157 |
+
else:
|
| 158 |
+
anns = self.dataset["annotations"]
|
| 159 |
+
anns = (
|
| 160 |
+
anns
|
| 161 |
+
if len(catIds) == 0
|
| 162 |
+
else [ann for ann in anns if ann["category_id"] in catIds]
|
| 163 |
+
)
|
| 164 |
+
anns = (
|
| 165 |
+
anns
|
| 166 |
+
if len(areaRng) == 0
|
| 167 |
+
else [
|
| 168 |
+
ann
|
| 169 |
+
for ann in anns
|
| 170 |
+
if ann["area"] > areaRng[0] and ann["area"] < areaRng[1]
|
| 171 |
+
]
|
| 172 |
+
)
|
| 173 |
+
if not iscrowd == None:
|
| 174 |
+
ids = [ann["id"] for ann in anns if ann["iscrowd"] == iscrowd]
|
| 175 |
+
else:
|
| 176 |
+
ids = [ann["id"] for ann in anns]
|
| 177 |
+
return ids
|
| 178 |
+
|
| 179 |
+
def getCatIds(self, catNms=[], supNms=[], catIds=[]):
|
| 180 |
+
"""
|
| 181 |
+
filtering parameters. default skips that filter.
|
| 182 |
+
:param catNms (str array) : get cats for given cat names
|
| 183 |
+
:param supNms (str array) : get cats for given supercategory names
|
| 184 |
+
:param catIds (int array) : get cats for given cat ids
|
| 185 |
+
:return: ids (int array) : integer array of cat ids
|
| 186 |
+
"""
|
| 187 |
+
catNms = catNms if _isArrayLike(catNms) else [catNms]
|
| 188 |
+
supNms = supNms if _isArrayLike(supNms) else [supNms]
|
| 189 |
+
catIds = catIds if _isArrayLike(catIds) else [catIds]
|
| 190 |
+
|
| 191 |
+
if len(catNms) == len(supNms) == len(catIds) == 0:
|
| 192 |
+
cats = self.dataset["categories"]
|
| 193 |
+
else:
|
| 194 |
+
cats = self.dataset["categories"]
|
| 195 |
+
cats = (
|
| 196 |
+
cats
|
| 197 |
+
if len(catNms) == 0
|
| 198 |
+
else [cat for cat in cats if cat["name"] in catNms]
|
| 199 |
+
)
|
| 200 |
+
cats = (
|
| 201 |
+
cats
|
| 202 |
+
if len(supNms) == 0
|
| 203 |
+
else [cat for cat in cats if cat["supercategory"] in supNms]
|
| 204 |
+
)
|
| 205 |
+
cats = (
|
| 206 |
+
cats
|
| 207 |
+
if len(catIds) == 0
|
| 208 |
+
else [cat for cat in cats if cat["id"] in catIds]
|
| 209 |
+
)
|
| 210 |
+
ids = [cat["id"] for cat in cats]
|
| 211 |
+
return ids
|
| 212 |
+
|
| 213 |
+
def getImgIds(self, imgIds=[], catIds=[]):
|
| 214 |
+
"""
|
| 215 |
+
Get img ids that satisfy given filter conditions.
|
| 216 |
+
:param imgIds (int array) : get imgs for given ids
|
| 217 |
+
:param catIds (int array) : get imgs with all given cats
|
| 218 |
+
:return: ids (int array) : integer array of img ids
|
| 219 |
+
"""
|
| 220 |
+
imgIds = imgIds if _isArrayLike(imgIds) else [imgIds]
|
| 221 |
+
catIds = catIds if _isArrayLike(catIds) else [catIds]
|
| 222 |
+
|
| 223 |
+
if len(imgIds) == len(catIds) == 0:
|
| 224 |
+
ids = self.imgs.keys()
|
| 225 |
+
else:
|
| 226 |
+
ids = set(imgIds)
|
| 227 |
+
for i, catId in enumerate(catIds):
|
| 228 |
+
if i == 0 and len(ids) == 0:
|
| 229 |
+
ids = set(self.catToImgs[catId])
|
| 230 |
+
else:
|
| 231 |
+
ids &= set(self.catToImgs[catId])
|
| 232 |
+
return list(ids)
|
| 233 |
+
|
| 234 |
+
def loadAnns(self, ids=[]):
|
| 235 |
+
"""
|
| 236 |
+
Load anns with the specified ids.
|
| 237 |
+
:param ids (int array) : integer ids specifying anns
|
| 238 |
+
:return: anns (object array) : loaded ann objects
|
| 239 |
+
"""
|
| 240 |
+
if _isArrayLike(ids):
|
| 241 |
+
return [self.anns[id] for id in ids]
|
| 242 |
+
elif type(ids) == int:
|
| 243 |
+
return [self.anns[ids]]
|
| 244 |
+
|
| 245 |
+
def loadCats(self, ids=[]):
|
| 246 |
+
"""
|
| 247 |
+
Load cats with the specified ids.
|
| 248 |
+
:param ids (int array) : integer ids specifying cats
|
| 249 |
+
:return: cats (object array) : loaded cat objects
|
| 250 |
+
"""
|
| 251 |
+
if _isArrayLike(ids):
|
| 252 |
+
return [self.cats[id] for id in ids]
|
| 253 |
+
elif type(ids) == int:
|
| 254 |
+
return [self.cats[ids]]
|
| 255 |
+
|
| 256 |
+
def loadImgs(self, ids=[]):
|
| 257 |
+
"""
|
| 258 |
+
Load anns with the specified ids.
|
| 259 |
+
:param ids (int array) : integer ids specifying img
|
| 260 |
+
:return: imgs (object array) : loaded img objects
|
| 261 |
+
"""
|
| 262 |
+
if _isArrayLike(ids):
|
| 263 |
+
return [self.imgs[id] for id in ids]
|
| 264 |
+
elif type(ids) == int:
|
| 265 |
+
return [self.imgs[ids]]
|
| 266 |
+
|
| 267 |
+
def showAnns(self, anns, draw_bbox=False):
|
| 268 |
+
"""
|
| 269 |
+
Display the specified annotations.
|
| 270 |
+
:param anns (array of object): annotations to display
|
| 271 |
+
:return: None
|
| 272 |
+
"""
|
| 273 |
+
if len(anns) == 0:
|
| 274 |
+
return 0
|
| 275 |
+
if "segmentation" in anns[0] or "keypoints" in anns[0]:
|
| 276 |
+
datasetType = "instances"
|
| 277 |
+
elif "caption" in anns[0]:
|
| 278 |
+
datasetType = "captions"
|
| 279 |
+
else:
|
| 280 |
+
raise Exception("datasetType not supported")
|
| 281 |
+
if datasetType == "instances":
|
| 282 |
+
ax = plt.gca()
|
| 283 |
+
ax.set_autoscale_on(False)
|
| 284 |
+
polygons = []
|
| 285 |
+
color = []
|
| 286 |
+
for ann in anns:
|
| 287 |
+
c = (np.random.random((1, 3)) * 0.6 + 0.4).tolist()[0]
|
| 288 |
+
if "segmentation" in ann:
|
| 289 |
+
if type(ann["segmentation"]) == list:
|
| 290 |
+
# polygon
|
| 291 |
+
for seg in ann["segmentation"]:
|
| 292 |
+
poly = np.array(seg).reshape((int(len(seg) / 2), 2))
|
| 293 |
+
polygons.append(Polygon(poly))
|
| 294 |
+
color.append(c)
|
| 295 |
+
else:
|
| 296 |
+
raise NotImplementedError(
|
| 297 |
+
"This type is not is not supported yet."
|
| 298 |
+
)
|
| 299 |
+
# # mask
|
| 300 |
+
# t = self.imgs[ann['image_id']]
|
| 301 |
+
# if type(ann['segmentation']['counts']) == list:
|
| 302 |
+
# rle = maskUtils.frPyObjects([ann['segmentation']], t['height'], t['width'])
|
| 303 |
+
# else:
|
| 304 |
+
# rle = [ann['segmentation']]
|
| 305 |
+
# m = maskUtils.decode(rle)
|
| 306 |
+
# img = np.ones( (m.shape[0], m.shape[1], 3) )
|
| 307 |
+
# if ann['iscrowd'] == 1:
|
| 308 |
+
# color_mask = np.array([2.0,166.0,101.0])/255
|
| 309 |
+
# if ann['iscrowd'] == 0:
|
| 310 |
+
# color_mask = np.random.random((1, 3)).tolist()[0]
|
| 311 |
+
# for i in range(3):
|
| 312 |
+
# img[:,:,i] = color_mask[i]
|
| 313 |
+
# ax.imshow(np.dstack( (img, m*0.5) ))
|
| 314 |
+
if "keypoints" in ann and type(ann["keypoints"]) == list:
|
| 315 |
+
# turn skeleton into zero-based index
|
| 316 |
+
sks = np.array(self.loadCats(ann["category_id"])[0]["skeleton"]) - 1
|
| 317 |
+
kp = np.array(ann["keypoints"])
|
| 318 |
+
x = kp[0::3]
|
| 319 |
+
y = kp[1::3]
|
| 320 |
+
v = kp[2::3]
|
| 321 |
+
for sk in sks:
|
| 322 |
+
if np.all(v[sk] > 0):
|
| 323 |
+
plt.plot(x[sk], y[sk], linewidth=3, color=c)
|
| 324 |
+
plt.plot(
|
| 325 |
+
x[v > 0],
|
| 326 |
+
y[v > 0],
|
| 327 |
+
"o",
|
| 328 |
+
markersize=8,
|
| 329 |
+
markerfacecolor=c,
|
| 330 |
+
markeredgecolor="k",
|
| 331 |
+
markeredgewidth=2,
|
| 332 |
+
)
|
| 333 |
+
plt.plot(
|
| 334 |
+
x[v > 1],
|
| 335 |
+
y[v > 1],
|
| 336 |
+
"o",
|
| 337 |
+
markersize=8,
|
| 338 |
+
markerfacecolor=c,
|
| 339 |
+
markeredgecolor=c,
|
| 340 |
+
markeredgewidth=2,
|
| 341 |
+
)
|
| 342 |
+
|
| 343 |
+
if draw_bbox:
|
| 344 |
+
[bbox_x, bbox_y, bbox_w, bbox_h] = ann["bbox"]
|
| 345 |
+
poly = [
|
| 346 |
+
[bbox_x, bbox_y],
|
| 347 |
+
[bbox_x, bbox_y + bbox_h],
|
| 348 |
+
[bbox_x + bbox_w, bbox_y + bbox_h],
|
| 349 |
+
[bbox_x + bbox_w, bbox_y],
|
| 350 |
+
]
|
| 351 |
+
np_poly = np.array(poly).reshape((4, 2))
|
| 352 |
+
polygons.append(Polygon(np_poly))
|
| 353 |
+
color.append(c)
|
| 354 |
+
|
| 355 |
+
p = PatchCollection(polygons, facecolor=color, linewidths=0, alpha=0.4)
|
| 356 |
+
ax.add_collection(p)
|
| 357 |
+
p = PatchCollection(
|
| 358 |
+
polygons, facecolor="none", edgecolors=color, linewidths=2
|
| 359 |
+
)
|
| 360 |
+
ax.add_collection(p)
|
| 361 |
+
elif datasetType == "captions":
|
| 362 |
+
for ann in anns:
|
| 363 |
+
print(ann["caption"])
|
| 364 |
+
|
| 365 |
+
def loadRes(self, resFile):
|
| 366 |
+
"""
|
| 367 |
+
Load result file and return a result api object.
|
| 368 |
+
:param resFile (str) : file name of result file
|
| 369 |
+
:return: res (obj) : result api object
|
| 370 |
+
"""
|
| 371 |
+
res = COCO()
|
| 372 |
+
res.dataset["images"] = [img for img in self.dataset["images"]]
|
| 373 |
+
|
| 374 |
+
print("Loading and preparing results...")
|
| 375 |
+
tic = time.time()
|
| 376 |
+
if type(resFile) == str or (PYTHON_VERSION == 2 and type(resFile) == unicode):
|
| 377 |
+
anns = json.load(open(resFile))
|
| 378 |
+
elif type(resFile) == np.ndarray:
|
| 379 |
+
anns = self.loadNumpyAnnotations(resFile)
|
| 380 |
+
else:
|
| 381 |
+
anns = resFile
|
| 382 |
+
assert type(anns) == list, "results in not an array of objects"
|
| 383 |
+
annsImgIds = [ann["image_id"] for ann in anns]
|
| 384 |
+
assert set(annsImgIds) == (
|
| 385 |
+
set(annsImgIds) & set(self.getImgIds())
|
| 386 |
+
), "Results do not correspond to current coco set"
|
| 387 |
+
if "caption" in anns[0]:
|
| 388 |
+
raise NotImplementedError("Evaluating caption is not supported yet.")
|
| 389 |
+
elif "bbox" in anns[0] and not anns[0]["bbox"] == []:
|
| 390 |
+
res.dataset["categories"] = copy.deepcopy(self.dataset["categories"])
|
| 391 |
+
for id, ann in enumerate(anns):
|
| 392 |
+
bb = ann["bbox"]
|
| 393 |
+
x1, x2, y1, y2 = [bb[0], bb[0] + bb[2], bb[1], bb[1] + bb[3]]
|
| 394 |
+
if not "segmentation" in ann:
|
| 395 |
+
ann["segmentation"] = [[x1, y1, x1, y2, x2, y2, x2, y1]]
|
| 396 |
+
ann["area"] = bb[2] * bb[3]
|
| 397 |
+
ann["id"] = id + 1
|
| 398 |
+
ann["iscrowd"] = 0
|
| 399 |
+
elif "segmentation" in anns[0]:
|
| 400 |
+
raise NotImplementedError("Evaluating caption is not supported yet.")
|
| 401 |
+
elif "keypoints" in anns[0]:
|
| 402 |
+
raise NotImplementedError("Evaluating caption is not supported yet.")
|
| 403 |
+
print("DONE (t={:0.2f}s)".format(time.time() - tic))
|
| 404 |
+
|
| 405 |
+
res.dataset["annotations"] = anns
|
| 406 |
+
res.createIndex()
|
| 407 |
+
return res
|
| 408 |
+
|
| 409 |
+
def download(self, tarDir=None, imgIds=[]):
|
| 410 |
+
"""
|
| 411 |
+
Download COCO images from mscoco.org server.
|
| 412 |
+
:param tarDir (str): COCO results directory name
|
| 413 |
+
imgIds (list): images to be downloaded
|
| 414 |
+
:return:
|
| 415 |
+
"""
|
| 416 |
+
if tarDir is None:
|
| 417 |
+
print("Please specify target directory")
|
| 418 |
+
return -1
|
| 419 |
+
if len(imgIds) == 0:
|
| 420 |
+
imgs = self.imgs.values()
|
| 421 |
+
else:
|
| 422 |
+
imgs = self.loadImgs(imgIds)
|
| 423 |
+
N = len(imgs)
|
| 424 |
+
if not os.path.exists(tarDir):
|
| 425 |
+
os.makedirs(tarDir)
|
| 426 |
+
for i, img in enumerate(imgs):
|
| 427 |
+
tic = time.time()
|
| 428 |
+
fname = os.path.join(tarDir, img["file_name"])
|
| 429 |
+
if not os.path.exists(fname):
|
| 430 |
+
urlretrieve(img["coco_url"], fname)
|
| 431 |
+
print(
|
| 432 |
+
"downloaded {}/{} images (t={:0.1f}s)".format(i, N, time.time() - tic)
|
| 433 |
+
)
|
| 434 |
+
|
| 435 |
+
def loadNumpyAnnotations(self, data):
|
| 436 |
+
"""
|
| 437 |
+
Convert result data from a numpy array [Nx7] where each row contains {imageID,x1,y1,w,h,score,class}
|
| 438 |
+
:param data (numpy.ndarray)
|
| 439 |
+
:return: annotations (python nested list)
|
| 440 |
+
"""
|
| 441 |
+
print("Converting ndarray to lists...")
|
| 442 |
+
assert type(data) == np.ndarray
|
| 443 |
+
print(data.shape)
|
| 444 |
+
assert data.shape[1] == 7
|
| 445 |
+
N = data.shape[0]
|
| 446 |
+
ann = []
|
| 447 |
+
for i in range(N):
|
| 448 |
+
if i % 1000000 == 0:
|
| 449 |
+
print("{}/{}".format(i, N))
|
| 450 |
+
ann += [
|
| 451 |
+
{
|
| 452 |
+
"image_id": int(data[i, 0]),
|
| 453 |
+
"bbox": [data[i, 1], data[i, 2], data[i, 3], data[i, 4]],
|
| 454 |
+
"score": data[i, 5],
|
| 455 |
+
"category_id": int(data[i, 6]),
|
| 456 |
+
}
|
| 457 |
+
]
|
| 458 |
+
return ann
|
| 459 |
+
|
| 460 |
+
def annToRLE(self, ann):
|
| 461 |
+
"""
|
| 462 |
+
Convert annotation which can be polygons, uncompressed RLE to RLE.
|
| 463 |
+
:return: binary mask (numpy 2D array)
|
| 464 |
+
"""
|
| 465 |
+
t = self.imgs[ann["image_id"]]
|
| 466 |
+
h, w = t["height"], t["width"]
|
| 467 |
+
segm = ann["segmentation"]
|
| 468 |
+
if type(segm) == list:
|
| 469 |
+
raise NotImplementedError("This type is not is not supported yet.")
|
| 470 |
+
# polygon -- a single object might consist of multiple parts
|
| 471 |
+
# we merge all parts into one mask rle code
|
| 472 |
+
# rles = maskUtils.frPyObjects(segm, h, w)
|
| 473 |
+
# rle = maskUtils.merge(rles)
|
| 474 |
+
elif type(segm["counts"]) == list:
|
| 475 |
+
raise NotImplementedError("This type is not is not supported yet.")
|
| 476 |
+
# uncompressed RLE
|
| 477 |
+
# rle = maskUtils.frPyObjects(segm, h, w)
|
| 478 |
+
else:
|
| 479 |
+
# rle
|
| 480 |
+
rle = ann["segmentation"]
|
| 481 |
+
return rle
|
| 482 |
+
|
| 483 |
+
def annToMask(self, ann):
|
| 484 |
+
"""
|
| 485 |
+
Convert annotation which can be polygons, uncompressed RLE, or RLE to binary mask.
|
| 486 |
+
:return: binary mask (numpy 2D array)
|
| 487 |
+
"""
|
| 488 |
+
rle = self.annToRLE(ann)
|
| 489 |
+
# m = maskUtils.decode(rle)
|
| 490 |
+
raise NotImplementedError("This type is not is not supported yet.")
|
| 491 |
+
return m
|
detection_metrics/pycocotools/cocoeval.py
ADDED
|
@@ -0,0 +1,631 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This code is basically a copy and paste from the original cocoapi repo:
|
| 2 |
+
# https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocotools/cocoeval.py
|
| 3 |
+
# with the following changes have been made:
|
| 4 |
+
# * Replace the usage of mask (maskUtils) by MaskEvaluator.
|
| 5 |
+
# * Comment out prints in the evaluate() function.
|
| 6 |
+
# * Include a return of the function evaluate. Inspired
|
| 7 |
+
# by @ybelkada (https://huggingface.co/spaces/ybelkada/cocoevaluate/)
|
| 8 |
+
|
| 9 |
+
__author__ = "tsungyi"
|
| 10 |
+
|
| 11 |
+
import copy
|
| 12 |
+
import datetime
|
| 13 |
+
import time
|
| 14 |
+
from collections import defaultdict
|
| 15 |
+
from packaging import version
|
| 16 |
+
|
| 17 |
+
import numpy as np
|
| 18 |
+
|
| 19 |
+
if version.parse(np.__version__) < version.parse("1.24"):
|
| 20 |
+
dtype_float = np.float
|
| 21 |
+
else:
|
| 22 |
+
dtype_float = np.float32
|
| 23 |
+
|
| 24 |
+
from .mask_utils import MaskEvaluator as maskUtils
|
| 25 |
+
|
| 26 |
+
class COCOeval:
|
| 27 |
+
# Interface for evaluating detection on the Microsoft COCO dataset.
|
| 28 |
+
#
|
| 29 |
+
# The usage for CocoEval is as follows:
|
| 30 |
+
# cocoGt=..., cocoDt=... # load dataset and results
|
| 31 |
+
# E = CocoEval(cocoGt,cocoDt); # initialize CocoEval object
|
| 32 |
+
# E.params.recThrs = ...; # set parameters as desired
|
| 33 |
+
# E.evaluate(); # run per image evaluation
|
| 34 |
+
# E.accumulate(); # accumulate per image results
|
| 35 |
+
# E.summarize(); # display summary metrics of results
|
| 36 |
+
# For example usage see evalDemo.m and http://mscoco.org/.
|
| 37 |
+
#
|
| 38 |
+
# The evaluation parameters are as follows (defaults in brackets):
|
| 39 |
+
# imgIds - [all] N img ids to use for evaluation
|
| 40 |
+
# catIds - [all] K cat ids to use for evaluation
|
| 41 |
+
# iouThrs - [.5:.05:.95] T=10 IoU thresholds for evaluation
|
| 42 |
+
# recThrs - [0:.01:1] R=101 recall thresholds for evaluation
|
| 43 |
+
# areaRng - [...] A=4 object area ranges for evaluation
|
| 44 |
+
# maxDets - [1 10 100] M=3 thresholds on max detections per image
|
| 45 |
+
# iouType - ['segm'] set iouType to 'segm', 'bbox' or 'keypoints'
|
| 46 |
+
# iouType replaced the now DEPRECATED useSegm parameter.
|
| 47 |
+
# useCats - [1] if true use category labels for evaluation
|
| 48 |
+
# Note: if useCats=0 category labels are ignored as in proposal scoring.
|
| 49 |
+
# Note: multiple areaRngs [Ax2] and maxDets [Mx1] can be specified.
|
| 50 |
+
#
|
| 51 |
+
# evaluate(): evaluates detections on every image and every category and
|
| 52 |
+
# concats the results into the "evalImgs" with fields:
|
| 53 |
+
# dtIds - [1xD] id for each of the D detections (dt)
|
| 54 |
+
# gtIds - [1xG] id for each of the G ground truths (gt)
|
| 55 |
+
# dtMatches - [TxD] matching gt id at each IoU or 0
|
| 56 |
+
# gtMatches - [TxG] matching dt id at each IoU or 0
|
| 57 |
+
# dtScores - [1xD] confidence of each dt
|
| 58 |
+
# gtIgnore - [1xG] ignore flag for each gt
|
| 59 |
+
# dtIgnore - [TxD] ignore flag for each dt at each IoU
|
| 60 |
+
#
|
| 61 |
+
# accumulate(): accumulates the per-image, per-category evaluation
|
| 62 |
+
# results in "evalImgs" into the dictionary "eval" with fields:
|
| 63 |
+
# params - parameters used for evaluation
|
| 64 |
+
# date - date evaluation was performed
|
| 65 |
+
# counts - [T,R,K,A,M] parameter dimensions (see above)
|
| 66 |
+
# precision - [TxRxKxAxM] precision for every evaluation setting
|
| 67 |
+
# recall - [TxKxAxM] max recall for every evaluation setting
|
| 68 |
+
# Note: precision and recall==-1 for settings with no gt objects.
|
| 69 |
+
#
|
| 70 |
+
# See also coco, mask, pycocoDemo, pycocoEvalDemo
|
| 71 |
+
#
|
| 72 |
+
# Microsoft COCO Toolbox. version 2.0
|
| 73 |
+
# Data, paper, and tutorials available at: http://mscoco.org/
|
| 74 |
+
# Code written by Piotr Dollar and Tsung-Yi Lin, 2015.
|
| 75 |
+
# Licensed under the Simplified BSD License [see coco/license.txt]
|
| 76 |
+
def __init__(self, cocoGt=None, cocoDt=None, iouType="segm"):
|
| 77 |
+
"""
|
| 78 |
+
Initialize CocoEval using coco APIs for gt and dt
|
| 79 |
+
:param cocoGt: coco object with ground truth annotations
|
| 80 |
+
:param cocoDt: coco object with detection results
|
| 81 |
+
:return: None
|
| 82 |
+
"""
|
| 83 |
+
if not iouType:
|
| 84 |
+
print("iouType not specified. use default iouType segm")
|
| 85 |
+
self.cocoGt = cocoGt # ground truth COCO API
|
| 86 |
+
self.cocoDt = cocoDt # detections COCO API
|
| 87 |
+
self.evalImgs = defaultdict(
|
| 88 |
+
list
|
| 89 |
+
) # per-image per-category evaluation results [KxAxI] elements
|
| 90 |
+
self.eval = {} # accumulated evaluation results
|
| 91 |
+
self._gts = defaultdict(list) # gt for evaluation
|
| 92 |
+
self._dts = defaultdict(list) # dt for evaluation
|
| 93 |
+
self.params = Params(iouType=iouType) # parameters
|
| 94 |
+
self._paramsEval = {} # parameters for evaluation
|
| 95 |
+
self.stats = [] # result summarization
|
| 96 |
+
self.ious = {} # ious between all gts and dts
|
| 97 |
+
if not cocoGt is None:
|
| 98 |
+
self.params.imgIds = sorted(cocoGt.getImgIds())
|
| 99 |
+
self.params.catIds = sorted(cocoGt.getCatIds())
|
| 100 |
+
|
| 101 |
+
def _prepare(self):
|
| 102 |
+
"""
|
| 103 |
+
Prepare ._gts and ._dts for evaluation based on params
|
| 104 |
+
:return: None
|
| 105 |
+
"""
|
| 106 |
+
|
| 107 |
+
def _toMask(anns, coco):
|
| 108 |
+
# modify ann['segmentation'] by reference
|
| 109 |
+
for ann in anns:
|
| 110 |
+
rle = coco.annToRLE(ann)
|
| 111 |
+
ann["segmentation"] = rle
|
| 112 |
+
|
| 113 |
+
p = self.params
|
| 114 |
+
if p.useCats:
|
| 115 |
+
gts = self.cocoGt.loadAnns(
|
| 116 |
+
self.cocoGt.getAnnIds(imgIds=p.imgIds, catIds=p.catIds)
|
| 117 |
+
)
|
| 118 |
+
dts = self.cocoDt.loadAnns(
|
| 119 |
+
self.cocoDt.getAnnIds(imgIds=p.imgIds, catIds=p.catIds)
|
| 120 |
+
)
|
| 121 |
+
else:
|
| 122 |
+
gts = self.cocoGt.loadAnns(self.cocoGt.getAnnIds(imgIds=p.imgIds))
|
| 123 |
+
dts = self.cocoDt.loadAnns(self.cocoDt.getAnnIds(imgIds=p.imgIds))
|
| 124 |
+
|
| 125 |
+
# convert ground truth to mask if iouType == 'segm'
|
| 126 |
+
if p.iouType == "segm":
|
| 127 |
+
_toMask(gts, self.cocoGt)
|
| 128 |
+
_toMask(dts, self.cocoDt)
|
| 129 |
+
# set ignore flag
|
| 130 |
+
for gt in gts:
|
| 131 |
+
gt["ignore"] = gt["ignore"] if "ignore" in gt else 0
|
| 132 |
+
gt["ignore"] = "iscrowd" in gt and gt["iscrowd"]
|
| 133 |
+
if p.iouType == "keypoints":
|
| 134 |
+
gt["ignore"] = (gt["num_keypoints"] == 0) or gt["ignore"]
|
| 135 |
+
self._gts = defaultdict(list) # gt for evaluation
|
| 136 |
+
self._dts = defaultdict(list) # dt for evaluation
|
| 137 |
+
for gt in gts:
|
| 138 |
+
self._gts[gt["image_id"], gt["category_id"]].append(gt)
|
| 139 |
+
for dt in dts:
|
| 140 |
+
self._dts[dt["image_id"], dt["category_id"]].append(dt)
|
| 141 |
+
self.evalImgs = defaultdict(list) # per-image per-category evaluation results
|
| 142 |
+
self.eval = {} # accumulated evaluation results
|
| 143 |
+
|
| 144 |
+
def evaluate(self):
|
| 145 |
+
"""
|
| 146 |
+
Run per image evaluation on given images and store results (a list of dict) in self.evalImgs
|
| 147 |
+
:return: None
|
| 148 |
+
"""
|
| 149 |
+
# tic = time.time()
|
| 150 |
+
# print("Running per image evaluation...")
|
| 151 |
+
p = self.params
|
| 152 |
+
# add backward compatibility if useSegm is specified in params
|
| 153 |
+
if not p.useSegm is None:
|
| 154 |
+
p.iouType = "segm" if p.useSegm == 1 else "bbox"
|
| 155 |
+
# print(
|
| 156 |
+
# "useSegm (deprecated) is not None. Running {} evaluation".format(
|
| 157 |
+
# p.iouType
|
| 158 |
+
# )
|
| 159 |
+
# )
|
| 160 |
+
# print("Evaluate annotation type *{}*".format(p.iouType))
|
| 161 |
+
p.imgIds = list(np.unique(p.imgIds))
|
| 162 |
+
if p.useCats:
|
| 163 |
+
p.catIds = list(np.unique(p.catIds))
|
| 164 |
+
p.maxDets = sorted(p.maxDets)
|
| 165 |
+
self.params = p
|
| 166 |
+
|
| 167 |
+
self._prepare()
|
| 168 |
+
# loop through images, area range, max detection number
|
| 169 |
+
catIds = p.catIds if p.useCats else [-1]
|
| 170 |
+
|
| 171 |
+
if p.iouType == "segm" or p.iouType == "bbox":
|
| 172 |
+
computeIoU = self.computeIoU
|
| 173 |
+
elif p.iouType == "keypoints":
|
| 174 |
+
computeIoU = self.computeOks
|
| 175 |
+
self.ious = {
|
| 176 |
+
(imgId, catId): computeIoU(imgId, catId)
|
| 177 |
+
for imgId in p.imgIds
|
| 178 |
+
for catId in catIds
|
| 179 |
+
}
|
| 180 |
+
|
| 181 |
+
evaluateImg = self.evaluateImg
|
| 182 |
+
maxDet = p.maxDets[-1]
|
| 183 |
+
self.evalImgs = [
|
| 184 |
+
evaluateImg(imgId, catId, areaRng, maxDet)
|
| 185 |
+
for catId in catIds
|
| 186 |
+
for areaRng in p.areaRng
|
| 187 |
+
for imgId in p.imgIds
|
| 188 |
+
]
|
| 189 |
+
self._paramsEval = copy.deepcopy(self.params)
|
| 190 |
+
ret_evalImgs = np.asarray(self.evalImgs).reshape(
|
| 191 |
+
len(catIds), len(p.areaRng), len(p.imgIds)
|
| 192 |
+
)
|
| 193 |
+
# toc = time.time()
|
| 194 |
+
# print("DONE (t={:0.2f}s).".format(toc - tic))
|
| 195 |
+
return ret_evalImgs
|
| 196 |
+
|
| 197 |
+
def computeIoU(self, imgId, catId):
|
| 198 |
+
p = self.params
|
| 199 |
+
if p.useCats:
|
| 200 |
+
gt = self._gts[imgId, catId]
|
| 201 |
+
dt = self._dts[imgId, catId]
|
| 202 |
+
else:
|
| 203 |
+
gt = [_ for cId in p.catIds for _ in self._gts[imgId, cId]]
|
| 204 |
+
dt = [_ for cId in p.catIds for _ in self._dts[imgId, cId]]
|
| 205 |
+
if len(gt) == 0 and len(dt) == 0:
|
| 206 |
+
return []
|
| 207 |
+
inds = np.argsort([-d["score"] for d in dt], kind="mergesort")
|
| 208 |
+
dt = [dt[i] for i in inds]
|
| 209 |
+
if len(dt) > p.maxDets[-1]:
|
| 210 |
+
dt = dt[0 : p.maxDets[-1]]
|
| 211 |
+
|
| 212 |
+
if p.iouType == "segm":
|
| 213 |
+
g = [g["segmentation"] for g in gt]
|
| 214 |
+
d = [d["segmentation"] for d in dt]
|
| 215 |
+
elif p.iouType == "bbox":
|
| 216 |
+
g = [g["bbox"] for g in gt]
|
| 217 |
+
d = [d["bbox"] for d in dt]
|
| 218 |
+
else:
|
| 219 |
+
raise Exception("unknown iouType for iou computation")
|
| 220 |
+
|
| 221 |
+
# compute iou between each dt and gt region
|
| 222 |
+
iscrowd = [int(o["iscrowd"]) for o in gt]
|
| 223 |
+
ious = maskUtils.iou(d, g, iscrowd)
|
| 224 |
+
return ious
|
| 225 |
+
|
| 226 |
+
def computeOks(self, imgId, catId):
|
| 227 |
+
p = self.params
|
| 228 |
+
# dimention here should be Nxm
|
| 229 |
+
gts = self._gts[imgId, catId]
|
| 230 |
+
dts = self._dts[imgId, catId]
|
| 231 |
+
inds = np.argsort([-d["score"] for d in dts], kind="mergesort")
|
| 232 |
+
dts = [dts[i] for i in inds]
|
| 233 |
+
if len(dts) > p.maxDets[-1]:
|
| 234 |
+
dts = dts[0 : p.maxDets[-1]]
|
| 235 |
+
# if len(gts) == 0 and len(dts) == 0:
|
| 236 |
+
if len(gts) == 0 or len(dts) == 0:
|
| 237 |
+
return []
|
| 238 |
+
ious = np.zeros((len(dts), len(gts)))
|
| 239 |
+
sigmas = p.kpt_oks_sigmas
|
| 240 |
+
vars = (sigmas * 2) ** 2
|
| 241 |
+
k = len(sigmas)
|
| 242 |
+
# compute oks between each detection and ground truth object
|
| 243 |
+
for j, gt in enumerate(gts):
|
| 244 |
+
# create bounds for ignore regions(double the gt bbox)
|
| 245 |
+
g = np.array(gt["keypoints"])
|
| 246 |
+
xg = g[0::3]
|
| 247 |
+
yg = g[1::3]
|
| 248 |
+
vg = g[2::3]
|
| 249 |
+
k1 = np.count_nonzero(vg > 0)
|
| 250 |
+
bb = gt["bbox"]
|
| 251 |
+
x0 = bb[0] - bb[2]
|
| 252 |
+
x1 = bb[0] + bb[2] * 2
|
| 253 |
+
y0 = bb[1] - bb[3]
|
| 254 |
+
y1 = bb[1] + bb[3] * 2
|
| 255 |
+
for i, dt in enumerate(dts):
|
| 256 |
+
d = np.array(dt["keypoints"])
|
| 257 |
+
xd = d[0::3]
|
| 258 |
+
yd = d[1::3]
|
| 259 |
+
if k1 > 0:
|
| 260 |
+
# measure the per-keypoint distance if keypoints visible
|
| 261 |
+
dx = xd - xg
|
| 262 |
+
dy = yd - yg
|
| 263 |
+
else:
|
| 264 |
+
# measure minimum distance to keypoints in (x0,y0) & (x1,y1)
|
| 265 |
+
z = np.zeros((k))
|
| 266 |
+
dx = np.max((z, x0 - xd), axis=0) + np.max((z, xd - x1), axis=0)
|
| 267 |
+
dy = np.max((z, y0 - yd), axis=0) + np.max((z, yd - y1), axis=0)
|
| 268 |
+
e = (dx**2 + dy**2) / vars / (gt["area"] + np.spacing(1)) / 2
|
| 269 |
+
if k1 > 0:
|
| 270 |
+
e = e[vg > 0]
|
| 271 |
+
ious[i, j] = np.sum(np.exp(-e)) / e.shape[0]
|
| 272 |
+
return ious
|
| 273 |
+
|
| 274 |
+
def evaluateImg(self, imgId, catId, aRng, maxDet):
|
| 275 |
+
"""
|
| 276 |
+
perform evaluation for single category and image
|
| 277 |
+
:return: dict (single image results)
|
| 278 |
+
"""
|
| 279 |
+
p = self.params
|
| 280 |
+
if p.useCats:
|
| 281 |
+
gt = self._gts[imgId, catId]
|
| 282 |
+
dt = self._dts[imgId, catId]
|
| 283 |
+
else:
|
| 284 |
+
gt = [_ for cId in p.catIds for _ in self._gts[imgId, cId]]
|
| 285 |
+
dt = [_ for cId in p.catIds for _ in self._dts[imgId, cId]]
|
| 286 |
+
if len(gt) == 0 and len(dt) == 0:
|
| 287 |
+
return None
|
| 288 |
+
|
| 289 |
+
for g in gt:
|
| 290 |
+
if g["ignore"] or (g["area"] < aRng[0] or g["area"] > aRng[1]):
|
| 291 |
+
g["_ignore"] = 1
|
| 292 |
+
else:
|
| 293 |
+
g["_ignore"] = 0
|
| 294 |
+
|
| 295 |
+
# sort dt highest score first, sort gt ignore last
|
| 296 |
+
gtind = np.argsort([g["_ignore"] for g in gt], kind="mergesort")
|
| 297 |
+
gt = [gt[i] for i in gtind]
|
| 298 |
+
dtind = np.argsort([-d["score"] for d in dt], kind="mergesort")
|
| 299 |
+
dt = [dt[i] for i in dtind[0:maxDet]]
|
| 300 |
+
iscrowd = [int(o["iscrowd"]) for o in gt]
|
| 301 |
+
# load computed ious
|
| 302 |
+
ious = (
|
| 303 |
+
self.ious[imgId, catId][:, gtind]
|
| 304 |
+
if len(self.ious[imgId, catId]) > 0
|
| 305 |
+
else self.ious[imgId, catId]
|
| 306 |
+
)
|
| 307 |
+
|
| 308 |
+
T = len(p.iouThrs)
|
| 309 |
+
G = len(gt)
|
| 310 |
+
D = len(dt)
|
| 311 |
+
gtm = np.zeros((T, G))
|
| 312 |
+
dtm = np.zeros((T, D))
|
| 313 |
+
gtIg = np.array([g["_ignore"] for g in gt])
|
| 314 |
+
dtIg = np.zeros((T, D))
|
| 315 |
+
if not len(ious) == 0:
|
| 316 |
+
for tind, t in enumerate(p.iouThrs):
|
| 317 |
+
for dind, d in enumerate(dt):
|
| 318 |
+
# information about best match so far (m=-1 -> unmatched)
|
| 319 |
+
iou = min([t, 1 - 1e-10])
|
| 320 |
+
m = -1
|
| 321 |
+
for gind, g in enumerate(gt):
|
| 322 |
+
# if this gt already matched, and not a crowd, continue
|
| 323 |
+
if gtm[tind, gind] > 0 and not iscrowd[gind]:
|
| 324 |
+
continue
|
| 325 |
+
# if dt matched to reg gt, and on ignore gt, stop
|
| 326 |
+
if m > -1 and gtIg[m] == 0 and gtIg[gind] == 1:
|
| 327 |
+
break
|
| 328 |
+
# continue to next gt unless better match made
|
| 329 |
+
if ious[dind, gind] < iou:
|
| 330 |
+
continue
|
| 331 |
+
# if match successful and best so far, store appropriately
|
| 332 |
+
iou = ious[dind, gind]
|
| 333 |
+
m = gind
|
| 334 |
+
# if match made store id of match for both dt and gt
|
| 335 |
+
if m == -1:
|
| 336 |
+
continue
|
| 337 |
+
dtIg[tind, dind] = gtIg[m]
|
| 338 |
+
dtm[tind, dind] = gt[m]["id"]
|
| 339 |
+
gtm[tind, m] = d["id"]
|
| 340 |
+
# set unmatched detections outside of area range to ignore
|
| 341 |
+
a = np.array([d["area"] < aRng[0] or d["area"] > aRng[1] for d in dt]).reshape(
|
| 342 |
+
(1, len(dt))
|
| 343 |
+
)
|
| 344 |
+
dtIg = np.logical_or(dtIg, np.logical_and(dtm == 0, np.repeat(a, T, 0)))
|
| 345 |
+
# store results for given image and category
|
| 346 |
+
return {
|
| 347 |
+
"image_id": imgId,
|
| 348 |
+
"category_id": catId,
|
| 349 |
+
"aRng": aRng,
|
| 350 |
+
"maxDet": maxDet,
|
| 351 |
+
"dtIds": [d["id"] for d in dt],
|
| 352 |
+
"gtIds": [g["id"] for g in gt],
|
| 353 |
+
"dtMatches": dtm,
|
| 354 |
+
"gtMatches": gtm,
|
| 355 |
+
"dtScores": [d["score"] for d in dt],
|
| 356 |
+
"gtIgnore": gtIg,
|
| 357 |
+
"dtIgnore": dtIg,
|
| 358 |
+
}
|
| 359 |
+
|
| 360 |
+
def accumulate(self, p=None):
|
| 361 |
+
"""
|
| 362 |
+
Accumulate per image evaluation results and store the result in self.eval
|
| 363 |
+
:param p: input params for evaluation
|
| 364 |
+
:return: None
|
| 365 |
+
"""
|
| 366 |
+
print("Accumulating evaluation results...")
|
| 367 |
+
tic = time.time()
|
| 368 |
+
if not self.evalImgs:
|
| 369 |
+
print("Please run evaluate() first")
|
| 370 |
+
# allows input customized parameters
|
| 371 |
+
if p is None:
|
| 372 |
+
p = self.params
|
| 373 |
+
p.catIds = p.catIds if p.useCats == 1 else [-1]
|
| 374 |
+
T = len(p.iouThrs)
|
| 375 |
+
R = len(p.recThrs)
|
| 376 |
+
K = len(p.catIds) if p.useCats else 1
|
| 377 |
+
A = len(p.areaRng)
|
| 378 |
+
M = len(p.maxDets)
|
| 379 |
+
precision = -np.ones(
|
| 380 |
+
(T, R, K, A, M)
|
| 381 |
+
) # -1 for the precision of absent categories
|
| 382 |
+
recall = -np.ones((T, K, A, M))
|
| 383 |
+
scores = -np.ones((T, R, K, A, M))
|
| 384 |
+
|
| 385 |
+
# create dictionary for future indexing
|
| 386 |
+
_pe = self._paramsEval
|
| 387 |
+
catIds = _pe.catIds if _pe.useCats else [-1]
|
| 388 |
+
setK = set(catIds)
|
| 389 |
+
setA = set(map(tuple, _pe.areaRng))
|
| 390 |
+
setM = set(_pe.maxDets)
|
| 391 |
+
setI = set(_pe.imgIds)
|
| 392 |
+
# get inds to evaluate
|
| 393 |
+
k_list = [n for n, k in enumerate(p.catIds) if k in setK]
|
| 394 |
+
m_list = [m for n, m in enumerate(p.maxDets) if m in setM]
|
| 395 |
+
a_list = [
|
| 396 |
+
n for n, a in enumerate(map(lambda x: tuple(x), p.areaRng)) if a in setA
|
| 397 |
+
]
|
| 398 |
+
i_list = [n for n, i in enumerate(p.imgIds) if i in setI]
|
| 399 |
+
I0 = len(_pe.imgIds)
|
| 400 |
+
A0 = len(_pe.areaRng)
|
| 401 |
+
# retrieve E at each category, area range, and max number of detections
|
| 402 |
+
for k, k0 in enumerate(k_list):
|
| 403 |
+
Nk = k0 * A0 * I0
|
| 404 |
+
for a, a0 in enumerate(a_list):
|
| 405 |
+
Na = a0 * I0
|
| 406 |
+
for m, maxDet in enumerate(m_list):
|
| 407 |
+
E = [self.evalImgs[Nk + Na + i] for i in i_list]
|
| 408 |
+
E = [e for e in E if not e is None]
|
| 409 |
+
if len(E) == 0:
|
| 410 |
+
continue
|
| 411 |
+
dtScores = np.concatenate([e["dtScores"][0:maxDet] for e in E])
|
| 412 |
+
|
| 413 |
+
# different sorting method generates slightly different results.
|
| 414 |
+
# mergesort is used to be consistent as Matlab implementation.
|
| 415 |
+
inds = np.argsort(-dtScores, kind="mergesort")
|
| 416 |
+
dtScoresSorted = dtScores[inds]
|
| 417 |
+
|
| 418 |
+
dtm = np.concatenate(
|
| 419 |
+
[e["dtMatches"][:, 0:maxDet] for e in E], axis=1
|
| 420 |
+
)[:, inds]
|
| 421 |
+
dtIg = np.concatenate(
|
| 422 |
+
[e["dtIgnore"][:, 0:maxDet] for e in E], axis=1
|
| 423 |
+
)[:, inds]
|
| 424 |
+
gtIg = np.concatenate([e["gtIgnore"] for e in E])
|
| 425 |
+
npig = np.count_nonzero(gtIg == 0)
|
| 426 |
+
if npig == 0:
|
| 427 |
+
continue
|
| 428 |
+
tps = np.logical_and(dtm, np.logical_not(dtIg))
|
| 429 |
+
fps = np.logical_and(np.logical_not(dtm), np.logical_not(dtIg))
|
| 430 |
+
|
| 431 |
+
tp_sum = np.cumsum(tps, axis=1).astype(dtype=dtype_float)
|
| 432 |
+
fp_sum = np.cumsum(fps, axis=1).astype(dtype=dtype_float)
|
| 433 |
+
for t, (tp, fp) in enumerate(zip(tp_sum, fp_sum)):
|
| 434 |
+
tp = np.array(tp)
|
| 435 |
+
fp = np.array(fp)
|
| 436 |
+
nd = len(tp)
|
| 437 |
+
rc = tp / npig
|
| 438 |
+
pr = tp / (fp + tp + np.spacing(1))
|
| 439 |
+
q = np.zeros((R,))
|
| 440 |
+
ss = np.zeros((R,))
|
| 441 |
+
|
| 442 |
+
if nd:
|
| 443 |
+
recall[t, k, a, m] = rc[-1]
|
| 444 |
+
else:
|
| 445 |
+
recall[t, k, a, m] = 0
|
| 446 |
+
|
| 447 |
+
# numpy is slow without cython optimization for accessing elements
|
| 448 |
+
# use python array gets significant speed improvement
|
| 449 |
+
pr = pr.tolist()
|
| 450 |
+
q = q.tolist()
|
| 451 |
+
|
| 452 |
+
for i in range(nd - 1, 0, -1):
|
| 453 |
+
if pr[i] > pr[i - 1]:
|
| 454 |
+
pr[i - 1] = pr[i]
|
| 455 |
+
|
| 456 |
+
inds = np.searchsorted(rc, p.recThrs, side="left")
|
| 457 |
+
try:
|
| 458 |
+
for ri, pi in enumerate(inds):
|
| 459 |
+
q[ri] = pr[pi]
|
| 460 |
+
ss[ri] = dtScoresSorted[pi]
|
| 461 |
+
except:
|
| 462 |
+
pass
|
| 463 |
+
precision[t, :, k, a, m] = np.array(q)
|
| 464 |
+
scores[t, :, k, a, m] = np.array(ss)
|
| 465 |
+
self.eval = {
|
| 466 |
+
"params": p,
|
| 467 |
+
"counts": [T, R, K, A, M],
|
| 468 |
+
"date": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
|
| 469 |
+
"precision": precision,
|
| 470 |
+
"recall": recall,
|
| 471 |
+
"scores": scores,
|
| 472 |
+
}
|
| 473 |
+
toc = time.time()
|
| 474 |
+
print("DONE (t={:0.2f}s).".format(toc - tic))
|
| 475 |
+
|
| 476 |
+
def summarize(self):
|
| 477 |
+
"""
|
| 478 |
+
Compute and display summary metrics for evaluation results.
|
| 479 |
+
Note this functin can *only* be applied on the default parameter setting
|
| 480 |
+
"""
|
| 481 |
+
|
| 482 |
+
def _summarize(ap=1, iouThr=None, areaRng="all", maxDets=100):
|
| 483 |
+
p = self.params
|
| 484 |
+
iStr = " {:<18} {} @[ IoU={:<9} | area={:>6s} | maxDets={:>3d} ] = {:0.3f}"
|
| 485 |
+
titleStr = "Average Precision" if ap == 1 else "Average Recall"
|
| 486 |
+
typeStr = "(AP)" if ap == 1 else "(AR)"
|
| 487 |
+
iouStr = (
|
| 488 |
+
"{:0.2f}:{:0.2f}".format(p.iouThrs[0], p.iouThrs[-1])
|
| 489 |
+
if iouThr is None
|
| 490 |
+
else "{:0.2f}".format(iouThr)
|
| 491 |
+
)
|
| 492 |
+
|
| 493 |
+
aind = [i for i, aRng in enumerate(p.areaRngLbl) if aRng == areaRng]
|
| 494 |
+
mind = [i for i, mDet in enumerate(p.maxDets) if mDet == maxDets]
|
| 495 |
+
if ap == 1:
|
| 496 |
+
# dimension of precision: [TxRxKxAxM]
|
| 497 |
+
s = self.eval["precision"]
|
| 498 |
+
# IoU
|
| 499 |
+
if iouThr is not None:
|
| 500 |
+
t = np.where(iouThr == p.iouThrs)[0]
|
| 501 |
+
s = s[t]
|
| 502 |
+
s = s[:, :, :, aind, mind]
|
| 503 |
+
else:
|
| 504 |
+
# dimension of recall: [TxKxAxM]
|
| 505 |
+
s = self.eval["recall"]
|
| 506 |
+
if iouThr is not None:
|
| 507 |
+
t = np.where(iouThr == p.iouThrs)[0]
|
| 508 |
+
s = s[t]
|
| 509 |
+
s = s[:, :, aind, mind]
|
| 510 |
+
if len(s[s > -1]) == 0:
|
| 511 |
+
mean_s = -1
|
| 512 |
+
else:
|
| 513 |
+
mean_s = np.mean(s[s > -1])
|
| 514 |
+
print(iStr.format(titleStr, typeStr, iouStr, areaRng, maxDets, mean_s))
|
| 515 |
+
return mean_s
|
| 516 |
+
|
| 517 |
+
def _summarizeDets():
|
| 518 |
+
stats = np.zeros((12,))
|
| 519 |
+
stats[0] = _summarize(1)
|
| 520 |
+
stats[1] = _summarize(1, iouThr=0.5, maxDets=self.params.maxDets[2])
|
| 521 |
+
stats[2] = _summarize(1, iouThr=0.75, maxDets=self.params.maxDets[2])
|
| 522 |
+
stats[3] = _summarize(1, areaRng="small", maxDets=self.params.maxDets[2])
|
| 523 |
+
stats[4] = _summarize(1, areaRng="medium", maxDets=self.params.maxDets[2])
|
| 524 |
+
stats[5] = _summarize(1, areaRng="large", maxDets=self.params.maxDets[2])
|
| 525 |
+
stats[6] = _summarize(0, maxDets=self.params.maxDets[0])
|
| 526 |
+
stats[7] = _summarize(0, maxDets=self.params.maxDets[1])
|
| 527 |
+
stats[8] = _summarize(0, maxDets=self.params.maxDets[2])
|
| 528 |
+
stats[9] = _summarize(0, areaRng="small", maxDets=self.params.maxDets[2])
|
| 529 |
+
stats[10] = _summarize(0, areaRng="medium", maxDets=self.params.maxDets[2])
|
| 530 |
+
stats[11] = _summarize(0, areaRng="large", maxDets=self.params.maxDets[2])
|
| 531 |
+
return stats
|
| 532 |
+
|
| 533 |
+
def _summarizeKps():
|
| 534 |
+
stats = np.zeros((10,))
|
| 535 |
+
stats[0] = _summarize(1, maxDets=20)
|
| 536 |
+
stats[1] = _summarize(1, maxDets=20, iouThr=0.5)
|
| 537 |
+
stats[2] = _summarize(1, maxDets=20, iouThr=0.75)
|
| 538 |
+
stats[3] = _summarize(1, maxDets=20, areaRng="medium")
|
| 539 |
+
stats[4] = _summarize(1, maxDets=20, areaRng="large")
|
| 540 |
+
stats[5] = _summarize(0, maxDets=20)
|
| 541 |
+
stats[6] = _summarize(0, maxDets=20, iouThr=0.5)
|
| 542 |
+
stats[7] = _summarize(0, maxDets=20, iouThr=0.75)
|
| 543 |
+
stats[8] = _summarize(0, maxDets=20, areaRng="medium")
|
| 544 |
+
stats[9] = _summarize(0, maxDets=20, areaRng="large")
|
| 545 |
+
return stats
|
| 546 |
+
|
| 547 |
+
if not self.eval:
|
| 548 |
+
raise Exception("Please run accumulate() first")
|
| 549 |
+
iouType = self.params.iouType
|
| 550 |
+
if iouType == "segm" or iouType == "bbox":
|
| 551 |
+
summarize = _summarizeDets
|
| 552 |
+
elif iouType == "keypoints":
|
| 553 |
+
summarize = _summarizeKps
|
| 554 |
+
self.stats = summarize()
|
| 555 |
+
|
| 556 |
+
def __str__(self):
|
| 557 |
+
self.summarize()
|
| 558 |
+
|
| 559 |
+
|
| 560 |
+
class Params:
|
| 561 |
+
"""
|
| 562 |
+
Params for coco evaluation api
|
| 563 |
+
"""
|
| 564 |
+
|
| 565 |
+
def setDetParams(self):
|
| 566 |
+
self.imgIds = []
|
| 567 |
+
self.catIds = []
|
| 568 |
+
# np.arange causes trouble. the data point on arange is slightly larger than the true value
|
| 569 |
+
self.iouThrs = np.linspace(
|
| 570 |
+
0.5, 0.95, int(np.round((0.95 - 0.5) / 0.05)) + 1, endpoint=True
|
| 571 |
+
)
|
| 572 |
+
self.recThrs = np.linspace(
|
| 573 |
+
0.0, 1.00, int(np.round((1.00 - 0.0) / 0.01)) + 1, endpoint=True
|
| 574 |
+
)
|
| 575 |
+
self.maxDets = [1, 10, 100]
|
| 576 |
+
self.areaRng = [
|
| 577 |
+
[0**2, 1e5**2],
|
| 578 |
+
[0**2, 32**2],
|
| 579 |
+
[32**2, 96**2],
|
| 580 |
+
[96**2, 1e5**2],
|
| 581 |
+
]
|
| 582 |
+
self.areaRngLbl = ["all", "small", "medium", "large"]
|
| 583 |
+
self.useCats = 1
|
| 584 |
+
|
| 585 |
+
def setKpParams(self):
|
| 586 |
+
self.imgIds = []
|
| 587 |
+
self.catIds = []
|
| 588 |
+
# np.arange causes trouble. the data point on arange is slightly larger than the true value
|
| 589 |
+
self.iouThrs = np.linspace(
|
| 590 |
+
0.5, 0.95, int(np.round((0.95 - 0.5) / 0.05)) + 1, endpoint=True
|
| 591 |
+
)
|
| 592 |
+
self.recThrs = np.linspace(
|
| 593 |
+
0.0, 1.00, int(np.round((1.00 - 0.0) / 0.01)) + 1, endpoint=True
|
| 594 |
+
)
|
| 595 |
+
self.maxDets = [20]
|
| 596 |
+
self.areaRng = [[0**2, 1e5**2], [32**2, 96**2], [96**2, 1e5**2]]
|
| 597 |
+
self.areaRngLbl = ["all", "medium", "large"]
|
| 598 |
+
self.useCats = 1
|
| 599 |
+
self.kpt_oks_sigmas = (
|
| 600 |
+
np.array(
|
| 601 |
+
[
|
| 602 |
+
0.26,
|
| 603 |
+
0.25,
|
| 604 |
+
0.25,
|
| 605 |
+
0.35,
|
| 606 |
+
0.35,
|
| 607 |
+
0.79,
|
| 608 |
+
0.79,
|
| 609 |
+
0.72,
|
| 610 |
+
0.72,
|
| 611 |
+
0.62,
|
| 612 |
+
0.62,
|
| 613 |
+
1.07,
|
| 614 |
+
1.07,
|
| 615 |
+
0.87,
|
| 616 |
+
0.87,
|
| 617 |
+
0.89,
|
| 618 |
+
0.89,
|
| 619 |
+
]
|
| 620 |
+
)
|
| 621 |
+
/ 10.0
|
| 622 |
+
)
|
| 623 |
+
|
| 624 |
+
def __init__(self, iouType="segm"):
|
| 625 |
+
if iouType == "bbox":
|
| 626 |
+
self.setDetParams()
|
| 627 |
+
else:
|
| 628 |
+
raise Exception("iouType not supported")
|
| 629 |
+
self.iouType = iouType
|
| 630 |
+
# useSegm is deprecated
|
| 631 |
+
self.useSegm = None
|
detection_metrics/pycocotools/mask.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__author__ = 'tsungyi'
|
| 2 |
+
|
| 3 |
+
from detection_metrics.pycocotools import _mask
|
| 4 |
+
|
| 5 |
+
# Interface for manipulating masks stored in RLE format.
|
| 6 |
+
#
|
| 7 |
+
# RLE is a simple yet efficient format for storing binary masks. RLE
|
| 8 |
+
# first divides a vector (or vectorized image) into a series of piecewise
|
| 9 |
+
# constant regions and then for each piece simply stores the length of
|
| 10 |
+
# that piece. For example, given M=[0 0 1 1 1 0 1] the RLE counts would
|
| 11 |
+
# be [2 3 1 1], or for M=[1 1 1 1 1 1 0] the counts would be [0 6 1]
|
| 12 |
+
# (note that the odd counts are always the numbers of zeros). Instead of
|
| 13 |
+
# storing the counts directly, additional compression is achieved with a
|
| 14 |
+
# variable bitrate representation based on a common scheme called LEB128.
|
| 15 |
+
#
|
| 16 |
+
# Compression is greatest given large piecewise constant regions.
|
| 17 |
+
# Specifically, the size of the RLE is proportional to the number of
|
| 18 |
+
# *boundaries* in M (or for an image the number of boundaries in the y
|
| 19 |
+
# direction). Assuming fairly simple shapes, the RLE representation is
|
| 20 |
+
# O(sqrt(n)) where n is number of pixels in the object. Hence space usage
|
| 21 |
+
# is substantially lower, especially for large simple objects (large n).
|
| 22 |
+
#
|
| 23 |
+
# Many common operations on masks can be computed directly using the RLE
|
| 24 |
+
# (without need for decoding). This includes computations such as area,
|
| 25 |
+
# union, intersection, etc. All of these operations are linear in the
|
| 26 |
+
# size of the RLE, in other words they are O(sqrt(n)) where n is the area
|
| 27 |
+
# of the object. Computing these operations on the original mask is O(n).
|
| 28 |
+
# Thus, using the RLE can result in substantial computational savings.
|
| 29 |
+
#
|
| 30 |
+
# The following API functions are defined:
|
| 31 |
+
# encode - Encode binary masks using RLE.
|
| 32 |
+
# decode - Decode binary masks encoded via RLE.
|
| 33 |
+
# merge - Compute union or intersection of encoded masks.
|
| 34 |
+
# iou - Compute intersection over union between masks.
|
| 35 |
+
# area - Compute area of encoded masks.
|
| 36 |
+
# toBbox - Get bounding boxes surrounding encoded masks.
|
| 37 |
+
# frPyObjects - Convert polygon, bbox, and uncompressed RLE to encoded RLE mask.
|
| 38 |
+
#
|
| 39 |
+
# Usage:
|
| 40 |
+
# Rs = encode( masks )
|
| 41 |
+
# masks = decode( Rs )
|
| 42 |
+
# R = merge( Rs, intersect=false )
|
| 43 |
+
# o = iou( dt, gt, iscrowd )
|
| 44 |
+
# a = area( Rs )
|
| 45 |
+
# bbs = toBbox( Rs )
|
| 46 |
+
# Rs = frPyObjects( [pyObjects], h, w )
|
| 47 |
+
#
|
| 48 |
+
# In the API the following formats are used:
|
| 49 |
+
# Rs - [dict] Run-length encoding of binary masks
|
| 50 |
+
# R - dict Run-length encoding of binary mask
|
| 51 |
+
# masks - [hxwxn] Binary mask(s) (must have type np.ndarray(dtype=uint8) in column-major order)
|
| 52 |
+
# iscrowd - [nx1] list of np.ndarray. 1 indicates corresponding gt image has crowd region to ignore
|
| 53 |
+
# bbs - [nx4] Bounding box(es) stored as [x y w h]
|
| 54 |
+
# poly - Polygon stored as [[x1 y1 x2 y2...],[x1 y1 ...],...] (2D list)
|
| 55 |
+
# dt,gt - May be either bounding boxes or encoded masks
|
| 56 |
+
# Both poly and bbs are 0-indexed (bbox=[0 0 1 1] encloses first pixel).
|
| 57 |
+
#
|
| 58 |
+
# Finally, a note about the intersection over union (iou) computation.
|
| 59 |
+
# The standard iou of a ground truth (gt) and detected (dt) object is
|
| 60 |
+
# iou(gt,dt) = area(intersect(gt,dt)) / area(union(gt,dt))
|
| 61 |
+
# For "crowd" regions, we use a modified criteria. If a gt object is
|
| 62 |
+
# marked as "iscrowd", we allow a dt to match any subregion of the gt.
|
| 63 |
+
# Choosing gt' in the crowd gt that best matches the dt can be done using
|
| 64 |
+
# gt'=intersect(dt,gt). Since by definition union(gt',dt)=dt, computing
|
| 65 |
+
# iou(gt,dt,iscrowd) = iou(gt',dt) = area(intersect(gt,dt)) / area(dt)
|
| 66 |
+
# For crowd gt regions we use this modified criteria above for the iou.
|
| 67 |
+
#
|
| 68 |
+
# To compile run "python setup.py build_ext --inplace"
|
| 69 |
+
# Please do not contact us for help with compiling.
|
| 70 |
+
#
|
| 71 |
+
# Microsoft COCO Toolbox. version 2.0
|
| 72 |
+
# Data, paper, and tutorials available at: http://mscoco.org/
|
| 73 |
+
# Code written by Piotr Dollar and Tsung-Yi Lin, 2015.
|
| 74 |
+
# Licensed under the Simplified BSD License [see coco/license.txt]
|
| 75 |
+
|
| 76 |
+
iou = _mask.iou
|
| 77 |
+
merge = _mask.merge
|
| 78 |
+
frPyObjects = _mask.frPyObjects
|
| 79 |
+
|
| 80 |
+
def encode(bimask):
|
| 81 |
+
if len(bimask.shape) == 3:
|
| 82 |
+
return _mask.encode(bimask)
|
| 83 |
+
elif len(bimask.shape) == 2:
|
| 84 |
+
h, w = bimask.shape
|
| 85 |
+
return _mask.encode(bimask.reshape((h, w, 1), order='F'))[0]
|
| 86 |
+
|
| 87 |
+
def decode(rleObjs):
|
| 88 |
+
if type(rleObjs) == list:
|
| 89 |
+
return _mask.decode(rleObjs)
|
| 90 |
+
else:
|
| 91 |
+
return _mask.decode([rleObjs])[:,:,0]
|
| 92 |
+
|
| 93 |
+
def area(rleObjs):
|
| 94 |
+
if type(rleObjs) == list:
|
| 95 |
+
return _mask.area(rleObjs)
|
| 96 |
+
else:
|
| 97 |
+
return _mask.area([rleObjs])[0]
|
| 98 |
+
|
| 99 |
+
def toBbox(rleObjs):
|
| 100 |
+
if type(rleObjs) == list:
|
| 101 |
+
return _mask.toBbox(rleObjs)
|
| 102 |
+
else:
|
| 103 |
+
return _mask.toBbox([rleObjs])[0]
|
detection_metrics/pycocotools/mask_utils.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This code is a copy and paste with small modifications of the code:
|
| 2 |
+
# https://github.com/rafaelpadilla/review_object_detection_metrics/blob/main/src/evaluators/coco_evaluator.py
|
| 3 |
+
|
| 4 |
+
from typing import List
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
class MaskEvaluator(object):
|
| 8 |
+
@staticmethod
|
| 9 |
+
def iou(
|
| 10 |
+
dt: List[List[float]], gt: List[List[float]], iscrowd: List[bool]
|
| 11 |
+
) -> np.ndarray:
|
| 12 |
+
"""
|
| 13 |
+
Calculate the intersection over union (IoU) between detection bounding boxes (dt) and \
|
| 14 |
+
ground truth bounding boxes (gt).
|
| 15 |
+
Reference: https://github.com/rafaelpadilla/review_object_detection_metrics
|
| 16 |
+
|
| 17 |
+
Args:
|
| 18 |
+
dt (List[List[float]]): List of detection bounding boxes in the \
|
| 19 |
+
format [x, y, width, height].
|
| 20 |
+
gt (List[List[float]]): List of ground-truth bounding boxes in the \
|
| 21 |
+
format [x, y, width, height].
|
| 22 |
+
iscrowd (List[bool]): List indicating if each ground-truth bounding box \
|
| 23 |
+
is a crowd region or not.
|
| 24 |
+
|
| 25 |
+
Returns:
|
| 26 |
+
np.ndarray: Array of IoU values of shape (len(dt), len(gt)).
|
| 27 |
+
"""
|
| 28 |
+
assert len(iscrowd) == len(gt), "iou(iscrowd=) must have the same length as gt"
|
| 29 |
+
if len(dt) == 0 or len(gt) == 0:
|
| 30 |
+
return []
|
| 31 |
+
ious = np.zeros((len(dt), len(gt)), dtype=np.float64)
|
| 32 |
+
for g_idx, g in enumerate(gt):
|
| 33 |
+
for d_idx, d in enumerate(dt):
|
| 34 |
+
ious[d_idx, g_idx] = _jaccard(d, g, iscrowd[g_idx])
|
| 35 |
+
return ious
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def _jaccard(a: List[float], b: List[float], iscrowd: bool) -> float:
|
| 39 |
+
"""
|
| 40 |
+
Calculate the Jaccard index (intersection over union) between two bounding boxes.
|
| 41 |
+
For "crowd" regions, we use a modified criteria. If a gt object is
|
| 42 |
+
marked as "iscrowd", we allow a dt to match any subregion of the gt.
|
| 43 |
+
Choosing gt' in the crowd gt that best matches the dt can be done using
|
| 44 |
+
gt'=intersect(dt,gt). Since by definition union(gt',dt)=dt, computing
|
| 45 |
+
iou(gt,dt,iscrowd) = iou(gt',dt) = area(intersect(gt,dt)) / area(dt)
|
| 46 |
+
For crowd gt regions we use this modified criteria above for the iou.
|
| 47 |
+
|
| 48 |
+
Args:
|
| 49 |
+
a (List[float]): Bounding box coordinates in the format [x, y, width, height].
|
| 50 |
+
b (List[float]): Bounding box coordinates in the format [x, y, width, height].
|
| 51 |
+
iscrowd (bool): Flag indicating if the second bounding box is a crowd region or not.
|
| 52 |
+
|
| 53 |
+
Returns:
|
| 54 |
+
float: Jaccard index between the two bounding boxes.
|
| 55 |
+
"""
|
| 56 |
+
eps = 4e-12
|
| 57 |
+
xa, ya, x2a, y2a = a[0], a[1], a[0] + a[2], a[1] + a[3]
|
| 58 |
+
xb, yb, x2b, y2b = b[0], b[1], b[0] + b[2], b[1] + b[3]
|
| 59 |
+
|
| 60 |
+
# innermost left x
|
| 61 |
+
xi = max(xa, xb)
|
| 62 |
+
# innermost right x
|
| 63 |
+
x2i = min(x2a, x2b)
|
| 64 |
+
# same for y
|
| 65 |
+
yi = max(ya, yb)
|
| 66 |
+
y2i = min(y2a, y2b)
|
| 67 |
+
|
| 68 |
+
# calculate areas
|
| 69 |
+
Aa = max(x2a - xa, 0.) * max(y2a - ya, 0.)
|
| 70 |
+
Ab = max(x2b - xb, 0.) * max(y2b - yb, 0.)
|
| 71 |
+
Ai = max(x2i - xi, 0.) * max(y2i - yi, 0.)
|
| 72 |
+
|
| 73 |
+
if iscrowd:
|
| 74 |
+
return Ai / (Aa + eps)
|
| 75 |
+
|
| 76 |
+
return Ai / (Aa + Ab - Ai + eps)
|
detection_metrics/utils.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import pickle
|
| 3 |
+
from typing import Dict, List, Tuple, Union
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
import torch.distributed as dist
|
| 8 |
+
from datasets import Dataset
|
| 9 |
+
|
| 10 |
+
from detection_metrics.pycocotools.cocoeval import COCOeval
|
| 11 |
+
|
| 12 |
+
# Typings
|
| 13 |
+
_TYPING_BOX = Tuple[float, float, float, float]
|
| 14 |
+
_TYPING_SCORES = List[float]
|
| 15 |
+
_TYPING_LABELS = List[int]
|
| 16 |
+
_TYPING_BOXES = List[_TYPING_BOX]
|
| 17 |
+
_TYPING_PRED_REF = Union[_TYPING_SCORES, _TYPING_LABELS, _TYPING_BOXES]
|
| 18 |
+
_TYPING_PREDICTION = Dict[str, _TYPING_PRED_REF]
|
| 19 |
+
_TYPING_REFERENCE = Dict[str, _TYPING_PRED_REF]
|
| 20 |
+
_TYPING_PREDICTIONS = Dict[int, _TYPING_PREDICTION]
|
| 21 |
+
|
| 22 |
+
def convert_to_xywh(boxes: torch.Tensor) -> torch.Tensor:
|
| 23 |
+
"""
|
| 24 |
+
Convert bounding boxes from (xmin, ymin, xmax, ymax) format to (x, y, width, height) format.
|
| 25 |
+
|
| 26 |
+
Args:
|
| 27 |
+
boxes (torch.Tensor): Tensor of shape (N, 4) representing bounding boxes in \
|
| 28 |
+
(xmin, ymin, xmax, ymax) format.
|
| 29 |
+
|
| 30 |
+
Returns:
|
| 31 |
+
torch.Tensor: Tensor of shape (N, 4) representing bounding boxes in (x, y, width, height) \
|
| 32 |
+
format.
|
| 33 |
+
"""
|
| 34 |
+
xmin, ymin, xmax, ymax = boxes.unbind(1)
|
| 35 |
+
return torch.stack((xmin, ymin, xmax - xmin, ymax - ymin), dim=1)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def create_common_coco_eval(
|
| 39 |
+
coco_eval: COCOeval, img_ids: List[int], eval_imgs: np.ndarray
|
| 40 |
+
) -> None:
|
| 41 |
+
"""
|
| 42 |
+
Create a common COCO evaluation by merging image IDs and evaluation images into the \
|
| 43 |
+
coco_eval object.
|
| 44 |
+
|
| 45 |
+
Args:
|
| 46 |
+
coco_eval: COCOeval evaluation object.
|
| 47 |
+
img_ids (List[int]): Tensor of image IDs.
|
| 48 |
+
eval_imgs (torch.Tensor): Tensor of evaluation images.
|
| 49 |
+
"""
|
| 50 |
+
img_ids, eval_imgs = merge(img_ids, eval_imgs)
|
| 51 |
+
img_ids = list(img_ids)
|
| 52 |
+
eval_imgs = list(eval_imgs.flatten())
|
| 53 |
+
|
| 54 |
+
coco_eval.evalImgs = eval_imgs
|
| 55 |
+
coco_eval.params.imgIds = img_ids
|
| 56 |
+
coco_eval._paramsEval = copy.deepcopy(coco_eval.params)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def merge(img_ids: List[int], eval_imgs: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
|
| 60 |
+
"""
|
| 61 |
+
Merge image IDs and evaluation images from different processes.
|
| 62 |
+
|
| 63 |
+
Args:
|
| 64 |
+
img_ids (List[int]): List of image ID arrays from different processes.
|
| 65 |
+
eval_imgs (np.ndarray): Evaluation images from different processes.
|
| 66 |
+
|
| 67 |
+
Returns:
|
| 68 |
+
Tuple[np.ndarray, np.ndarray]: Merged image IDs and evaluation images.
|
| 69 |
+
"""
|
| 70 |
+
all_img_ids = all_gather(img_ids)
|
| 71 |
+
all_eval_imgs = all_gather(eval_imgs)
|
| 72 |
+
|
| 73 |
+
merged_img_ids = []
|
| 74 |
+
for p in all_img_ids:
|
| 75 |
+
merged_img_ids.extend(p)
|
| 76 |
+
|
| 77 |
+
merged_eval_imgs = []
|
| 78 |
+
for p in all_eval_imgs:
|
| 79 |
+
merged_eval_imgs.append(p)
|
| 80 |
+
|
| 81 |
+
merged_img_ids = np.array(merged_img_ids)
|
| 82 |
+
merged_eval_imgs = np.concatenate(merged_eval_imgs, 2)
|
| 83 |
+
|
| 84 |
+
# keep only unique (and in sorted order) images
|
| 85 |
+
merged_img_ids, idx = np.unique(merged_img_ids, return_index=True)
|
| 86 |
+
merged_eval_imgs = merged_eval_imgs[..., idx]
|
| 87 |
+
|
| 88 |
+
return merged_img_ids, merged_eval_imgs
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def all_gather(data: List[int]) -> List[List[int]]:
|
| 92 |
+
"""
|
| 93 |
+
Run all_gather on arbitrary picklable data (not necessarily tensors).
|
| 94 |
+
|
| 95 |
+
Args:
|
| 96 |
+
data (List[int]): any picklable object
|
| 97 |
+
Returns:
|
| 98 |
+
List[List[int]]: list of data gathered from each rank
|
| 99 |
+
"""
|
| 100 |
+
world_size = get_world_size()
|
| 101 |
+
if world_size == 1:
|
| 102 |
+
return [data]
|
| 103 |
+
|
| 104 |
+
# serialized to a Tensor
|
| 105 |
+
buffer = pickle.dumps(data)
|
| 106 |
+
storage = torch.ByteStorage.from_buffer(buffer)
|
| 107 |
+
tensor = torch.ByteTensor(storage).to("cuda")
|
| 108 |
+
|
| 109 |
+
# obtain Tensor size of each rank
|
| 110 |
+
local_size = torch.tensor([tensor.numel()], device="cuda")
|
| 111 |
+
size_list = [torch.tensor([0], device="cuda") for _ in range(world_size)]
|
| 112 |
+
dist.all_gather(size_list, local_size)
|
| 113 |
+
size_list = [int(size.item()) for size in size_list]
|
| 114 |
+
max_size = max(size_list)
|
| 115 |
+
|
| 116 |
+
# receiving Tensor from all ranks
|
| 117 |
+
# we pad the tensor because torch all_gather does not support
|
| 118 |
+
# gathering tensors of different shapes
|
| 119 |
+
tensor_list = []
|
| 120 |
+
for _ in size_list:
|
| 121 |
+
tensor_list.append(torch.empty((max_size,), dtype=torch.uint8, device="cuda"))
|
| 122 |
+
if local_size != max_size:
|
| 123 |
+
padding = torch.empty(
|
| 124 |
+
size=(max_size - local_size,), dtype=torch.uint8, device="cuda"
|
| 125 |
+
)
|
| 126 |
+
tensor = torch.cat((tensor, padding), dim=0)
|
| 127 |
+
dist.all_gather(tensor_list, tensor)
|
| 128 |
+
|
| 129 |
+
data_list = []
|
| 130 |
+
for size, tensor in zip(size_list, tensor_list):
|
| 131 |
+
buffer = tensor.cpu().numpy().tobytes()[:size]
|
| 132 |
+
data_list.append(pickle.loads(buffer))
|
| 133 |
+
|
| 134 |
+
return data_list
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def get_world_size() -> int:
|
| 138 |
+
"""
|
| 139 |
+
Get the number of processes in the distributed environment.
|
| 140 |
+
|
| 141 |
+
Returns:
|
| 142 |
+
int: Number of processes.
|
| 143 |
+
"""
|
| 144 |
+
if not is_dist_avail_and_initialized():
|
| 145 |
+
return 1
|
| 146 |
+
return dist.get_world_size()
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def is_dist_avail_and_initialized() -> bool:
|
| 150 |
+
"""
|
| 151 |
+
Check if distributed environment is available and initialized.
|
| 152 |
+
|
| 153 |
+
Returns:
|
| 154 |
+
bool: True if distributed environment is available and initialized, False otherwise.
|
| 155 |
+
"""
|
| 156 |
+
return dist.is_available() and dist.is_initialized()
|
requirements.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch
|
| 2 |
+
torchvision
|
setup.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from detection_metrics import __version__
|
| 2 |
+
import subprocess
|
| 3 |
+
|
| 4 |
+
from setuptools import setup
|
| 5 |
+
from setuptools.command.develop import develop
|
| 6 |
+
from setuptools.command.egg_info import egg_info
|
| 7 |
+
from setuptools.command.install import install
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def custom_command():
|
| 11 |
+
subprocess.call(["pip", "install", "numpy", "cython"])
|
| 12 |
+
subprocess.call(["pip", "install", "-r", "requirements.txt", "--user"])
|
| 13 |
+
|
| 14 |
+
class CustomInstallCommand(install):
|
| 15 |
+
def run(self):
|
| 16 |
+
install.run(self)
|
| 17 |
+
custom_command()
|
| 18 |
+
|
| 19 |
+
class CustomDevelopCommand(develop):
|
| 20 |
+
def run(self):
|
| 21 |
+
develop.run(self)
|
| 22 |
+
custom_command()
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class CustomEggInfoCommand(egg_info):
|
| 26 |
+
def run(self):
|
| 27 |
+
egg_info.run(self)
|
| 28 |
+
custom_command()
|
| 29 |
+
|
| 30 |
+
setup(
|
| 31 |
+
name="detection_metrics",
|
| 32 |
+
description="COCO Metrics for Object Detection and Instance Segmentation",
|
| 33 |
+
version=__version__,
|
| 34 |
+
zip_safe=True,
|
| 35 |
+
packages=["detection_metrics", "detection_metrics.pycocotools"],
|
| 36 |
+
include_package_data=True,
|
| 37 |
+
cmdclass={
|
| 38 |
+
"install": CustomInstallCommand,
|
| 39 |
+
"develop": CustomDevelopCommand,
|
| 40 |
+
"egg_info": CustomEggInfoCommand,
|
| 41 |
+
},
|
| 42 |
+
)
|