|
from climateqa.engine.embeddings import get_embeddings_function |
|
embeddings_function = get_embeddings_function() |
|
|
|
|
|
import gradio as gr |
|
import pandas as pd |
|
import numpy as np |
|
import os |
|
import time |
|
import re |
|
import json |
|
from datetime import datetime |
|
from azure.storage.fileshare import ShareServiceClient |
|
|
|
from utils import create_user_id |
|
|
|
|
|
|
|
|
|
from climateqa.engine.llm import get_llm |
|
from climateqa.engine.rag import make_rag_chain |
|
from climateqa.engine.vectorstore import get_pinecone_vectorstore |
|
from climateqa.engine.retriever import ClimateQARetriever |
|
from climateqa.engine.embeddings import get_embeddings_function |
|
from climateqa.engine.prompts import audience_prompts |
|
from climateqa.sample_questions import QUESTIONS |
|
from climateqa.constants import POSSIBLE_REPORTS |
|
from climateqa.utils import get_image_from_azure_blob_storage |
|
|
|
|
|
try: |
|
from dotenv import load_dotenv |
|
load_dotenv() |
|
except Exception as e: |
|
pass |
|
|
|
|
|
theme = gr.themes.Base( |
|
primary_hue="blue", |
|
secondary_hue="red", |
|
font=[gr.themes.GoogleFont("Poppins"), "ui-sans-serif", "system-ui", "sans-serif"], |
|
) |
|
|
|
|
|
|
|
init_prompt = "" |
|
|
|
system_template = { |
|
"role": "system", |
|
"content": init_prompt, |
|
} |
|
|
|
account_key = os.environ["BLOB_ACCOUNT_KEY"] |
|
if len(account_key) == 86: |
|
account_key += "==" |
|
|
|
credential = { |
|
"account_key": account_key, |
|
"account_name": os.environ["BLOB_ACCOUNT_NAME"], |
|
} |
|
|
|
account_url = os.environ["BLOB_ACCOUNT_URL"] |
|
file_share_name = "climategpt" |
|
service = ShareServiceClient(account_url=account_url, credential=credential) |
|
share_client = service.get_share_client(file_share_name) |
|
|
|
user_id = create_user_id() |
|
|
|
|
|
|
|
def parse_output_llm_with_sources(output): |
|
|
|
content_parts = re.split(r'\[(Doc\s?\d+(?:,\s?Doc\s?\d+)*)\]', output) |
|
parts = [] |
|
for part in content_parts: |
|
if part.startswith("Doc"): |
|
subparts = part.split(",") |
|
subparts = [subpart.lower().replace("doc","").strip() for subpart in subparts] |
|
subparts = [f"<span class='doc-ref'><sup>{subpart}</sup></span>" for subpart in subparts] |
|
parts.append("".join(subparts)) |
|
else: |
|
parts.append(part) |
|
content_parts = "".join(parts) |
|
return content_parts |
|
|
|
|
|
|
|
vectorstore = get_pinecone_vectorstore(embeddings_function) |
|
llm = get_llm(max_tokens = 1024,temperature = 0.0) |
|
|
|
|
|
def make_pairs(lst): |
|
"""from a list of even lenght, make tupple pairs""" |
|
return [(lst[i], lst[i + 1]) for i in range(0, len(lst), 2)] |
|
|
|
|
|
def serialize_docs(docs): |
|
new_docs = [] |
|
for doc in docs: |
|
new_doc = {} |
|
new_doc["page_content"] = doc.page_content |
|
new_doc["metadata"] = doc.metadata |
|
new_docs.append(new_doc) |
|
return new_docs |
|
|
|
|
|
def chat(query,history,audience,sources,reports): |
|
"""taking a query and a message history, use a pipeline (reformulation, retriever, answering) to yield a tuple of: |
|
(messages in gradio format, messages in langchain format, source documents)""" |
|
|
|
if audience == "Children": |
|
audience_prompt = audience_prompts["children"] |
|
elif audience == "General public": |
|
audience_prompt = audience_prompts["general"] |
|
elif audience == "Experts": |
|
audience_prompt = audience_prompts["experts"] |
|
else: |
|
audience_prompt = audience_prompts["experts"] |
|
|
|
|
|
if len(sources) == 0: |
|
sources = ["IPCC"] |
|
|
|
if len(reports) == 0: |
|
reports = [] |
|
|
|
retriever = ClimateQARetriever(vectorstore=vectorstore,sources = sources,reports = reports,k_summary = 3,k_total = 10,threshold=0.7) |
|
rag_chain = make_rag_chain(retriever,llm) |
|
|
|
source_string = "" |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
inputs = {"query": query,"audience": audience_prompt} |
|
|
|
result = rag_chain.stream(inputs) |
|
|
|
reformulated_question_path_id = "/logs/flatten_dict/final_output" |
|
retriever_path_id = "/logs/Retriever/final_output" |
|
streaming_output_path_id = "/logs/AzureChatOpenAI:2/streamed_output_str/-" |
|
final_output_path_id = "/streamed_output/-" |
|
|
|
docs_html = "No sources found for this question" |
|
output_query = "" |
|
output_language = "" |
|
gallery = [] |
|
|
|
for output in result: |
|
|
|
if "language" in output: |
|
output_language = output["language"] |
|
if "question" in output: |
|
output_query = output["question"] |
|
if "docs" in output: |
|
|
|
try: |
|
docs = output['docs'] |
|
docs_html = [] |
|
for i, d in enumerate(docs, 1): |
|
docs_html.append(make_html_source(d, i)) |
|
docs_html = "".join(docs_html) |
|
except TypeError: |
|
print("No documents found") |
|
continue |
|
|
|
if "answer" in output: |
|
new_token = output["answer"] |
|
time.sleep(0.03) |
|
answer_yet = history[-1][1] + new_token |
|
answer_yet = parse_output_llm_with_sources(answer_yet) |
|
history[-1] = (query,answer_yet) |
|
|
|
yield history,docs_html,output_query,output_language,gallery |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
if os.getenv("GRADIO_ENV") != "local": |
|
timestamp = str(datetime.now().timestamp()) |
|
file = timestamp + ".json" |
|
prompt = history[-1][0] |
|
logs = { |
|
"user_id": str(user_id), |
|
"prompt": prompt, |
|
"query": prompt, |
|
"question":output_query, |
|
"docs":serialize_docs(docs), |
|
"answer": history[-1][1], |
|
"time": timestamp, |
|
} |
|
log_on_azure(file, logs, share_client) |
|
|
|
|
|
gallery = [x.metadata["image_path"] for x in docs if (len(x.metadata["image_path"]) > 0 and "IAS" in x.metadata["image_path"])] |
|
if len(gallery) > 0: |
|
gallery = list(set("|".join(gallery).split("|"))) |
|
gallery = [get_image_from_azure_blob_storage(x) for x in gallery] |
|
|
|
yield history,docs_html,output_query,output_language,gallery |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
def make_html_source(source,i): |
|
meta = source.metadata |
|
|
|
content = source.page_content.strip() |
|
return f""" |
|
<div class="card"> |
|
<div class="card-content"> |
|
<h2>Doc {i} - {meta['short_name']} - Page {int(meta['page_number'])}</h2> |
|
<p>{content}</p> |
|
</div> |
|
<div class="card-footer"> |
|
<span>{meta['name']}</span> |
|
<a href="{meta['url']}#page={int(meta['page_number'])}" target="_blank" class="pdf-link"> |
|
<span role="img" aria-label="Open PDF">🔗</span> |
|
</a> |
|
</div> |
|
</div> |
|
""" |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
def save_feedback(feed: str, user_id): |
|
if len(feed) > 1: |
|
timestamp = str(datetime.now().timestamp()) |
|
file = user_id + timestamp + ".json" |
|
logs = { |
|
"user_id": user_id, |
|
"feedback": feed, |
|
"time": timestamp, |
|
} |
|
log_on_azure(file, logs, share_client) |
|
return "Feedback submitted, thank you!" |
|
|
|
|
|
|
|
|
|
def log_on_azure(file, logs, share_client): |
|
logs = json.dumps(logs) |
|
file_client = share_client.get_file_client(file) |
|
print("Uploading logs to Azure Blob Storage") |
|
print("----------------------------------") |
|
print("") |
|
print(logs) |
|
file_client.upload_file(logs) |
|
print("Logs uploaded to Azure Blob Storage") |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
init_prompt = """ |
|
Hello, I am ClimateQ&A, a conversational assistant designed to help you understand climate change and biodiversity loss. I will answer your questions by **sifting through the IPCC and IPBES scientific reports**. |
|
|
|
❓ How to use |
|
- **Language**: You can ask me your questions in any language. |
|
- **Audience**: You can specify your audience (children, general public, experts) to get a more adapted answer. |
|
- **Sources**: You can choose to search in the IPCC or IPBES reports, or both. |
|
|
|
⚠️ Limitations |
|
*Please note that the AI is not perfect and may sometimes give irrelevant answers. If you are not satisfied with the answer, please ask a more specific question or report your feedback to help us improve the system.* |
|
|
|
What do you want to learn ? |
|
""" |
|
|
|
|
|
def vote(data: gr.LikeData): |
|
if data.liked: |
|
print(data.value) |
|
else: |
|
print(data) |
|
|
|
|
|
|
|
with gr.Blocks(title="Climate Q&A", css="style.css", theme=theme,elem_id = "main-component") as demo: |
|
|
|
|
|
with gr.Tab("ClimateQ&A"): |
|
|
|
with gr.Row(elem_id="chatbot-row"): |
|
with gr.Column(scale=2): |
|
|
|
chatbot = gr.Chatbot( |
|
value=[(None,init_prompt)], |
|
show_copy_button=True,show_label = False,elem_id="chatbot",layout = "panel", |
|
avatar_images = (None,"https://i.ibb.co/YNyd5W2/logo4.png"), |
|
) |
|
|
|
|
|
|
|
|
|
|
|
with gr.Row(elem_id = "input-message"): |
|
textbox=gr.Textbox(placeholder="Ask me anything here!",show_label=False,scale=1,lines = 1,interactive = True) |
|
|
|
|
|
with gr.Column(scale=1, variant="panel",elem_id = "right-panel"): |
|
|
|
|
|
with gr.Tabs() as tabs: |
|
with gr.TabItem("Examples",elem_id = "tab-examples",id = 0): |
|
|
|
examples_hidden = gr.Textbox(visible = False) |
|
first_key = list(QUESTIONS.keys())[0] |
|
dropdown_samples = gr.Dropdown(QUESTIONS.keys(),value = first_key,interactive = True,show_label = True,label = "Select a category of sample questions",elem_id = "dropdown-samples") |
|
|
|
samples = [] |
|
for i,key in enumerate(QUESTIONS.keys()): |
|
|
|
examples_visible = True if i == 0 else False |
|
|
|
with gr.Row(visible = examples_visible) as group_examples: |
|
|
|
examples_questions = gr.Examples( |
|
QUESTIONS[key], |
|
[examples_hidden], |
|
examples_per_page=8, |
|
run_on_click=False, |
|
elem_id=f"examples{i}", |
|
api_name=f"examples{i}", |
|
|
|
|
|
) |
|
|
|
samples.append(group_examples) |
|
|
|
|
|
with gr.Tab("Citations",elem_id = "tab-citations",id = 1): |
|
sources_textbox = gr.HTML(show_label=False, elem_id="sources-textbox") |
|
docs_textbox = gr.State("") |
|
|
|
with gr.Tab("Configuration",elem_id = "tab-config",id = 2): |
|
|
|
gr.Markdown("Reminder: You can talk in any language, ClimateQ&A is multi-lingual!") |
|
|
|
|
|
dropdown_sources = gr.CheckboxGroup( |
|
["IPCC", "IPBES"], |
|
label="Select source", |
|
value=["IPCC"], |
|
interactive=True, |
|
) |
|
|
|
dropdown_reports = gr.Dropdown( |
|
POSSIBLE_REPORTS, |
|
label="Or select specific reports", |
|
multiselect=True, |
|
value=None, |
|
interactive=True, |
|
) |
|
|
|
dropdown_audience = gr.Dropdown( |
|
["Children","General public","Experts"], |
|
label="Select audience", |
|
value="Experts", |
|
interactive=True, |
|
) |
|
|
|
output_query = gr.Textbox(label="Query used for retrieval",show_label = True,elem_id = "reformulated-query",lines = 2,interactive = False) |
|
output_language = gr.Textbox(label="Language",show_label = True,elem_id = "language",lines = 1,interactive = False) |
|
|
|
with gr.Tab("Figures",elem_id = "tab-images",id = 3): |
|
gallery = gr.Gallery() |
|
|
|
|
|
def start_chat(query,history): |
|
history = history + [(query,"")] |
|
history = [tuple(x) for x in history] |
|
print(history) |
|
return (gr.update(interactive = False),gr.update(selected=1),history) |
|
|
|
def finish_chat(): |
|
return (gr.update(interactive = True,value = "")) |
|
|
|
(textbox |
|
.submit(start_chat, [textbox,chatbot], [textbox,tabs,chatbot],queue = False,api_name = "start_chat_textbox") |
|
.success(chat, [textbox,chatbot,dropdown_audience, dropdown_sources,dropdown_reports], [chatbot,sources_textbox,output_query,output_language,gallery],concurrency_limit = 8,api_name = "chat_textbox") |
|
.success(finish_chat, None, [textbox],api_name = "finish_chat_textbox") |
|
) |
|
|
|
(examples_hidden |
|
.change(start_chat, [examples_hidden,chatbot], [textbox,tabs,chatbot],queue = False,api_name = "start_chat_examples") |
|
.success(chat, [examples_hidden,chatbot,dropdown_audience, dropdown_sources,dropdown_reports], [chatbot,sources_textbox,output_query,output_language,gallery],concurrency_limit = 8,api_name = "chat_examples") |
|
.success(finish_chat, None, [textbox],api_name = "finish_chat_examples") |
|
) |
|
|
|
|
|
def change_sample_questions(key): |
|
index = list(QUESTIONS.keys()).index(key) |
|
visible_bools = [False] * len(samples) |
|
visible_bools[index] = True |
|
return [gr.update(visible=visible_bools[i]) for i in range(len(samples))] |
|
|
|
|
|
|
|
dropdown_samples.change(change_sample_questions,dropdown_samples,samples) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
with gr.Tab("About ClimateQ&A",elem_classes = "max-height other-tabs"): |
|
with gr.Row(): |
|
with gr.Column(scale=1): |
|
gr.Markdown( |
|
""" |
|
<p><b>Climate change and environmental disruptions have become some of the most pressing challenges facing our planet today</b>. As global temperatures rise and ecosystems suffer, it is essential for individuals to understand the gravity of the situation in order to make informed decisions and advocate for appropriate policy changes.</p> |
|
<p>However, comprehending the vast and complex scientific information can be daunting, as the scientific consensus references, such as <b>the Intergovernmental Panel on Climate Change (IPCC) reports, span thousands of pages</b>. To bridge this gap and make climate science more accessible, we introduce <b>ClimateQ&A as a tool to distill expert-level knowledge into easily digestible insights about climate science.</b></p> |
|
<div class="tip-box"> |
|
<div class="tip-box-title"> |
|
<span class="light-bulb" role="img" aria-label="Light Bulb">💡</span> |
|
How does ClimateQ&A work? |
|
</div> |
|
ClimateQ&A harnesses modern OCR techniques to parse and preprocess IPCC reports. By leveraging state-of-the-art question-answering algorithms, <i>ClimateQ&A is able to sift through the extensive collection of climate scientific reports and identify relevant passages in response to user inquiries</i>. Furthermore, the integration of the ChatGPT API allows ClimateQ&A to present complex data in a user-friendly manner, summarizing key points and facilitating communication of climate science to a wider audience. |
|
</div> |
|
""" |
|
) |
|
|
|
with gr.Column(scale=1): |
|
gr.Markdown("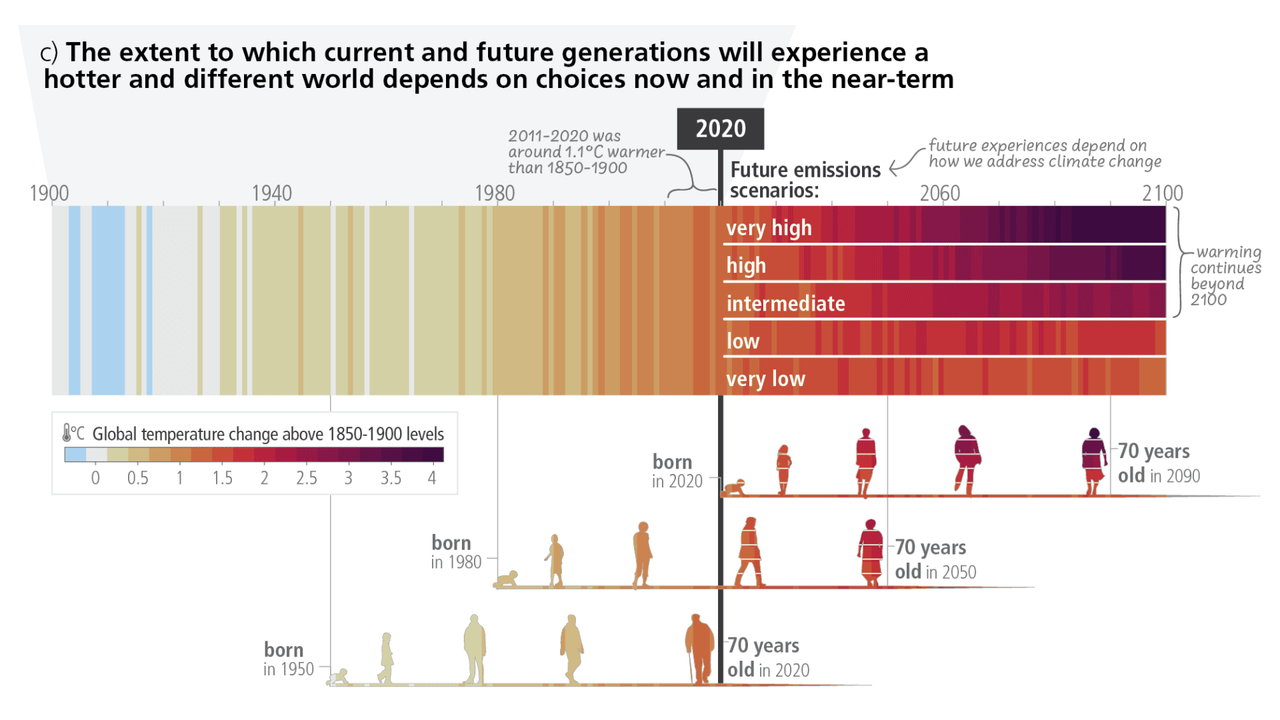") |
|
gr.Markdown("*Source : IPCC AR6 - Synthesis Report of the IPCC 6th assessment report (AR6)*") |
|
|
|
gr.Markdown("## How to use ClimateQ&A") |
|
with gr.Row(): |
|
with gr.Column(scale=1): |
|
gr.Markdown( |
|
""" |
|
### Getting started |
|
- In the chatbot section, simply type your climate-related question, and ClimateQ&A will provide an answer with references to relevant IPCC reports. |
|
- ClimateQ&A retrieves specific passages from the IPCC reports to help answer your question accurately. |
|
- Source information, including page numbers and passages, is displayed on the right side of the screen for easy verification. |
|
- Feel free to ask follow-up questions within the chatbot for a more in-depth understanding. |
|
- You can ask question in any language, ClimateQ&A is multi-lingual ! |
|
- ClimateQ&A integrates multiple sources (IPCC and IPBES, … ) to cover various aspects of environmental science, such as climate change and biodiversity. See all sources used below. |
|
""" |
|
) |
|
with gr.Column(scale=1): |
|
gr.Markdown( |
|
""" |
|
### Limitations |
|
<div class="warning-box"> |
|
<ul> |
|
<li>Please note that, like any AI, the model may occasionally generate an inaccurate or imprecise answer. Always refer to the provided sources to verify the validity of the information given. If you find any issues with the response, kindly provide feedback to help improve the system.</li> |
|
<li>ClimateQ&A is specifically designed for climate-related inquiries. If you ask a non-environmental question, the chatbot will politely remind you that its focus is on climate and environmental issues.</li> |
|
</div> |
|
""" |
|
) |
|
|
|
|
|
with gr.Tab("Contact, feedback and feature requests",elem_classes = "max-height other-tabs"): |
|
gr.Markdown( |
|
""" |
|
|
|
For any question or press request, contact Théo Alves Da Costa at <b>theo.alvesdacosta@ekimetrics.com</b> |
|
|
|
- ClimateQ&A welcomes community contributions. To participate, head over to the Community Tab and create a "New Discussion" to ask questions and share your insights. |
|
- Provide feedback through email, letting us know which insights you found accurate, useful, or not. Your input will help us improve the platform. |
|
- Only a few sources (see below) are integrated (all IPCC, IPBES), if you are a climate science researcher and net to sift through another report, please let us know. |
|
|
|
*This tool has been developed by the R&D lab at **Ekimetrics** (Jean Lelong, Nina Achache, Gabriel Olympie, Nicolas Chesneau, Natalia De la Calzada, Théo Alves Da Costa)* |
|
""" |
|
) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
with gr.Tab("Sources",elem_classes = "max-height other-tabs"): |
|
gr.Markdown(""" |
|
| Source | Report | URL | Number of pages | Release date | |
|
| --- | --- | --- | --- | --- | |
|
IPCC | Summary for Policymakers. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_SPM.pdf | 32 | 2021 |
|
IPCC | Full Report. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://report.ipcc.ch/ar6/wg1/IPCC_AR6_WGI_FullReport.pdf | 2409 | 2021 |
|
IPCC | Technical Summary. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_TS.pdf | 112 | 2021 |
|
IPCC | Summary for Policymakers. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg2/downloads/report/IPCC_AR6_WGII_SummaryForPolicymakers.pdf | 34 | 2022 |
|
IPCC | Technical Summary. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg2/downloads/report/IPCC_AR6_WGII_TechnicalSummary.pdf | 84 | 2022 |
|
IPCC | Full Report. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://report.ipcc.ch/ar6/wg2/IPCC_AR6_WGII_FullReport.pdf | 3068 | 2022 |
|
IPCC | Summary for Policymakers. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_SummaryForPolicymakers.pdf | 50 | 2022 |
|
IPCC | Technical Summary. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_TechnicalSummary.pdf | 102 | 2022 |
|
IPCC | Full Report. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_FullReport.pdf | 2258 | 2022 |
|
IPCC | Summary for Policymakers. In: Global Warming of 1.5°C. An IPCC Special Report on the impacts of global warming of 1.5°C above pre-industrial levels and related global greenhouse gas emission pathways, in the context of strengthening the global response to the threat of climate change, sustainable development, and efforts to eradicate poverty. | https://www.ipcc.ch/site/assets/uploads/sites/2/2022/06/SPM_version_report_LR.pdf | 24 | 2018 |
|
IPCC | Summary for Policymakers. In: Climate Change and Land: an IPCC special report on climate change, desertification, land degradation, sustainable land management, food security, and greenhouse gas fluxes in terrestrial ecosystems. | https://www.ipcc.ch/site/assets/uploads/sites/4/2022/11/SRCCL_SPM.pdf | 36 | 2019 |
|
IPCC | Summary for Policymakers. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/01_SROCC_SPM_FINAL.pdf | 36 | 2019 |
|
IPCC | Technical Summary. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/02_SROCC_TS_FINAL.pdf | 34 | 2019 |
|
IPCC | Chapter 1 - Framing and Context of the Report. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/03_SROCC_Ch01_FINAL.pdf | 60 | 2019 |
|
IPCC | Chapter 2 - High Mountain Areas. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/04_SROCC_Ch02_FINAL.pdf | 72 | 2019 |
|
IPCC | Chapter 3 - Polar Regions. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/05_SROCC_Ch03_FINAL.pdf | 118 | 2019 |
|
IPCC | Chapter 4 - Sea Level Rise and Implications for Low-Lying Islands, Coasts and Communities. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/06_SROCC_Ch04_FINAL.pdf | 126 | 2019 |
|
IPCC | Chapter 5 - Changing Ocean, Marine Ecosystems, and Dependent Communities. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/07_SROCC_Ch05_FINAL.pdf | 142 | 2019 |
|
IPCC | Chapter 6 - Extremes, Abrupt Changes and Managing Risk. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/08_SROCC_Ch06_FINAL.pdf | 68 | 2019 |
|
IPCC | Cross-Chapter Box 9: Integrative Cross-Chapter Box on Low-Lying Islands and Coasts. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2019/11/11_SROCC_CCB9-LLIC_FINAL.pdf | 18 | 2019 |
|
IPCC | Annex I: Glossary [Weyer, N.M. (ed.)]. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/10_SROCC_AnnexI-Glossary_FINAL.pdf | 28 | 2019 |
|
IPBES | Full Report. Global assessment report on biodiversity and ecosystem services of the IPBES. | https://zenodo.org/record/6417333/files/202206_IPBES%20GLOBAL%20REPORT_FULL_DIGITAL_MARCH%202022.pdf | 1148 | 2019 |
|
IPBES | Summary for Policymakers. Global assessment report on biodiversity and ecosystem services of the IPBES (Version 1). | https://zenodo.org/record/3553579/files/ipbes_global_assessment_report_summary_for_policymakers.pdf | 60 | 2019 |
|
IPBES | Full Report. Thematic assessment of the sustainable use of wild species of the IPBES. | https://zenodo.org/record/7755805/files/IPBES_ASSESSMENT_SUWS_FULL_REPORT.pdf | 1008 | 2022 |
|
IPBES | Summary for Policymakers. Summary for policymakers of the thematic assessment of the sustainable use of wild species of the IPBES. | https://zenodo.org/record/7411847/files/EN_SPM_SUSTAINABLE%20USE%20OF%20WILD%20SPECIES.pdf | 44 | 2022 |
|
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Africa. | https://zenodo.org/record/3236178/files/ipbes_assessment_report_africa_EN.pdf | 494 | 2018 |
|
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Africa. | https://zenodo.org/record/3236189/files/ipbes_assessment_spm_africa_EN.pdf | 52 | 2018 |
|
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for the Americas. | https://zenodo.org/record/3236253/files/ipbes_assessment_report_americas_EN.pdf | 660 | 2018 |
|
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for the Americas. | https://zenodo.org/record/3236292/files/ipbes_assessment_spm_americas_EN.pdf | 44 | 2018 |
|
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Asia and the Pacific. | https://zenodo.org/record/3237374/files/ipbes_assessment_report_ap_EN.pdf | 616 | 2018 |
|
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Asia and the Pacific. | https://zenodo.org/record/3237383/files/ipbes_assessment_spm_ap_EN.pdf | 44 | 2018 |
|
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Europe and Central Asia. | https://zenodo.org/record/3237429/files/ipbes_assessment_report_eca_EN.pdf | 894 | 2018 |
|
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Europe and Central Asia. | https://zenodo.org/record/3237468/files/ipbes_assessment_spm_eca_EN.pdf | 52 | 2018 |
|
IPBES | Full Report. Assessment Report on Land Degradation and Restoration. | https://zenodo.org/record/3237393/files/ipbes_assessment_report_ldra_EN.pdf | 748 | 2018 |
|
IPBES | IPBES Invasive Alien Species Assessment: Summary for Policymakers & 6 chapters | https://zenodo.org/records/10127924/files/Summary%20for%20policymakers_IPBES%20IAS%20Assessment.pdf | 56 + 1198 | 2023 |
|
""") |
|
|
|
with gr.Tab("Carbon Footprint",elem_classes = "max-height other-tabs"): |
|
gr.Markdown(""" |
|
|
|
Carbon emissions were measured during the development and inference process using CodeCarbon [https://github.com/mlco2/codecarbon](https://github.com/mlco2/codecarbon) |
|
|
|
| Phase | Description | Emissions | Source | |
|
| --- | --- | --- | --- | |
|
| Development | OCR and parsing all pdf documents with AI | 28gCO2e | CodeCarbon | |
|
| Development | Question Answering development | 114gCO2e | CodeCarbon | |
|
| Inference | Question Answering | ~0.102gCO2e / call | CodeCarbon | |
|
| Inference | API call to turbo-GPT | ~0.38gCO2e / call | https://medium.com/@chrispointon/the-carbon-footprint-of-chatgpt-e1bc14e4cc2a | |
|
|
|
Carbon Emissions are **relatively low but not negligible** compared to other usages: one question asked to ClimateQ&A is around 0.482gCO2e - equivalent to 2.2m by car (https://datagir.ademe.fr/apps/impact-co2/) |
|
Or around 2 to 4 times more than a typical Google search. |
|
""" |
|
) |
|
|
|
with gr.Tab("Changelog",elem_classes = "max-height other-tabs"): |
|
gr.Markdown(""" |
|
|
|
##### Upcoming features |
|
- Figures retrieval and multimodal system |
|
- Conversational chat |
|
- Intent routing |
|
- Local environment setup |
|
|
|
##### v1.2.1 - *2024-01-16* |
|
- BUG - corrected asynchronous bug failing the chatbot frequently |
|
|
|
##### v1.2.0 - *2023-11-27* |
|
- Added new IPBES assessment on Invasive Species (SPM and chapters) |
|
- Switched all the codebase to LCEL (Langchain Expression Language) |
|
- Added sample questions by category |
|
- Switched embeddings from old ``sentence-transformers/multi-qa-mpnet-base-dot-v1`` to ``BAAI/bge-base-en-v1.5`` |
|
- Report filtering to select directly the report you want to source your answers from |
|
- First naive version of a figures retrieval system by looking up the figures in the retrieved pages |
|
|
|
##### v1.1.0 - *2023-10-16* |
|
- ClimateQ&A on Hugging Face is finally working again with all the new features ! |
|
- Switched all python code to langchain codebase for cleaner code, easier maintenance and future features |
|
- Updated GPT model to August version |
|
- Added streaming response to improve UX |
|
- Created a custom Retriever chain to avoid calling the LLM if there is no documents retrieved |
|
- Use of HuggingFace embed on https://climateqa.com to avoid demultiplying deployments |
|
|
|
##### v1.0.0 - *2023-05-11* |
|
- First version of clean interface on https://climateqa.com |
|
- Add children mode on https://climateqa.com |
|
- Add follow-up questions https://climateqa.com |
|
""" |
|
) |
|
|
|
demo.queue() |
|
|
|
demo.launch(max_threads = 8) |
|
|

