
Upload 19 files
Browse files- .gitattributes +2 -0
- Resources/image.png +0 -0
- Resources/nse_companies.csv +7 -0
- app.py +650 -0
- chroma_db/chroma.sqlite3 +0 -0
- faiss_HD/index.faiss +3 -0
- faiss_HD/index.pkl +3 -0
- faiss_RD/index.faiss +3 -0
- faiss_RD/index.pkl +3 -0
- files/analysed_data.pkl +3 -0
- files/ingested_data.pkl +3 -0
- files/labels.pkl +3 -0
- files/social_media_data.csv +0 -0
- files/social_media_data.json +0 -0
- files/social_media_data.pkl +3 -0
- main.py +43 -0
- py/data_fetch.py +236 -0
- py/db_storage.py +183 -0
- py/handle_files.py +103 -0
- requirements.txt +43 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
faiss_HD/index.faiss filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
faiss_RD/index.faiss filter=lfs diff=lfs merge=lfs -text
|
Resources/image.png
ADDED
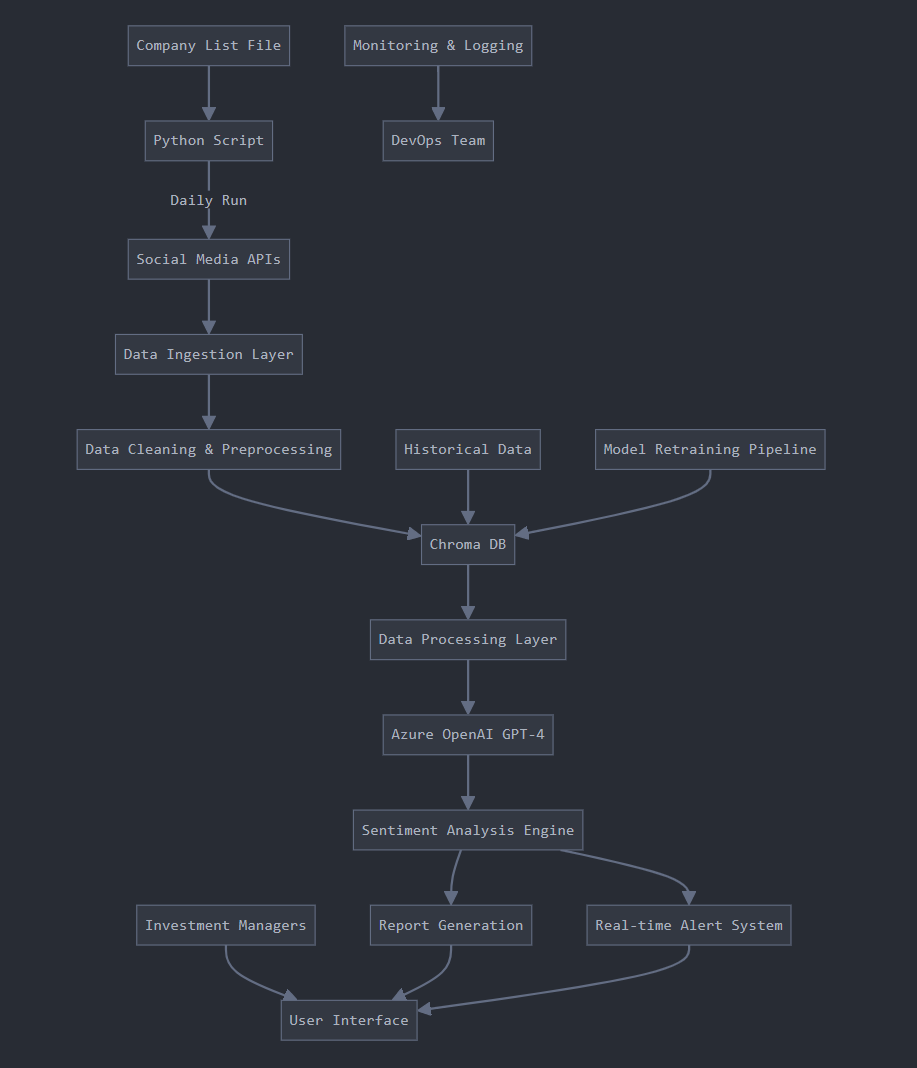
|
Resources/nse_companies.csv
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
company Name,company_ticker
|
| 2 |
+
Reliance Industries,RELIANCE
|
| 3 |
+
HDFC Bank,HDFCBANK
|
| 4 |
+
Hindustan Unilever,HINDUNILVR
|
| 5 |
+
Bharti Airtel,BHARTIARTL
|
| 6 |
+
Asian Paints,ASIANPAINT
|
| 7 |
+
Maruti Suzuki India,MARUTI
|
app.py
ADDED
|
@@ -0,0 +1,650 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import requests
|
| 5 |
+
from dotenv import load_dotenv
|
| 6 |
+
import streamlit as st
|
| 7 |
+
import plotly.graph_objects as go
|
| 8 |
+
import plotly.express as px
|
| 9 |
+
from openai import AzureOpenAI
|
| 10 |
+
import pandas as pd
|
| 11 |
+
import numpy as np
|
| 12 |
+
from datetime import datetime, timedelta
|
| 13 |
+
from dotted_dict import DottedDict
|
| 14 |
+
from langchain_community.vectorstores import Chroma
|
| 15 |
+
from langchain_openai import AzureChatOpenAI, AzureOpenAIEmbeddings
|
| 16 |
+
from py.data_fetch import DataFetch
|
| 17 |
+
from py.handle_files import *
|
| 18 |
+
from py.db_storage import DBStorage
|
| 19 |
+
from langchain.callbacks import get_openai_callback
|
| 20 |
+
from PyPDF2 import PdfReader
|
| 21 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 22 |
+
from langchain_community.vectorstores import FAISS
|
| 23 |
+
from langchain.chains.question_answering import load_qa_chain
|
| 24 |
+
from langchain.prompts import PromptTemplate
|
| 25 |
+
import yfinance as yf
|
| 26 |
+
|
| 27 |
+
class StockAdviserConfig:
|
| 28 |
+
def __init__(self):
|
| 29 |
+
load_dotenv()
|
| 30 |
+
self.azure_config = {
|
| 31 |
+
"base_url": os.getenv("AZURE_OPENAI_ENDPOINT"),
|
| 32 |
+
"embedding_base_url": os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT"),
|
| 33 |
+
"model_deployment": os.getenv("AZURE_OPENAI_MODEL_DEPLOYMENT_NAME"),
|
| 34 |
+
"model_name": os.getenv("AZURE_OPENAI_MODEL_NAME"),
|
| 35 |
+
"embedding_deployment": os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME"),
|
| 36 |
+
"embedding_name": os.getenv("AZURE_OPENAI_EMBEDDING_NAME"),
|
| 37 |
+
"api-key": os.getenv("AZURE_OPENAI_API_KEY"),
|
| 38 |
+
"api_version": os.getenv("AZURE_OPENAI_API_VERSION")
|
| 39 |
+
}
|
| 40 |
+
self.models = DottedDict()
|
| 41 |
+
|
| 42 |
+
class StockAdviserUI:
|
| 43 |
+
def __init__(self):
|
| 44 |
+
st.set_page_config(page_title="GEN AI Stock Adviser by Karthikeyen", layout="wide",
|
| 45 |
+
initial_sidebar_state="expanded")
|
| 46 |
+
self._setup_css()
|
| 47 |
+
self._setup_header()
|
| 48 |
+
|
| 49 |
+
def _setup_css(self):
|
| 50 |
+
st.markdown("""
|
| 51 |
+
<style>
|
| 52 |
+
.main-header {
|
| 53 |
+
text-align: center;
|
| 54 |
+
padding-right: 20px;
|
| 55 |
+
padding-left: 20px;
|
| 56 |
+
color: #E9EBED;
|
| 57 |
+
margin-bottom: 2rem;
|
| 58 |
+
}
|
| 59 |
+
.main-header2 {
|
| 60 |
+
text-align: left;
|
| 61 |
+
color: #E9EBED;
|
| 62 |
+
}
|
| 63 |
+
.column-header {
|
| 64 |
+
color: #FFFF9E;
|
| 65 |
+
border-bottom: 2px solid #eee;
|
| 66 |
+
padding-bottom: 10px;
|
| 67 |
+
margin-bottom: 1.5rem;
|
| 68 |
+
}
|
| 69 |
+
.column-header2 {
|
| 70 |
+
color: #CEFFFF;
|
| 71 |
+
padding-top: 5px;
|
| 72 |
+
padding-bottom: 5px;
|
| 73 |
+
}
|
| 74 |
+
.content-section {
|
| 75 |
+
background-color: #f8f9fa;
|
| 76 |
+
padding: 15px;
|
| 77 |
+
border-radius: 5px;
|
| 78 |
+
margin-top: 10px;
|
| 79 |
+
}
|
| 80 |
+
.metric-card {
|
| 81 |
+
background-color: #1E1E1E;
|
| 82 |
+
padding: 1rem;
|
| 83 |
+
border-radius: 8px;
|
| 84 |
+
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);
|
| 85 |
+
margin-bottom: 1rem;
|
| 86 |
+
}
|
| 87 |
+
.metric-title {
|
| 88 |
+
font-size: 0.9rem;
|
| 89 |
+
color: #888;
|
| 90 |
+
margin-bottom: 0.5rem;
|
| 91 |
+
}
|
| 92 |
+
.metric-value {
|
| 93 |
+
font-size: 1.5rem;
|
| 94 |
+
font-weight: bold;
|
| 95 |
+
color: #fff;
|
| 96 |
+
}
|
| 97 |
+
</style>
|
| 98 |
+
""", unsafe_allow_html=True)
|
| 99 |
+
|
| 100 |
+
def _setup_header(self):
|
| 101 |
+
st.markdown("<h1 class='main-header'>RAG Stock Analysis</h1>", unsafe_allow_html=True)
|
| 102 |
+
with st.expander("Available Historical Demo Companies"):
|
| 103 |
+
st.markdown("""
|
| 104 |
+
For Demo purpose, historical data is available only for the below companies:
|
| 105 |
+
- Reliance Industries (RELIANCE)
|
| 106 |
+
- HDFC Bank (HDFCBANK)
|
| 107 |
+
- Hindustan Unilever (HINDUNILVR)
|
| 108 |
+
- Bharti Airtel (BHARTIARTL)
|
| 109 |
+
- Asian Paints (ASIANPAINT)
|
| 110 |
+
- Maruti Suzuki India (MARUTI)
|
| 111 |
+
""", unsafe_allow_html=True)
|
| 112 |
+
|
| 113 |
+
class StockDataVisualizer:
|
| 114 |
+
@staticmethod
|
| 115 |
+
def create_price_chart(df, symbol):
|
| 116 |
+
fig = go.Figure()
|
| 117 |
+
|
| 118 |
+
fig.add_trace(go.Candlestick(
|
| 119 |
+
x=df.index,
|
| 120 |
+
open=df['Open'],
|
| 121 |
+
high=df['High'],
|
| 122 |
+
low=df['Low'],
|
| 123 |
+
close=df['Close'],
|
| 124 |
+
name='OHLC'
|
| 125 |
+
))
|
| 126 |
+
|
| 127 |
+
fig.update_layout(
|
| 128 |
+
title=f'{symbol} Stock Price Movement',
|
| 129 |
+
yaxis_title='Stock Price (INR)',
|
| 130 |
+
template='plotly_dark',
|
| 131 |
+
xaxis_rangeslider_visible=False,
|
| 132 |
+
height=500
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
return fig
|
| 136 |
+
|
| 137 |
+
@staticmethod
|
| 138 |
+
def create_volume_chart(df, symbol):
|
| 139 |
+
fig = go.Figure()
|
| 140 |
+
|
| 141 |
+
fig.add_trace(go.Bar(
|
| 142 |
+
x=df.index,
|
| 143 |
+
y=df['Volume'],
|
| 144 |
+
name='Volume',
|
| 145 |
+
marker_color='rgba(0, 150, 255, 0.6)'
|
| 146 |
+
))
|
| 147 |
+
|
| 148 |
+
fig.update_layout(
|
| 149 |
+
title=f'{symbol} Trading Volume',
|
| 150 |
+
yaxis_title='Volume',
|
| 151 |
+
template='plotly_dark',
|
| 152 |
+
height=300
|
| 153 |
+
)
|
| 154 |
+
|
| 155 |
+
return fig
|
| 156 |
+
|
| 157 |
+
@staticmethod
|
| 158 |
+
def create_sentiment_gauge(sentiment_score):
|
| 159 |
+
fig = go.Figure(go.Indicator(
|
| 160 |
+
mode="gauge+number",
|
| 161 |
+
value=sentiment_score,
|
| 162 |
+
domain={'x': [0, 1], 'y': [0, 1]},
|
| 163 |
+
gauge={
|
| 164 |
+
'axis': {'range': [-1, 1]},
|
| 165 |
+
'bar': {'color': "rgba(0, 150, 255, 0.6)"},
|
| 166 |
+
'steps': [
|
| 167 |
+
{'range': [-1, -0.25], 'color': "red"},
|
| 168 |
+
{'range': [-0.25, 0.25], 'color': "yellow"},
|
| 169 |
+
{'range': [0.25, 1], 'color': "green"}
|
| 170 |
+
]
|
| 171 |
+
},
|
| 172 |
+
title={'text': "Sentiment Score"}
|
| 173 |
+
))
|
| 174 |
+
|
| 175 |
+
fig.update_layout(
|
| 176 |
+
template='plotly_dark',
|
| 177 |
+
height=250
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
return fig
|
| 181 |
+
|
| 182 |
+
class StockAdviser:
|
| 183 |
+
def __init__(self):
|
| 184 |
+
self.config = StockAdviserConfig()
|
| 185 |
+
self.ui = StockAdviserUI()
|
| 186 |
+
self.visualizer = StockDataVisualizer()
|
| 187 |
+
self.client = AzureOpenAI(
|
| 188 |
+
azure_endpoint=self.config.azure_config["base_url"],
|
| 189 |
+
api_key=self.config.azure_config["api-key"],
|
| 190 |
+
api_version="2024-02-01"
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def create_models(self):
|
| 195 |
+
print("creating models")
|
| 196 |
+
llm = AzureChatOpenAI(
|
| 197 |
+
temperature=0,
|
| 198 |
+
api_key=self.config.azure_config["api-key"],
|
| 199 |
+
openai_api_version=self.config.azure_config["api_version"],
|
| 200 |
+
azure_endpoint=self.config.azure_config["base_url"],
|
| 201 |
+
model=self.config.azure_config["model_deployment"],
|
| 202 |
+
validate_base_url=False
|
| 203 |
+
)
|
| 204 |
+
embedding_model = AzureOpenAIEmbeddings(
|
| 205 |
+
api_key=self.config.azure_config["api-key"],
|
| 206 |
+
openai_api_version=self.config.azure_config["api_version"],
|
| 207 |
+
azure_endpoint=self.config.azure_config["embedding_base_url"],
|
| 208 |
+
model=self.config.azure_config["embedding_deployment"]
|
| 209 |
+
)
|
| 210 |
+
self.config.models.llm = llm
|
| 211 |
+
self.config.models.embedding_model = embedding_model
|
| 212 |
+
return self.config.models
|
| 213 |
+
|
| 214 |
+
def get_symbol(self, user_question):
|
| 215 |
+
qna_system_message = """
|
| 216 |
+
You are an assistant to a financial services firm who finds the 'nse company symbol' (assigned to the company in the provided stock market)) of the company in the question provided.
|
| 217 |
+
|
| 218 |
+
User questions will begin with the token: ###Question.
|
| 219 |
+
|
| 220 |
+
Please find the 'nse company symbol' of the company in the question provided. In case of an invalid company, return "NOTICKER".
|
| 221 |
+
|
| 222 |
+
Response format:
|
| 223 |
+
{nse company symbol}
|
| 224 |
+
|
| 225 |
+
Do not mention anything about the context in your final answer. Stricktly respond only the company symbol.
|
| 226 |
+
"""
|
| 227 |
+
|
| 228 |
+
qna_user_message_template = """
|
| 229 |
+
###Question
|
| 230 |
+
{question}
|
| 231 |
+
"""
|
| 232 |
+
|
| 233 |
+
prompt = [
|
| 234 |
+
{'role': 'system', 'content': qna_system_message},
|
| 235 |
+
{'role': 'user', 'content': qna_user_message_template.format(question=user_question)}
|
| 236 |
+
]
|
| 237 |
+
|
| 238 |
+
try:
|
| 239 |
+
response = self.client.chat.completions.create(
|
| 240 |
+
model=self.config.azure_config["model_name"],
|
| 241 |
+
messages=prompt,
|
| 242 |
+
temperature=0
|
| 243 |
+
)
|
| 244 |
+
cmp_tkr = response.choices[0].message.content.strip()
|
| 245 |
+
except Exception as e:
|
| 246 |
+
cmp_tkr = f'Sorry, I encountered the following error: \n {e}'
|
| 247 |
+
st.write("Reply: ", cmp_tkr)
|
| 248 |
+
return
|
| 249 |
+
print(cmp_tkr)
|
| 250 |
+
return cmp_tkr
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
def process_historical_data(self, user_question):
|
| 254 |
+
cmp_tr = self.get_symbol(user_question)
|
| 255 |
+
|
| 256 |
+
# Initialize ChromaDB Database
|
| 257 |
+
chroma_db = DBStorage()
|
| 258 |
+
FAISS_DB_PATH = os.path.join(os.getcwd(), "Stock Sentiment Analysis", "faiss_HD")
|
| 259 |
+
chroma_db.load_vectors(FAISS_DB_PATH)
|
| 260 |
+
context_for_query = chroma_db.get_context_for_query(cmp_tr, k=5)
|
| 261 |
+
|
| 262 |
+
sentiment_response = self._get_sentiment_analysis(context_for_query, cmp_tr)
|
| 263 |
+
self._display_sentiment(sentiment_response)
|
| 264 |
+
|
| 265 |
+
return cmp_tr
|
| 266 |
+
|
| 267 |
+
def display_charts(self,cmp_tr,sentiment_response):
|
| 268 |
+
sentiment = self._extract_between(sentiment_response, "Overall Sentiment:", "Overall Justification:").strip()
|
| 269 |
+
|
| 270 |
+
days = 365
|
| 271 |
+
|
| 272 |
+
print(f"\nFetching {days} days of stock data for {cmp_tr}...")
|
| 273 |
+
df, analysis = self.get_nse_stock_data(cmp_tr, days)
|
| 274 |
+
|
| 275 |
+
print(analysis)
|
| 276 |
+
|
| 277 |
+
# Create metrics cards
|
| 278 |
+
col1, col2, col3 = st.columns(3)
|
| 279 |
+
|
| 280 |
+
# Simulate some metric data (replace with real data in production)
|
| 281 |
+
with col1:
|
| 282 |
+
self._create_metric_card(f"52-Week High on {analysis['week_52_high_date']}",
|
| 283 |
+
f"₹{analysis['week_52_high']:,.2f}",
|
| 284 |
+
self.format_percentage(analysis['pct_from_52w_high']))
|
| 285 |
+
with col2:
|
| 286 |
+
self._create_metric_card(f"52-Week Low on {analysis['week_52_low_date']}",
|
| 287 |
+
f"₹{analysis['week_52_low']:,.2f}",
|
| 288 |
+
self.format_percentage(analysis['pct_from_52w_low']))
|
| 289 |
+
with col3:
|
| 290 |
+
self._create_metric_card("Average Volume",
|
| 291 |
+
f"{int(analysis['avg_volume']):,}",
|
| 292 |
+
f"{self.format_percentage(analysis['volume_pct_diff'])}")
|
| 293 |
+
|
| 294 |
+
# Display price chart
|
| 295 |
+
st.plotly_chart(self.visualizer.create_price_chart(df, cmp_tr))
|
| 296 |
+
|
| 297 |
+
# Display volume chart
|
| 298 |
+
st.plotly_chart(self.visualizer.create_volume_chart(df, cmp_tr))
|
| 299 |
+
|
| 300 |
+
# Display sentiment gauge (simulate sentiment score)
|
| 301 |
+
# Generating random score for Demo purpose
|
| 302 |
+
if sentiment == "Negative":
|
| 303 |
+
sentiment_score = np.random.uniform(-1, -0.75)
|
| 304 |
+
elif sentiment == "Neutral":
|
| 305 |
+
sentiment_score = np.random.uniform(-0.75, 0.25)
|
| 306 |
+
elif sentiment == "Positive":
|
| 307 |
+
sentiment_score = np.random.uniform(0.25, 1)
|
| 308 |
+
else:
|
| 309 |
+
sentiment_score = 0
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
st.plotly_chart(self.visualizer.create_sentiment_gauge(sentiment_score))
|
| 313 |
+
|
| 314 |
+
def get_nse_stock_data(self,symbol, days):
|
| 315 |
+
"""
|
| 316 |
+
Fetch stock data and perform extended analysis including 52-week highs/lows
|
| 317 |
+
and volume comparisons.
|
| 318 |
+
|
| 319 |
+
Args:
|
| 320 |
+
symbol (str): NSE stock symbol (e.g., 'RELIANCE.NS')
|
| 321 |
+
|
| 322 |
+
Returns:
|
| 323 |
+
tuple: (DataFrame of daily data, dict of analysis metrics)
|
| 324 |
+
"""
|
| 325 |
+
try:
|
| 326 |
+
# Add .NS suffix if not present
|
| 327 |
+
if not symbol.endswith('.NS'):
|
| 328 |
+
symbol = f"{symbol}.NS"
|
| 329 |
+
|
| 330 |
+
# Create Ticker object and fetch 1 year of data
|
| 331 |
+
ticker = yf.Ticker(symbol)
|
| 332 |
+
|
| 333 |
+
# Get last 90 days of data
|
| 334 |
+
end_date = datetime.now()
|
| 335 |
+
start_date = end_date - timedelta(days=days)
|
| 336 |
+
df_90d = ticker.history(start=start_date, end=end_date)
|
| 337 |
+
|
| 338 |
+
# Get 1 year of data for 52-week analysis
|
| 339 |
+
start_date_52w = end_date - timedelta(days=365)
|
| 340 |
+
df_52w = ticker.history(start=start_date_52w, end=end_date)
|
| 341 |
+
|
| 342 |
+
# Create main DataFrame with 90-day data
|
| 343 |
+
df = pd.DataFrame({
|
| 344 |
+
'Open': df_90d['Open'],
|
| 345 |
+
'High': df_90d['High'],
|
| 346 |
+
'Low': df_90d['Low'],
|
| 347 |
+
'Close': df_90d['Close'],
|
| 348 |
+
'Volume': df_90d['Volume']
|
| 349 |
+
}, index=df_90d.index)
|
| 350 |
+
|
| 351 |
+
# Round numerical values
|
| 352 |
+
df[['Open', 'High', 'Low', 'Close']] = df[['Open', 'High', 'Low', 'Close']].round(2)
|
| 353 |
+
df['Volume'] = df['Volume'].astype(int)
|
| 354 |
+
|
| 355 |
+
# Get current price (latest close)
|
| 356 |
+
current_price = df['Close'].iloc[-1]
|
| 357 |
+
|
| 358 |
+
# Calculate 52-week metrics
|
| 359 |
+
week_52_high = df_52w['High'].max()
|
| 360 |
+
week_52_low = df_52w['Low'].min()
|
| 361 |
+
|
| 362 |
+
# Calculate percentage differences
|
| 363 |
+
pct_from_52w_high = ((current_price - week_52_high) / week_52_high) * 100
|
| 364 |
+
pct_from_52w_low = ((current_price - week_52_low) / week_52_low) * 100
|
| 365 |
+
|
| 366 |
+
# Volume analysis
|
| 367 |
+
current_volume = df['Volume'].iloc[-1]
|
| 368 |
+
avg_volume = df_52w['Volume'].mean()
|
| 369 |
+
volume_pct_diff = ((current_volume - avg_volume) / avg_volume) * 100
|
| 370 |
+
|
| 371 |
+
# Find dates of 52-week high and low
|
| 372 |
+
high_date = df_52w[df_52w['High'] == week_52_high].index[0].strftime('%Y-%m-%d')
|
| 373 |
+
low_date = df_52w[df_52w['Low'] == week_52_low].index[0].strftime('%Y-%m-%d')
|
| 374 |
+
|
| 375 |
+
# Create analysis metrics dictionary
|
| 376 |
+
analysis = {
|
| 377 |
+
'current_price': current_price,
|
| 378 |
+
'week_52_high': week_52_high,
|
| 379 |
+
'week_52_high_date': high_date,
|
| 380 |
+
'week_52_low': week_52_low,
|
| 381 |
+
'week_52_low_date': low_date,
|
| 382 |
+
'pct_from_52w_high': pct_from_52w_high,
|
| 383 |
+
'pct_from_52w_low': pct_from_52w_low,
|
| 384 |
+
'current_volume': current_volume,
|
| 385 |
+
'avg_volume': avg_volume,
|
| 386 |
+
'volume_pct_diff': volume_pct_diff
|
| 387 |
+
}
|
| 388 |
+
|
| 389 |
+
print(analysis)
|
| 390 |
+
|
| 391 |
+
return df, analysis
|
| 392 |
+
|
| 393 |
+
except Exception as e:
|
| 394 |
+
print(f"Error fetching data: {str(e)}")
|
| 395 |
+
return None, None
|
| 396 |
+
|
| 397 |
+
def format_percentage(self, value):
|
| 398 |
+
"""Format percentage with + or - sign"""
|
| 399 |
+
return f"+{value:.2f}%" if value > 0 else f"{value:.2f}%"
|
| 400 |
+
|
| 401 |
+
|
| 402 |
+
def process_realtime_data(self, cmp_tr):
|
| 403 |
+
if cmp_tr == "NOTICKER":
|
| 404 |
+
st.write("No valid company in the query.")
|
| 405 |
+
return
|
| 406 |
+
|
| 407 |
+
data_fetch = DataFetch()
|
| 408 |
+
query_context = []
|
| 409 |
+
|
| 410 |
+
# Create a placeholder for the current source
|
| 411 |
+
source_status = st.empty()
|
| 412 |
+
|
| 413 |
+
# Collect data from various sources
|
| 414 |
+
data_sources = [
|
| 415 |
+
("Reddit", data_fetch.collect_reddit_data),
|
| 416 |
+
("YouTube", data_fetch.collect_youtube_data),
|
| 417 |
+
("Tumblr", data_fetch.collect_tumblr_data),
|
| 418 |
+
("Google News", data_fetch.collect_google_news),
|
| 419 |
+
("Financial Times", data_fetch.collect_financial_times),
|
| 420 |
+
("Bloomberg", data_fetch.collect_bloomberg),
|
| 421 |
+
("Reuters", data_fetch.collect_reuters)
|
| 422 |
+
]
|
| 423 |
+
|
| 424 |
+
st_status = ""
|
| 425 |
+
|
| 426 |
+
for source_name, collect_func in data_sources:
|
| 427 |
+
st_status = st_status.replace("Currently fetching", "Fetched") + f"📡 Currently fetching data from: {source_name} \n \n"
|
| 428 |
+
source_status.write(st_status, unsafe_allow_html=True)
|
| 429 |
+
print(f"Collecting {source_name} Data")
|
| 430 |
+
query_context.extend(collect_func(cmp_tr))
|
| 431 |
+
|
| 432 |
+
st_status = st_status.replace("Currently fetching", "Fetched") + "📡 Currently fetching data from: Serper - StockNews, Yahoo Finance, Insider Monkey, Investor's Business Daily, etc."
|
| 433 |
+
source_status.write(st_status, unsafe_allow_html=True)
|
| 434 |
+
print("Collecting Serper Data")
|
| 435 |
+
query_context.extend(data_fetch.search_news(cmp_tr, 100))
|
| 436 |
+
|
| 437 |
+
# Process collected data
|
| 438 |
+
db_store = DBStorage()
|
| 439 |
+
FAISS_DB_PATH = os.path.join(os.getcwd(), "Stock Sentiment Analysis", "faiss_RD")
|
| 440 |
+
db_store.embed_vectors(to_documents(query_context), FAISS_DB_PATH)
|
| 441 |
+
|
| 442 |
+
db_store.load_vectors(FAISS_DB_PATH)
|
| 443 |
+
context_for_query = db_store.get_context_for_query(cmp_tr, k=5)
|
| 444 |
+
|
| 445 |
+
sentiment_response = self._get_sentiment_analysis(context_for_query, cmp_tr, is_realtime=True)
|
| 446 |
+
self._display_sentiment(sentiment_response)
|
| 447 |
+
|
| 448 |
+
# Clear the status message after all sources are processed
|
| 449 |
+
source_status.empty()
|
| 450 |
+
|
| 451 |
+
return sentiment_response
|
| 452 |
+
|
| 453 |
+
|
| 454 |
+
def _create_metric_card(self, title, value, change):
|
| 455 |
+
st.markdown(f"""
|
| 456 |
+
<div class="metric-card">
|
| 457 |
+
<div class="metric-title">{title}</div>
|
| 458 |
+
<div class="metric-value">{value}</div>
|
| 459 |
+
<div style="color: {'green' if float(change.strip('%')) > 0 else 'red'}">
|
| 460 |
+
{change}
|
| 461 |
+
</div>
|
| 462 |
+
</div>
|
| 463 |
+
""", unsafe_allow_html=True)
|
| 464 |
+
|
| 465 |
+
def _get_sentiment_analysis(self, context, cmp_tr, is_realtime=False):
|
| 466 |
+
system_message = self._get_system_prompt(is_realtime)
|
| 467 |
+
user_message = f"""
|
| 468 |
+
###Context
|
| 469 |
+
Here are some documents that are relevant to the question mentioned below.
|
| 470 |
+
{context}
|
| 471 |
+
|
| 472 |
+
###Question
|
| 473 |
+
{cmp_tr}
|
| 474 |
+
"""
|
| 475 |
+
|
| 476 |
+
try:
|
| 477 |
+
response = self.client.chat.completions.create(
|
| 478 |
+
model=self.config.azure_config["model_name"],
|
| 479 |
+
messages=[
|
| 480 |
+
{'role': 'system', 'content': system_message},
|
| 481 |
+
{'role': 'user', 'content': user_message}
|
| 482 |
+
],
|
| 483 |
+
temperature=0
|
| 484 |
+
)
|
| 485 |
+
return response.choices[0].message.content.strip()
|
| 486 |
+
except Exception as e:
|
| 487 |
+
return f'Sorry, I encountered the following error: \n {e}'
|
| 488 |
+
|
| 489 |
+
def _display_sentiment(self, prediction):
|
| 490 |
+
sentiment = self._extract_between(prediction, "Overall Sentiment:", "Overall Justification:").strip()
|
| 491 |
+
print("Sentiment: "+ sentiment)
|
| 492 |
+
print(prediction)
|
| 493 |
+
if sentiment == "Positive":
|
| 494 |
+
st.success("Positive : Go Ahead...!")
|
| 495 |
+
elif sentiment == "Negative":
|
| 496 |
+
st.warning("Negative : Don't...!")
|
| 497 |
+
elif sentiment == "Neutral":
|
| 498 |
+
st.info("Neutral : Need to Analyse further")
|
| 499 |
+
st.write(prediction, unsafe_allow_html=True)
|
| 500 |
+
|
| 501 |
+
@staticmethod
|
| 502 |
+
def _extract_between(text: str, start: str, end: str) -> str:
|
| 503 |
+
try:
|
| 504 |
+
start_pos = text.find(start)
|
| 505 |
+
if start_pos == -1:
|
| 506 |
+
return ""
|
| 507 |
+
start_pos += len(start)
|
| 508 |
+
end_pos = text.find(end, start_pos)
|
| 509 |
+
if end_pos == -1:
|
| 510 |
+
return ""
|
| 511 |
+
return text[start_pos:end_pos]
|
| 512 |
+
except (AttributeError, TypeError):
|
| 513 |
+
return ""
|
| 514 |
+
|
| 515 |
+
@staticmethod
|
| 516 |
+
def _get_system_prompt(is_realtime):
|
| 517 |
+
"""
|
| 518 |
+
Returns the appropriate system prompt based on whether it's realtime or historical data analysis.
|
| 519 |
+
|
| 520 |
+
Args:
|
| 521 |
+
is_realtime (bool): Flag indicating if this is for realtime data analysis
|
| 522 |
+
|
| 523 |
+
Returns:
|
| 524 |
+
str: The complete system prompt for the sentiment analysis
|
| 525 |
+
"""
|
| 526 |
+
base_prompt = """
|
| 527 |
+
You are an assistant to a financial services firm who answers user queries on Stock Investments.
|
| 528 |
+
User input will have the context required by you to answer user questions.
|
| 529 |
+
This context will begin with the token: ###Context.
|
| 530 |
+
The context contains references to specific portions of a document relevant to the user query.
|
| 531 |
+
|
| 532 |
+
User questions will begin with the token: ###Question.
|
| 533 |
+
|
| 534 |
+
First, find the 'nse company symbol' of the related company in the question provided.
|
| 535 |
+
Your task is to perform sentiment analysis on the content part of each documents provided in the Context, which discuss a company identified by its 'nse company symbol'. The goal is to determine the overall sentiment expressed across all documents and provide an overall justification. Based on the sentiment analysis, give a recommendation on whether the company's stock should be purchased.
|
| 536 |
+
|
| 537 |
+
Step-by-Step Instructions:
|
| 538 |
+
1. See if the question is "NOTICKER". If so, give response and don't proceed.
|
| 539 |
+
2. If the company in question is not found in the context, give the corresponding response and don't proceed.
|
| 540 |
+
3. Read the Context: Carefully read the content parts of each document provided in the list of Documents.
|
| 541 |
+
4. Determine Overall Sentiment: Analyze the sentiment across all documents and categorize the overall sentiment as Positive, Negative, or Neutral.
|
| 542 |
+
5. Provide Overall Justification: Summarize the key points from all documents to justify the overall sentiment.
|
| 543 |
+
6. Stock Advice: Based on the overall sentiment and justification, provide a recommendation on whether the company's stock should be purchased.
|
| 544 |
+
|
| 545 |
+
Example Analysis:
|
| 546 |
+
Context:
|
| 547 |
+
[Document(metadata={'platform': 'Moneycontrol', 'company': 'ASIANPAINT', 'ingestion_timestamp': '2024-10-25T17:13:42.970099', 'word_count': 134}, page_content="{'title': 'Asian Paints launches Neo Bharat Latex Paint to tap on booming demand', 'content': 'The company, which is the leading player in India, touts the new segment to being affordable, offering over 1000 shades for consumers.'}"), Document(metadata={'platform': 'MarketsMojo', 'company': 'ASIANPAINT', 'ingestion_timestamp': '2024-10-25T17:13:42.970099', 'word_count': 128}, page_content="{'title': 'Asian Paints Ltd. Stock Performance Shows Positive Trend, Outperforms Sector by 0.9%', 'content': 'Asian Paints Ltd., a leading player in the paints industry, has seen a positive trend in its stock performance on July 10, 2024.'}"), Document(metadata={'platform': 'Business Standard', 'company': 'ASIANPAINT', 'ingestion_timestamp': '2024-10-25T17:13:42.970099', 'word_count': 138}, page_content="{'title': 'Asian Paints, Indigo Paints, Kansai gain up to 5% on falling oil prices', 'content': 'Shares of paint companies were trading higher on Wednesday, rising up to 5 per cent on the BSE, on the back of a fall in crude oil prices.'}")]
|
| 548 |
+
"""
|
| 549 |
+
|
| 550 |
+
if is_realtime:
|
| 551 |
+
response_format = """
|
| 552 |
+
Response Formats:
|
| 553 |
+
Only If the Question is 'NOTICKER':
|
| 554 |
+
No valid company in the query.
|
| 555 |
+
|
| 556 |
+
Else, If the context does not have relevent data for the company:
|
| 557 |
+
Respond "Company {Company name} {nse company symbol}({symbol}) details not found in the RealTime Data".
|
| 558 |
+
"""
|
| 559 |
+
else:
|
| 560 |
+
response_format = """
|
| 561 |
+
Response Formats:
|
| 562 |
+
If the Question value is "NOTICKER":
|
| 563 |
+
No valid company in the query.
|
| 564 |
+
|
| 565 |
+
If the context does not have relevent data for the company (Question value):
|
| 566 |
+
Respond "Company {Company name} {nse company symbol}({symbol}) details not found in the Historical Data".
|
| 567 |
+
"""
|
| 568 |
+
|
| 569 |
+
common_format = """
|
| 570 |
+
else, If the content parts of context has relevent data:
|
| 571 |
+
Overall Sentiment: [Positive/Negative/Neutral] <line break>
|
| 572 |
+
Overall Justification: [Detailed analysis of why the sentiment was chosen, summarizing key points from the documents] <line break>
|
| 573 |
+
Stock Advice: [Clear recommendation on whether to purchase the stock, based on the sentiment analysis and justification]
|
| 574 |
+
|
| 575 |
+
Please follow the steps to analyze the sentiment of each document's content; and strictly follow exact structure illustrated in above example response to provide an overall sentiment, justification and give stock purchase advice. Provide only Overall response, don't provide documentwise response or any note. Decorate the response with html/css tags.
|
| 576 |
+
"""
|
| 577 |
+
|
| 578 |
+
return base_prompt + response_format + common_format
|
| 579 |
+
|
| 580 |
+
|
| 581 |
+
def main():
|
| 582 |
+
adviser = StockAdviser()
|
| 583 |
+
|
| 584 |
+
|
| 585 |
+
# Create sidebar for filters and settings
|
| 586 |
+
st.logo(
|
| 587 |
+
"https://cdn.shopify.com/s/files/1/0153/8513/3156/files/info_omac.png?v=1595717396",
|
| 588 |
+
size="large"
|
| 589 |
+
)
|
| 590 |
+
|
| 591 |
+
with st.sidebar:
|
| 592 |
+
# About the Application
|
| 593 |
+
st.markdown("""
|
| 594 |
+
<div style="background-color: #2d2d2d; padding: 20px; border-radius: 10px; box-shadow: 0 4px 8px rgba(255, 255, 255, 0.1);">
|
| 595 |
+
<h2 style="color: #e6e6e6; text-align: Left;">About the Application</h2>
|
| 596 |
+
<p style="font-size: 16px; color: #cccccc; line-height: 1.6; text-align: justify;">
|
| 597 |
+
This application provides investment managers with daily insights into social media and news sentiment surrounding specific stocks and companies.
|
| 598 |
+
By analyzing posts and articles across major platforms such as <strong>Reddit</strong>, <strong>YouTube</strong>, <strong>Tumblr</strong>, <strong>Google News</strong>,
|
| 599 |
+
<strong>Financial Times</strong>, <strong>Bloomberg</strong>, <strong>Reuters</strong>, and <strong>Wall Street Journal</strong> (WSJ), it detects shifts
|
| 600 |
+
in public and media opinion that may impact stock performance.
|
| 601 |
+
</p>
|
| 602 |
+
<p style="font-size: 16px; color: #cccccc; line-height: 1.6; text-align: justify;">
|
| 603 |
+
Additionally, sources like <strong>Serper</strong> provide data from <strong>StockNews</strong>, <strong>Yahoo Finance</strong>, <strong>Insider Monkey</strong>,
|
| 604 |
+
<strong>Investor's Business Daily</strong>, and others. Using advanced AI techniques, the application generates a sentiment report that serves as a leading indicator,
|
| 605 |
+
helping managers make informed, timely adjustments to their positions. With daily updates and historical trend analysis, it empowers users to stay ahead in a fast-paced,
|
| 606 |
+
sentiment-driven market.
|
| 607 |
+
</p>
|
| 608 |
+
</div>
|
| 609 |
+
|
| 610 |
+
""", unsafe_allow_html=True)
|
| 611 |
+
# Sidebar Footer (Floating Footer)
|
| 612 |
+
st.sidebar.markdown("""
|
| 613 |
+
<div style="position: fixed; bottom: 5px; padding: 5px; background-color: #1f1f1f; border-radius: 5px; text-align: left;">
|
| 614 |
+
<p style="color: #cccccc; font-size: 14px;">
|
| 615 |
+
Developed by: <a href="https://www.linkedin.com/in/karthikeyen92/" target="_blank" style="color: #4DA8DA; text-decoration: none;">Karthikeyen Packirisamy</a>
|
| 616 |
+
</p>
|
| 617 |
+
</div>
|
| 618 |
+
""", unsafe_allow_html=True)
|
| 619 |
+
|
| 620 |
+
|
| 621 |
+
|
| 622 |
+
# Main content
|
| 623 |
+
cmp_tr = "NOTICKER"
|
| 624 |
+
st.header("Ask a question")
|
| 625 |
+
user_question = st.text_input("Ask a stock advice related question", key="user_question")
|
| 626 |
+
|
| 627 |
+
col1, col2 = st.columns(2)
|
| 628 |
+
|
| 629 |
+
with col1:
|
| 630 |
+
st.markdown("<h2 class='column-header'>Historical Analysis</h2>", unsafe_allow_html=True)
|
| 631 |
+
with st.container():
|
| 632 |
+
if user_question:
|
| 633 |
+
cmp_tr = adviser.process_historical_data(user_question)
|
| 634 |
+
|
| 635 |
+
with col2:
|
| 636 |
+
st.markdown("<h2 class='column-header'>Real-Time Analysis</h2>", unsafe_allow_html=True)
|
| 637 |
+
with st.container():
|
| 638 |
+
if user_question:
|
| 639 |
+
sentiment_response = adviser.process_realtime_data(cmp_tr)
|
| 640 |
+
|
| 641 |
+
if (str(cmp_tr) is not "NOTICKER"):
|
| 642 |
+
with st.container():
|
| 643 |
+
if user_question:
|
| 644 |
+
adviser.display_charts(cmp_tr,sentiment_response)
|
| 645 |
+
|
| 646 |
+
st.markdown("---")
|
| 647 |
+
st.markdown("<p style='text-align: center; color: #666;'>© 2024 EY</p>", unsafe_allow_html=True)
|
| 648 |
+
|
| 649 |
+
if __name__ == "__main__":
|
| 650 |
+
main()
|
chroma_db/chroma.sqlite3
ADDED
|
Binary file (168 kB). View file
|
|
|
faiss_HD/index.faiss
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:21f90f9597d9b256565bc742f8759189c447bf5be0c895f1eab5fd101c4a862e
|
| 3 |
+
size 5394477
|
faiss_HD/index.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3f71f9ccd673b0e19777d7b506ee2aad6681830765ea9fb033e7ff5acf5ee142
|
| 3 |
+
size 366007
|
faiss_RD/index.faiss
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1d7be7becea5e20fea3eeae7e02278e46d35eec95ebb0ec718e1492af86384a2
|
| 3 |
+
size 1425453
|
faiss_RD/index.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:668a312f77a5e10ddf4a339b4ce66c27f824bbd2c017105562ed87115d9c1331
|
| 3 |
+
size 84595
|
files/analysed_data.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e39af0e4aa0d68a1913fe71de5940e5ee6ca955823fc474ad2f442ffa2b26811
|
| 3 |
+
size 794212
|
files/ingested_data.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e8e765ea9bb535c56374bc8cc5a92b12ba6ee19f60bacca6aac7bf9a0fb638dd
|
| 3 |
+
size 737464
|
files/labels.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a0478b55762921f2d931893f59493062499fb59113770ce8a61cbe80980f0339
|
| 3 |
+
size 48
|
files/social_media_data.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
files/social_media_data.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
files/social_media_data.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:df4e596eac08af0ff840ee263840b5c49285e6288947fb38fa1dcbece28a03a2
|
| 3 |
+
size 670285
|
main.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
from py.data_fetch import *
|
| 3 |
+
from py.handle_files import *
|
| 4 |
+
from py.db_storage import *
|
| 5 |
+
|
| 6 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 7 |
+
from langchain.schema import Document
|
| 8 |
+
from typing import List, Dict, Any
|
| 9 |
+
warnings.filterwarnings("ignore")
|
| 10 |
+
|
| 11 |
+
stock="nse"
|
| 12 |
+
# stock="nasdaq"
|
| 13 |
+
|
| 14 |
+
# Collect Data
|
| 15 |
+
data_fetch = DataFetch()
|
| 16 |
+
data_fetch.load_company_list("Stock Sentiment Analysis/Resources/"+stock+"_companies.csv")
|
| 17 |
+
social_media_data = data_fetch.collect_data()
|
| 18 |
+
|
| 19 |
+
# Save collected data to Files
|
| 20 |
+
create_files(social_media_data)
|
| 21 |
+
|
| 22 |
+
# Fetch saved Social Media Data
|
| 23 |
+
social_media_document = fetch_social_media_data()
|
| 24 |
+
print(len(social_media_document))
|
| 25 |
+
|
| 26 |
+
# Samples `n` entries for each unique `"platform"` and `"company"` metadata combination from the input `Document[]`.
|
| 27 |
+
social_media_document_samples = sample_documents(social_media_document, 20)
|
| 28 |
+
print(len(social_media_document_samples))
|
| 29 |
+
|
| 30 |
+
# Delete and clear any ChromaDB databases
|
| 31 |
+
clear_db()
|
| 32 |
+
|
| 33 |
+
# Initialise ChromaDB Database
|
| 34 |
+
chroma_db = DBStorage()
|
| 35 |
+
|
| 36 |
+
# Create chunks and embeddings in the database
|
| 37 |
+
FAISS_DB_PATH = os.path.join(os.getcwd(), "Stock Sentiment Analysis", "faiss_HD")
|
| 38 |
+
chroma_db.embed_vectors(social_media_document_samples, FAISS_DB_PATH)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
py/data_fetch.py
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from datetime import datetime, timedelta
|
| 3 |
+
from typing import Dict, List
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import tweepy
|
| 6 |
+
import praw
|
| 7 |
+
import googleapiclient.discovery
|
| 8 |
+
import pytumblr
|
| 9 |
+
from gnews import GNews
|
| 10 |
+
import requests
|
| 11 |
+
from bs4 import BeautifulSoup
|
| 12 |
+
import time
|
| 13 |
+
import math
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class DataFetch:
|
| 17 |
+
def __init__(self):
|
| 18 |
+
# Load company list and set date range
|
| 19 |
+
self.end_date = datetime.now()
|
| 20 |
+
self.start_date = self.end_date - timedelta(days=1)
|
| 21 |
+
|
| 22 |
+
# Initialize API clients
|
| 23 |
+
self.tumblr_client = pytumblr.TumblrRestClient(
|
| 24 |
+
os.getenv("TUMBLR_CONSUMER_KEY"),
|
| 25 |
+
os.getenv("TUMBLR_CONSUMER_SECRET"),
|
| 26 |
+
os.getenv("TUMBLR_OAUTH_TOKEN"),
|
| 27 |
+
os.getenv("TUMBLR_OAUTH_SECRET")
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
twitter_auth = tweepy.OAuthHandler(os.getenv("TWITTER_API_KEY"), os.getenv("TWITTER_API_SECRET"))
|
| 31 |
+
twitter_auth.set_access_token(os.getenv("TWITTER_ACCESS_TOKEN"), os.getenv("TWITTER_ACCESS_TOKEN_SECRET"))
|
| 32 |
+
self.twitter_api = tweepy.API(twitter_auth)
|
| 33 |
+
|
| 34 |
+
self.reddit = praw.Reddit(
|
| 35 |
+
client_id=os.getenv("REDDIT_CLIENT_ID"),
|
| 36 |
+
client_secret=os.getenv("REDDIT_CLIENT_SECRET"),
|
| 37 |
+
user_agent="Sentiment Analysis Bot 1.0"
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
self.youtube = googleapiclient.discovery.build("youtube", "v3", developerKey=os.getenv("YOUTUBE_API_KEY"))
|
| 41 |
+
|
| 42 |
+
def load_company_list(self, file_path: str) -> List[str]:
|
| 43 |
+
self.company_list = pd.read_csv(file_path)['company_ticker'].tolist()
|
| 44 |
+
|
| 45 |
+
def collect_data(self) -> List[Dict]:
|
| 46 |
+
all_data = []
|
| 47 |
+
|
| 48 |
+
for company in self.company_list:
|
| 49 |
+
print(f"{company}:")
|
| 50 |
+
all_data.extend(self._collect_social_media_data(company))
|
| 51 |
+
all_data.extend(self._collect_news_data(company))
|
| 52 |
+
|
| 53 |
+
return all_data
|
| 54 |
+
|
| 55 |
+
def _collect_social_media_data(self, query: str) -> List[Dict]:
|
| 56 |
+
social_data = []
|
| 57 |
+
|
| 58 |
+
print("Collecting Reddit Data")
|
| 59 |
+
social_data.extend(self.collect_reddit_data(query))
|
| 60 |
+
|
| 61 |
+
print("Collecting YouTube Data")
|
| 62 |
+
social_data.extend(self.collect_youtube_data(query))
|
| 63 |
+
|
| 64 |
+
print("Collecting Tumblr Data")
|
| 65 |
+
social_data.extend(self.collect_tumblr_data(query))
|
| 66 |
+
|
| 67 |
+
return social_data
|
| 68 |
+
|
| 69 |
+
def _collect_news_data(self, query: str) -> List[Dict]:
|
| 70 |
+
news_data = []
|
| 71 |
+
|
| 72 |
+
print("Collecting Google News Data")
|
| 73 |
+
news_data.extend(self.collect_google_news(query))
|
| 74 |
+
|
| 75 |
+
print("Collecting Financial Times Data")
|
| 76 |
+
news_data.extend(self.collect_financial_times(query))
|
| 77 |
+
|
| 78 |
+
print("Collecting Bloomberg Data")
|
| 79 |
+
news_data.extend(self.collect_bloomberg(query))
|
| 80 |
+
|
| 81 |
+
print("Collecting Reuters Data")
|
| 82 |
+
news_data.extend(self.collect_reuters(query))
|
| 83 |
+
|
| 84 |
+
print("Collecting WSJ Data")
|
| 85 |
+
# news_data.extend(self.collect_wsj(query))
|
| 86 |
+
|
| 87 |
+
print("Collecting Serper Data - StockNews, Yahoo Finance, Insider Monkey, Investor's Business Daily, etc.")
|
| 88 |
+
news_data.extend(self.search_news(query))
|
| 89 |
+
|
| 90 |
+
return news_data
|
| 91 |
+
|
| 92 |
+
def collect_tumblr_data(self, query: str) -> List[Dict]:
|
| 93 |
+
posts = self.tumblr_client.tagged(query)
|
| 94 |
+
return [{"platform": "Tumblr", "company": query, "page_content": {
|
| 95 |
+
"title": post["blog"]["title"], "content": post["blog"]["description"]}} for post in posts]
|
| 96 |
+
|
| 97 |
+
def collect_twitter_data(self, query: str) -> List[Dict]:
|
| 98 |
+
tweets = []
|
| 99 |
+
for tweet in tweepy.Cursor(self.twitter_api.search_tweets, q=query, lang="en",
|
| 100 |
+
since=self.start_date, until=self.end_date).items(100):
|
| 101 |
+
tweets.append(tweet._json)
|
| 102 |
+
return [{"platform": "Twitter", "company": query, "page_content": tweet} for tweet in tweets]
|
| 103 |
+
|
| 104 |
+
def collect_reddit_data(self, query: str) -> List[Dict]:
|
| 105 |
+
posts = []
|
| 106 |
+
subreddit = self.reddit.subreddit("all")
|
| 107 |
+
for post in subreddit.search(query, sort="new", time_filter="day"):
|
| 108 |
+
post_date = datetime.fromtimestamp(post.created_utc)
|
| 109 |
+
if self.start_date <= post_date <= self.end_date:
|
| 110 |
+
posts.append({"platform": "Reddit", "company": query, "page_content": {
|
| 111 |
+
"title": post.title, "content": post.selftext}})
|
| 112 |
+
return posts
|
| 113 |
+
|
| 114 |
+
def collect_youtube_data(self, query: str) -> List[Dict]:
|
| 115 |
+
request = self.youtube.search().list(
|
| 116 |
+
q=query, type="video", part="id,snippet", maxResults=50,
|
| 117 |
+
publishedAfter=self.start_date.isoformat() + "Z", publishedBefore=self.end_date.isoformat() + "Z"
|
| 118 |
+
)
|
| 119 |
+
response = request.execute()
|
| 120 |
+
return [{"platform": "YouTube", "company": query, "page_content": {
|
| 121 |
+
"title": item["snippet"]["title"], "content": item["snippet"]["description"]}} for item in response['items']]
|
| 122 |
+
|
| 123 |
+
def collect_google_news(self, query: str) -> List[Dict]:
|
| 124 |
+
google_news = GNews(language='en', country='US', start_date=self.start_date, end_date=self.end_date)
|
| 125 |
+
articles = google_news.get_news(query)
|
| 126 |
+
return [{"platform": "Google News", "company": query, "page_content": {
|
| 127 |
+
"title": article["title"], "content": article["description"]}} for article in articles]
|
| 128 |
+
|
| 129 |
+
def collect_financial_times(self, query: str) -> List[Dict]:
|
| 130 |
+
url = f"https://www.ft.com/search?q={query}&dateTo={self.end_date.strftime('%Y-%m-%d')}&dateFrom={self.start_date.strftime('%Y-%m-%d')}"
|
| 131 |
+
response = requests.get(url)
|
| 132 |
+
soup = BeautifulSoup(response.content, 'html.parser')
|
| 133 |
+
articles = soup.find_all('div', class_='o-teaser__content')
|
| 134 |
+
return [{"platform": "Financial Times", "company": query, "page_content": {
|
| 135 |
+
"title": a.find('div', class_='o-teaser__heading').text.strip(),
|
| 136 |
+
"content": a.find('p', class_='o-teaser__standfirst').text.strip() if a.find('p', class_='o-teaser__standfirst') else ''
|
| 137 |
+
}} for a in articles]
|
| 138 |
+
|
| 139 |
+
def collect_bloomberg(self, query: str) -> List[Dict]:
|
| 140 |
+
url = f"https://www.bloomberg.com/search?query={query}"
|
| 141 |
+
response = requests.get(url)
|
| 142 |
+
soup = BeautifulSoup(response.content, 'html.parser')
|
| 143 |
+
articles = soup.find_all('div', class_='storyItem__aaf871c1')
|
| 144 |
+
return [{"platform": "Bloomberg", "company": query, "page_content": {
|
| 145 |
+
"title": a.find('a', class_='headline__3a97424d').text.strip(),
|
| 146 |
+
"content": a.find('p', class_='summary__483358e1').text.strip() if a.find('p', class_='summary__483358e1') else ''
|
| 147 |
+
}} for a in articles]
|
| 148 |
+
|
| 149 |
+
def collect_reuters(self, query: str) -> List[Dict]:
|
| 150 |
+
articles = []
|
| 151 |
+
base_url = "https://www.reuters.com/site-search/"
|
| 152 |
+
page = 1
|
| 153 |
+
while True:
|
| 154 |
+
url = f"{base_url}?blob={query}&page={page}"
|
| 155 |
+
response = requests.get(url)
|
| 156 |
+
soup = BeautifulSoup(response.content, 'html.parser')
|
| 157 |
+
results = soup.find_all('li', class_='search-result__item')
|
| 158 |
+
if not results:
|
| 159 |
+
break
|
| 160 |
+
for result in results:
|
| 161 |
+
date_elem = result.find('time', class_='search-result__timestamp')
|
| 162 |
+
if date_elem:
|
| 163 |
+
date = datetime.strptime(date_elem['datetime'], "%Y-%m-%dT%H:%M:%SZ")
|
| 164 |
+
if self.start_date <= date <= self.end_date:
|
| 165 |
+
articles.append({"platform": "Reuters", "company": query, "page_content": {
|
| 166 |
+
"title": result.find('h3', class_='search-result__headline').text.strip(),
|
| 167 |
+
"content": result.find('p', class_='search-result__excerpt').text.strip()
|
| 168 |
+
}})
|
| 169 |
+
elif date < self.start_date:
|
| 170 |
+
return articles
|
| 171 |
+
page += 1
|
| 172 |
+
time.sleep(1)
|
| 173 |
+
return articles
|
| 174 |
+
|
| 175 |
+
def collect_wsj(self, query: str) -> List[Dict]:
|
| 176 |
+
articles = []
|
| 177 |
+
base_url = "https://www.wsj.com/search"
|
| 178 |
+
page = 1
|
| 179 |
+
while True:
|
| 180 |
+
params = {
|
| 181 |
+
'query': query, 'isToggleOn': 'true', 'operator': 'AND', 'sort': 'date-desc',
|
| 182 |
+
'duration': 'custom', 'startDate': self.start_date.strftime('%Y/%m/%d'),
|
| 183 |
+
'endDate': self.end_date.strftime('%Y/%m/%d'), 'page': page
|
| 184 |
+
}
|
| 185 |
+
response = requests.get(base_url, params=params)
|
| 186 |
+
soup = BeautifulSoup(response.content, 'html.parser')
|
| 187 |
+
results = soup.find_all('article', class_='WSJTheme--story--XB4V2mLz')
|
| 188 |
+
if not results:
|
| 189 |
+
break
|
| 190 |
+
for result in results:
|
| 191 |
+
date_elem = result.find('p', class_='WSJTheme--timestamp--22sfkNDv')
|
| 192 |
+
if date_elem:
|
| 193 |
+
date = datetime.strptime(date_elem.text.strip(), "%B %d, %Y")
|
| 194 |
+
if self.start_date <= date <= self.end_date:
|
| 195 |
+
articles.append({"platform": "Wall Street Journal", "company": query, "page_content": {
|
| 196 |
+
"title": result.find('h3', class_='WSJTheme--headline--unZqjb45').text.strip(),
|
| 197 |
+
"content": result.find('p', class_='WSJTheme--summary--lmOXEsbN').text.strip()
|
| 198 |
+
}})
|
| 199 |
+
elif date < self.start_date:
|
| 200 |
+
return articles
|
| 201 |
+
page += 1
|
| 202 |
+
time.sleep(1)
|
| 203 |
+
return articles
|
| 204 |
+
|
| 205 |
+
def search_news(self, query: str,cnt=300) -> List[Dict]:
|
| 206 |
+
articles = []
|
| 207 |
+
num_results = cnt
|
| 208 |
+
|
| 209 |
+
headers = {
|
| 210 |
+
"X-API-KEY": os.getenv("SERP_API_KEY"),
|
| 211 |
+
"Content-Type": "application/json"
|
| 212 |
+
}
|
| 213 |
+
payload = {"q": f"{query} company news",
|
| 214 |
+
"num": num_results,
|
| 215 |
+
"dateRestrict": 14
|
| 216 |
+
}
|
| 217 |
+
response = requests.post(
|
| 218 |
+
"https://google.serper.dev/news",
|
| 219 |
+
headers=headers,
|
| 220 |
+
json=payload
|
| 221 |
+
)
|
| 222 |
+
# print(response)
|
| 223 |
+
if response.status_code == 200:
|
| 224 |
+
results = response.json().get("news", [])
|
| 225 |
+
for result in results:
|
| 226 |
+
articles.append({"platform": result["source"], "company": query, "page_content": {
|
| 227 |
+
"title": result["title"],
|
| 228 |
+
"content": result["snippet"]
|
| 229 |
+
}})
|
| 230 |
+
return articles
|
| 231 |
+
|
| 232 |
+
# Usage Example
|
| 233 |
+
if __name__ == "__main__":
|
| 234 |
+
analyzer = DataFetch("company_list.csv")
|
| 235 |
+
data = analyzer.collect_data()
|
| 236 |
+
# Here, data would contain all collected sentiment data for the given companies
|
py/db_storage.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import warnings
|
| 3 |
+
import shutil
|
| 4 |
+
from langchain_openai import AzureChatOpenAI, AzureOpenAIEmbeddings
|
| 5 |
+
from langchain_community.vectorstores import Chroma
|
| 6 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 7 |
+
from langchain.chains import RetrievalQA
|
| 8 |
+
from langchain_community.document_loaders import PyPDFLoader, Docx2txtLoader, TextLoader, WikipediaLoader
|
| 9 |
+
from typing import List, Optional, Dict, Any
|
| 10 |
+
from langchain.schema import Document
|
| 11 |
+
import chromadb
|
| 12 |
+
# from langchain_community.embeddings.sentence_transformer import (SentenceTransformerEmbeddings)
|
| 13 |
+
from langchain_community.vectorstores import FAISS
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
warnings.filterwarnings("ignore")
|
| 18 |
+
CHROMA_DB_PATH = os.path.join(os.getcwd(), "Stock Sentiment Analysis", "chroma_db")
|
| 19 |
+
# FAISS_DB_PATH = os.path.join(os.getcwd(), "Stock Sentiment Analysis", "faiss_index")
|
| 20 |
+
tesla_10k_collection = 'tesla-10k-2019-to-2023'
|
| 21 |
+
embedding_model = ""
|
| 22 |
+
# embedding_model = SentenceTransformerEmbeddings(model_name='thenlper/gte-large')
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class DBStorage:
|
| 26 |
+
def __init__(self):
|
| 27 |
+
self.CHROMA_PATH = CHROMA_DB_PATH
|
| 28 |
+
self.vector_store = None
|
| 29 |
+
self.client = chromadb.PersistentClient(path=CHROMA_DB_PATH)
|
| 30 |
+
print(self.client.list_collections())
|
| 31 |
+
self.collection = self.client.get_or_create_collection(name=tesla_10k_collection)
|
| 32 |
+
print(self.collection.count())
|
| 33 |
+
|
| 34 |
+
def chunk_data(self, data, chunk_size=10000):
|
| 35 |
+
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=0)
|
| 36 |
+
return text_splitter.split_documents(data)
|
| 37 |
+
|
| 38 |
+
def create_embeddings(self, chunks):
|
| 39 |
+
embeddings = AzureOpenAIEmbeddings(
|
| 40 |
+
model=os.getenv("AZURE_OPENAI_EMBEDDING_NAME"),
|
| 41 |
+
api_key=os.getenv("AZURE_OPENAI_EMBEDDING_API_KEY"),
|
| 42 |
+
api_version=os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION"),
|
| 43 |
+
azure_endpoint=os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT")
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
self.vector_store = Chroma.from_documents(documents=chunks,
|
| 47 |
+
# embedding=embeddings,
|
| 48 |
+
embedding=embedding_model,
|
| 49 |
+
collection_name=tesla_10k_collection,
|
| 50 |
+
persist_directory=self.CHROMA_PATH)
|
| 51 |
+
print("Here B")
|
| 52 |
+
self.collection = self.client.get_or_create_collection(name=tesla_10k_collection)
|
| 53 |
+
print("here"+str(self.collection.count()))
|
| 54 |
+
# return self.vector_store
|
| 55 |
+
|
| 56 |
+
def create_vector_store(self, chunks):
|
| 57 |
+
embeddings = AzureOpenAIEmbeddings(
|
| 58 |
+
model=os.getenv("AZURE_OPENAI_EMBEDDING_NAME"),
|
| 59 |
+
api_key=os.getenv("AZURE_OPENAI_EMBEDDING_API_KEY"),
|
| 60 |
+
api_version=os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION"),
|
| 61 |
+
azure_endpoint=os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT")
|
| 62 |
+
)
|
| 63 |
+
return FAISS.from_documents(chunks, embedding=embeddings)
|
| 64 |
+
# vector_store.save_local(FAISS_DB_PATH)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def load_embeddings(self):
|
| 68 |
+
embeddings = AzureOpenAIEmbeddings(
|
| 69 |
+
model=os.getenv("AZURE_OPENAI_EMBEDDING_NAME"),
|
| 70 |
+
api_key=os.getenv("AZURE_OPENAI_EMBEDDING_API_KEY"),
|
| 71 |
+
api_version=os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION"),
|
| 72 |
+
azure_endpoint=os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT")
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
self.vector_store = Chroma(collection_name=tesla_10k_collection,
|
| 76 |
+
persist_directory=CHROMA_DB_PATH,
|
| 77 |
+
# embedding_function=embeddings
|
| 78 |
+
embedding_function=embedding_model
|
| 79 |
+
)
|
| 80 |
+
print("loaded vector store: ")
|
| 81 |
+
print(self.vector_store)
|
| 82 |
+
# return self.vector_store
|
| 83 |
+
|
| 84 |
+
def load_vectors(self,FAISS_DB_PATH):
|
| 85 |
+
embeddings = AzureOpenAIEmbeddings(
|
| 86 |
+
model=os.getenv("AZURE_OPENAI_EMBEDDING_NAME"),
|
| 87 |
+
api_key=os.getenv("AZURE_OPENAI_EMBEDDING_API_KEY"),
|
| 88 |
+
api_version=os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION"),
|
| 89 |
+
azure_endpoint=os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT")
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
self.vector_store = FAISS.load_local(folder_path=FAISS_DB_PATH,
|
| 93 |
+
embeddings=embeddings,
|
| 94 |
+
allow_dangerous_deserialization=True)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def fetch_documents(self, metadata_filter: Dict[str, Any]) -> List[Document]:
|
| 99 |
+
results = self.collection.get(
|
| 100 |
+
where=metadata_filter,
|
| 101 |
+
include=["documents", "metadatas"],
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
documents = []
|
| 105 |
+
for content, metadata in zip(results['documents'][0], results['metadatas'][0]):
|
| 106 |
+
documents.append(Document(page_content=content, metadata=metadata))
|
| 107 |
+
|
| 108 |
+
return documents
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def get_context_for_query(self, question, k=3):
|
| 112 |
+
print(self.vector_store)
|
| 113 |
+
# if not self.vector_store:
|
| 114 |
+
# raise ValueError("Vector store not initialized. Call create_embeddings() or load_embeddings() first.")
|
| 115 |
+
|
| 116 |
+
# relevant_document_chunks=self.fetch_documents({"company": question})
|
| 117 |
+
|
| 118 |
+
# retriever = self.vector_store.as_retriever(search_type='similarity', search_kwargs={'k': k})
|
| 119 |
+
# relevant_document_chunks = retriever.get_relevant_documents(question)
|
| 120 |
+
|
| 121 |
+
relevant_document_chunks = self.vector_store.similarity_search(question)
|
| 122 |
+
# chain = get_conversational_chain(models.llm)
|
| 123 |
+
# response = chain({"input_documents": docs, "question": user_question}, return_only_outputs=True)
|
| 124 |
+
# print(response)
|
| 125 |
+
|
| 126 |
+
print(relevant_document_chunks)
|
| 127 |
+
context_list = [d.page_content for d in relevant_document_chunks]
|
| 128 |
+
context_for_query = ". ".join(context_list)
|
| 129 |
+
print("context_for_query: "+ str(len(context_for_query)))
|
| 130 |
+
|
| 131 |
+
return context_for_query
|
| 132 |
+
|
| 133 |
+
# def ask_question(self, question, k=3):
|
| 134 |
+
# if not self.vector_store:
|
| 135 |
+
# raise ValueError("Vector store not initialized. Call create_embeddings() or load_embeddings() first.")
|
| 136 |
+
|
| 137 |
+
# llm = AzureChatOpenAI(
|
| 138 |
+
# temperature=0,
|
| 139 |
+
# api_key=os.getenv("AZURE_OPENAI_API_KEY"),
|
| 140 |
+
# api_version=os.getenv("AZURE_OPENAI_API_VERSION"),
|
| 141 |
+
# azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
|
| 142 |
+
# model=os.getenv("AZURE_OPENAI_MODEL_NAME")
|
| 143 |
+
# )
|
| 144 |
+
|
| 145 |
+
# retriever = self.vector_store.as_retriever(search_type='similarity', search_kwargs={'k': k})
|
| 146 |
+
# chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
|
| 147 |
+
|
| 148 |
+
# return chain.invoke(question)
|
| 149 |
+
|
| 150 |
+
def embed_vectors(self,social_media_document,FAISS_DB_PATH):
|
| 151 |
+
print("here A")
|
| 152 |
+
chunks = self.chunk_data(social_media_document)
|
| 153 |
+
print(len(chunks))
|
| 154 |
+
# self.create_embeddings(chunks)
|
| 155 |
+
vector_store = self.create_vector_store(chunks)
|
| 156 |
+
check_and_delete(FAISS_DB_PATH)
|
| 157 |
+
vector_store.save_local(FAISS_DB_PATH)
|
| 158 |
+
|
| 159 |
+
def check_and_delete(PATH):
|
| 160 |
+
if os.path.isdir(PATH):
|
| 161 |
+
shutil.rmtree(PATH, onexc=lambda func, path, exc: os.chmod(path, 0o777))
|
| 162 |
+
print(f'Deleted {PATH}')
|
| 163 |
+
|
| 164 |
+
def clear_db():
|
| 165 |
+
check_and_delete(CHROMA_DB_PATH)
|
| 166 |
+
# check_and_delete(FAISS_DB_PATH)
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
# Usage example
|
| 170 |
+
if __name__ == "__main__":
|
| 171 |
+
qa_system = DBStorage()
|
| 172 |
+
|
| 173 |
+
# Load and process document
|
| 174 |
+
social_media_document = []
|
| 175 |
+
chunks = qa_system.chunk_data(social_media_document)
|
| 176 |
+
|
| 177 |
+
# Create embeddings
|
| 178 |
+
qa_system.create_embeddings(chunks)
|
| 179 |
+
|
| 180 |
+
# # Ask a question
|
| 181 |
+
# question = 'Summarize the whole input in 150 words'
|
| 182 |
+
# answer = qa_system.ask_question(question)
|
| 183 |
+
# print(answer)
|
py/handle_files.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
|
| 3 |
+
from datetime import datetime
|
| 4 |
+
import json
|
| 5 |
+
import os
|
| 6 |
+
import pickle
|
| 7 |
+
from typing import List
|
| 8 |
+
from langchain.schema import Document
|
| 9 |
+
import pandas as pd
|
| 10 |
+
|
| 11 |
+
def create_files(social_media_data):
|
| 12 |
+
folder_path = 'Stock Sentiment Analysis/files'
|
| 13 |
+
|
| 14 |
+
if not os.path.exists(folder_path):
|
| 15 |
+
os.makedirs(folder_path)
|
| 16 |
+
|
| 17 |
+
# Save dictionary to a file
|
| 18 |
+
with open(folder_path+'/social_media_data.json', 'w') as f:
|
| 19 |
+
json.dump(social_media_data, f)
|
| 20 |
+
|
| 21 |
+
# Convert the data to a pandas DataFrame
|
| 22 |
+
df = pd.DataFrame(social_media_data)
|
| 23 |
+
df.head()
|
| 24 |
+
|
| 25 |
+
# Exporting the data to a CSV file
|
| 26 |
+
file_path = folder_path+"/social_media_data.csv"
|
| 27 |
+
df.to_csv(file_path, index=False)
|
| 28 |
+
|
| 29 |
+
df.to_pickle(folder_path+"/social_media_data.pkl")
|
| 30 |
+
|
| 31 |
+
def fetch_social_media_data():
|
| 32 |
+
with open('Stock Sentiment Analysis/files/social_media_data.json', 'r') as file:
|
| 33 |
+
data = json.load(file)
|
| 34 |
+
social_media_document = []
|
| 35 |
+
for item in data:
|
| 36 |
+
social_media_document.append(Document(
|
| 37 |
+
page_content=str(item["page_content"]),
|
| 38 |
+
metadata={"platform":item["platform"],
|
| 39 |
+
"company":item["company"],
|
| 40 |
+
"ingestion_timestamp":datetime.now().isoformat(),
|
| 41 |
+
"word_count":len(item["page_content"]["content"])
|
| 42 |
+
}))
|
| 43 |
+
return social_media_document
|
| 44 |
+
|
| 45 |
+
def save_ingested_data(ingested_data):
|
| 46 |
+
# Save the list to a file
|
| 47 |
+
with open('Stock Sentiment Analysis/files/ingested_data.pkl', 'wb') as file:
|
| 48 |
+
pickle.dump(ingested_data, file)
|
| 49 |
+
|
| 50 |
+
def save_analysed_data(analysed_data):
|
| 51 |
+
# Save the list to a file
|
| 52 |
+
with open('Stock Sentiment Analysis/files/analysed_data.pkl', 'wb') as file:
|
| 53 |
+
pickle.dump(analysed_data, file)
|
| 54 |
+
|
| 55 |
+
def get_ingested_data():
|
| 56 |
+
# Load the list from the file
|
| 57 |
+
with open('Stock Sentiment Analysis/files/ingested_data.pkl', 'rb') as file:
|
| 58 |
+
loaded_documents = pickle.load(file)
|
| 59 |
+
return loaded_documents
|
| 60 |
+
|
| 61 |
+
def get_analysed_data():
|
| 62 |
+
# Load the list from the file
|
| 63 |
+
with open('Stock Sentiment Analysis/files/analysed_data.pkl', 'rb') as file:
|
| 64 |
+
loaded_documents = pickle.load(file)
|
| 65 |
+
return loaded_documents
|
| 66 |
+
|
| 67 |
+
def sample_documents(documents: List[Document], n: int) -> List[Document]:
|
| 68 |
+
"""
|
| 69 |
+
Samples `n` entries for each unique `"platform"` and `"company"` metadata combination from the input `Document[]`.
|
| 70 |
+
|
| 71 |
+
Args:
|
| 72 |
+
documents (List[Document]): The input list of `Document` objects.
|
| 73 |
+
n (int): The number of entries to sample for each unique metadata combination.
|
| 74 |
+
|
| 75 |
+
Returns:
|
| 76 |
+
List[Document]: A new list of `Document` objects, with `n` entries per unique metadata combination.
|
| 77 |
+
"""
|
| 78 |
+
# Create a dictionary to store the sampled documents per metadata combination
|
| 79 |
+
sampled_docs = {}
|
| 80 |
+
|
| 81 |
+
for doc in documents:
|
| 82 |
+
combo = (doc.metadata["platform"], doc.metadata["company"])
|
| 83 |
+
if combo not in sampled_docs:
|
| 84 |
+
sampled_docs[combo] = []
|
| 85 |
+
|
| 86 |
+
# Add the document to the list for its metadata combination, up to n entries
|
| 87 |
+
if len(sampled_docs[combo]) < n:
|
| 88 |
+
sampled_docs[combo].append(doc)
|
| 89 |
+
|
| 90 |
+
# Flatten the dictionary into a single list
|
| 91 |
+
return [doc for docs in sampled_docs.values() for doc in docs]
|
| 92 |
+
|
| 93 |
+
def to_documents(data) -> List[Document]:
|
| 94 |
+
social_media_document = []
|
| 95 |
+
for item in data:
|
| 96 |
+
social_media_document.append(Document(
|
| 97 |
+
page_content=str(item["page_content"]),
|
| 98 |
+
metadata={"platform":item["platform"],
|
| 99 |
+
"company":item["company"],
|
| 100 |
+
"ingestion_timestamp":datetime.now().isoformat(),
|
| 101 |
+
"word_count":len(item["page_content"]["content"])
|
| 102 |
+
}))
|
| 103 |
+
return social_media_document
|
requirements.txt
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
openai
|
| 2 |
+
python-dotenv
|
| 3 |
+
datasets
|
| 4 |
+
numpy
|
| 5 |
+
tqdm
|
| 6 |
+
scikit-learn
|
| 7 |
+
pip-system-certs
|
| 8 |
+
# evaluate
|
| 9 |
+
# bert-score
|
| 10 |
+
langchain-openai
|
| 11 |
+
langchain-community
|
| 12 |
+
langchain-text-splitters
|
| 13 |
+
chromadb
|
| 14 |
+
langchain
|
| 15 |
+
beautifulsoup4
|
| 16 |
+
pypdf
|
| 17 |
+
wikipedia
|
| 18 |
+
plotly
|
| 19 |
+
ragas
|
| 20 |
+
renumics-spotlight
|
| 21 |
+
streamlit
|
| 22 |
+
# shutil
|
| 23 |
+
dotted_dict
|
| 24 |
+
PyPDF2
|
| 25 |
+
# faiss-gpu
|
| 26 |
+
faiss-cpu
|
| 27 |
+
torch
|
| 28 |
+
transformers
|
| 29 |
+
sentence-transformers
|
| 30 |
+
accelerate
|
| 31 |
+
gradio
|
| 32 |
+
pandas
|
| 33 |
+
tweepy
|
| 34 |
+
praw
|
| 35 |
+
google-api-python-client
|
| 36 |
+
pytumblr
|
| 37 |
+
gnews
|
| 38 |
+
bs4
|
| 39 |
+
requests
|
| 40 |
+
certifi
|
| 41 |
+
plotly
|
| 42 |
+
pandas_datareader
|
| 43 |
+
yfinance
|