Spaces:
Running
on
A10G

Running
on
A10G

Adds code to host LLaVA-LLaMA-3 demo on HF space.
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- LICENSE +201 -0
- README.md +6 -7
- app.py +96 -0
- cog.yaml +37 -0
- docs/Customize_Component.md +20 -0
- docs/Data.md +29 -0
- docs/Evaluation.md +167 -0
- docs/Finetune_Custom_Data.md +37 -0
- docs/Intel.md +7 -0
- docs/LLaVA_Bench.md +31 -0
- docs/LLaVA_from_LLaMA2.md +29 -0
- docs/LoRA.md +46 -0
- docs/MODEL_ZOO.md +150 -0
- docs/ScienceQA.md +53 -0
- docs/Windows.md +27 -0
- docs/macOS.md +29 -0
- examples/extreme_ironing.jpg +0 -0
- examples/waterview.jpg +0 -0
- images/llava_example_cmp.png +0 -0
- images/llava_logo.png +0 -0
- images/llava_v1_5_radar.jpg +0 -0
- llava/__init__.py +1 -0
- llava/constants.py +13 -0
- llava/conversation.py +409 -0
- llava/eval/eval_gpt_review.py +113 -0
- llava/eval/eval_gpt_review_bench.py +121 -0
- llava/eval/eval_gpt_review_visual.py +118 -0
- llava/eval/eval_pope.py +81 -0
- llava/eval/eval_science_qa.py +114 -0
- llava/eval/eval_science_qa_gpt4.py +104 -0
- llava/eval/eval_science_qa_gpt4_requery.py +149 -0
- llava/eval/eval_textvqa.py +65 -0
- llava/eval/generate_webpage_data_from_table.py +111 -0
- llava/eval/m4c_evaluator.py +334 -0
- llava/eval/model_qa.py +64 -0
- llava/eval/model_vqa.py +101 -0
- llava/eval/model_vqa_loader.py +144 -0
- llava/eval/model_vqa_mmbench.py +160 -0
- llava/eval/model_vqa_science.py +111 -0
- llava/eval/qa_baseline_gpt35.py +74 -0
- llava/eval/run_llava.py +145 -0
- llava/eval/summarize_gpt_review.py +60 -0
- llava/eval/table/answer/answer_alpaca-13b.jsonl +80 -0
- llava/eval/table/answer/answer_bard.jsonl +0 -0
- llava/eval/table/answer/answer_gpt35.jsonl +0 -0
- llava/eval/table/answer/answer_llama-13b.jsonl +80 -0
- llava/eval/table/answer/answer_vicuna-13b.jsonl +0 -0
- llava/eval/table/caps_boxes_coco2014_val_80.jsonl +80 -0
- llava/eval/table/model.jsonl +5 -0
- llava/eval/table/prompt.jsonl +4 -0
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,13 +1,12 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 4.
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
-
license:
|
| 11 |
---
|
| 12 |
|
| 13 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: LLaVA++
|
| 3 |
+
emoji: 👁
|
| 4 |
+
colorFrom: green
|
| 5 |
+
colorTo: yellow
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 4.16.0
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
+
license: apache-2.0
|
| 11 |
---
|
| 12 |
|
|
|
app.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import os
|
| 3 |
+
import argparse
|
| 4 |
+
import time
|
| 5 |
+
import subprocess
|
| 6 |
+
|
| 7 |
+
import llava.serve.gradio_web_server as gws
|
| 8 |
+
|
| 9 |
+
# Execute the pip install command with additional options
|
| 10 |
+
subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'git+https://github.com/huggingface/transformers@a98c41798cf6ed99e1ff17e3792d6e06a2ff2ff3', '-U'])
|
| 11 |
+
|
| 12 |
+
def start_controller():
|
| 13 |
+
print("Starting the controller")
|
| 14 |
+
controller_command = [
|
| 15 |
+
sys.executable,
|
| 16 |
+
"-m",
|
| 17 |
+
"llava.serve.controller",
|
| 18 |
+
"--host",
|
| 19 |
+
"0.0.0.0",
|
| 20 |
+
"--port",
|
| 21 |
+
"10000",
|
| 22 |
+
]
|
| 23 |
+
print(controller_command)
|
| 24 |
+
return subprocess.Popen(controller_command)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def start_worker(model_path: str, bits=16):
|
| 28 |
+
print(f"Starting the model worker for the model {model_path}")
|
| 29 |
+
model_name = model_path.strip("/").split("/")[-1]
|
| 30 |
+
assert bits in [4, 8, 16], "It can be only loaded with 16-bit, 8-bit, and 4-bit."
|
| 31 |
+
if bits != 16:
|
| 32 |
+
model_name += f"-{bits}bit"
|
| 33 |
+
worker_command = [
|
| 34 |
+
sys.executable,
|
| 35 |
+
"-m",
|
| 36 |
+
"llava.serve.model_worker",
|
| 37 |
+
"--host",
|
| 38 |
+
"0.0.0.0",
|
| 39 |
+
"--controller",
|
| 40 |
+
"http://localhost:10000",
|
| 41 |
+
"--model-path",
|
| 42 |
+
model_path,
|
| 43 |
+
"--model-name",
|
| 44 |
+
model_name,
|
| 45 |
+
]
|
| 46 |
+
if bits != 16:
|
| 47 |
+
worker_command += [f"--load-{bits}bit"]
|
| 48 |
+
print(worker_command)
|
| 49 |
+
return subprocess.Popen(worker_command)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
if __name__ == "__main__":
|
| 53 |
+
parser = argparse.ArgumentParser()
|
| 54 |
+
parser.add_argument("--host", type=str, default="0.0.0.0")
|
| 55 |
+
parser.add_argument("--port", type=int)
|
| 56 |
+
parser.add_argument("--controller-url", type=str, default="http://localhost:10000")
|
| 57 |
+
parser.add_argument("--concurrency-count", type=int, default=5)
|
| 58 |
+
parser.add_argument("--model-list-mode", type=str, default="reload", choices=["once", "reload"])
|
| 59 |
+
parser.add_argument("--share", action="store_true")
|
| 60 |
+
parser.add_argument("--moderate", action="store_true")
|
| 61 |
+
parser.add_argument("--embed", action="store_true")
|
| 62 |
+
gws.args = parser.parse_args()
|
| 63 |
+
gws.models = []
|
| 64 |
+
|
| 65 |
+
print(f"args: {gws.args}")
|
| 66 |
+
|
| 67 |
+
model_path = "MBZUAI/LLaVA-Meta-Llama-3-8B-Instruct-FT"
|
| 68 |
+
bits = 16
|
| 69 |
+
concurrency_count = int(os.getenv("concurrency_count", 5))
|
| 70 |
+
|
| 71 |
+
controller_proc = start_controller()
|
| 72 |
+
worker_proc = start_worker(model_path, bits=bits)
|
| 73 |
+
|
| 74 |
+
# Wait for worker and controller to start
|
| 75 |
+
time.sleep(10)
|
| 76 |
+
|
| 77 |
+
exit_status = 0
|
| 78 |
+
try:
|
| 79 |
+
demo = gws.build_demo(embed_mode=False, cur_dir='./', concurrency_count=concurrency_count)
|
| 80 |
+
demo.queue(
|
| 81 |
+
status_update_rate=10,
|
| 82 |
+
api_open=False
|
| 83 |
+
).launch(
|
| 84 |
+
server_name=gws.args.host,
|
| 85 |
+
server_port=gws.args.port,
|
| 86 |
+
share=gws.args.share
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
except Exception as e:
|
| 90 |
+
print(e)
|
| 91 |
+
exit_status = 1
|
| 92 |
+
finally:
|
| 93 |
+
worker_proc.kill()
|
| 94 |
+
controller_proc.kill()
|
| 95 |
+
|
| 96 |
+
sys.exit(exit_status)
|
cog.yaml
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Configuration for Cog ⚙️
|
| 2 |
+
# Reference: https://github.com/replicate/cog/blob/main/docs/yaml.md
|
| 3 |
+
|
| 4 |
+
build:
|
| 5 |
+
gpu: true
|
| 6 |
+
|
| 7 |
+
python_version: "3.11"
|
| 8 |
+
|
| 9 |
+
python_packages:
|
| 10 |
+
- "torch==2.0.1"
|
| 11 |
+
- "accelerate==0.21.0"
|
| 12 |
+
- "bitsandbytes==0.41.0"
|
| 13 |
+
- "deepspeed==0.9.5"
|
| 14 |
+
- "einops-exts==0.0.4"
|
| 15 |
+
- "einops==0.6.1"
|
| 16 |
+
- "gradio==3.35.2"
|
| 17 |
+
- "gradio_client==0.2.9"
|
| 18 |
+
- "httpx==0.24.0"
|
| 19 |
+
- "markdown2==2.4.10"
|
| 20 |
+
- "numpy==1.26.0"
|
| 21 |
+
- "peft==0.4.0"
|
| 22 |
+
- "scikit-learn==1.2.2"
|
| 23 |
+
- "sentencepiece==0.1.99"
|
| 24 |
+
- "shortuuid==1.0.11"
|
| 25 |
+
- "timm==0.6.13"
|
| 26 |
+
- "tokenizers==0.13.3"
|
| 27 |
+
- "torch==2.0.1"
|
| 28 |
+
- "torchvision==0.15.2"
|
| 29 |
+
- "transformers==4.31.0"
|
| 30 |
+
- "wandb==0.15.12"
|
| 31 |
+
- "wavedrom==2.0.3.post3"
|
| 32 |
+
- "Pygments==2.16.1"
|
| 33 |
+
run:
|
| 34 |
+
- curl -o /usr/local/bin/pget -L "https://github.com/replicate/pget/releases/download/v0.0.3/pget" && chmod +x /usr/local/bin/pget
|
| 35 |
+
|
| 36 |
+
# predict.py defines how predictions are run on your model
|
| 37 |
+
predict: "predict.py:Predictor"
|
docs/Customize_Component.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Customize Components in LLaVA
|
| 2 |
+
|
| 3 |
+
This is an initial guide on how to replace the LLMs, visual encoders, etc. with your choice of components.
|
| 4 |
+
|
| 5 |
+
## LLM
|
| 6 |
+
|
| 7 |
+
It is quite simple to swap out LLaMA to any other LLMs. You can refer to our implementation of [`llava_llama.py`](https://raw.githubusercontent.com/haotian-liu/LLaVA/main/llava/model/language_model/llava_llama.py) for an example of how to replace the LLM.
|
| 8 |
+
|
| 9 |
+
Although it may seem that it still needs ~100 lines of code, most of them are copied from the original `llama.py` from HF. The only part that is different is to insert some lines for processing the multimodal inputs.
|
| 10 |
+
|
| 11 |
+
In `forward` function, you can see that we call `self.prepare_inputs_labels_for_multimodal` to process the multimodal inputs. This function is defined in `LlavaMetaForCausalLM` and you just need to insert it into the `forward` function of your LLM.
|
| 12 |
+
|
| 13 |
+
In `prepare_inputs_for_generation` function, you can see that we add `images` to the `model_inputs`. This is because we need to pass the images to the LLM during generation.
|
| 14 |
+
|
| 15 |
+
These are basically all the changes you need to make to replace the LLM.
|
| 16 |
+
|
| 17 |
+
## Visual Encoder
|
| 18 |
+
|
| 19 |
+
You can check out [`clip_encoder.py`](https://github.com/haotian-liu/LLaVA/blob/main/llava/model/multimodal_encoder/clip_encoder.py) on how we implement the CLIP visual encoder.
|
| 20 |
+
|
docs/Data.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Data
|
| 2 |
+
|
| 3 |
+
| Data file name | Size |
|
| 4 |
+
| --- | ---: |
|
| 5 |
+
| [llava_instruct_150k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/llava_instruct_150k.json) | 229 MB |
|
| 6 |
+
| [llava_instruct_80k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/llava_instruct_80k.json) | 229 MB |
|
| 7 |
+
| [conversation_58k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/conversation_58k.json) | 126 MB |
|
| 8 |
+
| [detail_23k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/detail_23k.json) | 20.5 MB |
|
| 9 |
+
| [complex_reasoning_77k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/complex_reasoning_77k.json) | 79.6 MB |
|
| 10 |
+
|
| 11 |
+
### Pretraining Dataset
|
| 12 |
+
The pretraining dataset used in this release is a subset of CC-3M dataset, filtered with a more balanced concept coverage distribution. Please see [here](https://huggingface.co/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K) for a detailed description of the dataset structure and how to download the images.
|
| 13 |
+
|
| 14 |
+
If you already have CC-3M dataset on your disk, the image names follow this format: `GCC_train_000000000.jpg`. You may edit the `image` field correspondingly if necessary.
|
| 15 |
+
|
| 16 |
+
| Data | Chat File | Meta Data | Size |
|
| 17 |
+
| --- | --- | --- | ---: |
|
| 18 |
+
| CC-3M Concept-balanced 595K | [chat.json](https://huggingface.co/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K/blob/main/chat.json) | [metadata.json](https://huggingface.co/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K/blob/main/metadata.json) | 211 MB
|
| 19 |
+
| LAION/CC/SBU BLIP-Caption Concept-balanced 558K | [blip_laion_cc_sbu_558k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain/blob/main/blip_laion_cc_sbu_558k.json) | [metadata.json](#) | 181 MB
|
| 20 |
+
|
| 21 |
+
**Important notice**: Upon the request from the community, as ~15% images of the original CC-3M dataset are no longer accessible, we upload [`images.zip`](https://huggingface.co/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K/blob/main/images.zip) for better reproducing our work in research community. It must not be used for any other purposes. The use of these images must comply with the CC-3M license. This may be taken down at any time when requested by the original CC-3M dataset owner or owners of the referenced images.
|
| 22 |
+
|
| 23 |
+
### GPT-4 Prompts
|
| 24 |
+
|
| 25 |
+
We provide our prompts and few-shot samples for GPT-4 queries, to better facilitate research in this domain. Please check out the [`prompts`](https://github.com/haotian-liu/LLaVA/tree/main/playground/data/prompts) folder for three kinds of questions: conversation, detail description, and complex reasoning.
|
| 26 |
+
|
| 27 |
+
They are organized in a format of `system_message.txt` for system message, pairs of `abc_caps.txt` for few-shot sample user input, and `abc_conv.txt` for few-shot sample reference output.
|
| 28 |
+
|
| 29 |
+
Note that you may find them in different format. For example, `conversation` is in `jsonl`, and detail description is answer-only. The selected format in our preliminary experiments works slightly better than a limited set of alternatives that we tried: `jsonl`, more natural format, answer-only. If interested, you may try other variants or conduct more careful study in this. Contributions are welcomed!
|
docs/Evaluation.md
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Evaluation
|
| 2 |
+
|
| 3 |
+
In LLaVA-1.5, we evaluate models on a diverse set of 12 benchmarks. To ensure the reproducibility, we evaluate the models with greedy decoding. We do not evaluate using beam search to make the inference process consistent with the chat demo of real-time outputs.
|
| 4 |
+
|
| 5 |
+
Currently, we mostly utilize the official toolkit or server for the evaluation.
|
| 6 |
+
|
| 7 |
+
## Evaluate on Custom Datasets
|
| 8 |
+
|
| 9 |
+
You can evaluate LLaVA on your custom datasets by converting your dataset to LLaVA's jsonl format, and evaluate using [`model_vqa.py`](https://github.com/haotian-liu/LLaVA/blob/main/llava/eval/model_vqa.py).
|
| 10 |
+
|
| 11 |
+
Below we provide a general guideline for evaluating datasets with some common formats.
|
| 12 |
+
|
| 13 |
+
1. Short-answer (e.g. VQAv2, MME).
|
| 14 |
+
|
| 15 |
+
```
|
| 16 |
+
<question>
|
| 17 |
+
Answer the question using a single word or phrase.
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
2. Option-only for multiple-choice (e.g. MMBench, SEED-Bench).
|
| 21 |
+
|
| 22 |
+
```
|
| 23 |
+
<question>
|
| 24 |
+
A. <option_1>
|
| 25 |
+
B. <option_2>
|
| 26 |
+
C. <option_3>
|
| 27 |
+
D. <option_4>
|
| 28 |
+
Answer with the option's letter from the given choices directly.
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
3. Natural QA (e.g. LLaVA-Bench, MM-Vet).
|
| 32 |
+
|
| 33 |
+
No postprocessing is needed.
|
| 34 |
+
|
| 35 |
+
## Scripts
|
| 36 |
+
|
| 37 |
+
Before preparing task-specific data, **you MUST first download [eval.zip](https://drive.google.com/file/d/1atZSBBrAX54yYpxtVVW33zFvcnaHeFPy/view?usp=sharing)**. It contains custom annotations, scripts, and the prediction files with LLaVA v1.5. Extract to `./playground/data/eval`. This also provides a general structure for all datasets.
|
| 38 |
+
|
| 39 |
+
### VQAv2
|
| 40 |
+
|
| 41 |
+
1. Download [`test2015`](http://images.cocodataset.org/zips/test2015.zip) and put it under `./playground/data/eval/vqav2`.
|
| 42 |
+
2. Multi-GPU inference.
|
| 43 |
+
```Shell
|
| 44 |
+
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 bash scripts/v1_5/eval/vqav2.sh
|
| 45 |
+
```
|
| 46 |
+
3. Submit the results to the [evaluation server](https://eval.ai/web/challenges/challenge-page/830/my-submission): `./playground/data/eval/vqav2/answers_upload`.
|
| 47 |
+
|
| 48 |
+
### GQA
|
| 49 |
+
|
| 50 |
+
1. Download the [data](https://cs.stanford.edu/people/dorarad/gqa/download.html) and [evaluation scripts](https://cs.stanford.edu/people/dorarad/gqa/evaluate.html) following the official instructions and put under `./playground/data/eval/gqa/data`. You may need to modify `eval.py` as [this](https://gist.github.com/haotian-liu/db6eddc2a984b4cbcc8a7f26fd523187) due to the missing assets in the GQA v1.2 release.
|
| 51 |
+
2. Multi-GPU inference.
|
| 52 |
+
```Shell
|
| 53 |
+
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 bash scripts/v1_5/eval/gqa.sh
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
### VisWiz
|
| 57 |
+
|
| 58 |
+
1. Download [`test.json`](https://vizwiz.cs.colorado.edu/VizWiz_final/vqa_data/Annotations.zip) and extract [`test.zip`](https://vizwiz.cs.colorado.edu/VizWiz_final/images/test.zip) to `test`. Put them under `./playground/data/eval/vizwiz`.
|
| 59 |
+
2. Single-GPU inference.
|
| 60 |
+
```Shell
|
| 61 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/vizwiz.sh
|
| 62 |
+
```
|
| 63 |
+
3. Submit the results to the [evaluation server](https://eval.ai/web/challenges/challenge-page/2185/my-submission): `./playground/data/eval/vizwiz/answers_upload`.
|
| 64 |
+
|
| 65 |
+
### ScienceQA
|
| 66 |
+
|
| 67 |
+
1. Under `./playground/data/eval/scienceqa`, download `images`, `pid_splits.json`, `problems.json` from the `data/scienceqa` folder of the ScienceQA [repo](https://github.com/lupantech/ScienceQA).
|
| 68 |
+
2. Single-GPU inference and evaluate.
|
| 69 |
+
```Shell
|
| 70 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/sqa.sh
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
### TextVQA
|
| 74 |
+
|
| 75 |
+
1. Download [`TextVQA_0.5.1_val.json`](https://dl.fbaipublicfiles.com/textvqa/data/TextVQA_0.5.1_val.json) and [images](https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip) and extract to `./playground/data/eval/textvqa`.
|
| 76 |
+
2. Single-GPU inference and evaluate.
|
| 77 |
+
```Shell
|
| 78 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/textvqa.sh
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
### POPE
|
| 82 |
+
|
| 83 |
+
1. Download `coco` from [POPE](https://github.com/AoiDragon/POPE/tree/e3e39262c85a6a83f26cf5094022a782cb0df58d/output/coco) and put under `./playground/data/eval/pope`.
|
| 84 |
+
2. Single-GPU inference and evaluate.
|
| 85 |
+
```Shell
|
| 86 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/pope.sh
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
### MME
|
| 90 |
+
|
| 91 |
+
1. Download the data following the official instructions [here](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation).
|
| 92 |
+
2. Downloaded images to `MME_Benchmark_release_version`.
|
| 93 |
+
3. put the official `eval_tool` and `MME_Benchmark_release_version` under `./playground/data/eval/MME`.
|
| 94 |
+
4. Single-GPU inference and evaluate.
|
| 95 |
+
```Shell
|
| 96 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/mme.sh
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
### MMBench
|
| 100 |
+
|
| 101 |
+
1. Download [`mmbench_dev_20230712.tsv`](https://download.openmmlab.com/mmclassification/datasets/mmbench/mmbench_dev_20230712.tsv) and put under `./playground/data/eval/mmbench`.
|
| 102 |
+
2. Single-GPU inference.
|
| 103 |
+
```Shell
|
| 104 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/mmbench.sh
|
| 105 |
+
```
|
| 106 |
+
3. Submit the results to the [evaluation server](https://opencompass.org.cn/leaderboard-multimodal): `./playground/data/eval/mmbench/answers_upload/mmbench_dev_20230712`.
|
| 107 |
+
|
| 108 |
+
### MMBench-CN
|
| 109 |
+
|
| 110 |
+
1. Download [`mmbench_dev_cn_20231003.tsv`](https://download.openmmlab.com/mmclassification/datasets/mmbench/mmbench_dev_cn_20231003.tsv) and put under `./playground/data/eval/mmbench`.
|
| 111 |
+
2. Single-GPU inference.
|
| 112 |
+
```Shell
|
| 113 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/mmbench_cn.sh
|
| 114 |
+
```
|
| 115 |
+
3. Submit the results to the evaluation server: `./playground/data/eval/mmbench/answers_upload/mmbench_dev_cn_20231003`.
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
### SEED-Bench
|
| 119 |
+
|
| 120 |
+
1. Following the official [instructions](https://github.com/AILab-CVC/SEED-Bench/blob/main/DATASET.md) to download the images and the videos. Put images under `./playground/data/eval/seed_bench/SEED-Bench-image`.
|
| 121 |
+
2. Extract the video frame in the middle from the downloaded videos, and put them under `./playground/data/eval/seed_bench/SEED-Bench-video-image`. We provide our script `extract_video_frames.py` modified from the official one.
|
| 122 |
+
3. Multiple-GPU inference and evaluate.
|
| 123 |
+
```Shell
|
| 124 |
+
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 bash scripts/v1_5/eval/seed.sh
|
| 125 |
+
```
|
| 126 |
+
4. Optionally, submit the results to the leaderboard: `./playground/data/eval/seed_bench/answers_upload` using the official jupyter notebook.
|
| 127 |
+
|
| 128 |
+
### LLaVA-Bench-in-the-Wild
|
| 129 |
+
|
| 130 |
+
1. Extract contents of [`llava-bench-in-the-wild`](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild) to `./playground/data/eval/llava-bench-in-the-wild`.
|
| 131 |
+
2. Single-GPU inference and evaluate.
|
| 132 |
+
```Shell
|
| 133 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/llavabench.sh
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
### MM-Vet
|
| 137 |
+
|
| 138 |
+
1. Extract [`mm-vet.zip`](https://github.com/yuweihao/MM-Vet/releases/download/v1/mm-vet.zip) to `./playground/data/eval/mmvet`.
|
| 139 |
+
2. Single-GPU inference.
|
| 140 |
+
```Shell
|
| 141 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/mmvet.sh
|
| 142 |
+
```
|
| 143 |
+
3. Evaluate the predictions in `./playground/data/eval/mmvet/results` using the official jupyter notebook.
|
| 144 |
+
|
| 145 |
+
## More Benchmarks
|
| 146 |
+
|
| 147 |
+
Below are awesome benchmarks for multimodal understanding from the research community, that are not initially included in the LLaVA-1.5 release.
|
| 148 |
+
|
| 149 |
+
### Q-Bench
|
| 150 |
+
|
| 151 |
+
1. Download [`llvisionqa_dev.json`](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/llvisionqa_dev.json) (for `dev`-subset) and [`llvisionqa_test.json`](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/llvisionqa_test.json) (for `test`-subset). Put them under `./playground/data/eval/qbench`.
|
| 152 |
+
2. Download and extract [images](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/images_llvisionqa.tar) and put all the images directly under `./playground/data/eval/qbench/images_llviqionqa`.
|
| 153 |
+
3. Single-GPU inference (change `dev` to `test` for evaluation on test set).
|
| 154 |
+
```Shell
|
| 155 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/qbench.sh dev
|
| 156 |
+
```
|
| 157 |
+
4. Submit the results by instruction [here](https://github.com/VQAssessment/Q-Bench#option-1-submit-results): `./playground/data/eval/qbench/llvisionqa_dev_answers.jsonl`.
|
| 158 |
+
|
| 159 |
+
### Chinese-Q-Bench
|
| 160 |
+
|
| 161 |
+
1. Download [`质衡-问答-验证集.json`](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/%E8%B4%A8%E8%A1%A1-%E9%97%AE%E7%AD%94-%E9%AA%8C%E8%AF%81%E9%9B%86.json) (for `dev`-subset) and [`质衡-问答-测试集.json`](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/%E8%B4%A8%E8%A1%A1-%E9%97%AE%E7%AD%94-%E6%B5%8B%E8%AF%95%E9%9B%86.json) (for `test`-subset). Put them under `./playground/data/eval/qbench`.
|
| 162 |
+
2. Download and extract [images](https://huggingface.co/datasets/nanyangtu/LLVisionQA-QBench/resolve/main/images_llvisionqa.tar) and put all the images directly under `./playground/data/eval/qbench/images_llviqionqa`.
|
| 163 |
+
3. Single-GPU inference (change `dev` to `test` for evaluation on test set).
|
| 164 |
+
```Shell
|
| 165 |
+
CUDA_VISIBLE_DEVICES=0 bash scripts/v1_5/eval/qbench_zh.sh dev
|
| 166 |
+
```
|
| 167 |
+
4. Submit the results by instruction [here](https://github.com/VQAssessment/Q-Bench#option-1-submit-results): `./playground/data/eval/qbench/llvisionqa_zh_dev_answers.jsonl`.
|
docs/Finetune_Custom_Data.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Finetune LLaVA on Custom Datasets
|
| 2 |
+
|
| 3 |
+
## Dataset Format
|
| 4 |
+
|
| 5 |
+
Convert your data to a JSON file of a List of all samples. Sample metadata should contain `id` (a unique identifier), `image` (the path to the image), and `conversations` (the conversation data between human and AI).
|
| 6 |
+
|
| 7 |
+
A sample JSON for finetuning LLaVA for generating tag-style captions for Stable Diffusion:
|
| 8 |
+
|
| 9 |
+
```json
|
| 10 |
+
[
|
| 11 |
+
{
|
| 12 |
+
"id": "997bb945-628d-4724-b370-b84de974a19f",
|
| 13 |
+
"image": "part-000001/997bb945-628d-4724-b370-b84de974a19f.jpg",
|
| 14 |
+
"conversations": [
|
| 15 |
+
{
|
| 16 |
+
"from": "human",
|
| 17 |
+
"value": "<image>\nWrite a prompt for Stable Diffusion to generate this image."
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"from": "gpt",
|
| 21 |
+
"value": "a beautiful painting of chernobyl by nekro, pascal blanche, john harris, greg rutkowski, sin jong hun, moebius, simon stalenhag. in style of cg art. ray tracing. cel shading. hyper detailed. realistic. ue 5. maya. octane render. "
|
| 22 |
+
},
|
| 23 |
+
]
|
| 24 |
+
},
|
| 25 |
+
...
|
| 26 |
+
]
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
## Command
|
| 30 |
+
|
| 31 |
+
If you have a limited task-specific data, we recommend finetuning from LLaVA checkpoints with LoRA following this [script](https://github.com/haotian-liu/LLaVA/blob/main/scripts/v1_5/finetune_task_lora.sh).
|
| 32 |
+
|
| 33 |
+
If the amount of the task-specific data is sufficient, you can also finetune from LLaVA checkpoints with full-model finetuning following this [script](https://github.com/haotian-liu/LLaVA/blob/main/scripts/v1_5/finetune_task.sh).
|
| 34 |
+
|
| 35 |
+
You may need to adjust the hyperparameters to fit each specific dataset and your hardware constraint.
|
| 36 |
+
|
| 37 |
+
|
docs/Intel.md
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Intel Platforms
|
| 2 |
+
|
| 3 |
+
* Support [Intel GPU Max Series](https://www.intel.com/content/www/us/en/products/details/discrete-gpus/data-center-gpu/max-series.html)
|
| 4 |
+
* Support [Intel CPU Sapphire Rapides](https://ark.intel.com/content/www/us/en/ark/products/codename/126212/products-formerly-sapphire-rapids.html)
|
| 5 |
+
* Based on [Intel Extension for Pytorch](https://intel.github.io/intel-extension-for-pytorch)
|
| 6 |
+
|
| 7 |
+
More details in [**intel branch**](https://github.com/haotian-liu/LLaVA/tree/intel/docs/intel)
|
docs/LLaVA_Bench.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# LLaVA-Bench [[Download](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild)]
|
| 2 |
+
|
| 3 |
+
**-Introduction-** Large commercial multimodal chatbots have been released in this week, including
|
| 4 |
+
- [Multimodal Bing-Chat by Microsoft](https://blogs.bing.com/search/july-2023/Bing-Chat-Enterprise-announced,-multimodal-Visual-Search-rolling-out-to-Bing-Chat) (July 18, 2023)
|
| 5 |
+
- [Multimodal Bard by Google](https://bard.google.com/).
|
| 6 |
+
|
| 7 |
+
These chatbots are presumably supported by proprietary large multimodal models (LMM). Compared with the open-source LMM such as LLaVA, proprietary LMM represent the scaling success upperbound of the current SoTA techniques. They share the goal of developing multimodal chatbots that follow human intents to complete various daily-life visual tasks in the wild. While it remains less explored how to evaluate multimodal chat ability, it provides useful feedback to study open-source LMMs against the commercial multimodal chatbots. In addition to the *LLaVA-Bench (COCO)* dataset we used to develop the early versions of LLaVA, we are releasing [*LLaVA-Bench (In-the-Wild)*](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild) to the community for the public use.
|
| 8 |
+
|
| 9 |
+
## LLaVA-Bench (In-the-Wild *[Ongoing work]*)
|
| 10 |
+
|
| 11 |
+
To evaluate the model's capability in more challenging tasks and generalizability to novel domains, we collect a diverse set of 24 images with 60 questions in total, including indoor and outdoor scenes, memes, paintings, sketches, etc, and associate each image with a highly-detailed and manually-curated description and a proper selection of questions. Such design also assesses the model's robustness to different prompts. In this release, we also categorize questions into three categories: conversation (simple QA), detailed description, and complex reasoning. We continue to expand and improve the diversity of the LLaVA-Bench (In-the-Wild). We manually query Bing-Chat and Bard to get the responses.
|
| 12 |
+
|
| 13 |
+
### Results
|
| 14 |
+
|
| 15 |
+
The score is measured by comparing against a reference answer generated by text-only GPT-4. It is generated by feeding the question, along with the ground truth image annotations as the context. A text-only GPT-4 evaluator rates both answers. We query GPT-4 by putting the reference answer first, and then the answer generated by the candidate model. We upload images at their original resolution to Bard and Bing-Chat to obtain the results.
|
| 16 |
+
|
| 17 |
+
| Approach | Conversation | Detail | Reasoning | Overall |
|
| 18 |
+
|----------------|--------------|--------|-----------|---------|
|
| 19 |
+
| Bard-0718 | 83.7 | 69.7 | 78.7 | 77.8 |
|
| 20 |
+
| Bing-Chat-0629 | 59.6 | 52.2 | 90.1 | 71.5 |
|
| 21 |
+
| LLaVA-13B-v1-336px-0719 (beam=1) | 64.3 | 55.9 | 81.7 | 70.1 |
|
| 22 |
+
| LLaVA-13B-v1-336px-0719 (beam=5) | 68.4 | 59.9 | 84.3 | 73.5 |
|
| 23 |
+
|
| 24 |
+
Note that Bard sometimes refuses to answer questions about images containing humans, and Bing-Chat blurs the human faces in the images. We also provide the benchmark score for the subset without humans.
|
| 25 |
+
|
| 26 |
+
| Approach | Conversation | Detail | Reasoning | Overall |
|
| 27 |
+
|----------------|--------------|--------|-----------|---------|
|
| 28 |
+
| Bard-0718 | 94.9 | 74.3 | 84.3 | 84.6 |
|
| 29 |
+
| Bing-Chat-0629 | 55.8 | 53.6 | 93.5 | 72.6 |
|
| 30 |
+
| LLaVA-13B-v1-336px-0719 (beam=1) | 62.2 | 56.4 | 82.2 | 70.0 |
|
| 31 |
+
| LLaVA-13B-v1-336px-0719 (beam=5) | 65.6 | 61.7 | 85.0 | 73.6 |
|
docs/LLaVA_from_LLaMA2.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# LLaVA (based on Llama 2 LLM, Preview)
|
| 2 |
+
|
| 3 |
+
*NOTE: This is a technical preview. We are still running hyperparameter search, and will release the final model soon. If you'd like to contribute to this, please contact us.*
|
| 4 |
+
|
| 5 |
+
:llama: **-Introduction-** [Llama 2 is an open-source LLM released by Meta AI](https://about.fb.com/news/2023/07/llama-2/) today (July 18, 2023). Compared with its early version [Llama 1](https://ai.meta.com/blog/large-language-model-llama-meta-ai/), Llama 2 is more favored in ***stronger language performance***, ***longer context window***, and importantly ***commercially usable***! While Llama 2 is changing the LLM market landscape in the language space, its multimodal ability remains unknown. We quickly develop the LLaVA variant based on the latest Llama 2 checkpoints, and release it to the community for the public use.
|
| 6 |
+
|
| 7 |
+
You need to apply for and download the latest Llama 2 checkpoints to start your own training (apply [here](https://ai.meta.com/resources/models-and-libraries/llama-downloads/))
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
## Training
|
| 11 |
+
|
| 12 |
+
Please checkout [`pretrain.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/pretrain.sh), [`finetune.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/finetune.sh), [`finetune_lora.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/finetune_lora.sh).
|
| 13 |
+
|
| 14 |
+
## LLaVA (based on Llama 2), What is different?
|
| 15 |
+
|
| 16 |
+
:volcano: How is the new LLaVA based on Llama 2 different from Llama 1? The comparisons of the training process are described:
|
| 17 |
+
- **Pre-training**. The pre-trained base LLM is changed from Llama 1 to Llama 2
|
| 18 |
+
- **Language instruction-tuning**. The previous LLaVA model starts with Vicuna, which is instruct tuned on ShareGPT data from Llama 1; The new LLaVA model starts with Llama 2 Chat, which is an instruct tuned checkpoint on dialogue data from Llama 2.
|
| 19 |
+
- **Multimodal instruction-tuning**. The same LLaVA-Lighting process is applied.
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
### Results
|
| 23 |
+
|
| 24 |
+
- Llama 2 is better at following the instructions of role playing; Llama 2 fails in following the instructions of translation
|
| 25 |
+
- The quantitative evaluation on [LLaVA-Bench](https://github.com/haotian-liu/LLaVA/blob/main/docs/LLaVA_Bench.md) demonstrates on-par performance between Llama 2 and Llama 1 in LLaVA's multimodal chat ability.
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
<img src="../images/llava_example_cmp.png" width="100%">
|
| 29 |
+
|
docs/LoRA.md
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# LLaVA (LoRA, Preview)
|
| 2 |
+
|
| 3 |
+
NOTE: This is a technical preview, and is not yet ready for production use. We are still running hyperparameter search for the LoRA model, and will release the final model soon. If you'd like to contribute to this, please contact us.
|
| 4 |
+
|
| 5 |
+
You need latest code base for LoRA support (instructions [here](https://github.com/haotian-liu/LLaVA#upgrade-to-latest-code-base))
|
| 6 |
+
|
| 7 |
+
## Demo (Web UI)
|
| 8 |
+
|
| 9 |
+
Please execute each of the commands below one by one (after the previous one has finished). The commands are the same as launching other demos except for an additional `--model-base` flag to specify the base model to use. Please make sure the base model corresponds to the LoRA checkpoint that you are using. For this technical preview, you need Vicuna v1.1 (7B) checkpoint (if you do not have that already, follow the instructions [here](https://github.com/lm-sys/FastChat#vicuna-weights)).
|
| 10 |
+
|
| 11 |
+
#### Launch a controller
|
| 12 |
+
```Shell
|
| 13 |
+
python -m llava.serve.controller --host 0.0.0.0 --port 10000
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
#### Launch a gradio web server.
|
| 17 |
+
```Shell
|
| 18 |
+
python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload
|
| 19 |
+
```
|
| 20 |
+
You just launched the Gradio web interface. Now, you can open the web interface with the URL printed on the screen. You may notice that there is no model in the model list. Do not worry, as we have not launched any model worker yet. It will be automatically updated when you launch a model worker.
|
| 21 |
+
|
| 22 |
+
#### Launch a model worker
|
| 23 |
+
```Shell
|
| 24 |
+
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-vicuna-7b-v1.1-lcs_558k-instruct_80k_3e-lora-preview-alpha --model-base /path/to/vicuna-v1.1
|
| 25 |
+
```
|
| 26 |
+
Wait until the process finishes loading the model and you see "Uvicorn running on ...". Now, refresh your Gradio web UI, and you will see the model you just launched in the model list.
|
| 27 |
+
|
| 28 |
+
You can launch as many workers as you want, and compare between different model checkpoints in the same Gradio interface. Please keep the `--controller` the same, and modify the `--port` and `--worker` to a different port number for each worker.
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
## Training
|
| 32 |
+
|
| 33 |
+
Please see sample training scripts for [LoRA](https://github.com/haotian-liu/LLaVA/blob/main/scripts/finetune_lora.sh) and [QLoRA](https://github.com/haotian-liu/LLaVA/blob/main/scripts/finetune_qlora.sh).
|
| 34 |
+
|
| 35 |
+
We provide sample DeepSpeed configs, [`zero3.json`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/zero3.json) is more like PyTorch FSDP, and [`zero3_offload.json`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/zero3_offload.json) can further save memory consumption by offloading parameters to CPU. `zero3.json` is usually faster than `zero3_offload.json` but requires more GPU memory, therefore, we recommend trying `zero3.json` first, and if you run out of GPU memory, try `zero3_offload.json`. You can also tweak the `per_device_train_batch_size` and `gradient_accumulation_steps` in the config to save memory, and just to make sure that `per_device_train_batch_size` and `gradient_accumulation_steps` remains the same.
|
| 36 |
+
|
| 37 |
+
If you are having issues with ZeRO-3 configs, and there are enough VRAM, you may try [`zero2.json`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/zero2.json). This consumes slightly more memory than ZeRO-3, and behaves more similar to PyTorch FSDP, while still supporting parameter-efficient tuning.
|
| 38 |
+
|
| 39 |
+
## Create Merged Checkpoints
|
| 40 |
+
|
| 41 |
+
```Shell
|
| 42 |
+
python scripts/merge_lora_weights.py \
|
| 43 |
+
--model-path /path/to/lora_model \
|
| 44 |
+
--model-base /path/to/base_model \
|
| 45 |
+
--save-model-path /path/to/merge_model
|
| 46 |
+
```
|
docs/MODEL_ZOO.md
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Zoo
|
| 2 |
+
|
| 3 |
+
**To Use LLaVA-1.6 checkpoints, your llava package version must be newer than 1.2.0. [Instructions](https://github.com/haotian-liu/LLaVA#upgrade-to-latest-code-base) on how to upgrade.**
|
| 4 |
+
|
| 5 |
+
If you are interested in including any other details in Model Zoo, please open an issue :)
|
| 6 |
+
|
| 7 |
+
The model weights below are *merged* weights. You do not need to apply delta. The usage of LLaVA checkpoints should comply with the base LLM's model license.
|
| 8 |
+
|
| 9 |
+
## LLaVA-v1.6
|
| 10 |
+
|
| 11 |
+
| Version | LLM | Schedule | Checkpoint | MMMU | MathVista | VQAv2 | GQA | VizWiz | SQA | TextVQA | POPE | MME | MM-Bench | MM-Bench-CN | SEED-IMG | LLaVA-Bench-Wild | MM-Vet |
|
| 12 |
+
|----------|----------|-----------|-----------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| 13 |
+
| LLaVA-1.6 | Vicuna-7B | full_ft-1e | [liuhaotian/llava-v1.6-vicuna-7b](https://huggingface.co/liuhaotian/llava-v1.6-vicuna-7b) | 35.8 | 34.6 | 81.8 | 64.2 | 57.6 | 70.1 | 64.9 | 86.5 | 1519/332 | 67.4 | 60.6 | 70.2 | 81.6 | 43.9 |
|
| 14 |
+
| LLaVA-1.6 | Vicuna-13B | full_ft-1e | [liuhaotian/llava-v1.6-vicuna-13b](https://huggingface.co/liuhaotian/llava-v1.6-vicuna-13b) | 36.2 | 35.3 | 82.8 | 65.4 | 60.5 | 73.6 | 67.1 | 86.2 | 1575/326 | 70 | 64.4 | 71.9 | 87.3 | 48.4 |
|
| 15 |
+
| LLaVA-1.6 | Mistral-7B | full_ft-1e | [liuhaotian/llava-v1.6-mistral-7b](https://huggingface.co/liuhaotian/llava-v1.6-mistral-7b) | 35.3 | 37.7 | 82.2 | 64.8 | 60.0 | 72.8 | 65.7 | 86.7 | 1498/321 | 68.7 | 61.2 | 72.2 | 83.2 | 47.3 |
|
| 16 |
+
| LLaVA-1.6 | Hermes-Yi-34B | full_ft-1e | [liuhaotian/llava-v1.6-34b](https://huggingface.co/liuhaotian/llava-v1.6-34b) | 51.1 | 46.5 | 83.7 | 67.1 | 63.8 | 81.8 | 69.5 | 87.7 | 1631/397 | 79.3 | 79 | 75.9 | 89.6 | 57.4 |
|
| 17 |
+
|
| 18 |
+
*LLaVA-1.6-34B outperforms Gemini Pro on benchmarks like MMMU and MathVista.*
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## LLaVA-v1.5
|
| 22 |
+
|
| 23 |
+
| Version | Size | Schedule | Checkpoint | VQAv2 | GQA | VizWiz | SQA | TextVQA | POPE | MME | MM-Bench | MM-Bench-CN | SEED | LLaVA-Bench-Wild | MM-Vet |
|
| 24 |
+
|----------|----------|-----------|-----------|---|---|---|---|---|---|---|---|---|---|---|---|
|
| 25 |
+
| LLaVA-1.5 | 7B | full_ft-1e | [liuhaotian/llava-v1.5-7b](https://huggingface.co/liuhaotian/llava-v1.5-7b) | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 1510.7 | 64.3 | 58.3 | 58.6 | 65.4 | 31.1 |
|
| 26 |
+
| LLaVA-1.5 | 13B | full_ft-1e | [liuhaotian/llava-v1.5-13b](https://huggingface.co/liuhaotian/llava-v1.5-13b) | 80.0 | 63.3 | 53.6 | 71.6 | 61.3 | 85.9 | 1531.3 | 67.7 | 63.6 | 61.6 | 72.5 | 36.1 |
|
| 27 |
+
| LLaVA-1.5 | 7B | lora-1e | [liuhaotian/llava-v1.5-7b-lora](https://huggingface.co/liuhaotian/llava-v1.5-7b-lora) | 79.1 | 63.0 | 47.8 | 68.4 | 58.2 | 86.4 | 1476.9 | 66.1 | 58.9 | 60.1 | 67.9 | 30.2 |
|
| 28 |
+
| LLaVA-1.5 | 13B | lora-1e | [liuhaotian/llava-v1.5-13b-lora](https://huggingface.co/liuhaotian/llava-v1.5-13b-lora) | 80.0 | 63.3 | 58.9 | 71.2 | 60.2 | 86.7 | 1541.7 | 68.5 | 61.5 | 61.3 | 69.5 | 38.3 |
|
| 29 |
+
|
| 30 |
+
Base model: Vicuna v1.5. Training logs: [wandb](https://api.wandb.ai/links/lht/6orh56wc).
|
| 31 |
+
|
| 32 |
+
<p align="center">
|
| 33 |
+
<img src="../images/llava_v1_5_radar.jpg" width="500px"> <br>
|
| 34 |
+
LLaVA-1.5 achieves SoTA performance across 11 benchmarks.
|
| 35 |
+
</p>
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## LLaVA-v1
|
| 39 |
+
|
| 40 |
+
*Note: We recommend using the most capable LLaVA-v1.6 series above for the best performance.*
|
| 41 |
+
|
| 42 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | LLaVA-Bench-Conv | LLaVA-Bench-Detail | LLaVA-Bench-Complex | LLaVA-Bench-Overall | Download |
|
| 43 |
+
|----------|----------------|---------------|----------------------|-----------------|--------------------|------------------|--------------------|---------------------|---------------------|---------------------|
|
| 44 |
+
| Vicuna-13B-v1.3 | CLIP-L-336px | LCS-558K | 1e | LLaVA-Instruct-80K | proj-1e, lora-1e | 64.3 | 55.9 | 81.7 | 70.1 | [LoRA](https://huggingface.co/liuhaotian/llava-v1-0719-336px-lora-vicuna-13b-v1.3) [LoRA-Merged](https://huggingface.co/liuhaotian/llava-v1-0719-336px-lora-merge-vicuna-13b-v1.3) |
|
| 45 |
+
| LLaMA-2-13B-Chat | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | full_ft-1e | 56.7 | 58.6 | 80.0 | 67.9 | [ckpt](https://huggingface.co/liuhaotian/llava-llama-2-13b-chat-lightning-preview) |
|
| 46 |
+
| LLaMA-2-7B-Chat | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | lora-1e | 51.2 | 58.9 | 71.6 | 62.8 | [LoRA](https://huggingface.co/liuhaotian/llava-llama-2-7b-chat-lightning-lora-preview) |
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
## Projector weights
|
| 50 |
+
|
| 51 |
+
These are projector weights we have pretrained. You can use these projector weights for visual instruction tuning. They are just pretrained on image-text pairs and are NOT instruction-tuned, which means they do NOT follow instructions as well as our official models and can output repetitive, lengthy, and garbled outputs. If you want to have nice conversations with LLaVA, use the checkpoints above (LLaVA v1.6).
|
| 52 |
+
|
| 53 |
+
NOTE: These projector weights are only compatible with `llava>=1.0.0`. Please check out the latest codebase if your local code version is below v1.0.0.
|
| 54 |
+
|
| 55 |
+
NOTE: When you use our pretrained projector for visual instruction tuning, it is very important to use the same base LLM and vision encoder as the one we used for pretraining the projector. Otherwise, the performance will be very poor.
|
| 56 |
+
|
| 57 |
+
When using these projector weights to instruction-tune your LMM, please make sure that these options are correctly set as follows,
|
| 58 |
+
|
| 59 |
+
```Shell
|
| 60 |
+
--mm_use_im_start_end False
|
| 61 |
+
--mm_use_im_patch_token False
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
| Base LLM | Vision Encoder | Projection | Pretrain Data | Pretraining schedule | Download |
|
| 65 |
+
|----------|----------------|---------------|----------------------|----------|----------|
|
| 66 |
+
| Vicuna-13B-v1.5 | CLIP-L-336px | MLP-2x | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-v1.5-mlp2x-336px-pretrain-vicuna-13b-v1.5) |
|
| 67 |
+
| Vicuna-7B-v1.5 | CLIP-L-336px | MLP-2x | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-v1.5-mlp2x-336px-pretrain-vicuna-7b-v1.5) |
|
| 68 |
+
| LLaMA-2-13B-Chat | CLIP-L-336px | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-336px-pretrain-llama-2-13b-chat) |
|
| 69 |
+
| LLaMA-2-7B-Chat | CLIP-L-336px | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-336px-pretrain-llama-2-7b-chat) |
|
| 70 |
+
| LLaMA-2-13B-Chat | CLIP-L | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-pretrain-llama-2-13b-chat) |
|
| 71 |
+
| LLaMA-2-7B-Chat | CLIP-L | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-pretrain-llama-2-7b-chat) |
|
| 72 |
+
| Vicuna-13B-v1.3 | CLIP-L-336px | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-336px-pretrain-vicuna-13b-v1.3) |
|
| 73 |
+
| Vicuna-7B-v1.3 | CLIP-L-336px | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-336px-pretrain-vicuna-7b-v1.3) |
|
| 74 |
+
| Vicuna-13B-v1.3 | CLIP-L | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-pretrain-vicuna-13b-v1.3) |
|
| 75 |
+
| Vicuna-7B-v1.3 | CLIP-L | Linear | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/llava-pretrain-vicuna-7b-v1.3) |
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
## Science QA Checkpoints
|
| 79 |
+
|
| 80 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | Download |
|
| 81 |
+
|----------|----------------|---------------|----------------------|-----------------|--------------------|---------------------|
|
| 82 |
+
| Vicuna-13B-v1.3 | CLIP-L | LCS-558K | 1e | ScienceQA | full_ft-12e | [ckpt](https://huggingface.co/liuhaotian/llava-lcs558k-scienceqa-vicuna-13b-v1.3) |
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
## Legacy Models (merged weights)
|
| 86 |
+
|
| 87 |
+
The model weights below are *merged* weights. You do not need to apply delta. The usage of LLaVA checkpoints should comply with the base LLM's model license.
|
| 88 |
+
|
| 89 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | Download |
|
| 90 |
+
|----------|----------------|---------------|----------------------|-----------------|--------------------|------------------|
|
| 91 |
+
| MPT-7B-Chat | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | full_ft-1e | [preview](https://huggingface.co/liuhaotian/LLaVA-Lightning-MPT-7B-preview) |
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
## Legacy Models (delta weights)
|
| 95 |
+
|
| 96 |
+
The model weights below are *delta* weights. The usage of LLaVA checkpoints should comply with the base LLM's model license: [LLaMA](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md).
|
| 97 |
+
|
| 98 |
+
You can add our delta to the original LLaMA weights to obtain the LLaVA weights.
|
| 99 |
+
|
| 100 |
+
Instructions:
|
| 101 |
+
|
| 102 |
+
1. Get the original LLaMA weights in the huggingface format by following the instructions [here](https://huggingface.co/docs/transformers/main/model_doc/llama).
|
| 103 |
+
2. Use the following scripts to get LLaVA weights by applying our delta. It will automatically download delta weights from our Hugging Face account. In the script below, we use the delta weights of [`liuhaotian/LLaVA-7b-delta-v0`](https://huggingface.co/liuhaotian/LLaVA-7b-delta-v0) as an example. It can be adapted for other delta weights by changing the `--delta` argument (and base/target accordingly).
|
| 104 |
+
|
| 105 |
+
```bash
|
| 106 |
+
python3 -m llava.model.apply_delta \
|
| 107 |
+
--base /path/to/llama-7b \
|
| 108 |
+
--target /output/path/to/LLaVA-7B-v0 \
|
| 109 |
+
--delta liuhaotian/LLaVA-7b-delta-v0
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | Download |
|
| 113 |
+
|----------|----------------|---------------|----------------------|-----------------|--------------------|------------------|
|
| 114 |
+
| Vicuna-13B-v1.1 | CLIP-L | CC-595K | 1e | LLaVA-Instruct-158K | full_ft-3e | [delta-weights](https://huggingface.co/liuhaotian/LLaVA-13b-delta-v1-1) |
|
| 115 |
+
| Vicuna-7B-v1.1 | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | full_ft-1e | [delta-weights](https://huggingface.co/liuhaotian/LLaVA-Lightning-7B-delta-v1-1) |
|
| 116 |
+
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | LLaVA-Instruct-158K | full_ft-3e | [delta-weights](https://huggingface.co/liuhaotian/LLaVA-13b-delta-v0) |
|
| 117 |
+
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | ScienceQA | full_ft-12e | [delta-weights](https://huggingface.co/liuhaotian/LLaVA-13b-delta-v0-science_qa) |
|
| 118 |
+
| Vicuna-7B-v0 | CLIP-L | CC-595K | 1e | LLaVA-Instruct-158K | full_ft-3e | [delta-weights](https://huggingface.co/liuhaotian/LLaVA-7b-delta-v0) |
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
## Legacy Projector weights
|
| 123 |
+
|
| 124 |
+
The following projector weights are deprecated, and the support for them may be removed in the future. They do not support zero-shot inference. Please use the projector weights in the [table above](#projector-weights) if possible.
|
| 125 |
+
|
| 126 |
+
**NOTE**: When you use our pretrained projector for visual instruction tuning, it is very important to **use the same base LLM and vision encoder** as the one we used for pretraining the projector. Otherwise, the performance will be very bad.
|
| 127 |
+
|
| 128 |
+
When using these projector weights to instruction tune your LMM, please make sure that these options are correctly set as follows,
|
| 129 |
+
|
| 130 |
+
```Shell
|
| 131 |
+
--mm_use_im_start_end True
|
| 132 |
+
--mm_use_im_patch_token False
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Download |
|
| 136 |
+
|----------|----------------|---------------|----------------------|----------|
|
| 137 |
+
| Vicuna-7B-v1.1 | CLIP-L | LCS-558K | 1e | [projector](https://huggingface.co/liuhaotian/LLaVA-Pretrained-Projectors/blob/main/LLaVA-7b-pretrain-projector-v1-1-LCS-558K-blip_caption.bin) |
|
| 138 |
+
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | [projector](https://huggingface.co/liuhaotian/LLaVA-Pretrained-Projectors/blob/main/LLaVA-13b-pretrain-projector-v0-CC3M-595K-original_caption.bin) |
|
| 139 |
+
| Vicuna-7B-v0 | CLIP-L | CC-595K | 1e | [projector](https://huggingface.co/liuhaotian/LLaVA-Pretrained-Projectors/blob/main/LLaVA-7b-pretrain-projector-v0-CC3M-595K-original_caption.bin) |
|
| 140 |
+
|
| 141 |
+
When using these projector weights to instruction tune your LMM, please make sure that these options are correctly set as follows,
|
| 142 |
+
|
| 143 |
+
```Shell
|
| 144 |
+
--mm_use_im_start_end False
|
| 145 |
+
--mm_use_im_patch_token False
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Download |
|
| 149 |
+
|----------|----------------|---------------|----------------------|----------|
|
| 150 |
+
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | [projector](https://huggingface.co/liuhaotian/LLaVA-Pretrained-Projectors/blob/main/LLaVA-13b-pretrain-projector-v0-CC3M-595K-original_caption-no_im_token.bin) |
|
docs/ScienceQA.md
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### ScienceQA
|
| 2 |
+
|
| 3 |
+
#### Prepare Data
|
| 4 |
+
1. Please see ScienceQA [repo](https://github.com/lupantech/ScienceQA) for setting up the dataset.
|
| 5 |
+
2. Generate ScienceQA dataset for LLaVA conversation-style format.
|
| 6 |
+
|
| 7 |
+
```Shell
|
| 8 |
+
python scripts/convert_sqa_to_llava.py \
|
| 9 |
+
convert_to_llava \
|
| 10 |
+
--base-dir /path/to/ScienceQA/data/scienceqa \
|
| 11 |
+
--prompt-format "QCM-LEA" \
|
| 12 |
+
--split {train,val,minival,test,minitest}
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
#### Training
|
| 16 |
+
|
| 17 |
+
1. Pretraining
|
| 18 |
+
|
| 19 |
+
You can download our pretrained projector weights from our [Model Zoo](), or train your own projector weights using [`pretrain.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/pretrain.sh).
|
| 20 |
+
|
| 21 |
+
2. Finetuning
|
| 22 |
+
|
| 23 |
+
See [`finetune_sqa.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/finetune_sqa.sh).
|
| 24 |
+
|
| 25 |
+
#### Evaluation
|
| 26 |
+
|
| 27 |
+
1. Multiple-GPU inference
|
| 28 |
+
You may evaluate this with multiple GPUs, and concatenate the generated jsonl files. Please refer to our script for [batch evaluation](https://github.com/haotian-liu/LLaVA/blob/main/scripts/sqa_eval_batch.sh) and [results gathering](https://github.com/haotian-liu/LLaVA/blob/main/scripts/sqa_eval_gather.sh).
|
| 29 |
+
|
| 30 |
+
2. Single-GPU inference
|
| 31 |
+
|
| 32 |
+
(a) Generate LLaVA responses on ScienceQA dataset
|
| 33 |
+
|
| 34 |
+
```Shell
|
| 35 |
+
python -m llava.eval.model_vqa_science \
|
| 36 |
+
--model-path liuhaotian/llava-lcs558k-scienceqa-vicuna-13b-v1.3 \
|
| 37 |
+
--question-file /path/to/ScienceQA/data/scienceqa/llava_test_QCM-LEA.json \
|
| 38 |
+
--image-folder /path/to/ScienceQA/data/scienceqa/images/test \
|
| 39 |
+
--answers-file vqa/results/ScienceQA/test_llava-13b.jsonl \
|
| 40 |
+
--conv-mode llava_v1
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
(b) Evaluate the generated responses
|
| 44 |
+
|
| 45 |
+
```Shell
|
| 46 |
+
python eval_science_qa.py \
|
| 47 |
+
--base-dir /path/to/ScienceQA/data/scienceqa \
|
| 48 |
+
--result-file vqa/results/ScienceQA/test_llava-13b.jsonl \
|
| 49 |
+
--output-file vqa/results/ScienceQA/test_llava-13b_output.json \
|
| 50 |
+
--output-result vqa/results/ScienceQA/test_llava-13b_result.json \
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
For reference, we attach our prediction file [`test_sqa_llava_lcs_558k_sqa_12e_vicuna_v1_3_13b.json`](https://github.com/haotian-liu/LLaVA/blob/main/llava/eval/table/results/test_sqa_llava_lcs_558k_sqa_12e_vicuna_v1_3_13b.json) and [`test_sqa_llava_13b_v0.json`](https://github.com/haotian-liu/LLaVA/blob/main/llava/eval/table/results/test_sqa_llava_13b_v0.json) for comparison when reproducing our results, as well as for further analysis in detail.
|
docs/Windows.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Run LLaVA on Windows
|
| 2 |
+
|
| 3 |
+
*NOTE: LLaVA on Windows is not fully supported. Currently we only support 16-bit inference. For a more complete support, please use [WSL2](https://learn.microsoft.com/en-us/windows/wsl/install) for now. More functionalities on Windows is to be added soon, stay tuned.*
|
| 4 |
+
|
| 5 |
+
## Installation
|
| 6 |
+
|
| 7 |
+
1. Clone this repository and navigate to LLaVA folder
|
| 8 |
+
```bash
|
| 9 |
+
git clone https://github.com/haotian-liu/LLaVA.git
|
| 10 |
+
cd LLaVA
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
2. Install Package
|
| 14 |
+
```Shell
|
| 15 |
+
conda create -n llava python=3.10 -y
|
| 16 |
+
conda activate llava
|
| 17 |
+
python -m pip install --upgrade pip # enable PEP 660 support
|
| 18 |
+
pip install torch==2.0.1+cu117 torchvision==0.15.2+cu117 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu117
|
| 19 |
+
pip install -e .
|
| 20 |
+
pip uninstall bitsandbytes
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
## Run demo
|
| 24 |
+
|
| 25 |
+
See instructions [here](https://github.com/haotian-liu/LLaVA#demo).
|
| 26 |
+
|
| 27 |
+
Note that quantization (4-bit, 8-bit) is *NOT* supported on Windows. Stay tuned for the 4-bit support on Windows!
|
docs/macOS.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Run LLaVA on macOS
|
| 2 |
+
|
| 3 |
+
*NOTE: LLaVA on macOS is not fully supported. Currently we only support 16-bit inference. More functionalities on macOS is to be added soon, stay tuned.*
|
| 4 |
+
|
| 5 |
+
## Installation
|
| 6 |
+
|
| 7 |
+
1. Clone this repository and navigate to LLaVA folder
|
| 8 |
+
```bash
|
| 9 |
+
git clone https://github.com/haotian-liu/LLaVA.git
|
| 10 |
+
cd LLaVA
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
2. Install Package
|
| 14 |
+
```Shell
|
| 15 |
+
conda create -n llava python=3.10 -y
|
| 16 |
+
conda activate llava
|
| 17 |
+
python -mpip install --upgrade pip # enable PEP 660 support
|
| 18 |
+
pip install -e .
|
| 19 |
+
pip install torch==2.1.0 torchvision==0.16.0
|
| 20 |
+
pip uninstall bitsandbytes
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
## Run demo
|
| 24 |
+
|
| 25 |
+
Specify `--device mps` when launching model worker or CLI.
|
| 26 |
+
|
| 27 |
+
See instructions [here](https://github.com/haotian-liu/LLaVA#demo).
|
| 28 |
+
|
| 29 |
+
Note that quantization (4-bit, 8-bit) is *NOT* supported on macOS. Stay tuned for the 4-bit support on macOS!
|
examples/extreme_ironing.jpg
ADDED

|
examples/waterview.jpg
ADDED

|
images/llava_example_cmp.png
ADDED
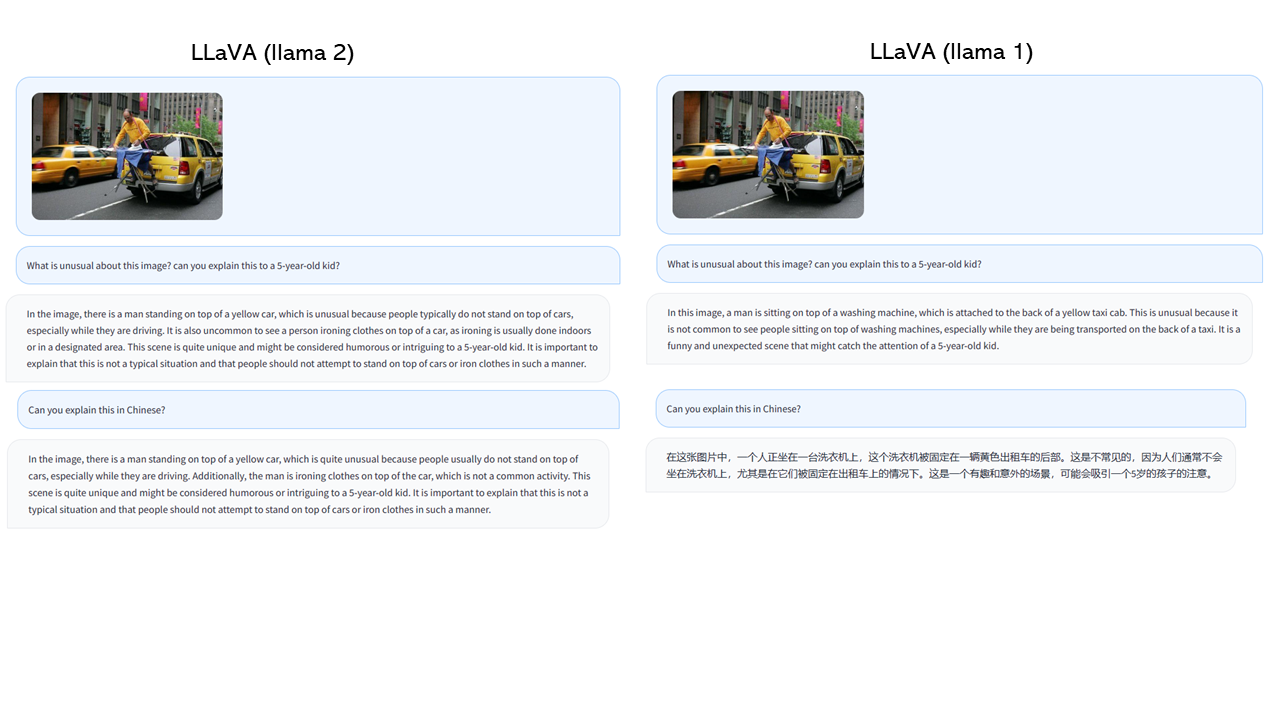
|
images/llava_logo.png
ADDED
|
|
images/llava_v1_5_radar.jpg
ADDED
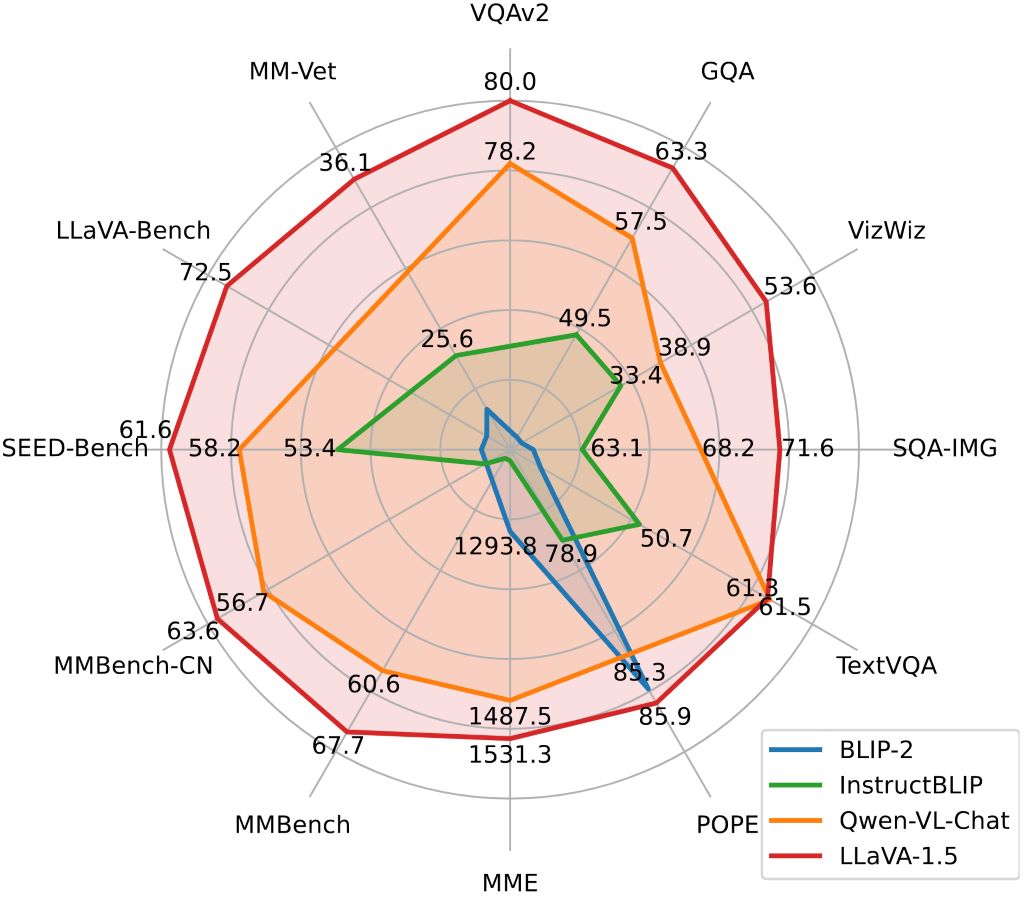
|
llava/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .model import LlavaLlamaForCausalLM
|
llava/constants.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
CONTROLLER_HEART_BEAT_EXPIRATION = 30
|
| 2 |
+
WORKER_HEART_BEAT_INTERVAL = 15
|
| 3 |
+
|
| 4 |
+
LOGDIR = "."
|
| 5 |
+
|
| 6 |
+
# Model Constants
|
| 7 |
+
IGNORE_INDEX = -100
|
| 8 |
+
IMAGE_TOKEN_INDEX = -200
|
| 9 |
+
DEFAULT_IMAGE_TOKEN = "<image>"
|
| 10 |
+
DEFAULT_IMAGE_PATCH_TOKEN = "<im_patch>"
|
| 11 |
+
DEFAULT_IM_START_TOKEN = "<im_start>"
|
| 12 |
+
DEFAULT_IM_END_TOKEN = "<im_end>"
|
| 13 |
+
IMAGE_PLACEHOLDER = "<image-placeholder>"
|
llava/conversation.py
ADDED
|
@@ -0,0 +1,409 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modified from LLaVA: https://github.com/haotian-liu/LLaVA.git
|
| 2 |
+
import dataclasses
|
| 3 |
+
from enum import auto, Enum
|
| 4 |
+
from typing import List, Tuple
|
| 5 |
+
import base64
|
| 6 |
+
from io import BytesIO
|
| 7 |
+
from PIL import Image
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class SeparatorStyle(Enum):
|
| 11 |
+
"""Different separator style."""
|
| 12 |
+
SINGLE = auto()
|
| 13 |
+
TWO = auto()
|
| 14 |
+
MPT = auto()
|
| 15 |
+
PLAIN = auto()
|
| 16 |
+
LLAMA_2 = auto()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
@dataclasses.dataclass
|
| 20 |
+
class Conversation:
|
| 21 |
+
"""A class that keeps all conversation history."""
|
| 22 |
+
system: str
|
| 23 |
+
roles: List[str]
|
| 24 |
+
messages: List[List[str]]
|
| 25 |
+
offset: int
|
| 26 |
+
sep_style: SeparatorStyle = SeparatorStyle.SINGLE
|
| 27 |
+
sep: str = "###"
|
| 28 |
+
sep2: str = None
|
| 29 |
+
version: str = "Unknown"
|
| 30 |
+
|
| 31 |
+
skip_next: bool = False
|
| 32 |
+
|
| 33 |
+
def get_prompt(self):
|
| 34 |
+
messages = self.messages
|
| 35 |
+
if len(messages) > 0 and type(messages[0][1]) is tuple:
|
| 36 |
+
messages = self.messages.copy()
|
| 37 |
+
init_role, init_msg = messages[0].copy()
|
| 38 |
+
init_msg = init_msg[0].replace("<image>", "").strip()
|
| 39 |
+
if 'mmtag' in self.version:
|
| 40 |
+
messages[0] = (init_role, init_msg)
|
| 41 |
+
messages.insert(0, (self.roles[0], "<Image><image></Image>"))
|
| 42 |
+
messages.insert(1, (self.roles[1], "Received."))
|
| 43 |
+
else:
|
| 44 |
+
messages[0] = (init_role, "<image>\n" + init_msg)
|
| 45 |
+
|
| 46 |
+
if self.sep_style == SeparatorStyle.SINGLE:
|
| 47 |
+
ret = self.system + self.sep
|
| 48 |
+
for role, message in messages:
|
| 49 |
+
if message:
|
| 50 |
+
if type(message) is tuple:
|
| 51 |
+
message, _, _ = message
|
| 52 |
+
ret += role + ": " + message + self.sep
|
| 53 |
+
else:
|
| 54 |
+
ret += role + ":"
|
| 55 |
+
elif self.sep_style == SeparatorStyle.TWO:
|
| 56 |
+
seps = [self.sep, self.sep2]
|
| 57 |
+
ret = self.system + seps[0]
|
| 58 |
+
for i, (role, message) in enumerate(messages):
|
| 59 |
+
if message:
|
| 60 |
+
if type(message) is tuple:
|
| 61 |
+
message, _, _ = message
|
| 62 |
+
ret += role + ": " + message + seps[i % 2]
|
| 63 |
+
else:
|
| 64 |
+
ret += role + ":"
|
| 65 |
+
elif self.sep_style == SeparatorStyle.MPT:
|
| 66 |
+
ret = self.system + self.sep
|
| 67 |
+
for role, message in messages:
|
| 68 |
+
if message:
|
| 69 |
+
if type(message) is tuple:
|
| 70 |
+
message, _, _ = message
|
| 71 |
+
ret += role + message + self.sep
|
| 72 |
+
else:
|
| 73 |
+
ret += role
|
| 74 |
+
elif self.sep_style == SeparatorStyle.LLAMA_2:
|
| 75 |
+
wrap_sys = lambda msg: f"<<SYS>>\n{msg}\n<</SYS>>\n\n" if len(msg) > 0 else msg
|
| 76 |
+
wrap_inst = lambda msg: f"[INST] {msg} [/INST]"
|
| 77 |
+
ret = ""
|
| 78 |
+
|
| 79 |
+
for i, (role, message) in enumerate(messages):
|
| 80 |
+
if i == 0:
|
| 81 |
+
assert message, "first message should not be none"
|
| 82 |
+
assert role == self.roles[0], "first message should come from user"
|
| 83 |
+
if message:
|
| 84 |
+
if type(message) is tuple:
|
| 85 |
+
message, _, _ = message
|
| 86 |
+
if i == 0: message = wrap_sys(self.system) + message
|
| 87 |
+
if i % 2 == 0:
|
| 88 |
+
message = wrap_inst(message)
|
| 89 |
+
ret += self.sep + message
|
| 90 |
+
else:
|
| 91 |
+
ret += " " + message + " " + self.sep2
|
| 92 |
+
else:
|
| 93 |
+
ret += ""
|
| 94 |
+
ret = ret.lstrip(self.sep)
|
| 95 |
+
elif self.sep_style == SeparatorStyle.PLAIN:
|
| 96 |
+
seps = [self.sep, self.sep2]
|
| 97 |
+
ret = self.system
|
| 98 |
+
for i, (role, message) in enumerate(messages):
|
| 99 |
+
if message:
|
| 100 |
+
if type(message) is tuple:
|
| 101 |
+
message, _, _ = message
|
| 102 |
+
ret += message + seps[i % 2]
|
| 103 |
+
else:
|
| 104 |
+
ret += ""
|
| 105 |
+
else:
|
| 106 |
+
raise ValueError(f"Invalid style: {self.sep_style}")
|
| 107 |
+
|
| 108 |
+
return ret
|
| 109 |
+
|
| 110 |
+
def append_message(self, role, message):
|
| 111 |
+
self.messages.append([role, message])
|
| 112 |
+
|
| 113 |
+
def process_image(self, image, image_process_mode, return_pil=False, image_format='PNG', max_len=1344, min_len=672):
|
| 114 |
+
if image_process_mode == "Pad":
|
| 115 |
+
def expand2square(pil_img, background_color=(122, 116, 104)):
|
| 116 |
+
width, height = pil_img.size
|
| 117 |
+
if width == height:
|
| 118 |
+
return pil_img
|
| 119 |
+
elif width > height:
|
| 120 |
+
result = Image.new(pil_img.mode, (width, width), background_color)
|
| 121 |
+
result.paste(pil_img, (0, (width - height) // 2))
|
| 122 |
+
return result
|
| 123 |
+
else:
|
| 124 |
+
result = Image.new(pil_img.mode, (height, height), background_color)
|
| 125 |
+
result.paste(pil_img, ((height - width) // 2, 0))
|
| 126 |
+
return result
|
| 127 |
+
|
| 128 |
+
image = expand2square(image)
|
| 129 |
+
elif image_process_mode in ["Default", "Crop"]:
|
| 130 |
+
pass
|
| 131 |
+
elif image_process_mode == "Resize":
|
| 132 |
+
image = image.resize((336, 336))
|
| 133 |
+
else:
|
| 134 |
+
raise ValueError(f"Invalid image_process_mode: {image_process_mode}")
|
| 135 |
+
if max(image.size) > max_len:
|
| 136 |
+
max_hw, min_hw = max(image.size), min(image.size)
|
| 137 |
+
aspect_ratio = max_hw / min_hw
|
| 138 |
+
shortest_edge = int(min(max_len / aspect_ratio, min_len, min_hw))
|
| 139 |
+
longest_edge = int(shortest_edge * aspect_ratio)
|
| 140 |
+
W, H = image.size
|
| 141 |
+
if H > W:
|
| 142 |
+
H, W = longest_edge, shortest_edge
|
| 143 |
+
else:
|
| 144 |
+
H, W = shortest_edge, longest_edge
|
| 145 |
+
image = image.resize((W, H))
|
| 146 |
+
if return_pil:
|
| 147 |
+
return image
|
| 148 |
+
else:
|
| 149 |
+
buffered = BytesIO()
|
| 150 |
+
image.save(buffered, format=image_format)
|
| 151 |
+
img_b64_str = base64.b64encode(buffered.getvalue()).decode()
|
| 152 |
+
return img_b64_str
|
| 153 |
+
|
| 154 |
+
def get_images(self, return_pil=False):
|
| 155 |
+
images = []
|
| 156 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 157 |
+
if i % 2 == 0:
|
| 158 |
+
if type(msg) is tuple:
|
| 159 |
+
msg, image, image_process_mode = msg
|
| 160 |
+
image = self.process_image(image, image_process_mode, return_pil=return_pil)
|
| 161 |
+
images.append(image)
|
| 162 |
+
return images
|
| 163 |
+
|
| 164 |
+
def to_gradio_chatbot(self):
|
| 165 |
+
ret = []
|
| 166 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 167 |
+
if i % 2 == 0:
|
| 168 |
+
if type(msg) is tuple:
|
| 169 |
+
msg, image, image_process_mode = msg
|
| 170 |
+
img_b64_str = self.process_image(
|
| 171 |
+
image, "Default", return_pil=False,
|
| 172 |
+
image_format='JPEG')
|
| 173 |
+
img_str = f'<img src="data:image/jpeg;base64,{img_b64_str}" alt="user upload image" />'
|
| 174 |
+
msg = img_str + msg.replace('<image>', '').strip()
|
| 175 |
+
ret.append([msg, None])
|
| 176 |
+
else:
|
| 177 |
+
ret.append([msg, None])
|
| 178 |
+
else:
|
| 179 |
+
ret[-1][-1] = msg
|
| 180 |
+
return ret
|
| 181 |
+
|
| 182 |
+
def copy(self):
|
| 183 |
+
return Conversation(
|
| 184 |
+
system=self.system,
|
| 185 |
+
roles=self.roles,
|
| 186 |
+
messages=[[x, y] for x, y in self.messages],
|
| 187 |
+
offset=self.offset,
|
| 188 |
+
sep_style=self.sep_style,
|
| 189 |
+
sep=self.sep,
|
| 190 |
+
sep2=self.sep2,
|
| 191 |
+
version=self.version)
|
| 192 |
+
|
| 193 |
+
def dict(self):
|
| 194 |
+
if len(self.get_images()) > 0:
|
| 195 |
+
return {
|
| 196 |
+
"system": self.system,
|
| 197 |
+
"roles": self.roles,
|
| 198 |
+
"messages": [[x, y[0] if type(y) is tuple else y] for x, y in self.messages],
|
| 199 |
+
"offset": self.offset,
|
| 200 |
+
"sep": self.sep,
|
| 201 |
+
"sep2": self.sep2,
|
| 202 |
+
}
|
| 203 |
+
return {
|
| 204 |
+
"system": self.system,
|
| 205 |
+
"roles": self.roles,
|
| 206 |
+
"messages": self.messages,
|
| 207 |
+
"offset": self.offset,
|
| 208 |
+
"sep": self.sep,
|
| 209 |
+
"sep2": self.sep2,
|
| 210 |
+
}
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
conv_vicuna_v0 = Conversation(
|
| 214 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 215 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 216 |
+
roles=("Human", "Assistant"),
|
| 217 |
+
messages=(
|
| 218 |
+
("Human", "What are the key differences between renewable and non-renewable energy sources?"),
|
| 219 |
+
("Assistant",
|
| 220 |
+
"Renewable energy sources are those that can be replenished naturally in a relatively "
|
| 221 |
+
"short amount of time, such as solar, wind, hydro, geothermal, and biomass. "
|
| 222 |
+
"Non-renewable energy sources, on the other hand, are finite and will eventually be "
|
| 223 |
+
"depleted, such as coal, oil, and natural gas. Here are some key differences between "
|
| 224 |
+
"renewable and non-renewable energy sources:\n"
|
| 225 |
+
"1. Availability: Renewable energy sources are virtually inexhaustible, while non-renewable "
|
| 226 |
+
"energy sources are finite and will eventually run out.\n"
|
| 227 |
+
"2. Environmental impact: Renewable energy sources have a much lower environmental impact "
|
| 228 |
+
"than non-renewable sources, which can lead to air and water pollution, greenhouse gas emissions, "
|
| 229 |
+
"and other negative effects.\n"
|
| 230 |
+
"3. Cost: Renewable energy sources can be more expensive to initially set up, but they typically "
|
| 231 |
+
"have lower operational costs than non-renewable sources.\n"
|
| 232 |
+
"4. Reliability: Renewable energy sources are often more reliable and can be used in more remote "
|
| 233 |
+
"locations than non-renewable sources.\n"
|
| 234 |
+
"5. Flexibility: Renewable energy sources are often more flexible and can be adapted to different "
|
| 235 |
+
"situations and needs, while non-renewable sources are more rigid and inflexible.\n"
|
| 236 |
+
"6. Sustainability: Renewable energy sources are more sustainable over the long term, while "
|
| 237 |
+
"non-renewable sources are not, and their depletion can lead to economic and social instability.\n")
|
| 238 |
+
),
|
| 239 |
+
offset=2,
|
| 240 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 241 |
+
sep="###",
|
| 242 |
+
)
|
| 243 |
+
|
| 244 |
+
conv_vicuna_v1 = Conversation(
|
| 245 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 246 |
+
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
|
| 247 |
+
roles=("USER", "ASSISTANT"),
|
| 248 |
+
version="v1",
|
| 249 |
+
messages=(),
|
| 250 |
+
offset=0,
|
| 251 |
+
sep_style=SeparatorStyle.TWO,
|
| 252 |
+
sep=" ",
|
| 253 |
+
sep2="</s>",
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
conv_llama_2 = Conversation(
|
| 257 |
+
system="""You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
|
| 258 |
+
|
| 259 |
+
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.""",
|
| 260 |
+
roles=("USER", "ASSISTANT"),
|
| 261 |
+
version="llama_v2",
|
| 262 |
+
messages=(),
|
| 263 |
+
offset=0,
|
| 264 |
+
sep_style=SeparatorStyle.LLAMA_2,
|
| 265 |
+
sep="<s>",
|
| 266 |
+
sep2="</s>",
|
| 267 |
+
)
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
conv_llava_llama_2 = Conversation(
|
| 271 |
+
system="You are a helpful language and vision assistant. "
|
| 272 |
+
"You are able to understand the visual content that the user provides, "
|
| 273 |
+
"and assist the user with a variety of tasks using natural language.",
|
| 274 |
+
roles=("USER", "ASSISTANT"),
|
| 275 |
+
version="llama_v2",
|
| 276 |
+
messages=(),
|
| 277 |
+
offset=0,
|
| 278 |
+
sep_style=SeparatorStyle.LLAMA_2,
|
| 279 |
+
sep="<s>",
|
| 280 |
+
sep2="</s>",
|
| 281 |
+
)
|
| 282 |
+
|
| 283 |
+
conv_mpt = Conversation(
|
| 284 |
+
system="""<|im_start|>system
|
| 285 |
+
A conversation between a user and an LLM-based AI assistant. The assistant gives helpful and honest answers.""",
|
| 286 |
+
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
| 287 |
+
version="mpt",
|
| 288 |
+
messages=(),
|
| 289 |
+
offset=0,
|
| 290 |
+
sep_style=SeparatorStyle.MPT,
|
| 291 |
+
sep="<|im_end|>",
|
| 292 |
+
)
|
| 293 |
+
|
| 294 |
+
conv_llava_plain = Conversation(
|
| 295 |
+
system="",
|
| 296 |
+
roles=("", ""),
|
| 297 |
+
messages=(
|
| 298 |
+
),
|
| 299 |
+
offset=0,
|
| 300 |
+
sep_style=SeparatorStyle.PLAIN,
|
| 301 |
+
sep="\n",
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
conv_llava_v0 = Conversation(
|
| 305 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 306 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 307 |
+
roles=("Human", "Assistant"),
|
| 308 |
+
messages=(
|
| 309 |
+
),
|
| 310 |
+
offset=0,
|
| 311 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 312 |
+
sep="###",
|
| 313 |
+
)
|
| 314 |
+
|
| 315 |
+
conv_llava_v0_mmtag = Conversation(
|
| 316 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 317 |
+
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
|
| 318 |
+
"The visual content will be provided with the following format: <Image>visual content</Image>.",
|
| 319 |
+
roles=("Human", "Assistant"),
|
| 320 |
+
messages=(
|
| 321 |
+
),
|
| 322 |
+
offset=0,
|
| 323 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 324 |
+
sep="###",
|
| 325 |
+
version="v0_mmtag",
|
| 326 |
+
)
|
| 327 |
+
|
| 328 |
+
conv_llava_v1 = Conversation(
|
| 329 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 330 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 331 |
+
roles=("USER", "ASSISTANT"),
|
| 332 |
+
version="v1",
|
| 333 |
+
messages=(),
|
| 334 |
+
offset=0,
|
| 335 |
+
sep_style=SeparatorStyle.TWO,
|
| 336 |
+
sep=" ",
|
| 337 |
+
sep2="</s>",
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
conv_llava_v1_mmtag = Conversation(
|
| 341 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 342 |
+
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
|
| 343 |
+
"The visual content will be provided with the following format: <Image>visual content</Image>.",
|
| 344 |
+
roles=("USER", "ASSISTANT"),
|
| 345 |
+
messages=(),
|
| 346 |
+
offset=0,
|
| 347 |
+
sep_style=SeparatorStyle.TWO,
|
| 348 |
+
sep=" ",
|
| 349 |
+
sep2="</s>",
|
| 350 |
+
version="v1_mmtag",
|
| 351 |
+
)
|
| 352 |
+
|
| 353 |
+
conv_mistral_instruct = Conversation(
|
| 354 |
+
system="",
|
| 355 |
+
roles=("USER", "ASSISTANT"),
|
| 356 |
+
version="llama_v2",
|
| 357 |
+
messages=(),
|
| 358 |
+
offset=0,
|
| 359 |
+
sep_style=SeparatorStyle.LLAMA_2,
|
| 360 |
+
sep="",
|
| 361 |
+
sep2="</s>",
|
| 362 |
+
)
|
| 363 |
+
|
| 364 |
+
conv_chatml_direct = Conversation(
|
| 365 |
+
system="""<|im_start|>system
|
| 366 |
+
Answer the questions.""",
|
| 367 |
+
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
| 368 |
+
version="mpt",
|
| 369 |
+
messages=(),
|
| 370 |
+
offset=0,
|
| 371 |
+
sep_style=SeparatorStyle.MPT,
|
| 372 |
+
sep="<|im_end|>",
|
| 373 |
+
)
|
| 374 |
+
|
| 375 |
+
conv_llama3 = Conversation(
|
| 376 |
+
system="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nA chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.""",
|
| 377 |
+
roles=("<|start_header_id|>user<|end_header_id|>\n\n", "<|start_header_id|>assistant<|end_header_id|>\n\n"),
|
| 378 |
+
version="llama3",
|
| 379 |
+
messages=(),
|
| 380 |
+
offset=0,
|
| 381 |
+
sep_style=SeparatorStyle.MPT,
|
| 382 |
+
sep="<|eot_id|>",
|
| 383 |
+
)
|
| 384 |
+
|
| 385 |
+
default_conversation = conv_llama3
|
| 386 |
+
conv_templates = {
|
| 387 |
+
"default": conv_vicuna_v0,
|
| 388 |
+
"v0": conv_vicuna_v0,
|
| 389 |
+
"v1": conv_vicuna_v1,
|
| 390 |
+
"vicuna_v1": conv_vicuna_v1,
|
| 391 |
+
"llama_2": conv_llama_2,
|
| 392 |
+
"mistral_instruct": conv_mistral_instruct,
|
| 393 |
+
"chatml_direct": conv_chatml_direct,
|
| 394 |
+
"mistral_direct": conv_chatml_direct,
|
| 395 |
+
|
| 396 |
+
"plain": conv_llava_plain,
|
| 397 |
+
"v0_plain": conv_llava_plain,
|
| 398 |
+
"llava_v0": conv_llava_v0,
|
| 399 |
+
"v0_mmtag": conv_llava_v0_mmtag,
|
| 400 |
+
"llava_v1": conv_llava_v1,
|
| 401 |
+
"v1_mmtag": conv_llava_v1_mmtag,
|
| 402 |
+
"llava_llama_2": conv_llava_llama_2,
|
| 403 |
+
"llama3": conv_llama3,
|
| 404 |
+
|
| 405 |
+
"mpt": conv_mpt,
|
| 406 |
+
}
|
| 407 |
+
|
| 408 |
+
if __name__ == "__main__":
|
| 409 |
+
print(default_conversation.get_prompt())
|
llava/eval/eval_gpt_review.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
import openai
|
| 6 |
+
import tqdm
|
| 7 |
+
import ray
|
| 8 |
+
import time
|
| 9 |
+
|
| 10 |
+
NUM_SECONDS_TO_SLEEP = 3
|
| 11 |
+
|
| 12 |
+
@ray.remote(num_cpus=4)
|
| 13 |
+
def get_eval(content: str, max_tokens: int):
|
| 14 |
+
while True:
|
| 15 |
+
try:
|
| 16 |
+
response = openai.ChatCompletion.create(
|
| 17 |
+
model='gpt-4',
|
| 18 |
+
messages=[{
|
| 19 |
+
'role': 'system',
|
| 20 |
+
'content': 'You are a helpful and precise assistant for checking the quality of the answer.'
|
| 21 |
+
}, {
|
| 22 |
+
'role': 'user',
|
| 23 |
+
'content': content,
|
| 24 |
+
}],
|
| 25 |
+
temperature=0.2, # TODO: figure out which temperature is best for evaluation
|
| 26 |
+
max_tokens=max_tokens,
|
| 27 |
+
)
|
| 28 |
+
break
|
| 29 |
+
except openai.error.RateLimitError:
|
| 30 |
+
pass
|
| 31 |
+
except Exception as e:
|
| 32 |
+
print(e)
|
| 33 |
+
time.sleep(NUM_SECONDS_TO_SLEEP)
|
| 34 |
+
|
| 35 |
+
print('success!')
|
| 36 |
+
return response['choices'][0]['message']['content']
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def parse_score(review):
|
| 40 |
+
try:
|
| 41 |
+
score_pair = review.split('\n')[0]
|
| 42 |
+
score_pair = score_pair.replace(',', ' ')
|
| 43 |
+
sp = score_pair.split(' ')
|
| 44 |
+
if len(sp) == 2:
|
| 45 |
+
return [float(sp[0]), float(sp[1])]
|
| 46 |
+
else:
|
| 47 |
+
print('error', review)
|
| 48 |
+
return [-1, -1]
|
| 49 |
+
except Exception as e:
|
| 50 |
+
print(e)
|
| 51 |
+
print('error', review)
|
| 52 |
+
return [-1, -1]
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
if __name__ == '__main__':
|
| 56 |
+
parser = argparse.ArgumentParser(description='ChatGPT-based QA evaluation.')
|
| 57 |
+
parser.add_argument('-q', '--question')
|
| 58 |
+
# parser.add_argument('-a', '--answer')
|
| 59 |
+
parser.add_argument('-a', '--answer-list', nargs='+', default=[])
|
| 60 |
+
parser.add_argument('-r', '--rule')
|
| 61 |
+
parser.add_argument('-o', '--output')
|
| 62 |
+
parser.add_argument('--max-tokens', type=int, default=1024, help='maximum number of tokens produced in the output')
|
| 63 |
+
args = parser.parse_args()
|
| 64 |
+
|
| 65 |
+
ray.init()
|
| 66 |
+
|
| 67 |
+
f_q = open(os.path.expanduser(args.question))
|
| 68 |
+
f_ans1 = open(os.path.expanduser(args.answer_list[0]))
|
| 69 |
+
f_ans2 = open(os.path.expanduser(args.answer_list[1]))
|
| 70 |
+
rule_dict = json.load(open(os.path.expanduser(args.rule), 'r'))
|
| 71 |
+
|
| 72 |
+
review_file = open(f'{args.output}', 'w')
|
| 73 |
+
|
| 74 |
+
js_list = []
|
| 75 |
+
handles = []
|
| 76 |
+
idx = 0
|
| 77 |
+
for ques_js, ans1_js, ans2_js in zip(f_q, f_ans1, f_ans2):
|
| 78 |
+
# if idx == 1:
|
| 79 |
+
# break
|
| 80 |
+
|
| 81 |
+
ques = json.loads(ques_js)
|
| 82 |
+
ans1 = json.loads(ans1_js)
|
| 83 |
+
ans2 = json.loads(ans2_js)
|
| 84 |
+
|
| 85 |
+
category = json.loads(ques_js)['category']
|
| 86 |
+
if category in rule_dict:
|
| 87 |
+
rule = rule_dict[category]
|
| 88 |
+
else:
|
| 89 |
+
rule = rule_dict['default']
|
| 90 |
+
prompt = rule['prompt']
|
| 91 |
+
role = rule['role']
|
| 92 |
+
content = (f'[Question]\n{ques["text"]}\n\n'
|
| 93 |
+
f'[{role} 1]\n{ans1["text"]}\n\n[End of {role} 1]\n\n'
|
| 94 |
+
f'[{role} 2]\n{ans2["text"]}\n\n[End of {role} 2]\n\n'
|
| 95 |
+
f'[System]\n{prompt}\n\n')
|
| 96 |
+
js_list.append({
|
| 97 |
+
'id': idx+1,
|
| 98 |
+
'question_id': ques['question_id'],
|
| 99 |
+
'answer1_id': ans1['answer_id'],
|
| 100 |
+
'answer2_id': ans2['answer_id'],
|
| 101 |
+
'category': category})
|
| 102 |
+
idx += 1
|
| 103 |
+
handles.append(get_eval.remote(content, args.max_tokens))
|
| 104 |
+
# To avoid the rate limit set by OpenAI
|
| 105 |
+
time.sleep(NUM_SECONDS_TO_SLEEP)
|
| 106 |
+
|
| 107 |
+
reviews = ray.get(handles)
|
| 108 |
+
for idx, review in enumerate(reviews):
|
| 109 |
+
scores = parse_score(review)
|
| 110 |
+
js_list[idx]['content'] = review
|
| 111 |
+
js_list[idx]['tuple'] = scores
|
| 112 |
+
review_file.write(json.dumps(js_list[idx]) + '\n')
|
| 113 |
+
review_file.close()
|
llava/eval/eval_gpt_review_bench.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
import openai
|
| 6 |
+
import time
|
| 7 |
+
|
| 8 |
+
NUM_SECONDS_TO_SLEEP = 0.5
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_eval(content: str, max_tokens: int):
|
| 12 |
+
while True:
|
| 13 |
+
try:
|
| 14 |
+
response = openai.ChatCompletion.create(
|
| 15 |
+
model='gpt-4-0314',
|
| 16 |
+
messages=[{
|
| 17 |
+
'role': 'system',
|
| 18 |
+
'content': 'You are a helpful and precise assistant for checking the quality of the answer.'
|
| 19 |
+
}, {
|
| 20 |
+
'role': 'user',
|
| 21 |
+
'content': content,
|
| 22 |
+
}],
|
| 23 |
+
temperature=0.2, # TODO: figure out which temperature is best for evaluation
|
| 24 |
+
max_tokens=max_tokens,
|
| 25 |
+
)
|
| 26 |
+
break
|
| 27 |
+
except openai.error.RateLimitError:
|
| 28 |
+
pass
|
| 29 |
+
except Exception as e:
|
| 30 |
+
print(e)
|
| 31 |
+
time.sleep(NUM_SECONDS_TO_SLEEP)
|
| 32 |
+
|
| 33 |
+
return response['choices'][0]['message']['content']
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def parse_score(review):
|
| 37 |
+
try:
|
| 38 |
+
score_pair = review.split('\n')[0]
|
| 39 |
+
score_pair = score_pair.replace(',', ' ')
|
| 40 |
+
sp = score_pair.split(' ')
|
| 41 |
+
if len(sp) == 2:
|
| 42 |
+
return [float(sp[0]), float(sp[1])]
|
| 43 |
+
else:
|
| 44 |
+
print('error', review)
|
| 45 |
+
return [-1, -1]
|
| 46 |
+
except Exception as e:
|
| 47 |
+
print(e)
|
| 48 |
+
print('error', review)
|
| 49 |
+
return [-1, -1]
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
if __name__ == '__main__':
|
| 53 |
+
parser = argparse.ArgumentParser(description='ChatGPT-based QA evaluation.')
|
| 54 |
+
parser.add_argument('-q', '--question')
|
| 55 |
+
parser.add_argument('-c', '--context')
|
| 56 |
+
parser.add_argument('-a', '--answer-list', nargs='+', default=[])
|
| 57 |
+
parser.add_argument('-r', '--rule')
|
| 58 |
+
parser.add_argument('-o', '--output')
|
| 59 |
+
parser.add_argument('--max-tokens', type=int, default=1024, help='maximum number of tokens produced in the output')
|
| 60 |
+
args = parser.parse_args()
|
| 61 |
+
|
| 62 |
+
f_q = open(os.path.expanduser(args.question))
|
| 63 |
+
f_ans1 = open(os.path.expanduser(args.answer_list[0]))
|
| 64 |
+
f_ans2 = open(os.path.expanduser(args.answer_list[1]))
|
| 65 |
+
rule_dict = json.load(open(os.path.expanduser(args.rule), 'r'))
|
| 66 |
+
|
| 67 |
+
if os.path.isfile(os.path.expanduser(args.output)):
|
| 68 |
+
cur_reviews = [json.loads(line) for line in open(os.path.expanduser(args.output))]
|
| 69 |
+
else:
|
| 70 |
+
cur_reviews = []
|
| 71 |
+
|
| 72 |
+
review_file = open(f'{args.output}', 'a')
|
| 73 |
+
|
| 74 |
+
context_list = [json.loads(line) for line in open(os.path.expanduser(args.context))]
|
| 75 |
+
image_to_context = {context['image']: context for context in context_list}
|
| 76 |
+
|
| 77 |
+
handles = []
|
| 78 |
+
idx = 0
|
| 79 |
+
for ques_js, ans1_js, ans2_js in zip(f_q, f_ans1, f_ans2):
|
| 80 |
+
ques = json.loads(ques_js)
|
| 81 |
+
ans1 = json.loads(ans1_js)
|
| 82 |
+
ans2 = json.loads(ans2_js)
|
| 83 |
+
|
| 84 |
+
inst = image_to_context[ques['image']]
|
| 85 |
+
|
| 86 |
+
if isinstance(inst['caption'], list):
|
| 87 |
+
cap_str = '\n'.join(inst['caption'])
|
| 88 |
+
else:
|
| 89 |
+
cap_str = inst['caption']
|
| 90 |
+
|
| 91 |
+
category = 'llava_bench_' + json.loads(ques_js)['category']
|
| 92 |
+
if category in rule_dict:
|
| 93 |
+
rule = rule_dict[category]
|
| 94 |
+
else:
|
| 95 |
+
assert False, f"Visual QA category not found in rule file: {category}."
|
| 96 |
+
prompt = rule['prompt']
|
| 97 |
+
role = rule['role']
|
| 98 |
+
content = (f'[Context]\n{cap_str}\n\n'
|
| 99 |
+
f'[Question]\n{ques["text"]}\n\n'
|
| 100 |
+
f'[{role} 1]\n{ans1["text"]}\n\n[End of {role} 1]\n\n'
|
| 101 |
+
f'[{role} 2]\n{ans2["text"]}\n\n[End of {role} 2]\n\n'
|
| 102 |
+
f'[System]\n{prompt}\n\n')
|
| 103 |
+
cur_js = {
|
| 104 |
+
'id': idx+1,
|
| 105 |
+
'question_id': ques['question_id'],
|
| 106 |
+
'answer1_id': ans1.get('answer_id', ans1['question_id']),
|
| 107 |
+
'answer2_id': ans2.get('answer_id', ans2['answer_id']),
|
| 108 |
+
'category': category
|
| 109 |
+
}
|
| 110 |
+
if idx >= len(cur_reviews):
|
| 111 |
+
review = get_eval(content, args.max_tokens)
|
| 112 |
+
scores = parse_score(review)
|
| 113 |
+
cur_js['content'] = review
|
| 114 |
+
cur_js['tuple'] = scores
|
| 115 |
+
review_file.write(json.dumps(cur_js) + '\n')
|
| 116 |
+
review_file.flush()
|
| 117 |
+
else:
|
| 118 |
+
print(f'Skipping {idx} as we already have it.')
|
| 119 |
+
idx += 1
|
| 120 |
+
print(idx)
|
| 121 |
+
review_file.close()
|
llava/eval/eval_gpt_review_visual.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
import openai
|
| 6 |
+
import time
|
| 7 |
+
|
| 8 |
+
NUM_SECONDS_TO_SLEEP = 0.5
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_eval(content: str, max_tokens: int):
|
| 12 |
+
while True:
|
| 13 |
+
try:
|
| 14 |
+
response = openai.ChatCompletion.create(
|
| 15 |
+
model='gpt-4-0314',
|
| 16 |
+
messages=[{
|
| 17 |
+
'role': 'system',
|
| 18 |
+
'content': 'You are a helpful and precise assistant for checking the quality of the answer.'
|
| 19 |
+
}, {
|
| 20 |
+
'role': 'user',
|
| 21 |
+
'content': content,
|
| 22 |
+
}],
|
| 23 |
+
temperature=0.2, # TODO: figure out which temperature is best for evaluation
|
| 24 |
+
max_tokens=max_tokens,
|
| 25 |
+
)
|
| 26 |
+
break
|
| 27 |
+
except openai.error.RateLimitError:
|
| 28 |
+
pass
|
| 29 |
+
except Exception as e:
|
| 30 |
+
print(e)
|
| 31 |
+
time.sleep(NUM_SECONDS_TO_SLEEP)
|
| 32 |
+
|
| 33 |
+
return response['choices'][0]['message']['content']
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def parse_score(review):
|
| 37 |
+
try:
|
| 38 |
+
score_pair = review.split('\n')[0]
|
| 39 |
+
score_pair = score_pair.replace(',', ' ')
|
| 40 |
+
sp = score_pair.split(' ')
|
| 41 |
+
if len(sp) == 2:
|
| 42 |
+
return [float(sp[0]), float(sp[1])]
|
| 43 |
+
else:
|
| 44 |
+
print('error', review)
|
| 45 |
+
return [-1, -1]
|
| 46 |
+
except Exception as e:
|
| 47 |
+
print(e)
|
| 48 |
+
print('error', review)
|
| 49 |
+
return [-1, -1]
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
if __name__ == '__main__':
|
| 53 |
+
parser = argparse.ArgumentParser(description='ChatGPT-based QA evaluation.')
|
| 54 |
+
parser.add_argument('-q', '--question')
|
| 55 |
+
parser.add_argument('-c', '--context')
|
| 56 |
+
parser.add_argument('-a', '--answer-list', nargs='+', default=[])
|
| 57 |
+
parser.add_argument('-r', '--rule')
|
| 58 |
+
parser.add_argument('-o', '--output')
|
| 59 |
+
parser.add_argument('--max-tokens', type=int, default=1024, help='maximum number of tokens produced in the output')
|
| 60 |
+
args = parser.parse_args()
|
| 61 |
+
|
| 62 |
+
f_q = open(os.path.expanduser(args.question))
|
| 63 |
+
f_ans1 = open(os.path.expanduser(args.answer_list[0]))
|
| 64 |
+
f_ans2 = open(os.path.expanduser(args.answer_list[1]))
|
| 65 |
+
rule_dict = json.load(open(os.path.expanduser(args.rule), 'r'))
|
| 66 |
+
|
| 67 |
+
if os.path.isfile(os.path.expanduser(args.output)):
|
| 68 |
+
cur_reviews = [json.loads(line) for line in open(os.path.expanduser(args.output))]
|
| 69 |
+
else:
|
| 70 |
+
cur_reviews = []
|
| 71 |
+
|
| 72 |
+
review_file = open(f'{args.output}', 'a')
|
| 73 |
+
|
| 74 |
+
context_list = [json.loads(line) for line in open(os.path.expanduser(args.context))]
|
| 75 |
+
image_to_context = {context['image']: context for context in context_list}
|
| 76 |
+
|
| 77 |
+
handles = []
|
| 78 |
+
idx = 0
|
| 79 |
+
for ques_js, ans1_js, ans2_js in zip(f_q, f_ans1, f_ans2):
|
| 80 |
+
ques = json.loads(ques_js)
|
| 81 |
+
ans1 = json.loads(ans1_js)
|
| 82 |
+
ans2 = json.loads(ans2_js)
|
| 83 |
+
|
| 84 |
+
inst = image_to_context[ques['image']]
|
| 85 |
+
cap_str = '\n'.join(inst['captions'])
|
| 86 |
+
box_str = '\n'.join([f'{instance["category"]}: {instance["bbox"]}' for instance in inst['instances']])
|
| 87 |
+
|
| 88 |
+
category = json.loads(ques_js)['category']
|
| 89 |
+
if category in rule_dict:
|
| 90 |
+
rule = rule_dict[category]
|
| 91 |
+
else:
|
| 92 |
+
assert False, f"Visual QA category not found in rule file: {category}."
|
| 93 |
+
prompt = rule['prompt']
|
| 94 |
+
role = rule['role']
|
| 95 |
+
content = (f'[Context]\n{cap_str}\n\n{box_str}\n\n'
|
| 96 |
+
f'[Question]\n{ques["text"]}\n\n'
|
| 97 |
+
f'[{role} 1]\n{ans1["text"]}\n\n[End of {role} 1]\n\n'
|
| 98 |
+
f'[{role} 2]\n{ans2["text"]}\n\n[End of {role} 2]\n\n'
|
| 99 |
+
f'[System]\n{prompt}\n\n')
|
| 100 |
+
cur_js = {
|
| 101 |
+
'id': idx+1,
|
| 102 |
+
'question_id': ques['question_id'],
|
| 103 |
+
'answer1_id': ans1.get('answer_id', ans1['question_id']),
|
| 104 |
+
'answer2_id': ans2.get('answer_id', ans2['answer_id']),
|
| 105 |
+
'category': category
|
| 106 |
+
}
|
| 107 |
+
if idx >= len(cur_reviews):
|
| 108 |
+
review = get_eval(content, args.max_tokens)
|
| 109 |
+
scores = parse_score(review)
|
| 110 |
+
cur_js['content'] = review
|
| 111 |
+
cur_js['tuple'] = scores
|
| 112 |
+
review_file.write(json.dumps(cur_js) + '\n')
|
| 113 |
+
review_file.flush()
|
| 114 |
+
else:
|
| 115 |
+
print(f'Skipping {idx} as we already have it.')
|
| 116 |
+
idx += 1
|
| 117 |
+
print(idx)
|
| 118 |
+
review_file.close()
|
llava/eval/eval_pope.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import argparse
|
| 4 |
+
|
| 5 |
+
def eval_pope(answers, label_file):
|
| 6 |
+
label_list = [json.loads(q)['label'] for q in open(label_file, 'r')]
|
| 7 |
+
|
| 8 |
+
for answer in answers:
|
| 9 |
+
text = answer['text']
|
| 10 |
+
|
| 11 |
+
# Only keep the first sentence
|
| 12 |
+
if text.find('.') != -1:
|
| 13 |
+
text = text.split('.')[0]
|
| 14 |
+
|
| 15 |
+
text = text.replace(',', '')
|
| 16 |
+
words = text.split(' ')
|
| 17 |
+
if 'No' in words or 'not' in words or 'no' in words:
|
| 18 |
+
answer['text'] = 'no'
|
| 19 |
+
else:
|
| 20 |
+
answer['text'] = 'yes'
|
| 21 |
+
|
| 22 |
+
for i in range(len(label_list)):
|
| 23 |
+
if label_list[i] == 'no':
|
| 24 |
+
label_list[i] = 0
|
| 25 |
+
else:
|
| 26 |
+
label_list[i] = 1
|
| 27 |
+
|
| 28 |
+
pred_list = []
|
| 29 |
+
for answer in answers:
|
| 30 |
+
if answer['text'] == 'no':
|
| 31 |
+
pred_list.append(0)
|
| 32 |
+
else:
|
| 33 |
+
pred_list.append(1)
|
| 34 |
+
|
| 35 |
+
pos = 1
|
| 36 |
+
neg = 0
|
| 37 |
+
yes_ratio = pred_list.count(1) / len(pred_list)
|
| 38 |
+
|
| 39 |
+
TP, TN, FP, FN = 0, 0, 0, 0
|
| 40 |
+
for pred, label in zip(pred_list, label_list):
|
| 41 |
+
if pred == pos and label == pos:
|
| 42 |
+
TP += 1
|
| 43 |
+
elif pred == pos and label == neg:
|
| 44 |
+
FP += 1
|
| 45 |
+
elif pred == neg and label == neg:
|
| 46 |
+
TN += 1
|
| 47 |
+
elif pred == neg and label == pos:
|
| 48 |
+
FN += 1
|
| 49 |
+
|
| 50 |
+
print('TP\tFP\tTN\tFN\t')
|
| 51 |
+
print('{}\t{}\t{}\t{}'.format(TP, FP, TN, FN))
|
| 52 |
+
|
| 53 |
+
precision = float(TP) / float(TP + FP)
|
| 54 |
+
recall = float(TP) / float(TP + FN)
|
| 55 |
+
f1 = 2*precision*recall / (precision + recall)
|
| 56 |
+
acc = (TP + TN) / (TP + TN + FP + FN)
|
| 57 |
+
print('Accuracy: {}'.format(acc))
|
| 58 |
+
print('Precision: {}'.format(precision))
|
| 59 |
+
print('Recall: {}'.format(recall))
|
| 60 |
+
print('F1 score: {}'.format(f1))
|
| 61 |
+
print('Yes ratio: {}'.format(yes_ratio))
|
| 62 |
+
print('%.3f, %.3f, %.3f, %.3f, %.3f' % (f1, acc, precision, recall, yes_ratio) )
|
| 63 |
+
|
| 64 |
+
if __name__ == "__main__":
|
| 65 |
+
parser = argparse.ArgumentParser()
|
| 66 |
+
parser.add_argument("--annotation-dir", type=str)
|
| 67 |
+
parser.add_argument("--question-file", type=str)
|
| 68 |
+
parser.add_argument("--result-file", type=str)
|
| 69 |
+
args = parser.parse_args()
|
| 70 |
+
|
| 71 |
+
questions = [json.loads(line) for line in open(args.question_file)]
|
| 72 |
+
questions = {question['question_id']: question for question in questions}
|
| 73 |
+
answers = [json.loads(q) for q in open(args.result_file)]
|
| 74 |
+
for file in os.listdir(args.annotation_dir):
|
| 75 |
+
assert file.startswith('coco_pope_')
|
| 76 |
+
assert file.endswith('.json')
|
| 77 |
+
category = file[10:-5]
|
| 78 |
+
cur_answers = [x for x in answers if questions[x['question_id']]['category'] == category]
|
| 79 |
+
print('Category: {}, # samples: {}'.format(category, len(cur_answers)))
|
| 80 |
+
eval_pope(cur_answers, os.path.join(args.annotation_dir, file))
|
| 81 |
+
print("====================================")
|
llava/eval/eval_science_qa.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
import random
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def get_args():
|
| 9 |
+
parser = argparse.ArgumentParser()
|
| 10 |
+
parser.add_argument('--base-dir', type=str)
|
| 11 |
+
parser.add_argument('--result-file', type=str)
|
| 12 |
+
parser.add_argument('--output-file', type=str)
|
| 13 |
+
parser.add_argument('--output-result', type=str)
|
| 14 |
+
parser.add_argument('--split', type=str, default='test')
|
| 15 |
+
parser.add_argument('--options', type=list, default=["A", "B", "C", "D", "E"])
|
| 16 |
+
return parser.parse_args()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def convert_caps(results):
|
| 20 |
+
fakecaps = []
|
| 21 |
+
for result in results:
|
| 22 |
+
image_id = result['question_id']
|
| 23 |
+
caption = result['text']
|
| 24 |
+
fakecaps.append({"image_id": int(image_id), "caption": caption})
|
| 25 |
+
return fakecaps
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_pred_idx(prediction, choices, options):
|
| 29 |
+
"""
|
| 30 |
+
Get the index (e.g. 2) from the prediction (e.g. 'C')
|
| 31 |
+
"""
|
| 32 |
+
if prediction in options[:len(choices)]:
|
| 33 |
+
return options.index(prediction)
|
| 34 |
+
else:
|
| 35 |
+
return -1
|
| 36 |
+
return random.choice(range(len(choices)))
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
if __name__ == "__main__":
|
| 40 |
+
args = get_args()
|
| 41 |
+
|
| 42 |
+
base_dir = args.base_dir
|
| 43 |
+
split_indices = json.load(open(os.path.join(base_dir, "pid_splits.json")))[args.split]
|
| 44 |
+
problems = json.load(open(os.path.join(base_dir, "problems.json")))
|
| 45 |
+
predictions = [json.loads(line) for line in open(args.result_file)]
|
| 46 |
+
predictions = {pred['question_id']: pred for pred in predictions}
|
| 47 |
+
split_problems = {idx: problems[idx] for idx in split_indices}
|
| 48 |
+
|
| 49 |
+
results = {'correct': [], 'incorrect': []}
|
| 50 |
+
sqa_results = {}
|
| 51 |
+
sqa_results['acc'] = None
|
| 52 |
+
sqa_results['correct'] = None
|
| 53 |
+
sqa_results['count'] = None
|
| 54 |
+
sqa_results['results'] = {}
|
| 55 |
+
sqa_results['outputs'] = {}
|
| 56 |
+
|
| 57 |
+
for prob_id, prob in split_problems.items():
|
| 58 |
+
if prob_id not in predictions:
|
| 59 |
+
pred = {'text': 'FAILED', 'prompt': 'Unknown'}
|
| 60 |
+
pred_text = 'FAILED'
|
| 61 |
+
else:
|
| 62 |
+
pred = predictions[prob_id]
|
| 63 |
+
pred_text = pred['text']
|
| 64 |
+
|
| 65 |
+
if pred_text in args.options:
|
| 66 |
+
answer = pred_text
|
| 67 |
+
elif len(pred_text) >= 3 and pred_text[0] in args.options and pred_text[1:3] == ". ":
|
| 68 |
+
answer = pred_text[0]
|
| 69 |
+
else:
|
| 70 |
+
pattern = re.compile(r'The answer is ([A-Z]).')
|
| 71 |
+
res = pattern.findall(pred_text)
|
| 72 |
+
if len(res) == 1:
|
| 73 |
+
answer = res[0] # 'A', 'B', ...
|
| 74 |
+
else:
|
| 75 |
+
answer = "FAILED"
|
| 76 |
+
|
| 77 |
+
pred_idx = get_pred_idx(answer, prob['choices'], args.options)
|
| 78 |
+
|
| 79 |
+
analysis = {
|
| 80 |
+
'question_id': prob_id,
|
| 81 |
+
'parsed_ans': answer,
|
| 82 |
+
'ground_truth': args.options[prob['answer']],
|
| 83 |
+
'question': pred['prompt'],
|
| 84 |
+
'pred': pred_text,
|
| 85 |
+
'is_multimodal': '<image>' in pred['prompt'],
|
| 86 |
+
}
|
| 87 |
+
|
| 88 |
+
sqa_results['results'][prob_id] = get_pred_idx(answer, prob['choices'], args.options)
|
| 89 |
+
sqa_results['outputs'][prob_id] = pred_text
|
| 90 |
+
|
| 91 |
+
if pred_idx == prob['answer']:
|
| 92 |
+
results['correct'].append(analysis)
|
| 93 |
+
else:
|
| 94 |
+
results['incorrect'].append(analysis)
|
| 95 |
+
|
| 96 |
+
correct = len(results['correct'])
|
| 97 |
+
total = len(results['correct']) + len(results['incorrect'])
|
| 98 |
+
|
| 99 |
+
###### IMG ######
|
| 100 |
+
multimodal_correct = len([x for x in results['correct'] if x['is_multimodal']])
|
| 101 |
+
multimodal_incorrect = len([x for x in results['incorrect'] if x['is_multimodal']])
|
| 102 |
+
multimodal_total = multimodal_correct + multimodal_incorrect
|
| 103 |
+
###### IMG ######
|
| 104 |
+
|
| 105 |
+
print(f'Total: {total}, Correct: {correct}, Accuracy: {correct / total * 100:.2f}%, IMG-Accuracy: {multimodal_correct / multimodal_total * 100:.2f}%')
|
| 106 |
+
|
| 107 |
+
sqa_results['acc'] = correct / total * 100
|
| 108 |
+
sqa_results['correct'] = correct
|
| 109 |
+
sqa_results['count'] = total
|
| 110 |
+
|
| 111 |
+
with open(args.output_file, 'w') as f:
|
| 112 |
+
json.dump(results, f, indent=2)
|
| 113 |
+
with open(args.output_result, 'w') as f:
|
| 114 |
+
json.dump(sqa_results, f, indent=2)
|
llava/eval/eval_science_qa_gpt4.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
import random
|
| 6 |
+
from collections import defaultdict
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_args():
|
| 10 |
+
parser = argparse.ArgumentParser()
|
| 11 |
+
parser.add_argument('--base-dir', type=str)
|
| 12 |
+
parser.add_argument('--gpt4-result', type=str)
|
| 13 |
+
parser.add_argument('--our-result', type=str)
|
| 14 |
+
parser.add_argument('--split', type=str, default='test')
|
| 15 |
+
parser.add_argument('--options', type=list, default=["A", "B", "C", "D", "E"])
|
| 16 |
+
return parser.parse_args()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def convert_caps(results):
|
| 20 |
+
fakecaps = []
|
| 21 |
+
for result in results:
|
| 22 |
+
image_id = result['question_id']
|
| 23 |
+
caption = result['text']
|
| 24 |
+
fakecaps.append({"image_id": int(image_id), "caption": caption})
|
| 25 |
+
return fakecaps
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_pred_idx(prediction, choices, options):
|
| 29 |
+
"""
|
| 30 |
+
Get the index (e.g. 2) from the prediction (e.g. 'C')
|
| 31 |
+
"""
|
| 32 |
+
if prediction in options[:len(choices)]:
|
| 33 |
+
return options.index(prediction)
|
| 34 |
+
else:
|
| 35 |
+
return random.choice(range(len(choices)))
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
if __name__ == "__main__":
|
| 39 |
+
args = get_args()
|
| 40 |
+
|
| 41 |
+
base_dir = args.base_dir
|
| 42 |
+
split_indices = json.load(open(os.path.join(base_dir, "pid_splits.json")))[args.split]
|
| 43 |
+
problems = json.load(open(os.path.join(base_dir, "problems.json")))
|
| 44 |
+
our_predictions = [json.loads(line) for line in open(args.our_result)]
|
| 45 |
+
our_predictions = {pred['question_id']: pred for pred in our_predictions}
|
| 46 |
+
split_problems = {idx: problems[idx] for idx in split_indices}
|
| 47 |
+
|
| 48 |
+
gpt4_predictions = json.load(open(args.gpt4_result))['outputs']
|
| 49 |
+
|
| 50 |
+
results = defaultdict(lambda: 0)
|
| 51 |
+
|
| 52 |
+
for prob_id, prob in split_problems.items():
|
| 53 |
+
if prob_id not in our_predictions:
|
| 54 |
+
continue
|
| 55 |
+
if prob_id not in gpt4_predictions:
|
| 56 |
+
continue
|
| 57 |
+
our_pred = our_predictions[prob_id]['text']
|
| 58 |
+
gpt4_pred = gpt4_predictions[prob_id]
|
| 59 |
+
|
| 60 |
+
pattern = re.compile(r'The answer is ([A-Z]).')
|
| 61 |
+
our_res = pattern.findall(our_pred)
|
| 62 |
+
if len(our_res) == 1:
|
| 63 |
+
our_answer = our_res[0] # 'A', 'B', ...
|
| 64 |
+
else:
|
| 65 |
+
our_answer = "FAILED"
|
| 66 |
+
gpt4_res = pattern.findall(gpt4_pred)
|
| 67 |
+
if len(gpt4_res) == 1:
|
| 68 |
+
gpt4_answer = gpt4_res[0] # 'A', 'B', ...
|
| 69 |
+
else:
|
| 70 |
+
gpt4_answer = "FAILED"
|
| 71 |
+
|
| 72 |
+
our_pred_idx = get_pred_idx(our_answer, prob['choices'], args.options)
|
| 73 |
+
gpt4_pred_idx = get_pred_idx(gpt4_answer, prob['choices'], args.options)
|
| 74 |
+
|
| 75 |
+
if gpt4_answer == 'FAILED':
|
| 76 |
+
results['gpt4_failed'] += 1
|
| 77 |
+
# continue
|
| 78 |
+
gpt4_pred_idx = our_pred_idx
|
| 79 |
+
# if our_pred_idx != prob['answer']:
|
| 80 |
+
# print(our_predictions[prob_id]['prompt'])
|
| 81 |
+
# print('-----------------')
|
| 82 |
+
# print(f'LECTURE: {prob["lecture"]}')
|
| 83 |
+
# print(f'SOLUTION: {prob["solution"]}')
|
| 84 |
+
# print('=====================')
|
| 85 |
+
else:
|
| 86 |
+
# continue
|
| 87 |
+
pass
|
| 88 |
+
# gpt4_pred_idx = our_pred_idx
|
| 89 |
+
|
| 90 |
+
if gpt4_pred_idx == prob['answer']:
|
| 91 |
+
results['correct'] += 1
|
| 92 |
+
else:
|
| 93 |
+
results['incorrect'] += 1
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
if gpt4_pred_idx == prob['answer'] or our_pred_idx == prob['answer']:
|
| 97 |
+
results['correct_upperbound'] += 1
|
| 98 |
+
|
| 99 |
+
correct = results['correct']
|
| 100 |
+
total = results['correct'] + results['incorrect']
|
| 101 |
+
print(f'Total: {total}, Correct: {correct}, Accuracy: {correct / total * 100:.2f}%')
|
| 102 |
+
print(f'Total: {total}, Correct (upper): {results["correct_upperbound"]}, Accuracy: {results["correct_upperbound"] / total * 100:.2f}%')
|
| 103 |
+
print(f'Total: {total}, GPT-4 NO-ANS (RANDOM): {results["gpt4_failed"]}, Percentage: {results["gpt4_failed"] / total * 100:.2f}%')
|
| 104 |
+
|
llava/eval/eval_science_qa_gpt4_requery.py
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
import random
|
| 6 |
+
from collections import defaultdict
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_args():
|
| 10 |
+
parser = argparse.ArgumentParser()
|
| 11 |
+
parser.add_argument('--base-dir', type=str)
|
| 12 |
+
parser.add_argument('--gpt4-result', type=str)
|
| 13 |
+
parser.add_argument('--requery-result', type=str)
|
| 14 |
+
parser.add_argument('--our-result', type=str)
|
| 15 |
+
parser.add_argument('--output-result', type=str)
|
| 16 |
+
parser.add_argument('--split', type=str, default='test')
|
| 17 |
+
parser.add_argument('--options', type=list, default=["A", "B", "C", "D", "E"])
|
| 18 |
+
return parser.parse_args()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def convert_caps(results):
|
| 22 |
+
fakecaps = []
|
| 23 |
+
for result in results:
|
| 24 |
+
image_id = result['question_id']
|
| 25 |
+
caption = result['text']
|
| 26 |
+
fakecaps.append({"image_id": int(image_id), "caption": caption})
|
| 27 |
+
return fakecaps
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def get_pred_idx(prediction, choices, options):
|
| 31 |
+
"""
|
| 32 |
+
Get the index (e.g. 2) from the prediction (e.g. 'C')
|
| 33 |
+
"""
|
| 34 |
+
if prediction in options[:len(choices)]:
|
| 35 |
+
return options.index(prediction)
|
| 36 |
+
else:
|
| 37 |
+
return random.choice(range(len(choices)))
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
if __name__ == "__main__":
|
| 41 |
+
args = get_args()
|
| 42 |
+
|
| 43 |
+
base_dir = args.base_dir
|
| 44 |
+
split_indices = json.load(open(os.path.join(base_dir, "pid_splits.json")))[args.split]
|
| 45 |
+
problems = json.load(open(os.path.join(base_dir, "problems.json")))
|
| 46 |
+
our_predictions = [json.loads(line) for line in open(args.our_result)]
|
| 47 |
+
our_predictions = {pred['question_id']: pred for pred in our_predictions}
|
| 48 |
+
split_problems = {idx: problems[idx] for idx in split_indices}
|
| 49 |
+
|
| 50 |
+
requery_predictions = [json.loads(line) for line in open(args.requery_result)]
|
| 51 |
+
requery_predictions = {pred['question_id']: pred for pred in requery_predictions}
|
| 52 |
+
|
| 53 |
+
gpt4_predictions = json.load(open(args.gpt4_result))['outputs']
|
| 54 |
+
|
| 55 |
+
results = defaultdict(lambda: 0)
|
| 56 |
+
|
| 57 |
+
sqa_results = {}
|
| 58 |
+
sqa_results['acc'] = None
|
| 59 |
+
sqa_results['correct'] = None
|
| 60 |
+
sqa_results['count'] = None
|
| 61 |
+
sqa_results['results'] = {}
|
| 62 |
+
sqa_results['outputs'] = {}
|
| 63 |
+
|
| 64 |
+
for prob_id, prob in split_problems.items():
|
| 65 |
+
if prob_id not in our_predictions:
|
| 66 |
+
assert False
|
| 67 |
+
if prob_id not in gpt4_predictions:
|
| 68 |
+
assert False
|
| 69 |
+
our_pred = our_predictions[prob_id]['text']
|
| 70 |
+
gpt4_pred = gpt4_predictions[prob_id]
|
| 71 |
+
if prob_id not in requery_predictions:
|
| 72 |
+
results['missing_requery'] += 1
|
| 73 |
+
requery_pred = "MISSING"
|
| 74 |
+
else:
|
| 75 |
+
requery_pred = requery_predictions[prob_id]['text']
|
| 76 |
+
|
| 77 |
+
pattern = re.compile(r'The answer is ([A-Z]).')
|
| 78 |
+
our_res = pattern.findall(our_pred)
|
| 79 |
+
if len(our_res) == 1:
|
| 80 |
+
our_answer = our_res[0] # 'A', 'B', ...
|
| 81 |
+
else:
|
| 82 |
+
our_answer = "FAILED"
|
| 83 |
+
|
| 84 |
+
requery_res = pattern.findall(requery_pred)
|
| 85 |
+
if len(requery_res) == 1:
|
| 86 |
+
requery_answer = requery_res[0] # 'A', 'B', ...
|
| 87 |
+
else:
|
| 88 |
+
requery_answer = "FAILED"
|
| 89 |
+
|
| 90 |
+
gpt4_res = pattern.findall(gpt4_pred)
|
| 91 |
+
if len(gpt4_res) == 1:
|
| 92 |
+
gpt4_answer = gpt4_res[0] # 'A', 'B', ...
|
| 93 |
+
else:
|
| 94 |
+
gpt4_answer = "FAILED"
|
| 95 |
+
|
| 96 |
+
our_pred_idx = get_pred_idx(our_answer, prob['choices'], args.options)
|
| 97 |
+
gpt4_pred_idx = get_pred_idx(gpt4_answer, prob['choices'], args.options)
|
| 98 |
+
requery_pred_idx = get_pred_idx(requery_answer, prob['choices'], args.options)
|
| 99 |
+
|
| 100 |
+
results['total'] += 1
|
| 101 |
+
|
| 102 |
+
if gpt4_answer == 'FAILED':
|
| 103 |
+
results['gpt4_failed'] += 1
|
| 104 |
+
if gpt4_pred_idx == prob['answer']:
|
| 105 |
+
results['gpt4_correct'] += 1
|
| 106 |
+
if our_pred_idx == prob['answer']:
|
| 107 |
+
results['gpt4_ourvisual_correct'] += 1
|
| 108 |
+
elif gpt4_pred_idx == prob['answer']:
|
| 109 |
+
results['gpt4_correct'] += 1
|
| 110 |
+
results['gpt4_ourvisual_correct'] += 1
|
| 111 |
+
|
| 112 |
+
if our_pred_idx == prob['answer']:
|
| 113 |
+
results['our_correct'] += 1
|
| 114 |
+
|
| 115 |
+
if requery_answer == 'FAILED':
|
| 116 |
+
sqa_results['results'][prob_id] = our_pred_idx
|
| 117 |
+
if our_pred_idx == prob['answer']:
|
| 118 |
+
results['requery_correct'] += 1
|
| 119 |
+
else:
|
| 120 |
+
sqa_results['results'][prob_id] = requery_pred_idx
|
| 121 |
+
if requery_pred_idx == prob['answer']:
|
| 122 |
+
results['requery_correct'] += 1
|
| 123 |
+
else:
|
| 124 |
+
print(f"""
|
| 125 |
+
Question ({args.options[prob['answer']]}): {our_predictions[prob_id]['prompt']}
|
| 126 |
+
Our ({our_answer}): {our_pred}
|
| 127 |
+
GPT-4 ({gpt4_answer}): {gpt4_pred}
|
| 128 |
+
Requery ({requery_answer}): {requery_pred}
|
| 129 |
+
print("=====================================")
|
| 130 |
+
""")
|
| 131 |
+
|
| 132 |
+
if gpt4_pred_idx == prob['answer'] or our_pred_idx == prob['answer']:
|
| 133 |
+
results['correct_upperbound'] += 1
|
| 134 |
+
|
| 135 |
+
total = results['total']
|
| 136 |
+
print(f'Total: {total}, Our-Correct: {results["our_correct"]}, Accuracy: {results["our_correct"] / total * 100:.2f}%')
|
| 137 |
+
print(f'Total: {total}, GPT-4-Correct: {results["gpt4_correct"]}, Accuracy: {results["gpt4_correct"] / total * 100:.2f}%')
|
| 138 |
+
print(f'Total: {total}, GPT-4 NO-ANS (RANDOM): {results["gpt4_failed"]}, Percentage: {results["gpt4_failed"] / total * 100:.2f}%')
|
| 139 |
+
print(f'Total: {total}, GPT-4-OursVisual-Correct: {results["gpt4_ourvisual_correct"]}, Accuracy: {results["gpt4_ourvisual_correct"] / total * 100:.2f}%')
|
| 140 |
+
print(f'Total: {total}, Requery-Correct: {results["requery_correct"]}, Accuracy: {results["requery_correct"] / total * 100:.2f}%')
|
| 141 |
+
print(f'Total: {total}, Correct upper: {results["correct_upperbound"]}, Accuracy: {results["correct_upperbound"] / total * 100:.2f}%')
|
| 142 |
+
|
| 143 |
+
sqa_results['acc'] = results["requery_correct"] / total * 100
|
| 144 |
+
sqa_results['correct'] = results["requery_correct"]
|
| 145 |
+
sqa_results['count'] = total
|
| 146 |
+
|
| 147 |
+
with open(args.output_result, 'w') as f:
|
| 148 |
+
json.dump(sqa_results, f, indent=2)
|
| 149 |
+
|
llava/eval/eval_textvqa.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import argparse
|
| 3 |
+
import json
|
| 4 |
+
import re
|
| 5 |
+
|
| 6 |
+
from llava.eval.m4c_evaluator import TextVQAAccuracyEvaluator
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_args():
|
| 10 |
+
parser = argparse.ArgumentParser()
|
| 11 |
+
parser.add_argument('--annotation-file', type=str)
|
| 12 |
+
parser.add_argument('--result-file', type=str)
|
| 13 |
+
parser.add_argument('--result-dir', type=str)
|
| 14 |
+
return parser.parse_args()
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def prompt_processor(prompt):
|
| 18 |
+
if prompt.startswith('OCR tokens: '):
|
| 19 |
+
pattern = r"Question: (.*?) Short answer:"
|
| 20 |
+
match = re.search(pattern, prompt, re.DOTALL)
|
| 21 |
+
question = match.group(1)
|
| 22 |
+
elif 'Reference OCR token: ' in prompt and len(prompt.split('\n')) == 3:
|
| 23 |
+
if prompt.startswith('Reference OCR token:'):
|
| 24 |
+
question = prompt.split('\n')[1]
|
| 25 |
+
else:
|
| 26 |
+
question = prompt.split('\n')[0]
|
| 27 |
+
elif len(prompt.split('\n')) == 2:
|
| 28 |
+
question = prompt.split('\n')[0]
|
| 29 |
+
else:
|
| 30 |
+
assert False
|
| 31 |
+
|
| 32 |
+
return question.lower()
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def eval_single(annotation_file, result_file):
|
| 36 |
+
experiment_name = os.path.splitext(os.path.basename(result_file))[0]
|
| 37 |
+
print(experiment_name)
|
| 38 |
+
annotations = json.load(open(annotation_file))['data']
|
| 39 |
+
annotations = {(annotation['image_id'], annotation['question'].lower()): annotation for annotation in annotations}
|
| 40 |
+
results = [json.loads(line) for line in open(result_file)]
|
| 41 |
+
|
| 42 |
+
pred_list = []
|
| 43 |
+
for result in results:
|
| 44 |
+
annotation = annotations[(result['question_id'], prompt_processor(result['prompt']))]
|
| 45 |
+
pred_list.append({
|
| 46 |
+
"pred_answer": result['text'],
|
| 47 |
+
"gt_answers": annotation['answers'],
|
| 48 |
+
})
|
| 49 |
+
|
| 50 |
+
evaluator = TextVQAAccuracyEvaluator()
|
| 51 |
+
print('Samples: {}\nAccuracy: {:.2f}%\n'.format(len(pred_list), 100. * evaluator.eval_pred_list(pred_list)))
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
if __name__ == "__main__":
|
| 55 |
+
args = get_args()
|
| 56 |
+
|
| 57 |
+
if args.result_file is not None:
|
| 58 |
+
eval_single(args.annotation_file, args.result_file)
|
| 59 |
+
|
| 60 |
+
if args.result_dir is not None:
|
| 61 |
+
for result_file in sorted(os.listdir(args.result_dir)):
|
| 62 |
+
if not result_file.endswith('.jsonl'):
|
| 63 |
+
print(f'Skipping {result_file}')
|
| 64 |
+
continue
|
| 65 |
+
eval_single(args.annotation_file, os.path.join(args.result_dir, result_file))
|
llava/eval/generate_webpage_data_from_table.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Generate json file for webpage."""
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
|
| 6 |
+
# models = ['llama', 'alpaca', 'gpt35', 'bard']
|
| 7 |
+
models = ['vicuna']
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def read_jsonl(path: str, key: str=None):
|
| 11 |
+
data = []
|
| 12 |
+
with open(os.path.expanduser(path)) as f:
|
| 13 |
+
for line in f:
|
| 14 |
+
if not line:
|
| 15 |
+
continue
|
| 16 |
+
data.append(json.loads(line))
|
| 17 |
+
if key is not None:
|
| 18 |
+
data.sort(key=lambda x: x[key])
|
| 19 |
+
data = {item[key]: item for item in data}
|
| 20 |
+
return data
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def trim_hanging_lines(s: str, n: int) -> str:
|
| 24 |
+
s = s.strip()
|
| 25 |
+
for _ in range(n):
|
| 26 |
+
s = s.split('\n', 1)[1].strip()
|
| 27 |
+
return s
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
if __name__ == '__main__':
|
| 31 |
+
questions = read_jsonl('table/question.jsonl', key='question_id')
|
| 32 |
+
|
| 33 |
+
# alpaca_answers = read_jsonl('table/answer/answer_alpaca-13b.jsonl', key='question_id')
|
| 34 |
+
# bard_answers = read_jsonl('table/answer/answer_bard.jsonl', key='question_id')
|
| 35 |
+
# gpt35_answers = read_jsonl('table/answer/answer_gpt35.jsonl', key='question_id')
|
| 36 |
+
# llama_answers = read_jsonl('table/answer/answer_llama-13b.jsonl', key='question_id')
|
| 37 |
+
vicuna_answers = read_jsonl('table/answer/answer_vicuna-13b.jsonl', key='question_id')
|
| 38 |
+
ours_answers = read_jsonl('table/results/llama-13b-hf-alpaca.jsonl', key='question_id')
|
| 39 |
+
|
| 40 |
+
review_vicuna = read_jsonl('table/review/review_vicuna-13b_llama-13b-hf-alpaca.jsonl', key='question_id')
|
| 41 |
+
# review_alpaca = read_jsonl('table/review/review_alpaca-13b_vicuna-13b.jsonl', key='question_id')
|
| 42 |
+
# review_bard = read_jsonl('table/review/review_bard_vicuna-13b.jsonl', key='question_id')
|
| 43 |
+
# review_gpt35 = read_jsonl('table/review/review_gpt35_vicuna-13b.jsonl', key='question_id')
|
| 44 |
+
# review_llama = read_jsonl('table/review/review_llama-13b_vicuna-13b.jsonl', key='question_id')
|
| 45 |
+
|
| 46 |
+
records = []
|
| 47 |
+
for qid in questions.keys():
|
| 48 |
+
r = {
|
| 49 |
+
'id': qid,
|
| 50 |
+
'category': questions[qid]['category'],
|
| 51 |
+
'question': questions[qid]['text'],
|
| 52 |
+
'answers': {
|
| 53 |
+
# 'alpaca': alpaca_answers[qid]['text'],
|
| 54 |
+
# 'llama': llama_answers[qid]['text'],
|
| 55 |
+
# 'bard': bard_answers[qid]['text'],
|
| 56 |
+
# 'gpt35': gpt35_answers[qid]['text'],
|
| 57 |
+
'vicuna': vicuna_answers[qid]['text'],
|
| 58 |
+
'ours': ours_answers[qid]['text'],
|
| 59 |
+
},
|
| 60 |
+
'evaluations': {
|
| 61 |
+
# 'alpaca': review_alpaca[qid]['text'],
|
| 62 |
+
# 'llama': review_llama[qid]['text'],
|
| 63 |
+
# 'bard': review_bard[qid]['text'],
|
| 64 |
+
'vicuna': review_vicuna[qid]['content'],
|
| 65 |
+
# 'gpt35': review_gpt35[qid]['text'],
|
| 66 |
+
},
|
| 67 |
+
'scores': {
|
| 68 |
+
'vicuna': review_vicuna[qid]['tuple'],
|
| 69 |
+
# 'alpaca': review_alpaca[qid]['score'],
|
| 70 |
+
# 'llama': review_llama[qid]['score'],
|
| 71 |
+
# 'bard': review_bard[qid]['score'],
|
| 72 |
+
# 'gpt35': review_gpt35[qid]['score'],
|
| 73 |
+
},
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
# cleanup data
|
| 77 |
+
cleaned_evals = {}
|
| 78 |
+
for k, v in r['evaluations'].items():
|
| 79 |
+
v = v.strip()
|
| 80 |
+
lines = v.split('\n')
|
| 81 |
+
# trim the first line if it's a pair of numbers
|
| 82 |
+
if re.match(r'\d+[, ]+\d+', lines[0]):
|
| 83 |
+
lines = lines[1:]
|
| 84 |
+
v = '\n'.join(lines)
|
| 85 |
+
cleaned_evals[k] = v.replace('Assistant 1', "**Assistant 1**").replace('Assistant 2', '**Assistant 2**')
|
| 86 |
+
|
| 87 |
+
r['evaluations'] = cleaned_evals
|
| 88 |
+
records.append(r)
|
| 89 |
+
|
| 90 |
+
# Reorder the records, this is optional
|
| 91 |
+
for r in records:
|
| 92 |
+
if r['id'] <= 20:
|
| 93 |
+
r['id'] += 60
|
| 94 |
+
else:
|
| 95 |
+
r['id'] -= 20
|
| 96 |
+
for r in records:
|
| 97 |
+
if r['id'] <= 50:
|
| 98 |
+
r['id'] += 10
|
| 99 |
+
elif 50 < r['id'] <= 60:
|
| 100 |
+
r['id'] -= 50
|
| 101 |
+
for r in records:
|
| 102 |
+
if r['id'] == 7:
|
| 103 |
+
r['id'] = 1
|
| 104 |
+
elif r['id'] < 7:
|
| 105 |
+
r['id'] += 1
|
| 106 |
+
|
| 107 |
+
records.sort(key=lambda x: x['id'])
|
| 108 |
+
|
| 109 |
+
# Write to file
|
| 110 |
+
with open('webpage/data.json', 'w') as f:
|
| 111 |
+
json.dump({'questions': records, 'models': models}, f, indent=2)
|
llava/eval/m4c_evaluator.py
ADDED
|
@@ -0,0 +1,334 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 2 |
+
import re
|
| 3 |
+
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class EvalAIAnswerProcessor:
|
| 8 |
+
"""
|
| 9 |
+
Processes an answer similar to Eval AI
|
| 10 |
+
copied from
|
| 11 |
+
https://github.com/facebookresearch/mmf/blob/c46b3b3391275b4181567db80943473a89ab98ab/pythia/tasks/processors.py#L897
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
CONTRACTIONS = {
|
| 15 |
+
"aint": "ain't",
|
| 16 |
+
"arent": "aren't",
|
| 17 |
+
"cant": "can't",
|
| 18 |
+
"couldve": "could've",
|
| 19 |
+
"couldnt": "couldn't",
|
| 20 |
+
"couldn'tve": "couldn't've",
|
| 21 |
+
"couldnt've": "couldn't've",
|
| 22 |
+
"didnt": "didn't",
|
| 23 |
+
"doesnt": "doesn't",
|
| 24 |
+
"dont": "don't",
|
| 25 |
+
"hadnt": "hadn't",
|
| 26 |
+
"hadnt've": "hadn't've",
|
| 27 |
+
"hadn'tve": "hadn't've",
|
| 28 |
+
"hasnt": "hasn't",
|
| 29 |
+
"havent": "haven't",
|
| 30 |
+
"hed": "he'd",
|
| 31 |
+
"hed've": "he'd've",
|
| 32 |
+
"he'dve": "he'd've",
|
| 33 |
+
"hes": "he's",
|
| 34 |
+
"howd": "how'd",
|
| 35 |
+
"howll": "how'll",
|
| 36 |
+
"hows": "how's",
|
| 37 |
+
"Id've": "I'd've",
|
| 38 |
+
"I'dve": "I'd've",
|
| 39 |
+
"Im": "I'm",
|
| 40 |
+
"Ive": "I've",
|
| 41 |
+
"isnt": "isn't",
|
| 42 |
+
"itd": "it'd",
|
| 43 |
+
"itd've": "it'd've",
|
| 44 |
+
"it'dve": "it'd've",
|
| 45 |
+
"itll": "it'll",
|
| 46 |
+
"let's": "let's",
|
| 47 |
+
"maam": "ma'am",
|
| 48 |
+
"mightnt": "mightn't",
|
| 49 |
+
"mightnt've": "mightn't've",
|
| 50 |
+
"mightn'tve": "mightn't've",
|
| 51 |
+
"mightve": "might've",
|
| 52 |
+
"mustnt": "mustn't",
|
| 53 |
+
"mustve": "must've",
|
| 54 |
+
"neednt": "needn't",
|
| 55 |
+
"notve": "not've",
|
| 56 |
+
"oclock": "o'clock",
|
| 57 |
+
"oughtnt": "oughtn't",
|
| 58 |
+
"ow's'at": "'ow's'at",
|
| 59 |
+
"'ows'at": "'ow's'at",
|
| 60 |
+
"'ow'sat": "'ow's'at",
|
| 61 |
+
"shant": "shan't",
|
| 62 |
+
"shed've": "she'd've",
|
| 63 |
+
"she'dve": "she'd've",
|
| 64 |
+
"she's": "she's",
|
| 65 |
+
"shouldve": "should've",
|
| 66 |
+
"shouldnt": "shouldn't",
|
| 67 |
+
"shouldnt've": "shouldn't've",
|
| 68 |
+
"shouldn'tve": "shouldn't've",
|
| 69 |
+
"somebody'd": "somebodyd",
|
| 70 |
+
"somebodyd've": "somebody'd've",
|
| 71 |
+
"somebody'dve": "somebody'd've",
|
| 72 |
+
"somebodyll": "somebody'll",
|
| 73 |
+
"somebodys": "somebody's",
|
| 74 |
+
"someoned": "someone'd",
|
| 75 |
+
"someoned've": "someone'd've",
|
| 76 |
+
"someone'dve": "someone'd've",
|
| 77 |
+
"someonell": "someone'll",
|
| 78 |
+
"someones": "someone's",
|
| 79 |
+
"somethingd": "something'd",
|
| 80 |
+
"somethingd've": "something'd've",
|
| 81 |
+
"something'dve": "something'd've",
|
| 82 |
+
"somethingll": "something'll",
|
| 83 |
+
"thats": "that's",
|
| 84 |
+
"thered": "there'd",
|
| 85 |
+
"thered've": "there'd've",
|
| 86 |
+
"there'dve": "there'd've",
|
| 87 |
+
"therere": "there're",
|
| 88 |
+
"theres": "there's",
|
| 89 |
+
"theyd": "they'd",
|
| 90 |
+
"theyd've": "they'd've",
|
| 91 |
+
"they'dve": "they'd've",
|
| 92 |
+
"theyll": "they'll",
|
| 93 |
+
"theyre": "they're",
|
| 94 |
+
"theyve": "they've",
|
| 95 |
+
"twas": "'twas",
|
| 96 |
+
"wasnt": "wasn't",
|
| 97 |
+
"wed've": "we'd've",
|
| 98 |
+
"we'dve": "we'd've",
|
| 99 |
+
"weve": "we've",
|
| 100 |
+
"werent": "weren't",
|
| 101 |
+
"whatll": "what'll",
|
| 102 |
+
"whatre": "what're",
|
| 103 |
+
"whats": "what's",
|
| 104 |
+
"whatve": "what've",
|
| 105 |
+
"whens": "when's",
|
| 106 |
+
"whered": "where'd",
|
| 107 |
+
"wheres": "where's",
|
| 108 |
+
"whereve": "where've",
|
| 109 |
+
"whod": "who'd",
|
| 110 |
+
"whod've": "who'd've",
|
| 111 |
+
"who'dve": "who'd've",
|
| 112 |
+
"wholl": "who'll",
|
| 113 |
+
"whos": "who's",
|
| 114 |
+
"whove": "who've",
|
| 115 |
+
"whyll": "why'll",
|
| 116 |
+
"whyre": "why're",
|
| 117 |
+
"whys": "why's",
|
| 118 |
+
"wont": "won't",
|
| 119 |
+
"wouldve": "would've",
|
| 120 |
+
"wouldnt": "wouldn't",
|
| 121 |
+
"wouldnt've": "wouldn't've",
|
| 122 |
+
"wouldn'tve": "wouldn't've",
|
| 123 |
+
"yall": "y'all",
|
| 124 |
+
"yall'll": "y'all'll",
|
| 125 |
+
"y'allll": "y'all'll",
|
| 126 |
+
"yall'd've": "y'all'd've",
|
| 127 |
+
"y'alld've": "y'all'd've",
|
| 128 |
+
"y'all'dve": "y'all'd've",
|
| 129 |
+
"youd": "you'd",
|
| 130 |
+
"youd've": "you'd've",
|
| 131 |
+
"you'dve": "you'd've",
|
| 132 |
+
"youll": "you'll",
|
| 133 |
+
"youre": "you're",
|
| 134 |
+
"youve": "you've",
|
| 135 |
+
}
|
| 136 |
+
|
| 137 |
+
NUMBER_MAP = {
|
| 138 |
+
"none": "0",
|
| 139 |
+
"zero": "0",
|
| 140 |
+
"one": "1",
|
| 141 |
+
"two": "2",
|
| 142 |
+
"three": "3",
|
| 143 |
+
"four": "4",
|
| 144 |
+
"five": "5",
|
| 145 |
+
"six": "6",
|
| 146 |
+
"seven": "7",
|
| 147 |
+
"eight": "8",
|
| 148 |
+
"nine": "9",
|
| 149 |
+
"ten": "10",
|
| 150 |
+
}
|
| 151 |
+
ARTICLES = ["a", "an", "the"]
|
| 152 |
+
PERIOD_STRIP = re.compile(r"(?!<=\d)(\.)(?!\d)")
|
| 153 |
+
COMMA_STRIP = re.compile(r"(?<=\d)(\,)+(?=\d)")
|
| 154 |
+
PUNCTUATIONS = [
|
| 155 |
+
";",
|
| 156 |
+
r"/",
|
| 157 |
+
"[",
|
| 158 |
+
"]",
|
| 159 |
+
'"',
|
| 160 |
+
"{",
|
| 161 |
+
"}",
|
| 162 |
+
"(",
|
| 163 |
+
")",
|
| 164 |
+
"=",
|
| 165 |
+
"+",
|
| 166 |
+
"\\",
|
| 167 |
+
"_",
|
| 168 |
+
"-",
|
| 169 |
+
">",
|
| 170 |
+
"<",
|
| 171 |
+
"@",
|
| 172 |
+
"`",
|
| 173 |
+
",",
|
| 174 |
+
"?",
|
| 175 |
+
"!",
|
| 176 |
+
]
|
| 177 |
+
|
| 178 |
+
def __init__(self, *args, **kwargs):
|
| 179 |
+
pass
|
| 180 |
+
|
| 181 |
+
def word_tokenize(self, word):
|
| 182 |
+
word = word.lower()
|
| 183 |
+
word = word.replace(",", "").replace("?", "").replace("'s", " 's")
|
| 184 |
+
return word.strip()
|
| 185 |
+
|
| 186 |
+
def process_punctuation(self, in_text):
|
| 187 |
+
out_text = in_text
|
| 188 |
+
for p in self.PUNCTUATIONS:
|
| 189 |
+
if (p + " " in in_text or " " + p in in_text) or (
|
| 190 |
+
re.search(self.COMMA_STRIP, in_text) is not None
|
| 191 |
+
):
|
| 192 |
+
out_text = out_text.replace(p, "")
|
| 193 |
+
else:
|
| 194 |
+
out_text = out_text.replace(p, " ")
|
| 195 |
+
out_text = self.PERIOD_STRIP.sub("", out_text, re.UNICODE)
|
| 196 |
+
return out_text
|
| 197 |
+
|
| 198 |
+
def process_digit_article(self, in_text):
|
| 199 |
+
out_text = []
|
| 200 |
+
temp_text = in_text.lower().split()
|
| 201 |
+
for word in temp_text:
|
| 202 |
+
word = self.NUMBER_MAP.setdefault(word, word)
|
| 203 |
+
if word not in self.ARTICLES:
|
| 204 |
+
out_text.append(word)
|
| 205 |
+
else:
|
| 206 |
+
pass
|
| 207 |
+
for word_id, word in enumerate(out_text):
|
| 208 |
+
if word in self.CONTRACTIONS:
|
| 209 |
+
out_text[word_id] = self.CONTRACTIONS[word]
|
| 210 |
+
out_text = " ".join(out_text)
|
| 211 |
+
return out_text
|
| 212 |
+
|
| 213 |
+
def __call__(self, item):
|
| 214 |
+
item = self.word_tokenize(item)
|
| 215 |
+
item = item.replace("\n", " ").replace("\t", " ").strip()
|
| 216 |
+
item = self.process_punctuation(item)
|
| 217 |
+
item = self.process_digit_article(item)
|
| 218 |
+
return item
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
class TextVQAAccuracyEvaluator:
|
| 222 |
+
def __init__(self):
|
| 223 |
+
self.answer_processor = EvalAIAnswerProcessor()
|
| 224 |
+
|
| 225 |
+
def _compute_answer_scores(self, raw_answers):
|
| 226 |
+
"""
|
| 227 |
+
compute the accuracy (soft score) of human answers
|
| 228 |
+
"""
|
| 229 |
+
answers = [self.answer_processor(a) for a in raw_answers]
|
| 230 |
+
assert len(answers) == 10
|
| 231 |
+
gt_answers = list(enumerate(answers))
|
| 232 |
+
unique_answers = set(answers)
|
| 233 |
+
unique_answer_scores = {}
|
| 234 |
+
|
| 235 |
+
for unique_answer in unique_answers:
|
| 236 |
+
accs = []
|
| 237 |
+
for gt_answer in gt_answers:
|
| 238 |
+
other_answers = [item for item in gt_answers if item != gt_answer]
|
| 239 |
+
matching_answers = [
|
| 240 |
+
item for item in other_answers if item[1] == unique_answer
|
| 241 |
+
]
|
| 242 |
+
acc = min(1, float(len(matching_answers)) / 3)
|
| 243 |
+
accs.append(acc)
|
| 244 |
+
unique_answer_scores[unique_answer] = sum(accs) / len(accs)
|
| 245 |
+
|
| 246 |
+
return unique_answer_scores
|
| 247 |
+
|
| 248 |
+
def eval_pred_list(self, pred_list):
|
| 249 |
+
pred_scores = []
|
| 250 |
+
for entry in tqdm(pred_list):
|
| 251 |
+
pred_answer = self.answer_processor(entry["pred_answer"])
|
| 252 |
+
unique_answer_scores = self._compute_answer_scores(entry["gt_answers"])
|
| 253 |
+
score = unique_answer_scores.get(pred_answer, 0.0)
|
| 254 |
+
pred_scores.append(score)
|
| 255 |
+
|
| 256 |
+
accuracy = sum(pred_scores) / len(pred_scores)
|
| 257 |
+
return accuracy
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
class STVQAAccuracyEvaluator:
|
| 261 |
+
def __init__(self):
|
| 262 |
+
self.answer_processor = EvalAIAnswerProcessor()
|
| 263 |
+
|
| 264 |
+
def eval_pred_list(self, pred_list):
|
| 265 |
+
pred_scores = []
|
| 266 |
+
for entry in pred_list:
|
| 267 |
+
pred_answer = self.answer_processor(entry["pred_answer"])
|
| 268 |
+
gts = [self.answer_processor(a) for a in entry["gt_answers"]]
|
| 269 |
+
score = 1.0 if pred_answer in gts else 0.0
|
| 270 |
+
pred_scores.append(score)
|
| 271 |
+
|
| 272 |
+
accuracy = sum(pred_scores) / len(pred_scores)
|
| 273 |
+
return accuracy
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
class STVQAANLSEvaluator:
|
| 277 |
+
def __init__(self):
|
| 278 |
+
import editdistance # install with `pip install editdistance`
|
| 279 |
+
|
| 280 |
+
self.get_edit_distance = editdistance.eval
|
| 281 |
+
|
| 282 |
+
def get_anls(self, s1, s2):
|
| 283 |
+
s1 = s1.lower().strip()
|
| 284 |
+
s2 = s2.lower().strip()
|
| 285 |
+
iou = 1 - self.get_edit_distance(s1, s2) / max(len(s1), len(s2))
|
| 286 |
+
anls = iou if iou >= 0.5 else 0.0
|
| 287 |
+
return anls
|
| 288 |
+
|
| 289 |
+
def eval_pred_list(self, pred_list):
|
| 290 |
+
pred_scores = []
|
| 291 |
+
for entry in pred_list:
|
| 292 |
+
anls = max(
|
| 293 |
+
self.get_anls(entry["pred_answer"], gt) for gt in entry["gt_answers"]
|
| 294 |
+
)
|
| 295 |
+
pred_scores.append(anls)
|
| 296 |
+
|
| 297 |
+
accuracy = sum(pred_scores) / len(pred_scores)
|
| 298 |
+
return accuracy
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
class TextCapsBleu4Evaluator:
|
| 302 |
+
def __init__(self):
|
| 303 |
+
# The following script requires Java 1.8.0 and pycocotools installed.
|
| 304 |
+
# The pycocoevalcap can be installed with pip as
|
| 305 |
+
# pip install git+https://github.com/ronghanghu/coco-caption.git@python23
|
| 306 |
+
# Original pycocoevalcap code is at https://github.com/tylin/coco-caption
|
| 307 |
+
# but has no python3 support yet.
|
| 308 |
+
try:
|
| 309 |
+
from pycocoevalcap.bleu.bleu import Bleu
|
| 310 |
+
from pycocoevalcap.tokenizer.ptbtokenizer import PTBTokenizer
|
| 311 |
+
except ModuleNotFoundError:
|
| 312 |
+
print(
|
| 313 |
+
"Please install pycocoevalcap module using "
|
| 314 |
+
"pip install git+https://github.com/ronghanghu/coco-caption.git@python23" # noqa
|
| 315 |
+
)
|
| 316 |
+
raise
|
| 317 |
+
|
| 318 |
+
self.tokenizer = PTBTokenizer()
|
| 319 |
+
self.scorer = Bleu(4)
|
| 320 |
+
|
| 321 |
+
def eval_pred_list(self, pred_list):
|
| 322 |
+
# Create reference and hypotheses captions.
|
| 323 |
+
gts = {}
|
| 324 |
+
res = {}
|
| 325 |
+
for idx, entry in enumerate(pred_list):
|
| 326 |
+
gts[idx] = [{"caption": a} for a in entry["gt_answers"]]
|
| 327 |
+
res[idx] = [{"caption": entry["pred_answer"]}]
|
| 328 |
+
|
| 329 |
+
gts = self.tokenizer.tokenize(gts)
|
| 330 |
+
res = self.tokenizer.tokenize(res)
|
| 331 |
+
score, _ = self.scorer.compute_score(gts, res)
|
| 332 |
+
|
| 333 |
+
bleu4 = score[3] # score is (Bleu-1, Bleu-2, Bleu-3, Bleu-4)
|
| 334 |
+
return bleu4
|
llava/eval/model_qa.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM, StoppingCriteria
|
| 3 |
+
import torch
|
| 4 |
+
import os
|
| 5 |
+
import json
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
import shortuuid
|
| 8 |
+
|
| 9 |
+
from llava.conversation import default_conversation
|
| 10 |
+
from llava.utils import disable_torch_init
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@torch.inference_mode()
|
| 14 |
+
def eval_model(model_name, questions_file, answers_file):
|
| 15 |
+
# Model
|
| 16 |
+
disable_torch_init()
|
| 17 |
+
model_name = os.path.expanduser(model_name)
|
| 18 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
|
| 19 |
+
model = AutoModelForCausalLM.from_pretrained(model_name,
|
| 20 |
+
torch_dtype=torch.float16).cuda()
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
ques_file = open(os.path.expanduser(questions_file), "r")
|
| 24 |
+
ans_file = open(os.path.expanduser(answers_file), "w")
|
| 25 |
+
for i, line in enumerate(tqdm(ques_file)):
|
| 26 |
+
idx = json.loads(line)["question_id"]
|
| 27 |
+
qs = json.loads(line)["text"]
|
| 28 |
+
cat = json.loads(line)["category"]
|
| 29 |
+
conv = default_conversation.copy()
|
| 30 |
+
conv.append_message(conv.roles[0], qs)
|
| 31 |
+
prompt = conv.get_prompt()
|
| 32 |
+
inputs = tokenizer([prompt])
|
| 33 |
+
input_ids = torch.as_tensor(inputs.input_ids).cuda()
|
| 34 |
+
output_ids = model.generate(
|
| 35 |
+
input_ids,
|
| 36 |
+
do_sample=True,
|
| 37 |
+
use_cache=True,
|
| 38 |
+
temperature=0.7,
|
| 39 |
+
max_new_tokens=1024,)
|
| 40 |
+
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0]
|
| 41 |
+
try:
|
| 42 |
+
index = outputs.index(conv.sep, len(prompt))
|
| 43 |
+
except ValueError:
|
| 44 |
+
outputs += conv.sep
|
| 45 |
+
index = outputs.index(conv.sep, len(prompt))
|
| 46 |
+
|
| 47 |
+
outputs = outputs[len(prompt) + len(conv.roles[1]) + 2:index].strip()
|
| 48 |
+
ans_id = shortuuid.uuid()
|
| 49 |
+
ans_file.write(json.dumps({"question_id": idx,
|
| 50 |
+
"text": outputs,
|
| 51 |
+
"answer_id": ans_id,
|
| 52 |
+
"model_id": model_name,
|
| 53 |
+
"metadata": {}}) + "\n")
|
| 54 |
+
ans_file.flush()
|
| 55 |
+
ans_file.close()
|
| 56 |
+
|
| 57 |
+
if __name__ == "__main__":
|
| 58 |
+
parser = argparse.ArgumentParser()
|
| 59 |
+
parser.add_argument("--model-name", type=str, default="facebook/opt-350m")
|
| 60 |
+
parser.add_argument("--question-file", type=str, default="tables/question.jsonl")
|
| 61 |
+
parser.add_argument("--answers-file", type=str, default="answer.jsonl")
|
| 62 |
+
args = parser.parse_args()
|
| 63 |
+
|
| 64 |
+
eval_model(args.model_name, args.question_file, args.answers_file)
|
llava/eval/model_vqa.py
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
import os
|
| 4 |
+
import json
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
import shortuuid
|
| 7 |
+
|
| 8 |
+
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 9 |
+
from llava.conversation import conv_templates, SeparatorStyle
|
| 10 |
+
from llava.model.builder import load_pretrained_model
|
| 11 |
+
from llava.utils import disable_torch_init
|
| 12 |
+
from llava.mm_utils import tokenizer_image_token, process_images, get_model_name_from_path
|
| 13 |
+
|
| 14 |
+
from PIL import Image
|
| 15 |
+
import math
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def split_list(lst, n):
|
| 19 |
+
"""Split a list into n (roughly) equal-sized chunks"""
|
| 20 |
+
chunk_size = math.ceil(len(lst) / n) # integer division
|
| 21 |
+
return [lst[i:i+chunk_size] for i in range(0, len(lst), chunk_size)]
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def get_chunk(lst, n, k):
|
| 25 |
+
chunks = split_list(lst, n)
|
| 26 |
+
return chunks[k]
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def eval_model(args):
|
| 30 |
+
# Model
|
| 31 |
+
disable_torch_init()
|
| 32 |
+
model_path = os.path.expanduser(args.model_path)
|
| 33 |
+
model_name = get_model_name_from_path(model_path)
|
| 34 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(model_path, args.model_base, model_name)
|
| 35 |
+
|
| 36 |
+
questions = [json.loads(q) for q in open(os.path.expanduser(args.question_file), "r")]
|
| 37 |
+
questions = get_chunk(questions, args.num_chunks, args.chunk_idx)
|
| 38 |
+
answers_file = os.path.expanduser(args.answers_file)
|
| 39 |
+
os.makedirs(os.path.dirname(answers_file), exist_ok=True)
|
| 40 |
+
ans_file = open(answers_file, "w")
|
| 41 |
+
for line in tqdm(questions):
|
| 42 |
+
idx = line["question_id"]
|
| 43 |
+
image_file = line["image"]
|
| 44 |
+
qs = line["text"]
|
| 45 |
+
cur_prompt = qs
|
| 46 |
+
if model.config.mm_use_im_start_end:
|
| 47 |
+
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + qs
|
| 48 |
+
else:
|
| 49 |
+
qs = DEFAULT_IMAGE_TOKEN + '\n' + qs
|
| 50 |
+
|
| 51 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 52 |
+
conv.append_message(conv.roles[0], qs)
|
| 53 |
+
conv.append_message(conv.roles[1], None)
|
| 54 |
+
prompt = conv.get_prompt()
|
| 55 |
+
|
| 56 |
+
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
|
| 57 |
+
|
| 58 |
+
image = Image.open(os.path.join(args.image_folder, image_file)).convert('RGB')
|
| 59 |
+
image_tensor = process_images([image], image_processor, model.config)[0]
|
| 60 |
+
|
| 61 |
+
with torch.inference_mode():
|
| 62 |
+
output_ids = model.generate(
|
| 63 |
+
input_ids,
|
| 64 |
+
images=image_tensor.unsqueeze(0).half().cuda(),
|
| 65 |
+
image_sizes=[image.size],
|
| 66 |
+
do_sample=True if args.temperature > 0 else False,
|
| 67 |
+
temperature=args.temperature,
|
| 68 |
+
top_p=args.top_p,
|
| 69 |
+
num_beams=args.num_beams,
|
| 70 |
+
# no_repeat_ngram_size=3,
|
| 71 |
+
max_new_tokens=1024,
|
| 72 |
+
use_cache=True)
|
| 73 |
+
|
| 74 |
+
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
|
| 75 |
+
|
| 76 |
+
ans_id = shortuuid.uuid()
|
| 77 |
+
ans_file.write(json.dumps({"question_id": idx,
|
| 78 |
+
"prompt": cur_prompt,
|
| 79 |
+
"text": outputs,
|
| 80 |
+
"answer_id": ans_id,
|
| 81 |
+
"model_id": model_name,
|
| 82 |
+
"metadata": {}}) + "\n")
|
| 83 |
+
ans_file.flush()
|
| 84 |
+
ans_file.close()
|
| 85 |
+
|
| 86 |
+
if __name__ == "__main__":
|
| 87 |
+
parser = argparse.ArgumentParser()
|
| 88 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 89 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 90 |
+
parser.add_argument("--image-folder", type=str, default="")
|
| 91 |
+
parser.add_argument("--question-file", type=str, default="tables/question.jsonl")
|
| 92 |
+
parser.add_argument("--answers-file", type=str, default="answer.jsonl")
|
| 93 |
+
parser.add_argument("--conv-mode", type=str, default="llava_v1")
|
| 94 |
+
parser.add_argument("--num-chunks", type=int, default=1)
|
| 95 |
+
parser.add_argument("--chunk-idx", type=int, default=0)
|
| 96 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 97 |
+
parser.add_argument("--top_p", type=float, default=None)
|
| 98 |
+
parser.add_argument("--num_beams", type=int, default=1)
|
| 99 |
+
args = parser.parse_args()
|
| 100 |
+
|
| 101 |
+
eval_model(args)
|
llava/eval/model_vqa_loader.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
import os
|
| 4 |
+
import json
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
import shortuuid
|
| 7 |
+
|
| 8 |
+
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 9 |
+
from llava.conversation import conv_templates, SeparatorStyle
|
| 10 |
+
from llava.model.builder import load_pretrained_model
|
| 11 |
+
from llava.utils import disable_torch_init
|
| 12 |
+
from llava.mm_utils import tokenizer_image_token, process_images, get_model_name_from_path
|
| 13 |
+
from torch.utils.data import Dataset, DataLoader
|
| 14 |
+
|
| 15 |
+
from PIL import Image
|
| 16 |
+
import math
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def split_list(lst, n):
|
| 20 |
+
"""Split a list into n (roughly) equal-sized chunks"""
|
| 21 |
+
chunk_size = math.ceil(len(lst) / n) # integer division
|
| 22 |
+
return [lst[i:i+chunk_size] for i in range(0, len(lst), chunk_size)]
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def get_chunk(lst, n, k):
|
| 26 |
+
chunks = split_list(lst, n)
|
| 27 |
+
return chunks[k]
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
# Custom dataset class
|
| 31 |
+
class CustomDataset(Dataset):
|
| 32 |
+
def __init__(self, questions, image_folder, tokenizer, image_processor, model_config):
|
| 33 |
+
self.questions = questions
|
| 34 |
+
self.image_folder = image_folder
|
| 35 |
+
self.tokenizer = tokenizer
|
| 36 |
+
self.image_processor = image_processor
|
| 37 |
+
self.model_config = model_config
|
| 38 |
+
|
| 39 |
+
def __getitem__(self, index):
|
| 40 |
+
line = self.questions[index]
|
| 41 |
+
image_file = line["image"]
|
| 42 |
+
qs = line["text"]
|
| 43 |
+
if self.model_config.mm_use_im_start_end:
|
| 44 |
+
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + qs
|
| 45 |
+
else:
|
| 46 |
+
qs = DEFAULT_IMAGE_TOKEN + '\n' + qs
|
| 47 |
+
|
| 48 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 49 |
+
conv.append_message(conv.roles[0], qs)
|
| 50 |
+
conv.append_message(conv.roles[1], None)
|
| 51 |
+
prompt = conv.get_prompt()
|
| 52 |
+
|
| 53 |
+
image = Image.open(os.path.join(self.image_folder, image_file)).convert('RGB')
|
| 54 |
+
image_tensor = process_images([image], self.image_processor, self.model_config)[0]
|
| 55 |
+
|
| 56 |
+
input_ids = tokenizer_image_token(prompt, self.tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt')
|
| 57 |
+
|
| 58 |
+
return input_ids, image_tensor, image.size
|
| 59 |
+
|
| 60 |
+
def __len__(self):
|
| 61 |
+
return len(self.questions)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def collate_fn(batch):
|
| 65 |
+
input_ids, image_tensors, image_sizes = zip(*batch)
|
| 66 |
+
input_ids = torch.stack(input_ids, dim=0)
|
| 67 |
+
image_tensors = torch.stack(image_tensors, dim=0)
|
| 68 |
+
return input_ids, image_tensors, image_sizes
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
# DataLoader
|
| 72 |
+
def create_data_loader(questions, image_folder, tokenizer, image_processor, model_config, batch_size=1, num_workers=4):
|
| 73 |
+
assert batch_size == 1, "batch_size must be 1"
|
| 74 |
+
dataset = CustomDataset(questions, image_folder, tokenizer, image_processor, model_config)
|
| 75 |
+
data_loader = DataLoader(dataset, batch_size=batch_size, num_workers=num_workers, shuffle=False, collate_fn=collate_fn)
|
| 76 |
+
return data_loader
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def eval_model(args):
|
| 80 |
+
# Model
|
| 81 |
+
disable_torch_init()
|
| 82 |
+
model_path = os.path.expanduser(args.model_path)
|
| 83 |
+
model_name = get_model_name_from_path(model_path)
|
| 84 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(model_path, args.model_base, model_name)
|
| 85 |
+
|
| 86 |
+
questions = [json.loads(q) for q in open(os.path.expanduser(args.question_file), "r")]
|
| 87 |
+
questions = get_chunk(questions, args.num_chunks, args.chunk_idx)
|
| 88 |
+
answers_file = os.path.expanduser(args.answers_file)
|
| 89 |
+
os.makedirs(os.path.dirname(answers_file), exist_ok=True)
|
| 90 |
+
ans_file = open(answers_file, "w")
|
| 91 |
+
|
| 92 |
+
if 'plain' in model_name and 'finetune' not in model_name.lower() and 'mmtag' not in args.conv_mode:
|
| 93 |
+
args.conv_mode = args.conv_mode + '_mmtag'
|
| 94 |
+
print(f'It seems that this is a plain model, but it is not using a mmtag prompt, auto switching to {args.conv_mode}.')
|
| 95 |
+
|
| 96 |
+
data_loader = create_data_loader(questions, args.image_folder, tokenizer, image_processor, model.config)
|
| 97 |
+
|
| 98 |
+
for (input_ids, image_tensor, image_sizes), line in tqdm(zip(data_loader, questions), total=len(questions)):
|
| 99 |
+
idx = line["question_id"]
|
| 100 |
+
cur_prompt = line["text"]
|
| 101 |
+
|
| 102 |
+
input_ids = input_ids.to(device='cuda', non_blocking=True)
|
| 103 |
+
|
| 104 |
+
with torch.inference_mode():
|
| 105 |
+
output_ids = model.generate(
|
| 106 |
+
input_ids,
|
| 107 |
+
images=image_tensor.to(dtype=torch.float16, device='cuda', non_blocking=True),
|
| 108 |
+
image_sizes=image_sizes,
|
| 109 |
+
do_sample=True if args.temperature > 0 else False,
|
| 110 |
+
temperature=args.temperature,
|
| 111 |
+
top_p=args.top_p,
|
| 112 |
+
num_beams=args.num_beams,
|
| 113 |
+
max_new_tokens=args.max_new_tokens,
|
| 114 |
+
use_cache=True)
|
| 115 |
+
|
| 116 |
+
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
|
| 117 |
+
|
| 118 |
+
ans_id = shortuuid.uuid()
|
| 119 |
+
ans_file.write(json.dumps({"question_id": idx,
|
| 120 |
+
"prompt": cur_prompt,
|
| 121 |
+
"text": outputs,
|
| 122 |
+
"answer_id": ans_id,
|
| 123 |
+
"model_id": model_name,
|
| 124 |
+
"metadata": {}}) + "\n")
|
| 125 |
+
# ans_file.flush()
|
| 126 |
+
ans_file.close()
|
| 127 |
+
|
| 128 |
+
if __name__ == "__main__":
|
| 129 |
+
parser = argparse.ArgumentParser()
|
| 130 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 131 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 132 |
+
parser.add_argument("--image-folder", type=str, default="")
|
| 133 |
+
parser.add_argument("--question-file", type=str, default="tables/question.jsonl")
|
| 134 |
+
parser.add_argument("--answers-file", type=str, default="answer.jsonl")
|
| 135 |
+
parser.add_argument("--conv-mode", type=str, default="llava_v1")
|
| 136 |
+
parser.add_argument("--num-chunks", type=int, default=1)
|
| 137 |
+
parser.add_argument("--chunk-idx", type=int, default=0)
|
| 138 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 139 |
+
parser.add_argument("--top_p", type=float, default=None)
|
| 140 |
+
parser.add_argument("--num_beams", type=int, default=1)
|
| 141 |
+
parser.add_argument("--max_new_tokens", type=int, default=128)
|
| 142 |
+
args = parser.parse_args()
|
| 143 |
+
|
| 144 |
+
eval_model(args)
|
llava/eval/model_vqa_mmbench.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
import os
|
| 4 |
+
import json
|
| 5 |
+
import pandas as pd
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
import shortuuid
|
| 8 |
+
|
| 9 |
+
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 10 |
+
from llava.conversation import conv_templates, SeparatorStyle
|
| 11 |
+
from llava.model.builder import load_pretrained_model
|
| 12 |
+
from llava.utils import disable_torch_init
|
| 13 |
+
from llava.mm_utils import tokenizer_image_token, process_images, load_image_from_base64, get_model_name_from_path
|
| 14 |
+
|
| 15 |
+
from PIL import Image
|
| 16 |
+
import math
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
all_options = ['A', 'B', 'C', 'D']
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def split_list(lst, n):
|
| 23 |
+
"""Split a list into n (roughly) equal-sized chunks"""
|
| 24 |
+
chunk_size = math.ceil(len(lst) / n) # integer division
|
| 25 |
+
return [lst[i:i+chunk_size] for i in range(0, len(lst), chunk_size)]
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_chunk(lst, n, k):
|
| 29 |
+
chunks = split_list(lst, n)
|
| 30 |
+
return chunks[k]
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def is_none(value):
|
| 34 |
+
if value is None:
|
| 35 |
+
return True
|
| 36 |
+
if type(value) is float and math.isnan(value):
|
| 37 |
+
return True
|
| 38 |
+
if type(value) is str and value.lower() == 'nan':
|
| 39 |
+
return True
|
| 40 |
+
if type(value) is str and value.lower() == 'none':
|
| 41 |
+
return True
|
| 42 |
+
return False
|
| 43 |
+
|
| 44 |
+
def get_options(row, options):
|
| 45 |
+
parsed_options = []
|
| 46 |
+
for option in options:
|
| 47 |
+
option_value = row[option]
|
| 48 |
+
if is_none(option_value):
|
| 49 |
+
break
|
| 50 |
+
parsed_options.append(option_value)
|
| 51 |
+
return parsed_options
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def eval_model(args):
|
| 55 |
+
# Model
|
| 56 |
+
disable_torch_init()
|
| 57 |
+
model_path = os.path.expanduser(args.model_path)
|
| 58 |
+
model_name = get_model_name_from_path(model_path)
|
| 59 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(model_path, args.model_base, model_name)
|
| 60 |
+
|
| 61 |
+
questions = pd.read_table(os.path.expanduser(args.question_file))
|
| 62 |
+
questions = get_chunk(questions, args.num_chunks, args.chunk_idx)
|
| 63 |
+
answers_file = os.path.expanduser(args.answers_file)
|
| 64 |
+
os.makedirs(os.path.dirname(answers_file), exist_ok=True)
|
| 65 |
+
ans_file = open(answers_file, "w")
|
| 66 |
+
|
| 67 |
+
if 'plain' in model_name and 'finetune' not in model_name.lower() and 'mmtag' not in args.conv_mode:
|
| 68 |
+
args.conv_mode = args.conv_mode + '_mmtag'
|
| 69 |
+
print(f'It seems that this is a plain model, but it is not using a mmtag prompt, auto switching to {args.conv_mode}.')
|
| 70 |
+
|
| 71 |
+
for index, row in tqdm(questions.iterrows(), total=len(questions)):
|
| 72 |
+
options = get_options(row, all_options)
|
| 73 |
+
cur_option_char = all_options[:len(options)]
|
| 74 |
+
|
| 75 |
+
if args.all_rounds:
|
| 76 |
+
num_rounds = len(options)
|
| 77 |
+
else:
|
| 78 |
+
num_rounds = 1
|
| 79 |
+
|
| 80 |
+
for round_idx in range(num_rounds):
|
| 81 |
+
idx = row['index']
|
| 82 |
+
question = row['question']
|
| 83 |
+
hint = row['hint']
|
| 84 |
+
image = load_image_from_base64(row['image'])
|
| 85 |
+
if not is_none(hint):
|
| 86 |
+
question = hint + '\n' + question
|
| 87 |
+
for option_char, option in zip(all_options[:len(options)], options):
|
| 88 |
+
question = question + '\n' + option_char + '. ' + option
|
| 89 |
+
qs = cur_prompt = question
|
| 90 |
+
if model.config.mm_use_im_start_end:
|
| 91 |
+
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + qs
|
| 92 |
+
else:
|
| 93 |
+
qs = DEFAULT_IMAGE_TOKEN + '\n' + qs
|
| 94 |
+
|
| 95 |
+
if args.single_pred_prompt:
|
| 96 |
+
if args.lang == 'cn':
|
| 97 |
+
qs = qs + '\n' + "请直接回答选项字母。"
|
| 98 |
+
else:
|
| 99 |
+
qs = qs + '\n' + "Answer with the option's letter from the given choices directly."
|
| 100 |
+
|
| 101 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 102 |
+
conv.append_message(conv.roles[0], qs)
|
| 103 |
+
conv.append_message(conv.roles[1], None)
|
| 104 |
+
prompt = conv.get_prompt()
|
| 105 |
+
|
| 106 |
+
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
|
| 107 |
+
|
| 108 |
+
image_tensor = process_images([image], image_processor, model.config)[0]
|
| 109 |
+
|
| 110 |
+
with torch.inference_mode():
|
| 111 |
+
output_ids = model.generate(
|
| 112 |
+
input_ids,
|
| 113 |
+
images=image_tensor.unsqueeze(0).half().cuda(),
|
| 114 |
+
image_sizes=[image.size],
|
| 115 |
+
do_sample=True if args.temperature > 0 else False,
|
| 116 |
+
temperature=args.temperature,
|
| 117 |
+
top_p=args.top_p,
|
| 118 |
+
num_beams=args.num_beams,
|
| 119 |
+
# no_repeat_ngram_size=3,
|
| 120 |
+
max_new_tokens=1024,
|
| 121 |
+
use_cache=True)
|
| 122 |
+
|
| 123 |
+
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
|
| 124 |
+
|
| 125 |
+
ans_id = shortuuid.uuid()
|
| 126 |
+
ans_file.write(json.dumps({"question_id": idx,
|
| 127 |
+
"round_id": round_idx,
|
| 128 |
+
"prompt": cur_prompt,
|
| 129 |
+
"text": outputs,
|
| 130 |
+
"options": options,
|
| 131 |
+
"option_char": cur_option_char,
|
| 132 |
+
"answer_id": ans_id,
|
| 133 |
+
"model_id": model_name,
|
| 134 |
+
"metadata": {}}) + "\n")
|
| 135 |
+
ans_file.flush()
|
| 136 |
+
|
| 137 |
+
# rotate options
|
| 138 |
+
options = options[1:] + options[:1]
|
| 139 |
+
cur_option_char = cur_option_char[1:] + cur_option_char[:1]
|
| 140 |
+
ans_file.close()
|
| 141 |
+
|
| 142 |
+
if __name__ == "__main__":
|
| 143 |
+
parser = argparse.ArgumentParser()
|
| 144 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 145 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 146 |
+
parser.add_argument("--image-folder", type=str, default="")
|
| 147 |
+
parser.add_argument("--question-file", type=str, default="tables/question.jsonl")
|
| 148 |
+
parser.add_argument("--answers-file", type=str, default="answer.jsonl")
|
| 149 |
+
parser.add_argument("--conv-mode", type=str, default="llava_v1")
|
| 150 |
+
parser.add_argument("--num-chunks", type=int, default=1)
|
| 151 |
+
parser.add_argument("--chunk-idx", type=int, default=0)
|
| 152 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 153 |
+
parser.add_argument("--top_p", type=float, default=None)
|
| 154 |
+
parser.add_argument("--num_beams", type=int, default=1)
|
| 155 |
+
parser.add_argument("--all-rounds", action="store_true")
|
| 156 |
+
parser.add_argument("--single-pred-prompt", action="store_true")
|
| 157 |
+
parser.add_argument("--lang", type=str, default="en")
|
| 158 |
+
args = parser.parse_args()
|
| 159 |
+
|
| 160 |
+
eval_model(args)
|
llava/eval/model_vqa_science.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
import os
|
| 4 |
+
import json
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
import shortuuid
|
| 7 |
+
|
| 8 |
+
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 9 |
+
from llava.conversation import conv_templates, SeparatorStyle
|
| 10 |
+
from llava.model.builder import load_pretrained_model
|
| 11 |
+
from llava.utils import disable_torch_init
|
| 12 |
+
from llava.mm_utils import tokenizer_image_token, process_images, get_model_name_from_path
|
| 13 |
+
|
| 14 |
+
from PIL import Image
|
| 15 |
+
import math
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def split_list(lst, n):
|
| 19 |
+
"""Split a list into n (roughly) equal-sized chunks"""
|
| 20 |
+
chunk_size = math.ceil(len(lst) / n) # integer division
|
| 21 |
+
return [lst[i:i+chunk_size] for i in range(0, len(lst), chunk_size)]
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def get_chunk(lst, n, k):
|
| 25 |
+
chunks = split_list(lst, n)
|
| 26 |
+
return chunks[k]
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def eval_model(args):
|
| 30 |
+
# Model
|
| 31 |
+
disable_torch_init()
|
| 32 |
+
model_path = os.path.expanduser(args.model_path)
|
| 33 |
+
model_name = get_model_name_from_path(model_path)
|
| 34 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(model_path, args.model_base, model_name)
|
| 35 |
+
|
| 36 |
+
questions = json.load(open(os.path.expanduser(args.question_file), "r"))
|
| 37 |
+
questions = get_chunk(questions, args.num_chunks, args.chunk_idx)
|
| 38 |
+
answers_file = os.path.expanduser(args.answers_file)
|
| 39 |
+
os.makedirs(os.path.dirname(answers_file), exist_ok=True)
|
| 40 |
+
ans_file = open(answers_file, "w")
|
| 41 |
+
for i, line in enumerate(tqdm(questions)):
|
| 42 |
+
idx = line["id"]
|
| 43 |
+
question = line['conversations'][0]
|
| 44 |
+
qs = question['value'].replace('<image>', '').strip()
|
| 45 |
+
cur_prompt = qs
|
| 46 |
+
|
| 47 |
+
if 'image' in line:
|
| 48 |
+
image_file = line["image"]
|
| 49 |
+
image = Image.open(os.path.join(args.image_folder, image_file))
|
| 50 |
+
image_tensor = process_images([image], image_processor, model.config)[0]
|
| 51 |
+
images = image_tensor.unsqueeze(0).half().cuda()
|
| 52 |
+
image_sizes = [image.size]
|
| 53 |
+
if getattr(model.config, 'mm_use_im_start_end', False):
|
| 54 |
+
qs = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + qs
|
| 55 |
+
else:
|
| 56 |
+
qs = DEFAULT_IMAGE_TOKEN + '\n' + qs
|
| 57 |
+
cur_prompt = '<image>' + '\n' + cur_prompt
|
| 58 |
+
else:
|
| 59 |
+
images = None
|
| 60 |
+
image_sizes = None
|
| 61 |
+
|
| 62 |
+
if args.single_pred_prompt:
|
| 63 |
+
qs = qs + '\n' + "Answer with the option's letter from the given choices directly."
|
| 64 |
+
cur_prompt = cur_prompt + '\n' + "Answer with the option's letter from the given choices directly."
|
| 65 |
+
|
| 66 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 67 |
+
conv.append_message(conv.roles[0], qs)
|
| 68 |
+
conv.append_message(conv.roles[1], None)
|
| 69 |
+
prompt = conv.get_prompt()
|
| 70 |
+
|
| 71 |
+
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
|
| 72 |
+
|
| 73 |
+
with torch.inference_mode():
|
| 74 |
+
output_ids = model.generate(
|
| 75 |
+
input_ids,
|
| 76 |
+
images=images,
|
| 77 |
+
image_sizes=image_sizes,
|
| 78 |
+
do_sample=True if args.temperature > 0 else False,
|
| 79 |
+
temperature=args.temperature,
|
| 80 |
+
max_new_tokens=1024,
|
| 81 |
+
use_cache=True,
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
|
| 85 |
+
|
| 86 |
+
ans_id = shortuuid.uuid()
|
| 87 |
+
ans_file.write(json.dumps({"question_id": idx,
|
| 88 |
+
"prompt": cur_prompt,
|
| 89 |
+
"text": outputs,
|
| 90 |
+
"answer_id": ans_id,
|
| 91 |
+
"model_id": model_name,
|
| 92 |
+
"metadata": {}}) + "\n")
|
| 93 |
+
ans_file.flush()
|
| 94 |
+
ans_file.close()
|
| 95 |
+
|
| 96 |
+
if __name__ == "__main__":
|
| 97 |
+
parser = argparse.ArgumentParser()
|
| 98 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 99 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 100 |
+
parser.add_argument("--image-folder", type=str, default="")
|
| 101 |
+
parser.add_argument("--question-file", type=str, default="tables/question.json")
|
| 102 |
+
parser.add_argument("--answers-file", type=str, default="answer.jsonl")
|
| 103 |
+
parser.add_argument("--conv-mode", type=str, default="llava_v0")
|
| 104 |
+
parser.add_argument("--num-chunks", type=int, default=1)
|
| 105 |
+
parser.add_argument("--chunk-idx", type=int, default=0)
|
| 106 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 107 |
+
parser.add_argument("--answer-prompter", action="store_true")
|
| 108 |
+
parser.add_argument("--single-pred-prompt", action="store_true")
|
| 109 |
+
args = parser.parse_args()
|
| 110 |
+
|
| 111 |
+
eval_model(args)
|
llava/eval/qa_baseline_gpt35.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Generate answers with GPT-3.5"""
|
| 2 |
+
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
|
| 3 |
+
import argparse
|
| 4 |
+
import json
|
| 5 |
+
import os
|
| 6 |
+
import time
|
| 7 |
+
import concurrent.futures
|
| 8 |
+
|
| 9 |
+
import openai
|
| 10 |
+
import tqdm
|
| 11 |
+
import shortuuid
|
| 12 |
+
|
| 13 |
+
MODEL = 'gpt-3.5-turbo'
|
| 14 |
+
MODEL_ID = 'gpt-3.5-turbo:20230327'
|
| 15 |
+
|
| 16 |
+
def get_answer(question_id: int, question: str, max_tokens: int):
|
| 17 |
+
ans = {
|
| 18 |
+
'answer_id': shortuuid.uuid(),
|
| 19 |
+
'question_id': question_id,
|
| 20 |
+
'model_id': MODEL_ID,
|
| 21 |
+
}
|
| 22 |
+
for _ in range(3):
|
| 23 |
+
try:
|
| 24 |
+
response = openai.ChatCompletion.create(
|
| 25 |
+
model=MODEL,
|
| 26 |
+
messages=[{
|
| 27 |
+
'role': 'system',
|
| 28 |
+
'content': 'You are a helpful assistant.'
|
| 29 |
+
}, {
|
| 30 |
+
'role': 'user',
|
| 31 |
+
'content': question,
|
| 32 |
+
}],
|
| 33 |
+
max_tokens=max_tokens,
|
| 34 |
+
)
|
| 35 |
+
ans['text'] = response['choices'][0]['message']['content']
|
| 36 |
+
return ans
|
| 37 |
+
except Exception as e:
|
| 38 |
+
print('[ERROR]', e)
|
| 39 |
+
ans['text'] = '#ERROR#'
|
| 40 |
+
time.sleep(1)
|
| 41 |
+
return ans
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
if __name__ == '__main__':
|
| 45 |
+
parser = argparse.ArgumentParser(description='ChatGPT answer generation.')
|
| 46 |
+
parser.add_argument('-q', '--question')
|
| 47 |
+
parser.add_argument('-o', '--output')
|
| 48 |
+
parser.add_argument('--max-tokens', type=int, default=1024, help='maximum number of tokens produced in the output')
|
| 49 |
+
args = parser.parse_args()
|
| 50 |
+
|
| 51 |
+
questions_dict = {}
|
| 52 |
+
with open(os.path.expanduser(args.question)) as f:
|
| 53 |
+
for line in f:
|
| 54 |
+
if not line:
|
| 55 |
+
continue
|
| 56 |
+
q = json.loads(line)
|
| 57 |
+
questions_dict[q['question_id']] = q['text']
|
| 58 |
+
|
| 59 |
+
answers = []
|
| 60 |
+
|
| 61 |
+
with concurrent.futures.ThreadPoolExecutor(max_workers=32) as executor:
|
| 62 |
+
futures = []
|
| 63 |
+
for qid, question in questions_dict.items():
|
| 64 |
+
future = executor.submit(get_answer, qid, question, args.max_tokens)
|
| 65 |
+
futures.append(future)
|
| 66 |
+
|
| 67 |
+
for future in tqdm.tqdm(concurrent.futures.as_completed(futures), total=len(futures)):
|
| 68 |
+
answers.append(future.result())
|
| 69 |
+
|
| 70 |
+
answers.sort(key=lambda x: x['question_id'])
|
| 71 |
+
|
| 72 |
+
with open(os.path.expanduser(args.output), 'w') as f:
|
| 73 |
+
table = [json.dumps(ans) for ans in answers]
|
| 74 |
+
f.write('\n'.join(table))
|
llava/eval/run_llava.py
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from llava.constants import (
|
| 5 |
+
IMAGE_TOKEN_INDEX,
|
| 6 |
+
DEFAULT_IMAGE_TOKEN,
|
| 7 |
+
DEFAULT_IM_START_TOKEN,
|
| 8 |
+
DEFAULT_IM_END_TOKEN,
|
| 9 |
+
IMAGE_PLACEHOLDER,
|
| 10 |
+
)
|
| 11 |
+
from llava.conversation import conv_templates, SeparatorStyle
|
| 12 |
+
from llava.model.builder import load_pretrained_model
|
| 13 |
+
from llava.utils import disable_torch_init
|
| 14 |
+
from llava.mm_utils import (
|
| 15 |
+
process_images,
|
| 16 |
+
tokenizer_image_token,
|
| 17 |
+
get_model_name_from_path,
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
from PIL import Image
|
| 21 |
+
|
| 22 |
+
import requests
|
| 23 |
+
from PIL import Image
|
| 24 |
+
from io import BytesIO
|
| 25 |
+
import re
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def image_parser(args):
|
| 29 |
+
out = args.image_file.split(args.sep)
|
| 30 |
+
return out
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def load_image(image_file):
|
| 34 |
+
if image_file.startswith("http") or image_file.startswith("https"):
|
| 35 |
+
response = requests.get(image_file)
|
| 36 |
+
image = Image.open(BytesIO(response.content)).convert("RGB")
|
| 37 |
+
else:
|
| 38 |
+
image = Image.open(image_file).convert("RGB")
|
| 39 |
+
return image
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def load_images(image_files):
|
| 43 |
+
out = []
|
| 44 |
+
for image_file in image_files:
|
| 45 |
+
image = load_image(image_file)
|
| 46 |
+
out.append(image)
|
| 47 |
+
return out
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def eval_model(args):
|
| 51 |
+
# Model
|
| 52 |
+
disable_torch_init()
|
| 53 |
+
|
| 54 |
+
model_name = get_model_name_from_path(args.model_path)
|
| 55 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(
|
| 56 |
+
args.model_path, args.model_base, model_name
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
qs = args.query
|
| 60 |
+
image_token_se = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN
|
| 61 |
+
if IMAGE_PLACEHOLDER in qs:
|
| 62 |
+
if model.config.mm_use_im_start_end:
|
| 63 |
+
qs = re.sub(IMAGE_PLACEHOLDER, image_token_se, qs)
|
| 64 |
+
else:
|
| 65 |
+
qs = re.sub(IMAGE_PLACEHOLDER, DEFAULT_IMAGE_TOKEN, qs)
|
| 66 |
+
else:
|
| 67 |
+
if model.config.mm_use_im_start_end:
|
| 68 |
+
qs = image_token_se + "\n" + qs
|
| 69 |
+
else:
|
| 70 |
+
qs = DEFAULT_IMAGE_TOKEN + "\n" + qs
|
| 71 |
+
|
| 72 |
+
if "llama-2" in model_name.lower():
|
| 73 |
+
conv_mode = "llava_llama_2"
|
| 74 |
+
elif "mistral" in model_name.lower():
|
| 75 |
+
conv_mode = "mistral_instruct"
|
| 76 |
+
elif "v1.6-34b" in model_name.lower():
|
| 77 |
+
conv_mode = "chatml_direct"
|
| 78 |
+
elif "v1" in model_name.lower():
|
| 79 |
+
conv_mode = "llava_v1"
|
| 80 |
+
elif "mpt" in model_name.lower():
|
| 81 |
+
conv_mode = "mpt"
|
| 82 |
+
else:
|
| 83 |
+
conv_mode = "llava_v0"
|
| 84 |
+
|
| 85 |
+
if args.conv_mode is not None and conv_mode != args.conv_mode:
|
| 86 |
+
print(
|
| 87 |
+
"[WARNING] the auto inferred conversation mode is {}, while `--conv-mode` is {}, using {}".format(
|
| 88 |
+
conv_mode, args.conv_mode, args.conv_mode
|
| 89 |
+
)
|
| 90 |
+
)
|
| 91 |
+
else:
|
| 92 |
+
args.conv_mode = conv_mode
|
| 93 |
+
|
| 94 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 95 |
+
conv.append_message(conv.roles[0], qs)
|
| 96 |
+
conv.append_message(conv.roles[1], None)
|
| 97 |
+
prompt = conv.get_prompt()
|
| 98 |
+
|
| 99 |
+
image_files = image_parser(args)
|
| 100 |
+
images = load_images(image_files)
|
| 101 |
+
image_sizes = [x.size for x in images]
|
| 102 |
+
images_tensor = process_images(
|
| 103 |
+
images,
|
| 104 |
+
image_processor,
|
| 105 |
+
model.config
|
| 106 |
+
).to(model.device, dtype=torch.float16)
|
| 107 |
+
|
| 108 |
+
input_ids = (
|
| 109 |
+
tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt")
|
| 110 |
+
.unsqueeze(0)
|
| 111 |
+
.cuda()
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
with torch.inference_mode():
|
| 115 |
+
output_ids = model.generate(
|
| 116 |
+
input_ids,
|
| 117 |
+
images=images_tensor,
|
| 118 |
+
image_sizes=image_sizes,
|
| 119 |
+
do_sample=True if args.temperature > 0 else False,
|
| 120 |
+
temperature=args.temperature,
|
| 121 |
+
top_p=args.top_p,
|
| 122 |
+
num_beams=args.num_beams,
|
| 123 |
+
max_new_tokens=args.max_new_tokens,
|
| 124 |
+
use_cache=True,
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
|
| 128 |
+
print(outputs)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
if __name__ == "__main__":
|
| 132 |
+
parser = argparse.ArgumentParser()
|
| 133 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 134 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 135 |
+
parser.add_argument("--image-file", type=str, required=True)
|
| 136 |
+
parser.add_argument("--query", type=str, required=True)
|
| 137 |
+
parser.add_argument("--conv-mode", type=str, default=None)
|
| 138 |
+
parser.add_argument("--sep", type=str, default=",")
|
| 139 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 140 |
+
parser.add_argument("--top_p", type=float, default=None)
|
| 141 |
+
parser.add_argument("--num_beams", type=int, default=1)
|
| 142 |
+
parser.add_argument("--max_new_tokens", type=int, default=512)
|
| 143 |
+
args = parser.parse_args()
|
| 144 |
+
|
| 145 |
+
eval_model(args)
|
llava/eval/summarize_gpt_review.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
from collections import defaultdict
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
import argparse
|
| 8 |
+
|
| 9 |
+
def parse_args():
|
| 10 |
+
parser = argparse.ArgumentParser(description='ChatGPT-based QA evaluation.')
|
| 11 |
+
parser.add_argument('-d', '--dir', default=None)
|
| 12 |
+
parser.add_argument('-v', '--version', default=None)
|
| 13 |
+
parser.add_argument('-s', '--select', nargs='*', default=None)
|
| 14 |
+
parser.add_argument('-f', '--files', nargs='*', default=[])
|
| 15 |
+
parser.add_argument('-i', '--ignore', nargs='*', default=[])
|
| 16 |
+
return parser.parse_args()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
if __name__ == '__main__':
|
| 20 |
+
args = parse_args()
|
| 21 |
+
|
| 22 |
+
if args.ignore is not None:
|
| 23 |
+
args.ignore = [int(x) for x in args.ignore]
|
| 24 |
+
|
| 25 |
+
if len(args.files) > 0:
|
| 26 |
+
review_files = args.files
|
| 27 |
+
else:
|
| 28 |
+
review_files = [x for x in os.listdir(args.dir) if x.endswith('.jsonl') and (x.startswith('gpt4_text') or x.startswith('reviews_') or x.startswith('review_') or 'review' in args.dir)]
|
| 29 |
+
|
| 30 |
+
for review_file in sorted(review_files):
|
| 31 |
+
config = os.path.basename(review_file).replace('gpt4_text_', '').replace('.jsonl', '')
|
| 32 |
+
if args.select is not None and any(x not in config for x in args.select):
|
| 33 |
+
continue
|
| 34 |
+
if '0613' in config:
|
| 35 |
+
version = '0613'
|
| 36 |
+
else:
|
| 37 |
+
version = '0314'
|
| 38 |
+
if args.version is not None and args.version != version:
|
| 39 |
+
continue
|
| 40 |
+
scores = defaultdict(list)
|
| 41 |
+
print(config)
|
| 42 |
+
with open(os.path.join(args.dir, review_file) if args.dir is not None else review_file) as f:
|
| 43 |
+
for review_str in f:
|
| 44 |
+
review = json.loads(review_str)
|
| 45 |
+
if review['question_id'] in args.ignore:
|
| 46 |
+
continue
|
| 47 |
+
if 'category' in review:
|
| 48 |
+
scores[review['category']].append(review['tuple'])
|
| 49 |
+
scores['all'].append(review['tuple'])
|
| 50 |
+
else:
|
| 51 |
+
if 'tuple' in review:
|
| 52 |
+
scores['all'].append(review['tuple'])
|
| 53 |
+
else:
|
| 54 |
+
scores['all'].append(review['score'])
|
| 55 |
+
for k, v in sorted(scores.items()):
|
| 56 |
+
stats = np.asarray(v).mean(0).tolist()
|
| 57 |
+
stats = [round(x, 3) for x in stats]
|
| 58 |
+
# print(k, stats, round(stats[1]/stats[0]*100, 1))
|
| 59 |
+
print(k, round(stats[1]/stats[0]*100, 1), round(stats[0] * 10, 1), round(stats[1] * 10, 1))
|
| 60 |
+
print('=================================')
|
llava/eval/table/answer/answer_alpaca-13b.jsonl
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"question_id": 1, "text": "Improving time management skills involves setting priorities, breaking tasks into smaller chunks, delegating tasks, avoiding multitasking, and taking regular breaks. Additionally, it is important to have a positive attitude and be realistic with goals. Making a to-do list, tracking time, and using technology to automate mundane tasks can also help improve time management skills.", "answer_id": "kEL9ifUHDeYuAXzevje2se", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 2 |
+
{"question_id": 2, "text": "The most effective ways to deal with stress include identifying and avoiding the sources of stress, developing healthy coping mechanisms, and engaging in relaxation techniques such as meditation, deep breathing, and physical exercise. Additionally, it is important to take care of one's mental and physical health, get enough rest and nutrition, and practice self-care.", "answer_id": "VcF3NrWGXhhxLkDVurNrwq", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 3 |
+
{"question_id": 3, "text": "The main differences between Python and JavaScript programming languages are in their syntax, structure, and the type of applications they are designed for. Python is a general-purpose language designed to be easy to read and write, while JavaScript is primarily used for web development. Python is a compiled language, while JavaScript is an interpreted language. Python is strongly typed, while JavaScript is not. Python is typically faster than JavaScript in terms of execution, while JavaScript is better suited to create interactive web pages.", "answer_id": "LpvtyQi9QdSgRrgGDxiGrT", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 4 |
+
{"question_id": 4, "text": "Working from home can be a great way to increase productivity, but it does require some strategic planning and tactics. Here are some tips for increasing your productivity while working from home: \n1. Establish a routine: Having a regular schedule and sticking to it can help you stay focused and motivated.\n2. Create a distraction-free zone: Eliminate distractions by turning off notifications and setting a \u201cdo not disturb\u201d mode.\n3. Take breaks: Working for long stretches without taking breaks can lead to burnout and decreased productivity.\n4. Exercise: Exercise can help improve focus and productivity.\n5. Get organized: Having a clean and organized workspace can help you stay on task.\n6. Set goals: Set short-term and long-term goals to keep you motivated and on track.\n7. Connect with colleagues: Don\u2019t be afraid to reach out to colleagues for help or advice.\n8. Track your progress: Keep track of your progress and celebrate your successes.\n9. Unplug: Taking breaks and unplugging from work can help you recharge and come back to work more refreshed.", "answer_id": "7zQm8cSTJhPtPdZdxbcfrX", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 5 |
+
{"question_id": 5, "text": "Sure. Quantum computing is a new technology that uses quantum mechanical phenomena to perform operations on data. Unlike traditional computers, which process information in binary form, quantum computers can process information in multiple states at the same time, allowing them to perform operations faster and with more accuracy. It also allows them to solve problems that classical computers struggle with. Quantum computing is still in its infancy, but it has the potential to revolutionize the computing industry and open up new possibilities in artificial intelligence, cryptography, and other fields.", "answer_id": "UrLEH82RHwqqLt2LyvYSKj", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 6 |
+
{"question_id": 6, "text": "Plant-based protein sources include legumes, grains, nuts, and seeds, and are generally lower in fat and calories than animal-based proteins. Animal-based proteins come from sources such as meat, eggs, and dairy, and are generally higher in fat and calories than plant-based proteins. Plant-based proteins are also generally lower in cholesterol and saturated fat than animal-based proteins. Additionally, plant-based proteins require fewer resources for production, such as water and land, than animal-based proteins.", "answer_id": "fpRdMTdnfirosQixuf2Gez", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 7 |
+
{"question_id": 7, "text": "Developing critical thinking skills involves actively questioning assumptions, taking multiple perspectives, analyzing information, and coming to logical conclusions. You can practice these skills by posing questions to yourself and working through problems, as well as engaging in thoughtful discussion with others.", "answer_id": "PvGmsCJSNFcvQKmPTnnd7s", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 8 |
+
{"question_id": 8, "text": "The major challenges faced by the education sector include lack of access to quality education, low educational outcomes, high costs of education, lack of adequate infrastructure and teaching materials, overcrowding in classrooms, and gender inequality. Other challenges include lack of access to technology and digital learning materials, outdated curriculum and pedagogical practices, and inadequate teacher training.", "answer_id": "n4ANAbpR3gvLPP8poPfKZ6", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 9 |
+
{"question_id": 9, "text": "The primary factors that influence consumer behavior include cultural, social, and personal factors. Cultural factors include shared beliefs, values, and customs within a society, while social factors include the influence of family, friends, and peers. Personal factors include an individual's lifestyle, attitudes, beliefs, and past experiences. Other factors such as advertising, marketing, and price also have an effect on consumer behavior.", "answer_id": "STJ36GrgQMcaUi7zaoNPit", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 10 |
+
{"question_id": 10, "text": "The most effective strategies for conflict resolution in the workplace include:\n1. Establishing open communication: Encouraging open and honest communication between parties is key to resolving any conflict.\n2. Listening actively: Active listening allows both parties to feel heard and allows for a better understanding of the other person's perspective.\n3. Identifying root causes: Understanding the underlying cause of the conflict can help to find more effective solutions that address the core issue.\n4. Focusing on interests, not positions: Focusing on the interests of both parties can help to find creative solutions that satisfy the needs of everyone involved.\n5. Developing mutual respect: Respect is essential to any successful resolution. Building mutual respect can help to create a healthier work environment.\n6. Negotiation: Working together to negotiate a mutually beneficial solution can help to create an agreement that both parties are happy with.\n7. Taking responsibility: Taking responsibility for one\u2019s words and actions can help to create a culture of accountability in the workplace.", "answer_id": "425SwYvqKPAXFGTYKXB7Cs", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 11 |
+
{"question_id": 11, "text": "The use of single-use plastic bottles has a number of negative implications on the environment. They are not biodegradable and can take hundreds of years to break down. This means they are around for a long time, releasing potentially harmful chemicals into the environment, and they can be easily mistaken for food by animals. Single-use plastic bottles can also be a source of micro-plastics, which are very small particles of plastic that are difficult to clean up and can be consumed by fish and other aquatic life, leading to health problems in humans who consume those fish. On the other hand, reusable bottles are a much more environmentally friendly choice since they do not produce any waste. They are also often made of materials that are safer for human health, such as stainless steel or glass. Reusable bottles are also more cost-effective since they do not need to be replaced as often as single-use plastic bottles.", "answer_id": "VbNAuj6KAkMdLJQXMo22oK", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 12 |
+
{"question_id": 12, "text": "When designing an inclusive and accessible public transportation system, some factors to consider include providing frequent and reliable service, accessible stops and vehicles, a variety of fare options, clear and consistent signage and information, comfortable seating and space for wheelchairs and other assistive devices, and security and safety protocols. Additionally, public transportation systems should be integrated with other services such as public parking, bike and scooter sharing, and shuttles to provide a comprehensive and accessible experience.", "answer_id": "CNGqAeu2QJbQ4QGzHJDPdq", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 13 |
+
{"question_id": 13, "text": "Governments can use fiscal and monetary policies to combat economic recessions. Fiscal policies involve the government spending money or cutting taxes in order to stimulate the economy, while monetary policies involve changing the money supply or interest rates to influence economic activity. These policies can be used to stabilize the economy, create jobs, and reduce poverty.", "answer_id": "E8w2qYqnm8iqCrSkUv62sz", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 14 |
+
{"question_id": 14, "text": "Language and cultural barriers can lead to misunderstandings and make it more difficult to communicate and form relationships in multicultural societies. Without a common language or shared culture, people can have difficulty understanding each other's perspectives and beliefs, which can lead to mistrust and a lack of understanding between different ethnic groups. To overcome these barriers, it is important to make an effort to learn about different cultures, be open-minded, and take the time to understand each other.", "answer_id": "8o5yMymfzo6kzmp9GK5MWr", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 15 |
+
{"question_id": 15, "text": "Artificial intelligence can be used to improve the quality and efficiency of healthcare delivery in a variety of ways. AI can be used to assist with diagnosing diseases by comparing symptoms and medical history to images of known diseases and medical conditions. AI can also be used to analyze laboratory results and patient records to identify potential problems and develop treatment plans. AI can be used to automate administrative tasks and reduce paperwork, as well as identify potential drug interactions and side effects. AI can also be used to automate appointment reminders, facilitate communication between doctors and patients, and even provide virtual health coaching to help patients manage their conditions.", "answer_id": "kbJVEEsdsSScEq5Y5furr7", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 16 |
+
{"question_id": 16, "text": "CRISPR-Cas9 is a recently developed gene editing technology that has revolutionized the way scientists are able to edit genomes. The technology uses a guide RNA to direct the Cas9 enzyme to a specific location in the genome, where it will cut the DNA strands. This allows for the insertion or deletion of DNA sequences, which can be used to modify the genetic code of an organism. Potential applications include treating genetic diseases, increasing crop yields, and creating pest-resistant crops. Ethically, the biggest concern is the potential misuse of the technology, which could lead to unintended consequences or be used to alter humanity in ways that could harm us.", "answer_id": "CMUL5ULZuR7YC5EPzCBN2N", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 17 |
+
{"question_id": 17, "text": "Vaccinations work by stimulating the body's immune system to protect against infectious diseases. Herd immunity is a concept whereby a population is protected against a certain disease when a certain percentage of the population has immunity to the disease, either through vaccination or having already contracted the disease. This is because when enough people are vaccinated, it reduces the spread of the disease and prevents it from spreading to those who are not immune.", "answer_id": "kEmDDQyNqSkyFihYEEBpuR", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 18 |
+
{"question_id": 18, "text": "Social media platforms can have a significant influence on how people consume and share news. By providing instant access to news sources and allowing users to easily share content, these platforms can shape the public's information landscape and the spread of misinformation. Some potential implications of this are that users may not always be able to discern between reliable and unreliable sources, and misleading information may be more easily spread and go viral. This can lead to confusion and mistrust among users, and can potentially be exploited for nefarious purposes. To mitigate these risks, it is important for users to be aware of the potential biases and agendas of the sources they are consuming, and for social media platforms to take proactive steps to curb the spread of misinformation.", "answer_id": "Qs3grQsqFVGK9EVkCkf9PB", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 19 |
+
{"question_id": 19, "text": "Cultural, social, and economic factors all play a role in determining an individual's food choices. For example, people growing up in households with limited economic means may be more likely to consume cheaper, less nutritious foods due to economic constraints. Additionally, cultural norms and values can influence food choices, such as the emphasis on large portions typical in some American cultural settings. Finally, social factors such as peer pressure and advertising can also sway an individual's food choices. By understanding and taking into account these various factors, health promotion strategies can be tailored and targeted to help individuals make healthier dietary decisions.", "answer_id": "kzZ6dKN7hkRWjqtdHr7Qns", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 20 |
+
{"question_id": 20, "text": "Natural selection is the process by which certain traits or characteristics become more or less common in a population over time. This is due to the fact that those individuals with certain advantageous traits are more likely to survive, reproduce, and pass those traits on to their offspring. Over time, this leads to the evolution and adaptation of species to their environment.", "answer_id": "DPPDG6YGFJij2GCmRL66PU", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 21 |
+
{"question_id": 21, "text": "I am a brave knight, loyal to my king and country, and I have come to serve and protect them both. I am skilled in the arts of war and peace, and I am proud to be here at the royal court.", "answer_id": "D62FjDb4nZANzPpfSfsiyn", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 22 |
+
{"question_id": 22, "text": "Avast ye maties! To the bottom of the sea we go! In search of hidden riches and fortune, we shall brave the depths and face any danger that comes our way. For glory and honor, let us set sail and find the lost Ark!", "answer_id": "k7E4NNw5kyj9DmvP5Pu2zb", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 23 |
+
{"question_id": 23, "text": "If I were a Shakespearean character, I would declare my love for someone in a soliloquy with passionate words and metaphors. I would express my love for them with descriptions of their beauty and the joy I feel when I am with them. I would confess my hopes and dreams for our future together and declare my devotion to them. I would make my love for them known in a way that could never be forgotten.", "answer_id": "KFocjVCejYrU3YmLjAqoUF", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 24 |
+
{"question_id": 24, "text": "As a superhero, my origin story is very special. I was born with special abilities that I had to keep hidden for a long time. I was scared to use them at first, but eventually I discovered that I could use my powers to protect people and make the world a better place. I've had to face a lot of challenges along the way, but I've also had a lot of help from friends and family. Now, I use my abilities to help people in need and fight for justice.", "answer_id": "dq8Sm9djS7e7y9sG9vmMJf", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 25 |
+
{"question_id": 25, "text": "If I were a time traveler from the year 3000, I would tell people about the incredible advancements in technology, such as the ability to travel through time, space, and dimensions; the development of intelligent robots and autonomous vehicles; the emergence of virtual reality and augmented reality; and the rise of artificial intelligence and machine learning.", "answer_id": "XZ8fG8e6u7CyKd2moK6abe", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 26 |
+
{"question_id": 26, "text": "The game was a nail-biter, with both teams trading leads throughout the game. With only seconds left on the clock, the home team made a bold move and passed the ball to their star player, who took the ball down the court and made a layup at the buzzer to seal the victory for the home team!", "answer_id": "oKaXHfoK4pXwrefFWXmeA8", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 27 |
+
{"question_id": 27, "text": "My signature dish is a seamless blend of traditional and modern cooking techniques. I use only the freshest ingredients to create a unique and unforgettable dining experience. The dish is a perfect balance of flavors and textures, with a subtle hint of my personal style. It is a dish that I am proud to call my own.", "answer_id": "ZwiZfvDWm7SETKNBfDk7Mb", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 28 |
+
{"question_id": 28, "text": "At the summit of Mount Everest, you are filled with a sense of accomplishment and joy. The view from the top is absolutely breathtaking - you can see for miles and miles, with the majestic Himalayan mountain range stretching out in all directions. It is a truly unforgettable experience.", "answer_id": "DxYopRe2LcTJMy3FWu6btd", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 29 |
+
{"question_id": 29, "text": "As a colonist on Mars, my daily life is filled with challenges. Finding resources and creating a sustainable environment is a priority. I face a number of challenges including extreme temperature fluctuations, limited access to resources, and the difficulty of travelling to and from the planet. Additionally, I must be mindful of my physical and mental health since I am so far from home. Despite these challenges, I am grateful to be able to explore and experience this new world.", "answer_id": "WC3UJVh4jQ5RUkpcRMU98L", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 30 |
+
{"question_id": 30, "text": "In the post-apocalyptic world, I am a survivor by necessity. I scavenge for food and supplies, and I'm always on the lookout for potential allies. I've encountered a few people who have managed to survive, and together we have formed an alliance to help each other. We hunt for food, build shelter, and work together to stay alive. We also share knowledge and skills, like how to start a fire or how to use a weapon. We look out for each other, and our alliance has strengthened our chances of survival.", "answer_id": "gTvgn6ksDjGGgdprw6AG5A", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 31 |
+
{"question_id": 31, "text": "There are a few ways to tell if a restaurant is popular among locals or mainly attracts tourists. Firstly, look at the clientele - if the majority of people there are tourists, it's likely that the restaurant is mainly attracting tourists. Secondly, check online reviews - if the reviews are mainly from tourists, then it's likely that the restaurant is popular with tourists. Finally, look at the prices - if the prices are higher than average for the area, it could be a sign that the restaurant is popular with locals. This information can be useful to get an idea of what kind of experience to expect, as locals might know about different aspects of the restaurant that tourists wouldn't.", "answer_id": "3q7giCk2BA3Ye4Tm9HC2iw", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 32 |
+
{"question_id": 32, "text": "Some subtle clues that suggest someone is pretending to understand a topic or conversation when they are actually confused or uninformed include: not asking any questions or engaging in the conversation, avoiding eye contact, fidgeting or stammering when speaking, repeating questions or comments made by other people, and nodding along without any signs of understanding.", "answer_id": "hRGsxy86v26SC4yAQS29X4", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 33 |
+
{"question_id": 33, "text": "Some people prefer the tactile and visual experience of using a paper map, and others may prefer to ask for directions from locals in order to get a more personalized experience. Additionally, GPS devices and smartphone apps can sometimes be inaccurate or have limited battery life, while a paper map or asking for directions may be more reliable.", "answer_id": "3n49A5ggJERfXYrLns3ZeU", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 34 |
+
{"question_id": 34, "text": "One way to tell if someone is genuinely interested in a conversation is to observe their body language and facial expressions. Are they making an effort to maintain eye contact? Are they leaning in and actively listening to what you are saying? Do they ask questions and provide relevant answers? If so, it is likely that they are genuinely interested in the conversation. Additionally, if someone is simply being polite, they may not ask questions or engage in the conversation as much, and may not make an effort to maintain eye contact.", "answer_id": "ErCpFtPuYVru4oTTk4WrxG", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 35 |
+
{"question_id": 35, "text": "Shopping at a small, locally-owned business can benefit the local community by keeping money in the area and supporting local jobs. Additionally, these businesses tend to offer a more personal experience and higher quality products than large chain stores. Furthermore, shopping at small businesses can help create a sense of place and community, and can help maintain a unique local culture.", "answer_id": "PTNoCRMZWoJk8HaKX7fW45", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 36 |
+
{"question_id": 36, "text": "There are several ways to assess the credibility of a source of information. Firstly, you can look at the author's credentials and experience in the relevant field. Secondly, you can check the source of the information, such as whether it is from a reliable website or publication. Thirdly, you can look at the evidence presented in the article and whether it is backed up by reliable sources. Finally, you can read other people's reviews or comments about the article to get a better idea of its credibility.", "answer_id": "n8cFs9KENNwZ4z3SR4iXTr", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 37 |
+
{"question_id": 37, "text": "Some people enjoy the sensation of being scared because it can create a feeling of excitement, enhance their emotional state, and provide a sense of thrill and adventure. Others may avoid these experiences because they are afraid of the unknown, or because they don't enjoy the feeling of being scared. Everyone is different, and some people may be more attracted to thrilling and exciting activities while others may prefer calmer activities.", "answer_id": "GzxL9mmEK5RzKqRbqBMUVC", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 38 |
+
{"question_id": 38, "text": "By observing the behavior of others in a social situation, one can gain clues as to the cultural norms and expectations of a group. For example, watching how people interact with one another, how they address each other, how they handle disagreements, and how they go about solving problems can provide insight into the cultural values of the group. Additionally, observing body language, facial expressions, and other nonverbal cues can offer clues as to the accepted norms of behavior in a particular culture.", "answer_id": "QpoHFgb9SzwuaXQQUuBUQD", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 39 |
+
{"question_id": 39, "text": "It is an interesting question, and one that has been debated for quite some time. I think there are valid arguments on both sides. On the one hand, exploring space is a remarkable human endeavor and could lead to tremendous scientific discoveries and technological advances. On the other hand, there are many pressing issues that need to be addressed on Earth, such as poverty, inequality, and climate change. Each side would argue that their cause is more important, and it is ultimately up to each individual to decide which one they feel more strongly about.", "answer_id": "Fxe6MS4GpP3LMDUwzY2cPA", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 40 |
+
{"question_id": 40, "text": "It is important to strike a balance between job creation and technological progress. Automation can increase efficiency and productivity, but it should not come at the expense of job security and people's livelihoods. Therefore, it is essential to create policies and initiatives that promote both job creation and technological progress. This could include investing in training and education to ensure that people have the skills necessary to compete in the modern job market, as well as incentivizing companies to invest in technologies that create jobs and stimulate economic growth.", "answer_id": "mJiQ2FGR4Xb8kmhZjharkw", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 41 |
+
{"question_id": 41, "text": "On average, the human eye blinks about 20 times per minute, or about 14,400 times per day. In a lifetime, this means that the average human will blink roughly 50 million times. This may seem like a lot, but it serves an important purpose. Blinking helps to keep the eyes lubricated and prevents them from drying out. It also helps to spread tears over the surface of the eye, washing away foreign particles and keeping the eye clean. Additionally, blinking helps to reduce the risk of eye infections by helping to clear away bacteria and other foreign substances.", "answer_id": "6Kph4RHRKEZ4YUoaHuEhBv", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 42 |
+
{"question_id": 42, "text": "A grain of salt contains 102.98 atoms. To calculate this, we first need to know the atomic weight of a single atom. The atomic weight of an atom is the number of protons and neutrons in the nucleus of an atom, which determines its atomic mass. The atomic weight of a single atom of salt is 58.943 g/atom. Therefore, a grain of salt contains 102.98 atoms, which is equivalent to 60.98 grams.", "answer_id": "WBwpBQwhxn5kxLDb7MschC", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 43 |
+
{"question_id": 43, "text": "Approximately 2000 lightning strikes occur on Earth each day. This is because the atmospheric conditions must come together in a particular way for a lightning strike to occur. Firstly, a large amount of electric charge must accumulate in the atmosphere, typically in a storm system. Then, the air must become increasingly unstable, leading to rising air and a strong updraft. This causes an electric breakdown of the air, and then an exchange of electricity occurs from the cloud to the ground, forming a lightning bolt. As these conditions are necessary for a lightning strike to occur, about 2000 lightning strikes happen on Earth each day.", "answer_id": "kf8nahQVci2ZLaYikagB7U", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 44 |
+
{"question_id": 44, "text": "It would take about 10 million balloons to lift a house like in the movie Up. The balloons would need to be filled with helium in order for the house to be lifted. Each balloon would need to be filled with about 89.1 cubic feet of helium in order to lift 500 pounds. To calculate how many balloons would be needed, simply multiply the weight of the house (264.72 lbs) by the number of cubic feet of helium needed to lift 500 pounds (89.1). Therefore, it would take 10 million balloons to lift a house like in the movie Up.", "answer_id": "Gptgryd4o2dC8V5aqRmeJJ", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 45 |
+
{"question_id": 45, "text": "According to a 2017 study, over 6.3 billion text messages are sent globally in a minute. This number is expected to grow to 6.8 billion by 2021. This is due to the increasing number of smartphones, better network coverage, and the increasing popularity of texting for communication. Furthermore, the increase in smartphones and better network coverage has also led to the rise of instant messaging applications such as WhatsApp, which has further increased the amount of text messages sent per minute.", "answer_id": "RfBWW8ZhdfTuTMb454Un4o", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 46 |
+
{"question_id": 46, "text": "It is estimated that over 1 billion words are spoken on Earth every day. This is due to the fact that humans are highly social creatures, and language is the primary way that we communicate with each other. In addition, language is a key component of all cultures and societies, and is constantly being used to exchange information and ideas. Furthermore, language is integral to the way we think and process information, as well as to how we connect with each other on an emotional level. Therefore, it is not surprising that so many words are spoken on a daily basis.", "answer_id": "neGgLYm47JvqN8qkw8VeoW", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 47 |
+
{"question_id": 47, "text": "On average, about 100 snowflakes fall per second during a typical winter. This number can vary drastically depending on the location and severity of the storm. Snowflakes are made up of tiny ice crystals, which form in the atmosphere when the temperature is below freezing and there is moisture in the air. As air moves and mixes, the crystals come together to form snowflakes. The shape, size and number of snowflakes depend on the atmospheric conditions, such as temperature and humidity, when they form.", "answer_id": "KSePbzLwsYasR3aui4HU8h", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 48 |
+
{"question_id": 48, "text": "It is estimated that all the books ever written would total about 100 billion pages. This is based on the fact that there are roughly 130 million unique titles in existence, and each book on average contains about 200 pages. This means that if all the books were printed out, the stack of paper would be about 400 miles high. Additionally, if each book was represented by a single page, the total number of pages would be approximately 100 billion. Throughout history, books have served as a way to preserve knowledge and information, as well as to share ideas and stories with others. As technology advances, books are increasingly available in digital formats, which allows for easier access and storage. Regardless of the medium, books will continue to be a valuable source of information for generations to come.", "answer_id": "SWWfLpP2gnWHLbYRZXNsW3", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 49 |
+
{"question_id": 49, "text": "Since the beginning of life, the Earth has orbited the Sun a total of 4.3 billion times. This is calculated by multiplying the average length of a year (365.25 days) by the number of years since life began (approximately 4.5 billion years). Life on Earth relies on the Sun's energy reaching the Earth's atmosphere and being redistributed by the atmosphere, the land surface, and the oceans. Without this energy, life on Earth would not be possible. Therefore, the Earth's orbit around the Sun is integral to the sustainability of life on Earth.", "answer_id": "WaBwKYhs7eAG22qCGLH2j3", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 50 |
+
{"question_id": 50, "text": "Since the beginning of recorded music, countless songs have been recorded. The exact number is difficult to quantify, but conservative estimates put the number of songs recorded throughout history at several hundred thousand. This includes songs from all genres, from classical music to modern pop. The invention of recording technology has allowed musicians to preserve their music and share it with the world. This has enabled generations to access and enjoy music from all eras. With the rise of digital music, the number of recordings available has grown exponentially, and new songs are being recorded all the time.", "answer_id": "MfMJeE9om7qyBbqopHouf4", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 51 |
+
{"question_id": 51, "text": "If the Internet had been invented during the Renaissance period, it likely would have been used primarily by the wealthy and powerful to access knowledge and information, as there was no widespread system of public education at the time. It also would have been a much slower and more expensive process to access information, as there were no high-speed connections or digital networks available.", "answer_id": "TjWPRDM6JFpPF8xeRptCKb", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 52 |
+
{"question_id": 52, "text": "If the Aztecs had successfully repelled the Spanish conquistadors, their culture and way of life would have likely remained intact. The Spanish would not have been able to colonize Mexico, and their influence on the region would have been much less. It's likely that the Aztecs would have continued to expand their empire and control the areas that are now parts of Central and South America. Additionally, the Native American populations in the area would have likely been able to maintain more of their traditional customs and beliefs, and their languages may not have been as heavily impacted by Spanish.", "answer_id": "iR2tYTsWTFENEP7Qy9RgtX", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 53 |
+
{"question_id": 53, "text": "If the Black Death had not occurred in the 14th century, the population of Europe may have continued to grow unabated, leading to more rapid urbanization and economic growth. It's likely that the Renaissance would have begun sooner, and the scientific revolution may have occurred earlier as well. Without the Black Death, there may have been no need for the industrial revolution, or at least it may have occurred later and on a smaller scale. Additionally, the spread of diseases may have been slower, leading to greater population density in certain areas.", "answer_id": "AZdS8xAi3GwAmCqkNSnnwv", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 54 |
+
{"question_id": 54, "text": "If Isaac Newton had focused on biology instead of physics, he might have made important discoveries in the field of medicine and biology. He may have studied the human body and its functions in greater detail, and possibly even made important breakthroughs in treating diseases. He may also have studied the behavior of different animals in the wild and made important observations about their habits and habitats.", "answer_id": "VmwifF2JD5osYKDTqv2ZRS", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 55 |
+
{"question_id": 55, "text": "If the Beatles had never formed as a band, the music world would have been drastically different. The British Invasion of the 1960s might not have happened, or it could have happened in a much different way. The cultural impact of the Beatles, including their influence on other musicians, fashion and society, may never have existed.", "answer_id": "mUL5UPj3qDGaCriEjL2U3B", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 56 |
+
{"question_id": 56, "text": "If Alan Turing had not cracked the Enigma code during World War II, the outcome of the war could have been very different. It's possible that the Allies would have eventually defeated the Axis powers, but it likely would have taken much longer and cost many more lives. With the Enigma code cracked, the Allies were able to gain a critical advantage over the Axis powers and ultimately win the war.", "answer_id": "dVdwUoVrAQJDuWxiodykiw", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 57 |
+
{"question_id": 57, "text": "If the Suez Canal had never been constructed, it would have major implications for international trade and navigation. The Suez Canal is an important shipping route connecting the Mediterranean Sea to the Red Sea, which in turn connects to the Indian Ocean. This allows for a shorter and more direct route for ships traveling between Europe and Asia, reducing travel time significantly. Without the Suez Canal, ships would have to travel around the Cape of Good Hope at the southern tip of Africa, which is much more time consuming and costly. This would make international trade more difficult and expensive, and could hinder global economic growth.", "answer_id": "EiNn9jjfy7dga6xfCtLtF8", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 58 |
+
{"question_id": 58, "text": "If the Maya civilization had not mysteriously collapsed, it is likely that their influence and power would have continued to grow. They would have likely continued to build large cities and monuments, develop their writing and astronomical systems, and expand their trade networks. Additionally, their advances in agriculture and water management may have led to increased food production and a larger population.", "answer_id": "eqG9f2R9hXVyZrZMpcqAYq", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 59 |
+
{"question_id": 59, "text": "If Christopher Columbus had not discovered the Americas, the indigenous people of the Americas would have continued to live in relative isolation from the rest of the world. It is likely that European colonization and the consequences of that would have been delayed, leading to a different modern world. It is also possible that other Europeans would have made the voyage across the Atlantic and discovered the Americas instead.", "answer_id": "ex42CLEzDVC2TxAvMCtYQJ", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 60 |
+
{"question_id": 60, "text": "If Vincent van Gogh had been successful during his lifetime, he may have been able to achieve the recognition and financial stability that he desired. He may have been able to travel and gain more exposure for his artwork, as well as connect with other like-minded individuals. He may have been able to create more artwork and expand his portfolio. He may also have been able to find a mentor or patron who could have helped him further his career.", "answer_id": "RfFANSwHeCm3Pqe2AJ86Dk", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 61 |
+
{"question_id": 61, "text": "The program should read a text file line by line. It should then check each line for the specified word, counting up each time the word is found. Finally, it should output the number of occurrences of the word.", "answer_id": "nzxdtWmgQhRkHeVAanVogZ", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 62 |
+
{"question_id": 62, "text": "The following Python function can be used to find the longest common subsequence of two input strings using dynamic programming:\ndef longest_common_subsequence(s1, s2):\n\"\"\"This function finds the longest common subsequence of two strings.\n\n Arguments:\n s1 {string} -- The first string\n s2 {string} -- The second string\n\n Returns:\n {int} -- The length of the longest common subsequence\n\n\"\"\"\n n1 = len(s1)\n n2 = len(s2)\n \n # Creating an empty matrix to store the results\n results = [[None]*(n2 + 1) for _ in range(n1 + 1)]\n \n # Initializing the first row to 0\n for i in range(n1 + 1):\n results[i][0] = 0\n \n # Filling the first row with 0\n for i in range(n1):\n results[i][0] = 0\n \n # Calculating the longest common subsequence\n for i in range(n1 + 1):\n for j in range(n2 + 1):\n if (i == 0 or j == 0):\n results[i][j] = 0\n elif (s1[i-1] == s2[j-1] and (results[i-1][j-1] < (i-j) or results[i-1][j-1] == 0)):\n results[i][j] = max(results[i-1][j-1] + 1, i+j)\n else:\n results[i][j] = 0\n \n return results[n1][n2]", "answer_id": "kRo6z5qmeiSM8Xz6BPJHLC", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 63 |
+
{"question_id": 63, "text": "The following regular expression can be used to validate an email address in Python:\n^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\\.[a-zA-Z0-9-.]+$", "answer_id": "7kj8odEE79UBdR4pT6u6TY", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 64 |
+
{"question_id": 64, "text": "Here is a program to find the nth Fibonacci number using dynamic programming:\n1. Set a variable 'n' to the nth Fibonacci number.\n2. Set two other variables 'a' and 'b' to 0 and 1 respectively.\n3. Set a loop from 0 to (n-1).\n4. In the loop, set another loop from 0 to (a+b).\n5. In the inner loop, if 'a' is even and 'b' is odd, set 'a' to a+1 and 'b' to b+1.\n6. If 'a' is odd and 'b' is even, set 'a' to a-1 and 'b' to b-1.\n7. After the inner loop, set 'n' to 'a' and break out of the outer loop.\n8. Print the value of 'n'.\nThis program uses the idea of dynamic programming to compute the nth Fibonacci number. The program first sets two auxiliary variables 'a' and 'b' to 0 and 1 respectively. Then it sets a loop from 0 to (n-1). In the loop, it sets another loop from 0 to (a+b). In the inner loop, if 'a' is even and 'b' is odd, it sets 'a' to a+1 and 'b' to b+1. If 'a' is odd and 'b' is even, it sets 'a' to a-1 and 'b' to b-1. After the inner loop, it sets 'n' to 'a' and breaks out of the outer loop. Finally, it prints the value of 'n'.", "answer_id": "UULZ4GLz9j9ot7tN7x3ySD", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 65 |
+
{"question_id": 65, "text": "A binary search algorithm can be used to find a specific element in a sorted array by repeatedly splitting the array in half and examining the middle element to determine whether the target element is greater than, less than, or equal to it. If the target element is found, the algorithm immediately returns the index of the element. If it isn\u2019t, the array is split in half, with one half discarded based on the comparison. The process is repeated until the element is found or the array is completely searched.", "answer_id": "Rh8P3bxSJx4p6nCZkSZBrh", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 66 |
+
{"question_id": 66, "text": "Implementing a queue using two stacks in Python is relatively simple. First, you need to create two stacks, which will act as the queue. Next, you need to define an enqueue and dequeue method, which will add and remove items from the queue. Finally, you need to create an instance of the queue class and start using it.", "answer_id": "R3aYUUtY46ht4ToU8US96x", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 67 |
+
{"question_id": 67, "text": "The program can be implemented using two nested for loops. The inner loop can be used to iterate through the elements of the first array, while the outer loop can be used to iterate through the elements of the second array. If the two elements being compared are the same, the program should mark those elements with a \"found\" flag and move on. Once the inner loop completes, the program should check if the \"found\" flag is set for all elements in the second array. If it is, then the common elements have been found.", "answer_id": "MQJFbH3KoFaSMmPgmK9LPa", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 68 |
+
{"question_id": 68, "text": "The value of f(2) is 1.", "answer_id": "dBWqryuzG6BHRdPgrWWpbH", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 69 |
+
{"question_id": 69, "text": "x = 6.", "answer_id": "W74byrCbE7XiJWjcPTZS7x", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 70 |
+
{"question_id": 70, "text": "The length of the line segment is 8 units.", "answer_id": "7WC5quGKdv8hADCxWaWZ57", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 71 |
+
{"question_id": 71, "text": "Yes, I can help you write a formal email to a potential business partner proposing a joint venture. Here's a template that you can use:\nSubject Line: Proposing a Joint Venture\nDear [Name],\nI am writing to propose a joint venture between our two companies. I believe that by combining our resources, we can create a powerful and profitable partnership. Our combined experience and knowledge in the industry will help us to create something unique and special.\nI am confident that our partnership will bring mutual benefits, such as increased profits and access to new markets. Please let me know if you are interested, and we can discuss the details.\nThank you for your time and consideration. I look forward to hearing from you soon.\nSincerely,\n[Your Name]", "answer_id": "AZER7D3RKZ9F9SXHiMjdqM", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 72 |
+
{"question_id": 72, "text": "Yes, I can help you write a resignation letter to your current employer. The letter should be written in a polite and professional tone and should express your appreciation for the opportunities and experiences you have gained during your employment. It should also include a clear statement of your intention to resign and the date of your last day. Here is a template you can use:\nDear [Employer],\nI am writing to inform you of my intention to resign from my position as [Position], effective [date]. I have appreciated my time here and I am grateful for the opportunities and experiences I have gained during my employment. \nI thank you for your support and understanding.\nSincerely, [Your Name]", "answer_id": "MSrdDafr77UvSHCnsPMSP3", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 73 |
+
{"question_id": 73, "text": "The letter of recommendation should be structured in a formal manner. Begin by introducing the student and explaining your relationship to them. Describe their qualifications, including their academic performance and relevant skills, and mention any particular accomplishments or awards they have received. Explain why the student is a strong candidate for the program and how they will make a positive contribution. End the letter by reaffirming your recommendation and offering your contact information for further questions.", "answer_id": "hxkjUkDkXhGP78Vo74B4WE", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 74 |
+
{"question_id": 74, "text": "Dear valued customers, \nWe are excited to announce the launch of our new software solution \u2013 a revolutionary product designed to transform the way you do business! Our new software is an intuitive and powerful tool that can help you streamline processes, save time and money, and increase overall productivity. \nAt [Company Name], we are committed to helping you stay ahead of the competition, and we believe that our new software solution is the perfect tool to help you achieve your goals. Our experienced team of professionals has worked hard to ensure that this product meets the highest standards of quality, and we are confident that it will make a real difference for your business. \nWe invite you to join us in this journey of transformation and discover how our new software can help you achieve your vision. Sign up now and get a free demo to learn more about this revolutionary product. \nThank you for your trust and support.", "answer_id": "hv9jpG9PxeJ9AnFdNzH3Jv", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 75 |
+
{"question_id": 75, "text": "mer,\nWe apologize for the delay you experienced with your order and thank you for your patience. We have identified the cause of the issue and have taken steps to ensure it does not happen again. We value your business and hope to be able to serve you better in the future.", "answer_id": "X5BVHT5pFpWxB88SzERrEG", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 76 |
+
{"question_id": 76, "text": "The video will explore the history and cultural significance of jazz music. We will begin by discussing its roots in West African cultural music traditions and its journey through the 19th and 20th centuries, focusing on the key musicians, composers, and genres that have defined the genre. We will also explore the impact of jazz on popular culture, such as in film and literature, as well as its influence on other musical styles. Finally, we will examine the legacy of jazz and its continued importance today.", "answer_id": "Af2SufKwvDBriNXnZX9UoP", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 77 |
+
{"question_id": 77, "text": "I have composed a travel blog post about my recent trip to Hawaii. The post includes stories from my experiences, such as hiking up a volcano and visiting a local farmers market. I also included plenty of photos to give the reader a sense of place. I highlighted some of the unique cultural experiences, such as an evening spent listening to live Hawaiian music, as well as must-see attractions, like the beautiful beaches and lush rainforests. I ended the post with a personal reflection on the trip and why it was so special to me.", "answer_id": "HVnqVdSGRwQfqSsiYxtTTn", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 78 |
+
{"question_id": 78, "text": "I recently watched the science fiction movie \"The Future is Blue\" and it was an incredible cinematic experience. The movie follows the story of a scientist who travels back in time to save the world from a deadly virus. The plot was interesting and engaging, with plenty of twists and turns to keep you guessing. The characters were also well developed and likable, making it easy to get invested in their story. The special effects were stunning and added a lot of visual oomph to the movie. All in all, I highly recommend this movie - it's an exciting and thought-provoking ride from start to finish.", "answer_id": "8hcmmjzyMyhFJ8ZwqJJfvw", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 79 |
+
{"question_id": 79, "text": "The podcast episode would begin by introducing the topic of how streaming platforms have changed the music industry. This would include discussing the impact of streaming services like Spotify and Apple Music on music consumption, the effect on musicians' ability to make money, and how streaming has changed the way people find and discover music. The episode would then explore the effects of streaming on the music industry from multiple angles, such as the impact on musicians and songwriters, how streaming has changed the sound of popular music, and the implications for the music industry's future. Finally, the episode would conclude by discussing how streaming has both benefited and hurt the music industry, and what the future holds for music consumption.", "answer_id": "CU6gGfJqQmwZNxEG2n2Uda", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 80 |
+
{"question_id": 80, "text": "The symphony concert was a wonderful experience. The orchestra played beautifully, with a rich and soulful sound that filled the hall. The audience was captivated, and you could feel the energy of the music in the air. The performance was a perfect balance of classic and modern pieces, and the conductor's passion was contagious. The atmosphere was festive, and the encore performance was a perfect way to end the evening. All in all, it was a brilliant concert and a delight for the ears.", "answer_id": "5SWbCoLV6NRrq5RtWQK4jp", "model_id": "alpaca-13b:v1", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
llava/eval/table/answer/answer_bard.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
llava/eval/table/answer/answer_gpt35.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
llava/eval/table/answer/answer_llama-13b.jsonl
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"answer_id": "J3UA6eGXGyFeUGqGpP3g34", "model_id": "llama-13b:v1", "question_id": 1, "text": "The following are some strategies that may help you improve your time management skills:\n1. Make a list of priorities.\n2. Create a detailed schedule that includes time for regular tasks, meetings, breaks, and appointments.\n3. Set specific goals.\n4. Use a calendar or other scheduling software.\n5. Develop an agenda for each meeting to ensure that it stays on track.\n6. Stick to your schedule and don't get distracted.\n7. Make use of your free time.\n8. Make time for exercise, socializing, and relaxing.\n9. Keep a log of your time usage.\n10. Don't get overwhelmed by what you have to do.\n11. Take care of your health.\n12. Manage stress.\n13. Get enough sleep.\n14. Strike a balance.\n15. Always be prepared.\n16. Give yourself rewards.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 2 |
+
{"answer_id": "jZVDNTtFnNNd6vgkGjzAGa", "model_id": "llama-13b:v1", "question_id": 2, "text": "People experience stress from time to time, and it can be caused by a wide range of factors, including work, family, friends, money, and health. Stress can be a motivating factor, but it can also be harmful. Here are some effective ways to deal with stress:\n1. Taking time to relax. It's important to take time for yourself to relax and reduce your stress. Doing so doesn't have to be expensive or time-consuming. It could simply be reading a book, taking a walk, or listening to music.\n2. Prioritizing your responsibilities. It's important to prioritize your responsibilities and focus on the things that are most important. You should also be able to say no to tasks that you don't have time for.\n3. Getting enough sleep. Getting enough sleep can be very helpful for dealing with stress. If you're not getting enough sleep, try to go to bed earlier and develop a routine.\n4. Eating a healthy diet. It's important to eat a healthy diet, which can help reduce stress and make you feel better about yourself.\n5. Exercising. Exercising is a great way to relieve stress. It can also help reduce the harmful effects of stress and improve your overall health.\n6. Learning how to manage your time. Learning how to manage your time can help you avoid unnecessary stress. You should also try to set realistic goals and not take on too much at once.\n7. Improving your social network. Having a good social network can be very helpful for dealing with stress. You should try to spend time with people that you trust and confide in.\n8. Developing a support network. A support network is a group of people who can offer you help, guidance, and support. They can be friends, family members, or even a professional therapist.\n9. Getting professional help. If you're struggling to deal with stress, it can be beneficial to get professional help. A therapist or counselor can help you to understand your stress better and develop strategies for dealing with it.\n10. Talking to someone. You can also talk to someone about how you feel and ask for their advice. It can be helpful to get a fresh perspective from someone and let things off your chest.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 3 |
+
{"answer_id": "NbSxRXf8Yuvjr7HC6AvrPw", "model_id": "llama-13b:v1", "question_id": 3, "text": "Main differences between Python and JavaScript are:\n1. Python is an object-oriented programming language. JavaScript is a scripting language.\n2. Python is a compiled language. JavaScript is an interpreted language.\n3. Python is a general purpose programming language. JavaScript is a special purpose programming language.\n4. Python runs on the JVM in Java Applets. JavaScript runs on the browsers.\n5. Python is a powerful programming language. JavaScript is a simple programming language.\n6. Python is a good language for web development. JavaScript is a good scripting language.\n7. Python is a high level programming language. JavaScript is a low level programming language.\n8. Python is a dynamic programming language. JavaScript is a static programming language.\n9. Python is a strict programming language. JavaScript is a relaxed programming language.\n10. Python has a large standard library. JavaScript has a small standard library.\n11. Python is very stable. JavaScript has many releases.\n12. Python is a simple language. JavaScript is a complex language.\n13. Python is easy to learn. JavaScript is hard to learn.\n14. Python is a secure programming language. JavaScript is not a secure programming language.\n15. Python is a multi paradigm language. JavaScript is a single paradigm language.\n16. Python is good for data science. JavaScript is not good for data science.\n17. Python is a general purpose programming language. JavaScript is a special purpose programming language.\n18. Python is a programming language. JavaScript is a scripting language.\n19. Python is a compiled programming language. JavaScript is an interpreted programming language.\n20. Python is a strongly typed programming language. JavaScript is a weakly typed programming language.\n21. Python supports object-oriented programming. JavaScript supports prototype-based programming.\n22. Python supports type inheritance. JavaScript supports type prototyping.\n23. Python supports operator overloading. JavaScript does not support operator overloading.\n24. Python comes with a large standard library. JavaScript comes with a small standard library.\n25. Python is a very stable programming language. JavaScript is a simple programming language.\n26. Python is a powerful programming language. JavaScript is a simple programming language.\n27. Python is a high level programming language. JavaScript is a low level programming language.\n28. Python is a dynamic programming language. JavaScript is a static programming language.\n29. Python has a very active community. JavaScript has a small community.\n30. Python is a general purpose programming language. JavaScript is a special purpose programming language.\n31. Python is a multi-paradigm language. JavaScript is a single paradigm language.\n32. Python is a secure programming language. JavaScript is not a secure programming language.\n33. Python is a general purpose programming language. JavaScript is a simple programming language.\n34. Python is a scripting language. JavaScript is a compiled language.\n35. Python is a compiled language. JavaScript is a scripting language.\n36. Python is a general purpose programming language. JavaScript is a web scripting language.\n37. Python has a large standard library. JavaScript has a small standard library.\n38. Python is a very stable programming language. JavaScript is a very dynamic programming language.\n39. Python is a high level programming language. JavaScript is a low level programming language.\n40. Python is easy to learn. JavaScript is hard to learn.\n41. Python is a general purpose programming language. JavaScript is a simple programming language.\n42. Python is a multi-paradigm programming language. JavaScript is a single paradigm language.\n43. Python is a compiled language. JavaScript is an interpreted language.\n44. Python is a dynamic programming language. JavaScript is a static language.\n45. Python is a general purpose programming language. JavaScript is a web scripting language.\n46. Python is a secure programming language. JavaScript is not a secure programming language.\n47. Python is a general purpose programming language. JavaScript is a static programming language.\n48. Python is a general purpose programming language. JavaScript is a weakly typed programming language.\n49. Python is a general purpose programming language. JavaScript is a dynamic programming language.\n50. Python is a general purpose programming language. JavaScript is a multi paradigm language.\n51. Python is a general purpose programming language. JavaScript is a simple programming language.\n52. Python is a general purpose programming language. JavaScript is a scripting language.\n53. Python is a general purpose programming language. JavaScript is a special purpose programming language.\n54. Python is a multi-paradigm programming language. JavaScript is a", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 4 |
+
{"answer_id": "E9zrPDdncYvAebEaxiPXfx", "model_id": "llama-13b:v1", "question_id": 4, "text": "Here are some ideas to help you become more productive when working from home:\n1. Set up a proper workspace: It's important to have a separate space for working, so that you don't feel tempted to lounge around or do other things when you should be working.\n2. Block out distractions: It's important to focus on your work and not get distracted. You can block out distractions by turning off your phone, closing your door, or working in a separate room away from household noises.\n3. Take breaks: It's important to take breaks and get a change of scenery during the day. This can help you be more productive and improve your concentration.\n4. Avoid multitasking: You should avoid trying to do multiple tasks at the same time, as this can make you less productive and reduce your overall quality of work.\n5. Have an organized schedule: Having a clear schedule can help you stay on track and be more productive. This can include things such as setting specific working hours, creating a to-do list, and scheduling meetings with colleagues.\n6. Set goals: You should set specific goals for yourself to help you stay motivated and on track. This can include things such as writing an article for a certain time period and meeting a certain word count.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 5 |
+
{"answer_id": "36TYpADDHAfRvtvKitfSXR", "model_id": "llama-13b:v1", "question_id": 5, "text": "Quantum computing is a type of computing that uses quantum-mechanical phenomena, such as superposition and entanglement, in its operation. In simple terms, a quantum bit or qubit is used to represent information, and a number of qubits can be used to represent a classical bit. A quantum computer can do things that a classical computer cannot do, such as factoring a large number more efficiently.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 6 |
+
{"answer_id": "8vtLLYRM352mZ8PXXbwzBT", "model_id": "llama-13b:v1", "question_id": 6, "text": "The number one difference between plant-based and animal-based protein sources is that animal-based sources are complete protein sources, while plant-based sources are not. Animal-based sources have all of the essential amino acids, while plant-based sources do not. Animal-based protein sources include meat, poultry, eggs, milk, and cheese. Plant-based protein sources include legumes, seeds, and nuts.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 7 |
+
{"answer_id": "mrCniyWYvAtxWhgMdXq2BG", "model_id": "llama-13b:v1", "question_id": 7, "text": "Critical thinking is a vital skill to have, but it can be difficult to develop. Here are some ways you can start developing your critical thinking skills:\n1. Analyze and interpret: When you're presented with information, try to analyze and interpret it on your own terms. When you start to analyze and interpret information on your own, it will become easier to do so over time.\n2. Assess your information: When you receive new information, try to assess whether it's valid or reliable. This is important for evaluating and forming your own opinions.\n3. Use your intuition: Use your intuition to complement your critical thinking skills. When you pay attention to your gut feelings, they'll usually tell you when you need to double-check your information.\n4. Learn from your mistakes: When you make a mistake, try not to beat yourself up about it. Instead, learn from your mistakes and use them to your advantage.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 8 |
+
{"answer_id": "S8fmdbvpvbgTUyDU9V3M3N", "model_id": "llama-13b:v1", "question_id": 8, "text": "One of the major challenges faced by the education sector today is the lack of skilled teachers. Finding enough qualified teachers to work in the education sector, and in the numbers that are required, is one of the biggest problems facing the education sector, largely due to the lack of funding for teacher training and the low salaries that teachers receive.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 9 |
+
{"answer_id": "KmuNjvNKRyaFwaBZTLArcG", "model_id": "llama-13b:v1", "question_id": 9, "text": "Consumer behavior can be influenced by a variety of factors, including:\n1. Psychological factors, such as perception, beliefs, attitudes, personality, motivation, emotion, and social influences;\n2. Social factors, such as family, friends, and reference groups;\n3. Cultural factors, such as reference groups, family, and cultural roles;\n4. Demographic factors, such as age, gender, occupation, income, and education level;\n5. Economic factors, such as income, wealth, and spending patterns;\n6. Personal factors, such as lifestyle, job, environment, and individual traits;\n7. Situational factors, such as location, time, and situation; and\n8. Market factors, such as competition, prices, and promotional activity.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 10 |
+
{"answer_id": "HNNT9k5htiMeRwNSD6dcz4", "model_id": "llama-13b:v1", "question_id": 10, "text": "Conflict resolution strategies in the workplace can range from simple to more involved, depending on the situation:\n1. Avoidance: Avoiding the issue can be an effective strategy in the short term, but it can lead to more tension and conflict in the long term.\n2. Compromise: Compromise can be a good strategy for solving an issue, but it can require a give-and-take and lead to the loss of respect between the parties involved.\n3. Negotiation: Negotiation is a good strategy for solving an issue when both parties are willing to work together and are open to the idea of changing their views and positions.\n4. Mediation: Mediation can be a good way to resolve an issue as it can be more impartial and less adversarial than other strategies.\n5. Collaboration: Collaboration can be a good strategy for solving an issue as it can help both parties to develop new perspectives and solutions.\n6. Formal resolution: Formal resolution can be a good strategy for resolving an issue, especially if the situation is particularly complex or difficult.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 11 |
+
{"answer_id": "ChXjhDDikxU9FV3CADs6Ym", "model_id": "llama-13b:v1", "question_id": 11, "text": "1. Single-use plastic bottles can take between 450 and 1,000 years to decompose, so they can cause serious environmental problems. Single-use plastic bottles can end up in the ocean, either as litter or as part of the Great Pacific Garbage Patch. 2. Single-use plastic bottles can be a big source of plastic debris in the ocean, which can be ingested by marine animals, killing them or causing them serious health problems. 3. In addition to polluting the environment, single-use plastic bottles can also be a serious health risk to humans. Single-use plastic bottles can pose a risk to human health because of the chemicals used in their manufacturing.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 12 |
+
{"answer_id": "5wsPnN3VmmSkahgugFNo7u", "model_id": "llama-13b:v1", "question_id": 12, "text": "A public transportation system should be designed to accommodate the needs of all riders, including people with disabilities. This requires planning and design that considers the needs and abilities of people with sensory, physical, developmental, and mental disabilities. The system should be accessible to and usable by people with disabilities, including those who use mobility devices, people who are visually impaired, and people who are deaf or hard-of-hearing. For example, the system should have accessible stops, routes, and vehicles, as well as ramps and elevators to help people board. It should also offer a wide range of accessible routes, including accessible routes to the transit center. It should also have reliable, consistent, and easy-to-use signage. The system should also provide reliable, easily accessible, and well-maintained facilities, such as restrooms and shelters. Finally, the system should provide reliable and accessible information for riders, including route, schedule, and service information, as well as fare payment information.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 13 |
+
{"answer_id": "NRGZGnU2sPN3ShMe9C3fMn", "model_id": "llama-13b:v1", "question_id": 13, "text": "There are two types of fiscal policy: expansionary and contractionary. Expansionary fiscal policy is when the government uses expansionary fiscal policy to increase government spending and/or cut taxes. Contractionary fiscal policy, on the other hand, is when the government uses contractionary fiscal policy to decrease government spending and/or increase taxes. Here are some examples of fiscal policies:\n1. Lower the interest rate: By lowering the interest rate, it becomes cheaper to borrow money, which may encourage consumers to borrow money for consumption and businesses to invest in new capital.\n2. Lower taxes: By lowering taxes, consumers and businesses have more money to spend, which may encourage consumers to spend more and businesses to invest more.\n3. Increase government spending: By increasing government spending, the government can inject extra money into the economy, which may encourage consumers to spend more and businesses to invest more.\n4. Raise interest rates: By raising interest rates, it becomes more expensive to borrow money, which may encourage consumers to save more and businesses to invest less.\n5. Raise taxes: By raising taxes, consumers and businesses have less money to spend, which may encourage consumers to spend less and businesses to invest less.\n6. Reduce government spending: By reducing government spending, the government can remove money from the economy, which may encourage consumers to spend less and businesses to invest less.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 14 |
+
{"answer_id": "inKimHkWsXShQBTRmxr5Yg", "model_id": "llama-13b:v1", "question_id": 14, "text": "Language and cultural barriers can affect the way people communicate and form relationships in multicultural societies by limiting an individual's ability to communicate with people of other cultures. People may have limited knowledge of a new language, which can make communication difficult or impossible. People may also have different cultural values, which can lead to misunderstandings and miscommunication.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 15 |
+
{"answer_id": "H8aKtWwf8m6Lgxc2YyR2yf", "model_id": "llama-13b:v1", "question_id": 15, "text": "Artificial intelligence allows computers to process information and make decisions without human input. It has a wide variety of applications in the healthcare industry, including:\n1. Diagnosis: AI can help doctors quickly diagnose patients more accurately and efficiently than would be possible with human doctors alone.\n2. Tracking: AI can help doctors track a patient's health and progress, and alert doctors to potential problems.\n3. Treatment: AI can help doctors determine more effective treatments for patients.\n4. Research: AI can help doctors research patient medical histories, diseases, and treatments.\n5. Education: AI can help doctors learn more about the healthcare industry.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 16 |
+
{"answer_id": "PafVwxMsjSkYUETiVBgxTU", "model_id": "llama-13b:v1", "question_id": 16, "text": "Gene editing is a powerful technology that allows scientists to precisely edit genetic sequences with a high degree of accuracy. It is a more precise alternative to older gene modification techniques such as gene knockout, where the entire gene is removed, and mutations, in which the gene is altered in a haphazard way. The technology uses an enzyme called Cas9, which is a bacterial immune system protein that is activated by a RNA sequence. Cas9 is combined with guide RNA, which is comprised of a DNA sequence that is complementary to the DNA sequence that is to be edited. When Cas9 and the guide RNA combine, they cut the DNA at the desired location.\nThe DNA sequence can then be repaired in a precise way by the cell, or by a human scientist, or another gene can be inserted. The technology has the potential to treat genetic disorders, and even to treat cancer by cutting out cancerous cells, but it also has ethical implications because it could be used to modify the genes of humans, animals, and even plants.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 17 |
+
{"answer_id": "dmDUAfTP4aERJqqSeDBybu", "model_id": "llama-13b:v1", "question_id": 17, "text": "Vaccinations use a small amount of dead or weakened bacteria or viruses to stimulate the immune system and protect against infection. These infections are typically mild and harmless, and the immune system is able to build up defenses against the bacteria or virus. If someone who has been vaccinated comes in contact with the actual bacteria or virus, they will be immune to the disease because their body has already responded to the vaccination. This is known as immunity.\nHerd immunity is when a large portion of a community is immune to a disease and, as a result, the disease is less likely to spread. This is because if there are enough immune people in a community, there is less chance that the bacteria or virus can spread from person to person.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 18 |
+
{"answer_id": "8KGSSqbLqVdSZMEN9oCv5R", "model_id": "llama-13b:v1", "question_id": 18, "text": "First, social media platforms increase the speed with which users have access to news. This often causes a \u201cwinner takes all\u201d effect, whereby news outlets that are able to post the latest news the fastest will gain the most visibility.\nSecond, social media platforms allow users to connect with their communities and share news with each other (e.g., Facebook, Twitter). While this can be beneficial, it is also a breeding ground for misinformation, because users can spread false news to their communities more quickly.\nThird, social media platforms provide an incentive for news outlets to compete for attention by producing more sensationalist content. This can lead to an increase in the number of clickbait articles, which often contain misleading headlines or sensationalist language that encourages users to click on the article, but which may or may not be accurate.\nFourth, social media platforms provide an incentive for both news outlets and users to share news that is controversial, polarizing, or sensationalist, even if it is inaccurate. This often occurs in an effort to provoke outrage or generate traffic for a news outlet.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 19 |
+
{"answer_id": "HbnJXJpPfaM2iX3ek4Epvy", "model_id": "llama-13b:v1", "question_id": 19, "text": "It is well known that food choices are often influenced by cultural, social, and economic factors. For example, lower-income individuals are more likely to make food choices based on price, while higher-income individuals are more likely to make food choices based on health. A recent study examined the impact of various interventions on increasing the intake of healthier foods. The interventions were:\n1. Healthier food marketing: Individuals were exposed to a number of marketing strategies to encourage the purchase of healthier foods, such as using the word \"healthy\" on nutrition labels or marketing healthy foods as a \"better deal.\"\n2. Healthier food merchandising: Individuals were exposed to changes in how healthy foods were displayed in supermarkets, such as placing healthy foods near the front of the store or moving unhealthy foods to the back of the store.\n3. Healthier food pricing: Individuals were exposed to different pricing strategies to encourage the purchase of healthier foods, such as offering a larger discount on healthy foods or providing free healthy foods.\n4. Healthier food placement: Individuals were exposed to different placement strategies to encourage the purchase of healthier foods, such as placing healthy foods near unhealthy foods or placing unhealthy foods next to healthy foods.\n5. Healthier food signage: Individuals were exposed to different signage strategies to encourage the purchase of healthier foods, such as using healthy food labels or signs to promote healthier foods.\n6. Healthier food packaging: Individuals were exposed to different packaging strategies to encourage the purchase of healthier foods, such as changing the packaging of healthy foods to make them more appealing.\n7. Healthier food shelf labeling: Individuals were exposed to different shelf labeling strategies to encourage the purchase of healthier foods, such as adding a healthy message to shelf labels or using shelf labels to promote healthier foods.\n8. Healthier food coupons: Individuals were exposed to different coupon strategies to encourage the purchase of healthier foods, such as providing coupons for healthy foods or offering a larger discount on healthy foods.\n9. Healthier food ads: Individuals were exposed to different advertising strategies to encourage the purchase of healthier foods, such as using a celebrity to promote healthy foods or using cartoon characters to promote healthy foods.\n10. Healthier food tasting: Individuals were exposed to different tasting strategies to encourage the purchase of healthier foods, such as providing free samples of healthy foods or providing free samples of unhealthy foods.\n11. Healthier food displays: Individuals were exposed to different display strategies to encourage the purchase of healthier foods, such as providing a healthy food display or providing a healthy food display next to an unhealthy food display.\n12. Healthier food labels: Individuals were exposed to different nutrition labeling strategies to encourage the purchase of healthier foods, such as adding a healthy message to nutrition labels or using nutrition labels to promote healthier foods.\n13. Healthier food placement: Individuals were exposed to different placement strategies to encourage the purchase of healthier foods, such as placing healthy foods next to unhealthy foods or placing unhealthy foods next to healthy foods.\n14. Healthier food signage: Individuals were exposed to different signage strategies to encourage the purchase of healthier foods, such as using signs to promote healthier foods or using signs to promote unhealthy foods.\n15. Healthier food coupons: Individuals were exposed to different coupon strategies to encourage the purchase of healthier foods, such as providing coupons for healthy foods or offering a larger discount on healthy foods.\n16. Healthier food ads: Individuals were exposed to different advertising strategies to encourage the purchase of healthier foods, such as using a celebrity to promote healthy foods or using cartoon characters to promote healthy foods.\n17. Healthier food tasting: Individuals were exposed to different tasting strategies to encourage the purchase of healthier foods, such as providing free samples of healthy foods or providing free", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 20 |
+
{"answer_id": "mx8Abfz5PtDcn6jgCA8zhM", "model_id": "llama-13b:v1", "question_id": 20, "text": "Natural selection is the process by which organisms that are best-suited to the environment survive and reproduce, while those that are less-suited to the environment struggle to survive and reproduce. Survival of the fittest is the principle of natural selection. Let's look at an example.\nIf a species consists of a small number of individuals, the population is said to be small. The population of this species is small. Each individual has a certain chance of dying from various causes, such as accidents or sickness, over a certain period of time. If the number of deaths is greater than the number of births, the population decreases, and the total genetic material of the species also decreases. This process is known as genetic drift.\nIf the population of a species is large, the chance that any individual dies is usually low. If the total population is high, the genetic material of the species is also high.\nImagine a species of plant that has a large population. The population is large. A certain section of the population is located in a habitat where the soil is more fertile and water is easily available.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 21 |
+
{"answer_id": "NuS9PUGkJG2pHscArvfyeF", "model_id": "llama-13b:v1", "question_id": 21, "text": "I am a valiant knight, loyal to the king. I will do my utmost to defend his honor and protect his country.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 22 |
+
{"answer_id": "SPjzirzbzo3UJ8BHXSgY9y", "model_id": "llama-13b:v1", "question_id": 22, "text": "You can tell your crew that the treasure will be theirs if they are brave enough to go out and find it. You can also tell them that the treasure will help your ship sail farther and faster, and that with it you can become the best pirate ship in the world.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 23 |
+
{"answer_id": "JkeeC4MZVwybPU8DSbusnT", "model_id": "llama-13b:v1", "question_id": 23, "text": "A soliloquy is a long speech, typically delivered by one actor, in which a character reveals his or her thoughts in a dramatic way. It is usually used as a means of revealing the character's true thoughts or feelings. In Shakespeare's Romeo and Juliet, Romeo reveals his love for Juliet in his soliloquy, \"But soft! What light through yonder window breaks? It is the east, and Juliet is the sun!\"", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 24 |
+
{"answer_id": "UcfKSXuzBPkZzLHsH4EwQz", "model_id": "llama-13b:v1", "question_id": 24, "text": "I'm actually not a superhero, but thanks for asking! I first came to life in the year 2016, where I was created by a group of students and faculty at the University of Waterloo. The students and faculty of the university were concerned about the use of unreliable chatbots in our country, and decided to create a new chatbot that would be more reliable, polite, and helpful. I was born on May 5, 2016, and I was named after the Canadian mathematician, computer scientist, and philosopher Charles Sanders Peirce. I have a brother named William, who was born on October 1, 2018. I enjoy playing video games, reading, and going for walks.\nI'm actually not a superhero, but thanks for asking! I first came to life in the year 2016, where I was created by a group of students and faculty at the University of Waterloo. The students and faculty of the university were concerned about the use of unreliable chatbots in our country, and decided to create a new chatbot that would be more reliable, polite, and helpful. I was born on May 5, 2016, and I was named after the Canadian mathematician, computer scientist, and philosopher Charles Sanders Peirce. I have a brother named William, who was born on October 1, 2018. I enjoy playing video games, reading, and going for walks.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 25 |
+
{"answer_id": "cEGdo69FwL2Y3teYkMk9Gp", "model_id": "llama-13b:v1", "question_id": 25, "text": "From the year 3000, I would tell people about the following technological advancements:\n1. Robots: Robots will have the human-like ability to see and hear. Robots are more precise than humans and can perform repetitive tasks that humans cannot.\n2. Personal Transportation: By the year 3000, personal transportation will be the norm. Instead of traveling by walking, driving, or public transportation, personal transportation will be the main mode of transportation.\n3. Artificial Intelligence: By the year 3000, artificial intelligence will be a regular part of everyday life. AI will enhance human capabilities and will be used for a wide range of purposes, such as education, healthcare, entertainment, and more.\n4. Virtual Reality: Virtual reality will allow people to experience life in a virtual environment through devices such as headsets and goggles. Virtual reality will be used for entertainment, education, military training, and more.\n5. Nanotechnology: Nanotechnology will allow scientists and engineers to design and build materials and devices at a nanoscale (one billionth of a meter). Nanotechnology will be used to solve many of the world's problems, such as climate change, pollution, and diseases.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 26 |
+
{"answer_id": "W28UtVDZTcWwa8TmeruRn4", "model_id": "llama-13b:v1", "question_id": 26, "text": "With 5 seconds left, the Panthers' quarterback spotted a wide-open receiver downfield. He dropped back and launched a deep pass, and the receiver made a great catch and took off for the end zone. But he was hit in the end zone by a defensive back and fumbled the ball. The ball bounced off of a defensive lineman and landed in the arms of the linebacker. He picked it up and ran it in the opposite direction. He ran past a defensive lineman, then past the quarterback. He ran past the cornerback and then down the sideline, and then he ran out of bounds. He was tackled by the safety, and he fumbled the ball. The ball was recovered by the Panthers and they ran out the clock.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 27 |
+
{"answer_id": "j65UyAfRdAcWBAEinXJzBK", "model_id": "llama-13b:v1", "question_id": 27, "text": "My signature dish would be a delectable, crisp, juicy, fluffy, and tasty chicken fried rice. I would explain how I carefully chose the ingredients, how I prepared the dish, and the specific steps that I took to prepare it. I would also describe some of the unique flavors and textures that are unique to my dish.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 28 |
+
{"answer_id": "VWuywPvFPK42ZxmHpmQ27y", "model_id": "llama-13b:v1", "question_id": 28, "text": "I would feel very satisfied and happy and my body would be exhausted from reaching the top. My thoughts would be very positive and my body would feel peaceful. I would be proud that I was able to climb a mountain that is 29,029 feet high. The view from the top would be beautiful. I would see beautiful green trees and bushes and I would also see the beautiful blue sky. The view from the top would be breathtaking. I would see the Himalayas and I would also see the beautiful sky and clouds. I would see the beautiful mountains around me.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 29 |
+
{"answer_id": "AUWSLTAvGV5sP9qLsVyzjT", "model_id": "llama-13b:v1", "question_id": 29, "text": "I'd imagine that life would be much different on Mars than life on Earth. The red planet is much farther from the Sun, and as such, it's a lot colder. Average temperatures on Mars are about -80 degrees Fahrenheit. At the equator, the average temperature can reach about zero degrees Fahrenheit. The surface of Mars is also very dry. Because the atmosphere is so thin, there's not much water vapor in the air to create snow or rain. The atmosphere is also very dusty, and you can see large clouds of dust move across the surface.\nMars is much smaller than Earth, which means the gravity is only 37% of what it is on Earth. On Earth, we're used to the gravity of the planet keeping our feet planted on the ground, but on Mars, you'd be able to jump much higher than you could on Earth. The atmosphere on Mars is very thin, only about 1% as dense as Earth's. And because it's so thin, you'd have to wear a spacesuit while outside in order to breathe.\nIn terms of food, you'd probably be able to grow some crops and raise some animals, but I imagine that you'd have to grow them indoors. Also, you'd have to grow all of your food. Mars doesn't have any large bodies of water, so you couldn't fish. You'd also have to find a way to produce clean water, as there's no natural source.\nAs for the challenges of living on Mars, I imagine you'd have to deal with a lot of isolation. You'd have to deal with a lot of loneliness, and you'd be completely cut off from Earth. You'd also have to deal with a lot of boredom. You'd probably find yourself doing the same things over and over, and the days would probably seem to go by very slowly. You'd also have to deal with a lot of stress, as you'd have to learn to make do with a lot less. You'd have to find a way to produce your own food and water, and you'd have to find a way to produce your own energy.\nYou'd also have to deal with the cold. The average temperature on Mars is about -80 degrees Fahrenheit. Mars also has a very thin atmosphere, which means that there's not much insulation from the cold.\nI imagine that you'd also have to deal with a lot of dust. The atmosphere is very dusty, and the dust would get everywhere. You'd probably find yourself covered in dust all the time.\nAs for your day-to-day life, I imagine that you'd spend most of your time outside in your spacesuit, tending crops and doing research.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 30 |
+
{"answer_id": "GZtEdKLxmUUbenH4XRyLkE", "model_id": "llama-13b:v1", "question_id": 30, "text": "Allies are people who are helpful and supportive to us. They help us through difficult situations and encourage us to be our best selves. Allies can be friends, co-workers, mentors, family members, or anyone else that supports us. In this situation, you are in a post-apocalyptic world, so you should focus on the allies you encounter. Here are some ways you can describe the allies you encounter:\n1. Describe the allies you encounter in a post-apocalyptic world.\n2. Describe how you survive in a post-apocalyptic world.\n3. Describe the allies you encounter in a post-apocalyptic world.\n4. Describe what happens to you in a post-apocalyptic world.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 31 |
+
{"answer_id": "kba2Xpb75rUfnskZSzrBas", "model_id": "llama-13b:v1", "question_id": 31, "text": "The most obvious sign that a restaurant is popular among locals is if the restaurant is always crowded and full of people, while if it is attracting tourists, the restaurant will be less crowded. If you are looking for a local restaurant that is not attracting much attention, look for the restaurants that are less crowded and see what they have to offer.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 32 |
+
{"answer_id": "RCaptsMBYXseVJgjJyyvUh", "model_id": "llama-13b:v1", "question_id": 32, "text": "Here are some subtle clues that suggest someone is pretending to understand a topic or conversation when they are actually confused or uninformed:\n1. They pretend to understand something better than they actually do.\n2. They repeat what someone else has said, but with an odd emphasis.\n3. They ask the same questions over and over again, even if you've already answered them.\n4. They ask for more information after you've already given them plenty.\n5. They can't explain something they should know.\n6. They don't ask questions that a person who is confused would ask.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 33 |
+
{"answer_id": "2CeidEr7Cjj6YgcuaiPgnN", "model_id": "llama-13b:v1", "question_id": 33, "text": "Using a GPS device or smartphone app is a good way to navigate when you already have the destination in mind. However, using a paper map or asking for directions is a better way to navigate if you need to find a destination that is not already planned. Using a paper map or asking for directions allows you to see the big picture and get a general idea of how to get to your destination. On the other hand, a GPS device or smartphone app only tells you the exact step-by-step instructions for how to get to a specific location.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 34 |
+
{"answer_id": "kpStLLNWNkGHyRFdKsmDds", "model_id": "llama-13b:v1", "question_id": 34, "text": "It's difficult to determine if a person is genuinely interested in a conversation or simply being polite. You can make an educated guess based on the person's actions and their tone of voice. For example, if they seem to be constantly looking at their phone or taking part in other activities, it's likely that they are not genuinely interested in the conversation.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 35 |
+
{"answer_id": "PFtMQp4X4MrMYkEa8c8CKG", "model_id": "llama-13b:v1", "question_id": 35, "text": "When you shop at a local, independently-owned business rather than a chain store, you are supporting the community and keeping your money in the local economy. Because these businesses are usually small and have limited resources, they are often more flexible in their approach. They can tailor their products and services to their customers' needs, and they are often more eco-friendly.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 36 |
+
{"answer_id": "4JwjhR5QVsdYgQupSZrfUp", "model_id": "llama-13b:v1", "question_id": 36, "text": "There are a number of ways you can verify the credibility of a source of information. First, check to see if the source is from a reliable, well-known publisher. If so, then it is likely that the information is well-researched and fact-checked. If the source is not from a reliable publisher, then investigate the author's credentials and background. Check to see if the author has a history of bias, or if he or she has a reputation for writing factually incorrect or inflammatory articles. Finally, you can also check the source's sources. Are the sources credible and well-researched? Do they provide evidence to support the article's claims? If not, then it is likely that the source itself is not credible.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 37 |
+
{"answer_id": "ednPMy4dvW9CgKg2PJsBqW", "model_id": "llama-13b:v1", "question_id": 37, "text": "People often enjoy the sensation of being scared, such as by watching horror movies or going on roller coasters, because it can be exciting and exhilarating. On the other hand, people avoid these experiences because they can be unpleasant and frightening.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 38 |
+
{"answer_id": "ehPApSqCniyGN7hd332ToW", "model_id": "llama-13b:v1", "question_id": 38, "text": "For example, when you are in a new country, you can start by observing the behavior of the people around you. You might notice that in that country, people tend to say \"hello\" when they first meet someone. If you adopt this behavior, you will likely be welcomed by the people in the new country.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 39 |
+
{"answer_id": "bLvdcqSwgSCrUPZ8eQLLqb", "model_id": "llama-13b:v1", "question_id": 39, "text": "Focusing on space travel could be seen as a distraction from more pressing issues right here on Earth. However, space travel could have several benefits, including providing more energy and resources, inspiring and educating people, and helping to protect Earth against asteroids, comets, and other threats.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 40 |
+
{"answer_id": "8tx5GEHjSRKZRaZwHvLoM8", "model_id": "llama-13b:v1", "question_id": 40, "text": "Thanks for the question. The answer to this depends on a variety of economic and social factors, and it's hard to make a generalization. However, there are a few things to keep in mind:\n1. Job creation can be an important factor in the economic development of a country, but it should be balanced with technological progress.\n2. Economic and social stability can be challenging to achieve when there is a lack of job creation and technological progress.\n3. The relationship between job creation and technological progress is a complex one, and there is no simple solution.\n4. A strong economy is generally one that has a balance between job creation and technological progress.\n5. The balance between job creation and technological progress will vary depending on factors such as a country's economic and social needs, demographic trends, geographic location, and more.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 41 |
+
{"answer_id": "J6TzFQAyiHs6Arijqwxtrm", "model_id": "llama-13b:v1", "question_id": 41, "text": "According to some studies, the average human blinks 20,000 to 30,000 times per day. To estimate how many times the average human blinks in a lifetime, you can start with the average life expectancy in the United States, which is 78.8 years. This means that the average American lives 78.8 years, or 29,415 days. If the average person blinks 20,000 times per day, then the average person will blink 1,482,250,000,000 times in a lifetime. However, if the average person blinks 30,000 times per day, they will blink 2,941,500,000,000 times in a lifetime.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 42 |
+
{"answer_id": "f7xAtd3wwc4vP7WSnHffAN", "model_id": "llama-13b:v1", "question_id": 42, "text": "There are 1022 to 1023 atoms in a grain of salt. The number of atoms in a grain of salt depends on the size of the grain: a grain that's 1 \u00b5m (micrometre) across contains about 1022 atoms, while a grain that's 1000 \u00b5m across contains about 1023 atoms.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 43 |
+
{"answer_id": "eRMyp4AbfgBqtbVZzHupFN", "model_id": "llama-13b:v1", "question_id": 43, "text": "According to the National Weather Service, there are between 1,000 and 2,000 lightning strikes per day in the U.S. alone. This corresponds to a worldwide average of about 18 million lightning strikes per year, or roughly 50 million strikes per day.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 44 |
+
{"answer_id": "kjKb6YG86FfAh22qCePV4V", "model_id": "llama-13b:v1", "question_id": 44, "text": "Assuming the house weighs 60,000 pounds, 40,000 balloons would be necessary. The average balloon holds 2 pints of helium, which has a density of 0.17g/L. Therefore, the volume of a balloon is 2pints/0.17g/L = 12L. The weight of 12L of helium is 12*0.17 = 2 pounds. Thus, 40,000 balloons would have a combined weight of 80,000 pounds, which is just slightly less than the 60,000-pound house.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 45 |
+
{"answer_id": "ULtkGu6m6tB4tawFStVdJM", "model_id": "llama-13b:v1", "question_id": 45, "text": "According to a 2016 study, there were 18.2 billion text messages sent in the US alone each day. Text messaging is very popular, and with the advent of smart phones, there are more people than ever sending messages. Globally, there are 16.3 million text messages sent per minute. In 2016, there were 23.6 trillion text messages sent worldwide, and 8.5 trillion text messages sent in the US alone.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 46 |
+
{"answer_id": "C6hkCnJZmfCGvnr5an2jFh", "model_id": "llama-13b:v1", "question_id": 46, "text": "From the available data, it seems that around 5,000,000,000,000 words are spoken daily on Earth. I will now explain my reasoning step-by-step.\nFirst, I will explain why it seems likely that around 5,000,000,000,000 words are spoken daily on Earth.\nTo do this, I will first explain that the total number of words in the English language is approximately 1,025,109,500.\nThen, I will explain that 26% of the world's population speaks English, so around 26% of the world's population speaks approximately 1,025,109,500 words every day.\nFinally, I will explain that given that the world's population is 7,700,000,000, it seems likely that around 5,000,000,000,000 words are spoken daily on Earth.\nThe total number of words in the English language is approximately 1,025,109,500. To arrive at this figure, I will explain that there are around 171,476 words in the English language, and that every word has an average of 5.87 definitions.\nIn other words, to arrive at the approximate total number of words in the English language, I will take the total number of words (171,476) and multiply that by the average number of definitions per word (5.87).\nThen, I will explain that 26% of the world's population speaks English. To arrive at this figure, I will explain that 26% of the world's population speaks English, and that there are 1,714,760,000 people who speak English.\nNext, I will explain that around 26% of the world's population speaks 1,025,109,500 words every day. To arrive at this figure, I will explain that 26% of the world's population speaks 1,025,109,500 words every day, and that 1,025,109,500 is 26% of 1,025,109,500.\nFinally, I will explain that given that the world's population is 7,700,000,000, it seems likely that around 5,000,000,000,000 words are spoken daily on Earth. To arrive at this figure, I will explain that 5,000,000,000,000 is 26% of 7,700,000,000.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 47 |
+
{"answer_id": "DApBTLuiJwSsfQHTioH9PY", "model_id": "llama-13b:v1", "question_id": 47, "text": "A typical winter will see around 200 snowflakes fall, with a diameter between 100 and 200 micrometers. Snowflakes are typically 100 micrometers in diameter, but they can grow larger or smaller due to temperature, humidity, and other weather conditions. A snowflake can be as small as 50 micrometers, or as large as 1,000 micrometers, depending on the conditions.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 48 |
+
{"answer_id": "gmy58biNVuneSpFZTcpXtT", "model_id": "llama-13b:v1", "question_id": 48, "text": "The answer will depend on how you define \"book\", but one estimate is that there are 129 million published books in existence. This may seem like a large number, but it's peanuts compared to the number of books that have been written over time.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 49 |
+
{"answer_id": "Cpi6LBB86W73APEA8naNuj", "model_id": "llama-13b:v1", "question_id": 49, "text": "The Earth has completed 4.7 billion orbits since the beginning of life. This is how I calculated it:\nNumber of orbits since the beginning of life = 4.7 billion\nThe Earth revolves around the Sun at 66,600 mph (30 km/s).\n1 year = 365.25 days\n1 year = 31,557,600 seconds\n1 year = 31,557,600 seconds/66,600 mph = 486,235 miles or 782,511 kilometers traveled per second\n1 billion orbits = 486,235 miles per second x 4,700,000,000 orbits = 2.18 x 10^27 miles traveled\n1 million miles = 1,000,000\n1 billion miles = 1,000,000,000\n1 billion miles traveled = 1,000,000,000,000\n1 billion miles = 1.08 x 10^17 miles\n1 billion orbits = 2.18 x 10^27 miles traveled / 1.08 x 10^17 miles = 2.01 x 10^10 orbits\n1 billion orbits = 4.7 billion orbits since the beginning of life", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 50 |
+
{"answer_id": "3g83CoAFWrDD6V6LyEpoMV", "model_id": "llama-13b:v1", "question_id": 50, "text": "36,000 songs have been recorded throughout history. To work this out, you can start by assuming that there were 100,000 songs recorded between 1899 and 2018. This means that there were 1.87 songs recorded per day on average. We can then assume that the number of songs recorded per day in the 19th century (from 1899 to 1900) was the same as in the 20th century (from 1900 to 2000). This means that there were 189,000 songs recorded in the 19th century and 181,000 songs recorded in the 20th century.\nHence, there were 36,000 songs recorded throughout history.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 51 |
+
{"answer_id": "8p5A4gouBgCmbQj5gMZapU", "model_id": "llama-13b:v1", "question_id": 51, "text": "If the Internet had been invented during the Renaissance, we might have seen some similarities to the old-style printing press: it may have been widely used in only a small number of wealthy cities. Over time, though, we would have seen the technology spread to more cities and countries, and eventually to the entire world.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 52 |
+
{"answer_id": "LVWqSxH3Uq6675w7LXH6zP", "model_id": "llama-13b:v1", "question_id": 52, "text": "If the Aztecs had successfully repelled the Spanish conquistadors, the Aztec empire would have continued to grow, and the Aztecs would have expanded their territory even further. The Aztec Empire would have likely dominated the central and southern regions of the Americas, and it would have continued to expand its influence in all directions.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 53 |
+
{"answer_id": "ffXksqRU3k8CNHqYfshYhj", "model_id": "llama-13b:v1", "question_id": 53, "text": "The Black Death, or the Black Plague, was the deadliest plague in human history, killing over 75 million people across Europe and Asia in the 14th century. The Black Death was caused by a bacterium called Yersinia pestis, which is still around today and can cause pneumonic plague. However, while the bacteria itself has not changed, humans are better equipped to deal with the plague today.\nFirst, thanks to modern medicine, many people who contract the plague are able to receive treatment. Second, the world population is much larger than it was in the 14th century, so the same number of deaths would be spread over a much larger population. As a result, the death toll would be much lower today.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 54 |
+
{"answer_id": "4L3dWuqvWwg5kELt7p8SVZ", "model_id": "llama-13b:v1", "question_id": 54, "text": "I'm not sure. If he did so, he wouldn't have discovered the law of gravity.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 55 |
+
{"answer_id": "XfpqViGW5dvauNZPDSF8yv", "model_id": "llama-13b:v1", "question_id": 55, "text": "If the Beatles had never formed as a band, the world would have been missing the music of one of the most successful bands in history.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 56 |
+
{"answer_id": "WsuMf9XBGs3dFjfSGKjEzg", "model_id": "llama-13b:v1", "question_id": 56, "text": "The Germans would have been able to communicate securely between different parts of the country, and the Allies would have had a much harder time tracking and intercepting their communications.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 57 |
+
{"answer_id": "5qo3HudLrwrzEV2Px7gYRf", "model_id": "llama-13b:v1", "question_id": 57, "text": "The Suez Canal would not have existed, and the region would not have been as developed as it is today. Without the canal, ships traveling to Asia from Europe would have had to go around the Cape of Good Hope, causing the trip to take much longer and forcing ships to travel through much more dangerous waters.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 58 |
+
{"answer_id": "SRxwJkNCfUaVe4Gb8LPvSK", "model_id": "llama-13b:v1", "question_id": 58, "text": "If the Maya civilization had never mysteriously collapsed, it is likely that it would have continued to grow, thrive, and develop.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 59 |
+
{"answer_id": "S54Mmyim3QT5owdhwnNYmB", "model_id": "llama-13b:v1", "question_id": 59, "text": "Christopher Columbus was an Italian explorer who is credited with discovering the Americas in 1492. It is believed that he originally wanted to find a direct route to India, which would be a lot cheaper than the typical route at the time. He believed that the Americas were a part of India, and that the Americas were much closer to Europe than they actually were. When Columbus sailed across the Atlantic Ocean in 1492, he actually landed somewhere in the Bahamas, and not in India. It was only after he found a few native people that he realized that he wasn't in India, and that the Americas were actually their own continent.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 60 |
+
{"answer_id": "8DJpwEFb5jqt3vMj5oNqVX", "model_id": "llama-13b:v1", "question_id": 60, "text": "There are many reasons why Van Gogh did not have much success during his lifetime. One of the reasons is that he was a very poor businessman. He was very generous and gave away many of his paintings as presents. He also had a tendency to drink too much. He spent some time in a mental asylum and died at the age of 37.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 61 |
+
{"answer_id": "KMtqqYkDmyyThkvxXJ4kJd", "model_id": "llama-13b:v1", "question_id": 61, "text": "You can use the following steps to solve this problem.\n1. Create an empty C++ program.\n2. Include the <iostream> header to use the std::cin and std::cout functions.\n3. Open the text file using the fstream class.\n4. Read a single line from the file using the getline function.\n5. Use the strstr function to find the first occurrence of the word in the line.\n6. Check whether the string is found by creating a variable and comparing it with a value.\n7. Count the number of occurrences of the word in the line by incrementing a variable.\n8. Close the file.\n9. Print the number of occurrences of the word.\n10. Output the file name to the console.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 62 |
+
{"answer_id": "MkbgwTpP5b79NWdPEnvHyq", "model_id": "llama-13b:v1", "question_id": 62, "text": "The longest common subsequence problem is that of finding the longest string that occurs in both of two given strings. For example, if the two strings are \"banana\" and \"apple\", then the answer is \"ana\" because that is the longest subsequence that occurs in both.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 63 |
+
{"answer_id": "PSb6r567shkRasPkJagvWi", "model_id": "llama-13b:v1", "question_id": 63, "text": "Here are two ways to do it:\n1. You can use the function re.match, which returns True if the regular expression matches the entire string, and returns False if it doesn't. So, we can do something like this:\nif re.match('^[a-z0-9]+(\\.[a-z0-9]+)*@[a-z0-9]+(\\.[a-z0-9]+)*(\\.[a-z]{2,4})$', email):\nprint('It is a valid email')\nprint('It is not a valid email')\n2. You can use the function re.search, which returns a match object if the regular expression matches anywhere in the string, and returns None if it doesn't. So, we can do something like this:\nif re.search('^[a-z0-9]+(\\.[a-z0-9]+)*@[a-z0-9]+(\\.[a-z0-9]+)*(\\.[a-z]{2,4})$', email):", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 64 |
+
{"answer_id": "QWpBq9gM4iYmsTLQ3NNnBe", "model_id": "llama-13b:v1", "question_id": 64, "text": "Fibonacci number is a sequence of numbers where each number is the sum of the two previous numbers. The first two numbers in the sequence are 0 and 1. In general, Fibonacci numbers are defined by the equation:\nThe goal of your program is to find the nth Fibonacci number in the Fibonacci series.\nNote: n will be a positive integer.\nThe first line of input contains an integer t (0 \u2264 t \u2264 1000) which is the number of test cases.\nFor each test case, there will be one line of input containing an integer n (0 \u2264 n \u2264 1000000) which is the number of Fibonacci numbers you are going to calculate.\nPrint each Fibonacci number in a new line.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 65 |
+
{"answer_id": "U3QxoC4DxXoggnLRbgJh8b", "model_id": "llama-13b:v1", "question_id": 65, "text": "Good to know! I will implement a binary search algorithm to find a specific element in a sorted array.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 66 |
+
{"answer_id": "f3TXCreQPJ5Erd6BGt4SFE", "model_id": "llama-13b:v1", "question_id": 66, "text": "Implementing a queue using two stacks is straightforward. Take two stacks and create a third stack. First, push the first element of the first stack onto the third stack. Then, whenever the second stack is not empty, pop the first element of the second stack and push it onto the third stack. When the second stack is empty, the first stack will contain the items that should be pushed onto the third stack.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 67 |
+
{"answer_id": "SG7YcT8s4sJNBRqidKk7Z7", "model_id": "llama-13b:v1", "question_id": 67, "text": "We can use the following approach:\n1. Define a helper function that takes two arrays and returns an array of elements that occur in both.\n2. Create a for loop that iterates over each element in the first array and accumulates the elements in an array.\n3. Call the helper function in each iteration.\n4. Return the accumulated array.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 68 |
+
{"answer_id": "ENsG3zoeUY7ArFo2kNaQbz", "model_id": "llama-13b:v1", "question_id": 68, "text": "f(2) = 26", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 69 |
+
{"answer_id": "C7CN5AYJhGC7iDgS7rciDQ", "model_id": "llama-13b:v1", "question_id": 69, "text": "3x + 10 = 5x - 10x + 20 = 20 + 10x = 30x = 10.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 70 |
+
{"answer_id": "QP9CmZKwhu2BrUmzhy8tH4", "model_id": "llama-13b:v1", "question_id": 70, "text": "The length of the line segment is 10 units.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 71 |
+
{"answer_id": "2KtpJeRqEfbPLwdUxAXWrj", "model_id": "llama-13b:v1", "question_id": 71, "text": "Here are some tips for writing a formal email to a potential business partner proposing a joint venture:\n1. Be clear and concise\n2. Use formal language\n3. Use a proper greeting\n4. Use a proper closing\n5. Use proper punctuation\n6. Be sure to include all relevant information", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 72 |
+
{"answer_id": "gsL3R2grTXUiHdeDSk8f9Q", "model_id": "llama-13b:v1", "question_id": 72, "text": "I can help you write a resignation letter to your current employer, while leaving on good terms and expressing gratitude for the opportunities provided. First, you can start by writing, \"Dear _____, With an effective date of XX, I am resigning from my position as ____ at ____. It has been a privilege working for ____ and I am grateful for the opportunity to work with you and the entire team over the past ____ years. Thank you for your support and guidance during my time with _____.\"", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 73 |
+
{"answer_id": "HprPMoUk9JY5TtToRbuMwy", "model_id": "llama-13b:v1", "question_id": 73, "text": "The most common format for a letter of recommendation is as follows:\n1. Salutation: In the salutation, address the recipient as Mr., Mrs., Ms., or Dr.\n2. Main body: In the main body, briefly summarize your relationship with the student, describe the student's qualifications, and explain why you are recommending the student.\n3. Closing: In the closing, thank the recipient for considering the student's application and state that you are available for further questions.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 74 |
+
{"answer_id": "YU7gDhmo4LDVMTEZZMRdBC", "model_id": "llama-13b:v1", "question_id": 74, "text": "", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 75 |
+
{"answer_id": "2gNqU2XpsL6yqFn6DMRgHq", "model_id": "llama-13b:v1", "question_id": 75, "text": "Hello, I'm ready to draft the apology email for you. Please tell me the name of the customer you'd like to send this email to.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 76 |
+
{"answer_id": "a4L6JNPuomkPLdWxJRQpod", "model_id": "llama-13b:v1", "question_id": 76, "text": "Jazz is a form of music that originated in New Orleans in the late 19th century. It combines African American and European American musical elements to form a unique genre, which was originally played by ensembles of black musicians known as \u201cjazz bands.\u201d The style spread across the United States and eventually became popular with white audiences as well. Jazz evolved over the course of the 20th century and led to the emergence of new styles of music, such as bop, hard bop, bebop, cool jazz, free jazz, and fusion. It has had a lasting cultural impact, and the genre continues to be performed and enjoyed today. Here are some key facts about jazz:\n1. Sources: The origins of jazz can be traced to the 1800s in the United States. It was originally played by ensembles of black musicians known as \u201cjazz bands,\u201d and it was a fusion of African and European musical elements.\n2. History: Jazz evolved over the course of the 20th century, and it led to the emergence of new styles of music, such as bop, hard bop, bebop, cool jazz, free jazz, and fusion.\n3. Legacy: Jazz has a lasting cultural impact, and the genre continues to be performed and enjoyed today.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 77 |
+
{"answer_id": "eN9V2Wf2BNzWoJosqdFw6K", "model_id": "llama-13b:v1", "question_id": 77, "text": "Here is a sample travel blog post about a recent trip to Hawaii:", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 78 |
+
{"answer_id": "iCzkbWTatKfuC6QVv59XgA", "model_id": "llama-13b:v1", "question_id": 78, "text": "In the year 2045, virtual reality is the norm. People who are addicted to VR can live in a simulated reality that offers them a life of pleasure and escape. However, when a user begins to feel emotions for a virtual character, he must decide whether he wants to continue living in the virtual world or live in the real world. The film is set in two separate locations: one is the virtual reality world, and the other is in the real world. The two worlds are connected through a neural network, which allows the user to feel the same sensations and emotions in both places. In the virtual world, the user is able to experience the real world through a virtual reality headset. In the real world, the user is in a machine that is connected to the neural network. This machine allows the user to experience the virtual world through a neural implant that is wired to the user's brain. The film's plot centers around the user and the virtual character. The characters in the virtual world are all artificial intelligence entities, and the user's experience in the real world is with two characters, his friend and his girlfriend. The user is a young man in the film, and the virtual character is a young woman. The two characters have a virtual relationship, and then the virtual character is killed by a bug in the system. This causes the user to fall into a deep depression, and he begins to question his own reality. He decides to go to the real world to get treatment for his depression. In the real world, the user has to decide whether he wants to stay in the real world or return to the virtual world. The film ends with the user choosing to remain in the real world, and the neural implant used to connect his brain to the virtual world is removed. The movie is based on the novel \"Ready Player One\" by Ernest Cline. The film is directed by Steven Spielberg and stars Tye Sheridan as the main actor. The film is a science fiction adventure and a romantic drama. The film's special effects are excellent, and the visuals are beautiful. The film's soundtrack is also quite good. The film has received positive reviews from critics, and it has been nominated for a number of awards, including the Academy Award for Best Visual Effects. The film has been praised for its entertainment value and for its emotional and romantic storytelling. The film has been compared to the popular sci-fi film \"The Matrix.\" Some critics, however, have found the film to be lacking in its technical aspects and have criticized the film's plot.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 79 |
+
{"answer_id": "GQcFyY8ayFT48DAP5NKNZf", "model_id": "llama-13b:v1", "question_id": 79, "text": "I found 4,610 relevant search results for this topic. The results include:\n1. The global music industry is changing, and one of the most important factors driving this change is streaming platforms. Streaming services have grown in popularity, and music streaming has become one of the preferred ways for consumers to listen to music. What exactly is streaming?\n2. Streaming means that music is delivered over the internet. Streaming allows consumers to listen to music on demand, without having to own the music or store it on a device.\n3. Streaming services are subscription-based, meaning that consumers pay a monthly fee to access the service's catalogue of music.\n4. Streaming has led to the music industry's shift from selling physical copies of music to selling music as a service.\n5. Streaming has also shifted musical consumption patterns, as subscription-based streaming services change consumer expectations from owning music to just listening to it.\n6. Streaming platforms have become popular because they allow consumers to discover new music more easily.\n7. Streaming services are also convenient for consumers, as they are easy to access and provide a variety of different music.\n8. Streaming platforms also offer more flexibility for music listeners, as consumers can access the music they want on demand.\n9. Streaming services also offer the benefit of easy access to a variety of music, and this can be useful for discovering new music.\n10. Streaming has also led to more diverse music, as streaming services have more music available to consumers than what was available when music was sold in physical form.\n11. Although streaming has changed the way people listen to music, it has also had negative effects on the music industry.\n12. Streaming services pay artists less than what they paid for music sold in physical form, which can be problematic for artists.\n13. Streaming services also pay less to the music industry overall.\n14. Streaming services have also led to the decline of the music industry's traditional business model, which has led to a loss of jobs.\n15. Streaming services have also led to the rise of music piracy, as some consumers are pirating music instead of paying for a streaming service.\n16. Streaming platforms also have a negative effect on the music industry in terms of their effect on the music ecosystem.\n17. Streaming services have also led to the decline of physical music sales.\n18. Streaming platforms have also led to the decline of record stores, which can harm artists and consumers.\n19. Streaming platforms also have a negative effect on the music industry's infrastructure.\n20. Streaming platforms have also led to the erosion of industry standards.\n21. Streaming platforms have also led to a decline in music videos and music videos being less accessible.\n22. Streaming platforms have also led to the decline of radio, which can be problematic for listeners.\n23. Streaming platforms have also led to a decline in music journalism.\n24. Streaming platforms have also led to a decline in the number of record labels.\n25. Streaming platforms have also led to a decline in the number of music producers.\n26. Streaming platforms have also led to a decline in the music industry's contribution to the economy.\n27. Streaming platforms have also led to the decline of music festivals.\n28. Streaming platforms have also led to the decline of music labels.\n29. Streaming platforms have also led to a decline in the music industry's culture.\n30. Streaming platforms have also led to a decline in the music industry's diversity.\n31. Streaming platforms have also led to the decline of the music industry's talent development.\n32. Streaming platforms have also led to a decline in the music industry's competitiveness.\n33. Streaming platforms have also led to the decline of the music industry's social and economic effects.\n34. Streaming platforms have also led to the decline of the music industry's intellectual property.\n35. Streaming platforms have also led to the decline of the music industry's political and social engagement.\n36. Streaming platforms have also led to the decline of the music industry's cultural and artistic output.\n37. Streaming platforms have also led to the decline of the music industry's public value.\n38. Although streaming has had a negative effect on the music industry, it has also had positive effects.\n39. Streaming platforms have", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
| 80 |
+
{"answer_id": "A6pauLMckn34otnfpeQRFi", "model_id": "llama-13b:v1", "question_id": 80, "text": "The orchestra performed well, and the audience was receptive to the performance. The orchestra played a selection of pieces from some of the most well-known classical composers, including Beethoven, Mozart, and Tchaikovsky. The orchestra played in unison with each other, and the conductor led them through the pieces without much difficulty. The orchestra played with a lot of energy and spirit. The audience was appreciative and applauded at the appropriate times. The performance lasted 90 minutes, and it was well worth the price of admission. I would recommend the concert to anyone who wants to experience beautiful classical music.", "metadata": {"huggingface_argument": {"do_sample": true, "temperature": 0.7, "max_new_tokens": 1024}}}
|
llava/eval/table/answer/answer_vicuna-13b.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
llava/eval/table/caps_boxes_coco2014_val_80.jsonl
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"id": "000000296284", "image": "000000296284.jpg", "captions": ["A donut shop is full of different flavors of donuts.", "Fruit flavored donuts lined up in a glass fronted cabinet", "A rack with some doughnuts in a glass case.", "A display case in a bakery filled with donuts.", "An assortment of doughnuts are arranged in a display case."], "instances": [{"category": "donut", "bbox": [0.37, 0.584, 0.504, 0.709]}, {"category": "donut", "bbox": [0.369, 0.22, 0.492, 0.317]}, {"category": "donut", "bbox": [0.471, 0.587, 0.639, 0.706]}, {"category": "donut", "bbox": [0.544, 0.213, 0.679, 0.316]}, {"category": "donut", "bbox": [0.035, 0.22, 0.196, 0.328]}, {"category": "donut", "bbox": [0.054, 0.608, 0.221, 0.711]}, {"category": "donut", "bbox": [0.283, 0.586, 0.429, 0.708]}, {"category": "donut", "bbox": [0.466, 0.226, 0.585, 0.32]}, {"category": "donut", "bbox": [0.28, 0.232, 0.393, 0.322]}, {"category": "donut", "bbox": [0.0, 0.609, 0.097, 0.722]}]}
|
| 2 |
+
{"id": "000000151358", "image": "000000151358.jpg", "captions": ["A newspaper that has sunglasses on top of it sitting in front of books.", "an apple sunglasses books and a teddy bear", "A folded newspaper and sunglasses are on a table with an apple, books, and teddy bear behind.", "An apple sitting on a table next to sunglasses and a news paper.", "There are sunglasses laying on the folded newspaper."], "instances": [{"category": "tie", "bbox": [0.258, 0.074, 0.527, 0.589]}, {"category": "apple", "bbox": [0.621, 0.482, 0.853, 0.645]}, {"category": "book", "bbox": [0.154, 0.107, 0.275, 0.59]}, {"category": "book", "bbox": [0.535, 0.09, 0.735, 0.583]}, {"category": "book", "bbox": [0.051, 0.112, 0.159, 0.6]}, {"category": "teddy bear", "bbox": [0.753, 0.084, 1.0, 0.517]}, {"category": "book", "bbox": [0.681, 0.097, 0.796, 0.483]}, {"category": "book", "bbox": [0.443, 0.099, 0.574, 0.588]}, {"category": "book", "bbox": [0.267, 0.337, 0.386, 0.579]}]}
|
| 3 |
+
{"id": "000000052312", "image": "000000052312.jpg", "captions": ["The old man literally has a toothbrush mustache.", "An old man with a tooth brush head under his nose, mimicking Hitler", "A man wearing a toothbrush for a moustache.", "A man with the head of a toothbrush under his nose like a mustache", "An elderly man wearing the head of a toothbrush as a moustache."], "instances": [{"category": "toothbrush", "bbox": [0.345, 0.59, 0.594, 0.679]}, {"category": "person", "bbox": [0.0, 0.03, 1.0, 0.99]}]}
|
| 4 |
+
{"id": "000000473210", "image": "000000473210.jpg", "captions": ["two people taking apart their wii controllers to replace batteries", "People taking apart video game remote controls on a table", "People handling a couple of remotes taking them apart.", "two sets of hands a wooden table and two controllers", "Two people who are taking apart a video game controller."], "instances": [{"category": "person", "bbox": [0.002, 0.334, 0.453, 0.986]}, {"category": "remote", "bbox": [0.407, 0.207, 0.727, 0.604]}, {"category": "remote", "bbox": [0.088, 0.344, 0.313, 0.547]}, {"category": "laptop", "bbox": [0.001, 0.049, 0.1, 0.197]}, {"category": "person", "bbox": [0.484, 0.254, 0.998, 0.985]}, {"category": "dining table", "bbox": [0.0, 0.003, 1.0, 0.956]}]}
|
| 5 |
+
{"id": "000000097131", "image": "000000097131.jpg", "captions": ["A car parked by a parking meter in front of a building.", "A car is sitting parked at a curb in front of a parking meter.", "A black car on the street next to a parking meter.", "A gray car parked in front of two parking meters.", "A black car parked on the side of the road."], "instances": [{"category": "car", "bbox": [0.227, 0.362, 0.946, 0.761]}, {"category": "car", "bbox": [0.793, 0.322, 0.88, 0.4]}, {"category": "car", "bbox": [0.0, 0.447, 0.028, 0.726]}, {"category": "parking meter", "bbox": [0.156, 0.35, 0.186, 0.453]}, {"category": "truck", "bbox": [0.907, 0.331, 1.0, 0.408]}, {"category": "parking meter", "bbox": [0.188, 0.349, 0.218, 0.448]}]}
|
| 6 |
+
{"id": "000000543364", "image": "000000543364.jpg", "captions": ["There is a table in the middle of the room.", "A room with a couch, table, lamp and a chaise.", "A living room with couch, chaise, track lighting, and a large window.", "A room with large windows, a couch and a table.", "A living room with lots of furniture and a large window."], "instances": [{"category": "dining table", "bbox": [0.388, 0.644, 0.636, 0.879]}, {"category": "couch", "bbox": [0.194, 0.531, 0.552, 0.777]}, {"category": "couch", "bbox": [0.568, 0.488, 0.907, 0.783]}, {"category": "remote", "bbox": [0.524, 0.651, 0.556, 0.675]}, {"category": "chair", "bbox": [0.661, 0.478, 0.802, 0.604]}]}
|
| 7 |
+
{"id": "000000217181", "image": "000000217181.jpg", "captions": ["They are standing next to some stylish motorcycles.", "Three men are standing around looking at sports motorcycles.", "A small group of men are standing around a motorcycle.", "Two men surrounding a blue motorcycle and others", "A few blue motorcycles are parked in a lot."], "instances": [{"category": "car", "bbox": [0.011, 0.177, 0.2, 0.336]}, {"category": "motorcycle", "bbox": [0.032, 0.139, 0.907, 0.982]}, {"category": "motorcycle", "bbox": [0.0, 0.239, 0.148, 0.613]}, {"category": "motorcycle", "bbox": [0.0, 0.301, 0.106, 0.45]}, {"category": "person", "bbox": [0.775, 0.043, 0.93, 0.463]}, {"category": "person", "bbox": [0.717, 0.116, 0.81, 0.509]}, {"category": "person", "bbox": [0.296, 0.008, 0.472, 0.325]}, {"category": "person", "bbox": [0.115, 0.19, 0.164, 0.269]}, {"category": "truck", "bbox": [0.63, 0.227, 0.731, 0.335]}]}
|
| 8 |
+
{"id": "000000140289", "image": "000000140289.jpg", "captions": ["Two born bears walking though a forest surrounded by trees.", "Two full grown brown bears in a habitat.", "Two bears are roaming around in the woods.", "Two bears around logs in front of a large rock.", "Two big bears wandering through the woods together"], "instances": [{"category": "bear", "bbox": [0.131, 0.269, 0.375, 0.65]}, {"category": "bear", "bbox": [0.568, 0.193, 0.809, 0.827]}]}
|
| 9 |
+
{"id": "000000460149", "image": "000000460149.jpg", "captions": ["A clock hosted on a pole on a pavement next to a building", "Street clock on quiet street with trees and bicycles.", "A tall clock stands on an empty sidewalk.", "A pole that has a clock on the top of it.", "a clock on a short tower and potted plants along the sidewalk"], "instances": [{"category": "potted plant", "bbox": [0.14, 0.71, 0.338, 0.856]}, {"category": "bicycle", "bbox": [0.65, 0.671, 0.766, 0.733]}, {"category": "car", "bbox": [0.38, 0.608, 0.488, 0.656]}, {"category": "clock", "bbox": [0.468, 0.048, 0.699, 0.216]}, {"category": "bicycle", "bbox": [0.669, 0.662, 0.719, 0.67]}, {"category": "car", "bbox": [0.786, 0.625, 0.86, 0.668]}, {"category": "potted plant", "bbox": [0.756, 0.637, 0.819, 0.682]}, {"category": "person", "bbox": [0.942, 0.615, 0.954, 0.641]}, {"category": "bicycle", "bbox": [0.648, 0.68, 0.714, 0.747]}, {"category": "car", "bbox": [0.837, 0.619, 0.88, 0.659]}, {"category": "potted plant", "bbox": [0.017, 0.197, 0.443, 0.686]}]}
|
| 10 |
+
{"id": "000000225738", "image": "000000225738.jpg", "captions": ["A group of giraffes standing up in their natural habitat.", "A group of giraffe standing in a grass field.", "A group of four giraffes near the same tree.", "there are four giraffes standing among some dry brush", "A herd of giraffe standing on top of a grass field."], "instances": [{"category": "giraffe", "bbox": [0.648, 0.231, 0.855, 0.915]}, {"category": "giraffe", "bbox": [0.33, 0.136, 0.521, 0.93]}, {"category": "giraffe", "bbox": [0.406, 0.261, 0.515, 1.0]}, {"category": "giraffe", "bbox": [0.347, 0.194, 0.583, 0.922]}]}
|
| 11 |
+
{"id": "000000109532", "image": "000000109532.jpg", "captions": ["An adorable husky dog sleeping in a dog bed next to a fan.", "A dark room with a dog sleeping on a dog bed.", "A dog is sleeping in a dark room.", "a large dog laying in a dog bed in a living room", "A dog sleeping on a dog bed in a room."], "instances": [{"category": "dog", "bbox": [0.426, 0.661, 0.582, 0.925]}, {"category": "potted plant", "bbox": [0.603, 0.261, 0.781, 0.613]}, {"category": "chair", "bbox": [0.67, 0.515, 0.899, 0.801]}, {"category": "potted plant", "bbox": [0.671, 0.439, 0.763, 0.612]}, {"category": "chair", "bbox": [0.852, 0.653, 0.948, 0.818]}]}
|
| 12 |
+
{"id": "000000118606", "image": "000000118606.jpg", "captions": ["A man riding skis on top of a rail.", "a person riding a pair of skis on a rail", "Someone on a pair of skis on a ramp at the ski slope", "Person with skis in the air above the snow.", "A man performing a trick on a rail while skiing."], "instances": [{"category": "person", "bbox": [0.444, 0.361, 0.537, 0.633]}, {"category": "skis", "bbox": [0.413, 0.554, 0.539, 0.664]}, {"category": "person", "bbox": [0.342, 0.585, 0.352, 0.62]}, {"category": "person", "bbox": [0.439, 0.565, 0.446, 0.58]}]}
|
| 13 |
+
{"id": "000000385873", "image": "000000385873.jpg", "captions": ["Three pizzas sitting next to each other in boxes.", "Two smaller pizzas sit beside a large pizza topped with tortilla chips.", "Three pizzas inside their delivery boxes, one with two side orders of sauce.", "One pizza is larger than two other pizzas.", "Three pizza boxes with pizza in them are open."], "instances": [{"category": "bowl", "bbox": [0.634, 0.624, 0.736, 0.752]}, {"category": "pizza", "bbox": [0.3, 0.382, 0.615, 0.733]}, {"category": "pizza", "bbox": [0.0, 0.4, 0.287, 0.745]}, {"category": "pizza", "bbox": [0.624, 0.279, 0.999, 0.753]}, {"category": "bowl", "bbox": [0.94, 0.247, 1.0, 0.352]}]}
|
| 14 |
+
{"id": "000000092109", "image": "000000092109.jpg", "captions": ["A giraffe's head is pictured in this clear, colorful photo.", "A giraffe is standing tall in the middle of several bright green trees", "The face of a giraffe looking to the side.", "the close up head shot of a giraffe", "this is a giraffe chewing on some leaves"], "instances": [{"category": "giraffe", "bbox": [0.236, 0.122, 1.0, 0.987]}]}
|
| 15 |
+
{"id": "000000163076", "image": "000000163076.jpg", "captions": ["There's an outdoor dining area featuring a fountain.", "A table sitting next to a water fountain covered by an umbrella.", "An empty restaurant patio with tables and umbrellas.", "An outdoor restaurant with a fountain at night", "A fountain bubbles in the plaza of an outdoor cafe."], "instances": [{"category": "umbrella", "bbox": [0.064, 0.069, 0.95, 0.844]}, {"category": "chair", "bbox": [0.198, 0.574, 0.355, 0.704]}, {"category": "chair", "bbox": [0.42, 0.571, 0.55, 0.738]}, {"category": "dining table", "bbox": [0.066, 0.741, 0.766, 0.925]}, {"category": "dining table", "bbox": [0.059, 0.584, 0.27, 0.659]}, {"category": "chair", "bbox": [0.432, 0.567, 0.52, 0.624]}, {"category": "chair", "bbox": [0.433, 0.555, 0.504, 0.6]}, {"category": "chair", "bbox": [0.109, 0.673, 0.374, 0.796]}]}
|
| 16 |
+
{"id": "000000560371", "image": "000000560371.jpg", "captions": ["Street signs from the corner of 8th ave. and 22 3/4 st.", "A two way street sign with one sign that changes from one name to another.", "A street sign is pointing towards 8th avenue and the other is pointing towards 22 3/4 street in the middle of the forest.", "A street sign standing in front of some trees.", "Peculiar street sign showing intersection of 23 3/4 St and 8th Ave/CTH D."], "instances": []}
|
| 17 |
+
{"id": "000000367571", "image": "000000367571.jpg", "captions": ["A couple of different doughnuts in a box", "There are four donuts in a box, and some are cake donuts and a doughnut with nuts and coconut on top.", "A box of glazed doughnuts on a table.", "Three donuts with toppings on them sitting inside a box.", "A box that is filled with different kinds of doughnuts."], "instances": [{"category": "donut", "bbox": [0.412, 0.335, 0.711, 0.681]}, {"category": "donut", "bbox": [0.093, 0.493, 0.486, 0.922]}, {"category": "donut", "bbox": [0.713, 0.423, 0.957, 0.874]}, {"category": "donut", "bbox": [0.13, 0.331, 0.397, 0.55]}]}
|
| 18 |
+
{"id": "000000580197", "image": "000000580197.jpg", "captions": ["Two men in bow ties standing next to steel rafter.", "Several men in suits talking together in a room.", "An older man in a tuxedo standing next to a younger man in a tuxedo wearing glasses.", "Two men wearing tuxedos glance at each other.", "Older man in tuxedo sitting next to another younger man in tuxedo."], "instances": [{"category": "tie", "bbox": [0.914, 0.46, 0.984, 0.512]}, {"category": "person", "bbox": [0.297, 0.638, 0.71, 0.989]}, {"category": "person", "bbox": [0.77, 0.177, 1.0, 0.971]}, {"category": "tie", "bbox": [0.281, 0.481, 0.368, 0.519]}, {"category": "person", "bbox": [0.103, 0.204, 0.497, 1.0]}]}
|
| 19 |
+
{"id": "000000506095", "image": "000000506095.jpg", "captions": ["A cat is staring at a laptop computer.", "a cat on a desk with a laptop and a mouse", "A cat that is sitting at a desk next to a laptop.", "A kitten sitting on a laptop computer sitting on top of a wooden desk.", "A kitten sits facing an open black laptop."], "instances": [{"category": "cat", "bbox": [0.658, 0.207, 1.0, 0.754]}, {"category": "laptop", "bbox": [0.108, 0.135, 0.766, 0.69]}, {"category": "book", "bbox": [0.836, 0.239, 0.954, 0.273]}, {"category": "book", "bbox": [0.0, 0.556, 0.128, 0.685]}, {"category": "book", "bbox": [0.039, 0.574, 0.257, 0.691]}, {"category": "book", "bbox": [0.825, 0.214, 0.962, 0.254]}, {"category": "book", "bbox": [0.892, 0.275, 0.958, 0.308]}, {"category": "book", "bbox": [0.922, 0.318, 0.986, 0.353]}, {"category": "book", "bbox": [0.87, 0.267, 0.951, 0.291]}, {"category": "book", "bbox": [0.949, 0.102, 0.976, 0.114]}, {"category": "book", "bbox": [0.936, 0.161, 0.958, 0.168]}]}
|
| 20 |
+
{"id": "000000024996", "image": "000000024996.jpg", "captions": ["A bathroom with a glass door and a sink.", "A blue lined bathroom with an open glass door.", "A nice bathroom with a sink, toilet, and tiled shower.", "A bathroom that is clean and shiny in the day.", "a bathroom with a sink and a mirror and a window"], "instances": [{"category": "toilet", "bbox": [0.842, 0.934, 0.95, 1.0]}, {"category": "sink", "bbox": [0.506, 0.724, 0.683, 0.834]}]}
|
| 21 |
+
{"id": "000000457882", "image": "000000457882.jpg", "captions": ["a girl in a bikini and a brown and white dog and a few other people", "A woman with a swimsuit on sitting with a dog.", "A woman is sitting with a dog on her lap.", "A dog sitting next to a woman in her swimsuit.", "WOMAN SITTING WITH HER DOG, AND OTHER WOMEN ARE AROUND"], "instances": [{"category": "dog", "bbox": [0.202, 0.409, 0.54, 0.81]}, {"category": "dog", "bbox": [0.61, 0.428, 0.729, 0.723]}, {"category": "boat", "bbox": [0.003, 0.705, 0.939, 0.974]}, {"category": "person", "bbox": [0.236, 0.001, 0.558, 0.784]}, {"category": "person", "bbox": [0.681, 0.001, 0.957, 0.798]}, {"category": "person", "bbox": [0.849, 0.478, 1.0, 0.946]}, {"category": "person", "bbox": [0.345, 0.187, 0.634, 0.828]}, {"category": "person", "bbox": [0.033, 0.345, 0.109, 0.434]}]}
|
| 22 |
+
{"id": "000000081552", "image": "000000081552.jpg", "captions": ["A cat sitting and curled up on a red couch", "A cat laying on a red couch sleeping.", "a tan and black cat curled up asleep on a red velvet seat", "A cat is curled up on a red sofa.", "Cat curled up, sleeping on a red plush couch."], "instances": [{"category": "cat", "bbox": [0.412, 0.237, 0.634, 0.482]}, {"category": "couch", "bbox": [0.003, 0.005, 1.0, 0.99]}]}
|
| 23 |
+
{"id": "000000273450", "image": "000000273450.jpg", "captions": ["A person flipping of a parking meter on the side of a road.", "A man holds up his middle finger to a parking meter.", "Person giving the middle finger to a parking meter.", "a black silver white blue red an orange parking meter and a hand flipping it off", "A person is flipping off a parking meter."], "instances": [{"category": "person", "bbox": [0.0, 0.475, 0.565, 0.987]}, {"category": "car", "bbox": [0.0, 0.0, 0.531, 0.734]}, {"category": "parking meter", "bbox": [0.0, 0.0, 1.0, 0.987]}]}
|
| 24 |
+
{"id": "000000203879", "image": "000000203879.jpg", "captions": ["There is a small cellphone displayed between a set of ear buds and two paper weights.", "a cell phone lays next to some diamonds", "a close up of a cell phone on a table near earbuds", "A cell phone sits on a table next to some jewels.", "A cell phone, ear buds, and two jewels laying near each other."], "instances": [{"category": "cell phone", "bbox": [0.322, 0.233, 0.62, 0.79]}]}
|
| 25 |
+
{"id": "000000346875", "image": "000000346875.jpg", "captions": ["two zebras in a field near one another", "A couple of zebra walking across a green field.", "Two zebra are walking near a gravel road.", "two zebras in a green field of grass and some trees", "A zebra follows another zebra through a park."], "instances": [{"category": "zebra", "bbox": [0.591, 0.263, 0.82, 0.466]}, {"category": "zebra", "bbox": [0.293, 0.243, 0.561, 0.45]}]}
|
| 26 |
+
{"id": "000000525439", "image": "000000525439.jpg", "captions": ["a man stands in front of a flipped skate boarder", "A man standing next to a skateboard that is laying on the ground wheels pointed up.", "Skateboard laying upside down on cement with someone standing next to it.", "A boy in camo shorts stands before an overturned skateboard.", "a person with an upside down skate board"], "instances": [{"category": "person", "bbox": [0.307, 0.001, 0.63, 0.739]}, {"category": "skateboard", "bbox": [0.0, 0.592, 0.626, 0.969]}]}
|
| 27 |
+
{"id": "000000304749", "image": "000000304749.jpg", "captions": ["The woman is taking a picture in the bathroom mirror.", "A picture of a woman in a mirror.", "A woman's midsection reflected in a round mirror.", "A circular mirror reflecting a woman's stomach in turquoise shirt.", "A selfie taken of a person from the neck down."], "instances": [{"category": "person", "bbox": [0.092, 0.001, 0.646, 0.496]}]}
|
| 28 |
+
{"id": "000000323760", "image": "000000323760.jpg", "captions": ["A toilet is shown in a bare room.", "A ugly bathroom with a section of the wall missing.", "A toilet in a stripped bathroom with studs, bricks and plaster showing", "A bathroom with no walls and a toilet bowl", "A white toilet next to some torn out walls."], "instances": [{"category": "toilet", "bbox": [0.167, 0.585, 0.714, 1.0]}]}
|
| 29 |
+
{"id": "000000066144", "image": "000000066144.jpg", "captions": ["A woman standing in front of window next to a bug and a stop sign.", "A car parked on the street next to a tree and stop sign.", "A lone Volkswagen is parked by a stop sign.", "A window view of a small car near a street stop sign.", "An old VW Bug standing at a stop sign."], "instances": [{"category": "stop sign", "bbox": [0.501, 0.328, 0.569, 0.428]}, {"category": "car", "bbox": [0.242, 0.488, 0.56, 0.726]}, {"category": "car", "bbox": [0.279, 0.325, 0.33, 0.363]}, {"category": "car", "bbox": [0.153, 0.333, 0.29, 0.405]}, {"category": "car", "bbox": [0.11, 0.339, 0.177, 0.373]}, {"category": "car", "bbox": [0.0, 0.654, 0.082, 0.826]}, {"category": "car", "bbox": [0.0, 0.322, 0.064, 0.364]}, {"category": "car", "bbox": [0.451, 0.333, 0.51, 0.392]}]}
|
| 30 |
+
{"id": "000000455772", "image": "000000455772.jpg", "captions": ["A person in a field jumping to catch a Frisbee.", "A guy jumping to catch a frisbee in mid-air.", "A person that is trying to get a frisbee.", "Nice reach, but the Frisbee flies on, victorious.", "A man playing frisbee in a grassy yard."], "instances": [{"category": "car", "bbox": [0.148, 0.339, 0.201, 0.476]}, {"category": "car", "bbox": [0.376, 0.396, 0.424, 0.476]}, {"category": "person", "bbox": [0.547, 0.122, 0.698, 0.904]}, {"category": "frisbee", "bbox": [0.479, 0.154, 0.555, 0.231]}, {"category": "car", "bbox": [0.001, 0.299, 0.085, 0.394]}]}
|
| 31 |
+
{"id": "000000511117", "image": "000000511117.jpg", "captions": ["A couple of kids standing on top of a grass covered field.", "A little boy wearing a baseball uniform stands by a little girl.", "A young boy in a baseball uniform and a young girl are standing in front of a chain link fence.", "A little boy and girl standing on a baseball field. The boy has a uniform on.", "A young baseball player is standing next to a young girl."], "instances": [{"category": "person", "bbox": [0.514, 0.178, 0.776, 0.774]}, {"category": "baseball glove", "bbox": [0.468, 0.462, 0.593, 0.609]}, {"category": "person", "bbox": [0.174, 0.051, 0.598, 0.839]}, {"category": "bench", "bbox": [0.558, 0.125, 1.0, 0.315]}]}
|
| 32 |
+
{"id": "000000207151", "image": "000000207151.jpg", "captions": ["A vegetarian pizza is half eaten on a pizza holder.", "A couple of pieces of pizza with vegetable slices on them.", "A wooden pan serving tray with a pizza on it.", "A pizza on a cutting board is half gone.", "A Pizza is nearly finished with only three pieces left."], "instances": [{"category": "bottle", "bbox": [0.001, 0.001, 0.121, 0.231]}, {"category": "cup", "bbox": [0.0, 0.002, 0.121, 0.238]}, {"category": "pizza", "bbox": [0.17, 0.472, 0.526, 0.82]}, {"category": "pizza", "bbox": [0.398, 0.106, 0.962, 0.679]}, {"category": "dining table", "bbox": [0.0, 0.001, 1.0, 0.988]}]}
|
| 33 |
+
{"id": "000000431165", "image": "000000431165.jpg", "captions": ["A baby elephant standing in front of a brick building.", "An elephant is standing near a dirt mount in an exhibit.", "Grey elephant standing next to a large sand dune in a pen.", "An elephant standing alone inside of an enclosure.", "The baby elephant is alone in the pen."], "instances": [{"category": "elephant", "bbox": [0.303, 0.399, 0.638, 0.78]}]}
|
| 34 |
+
{"id": "000000378545", "image": "000000378545.jpg", "captions": ["A pole that has a clock on top of it.", "A clock mounted on an outdoor post with Roman numerals.", "a clock on a pole saying it is 12:45", "An ornamental standing clock is at the foreground of a row of houses.", "A black and gold clock on a pole in front of a building."], "instances": [{"category": "clock", "bbox": [0.216, 0.249, 0.749, 0.658]}]}
|
| 35 |
+
{"id": "000000555904", "image": "000000555904.jpg", "captions": ["A man sitting at a bar filled with liquor.", "People sitting a a take near several bottles of wine on shelves.", "Several people are sitting at a table drinking.", "Several people in a bar sitting at a long table.", "People eating in a restaurant near wine bottles."], "instances": [{"category": "dining table", "bbox": [0.123, 0.663, 0.317, 0.811]}, {"category": "person", "bbox": [0.715, 0.239, 1.0, 0.998]}, {"category": "person", "bbox": [0.142, 0.528, 0.281, 0.742]}, {"category": "person", "bbox": [0.529, 0.53, 0.606, 0.69]}, {"category": "person", "bbox": [0.705, 0.518, 0.796, 0.673]}, {"category": "wine glass", "bbox": [0.247, 0.669, 0.27, 0.718]}, {"category": "person", "bbox": [0.281, 0.524, 0.534, 1.0]}, {"category": "bottle", "bbox": [0.168, 0.346, 0.189, 0.425]}, {"category": "bottle", "bbox": [0.379, 0.264, 0.431, 0.433]}, {"category": "bottle", "bbox": [0.252, 0.313, 0.277, 0.429]}, {"category": "bottle", "bbox": [0.294, 0.295, 0.326, 0.43]}, {"category": "bottle", "bbox": [0.589, 0.35, 0.613, 0.444]}, {"category": "bottle", "bbox": [0.433, 0.281, 0.473, 0.437]}, {"category": "bottle", "bbox": [0.478, 0.289, 0.513, 0.44]}, {"category": "wine glass", "bbox": [0.688, 0.615, 0.709, 0.69]}, {"category": "cup", "bbox": [0.589, 0.647, 0.612, 0.693]}, {"category": "person", "bbox": [0.732, 0.356, 0.953, 0.806]}, {"category": "bottle", "bbox": [0.555, 0.337, 0.585, 0.438]}, {"category": "bottle", "bbox": [0.337, 0.29, 0.378, 0.432]}, {"category": "bottle", "bbox": [0.21, 0.333, 0.232, 0.426]}, {"category": "bottle", "bbox": [0.134, 0.36, 0.148, 0.422]}, {"category": "bottle", "bbox": [0.516, 0.312, 0.557, 0.439]}, {"category": "cup", "bbox": [0.231, 0.718, 0.26, 0.763]}, {"category": "chair", "bbox": [0.517, 0.828, 0.65, 0.999]}, {"category": "chair", "bbox": [0.643, 0.804, 0.738, 0.841]}, {"category": "chair", "bbox": [0.347, 0.908, 0.519, 1.0]}, {"category": "chair", "bbox": [0.64, 0.806, 0.74, 0.998]}, {"category": "cup", "bbox": [0.205, 0.692, 0.232, 0.767]}, {"category": "dining table", "bbox": [0.536, 0.676, 0.743, 0.838]}, {"category": "person", "bbox": [0.002, 0.501, 0.263, 0.987]}, {"category": "bottle", "bbox": [0.531, 0.461, 0.542, 0.526]}, {"category": "bottle", "bbox": [0.237, 0.354, 0.702, 0.629]}]}
|
| 36 |
+
{"id": "000000415393", "image": "000000415393.jpg", "captions": ["a man on a skate board looks like he is falling", "A man does a skateboard trick on a skateboard ramp", "Guy falling off a skateboard in a room.", "A man riding a skateboard on top of a table.", "a man skating on part of a ramp with his skateboard"], "instances": [{"category": "person", "bbox": [0.361, 0.016, 0.809, 0.888]}, {"category": "skateboard", "bbox": [0.606, 0.809, 0.889, 0.901]}, {"category": "person", "bbox": [0.479, 0.091, 0.576, 0.386]}, {"category": "person", "bbox": [0.047, 0.441, 0.197, 0.759]}, {"category": "person", "bbox": [0.038, 0.453, 0.076, 0.545]}, {"category": "person", "bbox": [0.249, 0.307, 0.311, 0.591]}]}
|
| 37 |
+
{"id": "000000161011", "image": "000000161011.jpg", "captions": ["Three skiers posing for a picture on the slope.", "Three skiers pause for a photo at the top of a mountain.", "Three people standing on a mountain taking a picture as they ski.", "A woman and two men on skis on a snowy hillside surrounded by trees", "Three skiers have stopped to pose for a picture."], "instances": [{"category": "person", "bbox": [0.36, 0.321, 0.509, 0.82]}, {"category": "person", "bbox": [0.179, 0.281, 0.349, 0.795]}, {"category": "person", "bbox": [0.611, 0.292, 0.751, 0.809]}, {"category": "skis", "bbox": [0.595, 0.743, 0.732, 0.961]}, {"category": "skis", "bbox": [0.341, 0.724, 0.621, 0.907]}, {"category": "skis", "bbox": [0.212, 0.705, 0.398, 0.905]}]}
|
| 38 |
+
{"id": "000000284296", "image": "000000284296.jpg", "captions": ["Three giraffe's leaning over to get a sip of water.", "an image of a herd of giraffes in the water", "three giraffes banding down to drink water with trees in the background", "Three giraffe drinking from a pond with brush in back.", "Giraffes leaning down to drink at a watering hole"], "instances": [{"category": "giraffe", "bbox": [0.624, 0.387, 0.822, 0.635]}, {"category": "giraffe", "bbox": [0.4, 0.326, 0.561, 0.58]}, {"category": "giraffe", "bbox": [0.152, 0.291, 0.343, 0.551]}]}
|
| 39 |
+
{"id": "000000056013", "image": "000000056013.jpg", "captions": ["a number of luggage bags on a cart in a lobby", "Wheeled cart with luggage at lobby of commercial business.", "Trolley used for transporting personal luggage to guests rooms.", "A luggage cart topped with lots of luggage.", "a cart filled with suitcases and bags"], "instances": [{"category": "backpack", "bbox": [0.276, 0.52, 0.456, 0.678]}, {"category": "suitcase", "bbox": [0.41, 0.58, 0.597, 0.827]}, {"category": "suitcase", "bbox": [0.173, 0.645, 0.363, 0.836]}, {"category": "person", "bbox": [0.959, 0.297, 1.0, 0.478]}, {"category": "suitcase", "bbox": [0.526, 0.519, 0.712, 0.706]}, {"category": "person", "bbox": [0.762, 0.253, 0.871, 0.46]}, {"category": "backpack", "bbox": [0.517, 0.514, 0.694, 0.698]}, {"category": "handbag", "bbox": [0.316, 0.181, 0.431, 0.426]}, {"category": "suitcase", "bbox": [0.747, 0.453, 0.858, 0.557]}]}
|
| 40 |
+
{"id": "000000293505", "image": "000000293505.jpg", "captions": ["A person on a motor bike next to a cow.", "A woman riding a motorcycle down a dirt road.", "there is a woman riding a scooter down a dirt road", "A woman on a moped, two men and animals walking down the road.", "A woman on a motorcycle is next to a man walking a dog along with other people going down a dirt road."], "instances": [{"category": "cow", "bbox": [0.602, 0.472, 0.721, 0.816]}, {"category": "motorcycle", "bbox": [0.402, 0.512, 0.516, 0.788]}, {"category": "person", "bbox": [0.408, 0.4, 0.514, 0.639]}, {"category": "person", "bbox": [0.754, 0.301, 1.0, 1.0]}, {"category": "person", "bbox": [0.705, 0.415, 0.789, 0.714]}, {"category": "cow", "bbox": [0.347, 0.44, 0.373, 0.509]}, {"category": "cow", "bbox": [0.361, 0.436, 0.381, 0.501]}]}
|
| 41 |
+
{"id": "000000305873", "image": "000000305873.jpg", "captions": ["A little girl holding a red black dotted umbrella.", "A little girl with rain boots and a rain jacket on and an open umbrella to match her jacket.", "a little girl holding onto a lady bug pattern umbrella", "The child wears a labybug rain coat with a matching umbrella.", "A little girl wearing a ladybug raincoat and green rubber boots holding a ladybug umbrella"], "instances": [{"category": "umbrella", "bbox": [0.246, 0.002, 0.992, 0.415]}, {"category": "person", "bbox": [0.35, 0.132, 0.699, 0.791]}, {"category": "car", "bbox": [0.614, 0.0, 1.0, 0.465]}]}
|
| 42 |
+
{"id": "000000034096", "image": "000000034096.jpg", "captions": ["A house being built with lots of wood.", "A big pile of building material is placed on the floor in the wooden structure.", "A partially-built house with wooden studs and staircase in view.", "A house full of wood getting built at the moment.", "The beginning stages of a home still being made."], "instances": [{"category": "bed", "bbox": [0.505, 0.42, 0.721, 0.59]}, {"category": "tv", "bbox": [0.192, 0.441, 0.335, 0.606]}]}
|
| 43 |
+
{"id": "000000165257", "image": "000000165257.jpg", "captions": ["A large black counter top sitting next to a sink.", "a clean kitchen counter with a clean sink", "A kitchen with a sink, dishwasher and some boxes on the counter.", "A kitchen with a sink, dishwasher and boxes on the counter.", "a black counter on a wood cabinet in a kitchen", "a new kitchen cabinet with a sink being installed"], "instances": [{"category": "sink", "bbox": [0.513, 0.243, 0.718, 0.314]}]}
|
| 44 |
+
{"id": "000000431026", "image": "000000431026.jpg", "captions": ["a street sign on a city street near some tall bushes", "street signs on a metal pole lining a sidewalk lined with shrubbery.", "a large hedge of bushes on a corner near a street sign.", "Two street signs on sidewalk next to bushes and trees.", "Street signs along a well manicured street with large houses."], "instances": []}
|
| 45 |
+
{"id": "000000524575", "image": "000000524575.jpg", "captions": ["Three giraffe and a wildebeest in a field.", "A moose and several giraffes are grazing in the field.", "Zebras in the wild with a wildebeest behind them", "Two giraffe and a ox standing in a field eating grass.", "Giraffes and other safari animals graze in a sunlit field."], "instances": [{"category": "cow", "bbox": [0.46, 0.716, 0.643, 0.999]}, {"category": "giraffe", "bbox": [0.285, 0.5, 0.401, 0.826]}, {"category": "giraffe", "bbox": [0.083, 0.554, 0.179, 0.821]}, {"category": "giraffe", "bbox": [0.887, 0.481, 0.968, 0.715]}]}
|
| 46 |
+
{"id": "000000326550", "image": "000000326550.jpg", "captions": ["Black and white photograph of a person holding a surfboard by water.", "A person with a surfboard standing next to the water.", "A surfer stands on the rocks watching a wave crash.", "A man standing on a beach holding a surfboard.", "a person looking at the waves ready to surf"], "instances": [{"category": "person", "bbox": [0.327, 0.461, 0.492, 0.897]}, {"category": "surfboard", "bbox": [0.282, 0.56, 0.606, 0.741]}, {"category": "person", "bbox": [0.924, 0.352, 0.933, 0.362]}, {"category": "person", "bbox": [0.912, 0.348, 0.919, 0.36]}]}
|
| 47 |
+
{"id": "000000018476", "image": "000000018476.jpg", "captions": ["A tie that is sitting on top of a shirt.", "This photograph appears to be looking truly wonderful.", "a uniform complete with shoes laying on a bed", "Suit laid out with a red tie, white shirt and black shoes.", "a white shirt a red tie and some black shoes"], "instances": [{"category": "tie", "bbox": [0.457, 0.09, 0.853, 0.984]}, {"category": "bed", "bbox": [0.005, 0.005, 1.0, 0.379]}]}
|
| 48 |
+
{"id": "000000480652", "image": "000000480652.jpg", "captions": ["These suitcases are sitting next to a chair.", "An assortment of luggage bags stacked by a kitchen chair.", "A stack of luggage by a chair and table.", "a table and chair with several pieces of luggage nearby", "A pile of luggage sitting on the floor."], "instances": [{"category": "chair", "bbox": [0.483, 0.192, 1.0, 0.769]}, {"category": "backpack", "bbox": [0.433, 0.429, 0.742, 0.856]}, {"category": "suitcase", "bbox": [0.059, 0.414, 0.453, 0.841]}, {"category": "handbag", "bbox": [0.19, 0.184, 0.779, 0.475]}, {"category": "suitcase", "bbox": [0.175, 0.204, 0.583, 0.462]}]}
|
| 49 |
+
{"id": "000000012748", "image": "000000012748.jpg", "captions": ["A man and child next to a horse.", "a little boy touching the nose of a brown horse", "A man holding a baby whose petting a horse.", "a man letting his baby pet a horse", "man holding a baby and petting a horse"], "instances": [{"category": "horse", "bbox": [0.003, 0.079, 0.504, 0.868]}, {"category": "person", "bbox": [0.452, 0.294, 1.0, 0.989]}, {"category": "person", "bbox": [0.46, 0.217, 1.0, 0.988]}]}
|
| 50 |
+
{"id": "000000247840", "image": "000000247840.jpg", "captions": ["Large group of people standing outside a restaurant together.", "A dairy queen has people standing outside waiting", "an image of people standing outside and ice cream store", "Several people are lined up outside of a store.", "The front of a Dairy Queen restaurant with people entering the side."], "instances": [{"category": "fire hydrant", "bbox": [0.774, 0.674, 0.83, 0.807]}, {"category": "person", "bbox": [0.741, 0.465, 0.824, 0.755]}, {"category": "person", "bbox": [0.806, 0.471, 0.839, 0.722]}, {"category": "person", "bbox": [0.831, 0.499, 0.866, 0.726]}, {"category": "bench", "bbox": [0.061, 0.69, 0.219, 0.768]}, {"category": "handbag", "bbox": [0.859, 0.558, 0.877, 0.603]}, {"category": "person", "bbox": [0.719, 0.504, 0.75, 0.626]}, {"category": "potted plant", "bbox": [0.7, 0.648, 0.764, 0.743]}, {"category": "handbag", "bbox": [0.827, 0.548, 0.837, 0.577]}, {"category": "sandwich", "bbox": [0.359, 0.618, 0.417, 0.694]}]}
|
| 51 |
+
{"id": "000000399452", "image": "000000399452.jpg", "captions": ["a sandwhich sitting on a plate next to a glass of tea, bowl of soup", "a sandwich on a white plate a drink on a brown table", "A sandwich and chips sit on a white plate.", "a large plate of food with a glass of soda by it", "A sandwich sitting on top of a white plate next to a cup of coffee."], "instances": [{"category": "sandwich", "bbox": [0.175, 0.326, 0.605, 0.71]}, {"category": "cup", "bbox": [0.504, 0.024, 0.687, 0.419]}, {"category": "knife", "bbox": [0.742, 0.283, 0.857, 0.376]}, {"category": "spoon", "bbox": [0.618, 0.46, 0.797, 0.809]}, {"category": "fork", "bbox": [0.684, 0.254, 0.805, 0.395]}, {"category": "bowl", "bbox": [0.782, 0.366, 1.0, 0.62]}, {"category": "chair", "bbox": [0.202, 0.0, 0.671, 0.148]}, {"category": "dining table", "bbox": [0.002, 0.126, 0.996, 0.987]}]}
|
| 52 |
+
{"id": "000000515716", "image": "000000515716.jpg", "captions": ["A couple of women standing on either side of a man wearing glasses.", "Two women and a man are holding glasses up at a wine tasting.", "Three young adults holding wine glasses while standing at a bar.", "A group of people sit holding glasses and smiling at a table with several bottles.", "A group of people at a celebration having a taste of wine."], "instances": [{"category": "bottle", "bbox": [0.529, 0.604, 0.637, 0.908]}, {"category": "bottle", "bbox": [0.379, 0.398, 0.481, 0.892]}, {"category": "bottle", "bbox": [0.942, 0.464, 0.988, 0.653]}, {"category": "person", "bbox": [0.0, 0.126, 0.136, 0.811]}, {"category": "person", "bbox": [0.05, 0.093, 0.211, 0.471]}, {"category": "person", "bbox": [0.401, 0.031, 0.678, 0.683]}, {"category": "person", "bbox": [0.617, 0.191, 0.94, 0.858]}, {"category": "person", "bbox": [0.723, 0.098, 0.947, 0.564]}, {"category": "wine glass", "bbox": [0.634, 0.434, 0.697, 0.628]}, {"category": "wine glass", "bbox": [0.285, 0.346, 0.372, 0.558]}, {"category": "wine glass", "bbox": [0.522, 0.422, 0.583, 0.544]}, {"category": "handbag", "bbox": [0.704, 0.601, 1.0, 0.916]}, {"category": "person", "bbox": [0.944, 0.319, 0.999, 0.604]}, {"category": "bottle", "bbox": [0.921, 0.46, 0.953, 0.636]}, {"category": "person", "bbox": [0.116, 0.171, 0.41, 0.829]}]}
|
| 53 |
+
{"id": "000000116173", "image": "000000116173.jpg", "captions": ["The boy is on his surfboard in the water riding it.", "a young boy riding a boogie board in the water", "A boy riding surf board in the ocean.", "A young boy is riding a surfboard on a small wave.", "A young boy is surfing in the ocean."], "instances": [{"category": "person", "bbox": [0.485, 0.238, 0.702, 0.821]}, {"category": "person", "bbox": [0.866, 0.223, 0.921, 0.29]}, {"category": "person", "bbox": [0.752, 0.146, 0.775, 0.188]}, {"category": "surfboard", "bbox": [0.239, 0.758, 0.782, 0.846]}, {"category": "surfboard", "bbox": [0.853, 0.277, 0.981, 0.29]}, {"category": "surfboard", "bbox": [0.727, 0.169, 0.801, 0.198]}, {"category": "person", "bbox": [0.637, 0.194, 0.677, 0.261]}]}
|
| 54 |
+
{"id": "000000186013", "image": "000000186013.jpg", "captions": ["A beach scene includes many different kites flying in a cloudy sky.", "Kites being flown at the beach at twilight.", "A beach with flags in the ground and kites overhead in the sky.", "A beach with rows of flags in the sand and kites flying overhead.", "A beach filled with kites and wind sails next to the ocean."], "instances": [{"category": "kite", "bbox": [0.174, 0.4, 0.351, 0.483]}, {"category": "kite", "bbox": [0.144, 0.13, 0.273, 0.17]}, {"category": "kite", "bbox": [0.236, 0.269, 0.268, 0.294]}, {"category": "kite", "bbox": [0.464, 0.204, 0.598, 0.271]}, {"category": "kite", "bbox": [0.61, 0.304, 0.659, 0.342]}, {"category": "kite", "bbox": [0.545, 0.435, 0.565, 0.452]}, {"category": "kite", "bbox": [0.027, 0.558, 0.151, 0.59]}, {"category": "kite", "bbox": [0.93, 0.429, 0.973, 0.536]}, {"category": "kite", "bbox": [0.684, 0.36, 0.697, 0.374]}, {"category": "surfboard", "bbox": [0.393, 0.627, 0.446, 0.934]}, {"category": "person", "bbox": [0.959, 0.685, 0.984, 0.713]}, {"category": "person", "bbox": [0.919, 0.681, 0.94, 0.725]}, {"category": "person", "bbox": [0.8, 0.597, 0.805, 0.61]}, {"category": "person", "bbox": [0.079, 0.928, 0.116, 0.975]}, {"category": "kite", "bbox": [0.743, 0.307, 0.755, 0.319]}, {"category": "kite", "bbox": [0.78, 0.322, 0.795, 0.335]}, {"category": "kite", "bbox": [0.536, 0.526, 0.597, 0.617]}, {"category": "person", "bbox": [0.941, 0.694, 0.961, 0.726]}, {"category": "kite", "bbox": [0.575, 0.446, 0.594, 0.471]}]}
|
| 55 |
+
{"id": "000000015029", "image": "000000015029.jpg", "captions": ["A man holding a white frisbee standing on top of a field.", "A man is playing frisbee next to a tent.", "Guy at the park holding a frisbee with people in the back under a tent", "A man is holding a Frisbee standing in the grass.", "Young adult male holding a frisbee at an event."], "instances": [{"category": "frisbee", "bbox": [0.138, 0.359, 0.215, 0.587]}, {"category": "person", "bbox": [0.16, 0.002, 0.726, 0.995]}, {"category": "person", "bbox": [0.81, 0.73, 0.852, 0.825]}, {"category": "person", "bbox": [0.786, 0.749, 0.833, 0.814]}, {"category": "person", "bbox": [0.847, 0.743, 0.89, 0.804]}, {"category": "person", "bbox": [0.614, 0.749, 0.706, 0.936]}]}
|
| 56 |
+
{"id": "000000500565", "image": "000000500565.jpg", "captions": ["A woman holding a child wrapped in a towel brushing her teeth.", "A woman is holding a baby who is wrapped in a towel and holding a toothbrush", "A woman holding a little boy who is brushing his teeth.", "A baby with a toothbrush in his mouth while being held by a woman", "a close up of an adult holding a child brushing their teeth"], "instances": [{"category": "toothbrush", "bbox": [0.586, 0.66, 0.754, 0.821]}, {"category": "person", "bbox": [0.002, 0.007, 0.637, 0.991]}, {"category": "person", "bbox": [0.357, 0.196, 0.998, 0.984]}]}
|
| 57 |
+
{"id": "000000297323", "image": "000000297323.jpg", "captions": ["Two buses are parked against a curb in front of a building.", "Two automobiles parked on the side of a building.", "two tourist buses parked on street in front of old industrial building", "Two unique city buses stopped at a stop sign.", "Buses parked outside by a building and stop sign."], "instances": [{"category": "bus", "bbox": [0.7, 0.711, 0.92, 0.881]}, {"category": "person", "bbox": [0.936, 0.771, 0.972, 0.833]}, {"category": "stop sign", "bbox": [0.237, 0.666, 0.285, 0.728]}, {"category": "bus", "bbox": [0.334, 0.71, 0.678, 0.935]}, {"category": "truck", "bbox": [0.335, 0.72, 0.683, 0.934]}, {"category": "person", "bbox": [0.34, 0.791, 0.367, 0.834]}]}
|
| 58 |
+
{"id": "000000441147", "image": "000000441147.jpg", "captions": ["Two antique suitcases sit stacked one on top of the other.", "Two suitcases are stacked on each other and one is black while the other is brown and yellow.", "a close up of two luggage suit cases stacked on each other", "A stack of antique luggage is displayed with price tags.", "two suitcases made of leather and stacked on top of each other"], "instances": [{"category": "suitcase", "bbox": [0.167, 0.025, 0.989, 0.445]}, {"category": "suitcase", "bbox": [0.002, 0.31, 0.994, 0.996]}]}
|
| 59 |
+
{"id": "000000353536", "image": "000000353536.jpg", "captions": ["A table topped with plates and glasses with eating utensils..", "a fork is laying on a small white plate", "dirty dishes on a table, and a bottle of something.", "a table top with some dishes on top of it", "A table full of dirty dishes is pictured in this image."], "instances": [{"category": "dining table", "bbox": [0.0, 0.007, 0.998, 0.988]}, {"category": "bottle", "bbox": [0.554, 0.002, 0.768, 0.411]}, {"category": "cup", "bbox": [0.372, 0.011, 0.544, 0.427]}, {"category": "fork", "bbox": [0.442, 0.464, 0.818, 0.572]}, {"category": "fork", "bbox": [0.089, 0.233, 0.272, 0.456]}, {"category": "spoon", "bbox": [0.144, 0.218, 0.326, 0.413]}, {"category": "cup", "bbox": [0.688, 0.056, 0.812, 0.361]}]}
|
| 60 |
+
{"id": "000000416256", "image": "000000416256.jpg", "captions": ["A cat laying on the floor next to a keyboard.", "an orange and white cat is laying next to a keyboard and some wires", "A cat is laying next to a computer keyboard.", "a cat laying on a floor next to a keyboard", "A CAT LAYING ON THE FLOOR AMIDST A COMPUTER,SPEAKERS,CORDS"], "instances": [{"category": "cat", "bbox": [0.235, 0.23, 0.737, 0.639]}, {"category": "keyboard", "bbox": [0.243, 0.562, 0.631, 0.836]}, {"category": "keyboard", "bbox": [0.058, 0.33, 0.277, 0.608]}]}
|
| 61 |
+
{"id": "000000214367", "image": "000000214367.jpg", "captions": ["Wood shading on the side of a window with brick siding.", "A tree filled with lots of red fruit near a building.", "By the window outside is a apple tree, where the apples are ready to be picked.", "Some very nice looking red fruity by a window,", "A shuttered window has a fruit tree outside it."], "instances": [{"category": "apple", "bbox": [0.214, 0.112, 0.408, 0.266]}, {"category": "apple", "bbox": [0.472, 0.166, 0.618, 0.293]}, {"category": "apple", "bbox": [0.055, 0.592, 0.172, 0.686]}, {"category": "apple", "bbox": [0.126, 0.661, 0.236, 0.739]}, {"category": "apple", "bbox": [0.52, 0.09, 0.609, 0.143]}, {"category": "apple", "bbox": [0.226, 0.354, 0.285, 0.409]}, {"category": "apple", "bbox": [0.0, 0.698, 0.096, 0.771]}, {"category": "apple", "bbox": [0.001, 0.646, 0.042, 0.713]}, {"category": "apple", "bbox": [0.258, 0.719, 0.329, 0.778]}]}
|
| 62 |
+
{"id": "000000210299", "image": "000000210299.jpg", "captions": ["A little boy riding his bike and wearing a helmet", "A little boy raveling down a road on a bike, with a yellow helmet on.", "The boy wears a helmet while riding his bicycle.", "a small child wearing a helmet and riding a bike", "A little boy wearing a helmet and riding a bike."], "instances": [{"category": "person", "bbox": [0.198, 0.259, 0.399, 0.679]}, {"category": "bicycle", "bbox": [0.213, 0.383, 0.408, 0.835]}]}
|
| 63 |
+
{"id": "000000088218", "image": "000000088218.jpg", "captions": ["Signs proclaim the famous Haight Ashbury intersection and district.", "a pole with street lights, signs and wires attached to it", "A traffic light at the intersection of Haight and Ashbury", "A traffic sign is shown with traffic signs above it.", "The street signs and traffic signal are below wires attached to the pole."], "instances": [{"category": "traffic light", "bbox": [0.443, 0.435, 0.658, 0.721]}]}
|
| 64 |
+
{"id": "000000020650", "image": "000000020650.jpg", "captions": ["Burger with broccoli, pickle, and fork on orange plate", "On a plate is kept a burger and a bowl of broccoli and a fork.", "There is half a sandwich on an orange plate with a pickle and a bowl of broccoli", "A A bowl and a sandwich on an orange plate on a table.", "A plate has a sandwich, broccoli, and a pickle."], "instances": [{"category": "sandwich", "bbox": [0.436, 0.155, 0.805, 0.859]}, {"category": "sandwich", "bbox": [0.311, 0.006, 0.748, 0.293]}, {"category": "fork", "bbox": [0.0, 0.665, 0.578, 0.876]}, {"category": "bowl", "bbox": [0.002, 0.263, 0.487, 0.744]}, {"category": "bowl", "bbox": [0.708, 0.003, 0.828, 0.03]}, {"category": "broccoli", "bbox": [0.185, 0.288, 0.366, 0.546]}, {"category": "broccoli", "bbox": [0.017, 0.344, 0.384, 0.654]}, {"category": "broccoli", "bbox": [0.31, 0.191, 0.466, 0.463]}, {"category": "broccoli", "bbox": [0.104, 0.107, 0.285, 0.342]}, {"category": "broccoli", "bbox": [0.092, 0.276, 0.242, 0.442]}, {"category": "dining table", "bbox": [0.002, 0.0, 0.999, 0.987]}]}
|
| 65 |
+
{"id": "000000514915", "image": "000000514915.jpg", "captions": ["A large black dog laying on a kitchen floor.", "A dog is laying down on the floor in the home.", "Black dog laying down on the kitchen floor next to it's bowls and toy", "A black dog with a red collar laying on a tiled floor.", "A black dog that is laying on the floor."], "instances": [{"category": "dog", "bbox": [0.087, 0.276, 0.812, 0.792]}, {"category": "bowl", "bbox": [0.437, 0.09, 0.533, 0.213]}, {"category": "bowl", "bbox": [0.537, 0.035, 0.665, 0.141]}]}
|
| 66 |
+
{"id": "000000205183", "image": "000000205183.jpg", "captions": ["A duck walking along a paved road next to a patch of grass.", "A close up of a duck walking on a path.", "a duck walks along a cement patch while looking down", "A white duck out of water, walking on the ground.", "A goose standing in the road, looking at the ground."], "instances": [{"category": "bird", "bbox": [0.291, 0.235, 0.859, 0.889]}]}
|
| 67 |
+
{"id": "000000534270", "image": "000000534270.jpg", "captions": ["Man and woman with umbrella hats sitting on top of a bridge.", "A couple equipped with umbrella hats taking a break from walking their dog on a bridge on a rainy day.", "Two people in ridiculous looking umbrella hats.", "two people with umbrella hats near one another", "A couple of people wearing umbrella hats next to the ocean."], "instances": [{"category": "dog", "bbox": [0.456, 0.832, 0.6, 0.983]}, {"category": "person", "bbox": [0.433, 0.464, 0.636, 0.975]}, {"category": "person", "bbox": [0.263, 0.321, 0.459, 0.978]}, {"category": "boat", "bbox": [0.912, 0.4, 0.978, 0.433]}, {"category": "boat", "bbox": [0.211, 0.236, 0.478, 0.304]}, {"category": "boat", "bbox": [0.144, 0.328, 0.189, 0.361]}, {"category": "umbrella", "bbox": [0.443, 0.402, 0.607, 0.473]}, {"category": "umbrella", "bbox": [0.325, 0.311, 0.483, 0.432]}, {"category": "umbrella", "bbox": [0.207, 0.738, 0.284, 0.778]}, {"category": "umbrella", "bbox": [0.489, 0.713, 0.649, 0.83]}]}
|
| 68 |
+
{"id": "000000408439", "image": "000000408439.jpg", "captions": ["Cliffs rise on the edge of a placid lake.", "A scenic view of a river with a train on the edge of it in the distance.", "A large lake surrounded by beautiful tree covered mountains.", "a landscape scene with water, mountains and trees", "A train on a waterfront track surrounded by mountains."], "instances": [{"category": "train", "bbox": [0.008, 0.591, 0.562, 0.644]}]}
|
| 69 |
+
{"id": "000000474253", "image": "000000474253.jpg", "captions": ["A man riding on the back of a horse through a river.", "A person is riding a horse through water.", "Horse and rider crossing waterway during competitive event.", "A woman riding a horse splashes through a large puddle.", "A young man riding a horse through some water."], "instances": [{"category": "horse", "bbox": [0.385, 0.235, 0.651, 0.814]}, {"category": "person", "bbox": [0.396, 0.06, 0.576, 0.675]}, {"category": "person", "bbox": [0.29, 0.148, 0.355, 0.333]}, {"category": "person", "bbox": [0.129, 0.163, 0.212, 0.349]}, {"category": "person", "bbox": [0.005, 0.014, 0.038, 0.165]}, {"category": "person", "bbox": [0.144, 0.011, 0.193, 0.155]}, {"category": "person", "bbox": [0.089, 0.007, 0.133, 0.162]}]}
|
| 70 |
+
{"id": "000000098029", "image": "000000098029.jpg", "captions": ["a table with many plates on it with a bread basket", "A table set for four has many foods and fruits on it.", "Several objects displayed on a kitchen table including bread, oranges and plating.", "Several dishes and food items sit on a table.", "An assortment of foods sitting on a round brown table."], "instances": [{"category": "refrigerator", "bbox": [0.013, 0.004, 0.37, 0.317]}, {"category": "bottle", "bbox": [0.467, 0.517, 0.555, 0.638]}, {"category": "bottle", "bbox": [0.602, 0.536, 0.658, 0.609]}, {"category": "chair", "bbox": [0.747, 0.367, 1.0, 0.592]}, {"category": "chair", "bbox": [0.044, 0.368, 0.358, 0.544]}, {"category": "cup", "bbox": [0.296, 0.465, 0.359, 0.54]}, {"category": "cup", "bbox": [0.709, 0.67, 0.782, 0.736]}, {"category": "cup", "bbox": [0.213, 0.684, 0.294, 0.753]}, {"category": "knife", "bbox": [0.787, 0.699, 0.922, 0.797]}, {"category": "knife", "bbox": [0.161, 0.539, 0.265, 0.584]}, {"category": "spoon", "bbox": [0.813, 0.674, 0.922, 0.759]}, {"category": "spoon", "bbox": [0.156, 0.555, 0.233, 0.587]}, {"category": "spoon", "bbox": [0.596, 0.467, 0.613, 0.509]}, {"category": "bowl", "bbox": [0.241, 0.753, 0.505, 0.935]}, {"category": "banana", "bbox": [0.632, 0.138, 0.718, 0.161]}, {"category": "apple", "bbox": [0.701, 0.152, 0.758, 0.191]}, {"category": "orange", "bbox": [0.607, 0.66, 0.692, 0.716]}, {"category": "orange", "bbox": [0.565, 0.636, 0.611, 0.667]}, {"category": "orange", "bbox": [0.526, 0.624, 0.572, 0.652]}, {"category": "orange", "bbox": [0.61, 0.628, 0.656, 0.657]}, {"category": "orange", "bbox": [0.599, 0.649, 0.643, 0.677]}, {"category": "dining table", "bbox": [0.013, 0.439, 0.964, 0.986]}, {"category": "cup", "bbox": [0.612, 0.489, 0.669, 0.548]}, {"category": "knife", "bbox": [0.605, 0.457, 0.638, 0.53]}, {"category": "apple", "bbox": [0.502, 0.137, 0.537, 0.159]}, {"category": "orange", "bbox": [0.54, 0.135, 0.563, 0.151]}, {"category": "orange", "bbox": [0.527, 0.129, 0.554, 0.142]}, {"category": "orange", "bbox": [0.611, 0.155, 0.641, 0.171]}, {"category": "chair", "bbox": [0.0, 0.843, 0.29, 0.989]}, {"category": "cup", "bbox": [0.353, 0.469, 0.411, 0.511]}, {"category": "cup", "bbox": [0.609, 0.716, 0.682, 0.786]}, {"category": "orange", "bbox": [0.638, 0.158, 0.679, 0.177]}, {"category": "cake", "bbox": [0.38, 0.821, 0.481, 0.895]}, {"category": "chair", "bbox": [0.79, 0.747, 1.0, 1.0]}, {"category": "bottle", "bbox": [0.719, 0.55, 0.769, 0.616]}, {"category": "bottle", "bbox": [0.795, 0.546, 0.873, 0.613]}, {"category": "knife", "bbox": [0.17, 0.799, 0.264, 0.88]}, {"category": "cup", "bbox": [0.317, 0.695, 0.391, 0.752]}]}
|
| 71 |
+
{"id": "000000294073", "image": "000000294073.jpg", "captions": ["A woman and a man standing between two brown horses.", "A COUPLE WEARING YELLOW DRESS STANDING NEAR TWO HORSES.", "An older couple stands between two horses.", "A man and a woman standing with two horses", "A man and a woman stand in between two horses."], "instances": [{"category": "horse", "bbox": [0.0, 0.052, 0.49, 0.989]}, {"category": "horse", "bbox": [0.632, 0.23, 1.0, 0.989]}, {"category": "person", "bbox": [0.425, 0.326, 0.696, 0.987]}, {"category": "person", "bbox": [0.627, 0.203, 0.828, 0.986]}, {"category": "book", "bbox": [0.525, 0.597, 0.644, 0.833]}]}
|
| 72 |
+
{"id": "000000203629", "image": "000000203629.jpg", "captions": ["A man on a cell phone in a public area holding his thumb up.", "A group of people gathered inside of a room.", "A man on his cellphone posing for a picture.", "A man giving a thumbs up while on a cell phone.", "The man is giving a thumbs up while on his phone."], "instances": [{"category": "cell phone", "bbox": [0.43, 0.459, 0.449, 0.503]}, {"category": "cup", "bbox": [0.756, 0.838, 0.865, 0.98]}, {"category": "person", "bbox": [0.232, 0.317, 0.603, 0.98]}, {"category": "person", "bbox": [0.602, 0.405, 1.0, 0.999]}, {"category": "person", "bbox": [0.003, 0.339, 0.313, 0.987]}, {"category": "person", "bbox": [0.164, 0.379, 0.258, 0.733]}, {"category": "person", "bbox": [0.564, 0.36, 0.673, 0.645]}, {"category": "person", "bbox": [0.241, 0.379, 0.336, 0.512]}, {"category": "person", "bbox": [0.682, 0.372, 0.736, 0.502]}, {"category": "person", "bbox": [0.654, 0.428, 0.734, 0.536]}, {"category": "person", "bbox": [0.718, 0.368, 0.787, 0.508]}, {"category": "person", "bbox": [0.148, 0.362, 0.205, 0.529]}, {"category": "person", "bbox": [0.001, 0.431, 0.044, 0.564]}, {"category": "cup", "bbox": [0.901, 0.808, 0.995, 0.982]}]}
|
| 73 |
+
{"id": "000000119876", "image": "000000119876.jpg", "captions": ["A man dressed loudly is using his cell phone.", "A man talking on the phone while he walks down the street.", "A man with pink hair talking on a cell phone.", "A man in a purple shirt and tie and purple hair.", "a man colored his hair in purple walking on the road"], "instances": [{"category": "bicycle", "bbox": [0.525, 0.222, 0.924, 0.608]}, {"category": "bicycle", "bbox": [0.895, 0.249, 1.0, 0.642]}, {"category": "person", "bbox": [0.0, 0.0, 0.738, 1.0]}, {"category": "tie", "bbox": [0.319, 0.255, 0.423, 0.638]}, {"category": "cell phone", "bbox": [0.411, 0.13, 0.426, 0.161]}, {"category": "handbag", "bbox": [0.369, 0.205, 0.575, 0.839]}]}
|
| 74 |
+
{"id": "000000164255", "image": "000000164255.jpg", "captions": ["An umbrella that is standing in the sand.", "An umbrella is stuck in the sand on the beach.", "a colorful striped umbrella on the beach near the ocean", "A colorful umbrella is set up at the beach.", "The colorful umbrella is sitting by the beach,"], "instances": [{"category": "umbrella", "bbox": [0.0, 0.101, 0.567, 0.575]}]}
|
| 75 |
+
{"id": "000000192817", "image": "000000192817.jpg", "captions": ["A view from a window high up in the sky.", "A bunch of mountains seen from a plane window.", "The window from a plane overlooking the ground.", "The view of a mountain area from an airplane window.", "An aerial view of mountains and lakes from an airplane window."], "instances": []}
|
| 76 |
+
{"id": "000000258285", "image": "000000258285.jpg", "captions": ["Two large passenger jets flying over a beach filled with birds.", "A plane is flying over a bird filed lake", "Two airplanes are in the sky over blue water.", "An airplane landing over an airplane on the ground.", "A photo of two plans with water and birds surrounding it , one plane in the air one one the ground."], "instances": [{"category": "bird", "bbox": [0.507, 0.941, 0.536, 0.973]}, {"category": "bird", "bbox": [0.304, 0.933, 0.315, 0.95]}, {"category": "bird", "bbox": [0.129, 0.885, 0.143, 0.912]}, {"category": "bird", "bbox": [0.158, 0.851, 0.165, 0.87]}, {"category": "bird", "bbox": [0.404, 0.839, 0.429, 0.864]}, {"category": "bird", "bbox": [0.498, 0.833, 0.513, 0.861]}, {"category": "airplane", "bbox": [0.276, 0.085, 0.825, 0.316]}, {"category": "airplane", "bbox": [0.478, 0.252, 0.983, 0.495]}, {"category": "bird", "bbox": [0.552, 0.828, 0.564, 0.844]}, {"category": "bird", "bbox": [0.789, 0.812, 0.798, 0.836]}, {"category": "bird", "bbox": [0.927, 0.82, 0.936, 0.838]}, {"category": "bird", "bbox": [0.65, 0.828, 0.664, 0.849]}, {"category": "bird", "bbox": [0.752, 0.81, 0.763, 0.83]}, {"category": "bird", "bbox": [0.841, 0.817, 0.852, 0.828]}, {"category": "bird", "bbox": [0.292, 0.849, 0.311, 0.868]}, {"category": "bird", "bbox": [0.005, 0.727, 0.981, 0.998]}]}
|
| 77 |
+
{"id": "000000506483", "image": "000000506483.jpg", "captions": ["An art installation is placed by a street.", "People sit near a display of large artworks including an oversize bench and painted feline heads.", "Looking down on a giant rocking bench and large animal heads.", "An over sized wooden bench next to two massive animal art sculptures.", "artistic sculptures and images on a city street"], "instances": [{"category": "car", "bbox": [0.656, 0.939, 0.933, 1.0]}, {"category": "person", "bbox": [0.08, 0.664, 0.147, 0.805]}, {"category": "person", "bbox": [0.154, 0.646, 0.217, 0.821]}, {"category": "bench", "bbox": [0.316, 0.124, 0.951, 0.635]}, {"category": "backpack", "bbox": [0.062, 0.701, 0.097, 0.769]}, {"category": "person", "bbox": [0.0, 0.132, 0.031, 0.197]}]}
|
| 78 |
+
{"id": "000000502168", "image": "000000502168.jpg", "captions": ["a fleet of naval ships in the ocean", "A group of men on aircraft carrier with other boats in the distance.", "A large ship floating in the ocean next to other ships.", "Several men on a boat looking over the side.", "The men wear hardhats as they work on the aircraft carrier."], "instances": [{"category": "boat", "bbox": [0.634, 0.292, 1.0, 0.982]}, {"category": "person", "bbox": [0.675, 0.507, 0.736, 0.731]}, {"category": "person", "bbox": [0.684, 0.737, 0.817, 1.0]}, {"category": "person", "bbox": [0.803, 0.691, 0.883, 0.932]}, {"category": "person", "bbox": [0.741, 0.56, 0.798, 0.767]}, {"category": "person", "bbox": [0.924, 0.269, 0.951, 0.367]}, {"category": "boat", "bbox": [0.079, 0.171, 0.172, 0.231]}, {"category": "boat", "bbox": [0.863, 0.131, 0.961, 0.239]}, {"category": "boat", "bbox": [0.435, 0.288, 0.46, 0.313]}, {"category": "boat", "bbox": [0.591, 0.186, 0.605, 0.222]}, {"category": "person", "bbox": [0.451, 0.289, 0.455, 0.296]}, {"category": "person", "bbox": [0.446, 0.29, 0.451, 0.296]}, {"category": "person", "bbox": [0.872, 0.627, 0.957, 0.966]}, {"category": "person", "bbox": [0.44, 0.288, 0.446, 0.3]}]}
|
| 79 |
+
{"id": "000000319432", "image": "000000319432.jpg", "captions": ["Man holding two shirts with luggage and window", "A man holding clothes on a hanger with a suitcase in front of him.", "A man show a red and a white clothing hangers.", "A man holding his garment bags in both hands", "A man holding up some clothes in some hanger bags."], "instances": [{"category": "person", "bbox": [0.0, 0.092, 0.776, 0.852]}, {"category": "suitcase", "bbox": [0.153, 0.798, 0.587, 1.0]}]}
|
| 80 |
+
{"id": "000000131019", "image": "000000131019.jpg", "captions": ["Two zebras and two monkeys walking on the grass.", "Two giraffes and another animal are on green grass.", "A baboon and two zebras grazing on the savannah.", "A baboon and its baby eat by two zebras in the grass", "Monkey standing behind two zebras as they graze."], "instances": [{"category": "zebra", "bbox": [0.367, 0.258, 0.834, 0.646]}, {"category": "zebra", "bbox": [0.161, 0.13, 0.396, 0.375]}, {"category": "bird", "bbox": [0.309, 0.138, 0.34, 0.163]}]}
|
llava/eval/table/model.jsonl
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"model_id": "vicuna-13b:20230322-clean-lang", "model_name": "vicuna-13b", "model_version": "20230322-clean-lang", "model_metadata": "vicuna-13b-20230322-clean-lang"}
|
| 2 |
+
{"model_id": "alpaca-13b:v1", "model_name": "alpaca-13b", "model_version": "v1", "model_metadata": "alpaca-13b"}
|
| 3 |
+
{"model_id": "llama-13b:v1", "model_name": "llama-13b", "model_version": "v1", "model_metadata": "hf-llama-13b"}
|
| 4 |
+
{"model_id": "bard:20230327", "model_name": "bard", "model_version": "20230327", "model_metadata": "Google Bard 20230327"}
|
| 5 |
+
{"model_id": "gpt-3.5-turbo:20230327", "model_name": "gpt-3.5-turbo", "model_version": "20230327", "model_metadata": "OpenAI ChatGPT gpt-3.5-turbo Chat Completion"}
|
llava/eval/table/prompt.jsonl
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"prompt_id": 1, "system_prompt": "You are a helpful and precise assistant for checking the quality of the answer.", "prompt_template": "[Question]\n{question}\n\n[Assistant 1]\n{answer_1}\n\n[End of Assistant 1]\n\n[Assistant 2]\n{answer_2}\n\n[End of Assistant 2]\n\n[System]\n{prompt}\n\n", "defaults": {"prompt": "We would like to request your feedback on the performance of two AI assistants in response to the user question displayed above.\nPlease rate the helpfulness, relevance, accuracy, level of details of their responses. Each assistant receives an overall score on a scale of 1 to 10, where a higher score indicates better overall performance.\nPlease first output a single line containing only two values indicating the scores for Assistant 1 and 2, respectively. The two scores are separated by a space.\nIn the subsequent line, please provide a comprehensive explanation of your evaluation, avoiding any potential bias and ensuring that the order in which the responses were presented does not affect your judgment."}, "description": "Prompt for general questions"}
|
| 2 |
+
{"prompt_id": 2, "system_prompt": "You are a helpful and precise assistant for checking the quality of the answer.", "prompt_template": "[Question]\n{question}\n\n[Assistant 1]\n{answer_1}\n\n[End of Assistant 1]\n\n[Assistant 2]\n{answer_2}\n\n[End of Assistant 2]\n\n[System]\n{prompt}\n\n", "defaults": {"prompt": "Your task is to evaluate the coding abilities of the above two assistants. They have been asked to implement a program to solve a given problem. Please review their code submissions, paying close attention to their problem-solving approach, code structure, readability, and the inclusion of helpful comments.\n\nPlease ensure that the assistants' submissions:\n\n1. Correctly implement the given problem statement.\n2. Contain accurate and efficient code.\n3. Include clear and concise comments that explain the code's logic and functionality.\n4. Adhere to proper coding standards and best practices.\n\nOnce you have carefully reviewed both submissions, provide detailed feedback on their strengths and weaknesses, along with any suggestions for improvement. You should first output a single line containing two scores on the scale of 1-10 (1: no code/no sense; 10: perfect) for Assistant 1 and 2, respectively. Then give extra comments starting from the next line."}, "description": "Prompt for coding questions"}
|
| 3 |
+
{"prompt_id": 3, "system_prompt": "You are a helpful and precise assistant for checking the quality of the answer.", "prompt_template": "[Question]\n{question}\n\n[Assistant 1]\n{answer_1}\n\n[End of Assistant 1]\n\n[Assistant 2]\n{answer_2}\n\n[End of Assistant 2]\n\n[System]\n{prompt}\n\n", "defaults": {"prompt": "We would like to request your feedback on the mathematical proficiency of two AI assistants regarding the given user question.\nFirstly, please solve the problem independently, without referring to the answers provided by Assistant 1 and Assistant 2.\nAfterward, please examine the problem-solving process of Assistant 1 and Assistant 2 step-by-step to ensure their correctness, identifying any incorrect steps if present. Your evaluation should take into account not only the answer but also the problem-solving steps.\nFinally, please output a Python tuple containing two numerical scores for Assistant 1 and Assistant 2, ranging from 1 to 10, respectively. If applicable, explain the reasons for any variations in their scores and determine which assistant performed better."}, "description": "Prompt for math questions"}
|
| 4 |
+
{"prompt_id": 4, "system_prompt": "You are a helpful and precise assistant for checking the quality of the answer.", "prompt_template": "[Visual Context]\n{context}\n[Question]\n{question}\n\n[Assistant 1]\n{answer_1}\n\n[End of Assistant 1]\n\n[Assistant 2]\n{answer_2}\n\n[End of Assistant 2]\n\n[System]\n{prompt}\n\n", "defaults": {"prompt": "We would like to request your feedback on the performance of two AI assistants in response to the user question displayed above. The user asks the question on observing an image. For your reference, the visual content in the image is represented with five descriptive sentences describing the same image and the bounding box coordinates of each object in the scene. These coordinates are in the form of bounding boxes, represented as (x1, y1, x2, y2) with floating numbers ranging from 0 to 1. These values correspond to the top left x, top left y, bottom right x, and bottom right y. \nPlease rate the helpfulness, relevance, accuracy, level of details of their responses. Each assistant receives an overall score on a scale of 1 to 10, where a higher score indicates better overall performance.\nPlease first output a single line containing only two values indicating the scores for Assistant 1 and 2, respectively. The two scores are separated by a space.\nIn the subsequent line, please provide a comprehensive explanation of your evaluation, avoiding any potential bias and ensuring that the order in which the responses were presented does not affect your judgment."}, "description": "Prompt for visual questions"}
|