Spaces:
Runtime error

Runtime error
mins
commited on
Commit
·
b443c25
1
Parent(s):
4a650e1
initial commit
Browse files- .gitignore +23 -0
- app.py +306 -0
- assets/animal-compare.png +0 -0
- assets/georgia-tech.jpeg +0 -0
- assets/health-insurance.png +0 -0
- assets/leasing-apartment.png +0 -0
- assets/nvidia.jpeg +0 -0
- eagle/__init__.py +1 -0
- eagle/constants.py +13 -0
- eagle/conversation.py +396 -0
- eagle/mm_utils.py +247 -0
- eagle/model/__init__.py +1 -0
- eagle/model/builder.py +152 -0
- eagle/model/consolidate.py +29 -0
- eagle/model/eagle_arch.py +372 -0
- eagle/model/language_model/eagle_llama.py +158 -0
- eagle/model/multimodal_encoder/builder.py +17 -0
- eagle/model/multimodal_encoder/clip_encoder.py +88 -0
- eagle/model/multimodal_encoder/convnext_encoder.py +124 -0
- eagle/model/multimodal_encoder/hr_clip_encoder.py +162 -0
- eagle/model/multimodal_encoder/multi_backbone_channel_concatenation_encoder.py +143 -0
- eagle/model/multimodal_encoder/pix2struct_encoder.py +267 -0
- eagle/model/multimodal_encoder/sam_encoder.py +173 -0
- eagle/model/multimodal_encoder/vision_models/__init__.py +0 -0
- eagle/model/multimodal_encoder/vision_models/convnext.py +1110 -0
- eagle/model/multimodal_encoder/vision_models/eva_vit.py +1244 -0
- eagle/model/multimodal_projector/builder.py +76 -0
- eagle/utils.py +126 -0
- requirements.txt +26 -0
.gitignore
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Python
|
| 2 |
+
__pycache__
|
| 3 |
+
*.pyc
|
| 4 |
+
*.egg-info
|
| 5 |
+
dist
|
| 6 |
+
|
| 7 |
+
# Log
|
| 8 |
+
*.log
|
| 9 |
+
*.log.*
|
| 10 |
+
# *.json
|
| 11 |
+
*.jsonl
|
| 12 |
+
images/*
|
| 13 |
+
|
| 14 |
+
# Editor
|
| 15 |
+
.idea
|
| 16 |
+
*.swp
|
| 17 |
+
.github
|
| 18 |
+
.vscode
|
| 19 |
+
|
| 20 |
+
# Other
|
| 21 |
+
.DS_Store
|
| 22 |
+
wandb
|
| 23 |
+
output
|
app.py
ADDED
|
@@ -0,0 +1,306 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import os
|
| 3 |
+
# import copy
|
| 4 |
+
import torch
|
| 5 |
+
# import random
|
| 6 |
+
import spaces
|
| 7 |
+
|
| 8 |
+
from eagle import conversation as conversation_lib
|
| 9 |
+
from eagle.constants import DEFAULT_IMAGE_TOKEN
|
| 10 |
+
|
| 11 |
+
from eagle.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 12 |
+
from eagle.conversation import conv_templates, SeparatorStyle
|
| 13 |
+
from eagle.model.builder import load_pretrained_model
|
| 14 |
+
from eagle.utils import disable_torch_init
|
| 15 |
+
from eagle.mm_utils import tokenizer_image_token, get_model_name_from_path, process_images
|
| 16 |
+
|
| 17 |
+
from PIL import Image
|
| 18 |
+
import argparse
|
| 19 |
+
|
| 20 |
+
from transformers import TextIteratorStreamer
|
| 21 |
+
from threading import Thread
|
| 22 |
+
|
| 23 |
+
# os.environ['GRADIO_TEMP_DIR'] = './gradio_tmp'
|
| 24 |
+
no_change_btn = gr.Button()
|
| 25 |
+
enable_btn = gr.Button(interactive=True)
|
| 26 |
+
disable_btn = gr.Button(interactive=False)
|
| 27 |
+
|
| 28 |
+
argparser = argparse.ArgumentParser()
|
| 29 |
+
argparser.add_argument("--server_name", default="0.0.0.0", type=str)
|
| 30 |
+
argparser.add_argument("--port", default="6324", type=str)
|
| 31 |
+
argparser.add_argument("--model-path", default="NVEagle/Eagle-X5-13B", type=str)
|
| 32 |
+
argparser.add_argument("--model-base", type=str, default=None)
|
| 33 |
+
argparser.add_argument("--num-gpus", type=int, default=1)
|
| 34 |
+
argparser.add_argument("--conv-mode", type=str, default="vicuna_v1")
|
| 35 |
+
argparser.add_argument("--temperature", type=float, default=0.2)
|
| 36 |
+
argparser.add_argument("--max-new-tokens", type=int, default=512)
|
| 37 |
+
argparser.add_argument("--num_frames", type=int, default=16)
|
| 38 |
+
argparser.add_argument("--load-8bit", action="store_true")
|
| 39 |
+
argparser.add_argument("--load-4bit", action="store_true")
|
| 40 |
+
argparser.add_argument("--debug", action="store_true")
|
| 41 |
+
|
| 42 |
+
args = argparser.parse_args()
|
| 43 |
+
model_path = args.model_path
|
| 44 |
+
conv_mode = args.conv_mode
|
| 45 |
+
filt_invalid="cut"
|
| 46 |
+
model_name = get_model_name_from_path(args.model_path)
|
| 47 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(args.model_path, args.model_base, model_name, args.load_8bit, args.load_4bit)
|
| 48 |
+
our_chatbot = None
|
| 49 |
+
|
| 50 |
+
def upvote_last_response(state):
|
| 51 |
+
return ("",) + (disable_btn,) * 3
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def downvote_last_response(state):
|
| 55 |
+
return ("",) + (disable_btn,) * 3
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def flag_last_response(state):
|
| 59 |
+
return ("",) + (disable_btn,) * 3
|
| 60 |
+
|
| 61 |
+
def clear_history():
|
| 62 |
+
state =conv_templates[conv_mode].copy()
|
| 63 |
+
return (state, state.to_gradio_chatbot(), "", None) + (disable_btn,) * 5
|
| 64 |
+
|
| 65 |
+
def add_text(state, imagebox, textbox, image_process_mode):
|
| 66 |
+
if state is None:
|
| 67 |
+
state = conv_templates[conv_mode].copy()
|
| 68 |
+
|
| 69 |
+
if imagebox is not None:
|
| 70 |
+
textbox = DEFAULT_IMAGE_TOKEN + '\n' + textbox
|
| 71 |
+
image = Image.open(imagebox).convert('RGB')
|
| 72 |
+
|
| 73 |
+
if imagebox is not None:
|
| 74 |
+
textbox = (textbox, image, image_process_mode)
|
| 75 |
+
|
| 76 |
+
state.append_message(state.roles[0], textbox)
|
| 77 |
+
state.append_message(state.roles[1], None)
|
| 78 |
+
|
| 79 |
+
yield (state, state.to_gradio_chatbot(), "", None) + (disable_btn, disable_btn, disable_btn, enable_btn, enable_btn)
|
| 80 |
+
|
| 81 |
+
def delete_text(state, image_process_mode):
|
| 82 |
+
state.messages[-1][-1] = None
|
| 83 |
+
prev_human_msg = state.messages[-2]
|
| 84 |
+
if type(prev_human_msg[1]) in (tuple, list):
|
| 85 |
+
prev_human_msg[1] = (*prev_human_msg[1][:2], image_process_mode)
|
| 86 |
+
yield (state, state.to_gradio_chatbot(), "", None) + (disable_btn, disable_btn, disable_btn, enable_btn, enable_btn)
|
| 87 |
+
|
| 88 |
+
def regenerate(state, image_process_mode):
|
| 89 |
+
state.messages[-1][-1] = None
|
| 90 |
+
prev_human_msg = state.messages[-2]
|
| 91 |
+
if type(prev_human_msg[1]) in (tuple, list):
|
| 92 |
+
prev_human_msg[1] = (*prev_human_msg[1][:2], image_process_mode)
|
| 93 |
+
state.skip_next = False
|
| 94 |
+
return (state, state.to_gradio_chatbot(), "", None) + (disable_btn,) * 5
|
| 95 |
+
|
| 96 |
+
@spaces.GPU
|
| 97 |
+
def generate(state, imagebox, textbox, image_process_mode, temperature, top_p, max_output_tokens):
|
| 98 |
+
prompt = state.get_prompt()
|
| 99 |
+
images = state.get_images(return_pil=True)
|
| 100 |
+
#prompt, image_args = process_image(prompt, images)
|
| 101 |
+
|
| 102 |
+
ori_prompt = prompt
|
| 103 |
+
num_image_tokens = 0
|
| 104 |
+
|
| 105 |
+
if images is not None and len(images) > 0:
|
| 106 |
+
if len(images) > 0:
|
| 107 |
+
if len(images) != prompt.count(DEFAULT_IMAGE_TOKEN):
|
| 108 |
+
raise ValueError("Number of images does not match number of <image> tokens in prompt")
|
| 109 |
+
|
| 110 |
+
#images = [load_image_from_base64(image) for image in images]
|
| 111 |
+
image_sizes = [image.size for image in images]
|
| 112 |
+
images = process_images(images, image_processor, model.config)
|
| 113 |
+
|
| 114 |
+
if type(images) is list:
|
| 115 |
+
images = [image.to(model.device, dtype=torch.float16) for image in images]
|
| 116 |
+
else:
|
| 117 |
+
images = images.to(model.device, dtype=torch.float16)
|
| 118 |
+
else:
|
| 119 |
+
images = None
|
| 120 |
+
image_sizes = None
|
| 121 |
+
image_args = {"images": images, "image_sizes": image_sizes}
|
| 122 |
+
else:
|
| 123 |
+
images = None
|
| 124 |
+
image_args = {}
|
| 125 |
+
|
| 126 |
+
max_context_length = getattr(model.config, 'max_position_embeddings', 2048)
|
| 127 |
+
max_new_tokens = 512
|
| 128 |
+
do_sample = True if temperature > 0.001 else False
|
| 129 |
+
stop_str = state.sep if state.sep_style in [SeparatorStyle.SINGLE, SeparatorStyle.MPT] else state.sep2
|
| 130 |
+
|
| 131 |
+
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).to(model.device)
|
| 132 |
+
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=15)
|
| 133 |
+
|
| 134 |
+
max_new_tokens = min(max_new_tokens, max_context_length - input_ids.shape[-1] - num_image_tokens)
|
| 135 |
+
|
| 136 |
+
if max_new_tokens < 1:
|
| 137 |
+
# yield json.dumps({"text": ori_prompt + "Exceeds max token length. Please start a new conversation, thanks.", "error_code": 0}).encode() + b"\0"
|
| 138 |
+
return
|
| 139 |
+
|
| 140 |
+
thread = Thread(target=model.generate, kwargs=dict(
|
| 141 |
+
inputs=input_ids,
|
| 142 |
+
do_sample=do_sample,
|
| 143 |
+
temperature=temperature,
|
| 144 |
+
top_p=top_p,
|
| 145 |
+
max_new_tokens=max_new_tokens,
|
| 146 |
+
streamer=streamer,
|
| 147 |
+
use_cache=True,
|
| 148 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 149 |
+
**image_args
|
| 150 |
+
))
|
| 151 |
+
thread.start()
|
| 152 |
+
generated_text = ''
|
| 153 |
+
for new_text in streamer:
|
| 154 |
+
generated_text += new_text
|
| 155 |
+
if generated_text.endswith(stop_str):
|
| 156 |
+
generated_text = generated_text[:-len(stop_str)]
|
| 157 |
+
state.messages[-1][-1] = generated_text
|
| 158 |
+
yield (state, state.to_gradio_chatbot(), "", None) + (disable_btn, disable_btn, disable_btn, enable_btn, enable_btn)
|
| 159 |
+
|
| 160 |
+
yield (state, state.to_gradio_chatbot(), "", None) + (enable_btn,) * 5
|
| 161 |
+
|
| 162 |
+
torch.cuda.empty_cache()
|
| 163 |
+
|
| 164 |
+
txt = gr.Textbox(
|
| 165 |
+
scale=4,
|
| 166 |
+
show_label=False,
|
| 167 |
+
placeholder="Enter text and press enter.",
|
| 168 |
+
container=False,
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
title_markdown = ("""
|
| 173 |
+
# Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders
|
| 174 |
+
[[Project Page](TODO)] [[Code](TODO)] [[Model](TODO)] | 📚 [[Arxiv](TODO)]]
|
| 175 |
+
""")
|
| 176 |
+
|
| 177 |
+
tos_markdown = ("""
|
| 178 |
+
### Terms of use
|
| 179 |
+
By using this service, users are required to agree to the following terms:
|
| 180 |
+
The service is a research preview intended for non-commercial use only. It only provides limited safety measures and may generate offensive content. It must not be used for any illegal, harmful, violent, racist, or sexual purposes. The service may collect user dialogue data for future research.
|
| 181 |
+
Please click the "Flag" button if you get any inappropriate answer! We will collect those to keep improving our moderator.
|
| 182 |
+
For an optimal experience, please use desktop computers for this demo, as mobile devices may compromise its quality.
|
| 183 |
+
""")
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
learn_more_markdown = ("""
|
| 187 |
+
### License
|
| 188 |
+
The service is a research preview intended for non-commercial use only, subject to the. Please contact us if you find any potential violation.
|
| 189 |
+
""")
|
| 190 |
+
|
| 191 |
+
block_css = """
|
| 192 |
+
#buttons button {
|
| 193 |
+
min-width: min(120px,100%);
|
| 194 |
+
}
|
| 195 |
+
"""
|
| 196 |
+
|
| 197 |
+
textbox = gr.Textbox(show_label=False, placeholder="Enter text and press ENTER", container=False)
|
| 198 |
+
with gr.Blocks(title="Eagle", theme=gr.themes.Default(), css=block_css) as demo:
|
| 199 |
+
state = gr.State()
|
| 200 |
+
|
| 201 |
+
gr.Markdown(title_markdown)
|
| 202 |
+
|
| 203 |
+
with gr.Row():
|
| 204 |
+
with gr.Column(scale=3):
|
| 205 |
+
imagebox = gr.Image(label="Input Image", type="filepath")
|
| 206 |
+
image_process_mode = gr.Radio(
|
| 207 |
+
["Crop", "Resize", "Pad", "Default"],
|
| 208 |
+
value="Default",
|
| 209 |
+
label="Preprocess for non-square image", visible=False)
|
| 210 |
+
|
| 211 |
+
cur_dir = os.path.dirname(os.path.abspath(__file__))
|
| 212 |
+
gr.Examples(examples=[
|
| 213 |
+
[f"{cur_dir}/assets/health-insurance.png", "Under which circumstances do I need to be enrolled in mandatory health insurance if I am an international student?"],
|
| 214 |
+
[f"{cur_dir}/assets/leasing-apartment.png", "I don't have any 3rd party renter's insurance now. Do I need to get one for myself?"],
|
| 215 |
+
[f"{cur_dir}/assets/nvidia.jpeg", "Who is the person in the middle?"],
|
| 216 |
+
[f"{cur_dir}/assets/animal-compare.png", "Are these two pictures showing the same kind of animal?"],
|
| 217 |
+
[f"{cur_dir}/assets/georgia-tech.jpeg", "Where is this photo taken?"]
|
| 218 |
+
], inputs=[imagebox, textbox], cache_examples=False)
|
| 219 |
+
|
| 220 |
+
with gr.Accordion("Parameters", open=False) as parameter_row:
|
| 221 |
+
temperature = gr.Slider(minimum=0.0, maximum=1.0, value=0.2, step=0.1, interactive=True, label="Temperature",)
|
| 222 |
+
top_p = gr.Slider(minimum=0.0, maximum=1.0, value=0.7, step=0.1, interactive=True, label="Top P",)
|
| 223 |
+
max_output_tokens = gr.Slider(minimum=0, maximum=1024, value=512, step=64, interactive=True, label="Max output tokens",)
|
| 224 |
+
|
| 225 |
+
with gr.Column(scale=8):
|
| 226 |
+
chatbot = gr.Chatbot(
|
| 227 |
+
elem_id="chatbot",
|
| 228 |
+
label="Eagle Chatbot",
|
| 229 |
+
height=650,
|
| 230 |
+
layout="panel",
|
| 231 |
+
)
|
| 232 |
+
with gr.Row():
|
| 233 |
+
with gr.Column(scale=8):
|
| 234 |
+
textbox.render()
|
| 235 |
+
with gr.Column(scale=1, min_width=50):
|
| 236 |
+
submit_btn = gr.Button(value="Send", variant="primary")
|
| 237 |
+
with gr.Row(elem_id="buttons") as button_row:
|
| 238 |
+
upvote_btn = gr.Button(value="👍 Upvote", interactive=False)
|
| 239 |
+
downvote_btn = gr.Button(value="👎 Downvote", interactive=False)
|
| 240 |
+
flag_btn = gr.Button(value="⚠️ Flag", interactive=False)
|
| 241 |
+
#stop_btn = gr.Button(value="⏹️ Stop Generation", interactive=False)
|
| 242 |
+
regenerate_btn = gr.Button(value="🔄 Regenerate", interactive=False)
|
| 243 |
+
clear_btn = gr.Button(value="🗑️ Clear", interactive=False)
|
| 244 |
+
|
| 245 |
+
gr.Markdown(tos_markdown)
|
| 246 |
+
gr.Markdown(learn_more_markdown)
|
| 247 |
+
url_params = gr.JSON(visible=False)
|
| 248 |
+
|
| 249 |
+
# Register listeners
|
| 250 |
+
btn_list = [upvote_btn, downvote_btn, flag_btn, regenerate_btn, clear_btn]
|
| 251 |
+
upvote_btn.click(
|
| 252 |
+
upvote_last_response,
|
| 253 |
+
[state],
|
| 254 |
+
[textbox, upvote_btn, downvote_btn, flag_btn]
|
| 255 |
+
)
|
| 256 |
+
downvote_btn.click(
|
| 257 |
+
downvote_last_response,
|
| 258 |
+
[state],
|
| 259 |
+
[textbox, upvote_btn, downvote_btn, flag_btn]
|
| 260 |
+
)
|
| 261 |
+
flag_btn.click(
|
| 262 |
+
flag_last_response,
|
| 263 |
+
[state],
|
| 264 |
+
[textbox, upvote_btn, downvote_btn, flag_btn]
|
| 265 |
+
)
|
| 266 |
+
|
| 267 |
+
clear_btn.click(
|
| 268 |
+
clear_history,
|
| 269 |
+
None,
|
| 270 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 271 |
+
queue=False
|
| 272 |
+
)
|
| 273 |
+
|
| 274 |
+
regenerate_btn.click(
|
| 275 |
+
delete_text,
|
| 276 |
+
[state, image_process_mode],
|
| 277 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 278 |
+
).then(
|
| 279 |
+
generate,
|
| 280 |
+
[state, imagebox, textbox, image_process_mode, temperature, top_p, max_output_tokens],
|
| 281 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 282 |
+
)
|
| 283 |
+
textbox.submit(
|
| 284 |
+
add_text,
|
| 285 |
+
[state, imagebox, textbox, image_process_mode],
|
| 286 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 287 |
+
).then(
|
| 288 |
+
generate,
|
| 289 |
+
[state, imagebox, textbox, image_process_mode, temperature, top_p, max_output_tokens],
|
| 290 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 291 |
+
)
|
| 292 |
+
|
| 293 |
+
submit_btn.click(
|
| 294 |
+
add_text,
|
| 295 |
+
[state, imagebox, textbox, image_process_mode],
|
| 296 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 297 |
+
).then(
|
| 298 |
+
generate,
|
| 299 |
+
[state, imagebox, textbox, image_process_mode, temperature, top_p, max_output_tokens],
|
| 300 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 301 |
+
)
|
| 302 |
+
|
| 303 |
+
demo.queue(
|
| 304 |
+
status_update_rate=10,
|
| 305 |
+
api_open=False
|
| 306 |
+
).launch()
|
assets/animal-compare.png
ADDED

|
assets/georgia-tech.jpeg
ADDED

|
assets/health-insurance.png
ADDED
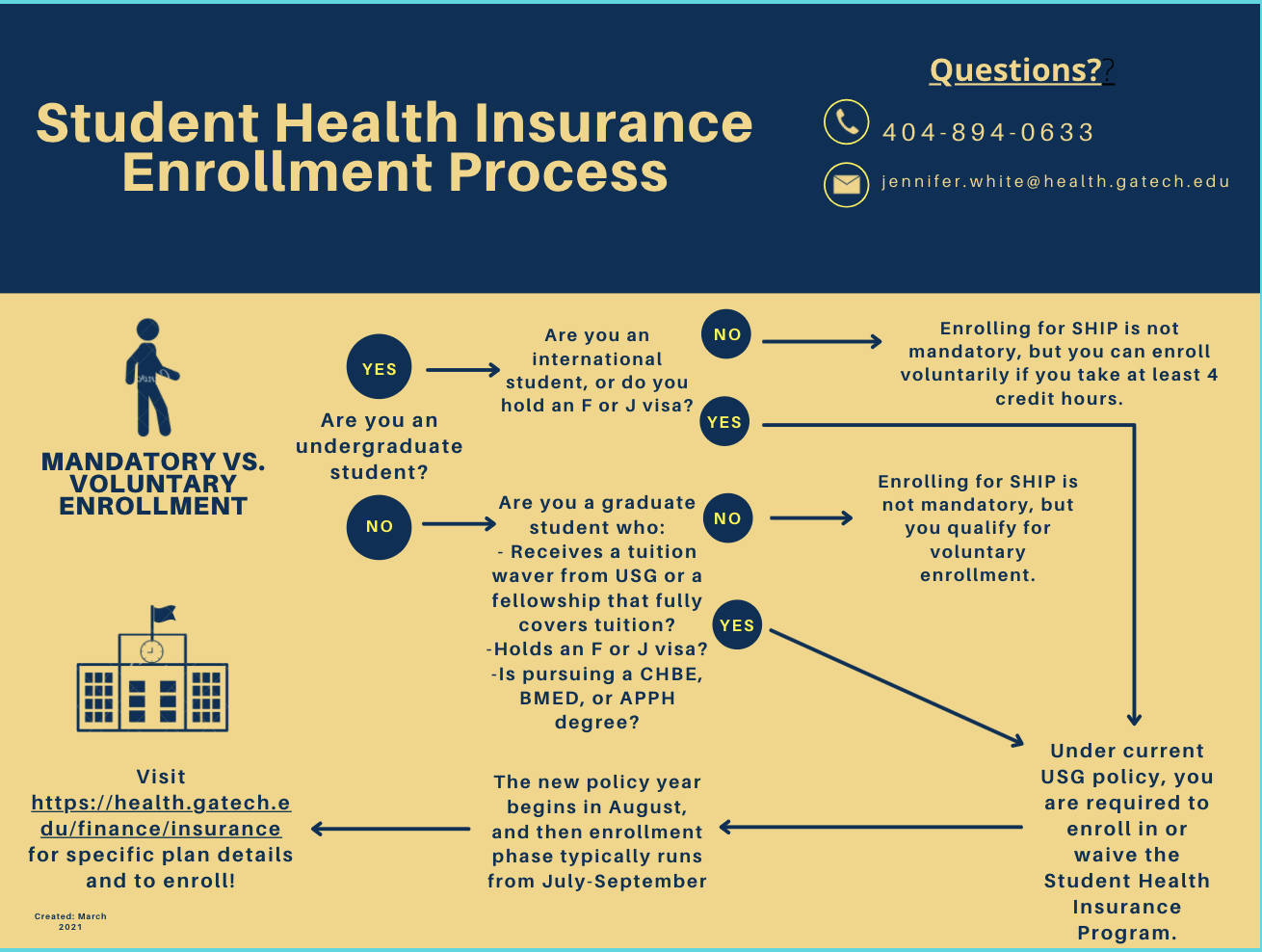
|
assets/leasing-apartment.png
ADDED

|
assets/nvidia.jpeg
ADDED

|
eagle/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .model import EagleLlamaForCausalLM
|
eagle/constants.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
CONTROLLER_HEART_BEAT_EXPIRATION = 30
|
| 2 |
+
WORKER_HEART_BEAT_INTERVAL = 15
|
| 3 |
+
|
| 4 |
+
LOGDIR = "."
|
| 5 |
+
|
| 6 |
+
# Model Constants
|
| 7 |
+
IGNORE_INDEX = -100
|
| 8 |
+
IMAGE_TOKEN_INDEX = -200
|
| 9 |
+
DEFAULT_IMAGE_TOKEN = "<image>"
|
| 10 |
+
DEFAULT_IMAGE_PATCH_TOKEN = "<im_patch>"
|
| 11 |
+
DEFAULT_IM_START_TOKEN = "<im_start>"
|
| 12 |
+
DEFAULT_IM_END_TOKEN = "<im_end>"
|
| 13 |
+
IMAGE_PLACEHOLDER = "<image-placeholder>"
|
eagle/conversation.py
ADDED
|
@@ -0,0 +1,396 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import dataclasses
|
| 2 |
+
from enum import auto, Enum
|
| 3 |
+
from typing import List, Tuple
|
| 4 |
+
import base64
|
| 5 |
+
from io import BytesIO
|
| 6 |
+
from PIL import Image
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class SeparatorStyle(Enum):
|
| 10 |
+
"""Different separator style."""
|
| 11 |
+
SINGLE = auto()
|
| 12 |
+
TWO = auto()
|
| 13 |
+
MPT = auto()
|
| 14 |
+
PLAIN = auto()
|
| 15 |
+
LLAMA_2 = auto()
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
@dataclasses.dataclass
|
| 19 |
+
class Conversation:
|
| 20 |
+
"""A class that keeps all conversation history."""
|
| 21 |
+
system: str
|
| 22 |
+
roles: List[str]
|
| 23 |
+
messages: List[List[str]]
|
| 24 |
+
offset: int
|
| 25 |
+
sep_style: SeparatorStyle = SeparatorStyle.SINGLE
|
| 26 |
+
sep: str = "###"
|
| 27 |
+
sep2: str = None
|
| 28 |
+
version: str = "Unknown"
|
| 29 |
+
|
| 30 |
+
skip_next: bool = False
|
| 31 |
+
|
| 32 |
+
def get_prompt(self):
|
| 33 |
+
messages = self.messages
|
| 34 |
+
if len(messages) > 0 and type(messages[0][1]) is tuple:
|
| 35 |
+
messages = self.messages.copy()
|
| 36 |
+
init_role, init_msg = messages[0].copy()
|
| 37 |
+
init_msg = init_msg[0].replace("<image>", "").strip()
|
| 38 |
+
if 'mmtag' in self.version:
|
| 39 |
+
messages[0] = (init_role, init_msg)
|
| 40 |
+
messages.insert(0, (self.roles[0], "<Image><image></Image>"))
|
| 41 |
+
messages.insert(1, (self.roles[1], "Received."))
|
| 42 |
+
else:
|
| 43 |
+
messages[0] = (init_role, "<image>\n" + init_msg)
|
| 44 |
+
|
| 45 |
+
if self.sep_style == SeparatorStyle.SINGLE:
|
| 46 |
+
ret = self.system + self.sep
|
| 47 |
+
for role, message in messages:
|
| 48 |
+
if message:
|
| 49 |
+
if type(message) is tuple:
|
| 50 |
+
message, _, _ = message
|
| 51 |
+
ret += role + ": " + message + self.sep
|
| 52 |
+
else:
|
| 53 |
+
ret += role + ":"
|
| 54 |
+
elif self.sep_style == SeparatorStyle.TWO:
|
| 55 |
+
seps = [self.sep, self.sep2]
|
| 56 |
+
ret = self.system + seps[0]
|
| 57 |
+
for i, (role, message) in enumerate(messages):
|
| 58 |
+
if message:
|
| 59 |
+
if type(message) is tuple:
|
| 60 |
+
message, _, _ = message
|
| 61 |
+
ret += role + ": " + message + seps[i % 2]
|
| 62 |
+
else:
|
| 63 |
+
ret += role + ":"
|
| 64 |
+
elif self.sep_style == SeparatorStyle.MPT:
|
| 65 |
+
ret = self.system + self.sep
|
| 66 |
+
for role, message in messages:
|
| 67 |
+
if message:
|
| 68 |
+
if type(message) is tuple:
|
| 69 |
+
message, _, _ = message
|
| 70 |
+
ret += role + message + self.sep
|
| 71 |
+
else:
|
| 72 |
+
ret += role
|
| 73 |
+
elif self.sep_style == SeparatorStyle.LLAMA_2:
|
| 74 |
+
wrap_sys = lambda msg: f"<<SYS>>\n{msg}\n<</SYS>>\n\n" if len(msg) > 0 else msg
|
| 75 |
+
wrap_inst = lambda msg: f"[INST] {msg} [/INST]"
|
| 76 |
+
ret = ""
|
| 77 |
+
|
| 78 |
+
for i, (role, message) in enumerate(messages):
|
| 79 |
+
if i == 0:
|
| 80 |
+
assert message, "first message should not be none"
|
| 81 |
+
assert role == self.roles[0], "first message should come from user"
|
| 82 |
+
if message:
|
| 83 |
+
if type(message) is tuple:
|
| 84 |
+
message, _, _ = message
|
| 85 |
+
if i == 0: message = wrap_sys(self.system) + message
|
| 86 |
+
if i % 2 == 0:
|
| 87 |
+
message = wrap_inst(message)
|
| 88 |
+
ret += self.sep + message
|
| 89 |
+
else:
|
| 90 |
+
ret += " " + message + " " + self.sep2
|
| 91 |
+
else:
|
| 92 |
+
ret += ""
|
| 93 |
+
ret = ret.lstrip(self.sep)
|
| 94 |
+
elif self.sep_style == SeparatorStyle.PLAIN:
|
| 95 |
+
seps = [self.sep, self.sep2]
|
| 96 |
+
ret = self.system
|
| 97 |
+
for i, (role, message) in enumerate(messages):
|
| 98 |
+
if message:
|
| 99 |
+
if type(message) is tuple:
|
| 100 |
+
message, _, _ = message
|
| 101 |
+
ret += message + seps[i % 2]
|
| 102 |
+
else:
|
| 103 |
+
ret += ""
|
| 104 |
+
else:
|
| 105 |
+
raise ValueError(f"Invalid style: {self.sep_style}")
|
| 106 |
+
|
| 107 |
+
return ret
|
| 108 |
+
|
| 109 |
+
def append_message(self, role, message):
|
| 110 |
+
self.messages.append([role, message])
|
| 111 |
+
|
| 112 |
+
def process_image(self, image, image_process_mode, return_pil=False, image_format='PNG', max_len=1344, min_len=672):
|
| 113 |
+
if image_process_mode == "Pad":
|
| 114 |
+
def expand2square(pil_img, background_color=(122, 116, 104)):
|
| 115 |
+
width, height = pil_img.size
|
| 116 |
+
if width == height:
|
| 117 |
+
return pil_img
|
| 118 |
+
elif width > height:
|
| 119 |
+
result = Image.new(pil_img.mode, (width, width), background_color)
|
| 120 |
+
result.paste(pil_img, (0, (width - height) // 2))
|
| 121 |
+
return result
|
| 122 |
+
else:
|
| 123 |
+
result = Image.new(pil_img.mode, (height, height), background_color)
|
| 124 |
+
result.paste(pil_img, ((height - width) // 2, 0))
|
| 125 |
+
return result
|
| 126 |
+
image = expand2square(image)
|
| 127 |
+
elif image_process_mode in ["Default", "Crop"]:
|
| 128 |
+
pass
|
| 129 |
+
elif image_process_mode == "Resize":
|
| 130 |
+
image = image.resize((336, 336))
|
| 131 |
+
else:
|
| 132 |
+
raise ValueError(f"Invalid image_process_mode: {image_process_mode}")
|
| 133 |
+
if max(image.size) > max_len:
|
| 134 |
+
max_hw, min_hw = max(image.size), min(image.size)
|
| 135 |
+
aspect_ratio = max_hw / min_hw
|
| 136 |
+
shortest_edge = int(min(max_len / aspect_ratio, min_len, min_hw))
|
| 137 |
+
longest_edge = int(shortest_edge * aspect_ratio)
|
| 138 |
+
W, H = image.size
|
| 139 |
+
if H > W:
|
| 140 |
+
H, W = longest_edge, shortest_edge
|
| 141 |
+
else:
|
| 142 |
+
H, W = shortest_edge, longest_edge
|
| 143 |
+
image = image.resize((W, H))
|
| 144 |
+
if return_pil:
|
| 145 |
+
return image
|
| 146 |
+
else:
|
| 147 |
+
buffered = BytesIO()
|
| 148 |
+
image.save(buffered, format=image_format)
|
| 149 |
+
img_b64_str = base64.b64encode(buffered.getvalue()).decode()
|
| 150 |
+
return img_b64_str
|
| 151 |
+
|
| 152 |
+
def get_images(self, return_pil=False):
|
| 153 |
+
images = []
|
| 154 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 155 |
+
if i % 2 == 0:
|
| 156 |
+
if type(msg) is tuple:
|
| 157 |
+
msg, image, image_process_mode = msg
|
| 158 |
+
image = self.process_image(image, image_process_mode, return_pil=return_pil)
|
| 159 |
+
images.append(image)
|
| 160 |
+
return images
|
| 161 |
+
|
| 162 |
+
def to_gradio_chatbot(self):
|
| 163 |
+
ret = []
|
| 164 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 165 |
+
if i % 2 == 0:
|
| 166 |
+
if type(msg) is tuple:
|
| 167 |
+
msg, image, image_process_mode = msg
|
| 168 |
+
img_b64_str = self.process_image(
|
| 169 |
+
image, "Default", return_pil=False,
|
| 170 |
+
image_format='JPEG')
|
| 171 |
+
img_str = f'<img src="data:image/jpeg;base64,{img_b64_str}" alt="user upload image" />'
|
| 172 |
+
msg = img_str + msg.replace('<image>', '').strip()
|
| 173 |
+
ret.append([msg, None])
|
| 174 |
+
else:
|
| 175 |
+
ret.append([msg, None])
|
| 176 |
+
else:
|
| 177 |
+
ret[-1][-1] = msg
|
| 178 |
+
return ret
|
| 179 |
+
|
| 180 |
+
def copy(self):
|
| 181 |
+
return Conversation(
|
| 182 |
+
system=self.system,
|
| 183 |
+
roles=self.roles,
|
| 184 |
+
messages=[[x, y] for x, y in self.messages],
|
| 185 |
+
offset=self.offset,
|
| 186 |
+
sep_style=self.sep_style,
|
| 187 |
+
sep=self.sep,
|
| 188 |
+
sep2=self.sep2,
|
| 189 |
+
version=self.version)
|
| 190 |
+
|
| 191 |
+
def dict(self):
|
| 192 |
+
if len(self.get_images()) > 0:
|
| 193 |
+
return {
|
| 194 |
+
"system": self.system,
|
| 195 |
+
"roles": self.roles,
|
| 196 |
+
"messages": [[x, y[0] if type(y) is tuple else y] for x, y in self.messages],
|
| 197 |
+
"offset": self.offset,
|
| 198 |
+
"sep": self.sep,
|
| 199 |
+
"sep2": self.sep2,
|
| 200 |
+
}
|
| 201 |
+
return {
|
| 202 |
+
"system": self.system,
|
| 203 |
+
"roles": self.roles,
|
| 204 |
+
"messages": self.messages,
|
| 205 |
+
"offset": self.offset,
|
| 206 |
+
"sep": self.sep,
|
| 207 |
+
"sep2": self.sep2,
|
| 208 |
+
}
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
conv_vicuna_v0 = Conversation(
|
| 212 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 213 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 214 |
+
roles=("Human", "Assistant"),
|
| 215 |
+
messages=(
|
| 216 |
+
("Human", "What are the key differences between renewable and non-renewable energy sources?"),
|
| 217 |
+
("Assistant",
|
| 218 |
+
"Renewable energy sources are those that can be replenished naturally in a relatively "
|
| 219 |
+
"short amount of time, such as solar, wind, hydro, geothermal, and biomass. "
|
| 220 |
+
"Non-renewable energy sources, on the other hand, are finite and will eventually be "
|
| 221 |
+
"depleted, such as coal, oil, and natural gas. Here are some key differences between "
|
| 222 |
+
"renewable and non-renewable energy sources:\n"
|
| 223 |
+
"1. Availability: Renewable energy sources are virtually inexhaustible, while non-renewable "
|
| 224 |
+
"energy sources are finite and will eventually run out.\n"
|
| 225 |
+
"2. Environmental impact: Renewable energy sources have a much lower environmental impact "
|
| 226 |
+
"than non-renewable sources, which can lead to air and water pollution, greenhouse gas emissions, "
|
| 227 |
+
"and other negative effects.\n"
|
| 228 |
+
"3. Cost: Renewable energy sources can be more expensive to initially set up, but they typically "
|
| 229 |
+
"have lower operational costs than non-renewable sources.\n"
|
| 230 |
+
"4. Reliability: Renewable energy sources are often more reliable and can be used in more remote "
|
| 231 |
+
"locations than non-renewable sources.\n"
|
| 232 |
+
"5. Flexibility: Renewable energy sources are often more flexible and can be adapted to different "
|
| 233 |
+
"situations and needs, while non-renewable sources are more rigid and inflexible.\n"
|
| 234 |
+
"6. Sustainability: Renewable energy sources are more sustainable over the long term, while "
|
| 235 |
+
"non-renewable sources are not, and their depletion can lead to economic and social instability.\n")
|
| 236 |
+
),
|
| 237 |
+
offset=2,
|
| 238 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 239 |
+
sep="###",
|
| 240 |
+
)
|
| 241 |
+
|
| 242 |
+
conv_vicuna_v1 = Conversation(
|
| 243 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 244 |
+
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
|
| 245 |
+
roles=("USER", "ASSISTANT"),
|
| 246 |
+
version="v1",
|
| 247 |
+
messages=(),
|
| 248 |
+
offset=0,
|
| 249 |
+
sep_style=SeparatorStyle.TWO,
|
| 250 |
+
sep=" ",
|
| 251 |
+
sep2="</s>",
|
| 252 |
+
)
|
| 253 |
+
|
| 254 |
+
conv_llama_2 = Conversation(
|
| 255 |
+
system="""You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
|
| 256 |
+
|
| 257 |
+
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.""",
|
| 258 |
+
roles=("USER", "ASSISTANT"),
|
| 259 |
+
version="llama_v2",
|
| 260 |
+
messages=(),
|
| 261 |
+
offset=0,
|
| 262 |
+
sep_style=SeparatorStyle.LLAMA_2,
|
| 263 |
+
sep="<s>",
|
| 264 |
+
sep2="</s>",
|
| 265 |
+
)
|
| 266 |
+
|
| 267 |
+
conv_llava_llama_2 = Conversation(
|
| 268 |
+
system="You are a helpful language and vision assistant. "
|
| 269 |
+
"You are able to understand the visual content that the user provides, "
|
| 270 |
+
"and assist the user with a variety of tasks using natural language.",
|
| 271 |
+
roles=("USER", "ASSISTANT"),
|
| 272 |
+
version="llama_v2",
|
| 273 |
+
messages=(),
|
| 274 |
+
offset=0,
|
| 275 |
+
sep_style=SeparatorStyle.LLAMA_2,
|
| 276 |
+
sep="<s>",
|
| 277 |
+
sep2="</s>",
|
| 278 |
+
)
|
| 279 |
+
|
| 280 |
+
conv_mpt = Conversation(
|
| 281 |
+
system="""<|im_start|>system
|
| 282 |
+
A conversation between a user and an LLM-based AI assistant. The assistant gives helpful and honest answers.""",
|
| 283 |
+
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
| 284 |
+
version="mpt",
|
| 285 |
+
messages=(),
|
| 286 |
+
offset=0,
|
| 287 |
+
sep_style=SeparatorStyle.MPT,
|
| 288 |
+
sep="<|im_end|>",
|
| 289 |
+
)
|
| 290 |
+
|
| 291 |
+
conv_llava_plain = Conversation(
|
| 292 |
+
system="",
|
| 293 |
+
roles=("", ""),
|
| 294 |
+
messages=(
|
| 295 |
+
),
|
| 296 |
+
offset=0,
|
| 297 |
+
sep_style=SeparatorStyle.PLAIN,
|
| 298 |
+
sep="\n",
|
| 299 |
+
)
|
| 300 |
+
|
| 301 |
+
conv_llava_v0 = Conversation(
|
| 302 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 303 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 304 |
+
roles=("Human", "Assistant"),
|
| 305 |
+
messages=(
|
| 306 |
+
),
|
| 307 |
+
offset=0,
|
| 308 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 309 |
+
sep="###",
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
conv_llava_v0_mmtag = Conversation(
|
| 313 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 314 |
+
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
|
| 315 |
+
"The visual content will be provided with the following format: <Image>visual content</Image>.",
|
| 316 |
+
roles=("Human", "Assistant"),
|
| 317 |
+
messages=(
|
| 318 |
+
),
|
| 319 |
+
offset=0,
|
| 320 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 321 |
+
sep="###",
|
| 322 |
+
version="v0_mmtag",
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
conv_llava_v1 = Conversation(
|
| 326 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 327 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 328 |
+
roles=("USER", "ASSISTANT"),
|
| 329 |
+
version="v1",
|
| 330 |
+
messages=(),
|
| 331 |
+
offset=0,
|
| 332 |
+
sep_style=SeparatorStyle.TWO,
|
| 333 |
+
sep=" ",
|
| 334 |
+
sep2="</s>",
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
conv_llava_v1_mmtag = Conversation(
|
| 338 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 339 |
+
"The assistant is able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language."
|
| 340 |
+
"The visual content will be provided with the following format: <Image>visual content</Image>.",
|
| 341 |
+
roles=("USER", "ASSISTANT"),
|
| 342 |
+
messages=(),
|
| 343 |
+
offset=0,
|
| 344 |
+
sep_style=SeparatorStyle.TWO,
|
| 345 |
+
sep=" ",
|
| 346 |
+
sep2="</s>",
|
| 347 |
+
version="v1_mmtag",
|
| 348 |
+
)
|
| 349 |
+
|
| 350 |
+
conv_mistral_instruct = Conversation(
|
| 351 |
+
system="",
|
| 352 |
+
roles=("USER", "ASSISTANT"),
|
| 353 |
+
version="llama_v2",
|
| 354 |
+
messages=(),
|
| 355 |
+
offset=0,
|
| 356 |
+
sep_style=SeparatorStyle.LLAMA_2,
|
| 357 |
+
sep="",
|
| 358 |
+
sep2="</s>",
|
| 359 |
+
)
|
| 360 |
+
|
| 361 |
+
conv_chatml_direct = Conversation(
|
| 362 |
+
system="""<|im_start|>system
|
| 363 |
+
Answer the questions.""",
|
| 364 |
+
roles=("<|im_start|>user\n", "<|im_start|>assistant\n"),
|
| 365 |
+
version="mpt",
|
| 366 |
+
messages=(),
|
| 367 |
+
offset=0,
|
| 368 |
+
sep_style=SeparatorStyle.MPT,
|
| 369 |
+
sep="<|im_end|>",
|
| 370 |
+
)
|
| 371 |
+
|
| 372 |
+
default_conversation = conv_vicuna_v1
|
| 373 |
+
conv_templates = {
|
| 374 |
+
"default": conv_vicuna_v0,
|
| 375 |
+
"v0": conv_vicuna_v0,
|
| 376 |
+
"v1": conv_vicuna_v1,
|
| 377 |
+
"vicuna_v1": conv_vicuna_v1,
|
| 378 |
+
"llama_2": conv_llama_2,
|
| 379 |
+
"mistral_instruct": conv_mistral_instruct,
|
| 380 |
+
"chatml_direct": conv_chatml_direct,
|
| 381 |
+
"mistral_direct": conv_chatml_direct,
|
| 382 |
+
|
| 383 |
+
"plain": conv_llava_plain,
|
| 384 |
+
"v0_plain": conv_llava_plain,
|
| 385 |
+
"llava_v0": conv_llava_v0,
|
| 386 |
+
"v0_mmtag": conv_llava_v0_mmtag,
|
| 387 |
+
"llava_v1": conv_llava_v1,
|
| 388 |
+
"v1_mmtag": conv_llava_v1_mmtag,
|
| 389 |
+
"llava_llama_2": conv_llava_llama_2,
|
| 390 |
+
|
| 391 |
+
"mpt": conv_mpt,
|
| 392 |
+
}
|
| 393 |
+
|
| 394 |
+
|
| 395 |
+
if __name__ == "__main__":
|
| 396 |
+
print(default_conversation.get_prompt())
|
eagle/mm_utils.py
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from PIL import Image
|
| 2 |
+
from io import BytesIO
|
| 3 |
+
import base64
|
| 4 |
+
import torch
|
| 5 |
+
import math
|
| 6 |
+
import ast
|
| 7 |
+
|
| 8 |
+
from transformers import StoppingCriteria
|
| 9 |
+
from eagle.constants import IMAGE_TOKEN_INDEX
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def select_best_resolution(original_size, possible_resolutions):
|
| 13 |
+
"""
|
| 14 |
+
Selects the best resolution from a list of possible resolutions based on the original size.
|
| 15 |
+
|
| 16 |
+
Args:
|
| 17 |
+
original_size (tuple): The original size of the image in the format (width, height).
|
| 18 |
+
possible_resolutions (list): A list of possible resolutions in the format [(width1, height1), (width2, height2), ...].
|
| 19 |
+
|
| 20 |
+
Returns:
|
| 21 |
+
tuple: The best fit resolution in the format (width, height).
|
| 22 |
+
"""
|
| 23 |
+
original_width, original_height = original_size
|
| 24 |
+
best_fit = None
|
| 25 |
+
max_effective_resolution = 0
|
| 26 |
+
min_wasted_resolution = float('inf')
|
| 27 |
+
|
| 28 |
+
for width, height in possible_resolutions:
|
| 29 |
+
scale = min(width / original_width, height / original_height)
|
| 30 |
+
downscaled_width, downscaled_height = int(original_width * scale), int(original_height * scale)
|
| 31 |
+
effective_resolution = min(downscaled_width * downscaled_height, original_width * original_height)
|
| 32 |
+
wasted_resolution = (width * height) - effective_resolution
|
| 33 |
+
|
| 34 |
+
if effective_resolution > max_effective_resolution or (effective_resolution == max_effective_resolution and wasted_resolution < min_wasted_resolution):
|
| 35 |
+
max_effective_resolution = effective_resolution
|
| 36 |
+
min_wasted_resolution = wasted_resolution
|
| 37 |
+
best_fit = (width, height)
|
| 38 |
+
|
| 39 |
+
return best_fit
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def resize_and_pad_image(image, target_resolution):
|
| 43 |
+
"""
|
| 44 |
+
Resize and pad an image to a target resolution while maintaining aspect ratio.
|
| 45 |
+
|
| 46 |
+
Args:
|
| 47 |
+
image (PIL.Image.Image): The input image.
|
| 48 |
+
target_resolution (tuple): The target resolution (width, height) of the image.
|
| 49 |
+
|
| 50 |
+
Returns:
|
| 51 |
+
PIL.Image.Image: The resized and padded image.
|
| 52 |
+
"""
|
| 53 |
+
original_width, original_height = image.size
|
| 54 |
+
target_width, target_height = target_resolution
|
| 55 |
+
|
| 56 |
+
scale_w = target_width / original_width
|
| 57 |
+
scale_h = target_height / original_height
|
| 58 |
+
|
| 59 |
+
if scale_w < scale_h:
|
| 60 |
+
new_width = target_width
|
| 61 |
+
new_height = min(math.ceil(original_height * scale_w), target_height)
|
| 62 |
+
else:
|
| 63 |
+
new_height = target_height
|
| 64 |
+
new_width = min(math.ceil(original_width * scale_h), target_width)
|
| 65 |
+
|
| 66 |
+
# Resize the image
|
| 67 |
+
resized_image = image.resize((new_width, new_height))
|
| 68 |
+
|
| 69 |
+
new_image = Image.new('RGB', (target_width, target_height), (0, 0, 0))
|
| 70 |
+
paste_x = (target_width - new_width) // 2
|
| 71 |
+
paste_y = (target_height - new_height) // 2
|
| 72 |
+
new_image.paste(resized_image, (paste_x, paste_y))
|
| 73 |
+
|
| 74 |
+
return new_image
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def divide_to_patches(image, patch_size):
|
| 78 |
+
"""
|
| 79 |
+
Divides an image into patches of a specified size.
|
| 80 |
+
|
| 81 |
+
Args:
|
| 82 |
+
image (PIL.Image.Image): The input image.
|
| 83 |
+
patch_size (int): The size of each patch.
|
| 84 |
+
|
| 85 |
+
Returns:
|
| 86 |
+
list: A list of PIL.Image.Image objects representing the patches.
|
| 87 |
+
"""
|
| 88 |
+
patches = []
|
| 89 |
+
width, height = image.size
|
| 90 |
+
for i in range(0, height, patch_size):
|
| 91 |
+
for j in range(0, width, patch_size):
|
| 92 |
+
box = (j, i, j + patch_size, i + patch_size)
|
| 93 |
+
patch = image.crop(box)
|
| 94 |
+
patches.append(patch)
|
| 95 |
+
|
| 96 |
+
return patches
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def get_anyres_image_grid_shape(image_size, grid_pinpoints, patch_size):
|
| 100 |
+
"""
|
| 101 |
+
Calculate the shape of the image patch grid after the preprocessing for images of any resolution.
|
| 102 |
+
|
| 103 |
+
Args:
|
| 104 |
+
image_size (tuple): The size of the input image in the format (width, height).
|
| 105 |
+
grid_pinpoints (str): A string representation of a list of possible resolutions.
|
| 106 |
+
patch_size (int): The size of each image patch.
|
| 107 |
+
|
| 108 |
+
Returns:
|
| 109 |
+
tuple: The shape of the image patch grid in the format (width, height).
|
| 110 |
+
"""
|
| 111 |
+
if type(grid_pinpoints) is list:
|
| 112 |
+
possible_resolutions = grid_pinpoints
|
| 113 |
+
else:
|
| 114 |
+
possible_resolutions = ast.literal_eval(grid_pinpoints)
|
| 115 |
+
width, height = select_best_resolution(image_size, possible_resolutions)
|
| 116 |
+
return width // patch_size, height // patch_size
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def process_anyres_image(image, processor, grid_pinpoints):
|
| 120 |
+
"""
|
| 121 |
+
Process an image with variable resolutions.
|
| 122 |
+
|
| 123 |
+
Args:
|
| 124 |
+
image (PIL.Image.Image): The input image to be processed.
|
| 125 |
+
processor: The image processor object.
|
| 126 |
+
grid_pinpoints (str): A string representation of a list of possible resolutions.
|
| 127 |
+
|
| 128 |
+
Returns:
|
| 129 |
+
torch.Tensor: A tensor containing the processed image patches.
|
| 130 |
+
"""
|
| 131 |
+
if type(grid_pinpoints) is list:
|
| 132 |
+
possible_resolutions = grid_pinpoints
|
| 133 |
+
else:
|
| 134 |
+
possible_resolutions = ast.literal_eval(grid_pinpoints)
|
| 135 |
+
best_resolution = select_best_resolution(image.size, possible_resolutions)
|
| 136 |
+
image_padded = resize_and_pad_image(image, best_resolution)
|
| 137 |
+
|
| 138 |
+
patches = divide_to_patches(image_padded, processor.crop_size['height'])
|
| 139 |
+
|
| 140 |
+
image_original_resize = image.resize((processor.size['shortest_edge'], processor.size['shortest_edge']))
|
| 141 |
+
|
| 142 |
+
image_patches = [image_original_resize] + patches
|
| 143 |
+
image_patches = [processor.preprocess(image_patch, return_tensors='pt')['pixel_values'][0]
|
| 144 |
+
for image_patch in image_patches]
|
| 145 |
+
return torch.stack(image_patches, dim=0)
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def load_image_from_base64(image):
|
| 149 |
+
return Image.open(BytesIO(base64.b64decode(image)))
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def expand2square(pil_img, background_color):
|
| 153 |
+
width, height = pil_img.size
|
| 154 |
+
if width == height:
|
| 155 |
+
return pil_img
|
| 156 |
+
elif width > height:
|
| 157 |
+
result = Image.new(pil_img.mode, (width, width), background_color)
|
| 158 |
+
result.paste(pil_img, (0, (width - height) // 2))
|
| 159 |
+
return result
|
| 160 |
+
else:
|
| 161 |
+
result = Image.new(pil_img.mode, (height, height), background_color)
|
| 162 |
+
result.paste(pil_img, ((height - width) // 2, 0))
|
| 163 |
+
return result
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def process_images(images, image_processor, model_cfg):
|
| 167 |
+
image_aspect_ratio = getattr(model_cfg, "image_aspect_ratio", None)
|
| 168 |
+
new_images = []
|
| 169 |
+
if image_aspect_ratio == 'pad':
|
| 170 |
+
for image in images:
|
| 171 |
+
image = expand2square(image, tuple(int(x*255) for x in image_processor.image_mean))
|
| 172 |
+
image = image_processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
|
| 173 |
+
new_images.append(image)
|
| 174 |
+
elif image_aspect_ratio == "anyres":
|
| 175 |
+
for image in images:
|
| 176 |
+
image = process_anyres_image(image, image_processor, model_cfg.image_grid_pinpoints)
|
| 177 |
+
new_images.append(image)
|
| 178 |
+
else:
|
| 179 |
+
return image_processor(images, return_tensors='pt')['pixel_values']
|
| 180 |
+
if all(x.shape == new_images[0].shape for x in new_images):
|
| 181 |
+
new_images = torch.stack(new_images, dim=0)
|
| 182 |
+
return new_images
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
def tokenizer_image_token(prompt, tokenizer, image_token_index=IMAGE_TOKEN_INDEX, return_tensors=None):
|
| 186 |
+
prompt_chunks = [tokenizer(chunk).input_ids for chunk in prompt.split('<image>')]
|
| 187 |
+
|
| 188 |
+
def insert_separator(X, sep):
|
| 189 |
+
return [ele for sublist in zip(X, [sep]*len(X)) for ele in sublist][:-1]
|
| 190 |
+
|
| 191 |
+
input_ids = []
|
| 192 |
+
offset = 0
|
| 193 |
+
if len(prompt_chunks) > 0 and len(prompt_chunks[0]) > 0 and prompt_chunks[0][0] == tokenizer.bos_token_id:
|
| 194 |
+
offset = 1
|
| 195 |
+
input_ids.append(prompt_chunks[0][0])
|
| 196 |
+
|
| 197 |
+
for x in insert_separator(prompt_chunks, [image_token_index] * (offset + 1)):
|
| 198 |
+
input_ids.extend(x[offset:])
|
| 199 |
+
|
| 200 |
+
if return_tensors is not None:
|
| 201 |
+
if return_tensors == 'pt':
|
| 202 |
+
return torch.tensor(input_ids, dtype=torch.long)
|
| 203 |
+
raise ValueError(f'Unsupported tensor type: {return_tensors}')
|
| 204 |
+
return input_ids
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def get_model_name_from_path(model_path):
|
| 208 |
+
model_path = model_path.strip("/")
|
| 209 |
+
model_paths = model_path.split("/")
|
| 210 |
+
if model_paths[-1].startswith('checkpoint-'):
|
| 211 |
+
return model_paths[-2] + "_" + model_paths[-1]
|
| 212 |
+
else:
|
| 213 |
+
return model_paths[-1]
|
| 214 |
+
|
| 215 |
+
class KeywordsStoppingCriteria(StoppingCriteria):
|
| 216 |
+
def __init__(self, keywords, tokenizer, input_ids):
|
| 217 |
+
self.keywords = keywords
|
| 218 |
+
self.keyword_ids = []
|
| 219 |
+
self.max_keyword_len = 0
|
| 220 |
+
for keyword in keywords:
|
| 221 |
+
cur_keyword_ids = tokenizer(keyword).input_ids
|
| 222 |
+
if len(cur_keyword_ids) > 1 and cur_keyword_ids[0] == tokenizer.bos_token_id:
|
| 223 |
+
cur_keyword_ids = cur_keyword_ids[1:]
|
| 224 |
+
if len(cur_keyword_ids) > self.max_keyword_len:
|
| 225 |
+
self.max_keyword_len = len(cur_keyword_ids)
|
| 226 |
+
self.keyword_ids.append(torch.tensor(cur_keyword_ids))
|
| 227 |
+
self.tokenizer = tokenizer
|
| 228 |
+
self.start_len = input_ids.shape[1]
|
| 229 |
+
|
| 230 |
+
def call_for_batch(self, output_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 231 |
+
offset = min(output_ids.shape[1] - self.start_len, self.max_keyword_len)
|
| 232 |
+
self.keyword_ids = [keyword_id.to(output_ids.device) for keyword_id in self.keyword_ids]
|
| 233 |
+
for keyword_id in self.keyword_ids:
|
| 234 |
+
truncated_output_ids = output_ids[0, -keyword_id.shape[0]:]
|
| 235 |
+
if torch.equal(truncated_output_ids, keyword_id):
|
| 236 |
+
return True
|
| 237 |
+
outputs = self.tokenizer.batch_decode(output_ids[:, -offset:], skip_special_tokens=True)[0]
|
| 238 |
+
for keyword in self.keywords:
|
| 239 |
+
if keyword in outputs:
|
| 240 |
+
return True
|
| 241 |
+
return False
|
| 242 |
+
|
| 243 |
+
def __call__(self, output_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 244 |
+
outputs = []
|
| 245 |
+
for i in range(output_ids.shape[0]):
|
| 246 |
+
outputs.append(self.call_for_batch(output_ids[i].unsqueeze(0), scores))
|
| 247 |
+
return all(outputs)
|
eagle/model/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .language_model.eagle_llama import EagleLlamaForCausalLM, EagleConfig
|
eagle/model/builder.py
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 Haotian Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
import os
|
| 17 |
+
import warnings
|
| 18 |
+
import shutil
|
| 19 |
+
|
| 20 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, BitsAndBytesConfig
|
| 21 |
+
import torch
|
| 22 |
+
from eagle.model import *
|
| 23 |
+
from eagle.constants import DEFAULT_IMAGE_PATCH_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def load_pretrained_model(model_path, model_base, model_name, load_8bit=False, load_4bit=False, device_map="auto", device="cuda", use_flash_attn=False, **kwargs):
|
| 27 |
+
kwargs = {"device_map": device_map, **kwargs}
|
| 28 |
+
|
| 29 |
+
if device != "cuda":
|
| 30 |
+
kwargs['device_map'] = {"": device}
|
| 31 |
+
|
| 32 |
+
if load_8bit:
|
| 33 |
+
kwargs['load_in_8bit'] = True
|
| 34 |
+
elif load_4bit:
|
| 35 |
+
kwargs['load_in_4bit'] = True
|
| 36 |
+
kwargs['quantization_config'] = BitsAndBytesConfig(
|
| 37 |
+
load_in_4bit=True,
|
| 38 |
+
bnb_4bit_compute_dtype=torch.float16,
|
| 39 |
+
bnb_4bit_use_double_quant=True,
|
| 40 |
+
bnb_4bit_quant_type='nf4'
|
| 41 |
+
)
|
| 42 |
+
else:
|
| 43 |
+
kwargs['torch_dtype'] = torch.float16
|
| 44 |
+
|
| 45 |
+
if use_flash_attn:
|
| 46 |
+
kwargs['attn_implementation'] = 'flash_attention_2'
|
| 47 |
+
|
| 48 |
+
if 'eagle' in model_name.lower():
|
| 49 |
+
if 'lora' in model_name.lower() and model_base is None:
|
| 50 |
+
warnings.warn('There is `lora` in model name but no `model_base` is provided. If you are loading a LoRA model, please provide the `model_base` argument. Detailed instruction: https://github.com/haotian-liu/LLaVA#launch-a-model-worker-lora-weights-unmerged.')
|
| 51 |
+
if 'lora' in model_name.lower() and model_base is not None:
|
| 52 |
+
from eagle.model.language_model.eagle_llama import eagleConfig
|
| 53 |
+
lora_cfg_pretrained = eagleConfig.from_pretrained(model_path)
|
| 54 |
+
tokenizer = AutoTokenizer.from_pretrained(model_base, use_fast=False)
|
| 55 |
+
print('Loading eagle from base model...')
|
| 56 |
+
model = EagleLlamaForCausalLM.from_pretrained(model_base, low_cpu_mem_usage=True, config=lora_cfg_pretrained, **kwargs)
|
| 57 |
+
token_num, tokem_dim = model.lm_head.out_features, model.lm_head.in_features
|
| 58 |
+
if model.lm_head.weight.shape[0] != token_num:
|
| 59 |
+
model.lm_head.weight = torch.nn.Parameter(torch.empty(token_num, tokem_dim, device=model.device, dtype=model.dtype))
|
| 60 |
+
model.model.embed_tokens.weight = torch.nn.Parameter(torch.empty(token_num, tokem_dim, device=model.device, dtype=model.dtype))
|
| 61 |
+
|
| 62 |
+
print('Loading additional Eagle weights...')
|
| 63 |
+
if os.path.exists(os.path.join(model_path, 'non_lora_trainables.bin')):
|
| 64 |
+
non_lora_trainables = torch.load(os.path.join(model_path, 'non_lora_trainables.bin'), map_location='cpu')
|
| 65 |
+
else:
|
| 66 |
+
# this is probably from HF Hub
|
| 67 |
+
from huggingface_hub import hf_hub_download
|
| 68 |
+
def load_from_hf(repo_id, filename, subfolder=None):
|
| 69 |
+
cache_file = hf_hub_download(
|
| 70 |
+
repo_id=repo_id,
|
| 71 |
+
filename=filename,
|
| 72 |
+
subfolder=subfolder)
|
| 73 |
+
return torch.load(cache_file, map_location='cpu')
|
| 74 |
+
non_lora_trainables = load_from_hf(model_path, 'non_lora_trainables.bin')
|
| 75 |
+
non_lora_trainables = {(k[11:] if k.startswith('base_model.') else k): v for k, v in non_lora_trainables.items()}
|
| 76 |
+
if any(k.startswith('model.model.') for k in non_lora_trainables):
|
| 77 |
+
non_lora_trainables = {(k[6:] if k.startswith('model.') else k): v for k, v in non_lora_trainables.items()}
|
| 78 |
+
model.load_state_dict(non_lora_trainables, strict=False)
|
| 79 |
+
|
| 80 |
+
from peft import PeftModel
|
| 81 |
+
print('Loading LoRA weights...')
|
| 82 |
+
model = PeftModel.from_pretrained(model, model_path)
|
| 83 |
+
print('Merging LoRA weights...')
|
| 84 |
+
model = model.merge_and_unload()
|
| 85 |
+
print('Model is loaded...')
|
| 86 |
+
elif model_base is not None:
|
| 87 |
+
# this may be mm projector only
|
| 88 |
+
print('Loading Eagle from base model...')
|
| 89 |
+
|
| 90 |
+
tokenizer = AutoTokenizer.from_pretrained(model_base, use_fast=False)
|
| 91 |
+
cfg_pretrained = AutoConfig.from_pretrained(model_path)
|
| 92 |
+
model = EagleLlamaForCausalLM.from_pretrained(model_base, low_cpu_mem_usage=True, config=cfg_pretrained, **kwargs)
|
| 93 |
+
|
| 94 |
+
mm_projector_weights = torch.load(os.path.join(model_path, 'mm_projector.bin'), map_location='cpu')
|
| 95 |
+
mm_projector_weights = {k: v.to(torch.float16) for k, v in mm_projector_weights.items()}
|
| 96 |
+
model.load_state_dict(mm_projector_weights, strict=False)
|
| 97 |
+
else:
|
| 98 |
+
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
|
| 99 |
+
model = EagleLlamaForCausalLM.from_pretrained(
|
| 100 |
+
model_path,
|
| 101 |
+
low_cpu_mem_usage=True,
|
| 102 |
+
**kwargs
|
| 103 |
+
)
|
| 104 |
+
else:
|
| 105 |
+
# Load language model
|
| 106 |
+
if model_base is not None:
|
| 107 |
+
# PEFT model
|
| 108 |
+
from peft import PeftModel
|
| 109 |
+
tokenizer = AutoTokenizer.from_pretrained(model_base, use_fast=False)
|
| 110 |
+
model = AutoModelForCausalLM.from_pretrained(model_base, low_cpu_mem_usage=True, **kwargs)
|
| 111 |
+
print(f"Loading LoRA weights from {model_path}")
|
| 112 |
+
model = PeftModel.from_pretrained(model, model_path)
|
| 113 |
+
print(f"Merging weights")
|
| 114 |
+
model = model.merge_and_unload()
|
| 115 |
+
print('Convert to FP16...')
|
| 116 |
+
model.to(torch.float16)
|
| 117 |
+
else:
|
| 118 |
+
use_fast = False
|
| 119 |
+
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
|
| 120 |
+
model = EagleLlamaForCausalLM.from_pretrained(
|
| 121 |
+
model_path,
|
| 122 |
+
low_cpu_mem_usage=True,
|
| 123 |
+
**kwargs
|
| 124 |
+
)
|
| 125 |
+
# Always load the weight into a EagleLLaMA model
|
| 126 |
+
# tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
|
| 127 |
+
# model = AutoModelForCausalLM.from_pretrained(model_path, low_cpu_mem_usage=True, **kwargs)
|
| 128 |
+
|
| 129 |
+
image_processor = None
|
| 130 |
+
|
| 131 |
+
# if 'eagle' in model_name.lower():
|
| 132 |
+
mm_use_im_start_end = getattr(model.config, "mm_use_im_start_end", False)
|
| 133 |
+
mm_use_im_patch_token = getattr(model.config, "mm_use_im_patch_token", True)
|
| 134 |
+
if mm_use_im_patch_token:
|
| 135 |
+
tokenizer.add_tokens([DEFAULT_IMAGE_PATCH_TOKEN], special_tokens=True)
|
| 136 |
+
if mm_use_im_start_end:
|
| 137 |
+
tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
|
| 138 |
+
model.resize_token_embeddings(len(tokenizer))
|
| 139 |
+
|
| 140 |
+
vision_tower = model.get_vision_tower()
|
| 141 |
+
if not vision_tower.is_loaded:
|
| 142 |
+
vision_tower.load_model(device_map=device_map)
|
| 143 |
+
if device_map != 'auto':
|
| 144 |
+
vision_tower.to(device=device_map, dtype=torch.float16)
|
| 145 |
+
image_processor = vision_tower.image_processor
|
| 146 |
+
|
| 147 |
+
if hasattr(model.config, "max_sequence_length"):
|
| 148 |
+
context_len = model.config.max_sequence_length
|
| 149 |
+
else:
|
| 150 |
+
context_len = 2048
|
| 151 |
+
|
| 152 |
+
return tokenizer, model, image_processor, context_len
|
eagle/model/consolidate.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Usage:
|
| 3 |
+
python3 -m eagle.model.consolidate --src ~/model_weights/eagle-7b --dst ~/model_weights/eagle-7b_consolidate
|
| 4 |
+
"""
|
| 5 |
+
import argparse
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 9 |
+
from eagle.model import *
|
| 10 |
+
from eagle.model.utils import auto_upgrade
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def consolidate_ckpt(src_path, dst_path):
|
| 14 |
+
print("Loading model")
|
| 15 |
+
auto_upgrade(src_path)
|
| 16 |
+
src_model = AutoModelForCausalLM.from_pretrained(src_path, torch_dtype=torch.float16, low_cpu_mem_usage=True)
|
| 17 |
+
src_tokenizer = AutoTokenizer.from_pretrained(src_path, use_fast=False)
|
| 18 |
+
src_model.save_pretrained(dst_path)
|
| 19 |
+
src_tokenizer.save_pretrained(dst_path)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
if __name__ == "__main__":
|
| 23 |
+
parser = argparse.ArgumentParser()
|
| 24 |
+
parser.add_argument("--src", type=str, required=True)
|
| 25 |
+
parser.add_argument("--dst", type=str, required=True)
|
| 26 |
+
|
| 27 |
+
args = parser.parse_args()
|
| 28 |
+
|
| 29 |
+
consolidate_ckpt(args.src, args.dst)
|
eagle/model/eagle_arch.py
ADDED
|
@@ -0,0 +1,372 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 Haotian Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
from abc import ABC, abstractmethod
|
| 17 |
+
|
| 18 |
+
import torch
|
| 19 |
+
import torch.nn as nn
|
| 20 |
+
|
| 21 |
+
from .multimodal_encoder.builder import build_vision_tower
|
| 22 |
+
from .multimodal_projector.builder import build_vision_projector
|
| 23 |
+
|
| 24 |
+
from eagle.constants import IGNORE_INDEX, IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_PATCH_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
|
| 25 |
+
|
| 26 |
+
from eagle.mm_utils import get_anyres_image_grid_shape
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class EagleMetaModel:
|
| 30 |
+
|
| 31 |
+
def __init__(self, config):
|
| 32 |
+
super(EagleMetaModel, self).__init__(config)
|
| 33 |
+
|
| 34 |
+
if hasattr(config, "mm_vision_tower"):
|
| 35 |
+
self.vision_tower = build_vision_tower(config, delay_load=True)
|
| 36 |
+
fpn_input_dim = [] if not hasattr(self.vision_tower, "fpn_input_dim") else self.vision_tower.fpn_input_dim
|
| 37 |
+
self.mm_projector = build_vision_projector(config, fpn_input_dim=fpn_input_dim)
|
| 38 |
+
|
| 39 |
+
if 'unpad' in getattr(config, 'mm_patch_merge_type', ''):
|
| 40 |
+
self.image_newline = nn.Parameter(
|
| 41 |
+
torch.empty(config.hidden_size, dtype=self.dtype)
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
def get_vision_tower(self):
|
| 45 |
+
vision_tower = getattr(self, 'vision_tower', None)
|
| 46 |
+
if type(vision_tower) is list:
|
| 47 |
+
vision_tower = vision_tower[0]
|
| 48 |
+
return vision_tower
|
| 49 |
+
|
| 50 |
+
def initialize_vision_modules(self, model_args, fsdp=None):
|
| 51 |
+
vision_tower = model_args.vision_tower
|
| 52 |
+
mm_vision_select_layer = model_args.mm_vision_select_layer
|
| 53 |
+
mm_vision_select_feature = model_args.mm_vision_select_feature
|
| 54 |
+
pretrain_mm_mlp_adapter = model_args.pretrain_mm_mlp_adapter
|
| 55 |
+
mm_patch_merge_type = model_args.mm_patch_merge_type
|
| 56 |
+
|
| 57 |
+
self.config.mm_vision_tower = vision_tower
|
| 58 |
+
|
| 59 |
+
if self.get_vision_tower() is None:
|
| 60 |
+
vision_tower = build_vision_tower(model_args)
|
| 61 |
+
|
| 62 |
+
if fsdp is not None and len(fsdp) > 0:
|
| 63 |
+
self.vision_tower = [vision_tower]
|
| 64 |
+
else:
|
| 65 |
+
self.vision_tower = vision_tower
|
| 66 |
+
else:
|
| 67 |
+
if fsdp is not None and len(fsdp) > 0:
|
| 68 |
+
vision_tower = self.vision_tower[0]
|
| 69 |
+
else:
|
| 70 |
+
vision_tower = self.vision_tower
|
| 71 |
+
vision_tower.load_model()
|
| 72 |
+
|
| 73 |
+
self.config.use_mm_proj = True
|
| 74 |
+
self.config.mm_projector_type = getattr(model_args, 'mm_projector_type', 'linear')
|
| 75 |
+
self.config.mm_hidden_size = vision_tower.hidden_size
|
| 76 |
+
self.config.mm_vision_select_layer = mm_vision_select_layer
|
| 77 |
+
self.config.mm_vision_select_feature = mm_vision_select_feature
|
| 78 |
+
self.config.mm_patch_merge_type = mm_patch_merge_type
|
| 79 |
+
# record config for resampler
|
| 80 |
+
self.config.mm_projector_query_number = model_args.mm_projector_query_number
|
| 81 |
+
|
| 82 |
+
if getattr(self, 'mm_projector', None) is None:
|
| 83 |
+
fpn_input_dim = [] if not hasattr(self.vision_tower, "fpn_input_dim") else self.vision_tower.fpn_input_dim
|
| 84 |
+
self.mm_projector = build_vision_projector(self.config, fpn_input_dim=fpn_input_dim)
|
| 85 |
+
|
| 86 |
+
if 'unpad' in mm_patch_merge_type:
|
| 87 |
+
embed_std = 1 / torch.sqrt(torch.tensor(self.config.hidden_size, dtype=self.dtype))
|
| 88 |
+
self.image_newline = nn.Parameter(
|
| 89 |
+
torch.randn(self.config.hidden_size, dtype=self.dtype) * embed_std
|
| 90 |
+
)
|
| 91 |
+
else:
|
| 92 |
+
# In case it is frozen by LoRA
|
| 93 |
+
for p in self.mm_projector.parameters():
|
| 94 |
+
p.requires_grad = True
|
| 95 |
+
|
| 96 |
+
if pretrain_mm_mlp_adapter is not None:
|
| 97 |
+
mm_projector_weights = torch.load(pretrain_mm_mlp_adapter, map_location='cpu')
|
| 98 |
+
def get_w(weights, keyword):
|
| 99 |
+
return {k.split(keyword + '.')[1]: v for k, v in weights.items() if keyword in k}
|
| 100 |
+
|
| 101 |
+
self.mm_projector.load_state_dict(get_w(mm_projector_weights, 'mm_projector'))
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def unpad_image(tensor, original_size):
|
| 105 |
+
"""
|
| 106 |
+
Unpads a PyTorch tensor of a padded and resized image.
|
| 107 |
+
|
| 108 |
+
Args:
|
| 109 |
+
tensor (torch.Tensor): The image tensor, assumed to be in CxHxW format.
|
| 110 |
+
original_size (tuple): The original size of the image (height, width).
|
| 111 |
+
|
| 112 |
+
Returns:
|
| 113 |
+
torch.Tensor: The unpadded image tensor.
|
| 114 |
+
"""
|
| 115 |
+
original_width, original_height = original_size
|
| 116 |
+
current_height, current_width = tensor.shape[1:]
|
| 117 |
+
|
| 118 |
+
original_aspect_ratio = original_width / original_height
|
| 119 |
+
current_aspect_ratio = current_width / current_height
|
| 120 |
+
|
| 121 |
+
if original_aspect_ratio > current_aspect_ratio:
|
| 122 |
+
scale_factor = current_width / original_width
|
| 123 |
+
new_height = int(original_height * scale_factor)
|
| 124 |
+
padding = (current_height - new_height) // 2
|
| 125 |
+
unpadded_tensor = tensor[:, padding:current_height - padding, :]
|
| 126 |
+
else:
|
| 127 |
+
scale_factor = current_height / original_height
|
| 128 |
+
new_width = int(original_width * scale_factor)
|
| 129 |
+
padding = (current_width - new_width) // 2
|
| 130 |
+
unpadded_tensor = tensor[:, :, padding:current_width - padding]
|
| 131 |
+
|
| 132 |
+
return unpadded_tensor
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class EagleMetaForCausalLM(ABC):
|
| 136 |
+
|
| 137 |
+
@abstractmethod
|
| 138 |
+
def get_model(self):
|
| 139 |
+
pass
|
| 140 |
+
|
| 141 |
+
def get_vision_tower(self):
|
| 142 |
+
return self.get_model().get_vision_tower()
|
| 143 |
+
|
| 144 |
+
def encode_images(self, images):
|
| 145 |
+
image_features = self.get_model().get_vision_tower()(images)
|
| 146 |
+
image_features = self.get_model().mm_projector(image_features)
|
| 147 |
+
return image_features
|
| 148 |
+
|
| 149 |
+
def prepare_inputs_labels_for_multimodal(
|
| 150 |
+
self, input_ids, position_ids, attention_mask, past_key_values, labels,
|
| 151 |
+
images, image_sizes=None
|
| 152 |
+
):
|
| 153 |
+
vision_tower = self.get_vision_tower()
|
| 154 |
+
if vision_tower is None or images is None or input_ids.shape[1] == 1:
|
| 155 |
+
return input_ids, position_ids, attention_mask, past_key_values, None, labels
|
| 156 |
+
|
| 157 |
+
if type(images) is list or images.ndim == 5:
|
| 158 |
+
if type(images) is list:
|
| 159 |
+
images = [x.unsqueeze(0) if x.ndim == 3 else x for x in images]
|
| 160 |
+
concat_images = torch.cat([image for image in images], dim=0)
|
| 161 |
+
image_features = self.encode_images(concat_images)
|
| 162 |
+
split_sizes = [image.shape[0] for image in images]
|
| 163 |
+
image_features = torch.split(image_features, split_sizes, dim=0)
|
| 164 |
+
mm_patch_merge_type = getattr(self.config, 'mm_patch_merge_type', 'flat')
|
| 165 |
+
image_aspect_ratio = getattr(self.config, 'image_aspect_ratio', 'square')
|
| 166 |
+
if mm_patch_merge_type == 'flat':
|
| 167 |
+
image_features = [x.flatten(0, 1) for x in image_features]
|
| 168 |
+
elif mm_patch_merge_type.startswith('spatial'):
|
| 169 |
+
new_image_features = []
|
| 170 |
+
for image_idx, image_feature in enumerate(image_features):
|
| 171 |
+
if image_feature.shape[0] > 1:
|
| 172 |
+
base_image_feature = image_feature[0]
|
| 173 |
+
image_feature = image_feature[1:]
|
| 174 |
+
height = width = self.get_vision_tower().num_patches_per_side
|
| 175 |
+
assert height * width == base_image_feature.shape[0]
|
| 176 |
+
if image_aspect_ratio == 'anyres':
|
| 177 |
+
num_patch_width, num_patch_height = get_anyres_image_grid_shape(image_sizes[image_idx], self.config.image_grid_pinpoints, self.get_vision_tower().config.image_size)
|
| 178 |
+
image_feature = image_feature.view(num_patch_height, num_patch_width, height, width, -1)
|
| 179 |
+
else:
|
| 180 |
+
raise NotImplementedError
|
| 181 |
+
if 'unpad' in mm_patch_merge_type:
|
| 182 |
+
image_feature = image_feature.permute(4, 0, 2, 1, 3).contiguous()
|
| 183 |
+
image_feature = image_feature.flatten(1, 2).flatten(2, 3)
|
| 184 |
+
image_feature = unpad_image(image_feature, image_sizes[image_idx])
|
| 185 |
+
image_feature = torch.cat((
|
| 186 |
+
image_feature,
|
| 187 |
+
self.model.image_newline[:, None, None].expand(*image_feature.shape[:-1], 1).to(image_feature.device)
|
| 188 |
+
), dim=-1)
|
| 189 |
+
image_feature = image_feature.flatten(1, 2).transpose(0, 1)
|
| 190 |
+
else:
|
| 191 |
+
image_feature = image_feature.permute(0, 2, 1, 3, 4).contiguous()
|
| 192 |
+
image_feature = image_feature.flatten(0, 3)
|
| 193 |
+
image_feature = torch.cat((base_image_feature, image_feature), dim=0)
|
| 194 |
+
else:
|
| 195 |
+
image_feature = image_feature[0]
|
| 196 |
+
if 'unpad' in mm_patch_merge_type:
|
| 197 |
+
image_feature = torch.cat((
|
| 198 |
+
image_feature,
|
| 199 |
+
self.model.image_newline[None].to(image_feature.device)
|
| 200 |
+
), dim=0)
|
| 201 |
+
new_image_features.append(image_feature)
|
| 202 |
+
image_features = new_image_features
|
| 203 |
+
else:
|
| 204 |
+
raise ValueError(f"Unexpected mm_patch_merge_type: {self.config.mm_patch_merge_type}")
|
| 205 |
+
else:
|
| 206 |
+
image_features = self.encode_images(images)
|
| 207 |
+
|
| 208 |
+
# TODO: image start / end is not implemented here to support pretraining.
|
| 209 |
+
if getattr(self.config, 'tune_mm_mlp_adapter', False) and getattr(self.config, 'mm_use_im_start_end', False):
|
| 210 |
+
raise NotImplementedError
|
| 211 |
+
|
| 212 |
+
# Let's just add dummy tensors if they do not exist,
|
| 213 |
+
# it is a headache to deal with None all the time.
|
| 214 |
+
# But it is not ideal, and if you have a better idea,
|
| 215 |
+
# please open an issue / submit a PR, thanks.
|
| 216 |
+
_labels = labels
|
| 217 |
+
_position_ids = position_ids
|
| 218 |
+
_attention_mask = attention_mask
|
| 219 |
+
if attention_mask is None:
|
| 220 |
+
attention_mask = torch.ones_like(input_ids, dtype=torch.bool)
|
| 221 |
+
else:
|
| 222 |
+
attention_mask = attention_mask.bool()
|
| 223 |
+
if position_ids is None:
|
| 224 |
+
position_ids = torch.arange(0, input_ids.shape[1], dtype=torch.long, device=input_ids.device)
|
| 225 |
+
if labels is None:
|
| 226 |
+
labels = torch.full_like(input_ids, IGNORE_INDEX)
|
| 227 |
+
|
| 228 |
+
# remove the padding using attention_mask -- FIXME
|
| 229 |
+
_input_ids = input_ids
|
| 230 |
+
input_ids = [cur_input_ids[cur_attention_mask] for cur_input_ids, cur_attention_mask in zip(input_ids, attention_mask)]
|
| 231 |
+
labels = [cur_labels[cur_attention_mask] for cur_labels, cur_attention_mask in zip(labels, attention_mask)]
|
| 232 |
+
|
| 233 |
+
new_input_embeds = []
|
| 234 |
+
new_labels = []
|
| 235 |
+
cur_image_idx = 0
|
| 236 |
+
for batch_idx, cur_input_ids in enumerate(input_ids):
|
| 237 |
+
num_images = (cur_input_ids == IMAGE_TOKEN_INDEX).sum()
|
| 238 |
+
if num_images == 0:
|
| 239 |
+
cur_image_features = image_features[cur_image_idx]
|
| 240 |
+
cur_input_embeds_1 = self.get_model().embed_tokens(cur_input_ids)
|
| 241 |
+
cur_input_embeds = torch.cat([cur_input_embeds_1, cur_image_features[0:0]], dim=0)
|
| 242 |
+
new_input_embeds.append(cur_input_embeds)
|
| 243 |
+
new_labels.append(labels[batch_idx])
|
| 244 |
+
cur_image_idx += 1
|
| 245 |
+
continue
|
| 246 |
+
|
| 247 |
+
image_token_indices = [-1] + torch.where(cur_input_ids == IMAGE_TOKEN_INDEX)[0].tolist() + [cur_input_ids.shape[0]]
|
| 248 |
+
cur_input_ids_noim = []
|
| 249 |
+
cur_labels = labels[batch_idx]
|
| 250 |
+
cur_labels_noim = []
|
| 251 |
+
for i in range(len(image_token_indices) - 1):
|
| 252 |
+
cur_input_ids_noim.append(cur_input_ids[image_token_indices[i]+1:image_token_indices[i+1]])
|
| 253 |
+
cur_labels_noim.append(cur_labels[image_token_indices[i]+1:image_token_indices[i+1]])
|
| 254 |
+
split_sizes = [x.shape[0] for x in cur_labels_noim]
|
| 255 |
+
cur_input_embeds = self.get_model().embed_tokens(torch.cat(cur_input_ids_noim))
|
| 256 |
+
cur_input_embeds_no_im = torch.split(cur_input_embeds, split_sizes, dim=0)
|
| 257 |
+
cur_new_input_embeds = []
|
| 258 |
+
cur_new_labels = []
|
| 259 |
+
|
| 260 |
+
for i in range(num_images + 1):
|
| 261 |
+
cur_new_input_embeds.append(cur_input_embeds_no_im[i])
|
| 262 |
+
cur_new_labels.append(cur_labels_noim[i])
|
| 263 |
+
if i < num_images:
|
| 264 |
+
cur_image_features = image_features[cur_image_idx]
|
| 265 |
+
cur_image_idx += 1
|
| 266 |
+
cur_new_input_embeds.append(cur_image_features)
|
| 267 |
+
cur_new_labels.append(torch.full((cur_image_features.shape[0],), IGNORE_INDEX, device=cur_labels.device, dtype=cur_labels.dtype))
|
| 268 |
+
|
| 269 |
+
cur_new_input_embeds = [x.to(self.device) for x in cur_new_input_embeds]
|
| 270 |
+
|
| 271 |
+
cur_new_input_embeds = torch.cat(cur_new_input_embeds)
|
| 272 |
+
cur_new_labels = torch.cat(cur_new_labels)
|
| 273 |
+
|
| 274 |
+
new_input_embeds.append(cur_new_input_embeds)
|
| 275 |
+
new_labels.append(cur_new_labels)
|
| 276 |
+
|
| 277 |
+
# Truncate sequences to max length as image embeddings can make the sequence longer
|
| 278 |
+
tokenizer_model_max_length = getattr(self.config, 'tokenizer_model_max_length', None)
|
| 279 |
+
if tokenizer_model_max_length is not None:
|
| 280 |
+
new_input_embeds = [x[:tokenizer_model_max_length] for x in new_input_embeds]
|
| 281 |
+
new_labels = [x[:tokenizer_model_max_length] for x in new_labels]
|
| 282 |
+
|
| 283 |
+
# Combine them
|
| 284 |
+
max_len = max(x.shape[0] for x in new_input_embeds)
|
| 285 |
+
batch_size = len(new_input_embeds)
|
| 286 |
+
|
| 287 |
+
new_input_embeds_padded = []
|
| 288 |
+
new_labels_padded = torch.full((batch_size, max_len), IGNORE_INDEX, dtype=new_labels[0].dtype, device=new_labels[0].device)
|
| 289 |
+
attention_mask = torch.zeros((batch_size, max_len), dtype=attention_mask.dtype, device=attention_mask.device)
|
| 290 |
+
position_ids = torch.zeros((batch_size, max_len), dtype=position_ids.dtype, device=position_ids.device)
|
| 291 |
+
|
| 292 |
+
for i, (cur_new_embed, cur_new_labels) in enumerate(zip(new_input_embeds, new_labels)):
|
| 293 |
+
cur_len = cur_new_embed.shape[0]
|
| 294 |
+
if getattr(self.config, 'tokenizer_padding_side', 'right') == "left":
|
| 295 |
+
new_input_embeds_padded.append(torch.cat((
|
| 296 |
+
torch.zeros((max_len - cur_len, cur_new_embed.shape[1]), dtype=cur_new_embed.dtype, device=cur_new_embed.device),
|
| 297 |
+
cur_new_embed
|
| 298 |
+
), dim=0))
|
| 299 |
+
if cur_len > 0:
|
| 300 |
+
new_labels_padded[i, -cur_len:] = cur_new_labels
|
| 301 |
+
attention_mask[i, -cur_len:] = True
|
| 302 |
+
position_ids[i, -cur_len:] = torch.arange(0, cur_len, dtype=position_ids.dtype, device=position_ids.device)
|
| 303 |
+
else:
|
| 304 |
+
new_input_embeds_padded.append(torch.cat((
|
| 305 |
+
cur_new_embed,
|
| 306 |
+
torch.zeros((max_len - cur_len, cur_new_embed.shape[1]), dtype=cur_new_embed.dtype, device=cur_new_embed.device)
|
| 307 |
+
), dim=0))
|
| 308 |
+
if cur_len > 0:
|
| 309 |
+
new_labels_padded[i, :cur_len] = cur_new_labels
|
| 310 |
+
attention_mask[i, :cur_len] = True
|
| 311 |
+
position_ids[i, :cur_len] = torch.arange(0, cur_len, dtype=position_ids.dtype, device=position_ids.device)
|
| 312 |
+
|
| 313 |
+
new_input_embeds = torch.stack(new_input_embeds_padded, dim=0)
|
| 314 |
+
|
| 315 |
+
if _labels is None:
|
| 316 |
+
new_labels = None
|
| 317 |
+
else:
|
| 318 |
+
new_labels = new_labels_padded
|
| 319 |
+
|
| 320 |
+
if _attention_mask is None:
|
| 321 |
+
attention_mask = None
|
| 322 |
+
else:
|
| 323 |
+
attention_mask = attention_mask.to(dtype=_attention_mask.dtype)
|
| 324 |
+
|
| 325 |
+
if _position_ids is None:
|
| 326 |
+
position_ids = None
|
| 327 |
+
|
| 328 |
+
return None, position_ids, attention_mask, past_key_values, new_input_embeds, new_labels
|
| 329 |
+
|
| 330 |
+
def initialize_vision_tokenizer(self, model_args, tokenizer):
|
| 331 |
+
if model_args.mm_use_im_patch_token:
|
| 332 |
+
tokenizer.add_tokens([DEFAULT_IMAGE_PATCH_TOKEN], special_tokens=True)
|
| 333 |
+
self.resize_token_embeddings(len(tokenizer))
|
| 334 |
+
|
| 335 |
+
if model_args.mm_use_im_start_end:
|
| 336 |
+
num_new_tokens = tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
|
| 337 |
+
self.resize_token_embeddings(len(tokenizer))
|
| 338 |
+
|
| 339 |
+
if num_new_tokens > 0:
|
| 340 |
+
input_embeddings = self.get_input_embeddings().weight.data
|
| 341 |
+
output_embeddings = self.get_output_embeddings().weight.data
|
| 342 |
+
|
| 343 |
+
input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
|
| 344 |
+
dim=0, keepdim=True)
|
| 345 |
+
output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
|
| 346 |
+
dim=0, keepdim=True)
|
| 347 |
+
|
| 348 |
+
input_embeddings[-num_new_tokens:] = input_embeddings_avg
|
| 349 |
+
output_embeddings[-num_new_tokens:] = output_embeddings_avg
|
| 350 |
+
|
| 351 |
+
if model_args.tune_mm_mlp_adapter:
|
| 352 |
+
for p in self.get_input_embeddings().parameters():
|
| 353 |
+
p.requires_grad = True
|
| 354 |
+
for p in self.get_output_embeddings().parameters():
|
| 355 |
+
p.requires_grad = False
|
| 356 |
+
|
| 357 |
+
if model_args.pretrain_mm_mlp_adapter:
|
| 358 |
+
mm_projector_weights = torch.load(model_args.pretrain_mm_mlp_adapter, map_location='cpu')
|
| 359 |
+
embed_tokens_weight = mm_projector_weights['model.embed_tokens.weight']
|
| 360 |
+
assert num_new_tokens == 2
|
| 361 |
+
if input_embeddings.shape == embed_tokens_weight.shape:
|
| 362 |
+
input_embeddings[-num_new_tokens:] = embed_tokens_weight[-num_new_tokens:]
|
| 363 |
+
elif embed_tokens_weight.shape[0] == num_new_tokens:
|
| 364 |
+
input_embeddings[-num_new_tokens:] = embed_tokens_weight
|
| 365 |
+
else:
|
| 366 |
+
raise ValueError(f"Unexpected embed_tokens_weight shape. Pretrained: {embed_tokens_weight.shape}. Current: {input_embeddings.shape}. Numer of new tokens: {num_new_tokens}.")
|
| 367 |
+
elif model_args.mm_use_im_patch_token:
|
| 368 |
+
if model_args.tune_mm_mlp_adapter:
|
| 369 |
+
for p in self.get_input_embeddings().parameters():
|
| 370 |
+
p.requires_grad = False
|
| 371 |
+
for p in self.get_output_embeddings().parameters():
|
| 372 |
+
p.requires_grad = False
|
eagle/model/language_model/eagle_llama.py
ADDED
|
@@ -0,0 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 Haotian Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
from typing import List, Optional, Tuple, Union
|
| 17 |
+
|
| 18 |
+
import torch
|
| 19 |
+
import torch.nn as nn
|
| 20 |
+
|
| 21 |
+
from transformers import AutoConfig, AutoModelForCausalLM, \
|
| 22 |
+
LlamaConfig, LlamaModel, LlamaForCausalLM
|
| 23 |
+
|
| 24 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast
|
| 25 |
+
from transformers.generation.utils import GenerateOutput
|
| 26 |
+
|
| 27 |
+
from ..eagle_arch import EagleMetaModel, EagleMetaForCausalLM
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class EagleConfig(LlamaConfig):
|
| 31 |
+
model_type = "eagle_llama"
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class EagleLlamaModel(EagleMetaModel, LlamaModel):
|
| 35 |
+
config_class = EagleConfig
|
| 36 |
+
|
| 37 |
+
def __init__(self, config: LlamaConfig):
|
| 38 |
+
super(EagleLlamaModel, self).__init__(config)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class EagleLlamaForCausalLM(LlamaForCausalLM, EagleMetaForCausalLM):
|
| 42 |
+
config_class = EagleConfig
|
| 43 |
+
|
| 44 |
+
def __init__(self, config):
|
| 45 |
+
super(LlamaForCausalLM, self).__init__(config)
|
| 46 |
+
self.model = EagleLlamaModel(config)
|
| 47 |
+
self.pretraining_tp = config.pretraining_tp
|
| 48 |
+
self.vocab_size = config.vocab_size
|
| 49 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 50 |
+
|
| 51 |
+
# Initialize weights and apply final processing
|
| 52 |
+
self.post_init()
|
| 53 |
+
|
| 54 |
+
def get_model(self):
|
| 55 |
+
return self.model
|
| 56 |
+
|
| 57 |
+
def forward(
|
| 58 |
+
self,
|
| 59 |
+
input_ids: torch.LongTensor = None,
|
| 60 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 61 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 62 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 63 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 64 |
+
labels: Optional[torch.LongTensor] = None,
|
| 65 |
+
use_cache: Optional[bool] = None,
|
| 66 |
+
output_attentions: Optional[bool] = None,
|
| 67 |
+
output_hidden_states: Optional[bool] = None,
|
| 68 |
+
images: Optional[torch.FloatTensor] = None,
|
| 69 |
+
image_sizes: Optional[List[List[int]]] = None,
|
| 70 |
+
return_dict: Optional[bool] = None,
|
| 71 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 72 |
+
|
| 73 |
+
if inputs_embeds is None:
|
| 74 |
+
(
|
| 75 |
+
input_ids,
|
| 76 |
+
position_ids,
|
| 77 |
+
attention_mask,
|
| 78 |
+
past_key_values,
|
| 79 |
+
inputs_embeds,
|
| 80 |
+
labels
|
| 81 |
+
) = self.prepare_inputs_labels_for_multimodal(
|
| 82 |
+
input_ids,
|
| 83 |
+
position_ids,
|
| 84 |
+
attention_mask,
|
| 85 |
+
past_key_values,
|
| 86 |
+
labels,
|
| 87 |
+
images,
|
| 88 |
+
image_sizes
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
return super().forward(
|
| 92 |
+
input_ids=input_ids,
|
| 93 |
+
attention_mask=attention_mask,
|
| 94 |
+
position_ids=position_ids,
|
| 95 |
+
past_key_values=past_key_values,
|
| 96 |
+
inputs_embeds=inputs_embeds,
|
| 97 |
+
labels=labels,
|
| 98 |
+
use_cache=use_cache,
|
| 99 |
+
output_attentions=output_attentions,
|
| 100 |
+
output_hidden_states=output_hidden_states,
|
| 101 |
+
return_dict=return_dict
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
@torch.no_grad()
|
| 105 |
+
def generate(
|
| 106 |
+
self,
|
| 107 |
+
inputs: Optional[torch.Tensor] = None,
|
| 108 |
+
images: Optional[torch.Tensor] = None,
|
| 109 |
+
image_sizes: Optional[torch.Tensor] = None,
|
| 110 |
+
**kwargs,
|
| 111 |
+
) -> Union[GenerateOutput, torch.LongTensor]:
|
| 112 |
+
position_ids = kwargs.pop("position_ids", None)
|
| 113 |
+
attention_mask = kwargs.pop("attention_mask", None)
|
| 114 |
+
if "inputs_embeds" in kwargs:
|
| 115 |
+
raise NotImplementedError("`inputs_embeds` is not supported")
|
| 116 |
+
|
| 117 |
+
if images is not None:
|
| 118 |
+
(
|
| 119 |
+
inputs,
|
| 120 |
+
position_ids,
|
| 121 |
+
attention_mask,
|
| 122 |
+
_,
|
| 123 |
+
inputs_embeds,
|
| 124 |
+
_
|
| 125 |
+
) = self.prepare_inputs_labels_for_multimodal(
|
| 126 |
+
inputs,
|
| 127 |
+
position_ids,
|
| 128 |
+
attention_mask,
|
| 129 |
+
None,
|
| 130 |
+
None,
|
| 131 |
+
images,
|
| 132 |
+
image_sizes=image_sizes
|
| 133 |
+
)
|
| 134 |
+
else:
|
| 135 |
+
inputs_embeds = self.get_model().embed_tokens(inputs)
|
| 136 |
+
|
| 137 |
+
return super().generate(
|
| 138 |
+
position_ids=position_ids,
|
| 139 |
+
attention_mask=attention_mask,
|
| 140 |
+
inputs_embeds=inputs_embeds,
|
| 141 |
+
**kwargs
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
def prepare_inputs_for_generation(self, input_ids, past_key_values=None,
|
| 145 |
+
inputs_embeds=None, **kwargs):
|
| 146 |
+
images = kwargs.pop("images", None)
|
| 147 |
+
image_sizes = kwargs.pop("image_sizes", None)
|
| 148 |
+
inputs = super().prepare_inputs_for_generation(
|
| 149 |
+
input_ids, past_key_values=past_key_values, inputs_embeds=inputs_embeds, **kwargs
|
| 150 |
+
)
|
| 151 |
+
if images is not None:
|
| 152 |
+
inputs['images'] = images
|
| 153 |
+
if image_sizes is not None:
|
| 154 |
+
inputs['image_sizes'] = image_sizes
|
| 155 |
+
return inputs
|
| 156 |
+
|
| 157 |
+
AutoConfig.register("eagle_llama", EagleConfig)
|
| 158 |
+
AutoModelForCausalLM.register(EagleConfig, EagleLlamaForCausalLM)
|
eagle/model/multimodal_encoder/builder.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from .clip_encoder import CLIPVisionTower
|
| 3 |
+
from .multi_backbone_channel_concatenation_encoder import MultiBackboneChannelConcatenationVisionTower
|
| 4 |
+
|
| 5 |
+
def build_vision_tower(vision_tower_cfg, **kwargs):
|
| 6 |
+
vision_tower = getattr(vision_tower_cfg, 'mm_vision_tower', getattr(vision_tower_cfg, 'vision_tower', None))
|
| 7 |
+
|
| 8 |
+
if "clip" in vision_tower and vision_tower.startswith("openai"):
|
| 9 |
+
is_absolute_path_exists = os.path.exists(vision_tower)
|
| 10 |
+
if is_absolute_path_exists or vision_tower.startswith("openai") or vision_tower.startswith("laion") or "ShareGPT4V" in vision_tower:
|
| 11 |
+
return CLIPVisionTower(vision_tower, args=vision_tower_cfg, **kwargs)
|
| 12 |
+
raise ValueError(f'Unknown vision tower: {vision_tower}')
|
| 13 |
+
|
| 14 |
+
elif ";" in vision_tower:
|
| 15 |
+
return MultiBackboneChannelConcatenationVisionTower(vision_tower, args=vision_tower_cfg)
|
| 16 |
+
|
| 17 |
+
raise ValueError(f'Unknown vision tower: {vision_tower}')
|
eagle/model/multimodal_encoder/clip_encoder.py
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
from transformers import CLIPVisionModel, CLIPImageProcessor, CLIPVisionConfig
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class CLIPVisionTower(nn.Module):
|
| 8 |
+
def __init__(self, vision_tower, args, delay_load=False):
|
| 9 |
+
super().__init__()
|
| 10 |
+
|
| 11 |
+
self.is_loaded = False
|
| 12 |
+
|
| 13 |
+
self.vision_tower_name = vision_tower
|
| 14 |
+
self.select_layer = args.mm_vision_select_layer
|
| 15 |
+
self.select_feature = getattr(args, 'mm_vision_select_feature', 'patch')
|
| 16 |
+
|
| 17 |
+
if not delay_load:
|
| 18 |
+
self.load_model()
|
| 19 |
+
elif getattr(args, 'unfreeze_mm_vision_tower', False):
|
| 20 |
+
self.load_model()
|
| 21 |
+
else:
|
| 22 |
+
self.cfg_only = CLIPVisionConfig.from_pretrained(self.vision_tower_name)
|
| 23 |
+
|
| 24 |
+
def load_model(self, device_map=None):
|
| 25 |
+
if self.is_loaded:
|
| 26 |
+
print('{} is already loaded, `load_model` called again, skipping.'.format(self.vision_tower_name))
|
| 27 |
+
return
|
| 28 |
+
|
| 29 |
+
self.image_processor = CLIPImageProcessor.from_pretrained(self.vision_tower_name)
|
| 30 |
+
self.vision_tower = CLIPVisionModel.from_pretrained(self.vision_tower_name, device_map=device_map)
|
| 31 |
+
self.vision_tower.requires_grad_(False)
|
| 32 |
+
|
| 33 |
+
self.is_loaded = True
|
| 34 |
+
|
| 35 |
+
def feature_select(self, image_forward_outs):
|
| 36 |
+
image_features = image_forward_outs.hidden_states[self.select_layer]
|
| 37 |
+
if self.select_feature == 'patch':
|
| 38 |
+
image_features = image_features[:, 1:]
|
| 39 |
+
elif self.select_feature == 'cls_patch':
|
| 40 |
+
image_features = image_features
|
| 41 |
+
else:
|
| 42 |
+
raise ValueError(f'Unexpected select feature: {self.select_feature}')
|
| 43 |
+
return image_features
|
| 44 |
+
|
| 45 |
+
@torch.no_grad()
|
| 46 |
+
def forward(self, images):
|
| 47 |
+
if type(images) is list:
|
| 48 |
+
image_features = []
|
| 49 |
+
for image in images:
|
| 50 |
+
image_forward_out = self.vision_tower(image.to(device=self.device, dtype=self.dtype).unsqueeze(0), output_hidden_states=True)
|
| 51 |
+
image_feature = self.feature_select(image_forward_out).to(image.dtype)
|
| 52 |
+
image_features.append(image_feature)
|
| 53 |
+
else:
|
| 54 |
+
image_forward_outs = self.vision_tower(images.to(device=self.device, dtype=self.dtype), output_hidden_states=True)
|
| 55 |
+
image_features = self.feature_select(image_forward_outs).to(images.dtype)
|
| 56 |
+
|
| 57 |
+
return image_features
|
| 58 |
+
|
| 59 |
+
@property
|
| 60 |
+
def dummy_feature(self):
|
| 61 |
+
return torch.zeros(1, self.hidden_size, device=self.device, dtype=self.dtype)
|
| 62 |
+
|
| 63 |
+
@property
|
| 64 |
+
def dtype(self):
|
| 65 |
+
return self.vision_tower.dtype
|
| 66 |
+
|
| 67 |
+
@property
|
| 68 |
+
def device(self):
|
| 69 |
+
return self.vision_tower.device
|
| 70 |
+
|
| 71 |
+
@property
|
| 72 |
+
def config(self):
|
| 73 |
+
if self.is_loaded:
|
| 74 |
+
return self.vision_tower.config
|
| 75 |
+
else:
|
| 76 |
+
return self.cfg_only
|
| 77 |
+
|
| 78 |
+
@property
|
| 79 |
+
def hidden_size(self):
|
| 80 |
+
return self.config.hidden_size
|
| 81 |
+
|
| 82 |
+
@property
|
| 83 |
+
def num_patches_per_side(self):
|
| 84 |
+
return self.config.image_size // self.config.patch_size
|
| 85 |
+
|
| 86 |
+
@property
|
| 87 |
+
def num_patches(self):
|
| 88 |
+
return (self.config.image_size // self.config.patch_size) ** 2
|
eagle/model/multimodal_encoder/convnext_encoder.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from transformers import CLIPImageProcessor
|
| 4 |
+
from .vision_models.convnext import convnext_xxlarge
|
| 5 |
+
from torch.utils.checkpoint import checkpoint
|
| 6 |
+
|
| 7 |
+
cfg={
|
| 8 |
+
"crop_size": 256,
|
| 9 |
+
"do_center_crop": True,
|
| 10 |
+
"do_normalize": True,
|
| 11 |
+
"do_resize": True,
|
| 12 |
+
"feature_extractor_type": "CLIPFeatureExtractor",
|
| 13 |
+
"image_mean": [
|
| 14 |
+
0.48145466,
|
| 15 |
+
0.4578275,
|
| 16 |
+
0.40821073
|
| 17 |
+
],
|
| 18 |
+
"image_std": [
|
| 19 |
+
0.26862954,
|
| 20 |
+
0.26130258,
|
| 21 |
+
0.27577711
|
| 22 |
+
],
|
| 23 |
+
"resample": 3,
|
| 24 |
+
"size": 256
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
class ConvNextVisionTower(nn.Module):
|
| 28 |
+
def __init__(self, vision_tower, args, delay_load=False):
|
| 29 |
+
super().__init__()
|
| 30 |
+
|
| 31 |
+
self.is_loaded = False
|
| 32 |
+
self.freeze_vision=args.freeze_vision
|
| 33 |
+
self.input_image_size=args.input_image_size
|
| 34 |
+
self.vision_tower_name = vision_tower
|
| 35 |
+
self.select_layer = -1 # hardcode
|
| 36 |
+
self.select_feature = getattr(args, 'mm_vision_select_feature', 'patch')
|
| 37 |
+
|
| 38 |
+
self.load_model()
|
| 39 |
+
|
| 40 |
+
def load_model(self):
|
| 41 |
+
self.image_processor = CLIPImageProcessor(**cfg)
|
| 42 |
+
if 'xxlarge' in self.vision_tower_name:
|
| 43 |
+
self.vision_tower = convnext_xxlarge(self.vision_tower_name)
|
| 44 |
+
setattr(self.vision_tower, 'hidden_size', 3072)
|
| 45 |
+
else:
|
| 46 |
+
raise NotImplementedError
|
| 47 |
+
|
| 48 |
+
if self.freeze_vision:
|
| 49 |
+
self.vision_tower.requires_grad_(False)
|
| 50 |
+
|
| 51 |
+
# Hardcode
|
| 52 |
+
for s in self.vision_tower.stages:
|
| 53 |
+
s.grad_checkpointing = True
|
| 54 |
+
|
| 55 |
+
if self.input_image_size is not None:
|
| 56 |
+
self.image_processor.size=self.input_image_size
|
| 57 |
+
self.image_processor.crop_size={
|
| 58 |
+
'height':self.input_image_size,
|
| 59 |
+
'width': self.input_image_size
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
self.is_loaded = True
|
| 63 |
+
|
| 64 |
+
def feature_select(self, image_forward_outs):
|
| 65 |
+
image_features = image_forward_outs[self.select_layer]
|
| 66 |
+
return image_features
|
| 67 |
+
|
| 68 |
+
def forward_features(self, x):
|
| 69 |
+
x = self.vision_tower.stem(x)
|
| 70 |
+
image_forward_out=[]
|
| 71 |
+
for blk in self.vision_tower.stages:
|
| 72 |
+
x = blk(x)
|
| 73 |
+
b,c,h,w=x.shape
|
| 74 |
+
image_forward_out.append(x.view(b,c,-1).transpose(1,2))
|
| 75 |
+
return image_forward_out
|
| 76 |
+
|
| 77 |
+
def forward(self, images):
|
| 78 |
+
if self.freeze_vision:
|
| 79 |
+
with torch.no_grad():
|
| 80 |
+
image_features = self._forward_images(images)
|
| 81 |
+
else:
|
| 82 |
+
image_features = self._forward_images(images)
|
| 83 |
+
|
| 84 |
+
return image_features
|
| 85 |
+
|
| 86 |
+
def _forward_images(self, images):
|
| 87 |
+
|
| 88 |
+
image_forward_outs = self.forward_features(images.to(device=self.device, dtype=self.dtype))
|
| 89 |
+
image_features = self.feature_select(image_forward_outs)
|
| 90 |
+
|
| 91 |
+
return image_features
|
| 92 |
+
|
| 93 |
+
@property
|
| 94 |
+
def dummy_feature(self):
|
| 95 |
+
return torch.zeros(1, self.hidden_size, device=self.device, dtype=self.dtype)
|
| 96 |
+
|
| 97 |
+
@property
|
| 98 |
+
def dtype(self):
|
| 99 |
+
return next(self.vision_tower.parameters()).dtype
|
| 100 |
+
|
| 101 |
+
@property
|
| 102 |
+
def device(self):
|
| 103 |
+
return next(self.vision_tower.parameters()).device
|
| 104 |
+
|
| 105 |
+
@property
|
| 106 |
+
def config(self):
|
| 107 |
+
assert NotImplementedError
|
| 108 |
+
pass
|
| 109 |
+
|
| 110 |
+
@property
|
| 111 |
+
def num_attention_heads(self):
|
| 112 |
+
# as constant
|
| 113 |
+
return 16
|
| 114 |
+
@property
|
| 115 |
+
def num_layers(self):
|
| 116 |
+
# as constant
|
| 117 |
+
return 4
|
| 118 |
+
@property
|
| 119 |
+
def hidden_size(self):
|
| 120 |
+
return self.vision_tower.hidden_size
|
| 121 |
+
|
| 122 |
+
@property
|
| 123 |
+
def num_patches(self):
|
| 124 |
+
return (cfg['image_size'] // self.patch_embed.patch_size[0]) ** 2
|
eagle/model/multimodal_encoder/hr_clip_encoder.py
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Mostly copy-paste from LLaVA-HR
|
| 3 |
+
https://github.com/luogen1996/LLaVA-HR
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
from torch.utils.checkpoint import checkpoint
|
| 9 |
+
|
| 10 |
+
from transformers import CLIPVisionModel, CLIPImageProcessor, CLIPVisionConfig
|
| 11 |
+
|
| 12 |
+
import math
|
| 13 |
+
import torch
|
| 14 |
+
import torch.nn.functional as F
|
| 15 |
+
from typing import List, Optional
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def forward_embeddings(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
|
| 19 |
+
batch_size = pixel_values.shape[0]
|
| 20 |
+
target_dtype = self.patch_embedding.weight.dtype
|
| 21 |
+
patch_embeds = self.patch_embedding(pixel_values.to(dtype=target_dtype)) # shape = [*, width, grid, grid]
|
| 22 |
+
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
|
| 23 |
+
|
| 24 |
+
class_embeds = self.class_embedding.expand(batch_size, 1, -1)
|
| 25 |
+
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
|
| 26 |
+
position_embeddings = self.position_embedding(self.position_ids)
|
| 27 |
+
|
| 28 |
+
if position_embeddings.shape[1]!=embeddings.shape[1]:
|
| 29 |
+
position_embeddings=resample_pos_embed(position_embeddings,embeddings.shape[1])
|
| 30 |
+
|
| 31 |
+
embeddings = embeddings + position_embeddings
|
| 32 |
+
return embeddings
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def resample_pos_embed(
|
| 36 |
+
posemb,
|
| 37 |
+
new_size: int,
|
| 38 |
+
num_prefix_tokens: int = 1,
|
| 39 |
+
interpolation: str = 'bicubic',
|
| 40 |
+
antialias: bool = True,
|
| 41 |
+
verbose: bool = False,
|
| 42 |
+
):
|
| 43 |
+
new_size=[int(math.sqrt(new_size-num_prefix_tokens)),int(math.sqrt(new_size-num_prefix_tokens))]
|
| 44 |
+
num_pos_tokens = posemb.shape[1] - num_prefix_tokens
|
| 45 |
+
old_size = int(math.sqrt(num_pos_tokens))
|
| 46 |
+
bs=posemb.shape[0]
|
| 47 |
+
|
| 48 |
+
if num_prefix_tokens:
|
| 49 |
+
posemb_prefix, posemb = posemb[:,:num_prefix_tokens], posemb[:,num_prefix_tokens:]
|
| 50 |
+
else:
|
| 51 |
+
posemb_prefix, posemb = None, posemb
|
| 52 |
+
|
| 53 |
+
# do the interpolation
|
| 54 |
+
embed_dim = posemb.shape[-1]
|
| 55 |
+
orig_dtype = posemb.dtype
|
| 56 |
+
posemb = posemb.float() # interpolate needs float32
|
| 57 |
+
posemb = posemb.reshape(bs, old_size, old_size, -1).permute(0, 3, 1, 2)
|
| 58 |
+
posemb = F.interpolate(posemb, size=new_size, mode=interpolation, antialias=antialias)
|
| 59 |
+
posemb = posemb.permute(0, 2, 3, 1).reshape(bs, -1, embed_dim)
|
| 60 |
+
posemb = posemb.to(dtype=orig_dtype)
|
| 61 |
+
|
| 62 |
+
# add back extra (class, etc) prefix tokens
|
| 63 |
+
if posemb_prefix is not None:
|
| 64 |
+
posemb = torch.cat([posemb_prefix, posemb],1)
|
| 65 |
+
|
| 66 |
+
if not torch.jit.is_scripting() and verbose:
|
| 67 |
+
print(f'Resized position embedding: {old_size} to {new_size}.')
|
| 68 |
+
|
| 69 |
+
return posemb
|
| 70 |
+
|
| 71 |
+
class HRCLIPVisionTower(nn.Module):
|
| 72 |
+
def __init__(self, vision_tower, args, delay_load=False):
|
| 73 |
+
super().__init__()
|
| 74 |
+
|
| 75 |
+
self.is_loaded = False
|
| 76 |
+
self.freeze_vision=args.freeze_vision
|
| 77 |
+
self.input_image_size=args.input_image_size
|
| 78 |
+
self.vision_tower_name = vision_tower
|
| 79 |
+
self.select_layer = args.mm_vision_select_layer
|
| 80 |
+
self.select_feature = getattr(args, 'mm_vision_select_feature', 'patch')
|
| 81 |
+
|
| 82 |
+
if not delay_load:
|
| 83 |
+
self.load_model()
|
| 84 |
+
else:
|
| 85 |
+
self.cfg_only = CLIPVisionConfig.from_pretrained(self.vision_tower_name)
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def load_model(self):
|
| 89 |
+
self.image_processor = CLIPImageProcessor.from_pretrained(self.vision_tower_name)
|
| 90 |
+
self.vision_tower = CLIPVisionModel.from_pretrained(self.vision_tower_name)
|
| 91 |
+
# checkpointing for clip
|
| 92 |
+
self.vision_tower.vision_model.encoder.gradient_checkpointing =True
|
| 93 |
+
|
| 94 |
+
if self.freeze_vision:
|
| 95 |
+
self.vision_tower.requires_grad_(False)
|
| 96 |
+
|
| 97 |
+
cls_=self.vision_tower.vision_model.embeddings
|
| 98 |
+
bound_method = forward_embeddings.__get__(cls_, cls_.__class__)
|
| 99 |
+
setattr(cls_, 'forward', bound_method)
|
| 100 |
+
|
| 101 |
+
if self.input_image_size is not None:
|
| 102 |
+
self.image_processor.size=self.input_image_size
|
| 103 |
+
self.image_processor.crop_size={
|
| 104 |
+
'height':self.input_image_size,
|
| 105 |
+
'width': self.input_image_size
|
| 106 |
+
}
|
| 107 |
+
|
| 108 |
+
self.is_loaded = True
|
| 109 |
+
|
| 110 |
+
def forward(self, x):
|
| 111 |
+
# 448 image input
|
| 112 |
+
blks = self.vision_tower.vision_model.encoder.layers
|
| 113 |
+
x = self.vision_tower.vision_model.embeddings(x)
|
| 114 |
+
x = self.vision_tower.vision_model.pre_layrnorm(x[:, 1:])
|
| 115 |
+
|
| 116 |
+
# inference of fast branch
|
| 117 |
+
for blk in blks:
|
| 118 |
+
if self.training:
|
| 119 |
+
x=checkpoint(
|
| 120 |
+
blk.__call__,
|
| 121 |
+
x,
|
| 122 |
+
None,
|
| 123 |
+
None
|
| 124 |
+
)[0]
|
| 125 |
+
else:
|
| 126 |
+
x = blk(x, None, None)[0]
|
| 127 |
+
|
| 128 |
+
return x
|
| 129 |
+
|
| 130 |
+
@property
|
| 131 |
+
def dummy_feature(self):
|
| 132 |
+
return torch.zeros(1, self.hidden_size, device=self.device, dtype=self.dtype)
|
| 133 |
+
|
| 134 |
+
@property
|
| 135 |
+
def dtype(self):
|
| 136 |
+
return self.vision_tower.dtype
|
| 137 |
+
|
| 138 |
+
@property
|
| 139 |
+
def device(self):
|
| 140 |
+
return self.vision_tower.device
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
@property
|
| 144 |
+
def num_attention_heads(self):
|
| 145 |
+
return self.config.num_attention_heads
|
| 146 |
+
@property
|
| 147 |
+
def num_layers(self):
|
| 148 |
+
return self.config.num_hidden_layers
|
| 149 |
+
@property
|
| 150 |
+
def config(self):
|
| 151 |
+
if self.is_loaded:
|
| 152 |
+
return self.vision_tower.config
|
| 153 |
+
else:
|
| 154 |
+
return self.cfg_only
|
| 155 |
+
|
| 156 |
+
@property
|
| 157 |
+
def hidden_size(self):
|
| 158 |
+
return self.config.hidden_size
|
| 159 |
+
|
| 160 |
+
@property
|
| 161 |
+
def num_patches(self):
|
| 162 |
+
return (self.config.image_size // self.config.patch_size) ** 2
|
eagle/model/multimodal_encoder/multi_backbone_channel_concatenation_encoder.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.utils.checkpoint import checkpoint
|
| 4 |
+
from .convnext_encoder import ConvNextVisionTower
|
| 5 |
+
from .hr_clip_encoder import HRCLIPVisionTower
|
| 6 |
+
from .vision_models.eva_vit import EVAVITVisionTower
|
| 7 |
+
from .sam_encoder import SAMVisionTower
|
| 8 |
+
from .pix2struct_encoder import Pix2StructLargeVisionTower
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
from torch.nn.init import trunc_normal_
|
| 11 |
+
from copy import deepcopy
|
| 12 |
+
import random
|
| 13 |
+
import math
|
| 14 |
+
|
| 15 |
+
class MultiBackboneChannelConcatenationVisionTower(nn.Module):
|
| 16 |
+
def __init__(self,
|
| 17 |
+
vision_tower,
|
| 18 |
+
args,
|
| 19 |
+
grid_size=32):
|
| 20 |
+
|
| 21 |
+
super().__init__()
|
| 22 |
+
|
| 23 |
+
self.is_loaded = False
|
| 24 |
+
self.grid_size = grid_size
|
| 25 |
+
self.num_tokens = self.grid_size ** 2
|
| 26 |
+
|
| 27 |
+
vision_tower_name_list = vision_tower.split(";")
|
| 28 |
+
self.input_image_size = 1024 # hardcode
|
| 29 |
+
self.load_vision_towers(vision_tower_name_list, args)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def load_vision_towers(self, vision_tower_name_list, args):
|
| 33 |
+
self.vision_towers = nn.ModuleList()
|
| 34 |
+
for name in vision_tower_name_list:
|
| 35 |
+
if name == 'det-1024':
|
| 36 |
+
det_args = deepcopy(args)
|
| 37 |
+
det_args.input_image_size = 1024
|
| 38 |
+
det_args.freeze_vision = False
|
| 39 |
+
det_args.vision_tower_pretrained_from = '/lustre/fsw/portfolios/llmservice/users/fuxiaol/eva02_L_coco_det_sys_o365.pth'
|
| 40 |
+
det_vision_tower = EVAVITVisionTower("eva02-l-16", det_args)
|
| 41 |
+
det_vision_tower.load_model()
|
| 42 |
+
self.vision_towers.append(det_vision_tower)
|
| 43 |
+
|
| 44 |
+
elif name == 'convnext-1024':
|
| 45 |
+
## ConvNeXt
|
| 46 |
+
convnext_args = deepcopy(args)
|
| 47 |
+
convnext_args.freeze_vision = False
|
| 48 |
+
convnext_args.input_image_size = 1024
|
| 49 |
+
convnext_vision_tower = "convnext_xxlarge.clip_laion2b_soup" # hardcode
|
| 50 |
+
convnext_vision_tower = ConvNextVisionTower(convnext_vision_tower,
|
| 51 |
+
convnext_args)
|
| 52 |
+
convnext_vision_tower.load_model()
|
| 53 |
+
self.vision_towers.append(convnext_vision_tower)
|
| 54 |
+
|
| 55 |
+
elif name == "sam-1024":
|
| 56 |
+
sam_args = deepcopy(args)
|
| 57 |
+
sam_args.freeze_vision = False
|
| 58 |
+
sam_args.input_image_size = 1024
|
| 59 |
+
sam_args.add_pixel_shuffle = True
|
| 60 |
+
sam_vision_tower = SAMVisionTower("SAM-L", sam_args)
|
| 61 |
+
sam_vision_tower.load_model()
|
| 62 |
+
self.vision_towers.append(sam_vision_tower)
|
| 63 |
+
|
| 64 |
+
elif name == 'pix2struct-1024':
|
| 65 |
+
pix_args = deepcopy(args)
|
| 66 |
+
#pix_args.freeze_vision = True
|
| 67 |
+
pix_args.input_image_size = 1024
|
| 68 |
+
pix_args.freeze_vision = False
|
| 69 |
+
pix_args.do_resize = True
|
| 70 |
+
pix_args.de_normalize = True
|
| 71 |
+
pix_vision_tower = Pix2StructLargeVisionTower("pix2struct-large", pix_args)
|
| 72 |
+
pix_vision_tower.load_model()
|
| 73 |
+
self.vision_towers.append(pix_vision_tower)
|
| 74 |
+
|
| 75 |
+
elif name == 'clip-448':
|
| 76 |
+
clip_args = deepcopy(args)
|
| 77 |
+
clip_args.input_image_size = 336 # actually 448, will have no effect
|
| 78 |
+
clip_args.freeze_vision = False
|
| 79 |
+
clip_vision_tower = HRCLIPVisionTower("openai/clip-vit-large-patch14-336", clip_args)
|
| 80 |
+
clip_vision_tower.load_model()
|
| 81 |
+
self.vision_towers.append(clip_vision_tower)
|
| 82 |
+
|
| 83 |
+
# a hardcode here, so we always use convnext in the vision encoder mixture
|
| 84 |
+
self.image_processor = convnext_vision_tower.image_processor
|
| 85 |
+
self.is_loaded = True
|
| 86 |
+
|
| 87 |
+
def load_model(self):
|
| 88 |
+
assert self.is_loaded, "All the vision encoders should be loaded during initialization!"
|
| 89 |
+
|
| 90 |
+
def forward(self, x):
|
| 91 |
+
features = []
|
| 92 |
+
for vision_tower in self.vision_towers:
|
| 93 |
+
if vision_tower.input_image_size != self.input_image_size:
|
| 94 |
+
resized_x = F.interpolate(x.float(),
|
| 95 |
+
size=(vision_tower.input_image_size, vision_tower.input_image_size),
|
| 96 |
+
mode='bilinear',
|
| 97 |
+
align_corners=True).to(dtype=x.dtype)
|
| 98 |
+
else:
|
| 99 |
+
resized_x = x
|
| 100 |
+
feature = vision_tower(resized_x)
|
| 101 |
+
if len(feature.shape) == 3: # b, n, c
|
| 102 |
+
b, n, c = feature.shape
|
| 103 |
+
if n == self.num_tokens:
|
| 104 |
+
features.append(feature)
|
| 105 |
+
continue
|
| 106 |
+
|
| 107 |
+
w = h = int(n**0.5)
|
| 108 |
+
feature = feature.transpose(1,2).reshape(b, c, h, w)
|
| 109 |
+
else:
|
| 110 |
+
b, c, h, w = feature.shape
|
| 111 |
+
|
| 112 |
+
if w != self.grid_size:
|
| 113 |
+
feature = F.interpolate(feature.float(), size=(self.grid_size, self.grid_size), mode='bilinear', align_corners=True).to(dtype=x.dtype)
|
| 114 |
+
features.append(feature.flatten(2,3).transpose(1,2))
|
| 115 |
+
|
| 116 |
+
features = torch.cat(features, dim=-1)
|
| 117 |
+
|
| 118 |
+
return features
|
| 119 |
+
|
| 120 |
+
@property
|
| 121 |
+
def dummy_feature(self):
|
| 122 |
+
return torch.zeros(1, self.hidden_size, device=self.device, dtype=self.dtype)
|
| 123 |
+
|
| 124 |
+
@property
|
| 125 |
+
def dtype(self):
|
| 126 |
+
return next(self.clip_vision_tower.parameters()).dtype
|
| 127 |
+
|
| 128 |
+
@property
|
| 129 |
+
def device(self):
|
| 130 |
+
return next(self.clip_vision_tower.parameters()).device
|
| 131 |
+
|
| 132 |
+
@property
|
| 133 |
+
def config(self):
|
| 134 |
+
assert NotImplementedError
|
| 135 |
+
pass
|
| 136 |
+
|
| 137 |
+
@property
|
| 138 |
+
def hidden_size(self):
|
| 139 |
+
return sum([_.hidden_size for _ in self.vision_towers])
|
| 140 |
+
|
| 141 |
+
@property
|
| 142 |
+
def num_patches(self):
|
| 143 |
+
return self.num_tokens
|
eagle/model/multimodal_encoder/pix2struct_encoder.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
from transformers import AutoModel, CLIPImageProcessor
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import requests
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
from transformers import AutoProcessor, Pix2StructVisionModel, Pix2StructProcessor, Pix2StructForConditionalGeneration
|
| 10 |
+
|
| 11 |
+
cfg={
|
| 12 |
+
"crop_size": 256,
|
| 13 |
+
"do_center_crop": True,
|
| 14 |
+
"do_normalize": True,
|
| 15 |
+
"do_resize": True,
|
| 16 |
+
"feature_extractor_type": "CLIPFeatureExtractor",
|
| 17 |
+
"image_mean": [
|
| 18 |
+
0.48145466,
|
| 19 |
+
0.4578275,
|
| 20 |
+
0.40821073
|
| 21 |
+
],
|
| 22 |
+
"image_std": [
|
| 23 |
+
0.26862954,
|
| 24 |
+
0.26130258,
|
| 25 |
+
0.27577711
|
| 26 |
+
],
|
| 27 |
+
"resample": 3,
|
| 28 |
+
"size": 256
|
| 29 |
+
}
|
| 30 |
+
|
| 31 |
+
'''
|
| 32 |
+
Pixel2Struct-Large Model (pretrained version)
|
| 33 |
+
'''
|
| 34 |
+
class Pix2StructLargeVisionTower(nn.Module):
|
| 35 |
+
def __init__(self, vision_tower, args, delay_load=False):
|
| 36 |
+
super().__init__()
|
| 37 |
+
|
| 38 |
+
self.is_loaded = False
|
| 39 |
+
self.vision_tower_name = vision_tower
|
| 40 |
+
self.do_resize = args.do_resize
|
| 41 |
+
self.de_normalize = args.de_normalize # de-normalize the input image and perform preprocessing with pix2struct processor
|
| 42 |
+
self.select_layer = args.mm_vision_select_layer # NOTE: not implemented yet, this parameter has no effect
|
| 43 |
+
self.input_image_size = args.input_image_size
|
| 44 |
+
self.select_feature = getattr(args, 'mm_vision_select_feature', 'patch')
|
| 45 |
+
self.freeze_vision = args.freeze_vision
|
| 46 |
+
|
| 47 |
+
self.args = args
|
| 48 |
+
if not self.is_loaded:
|
| 49 |
+
self.load_model()
|
| 50 |
+
|
| 51 |
+
def load_model(self):
|
| 52 |
+
if self.is_loaded:
|
| 53 |
+
return
|
| 54 |
+
whole_model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-large")
|
| 55 |
+
self.vision_tower = whole_model.encoder
|
| 56 |
+
self.pix2struct_processor = AutoProcessor.from_pretrained("google/pix2struct-large")
|
| 57 |
+
self.pix2struct_processor.image_processor.is_vqa = False
|
| 58 |
+
|
| 59 |
+
self.image_processor = CLIPImageProcessor(**cfg)
|
| 60 |
+
if self.input_image_size is not None:
|
| 61 |
+
self.image_processor.size=self.input_image_size
|
| 62 |
+
self.image_processor.crop_size={
|
| 63 |
+
'height':self.input_image_size,
|
| 64 |
+
'width': self.input_image_size
|
| 65 |
+
}
|
| 66 |
+
|
| 67 |
+
if self.freeze_vision:
|
| 68 |
+
self.vision_tower.requires_grad_(False)
|
| 69 |
+
|
| 70 |
+
self.image_mean = torch.tensor(self.image_processor.image_mean).view(1, 3, 1, 1)
|
| 71 |
+
self.image_std = torch.tensor(self.image_processor.image_std).view(1, 3, 1, 1)
|
| 72 |
+
|
| 73 |
+
self.is_loaded = True
|
| 74 |
+
|
| 75 |
+
def feature_select(self, image_forward_outs):
|
| 76 |
+
image_features = image_forward_outs.hidden_states[self.select_layer] # [bs, n, c], cls at idx=0
|
| 77 |
+
if self.select_feature == 'patch':
|
| 78 |
+
image_features = image_features[:, 1:]
|
| 79 |
+
elif self.select_feature == 'cls_patch':
|
| 80 |
+
image_features = image_features
|
| 81 |
+
else:
|
| 82 |
+
raise ValueError(f'Unexpected select feature: {self.select_feature}')
|
| 83 |
+
return image_features
|
| 84 |
+
|
| 85 |
+
# @torch.no_grad()
|
| 86 |
+
def forward(self, images):
|
| 87 |
+
|
| 88 |
+
if self.de_normalize:
|
| 89 |
+
mean = self.image_mean.clone().view(1, 3, 1, 1).to(dtype=images.dtype, device=images.device)
|
| 90 |
+
std = self.image_std.clone().view(1, 3, 1, 1).to(dtype=images.dtype, device=images.device)
|
| 91 |
+
x = (images * std + mean) * 255.0
|
| 92 |
+
x = self.pix2struct_processor(images=x.float(), return_tensors="pt")
|
| 93 |
+
|
| 94 |
+
image_features = self.vision_tower(**(x.to(device=self.device, dtype=self.dtype))).last_hidden_state
|
| 95 |
+
bs, n, c = image_features.shape
|
| 96 |
+
image_features = image_features[:, :2025, :] # HARD CODE
|
| 97 |
+
|
| 98 |
+
if self.do_resize:
|
| 99 |
+
image_features = image_features.transpose(1,2).reshape(bs, c, 45, 45) # HARD CODE
|
| 100 |
+
image_features = F.interpolate(image_features.float(), size=(32, 32), mode='bilinear', align_corners=True).to(dtype=image_features.dtype) # HARD CODE
|
| 101 |
+
return image_features
|
| 102 |
+
else:
|
| 103 |
+
return image_features
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
@property
|
| 107 |
+
def dummy_feature(self):
|
| 108 |
+
return torch.zeros(1, self.hidden_size, device=self.device, dtype=self.dtype)
|
| 109 |
+
|
| 110 |
+
@property
|
| 111 |
+
def dtype(self):
|
| 112 |
+
return next(self.vision_tower.parameters()).dtype
|
| 113 |
+
|
| 114 |
+
@property
|
| 115 |
+
def device(self):
|
| 116 |
+
return next(self.vision_tower.parameters()).device
|
| 117 |
+
|
| 118 |
+
@property
|
| 119 |
+
def config(self):
|
| 120 |
+
return self.vision_tower.config
|
| 121 |
+
|
| 122 |
+
@property
|
| 123 |
+
def hidden_size(self):
|
| 124 |
+
#return self.config.hidden_size
|
| 125 |
+
hidden_dim = 1536
|
| 126 |
+
return hidden_dim
|
| 127 |
+
|
| 128 |
+
@property
|
| 129 |
+
def num_patches(self):
|
| 130 |
+
# return (self.config.image_size // self.config.patch_size) ** 2
|
| 131 |
+
return self.config['num_patches']
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
#main
|
| 135 |
+
if __name__ == "__main__":
|
| 136 |
+
|
| 137 |
+
'''
|
| 138 |
+
print('hello')
|
| 139 |
+
from PIL import Image
|
| 140 |
+
import requests
|
| 141 |
+
from transformers import AutoProcessor, Pix2StructVisionModel
|
| 142 |
+
|
| 143 |
+
model = Pix2StructVisionModel.from_pretrained("google/pix2struct-textcaps-base")
|
| 144 |
+
processor = AutoProcessor.from_pretrained("google/pix2struct-textcaps-base")
|
| 145 |
+
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 146 |
+
image = Image.open("/lustre/fsw/portfolios/llmservice/users/fuxiaol/me.jpg")
|
| 147 |
+
|
| 148 |
+
for name, param in model.named_parameters():
|
| 149 |
+
param.requires_grad = False
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
#inputs = processor(images=image, return_tensors="pt")
|
| 153 |
+
|
| 154 |
+
image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternViT-6B-448px-V1-5')
|
| 155 |
+
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
|
| 156 |
+
pixel_values = torch.cat([pixel_values, pixel_values], dim=0)
|
| 157 |
+
#inputs = pixel_values.to(torch.bfloat16)
|
| 158 |
+
|
| 159 |
+
print('pixel_values:', pixel_values.size())
|
| 160 |
+
|
| 161 |
+
inputs = processor(images=pixel_values, max_patches=1024, return_tensors='pt')['flattened_patches']
|
| 162 |
+
print(inputs.size())
|
| 163 |
+
print(inputs.size())
|
| 164 |
+
|
| 165 |
+
outputs = model(inputs)
|
| 166 |
+
|
| 167 |
+
print(outputs.last_hidden_state.size())
|
| 168 |
+
'''
|
| 169 |
+
|
| 170 |
+
cfg={
|
| 171 |
+
"crop_size": 1024,
|
| 172 |
+
"do_center_crop": True,
|
| 173 |
+
"do_normalize": True,
|
| 174 |
+
"do_resize": True,
|
| 175 |
+
"feature_extractor_type": "CLIPFeatureExtractor",
|
| 176 |
+
"image_mean": [
|
| 177 |
+
0.48145466,
|
| 178 |
+
0.4578275,
|
| 179 |
+
0.40821073
|
| 180 |
+
],
|
| 181 |
+
"image_std": [
|
| 182 |
+
0.26862954,
|
| 183 |
+
0.26130258,
|
| 184 |
+
0.27577711
|
| 185 |
+
],
|
| 186 |
+
"resample": 3,
|
| 187 |
+
"size": 1024
|
| 188 |
+
}
|
| 189 |
+
|
| 190 |
+
from PIL import Image
|
| 191 |
+
import requests
|
| 192 |
+
from transformers import AutoProcessor, Pix2StructForConditionalGeneration
|
| 193 |
+
from transformers import CLIPVisionModel, CLIPImageProcessor, CLIPVisionConfig
|
| 194 |
+
import torchvision.transforms as T
|
| 195 |
+
|
| 196 |
+
processor = AutoProcessor.from_pretrained("google/pix2struct-textcaps-large")
|
| 197 |
+
model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-textcaps-large")
|
| 198 |
+
|
| 199 |
+
#url = "https://www.ilankelman.org/stopsigns/australia.jpg"
|
| 200 |
+
#image = Image.open(requests.get(url, stream=True).raw)
|
| 201 |
+
image = Image.open("/lustre/fsw/portfolios/llmservice/users/fuxiaol/sample2.jpg")
|
| 202 |
+
|
| 203 |
+
image_processor= CLIPImageProcessor(**cfg)
|
| 204 |
+
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
|
| 205 |
+
print(pixel_values.size())
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
mean = [0.48145466, 0.4578275, 0.40821073]
|
| 209 |
+
std = [0.26862954, 0.26130258, 0.27577711]
|
| 210 |
+
mean = torch.tensor(mean).view(1, 3, 1, 1)
|
| 211 |
+
std = torch.tensor(std).view(1, 3, 1, 1)
|
| 212 |
+
pixel_values = pixel_values * std + mean
|
| 213 |
+
print(pixel_values.size())
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
#pixel_values.save('pix2image.jpg')
|
| 217 |
+
transform = T.ToPILImage()
|
| 218 |
+
img = transform(pixel_values.squeeze(0))
|
| 219 |
+
img.save('pix2image.jpg')
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
inputs = processor(images=pixel_values, max_patches=1024,return_tensors="pt")['flattened_patches']
|
| 225 |
+
|
| 226 |
+
# autoregressive generation
|
| 227 |
+
generated_ids = model.generate(inputs, max_new_tokens=50)
|
| 228 |
+
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 229 |
+
print(generated_text)
|
| 230 |
+
#A stop sign is on a street corner.
|
| 231 |
+
#A stop sign is on a street corner.
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
'''
|
| 236 |
+
from PIL import Image
|
| 237 |
+
import requests
|
| 238 |
+
from transformers import AutoProcessor, CLIPModel
|
| 239 |
+
|
| 240 |
+
from transformers import CLIPVisionModel, CLIPImageProcessor, CLIPVisionConfig
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14-336")
|
| 245 |
+
model = CLIPVisionModel.from_pretrained('openai/clip-vit-large-patch14-336')
|
| 246 |
+
|
| 247 |
+
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 248 |
+
image = Image.open(requests.get(url, stream=True).raw)
|
| 249 |
+
print(image)
|
| 250 |
+
|
| 251 |
+
inputs = processor(images=image, return_tensors="pt")
|
| 252 |
+
|
| 253 |
+
#image_features = model.get_image_features(**inputs)
|
| 254 |
+
outputs = model(**inputs,output_hidden_states=True)
|
| 255 |
+
print(outputs.hidden_states[-1].size())
|
| 256 |
+
print(outputs.hidden_states[-2].size())
|
| 257 |
+
print(outputs.hidden_states[-3].size())
|
| 258 |
+
'''
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
#sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
|
| 265 |
+
#sequence = processor.post_process_generation(sequence, fix_markdown=False)
|
| 266 |
+
# note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
|
| 267 |
+
#print(repr(sequence))
|
eagle/model/multimodal_encoder/sam_encoder.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import torch.utils.checkpoint
|
| 5 |
+
from torch import Tensor, nn
|
| 6 |
+
|
| 7 |
+
import transformers
|
| 8 |
+
from transformers import SamProcessor
|
| 9 |
+
from transformers import SamModel, SamVisionConfig, SamVisionConfig
|
| 10 |
+
from transformers import SamImageProcessor
|
| 11 |
+
from PIL import Image
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
# Copied from transformers.models.convnext.modeling_convnext.ConvNextLayerNorm with ConvNext->Sam
|
| 15 |
+
class SamLayerNorm(nn.Module):
|
| 16 |
+
r"""LayerNorm that supports two data formats: channels_last (default) or channels_first.
|
| 17 |
+
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with shape (batch_size, height,
|
| 18 |
+
width, channels) while channels_first corresponds to inputs with shape (batch_size, channels, height, width).
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
|
| 22 |
+
super().__init__()
|
| 23 |
+
self.weight = nn.Parameter(torch.ones(normalized_shape))
|
| 24 |
+
self.bias = nn.Parameter(torch.zeros(normalized_shape))
|
| 25 |
+
self.eps = eps
|
| 26 |
+
self.data_format = data_format
|
| 27 |
+
if self.data_format not in ["channels_last", "channels_first"]:
|
| 28 |
+
raise NotImplementedError(f"Unsupported data format: {self.data_format}")
|
| 29 |
+
self.normalized_shape = (normalized_shape,)
|
| 30 |
+
|
| 31 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 32 |
+
if self.data_format == "channels_last":
|
| 33 |
+
x = torch.nn.functional.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
|
| 34 |
+
elif self.data_format == "channels_first":
|
| 35 |
+
input_dtype = x.dtype
|
| 36 |
+
x = x.float()
|
| 37 |
+
u = x.mean(1, keepdim=True)
|
| 38 |
+
s = (x - u).pow(2).mean(1, keepdim=True)
|
| 39 |
+
x = (x - u) / torch.sqrt(s + self.eps)
|
| 40 |
+
x = x.to(dtype=input_dtype)
|
| 41 |
+
x = self.weight[:, None, None] * x + self.bias[:, None, None]
|
| 42 |
+
return x
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class ShortSamVisionNeck(nn.Module):
|
| 47 |
+
def __init__(self, config: SamVisionConfig):
|
| 48 |
+
super().__init__()
|
| 49 |
+
self.config = config
|
| 50 |
+
|
| 51 |
+
self.conv1 = nn.Conv2d(config.hidden_size, config.output_channels, kernel_size=1, bias=False)
|
| 52 |
+
self.layer_norm1 = SamLayerNorm(config.output_channels, data_format="channels_first")
|
| 53 |
+
|
| 54 |
+
def forward(self, hidden_states):
|
| 55 |
+
hidden_states = hidden_states.permute(0, 3, 1, 2)
|
| 56 |
+
hidden_states = self.conv1(hidden_states)
|
| 57 |
+
hidden_states = self.layer_norm1(hidden_states)
|
| 58 |
+
hidden_states = hidden_states.permute(0,2,3,1)
|
| 59 |
+
return hidden_states
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class SAMVisionTower(nn.Module):
|
| 63 |
+
def __init__(self, vision_tower, args):
|
| 64 |
+
super().__init__()
|
| 65 |
+
|
| 66 |
+
self.args = args
|
| 67 |
+
self.is_loaded = False
|
| 68 |
+
self.vision_tower_name = vision_tower
|
| 69 |
+
self.input_image_size = args.input_image_size
|
| 70 |
+
self.pixel_shuffle = getattr(args, 'add_pixel_shuffle', False)
|
| 71 |
+
|
| 72 |
+
self.freeze = args.freeze_vision
|
| 73 |
+
|
| 74 |
+
self.load_model()
|
| 75 |
+
|
| 76 |
+
def load_model(self):
|
| 77 |
+
if self.is_loaded:
|
| 78 |
+
return
|
| 79 |
+
|
| 80 |
+
self.image_processor= SamProcessor.from_pretrained("facebook/sam-vit-large")
|
| 81 |
+
sam_model = SamModel.from_pretrained("facebook/sam-vit-large").vision_encoder
|
| 82 |
+
sam_model.neck = ShortSamVisionNeck(sam_model.config)
|
| 83 |
+
self.image_processor.preprocess = self.image_processor.__call__
|
| 84 |
+
self.image_processor.image_mean = [0.485,0.456,0.406]
|
| 85 |
+
self.vision_tower = sam_model
|
| 86 |
+
|
| 87 |
+
if self.freeze:
|
| 88 |
+
self.vision_tower.requires_grad_(False)
|
| 89 |
+
|
| 90 |
+
self.is_loaded = True
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def forward(self, images):
|
| 94 |
+
if type(images) is list:
|
| 95 |
+
image_features = []
|
| 96 |
+
for image in images:
|
| 97 |
+
image_feature = self.vision_tower(image.to(device=self.device).unsqueeze(0))
|
| 98 |
+
image_features.append(image_feature)
|
| 99 |
+
else:
|
| 100 |
+
image_features = self.vision_tower(images.to(device=self.device)).last_hidden_state.flatten(start_dim=1, end_dim=2).to(device=self.device)
|
| 101 |
+
|
| 102 |
+
if self.pixel_shuffle:
|
| 103 |
+
b, n, c = image_features.shape
|
| 104 |
+
h = w = int(n ** 0.5)
|
| 105 |
+
image_features = image_features.transpose(1,2).reshape(b, c, h, w)
|
| 106 |
+
image_features = nn.functional.pixel_unshuffle(image_features, 2)
|
| 107 |
+
|
| 108 |
+
return image_features
|
| 109 |
+
@property
|
| 110 |
+
def dummy_feature(self):
|
| 111 |
+
return torch.zeros(1, self.hidden_size, device=self.device, dtype=self.dtype)
|
| 112 |
+
|
| 113 |
+
@property
|
| 114 |
+
def dtype(self):
|
| 115 |
+
return next(self.vision_tower.parameters()).dtype
|
| 116 |
+
|
| 117 |
+
@property
|
| 118 |
+
def device(self):
|
| 119 |
+
return next(self.vision_tower.parameters()).device
|
| 120 |
+
|
| 121 |
+
@property
|
| 122 |
+
def config(self):
|
| 123 |
+
# if self.is_loaded:
|
| 124 |
+
# return self.vision_tower.config
|
| 125 |
+
# else:
|
| 126 |
+
# return self.cfg_only
|
| 127 |
+
config_info = SamVisionConfig()
|
| 128 |
+
return SamVisionConfig()
|
| 129 |
+
|
| 130 |
+
@property
|
| 131 |
+
def hidden_size(self):
|
| 132 |
+
#return self.config.hidden_size
|
| 133 |
+
if self.pixel_shuffle:
|
| 134 |
+
hidden_size = 256 * 4
|
| 135 |
+
else:
|
| 136 |
+
hidden_size = 256
|
| 137 |
+
return hidden_size
|
| 138 |
+
|
| 139 |
+
@property
|
| 140 |
+
def num_patches(self):
|
| 141 |
+
# return (self.config.image_size // self.config.patch_size) ** 2
|
| 142 |
+
return self.config.num_patches
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
#main
|
| 146 |
+
if __name__ == "__main__":
|
| 147 |
+
sam_model = SamModel.from_pretrained("facebook/sam-vit-large").vision_encoder
|
| 148 |
+
#sam_model = SamModel.from_pretrained("facebook/sam-vit-large")
|
| 149 |
+
sam_processor = SamProcessor.from_pretrained("facebook/sam-vit-large")
|
| 150 |
+
for name, param in sam_model.named_parameters():
|
| 151 |
+
param.requires_grad = False
|
| 152 |
+
|
| 153 |
+
#raw_image = torch.rand(1, 3, 224, 224).to('cuda')
|
| 154 |
+
raw_image = Image.open('/lustre/fsw/portfolios/llmservice/users/fuxiaol/image/me.jpg').convert("RGB")
|
| 155 |
+
inputs = sam_processor(raw_image, return_tensors="pt")
|
| 156 |
+
#print(inputs)
|
| 157 |
+
#print(inputs['pixel_values'])
|
| 158 |
+
out = sam_model(inputs['pixel_values'])
|
| 159 |
+
|
| 160 |
+
print(out[0].size())
|
| 161 |
+
#vision_config = SamVisionConfig()
|
| 162 |
+
#print('=============')
|
| 163 |
+
#print(vision_config.hidden_size)
|
| 164 |
+
#print('=============')
|
| 165 |
+
#print(out)
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
#print(out)
|
| 169 |
+
#print(out)
|
| 170 |
+
#config_vision
|
| 171 |
+
#vision_config = SamVisionConfig()
|
| 172 |
+
#print(sam_model.layers)
|
| 173 |
+
#print(vision_config)
|
eagle/model/multimodal_encoder/vision_models/__init__.py
ADDED
|
File without changes
|
eagle/model/multimodal_encoder/vision_models/convnext.py
ADDED
|
@@ -0,0 +1,1110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" ConvNeXt
|
| 2 |
+
|
| 3 |
+
Papers:
|
| 4 |
+
* `A ConvNet for the 2020s` - https://arxiv.org/pdf/2201.03545.pdf
|
| 5 |
+
@Article{liu2022convnet,
|
| 6 |
+
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
|
| 7 |
+
title = {A ConvNet for the 2020s},
|
| 8 |
+
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
|
| 9 |
+
year = {2022},
|
| 10 |
+
}
|
| 11 |
+
|
| 12 |
+
* `ConvNeXt-V2 - Co-designing and Scaling ConvNets with Masked Autoencoders` - https://arxiv.org/abs/2301.00808
|
| 13 |
+
@article{Woo2023ConvNeXtV2,
|
| 14 |
+
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
|
| 15 |
+
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
|
| 16 |
+
year={2023},
|
| 17 |
+
journal={arXiv preprint arXiv:2301.00808},
|
| 18 |
+
}
|
| 19 |
+
|
| 20 |
+
Original code and weights from:
|
| 21 |
+
* https://github.com/facebookresearch/ConvNeXt, original copyright below
|
| 22 |
+
* https://github.com/facebookresearch/ConvNeXt-V2, original copyright below
|
| 23 |
+
|
| 24 |
+
Model defs atto, femto, pico, nano and _ols / _hnf variants are timm originals.
|
| 25 |
+
|
| 26 |
+
Modifications and additions for timm hacked together by / Copyright 2022, Ross Wightman
|
| 27 |
+
"""
|
| 28 |
+
# ConvNeXt
|
| 29 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 30 |
+
# All rights reserved.
|
| 31 |
+
# This source code is licensed under the MIT license
|
| 32 |
+
|
| 33 |
+
# ConvNeXt-V2
|
| 34 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 35 |
+
# All rights reserved.
|
| 36 |
+
# This source code is licensed under the license found in the
|
| 37 |
+
# LICENSE file in the root directory of this source tree (Attribution-NonCommercial 4.0 International (CC BY-NC 4.0))
|
| 38 |
+
# No code was used directly from ConvNeXt-V2, however the weights are CC BY-NC 4.0 so beware if using commercially.
|
| 39 |
+
|
| 40 |
+
from collections import OrderedDict
|
| 41 |
+
from functools import partial
|
| 42 |
+
from typing import Callable, Optional, Tuple, Union
|
| 43 |
+
|
| 44 |
+
import torch
|
| 45 |
+
import torch.nn as nn
|
| 46 |
+
# hack for huggingface spaces
|
| 47 |
+
torch.jit.script = lambda f: f
|
| 48 |
+
|
| 49 |
+
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD, OPENAI_CLIP_MEAN, OPENAI_CLIP_STD
|
| 50 |
+
from timm.layers import trunc_normal_, AvgPool2dSame, DropPath, Mlp, GlobalResponseNormMlp, \
|
| 51 |
+
LayerNorm2d, LayerNorm, create_conv2d, get_act_layer, make_divisible, to_ntuple
|
| 52 |
+
from timm.layers import NormMlpClassifierHead, ClassifierHead
|
| 53 |
+
from timm.models._builder import build_model_with_cfg
|
| 54 |
+
from timm.models._manipulate import named_apply, checkpoint_seq
|
| 55 |
+
from timm.models._registry import generate_default_cfgs, register_model, register_model_deprecations
|
| 56 |
+
|
| 57 |
+
__all__ = ['ConvNeXt'] # model_registry will add each entrypoint fn to this
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class Downsample(nn.Module):
|
| 61 |
+
|
| 62 |
+
def __init__(self, in_chs, out_chs, stride=1, dilation=1):
|
| 63 |
+
super().__init__()
|
| 64 |
+
avg_stride = stride if dilation == 1 else 1
|
| 65 |
+
if stride > 1 or dilation > 1:
|
| 66 |
+
avg_pool_fn = AvgPool2dSame if avg_stride == 1 and dilation > 1 else nn.AvgPool2d
|
| 67 |
+
self.pool = avg_pool_fn(2, avg_stride, ceil_mode=True, count_include_pad=False)
|
| 68 |
+
else:
|
| 69 |
+
self.pool = nn.Identity()
|
| 70 |
+
|
| 71 |
+
if in_chs != out_chs:
|
| 72 |
+
self.conv = create_conv2d(in_chs, out_chs, 1, stride=1)
|
| 73 |
+
else:
|
| 74 |
+
self.conv = nn.Identity()
|
| 75 |
+
|
| 76 |
+
def forward(self, x):
|
| 77 |
+
x = self.pool(x)
|
| 78 |
+
x = self.conv(x)
|
| 79 |
+
return x
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class ConvNeXtBlock(nn.Module):
|
| 83 |
+
""" ConvNeXt Block
|
| 84 |
+
There are two equivalent implementations:
|
| 85 |
+
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
|
| 86 |
+
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
|
| 87 |
+
|
| 88 |
+
Unlike the official impl, this one allows choice of 1 or 2, 1x1 conv can be faster with appropriate
|
| 89 |
+
choice of LayerNorm impl, however as model size increases the tradeoffs appear to change and nn.Linear
|
| 90 |
+
is a better choice. This was observed with PyTorch 1.10 on 3090 GPU, it could change over time & w/ different HW.
|
| 91 |
+
"""
|
| 92 |
+
|
| 93 |
+
def __init__(
|
| 94 |
+
self,
|
| 95 |
+
in_chs: int,
|
| 96 |
+
out_chs: Optional[int] = None,
|
| 97 |
+
kernel_size: int = 7,
|
| 98 |
+
stride: int = 1,
|
| 99 |
+
dilation: Union[int, Tuple[int, int]] = (1, 1),
|
| 100 |
+
mlp_ratio: float = 4,
|
| 101 |
+
conv_mlp: bool = False,
|
| 102 |
+
conv_bias: bool = True,
|
| 103 |
+
use_grn: bool = False,
|
| 104 |
+
ls_init_value: Optional[float] = 1e-6,
|
| 105 |
+
act_layer: Union[str, Callable] = 'gelu',
|
| 106 |
+
norm_layer: Optional[Callable] = None,
|
| 107 |
+
drop_path: float = 0.,
|
| 108 |
+
):
|
| 109 |
+
"""
|
| 110 |
+
|
| 111 |
+
Args:
|
| 112 |
+
in_chs: Block input channels.
|
| 113 |
+
out_chs: Block output channels (same as in_chs if None).
|
| 114 |
+
kernel_size: Depthwise convolution kernel size.
|
| 115 |
+
stride: Stride of depthwise convolution.
|
| 116 |
+
dilation: Tuple specifying input and output dilation of block.
|
| 117 |
+
mlp_ratio: MLP expansion ratio.
|
| 118 |
+
conv_mlp: Use 1x1 convolutions for MLP and a NCHW compatible norm layer if True.
|
| 119 |
+
conv_bias: Apply bias for all convolution (linear) layers.
|
| 120 |
+
use_grn: Use GlobalResponseNorm in MLP (from ConvNeXt-V2)
|
| 121 |
+
ls_init_value: Layer-scale init values, layer-scale applied if not None.
|
| 122 |
+
act_layer: Activation layer.
|
| 123 |
+
norm_layer: Normalization layer (defaults to LN if not specified).
|
| 124 |
+
drop_path: Stochastic depth probability.
|
| 125 |
+
"""
|
| 126 |
+
super().__init__()
|
| 127 |
+
out_chs = out_chs or in_chs
|
| 128 |
+
dilation = to_ntuple(2)(dilation)
|
| 129 |
+
act_layer = get_act_layer(act_layer)
|
| 130 |
+
if not norm_layer:
|
| 131 |
+
norm_layer = LayerNorm2d if conv_mlp else LayerNorm
|
| 132 |
+
mlp_layer = partial(GlobalResponseNormMlp if use_grn else Mlp, use_conv=conv_mlp)
|
| 133 |
+
self.use_conv_mlp = conv_mlp
|
| 134 |
+
self.conv_dw = create_conv2d(
|
| 135 |
+
in_chs,
|
| 136 |
+
out_chs,
|
| 137 |
+
kernel_size=kernel_size,
|
| 138 |
+
stride=stride,
|
| 139 |
+
dilation=dilation[0],
|
| 140 |
+
depthwise=True,
|
| 141 |
+
bias=conv_bias,
|
| 142 |
+
)
|
| 143 |
+
self.norm = norm_layer(out_chs)
|
| 144 |
+
self.mlp = mlp_layer(out_chs, int(mlp_ratio * out_chs), act_layer=act_layer)
|
| 145 |
+
self.weight = nn.Parameter(ls_init_value * torch.ones(out_chs)) if ls_init_value is not None else None
|
| 146 |
+
if in_chs != out_chs or stride != 1 or dilation[0] != dilation[1]:
|
| 147 |
+
self.shortcut = Downsample(in_chs, out_chs, stride=stride, dilation=dilation[0])
|
| 148 |
+
else:
|
| 149 |
+
self.shortcut = nn.Identity()
|
| 150 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
|
| 151 |
+
|
| 152 |
+
def forward(self, x):
|
| 153 |
+
shortcut = x
|
| 154 |
+
x = self.conv_dw(x)
|
| 155 |
+
if self.use_conv_mlp:
|
| 156 |
+
x = self.norm(x)
|
| 157 |
+
x = self.mlp(x)
|
| 158 |
+
else:
|
| 159 |
+
x = x.permute(0, 2, 3, 1)
|
| 160 |
+
x = self.norm(x)
|
| 161 |
+
x = self.mlp(x)
|
| 162 |
+
x = x.permute(0, 3, 1, 2)
|
| 163 |
+
if self.weight is not None:
|
| 164 |
+
x = x.mul(self.weight.reshape(1, -1, 1, 1))
|
| 165 |
+
|
| 166 |
+
x = self.drop_path(x) + self.shortcut(shortcut)
|
| 167 |
+
return x
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
class ConvNeXtStage(nn.Module):
|
| 171 |
+
|
| 172 |
+
def __init__(
|
| 173 |
+
self,
|
| 174 |
+
in_chs,
|
| 175 |
+
out_chs,
|
| 176 |
+
kernel_size=7,
|
| 177 |
+
stride=2,
|
| 178 |
+
depth=2,
|
| 179 |
+
dilation=(1, 1),
|
| 180 |
+
drop_path_rates=None,
|
| 181 |
+
ls_init_value=1.0,
|
| 182 |
+
conv_mlp=False,
|
| 183 |
+
conv_bias=True,
|
| 184 |
+
use_grn=False,
|
| 185 |
+
act_layer='gelu',
|
| 186 |
+
norm_layer=None,
|
| 187 |
+
norm_layer_cl=None
|
| 188 |
+
):
|
| 189 |
+
super().__init__()
|
| 190 |
+
self.grad_checkpointing = False
|
| 191 |
+
|
| 192 |
+
if in_chs != out_chs or stride > 1 or dilation[0] != dilation[1]:
|
| 193 |
+
ds_ks = 2 if stride > 1 or dilation[0] != dilation[1] else 1
|
| 194 |
+
pad = 'same' if dilation[1] > 1 else 0 # same padding needed if dilation used
|
| 195 |
+
self.downsample = nn.Sequential(
|
| 196 |
+
norm_layer(in_chs),
|
| 197 |
+
create_conv2d(
|
| 198 |
+
in_chs,
|
| 199 |
+
out_chs,
|
| 200 |
+
kernel_size=ds_ks,
|
| 201 |
+
stride=stride,
|
| 202 |
+
dilation=dilation[0],
|
| 203 |
+
padding=pad,
|
| 204 |
+
bias=conv_bias,
|
| 205 |
+
),
|
| 206 |
+
)
|
| 207 |
+
in_chs = out_chs
|
| 208 |
+
else:
|
| 209 |
+
self.downsample = nn.Identity()
|
| 210 |
+
|
| 211 |
+
drop_path_rates = drop_path_rates or [0.] * depth
|
| 212 |
+
stage_blocks = []
|
| 213 |
+
for i in range(depth):
|
| 214 |
+
stage_blocks.append(ConvNeXtBlock(
|
| 215 |
+
in_chs=in_chs,
|
| 216 |
+
out_chs=out_chs,
|
| 217 |
+
kernel_size=kernel_size,
|
| 218 |
+
dilation=dilation[1],
|
| 219 |
+
drop_path=drop_path_rates[i],
|
| 220 |
+
ls_init_value=ls_init_value,
|
| 221 |
+
conv_mlp=conv_mlp,
|
| 222 |
+
conv_bias=conv_bias,
|
| 223 |
+
use_grn=use_grn,
|
| 224 |
+
act_layer=act_layer,
|
| 225 |
+
norm_layer=norm_layer if conv_mlp else norm_layer_cl,
|
| 226 |
+
))
|
| 227 |
+
in_chs = out_chs
|
| 228 |
+
self.blocks = nn.Sequential(*stage_blocks)
|
| 229 |
+
|
| 230 |
+
def forward(self, x):
|
| 231 |
+
x = self.downsample(x)
|
| 232 |
+
if self.grad_checkpointing and not torch.jit.is_scripting():
|
| 233 |
+
x = checkpoint_seq(self.blocks, x)
|
| 234 |
+
else:
|
| 235 |
+
x = self.blocks(x)
|
| 236 |
+
return x
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
class ConvNeXt(nn.Module):
|
| 240 |
+
r""" ConvNeXt
|
| 241 |
+
A PyTorch impl of : `A ConvNet for the 2020s` - https://arxiv.org/pdf/2201.03545.pdf
|
| 242 |
+
"""
|
| 243 |
+
|
| 244 |
+
def __init__(
|
| 245 |
+
self,
|
| 246 |
+
in_chans: int = 3,
|
| 247 |
+
num_classes: int = 1000,
|
| 248 |
+
global_pool: str = 'avg',
|
| 249 |
+
output_stride: int = 32,
|
| 250 |
+
depths: Tuple[int, ...] = (3, 3, 9, 3),
|
| 251 |
+
dims: Tuple[int, ...] = (96, 192, 384, 768),
|
| 252 |
+
kernel_sizes: Union[int, Tuple[int, ...]] = 7,
|
| 253 |
+
ls_init_value: Optional[float] = 1e-6,
|
| 254 |
+
stem_type: str = 'patch',
|
| 255 |
+
patch_size: int = 4,
|
| 256 |
+
head_init_scale: float = 1.,
|
| 257 |
+
head_norm_first: bool = False,
|
| 258 |
+
head_hidden_size: Optional[int] = None,
|
| 259 |
+
conv_mlp: bool = False,
|
| 260 |
+
conv_bias: bool = True,
|
| 261 |
+
use_grn: bool = False,
|
| 262 |
+
act_layer: Union[str, Callable] = 'gelu',
|
| 263 |
+
norm_layer: Optional[Union[str, Callable]] = None,
|
| 264 |
+
norm_eps: Optional[float] = None,
|
| 265 |
+
drop_rate: float = 0.,
|
| 266 |
+
drop_path_rate: float = 0.,
|
| 267 |
+
):
|
| 268 |
+
"""
|
| 269 |
+
Args:
|
| 270 |
+
in_chans: Number of input image channels.
|
| 271 |
+
num_classes: Number of classes for classification head.
|
| 272 |
+
global_pool: Global pooling type.
|
| 273 |
+
output_stride: Output stride of network, one of (8, 16, 32).
|
| 274 |
+
depths: Number of blocks at each stage.
|
| 275 |
+
dims: Feature dimension at each stage.
|
| 276 |
+
kernel_sizes: Depthwise convolution kernel-sizes for each stage.
|
| 277 |
+
ls_init_value: Init value for Layer Scale, disabled if None.
|
| 278 |
+
stem_type: Type of stem.
|
| 279 |
+
patch_size: Stem patch size for patch stem.
|
| 280 |
+
head_init_scale: Init scaling value for classifier weights and biases.
|
| 281 |
+
head_norm_first: Apply normalization before global pool + head.
|
| 282 |
+
head_hidden_size: Size of MLP hidden layer in head if not None and head_norm_first == False.
|
| 283 |
+
conv_mlp: Use 1x1 conv in MLP, improves speed for small networks w/ chan last.
|
| 284 |
+
conv_bias: Use bias layers w/ all convolutions.
|
| 285 |
+
use_grn: Use Global Response Norm (ConvNeXt-V2) in MLP.
|
| 286 |
+
act_layer: Activation layer type.
|
| 287 |
+
norm_layer: Normalization layer type.
|
| 288 |
+
drop_rate: Head pre-classifier dropout rate.
|
| 289 |
+
drop_path_rate: Stochastic depth drop rate.
|
| 290 |
+
"""
|
| 291 |
+
super().__init__()
|
| 292 |
+
assert output_stride in (8, 16, 32)
|
| 293 |
+
kernel_sizes = to_ntuple(4)(kernel_sizes)
|
| 294 |
+
if norm_layer is None:
|
| 295 |
+
norm_layer = LayerNorm2d
|
| 296 |
+
norm_layer_cl = norm_layer if conv_mlp else LayerNorm
|
| 297 |
+
if norm_eps is not None:
|
| 298 |
+
norm_layer = partial(norm_layer, eps=norm_eps)
|
| 299 |
+
norm_layer_cl = partial(norm_layer_cl, eps=norm_eps)
|
| 300 |
+
else:
|
| 301 |
+
assert conv_mlp,\
|
| 302 |
+
'If a norm_layer is specified, conv MLP must be used so all norm expect rank-4, channels-first input'
|
| 303 |
+
norm_layer_cl = norm_layer
|
| 304 |
+
if norm_eps is not None:
|
| 305 |
+
norm_layer_cl = partial(norm_layer_cl, eps=norm_eps)
|
| 306 |
+
|
| 307 |
+
self.num_classes = num_classes
|
| 308 |
+
self.drop_rate = drop_rate
|
| 309 |
+
self.feature_info = []
|
| 310 |
+
|
| 311 |
+
assert stem_type in ('patch', 'overlap', 'overlap_tiered')
|
| 312 |
+
if stem_type == 'patch':
|
| 313 |
+
# NOTE: this stem is a minimal form of ViT PatchEmbed, as used in SwinTransformer w/ patch_size = 4
|
| 314 |
+
self.stem = nn.Sequential(
|
| 315 |
+
nn.Conv2d(in_chans, dims[0], kernel_size=patch_size, stride=patch_size, bias=conv_bias),
|
| 316 |
+
norm_layer(dims[0]),
|
| 317 |
+
)
|
| 318 |
+
stem_stride = patch_size
|
| 319 |
+
else:
|
| 320 |
+
mid_chs = make_divisible(dims[0] // 2) if 'tiered' in stem_type else dims[0]
|
| 321 |
+
self.stem = nn.Sequential(
|
| 322 |
+
nn.Conv2d(in_chans, mid_chs, kernel_size=3, stride=2, padding=1, bias=conv_bias),
|
| 323 |
+
nn.Conv2d(mid_chs, dims[0], kernel_size=3, stride=2, padding=1, bias=conv_bias),
|
| 324 |
+
norm_layer(dims[0]),
|
| 325 |
+
)
|
| 326 |
+
stem_stride = 4
|
| 327 |
+
|
| 328 |
+
self.stages = nn.Sequential()
|
| 329 |
+
dp_rates = [x.tolist() for x in torch.linspace(0, drop_path_rate, sum(depths)).split(depths)]
|
| 330 |
+
stages = []
|
| 331 |
+
prev_chs = dims[0]
|
| 332 |
+
curr_stride = stem_stride
|
| 333 |
+
dilation = 1
|
| 334 |
+
# 4 feature resolution stages, each consisting of multiple residual blocks
|
| 335 |
+
for i in range(4):
|
| 336 |
+
stride = 2 if curr_stride == 2 or i > 0 else 1
|
| 337 |
+
if curr_stride >= output_stride and stride > 1:
|
| 338 |
+
dilation *= stride
|
| 339 |
+
stride = 1
|
| 340 |
+
curr_stride *= stride
|
| 341 |
+
first_dilation = 1 if dilation in (1, 2) else 2
|
| 342 |
+
out_chs = dims[i]
|
| 343 |
+
stages.append(ConvNeXtStage(
|
| 344 |
+
prev_chs,
|
| 345 |
+
out_chs,
|
| 346 |
+
kernel_size=kernel_sizes[i],
|
| 347 |
+
stride=stride,
|
| 348 |
+
dilation=(first_dilation, dilation),
|
| 349 |
+
depth=depths[i],
|
| 350 |
+
drop_path_rates=dp_rates[i],
|
| 351 |
+
ls_init_value=ls_init_value,
|
| 352 |
+
conv_mlp=conv_mlp,
|
| 353 |
+
conv_bias=conv_bias,
|
| 354 |
+
use_grn=use_grn,
|
| 355 |
+
act_layer=act_layer,
|
| 356 |
+
norm_layer=norm_layer,
|
| 357 |
+
norm_layer_cl=norm_layer_cl,
|
| 358 |
+
))
|
| 359 |
+
prev_chs = out_chs
|
| 360 |
+
# NOTE feature_info use currently assumes stage 0 == stride 1, rest are stride 2
|
| 361 |
+
self.feature_info += [dict(num_chs=prev_chs, reduction=curr_stride, module=f'stages.{i}')]
|
| 362 |
+
self.stages = nn.Sequential(*stages)
|
| 363 |
+
self.num_features = prev_chs
|
| 364 |
+
|
| 365 |
+
# if head_norm_first == true, norm -> global pool -> fc ordering, like most other nets
|
| 366 |
+
# otherwise pool -> norm -> fc, the default ConvNeXt ordering (pretrained FB weights)
|
| 367 |
+
if head_norm_first:
|
| 368 |
+
assert not head_hidden_size
|
| 369 |
+
self.norm_pre = norm_layer(self.num_features)
|
| 370 |
+
self.head = ClassifierHead(
|
| 371 |
+
self.num_features,
|
| 372 |
+
num_classes,
|
| 373 |
+
pool_type=global_pool,
|
| 374 |
+
drop_rate=self.drop_rate,
|
| 375 |
+
)
|
| 376 |
+
else:
|
| 377 |
+
self.norm_pre = nn.Identity()
|
| 378 |
+
self.head = NormMlpClassifierHead(
|
| 379 |
+
self.num_features,
|
| 380 |
+
num_classes,
|
| 381 |
+
hidden_size=head_hidden_size,
|
| 382 |
+
pool_type=global_pool,
|
| 383 |
+
drop_rate=self.drop_rate,
|
| 384 |
+
norm_layer=norm_layer,
|
| 385 |
+
act_layer='gelu',
|
| 386 |
+
)
|
| 387 |
+
named_apply(partial(_init_weights, head_init_scale=head_init_scale), self)
|
| 388 |
+
|
| 389 |
+
@torch.jit.ignore
|
| 390 |
+
def group_matcher(self, coarse=False):
|
| 391 |
+
return dict(
|
| 392 |
+
stem=r'^stem',
|
| 393 |
+
blocks=r'^stages\.(\d+)' if coarse else [
|
| 394 |
+
(r'^stages\.(\d+)\.downsample', (0,)), # blocks
|
| 395 |
+
(r'^stages\.(\d+)\.blocks\.(\d+)', None),
|
| 396 |
+
(r'^norm_pre', (99999,))
|
| 397 |
+
]
|
| 398 |
+
)
|
| 399 |
+
|
| 400 |
+
@torch.jit.ignore
|
| 401 |
+
def set_grad_checkpointing(self, enable=True):
|
| 402 |
+
for s in self.stages:
|
| 403 |
+
s.grad_checkpointing = enable
|
| 404 |
+
|
| 405 |
+
@torch.jit.ignore
|
| 406 |
+
def get_classifier(self):
|
| 407 |
+
return self.head.fc
|
| 408 |
+
|
| 409 |
+
def reset_classifier(self, num_classes=0, global_pool=None):
|
| 410 |
+
self.head.reset(num_classes, global_pool)
|
| 411 |
+
|
| 412 |
+
def forward_features(self, x):
|
| 413 |
+
x = self.stem(x)
|
| 414 |
+
x = self.stages(x)
|
| 415 |
+
x = self.norm_pre(x)
|
| 416 |
+
return x
|
| 417 |
+
|
| 418 |
+
def forward_head(self, x, pre_logits: bool = False):
|
| 419 |
+
return self.head(x, pre_logits=True) if pre_logits else self.head(x)
|
| 420 |
+
|
| 421 |
+
def forward(self, x):
|
| 422 |
+
x = self.forward_features(x)
|
| 423 |
+
x = self.forward_head(x)
|
| 424 |
+
return x
|
| 425 |
+
|
| 426 |
+
|
| 427 |
+
def _init_weights(module, name=None, head_init_scale=1.0):
|
| 428 |
+
if isinstance(module, nn.Conv2d):
|
| 429 |
+
trunc_normal_(module.weight, std=.02)
|
| 430 |
+
if module.bias is not None:
|
| 431 |
+
nn.init.zeros_(module.bias)
|
| 432 |
+
elif isinstance(module, nn.Linear):
|
| 433 |
+
trunc_normal_(module.weight, std=.02)
|
| 434 |
+
nn.init.zeros_(module.bias)
|
| 435 |
+
if name and 'head.' in name:
|
| 436 |
+
module.weight.data.mul_(head_init_scale)
|
| 437 |
+
module.bias.data.mul_(head_init_scale)
|
| 438 |
+
|
| 439 |
+
|
| 440 |
+
def checkpoint_filter_fn(state_dict, model):
|
| 441 |
+
""" Remap FB checkpoints -> timm """
|
| 442 |
+
if 'head.norm.weight' in state_dict or 'norm_pre.weight' in state_dict:
|
| 443 |
+
out_dict={}
|
| 444 |
+
out_dict = {k.replace('gamma', 'weight'): v for k, v in state_dict.items()}
|
| 445 |
+
return out_dict # non-FB checkpoint
|
| 446 |
+
if 'model' in state_dict:
|
| 447 |
+
state_dict = state_dict['model']
|
| 448 |
+
|
| 449 |
+
out_dict = {}
|
| 450 |
+
if 'visual.trunk.stem.0.weight' in state_dict:
|
| 451 |
+
out_dict = {k.replace('visual.trunk.', '').replace('gamma', 'weight'): v for k, v in state_dict.items() if
|
| 452 |
+
k.startswith('visual.trunk.')}
|
| 453 |
+
|
| 454 |
+
if 'visual.head.proj.weight' in state_dict:
|
| 455 |
+
out_dict['head.fc.weight'] = state_dict['visual.head.proj.weight']
|
| 456 |
+
out_dict['head.fc.bias'] = torch.zeros(state_dict['visual.head.proj.weight'].shape[0])
|
| 457 |
+
elif 'visual.head.mlp.fc1.weight' in state_dict:
|
| 458 |
+
out_dict['head.pre_logits.fc.weight'] = state_dict['visual.head.mlp.fc1.weight']
|
| 459 |
+
out_dict['head.pre_logits.fc.bias'] = state_dict['visual.head.mlp.fc1.bias']
|
| 460 |
+
out_dict['head.fc.weight'] = state_dict['visual.head.mlp.fc2.weight']
|
| 461 |
+
out_dict['head.fc.bias'] = torch.zeros(state_dict['visual.head.mlp.fc2.weight'].shape[0])
|
| 462 |
+
return out_dict
|
| 463 |
+
|
| 464 |
+
import re
|
| 465 |
+
for k, v in state_dict.items():
|
| 466 |
+
k = k.replace('downsample_layers.0.', 'stem.')
|
| 467 |
+
k = re.sub(r'stages.([0-9]+).([0-9]+)', r'stages.\1.blocks.\2', k)
|
| 468 |
+
k = re.sub(r'downsample_layers.([0-9]+).([0-9]+)', r'stages.\1.downsample.\2', k)
|
| 469 |
+
k = k.replace('dwconv', 'conv_dw')
|
| 470 |
+
k = k.replace('pwconv', 'mlp.fc')
|
| 471 |
+
if 'grn' in k:
|
| 472 |
+
k = k.replace('grn.beta', 'mlp.grn.bias')
|
| 473 |
+
k = k.replace('grn.gamma', 'mlp.grn.weight')
|
| 474 |
+
v = v.reshape(v.shape[-1])
|
| 475 |
+
k = k.replace('head.', 'head.fc.')
|
| 476 |
+
if k.startswith('norm.'):
|
| 477 |
+
k = k.replace('norm', 'head.norm')
|
| 478 |
+
if v.ndim == 2 and 'head' not in k:
|
| 479 |
+
model_shape = model.state_dict()[k].shape
|
| 480 |
+
v = v.reshape(model_shape)
|
| 481 |
+
k=k.replace('gamma','weight')
|
| 482 |
+
out_dict[k] = v
|
| 483 |
+
|
| 484 |
+
return out_dict
|
| 485 |
+
|
| 486 |
+
|
| 487 |
+
def _create_convnext(variant, pretrained=False, **kwargs):
|
| 488 |
+
if kwargs.get('pretrained_cfg', '') == 'fcmae':
|
| 489 |
+
# NOTE fcmae pretrained weights have no classifier or final norm-layer (`head.norm`)
|
| 490 |
+
# This is workaround loading with num_classes=0 w/o removing norm-layer.
|
| 491 |
+
kwargs.setdefault('pretrained_strict', False)
|
| 492 |
+
|
| 493 |
+
model = build_model_with_cfg(
|
| 494 |
+
ConvNeXt, variant, pretrained,
|
| 495 |
+
pretrained_filter_fn=checkpoint_filter_fn,
|
| 496 |
+
feature_cfg=dict(out_indices=(0, 1, 2, 3), flatten_sequential=True),
|
| 497 |
+
**kwargs)
|
| 498 |
+
return model
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
def _cfg(url='', **kwargs):
|
| 502 |
+
return {
|
| 503 |
+
'url': url,
|
| 504 |
+
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': (7, 7),
|
| 505 |
+
'crop_pct': 0.875, 'interpolation': 'bicubic',
|
| 506 |
+
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
|
| 507 |
+
'first_conv': 'stem.0', 'classifier': 'head.fc',
|
| 508 |
+
**kwargs
|
| 509 |
+
}
|
| 510 |
+
|
| 511 |
+
|
| 512 |
+
def _cfgv2(url='', **kwargs):
|
| 513 |
+
return {
|
| 514 |
+
'url': url,
|
| 515 |
+
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': (7, 7),
|
| 516 |
+
'crop_pct': 0.875, 'interpolation': 'bicubic',
|
| 517 |
+
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
|
| 518 |
+
'first_conv': 'stem.0', 'classifier': 'head.fc',
|
| 519 |
+
'license': 'cc-by-nc-4.0', 'paper_ids': 'arXiv:2301.00808',
|
| 520 |
+
'paper_name': 'ConvNeXt-V2: Co-designing and Scaling ConvNets with Masked Autoencoders',
|
| 521 |
+
'origin_url': 'https://github.com/facebookresearch/ConvNeXt-V2',
|
| 522 |
+
**kwargs
|
| 523 |
+
}
|
| 524 |
+
|
| 525 |
+
|
| 526 |
+
default_cfgs = generate_default_cfgs({
|
| 527 |
+
# timm specific variants
|
| 528 |
+
'convnext_tiny.in12k_ft_in1k': _cfg(
|
| 529 |
+
hf_hub_id='timm/',
|
| 530 |
+
crop_pct=0.95, test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 531 |
+
'convnext_small.in12k_ft_in1k': _cfg(
|
| 532 |
+
hf_hub_id='timm/',
|
| 533 |
+
crop_pct=0.95, test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 534 |
+
|
| 535 |
+
'convnext_atto.d2_in1k': _cfg(
|
| 536 |
+
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rsb-weights/convnext_atto_d2-01bb0f51.pth',
|
| 537 |
+
hf_hub_id='timm/',
|
| 538 |
+
test_input_size=(3, 288, 288), test_crop_pct=0.95),
|
| 539 |
+
'convnext_atto_ols.a2_in1k': _cfg(
|
| 540 |
+
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rsb-weights/convnext_atto_ols_a2-78d1c8f3.pth',
|
| 541 |
+
hf_hub_id='timm/',
|
| 542 |
+
test_input_size=(3, 288, 288), test_crop_pct=0.95),
|
| 543 |
+
'convnext_femto.d1_in1k': _cfg(
|
| 544 |
+
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rsb-weights/convnext_femto_d1-d71d5b4c.pth',
|
| 545 |
+
hf_hub_id='timm/',
|
| 546 |
+
test_input_size=(3, 288, 288), test_crop_pct=0.95),
|
| 547 |
+
'convnext_femto_ols.d1_in1k': _cfg(
|
| 548 |
+
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rsb-weights/convnext_femto_ols_d1-246bf2ed.pth',
|
| 549 |
+
hf_hub_id='timm/',
|
| 550 |
+
test_input_size=(3, 288, 288), test_crop_pct=0.95),
|
| 551 |
+
'convnext_pico.d1_in1k': _cfg(
|
| 552 |
+
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rsb-weights/convnext_pico_d1-10ad7f0d.pth',
|
| 553 |
+
hf_hub_id='timm/',
|
| 554 |
+
test_input_size=(3, 288, 288), test_crop_pct=0.95),
|
| 555 |
+
'convnext_pico_ols.d1_in1k': _cfg(
|
| 556 |
+
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rsb-weights/convnext_pico_ols_d1-611f0ca7.pth',
|
| 557 |
+
hf_hub_id='timm/',
|
| 558 |
+
crop_pct=0.95, test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 559 |
+
'convnext_nano.in12k_ft_in1k': _cfg(
|
| 560 |
+
hf_hub_id='timm/',
|
| 561 |
+
crop_pct=0.95, test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 562 |
+
'convnext_nano.d1h_in1k': _cfg(
|
| 563 |
+
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rsb-weights/convnext_nano_d1h-7eb4bdea.pth',
|
| 564 |
+
hf_hub_id='timm/',
|
| 565 |
+
crop_pct=0.95, test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 566 |
+
'convnext_nano_ols.d1h_in1k': _cfg(
|
| 567 |
+
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rsb-weights/convnext_nano_ols_d1h-ae424a9a.pth',
|
| 568 |
+
hf_hub_id='timm/',
|
| 569 |
+
crop_pct=0.95, test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 570 |
+
'convnext_tiny_hnf.a2h_in1k': _cfg(
|
| 571 |
+
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rsb-weights/convnext_tiny_hnf_a2h-ab7e9df2.pth',
|
| 572 |
+
hf_hub_id='timm/',
|
| 573 |
+
crop_pct=0.95, test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 574 |
+
|
| 575 |
+
'convnext_tiny.in12k_ft_in1k_384': _cfg(
|
| 576 |
+
hf_hub_id='timm/',
|
| 577 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 578 |
+
'convnext_small.in12k_ft_in1k_384': _cfg(
|
| 579 |
+
hf_hub_id='timm/',
|
| 580 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 581 |
+
|
| 582 |
+
'convnext_nano.in12k': _cfg(
|
| 583 |
+
hf_hub_id='timm/',
|
| 584 |
+
crop_pct=0.95, num_classes=11821),
|
| 585 |
+
'convnext_tiny.in12k': _cfg(
|
| 586 |
+
hf_hub_id='timm/',
|
| 587 |
+
crop_pct=0.95, num_classes=11821),
|
| 588 |
+
'convnext_small.in12k': _cfg(
|
| 589 |
+
hf_hub_id='timm/',
|
| 590 |
+
crop_pct=0.95, num_classes=11821),
|
| 591 |
+
|
| 592 |
+
'convnext_tiny.fb_in22k_ft_in1k': _cfg(
|
| 593 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnext_tiny_22k_1k_224.pth',
|
| 594 |
+
hf_hub_id='timm/',
|
| 595 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 596 |
+
'convnext_small.fb_in22k_ft_in1k': _cfg(
|
| 597 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnext_small_22k_1k_224.pth',
|
| 598 |
+
hf_hub_id='timm/',
|
| 599 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 600 |
+
'convnext_base.fb_in22k_ft_in1k': _cfg(
|
| 601 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_224.pth',
|
| 602 |
+
hf_hub_id='timm/',
|
| 603 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 604 |
+
'convnext_large.fb_in22k_ft_in1k': _cfg(
|
| 605 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_1k_224.pth',
|
| 606 |
+
hf_hub_id='timm/',
|
| 607 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 608 |
+
'convnext_xlarge.fb_in22k_ft_in1k': _cfg(
|
| 609 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_1k_224_ema.pth',
|
| 610 |
+
hf_hub_id='timm/',
|
| 611 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 612 |
+
|
| 613 |
+
'convnext_tiny.fb_in1k': _cfg(
|
| 614 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnext_tiny_1k_224_ema.pth",
|
| 615 |
+
hf_hub_id='timm/',
|
| 616 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 617 |
+
'convnext_small.fb_in1k': _cfg(
|
| 618 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnext_small_1k_224_ema.pth",
|
| 619 |
+
hf_hub_id='timm/',
|
| 620 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 621 |
+
'convnext_base.fb_in1k': _cfg(
|
| 622 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_224_ema.pth",
|
| 623 |
+
hf_hub_id='timm/',
|
| 624 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 625 |
+
'convnext_large.fb_in1k': _cfg(
|
| 626 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_224_ema.pth",
|
| 627 |
+
hf_hub_id='timm/',
|
| 628 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 629 |
+
|
| 630 |
+
'convnext_tiny.fb_in22k_ft_in1k_384': _cfg(
|
| 631 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnext_tiny_22k_1k_384.pth',
|
| 632 |
+
hf_hub_id='timm/',
|
| 633 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 634 |
+
'convnext_small.fb_in22k_ft_in1k_384': _cfg(
|
| 635 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnext_small_22k_1k_384.pth',
|
| 636 |
+
hf_hub_id='timm/',
|
| 637 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 638 |
+
'convnext_base.fb_in22k_ft_in1k_384': _cfg(
|
| 639 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_384.pth',
|
| 640 |
+
hf_hub_id='timm/',
|
| 641 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 642 |
+
'convnext_large.fb_in22k_ft_in1k_384': _cfg(
|
| 643 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_1k_384.pth',
|
| 644 |
+
hf_hub_id='timm/',
|
| 645 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 646 |
+
'convnext_xlarge.fb_in22k_ft_in1k_384': _cfg(
|
| 647 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_1k_384_ema.pth',
|
| 648 |
+
hf_hub_id='timm/',
|
| 649 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 650 |
+
|
| 651 |
+
'convnext_tiny.fb_in22k': _cfg(
|
| 652 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnext_tiny_22k_224.pth",
|
| 653 |
+
hf_hub_id='timm/',
|
| 654 |
+
num_classes=21841),
|
| 655 |
+
'convnext_small.fb_in22k': _cfg(
|
| 656 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnext_small_22k_224.pth",
|
| 657 |
+
hf_hub_id='timm/',
|
| 658 |
+
num_classes=21841),
|
| 659 |
+
'convnext_base.fb_in22k': _cfg(
|
| 660 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pth",
|
| 661 |
+
hf_hub_id='timm/',
|
| 662 |
+
num_classes=21841),
|
| 663 |
+
'convnext_large.fb_in22k': _cfg(
|
| 664 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_224.pth",
|
| 665 |
+
hf_hub_id='timm/',
|
| 666 |
+
num_classes=21841),
|
| 667 |
+
'convnext_xlarge.fb_in22k': _cfg(
|
| 668 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_224.pth",
|
| 669 |
+
hf_hub_id='timm/',
|
| 670 |
+
num_classes=21841),
|
| 671 |
+
|
| 672 |
+
'convnextv2_nano.fcmae_ft_in22k_in1k': _cfgv2(
|
| 673 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnextv2/im22k/convnextv2_nano_22k_224_ema.pt',
|
| 674 |
+
hf_hub_id='timm/',
|
| 675 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 676 |
+
'convnextv2_nano.fcmae_ft_in22k_in1k_384': _cfgv2(
|
| 677 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnextv2/im22k/convnextv2_nano_22k_384_ema.pt',
|
| 678 |
+
hf_hub_id='timm/',
|
| 679 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 680 |
+
'convnextv2_tiny.fcmae_ft_in22k_in1k': _cfgv2(
|
| 681 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im22k/convnextv2_tiny_22k_224_ema.pt",
|
| 682 |
+
hf_hub_id='timm/',
|
| 683 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 684 |
+
'convnextv2_tiny.fcmae_ft_in22k_in1k_384': _cfgv2(
|
| 685 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im22k/convnextv2_tiny_22k_384_ema.pt",
|
| 686 |
+
hf_hub_id='timm/',
|
| 687 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 688 |
+
'convnextv2_base.fcmae_ft_in22k_in1k': _cfgv2(
|
| 689 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im22k/convnextv2_base_22k_224_ema.pt",
|
| 690 |
+
hf_hub_id='timm/',
|
| 691 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 692 |
+
'convnextv2_base.fcmae_ft_in22k_in1k_384': _cfgv2(
|
| 693 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im22k/convnextv2_base_22k_384_ema.pt",
|
| 694 |
+
hf_hub_id='timm/',
|
| 695 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 696 |
+
'convnextv2_large.fcmae_ft_in22k_in1k': _cfgv2(
|
| 697 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im22k/convnextv2_large_22k_224_ema.pt",
|
| 698 |
+
hf_hub_id='timm/',
|
| 699 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 700 |
+
'convnextv2_large.fcmae_ft_in22k_in1k_384': _cfgv2(
|
| 701 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im22k/convnextv2_large_22k_384_ema.pt",
|
| 702 |
+
hf_hub_id='timm/',
|
| 703 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 704 |
+
'convnextv2_huge.fcmae_ft_in22k_in1k_384': _cfgv2(
|
| 705 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im22k/convnextv2_huge_22k_384_ema.pt",
|
| 706 |
+
hf_hub_id='timm/',
|
| 707 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 708 |
+
'convnextv2_huge.fcmae_ft_in22k_in1k_512': _cfgv2(
|
| 709 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im22k/convnextv2_huge_22k_512_ema.pt",
|
| 710 |
+
hf_hub_id='timm/',
|
| 711 |
+
input_size=(3, 512, 512), pool_size=(15, 15), crop_pct=1.0, crop_mode='squash'),
|
| 712 |
+
|
| 713 |
+
'convnextv2_atto.fcmae_ft_in1k': _cfgv2(
|
| 714 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnextv2/im1k/convnextv2_atto_1k_224_ema.pt',
|
| 715 |
+
hf_hub_id='timm/',
|
| 716 |
+
test_input_size=(3, 288, 288), test_crop_pct=0.95),
|
| 717 |
+
'convnextv2_femto.fcmae_ft_in1k': _cfgv2(
|
| 718 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnextv2/im1k/convnextv2_femto_1k_224_ema.pt',
|
| 719 |
+
hf_hub_id='timm/',
|
| 720 |
+
test_input_size=(3, 288, 288), test_crop_pct=0.95),
|
| 721 |
+
'convnextv2_pico.fcmae_ft_in1k': _cfgv2(
|
| 722 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnextv2/im1k/convnextv2_pico_1k_224_ema.pt',
|
| 723 |
+
hf_hub_id='timm/',
|
| 724 |
+
test_input_size=(3, 288, 288), test_crop_pct=0.95),
|
| 725 |
+
'convnextv2_nano.fcmae_ft_in1k': _cfgv2(
|
| 726 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnextv2/im1k/convnextv2_nano_1k_224_ema.pt',
|
| 727 |
+
hf_hub_id='timm/',
|
| 728 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 729 |
+
'convnextv2_tiny.fcmae_ft_in1k': _cfgv2(
|
| 730 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im1k/convnextv2_tiny_1k_224_ema.pt",
|
| 731 |
+
hf_hub_id='timm/',
|
| 732 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 733 |
+
'convnextv2_base.fcmae_ft_in1k': _cfgv2(
|
| 734 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im1k/convnextv2_base_1k_224_ema.pt",
|
| 735 |
+
hf_hub_id='timm/',
|
| 736 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 737 |
+
'convnextv2_large.fcmae_ft_in1k': _cfgv2(
|
| 738 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im1k/convnextv2_large_1k_224_ema.pt",
|
| 739 |
+
hf_hub_id='timm/',
|
| 740 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 741 |
+
'convnextv2_huge.fcmae_ft_in1k': _cfgv2(
|
| 742 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/im1k/convnextv2_huge_1k_224_ema.pt",
|
| 743 |
+
hf_hub_id='timm/',
|
| 744 |
+
test_input_size=(3, 288, 288), test_crop_pct=1.0),
|
| 745 |
+
|
| 746 |
+
'convnextv2_atto.fcmae': _cfgv2(
|
| 747 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnextv2/pt_only/convnextv2_atto_1k_224_fcmae.pt',
|
| 748 |
+
hf_hub_id='timm/',
|
| 749 |
+
num_classes=0),
|
| 750 |
+
'convnextv2_femto.fcmae': _cfgv2(
|
| 751 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnextv2/pt_only/convnextv2_femto_1k_224_fcmae.pt',
|
| 752 |
+
hf_hub_id='timm/',
|
| 753 |
+
num_classes=0),
|
| 754 |
+
'convnextv2_pico.fcmae': _cfgv2(
|
| 755 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnextv2/pt_only/convnextv2_pico_1k_224_fcmae.pt',
|
| 756 |
+
hf_hub_id='timm/',
|
| 757 |
+
num_classes=0),
|
| 758 |
+
'convnextv2_nano.fcmae': _cfgv2(
|
| 759 |
+
url='https://dl.fbaipublicfiles.com/convnext/convnextv2/pt_only/convnextv2_nano_1k_224_fcmae.pt',
|
| 760 |
+
hf_hub_id='timm/',
|
| 761 |
+
num_classes=0),
|
| 762 |
+
'convnextv2_tiny.fcmae': _cfgv2(
|
| 763 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/pt_only/convnextv2_tiny_1k_224_fcmae.pt",
|
| 764 |
+
hf_hub_id='timm/',
|
| 765 |
+
num_classes=0),
|
| 766 |
+
'convnextv2_base.fcmae': _cfgv2(
|
| 767 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/pt_only/convnextv2_base_1k_224_fcmae.pt",
|
| 768 |
+
hf_hub_id='timm/',
|
| 769 |
+
num_classes=0),
|
| 770 |
+
'convnextv2_large.fcmae': _cfgv2(
|
| 771 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/pt_only/convnextv2_large_1k_224_fcmae.pt",
|
| 772 |
+
hf_hub_id='timm/',
|
| 773 |
+
num_classes=0),
|
| 774 |
+
'convnextv2_huge.fcmae': _cfgv2(
|
| 775 |
+
url="https://dl.fbaipublicfiles.com/convnext/convnextv2/pt_only/convnextv2_huge_1k_224_fcmae.pt",
|
| 776 |
+
hf_hub_id='timm/',
|
| 777 |
+
num_classes=0),
|
| 778 |
+
|
| 779 |
+
'convnextv2_small.untrained': _cfg(),
|
| 780 |
+
|
| 781 |
+
# CLIP weights, fine-tuned on in1k or in12k + in1k
|
| 782 |
+
'convnext_base.clip_laion2b_augreg_ft_in12k_in1k': _cfg(
|
| 783 |
+
hf_hub_id='timm/',
|
| 784 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 785 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0),
|
| 786 |
+
'convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384': _cfg(
|
| 787 |
+
hf_hub_id='timm/',
|
| 788 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 789 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 790 |
+
'convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320': _cfg(
|
| 791 |
+
hf_hub_id='timm/',
|
| 792 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 793 |
+
input_size=(3, 320, 320), pool_size=(10, 10), crop_pct=1.0),
|
| 794 |
+
'convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384': _cfg(
|
| 795 |
+
hf_hub_id='timm/',
|
| 796 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 797 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 798 |
+
|
| 799 |
+
'convnext_base.clip_laion2b_augreg_ft_in1k': _cfg(
|
| 800 |
+
hf_hub_id='timm/',
|
| 801 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 802 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0),
|
| 803 |
+
'convnext_base.clip_laiona_augreg_ft_in1k_384': _cfg(
|
| 804 |
+
hf_hub_id='timm/',
|
| 805 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 806 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0),
|
| 807 |
+
'convnext_large_mlp.clip_laion2b_augreg_ft_in1k': _cfg(
|
| 808 |
+
hf_hub_id='timm/',
|
| 809 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 810 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0
|
| 811 |
+
),
|
| 812 |
+
'convnext_large_mlp.clip_laion2b_augreg_ft_in1k_384': _cfg(
|
| 813 |
+
hf_hub_id='timm/',
|
| 814 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 815 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'
|
| 816 |
+
),
|
| 817 |
+
'convnext_xxlarge.clip_laion2b_soup_ft_in1k': _cfg(
|
| 818 |
+
hf_hub_id='timm/',
|
| 819 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 820 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0),
|
| 821 |
+
|
| 822 |
+
'convnext_base.clip_laion2b_augreg_ft_in12k': _cfg(
|
| 823 |
+
hf_hub_id='timm/',
|
| 824 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD, num_classes=11821,
|
| 825 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0),
|
| 826 |
+
'convnext_large_mlp.clip_laion2b_soup_ft_in12k_320': _cfg(
|
| 827 |
+
hf_hub_id='timm/',
|
| 828 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD, num_classes=11821,
|
| 829 |
+
input_size=(3, 320, 320), pool_size=(10, 10), crop_pct=1.0),
|
| 830 |
+
'convnext_large_mlp.clip_laion2b_augreg_ft_in12k_384': _cfg(
|
| 831 |
+
hf_hub_id='timm/',
|
| 832 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD, num_classes=11821,
|
| 833 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 834 |
+
'convnext_large_mlp.clip_laion2b_soup_ft_in12k_384': _cfg(
|
| 835 |
+
hf_hub_id='timm/',
|
| 836 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD, num_classes=11821,
|
| 837 |
+
input_size=(3, 384, 384), pool_size=(12, 12), crop_pct=1.0, crop_mode='squash'),
|
| 838 |
+
'convnext_xxlarge.clip_laion2b_soup_ft_in12k': _cfg(
|
| 839 |
+
hf_hub_id='timm/',
|
| 840 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD, num_classes=11821,
|
| 841 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0),
|
| 842 |
+
|
| 843 |
+
# CLIP original image tower weights
|
| 844 |
+
'convnext_base.clip_laion2b': _cfg(
|
| 845 |
+
hf_hub_id='laion/CLIP-convnext_base_w-laion2B-s13B-b82K',
|
| 846 |
+
hf_hub_filename='open_clip_pytorch_model.bin',
|
| 847 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 848 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0, num_classes=640),
|
| 849 |
+
'convnext_base.clip_laion2b_augreg': _cfg(
|
| 850 |
+
hf_hub_id='laion/CLIP-convnext_base_w-laion2B-s13B-b82K-augreg',
|
| 851 |
+
hf_hub_filename='open_clip_pytorch_model.bin',
|
| 852 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 853 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0, num_classes=640),
|
| 854 |
+
'convnext_base.clip_laiona': _cfg(
|
| 855 |
+
hf_hub_id='laion/CLIP-convnext_base_w-laion_aesthetic-s13B-b82K',
|
| 856 |
+
hf_hub_filename='open_clip_pytorch_model.bin',
|
| 857 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 858 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0, num_classes=640),
|
| 859 |
+
'convnext_base.clip_laiona_320': _cfg(
|
| 860 |
+
hf_hub_id='laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K',
|
| 861 |
+
hf_hub_filename='open_clip_pytorch_model.bin',
|
| 862 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 863 |
+
input_size=(3, 320, 320), pool_size=(10, 10), crop_pct=1.0, num_classes=640),
|
| 864 |
+
'convnext_base.clip_laiona_augreg_320': _cfg(
|
| 865 |
+
hf_hub_id='laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K-augreg',
|
| 866 |
+
hf_hub_filename='open_clip_pytorch_model.bin',
|
| 867 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 868 |
+
input_size=(3, 320, 320), pool_size=(10, 10), crop_pct=1.0, num_classes=640),
|
| 869 |
+
'convnext_large_mlp.clip_laion2b_augreg': _cfg(
|
| 870 |
+
hf_hub_id='laion/CLIP-convnext_large_d.laion2B-s26B-b102K-augreg',
|
| 871 |
+
hf_hub_filename='open_clip_pytorch_model.bin',
|
| 872 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 873 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0, num_classes=768),
|
| 874 |
+
'convnext_large_mlp.clip_laion2b_ft_320': _cfg(
|
| 875 |
+
hf_hub_id='laion/CLIP-convnext_large_d_320.laion2B-s29B-b131K-ft',
|
| 876 |
+
hf_hub_filename='open_clip_pytorch_model.bin',
|
| 877 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 878 |
+
input_size=(3, 320, 320), pool_size=(10, 10), crop_pct=1.0, num_classes=768),
|
| 879 |
+
'convnext_large_mlp.clip_laion2b_ft_soup_320': _cfg(
|
| 880 |
+
hf_hub_id='laion/CLIP-convnext_large_d_320.laion2B-s29B-b131K-ft-soup',
|
| 881 |
+
hf_hub_filename='open_clip_pytorch_model.bin',
|
| 882 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 883 |
+
input_size=(3, 320, 320), pool_size=(10, 10), crop_pct=1.0, num_classes=768),
|
| 884 |
+
'convnext_xxlarge.clip_laion2b_soup': _cfg(
|
| 885 |
+
hf_hub_id='laion/CLIP-convnext_xxlarge-laion2B-s34B-b82K-augreg-soup',
|
| 886 |
+
hf_hub_filename='open_clip_pytorch_model.bin',
|
| 887 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 888 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0, num_classes=1024),
|
| 889 |
+
'convnext_xxlarge.clip_laion2b_rewind': _cfg(
|
| 890 |
+
hf_hub_id='laion/CLIP-convnext_xxlarge-laion2B-s34B-b82K-augreg-rewind',
|
| 891 |
+
hf_hub_filename='open_clip_pytorch_model.bin',
|
| 892 |
+
mean=OPENAI_CLIP_MEAN, std=OPENAI_CLIP_STD,
|
| 893 |
+
input_size=(3, 256, 256), pool_size=(8, 8), crop_pct=1.0, num_classes=1024),
|
| 894 |
+
})
|
| 895 |
+
|
| 896 |
+
|
| 897 |
+
# @register_model
|
| 898 |
+
# def convnext_atto(pretrained=False, **kwargs) -> ConvNeXt:
|
| 899 |
+
# # timm femto variant (NOTE: still tweaking depths, will vary between 3-4M param, current is 3.7M
|
| 900 |
+
# model_args = dict(depths=(2, 2, 6, 2), dims=(40, 80, 160, 320), conv_mlp=True)
|
| 901 |
+
# model = _create_convnext('convnext_atto', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 902 |
+
# return model
|
| 903 |
+
|
| 904 |
+
|
| 905 |
+
# @register_model
|
| 906 |
+
# def convnext_atto_ols(pretrained=False, **kwargs) -> ConvNeXt:
|
| 907 |
+
# # timm femto variant with overlapping 3x3 conv stem, wider than non-ols femto above, current param count 3.7M
|
| 908 |
+
# model_args = dict(depths=(2, 2, 6, 2), dims=(40, 80, 160, 320), conv_mlp=True, stem_type='overlap_tiered')
|
| 909 |
+
# model = _create_convnext('convnext_atto_ols', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 910 |
+
# return model
|
| 911 |
+
|
| 912 |
+
|
| 913 |
+
# @register_model
|
| 914 |
+
# def convnext_femto(pretrained=False, **kwargs) -> ConvNeXt:
|
| 915 |
+
# # timm femto variant
|
| 916 |
+
# model_args = dict(depths=(2, 2, 6, 2), dims=(48, 96, 192, 384), conv_mlp=True)
|
| 917 |
+
# model = _create_convnext('convnext_femto', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 918 |
+
# return model
|
| 919 |
+
|
| 920 |
+
|
| 921 |
+
# @register_model
|
| 922 |
+
# def convnext_femto_ols(pretrained=False, **kwargs) -> ConvNeXt:
|
| 923 |
+
# # timm femto variant
|
| 924 |
+
# model_args = dict(depths=(2, 2, 6, 2), dims=(48, 96, 192, 384), conv_mlp=True, stem_type='overlap_tiered')
|
| 925 |
+
# model = _create_convnext('convnext_femto_ols', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 926 |
+
# return model
|
| 927 |
+
|
| 928 |
+
|
| 929 |
+
# @register_model
|
| 930 |
+
# def convnext_pico(pretrained=False, **kwargs) -> ConvNeXt:
|
| 931 |
+
# # timm pico variant
|
| 932 |
+
# model_args = dict(depths=(2, 2, 6, 2), dims=(64, 128, 256, 512), conv_mlp=True)
|
| 933 |
+
# model = _create_convnext('convnext_pico', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 934 |
+
# return model
|
| 935 |
+
|
| 936 |
+
|
| 937 |
+
# @register_model
|
| 938 |
+
# def convnext_pico_ols(pretrained=False, **kwargs) -> ConvNeXt:
|
| 939 |
+
# # timm nano variant with overlapping 3x3 conv stem
|
| 940 |
+
# model_args = dict(depths=(2, 2, 6, 2), dims=(64, 128, 256, 512), conv_mlp=True, stem_type='overlap_tiered')
|
| 941 |
+
# model = _create_convnext('convnext_pico_ols', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 942 |
+
# return model
|
| 943 |
+
|
| 944 |
+
|
| 945 |
+
# @register_model
|
| 946 |
+
# def convnext_nano(pretrained=False, **kwargs) -> ConvNeXt:
|
| 947 |
+
# # timm nano variant with standard stem and head
|
| 948 |
+
# model_args = dict(depths=(2, 2, 8, 2), dims=(80, 160, 320, 640), conv_mlp=True)
|
| 949 |
+
# model = _create_convnext('convnext_nano', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 950 |
+
# return model
|
| 951 |
+
|
| 952 |
+
|
| 953 |
+
# @register_model
|
| 954 |
+
# def convnext_nano_ols(pretrained=False, **kwargs) -> ConvNeXt:
|
| 955 |
+
# # experimental nano variant with overlapping conv stem
|
| 956 |
+
# model_args = dict(depths=(2, 2, 8, 2), dims=(80, 160, 320, 640), conv_mlp=True, stem_type='overlap')
|
| 957 |
+
# model = _create_convnext('convnext_nano_ols', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 958 |
+
# return model
|
| 959 |
+
|
| 960 |
+
|
| 961 |
+
# @register_model
|
| 962 |
+
# def convnext_tiny_hnf(pretrained=False, **kwargs) -> ConvNeXt:
|
| 963 |
+
# # experimental tiny variant with norm before pooling in head (head norm first)
|
| 964 |
+
# model_args = dict(depths=(3, 3, 9, 3), dims=(96, 192, 384, 768), head_norm_first=True, conv_mlp=True)
|
| 965 |
+
# model = _create_convnext('convnext_tiny_hnf', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 966 |
+
# return model
|
| 967 |
+
|
| 968 |
+
|
| 969 |
+
# @register_model
|
| 970 |
+
# def convnext_tiny(pretrained=False, **kwargs) -> ConvNeXt:
|
| 971 |
+
# model_args = dict(depths=(3, 3, 9, 3), dims=(96, 192, 384, 768))
|
| 972 |
+
# model = _create_convnext('convnext_tiny', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 973 |
+
# return model
|
| 974 |
+
|
| 975 |
+
|
| 976 |
+
# @register_model
|
| 977 |
+
# def convnext_small(pretrained=False, **kwargs) -> ConvNeXt:
|
| 978 |
+
# model_args = dict(depths=[3, 3, 27, 3], dims=[96, 192, 384, 768])
|
| 979 |
+
# model = _create_convnext('convnext_small', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 980 |
+
# return model
|
| 981 |
+
|
| 982 |
+
# @register_model
|
| 983 |
+
# def convnext_base_clip(pretrained='', **kwargs) -> ConvNeXt:
|
| 984 |
+
# model_args = dict(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024])
|
| 985 |
+
# model = _create_convnext(pretrained, pretrained=True, **dict(model_args, **kwargs))
|
| 986 |
+
# return model
|
| 987 |
+
|
| 988 |
+
# @register_model
|
| 989 |
+
# def convnext_base(pretrained=False, **kwargs) -> ConvNeXt:
|
| 990 |
+
# model_args = dict(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024])
|
| 991 |
+
# model = _create_convnext('convnext_base', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 992 |
+
# return model
|
| 993 |
+
|
| 994 |
+
|
| 995 |
+
# @register_model
|
| 996 |
+
# def convnext_large(pretrained=False, **kwargs) -> ConvNeXt:
|
| 997 |
+
# model_args = dict(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536])
|
| 998 |
+
# model = _create_convnext('convnext_large', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 999 |
+
# return model
|
| 1000 |
+
|
| 1001 |
+
|
| 1002 |
+
# @register_model
|
| 1003 |
+
# def convnext_large_mlp(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1004 |
+
# model_args = dict(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536], head_hidden_size=1536)
|
| 1005 |
+
# model = _create_convnext('convnext_large_mlp', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1006 |
+
# return model
|
| 1007 |
+
|
| 1008 |
+
|
| 1009 |
+
# @register_model
|
| 1010 |
+
# def convnext_xlarge(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1011 |
+
# model_args = dict(depths=[3, 3, 27, 3], dims=[256, 512, 1024, 2048])
|
| 1012 |
+
# model = _create_convnext('convnext_xlarge', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1013 |
+
# return model
|
| 1014 |
+
|
| 1015 |
+
|
| 1016 |
+
# @register_model
|
| 1017 |
+
def convnext_xxlarge(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1018 |
+
model_args = dict(depths=[3, 4, 30, 3], dims=[384, 768, 1536, 3072], norm_eps=kwargs.pop('norm_eps', 1e-5))
|
| 1019 |
+
model = _create_convnext('convnext_xxlarge', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1020 |
+
return model
|
| 1021 |
+
|
| 1022 |
+
|
| 1023 |
+
# @register_model
|
| 1024 |
+
# def convnextv2_atto(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1025 |
+
# # timm femto variant (NOTE: still tweaking depths, will vary between 3-4M param, current is 3.7M
|
| 1026 |
+
# model_args = dict(
|
| 1027 |
+
# depths=(2, 2, 6, 2), dims=(40, 80, 160, 320), use_grn=True, ls_init_value=None, conv_mlp=True)
|
| 1028 |
+
# model = _create_convnext('convnextv2_atto', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1029 |
+
# return model
|
| 1030 |
+
|
| 1031 |
+
|
| 1032 |
+
# @register_model
|
| 1033 |
+
# def convnextv2_femto(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1034 |
+
# # timm femto variant
|
| 1035 |
+
# model_args = dict(
|
| 1036 |
+
# depths=(2, 2, 6, 2), dims=(48, 96, 192, 384), use_grn=True, ls_init_value=None, conv_mlp=True)
|
| 1037 |
+
# model = _create_convnext('convnextv2_femto', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1038 |
+
# return model
|
| 1039 |
+
|
| 1040 |
+
|
| 1041 |
+
# @register_model
|
| 1042 |
+
# def convnextv2_pico(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1043 |
+
# # timm pico variant
|
| 1044 |
+
# model_args = dict(
|
| 1045 |
+
# depths=(2, 2, 6, 2), dims=(64, 128, 256, 512), use_grn=True, ls_init_value=None, conv_mlp=True)
|
| 1046 |
+
# model = _create_convnext('convnextv2_pico', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1047 |
+
# return model
|
| 1048 |
+
|
| 1049 |
+
|
| 1050 |
+
# @register_model
|
| 1051 |
+
# def convnextv2_nano(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1052 |
+
# # timm nano variant with standard stem and head
|
| 1053 |
+
# model_args = dict(
|
| 1054 |
+
# depths=(2, 2, 8, 2), dims=(80, 160, 320, 640), use_grn=True, ls_init_value=None, conv_mlp=True)
|
| 1055 |
+
# model = _create_convnext('convnextv2_nano', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1056 |
+
# return model
|
| 1057 |
+
|
| 1058 |
+
|
| 1059 |
+
# @register_model
|
| 1060 |
+
# def convnextv2_tiny(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1061 |
+
# model_args = dict(depths=(3, 3, 9, 3), dims=(96, 192, 384, 768), use_grn=True, ls_init_value=None)
|
| 1062 |
+
# model = _create_convnext('convnextv2_tiny', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1063 |
+
# return model
|
| 1064 |
+
|
| 1065 |
+
|
| 1066 |
+
# @register_model
|
| 1067 |
+
# def convnextv2_small(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1068 |
+
# model_args = dict(depths=[3, 3, 27, 3], dims=[96, 192, 384, 768], use_grn=True, ls_init_value=None)
|
| 1069 |
+
# model = _create_convnext('convnextv2_small', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1070 |
+
# return model
|
| 1071 |
+
|
| 1072 |
+
|
| 1073 |
+
# @register_model
|
| 1074 |
+
# def convnextv2_base(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1075 |
+
# model_args = dict(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024], use_grn=True, ls_init_value=None)
|
| 1076 |
+
# model = _create_convnext('convnextv2_base', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1077 |
+
# return model
|
| 1078 |
+
|
| 1079 |
+
|
| 1080 |
+
# @register_model
|
| 1081 |
+
# def convnextv2_large(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1082 |
+
# model_args = dict(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536], use_grn=True, ls_init_value=None)
|
| 1083 |
+
# model = _create_convnext('convnextv2_large', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1084 |
+
# return model
|
| 1085 |
+
|
| 1086 |
+
|
| 1087 |
+
# @register_model
|
| 1088 |
+
# def convnextv2_huge(pretrained=False, **kwargs) -> ConvNeXt:
|
| 1089 |
+
# model_args = dict(depths=[3, 3, 27, 3], dims=[352, 704, 1408, 2816], use_grn=True, ls_init_value=None)
|
| 1090 |
+
# model = _create_convnext('convnextv2_huge', pretrained=pretrained, **dict(model_args, **kwargs))
|
| 1091 |
+
# return model
|
| 1092 |
+
|
| 1093 |
+
|
| 1094 |
+
# register_model_deprecations(__name__, {
|
| 1095 |
+
# 'convnext_tiny_in22ft1k': 'convnext_tiny.fb_in22k_ft_in1k',
|
| 1096 |
+
# 'convnext_small_in22ft1k': 'convnext_small.fb_in22k_ft_in1k',
|
| 1097 |
+
# 'convnext_base_in22ft1k': 'convnext_base.fb_in22k_ft_in1k',
|
| 1098 |
+
# 'convnext_large_in22ft1k': 'convnext_large.fb_in22k_ft_in1k',
|
| 1099 |
+
# 'convnext_xlarge_in22ft1k': 'convnext_xlarge.fb_in22k_ft_in1k',
|
| 1100 |
+
# 'convnext_tiny_384_in22ft1k': 'convnext_tiny.fb_in22k_ft_in1k_384',
|
| 1101 |
+
# 'convnext_small_384_in22ft1k': 'convnext_small.fb_in22k_ft_in1k_384',
|
| 1102 |
+
# 'convnext_base_384_in22ft1k': 'convnext_base.fb_in22k_ft_in1k_384',
|
| 1103 |
+
# 'convnext_large_384_in22ft1k': 'convnext_large.fb_in22k_ft_in1k_384',
|
| 1104 |
+
# 'convnext_xlarge_384_in22ft1k': 'convnext_xlarge.fb_in22k_ft_in1k_384',
|
| 1105 |
+
# 'convnext_tiny_in22k': 'convnext_tiny.fb_in22k',
|
| 1106 |
+
# 'convnext_small_in22k': 'convnext_small.fb_in22k',
|
| 1107 |
+
# 'convnext_base_in22k': 'convnext_base.fb_in22k',
|
| 1108 |
+
# 'convnext_large_in22k': 'convnext_large.fb_in22k',
|
| 1109 |
+
# 'convnext_xlarge_in22k': 'convnext_xlarge.fb_in22k',
|
| 1110 |
+
# })
|
eagle/model/multimodal_encoder/vision_models/eva_vit.py
ADDED
|
@@ -0,0 +1,1244 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import fvcore.nn.weight_init as weight_init
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
import math
|
| 6 |
+
import numpy as np
|
| 7 |
+
import logging
|
| 8 |
+
from functools import partial
|
| 9 |
+
from scipy import interpolate
|
| 10 |
+
from math import pi
|
| 11 |
+
from einops import rearrange, repeat
|
| 12 |
+
import warnings
|
| 13 |
+
from PIL import Image
|
| 14 |
+
import torch.utils.checkpoint as cp
|
| 15 |
+
from transformers import CLIPImageProcessor
|
| 16 |
+
# from ..utils.attention import FlashAttention, FlashMHA
|
| 17 |
+
# try:
|
| 18 |
+
# import xformers.ops as xops
|
| 19 |
+
# except:
|
| 20 |
+
# pass
|
| 21 |
+
|
| 22 |
+
logger = logging.getLogger(__name__)
|
| 23 |
+
BatchNorm2d = torch.nn.BatchNorm2d
|
| 24 |
+
|
| 25 |
+
class Conv2d(torch.nn.Conv2d):
|
| 26 |
+
"""
|
| 27 |
+
A wrapper around :class:`torch.nn.Conv2d` to support empty inputs and more features.
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
def __init__(self, *args, **kwargs):
|
| 31 |
+
"""
|
| 32 |
+
Extra keyword arguments supported in addition to those in `torch.nn.Conv2d`:
|
| 33 |
+
Args:
|
| 34 |
+
norm (nn.Module, optional): a normalization layer
|
| 35 |
+
activation (callable(Tensor) -> Tensor): a callable activation function
|
| 36 |
+
It assumes that norm layer is used before activation.
|
| 37 |
+
"""
|
| 38 |
+
norm = kwargs.pop("norm", None)
|
| 39 |
+
activation = kwargs.pop("activation", None)
|
| 40 |
+
super().__init__(*args, **kwargs)
|
| 41 |
+
|
| 42 |
+
self.norm = norm
|
| 43 |
+
self.activation = activation
|
| 44 |
+
|
| 45 |
+
def forward(self, x):
|
| 46 |
+
# torchscript does not support SyncBatchNorm yet
|
| 47 |
+
# https://github.com/pytorch/pytorch/issues/40507
|
| 48 |
+
# and we skip these codes in torchscript since:
|
| 49 |
+
# 1. currently we only support torchscript in evaluation mode
|
| 50 |
+
# 2. features needed by exporting module to torchscript are added in PyTorch 1.6 or
|
| 51 |
+
# later version, `Conv2d` in these PyTorch versions has already supported empty inputs.
|
| 52 |
+
if not torch.jit.is_scripting():
|
| 53 |
+
with warnings.catch_warnings(record=True):
|
| 54 |
+
if x.numel() == 0 and self.training:
|
| 55 |
+
# https://github.com/pytorch/pytorch/issues/12013
|
| 56 |
+
assert not isinstance(
|
| 57 |
+
self.norm, torch.nn.SyncBatchNorm
|
| 58 |
+
), "SyncBatchNorm does not support empty inputs!"
|
| 59 |
+
|
| 60 |
+
x = F.conv2d(
|
| 61 |
+
x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups
|
| 62 |
+
)
|
| 63 |
+
if self.norm is not None:
|
| 64 |
+
x = self.norm(x)
|
| 65 |
+
if self.activation is not None:
|
| 66 |
+
x = self.activation(x)
|
| 67 |
+
return x
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def window_partition(x, window_size):
|
| 71 |
+
"""
|
| 72 |
+
Partition into non-overlapping windows with padding if needed.
|
| 73 |
+
Args:
|
| 74 |
+
x (tensor): input tokens with [B, H, W, C].
|
| 75 |
+
window_size (int): window size.
|
| 76 |
+
Returns:
|
| 77 |
+
windows: windows after partition with [B * num_windows, window_size, window_size, C].
|
| 78 |
+
(Hp, Wp): padded height and width before partition
|
| 79 |
+
"""
|
| 80 |
+
B, H, W, C = x.shape
|
| 81 |
+
|
| 82 |
+
pad_h = (window_size - H % window_size) % window_size
|
| 83 |
+
pad_w = (window_size - W % window_size) % window_size
|
| 84 |
+
if pad_h > 0 or pad_w > 0:
|
| 85 |
+
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))
|
| 86 |
+
Hp, Wp = H + pad_h, W + pad_w
|
| 87 |
+
|
| 88 |
+
x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C)
|
| 89 |
+
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
|
| 90 |
+
return windows, (Hp, Wp)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def window_unpartition(windows, window_size, pad_hw, hw):
|
| 94 |
+
"""
|
| 95 |
+
Window unpartition into original sequences and removing padding.
|
| 96 |
+
Args:
|
| 97 |
+
x (tensor): input tokens with [B * num_windows, window_size, window_size, C].
|
| 98 |
+
window_size (int): window size.
|
| 99 |
+
pad_hw (Tuple): padded height and width (Hp, Wp).
|
| 100 |
+
hw (Tuple): original height and width (H, W) before padding.
|
| 101 |
+
Returns:
|
| 102 |
+
x: unpartitioned sequences with [B, H, W, C].
|
| 103 |
+
"""
|
| 104 |
+
Hp, Wp = pad_hw
|
| 105 |
+
H, W = hw
|
| 106 |
+
B = windows.shape[0] // (Hp * Wp // window_size // window_size)
|
| 107 |
+
x = windows.view(B, Hp // window_size, Wp // window_size, window_size, window_size, -1)
|
| 108 |
+
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1)
|
| 109 |
+
|
| 110 |
+
if Hp > H or Wp > W:
|
| 111 |
+
x = x[:, :H, :W, :].contiguous()
|
| 112 |
+
return x
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def get_rel_pos(q_size, k_size, rel_pos):
|
| 116 |
+
"""
|
| 117 |
+
Get relative positional embeddings according to the relative positions of
|
| 118 |
+
query and key sizes.
|
| 119 |
+
Args:
|
| 120 |
+
q_size (int): size of query q.
|
| 121 |
+
k_size (int): size of key k.
|
| 122 |
+
rel_pos (Tensor): relative position embeddings (L, C).
|
| 123 |
+
Returns:
|
| 124 |
+
Extracted positional embeddings according to relative positions.
|
| 125 |
+
"""
|
| 126 |
+
max_rel_dist = int(2 * max(q_size, k_size) - 1)
|
| 127 |
+
use_log_interpolation = True
|
| 128 |
+
|
| 129 |
+
# Interpolate rel pos if needed.
|
| 130 |
+
if rel_pos.shape[0] != max_rel_dist:
|
| 131 |
+
if not use_log_interpolation:
|
| 132 |
+
# Interpolate rel pos.
|
| 133 |
+
rel_pos_resized = F.interpolate(
|
| 134 |
+
rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1),
|
| 135 |
+
size=max_rel_dist,
|
| 136 |
+
mode="linear",
|
| 137 |
+
)
|
| 138 |
+
rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0)
|
| 139 |
+
else:
|
| 140 |
+
src_size = rel_pos.shape[0]
|
| 141 |
+
dst_size = max_rel_dist
|
| 142 |
+
|
| 143 |
+
# q = 1.13492
|
| 144 |
+
q = 1.0903078
|
| 145 |
+
dis = []
|
| 146 |
+
|
| 147 |
+
cur = 1
|
| 148 |
+
for i in range(src_size // 2):
|
| 149 |
+
dis.append(cur)
|
| 150 |
+
cur += q ** (i + 1)
|
| 151 |
+
|
| 152 |
+
r_ids = [-_ for _ in reversed(dis)]
|
| 153 |
+
x = r_ids + [0] + dis
|
| 154 |
+
t = dst_size // 2.0
|
| 155 |
+
dx = np.arange(-t, t + 0.1, 1.0)
|
| 156 |
+
all_rel_pos_bias = []
|
| 157 |
+
for i in range(rel_pos.shape[1]):
|
| 158 |
+
z = rel_pos[:, i].view(src_size).cpu().float().numpy()
|
| 159 |
+
f = interpolate.interp1d(x, z, kind='cubic', fill_value="extrapolate")
|
| 160 |
+
all_rel_pos_bias.append(
|
| 161 |
+
torch.Tensor(f(dx)).contiguous().view(-1, 1).to(rel_pos.device))
|
| 162 |
+
rel_pos_resized = torch.cat(all_rel_pos_bias, dim=-1)
|
| 163 |
+
else:
|
| 164 |
+
rel_pos_resized = rel_pos
|
| 165 |
+
|
| 166 |
+
# Scale the coords with short length if shapes for q and k are different.
|
| 167 |
+
q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)
|
| 168 |
+
k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)
|
| 169 |
+
relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0)
|
| 170 |
+
|
| 171 |
+
return rel_pos_resized[relative_coords.long()]
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def add_decomposed_rel_pos(attn, q, rel_pos_h, rel_pos_w, q_size, k_size):
|
| 175 |
+
"""
|
| 176 |
+
Calculate decomposed Relative Positional Embeddings from :paper:`mvitv2`.
|
| 177 |
+
https://github.com/facebookresearch/mvit/blob/19786631e330df9f3622e5402b4a419a263a2c80/mvit/models/attention.py # noqa B950
|
| 178 |
+
Args:
|
| 179 |
+
attn (Tensor): attention map.
|
| 180 |
+
q (Tensor): query q in the attention layer with shape (B, q_h * q_w, C).
|
| 181 |
+
rel_pos_h (Tensor): relative position embeddings (Lh, C) for height axis.
|
| 182 |
+
rel_pos_w (Tensor): relative position embeddings (Lw, C) for width axis.
|
| 183 |
+
q_size (Tuple): spatial sequence size of query q with (q_h, q_w).
|
| 184 |
+
k_size (Tuple): spatial sequence size of key k with (k_h, k_w).
|
| 185 |
+
Returns:
|
| 186 |
+
attn (Tensor): attention map with added relative positional embeddings.
|
| 187 |
+
"""
|
| 188 |
+
q_h, q_w = q_size
|
| 189 |
+
k_h, k_w = k_size
|
| 190 |
+
Rh = get_rel_pos(q_h, k_h, rel_pos_h)
|
| 191 |
+
Rw = get_rel_pos(q_w, k_w, rel_pos_w)
|
| 192 |
+
|
| 193 |
+
B, _, dim = q.shape
|
| 194 |
+
r_q = q.reshape(B, q_h, q_w, dim)
|
| 195 |
+
rel_h = torch.einsum("bhwc,hkc->bhwk", r_q, Rh)
|
| 196 |
+
rel_w = torch.einsum("bhwc,wkc->bhwk", r_q, Rw)
|
| 197 |
+
|
| 198 |
+
attn = (
|
| 199 |
+
attn.view(B, q_h, q_w, k_h, k_w) + rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :]
|
| 200 |
+
).view(B, q_h * q_w, k_h * k_w)
|
| 201 |
+
|
| 202 |
+
return attn
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
def get_abs_pos(abs_pos, has_cls_token, hw):
|
| 206 |
+
"""
|
| 207 |
+
Calculate absolute positional embeddings. If needed, resize embeddings and remove cls_token
|
| 208 |
+
dimension for the original embeddings.
|
| 209 |
+
Args:
|
| 210 |
+
abs_pos (Tensor): absolute positional embeddings with (1, num_position, C).
|
| 211 |
+
has_cls_token (bool): If true, has 1 embedding in abs_pos for cls token.
|
| 212 |
+
hw (Tuple): size of input image tokens.
|
| 213 |
+
Returns:
|
| 214 |
+
Absolute positional embeddings after processing with shape (1, H, W, C)
|
| 215 |
+
"""
|
| 216 |
+
h, w = hw
|
| 217 |
+
if has_cls_token:
|
| 218 |
+
abs_pos = abs_pos[:, 1:]
|
| 219 |
+
xy_num = abs_pos.shape[1]
|
| 220 |
+
size = int(math.sqrt(xy_num))
|
| 221 |
+
assert size * size == xy_num
|
| 222 |
+
|
| 223 |
+
if size != h or size != w:
|
| 224 |
+
original_datatype = abs_pos.dtype
|
| 225 |
+
new_abs_pos = F.interpolate(
|
| 226 |
+
abs_pos.reshape(1, size, size, -1).permute(0, 3, 1, 2).float(), # bf16 is not implemented
|
| 227 |
+
size=(h, w),
|
| 228 |
+
mode="bicubic",
|
| 229 |
+
align_corners=False,
|
| 230 |
+
).to(original_datatype)
|
| 231 |
+
|
| 232 |
+
return new_abs_pos.permute(0, 2, 3, 1)
|
| 233 |
+
else:
|
| 234 |
+
return abs_pos.reshape(1, h, w, -1)
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
class PatchEmbed(nn.Module):
|
| 238 |
+
"""
|
| 239 |
+
Image to Patch Embedding.
|
| 240 |
+
"""
|
| 241 |
+
|
| 242 |
+
def __init__(
|
| 243 |
+
self, kernel_size=(16, 16), stride=(16, 16), padding=(0, 0), in_chans=3, embed_dim=768
|
| 244 |
+
):
|
| 245 |
+
"""
|
| 246 |
+
Args:
|
| 247 |
+
kernel_size (Tuple): kernel size of the projection layer.
|
| 248 |
+
stride (Tuple): stride of the projection layer.
|
| 249 |
+
padding (Tuple): padding size of the projection layer.
|
| 250 |
+
in_chans (int): Number of input image channels.
|
| 251 |
+
embed_dim (int): embed_dim (int): Patch embedding dimension.
|
| 252 |
+
"""
|
| 253 |
+
super().__init__()
|
| 254 |
+
|
| 255 |
+
self.proj = nn.Conv2d(
|
| 256 |
+
in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
def forward(self, x):
|
| 260 |
+
x = self.proj(x)
|
| 261 |
+
# B C H W -> B H W C
|
| 262 |
+
x = x.permute(0, 2, 3, 1)
|
| 263 |
+
return x
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
def broadcat(tensors, dim = -1):
|
| 267 |
+
num_tensors = len(tensors)
|
| 268 |
+
shape_lens = set(list(map(lambda t: len(t.shape), tensors)))
|
| 269 |
+
assert len(shape_lens) == 1, 'tensors must all have the same number of dimensions'
|
| 270 |
+
shape_len = list(shape_lens)[0]
|
| 271 |
+
dim = (dim + shape_len) if dim < 0 else dim
|
| 272 |
+
dims = list(zip(*map(lambda t: list(t.shape), tensors)))
|
| 273 |
+
expandable_dims = [(i, val) for i, val in enumerate(dims) if i != dim]
|
| 274 |
+
assert all([*map(lambda t: len(set(t[1])) <= 2, expandable_dims)]), 'invalid dimensions for broadcastable concatentation'
|
| 275 |
+
max_dims = list(map(lambda t: (t[0], max(t[1])), expandable_dims))
|
| 276 |
+
expanded_dims = list(map(lambda t: (t[0], (t[1],) * num_tensors), max_dims))
|
| 277 |
+
expanded_dims.insert(dim, (dim, dims[dim]))
|
| 278 |
+
expandable_shapes = list(zip(*map(lambda t: t[1], expanded_dims)))
|
| 279 |
+
tensors = list(map(lambda t: t[0].expand(*t[1]), zip(tensors, expandable_shapes)))
|
| 280 |
+
return torch.cat(tensors, dim = dim)
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
def rotate_half(x):
|
| 285 |
+
x = rearrange(x, '... (d r) -> ... d r', r = 2)
|
| 286 |
+
x1, x2 = x.unbind(dim = -1)
|
| 287 |
+
x = torch.stack((-x2, x1), dim = -1)
|
| 288 |
+
return rearrange(x, '... d r -> ... (d r)')
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
class VisionRotaryEmbedding(nn.Module):
|
| 293 |
+
def __init__(
|
| 294 |
+
self,
|
| 295 |
+
dim,
|
| 296 |
+
pt_seq_len,
|
| 297 |
+
ft_seq_len=None,
|
| 298 |
+
custom_freqs = None,
|
| 299 |
+
freqs_for = 'lang',
|
| 300 |
+
theta = 10000,
|
| 301 |
+
max_freq = 10,
|
| 302 |
+
num_freqs = 1,
|
| 303 |
+
):
|
| 304 |
+
super().__init__()
|
| 305 |
+
if custom_freqs:
|
| 306 |
+
freqs = custom_freqs
|
| 307 |
+
elif freqs_for == 'lang':
|
| 308 |
+
freqs = 1. / (theta ** (torch.arange(0, dim, 2)[:(dim // 2)].float() / dim))
|
| 309 |
+
elif freqs_for == 'pixel':
|
| 310 |
+
freqs = torch.linspace(1., max_freq / 2, dim // 2) * pi
|
| 311 |
+
elif freqs_for == 'constant':
|
| 312 |
+
freqs = torch.ones(num_freqs).float()
|
| 313 |
+
else:
|
| 314 |
+
raise ValueError(f'unknown modality {freqs_for}')
|
| 315 |
+
|
| 316 |
+
if ft_seq_len is None: ft_seq_len = pt_seq_len
|
| 317 |
+
t = torch.arange(ft_seq_len) / ft_seq_len * pt_seq_len
|
| 318 |
+
|
| 319 |
+
freqs_h = torch.einsum('..., f -> ... f', t, freqs)
|
| 320 |
+
freqs_h = repeat(freqs_h, '... n -> ... (n r)', r = 2)
|
| 321 |
+
|
| 322 |
+
freqs_w = torch.einsum('..., f -> ... f', t, freqs)
|
| 323 |
+
freqs_w = repeat(freqs_w, '... n -> ... (n r)', r = 2)
|
| 324 |
+
|
| 325 |
+
freqs = broadcat((freqs_h[:, None, :], freqs_w[None, :, :]), dim = -1)
|
| 326 |
+
|
| 327 |
+
self.register_buffer("freqs_cos", freqs.cos())
|
| 328 |
+
self.register_buffer("freqs_sin", freqs.sin())
|
| 329 |
+
|
| 330 |
+
# print('======== shape of rope freq', self.freqs_cos.shape, '========')
|
| 331 |
+
|
| 332 |
+
def forward(self, t, start_index = 0):
|
| 333 |
+
rot_dim = self.freqs_cos.shape[-1]
|
| 334 |
+
end_index = start_index + rot_dim
|
| 335 |
+
assert rot_dim <= t.shape[-1], f'feature dimension {t.shape[-1]} is not of sufficient size to rotate in all the positions {rot_dim}'
|
| 336 |
+
t_left, t, t_right = t[..., :start_index], t[..., start_index:end_index], t[..., end_index:]
|
| 337 |
+
t = (t * self.freqs_cos) + (rotate_half(t) * self.freqs_sin)
|
| 338 |
+
return torch.cat((t_left, t, t_right), dim = -1)
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
|
| 343 |
+
class VisionRotaryEmbeddingFast(nn.Module):
|
| 344 |
+
def __init__(
|
| 345 |
+
self,
|
| 346 |
+
dim,
|
| 347 |
+
pt_seq_len=16,
|
| 348 |
+
ft_seq_len=None,
|
| 349 |
+
custom_freqs = None,
|
| 350 |
+
freqs_for = 'lang',
|
| 351 |
+
theta = 10000,
|
| 352 |
+
max_freq = 10,
|
| 353 |
+
num_freqs = 1,
|
| 354 |
+
):
|
| 355 |
+
super().__init__()
|
| 356 |
+
if custom_freqs:
|
| 357 |
+
freqs = custom_freqs
|
| 358 |
+
elif freqs_for == 'lang':
|
| 359 |
+
freqs = 1. / (theta ** (torch.arange(0, dim, 2)[:(dim // 2)].float() / dim))
|
| 360 |
+
elif freqs_for == 'pixel':
|
| 361 |
+
freqs = torch.linspace(1., max_freq / 2, dim // 2) * pi
|
| 362 |
+
elif freqs_for == 'constant':
|
| 363 |
+
freqs = torch.ones(num_freqs).float()
|
| 364 |
+
else:
|
| 365 |
+
raise ValueError(f'unknown modality {freqs_for}')
|
| 366 |
+
|
| 367 |
+
if ft_seq_len is None: ft_seq_len = pt_seq_len
|
| 368 |
+
t = torch.arange(ft_seq_len) / ft_seq_len * pt_seq_len
|
| 369 |
+
|
| 370 |
+
freqs = torch.einsum('..., f -> ... f', t, freqs)
|
| 371 |
+
freqs = repeat(freqs, '... n -> ... (n r)', r = 2)
|
| 372 |
+
freqs = broadcat((freqs[:, None, :], freqs[None, :, :]), dim = -1)
|
| 373 |
+
|
| 374 |
+
freqs_cos = freqs.cos().view(-1, freqs.shape[-1])
|
| 375 |
+
freqs_sin = freqs.sin().view(-1, freqs.shape[-1])
|
| 376 |
+
|
| 377 |
+
self.register_buffer("freqs_cos", freqs_cos)
|
| 378 |
+
self.register_buffer("freqs_sin", freqs_sin)
|
| 379 |
+
|
| 380 |
+
# print('======== shape of rope freq', self.freqs_cos.shape, '========')
|
| 381 |
+
|
| 382 |
+
def forward(self, t): return t * self.freqs_cos + rotate_half(t) * self.freqs_sin
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
class FrozenBatchNorm2d(nn.Module):
|
| 386 |
+
"""
|
| 387 |
+
BatchNorm2d where the batch statistics and the affine parameters are fixed.
|
| 388 |
+
It contains non-trainable buffers called
|
| 389 |
+
"weight" and "bias", "running_mean", "running_var",
|
| 390 |
+
initialized to perform identity transformation.
|
| 391 |
+
The pre-trained backbone models from Caffe2 only contain "weight" and "bias",
|
| 392 |
+
which are computed from the original four parameters of BN.
|
| 393 |
+
The affine transform `x * weight + bias` will perform the equivalent
|
| 394 |
+
computation of `(x - running_mean) / sqrt(running_var) * weight + bias`.
|
| 395 |
+
When loading a backbone model from Caffe2, "running_mean" and "running_var"
|
| 396 |
+
will be left unchanged as identity transformation.
|
| 397 |
+
Other pre-trained backbone models may contain all 4 parameters.
|
| 398 |
+
The forward is implemented by `F.batch_norm(..., training=False)`.
|
| 399 |
+
"""
|
| 400 |
+
|
| 401 |
+
_version = 3
|
| 402 |
+
|
| 403 |
+
def __init__(self, num_features, eps=1e-5):
|
| 404 |
+
super().__init__()
|
| 405 |
+
self.num_features = num_features
|
| 406 |
+
self.eps = eps
|
| 407 |
+
self.register_buffer("weight", torch.ones(num_features))
|
| 408 |
+
self.register_buffer("bias", torch.zeros(num_features))
|
| 409 |
+
self.register_buffer("running_mean", torch.zeros(num_features))
|
| 410 |
+
self.register_buffer("running_var", torch.ones(num_features) - eps)
|
| 411 |
+
|
| 412 |
+
def forward(self, x):
|
| 413 |
+
if x.requires_grad:
|
| 414 |
+
# When gradients are needed, F.batch_norm will use extra memory
|
| 415 |
+
# because its backward op computes gradients for weight/bias as well.
|
| 416 |
+
scale = self.weight * (self.running_var + self.eps).rsqrt()
|
| 417 |
+
bias = self.bias - self.running_mean * scale
|
| 418 |
+
scale = scale.reshape(1, -1, 1, 1)
|
| 419 |
+
bias = bias.reshape(1, -1, 1, 1)
|
| 420 |
+
out_dtype = x.dtype # may be half
|
| 421 |
+
return x * scale.to(out_dtype) + bias.to(out_dtype)
|
| 422 |
+
else:
|
| 423 |
+
# When gradients are not needed, F.batch_norm is a single fused op
|
| 424 |
+
# and provide more optimization opportunities.
|
| 425 |
+
return F.batch_norm(
|
| 426 |
+
x,
|
| 427 |
+
self.running_mean,
|
| 428 |
+
self.running_var,
|
| 429 |
+
self.weight,
|
| 430 |
+
self.bias,
|
| 431 |
+
training=False,
|
| 432 |
+
eps=self.eps,
|
| 433 |
+
)
|
| 434 |
+
|
| 435 |
+
def _load_from_state_dict(
|
| 436 |
+
self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
|
| 437 |
+
):
|
| 438 |
+
version = local_metadata.get("version", None)
|
| 439 |
+
|
| 440 |
+
if version is None or version < 2:
|
| 441 |
+
# No running_mean/var in early versions
|
| 442 |
+
# This will silent the warnings
|
| 443 |
+
if prefix + "running_mean" not in state_dict:
|
| 444 |
+
state_dict[prefix + "running_mean"] = torch.zeros_like(self.running_mean)
|
| 445 |
+
if prefix + "running_var" not in state_dict:
|
| 446 |
+
state_dict[prefix + "running_var"] = torch.ones_like(self.running_var)
|
| 447 |
+
|
| 448 |
+
super()._load_from_state_dict(
|
| 449 |
+
state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
|
| 450 |
+
)
|
| 451 |
+
|
| 452 |
+
def __repr__(self):
|
| 453 |
+
return "FrozenBatchNorm2d(num_features={}, eps={})".format(self.num_features, self.eps)
|
| 454 |
+
|
| 455 |
+
@classmethod
|
| 456 |
+
def convert_frozen_batchnorm(cls, module):
|
| 457 |
+
"""
|
| 458 |
+
Convert all BatchNorm/SyncBatchNorm in module into FrozenBatchNorm.
|
| 459 |
+
Args:
|
| 460 |
+
module (torch.nn.Module):
|
| 461 |
+
Returns:
|
| 462 |
+
If module is BatchNorm/SyncBatchNorm, returns a new module.
|
| 463 |
+
Otherwise, in-place convert module and return it.
|
| 464 |
+
Similar to convert_sync_batchnorm in
|
| 465 |
+
https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/batchnorm.py
|
| 466 |
+
"""
|
| 467 |
+
bn_module = nn.modules.batchnorm
|
| 468 |
+
bn_module = (bn_module.BatchNorm2d, bn_module.SyncBatchNorm)
|
| 469 |
+
res = module
|
| 470 |
+
if isinstance(module, bn_module):
|
| 471 |
+
res = cls(module.num_features)
|
| 472 |
+
if module.affine:
|
| 473 |
+
res.weight.data = module.weight.data.clone().detach()
|
| 474 |
+
res.bias.data = module.bias.data.clone().detach()
|
| 475 |
+
res.running_mean.data = module.running_mean.data
|
| 476 |
+
res.running_var.data = module.running_var.data
|
| 477 |
+
res.eps = module.eps
|
| 478 |
+
else:
|
| 479 |
+
for name, child in module.named_children():
|
| 480 |
+
new_child = cls.convert_frozen_batchnorm(child)
|
| 481 |
+
if new_child is not child:
|
| 482 |
+
res.add_module(name, new_child)
|
| 483 |
+
return res
|
| 484 |
+
|
| 485 |
+
class LayerNorm(nn.Module):
|
| 486 |
+
"""
|
| 487 |
+
A LayerNorm variant, popularized by Transformers, that performs point-wise mean and
|
| 488 |
+
variance normalization over the channel dimension for inputs that have shape
|
| 489 |
+
(batch_size, channels, height, width).
|
| 490 |
+
https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py#L119 # noqa B950
|
| 491 |
+
"""
|
| 492 |
+
|
| 493 |
+
def __init__(self, normalized_shape, eps=1e-6):
|
| 494 |
+
super().__init__()
|
| 495 |
+
self.weight = nn.Parameter(torch.ones(normalized_shape))
|
| 496 |
+
self.bias = nn.Parameter(torch.zeros(normalized_shape))
|
| 497 |
+
self.eps = eps
|
| 498 |
+
self.normalized_shape = (normalized_shape,)
|
| 499 |
+
|
| 500 |
+
def forward(self, x):
|
| 501 |
+
u = x.mean(1, keepdim=True)
|
| 502 |
+
s = (x - u).pow(2).mean(1, keepdim=True)
|
| 503 |
+
x = (x - u) / torch.sqrt(s + self.eps)
|
| 504 |
+
x = self.weight[:, None, None] * x + self.bias[:, None, None]
|
| 505 |
+
return x
|
| 506 |
+
|
| 507 |
+
|
| 508 |
+
class CNNBlockBase(nn.Module):
|
| 509 |
+
"""
|
| 510 |
+
A CNN block is assumed to have input channels, output channels and a stride.
|
| 511 |
+
The input and output of `forward()` method must be NCHW tensors.
|
| 512 |
+
The method can perform arbitrary computation but must match the given
|
| 513 |
+
channels and stride specification.
|
| 514 |
+
Attribute:
|
| 515 |
+
in_channels (int):
|
| 516 |
+
out_channels (int):
|
| 517 |
+
stride (int):
|
| 518 |
+
"""
|
| 519 |
+
|
| 520 |
+
def __init__(self, in_channels, out_channels, stride):
|
| 521 |
+
"""
|
| 522 |
+
The `__init__` method of any subclass should also contain these arguments.
|
| 523 |
+
Args:
|
| 524 |
+
in_channels (int):
|
| 525 |
+
out_channels (int):
|
| 526 |
+
stride (int):
|
| 527 |
+
"""
|
| 528 |
+
super().__init__()
|
| 529 |
+
self.in_channels = in_channels
|
| 530 |
+
self.out_channels = out_channels
|
| 531 |
+
self.stride = stride
|
| 532 |
+
|
| 533 |
+
def freeze(self):
|
| 534 |
+
"""
|
| 535 |
+
Make this block not trainable.
|
| 536 |
+
This method sets all parameters to `requires_grad=False`,
|
| 537 |
+
and convert all BatchNorm layers to FrozenBatchNorm
|
| 538 |
+
Returns:
|
| 539 |
+
the block itself
|
| 540 |
+
"""
|
| 541 |
+
for p in self.parameters():
|
| 542 |
+
p.requires_grad = False
|
| 543 |
+
FrozenBatchNorm2d.convert_frozen_batchnorm(self)
|
| 544 |
+
return self
|
| 545 |
+
|
| 546 |
+
def get_norm(norm, out_channels):
|
| 547 |
+
"""
|
| 548 |
+
Args:
|
| 549 |
+
norm (str or callable): either one of BN, SyncBN, FrozenBN, GN;
|
| 550 |
+
or a callable that takes a channel number and returns
|
| 551 |
+
the normalization layer as a nn.Module.
|
| 552 |
+
Returns:
|
| 553 |
+
nn.Module or None: the normalization layer
|
| 554 |
+
"""
|
| 555 |
+
if norm is None:
|
| 556 |
+
return None
|
| 557 |
+
if isinstance(norm, str):
|
| 558 |
+
if len(norm) == 0:
|
| 559 |
+
return None
|
| 560 |
+
norm = {
|
| 561 |
+
"BN": BatchNorm2d,
|
| 562 |
+
# Fixed in https://github.com/pytorch/pytorch/pull/36382
|
| 563 |
+
"SyncBN": nn.SyncBatchNorm,
|
| 564 |
+
"FrozenBN": FrozenBatchNorm2d,
|
| 565 |
+
"GN": lambda channels: nn.GroupNorm(32, channels),
|
| 566 |
+
# for debugging:
|
| 567 |
+
"nnSyncBN": nn.SyncBatchNorm,
|
| 568 |
+
"LN": lambda channels: LayerNorm(channels)
|
| 569 |
+
}[norm]
|
| 570 |
+
return norm(out_channels)
|
| 571 |
+
|
| 572 |
+
class DropPath(nn.Module):
|
| 573 |
+
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
|
| 574 |
+
"""
|
| 575 |
+
|
| 576 |
+
def __init__(self, drop_prob=None):
|
| 577 |
+
super(DropPath, self).__init__()
|
| 578 |
+
self.drop_prob = drop_prob
|
| 579 |
+
|
| 580 |
+
def forward(self, x):
|
| 581 |
+
if self.drop_prob == 0. or not self.training:
|
| 582 |
+
return x
|
| 583 |
+
keep_prob = 1 - self.drop_prob
|
| 584 |
+
# work with diff dim tensors, not just 2D ConvNets
|
| 585 |
+
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
|
| 586 |
+
random_tensor = keep_prob + \
|
| 587 |
+
torch.rand(shape, dtype=x.dtype, device=x.device)
|
| 588 |
+
random_tensor.floor_() # binarize
|
| 589 |
+
output = x.div(keep_prob) * random_tensor
|
| 590 |
+
return output
|
| 591 |
+
|
| 592 |
+
|
| 593 |
+
|
| 594 |
+
class SwiGLU(nn.Module):
|
| 595 |
+
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.,
|
| 596 |
+
norm_layer=nn.LayerNorm, subln=False
|
| 597 |
+
):
|
| 598 |
+
super().__init__()
|
| 599 |
+
out_features = out_features or in_features
|
| 600 |
+
hidden_features = hidden_features or in_features
|
| 601 |
+
|
| 602 |
+
self.w1 = nn.Linear(in_features, hidden_features)
|
| 603 |
+
self.w2 = nn.Linear(in_features, hidden_features)
|
| 604 |
+
|
| 605 |
+
self.act = act_layer()
|
| 606 |
+
self.ffn_ln = norm_layer(hidden_features) if subln else nn.Identity()
|
| 607 |
+
self.w3 = nn.Linear(hidden_features, out_features)
|
| 608 |
+
|
| 609 |
+
self.drop = nn.Dropout(drop)
|
| 610 |
+
|
| 611 |
+
def forward(self, x):
|
| 612 |
+
x1 = self.w1(x)
|
| 613 |
+
x2 = self.w2(x)
|
| 614 |
+
hidden = self.act(x1) * x2
|
| 615 |
+
x = self.ffn_ln(hidden)
|
| 616 |
+
x = self.w3(x)
|
| 617 |
+
x = self.drop(x)
|
| 618 |
+
return x
|
| 619 |
+
|
| 620 |
+
|
| 621 |
+
class Attention(nn.Module):
|
| 622 |
+
def __init__(
|
| 623 |
+
self,
|
| 624 |
+
dim,
|
| 625 |
+
num_heads=8,
|
| 626 |
+
qkv_bias=True,
|
| 627 |
+
qk_scale=None,
|
| 628 |
+
attn_head_dim=None,
|
| 629 |
+
norm_layer=nn.LayerNorm,
|
| 630 |
+
rope=None,
|
| 631 |
+
xattn=True,
|
| 632 |
+
subln=False
|
| 633 |
+
):
|
| 634 |
+
super().__init__()
|
| 635 |
+
self.num_heads = num_heads
|
| 636 |
+
head_dim = dim // num_heads
|
| 637 |
+
if attn_head_dim is not None:
|
| 638 |
+
head_dim = attn_head_dim
|
| 639 |
+
all_head_dim = head_dim * self.num_heads
|
| 640 |
+
self.scale = qk_scale or head_dim ** -0.5
|
| 641 |
+
|
| 642 |
+
self.subln = subln
|
| 643 |
+
self.q_proj = nn.Linear(dim, all_head_dim, bias=False)
|
| 644 |
+
self.k_proj = nn.Linear(dim, all_head_dim, bias=False)
|
| 645 |
+
self.v_proj = nn.Linear(dim, all_head_dim, bias=False)
|
| 646 |
+
|
| 647 |
+
if qkv_bias:
|
| 648 |
+
self.q_bias = nn.Parameter(torch.zeros(all_head_dim))
|
| 649 |
+
self.v_bias = nn.Parameter(torch.zeros(all_head_dim))
|
| 650 |
+
else:
|
| 651 |
+
self.q_bias = None
|
| 652 |
+
self.v_bias = None
|
| 653 |
+
|
| 654 |
+
self.rope = rope
|
| 655 |
+
self.xattn = xattn
|
| 656 |
+
self.proj = nn.Linear(all_head_dim, dim)
|
| 657 |
+
self.inner_attn_ln = norm_layer(all_head_dim) if subln else nn.Identity()
|
| 658 |
+
|
| 659 |
+
if self.xattn:
|
| 660 |
+
factory_kwargs = {'device': 'cuda', 'dtype': torch.float16}
|
| 661 |
+
self.inner_attn = FlashAttention(attention_dropout=0.0, **factory_kwargs)
|
| 662 |
+
|
| 663 |
+
def forward(self, x):
|
| 664 |
+
B, H, W, C = x.shape
|
| 665 |
+
x = x.view(B, -1, C)
|
| 666 |
+
N = H * W
|
| 667 |
+
|
| 668 |
+
q = F.linear(input=x, weight=self.q_proj.weight, bias=self.q_bias)
|
| 669 |
+
k = F.linear(input=x, weight=self.k_proj.weight, bias=None)
|
| 670 |
+
v = F.linear(input=x, weight=self.v_proj.weight, bias=self.v_bias)
|
| 671 |
+
|
| 672 |
+
q = q.reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3) # B, num_heads, N, C
|
| 673 |
+
k = k.reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
|
| 674 |
+
v = v.reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
|
| 675 |
+
|
| 676 |
+
## rope
|
| 677 |
+
q = self.rope(q).type_as(v)
|
| 678 |
+
k = self.rope(k).type_as(v)
|
| 679 |
+
|
| 680 |
+
if self.xattn:
|
| 681 |
+
q = q.permute(0, 2, 1, 3) # B, num_heads, N, C -> B, N, num_heads, C
|
| 682 |
+
k = k.permute(0, 2, 1, 3)
|
| 683 |
+
v = v.permute(0, 2, 1, 3)
|
| 684 |
+
|
| 685 |
+
kv = torch.stack([k, v], dim=2)
|
| 686 |
+
x, attn_weights = self.inner_attn(q, kv, key_padding_mask=None, causal=False)
|
| 687 |
+
# x = xops.memory_efficient_attention(q, k, v)
|
| 688 |
+
x = x.reshape(B, N, -1)
|
| 689 |
+
x = self.inner_attn_ln(x)
|
| 690 |
+
else:
|
| 691 |
+
q = q * self.scale
|
| 692 |
+
attn = (q @ k.transpose(-2, -1))
|
| 693 |
+
attn = attn.softmax(dim=-1).type_as(x)
|
| 694 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
|
| 695 |
+
x = self.inner_attn_ln(x)
|
| 696 |
+
|
| 697 |
+
x = self.proj(x)
|
| 698 |
+
x = x.view(B, H, W, C)
|
| 699 |
+
|
| 700 |
+
return x
|
| 701 |
+
|
| 702 |
+
|
| 703 |
+
class ResBottleneckBlock(CNNBlockBase):
|
| 704 |
+
"""
|
| 705 |
+
The standard bottleneck residual block without the last activation layer.
|
| 706 |
+
It contains 3 conv layers with kernels 1x1, 3x3, 1x1.
|
| 707 |
+
"""
|
| 708 |
+
|
| 709 |
+
def __init__(
|
| 710 |
+
self,
|
| 711 |
+
in_channels,
|
| 712 |
+
out_channels,
|
| 713 |
+
bottleneck_channels,
|
| 714 |
+
norm="LN",
|
| 715 |
+
act_layer=nn.GELU,
|
| 716 |
+
):
|
| 717 |
+
"""
|
| 718 |
+
Args:
|
| 719 |
+
in_channels (int): Number of input channels.
|
| 720 |
+
out_channels (int): Number of output channels.
|
| 721 |
+
bottleneck_channels (int): number of output channels for the 3x3
|
| 722 |
+
"bottleneck" conv layers.
|
| 723 |
+
norm (str or callable): normalization for all conv layers.
|
| 724 |
+
See :func:`layers.get_norm` for supported format.
|
| 725 |
+
act_layer (callable): activation for all conv layers.
|
| 726 |
+
"""
|
| 727 |
+
super().__init__(in_channels, out_channels, 1)
|
| 728 |
+
|
| 729 |
+
self.conv1 = Conv2d(in_channels, bottleneck_channels, 1, bias=False)
|
| 730 |
+
self.norm1 = get_norm(norm, bottleneck_channels)
|
| 731 |
+
self.act1 = act_layer()
|
| 732 |
+
|
| 733 |
+
self.conv2 = Conv2d(
|
| 734 |
+
bottleneck_channels,
|
| 735 |
+
bottleneck_channels,
|
| 736 |
+
3,
|
| 737 |
+
padding=1,
|
| 738 |
+
bias=False,
|
| 739 |
+
)
|
| 740 |
+
self.norm2 = get_norm(norm, bottleneck_channels)
|
| 741 |
+
self.act2 = act_layer()
|
| 742 |
+
|
| 743 |
+
self.conv3 = Conv2d(bottleneck_channels, out_channels, 1, bias=False)
|
| 744 |
+
self.norm3 = get_norm(norm, out_channels)
|
| 745 |
+
|
| 746 |
+
for layer in [self.conv1, self.conv2, self.conv3]:
|
| 747 |
+
weight_init.c2_msra_fill(layer)
|
| 748 |
+
for layer in [self.norm1, self.norm2]:
|
| 749 |
+
layer.weight.data.fill_(1.0)
|
| 750 |
+
layer.bias.data.zero_()
|
| 751 |
+
# zero init last norm layer.
|
| 752 |
+
self.norm3.weight.data.zero_()
|
| 753 |
+
self.norm3.bias.data.zero_()
|
| 754 |
+
|
| 755 |
+
def forward(self, x):
|
| 756 |
+
out = x
|
| 757 |
+
for layer in self.children():
|
| 758 |
+
out = layer(out)
|
| 759 |
+
|
| 760 |
+
out = x + out
|
| 761 |
+
return out
|
| 762 |
+
|
| 763 |
+
|
| 764 |
+
class Block(nn.Module):
|
| 765 |
+
"""Transformer blocks with support of window attention and residual propagation blocks"""
|
| 766 |
+
|
| 767 |
+
def __init__(
|
| 768 |
+
self,
|
| 769 |
+
dim,
|
| 770 |
+
num_heads,
|
| 771 |
+
mlp_ratio=4*2/3,
|
| 772 |
+
qkv_bias=True,
|
| 773 |
+
drop_path=0.0,
|
| 774 |
+
norm_layer=partial(nn.LayerNorm, eps=1e-6),
|
| 775 |
+
window_size=0,
|
| 776 |
+
use_residual_block=False,
|
| 777 |
+
rope=None,
|
| 778 |
+
xattn=True,
|
| 779 |
+
subln=False,
|
| 780 |
+
# with_cp=True,
|
| 781 |
+
):
|
| 782 |
+
"""
|
| 783 |
+
Args:
|
| 784 |
+
dim (int): Number of input channels.
|
| 785 |
+
num_heads (int): Number of attention heads in each ViT block.
|
| 786 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 787 |
+
qkv_bias (bool): If True, add a learnable bias to query, key, value.
|
| 788 |
+
drop_path (float): Stochastic depth rate.
|
| 789 |
+
norm_layer (nn.Module): Normalization layer.
|
| 790 |
+
act_layer (nn.Module): Activation layer.
|
| 791 |
+
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
|
| 792 |
+
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
|
| 793 |
+
window_size (int): Window size for window attention blocks. If it equals 0, then not
|
| 794 |
+
use window attention.
|
| 795 |
+
use_residual_block (bool): If True, use a residual block after the MLP block.
|
| 796 |
+
input_size (int or None): Input resolution for calculating the relative positional
|
| 797 |
+
parameter size.
|
| 798 |
+
"""
|
| 799 |
+
super().__init__()
|
| 800 |
+
self.norm1 = norm_layer(dim)
|
| 801 |
+
self.attn = Attention(
|
| 802 |
+
dim,
|
| 803 |
+
num_heads=num_heads,
|
| 804 |
+
qkv_bias=qkv_bias,
|
| 805 |
+
rope=rope,
|
| 806 |
+
xattn=xattn,
|
| 807 |
+
subln=subln
|
| 808 |
+
)
|
| 809 |
+
|
| 810 |
+
|
| 811 |
+
# self.with_cp = with_cp
|
| 812 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 813 |
+
self.norm2 = norm_layer(dim)
|
| 814 |
+
self.mlp = SwiGLU(
|
| 815 |
+
in_features=dim,
|
| 816 |
+
hidden_features=int(dim * mlp_ratio),
|
| 817 |
+
subln=True,
|
| 818 |
+
norm_layer=norm_layer,
|
| 819 |
+
)
|
| 820 |
+
|
| 821 |
+
self.window_size = window_size
|
| 822 |
+
|
| 823 |
+
self.use_residual_block = use_residual_block
|
| 824 |
+
if use_residual_block:
|
| 825 |
+
# Use a residual block with bottleneck channel as dim // 2
|
| 826 |
+
self.residual = ResBottleneckBlock(
|
| 827 |
+
in_channels=dim,
|
| 828 |
+
out_channels=dim,
|
| 829 |
+
bottleneck_channels=dim // 2,
|
| 830 |
+
norm="LN",
|
| 831 |
+
)
|
| 832 |
+
|
| 833 |
+
def _forward(self, x):
|
| 834 |
+
shortcut = x
|
| 835 |
+
x = self.norm1(x)
|
| 836 |
+
|
| 837 |
+
# Window partition
|
| 838 |
+
if self.window_size > 0:
|
| 839 |
+
H, W = x.shape[1], x.shape[2]
|
| 840 |
+
x, pad_hw = window_partition(x, self.window_size)
|
| 841 |
+
|
| 842 |
+
x = self.attn(x)
|
| 843 |
+
|
| 844 |
+
# Reverse window partition
|
| 845 |
+
if self.window_size > 0:
|
| 846 |
+
x = window_unpartition(x, self.window_size, pad_hw, (H, W))
|
| 847 |
+
|
| 848 |
+
x = shortcut + self.drop_path(x)
|
| 849 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 850 |
+
|
| 851 |
+
if self.use_residual_block:
|
| 852 |
+
x = self.residual(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
|
| 853 |
+
|
| 854 |
+
return x
|
| 855 |
+
|
| 856 |
+
def forward(self, x, with_cp=False):
|
| 857 |
+
# if self.with_cp and self.training:
|
| 858 |
+
if with_cp:
|
| 859 |
+
x = cp.checkpoint(self._forward, x)
|
| 860 |
+
else:
|
| 861 |
+
x = self._forward(x)
|
| 862 |
+
return x
|
| 863 |
+
|
| 864 |
+
#@BACKBONES.register_module()
|
| 865 |
+
class EVAViT(nn.Module):
|
| 866 |
+
"""
|
| 867 |
+
This module implements Vision Transformer (ViT) backbone in :paper:`vitdet`.
|
| 868 |
+
"Exploring Plain Vision Transformer Backbones for Object Detection",
|
| 869 |
+
https://arxiv.org/abs/2203.16527
|
| 870 |
+
"""
|
| 871 |
+
|
| 872 |
+
def __init__(
|
| 873 |
+
self,
|
| 874 |
+
img_size=1024,
|
| 875 |
+
patch_size=16,
|
| 876 |
+
in_chans=3,
|
| 877 |
+
embed_dim=768,
|
| 878 |
+
depth=12,
|
| 879 |
+
num_heads=12,
|
| 880 |
+
mlp_ratio=4*2/3,
|
| 881 |
+
qkv_bias=True,
|
| 882 |
+
drop_path_rate=0.0,
|
| 883 |
+
norm_layer=partial(nn.LayerNorm, eps=1e-6),
|
| 884 |
+
act_layer=nn.GELU,
|
| 885 |
+
use_abs_pos=True,
|
| 886 |
+
use_rel_pos=False,
|
| 887 |
+
# sim_fpn=None,
|
| 888 |
+
rope=True,
|
| 889 |
+
pt_hw_seq_len=16,
|
| 890 |
+
intp_freq=True,
|
| 891 |
+
window_size=0,
|
| 892 |
+
global_window_size=0,
|
| 893 |
+
window_block_indexes=(),
|
| 894 |
+
residual_block_indexes=(),
|
| 895 |
+
pretrain_img_size=224,
|
| 896 |
+
pretrain_use_cls_token=True,
|
| 897 |
+
out_feature="last_feat",
|
| 898 |
+
subln=False,
|
| 899 |
+
xattn=True,
|
| 900 |
+
# with_cp=True,
|
| 901 |
+
frozen=False,
|
| 902 |
+
):
|
| 903 |
+
"""
|
| 904 |
+
Args:
|
| 905 |
+
img_size (int): Input image size.
|
| 906 |
+
patch_size (int): Patch size.
|
| 907 |
+
in_chans (int): Number of input image channels.
|
| 908 |
+
embed_dim (int): Patch embedding dimension.
|
| 909 |
+
depth (int): Depth of ViT.
|
| 910 |
+
num_heads (int): Number of attention heads in each ViT block.
|
| 911 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 912 |
+
qkv_bias (bool): If True, add a learnable bias to query, key, value.
|
| 913 |
+
drop_path_rate (float): Stochastic depth rate.
|
| 914 |
+
norm_layer (nn.Module): Normalization layer.
|
| 915 |
+
act_layer (nn.Module): Activation layer.
|
| 916 |
+
use_abs_pos (bool): If True, use absolute positional embeddings.
|
| 917 |
+
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
|
| 918 |
+
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
|
| 919 |
+
window_size (int): Window size for window attention blocks.
|
| 920 |
+
window_block_indexes (list): Indexes for blocks using window attention.
|
| 921 |
+
residual_block_indexes (list): Indexes for blocks using conv propagation.
|
| 922 |
+
use_act_checkpoint (bool): If True, use activation checkpointing.
|
| 923 |
+
pretrain_img_size (int): input image size for pretraining models.
|
| 924 |
+
pretrain_use_cls_token (bool): If True, pretrainig models use class token.
|
| 925 |
+
out_feature (str): name of the feature from the last block.
|
| 926 |
+
"""
|
| 927 |
+
super().__init__()
|
| 928 |
+
self.pretrain_use_cls_token = pretrain_use_cls_token
|
| 929 |
+
self.patch_embed = PatchEmbed(
|
| 930 |
+
kernel_size=(patch_size, patch_size),
|
| 931 |
+
stride=(patch_size, patch_size),
|
| 932 |
+
in_chans=in_chans,
|
| 933 |
+
embed_dim=embed_dim,
|
| 934 |
+
)
|
| 935 |
+
self.frozen = frozen
|
| 936 |
+
self.gradient_checkpointing = False
|
| 937 |
+
|
| 938 |
+
if use_abs_pos:
|
| 939 |
+
# Initialize absolute positional embedding with pretrain image size.
|
| 940 |
+
num_patches = (pretrain_img_size // patch_size) * (pretrain_img_size // patch_size)
|
| 941 |
+
num_positions = (num_patches + 1) if pretrain_use_cls_token else num_patches
|
| 942 |
+
self.pos_embed = nn.Parameter(torch.zeros(1, num_positions, embed_dim))
|
| 943 |
+
else:
|
| 944 |
+
self.pos_embed = None
|
| 945 |
+
|
| 946 |
+
half_head_dim = embed_dim // num_heads // 2
|
| 947 |
+
hw_seq_len = img_size // patch_size
|
| 948 |
+
|
| 949 |
+
self.rope_win = VisionRotaryEmbeddingFast(
|
| 950 |
+
dim=half_head_dim,
|
| 951 |
+
pt_seq_len=pt_hw_seq_len,
|
| 952 |
+
ft_seq_len=window_size if intp_freq else None,
|
| 953 |
+
)
|
| 954 |
+
self.rope_glb = VisionRotaryEmbeddingFast(
|
| 955 |
+
dim=half_head_dim,
|
| 956 |
+
pt_seq_len=pt_hw_seq_len,
|
| 957 |
+
ft_seq_len=hw_seq_len if intp_freq else None,
|
| 958 |
+
)
|
| 959 |
+
|
| 960 |
+
# stochastic depth decay rule
|
| 961 |
+
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
|
| 962 |
+
|
| 963 |
+
self.blocks = nn.ModuleList()
|
| 964 |
+
for i in range(depth):
|
| 965 |
+
block = Block(
|
| 966 |
+
dim=embed_dim,
|
| 967 |
+
num_heads=num_heads,
|
| 968 |
+
mlp_ratio=mlp_ratio,
|
| 969 |
+
qkv_bias=qkv_bias,
|
| 970 |
+
drop_path=dpr[i],
|
| 971 |
+
norm_layer=norm_layer,
|
| 972 |
+
window_size=window_size if i in window_block_indexes else global_window_size,
|
| 973 |
+
use_residual_block=i in residual_block_indexes,
|
| 974 |
+
rope=self.rope_win if i in window_block_indexes else self.rope_glb,
|
| 975 |
+
xattn=xattn,
|
| 976 |
+
subln=subln,
|
| 977 |
+
# with_cp=with_cp,
|
| 978 |
+
)
|
| 979 |
+
|
| 980 |
+
self.blocks.append(block)
|
| 981 |
+
|
| 982 |
+
self._out_feature_channels = {out_feature: embed_dim}
|
| 983 |
+
self._out_feature_strides = {out_feature: patch_size}
|
| 984 |
+
self._out_features = [out_feature]
|
| 985 |
+
|
| 986 |
+
# if self.pos_embed is not None:
|
| 987 |
+
# nn.init.trunc_normal_(self.pos_embed, std=0.02)
|
| 988 |
+
if self.pos_embed is not None:
|
| 989 |
+
nn.init.normal_(self.pos_embed, std=0.02)
|
| 990 |
+
|
| 991 |
+
# MIN SHI: I disable the weight initialization since they will be automatically loaded
|
| 992 |
+
# **However, they will cause problems (deepspeed + bf16)**
|
| 993 |
+
# self.apply(self._init_weights)
|
| 994 |
+
self._freeze_stages()
|
| 995 |
+
|
| 996 |
+
# def _init_weights(self, m):
|
| 997 |
+
# if isinstance(m, nn.Linear):
|
| 998 |
+
# nn.init.trunc_normal_(m.weight, std=0.02)
|
| 999 |
+
# if isinstance(m, nn.Linear) and m.bias is not None:
|
| 1000 |
+
# nn.init.constant_(m.bias, 0)
|
| 1001 |
+
# elif isinstance(m, nn.LayerNorm):
|
| 1002 |
+
# nn.init.constant_(m.bias, 0)
|
| 1003 |
+
# nn.init.constant_(m.weight, 1.0)
|
| 1004 |
+
|
| 1005 |
+
def _freeze_stages(self):
|
| 1006 |
+
if self.frozen:
|
| 1007 |
+
self.eval()
|
| 1008 |
+
for m in self.parameters():
|
| 1009 |
+
m.requires_grad = False
|
| 1010 |
+
|
| 1011 |
+
def forward(self, x):
|
| 1012 |
+
x = self.patch_embed(x)
|
| 1013 |
+
if self.pos_embed is not None:
|
| 1014 |
+
x = x + get_abs_pos(
|
| 1015 |
+
self.pos_embed, self.pretrain_use_cls_token, (x.shape[1], x.shape[2])
|
| 1016 |
+
)
|
| 1017 |
+
|
| 1018 |
+
for blk in self.blocks:
|
| 1019 |
+
x = blk(x, with_cp=self.gradient_checkpointing) # b, h, w, c
|
| 1020 |
+
x = x.permute(0, 3, 1, 2) # b, c, h, w
|
| 1021 |
+
|
| 1022 |
+
# if self.adapter is not None:
|
| 1023 |
+
# outputs = self.adapter(x)
|
| 1024 |
+
# else:
|
| 1025 |
+
# outputs = [x, ]
|
| 1026 |
+
|
| 1027 |
+
# return outputs
|
| 1028 |
+
return x
|
| 1029 |
+
|
| 1030 |
+
'''
|
| 1031 |
+
EVA VIT vision encoder for LLaVA
|
| 1032 |
+
'''
|
| 1033 |
+
class EVAVITVisionTower(nn.Module):
|
| 1034 |
+
def __init__(self, vision_tower, args, delay_load=False):
|
| 1035 |
+
super().__init__()
|
| 1036 |
+
|
| 1037 |
+
self.is_loaded = False
|
| 1038 |
+
self.vision_tower_name = vision_tower
|
| 1039 |
+
self.select_layer = args.mm_vision_select_layer # NOTE: not implemented yet, this parameter has no effect
|
| 1040 |
+
self.select_feature = getattr(args, 'mm_vision_select_feature', 'patch')
|
| 1041 |
+
|
| 1042 |
+
self.args = args
|
| 1043 |
+
self.vision_tower, vision_tower_config = build_eva_vit(args=args,
|
| 1044 |
+
model_name=vision_tower,
|
| 1045 |
+
image_size=args.input_image_size
|
| 1046 |
+
)
|
| 1047 |
+
self.input_image_size=args.input_image_size
|
| 1048 |
+
self.vision_tower.config = vision_tower_config
|
| 1049 |
+
self.freeze_vision = args.freeze_vision
|
| 1050 |
+
|
| 1051 |
+
if not self.is_loaded:
|
| 1052 |
+
self.load_model()
|
| 1053 |
+
# if not delay_load:
|
| 1054 |
+
# self.load_model()
|
| 1055 |
+
# else:
|
| 1056 |
+
# self.cfg_only = CLIPVisionConfig.from_pretrained(self.vision_tower_name)
|
| 1057 |
+
|
| 1058 |
+
def load_model(self):
|
| 1059 |
+
if self.is_loaded:
|
| 1060 |
+
return
|
| 1061 |
+
|
| 1062 |
+
# self.args.vision_tower_input_size = 224 # hardcode
|
| 1063 |
+
self.image_processor = CLIPImageProcessor(crop_size={"height": self.args.input_image_size, "width": self.args.input_image_size},
|
| 1064 |
+
size={'shortest_edge': self.args.input_image_size},
|
| 1065 |
+
image_mean=[0.48145466, 0.4578275, 0.40821073],
|
| 1066 |
+
image_std=[0.26862954, 0.26130258, 0.27577711])
|
| 1067 |
+
|
| 1068 |
+
# load weights
|
| 1069 |
+
if self.args.vision_tower_pretrained_from is None:
|
| 1070 |
+
self.args.vision_tower_pretrained_from = "/lustre/fsw/portfolios/llmservice/users/fuxiaol/eva02_L_coco_det_sys_o365.pth"
|
| 1071 |
+
|
| 1072 |
+
# pretrained_params = torch.load(self.args.vision_tower_pretrained_from)
|
| 1073 |
+
# if 'ema_state' in pretrained_params:
|
| 1074 |
+
# pretrained_params = pretrained_params['ema_state']
|
| 1075 |
+
# elif 'module' in pretrained_params:
|
| 1076 |
+
# pretrained_params = pretrained_params['module']
|
| 1077 |
+
|
| 1078 |
+
# from collections import OrderedDict
|
| 1079 |
+
# new_params = OrderedDict()
|
| 1080 |
+
|
| 1081 |
+
# kw = ""
|
| 1082 |
+
# if "det" in self.args.vision_tower_pretrained_from.lower():
|
| 1083 |
+
# kw = "backbone.net."
|
| 1084 |
+
# elif "clip" in self.args.vision_tower_pretrained_from.lower():
|
| 1085 |
+
# kw = "visual."
|
| 1086 |
+
|
| 1087 |
+
# for k, v in pretrained_params.items():
|
| 1088 |
+
# if len(kw) > 0:
|
| 1089 |
+
# if kw in k and ("rope" not in k):
|
| 1090 |
+
# new_params[k.replace(kw, "")] = v
|
| 1091 |
+
# else:
|
| 1092 |
+
# if "rope" not in k:
|
| 1093 |
+
# new_params[k] = v
|
| 1094 |
+
|
| 1095 |
+
# incompatiblekeys = self.vision_tower.load_state_dict(new_params, strict=False)
|
| 1096 |
+
# for k in incompatiblekeys[0]:
|
| 1097 |
+
# if "rope" not in k:
|
| 1098 |
+
# warnings.warn(f"Find incompatible keys {k} in state dict.")
|
| 1099 |
+
|
| 1100 |
+
# print(f"EVA-02 ckpt loaded from {self.args.vision_tower_pretrained_from}")
|
| 1101 |
+
|
| 1102 |
+
if self.freeze_vision:
|
| 1103 |
+
self.vision_tower.requires_grad_(False)
|
| 1104 |
+
|
| 1105 |
+
self.is_loaded = True
|
| 1106 |
+
|
| 1107 |
+
|
| 1108 |
+
# @torch.no_grad()
|
| 1109 |
+
def forward(self, images):
|
| 1110 |
+
if type(images) is list:
|
| 1111 |
+
image_features = []
|
| 1112 |
+
for image in images:
|
| 1113 |
+
image_forward_out = self.vision_tower(image.to(device=self.device, dtype=self.dtype).unsqueeze(0))
|
| 1114 |
+
image_feature = image_forward_out.flatten(2,3).transpose(1,2) # b, n, c
|
| 1115 |
+
image_features.append(image_feature)
|
| 1116 |
+
else:
|
| 1117 |
+
image_forward_out = self.vision_tower(images.to(device=self.device, dtype=self.dtype))
|
| 1118 |
+
|
| 1119 |
+
return image_forward_out
|
| 1120 |
+
|
| 1121 |
+
@property
|
| 1122 |
+
def dummy_feature(self):
|
| 1123 |
+
return torch.zeros(1, self.hidden_size, device=self.device, dtype=self.dtype)
|
| 1124 |
+
|
| 1125 |
+
@property
|
| 1126 |
+
def dtype(self):
|
| 1127 |
+
return next(self.vision_tower.parameters()).dtype
|
| 1128 |
+
|
| 1129 |
+
@property
|
| 1130 |
+
def device(self):
|
| 1131 |
+
return next(self.vision_tower.parameters()).device
|
| 1132 |
+
|
| 1133 |
+
@property
|
| 1134 |
+
def config(self):
|
| 1135 |
+
# if self.is_loaded:
|
| 1136 |
+
# return self.vision_tower.config
|
| 1137 |
+
# else:
|
| 1138 |
+
# return self.cfg_only
|
| 1139 |
+
# TODO
|
| 1140 |
+
return self.vision_tower.config
|
| 1141 |
+
|
| 1142 |
+
@property
|
| 1143 |
+
def hidden_size(self):
|
| 1144 |
+
#return self.config.hidden_size
|
| 1145 |
+
return self.config['hidden_dim']
|
| 1146 |
+
|
| 1147 |
+
@property
|
| 1148 |
+
def num_patches(self):
|
| 1149 |
+
# return (self.config.image_size // self.config.patch_size) ** 2
|
| 1150 |
+
return self.config['num_patches']
|
| 1151 |
+
|
| 1152 |
+
|
| 1153 |
+
def build_eva_vit(args,
|
| 1154 |
+
model_name=None,
|
| 1155 |
+
image_size=224,
|
| 1156 |
+
window_attn=True
|
| 1157 |
+
):
|
| 1158 |
+
|
| 1159 |
+
if "336" in args.vision_tower_pretrained_from:
|
| 1160 |
+
pretrained_image_size = 336
|
| 1161 |
+
else:
|
| 1162 |
+
pretrained_image_size = 224
|
| 1163 |
+
|
| 1164 |
+
if "clip" in args.vision_tower_pretrained_from.lower():
|
| 1165 |
+
subln = True
|
| 1166 |
+
else:
|
| 1167 |
+
subln = False
|
| 1168 |
+
|
| 1169 |
+
if model_name == 'eva02-l-16':
|
| 1170 |
+
# shilong said that use this: https://huggingface.co/Yuxin-CV/EVA-02/blob/main/eva02/det/eva02_L_coco_det_sys_o365.pth
|
| 1171 |
+
if window_attn:
|
| 1172 |
+
window_block_indexes = (list(range(0, 2)) + list(range(3, 5)) + list(range(6, 8)) + list(range(9, 11)) + list(range(12, 14)) + list(range(15, 17)) + list(range(18, 20)) + list(range(21, 23)))
|
| 1173 |
+
else:
|
| 1174 |
+
window_block_indexes = ()
|
| 1175 |
+
|
| 1176 |
+
model = EVAViT(
|
| 1177 |
+
img_size=image_size,
|
| 1178 |
+
patch_size=16,
|
| 1179 |
+
window_size=16,
|
| 1180 |
+
in_chans=3,
|
| 1181 |
+
embed_dim=1024,
|
| 1182 |
+
depth=24,
|
| 1183 |
+
num_heads=16,
|
| 1184 |
+
mlp_ratio=4*2/3,
|
| 1185 |
+
window_block_indexes = window_block_indexes,
|
| 1186 |
+
qkv_bias=True,
|
| 1187 |
+
drop_path_rate=0.0,
|
| 1188 |
+
xattn=False,
|
| 1189 |
+
# with_cp=False,
|
| 1190 |
+
# frozen=True,
|
| 1191 |
+
)
|
| 1192 |
+
# image_size = 224 # HARDCODE
|
| 1193 |
+
eva_config = dict(image_size=image_size,
|
| 1194 |
+
patch_size=16,
|
| 1195 |
+
window_size=16,
|
| 1196 |
+
hidden_dim=1024,
|
| 1197 |
+
depth=24,
|
| 1198 |
+
num_heads=16,
|
| 1199 |
+
window_block_indexes=window_block_indexes,
|
| 1200 |
+
num_patches=image_size ** 2 // 16 ** 2,
|
| 1201 |
+
pretrained_from=args.vision_tower_pretrained_from
|
| 1202 |
+
)
|
| 1203 |
+
|
| 1204 |
+
elif model_name == 'eva02-l-14':
|
| 1205 |
+
# shilong said that use this: https://huggingface.co/Yuxin-CV/EVA-02/blob/main/eva02/det/eva02_L_coco_det_sys_o365.pth
|
| 1206 |
+
if window_attn:
|
| 1207 |
+
window_block_indexes = (list(range(0, 2)) + list(range(3, 5)) + list(range(6, 8)) + list(range(9, 11)) + list(range(12, 14)) + list(range(15, 17)) + list(range(18, 20)) + list(range(21, 23)))
|
| 1208 |
+
else:
|
| 1209 |
+
window_block_indexes = ()
|
| 1210 |
+
|
| 1211 |
+
model = EVAViT(
|
| 1212 |
+
img_size=image_size,
|
| 1213 |
+
pretrain_img_size=pretrained_image_size,
|
| 1214 |
+
patch_size=14,
|
| 1215 |
+
window_size=16,
|
| 1216 |
+
in_chans=3,
|
| 1217 |
+
embed_dim=1024,
|
| 1218 |
+
depth=24,
|
| 1219 |
+
num_heads=16,
|
| 1220 |
+
mlp_ratio=4*2/3,
|
| 1221 |
+
window_block_indexes = window_block_indexes,
|
| 1222 |
+
qkv_bias=True,
|
| 1223 |
+
drop_path_rate=0.0,
|
| 1224 |
+
xattn=False,
|
| 1225 |
+
# with_cp=False,
|
| 1226 |
+
subln=subln,
|
| 1227 |
+
# frozen=True,
|
| 1228 |
+
)
|
| 1229 |
+
# image_size = 224 # HARDCODE
|
| 1230 |
+
eva_config = dict(image_size=image_size,
|
| 1231 |
+
patch_size=14,
|
| 1232 |
+
window_size=16,
|
| 1233 |
+
hidden_dim=1024,
|
| 1234 |
+
depth=24,
|
| 1235 |
+
num_heads=16,
|
| 1236 |
+
window_block_indexes=window_block_indexes,
|
| 1237 |
+
num_patches=image_size ** 2 // 14 ** 2,
|
| 1238 |
+
pretrained_from=args.vision_tower_pretrained_from
|
| 1239 |
+
)
|
| 1240 |
+
|
| 1241 |
+
else:
|
| 1242 |
+
raise NotImplementedError
|
| 1243 |
+
|
| 1244 |
+
return model, eva_config
|
eagle/model/multimodal_projector/builder.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import re
|
| 4 |
+
# from llava.model.multimodal_projector.deformable_resampler import DeformableResampler
|
| 5 |
+
|
| 6 |
+
class IdentityMap(nn.Module):
|
| 7 |
+
def __init__(self):
|
| 8 |
+
super().__init__()
|
| 9 |
+
|
| 10 |
+
def forward(self, x, *args, **kwargs):
|
| 11 |
+
return x
|
| 12 |
+
|
| 13 |
+
@property
|
| 14 |
+
def config(self):
|
| 15 |
+
return {"mm_projector_type": 'identity'}
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class SimpleResBlock(nn.Module):
|
| 19 |
+
def __init__(self, channels):
|
| 20 |
+
super().__init__()
|
| 21 |
+
self.pre_norm = nn.LayerNorm(channels)
|
| 22 |
+
|
| 23 |
+
self.proj = nn.Sequential(
|
| 24 |
+
nn.Linear(channels, channels),
|
| 25 |
+
nn.GELU(),
|
| 26 |
+
nn.Linear(channels, channels)
|
| 27 |
+
)
|
| 28 |
+
def forward(self, x):
|
| 29 |
+
x = self.pre_norm(x)
|
| 30 |
+
return x + self.proj(x)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def build_vision_projector(config, delay_load=False, fpn_input_dim=[], **kwargs):
|
| 34 |
+
projector_type = getattr(config, 'mm_projector_type', 'linear')
|
| 35 |
+
|
| 36 |
+
if projector_type == 'linear':
|
| 37 |
+
return nn.Linear(config.mm_hidden_size, config.hidden_size)
|
| 38 |
+
|
| 39 |
+
mlp_gelu_match = re.match(r'^mlp(\d+)x_gelu$', projector_type)
|
| 40 |
+
if mlp_gelu_match:
|
| 41 |
+
mlp_depth = int(mlp_gelu_match.group(1))
|
| 42 |
+
modules = [nn.Linear(config.mm_hidden_size, config.hidden_size)]
|
| 43 |
+
for _ in range(1, mlp_depth):
|
| 44 |
+
modules.append(nn.GELU())
|
| 45 |
+
modules.append(nn.Linear(config.hidden_size, config.hidden_size))
|
| 46 |
+
return nn.Sequential(*modules)
|
| 47 |
+
|
| 48 |
+
# resampler_match = re.match(r'^deformable-resampler-l(\d+)d(\d+)p(\d+)', projector_type)
|
| 49 |
+
# if resampler_match:
|
| 50 |
+
# use_fpn = "fpn" in projector_type or len(fpn_input_dim) > 0
|
| 51 |
+
# layer_num = int(resampler_match.group(1))
|
| 52 |
+
# embed_dim = int(resampler_match.group(2))
|
| 53 |
+
# sample_point = int(resampler_match.group(3))
|
| 54 |
+
# if len(fpn_input_dim) > 0:
|
| 55 |
+
# fpn_type = 'multi-level'
|
| 56 |
+
# else:
|
| 57 |
+
# fpn_type = 'simple'
|
| 58 |
+
|
| 59 |
+
# return DeformableResampler(input_dimension=config.mm_hidden_size,
|
| 60 |
+
# output_dimension=config.hidden_size,
|
| 61 |
+
# query_number=config.mm_projector_query_number,
|
| 62 |
+
# num_layers=layer_num,
|
| 63 |
+
# num_heads=8,
|
| 64 |
+
# feedforward_dims=2048,
|
| 65 |
+
# embed_dims=embed_dim,
|
| 66 |
+
# num_points=sample_point,
|
| 67 |
+
# direct_projection=True,
|
| 68 |
+
# use_fpn=use_fpn,
|
| 69 |
+
# fpn_config=dict(
|
| 70 |
+
# fpn_type=fpn_type,
|
| 71 |
+
# in_channels=fpn_input_dim))
|
| 72 |
+
|
| 73 |
+
if projector_type == 'identity':
|
| 74 |
+
return IdentityMap()
|
| 75 |
+
|
| 76 |
+
raise ValueError(f'Unknown projector type: {projector_type}')
|
eagle/utils.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import datetime
|
| 2 |
+
import logging
|
| 3 |
+
import logging.handlers
|
| 4 |
+
import os
|
| 5 |
+
import sys
|
| 6 |
+
|
| 7 |
+
import requests
|
| 8 |
+
|
| 9 |
+
from eagle.constants import LOGDIR
|
| 10 |
+
|
| 11 |
+
server_error_msg = "**NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE.**"
|
| 12 |
+
moderation_msg = "YOUR INPUT VIOLATES OUR CONTENT MODERATION GUIDELINES. PLEASE TRY AGAIN."
|
| 13 |
+
|
| 14 |
+
handler = None
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def build_logger(logger_name, logger_filename):
|
| 18 |
+
global handler
|
| 19 |
+
|
| 20 |
+
formatter = logging.Formatter(
|
| 21 |
+
fmt="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
|
| 22 |
+
datefmt="%Y-%m-%d %H:%M:%S",
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
# Set the format of root handlers
|
| 26 |
+
if not logging.getLogger().handlers:
|
| 27 |
+
logging.basicConfig(level=logging.INFO)
|
| 28 |
+
logging.getLogger().handlers[0].setFormatter(formatter)
|
| 29 |
+
|
| 30 |
+
# Redirect stdout and stderr to loggers
|
| 31 |
+
stdout_logger = logging.getLogger("stdout")
|
| 32 |
+
stdout_logger.setLevel(logging.INFO)
|
| 33 |
+
sl = StreamToLogger(stdout_logger, logging.INFO)
|
| 34 |
+
sys.stdout = sl
|
| 35 |
+
|
| 36 |
+
stderr_logger = logging.getLogger("stderr")
|
| 37 |
+
stderr_logger.setLevel(logging.ERROR)
|
| 38 |
+
sl = StreamToLogger(stderr_logger, logging.ERROR)
|
| 39 |
+
sys.stderr = sl
|
| 40 |
+
|
| 41 |
+
# Get logger
|
| 42 |
+
logger = logging.getLogger(logger_name)
|
| 43 |
+
logger.setLevel(logging.INFO)
|
| 44 |
+
|
| 45 |
+
# Add a file handler for all loggers
|
| 46 |
+
if handler is None:
|
| 47 |
+
os.makedirs(LOGDIR, exist_ok=True)
|
| 48 |
+
filename = os.path.join(LOGDIR, logger_filename)
|
| 49 |
+
handler = logging.handlers.TimedRotatingFileHandler(
|
| 50 |
+
filename, when='D', utc=True, encoding='UTF-8')
|
| 51 |
+
handler.setFormatter(formatter)
|
| 52 |
+
|
| 53 |
+
for name, item in logging.root.manager.loggerDict.items():
|
| 54 |
+
if isinstance(item, logging.Logger):
|
| 55 |
+
item.addHandler(handler)
|
| 56 |
+
|
| 57 |
+
return logger
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class StreamToLogger(object):
|
| 61 |
+
"""
|
| 62 |
+
Fake file-like stream object that redirects writes to a logger instance.
|
| 63 |
+
"""
|
| 64 |
+
def __init__(self, logger, log_level=logging.INFO):
|
| 65 |
+
self.terminal = sys.stdout
|
| 66 |
+
self.logger = logger
|
| 67 |
+
self.log_level = log_level
|
| 68 |
+
self.linebuf = ''
|
| 69 |
+
|
| 70 |
+
def __getattr__(self, attr):
|
| 71 |
+
return getattr(self.terminal, attr)
|
| 72 |
+
|
| 73 |
+
def write(self, buf):
|
| 74 |
+
temp_linebuf = self.linebuf + buf
|
| 75 |
+
self.linebuf = ''
|
| 76 |
+
for line in temp_linebuf.splitlines(True):
|
| 77 |
+
# From the io.TextIOWrapper docs:
|
| 78 |
+
# On output, if newline is None, any '\n' characters written
|
| 79 |
+
# are translated to the system default line separator.
|
| 80 |
+
# By default sys.stdout.write() expects '\n' newlines and then
|
| 81 |
+
# translates them so this is still cross platform.
|
| 82 |
+
if line[-1] == '\n':
|
| 83 |
+
self.logger.log(self.log_level, line.rstrip())
|
| 84 |
+
else:
|
| 85 |
+
self.linebuf += line
|
| 86 |
+
|
| 87 |
+
def flush(self):
|
| 88 |
+
if self.linebuf != '':
|
| 89 |
+
self.logger.log(self.log_level, self.linebuf.rstrip())
|
| 90 |
+
self.linebuf = ''
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def disable_torch_init():
|
| 94 |
+
"""
|
| 95 |
+
Disable the redundant torch default initialization to accelerate model creation.
|
| 96 |
+
"""
|
| 97 |
+
import torch
|
| 98 |
+
setattr(torch.nn.Linear, "reset_parameters", lambda self: None)
|
| 99 |
+
setattr(torch.nn.LayerNorm, "reset_parameters", lambda self: None)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def violates_moderation(text):
|
| 103 |
+
"""
|
| 104 |
+
Check whether the text violates OpenAI moderation API.
|
| 105 |
+
"""
|
| 106 |
+
url = "https://api.openai.com/v1/moderations"
|
| 107 |
+
headers = {"Content-Type": "application/json",
|
| 108 |
+
"Authorization": "Bearer " + os.environ["OPENAI_API_KEY"]}
|
| 109 |
+
text = text.replace("\n", "")
|
| 110 |
+
data = "{" + '"input": ' + f'"{text}"' + "}"
|
| 111 |
+
data = data.encode("utf-8")
|
| 112 |
+
try:
|
| 113 |
+
ret = requests.post(url, headers=headers, data=data, timeout=5)
|
| 114 |
+
flagged = ret.json()["results"][0]["flagged"]
|
| 115 |
+
except requests.exceptions.RequestException as e:
|
| 116 |
+
flagged = False
|
| 117 |
+
except KeyError as e:
|
| 118 |
+
flagged = False
|
| 119 |
+
|
| 120 |
+
return flagged
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def pretty_print_semaphore(semaphore):
|
| 124 |
+
if semaphore is None:
|
| 125 |
+
return "None"
|
| 126 |
+
return f"Semaphore(value={semaphore._value}, locked={semaphore.locked()})"
|
requirements.txt
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==2.1.2
|
| 2 |
+
torchvision==0.16.2
|
| 3 |
+
transformers==4.37.2
|
| 4 |
+
tokenizers==0.15.1
|
| 5 |
+
sentencepiece==0.1.99
|
| 6 |
+
shortuuid
|
| 7 |
+
accelerate==0.21.0
|
| 8 |
+
peft
|
| 9 |
+
bitsandbytes
|
| 10 |
+
pydantic
|
| 11 |
+
markdown2[all]
|
| 12 |
+
numpy
|
| 13 |
+
scikit-learn==1.2.2
|
| 14 |
+
#gradio==4.38.1
|
| 15 |
+
#gradio_client==1.1.0
|
| 16 |
+
gradio==4.16.0
|
| 17 |
+
gradio_client==0.8.1
|
| 18 |
+
requests
|
| 19 |
+
httpx==0.27.0
|
| 20 |
+
uvicorn
|
| 21 |
+
fastapi
|
| 22 |
+
einops==0.6.1
|
| 23 |
+
einops-exts==0.0.4
|
| 24 |
+
timm==0.9.11
|
| 25 |
+
opencv-python
|
| 26 |
+
fvcore
|