
Add all files and directories
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +168 -0
- CLA.md +24 -0
- LICENSE +674 -0
- benchmark.py +157 -0
- chunk_convert.py +22 -0
- chunk_convert.sh +47 -0
- convert.py +131 -0
- convert_single.py +35 -0
- data/.gitignore +3 -0
- data/examples/marker/multicolcnn.md +350 -0
- data/examples/marker/switch_transformers.md +0 -0
- data/examples/marker/thinkos.md +0 -0
- data/examples/marker/thinkpython.md +0 -0
- data/examples/nougat/multicolcnn.md +245 -0
- data/examples/nougat/switch_transformers.md +528 -0
- data/examples/nougat/thinkos.md +0 -0
- data/examples/nougat/thinkpython.md +0 -0
- data/images/overall.png +0 -0
- data/images/per_doc.png +0 -0
- data/latex_to_md.sh +34 -0
- docs/install_ocrmypdf.md +29 -0
- marker/benchmark/scoring.py +40 -0
- marker/cleaners/bullets.py +8 -0
- marker/cleaners/code.py +131 -0
- marker/cleaners/fontstyle.py +30 -0
- marker/cleaners/headers.py +82 -0
- marker/cleaners/headings.py +59 -0
- marker/cleaners/text.py +8 -0
- marker/convert.py +162 -0
- marker/debug/data.py +76 -0
- marker/equations/equations.py +183 -0
- marker/equations/inference.py +50 -0
- marker/images/extract.py +72 -0
- marker/images/save.py +18 -0
- marker/layout/layout.py +48 -0
- marker/layout/order.py +69 -0
- marker/logger.py +12 -0
- marker/models.py +58 -0
- marker/ocr/detection.py +30 -0
- marker/ocr/heuristics.py +74 -0
- marker/ocr/lang.py +36 -0
- marker/ocr/recognition.py +168 -0
- marker/ocr/tesseract.py +97 -0
- marker/ocr/utils.py +10 -0
- marker/output.py +39 -0
- marker/pdf/extract_text.py +121 -0
- marker/pdf/images.py +27 -0
- marker/pdf/utils.py +75 -0
- marker/postprocessors/editor.py +116 -0
- marker/postprocessors/markdown.py +190 -0
.gitignore
ADDED
|
@@ -0,0 +1,168 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
private.py
|
| 2 |
+
.DS_Store
|
| 3 |
+
local.env
|
| 4 |
+
experiments
|
| 5 |
+
test_data
|
| 6 |
+
training
|
| 7 |
+
wandb
|
| 8 |
+
|
| 9 |
+
# Byte-compiled / optimized / DLL files
|
| 10 |
+
__pycache__/
|
| 11 |
+
*.py[cod]
|
| 12 |
+
*$py.class
|
| 13 |
+
|
| 14 |
+
# C extensions
|
| 15 |
+
*.so
|
| 16 |
+
|
| 17 |
+
# Distribution / packaging
|
| 18 |
+
.Python
|
| 19 |
+
build/
|
| 20 |
+
develop-eggs/
|
| 21 |
+
dist/
|
| 22 |
+
downloads/
|
| 23 |
+
eggs/
|
| 24 |
+
.eggs/
|
| 25 |
+
lib/
|
| 26 |
+
lib64/
|
| 27 |
+
parts/
|
| 28 |
+
sdist/
|
| 29 |
+
var/
|
| 30 |
+
wheels/
|
| 31 |
+
share/python-wheels/
|
| 32 |
+
*.egg-info/
|
| 33 |
+
.installed.cfg
|
| 34 |
+
*.egg
|
| 35 |
+
MANIFEST
|
| 36 |
+
|
| 37 |
+
# PyInstaller
|
| 38 |
+
# Usually these files are written by a python script from a template
|
| 39 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 40 |
+
*.manifest
|
| 41 |
+
*.spec
|
| 42 |
+
|
| 43 |
+
# Installer logs
|
| 44 |
+
pip-log.txt
|
| 45 |
+
pip-delete-this-directory.txt
|
| 46 |
+
|
| 47 |
+
# Unit test / coverage reports
|
| 48 |
+
htmlcov/
|
| 49 |
+
.tox/
|
| 50 |
+
.nox/
|
| 51 |
+
.coverage
|
| 52 |
+
.coverage.*
|
| 53 |
+
.cache
|
| 54 |
+
nosetests.xml
|
| 55 |
+
coverage.xml
|
| 56 |
+
*.cover
|
| 57 |
+
*.py,cover
|
| 58 |
+
.hypothesis/
|
| 59 |
+
.pytest_cache/
|
| 60 |
+
cover/
|
| 61 |
+
|
| 62 |
+
# Translations
|
| 63 |
+
*.mo
|
| 64 |
+
*.pot
|
| 65 |
+
|
| 66 |
+
# Django stuff:
|
| 67 |
+
*.log
|
| 68 |
+
local_settings.py
|
| 69 |
+
db.sqlite3
|
| 70 |
+
db.sqlite3-journal
|
| 71 |
+
|
| 72 |
+
# Flask stuff:
|
| 73 |
+
instance/
|
| 74 |
+
.webassets-cache
|
| 75 |
+
|
| 76 |
+
# Scrapy stuff:
|
| 77 |
+
.scrapy
|
| 78 |
+
|
| 79 |
+
# Sphinx documentation
|
| 80 |
+
docs/_build/
|
| 81 |
+
|
| 82 |
+
# PyBuilder
|
| 83 |
+
.pybuilder/
|
| 84 |
+
target/
|
| 85 |
+
|
| 86 |
+
# Jupyter Notebook
|
| 87 |
+
.ipynb_checkpoints
|
| 88 |
+
|
| 89 |
+
# IPython
|
| 90 |
+
profile_default/
|
| 91 |
+
ipython_config.py
|
| 92 |
+
|
| 93 |
+
# pyenv
|
| 94 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 95 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 96 |
+
# .python-version
|
| 97 |
+
|
| 98 |
+
# pipenv
|
| 99 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 100 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 101 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 102 |
+
# install all needed dependencies.
|
| 103 |
+
#Pipfile.lock
|
| 104 |
+
|
| 105 |
+
# poetry
|
| 106 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 107 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 108 |
+
# commonly ignored for libraries.
|
| 109 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 110 |
+
#poetry.lock
|
| 111 |
+
|
| 112 |
+
# pdm
|
| 113 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 114 |
+
#pdm.lock
|
| 115 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 116 |
+
# in version control.
|
| 117 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 118 |
+
.pdm.toml
|
| 119 |
+
|
| 120 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 121 |
+
__pypackages__/
|
| 122 |
+
|
| 123 |
+
# Celery stuff
|
| 124 |
+
celerybeat-schedule
|
| 125 |
+
celerybeat.pid
|
| 126 |
+
|
| 127 |
+
# SageMath parsed files
|
| 128 |
+
*.sage.py
|
| 129 |
+
|
| 130 |
+
# Environments
|
| 131 |
+
.env
|
| 132 |
+
.venv
|
| 133 |
+
env/
|
| 134 |
+
venv/
|
| 135 |
+
ENV/
|
| 136 |
+
env.bak/
|
| 137 |
+
venv.bak/
|
| 138 |
+
|
| 139 |
+
# Spyder project settings
|
| 140 |
+
.spyderproject
|
| 141 |
+
.spyproject
|
| 142 |
+
|
| 143 |
+
# Rope project settings
|
| 144 |
+
.ropeproject
|
| 145 |
+
|
| 146 |
+
# mkdocs documentation
|
| 147 |
+
/site
|
| 148 |
+
|
| 149 |
+
# mypy
|
| 150 |
+
.mypy_cache/
|
| 151 |
+
.dmypy.json
|
| 152 |
+
dmypy.json
|
| 153 |
+
|
| 154 |
+
# Pyre type checker
|
| 155 |
+
.pyre/
|
| 156 |
+
|
| 157 |
+
# pytype static type analyzer
|
| 158 |
+
.pytype/
|
| 159 |
+
|
| 160 |
+
# Cython debug symbols
|
| 161 |
+
cython_debug/
|
| 162 |
+
|
| 163 |
+
# PyCharm
|
| 164 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 165 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 166 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 167 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 168 |
+
.idea/
|
CLA.md
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Marker Contributor Agreement
|
| 2 |
+
|
| 3 |
+
This Marker Contributor Agreement ("MCA") applies to any contribution that you make to any product or project managed by us (the "project"), and sets out the intellectual property rights you grant to us in the contributed materials. The term "us" shall mean Vikas Paruchuri. The term "you" shall mean the person or entity identified below.
|
| 4 |
+
|
| 5 |
+
If you agree to be bound by these terms, sign by writing "I have read the CLA document and I hereby sign the CLA" in response to the CLA bot Github comment. Read this agreement carefully before signing. These terms and conditions constitute a binding legal agreement.
|
| 6 |
+
|
| 7 |
+
1. The term 'contribution' or 'contributed materials' means any source code, object code, patch, tool, sample, graphic, specification, manual, documentation, or any other material posted or submitted by you to the project.
|
| 8 |
+
2. With respect to any worldwide copyrights, or copyright applications and registrations, in your contribution:
|
| 9 |
+
- you hereby assign to us joint ownership, and to the extent that such assignment is or becomes invalid, ineffective or unenforceable, you hereby grant to us a perpetual, irrevocable, non-exclusive, worldwide, no-charge, royalty free, unrestricted license to exercise all rights under those copyrights. This includes, at our option, the right to sublicense these same rights to third parties through multiple levels of sublicensees or other licensing arrangements, including dual-license structures for commercial customers;
|
| 10 |
+
- you agree that each of us can do all things in relation to your contribution as if each of us were the sole owners, and if one of us makes a derivative work of your contribution, the one who makes the derivative work (or has it made will be the sole owner of that derivative work;
|
| 11 |
+
- you agree that you will not assert any moral rights in your contribution against us, our licensees or transferees;
|
| 12 |
+
- you agree that we may register a copyright in your contribution and exercise all ownership rights associated with it; and
|
| 13 |
+
- you agree that neither of us has any duty to consult with, obtain the consent of, pay or render an accounting to the other for any use or distribution of vour contribution.
|
| 14 |
+
3. With respect to any patents you own, or that you can license without payment to any third party, you hereby grant to us a perpetual, irrevocable, non-exclusive, worldwide, no-charge, royalty-free license to:
|
| 15 |
+
- make, have made, use, sell, offer to sell, import, and otherwise transfer your contribution in whole or in part, alone or in combination with or included in any product, work or materials arising out of the project to which your contribution was submitted, and
|
| 16 |
+
- at our option, to sublicense these same rights to third parties through multiple levels of sublicensees or other licensing arrangements.
|
| 17 |
+
If you or your affiliates institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the contribution or any project it was submitted to constitutes direct or contributory patent infringement, then any patent licenses granted to you under this agreement for that contribution shall terminate as of the date such litigation is filed.
|
| 18 |
+
4. Except as set out above, you keep all right, title, and interest in your contribution. The rights that you grant to us under these terms are effective on the date you first submitted a contribution to us, even if your submission took place before the date you sign these terms. Any contribution we make available under any license will also be made available under a suitable FSF (Free Software Foundation) or OSI (Open Source Initiative) approved license.
|
| 19 |
+
5. You covenant, represent, warrant and agree that:
|
| 20 |
+
- each contribution that you submit is and shall be an original work of authorship and you can legally grant the rights set out in this MCA;
|
| 21 |
+
- to the best of your knowledge, each contribution will not violate any third party's copyrights, trademarks, patents, or other intellectual property rights; and
|
| 22 |
+
- each contribution shall be in compliance with U.S. export control laws and other applicable export and import laws.
|
| 23 |
+
You agree to notify us if you become aware of any circumstance which would make any of the foregoing representations inaccurate in any respect. Vikas Paruchuri may publicly disclose your participation in the project, including the fact that you have signed the MCA.
|
| 24 |
+
6. This MCA is governed by the laws of the State of California and applicable U.S. Federal law. Any choice of law rules will not apply.
|
LICENSE
ADDED
|
@@ -0,0 +1,674 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GNU GENERAL PUBLIC LICENSE
|
| 2 |
+
Version 3, 29 June 2007
|
| 3 |
+
|
| 4 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 5 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 6 |
+
of this license document, but changing it is not allowed.
|
| 7 |
+
|
| 8 |
+
Preamble
|
| 9 |
+
|
| 10 |
+
The GNU General Public License is a free, copyleft license for
|
| 11 |
+
software and other kinds of works.
|
| 12 |
+
|
| 13 |
+
The licenses for most software and other practical works are designed
|
| 14 |
+
to take away your freedom to share and change the works. By contrast,
|
| 15 |
+
the GNU General Public License is intended to guarantee your freedom to
|
| 16 |
+
share and change all versions of a program--to make sure it remains free
|
| 17 |
+
software for all its users. We, the Free Software Foundation, use the
|
| 18 |
+
GNU General Public License for most of our software; it applies also to
|
| 19 |
+
any other work released this way by its authors. You can apply it to
|
| 20 |
+
your programs, too.
|
| 21 |
+
|
| 22 |
+
When we speak of free software, we are referring to freedom, not
|
| 23 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 24 |
+
have the freedom to distribute copies of free software (and charge for
|
| 25 |
+
them if you wish), that you receive source code or can get it if you
|
| 26 |
+
want it, that you can change the software or use pieces of it in new
|
| 27 |
+
free programs, and that you know you can do these things.
|
| 28 |
+
|
| 29 |
+
To protect your rights, we need to prevent others from denying you
|
| 30 |
+
these rights or asking you to surrender the rights. Therefore, you have
|
| 31 |
+
certain responsibilities if you distribute copies of the software, or if
|
| 32 |
+
you modify it: responsibilities to respect the freedom of others.
|
| 33 |
+
|
| 34 |
+
For example, if you distribute copies of such a program, whether
|
| 35 |
+
gratis or for a fee, you must pass on to the recipients the same
|
| 36 |
+
freedoms that you received. You must make sure that they, too, receive
|
| 37 |
+
or can get the source code. And you must show them these terms so they
|
| 38 |
+
know their rights.
|
| 39 |
+
|
| 40 |
+
Developers that use the GNU GPL protect your rights with two steps:
|
| 41 |
+
(1) assert copyright on the software, and (2) offer you this License
|
| 42 |
+
giving you legal permission to copy, distribute and/or modify it.
|
| 43 |
+
|
| 44 |
+
For the developers' and authors' protection, the GPL clearly explains
|
| 45 |
+
that there is no warranty for this free software. For both users' and
|
| 46 |
+
authors' sake, the GPL requires that modified versions be marked as
|
| 47 |
+
changed, so that their problems will not be attributed erroneously to
|
| 48 |
+
authors of previous versions.
|
| 49 |
+
|
| 50 |
+
Some devices are designed to deny users access to install or run
|
| 51 |
+
modified versions of the software inside them, although the manufacturer
|
| 52 |
+
can do so. This is fundamentally incompatible with the aim of
|
| 53 |
+
protecting users' freedom to change the software. The systematic
|
| 54 |
+
pattern of such abuse occurs in the area of products for individuals to
|
| 55 |
+
use, which is precisely where it is most unacceptable. Therefore, we
|
| 56 |
+
have designed this version of the GPL to prohibit the practice for those
|
| 57 |
+
products. If such problems arise substantially in other domains, we
|
| 58 |
+
stand ready to extend this provision to those domains in future versions
|
| 59 |
+
of the GPL, as needed to protect the freedom of users.
|
| 60 |
+
|
| 61 |
+
Finally, every program is threatened constantly by software patents.
|
| 62 |
+
States should not allow patents to restrict development and use of
|
| 63 |
+
software on general-purpose computers, but in those that do, we wish to
|
| 64 |
+
avoid the special danger that patents applied to a free program could
|
| 65 |
+
make it effectively proprietary. To prevent this, the GPL assures that
|
| 66 |
+
patents cannot be used to render the program non-free.
|
| 67 |
+
|
| 68 |
+
The precise terms and conditions for copying, distribution and
|
| 69 |
+
modification follow.
|
| 70 |
+
|
| 71 |
+
TERMS AND CONDITIONS
|
| 72 |
+
|
| 73 |
+
0. Definitions.
|
| 74 |
+
|
| 75 |
+
"This License" refers to version 3 of the GNU General Public License.
|
| 76 |
+
|
| 77 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 78 |
+
works, such as semiconductor masks.
|
| 79 |
+
|
| 80 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 81 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 82 |
+
"recipients" may be individuals or organizations.
|
| 83 |
+
|
| 84 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 85 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 86 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 87 |
+
earlier work or a work "based on" the earlier work.
|
| 88 |
+
|
| 89 |
+
A "covered work" means either the unmodified Program or a work based
|
| 90 |
+
on the Program.
|
| 91 |
+
|
| 92 |
+
To "propagate" a work means to do anything with it that, without
|
| 93 |
+
permission, would make you directly or secondarily liable for
|
| 94 |
+
infringement under applicable copyright law, except executing it on a
|
| 95 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 96 |
+
distribution (with or without modification), making available to the
|
| 97 |
+
public, and in some countries other activities as well.
|
| 98 |
+
|
| 99 |
+
To "convey" a work means any kind of propagation that enables other
|
| 100 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 101 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 102 |
+
|
| 103 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 104 |
+
to the extent that it includes a convenient and prominently visible
|
| 105 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 106 |
+
tells the user that there is no warranty for the work (except to the
|
| 107 |
+
extent that warranties are provided), that licensees may convey the
|
| 108 |
+
work under this License, and how to view a copy of this License. If
|
| 109 |
+
the interface presents a list of user commands or options, such as a
|
| 110 |
+
menu, a prominent item in the list meets this criterion.
|
| 111 |
+
|
| 112 |
+
1. Source Code.
|
| 113 |
+
|
| 114 |
+
The "source code" for a work means the preferred form of the work
|
| 115 |
+
for making modifications to it. "Object code" means any non-source
|
| 116 |
+
form of a work.
|
| 117 |
+
|
| 118 |
+
A "Standard Interface" means an interface that either is an official
|
| 119 |
+
standard defined by a recognized standards body, or, in the case of
|
| 120 |
+
interfaces specified for a particular programming language, one that
|
| 121 |
+
is widely used among developers working in that language.
|
| 122 |
+
|
| 123 |
+
The "System Libraries" of an executable work include anything, other
|
| 124 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 125 |
+
packaging a Major Component, but which is not part of that Major
|
| 126 |
+
Component, and (b) serves only to enable use of the work with that
|
| 127 |
+
Major Component, or to implement a Standard Interface for which an
|
| 128 |
+
implementation is available to the public in source code form. A
|
| 129 |
+
"Major Component", in this context, means a major essential component
|
| 130 |
+
(kernel, window system, and so on) of the specific operating system
|
| 131 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 132 |
+
produce the work, or an object code interpreter used to run it.
|
| 133 |
+
|
| 134 |
+
The "Corresponding Source" for a work in object code form means all
|
| 135 |
+
the source code needed to generate, install, and (for an executable
|
| 136 |
+
work) run the object code and to modify the work, including scripts to
|
| 137 |
+
control those activities. However, it does not include the work's
|
| 138 |
+
System Libraries, or general-purpose tools or generally available free
|
| 139 |
+
programs which are used unmodified in performing those activities but
|
| 140 |
+
which are not part of the work. For example, Corresponding Source
|
| 141 |
+
includes interface definition files associated with source files for
|
| 142 |
+
the work, and the source code for shared libraries and dynamically
|
| 143 |
+
linked subprograms that the work is specifically designed to require,
|
| 144 |
+
such as by intimate data communication or control flow between those
|
| 145 |
+
subprograms and other parts of the work.
|
| 146 |
+
|
| 147 |
+
The Corresponding Source need not include anything that users
|
| 148 |
+
can regenerate automatically from other parts of the Corresponding
|
| 149 |
+
Source.
|
| 150 |
+
|
| 151 |
+
The Corresponding Source for a work in source code form is that
|
| 152 |
+
same work.
|
| 153 |
+
|
| 154 |
+
2. Basic Permissions.
|
| 155 |
+
|
| 156 |
+
All rights granted under this License are granted for the term of
|
| 157 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 158 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 159 |
+
permission to run the unmodified Program. The output from running a
|
| 160 |
+
covered work is covered by this License only if the output, given its
|
| 161 |
+
content, constitutes a covered work. This License acknowledges your
|
| 162 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 163 |
+
|
| 164 |
+
You may make, run and propagate covered works that you do not
|
| 165 |
+
convey, without conditions so long as your license otherwise remains
|
| 166 |
+
in force. You may convey covered works to others for the sole purpose
|
| 167 |
+
of having them make modifications exclusively for you, or provide you
|
| 168 |
+
with facilities for running those works, provided that you comply with
|
| 169 |
+
the terms of this License in conveying all material for which you do
|
| 170 |
+
not control copyright. Those thus making or running the covered works
|
| 171 |
+
for you must do so exclusively on your behalf, under your direction
|
| 172 |
+
and control, on terms that prohibit them from making any copies of
|
| 173 |
+
your copyrighted material outside their relationship with you.
|
| 174 |
+
|
| 175 |
+
Conveying under any other circumstances is permitted solely under
|
| 176 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 177 |
+
makes it unnecessary.
|
| 178 |
+
|
| 179 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 180 |
+
|
| 181 |
+
No covered work shall be deemed part of an effective technological
|
| 182 |
+
measure under any applicable law fulfilling obligations under article
|
| 183 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 184 |
+
similar laws prohibiting or restricting circumvention of such
|
| 185 |
+
measures.
|
| 186 |
+
|
| 187 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 188 |
+
circumvention of technological measures to the extent such circumvention
|
| 189 |
+
is effected by exercising rights under this License with respect to
|
| 190 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 191 |
+
modification of the work as a means of enforcing, against the work's
|
| 192 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 193 |
+
technological measures.
|
| 194 |
+
|
| 195 |
+
4. Conveying Verbatim Copies.
|
| 196 |
+
|
| 197 |
+
You may convey verbatim copies of the Program's source code as you
|
| 198 |
+
receive it, in any medium, provided that you conspicuously and
|
| 199 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 200 |
+
keep intact all notices stating that this License and any
|
| 201 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 202 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 203 |
+
recipients a copy of this License along with the Program.
|
| 204 |
+
|
| 205 |
+
You may charge any price or no price for each copy that you convey,
|
| 206 |
+
and you may offer support or warranty protection for a fee.
|
| 207 |
+
|
| 208 |
+
5. Conveying Modified Source Versions.
|
| 209 |
+
|
| 210 |
+
You may convey a work based on the Program, or the modifications to
|
| 211 |
+
produce it from the Program, in the form of source code under the
|
| 212 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 213 |
+
|
| 214 |
+
a) The work must carry prominent notices stating that you modified
|
| 215 |
+
it, and giving a relevant date.
|
| 216 |
+
|
| 217 |
+
b) The work must carry prominent notices stating that it is
|
| 218 |
+
released under this License and any conditions added under section
|
| 219 |
+
7. This requirement modifies the requirement in section 4 to
|
| 220 |
+
"keep intact all notices".
|
| 221 |
+
|
| 222 |
+
c) You must license the entire work, as a whole, under this
|
| 223 |
+
License to anyone who comes into possession of a copy. This
|
| 224 |
+
License will therefore apply, along with any applicable section 7
|
| 225 |
+
additional terms, to the whole of the work, and all its parts,
|
| 226 |
+
regardless of how they are packaged. This License gives no
|
| 227 |
+
permission to license the work in any other way, but it does not
|
| 228 |
+
invalidate such permission if you have separately received it.
|
| 229 |
+
|
| 230 |
+
d) If the work has interactive user interfaces, each must display
|
| 231 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 232 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 233 |
+
work need not make them do so.
|
| 234 |
+
|
| 235 |
+
A compilation of a covered work with other separate and independent
|
| 236 |
+
works, which are not by their nature extensions of the covered work,
|
| 237 |
+
and which are not combined with it such as to form a larger program,
|
| 238 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 239 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 240 |
+
used to limit the access or legal rights of the compilation's users
|
| 241 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 242 |
+
in an aggregate does not cause this License to apply to the other
|
| 243 |
+
parts of the aggregate.
|
| 244 |
+
|
| 245 |
+
6. Conveying Non-Source Forms.
|
| 246 |
+
|
| 247 |
+
You may convey a covered work in object code form under the terms
|
| 248 |
+
of sections 4 and 5, provided that you also convey the
|
| 249 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 250 |
+
in one of these ways:
|
| 251 |
+
|
| 252 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 253 |
+
(including a physical distribution medium), accompanied by the
|
| 254 |
+
Corresponding Source fixed on a durable physical medium
|
| 255 |
+
customarily used for software interchange.
|
| 256 |
+
|
| 257 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 258 |
+
(including a physical distribution medium), accompanied by a
|
| 259 |
+
written offer, valid for at least three years and valid for as
|
| 260 |
+
long as you offer spare parts or customer support for that product
|
| 261 |
+
model, to give anyone who possesses the object code either (1) a
|
| 262 |
+
copy of the Corresponding Source for all the software in the
|
| 263 |
+
product that is covered by this License, on a durable physical
|
| 264 |
+
medium customarily used for software interchange, for a price no
|
| 265 |
+
more than your reasonable cost of physically performing this
|
| 266 |
+
conveying of source, or (2) access to copy the
|
| 267 |
+
Corresponding Source from a network server at no charge.
|
| 268 |
+
|
| 269 |
+
c) Convey individual copies of the object code with a copy of the
|
| 270 |
+
written offer to provide the Corresponding Source. This
|
| 271 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 272 |
+
only if you received the object code with such an offer, in accord
|
| 273 |
+
with subsection 6b.
|
| 274 |
+
|
| 275 |
+
d) Convey the object code by offering access from a designated
|
| 276 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 277 |
+
Corresponding Source in the same way through the same place at no
|
| 278 |
+
further charge. You need not require recipients to copy the
|
| 279 |
+
Corresponding Source along with the object code. If the place to
|
| 280 |
+
copy the object code is a network server, the Corresponding Source
|
| 281 |
+
may be on a different server (operated by you or a third party)
|
| 282 |
+
that supports equivalent copying facilities, provided you maintain
|
| 283 |
+
clear directions next to the object code saying where to find the
|
| 284 |
+
Corresponding Source. Regardless of what server hosts the
|
| 285 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 286 |
+
available for as long as needed to satisfy these requirements.
|
| 287 |
+
|
| 288 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 289 |
+
you inform other peers where the object code and Corresponding
|
| 290 |
+
Source of the work are being offered to the general public at no
|
| 291 |
+
charge under subsection 6d.
|
| 292 |
+
|
| 293 |
+
A separable portion of the object code, whose source code is excluded
|
| 294 |
+
from the Corresponding Source as a System Library, need not be
|
| 295 |
+
included in conveying the object code work.
|
| 296 |
+
|
| 297 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 298 |
+
tangible personal property which is normally used for personal, family,
|
| 299 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 300 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 301 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 302 |
+
product received by a particular user, "normally used" refers to a
|
| 303 |
+
typical or common use of that class of product, regardless of the status
|
| 304 |
+
of the particular user or of the way in which the particular user
|
| 305 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 306 |
+
is a consumer product regardless of whether the product has substantial
|
| 307 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 308 |
+
the only significant mode of use of the product.
|
| 309 |
+
|
| 310 |
+
"Installation Information" for a User Product means any methods,
|
| 311 |
+
procedures, authorization keys, or other information required to install
|
| 312 |
+
and execute modified versions of a covered work in that User Product from
|
| 313 |
+
a modified version of its Corresponding Source. The information must
|
| 314 |
+
suffice to ensure that the continued functioning of the modified object
|
| 315 |
+
code is in no case prevented or interfered with solely because
|
| 316 |
+
modification has been made.
|
| 317 |
+
|
| 318 |
+
If you convey an object code work under this section in, or with, or
|
| 319 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 320 |
+
part of a transaction in which the right of possession and use of the
|
| 321 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 322 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 323 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 324 |
+
by the Installation Information. But this requirement does not apply
|
| 325 |
+
if neither you nor any third party retains the ability to install
|
| 326 |
+
modified object code on the User Product (for example, the work has
|
| 327 |
+
been installed in ROM).
|
| 328 |
+
|
| 329 |
+
The requirement to provide Installation Information does not include a
|
| 330 |
+
requirement to continue to provide support service, warranty, or updates
|
| 331 |
+
for a work that has been modified or installed by the recipient, or for
|
| 332 |
+
the User Product in which it has been modified or installed. Access to a
|
| 333 |
+
network may be denied when the modification itself materially and
|
| 334 |
+
adversely affects the operation of the network or violates the rules and
|
| 335 |
+
protocols for communication across the network.
|
| 336 |
+
|
| 337 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 338 |
+
in accord with this section must be in a format that is publicly
|
| 339 |
+
documented (and with an implementation available to the public in
|
| 340 |
+
source code form), and must require no special password or key for
|
| 341 |
+
unpacking, reading or copying.
|
| 342 |
+
|
| 343 |
+
7. Additional Terms.
|
| 344 |
+
|
| 345 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 346 |
+
License by making exceptions from one or more of its conditions.
|
| 347 |
+
Additional permissions that are applicable to the entire Program shall
|
| 348 |
+
be treated as though they were included in this License, to the extent
|
| 349 |
+
that they are valid under applicable law. If additional permissions
|
| 350 |
+
apply only to part of the Program, that part may be used separately
|
| 351 |
+
under those permissions, but the entire Program remains governed by
|
| 352 |
+
this License without regard to the additional permissions.
|
| 353 |
+
|
| 354 |
+
When you convey a copy of a covered work, you may at your option
|
| 355 |
+
remove any additional permissions from that copy, or from any part of
|
| 356 |
+
it. (Additional permissions may be written to require their own
|
| 357 |
+
removal in certain cases when you modify the work.) You may place
|
| 358 |
+
additional permissions on material, added by you to a covered work,
|
| 359 |
+
for which you have or can give appropriate copyright permission.
|
| 360 |
+
|
| 361 |
+
Notwithstanding any other provision of this License, for material you
|
| 362 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 363 |
+
that material) supplement the terms of this License with terms:
|
| 364 |
+
|
| 365 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 366 |
+
terms of sections 15 and 16 of this License; or
|
| 367 |
+
|
| 368 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 369 |
+
author attributions in that material or in the Appropriate Legal
|
| 370 |
+
Notices displayed by works containing it; or
|
| 371 |
+
|
| 372 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 373 |
+
requiring that modified versions of such material be marked in
|
| 374 |
+
reasonable ways as different from the original version; or
|
| 375 |
+
|
| 376 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 377 |
+
authors of the material; or
|
| 378 |
+
|
| 379 |
+
e) Declining to grant rights under trademark law for use of some
|
| 380 |
+
trade names, trademarks, or service marks; or
|
| 381 |
+
|
| 382 |
+
f) Requiring indemnification of licensors and authors of that
|
| 383 |
+
material by anyone who conveys the material (or modified versions of
|
| 384 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 385 |
+
any liability that these contractual assumptions directly impose on
|
| 386 |
+
those licensors and authors.
|
| 387 |
+
|
| 388 |
+
All other non-permissive additional terms are considered "further
|
| 389 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 390 |
+
received it, or any part of it, contains a notice stating that it is
|
| 391 |
+
governed by this License along with a term that is a further
|
| 392 |
+
restriction, you may remove that term. If a license document contains
|
| 393 |
+
a further restriction but permits relicensing or conveying under this
|
| 394 |
+
License, you may add to a covered work material governed by the terms
|
| 395 |
+
of that license document, provided that the further restriction does
|
| 396 |
+
not survive such relicensing or conveying.
|
| 397 |
+
|
| 398 |
+
If you add terms to a covered work in accord with this section, you
|
| 399 |
+
must place, in the relevant source files, a statement of the
|
| 400 |
+
additional terms that apply to those files, or a notice indicating
|
| 401 |
+
where to find the applicable terms.
|
| 402 |
+
|
| 403 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 404 |
+
form of a separately written license, or stated as exceptions;
|
| 405 |
+
the above requirements apply either way.
|
| 406 |
+
|
| 407 |
+
8. Termination.
|
| 408 |
+
|
| 409 |
+
You may not propagate or modify a covered work except as expressly
|
| 410 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 411 |
+
modify it is void, and will automatically terminate your rights under
|
| 412 |
+
this License (including any patent licenses granted under the third
|
| 413 |
+
paragraph of section 11).
|
| 414 |
+
|
| 415 |
+
However, if you cease all violation of this License, then your
|
| 416 |
+
license from a particular copyright holder is reinstated (a)
|
| 417 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 418 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 419 |
+
holder fails to notify you of the violation by some reasonable means
|
| 420 |
+
prior to 60 days after the cessation.
|
| 421 |
+
|
| 422 |
+
Moreover, your license from a particular copyright holder is
|
| 423 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 424 |
+
violation by some reasonable means, this is the first time you have
|
| 425 |
+
received notice of violation of this License (for any work) from that
|
| 426 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 427 |
+
your receipt of the notice.
|
| 428 |
+
|
| 429 |
+
Termination of your rights under this section does not terminate the
|
| 430 |
+
licenses of parties who have received copies or rights from you under
|
| 431 |
+
this License. If your rights have been terminated and not permanently
|
| 432 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 433 |
+
material under section 10.
|
| 434 |
+
|
| 435 |
+
9. Acceptance Not Required for Having Copies.
|
| 436 |
+
|
| 437 |
+
You are not required to accept this License in order to receive or
|
| 438 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 439 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 440 |
+
to receive a copy likewise does not require acceptance. However,
|
| 441 |
+
nothing other than this License grants you permission to propagate or
|
| 442 |
+
modify any covered work. These actions infringe copyright if you do
|
| 443 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 444 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 445 |
+
|
| 446 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 447 |
+
|
| 448 |
+
Each time you convey a covered work, the recipient automatically
|
| 449 |
+
receives a license from the original licensors, to run, modify and
|
| 450 |
+
propagate that work, subject to this License. You are not responsible
|
| 451 |
+
for enforcing compliance by third parties with this License.
|
| 452 |
+
|
| 453 |
+
An "entity transaction" is a transaction transferring control of an
|
| 454 |
+
organization, or substantially all assets of one, or subdividing an
|
| 455 |
+
organization, or merging organizations. If propagation of a covered
|
| 456 |
+
work results from an entity transaction, each party to that
|
| 457 |
+
transaction who receives a copy of the work also receives whatever
|
| 458 |
+
licenses to the work the party's predecessor in interest had or could
|
| 459 |
+
give under the previous paragraph, plus a right to possession of the
|
| 460 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 461 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 462 |
+
|
| 463 |
+
You may not impose any further restrictions on the exercise of the
|
| 464 |
+
rights granted or affirmed under this License. For example, you may
|
| 465 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 466 |
+
rights granted under this License, and you may not initiate litigation
|
| 467 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 468 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 469 |
+
sale, or importing the Program or any portion of it.
|
| 470 |
+
|
| 471 |
+
11. Patents.
|
| 472 |
+
|
| 473 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 474 |
+
License of the Program or a work on which the Program is based. The
|
| 475 |
+
work thus licensed is called the contributor's "contributor version".
|
| 476 |
+
|
| 477 |
+
A contributor's "essential patent claims" are all patent claims
|
| 478 |
+
owned or controlled by the contributor, whether already acquired or
|
| 479 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 480 |
+
by this License, of making, using, or selling its contributor version,
|
| 481 |
+
but do not include claims that would be infringed only as a
|
| 482 |
+
consequence of further modification of the contributor version. For
|
| 483 |
+
purposes of this definition, "control" includes the right to grant
|
| 484 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 485 |
+
this License.
|
| 486 |
+
|
| 487 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 488 |
+
patent license under the contributor's essential patent claims, to
|
| 489 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 490 |
+
propagate the contents of its contributor version.
|
| 491 |
+
|
| 492 |
+
In the following three paragraphs, a "patent license" is any express
|
| 493 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 494 |
+
(such as an express permission to practice a patent or covenant not to
|
| 495 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 496 |
+
party means to make such an agreement or commitment not to enforce a
|
| 497 |
+
patent against the party.
|
| 498 |
+
|
| 499 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 500 |
+
and the Corresponding Source of the work is not available for anyone
|
| 501 |
+
to copy, free of charge and under the terms of this License, through a
|
| 502 |
+
publicly available network server or other readily accessible means,
|
| 503 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 504 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 505 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 506 |
+
consistent with the requirements of this License, to extend the patent
|
| 507 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 508 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 509 |
+
covered work in a country, or your recipient's use of the covered work
|
| 510 |
+
in a country, would infringe one or more identifiable patents in that
|
| 511 |
+
country that you have reason to believe are valid.
|
| 512 |
+
|
| 513 |
+
If, pursuant to or in connection with a single transaction or
|
| 514 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 515 |
+
covered work, and grant a patent license to some of the parties
|
| 516 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 517 |
+
or convey a specific copy of the covered work, then the patent license
|
| 518 |
+
you grant is automatically extended to all recipients of the covered
|
| 519 |
+
work and works based on it.
|
| 520 |
+
|
| 521 |
+
A patent license is "discriminatory" if it does not include within
|
| 522 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 523 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 524 |
+
specifically granted under this License. You may not convey a covered
|
| 525 |
+
work if you are a party to an arrangement with a third party that is
|
| 526 |
+
in the business of distributing software, under which you make payment
|
| 527 |
+
to the third party based on the extent of your activity of conveying
|
| 528 |
+
the work, and under which the third party grants, to any of the
|
| 529 |
+
parties who would receive the covered work from you, a discriminatory
|
| 530 |
+
patent license (a) in connection with copies of the covered work
|
| 531 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 532 |
+
for and in connection with specific products or compilations that
|
| 533 |
+
contain the covered work, unless you entered into that arrangement,
|
| 534 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 535 |
+
|
| 536 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 537 |
+
any implied license or other defenses to infringement that may
|
| 538 |
+
otherwise be available to you under applicable patent law.
|
| 539 |
+
|
| 540 |
+
12. No Surrender of Others' Freedom.
|
| 541 |
+
|
| 542 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 543 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 544 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 545 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 546 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 547 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 548 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 549 |
+
the Program, the only way you could satisfy both those terms and this
|
| 550 |
+
License would be to refrain entirely from conveying the Program.
|
| 551 |
+
|
| 552 |
+
13. Use with the GNU Affero General Public License.
|
| 553 |
+
|
| 554 |
+
Notwithstanding any other provision of this License, you have
|
| 555 |
+
permission to link or combine any covered work with a work licensed
|
| 556 |
+
under version 3 of the GNU Affero General Public License into a single
|
| 557 |
+
combined work, and to convey the resulting work. The terms of this
|
| 558 |
+
License will continue to apply to the part which is the covered work,
|
| 559 |
+
but the special requirements of the GNU Affero General Public License,
|
| 560 |
+
section 13, concerning interaction through a network will apply to the
|
| 561 |
+
combination as such.
|
| 562 |
+
|
| 563 |
+
14. Revised Versions of this License.
|
| 564 |
+
|
| 565 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 566 |
+
the GNU General Public License from time to time. Such new versions will
|
| 567 |
+
be similar in spirit to the present version, but may differ in detail to
|
| 568 |
+
address new problems or concerns.
|
| 569 |
+
|
| 570 |
+
Each version is given a distinguishing version number. If the
|
| 571 |
+
Program specifies that a certain numbered version of the GNU General
|
| 572 |
+
Public License "or any later version" applies to it, you have the
|
| 573 |
+
option of following the terms and conditions either of that numbered
|
| 574 |
+
version or of any later version published by the Free Software
|
| 575 |
+
Foundation. If the Program does not specify a version number of the
|
| 576 |
+
GNU General Public License, you may choose any version ever published
|
| 577 |
+
by the Free Software Foundation.
|
| 578 |
+
|
| 579 |
+
If the Program specifies that a proxy can decide which future
|
| 580 |
+
versions of the GNU General Public License can be used, that proxy's
|
| 581 |
+
public statement of acceptance of a version permanently authorizes you
|
| 582 |
+
to choose that version for the Program.
|
| 583 |
+
|
| 584 |
+
Later license versions may give you additional or different
|
| 585 |
+
permissions. However, no additional obligations are imposed on any
|
| 586 |
+
author or copyright holder as a result of your choosing to follow a
|
| 587 |
+
later version.
|
| 588 |
+
|
| 589 |
+
15. Disclaimer of Warranty.
|
| 590 |
+
|
| 591 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 592 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 593 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 594 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 595 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 596 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 597 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 598 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 599 |
+
|
| 600 |
+
16. Limitation of Liability.
|
| 601 |
+
|
| 602 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 603 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 604 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 605 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 606 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 607 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 608 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 609 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 610 |
+
SUCH DAMAGES.
|
| 611 |
+
|
| 612 |
+
17. Interpretation of Sections 15 and 16.
|
| 613 |
+
|
| 614 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 615 |
+
above cannot be given local legal effect according to their terms,
|
| 616 |
+
reviewing courts shall apply local law that most closely approximates
|
| 617 |
+
an absolute waiver of all civil liability in connection with the
|
| 618 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 619 |
+
copy of the Program in return for a fee.
|
| 620 |
+
|
| 621 |
+
END OF TERMS AND CONDITIONS
|
| 622 |
+
|
| 623 |
+
How to Apply These Terms to Your New Programs
|
| 624 |
+
|
| 625 |
+
If you develop a new program, and you want it to be of the greatest
|
| 626 |
+
possible use to the public, the best way to achieve this is to make it
|
| 627 |
+
free software which everyone can redistribute and change under these terms.
|
| 628 |
+
|
| 629 |
+
To do so, attach the following notices to the program. It is safest
|
| 630 |
+
to attach them to the start of each source file to most effectively
|
| 631 |
+
state the exclusion of warranty; and each file should have at least
|
| 632 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 633 |
+
|
| 634 |
+
Marker pdf to markdown converter
|
| 635 |
+
Copyright (C) 2023 Vikas Paruchuri
|
| 636 |
+
|
| 637 |
+
This program is free software: you can redistribute it and/or modify
|
| 638 |
+
it under the terms of the GNU General Public License as published by
|
| 639 |
+
the Free Software Foundation, either version 3 of the License, or
|
| 640 |
+
(at your option) any later version.
|
| 641 |
+
|
| 642 |
+
This program is distributed in the hope that it will be useful,
|
| 643 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 644 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 645 |
+
GNU General Public License for more details.
|
| 646 |
+
|
| 647 |
+
You should have received a copy of the GNU General Public License
|
| 648 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 649 |
+
|
| 650 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 651 |
+
|
| 652 |
+
If the program does terminal interaction, make it output a short
|
| 653 |
+
notice like this when it starts in an interactive mode:
|
| 654 |
+
|
| 655 |
+
Marker Copyright (C) 2023 Vikas Paruchuri
|
| 656 |
+
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
|
| 657 |
+
This is free software, and you are welcome to redistribute it
|
| 658 |
+
under certain conditions; type `show c' for details.
|
| 659 |
+
|
| 660 |
+
The hypothetical commands `show w' and `show c' should show the appropriate
|
| 661 |
+
parts of the General Public License. Of course, your program's commands
|
| 662 |
+
might be different; for a GUI interface, you would use an "about box".
|
| 663 |
+
|
| 664 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 665 |
+
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
| 666 |
+
For more information on this, and how to apply and follow the GNU GPL, see
|
| 667 |
+
<https://www.gnu.org/licenses/>.
|
| 668 |
+
|
| 669 |
+
The GNU General Public License does not permit incorporating your program
|
| 670 |
+
into proprietary programs. If your program is a subroutine library, you
|
| 671 |
+
may consider it more useful to permit linking proprietary applications with
|
| 672 |
+
the library. If this is what you want to do, use the GNU Lesser General
|
| 673 |
+
Public License instead of this License. But first, please read
|
| 674 |
+
<https://www.gnu.org/licenses/why-not-lgpl.html>.
|
benchmark.py
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import tempfile
|
| 3 |
+
import time
|
| 4 |
+
from collections import defaultdict
|
| 5 |
+
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
import pypdfium2 as pdfium
|
| 8 |
+
|
| 9 |
+
from marker.convert import convert_single_pdf
|
| 10 |
+
from marker.logger import configure_logging
|
| 11 |
+
from marker.models import load_all_models
|
| 12 |
+
from marker.benchmark.scoring import score_text
|
| 13 |
+
from marker.pdf.extract_text import naive_get_text
|
| 14 |
+
import json
|
| 15 |
+
import os
|
| 16 |
+
import subprocess
|
| 17 |
+
import shutil
|
| 18 |
+
from tabulate import tabulate
|
| 19 |
+
import torch
|
| 20 |
+
|
| 21 |
+
configure_logging()
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def start_memory_profiling():
|
| 25 |
+
torch.cuda.memory._record_memory_history(
|
| 26 |
+
max_entries=100000
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def stop_memory_profiling(memory_file):
|
| 31 |
+
try:
|
| 32 |
+
torch.cuda.memory._dump_snapshot(memory_file)
|
| 33 |
+
except Exception as e:
|
| 34 |
+
logger.error(f"Failed to capture memory snapshot {e}")
|
| 35 |
+
|
| 36 |
+
# Stop recording memory snapshot history.
|
| 37 |
+
torch.cuda.memory._record_memory_history(enabled=None)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def nougat_prediction(pdf_filename, batch_size=1):
|
| 41 |
+
out_dir = tempfile.mkdtemp()
|
| 42 |
+
subprocess.run(["nougat", pdf_filename, "-o", out_dir, "--no-skipping", "--recompute", "--batchsize", str(batch_size)], check=True)
|
| 43 |
+
md_file = os.listdir(out_dir)[0]
|
| 44 |
+
with open(os.path.join(out_dir, md_file), "r") as f:
|
| 45 |
+
data = f.read()
|
| 46 |
+
shutil.rmtree(out_dir)
|
| 47 |
+
return data
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def main():
|
| 51 |
+
parser = argparse.ArgumentParser(description="Benchmark PDF to MD conversion. Needs source pdfs, and a refernece folder with the correct markdown.")
|
| 52 |
+
parser.add_argument("in_folder", help="Input PDF files")
|
| 53 |
+
parser.add_argument("reference_folder", help="Reference folder with reference markdown files")
|
| 54 |
+
parser.add_argument("out_file", help="Output filename")
|
| 55 |
+
parser.add_argument("--nougat", action="store_true", help="Run nougat and compare", default=False)
|
| 56 |
+
# Nougat batch size 1 uses about as much VRAM as default marker settings
|
| 57 |
+
parser.add_argument("--marker_batch_multiplier", type=int, default=1, help="Batch size multiplier to use for marker when making predictions.")
|
| 58 |
+
parser.add_argument("--nougat_batch_size", type=int, default=1, help="Batch size to use for nougat when making predictions.")
|
| 59 |
+
parser.add_argument("--md_out_path", type=str, default=None, help="Output path for generated markdown files")
|
| 60 |
+
parser.add_argument("--profile_memory", action="store_true", help="Profile memory usage", default=False)
|
| 61 |
+
|
| 62 |
+
args = parser.parse_args()
|
| 63 |
+
|
| 64 |
+
methods = ["marker"]
|
| 65 |
+
if args.nougat:
|
| 66 |
+
methods.append("nougat")
|
| 67 |
+
|
| 68 |
+
if args.profile_memory:
|
| 69 |
+
start_memory_profiling()
|
| 70 |
+
|
| 71 |
+
model_lst = load_all_models()
|
| 72 |
+
|
| 73 |
+
if args.profile_memory:
|
| 74 |
+
stop_memory_profiling("model_load.pickle")
|
| 75 |
+
|
| 76 |
+
scores = defaultdict(dict)
|
| 77 |
+
benchmark_files = os.listdir(args.in_folder)
|
| 78 |
+
benchmark_files = [b for b in benchmark_files if b.endswith(".pdf")]
|
| 79 |
+
times = defaultdict(dict)
|
| 80 |
+
pages = defaultdict(int)
|
| 81 |
+
|
| 82 |
+
for idx, fname in tqdm(enumerate(benchmark_files)):
|
| 83 |
+
md_filename = fname.rsplit(".", 1)[0] + ".md"
|
| 84 |
+
|
| 85 |
+
reference_filename = os.path.join(args.reference_folder, md_filename)
|
| 86 |
+
with open(reference_filename, "r", encoding="utf-8") as f:
|
| 87 |
+
reference = f.read()
|
| 88 |
+
|
| 89 |
+
pdf_filename = os.path.join(args.in_folder, fname)
|
| 90 |
+
doc = pdfium.PdfDocument(pdf_filename)
|
| 91 |
+
pages[fname] = len(doc)
|
| 92 |
+
|
| 93 |
+
for method in methods:
|
| 94 |
+
start = time.time()
|
| 95 |
+
if method == "marker":
|
| 96 |
+
if args.profile_memory:
|
| 97 |
+
start_memory_profiling()
|
| 98 |
+
full_text, _, out_meta = convert_single_pdf(pdf_filename, model_lst, batch_multiplier=args.marker_batch_multiplier)
|
| 99 |
+
if args.profile_memory:
|
| 100 |
+
stop_memory_profiling(f"marker_memory_{idx}.pickle")
|
| 101 |
+
elif method == "nougat":
|
| 102 |
+
full_text = nougat_prediction(pdf_filename, batch_size=args.nougat_batch_size)
|
| 103 |
+
elif method == "naive":
|
| 104 |
+
full_text = naive_get_text(doc)
|
| 105 |
+
else:
|
| 106 |
+
raise ValueError(f"Unknown method {method}")
|
| 107 |
+
|
| 108 |
+
times[method][fname] = time.time() - start
|
| 109 |
+
|
| 110 |
+
score = score_text(full_text, reference)
|
| 111 |
+
scores[method][fname] = score
|
| 112 |
+
|
| 113 |
+
if args.md_out_path:
|
| 114 |
+
md_out_filename = f"{method}_{md_filename}"
|
| 115 |
+
with open(os.path.join(args.md_out_path, md_out_filename), "w+") as f:
|
| 116 |
+
f.write(full_text)
|
| 117 |
+
|
| 118 |
+
total_pages = sum(pages.values())
|
| 119 |
+
with open(args.out_file, "w+") as f:
|
| 120 |
+
write_data = defaultdict(dict)
|
| 121 |
+
for method in methods:
|
| 122 |
+
total_time = sum(times[method].values())
|
| 123 |
+
file_stats = {
|
| 124 |
+
fname:
|
| 125 |
+
{
|
| 126 |
+
"time": times[method][fname],
|
| 127 |
+
"score": scores[method][fname],
|
| 128 |
+
"pages": pages[fname]
|
| 129 |
+
}
|
| 130 |
+
|
| 131 |
+
for fname in benchmark_files
|
| 132 |
+
}
|
| 133 |
+
write_data[method] = {
|
| 134 |
+
"files": file_stats,
|
| 135 |
+
"avg_score": sum(scores[method].values()) / len(scores[method]),
|
| 136 |
+
"time_per_page": total_time / total_pages,
|
| 137 |
+
"time_per_doc": total_time / len(scores[method])
|
| 138 |
+
}
|
| 139 |
+
|
| 140 |
+
json.dump(write_data, f, indent=4)
|
| 141 |
+
|
| 142 |
+
summary_table = []
|
| 143 |
+
score_table = []
|
| 144 |
+
score_headers = benchmark_files
|
| 145 |
+
for method in methods:
|
| 146 |
+
summary_table.append([method, write_data[method]["avg_score"], write_data[method]["time_per_page"], write_data[method]["time_per_doc"]])
|
| 147 |
+
score_table.append([method, *[write_data[method]["files"][h]["score"] for h in score_headers]])
|
| 148 |
+
|
| 149 |
+
print(tabulate(summary_table, headers=["Method", "Average Score", "Time per page", "Time per document"]))
|
| 150 |
+
print("")
|
| 151 |
+
print("Scores by file")
|
| 152 |
+
print(tabulate(score_table, headers=["Method", *score_headers]))
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
if __name__ == "__main__":
|
| 156 |
+
main()
|
| 157 |
+
|
chunk_convert.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import subprocess
|
| 3 |
+
import pkg_resources
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def main():
|
| 7 |
+
parser = argparse.ArgumentParser(description="Convert a folder of PDFs to a folder of markdown files in chunks.")
|
| 8 |
+
parser.add_argument("in_folder", help="Input folder with pdfs.")
|
| 9 |
+
parser.add_argument("out_folder", help="Output folder")
|
| 10 |
+
args = parser.parse_args()
|
| 11 |
+
|
| 12 |
+
script_path = pkg_resources.resource_filename(__name__, 'chunk_convert.sh')
|
| 13 |
+
|
| 14 |
+
# Construct the command
|
| 15 |
+
cmd = f"{script_path} {args.in_folder} {args.out_folder}"
|
| 16 |
+
|
| 17 |
+
# Execute the shell script
|
| 18 |
+
subprocess.run(cmd, shell=True, check=True)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
if __name__ == "__main__":
|
| 22 |
+
main()
|
chunk_convert.sh
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
trap 'pkill -P $$' SIGINT
|
| 4 |
+
|
| 5 |
+
# Check if NUM_DEVICES is set
|
| 6 |
+
if [[ -z "$NUM_DEVICES" ]]; then
|
| 7 |
+
echo "Please set the NUM_DEVICES environment variable."
|
| 8 |
+
exit 1
|
| 9 |
+
fi
|
| 10 |
+
|
| 11 |
+
if [[ -z "$NUM_WORKERS" ]]; then
|
| 12 |
+
echo "Please set the NUM_WORKERS environment variable."
|
| 13 |
+
exit 1
|
| 14 |
+
fi
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
# Get input folder and output folder from args
|
| 18 |
+
if [[ -z "$1" ]]; then
|
| 19 |
+
echo "Please provide an input folder."
|
| 20 |
+
exit 1
|
| 21 |
+
fi
|
| 22 |
+
|
| 23 |
+
if [[ -z "$2" ]]; then
|
| 24 |
+
echo "Please provide an output folder."
|
| 25 |
+
exit 1
|
| 26 |
+
fi
|
| 27 |
+
|
| 28 |
+
INPUT_FOLDER=$1
|
| 29 |
+
OUTPUT_FOLDER=$2
|
| 30 |
+
|
| 31 |
+
# Loop from 0 to NUM_DEVICES and run the Python script in parallel
|
| 32 |
+
for (( i=0; i<$NUM_DEVICES; i++ )); do
|
| 33 |
+
DEVICE_NUM=$i
|
| 34 |
+
export DEVICE_NUM
|
| 35 |
+
export NUM_DEVICES
|
| 36 |
+
export NUM_WORKERS
|
| 37 |
+
echo "Running convert.py on GPU $DEVICE_NUM"
|
| 38 |
+
cmd="CUDA_VISIBLE_DEVICES=$DEVICE_NUM marker $INPUT_FOLDER $OUTPUT_FOLDER --num_chunks $NUM_DEVICES --chunk_idx $DEVICE_NUM --workers $NUM_WORKERS"
|
| 39 |
+
[[ -n "$METADATA_FILE" ]] && cmd="$cmd --metadata_file $METADATA_FILE"
|
| 40 |
+
[[ -n "$MIN_LENGTH" ]] && cmd="$cmd --min_length $MIN_LENGTH"
|
| 41 |
+
eval $cmd &
|
| 42 |
+
|
| 43 |
+
sleep 5
|
| 44 |
+
done
|
| 45 |
+
|
| 46 |
+
# Wait for all background processes to finish
|
| 47 |
+
wait
|
convert.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
from typing import Dict, Optional
|
| 4 |
+
|
| 5 |
+
import ray
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
import math
|
| 8 |
+
|
| 9 |
+
from marker.convert import convert_single_pdf
|
| 10 |
+
from marker.output import markdown_exists, save_markdown
|
| 11 |
+
from marker.pdf.utils import find_filetype
|
| 12 |
+
from marker.pdf.extract_text import get_length_of_text
|
| 13 |
+
from marker.models import load_all_models
|
| 14 |
+
from marker.settings import settings
|
| 15 |
+
from marker.logger import configure_logging
|
| 16 |
+
import traceback
|
| 17 |
+
import json
|
| 18 |
+
|
| 19 |
+
configure_logging()
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
@ray.remote(num_cpus=settings.RAY_CORES_PER_WORKER, num_gpus=.05 if settings.CUDA else 0)
|
| 23 |
+
def process_single_pdf(filepath: str, out_folder: str, model_refs, metadata: Optional[Dict] = None, min_length: Optional[int] = None):
|
| 24 |
+
fname = os.path.basename(filepath)
|
| 25 |
+
if markdown_exists(out_folder, fname):
|
| 26 |
+
return
|
| 27 |
+
|
| 28 |
+
try:
|
| 29 |
+
# Skip trying to convert files that don't have a lot of embedded text
|
| 30 |
+
# This can indicate that they were scanned, and not OCRed properly
|
| 31 |
+
# Usually these files are not recent/high-quality
|
| 32 |
+
if min_length:
|
| 33 |
+
filetype = find_filetype(filepath)
|
| 34 |
+
if filetype == "other":
|
| 35 |
+
return 0
|
| 36 |
+
|
| 37 |
+
length = get_length_of_text(filepath)
|
| 38 |
+
if length < min_length:
|
| 39 |
+
return
|
| 40 |
+
|
| 41 |
+
full_text, images, out_metadata = convert_single_pdf(filepath, model_refs, metadata=metadata)
|
| 42 |
+
if len(full_text.strip()) > 0:
|
| 43 |
+
save_markdown(out_folder, fname, full_text, images, out_metadata)
|
| 44 |
+
else:
|
| 45 |
+
print(f"Empty file: {filepath}. Could not convert.")
|
| 46 |
+
except Exception as e:
|
| 47 |
+
print(f"Error converting {filepath}: {e}")
|
| 48 |
+
print(traceback.format_exc())
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def main():
|
| 52 |
+
parser = argparse.ArgumentParser(description="Convert multiple pdfs to markdown.")
|
| 53 |
+
parser.add_argument("in_folder", help="Input folder with pdfs.")
|
| 54 |
+
parser.add_argument("out_folder", help="Output folder")
|
| 55 |
+
parser.add_argument("--chunk_idx", type=int, default=0, help="Chunk index to convert")
|
| 56 |
+
parser.add_argument("--num_chunks", type=int, default=1, help="Number of chunks being processed in parallel")
|
| 57 |
+
parser.add_argument("--max", type=int, default=None, help="Maximum number of pdfs to convert")
|
| 58 |
+
parser.add_argument("--workers", type=int, default=5, help="Number of worker processes to use")
|
| 59 |
+
parser.add_argument("--metadata_file", type=str, default=None, help="Metadata json file to use for filtering")
|
| 60 |
+
parser.add_argument("--min_length", type=int, default=None, help="Minimum length of pdf to convert")
|
| 61 |
+
|
| 62 |
+
args = parser.parse_args()
|
| 63 |
+
|
| 64 |
+
in_folder = os.path.abspath(args.in_folder)
|
| 65 |
+
out_folder = os.path.abspath(args.out_folder)
|
| 66 |
+
files = [os.path.join(in_folder, f) for f in os.listdir(in_folder)]
|
| 67 |
+
files = [f for f in files if os.path.isfile(f)]
|
| 68 |
+
os.makedirs(out_folder, exist_ok=True)
|
| 69 |
+
|
| 70 |
+
# Handle chunks if we're processing in parallel
|
| 71 |
+
# Ensure we get all files into a chunk
|
| 72 |
+
chunk_size = math.ceil(len(files) / args.num_chunks)
|
| 73 |
+
start_idx = args.chunk_idx * chunk_size
|
| 74 |
+
end_idx = start_idx + chunk_size
|
| 75 |
+
files_to_convert = files[start_idx:end_idx]
|
| 76 |
+
|
| 77 |
+
# Limit files converted if needed
|
| 78 |
+
if args.max:
|
| 79 |
+
files_to_convert = files_to_convert[:args.max]
|
| 80 |
+
|
| 81 |
+
metadata = {}
|
| 82 |
+
if args.metadata_file:
|
| 83 |
+
metadata_file = os.path.abspath(args.metadata_file)
|
| 84 |
+
with open(metadata_file, "r") as f:
|
| 85 |
+
metadata = json.load(f)
|
| 86 |
+
|
| 87 |
+
total_processes = min(len(files_to_convert), args.workers)
|
| 88 |
+
|
| 89 |
+
ray.init(
|
| 90 |
+
num_cpus=total_processes,
|
| 91 |
+
num_gpus=1 if settings.CUDA else 0,
|
| 92 |
+
storage=settings.RAY_CACHE_PATH,
|
| 93 |
+
_temp_dir=settings.RAY_CACHE_PATH,
|
| 94 |
+
log_to_driver=settings.DEBUG
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
model_lst = load_all_models()
|
| 98 |
+
model_refs = ray.put(model_lst)
|
| 99 |
+
|
| 100 |
+
# Dynamically set GPU allocation per task based on GPU ram
|
| 101 |
+
gpu_frac = settings.VRAM_PER_TASK / settings.INFERENCE_RAM if settings.CUDA else 0
|
| 102 |
+
|
| 103 |
+
print(f"Converting {len(files_to_convert)} pdfs in chunk {args.chunk_idx + 1}/{args.num_chunks} with {total_processes} processes, and storing in {out_folder}")
|
| 104 |
+
futures = [
|
| 105 |
+
process_single_pdf.options(num_gpus=gpu_frac).remote(
|
| 106 |
+
filepath,
|
| 107 |
+
out_folder,
|
| 108 |
+
model_refs,
|
| 109 |
+
metadata=metadata.get(os.path.basename(filepath)),
|
| 110 |
+
min_length=args.min_length
|
| 111 |
+
) for filepath in files_to_convert
|
| 112 |
+
]
|
| 113 |
+
|
| 114 |
+
# Run all ray conversion tasks
|
| 115 |
+
progress_bar = tqdm(total=len(futures))
|
| 116 |
+
while len(futures) > 0:
|
| 117 |
+
finished, futures = ray.wait(
|
| 118 |
+
futures, timeout=7.0
|
| 119 |
+
)
|
| 120 |
+
finished_lst = ray.get(finished)
|
| 121 |
+
if isinstance(finished_lst, list):
|
| 122 |
+
progress_bar.update(len(finished_lst))
|
| 123 |
+
else:
|
| 124 |
+
progress_bar.update(1)
|
| 125 |
+
|
| 126 |
+
# Shutdown ray to free resources
|
| 127 |
+
ray.shutdown()
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
if __name__ == "__main__":
|
| 131 |
+
main()
|
convert_single.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
from marker.convert import convert_single_pdf
|
| 5 |
+
from marker.logger import configure_logging
|
| 6 |
+
from marker.models import load_all_models
|
| 7 |
+
|
| 8 |
+
from marker.output import save_markdown
|
| 9 |
+
|
| 10 |
+
configure_logging()
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def main():
|
| 14 |
+
parser = argparse.ArgumentParser()
|
| 15 |
+
parser.add_argument("filename", help="PDF file to parse")
|
| 16 |
+
parser.add_argument("output", help="Output base folder path")
|
| 17 |
+
parser.add_argument("--max_pages", type=int, default=None, help="Maximum number of pages to parse")
|
| 18 |
+
parser.add_argument("--langs", type=str, help="Languages to use for OCR, comma separated", default=None)
|
| 19 |
+
parser.add_argument("--batch_multiplier", type=int, default=2, help="How much to increase batch sizes")
|
| 20 |
+
args = parser.parse_args()
|
| 21 |
+
|
| 22 |
+
langs = args.langs.split(",") if args.langs else None
|
| 23 |
+
|
| 24 |
+
fname = args.filename
|
| 25 |
+
model_lst = load_all_models()
|
| 26 |
+
full_text, images, out_meta = convert_single_pdf(fname, model_lst, max_pages=args.max_pages, langs=langs, batch_multiplier=args.batch_multiplier)
|
| 27 |
+
|
| 28 |
+
fname = os.path.basename(fname)
|
| 29 |
+
subfolder_path = save_markdown(args.output, fname, full_text, images, out_meta)
|
| 30 |
+
|
| 31 |
+
print(f"Saved markdown to the {subfolder_path} folder")
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
if __name__ == "__main__":
|
| 35 |
+
main()
|
data/.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
latex
|
| 2 |
+
pdfs
|
| 3 |
+
references
|
data/examples/marker/multicolcnn.md
ADDED
|
@@ -0,0 +1,350 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# An Aggregated Multicolumn Dilated Convolution Network For Perspective-Free Counting
|
| 2 |
+
|
| 3 |
+
Diptodip Deb Georgia Institute of Technology diptodipdeb@gatech.edu Jonathan Ventura University of Colorado Colorado Springs jventura@uccs.edu
|
| 4 |
+
|
| 5 |
+
## Abstract
|
| 6 |
+
|
| 7 |
+
We propose the use of dilated filters to construct an aggregation module in a multicolumn convolutional neural network for perspective-free counting. Counting is a common problem in computer vision (e.g. traffic on the street or pedestrians in a crowd). Modern approaches to the counting problem involve the production of a density map via regression whose integral is equal to the number of objects in the image. However, objects in the image can occur at different scales (e.g. due to perspective effects) which can make it difficult for a learning agent to learn the proper density map. While the use of multiple columns to extract multiscale information from images has been shown before, our approach aggregates the multiscale information gathered by the multicolumn convolutional neural network to improve performance. Our experiments show that our proposed network outperforms the state-of-the-art on many benchmark datasets, and also that using our aggregation module in combination with a higher number of columns is beneficial for multiscale counting.
|
| 8 |
+
|
| 9 |
+
## 1. Introduction
|
| 10 |
+
|
| 11 |
+
Learning to count the number of objects in an image is a deceptively difficult problem with many interesting applications, such as surveillance [20], traffic monitoring [14] and medical image analysis [22]. In many of these application areas, the objects to be counted vary widely in appearance, size and shape, and labeled training data is typically sparse.
|
| 12 |
+
|
| 13 |
+
These factors pose a significant computer vision and machine learning challenge.
|
| 14 |
+
|
| 15 |
+
Lempitsky et al. [15] showed that it is possible to learn to count without learning to explicitly detect and localize individual objects. Instead, they propose learning to predict a density map whose integral over the image equals the number of objects in the image. This approach has been adopted by many later works (Cf. [18, 28]).
|
| 16 |
+
|
| 17 |
+
However, in many counting problems, such as those counting cells in a microscope image, pedestrians in a crowd, or vehicles in a traffic jam, regressors trained on a single image scale are not reliable [18]. This is due to a variety of challenges including overlap of objects and perspective effects which cause significant variance in object shape, size and appearance.
|
| 18 |
+
|
| 19 |
+
The most successful recent approaches address this issue by explicitly incorporating multi-scale information in the network [18,28]. These approaches either combine multiple networks which take input patches of different sizes [18]
|
| 20 |
+
or combine multiple filtering paths ("columns") which have different size filters [28].
|
| 21 |
+
|
| 22 |
+
Following on the intuition that multiscale integration is key to achieving good counting performance, we propose to incorporate dilated filters [25] into a multicolumn convolutional neural network design [28]. Dilated filters exponentially increase the network's receptive field without an exponential increase in parameters, allowing for efficient use of multiscale information. Convolutional neural networks with dilated filters have proven to provide competitive performance in image segmentation where multiscale analysis is also critical [25, 26]. By incorporating dilated filters into the multicolumn network design, we greatly increase the ability of the network to selectively aggregate multiscale information, without the need for explicit perspective maps during training and testing. We propose the
|
| 23 |
+
"aggregated multicolumn dilated convolution network" or AMDCN which uses dilations to aggregate multiscale information. Our extensive experimental evaluation shows that this proposed network outperforms previous methods on many benchmark datasets.
|
| 24 |
+
|
| 25 |
+
## 2. Related Work
|
| 26 |
+
|
| 27 |
+
Counting using a supervised regressor to formulate a density map was first shown by [15]. In this paper, Lempitsky et al. show that the minimal annotation of a single dot blurred by a Gaussian kernel produces a sufficient density map to train a network to count. All of the counting methods that we examine as well as the method we use in
|
| 28 |
+
|
| 29 |
+

|
| 30 |
+
|
| 31 |
+
D
|
| 32 |
+
our paper follow this method of producing a density map via regression. This is particularly advantageous because a sufficiently accurate regressor can also locate the objects in the image via this method. However, the Lempitsky paper ignores the issue of perspective scaling and other scaling issues. The work of [27] introduces CNNs (convolutional neural networks) for the purposes of crowd counting, but performs regression on similarly scaled image patches.
|
| 33 |
+
|
| 34 |
+
These issues are addressed by the work of [18]. Rubio et al. show that a fully convolutional neural network can be used to produce a supervised regressor that produces density maps as in [15]. They further demonstrate a method dubbed HydraCNN which essentially combines multiple convolutional networks that take in differently scaled image patches in order to incorporate multiscale, global information from the image. The premise of this method is that a single regressor will fail to accurately represent the difference in values of the features of an image caused by perspective shifts (scaling effects) [18].
|
| 35 |
+
|
| 36 |
+
However, the architectures of both [18] and [27] are not fully convolutional due to requiring multiple image patches and, as discussed in [25], the experiments of [11, 17] and [9, 12, 16] leave it unclear as to whether rescaling patches of the image is truly necessary in order to solve dense prediction problems via convolutional neural networks. Moreover, these approaches seem to saturate in performance at three columns, which means the network is extracting information from fewer scales. The work of [25] proposes the use of dilated convolutions as a simpler alternative that does not require sampling of rescaled image patches to provide global, scale-aware information to the network. A fully convolutional approach to multiscale counting has been proposed by [28], in which a multicolumn convolutional network gathers features of different scales by using convolutions of increasing kernel sizes from column to column instead of scaling image patches. Further, DeepLab has used dilated convolutions in multiple columns to extract scale information for segmentation [8]. We build on these approaches with our aggregator module as described in Section 3.1, which should allow for extracting information from more scales.
|
| 37 |
+
|
| 38 |
+
It should be noted that other methods of counting exist, including training a network to recognize deep object features via only providing the counts of the objects of interest in an image [21] and using CNNs (convolutional neural networks) along with boosting in order to improve the results
|
| 39 |
+
|
| 40 |
+

|
| 41 |
+
|
| 42 |
+
of regression for production of density maps [24]. In the same spirit, [4] combines deep and shallow convolutions within the same network, providing accurate counting of dense objects (e.g. the UCF50 crowd dataset).
|
| 43 |
+
|
| 44 |
+
In this paper, however, we aim to apply the dilated convolution method of [25], which has shown to be able to incorporate multiscale perspective information without using multiple inputs or a complicated network architecture, as well as the multicolumn approach of [8, 28] to aggregate multiscale information for the counting problem.
|
| 45 |
+
|
| 46 |
+
## 3. Method 3.1. Dilated Convolutions For Multicolumn Networks
|
| 47 |
+
|
| 48 |
+
We propose the use of dilated convolutions as an attractive alternative to the architecture of the HydraCNN
|
| 49 |
+
[18], which seems to saturate in performance at 3 or more columns. We refer to our proposed network as the aggregated multicolumn dilated convolution network1, henceforth shortened as the AMDCN. The architecture of the AMDCN is inspired by the multicolumn counting network of [28]. Extracting features from multiple scales is a good idea when attempting to perform perspective-free counting and increasing the convolution kernel size across columns is an efficient method of doing so. However, the number of parameters increases exponentially as larger kernels are used in these columns to extract features at larger scales. Therefore, we propose using dilated convolutions rather than larger kernels.
|
| 50 |
+
|
| 51 |
+
Dilated convolutions, as discussed in [25], allow for the exponential increase of the receptive field with a linear increase in the number of parameters with respect to each hidden layer.
|
| 52 |
+
|
| 53 |
+
In a traditional 2D convolution, we define a real valued function F : Z
|
| 54 |
+
2 → R, an input Ωr = [−*r, r*]
|
| 55 |
+
2 ∈ Z
|
| 56 |
+
2, and a filter function k : Ωr → R. In this case, a convolution operation as defined in [25] is given by
|
| 57 |
+
|
| 58 |
+
$$(F*k)({\bf p})=\sum_{{\bf s}+{\bf t}={\bf p}}F({\bf s})k({\bf t}).\qquad\qquad(1)$$
|
| 59 |
+
|
| 60 |
+
A dilated convolution is essentially a generalization of the traditional 2D convolution that allows the operation to skip some inputs. This enables an increase in the size of the filter (i.e. the size of the receptive field) without losing resolution. Formally, we define from [25] the dilated convolution as
|
| 61 |
+
|
| 62 |
+
$$(F*_{l}k)(\mathbf{p})=\sum_{\mathbf{s}+l\mathbf{t}=\mathbf{p}}F(\mathbf{s})k(\mathbf{t})$$
|
| 63 |
+
$${\mathrm{(2)}}$$
|
| 64 |
+
F(s)k(t) (2)
|
| 65 |
+
where l is the index of the current layer of the convolution.
|
| 66 |
+
|
| 67 |
+
Using dilations to construct the aggregator in combination with the multicolumn idea will allow for the construction of a network with more than just 3 or 4 columns as in [28] and [8], because the aggregator should prevent the saturation of performance with increasing numbers of columns. Therefore the network will be able to extract useful features from more scales. We take advantage of dilations within the columns as well to provide large receptive fields with fewer parameters.
|
| 68 |
+
|
| 69 |
+
Looking at more scales should allow for more accurate regression of the density map. However, because not all scales will be relevant, we extend the network beyond a simple 1 × 1 convolution after the merged columns. Instead, we construct a second part of the network, the aggregator, which sets our method apart from [28], [8], and other multicolumn networks. This aggregator is another series of dilated convolutions that should appropriately consolidate the multiscale information collected by the columns. This is a capability of dilated convolutions observed by [25].
|
| 70 |
+
|
| 71 |
+
While papers such as [28] and [8] have shown that multiple columns and dilated columns are useful in extracting multiscale information, we argue in this paper that the simple aggregator module built using dilated convolutions is able to effectively make use multiscale information from multiple columns. We show compelling evidence for these claims in Section 4.5.
|
| 72 |
+
|
| 73 |
+
The network as shown in Figure 1 contains 5 columns.
|
| 74 |
+
|
| 75 |
+
Note that dilations allow us to use more columns for counting than [28] or [8]. Each column looks at a larger scale than the previous (the exact dilations can also be seen in Figure 1). There are 32 feature maps for each convolution, and all inputs are zero padded prior to each convolution in order to maintain the same data shape from input to output. That is, an image input to this network will result in a density map of the same dimensions. All activations in the specified network are ReLUs. Our input pixel values are floating point 32 bit values from 0 to 1. We center our inputs at 0 by subtracting the per channel mean from each channel. When training, we use a scaled mean absolute error for our loss function:
|
| 76 |
+
|
| 77 |
+
$$L={\frac{1}{n}}\sum_{i=1}^{n}\vert{\hat{y}}_{i}-\gamma y_{i}\vert$$
|
| 78 |
+
|
| 79 |
+
where γ is the scale factor, yˆiis the prediction, yiis the true value, and n is the number of pixels. We use a scaled mean absolute error because the target values are so small that it is numerically unstable to regress to these values. At testing time, when retrieving the output density map from the network, we scale the pixel values by γ
|
| 80 |
+
−1to obtain the correct value. This approach is more numerically stable and avoids having the network learn to output only zeros by weighting the nonzero values highly. For all our datasets, we set γ = 255.
|
| 81 |
+
|
| 82 |
+
## 3.2. Experiments
|
| 83 |
+
|
| 84 |
+
We evaluated the performance of dilated convolutions against various counting methods on a variety of common counting datasets: UCF50 crowd data, TRANCOS traffic data [18], UCSD crowd data [5], and WorldExpo crowd data [27]. For each of these data sets, we used labels given by the corresponding density map for each image. An example of this is shown in Figure 2. We have performed experiments on the four different splits of the UCSD data as used in [18] and the split of the UCSD data as used in [28] (which we call the original split). We also evaluated the performance of our network on the TRANCOS traffic dataset [14]. We have also experimented with higher density datasets for crowd counting, namely WorldExpo and UCF.
|
| 85 |
+
|
| 86 |
+
We have observed that multicolumn dilations produce density maps (and therefore counts) that often have lower loss than those of HydraCNN [18] and [28]. We measure density map regression loss via a scaled mean absolute error loss during training. We compare accuracy of the counts via mean absolute error for the crowd datasets and the GAME
|
| 87 |
+
metric in the TRANCOS dataset as explained in Section 3.2.2. Beyond the comparison to HydraCNN, we will also compare to other recent convolutional counting methods, especially those of [21], [24], and [4] where possible.
|
| 88 |
+
|
| 89 |
+
For all datasets, we generally use patched input images and ground truth density maps produced by summing a Gaussian of a fixed size (σ) for each object for training.
|
| 90 |
+
|
| 91 |
+
This size varies from dataset to dataset, but remains constant within a dataset with the exception of cases in which a perspective map is used. This is explained per dataset. All experiments were performed using Keras with the Adam optimizer [10]. The learning rates used are detailed per dataset.
|
| 92 |
+
|
| 93 |
+
For testing, we also use patches that can either be directly pieced together or overlapped and averaged except in the case of UCF, for which we run our network on the full image.
|
| 94 |
+
|
| 95 |
+
$$(3)$$
|
| 96 |
+
|
| 97 |
+
Furthermore, we performed a set of experiments in which we varied the number of columns from 1 to 5 (simply by including or not including the columns as specified in Figure 1, starting with the smallest filter column and adding larger filter columns one by one). Essentially, the network is allowed to extract information at larger and larger scales in addition to the smaller scales as we include each column. We then performed the same set of experiments, varying the number of columns, but with the aggregator module removed. We perform these experiments on the original split of UCSD as specified in Section 3.2.3 and [5], the TRANCOS dataset, and the WorldExpo dataset because these are relatively large and well defined datasets. We limit the number of epochs to 10 for all of these sets of experiments in order to control for the effect of learning time, and also compare all results using MAE for consistency. These experiments are key to determining the efficacy of the aggregator in effectively combining multiscale information and in providing evidence to support the use of multiple columns to extract multiscale information from images. We report the results of these ablation studies in Section 4.5.
|
| 98 |
+
|
| 99 |
+
## 3.2.1 Ucf50 Crowd Counting
|
| 100 |
+
|
| 101 |
+
UCF is a particularly challenging crowd counting dataset.
|
| 102 |
+
|
| 103 |
+
There are only 50 images in the whole dataset and they are all of varying sizes and from different scenes. The number of people also varies between images from less than 100 to the thousands. The average image has on the order of 1000 people. The difficulty is due to the combination of the very low number of images in the dataset and the fact that the images are all of varying scenes, making high quality generalization crucial. Furthermore, perspective effects are particularly noticeable for many images in this dataset. Despite this, there is no perspective information available for this dataset.
|
| 104 |
+
|
| 105 |
+
We take 1600 random patches of size 150 × 150 for the training. For testing, we do not densely scan the image as in [18] but instead test on the whole image. In order to standardize the image sizes, we pad each image out with zeros until all images are 1024 × 1024. We then suppress output in the regions where we added padding when testing.
|
| 106 |
+
|
| 107 |
+
This provides a cleaner resulting density map for these large crowds. The ground truth density maps are produced by annotating each object with a Gaussian of σ = 15.
|
| 108 |
+
|
| 109 |
+
## 3.2.2 Trancos Traffic Counting
|
| 110 |
+
|
| 111 |
+
TRANCOS is a traffic counting dataset that comes with its own metric [14]. This metric is known as *GAME*, which stands for Grid Average Mean absolute Error. *GAME* splits a given density map into 4 L grids, or subarrays, and obtains a mean absolute error within each grid separately.
|
| 112 |
+
|
| 113 |
+
The value of L is a parameter chosen by the user. These individual errors are summed to obtain the final error for a particular image. The intuition behind this metric is that it is desirable to penalize a density map whose overall count might match the ground truth, but whose shape does not match the ground truth [14]. More formally, we define
|
| 114 |
+
|
| 115 |
+
$$G A M E(L)={\frac{1}{N}}\cdot\sum_{n=1}^{N}\left(\sum_{l=1}^{4^{L}}\!\left|e_{n}^{l}-t_{n}^{l}\right|\right)\qquad(4)$$
|
| 116 |
+
|
| 117 |
+
where N refers to the number of images, L is the level parameter for *GAME*, e l n is the predicted or estimated count in region l of image n and t l n is the ground truth count in region l of image n [14].
|
| 118 |
+
|
| 119 |
+
For training this dataset, we take 1600 randomly sampled patches of size 80 × 80. For testing this dataset, we take 80 × 80 non-overlapping patches which we can stitch back together into the full-sized 640 × 480 images. We trained the AMDCN network with density maps produced with a Gaussian of σ = 15 as specified in [18].
|
| 120 |
+
|
| 121 |
+
## 3.2.3 Ucsd Crowd Counting
|
| 122 |
+
|
| 123 |
+
The UCSD crowd counting dataset consists of frames of video of a sidewalk. There are relatively few people in view at any given time (approximately 25 on average). Furthermore, because the dataset comes from a video, there are many nearly identical images in the dataset. For this dataset, there have been two different ways to split the data into train and test sets. Therefore, we report results using both methods of splitting the data. The first method consists of four different splits: maximal, downscale, upscale, and minimal.
|
| 124 |
+
|
| 125 |
+
Minimal is particularly challenging as the train set contains only 10 images. Moreover, upscale appears to be the easiest for the majority of methods [18]. The second method of splitting this data is much more succinct, leaving 1200 images in the testing set and 800 images in the training set [28]. This split comes from the original paper, so we call it the original split [5].
|
| 126 |
+
|
| 127 |
+
For this dataset, each object is annotated with a 2D Gaussian of covariance Σ = 8 · 12×2. The ground truth map is produced by summing these. When we make use of the perspective maps provided, we divide Σ by the perspective map value at that pixel x, represented by M(x). The provided perspective map for UCSD contains both a horizontal and vertical direction so we take the square root of the provided combined value. For training, we take 1600 random 79 × 119 pixel patches and for testing, we split each test image up into quadrants (which have dimension 79 × 119).
|
| 128 |
+
|
| 129 |
+
There are two different ways to split the dataset into training and testing sets. We have experimented on the split that gave [18] the best results as well as the split used in [28].
|
| 130 |
+
|
| 131 |
+
First, we split the dataset into four separate groups of training and testing sets as used in [18] and originally defined by [20]. These groups are "upscale," "maximal,"
|
| 132 |
+
"minimal," and "downscale." We see in Table 3 that the
|
| 133 |
+
"upscale" split and "downscale" split give us state of the art results on counting for this dataset. For this experiment, we sampled 1600 random patches of size 119 × 79 pixels
|
| 134 |
+
(width and height respectively) for the training set and split the test set images into 119 × 79 quadrants that could be reconstructed by piecing them together without overlap. We also added left-right flips of each image to our training data.
|
| 135 |
+
|
| 136 |
+
We then evaluate the original split. For this experiment, we similarly sampled 1600 random patches of size 119×79 pixels (width and height respectively) for the training set and split the test set images into 119 × 79 quadrants that could be reconstructed by piecing them together without overlap.
|
| 137 |
+
|
| 138 |
+
## 3.2.4 Worldexpo '10 Crowd Counting
|
| 139 |
+
|
| 140 |
+
The WorldExpo dataset [27] contains a larger number of people (approximately 50 on average, which is double that of UCSD) and contains images from multiple locations.
|
| 141 |
+
|
| 142 |
+
Perspective effects are also much more noticeable in this dataset as compared to UCSD. These qualities of the dataset serve to increase the difficulty of counting. Like UCSD, the WorldExpo dataset was constructed from frames of video recordings of crowds. This means that, unlike UCF, this dataset contains a relatively large number of training and testing images. We experiment on this dataset with and without perspective information.
|
| 143 |
+
|
| 144 |
+
Without perspective maps, we generate label density maps for this dataset in the same manner as previously described: a 2D Gaussian with σ = 15. We take 16000 150 × 150 randomly sampled patches for training. For testing, we densely scan the image, producing 150 × 150 patches at a stride of 100.
|
| 145 |
+
|
| 146 |
+
When perspective maps are used, however, we follow the procedure as described in [27], which involves estimating a
|
| 147 |
+
"crowd density distribution kernel" as the sum of two 2D
|
| 148 |
+
Gaussians: a symmetric Gaussian for the head and an ellipsoid Gaussian for the body. These are scaled by the perspective map M provided, where M(x) gives the number of pixels that represents a meter at pixel x [27]. Note that the meaning of this perspective map is distinct from the meaning of the perspective map provided for the UCSD dataset.
|
| 149 |
+
|
| 150 |
+
Using this information, the density contribution from a person with head pixel x is given by the following sum of normalized Gaussians:
|
| 151 |
+
|
| 152 |
+
$$D_{\bf x}=\frac{1}{||Z||}({\cal N}_{h}({\bf x},\sigma_{h})+{\cal N}_{b}({\bf x}_{b},\Sigma_{b}))\qquad\qquad(5)$$
|
| 153 |
+
|
| 154 |
+
where xb is the center of the body, which is 0.875 meters down from the head on average, and can be determined from the perspective map M and the head center x [27]. We sum these Gaussians for each person to pro-
|
| 155 |
+
Table 1. Mean absolute error of various methods on UCF crowds
|
| 156 |
+
|
| 157 |
+
| Method | MAE |
|
| 158 |
+
|--------------|--------|
|
| 159 |
+
| AMDCN | 290.82 |
|
| 160 |
+
| Hydra2s [18] | 333.73 |
|
| 161 |
+
| MCNN [28] | 377.60 |
|
| 162 |
+
| [27] | 467.00 |
|
| 163 |
+
| [23] | 295.80 |
|
| 164 |
+
| [3] | 318.10 |
|
| 165 |
+
|
| 166 |
+
duce the final density map. We set σ = 0.2M(x) for Nh and σx = 0.2M(x), σy = 0.5M(x) for Σb in Nb.
|
| 167 |
+
|
| 168 |
+
## 4. Results 4.1. Ucf Crowd Counting
|
| 169 |
+
|
| 170 |
+
The UCF dataset is particularly challenging due to the large number of people in the images, the variety of the scenes, as well as the low number of training images. We see in Figure 2 that because the UCF dataset has over 1000 people on average in each image, the shapes output by the network in the density map are not as well defined or separated as in the UCSD dataset.
|
| 171 |
+
|
| 172 |
+
We report a state of the art result on this dataset in Table 1, following the standard protocol of 5-fold cross validation. Our MAE on the dataset is 290.82, which is approximately 5 lower than the previous state of the art, HydraCNN [18]. This is particularly indicative of the power of an aggregated multicolumn dilation network. Despite not making use of perspective information, the AMDCN is still able to produce highly accurate density maps for UCF.
|
| 173 |
+
|
| 174 |
+
## 4.2. Trancos Traffic Counting
|
| 175 |
+
|
| 176 |
+
Our network performs very well on the TRANCOS
|
| 177 |
+
dataset. Indeed, as confirmed by the GAME score, AMDCN produces the most accurate count and shape combined as compared to other methods. Table 2 shows that we achieve state of the art results as measured by the *GAME*
|
| 178 |
+
metric [14] across all levels.
|
| 179 |
+
|
| 180 |
+
## 4.3. Ucsd Crowd Counting
|
| 181 |
+
|
| 182 |
+
Results are shown in Table 3 and Figure 3. We see that the "original" split as defined by the creators of the dataset in [5] and used in [28] gives us somewhat worse results for counting on this dataset. Results were consistent over multiple trainings. Again, including the perspective map does not seem to increase performance on this dataset. Despite this, we see in Table 3 and Figure 3 that the results are comparable to the state of the art. In fact, for two of the splits, our proposed network beats the state of the art. For the upscale split, the AMDCN is the state of the art by a large relative margin. This is compelling because it shows that accurate perspective-free counting can be achieved without
|
| 183 |
+
|
| 184 |
+
| Method | GAME | GAME | GAME | GAME | | |
|
| 185 |
+
|-----------------------------------------------|--------|--------|--------|--------|-------|-------|
|
| 186 |
+
| (L=0) | (L=1) | (L=2) | (L=3) | | | |
|
| 187 |
+
| AMDCN | 9.77 | 13.16 | 15.00 | 15.87 | | |
|
| 188 |
+
| [18] | 10.99 | 13.75 | 16.69 | 19.32 | | |
|
| 189 |
+
| [15] | + | SIFT | 13.76 | 16.72 | 20.72 | 24.36 |
|
| 190 |
+
| from [14] [13] + RGB Norm + Filters from [14] | 17.68 | 19.97 | 23.54 | 25.84 | | |
|
| 191 |
+
| HOG-2 | 13.29 | 18.05 | 23.65 | 28.41 | | |
|
| 192 |
+
| from [14] | | | | | | |
|
| 193 |
+
|
| 194 |
+
creating image pyramids or requiring perspective maps as labels using the techniques presented by the AMDCN.
|
| 195 |
+
|
| 196 |
+
## 4.4. Worldexpo '10 Crowd Counting
|
| 197 |
+
|
| 198 |
+
Our network performs reasonably well on the more challenging WorldExpo dataset. While it does not beat the state of the art, our results are comparable. What is more, we do not need to use the perspective maps to obtain these results.
|
| 199 |
+
|
| 200 |
+
As seen in Table 4, the AMDCN is capable of incorporating the perspective effects without scaling the Gaussians with perspective information. This shows that it is possible to achieve counting results that approach the state of the art with much simpler labels for the counting training data.
|
| 201 |
+
|
| 202 |
+
## 4.5. Ablation Studies
|
| 203 |
+
|
| 204 |
+
We report the results of the ablation studies in Figure 4. We note from these plots that while there is variation in performance, a few trends stand out. Most importantly, the lowest errors are consistently with a combination of a larger number of columns and including the aggregator module.
|
| 205 |
+
|
| 206 |
+
Notably for the TRANCOS dataset, including the aggregator consistently improves performance. Generally, the aggregator tends to decrease the variance in performance of the network. Some of the variance that we see in the plots can be explained by: (1) for lower numbers of columns, including an aggregator is not as likely to help as there is not much separation of multiscale information across columns and (2) for the UCSD dataset, there is less of a perspective effect than TRANCOS and WorldExpo so a simpler network is more likely to perform comparably to a larger network. These results verify the notion that using more columns increases accuracy, and also support our justification for the use of the aggregator module.
|
| 207 |
+
|
| 208 |
+

|
| 209 |
+
|
| 210 |
+

|
| 211 |
+
|
| 212 |
+
| Method | maximal | downscale | upscale | minimal | original |
|
| 213 |
+
|-----------------------------------------|-----------|-------------|-----------|-----------|------------|
|
| 214 |
+
| AMDCN (without perspective information) | 1.63 | 1.43 | 0.63 | 1.71 | 1.74 |
|
| 215 |
+
| AMDCN (with perspective information) | 1.60 | 1.24 | 1.37 | 1.59 | 1.72 |
|
| 216 |
+
| [18] (with perspective information) | 1.65 | 1.79 | 1.11 | 1.50 | - |
|
| 217 |
+
| [18] (without perspective information) | 2.22 | 1.93 | 1.37 | 2.38 | - |
|
| 218 |
+
| [15] | 1.70 | 1.28 | 1.59 | 2.02 | - |
|
| 219 |
+
| [13] | 1.70 | 2.16 | 1.61 | 2.20 | - |
|
| 220 |
+
| [19] | 1.43 | 1.30 | 1.59 | 1.62 | - |
|
| 221 |
+
| [2] | 1.24 | 1.31 | 1.69 | 1.49 | - |
|
| 222 |
+
| [27] | 1.70 | 1.26 | 1.59 | 1.52 | 1.60 |
|
| 223 |
+
| [28] | - | - | - | - | 1.07 |
|
| 224 |
+
| [1, 28] | - | - | - | - | 2.16 |
|
| 225 |
+
| [7] | - | - | - | - | 2.25 |
|
| 226 |
+
| [5] | - | - | - | - | 2.24 |
|
| 227 |
+
| [6] | - | - | - | - | 2.07 |
|
| 228 |
+
|
| 229 |
+
## 5. Conclusion 5.1. Summary
|
| 230 |
+
|
| 231 |
+
We have proposed the use of aggregated multicolumn dilated convolutions, the AMDCN, as an alternative to the HydraCNN [18] or multicolumn CNN [28] for the vision task of counting objects in images. Inspired by the multicolumn approach to multiscale problems, we also employ dilations to increase the receptive field of our columns. We then aggregate this multiscale information using another series of dilated convolutions to enable a wide network and detect features at more scales. This method takes advantage of the ability of dilated convolutions to provide exponentially increasing receptive fields. We have performed experiments on the challenging UCF crowd counting dataset, the TRANCOS traffic dataset, multiple splits of the UCSD
|
| 232 |
+
crowd counting dataset, and the WorldExpo crowd counting dataset.
|
| 233 |
+
|
| 234 |
+

|
| 235 |
+
|
| 236 |
+
| Method | MAE |
|
| 237 |
+
|-------------------------------------|-------|
|
| 238 |
+
| AMDCN (without perspective information) | 16.6 |
|
| 239 |
+
| AMDCN (with perspective information) | 14.9 |
|
| 240 |
+
| LBP+RR [28] (with perspective information) | 31.0 |
|
| 241 |
+
| MCNN [28] (with perspective information) | 11.6 |
|
| 242 |
+
| [27] (with perspective information) | 12.9 |
|
| 243 |
+
|
| 244 |
+
We obtain superior or comparable results in most of these datasets. The AMDCN is capable of outperforming these approaches completely especially when perspective information is not provided, as in UCF and TRANCOS. These results show that the AMDCN performs surprisingly well and is also robust to scale effects. Further, our ablation study of removing the aggregator network shows that using more columns and an aggregator provides the best accuracy for counting - especially so when there is no perspective information.
|
| 245 |
+
|
| 246 |
+
## 5.2. Future Work
|
| 247 |
+
|
| 248 |
+
In addition to an analysis of performance on counting, a density regressor can also be used to locate objects in the image. As mentioned previously, if the regressor is accurate and precise enough, the resulting density map can be used to locate the objects in the image. We expect that in order to do this, one must regress each object to a single point rather than a region specified by a Gaussian. Perhaps this might be accomplished by applying non-maxima suppression to the final layer activations.
|
| 249 |
+
|
| 250 |
+
Indeed, the method of applying dilated filters to a multicolumn convolutional network in order to enable extracting features of a large number of scales can be applied to various other dense prediction tasks, such as object segmentation at multiple scales or single image depth map prediction.
|
| 251 |
+
|
| 252 |
+
Though we have only conducted experiments on counting and used 5 columns, the architecture presented can be extended and adapted to a variety of tasks that require information at multiple scales.
|
| 253 |
+
|
| 254 |
+
## Acknowledgment
|
| 255 |
+
|
| 256 |
+
This material is based upon work supported by the National Science Foundation under Grant No. 1359275 and 1659788. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation. Furthermore, we acknowledge Kyle Yee and Sridhama Prakhya for their helpful conversations and insights during the research process.
|
| 257 |
+
|
| 258 |
+
## References
|
| 259 |
+
|
| 260 |
+
[1] S. An, W. Liu, and S. Venkatesh. Face recognition using kernel ridge regression. In Computer Vision and
|
| 261 |
+
Pattern Recognition, 2007. CVPR'07. IEEE Conference on, pages 1–7. IEEE, 2007.
|
| 262 |
+
[2] C. Arteta, V. Lempitsky, J. A. Noble, and A. Zisserman. Interactive object counting. In *European Conference on Computer Vision*, pages 504–518. Springer,
|
| 263 |
+
2014.
|
| 264 |
+
[3] D. Babu Sam, S. Surya, and R. Venkatesh Babu.
|
| 265 |
+
Switching convolutional neural network for crowd
|
| 266 |
+
[15] V. Lempitsky and A. Zisserman. Learning to count objects in images. In *Advances in Neural Information*
|
| 267 |
+
Processing Systems, pages 1324–1332, 2010.
|
| 268 |
+
|
| 269 |
+
[16] G. Lin, C. Shen, A. van den Hengel, and I. Reid. Efficient piecewise training of deep structured models for semantic segmentation. In Proceedings of the IEEE
|
| 270 |
+
Conference on Computer Vision and Pattern Recognition, pages 3194–3203, 2016.
|
| 271 |
+
|
| 272 |
+
[17] H. Noh, S. Hong, and B. Han. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pages 1520–1528, 2015.
|
| 273 |
+
|
| 274 |
+
[18] D. Onoro-Rubio and R. J. Lopez-Sastre. Towards ´
|
| 275 |
+
perspective-free object counting with deep learning.
|
| 276 |
+
|
| 277 |
+
In *European Conference on Computer Vision*, pages 615–629. Springer, 2016.
|
| 278 |
+
|
| 279 |
+
[19] V.-Q. Pham, T. Kozakaya, O. Yamaguchi, and R. Okada. Count forest: Co-voting uncertain number of targets using random forest for crowd density estimation. In Proceedings of the IEEE International Conference on Computer Vision, pages 3253–3261, 2015.
|
| 280 |
+
|
| 281 |
+
[20] D. Ryan, S. Denman, C. Fookes, and S. Sridharan.
|
| 282 |
+
|
| 283 |
+
Crowd counting using multiple local features. In Digital Image Computing: Techniques and Applications, 2009. DICTA'09., pages 81–88. IEEE, 2009.
|
| 284 |
+
|
| 285 |
+
[21] S. Segu´ı, O. Pujol, and J. Vitria. Learning to count with deep object features. In *Proceedings of the IEEE*
|
| 286 |
+
Conference on Computer Vision and Pattern Recognition Workshops, pages 90–96, 2015.
|
| 287 |
+
|
| 288 |
+
[22] J. Selinummi, O. Yli-Harja, and J. A. Puhakka. Software for quantification of labeled bacteria from digital microscope images by automated image analysis.
|
| 289 |
+
|
| 290 |
+
Biotechniques, 39(6):859, 2005.
|
| 291 |
+
|
| 292 |
+
[23] V. A. Sindagi and V. M. Patel. Generating high-quality crowd density maps using contextual pyramid cnns.
|
| 293 |
+
|
| 294 |
+
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1861–1870, 2017.
|
| 295 |
+
|
| 296 |
+
[24] E. Walach and L. Wolf. Learning to count with cnn boosting. In *European Conference on Computer Vision*, pages 660–676. Springer, 2016.
|
| 297 |
+
|
| 298 |
+
[25] F. Yu and V. Koltun. Multi-scale context aggregation by dilated convolutions. *arXiv preprint*
|
| 299 |
+
arXiv:1511.07122, 2015.
|
| 300 |
+
|
| 301 |
+
[26] F. Yu, V. Koltun, and T. Funkhouser. Dilated residual networks. *arXiv preprint arXiv:1705.09914*, 2017.
|
| 302 |
+
|
| 303 |
+
[27] C. Zhang, H. Li, X. Wang, and X. Yang. Crossscene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE Conference on counting. In *Proceedings of the IEEE Conference*
|
| 304 |
+
on Computer Vision and Pattern Recognition, pages 5744���5752, 2017.
|
| 305 |
+
|
| 306 |
+
[4] L. Boominathan, S. S. Kruthiventi, and R. V. Babu.
|
| 307 |
+
|
| 308 |
+
Crowdnet: A deep convolutional network for dense crowd counting. In Proceedings of the 2016 ACM on Multimedia Conference, pages 640–644. ACM, 2016.
|
| 309 |
+
|
| 310 |
+
[5] A. B. Chan, Z.-S. J. Liang, and N. Vasconcelos. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Computer Vision and Pattern Recognition, 2008. CVPR 2008.
|
| 311 |
+
|
| 312 |
+
IEEE Conference on, pages 1–7. IEEE, 2008.
|
| 313 |
+
|
| 314 |
+
[6] K. Chen, S. Gong, T. Xiang, and C. Change Loy. Cumulative attribute space for age and crowd density estimation. In *Proceedings of the IEEE conference on*
|
| 315 |
+
computer vision and pattern recognition, pages 2467–
|
| 316 |
+
2474, 2013.
|
| 317 |
+
|
| 318 |
+
[7] K. Chen, C. C. Loy, S. Gong, and T. Xiang. Feature mining for localised crowd counting.
|
| 319 |
+
|
| 320 |
+
[8] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. *IEEE Transactions on Pattern Analysis and Machine Intelligence*, 2017.
|
| 321 |
+
|
| 322 |
+
[9] L.-C. Chen, Y. Yang, J. Wang, W. Xu, and A. L. Yuille.
|
| 323 |
+
|
| 324 |
+
Attention to scale: Scale-aware semantic image segmentation. In *Proceedings of the IEEE Conference*
|
| 325 |
+
on Computer Vision and Pattern Recognition, pages 3640–3649, 2016.
|
| 326 |
+
|
| 327 |
+
[10] F. Chollet et al. Keras. https://github.com/
|
| 328 |
+
fchollet/keras, 2015.
|
| 329 |
+
|
| 330 |
+
[11] A. Dosovitskiy, P. Fischer, E. Ilg, P. Hausser, C. Hazirbas, V. Golkov, P. van der Smagt, D. Cremers, and T. Brox. Flownet: Learning optical flow with convolutional networks. In *Proceedings of the IEEE International Conference on Computer Vision*, pages 2758–
|
| 331 |
+
2766, 2015.
|
| 332 |
+
|
| 333 |
+
[12] C. Farabet, C. Couprie, L. Najman, and Y. LeCun. Learning hierarchical features for scene labeling. *IEEE transactions on pattern analysis and machine intelligence*, 35(8):1915–1929, 2013.
|
| 334 |
+
|
| 335 |
+
[13] L. Fiaschi, U. Kothe, R. Nair, and F. A. Hamprecht. ¨
|
| 336 |
+
Learning to count with regression forest and structured labels. In *Pattern Recognition (ICPR), 2012 21st International Conference on*, pages 2685–2688. IEEE,
|
| 337 |
+
2012.
|
| 338 |
+
|
| 339 |
+
[14] R. Guerrero-Gomez-Olmedo, B. Torre-Jim ´ enez, S. M. ´
|
| 340 |
+
Lopez-Sastre, Roberto Basc ´ on, and D. O ´ noro Rubio. ˜
|
| 341 |
+
Extremely overlapping vehicle counting. In *Iberian*
|
| 342 |
+
Conference on Pattern Recognition and Image Analysis (IbPRIA), 2015.
|
| 343 |
+
|
| 344 |
+
Computer Vision and Pattern Recognition, pages 833–
|
| 345 |
+
841, 2015.
|
| 346 |
+
|
| 347 |
+
[28] Y. Zhang, D. Zhou, S. Chen, S. Gao, and Y. Ma.
|
| 348 |
+
|
| 349 |
+
Single-image crowd counting via multi-column convolutional neural network. In *Proceedings of the IEEE*
|
| 350 |
+
Conference on Computer Vision and Pattern Recognition, pages 589–597, 2016.
|
data/examples/marker/switch_transformers.md
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/examples/marker/thinkos.md
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/examples/marker/thinkpython.md
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/examples/nougat/multicolcnn.md
ADDED
|
@@ -0,0 +1,245 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# An Aggregated Multicolumn Dilated Convolution Network
|
| 2 |
+
|
| 3 |
+
for Perspective-Free Counting
|
| 4 |
+
|
| 5 |
+
Diptodip Deb
|
| 6 |
+
|
| 7 |
+
Georgia Institute of Technology
|
| 8 |
+
|
| 9 |
+
diptodipdeb@gatech.edu
|
| 10 |
+
|
| 11 |
+
Jonathan Ventura
|
| 12 |
+
|
| 13 |
+
University of Colorado Colorado Springs
|
| 14 |
+
|
| 15 |
+
jventura@uccs.edu
|
| 16 |
+
|
| 17 |
+
###### Abstract
|
| 18 |
+
|
| 19 |
+
We propose the use of dilated filters to construct an aggregation module in a multicolumn convolutional neural network for perspective-free counting. Counting is a common problem in computer vision (e.g. traffic on the street or pedestrians in a crowd). Modern approaches to the counting problem involve the production of a density map via regression whose integral is equal to the number of objects in the image. However, objects in the image can occur at different scales (e.g. due to perspective effects) which can make it difficult for a learning agent to learn the proper density map. While the use of multiple columns to extract multiscale information from images has been shown before, our approach aggregates the multiscale information gathered by the multicolumn convolutional neural network to improve performance. Our experiments show that our proposed network outperforms the state-of-the-art on many benchmark datasets, and also that using our aggregation module in combination with a higher number of columns is beneficial for multiscale counting.
|
| 20 |
+
|
| 21 |
+
## 1 Introduction
|
| 22 |
+
|
| 23 |
+
Learning to count the number of objects in an image is a deceptively difficult problem with many interesting applications, such as surveillance [20], traffic monitoring [14] and medical image analysis [22]. In many of these application areas, the objects to be counted vary widely in appearance, size and shape, and labeled training data is typically sparse. These factors pose a significant computer vision and machine learning challenge.
|
| 24 |
+
|
| 25 |
+
Lempitsky et al. [15] showed that it is possible to learn to count without learning to explicitly detect and localize individual objects. Instead, they propose learning to predict a density map whose integral over the image equals the number of objects in the image. This approach has been adopted by many later works (Cf. [18, 28]).
|
| 26 |
+
|
| 27 |
+
However, in many counting problems, such as those counting cells in a microscope image, pedestrians in a crowd, or vehicles in a traffic jam, regressors trained on a single image scale are not reliable [18]. This is due to a variety of challenges including overlap of objects and perspective effects which cause significant variance in object shape, size and appearance.
|
| 28 |
+
|
| 29 |
+
The most successful recent approaches address this issue by explicitly incorporating multi-scale information in the network [18, 28]. These approaches either combine multiple networks which take input patches of different sizes [18] or combine multiple filtering paths ("columns") which have different size filters [28].
|
| 30 |
+
|
| 31 |
+
Following on the intuition that multiscale integration is key to achieving good counting performance, we propose to incorporate dilated filters [25] into a multicolumn convolutional neural network design [28]. Dilated filters exponentially increase the network's receptive field without an exponential increase in parameters, allowing for efficient use of multiscale information. Convolutional neural networks with dilated filters have proven to provide competitive performance in image segmentation where multiscale analysis is also critical [25, 26]. By incorporating dilated filters into the multicolumn network design, we greatly increase the ability of the network to selectively aggregate multiscale information, without the need for explicit perspective maps during training and testing. We propose the "aggregated multicolumn dilated convolution network" or AMDCN which uses dilations to aggregate multiscale information. Our extensive experimental evaluation shows that this proposed network outperforms previous methods on many benchmark datasets.
|
| 32 |
+
|
| 33 |
+
## 2 Related Work
|
| 34 |
+
|
| 35 |
+
Counting using a supervised regressor to formulate a density map was first shown by [15]. In this paper, Lempitsky et al. show that the minimal annotation of a single dot blurred by a Gaussian kernel produces a sufficient density map to train a network to count. All of the counting methods that we examine as well as the method we use inour paper follow this method of producing a density map via regression. This is particularly advantageous because a sufficiently accurate regressor can also locate the objects in the image via this method. However, the Lempitsky paper ignores the issue of perspective scaling and other scaling issues. The work of [27] introduces CNNs (convolutional neural networks) for the purposes of crowd counting, but performs regression on similarly scaled image patches.
|
| 36 |
+
|
| 37 |
+
These issues are addressed by the work of [18]. Rubio et al. show that a fully convolutional neural network can be used to produce a supervised regressor that produces density maps as in [15]. They further demonstrate a method dubbed HydraCNN which essentially combines multiple convolutional networks that take in differently scaled image patches in order to incorporate multiscale, global information from the image. The premise of this method is that a single regressor will fail to accurately represent the difference in values of the features of an image caused by perspective shifts (scaling effects) [18].
|
| 38 |
+
|
| 39 |
+
However, the architectures of both [18] and [27] are not fully convolutional due to requiring multiple image patches and, as discussed in [25], the experiments of [11, 17] and [9, 12, 16] leave it unclear as to whether rescaling patches of the image is truly necessary in order to solve dense prediction problems via convolutional neural networks. Moreover, these approaches seem to saturate in performance at three columns, which means the network is extracting information from fewer scales. The work of [25] proposes the use of dilated convolutions as a simpler alternative that does not require sampling of rescaled image patches to provide global, scale-aware information to the network. A fully convolutional approach to multiscale counting has been proposed by [28], in which a multicolumn convolutional network gathers features of different scales by using convolutions of increasing kernel sizes from column to column instead of scaling image patches. Further, DeepLab has used dilated convolutions in multiple columns to extract scale information for segmentation [8]. We build on these approaches with our aggregator module as described in Section 3.1, which should allow for extracting information from more scales.
|
| 40 |
+
|
| 41 |
+
It should be noted that other methods of counting exist, including training a network to recognize deep object features via only providing the counts of the objects of interest in an image [21] and using CNNs (convolutional neural networks) along with boosting in order to improve the results
|
| 42 |
+
|
| 43 |
+
Figure 1: Fully convolutional architecture diagram (not to scale). Arrows show separate columns that all take the same input. At the end of the columns, the feature maps are merged (concatenated) together and passed to another series of dilated convolutions: the aggregator, which can aggregate the multiscale information collected by the columns [25]. The input image is I with C channels. The output single channel density map is D, and integrating over this map (summing the pixels) results in the final count. Initial filter sizes are labeled with brackets or lines. Convolution operations are shown as flat rectangles, feature maps are shown as prisms. The number below each filter represents the dilation rate (1 means no dilation).
|
| 44 |
+
|
| 45 |
+
of regression for production of density maps [24]. In the same spirit, [4] combines deep and shallow convolutions within the same network, providing accurate counting of dense objects (e.g. the UCF50 crowd dataset).
|
| 46 |
+
|
| 47 |
+
In this paper, however, we aim to apply the dilated convolution method of [25], which has shown to be able to incorporate multiscale perspective information without using multiple inputs or a complicated network architecture, as well as the multicolumn approach of [8, 28] to aggregate multiscale information for the counting problem.
|
| 48 |
+
|
| 49 |
+
## 3 Method
|
| 50 |
+
|
| 51 |
+
### Dilated Convolutions for Multicolumn Networks
|
| 52 |
+
|
| 53 |
+
We propose the use of dilated convolutions as an attractive alternative to the architecture of the HydraCNN [18], which seems to saturate in performance at 3 or more columns. We refer to our proposed network as the aggregated multicolumn dilated convolution network1, henceforth shortened as the AMDCN. The architecture of the AMDCN is inspired by the multicolumn counting network of [28]. Extracting features from multiple scales is a good idea when attempting to perform perspective-free counting and increasing the convolution kernel size across columns is an efficient method of doing so. However, the number of parameters increases exponentially as larger kernels are used in these columns to extract features at larger scales. Therefore, we propose using dilated convolutions rather than larger kernels.
|
| 54 |
+
|
| 55 |
+
Footnote 1: Implementation available on [https://github.com/dipotdip/counting](https://github.com/dipotdip/counting).
|
| 56 |
+
|
| 57 |
+
Dilated convolutions, as discussed in [25], allow for the exponential increase of the receptive field with a linear increase in the number of parameters with respect to each hidden layer.
|
| 58 |
+
|
| 59 |
+
In a traditional 2D convolution, we define a real valued function \(F:\mathbb{Z}^{2}\rightarrow\mathbb{R}\), an input \(\Omega_{r}=[-r,r]^{2}\in\mathbb{Z}^{2}\), and a filter function \(k:\Omega_{r}\rightarrow\mathbb{R}\). In this case, a convolution operation as defined in [25] is given by
|
| 60 |
+
|
| 61 |
+
\[(F*k)(\mathbf{p})=\sum_{\mathbf{s}+\mathbf{t}=\mathbf{p}}F(\mathbf{s})k( \mathbf{t}). \tag{1}\]
|
| 62 |
+
|
| 63 |
+
A dilated convolution is essentially a generalization of the traditional 2D convolution that allows the operation to skip some inputs. This enables an increase in the size of the filter (i.e. the size of the receptive field) without losing resolution. Formally, we define from [25] the dilated convolution as
|
| 64 |
+
|
| 65 |
+
\[(F*_{l}k)(\mathbf{p})=\sum_{\mathbf{s}+l\mathbf{t}=\mathbf{p}}F(\mathbf{s})k( \mathbf{t}) \tag{2}\]
|
| 66 |
+
|
| 67 |
+
where \(l\) is the index of the current layer of the convolution.
|
| 68 |
+
|
| 69 |
+
Using dilations to construct the aggregator in combination with the multicolumn idea will allow for the construction of a network with more than just 3 or 4 columns as in [28] and [8], because the aggregator should prevent the saturation of performance with increasing numbers of columns. Therefore the network will be able to extract useful features from more scales. We take advantage of dilations within the columns as well to provide large receptive fields with fewer parameters.
|
| 70 |
+
|
| 71 |
+
Looking at more scales should allow for more accurate regression of the density map. However, because not all scales will be relevant, we extend the network beyond a simple \(1\times 1\) convolution after the merged columns. Instead, we construct a second part of the network, the aggregator, which sets our method apart from [28, 8], and other multicolumn networks. This aggregator is another series of dilated convolutions that should appropriately consolidate the multiscale information collected by the columns. This is a capability of dilated convolutions observed by [25]. While papers such as [28] and [8] have shown that multiple columns and dilated columns are useful in extracting multi-scale information, we argue in this paper that the simple aggregator module built using dilated convolutions is able to effectively make use multiscale information from multiple columns. We show compelling evidence for these claims in Section 4.5.
|
| 72 |
+
|
| 73 |
+
The network as shown in Figure 1 contains 5 columns. Note that dilations allow us to use more columns for counting than [28] or [8]. Each column looks at a larger scale than the previous (the exact dilations can also be seen in Figure 1). There are 32 feature maps for each convolution, and all inputs are zero padded prior to each convolution in order to maintain the same data shape from input to output. That is, an image input to this network will result in a density map of the same dimensions. All activations in the specified network are ReLUs. Our input pixel values are floating point 32 bit values from 0 to 1. We center our inputs at 0 by subtracting the per channel mean from each channel. When
|
| 74 |
+
|
| 75 |
+
Figure 2: UCF sample results. Left: input counting image. Middle: Ground truth density map. Right: AMDCN prediction of density map on test image. The network never saw these images during training. All density maps are one channel only (i.e. grayscale), but are colored here for clarity.
|
| 76 |
+
|
| 77 |
+
training, we use a scaled mean absolute error for our loss function:
|
| 78 |
+
|
| 79 |
+
\[L=\frac{1}{n}\sum_{i=1}^{n}|\hat{y}_{i}-\gamma y_{i}| \tag{3}\]
|
| 80 |
+
|
| 81 |
+
where \(\gamma\) is the scale factor, \(\hat{y}_{i}\) is the prediction, \(y_{i}\) is the true value, and \(n\) is the number of pixels. We use a scaled mean absolute error because the target values are so small that it is numerically unstable to regress to these values. At testing time, when retrieving the output density map from the network, we scale the pixel values by \(\gamma^{-1}\) to obtain the correct value. This approach is more numerically stable and avoids having the network learn to output only zeros by weighting the nonzero values highly. For all our datasets, we set \(\gamma=255\).
|
| 82 |
+
|
| 83 |
+
### Experiments
|
| 84 |
+
|
| 85 |
+
We evaluated the performance of dilated convolutions against various counting methods on a variety of common counting datasets: UCF50 crowd data, TRANCOS traffic data [18], UCSD crowd data [5], and WorldExpo crowd data [27]. For each of these data sets, we used labels given by the corresponding density map for each image. An example of this is shown in Figure 2. We have performed experiments on the four different splits of the UCSD data as used in [18] and the split of the UCSD data as used in [28] (which we call the original split). We also evaluated the performance of our network on the TRANCOS traffic dataset [14]. We have also experimented with higher density datasets for crowd counting, namely WorldExpo and UCF.
|
| 86 |
+
|
| 87 |
+
We have observed that multicolumn dilations produce density maps (and therefore counts) that often have lower loss than those of HydraCNN [18] and [28]. We measure density map regression loss via a scaled mean absolute error loss during training. We compare accuracy of the counts via mean absolute error for the crowd datasets and the GAME metric in the TRANCOS dataset as explained in Section 3.2.2. Beyond the comparison to HydraCNN, we will also compare to other recent convolutional counting methods, especially those of [21], [24], and [4] where possible.
|
| 88 |
+
|
| 89 |
+
For all datasets, we generally use patched input images and ground truth density maps produced by summing a Gaussian of a fixed size (\(\sigma\)) for each object for training. This size varies from dataset to dataset, but remains constant within a dataset with the exception of cases in which a perspective map is used. This is explained per dataset. All experiments were performed using Keras with the Adam optimizer [10]. The learning rates used are detailed per dataset. For testing, we also use patches that can either be directly pieced together or overlapped and averaged except in the case of UCF, for which we run our network on the full image.
|
| 90 |
+
|
| 91 |
+
Furthermore, we performed a set of experiments in which we varied the number of columns from 1 to 5 (simply by including or not including the columns as specified in Figure 1, starting with the smallest filter column and adding larger filter columns one by one). Essentially, the network is allowed to extract information at larger and larger scales in addition to the smaller scales as we include each column. We then performed the same set of experiments, varying the number of columns, but with the aggregator module removed. We perform these experiments on the original split of UCSD as specified in Section 3.2.3 and [5], the TRANCOS dataset, and the WorldExpo dataset because these are relatively large and well defined datasets. We limit the number of epochs to 10 for all of these sets of experiments in order to control for the effect of learning time, and also compare all results using MAE for consistency. These experiments are key to determining the efficacy of the aggregator in effectively combining multiscale information and in providing evidence to support the use of multiple columns to extract multiscale information from images. We report the results of these ablation studies in Section 4.5.
|
| 92 |
+
|
| 93 |
+
#### 3.2.1 UCF50 Crowd Counting
|
| 94 |
+
|
| 95 |
+
UCF is a particularly challenging crowd counting dataset. There are only 50 images in the whole dataset and they are all of varying sizes and from different scenes. The number of people also varies between images from less than 100 to the thousands. The average image has on the order of 1000 people. The difficulty is due to the combination of the very low number of images in the dataset and the fact that the images are all of varying scenes, making high quality generalization crucial. Furthermore, perspective effects are particularly noticeable for many images in this dataset. Despite this, there is no perspective information available for this dataset.
|
| 96 |
+
|
| 97 |
+
We take 1600 random patches of size \(150\times 150\) for the training. For testing, we do not densely scan the image as in [18] but instead test on the whole image. In order to standardize the image sizes, we pad each image out with zeros until all images are \(1024\times 1024\). We then suppress output in the regions where we added padding when testing. This provides a cleaner resulting density map for these large crowds. The ground truth density maps are produced by annotating each object with a Gaussian of \(\sigma=15\).
|
| 98 |
+
|
| 99 |
+
#### 3.2.2 TRANCOS Traffic Counting
|
| 100 |
+
|
| 101 |
+
TRANCOS is a traffic counting dataset that comes with its own metric [14]. This metric is known as \(GAME\), which stands for Grid Average Mean absolute Error. \(GAME\) splits a given density map into \(4^{L}\) grids, or subarrays, and obtains a mean absolute error within each grid separately. The value of \(L\) is a parameter chosen by the user. Theseindividual errors are summed to obtain the final error for a particular image. The intuition behind this metric is that it is desirable to penalize a density map whose overall count might match the ground truth, but whose shape does not match the ground truth [14]. More formally, we define
|
| 102 |
+
|
| 103 |
+
\[GAME(L)=\frac{1}{N}\cdot\sum_{n=1}^{N}\left(\sum_{l=1}^{4^{L}}\lvert e_{n}^{l}-t_{ n}^{l}\rvert\right) \tag{4}\]
|
| 104 |
+
|
| 105 |
+
where \(N\) refers to the number of images, \(L\) is the level parameter for \(GAME\), \(e_{n}^{l}\) is the predicted or estimated count in region \(l\) of image \(n\) and \(t_{n}^{l}\) is the ground truth count in region \(l\) of image \(n\)[14].
|
| 106 |
+
|
| 107 |
+
For training this dataset, we take 1600 randomly sampled patches of size \(80\times 80\). For testing this dataset, we take \(80\times 80\) non-overlapping patches which we can stitch back together into the full-sized \(640\times 480\) images. We trained the AMDCN network with density maps produced with a Gaussian of \(\sigma=15\) as specified in [18].
|
| 108 |
+
|
| 109 |
+
#### 3.2.3 UCSD Crowd Counting
|
| 110 |
+
|
| 111 |
+
The UCSD crowd counting dataset consists of frames of video of a sidewalk. There are relatively few people in view at any given time (approximately 25 on average). Furthermore, because the dataset comes from a video, there are many nearly identical images in the dataset. For this dataset, there have been two different ways to split the data into train and test sets. Therefore, we report results using both methods of splitting the data. The first method consists of four different splits: maximal, downscale, upscale, and minimal. Minimal is particularly challenging as the train set contains only 10 images. Moreover, upscale appears to be the easiest for the majority of methods [18]. The second method of splitting this data is much more succinct, leaving 1200 images in the testing set and 800 images in the training set [28]. This split comes from the original paper, so we call it the original split [5].
|
| 112 |
+
|
| 113 |
+
For this dataset, each object is annotated with a 2D Gaussian of covariance \(\Sigma=8\cdot\mathbf{1}_{2\times 2}\). The ground truth map is produced by summing these. When we make use of the perspective maps provided, we divide \(\Sigma\) by the perspective map value at that pixel \(\mathbf{x}\), represented by \(M(\mathbf{x})\). The provided perspective map for UCSD contains both a horizontal and vertical direction so we take the square root of the provided combined value. For training, we take 1600 random \(79\times 119\) pixel patches and for testing, we split each test image up into quadrants (which have dimension \(79\times 119\)). There are two different ways to split the dataset into training and testing sets. We have experimented on the split that gave [18] the best results as well as the split used in [28].
|
| 114 |
+
|
| 115 |
+
First, we split the dataset into four separate groups of training and testing sets as used in [18] and originally defined by [20]. These groups are "upscale," "maximal," "minimal," and "downscale." We see in Table 3 that the "upscale" split and "downscale" split give us state of the art results on counting for this dataset. For this experiment, we sampled 1600 random patches of size \(119\times 79\) pixels (width and height respectively) for the training set and split the test set images into \(119\times 79\) quadrants that could be reconstructed by piecing them together without overlap. We also added left-right flips of each image to our training data.
|
| 116 |
+
|
| 117 |
+
We then evaluate the original split. For this experiment, we similarly sampled 1600 random patches of size \(119\times 79\) pixels (width and height respectively) for the training set and split the test set images into \(119\times 79\) quadrants that could be reconstructed by piecing them together without overlap.
|
| 118 |
+
|
| 119 |
+
#### 3.2.4 WorldExpo '10 Crowd Counting
|
| 120 |
+
|
| 121 |
+
The WorldExpo dataset [27] contains a larger number of people (approximately 50 on average, which is double that of UCSD) and contains images from multiple locations. Perspective effects are also much more noticeable in this dataset as compared to UCSD. These qualities of the dataset serve to increase the difficulty of counting. Like UCSD, the WorldExpo dataset was constructed from frames of video recordings of crowds. This means that, unlike UCF, this dataset contains a relatively large number of training and testing images. We experiment on this dataset with and without perspective information.
|
| 122 |
+
|
| 123 |
+
Without perspective maps, we generate label density maps for this dataset in the same manner as previously described: a 2D Gaussian with \(\sigma=15\). We take 16000 \(150\times 150\) randomly sampled patches for training. For testing, we densely scan the image, producing \(150\times 150\) patches at a stride of 100.
|
| 124 |
+
|
| 125 |
+
When perspective maps are used, however, we follow the procedure as described in [27], which involves estimating a "crowd density distribution kernel" as the sum of two 2D Gaussians: a symmetric Gaussian for the head and an ellipsoid Gaussian for the body. These are scaled by the perspective map \(M\) provided, where \(M(\mathbf{x})\) gives the number of pixels that represents a meter at pixel \(\mathbf{x}\)[27]. Note that the meaning of this perspective map is distinct from the meaning of the perspective map provided for the UCSD dataset. Using this information, the density contribution from a person with head pixel \(\mathbf{x}\) is given by the following sum of normalized Gaussians:
|
| 126 |
+
|
| 127 |
+
\[D_{\mathbf{x}}=\frac{1}{||Z||}(\mathcal{N}_{h}(\mathbf{x},\sigma_{h})+\mathcal{ N}_{b}(\mathbf{x}_{b},\Sigma_{b})) \tag{5}\]
|
| 128 |
+
|
| 129 |
+
where \(\mathbf{x}_{b}\) is the center of the body, which is 0.875 meters down from the head on average, and can be determined from the perspective map \(M\) and the head center \(\mathbf{x}\)[27]. We sum these Gaussians for each person to pro duce the final density map. We set \(\sigma=0.2M(\mathbf{x})\) for \(\mathcal{N}_{h}\) and \(\sigma_{x}=0.2M(\mathbf{x}),\sigma_{y}=0.5M(\mathbf{x})\) for \(\Sigma_{b}\) in \(\mathcal{N}_{b}\).
|
| 130 |
+
|
| 131 |
+
## 4 Results
|
| 132 |
+
|
| 133 |
+
### UCF Crowd Counting
|
| 134 |
+
|
| 135 |
+
The UCF dataset is particularly challenging due to the large number of people in the images, the variety of the scenes, as well as the low number of training images. We see in Figure 2 that because the UCF dataset has over 1000 people on average in each image, the shapes output by the network in the density map are not as well defined or separated as in the UCSD dataset.
|
| 136 |
+
|
| 137 |
+
We report a state of the art result on this dataset in Table 1, following the standard protocol of 5-fold cross validation. Our MAE on the dataset is 290.82, which is approximately 5 lower than the previous state of the art, HydraCNN [18]. This is particularly indicative of the power of an aggregated multicolumn dilation network. Despite not making use of perspective information, the AMDCN is still able to produce highly accurate density maps for UCF.
|
| 138 |
+
|
| 139 |
+
### TranCOS Traffic Counting
|
| 140 |
+
|
| 141 |
+
Our network performs very well on the TRANCOS dataset. Indeed, as confirmed by the GAME score, AMDCN produces the most accurate count and shape combined as compared to other methods. Table 2 shows that we achieve state of the art results as measured by the \(GAME\) metric [14] across all levels.
|
| 142 |
+
|
| 143 |
+
### UCSD Crowd Counting
|
| 144 |
+
|
| 145 |
+
Results are shown in Table 3 and Figure 3. We see that the "original" split as defined by the creators of the dataset in [5] and used in [28] gives us somewhat worse results for counting on this dataset. Results were consistent over multiple trainings. Again, including the perspective map does not seem to increase performance on this dataset. Despite this, we see in Table 3 and Figure 3 that the results are comparable to the state of the art. In fact, for two of the splits, our proposed network beats the state of the art. For the up-scale split, the AMDCN is the state of the art by a large relative margin. This is compelling because it shows that accurate perspective-free counting can be achieved without creating image pyramids or requiring perspective maps as labels using the techniques presented by the AMDCN.
|
| 146 |
+
|
| 147 |
+
### WorldExpo '10 Crowd Counting
|
| 148 |
+
|
| 149 |
+
Our network performs reasonably well on the more challenging WorldExpo dataset. While it does not beat the state of the art, our results are comparable. What is more, we do not need to use the perspective maps to obtain these results. As seen in Table 4, the AMDCN is capable of incorporating the perspective effects without scaling the Gaussians with perspective information. This shows that it is possible to achieve counting results that approach the state of the art with much simpler labels for the counting training data.
|
| 150 |
+
|
| 151 |
+
### Ablation Studies
|
| 152 |
+
|
| 153 |
+
We report the results of the ablation studies in Figure 4. We note from these plots that while there is variation in performance, a few trends stand out. Most importantly, the lowest errors are consistently with a combination of a larger number of columns and including the aggregator module. Notably for the TRANCOS dataset, including the aggregator consistently improves performance. Generally, the aggregator tends to decrease the variance in performance of the network. Some of the variance that we see in the plots can be explained by: (1) for lower numbers of columns, including an aggregator is not as likely to help as there is not much separation of multiscale information across columns and (2) for the UCSD dataset, there is less of a perspective effect than TRANCOS and WorldExpo so a simpler network is more likely to perform comparably to a larger network. These results verify the notion that using more columns increases accuracy, and also support our justification for the use of the aggregator module.
|
| 154 |
+
|
| 155 |
+
\begin{table}
|
| 156 |
+
\begin{tabular}{|l|l|} \hline
|
| 157 |
+
**Method** & **MAE** \\ \hline AMDCN & **290.82** \\ \hline Hydra2s [18] & 333.73 \\ \hline MCNN [28] & 377.60 \\ \hline [27] & 467.00 \\ \hline [23] & 295.80 \\ \hline [3] & 318.10 \\ \hline \end{tabular}
|
| 158 |
+
\end{table}
|
| 159 |
+
Table 1: Mean absolute error of various methods on UCF crowds
|
| 160 |
+
|
| 161 |
+
\begin{table}
|
| 162 |
+
\begin{tabular}{|c|l|l|l|l|} \hline
|
| 163 |
+
**Method** & \begin{tabular}{l} **GAME** \\ **(L=0)** \\ \end{tabular} & \begin{tabular}{l} **GAME** \\ **(L=1)** \\ \end{tabular} & \begin{tabular}{l} **GAME** \\ **(L=2)** \\ \end{tabular} &
|
| 164 |
+
\begin{tabular}{l} **GAME** \\ **(L=3)** \\ \end{tabular} \\ \hline AMDCN & **9.77** & **13.16** & **15.00** & **15.87** \\ \hline [18] & 10.99 & 13.75 & 16.69 & 19.32 \\ \hline [15] + SIFT from [14] & 13.76 & 16.72 & 20.72 & 24.36 \\ \hline [13] + RGB Norm + Filters from [14] & 17.68 & 19.97 & 23.54 & 25.84 \\ \hline HOG-2 from [14] & 13.29 & 18.05 & 23.65 & 28.41 \\ \hline \end{tabular}
|
| 165 |
+
\end{table}
|
| 166 |
+
Table 2: Mean absolute error of various methods on TRANCOS traffic
|
| 167 |
+
|
| 168 |
+
## 5 Conclusion
|
| 169 |
+
|
| 170 |
+
### Summary
|
| 171 |
+
|
| 172 |
+
We have proposed the use of aggregated multicolumn dilated convolutions, the AMDCN, as an alternative to the HydraCNN [18] or multicolumn CNN [28] for the vision task of counting objects in images. Inspired by the multicolumn approach to multiscale problems, we also employ dilations to increase the receptive field of our columns. We then aggregate this multiscale information using another series of dilated convolutions to enable a wide network and detect features at more scales. This method takes advantage of the ability of dilated convolutions to provide exponentially increasing receptive fields. We have performed experiments on the challenging UCF crowd counting dataset, the TRANCOS traffic dataset, multiple splits of the UCSD crowd counting dataset, and the WorldExpo crowd counting dataset.
|
| 173 |
+
|
| 174 |
+
\begin{table}
|
| 175 |
+
\begin{tabular}{|l|l|l|l|l|l|} \hline
|
| 176 |
+
**Method** & **maximal** & **downscale** & **upscale** & **minimal** & **original** \\ \hline AMDCN (**without perspective information**) & 1.63 & 1.43 & **0.63** & 1.71 & 1.74 \\ \hline AMDCN (with perspective information) & 1.60 & **1.24** & 1.37 & 1.59 & 1.72 \\ \hline
|
| 177 |
+
[18] (with perspective information) & 1.65 & 1.79 & 1.11 & 1.50 & - \\ \hline
|
| 178 |
+
[18] (without perspective information) & 2.22 & 1.93 & 1.37 & 2.38 & - \\ \hline
|
| 179 |
+
[15] & 1.70 & 1.28 & 1.59 & 2.02 & - \\ \hline
|
| 180 |
+
[13] & 1.70 & 2.16 & 1.61 & 2.20 & - \\ \hline
|
| 181 |
+
[19] & 1.43 & 1.30 & 1.59 & 1.62 & - \\ \hline
|
| 182 |
+
[2] & **1.24** & 1.31 & 1.69 & **1.49** & - \\ \hline
|
| 183 |
+
[27] & 1.70 & 1.26 & 1.59 & 1.52 & 1.60 \\ \hline
|
| 184 |
+
[28] & - & - & - & - & **1.07** \\ \hline
|
| 185 |
+
[1, 28] & - & - & - & - & 2.16 \\ \hline
|
| 186 |
+
[7] & - & - & - & - & 2.25 \\ \hline
|
| 187 |
+
[5] & - & - & - & - & 2.24 \\ \hline
|
| 188 |
+
[6] & - & - & - & - & 2.07 \\ \hline \end{tabular}
|
| 189 |
+
\end{table}
|
| 190 |
+
Table 3: Mean absolute error of various methods on UCSD crowds
|
| 191 |
+
|
| 192 |
+
Figure 3: UCSD crowd counting dataset. Both plots show comparisons of predicted and ground truth counts over time. While AMDCN does not beat the state of the art on the original split, the predictions still follow the true counts reasonably. The jump in the original split is due to that testing set including multiple scenes of highly varying counts.
|
| 193 |
+
|
| 194 |
+
We obtain superior or comparable results in most of these datasets. The AMDCN is capable of outperforming these approaches completely especially when perspective information is not provided, as in UCF and TRANCOS. These results show that the AMDCN performs surprisingly well and is also robust to scale effects. Further, our ablation study of removing the aggregator network shows that using more columns and an aggregator provides the best accuracy for counting -- especially so when there is no perspective information.
|
| 195 |
+
|
| 196 |
+
### Future Work
|
| 197 |
+
|
| 198 |
+
In addition to an analysis of performance on counting, a density regressor can also be used to locate objects in the image. As mentioned previously, if the regressor is accurate and precise enough, the resulting density map can be used to locate the objects in the image. We expect that in order to do this, one must regress each object to a single point rather than a region specified by a Gaussian. Perhaps this might be accomplished by applying non-maxima suppression to the final layer activations.
|
| 199 |
+
|
| 200 |
+
Indeed, the method of applying dilated filters to a multi-column convolutional network in order to enable extracting features of a large number of scales can be applied to various other dense prediction tasks, such as object segmentation at multiple scales or single image depth map prediction. Though we have only conducted experiments on counting and used 5 columns, the architecture presented can be extended and adapted to a variety of tasks that require information at multiple scales.
|
| 201 |
+
|
| 202 |
+
## Acknowledgment
|
| 203 |
+
|
| 204 |
+
This material is based upon work supported by the National Science Foundation under Grant No. 1359275 and 1659788. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation. Furthermore, we acknowledge Kyle Yee and Sridhama Prakhya for their helpful conversations and insights during the research process.
|
| 205 |
+
|
| 206 |
+
## References
|
| 207 |
+
|
| 208 |
+
* [1] S. An, W. Liu, and S. Venkatesh. Face recognition using kernel ridge regression. In _Computer Vision and Pattern Recognition, 2007. CVPR'07. IEEE Conference on_, pages 1-7. IEEE, 2007.
|
| 209 |
+
* [2] C. Arteta, V. Lempitsky, J. A. Noble, and A. Zisserman. Interactive object counting. In _European Conference on Computer Vision_, pages 504-518. Springer, 2014.
|
| 210 |
+
* [3] D. Babu Sam, S. Surya, and R. Venkatesh Babu. Switching convolutional neural network for crowd
|
| 211 |
+
|
| 212 |
+
\begin{table}
|
| 213 |
+
\begin{tabular}{|l|c|} \hline
|
| 214 |
+
**Method** & **MAE** \\ \hline AMDCN **(without perspective information)** & 16.6 \\ \hline AMDCN (with perspective information) & 14.9 \\ \hline LBP+RR [28] (with perspective information) & 31.0 \\ \hline MCNN [28] (with perspective information) & **11.6** \\ \hline
|
| 215 |
+
[27] (with perspective information) & 12.9 \\ \hline \end{tabular}
|
| 216 |
+
\end{table}
|
| 217 |
+
Table 4: Mean absolute error of various methods on WorldExpo crowds
|
| 218 |
+
|
| 219 |
+
Figure 4: Ablation studies on various datasets in which the number of columns is varied and the aggregator is included or not included. The results generally support the use of more columns and an aggregator module.
|
| 220 |
+
|
| 221 |
+
counting. In _Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_, pages 5744-5752, 2017.
|
| 222 |
+
* [4] L. Boominathan, S. S. Kruthiventi, and R. V. Babu. Crowdnet: A deep convolutional network for dense crowd counting. In _Proceedings of the 2016 ACM on Multimedia Conference_, pages 640-644. ACM, 2016.
|
| 223 |
+
* [5] A. B. Chan, Z.-S. J. Liang, and N. Vasconcelos. Privacy preserving crowd monitoring: Counting people without people models or tracking. In _Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on_, pages 1-7. IEEE, 2008.
|
| 224 |
+
* [6] K. Chen, S. Gong, T. Xiang, and C. Change Loy. Cumulative attribute space for age and crowd density estimation. In _Proceedings of the IEEE conference on computer vision and pattern recognition_, pages 2467-2474, 2013.
|
| 225 |
+
* [7] K. Chen, C. C. Loy, S. Gong, and T. Xiang. Feature mining for localised crowd counting.
|
| 226 |
+
* [8] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. _IEEE Transactions on Pattern Analysis and Machine Intelligence_, 2017.
|
| 227 |
+
* [9] L.-C. Chen, Y. Yang, J. Wang, W. Xu, and A. L. Yuille. Attention to scale: Scale-aware semantic image segmentation. In _Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_, pages 3640-3649, 2016.
|
| 228 |
+
* [10] F. Chollet et al. Keras. [https://github.com/fchollet/keras](https://github.com/fchollet/keras), 2015.
|
| 229 |
+
* [11] A. Dosovitskiy, P. Fischer, E. Ilg, P. Hausser, C. Hazirbas, V. Golkov, P. van der Smagt, D. Cremers, and T. Brox. Flownet: Learning optical flow with convolutional networks. In _Proceedings of the IEEE International Conference on Computer Vision_, pages 2758-2766, 2015.
|
| 230 |
+
* [12] C. Farabet, C. Couprie, L. Najman, and Y. LeCun. Learning hierarchical features for scene labeling. _IEEE transactions on pattern analysis and machine intelligence_, 35(8):1915-1929, 2013.
|
| 231 |
+
* [13] L. Fiaschi, U. Kothe, R. Nair, and F. A. Hamprecht. Learning to count with regression forest and structured labels. In _Pattern Recognition (ICPR), 2012 21st International Conference on_, pages 2685-2688. IEEE, 2012.
|
| 232 |
+
* [14] R. Guerrero-Gomez-Olmedo, B. Torre-Jimenez, S. M. Lopez-Sastre, Roberto Bascon, and D. Onoro Rubio. Extremely overlapping vehicle counting. In _Iberian Conference on Pattern Recognition and Image Analysis (IbPRIA)_, 2015.
|
| 233 |
+
* [15] V. Lempitsky and A. Zisserman. Learning to count objects in images. In _Advances in Neural Information Processing Systems_, pages 1324-1332, 2010.
|
| 234 |
+
* [16] G. Lin, C. Shen, A. van den Hengel, and I. Reid. Efficient piecewise training of deep structured models for semantic segmentation. In _Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_, pages 3194-3203, 2016.
|
| 235 |
+
* [17] H. Noh, S. Hong, and B. Han. Learning deconvolution network for semantic segmentation. In _Proceedings of the IEEE International Conference on Computer Vision_, pages 1520-1528, 2015.
|
| 236 |
+
* [18] D. Onoro-Rubio and R. J. Lopez-Sastre. Towards perspective-free object counting with deep learning. In _European Conference on Computer Vision_, pages 615-629. Springer, 2016.
|
| 237 |
+
* [19] V.-Q. Pham, T. Kozakaya, O. Yamaguchi, and R. Okada. Count forest: Co-voting uncertain number of targets using random forest for crowd density estimation. In _Proceedings of the IEEE International Conference on Computer Vision_, pages 3253-3261, 2015.
|
| 238 |
+
* [20] D. Ryan, S. Denman, C. Fookes, and S. Sridharan. Crowd counting using multiple local features. In _Digital Image Computing: Techniques and Applications, 2009. DICTA'09._, pages 81-88. IEEE, 2009.
|
| 239 |
+
* [21] S. Segui, O. Pujol, and J. Vitria. Learning to count with deep object features. In _Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops_, pages 90-96, 2015.
|
| 240 |
+
* [22] J. Selinummi, O. Yli-Harja, and J. A. Puhakka. Software for quantification of labeled bacteria from digital microscope images by automated image analysis. _Biotechniques_, 39(6):859, 2005.
|
| 241 |
+
* [23] V. A. Sindagi and V. M. Patel. Generating high-quality crowd density maps using contextual pyramid cnns. In _Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_, pages 1861-1870, 2017.
|
| 242 |
+
* [24] E. Walach and L. Wolf. Learning to count with cnn boosting. In _European Conference on Computer Vision_, pages 660-676. Springer, 2016.
|
| 243 |
+
* [25] F. Yu and V. Koltun. Multi-scale context aggregation by dilated convolutions. _arXiv preprint arXiv:1511.07122_, 2015.
|
| 244 |
+
* [26] F. Yu, V. Koltun, and T. Funkhouser. Dilated residual networks. _arXiv preprint arXiv:1705.09914_, 2017.
|
| 245 |
+
* [27] C. Zhang, H. Li, X. Wang, and X. Yang. Cross-scene crowd counting via deep convolutional neural networks. In _Proceedings of the IEEE Conference on * [28] Y. Zhang, D. Zhou, S. Chen, S. Gao, and Y. Ma. Single-image crowd counting via multi-column convolutional neural network. In _Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_, pages 589-597, 2016.
|
data/examples/nougat/switch_transformers.md
ADDED
|
@@ -0,0 +1,528 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
|
| 2 |
+
|
| 3 |
+
William Fedus
|
| 4 |
+
|
| 5 |
+
1. JAX code for Switch Transformer and all model checkpoints are available at [https://github.com/google-research/t5x](https://github.com/google-research/t5x)
|
| 6 |
+
|
| 7 |
+
1. Jianfedus@google.com
|
| 8 |
+
|
| 9 |
+
Barret Zoph
|
| 10 |
+
|
| 11 |
+
barretzoph@google.com
|
| 12 |
+
|
| 13 |
+
Noam Shazeer
|
| 14 |
+
|
| 15 |
+
noam@google.com
|
| 16 |
+
|
| 17 |
+
Google, Mountain View, CA 94043, USA
|
| 18 |
+
|
| 19 |
+
###### Abstract
|
| 20 |
+
|
| 21 |
+
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) models defy this and instead select _different_ parameters for each incoming example. The result is a sparsely-activated model--with an outrageous number of parameters--but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs, and training instability. We address these with the introduction of the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques mitigate the instabilities, and we show large sparse models may be trained, for the first time, with lower precision (bfloat16) formats. We design models based off T5-Base and T5-Large (Raffel et al., 2019) to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the "Colossal Clean Crawled Corpus", and achieve a 4x speedup over the T5-XXL model.12
|
| 22 |
+
|
| 23 |
+
Footnote 1: License: CC-BY 4.0, see [https://creativecommons.org/licenses/by/4.0/](https://creativecommons.org/licenses/by/4.0/). Attribution requirements are provided at [http://jmlr.org/papers/v23/21-0998.html](http://jmlr.org/papers/v23/21-0998.html).
|
| 24 |
+
|
| 25 |
+
mixture-of-experts, natural language processing, sparsity, large-scale machine learning, distributed computing
|
| 26 |
+
###### Contents
|
| 27 |
+
|
| 28 |
+
* 1 Introduction
|
| 29 |
+
* 2 Switch Transformer
|
| 30 |
+
* 2.1 Simplifying Sparse Routing
|
| 31 |
+
* 2.2 Efficient Sparse Routing
|
| 32 |
+
* 2.3 Putting It All Together: The Switch Transformer
|
| 33 |
+
* 2.4 Improved Training and Fine-Tuning Techniques
|
| 34 |
+
* 3 Scaling Properties
|
| 35 |
+
* 3.1 Scaling Results on a Step-Basis
|
| 36 |
+
* 3.2 Scaling Results on a Time-Basis
|
| 37 |
+
* 3.3 Scaling Versus a Larger Dense Model
|
| 38 |
+
* 4 Downstream Results
|
| 39 |
+
* 4.1 Fine-Tuning
|
| 40 |
+
* 4.2 Distillation
|
| 41 |
+
* 4.3 Multilingual Learning
|
| 42 |
+
* 5 Designing Models with Data, Model, and Expert-Parallelism
|
| 43 |
+
* 5.1 Data Parallelism
|
| 44 |
+
* 5.2 Model Parallelism
|
| 45 |
+
* 5.3 Model and Data Parallelism
|
| 46 |
+
* 5.4 Expert and Data Parallelism
|
| 47 |
+
* 5.5 Expert, Model and Data Parallelism
|
| 48 |
+
* 5.6 Towards Trillion Parameter Models
|
| 49 |
+
* 6 Related Work
|
| 50 |
+
* 7 Discussion
|
| 51 |
+
* 8 Future Work
|
| 52 |
+
* 9 Conclusion
|
| 53 |
+
* A Switch for Attention
|
| 54 |
+
* B Preventing Token Dropping with _No-Token-Left-Behind_
|
| 55 |
+
* C Encouraging Exploration Across Experts
|
| 56 |
+
* D Switch Transformers in Lower Compute Regimes
|
| 57 |
+
* E Relation of Upstream to Downstream Model Performance
|
| 58 |
+
* F Pseudo Code for Switch Transformers
|
| 59 |
+
|
| 60 |
+
## 1 Introduction
|
| 61 |
+
|
| 62 |
+
Large scale training has been an effective path towards flexible and powerful neural language models (Radford et al., 2018; Kaplan et al., 2020; Brown et al., 2020). Simple architectures--backed by a generous computational budget, data set size and parameter count--surpass more complicated algorithms (Sutton, 2019). An approach followed in Radford et al. (2018); Raffel et al. (2019); Brown et al. (2020) expands the model size of a densely-activated Transformer (Vaswani et al., 2017). While effective, it is also extremely computationally intensive (Strubell et al., 2019). Inspired by the success of model scale, but seeking greater computational efficiency, we instead propose a _sparsely-activated_ expert model: the Switch Transformer. In our case the sparsity comes from activating a _subset_ of the neural network weights for each incoming example.
|
| 63 |
+
|
| 64 |
+
Sparse training is an active area of research and engineering (Gray et al., 2017; Gale et al., 2020), but as of today, machine learning libraries and hardware accelerators still cater to dense matrix multiplications. To have an efficient sparse algorithm, we start with the Mixture-of-Expert (MoE) paradigm (Jacobs et al., 1991; Jordan and Jacobs, 1994; Shazeer et al., 2017), and simplify it to yield training stability and computational benefits. MoE models have had notable successes in machine translation (Shazeer et al., 2017, 2018; Lepikhin et al., 2020), however, widespread adoption is hindered by complexity, communication costs, and training instabilities.
|
| 65 |
+
|
| 66 |
+
We address these issues, and then go beyond translation, to find that these class of algorithms are broadly valuable in natural language. We measure superior scaling on a diverse set of natural language tasks and across three regimes in NLP: pre-training, fine-tuning and multi-task training. While this work focuses on scale, we also show that the Switch Transformer architecture not only excels in the domain of supercomputers, but is
|
| 67 |
+
|
| 68 |
+
Figure 1: Scaling and sample efficiency of Switch Transformers. Left Plot: Scaling properties for increasingly sparse (more experts) Switch Transformers. Right Plot: Negative log perplexity comparing Switch Transformers to T5 (Raffel et al., 2019) models using the same compute budget.
|
| 69 |
+
|
| 70 |
+
beneficial even with only a few computational cores. Further, our large sparse models can be distilled (Hinton et al., 2015) into small dense versions while preserving 30% of the sparse model quality gain. Our contributions are the following:
|
| 71 |
+
|
| 72 |
+
* The Switch Transformer architecture, which simplifies and improves over Mixture of Experts.
|
| 73 |
+
* Scaling properties and a benchmark against the strongly tuned T5 model (Raffel et al., 2019) where we measure 7x+ pre-training speedups while still using the same FLOPS per token. We further show the improvements hold even with limited computational resources, using as few as two experts.
|
| 74 |
+
* Successful distillation of sparse pre-trained and specialized fine-tuned models into small dense models. We reduce the model size by up to 99% while preserving 30% of the quality gains of the large sparse teacher.
|
| 75 |
+
* Improved pre-training and fine-tuning techniques: **(1)** selective precision training that enables training with lower bfloat16 precision **(2)** an initialization scheme that allows for scaling to a larger number of experts and **(3)** increased expert regularization that improves sparse model fine-tuning and multi-task training.
|
| 76 |
+
* A measurement of the pre-training benefits on multilingual data where we find a universal improvement across all 101 languages and with 91% of languages benefiting from 4x+ speedups over the mT5 baseline (Xue et al., 2020).
|
| 77 |
+
* An increase in the scale of neural language models achieved by efficiently combining data, model, and expert-parallelism to create models with up to a trillion parameters. These models improve the pre-training speed of a strongly tuned T5-XXL baseline by 4x.
|
| 78 |
+
|
| 79 |
+
## 2 Switch Transformer
|
| 80 |
+
|
| 81 |
+
The guiding design principle for Switch Transformers is to maximize the parameter count of a Transformer model (Vaswani et al., 2017) in a simple and computationally efficient way. The benefit of scale was exhaustively studied in Kaplan et al. (2020) which uncovered power-law scaling with model size, data set size and computational budget. Importantly, this work advocates training large models on relatively small amounts of data as the computationally optimal approach.
|
| 82 |
+
|
| 83 |
+
Heading these results, we investigate a fourth axis: increase the _parameter count_ while keeping the floating point operations (FLOPs) per example constant. Our hypothesis is that the parameter count, independent of total computation performed, is a separately important axis on which to scale. We achieve this by designing a sparsely activated model that efficiently uses hardware designed for dense matrix multiplications such as GPUs and TPUs. Our work here focuses on TPU architectures, but these class of models may be similarly trained on GPU clusters. In our distributed training setup, our sparsely activated layers split _unique_ weights on different devices. Therefore, the weights of the model increase with the number of devices, all while maintaining a manageable memory and computational footprint on each device.
|
| 84 |
+
|
| 85 |
+
### Simplifying Sparse Routing
|
| 86 |
+
|
| 87 |
+
**Mixture of Expert Routing.** Shazeer et al. (2017) proposed a natural language Mixture-of-Experts (MoE) layer which takes as an input a token representation \(x\) and then routes this to the best determined top-\(k\) experts, selected from a set \(\{E_{i}(x)\}_{i=1}^{N}\) of \(N\) experts. The router variable \(W_{r}\) produces logits \(h(x)=W_{r}\cdot x\) which are normalized via a softmax distribution over the available \(N\) experts at that layer. The gate-value for expert \(i\) is given by,
|
| 88 |
+
|
| 89 |
+
\[p_{i}(x)=\frac{e^{h(x)_{i}}}{\sum_{j}^{N}e^{h(x)_{j}}}. \tag{1}\]
|
| 90 |
+
|
| 91 |
+
The top-\(k\) gate values are selected for routing the token \(x\). If \(\mathcal{T}\) is the set of selected top-\(k\) indices then the output computation of the layer is the linearly weighted combination of each expert's computation on the token by the gate value,
|
| 92 |
+
|
| 93 |
+
\[y=\sum_{i\in\mathcal{T}}p_{i}(x)E_{i}(x). \tag{2}\]
|
| 94 |
+
|
| 95 |
+
**Switch Routing: Rethinking Mixture-of-Experts.** Shazeer et al. (2017) conjectured that routing to \(k>1\) experts was necessary in order to have non-trivial gradients to the routing functions. The authors intuited that learning to route would not work without the ability to compare at least two experts. Ramachandran and Le (2018) went further to
|
| 96 |
+
|
| 97 |
+
Figure 2: Illustration of a Switch Transformer encoder block. We replace the dense feed forward network (FFN) layer present in the Transformer with a sparse Switch FFN layer (light blue). The layer operates independently on the tokens in the sequence. We diagram two tokens (\(x_{1}=\) “More” and \(x_{2}=\) “Parameters” below) being routed (solid lines) across four FFN experts, where the router independently routes each token. The switch FFN layer returns the output of the selected FFN multiplied by the router gate value (dotted-line).
|
| 98 |
+
|
| 99 |
+
study the top-\(k\) decision and found that higher \(k\)-values in lower layers in the model were important for models with many routing layers. Contrary to these ideas, we instead use a simplified strategy where we route to only a _single_ expert. We show this simplification preserves model quality, reduces routing computation and performs better. This \(k=1\) routing strategy is later referred to as a Switch layer. Note that for both MoE and Switch Routing, the gate value \(p_{i}(x)\) in Equation 2 permits differentiability of the router.
|
| 100 |
+
|
| 101 |
+
The benefits for the Switch layer are three-fold: **(1)** The router computation is reduced as we are only routing a token to a single expert. **(2)** The batch size (expert capacity) of each expert can be at least halved since each token is only being routed to a single expert.3
|
| 102 |
+
|
| 103 |
+
Footnote 3: See Section 2.2 for a technical description.
|
| 104 |
+
|
| 105 |
+
**(3)** The routing implementation is simplified and communication costs are reduced. Figure 3 shows an example of routing with different expert capacity factors.
|
| 106 |
+
|
| 107 |
+
### Efficient Sparse Routing
|
| 108 |
+
|
| 109 |
+
We use Mesh-Tensorflow (MTF) (Shazeer et al., 2018) which is a library, with similar semantics and API to Tensorflow (Abadi et al., 2016) that facilitates efficient distributed data and model parallel architectures. It does so by abstracting the physical set of cores to a logical mesh of processors. Tensors and computations may then be sharded per named dimensions, facilitating easy partitioning of models across dimensions. We design our model with TPUs in mind, which require statically declared sizes. Below we describe our distributed Switch Transformer implementation.
|
| 110 |
+
|
| 111 |
+
Figure 3: Illustration of token routing dynamics. Each expert processes a fixed batch-size of tokens modulated by the _capacity factor_. Each token is routed to the expert with the highest router probability, but each expert has a fixed batch size of (total_tokens / num_experts) \(\times\) capacity_factor. If the tokens are unevenly dispatched then certain experts will overflow (denoted by dotted red lines), resulting in these tokens not being processed by this layer. A larger capacity factor alleviates this overflow issue, but also increases computation and communication costs (depicted by padded white/empty slots).
|
| 112 |
+
|
| 113 |
+
**Distributed Switch Implementation.** All of our tensor shapes are statically determined at compilation time, but our computation is _dynamic_ due to the routing decisions at training and inference. Because of this, one important technical consideration is how to set the _expert capacity_. The expert capacity--the number of tokens each expert computes--is set by evenly dividing the number of tokens in the batch across the number of experts, and then further expanding by a _capacity factor_,
|
| 114 |
+
|
| 115 |
+
\[\text{expert capacity}= \left(\frac{\text{tokens per batch}}{\text{number of experts}}\right) \times\text{capacity factor}. \tag{3}\]
|
| 116 |
+
|
| 117 |
+
A capacity factor greater than 1.0 creates additional buffer to accommodate for when tokens are not perfectly balanced across experts. If too many tokens are routed to an expert (referred to later as dropped tokens), computation is skipped and the token representation is passed directly to the next layer through the residual connection. Increasing the expert capacity is not without drawbacks, however, since high values will result in wasted computation and memory. This trade-off is explained in Figure 3. Empirically we find ensuring lower rates of dropped tokens are important for the scaling of sparse expert-models. Throughout our experiments we didn't notice any dependency on the number of experts for the number of tokens dropped (typically \(<1\%\)). Using the auxiliary load balancing loss (next section) with a high enough coefficient ensured good load balancing. We study the impact that these design decisions have on model quality and speed in Table 1.
|
| 118 |
+
|
| 119 |
+
**A Differentiable Load Balancing Loss.** To encourage a balanced load across experts we add an auxiliary loss (Shazeer et al., 2017, 2018; Lepikhin et al., 2020). As in Shazeer et al. (2018); Lepikhin et al. (2020), Switch Transformers simplifies the original design in Shazeer et al. (2017) which had separate load-balancing and importance-weighting losses. For each Switch layer, this auxiliary loss is added to the total model loss during training. Given \(N\) experts indexed by \(i=1\) to \(N\) and a batch \(\mathcal{B}\) with \(T\) tokens, the auxiliary loss is computed as the scaled dot-product between vectors \(f\) and \(P\),
|
| 120 |
+
|
| 121 |
+
\[\text{loss}=\alpha\cdot N\cdot\sum_{i=1}^{N}f_{i}\cdot P_{i} \tag{4}\]
|
| 122 |
+
|
| 123 |
+
where \(f_{i}\) is the fraction of tokens dispatched to expert \(i\),
|
| 124 |
+
|
| 125 |
+
\[f_{i}=\frac{1}{T}\sum_{x\in\mathcal{B}}\mathbbm{1}\{\text{argmax}\:p(x)=i\} \tag{5}\]
|
| 126 |
+
|
| 127 |
+
and \(P_{i}\) is the fraction of the router probability allocated for expert \(i\), 2
|
| 128 |
+
|
| 129 |
+
Footnote 2: A potential source of confusion: \(p_{i}(x)\) is the probability of routing token \(x\) to expert \(i\). \(P_{i}\) is the probability fraction to expert \(i\) across _all tokens_ in the batch \(\mathcal{B}\).
|
| 130 |
+
|
| 131 |
+
\[P_{i}=\frac{1}{T}\sum_{x\in\mathcal{B}}p_{i}(x). \tag{6}\]
|
| 132 |
+
|
| 133 |
+
Since we seek uniform routing of the batch of tokens across the \(N\) experts, we desire both vectors to have values of \(1/N\). The auxiliary loss of Equation 4 encourages uniform routing since it is minimized under a uniform distribution. The objective can also be differentiated asthe \(P\)-vector is differentiable, but the \(f\)-vector is not. The final loss is multiplied by expert count \(N\) to keep the loss constant as the number of experts varies since under uniform routing \(\sum_{i=1}^{N}(f_{i}\cdot P_{1})=\sum_{i=1}^{N}(\frac{1}{N}\cdot\frac{1}{N})= \frac{1}{N}\). Finally, a hyper-parameter \(\alpha\) is a multiplicative coefficient for these auxiliary losses; throughout this work we use an \(\alpha=10^{-2}\) which was sufficiently large to ensure load balancing while small enough to not to overwhelm the primary cross-entropy objective. We swept hyper-parameter ranges of \(\alpha\) from \(10^{-1}\) to \(10^{-5}\) in powers of 10 and found \(10^{-2}\) balanced load quickly without interfering with training loss.
|
| 134 |
+
|
| 135 |
+
### Putting It All Together: The Switch Transformer
|
| 136 |
+
|
| 137 |
+
Our first test of the Switch Transformer starts with pre-training on the "Colossal Clean Crawled Corpus" (C4), introduced in (Raffel et al., 2019). For our pre-training objective, we use a masked language modeling task (Taylor, 1953; Fedus et al., 2018; Devlin et al., 2018) where the model is trained to predict missing tokens. In our pre-training setting, as determined in Raffel et al. (2019) to be optimal, we drop out 15% of tokens and then replace the masked sequence with a single sentinel token. To compare our models, we record the negative log perplexity.4 Throughout all tables in the paper, \(\uparrow\) indicates that a higher value for that metric is better and vice-versa for \(\downarrow\). A comparison of all the models studied in this work are in Table 9.
|
| 138 |
+
|
| 139 |
+
Footnote 4: We use log base-\(e\) for this metric so the units are nats.
|
| 140 |
+
|
| 141 |
+
A head-to-head comparison of the Switch Transformer and the MoE Transformer is presented in Table 1. Our Switch Transformer model is FLOP-matched to 'T5-Base' (Raffel et al., 2019) (same amount of computation per token is applied). The MoE Transformer, using top-2 routing, has two experts which each apply a separate FFN to each token and thus its FLOPS are larger. All models were trained for the same number of steps on identical hardware. Note that the MoE model going from capacity factor 2.0 to 1.25 actually slows down (840 to 790) in the above experiment setup, which is unexpected.5
|
| 142 |
+
|
| 143 |
+
Footnote 5: Note that speed measurements are both a function of the algorithm and the implementation details. Switch Transformer reduces the necessary computation relative to MoE (algorithm), but the final speed differences are impacted by low-level optimizations (implementation).
|
| 144 |
+
|
| 145 |
+
We highlight three key findings from Table 1: **(1)** Switch Transformers outperform both carefully tuned dense models and MoE Transformers on a speed-quality basis. For a fixed amount of computation and wall-clock time, Switch Transformers achieve the best result. **(2)** The Switch Transformer has a smaller computational footprint than the MoE counterpart. If we increase its size to match the training speed of the MoE Transformer, we find this outperforms all MoE and Dense models on a per step basis as well. **(3)** Switch Transformers perform better at lower capacity factors (1.0, 1.25). Smaller expert capacities are indicative of the scenario in the large model regime where model memory is very scarce and the capacity factor will want to be made as small as possible.
|
| 146 |
+
|
| 147 |
+
### Improved Training and Fine-Tuning Techniques
|
| 148 |
+
|
| 149 |
+
Sparse expert models may introduce training difficulties over a vanilla Transformer. Instability can result because of the hard-switching (routing) decisions at each of these layers. Further, low precision formats like bfloat16 (Wang and Kanwar, 2019) can exacerbate issuesin the softmax computation for our router. We describe training difficulties here and the methods we use to overcome them to achieve stable and scalable training.
|
| 150 |
+
|
| 151 |
+
**Selective precision with large sparse models.** Model instability hinders the ability to train using efficient bfloat16 precision, and as a result, Lepikhin et al. (2020) trains with float32 precision throughout their MoE Transformer. However, we show that by instead _selectively casting_ to float32 precision within a localized part of the model, stability may be achieved, without incurring expensive communication cost of float32 tensors. This technique is inline with modern mixed precision training strategies where certain parts of the model and gradient updates are done in higher precision Micikevicius et al. (2017). Table 2 shows that our approach permits nearly equal speed to bfloat16 training while conferring the training stability of float32.
|
| 152 |
+
|
| 153 |
+
To achieve this, we cast the router input to float32 precision. The router function takes the tokens as input and produces the dispatch and combine tensors used for the selection and recombination of expert computation (refer to Code Block 15 in the Appendix for details). Importantly, the float32 precision is only used _within_ the body of the router function--on computations local to that device. Because the resulting dispatch and combine tensors are recast to bfloat16 precision at the end of the function, no expensive float32 tensors
|
| 154 |
+
|
| 155 |
+
\begin{table}
|
| 156 |
+
\begin{tabular}{c c c c c} \hline \hline Model & Capacity & Quality after & Time to Quality & Speed (\(\uparrow\)) \\ & Factor & 100k steps (\(\uparrow\)) & Threshold (\(\downarrow\)) & (examples/sec) \\ & & (Neg. Log Perp.) & (hours) & \\ \hline T5-Base & — & -1.731 & Not achieved\({}^{\dagger}\) & 1600 \\ T5-Large & — & -1.550 & 131.1 & 470 \\ \hline MoE-Base & 2.0 & -1.547 & 68.7 & 840 \\ Switch-Base & 2.0 & -1.554 & 72.8 & 860 \\ \hline MoE-Base & 1.25 & -1.559 & 80.7 & 790 \\ Switch-Base & 1.25 & -1.553 & 65.0 & 910 \\ \hline MoE-Base & 1.0 & -1.572 & 80.1 & 860 \\ Switch-Base & 1.0 & -1.561 & **62.8** & 1000 \\ Switch-Base+ & 1.0 & **-1.534** & 67.6 & 780 \\ \hline \hline \end{tabular}
|
| 157 |
+
\end{table}
|
| 158 |
+
Table 1: Benchmarking Switch versus MoE. Head-to-head comparison measuring per step and per time benefits of the Switch Transformer over the MoE Transformer and T5 dense baselines. We measure quality by the negative log perplexity and the time to reach an arbitrary chosen quality threshold of Neg. Log Perp.=-1.50. All MoE and Switch Transformer models use 128 experts, with experts at every other feed-forward layer. For Switch-Base+, we increase the model size until it matches the speed of the MoE model by increasing the model hidden-size from 768 to 896 and the number of heads from 14 to 16. All models are trained with the same amount of computation (32 cores) and on the same hardware (TPUv3). Further note that all our models required pre-training beyond 100k steps to achieve our level threshold of -1.50. \(\dagger\) T5-Base did not achieve this negative log perplexity in the 100k steps the models were trained.
|
| 159 |
+
|
| 160 |
+
are broadcast through all-to-all communication operations, but we still benefit from the increased stability of float32.
|
| 161 |
+
|
| 162 |
+
**Smalller parameter initialization for stability**. Appropriate initialization is critical to successful training in deep learning and we especially observe this to be true for Switch Transformer. We initialize our weight matrices by drawing elements from a truncated normal distribution with mean \(\mu=0\) and standard deviation \(\sigma=\sqrt{s/n}\) where \(s\) is a scale hyper-parameter and \(n\) is the number of input units in the weight tensor (e.g. fan-in).6
|
| 163 |
+
|
| 164 |
+
Footnote 6: Values greater than two standard deviations from the mean are resampled.
|
| 165 |
+
|
| 166 |
+
As an additional remedy to the instability, we recommend reducing the default Transformer initialization scale \(s=1.0\) by a factor of 10. This both improves quality and reduces the likelihood of destabilized training in our experiments. Table 3 measures the improvement of the model quality and reduction of the variance early in training.
|
| 167 |
+
|
| 168 |
+
We find that the average model quality, as measured by the Neg. Log Perp., is dramatically improved and there is a far reduced variance across runs. Further, this same initialization scheme is broadly effective for models spanning several orders of magnitude. We use the same approach to stably train models as small as our 223M parameter baseline to enormous models in excess of one tr
|
| 169 |
+
|
| 170 |
+
\begin{table}
|
| 171 |
+
\begin{tabular}{c c c} \hline \hline Model & Quality & Speed \\ (precision) & (Neg. Log Perp.) (\(\uparrow\)) & (Examples/sec) (\(\uparrow\)) \\ \hline Switch-Base (float32) & -1.718 & 1160 \\ Switch-Base (bfloat16) & -3.780 [_diverged_] & **1390** \\ Switch-Base (Selective precision) & **-1.716** & 1390 \\ \hline \hline \end{tabular}
|
| 172 |
+
\end{table}
|
| 173 |
+
Table 2: Selective precision. We cast the local routing operations to float32 while preserving bfloat16 precision elsewhere to stabilize our model while achieving nearly equal speed to (unstable) bfloat16-precision training. We measure the quality of a 32 expert model after a fixed step count early in training its speed performance. For both Switch-Base in float32 and with Selective precision we notice similar learning dynamics.
|
| 174 |
+
|
| 175 |
+
\begin{table}
|
| 176 |
+
\begin{tabular}{c c c} \hline \hline Model (Initialization scale) & Average Quality & Std. Dev. of Quality \\ & (Neg. Log Perp.) & (Neg. Log Perp.) \\ \hline Switch-Base (0.1x-init) & **-2.72** & **0.01** \\ Switch-Base (1.0x-init) & -3.60 & 0.68 \\ \hline \hline \end{tabular}
|
| 177 |
+
\end{table}
|
| 178 |
+
Table 3: Reduced initialization scale improves stability. Reducing the initialization scale results in better model quality and more stable training of Switch Transformer. Here we record the average and standard deviation of model quality, measured by the negative log perplexity, of a 32 expert model after 3.5k steps (3 random seeds each).
|
| 179 |
+
|
| 180 |
+
**Regularizing large sparse models.** Our paper considers the common NLP approach of pre-training on a large corpus followed by fine-tuning on smaller downstream tasks such as summarization or question answering. One issue that naturally arises is overfitting since many fine-tuning tasks have very few examples. During fine-tuning of standard Transformers, Raffel et al. (2019) use dropout (Srivastava et al., 2014) at each layer to prevent overfitting. Our Switch Transformers have significantly more parameters than the FLOP matched dense baseline, which can lead to more severe overfitting on these smaller downstream tasks.
|
| 181 |
+
|
| 182 |
+
We thus propose a simple way to alleviate this issue during fine-tuning: increase the dropout inside the experts, which we name as _expert dropout_. During fine-tuning we simply increase the dropout rate by a significant amount only at the interim feed-forward computation at each expert layer. Table 4 has the results for our expert dropout protocol. We observe that simply increasing the dropout across all layers leads to worse performance. However, setting a smaller dropout rate (0.1) at non-expert layers and a much larger dropout rate (0.4) at expert layers leads to performance improvements on four smaller downstream tasks.
|
| 183 |
+
|
| 184 |
+
## 3 Scaling Properties
|
| 185 |
+
|
| 186 |
+
We present a study of the _scaling properties_ of the Switch Transformer architecture during pre-training. Per Kaplan et al. (2020), we consider a regime where the model is not bottlenecked by either the computational budget or amount of data. To avoid the data bottleneck, we use the large C4 corpus with over 180B target tokens (Raffel et al., 2019) and we train until diminishing returns are observed.
|
| 187 |
+
|
| 188 |
+
The number of experts is the most efficient dimension for scaling our model. Increasing the experts keeps the computational cost approximately fixed since the model only selects one expert per token, regardless of the number of experts to choose from. The router must compute a probability distribution over more experts, however, this is a lightweight computation of cost \(O(d_{model}\times\text{num experts})\) where \(d_{model}\) is the embedding dimension of
|
| 189 |
+
|
| 190 |
+
\begin{table}
|
| 191 |
+
\begin{tabular}{c c c c c} \hline \hline Model (dropout) & GLUE & CNNDM & SQuAD & SuperGLUE \\ \hline T5-Base (d=0.1) & 82.9 & **19.6** & 83.5 & 72.4 \\ Switch-Base (d=0.1) & 84.7 & 19.1 & **83.7** & **73.0** \\ Switch-Base (d=0.2) & 84.4 & 19.2 & **83.9** & **73.2** \\ Switch-Base (d=0.3) & 83.9 & 19.6 & 83.4 & 70.7 \\ Switch-Base (d=0.1, ed=0.4) & **85.2** & **19.6** & **83.7** & **73.0** \\ \hline \hline \end{tabular}
|
| 192 |
+
\end{table}
|
| 193 |
+
Table 4: Fine-tuning regularization results. A sweep of dropout rates while fine-tuning Switch Transformer models pre-trained on 34B tokens of the C4 data set (higher numbers are better). We observe that using a lower standard dropout rate at all non-expert layer, with a much larger dropout rate on the expert feed-forward layers, to perform the best.
|
| 194 |
+
|
| 195 |
+
tokens passed between the layers. In this section, we consider the scaling properties on a step-basis and a time-basis with a fixed computational budget.
|
| 196 |
+
|
| 197 |
+
### Scaling Results on a Step-Basis
|
| 198 |
+
|
| 199 |
+
Figure 4 demonstrates consistent scaling benefits with the number of experts when training all models for a fixed number of steps. We observe a clear trend: when keeping the FLOPS per token fixed, having more parameters (experts) speeds up training. The left Figure demonstrates consistent scaling properties (with fixed FLOPS per token) between sparse model parameters and test loss. This reveals the advantage of scaling along this additional axis of sparse model parameters. Our right Figure measures sample efficiency of a dense model variant and four FLOP-matched sparse variants. We find that increasing the number of experts leads to more sample efficient models. Our Switch-Base 64 expert model achieves the same performance of the T5-Base model at step 60k at step 450k, which is a 7.5x speedup in terms of step time. In addition, consistent with the findings of Kaplan et al. (2020), we find that larger models are also more _sample efficient_--learning more quickly for a fixed number of observed tokens.
|
| 200 |
+
|
| 201 |
+
Figure 4: Scaling properties of the Switch Transformer. Left Plot: We measure the quality improvement, as measured by perplexity, as the parameters increase by scaling the number of experts. The top-left point corresponds to the T5-Base model with 223M parameters. Moving from top-left to bottom-right, we double the number of experts from 2, 4, 8 and so on until the bottom-right point of a 256 expert model with 14.7B parameters. Despite all models using an equal computational budget, we observe consistent improvements scaling the number of experts. Right Plot: Negative log perplexity per step sweeping over the number of experts. The dense baseline is shown with the purple line and we note improved sample efficiency of our Switch-Base models.
|
| 202 |
+
|
| 203 |
+
### Scaling Results on a Time-Basis
|
| 204 |
+
|
| 205 |
+
Figure 4 demonstrates that on a step basis, as we increase the number of experts, the performance consistently improves. While our models have roughly the same amount of FLOPS per token as the baseline, our Switch Transformers incurs additional communication costs across devices as well as the extra computation of the routing mechanism. Therefore, the increased sample efficiency observed on a step-basis doesn't necessarily translate to a better model quality as measured by wall-clock. This raises the question:
|
| 206 |
+
|
| 207 |
+
_For a fixed training duration and computational budget, should one train a dense or a sparse model?_
|
| 208 |
+
|
| 209 |
+
Figures 5 and 6 address this question. Figure 5 measures the pre-training model quality as a function of time. For a fixed training duration and computational budget, Switch Transformers yield a substantial speed-up. In this setting, our Switch-Base 64 expert model trains in _one-seventh_ the time that it would take the T5-Base to get similar perplexity.
|
| 210 |
+
|
| 211 |
+
### Scaling Versus a Larger Dense Model
|
| 212 |
+
|
| 213 |
+
The above analysis shows that a computationally-matched dense model is outpaced by its Switch counterpart. Figure 6 considers a different scenario: what if we instead had allocated our resources to a larger dense model? We do so now, measuring Switch-Base against the next strong baseline, _T5-Large_. But despite T5-Large applying 3.5x more FLOPs per token,
|
| 214 |
+
|
| 215 |
+
Figure 5: Speed advantage of Switch Transformer. All models trained on 32 TPUv3 cores with equal FLOPs per example. For a fixed amount of computation and training time, Switch Transformers significantly outperform the dense Transformer baseline. Our 64 expert Switch-Base model achieves the same quality in _one-seventh_ the time of the T5-Base and continues to improve.
|
| 216 |
+
|
| 217 |
+
Switch-Base is still more sample efficient and yields a 2.5x speedup. Furthermore, more gains can be had simply by designing a new, larger sparse version, Switch-Large, which is FLOP-matched to T5-Large. We do this and demonstrate superior scaling and fine-tuning in the following section.
|
| 218 |
+
|
| 219 |
+
## 4 Downstream Results
|
| 220 |
+
|
| 221 |
+
Section 3 demonstrated the superior scaling properties while pre-training, but we now validate that these gains translate to improved language learning abilities on downstream tasks. We begin by fine-tuning on a diverse set of NLP tasks. Next we study reducing the memory footprint of our sparse models by over 90% by distilling into small--and easily deployed--dense baselines. Finally, we conclude this section measuring the improvements in a multi-task, multilingual setting, where we show that Switch Transformers are strong multi-task learners, improving over the multilingual T5-base model across all 101 languages.
|
| 222 |
+
|
| 223 |
+
### Fine-Tuning
|
| 224 |
+
|
| 225 |
+
**Baseline and Switch models used for fine-tuning.** Our baselines are the highly-tuned 223M parameter T5-Base model and the 739M parameter T5-Large model (Raffel et al., 2019). For both versions, we design a FLOP-matched Switch Transformer, with many more parameters, which is summarized in Table 9.7 Our baselines differ slightly from those in Raffel et al. (2019) because we pre-train on an improved C4 corpus which removes intra-example text duplication and thus increases the efficacy as a pre-training task Lee et al.
|
| 226 |
+
|
| 227 |
+
Figure 6: Scaling Transformer models with Switch layers or with standard dense model scaling. Left Plot: Switch-Base is more sample efficient than both the T5-Base, and T5-Large variant, which applies 3.5x more FLOPS per token. Right Plot: As before, on a wall-clock basis, we find that Switch-Base is still faster, and yields a 2.5x speedup over T5-Large.
|
| 228 |
+
|
| 229 |
+
(2021). In our protocol we pre-train with \(2^{20}\) (1,048,576) tokens per batch for 550k steps amounting to 576B total tokens. We then fine-tune across a diverse set of tasks using a dropout rate of 0.1 for all layers except the Switch layers, which use a dropout rate of 0.4 (see Table 4). We fine-tune using a batch-size of 1M for 16k steps and for each task, we evaluate model quality every 200-steps and report the peak performance as computed on the validation set.
|
| 230 |
+
|
| 231 |
+
**Fine-tuning tasks and data sets.** We select tasks probing language capabilities including question answering, summarization and knowledge about the world. The language benchmarks GLUE (Wang et al., 2018) and SuperGLUE (Wang et al., 2019) are handled as composite mixtures with all the tasks blended in proportion to the amount of tokens present in each. These benchmarks consist of tasks requiring sentiment analysis (SST-2), word sense disambiguation (WIC), sentence similarty (MRPC, STS-B, QQP), natural language inference (MNLI, QNLI, RTE, CB), question answering (MultiRC, RECORD, BoolQ), coreference resolution (WNLI, WSC) and sentence completion (COPA) and sentence acceptability (CoLA). The CNNDM (Hermann et al., 2015) and BBC XSum (Narayan et al., 2018) data sets are used to measure the ability to summarize articles. Question answering is probed with the SQuAD data set (Rajpurkar et al., 2016) and the ARC Reasoning Challenge (Clark et al., 2018). And as in Roberts et al. (2020), we evaluate the knowledge of our models by fine-tuning on three closed-book question answering data sets: Natural Questions (Kwiatkowski et al., 2019), Web Questions (Berant et al., 2013) and Trivia QA (Joshi et al., 2017). Closed-book refers to questions posed with no supplemental reference or context material. To gauge the model's common sense reasoning we evaluate it on the Winogrande Schema Challenge (Sakaguchi et al., 2020). And finally, we test our model's natural language inference capabilities on the Adversarial NLI Benchmark (Nie et al., 2019).
|
| 232 |
+
|
| 233 |
+
**Fine-tuning metrics.** The following evaluation metrics are used throughout the paper: We report the average scores across all subtasks for GLUE and SuperGLUE. The Rouge-2 metric is used both the CNNDM and XSum. In SQuAD and the closed book tasks (Web, Natural, and Trivia Questions) we report the percentage of answers exactly matching the target (refer to Roberts et al. (2020) for further details and deficiency of this measure). Finally, in ARC Easy, ARC Challenge, ANLI, and Winogrande we report the accuracy of the generated responses.
|
| 234 |
+
|
| 235 |
+
**Fine-tuning results.** We observe significant downstream improvements across many natural language tasks. Notable improvements come from SuperGLUE, where we find FLOP-matched Switch variants improve by 4.4 and 2 percentage points over the T5-Base and T5-Large baselines, respectively as well as large improvements in Winogrande, closed book Trivia QA, and XSum.8 In our fine-tuning study, the only tasks where we do not observe gains are on the AI2 Reasoning Challenge (ARC) data sets where the T5-Base outperforms Switch-Base on the challenge data set and T5-Large outperforms Switch-Large on the easy data set. Taken as a whole, we observe significant improvements spanning both reasoning and knowledge-heavy tasks. This validates our architecture, not just as one that pre-trains well, but can translate quality improvements to downstream tasks via fine-tuning.
|
| 236 |
+
|
| 237 |
+
### Distillation
|
| 238 |
+
|
| 239 |
+
Deploying massive neural networks with billions, or trillions, of parameters is inconvenient. To alleviate this, we study distilling (Hinton et al., 2015) large sparse models into small dense models. Future work could additionally study distilling large models into smaller _sparse_ models.
|
| 240 |
+
|
| 241 |
+
**Distillation techniques.** In Table 6 we study a variety of distillation techniques. These techniques are built off of Sanh et al. (2019), who study distillation methods for BERT models. We find that initializing the dense model with the non-expert weights yields a modest improvement. This is possible since all models are FLOP matched, so non-expert layers will have the same dimensions. Since expert layers are usually only added at every or every other FFN layer in a Transformer, this allows for many of the weights to be initialized with trained parameters. Furthermore, we observe a distillation improvement using a mixture of 0.25 for the teacher probabilities and 0.75 for the ground truth label. By combining both techniques we preserve \(\approx 30\%\) of the quality gains from the larger sparse models with only \(\approx 1/20^{th}\) of the parameters. The quality gain refers to the percent of
|
| 242 |
+
|
| 243 |
+
\begin{table}
|
| 244 |
+
\begin{tabular}{c c c c c} \hline \hline Model & GLUE & SQuAD & SuperGLUE & Winogrande (XL) \\ \hline T5-Base & 84.3 & 85.5 & 75.1 & 66.6 \\ Switch-Base & **86.7** & **87.2** & **79.5** & **73.3** \\ T5-Large & 87.8 & 88.1 & 82.7 & 79.1 \\ Switch-Large & **88.5** & **88.6** & **84.7** & **83.0** \\ \hline \hline Model & XSum & ANLI (R3) & ARC Easy & ARC Chal. \\ \hline T5-Base & 18.7 & 51.8 & 56.7 & **35.5** \\ Switch-Base & **20.3** & **54.0** & **61.3** & 32.8 \\ T5-Large & 20.9 & 56.6 & **68.8** & **35.5** \\ Switch-Large & **22.3** & **58.6** & 66.0 & **35.5** \\ \hline \hline Model & CB Web QA & CB Natural QA & CB Trivia QA & \\ \hline T5-Base & 26.6 & 25.8 & 24.5 & \\ Switch-Base & **27.4** & **26.8** & **30.7** & \\ T5-Large & 27.7 & 27.6 & 29.5 & \\ Switch-Large & **31.3** & **29.5** & **36.9** & \\ \hline \hline \end{tabular}
|
| 245 |
+
\end{table}
|
| 246 |
+
Table 5: Fine-tuning results. Fine-tuning results of T5 baselines and Switch models across a diverse set of natural language tests (validation sets; higher numbers are better). We compare FLOP-matched Switch models to the T5-Base and T5-Large baselines. For most tasks considered, we find significant improvements of the Switch-variants. We observe gains across both model sizes and across both reasoning and knowledge-heavy language tasks.
|
| 247 |
+
|
| 248 |
+
the quality difference between Switch-Base (Teacher) and T5-Base (Student). Therefore, a quality gain of 100% implies the Student equals the performance of the Teacher.
|
| 249 |
+
|
| 250 |
+
**Achievable compression rates.** Using our best distillation technique described in Table 6, we distill a wide variety of sparse models into dense models. We distill Switch-Base versions, sweeping over an increasing number of experts, which corresponds to varying between 1.1B to 14.7B parameters. Through distillation, we can preserve 37% of the quality gain of the 1.1B parameter model while compressing 82%. At the extreme, where we compress the model 99%, we are still able to maintain 28% of the teacher's model quality improvement.
|
| 251 |
+
|
| 252 |
+
**Distilling a fine-tuned model.** We conclude this with a study of distilling a fine-tuned sparse model into a dense model. Table 8 shows results of distilling a 7.4B parameter Switch-Base model, fine-tuned on the SuperGLUE task, into the 223M T5-Base. Similar to our pre-training results, we find we are able to preserve 30% of the gains of the sparse model when distilling into a FLOP matched dense variant. One potential future avenue, not considered here, may examine the specific experts being used for fine-tuning tasks and extracting them to achieve better model compression.
|
| 253 |
+
|
| 254 |
+
### Multilingual Learning
|
| 255 |
+
|
| 256 |
+
In our final set of downstream experiments, we measure the model quality and speed trade-offs while pre-training on a mixture of 101 different languages. We build and benchmark off the recent work of mT5 (Xue et al., 2020), a multilingual extension to T5. We pre-train on the multilingual variant of the Common Crawl data set (mC4) spanning 101 languages introduced in mT5, but due to script variants within certain languages, the mixture contains 107 tasks.
|
| 257 |
+
|
| 258 |
+
In Figure 7 we plot the quality improvement in negative log perplexity for all languages of a FLOP-matched Switch model, mSwitch-Base to the T5 base variant, mT5-Base. After
|
| 259 |
+
|
| 260 |
+
\begin{table}
|
| 261 |
+
\begin{tabular}{l r r} \hline \hline Technique & Parameters & Quality (\(\uparrow\)) \\ \hline T5-Base & 223M & -1.636 \\ Switch-Base & 3,800M & -1.444 \\ \hline Distillation & 223M & (3\%) -1.631 \\ + Init. non-expert weights from teacher & 223M & (20\%) -1.598 \\ + 0.75 mix of hard and soft loss & 223M & (29\%) -1.580 \\ \hline Initialization Baseline (no distillation) & & \\ Init. non-expert weights from teacher & 223M & -1.639 \\ \hline \hline \end{tabular}
|
| 262 |
+
\end{table}
|
| 263 |
+
Table 6: Distilling Switch Transformers for Language Modeling. Initializing T5-Base with the non-expert weights from Switch-Base and using a loss from a mixture of teacher and ground-truth labels obtains the best performance. We can distill 30% of the performance improvement of a large sparse model with 100x more parameters back into a small dense model. For a final baseline, we find no improvement of T5-Base initialized with the expert weights, but trained normally without distillation.
|
| 264 |
+
|
| 265 |
+
pre-training both versions for 1M steps, we find that on _all_ 101 languages considered, Switch Transformer increases the final negative log perplexity over the baseline. In Figure 8, we present a different view and now histogram the per step _speed-up_ of using Switch Transformer over the mT5-Base.9 We find a mean speed-up over mT5-Base of 5x and that 91% of languages achieve at least a 4x speedup. This presents evidence that Switch Transformers are effective multi-task and multi-lingual learners.
|
| 266 |
+
|
| 267 |
+
Footnote 9: The speedup on a step basis is computed as the ratio of the number of steps for the baseline divided by the number of steps required by our model to reach that same quality.
|
| 268 |
+
|
| 269 |
+
## 5 Designing Models with Data, Model, and Expert-Parallelism
|
| 270 |
+
|
| 271 |
+
Arbitrarily increasing the number of experts is subject to diminishing returns (Figure 4). Here we describe _complementary_ scaling strategies. The common way to scale a Transformer is to increase dimensions in tandem, like \(d_{model}\) or \(d_{ff}\). This increases both the parameters
|
| 272 |
+
|
| 273 |
+
\begin{table}
|
| 274 |
+
\begin{tabular}{c c|c c c c c} \hline \hline & Dense & \multicolumn{5}{c}{Sparse} \\ \hline Parameters & 223M & 1.1B & 2.0B & 3.8B & 7.4B & 14.7B \\ \hline Pre-trained Neg. Log Perp. (\(\uparrow\)) & -1.636 & -1.505 & -1.474 & -1.444 & -1.432 & -1.427 \\ Distilled Neg. Log Perp. (\(\uparrow\)) & — & -1.587 & -1.585 & -1.579 & -1.582 & -1.578 \\ Percent of Teacher Performance & — & 37\% & 32\% & 30 \% & 27 \% & 28 \% \\ Compression Percent & — & 82 \% & 90 \% & 95 \% & 97 \% & 99 \% \\ \hline \hline \end{tabular}
|
| 275 |
+
\end{table}
|
| 276 |
+
Table 7: Distillation compression rates. We measure the quality when distilling large sparse models into a dense baseline. Our baseline, T5-Base, has a -1.636 Neg. Log Perp. quality. In the right columns, we then distill increasingly large sparse models into this same architecture. Through a combination of weight-initialization and a mixture of hard and soft losses, we can shrink our sparse teachers by 95%+ while preserving 30% of the quality gain. However, for significantly better and larger pre-trained teachers, we expect larger student models would be necessary to achieve these compression rates.
|
| 277 |
+
|
| 278 |
+
\begin{table}
|
| 279 |
+
\begin{tabular}{c c c|c} \hline \hline Model & Parameters & FLOPS & SuperGLUE (\(\uparrow\)) \\ \hline T5-Base & 223M & 124B & 74.6 \\ Switch-Base & 7410M & 124B & 81.3 \\ Distilled T5-Base & 223M & 124B & (30\%) 76.6 \\ \hline \hline \end{tabular}
|
| 280 |
+
\end{table}
|
| 281 |
+
Table 8: Distilling a fine-tuned SuperGLUE model. We distill a Switch-Base model fine-tuned on the SuperGLUE tasks into a T5-Base model. We observe that on smaller data sets our large sparse model can be an effective teacher for distillation. We find that we again achieve 30% of the teacher’s performance on a 97% compressed model.
|
| 282 |
+
|
| 283 |
+
and computation performed and is ultimately limited by the memory per accelerator. Once it exceeds the size of the accelerator's memory, single program multiple data (SPMD) model-parallelism can be employed. This section studies the trade-offs of combining data, model, and expert-parallelism.
|
| 284 |
+
|
| 285 |
+
**Reviewing the Feed-Forward Network (FFN) Layer.** We use the FFN layer as an example of how data, model and expert-parallelism works in Mesh TensorFlow (Shazeer et al., 2018) and review it briefly here. We assume \(B\) tokens in the batch, each of dimension
|
| 286 |
+
|
| 287 |
+
Figure 8: Multilingual pre-training on 101 languages. We histogram for each language, the step speedup of Switch Transformers over the FLOP matched T5 dense baseline to reach the same quality. Over all 101 languages, we achieve a mean step speed-up over mT5-Base of 5x and, for 91% of languages, we record a 4x, or greater, speedup to reach the final perplexity of mT5-Base.
|
| 288 |
+
|
| 289 |
+
Figure 7: Multilingual pre-training on 101 languages. Improvements of Switch T5 Base model over dense baseline when multi-task training on 101 languages. We observe Switch Transformers to do quite well in the multi-task training setup and yield improvements on all 101 languages.
|
| 290 |
+
|
| 291 |
+
\(d_{model}\). Both the input (\(x\)) and output (\(y\)) of the FFN are of size [\(B\), \(d_{model}\)] and the intermediate (\(h\)) is of size [\(B\), \(d_{ff}\)] where \(d_{ff}\) is typically several times larger than \(d_{model}\). In the FFN, the intermediate is \(h=xW_{in}\) and then the output of the layer is \(y=ReLU(h)W_{out}\). Thus \(W_{in}\) and \(W_{out}\) are applied independently to each token and have sizes [\(d_{model}\), \(d_{ff}\)] and [\(d_{ff}\), \(d_{model}\)].
|
| 292 |
+
|
| 293 |
+
We describe two aspects of partitioning: how the _weights_ and _batches of data_ divide over cores, depicted in Figure 9. We denote all cores available as \(N\) which Mesh Tensorflow may then remap into a logical multidimensional mesh of processors. Here we create a two-dimensional logical mesh, with one dimension representing the number of ways for data-parallel sharding (\(n\)) and the other, the model-parallel sharding (\(m\)). The total cores must equal the ways to shard across both data and model-parallelism, e.g. \(N=n\times m\). To shard the layer across cores, the tensors containing that batch of \(B\) tokens are sharded across \(n\) data-parallel cores, so each core contains \(B/n\) tokens. Tensors and variables with \(d_{ff}\) are then sharded across \(m\) model-parallel cores. For the variants with experts-layers, we consider \(E\) experts, each of which can process up to \(C\) tokens.
|
| 294 |
+
|
| 295 |
+
### Data Parallelism
|
| 296 |
+
|
| 297 |
+
When training data parallel models, which is the standard for distributed training, then all cores are allocated to the data-parallel dimension or \(n=N,m=1\). This has the advantage that no communication is needed until the entire forward and backward pass is finished and the gradients need to be then aggregated across all cores. This corresponds to the left-most column of Figure 9.
|
| 298 |
+
|
| 299 |
+
### Model Parallelism
|
| 300 |
+
|
| 301 |
+
We now consider a scenario where all cores are allocated exclusively to the model-parallel dimension and so \(n=1,m=N\). Now all cores must keep the full \(B\) tokens and each core will contain a unique slice of the weights. For each forward and backward pass, a communication cost is now incurred. Each core sends a tensor of [\(B\), \(d_{model}\)] to compute the second matrix multiplication \(ReLU(h)W_{out}\) because the \(d_{ff}\) dimension is partitioned and must be summed over. As a general rule, whenever a dimension that is partitioned across cores must be summed, then an all-reduce operation is added for both the forward and backward pass. This contrasts with pure data parallelism where an all-reduce only occurs at the end of the entire forward and backward pass.
|
| 302 |
+
|
| 303 |
+
### Model and Data Parallelism
|
| 304 |
+
|
| 305 |
+
It is common to mix both model and data parallelism for large scale models, which was done in the largest T5 models (Raffel et al., 2019; Xue et al., 2020) and in GPT-3 (Brown et al., 2020). With a total of \(N=n\times m\) cores, now each core will be responsible for \(B/n\) tokens and \(d_{ff}/m\) of both the weights and intermediate activation. In the forward and backward pass each core communicates a tensor of size \([B/n,d_{model}]\) in an all-reduce operation.
|
| 306 |
+
|
| 307 |
+
Figure 9: Data and weight partitioning strategies. Each 4\(\times\)4 dotted-line grid represents 16 cores and the shaded squares are the data contained on that core (either model weights or batch of tokens). We illustrate both how the model weights and the data tensors are split for each strategy. **First Row:** illustration of how _model weights_ are split across the cores. Shapes of different sizes in this row represent larger weight matrices in the Feed Forward Network (FFN) layers (e.g larger \(d_{ff}\) sizes). Each color of the shaded squares identifies a unique weight matrix. The number of parameters _per core_ is fixed, but larger weight matrices will apply more computation to each token. **Second Row:** illustration of how the _data batch_ is split across cores. Each core holds the same number of tokens which maintains a fixed memory usage across all strategies. The partitioning strategies have different properties of allowing each core to either have the same tokens or different tokens across cores, which is what the different colors symbolize.
|
| 308 |
+
|
| 309 |
+
### Expert and Data Parallelism
|
| 310 |
+
|
| 311 |
+
Next we describe the partitioning strategy for expert and data parallelism. Switch Transformers will allocate all of their cores to the data partitioning dimension \(n\), which will also correspond to the number of experts in the model. For each token per core a router locally computes assignments to the experts. The output is a binary matrix of size [\(n\), \(B/n\), \(E\), \(C\)] which is partitioned across the first dimension and determines expert assignment. This binary matrix is then used to do a gather via matrix multiplication with the input tensor of [\(n\), \(B/n\), \(d_{model}\)].
|
| 312 |
+
|
| 313 |
+
\[\text{einsum}([n,B/n,d_{model}],[n,B/n,E,C],\text{dimension}=[B/n]) \tag{7}\]
|
| 314 |
+
|
| 315 |
+
resulting in the final tensor of shape [\(n\), \(E\), \(C\), \(d_{model}\)], which is sharded across the first dimension. Because each core has its own expert, we do an all-to-all communication of size [\(E\), \(C\), \(d_{model}\)] to now shard the \(E\) dimension instead of the \(n\)-dimension. There are additional communication costs of bfloat16 tensors of size \(E\times C\times d_{model}\) in the forward pass to analogously receive the tokens from each expert located on different cores. See Appendix F for a detailed analysis of the expert partitioning code.
|
| 316 |
+
|
| 317 |
+
### Expert, Model and Data Parallelism
|
| 318 |
+
|
| 319 |
+
In the design of our best model, we seek to balance the FLOPS per token and the parameter count. When we scale the number of experts, we increase the number of parameters, but do not change the FLOPs per token. In order to increase FLOPs, we must also increase the \(d_{ff}\) dimension (which also increases parameters, but at a slower rate). This presents a trade-off: as we increase \(d_{ff}\) we will run out of memory per core, which then necessitates increasing \(m\). But since we have a fixed number of cores \(N\), and \(N=n\times m\), we must decrease \(n\), which forces use of a smaller batch-size (in order to hold tokens per core constant).
|
| 320 |
+
|
| 321 |
+
When combining both model and expert-parallelism, we will have all-to-all communication costs from routing the tokens to the correct experts along with the internal all-reduce communications from the model parallelism. Balancing the FLOPS, communication costs and memory per core becomes quite complex when combining all three methods where the best mapping is empirically determined. See our further analysis in section 5.6 for how the number of experts effects the downstream performance as well.
|
| 322 |
+
|
| 323 |
+
### Towards Trillion Parameter Models
|
| 324 |
+
|
| 325 |
+
Combining expert, model and data parallelism, we design two large Switch Transformer models, one with 395 billion and 1.6 trillion parameters, respectively. We study how these models perform on both up-stream pre-training as language models and their downstream fine-tuning performance. The parameters, FLOPs per sequence and hyper-parameters of the two different models are listed below in Table 9. Standard hyper-parameters of the Transformer, including \(d_{model}\), \(d_{ff}\), \(d_{kv}\), number of heads and number of layers are described, as well as a less common feature, \(FFN_{GEGLU}\), which refers to a variation of the FFN layer where the expansion matrix is substituted with two sets of weights which are non-linearly combined (Shazeer, 2020).
|
| 326 |
+
|
| 327 |
+
The Switch-C model is designed using only expert-parallelism, and no model-parallelism, as described earlier in Section 5.4. As a result, the hyper-parameters controlling the width,depth, number of heads, and so on, are all much smaller than the T5-XXL model. In contrast, the Switch-XXL is FLOP-matched to the T5-XXL model, which allows for larger dimensions of the hyper-parameters, but at the expense of additional communication costs induced by model-parallelism (see Section 5.5 for more details).
|
| 328 |
+
|
| 329 |
+
**Sample efficiency versus T5-XXL.** In the final two columns of Table 9 we record the negative log perplexity on the C4 corpus after 250k and 500k steps, respectively. After 250k steps, we find both Switch Transformer variants to improve over the T5-XXL version's negative log perplexity by over 0.061.10 To contextualize the significance of a gap of 0.061, we note that the T5-XXL model had to train for an _additional_ 250k steps to increase 0.052. The gap continues to increase with additional training, with the Switch-XXL model out-performing the T5-XXL by 0.087 by 500k steps.
|
| 330 |
+
|
| 331 |
+
Footnote 10: This reported quality difference is a lower bound, and may actually be larger. The T5-XXL was pre-trained on an easier C4 data set which included duplicated, and thus easily copied, snippets within examples.
|
| 332 |
+
|
| 333 |
+
**Training instability.** However, as described in the introduction, large sparse models can be unstable, and as we increase the scale, we encounter some sporadic issues. We find that the larger Switch-C model, with 1.6T parameters and 2048 experts, exhibits no training instability at all. Instead, the Switch XXL version, with nearly 10x larger FLOPs per sequence, is sometimes unstable. As a result, though this is our better model on a step-basis, we do not pre-train for a full 1M steps, in-line with the final reported results of T5 (Raffel et al., 2019).
|
| 334 |
+
|
| 335 |
+
\begin{table}
|
| 336 |
+
\begin{tabular}{c|c c c c c c c} \hline \hline Model & Parameters & FLOPs/seq & \(d_{\text{mubd}}\) & \(FFN_{\text{CEGLU}}\) & \(d_{ff}\) & \(d_{\text{ks}}\) & Num. Heads \\ \hline T5-Base & 0.2B & 124B & 768 & ✓ & 2048 & 64 & 12 \\ T5-Large & 0.7B & 425B & 1024 & ✓ & 2816 & 64 & 16 \\ T5-XXL & 11B & 6.3T & 4096 & ✓ & 10240 & 64 & 64 \\ \hline Switch-Base & 7B & 124B & 768 & ✓ & 2048 & 64 & 12 \\ Switch-Large & 26B & 425B & 1024 & ✓ & 2816 & 64 & 16 \\ Switch-XXL & 395B & 6.3T & 4096 & ✓ & 10240 & 64 & 64 \\ Switch-C & 1571B & 890B & 2080 & & 6144 & 64 & 32 \\ \hline \hline Model & Expert Freq. & Num. Layers & Num Experts & Neg. Log Perp. @250k & Neg. Log Perp. @ 500k & \\ \hline T5-Base & – & 12 & – & -1.599 & -1.556 & \\ T5-Large & – & 24 & – & -1.402 & -1.350 & \\ T5-XXL & – & 24 & – & -1.147 & -1.095 & \\ \hline Switch-Base & 1/2 & 12 & 128 & -1.370 & -1.306 & \\ Switch-Large & 1/2 & 24 & 128 & -1.248 & -1.177 & \\ Switch-XXL & 1/2 & 24 & 64 & -**1.086** & **-1.008** & \\ Switch-C & 1 & 15 & 2048 & -1.096 & -1.043 & \\ \hline \hline \end{tabular}
|
| 337 |
+
\end{table}
|
| 338 |
+
Table 9: Switch model design and pre-training performance. We compare the hyper-parameters and pre-training performance of the T5 models to our Switch Transformer variants. The last two columns record the pre-training model quality on the C4 data set after 250k and 500k steps, respectively. We observe that the Switch-C Transformer variant is 4x faster to a fixed perplexity (with the same compute budget) than the T5-XXL model, with the gap increasing as training progresses.
|
| 339 |
+
|
| 340 |
+
**Reasoning fine-tuning performance.** As a preliminary assessment of the model quality, we use a Switch-XXL model partially pre-trained on 503B tokens, or approximately half the text used by the T5-XXL model. Using this checkpoint, we conduct multi-task training for efficiency, where all tasks are learned jointly, rather than individually fine-tuned. We find that SQuAD accuracy on the validation set increases to 89.7 versus state-of-the-art of 91.3. Next, the average SuperGLUE test score is recorded at 87.5 versus the T5 version obtaining a score of 89.3 compared to the state-of-the-art of 90.0 (Wang et al., 2019). On ANLI (Nie et al., 2019), Switch XXL improves over the prior state-of-the-art to get a 65.7 accuracy versus the prior best of 49.4 (Yang et al., 2020). We note that while the Switch-XXL has state-of-the-art Neg. Log Perp. on the upstream pre-training task, its gains have not yet fully translated to SOTA downstream performance. We study this issue more in Appendix E.
|
| 341 |
+
|
| 342 |
+
**Knowledge-based fine-tuning performance.** Finally, we also conduct an early examination of the model's knowledge with three closed-book knowledge-based tasks: Natural Questions, WebQuestions and TriviaQA, without additional pre-training using Salient Span Masking (Guu et al., 2020). In all three cases, we observe improvements over the prior state-of-the-art T5-XXL model (without SSM). Natural Questions exact match increases to 34.4 versus the prior best of 32.8, Web Questions increases to 41.0 over 37.2, and TriviaQA increases to 47.5 versus 42.9.
|
| 343 |
+
|
| 344 |
+
Summing up, despite training on less than half the data of other models, we already find comparable, and sometimes state-of-the-art, model quality. Currently, the Switch Transformer translates substantial upstream gains better to knowledge-based tasks, than reasoning-tasks (see Appendix E). Extracting stronger fine-tuning performance from large expert models is an active research question, and the pre-training perplexity indicates future improvements should be possible.
|
| 345 |
+
|
| 346 |
+
## 6 Related Work
|
| 347 |
+
|
| 348 |
+
The importance of scale in neural networks is widely recognized and several approaches have been proposed. Recent works have scaled models to billions of parameters through using model parallelism (e.g. splitting weights and tensors across multiple cores) (Shazeer et al., 2018; Rajbhandari et al., 2019; Raffel et al., 2019; Brown et al., 2020; Shoeybi et al., 2019). Alternatively, Harlap et al. (2018); Huang et al. (2019) propose using pipeline based model parallelism, where different layers are split across devices and micro-batches are _pipelined_ to the different layers. Finally, Product Key networks (Lample et al., 2019) were proposed to scale up the capacity of neural networks by doing a lookup for learnable embeddings based on the incoming token representations to a given layer.
|
| 349 |
+
|
| 350 |
+
Our work studies a specific model in a class of methods that do _conditional_ computation, where computation decisions are made dynamically based on the input. Cho and Bengio (2014) proposed adaptively selecting weights based on certain bit patterns occuring in the model hidden-states. Eigen et al. (2013) built stacked expert layers with dense matrix multiplications and ReLU activations and showed promising results on jittered MNIST and monotone speech. In computer vision Puigcerver et al. (2020) manually route tokens based on semantic classes during upstream pre-training and then select the relevant experts to be used according to the downstream task.
|
| 351 |
+
|
| 352 |
+
Mixture of Experts (MoE), in the context of modern deep learning architectures, was proven effective in Shazeer et al. (2017). That work added an MoE layer which was stacked between LSTM (Hochreiter and Schmidhuber, 1997) layers, and tokens were separately routed to combinations of experts. This resulted in state-of-the-art results in language modeling and machine translation benchmarks. The MoE layer was reintroduced into the Transformer architecture by the Mesh Tensorflow library (Shazeer et al., 2018) where MoE layers were introduced as a substitute of the FFN layers, however, there were no accompanying NLP results. More recently, through advances in machine learning infrastructure, GShard (Lepikhin et al., 2020), which extended the XLA compiler, used the MoE Transformer to dramatically improve machine translation across 100 languages. Finally Fan et al. (2021) chooses a different deterministic MoE strategy to split the model parameters into non-overlapping groups of languages.
|
| 353 |
+
|
| 354 |
+
Sparsity along the sequence length dimension (\(L\)) in the Transformer _attention patterns_ has been a successful technique to reduce the attention complexity from \(O(L^{2})\)(Child et al., 2019; Correia et al., 2019; Sukhbaatar et al., 2019; Kitaev et al., 2020; Zaheer et al., 2020; Beltagy et al., 2020). This has enabled learning longer sequences than previously possible. This version of the Switch Transformer does not employ attention sparsity, but these techniques are complimentary, and, as future work, these could be combined to potentially improve learning on tasks requiring long contexts.
|
| 355 |
+
|
| 356 |
+
## 7 Discussion
|
| 357 |
+
|
| 358 |
+
We pose and discuss questions about the Switch Transformer, and sparse expert models generally, where sparsity refers to weights, not on attention patterns.
|
| 359 |
+
|
| 360 |
+
**Isn't Switch Transformer better due to sheer parameter count?** Yes, and by design! Parameters, independent of the total FLOPs used, are a useful axis to scale neural language models. Large models have been exhaustively shown to perform better (Kaplan et al., 2020). But in this case, our model is more sample efficient and faster while using the same computational resources.
|
| 361 |
+
|
| 362 |
+
**I don't have access to a supercomputer--is this still useful for me?** Though this work has focused on extremely large models, we also find that models with as few as two experts improves performance while easily fitting within memory constraints of commonly available GPUs or TPUs (details in Appendix D). We therefore believe our techniques are useful in small-scale settings.
|
| 363 |
+
|
| 364 |
+
**Do sparse models outperform dense models on the speed-accuracy Pareto curve?** Yes. Across a wide variety of different models sizes, sparse models outperform dense models per step and on wall clock time. Our controlled experiments show for a fixed amount of computation and time, sparse models outperform dense models.
|
| 365 |
+
|
| 366 |
+
**I can't deploy a trillion parameter model--can we shrink these models?** We cannot fully preserve the model quality, but compression rates of 10 to 100x are achievable by distilling our sparse models into dense models while achieving \(\approx\)30% of the quality gain of the expert model.
|
| 367 |
+
|
| 368 |
+
**Why use Switch Transformer instead of a model-parallel dense model?** On a time basis, Switch Transformers can be far more efficient than dense-models with sharded parameters (Figure 6). Also, we point out that this decision is _not_ mutually exclusive--wecan, and do, use model-parallelism in Switch Transformers, increasing the FLOPs per token, but incurring the slowdown of conventional model-parallelism.
|
| 369 |
+
|
| 370 |
+
**Why aren't sparse models widely used already?** The motivation to try sparse models has been stymied by the massive success of scaling dense models (the success of which is partially driven by co-adaptation with deep learning hardware as argued in Hooker (2020)). Further, sparse models have been subject to multiple issues including (1) model complexity, (2) training difficulties, and (3) communication costs. Switch Transformer makes strides to alleviate these issues.
|
| 371 |
+
|
| 372 |
+
## 8 Future Work
|
| 373 |
+
|
| 374 |
+
This paper lays out a simplified architecture, improved training procedures, and a study of how sparse models scale. However, there remain many open future directions which we briefly describe here:
|
| 375 |
+
|
| 376 |
+
1. A significant challenge is further improving training stability for the largest models. While our stability techniques were effective for our Switch-Base, Switch-Large and Switch-C models (no observed instability), they were not sufficient for Switch-XXL. We have taken early steps towards stabilizing these models, which we think may be generally useful for large models, including using regularizers for improving stability and adapted forms of gradient clipping, but this remains unsolved.
|
| 377 |
+
2. Generally we find that improved pre-training quality leads to better downstream results (Appendix E), though we sometimes encounter striking anomalies. For instance, despite similar perplexities modeling the C4 data set, the 1.6T parameter Switch-C achieves only an 87.7 exact match score in SQuAD, which compares unfavorably to 89.6 for the smaller Switch-XXL model. One notable difference is that the Switch-XXL model applies \(\approx\)10x the FLOPS per token than the Switch-C model, even though it has \(\approx\)4x less unique parameters (395B vs 1.6T). This suggests a poorly understood dependence between fine-tuning quality, _FLOPS per token_ and _number of parameters_.
|
| 378 |
+
3. Perform a comprehensive study of scaling relationships to guide the design of architectures blending data, model and expert-parallelism. Ideally, given the specs of a hardware configuration (computation, memory, communication) one could more rapidly design an optimal model. And, vice versa, this may also help in the design of future hardware.
|
| 379 |
+
4. Our work falls within the family of adaptive computation algorithms. Our approach always used identical, homogeneous experts, but future designs (facilitated by more flexible infrastructure) could support _heterogeneous_ experts. This would enable more flexible adaptation by routing to larger experts when more computation is desired--perhaps for harder examples.
|
| 380 |
+
5. Investigating expert layers outside the FFN layer of the Transformer. We find preliminary evidence that this similarly can improve model quality. In Appendix A, we report quality improvement adding these inside Self-Attention layers, where our layer replaces the weight matrices which produce Q, K, V. However, due to training instabilities with the bfloat16 format, we instead leave this as an area for future work.
|
| 381 |
+
6. Examining Switch Transformer in new and across different modalities. We have thus far only considered language, but we believe that model sparsity can similarly provide advantages in new modalities, as well as multi-modal networks.
|
| 382 |
+
|
| 383 |
+
This list could easily be extended, but we hope this gives a flavor for the types of challenges that we are thinking about and what we suspect are promising future directions.
|
| 384 |
+
|
| 385 |
+
## 9 Conclusion
|
| 386 |
+
|
| 387 |
+
Switch Transformers are scalable and effective natural language learners. We simplify Mixture of Experts to produce an architecture that is easy to understand, stable to train and vastly more sample efficient than equivalently-sized dense models. We find that these models excel across a diverse set of natural language tasks and in different training regimes, including pre-training, fine-tuning and multi-task training. These advances make it possible to train models with hundreds of billion to trillion parameters and which achieve substantial speedups relative to dense T5 baselines. We hope our work motivates sparse models as an effective architecture and that this encourages researchers and practitioners to consider these flexible models in natural language tasks, and beyond.
|
| 388 |
+
|
| 389 |
+
The authors would like to thank Margaret Li who provided months of key insights into algorithmic improvements and suggestions for empirical studies. Hugo Larochelle for sage advising and clarifying comments on the draft, Irwan Bello for detailed comments and careful revisions, Colin Raffel and Adam Roberts for timely advice on neural language models and the T5 code-base, Yoshua Bengio for advising and encouragement on research in adaptive computation, Jascha Sohl-dickstein for interesting new directions for stabilizing new large scale models and paper revisions, and the Google Brain Team for useful discussions on the paper. Blake Hechtman who provided invaluable help in profiling and improving the training performance of our models.
|
| 390 |
+
|
| 391 |
+
## Appendix A Switch for Attention
|
| 392 |
+
|
| 393 |
+
Shazeer et al. (2018); Lepikhin et al. (2020) designed MoE Transformers (Shazeer et al., 2017) by adding MoE layers into the dense feedfoward network (FFN) computations of the Transformer. Similarly, our work also replaced the FFN layer in the Transformer, but we briefly explore here an alternate design. We add Switch layers into the Transformer _Self-Attention_ layers. To do so, we replace the trainable weight matrices that produce the queries, keys and values with Switch layers as seen in Figure 10.
|
| 394 |
+
|
| 395 |
+
Table 10 records the quality after a fixed number of steps as well as training time for several variants. Though we find improvements, we also found these layers to be more unstable when using bfloat16 precision and thus we did not include them in the final variant.
|
| 396 |
+
|
| 397 |
+
However, when these layers do train stably, we believe the preliminary positive results suggests a future promising direction.
|
| 398 |
+
|
| 399 |
+
\begin{table}
|
| 400 |
+
\begin{tabular}{c|c c c c} \hline \hline Model & Precision & Quality & Quality & Speed \\ & & @100k Steps (\(\uparrow\)) & @16H (\(\uparrow\)) & (ex/sec) (\(\uparrow\)) \\ \hline Experts FF & float32 & -1.548 & -1.614 & 1480 \\ Expert Attention & float32 & -1.524 & **-1.606** & 1330 \\ Expert Attention & bfloat16 & [diverges] & [diverges] & – \\ Experts FF + Attention & float32 & **-1.513** & -1.607 & 1240 \\ Expert FF + Attention & bfloat16 & [diverges] & [diverges] & – \\ \hline \hline \end{tabular}
|
| 401 |
+
\end{table}
|
| 402 |
+
Table 10: Switch attention layer results. All models have 32 experts and train with 524k tokens per batch. Experts FF is when experts replace the FFN in the Transformer, which is our standard setup throughout the paper. Experts FF + Attention is when experts are used to replace both the FFN and the Self-Attention layers. When training with bfloat16 precision the models that have experts attention diverge.
|
| 403 |
+
|
| 404 |
+
Figure 10: Switch layers in attention. We diagram how to incorporate the Switch layer into the Self-Attention transformer block. For each token (here we show two tokens, \(x_{1}\) = “More” and \(x_{2}\) = “Parameters”), one set of weights produces the query and the other set of unique weights produces the shared keys and values. We experimented with each expert being a linear operation, as well as a FFN, as was the case throughout this work. While we found quality improvements using this, we found this to be more unstable when used with low precision number formats, and thus leave it for future work.
|
| 405 |
+
|
| 406 |
+
## Appendix B Preventing Token Dropping with _No-Token-Left-Behind_
|
| 407 |
+
|
| 408 |
+
Due to software constraints on TPU accelerators, the shapes of our Tensors must be statically sized. As a result, each expert has a finite and fixed capacity to process token representations. This, however, presents an issue for our model which dynamically routes tokens at run-time that may result in an uneven distribution over experts. If the number of tokens sent to an expert is less than the expert capacity, then the computation may simply be padded - an inefficient use of the hardware, but mathematically correct. However, when the number of tokens sent to an expert is larger than its capacity (expert overflow), a protocol is needed to handle this. Lepikhin et al. (2020) adapts a Mixture-of-Expert model and addresses expert overflow by passing its representation to the next layer without processing through a residual connection which we also follow.
|
| 409 |
+
|
| 410 |
+
We suspected that having no computation applied to tokens could be very wasteful, especially since if there is overflow on one expert, that means another expert will have extra capacity. With this intuition we create _No-Token-Left-Behind_, which iteratively reroutes any tokens that are at first routed to an expert that is overflowing. Figure 11 shows a graphical description of this method, which will allow us to guarantee almost no tokens will be dropped during training and inference. We hypothesised that this could improve performance and further stabilize training, but we found no empirical benefits. We suspect that once the network learns associations between different tokens and experts, if this association is changed (e.g. sending a token to its second highest expert) then performance could be degraded.
|
| 411 |
+
|
| 412 |
+
## Appendix C Encouraging Exploration Across Experts
|
| 413 |
+
|
| 414 |
+
At each expert-layer, the router determines to which expert to send the token. This is a discrete decision over the available experts, conditioned on information about the token's representation. Based on the incoming token representation, the router determines the best expert, however, it receives no counterfactual information about how well it would have done selecting an alternate expert. As in reinforcement learning, a classic exploration-exploitation dilemma arises (Sutton and Barto, 2018). These issues have been similarly noted and addressed differently by Rosenbaum et al. (2017) which demonstrated success in multi-task learning. This particular setting most closely matches that of a contextual bandit (Robbins, 1952). Deterministically selecting the top expert always amounts to an exploitative strategy - we consider balancing exploration to seek better expert assignment.
|
| 415 |
+
|
| 416 |
+
To introduce exploration, we consider several approaches: 1) deterministic or argmax 2) sampling from the softmax distribution 3) input dropout on the incoming representation 4) multiplicative jitter noise on the incoming representation. The resulting impact on model quality is reported in Table 11. Throughout this work, we use input jitter to inject noise as we have found it to empirically perform the best.
|
| 417 |
+
|
| 418 |
+
## Appendix D Switch Transformers in Lower Compute Regimes
|
| 419 |
+
|
| 420 |
+
Switch Transformer is also an effective architecture at small scales as well as in regimes with thousands of cores and trillions of parameters. Many of our prior experiments wereat the scale of 10B+ parameter models, but we show in Figure 12 as few as 2 experts produce compelling gains over a FLOP-matched counterpart. Even if a super computer is not readily available, training Switch Transformers with 2, 4, or 8 experts (as we typically recommend one expert per core) results in solid improvements over T5 dense baselines.
|
| 421 |
+
|
| 422 |
+
Figure 11: Diagram of the _No-Token-Left-Behind Routing_. Stage 1 is equivalent to Switch routing where tokens are routed to the expert with the highest probability from the router. In Stage 2 we look at all tokens that have overflowed and route them to the expert with which has the second highest probability. Tokens can still be overflowed if their second highest expert has too many tokens, but this allows most of the tokens to be routed. This process can be iterated to guarantee virtually no tokens are dropped at all.
|
| 423 |
+
|
| 424 |
+
\begin{table}
|
| 425 |
+
\begin{tabular}{c c} \hline Model & Quality (Neg. Log Perp.) (\(\uparrow\)) \\ \hline Argmax & -1.471 \\ Sample softmax & -1.570 \\ Input dropout & -1.480 \\ Input jitter & **-1.468** \\ \hline \end{tabular}
|
| 426 |
+
\end{table}
|
| 427 |
+
Table 11: Router Exploration Strategies. Quality of the Switch Transformer, measured by the negative log perplexity, under different randomness-strategies for selecting the expert (lower is better). There is no material speed performance difference between the variants.
|
| 428 |
+
|
| 429 |
+
Figure 12: Switch Transformer with few experts. Switch Transformer improves over the baseline even with very few experts. Here we show scaling properties at very small scales, where we improve over the T5-Base model using 2, 4, and 8 experts.
|
| 430 |
+
|
| 431 |
+
## Appendix E Relation of Upstream to Downstream Model Performance
|
| 432 |
+
|
| 433 |
+
There is no guarantee that a model's quality on a pre-training objective will translate to downstream task results. Figure 13 presents the correlation of the upstream model quality, for both dense and Switch models, on the C4 pre-training task with two downstream task measures: average SuperGLUE performance and TriviaQA score. We choose these two tasks as one probes the model's reasoning and the other factual knowledge.
|
| 434 |
+
|
| 435 |
+
We find a consistent correlation, indicating that for both baseline and Switch models, improved pre-training leads to better downstream results. Additionally, for a fixed upstream perplexity we find that both Switch and dense models perform similarly in the small to medium model size regime. However, in the largest model regime (T5-11B/T5-XXL) our largest Switch models, as mentioned in Section 5.6, do not always translate their upstream perplexity well to downstream fine-tuning on the SuperGLUE task. This warrants future investigation and study to fully realize the potential of sparse models. Understanding the fine-tuning dynamics with expert-models is very complicated and is dependent on regularization, load-balancing, and fine-tuning hyper-parameters.
|
| 436 |
+
|
| 437 |
+
Figure 13: Upstream pre-trained quality to downstream model quality. We correlate the upstream performance with downstream quality on both SuperGLUE and TriviaQA (SOTA recorded without SSM), reasoning and knowledge-heavy benchmarks, respectively (validation sets). We find that, as with the baseline, the Switch model scales with improvements in the upstream pre-training task. For SuperGLUE, we find a loosely linear relation between negative log perplexity and the average SuperGLUE score. However, the dense model often performs better for a fixed perplexity, particularly in the large-scale regime. Conversely, on the knowledge-heavy task, TriviaQA, we find that the Switch Transformer may follow an improved scaling relationship – for a given upstream perplexity, it does better than a dense counterpart. Further statistics (expensive to collect and left to future work) would be necessary to confirm these observations.
|
| 438 |
+
|
| 439 |
+
## Appendix F Pseudo Code for Switch Transformers
|
| 440 |
+
|
| 441 |
+
Pseudocode for Switch Transformers in Mesh Tensorflow (Shazeer et al., 2018). No model parallelism is being used for the below code (see 5.4 for more details).
|
| 442 |
+
|
| 443 |
+
Figure 14: Pseudo code for the load balance loss for Switch Transformers in Mesh Tensorflow.
|
| 444 |
+
|
| 445 |
+
importmesh_tensorflowasntf defrouter(inputs,capacity_factor): """Producethecombineanddispatchtensorsusedforsendingand receivingtokensfromtheirhighestprobabilityexpert.""" #Corelayoutissplitacrossnum_coresforalltensorsandoperations. #inputsshape:[num_cores,tokens_per_core,d_model] router_weights=ntf.Variable(shape=[d_model,num_experts])
|
| 446 |
+
#router_logitsshape:[num_cores,tokens_per_core,num_experts] router_logits=ntf.einsum([inputs,router_weights],reduced_dim=d_model) ifis_training: #Addnoiseforexplorationacrossexperts. router_logits+=ntf.random_uniform(shape=router_logits.shape,minval=1-eps,maxval=1+eps)
|
| 447 |
+
#Convertinputtosoftmaxoperationfrombfloati6float32forstability. router_logits=ntf.to_float32(router_logits)
|
| 448 |
+
#Probabilitiesforeachtokenofwhatexpertistshouldbesentto. router_probs=ntf.softmax(router_logits,axis=-1)
|
| 449 |
+
#Getthetop-1expertforeachtoken.expert_gateisthetop-1probability #fromtherouterforeachtoken.expert_indexiswhatexpertachtoken #isgoingtoberoutedto. #expert_gateshape:[num_cores,tokens_per_core] #expert_indexis:[num_cores,tokens_per_core] expert_gate,expert_index=ntf.top_1(router_probs,reduced_dim=num_experts)
|
| 450 |
+
#expert_maskshape:[num_cores,tokens_per_core,num_experts] expert_mask=ntf.one_hot(expert_index,dimension=num_experts)
|
| 451 |
+
#Computeloadbalancingloss. aux_loss=load_balance_loss(router_probs,expert_mask)
|
| 452 |
+
#Expertshaveafixedcapacity,ensurewedoatececedit.Construct #thebatchindices,toeachexpert,withposition_in_expert #makewatthatmorethatexpert_capacitysamplescanberoutedto #eachexpert. position_in_expert=ntf.cumsum(expert_mask,dimension=tokens_per_core)*expert_mask
|
| 453 |
+
#Keeponlytokensthatfitwithinexpert_capacity. expert_mask+=ntf.less(position_in_expert,expert_capacity) expert_mask_flat=ntf.reduce_sum(expert_mask,reduced_dim=experts_dim)
|
| 454 |
+
#Maskouttheexpertshaveoverflow
|
| 455 |
+
|
| 456 |
+
importmesh_tensorflowasntf defswitch_layer(inputs,n,capacity_factor,num_experts): """Distributedswitchtransformerfeed-forwardlayer.""" #num_cores(n)=totalcoresfortrainingthemodel(scalar). #d_model=modelhiddensize(scalar). #num_experts=totalnumberofexperts. #capacity_factor=extrabufferforeachexpert. #inputsshape:[batch,seq_len,d_model] batch,seq_len,d_model=inputs.get_shape() #Eachcorewillroutetokens_per_coretokenstothecorrectexperts. tokens_per_core=batch*seq_len/num_cores
|
| 457 |
+
#Eachexpertwillhaveshape[num_cores,expert_capacity,d_model]. #Eachcoreisresponsibleforsendingexpert_capacitytokens
|
| 458 |
+
#toeachexpert.expert_capacity=tokens_per_core*capacity_factor/num_experts
|
| 459 |
+
#Reshapetosetuppercoreexpertdispatching. #shape:[batch,seq_len,d_model]->[num_cores,tokens_per_core,d_model] #Corelayout:[n,i,j]->[n,i,j]inputs=ntf.reshape(inputs,[num_cores,tokens_per_core,d_model])
|
| 460 |
+
#Corelayout:[n,i,j]->[
|
| 461 |
+
|
| 462 |
+
## References
|
| 463 |
+
|
| 464 |
+
* Abadi et al. (2016) Martin Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. Tensorflow: A system for large-scale machine learning. In _12th \(\{\)USENIX\(\}\) symposium on operating systems design and implementation (\(\{\)OSDI\(\}\) 16)_, pages 265-283, 2016.
|
| 465 |
+
* Beltagy et al. (2020) Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. _arXiv preprint arXiv:2004.05150_, 2020.
|
| 466 |
+
* Berant et al. (2013) Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic parsing on free-base from question-answer pairs. In _Proceedings of the 2013 conference on empirical methods in natural language processing_, pages 1533-1544, 2013.
|
| 467 |
+
* Brown et al. (2020) Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. _arXiv preprint arXiv:2005.14165_, 2020.
|
| 468 |
+
* Child et al. (2019) Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. _arXiv preprint arXiv:1904.10509_, 2019.
|
| 469 |
+
* Cho and Bengio (2014) Kyunghyun Cho and Yoshua Bengio. Exponentially increasing the capacity-to-computation ratio for conditional computation in deep learning. _arXiv preprint arXiv:1406.7362_, 2014.
|
| 470 |
+
* Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. _arXiv preprint arXiv:1803.05457_, 2018.
|
| 471 |
+
* Correia et al. (2019) Goncalo M Correia, Vlad Niculae, and Andre FT Martins. Adaptively sparse transformers. _arXiv preprint arXiv:1909.00015_, 2019.
|
| 472 |
+
* Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. _arXiv preprint arXiv:1810.04805_, 2018.
|
| 473 |
+
* Eigen et al. (2013) David Eigen, Marc'Aurelio Ranzato, and Ilya Sutskever. Learning factored representations in a deep mixture of experts. _arXiv preprint arXiv:1312.4314_, 2013.
|
| 474 |
+
* Fan et al. (2021) Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, et al. Beyond english-centric multilingual machine translation. _Journal of Machine Learning Research_, 22(107):1-48, 2021.
|
| 475 |
+
* Fedus et al. (2018) William Fedus, Ian Goodfellow, and Andrew M Dai. Maskgan: Better text generation via filling in the_. _arXiv preprint arXiv:1801.07736_, 2018.
|
| 476 |
+
* Gale et al. (2020) Trevor Gale, Matei Zaharia, Cliff Young, and Erich Elsen. Sparse gpu kernels for deep learning. _arXiv preprint arXiv:2006.10901_, 2020.
|
| 477 |
+
* Gray et al. (2017) Scott Gray, Alec Radford, and Diederik P Kingma. Gpu kernels for block-sparse weights. _[https://openai.com/blog/block-sparse-gpu-kernels/_](https://openai.com/blog/block-sparse-gpu-kernels/_), 2017.
|
| 478 |
+
|
| 479 |
+
* Guu et al. (2020) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. Realm: Retrieval-augmented language model pre-training. _arXiv preprint arXiv:2002.08909_, 2020.
|
| 480 |
+
* Harlap et al. (2018) Aaron Harlap, Deepak Narayanan, Amar Phanishayee, Vivek Seshadri, Nikhil Devanur, Greg Ganger, and Phil Gibbons. Pipedream: Fast and efficient pipeline parallel dnn training. _arXiv preprint arXiv:1806.03377_, 2018.
|
| 481 |
+
* Hermann et al. (2015) Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, editors, _Advances in Neural Information Processing Systems_, volume 28, pages 1693-1701. Curran Associates, Inc., 2015. URL [https://proceedings.neurips.cc/paper/2015/file/afdec7005cc9f14302cd0474fd0f3c96-Paper.pdf](https://proceedings.neurips.cc/paper/2015/file/afdec7005cc9f14302cd0474fd0f3c96-Paper.pdf).
|
| 482 |
+
* Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. _arXiv preprint arXiv:1503.02531_, 2015.
|
| 483 |
+
* Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jurgen Schmidhuber. Long short-term memory. _Neural computation_, 9(8):1735-1780, 1997.
|
| 484 |
+
* Hooker (2020) Sara Hooker. The hardware lottery. _arXiv preprint arXiv:2009.06489_, 2020.
|
| 485 |
+
* Huang et al. (2019) Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In _Advances in neural information processing systems_, pages 103-112, 2019.
|
| 486 |
+
* Jacobs et al. (1991) Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts. _Neural computation_, 3(1):79-87, 1991.
|
| 487 |
+
* Jordan and Jacobs (1994) Michael I Jordan and Robert A Jacobs. Hierarchical mixtures of experts and the em algorithm. _Neural computation_, 6(2):181-214, 1994.
|
| 488 |
+
* Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. _arXiv preprint arXiv:1705.03551_, 2017.
|
| 489 |
+
* Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. _arXiv preprint arXiv:2001.08361_, 2020.
|
| 490 |
+
* Kitaev et al. (2020) Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. _arXiv preprint arXiv:2001.04451_, 2020.
|
| 491 |
+
* Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research. _Transactions of the Association for Computational Linguistics_, 7:453-466, 2019.
|
| 492 |
+
|
| 493 |
+
* Lample et al. (2019) Guillaume Lample, Alexandre Sablayrolles, Marc'Aurelio Ranzato, Ludovic Denoyer, and Herve Jegou. Large memory layers with product keys. In _Advances in Neural Information Processing Systems_, pages 8548-8559, 2019.
|
| 494 |
+
* Lee et al. (2021) Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini. Deduplicating training data makes language models better. _arXiv preprint arXiv:2107.06499_, 2021.
|
| 495 |
+
* Lepikhin et al. (2020) Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. _arXiv preprint arXiv:2006.16668_, 2020.
|
| 496 |
+
* Micikevicius et al. (2017) Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, et al. Mixed precision training. _arXiv preprint arXiv:1710.03740_, 2017.
|
| 497 |
+
* Narayan et al. (2018) Shashi Narayan, Shay B Cohen, and Mirella Lapata. Don't give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. _arXiv preprint arXiv:1808.08745_, 2018.
|
| 498 |
+
* Nie et al. (2019) Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. Adversarial nli: A new benchmark for natural language understanding. _arXiv preprint arXiv:1910.14599_, 2019.
|
| 499 |
+
* Puigcerver et al. (2020) Joan Puigcerver, Carlos Riquelme, Basil Mustafa, Cedric Renggli, Andre Susano Pinto, Sylvain Gelly, Daniel Keysers, and Neil Houlsby. Scalable transfer learning with expert models. _arXiv preprint arXiv:2009.13239_, 2020.
|
| 500 |
+
* Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training, 2018.
|
| 501 |
+
* Raffel et al. (2019) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. _arXiv preprint arXiv:1910.10683_, 2019.
|
| 502 |
+
* Rajbhandari et al. (2019) Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimization towards training a trillion parameter models. _arXiv preprint arXiv:1910.02054_, 2019.
|
| 503 |
+
* Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. _arXiv preprint arXiv:1606.05250_, 2016.
|
| 504 |
+
* Ramachandran and Le (2018) Prajit Ramachandran and Quoc V Le. Diversity and depth in per-example routing models. In _International Conference on Learning Representations_, 2018.
|
| 505 |
+
* Robbins (1952) Herbert Robbins. Some aspects of the sequential design of experiments. _Bulletin of the American Mathematical Society_, 58(5):527-535, 1952.
|
| 506 |
+
|
| 507 |
+
* Roberts et al. (2020) Adam Roberts, Colin Raffel, and Noam Shazeer. How much knowledge can you pack into the parameters of a language model? _arXiv preprint arXiv:2002.08910_, 2020.
|
| 508 |
+
* Rosenbaum et al. (2017) Clemens Rosenbaum, Tim Klinger, and Matthew Riemer. Routing networks: Adaptive selection of non-linear functions for multi-task learning. _arXiv preprint arXiv:1711.01239_, 2017.
|
| 509 |
+
* Sakaguchi et al. (2020) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. In _Proceedings of the AAAI Conference on Artificial Intelligence_, volume 34, pages 8732-8740, 2020.
|
| 510 |
+
* Sanh et al. (2019) Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter, 2019.
|
| 511 |
+
* Shazeer (2020) Noam Shazeer. Glu variants improve transformer, 2020.
|
| 512 |
+
* Shazeer et al. (2017) Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. _arXiv preprint arXiv:1701.06538_, 2017.
|
| 513 |
+
* Shazeer et al. (2018) Noam Shazeer, Youlong Cheng, Niki Parmar, Dustin Tran, Ashish Vaswani, Penporn Koanantakool, Peter Hawkins, HyoukJoong Lee, Mingsheng Hong, Cliff Young, et al. Mesh-tensorflow: Deep learning for supercomputers. In _Advances in Neural Information Processing Systems_, pages 10414-10423, 2018.
|
| 514 |
+
* Shoeybi et al. (2019) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using gpu model parallelism. _arXiv preprint arXiv:1909.08053_, 2019.
|
| 515 |
+
* Srivastava et al. (2014) Nitish Srivastava, Geoffrey E. Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. _Journal of Machine Learning Research_, 15(1):1929-1958, 2014. URL [http://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf](http://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf).
|
| 516 |
+
* Strubell et al. (2019) Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in nlp. _arXiv preprint arXiv:1906.02243_, 2019.
|
| 517 |
+
* Sukhbaatar et al. (2019) Sainbayar Sukhbaatar, Edouard Grave, Piotr Bojanowski, and Armand Joulin. Adaptive attention span in transformers. _arXiv preprint arXiv:1905.07799_, 2019.
|
| 518 |
+
* Sutton (2019) Rich Sutton. The Bitter Lesson. _[http://www.incompleteideas.net/IncIdeas/BitterLesson.html_](http://www.incompleteideas.net/IncIdeas/BitterLesson.html_), 2019.
|
| 519 |
+
* Sutton and Barto (2018) Richard S Sutton and Andrew G Barto. _Reinforcement learning: An introduction_. Stanford University, 2018.
|
| 520 |
+
* Taylor (1953) Wilson L Taylor. "cloze procedure": A new tool for measuring readability. _Journalism quarterly_, 30(4):415-433, 1953.
|
| 521 |
+
|
| 522 |
+
* Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In _Advances in neural information processing systems_, pages 5998-6008, 2017.
|
| 523 |
+
* Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. _arXiv preprint arXiv:1804.07461_, 2018.
|
| 524 |
+
* Wang et al. (2019) Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Superglue: A stickier benchmark for general-purpose language understanding systems. In _Advances in Neural Information Processing Systems_, pages 3266-3280, 2019.
|
| 525 |
+
* Wang and Kanwar (2019) Shibo Wang and Pankaj Kanwar. Bfloat16: The secret to high performance on cloud tpus. _Google Cloud Blog_, 2019.
|
| 526 |
+
* Xue et al. (2020) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. mt5: A massively multilingual pre-trained text-to-text transformer. _arXiv preprint arXiv:2010.11934_, 2020.
|
| 527 |
+
* Yang et al. (2020) Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. Xlnet: Generalized autoregressive pretraining for language understanding, 2020.
|
| 528 |
+
* Zaheer et al. (2020) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences. _arXiv preprint arXiv:2007.14062_, 2020.
|
data/examples/nougat/thinkos.md
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/examples/nougat/thinkpython.md
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/images/overall.png
ADDED

|
data/images/per_doc.png
ADDED
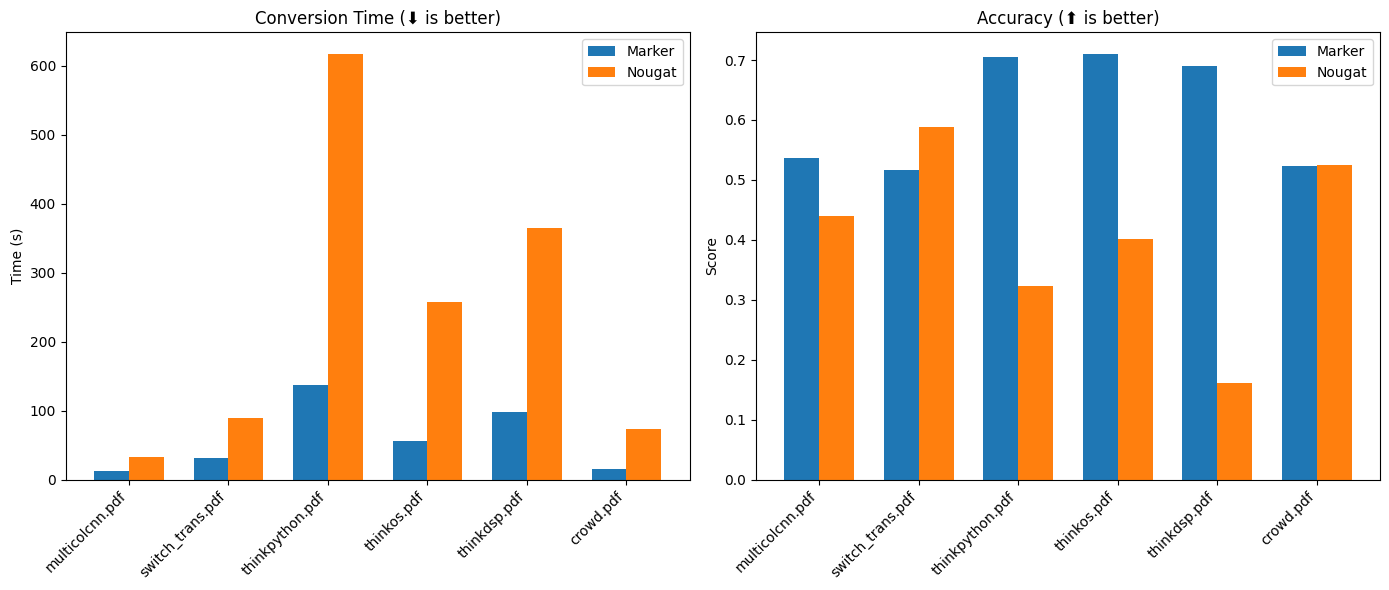
|
data/latex_to_md.sh
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# List all .tex files in the latex folder
|
| 4 |
+
FILES=$(find latex -name "*.tex")
|
| 5 |
+
|
| 6 |
+
for f in $FILES
|
| 7 |
+
do
|
| 8 |
+
echo "Processing $f file..."
|
| 9 |
+
base_name=$(basename "$f" .tex)
|
| 10 |
+
out_file="references/${base_name}.md"
|
| 11 |
+
|
| 12 |
+
pandoc --wrap=none \
|
| 13 |
+
--no-highlight \
|
| 14 |
+
--strip-comments \
|
| 15 |
+
--from=latex \
|
| 16 |
+
--to=commonmark_x+pipe_tables \
|
| 17 |
+
"$f" \
|
| 18 |
+
-o "$out_file"
|
| 19 |
+
# Replace non-breaking spaces
|
| 20 |
+
sed -i .bak 's/ / /g' "$out_file"
|
| 21 |
+
sed -i .bak 's/ / /g' "$out_file"
|
| 22 |
+
sed -i .bak 's/ / /g' "$out_file"
|
| 23 |
+
sed -i .bak 's/ / /g' "$out_file"
|
| 24 |
+
sed -i.bak -E 's/`\\cite`//g; s/<[^>]*>//g; s/\{[^}]*\}//g; s/\\cite\{[^}]*\}//g' "$out_file"
|
| 25 |
+
sed -i.bak -E '
|
| 26 |
+
s/`\\cite`//g; # Remove \cite commands inside backticks
|
| 27 |
+
s/::: //g; # Remove the leading ::: for content markers
|
| 28 |
+
s/\[//g; # Remove opening square bracket
|
| 29 |
+
s/\]//g; # Remove closing square bracket
|
| 30 |
+
' "$out_file"
|
| 31 |
+
# Remove .bak file
|
| 32 |
+
rm "$out_file.bak"
|
| 33 |
+
done
|
| 34 |
+
|
docs/install_ocrmypdf.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Linux
|
| 2 |
+
|
| 3 |
+
- Run `apt-get install ocrmypdf`
|
| 4 |
+
- Install ghostscript > 9.55 by following [these instructions](https://ghostscript.readthedocs.io/en/latest/Install.html) or running `scripts/install/ghostscript_install.sh`.
|
| 5 |
+
- Run `pip install ocrmypdf`
|
| 6 |
+
- Install any tesseract language packages that you want (example `apt-get install tesseract-ocr-eng`)
|
| 7 |
+
- Set the tesseract data folder path
|
| 8 |
+
- Find the tesseract data folder `tessdata` with `find / -name tessdata`. Make sure to use the one corresponding to the latest tesseract version if you have multiple.
|
| 9 |
+
- Create a `local.env` file in the root `marker` folder with `TESSDATA_PREFIX=/path/to/tessdata` inside it
|
| 10 |
+
|
| 11 |
+
## Mac
|
| 12 |
+
|
| 13 |
+
Only needed if using `ocrmypdf` as the ocr backend.
|
| 14 |
+
|
| 15 |
+
- Run `brew install ocrmypdf`
|
| 16 |
+
- Run `brew install tesseract-lang` to add language support
|
| 17 |
+
- Run `pip install ocrmypdf`
|
| 18 |
+
- Set the tesseract data folder path
|
| 19 |
+
- Find the tesseract data folder `tessdata` with `brew list tesseract`
|
| 20 |
+
- Create a `local.env` file in the root `marker` folder with `TESSDATA_PREFIX=/path/to/tessdata` inside it
|
| 21 |
+
|
| 22 |
+
## Windows
|
| 23 |
+
|
| 24 |
+
- Install `ocrmypdf` and ghostscript by following [these instructions](https://ocrmypdf.readthedocs.io/en/latest/installation.html#installing-on-windows)
|
| 25 |
+
- Run `pip install ocrmypdf`
|
| 26 |
+
- Install any tesseract language packages you want
|
| 27 |
+
- Set the tesseract data folder path
|
| 28 |
+
- Find the tesseract data folder `tessdata` with `brew list tesseract`
|
| 29 |
+
- Create a `local.env` file in the root `marker` folder with `TESSDATA_PREFIX=/path/to/tessdata` inside it
|
marker/benchmark/scoring.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
from rapidfuzz import fuzz
|
| 4 |
+
import re
|
| 5 |
+
import regex
|
| 6 |
+
from statistics import mean
|
| 7 |
+
|
| 8 |
+
CHUNK_MIN_CHARS = 25
|
| 9 |
+
|
| 10 |
+
def chunk_text(text, chunk_len=500):
|
| 11 |
+
chunks = [text[i:i+chunk_len] for i in range(0, len(text), chunk_len)]
|
| 12 |
+
chunks = [c for c in chunks if c.strip() and len(c) > CHUNK_MIN_CHARS]
|
| 13 |
+
return chunks
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def overlap_score(hypothesis_chunks, reference_chunks):
|
| 17 |
+
length_modifier = len(hypothesis_chunks) / len(reference_chunks)
|
| 18 |
+
search_distance = max(len(reference_chunks) // 5, 10)
|
| 19 |
+
chunk_scores = []
|
| 20 |
+
for i, hyp_chunk in enumerate(hypothesis_chunks):
|
| 21 |
+
max_score = 0
|
| 22 |
+
total_len = 0
|
| 23 |
+
i_offset = int(i * length_modifier)
|
| 24 |
+
chunk_range = range(max(0, i_offset-search_distance), min(len(reference_chunks), i_offset+search_distance))
|
| 25 |
+
for j in chunk_range:
|
| 26 |
+
ref_chunk = reference_chunks[j]
|
| 27 |
+
score = fuzz.ratio(hyp_chunk, ref_chunk, score_cutoff=30) / 100
|
| 28 |
+
if score > max_score:
|
| 29 |
+
max_score = score
|
| 30 |
+
total_len = len(ref_chunk)
|
| 31 |
+
chunk_scores.append(max_score)
|
| 32 |
+
return chunk_scores
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def score_text(hypothesis, reference):
|
| 36 |
+
# Returns a 0-1 alignment score
|
| 37 |
+
hypothesis_chunks = chunk_text(hypothesis)
|
| 38 |
+
reference_chunks = chunk_text(reference)
|
| 39 |
+
chunk_scores = overlap_score(hypothesis_chunks, reference_chunks)
|
| 40 |
+
return mean(chunk_scores)
|
marker/cleaners/bullets.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def replace_bullets(text):
|
| 5 |
+
# Replace bullet characters with a -
|
| 6 |
+
bullet_pattern = r"(^|[\n ])[•●○■▪▫–—]( )"
|
| 7 |
+
replaced_string = re.sub(bullet_pattern, r"\1-\2", text)
|
| 8 |
+
return replaced_string
|
marker/cleaners/code.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import Counter
|
| 2 |
+
from statistics import mean, median
|
| 3 |
+
|
| 4 |
+
from marker.schema.block import Span, Line
|
| 5 |
+
from marker.schema.page import Page
|
| 6 |
+
import re
|
| 7 |
+
from typing import List
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def is_code_linelen(lines, thresh=80):
|
| 11 |
+
# Decide based on chars per newline threshold
|
| 12 |
+
total_alnum_chars = sum(len(re.findall(r'\w', line.prelim_text)) for line in lines)
|
| 13 |
+
total_newlines = max(len(lines) - 1, 1)
|
| 14 |
+
|
| 15 |
+
if total_alnum_chars == 0:
|
| 16 |
+
return False
|
| 17 |
+
|
| 18 |
+
ratio = total_alnum_chars / total_newlines
|
| 19 |
+
return ratio < thresh
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def comment_count(lines):
|
| 23 |
+
pattern = re.compile(r"^(//|#|'|--|/\*|'''|\"\"\"|--\[\[|<!--|%|%{|\(\*)")
|
| 24 |
+
return sum([1 for line in lines if pattern.match(line)])
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def identify_code_blocks(pages: List[Page]):
|
| 28 |
+
code_block_count = 0
|
| 29 |
+
font_sizes = []
|
| 30 |
+
line_heights = []
|
| 31 |
+
for page in pages:
|
| 32 |
+
font_sizes += page.get_font_sizes()
|
| 33 |
+
line_heights += page.get_line_heights()
|
| 34 |
+
|
| 35 |
+
avg_font_size = None
|
| 36 |
+
avg_line_height = None
|
| 37 |
+
if len(font_sizes) > 0:
|
| 38 |
+
avg_line_height = median(line_heights)
|
| 39 |
+
avg_font_size = mean(font_sizes)
|
| 40 |
+
|
| 41 |
+
for page in pages:
|
| 42 |
+
for block in page.blocks:
|
| 43 |
+
if block.block_type != "Text":
|
| 44 |
+
last_block = block
|
| 45 |
+
continue
|
| 46 |
+
|
| 47 |
+
# Ensure we have lines and spans
|
| 48 |
+
if len(block.lines) == 0:
|
| 49 |
+
continue
|
| 50 |
+
if sum([len(line.spans) for line in block.lines]) == 0:
|
| 51 |
+
continue
|
| 52 |
+
|
| 53 |
+
min_start = block.get_min_line_start()
|
| 54 |
+
|
| 55 |
+
is_indent = []
|
| 56 |
+
line_fonts = []
|
| 57 |
+
line_font_sizes = []
|
| 58 |
+
block_line_heights = []
|
| 59 |
+
for line in block.lines:
|
| 60 |
+
line_fonts += [span.font for span in line.spans]
|
| 61 |
+
line_font_sizes += [span.font_size for span in line.spans]
|
| 62 |
+
block_line_heights.append(line.bbox[3] - line.bbox[1])
|
| 63 |
+
|
| 64 |
+
is_indent.append(line.bbox[0] > min_start)
|
| 65 |
+
|
| 66 |
+
comment_lines = comment_count([line.prelim_text for line in block.lines])
|
| 67 |
+
is_code = [
|
| 68 |
+
len(block.lines) > 3,
|
| 69 |
+
is_code_linelen(block.lines),
|
| 70 |
+
sum(is_indent) + comment_lines > len(block.lines) * .7, # Indentation and comments are a majority
|
| 71 |
+
]
|
| 72 |
+
|
| 73 |
+
if avg_font_size is not None:
|
| 74 |
+
font_checks = [
|
| 75 |
+
mean(line_font_sizes) <= avg_font_size * .8, # Lower than average font size and line height
|
| 76 |
+
mean(block_line_heights) < avg_line_height * .8
|
| 77 |
+
]
|
| 78 |
+
is_code += font_checks
|
| 79 |
+
|
| 80 |
+
if all(is_code):
|
| 81 |
+
code_block_count += 1
|
| 82 |
+
block.block_type = "Code"
|
| 83 |
+
|
| 84 |
+
return code_block_count
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def indent_blocks(pages: List[Page]):
|
| 88 |
+
span_counter = 0
|
| 89 |
+
for page in pages:
|
| 90 |
+
for block in page.blocks:
|
| 91 |
+
if block.block_type != "Code":
|
| 92 |
+
continue
|
| 93 |
+
|
| 94 |
+
lines = []
|
| 95 |
+
min_left = 1000 # will contain x- coord of column 0
|
| 96 |
+
col_width = 0 # width of 1 char
|
| 97 |
+
for line in block.lines:
|
| 98 |
+
text = ""
|
| 99 |
+
min_left = min(line.bbox[0], min_left)
|
| 100 |
+
for span in line.spans:
|
| 101 |
+
if col_width == 0 and len(span.text) > 0:
|
| 102 |
+
col_width = (span.bbox[2] - span.bbox[0]) / len(span.text)
|
| 103 |
+
text += span.text
|
| 104 |
+
lines.append((line.bbox, text))
|
| 105 |
+
|
| 106 |
+
block_text = ""
|
| 107 |
+
blank_line = False
|
| 108 |
+
for line in lines:
|
| 109 |
+
text = line[1]
|
| 110 |
+
if col_width == 0:
|
| 111 |
+
prefix = ""
|
| 112 |
+
else:
|
| 113 |
+
prefix = " " * int((line[0][0] - min_left) / col_width)
|
| 114 |
+
current_line_blank = len(text.strip()) == 0
|
| 115 |
+
if blank_line and current_line_blank:
|
| 116 |
+
# Don't put multiple blank lines in a row
|
| 117 |
+
continue
|
| 118 |
+
|
| 119 |
+
block_text += prefix + text + "\n"
|
| 120 |
+
blank_line = current_line_blank
|
| 121 |
+
|
| 122 |
+
new_span = Span(
|
| 123 |
+
text=block_text,
|
| 124 |
+
bbox=block.bbox,
|
| 125 |
+
span_id=f"{span_counter}_fix_code",
|
| 126 |
+
font=block.lines[0].spans[0].font,
|
| 127 |
+
font_weight=block.lines[0].spans[0].font_weight,
|
| 128 |
+
font_size=block.lines[0].spans[0].font_size,
|
| 129 |
+
)
|
| 130 |
+
span_counter += 1
|
| 131 |
+
block.lines = [Line(spans=[new_span], bbox=block.bbox)]
|
marker/cleaners/fontstyle.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
from marker.schema.page import Page
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def find_bold_italic(pages: List[Page], bold_min_weight=600):
|
| 7 |
+
font_weights = []
|
| 8 |
+
for page in pages:
|
| 9 |
+
for block in page.blocks:
|
| 10 |
+
# We don't want to bias our font stats
|
| 11 |
+
if block.block_type in ["Title", "Section-header"]:
|
| 12 |
+
continue
|
| 13 |
+
for line in block.lines:
|
| 14 |
+
for span in line.spans:
|
| 15 |
+
if "bold" in span.font.lower():
|
| 16 |
+
span.bold = True
|
| 17 |
+
if "ital" in span.font.lower():
|
| 18 |
+
span.italic = True
|
| 19 |
+
|
| 20 |
+
font_weights.append(span.font_weight)
|
| 21 |
+
|
| 22 |
+
if len(font_weights) == 0:
|
| 23 |
+
return
|
| 24 |
+
|
| 25 |
+
for page in pages:
|
| 26 |
+
for block in page.blocks:
|
| 27 |
+
for line in block.lines:
|
| 28 |
+
for span in line.spans:
|
| 29 |
+
if span.font_weight >= bold_min_weight:
|
| 30 |
+
span.bold = True
|
marker/cleaners/headers.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from collections import Counter
|
| 3 |
+
from rapidfuzz import fuzz
|
| 4 |
+
|
| 5 |
+
from marker.schema.merged import FullyMergedBlock
|
| 6 |
+
from typing import List, Tuple
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def filter_common_elements(lines, page_count, threshold=.6):
|
| 10 |
+
# We can't filter if we don't have enough pages to find common elements
|
| 11 |
+
if page_count < 3:
|
| 12 |
+
return []
|
| 13 |
+
text = [s.text for line in lines for s in line.spans if len(s.text) > 4]
|
| 14 |
+
counter = Counter(text)
|
| 15 |
+
common = [k for k, v in counter.items() if v > page_count * threshold]
|
| 16 |
+
bad_span_ids = [s.span_id for line in lines for s in line.spans if s.text in common]
|
| 17 |
+
return bad_span_ids
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def filter_header_footer(all_page_blocks, max_selected_lines=2):
|
| 21 |
+
first_lines = []
|
| 22 |
+
last_lines = []
|
| 23 |
+
for page in all_page_blocks:
|
| 24 |
+
nonblank_lines = page.get_nonblank_lines()
|
| 25 |
+
first_lines.extend(nonblank_lines[:max_selected_lines])
|
| 26 |
+
last_lines.extend(nonblank_lines[-max_selected_lines:])
|
| 27 |
+
|
| 28 |
+
bad_span_ids = filter_common_elements(first_lines, len(all_page_blocks))
|
| 29 |
+
bad_span_ids += filter_common_elements(last_lines, len(all_page_blocks))
|
| 30 |
+
return bad_span_ids
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def replace_leading_trailing_digits(string, replacement):
|
| 34 |
+
string = re.sub(r'^\d+', replacement, string)
|
| 35 |
+
string = re.sub(r'\d+$', replacement, string)
|
| 36 |
+
return string
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def find_overlap_elements(lst: List[Tuple[str, int]], string_match_thresh=.9, min_overlap=.05) -> List[int]:
|
| 40 |
+
# Initialize a list to store the elements that meet the criteria
|
| 41 |
+
result = []
|
| 42 |
+
titles = [l[0] for l in lst]
|
| 43 |
+
|
| 44 |
+
for i, (str1, id_num) in enumerate(lst):
|
| 45 |
+
overlap_count = 0 # Count the number of elements that overlap by at least 80%
|
| 46 |
+
|
| 47 |
+
for j, str2 in enumerate(titles):
|
| 48 |
+
if i != j and fuzz.ratio(str1, str2) >= string_match_thresh * 100:
|
| 49 |
+
overlap_count += 1
|
| 50 |
+
|
| 51 |
+
# Check if the element overlaps with at least 50% of other elements
|
| 52 |
+
if overlap_count >= max(3.0, len(lst) * min_overlap):
|
| 53 |
+
result.append(id_num)
|
| 54 |
+
|
| 55 |
+
return result
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def filter_common_titles(merged_blocks: List[FullyMergedBlock]) -> List[FullyMergedBlock]:
|
| 59 |
+
titles = []
|
| 60 |
+
for i, block in enumerate(merged_blocks):
|
| 61 |
+
if block.block_type in ["Title", "Section-header"]:
|
| 62 |
+
text = block.text
|
| 63 |
+
if text.strip().startswith("#"):
|
| 64 |
+
text = re.sub(r'#+', '', text)
|
| 65 |
+
text = text.strip()
|
| 66 |
+
# Remove page numbers from start/end
|
| 67 |
+
text = replace_leading_trailing_digits(text, "").strip()
|
| 68 |
+
titles.append((text, i))
|
| 69 |
+
|
| 70 |
+
bad_block_ids = find_overlap_elements(titles)
|
| 71 |
+
|
| 72 |
+
new_blocks = []
|
| 73 |
+
for i, block in enumerate(merged_blocks):
|
| 74 |
+
if i in bad_block_ids:
|
| 75 |
+
continue
|
| 76 |
+
new_blocks.append(block)
|
| 77 |
+
|
| 78 |
+
return new_blocks
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
|
marker/cleaners/headings.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
from marker.settings import settings
|
| 4 |
+
from marker.schema.bbox import rescale_bbox
|
| 5 |
+
from marker.schema.block import bbox_from_lines
|
| 6 |
+
from marker.schema.page import Page
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def split_heading_blocks(pages: List[Page]):
|
| 10 |
+
# Heading lines can be combined into regular text blocks sometimes by pdftext
|
| 11 |
+
# Split up heading lines into separate blocks properly
|
| 12 |
+
for page in pages:
|
| 13 |
+
page_heading_boxes = [b for b in page.layout.bboxes if b.label in ["Title", "Section-header"]]
|
| 14 |
+
page_heading_boxes = [(rescale_bbox(page.layout.image_bbox, page.bbox, b.bbox), b.label) for b in page_heading_boxes]
|
| 15 |
+
|
| 16 |
+
new_blocks = []
|
| 17 |
+
for block_idx, block in enumerate(page.blocks):
|
| 18 |
+
if block.block_type not in ["Text"]:
|
| 19 |
+
new_blocks.append(block)
|
| 20 |
+
continue
|
| 21 |
+
|
| 22 |
+
heading_lines = []
|
| 23 |
+
for line_idx, line in enumerate(block.lines):
|
| 24 |
+
for (heading_box, label) in page_heading_boxes:
|
| 25 |
+
if line.intersection_pct(heading_box) > settings.BBOX_INTERSECTION_THRESH:
|
| 26 |
+
heading_lines.append((line_idx, label))
|
| 27 |
+
break
|
| 28 |
+
|
| 29 |
+
if len(heading_lines) == 0:
|
| 30 |
+
new_blocks.append(block)
|
| 31 |
+
continue
|
| 32 |
+
|
| 33 |
+
# Split up the block into separate blocks around headers
|
| 34 |
+
start = 0
|
| 35 |
+
for (heading_line, label) in heading_lines:
|
| 36 |
+
if start < heading_line:
|
| 37 |
+
copied_block = block.copy()
|
| 38 |
+
copied_block.lines = block.lines[start:heading_line]
|
| 39 |
+
copied_block.bbox = bbox_from_lines(copied_block.lines)
|
| 40 |
+
new_blocks.append(copied_block)
|
| 41 |
+
|
| 42 |
+
copied_block = block.copy()
|
| 43 |
+
copied_block.lines = block.lines[heading_line:heading_line + 1]
|
| 44 |
+
copied_block.block_type = label
|
| 45 |
+
copied_block.bbox = bbox_from_lines(copied_block.lines)
|
| 46 |
+
new_blocks.append(copied_block)
|
| 47 |
+
|
| 48 |
+
start = heading_line + 1
|
| 49 |
+
if start >= len(block.lines):
|
| 50 |
+
break
|
| 51 |
+
|
| 52 |
+
# Add any remaining lines
|
| 53 |
+
if start < len(block.lines):
|
| 54 |
+
copied_block = block.copy()
|
| 55 |
+
copied_block.lines = block.lines[start:]
|
| 56 |
+
copied_block.bbox = bbox_from_lines(copied_block.lines)
|
| 57 |
+
new_blocks.append(copied_block)
|
| 58 |
+
|
| 59 |
+
page.blocks = new_blocks
|
marker/cleaners/text.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def cleanup_text(full_text):
|
| 5 |
+
full_text = re.sub(r'\n{3,}', '\n\n', full_text)
|
| 6 |
+
full_text = re.sub(r'(\n\s){3,}', '\n\n', full_text)
|
| 7 |
+
full_text = full_text.replace('\xa0', ' ') # Replace non-breaking spaces
|
| 8 |
+
return full_text
|
marker/convert.py
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
warnings.filterwarnings("ignore", category=UserWarning) # Filter torch pytree user warnings
|
| 3 |
+
|
| 4 |
+
import pypdfium2 as pdfium
|
| 5 |
+
from PIL import Image
|
| 6 |
+
|
| 7 |
+
from marker.utils import flush_cuda_memory
|
| 8 |
+
from marker.tables.table import format_tables
|
| 9 |
+
from marker.debug.data import dump_bbox_debug_data
|
| 10 |
+
from marker.layout.layout import surya_layout, annotate_block_types
|
| 11 |
+
from marker.layout.order import surya_order, sort_blocks_in_reading_order
|
| 12 |
+
from marker.ocr.lang import replace_langs_with_codes, validate_langs
|
| 13 |
+
from marker.ocr.detection import surya_detection
|
| 14 |
+
from marker.ocr.recognition import run_ocr
|
| 15 |
+
from marker.pdf.extract_text import get_text_blocks
|
| 16 |
+
from marker.cleaners.headers import filter_header_footer, filter_common_titles
|
| 17 |
+
from marker.equations.equations import replace_equations
|
| 18 |
+
from marker.pdf.utils import find_filetype
|
| 19 |
+
from marker.postprocessors.editor import edit_full_text
|
| 20 |
+
from marker.cleaners.code import identify_code_blocks, indent_blocks
|
| 21 |
+
from marker.cleaners.bullets import replace_bullets
|
| 22 |
+
from marker.cleaners.headings import split_heading_blocks
|
| 23 |
+
from marker.cleaners.fontstyle import find_bold_italic
|
| 24 |
+
from marker.postprocessors.markdown import merge_spans, merge_lines, get_full_text
|
| 25 |
+
from marker.cleaners.text import cleanup_text
|
| 26 |
+
from marker.images.extract import extract_images
|
| 27 |
+
from marker.images.save import images_to_dict
|
| 28 |
+
|
| 29 |
+
from typing import List, Dict, Tuple, Optional
|
| 30 |
+
from marker.settings import settings
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def convert_single_pdf(
|
| 34 |
+
fname: str,
|
| 35 |
+
model_lst: List,
|
| 36 |
+
max_pages=None,
|
| 37 |
+
metadata: Optional[Dict]=None,
|
| 38 |
+
langs: Optional[List[str]] = None,
|
| 39 |
+
batch_multiplier: int = 1
|
| 40 |
+
) -> Tuple[str, Dict[str, Image.Image], Dict]:
|
| 41 |
+
# Set language needed for OCR
|
| 42 |
+
if langs is None:
|
| 43 |
+
langs = [settings.DEFAULT_LANG]
|
| 44 |
+
|
| 45 |
+
if metadata:
|
| 46 |
+
langs = metadata.get("languages", langs)
|
| 47 |
+
|
| 48 |
+
langs = replace_langs_with_codes(langs)
|
| 49 |
+
validate_langs(langs)
|
| 50 |
+
|
| 51 |
+
# Find the filetype
|
| 52 |
+
filetype = find_filetype(fname)
|
| 53 |
+
|
| 54 |
+
# Setup output metadata
|
| 55 |
+
out_meta = {
|
| 56 |
+
"languages": langs,
|
| 57 |
+
"filetype": filetype,
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
if filetype == "other": # We can't process this file
|
| 61 |
+
return "", out_meta
|
| 62 |
+
|
| 63 |
+
# Get initial text blocks from the pdf
|
| 64 |
+
doc = pdfium.PdfDocument(fname)
|
| 65 |
+
pages, toc = get_text_blocks(
|
| 66 |
+
doc,
|
| 67 |
+
max_pages=max_pages,
|
| 68 |
+
)
|
| 69 |
+
out_meta.update({
|
| 70 |
+
"toc": toc,
|
| 71 |
+
"pages": len(pages),
|
| 72 |
+
})
|
| 73 |
+
|
| 74 |
+
# Unpack models from list
|
| 75 |
+
texify_model, layout_model, order_model, edit_model, detection_model, ocr_model = model_lst
|
| 76 |
+
|
| 77 |
+
# Identify text lines on pages
|
| 78 |
+
surya_detection(doc, pages, detection_model, batch_multiplier=batch_multiplier)
|
| 79 |
+
flush_cuda_memory()
|
| 80 |
+
|
| 81 |
+
# OCR pages as needed
|
| 82 |
+
pages, ocr_stats = run_ocr(doc, pages, langs, ocr_model, batch_multiplier=batch_multiplier)
|
| 83 |
+
flush_cuda_memory()
|
| 84 |
+
|
| 85 |
+
out_meta["ocr_stats"] = ocr_stats
|
| 86 |
+
if len([b for p in pages for b in p.blocks]) == 0:
|
| 87 |
+
print(f"Could not extract any text blocks for {fname}")
|
| 88 |
+
return "", out_meta
|
| 89 |
+
|
| 90 |
+
surya_layout(doc, pages, layout_model, batch_multiplier=batch_multiplier)
|
| 91 |
+
flush_cuda_memory()
|
| 92 |
+
|
| 93 |
+
# Find headers and footers
|
| 94 |
+
bad_span_ids = filter_header_footer(pages)
|
| 95 |
+
out_meta["block_stats"] = {"header_footer": len(bad_span_ids)}
|
| 96 |
+
|
| 97 |
+
# Add block types in
|
| 98 |
+
annotate_block_types(pages)
|
| 99 |
+
|
| 100 |
+
# Dump debug data if flags are set
|
| 101 |
+
dump_bbox_debug_data(doc, pages)
|
| 102 |
+
|
| 103 |
+
# Find reading order for blocks
|
| 104 |
+
# Sort blocks by reading order
|
| 105 |
+
surya_order(doc, pages, order_model, batch_multiplier=batch_multiplier)
|
| 106 |
+
sort_blocks_in_reading_order(pages)
|
| 107 |
+
flush_cuda_memory()
|
| 108 |
+
|
| 109 |
+
# Fix code blocks
|
| 110 |
+
code_block_count = identify_code_blocks(pages)
|
| 111 |
+
out_meta["block_stats"]["code"] = code_block_count
|
| 112 |
+
indent_blocks(pages)
|
| 113 |
+
|
| 114 |
+
# Fix table blocks
|
| 115 |
+
table_count = format_tables(pages)
|
| 116 |
+
out_meta["block_stats"]["table"] = table_count
|
| 117 |
+
|
| 118 |
+
for page in pages:
|
| 119 |
+
for block in page.blocks:
|
| 120 |
+
block.filter_spans(bad_span_ids)
|
| 121 |
+
block.filter_bad_span_types()
|
| 122 |
+
|
| 123 |
+
filtered, eq_stats = replace_equations(
|
| 124 |
+
doc,
|
| 125 |
+
pages,
|
| 126 |
+
texify_model,
|
| 127 |
+
batch_multiplier=batch_multiplier
|
| 128 |
+
)
|
| 129 |
+
flush_cuda_memory()
|
| 130 |
+
out_meta["block_stats"]["equations"] = eq_stats
|
| 131 |
+
|
| 132 |
+
# Extract images and figures
|
| 133 |
+
if settings.EXTRACT_IMAGES:
|
| 134 |
+
extract_images(doc, pages)
|
| 135 |
+
|
| 136 |
+
# Split out headers
|
| 137 |
+
split_heading_blocks(pages)
|
| 138 |
+
find_bold_italic(pages)
|
| 139 |
+
|
| 140 |
+
# Copy to avoid changing original data
|
| 141 |
+
merged_lines = merge_spans(filtered)
|
| 142 |
+
text_blocks = merge_lines(merged_lines)
|
| 143 |
+
text_blocks = filter_common_titles(text_blocks)
|
| 144 |
+
full_text = get_full_text(text_blocks)
|
| 145 |
+
|
| 146 |
+
# Handle empty blocks being joined
|
| 147 |
+
full_text = cleanup_text(full_text)
|
| 148 |
+
|
| 149 |
+
# Replace bullet characters with a -
|
| 150 |
+
full_text = replace_bullets(full_text)
|
| 151 |
+
|
| 152 |
+
# Postprocess text with editor model
|
| 153 |
+
full_text, edit_stats = edit_full_text(
|
| 154 |
+
full_text,
|
| 155 |
+
edit_model,
|
| 156 |
+
batch_multiplier=batch_multiplier
|
| 157 |
+
)
|
| 158 |
+
flush_cuda_memory()
|
| 159 |
+
out_meta["postprocess_stats"] = {"edit": edit_stats}
|
| 160 |
+
doc_images = images_to_dict(pages)
|
| 161 |
+
|
| 162 |
+
return full_text, doc_images, out_meta
|
marker/debug/data.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import base64
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
from typing import List
|
| 5 |
+
|
| 6 |
+
from marker.pdf.images import render_image
|
| 7 |
+
from marker.schema.page import Page
|
| 8 |
+
from marker.settings import settings
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import io
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def dump_equation_debug_data(doc, images, converted_spans):
|
| 14 |
+
if not settings.DEBUG_DATA_FOLDER or settings.DEBUG_LEVEL == 0:
|
| 15 |
+
return
|
| 16 |
+
|
| 17 |
+
if len(images) == 0:
|
| 18 |
+
return
|
| 19 |
+
|
| 20 |
+
# We attempted one conversion per image
|
| 21 |
+
assert len(converted_spans) == len(images)
|
| 22 |
+
|
| 23 |
+
data_lines = []
|
| 24 |
+
for idx, (pil_image, converted_span) in enumerate(zip(images, converted_spans)):
|
| 25 |
+
if converted_span is None:
|
| 26 |
+
continue
|
| 27 |
+
# Image is a BytesIO object
|
| 28 |
+
img_bytes = io.BytesIO()
|
| 29 |
+
pil_image.save(img_bytes, format="WEBP", lossless=True)
|
| 30 |
+
b64_image = base64.b64encode(img_bytes.getvalue()).decode("utf-8")
|
| 31 |
+
data_lines.append({
|
| 32 |
+
"image": b64_image,
|
| 33 |
+
"text": converted_span.text,
|
| 34 |
+
"bbox": converted_span.bbox
|
| 35 |
+
})
|
| 36 |
+
|
| 37 |
+
# Remove extension from doc name
|
| 38 |
+
doc_base = os.path.basename(doc.name).rsplit(".", 1)[0]
|
| 39 |
+
|
| 40 |
+
debug_file = os.path.join(settings.DEBUG_DATA_FOLDER, f"{doc_base}_equations.json")
|
| 41 |
+
with open(debug_file, "w+") as f:
|
| 42 |
+
json.dump(data_lines, f)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def dump_bbox_debug_data(doc, blocks: List[Page]):
|
| 46 |
+
if not settings.DEBUG_DATA_FOLDER or settings.DEBUG_LEVEL < 2:
|
| 47 |
+
return
|
| 48 |
+
|
| 49 |
+
# Remove extension from doc name
|
| 50 |
+
doc_base = os.path.basename(doc.name).rsplit(".", 1)[0]
|
| 51 |
+
|
| 52 |
+
debug_file = os.path.join(settings.DEBUG_DATA_FOLDER, f"{doc_base}_bbox.json")
|
| 53 |
+
debug_data = []
|
| 54 |
+
for idx, page_blocks in enumerate(blocks):
|
| 55 |
+
page = doc[idx]
|
| 56 |
+
|
| 57 |
+
png_image = render_image(page, dpi=settings.TEXIFY_DPI)
|
| 58 |
+
width, height = png_image.size
|
| 59 |
+
max_dimension = 6000
|
| 60 |
+
if width > max_dimension or height > max_dimension:
|
| 61 |
+
scaling_factor = min(max_dimension / width, max_dimension / height)
|
| 62 |
+
png_image = png_image.resize((int(width * scaling_factor), int(height * scaling_factor)), Image.ANTIALIAS)
|
| 63 |
+
|
| 64 |
+
img_bytes = io.BytesIO()
|
| 65 |
+
png_image.save(img_bytes, format="WEBP", lossless=True, quality=100)
|
| 66 |
+
b64_image = base64.b64encode(img_bytes.getvalue()).decode("utf-8")
|
| 67 |
+
|
| 68 |
+
page_data = page_blocks.model_dump()
|
| 69 |
+
page_data["image"] = b64_image
|
| 70 |
+
debug_data.append(page_data)
|
| 71 |
+
|
| 72 |
+
with open(debug_file, "w+") as f:
|
| 73 |
+
json.dump(debug_data, f)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
|
marker/equations/equations.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import defaultdict
|
| 2 |
+
from copy import deepcopy
|
| 3 |
+
from typing import List
|
| 4 |
+
|
| 5 |
+
from marker.debug.data import dump_equation_debug_data
|
| 6 |
+
from marker.equations.inference import get_total_texify_tokens, get_latex_batched
|
| 7 |
+
from marker.pdf.images import render_bbox_image
|
| 8 |
+
from marker.schema.bbox import rescale_bbox
|
| 9 |
+
from marker.schema.page import Page
|
| 10 |
+
from marker.schema.block import Line, Span, Block, bbox_from_lines, split_block_lines, find_insert_block
|
| 11 |
+
from marker.settings import settings
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def find_equation_blocks(page, processor):
|
| 15 |
+
equation_blocks = []
|
| 16 |
+
equation_regions = [l.bbox for l in page.layout.bboxes if l.label in ["Formula"]]
|
| 17 |
+
equation_regions = [rescale_bbox(page.layout.image_bbox, page.bbox, b) for b in equation_regions]
|
| 18 |
+
|
| 19 |
+
lines_to_remove = defaultdict(list)
|
| 20 |
+
insert_points = {}
|
| 21 |
+
equation_lines = defaultdict(list)
|
| 22 |
+
for region_idx, region in enumerate(equation_regions):
|
| 23 |
+
for block_idx, block in enumerate(page.blocks):
|
| 24 |
+
for line_idx, line in enumerate(block.lines):
|
| 25 |
+
if line.intersection_pct(region) > settings.BBOX_INTERSECTION_THRESH:
|
| 26 |
+
# We will remove this line from the block
|
| 27 |
+
lines_to_remove[region_idx].append((block_idx, line_idx))
|
| 28 |
+
equation_lines[region_idx].append(line)
|
| 29 |
+
|
| 30 |
+
if region_idx not in insert_points:
|
| 31 |
+
insert_points[region_idx] = (block_idx, line_idx)
|
| 32 |
+
|
| 33 |
+
# Account for regions where the lines were not detected
|
| 34 |
+
for region_idx, region in enumerate(equation_regions):
|
| 35 |
+
if region_idx in insert_points:
|
| 36 |
+
continue
|
| 37 |
+
|
| 38 |
+
insert_points[region_idx] = (find_insert_block(page.blocks, region), 0)
|
| 39 |
+
|
| 40 |
+
block_lines_to_remove = defaultdict(set)
|
| 41 |
+
for region_idx, equation_region in enumerate(equation_regions):
|
| 42 |
+
if region_idx not in equation_lines or len(equation_lines[region_idx]) == 0:
|
| 43 |
+
block_text = ""
|
| 44 |
+
total_tokens = 0
|
| 45 |
+
else:
|
| 46 |
+
equation_block = equation_lines[region_idx]
|
| 47 |
+
block_text = " ".join([line.prelim_text for line in equation_block])
|
| 48 |
+
total_tokens = get_total_texify_tokens(block_text, processor)
|
| 49 |
+
|
| 50 |
+
equation_insert = insert_points[region_idx]
|
| 51 |
+
equation_insert_line_idx = equation_insert[1]
|
| 52 |
+
equation_insert_line_idx -= len(
|
| 53 |
+
[x for x in lines_to_remove[region_idx] if x[0] == equation_insert[0] and x[1] < equation_insert[1]])
|
| 54 |
+
|
| 55 |
+
selected_blocks = [equation_insert[0], equation_insert_line_idx, total_tokens, block_text, equation_region]
|
| 56 |
+
if total_tokens < settings.TEXIFY_MODEL_MAX:
|
| 57 |
+
# Account for the lines we're about to remove
|
| 58 |
+
for item in lines_to_remove[region_idx]:
|
| 59 |
+
block_lines_to_remove[item[0]].add(item[1])
|
| 60 |
+
equation_blocks.append(selected_blocks)
|
| 61 |
+
|
| 62 |
+
# Remove the lines from the blocks
|
| 63 |
+
for block_idx, bad_lines in block_lines_to_remove.items():
|
| 64 |
+
block = page.blocks[block_idx]
|
| 65 |
+
block.lines = [line for idx, line in enumerate(block.lines) if idx not in bad_lines]
|
| 66 |
+
|
| 67 |
+
return equation_blocks
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def increment_insert_points(page_equation_blocks, insert_block_idx, insert_count):
|
| 71 |
+
for idx, (block_idx, line_idx, token_count, block_text, equation_bbox) in enumerate(page_equation_blocks):
|
| 72 |
+
if block_idx >= insert_block_idx:
|
| 73 |
+
page_equation_blocks[idx][0] += insert_count
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def insert_latex_block(page_blocks: Page, page_equation_blocks, predictions, pnum, processor):
|
| 77 |
+
converted_spans = []
|
| 78 |
+
idx = 0
|
| 79 |
+
success_count = 0
|
| 80 |
+
fail_count = 0
|
| 81 |
+
for block_number, (insert_block_idx, insert_line_idx, token_count, block_text, equation_bbox) in enumerate(page_equation_blocks):
|
| 82 |
+
latex_text = predictions[block_number]
|
| 83 |
+
conditions = [
|
| 84 |
+
get_total_texify_tokens(latex_text, processor) < settings.TEXIFY_MODEL_MAX, # Make sure we didn't get to the overall token max, indicates run-on
|
| 85 |
+
len(latex_text) > len(block_text) * .7,
|
| 86 |
+
len(latex_text.strip()) > 0
|
| 87 |
+
]
|
| 88 |
+
|
| 89 |
+
new_block = Block(
|
| 90 |
+
lines=[Line(
|
| 91 |
+
spans=[
|
| 92 |
+
Span(
|
| 93 |
+
text=block_text.replace("\n", " "),
|
| 94 |
+
bbox=equation_bbox,
|
| 95 |
+
span_id=f"{pnum}_{idx}_fixeq",
|
| 96 |
+
font="Latex",
|
| 97 |
+
font_weight=0,
|
| 98 |
+
font_size=0
|
| 99 |
+
)
|
| 100 |
+
],
|
| 101 |
+
bbox=equation_bbox
|
| 102 |
+
)],
|
| 103 |
+
bbox=equation_bbox,
|
| 104 |
+
block_type="Formula",
|
| 105 |
+
pnum=pnum
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
if not all(conditions):
|
| 109 |
+
fail_count += 1
|
| 110 |
+
else:
|
| 111 |
+
success_count += 1
|
| 112 |
+
new_block.lines[0].spans[0].text = latex_text.replace("\n", " ")
|
| 113 |
+
converted_spans.append(deepcopy(new_block.lines[0].spans[0]))
|
| 114 |
+
|
| 115 |
+
# Add in the new LaTeX block
|
| 116 |
+
if insert_line_idx == 0:
|
| 117 |
+
page_blocks.blocks.insert(insert_block_idx, new_block)
|
| 118 |
+
increment_insert_points(page_equation_blocks, insert_block_idx, 1)
|
| 119 |
+
elif insert_line_idx >= len(page_blocks.blocks[insert_block_idx].lines):
|
| 120 |
+
page_blocks.blocks.insert(insert_block_idx + 1, new_block)
|
| 121 |
+
increment_insert_points(page_equation_blocks, insert_block_idx + 1, 1)
|
| 122 |
+
else:
|
| 123 |
+
new_blocks = []
|
| 124 |
+
for block_idx, block in enumerate(page_blocks.blocks):
|
| 125 |
+
if block_idx == insert_block_idx:
|
| 126 |
+
split_block = split_block_lines(block, insert_line_idx)
|
| 127 |
+
new_blocks.append(split_block[0])
|
| 128 |
+
new_blocks.append(new_block)
|
| 129 |
+
new_blocks.append(split_block[1])
|
| 130 |
+
increment_insert_points(page_equation_blocks, insert_block_idx, 2)
|
| 131 |
+
else:
|
| 132 |
+
new_blocks.append(block)
|
| 133 |
+
page_blocks.blocks = new_blocks
|
| 134 |
+
|
| 135 |
+
return success_count, fail_count, converted_spans
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def replace_equations(doc, pages: List[Page], texify_model, batch_multiplier=1):
|
| 139 |
+
unsuccessful_ocr = 0
|
| 140 |
+
successful_ocr = 0
|
| 141 |
+
|
| 142 |
+
# Find potential equation regions, and length of text in each region
|
| 143 |
+
equation_blocks = []
|
| 144 |
+
for pnum, page in enumerate(pages):
|
| 145 |
+
equation_blocks.append(find_equation_blocks(page, texify_model.processor))
|
| 146 |
+
|
| 147 |
+
eq_count = sum([len(x) for x in equation_blocks])
|
| 148 |
+
|
| 149 |
+
images = []
|
| 150 |
+
token_counts = []
|
| 151 |
+
for page_idx, page_equation_blocks in enumerate(equation_blocks):
|
| 152 |
+
page_obj = doc[page_idx]
|
| 153 |
+
for equation_idx, (insert_block_idx, insert_line_idx, token_count, block_text, equation_bbox) in enumerate(page_equation_blocks):
|
| 154 |
+
png_image = render_bbox_image(page_obj, pages[page_idx], equation_bbox)
|
| 155 |
+
|
| 156 |
+
images.append(png_image)
|
| 157 |
+
token_counts.append(token_count)
|
| 158 |
+
|
| 159 |
+
# Make batched predictions
|
| 160 |
+
predictions = get_latex_batched(images, token_counts, texify_model, batch_multiplier=batch_multiplier)
|
| 161 |
+
|
| 162 |
+
# Replace blocks with predictions
|
| 163 |
+
page_start = 0
|
| 164 |
+
converted_spans = []
|
| 165 |
+
for page_idx, page_equation_blocks in enumerate(equation_blocks):
|
| 166 |
+
page_equation_count = len(page_equation_blocks)
|
| 167 |
+
page_predictions = predictions[page_start:page_start + page_equation_count]
|
| 168 |
+
success_count, fail_count, converted_span = insert_latex_block(
|
| 169 |
+
pages[page_idx],
|
| 170 |
+
page_equation_blocks,
|
| 171 |
+
page_predictions,
|
| 172 |
+
page_idx,
|
| 173 |
+
texify_model.processor
|
| 174 |
+
)
|
| 175 |
+
converted_spans.extend(converted_span)
|
| 176 |
+
page_start += page_equation_count
|
| 177 |
+
successful_ocr += success_count
|
| 178 |
+
unsuccessful_ocr += fail_count
|
| 179 |
+
|
| 180 |
+
# If debug mode is on, dump out conversions for comparison
|
| 181 |
+
dump_equation_debug_data(doc, images, converted_spans)
|
| 182 |
+
|
| 183 |
+
return pages, {"successful_ocr": successful_ocr, "unsuccessful_ocr": unsuccessful_ocr, "equations": eq_count}
|
marker/equations/inference.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from texify.inference import batch_inference
|
| 2 |
+
|
| 3 |
+
from marker.settings import settings
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_batch_size():
|
| 10 |
+
if settings.TEXIFY_BATCH_SIZE is not None:
|
| 11 |
+
return settings.TEXIFY_BATCH_SIZE
|
| 12 |
+
elif settings.TORCH_DEVICE_MODEL == "cuda":
|
| 13 |
+
return 6
|
| 14 |
+
elif settings.TORCH_DEVICE_MODEL == "mps":
|
| 15 |
+
return 6
|
| 16 |
+
return 2
|
| 17 |
+
|
| 18 |
+
def get_latex_batched(images, token_counts, texify_model, batch_multiplier=1):
|
| 19 |
+
if len(images) == 0:
|
| 20 |
+
return []
|
| 21 |
+
|
| 22 |
+
predictions = [""] * len(images)
|
| 23 |
+
batch_size = get_batch_size() * batch_multiplier
|
| 24 |
+
|
| 25 |
+
for i in range(0, len(images), batch_size):
|
| 26 |
+
# Dynamically set max length to save inference time
|
| 27 |
+
min_idx = i
|
| 28 |
+
max_idx = min(min_idx + batch_size, len(images))
|
| 29 |
+
max_length = max(token_counts[min_idx:max_idx])
|
| 30 |
+
max_length = min(max_length, settings.TEXIFY_MODEL_MAX)
|
| 31 |
+
max_length += settings.TEXIFY_TOKEN_BUFFER
|
| 32 |
+
|
| 33 |
+
model_output = batch_inference(images[min_idx:max_idx], texify_model, texify_model.processor, max_tokens=max_length)
|
| 34 |
+
|
| 35 |
+
for j, output in enumerate(model_output):
|
| 36 |
+
token_count = get_total_texify_tokens(output, texify_model.processor)
|
| 37 |
+
if token_count >= max_length - 1:
|
| 38 |
+
output = ""
|
| 39 |
+
|
| 40 |
+
image_idx = i + j
|
| 41 |
+
predictions[image_idx] = output
|
| 42 |
+
return predictions
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def get_total_texify_tokens(text, processor):
|
| 46 |
+
tokenizer = processor.tokenizer
|
| 47 |
+
tokens = tokenizer(text)
|
| 48 |
+
return len(tokens["input_ids"])
|
| 49 |
+
|
| 50 |
+
|
marker/images/extract.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from marker.images.save import get_image_filename
|
| 2 |
+
from marker.pdf.images import render_bbox_image
|
| 3 |
+
from marker.schema.bbox import rescale_bbox
|
| 4 |
+
from marker.schema.block import find_insert_block, Span, Line
|
| 5 |
+
from marker.settings import settings
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def find_image_blocks(page):
|
| 9 |
+
image_blocks = []
|
| 10 |
+
image_regions = [l.bbox for l in page.layout.bboxes if l.label in ["Figure", "Picture"]]
|
| 11 |
+
image_regions = [rescale_bbox(page.layout.image_bbox, page.bbox, b) for b in image_regions]
|
| 12 |
+
|
| 13 |
+
insert_points = {}
|
| 14 |
+
for region_idx, region in enumerate(image_regions):
|
| 15 |
+
for block_idx, block in enumerate(page.blocks):
|
| 16 |
+
for line_idx, line in enumerate(block.lines):
|
| 17 |
+
if line.intersection_pct(region) > settings.BBOX_INTERSECTION_THRESH:
|
| 18 |
+
line.spans = [] # We will remove this line from the block
|
| 19 |
+
|
| 20 |
+
if region_idx not in insert_points:
|
| 21 |
+
insert_points[region_idx] = (block_idx, line_idx)
|
| 22 |
+
|
| 23 |
+
# Account for images with no detected lines
|
| 24 |
+
for region_idx, region in enumerate(image_regions):
|
| 25 |
+
if region_idx in insert_points:
|
| 26 |
+
continue
|
| 27 |
+
|
| 28 |
+
insert_points[region_idx] = (find_insert_block(page.blocks, region), 0)
|
| 29 |
+
|
| 30 |
+
for region_idx, image_region in enumerate(image_regions):
|
| 31 |
+
image_insert = insert_points[region_idx]
|
| 32 |
+
image_blocks.append([image_insert[0], image_insert[1], image_region])
|
| 33 |
+
|
| 34 |
+
return image_blocks
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def extract_page_images(page_obj, page):
|
| 38 |
+
page.images = []
|
| 39 |
+
image_blocks = find_image_blocks(page)
|
| 40 |
+
|
| 41 |
+
for image_idx, (block_idx, line_idx, bbox) in enumerate(image_blocks):
|
| 42 |
+
block = page.blocks[block_idx]
|
| 43 |
+
image = render_bbox_image(page_obj, page, bbox)
|
| 44 |
+
image_filename = get_image_filename(page, image_idx)
|
| 45 |
+
image_markdown = f"\n\n\n\n"
|
| 46 |
+
image_span = Span(
|
| 47 |
+
bbox=bbox,
|
| 48 |
+
text=image_markdown,
|
| 49 |
+
font="Image",
|
| 50 |
+
rotation=0,
|
| 51 |
+
font_weight=0,
|
| 52 |
+
font_size=0,
|
| 53 |
+
image=True,
|
| 54 |
+
span_id=f"image_{image_idx}"
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
# Sometimes, the block has zero lines
|
| 58 |
+
if len(block.lines) > line_idx:
|
| 59 |
+
block.lines[line_idx].spans.append(image_span)
|
| 60 |
+
else:
|
| 61 |
+
line = Line(
|
| 62 |
+
bbox=bbox,
|
| 63 |
+
spans=[image_span]
|
| 64 |
+
)
|
| 65 |
+
block.lines.append(line)
|
| 66 |
+
page.images.append(image)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def extract_images(doc, pages):
|
| 70 |
+
for page_idx, page in enumerate(pages):
|
| 71 |
+
page_obj = doc[page_idx]
|
| 72 |
+
extract_page_images(page_obj, page)
|
marker/images/save.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
from marker.schema.page import Page
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def get_image_filename(page: Page, image_idx):
|
| 7 |
+
return f"{page.pnum}_image_{image_idx}.png"
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def images_to_dict(pages: List[Page]):
|
| 11 |
+
images = {}
|
| 12 |
+
for page in pages:
|
| 13 |
+
if page.images is None:
|
| 14 |
+
continue
|
| 15 |
+
for image_idx, image in enumerate(page.images):
|
| 16 |
+
image_filename = get_image_filename(page, image_idx)
|
| 17 |
+
images[image_filename] = image
|
| 18 |
+
return images
|
marker/layout/layout.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
from surya.layout import batch_layout_detection
|
| 4 |
+
|
| 5 |
+
from marker.pdf.images import render_image
|
| 6 |
+
from marker.schema.bbox import rescale_bbox
|
| 7 |
+
from marker.schema.page import Page
|
| 8 |
+
from marker.settings import settings
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_batch_size():
|
| 12 |
+
if settings.LAYOUT_BATCH_SIZE is not None:
|
| 13 |
+
return settings.LAYOUT_BATCH_SIZE
|
| 14 |
+
elif settings.TORCH_DEVICE_MODEL == "cuda":
|
| 15 |
+
return 6
|
| 16 |
+
return 6
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def surya_layout(doc, pages: List[Page], layout_model, batch_multiplier=1):
|
| 20 |
+
images = [render_image(doc[pnum], dpi=settings.SURYA_LAYOUT_DPI) for pnum in range(len(pages))]
|
| 21 |
+
text_detection_results = [p.text_lines for p in pages]
|
| 22 |
+
|
| 23 |
+
processor = layout_model.processor
|
| 24 |
+
layout_results = batch_layout_detection(images, layout_model, processor, detection_results=text_detection_results, batch_size=get_batch_size() * batch_multiplier)
|
| 25 |
+
for page, layout_result in zip(pages, layout_results):
|
| 26 |
+
page.layout = layout_result
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def annotate_block_types(pages: List[Page]):
|
| 30 |
+
for page in pages:
|
| 31 |
+
max_intersections = {}
|
| 32 |
+
for i, block in enumerate(page.blocks):
|
| 33 |
+
for j, layout_block in enumerate(page.layout.bboxes):
|
| 34 |
+
layout_bbox = layout_block.bbox
|
| 35 |
+
layout_bbox = rescale_bbox(page.layout.image_bbox, page.bbox, layout_bbox)
|
| 36 |
+
intersection_pct = block.intersection_pct(layout_bbox)
|
| 37 |
+
if i not in max_intersections:
|
| 38 |
+
max_intersections[i] = (intersection_pct, j)
|
| 39 |
+
elif intersection_pct > max_intersections[i][0]:
|
| 40 |
+
max_intersections[i] = (intersection_pct, j)
|
| 41 |
+
|
| 42 |
+
for i, block in enumerate(page.blocks):
|
| 43 |
+
block = page.blocks[i]
|
| 44 |
+
block_type = "Text"
|
| 45 |
+
if i in max_intersections:
|
| 46 |
+
j = max_intersections[i][1]
|
| 47 |
+
block_type = page.layout.bboxes[j].label
|
| 48 |
+
block.block_type = block_type
|
marker/layout/order.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import defaultdict
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
from surya.ordering import batch_ordering
|
| 5 |
+
|
| 6 |
+
from marker.pdf.images import render_image
|
| 7 |
+
from marker.pdf.utils import sort_block_group
|
| 8 |
+
from marker.schema.bbox import rescale_bbox
|
| 9 |
+
from marker.schema.page import Page
|
| 10 |
+
from marker.settings import settings
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def get_batch_size():
|
| 14 |
+
if settings.ORDER_BATCH_SIZE is not None:
|
| 15 |
+
return settings.ORDER_BATCH_SIZE
|
| 16 |
+
elif settings.TORCH_DEVICE_MODEL == "cuda":
|
| 17 |
+
return 6
|
| 18 |
+
elif settings.TORCH_DEVICE_MODEL == "mps":
|
| 19 |
+
return 6
|
| 20 |
+
return 6
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def surya_order(doc, pages: List[Page], order_model, batch_multiplier=1):
|
| 24 |
+
images = [render_image(doc[pnum], dpi=settings.SURYA_ORDER_DPI) for pnum in range(len(pages))]
|
| 25 |
+
|
| 26 |
+
# Get bboxes for all pages
|
| 27 |
+
bboxes = []
|
| 28 |
+
for page in pages:
|
| 29 |
+
bbox = [b.bbox for b in page.layout.bboxes][:settings.ORDER_MAX_BBOXES]
|
| 30 |
+
bboxes.append(bbox)
|
| 31 |
+
|
| 32 |
+
processor = order_model.processor
|
| 33 |
+
order_results = batch_ordering(images, bboxes, order_model, processor, batch_size=get_batch_size() * batch_multiplier)
|
| 34 |
+
for page, order_result in zip(pages, order_results):
|
| 35 |
+
page.order = order_result
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def sort_blocks_in_reading_order(pages: List[Page]):
|
| 39 |
+
for page in pages:
|
| 40 |
+
order = page.order
|
| 41 |
+
block_positions = {}
|
| 42 |
+
max_position = 0
|
| 43 |
+
for i, block in enumerate(page.blocks):
|
| 44 |
+
for order_box in order.bboxes:
|
| 45 |
+
order_bbox = order_box.bbox
|
| 46 |
+
position = order_box.position
|
| 47 |
+
order_bbox = rescale_bbox(order.image_bbox, page.bbox, order_bbox)
|
| 48 |
+
block_intersection = block.intersection_pct(order_bbox)
|
| 49 |
+
if i not in block_positions:
|
| 50 |
+
block_positions[i] = (block_intersection, position)
|
| 51 |
+
elif block_intersection > block_positions[i][0]:
|
| 52 |
+
block_positions[i] = (block_intersection, position)
|
| 53 |
+
max_position = max(max_position, position)
|
| 54 |
+
block_groups = defaultdict(list)
|
| 55 |
+
for i, block in enumerate(page.blocks):
|
| 56 |
+
if i in block_positions:
|
| 57 |
+
position = block_positions[i][1]
|
| 58 |
+
else:
|
| 59 |
+
max_position += 1
|
| 60 |
+
position = max_position
|
| 61 |
+
|
| 62 |
+
block_groups[position].append(block)
|
| 63 |
+
|
| 64 |
+
new_blocks = []
|
| 65 |
+
for position in sorted(block_groups.keys()):
|
| 66 |
+
block_group = sort_block_group(block_groups[position])
|
| 67 |
+
new_blocks.extend(block_group)
|
| 68 |
+
|
| 69 |
+
page.blocks = new_blocks
|
marker/logger.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import warnings
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def configure_logging():
|
| 6 |
+
logging.basicConfig(level=logging.WARNING)
|
| 7 |
+
|
| 8 |
+
logging.getLogger('pdfminer').setLevel(logging.ERROR)
|
| 9 |
+
logging.getLogger('PIL').setLevel(logging.ERROR)
|
| 10 |
+
logging.getLogger('fitz').setLevel(logging.ERROR)
|
| 11 |
+
logging.getLogger('ocrmypdf').setLevel(logging.ERROR)
|
| 12 |
+
warnings.simplefilter(action='ignore', category=FutureWarning)
|
marker/models.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from marker.postprocessors.editor import load_editing_model
|
| 2 |
+
from surya.model.detection import segformer
|
| 3 |
+
from texify.model.model import load_model as load_texify_model
|
| 4 |
+
from texify.model.processor import load_processor as load_texify_processor
|
| 5 |
+
from marker.settings import settings
|
| 6 |
+
from surya.model.recognition.model import load_model as load_recognition_model
|
| 7 |
+
from surya.model.recognition.processor import load_processor as load_recognition_processor
|
| 8 |
+
from surya.model.ordering.model import load_model as load_order_model
|
| 9 |
+
from surya.model.ordering.processor import load_processor as load_order_processor
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def setup_recognition_model(langs):
|
| 13 |
+
rec_model = load_recognition_model(langs=langs)
|
| 14 |
+
rec_processor = load_recognition_processor()
|
| 15 |
+
rec_model.processor = rec_processor
|
| 16 |
+
return rec_model
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def setup_detection_model():
|
| 20 |
+
model = segformer.load_model()
|
| 21 |
+
processor = segformer.load_processor()
|
| 22 |
+
model.processor = processor
|
| 23 |
+
return model
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def setup_texify_model():
|
| 27 |
+
texify_model = load_texify_model(checkpoint=settings.TEXIFY_MODEL_NAME, device=settings.TORCH_DEVICE_MODEL, dtype=settings.TEXIFY_DTYPE)
|
| 28 |
+
texify_processor = load_texify_processor()
|
| 29 |
+
texify_model.processor = texify_processor
|
| 30 |
+
return texify_model
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def setup_layout_model():
|
| 34 |
+
model = segformer.load_model(checkpoint=settings.LAYOUT_MODEL_CHECKPOINT)
|
| 35 |
+
processor = segformer.load_processor(checkpoint=settings.LAYOUT_MODEL_CHECKPOINT)
|
| 36 |
+
model.processor = processor
|
| 37 |
+
return model
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def setup_order_model():
|
| 41 |
+
model = load_order_model()
|
| 42 |
+
processor = load_order_processor()
|
| 43 |
+
model.processor = processor
|
| 44 |
+
return model
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def load_all_models(langs=None):
|
| 48 |
+
# langs is optional list of languages to prune from recognition MoE model
|
| 49 |
+
detection = setup_detection_model()
|
| 50 |
+
layout = setup_layout_model()
|
| 51 |
+
order = setup_order_model()
|
| 52 |
+
edit = load_editing_model()
|
| 53 |
+
|
| 54 |
+
# Only load recognition model if we'll need it for all pdfs
|
| 55 |
+
ocr = setup_recognition_model(langs) if (settings.OCR_ENGINE == "surya" and settings.OCR_ALL_PAGES) else None
|
| 56 |
+
texify = setup_texify_model()
|
| 57 |
+
model_lst = [texify, layout, order, edit, detection, ocr]
|
| 58 |
+
return model_lst
|
marker/ocr/detection.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
from pypdfium2 import PdfDocument
|
| 4 |
+
from surya.detection import batch_text_detection
|
| 5 |
+
|
| 6 |
+
from marker.pdf.images import render_image
|
| 7 |
+
from marker.schema.page import Page
|
| 8 |
+
from marker.settings import settings
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_batch_size():
|
| 12 |
+
if settings.DETECTOR_BATCH_SIZE is not None:
|
| 13 |
+
return settings.DETECTOR_BATCH_SIZE
|
| 14 |
+
elif settings.TORCH_DEVICE_MODEL == "cuda":
|
| 15 |
+
return 4
|
| 16 |
+
return 4
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def surya_detection(doc: PdfDocument, pages: List[Page], det_model, batch_multiplier=1):
|
| 20 |
+
processor = det_model.processor
|
| 21 |
+
max_len = min(len(pages), len(doc))
|
| 22 |
+
images = [render_image(doc[pnum], dpi=settings.SURYA_DETECTOR_DPI) for pnum in range(max_len)]
|
| 23 |
+
|
| 24 |
+
predictions = batch_text_detection(images, det_model, processor, batch_size=get_batch_size() * batch_multiplier)
|
| 25 |
+
for (page, pred) in zip(pages, predictions):
|
| 26 |
+
page.text_lines = pred
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
|
marker/ocr/heuristics.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
from marker.ocr.utils import alphanum_ratio
|
| 5 |
+
from marker.schema.bbox import rescale_bbox, box_intersection_pct
|
| 6 |
+
from marker.schema.page import Page
|
| 7 |
+
from marker.settings import settings
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def should_ocr_page(page: Page, no_text: bool):
|
| 11 |
+
detected_lines_found = detected_line_coverage(page)
|
| 12 |
+
|
| 13 |
+
# OCR page if we got minimal text, or if we got too many spaces
|
| 14 |
+
conditions = [
|
| 15 |
+
no_text , # Full doc has no text, and needs full OCR
|
| 16 |
+
(len(page.prelim_text) > 0 and detect_bad_ocr(page.prelim_text)), # Bad OCR
|
| 17 |
+
detected_lines_found is False, # didn't extract text for all detected lines
|
| 18 |
+
]
|
| 19 |
+
|
| 20 |
+
return any(conditions) or settings.OCR_ALL_PAGES
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def detect_bad_ocr(text, space_threshold=.7, newline_threshold=.6, alphanum_threshold=.3):
|
| 24 |
+
if len(text) == 0:
|
| 25 |
+
# Assume OCR failed if we have no text
|
| 26 |
+
return True
|
| 27 |
+
|
| 28 |
+
spaces = len(re.findall(r'\s+', text))
|
| 29 |
+
alpha_chars = len(re.sub(r'\s+', '', text))
|
| 30 |
+
if spaces / (alpha_chars + spaces) > space_threshold:
|
| 31 |
+
return True
|
| 32 |
+
|
| 33 |
+
newlines = len(re.findall(r'\n+', text))
|
| 34 |
+
non_newlines = len(re.sub(r'\n+', '', text))
|
| 35 |
+
if newlines / (newlines + non_newlines) > newline_threshold:
|
| 36 |
+
return True
|
| 37 |
+
|
| 38 |
+
if alphanum_ratio(text) < alphanum_threshold: # Garbled text
|
| 39 |
+
return True
|
| 40 |
+
|
| 41 |
+
invalid_chars = len([c for c in text if c in settings.INVALID_CHARS])
|
| 42 |
+
if invalid_chars > max(4.0, len(text) * .03):
|
| 43 |
+
return True
|
| 44 |
+
|
| 45 |
+
return False
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def no_text_found(pages: List[Page]):
|
| 49 |
+
full_text = ""
|
| 50 |
+
for page in pages:
|
| 51 |
+
full_text += page.prelim_text
|
| 52 |
+
return len(full_text.strip()) == 0
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def detected_line_coverage(page: Page, intersect_thresh=.5, detection_thresh=.65):
|
| 56 |
+
found_lines = 0
|
| 57 |
+
for detected_line in page.text_lines.bboxes:
|
| 58 |
+
|
| 59 |
+
# Get bbox and rescale to match dimensions of original page
|
| 60 |
+
detected_bbox = detected_line.bbox
|
| 61 |
+
detected_bbox = rescale_bbox(page.text_lines.image_bbox, page.bbox, detected_bbox)
|
| 62 |
+
|
| 63 |
+
total_intersection = 0
|
| 64 |
+
for block in page.blocks:
|
| 65 |
+
for line in block.lines:
|
| 66 |
+
intersection_pct = box_intersection_pct(detected_bbox, line.bbox)
|
| 67 |
+
total_intersection += intersection_pct
|
| 68 |
+
if total_intersection > intersect_thresh:
|
| 69 |
+
found_lines += 1
|
| 70 |
+
|
| 71 |
+
total_lines = len(page.text_lines.bboxes)
|
| 72 |
+
if total_lines == 0:
|
| 73 |
+
return False
|
| 74 |
+
return found_lines / total_lines > detection_thresh
|
marker/ocr/lang.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
from surya.languages import CODE_TO_LANGUAGE, LANGUAGE_TO_CODE
|
| 4 |
+
from surya.model.recognition.tokenizer import _tokenize as lang_tokenize
|
| 5 |
+
|
| 6 |
+
from marker.ocr.tesseract import LANGUAGE_TO_TESSERACT_CODE, TESSERACT_CODE_TO_LANGUAGE
|
| 7 |
+
from marker.settings import settings
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def langs_to_ids(langs: List[str]):
|
| 11 |
+
unique_langs = list(set(langs))
|
| 12 |
+
_, lang_tokens = lang_tokenize("", unique_langs)
|
| 13 |
+
return lang_tokens
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def replace_langs_with_codes(langs):
|
| 17 |
+
if settings.OCR_ENGINE == "surya":
|
| 18 |
+
for i, lang in enumerate(langs):
|
| 19 |
+
if lang.title() in LANGUAGE_TO_CODE:
|
| 20 |
+
langs[i] = LANGUAGE_TO_CODE[lang.title()]
|
| 21 |
+
else:
|
| 22 |
+
for i, lang in enumerate(langs):
|
| 23 |
+
if lang in LANGUAGE_TO_CODE:
|
| 24 |
+
langs[i] = LANGUAGE_TO_TESSERACT_CODE[lang]
|
| 25 |
+
return langs
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def validate_langs(langs):
|
| 29 |
+
if settings.OCR_ENGINE == "surya":
|
| 30 |
+
for lang in langs:
|
| 31 |
+
if lang not in CODE_TO_LANGUAGE:
|
| 32 |
+
raise ValueError(f"Invalid language code {lang} for Surya OCR")
|
| 33 |
+
else:
|
| 34 |
+
for lang in langs:
|
| 35 |
+
if lang not in TESSERACT_CODE_TO_LANGUAGE:
|
| 36 |
+
raise ValueError(f"Invalid language code {lang} for Tesseract")
|
marker/ocr/recognition.py
ADDED
|
@@ -0,0 +1,168 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from itertools import repeat
|
| 2 |
+
from typing import List, Optional, Dict
|
| 3 |
+
|
| 4 |
+
import pypdfium2 as pdfium
|
| 5 |
+
import io
|
| 6 |
+
from concurrent.futures import ThreadPoolExecutor
|
| 7 |
+
|
| 8 |
+
from surya.ocr import run_recognition
|
| 9 |
+
|
| 10 |
+
from marker.models import setup_recognition_model
|
| 11 |
+
from marker.ocr.heuristics import should_ocr_page, no_text_found, detect_bad_ocr
|
| 12 |
+
from marker.ocr.lang import langs_to_ids
|
| 13 |
+
from marker.pdf.images import render_image
|
| 14 |
+
from marker.schema.page import Page
|
| 15 |
+
from marker.schema.block import Block, Line, Span
|
| 16 |
+
from marker.settings import settings
|
| 17 |
+
from marker.pdf.extract_text import get_text_blocks
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_batch_size():
|
| 21 |
+
if settings.RECOGNITION_BATCH_SIZE is not None:
|
| 22 |
+
return settings.RECOGNITION_BATCH_SIZE
|
| 23 |
+
elif settings.TORCH_DEVICE_MODEL == "cuda":
|
| 24 |
+
return 32
|
| 25 |
+
elif settings.TORCH_DEVICE_MODEL == "mps":
|
| 26 |
+
return 32
|
| 27 |
+
return 32
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def run_ocr(doc, pages: List[Page], langs: List[str], rec_model, batch_multiplier=1) -> (List[Page], Dict):
|
| 31 |
+
ocr_pages = 0
|
| 32 |
+
ocr_success = 0
|
| 33 |
+
ocr_failed = 0
|
| 34 |
+
no_text = no_text_found(pages)
|
| 35 |
+
ocr_idxs = []
|
| 36 |
+
for pnum, page in enumerate(pages):
|
| 37 |
+
ocr_needed = should_ocr_page(page, no_text)
|
| 38 |
+
if ocr_needed:
|
| 39 |
+
ocr_idxs.append(pnum)
|
| 40 |
+
ocr_pages += 1
|
| 41 |
+
|
| 42 |
+
# No pages need OCR
|
| 43 |
+
if ocr_pages == 0:
|
| 44 |
+
return pages, {"ocr_pages": 0, "ocr_failed": 0, "ocr_success": 0, "ocr_engine": "none"}
|
| 45 |
+
|
| 46 |
+
ocr_method = settings.OCR_ENGINE
|
| 47 |
+
if ocr_method is None:
|
| 48 |
+
return pages, {"ocr_pages": 0, "ocr_failed": 0, "ocr_success": 0, "ocr_engine": "none"}
|
| 49 |
+
elif ocr_method == "surya":
|
| 50 |
+
# Load model just in time if we're not OCRing everything
|
| 51 |
+
del_rec_model = False
|
| 52 |
+
if rec_model is None:
|
| 53 |
+
lang_tokens = langs_to_ids(langs)
|
| 54 |
+
rec_model = setup_recognition_model(lang_tokens)
|
| 55 |
+
del_rec_model = True
|
| 56 |
+
|
| 57 |
+
new_pages = surya_recognition(doc, ocr_idxs, langs, rec_model, pages, batch_multiplier=batch_multiplier)
|
| 58 |
+
|
| 59 |
+
if del_rec_model:
|
| 60 |
+
del rec_model
|
| 61 |
+
elif ocr_method == "ocrmypdf":
|
| 62 |
+
new_pages = tesseract_recognition(doc, ocr_idxs, langs)
|
| 63 |
+
else:
|
| 64 |
+
raise ValueError(f"Unknown OCR method {ocr_method}")
|
| 65 |
+
|
| 66 |
+
for orig_idx, page in zip(ocr_idxs, new_pages):
|
| 67 |
+
if detect_bad_ocr(page.prelim_text) or len(page.prelim_text) == 0:
|
| 68 |
+
ocr_failed += 1
|
| 69 |
+
else:
|
| 70 |
+
ocr_success += 1
|
| 71 |
+
pages[orig_idx] = page
|
| 72 |
+
|
| 73 |
+
return pages, {"ocr_pages": ocr_pages, "ocr_failed": ocr_failed, "ocr_success": ocr_success, "ocr_engine": ocr_method}
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def surya_recognition(doc, page_idxs, langs: List[str], rec_model, pages: List[Page], batch_multiplier=1) -> List[Optional[Page]]:
|
| 77 |
+
images = [render_image(doc[pnum], dpi=settings.SURYA_OCR_DPI) for pnum in page_idxs]
|
| 78 |
+
processor = rec_model.processor
|
| 79 |
+
selected_pages = [p for i, p in enumerate(pages) if i in page_idxs]
|
| 80 |
+
|
| 81 |
+
surya_langs = [langs] * len(page_idxs)
|
| 82 |
+
detection_results = [p.text_lines.bboxes for p in selected_pages]
|
| 83 |
+
polygons = [[b.polygon for b in bboxes] for bboxes in detection_results]
|
| 84 |
+
|
| 85 |
+
results = run_recognition(images, surya_langs, rec_model, processor, polygons=polygons, batch_size=get_batch_size() * batch_multiplier)
|
| 86 |
+
|
| 87 |
+
new_pages = []
|
| 88 |
+
for (page_idx, result, old_page) in zip(page_idxs, results, selected_pages):
|
| 89 |
+
text_lines = old_page.text_lines
|
| 90 |
+
ocr_results = result.text_lines
|
| 91 |
+
blocks = []
|
| 92 |
+
for i, line in enumerate(ocr_results):
|
| 93 |
+
block = Block(
|
| 94 |
+
bbox=line.bbox,
|
| 95 |
+
pnum=page_idx,
|
| 96 |
+
lines=[Line(
|
| 97 |
+
bbox=line.bbox,
|
| 98 |
+
spans=[Span(
|
| 99 |
+
text=line.text,
|
| 100 |
+
bbox=line.bbox,
|
| 101 |
+
span_id=f"{page_idx}_{i}",
|
| 102 |
+
font="",
|
| 103 |
+
font_weight=0,
|
| 104 |
+
font_size=0,
|
| 105 |
+
)
|
| 106 |
+
]
|
| 107 |
+
)]
|
| 108 |
+
)
|
| 109 |
+
blocks.append(block)
|
| 110 |
+
page = Page(
|
| 111 |
+
blocks=blocks,
|
| 112 |
+
pnum=page_idx,
|
| 113 |
+
bbox=result.image_bbox,
|
| 114 |
+
rotation=0,
|
| 115 |
+
text_lines=text_lines,
|
| 116 |
+
ocr_method="surya"
|
| 117 |
+
)
|
| 118 |
+
new_pages.append(page)
|
| 119 |
+
return new_pages
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def tesseract_recognition(doc, page_idxs, langs: List[str]) -> List[Optional[Page]]:
|
| 123 |
+
pdf_pages = generate_single_page_pdfs(doc, page_idxs)
|
| 124 |
+
with ThreadPoolExecutor(max_workers=settings.OCR_PARALLEL_WORKERS) as executor:
|
| 125 |
+
pages = list(executor.map(_tesseract_recognition, pdf_pages, repeat(langs, len(pdf_pages))))
|
| 126 |
+
|
| 127 |
+
return pages
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def generate_single_page_pdfs(doc, page_idxs) -> List[io.BytesIO]:
|
| 131 |
+
pdf_pages = []
|
| 132 |
+
for page_idx in page_idxs:
|
| 133 |
+
blank_doc = pdfium.PdfDocument.new()
|
| 134 |
+
blank_doc.import_pages(doc, pages=[page_idx])
|
| 135 |
+
assert len(blank_doc) == 1, "Failed to import page"
|
| 136 |
+
|
| 137 |
+
in_pdf = io.BytesIO()
|
| 138 |
+
blank_doc.save(in_pdf)
|
| 139 |
+
in_pdf.seek(0)
|
| 140 |
+
pdf_pages.append(in_pdf)
|
| 141 |
+
return pdf_pages
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def _tesseract_recognition(in_pdf, langs: List[str]) -> Optional[Page]:
|
| 145 |
+
import ocrmypdf
|
| 146 |
+
out_pdf = io.BytesIO()
|
| 147 |
+
|
| 148 |
+
ocrmypdf.ocr(
|
| 149 |
+
in_pdf,
|
| 150 |
+
out_pdf,
|
| 151 |
+
language=langs[0],
|
| 152 |
+
output_type="pdf",
|
| 153 |
+
redo_ocr=None,
|
| 154 |
+
force_ocr=True,
|
| 155 |
+
progress_bar=False,
|
| 156 |
+
optimize=False,
|
| 157 |
+
fast_web_view=1e6,
|
| 158 |
+
skip_big=15, # skip images larger than 15 megapixels
|
| 159 |
+
tesseract_timeout=settings.TESSERACT_TIMEOUT,
|
| 160 |
+
tesseract_non_ocr_timeout=settings.TESSERACT_TIMEOUT,
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
new_doc = pdfium.PdfDocument(out_pdf.getvalue())
|
| 164 |
+
|
| 165 |
+
blocks, _ = get_text_blocks(new_doc, max_pages=1)
|
| 166 |
+
page = blocks[0]
|
| 167 |
+
page.ocr_method = "tesseract"
|
| 168 |
+
return page
|
marker/ocr/tesseract.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
LANGUAGE_TO_TESSERACT_CODE = {
|
| 2 |
+
'Afrikaans': 'afr',
|
| 3 |
+
'Amharic': 'amh',
|
| 4 |
+
'Arabic': 'ara',
|
| 5 |
+
'Assamese': 'asm',
|
| 6 |
+
'Azerbaijani': 'aze',
|
| 7 |
+
'Belarusian': 'bel',
|
| 8 |
+
'Bulgarian': 'bul',
|
| 9 |
+
'Bengali': 'ben',
|
| 10 |
+
'Breton': 'bre',
|
| 11 |
+
'Bosnian': 'bos',
|
| 12 |
+
'Catalan': 'cat',
|
| 13 |
+
'Czech': 'ces',
|
| 14 |
+
'Welsh': 'cym',
|
| 15 |
+
'Danish': 'dan',
|
| 16 |
+
'German': 'deu',
|
| 17 |
+
'Greek': 'ell',
|
| 18 |
+
'English': 'eng',
|
| 19 |
+
'Esperanto': 'epo',
|
| 20 |
+
'Spanish': 'spa',
|
| 21 |
+
'Estonian': 'est',
|
| 22 |
+
'Basque': 'eus',
|
| 23 |
+
'Persian': 'fas',
|
| 24 |
+
'Finnish': 'fin',
|
| 25 |
+
'French': 'fra',
|
| 26 |
+
'Western Frisian': 'fry',
|
| 27 |
+
'Irish': 'gle',
|
| 28 |
+
'Scottish Gaelic': 'gla',
|
| 29 |
+
'Galician': 'glg',
|
| 30 |
+
'Gujarati': 'guj',
|
| 31 |
+
'Hausa': 'hau',
|
| 32 |
+
'Hebrew': 'heb',
|
| 33 |
+
'Hindi': 'hin',
|
| 34 |
+
'Croatian': 'hrv',
|
| 35 |
+
'Hungarian': 'hun',
|
| 36 |
+
'Armenian': 'hye',
|
| 37 |
+
'Indonesian': 'ind',
|
| 38 |
+
'Icelandic': 'isl',
|
| 39 |
+
'Italian': 'ita',
|
| 40 |
+
'Japanese': 'jpn',
|
| 41 |
+
'Javanese': 'jav',
|
| 42 |
+
'Georgian': 'kat',
|
| 43 |
+
'Kazakh': 'kaz',
|
| 44 |
+
'Khmer': 'khm',
|
| 45 |
+
'Kannada': 'kan',
|
| 46 |
+
'Korean': 'kor',
|
| 47 |
+
'Kurdish': 'kur',
|
| 48 |
+
'Kyrgyz': 'kir',
|
| 49 |
+
'Latin': 'lat',
|
| 50 |
+
'Lao': 'lao',
|
| 51 |
+
'Lithuanian': 'lit',
|
| 52 |
+
'Latvian': 'lav',
|
| 53 |
+
'Malagasy': 'mlg',
|
| 54 |
+
'Macedonian': 'mkd',
|
| 55 |
+
'Malayalam': 'mal',
|
| 56 |
+
'Mongolian': 'mon',
|
| 57 |
+
'Marathi': 'mar',
|
| 58 |
+
'Malay': 'msa',
|
| 59 |
+
'Burmese': 'mya',
|
| 60 |
+
'Nepali': 'nep',
|
| 61 |
+
'Dutch': 'nld',
|
| 62 |
+
'Norwegian': 'nor',
|
| 63 |
+
'Oromo': 'orm',
|
| 64 |
+
'Oriya': 'ori',
|
| 65 |
+
'Punjabi': 'pan',
|
| 66 |
+
'Polish': 'pol',
|
| 67 |
+
'Pashto': 'pus',
|
| 68 |
+
'Portuguese': 'por',
|
| 69 |
+
'Romanian': 'ron',
|
| 70 |
+
'Russian': 'rus',
|
| 71 |
+
'Sanskrit': 'san',
|
| 72 |
+
'Sindhi': 'snd',
|
| 73 |
+
'Sinhala': 'sin',
|
| 74 |
+
'Slovak': 'slk',
|
| 75 |
+
'Slovenian': 'slv',
|
| 76 |
+
'Somali': 'som',
|
| 77 |
+
'Albanian': 'sqi',
|
| 78 |
+
'Serbian': 'srp',
|
| 79 |
+
'Sundanese': 'sun',
|
| 80 |
+
'Swedish': 'swe',
|
| 81 |
+
'Swahili': 'swa',
|
| 82 |
+
'Tamil': 'tam',
|
| 83 |
+
'Telugu': 'tel',
|
| 84 |
+
'Thai': 'tha',
|
| 85 |
+
'Tagalog': 'tgl',
|
| 86 |
+
'Turkish': 'tur',
|
| 87 |
+
'Uyghur': 'uig',
|
| 88 |
+
'Ukrainian': 'ukr',
|
| 89 |
+
'Urdu': 'urd',
|
| 90 |
+
'Uzbek': 'uzb',
|
| 91 |
+
'Vietnamese': 'vie',
|
| 92 |
+
'Xhosa': 'xho',
|
| 93 |
+
'Yiddish': 'yid',
|
| 94 |
+
'Chinese': 'chi_sim',
|
| 95 |
+
}
|
| 96 |
+
|
| 97 |
+
TESSERACT_CODE_TO_LANGUAGE = {v:k for k,v in LANGUAGE_TO_TESSERACT_CODE.items()}
|
marker/ocr/utils.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def alphanum_ratio(text):
|
| 2 |
+
text = text.replace(" ", "")
|
| 3 |
+
text = text.replace("\n", "")
|
| 4 |
+
alphanumeric_count = sum([1 for c in text if c.isalnum()])
|
| 5 |
+
|
| 6 |
+
if len(text) == 0:
|
| 7 |
+
return 1
|
| 8 |
+
|
| 9 |
+
ratio = alphanumeric_count / len(text)
|
| 10 |
+
return ratio
|
marker/output.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def get_subfolder_path(out_folder, fname):
|
| 6 |
+
subfolder_name = fname.split(".")[0]
|
| 7 |
+
subfolder_path = os.path.join(out_folder, subfolder_name)
|
| 8 |
+
return subfolder_path
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_markdown_filepath(out_folder, fname):
|
| 12 |
+
subfolder_path = get_subfolder_path(out_folder, fname)
|
| 13 |
+
out_filename = fname.rsplit(".", 1)[0] + ".md"
|
| 14 |
+
out_filename = os.path.join(subfolder_path, out_filename)
|
| 15 |
+
return out_filename
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def markdown_exists(out_folder, fname):
|
| 19 |
+
out_filename = get_markdown_filepath(out_folder, fname)
|
| 20 |
+
return os.path.exists(out_filename)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def save_markdown(out_folder, fname, full_text, images, out_metadata):
|
| 24 |
+
subfolder_path = get_subfolder_path(out_folder, fname)
|
| 25 |
+
os.makedirs(subfolder_path, exist_ok=True)
|
| 26 |
+
|
| 27 |
+
markdown_filepath = get_markdown_filepath(out_folder, fname)
|
| 28 |
+
out_meta_filepath = markdown_filepath.rsplit(".", 1)[0] + "_meta.json"
|
| 29 |
+
|
| 30 |
+
with open(markdown_filepath, "w+", encoding='utf-8') as f:
|
| 31 |
+
f.write(full_text)
|
| 32 |
+
with open(out_meta_filepath, "w+") as f:
|
| 33 |
+
f.write(json.dumps(out_metadata, indent=4))
|
| 34 |
+
|
| 35 |
+
for filename, image in images.items():
|
| 36 |
+
image_filepath = os.path.join(subfolder_path, filename)
|
| 37 |
+
image.save(image_filepath, "PNG")
|
| 38 |
+
|
| 39 |
+
return subfolder_path
|
marker/pdf/extract_text.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List, Optional, Dict
|
| 3 |
+
|
| 4 |
+
import pypdfium2 as pdfium
|
| 5 |
+
import pypdfium2.internal as pdfium_i
|
| 6 |
+
|
| 7 |
+
from marker.pdf.utils import font_flags_decomposer
|
| 8 |
+
from marker.settings import settings
|
| 9 |
+
from marker.schema.block import Span, Line, Block
|
| 10 |
+
from marker.schema.page import Page
|
| 11 |
+
from pdftext.extraction import dictionary_output
|
| 12 |
+
|
| 13 |
+
os.environ["TESSDATA_PREFIX"] = settings.TESSDATA_PREFIX
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def pdftext_format_to_blocks(page, pnum: int) -> Page:
|
| 17 |
+
page_blocks = []
|
| 18 |
+
span_id = 0
|
| 19 |
+
for block_idx, block in enumerate(page["blocks"]):
|
| 20 |
+
block_lines = []
|
| 21 |
+
for l in block["lines"]:
|
| 22 |
+
spans = []
|
| 23 |
+
for i, s in enumerate(l["spans"]):
|
| 24 |
+
block_text = s["text"]
|
| 25 |
+
# Remove trailing newlines and carriage returns (tesseract)
|
| 26 |
+
while len(block_text) > 0 and block_text[-1] in ["\n", "\r"]:
|
| 27 |
+
block_text = block_text[:-1]
|
| 28 |
+
|
| 29 |
+
block_text = block_text.replace("-\n", "") # Remove hyphenated line breaks
|
| 30 |
+
span_obj = Span(
|
| 31 |
+
text=block_text, # Remove end of line newlines, not spaces
|
| 32 |
+
bbox=s["bbox"],
|
| 33 |
+
span_id=f"{pnum}_{span_id}",
|
| 34 |
+
font=f"{s['font']['name']}_{font_flags_decomposer(s['font']['flags'])}", # Add font flags to end of font
|
| 35 |
+
font_weight=s["font"]["weight"],
|
| 36 |
+
font_size=s["font"]["size"],
|
| 37 |
+
)
|
| 38 |
+
spans.append(span_obj) # Text, bounding box, span id
|
| 39 |
+
span_id += 1
|
| 40 |
+
line_obj = Line(
|
| 41 |
+
spans=spans,
|
| 42 |
+
bbox=l["bbox"],
|
| 43 |
+
)
|
| 44 |
+
# Only select valid lines, with positive bboxes
|
| 45 |
+
if line_obj.area >= 0:
|
| 46 |
+
block_lines.append(line_obj)
|
| 47 |
+
block_obj = Block(
|
| 48 |
+
lines=block_lines,
|
| 49 |
+
bbox=block["bbox"],
|
| 50 |
+
pnum=pnum
|
| 51 |
+
)
|
| 52 |
+
# Only select blocks with lines
|
| 53 |
+
if len(block_lines) > 0:
|
| 54 |
+
page_blocks.append(block_obj)
|
| 55 |
+
|
| 56 |
+
page_bbox = page["bbox"]
|
| 57 |
+
page_width = abs(page_bbox[2] - page_bbox[0])
|
| 58 |
+
page_height = abs(page_bbox[3] - page_bbox[1])
|
| 59 |
+
rotation = page["rotation"]
|
| 60 |
+
|
| 61 |
+
# Flip width and height if rotated
|
| 62 |
+
if rotation == 90 or rotation == 270:
|
| 63 |
+
page_width, page_height = page_height, page_width
|
| 64 |
+
|
| 65 |
+
char_blocks = page["blocks"]
|
| 66 |
+
page_bbox = [0, 0, page_width, page_height]
|
| 67 |
+
out_page = Page(
|
| 68 |
+
blocks=page_blocks,
|
| 69 |
+
pnum=page["page"],
|
| 70 |
+
bbox=page_bbox,
|
| 71 |
+
rotation=rotation,
|
| 72 |
+
char_blocks=char_blocks
|
| 73 |
+
)
|
| 74 |
+
return out_page
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def get_text_blocks(doc, max_pages: Optional[int] = None) -> (List[Page], Dict):
|
| 78 |
+
toc = get_toc(doc)
|
| 79 |
+
|
| 80 |
+
page_range = range(len(doc))
|
| 81 |
+
if max_pages:
|
| 82 |
+
range_end = min(max_pages, len(doc))
|
| 83 |
+
page_range = range(range_end)
|
| 84 |
+
|
| 85 |
+
char_blocks = dictionary_output(doc, page_range=page_range, keep_chars=True)
|
| 86 |
+
marker_blocks = [pdftext_format_to_blocks(page, pnum) for pnum, page in enumerate(char_blocks)]
|
| 87 |
+
|
| 88 |
+
return marker_blocks, toc
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def naive_get_text(doc):
|
| 92 |
+
full_text = ""
|
| 93 |
+
for page_idx in range(len(doc)):
|
| 94 |
+
page = doc.get_page(page_idx)
|
| 95 |
+
text_page = page.get_textpage()
|
| 96 |
+
full_text += text_page.get_text_bounded() + "\n"
|
| 97 |
+
return full_text
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def get_toc(doc, max_depth=15):
|
| 101 |
+
toc = doc.get_toc(max_depth=max_depth)
|
| 102 |
+
toc_list = []
|
| 103 |
+
for item in toc:
|
| 104 |
+
list_item = {
|
| 105 |
+
"title": item.title,
|
| 106 |
+
"level": item.level,
|
| 107 |
+
"is_closed": item.is_closed,
|
| 108 |
+
"n_kids": item.n_kids,
|
| 109 |
+
"page_index": item.page_index,
|
| 110 |
+
"view_mode": pdfium_i.ViewmodeToStr.get(item.view_mode),
|
| 111 |
+
"view_pos": item.view_pos,
|
| 112 |
+
}
|
| 113 |
+
toc_list.append(list_item)
|
| 114 |
+
return toc_list
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def get_length_of_text(fname: str) -> int:
|
| 118 |
+
doc = pdfium.PdfDocument(fname)
|
| 119 |
+
text = naive_get_text(doc).strip()
|
| 120 |
+
|
| 121 |
+
return len(text)
|
marker/pdf/images.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pypdfium2 as pdfium
|
| 2 |
+
from pypdfium2 import PdfPage
|
| 3 |
+
|
| 4 |
+
from marker.schema.page import Page
|
| 5 |
+
from marker.schema.bbox import rescale_bbox
|
| 6 |
+
from marker.settings import settings
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def render_image(page: pdfium.PdfPage, dpi):
|
| 10 |
+
image = page.render(
|
| 11 |
+
scale=dpi / 72,
|
| 12 |
+
draw_annots=False
|
| 13 |
+
).to_pil()
|
| 14 |
+
image = image.convert("RGB")
|
| 15 |
+
return image
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def render_bbox_image(page_obj: PdfPage, page: Page, bbox):
|
| 19 |
+
png_image = render_image(page_obj, settings.IMAGE_DPI)
|
| 20 |
+
# Rescale original pdf bbox bounds to match png image size
|
| 21 |
+
png_bbox = [0, 0, png_image.size[0], png_image.size[1]]
|
| 22 |
+
rescaled_merged = rescale_bbox(page.bbox, png_bbox, bbox)
|
| 23 |
+
|
| 24 |
+
# Crop out only the equation image
|
| 25 |
+
png_image = png_image.crop(rescaled_merged)
|
| 26 |
+
png_image = png_image.convert("RGB")
|
| 27 |
+
return png_image
|
marker/pdf/utils.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
import filetype
|
| 4 |
+
|
| 5 |
+
from marker.settings import settings
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def find_filetype(fpath):
|
| 9 |
+
kind = filetype.guess(fpath)
|
| 10 |
+
if kind is None:
|
| 11 |
+
print(f"Could not determine filetype for {fpath}")
|
| 12 |
+
return "other"
|
| 13 |
+
|
| 14 |
+
mimetype = kind.mime
|
| 15 |
+
|
| 16 |
+
# Get extensions from mimetype
|
| 17 |
+
# The mimetype is not always consistent, so use in to check the most common formats
|
| 18 |
+
if "pdf" in mimetype:
|
| 19 |
+
return "pdf"
|
| 20 |
+
elif mimetype in settings.SUPPORTED_FILETYPES:
|
| 21 |
+
return settings.SUPPORTED_FILETYPES[mimetype]
|
| 22 |
+
else:
|
| 23 |
+
print(f"Found nonstandard filetype {mimetype}")
|
| 24 |
+
return "other"
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def font_flags_decomposer(flags: Optional[int]) -> str:
|
| 28 |
+
if flags is None:
|
| 29 |
+
return ""
|
| 30 |
+
|
| 31 |
+
flag_descriptions = []
|
| 32 |
+
if flags & (1 << 0): # PDFFONT_FIXEDPITCH
|
| 33 |
+
flag_descriptions.append("fixed_pitch")
|
| 34 |
+
if flags & (1 << 1): # PDFFONT_SERIF
|
| 35 |
+
flag_descriptions.append("serif")
|
| 36 |
+
if flags & (1 << 2): # PDFFONT_SYMBOLIC
|
| 37 |
+
flag_descriptions.append("symbolic")
|
| 38 |
+
if flags & (1 << 3): # PDFFONT_SCRIPT
|
| 39 |
+
flag_descriptions.append("script")
|
| 40 |
+
if flags & (1 << 5): # PDFFONT_NONSYMBOLIC
|
| 41 |
+
flag_descriptions.append("non_symbolic")
|
| 42 |
+
if flags & (1 << 6): # PDFFONT_ITALIC
|
| 43 |
+
flag_descriptions.append("italic")
|
| 44 |
+
if flags & (1 << 16): # PDFFONT_ALLCAP
|
| 45 |
+
flag_descriptions.append("all_cap")
|
| 46 |
+
if flags & (1 << 17): # PDFFONT_SMALLCAP
|
| 47 |
+
flag_descriptions.append("small_cap")
|
| 48 |
+
if flags & (1 << 18): # PDFFONT_FORCEBOLD
|
| 49 |
+
flag_descriptions.append("bold")
|
| 50 |
+
if flags & (1 << 19): # PDFFONT_USEEXTERNATTR
|
| 51 |
+
flag_descriptions.append("use_extern_attr")
|
| 52 |
+
|
| 53 |
+
return "_".join(flag_descriptions)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def sort_block_group(blocks, tolerance=1.25):
|
| 57 |
+
vertical_groups = {}
|
| 58 |
+
for block in blocks:
|
| 59 |
+
if hasattr(block, "bbox"):
|
| 60 |
+
bbox = block.bbox
|
| 61 |
+
else:
|
| 62 |
+
bbox = block["bbox"]
|
| 63 |
+
|
| 64 |
+
group_key = round(bbox[1] / tolerance) * tolerance
|
| 65 |
+
if group_key not in vertical_groups:
|
| 66 |
+
vertical_groups[group_key] = []
|
| 67 |
+
vertical_groups[group_key].append(block)
|
| 68 |
+
|
| 69 |
+
# Sort each group horizontally and flatten the groups into a single list
|
| 70 |
+
sorted_blocks = []
|
| 71 |
+
for _, group in sorted(vertical_groups.items()):
|
| 72 |
+
sorted_group = sorted(group, key=lambda x: x.bbox[0] if hasattr(x, "bbox") else x["bbox"][0])
|
| 73 |
+
sorted_blocks.extend(sorted_group)
|
| 74 |
+
|
| 75 |
+
return sorted_blocks
|
marker/postprocessors/editor.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import defaultdict
|
| 2 |
+
from itertools import chain
|
| 3 |
+
from typing import Optional
|
| 4 |
+
|
| 5 |
+
from marker.settings import settings
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
from marker.postprocessors.t5 import T5ForTokenClassification, byt5_tokenize
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_batch_size():
|
| 12 |
+
if settings.EDITOR_BATCH_SIZE is not None:
|
| 13 |
+
return settings.EDITOR_BATCH_SIZE
|
| 14 |
+
elif settings.TORCH_DEVICE_MODEL == "cuda":
|
| 15 |
+
return 12
|
| 16 |
+
return 6
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def load_editing_model():
|
| 20 |
+
if not settings.ENABLE_EDITOR_MODEL:
|
| 21 |
+
return None
|
| 22 |
+
|
| 23 |
+
model = T5ForTokenClassification.from_pretrained(
|
| 24 |
+
settings.EDITOR_MODEL_NAME,
|
| 25 |
+
torch_dtype=settings.MODEL_DTYPE,
|
| 26 |
+
).to(settings.TORCH_DEVICE_MODEL)
|
| 27 |
+
model.eval()
|
| 28 |
+
|
| 29 |
+
model.config.label2id = {
|
| 30 |
+
"equal": 0,
|
| 31 |
+
"delete": 1,
|
| 32 |
+
"newline-1": 2,
|
| 33 |
+
"space-1": 3,
|
| 34 |
+
}
|
| 35 |
+
model.config.id2label = {v: k for k, v in model.config.label2id.items()}
|
| 36 |
+
return model
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def edit_full_text(text: str, model: Optional[T5ForTokenClassification], batch_multiplier=1) -> (str, dict):
|
| 40 |
+
if not model:
|
| 41 |
+
return text, {}
|
| 42 |
+
|
| 43 |
+
batch_size = get_batch_size() * batch_multiplier
|
| 44 |
+
tokenized = byt5_tokenize(text, settings.EDITOR_MAX_LENGTH)
|
| 45 |
+
input_ids = tokenized["input_ids"]
|
| 46 |
+
char_token_lengths = tokenized["char_token_lengths"]
|
| 47 |
+
|
| 48 |
+
# Run model
|
| 49 |
+
token_masks = []
|
| 50 |
+
for i in range(0, len(input_ids), batch_size):
|
| 51 |
+
batch_input_ids = tokenized["input_ids"][i: i + batch_size]
|
| 52 |
+
batch_input_ids = torch.tensor(batch_input_ids, device=model.device)
|
| 53 |
+
batch_attention_mask = tokenized["attention_mask"][i: i + batch_size]
|
| 54 |
+
batch_attention_mask = torch.tensor(batch_attention_mask, device=model.device)
|
| 55 |
+
with torch.inference_mode():
|
| 56 |
+
predictions = model(batch_input_ids, attention_mask=batch_attention_mask)
|
| 57 |
+
|
| 58 |
+
logits = predictions.logits.cpu()
|
| 59 |
+
|
| 60 |
+
# If the max probability is less than a threshold, we assume it's a bad prediction
|
| 61 |
+
# We want to be conservative to not edit the text too much
|
| 62 |
+
probs = F.softmax(logits, dim=-1)
|
| 63 |
+
max_prob = torch.max(probs, dim=-1)
|
| 64 |
+
cutoff_prob = max_prob.values < settings.EDITOR_CUTOFF_THRESH
|
| 65 |
+
labels = logits.argmax(-1)
|
| 66 |
+
labels[cutoff_prob] = model.config.label2id["equal"]
|
| 67 |
+
labels = labels.squeeze().tolist()
|
| 68 |
+
if len(labels) == settings.EDITOR_MAX_LENGTH:
|
| 69 |
+
labels = [labels]
|
| 70 |
+
labels = list(chain.from_iterable(labels))
|
| 71 |
+
token_masks.extend(labels)
|
| 72 |
+
|
| 73 |
+
# List of characters in the text
|
| 74 |
+
flat_input_ids = list(chain.from_iterable(input_ids))
|
| 75 |
+
|
| 76 |
+
# Strip special tokens 0,1. Keep unknown token, although it should never be used
|
| 77 |
+
assert len(token_masks) == len(flat_input_ids)
|
| 78 |
+
token_masks = [mask for mask, token in zip(token_masks, flat_input_ids) if token >= 2]
|
| 79 |
+
|
| 80 |
+
assert len(token_masks) == len(list(text.encode("utf-8")))
|
| 81 |
+
|
| 82 |
+
edit_stats = defaultdict(int)
|
| 83 |
+
out_text = []
|
| 84 |
+
start = 0
|
| 85 |
+
for i, char in enumerate(text):
|
| 86 |
+
char_token_length = char_token_lengths[i]
|
| 87 |
+
masks = token_masks[start: start + char_token_length]
|
| 88 |
+
labels = [model.config.id2label[mask] for mask in masks]
|
| 89 |
+
if all(l == "delete" for l in labels):
|
| 90 |
+
# If we delete whitespace, roll with it, otherwise ignore
|
| 91 |
+
if char.strip():
|
| 92 |
+
out_text.append(char)
|
| 93 |
+
else:
|
| 94 |
+
edit_stats["delete"] += 1
|
| 95 |
+
elif labels[0] == "newline-1":
|
| 96 |
+
out_text.append("\n")
|
| 97 |
+
out_text.append(char)
|
| 98 |
+
edit_stats["newline-1"] += 1
|
| 99 |
+
elif labels[0] == "space-1":
|
| 100 |
+
out_text.append(" ")
|
| 101 |
+
out_text.append(char)
|
| 102 |
+
edit_stats["space-1"] += 1
|
| 103 |
+
else:
|
| 104 |
+
out_text.append(char)
|
| 105 |
+
edit_stats["equal"] += 1
|
| 106 |
+
|
| 107 |
+
start += char_token_length
|
| 108 |
+
|
| 109 |
+
out_text = "".join(out_text)
|
| 110 |
+
return out_text, edit_stats
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
|
marker/postprocessors/markdown.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from marker.schema.merged import MergedLine, MergedBlock, FullyMergedBlock
|
| 2 |
+
from marker.schema.page import Page
|
| 3 |
+
import re
|
| 4 |
+
import regex
|
| 5 |
+
from typing import List
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def escape_markdown(text):
|
| 9 |
+
# List of characters that need to be escaped in markdown
|
| 10 |
+
characters_to_escape = r"[#]"
|
| 11 |
+
# Escape each of these characters with a backslash
|
| 12 |
+
escaped_text = re.sub(characters_to_escape, r'\\\g<0>', text)
|
| 13 |
+
return escaped_text
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def surround_text(s, char_to_insert):
|
| 17 |
+
leading_whitespace = re.match(r'^(\s*)', s).group(1)
|
| 18 |
+
trailing_whitespace = re.search(r'(\s*)$', s).group(1)
|
| 19 |
+
stripped_string = s.strip()
|
| 20 |
+
modified_string = char_to_insert + stripped_string + char_to_insert
|
| 21 |
+
final_string = leading_whitespace + modified_string + trailing_whitespace
|
| 22 |
+
return final_string
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def merge_spans(pages: List[Page]) -> List[List[MergedBlock]]:
|
| 26 |
+
merged_blocks = []
|
| 27 |
+
for page in pages:
|
| 28 |
+
page_blocks = []
|
| 29 |
+
for blocknum, block in enumerate(page.blocks):
|
| 30 |
+
block_lines = []
|
| 31 |
+
for linenum, line in enumerate(block.lines):
|
| 32 |
+
line_text = ""
|
| 33 |
+
if len(line.spans) == 0:
|
| 34 |
+
continue
|
| 35 |
+
fonts = []
|
| 36 |
+
for i, span in enumerate(line.spans):
|
| 37 |
+
font = span.font.lower()
|
| 38 |
+
next_span = None
|
| 39 |
+
next_idx = 1
|
| 40 |
+
while len(line.spans) > i + next_idx:
|
| 41 |
+
next_span = line.spans[i + next_idx]
|
| 42 |
+
next_idx += 1
|
| 43 |
+
if len(next_span.text.strip()) > 2:
|
| 44 |
+
break
|
| 45 |
+
|
| 46 |
+
fonts.append(font)
|
| 47 |
+
span_text = span.text
|
| 48 |
+
|
| 49 |
+
# Don't bold or italicize very short sequences
|
| 50 |
+
# Avoid bolding first and last sequence so lines can be joined properly
|
| 51 |
+
if len(span_text) > 3 and 0 < i < len(line.spans) - 1:
|
| 52 |
+
if span.italic and (not next_span or not next_span.italic):
|
| 53 |
+
span_text = surround_text(span_text, "*")
|
| 54 |
+
elif span.bold and (not next_span or not next_span.bold):
|
| 55 |
+
span_text = surround_text(span_text, "**")
|
| 56 |
+
line_text += span_text
|
| 57 |
+
block_lines.append(MergedLine(
|
| 58 |
+
text=line_text,
|
| 59 |
+
fonts=fonts,
|
| 60 |
+
bbox=line.bbox
|
| 61 |
+
))
|
| 62 |
+
if len(block_lines) > 0:
|
| 63 |
+
page_blocks.append(MergedBlock(
|
| 64 |
+
lines=block_lines,
|
| 65 |
+
pnum=block.pnum,
|
| 66 |
+
bbox=block.bbox,
|
| 67 |
+
block_type=block.block_type
|
| 68 |
+
))
|
| 69 |
+
merged_blocks.append(page_blocks)
|
| 70 |
+
|
| 71 |
+
return merged_blocks
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def block_surround(text, block_type):
|
| 75 |
+
if block_type == "Section-header":
|
| 76 |
+
if not text.startswith("#"):
|
| 77 |
+
text = "\n## " + text.strip().title() + "\n"
|
| 78 |
+
elif block_type == "Title":
|
| 79 |
+
if not text.startswith("#"):
|
| 80 |
+
text = "# " + text.strip().title() + "\n"
|
| 81 |
+
elif block_type == "Table":
|
| 82 |
+
text = "\n" + text + "\n"
|
| 83 |
+
elif block_type == "List-item":
|
| 84 |
+
text = escape_markdown(text)
|
| 85 |
+
elif block_type == "Code":
|
| 86 |
+
text = "\n```\n" + text + "\n```\n"
|
| 87 |
+
elif block_type == "Text":
|
| 88 |
+
text = escape_markdown(text)
|
| 89 |
+
elif block_type == "Formula":
|
| 90 |
+
if text.strip().startswith("$$") and text.strip().endswith("$$"):
|
| 91 |
+
text = text.strip()
|
| 92 |
+
text = "\n" + text + "\n"
|
| 93 |
+
return text
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def line_separator(line1, line2, block_type, is_continuation=False):
|
| 97 |
+
# Should cover latin-derived languages and russian
|
| 98 |
+
lowercase_letters = r'\p{Lo}|\p{Ll}|\d'
|
| 99 |
+
hyphens = r'-—¬'
|
| 100 |
+
# Remove hyphen in current line if next line and current line appear to be joined
|
| 101 |
+
hyphen_pattern = regex.compile(rf'.*[{lowercase_letters}][{hyphens}]\s?$', regex.DOTALL)
|
| 102 |
+
if line1 and hyphen_pattern.match(line1) and regex.match(rf"^\s?[{lowercase_letters}]", line2):
|
| 103 |
+
# Split on — or - from the right
|
| 104 |
+
line1 = regex.split(rf"[{hyphens}]\s?$", line1)[0]
|
| 105 |
+
return line1.rstrip() + line2.lstrip()
|
| 106 |
+
|
| 107 |
+
all_letters = r'\p{L}|\d'
|
| 108 |
+
sentence_continuations = r',;\(\—\"\'\*'
|
| 109 |
+
sentence_ends = r'。ๆ\.?!'
|
| 110 |
+
line_end_pattern = regex.compile(rf'.*[{lowercase_letters}][{sentence_continuations}]?\s?$', regex.DOTALL)
|
| 111 |
+
line_start_pattern = regex.compile(rf'^\s?[{all_letters}]', regex.DOTALL)
|
| 112 |
+
sentence_end_pattern = regex.compile(rf'.*[{sentence_ends}]\s?$', regex.DOTALL)
|
| 113 |
+
|
| 114 |
+
text_blocks = ["Text", "List-item", "Footnote", "Caption", "Figure"]
|
| 115 |
+
if block_type in ["Title", "Section-header"]:
|
| 116 |
+
return line1.rstrip() + " " + line2.lstrip()
|
| 117 |
+
elif block_type == "Formula":
|
| 118 |
+
return line1 + "\n" + line2
|
| 119 |
+
elif line_end_pattern.match(line1) and line_start_pattern.match(line2) and block_type in text_blocks:
|
| 120 |
+
return line1.rstrip() + " " + line2.lstrip()
|
| 121 |
+
elif is_continuation:
|
| 122 |
+
return line1.rstrip() + " " + line2.lstrip()
|
| 123 |
+
elif block_type in text_blocks and sentence_end_pattern.match(line1):
|
| 124 |
+
return line1 + "\n\n" + line2
|
| 125 |
+
elif block_type == "Table":
|
| 126 |
+
return line1 + "\n\n" + line2
|
| 127 |
+
else:
|
| 128 |
+
return line1 + "\n" + line2
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def block_separator(line1, line2, block_type1, block_type2):
|
| 132 |
+
sep = "\n"
|
| 133 |
+
if block_type1 == "Text":
|
| 134 |
+
sep = "\n\n"
|
| 135 |
+
|
| 136 |
+
return sep + line2
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def merge_lines(blocks: List[List[MergedBlock]]):
|
| 140 |
+
text_blocks = []
|
| 141 |
+
prev_type = None
|
| 142 |
+
prev_line = None
|
| 143 |
+
block_text = ""
|
| 144 |
+
block_type = ""
|
| 145 |
+
|
| 146 |
+
for page in blocks:
|
| 147 |
+
for block in page:
|
| 148 |
+
block_type = block.block_type
|
| 149 |
+
if block_type != prev_type and prev_type:
|
| 150 |
+
text_blocks.append(
|
| 151 |
+
FullyMergedBlock(
|
| 152 |
+
text=block_surround(block_text, prev_type),
|
| 153 |
+
block_type=prev_type
|
| 154 |
+
)
|
| 155 |
+
)
|
| 156 |
+
block_text = ""
|
| 157 |
+
|
| 158 |
+
prev_type = block_type
|
| 159 |
+
# Join lines in the block together properly
|
| 160 |
+
for i, line in enumerate(block.lines):
|
| 161 |
+
line_height = line.bbox[3] - line.bbox[1]
|
| 162 |
+
prev_line_height = prev_line.bbox[3] - prev_line.bbox[1] if prev_line else 0
|
| 163 |
+
prev_line_x = prev_line.bbox[0] if prev_line else 0
|
| 164 |
+
prev_line = line
|
| 165 |
+
is_continuation = line_height == prev_line_height and line.bbox[0] == prev_line_x
|
| 166 |
+
if block_text:
|
| 167 |
+
block_text = line_separator(block_text, line.text, block_type, is_continuation)
|
| 168 |
+
else:
|
| 169 |
+
block_text = line.text
|
| 170 |
+
|
| 171 |
+
# Append the final block
|
| 172 |
+
text_blocks.append(
|
| 173 |
+
FullyMergedBlock(
|
| 174 |
+
text=block_surround(block_text, prev_type),
|
| 175 |
+
block_type=block_type
|
| 176 |
+
)
|
| 177 |
+
)
|
| 178 |
+
return text_blocks
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def get_full_text(text_blocks):
|
| 182 |
+
full_text = ""
|
| 183 |
+
prev_block = None
|
| 184 |
+
for block in text_blocks:
|
| 185 |
+
if prev_block:
|
| 186 |
+
full_text += block_separator(prev_block.text, block.text, prev_block.block_type, block.block_type)
|
| 187 |
+
else:
|
| 188 |
+
full_text += block.text
|
| 189 |
+
prev_block = block
|
| 190 |
+
return full_text
|