Spaces:
Running

Running
update files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- Dockerfile +34 -0
- README.md +144 -11
- README_EN.md +155 -0
- assets/demoImage.png +3 -0
- assets/gradio-image.jpeg +0 -0
- beautyPlugin/GrindSkin.py +43 -0
- beautyPlugin/MakeBeautiful.py +45 -0
- beautyPlugin/MakeWhiter.py +108 -0
- beautyPlugin/ThinFace.py +267 -0
- beautyPlugin/__init__.py +4 -0
- beautyPlugin/lut_image/1.png +0 -0
- beautyPlugin/lut_image/3.png +0 -0
- beautyPlugin/lut_image/lutOrigin.png +0 -0
- deploy_api.py +138 -0
- hivision_modnet.onnx +3 -0
- hivisionai/__init__.py +0 -0
- hivisionai/app.py +452 -0
- hivisionai/hyService/__init__.py +0 -0
- hivisionai/hyService/cloudService.py +406 -0
- hivisionai/hyService/dbTools.py +337 -0
- hivisionai/hyService/error.py +20 -0
- hivisionai/hyService/serviceTest.py +34 -0
- hivisionai/hyService/utils.py +92 -0
- hivisionai/hyTrain/APIs.py +197 -0
- hivisionai/hyTrain/DataProcessing.py +37 -0
- hivisionai/hyTrain/__init__.py +0 -0
- hivisionai/hycv/FaceDetection68/__init__.py +8 -0
- hivisionai/hycv/FaceDetection68/__pycache__/__init__.cpython-310.pyc +0 -0
- hivisionai/hycv/FaceDetection68/__pycache__/faceDetection68.cpython-310.pyc +0 -0
- hivisionai/hycv/FaceDetection68/faceDetection68.py +443 -0
- hivisionai/hycv/__init__.py +1 -0
- hivisionai/hycv/__pycache__/__init__.cpython-310.pyc +0 -0
- hivisionai/hycv/__pycache__/error.cpython-310.pyc +0 -0
- hivisionai/hycv/__pycache__/face_tools.cpython-310.pyc +0 -0
- hivisionai/hycv/__pycache__/idphoto.cpython-310.pyc +0 -0
- hivisionai/hycv/__pycache__/matting_tools.cpython-310.pyc +0 -0
- hivisionai/hycv/__pycache__/tensor2numpy.cpython-310.pyc +0 -0
- hivisionai/hycv/__pycache__/utils.cpython-310.pyc +0 -0
- hivisionai/hycv/__pycache__/vision.cpython-310.pyc +0 -0
- hivisionai/hycv/error.py +16 -0
- hivisionai/hycv/face_tools.py +427 -0
- hivisionai/hycv/idphoto.py +2 -0
- hivisionai/hycv/idphotoTool/__init__.py +0 -0
- hivisionai/hycv/idphotoTool/__pycache__/__init__.cpython-310.pyc +0 -0
- hivisionai/hycv/idphotoTool/__pycache__/cuny_tools.cpython-310.pyc +0 -0
- hivisionai/hycv/idphotoTool/__pycache__/idphoto_change_cloth.cpython-310.pyc +0 -0
- hivisionai/hycv/idphotoTool/__pycache__/idphoto_cut.cpython-310.pyc +0 -0
- hivisionai/hycv/idphotoTool/__pycache__/move_image.cpython-310.pyc +0 -0
- hivisionai/hycv/idphotoTool/__pycache__/neck_processing.cpython-310.pyc +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/demoImage.png filter=lfs diff=lfs merge=lfs -text
|
Dockerfile
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM ubuntu:22.04
|
| 2 |
+
|
| 3 |
+
# apt换源,安装pip
|
| 4 |
+
RUN echo "==> 换成阿里源,并更新..." && \
|
| 5 |
+
sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list && \
|
| 6 |
+
sed -i s@/security.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list && \
|
| 7 |
+
apt-get clean && \
|
| 8 |
+
apt-get update
|
| 9 |
+
|
| 10 |
+
# 安装python3.10
|
| 11 |
+
RUN apt-get install -y python3 curl && \
|
| 12 |
+
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py && \
|
| 13 |
+
python3 get-pip.py && \
|
| 14 |
+
pip3 install -U pip && \
|
| 15 |
+
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
|
| 16 |
+
|
| 17 |
+
# 安装ffmpeg等库
|
| 18 |
+
RUN apt-get install libpython3.10-dev ffmpeg libgl1-mesa-glx libglib2.0-0 cmake -y && \
|
| 19 |
+
pip3 install --no-cache-dir cmake
|
| 20 |
+
|
| 21 |
+
WORKDIR /app
|
| 22 |
+
|
| 23 |
+
COPY . .
|
| 24 |
+
|
| 25 |
+
RUN pip3 install -r requirements.txt
|
| 26 |
+
|
| 27 |
+
RUN echo "==> Clean up..." && \
|
| 28 |
+
rm -rf ~/.cache/pip
|
| 29 |
+
|
| 30 |
+
# 指定工作目录
|
| 31 |
+
|
| 32 |
+
EXPOSE 8080
|
| 33 |
+
|
| 34 |
+
ENTRYPOINT ["python3", "deploy_api.py"]
|
README.md
CHANGED
|
@@ -1,13 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
-
title: HivisionIDPhotos
|
| 3 |
-
emoji: 🐢
|
| 4 |
-
colorFrom: blue
|
| 5 |
-
colorTo: indigo
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 4.42.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
license: apache-2.0
|
| 11 |
-
---
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<h1>HivisionIDPhoto</h1>
|
| 3 |
+
|
| 4 |
+
[English](README_EN.md) / 中文
|
| 5 |
+
|
| 6 |
+
[](https://github.com/xiaolin199912/HivisionIDPhotos)
|
| 7 |
+
[](https://swanhub.co/ZeYiLin/HivisionIDPhotos/demo)
|
| 8 |
+
[](https://zhuanlan.zhihu.com/p/638254028)
|
| 9 |
+
|
| 10 |
+
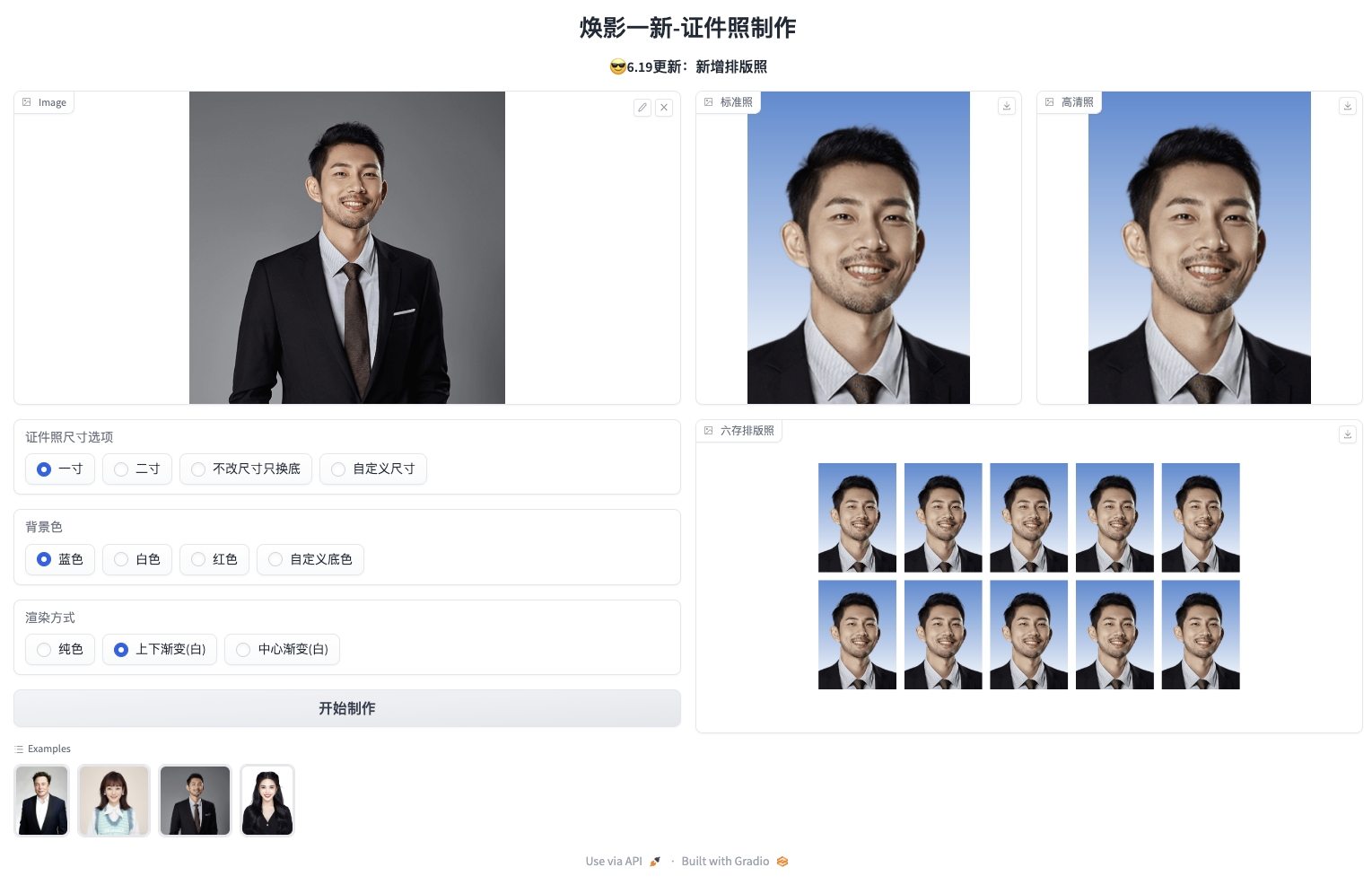
<img src="assets/demoImage.png" width=900>
|
| 11 |
+
</div>
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
# 🤩项目更新
|
| 15 |
+
- 在线体验: [](https://swanhub.co/ZeYiLin/HivisionIDPhotos/demo)
|
| 16 |
+
- 2023.12.1: 更新**API部署(基于fastapi)**
|
| 17 |
+
- 2023.6.20: 更新**预设尺寸菜单**
|
| 18 |
+
- 2023.6.19: 更新**排版照**
|
| 19 |
+
- 2023.6.13: 更新**中心渐变色**
|
| 20 |
+
- 2023.6.11: 更新**上下渐变色**
|
| 21 |
+
- 2023.6.8: 更新**自定义尺寸**
|
| 22 |
+
- 2023.6.4: 更新**自定义底色、人脸检测Bug通知**
|
| 23 |
+
- 2023.5.10: 更新**不改尺寸只换底**
|
| 24 |
+
|
| 25 |
+
# Overview
|
| 26 |
+
|
| 27 |
+
> 🚀谢谢你对我们的工作感兴趣。您可能还想查看我们在图像领域的其他成果,欢迎来信:zeyi.lin@swanhub.co.
|
| 28 |
+
|
| 29 |
+
HivisionIDPhoto旨在开发一种实用的证件照智能制作算法。
|
| 30 |
+
|
| 31 |
+
它利用一套完善的模型工作流程,实现对多种用户拍照场景的识别、抠图与证件照生成。
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
**HivisionIDPhoto可以做到:**
|
| 35 |
+
|
| 36 |
+
1. 轻量级抠图
|
| 37 |
+
2. 根据不同尺寸规格生成不同的标准证件照、六寸排版照
|
| 38 |
+
3. 美颜(waiting)
|
| 39 |
+
4. 智能换正装(waiting)
|
| 40 |
+
|
| 41 |
+
<div align="center">
|
| 42 |
+
<img src="assets/gradio-image.jpeg" width=900>
|
| 43 |
+
</div>
|
| 44 |
+
|
| 45 |
+
|
| 46 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 47 |
|
| 48 |
+
如果HivisionIDPhoto对你有帮助,请star这个repo或推荐给你的朋友,解决证件照应急制作问题!
|
| 49 |
+
|
| 50 |
+
<br>
|
| 51 |
+
|
| 52 |
+
# 🔧环境安装与依赖
|
| 53 |
+
|
| 54 |
+
- Python >= 3.7(项目主要测试在python 3.10)
|
| 55 |
+
- onnxruntime
|
| 56 |
+
- OpenCV
|
| 57 |
+
- Option: Linux, Windows, MacOS
|
| 58 |
+
|
| 59 |
+
**1. 克隆项目**
|
| 60 |
+
|
| 61 |
+
```bash
|
| 62 |
+
git clone https://github.com/Zeyi-Lin/HivisionIDPhotos.git
|
| 63 |
+
cd HivisionIDPhotos
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
**2. 安装依赖环境**
|
| 67 |
+
|
| 68 |
+
```bash
|
| 69 |
+
pip install -r requirements.txt
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
**3. 下载权重文件**
|
| 73 |
+
|
| 74 |
+
在我们的[Release](https://github.com/Zeyi-Lin/HivisionIDPhotos/releases/tag/pretrained-model)下载权重文件`hivision_modnet.onnx`,存到根目录下。
|
| 75 |
+
|
| 76 |
+
<br>
|
| 77 |
+
|
| 78 |
+
# 运行Gradio Demo
|
| 79 |
+
|
| 80 |
+
```bash
|
| 81 |
+
python app.py
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
运行程序将生成一个本地Web页面,在页面中可完成证件照的操作与交互。
|
| 85 |
+
|
| 86 |
+
<br>
|
| 87 |
+
|
| 88 |
+
# 部署API服务
|
| 89 |
+
|
| 90 |
+
```
|
| 91 |
+
python deploy_api.py
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
**请求API服务(Python)**
|
| 96 |
+
|
| 97 |
+
用Python给服务发送请求:
|
| 98 |
+
|
| 99 |
+
证件照制作(输入1张照片,获得1张标准证件照和1张高清证件照的4通道透明png):
|
| 100 |
+
|
| 101 |
+
```bash
|
| 102 |
+
python requests_api.py -u http://127.0.0.1:8080 -i test.jpg -o ./idphoto.png -s '(413,295)'
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
增加底色(输入1张4通道透明png,获得1张增加了底色的图像):
|
| 106 |
+
|
| 107 |
+
```bash
|
| 108 |
+
python requests_api.py -u http://127.0.0.1:8080 -t add_background -i ./idphoto.png -o ./idhoto_ab.jpg -c '(0,0,0)'
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
得到六寸排版照(输入1张3通道照片,获得1张六寸排版照):
|
| 112 |
+
|
| 113 |
+
```bash
|
| 114 |
+
python requests_api.py -u http://127.0.0.1:8080 -t generate_layout_photos -i ./idhoto_ab.jpg -o ./idhoto_layout.jpg -s '(413,295)'
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
<br>
|
| 118 |
+
|
| 119 |
+
# 🐳Docker部署
|
| 120 |
+
|
| 121 |
+
在确保将模型权重文件[hivision_modnet.onnx](https://github.com/Zeyi-Lin/HivisionIDPhotos/releases/tag/pretrained-model)放到根目录下后,在根目录执行:
|
| 122 |
+
|
| 123 |
+
```bash
|
| 124 |
+
docker build -t hivision_idphotos .
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
等待镜像封装完毕后,运行以下指令,即可开启API服务:
|
| 128 |
+
|
| 129 |
+
```bash
|
| 130 |
+
docker run -p 8080:8080 hivision_idphotos
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
<br>
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
# 引用项目
|
| 137 |
+
|
| 138 |
+
1. MTCNN: https://github.com/ipazc/mtcnn
|
| 139 |
+
2. ModNet: https://github.com/ZHKKKe/MODNet
|
| 140 |
+
|
| 141 |
+
<br>
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
# 📧联系我们
|
| 145 |
+
|
| 146 |
+
如果您有任何问题,请发邮件至 zeyi.lin@swanhub.co
|
README_EN.md
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<h1>HivisionIDPhoto</h1>
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
English / [中文](README.md)
|
| 6 |
+
|
| 7 |
+
[](https://github.com/xiaolin199912/HivisionIDPhotos)
|
| 8 |
+
[](https://swanhub.co/ZeYiLin/HivisionIDPhotos/demo)
|
| 9 |
+
[](https://zhuanlan.zhihu.com/p/638254028)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
<img src="assets/demoImage.png" width=900>
|
| 13 |
+
</div>
|
| 14 |
+
|
| 15 |
+
</div>
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# 🤩Project Update
|
| 19 |
+
|
| 20 |
+
- Online Demo: [](https://swanhub.co/ZeYiLin/HivisionIDPhotos/demo)
|
| 21 |
+
- 2023.12.1: Update **API deployment (based on fastapi)**
|
| 22 |
+
- 2023.6.20: Update **Preset size menu**
|
| 23 |
+
- 2023.6.19: Update **Layout photos**
|
| 24 |
+
- 2023.6.13: Update **Center gradient color**
|
| 25 |
+
- 2023.6.11: Update **Top and bottom gradient color**
|
| 26 |
+
- 2023.6.8: Update **Custom size**
|
| 27 |
+
- 2023.6.4: Update **Custom background color, face detection bug notification**
|
| 28 |
+
- 2023.5.10: Update **Change the background without changing the size**
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
<br>
|
| 32 |
+
|
| 33 |
+
# Overview
|
| 34 |
+
|
| 35 |
+
> 🚀Thank you for your interest in our work. You may also want to check out our other achievements in the field of image processing. Please feel free to contact us at zeyi.lin@swanhub.co.
|
| 36 |
+
|
| 37 |
+
HivisionIDPhoto aims to develop a practical intelligent algorithm for producing ID photos. It uses a complete set of model workflows to recognize various user photo scenarios, perform image segmentation, and generate ID photos.
|
| 38 |
+
|
| 39 |
+
**HivisionIDPhoto can:**
|
| 40 |
+
|
| 41 |
+
1. Perform lightweight image segmentation
|
| 42 |
+
2. Generate standard ID photos and six-inch layout photos according to different size specifications
|
| 43 |
+
3. Provide beauty features (waiting)
|
| 44 |
+
4. Provide intelligent formal wear replacement (waiting)
|
| 45 |
+
|
| 46 |
+
<div align="center">
|
| 47 |
+
<img src="assets/gradio-image.jpeg" width=900>
|
| 48 |
+
</div>
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
---
|
| 52 |
+
|
| 53 |
+
If HivisionIDPhoto is helpful to you, please star this repo or recommend it to your friends to solve the problem of emergency ID photo production!
|
| 54 |
+
|
| 55 |
+
<br>
|
| 56 |
+
|
| 57 |
+
# 🔧Environment Dependencies and Installation
|
| 58 |
+
|
| 59 |
+
- Python >= 3.7(The main test of the project is in Python 3.10.)
|
| 60 |
+
- onnxruntime
|
| 61 |
+
- OpenCV
|
| 62 |
+
- Option: Linux, Windows, MacOS
|
| 63 |
+
|
| 64 |
+
### Installation
|
| 65 |
+
|
| 66 |
+
1. Clone repo
|
| 67 |
+
|
| 68 |
+
```bash
|
| 69 |
+
git clone https://github.com/Zeyi-Lin/HivisionIDPhotos.git
|
| 70 |
+
cd HivisionIDPhotos
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
2. Install dependent packages
|
| 74 |
+
|
| 75 |
+
```
|
| 76 |
+
pip install -r requirements.txt
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
**3. Download Pretrain file**
|
| 80 |
+
|
| 81 |
+
Download the weight file `hivision_modnet.onnx` from our [Release](https://github.com/Zeyi-Lin/HivisionIDPhotos/releases/tag/pretrained-model) and save it to the root directory.
|
| 82 |
+
|
| 83 |
+
<br>
|
| 84 |
+
|
| 85 |
+
# Gradio Demo
|
| 86 |
+
|
| 87 |
+
```bash
|
| 88 |
+
python app.py
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
Running the program will generate a local web page, where operations and interactions with ID photos can be completed.
|
| 92 |
+
|
| 93 |
+
<br>
|
| 94 |
+
|
| 95 |
+
# Deploy API service
|
| 96 |
+
|
| 97 |
+
```
|
| 98 |
+
python deploy_api.py
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
**Request API service (Python)**
|
| 102 |
+
|
| 103 |
+
Use Python to send a request to the service:
|
| 104 |
+
|
| 105 |
+
ID photo production (input 1 photo, get 1 standard ID photo and 1 high-definition ID photo 4-channel transparent png):
|
| 106 |
+
|
| 107 |
+
```bash
|
| 108 |
+
python requests_api.py -u http://127.0.0.1:8080 -i test.jpg -o ./idphoto.png -s '(413,295)'
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
Add background color (input 1 4-channel transparent png, get 1 image with added background color):
|
| 112 |
+
|
| 113 |
+
```bash
|
| 114 |
+
python requests_api.py -u http://127.0.0.1:8080 -t add_background -i ./idphoto.png -o ./idhoto_ab.jpg -c '(0,0,0)'
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
Get a six-inch layout photo (input a 3-channel photo, get a six-inch layout photo):
|
| 118 |
+
|
| 119 |
+
```bash
|
| 120 |
+
python requests_api.py -u http://127.0.0.1:8080 -t generate_layout_photos -i ./idhoto_ab.jpg -o ./idhoto_layout.jpg -s '(413,295)'
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
<br>
|
| 124 |
+
|
| 125 |
+
# 🐳Docker deployment
|
| 126 |
+
|
| 127 |
+
After ensuring that the model weight file [hivision_modnet.onnx](https://github.com/Zeyi-Lin/HivisionIDPhotos/releases/tag/pretrained-model) is placed in the root directory, execute in the root directory:
|
| 128 |
+
|
| 129 |
+
```bash
|
| 130 |
+
docker build -t hivision_idphotos .
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
After the image is packaged, run the following command to start the API service:
|
| 134 |
+
|
| 135 |
+
```bash
|
| 136 |
+
docker run -p 8080:8080 hivision_idphotos
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
<br>
|
| 140 |
+
|
| 141 |
+
# Reference Projects
|
| 142 |
+
|
| 143 |
+
1. MTCNN: https://github.com/ipazc/mtcnn
|
| 144 |
+
2. ModNet: https://github.com/ZHKKKe/MODNet
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
<br>
|
| 148 |
+
|
| 149 |
+
# 📧Contact
|
| 150 |
+
|
| 151 |
+
If you have any questions, please email Zeyi.lin@swanhub.co
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
Copyright © 2023, ZeYiLin. All Rights Reserved.
|
| 155 |
+
|
assets/demoImage.png
ADDED

|
Git LFS Details
|
assets/gradio-image.jpeg
ADDED
|
beautyPlugin/GrindSkin.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
@author: cuny
|
| 3 |
+
@file: GrindSkin.py
|
| 4 |
+
@time: 2022/7/2 14:44
|
| 5 |
+
@description:
|
| 6 |
+
磨皮算法
|
| 7 |
+
"""
|
| 8 |
+
import cv2
|
| 9 |
+
import numpy as np
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def grindSkin(src, grindDegree: int = 3, detailDegree: int = 1, strength: int = 9):
|
| 13 |
+
"""
|
| 14 |
+
Dest =(Src * (100 - Opacity) + (Src + 2 * GaussBlur(EPFFilter(Src) - Src)) * Opacity) /100
|
| 15 |
+
人像磨皮方案,后续会考虑使用一些皮肤区域检测算法来实现仅皮肤区域磨皮,增加算法的精细程度——或者使用人脸关键点
|
| 16 |
+
https://www.cnblogs.com/Imageshop/p/4709710.html
|
| 17 |
+
Args:
|
| 18 |
+
src: 原图
|
| 19 |
+
grindDegree: 磨皮程度调节参数
|
| 20 |
+
detailDegree: 细节程度调节参数
|
| 21 |
+
strength: 融合程度,作为磨皮强度(0 - 10)
|
| 22 |
+
|
| 23 |
+
Returns:
|
| 24 |
+
磨皮后的图像
|
| 25 |
+
"""
|
| 26 |
+
if strength <= 0:
|
| 27 |
+
return src
|
| 28 |
+
dst = src.copy()
|
| 29 |
+
opacity = min(10., strength) / 10.
|
| 30 |
+
dx = grindDegree * 5 # 双边滤波参数之一
|
| 31 |
+
fc = grindDegree * 12.5 # 双边滤波参数之一
|
| 32 |
+
temp1 = cv2.bilateralFilter(src[:, :, :3], dx, fc, fc)
|
| 33 |
+
temp2 = cv2.subtract(temp1, src[:, :, :3])
|
| 34 |
+
temp3 = cv2.GaussianBlur(temp2, (2 * detailDegree - 1, 2 * detailDegree - 1), 0)
|
| 35 |
+
temp4 = cv2.add(cv2.add(temp3, temp3), src[:, :, :3])
|
| 36 |
+
dst[:, :, :3] = cv2.addWeighted(temp4, opacity, src[:, :, :3], 1 - opacity, 0.0)
|
| 37 |
+
return dst
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
if __name__ == "__main__":
|
| 41 |
+
input_image = cv2.imread("test_image/7.jpg")
|
| 42 |
+
output_image = grindSkin(src=input_image)
|
| 43 |
+
cv2.imwrite("grindSkinCompare.png", np.hstack((input_image, output_image)))
|
beautyPlugin/MakeBeautiful.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
@author: cuny
|
| 3 |
+
@file: MakeBeautiful.py
|
| 4 |
+
@time: 2022/7/7 20:23
|
| 5 |
+
@description:
|
| 6 |
+
美颜工具集合文件,作为暴露在外的插件接口
|
| 7 |
+
"""
|
| 8 |
+
from .GrindSkin import grindSkin
|
| 9 |
+
from .MakeWhiter import MakeWhiter
|
| 10 |
+
from .ThinFace import thinFace
|
| 11 |
+
import numpy as np
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def makeBeautiful(input_image: np.ndarray,
|
| 15 |
+
landmark,
|
| 16 |
+
thinStrength: int,
|
| 17 |
+
thinPlace: int,
|
| 18 |
+
grindStrength: int,
|
| 19 |
+
whiterStrength: int
|
| 20 |
+
) -> np.ndarray:
|
| 21 |
+
"""
|
| 22 |
+
美颜工具的接口函数,用于实现美颜效果
|
| 23 |
+
Args:
|
| 24 |
+
input_image: 输入的图像
|
| 25 |
+
landmark: 瘦脸需要的人脸关键点信息,为fd68返回的第二个参数
|
| 26 |
+
thinStrength: 瘦脸强度,为0-10(如果更高其实也没什么问题),当强度为0或者更低时,则不瘦脸
|
| 27 |
+
thinPlace: 选择瘦脸区域,为0-2之间的值,越大瘦脸的点越靠下
|
| 28 |
+
grindStrength: 磨皮强度,为0-10(如果更高其实也没什么问题),当强度为0或者更低时,则不磨皮
|
| 29 |
+
whiterStrength: 美白强度,为0-10(如果更高其实也没什么问题),当强度为0或者更低时,则不美白
|
| 30 |
+
Returns:
|
| 31 |
+
output_image 输出图像
|
| 32 |
+
"""
|
| 33 |
+
try:
|
| 34 |
+
_, _, _ = input_image.shape
|
| 35 |
+
except ValueError:
|
| 36 |
+
raise TypeError("输入图像必须为3通道或者4通道!")
|
| 37 |
+
# 三通道或者四通道图像
|
| 38 |
+
# 首先进行瘦脸
|
| 39 |
+
input_image = thinFace(input_image, landmark, place=thinPlace, strength=thinStrength)
|
| 40 |
+
# 其次进行磨皮
|
| 41 |
+
input_image = grindSkin(src=input_image, strength=grindStrength)
|
| 42 |
+
# 最后进行美白
|
| 43 |
+
makeWhiter = MakeWhiter()
|
| 44 |
+
input_image = makeWhiter.run(input_image, strength=whiterStrength)
|
| 45 |
+
return input_image
|
beautyPlugin/MakeWhiter.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
@author: cuny
|
| 3 |
+
@file: MakeWhiter.py
|
| 4 |
+
@time: 2022/7/2 14:28
|
| 5 |
+
@description:
|
| 6 |
+
美白算法
|
| 7 |
+
"""
|
| 8 |
+
import os
|
| 9 |
+
import cv2
|
| 10 |
+
import math
|
| 11 |
+
import numpy as np
|
| 12 |
+
local_path = os.path.dirname(__file__)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class MakeWhiter(object):
|
| 16 |
+
class __LutWhite:
|
| 17 |
+
"""
|
| 18 |
+
美白的内部类
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
def __init__(self, lut):
|
| 22 |
+
cube64rows = 8
|
| 23 |
+
cube64size = 64
|
| 24 |
+
cube256size = 256
|
| 25 |
+
cubeScale = int(cube256size / cube64size) # 4
|
| 26 |
+
|
| 27 |
+
reshapeLut = np.zeros((cube256size, cube256size, cube256size, 3))
|
| 28 |
+
for i in range(cube64size):
|
| 29 |
+
tmp = math.floor(i / cube64rows)
|
| 30 |
+
cx = int((i - tmp * cube64rows) * cube64size)
|
| 31 |
+
cy = int(tmp * cube64size)
|
| 32 |
+
cube64 = lut[cy:cy + cube64size, cx:cx + cube64size] # cube64 in lut(512*512 (512=8*64))
|
| 33 |
+
_rows, _cols, _ = cube64.shape
|
| 34 |
+
if _rows == 0 or _cols == 0:
|
| 35 |
+
continue
|
| 36 |
+
cube256 = cv2.resize(cube64, (cube256size, cube256size))
|
| 37 |
+
i = i * cubeScale
|
| 38 |
+
for k in range(cubeScale):
|
| 39 |
+
reshapeLut[i + k] = cube256
|
| 40 |
+
self.lut = reshapeLut
|
| 41 |
+
|
| 42 |
+
def imageInLut(self, src):
|
| 43 |
+
arr = src.copy()
|
| 44 |
+
bs = arr[:, :, 0]
|
| 45 |
+
gs = arr[:, :, 1]
|
| 46 |
+
rs = arr[:, :, 2]
|
| 47 |
+
arr[:, :] = self.lut[bs, gs, rs]
|
| 48 |
+
return arr
|
| 49 |
+
|
| 50 |
+
def __init__(self, lutImage: np.ndarray = None):
|
| 51 |
+
self.__lutWhiten = None
|
| 52 |
+
if lutImage is not None:
|
| 53 |
+
self.__lutWhiten = self.__LutWhite(lutImage)
|
| 54 |
+
|
| 55 |
+
def setLut(self, lutImage: np.ndarray):
|
| 56 |
+
self.__lutWhiten = self.__LutWhite(lutImage)
|
| 57 |
+
|
| 58 |
+
@staticmethod
|
| 59 |
+
def generate_identify_color_matrix(size: int = 512, channel: int = 3) -> np.ndarray:
|
| 60 |
+
"""
|
| 61 |
+
用于生成一张初始的查找表
|
| 62 |
+
Args:
|
| 63 |
+
size: 查找表尺寸,默认为512
|
| 64 |
+
channel: 查找表通道数,默认为3
|
| 65 |
+
|
| 66 |
+
Returns:
|
| 67 |
+
返回生成的查找表图像
|
| 68 |
+
"""
|
| 69 |
+
img = np.zeros((size, size, channel), dtype=np.uint8)
|
| 70 |
+
for by in range(size // 64):
|
| 71 |
+
for bx in range(size // 64):
|
| 72 |
+
for g in range(64):
|
| 73 |
+
for r in range(64):
|
| 74 |
+
x = r + bx * 64
|
| 75 |
+
y = g + by * 64
|
| 76 |
+
img[y][x][0] = int(r * 255.0 / 63.0 + 0.5)
|
| 77 |
+
img[y][x][1] = int(g * 255.0 / 63.0 + 0.5)
|
| 78 |
+
img[y][x][2] = int((bx + by * 8.0) * 255.0 / 63.0 + 0.5)
|
| 79 |
+
return cv2.cvtColor(img, cv2.COLOR_RGB2BGR).clip(0, 255).astype('uint8')
|
| 80 |
+
|
| 81 |
+
def run(self, src: np.ndarray, strength: int) -> np.ndarray:
|
| 82 |
+
"""
|
| 83 |
+
美白图像
|
| 84 |
+
Args:
|
| 85 |
+
src: 原图
|
| 86 |
+
strength: 美白强度,0 - 10
|
| 87 |
+
Returns:
|
| 88 |
+
美白后的图像
|
| 89 |
+
"""
|
| 90 |
+
dst = src.copy()
|
| 91 |
+
strength = min(10, int(strength)) / 10.
|
| 92 |
+
if strength <= 0:
|
| 93 |
+
return dst
|
| 94 |
+
self.setLut(cv2.imread(f"{local_path}/lut_image/3.png", -1))
|
| 95 |
+
_, _, c = src.shape
|
| 96 |
+
img = self.__lutWhiten.imageInLut(src[:, :, :3])
|
| 97 |
+
dst[:, :, :3] = cv2.addWeighted(src[:, :, :3], 1 - strength, img, strength, 0)
|
| 98 |
+
return dst
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
if __name__ == "__main__":
|
| 102 |
+
# makeLut = MakeWhiter()
|
| 103 |
+
# cv2.imwrite("lutOrigin.png", makeLut.generate_identify_color_matrix())
|
| 104 |
+
input_image = cv2.imread("test_image/7.jpg", -1)
|
| 105 |
+
lut_image = cv2.imread("lut_image/3.png")
|
| 106 |
+
makeWhiter = MakeWhiter(lut_image)
|
| 107 |
+
output_image = makeWhiter.run(input_image, 10)
|
| 108 |
+
cv2.imwrite("makeWhiterCompare.png", np.hstack((input_image, output_image)))
|
beautyPlugin/ThinFace.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
@author: cuny
|
| 3 |
+
@file: ThinFace.py
|
| 4 |
+
@time: 2022/7/2 15:50
|
| 5 |
+
@description:
|
| 6 |
+
瘦脸算法,用到了图像局部平移法
|
| 7 |
+
先使用人脸关键点检测,然后再使用图像局部平移法
|
| 8 |
+
需要注意的是,这部分不会包含dlib人脸关键点检测,因为考虑到模型载入的问题
|
| 9 |
+
"""
|
| 10 |
+
import cv2
|
| 11 |
+
import math
|
| 12 |
+
import numpy as np
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class TranslationWarp(object):
|
| 16 |
+
"""
|
| 17 |
+
本类包含瘦脸算法,由于瘦脸算法包含了很多个版本,所以以类的方式呈现
|
| 18 |
+
前两个算法没什么好讲的,网上资料很多
|
| 19 |
+
第三个采用numpy内部的自定义函数处理,在处理速度上有一些提升
|
| 20 |
+
最后采用cv2.map算法,处理速度大幅度提升
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
# 瘦脸
|
| 24 |
+
@staticmethod
|
| 25 |
+
def localTranslationWarp(srcImg, startX, startY, endX, endY, radius):
|
| 26 |
+
# 双线性插值法
|
| 27 |
+
def BilinearInsert(src, ux, uy):
|
| 28 |
+
w, h, c = src.shape
|
| 29 |
+
if c == 3:
|
| 30 |
+
x1 = int(ux)
|
| 31 |
+
x2 = x1 + 1
|
| 32 |
+
y1 = int(uy)
|
| 33 |
+
y2 = y1 + 1
|
| 34 |
+
part1 = src[y1, x1].astype(np.float64) * (float(x2) - ux) * (float(y2) - uy)
|
| 35 |
+
part2 = src[y1, x2].astype(np.float64) * (ux - float(x1)) * (float(y2) - uy)
|
| 36 |
+
part3 = src[y2, x1].astype(np.float64) * (float(x2) - ux) * (uy - float(y1))
|
| 37 |
+
part4 = src[y2, x2].astype(np.float64) * (ux - float(x1)) * (uy - float(y1))
|
| 38 |
+
insertValue = part1 + part2 + part3 + part4
|
| 39 |
+
return insertValue.astype(np.int8)
|
| 40 |
+
|
| 41 |
+
ddradius = float(radius * radius) # 圆的半径
|
| 42 |
+
copyImg = srcImg.copy() # copy后的图像矩阵
|
| 43 |
+
# 计算公式中的|m-c|^2
|
| 44 |
+
ddmc = (endX - startX) * (endX - startX) + (endY - startY) * (endY - startY)
|
| 45 |
+
H, W, C = srcImg.shape # 获取图像的形状
|
| 46 |
+
for i in range(W):
|
| 47 |
+
for j in range(H):
|
| 48 |
+
# # 计算该点是否在形变圆的范围之内
|
| 49 |
+
# # 优化,第一步,直接判断是会在(startX,startY)的矩阵框中
|
| 50 |
+
if math.fabs(i - startX) > radius and math.fabs(j - startY) > radius:
|
| 51 |
+
continue
|
| 52 |
+
distance = (i - startX) * (i - startX) + (j - startY) * (j - startY)
|
| 53 |
+
if distance < ddradius:
|
| 54 |
+
# 计算出(i,j)坐标的原坐标
|
| 55 |
+
# 计算公式中右边平方号里的部分
|
| 56 |
+
ratio = (ddradius - distance) / (ddradius - distance + ddmc)
|
| 57 |
+
ratio = ratio * ratio
|
| 58 |
+
# 映射原位置
|
| 59 |
+
UX = i - ratio * (endX - startX)
|
| 60 |
+
UY = j - ratio * (endY - startY)
|
| 61 |
+
|
| 62 |
+
# 根据双线性插值法得到UX,UY的值
|
| 63 |
+
# start_ = time.time()
|
| 64 |
+
value = BilinearInsert(srcImg, UX, UY)
|
| 65 |
+
# print(f"双线性插值耗时;{time.time() - start_}")
|
| 66 |
+
# 改变当前 i ,j的值
|
| 67 |
+
copyImg[j, i] = value
|
| 68 |
+
return copyImg
|
| 69 |
+
|
| 70 |
+
# 瘦脸pro1, 限制了for循环的遍历次数
|
| 71 |
+
@staticmethod
|
| 72 |
+
def localTranslationWarpLimitFor(srcImg, startP: np.matrix, endP: np.matrix, radius: float):
|
| 73 |
+
startX, startY = startP[0, 0], startP[0, 1]
|
| 74 |
+
endX, endY = endP[0, 0], endP[0, 1]
|
| 75 |
+
|
| 76 |
+
# 双线性插值法
|
| 77 |
+
def BilinearInsert(src, ux, uy):
|
| 78 |
+
w, h, c = src.shape
|
| 79 |
+
if c == 3:
|
| 80 |
+
x1 = int(ux)
|
| 81 |
+
x2 = x1 + 1
|
| 82 |
+
y1 = int(uy)
|
| 83 |
+
y2 = y1 + 1
|
| 84 |
+
part1 = src[y1, x1].astype(np.float64) * (float(x2) - ux) * (float(y2) - uy)
|
| 85 |
+
part2 = src[y1, x2].astype(np.float64) * (ux - float(x1)) * (float(y2) - uy)
|
| 86 |
+
part3 = src[y2, x1].astype(np.float64) * (float(x2) - ux) * (uy - float(y1))
|
| 87 |
+
part4 = src[y2, x2].astype(np.float64) * (ux - float(x1)) * (uy - float(y1))
|
| 88 |
+
insertValue = part1 + part2 + part3 + part4
|
| 89 |
+
return insertValue.astype(np.int8)
|
| 90 |
+
|
| 91 |
+
ddradius = float(radius * radius) # 圆的半径
|
| 92 |
+
copyImg = srcImg.copy() # copy后的图像矩阵
|
| 93 |
+
# 计算公式中的|m-c|^2
|
| 94 |
+
ddmc = (endX - startX) ** 2 + (endY - startY) ** 2
|
| 95 |
+
# 计算正方形的左上角起始点
|
| 96 |
+
startTX, startTY = (startX - math.floor(radius + 1), startY - math.floor((radius + 1)))
|
| 97 |
+
# 计算正方形的右下角的结束点
|
| 98 |
+
endTX, endTY = (startX + math.floor(radius + 1), startY + math.floor((radius + 1)))
|
| 99 |
+
# 剪切srcImg
|
| 100 |
+
srcImg = srcImg[startTY: endTY + 1, startTX: endTX + 1, :]
|
| 101 |
+
# db.cv_show(srcImg)
|
| 102 |
+
# 裁剪后的图像相当于在x,y都减少了startX - math.floor(radius + 1)
|
| 103 |
+
# 原本的endX, endY在切后的坐标点
|
| 104 |
+
endX, endY = (endX - startX + math.floor(radius + 1), endY - startY + math.floor(radius + 1))
|
| 105 |
+
# 原本的startX, startY剪切后的坐标点
|
| 106 |
+
startX, startY = (math.floor(radius + 1), math.floor(radius + 1))
|
| 107 |
+
H, W, C = srcImg.shape # 获取图像的形状
|
| 108 |
+
for i in range(W):
|
| 109 |
+
for j in range(H):
|
| 110 |
+
# 计算该点是否在形变圆的范围之内
|
| 111 |
+
# 优化,第一步,直接判断是会在(startX,startY)的矩阵框中
|
| 112 |
+
# if math.fabs(i - startX) > radius and math.fabs(j - startY) > radius:
|
| 113 |
+
# continue
|
| 114 |
+
distance = (i - startX) * (i - startX) + (j - startY) * (j - startY)
|
| 115 |
+
if distance < ddradius:
|
| 116 |
+
# 计算出(i,j)坐标的原坐标
|
| 117 |
+
# 计算公式中右边平方号里的部分
|
| 118 |
+
ratio = (ddradius - distance) / (ddradius - distance + ddmc)
|
| 119 |
+
ratio = ratio * ratio
|
| 120 |
+
# 映射原位置
|
| 121 |
+
UX = i - ratio * (endX - startX)
|
| 122 |
+
UY = j - ratio * (endY - startY)
|
| 123 |
+
|
| 124 |
+
# 根据双线性插值法得到UX,UY的值
|
| 125 |
+
# start_ = time.time()
|
| 126 |
+
value = BilinearInsert(srcImg, UX, UY)
|
| 127 |
+
# print(f"双线性插值耗时;{time.time() - start_}")
|
| 128 |
+
# 改变当前 i ,j的值
|
| 129 |
+
copyImg[j + startTY, i + startTX] = value
|
| 130 |
+
return copyImg
|
| 131 |
+
|
| 132 |
+
# # 瘦脸pro2,采用了numpy自定义函数做处理
|
| 133 |
+
# def localTranslationWarpNumpy(self, srcImg, startP: np.matrix, endP: np.matrix, radius: float):
|
| 134 |
+
# startX , startY = startP[0, 0], startP[0, 1]
|
| 135 |
+
# endX, endY = endP[0, 0], endP[0, 1]
|
| 136 |
+
# ddradius = float(radius * radius) # 圆的半径
|
| 137 |
+
# copyImg = srcImg.copy() # copy后的图像矩阵
|
| 138 |
+
# # 计算公式中的|m-c|^2
|
| 139 |
+
# ddmc = (endX - startX)**2 + (endY - startY)**2
|
| 140 |
+
# # 计算正方形的左上角起始点
|
| 141 |
+
# startTX, startTY = (startX - math.floor(radius + 1), startY - math.floor((radius + 1)))
|
| 142 |
+
# # 计算正方形的右下角的结束点
|
| 143 |
+
# endTX, endTY = (startX + math.floor(radius + 1), startY + math.floor((radius + 1)))
|
| 144 |
+
# # 剪切srcImg
|
| 145 |
+
# self.thinImage = srcImg[startTY : endTY + 1, startTX : endTX + 1, :]
|
| 146 |
+
# # s = self.thinImage
|
| 147 |
+
# # db.cv_show(srcImg)
|
| 148 |
+
# # 裁剪后的图像相当于在x,y都减少了startX - math.floor(radius + 1)
|
| 149 |
+
# # 原本的endX, endY在切后的坐标点
|
| 150 |
+
# endX, endY = (endX - startX + math.floor(radius + 1), endY - startY + math.floor(radius + 1))
|
| 151 |
+
# # 原本的startX, startY剪切后的坐标点
|
| 152 |
+
# startX ,startY = (math.floor(radius + 1), math.floor(radius + 1))
|
| 153 |
+
# H, W, C = self.thinImage.shape # 获取图像的形状
|
| 154 |
+
# index_m = np.arange(H * W).reshape((H, W))
|
| 155 |
+
# triangle_ufunc = np.frompyfunc(self.process, 9, 3)
|
| 156 |
+
# # start_ = time.time()
|
| 157 |
+
# finalImgB, finalImgG, finalImgR = triangle_ufunc(index_m, self, W, ddradius, ddmc, startX, startY, endX, endY)
|
| 158 |
+
# finaleImg = np.dstack((finalImgB, finalImgG, finalImgR)).astype(np.uint8)
|
| 159 |
+
# finaleImg = np.fliplr(np.rot90(finaleImg, -1))
|
| 160 |
+
# copyImg[startTY: endTY + 1, startTX: endTX + 1, :] = finaleImg
|
| 161 |
+
# # print(f"图像处理耗时;{time.time() - start_}")
|
| 162 |
+
# # db.cv_show(copyImg)
|
| 163 |
+
# return copyImg
|
| 164 |
+
|
| 165 |
+
# 瘦脸pro3,采用opencv内置函数
|
| 166 |
+
@staticmethod
|
| 167 |
+
def localTranslationWarpFastWithStrength(srcImg, startP: np.matrix, endP: np.matrix, radius, strength: float = 100.):
|
| 168 |
+
"""
|
| 169 |
+
采用opencv内置函数
|
| 170 |
+
Args:
|
| 171 |
+
srcImg: 源图像
|
| 172 |
+
startP: 起点位置
|
| 173 |
+
endP: 终点位置
|
| 174 |
+
radius: 处理半径
|
| 175 |
+
strength: 瘦脸强度,一般取100以上
|
| 176 |
+
|
| 177 |
+
Returns:
|
| 178 |
+
|
| 179 |
+
"""
|
| 180 |
+
startX, startY = startP[0, 0], startP[0, 1]
|
| 181 |
+
endX, endY = endP[0, 0], endP[0, 1]
|
| 182 |
+
ddradius = float(radius * radius)
|
| 183 |
+
# copyImg = np.zeros(srcImg.shape, np.uint8)
|
| 184 |
+
# copyImg = srcImg.copy()
|
| 185 |
+
|
| 186 |
+
maskImg = np.zeros(srcImg.shape[:2], np.uint8)
|
| 187 |
+
cv2.circle(maskImg, (startX, startY), math.ceil(radius), (255, 255, 255), -1)
|
| 188 |
+
|
| 189 |
+
K0 = 100 / strength
|
| 190 |
+
|
| 191 |
+
# 计算公式中的|m-c|^2
|
| 192 |
+
ddmc_x = (endX - startX) * (endX - startX)
|
| 193 |
+
ddmc_y = (endY - startY) * (endY - startY)
|
| 194 |
+
H, W, C = srcImg.shape
|
| 195 |
+
|
| 196 |
+
mapX = np.vstack([np.arange(W).astype(np.float32).reshape(1, -1)] * H)
|
| 197 |
+
mapY = np.hstack([np.arange(H).astype(np.float32).reshape(-1, 1)] * W)
|
| 198 |
+
|
| 199 |
+
distance_x = (mapX - startX) * (mapX - startX)
|
| 200 |
+
distance_y = (mapY - startY) * (mapY - startY)
|
| 201 |
+
distance = distance_x + distance_y
|
| 202 |
+
K1 = np.sqrt(distance)
|
| 203 |
+
ratio_x = (ddradius - distance_x) / (ddradius - distance_x + K0 * ddmc_x)
|
| 204 |
+
ratio_y = (ddradius - distance_y) / (ddradius - distance_y + K0 * ddmc_y)
|
| 205 |
+
ratio_x = ratio_x * ratio_x
|
| 206 |
+
ratio_y = ratio_y * ratio_y
|
| 207 |
+
|
| 208 |
+
UX = mapX - ratio_x * (endX - startX) * (1 - K1 / radius)
|
| 209 |
+
UY = mapY - ratio_y * (endY - startY) * (1 - K1 / radius)
|
| 210 |
+
|
| 211 |
+
np.copyto(UX, mapX, where=maskImg == 0)
|
| 212 |
+
np.copyto(UY, mapY, where=maskImg == 0)
|
| 213 |
+
UX = UX.astype(np.float32)
|
| 214 |
+
UY = UY.astype(np.float32)
|
| 215 |
+
copyImg = cv2.remap(srcImg, UX, UY, interpolation=cv2.INTER_LINEAR)
|
| 216 |
+
return copyImg
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
def thinFace(src, landmark, place: int = 0, strength=30.):
|
| 220 |
+
"""
|
| 221 |
+
瘦脸程序接口,输入人脸关键点信息和强度,即可实现瘦脸
|
| 222 |
+
注意处理四通道图像
|
| 223 |
+
Args:
|
| 224 |
+
src: 原图
|
| 225 |
+
landmark: 关键点信息
|
| 226 |
+
place: 选择瘦脸区域,为0-4之间的值
|
| 227 |
+
strength: 瘦脸强度,输入值在0-10之间,如果小于或者等于0,则不瘦脸
|
| 228 |
+
|
| 229 |
+
Returns:
|
| 230 |
+
瘦脸后的图像
|
| 231 |
+
"""
|
| 232 |
+
strength = min(100., strength * 10.)
|
| 233 |
+
if strength <= 0.:
|
| 234 |
+
return src
|
| 235 |
+
# 也可以设置瘦脸区域
|
| 236 |
+
place = max(0, min(4, int(place)))
|
| 237 |
+
left_landmark = landmark[4 + place]
|
| 238 |
+
left_landmark_down = landmark[6 + place]
|
| 239 |
+
right_landmark = landmark[13 + place]
|
| 240 |
+
right_landmark_down = landmark[15 + place]
|
| 241 |
+
endPt = landmark[58]
|
| 242 |
+
# 计算第4个点到第6个点的距离作为瘦脸距离
|
| 243 |
+
r_left = math.sqrt(
|
| 244 |
+
(left_landmark[0, 0] - left_landmark_down[0, 0]) ** 2 +
|
| 245 |
+
(left_landmark[0, 1] - left_landmark_down[0, 1]) ** 2
|
| 246 |
+
)
|
| 247 |
+
|
| 248 |
+
# 计算第14个点到第16个点的距离作为瘦脸距离
|
| 249 |
+
r_right = math.sqrt((right_landmark[0, 0] - right_landmark_down[0, 0]) ** 2 +
|
| 250 |
+
(right_landmark[0, 1] - right_landmark_down[0, 1]) ** 2)
|
| 251 |
+
# 瘦左边脸
|
| 252 |
+
thin_image = TranslationWarp.localTranslationWarpFastWithStrength(src, left_landmark[0], endPt[0], r_left, strength)
|
| 253 |
+
# 瘦右边脸
|
| 254 |
+
thin_image = TranslationWarp.localTranslationWarpFastWithStrength(thin_image, right_landmark[0], endPt[0], r_right, strength)
|
| 255 |
+
return thin_image
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
if __name__ == "__main__":
|
| 259 |
+
import os
|
| 260 |
+
from hycv.FaceDetection68.faceDetection68 import FaceDetection68
|
| 261 |
+
local_file = os.path.dirname(__file__)
|
| 262 |
+
PREDICTOR_PATH = f"{local_file}/weights/shape_predictor_68_face_landmarks.dat" # 关键点检测模型路径
|
| 263 |
+
fd68 = FaceDetection68(model_path=PREDICTOR_PATH)
|
| 264 |
+
input_image = cv2.imread("test_image/4.jpg", -1)
|
| 265 |
+
_, landmark_, _ = fd68.facePoints(input_image)
|
| 266 |
+
output_image = thinFace(input_image, landmark_, strength=30.2)
|
| 267 |
+
cv2.imwrite("thinFaceCompare.png", np.hstack((input_image, output_image)))
|
beautyPlugin/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .MakeBeautiful import makeBeautiful
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
|
beautyPlugin/lut_image/1.png
ADDED

|
beautyPlugin/lut_image/3.png
ADDED

|
beautyPlugin/lut_image/lutOrigin.png
ADDED

|
deploy_api.py
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fastapi import FastAPI, UploadFile, Form
|
| 2 |
+
import onnxruntime
|
| 3 |
+
from src.face_judgement_align import IDphotos_create
|
| 4 |
+
from src.layoutCreate import generate_layout_photo, generate_layout_image
|
| 5 |
+
from hivisionai.hycv.vision import add_background
|
| 6 |
+
import base64
|
| 7 |
+
import numpy as np
|
| 8 |
+
import cv2
|
| 9 |
+
import ast
|
| 10 |
+
|
| 11 |
+
app = FastAPI()
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
# 将图像转换为Base64编码
|
| 15 |
+
|
| 16 |
+
def numpy_2_base64(img: np.ndarray):
|
| 17 |
+
retval, buffer = cv2.imencode('.png', img)
|
| 18 |
+
base64_image = base64.b64encode(buffer).decode('utf-8')
|
| 19 |
+
|
| 20 |
+
return base64_image
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
# 证件照智能制作接口
|
| 24 |
+
@app.post("/idphoto")
|
| 25 |
+
async def idphoto_inference(input_image: UploadFile,
|
| 26 |
+
size: str = Form(...),
|
| 27 |
+
head_measure_ratio=0.2,
|
| 28 |
+
head_height_ratio=0.45,
|
| 29 |
+
top_distance_max=0.12,
|
| 30 |
+
top_distance_min=0.10):
|
| 31 |
+
image_bytes = await input_image.read()
|
| 32 |
+
nparr = np.frombuffer(image_bytes, np.uint8)
|
| 33 |
+
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
|
| 34 |
+
|
| 35 |
+
# 将字符串转为元组
|
| 36 |
+
size = ast.literal_eval(size)
|
| 37 |
+
|
| 38 |
+
result_image_hd, result_image_standard, typography_arr, typography_rotate, \
|
| 39 |
+
_, _, _, _, status = IDphotos_create(img,
|
| 40 |
+
size=size,
|
| 41 |
+
head_measure_ratio=head_measure_ratio,
|
| 42 |
+
head_height_ratio=head_height_ratio,
|
| 43 |
+
align=False,
|
| 44 |
+
beauty=False,
|
| 45 |
+
fd68=None,
|
| 46 |
+
human_sess=sess,
|
| 47 |
+
IS_DEBUG=False,
|
| 48 |
+
top_distance_max=top_distance_max,
|
| 49 |
+
top_distance_min=top_distance_min)
|
| 50 |
+
|
| 51 |
+
# 如果检测到人脸数量不等于1(照片无人脸 or 多人脸)
|
| 52 |
+
if status == 0:
|
| 53 |
+
result_messgae = {
|
| 54 |
+
"status": False
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
# 如果检测到人脸数量等于1, 则返回标准证和高清照结果(png 4通道图像)
|
| 58 |
+
else:
|
| 59 |
+
result_messgae = {
|
| 60 |
+
"status": True,
|
| 61 |
+
"img_output_standard": numpy_2_base64(result_image_standard),
|
| 62 |
+
"img_output_standard_hd": numpy_2_base64(result_image_hd),
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
return result_messgae
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
# 透明图像添加纯色背景接口
|
| 69 |
+
@app.post("/add_background")
|
| 70 |
+
async def photo_add_background(input_image: UploadFile,
|
| 71 |
+
color: str = Form(...)):
|
| 72 |
+
|
| 73 |
+
# 读取图像
|
| 74 |
+
image_bytes = await input_image.read()
|
| 75 |
+
nparr = np.frombuffer(image_bytes, np.uint8)
|
| 76 |
+
img = cv2.imdecode(nparr, cv2.IMREAD_UNCHANGED)
|
| 77 |
+
|
| 78 |
+
# 将字符串转为元组
|
| 79 |
+
color = ast.literal_eval(color)
|
| 80 |
+
# 将元祖的0和2号数字交换
|
| 81 |
+
color = (color[2], color[1], color[0])
|
| 82 |
+
|
| 83 |
+
# try:
|
| 84 |
+
result_messgae = {
|
| 85 |
+
"status": True,
|
| 86 |
+
"image": numpy_2_base64(add_background(img, bgr=color)),
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
# except Exception as e:
|
| 90 |
+
# print(e)
|
| 91 |
+
# result_messgae = {
|
| 92 |
+
# "status": False,
|
| 93 |
+
# "error": e
|
| 94 |
+
# }
|
| 95 |
+
|
| 96 |
+
return result_messgae
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
# 六寸排版照生成接口
|
| 100 |
+
@app.post("/generate_layout_photos")
|
| 101 |
+
async def generate_layout_photos(input_image: UploadFile, size: str = Form(...)):
|
| 102 |
+
try:
|
| 103 |
+
image_bytes = await input_image.read()
|
| 104 |
+
nparr = np.frombuffer(image_bytes, np.uint8)
|
| 105 |
+
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
|
| 106 |
+
|
| 107 |
+
size = ast.literal_eval(size)
|
| 108 |
+
|
| 109 |
+
typography_arr, typography_rotate = generate_layout_photo(input_height=size[0],
|
| 110 |
+
input_width=size[1])
|
| 111 |
+
|
| 112 |
+
result_layout_image = generate_layout_image(img, typography_arr,
|
| 113 |
+
typography_rotate,
|
| 114 |
+
height=size[0],
|
| 115 |
+
width=size[1])
|
| 116 |
+
|
| 117 |
+
result_messgae = {
|
| 118 |
+
"status": True,
|
| 119 |
+
"image": numpy_2_base64(result_layout_image),
|
| 120 |
+
}
|
| 121 |
+
|
| 122 |
+
except Exception as e:
|
| 123 |
+
result_messgae = {
|
| 124 |
+
"status": False,
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
return result_messgae
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
if __name__ == "__main__":
|
| 131 |
+
import uvicorn
|
| 132 |
+
|
| 133 |
+
# 加载权重文件
|
| 134 |
+
HY_HUMAN_MATTING_WEIGHTS_PATH = "./hivision_modnet.onnx"
|
| 135 |
+
sess = onnxruntime.InferenceSession(HY_HUMAN_MATTING_WEIGHTS_PATH)
|
| 136 |
+
|
| 137 |
+
# 在8080端口运行推理服务
|
| 138 |
+
uvicorn.run(app, host="0.0.0.0", port=8080)
|
hivision_modnet.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7e0cb9a2a841b426dd0daf1a788ec398dab059bc039041d62b15636c0783bc56
|
| 3 |
+
size 25888609
|
hivisionai/__init__.py
ADDED
|
File without changes
|
hivisionai/app.py
ADDED
|
@@ -0,0 +1,452 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
@Time : 2022/8/27 14:17
|
| 5 |
+
@Author : cuny
|
| 6 |
+
@File : app.py
|
| 7 |
+
@Software : PyCharm
|
| 8 |
+
@Introduce:
|
| 9 |
+
查看包版本等一系列操作
|
| 10 |
+
"""
|
| 11 |
+
import os
|
| 12 |
+
import sys
|
| 13 |
+
import json
|
| 14 |
+
import shutil
|
| 15 |
+
import zipfile
|
| 16 |
+
import requests
|
| 17 |
+
from argparse import ArgumentParser
|
| 18 |
+
from importlib.metadata import version
|
| 19 |
+
try: # 加上这个try的原因在于本地环境和云函数端的import形式有所不同
|
| 20 |
+
from qcloud_cos import CosConfig
|
| 21 |
+
from qcloud_cos import CosS3Client
|
| 22 |
+
except ImportError:
|
| 23 |
+
try:
|
| 24 |
+
from qcloud_cos_v5 import CosConfig
|
| 25 |
+
from qcloud_cos_v5 import CosS3Client
|
| 26 |
+
from qcloud_cos.cos_exception import CosServiceError
|
| 27 |
+
except ImportError:
|
| 28 |
+
raise ImportError("请下载腾讯云COS相关代码包:pip install cos-python-sdk-v5")
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class HivisionaiParams(object):
|
| 32 |
+
"""
|
| 33 |
+
定义一些基本常量
|
| 34 |
+
"""
|
| 35 |
+
# 文件所在路径
|
| 36 |
+
# 包名称
|
| 37 |
+
package_name = "HY-sdk"
|
| 38 |
+
# 腾讯云相关变量
|
| 39 |
+
region = "ap-beijing"
|
| 40 |
+
zip_key = "HY-sdk/" # zip存储的云端文件夹路径,这里改了publish.yml也需要更改
|
| 41 |
+
# 云端用户配置,如果在cloud_config_save不存在,就需要下载此文件
|
| 42 |
+
user_url = "https://hy-sdk-config-1305323352.cos.ap-beijing.myqcloud.com/sdk-user/user_config.json"
|
| 43 |
+
bucket = "cloud-public-static-1306602019"
|
| 44 |
+
# 压缩包类型
|
| 45 |
+
file_format = ".zip"
|
| 46 |
+
# 下载路径(.hivisionai文件夹路径)
|
| 47 |
+
download_path = os.path.expandvars('$HOME')
|
| 48 |
+
# zip文件、zip解压缩文件的存放路径
|
| 49 |
+
save_folder = f"{os.path.expandvars('$HOME')}/.hivisionai/sdk"
|
| 50 |
+
# 腾讯云配置文件存放路径
|
| 51 |
+
cloud_config_save = f"{os.path.expandvars('$HOME')}/.hivisionai/user_config.json"
|
| 52 |
+
# 项目路径
|
| 53 |
+
hivisionai_path = os.path.dirname(os.path.dirname(__file__))
|
| 54 |
+
# 使用hivisionai的路径
|
| 55 |
+
getcwd = os.getcwd()
|
| 56 |
+
# HY-func的依赖配置
|
| 57 |
+
# 每个依赖会包含三个参数,保存路径(save_path,相对于HY_func的路径)、下载url(url)
|
| 58 |
+
functionDependence = {
|
| 59 |
+
"configs": [
|
| 60 |
+
# --------- 配置文件部分
|
| 61 |
+
# _lib
|
| 62 |
+
{
|
| 63 |
+
"url": "https://hy-sdk-config-1305323352.cos.ap-beijing.myqcloud.com/hy-func/_lib/config/aliyun-human-matting-api.json",
|
| 64 |
+
"save_path": "_lib/config/aliyun-human-matting-api.json"
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
"url": "https://hy-sdk-config-1305323352.cos.ap-beijing.myqcloud.com/hy-func/_lib/config/megvii-face-plus-api.json",
|
| 68 |
+
"save_path": "_lib/config/megvii-face-plus-api.json"
|
| 69 |
+
},
|
| 70 |
+
{
|
| 71 |
+
"url": "https://hy-sdk-config-1305323352.cos.ap-beijing.myqcloud.com/hy-func/_lib/config/volcano-face-change-api.json",
|
| 72 |
+
"save_path": "_lib/config/volcano-face-change-api.json"
|
| 73 |
+
},
|
| 74 |
+
# _service
|
| 75 |
+
{
|
| 76 |
+
"url": "https://hy-sdk-config-1305323352.cos.ap-beijing.myqcloud.com/hy-func/_service/config/func_error_conf.json",
|
| 77 |
+
"save_path": "_service/utils/config/func_error_conf.json"
|
| 78 |
+
},
|
| 79 |
+
{
|
| 80 |
+
"url": "https://hy-sdk-config-1305323352.cos.ap-beijing.myqcloud.com/hy-func/_service/config/service_config.json",
|
| 81 |
+
"save_path": "_service/utils/config/service_config.json"
|
| 82 |
+
},
|
| 83 |
+
# --------- 模型部分
|
| 84 |
+
# 模型部分存储在Notion文档当中
|
| 85 |
+
# https://www.notion.so/HY-func-cc6cc41ba6e94b36b8fa5f5d67d1683f
|
| 86 |
+
],
|
| 87 |
+
"weights": "https://www.notion.so/HY-func-cc6cc41ba6e94b36b8fa5f5d67d1683f"
|
| 88 |
+
}
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
class HivisionaiUtils(object):
|
| 92 |
+
"""
|
| 93 |
+
本类为一些基本工具类,包含代码复用相关内容
|
| 94 |
+
"""
|
| 95 |
+
@staticmethod
|
| 96 |
+
def get_client():
|
| 97 |
+
"""获取cos客户端对象"""
|
| 98 |
+
def get_secret():
|
| 99 |
+
# 首先判断cloud_config_save下是否存在
|
| 100 |
+
if not os.path.exists(HivisionaiParams.cloud_config_save):
|
| 101 |
+
print("Downloading user_config...")
|
| 102 |
+
resp = requests.get(HivisionaiParams.user_url)
|
| 103 |
+
open(HivisionaiParams.cloud_config_save, "wb").write(resp.content)
|
| 104 |
+
config = json.load(open(HivisionaiParams.cloud_config_save, "r"))
|
| 105 |
+
return config["secret_id"], config["secret_key"]
|
| 106 |
+
# todo 接入HY-Auth-Sync
|
| 107 |
+
secret_id, secret_key = get_secret()
|
| 108 |
+
return CosS3Client(CosConfig(Region=HivisionaiParams.region, Secret_id=secret_id, Secret_key=secret_key))
|
| 109 |
+
|
| 110 |
+
def get_all_versions(self):
|
| 111 |
+
"""获取云端的所有版本号"""
|
| 112 |
+
def getAllVersion_base():
|
| 113 |
+
"""
|
| 114 |
+
返回cos存储桶内部的某个文件夹的内部名称
|
| 115 |
+
ps:如果需要修改默认的存储桶配置,请在代码运行的时候加入代码 s.bucket = 存储桶名称 (s是对象实例)
|
| 116 |
+
返回的内容存储在response["Content"],不过返回的数据大小是有限制的,具体内容还是请看官方文档。
|
| 117 |
+
Returns:
|
| 118 |
+
[版本列表]
|
| 119 |
+
"""
|
| 120 |
+
resp = client.list_objects(
|
| 121 |
+
Bucket=HivisionaiParams.bucket,
|
| 122 |
+
Prefix=HivisionaiParams.zip_key,
|
| 123 |
+
Marker=marker
|
| 124 |
+
)
|
| 125 |
+
versions_list.extend([x["Key"].split("/")[-1].split(HivisionaiParams.file_format)[0] for x in resp["Contents"] if int(x["Size"]) > 0])
|
| 126 |
+
if resp['IsTruncated'] == 'false': # 接下来没有数据了,就退出
|
| 127 |
+
return ""
|
| 128 |
+
else:
|
| 129 |
+
return resp['NextMarker']
|
| 130 |
+
client = self.get_client()
|
| 131 |
+
marker = ""
|
| 132 |
+
versions_list = []
|
| 133 |
+
while True: # 轮询
|
| 134 |
+
try:
|
| 135 |
+
marker = getAllVersion_base()
|
| 136 |
+
except KeyError as e:
|
| 137 |
+
print(e)
|
| 138 |
+
raise
|
| 139 |
+
if len(marker) == 0: # 没有数据了
|
| 140 |
+
break
|
| 141 |
+
return versions_list
|
| 142 |
+
|
| 143 |
+
def get_newest_version(self):
|
| 144 |
+
"""获取最新的版本号"""
|
| 145 |
+
versions_list = self.get_all_versions()
|
| 146 |
+
# reverse=True,降序
|
| 147 |
+
versions_list.sort(key=lambda x: int(x.split(".")[-1]), reverse=True)
|
| 148 |
+
versions_list.sort(key=lambda x: int(x.split(".")[-2]), reverse=True)
|
| 149 |
+
versions_list.sort(key=lambda x: int(x.split(".")[-3]), reverse=True)
|
| 150 |
+
return versions_list[0]
|
| 151 |
+
|
| 152 |
+
def download_version(self, v):
|
| 153 |
+
"""
|
| 154 |
+
在存储桶中下载文件,将下载好的文件解压至本地
|
| 155 |
+
Args:
|
| 156 |
+
v: 版本号,x.x.x
|
| 157 |
+
|
| 158 |
+
Returns:
|
| 159 |
+
None
|
| 160 |
+
"""
|
| 161 |
+
file_name = v + HivisionaiParams.file_format
|
| 162 |
+
client = self.get_client()
|
| 163 |
+
print(f"Download to {HivisionaiParams.save_folder}...")
|
| 164 |
+
try:
|
| 165 |
+
resp = client.get_object(HivisionaiParams.bucket, HivisionaiParams.zip_key + "/" + file_name)
|
| 166 |
+
contents = resp["Body"].get_raw_stream().read()
|
| 167 |
+
except CosServiceError:
|
| 168 |
+
print(f"[{file_name}.zip] does not exist, please check your version!")
|
| 169 |
+
sys.exit()
|
| 170 |
+
if not os.path.exists(HivisionaiParams.save_folder):
|
| 171 |
+
os.makedirs(HivisionaiParams.save_folder)
|
| 172 |
+
open(os.path.join(HivisionaiParams.save_folder, file_name), "wb").write(contents)
|
| 173 |
+
print("Download success!")
|
| 174 |
+
|
| 175 |
+
@staticmethod
|
| 176 |
+
def download_dependence(path=None):
|
| 177 |
+
"""
|
| 178 |
+
一键下载HY-sdk所需要的所有依赖,需要注意的是,本方法必须在运行pip install之后使用(运行完pip install之后才会出现hivisionai文件夹)
|
| 179 |
+
Args:
|
| 180 |
+
path: 文件路径,精确到hivisionai文件夹的上一个目录,如果为None,则默认下载到python环境下hivisionai安装的目录
|
| 181 |
+
|
| 182 |
+
Returns:
|
| 183 |
+
下载相应内容到指定位置
|
| 184 |
+
"""
|
| 185 |
+
# print("指定的下载路径:", path) # 此时在path路径下必然存在一个hivisionai文件夹
|
| 186 |
+
# print("系统安装的hivisionai库的路径:", HivisionaiParams.hivisionai_path)
|
| 187 |
+
print("Dependence downloading...")
|
| 188 |
+
if path is None:
|
| 189 |
+
path = HivisionaiParams.hivisionai_path
|
| 190 |
+
# ----------------下载mtcnn模型文件
|
| 191 |
+
mtcnn_path = os.path.join(path, "hivisionai/hycv/mtcnn_onnx/weights")
|
| 192 |
+
base_url = "https://linimages.oss-cn-beijing.aliyuncs.com/"
|
| 193 |
+
onnx_files = ["pnet.onnx", "rnet.onnx", "onet.onnx"]
|
| 194 |
+
print(f"Downloading mtcnn model in {mtcnn_path}")
|
| 195 |
+
if not os.path.exists(mtcnn_path):
|
| 196 |
+
os.mkdir(mtcnn_path)
|
| 197 |
+
for onnx_file in onnx_files:
|
| 198 |
+
if not os.path.exists(os.path.join(mtcnn_path, onnx_file)):
|
| 199 |
+
# download onnx model
|
| 200 |
+
onnx_url = base_url + onnx_file
|
| 201 |
+
print("Downloading Onnx Model in:", onnx_url)
|
| 202 |
+
r = requests.get(onnx_url, stream=True)
|
| 203 |
+
if r.status_code == 200:
|
| 204 |
+
open(os.path.join(mtcnn_path, onnx_file), 'wb').write(r.content) # 将内容写入文件
|
| 205 |
+
print(f"Download finished -- {onnx_file}")
|
| 206 |
+
del r
|
| 207 |
+
# ----------------
|
| 208 |
+
print("Dependence download finished...")
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class HivisionaiApps(object):
|
| 212 |
+
"""
|
| 213 |
+
本类为app对外暴露的接口,为了代码规整性,这里使用类来对暴露接口进行调整
|
| 214 |
+
"""
|
| 215 |
+
@staticmethod
|
| 216 |
+
def show_cloud_version():
|
| 217 |
+
"""查看在cos中的所有HY-sdk版本"""
|
| 218 |
+
print("Connect to COS...")
|
| 219 |
+
versions_list = hivisionai_utils.get_all_versions()
|
| 220 |
+
# reverse=True,降序
|
| 221 |
+
versions_list.sort(key=lambda x: int(x.split(".")[-1]), reverse=True)
|
| 222 |
+
versions_list.sort(key=lambda x: int(x.split(".")[-2]), reverse=True)
|
| 223 |
+
versions_list.sort(key=lambda x: int(x.split(".")[-3]), reverse=True)
|
| 224 |
+
if len(versions_list) == 0:
|
| 225 |
+
print("There is no version currently, please release it first!")
|
| 226 |
+
sys.exit()
|
| 227 |
+
versions = "The currently existing versions (Keep 10): \n"
|
| 228 |
+
for i, v in enumerate(versions_list):
|
| 229 |
+
versions += str(v) + " "
|
| 230 |
+
if i == 9:
|
| 231 |
+
break
|
| 232 |
+
print(versions)
|
| 233 |
+
|
| 234 |
+
@staticmethod
|
| 235 |
+
def upgrade(v: str, enforce: bool = False, save_cached: bool = False):
|
| 236 |
+
"""
|
| 237 |
+
自动升级HY-sdk到指定版本
|
| 238 |
+
Args:
|
| 239 |
+
v: 指定的版本号,格式为x.x.x
|
| 240 |
+
enforce: 是否需要强制执行更新命令
|
| 241 |
+
save_cached: 是否保存下载的wheel文件,默认为否
|
| 242 |
+
Returns:
|
| 243 |
+
None
|
| 244 |
+
"""
|
| 245 |
+
def check_format():
|
| 246 |
+
# noinspection PyBroadException
|
| 247 |
+
try:
|
| 248 |
+
major, minor, patch = v.split(".")
|
| 249 |
+
int(major)
|
| 250 |
+
int(minor)
|
| 251 |
+
int(patch)
|
| 252 |
+
except Exception as e:
|
| 253 |
+
print(f"Illegal version number!\n{e}")
|
| 254 |
+
pass
|
| 255 |
+
print("Upgrading, please wait a moment...")
|
| 256 |
+
if v == "-1":
|
| 257 |
+
v = hivisionai_utils.get_newest_version()
|
| 258 |
+
# 检查format的格式
|
| 259 |
+
check_format()
|
| 260 |
+
if v == version(HivisionaiParams.package_name) and not enforce:
|
| 261 |
+
print(f"Current version: {v} already exists, skip installation.")
|
| 262 |
+
sys.exit()
|
| 263 |
+
hivisionai_utils.download_version(v)
|
| 264 |
+
# 下载完毕(下载至save_folder),解压文件
|
| 265 |
+
target_zip = os.path.join(HivisionaiParams.save_folder, f"{v}.zip")
|
| 266 |
+
assert zipfile.is_zipfile(target_zip), "Decompression failed, and the target was not a zip file."
|
| 267 |
+
new_dir = target_zip.replace('.zip', '') # 解压的文件名
|
| 268 |
+
if os.path.exists(new_dir): # 判断文件夹是否存在
|
| 269 |
+
shutil.rmtree(new_dir)
|
| 270 |
+
os.mkdir(new_dir) # 新建文件夹
|
| 271 |
+
f = zipfile.ZipFile(target_zip)
|
| 272 |
+
f.extractall(new_dir) # 提取zip文件
|
| 273 |
+
print("Decompressed, begin to install...")
|
| 274 |
+
os.system(f'pip3 install {os.path.join(new_dir, "**.whl")}')
|
| 275 |
+
# 开始自动下载必要的模型依赖
|
| 276 |
+
hivisionai_utils.download_dependence()
|
| 277 |
+
# 安装完毕,如果save_cached为真,删除"$HOME/.hivisionai/sdk"内部的所有文件元素
|
| 278 |
+
if save_cached is True:
|
| 279 |
+
os.system(f'rm -rf {HivisionaiParams.save_folder}/**')
|
| 280 |
+
|
| 281 |
+
@staticmethod
|
| 282 |
+
def export(path):
|
| 283 |
+
"""
|
| 284 |
+
输出最新版本的文件到命令运行的path目录
|
| 285 |
+
Args:
|
| 286 |
+
path: 用户输入的路径
|
| 287 |
+
|
| 288 |
+
Returns:
|
| 289 |
+
输出最新的hivisionai到path目录
|
| 290 |
+
"""
|
| 291 |
+
# print(f"当前路径: {os.path.join(HivisionaiParams.getcwd, path)}")
|
| 292 |
+
# print(f"文件路径: {os.path.dirname(__file__)}")
|
| 293 |
+
export_path = os.path.join(HivisionaiParams.getcwd, path)
|
| 294 |
+
# 判断输出路径存不存在,如果不存在,就报错
|
| 295 |
+
assert os.path.exists(export_path), f"{export_path} dose not Exists!"
|
| 296 |
+
v = hivisionai_utils.get_newest_version()
|
| 297 |
+
# 下载文件到.hivisionai/sdk当中
|
| 298 |
+
hivisionai_utils.download_version(v)
|
| 299 |
+
# 下载完毕(下载至save_folder),解压文件
|
| 300 |
+
target_zip = os.path.join(HivisionaiParams.save_folder, f"{v}.zip")
|
| 301 |
+
assert zipfile.is_zipfile(target_zip), "Decompression failed, and the target was not a zip file."
|
| 302 |
+
new_dir = os.path.basename(target_zip.replace('.zip', '')) # 解压的文件名
|
| 303 |
+
new_dir = os.path.join(export_path, new_dir) # 解压的文件路径
|
| 304 |
+
if os.path.exists(new_dir): # 判断文件夹是否存在
|
| 305 |
+
shutil.rmtree(new_dir)
|
| 306 |
+
os.mkdir(new_dir) # 新建文件夹
|
| 307 |
+
f = zipfile.ZipFile(target_zip)
|
| 308 |
+
f.extractall(new_dir) # 提取zip文件
|
| 309 |
+
print("Decompressed, begin to export...")
|
| 310 |
+
# 强制删除bin/hivisionai和hivisionai/以及HY_sdk-**
|
| 311 |
+
bin_path = os.path.join(export_path, "bin")
|
| 312 |
+
hivisionai_path = os.path.join(export_path, "hivisionai")
|
| 313 |
+
sdk_path = os.path.join(export_path, "HY_sdk-**")
|
| 314 |
+
os.system(f"rm -rf {bin_path} {hivisionai_path} {sdk_path}")
|
| 315 |
+
# 删除完毕,开始export
|
| 316 |
+
os.system(f'pip3 install {os.path.join(new_dir, "**.whl")} -t {export_path}')
|
| 317 |
+
hivisionai_utils.download_dependence(export_path)
|
| 318 |
+
# 将下载下来的文件夹删除
|
| 319 |
+
os.system(f'rm -rf {target_zip} && rm -rf {new_dir}')
|
| 320 |
+
print("Done.")
|
| 321 |
+
|
| 322 |
+
@staticmethod
|
| 323 |
+
def hy_func_init(force):
|
| 324 |
+
"""
|
| 325 |
+
在HY-func目录下使用hivisionai --init,可以自动将需要的依赖下载到指定位置
|
| 326 |
+
不过对于比较大的模型——修复模型而言,需要手动下载
|
| 327 |
+
Args:
|
| 328 |
+
force: 如果force为True,则会强制重新下载所有的内容,包括修复模型这种比较大的模型
|
| 329 |
+
Returns:
|
| 330 |
+
程序执行完毕,会将一些必要的依赖也下载完毕
|
| 331 |
+
"""
|
| 332 |
+
cwd = HivisionaiParams.getcwd
|
| 333 |
+
# 判断当前文件夹是否是HY-func
|
| 334 |
+
dirName = os.path.basename(cwd)
|
| 335 |
+
assert dirName == "HY-func", "请在正确的文件目录下初始化HY-func!"
|
| 336 |
+
# 需要下载的内容会存放在HivisionaiParams的functionDependence���量下
|
| 337 |
+
functionDependence = HivisionaiParams.functionDependence
|
| 338 |
+
# 下载配置文件
|
| 339 |
+
configs = functionDependence["configs"]
|
| 340 |
+
print("正在下载配置文件...")
|
| 341 |
+
for config in configs:
|
| 342 |
+
if not force and os.path.exists(config['save_path']):
|
| 343 |
+
print(f"[pass]: {os.path.basename(config['url'])}")
|
| 344 |
+
continue
|
| 345 |
+
print(f"[Download]: {config['url']}")
|
| 346 |
+
resp = requests.get(config['url'])
|
| 347 |
+
# json文件存储在text区域,但是其他的不一定
|
| 348 |
+
open(os.path.join(cwd, config['save_path']), 'w').write(resp.text)
|
| 349 |
+
# 其他文件,提示访问notion文档
|
| 350 |
+
print(f"[NOTICE]: 一切准备就绪,请访问下面的文档下载剩下的模型文件:\n{functionDependence['weights']}")
|
| 351 |
+
|
| 352 |
+
@staticmethod
|
| 353 |
+
def hy_func_deploy(functionName: str = None, functionPath: str = None):
|
| 354 |
+
"""
|
| 355 |
+
在HY-func目录下使用此命令,并且随附功能函数的名称,就可以将HY-func的部署版放到桌面上
|
| 356 |
+
但是需要注意的是,本方式不适合修复功能使用,修复功能依旧需要手动制作镜像
|
| 357 |
+
Args:
|
| 358 |
+
functionName: 功能函数名称
|
| 359 |
+
functionPath: 需要注册的HY-func路径
|
| 360 |
+
|
| 361 |
+
Returns:
|
| 362 |
+
程序执行完毕,桌面会出现一个同名文件夹
|
| 363 |
+
"""
|
| 364 |
+
# 为了代码撰写的方便,这里仅仅把模型文件删除,其余配置文件保留
|
| 365 |
+
# 为了实现在任意位置输入hivisionai --deploy funcName都能成功,在使用前需要在.hivisionai/user_config.json中注册
|
| 366 |
+
# print(functionName, functionPath)
|
| 367 |
+
if functionPath is not None:
|
| 368 |
+
# 更新/添加路径
|
| 369 |
+
# functionPath为相对于使用路径的路径
|
| 370 |
+
assert os.path.basename(functionPath) == "HY-func", "所指向路径非HY-func!"
|
| 371 |
+
func_path = os.path.join(HivisionaiParams.getcwd, functionPath)
|
| 372 |
+
assert os.path.join(func_path), f"路径不存在: {func_path}"
|
| 373 |
+
# functionPath的路径写到user_config当中
|
| 374 |
+
user_config = json.load(open(HivisionaiParams.cloud_config_save, 'rb'))
|
| 375 |
+
user_config["func_path"] = func_path
|
| 376 |
+
open(HivisionaiParams.cloud_config_save, 'w').write(json.dumps(user_config))
|
| 377 |
+
print("HY-func全局路径保存成功!")
|
| 378 |
+
try:
|
| 379 |
+
user_config = json.load(open(HivisionaiParams.cloud_config_save, 'rb'))
|
| 380 |
+
func_path = user_config['func_path']
|
| 381 |
+
except KeyError:
|
| 382 |
+
return print("请先使用-p命令注册全局HY-func路径!")
|
| 383 |
+
# 此时func_path必然存在
|
| 384 |
+
# print(os.listdir(func_path))
|
| 385 |
+
assert functionName in os.listdir(func_path), functionName + "功能不存在!"
|
| 386 |
+
func_path_deploy = os.path.join(func_path, functionName)
|
| 387 |
+
# 开始复制文件到指定目录
|
| 388 |
+
# 我们默认移动到Desktop目录下,如果没有此目录,需要先创建一个
|
| 389 |
+
target_dir = os.path.join(HivisionaiParams.download_path, "Desktop")
|
| 390 |
+
assert os.path.exists(target_dir), target_dir + "文件路径不存在,你需要先创建一下!"
|
| 391 |
+
# 开始移动
|
| 392 |
+
target_dir = os.path.join(target_dir, functionName)
|
| 393 |
+
print("正在复制需要部署的文件...")
|
| 394 |
+
os.system(f"rm -rf {target_dir}")
|
| 395 |
+
os.system(f'cp -rf {func_path_deploy} {target_dir}')
|
| 396 |
+
os.system(f"cp -rf {os.path.join(func_path, '_lib')} {target_dir}")
|
| 397 |
+
os.system(f"cp -rf {os.path.join(func_path, '_service')} {target_dir}")
|
| 398 |
+
# 生成最新的hivisionai
|
| 399 |
+
print("正在生成hivisionai代码包...")
|
| 400 |
+
os.system(f'hivisionai -t {target_dir}')
|
| 401 |
+
# 移动完毕,删除模型文件
|
| 402 |
+
print("移动完毕,正在删除不需要的文件...")
|
| 403 |
+
# 模型文件
|
| 404 |
+
os.system(f"rm -rf {os.path.join(target_dir, '_lib', 'weights', '**')}")
|
| 405 |
+
# hivisionai生成时的多余文件
|
| 406 |
+
os.system(f"rm -rf {os.path.join(target_dir, 'bin')} {os.path.join(target_dir, 'HY_sdk**')}")
|
| 407 |
+
print("部署文件生成成功,你可以开始部署了!")
|
| 408 |
+
|
| 409 |
+
|
| 410 |
+
hivisionai_utils = HivisionaiUtils()
|
| 411 |
+
|
| 412 |
+
|
| 413 |
+
def entry_point():
|
| 414 |
+
parser = ArgumentParser()
|
| 415 |
+
# 查看版本号
|
| 416 |
+
parser.add_argument("-v", "--version", action="store_true", help="View the current HY-sdk version, which does not represent the final cloud version.")
|
| 417 |
+
# 自动更新
|
| 418 |
+
parser.add_argument("-u", "--upgrade", nargs='?', const="-1", type=str, help="Automatically update HY-sdk to the latest version")
|
| 419 |
+
# 查找云端的HY-sdk版本
|
| 420 |
+
parser.add_argument("-l", "--list", action="store_true", help="Find HY-sdk versions of the cloud, and keep up to ten")
|
| 421 |
+
# 下载云端的版本到本地路径
|
| 422 |
+
parser.add_argument("-t", "--export", nargs='?', const="./", help="Add a path parameter to automatically download the latest version of sdk to this path. If there are no parameters, the default is the current path")
|
| 423 |
+
# 强制更新附带参数,当一个功能需要强制执行一遍的时候,需要附带此参数
|
| 424 |
+
parser.add_argument("-f", "--force", action="store_true", help="Enforcement of other functions, execution of a single parameter is meaningless")
|
| 425 |
+
# 初始化HY-func
|
| 426 |
+
parser.add_argument("--init", action="store_true", help="Initialization HY-func")
|
| 427 |
+
# 部署HY-func
|
| 428 |
+
parser.add_argument("-d", "--deploy", nargs='?', const="-1", type=str, help="Deploy HY-func")
|
| 429 |
+
# 涉及注册一些自定义内容的时候,需要附带此参数,并写上自定义内容
|
| 430 |
+
parser.add_argument("-p", "--param", nargs='?', const="-1", type=str, help="When registering some custom content, you need to attach this parameter and write the custom content.")
|
| 431 |
+
args = parser.parse_args()
|
| 432 |
+
if args.version:
|
| 433 |
+
print(version(HivisionaiParams.package_name))
|
| 434 |
+
sys.exit()
|
| 435 |
+
if args.upgrade:
|
| 436 |
+
HivisionaiApps.upgrade(args.upgrade, args.force)
|
| 437 |
+
sys.exit()
|
| 438 |
+
if args.list:
|
| 439 |
+
HivisionaiApps.show_cloud_version()
|
| 440 |
+
sys.exit()
|
| 441 |
+
if args.export:
|
| 442 |
+
HivisionaiApps.export(args.export)
|
| 443 |
+
sys.exit()
|
| 444 |
+
if args.init:
|
| 445 |
+
HivisionaiApps.hy_func_init(args.force)
|
| 446 |
+
sys.exit()
|
| 447 |
+
if args.deploy:
|
| 448 |
+
HivisionaiApps.hy_func_deploy(args.deploy, args.param)
|
| 449 |
+
|
| 450 |
+
|
| 451 |
+
if __name__ == "__main__":
|
| 452 |
+
entry_point()
|
hivisionai/hyService/__init__.py
ADDED
|
File without changes
|
hivisionai/hyService/cloudService.py
ADDED
|
@@ -0,0 +1,406 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
焕影小程序功能服务端的基本工具函数,以类的形式封装
|
| 3 |
+
"""
|
| 4 |
+
try: # 加上这个try的原因在于本地环境和云函数端的import形式有所不同
|
| 5 |
+
from qcloud_cos import CosConfig
|
| 6 |
+
from qcloud_cos import CosS3Client
|
| 7 |
+
except ImportError:
|
| 8 |
+
try:
|
| 9 |
+
from qcloud_cos_v5 import CosConfig
|
| 10 |
+
from qcloud_cos_v5 import CosS3Client
|
| 11 |
+
except ImportError:
|
| 12 |
+
raise ImportError("请下载腾讯云COS相关代码包:pip install cos-python-sdk-v5")
|
| 13 |
+
import requests
|
| 14 |
+
import datetime
|
| 15 |
+
import json
|
| 16 |
+
from .error import ProcessError
|
| 17 |
+
import os
|
| 18 |
+
local_path_ = os.path.dirname(__file__)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class GetConfig(object):
|
| 22 |
+
@staticmethod
|
| 23 |
+
def hy_sdk_client(Id:str, Key:str):
|
| 24 |
+
# 从cos中寻找文件
|
| 25 |
+
REGION: str = 'ap-beijing'
|
| 26 |
+
TOKEN = None
|
| 27 |
+
SCHEME: str = 'https'
|
| 28 |
+
BUCKET: str = 'hy-sdk-config-1305323352'
|
| 29 |
+
client_config = CosConfig(Region=REGION,
|
| 30 |
+
SecretId=Id,
|
| 31 |
+
SecretKey=Key,
|
| 32 |
+
Token=TOKEN,
|
| 33 |
+
Scheme=SCHEME)
|
| 34 |
+
return CosS3Client(client_config), BUCKET
|
| 35 |
+
|
| 36 |
+
def load_json(self, path:str, default_download=False):
|
| 37 |
+
try:
|
| 38 |
+
if os.path.isdir(path):
|
| 39 |
+
raise ProcessError("请输入具体的配置文件路径,而非文件夹!")
|
| 40 |
+
if default_download is True:
|
| 41 |
+
print(f"\033[34m 默认强制重新下载配置文件...\033[0m")
|
| 42 |
+
raise FileNotFoundError
|
| 43 |
+
with open(path) as f:
|
| 44 |
+
config = json.load(f)
|
| 45 |
+
return config
|
| 46 |
+
except FileNotFoundError:
|
| 47 |
+
dir_name = os.path.dirname(path)
|
| 48 |
+
try:
|
| 49 |
+
os.makedirs(dir_name)
|
| 50 |
+
except FileExistsError:
|
| 51 |
+
pass
|
| 52 |
+
base_name = os.path.basename(path)
|
| 53 |
+
print(f"\033[34m 正在从COS中下载配置文件...\033[0m")
|
| 54 |
+
print(f"\033[31m 请注意,接下来会在{dir_name}路径下生成文件{base_name}...\033[0m")
|
| 55 |
+
Id = input("请输入SecretId:")
|
| 56 |
+
Key = input("请输入SecretKey:")
|
| 57 |
+
client, bucket = self.hy_sdk_client(Id, Key)
|
| 58 |
+
data_bytes = client.get_object(Bucket=bucket,Key=base_name)["Body"].get_raw_stream().read()
|
| 59 |
+
data = json.loads(data_bytes.decode("utf-8"))
|
| 60 |
+
# data["SecretId"] = Id # 未来可以把这个加上
|
| 61 |
+
# data["SecretKey"] = Key
|
| 62 |
+
with open(path, "w") as f:
|
| 63 |
+
data_str = json.dumps(data, ensure_ascii=False)
|
| 64 |
+
# 如果 ensure_ascii 是 true (即默认值),输出保证将所有输入的非 ASCII 字符转义。
|
| 65 |
+
# 如果 ensure_ascii 是 false,这些字符会原样输出。
|
| 66 |
+
f.write(data_str)
|
| 67 |
+
f.close()
|
| 68 |
+
print(f"\033[32m 配置文件保存成功\033[0m")
|
| 69 |
+
return data
|
| 70 |
+
except json.decoder.JSONDecodeError:
|
| 71 |
+
print(f"\033[31m WARNING: 配置文件为空!\033[0m")
|
| 72 |
+
return {}
|
| 73 |
+
|
| 74 |
+
def load_file(self, cloud_path:str, local_path:str):
|
| 75 |
+
"""
|
| 76 |
+
从COS中下载文件到本地,本函数将会被默认执行的,在使用的时候建议加一些限制.
|
| 77 |
+
:param cloud_path: 云端的文件路径
|
| 78 |
+
:param local_path: 将云端文件保存在本地的路径
|
| 79 |
+
"""
|
| 80 |
+
if os.path.isdir(cloud_path):
|
| 81 |
+
raise ProcessError("请输入具体的云端文件路径,而非文件夹!")
|
| 82 |
+
if os.path.isdir(local_path):
|
| 83 |
+
raise ProcessError("请输入具体的本地文件路径,而非文件夹!")
|
| 84 |
+
dir_name = os.path.dirname(local_path)
|
| 85 |
+
base_name = os.path.basename(local_path)
|
| 86 |
+
try:
|
| 87 |
+
os.makedirs(dir_name)
|
| 88 |
+
except FileExistsError:
|
| 89 |
+
pass
|
| 90 |
+
cloud_name = os.path.basename(cloud_path)
|
| 91 |
+
print(f"\033[31m 请注意,接下来会在{dir_name}路径下生成文件{base_name}\033[0m")
|
| 92 |
+
Id = input("请输入SecretId:")
|
| 93 |
+
Key = input("请输入SecretKey:")
|
| 94 |
+
client, bucket = self.hy_sdk_client(Id, Key)
|
| 95 |
+
print(f"\033[34m 正在从COS中下载文件: {cloud_name}, 此过程可能耗费一些时间...\033[0m")
|
| 96 |
+
data_bytes = client.get_object(Bucket=bucket,Key=cloud_path)["Body"].get_raw_stream().read()
|
| 97 |
+
# data["SecretId"] = Id # 未来可以把这个加上
|
| 98 |
+
# data["SecretKey"] = Key
|
| 99 |
+
with open(local_path, "wb") as f:
|
| 100 |
+
# 如果 ensure_ascii 是 true (即默认值),输出保证将所有输入的非 ASCII 字符转义。
|
| 101 |
+
# 如果 ensure_ascii 是 false,这些字符会原样输出。
|
| 102 |
+
f.write(data_bytes)
|
| 103 |
+
f.close()
|
| 104 |
+
print(f"\033[32m 文件保存成功\033[0m")
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
class CosConf(GetConfig):
|
| 108 |
+
"""
|
| 109 |
+
从安全的角度出发,将一些默认配置文件上传至COS中,接下来使用COS和它的子类的时候,在第一次使用时需要输入Cuny给的id和key
|
| 110 |
+
用于连接cos存储桶,下载配置文��.
|
| 111 |
+
当然,在service_default_download = False的时候,如果在运行路径下已经有conf/service_config.json文件了,
|
| 112 |
+
那么就不用再次下载了,也不用输入id和key
|
| 113 |
+
事实上这只需要运行一次,因为配置文件将会被下载至源码文件夹中
|
| 114 |
+
如果要自定义路径,请在继承的子类中编写__init__函数,将service_path定向到指定路径
|
| 115 |
+
"""
|
| 116 |
+
def __init__(self) -> None:
|
| 117 |
+
# 下面这些参数是类的共享参数
|
| 118 |
+
self.__SECRET_ID: str = None # 服务的id
|
| 119 |
+
self.__SECRET_KEY: str = None # 服务的key
|
| 120 |
+
self.__REGION: str = None # 服务的存储桶地区
|
| 121 |
+
self.__TOKEN: str = None # 服务的token,目前一直是None
|
| 122 |
+
self.__SCHEME: str = None # 服务的访问协议,默认实际上是https
|
| 123 |
+
self.__BUCKET: str = None # 服务的存储桶
|
| 124 |
+
self.__SERVICE_CONFIG: dict = None # 服务的配置文件
|
| 125 |
+
self.service_path: str = f"{local_path_}/conf/service_config.json"
|
| 126 |
+
# 配置文件路径,默认是函数运行的路径下的conf文件夹
|
| 127 |
+
self.service_default_download = False # 是否在每次访问配置的时候都重新下载文件
|
| 128 |
+
|
| 129 |
+
@property
|
| 130 |
+
def service_config(self):
|
| 131 |
+
if self.__SERVICE_CONFIG is None or self.service_default_download is True:
|
| 132 |
+
self.__SERVICE_CONFIG = self.load_json(self.service_path, self.service_default_download)
|
| 133 |
+
return self.__SERVICE_CONFIG
|
| 134 |
+
|
| 135 |
+
@property
|
| 136 |
+
def client(self):
|
| 137 |
+
client_config = CosConfig(Region=self.region,
|
| 138 |
+
SecretId=self.secret_id,
|
| 139 |
+
SecretKey=self.secret_key,
|
| 140 |
+
Token=self.token,
|
| 141 |
+
Scheme=self.scheme)
|
| 142 |
+
return CosS3Client(client_config)
|
| 143 |
+
|
| 144 |
+
def get_key(self, key:str):
|
| 145 |
+
try:
|
| 146 |
+
data = self.service_config[key]
|
| 147 |
+
if data == "None":
|
| 148 |
+
return None
|
| 149 |
+
else:
|
| 150 |
+
return data
|
| 151 |
+
except KeyError:
|
| 152 |
+
print(f"\033[31m没有对应键值{key},默认返回None\033[0m")
|
| 153 |
+
return None
|
| 154 |
+
|
| 155 |
+
@property
|
| 156 |
+
def secret_id(self):
|
| 157 |
+
if self.__SECRET_ID is None:
|
| 158 |
+
self.__SECRET_ID = self.get_key("SECRET_ID")
|
| 159 |
+
return self.__SECRET_ID
|
| 160 |
+
|
| 161 |
+
@secret_id.setter
|
| 162 |
+
def secret_id(self, value:str):
|
| 163 |
+
self.__SECRET_ID = value
|
| 164 |
+
|
| 165 |
+
@property
|
| 166 |
+
def secret_key(self):
|
| 167 |
+
if self.__SECRET_KEY is None:
|
| 168 |
+
self.__SECRET_KEY = self.get_key("SECRET_KEY")
|
| 169 |
+
return self.__SECRET_KEY
|
| 170 |
+
|
| 171 |
+
@secret_key.setter
|
| 172 |
+
def secret_key(self, value:str):
|
| 173 |
+
self.__SECRET_KEY = value
|
| 174 |
+
|
| 175 |
+
@property
|
| 176 |
+
def region(self):
|
| 177 |
+
if self.__REGION is None:
|
| 178 |
+
self.__REGION = self.get_key("REGION")
|
| 179 |
+
return self.__REGION
|
| 180 |
+
|
| 181 |
+
@region.setter
|
| 182 |
+
def region(self, value:str):
|
| 183 |
+
self.__REGION = value
|
| 184 |
+
|
| 185 |
+
@property
|
| 186 |
+
def token(self):
|
| 187 |
+
# if self.__TOKEN is None:
|
| 188 |
+
# self.__TOKEN = self.get_key("TOKEN")
|
| 189 |
+
# 这里可以注释掉
|
| 190 |
+
return self.__TOKEN
|
| 191 |
+
|
| 192 |
+
@token.setter
|
| 193 |
+
def token(self, value:str):
|
| 194 |
+
self.__TOKEN= value
|
| 195 |
+
|
| 196 |
+
@property
|
| 197 |
+
def scheme(self):
|
| 198 |
+
if self.__SCHEME is None:
|
| 199 |
+
self.__SCHEME = self.get_key("SCHEME")
|
| 200 |
+
return self.__SCHEME
|
| 201 |
+
|
| 202 |
+
@scheme.setter
|
| 203 |
+
def scheme(self, value:str):
|
| 204 |
+
self.__SCHEME = value
|
| 205 |
+
|
| 206 |
+
@property
|
| 207 |
+
def bucket(self):
|
| 208 |
+
if self.__BUCKET is None:
|
| 209 |
+
self.__BUCKET = self.get_key("BUCKET")
|
| 210 |
+
return self.__BUCKET
|
| 211 |
+
|
| 212 |
+
@bucket.setter
|
| 213 |
+
def bucket(self, value):
|
| 214 |
+
self.__BUCKET = value
|
| 215 |
+
|
| 216 |
+
def downloadFile_COS(self, key, bucket:str=None, if_read:bool=False):
|
| 217 |
+
"""
|
| 218 |
+
从COS下载对象(二进制数据), 如果下载失败就返回None
|
| 219 |
+
"""
|
| 220 |
+
CosBucket = self.bucket if bucket is None else bucket
|
| 221 |
+
try:
|
| 222 |
+
# 将本类的Debug继承给抛弃了
|
| 223 |
+
# self.debug_print(f"Download from {CosBucket}", font_color="blue")
|
| 224 |
+
obj = self.client.get_object(
|
| 225 |
+
Bucket=CosBucket,
|
| 226 |
+
Key=key
|
| 227 |
+
)
|
| 228 |
+
if if_read is True:
|
| 229 |
+
data = obj["Body"].get_raw_stream().read() # byte
|
| 230 |
+
return data
|
| 231 |
+
else:
|
| 232 |
+
return obj
|
| 233 |
+
except Exception as e:
|
| 234 |
+
print(f"\033[31m下载失败! 错误描述:{e}\033[0m")
|
| 235 |
+
return None
|
| 236 |
+
|
| 237 |
+
def showFileList_COS_base(self, key, bucket, marker:str=""):
|
| 238 |
+
"""
|
| 239 |
+
返回cos存储桶内部的某个文件夹的内部名称
|
| 240 |
+
:param key: cos云端的存储路径
|
| 241 |
+
:param bucket: cos存储桶名称,如果没指定名称(None)就会寻找默认的存储桶
|
| 242 |
+
:param marker: 标记,用于记录上次查询到哪里了
|
| 243 |
+
ps:如果需要修改默认的存储桶配置,请在代码运行的时候加入代码 s.bucket = 存储桶名称 (s是对象实例)
|
| 244 |
+
返回的内容存储在response["Content"],不过返回的��据大小是有限制的,具体内容还是请看官方文档。
|
| 245 |
+
"""
|
| 246 |
+
response = self.client.list_objects(
|
| 247 |
+
Bucket=bucket,
|
| 248 |
+
Prefix=key,
|
| 249 |
+
Marker=marker
|
| 250 |
+
)
|
| 251 |
+
return response
|
| 252 |
+
|
| 253 |
+
def showFileList_COS(self, key, bucket:str=None)->list:
|
| 254 |
+
"""
|
| 255 |
+
实现查询存储桶中所有对象的操作,因为cos的sdk有返回数据包大小的限制,所以我们需要进行一定的改动
|
| 256 |
+
"""
|
| 257 |
+
marker = ""
|
| 258 |
+
file_list = []
|
| 259 |
+
CosBucket = self.bucket if bucket is None else bucket
|
| 260 |
+
while True: # 轮询
|
| 261 |
+
response = self.showFileList_COS_base(key, CosBucket, marker)
|
| 262 |
+
try:
|
| 263 |
+
file_list.extend(response["Contents"])
|
| 264 |
+
except KeyError as e:
|
| 265 |
+
print(e)
|
| 266 |
+
raise
|
| 267 |
+
if response['IsTruncated'] == 'false': # 接下来没有数据了,就退出
|
| 268 |
+
break
|
| 269 |
+
marker = response['NextMarker']
|
| 270 |
+
return file_list
|
| 271 |
+
|
| 272 |
+
def uploadFile_COS(self, buffer, key, bucket:str=None):
|
| 273 |
+
"""
|
| 274 |
+
从COS上传数据,需要注意的是必须得是二进制文件
|
| 275 |
+
"""
|
| 276 |
+
CosBucket = self.bucket if bucket is None else bucket
|
| 277 |
+
try:
|
| 278 |
+
self.client.put_object(
|
| 279 |
+
Bucket=CosBucket,
|
| 280 |
+
Body=buffer,
|
| 281 |
+
Key=key
|
| 282 |
+
)
|
| 283 |
+
return True
|
| 284 |
+
except Exception as e:
|
| 285 |
+
print(e)
|
| 286 |
+
return False
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
class FuncDiary(CosConf):
|
| 290 |
+
filter_dict = {"60a5e13da00e6e0001fd53c8": "Cuny",
|
| 291 |
+
"612c290f3a9af4000170faad": "守望平凡",
|
| 292 |
+
"614de96e1259260001506d6c": "林泽毅-焕影一新"}
|
| 293 |
+
|
| 294 |
+
def __init__(self, func_name: str, uid: str, error_conf_path: str = f"{local_path_}/conf/func_error_conf.json"):
|
| 295 |
+
"""
|
| 296 |
+
日志类的实例化
|
| 297 |
+
Args:
|
| 298 |
+
func_name: 功能名称,影响了日志投递的路径
|
| 299 |
+
"""
|
| 300 |
+
super().__init__()
|
| 301 |
+
# 配置文件路径,默认是函数运行的路径下的conf文件夹
|
| 302 |
+
self.service_path: str = os.path.join(os.path.dirname(error_conf_path), "service_config.json")
|
| 303 |
+
self.error_dict = self.load_json(path=error_conf_path)
|
| 304 |
+
self.__up: str = f"wx/invokeFunction_c/{datetime.datetime.now().strftime('%Y/%m/%d/%H')}/{func_name}/"
|
| 305 |
+
self.func_name: str = func_name
|
| 306 |
+
# 下面这个属性是的日志名称的前缀
|
| 307 |
+
self.__start_time = datetime.datetime.now().timestamp()
|
| 308 |
+
h_point = datetime.datetime.strptime(datetime.datetime.now().strftime('%Y/%m/%d/%H'), '%Y/%m/%d/%H')
|
| 309 |
+
h_point_timestamp = h_point.timestamp()
|
| 310 |
+
self.__prefix = int(self.__start_time - h_point_timestamp).__str__() + "_"
|
| 311 |
+
self.__uid = uid
|
| 312 |
+
self.__diary = None
|
| 313 |
+
|
| 314 |
+
def __str__(self):
|
| 315 |
+
return f"<{self.func_name}> DIARY for {self.__uid}"
|
| 316 |
+
|
| 317 |
+
@property
|
| 318 |
+
def content(self):
|
| 319 |
+
return self.__diary
|
| 320 |
+
|
| 321 |
+
@content.setter
|
| 322 |
+
def content(self, value: str):
|
| 323 |
+
if not isinstance(value, dict):
|
| 324 |
+
raise TypeError("content 只能是字典!")
|
| 325 |
+
if "status" in value:
|
| 326 |
+
raise KeyError("status字段已被默认占用,请在日志信息中更换字段名称!")
|
| 327 |
+
if self.__diary is None:
|
| 328 |
+
self.__diary = value
|
| 329 |
+
else:
|
| 330 |
+
raise PermissionError("为了减小日志对整体代码的影响,<content>只能被覆写一次!")
|
| 331 |
+
|
| 332 |
+
def uploadDiary_COS(self, status_id: str, suffix: str = "", bucket: str = "hy-hcy-data-logs-1306602019"):
|
| 333 |
+
if self.__diary is None:
|
| 334 |
+
self.__diary = {"status": self.error_dict[status_id]}
|
| 335 |
+
if status_id == "0000":
|
| 336 |
+
self.__up += f"True/{self.__uid}/"
|
| 337 |
+
else:
|
| 338 |
+
self.__up += f"False/{self.__uid}/"
|
| 339 |
+
interval = int(10 * (datetime.datetime.now().timestamp() - self.__start_time))
|
| 340 |
+
prefix = self.__prefix + status_id + "_" + interval.__str__()
|
| 341 |
+
self.__diary["status"] = self.error_dict[status_id]
|
| 342 |
+
name = prefix + "_" + suffix if len(suffix) != 0 else prefix
|
| 343 |
+
self.uploadFile_COS(buffer=json.dumps(self.__diary), key=self.__up + name, bucket=bucket)
|
| 344 |
+
print(f"{self}上传成功.")
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
class ResponseWebSocket(CosConf):
|
| 348 |
+
# 网关推送地址
|
| 349 |
+
__HOST:str = None
|
| 350 |
+
@property
|
| 351 |
+
def sendBackHost(self):
|
| 352 |
+
if self.__HOST is None:
|
| 353 |
+
self.__HOST = self.get_key("HOST")
|
| 354 |
+
return self.__HOST
|
| 355 |
+
|
| 356 |
+
@sendBackHost.setter
|
| 357 |
+
def sendBackHost(self, value):
|
| 358 |
+
self.__HOST = value
|
| 359 |
+
|
| 360 |
+
def sendMsg_toWebSocket(self, message,connectionID:str = None):
|
| 361 |
+
if connectionID is not None:
|
| 362 |
+
retmsg = {'websocket': {}}
|
| 363 |
+
retmsg['websocket']['action'] = "data send"
|
| 364 |
+
retmsg['websocket']['secConnectionID'] = connectionID
|
| 365 |
+
retmsg['websocket']['dataType'] = 'text'
|
| 366 |
+
retmsg['websocket']['data'] = json.dumps(message)
|
| 367 |
+
requests.post(self.sendBackHost, json=retmsg)
|
| 368 |
+
print("send success!")
|
| 369 |
+
else:
|
| 370 |
+
pass
|
| 371 |
+
|
| 372 |
+
@staticmethod
|
| 373 |
+
def create_Msg(status, msg):
|
| 374 |
+
"""
|
| 375 |
+
本方法用于创建一个用于发送到WebSocket客户端的数据
|
| 376 |
+
输入的信息部分,需要有如下几个参数:
|
| 377 |
+
1. id,固定为"return-result"
|
| 378 |
+
2. status,如果输入为1则status=true, 如果输入为-1则status=false
|
| 379 |
+
3. obj_key, 图片的云端路径, 这是输入的msg本身自带的
|
| 380 |
+
"""
|
| 381 |
+
msg['status'] = "false" if status == -1 else 'true' # 其实最好还是用bool
|
| 382 |
+
msg['id'] = "async-back-msg"
|
| 383 |
+
msg['type'] = "funcType"
|
| 384 |
+
msg["format"] = "imageType"
|
| 385 |
+
return msg
|
| 386 |
+
|
| 387 |
+
|
| 388 |
+
# 功能服务类
|
| 389 |
+
class Service(ResponseWebSocket):
|
| 390 |
+
"""
|
| 391 |
+
服务的主函数,封装了cos上传/下载功能以及与api网关的一键通讯
|
| 392 |
+
将类的实例变成一个可被调用的对象,在服务运行的时候,只需要运行该对象即可
|
| 393 |
+
当然,因为是类,所以支持继承和修改
|
| 394 |
+
"""
|
| 395 |
+
@classmethod
|
| 396 |
+
def process(cls, *args, **kwargs):
|
| 397 |
+
"""
|
| 398 |
+
处理函数,在使用的时候请将之重构
|
| 399 |
+
"""
|
| 400 |
+
pass
|
| 401 |
+
|
| 402 |
+
@classmethod
|
| 403 |
+
def __call__(cls, *args, **kwargs):
|
| 404 |
+
pass
|
| 405 |
+
|
| 406 |
+
|
hivisionai/hyService/dbTools.py
ADDED
|
@@ -0,0 +1,337 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import pymongo
|
| 3 |
+
import datetime
|
| 4 |
+
import time
|
| 5 |
+
from .cloudService import GetConfig
|
| 6 |
+
local_path = os.path.dirname(__file__)
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class DBUtils(GetConfig):
|
| 10 |
+
"""
|
| 11 |
+
从安全的角度出发,将一些默认配置文件上传至COS中,接下来使用COS和它的子类的时候,在第一次使用时需要输入Cuny给的id和key
|
| 12 |
+
用于连接数据库等对象
|
| 13 |
+
当然,在db_default_download = False的时候,如果在运行路径下已经有配置文件了,
|
| 14 |
+
那么就不用再次下载了,也不用输入id和key
|
| 15 |
+
事实上这只需要运行一次,因为配置文件将会被下载至源码文件夹中
|
| 16 |
+
如果要自定义路径,请在继承的子类中编写__init__函数,将service_path定向到指定路径
|
| 17 |
+
"""
|
| 18 |
+
__BASE_DIR: dict = None
|
| 19 |
+
__PARAMS_DIR: dict = None
|
| 20 |
+
db_base_path: str = f"{local_path}/conf/base_config.json"
|
| 21 |
+
db_params_path: str = f"{local_path}/conf/params.json"
|
| 22 |
+
db_default_download: bool = False
|
| 23 |
+
|
| 24 |
+
@property
|
| 25 |
+
def base_config(self):
|
| 26 |
+
if self.__BASE_DIR is None:
|
| 27 |
+
self.__BASE_DIR = self.load_json(self.db_base_path, self.db_default_download)
|
| 28 |
+
return self.__BASE_DIR
|
| 29 |
+
|
| 30 |
+
@property
|
| 31 |
+
def db_config(self):
|
| 32 |
+
return self.base_config["database_config"]
|
| 33 |
+
|
| 34 |
+
@property
|
| 35 |
+
def params_config(self):
|
| 36 |
+
if self.__PARAMS_DIR is None:
|
| 37 |
+
self.__PARAMS_DIR = self.load_json(self.db_params_path, self.db_default_download)
|
| 38 |
+
return self.__PARAMS_DIR
|
| 39 |
+
|
| 40 |
+
@property
|
| 41 |
+
def size_dir(self):
|
| 42 |
+
return self.params_config["size_config"]
|
| 43 |
+
|
| 44 |
+
@property
|
| 45 |
+
def func_dir(self):
|
| 46 |
+
return self.params_config["func_config"]
|
| 47 |
+
|
| 48 |
+
@property
|
| 49 |
+
def wx_config(self):
|
| 50 |
+
return self.base_config["wx_config"]
|
| 51 |
+
|
| 52 |
+
def get_dbClient(self):
|
| 53 |
+
return pymongo.MongoClient(self.db_config["connect_url"])
|
| 54 |
+
|
| 55 |
+
@staticmethod
|
| 56 |
+
def get_time(yyyymmdd=None, delta_date=0):
|
| 57 |
+
"""
|
| 58 |
+
给出当前的时间
|
| 59 |
+
:param yyyymmdd: 以yyyymmdd给出的日期时间
|
| 60 |
+
:param delta_date: 获取减去delta_day后的时间,默认为0就是当天
|
| 61 |
+
时间格式:yyyy_mm_dd
|
| 62 |
+
"""
|
| 63 |
+
if yyyymmdd is None:
|
| 64 |
+
now_time = (datetime.datetime.now() - datetime.timedelta(delta_date)).strftime("%Y-%m-%d")
|
| 65 |
+
return now_time
|
| 66 |
+
# 输入了yyyymmdd的数据和delta_date,通过这两个数据返回距离yyyymmdd delta_date天的时间
|
| 67 |
+
pre_time = datetime.datetime(int(yyyymmdd[0:4]), int(yyyymmdd[4:6]), int(yyyymmdd[6:8]))
|
| 68 |
+
return (pre_time - datetime.timedelta(delta_date)).strftime("%Y-%m-%d")
|
| 69 |
+
|
| 70 |
+
# 获得时间戳
|
| 71 |
+
def get_timestamp(self, date_time:str=None) -> int:
|
| 72 |
+
"""
|
| 73 |
+
输入的日期形式为:"2021-11-29 16:39:45.999"
|
| 74 |
+
真正必须输入的是前十个字符,及精确到日期,后面的时间可以不输入,不输入则默认置零
|
| 75 |
+
"""
|
| 76 |
+
def standardDateTime(dt:str) -> str:
|
| 77 |
+
"""
|
| 78 |
+
规范化时间字符串
|
| 79 |
+
"""
|
| 80 |
+
if len(dt) < 10:
|
| 81 |
+
raise ValueError("你必须至少输入准确到天的日期!比如:2021-11-29")
|
| 82 |
+
elif len(dt) == 10:
|
| 83 |
+
return dt + " 00:00:00.0"
|
| 84 |
+
else:
|
| 85 |
+
try:
|
| 86 |
+
date, time = dt.split(" ")
|
| 87 |
+
except ValueError:
|
| 88 |
+
raise ValueError("你只能也必须在日期与具体时间之间增加一个空格,其他地方不能出现空格!")
|
| 89 |
+
while len(time) < 10:
|
| 90 |
+
if len(time) in (2, 5):
|
| 91 |
+
time += ":"
|
| 92 |
+
elif len(time) == 8:
|
| 93 |
+
time += "."
|
| 94 |
+
else:
|
| 95 |
+
time += "0"
|
| 96 |
+
return date + " " + time
|
| 97 |
+
if date_time is None:
|
| 98 |
+
# 默认返回当前时间(str), date_time精确到毫秒
|
| 99 |
+
date_time = datetime.datetime.now()
|
| 100 |
+
# 转换成时间戳
|
| 101 |
+
else:
|
| 102 |
+
date_time = standardDateTime(dt=date_time)
|
| 103 |
+
date_time = datetime.datetime.strptime(date_time, "%Y-%m-%d %H:%M:%S.%f")
|
| 104 |
+
timestamp_ms = int(time.mktime(date_time.timetuple()) * 1000.0 + date_time.microsecond / 1000.0)
|
| 105 |
+
return timestamp_ms
|
| 106 |
+
|
| 107 |
+
@staticmethod
|
| 108 |
+
def get_standardTime(yyyy_mm_dd: str):
|
| 109 |
+
return yyyy_mm_dd[0:4] + yyyy_mm_dd[5:7] + yyyy_mm_dd[8:10]
|
| 110 |
+
|
| 111 |
+
def find_oneDay_data(self, db_name: str, collection_name: str, date: str = None) -> dict:
|
| 112 |
+
"""
|
| 113 |
+
获取指定天数的数据,如果date is None,就自动寻找距今最近的有数据的那一天的数据
|
| 114 |
+
"""
|
| 115 |
+
df = None # 应该被返回的数据
|
| 116 |
+
collection = self.get_dbClient()[db_name][collection_name]
|
| 117 |
+
if date is None: # 自动寻找前几天的数据,最多三十天
|
| 118 |
+
for delta_date in range(1, 31):
|
| 119 |
+
date_yyyymmdd = self.get_standardTime(self.get_time(delta_date=delta_date))
|
| 120 |
+
filter_ = {"date": date_yyyymmdd}
|
| 121 |
+
df = collection.find_one(filter=filter_)
|
| 122 |
+
if df is not None:
|
| 123 |
+
del df["_id"]
|
| 124 |
+
break
|
| 125 |
+
else:
|
| 126 |
+
filter_ = {"date": date}
|
| 127 |
+
df = collection.find_one(filter=filter_)
|
| 128 |
+
if df is not None:
|
| 129 |
+
del df["_id"]
|
| 130 |
+
return df
|
| 131 |
+
|
| 132 |
+
def find_daysData_byPeriod(self, date_period: tuple, db_name: str, col_name: str):
|
| 133 |
+
# 给出一个指定的范围日期,返回相应的数据(日期的两头都会被寻找)
|
| 134 |
+
# 这个函数我们默认数据库中的数据是连续的,即不会出现在 20211221 到 20211229 之间有一天没有数据的情况
|
| 135 |
+
if len(date_period) != 2:
|
| 136 |
+
raise ValueError("date_period数据结构:(开始日期,截止日期)")
|
| 137 |
+
start, end = date_period # yyyymmdd
|
| 138 |
+
delta_date = int(end) - int(start)
|
| 139 |
+
if delta_date < 0:
|
| 140 |
+
raise ValueError("传入的日期有误!")
|
| 141 |
+
collection = self.get_dbClient()[db_name][col_name]
|
| 142 |
+
date = start
|
| 143 |
+
while int(date) <= int(end):
|
| 144 |
+
yield collection.find_one(filter={"date": date})
|
| 145 |
+
date = self.get_standardTime(self.get_time(date, -1))
|
| 146 |
+
|
| 147 |
+
@staticmethod
|
| 148 |
+
def find_biggest_valueDict(dict_: dict):
|
| 149 |
+
# 寻找字典中数值最大的字段,要求输入的字典的字段值全为数字
|
| 150 |
+
while len(dict_) > 0:
|
| 151 |
+
max_value = 0
|
| 152 |
+
p = None
|
| 153 |
+
for key in dict_:
|
| 154 |
+
if dict_[key] > max_value:
|
| 155 |
+
p = key
|
| 156 |
+
max_value = dict_[key]
|
| 157 |
+
yield p, max_value
|
| 158 |
+
del dict_[p]
|
| 159 |
+
|
| 160 |
+
def copy_andAdd_dict(self, dict_base, dict_):
|
| 161 |
+
# 深度拷贝字典,将后者赋值给前者
|
| 162 |
+
# 如果后者的键名在前者已经存在,则直接相加。这就要求两者的数据是数值型
|
| 163 |
+
for key in dict_:
|
| 164 |
+
if key not in dict_base:
|
| 165 |
+
dict_base[key] = dict_[key]
|
| 166 |
+
else:
|
| 167 |
+
if isinstance(dict_[key], int) or isinstance(dict_[key], float):
|
| 168 |
+
dict_base[key] = round(dict_[key] + dict_base[key], 2)
|
| 169 |
+
else:
|
| 170 |
+
dict_base[key] = self.copy_andAdd_dict(dict_base[key], dict_[key])
|
| 171 |
+
return dict_base
|
| 172 |
+
|
| 173 |
+
@staticmethod
|
| 174 |
+
def compare_data(dict1: dict, dict2: dict, suffix: str, save: int, **kwargs):
|
| 175 |
+
"""
|
| 176 |
+
有两个字典,并且通过kwargs会传输一个新的字典,根据字典中的键值我们进行比对,处理成相应的数据格式
|
| 177 |
+
并且在dict1中,生成一个新的键值,为kwargs中的元素+suffix
|
| 178 |
+
save:保留几位小数
|
| 179 |
+
"""
|
| 180 |
+
new_dict = dict1.copy()
|
| 181 |
+
for key in kwargs:
|
| 182 |
+
try:
|
| 183 |
+
if kwargs[key] not in dict2 or int(dict2[kwargs[key]]) == -1 or float(dict1[kwargs[key]]) <= 0.0:
|
| 184 |
+
# 数据不存在
|
| 185 |
+
data_new = 5002
|
| 186 |
+
else:
|
| 187 |
+
try:
|
| 188 |
+
data_new = round(
|
| 189 |
+
((float(dict1[kwargs[key]]) - float(dict2[kwargs[key]])) / float(dict2[kwargs[key]])) * 100
|
| 190 |
+
, save)
|
| 191 |
+
except ZeroDivisionError:
|
| 192 |
+
data_new = 5002
|
| 193 |
+
if data_new == 0.0:
|
| 194 |
+
data_new = 0
|
| 195 |
+
except TypeError as e:
|
| 196 |
+
print(e)
|
| 197 |
+
data_new = 5002 # 如果没有之前的数据,默认返回0
|
| 198 |
+
new_dict[kwargs[key] + suffix] = data_new
|
| 199 |
+
return new_dict
|
| 200 |
+
|
| 201 |
+
@staticmethod
|
| 202 |
+
def sum_dictList_byKey(dictList: list, **kwargs) -> dict:
|
| 203 |
+
"""
|
| 204 |
+
有一个列表,列表中的元素为字典,并且所有字典都有一个键值为key的字段,字段值为数字
|
| 205 |
+
我们将每一个字典的key字段提取后相加,得到该字段值之和.
|
| 206 |
+
"""
|
| 207 |
+
sum_num = {}
|
| 208 |
+
if kwargs is None:
|
| 209 |
+
raise ImportError("Please input at least ONE key")
|
| 210 |
+
for key in kwargs:
|
| 211 |
+
sum_num[kwargs[key]] = 0
|
| 212 |
+
for dict_ in dictList:
|
| 213 |
+
if not isinstance(dict_, dict):
|
| 214 |
+
raise TypeError("object is not DICT!")
|
| 215 |
+
for key in kwargs:
|
| 216 |
+
sum_num[kwargs[key]] += dict_[kwargs[key]]
|
| 217 |
+
return sum_num
|
| 218 |
+
|
| 219 |
+
@staticmethod
|
| 220 |
+
def sum_2ListDict(list_dict1: list, list_dict2: list, key_name, data_name):
|
| 221 |
+
"""
|
| 222 |
+
有两个列表,列表内的元素为字典,我们根据key所对应的键值寻找列表中键值相同的两个元素,将他们的data对应的键值相加
|
| 223 |
+
生成新的列表字典(其余键值被删除)
|
| 224 |
+
key仅在一个列表中存在,则直接加入新的列表字典
|
| 225 |
+
"""
|
| 226 |
+
sum_list = []
|
| 227 |
+
|
| 228 |
+
def find_sameKey(kn, key_, ld: list) -> int:
|
| 229 |
+
for dic_ in ld:
|
| 230 |
+
if dic_[kn] == key_:
|
| 231 |
+
post_ = ld.index(dic_)
|
| 232 |
+
return post_
|
| 233 |
+
return -1
|
| 234 |
+
|
| 235 |
+
for dic in list_dict1:
|
| 236 |
+
key = dic[key_name] # 键名
|
| 237 |
+
post = find_sameKey(key_name, key, list_dict2) # 在list2中寻找相同的位置
|
| 238 |
+
data = dic[data_name] + list_dict2[post][data_name] if post != -1 else dic[data_name]
|
| 239 |
+
sum_list.append({key_name: key, data_name: data})
|
| 240 |
+
return sum_list
|
| 241 |
+
|
| 242 |
+
@staticmethod
|
| 243 |
+
def find_biggest_dictList(dictList: list, key: str = "key", data: str = "value"):
|
| 244 |
+
"""
|
| 245 |
+
有一个列表,里面每一个元素都是一个字典
|
| 246 |
+
这些字典有一些共通性质,那就是里面都有一个key键名和一个data键名,后者的键值必须是数字
|
| 247 |
+
我们根据data键值的大小进行生成,每一次返回列表中data键值最大的数和它的key键值
|
| 248 |
+
"""
|
| 249 |
+
while len(dictList) > 0:
|
| 250 |
+
point = 0
|
| 251 |
+
biggest_num = int(dictList[0][data])
|
| 252 |
+
biggest_key = dictList[0][key]
|
| 253 |
+
for i in range(len(dictList)):
|
| 254 |
+
num = int(dictList[i][data])
|
| 255 |
+
if num > biggest_num:
|
| 256 |
+
point = i
|
| 257 |
+
biggest_num = int(dictList[i][data])
|
| 258 |
+
biggest_key = dictList[i][key]
|
| 259 |
+
yield str(biggest_key), biggest_num
|
| 260 |
+
del dictList[point]
|
| 261 |
+
|
| 262 |
+
def get_share_data(self, date_yyyymmdd: str):
|
| 263 |
+
# 获得用户界面情况
|
| 264 |
+
visitPage = self.find_oneDay_data(date=date_yyyymmdd,
|
| 265 |
+
db_name="cuny-user-analysis",
|
| 266 |
+
collection_name="daily-userVisitPage")
|
| 267 |
+
if visitPage is not None:
|
| 268 |
+
# 这一部分没有得到数据是可以容忍的.不用抛出模态框错误
|
| 269 |
+
# 获得昨日用户分享情况
|
| 270 |
+
sum_num = self.sum_dictList_byKey(dictList=visitPage["data_list"],
|
| 271 |
+
key1="page_share_pv",
|
| 272 |
+
key2="page_share_uv")
|
| 273 |
+
else:
|
| 274 |
+
# 此时将分享次数等置为-1
|
| 275 |
+
sum_num = {"page_share_pv": -1, "page_share_uv": -1}
|
| 276 |
+
return sum_num
|
| 277 |
+
|
| 278 |
+
@staticmethod
|
| 279 |
+
def compare_date(date1_yyyymmdd: str, date2_yyyymmdd: str):
|
| 280 |
+
# 如果date1是date2的昨天,那么就返回True
|
| 281 |
+
date1 = int(date1_yyyymmdd)
|
| 282 |
+
date2 = int(date2_yyyymmdd)
|
| 283 |
+
return True if date2 - date1 == 1 else False
|
| 284 |
+
|
| 285 |
+
def change_time(self, date_yyyymmdd: str, mode: int):
|
| 286 |
+
# 将yyyymmdd的数据分开为相应的数据形式
|
| 287 |
+
if mode == 1:
|
| 288 |
+
if self.compare_date(date_yyyymmdd, self.get_standardTime(self.get_time(delta_date=0))) is False:
|
| 289 |
+
return date_yyyymmdd[0:4] + "年" + date_yyyymmdd[4:6] + "月" + date_yyyymmdd[6:8] + "日"
|
| 290 |
+
else:
|
| 291 |
+
return "昨日"
|
| 292 |
+
elif mode == 2:
|
| 293 |
+
date = date_yyyymmdd[0:4] + "." + date_yyyymmdd[4:6] + "." + date_yyyymmdd[6:8]
|
| 294 |
+
if self.compare_date(date_yyyymmdd, self.get_standardTime(self.get_time(delta_date=0))) is True:
|
| 295 |
+
return date + "~" + date + " | 昨日"
|
| 296 |
+
else:
|
| 297 |
+
return date + "~" + date
|
| 298 |
+
|
| 299 |
+
@staticmethod
|
| 300 |
+
def changeList_dict2List_list(dl: list, order: list):
|
| 301 |
+
"""
|
| 302 |
+
列表内是一个个字典,本函数将字典拆解,以order的形式排列键值为列表
|
| 303 |
+
考虑到一些格式的问题,这里我采用生成器的形式封装
|
| 304 |
+
"""
|
| 305 |
+
for dic in dl:
|
| 306 |
+
# dic是列表内的字典元素
|
| 307 |
+
tmp = []
|
| 308 |
+
for key_name in order:
|
| 309 |
+
key = dic[key_name]
|
| 310 |
+
tmp.append(key)
|
| 311 |
+
yield tmp
|
| 312 |
+
|
| 313 |
+
def dict_mapping(self, dict_name: str, id_: str):
|
| 314 |
+
"""
|
| 315 |
+
进行字典映射,输入字典名称和键名,返回具体的键值
|
| 316 |
+
如果不存在,则原路返回键名
|
| 317 |
+
"""
|
| 318 |
+
try:
|
| 319 |
+
return getattr(self, dict_name)[id_]
|
| 320 |
+
except KeyError:
|
| 321 |
+
return id_
|
| 322 |
+
except AttributeError:
|
| 323 |
+
print(f"[WARNING]: 本对象内部不存在{dict_name}!")
|
| 324 |
+
return id_
|
| 325 |
+
|
| 326 |
+
@staticmethod
|
| 327 |
+
def dictAddKey(dic: dict, dic_tmp: dict, **kwargs):
|
| 328 |
+
"""
|
| 329 |
+
往字典中加入参数,可迭代
|
| 330 |
+
"""
|
| 331 |
+
for key in kwargs:
|
| 332 |
+
dic[key] = dic_tmp[key]
|
| 333 |
+
return dic
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
if __name__ == "__main__":
|
| 337 |
+
dbu = DBUtils()
|
hivisionai/hyService/error.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
@author: cuny
|
| 3 |
+
@fileName: error.py
|
| 4 |
+
@create_time: 2022/03/10 下午3:14
|
| 5 |
+
@introduce:
|
| 6 |
+
保存一些定义的错误类型
|
| 7 |
+
"""
|
| 8 |
+
class ProcessError(Exception):
|
| 9 |
+
def __init__(self, err):
|
| 10 |
+
super().__init__(err)
|
| 11 |
+
self.err = err
|
| 12 |
+
def __str__(self):
|
| 13 |
+
return self.err
|
| 14 |
+
|
| 15 |
+
class WrongImageType(TypeError):
|
| 16 |
+
def __init__(self, err):
|
| 17 |
+
super().__init__(err)
|
| 18 |
+
self.err = err
|
| 19 |
+
def __str__(self):
|
| 20 |
+
return self.err
|
hivisionai/hyService/serviceTest.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
用于测试云端或者本地服务的运行是否成功
|
| 3 |
+
"""
|
| 4 |
+
import requests
|
| 5 |
+
import functools
|
| 6 |
+
import cv2
|
| 7 |
+
import time
|
| 8 |
+
|
| 9 |
+
def httpPostTest(url, msg:dict):
|
| 10 |
+
"""
|
| 11 |
+
以post请求访问api,携带msg(dict)信息
|
| 12 |
+
"""
|
| 13 |
+
re = requests.post(url=url, json=msg)
|
| 14 |
+
print(re.text)
|
| 15 |
+
return re
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def localTestImageFunc(path):
|
| 19 |
+
"""
|
| 20 |
+
在本地端测试算法,需要注意的是本装饰器只支持测试和图像相关算法
|
| 21 |
+
path代表测试图像的路径,其余参数请写入被装饰的函数中,并且只支持标签形式输入
|
| 22 |
+
被测试的函数的第一个输入参数必须为图像矩阵(以cv2读入)
|
| 23 |
+
"""
|
| 24 |
+
def decorator(func):
|
| 25 |
+
@functools.wraps(func)
|
| 26 |
+
def wrapper(**kwargs):
|
| 27 |
+
start = time.time()
|
| 28 |
+
image = cv2.imread(path)
|
| 29 |
+
image_out = func(image) if len(kwargs) == 0 else func(image, kwargs)
|
| 30 |
+
print("END.\n处理时间(不计算加载模型时间){}秒:".format(round(time.time()-start, 2)))
|
| 31 |
+
cv2.imshow("test", image_out)
|
| 32 |
+
cv2.waitKey(0)
|
| 33 |
+
return wrapper
|
| 34 |
+
return decorator
|
hivisionai/hyService/utils.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
@author: cuny
|
| 3 |
+
@fileName: utils.py
|
| 4 |
+
@create_time: 2021/12/29 下午1:29
|
| 5 |
+
@introduce:
|
| 6 |
+
焕影服务的一些工具函数,涉及两类:
|
| 7 |
+
1. 开发debug时候的工具函数
|
| 8 |
+
2. 初始化COS配置时的工具函数
|
| 9 |
+
"""
|
| 10 |
+
import cv2
|
| 11 |
+
from .error import WrongImageType
|
| 12 |
+
import numpy as np
|
| 13 |
+
|
| 14 |
+
class Debug(object):
|
| 15 |
+
color_dir:dict = {
|
| 16 |
+
"red":"31m",
|
| 17 |
+
"green":"32m",
|
| 18 |
+
"yellow":"33m",
|
| 19 |
+
"blue":"34m",
|
| 20 |
+
"common":"38m"
|
| 21 |
+
} # 颜色值
|
| 22 |
+
__DEBUG:bool = True
|
| 23 |
+
|
| 24 |
+
@property
|
| 25 |
+
def debug(self):
|
| 26 |
+
return self.__DEBUG
|
| 27 |
+
|
| 28 |
+
@debug.setter
|
| 29 |
+
def debug(self, value):
|
| 30 |
+
if not isinstance(value, bool):
|
| 31 |
+
raise TypeError("你必须设定debug的值为bool的True或者False")
|
| 32 |
+
print(f"设置debug为: {value}")
|
| 33 |
+
self.__DEBUG = value
|
| 34 |
+
|
| 35 |
+
def debug_print(self, text, **kwargs):
|
| 36 |
+
if self.debug is True:
|
| 37 |
+
key = self.color_dir["common"] if "font_color" not in kwargs else self.color_dir[kwargs["font_color"]]
|
| 38 |
+
print(f"\033[{key}{text}\033[0m")
|
| 39 |
+
|
| 40 |
+
@staticmethod
|
| 41 |
+
def resize_image_esp(input_image, esp=2000):
|
| 42 |
+
"""
|
| 43 |
+
输入:
|
| 44 |
+
input_path:numpy图片
|
| 45 |
+
esp:限制的最大边长
|
| 46 |
+
"""
|
| 47 |
+
# resize函数=>可以让原图压缩到最大边为esp的尺寸(不改变比例)
|
| 48 |
+
width = input_image.shape[0]
|
| 49 |
+
length = input_image.shape[1]
|
| 50 |
+
max_num = max(width, length)
|
| 51 |
+
|
| 52 |
+
if max_num > esp:
|
| 53 |
+
print("Image resizing...")
|
| 54 |
+
if width == max_num:
|
| 55 |
+
length = int((esp / width) * length)
|
| 56 |
+
width = esp
|
| 57 |
+
|
| 58 |
+
else:
|
| 59 |
+
width = int((esp / length) * width)
|
| 60 |
+
length = esp
|
| 61 |
+
print(length, width)
|
| 62 |
+
im_resize = cv2.resize(input_image, (length, width), interpolation=cv2.INTER_AREA)
|
| 63 |
+
return im_resize
|
| 64 |
+
else:
|
| 65 |
+
return input_image
|
| 66 |
+
|
| 67 |
+
def cv_show(self, *args, **kwargs):
|
| 68 |
+
def check_images(img):
|
| 69 |
+
# 判断是否是矩阵类型
|
| 70 |
+
if not isinstance(img, np.ndarray):
|
| 71 |
+
raise WrongImageType("输入的图像必须是 np.ndarray 类型!")
|
| 72 |
+
if self.debug is True:
|
| 73 |
+
size = 500 if "size" not in kwargs else kwargs["size"] # 默认缩放尺寸为最大边500像素点
|
| 74 |
+
if len(args) == 0:
|
| 75 |
+
raise ProcessError("你必须传入若干图像信息!")
|
| 76 |
+
flag = False
|
| 77 |
+
base = None
|
| 78 |
+
for image in args:
|
| 79 |
+
check_images(image)
|
| 80 |
+
if flag is False:
|
| 81 |
+
image = self.resize_image_esp(image, size)
|
| 82 |
+
h, w = image.shape[0], image.shape[1]
|
| 83 |
+
flag = (w, h)
|
| 84 |
+
base = image
|
| 85 |
+
else:
|
| 86 |
+
image = cv2.resize(image, flag)
|
| 87 |
+
base = np.hstack((base, image))
|
| 88 |
+
title = "cv_show" if "winname" not in kwargs else kwargs["winname"]
|
| 89 |
+
cv2.imshow(title, base)
|
| 90 |
+
cv2.waitKey(0)
|
| 91 |
+
else:
|
| 92 |
+
pass
|
hivisionai/hyTrain/APIs.py
ADDED
|
@@ -0,0 +1,197 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import requests, os
|
| 2 |
+
import json
|
| 3 |
+
import hashlib, base64, hmac
|
| 4 |
+
import sys
|
| 5 |
+
import oss2
|
| 6 |
+
from aliyunsdkimageseg.request.v20191230.SegmentBodyRequest import SegmentBodyRequest
|
| 7 |
+
from aliyunsdkimageseg.request.v20191230.SegmentSkinRequest import SegmentSkinRequest
|
| 8 |
+
from aliyunsdkfacebody.request.v20191230.DetectFaceRequest import DetectFaceRequest
|
| 9 |
+
from aliyunsdkcore.client import AcsClient
|
| 10 |
+
|
| 11 |
+
# 头像抠图参数配置
|
| 12 |
+
def params_of_head(photo_base64, photo_type):
|
| 13 |
+
print ('测试头像抠图接口 ...')
|
| 14 |
+
host = 'https://person.market.alicloudapi.com'
|
| 15 |
+
uri = '/segment/person/headrgba' # 头像抠图返回透明PNG图
|
| 16 |
+
# uri = '/segment/person/head' # 头像抠图返回alpha图
|
| 17 |
+
# uri = '/segment/person/headborder' # 头像抠图返回带白边的透明PNG图
|
| 18 |
+
return host, uri, {
|
| 19 |
+
'photo': photo_base64,
|
| 20 |
+
'type': photo_type,
|
| 21 |
+
'face_required': 0, # 可选,检测是否必须带有人脸才进行抠图处理,0为检测,1为不检测,默认为0
|
| 22 |
+
'border_ratio': 0.3, # 可选,仅带白边接口可用,
|
| 23 |
+
# 在头像边缘增加白边(或者其他颜色)宽度,取值为0-0.5,
|
| 24 |
+
# 这个宽度是相对于图片宽度和高度最大值的比例,
|
| 25 |
+
# 比如原图尺寸为640x480,border_ratio为0.2,
|
| 26 |
+
# 则添加的白边的宽度为:max(640,480) * 0.2 = 96个像素
|
| 27 |
+
'margin_color': '#ff0000' # 可选,仅带白边接口可用,
|
| 28 |
+
# 在头像边缘增加边框的颜色,默认为白色
|
| 29 |
+
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
# 头像抠图API
|
| 33 |
+
def wanxing_get_head_api(file_name='/home/parallels/Desktop/change_cloth/input_image/03.jpg',
|
| 34 |
+
output_path="./head.png",
|
| 35 |
+
app_key='204014294',
|
| 36 |
+
secret="pI2uo7AhCFjnaZWYrCCAEjmsZJbK6vzy",
|
| 37 |
+
stage='RELEASE'):
|
| 38 |
+
info = sys.version_info
|
| 39 |
+
if info[0] < 3:
|
| 40 |
+
is_python3 = False
|
| 41 |
+
else:
|
| 42 |
+
is_python3 = True
|
| 43 |
+
|
| 44 |
+
with open(file_name, 'rb') as fp:
|
| 45 |
+
photo_base64 = base64.b64encode(fp.read())
|
| 46 |
+
if is_python3:
|
| 47 |
+
photo_base64 = photo_base64.decode('utf8')
|
| 48 |
+
|
| 49 |
+
_, photo_type = os.path.splitext(file_name)
|
| 50 |
+
photo_type = photo_type.lstrip('.')
|
| 51 |
+
# print(photo_type)
|
| 52 |
+
# print(photo_base64)
|
| 53 |
+
|
| 54 |
+
# host, uri, body_json = params_of_portrait_matting(photo_base64, photo_type)
|
| 55 |
+
# host, uri, body_json = params_of_object_matting(photo_base64)
|
| 56 |
+
# host, uri, body_json = params_of_idphoto(photo_base64, photo_type)
|
| 57 |
+
host, uri, body_json = params_of_head(photo_base64, photo_type)
|
| 58 |
+
# host, uri, body_json = params_of_crop(photo_base64)
|
| 59 |
+
api = host + uri
|
| 60 |
+
|
| 61 |
+
body = json.dumps(body_json)
|
| 62 |
+
md5lib = hashlib.md5()
|
| 63 |
+
if is_python3:
|
| 64 |
+
md5lib.update(body.encode('utf8'))
|
| 65 |
+
else:
|
| 66 |
+
md5lib.update(body)
|
| 67 |
+
body_md5 = md5lib.digest()
|
| 68 |
+
body_md5 = base64.b64encode(body_md5)
|
| 69 |
+
if is_python3:
|
| 70 |
+
body_md5 = body_md5.decode('utf8')
|
| 71 |
+
|
| 72 |
+
method = 'POST'
|
| 73 |
+
accept = 'application/json'
|
| 74 |
+
content_type = 'application/octet-stream; charset=utf-8'
|
| 75 |
+
date_str = ''
|
| 76 |
+
headers = ''
|
| 77 |
+
|
| 78 |
+
string_to_sign = method + '\n' \
|
| 79 |
+
+ accept + '\n' \
|
| 80 |
+
+ body_md5 + '\n' \
|
| 81 |
+
+ content_type + '\n' \
|
| 82 |
+
+ date_str + '\n' \
|
| 83 |
+
+ headers \
|
| 84 |
+
+ uri
|
| 85 |
+
if is_python3:
|
| 86 |
+
signed = hmac.new(secret.encode('utf8'),
|
| 87 |
+
string_to_sign.encode('utf8'),
|
| 88 |
+
digestmod=hashlib.sha256).digest()
|
| 89 |
+
else:
|
| 90 |
+
signed = hmac.new(secret, string_to_sign, digestmod=hashlib.sha256).digest()
|
| 91 |
+
signed = base64.b64encode(signed)
|
| 92 |
+
if is_python3:
|
| 93 |
+
signed = signed.decode('utf8')
|
| 94 |
+
|
| 95 |
+
headers = {
|
| 96 |
+
'Accept': accept,
|
| 97 |
+
'Content-MD5': body_md5,
|
| 98 |
+
'Content-Type': content_type,
|
| 99 |
+
'X-Ca-Key': app_key,
|
| 100 |
+
'X-Ca-Stage': stage,
|
| 101 |
+
'X-Ca-Signature': signed
|
| 102 |
+
}
|
| 103 |
+
#print signed
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
resp = requests.post(api, data=body, headers=headers)
|
| 107 |
+
# for u,v in resp.headers.items():
|
| 108 |
+
# print(u+": " + v)
|
| 109 |
+
try:
|
| 110 |
+
res = resp.content
|
| 111 |
+
res = json.loads(res)
|
| 112 |
+
# print ('res:', res)
|
| 113 |
+
if str(res['status']) == '0':
|
| 114 |
+
# print ('成功!')
|
| 115 |
+
file_object = requests.get(res["data"]["result"])
|
| 116 |
+
# print(file_object)
|
| 117 |
+
with open(output_path, 'wb') as local_file:
|
| 118 |
+
local_file.write(file_object.content)
|
| 119 |
+
|
| 120 |
+
# image = cv2.imread("./test_head.png", -1)
|
| 121 |
+
# return image
|
| 122 |
+
else:
|
| 123 |
+
pass
|
| 124 |
+
# print ('失败!')
|
| 125 |
+
except:
|
| 126 |
+
print('failed parse:', resp)
|
| 127 |
+
|
| 128 |
+
# 阿里云抠图API
|
| 129 |
+
def aliyun_human_matting_api(input_path, output_path, type="human"):
|
| 130 |
+
auth = oss2.Auth('LTAI5tP2NxdzSFfpKYxZFCuJ', 'VzbGdUbRawuMAitekP3ORfrw0i3NEX')
|
| 131 |
+
bucket = oss2.Bucket(auth, 'https://oss-cn-shanghai.aliyuncs.com', 'huanying-api')
|
| 132 |
+
key = os.path.basename(input_path)
|
| 133 |
+
origin_image = input_path
|
| 134 |
+
try:
|
| 135 |
+
bucket.put_object_from_file(key, origin_image, headers={"Connection":"close"})
|
| 136 |
+
except Exception as e:
|
| 137 |
+
print(e)
|
| 138 |
+
|
| 139 |
+
url = bucket.sign_url('GET', key, 10 * 60)
|
| 140 |
+
client = AcsClient('LTAI5tP2NxdzSFfpKYxZFCuJ', 'VzbGdUbRawuMAitekP3ORfrw0i3NEX', 'cn-shanghai')
|
| 141 |
+
if type == "human":
|
| 142 |
+
request = SegmentBodyRequest()
|
| 143 |
+
elif type == "skin":
|
| 144 |
+
request = SegmentSkinRequest()
|
| 145 |
+
request.set_accept_format('json')
|
| 146 |
+
request.set_ImageURL(url)
|
| 147 |
+
|
| 148 |
+
try:
|
| 149 |
+
response = client.do_action_with_exception(request)
|
| 150 |
+
response_dict = eval(str(response, encoding='utf-8'))
|
| 151 |
+
if type == "human":
|
| 152 |
+
output_url = response_dict['Data']['ImageURL']
|
| 153 |
+
elif type == "skin":
|
| 154 |
+
output_url = response_dict['Data']['Elements'][0]['URL']
|
| 155 |
+
file_object = requests.get(output_url)
|
| 156 |
+
with open(output_path, 'wb') as local_file:
|
| 157 |
+
local_file.write(file_object.content)
|
| 158 |
+
bucket.delete_object(key)
|
| 159 |
+
except Exception as e:
|
| 160 |
+
print(e)
|
| 161 |
+
response = client.do_action_with_exception(request)
|
| 162 |
+
response_dict = eval(str(response, encoding='utf-8'))
|
| 163 |
+
print(response_dict)
|
| 164 |
+
output_url = response_dict['Data']['ImageURL']
|
| 165 |
+
file_object = requests.get(output_url)
|
| 166 |
+
with open(output_path, 'wb') as local_file:
|
| 167 |
+
local_file.write(file_object.content)
|
| 168 |
+
bucket.delete_object(key)
|
| 169 |
+
|
| 170 |
+
# 阿里云人脸检测API
|
| 171 |
+
def aliyun_face_detect_api(input_path, type="human"):
|
| 172 |
+
auth = oss2.Auth('LTAI5tP2NxdzSFfpKYxZFCuJ', 'VzbGdUbRawuMAitekP3ORfrw0i3NEX')
|
| 173 |
+
bucket = oss2.Bucket(auth, 'https://oss-cn-shanghai.aliyuncs.com', 'huanying-api')
|
| 174 |
+
key = os.path.basename(input_path)
|
| 175 |
+
origin_image = input_path
|
| 176 |
+
try:
|
| 177 |
+
bucket.put_object_from_file(key, origin_image, headers={"Connection":"close"})
|
| 178 |
+
except Exception as e:
|
| 179 |
+
print(e)
|
| 180 |
+
|
| 181 |
+
url = bucket.sign_url('GET', key, 10 * 60)
|
| 182 |
+
client = AcsClient('LTAI5tP2NxdzSFfpKYxZFCuJ', 'VzbGdUbRawuMAitekP3ORfrw0i3NEX', 'cn-shanghai')
|
| 183 |
+
if type == "human":
|
| 184 |
+
request = DetectFaceRequest()
|
| 185 |
+
request.set_accept_format('json')
|
| 186 |
+
request.set_ImageURL(url)
|
| 187 |
+
try:
|
| 188 |
+
response = client.do_action_with_exception(request)
|
| 189 |
+
response_json = json.loads(str(response, encoding='utf-8'))
|
| 190 |
+
print(response_json["Data"]["PoseList"][-1])
|
| 191 |
+
bucket.delete_object(key)
|
| 192 |
+
return response_json["Data"]["PoseList"][-1]
|
| 193 |
+
except Exception as e:
|
| 194 |
+
print(e)
|
| 195 |
+
|
| 196 |
+
if __name__ == "__main__":
|
| 197 |
+
wanxing_get_head_api()
|
hivisionai/hyTrain/DataProcessing.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import random
|
| 3 |
+
from scipy.ndimage import grey_erosion, grey_dilation
|
| 4 |
+
import numpy as np
|
| 5 |
+
from glob import glob
|
| 6 |
+
import random
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def make_a_and_trimaps(input_image, resize=(512, 512)):
|
| 10 |
+
image = cv2.resize(input_image, resize)
|
| 11 |
+
b, g, r, a = cv2.split(image)
|
| 12 |
+
|
| 13 |
+
a_scale_resize = a / 255
|
| 14 |
+
trimap = (a_scale_resize >= 0.95).astype("float32")
|
| 15 |
+
not_bg = (a_scale_resize > 0).astype("float32")
|
| 16 |
+
d_size = a.shape[0] // 256 * random.randint(10, 20)
|
| 17 |
+
e_size = a.shape[0] // 256 * random.randint(10, 20)
|
| 18 |
+
trimap[np.where((grey_dilation(not_bg, size=(d_size, d_size))
|
| 19 |
+
- grey_erosion(trimap, size=(e_size, e_size))) != 0)] = 0.5
|
| 20 |
+
|
| 21 |
+
return a, trimap*255
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def get_filedir_filelist(input_path):
|
| 25 |
+
return glob(input_path+"/*")
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def extChange(filedir, ext="png"):
|
| 29 |
+
ext_origin = str(filedir).split(".")[-1]
|
| 30 |
+
return filedir.replace(ext_origin, ext)
|
| 31 |
+
|
| 32 |
+
def random_image_crop(input_image:np.array, crop_size=(512,512)):
|
| 33 |
+
height, width = input_image.shape[0], input_image.shape[1]
|
| 34 |
+
crop_height, crop_width = crop_size[0], crop_size[1]
|
| 35 |
+
x = random.randint(0, width-crop_width)
|
| 36 |
+
y = random.randint(0, height-crop_height)
|
| 37 |
+
return input_image[y:y+crop_height, x:x+crop_width]
|
hivisionai/hyTrain/__init__.py
ADDED
|
File without changes
|
hivisionai/hycv/FaceDetection68/__init__.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
@author: cuny
|
| 3 |
+
@fileName: __init__.py
|
| 4 |
+
@create_time: 2022/01/03 下午9:39
|
| 5 |
+
@introduce:
|
| 6 |
+
人脸68关键点检测sdk的__init__包,实际上是对dlib的封装
|
| 7 |
+
"""
|
| 8 |
+
from .faceDetection68 import FaceDetection68, PoseEstimator68
|
hivisionai/hycv/FaceDetection68/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (481 Bytes). View file
|
|
|
hivisionai/hycv/FaceDetection68/__pycache__/faceDetection68.cpython-310.pyc
ADDED
|
Binary file (11.9 kB). View file
|
|
|
hivisionai/hycv/FaceDetection68/faceDetection68.py
ADDED
|
@@ -0,0 +1,443 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
@author: cuny
|
| 3 |
+
@fileName: faceDetection68.py
|
| 4 |
+
@create_time: 2022/01/03 下午10:20
|
| 5 |
+
@introduce:
|
| 6 |
+
人脸68关键点检测主文件,以类的形式封装
|
| 7 |
+
"""
|
| 8 |
+
from hivisionai.hyService.cloudService import GetConfig
|
| 9 |
+
import os
|
| 10 |
+
import cv2
|
| 11 |
+
import dlib
|
| 12 |
+
import numpy as np
|
| 13 |
+
local_file = os.path.dirname(__file__)
|
| 14 |
+
PREDICTOR_PATH = f"{local_file}/weights/shape_predictor_68_face_landmarks.dat" # 关键点检测模型路径
|
| 15 |
+
MODULE3D_PATH = f"{local_file}/weights/68_points_3D_model.txt" # 3d的68点配置文件路径
|
| 16 |
+
|
| 17 |
+
# 定义一个人脸检测错误的错误类
|
| 18 |
+
class FaceError(Exception):
|
| 19 |
+
def __init__(self, err):
|
| 20 |
+
super().__init__(err)
|
| 21 |
+
self.err = err
|
| 22 |
+
def __str__(self):
|
| 23 |
+
return self.err
|
| 24 |
+
|
| 25 |
+
class FaceConfig68(object):
|
| 26 |
+
face_area:list = None # 一些其他的参数,在本类中实际没啥用
|
| 27 |
+
FACE_POINTS = list(range(17, 68)) # 人脸轮廓点索引
|
| 28 |
+
MOUTH_POINTS = list(range(48, 61)) # 嘴巴点索引
|
| 29 |
+
RIGHT_BROW_POINTS = list(range(17, 22)) # 右眉毛索引
|
| 30 |
+
LEFT_BROW_POINTS = list(range(22, 27)) # 左眉毛索引
|
| 31 |
+
RIGHT_EYE_POINTS = list(range(36, 42)) # 右眼索引
|
| 32 |
+
LEFT_EYE_POINTS = list(range(42, 48)) # 左眼索引
|
| 33 |
+
NOSE_POINTS = list(range(27, 35)) # 鼻子索引
|
| 34 |
+
JAW_POINTS = list(range(0, 17)) # 下巴索引
|
| 35 |
+
LEFT_FACE = list(range(42, 48)) + list(range(22, 27)) # 左半边脸索引
|
| 36 |
+
RIGHT_FACE = list(range(36, 42)) + list(range(17, 22)) # 右半边脸索引
|
| 37 |
+
JAW_END = 17 # 下巴结束点
|
| 38 |
+
FACE_START = 0 # 人脸识别开始
|
| 39 |
+
FACE_END = 68 # 人脸识别结束
|
| 40 |
+
# 下面这个是整张脸的mark点,可以用:
|
| 41 |
+
# for group in self.OVERLAY_POINTS:
|
| 42 |
+
# cv2.fillConvexPoly(face_mask, cv2.convexHull(dst_matrix[group]), (255, 255, 255))
|
| 43 |
+
# 来形成人脸蒙版
|
| 44 |
+
OVERLAY_POINTS = [
|
| 45 |
+
JAW_POINTS,
|
| 46 |
+
LEFT_FACE,
|
| 47 |
+
RIGHT_FACE
|
| 48 |
+
]
|
| 49 |
+
|
| 50 |
+
class FaceDetection68(FaceConfig68):
|
| 51 |
+
"""
|
| 52 |
+
人脸68关键点检测主类,当然使用的是dlib开源包
|
| 53 |
+
"""
|
| 54 |
+
def __init__(self, model_path:str=None, default_download:bool=False, *args, **kwargs):
|
| 55 |
+
# 初始化,检查并下载模型
|
| 56 |
+
self.model_path = PREDICTOR_PATH if model_path is None else model_path
|
| 57 |
+
if not os.path.exists(self.model_path) or default_download: # 下载配置
|
| 58 |
+
gc = GetConfig()
|
| 59 |
+
gc.load_file(cloud_path="weights/shape_predictor_68_face_landmarks.dat",
|
| 60 |
+
local_path=self.model_path)
|
| 61 |
+
self.__detector = None
|
| 62 |
+
self.__predictor = None
|
| 63 |
+
|
| 64 |
+
@property
|
| 65 |
+
def detector(self):
|
| 66 |
+
if self.__detector is None:
|
| 67 |
+
self.__detector = dlib.get_frontal_face_detector() # 获取人脸分类器
|
| 68 |
+
return self.__detector
|
| 69 |
+
@property
|
| 70 |
+
def predictor(self):
|
| 71 |
+
if self.__predictor is None:
|
| 72 |
+
self.__predictor = dlib.shape_predictor(self.model_path) # 输入模型,构建特征提取器
|
| 73 |
+
return self.__predictor
|
| 74 |
+
|
| 75 |
+
@staticmethod
|
| 76 |
+
def draw_face(img:np.ndarray, dets:dlib.rectangles, *args, **kwargs):
|
| 77 |
+
# 画人脸检测框, 为了一些兼容操作我没有设置默认显示,可以在运行完本函数后将返回值进行self.cv_show()
|
| 78 |
+
tmp = img.copy()
|
| 79 |
+
for face in dets:
|
| 80 |
+
# 左上角(x1,y1),右下角(x2,y2)
|
| 81 |
+
x1, y1, x2, y2 = face.left(), face.top(), face.right(), face.bottom()
|
| 82 |
+
# print(x1, y1, x2, y2)
|
| 83 |
+
cv2.rectangle(tmp, (x1, y1), (x2, y2), (0, 255, 0), 2)
|
| 84 |
+
return tmp
|
| 85 |
+
|
| 86 |
+
@staticmethod
|
| 87 |
+
def draw_points(img:np.ndarray, landmarks:np.matrix, if_num:int=False, *args, **kwargs):
|
| 88 |
+
"""
|
| 89 |
+
画人脸关键点, 为了一些兼容操作我没有设置默认显示,可以在运行完本函数后将返回值进行self.cv_show()
|
| 90 |
+
:param img: 输入的是人脸检测的图,必须是3通道或者灰度图
|
| 91 |
+
:param if_num: 是否在画关键点的同时画上编号
|
| 92 |
+
:param landmarks: 输入的关键点矩阵信息
|
| 93 |
+
"""
|
| 94 |
+
tmp = img.copy()
|
| 95 |
+
h, w, c = tmp.shape
|
| 96 |
+
r = int(h / 100) - 2 if h > w else int(w / 100) - 2
|
| 97 |
+
for idx, point in enumerate(landmarks):
|
| 98 |
+
# 68点的坐标
|
| 99 |
+
pos = (point[0, 0], point[0, 1])
|
| 100 |
+
# 利用cv2.circle给每个特征点画一个圈,共68个
|
| 101 |
+
cv2.circle(tmp, pos, r, color=(0, 0, 255), thickness=-1) # bgr
|
| 102 |
+
if if_num is True:
|
| 103 |
+
# 利用cv2.putText输出1-68
|
| 104 |
+
font = cv2.FONT_HERSHEY_SIMPLEX
|
| 105 |
+
cv2.putText(tmp, str(idx + 1), pos, font, 0.8, (0, 0, 255), 1, cv2.LINE_AA)
|
| 106 |
+
return tmp
|
| 107 |
+
|
| 108 |
+
@staticmethod
|
| 109 |
+
def resize_image_esp(input_image_, esp=2000):
|
| 110 |
+
"""
|
| 111 |
+
输入:
|
| 112 |
+
input_path:numpy图片
|
| 113 |
+
esp:限制的最大边长
|
| 114 |
+
"""
|
| 115 |
+
# resize函数=>可以让原图压缩到最大边为esp的尺寸(不改变比例)
|
| 116 |
+
width = input_image_.shape[0]
|
| 117 |
+
|
| 118 |
+
length = input_image_.shape[1]
|
| 119 |
+
max_num = max(width, length)
|
| 120 |
+
|
| 121 |
+
if max_num > esp:
|
| 122 |
+
print("Image resizing...")
|
| 123 |
+
if width == max_num:
|
| 124 |
+
length = int((esp / width) * length)
|
| 125 |
+
width = esp
|
| 126 |
+
|
| 127 |
+
else:
|
| 128 |
+
width = int((esp / length) * width)
|
| 129 |
+
length = esp
|
| 130 |
+
print(length, width)
|
| 131 |
+
im_resize = cv2.resize(input_image_, (length, width), interpolation=cv2.INTER_AREA)
|
| 132 |
+
return im_resize
|
| 133 |
+
else:
|
| 134 |
+
return input_image_
|
| 135 |
+
|
| 136 |
+
def facesPoints(self, img:np.ndarray, esp:int=None, det_num:int=1,*args, **kwargs):
|
| 137 |
+
"""
|
| 138 |
+
:param img: 输入的是人脸检测的图,必须是3通道或者灰度图
|
| 139 |
+
:param esp: 如果输入了具体数值,会将图片的最大边长缩放至esp,另一边等比例缩放
|
| 140 |
+
:param det_num: 人脸检测的迭代次数, 采样次数越多,越有利于检测到更多的人脸
|
| 141 |
+
:return
|
| 142 |
+
返回人脸检测框对象dets, 人脸关键点矩阵列表(列表中每个元素为一个人脸的关键点矩阵), 人脸关键点元组列表(列表中每个元素为一个人脸的关键点列表)
|
| 143 |
+
"""
|
| 144 |
+
# win = dlib.image_window()
|
| 145 |
+
# win.clear_overlay()
|
| 146 |
+
# win.set_image(img)
|
| 147 |
+
# dlib的人脸检测装置
|
| 148 |
+
if esp is not None:
|
| 149 |
+
img = self.resize_image_esp(input_image_=img, esp=esp)
|
| 150 |
+
dets = self.detector(img, det_num)
|
| 151 |
+
# self.draw_face(img, dets)
|
| 152 |
+
# font_color = "green" if len(dets) == 1 else "red"
|
| 153 |
+
# dg.debug_print("Number of faces detected: {}".format(len(dets)), font_color=font_color)
|
| 154 |
+
landmarkList = []
|
| 155 |
+
pointsList = []
|
| 156 |
+
for d in dets:
|
| 157 |
+
shape = self.predictor(img, d)
|
| 158 |
+
landmark = np.matrix([[p.x, p.y] for p in shape.parts()])
|
| 159 |
+
landmarkList.append(landmark)
|
| 160 |
+
point_list = []
|
| 161 |
+
for p in landmark.tolist():
|
| 162 |
+
point_list.append((p[0], p[1]))
|
| 163 |
+
pointsList.append(point_list)
|
| 164 |
+
# dg.debug_print("Key point detection SUCCESS.", font_color="green")
|
| 165 |
+
return dets, landmarkList, pointsList
|
| 166 |
+
|
| 167 |
+
def facePoints(self, img:np.ndarray, esp:int=None, det_num:int=1, *args, **kwargs):
|
| 168 |
+
"""
|
| 169 |
+
本函数与facesPoints大致类似,主要区别在于本函数默认只能返回一个人脸关键点参数
|
| 170 |
+
"""
|
| 171 |
+
# win = dlib.image_window()
|
| 172 |
+
# win.clear_overlay()
|
| 173 |
+
# win.set_image(img)
|
| 174 |
+
# dlib的人脸检测装置, 参数1表示对图片进行上采样一次,采样次数越多,越有利于检测到更多的人脸
|
| 175 |
+
if esp is not None:
|
| 176 |
+
img = self.resize_image_esp(input_image_=img, esp=esp)
|
| 177 |
+
dets = self.detector(img, det_num)
|
| 178 |
+
# self.draw_face(img, dets)
|
| 179 |
+
font_color = "green" if len(dets) == 1 else "red"
|
| 180 |
+
# dg.debug_print("Number of faces detected: {}".format(len(dets)), font_color=font_color)
|
| 181 |
+
if font_color=="red":
|
| 182 |
+
# 本检测函数必然只能检测出一张人脸
|
| 183 |
+
raise FaceError("Face detection error!!!")
|
| 184 |
+
d = dets[0] # 唯一人脸
|
| 185 |
+
shape = self.predictor(img, d)
|
| 186 |
+
landmark = np.matrix([[p.x, p.y] for p in shape.parts()])
|
| 187 |
+
# print("face_landmark:", landmark) # 打印关键点矩阵
|
| 188 |
+
# shape = predictor(img, )
|
| 189 |
+
# dlib.hit_enter_to_continue()
|
| 190 |
+
# 返回关键点矩阵,关键点,
|
| 191 |
+
point_list = []
|
| 192 |
+
for p in landmark.tolist():
|
| 193 |
+
point_list.append((p[0], p[1]))
|
| 194 |
+
# dg.debug_print("Key point detection SUCCESS.", font_color="green")
|
| 195 |
+
# 最后的一个返回参数只会被计算一次,用于标明脸部框的位置
|
| 196 |
+
# [人脸框左上角纵坐标(top),左上角横坐标(left),人脸框宽度(width),人脸框高度(height)]
|
| 197 |
+
return dets, landmark, point_list
|
| 198 |
+
|
| 199 |
+
class PoseEstimator68(object):
|
| 200 |
+
"""
|
| 201 |
+
Estimate head pose according to the facial landmarks
|
| 202 |
+
本类将实现但输入图的人脸姿态检测
|
| 203 |
+
"""
|
| 204 |
+
def __init__(self, img:np.ndarray, params_path:str=None, default_download:bool=False):
|
| 205 |
+
self.params_path = MODULE3D_PATH if params_path is None else params_path
|
| 206 |
+
if not os.path.exists(self.params_path) or default_download:
|
| 207 |
+
gc = GetConfig()
|
| 208 |
+
gc.load_file(cloud_path="weights/68_points_3D_model.txt",
|
| 209 |
+
local_path=self.params_path)
|
| 210 |
+
h, w, c = img.shape
|
| 211 |
+
self.size = (h, w)
|
| 212 |
+
# 3D model points.
|
| 213 |
+
self.model_points = np.array([
|
| 214 |
+
(0.0, 0.0, 0.0), # Nose tip
|
| 215 |
+
(0.0, -330.0, -65.0), # Chin
|
| 216 |
+
(-225.0, 170.0, -135.0), # Left eye left corner
|
| 217 |
+
(225.0, 170.0, -135.0), # Right eye right corner
|
| 218 |
+
(-150.0, -150.0, -125.0), # Mouth left corner
|
| 219 |
+
(150.0, -150.0, -125.0) # Mouth right corner
|
| 220 |
+
]) / 4.5
|
| 221 |
+
self.model_points_68 = self._get_full_model_points()
|
| 222 |
+
|
| 223 |
+
# Camera internals
|
| 224 |
+
self.focal_length = self.size[1]
|
| 225 |
+
self.camera_center = (self.size[1] / 2, self.size[0] / 2)
|
| 226 |
+
self.camera_matrix = np.array(
|
| 227 |
+
[[self.focal_length, 0, self.camera_center[0]],
|
| 228 |
+
[0, self.focal_length, self.camera_center[1]],
|
| 229 |
+
[0, 0, 1]], dtype="double")
|
| 230 |
+
|
| 231 |
+
# Assuming no lens distortion
|
| 232 |
+
self.dist_coeefs = np.zeros((4, 1))
|
| 233 |
+
|
| 234 |
+
# Rotation vector and translation vector
|
| 235 |
+
self.r_vec = np.array([[0.01891013], [0.08560084], [-3.14392813]])
|
| 236 |
+
self.t_vec = np.array(
|
| 237 |
+
[[-14.97821226], [-10.62040383], [-2053.03596872]])
|
| 238 |
+
# self.r_vec = None
|
| 239 |
+
# self.t_vec = None
|
| 240 |
+
|
| 241 |
+
def _get_full_model_points(self):
|
| 242 |
+
"""Get all 68 3D model points from file"""
|
| 243 |
+
raw_value = []
|
| 244 |
+
with open(self.params_path) as file:
|
| 245 |
+
for line in file:
|
| 246 |
+
raw_value.append(line)
|
| 247 |
+
model_points = np.array(raw_value, dtype=np.float32)
|
| 248 |
+
model_points = np.reshape(model_points, (3, -1)).T
|
| 249 |
+
|
| 250 |
+
# Transform the model into a front view.
|
| 251 |
+
# model_points[:, 0] *= -1
|
| 252 |
+
model_points[:, 1] *= -1
|
| 253 |
+
model_points[:, 2] *= -1
|
| 254 |
+
return model_points
|
| 255 |
+
|
| 256 |
+
def show_3d_model(self):
|
| 257 |
+
from matplotlib import pyplot
|
| 258 |
+
from mpl_toolkits.mplot3d import Axes3D
|
| 259 |
+
fig = pyplot.figure()
|
| 260 |
+
ax = Axes3D(fig)
|
| 261 |
+
|
| 262 |
+
x = self.model_points_68[:, 0]
|
| 263 |
+
y = self.model_points_68[:, 1]
|
| 264 |
+
z = self.model_points_68[:, 2]
|
| 265 |
+
|
| 266 |
+
ax.scatter(x, y, z)
|
| 267 |
+
ax.axis('auto')
|
| 268 |
+
pyplot.xlabel('x')
|
| 269 |
+
pyplot.ylabel('y')
|
| 270 |
+
pyplot.show()
|
| 271 |
+
|
| 272 |
+
def solve_pose(self, image_points):
|
| 273 |
+
"""
|
| 274 |
+
Solve pose from image points
|
| 275 |
+
Return (rotation_vector, translation_vector) as pose.
|
| 276 |
+
"""
|
| 277 |
+
assert image_points.shape[0] == self.model_points_68.shape[0], "3D points and 2D points should be of same number."
|
| 278 |
+
(_, rotation_vector, translation_vector) = cv2.solvePnP(
|
| 279 |
+
self.model_points, image_points, self.camera_matrix, self.dist_coeefs)
|
| 280 |
+
|
| 281 |
+
# (success, rotation_vector, translation_vector) = cv2.solvePnP(
|
| 282 |
+
# self.model_points,
|
| 283 |
+
# image_points,
|
| 284 |
+
# self.camera_matrix,
|
| 285 |
+
# self.dist_coeefs,
|
| 286 |
+
# rvec=self.r_vec,
|
| 287 |
+
# tvec=self.t_vec,
|
| 288 |
+
# useExtrinsicGuess=True)
|
| 289 |
+
return rotation_vector, translation_vector
|
| 290 |
+
|
| 291 |
+
def solve_pose_by_68_points(self, image_points):
|
| 292 |
+
"""
|
| 293 |
+
Solve pose from all the 68 image points
|
| 294 |
+
Return (rotation_vector, translation_vector) as pose.
|
| 295 |
+
"""
|
| 296 |
+
if self.r_vec is None:
|
| 297 |
+
(_, rotation_vector, translation_vector) = cv2.solvePnP(
|
| 298 |
+
self.model_points_68, image_points, self.camera_matrix, self.dist_coeefs)
|
| 299 |
+
self.r_vec = rotation_vector
|
| 300 |
+
self.t_vec = translation_vector
|
| 301 |
+
|
| 302 |
+
(_, rotation_vector, translation_vector) = cv2.solvePnP(
|
| 303 |
+
self.model_points_68,
|
| 304 |
+
image_points,
|
| 305 |
+
self.camera_matrix,
|
| 306 |
+
self.dist_coeefs,
|
| 307 |
+
rvec=self.r_vec,
|
| 308 |
+
tvec=self.t_vec,
|
| 309 |
+
useExtrinsicGuess=True)
|
| 310 |
+
|
| 311 |
+
return rotation_vector, translation_vector
|
| 312 |
+
|
| 313 |
+
# def draw_annotation_box(self, image, rotation_vector, translation_vector, color=(255, 255, 255), line_width=2):
|
| 314 |
+
# """Draw a 3D box as annotation of pose"""
|
| 315 |
+
# point_3d = []
|
| 316 |
+
# rear_size = 75
|
| 317 |
+
# rear_depth = 0
|
| 318 |
+
# point_3d.append((-rear_size, -rear_size, rear_depth))
|
| 319 |
+
# point_3d.append((-rear_size, rear_size, rear_depth))
|
| 320 |
+
# point_3d.append((rear_size, rear_size, rear_depth))
|
| 321 |
+
# point_3d.append((rear_size, -rear_size, rear_depth))
|
| 322 |
+
# point_3d.append((-rear_size, -rear_size, rear_depth))
|
| 323 |
+
#
|
| 324 |
+
# front_size = 100
|
| 325 |
+
# front_depth = 100
|
| 326 |
+
# point_3d.append((-front_size, -front_size, front_depth))
|
| 327 |
+
# point_3d.append((-front_size, front_size, front_depth))
|
| 328 |
+
# point_3d.append((front_size, front_size, front_depth))
|
| 329 |
+
# point_3d.append((front_size, -front_size, front_depth))
|
| 330 |
+
# point_3d.append((-front_size, -front_size, front_depth))
|
| 331 |
+
# point_3d = np.array(point_3d, dtype=np.float64).reshape(-1, 3)
|
| 332 |
+
#
|
| 333 |
+
# # Map to 2d image points
|
| 334 |
+
# (point_2d, _) = cv2.projectPoints(point_3d,
|
| 335 |
+
# rotation_vector,
|
| 336 |
+
# translation_vector,
|
| 337 |
+
# self.camera_matrix,
|
| 338 |
+
# self.dist_coeefs)
|
| 339 |
+
# point_2d = np.int32(point_2d.reshape(-1, 2))
|
| 340 |
+
#
|
| 341 |
+
# # Draw all the lines
|
| 342 |
+
# cv2.polylines(image, [point_2d], True, color, line_width, cv2.LINE_AA)
|
| 343 |
+
# cv2.line(image, tuple(point_2d[1]), tuple(
|
| 344 |
+
# point_2d[6]), color, line_width, cv2.LINE_AA)
|
| 345 |
+
# cv2.line(image, tuple(point_2d[2]), tuple(
|
| 346 |
+
# point_2d[7]), color, line_width, cv2.LINE_AA)
|
| 347 |
+
# cv2.line(image, tuple(point_2d[3]), tuple(
|
| 348 |
+
# point_2d[8]), color, line_width, cv2.LINE_AA)
|
| 349 |
+
#
|
| 350 |
+
# def draw_axis(self, img, R, t):
|
| 351 |
+
# points = np.float32(
|
| 352 |
+
# [[30, 0, 0], [0, 30, 0], [0, 0, 30], [0, 0, 0]]).reshape(-1, 3)
|
| 353 |
+
#
|
| 354 |
+
# axisPoints, _ = cv2.projectPoints(
|
| 355 |
+
# points, R, t, self.camera_matrix, self.dist_coeefs)
|
| 356 |
+
#
|
| 357 |
+
# img = cv2.line(img, tuple(axisPoints[3].ravel()), tuple(
|
| 358 |
+
# axisPoints[0].ravel()), (255, 0, 0), 3)
|
| 359 |
+
# img = cv2.line(img, tuple(axisPoints[3].ravel()), tuple(
|
| 360 |
+
# axisPoints[1].ravel()), (0, 255, 0), 3)
|
| 361 |
+
# img = cv2.line(img, tuple(axisPoints[3].ravel()), tuple(
|
| 362 |
+
# axisPoints[2].ravel()), (0, 0, 255), 3)
|
| 363 |
+
|
| 364 |
+
def draw_axes(self, img, R, t):
|
| 365 |
+
"""
|
| 366 |
+
OX is drawn in red, OY in green and OZ in blue.
|
| 367 |
+
"""
|
| 368 |
+
return cv2.drawFrameAxes(img, self.camera_matrix, self.dist_coeefs, R, t, 30)
|
| 369 |
+
|
| 370 |
+
@staticmethod
|
| 371 |
+
def get_pose_marks(marks):
|
| 372 |
+
"""Get marks ready for pose estimation from 68 marks"""
|
| 373 |
+
pose_marks = [marks[30], marks[8], marks[36], marks[45], marks[48], marks[54]]
|
| 374 |
+
return pose_marks
|
| 375 |
+
|
| 376 |
+
@staticmethod
|
| 377 |
+
def rot_params_rm(R):
|
| 378 |
+
from math import pi,atan2,asin, fabs
|
| 379 |
+
# x轴
|
| 380 |
+
pitch = (180 * atan2(-R[2][1], R[2][2]) / pi)
|
| 381 |
+
f = (0 > pitch) - (0 < pitch)
|
| 382 |
+
pitch = f * (180 - fabs(pitch))
|
| 383 |
+
# y轴
|
| 384 |
+
yaw = -(180 * asin(R[2][0]) / pi)
|
| 385 |
+
# z轴
|
| 386 |
+
roll = (180 * atan2(-R[1][0], R[0][0]) / pi)
|
| 387 |
+
f = (0 > roll) - (0 < roll)
|
| 388 |
+
roll = f * (180 - fabs(roll))
|
| 389 |
+
if not fabs(roll) < 90.0:
|
| 390 |
+
roll = f * (180 - fabs(roll))
|
| 391 |
+
rot_params = [pitch, yaw, roll]
|
| 392 |
+
return rot_params
|
| 393 |
+
|
| 394 |
+
@staticmethod
|
| 395 |
+
def rot_params_rv(rvec_):
|
| 396 |
+
from math import pi, atan2, asin, fabs
|
| 397 |
+
R = cv2.Rodrigues(rvec_)[0]
|
| 398 |
+
# x轴
|
| 399 |
+
pitch = (180 * atan2(-R[2][1], R[2][2]) / pi)
|
| 400 |
+
f = (0 > pitch) - (0 < pitch)
|
| 401 |
+
pitch = f * (180 - fabs(pitch))
|
| 402 |
+
# y轴
|
| 403 |
+
yaw = -(180 * asin(R[2][0]) / pi)
|
| 404 |
+
# z轴
|
| 405 |
+
roll = (180 * atan2(-R[1][0], R[0][0]) / pi)
|
| 406 |
+
f = (0 > roll) - (0 < roll)
|
| 407 |
+
roll = f * (180 - fabs(roll))
|
| 408 |
+
rot_params = [pitch, yaw, roll]
|
| 409 |
+
return rot_params
|
| 410 |
+
|
| 411 |
+
def imageEulerAngle(self, img_points):
|
| 412 |
+
# 这里的img_points对应的是facePoints的第三个返回值,注意是facePoints而非facesPoints
|
| 413 |
+
# 对于facesPoints而言,需要把第三个返回值逐一取出再输入
|
| 414 |
+
# 把列表转为矩阵,且编码形式为float64
|
| 415 |
+
img_points = np.array(img_points, dtype=np.float64)
|
| 416 |
+
rvec, tvec = self.solve_pose_by_68_points(img_points)
|
| 417 |
+
# 旋转向量转旋转矩阵
|
| 418 |
+
R = cv2.Rodrigues(rvec)[0]
|
| 419 |
+
# theta = np.linalg.norm(rvec)
|
| 420 |
+
# r = rvec / theta
|
| 421 |
+
# R_ = np.array([[0, -r[2][0], r[1][0]],
|
| 422 |
+
# [r[2][0], 0, -r[0][0]],
|
| 423 |
+
# [-r[1][0], r[0][0], 0]])
|
| 424 |
+
# R = np.cos(theta) * np.eye(3) + (1 - np.cos(theta)) * r * r.T + np.sin(theta) * R_
|
| 425 |
+
# 旋转矩阵转欧拉角
|
| 426 |
+
eulerAngle = self.rot_params_rm(R)
|
| 427 |
+
# 返回一个元组和欧拉角列表
|
| 428 |
+
return (rvec, tvec, R), eulerAngle
|
| 429 |
+
|
| 430 |
+
|
| 431 |
+
# if __name__ == "__main__":
|
| 432 |
+
# # 示例
|
| 433 |
+
# from hyService.utils import Debug
|
| 434 |
+
# dg = Debug()
|
| 435 |
+
# image_input = cv2.imread("./test.jpg") # 读取一张图片, 必须是三通道或者灰度图
|
| 436 |
+
# fd68 = FaceDetection68() # 初始化人脸关键点检测类
|
| 437 |
+
# dets_, landmark_, point_list_ = fd68.facePoints(image_input) # 输入图片. 检测单张人脸
|
| 438 |
+
# # dets_, landmark_, point_list_ = fd68.facesPoints(input_image) # 输入图片. 检测多张人脸
|
| 439 |
+
# img = fd68.draw_points(image_input, landmark_)
|
| 440 |
+
# dg.cv_show(img)
|
| 441 |
+
# pe = PoseEstimator68(image_input)
|
| 442 |
+
# _, ea = pe.imageEulerAngle(point_list_) # 输入关键点列表, 如果要使用facesPoints,则输入的是point_list_[i]
|
| 443 |
+
# print(ea) # 结果
|
hivisionai/hycv/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .utils import cover_mask, get_box, get_box_pro, filtering, cut, zoom_image_without_change_size
|
hivisionai/hycv/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (363 Bytes). View file
|
|
|
hivisionai/hycv/__pycache__/error.cpython-310.pyc
ADDED
|
Binary file (1.1 kB). View file
|
|
|
hivisionai/hycv/__pycache__/face_tools.cpython-310.pyc
ADDED
|
Binary file (10.3 kB). View file
|
|
|
hivisionai/hycv/__pycache__/idphoto.cpython-310.pyc
ADDED
|
Binary file (339 Bytes). View file
|
|
|
hivisionai/hycv/__pycache__/matting_tools.cpython-310.pyc
ADDED
|
Binary file (1.52 kB). View file
|
|
|
hivisionai/hycv/__pycache__/tensor2numpy.cpython-310.pyc
ADDED
|
Binary file (2.28 kB). View file
|
|
|
hivisionai/hycv/__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (15.6 kB). View file
|
|
|
hivisionai/hycv/__pycache__/vision.cpython-310.pyc
ADDED
|
Binary file (11 kB). View file
|
|
|
hivisionai/hycv/error.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
定义hycv的一些错误类型,其实和hyService大致相同
|
| 3 |
+
"""
|
| 4 |
+
class ProcessError(Exception):
|
| 5 |
+
def __init__(self, err):
|
| 6 |
+
super().__init__(err)
|
| 7 |
+
self.err = err
|
| 8 |
+
def __str__(self):
|
| 9 |
+
return self.err
|
| 10 |
+
|
| 11 |
+
class WrongImageType(TypeError):
|
| 12 |
+
def __init__(self, err):
|
| 13 |
+
super().__init__(err)
|
| 14 |
+
self.err = err
|
| 15 |
+
def __str__(self):
|
| 16 |
+
return self.err
|
hivisionai/hycv/face_tools.py
ADDED
|
@@ -0,0 +1,427 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import os
|
| 3 |
+
import onnxruntime
|
| 4 |
+
from .mtcnn_onnx.detector import detect_faces
|
| 5 |
+
from .tensor2numpy import *
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import requests
|
| 8 |
+
from os.path import exists
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def download_img(img_url, base_dir):
|
| 12 |
+
print("Downloading Onnx Model in:", img_url)
|
| 13 |
+
r = requests.get(img_url, stream=True)
|
| 14 |
+
filename = img_url.split("/")[-1]
|
| 15 |
+
# print(r.status_code) # 返回状态码
|
| 16 |
+
if r.status_code == 200:
|
| 17 |
+
open(f'{base_dir}/{filename}', 'wb').write(r.content) # 将内容写入图片
|
| 18 |
+
print(f"Download Finshed -- {filename}")
|
| 19 |
+
del r
|
| 20 |
+
|
| 21 |
+
class BBox(object):
|
| 22 |
+
# bbox is a list of [left, right, top, bottom]
|
| 23 |
+
def __init__(self, bbox):
|
| 24 |
+
self.left = bbox[0]
|
| 25 |
+
self.right = bbox[1]
|
| 26 |
+
self.top = bbox[2]
|
| 27 |
+
self.bottom = bbox[3]
|
| 28 |
+
self.x = bbox[0]
|
| 29 |
+
self.y = bbox[2]
|
| 30 |
+
self.w = bbox[1] - bbox[0]
|
| 31 |
+
self.h = bbox[3] - bbox[2]
|
| 32 |
+
|
| 33 |
+
# scale to [0,1]
|
| 34 |
+
def projectLandmark(self, landmark):
|
| 35 |
+
landmark_= np.asarray(np.zeros(landmark.shape))
|
| 36 |
+
for i, point in enumerate(landmark):
|
| 37 |
+
landmark_[i] = ((point[0]-self.x)/self.w, (point[1]-self.y)/self.h)
|
| 38 |
+
return landmark_
|
| 39 |
+
|
| 40 |
+
# landmark of (5L, 2L) from [0,1] to real range
|
| 41 |
+
def reprojectLandmark(self, landmark):
|
| 42 |
+
landmark_= np.asarray(np.zeros(landmark.shape))
|
| 43 |
+
for i, point in enumerate(landmark):
|
| 44 |
+
x = point[0] * self.w + self.x
|
| 45 |
+
y = point[1] * self.h + self.y
|
| 46 |
+
landmark_[i] = (x, y)
|
| 47 |
+
return landmark_
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def face_detect_mtcnn(input_image, color_key=None, filter=None):
|
| 51 |
+
"""
|
| 52 |
+
Inputs:
|
| 53 |
+
- input_image: OpenCV Numpy.array
|
| 54 |
+
- color_key: 当color_key等于"RGB"时,将不进行转换操作
|
| 55 |
+
- filter:当filter等于True时,将抛弃掉置信度小于0.98或人脸框面积小于3600的人脸
|
| 56 |
+
return:
|
| 57 |
+
- faces: 带有人脸信息的变量
|
| 58 |
+
- landmarks: face alignment
|
| 59 |
+
"""
|
| 60 |
+
if color_key != "RGB":
|
| 61 |
+
input_image = cv2.cvtColor(input_image, cv2.COLOR_BGR2RGB)
|
| 62 |
+
|
| 63 |
+
input_image = Image.fromarray(input_image)
|
| 64 |
+
faces, landmarks = detect_faces(input_image)
|
| 65 |
+
|
| 66 |
+
if filter:
|
| 67 |
+
face_clean = []
|
| 68 |
+
for face in faces:
|
| 69 |
+
confidence = face[-1]
|
| 70 |
+
x1 = face[0]
|
| 71 |
+
y1 = face[1]
|
| 72 |
+
x2 = face[2]
|
| 73 |
+
y2 = face[3]
|
| 74 |
+
w = x2 - x1 + 1
|
| 75 |
+
h = y2 - y1 + 1
|
| 76 |
+
measure = w * h
|
| 77 |
+
if confidence >= 0.98 and measure > 3600:
|
| 78 |
+
# 如果检测到的人脸置信度小于0.98或人脸框面积小于3600,则抛弃该人脸
|
| 79 |
+
face_clean.append(face)
|
| 80 |
+
faces = face_clean
|
| 81 |
+
|
| 82 |
+
return faces, landmarks
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def mtcnn_bbox(face, width, height):
|
| 86 |
+
x1 = face[0]
|
| 87 |
+
y1 = face[1]
|
| 88 |
+
x2 = face[2]
|
| 89 |
+
y2 = face[3]
|
| 90 |
+
w = x2 - x1 + 1
|
| 91 |
+
h = y2 - y1 + 1
|
| 92 |
+
|
| 93 |
+
size = int(max([w, h]) * 1.1)
|
| 94 |
+
cx = x1 + w // 2
|
| 95 |
+
cy = y1 + h // 2
|
| 96 |
+
x1 = cx - size // 2
|
| 97 |
+
x2 = x1 + size
|
| 98 |
+
y1 = cy - size // 2
|
| 99 |
+
y2 = y1 + size
|
| 100 |
+
|
| 101 |
+
dx = max(0, -x1)
|
| 102 |
+
dy = max(0, -y1)
|
| 103 |
+
x1 = max(0, x1)
|
| 104 |
+
y1 = max(0, y1)
|
| 105 |
+
|
| 106 |
+
edx = max(0, x2 - width)
|
| 107 |
+
edy = max(0, y2 - height)
|
| 108 |
+
x2 = min(width, x2)
|
| 109 |
+
y2 = min(height, y2)
|
| 110 |
+
|
| 111 |
+
return x1, x2, y1, y2, dx, dy, edx, edy
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def mtcnn_cropped_face(face_box, image, width, height):
|
| 115 |
+
x1, x2, y1, y2, dx, dy, edx, edy = mtcnn_bbox(face_box, width, height)
|
| 116 |
+
new_bbox = list(map(int, [x1, x2, y1, y2]))
|
| 117 |
+
new_bbox = BBox(new_bbox)
|
| 118 |
+
cropped = image[new_bbox.top:new_bbox.bottom, new_bbox.left:new_bbox.right]
|
| 119 |
+
if (dx > 0 or dy > 0 or edx > 0 or edy > 0):
|
| 120 |
+
cropped = cv2.copyMakeBorder(cropped, int(dy), int(edy), int(dx), int(edx), cv2.BORDER_CONSTANT, 0)
|
| 121 |
+
return cropped, new_bbox
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def face_landmark_56(input_image, faces_box=None):
|
| 125 |
+
basedir = os.path.dirname(os.path.realpath(__file__)).split("mtcnn.py")[0]
|
| 126 |
+
mean = np.asarray([0.485, 0.456, 0.406])
|
| 127 |
+
std = np.asarray([0.229, 0.224, 0.225])
|
| 128 |
+
base_url = "https://linimages.oss-cn-beijing.aliyuncs.com/"
|
| 129 |
+
|
| 130 |
+
if not exists(f"{basedir}/mtcnn_onnx/weights/landmark_detection_56_se_external.onnx"):
|
| 131 |
+
# download onnx model
|
| 132 |
+
download_img(img_url=base_url + "landmark_detection_56_se_external.onnx",
|
| 133 |
+
base_dir=f"{basedir}/mtcnn_onnx/weights")
|
| 134 |
+
|
| 135 |
+
ort_session = onnxruntime.InferenceSession(f"{basedir}/mtcnn_onnx/weights/landmark_detection_56_se_external.onnx")
|
| 136 |
+
out_size = 56
|
| 137 |
+
|
| 138 |
+
height, width, _ = input_image.shape
|
| 139 |
+
if faces_box is None:
|
| 140 |
+
faces_box, _ = face_detect_mtcnn(input_image)
|
| 141 |
+
|
| 142 |
+
if len(faces_box) == 0:
|
| 143 |
+
print('NO face is detected!')
|
| 144 |
+
return None
|
| 145 |
+
else:
|
| 146 |
+
landmarks = []
|
| 147 |
+
for face_box in faces_box:
|
| 148 |
+
cropped, new_bbox = mtcnn_cropped_face(face_box, input_image, width, height)
|
| 149 |
+
cropped_face = cv2.resize(cropped, (out_size, out_size))
|
| 150 |
+
|
| 151 |
+
test_face = NNormalize(cropped_face, mean=mean, std=std)
|
| 152 |
+
test_face = NTo_Tensor(test_face)
|
| 153 |
+
test_face = NUnsqueeze(test_face)
|
| 154 |
+
|
| 155 |
+
ort_inputs = {ort_session.get_inputs()[0].name: test_face}
|
| 156 |
+
ort_outs = ort_session.run(None, ort_inputs)
|
| 157 |
+
|
| 158 |
+
landmark = ort_outs[0]
|
| 159 |
+
|
| 160 |
+
landmark = landmark.reshape(-1, 2)
|
| 161 |
+
landmark = new_bbox.reprojectLandmark(landmark)
|
| 162 |
+
landmarks.append(landmark)
|
| 163 |
+
|
| 164 |
+
return landmarks
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
REFERENCE_FACIAL_POINTS = [
|
| 169 |
+
[30.29459953, 51.69630051],
|
| 170 |
+
[65.53179932, 51.50139999],
|
| 171 |
+
[48.02519989, 71.73660278],
|
| 172 |
+
[33.54930115, 92.3655014],
|
| 173 |
+
[62.72990036, 92.20410156]
|
| 174 |
+
]
|
| 175 |
+
|
| 176 |
+
DEFAULT_CROP_SIZE = (96, 112)
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
def _umeyama(src, dst, estimate_scale=True, scale=1.0):
|
| 180 |
+
"""Estimate N-D similarity transformation with or without scaling.
|
| 181 |
+
Parameters
|
| 182 |
+
----------
|
| 183 |
+
src : (M, N) array
|
| 184 |
+
Source coordinates.
|
| 185 |
+
dst : (M, N) array
|
| 186 |
+
Destination coordinates.
|
| 187 |
+
estimate_scale : bool
|
| 188 |
+
Whether to estimate scaling factor.
|
| 189 |
+
Returns
|
| 190 |
+
-------
|
| 191 |
+
T : (N + 1, N + 1)
|
| 192 |
+
The homogeneous similarity transformation matrix. The matrix contains
|
| 193 |
+
NaN values only if the problem is not well-conditioned.
|
| 194 |
+
References
|
| 195 |
+
----------
|
| 196 |
+
.. [1] "Least-squares estimation of transformation parameters between two
|
| 197 |
+
point patterns", Shinji Umeyama, PAMI 1991, :DOI:`10.1109/34.88573`
|
| 198 |
+
"""
|
| 199 |
+
|
| 200 |
+
num = src.shape[0]
|
| 201 |
+
dim = src.shape[1]
|
| 202 |
+
|
| 203 |
+
# Compute mean of src and dst.
|
| 204 |
+
src_mean = src.mean(axis=0)
|
| 205 |
+
dst_mean = dst.mean(axis=0)
|
| 206 |
+
|
| 207 |
+
# Subtract mean from src and dst.
|
| 208 |
+
src_demean = src - src_mean
|
| 209 |
+
dst_demean = dst - dst_mean
|
| 210 |
+
|
| 211 |
+
# Eq. (38).
|
| 212 |
+
A = dst_demean.T @ src_demean / num
|
| 213 |
+
|
| 214 |
+
# Eq. (39).
|
| 215 |
+
d = np.ones((dim,), dtype=np.double)
|
| 216 |
+
if np.linalg.det(A) < 0:
|
| 217 |
+
d[dim - 1] = -1
|
| 218 |
+
|
| 219 |
+
T = np.eye(dim + 1, dtype=np.double)
|
| 220 |
+
|
| 221 |
+
U, S, V = np.linalg.svd(A)
|
| 222 |
+
|
| 223 |
+
# Eq. (40) and (43).
|
| 224 |
+
rank = np.linalg.matrix_rank(A)
|
| 225 |
+
if rank == 0:
|
| 226 |
+
return np.nan * T
|
| 227 |
+
elif rank == dim - 1:
|
| 228 |
+
if np.linalg.det(U) * np.linalg.det(V) > 0:
|
| 229 |
+
T[:dim, :dim] = U @ V
|
| 230 |
+
else:
|
| 231 |
+
s = d[dim - 1]
|
| 232 |
+
d[dim - 1] = -1
|
| 233 |
+
T[:dim, :dim] = U @ np.diag(d) @ V
|
| 234 |
+
d[dim - 1] = s
|
| 235 |
+
else:
|
| 236 |
+
T[:dim, :dim] = U @ np.diag(d) @ V
|
| 237 |
+
|
| 238 |
+
if estimate_scale:
|
| 239 |
+
# Eq. (41) and (42).
|
| 240 |
+
scale = 1.0 / src_demean.var(axis=0).sum() * (S @ d)
|
| 241 |
+
else:
|
| 242 |
+
scale = scale
|
| 243 |
+
|
| 244 |
+
T[:dim, dim] = dst_mean - scale * (T[:dim, :dim] @ src_mean.T)
|
| 245 |
+
T[:dim, :dim] *= scale
|
| 246 |
+
|
| 247 |
+
return T, scale
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
class FaceWarpException(Exception):
|
| 251 |
+
def __str__(self):
|
| 252 |
+
return 'In File {}:{}'.format(
|
| 253 |
+
__file__, super.__str__(self))
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
def get_reference_facial_points_5(output_size=None,
|
| 257 |
+
inner_padding_factor=0.0,
|
| 258 |
+
outer_padding=(0, 0),
|
| 259 |
+
default_square=False):
|
| 260 |
+
tmp_5pts = np.array(REFERENCE_FACIAL_POINTS)
|
| 261 |
+
tmp_crop_size = np.array(DEFAULT_CROP_SIZE)
|
| 262 |
+
|
| 263 |
+
# 0) make the inner region a square
|
| 264 |
+
if default_square:
|
| 265 |
+
size_diff = max(tmp_crop_size) - tmp_crop_size
|
| 266 |
+
tmp_5pts += size_diff / 2
|
| 267 |
+
tmp_crop_size += size_diff
|
| 268 |
+
|
| 269 |
+
if (output_size and
|
| 270 |
+
output_size[0] == tmp_crop_size[0] and
|
| 271 |
+
output_size[1] == tmp_crop_size[1]):
|
| 272 |
+
print('output_size == DEFAULT_CROP_SIZE {}: return default reference points'.format(tmp_crop_size))
|
| 273 |
+
return tmp_5pts
|
| 274 |
+
|
| 275 |
+
if (inner_padding_factor == 0 and
|
| 276 |
+
outer_padding == (0, 0)):
|
| 277 |
+
if output_size is None:
|
| 278 |
+
print('No paddings to do: return default reference points')
|
| 279 |
+
return tmp_5pts
|
| 280 |
+
else:
|
| 281 |
+
raise FaceWarpException(
|
| 282 |
+
'No paddings to do, output_size must be None or {}'.format(tmp_crop_size))
|
| 283 |
+
|
| 284 |
+
# check output size
|
| 285 |
+
if not (0 <= inner_padding_factor <= 1.0):
|
| 286 |
+
raise FaceWarpException('Not (0 <= inner_padding_factor <= 1.0)')
|
| 287 |
+
|
| 288 |
+
if ((inner_padding_factor > 0 or outer_padding[0] > 0 or outer_padding[1] > 0)
|
| 289 |
+
and output_size is None):
|
| 290 |
+
output_size = tmp_crop_size * \
|
| 291 |
+
(1 + inner_padding_factor * 2).astype(np.int32)
|
| 292 |
+
output_size += np.array(outer_padding)
|
| 293 |
+
print(' deduced from paddings, output_size = ', output_size)
|
| 294 |
+
|
| 295 |
+
if not (outer_padding[0] < output_size[0]
|
| 296 |
+
and outer_padding[1] < output_size[1]):
|
| 297 |
+
raise FaceWarpException('Not (outer_padding[0] < output_size[0]'
|
| 298 |
+
'and outer_padding[1] < output_size[1])')
|
| 299 |
+
|
| 300 |
+
# 1) pad the inner region according inner_padding_factor
|
| 301 |
+
# print('---> STEP1: pad the inner region according inner_padding_factor')
|
| 302 |
+
if inner_padding_factor > 0:
|
| 303 |
+
size_diff = tmp_crop_size * inner_padding_factor * 2
|
| 304 |
+
tmp_5pts += size_diff / 2
|
| 305 |
+
tmp_crop_size += np.round(size_diff).astype(np.int32)
|
| 306 |
+
|
| 307 |
+
# print(' crop_size = ', tmp_crop_size)
|
| 308 |
+
# print(' reference_5pts = ', tmp_5pts)
|
| 309 |
+
|
| 310 |
+
# 2) resize the padded inner region
|
| 311 |
+
# print('---> STEP2: resize the padded inner region')
|
| 312 |
+
size_bf_outer_pad = np.array(output_size) - np.array(outer_padding) * 2
|
| 313 |
+
# print(' crop_size = ', tmp_crop_size)
|
| 314 |
+
# print(' size_bf_outer_pad = ', size_bf_outer_pad)
|
| 315 |
+
|
| 316 |
+
if size_bf_outer_pad[0] * tmp_crop_size[1] != size_bf_outer_pad[1] * tmp_crop_size[0]:
|
| 317 |
+
raise FaceWarpException('Must have (output_size - outer_padding)'
|
| 318 |
+
'= some_scale * (crop_size * (1.0 + inner_padding_factor)')
|
| 319 |
+
|
| 320 |
+
scale_factor = size_bf_outer_pad[0].astype(np.float32) / tmp_crop_size[0]
|
| 321 |
+
# print(' resize scale_factor = ', scale_factor)
|
| 322 |
+
tmp_5pts = tmp_5pts * scale_factor
|
| 323 |
+
# size_diff = tmp_crop_size * (scale_factor - min(scale_factor))
|
| 324 |
+
# tmp_5pts = tmp_5pts + size_diff / 2
|
| 325 |
+
tmp_crop_size = size_bf_outer_pad
|
| 326 |
+
# print(' crop_size = ', tmp_crop_size)
|
| 327 |
+
# print(' reference_5pts = ', tmp_5pts)
|
| 328 |
+
|
| 329 |
+
# 3) add outer_padding to make output_size
|
| 330 |
+
reference_5point = tmp_5pts + np.array(outer_padding)
|
| 331 |
+
tmp_crop_size = output_size
|
| 332 |
+
# print('---> STEP3: add outer_padding to make output_size')
|
| 333 |
+
# print(' crop_size = ', tmp_crop_size)
|
| 334 |
+
# print(' reference_5pts = ', tmp_5pts)
|
| 335 |
+
#
|
| 336 |
+
# print('===> end get_reference_facial_points\n')
|
| 337 |
+
|
| 338 |
+
return reference_5point
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
def get_affine_transform_matrix(src_pts, dst_pts):
|
| 342 |
+
tfm = np.float32([[1, 0, 0], [0, 1, 0]])
|
| 343 |
+
n_pts = src_pts.shape[0]
|
| 344 |
+
ones = np.ones((n_pts, 1), src_pts.dtype)
|
| 345 |
+
src_pts_ = np.hstack([src_pts, ones])
|
| 346 |
+
dst_pts_ = np.hstack([dst_pts, ones])
|
| 347 |
+
|
| 348 |
+
A, res, rank, s = np.linalg.lstsq(src_pts_, dst_pts_)
|
| 349 |
+
|
| 350 |
+
if rank == 3:
|
| 351 |
+
tfm = np.float32([
|
| 352 |
+
[A[0, 0], A[1, 0], A[2, 0]],
|
| 353 |
+
[A[0, 1], A[1, 1], A[2, 1]]
|
| 354 |
+
])
|
| 355 |
+
elif rank == 2:
|
| 356 |
+
tfm = np.float32([
|
| 357 |
+
[A[0, 0], A[1, 0], 0],
|
| 358 |
+
[A[0, 1], A[1, 1], 0]
|
| 359 |
+
])
|
| 360 |
+
|
| 361 |
+
return tfm
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
def warp_and_crop_face(src_img,
|
| 365 |
+
facial_pts,
|
| 366 |
+
reference_pts=None,
|
| 367 |
+
crop_size=(96, 112),
|
| 368 |
+
align_type='smilarity'): #smilarity cv2_affine affine
|
| 369 |
+
if reference_pts is None:
|
| 370 |
+
if crop_size[0] == 96 and crop_size[1] == 112:
|
| 371 |
+
reference_pts = REFERENCE_FACIAL_POINTS
|
| 372 |
+
else:
|
| 373 |
+
default_square = False
|
| 374 |
+
inner_padding_factor = 0
|
| 375 |
+
outer_padding = (0, 0)
|
| 376 |
+
output_size = crop_size
|
| 377 |
+
|
| 378 |
+
reference_pts = get_reference_facial_points_5(output_size,
|
| 379 |
+
inner_padding_factor,
|
| 380 |
+
outer_padding,
|
| 381 |
+
default_square)
|
| 382 |
+
|
| 383 |
+
ref_pts = np.float32(reference_pts)
|
| 384 |
+
ref_pts_shp = ref_pts.shape
|
| 385 |
+
if max(ref_pts_shp) < 3 or min(ref_pts_shp) != 2:
|
| 386 |
+
raise FaceWarpException(
|
| 387 |
+
'reference_pts.shape must be (K,2) or (2,K) and K>2')
|
| 388 |
+
|
| 389 |
+
if ref_pts_shp[0] == 2:
|
| 390 |
+
ref_pts = ref_pts.T
|
| 391 |
+
|
| 392 |
+
src_pts = np.float32(facial_pts)
|
| 393 |
+
src_pts_shp = src_pts.shape
|
| 394 |
+
if max(src_pts_shp) < 3 or min(src_pts_shp) != 2:
|
| 395 |
+
raise FaceWarpException(
|
| 396 |
+
'facial_pts.shape must be (K,2) or (2,K) and K>2')
|
| 397 |
+
|
| 398 |
+
if src_pts_shp[0] == 2:
|
| 399 |
+
src_pts = src_pts.T
|
| 400 |
+
|
| 401 |
+
if src_pts.shape != ref_pts.shape:
|
| 402 |
+
raise FaceWarpException(
|
| 403 |
+
'facial_pts and reference_pts must have the same shape')
|
| 404 |
+
|
| 405 |
+
if align_type == 'cv2_affine':
|
| 406 |
+
tfm = cv2.getAffineTransform(src_pts[0:3], ref_pts[0:3])
|
| 407 |
+
tfm_inv = cv2.getAffineTransform(ref_pts[0:3], src_pts[0:3])
|
| 408 |
+
elif align_type == 'affine':
|
| 409 |
+
tfm = get_affine_transform_matrix(src_pts, ref_pts)
|
| 410 |
+
tfm_inv = get_affine_transform_matrix(ref_pts, src_pts)
|
| 411 |
+
else:
|
| 412 |
+
params, scale = _umeyama(src_pts, ref_pts)
|
| 413 |
+
tfm = params[:2, :]
|
| 414 |
+
|
| 415 |
+
params, _ = _umeyama(ref_pts, src_pts, False, scale=1.0/scale)
|
| 416 |
+
tfm_inv = params[:2, :]
|
| 417 |
+
|
| 418 |
+
face_img = cv2.warpAffine(src_img, tfm, (crop_size[0], crop_size[1]), flags=3)
|
| 419 |
+
|
| 420 |
+
return face_img, tfm_inv
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
if __name__ == "__main__":
|
| 424 |
+
image = cv2.imread("/home/parallels/Desktop/IDPhotos/input_image/03.jpg")
|
| 425 |
+
face_detect_mtcnn(image)
|
| 426 |
+
|
| 427 |
+
|
hivisionai/hycv/idphoto.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .idphotoTool.idphoto_cut import IDphotos_create
|
| 2 |
+
from .idphotoTool.idphoto_change_cloth import change_cloth
|
hivisionai/hycv/idphotoTool/__init__.py
ADDED
|
File without changes
|
hivisionai/hycv/idphotoTool/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (220 Bytes). View file
|
|
|
hivisionai/hycv/idphotoTool/__pycache__/cuny_tools.cpython-310.pyc
ADDED
|
Binary file (16.8 kB). View file
|
|
|
hivisionai/hycv/idphotoTool/__pycache__/idphoto_change_cloth.cpython-310.pyc
ADDED
|
Binary file (5.02 kB). View file
|
|
|
hivisionai/hycv/idphotoTool/__pycache__/idphoto_cut.cpython-310.pyc
ADDED
|
Binary file (8.71 kB). View file
|
|
|
hivisionai/hycv/idphotoTool/__pycache__/move_image.cpython-310.pyc
ADDED
|
Binary file (3.14 kB). View file
|
|
|
hivisionai/hycv/idphotoTool/__pycache__/neck_processing.cpython-310.pyc
ADDED
|
Binary file (9.13 kB). View file
|
|
|