Spaces:
Running
on
Zero

Running
on
Zero
Commit
·
9d3c2b7
1
Parent(s):
3839d6c
add files
Browse files- app.py +121 -147
- assets/LADD.png +0 -0
- assets/MMDiT1.png +0 -0
- assets/MMDiT_block1.png +0 -0
- assets/discriminator.png +0 -0
- assets/discriminator_head.png +0 -0
- assets/pipeline.png +0 -0
- kandinsky/.DS_Store +0 -0
- kandinsky/__init__.py +157 -0
- kandinsky/model/__init__.py +0 -0
- kandinsky/model/__pycache__/__init__.cpython-311.pyc +0 -0
- kandinsky/model/__pycache__/dit.cpython-311.pyc +0 -0
- kandinsky/model/__pycache__/dit_i2v.cpython-311.pyc +0 -0
- kandinsky/model/__pycache__/nn.cpython-311.pyc +0 -0
- kandinsky/model/__pycache__/nn_i2v.cpython-311.pyc +0 -0
- kandinsky/model/__pycache__/text_embedders.cpython-311.pyc +0 -0
- kandinsky/model/__pycache__/utils.cpython-311.pyc +0 -0
- kandinsky/model/dit.py +201 -0
- kandinsky/model/nn.py +292 -0
- kandinsky/model/text_embedders.py +62 -0
- kandinsky/model/utils.py +107 -0
- kandinsky/t2v_pipeline.py +201 -0
app.py
CHANGED
|
@@ -1,154 +1,128 @@
|
|
| 1 |
import gradio as gr
|
| 2 |
-
import
|
| 3 |
-
import
|
| 4 |
-
|
| 5 |
-
# import spaces #[uncomment to use ZeroGPU]
|
| 6 |
-
from diffusers import DiffusionPipeline
|
| 7 |
import torch
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
if torch.cuda.is_available():
|
| 13 |
-
torch_dtype = torch.float16
|
| 14 |
-
else:
|
| 15 |
-
torch_dtype = torch.float32
|
| 16 |
-
|
| 17 |
-
pipe = DiffusionPipeline.from_pretrained(model_repo_id, torch_dtype=torch_dtype)
|
| 18 |
-
pipe = pipe.to(device)
|
| 19 |
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
#
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
):
|
| 36 |
-
if
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
)
|
| 50 |
-
|
| 51 |
-
return
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
with gr.Row():
|
| 120 |
-
guidance_scale = gr.Slider(
|
| 121 |
-
label="Guidance scale",
|
| 122 |
-
minimum=0.0,
|
| 123 |
-
maximum=10.0,
|
| 124 |
-
step=0.1,
|
| 125 |
-
value=0.0, # Replace with defaults that work for your model
|
| 126 |
-
)
|
| 127 |
-
|
| 128 |
-
num_inference_steps = gr.Slider(
|
| 129 |
-
label="Number of inference steps",
|
| 130 |
-
minimum=1,
|
| 131 |
-
maximum=50,
|
| 132 |
-
step=1,
|
| 133 |
-
value=2, # Replace with defaults that work for your model
|
| 134 |
-
)
|
| 135 |
-
|
| 136 |
-
gr.Examples(examples=examples, inputs=[prompt])
|
| 137 |
-
gr.on(
|
| 138 |
-
triggers=[run_button.click, prompt.submit],
|
| 139 |
-
fn=infer,
|
| 140 |
-
inputs=[
|
| 141 |
-
prompt,
|
| 142 |
-
negative_prompt,
|
| 143 |
-
seed,
|
| 144 |
-
randomize_seed,
|
| 145 |
-
width,
|
| 146 |
-
height,
|
| 147 |
-
guidance_scale,
|
| 148 |
-
num_inference_steps,
|
| 149 |
-
],
|
| 150 |
-
outputs=[result, seed],
|
| 151 |
-
)
|
| 152 |
|
| 153 |
if __name__ == "__main__":
|
| 154 |
-
demo.
|
|
|
|
|
|
| 1 |
import gradio as gr
|
| 2 |
+
import spaces
|
| 3 |
+
#import gradio.helpers
|
|
|
|
|
|
|
|
|
|
| 4 |
import torch
|
| 5 |
+
import os
|
| 6 |
+
from glob import glob
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
from typing import Optional
|
| 9 |
|
| 10 |
+
from diffusers import StableVideoDiffusionPipeline
|
| 11 |
+
from diffusers.utils import load_image, export_to_video
|
| 12 |
+
from PIL import Image
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
|
| 14 |
+
import uuid
|
| 15 |
+
import random
|
| 16 |
+
from huggingface_hub import hf_hub_download
|
| 17 |
+
|
| 18 |
+
#gradio.helpers.CACHED_FOLDER = '/data/cache'
|
| 19 |
+
|
| 20 |
+
pipe = StableVideoDiffusionPipeline.from_pretrained(
|
| 21 |
+
"multimodalart/stable-video-diffusion", torch_dtype=torch.float16, variant="fp16"
|
| 22 |
+
)
|
| 23 |
+
pipe.to("cuda")
|
| 24 |
+
#pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
|
| 25 |
+
#pipe.vae = torch.compile(pipe.vae, mode="reduce-overhead", fullgraph=True)
|
| 26 |
+
|
| 27 |
+
max_64_bit_int = 2**63 - 1
|
| 28 |
+
|
| 29 |
+
@spaces.GPU(duration=120)
|
| 30 |
+
def sample(
|
| 31 |
+
image: Image,
|
| 32 |
+
seed: Optional[int] = 42,
|
| 33 |
+
randomize_seed: bool = True,
|
| 34 |
+
motion_bucket_id: int = 127,
|
| 35 |
+
fps_id: int = 6,
|
| 36 |
+
version: str = "svd_xt",
|
| 37 |
+
cond_aug: float = 0.02,
|
| 38 |
+
decoding_t: int = 3, # Number of frames decoded at a time! This eats most VRAM. Reduce if necessary.
|
| 39 |
+
device: str = "cuda",
|
| 40 |
+
output_folder: str = "outputs",
|
| 41 |
+
progress=gr.Progress(track_tqdm=True)
|
| 42 |
):
|
| 43 |
+
if image.mode == "RGBA":
|
| 44 |
+
image = image.convert("RGB")
|
| 45 |
+
|
| 46 |
+
if(randomize_seed):
|
| 47 |
+
seed = random.randint(0, max_64_bit_int)
|
| 48 |
+
generator = torch.manual_seed(seed)
|
| 49 |
+
|
| 50 |
+
os.makedirs(output_folder, exist_ok=True)
|
| 51 |
+
base_count = len(glob(os.path.join(output_folder, "*.mp4")))
|
| 52 |
+
video_path = os.path.join(output_folder, f"{base_count:06d}.mp4")
|
| 53 |
+
|
| 54 |
+
frames = pipe(image, decode_chunk_size=decoding_t, generator=generator, motion_bucket_id=motion_bucket_id, noise_aug_strength=0.1, num_frames=25).frames[0]
|
| 55 |
+
export_to_video(frames, video_path, fps=fps_id)
|
| 56 |
+
torch.manual_seed(seed)
|
| 57 |
+
|
| 58 |
+
return video_path, seed
|
| 59 |
+
|
| 60 |
+
def resize_image(image, output_size=(1024, 576)):
|
| 61 |
+
# Calculate aspect ratios
|
| 62 |
+
target_aspect = output_size[0] / output_size[1] # Aspect ratio of the desired size
|
| 63 |
+
image_aspect = image.width / image.height # Aspect ratio of the original image
|
| 64 |
+
|
| 65 |
+
# Resize then crop if the original image is larger
|
| 66 |
+
if image_aspect > target_aspect:
|
| 67 |
+
# Resize the image to match the target height, maintaining aspect ratio
|
| 68 |
+
new_height = output_size[1]
|
| 69 |
+
new_width = int(new_height * image_aspect)
|
| 70 |
+
resized_image = image.resize((new_width, new_height), Image.LANCZOS)
|
| 71 |
+
# Calculate coordinates for cropping
|
| 72 |
+
left = (new_width - output_size[0]) / 2
|
| 73 |
+
top = 0
|
| 74 |
+
right = (new_width + output_size[0]) / 2
|
| 75 |
+
bottom = output_size[1]
|
| 76 |
+
else:
|
| 77 |
+
# Resize the image to match the target width, maintaining aspect ratio
|
| 78 |
+
new_width = output_size[0]
|
| 79 |
+
new_height = int(new_width / image_aspect)
|
| 80 |
+
resized_image = image.resize((new_width, new_height), Image.LANCZOS)
|
| 81 |
+
# Calculate coordinates for cropping
|
| 82 |
+
left = 0
|
| 83 |
+
top = (new_height - output_size[1]) / 2
|
| 84 |
+
right = output_size[0]
|
| 85 |
+
bottom = (new_height + output_size[1]) / 2
|
| 86 |
+
|
| 87 |
+
# Crop the image
|
| 88 |
+
cropped_image = resized_image.crop((left, top, right, bottom))
|
| 89 |
+
return cropped_image
|
| 90 |
+
|
| 91 |
+
with gr.Blocks() as demo:
|
| 92 |
+
gr.Markdown('''# Community demo for Stable Video Diffusion - Img2Vid - XT ([model](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt), [paper](https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets), [stability's ui waitlist](https://stability.ai/contact))
|
| 93 |
+
#### Research release ([_non-commercial_](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt/blob/main/LICENSE)): generate `4s` vid from a single image at (`25 frames` at `6 fps`). this demo uses [🧨 diffusers for low VRAM and fast generation](https://huggingface.co/docs/diffusers/main/en/using-diffusers/svd).
|
| 94 |
+
''')
|
| 95 |
+
with gr.Row():
|
| 96 |
+
with gr.Column():
|
| 97 |
+
image = gr.Image(label="Upload your image", type="pil")
|
| 98 |
+
generate_btn = gr.Button("Generate")
|
| 99 |
+
video = gr.Video()
|
| 100 |
+
with gr.Accordion("Advanced options", open=False):
|
| 101 |
+
seed = gr.Slider(label="Seed", value=42, randomize=True, minimum=0, maximum=max_64_bit_int, step=1)
|
| 102 |
+
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
|
| 103 |
+
motion_bucket_id = gr.Slider(label="Motion bucket id", info="Controls how much motion to add/remove from the image", value=127, minimum=1, maximum=255)
|
| 104 |
+
fps_id = gr.Slider(label="Frames per second", info="The length of your video in seconds will be 25/fps", value=6, minimum=5, maximum=30)
|
| 105 |
+
|
| 106 |
+
image.upload(fn=resize_image, inputs=image, outputs=image, queue=False)
|
| 107 |
+
generate_btn.click(fn=sample, inputs=[image, seed, randomize_seed, motion_bucket_id, fps_id], outputs=[video, seed], api_name="video")
|
| 108 |
+
gr.Examples(
|
| 109 |
+
examples=[
|
| 110 |
+
"images/blink_meme.png",
|
| 111 |
+
"images/confused2_meme.png",
|
| 112 |
+
"images/disaster_meme.png",
|
| 113 |
+
"images/distracted_meme.png",
|
| 114 |
+
"images/hide_meme.png",
|
| 115 |
+
"images/nazare_meme.png",
|
| 116 |
+
"images/success_meme.png",
|
| 117 |
+
"images/willy_meme.png",
|
| 118 |
+
"images/wink_meme.png"
|
| 119 |
+
],
|
| 120 |
+
inputs=image,
|
| 121 |
+
outputs=[video, seed],
|
| 122 |
+
fn=sample,
|
| 123 |
+
cache_examples="lazy",
|
| 124 |
+
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 125 |
|
| 126 |
if __name__ == "__main__":
|
| 127 |
+
#demo.queue(max_size=20, api_open=False)
|
| 128 |
+
demo.launch(share=True, show_api=False)
|
assets/LADD.png
ADDED
|
assets/MMDiT1.png
ADDED
|
assets/MMDiT_block1.png
ADDED
|
assets/discriminator.png
ADDED
|
assets/discriminator_head.png
ADDED
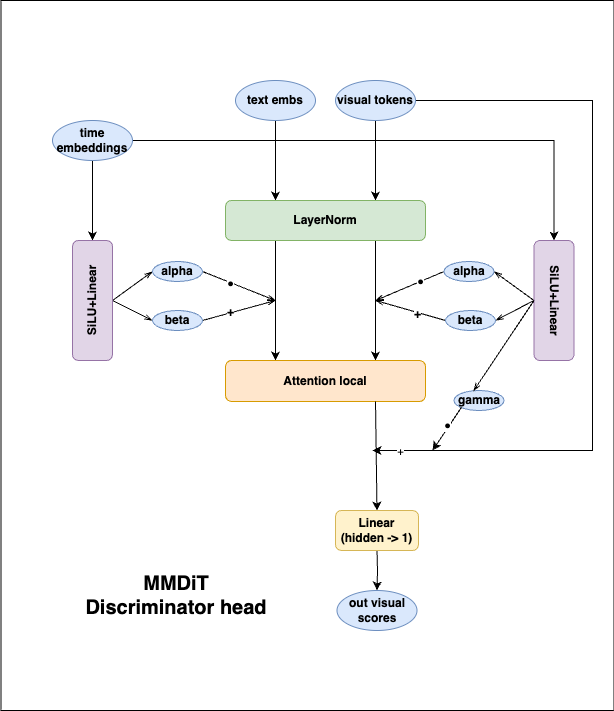
|
assets/pipeline.png
ADDED
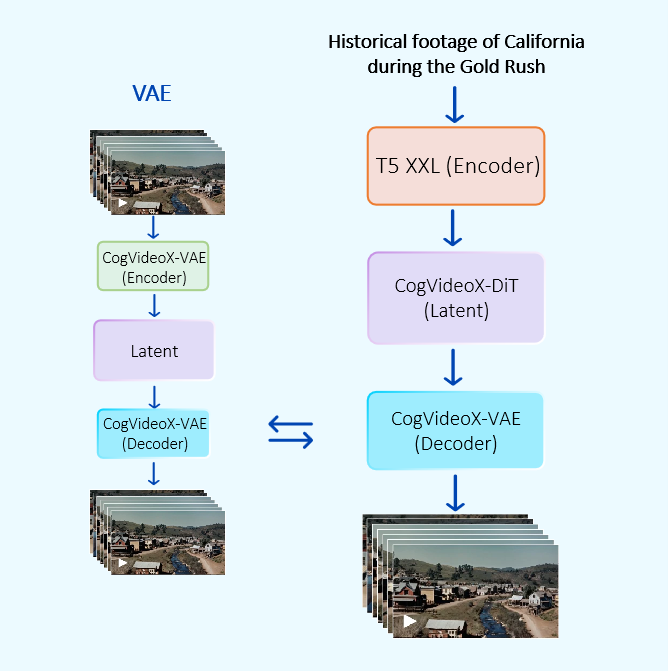
|
kandinsky/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
kandinsky/__init__.py
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import Optional, Union
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from omegaconf import OmegaConf
|
| 6 |
+
from .model.dit import get_dit, parallelize
|
| 7 |
+
from .model.text_embedders import get_text_embedder
|
| 8 |
+
from diffusers import AutoencoderKLCogVideoX, CogVideoXDDIMScheduler
|
| 9 |
+
from omegaconf.dictconfig import DictConfig
|
| 10 |
+
from huggingface_hub import hf_hub_download, snapshot_download
|
| 11 |
+
|
| 12 |
+
from .t2v_pipeline import Kandinsky4T2VPipeline
|
| 13 |
+
|
| 14 |
+
from torch.distributed.device_mesh import DeviceMesh, init_device_mesh
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def get_T2V_pipeline(
|
| 18 |
+
device_map: Union[str, torch.device, dict],
|
| 19 |
+
resolution: int = 512,
|
| 20 |
+
cache_dir: str = './weights/',
|
| 21 |
+
dit_path: str = None,
|
| 22 |
+
text_encoder_path: str = None,
|
| 23 |
+
tokenizer_path: str = None,
|
| 24 |
+
vae_path: str = None,
|
| 25 |
+
scheduler_path: str = None,
|
| 26 |
+
conf_path: str = None,
|
| 27 |
+
) -> Kandinsky4T2VPipeline:
|
| 28 |
+
|
| 29 |
+
assert resolution in [512]
|
| 30 |
+
|
| 31 |
+
if not isinstance(device_map, dict):
|
| 32 |
+
device_map = {
|
| 33 |
+
'dit': device_map,
|
| 34 |
+
'vae': device_map,
|
| 35 |
+
'text_embedder': device_map
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
try:
|
| 39 |
+
local_rank, world_size = int(os.environ["LOCAL_RANK"]), int(os.environ["WORLD_SIZE"])
|
| 40 |
+
except:
|
| 41 |
+
local_rank, world_size = 0, 1
|
| 42 |
+
|
| 43 |
+
if world_size > 1:
|
| 44 |
+
device_mesh = init_device_mesh("cuda", (world_size,), mesh_dim_names=("tensor_parallel",))
|
| 45 |
+
device_map["dit"] = torch.device(f'cuda:{local_rank}')
|
| 46 |
+
|
| 47 |
+
os.makedirs(cache_dir, exist_ok=True)
|
| 48 |
+
|
| 49 |
+
if dit_path is None:
|
| 50 |
+
dit_path = hf_hub_download(
|
| 51 |
+
repo_id="ai-forever/kandinsky4", filename=f"kandinsky4_distil_{resolution}.pt", local_dir=cache_dir
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
if vae_path is None:
|
| 55 |
+
vae_path = snapshot_download(
|
| 56 |
+
repo_id="THUDM/CogVideoX-5b", allow_patterns='vae/*', local_dir=cache_dir
|
| 57 |
+
)
|
| 58 |
+
vae_path = os.path.join(cache_dir, f"vae/")
|
| 59 |
+
|
| 60 |
+
if scheduler_path is None:
|
| 61 |
+
scheduler_path = snapshot_download(
|
| 62 |
+
repo_id="THUDM/CogVideoX-5b", allow_patterns='scheduler/*', local_dir=cache_dir
|
| 63 |
+
)
|
| 64 |
+
scheduler_path = os.path.join(cache_dir, f"scheduler/")
|
| 65 |
+
|
| 66 |
+
if text_encoder_path is None:
|
| 67 |
+
text_encoder_path = snapshot_download(
|
| 68 |
+
repo_id="THUDM/CogVideoX-5b", allow_patterns='text_encoder/*', local_dir=cache_dir
|
| 69 |
+
)
|
| 70 |
+
text_encoder_path = os.path.join(cache_dir, f"text_encoder/")
|
| 71 |
+
|
| 72 |
+
if tokenizer_path is None:
|
| 73 |
+
tokenizer_path = snapshot_download(
|
| 74 |
+
repo_id="THUDM/CogVideoX-5b", allow_patterns='tokenizer/*', local_dir=cache_dir
|
| 75 |
+
)
|
| 76 |
+
tokenizer_path = os.path.join(cache_dir, f"tokenizer/")
|
| 77 |
+
|
| 78 |
+
if conf_path is None:
|
| 79 |
+
conf = get_default_conf(vae_path, text_encoder_path, tokenizer_path, scheduler_path, dit_path)
|
| 80 |
+
else:
|
| 81 |
+
conf = OmegaConf.load(conf_path)
|
| 82 |
+
|
| 83 |
+
dit = get_dit(conf.dit)
|
| 84 |
+
dit = dit.to(dtype=torch.bfloat16, device=device_map["dit"])
|
| 85 |
+
|
| 86 |
+
noise_scheduler = CogVideoXDDIMScheduler.from_pretrained(conf.dit.scheduler)
|
| 87 |
+
|
| 88 |
+
if world_size > 1:
|
| 89 |
+
dit = parallelize(dit, device_mesh["tensor_parallel"])
|
| 90 |
+
|
| 91 |
+
text_embedder = get_text_embedder(conf)
|
| 92 |
+
text_embedder = text_embedder.freeze()
|
| 93 |
+
if local_rank == 0:
|
| 94 |
+
text_embedder = text_embedder.to(device=device_map["text_embedder"], dtype=torch.bfloat16)
|
| 95 |
+
|
| 96 |
+
vae = AutoencoderKLCogVideoX.from_pretrained(conf.vae.checkpoint_path)
|
| 97 |
+
vae = vae.eval()
|
| 98 |
+
if local_rank == 0:
|
| 99 |
+
vae = vae.to(device_map["vae"], dtype=torch.bfloat16)
|
| 100 |
+
|
| 101 |
+
return Kandinsky4T2VPipeline(
|
| 102 |
+
device_map=device_map,
|
| 103 |
+
dit=dit,
|
| 104 |
+
text_embedder=text_embedder,
|
| 105 |
+
vae=vae,
|
| 106 |
+
noise_scheduler=noise_scheduler,
|
| 107 |
+
resolution=resolution,
|
| 108 |
+
local_dit_rank=local_rank,
|
| 109 |
+
world_size=world_size,
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def get_default_conf(
|
| 114 |
+
vae_path,
|
| 115 |
+
text_encoder_path,
|
| 116 |
+
tokenizer_path,
|
| 117 |
+
scheduler_path,
|
| 118 |
+
dit_path,
|
| 119 |
+
) -> DictConfig:
|
| 120 |
+
dit_params = {
|
| 121 |
+
'in_visual_dim': 16,
|
| 122 |
+
'in_text_dim': 4096,
|
| 123 |
+
'out_visual_dim': 16,
|
| 124 |
+
'time_dim': 512,
|
| 125 |
+
'patch_size': [1, 2, 2],
|
| 126 |
+
'model_dim': 3072,
|
| 127 |
+
'ff_dim': 12288,
|
| 128 |
+
'num_blocks': 21,
|
| 129 |
+
'axes_dims': [16, 24, 24]
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
conf = {
|
| 133 |
+
'vae':
|
| 134 |
+
{
|
| 135 |
+
'checkpoint_path': vae_path
|
| 136 |
+
},
|
| 137 |
+
'text_embedder':
|
| 138 |
+
{
|
| 139 |
+
'emb_size': 4096,
|
| 140 |
+
'tokens_lenght': 224,
|
| 141 |
+
'params':
|
| 142 |
+
{
|
| 143 |
+
'checkpoint_path': text_encoder_path,
|
| 144 |
+
'tokenizer_path': tokenizer_path
|
| 145 |
+
}
|
| 146 |
+
},
|
| 147 |
+
'dit':
|
| 148 |
+
{
|
| 149 |
+
'scheduler': scheduler_path,
|
| 150 |
+
'checkpoint_path': dit_path,
|
| 151 |
+
'params': dit_params
|
| 152 |
+
|
| 153 |
+
},
|
| 154 |
+
'resolution': 512,
|
| 155 |
+
}
|
| 156 |
+
|
| 157 |
+
return DictConfig(conf)
|
kandinsky/model/__init__.py
ADDED
|
File without changes
|
kandinsky/model/__pycache__/__init__.cpython-311.pyc
ADDED
|
Binary file (171 Bytes). View file
|
|
|
kandinsky/model/__pycache__/dit.cpython-311.pyc
ADDED
|
Binary file (11.2 kB). View file
|
|
|
kandinsky/model/__pycache__/dit_i2v.cpython-311.pyc
ADDED
|
Binary file (11.5 kB). View file
|
|
|
kandinsky/model/__pycache__/nn.cpython-311.pyc
ADDED
|
Binary file (24.9 kB). View file
|
|
|
kandinsky/model/__pycache__/nn_i2v.cpython-311.pyc
ADDED
|
Binary file (7.18 kB). View file
|
|
|
kandinsky/model/__pycache__/text_embedders.cpython-311.pyc
ADDED
|
Binary file (4.14 kB). View file
|
|
|
kandinsky/model/__pycache__/utils.cpython-311.pyc
ADDED
|
Binary file (8.02 kB). View file
|
|
|
kandinsky/model/dit.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
from diffusers import CogVideoXDDIMScheduler
|
| 8 |
+
|
| 9 |
+
from .nn import TimeEmbeddings, TextEmbeddings, VisualEmbeddings, RoPE3D, Modulation, MultiheadSelfAttention, MultiheadSelfAttentionTP, FeedForward, OutLayer
|
| 10 |
+
from .utils import exist
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
from torch.distributed.tensor.parallel import (
|
| 14 |
+
ColwiseParallel,
|
| 15 |
+
PrepareModuleInput,
|
| 16 |
+
PrepareModuleOutput,
|
| 17 |
+
RowwiseParallel,
|
| 18 |
+
SequenceParallel,
|
| 19 |
+
parallelize_module,
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
from torch.distributed._tensor import Replicate, Shard
|
| 23 |
+
|
| 24 |
+
def parallelize(model, tp_mesh):
|
| 25 |
+
if tp_mesh.size() > 1:
|
| 26 |
+
|
| 27 |
+
plan = {
|
| 28 |
+
"in_layer":ColwiseParallel(),
|
| 29 |
+
"out_layer": RowwiseParallel(
|
| 30 |
+
output_layouts=Replicate(),
|
| 31 |
+
)
|
| 32 |
+
}
|
| 33 |
+
parallelize_module(model.time_embeddings, tp_mesh, plan)
|
| 34 |
+
|
| 35 |
+
plan = {
|
| 36 |
+
"in_layer": ColwiseParallel(output_layouts=Replicate(),)
|
| 37 |
+
}
|
| 38 |
+
parallelize_module(model.text_embeddings, tp_mesh, plan)
|
| 39 |
+
parallelize_module(model.visual_embeddings, tp_mesh, plan)
|
| 40 |
+
|
| 41 |
+
for i, doubled_transformer_block in enumerate(model.transformer_blocks):
|
| 42 |
+
for j, transformer_block in enumerate(doubled_transformer_block):
|
| 43 |
+
transformer_block.self_attention = MultiheadSelfAttentionTP(transformer_block.self_attention)
|
| 44 |
+
plan = {
|
| 45 |
+
#text modulation
|
| 46 |
+
"text_modulation": PrepareModuleInput(
|
| 47 |
+
input_layouts=(None, None),
|
| 48 |
+
desired_input_layouts=(Replicate(), None),
|
| 49 |
+
),
|
| 50 |
+
"text_modulation.out_layer": ColwiseParallel(output_layouts=Replicate(),),
|
| 51 |
+
#visual modulation
|
| 52 |
+
"visual_modulation": PrepareModuleInput(
|
| 53 |
+
input_layouts=(None, None),
|
| 54 |
+
desired_input_layouts=(Replicate(), None),
|
| 55 |
+
),
|
| 56 |
+
"visual_modulation.out_layer": ColwiseParallel(output_layouts=Replicate(), use_local_output=True),
|
| 57 |
+
|
| 58 |
+
#self_attention_norm
|
| 59 |
+
"self_attention_norm": SequenceParallel(sequence_dim=0, use_local_output=True), # TODO надо ли вообще это??? если у нас смешанный ввод нескольких видосом может быть
|
| 60 |
+
|
| 61 |
+
#self_attention
|
| 62 |
+
"self_attention.to_query": ColwiseParallel(
|
| 63 |
+
input_layouts=Replicate(),
|
| 64 |
+
),
|
| 65 |
+
"self_attention.to_key": ColwiseParallel(
|
| 66 |
+
input_layouts=Replicate(),
|
| 67 |
+
),
|
| 68 |
+
"self_attention.to_value": ColwiseParallel(
|
| 69 |
+
input_layouts=Replicate(),
|
| 70 |
+
),
|
| 71 |
+
|
| 72 |
+
"self_attention.query_norm": SequenceParallel(sequence_dim=0, use_local_output=True),
|
| 73 |
+
"self_attention.key_norm": SequenceParallel(sequence_dim=0, use_local_output=True),
|
| 74 |
+
|
| 75 |
+
"self_attention.output_layer": RowwiseParallel(
|
| 76 |
+
# input_layouts=(Shard(0), ),
|
| 77 |
+
output_layouts=Replicate(),
|
| 78 |
+
),
|
| 79 |
+
|
| 80 |
+
#feed_forward_norm
|
| 81 |
+
"feed_forward_norm": SequenceParallel(sequence_dim=0, use_local_output=True),
|
| 82 |
+
|
| 83 |
+
#feed_forward
|
| 84 |
+
"feed_forward.in_layer": ColwiseParallel(),
|
| 85 |
+
"feed_forward.out_layer": RowwiseParallel(),
|
| 86 |
+
}
|
| 87 |
+
self_attn = transformer_block.self_attention
|
| 88 |
+
self_attn.num_heads = self_attn.num_heads // tp_mesh.size()
|
| 89 |
+
parallelize_module(transformer_block, tp_mesh, plan)
|
| 90 |
+
|
| 91 |
+
plan = {
|
| 92 |
+
"modulation_out":ColwiseParallel(output_layouts=Replicate(),),
|
| 93 |
+
"out_layer": ColwiseParallel(output_layouts=Replicate(),),
|
| 94 |
+
}
|
| 95 |
+
parallelize_module(model.out_layer, tp_mesh, plan)
|
| 96 |
+
|
| 97 |
+
plan={
|
| 98 |
+
"time_embeddings": PrepareModuleInput(desired_input_layouts=Replicate(),),
|
| 99 |
+
"text_embeddings": PrepareModuleInput(desired_input_layouts=Replicate(),),
|
| 100 |
+
"visual_embeddings": PrepareModuleInput(desired_input_layouts=Replicate(),),
|
| 101 |
+
"out_layer": PrepareModuleInput(
|
| 102 |
+
input_layouts=(None, None, None, None),
|
| 103 |
+
desired_input_layouts=(Replicate(), Replicate(), Replicate(), None)),
|
| 104 |
+
}
|
| 105 |
+
parallelize_module(model, tp_mesh, {})
|
| 106 |
+
return model
|
| 107 |
+
|
| 108 |
+
class TransformerBlock(nn.Module):
|
| 109 |
+
|
| 110 |
+
def __init__(self, model_dim, time_dim, ff_dim, head_dim=64):
|
| 111 |
+
super().__init__()
|
| 112 |
+
self.visual_modulation = Modulation(time_dim, model_dim)
|
| 113 |
+
self.text_modulation = Modulation(time_dim, model_dim)
|
| 114 |
+
|
| 115 |
+
self.self_attention_norm = nn.LayerNorm(model_dim, elementwise_affine=True)
|
| 116 |
+
self.self_attention = MultiheadSelfAttention(model_dim, head_dim)
|
| 117 |
+
|
| 118 |
+
self.feed_forward_norm = nn.LayerNorm(model_dim, elementwise_affine=True)
|
| 119 |
+
self.feed_forward = FeedForward(model_dim, ff_dim)
|
| 120 |
+
|
| 121 |
+
def forward(self, visual_embed, text_embed, time_embed, rope, visual_cu_seqlens, text_cu_seqlens, num_groups, attention_type):
|
| 122 |
+
visual_shape = visual_embed.shape[:-1]
|
| 123 |
+
visual_self_attn_params, visual_ff_params = self.visual_modulation(time_embed, visual_cu_seqlens)
|
| 124 |
+
text_self_attn_params, text_ff_params = self.text_modulation(time_embed, text_cu_seqlens)
|
| 125 |
+
|
| 126 |
+
visual_shift, visual_scale, visual_gate = torch.chunk(visual_self_attn_params, 3, dim=-1)
|
| 127 |
+
text_shift, text_scale, text_gate = torch.chunk(text_self_attn_params, 3, dim=-1)
|
| 128 |
+
visual_out = self.self_attention_norm(visual_embed) * (visual_scale[:, None, None] + 1.) + visual_shift[:, None, None]
|
| 129 |
+
text_out = self.self_attention_norm(text_embed) * (text_scale + 1.) + text_shift
|
| 130 |
+
visual_out, text_out = self.self_attention(visual_out, text_out, rope, visual_cu_seqlens, text_cu_seqlens, num_groups, attention_type)
|
| 131 |
+
|
| 132 |
+
visual_embed = visual_embed + visual_gate[:, None, None] * visual_out
|
| 133 |
+
text_embed = text_embed + text_gate * text_out
|
| 134 |
+
|
| 135 |
+
visual_shift, visual_scale, visual_gate = torch.chunk(visual_ff_params, 3, dim=-1)
|
| 136 |
+
visual_out = self.feed_forward_norm(visual_embed) * (visual_scale[:, None, None] + 1.) + visual_shift[:, None, None]
|
| 137 |
+
visual_embed = visual_embed + visual_gate[:, None, None] * self.feed_forward(visual_out)
|
| 138 |
+
|
| 139 |
+
text_shift, text_scale, text_gate = torch.chunk(text_ff_params, 3, dim=-1)
|
| 140 |
+
text_out = self.feed_forward_norm(text_embed) * (text_scale + 1.) + text_shift
|
| 141 |
+
text_embed = text_embed + text_gate * self.feed_forward(text_out)
|
| 142 |
+
return visual_embed, text_embed
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
class DiffusionTransformer3D(nn.Module):
|
| 146 |
+
|
| 147 |
+
def __init__(
|
| 148 |
+
self,
|
| 149 |
+
in_visual_dim=4,
|
| 150 |
+
in_text_dim=2048,
|
| 151 |
+
time_dim=512,
|
| 152 |
+
out_visual_dim=4,
|
| 153 |
+
patch_size=(1, 2, 2),
|
| 154 |
+
model_dim=2048,
|
| 155 |
+
ff_dim=5120,
|
| 156 |
+
num_blocks=8,
|
| 157 |
+
axes_dims=(16, 24, 24),
|
| 158 |
+
):
|
| 159 |
+
super().__init__()
|
| 160 |
+
head_dim = sum(axes_dims)
|
| 161 |
+
self.in_visual_dim = in_visual_dim
|
| 162 |
+
self.model_dim = model_dim
|
| 163 |
+
self.num_blocks = num_blocks
|
| 164 |
+
|
| 165 |
+
self.time_embeddings = TimeEmbeddings(model_dim, time_dim)
|
| 166 |
+
self.text_embeddings = TextEmbeddings(in_text_dim, model_dim)
|
| 167 |
+
self.visual_embeddings = VisualEmbeddings(in_visual_dim, model_dim, patch_size)
|
| 168 |
+
self.rope_embeddings = RoPE3D(axes_dims)
|
| 169 |
+
|
| 170 |
+
self.transformer_blocks = nn.ModuleList([
|
| 171 |
+
nn.ModuleList([
|
| 172 |
+
TransformerBlock(model_dim, time_dim, ff_dim, head_dim),
|
| 173 |
+
TransformerBlock(model_dim, time_dim, ff_dim, head_dim),
|
| 174 |
+
]) for _ in range(num_blocks)
|
| 175 |
+
])
|
| 176 |
+
|
| 177 |
+
self.out_layer = OutLayer(model_dim, time_dim, out_visual_dim, patch_size)
|
| 178 |
+
|
| 179 |
+
def forward(self, x, text_embed, time, visual_cu_seqlens, text_cu_seqlens, num_groups=(1, 1, 1), scale_factor=(1., 1., 1.)):
|
| 180 |
+
time_embed = self.time_embeddings(time)
|
| 181 |
+
text_embed = self.text_embeddings(text_embed)
|
| 182 |
+
visual_embed = self.visual_embeddings(x)
|
| 183 |
+
rope = self.rope_embeddings(visual_embed, visual_cu_seqlens, scale_factor)
|
| 184 |
+
|
| 185 |
+
for i, (local_attention, global_attention) in enumerate(self.transformer_blocks):
|
| 186 |
+
visual_embed, text_embed = local_attention(
|
| 187 |
+
visual_embed, text_embed, time_embed, rope, visual_cu_seqlens, text_cu_seqlens, num_groups, 'local'
|
| 188 |
+
)
|
| 189 |
+
visual_embed, text_embed = global_attention(
|
| 190 |
+
visual_embed, text_embed, time_embed, rope, visual_cu_seqlens, text_cu_seqlens, num_groups, 'global'
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
return self.out_layer(visual_embed, text_embed, time_embed, visual_cu_seqlens)
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def get_dit(conf):
|
| 197 |
+
dit = DiffusionTransformer3D(**conf.params)
|
| 198 |
+
state_dict = torch.load(conf.checkpoint_path, weights_only=True, map_location=torch.device('cpu'))
|
| 199 |
+
dit.load_state_dict(state_dict, strict=False)
|
| 200 |
+
return dit
|
| 201 |
+
|
kandinsky/model/nn.py
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
import math
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
from flash_attn import flash_attn_varlen_qkvpacked_func
|
| 7 |
+
|
| 8 |
+
from .utils import exist, get_freqs, cat_interleave, split_interleave, to_1dimension, to_3dimension
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def apply_rotary(x, rope):
|
| 12 |
+
x_ = x.reshape(*x.shape[:-1], -1, 1, 2).to(torch.float32)
|
| 13 |
+
x_out = rope[..., 0] * x_[..., 0] + rope[..., 1] * x_[..., 1]
|
| 14 |
+
return x_out.reshape(*x.shape)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class TimeEmbeddings(nn.Module):
|
| 18 |
+
|
| 19 |
+
def __init__(self, model_dim, time_dim, max_period=10000.):
|
| 20 |
+
super().__init__()
|
| 21 |
+
assert model_dim % 2 == 0
|
| 22 |
+
self.freqs = get_freqs(model_dim // 2, max_period)
|
| 23 |
+
|
| 24 |
+
self.in_layer = nn.Linear(model_dim, time_dim, bias=True)
|
| 25 |
+
self.activation = nn.SiLU()
|
| 26 |
+
self.out_layer = nn.Linear(time_dim, time_dim, bias=True)
|
| 27 |
+
|
| 28 |
+
def forward(self, time):
|
| 29 |
+
args = torch.outer(time, self.freqs.to(device=time.device))
|
| 30 |
+
time_embed = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
|
| 31 |
+
return self.out_layer(self.activation(self.in_layer(time_embed)))
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class TextEmbeddings(nn.Module):
|
| 35 |
+
|
| 36 |
+
def __init__(self, text_dim, model_dim):
|
| 37 |
+
super().__init__()
|
| 38 |
+
self.in_layer = nn.Linear(text_dim, model_dim, bias=True)
|
| 39 |
+
|
| 40 |
+
def forward(self, text_embed):
|
| 41 |
+
return self.in_layer(text_embed)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class VisualEmbeddings(nn.Module):
|
| 45 |
+
|
| 46 |
+
def __init__(self, visual_dim, model_dim, patch_size):
|
| 47 |
+
super().__init__()
|
| 48 |
+
self.patch_size = patch_size
|
| 49 |
+
self.in_layer = nn.Linear(math.prod(patch_size) * visual_dim, model_dim)
|
| 50 |
+
|
| 51 |
+
def forward(self, x):
|
| 52 |
+
duration, height, width, dim = x.shape
|
| 53 |
+
x = x.view(
|
| 54 |
+
duration // self.patch_size[0], self.patch_size[0],
|
| 55 |
+
height // self.patch_size[1], self.patch_size[1],
|
| 56 |
+
width // self.patch_size[2], self.patch_size[2], dim
|
| 57 |
+
).permute(0, 2, 4, 1, 3, 5, 6).flatten(3, 6)
|
| 58 |
+
return self.in_layer(x)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class RoPE3D(nn.Module):
|
| 62 |
+
|
| 63 |
+
def __init__(self, axes_dims, max_pos=(128, 128, 128), max_period=10000.):
|
| 64 |
+
super().__init__()
|
| 65 |
+
for i, (axes_dim, ax_max_pos) in enumerate(zip(axes_dims, max_pos)):
|
| 66 |
+
freq = get_freqs(axes_dim // 2, max_period)
|
| 67 |
+
pos = torch.arange(ax_max_pos, dtype=freq.dtype)
|
| 68 |
+
self.register_buffer(f'args_{i}', torch.outer(pos, freq))
|
| 69 |
+
|
| 70 |
+
def args(self, i, cu_seqlens):
|
| 71 |
+
args = self.__getattr__(f'args_{i}')
|
| 72 |
+
if torch.is_tensor(cu_seqlens):
|
| 73 |
+
args = torch.cat([args[:end] for end in torch.diff(cu_seqlens)])
|
| 74 |
+
else:
|
| 75 |
+
args = args[:cu_seqlens]
|
| 76 |
+
return args
|
| 77 |
+
|
| 78 |
+
def forward(self, x, cu_seqlens, scale_factor=(1., 1., 1.)):
|
| 79 |
+
duration, height, width = x.shape[:-1]
|
| 80 |
+
args = [
|
| 81 |
+
self.args(i, ax_cu_seqlens) / ax_scale_factor
|
| 82 |
+
for i, (ax_cu_seqlens, ax_scale_factor) in enumerate(zip([cu_seqlens, height, width], scale_factor))
|
| 83 |
+
]
|
| 84 |
+
args = torch.cat([
|
| 85 |
+
args[0].view(duration, 1, 1, -1).repeat(1, height, width, 1),
|
| 86 |
+
args[1].view(1, height, 1, -1).repeat(duration, 1, width, 1),
|
| 87 |
+
args[2].view(1, 1, width, -1).repeat(duration, height, 1, 1)
|
| 88 |
+
], dim=-1)
|
| 89 |
+
rope = torch.stack([torch.cos(args), -torch.sin(args), torch.sin(args), torch.cos(args)], dim=-1)
|
| 90 |
+
rope = rope.view(*rope.shape[:-1], 2, 2)
|
| 91 |
+
return rope.unsqueeze(-4)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
class Modulation(nn.Module):
|
| 95 |
+
|
| 96 |
+
def __init__(self, time_dim, model_dim):
|
| 97 |
+
super().__init__()
|
| 98 |
+
self.activation = nn.SiLU()
|
| 99 |
+
self.out_layer = nn.Linear(time_dim, 6 * model_dim)
|
| 100 |
+
self.out_layer.weight.data.zero_()
|
| 101 |
+
self.out_layer.bias.data.zero_()
|
| 102 |
+
|
| 103 |
+
def forward(self, x, cu_seqlens):
|
| 104 |
+
modulation_params = self.out_layer(self.activation(x))
|
| 105 |
+
modulation_params = modulation_params.repeat_interleave(torch.diff(cu_seqlens), dim=0)
|
| 106 |
+
self_attn_params, ff_params = torch.chunk(modulation_params, 2, dim=-1)
|
| 107 |
+
return self_attn_params, ff_params
|
| 108 |
+
|
| 109 |
+
class MultiheadSelfAttention(nn.Module):
|
| 110 |
+
|
| 111 |
+
def __init__(self, num_channels, head_dim=64, attention_type='flash'):
|
| 112 |
+
super().__init__()
|
| 113 |
+
assert num_channels % head_dim == 0
|
| 114 |
+
self.attention_type = attention_type
|
| 115 |
+
self.num_heads = num_channels // head_dim
|
| 116 |
+
|
| 117 |
+
self.to_query_key_value = nn.Linear(num_channels, 3 * num_channels, bias=True)
|
| 118 |
+
self.query_norm = nn.LayerNorm(head_dim)
|
| 119 |
+
self.key_norm = nn.LayerNorm(head_dim)
|
| 120 |
+
|
| 121 |
+
self.output_layer = nn.Linear(num_channels, num_channels, bias=True)
|
| 122 |
+
|
| 123 |
+
def scaled_dot_product_attention(
|
| 124 |
+
self, visual_query_key_value, text_query_key_value, visual_cu_seqlens, text_cu_seqlens, num_groups, attention_type,
|
| 125 |
+
return_attn_probs=False
|
| 126 |
+
):
|
| 127 |
+
if self.attention_type == 'flash':
|
| 128 |
+
visual_shape, text_len = visual_query_key_value.shape[:3], text_cu_seqlens[1]
|
| 129 |
+
visual_query_key_value, visual_cu_seqlens = to_1dimension(
|
| 130 |
+
visual_query_key_value, visual_cu_seqlens, visual_shape, num_groups, attention_type
|
| 131 |
+
)
|
| 132 |
+
text_query_key_value = text_query_key_value.unsqueeze(0).expand(math.prod(num_groups), *text_query_key_value.size())
|
| 133 |
+
query_key_value = cat_interleave(visual_query_key_value, text_query_key_value, visual_cu_seqlens, text_cu_seqlens)
|
| 134 |
+
cu_seqlens = visual_cu_seqlens + text_cu_seqlens
|
| 135 |
+
|
| 136 |
+
max_seqlen = torch.diff(cu_seqlens).max()
|
| 137 |
+
query_key_value = query_key_value.flatten(0, 1)
|
| 138 |
+
large_cu_seqlens = torch.cat([cu_seqlens + i * cu_seqlens[-1] for i in range(math.prod(num_groups))])
|
| 139 |
+
out, softmax_lse, _ = flash_attn_varlen_qkvpacked_func(query_key_value, large_cu_seqlens, max_seqlen, return_attn_probs=True)
|
| 140 |
+
out = out.reshape(math.prod(num_groups), -1, *out.shape[1:]).flatten(-2, -1)
|
| 141 |
+
|
| 142 |
+
visual_out, text_out = split_interleave(out, cu_seqlens, text_len)
|
| 143 |
+
visual_out = to_3dimension(visual_out, visual_shape, num_groups, attention_type)
|
| 144 |
+
if return_attn_probs:
|
| 145 |
+
return (visual_out, text_out), softmax_lse, None
|
| 146 |
+
return visual_out, text_out
|
| 147 |
+
|
| 148 |
+
def forward(self, visual_embed, text_embed, rope, visual_cu_seqlens, text_cu_seqlens, num_groups, attention_type):
|
| 149 |
+
visual_shape = visual_embed.shape[:-1]
|
| 150 |
+
visual_query_key_value = self.to_query_key_value(visual_embed)
|
| 151 |
+
|
| 152 |
+
visual_query, visual_key, visual_value = torch.chunk(visual_query_key_value, 3, dim=-1)
|
| 153 |
+
visual_query = self.query_norm(visual_query.reshape(*visual_shape, self.num_heads, -1)).type_as(visual_query)
|
| 154 |
+
visual_key = self.key_norm(visual_key.reshape(*visual_shape, self.num_heads, -1)).type_as(visual_key)
|
| 155 |
+
visual_value = visual_value.reshape(*visual_shape, self.num_heads, -1)
|
| 156 |
+
visual_query = apply_rotary(visual_query, rope).type_as(visual_query)
|
| 157 |
+
visual_key = apply_rotary(visual_key, rope).type_as(visual_key)
|
| 158 |
+
visual_query_key_value = torch.stack([visual_query, visual_key, visual_value], dim=3)
|
| 159 |
+
|
| 160 |
+
text_len = text_embed.shape[0]
|
| 161 |
+
text_query_key_value = self.to_query_key_value(text_embed)
|
| 162 |
+
text_query, text_key, text_value = torch.chunk(text_query_key_value, 3, dim=-1)
|
| 163 |
+
text_query = self.query_norm(text_query.reshape(text_len, self.num_heads, -1)).type_as(text_query)
|
| 164 |
+
text_key = self.key_norm(text_key.reshape(text_len, self.num_heads, -1)).type_as(text_key)
|
| 165 |
+
text_value = text_value.reshape(text_len, self.num_heads, -1)
|
| 166 |
+
text_query_key_value = torch.stack([text_query, text_key, text_value], dim=1)
|
| 167 |
+
|
| 168 |
+
visual_out, text_out = self.scaled_dot_product_attention(
|
| 169 |
+
visual_query_key_value, text_query_key_value, visual_cu_seqlens, text_cu_seqlens, num_groups, attention_type
|
| 170 |
+
)
|
| 171 |
+
visual_out = self.output_layer(visual_out)
|
| 172 |
+
text_out = self.output_layer(text_out)
|
| 173 |
+
|
| 174 |
+
return visual_out, text_out
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
class MultiheadSelfAttentionTP(nn.Module):
|
| 178 |
+
|
| 179 |
+
def __init__(self, initial_multihead_self_attention):
|
| 180 |
+
super().__init__()
|
| 181 |
+
num_channels = initial_multihead_self_attention.to_query_key_value.weight.shape[1]
|
| 182 |
+
self.num_heads = initial_multihead_self_attention.num_heads
|
| 183 |
+
head_dim = num_channels // self.num_heads
|
| 184 |
+
self.attention_type = initial_multihead_self_attention.attention_type
|
| 185 |
+
|
| 186 |
+
self.to_query = nn.Linear(num_channels, num_channels, bias=True)
|
| 187 |
+
self.to_key = nn.Linear(num_channels, num_channels, bias=True)
|
| 188 |
+
self.to_value = nn.Linear(num_channels, num_channels, bias=True)
|
| 189 |
+
|
| 190 |
+
weight = initial_multihead_self_attention.to_query_key_value.weight
|
| 191 |
+
bias = initial_multihead_self_attention.to_query_key_value.bias
|
| 192 |
+
self.to_query.weight = torch.nn.Parameter(weight[:num_channels])
|
| 193 |
+
self.to_key.weight = torch.nn.Parameter(weight[num_channels:2 * num_channels])
|
| 194 |
+
self.to_value.weight = torch.nn.Parameter(weight[2 * num_channels:])
|
| 195 |
+
self.to_query.bias = torch.nn.Parameter(bias[:num_channels])
|
| 196 |
+
self.to_key.bias = torch.nn.Parameter(bias[num_channels:2 * num_channels])
|
| 197 |
+
self.to_value.bias = torch.nn.Parameter(bias[2 * num_channels:])
|
| 198 |
+
|
| 199 |
+
self.query_norm = initial_multihead_self_attention.query_norm
|
| 200 |
+
self.key_norm = initial_multihead_self_attention.key_norm
|
| 201 |
+
self.output_layer = initial_multihead_self_attention.output_layer
|
| 202 |
+
|
| 203 |
+
def scaled_dot_product_attention(
|
| 204 |
+
self, visual_query_key_value, text_query_key_value, visual_cu_seqlens, text_cu_seqlens, num_groups, attention_type,
|
| 205 |
+
return_attn_probs=False
|
| 206 |
+
):
|
| 207 |
+
if self.attention_type == 'flash':
|
| 208 |
+
visual_shape, text_len = visual_query_key_value.shape[:3], text_cu_seqlens[1]
|
| 209 |
+
visual_query_key_value, visual_cu_seqlens = to_1dimension(
|
| 210 |
+
visual_query_key_value, visual_cu_seqlens, visual_shape, num_groups, attention_type
|
| 211 |
+
)
|
| 212 |
+
text_query_key_value = text_query_key_value.unsqueeze(0).expand(math.prod(num_groups), *text_query_key_value.size())
|
| 213 |
+
query_key_value = cat_interleave(visual_query_key_value, text_query_key_value, visual_cu_seqlens, text_cu_seqlens)
|
| 214 |
+
cu_seqlens = visual_cu_seqlens + text_cu_seqlens
|
| 215 |
+
|
| 216 |
+
max_seqlen = torch.diff(cu_seqlens).max()
|
| 217 |
+
query_key_value = query_key_value.flatten(0, 1)
|
| 218 |
+
large_cu_seqlens = torch.cat([cu_seqlens + i * cu_seqlens[-1] for i in range(math.prod(num_groups))])
|
| 219 |
+
out, softmax_lse, _ = flash_attn_varlen_qkvpacked_func(query_key_value, large_cu_seqlens, max_seqlen, return_attn_probs=True)
|
| 220 |
+
out = out.reshape(math.prod(num_groups), -1, *out.shape[1:]).flatten(-2, -1)
|
| 221 |
+
|
| 222 |
+
visual_out, text_out = split_interleave(out, cu_seqlens, text_len)
|
| 223 |
+
visual_out = to_3dimension(visual_out, visual_shape, num_groups, attention_type)
|
| 224 |
+
if return_attn_probs:
|
| 225 |
+
return (visual_out, text_out), softmax_lse, None
|
| 226 |
+
return visual_out, text_out
|
| 227 |
+
|
| 228 |
+
def forward(self, visual_embed, text_embed, rope, visual_cu_seqlens, text_cu_seqlens, num_groups, attention_type):
|
| 229 |
+
visual_shape = visual_embed.shape[:-1]
|
| 230 |
+
visual_query, visual_key, visual_value = self.to_query(visual_embed), self.to_key(visual_embed), self.to_value(visual_embed)
|
| 231 |
+
visual_query = self.query_norm(visual_query.reshape(*visual_shape, self.num_heads, -1)).type_as(visual_query)
|
| 232 |
+
visual_key = self.key_norm(visual_key.reshape(*visual_shape, self.num_heads, -1)).type_as(visual_key)
|
| 233 |
+
visual_value = visual_value.reshape(*visual_shape, self.num_heads, -1)
|
| 234 |
+
visual_query = apply_rotary(visual_query, rope).type_as(visual_query)
|
| 235 |
+
visual_key = apply_rotary(visual_key, rope).type_as(visual_key)
|
| 236 |
+
visual_query_key_value = torch.stack([visual_query, visual_key, visual_value], dim=3)
|
| 237 |
+
|
| 238 |
+
text_len = text_embed.shape[0]
|
| 239 |
+
text_query, text_key, text_value = self.to_query(text_embed), self.to_key(text_embed), self.to_value(text_embed)
|
| 240 |
+
text_query = self.query_norm(text_query.reshape(text_len, self.num_heads, -1)).type_as(text_query)
|
| 241 |
+
text_key = self.key_norm(text_key.reshape(text_len, self.num_heads, -1)).type_as(text_key)
|
| 242 |
+
text_value = text_value.reshape(text_len, self.num_heads, -1)
|
| 243 |
+
text_query_key_value = torch.stack([text_query, text_key, text_value], dim=1)
|
| 244 |
+
|
| 245 |
+
visual_out, text_out = self.scaled_dot_product_attention(
|
| 246 |
+
visual_query_key_value, text_query_key_value, visual_cu_seqlens, text_cu_seqlens, num_groups, attention_type
|
| 247 |
+
)
|
| 248 |
+
visual_out = self.output_layer(visual_out)
|
| 249 |
+
text_out = self.output_layer(text_out)
|
| 250 |
+
|
| 251 |
+
return visual_out, text_out
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
class FeedForward(nn.Module):
|
| 256 |
+
|
| 257 |
+
def __init__(self, dim, ff_dim):
|
| 258 |
+
super().__init__()
|
| 259 |
+
self.in_layer = nn.Linear(dim, ff_dim, bias=True)
|
| 260 |
+
self.activation = nn.GELU()
|
| 261 |
+
self.out_layer = nn.Linear(ff_dim, dim, bias=True)
|
| 262 |
+
|
| 263 |
+
def forward(self, x):
|
| 264 |
+
return self.out_layer(self.activation(self.in_layer(x)))
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
class OutLayer(nn.Module):
|
| 268 |
+
|
| 269 |
+
def __init__(self, model_dim, time_dim, visual_dim, patch_size):
|
| 270 |
+
super().__init__()
|
| 271 |
+
self.patch_size = patch_size
|
| 272 |
+
self.norm = nn.LayerNorm(model_dim, elementwise_affine=True)
|
| 273 |
+
self.out_layer = nn.Linear(model_dim, math.prod(patch_size) * visual_dim, bias=True)
|
| 274 |
+
|
| 275 |
+
self.modulation_activation = nn.SiLU()
|
| 276 |
+
self.modulation_out = nn.Linear(time_dim, 2 * model_dim, bias=True)
|
| 277 |
+
self.modulation_out.weight.data.zero_()
|
| 278 |
+
self.modulation_out.bias.data.zero_()
|
| 279 |
+
|
| 280 |
+
def forward(self, visual_embed, text_embed, time_embed, visual_cu_seqlens):
|
| 281 |
+
modulation_params = self.modulation_out(self.modulation_activation(time_embed))
|
| 282 |
+
modulation_params = modulation_params.repeat_interleave(torch.diff(visual_cu_seqlens), dim=0)
|
| 283 |
+
shift, scale = torch.chunk(modulation_params, 2, dim=-1)
|
| 284 |
+
visual_embed = self.norm(visual_embed) * (scale[:, None, None, :] + 1) + shift[:, None, None, :]
|
| 285 |
+
x = self.out_layer(visual_embed)
|
| 286 |
+
|
| 287 |
+
duration, height, width, dim = x.shape
|
| 288 |
+
x = x.view(
|
| 289 |
+
duration, height, width,
|
| 290 |
+
-1, self.patch_size[0], self.patch_size[1], self.patch_size[2]
|
| 291 |
+
).permute(0, 4, 1, 5, 2, 6, 3).flatten(0, 1).flatten(1, 2).flatten(2, 3)
|
| 292 |
+
return x
|
kandinsky/model/text_embedders.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import sys
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
from .utils import freeze
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class BaseEmbedder:
|
| 10 |
+
def __init__(self, conf):
|
| 11 |
+
self.checkpoint_path = conf.text_embedder.params.checkpoint_path
|
| 12 |
+
self.tokenizer_path = conf.text_embedder.params.tokenizer_path
|
| 13 |
+
self.max_length = conf.text_embedder.tokens_lenght
|
| 14 |
+
self.llm = None
|
| 15 |
+
|
| 16 |
+
def to(self, device='cpu', dtype=torch.float32):
|
| 17 |
+
self.llm = self.llm.to(device=device, dtype=dtype)
|
| 18 |
+
return self
|
| 19 |
+
|
| 20 |
+
def freeze(self):
|
| 21 |
+
self.llm = freeze(self.llm)
|
| 22 |
+
return self
|
| 23 |
+
|
| 24 |
+
def compile(self):
|
| 25 |
+
self.llm = torch.compile(self.llm)
|
| 26 |
+
return self
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class EmbedderWithTokenizer(BaseEmbedder):
|
| 30 |
+
|
| 31 |
+
def __init__(self, conf):
|
| 32 |
+
super().__init__(conf)
|
| 33 |
+
self.tokenizer = None
|
| 34 |
+
|
| 35 |
+
def tokenize(self, text):
|
| 36 |
+
model_input = self.tokenizer(
|
| 37 |
+
text,
|
| 38 |
+
max_length=self.max_length,
|
| 39 |
+
truncation=True,
|
| 40 |
+
add_special_tokens=True,
|
| 41 |
+
padding='max_length',
|
| 42 |
+
return_tensors='pt'
|
| 43 |
+
)
|
| 44 |
+
return model_input.input_ids.to(self.llm.device)
|
| 45 |
+
|
| 46 |
+
def __call__(self, text):
|
| 47 |
+
return self.llm(self.tokenize(text), output_hidden_states=True)[0]
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class T5TextEmbedder(EmbedderWithTokenizer):
|
| 51 |
+
|
| 52 |
+
def __init__(self, conf):
|
| 53 |
+
from transformers import T5EncoderModel, T5Tokenizer
|
| 54 |
+
|
| 55 |
+
super().__init__(conf)
|
| 56 |
+
|
| 57 |
+
self.llm = T5EncoderModel.from_pretrained(self.checkpoint_path)
|
| 58 |
+
self.tokenizer = T5Tokenizer.from_pretrained(self.tokenizer_path, clean_up_tokenization_spaces=False)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def get_text_embedder(conf):
|
| 62 |
+
return T5TextEmbedder(conf)
|
kandinsky/model/utils.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def exist(item):
|
| 7 |
+
return item is not None
|
| 8 |
+
|
| 9 |
+
def freeze(model):
|
| 10 |
+
for p in model.parameters():
|
| 11 |
+
p.requires_grad = False
|
| 12 |
+
return model
|
| 13 |
+
|
| 14 |
+
def get_freqs(dim, max_period=10000.):
|
| 15 |
+
freqs = torch.exp(
|
| 16 |
+
-math.log(max_period) * torch.arange(start=0, end=dim, dtype=torch.float32) / dim
|
| 17 |
+
)
|
| 18 |
+
return freqs
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def get_group_sizes(shape, num_groups):
|
| 22 |
+
return [*map(lambda x: x[0] // x[1], zip(shape, num_groups))]
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def rescale_group_rope(num_groups, scale_factor, rescale_factor):
|
| 26 |
+
num_groups = [*map(lambda x: int(x[0] / x[1]), zip(num_groups, rescale_factor))]
|
| 27 |
+
scale_factor = [*map(lambda x: x[0] / x[1], zip(scale_factor, rescale_factor))]
|
| 28 |
+
return num_groups, scale_factor
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def cat_interleave(visual_query_key_value, text_query_key_value, visual_cu_seqlens, text_cu_seqlens):
|
| 32 |
+
query_key_value = []
|
| 33 |
+
for local_visual_query_key_value, local_text_query_key_value in zip(
|
| 34 |
+
torch.split(visual_query_key_value, torch.diff(visual_cu_seqlens).tolist(), dim=1),
|
| 35 |
+
torch.split(text_query_key_value, torch.diff(text_cu_seqlens).tolist(), dim=1)
|
| 36 |
+
):
|
| 37 |
+
query_key_value += [local_visual_query_key_value, local_text_query_key_value]
|
| 38 |
+
query_key_value = torch.cat(query_key_value, dim=1)
|
| 39 |
+
return query_key_value
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def split_interleave(out, cu_seqlens, split_len):
|
| 43 |
+
visual_out, text_out = [], []
|
| 44 |
+
for local_out in torch.split(out, torch.diff(cu_seqlens).tolist(), dim=1):
|
| 45 |
+
visual_out.append(local_out[:, :-split_len])
|
| 46 |
+
text_out.append(local_out[0, -split_len:])
|
| 47 |
+
visual_out, text_out = torch.cat(visual_out, dim=1), torch.cat(text_out, dim=0)
|
| 48 |
+
return visual_out, text_out
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def local_patching(x, shape, group_size, dim=0):
|
| 52 |
+
duration, height, width = shape
|
| 53 |
+
g1, g2, g3 = group_size
|
| 54 |
+
x = x.reshape(*x.shape[:dim], duration//g1, g1, height//g2, g2, width//g3, g3, *x.shape[dim+3:])
|
| 55 |
+
x = x.permute(
|
| 56 |
+
*range(len(x.shape[:dim])),
|
| 57 |
+
dim, dim+2, dim+4, dim+1, dim+3, dim+5,
|
| 58 |
+
*range(dim+6, len(x.shape))
|
| 59 |
+
)
|
| 60 |
+
x = x.flatten(dim, dim+2).flatten(dim+1, dim+3)
|
| 61 |
+
return x
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def local_merge(x, shape, group_size, dim=0):
|
| 65 |
+
duration, height, width = shape
|
| 66 |
+
g1, g2, g3 = group_size
|
| 67 |
+
x = x.reshape(*x.shape[:dim], duration//g1, height//g2, width//g3, g1, g2, g3, *x.shape[dim+2:])
|
| 68 |
+
x = x.permute(
|
| 69 |
+
*range(len(x.shape[:dim])),
|
| 70 |
+
dim, dim+3, dim+1, dim+4, dim+2, dim+5,
|
| 71 |
+
*range(dim+6, len(x.shape))
|
| 72 |
+
)
|
| 73 |
+
x = x.flatten(dim, dim+1).flatten(dim+1, dim+2).flatten(dim+2, dim+3)
|
| 74 |
+
return x
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def global_patching(x, shape, group_size, dim=0):
|
| 78 |
+
latent_group_size = [axis // axis_group_size for axis, axis_group_size in zip(shape, group_size)]
|
| 79 |
+
x = local_patching(x, shape, latent_group_size, dim)
|
| 80 |
+
x = x.transpose(dim, dim+1)
|
| 81 |
+
return x
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def global_merge(x, shape, group_size, dim=0):
|
| 85 |
+
latent_group_size = [axis // axis_group_size for axis, axis_group_size in zip(shape, group_size)]
|
| 86 |
+
x = x.transpose(dim, dim+1)
|
| 87 |
+
x = local_merge(x, shape, latent_group_size, dim)
|
| 88 |
+
return x
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def to_1dimension(visual_embed, visual_cu_seqlens, visual_shape, num_groups, attention_type):
|
| 92 |
+
group_size = get_group_sizes(visual_shape, num_groups)
|
| 93 |
+
if attention_type == 'local':
|
| 94 |
+
visual_embed = local_patching(visual_embed, visual_shape, group_size, dim=0)
|
| 95 |
+
if attention_type == 'global':
|
| 96 |
+
visual_embed = global_patching(visual_embed, visual_shape, group_size, dim=0)
|
| 97 |
+
visual_cu_seqlens = visual_cu_seqlens * math.prod(group_size[1:])
|
| 98 |
+
return visual_embed, visual_cu_seqlens
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def to_3dimension(visual_embed, visual_shape, num_groups, attention_type):
|
| 102 |
+
group_size = get_group_sizes(visual_shape, num_groups)
|
| 103 |
+
if attention_type == 'local':
|
| 104 |
+
x = local_merge(visual_embed, visual_shape, group_size, dim=0)
|
| 105 |
+
if attention_type == 'global':
|
| 106 |
+
x = global_merge(visual_embed, visual_shape, group_size, dim=0)
|
| 107 |
+
return x
|
kandinsky/t2v_pipeline.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Union, List
|
| 2 |
+
|
| 3 |
+
import PIL
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
from tqdm.auto import tqdm
|
| 8 |
+
import torch
|
| 9 |
+
import torchvision
|
| 10 |
+
from torchvision.transforms import ToPILImage
|
| 11 |
+
from einops import repeat
|
| 12 |
+
from diffusers import AutoencoderKLCogVideoX
|
| 13 |
+
from diffusers import CogVideoXDDIMScheduler
|
| 14 |
+
|
| 15 |
+
from .model.dit import DiffusionTransformer3D
|
| 16 |
+
from .model.text_embedders import T5TextEmbedder
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
@torch.no_grad()
|
| 20 |
+
def predict_x_0(noise_scheduler, model_output, timesteps, sample, device):
|
| 21 |
+
init_alpha_device = noise_scheduler.alphas_cumprod.device
|
| 22 |
+
alphas = noise_scheduler.alphas_cumprod.to(device)
|
| 23 |
+
|
| 24 |
+
alpha_prod_t = alphas[timesteps][:, None, None, None]
|
| 25 |
+
beta_prod_t = 1 - alpha_prod_t
|
| 26 |
+
|
| 27 |
+
pred_original_sample = (alpha_prod_t ** 0.5) * sample - (beta_prod_t ** 0.5) * model_output
|
| 28 |
+
noise_scheduler.alphas_cumprod.to(init_alpha_device)
|
| 29 |
+
return pred_original_sample
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
@torch.no_grad()
|
| 33 |
+
def get_velocity(
|
| 34 |
+
model, x, t, text_embed, visual_cu_seqlens, text_cu_seqlens,
|
| 35 |
+
num_goups=(1, 1, 1), scale_factor=(1., 1., 1.)
|
| 36 |
+
):
|
| 37 |
+
pred_velocity = model(x, text_embed, t, visual_cu_seqlens, text_cu_seqlens, num_goups, scale_factor)
|
| 38 |
+
|
| 39 |
+
return pred_velocity
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
@torch.no_grad()
|
| 43 |
+
def diffusion_generate_renoise(
|
| 44 |
+
model, noise_scheduler, shape, device, num_steps, text_embed, visual_cu_seqlens, text_cu_seqlens,
|
| 45 |
+
num_goups=(1, 1, 1), scale_factor=(1., 1., 1.), progress=False, seed=6554
|
| 46 |
+
):
|
| 47 |
+
generator = torch.Generator()
|
| 48 |
+
if seed is not None:
|
| 49 |
+
generator.manual_seed(seed)
|
| 50 |
+
|
| 51 |
+
img = torch.randn(*shape, generator=generator).to(torch.bfloat16).to(device)
|
| 52 |
+
noise_scheduler.set_timesteps(num_steps, device=device)
|
| 53 |
+
|
| 54 |
+
timesteps = noise_scheduler.timesteps
|
| 55 |
+
if progress:
|
| 56 |
+
timesteps = tqdm(timesteps)
|
| 57 |
+
for time in timesteps:
|
| 58 |
+
model_time = time.unsqueeze(0).repeat(visual_cu_seqlens.shape[0] - 1)
|
| 59 |
+
noise = torch.randn(img.shape, generator=generator).to(torch.bfloat16).to(device)
|
| 60 |
+
img = noise_scheduler.add_noise(img, noise, time)
|
| 61 |
+
|
| 62 |
+
pred_velocity = get_velocity(
|
| 63 |
+
model, img.to(torch.bfloat16), model_time,
|
| 64 |
+
text_embed.to(torch.bfloat16), visual_cu_seqlens,
|
| 65 |
+
text_cu_seqlens, num_goups, scale_factor
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
img = predict_x_0(noise_scheduler=noise_scheduler, model_output=pred_velocity.to(device), timesteps=model_time.to(device), sample=img.to(device), device=device)
|
| 69 |
+
|
| 70 |
+
return img
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
class Kandinsky4T2VPipeline:
|
| 74 |
+
def __init__(
|
| 75 |
+
self,
|
| 76 |
+
device_map: Union[str, torch.device, dict], # {"dit": cuda:0, "vae": cuda:1, "text_embedder": cuda:1 }
|
| 77 |
+
dit: DiffusionTransformer3D,
|
| 78 |
+
text_embedder: T5TextEmbedder,
|
| 79 |
+
vae: AutoencoderKLCogVideoX,
|
| 80 |
+
noise_scheduler: CogVideoXDDIMScheduler, # TODO base class
|
| 81 |
+
resolution: int = 512,
|
| 82 |
+
local_dit_rank=0,
|
| 83 |
+
world_size=1,
|
| 84 |
+
):
|
| 85 |
+
if resolution not in [512]:
|
| 86 |
+
raise ValueError("Resolution can be only 512")
|
| 87 |
+
|
| 88 |
+
self.dit = dit
|
| 89 |
+
self.noise_scheduler = noise_scheduler
|
| 90 |
+
self.text_embedder = text_embedder
|
| 91 |
+
self.vae = vae
|
| 92 |
+
|
| 93 |
+
self.resolution = resolution
|
| 94 |
+
|
| 95 |
+
self.device_map = device_map
|
| 96 |
+
self.local_dit_rank = local_dit_rank
|
| 97 |
+
self.world_size = world_size
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
self.RESOLUTIONS = {
|
| 101 |
+
512: [(512, 512), (352, 736), (736, 352), (384, 672), (672, 384), (480, 544), (544, 480)],
|
| 102 |
+
}
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def __call__(
|
| 106 |
+
self,
|
| 107 |
+
text: str,
|
| 108 |
+
save_path: str = "./test.mp4",
|
| 109 |
+
bs: int = 1,
|
| 110 |
+
time_length: int = 12, # time in seconds 0 if you want generate image
|
| 111 |
+
width: int = 512,
|
| 112 |
+
height: int = 512,
|
| 113 |
+
seed: int = None,
|
| 114 |
+
return_frames: bool = False
|
| 115 |
+
):
|
| 116 |
+
num_steps = 4
|
| 117 |
+
|
| 118 |
+
# SEED
|
| 119 |
+
if seed is None:
|
| 120 |
+
if self.local_dit_rank == 0:
|
| 121 |
+
seed = torch.randint(2 ** 63 - 1, (1,)).to(self.local_dit_rank)
|
| 122 |
+
else:
|
| 123 |
+
seed = torch.empty((1,), dtype=torch.int64).to(self.local_dit_rank)
|
| 124 |
+
|
| 125 |
+
if self.world_size > 1:
|
| 126 |
+
torch.distributed.broadcast(seed, 0)
|
| 127 |
+
|
| 128 |
+
seed = seed.item()
|
| 129 |
+
|
| 130 |
+
assert bs == 1
|
| 131 |
+
|
| 132 |
+
if self.resolution != 512:
|
| 133 |
+
raise NotImplementedError(f"Only 512 resolution is available for now")
|
| 134 |
+
|
| 135 |
+
if (height, width) not in self.RESOLUTIONS[self.resolution]:
|
| 136 |
+
raise ValueError(f"Wrong height, width pair. Available (height, width) are: {self.RESOLUTIONS[self.resolution]}")
|
| 137 |
+
|
| 138 |
+
if num_steps != 4:
|
| 139 |
+
raise NotImplementedError(f"In the distilled version number of steps have to be strictly equal to 4")
|
| 140 |
+
|
| 141 |
+
# PREPARATION
|
| 142 |
+
num_frames = 1 if time_length == 0 else time_length * 8 // 4 + 1
|
| 143 |
+
|
| 144 |
+
num_groups = (1, 1, 1) if self.resolution == 512 else (1, 2, 2)
|
| 145 |
+
scale_factor = (1., 1., 1.) if self.resolution == 512 else (1., 2., 2.)
|
| 146 |
+
|
| 147 |
+
# TEXT EMBEDDER
|
| 148 |
+
if self.local_dit_rank == 0:
|
| 149 |
+
with torch.no_grad():
|
| 150 |
+
text_embed = self.text_embedder(text).squeeze(0).to(self.local_dit_rank, dtype=torch.bfloat16)
|
| 151 |
+
else:
|
| 152 |
+
text_embed = torch.empty(224, 4096, dtype=torch.bfloat16).to(self.local_dit_rank)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
if self.world_size > 1:
|
| 156 |
+
torch.distributed.broadcast(text_embed, 0)
|
| 157 |
+
|
| 158 |
+
torch.cuda.empty_cache()
|
| 159 |
+
|
| 160 |
+
visual_cu_seqlens = num_frames * torch.arange(bs + 1, dtype=torch.int32, device=self.device_map["dit"])
|
| 161 |
+
text_cu_seqlens = text_embed.shape[0] * torch.arange(bs + 1, dtype=torch.int32, device=self.device_map["dit"])
|
| 162 |
+
bs_text_embed = text_embed.repeat(bs, 1).to(self.device_map["dit"])
|
| 163 |
+
shape = (bs * num_frames, height // 8, width // 8, 16)
|
| 164 |
+
|
| 165 |
+
# DIT
|
| 166 |
+
with torch.no_grad():
|
| 167 |
+
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
|
| 168 |
+
images = diffusion_generate_renoise(
|
| 169 |
+
self.dit, self.noise_scheduler, shape, self.device_map["dit"],
|
| 170 |
+
num_steps, bs_text_embed, visual_cu_seqlens, text_cu_seqlens,
|
| 171 |
+
num_groups, scale_factor, progress=True, seed=seed,
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
torch.cuda.empty_cache()
|
| 175 |
+
|
| 176 |
+
# VAE
|
| 177 |
+
if self.local_dit_rank == 0:
|
| 178 |
+
self.vae.num_latent_frames_batch_size = 1 if time_length == 0 else 2
|
| 179 |
+
with torch.no_grad():
|
| 180 |
+
images = 1 / self.vae.config.scaling_factor * images.to(device=self.device_map["vae"], dtype=torch.bfloat16)
|
| 181 |
+
images = images.permute(0, 3, 1, 2) if time_length == 0 else images.permute(3, 0, 1, 2)
|
| 182 |
+
images = self.vae.decode(images.unsqueeze(2 if time_length == 0 else 0)).sample.float()
|
| 183 |
+
images = torch.clip((images + 1.) / 2., 0., 1.)
|
| 184 |
+
|
| 185 |
+
torch.cuda.empty_cache()
|
| 186 |
+
|
| 187 |
+
if self.local_dit_rank == 0:
|
| 188 |
+
# RESULTS
|
| 189 |
+
if time_length == 0:
|
| 190 |
+
return_images = []
|
| 191 |
+
for i, image in enumerate(images.squeeze(2).cpu()):
|
| 192 |
+
return_images.append(ToPILImage()(image))
|
| 193 |
+
return return_images
|
| 194 |
+
else:
|
| 195 |
+
if return_frames:
|
| 196 |
+
return_images = []
|
| 197 |
+
for i, image in enumerate(images.squeeze(0).float().permute(1, 0, 2, 3).cpu()):
|
| 198 |
+
return_images.append(ToPILImage()(image))
|
| 199 |
+
return return_images
|
| 200 |
+
else:
|
| 201 |
+
torchvision.io.write_video(save_path, 255. * images.squeeze(0).float().permute(1, 2, 3, 0).cpu().numpy(), fps=8, options = {"crf": "5"})
|