Spaces:
Running

Running
INIT
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- app.py +81 -0
- data/__pycache__/dataset.cpython-36.pyc +0 -0
- data/__pycache__/dataset.cpython-37.pyc +0 -0
- data/__pycache__/dataset.cpython-38.pyc +0 -0
- data/__pycache__/dataset.cpython-39.pyc +0 -0
- data/create_data.py +18 -0
- data/dataset.py +247 -0
- data/prepare_data.py +458 -0
- files/.DS_Store +0 -0
- files/english_words.txt +0 -0
- files/example_data/style-1/im_0.png +0 -0
- files/example_data/style-1/im_1.png +0 -0
- files/example_data/style-1/im_10.png +0 -0
- files/example_data/style-1/im_11.png +0 -0
- files/example_data/style-1/im_12.png +0 -0
- files/example_data/style-1/im_13.png +0 -0
- files/example_data/style-1/im_14.png +0 -0
- files/example_data/style-1/im_2.png +0 -0
- files/example_data/style-1/im_3.png +0 -0
- files/example_data/style-1/im_4.png +0 -0
- files/example_data/style-1/im_5.png +0 -0
- files/example_data/style-1/im_6.png +0 -0
- files/example_data/style-1/im_7.png +0 -0
- files/example_data/style-1/im_8.png +0 -0
- files/example_data/style-1/im_9.png +0 -0
- files/example_data/style-10/im_0.png +0 -0
- files/example_data/style-10/im_1.png +0 -0
- files/example_data/style-10/im_10.png +0 -0
- files/example_data/style-10/im_11.png +0 -0
- files/example_data/style-10/im_12.png +0 -0
- files/example_data/style-10/im_13.png +0 -0
- files/example_data/style-10/im_14.png +0 -0
- files/example_data/style-10/im_2.png +0 -0
- files/example_data/style-10/im_3.png +0 -0
- files/example_data/style-10/im_4.png +0 -0
- files/example_data/style-10/im_5.png +0 -0
- files/example_data/style-10/im_6.png +0 -0
- files/example_data/style-10/im_7.png +0 -0
- files/example_data/style-10/im_8.png +0 -0
- files/example_data/style-10/im_9.png +0 -0
- files/example_data/style-102/im_0.png +0 -0
- files/example_data/style-102/im_1.png +0 -0
- files/example_data/style-102/im_10.png +0 -0
- files/example_data/style-102/im_11.png +0 -0
- files/example_data/style-102/im_12.png +0 -0
- files/example_data/style-102/im_13.png +0 -0
- files/example_data/style-102/im_14.png +0 -0
- files/example_data/style-102/im_2.png +0 -0
- files/example_data/style-102/im_3.png +0 -0
- files/example_data/style-102/im_4.png +0 -0
app.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import numpy as np
|
| 4 |
+
from io import BytesIO
|
| 5 |
+
import glob
|
| 6 |
+
import os
|
| 7 |
+
import time
|
| 8 |
+
from data.dataset import load_itw_samples, crop_
|
| 9 |
+
import torch
|
| 10 |
+
import cv2
|
| 11 |
+
import os
|
| 12 |
+
import numpy as np
|
| 13 |
+
from models.model import TRGAN
|
| 14 |
+
from params import *
|
| 15 |
+
from torch import nn
|
| 16 |
+
from data.dataset import get_transform
|
| 17 |
+
import pickle
|
| 18 |
+
from PIL import Image
|
| 19 |
+
import tqdm
|
| 20 |
+
import shutil
|
| 21 |
+
model_path = 'files/iam_model.pth'
|
| 22 |
+
|
| 23 |
+
batch_size = 1
|
| 24 |
+
print ('(1) Loading model...')
|
| 25 |
+
model = TRGAN(batch_size = batch_size)
|
| 26 |
+
model.netG.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')) )
|
| 27 |
+
print (model_path+' : Model loaded Successfully')
|
| 28 |
+
model.eval()
|
| 29 |
+
|
| 30 |
+
# Define a function to generate an image based on text and images
|
| 31 |
+
def generate_image(text,folder, _ch3, images):
|
| 32 |
+
# Your image generation logic goes here (replace with your actual implementation)
|
| 33 |
+
# For demonstration purposes, we'll just concatenate the uploaded images horizontally.
|
| 34 |
+
if images:
|
| 35 |
+
style_inputs, width_length = load_itw_samples(images)
|
| 36 |
+
elif folder:
|
| 37 |
+
style_inputs, width_length = load_itw_samples(folder)
|
| 38 |
+
else:
|
| 39 |
+
return None
|
| 40 |
+
# Load images
|
| 41 |
+
text = text.replace("\n", "").replace("\t", "")
|
| 42 |
+
text_encode = [j.encode() for j in text.split(' ')]
|
| 43 |
+
eval_text_encode, eval_len_text = model.netconverter.encode(text_encode)
|
| 44 |
+
eval_text_encode = eval_text_encode.to('cuda').repeat(batch_size, 1, 1)
|
| 45 |
+
|
| 46 |
+
input_styles, page_val = model._generate_page(style_inputs.to(DEVICE).clone(), width_length, eval_text_encode, eval_len_text, no_concat = True)
|
| 47 |
+
page_val = crop_(page_val[0]*255)
|
| 48 |
+
input_styles = crop_(input_styles[0]*255)
|
| 49 |
+
|
| 50 |
+
max_width = max(page_val.shape[1],input_styles.shape[1])
|
| 51 |
+
|
| 52 |
+
if page_val.shape[1]!=max_width:
|
| 53 |
+
page_val = np.concatenate([page_val, np.ones((page_val.shape[0],max_width-page_val.shape[1]))*255], 1)
|
| 54 |
+
else:
|
| 55 |
+
input_styles = np.concatenate([input_styles, np.ones((input_styles.shape[0],max_width-input_styles.shape[1]))*255], 1)
|
| 56 |
+
|
| 57 |
+
upper_pad = np.ones((45,input_styles.shape[1]))*255
|
| 58 |
+
input_styles = np.concatenate([upper_pad, input_styles], 0)
|
| 59 |
+
page_val = np.concatenate([upper_pad, page_val], 0)
|
| 60 |
+
|
| 61 |
+
page_val = Image.fromarray(page_val).convert('RGB')
|
| 62 |
+
input_styles = Image.fromarray(input_styles).convert('RGB')
|
| 63 |
+
|
| 64 |
+
return input_styles, page_val
|
| 65 |
+
|
| 66 |
+
# Define Gradio Interface
|
| 67 |
+
iface = gr.Interface(
|
| 68 |
+
fn=generate_image,
|
| 69 |
+
inputs=[
|
| 70 |
+
gr.Textbox(value = "In the quiet hum of everyday life, the dance of existence unfolds. Time, an ever-flowing river, carries the stories of triumph and heartache. Each fleeting moment is a brushstroke on the canvas of our memories. Within the tapestry of human connection, threads of empathy weave a fabric that binds us all. Nature's symphony plays, a harmonious blend of rustling leaves and birdsong. In the labyrinth of possibility, dreams take flight. Beneath the veneer of routine, lies the extraordinary. Embrace the kaleidoscope of experience, for in the ordinary, the extraordinary often reveals itself.",label = "Input text"),
|
| 71 |
+
gr.Dropdown(value = "files/example_data/style-30", choices=glob.glob('files/example_data/*'), label="Choose from provided writer styles"),
|
| 72 |
+
gr.Markdown("### OR"),
|
| 73 |
+
gr.File(label="Upload multiple word images", file_count="multiple")
|
| 74 |
+
],
|
| 75 |
+
outputs=[#gr.Markdown("## Output"),
|
| 76 |
+
gr.Image(type="pil", label="Style Image"),
|
| 77 |
+
gr.Image(type="pil", label="Generated Image")]
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
# Launch the Gradio Interface
|
| 81 |
+
iface.launch(debug=True, share=True)
|
data/__pycache__/dataset.cpython-36.pyc
ADDED
|
Binary file (6.37 kB). View file
|
|
|
data/__pycache__/dataset.cpython-37.pyc
ADDED
|
Binary file (6.39 kB). View file
|
|
|
data/__pycache__/dataset.cpython-38.pyc
ADDED
|
Binary file (7.77 kB). View file
|
|
|
data/__pycache__/dataset.cpython-39.pyc
ADDED
|
Binary file (5.96 kB). View file
|
|
|
data/create_data.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
import torch
|
| 3 |
+
from torch.utils.data import Dataset
|
| 4 |
+
from torch.utils.data import sampler
|
| 5 |
+
import lmdb
|
| 6 |
+
import torchvision.transforms as transforms
|
| 7 |
+
import six
|
| 8 |
+
import sys
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import numpy as np
|
| 11 |
+
import os
|
| 12 |
+
import sys
|
| 13 |
+
import pickle
|
| 14 |
+
import numpy as np
|
| 15 |
+
|
| 16 |
+
import glob
|
| 17 |
+
|
| 18 |
+
glob.glob('/nfs/users/ext_ankan.bhunia/Handwritten_data/CVL/cvl-database-1-1/*/words/*/*tif')
|
data/dataset.py
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
|
| 2 |
+
# SPDX-License-Identifier: MIT
|
| 3 |
+
|
| 4 |
+
import random
|
| 5 |
+
import torch
|
| 6 |
+
from torch.utils.data import Dataset
|
| 7 |
+
from torch.utils.data import sampler
|
| 8 |
+
#import lmdb
|
| 9 |
+
import torchvision.transforms as transforms
|
| 10 |
+
import six
|
| 11 |
+
import sys
|
| 12 |
+
from PIL import Image
|
| 13 |
+
import numpy as np
|
| 14 |
+
import os
|
| 15 |
+
import sys
|
| 16 |
+
import pickle
|
| 17 |
+
import numpy as np
|
| 18 |
+
from params import *
|
| 19 |
+
import glob, cv2
|
| 20 |
+
import torchvision.transforms as transforms
|
| 21 |
+
|
| 22 |
+
def crop_(input):
|
| 23 |
+
image = Image.fromarray(input)
|
| 24 |
+
image = image.convert('L')
|
| 25 |
+
binary_image = image.point(lambda x: 0 if x > 127 else 255, '1')
|
| 26 |
+
bbox = binary_image.getbbox()
|
| 27 |
+
cropped_image = image.crop(bbox)
|
| 28 |
+
return np.array(cropped_image)
|
| 29 |
+
|
| 30 |
+
def get_transform(grayscale=False, convert=True):
|
| 31 |
+
|
| 32 |
+
transform_list = []
|
| 33 |
+
if grayscale:
|
| 34 |
+
transform_list.append(transforms.Grayscale(1))
|
| 35 |
+
|
| 36 |
+
if convert:
|
| 37 |
+
transform_list += [transforms.ToTensor()]
|
| 38 |
+
if grayscale:
|
| 39 |
+
transform_list += [transforms.Normalize((0.5,), (0.5,))]
|
| 40 |
+
else:
|
| 41 |
+
transform_list += [transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
|
| 42 |
+
|
| 43 |
+
return transforms.Compose(transform_list)
|
| 44 |
+
|
| 45 |
+
def load_itw_samples(folder_path, num_samples = 15):
|
| 46 |
+
if isinstance(folder_path, str):
|
| 47 |
+
paths = glob.glob(f'{folder_path}/*')
|
| 48 |
+
else:
|
| 49 |
+
paths = folder_path
|
| 50 |
+
paths = np.random.choice(paths, num_samples, replace = len(paths)<=num_samples)
|
| 51 |
+
|
| 52 |
+
words = [os.path.basename(path_i)[:-4] for path_i in paths]
|
| 53 |
+
|
| 54 |
+
imgs = [np.array(Image.open(i).convert('L')) for i in paths]
|
| 55 |
+
|
| 56 |
+
imgs = [crop_(im) for im in imgs]
|
| 57 |
+
imgs = [cv2.resize(imgs_i, (int(32*(imgs_i.shape[1]/imgs_i.shape[0])), 32)) for imgs_i in imgs]
|
| 58 |
+
max_width = 192
|
| 59 |
+
|
| 60 |
+
imgs_pad = []
|
| 61 |
+
imgs_wids = []
|
| 62 |
+
|
| 63 |
+
trans_fn = get_transform(grayscale=True)
|
| 64 |
+
|
| 65 |
+
for img in imgs:
|
| 66 |
+
|
| 67 |
+
img = 255 - img
|
| 68 |
+
img_height, img_width = img.shape[0], img.shape[1]
|
| 69 |
+
outImg = np.zeros(( img_height, max_width), dtype='float32')
|
| 70 |
+
outImg[:, :img_width] = img[:, :max_width]
|
| 71 |
+
|
| 72 |
+
img = 255 - outImg
|
| 73 |
+
|
| 74 |
+
imgs_pad.append(trans_fn((Image.fromarray(img))))
|
| 75 |
+
imgs_wids.append(img_width)
|
| 76 |
+
|
| 77 |
+
imgs_pad = torch.cat(imgs_pad, 0)
|
| 78 |
+
|
| 79 |
+
return imgs_pad.unsqueeze(0), torch.Tensor(imgs_wids).unsqueeze(0)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class TextDataset():
|
| 83 |
+
|
| 84 |
+
def __init__(self, base_path = DATASET_PATHS, num_examples = 15, target_transform=None):
|
| 85 |
+
|
| 86 |
+
self.NUM_EXAMPLES = num_examples
|
| 87 |
+
|
| 88 |
+
#base_path = DATASET_PATHS
|
| 89 |
+
file_to_store = open(base_path, "rb")
|
| 90 |
+
self.IMG_DATA = pickle.load(file_to_store)['train']
|
| 91 |
+
self.IMG_DATA = dict(list( self.IMG_DATA.items())) #[:NUM_WRITERS])
|
| 92 |
+
if 'None' in self.IMG_DATA.keys():
|
| 93 |
+
del self.IMG_DATA['None']
|
| 94 |
+
self.author_id = list(self.IMG_DATA.keys())
|
| 95 |
+
|
| 96 |
+
self.transform = get_transform(grayscale=True)
|
| 97 |
+
self.target_transform = target_transform
|
| 98 |
+
|
| 99 |
+
self.collate_fn = TextCollator()
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def __len__(self):
|
| 103 |
+
return len(self.author_id)
|
| 104 |
+
|
| 105 |
+
def __getitem__(self, index):
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
NUM_SAMPLES = self.NUM_EXAMPLES
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
author_id = self.author_id[index]
|
| 113 |
+
|
| 114 |
+
self.IMG_DATA_AUTHOR = self.IMG_DATA[author_id]
|
| 115 |
+
random_idxs = np.random.choice(len(self.IMG_DATA_AUTHOR), NUM_SAMPLES, replace = True)
|
| 116 |
+
|
| 117 |
+
rand_id_real = np.random.choice(len(self.IMG_DATA_AUTHOR))
|
| 118 |
+
real_img = self.transform(self.IMG_DATA_AUTHOR[rand_id_real]['img'].convert('L'))
|
| 119 |
+
real_labels = self.IMG_DATA_AUTHOR[rand_id_real]['label'].encode()
|
| 120 |
+
|
| 121 |
+
imgs = [np.array(self.IMG_DATA_AUTHOR[idx]['img'].convert('L')) for idx in random_idxs]
|
| 122 |
+
labels = [self.IMG_DATA_AUTHOR[idx]['label'].encode() for idx in random_idxs]
|
| 123 |
+
|
| 124 |
+
max_width = 192 #[img.shape[1] for img in imgs]
|
| 125 |
+
|
| 126 |
+
imgs_pad = []
|
| 127 |
+
imgs_wids = []
|
| 128 |
+
|
| 129 |
+
for img in imgs:
|
| 130 |
+
|
| 131 |
+
img = 255 - img
|
| 132 |
+
img_height, img_width = img.shape[0], img.shape[1]
|
| 133 |
+
outImg = np.zeros(( img_height, max_width), dtype='float32')
|
| 134 |
+
outImg[:, :img_width] = img[:, :max_width]
|
| 135 |
+
|
| 136 |
+
img = 255 - outImg
|
| 137 |
+
|
| 138 |
+
imgs_pad.append(self.transform((Image.fromarray(img))))
|
| 139 |
+
imgs_wids.append(img_width)
|
| 140 |
+
|
| 141 |
+
imgs_pad = torch.cat(imgs_pad, 0)
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
item = {'simg': imgs_pad, 'swids':imgs_wids, 'img' : real_img, 'label':real_labels,'img_path':'img_path', 'idx':'indexes', 'wcl':index}
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
return item
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class TextDatasetval():
|
| 154 |
+
|
| 155 |
+
def __init__(self, base_path = DATASET_PATHS, num_examples = 15, target_transform=None):
|
| 156 |
+
|
| 157 |
+
self.NUM_EXAMPLES = num_examples
|
| 158 |
+
#base_path = DATASET_PATHS
|
| 159 |
+
file_to_store = open(base_path, "rb")
|
| 160 |
+
self.IMG_DATA = pickle.load(file_to_store)['test']
|
| 161 |
+
self.IMG_DATA = dict(list( self.IMG_DATA.items()))#[NUM_WRITERS:])
|
| 162 |
+
if 'None' in self.IMG_DATA.keys():
|
| 163 |
+
del self.IMG_DATA['None']
|
| 164 |
+
self.author_id = list(self.IMG_DATA.keys())
|
| 165 |
+
|
| 166 |
+
self.transform = get_transform(grayscale=True)
|
| 167 |
+
self.target_transform = target_transform
|
| 168 |
+
|
| 169 |
+
self.collate_fn = TextCollator()
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def __len__(self):
|
| 173 |
+
return len(self.author_id)
|
| 174 |
+
|
| 175 |
+
def __getitem__(self, index):
|
| 176 |
+
|
| 177 |
+
NUM_SAMPLES = self.NUM_EXAMPLES
|
| 178 |
+
|
| 179 |
+
author_id = self.author_id[index]
|
| 180 |
+
|
| 181 |
+
self.IMG_DATA_AUTHOR = self.IMG_DATA[author_id]
|
| 182 |
+
random_idxs = np.random.choice(len(self.IMG_DATA_AUTHOR), NUM_SAMPLES, replace = True)
|
| 183 |
+
|
| 184 |
+
rand_id_real = np.random.choice(len(self.IMG_DATA_AUTHOR))
|
| 185 |
+
real_img = self.transform(self.IMG_DATA_AUTHOR[rand_id_real]['img'].convert('L'))
|
| 186 |
+
real_labels = self.IMG_DATA_AUTHOR[rand_id_real]['label'].encode()
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
imgs = [np.array(self.IMG_DATA_AUTHOR[idx]['img'].convert('L')) for idx in random_idxs]
|
| 190 |
+
labels = [self.IMG_DATA_AUTHOR[idx]['label'].encode() for idx in random_idxs]
|
| 191 |
+
|
| 192 |
+
max_width = 192 #[img.shape[1] for img in imgs]
|
| 193 |
+
|
| 194 |
+
imgs_pad = []
|
| 195 |
+
imgs_wids = []
|
| 196 |
+
|
| 197 |
+
for img in imgs:
|
| 198 |
+
|
| 199 |
+
img = 255 - img
|
| 200 |
+
img_height, img_width = img.shape[0], img.shape[1]
|
| 201 |
+
outImg = np.zeros(( img_height, max_width), dtype='float32')
|
| 202 |
+
outImg[:, :img_width] = img[:, :max_width]
|
| 203 |
+
|
| 204 |
+
img = 255 - outImg
|
| 205 |
+
|
| 206 |
+
imgs_pad.append(self.transform((Image.fromarray(img))))
|
| 207 |
+
imgs_wids.append(img_width)
|
| 208 |
+
|
| 209 |
+
imgs_pad = torch.cat(imgs_pad, 0)
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
item = {'simg': imgs_pad, 'swids':imgs_wids, 'img' : real_img, 'label':real_labels,'img_path':'img_path', 'idx':'indexes', 'wcl':index}
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
return item
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
class TextCollator(object):
|
| 222 |
+
def __init__(self):
|
| 223 |
+
self.resolution = resolution
|
| 224 |
+
|
| 225 |
+
def __call__(self, batch):
|
| 226 |
+
|
| 227 |
+
img_path = [item['img_path'] for item in batch]
|
| 228 |
+
width = [item['img'].shape[2] for item in batch]
|
| 229 |
+
indexes = [item['idx'] for item in batch]
|
| 230 |
+
simgs = torch.stack([item['simg'] for item in batch], 0)
|
| 231 |
+
wcls = torch.Tensor([item['wcl'] for item in batch])
|
| 232 |
+
swids = torch.Tensor([item['swids'] for item in batch])
|
| 233 |
+
imgs = torch.ones([len(batch), batch[0]['img'].shape[0], batch[0]['img'].shape[1], max(width)], dtype=torch.float32)
|
| 234 |
+
for idx, item in enumerate(batch):
|
| 235 |
+
try:
|
| 236 |
+
imgs[idx, :, :, 0:item['img'].shape[2]] = item['img']
|
| 237 |
+
except:
|
| 238 |
+
print(imgs.shape)
|
| 239 |
+
item = {'img': imgs, 'img_path':img_path, 'idx':indexes, 'simg': simgs, 'swids': swids, 'wcl':wcls}
|
| 240 |
+
if 'label' in batch[0].keys():
|
| 241 |
+
labels = [item['label'] for item in batch]
|
| 242 |
+
item['label'] = labels
|
| 243 |
+
if 'z' in batch[0].keys():
|
| 244 |
+
z = torch.stack([item['z'] for item in batch])
|
| 245 |
+
item['z'] = z
|
| 246 |
+
return item
|
| 247 |
+
|
data/prepare_data.py
ADDED
|
@@ -0,0 +1,458 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
|
| 3 |
+
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
|
| 4 |
+
# SPDX-License-Identifier: MIT
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import lmdb, tqdm
|
| 8 |
+
import cv2
|
| 9 |
+
import numpy as np
|
| 10 |
+
import argparse
|
| 11 |
+
import shutil
|
| 12 |
+
import sys
|
| 13 |
+
from PIL import Image
|
| 14 |
+
import random
|
| 15 |
+
import io
|
| 16 |
+
import xmltodict
|
| 17 |
+
import html
|
| 18 |
+
from sklearn.decomposition import PCA
|
| 19 |
+
import math
|
| 20 |
+
from tqdm import tqdm
|
| 21 |
+
from itertools import compress
|
| 22 |
+
import glob
|
| 23 |
+
def checkImageIsValid(imageBin):
|
| 24 |
+
if imageBin is None:
|
| 25 |
+
return False
|
| 26 |
+
imageBuf = np.fromstring(imageBin, dtype=np.uint8)
|
| 27 |
+
img = cv2.imdecode(imageBuf, cv2.IMREAD_GRAYSCALE)
|
| 28 |
+
imgH, imgW = img.shape[0], img.shape[1]
|
| 29 |
+
if imgH * imgW == 0:
|
| 30 |
+
return False
|
| 31 |
+
return True
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def writeCache(env, cache):
|
| 35 |
+
with env.begin(write=True) as txn:
|
| 36 |
+
for k, v in cache.items():
|
| 37 |
+
if type(k) == str:
|
| 38 |
+
k = k.encode()
|
| 39 |
+
if type(v) == str:
|
| 40 |
+
v = v.encode()
|
| 41 |
+
txn.put(k, v)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def find_rot_angle(idx_letters):
|
| 45 |
+
idx_letters = np.array(idx_letters).transpose()
|
| 46 |
+
pca = PCA(n_components=2)
|
| 47 |
+
pca.fit(idx_letters)
|
| 48 |
+
comp = pca.components_
|
| 49 |
+
angle = math.atan(comp[0][0]/comp[0][1])
|
| 50 |
+
return math.degrees(angle)
|
| 51 |
+
|
| 52 |
+
def read_data_from_folder(folder_path):
|
| 53 |
+
image_path_list = []
|
| 54 |
+
label_list = []
|
| 55 |
+
pics = os.listdir(folder_path)
|
| 56 |
+
pics.sort(key=lambda i: len(i))
|
| 57 |
+
for pic in pics:
|
| 58 |
+
image_path_list.append(folder_path + '/' + pic)
|
| 59 |
+
label_list.append(pic.split('_')[0])
|
| 60 |
+
return image_path_list, label_list
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def read_data_from_file(file_path):
|
| 64 |
+
image_path_list = []
|
| 65 |
+
label_list = []
|
| 66 |
+
f = open(file_path)
|
| 67 |
+
while True:
|
| 68 |
+
line1 = f.readline()
|
| 69 |
+
line2 = f.readline()
|
| 70 |
+
if not line1 or not line2:
|
| 71 |
+
break
|
| 72 |
+
line1 = line1.replace('\r', '').replace('\n', '')
|
| 73 |
+
line2 = line2.replace('\r', '').replace('\n', '')
|
| 74 |
+
image_path_list.append(line1)
|
| 75 |
+
label_list.append(line2)
|
| 76 |
+
|
| 77 |
+
return image_path_list, label_list
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def show_demo(demo_number, image_path_list, label_list):
|
| 81 |
+
print('\nShow some demo to prevent creating wrong lmdb data')
|
| 82 |
+
print('The first line is the path to image and the second line is the image label')
|
| 83 |
+
for i in range(demo_number):
|
| 84 |
+
print('image: %s\nlabel: %s\n' % (image_path_list[i], label_list[i]))
|
| 85 |
+
|
| 86 |
+
def create_img_label_list(top_dir,dataset, mode, words, author_number, remove_punc):
|
| 87 |
+
root_dir = os.path.join(top_dir, dataset)
|
| 88 |
+
output_dir = root_dir + (dataset=='IAM')*('/words'*words + '/lines'*(not words))
|
| 89 |
+
image_path_list, label_list = [], []
|
| 90 |
+
author_id = 'None'
|
| 91 |
+
mode = 'all'
|
| 92 |
+
if dataset=='CVL':
|
| 93 |
+
root_dir = os.path.join(root_dir, 'cvl-database-1-1')
|
| 94 |
+
if words:
|
| 95 |
+
images_name = 'words'
|
| 96 |
+
else:
|
| 97 |
+
images_name = 'lines'
|
| 98 |
+
if mode == 'tr' or mode == 'val':
|
| 99 |
+
mode_dir = ['trainset']
|
| 100 |
+
elif mode == 'te':
|
| 101 |
+
mode_dir = ['testset']
|
| 102 |
+
elif mode == 'all':
|
| 103 |
+
mode_dir = ['testset', 'trainset']
|
| 104 |
+
idx = 1
|
| 105 |
+
for mod in mode_dir:
|
| 106 |
+
images_dir = os.path.join(root_dir, mod, images_name)
|
| 107 |
+
for path, subdirs, files in os.walk(images_dir):
|
| 108 |
+
for name in files:
|
| 109 |
+
if (mode == 'tr' and idx >= 10000) or (
|
| 110 |
+
mode == 'val' and idx < 10000) or mode == 'te' or mode == 'all' or mode == 'tr_3te':
|
| 111 |
+
if os.path.splitext(name)[0].split('-')[1] == '6':
|
| 112 |
+
continue
|
| 113 |
+
label = os.path.splitext(name)[0].split('-')[-1]
|
| 114 |
+
|
| 115 |
+
imagePath = os.path.join(path, name)
|
| 116 |
+
label_list.append(label)
|
| 117 |
+
image_path_list.append(imagePath)
|
| 118 |
+
idx += 1
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
elif dataset=='IAM':
|
| 123 |
+
labels_name = 'original'
|
| 124 |
+
if mode=='all':
|
| 125 |
+
mode = ['te', 'va1', 'va2', 'tr']
|
| 126 |
+
elif mode=='valtest':
|
| 127 |
+
mode=['te', 'va1', 'va2']
|
| 128 |
+
else:
|
| 129 |
+
mode = [mode]
|
| 130 |
+
if words:
|
| 131 |
+
images_name = 'wordImages'
|
| 132 |
+
else:
|
| 133 |
+
images_name = 'lineImages'
|
| 134 |
+
images_dir = os.path.join(root_dir, images_name)
|
| 135 |
+
labels_dir = os.path.join(root_dir, labels_name)
|
| 136 |
+
full_ann_files = []
|
| 137 |
+
im_dirs = []
|
| 138 |
+
line_ann_dirs = []
|
| 139 |
+
image_path_list, label_list = [], []
|
| 140 |
+
for mod in mode:
|
| 141 |
+
part_file = os.path.join(root_dir, 'original_partition', mod + '.lst')
|
| 142 |
+
with open(part_file)as fp:
|
| 143 |
+
for line in fp:
|
| 144 |
+
name = line.split('-')
|
| 145 |
+
if int(name[-1][:-1]) == 0:
|
| 146 |
+
anno_file = os.path.join(labels_dir, '-'.join(name[:2]) + '.xml')
|
| 147 |
+
full_ann_files.append(anno_file)
|
| 148 |
+
im_dir = os.path.join(images_dir, name[0], '-'.join(name[:2]))
|
| 149 |
+
im_dirs.append(im_dir)
|
| 150 |
+
|
| 151 |
+
if author_number >= 0:
|
| 152 |
+
full_ann_files = [full_ann_files[author_number]]
|
| 153 |
+
im_dirs = [im_dirs[author_number]]
|
| 154 |
+
author_id = im_dirs[0].split('/')[-1]
|
| 155 |
+
|
| 156 |
+
lables_to_skip = ['.', '', ',', '"', "'", '(', ')', ':', ';', '!']
|
| 157 |
+
for i, anno_file in enumerate(full_ann_files):
|
| 158 |
+
with open(anno_file) as f:
|
| 159 |
+
try:
|
| 160 |
+
line = f.read()
|
| 161 |
+
annotation_content = xmltodict.parse(line)
|
| 162 |
+
lines = annotation_content['form']['handwritten-part']['line']
|
| 163 |
+
if words:
|
| 164 |
+
lines_list = []
|
| 165 |
+
for j in range(len(lines)):
|
| 166 |
+
lines_list.extend(lines[j]['word'])
|
| 167 |
+
lines = lines_list
|
| 168 |
+
except:
|
| 169 |
+
print('line is not decodable')
|
| 170 |
+
for line in lines:
|
| 171 |
+
try:
|
| 172 |
+
label = html.unescape(line['@text'])
|
| 173 |
+
except:
|
| 174 |
+
continue
|
| 175 |
+
if remove_punc and label in lables_to_skip:
|
| 176 |
+
continue
|
| 177 |
+
id = line['@id']
|
| 178 |
+
imagePath = os.path.join(im_dirs[i], id + '.png')
|
| 179 |
+
image_path_list.append(imagePath)
|
| 180 |
+
label_list.append(label)
|
| 181 |
+
|
| 182 |
+
elif dataset=='RIMES':
|
| 183 |
+
if mode=='tr':
|
| 184 |
+
images_dir = os.path.join(root_dir, 'orig','training_WR')
|
| 185 |
+
gt_file = os.path.join(root_dir, 'orig',
|
| 186 |
+
'groundtruth_training_icdar2011.txt')
|
| 187 |
+
elif mode=='te':
|
| 188 |
+
images_dir = os.path.join(root_dir, 'orig', 'testdataset_ICDAR')
|
| 189 |
+
gt_file = os.path.join(root_dir, 'orig',
|
| 190 |
+
'ground_truth_test_icdar2011.txt')
|
| 191 |
+
elif mode=='val':
|
| 192 |
+
images_dir = os.path.join(root_dir, 'orig', 'valdataset_ICDAR')
|
| 193 |
+
gt_file = os.path.join(root_dir, 'orig',
|
| 194 |
+
'ground_truth_validation_icdar2011.txt')
|
| 195 |
+
with open(gt_file, 'r') as f:
|
| 196 |
+
lines = f.readlines()
|
| 197 |
+
image_path_list = [os.path.join(images_dir, line.split(' ')[0]) for line in lines if len(line.split(' ')) > 1]
|
| 198 |
+
|
| 199 |
+
label_list = [line.split(' ')[1][:-1] for line in lines if len(line.split(' ')) > 1]
|
| 200 |
+
|
| 201 |
+
return image_path_list, label_list, output_dir, author_id
|
| 202 |
+
|
| 203 |
+
def createDataset(IMG_DATA, image_path_list, label_list, outputPath, mode, author_id, remove_punc, resize, imgH, init_gap, h_gap, charminW, charmaxW, discard_wide, discard_narr, labeled):
|
| 204 |
+
assert (len(image_path_list) == len(label_list))
|
| 205 |
+
nSamples = len(image_path_list)
|
| 206 |
+
|
| 207 |
+
outputPath = outputPath + (resize=='charResize') * ('/h%schar%sto%s/'%(imgH, charminW, charmaxW)) + (resize=='keepRatio') * ('/h%s/'%(imgH)) \
|
| 208 |
+
+ (resize=='noResize') * ('/noResize/') + (author_id!='None') * ('single_authors/'+author_id+'/' ) \
|
| 209 |
+
+ mode + (resize!='noResize') * (('_initGap%s'%(init_gap)) * (init_gap>0) + ('_hGap%s'%(h_gap)) * (h_gap>0) \
|
| 210 |
+
+ '_NoDiscard_wide' * (not discard_wide) + '_NoDiscard_wide' * (not discard_narr))+'_unlabeld' * (not labeled) +\
|
| 211 |
+
(('IAM' in outputPath) and remove_punc) *'_removePunc'
|
| 212 |
+
|
| 213 |
+
outputPath_ = '/root/Handwritten_data/IAM/authors' + (resize=='charResize') * ('/h%schar%sto%s/'%(imgH, charminW, charmaxW)) + (resize=='keepRatio') * ('/h%s/'%(imgH)) \
|
| 214 |
+
+ (resize=='noResize') * ('/noResize/') + (author_id!='None') * ('single_authors/'+author_id+'/' ) \
|
| 215 |
+
+ mode + (resize!='noResize') * (('_initGap%s'%(init_gap)) * (init_gap>0) + ('_hGap%s'%(h_gap)) * (h_gap>0) \
|
| 216 |
+
+ '_NoDiscard_wide' * (not discard_wide) + '_NoDiscard_wide' * (not discard_narr))+'_unlabeld' * (not labeled) +\
|
| 217 |
+
(('IAM' in outputPath) and remove_punc) *'_removePunc'
|
| 218 |
+
print(outputPath)
|
| 219 |
+
if os.path.exists(outputPath):
|
| 220 |
+
shutil.rmtree(outputPath)
|
| 221 |
+
os.makedirs(outputPath)
|
| 222 |
+
else:
|
| 223 |
+
os.makedirs(outputPath)
|
| 224 |
+
env = lmdb.open(outputPath, map_size=1099511627776)
|
| 225 |
+
cache = {}
|
| 226 |
+
cnt = 1
|
| 227 |
+
discard_wide = False
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
for i in tqdm(range(nSamples)):
|
| 233 |
+
imagePath = image_path_list[i]
|
| 234 |
+
#author_id = image_path_list[i].split('/')[-2]
|
| 235 |
+
label = label_list[i]
|
| 236 |
+
if not os.path.exists(imagePath):
|
| 237 |
+
print('%s does not exist' % imagePath)
|
| 238 |
+
continue
|
| 239 |
+
try:
|
| 240 |
+
im = Image.open(imagePath)
|
| 241 |
+
except:
|
| 242 |
+
continue
|
| 243 |
+
if resize in ['charResize', 'keepRatio']:
|
| 244 |
+
width, height = im.size
|
| 245 |
+
new_height = imgH - (h_gap * 2)
|
| 246 |
+
len_word = len(label)
|
| 247 |
+
width = int(width * imgH / height)
|
| 248 |
+
new_width = width
|
| 249 |
+
if resize=='charResize':
|
| 250 |
+
if (width/len_word > (charmaxW-1)) or (width/len_word < charminW) :
|
| 251 |
+
if discard_wide and width/len_word > 3*((charmaxW-1)):
|
| 252 |
+
print('%s has a width larger than max image width' % imagePath)
|
| 253 |
+
continue
|
| 254 |
+
if discard_narr and (width / len_word) < (charminW/3):
|
| 255 |
+
print('%s has a width smaller than min image width' % imagePath)
|
| 256 |
+
continue
|
| 257 |
+
else:
|
| 258 |
+
new_width = len_word * random.randrange(charminW, charmaxW)
|
| 259 |
+
|
| 260 |
+
# reshapeRun all_gather on arbitrary picklable data (not necessarily tensors) the image to the new dimensions
|
| 261 |
+
im = im.resize((new_width, new_height))
|
| 262 |
+
# append with 256 to add left, upper and lower white edges
|
| 263 |
+
init_w = int(random.normalvariate(init_gap, init_gap / 2))
|
| 264 |
+
new_im = Image.new("RGB", (new_width+init_gap, imgH), color=(256,256,256))
|
| 265 |
+
new_im.paste(im, (abs(init_w), h_gap))
|
| 266 |
+
im = new_im
|
| 267 |
+
|
| 268 |
+
if author_id in IMG_DATA.keys():
|
| 269 |
+
IMG_DATA[author_id].append({'img':im, 'label':label})
|
| 270 |
+
|
| 271 |
+
else:
|
| 272 |
+
IMG_DATA[author_id] = []
|
| 273 |
+
IMG_DATA[author_id].append({'img':im, 'label':label})
|
| 274 |
+
|
| 275 |
+
imgByteArr = io.BytesIO()
|
| 276 |
+
#im.save(os.path.join(outputPath, 'IMG_'+str(cnt)+'_'+str(label)+'.jpg'))
|
| 277 |
+
im.save(imgByteArr, format='tiff')
|
| 278 |
+
wordBin = imgByteArr.getvalue()
|
| 279 |
+
imageKey = 'image-%09d' % cnt
|
| 280 |
+
labelKey = 'label-%09d' % cnt
|
| 281 |
+
|
| 282 |
+
cache[imageKey] = wordBin
|
| 283 |
+
if labeled:
|
| 284 |
+
cache[labelKey] = label
|
| 285 |
+
if cnt % 1000 == 0:
|
| 286 |
+
writeCache(env, cache)
|
| 287 |
+
cache = {}
|
| 288 |
+
print('Written %d / %d' % (cnt, nSamples))
|
| 289 |
+
cnt += 1
|
| 290 |
+
|
| 291 |
+
nSamples = cnt - 1
|
| 292 |
+
cache['num-samples'] = str(nSamples)
|
| 293 |
+
writeCache(env, cache)
|
| 294 |
+
env.close()
|
| 295 |
+
print('Created dataset with %d samples' % nSamples)
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
|
| 333 |
+
|
| 334 |
+
return IMG_DATA
|
| 335 |
+
|
| 336 |
+
def createDict(label_list, top_dir, dataset, mode, words, remove_punc):
|
| 337 |
+
lex_name = dataset+'_' + mode + (dataset in ['IAM','RIMES'])*('_words' * words) + (dataset=='IAM') * ('_removePunc' * remove_punc)
|
| 338 |
+
all_words = '-'.join(label_list).split('-')
|
| 339 |
+
unique_words = []
|
| 340 |
+
words = []
|
| 341 |
+
for x in tqdm(all_words):
|
| 342 |
+
if x!='' and x!=' ':
|
| 343 |
+
words.append(x)
|
| 344 |
+
if x not in unique_words:
|
| 345 |
+
unique_words.append(x)
|
| 346 |
+
print(len(words))
|
| 347 |
+
print(len(unique_words))
|
| 348 |
+
with open(os.path.join(top_dir, 'Lexicon', lex_name+'_stratified.txt'), "w") as file:
|
| 349 |
+
file.write("\n".join(unique_words))
|
| 350 |
+
file.close()
|
| 351 |
+
with open(os.path.join(top_dir, 'Lexicon', lex_name + '_NOTstratified.txt'), "w") as file:
|
| 352 |
+
file.write("\n".join(words))
|
| 353 |
+
file.close()
|
| 354 |
+
|
| 355 |
+
def printAlphabet(label_list):
|
| 356 |
+
# get all unique alphabets - ignoring alphabet longer than one char
|
| 357 |
+
all_chars = ''.join(label_list)
|
| 358 |
+
unique_chars = []
|
| 359 |
+
for x in all_chars:
|
| 360 |
+
if x not in unique_chars and len(x) == 1:
|
| 361 |
+
unique_chars.append(x)
|
| 362 |
+
|
| 363 |
+
# for unique_char in unique_chars:
|
| 364 |
+
print(''.join(unique_chars))
|
| 365 |
+
|
| 366 |
+
if __name__ == '__main__':
|
| 367 |
+
|
| 368 |
+
TRAIN_IDX = 'gan.iam.tr_va.gt.filter27'
|
| 369 |
+
TEST_IDX = 'gan.iam.test.gt.filter27'
|
| 370 |
+
IAM_WORD_DATASET_PATH = '../../data/IAM/nfs/users/ext_ankan.bhunia/data/Handwritten_data/IAM/wordImages/'
|
| 371 |
+
XMLS_PATH = '../../data/IAM/nfs/users/ext_ankan.bhunia/data/Handwritten_data/IAM/xmls/'
|
| 372 |
+
word_paths = {i.split('/')[-1][:-4]:i for i in glob.glob(IAM_WORD_DATASET_PATH + '*/*/*.png')}
|
| 373 |
+
id_to_wid = {i.split('/')[-1][:-4]:xmltodict.parse(open(i).read())['form']['@writer-id'] for i in glob.glob(XMLS_PATH+'/**')}
|
| 374 |
+
trainslist = [i[:-1] for i in open(TRAIN_IDX, 'r').readlines()]
|
| 375 |
+
testslist = [i[:-1] for i in open(TEST_IDX, 'r').readlines()]
|
| 376 |
+
|
| 377 |
+
dict_ = {'train':{}, 'test':{}}
|
| 378 |
+
|
| 379 |
+
for i in trainslist:
|
| 380 |
+
|
| 381 |
+
author_id = i.split(',')[0]
|
| 382 |
+
file_id, string = i.split(',')[1].split(' ')
|
| 383 |
+
|
| 384 |
+
file_path = word_paths[file_id]
|
| 385 |
+
|
| 386 |
+
if author_id in dict_['train']:
|
| 387 |
+
dict_['train'][author_id].append({'path':file_path, 'label':string})
|
| 388 |
+
else:
|
| 389 |
+
dict_['train'][author_id] = [{'path':file_path, 'label':string}]
|
| 390 |
+
|
| 391 |
+
for i in testslist:
|
| 392 |
+
|
| 393 |
+
author_id = i.split(',')[0]
|
| 394 |
+
file_id, string = i.split(',')[1].split(' ')
|
| 395 |
+
|
| 396 |
+
file_path = word_paths[file_id]
|
| 397 |
+
|
| 398 |
+
if author_id in dict_['test']:
|
| 399 |
+
dict_['test'][author_id].append({'path':file_path, 'label':string})
|
| 400 |
+
else:
|
| 401 |
+
dict_['test'][author_id] = [{'path':file_path, 'label':string}]
|
| 402 |
+
|
| 403 |
+
|
| 404 |
+
create_Dict = True # create a dictionary of the generated dataset
|
| 405 |
+
dataset = 'IAM' #CVL/IAM/RIMES/gw
|
| 406 |
+
mode = 'all' # tr/te/val/va1/va2/all
|
| 407 |
+
labeled = True
|
| 408 |
+
top_dir = '../../data/IAM/nfs/users/ext_ankan.bhunia/data/Handwritten_data/'
|
| 409 |
+
# parameter relevant for IAM/RIMES:
|
| 410 |
+
words = True # use words images, otherwise use lines
|
| 411 |
+
#parameters relevant for IAM:
|
| 412 |
+
author_number = -1 # use only images of a specific writer. If the value is -1, use all writers, otherwise use the index of this specific writer
|
| 413 |
+
remove_punc = True # remove images which include only one punctuation mark from the list ['.', '', ',', '"', "'", '(', ')', ':', ';', '!']
|
| 414 |
+
|
| 415 |
+
resize = 'charResize' # charResize|keepRatio|noResize - type of resize,
|
| 416 |
+
# char - resize so that each character's width will be in a specific range (inside this range the width will be chosen randomly),
|
| 417 |
+
# keepRatio - resize to a specific image height while keeping the height-width aspect-ratio the same.
|
| 418 |
+
# noResize - do not resize the image
|
| 419 |
+
imgH = 32 # height of the resized image
|
| 420 |
+
init_gap = 0 # insert a gap before the beginning of the text with this number of pixels
|
| 421 |
+
charmaxW = 17 # The maximum character width
|
| 422 |
+
charminW = 16 # The minimum character width
|
| 423 |
+
h_gap = 0 # Insert a gap below and above the text
|
| 424 |
+
discard_wide = True # Discard images which have a character width 3 times larger than the maximum allowed character size (instead of resizing them) - this helps discard outlier images
|
| 425 |
+
discard_narr = True # Discard images which have a character width 3 times smaller than the minimum allowed charcter size.
|
| 426 |
+
|
| 427 |
+
|
| 428 |
+
IMG_DATA = {}
|
| 429 |
+
|
| 430 |
+
|
| 431 |
+
|
| 432 |
+
for idx_auth in range(1669999):
|
| 433 |
+
|
| 434 |
+
|
| 435 |
+
|
| 436 |
+
print ('Processing '+ str(idx_auth))
|
| 437 |
+
image_path_list, label_list, outputPath, author_id = create_img_label_list(top_dir,dataset, mode, words, idx_auth, remove_punc)
|
| 438 |
+
IMG_DATA[author_id] = []
|
| 439 |
+
# in a previous version we also cut the white edges of the image to keep a tight rectangle around the word but it
|
| 440 |
+
# seems in all the datasets we use this is already the case so I removed it. If there are problems maybe we should add this back.
|
| 441 |
+
IMG_DATA = createDataset(IMG_DATA, image_path_list, label_list, outputPath, mode, author_id, remove_punc, resize, imgH, init_gap, h_gap, charminW, charmaxW, discard_wide, discard_narr, labeled)
|
| 442 |
+
|
| 443 |
+
|
| 444 |
+
#if create_Dict:
|
| 445 |
+
# createDict(label_list, top_dir, dataset, mode, words, remove_punc)
|
| 446 |
+
#printAlphabet(label_list)
|
| 447 |
+
import pickle
|
| 448 |
+
|
| 449 |
+
dict_ = {}
|
| 450 |
+
for id_ in IMG_DATA.keys():
|
| 451 |
+
author_id = id_to_wid[id_]
|
| 452 |
+
|
| 453 |
+
if author_id in dict_.keys():
|
| 454 |
+
dict_[author_id].extend(IMG_DATA[id_])
|
| 455 |
+
else:
|
| 456 |
+
dict_[author_id] = IMG_DATA[id_]
|
| 457 |
+
|
| 458 |
+
#pickle.dump(IMG_DATA, '/root/IAM')
|
files/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
files/english_words.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
files/example_data/style-1/im_0.png
ADDED

|
files/example_data/style-1/im_1.png
ADDED
|
files/example_data/style-1/im_10.png
ADDED

|
files/example_data/style-1/im_11.png
ADDED
|
files/example_data/style-1/im_12.png
ADDED
|
files/example_data/style-1/im_13.png
ADDED

|
files/example_data/style-1/im_14.png
ADDED

|
files/example_data/style-1/im_2.png
ADDED

|
files/example_data/style-1/im_3.png
ADDED

|
files/example_data/style-1/im_4.png
ADDED

|
files/example_data/style-1/im_5.png
ADDED

|
files/example_data/style-1/im_6.png
ADDED
|
files/example_data/style-1/im_7.png
ADDED

|
files/example_data/style-1/im_8.png
ADDED

|
files/example_data/style-1/im_9.png
ADDED
|
files/example_data/style-10/im_0.png
ADDED

|
files/example_data/style-10/im_1.png
ADDED

|
files/example_data/style-10/im_10.png
ADDED

|
files/example_data/style-10/im_11.png
ADDED

|
files/example_data/style-10/im_12.png
ADDED

|
files/example_data/style-10/im_13.png
ADDED

|
files/example_data/style-10/im_14.png
ADDED
|
files/example_data/style-10/im_2.png
ADDED
|
files/example_data/style-10/im_3.png
ADDED
|
files/example_data/style-10/im_4.png
ADDED

|
files/example_data/style-10/im_5.png
ADDED

|
files/example_data/style-10/im_6.png
ADDED
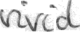
|
files/example_data/style-10/im_7.png
ADDED
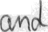
|
files/example_data/style-10/im_8.png
ADDED

|
files/example_data/style-10/im_9.png
ADDED
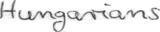
|
files/example_data/style-102/im_0.png
ADDED
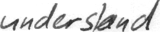
|
files/example_data/style-102/im_1.png
ADDED
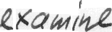
|
files/example_data/style-102/im_10.png
ADDED
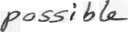
|
files/example_data/style-102/im_11.png
ADDED
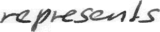
|
files/example_data/style-102/im_12.png
ADDED
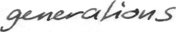
|
files/example_data/style-102/im_13.png
ADDED
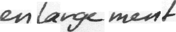
|
files/example_data/style-102/im_14.png
ADDED

|
files/example_data/style-102/im_2.png
ADDED

|
files/example_data/style-102/im_3.png
ADDED
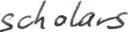
|
files/example_data/style-102/im_4.png
ADDED
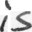
|