Spaces:
Running

Running
Merge pull request #4 from lfoppiano/add-ner
Browse files- README.md +5 -3
- client.py +225 -0
- docs/images/screenshot2.png +0 -0
- grobid_client_generic.py +264 -0
- grobid_processors.py +8 -7
- streamlit_app.py +43 -4
README.md
CHANGED
|
@@ -12,13 +12,15 @@ license: apache-2.0
|
|
| 12 |
|
| 13 |
# DocumentIQA: Scientific Document Insight QA
|
| 14 |
|
|
|
|
|
|
|
| 15 |
## Introduction
|
| 16 |
|
| 17 |
Question/Answering on scientific documents using LLMs (OpenAI, Mistral, ~~LLama2,~~ etc..).
|
| 18 |
This application is the frontend for testing the RAG (Retrieval Augmented Generation) on scientific documents, that we are developing at NIMS.
|
| 19 |
-
Differently to most of the project, we focus on scientific articles
|
| 20 |
|
| 21 |
-
**
|
| 22 |
|
| 23 |
**Demos**:
|
| 24 |
- (on HuggingFace spaces): https://lfoppiano-document-qa.hf.space/
|
|
@@ -31,7 +33,7 @@ Differently to most of the project, we focus on scientific articles and we are u
|
|
| 31 |
- Upload a scientific article as PDF document. You will see a spinner or loading indicator while the processing is in progress.
|
| 32 |
- Once the spinner stops, you can proceed to ask your questions
|
| 33 |
|
| 34 |
-
 that provide and cleaner results than the raw PDF2Text converter (which is comparable with most of other solutions).
|
| 22 |
|
| 23 |
+
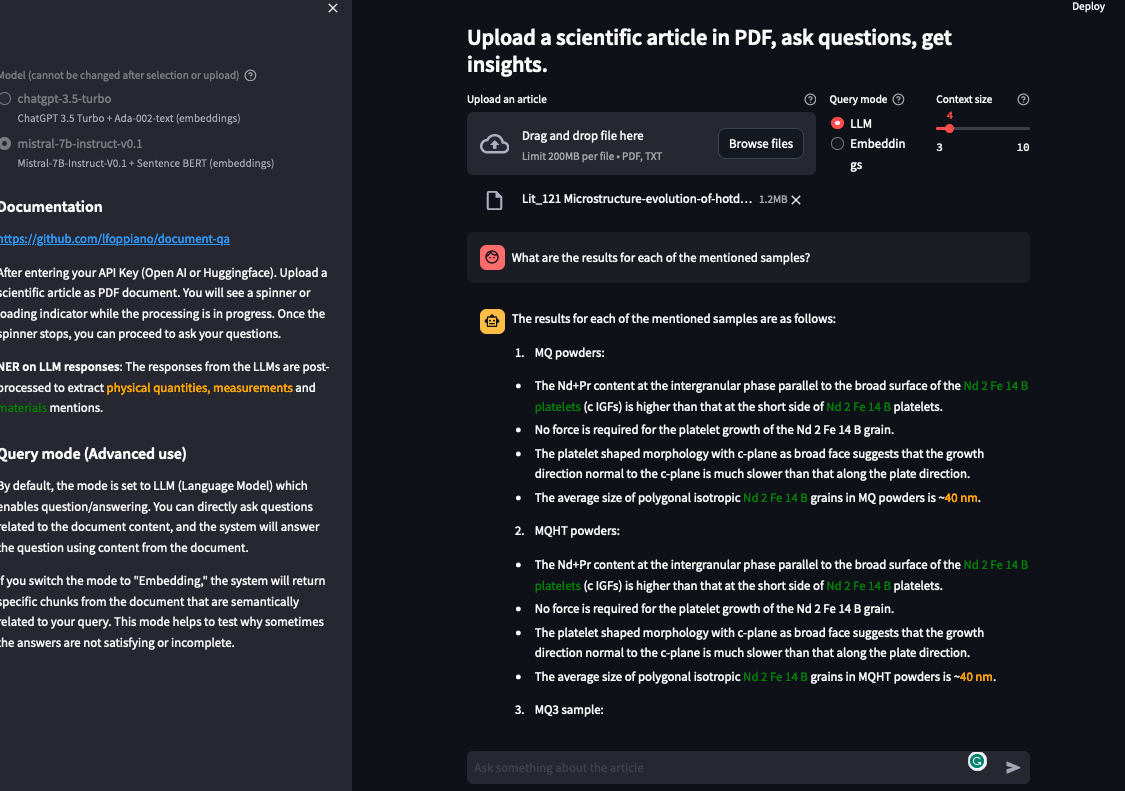
**NER in LLM response**: The responses from the LLMs are post-processed to extract <span stype="color:yellow">physical quantities, measurements</span> (with [grobid-quantities](https://github.com/kermitt2/grobid-quantities)) and <span stype="color:blue">materials</span> mentions (with [grobid-superconductors](https://github.com/lfoppiano/grobid-superconductors)).
|
| 24 |
|
| 25 |
**Demos**:
|
| 26 |
- (on HuggingFace spaces): https://lfoppiano-document-qa.hf.space/
|
|
|
|
| 33 |
- Upload a scientific article as PDF document. You will see a spinner or loading indicator while the processing is in progress.
|
| 34 |
- Once the spinner stops, you can proceed to ask your questions
|
| 35 |
|
| 36 |
+

|
| 37 |
|
| 38 |
### Options
|
| 39 |
#### Context size
|
client.py
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" Generic API Client """
|
| 2 |
+
from copy import deepcopy
|
| 3 |
+
import json
|
| 4 |
+
import requests
|
| 5 |
+
|
| 6 |
+
try:
|
| 7 |
+
from urlparse import urljoin
|
| 8 |
+
except ImportError:
|
| 9 |
+
from urllib.parse import urljoin
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class ApiClient(object):
|
| 13 |
+
""" Client to interact with a generic Rest API.
|
| 14 |
+
|
| 15 |
+
Subclasses should implement functionality accordingly with the provided
|
| 16 |
+
service methods, i.e. ``get``, ``post``, ``put`` and ``delete``.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
accept_type = 'application/xml'
|
| 20 |
+
api_base = None
|
| 21 |
+
|
| 22 |
+
def __init__(
|
| 23 |
+
self,
|
| 24 |
+
base_url,
|
| 25 |
+
username=None,
|
| 26 |
+
api_key=None,
|
| 27 |
+
status_endpoint=None,
|
| 28 |
+
timeout=60
|
| 29 |
+
):
|
| 30 |
+
""" Initialise client.
|
| 31 |
+
|
| 32 |
+
Args:
|
| 33 |
+
base_url (str): The base URL to the service being used.
|
| 34 |
+
username (str): The username to authenticate with.
|
| 35 |
+
api_key (str): The API key to authenticate with.
|
| 36 |
+
timeout (int): Maximum time before timing out.
|
| 37 |
+
"""
|
| 38 |
+
self.base_url = base_url
|
| 39 |
+
self.username = username
|
| 40 |
+
self.api_key = api_key
|
| 41 |
+
self.status_endpoint = urljoin(self.base_url, status_endpoint)
|
| 42 |
+
self.timeout = timeout
|
| 43 |
+
|
| 44 |
+
@staticmethod
|
| 45 |
+
def encode(request, data):
|
| 46 |
+
""" Add request content data to request body, set Content-type header.
|
| 47 |
+
|
| 48 |
+
Should be overridden by subclasses if not using JSON encoding.
|
| 49 |
+
|
| 50 |
+
Args:
|
| 51 |
+
request (HTTPRequest): The request object.
|
| 52 |
+
data (dict, None): Data to be encoded.
|
| 53 |
+
|
| 54 |
+
Returns:
|
| 55 |
+
HTTPRequest: The request object.
|
| 56 |
+
"""
|
| 57 |
+
if data is None:
|
| 58 |
+
return request
|
| 59 |
+
|
| 60 |
+
request.add_header('Content-Type', 'application/json')
|
| 61 |
+
request.extracted_data = json.dumps(data)
|
| 62 |
+
|
| 63 |
+
return request
|
| 64 |
+
|
| 65 |
+
@staticmethod
|
| 66 |
+
def decode(response):
|
| 67 |
+
""" Decode the returned data in the response.
|
| 68 |
+
|
| 69 |
+
Should be overridden by subclasses if something else than JSON is
|
| 70 |
+
expected.
|
| 71 |
+
|
| 72 |
+
Args:
|
| 73 |
+
response (HTTPResponse): The response object.
|
| 74 |
+
|
| 75 |
+
Returns:
|
| 76 |
+
dict or None.
|
| 77 |
+
"""
|
| 78 |
+
try:
|
| 79 |
+
return response.json()
|
| 80 |
+
except ValueError as e:
|
| 81 |
+
return e.message
|
| 82 |
+
|
| 83 |
+
def get_credentials(self):
|
| 84 |
+
""" Returns parameters to be added to authenticate the request.
|
| 85 |
+
|
| 86 |
+
This lives on its own to make it easier to re-implement it if needed.
|
| 87 |
+
|
| 88 |
+
Returns:
|
| 89 |
+
dict: A dictionary containing the credentials.
|
| 90 |
+
"""
|
| 91 |
+
return {"username": self.username, "api_key": self.api_key}
|
| 92 |
+
|
| 93 |
+
def call_api(
|
| 94 |
+
self,
|
| 95 |
+
method,
|
| 96 |
+
url,
|
| 97 |
+
headers=None,
|
| 98 |
+
params=None,
|
| 99 |
+
data=None,
|
| 100 |
+
files=None,
|
| 101 |
+
timeout=None,
|
| 102 |
+
):
|
| 103 |
+
""" Call API.
|
| 104 |
+
|
| 105 |
+
This returns object containing data, with error details if applicable.
|
| 106 |
+
|
| 107 |
+
Args:
|
| 108 |
+
method (str): The HTTP method to use.
|
| 109 |
+
url (str): Resource location relative to the base URL.
|
| 110 |
+
headers (dict or None): Extra request headers to set.
|
| 111 |
+
params (dict or None): Query-string parameters.
|
| 112 |
+
data (dict or None): Request body contents for POST or PUT requests.
|
| 113 |
+
files (dict or None: Files to be passed to the request.
|
| 114 |
+
timeout (int): Maximum time before timing out.
|
| 115 |
+
|
| 116 |
+
Returns:
|
| 117 |
+
ResultParser or ErrorParser.
|
| 118 |
+
"""
|
| 119 |
+
headers = deepcopy(headers) or {}
|
| 120 |
+
headers['Accept'] = self.accept_type if 'Accept' not in headers else headers['Accept']
|
| 121 |
+
params = deepcopy(params) or {}
|
| 122 |
+
data = data or {}
|
| 123 |
+
files = files or {}
|
| 124 |
+
#if self.username is not None and self.api_key is not None:
|
| 125 |
+
# params.update(self.get_credentials())
|
| 126 |
+
r = requests.request(
|
| 127 |
+
method,
|
| 128 |
+
url,
|
| 129 |
+
headers=headers,
|
| 130 |
+
params=params,
|
| 131 |
+
files=files,
|
| 132 |
+
data=data,
|
| 133 |
+
timeout=timeout,
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
return r, r.status_code
|
| 137 |
+
|
| 138 |
+
def get(self, url, params=None, **kwargs):
|
| 139 |
+
""" Call the API with a GET request.
|
| 140 |
+
|
| 141 |
+
Args:
|
| 142 |
+
url (str): Resource location relative to the base URL.
|
| 143 |
+
params (dict or None): Query-string parameters.
|
| 144 |
+
|
| 145 |
+
Returns:
|
| 146 |
+
ResultParser or ErrorParser.
|
| 147 |
+
"""
|
| 148 |
+
return self.call_api(
|
| 149 |
+
"GET",
|
| 150 |
+
url,
|
| 151 |
+
params=params,
|
| 152 |
+
**kwargs
|
| 153 |
+
)
|
| 154 |
+
|
| 155 |
+
def delete(self, url, params=None, **kwargs):
|
| 156 |
+
""" Call the API with a DELETE request.
|
| 157 |
+
|
| 158 |
+
Args:
|
| 159 |
+
url (str): Resource location relative to the base URL.
|
| 160 |
+
params (dict or None): Query-string parameters.
|
| 161 |
+
|
| 162 |
+
Returns:
|
| 163 |
+
ResultParser or ErrorParser.
|
| 164 |
+
"""
|
| 165 |
+
return self.call_api(
|
| 166 |
+
"DELETE",
|
| 167 |
+
url,
|
| 168 |
+
params=params,
|
| 169 |
+
**kwargs
|
| 170 |
+
)
|
| 171 |
+
|
| 172 |
+
def put(self, url, params=None, data=None, files=None, **kwargs):
|
| 173 |
+
""" Call the API with a PUT request.
|
| 174 |
+
|
| 175 |
+
Args:
|
| 176 |
+
url (str): Resource location relative to the base URL.
|
| 177 |
+
params (dict or None): Query-string parameters.
|
| 178 |
+
data (dict or None): Request body contents.
|
| 179 |
+
files (dict or None: Files to be passed to the request.
|
| 180 |
+
|
| 181 |
+
Returns:
|
| 182 |
+
An instance of ResultParser or ErrorParser.
|
| 183 |
+
"""
|
| 184 |
+
return self.call_api(
|
| 185 |
+
"PUT",
|
| 186 |
+
url,
|
| 187 |
+
params=params,
|
| 188 |
+
data=data,
|
| 189 |
+
files=files,
|
| 190 |
+
**kwargs
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
def post(self, url, params=None, data=None, files=None, **kwargs):
|
| 194 |
+
""" Call the API with a POST request.
|
| 195 |
+
|
| 196 |
+
Args:
|
| 197 |
+
url (str): Resource location relative to the base URL.
|
| 198 |
+
params (dict or None): Query-string parameters.
|
| 199 |
+
data (dict or None): Request body contents.
|
| 200 |
+
files (dict or None: Files to be passed to the request.
|
| 201 |
+
|
| 202 |
+
Returns:
|
| 203 |
+
An instance of ResultParser or ErrorParser.
|
| 204 |
+
"""
|
| 205 |
+
return self.call_api(
|
| 206 |
+
method="POST",
|
| 207 |
+
url=url,
|
| 208 |
+
params=params,
|
| 209 |
+
data=data,
|
| 210 |
+
files=files,
|
| 211 |
+
**kwargs
|
| 212 |
+
)
|
| 213 |
+
|
| 214 |
+
def service_status(self, **kwargs):
|
| 215 |
+
""" Call the API to get the status of the service.
|
| 216 |
+
|
| 217 |
+
Returns:
|
| 218 |
+
An instance of ResultParser or ErrorParser.
|
| 219 |
+
"""
|
| 220 |
+
return self.call_api(
|
| 221 |
+
'GET',
|
| 222 |
+
self.status_endpoint,
|
| 223 |
+
params={'format': 'json'},
|
| 224 |
+
**kwargs
|
| 225 |
+
)
|
docs/images/screenshot2.png
ADDED
|
grobid_client_generic.py
ADDED
|
@@ -0,0 +1,264 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
import time
|
| 4 |
+
|
| 5 |
+
import requests
|
| 6 |
+
import yaml
|
| 7 |
+
|
| 8 |
+
from commons.client import ApiClient
|
| 9 |
+
|
| 10 |
+
'''
|
| 11 |
+
This client is a generic client for any Grobid application and sub-modules.
|
| 12 |
+
At the moment, it supports only single document processing.
|
| 13 |
+
|
| 14 |
+
Source: https://github.com/kermitt2/grobid-client-python
|
| 15 |
+
'''
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class GrobidClientGeneric(ApiClient):
|
| 19 |
+
|
| 20 |
+
def __init__(self, config_path=None, ping=False):
|
| 21 |
+
self.config = None
|
| 22 |
+
if config_path is not None:
|
| 23 |
+
self.config = self.load_yaml_config_from_file(path=config_path)
|
| 24 |
+
super().__init__(self.config['grobid']['server'])
|
| 25 |
+
|
| 26 |
+
if ping:
|
| 27 |
+
result = self.ping_grobid()
|
| 28 |
+
if not result:
|
| 29 |
+
raise Exception("Grobid is down.")
|
| 30 |
+
|
| 31 |
+
os.environ['NO_PROXY'] = "nims.go.jp"
|
| 32 |
+
|
| 33 |
+
@staticmethod
|
| 34 |
+
def load_json_config_from_file(self, path='./config.json', ping=False):
|
| 35 |
+
"""
|
| 36 |
+
Load the json configuration
|
| 37 |
+
"""
|
| 38 |
+
config = {}
|
| 39 |
+
with open(path, 'r') as fp:
|
| 40 |
+
config = json.load(fp)
|
| 41 |
+
|
| 42 |
+
if ping:
|
| 43 |
+
result = self.ping_grobid()
|
| 44 |
+
if not result:
|
| 45 |
+
raise Exception("Grobid is down.")
|
| 46 |
+
|
| 47 |
+
return config
|
| 48 |
+
|
| 49 |
+
def load_yaml_config_from_file(self, path='./config.yaml'):
|
| 50 |
+
"""
|
| 51 |
+
Load the YAML configuration
|
| 52 |
+
"""
|
| 53 |
+
config = {}
|
| 54 |
+
try:
|
| 55 |
+
with open(path, 'r') as the_file:
|
| 56 |
+
raw_configuration = the_file.read()
|
| 57 |
+
|
| 58 |
+
config = yaml.safe_load(raw_configuration)
|
| 59 |
+
except Exception as e:
|
| 60 |
+
print("Configuration could not be loaded: ", str(e))
|
| 61 |
+
exit(1)
|
| 62 |
+
|
| 63 |
+
return config
|
| 64 |
+
|
| 65 |
+
def set_config(self, config, ping=False):
|
| 66 |
+
self.config = config
|
| 67 |
+
if ping:
|
| 68 |
+
try:
|
| 69 |
+
result = self.ping_grobid()
|
| 70 |
+
if not result:
|
| 71 |
+
raise Exception("Grobid is down.")
|
| 72 |
+
except Exception as e:
|
| 73 |
+
raise Exception("Grobid is down or other problems were encountered. ", e)
|
| 74 |
+
|
| 75 |
+
def ping_grobid(self):
|
| 76 |
+
# test if the server is up and running...
|
| 77 |
+
ping_url = self.get_grobid_url("ping")
|
| 78 |
+
|
| 79 |
+
r = requests.get(ping_url)
|
| 80 |
+
status = r.status_code
|
| 81 |
+
|
| 82 |
+
if status != 200:
|
| 83 |
+
print('GROBID server does not appear up and running ' + str(status))
|
| 84 |
+
return False
|
| 85 |
+
else:
|
| 86 |
+
print("GROBID server is up and running")
|
| 87 |
+
return True
|
| 88 |
+
|
| 89 |
+
def get_grobid_url(self, action):
|
| 90 |
+
grobid_config = self.config['grobid']
|
| 91 |
+
base_url = grobid_config['server']
|
| 92 |
+
action_url = base_url + grobid_config['url_mapping'][action]
|
| 93 |
+
|
| 94 |
+
return action_url
|
| 95 |
+
|
| 96 |
+
def process_texts(self, input, method_name='superconductors', params={}, headers={"Accept": "application/json"}):
|
| 97 |
+
|
| 98 |
+
files = {
|
| 99 |
+
'texts': input
|
| 100 |
+
}
|
| 101 |
+
|
| 102 |
+
the_url = self.get_grobid_url(method_name)
|
| 103 |
+
params, the_url = self.get_params_from_url(the_url)
|
| 104 |
+
|
| 105 |
+
res, status = self.post(
|
| 106 |
+
url=the_url,
|
| 107 |
+
files=files,
|
| 108 |
+
data=params,
|
| 109 |
+
headers=headers
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
if status == 503:
|
| 113 |
+
time.sleep(self.config['sleep_time'])
|
| 114 |
+
return self.process_texts(input, method_name, params, headers)
|
| 115 |
+
elif status != 200:
|
| 116 |
+
print('Processing failed with error ' + str(status))
|
| 117 |
+
return status, None
|
| 118 |
+
else:
|
| 119 |
+
return status, json.loads(res.text)
|
| 120 |
+
|
| 121 |
+
def process_text(self, input, method_name='superconductors', params={}, headers={"Accept": "application/json"}):
|
| 122 |
+
|
| 123 |
+
files = {
|
| 124 |
+
'text': input
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
the_url = self.get_grobid_url(method_name)
|
| 128 |
+
params, the_url = self.get_params_from_url(the_url)
|
| 129 |
+
|
| 130 |
+
res, status = self.post(
|
| 131 |
+
url=the_url,
|
| 132 |
+
files=files,
|
| 133 |
+
data=params,
|
| 134 |
+
headers=headers
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
if status == 503:
|
| 138 |
+
time.sleep(self.config['sleep_time'])
|
| 139 |
+
return self.process_text(input, method_name, params, headers)
|
| 140 |
+
elif status != 200:
|
| 141 |
+
print('Processing failed with error ' + str(status))
|
| 142 |
+
return status, None
|
| 143 |
+
else:
|
| 144 |
+
return status, json.loads(res.text)
|
| 145 |
+
|
| 146 |
+
def process(self, form_data: dict, method_name='superconductors', params={}, headers={"Accept": "application/json"}):
|
| 147 |
+
|
| 148 |
+
the_url = self.get_grobid_url(method_name)
|
| 149 |
+
params, the_url = self.get_params_from_url(the_url)
|
| 150 |
+
|
| 151 |
+
res, status = self.post(
|
| 152 |
+
url=the_url,
|
| 153 |
+
files=form_data,
|
| 154 |
+
data=params,
|
| 155 |
+
headers=headers
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
if status == 503:
|
| 159 |
+
time.sleep(self.config['sleep_time'])
|
| 160 |
+
return self.process_text(input, method_name, params, headers)
|
| 161 |
+
elif status != 200:
|
| 162 |
+
print('Processing failed with error ' + str(status))
|
| 163 |
+
else:
|
| 164 |
+
return res.text
|
| 165 |
+
|
| 166 |
+
def process_pdf_batch(self, pdf_files, params={}):
|
| 167 |
+
pass
|
| 168 |
+
|
| 169 |
+
def process_pdf(self, pdf_file, method_name, params={}, headers={"Accept": "application/json"}, verbose=False,
|
| 170 |
+
retry=None):
|
| 171 |
+
|
| 172 |
+
files = {
|
| 173 |
+
'input': (
|
| 174 |
+
pdf_file,
|
| 175 |
+
open(pdf_file, 'rb'),
|
| 176 |
+
'application/pdf',
|
| 177 |
+
{'Expires': '0'}
|
| 178 |
+
)
|
| 179 |
+
}
|
| 180 |
+
|
| 181 |
+
the_url = self.get_grobid_url(method_name)
|
| 182 |
+
|
| 183 |
+
params, the_url = self.get_params_from_url(the_url)
|
| 184 |
+
|
| 185 |
+
res, status = self.post(
|
| 186 |
+
url=the_url,
|
| 187 |
+
files=files,
|
| 188 |
+
data=params,
|
| 189 |
+
headers=headers
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
if status == 503 or status == 429:
|
| 193 |
+
if retry is None:
|
| 194 |
+
retry = self.config['max_retry'] - 1
|
| 195 |
+
else:
|
| 196 |
+
if retry - 1 == 0:
|
| 197 |
+
if verbose:
|
| 198 |
+
print("re-try exhausted. Aborting request")
|
| 199 |
+
return None, status
|
| 200 |
+
else:
|
| 201 |
+
retry -= 1
|
| 202 |
+
|
| 203 |
+
sleep_time = self.config['sleep_time']
|
| 204 |
+
if verbose:
|
| 205 |
+
print("Server is saturated, waiting", sleep_time, "seconds and trying again. ")
|
| 206 |
+
time.sleep(sleep_time)
|
| 207 |
+
return self.process_pdf(pdf_file, method_name, params, headers, verbose=verbose, retry=retry)
|
| 208 |
+
elif status != 200:
|
| 209 |
+
desc = None
|
| 210 |
+
if res.content:
|
| 211 |
+
c = json.loads(res.text)
|
| 212 |
+
desc = c['description'] if 'description' in c else None
|
| 213 |
+
return desc, status
|
| 214 |
+
elif status == 204:
|
| 215 |
+
# print('No content returned. Moving on. ')
|
| 216 |
+
return None, status
|
| 217 |
+
else:
|
| 218 |
+
return res.text, status
|
| 219 |
+
|
| 220 |
+
def get_params_from_url(self, the_url):
|
| 221 |
+
params = {}
|
| 222 |
+
if "?" in the_url:
|
| 223 |
+
split = the_url.split("?")
|
| 224 |
+
the_url = split[0]
|
| 225 |
+
params = split[1]
|
| 226 |
+
|
| 227 |
+
params = {param.split("=")[0]: param.split("=")[1] for param in params.split("&")}
|
| 228 |
+
return params, the_url
|
| 229 |
+
|
| 230 |
+
def process_json(self, text, method_name="processJson", params={}, headers={"Accept": "application/json"},
|
| 231 |
+
verbose=False):
|
| 232 |
+
files = {
|
| 233 |
+
'input': (
|
| 234 |
+
None,
|
| 235 |
+
text,
|
| 236 |
+
'application/json',
|
| 237 |
+
{'Expires': '0'}
|
| 238 |
+
)
|
| 239 |
+
}
|
| 240 |
+
|
| 241 |
+
the_url = self.get_grobid_url(method_name)
|
| 242 |
+
|
| 243 |
+
params, the_url = self.get_params_from_url(the_url)
|
| 244 |
+
|
| 245 |
+
res, status = self.post(
|
| 246 |
+
url=the_url,
|
| 247 |
+
files=files,
|
| 248 |
+
data=params,
|
| 249 |
+
headers=headers
|
| 250 |
+
)
|
| 251 |
+
|
| 252 |
+
if status == 503:
|
| 253 |
+
time.sleep(self.config['sleep_time'])
|
| 254 |
+
return self.process_json(text, method_name, params, headers), status
|
| 255 |
+
elif status != 200:
|
| 256 |
+
if verbose:
|
| 257 |
+
print('Processing failed with error ', status)
|
| 258 |
+
return None, status
|
| 259 |
+
elif status == 204:
|
| 260 |
+
if verbose:
|
| 261 |
+
print('No content returned. Moving on. ')
|
| 262 |
+
return None, status
|
| 263 |
+
else:
|
| 264 |
+
return res.text, status
|
grobid_processors.py
CHANGED
|
@@ -412,7 +412,8 @@ class GrobidMaterialsProcessor(BaseProcessor):
|
|
| 412 |
self.grobid_superconductors_client = grobid_superconductors_client
|
| 413 |
|
| 414 |
def extract_materials(self, text):
|
| 415 |
-
|
|
|
|
| 416 |
|
| 417 |
if status != 200:
|
| 418 |
result = {}
|
|
@@ -420,10 +421,10 @@ class GrobidMaterialsProcessor(BaseProcessor):
|
|
| 420 |
spans = []
|
| 421 |
|
| 422 |
if 'passages' in result:
|
| 423 |
-
materials = self.parse_superconductors_output(result,
|
| 424 |
|
| 425 |
for m in materials:
|
| 426 |
-
item = {"text":
|
| 427 |
|
| 428 |
item['offset_start'] = m['offset_start']
|
| 429 |
item['offset_end'] = m['offset_end']
|
|
@@ -502,12 +503,12 @@ class GrobidMaterialsProcessor(BaseProcessor):
|
|
| 502 |
class GrobidAggregationProcessor(GrobidProcessor, GrobidQuantitiesProcessor, GrobidMaterialsProcessor):
|
| 503 |
def __init__(self, grobid_client, grobid_quantities_client=None, grobid_superconductors_client=None):
|
| 504 |
GrobidProcessor.__init__(self, grobid_client)
|
| 505 |
-
GrobidQuantitiesProcessor
|
| 506 |
-
GrobidMaterialsProcessor
|
| 507 |
|
| 508 |
def process_single_text(self, text):
|
| 509 |
-
extracted_quantities_spans = extract_quantities(
|
| 510 |
-
extracted_materials_spans = extract_materials(
|
| 511 |
all_entities = extracted_quantities_spans + extracted_materials_spans
|
| 512 |
entities = self.prune_overlapping_annotations(all_entities)
|
| 513 |
return entities
|
|
|
|
| 412 |
self.grobid_superconductors_client = grobid_superconductors_client
|
| 413 |
|
| 414 |
def extract_materials(self, text):
|
| 415 |
+
preprocessed_text = text.strip()
|
| 416 |
+
status, result = self.grobid_superconductors_client.process_text(preprocessed_text, "processText_disable_linking")
|
| 417 |
|
| 418 |
if status != 200:
|
| 419 |
result = {}
|
|
|
|
| 421 |
spans = []
|
| 422 |
|
| 423 |
if 'passages' in result:
|
| 424 |
+
materials = self.parse_superconductors_output(result, preprocessed_text)
|
| 425 |
|
| 426 |
for m in materials:
|
| 427 |
+
item = {"text": preprocessed_text[m['offset_start']:m['offset_end']]}
|
| 428 |
|
| 429 |
item['offset_start'] = m['offset_start']
|
| 430 |
item['offset_end'] = m['offset_end']
|
|
|
|
| 503 |
class GrobidAggregationProcessor(GrobidProcessor, GrobidQuantitiesProcessor, GrobidMaterialsProcessor):
|
| 504 |
def __init__(self, grobid_client, grobid_quantities_client=None, grobid_superconductors_client=None):
|
| 505 |
GrobidProcessor.__init__(self, grobid_client)
|
| 506 |
+
self.gqp = GrobidQuantitiesProcessor(grobid_quantities_client)
|
| 507 |
+
self.gmp = GrobidMaterialsProcessor(grobid_superconductors_client)
|
| 508 |
|
| 509 |
def process_single_text(self, text):
|
| 510 |
+
extracted_quantities_spans = self.gqp.extract_quantities(text)
|
| 511 |
+
extracted_materials_spans = self.gmp.extract_materials(text)
|
| 512 |
all_entities = extracted_quantities_spans + extracted_materials_spans
|
| 513 |
entities = self.prune_overlapping_annotations(all_entities)
|
| 514 |
return entities
|
streamlit_app.py
CHANGED
|
@@ -1,8 +1,10 @@
|
|
| 1 |
import os
|
|
|
|
| 2 |
from hashlib import blake2b
|
| 3 |
from tempfile import NamedTemporaryFile
|
| 4 |
|
| 5 |
import dotenv
|
|
|
|
| 6 |
from langchain.llms.huggingface_hub import HuggingFaceHub
|
| 7 |
|
| 8 |
dotenv.load_dotenv(override=True)
|
|
@@ -12,6 +14,8 @@ from langchain.chat_models import PromptLayerChatOpenAI
|
|
| 12 |
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceEmbeddings
|
| 13 |
|
| 14 |
from document_qa_engine import DocumentQAEngine
|
|
|
|
|
|
|
| 15 |
|
| 16 |
if 'rqa' not in st.session_state:
|
| 17 |
st.session_state['rqa'] = None
|
|
@@ -38,7 +42,6 @@ if 'git_rev' not in st.session_state:
|
|
| 38 |
if "messages" not in st.session_state:
|
| 39 |
st.session_state.messages = []
|
| 40 |
|
| 41 |
-
|
| 42 |
def new_file():
|
| 43 |
st.session_state['loaded_embeddings'] = None
|
| 44 |
st.session_state['doc_id'] = None
|
|
@@ -66,6 +69,33 @@ def init_qa(model):
|
|
| 66 |
|
| 67 |
return DocumentQAEngine(chat, embeddings, grobid_url=os.environ['GROBID_URL'])
|
| 68 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 69 |
|
| 70 |
def get_file_hash(fname):
|
| 71 |
hash_md5 = blake2b()
|
|
@@ -84,7 +114,7 @@ def play_old_messages():
|
|
| 84 |
elif message['role'] == 'assistant':
|
| 85 |
with st.chat_message("assistant"):
|
| 86 |
if mode == "LLM":
|
| 87 |
-
st.markdown(message['content'])
|
| 88 |
else:
|
| 89 |
st.write(message['content'])
|
| 90 |
|
|
@@ -147,6 +177,7 @@ with st.sidebar:
|
|
| 147 |
st.markdown(
|
| 148 |
"""After entering your API Key (Open AI or Huggingface). Upload a scientific article as PDF document. You will see a spinner or loading indicator while the processing is in progress. Once the spinner stops, you can proceed to ask your questions.""")
|
| 149 |
|
|
|
|
| 150 |
if st.session_state['git_rev'] != "unknown":
|
| 151 |
st.markdown("**Revision number**: [" + st.session_state[
|
| 152 |
'git_rev'] + "](https://github.com/lfoppiano/document-qa/commit/" + st.session_state['git_rev'] + ")")
|
|
@@ -168,6 +199,7 @@ if uploaded_file and not st.session_state.loaded_embeddings:
|
|
| 168 |
chunk_size=250,
|
| 169 |
perc_overlap=0.1)
|
| 170 |
st.session_state['loaded_embeddings'] = True
|
|
|
|
| 171 |
|
| 172 |
# timestamp = datetime.utcnow()
|
| 173 |
|
|
@@ -175,7 +207,7 @@ if st.session_state.loaded_embeddings and question and len(question) > 0 and st.
|
|
| 175 |
for message in st.session_state.messages:
|
| 176 |
with st.chat_message(message["role"]):
|
| 177 |
if message['mode'] == "LLM":
|
| 178 |
-
st.markdown(message["content"])
|
| 179 |
elif message['mode'] == "Embeddings":
|
| 180 |
st.write(message["content"])
|
| 181 |
|
|
@@ -196,7 +228,14 @@ if st.session_state.loaded_embeddings and question and len(question) > 0 and st.
|
|
| 196 |
|
| 197 |
with st.chat_message("assistant"):
|
| 198 |
if mode == "LLM":
|
| 199 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 200 |
else:
|
| 201 |
st.write(text_response)
|
| 202 |
st.session_state.messages.append({"role": "assistant", "mode": mode, "content": text_response})
|
|
|
|
| 1 |
import os
|
| 2 |
+
import re
|
| 3 |
from hashlib import blake2b
|
| 4 |
from tempfile import NamedTemporaryFile
|
| 5 |
|
| 6 |
import dotenv
|
| 7 |
+
from grobid_quantities.quantities import QuantitiesAPI
|
| 8 |
from langchain.llms.huggingface_hub import HuggingFaceHub
|
| 9 |
|
| 10 |
dotenv.load_dotenv(override=True)
|
|
|
|
| 14 |
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceEmbeddings
|
| 15 |
|
| 16 |
from document_qa_engine import DocumentQAEngine
|
| 17 |
+
from grobid_processors import GrobidAggregationProcessor, decorate_text_with_annotations
|
| 18 |
+
from grobid_client_generic import GrobidClientGeneric
|
| 19 |
|
| 20 |
if 'rqa' not in st.session_state:
|
| 21 |
st.session_state['rqa'] = None
|
|
|
|
| 42 |
if "messages" not in st.session_state:
|
| 43 |
st.session_state.messages = []
|
| 44 |
|
|
|
|
| 45 |
def new_file():
|
| 46 |
st.session_state['loaded_embeddings'] = None
|
| 47 |
st.session_state['doc_id'] = None
|
|
|
|
| 69 |
|
| 70 |
return DocumentQAEngine(chat, embeddings, grobid_url=os.environ['GROBID_URL'])
|
| 71 |
|
| 72 |
+
@st.cache_resource
|
| 73 |
+
def init_ner():
|
| 74 |
+
quantities_client = QuantitiesAPI(os.environ['GROBID_QUANTITIES_URL'], check_server=True)
|
| 75 |
+
|
| 76 |
+
materials_client = GrobidClientGeneric(ping=True)
|
| 77 |
+
config_materials = {
|
| 78 |
+
'grobid': {
|
| 79 |
+
"server": os.environ['GROBID_MATERIALS_URL'],
|
| 80 |
+
'sleep_time': 5,
|
| 81 |
+
'timeout': 60,
|
| 82 |
+
'url_mapping': {
|
| 83 |
+
'processText_disable_linking': "/service/process/text?disableLinking=True",
|
| 84 |
+
# 'processText_disable_linking': "/service/process/text"
|
| 85 |
+
}
|
| 86 |
+
}
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
materials_client.set_config(config_materials)
|
| 90 |
+
|
| 91 |
+
gqa = GrobidAggregationProcessor(None,
|
| 92 |
+
grobid_quantities_client=quantities_client,
|
| 93 |
+
grobid_superconductors_client=materials_client
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
return gqa
|
| 97 |
+
|
| 98 |
+
gqa = init_ner()
|
| 99 |
|
| 100 |
def get_file_hash(fname):
|
| 101 |
hash_md5 = blake2b()
|
|
|
|
| 114 |
elif message['role'] == 'assistant':
|
| 115 |
with st.chat_message("assistant"):
|
| 116 |
if mode == "LLM":
|
| 117 |
+
st.markdown(message['content'], unsafe_allow_html=True)
|
| 118 |
else:
|
| 119 |
st.write(message['content'])
|
| 120 |
|
|
|
|
| 177 |
st.markdown(
|
| 178 |
"""After entering your API Key (Open AI or Huggingface). Upload a scientific article as PDF document. You will see a spinner or loading indicator while the processing is in progress. Once the spinner stops, you can proceed to ask your questions.""")
|
| 179 |
|
| 180 |
+
st.markdown('**NER on LLM responses**: The responses from the LLMs are post-processed to extract <span style="color:orange">physical quantities, measurements</span> and <span style="color:green">materials</span> mentions.', unsafe_allow_html=True)
|
| 181 |
if st.session_state['git_rev'] != "unknown":
|
| 182 |
st.markdown("**Revision number**: [" + st.session_state[
|
| 183 |
'git_rev'] + "](https://github.com/lfoppiano/document-qa/commit/" + st.session_state['git_rev'] + ")")
|
|
|
|
| 199 |
chunk_size=250,
|
| 200 |
perc_overlap=0.1)
|
| 201 |
st.session_state['loaded_embeddings'] = True
|
| 202 |
+
st.session_state.messages = []
|
| 203 |
|
| 204 |
# timestamp = datetime.utcnow()
|
| 205 |
|
|
|
|
| 207 |
for message in st.session_state.messages:
|
| 208 |
with st.chat_message(message["role"]):
|
| 209 |
if message['mode'] == "LLM":
|
| 210 |
+
st.markdown(message["content"], unsafe_allow_html=True)
|
| 211 |
elif message['mode'] == "Embeddings":
|
| 212 |
st.write(message["content"])
|
| 213 |
|
|
|
|
| 228 |
|
| 229 |
with st.chat_message("assistant"):
|
| 230 |
if mode == "LLM":
|
| 231 |
+
entities = gqa.process_single_text(text_response)
|
| 232 |
+
# for entity in entities:
|
| 233 |
+
# entity
|
| 234 |
+
decorated_text = decorate_text_with_annotations(text_response.strip(), entities)
|
| 235 |
+
decorated_text = decorated_text.replace('class="label material"', 'style="color:green"')
|
| 236 |
+
decorated_text = re.sub(r'class="label[^"]+"', 'style="color:orange"', decorated_text)
|
| 237 |
+
st.markdown(decorated_text, unsafe_allow_html=True)
|
| 238 |
+
text_response = decorated_text
|
| 239 |
else:
|
| 240 |
st.write(text_response)
|
| 241 |
st.session_state.messages.append({"role": "assistant", "mode": mode, "content": text_response})
|