Spaces:
Running
on
Zero

Running
on
Zero
Initial commit
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- LICENSE +21 -0
- README.md +177 -13
- agent/dreamer.py +462 -0
- agent/dreamer.yaml +9 -0
- agent/dreamer_utils.py +1040 -0
- agent/genrl.py +124 -0
- agent/genrl.yaml +22 -0
- agent/plan2explore.py +108 -0
- agent/plan2explore.yaml +9 -0
- agent/video_utils.py +240 -0
- app.py +80 -0
- assets/GenRL_fig1.png +0 -0
- assets/dashboard.png +0 -0
- assets/video_samples/a_spider_walking_on_the_floor.mp4 +0 -0
- assets/video_samples/backflip.mp4 +0 -0
- assets/video_samples/dancing.mp4 +0 -0
- assets/video_samples/dead_spider_white.gif +0 -0
- assets/video_samples/dog_running_seen_from_the_side.mp4 +0 -0
- assets/video_samples/doing_splits.mp4 +0 -0
- assets/video_samples/flex.mp4 +0 -0
- assets/video_samples/headstand.mp4 +0 -0
- assets/video_samples/karate_kick.mp4 +0 -0
- assets/video_samples/lying_down_with_legs_up.mp4 +0 -0
- assets/video_samples/person_standing_up_with_hands_up_seen_from_the_side.mp4 +0 -0
- assets/video_samples/punching.mp4 +0 -0
- collect_data.py +326 -0
- collect_data.yaml +54 -0
- conf/defaults/dreamer_v2.yaml +38 -0
- conf/defaults/dreamer_v3.yaml +38 -0
- conf/defaults/genrl.yaml +37 -0
- conf/env/dmc_pixels.yaml +8 -0
- conf/train_mode/train_behavior.yaml +5 -0
- conf/train_mode/train_model.yaml +6 -0
- demo/demo_test.py +23 -0
- demo/t2v.py +115 -0
- envs/__init__.py +0 -0
- envs/custom_dmc_tasks/__init__.py +13 -0
- envs/custom_dmc_tasks/cheetah.py +247 -0
- envs/custom_dmc_tasks/cheetah.xml +74 -0
- envs/custom_dmc_tasks/jaco.py +222 -0
- envs/custom_dmc_tasks/quadruped.py +683 -0
- envs/custom_dmc_tasks/quadruped.xml +328 -0
- envs/custom_dmc_tasks/stickman.py +647 -0
- envs/custom_dmc_tasks/stickman.xml +108 -0
- envs/custom_dmc_tasks/walker.py +489 -0
- envs/custom_dmc_tasks/walker.xml +71 -0
- envs/kitchen_extra.py +299 -0
- envs/main.py +743 -0
- notebooks/demo_videoclip.ipynb +124 -0
- notebooks/text2video.ipynb +161 -0
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) Pietro Mazzaglia
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,13 +1,177 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GenRL: Multimodal foundation world models for generalist embodied agents
|
| 2 |
+
|
| 3 |
+
<p align="center">
|
| 4 |
+
<img src='assets/GenRL_fig1.png' width=90%>
|
| 5 |
+
</p>
|
| 6 |
+
|
| 7 |
+
<p align="center">
|
| 8 |
+
<a href="https://mazpie.github.io/genrl">Website</a>  | <a href="https://huggingface.co/mazpie/genrl_models"> Models 🤗</a>  | <a href="https://huggingface.co/datasets/mazpie/genrl_datasets"> Datasets 🤗</a>  | <a href="./demo/"> Gradio demo</a>  | <a href="./notebooks/"> Notebooks</a> 
|
| 9 |
+
<br>
|
| 10 |
+
|
| 11 |
+
## Get started
|
| 12 |
+
|
| 13 |
+
### Creating the environment
|
| 14 |
+
|
| 15 |
+
We recommend using `conda` to create the environment
|
| 16 |
+
|
| 17 |
+
```
|
| 18 |
+
conda create --name genrl python=3.10
|
| 19 |
+
|
| 20 |
+
conda activate genrl
|
| 21 |
+
|
| 22 |
+
pip install -r requirements.txt
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
### Downloading InternVideo2
|
| 26 |
+
|
| 27 |
+
Download InternVideo 2 [[here]](https://huggingface.co/OpenGVLab/InternVideo2-Stage2_1B-224p-f4/blob/main/InternVideo2-stage2_1b-224p-f4.pt).
|
| 28 |
+
|
| 29 |
+
Place in the `models` folder.
|
| 30 |
+
|
| 31 |
+
Note: the file access is restricted, so you'll need an HuggingFace account to request access to the file.
|
| 32 |
+
|
| 33 |
+
Note: By default, the code expects the model to be placed in the `models` folder. The variable `MODELS_ROOT_PATH` indicating where the model should be place is set in `tools/genrl_utils.py`.
|
| 34 |
+
|
| 35 |
+
## Data
|
| 36 |
+
|
| 37 |
+
### Download datasets
|
| 38 |
+
|
| 39 |
+
The datasets used to pre-trained the models can be downloaded [[here]](https://huggingface.co/datasets/mazpie/genrl_datasets).
|
| 40 |
+
|
| 41 |
+
The file are `tar.gz` and can be extracted using the `tar` utility on Linux. For example:
|
| 42 |
+
|
| 43 |
+
```
|
| 44 |
+
tar -zxvf walker_data.tar.gz
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
### Collecting and pre-processing data
|
| 48 |
+
|
| 49 |
+
If you don't want to download our datasets, you collect and pre-process the data on your own.
|
| 50 |
+
|
| 51 |
+
Data can be collected running a DreamerV3 agent on a task, by running:
|
| 52 |
+
|
| 53 |
+
```
|
| 54 |
+
python3 collect_data.py agent=dreamer task=stickman_walk
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
or the Plan2Explore agent, by running:
|
| 58 |
+
|
| 59 |
+
```
|
| 60 |
+
python3 collect_data.py agent=plan2explore conf/defaults=dreamer_v2 task=stickman_walk
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
A repo for the experiment will be created under the directory `exp_local`, such as: `exp_local/YYYY.MM.DD/HHMMSS_agentname`. The data can then be found in the `buffer` subdirectory.
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
After obtaining the data, it should be processed to obtain the video embeddings for each frame sequence in the episodes. The processing can be done by running:
|
| 67 |
+
|
| 68 |
+
```
|
| 69 |
+
python3 process_dataset.py dataset_dir=data/stickman_example
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
where `data/stickman_example` is replaced by the folder of the data you want to process.
|
| 73 |
+
|
| 74 |
+
## Agents
|
| 75 |
+
|
| 76 |
+
### Downloading pre-trained models
|
| 77 |
+
|
| 78 |
+
If you want to test our work, without having to pre-train the models, you can do this by using our pre-trained models.
|
| 79 |
+
|
| 80 |
+
Pretrained models can be found [[here]](https://huggingface.co/mazpie/genrl_models)
|
| 81 |
+
|
| 82 |
+
Here's a snippet to download them easily:
|
| 83 |
+
|
| 84 |
+
```
|
| 85 |
+
import os
|
| 86 |
+
from huggingface_hub import hf_hub_download
|
| 87 |
+
|
| 88 |
+
def download_model(model_folder, model_filename):
|
| 89 |
+
REPO_ID = 'mazpie/genrl_models'
|
| 90 |
+
filename_list = [model_filename]
|
| 91 |
+
if not os.path.exists(model_folder):
|
| 92 |
+
os.makedirs(model_folder)
|
| 93 |
+
for filename in filename_list:
|
| 94 |
+
local_file = os.path.join(model_folder, filename)
|
| 95 |
+
if not os.path.exists(local_file):
|
| 96 |
+
hf_hub_download(repo_id=REPO_ID, filename=filename, local_dir=model_folder, local_dir_use_symlinks=False)
|
| 97 |
+
|
| 98 |
+
download_model('models', 'genrl_stickman_500k_2.pt')
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
Pre-trained models can be used by setting `snapshot_load_dir=...` when running `train.py`.
|
| 102 |
+
|
| 103 |
+
Note: the pre-trained models are not trained to solve any tasks. They only contain a pre-trained multimodal foundation world model (world model + connector and aligner).
|
| 104 |
+
|
| 105 |
+
### Training multimodal foundation world models
|
| 106 |
+
|
| 107 |
+
In order to train a multimodal foundation world model from data, you should run something like:
|
| 108 |
+
|
| 109 |
+
```
|
| 110 |
+
# Note: frames = update steps
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
python3 train.py task=stickman_walk replay_load_dir=data/stickman_example num_train_frames=500_010 visual_every_frames=25_000 train_world_model=True train_connector=True reset_world_model=True reset_connector=True
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
### Behavior learning
|
| 117 |
+
|
| 118 |
+
After pre-training a model, you can train the behavior for a task using:
|
| 119 |
+
|
| 120 |
+
```
|
| 121 |
+
python3 train.py task=stickman_walk snapshot_load_dir=models/genrl_stickman_500k_2.pt num_train_frames=50_010 batch_size=32 batch_length=32 agent.imag_reward_fn=video_text_reward eval_modality=task_imag
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
Data-free RL can be performed by additionaly passing the option:
|
| 125 |
+
|
| 126 |
+
`train_from_data=False`
|
| 127 |
+
|
| 128 |
+
The prompts for each task can be found and edited in `tools/genrl_utils.py`. However, you can also pass a custom prompt for a task by passing the option:
|
| 129 |
+
|
| 130 |
+
`+agent.imag_reward_args.task_prompt=custom_prompt`
|
| 131 |
+
|
| 132 |
+
## Other utilities
|
| 133 |
+
|
| 134 |
+
### Gradio demo
|
| 135 |
+
|
| 136 |
+
There's a gradio demo that can be found at `demo/app.py`.
|
| 137 |
+
|
| 138 |
+
If launching demo like a standard Python program with:
|
| 139 |
+
|
| 140 |
+
```
|
| 141 |
+
python3 demo/app.py
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
it will return a local endpoint (e.g. http://127.0.0.1:7860) where to access a dashboard to play with GenRL.
|
| 145 |
+
|
| 146 |
+
<p align="center">
|
| 147 |
+
<img src='assets/dashboard.png' width=75%>
|
| 148 |
+
</p>
|
| 149 |
+
|
| 150 |
+
### Notebooks
|
| 151 |
+
|
| 152 |
+
You can find several notebooks to test our code in the `notebooks` directory.
|
| 153 |
+
|
| 154 |
+
`demo_videoclip` : can be used to test the correct functioning of the InternVideo2 component
|
| 155 |
+
|
| 156 |
+
`text2video` : utility to generate video reconstructions from text prompts
|
| 157 |
+
|
| 158 |
+
`video2video` : utility to generate video reconstructions from video prompts
|
| 159 |
+
|
| 160 |
+
`visualize_dataset_episodes` : utility to generate videos from the episodes in a given dataset
|
| 161 |
+
|
| 162 |
+
`visualize_env` : used to play with the environment and, for instance, understand how the reward function of each task works
|
| 163 |
+
|
| 164 |
+
### Stickman environment
|
| 165 |
+
|
| 166 |
+
We introduced the Stickman environment as a simplified 2D version of the Humanoid environment.
|
| 167 |
+
|
| 168 |
+
This can be found in the `envs/custom_dmc_tasks` folder. You will find an `.xml` model and a `.py` files containing the tasks.
|
| 169 |
+
|
| 170 |
+
## Acknowledgments
|
| 171 |
+
|
| 172 |
+
We would like to thank the authors of the following repositories for their useful code and models:
|
| 173 |
+
|
| 174 |
+
* [InternVideo2](https://github.com/OpenGVLab/InternVideo)
|
| 175 |
+
* [Franka Kitchen](https://github.com/google-research/relay-policy-learning)
|
| 176 |
+
* [DreamerV3](https://github.com/danijar/dreamerv3)
|
| 177 |
+
* [DreamerV3-torch](https://github.com/NM512/dreamerv3-torch)
|
agent/dreamer.py
ADDED
|
@@ -0,0 +1,462 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
import tools.utils as utils
|
| 5 |
+
import agent.dreamer_utils as common
|
| 6 |
+
from collections import OrderedDict
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
from tools.genrl_utils import *
|
| 10 |
+
|
| 11 |
+
def stop_gradient(x):
|
| 12 |
+
return x.detach()
|
| 13 |
+
|
| 14 |
+
Module = nn.Module
|
| 15 |
+
|
| 16 |
+
def env_reward(agent, seq):
|
| 17 |
+
return agent.wm.heads['reward'](seq['feat']).mean
|
| 18 |
+
|
| 19 |
+
class DreamerAgent(Module):
|
| 20 |
+
|
| 21 |
+
def __init__(self,
|
| 22 |
+
name, cfg, obs_space, act_spec, **kwargs):
|
| 23 |
+
super().__init__()
|
| 24 |
+
self.name = name
|
| 25 |
+
self.cfg = cfg
|
| 26 |
+
self.cfg.update(**kwargs)
|
| 27 |
+
self.obs_space = obs_space
|
| 28 |
+
self.act_spec = act_spec
|
| 29 |
+
self._use_amp = (cfg.precision == 16)
|
| 30 |
+
self.device = cfg.device
|
| 31 |
+
self.act_dim = act_spec.shape[0]
|
| 32 |
+
self.wm = WorldModel(cfg, obs_space, self.act_dim,)
|
| 33 |
+
self.instantiate_acting_behavior()
|
| 34 |
+
|
| 35 |
+
self.to(cfg.device)
|
| 36 |
+
self.requires_grad_(requires_grad=False)
|
| 37 |
+
|
| 38 |
+
def instantiate_acting_behavior(self,):
|
| 39 |
+
self._acting_behavior = ActorCritic(self.cfg, self.act_spec, self.wm.inp_size).to(self.device)
|
| 40 |
+
|
| 41 |
+
def act(self, obs, meta, step, eval_mode, state):
|
| 42 |
+
if self.cfg.only_random_actions:
|
| 43 |
+
return np.random.uniform(-1, 1, self.act_dim,).astype(self.act_spec.dtype), (None, None)
|
| 44 |
+
obs = {k : torch.as_tensor(np.copy(v), device=self.device).unsqueeze(0) for k, v in obs.items()}
|
| 45 |
+
if state is None:
|
| 46 |
+
latent = self.wm.rssm.initial(len(obs['reward']))
|
| 47 |
+
action = torch.zeros((len(obs['reward']),) + self.act_spec.shape, device=self.device)
|
| 48 |
+
else:
|
| 49 |
+
latent, action = state
|
| 50 |
+
embed = self.wm.encoder(self.wm.preprocess(obs))
|
| 51 |
+
should_sample = (not eval_mode) or (not self.cfg.eval_state_mean)
|
| 52 |
+
latent, _ = self.wm.rssm.obs_step(latent, action, embed, obs['is_first'], should_sample)
|
| 53 |
+
feat = self.wm.rssm.get_feat(latent)
|
| 54 |
+
if eval_mode:
|
| 55 |
+
actor = self._acting_behavior.actor(feat)
|
| 56 |
+
try:
|
| 57 |
+
action = actor.mean
|
| 58 |
+
except:
|
| 59 |
+
action = actor._mean
|
| 60 |
+
else:
|
| 61 |
+
actor = self._acting_behavior.actor(feat)
|
| 62 |
+
action = actor.sample()
|
| 63 |
+
new_state = (latent, action)
|
| 64 |
+
return action.cpu().numpy()[0], new_state
|
| 65 |
+
|
| 66 |
+
def update_wm(self, data, step):
|
| 67 |
+
metrics = {}
|
| 68 |
+
state, outputs, mets = self.wm.update(data, state=None)
|
| 69 |
+
outputs['is_terminal'] = data['is_terminal']
|
| 70 |
+
metrics.update(mets)
|
| 71 |
+
return state, outputs, metrics
|
| 72 |
+
|
| 73 |
+
def update_acting_behavior(self, state=None, outputs=None, metrics={}, data=None, reward_fn=None):
|
| 74 |
+
if self.cfg.only_random_actions:
|
| 75 |
+
return {}, metrics
|
| 76 |
+
if outputs is not None:
|
| 77 |
+
post = outputs['post']
|
| 78 |
+
is_terminal = outputs['is_terminal']
|
| 79 |
+
else:
|
| 80 |
+
data = self.wm.preprocess(data)
|
| 81 |
+
embed = self.wm.encoder(data)
|
| 82 |
+
post, _ = self.wm.rssm.observe(
|
| 83 |
+
embed, data['action'], data['is_first'])
|
| 84 |
+
is_terminal = data['is_terminal']
|
| 85 |
+
#
|
| 86 |
+
start = {k: stop_gradient(v) for k,v in post.items()}
|
| 87 |
+
if reward_fn is None:
|
| 88 |
+
acting_reward_fn = lambda seq: globals()[self.cfg.acting_reward_fn](self, seq) #.mode()
|
| 89 |
+
else:
|
| 90 |
+
acting_reward_fn = lambda seq: reward_fn(self, seq) #.mode()
|
| 91 |
+
metrics.update(self._acting_behavior.update(self.wm, start, is_terminal, acting_reward_fn))
|
| 92 |
+
return start, metrics
|
| 93 |
+
|
| 94 |
+
def update(self, data, step):
|
| 95 |
+
state, outputs, metrics = self.update_wm(data, step)
|
| 96 |
+
start, metrics = self.update_acting_behavior(state, outputs, metrics, data)
|
| 97 |
+
return state, metrics
|
| 98 |
+
|
| 99 |
+
def report(self, data):
|
| 100 |
+
report = {}
|
| 101 |
+
data = self.wm.preprocess(data)
|
| 102 |
+
for key in self.wm.heads['decoder'].cnn_keys:
|
| 103 |
+
name = key.replace('/', '_')
|
| 104 |
+
report[f'openl_{name}'] = self.wm.video_pred(data, key)
|
| 105 |
+
for fn in getattr(self.cfg, 'additional_report_fns', []):
|
| 106 |
+
call_fn = globals()[fn]
|
| 107 |
+
additional_report = call_fn(self, data)
|
| 108 |
+
report.update(additional_report)
|
| 109 |
+
return report
|
| 110 |
+
|
| 111 |
+
def get_meta_specs(self):
|
| 112 |
+
return tuple()
|
| 113 |
+
|
| 114 |
+
def init_meta(self):
|
| 115 |
+
return OrderedDict()
|
| 116 |
+
|
| 117 |
+
def update_meta(self, meta, global_step, time_step, finetune=False):
|
| 118 |
+
return meta
|
| 119 |
+
|
| 120 |
+
class WorldModel(Module):
|
| 121 |
+
def __init__(self, config, obs_space, act_dim,):
|
| 122 |
+
super().__init__()
|
| 123 |
+
shapes = {k: tuple(v.shape) for k, v in obs_space.items()}
|
| 124 |
+
self.shapes = shapes
|
| 125 |
+
self.cfg = config
|
| 126 |
+
self.device = config.device
|
| 127 |
+
self.encoder = common.Encoder(shapes, **config.encoder)
|
| 128 |
+
# Computing embed dim
|
| 129 |
+
with torch.no_grad():
|
| 130 |
+
zeros = {k: torch.zeros( (1,) + v) for k, v in shapes.items()}
|
| 131 |
+
outs = self.encoder(zeros)
|
| 132 |
+
embed_dim = outs.shape[1]
|
| 133 |
+
self.embed_dim = embed_dim
|
| 134 |
+
self.rssm = common.EnsembleRSSM(**config.rssm, action_dim=act_dim, embed_dim=embed_dim, device=self.device,)
|
| 135 |
+
self.heads = {}
|
| 136 |
+
self._use_amp = (config.precision == 16)
|
| 137 |
+
self.inp_size = self.rssm.get_feat_size()
|
| 138 |
+
self.decoder_input_fn = getattr(self.rssm, f'get_{config.decoder_inputs}')
|
| 139 |
+
self.decoder_input_size = getattr(self.rssm, f'get_{config.decoder_inputs}_size')()
|
| 140 |
+
self.heads['decoder'] = common.Decoder(shapes, **config.decoder, embed_dim=self.decoder_input_size, image_dist=config.image_dist)
|
| 141 |
+
self.heads['reward'] = common.MLP(self.inp_size, (1,), **config.reward_head)
|
| 142 |
+
# zero init
|
| 143 |
+
with torch.no_grad():
|
| 144 |
+
for p in self.heads['reward']._out.parameters():
|
| 145 |
+
p.data = p.data * 0
|
| 146 |
+
#
|
| 147 |
+
if config.pred_discount:
|
| 148 |
+
self.heads['discount'] = common.MLP(self.inp_size, (1,), **config.discount_head)
|
| 149 |
+
for name in config.grad_heads:
|
| 150 |
+
assert name in self.heads, name
|
| 151 |
+
self.grad_heads = config.grad_heads
|
| 152 |
+
self.heads = nn.ModuleDict(self.heads)
|
| 153 |
+
self.model_opt = common.Optimizer('model', self.parameters(), **config.model_opt, use_amp=self._use_amp)
|
| 154 |
+
self.e2e_update_fns = {}
|
| 155 |
+
self.detached_update_fns = {}
|
| 156 |
+
self.eval()
|
| 157 |
+
|
| 158 |
+
def add_module_to_update(self, name, module, update_fn, detached=False):
|
| 159 |
+
self.add_module(name, module)
|
| 160 |
+
if detached:
|
| 161 |
+
self.detached_update_fns[name] = update_fn
|
| 162 |
+
else:
|
| 163 |
+
self.e2e_update_fns[name] = update_fn
|
| 164 |
+
self.model_opt = common.Optimizer('model', self.parameters(), **self.cfg.model_opt, use_amp=self._use_amp)
|
| 165 |
+
|
| 166 |
+
def update(self, data, state=None):
|
| 167 |
+
self.train()
|
| 168 |
+
with common.RequiresGrad(self):
|
| 169 |
+
with torch.cuda.amp.autocast(enabled=self._use_amp):
|
| 170 |
+
if getattr(self.cfg, "freeze_decoder", False):
|
| 171 |
+
self.heads['decoder'].requires_grad_(False)
|
| 172 |
+
if getattr(self.cfg, "freeze_post", False) or getattr(self.cfg, "freeze_model", False):
|
| 173 |
+
self.heads['decoder'].requires_grad_(False)
|
| 174 |
+
self.encoder.requires_grad_(False)
|
| 175 |
+
# Updating only prior
|
| 176 |
+
self.grad_heads = []
|
| 177 |
+
self.rssm.requires_grad_(False)
|
| 178 |
+
if not getattr(self.cfg, "freeze_model", False):
|
| 179 |
+
self.rssm._ensemble_img_out.requires_grad_(True)
|
| 180 |
+
self.rssm._ensemble_img_dist.requires_grad_(True)
|
| 181 |
+
model_loss, state, outputs, metrics = self.loss(data, state)
|
| 182 |
+
model_loss, metrics = self.update_additional_e2e_modules(data, outputs, model_loss, metrics)
|
| 183 |
+
metrics.update(self.model_opt(model_loss, self.parameters()))
|
| 184 |
+
if len(self.detached_update_fns) > 0:
|
| 185 |
+
detached_loss, metrics = self.update_additional_detached_modules(data, outputs, metrics)
|
| 186 |
+
self.eval()
|
| 187 |
+
return state, outputs, metrics
|
| 188 |
+
|
| 189 |
+
def update_additional_detached_modules(self, data, outputs, metrics):
|
| 190 |
+
# additional detached losses
|
| 191 |
+
detached_loss = 0
|
| 192 |
+
for k in self.detached_update_fns:
|
| 193 |
+
detached_module = getattr(self, k)
|
| 194 |
+
with common.RequiresGrad(detached_module):
|
| 195 |
+
with torch.cuda.amp.autocast(enabled=self._use_amp):
|
| 196 |
+
add_loss, add_metrics = self.detached_update_fns[k](self, k, data, outputs, metrics)
|
| 197 |
+
metrics.update(add_metrics)
|
| 198 |
+
opt_metrics = self.model_opt(add_loss, detached_module.parameters())
|
| 199 |
+
metrics.update({ f'{k}_{m}' : opt_metrics[m] for m in opt_metrics})
|
| 200 |
+
return detached_loss, metrics
|
| 201 |
+
|
| 202 |
+
def update_additional_e2e_modules(self, data, outputs, model_loss, metrics):
|
| 203 |
+
# additional e2e losses
|
| 204 |
+
for k in self.e2e_update_fns:
|
| 205 |
+
add_loss, add_metrics = self.e2e_update_fns[k](self, k, data, outputs, metrics)
|
| 206 |
+
model_loss += add_loss
|
| 207 |
+
metrics.update(add_metrics)
|
| 208 |
+
return model_loss, metrics
|
| 209 |
+
|
| 210 |
+
def observe_data(self, data, state=None):
|
| 211 |
+
data = self.preprocess(data)
|
| 212 |
+
embed = self.encoder(data)
|
| 213 |
+
post, prior = self.rssm.observe(
|
| 214 |
+
embed, data['action'], data['is_first'], state)
|
| 215 |
+
kl_loss, kl_value = self.rssm.kl_loss(post, prior, **self.cfg.kl)
|
| 216 |
+
outs = dict(embed=embed, post=post, prior=prior, is_terminal=data['is_terminal'])
|
| 217 |
+
return outs, { 'model_kl' : kl_value.mean() }
|
| 218 |
+
|
| 219 |
+
def loss(self, data, state=None):
|
| 220 |
+
data = self.preprocess(data)
|
| 221 |
+
embed = self.encoder(data)
|
| 222 |
+
post, prior = self.rssm.observe(
|
| 223 |
+
embed, data['action'], data['is_first'], state)
|
| 224 |
+
kl_loss, kl_value = self.rssm.kl_loss(post, prior, **self.cfg.kl)
|
| 225 |
+
assert len(kl_loss.shape) == 0 or (len(kl_loss.shape) == 1 and kl_loss.shape[0] == 1), kl_loss.shape
|
| 226 |
+
likes = {}
|
| 227 |
+
losses = {'kl': kl_loss}
|
| 228 |
+
feat = self.rssm.get_feat(post)
|
| 229 |
+
for name, head in self.heads.items():
|
| 230 |
+
grad_head = (name in self.grad_heads)
|
| 231 |
+
if name == 'decoder':
|
| 232 |
+
inp = self.decoder_input_fn(post)
|
| 233 |
+
else:
|
| 234 |
+
inp = feat
|
| 235 |
+
inp = inp if grad_head else stop_gradient(inp)
|
| 236 |
+
out = head(inp)
|
| 237 |
+
dists = out if isinstance(out, dict) else {name: out}
|
| 238 |
+
for key, dist in dists.items():
|
| 239 |
+
like = dist.log_prob(data[key])
|
| 240 |
+
likes[key] = like
|
| 241 |
+
losses[key] = -like.mean()
|
| 242 |
+
model_loss = sum(
|
| 243 |
+
self.cfg.loss_scales.get(k, 1.0) * v for k, v in losses.items())
|
| 244 |
+
outs = dict(
|
| 245 |
+
embed=embed, feat=feat, post=post,
|
| 246 |
+
prior=prior, likes=likes, kl=kl_value)
|
| 247 |
+
metrics = {f'{name}_loss': value for name, value in losses.items()}
|
| 248 |
+
metrics['model_kl'] = kl_value.mean()
|
| 249 |
+
metrics['prior_ent'] = self.rssm.get_dist(prior).entropy().mean()
|
| 250 |
+
metrics['post_ent'] = self.rssm.get_dist(post).entropy().mean()
|
| 251 |
+
last_state = {k: v[:, -1] for k, v in post.items()}
|
| 252 |
+
return model_loss, last_state, outs, metrics
|
| 253 |
+
|
| 254 |
+
def imagine(self, policy, start, is_terminal, horizon, task_cond=None, eval_policy=False):
|
| 255 |
+
flatten = lambda x: x.reshape([-1] + list(x.shape[2:]))
|
| 256 |
+
start = {k: flatten(v) for k, v in start.items()}
|
| 257 |
+
start['feat'] = self.rssm.get_feat(start)
|
| 258 |
+
inp = start['feat'] if task_cond is None else torch.cat([start['feat'], task_cond], dim=-1)
|
| 259 |
+
policy_dist = policy(inp)
|
| 260 |
+
start['action'] = torch.zeros_like(policy_dist.sample(), device=self.device) #.mode())
|
| 261 |
+
seq = {k: [v] for k, v in start.items()}
|
| 262 |
+
if task_cond is not None: seq['task'] = [task_cond]
|
| 263 |
+
for _ in range(horizon):
|
| 264 |
+
inp = seq['feat'][-1] if task_cond is None else torch.cat([seq['feat'][-1], task_cond], dim=-1)
|
| 265 |
+
policy_dist = policy(stop_gradient(inp))
|
| 266 |
+
action = policy_dist.sample() if not eval_policy else policy_dist.mean
|
| 267 |
+
state = self.rssm.img_step({k: v[-1] for k, v in seq.items()}, action)
|
| 268 |
+
feat = self.rssm.get_feat(state)
|
| 269 |
+
for key, value in {**state, 'action': action, 'feat': feat}.items():
|
| 270 |
+
seq[key].append(value)
|
| 271 |
+
if task_cond is not None: seq['task'].append(task_cond)
|
| 272 |
+
# shape will be (T, B, *DIMS)
|
| 273 |
+
seq = {k: torch.stack(v, 0) for k, v in seq.items()}
|
| 274 |
+
if 'discount' in self.heads:
|
| 275 |
+
disc = self.heads['discount'](seq['feat']).mean()
|
| 276 |
+
if is_terminal is not None:
|
| 277 |
+
# Override discount prediction for the first step with the true
|
| 278 |
+
# discount factor from the replay buffer.
|
| 279 |
+
true_first = 1.0 - flatten(is_terminal)
|
| 280 |
+
disc = torch.cat([true_first[None], disc[1:]], 0)
|
| 281 |
+
else:
|
| 282 |
+
disc = torch.ones(list(seq['feat'].shape[:-1]) + [1], device=self.device)
|
| 283 |
+
seq['discount'] = disc * self.cfg.discount
|
| 284 |
+
# Shift discount factors because they imply whether the following state
|
| 285 |
+
# will be valid, not whether the current state is valid.
|
| 286 |
+
seq['weight'] = torch.cumprod(torch.cat([torch.ones_like(disc[:1], device=self.device), disc[:-1]], 0), 0)
|
| 287 |
+
return seq
|
| 288 |
+
|
| 289 |
+
def preprocess(self, obs):
|
| 290 |
+
obs = obs.copy()
|
| 291 |
+
for key, value in obs.items():
|
| 292 |
+
if key.startswith('log_'):
|
| 293 |
+
continue
|
| 294 |
+
if value.dtype in [np.uint8, torch.uint8]:
|
| 295 |
+
value = value / 255.0 - 0.5
|
| 296 |
+
obs[key] = value
|
| 297 |
+
obs['reward'] = {
|
| 298 |
+
'identity': nn.Identity(),
|
| 299 |
+
'sign': torch.sign,
|
| 300 |
+
'tanh': torch.tanh,
|
| 301 |
+
}[self.cfg.clip_rewards](obs['reward'])
|
| 302 |
+
obs['discount'] = (1.0 - obs['is_terminal'].float())
|
| 303 |
+
if len(obs['discount'].shape) < len(obs['reward'].shape):
|
| 304 |
+
obs['discount'] = obs['discount'].unsqueeze(-1)
|
| 305 |
+
return obs
|
| 306 |
+
|
| 307 |
+
def video_pred(self, data, key, nvid=8):
|
| 308 |
+
decoder = self.heads['decoder'] # B, T, C, H, W
|
| 309 |
+
truth = data[key][:nvid] + 0.5
|
| 310 |
+
embed = self.encoder(data)
|
| 311 |
+
states, _ = self.rssm.observe(
|
| 312 |
+
embed[:nvid, :5], data['action'][:nvid, :5], data['is_first'][:nvid, :5])
|
| 313 |
+
recon = decoder(self.decoder_input_fn(states))[key].mean[:nvid] # mode
|
| 314 |
+
init = {k: v[:, -1] for k, v in states.items()}
|
| 315 |
+
prior = self.rssm.imagine(data['action'][:nvid, 5:], init)
|
| 316 |
+
prior_recon = decoder(self.decoder_input_fn(prior))[key].mean # mode
|
| 317 |
+
model = torch.clip(torch.cat([recon[:, :5] + 0.5, prior_recon + 0.5], 1), 0, 1)
|
| 318 |
+
error = (model - truth + 1) / 2
|
| 319 |
+
video = torch.cat([truth, model, error], 3)
|
| 320 |
+
B, T, C, H, W = video.shape
|
| 321 |
+
return video
|
| 322 |
+
|
| 323 |
+
class ActorCritic(Module):
|
| 324 |
+
def __init__(self, config, act_spec, feat_size, name=''):
|
| 325 |
+
super().__init__()
|
| 326 |
+
self.name = name
|
| 327 |
+
self.cfg = config
|
| 328 |
+
self.act_spec = act_spec
|
| 329 |
+
self._use_amp = (config.precision == 16)
|
| 330 |
+
self.device = config.device
|
| 331 |
+
|
| 332 |
+
if getattr(self.cfg, 'discrete_actions', False):
|
| 333 |
+
self.cfg.actor.dist = 'onehot'
|
| 334 |
+
|
| 335 |
+
self.actor_grad = getattr(self.cfg, f'{self.name}_actor_grad'.strip('_'))
|
| 336 |
+
|
| 337 |
+
inp_size = feat_size
|
| 338 |
+
self.actor = common.MLP(inp_size, act_spec.shape[0], **self.cfg.actor)
|
| 339 |
+
self.critic = common.MLP(inp_size, (1,), **self.cfg.critic)
|
| 340 |
+
if self.cfg.slow_target:
|
| 341 |
+
self._target_critic = common.MLP(inp_size, (1,), **self.cfg.critic)
|
| 342 |
+
self._updates = 0 # tf.Variable(0, tf.int64)
|
| 343 |
+
else:
|
| 344 |
+
self._target_critic = self.critic
|
| 345 |
+
self.actor_opt = common.Optimizer('actor', self.actor.parameters(), **self.cfg.actor_opt, use_amp=self._use_amp)
|
| 346 |
+
self.critic_opt = common.Optimizer('critic', self.critic.parameters(), **self.cfg.critic_opt, use_amp=self._use_amp)
|
| 347 |
+
|
| 348 |
+
if self.cfg.reward_ema:
|
| 349 |
+
# register ema_vals to nn.Module for enabling torch.save and torch.load
|
| 350 |
+
self.register_buffer("ema_vals", torch.zeros((2,)).to(self.device))
|
| 351 |
+
self.reward_ema = common.RewardEMA(device=self.device)
|
| 352 |
+
self.rewnorm = common.StreamNorm(momentum=1, scale=1.0, device=self.device)
|
| 353 |
+
else:
|
| 354 |
+
self.rewnorm = common.StreamNorm(**self.cfg.reward_norm, device=self.device)
|
| 355 |
+
|
| 356 |
+
# zero init
|
| 357 |
+
with torch.no_grad():
|
| 358 |
+
for p in self.critic._out.parameters():
|
| 359 |
+
p.data = p.data * 0
|
| 360 |
+
# hard copy critic initial params
|
| 361 |
+
for s, d in zip(self.critic.parameters(), self._target_critic.parameters()):
|
| 362 |
+
d.data = s.data
|
| 363 |
+
#
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
def update(self, world_model, start, is_terminal, reward_fn):
|
| 367 |
+
metrics = {}
|
| 368 |
+
hor = self.cfg.imag_horizon
|
| 369 |
+
# The weights are is_terminal flags for the imagination start states.
|
| 370 |
+
# Technically, they should multiply the losses from the second trajectory
|
| 371 |
+
# step onwards, which is the first imagined step. However, we are not
|
| 372 |
+
# training the action that led into the first step anyway, so we can use
|
| 373 |
+
# them to scale the whole sequence.
|
| 374 |
+
with common.RequiresGrad(self.actor):
|
| 375 |
+
with torch.cuda.amp.autocast(enabled=self._use_amp):
|
| 376 |
+
seq = world_model.imagine(self.actor, start, is_terminal, hor)
|
| 377 |
+
reward = reward_fn(seq)
|
| 378 |
+
seq['reward'], mets1 = self.rewnorm(reward)
|
| 379 |
+
mets1 = {f'reward_{k}': v for k, v in mets1.items()}
|
| 380 |
+
target, mets2, baseline = self.target(seq)
|
| 381 |
+
actor_loss, mets3 = self.actor_loss(seq, target, baseline)
|
| 382 |
+
metrics.update(self.actor_opt(actor_loss, self.actor.parameters()))
|
| 383 |
+
with common.RequiresGrad(self.critic):
|
| 384 |
+
with torch.cuda.amp.autocast(enabled=self._use_amp):
|
| 385 |
+
seq = {k: stop_gradient(v) for k,v in seq.items()}
|
| 386 |
+
critic_loss, mets4 = self.critic_loss(seq, target)
|
| 387 |
+
metrics.update(self.critic_opt(critic_loss, self.critic.parameters()))
|
| 388 |
+
metrics.update(**mets1, **mets2, **mets3, **mets4)
|
| 389 |
+
self.update_slow_target() # Variables exist after first forward pass.
|
| 390 |
+
return { f'{self.name}_{k}'.strip('_') : v for k,v in metrics.items() }
|
| 391 |
+
|
| 392 |
+
def actor_loss(self, seq, target, baseline): #, step):
|
| 393 |
+
# Two state-actions are lost at the end of the trajectory, one for the boostrap
|
| 394 |
+
# value prediction and one because the corresponding action does not lead
|
| 395 |
+
# anywhere anymore. One target is lost at the start of the trajectory
|
| 396 |
+
# because the initial state comes from the replay buffer.
|
| 397 |
+
policy = self.actor(stop_gradient(seq['feat'][:-2])) # actions are the ones in [1:-1]
|
| 398 |
+
|
| 399 |
+
metrics = {}
|
| 400 |
+
if self.cfg.reward_ema:
|
| 401 |
+
offset, scale = self.reward_ema(target, self.ema_vals)
|
| 402 |
+
normed_target = (target - offset) / scale
|
| 403 |
+
normed_baseline = (baseline - offset) / scale
|
| 404 |
+
# adv = normed_target - normed_baseline
|
| 405 |
+
metrics['normed_target_mean'] = normed_target.mean()
|
| 406 |
+
metrics['normed_target_std'] = normed_target.std()
|
| 407 |
+
metrics["reward_ema_005"] = self.ema_vals[0]
|
| 408 |
+
metrics["reward_ema_095"] = self.ema_vals[1]
|
| 409 |
+
else:
|
| 410 |
+
normed_target = target
|
| 411 |
+
normed_baseline = baseline
|
| 412 |
+
|
| 413 |
+
if self.actor_grad == 'dynamics':
|
| 414 |
+
objective = normed_target[1:]
|
| 415 |
+
elif self.actor_grad == 'reinforce':
|
| 416 |
+
advantage = normed_target[1:] - normed_baseline[1:]
|
| 417 |
+
objective = policy.log_prob(stop_gradient(seq['action'][1:-1]))[:,:,None] * advantage
|
| 418 |
+
else:
|
| 419 |
+
raise NotImplementedError(self.actor_grad)
|
| 420 |
+
|
| 421 |
+
ent = policy.entropy()[:,:,None]
|
| 422 |
+
ent_scale = self.cfg.actor_ent
|
| 423 |
+
objective += ent_scale * ent
|
| 424 |
+
metrics['actor_ent'] = ent.mean()
|
| 425 |
+
metrics['actor_ent_scale'] = ent_scale
|
| 426 |
+
|
| 427 |
+
weight = stop_gradient(seq['weight'])
|
| 428 |
+
actor_loss = -(weight[:-2] * objective).mean()
|
| 429 |
+
return actor_loss, metrics
|
| 430 |
+
|
| 431 |
+
def critic_loss(self, seq, target):
|
| 432 |
+
feat = seq['feat'][:-1]
|
| 433 |
+
target = stop_gradient(target)
|
| 434 |
+
weight = stop_gradient(seq['weight'])
|
| 435 |
+
dist = self.critic(feat)
|
| 436 |
+
critic_loss = -(dist.log_prob(target)[:,:,None] * weight[:-1]).mean()
|
| 437 |
+
metrics = {'critic': dist.mean.mean() }
|
| 438 |
+
return critic_loss, metrics
|
| 439 |
+
|
| 440 |
+
def target(self, seq):
|
| 441 |
+
reward = seq['reward']
|
| 442 |
+
disc = seq['discount']
|
| 443 |
+
value = self._target_critic(seq['feat']).mean
|
| 444 |
+
# Skipping last time step because it is used for bootstrapping.
|
| 445 |
+
target = common.lambda_return(
|
| 446 |
+
reward[:-1], value[:-1], disc[:-1],
|
| 447 |
+
bootstrap=value[-1],
|
| 448 |
+
lambda_=self.cfg.discount_lambda,
|
| 449 |
+
axis=0)
|
| 450 |
+
metrics = {}
|
| 451 |
+
metrics['critic_slow'] = value.mean()
|
| 452 |
+
metrics['critic_target'] = target.mean()
|
| 453 |
+
return target, metrics, value[:-1]
|
| 454 |
+
|
| 455 |
+
def update_slow_target(self):
|
| 456 |
+
if self.cfg.slow_target:
|
| 457 |
+
if self._updates % self.cfg.slow_target_update == 0:
|
| 458 |
+
mix = 1.0 if self._updates == 0 else float(
|
| 459 |
+
self.cfg.slow_target_fraction)
|
| 460 |
+
for s, d in zip(self.critic.parameters(), self._target_critic.parameters()):
|
| 461 |
+
d.data = mix * s.data + (1 - mix) * d.data
|
| 462 |
+
self._updates += 1
|
agent/dreamer.yaml
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package agent
|
| 2 |
+
_target_: agent.dreamer.DreamerAgent
|
| 3 |
+
name: dreamer
|
| 4 |
+
cfg: ???
|
| 5 |
+
obs_space: ???
|
| 6 |
+
act_spec: ???
|
| 7 |
+
grad_heads: [decoder, reward]
|
| 8 |
+
reward_norm: {momentum: 1.0, scale: 1.0, eps: 1e-8}
|
| 9 |
+
actor_ent: 3e-4
|
agent/dreamer_utils.py
ADDED
|
@@ -0,0 +1,1040 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
import tools.utils as utils
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch
|
| 8 |
+
import torch.distributions as D
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
|
| 11 |
+
Module = nn.Module
|
| 12 |
+
|
| 13 |
+
def symlog(x):
|
| 14 |
+
return torch.sign(x) * torch.log(torch.abs(x) + 1.0)
|
| 15 |
+
|
| 16 |
+
def symexp(x):
|
| 17 |
+
return torch.sign(x) * (torch.exp(torch.abs(x)) - 1.0)
|
| 18 |
+
|
| 19 |
+
def signed_hyperbolic(x: torch.Tensor, eps: float = 1e-3) -> torch.Tensor:
|
| 20 |
+
"""Signed hyperbolic transform, inverse of signed_parabolic."""
|
| 21 |
+
return torch.sign(x) * (torch.sqrt(torch.abs(x) + 1) - 1) + eps * x
|
| 22 |
+
|
| 23 |
+
def signed_parabolic(x: torch.Tensor, eps: float = 1e-3) -> torch.Tensor:
|
| 24 |
+
"""Signed parabolic transform, inverse of signed_hyperbolic."""
|
| 25 |
+
z = torch.sqrt(1 + 4 * eps * (eps + 1 + torch.abs(x))) / 2 / eps - 1 / 2 / eps
|
| 26 |
+
return torch.sign(x) * (torch.square(z) - 1)
|
| 27 |
+
|
| 28 |
+
class SampleDist:
|
| 29 |
+
def __init__(self, dist: D.Distribution, samples=100):
|
| 30 |
+
self._dist = dist
|
| 31 |
+
self._samples = samples
|
| 32 |
+
|
| 33 |
+
@property
|
| 34 |
+
def name(self):
|
| 35 |
+
return 'SampleDist'
|
| 36 |
+
|
| 37 |
+
def __getattr__(self, name):
|
| 38 |
+
return getattr(self._dist, name)
|
| 39 |
+
|
| 40 |
+
@property
|
| 41 |
+
def mean(self):
|
| 42 |
+
sample = self._dist.rsample((self._samples,))
|
| 43 |
+
return torch.mean(sample, 0)
|
| 44 |
+
|
| 45 |
+
def mode(self):
|
| 46 |
+
dist = self._dist.expand((self._samples, *self._dist.batch_shape))
|
| 47 |
+
sample = dist.rsample()
|
| 48 |
+
logprob = dist.log_prob(sample)
|
| 49 |
+
batch_size = sample.size(1)
|
| 50 |
+
feature_size = sample.size(2)
|
| 51 |
+
indices = torch.argmax(logprob, dim=0).reshape(1, batch_size, 1).expand(1, batch_size, feature_size)
|
| 52 |
+
return torch.gather(sample, 0, indices).squeeze(0)
|
| 53 |
+
|
| 54 |
+
def entropy(self):
|
| 55 |
+
sample = self._dist.rsample((self._samples,))
|
| 56 |
+
logprob = self._dist.log_prob(sample)
|
| 57 |
+
return -torch.mean(logprob, 0)
|
| 58 |
+
|
| 59 |
+
def sample(self):
|
| 60 |
+
return self._dist.rsample()
|
| 61 |
+
|
| 62 |
+
class MSEDist:
|
| 63 |
+
def __init__(self, mode, agg="sum"):
|
| 64 |
+
self._mode = mode
|
| 65 |
+
self._agg = agg
|
| 66 |
+
|
| 67 |
+
@property
|
| 68 |
+
def mean(self):
|
| 69 |
+
return self._mode
|
| 70 |
+
|
| 71 |
+
def mode(self):
|
| 72 |
+
return self._mode
|
| 73 |
+
|
| 74 |
+
def log_prob(self, value):
|
| 75 |
+
assert self._mode.shape == value.shape, (self._mode.shape, value.shape)
|
| 76 |
+
distance = (self._mode - value) ** 2
|
| 77 |
+
if self._agg == "mean":
|
| 78 |
+
loss = distance.mean(list(range(len(distance.shape)))[2:])
|
| 79 |
+
elif self._agg == "sum":
|
| 80 |
+
loss = distance.sum(list(range(len(distance.shape)))[2:])
|
| 81 |
+
else:
|
| 82 |
+
raise NotImplementedError(self._agg)
|
| 83 |
+
return -loss
|
| 84 |
+
|
| 85 |
+
class SymlogDist:
|
| 86 |
+
|
| 87 |
+
def __init__(self, mode, dims, dist='mse', agg='sum', tol=1e-8):
|
| 88 |
+
self._mode = mode
|
| 89 |
+
self._dims = tuple([-x for x in range(1, dims + 1)])
|
| 90 |
+
self._dist = dist
|
| 91 |
+
self._agg = agg
|
| 92 |
+
self._tol = tol
|
| 93 |
+
self.batch_shape = mode.shape[:len(mode.shape) - dims]
|
| 94 |
+
self.event_shape = mode.shape[len(mode.shape) - dims:]
|
| 95 |
+
|
| 96 |
+
def mode(self):
|
| 97 |
+
return symexp(self._mode)
|
| 98 |
+
|
| 99 |
+
def mean(self):
|
| 100 |
+
return symexp(self._mode)
|
| 101 |
+
|
| 102 |
+
def log_prob(self, value):
|
| 103 |
+
assert self._mode.shape == value.shape, (self._mode.shape, value.shape)
|
| 104 |
+
if self._dist == 'mse':
|
| 105 |
+
distance = (self._mode - symlog(value)) ** 2
|
| 106 |
+
distance = torch.where(distance < self._tol, torch.tensor([0.], dtype=distance.dtype, device=distance.device), distance)
|
| 107 |
+
elif self._dist == 'abs':
|
| 108 |
+
distance = torch.abs(self._mode - symlog(value))
|
| 109 |
+
distance = torch.where(distance < self._tol, torch.tensor([0.], dtype=distance.dtype, device=distance.device), distance)
|
| 110 |
+
else:
|
| 111 |
+
raise NotImplementedError(self._dist)
|
| 112 |
+
if self._agg == 'mean':
|
| 113 |
+
loss = distance.mean(self._dims)
|
| 114 |
+
elif self._agg == 'sum':
|
| 115 |
+
loss = distance.sum(self._dims)
|
| 116 |
+
else:
|
| 117 |
+
raise NotImplementedError(self._agg)
|
| 118 |
+
return -loss
|
| 119 |
+
|
| 120 |
+
class TwoHotDist:
|
| 121 |
+
def __init__(
|
| 122 |
+
self,
|
| 123 |
+
logits,
|
| 124 |
+
low=-20.0,
|
| 125 |
+
high=20.0,
|
| 126 |
+
transfwd=symlog,
|
| 127 |
+
transbwd=symexp,
|
| 128 |
+
):
|
| 129 |
+
assert logits.shape[-1] == 255
|
| 130 |
+
self.logits = logits
|
| 131 |
+
self.probs = torch.softmax(logits, -1)
|
| 132 |
+
self.buckets = torch.linspace(low, high, steps=255).to(logits.device)
|
| 133 |
+
self.width = (self.buckets[-1] - self.buckets[0]) / 255
|
| 134 |
+
self.transfwd = transfwd
|
| 135 |
+
self.transbwd = transbwd
|
| 136 |
+
|
| 137 |
+
@property
|
| 138 |
+
def mean(self):
|
| 139 |
+
_mean = self.probs * self.buckets
|
| 140 |
+
return self.transbwd(torch.sum(_mean, dim=-1, keepdim=True))
|
| 141 |
+
|
| 142 |
+
@property
|
| 143 |
+
def mode(self):
|
| 144 |
+
return self.mean
|
| 145 |
+
|
| 146 |
+
# Inside OneHotCategorical, log_prob is calculated using only max element in targets
|
| 147 |
+
def log_prob(self, x):
|
| 148 |
+
x = self.transfwd(x)
|
| 149 |
+
# x(time, batch, 1)
|
| 150 |
+
below = torch.sum((self.buckets <= x[..., None]).to(torch.int32), dim=-1) - 1
|
| 151 |
+
above = len(self.buckets) - torch.sum(
|
| 152 |
+
(self.buckets > x[..., None]).to(torch.int32), dim=-1
|
| 153 |
+
)
|
| 154 |
+
# this is implemented using clip at the original repo as the gradients are not backpropagated for the out of limits.
|
| 155 |
+
below = torch.clip(below, 0, len(self.buckets) - 1)
|
| 156 |
+
above = torch.clip(above, 0, len(self.buckets) - 1)
|
| 157 |
+
equal = below == above
|
| 158 |
+
|
| 159 |
+
dist_to_below = torch.where(equal, 1, torch.abs(self.buckets[below] - x))
|
| 160 |
+
dist_to_above = torch.where(equal, 1, torch.abs(self.buckets[above] - x))
|
| 161 |
+
total = dist_to_below + dist_to_above
|
| 162 |
+
weight_below = dist_to_above / total
|
| 163 |
+
weight_above = dist_to_below / total
|
| 164 |
+
target = (
|
| 165 |
+
F.one_hot(below, num_classes=len(self.buckets)) * weight_below[..., None]
|
| 166 |
+
+ F.one_hot(above, num_classes=len(self.buckets)) * weight_above[..., None]
|
| 167 |
+
)
|
| 168 |
+
log_pred = self.logits - torch.logsumexp(self.logits, -1, keepdim=True)
|
| 169 |
+
target = target.squeeze(-2)
|
| 170 |
+
|
| 171 |
+
return (target * log_pred).sum(-1)
|
| 172 |
+
|
| 173 |
+
def log_prob_target(self, target):
|
| 174 |
+
log_pred = super().logits - torch.logsumexp(super().logits, -1, keepdim=True)
|
| 175 |
+
return (target * log_pred).sum(-1)
|
| 176 |
+
|
| 177 |
+
class OneHotDist(D.OneHotCategorical):
|
| 178 |
+
|
| 179 |
+
def __init__(self, logits=None, probs=None, unif_mix=0.99):
|
| 180 |
+
super().__init__(logits=logits, probs=probs)
|
| 181 |
+
probs = super().probs
|
| 182 |
+
probs = unif_mix * probs + (1 - unif_mix) * torch.ones_like(probs, device=probs.device) / probs.shape[-1]
|
| 183 |
+
super().__init__(probs=probs)
|
| 184 |
+
|
| 185 |
+
def mode(self):
|
| 186 |
+
_mode = F.one_hot(torch.argmax(super().logits, axis=-1), super().logits.shape[-1])
|
| 187 |
+
return _mode.detach() + super().logits - super().logits.detach()
|
| 188 |
+
|
| 189 |
+
def sample(self, sample_shape=(), seed=None):
|
| 190 |
+
if seed is not None:
|
| 191 |
+
raise ValueError('need to check')
|
| 192 |
+
sample = super().sample(sample_shape)
|
| 193 |
+
probs = super().probs
|
| 194 |
+
while len(probs.shape) < len(sample.shape):
|
| 195 |
+
probs = probs[None]
|
| 196 |
+
sample += probs - probs.detach() # ST-gradients
|
| 197 |
+
return sample
|
| 198 |
+
|
| 199 |
+
class BernoulliDist(D.Bernoulli):
|
| 200 |
+
def __init__(self, logits=None, probs=None):
|
| 201 |
+
super().__init__(logits=logits, probs=probs)
|
| 202 |
+
|
| 203 |
+
def sample(self, sample_shape=(), seed=None):
|
| 204 |
+
if seed is not None:
|
| 205 |
+
raise ValueError('need to check')
|
| 206 |
+
sample = super().sample(sample_shape)
|
| 207 |
+
probs = super().probs
|
| 208 |
+
while len(probs.shape) < len(sample.shape):
|
| 209 |
+
probs = probs[None]
|
| 210 |
+
sample += probs - probs.detach() # ST-gradients
|
| 211 |
+
return sample
|
| 212 |
+
|
| 213 |
+
def static_scan_for_lambda_return(fn, inputs, start):
|
| 214 |
+
last = start
|
| 215 |
+
indices = range(inputs[0].shape[0])
|
| 216 |
+
indices = reversed(indices)
|
| 217 |
+
flag = True
|
| 218 |
+
for index in indices:
|
| 219 |
+
inp = lambda x: (_input[x].unsqueeze(0) for _input in inputs)
|
| 220 |
+
last = fn(last, *inp(index))
|
| 221 |
+
if flag:
|
| 222 |
+
outputs = last
|
| 223 |
+
flag = False
|
| 224 |
+
else:
|
| 225 |
+
outputs = torch.cat([last, outputs], dim=0)
|
| 226 |
+
return outputs
|
| 227 |
+
|
| 228 |
+
def lambda_return(
|
| 229 |
+
reward, value, pcont, bootstrap, lambda_, axis):
|
| 230 |
+
# Setting lambda=1 gives a discounted Monte Carlo return.
|
| 231 |
+
# Setting lambda=0 gives a fixed 1-step return.
|
| 232 |
+
#assert reward.shape.ndims == value.shape.ndims, (reward.shape, value.shape)
|
| 233 |
+
assert len(reward.shape) == len(value.shape), (reward.shape, value.shape)
|
| 234 |
+
if isinstance(pcont, (int, float)):
|
| 235 |
+
pcont = pcont * torch.ones_like(reward, device=reward.device)
|
| 236 |
+
dims = list(range(len(reward.shape)))
|
| 237 |
+
dims = [axis] + dims[1:axis] + [0] + dims[axis + 1:]
|
| 238 |
+
if axis != 0:
|
| 239 |
+
reward = reward.permute(dims)
|
| 240 |
+
value = value.permute(dims)
|
| 241 |
+
pcont = pcont.permute(dims)
|
| 242 |
+
if bootstrap is None:
|
| 243 |
+
bootstrap = torch.zeros_like(value[-1], device=reward.device)
|
| 244 |
+
if len(bootstrap.shape) < len(value.shape):
|
| 245 |
+
bootstrap = bootstrap[None]
|
| 246 |
+
next_values = torch.cat([value[1:], bootstrap], 0)
|
| 247 |
+
inputs = reward + pcont * next_values * (1 - lambda_)
|
| 248 |
+
returns = static_scan_for_lambda_return(
|
| 249 |
+
lambda agg, cur0, cur1: cur0 + cur1 * lambda_ * agg,
|
| 250 |
+
(inputs, pcont), bootstrap)
|
| 251 |
+
if axis != 0:
|
| 252 |
+
returns = returns.permute(dims)
|
| 253 |
+
return returns
|
| 254 |
+
|
| 255 |
+
def static_scan(fn, inputs, start, reverse=False, unpack=False):
|
| 256 |
+
last = start
|
| 257 |
+
indices = range(inputs[0].shape[0])
|
| 258 |
+
flag = True
|
| 259 |
+
for index in indices:
|
| 260 |
+
inp = lambda x: (_input[x] for _input in inputs)
|
| 261 |
+
if unpack:
|
| 262 |
+
last = fn(last, *[inp[index] for inp in inputs])
|
| 263 |
+
else:
|
| 264 |
+
last = fn(last, inp(index))
|
| 265 |
+
if flag:
|
| 266 |
+
if type(last) == type({}):
|
| 267 |
+
outputs = {key: [value] for key, value in last.items()}
|
| 268 |
+
else:
|
| 269 |
+
outputs = []
|
| 270 |
+
for _last in last:
|
| 271 |
+
if type(_last) == type({}):
|
| 272 |
+
outputs.append({key: [value] for key, value in _last.items()})
|
| 273 |
+
else:
|
| 274 |
+
outputs.append([_last])
|
| 275 |
+
flag = False
|
| 276 |
+
else:
|
| 277 |
+
if type(last) == type({}):
|
| 278 |
+
for key in last.keys():
|
| 279 |
+
outputs[key].append(last[key])
|
| 280 |
+
else:
|
| 281 |
+
for j in range(len(outputs)):
|
| 282 |
+
if type(last[j]) == type({}):
|
| 283 |
+
for key in last[j].keys():
|
| 284 |
+
outputs[j][key].append(last[j][key])
|
| 285 |
+
else:
|
| 286 |
+
outputs[j].append(last[j])
|
| 287 |
+
# Stack everything at the end
|
| 288 |
+
if type(last) == type({}):
|
| 289 |
+
for key in last.keys():
|
| 290 |
+
outputs[key] = torch.stack(outputs[key], dim=0)
|
| 291 |
+
else:
|
| 292 |
+
for j in range(len(outputs)):
|
| 293 |
+
if type(last[j]) == type({}):
|
| 294 |
+
for key in last[j].keys():
|
| 295 |
+
outputs[j][key] = torch.stack(outputs[j][key], dim=0)
|
| 296 |
+
else:
|
| 297 |
+
outputs[j] = torch.stack(outputs[j], dim=0)
|
| 298 |
+
if type(last) == type({}):
|
| 299 |
+
outputs = [outputs]
|
| 300 |
+
return outputs
|
| 301 |
+
|
| 302 |
+
class EnsembleRSSM(Module):
|
| 303 |
+
|
| 304 |
+
def __init__(
|
| 305 |
+
self, ensemble=5, stoch=30, deter=200, hidden=200, discrete=False,
|
| 306 |
+
act='SiLU', norm='none', std_act='softplus', min_std=0.1, action_dim=None, embed_dim=1536, device='cuda',
|
| 307 |
+
single_obs_posterior=False, cell_input='stoch', cell_type='gru',):
|
| 308 |
+
super().__init__()
|
| 309 |
+
assert action_dim is not None
|
| 310 |
+
self.device = device
|
| 311 |
+
self._embed_dim = embed_dim
|
| 312 |
+
self._action_dim = action_dim
|
| 313 |
+
self._ensemble = ensemble
|
| 314 |
+
self._stoch = stoch
|
| 315 |
+
self._deter = deter
|
| 316 |
+
self._hidden = hidden
|
| 317 |
+
self._discrete = discrete
|
| 318 |
+
self._act = get_act(act)
|
| 319 |
+
self._norm = norm
|
| 320 |
+
self._std_act = std_act
|
| 321 |
+
self._min_std = min_std
|
| 322 |
+
self._cell_type = cell_type
|
| 323 |
+
self.cell_input = cell_input
|
| 324 |
+
if cell_type == 'gru':
|
| 325 |
+
self._cell = GRUCell(self._hidden, self._deter, norm=True, device=self.device)
|
| 326 |
+
else:
|
| 327 |
+
raise NotImplementedError(f"{cell_type} not implemented")
|
| 328 |
+
self.single_obs_posterior = single_obs_posterior
|
| 329 |
+
|
| 330 |
+
if discrete:
|
| 331 |
+
self._ensemble_img_dist = nn.ModuleList([ nn.Linear(hidden, stoch*discrete) for _ in range(ensemble)])
|
| 332 |
+
self._obs_dist = nn.Linear(hidden, stoch*discrete)
|
| 333 |
+
else:
|
| 334 |
+
self._ensemble_img_dist = nn.ModuleList([ nn.Linear(hidden, 2*stoch) for _ in range(ensemble)])
|
| 335 |
+
self._obs_dist = nn.Linear(hidden, 2*stoch)
|
| 336 |
+
|
| 337 |
+
# Layer that projects (stoch, input) to cell_state space
|
| 338 |
+
cell_state_input_size = getattr(self, f'get_{self.cell_input}_size')()
|
| 339 |
+
self._img_in = nn.Sequential(nn.Linear(cell_state_input_size + action_dim, hidden, bias=norm != 'none'), NormLayer(norm, hidden))
|
| 340 |
+
# Layer that project deter -> hidden [before projecting hidden -> stoch]
|
| 341 |
+
self._ensemble_img_out = nn.ModuleList([ nn.Sequential(nn.Linear(self.get_deter_size(), hidden, bias=norm != 'none'), NormLayer(norm, hidden)) for _ in range(ensemble)])
|
| 342 |
+
|
| 343 |
+
if self.single_obs_posterior:
|
| 344 |
+
self._obs_out = nn.Sequential(nn.Linear(embed_dim, hidden, bias=norm != 'none'), NormLayer(norm, hidden))
|
| 345 |
+
else:
|
| 346 |
+
self._obs_out = nn.Sequential(nn.Linear(deter + embed_dim, hidden, bias=norm != 'none'), NormLayer(norm, hidden))
|
| 347 |
+
|
| 348 |
+
def initial(self, batch_size):
|
| 349 |
+
if self._discrete:
|
| 350 |
+
state = dict(
|
| 351 |
+
logit=torch.zeros([batch_size, self._stoch, self._discrete], device=self.device),
|
| 352 |
+
stoch=torch.zeros([batch_size, self._stoch, self._discrete], device=self.device),
|
| 353 |
+
deter=self._cell.get_initial_state(None, batch_size))
|
| 354 |
+
else:
|
| 355 |
+
state = dict(
|
| 356 |
+
mean=torch.zeros([batch_size, self._stoch], device=self.device),
|
| 357 |
+
std=torch.zeros([batch_size, self._stoch], device=self.device),
|
| 358 |
+
stoch=torch.zeros([batch_size, self._stoch], device=self.device),
|
| 359 |
+
deter=self._cell.get_initial_state(None, batch_size))
|
| 360 |
+
return state
|
| 361 |
+
|
| 362 |
+
def observe(self, embed, action, is_first, state=None):
|
| 363 |
+
swap = lambda x: x.permute([1, 0] + list(range(2, len(x.shape))))
|
| 364 |
+
if state is None: state = self.initial(action.shape[0])
|
| 365 |
+
|
| 366 |
+
post, prior = static_scan(
|
| 367 |
+
lambda prev, inputs: self.obs_step(prev[0], *inputs),
|
| 368 |
+
(swap(action), swap(embed), swap(is_first)), (state, state))
|
| 369 |
+
post = {k: swap(v) for k, v in post.items()}
|
| 370 |
+
prior = {k: swap(v) for k, v in prior.items()}
|
| 371 |
+
return post, prior
|
| 372 |
+
|
| 373 |
+
def imagine(self, action, state=None, sample=True):
|
| 374 |
+
swap = lambda x: x.permute([1, 0] + list(range(2, len(x.shape))))
|
| 375 |
+
if state is None:
|
| 376 |
+
state = self.initial(action.shape[0])
|
| 377 |
+
assert isinstance(state, dict), state
|
| 378 |
+
action = swap(action)
|
| 379 |
+
prior = static_scan(self.img_step, [action, float(sample) + torch.zeros(action.shape[0])], state, unpack=True)[0]
|
| 380 |
+
prior = {k: swap(v) for k, v in prior.items()}
|
| 381 |
+
return prior
|
| 382 |
+
|
| 383 |
+
def get_stoch_size(self,):
|
| 384 |
+
if self._discrete:
|
| 385 |
+
return self._stoch * self._discrete
|
| 386 |
+
else:
|
| 387 |
+
return self._stoch
|
| 388 |
+
|
| 389 |
+
def get_deter_size(self,):
|
| 390 |
+
return self._cell.state_size
|
| 391 |
+
|
| 392 |
+
def get_feat_size(self,):
|
| 393 |
+
return self.get_deter_size() + self.get_stoch_size()
|
| 394 |
+
|
| 395 |
+
def get_stoch(self, state):
|
| 396 |
+
stoch = state['stoch']
|
| 397 |
+
if self._discrete:
|
| 398 |
+
shape = list(stoch.shape[:-2]) + [self._stoch * self._discrete]
|
| 399 |
+
stoch = stoch.reshape(shape)
|
| 400 |
+
return stoch
|
| 401 |
+
|
| 402 |
+
def get_deter(self, state):
|
| 403 |
+
return state['deter']
|
| 404 |
+
|
| 405 |
+
def get_feat(self, state):
|
| 406 |
+
deter = self.get_deter(state)
|
| 407 |
+
stoch = self.get_stoch(state)
|
| 408 |
+
return torch.cat([stoch, deter], -1)
|
| 409 |
+
|
| 410 |
+
def get_dist(self, state, ensemble=False):
|
| 411 |
+
if ensemble:
|
| 412 |
+
state = self._suff_stats_ensemble(state['deter'])
|
| 413 |
+
if self._discrete:
|
| 414 |
+
logit = state['logit']
|
| 415 |
+
dist = D.Independent(OneHotDist(logit.float()), 1)
|
| 416 |
+
else:
|
| 417 |
+
mean, std = state['mean'], state['std']
|
| 418 |
+
dist = D.Independent(D.Normal(mean, std), 1)
|
| 419 |
+
dist.sample = dist.rsample
|
| 420 |
+
return dist
|
| 421 |
+
|
| 422 |
+
def get_unif_dist(self, state):
|
| 423 |
+
if self._discrete:
|
| 424 |
+
logit = state['logit']
|
| 425 |
+
dist = D.Independent(OneHotDist(torch.ones_like(logit, device=logit.device)), 1)
|
| 426 |
+
else:
|
| 427 |
+
mean, std = state['mean'], state['std']
|
| 428 |
+
dist = D.Independent(D.Normal(torch.zeros_like(mean, device=mean.device), torch.ones_like(std, device=std.device)), 1)
|
| 429 |
+
dist.sample = dist.rsample
|
| 430 |
+
return dist
|
| 431 |
+
|
| 432 |
+
def obs_step(self, prev_state, prev_action, embed, is_first, should_sample=True):
|
| 433 |
+
if is_first.any():
|
| 434 |
+
prev_state = { k: torch.einsum('b,b...->b...', 1.0 - is_first.float(), x) for k, x in prev_state.items() }
|
| 435 |
+
prev_action = torch.einsum('b,b...->b...', 1.0 - is_first.float(), prev_action)
|
| 436 |
+
#
|
| 437 |
+
prior = self.img_step(prev_state, prev_action, should_sample)
|
| 438 |
+
stoch, stats = self.get_post_stoch(embed, prior, should_sample)
|
| 439 |
+
post = {'stoch': stoch, 'deter': prior['deter'], **stats}
|
| 440 |
+
return post, prior
|
| 441 |
+
|
| 442 |
+
def get_post_stoch(self, embed, prior, should_sample=True):
|
| 443 |
+
if self.single_obs_posterior:
|
| 444 |
+
x = embed
|
| 445 |
+
else:
|
| 446 |
+
x = torch.cat([prior['deter'], embed], -1)
|
| 447 |
+
x = self._obs_out(x)
|
| 448 |
+
x = self._act(x)
|
| 449 |
+
|
| 450 |
+
bs = list(x.shape[:-1])
|
| 451 |
+
x = x.reshape([-1, x.shape[-1]])
|
| 452 |
+
stats = self._suff_stats_layer('_obs_dist', x)
|
| 453 |
+
stats = { k: v.reshape( bs + list(v.shape[1:])) for k, v in stats.items()}
|
| 454 |
+
|
| 455 |
+
dist = self.get_dist(stats)
|
| 456 |
+
stoch = dist.sample() if should_sample else dist.mode()
|
| 457 |
+
return stoch, stats
|
| 458 |
+
|
| 459 |
+
def img_step(self, prev_state, prev_action, sample=True,):
|
| 460 |
+
prev_state_input = getattr(self, f'get_{self.cell_input}')(prev_state)
|
| 461 |
+
x = torch.cat([prev_state_input, prev_action], -1)
|
| 462 |
+
x = self._img_in(x)
|
| 463 |
+
x = self._act(x)
|
| 464 |
+
deter = prev_state['deter']
|
| 465 |
+
if self._cell_type == 'gru':
|
| 466 |
+
x, deter = self._cell(x, [deter])
|
| 467 |
+
temp_state = {'deter' : deter[0] }
|
| 468 |
+
else:
|
| 469 |
+
raise NotImplementedError(f"no {self._cell_type} cell method")
|
| 470 |
+
deter = deter[0] # It's wrapped in a list.
|
| 471 |
+
stoch, stats = self.get_stoch_stats_from_deter_state(temp_state, sample)
|
| 472 |
+
prior = {'stoch': stoch, 'deter': deter, **stats}
|
| 473 |
+
return prior
|
| 474 |
+
|
| 475 |
+
def get_stoch_stats_from_deter_state(self, temp_state, sample=True):
|
| 476 |
+
stats = self._suff_stats_ensemble(self.get_deter(temp_state))
|
| 477 |
+
index = torch.randint(0, self._ensemble, ())
|
| 478 |
+
stats = {k: v[index] for k, v in stats.items()}
|
| 479 |
+
dist = self.get_dist(stats)
|
| 480 |
+
if sample:
|
| 481 |
+
stoch = dist.sample()
|
| 482 |
+
else:
|
| 483 |
+
try:
|
| 484 |
+
stoch = dist.mode()
|
| 485 |
+
except:
|
| 486 |
+
stoch = dist.mean
|
| 487 |
+
return stoch, stats
|
| 488 |
+
|
| 489 |
+
def _suff_stats_ensemble(self, inp):
|
| 490 |
+
bs = list(inp.shape[:-1])
|
| 491 |
+
inp = inp.reshape([-1, inp.shape[-1]])
|
| 492 |
+
stats = []
|
| 493 |
+
for k in range(self._ensemble):
|
| 494 |
+
x = self._ensemble_img_out[k](inp)
|
| 495 |
+
x = self._act(x)
|
| 496 |
+
stats.append(self._suff_stats_layer('_ensemble_img_dist', x, k=k))
|
| 497 |
+
stats = {
|
| 498 |
+
k: torch.stack([x[k] for x in stats], 0)
|
| 499 |
+
for k, v in stats[0].items()}
|
| 500 |
+
stats = {
|
| 501 |
+
k: v.reshape([v.shape[0]] + bs + list(v.shape[2:]))
|
| 502 |
+
for k, v in stats.items()}
|
| 503 |
+
return stats
|
| 504 |
+
|
| 505 |
+
def _suff_stats_layer(self, name, x, k=None):
|
| 506 |
+
layer = getattr(self, name)
|
| 507 |
+
if k is not None:
|
| 508 |
+
layer = layer[k]
|
| 509 |
+
x = layer(x)
|
| 510 |
+
if self._discrete:
|
| 511 |
+
logit = x.reshape(list(x.shape[:-1]) + [self._stoch, self._discrete])
|
| 512 |
+
return {'logit': logit}
|
| 513 |
+
else:
|
| 514 |
+
mean, std = torch.chunk(x, 2, -1)
|
| 515 |
+
std = {
|
| 516 |
+
'softplus': lambda: F.softplus(std),
|
| 517 |
+
'sigmoid': lambda: torch.sigmoid(std),
|
| 518 |
+
'sigmoid2': lambda: 2 * torch.sigmoid(std / 2),
|
| 519 |
+
}[self._std_act]()
|
| 520 |
+
std = std + self._min_std
|
| 521 |
+
return {'mean': mean, 'std': std}
|
| 522 |
+
|
| 523 |
+
def vq_loss(self, post, prior, balance):
|
| 524 |
+
dim_repr = prior['output'].shape[-1]
|
| 525 |
+
# Vectors and codes are the same, but vectors have gradients
|
| 526 |
+
dyn_loss = balance * F.mse_loss(prior['output'], post['vectors'].detach()) + (1 - balance) * F.mse_loss(prior['output'].detach(), post['vectors'])
|
| 527 |
+
dyn_loss += balance * F.mse_loss(prior['output'], post['codes'].detach()) + (1 - balance) * F.mse_loss(prior['output'].detach(), post['codes'])
|
| 528 |
+
dyn_loss /= 2
|
| 529 |
+
vq_loss = 0.25 * F.mse_loss(post['output'], post['codes'].detach()) + F.mse_loss(post['output'].detach(), post['codes'])
|
| 530 |
+
|
| 531 |
+
loss = vq_loss + dyn_loss
|
| 532 |
+
return loss * dim_repr, dyn_loss * dim_repr
|
| 533 |
+
|
| 534 |
+
def kl_loss(self, post, prior, forward, balance, free, free_avg,):
|
| 535 |
+
kld = D.kl_divergence
|
| 536 |
+
sg = lambda x: {k: v.detach() for k, v in x.items()}
|
| 537 |
+
lhs, rhs = (prior, post) if forward else (post, prior)
|
| 538 |
+
mix = balance if forward else (1 - balance)
|
| 539 |
+
dtype = post['stoch'].dtype
|
| 540 |
+
device = post['stoch'].device
|
| 541 |
+
free_tensor = torch.tensor([free], dtype=dtype, device=device)
|
| 542 |
+
if balance == 0.5:
|
| 543 |
+
value = kld(self.get_dist(lhs), self.get_dist(rhs))
|
| 544 |
+
loss = torch.maximum(value, free_tensor).mean()
|
| 545 |
+
else:
|
| 546 |
+
value_lhs = value = kld(self.get_dist(lhs), self.get_dist(sg(rhs)))
|
| 547 |
+
value_rhs = kld(self.get_dist(sg(lhs)), self.get_dist(rhs))
|
| 548 |
+
if free_avg:
|
| 549 |
+
loss_lhs = torch.maximum(value_lhs.mean(), free_tensor)
|
| 550 |
+
loss_rhs = torch.maximum(value_rhs.mean(), free_tensor)
|
| 551 |
+
else:
|
| 552 |
+
loss_lhs = torch.maximum(value_lhs, free_tensor).mean()
|
| 553 |
+
loss_rhs = torch.maximum(value_rhs, free_tensor).mean()
|
| 554 |
+
loss = mix * loss_lhs + (1 - mix) * loss_rhs
|
| 555 |
+
return loss, value
|
| 556 |
+
|
| 557 |
+
|
| 558 |
+
class Encoder(Module):
|
| 559 |
+
|
| 560 |
+
def __init__(
|
| 561 |
+
self, shapes, cnn_keys=r'.*', mlp_keys=r'.*', act='SiLU', norm='none',
|
| 562 |
+
cnn_depth=48, cnn_kernels=(4, 4, 4, 4), mlp_layers=[400, 400, 400, 400], symlog_inputs=False,):
|
| 563 |
+
super().__init__()
|
| 564 |
+
self.shapes = shapes
|
| 565 |
+
self.cnn_keys = [
|
| 566 |
+
k for k, v in shapes.items() if re.match(cnn_keys, k) and len(v) == 3]
|
| 567 |
+
self.mlp_keys = [
|
| 568 |
+
k for k, v in shapes.items() if re.match(mlp_keys, k) and len(v) == 1]
|
| 569 |
+
print('Encoder CNN inputs:', list(self.cnn_keys))
|
| 570 |
+
print('Encoder MLP inputs:', list(self.mlp_keys))
|
| 571 |
+
self._act = get_act(act)
|
| 572 |
+
self._norm = norm
|
| 573 |
+
self._cnn_depth = cnn_depth
|
| 574 |
+
self._cnn_kernels = cnn_kernels
|
| 575 |
+
self._mlp_layers = mlp_layers
|
| 576 |
+
self._symlog_inputs = symlog_inputs
|
| 577 |
+
|
| 578 |
+
if len(self.cnn_keys) > 0:
|
| 579 |
+
self._conv_model = []
|
| 580 |
+
for i, kernel in enumerate(self._cnn_kernels):
|
| 581 |
+
if i == 0:
|
| 582 |
+
prev_depth = 3
|
| 583 |
+
else:
|
| 584 |
+
prev_depth = 2 ** (i-1) * self._cnn_depth
|
| 585 |
+
depth = 2 ** i * self._cnn_depth
|
| 586 |
+
self._conv_model.append(nn.Conv2d(prev_depth, depth, kernel, stride=2))
|
| 587 |
+
self._conv_model.append(ImgChLayerNorm(depth) if norm == 'layer' else NormLayer(norm,depth))
|
| 588 |
+
self._conv_model.append(self._act)
|
| 589 |
+
self._conv_model = nn.Sequential(*self._conv_model)
|
| 590 |
+
if len(self.mlp_keys) > 0:
|
| 591 |
+
self._mlp_model = []
|
| 592 |
+
for i, width in enumerate(self._mlp_layers):
|
| 593 |
+
if i == 0:
|
| 594 |
+
prev_width = np.sum([shapes[k] for k in self.mlp_keys])
|
| 595 |
+
else:
|
| 596 |
+
prev_width = self._mlp_layers[i-1]
|
| 597 |
+
self._mlp_model.append(nn.Linear(prev_width, width, bias=norm != 'none'))
|
| 598 |
+
self._mlp_model.append(NormLayer(norm, width))
|
| 599 |
+
self._mlp_model.append(self._act)
|
| 600 |
+
if len(self._mlp_model) == 0:
|
| 601 |
+
self._mlp_model.append(nn.Identity())
|
| 602 |
+
self._mlp_model = nn.Sequential(*self._mlp_model)
|
| 603 |
+
|
| 604 |
+
def forward(self, data):
|
| 605 |
+
key, shape = list(self.shapes.items())[0]
|
| 606 |
+
batch_dims = data[key].shape[:-len(shape)]
|
| 607 |
+
data = {
|
| 608 |
+
k: v.reshape((-1,) + tuple(v.shape)[len(batch_dims):])
|
| 609 |
+
for k, v in data.items()}
|
| 610 |
+
outputs = []
|
| 611 |
+
if self.cnn_keys:
|
| 612 |
+
outputs.append(self._cnn({k: data[k] for k in self.cnn_keys}))
|
| 613 |
+
if self.mlp_keys:
|
| 614 |
+
outputs.append(self._mlp({k: data[k] for k in self.mlp_keys}))
|
| 615 |
+
output = torch.cat(outputs, -1)
|
| 616 |
+
return output.reshape(batch_dims + output.shape[1:])
|
| 617 |
+
|
| 618 |
+
def _cnn(self, data):
|
| 619 |
+
x = torch.cat(list(data.values()), -1)
|
| 620 |
+
x = self._conv_model(x)
|
| 621 |
+
return x.reshape(tuple(x.shape[:-3]) + (-1,))
|
| 622 |
+
|
| 623 |
+
def _mlp(self, data):
|
| 624 |
+
x = torch.cat(list(data.values()), -1)
|
| 625 |
+
if self._symlog_inputs:
|
| 626 |
+
x = symlog(x)
|
| 627 |
+
x = self._mlp_model(x)
|
| 628 |
+
return x
|
| 629 |
+
|
| 630 |
+
|
| 631 |
+
class Decoder(Module):
|
| 632 |
+
|
| 633 |
+
def __init__(
|
| 634 |
+
self, shapes, cnn_keys=r'.*', mlp_keys=r'.*', act='SiLU', norm='none',
|
| 635 |
+
cnn_depth=48, cnn_kernels=(4, 4, 4, 4), mlp_layers=[400, 400, 400, 400], embed_dim=1024, mlp_dist='mse', image_dist='mse'):
|
| 636 |
+
super().__init__()
|
| 637 |
+
self._embed_dim = embed_dim
|
| 638 |
+
self._shapes = shapes
|
| 639 |
+
self.cnn_keys = [
|
| 640 |
+
k for k, v in shapes.items() if re.match(cnn_keys, k) and len(v) == 3]
|
| 641 |
+
self.mlp_keys = [
|
| 642 |
+
k for k, v in shapes.items() if re.match(mlp_keys, k) and len(v) == 1]
|
| 643 |
+
print('Decoder CNN outputs:', list(self.cnn_keys))
|
| 644 |
+
print('Decoder MLP outputs:', list(self.mlp_keys))
|
| 645 |
+
self._act = get_act(act)
|
| 646 |
+
self._norm = norm
|
| 647 |
+
self._cnn_depth = cnn_depth
|
| 648 |
+
self._cnn_kernels = cnn_kernels
|
| 649 |
+
self._mlp_layers = mlp_layers
|
| 650 |
+
self.channels = {k: self._shapes[k][0] for k in self.cnn_keys}
|
| 651 |
+
self._mlp_dist = mlp_dist
|
| 652 |
+
self._image_dist = image_dist
|
| 653 |
+
|
| 654 |
+
if len(self.cnn_keys) > 0:
|
| 655 |
+
|
| 656 |
+
self._conv_in = nn.Sequential(nn.Linear(embed_dim, 32*self._cnn_depth))
|
| 657 |
+
self._conv_model = []
|
| 658 |
+
for i, kernel in enumerate(self._cnn_kernels):
|
| 659 |
+
if i == 0:
|
| 660 |
+
prev_depth = 32*self._cnn_depth
|
| 661 |
+
else:
|
| 662 |
+
prev_depth = 2 ** (len(self._cnn_kernels) - (i - 1) - 2) * self._cnn_depth
|
| 663 |
+
depth = 2 ** (len(self._cnn_kernels) - i - 2) * self._cnn_depth
|
| 664 |
+
act, norm = self._act, self._norm
|
| 665 |
+
# Last layer is dist layer
|
| 666 |
+
if i == len(self._cnn_kernels) - 1:
|
| 667 |
+
depth, act, norm = sum(self.channels.values()), nn.Identity(), 'none'
|
| 668 |
+
self._conv_model.append(nn.ConvTranspose2d(prev_depth, depth, kernel, stride=2))
|
| 669 |
+
self._conv_model.append(ImgChLayerNorm(depth) if norm == 'layer' else NormLayer(norm, depth))
|
| 670 |
+
self._conv_model.append(act)
|
| 671 |
+
self._conv_model = nn.Sequential(*self._conv_model)
|
| 672 |
+
if len(self.mlp_keys) > 0:
|
| 673 |
+
self._mlp_model = []
|
| 674 |
+
for i, width in enumerate(self._mlp_layers):
|
| 675 |
+
if i == 0:
|
| 676 |
+
prev_width = embed_dim
|
| 677 |
+
else:
|
| 678 |
+
prev_width = self._mlp_layers[i-1]
|
| 679 |
+
self._mlp_model.append(nn.Linear(prev_width, width, bias=self._norm != 'none'))
|
| 680 |
+
self._mlp_model.append(NormLayer(self._norm, width))
|
| 681 |
+
self._mlp_model.append(self._act)
|
| 682 |
+
self._mlp_model = nn.Sequential(*self._mlp_model)
|
| 683 |
+
for key, shape in { k : shapes[k] for k in self.mlp_keys }.items():
|
| 684 |
+
self.add_module(f'dense_{key}', DistLayer(width, shape, dist=self._mlp_dist))
|
| 685 |
+
|
| 686 |
+
def forward(self, features):
|
| 687 |
+
outputs = {}
|
| 688 |
+
|
| 689 |
+
if self.cnn_keys:
|
| 690 |
+
outputs.update(self._cnn(features))
|
| 691 |
+
if self.mlp_keys:
|
| 692 |
+
outputs.update(self._mlp(features))
|
| 693 |
+
return outputs
|
| 694 |
+
|
| 695 |
+
def _cnn(self, features):
|
| 696 |
+
x = self._conv_in(features)
|
| 697 |
+
x = x.reshape([-1, 32 * self._cnn_depth, 1, 1,])
|
| 698 |
+
x = self._conv_model(x)
|
| 699 |
+
x = x.reshape(list(features.shape[:-1]) + list(x.shape[1:]))
|
| 700 |
+
if len(x.shape) == 5:
|
| 701 |
+
means = torch.split(x, list(self.channels.values()), 2)
|
| 702 |
+
else:
|
| 703 |
+
means = torch.split(x, list(self.channels.values()), 1)
|
| 704 |
+
image_dist = dict(mse=lambda x : MSEDist(x), normal_unit_std=lambda x : D.Independent(D.Normal(x, 1.0), 3))[self._image_dist]
|
| 705 |
+
dists = { key: image_dist(mean) for (key, shape), mean in zip(self.channels.items(), means)}
|
| 706 |
+
return dists
|
| 707 |
+
|
| 708 |
+
def _mlp(self, features):
|
| 709 |
+
shapes = {k: self._shapes[k] for k in self.mlp_keys}
|
| 710 |
+
x = features
|
| 711 |
+
x = self._mlp_model(x)
|
| 712 |
+
dists = {}
|
| 713 |
+
for key, shape in shapes.items():
|
| 714 |
+
dists[key] = getattr(self, f'dense_{key}')(x)
|
| 715 |
+
return dists
|
| 716 |
+
|
| 717 |
+
|
| 718 |
+
class MLP(Module):
|
| 719 |
+
|
| 720 |
+
def __init__(self, in_shape, shape, layers, units, act='SiLU', norm='none', **out):
|
| 721 |
+
super().__init__()
|
| 722 |
+
self._in_shape = in_shape
|
| 723 |
+
if out['dist'] == 'twohot':
|
| 724 |
+
shape = 255
|
| 725 |
+
self._shape = (shape,) if isinstance(shape, int) else shape
|
| 726 |
+
self._layers = layers
|
| 727 |
+
self._units = units
|
| 728 |
+
self._norm = norm
|
| 729 |
+
self._act = get_act(act)
|
| 730 |
+
self._out = out
|
| 731 |
+
|
| 732 |
+
last_units = in_shape
|
| 733 |
+
for index in range(self._layers):
|
| 734 |
+
self.add_module(f'dense{index}', nn.Linear(last_units, units, bias=norm != 'none'))
|
| 735 |
+
self.add_module(f'norm{index}', NormLayer(norm, units))
|
| 736 |
+
last_units = units
|
| 737 |
+
self._out = DistLayer(units, shape, **out)
|
| 738 |
+
|
| 739 |
+
def forward(self, features):
|
| 740 |
+
x = features
|
| 741 |
+
x = x.reshape([-1, x.shape[-1]])
|
| 742 |
+
for index in range(self._layers):
|
| 743 |
+
x = getattr(self, f'dense{index}')(x)
|
| 744 |
+
x = getattr(self, f'norm{index}')(x)
|
| 745 |
+
x = self._act(x)
|
| 746 |
+
x = x.reshape(list(features.shape[:-1]) + [x.shape[-1]])
|
| 747 |
+
return self._out(x)
|
| 748 |
+
|
| 749 |
+
|
| 750 |
+
class GRUCell(Module):
|
| 751 |
+
|
| 752 |
+
def __init__(self, inp_size, size, norm=False, act='Tanh', update_bias=-1, device='cuda', **kwargs):
|
| 753 |
+
super().__init__()
|
| 754 |
+
self._inp_size = inp_size
|
| 755 |
+
self._size = size
|
| 756 |
+
self._act = get_act(act)
|
| 757 |
+
self._norm = norm
|
| 758 |
+
self._update_bias = update_bias
|
| 759 |
+
self.device = device
|
| 760 |
+
self._layer = nn.Linear(inp_size + size, 3 * size, bias=(not norm), **kwargs)
|
| 761 |
+
if norm:
|
| 762 |
+
self._norm = nn.LayerNorm(3*size)
|
| 763 |
+
|
| 764 |
+
def get_initial_state(self, inputs=None, batch_size=None, dtype=None):
|
| 765 |
+
return torch.zeros((batch_size), self._size, device=self.device)
|
| 766 |
+
|
| 767 |
+
@property
|
| 768 |
+
def state_size(self):
|
| 769 |
+
return self._size
|
| 770 |
+
|
| 771 |
+
def forward(self, inputs, deter_state):
|
| 772 |
+
"""
|
| 773 |
+
inputs : non-linear combination of previous stoch and action
|
| 774 |
+
deter_state : prev hidden state of the cell
|
| 775 |
+
"""
|
| 776 |
+
deter_state = deter_state[0] # State is wrapped in a list.
|
| 777 |
+
parts = self._layer(torch.cat([inputs, deter_state], -1))
|
| 778 |
+
if self._norm:
|
| 779 |
+
parts = self._norm(parts)
|
| 780 |
+
reset, cand, update = torch.chunk(parts, 3, -1)
|
| 781 |
+
reset = torch.sigmoid(reset)
|
| 782 |
+
cand = self._act(reset * cand)
|
| 783 |
+
update = torch.sigmoid(update + self._update_bias)
|
| 784 |
+
output = update * cand + (1 - update) * deter_state
|
| 785 |
+
return output, [output]
|
| 786 |
+
|
| 787 |
+
class DistLayer(Module):
|
| 788 |
+
|
| 789 |
+
def __init__(
|
| 790 |
+
self, in_dim, shape, dist='mse', min_std=0.1, max_std=1.0, init_std=0.0, bias=True):
|
| 791 |
+
super().__init__()
|
| 792 |
+
self._in_dim = in_dim
|
| 793 |
+
self._shape = shape if type(shape) in [list,tuple] else [shape]
|
| 794 |
+
self._dist = dist
|
| 795 |
+
self._min_std = min_std
|
| 796 |
+
self._init_std = init_std
|
| 797 |
+
self._max_std = max_std
|
| 798 |
+
self._out = nn.Linear(in_dim, int(np.prod(shape)) , bias=bias)
|
| 799 |
+
if dist in ('normal', 'tanh_normal', 'trunc_normal'):
|
| 800 |
+
self._std = nn.Linear(in_dim, int(np.prod(shape)) )
|
| 801 |
+
|
| 802 |
+
def forward(self, inputs):
|
| 803 |
+
out = self._out(inputs)
|
| 804 |
+
out = out.reshape(list(inputs.shape[:-1]) + list(self._shape))
|
| 805 |
+
if self._dist in ('normal', 'tanh_normal', 'trunc_normal'):
|
| 806 |
+
std = self._std(inputs)
|
| 807 |
+
std = std.reshape(list(inputs.shape[:-1]) + list(self._shape))
|
| 808 |
+
if self._dist == 'mse':
|
| 809 |
+
return MSEDist(out,)
|
| 810 |
+
if self._dist == 'normal_unit_std':
|
| 811 |
+
dist = D.Normal(out, 1.0)
|
| 812 |
+
dist.sample = dist.rsample
|
| 813 |
+
return D.Independent(dist, len(self._shape))
|
| 814 |
+
if self._dist == 'normal':
|
| 815 |
+
mean = torch.tanh(out)
|
| 816 |
+
std = (self._max_std - self._min_std) * torch.sigmoid(std + 2.0) + self._min_std
|
| 817 |
+
dist = D.Normal(mean, std)
|
| 818 |
+
dist.sample = dist.rsample
|
| 819 |
+
return D.Independent(dist, len(self._shape))
|
| 820 |
+
if self._dist == 'binary':
|
| 821 |
+
out = torch.sigmoid(out)
|
| 822 |
+
dist = BernoulliDist(out)
|
| 823 |
+
return D.Independent(dist, len(self._shape))
|
| 824 |
+
if self._dist == 'tanh_normal':
|
| 825 |
+
mean = 5 * torch.tanh(out / 5)
|
| 826 |
+
std = F.softplus(std + self._init_std) + self._min_std
|
| 827 |
+
dist = utils.SquashedNormal(mean, std)
|
| 828 |
+
dist = D.Independent(dist, len(self._shape))
|
| 829 |
+
return SampleDist(dist)
|
| 830 |
+
if self._dist == 'trunc_normal':
|
| 831 |
+
mean = torch.tanh(out)
|
| 832 |
+
std = 2 * torch.sigmoid((std + self._init_std) / 2) + self._min_std
|
| 833 |
+
dist = utils.TruncatedNormal(mean, std)
|
| 834 |
+
return D.Independent(dist, 1)
|
| 835 |
+
if self._dist == 'onehot':
|
| 836 |
+
return OneHotDist(out.float())
|
| 837 |
+
if self._dist == 'twohot':
|
| 838 |
+
return TwoHotDist(out.float())
|
| 839 |
+
if self._dist == 'symlog_mse':
|
| 840 |
+
return SymlogDist(out, len(self._shape), 'mse')
|
| 841 |
+
raise NotImplementedError(self._dist)
|
| 842 |
+
|
| 843 |
+
|
| 844 |
+
class NormLayer(Module):
|
| 845 |
+
|
| 846 |
+
def __init__(self, name, dim=None):
|
| 847 |
+
super().__init__()
|
| 848 |
+
if name == 'none':
|
| 849 |
+
self._layer = None
|
| 850 |
+
elif name == 'layer':
|
| 851 |
+
assert dim != None
|
| 852 |
+
self._layer = nn.LayerNorm(dim)
|
| 853 |
+
else:
|
| 854 |
+
raise NotImplementedError(name)
|
| 855 |
+
|
| 856 |
+
def forward(self, features):
|
| 857 |
+
if self._layer is None:
|
| 858 |
+
return features
|
| 859 |
+
return self._layer(features)
|
| 860 |
+
|
| 861 |
+
|
| 862 |
+
def get_act(name):
|
| 863 |
+
if name == 'none':
|
| 864 |
+
return nn.Identity()
|
| 865 |
+
elif hasattr(nn, name):
|
| 866 |
+
return getattr(nn, name)()
|
| 867 |
+
else:
|
| 868 |
+
raise NotImplementedError(name)
|
| 869 |
+
|
| 870 |
+
|
| 871 |
+
class Optimizer:
|
| 872 |
+
|
| 873 |
+
def __init__(
|
| 874 |
+
self, name, parameters, lr, eps=1e-4, clip=None, wd=None,
|
| 875 |
+
opt='adam', wd_pattern=r'.*', use_amp=False):
|
| 876 |
+
assert 0 <= wd < 1
|
| 877 |
+
assert not clip or 1 <= clip
|
| 878 |
+
self._name = name
|
| 879 |
+
self._clip = clip
|
| 880 |
+
self._wd = wd
|
| 881 |
+
self._wd_pattern = wd_pattern
|
| 882 |
+
self._opt = {
|
| 883 |
+
'adam': lambda: torch.optim.Adam(parameters, lr, eps=eps),
|
| 884 |
+
'nadam': lambda: torch.optim.Nadam(parameters, lr, eps=eps),
|
| 885 |
+
'adamax': lambda: torch.optim.Adamax(parameters, lr, eps=eps),
|
| 886 |
+
'sgd': lambda: torch.optim.SGD(parameters, lr),
|
| 887 |
+
'momentum': lambda: torch.optim.SGD(lr, momentum=0.9),
|
| 888 |
+
}[opt]()
|
| 889 |
+
self._scaler = torch.cuda.amp.GradScaler(enabled=use_amp)
|
| 890 |
+
self._once = True
|
| 891 |
+
|
| 892 |
+
def __call__(self, loss, params):
|
| 893 |
+
params = list(params)
|
| 894 |
+
assert len(loss.shape) == 0 or (len(loss.shape) == 1 and loss.shape[0] == 1), (self._name, loss.shape)
|
| 895 |
+
metrics = {}
|
| 896 |
+
|
| 897 |
+
# Count parameters.
|
| 898 |
+
if self._once:
|
| 899 |
+
count = sum(p.numel() for p in params if p.requires_grad)
|
| 900 |
+
print(f'Found {count} {self._name} parameters.')
|
| 901 |
+
self._once = False
|
| 902 |
+
|
| 903 |
+
# Check loss.
|
| 904 |
+
metrics[f'{self._name}_loss'] = loss.detach().cpu().numpy()
|
| 905 |
+
|
| 906 |
+
# Compute scaled gradient.
|
| 907 |
+
self._scaler.scale(loss).backward()
|
| 908 |
+
self._scaler.unscale_(self._opt)
|
| 909 |
+
|
| 910 |
+
# Gradient clipping.
|
| 911 |
+
if self._clip:
|
| 912 |
+
norm = torch.nn.utils.clip_grad_norm_(params, self._clip)
|
| 913 |
+
metrics[f'{self._name}_grad_norm'] = norm.item()
|
| 914 |
+
|
| 915 |
+
# Weight decay.
|
| 916 |
+
if self._wd:
|
| 917 |
+
self._apply_weight_decay(params)
|
| 918 |
+
|
| 919 |
+
# # Apply gradients.
|
| 920 |
+
self._scaler.step(self._opt)
|
| 921 |
+
self._scaler.update()
|
| 922 |
+
|
| 923 |
+
self._opt.zero_grad()
|
| 924 |
+
return metrics
|
| 925 |
+
|
| 926 |
+
def _apply_weight_decay(self, varibs):
|
| 927 |
+
nontrivial = (self._wd_pattern != r'.*')
|
| 928 |
+
if nontrivial:
|
| 929 |
+
raise NotImplementedError('Non trivial weight decay')
|
| 930 |
+
else:
|
| 931 |
+
for var in varibs:
|
| 932 |
+
var.data = (1 - self._wd) * var.data
|
| 933 |
+
|
| 934 |
+
class StreamNorm:
|
| 935 |
+
|
| 936 |
+
def __init__(self, shape=(), momentum=0.99, scale=1.0, eps=1e-8, device='cuda'):
|
| 937 |
+
# Momentum of 0 normalizes only based on the current batch.
|
| 938 |
+
# Momentum of 1 disables normalization.
|
| 939 |
+
self.device = device
|
| 940 |
+
self._shape = tuple(shape)
|
| 941 |
+
self._momentum = momentum
|
| 942 |
+
self._scale = scale
|
| 943 |
+
self._eps = eps
|
| 944 |
+
self.mag = None # torch.ones(shape).to(self.device)
|
| 945 |
+
|
| 946 |
+
self.step = 0
|
| 947 |
+
self.mean = None # torch.zeros(shape).to(self.device)
|
| 948 |
+
self.square_mean = None # torch.zeros(shape).to(self.device)
|
| 949 |
+
|
| 950 |
+
def reset(self):
|
| 951 |
+
self.step = 0
|
| 952 |
+
self.mag = None # torch.ones_like(self.mag).to(self.device)
|
| 953 |
+
self.mean = None # torch.zeros_like(self.mean).to(self.device)
|
| 954 |
+
self.square_mean = None # torch.zeros_like(self.square_mean).to(self.device)
|
| 955 |
+
|
| 956 |
+
def __call__(self, inputs):
|
| 957 |
+
metrics = {}
|
| 958 |
+
self.update(inputs)
|
| 959 |
+
metrics['mean'] = inputs.mean()
|
| 960 |
+
metrics['std'] = inputs.std()
|
| 961 |
+
outputs = self.transform(inputs)
|
| 962 |
+
metrics['normed_mean'] = outputs.mean()
|
| 963 |
+
metrics['normed_std'] = outputs.std()
|
| 964 |
+
return outputs, metrics
|
| 965 |
+
|
| 966 |
+
def update(self, inputs):
|
| 967 |
+
self.step += 1
|
| 968 |
+
batch = inputs.reshape((-1,) + self._shape)
|
| 969 |
+
|
| 970 |
+
mag = torch.abs(batch).mean(0)
|
| 971 |
+
if self.mag is not None:
|
| 972 |
+
self.mag.data = self._momentum * self.mag.data + (1 - self._momentum) * mag
|
| 973 |
+
else:
|
| 974 |
+
self.mag = mag.clone().detach()
|
| 975 |
+
|
| 976 |
+
mean = torch.mean(batch)
|
| 977 |
+
if self.mean is not None:
|
| 978 |
+
self.mean.data = self._momentum * self.mean.data + (1 - self._momentum) * mean
|
| 979 |
+
else:
|
| 980 |
+
self.mean = mean.clone().detach()
|
| 981 |
+
|
| 982 |
+
square_mean = torch.mean(batch * batch)
|
| 983 |
+
if self.square_mean is not None:
|
| 984 |
+
self.square_mean.data = self._momentum * self.square_mean.data + (1 - self._momentum) * square_mean
|
| 985 |
+
else:
|
| 986 |
+
self.square_mean = square_mean.clone().detach()
|
| 987 |
+
|
| 988 |
+
def transform(self, inputs):
|
| 989 |
+
if self._momentum == 1:
|
| 990 |
+
return inputs
|
| 991 |
+
values = inputs.reshape((-1,) + self._shape)
|
| 992 |
+
values /= self.mag[None] + self._eps
|
| 993 |
+
values *= self._scale
|
| 994 |
+
return values.reshape(inputs.shape)
|
| 995 |
+
|
| 996 |
+
def corrected_mean_var_std(self,):
|
| 997 |
+
corr = 1 # 1 - self._momentum ** self.step # NOTE: this led to exploding values for first few iterations
|
| 998 |
+
corr_mean = self.mean / corr
|
| 999 |
+
corr_var = (self.square_mean / corr) - self.mean ** 2
|
| 1000 |
+
corr_std = torch.sqrt(torch.maximum(corr_var, torch.zeros_like(corr_var, device=self.device)) + self._eps)
|
| 1001 |
+
return corr_mean, corr_var, corr_std
|
| 1002 |
+
|
| 1003 |
+
class RequiresGrad:
|
| 1004 |
+
|
| 1005 |
+
def __init__(self, model):
|
| 1006 |
+
self._model = model
|
| 1007 |
+
|
| 1008 |
+
def __enter__(self):
|
| 1009 |
+
self._model.requires_grad_(requires_grad=True)
|
| 1010 |
+
|
| 1011 |
+
def __exit__(self, *args):
|
| 1012 |
+
self._model.requires_grad_(requires_grad=False)
|
| 1013 |
+
|
| 1014 |
+
class RewardEMA:
|
| 1015 |
+
"""running mean and std"""
|
| 1016 |
+
|
| 1017 |
+
def __init__(self, device, alpha=1e-2):
|
| 1018 |
+
self.device = device
|
| 1019 |
+
self.alpha = alpha
|
| 1020 |
+
self.range = torch.tensor([0.05, 0.95]).to(device)
|
| 1021 |
+
|
| 1022 |
+
def __call__(self, x, ema_vals):
|
| 1023 |
+
flat_x = torch.flatten(x.detach())
|
| 1024 |
+
x_quantile = torch.quantile(input=flat_x, q=self.range)
|
| 1025 |
+
# this should be in-place operation
|
| 1026 |
+
ema_vals[:] = self.alpha * x_quantile + (1 - self.alpha) * ema_vals
|
| 1027 |
+
scale = torch.clip(ema_vals[1] - ema_vals[0], min=1.0)
|
| 1028 |
+
offset = ema_vals[0]
|
| 1029 |
+
return offset.detach(), scale.detach()
|
| 1030 |
+
|
| 1031 |
+
class ImgChLayerNorm(nn.Module):
|
| 1032 |
+
def __init__(self, ch, eps=1e-03):
|
| 1033 |
+
super(ImgChLayerNorm, self).__init__()
|
| 1034 |
+
self.norm = torch.nn.LayerNorm(ch, eps=eps)
|
| 1035 |
+
|
| 1036 |
+
def forward(self, x):
|
| 1037 |
+
x = x.permute(0, 2, 3, 1)
|
| 1038 |
+
x = self.norm(x)
|
| 1039 |
+
x = x.permute(0, 3, 1, 2)
|
| 1040 |
+
return x
|
agent/genrl.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from agent.dreamer import DreamerAgent, ActorCritic, stop_gradient, env_reward
|
| 3 |
+
import agent.dreamer_utils as common
|
| 4 |
+
import agent.video_utils as video_utils
|
| 5 |
+
from tools.genrl_utils import *
|
| 6 |
+
|
| 7 |
+
def connector_update_fn(self, module_name, data, outputs, metrics):
|
| 8 |
+
connector = getattr(self, module_name)
|
| 9 |
+
n_frames = connector.n_frames
|
| 10 |
+
B, T = data['observation'].shape[:2]
|
| 11 |
+
|
| 12 |
+
# video embed are actions
|
| 13 |
+
if getattr(self.cfg, "viclip_encode", False):
|
| 14 |
+
video_embed = data['clip_video']
|
| 15 |
+
else:
|
| 16 |
+
# Obtaining video embed
|
| 17 |
+
with torch.no_grad():
|
| 18 |
+
viclip_model = getattr(self, 'viclip_model')
|
| 19 |
+
processed_obs = viclip_model.preprocess_transf(data['observation'].reshape(B*T, *data['observation'].shape[2:]) / 255)
|
| 20 |
+
reshaped_obs = processed_obs.reshape(B * (T // n_frames), n_frames, 3,224,224)
|
| 21 |
+
video_embed = viclip_model.get_vid_features(reshaped_obs.to(viclip_model.device))
|
| 22 |
+
|
| 23 |
+
# Get posterior states from original model
|
| 24 |
+
wm_post = outputs['post']
|
| 25 |
+
return connector.update(video_embed, wm_post)
|
| 26 |
+
|
| 27 |
+
class GenRLAgent(DreamerAgent):
|
| 28 |
+
def __init__(self, **kwargs):
|
| 29 |
+
super().__init__(**kwargs)
|
| 30 |
+
|
| 31 |
+
self.n_frames = 8 # NOTE: this should become an hyperparam if changing the model
|
| 32 |
+
self.viclip_emb_dim = 512 # NOTE: this should become an hyperparam if changing the model
|
| 33 |
+
|
| 34 |
+
assert self.cfg.batch_length % self.n_frames == 0, "Fix batch length param"
|
| 35 |
+
|
| 36 |
+
if 'clip_video' in self.obs_space:
|
| 37 |
+
self.viclip_emb_dim = self.obs_space['clip_video'].shape[0]
|
| 38 |
+
|
| 39 |
+
connector = video_utils.VideoSSM(**self.cfg.connector, **self.cfg.connector_rssm, connector_kl=self.cfg.connector_kl,
|
| 40 |
+
n_frames=self.n_frames, action_dim=self.viclip_emb_dim + self.n_frames,
|
| 41 |
+
clip_add_noise=self.cfg.clip_add_noise, clip_lafite_noise=self.cfg.clip_lafite_noise,
|
| 42 |
+
device=self.device, cell_input='stoch')
|
| 43 |
+
|
| 44 |
+
connector.to(self.device)
|
| 45 |
+
|
| 46 |
+
self.wm.add_module_to_update('connector', connector, connector_update_fn, detached=self.cfg.connector.detached_post)
|
| 47 |
+
|
| 48 |
+
if getattr(self.cfg, 'imag_reward_fn', None) is not None:
|
| 49 |
+
self.instantiate_imag_behavior()
|
| 50 |
+
|
| 51 |
+
def instantiate_imag_behavior(self):
|
| 52 |
+
self._imag_behavior = ActorCritic(self.cfg, self.act_spec, self.wm.inp_size, name='imag').to(self.device)
|
| 53 |
+
self._imag_behavior.rewnorm = common.StreamNorm(**self.cfg.imag_reward_norm, device=self.device)
|
| 54 |
+
|
| 55 |
+
def finetune_mode(self,):
|
| 56 |
+
self._acting_behavior = self._imag_behavior
|
| 57 |
+
self.wm.detached_update_fns = {}
|
| 58 |
+
self.wm.e2e_update_fns = {}
|
| 59 |
+
self.wm.grad_heads.append('reward')
|
| 60 |
+
|
| 61 |
+
def update_wm(self, data, step):
|
| 62 |
+
return super().update_wm(data, step)
|
| 63 |
+
|
| 64 |
+
def report(self, data, key='observation', nvid=8):
|
| 65 |
+
# Redefine data with trim
|
| 66 |
+
n_frames = self.wm.connector.n_frames
|
| 67 |
+
obs = data['observation'][:nvid, n_frames:]
|
| 68 |
+
B, T = obs.shape[:2]
|
| 69 |
+
|
| 70 |
+
report_data = super().report(data)
|
| 71 |
+
wm = self.wm
|
| 72 |
+
n_frames = wm.connector.n_frames
|
| 73 |
+
|
| 74 |
+
# Init is same as Dreamer for reporting
|
| 75 |
+
truth = data[key][:nvid] / 255
|
| 76 |
+
decoder = wm.heads['decoder'] # B, T, C, H, W
|
| 77 |
+
preprocessed_data = self.wm.preprocess(data)
|
| 78 |
+
|
| 79 |
+
embed = wm.encoder(preprocessed_data)
|
| 80 |
+
states, _ = wm.rssm.observe(embed[:nvid, :n_frames], data['action'][:nvid, :n_frames], data['is_first'][:nvid, :n_frames])
|
| 81 |
+
recon = decoder(wm.decoder_input_fn(states))[key].mean[:nvid] # mode
|
| 82 |
+
dreamer_init = {k: v[:, -1] for k, v in states.items()}
|
| 83 |
+
|
| 84 |
+
# video embed are actions
|
| 85 |
+
if getattr(self.cfg, "viclip_encode", False):
|
| 86 |
+
video_embed = data['clip_video'][:nvid,n_frames*2-1::n_frames]
|
| 87 |
+
else:
|
| 88 |
+
# Obtain embed
|
| 89 |
+
processed_obs = wm.viclip_model.preprocess_transf(obs.reshape(B*T, *obs.shape[2:]) / 255)
|
| 90 |
+
reshaped_obs = processed_obs.reshape(B * (T // n_frames), n_frames, 3,224,224)
|
| 91 |
+
video_embed = wm.viclip_model.get_vid_features(reshaped_obs.to(wm.viclip_model.device))
|
| 92 |
+
|
| 93 |
+
video_embed = video_embed.to(self.device)
|
| 94 |
+
|
| 95 |
+
# Get actions
|
| 96 |
+
video_embed = video_embed.reshape(B, T // n_frames, -1).unsqueeze(2).repeat(1,1,n_frames, 1).reshape(B, T, -1)
|
| 97 |
+
prior = wm.connector.video_imagine(video_embed, dreamer_init, reset_every_n_frames=False)
|
| 98 |
+
prior_recon = decoder(wm.decoder_input_fn(prior))[key].mean # mode
|
| 99 |
+
model = torch.clip(torch.cat([recon[:, :n_frames] + 0.5, prior_recon + 0.5], 1), 0, 1)
|
| 100 |
+
error = (model - truth + 1) / 2
|
| 101 |
+
|
| 102 |
+
# Add video to logs
|
| 103 |
+
video = torch.cat([truth, model, error], 3)
|
| 104 |
+
report_data['video_clip_pred'] = video
|
| 105 |
+
|
| 106 |
+
return report_data
|
| 107 |
+
|
| 108 |
+
def update_imag_behavior(self, state=None, outputs=None, metrics={}, seq_data=None,):
|
| 109 |
+
if getattr(self.cfg, 'imag_reward_fn', None) is None:
|
| 110 |
+
return outputs['post'], metrics
|
| 111 |
+
if outputs is not None:
|
| 112 |
+
post = outputs['post']
|
| 113 |
+
is_terminal = outputs['is_terminal']
|
| 114 |
+
else:
|
| 115 |
+
seq_data = self.wm.preprocess(seq_data)
|
| 116 |
+
embed = self.wm.encoder(seq_data)
|
| 117 |
+
post, _ = self.wm.rssm.observe(
|
| 118 |
+
embed, seq_data['action'], seq_data['is_first'])
|
| 119 |
+
is_terminal = seq_data['is_terminal']
|
| 120 |
+
#
|
| 121 |
+
start = {k: stop_gradient(v) for k,v in post.items()}
|
| 122 |
+
imag_reward_fn = lambda seq: globals()[self.cfg.imag_reward_fn](self, seq, **self.cfg.imag_reward_args)
|
| 123 |
+
metrics.update(self._imag_behavior.update(self.wm, start, is_terminal, imag_reward_fn,))
|
| 124 |
+
return start, metrics
|
agent/genrl.yaml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package agent
|
| 2 |
+
_target_: agent.genrl.GenRLAgent
|
| 3 |
+
name: genrl
|
| 4 |
+
cfg: ???
|
| 5 |
+
obs_space: ???
|
| 6 |
+
act_spec: ???
|
| 7 |
+
grad_heads: [decoder]
|
| 8 |
+
reward_norm: {momentum: 1.0, scale: 1.0, eps: 1e-8}
|
| 9 |
+
actor_ent: 0
|
| 10 |
+
additional_report_fns: ['report_text2video']
|
| 11 |
+
|
| 12 |
+
clip_add_noise: 0.0
|
| 13 |
+
clip_lafite_noise: 0.5
|
| 14 |
+
|
| 15 |
+
connector: { token_dropout: 0, loss_scale: 1, denoising_ae: True, detached_post: True, temporal_embeds: False, rescale_embeds: True}
|
| 16 |
+
connector_rssm: {ensemble: 1, hidden: 1024, deter: 1024, stoch: 32, discrete: 32, norm: layer, std_act: softplus, min_std: 0.1, single_obs_posterior: false, learn_initial: True } # act: elu,
|
| 17 |
+
connector_kl: {free: 0.0, forward: True, balance: 0.8, free_avg: False, } # note forward is true by default
|
| 18 |
+
|
| 19 |
+
imag_reward_fn: null
|
| 20 |
+
imag_reward_norm: {momentum: 1.00, scale: 1.0, eps: 1e-8}
|
| 21 |
+
imag_reward_args: {score_fn: 'max_cosine', sample_for_target: False, align_initial : False, weighted_align : False, align_sequence: True, skip_first_target: True }
|
| 22 |
+
# +imag_reward_args.task_prompt
|
agent/plan2explore.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
from agent.dreamer import DreamerAgent, stop_gradient
|
| 6 |
+
import agent.dreamer_utils as common
|
| 7 |
+
|
| 8 |
+
class Disagreement(nn.Module):
|
| 9 |
+
def __init__(self, obs_dim, action_dim, hidden_dim, n_models=5, pred_dim=None):
|
| 10 |
+
super().__init__()
|
| 11 |
+
if pred_dim is None: pred_dim = obs_dim
|
| 12 |
+
self.ensemble = nn.ModuleList([
|
| 13 |
+
nn.Sequential(nn.Linear(obs_dim + action_dim, hidden_dim),
|
| 14 |
+
nn.ReLU(), nn.Linear(hidden_dim, pred_dim))
|
| 15 |
+
for _ in range(n_models)
|
| 16 |
+
])
|
| 17 |
+
|
| 18 |
+
def forward(self, obs, action, next_obs):
|
| 19 |
+
assert obs.shape[0] == next_obs.shape[0]
|
| 20 |
+
assert obs.shape[0] == action.shape[0]
|
| 21 |
+
|
| 22 |
+
errors = []
|
| 23 |
+
for model in self.ensemble:
|
| 24 |
+
next_obs_hat = model(torch.cat([obs, action], dim=-1))
|
| 25 |
+
model_error = torch.norm(next_obs - next_obs_hat,
|
| 26 |
+
dim=-1,
|
| 27 |
+
p=2,
|
| 28 |
+
keepdim=True)
|
| 29 |
+
errors.append(model_error)
|
| 30 |
+
|
| 31 |
+
return torch.cat(errors, dim=1)
|
| 32 |
+
|
| 33 |
+
def get_disagreement(self, obs, action):
|
| 34 |
+
assert obs.shape[0] == action.shape[0]
|
| 35 |
+
|
| 36 |
+
preds = []
|
| 37 |
+
for model in self.ensemble:
|
| 38 |
+
next_obs_hat = model(torch.cat([obs, action], dim=-1))
|
| 39 |
+
preds.append(next_obs_hat)
|
| 40 |
+
preds = torch.stack(preds, dim=0)
|
| 41 |
+
return torch.var(preds, dim=0).mean(dim=-1)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class Plan2Explore(DreamerAgent):
|
| 45 |
+
def __init__(self, **kwargs):
|
| 46 |
+
super().__init__(**kwargs)
|
| 47 |
+
in_dim = self.wm.inp_size
|
| 48 |
+
pred_dim = self.wm.embed_dim
|
| 49 |
+
self.hidden_dim = pred_dim
|
| 50 |
+
self.reward_free = True
|
| 51 |
+
|
| 52 |
+
self.disagreement = Disagreement(in_dim, self.act_dim,
|
| 53 |
+
self.hidden_dim, pred_dim=pred_dim).to(self.device)
|
| 54 |
+
|
| 55 |
+
# optimizers
|
| 56 |
+
self.disagreement_opt = common.Optimizer('disagreement', self.disagreement.parameters(), **self.cfg.model_opt, use_amp=self._use_amp)
|
| 57 |
+
self.disagreement.train()
|
| 58 |
+
self.requires_grad_(requires_grad=False)
|
| 59 |
+
|
| 60 |
+
def update_disagreement(self, obs, action, next_obs, step):
|
| 61 |
+
metrics = dict()
|
| 62 |
+
|
| 63 |
+
error = self.disagreement(obs, action, next_obs)
|
| 64 |
+
|
| 65 |
+
loss = error.mean()
|
| 66 |
+
|
| 67 |
+
metrics.update(self.disagreement_opt(loss, self.disagreement.parameters()))
|
| 68 |
+
|
| 69 |
+
metrics['disagreement_loss'] = loss.item()
|
| 70 |
+
|
| 71 |
+
return metrics
|
| 72 |
+
|
| 73 |
+
def compute_intr_reward(self, seq):
|
| 74 |
+
obs, action = seq['feat'][:-1], stop_gradient(seq['action'][1:])
|
| 75 |
+
intr_rew = torch.zeros(list(seq['action'].shape[:-1]) + [1], device=self.device)
|
| 76 |
+
if len(action.shape) > 2:
|
| 77 |
+
B, T, _ = action.shape
|
| 78 |
+
obs = obs.reshape(B*T, -1)
|
| 79 |
+
action = action.reshape(B*T, -1)
|
| 80 |
+
reward = self.disagreement.get_disagreement(obs, action).reshape(B, T, 1)
|
| 81 |
+
else:
|
| 82 |
+
reward = self.disagreement.get_disagreement(obs, action).unsqueeze(-1)
|
| 83 |
+
intr_rew[1:] = reward
|
| 84 |
+
return intr_rew
|
| 85 |
+
|
| 86 |
+
def update(self, data, step):
|
| 87 |
+
metrics = {}
|
| 88 |
+
B, T, _ = data['action'].shape
|
| 89 |
+
state, outputs, mets = self.wm.update(data, state=None)
|
| 90 |
+
metrics.update(mets)
|
| 91 |
+
start = outputs['post']
|
| 92 |
+
start = {k: stop_gradient(v) for k,v in start.items()}
|
| 93 |
+
if self.reward_free:
|
| 94 |
+
T = T-1
|
| 95 |
+
inp = stop_gradient(outputs['feat'][:, :-1]).reshape(B*T, -1)
|
| 96 |
+
action = data['action'][:, 1:].reshape(B*T, -1)
|
| 97 |
+
out = stop_gradient(outputs['embed'][:,1:]).reshape(B*T,-1)
|
| 98 |
+
with common.RequiresGrad(self.disagreement):
|
| 99 |
+
with torch.cuda.amp.autocast(enabled=self._use_amp):
|
| 100 |
+
metrics.update(
|
| 101 |
+
self.update_disagreement(inp, action, out, step))
|
| 102 |
+
metrics.update(self._acting_behavior.update(
|
| 103 |
+
self.wm, start, data['is_terminal'], reward_fn=self.compute_intr_reward))
|
| 104 |
+
else:
|
| 105 |
+
reward_fn = lambda seq: self.wm.heads['reward'](seq['feat']).mean
|
| 106 |
+
metrics.update(self._acting_behavior.update(
|
| 107 |
+
self.wm, start, data['is_terminal'], reward_fn))
|
| 108 |
+
return state, metrics
|
agent/plan2explore.yaml
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package agent
|
| 2 |
+
_target_: agent.plan2explore.Plan2Explore
|
| 3 |
+
name: plan2explore
|
| 4 |
+
cfg: ???
|
| 5 |
+
obs_space: ???
|
| 6 |
+
act_spec: ???
|
| 7 |
+
grad_heads: [decoder]
|
| 8 |
+
reward_norm: {momentum: 0.95, scale: 1.0, eps: 1e-8}
|
| 9 |
+
actor_ent: 0
|
agent/video_utils.py
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import agent.dreamer_utils as common
|
| 5 |
+
from collections import defaultdict
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
class ResidualLinear(nn.Module):
|
| 9 |
+
def __init__(self, in_channels, out_channels, norm='layer', act='SiLU', prenorm=False):
|
| 10 |
+
super().__init__()
|
| 11 |
+
self.norm_layer = common.NormLayer(norm, in_channels if prenorm else out_channels)
|
| 12 |
+
self.act = common.get_act(act)
|
| 13 |
+
self.layer = nn.Linear(in_channels, out_channels)
|
| 14 |
+
self.prenorm = prenorm
|
| 15 |
+
self.res_proj = nn.Identity() if in_channels == out_channels else nn.Linear(in_channels, out_channels)
|
| 16 |
+
|
| 17 |
+
def forward(self, x):
|
| 18 |
+
if self.prenorm:
|
| 19 |
+
h = self.norm_layer(x)
|
| 20 |
+
h = self.layer(h)
|
| 21 |
+
else:
|
| 22 |
+
h = self.layer(x)
|
| 23 |
+
h = self.norm_layer(h)
|
| 24 |
+
h = self.act(h)
|
| 25 |
+
return h + self.res_proj(x)
|
| 26 |
+
|
| 27 |
+
class UNetDenoiser(nn.Module):
|
| 28 |
+
def __init__(self, in_channels : int, mid_channels : int, n_layers : int, norm='layer', act= 'SiLU', ):
|
| 29 |
+
super().__init__()
|
| 30 |
+
out_channels = in_channels
|
| 31 |
+
self.down = nn.ModuleList()
|
| 32 |
+
for i in range(n_layers):
|
| 33 |
+
if i == (n_layers - 1):
|
| 34 |
+
self.down.append(ResidualLinear(in_channels, mid_channels, norm=norm, act=act))
|
| 35 |
+
else:
|
| 36 |
+
self.down.append(ResidualLinear(in_channels, in_channels, norm=norm, act=act))
|
| 37 |
+
|
| 38 |
+
self.mid = nn.ModuleList()
|
| 39 |
+
for i in range(n_layers):
|
| 40 |
+
self.mid.append(ResidualLinear(mid_channels, mid_channels, norm=norm, act=act))
|
| 41 |
+
|
| 42 |
+
self.up = nn.ModuleList()
|
| 43 |
+
for i in range(n_layers):
|
| 44 |
+
if i == 0:
|
| 45 |
+
self.up.append(ResidualLinear(mid_channels * 2, out_channels, norm='none', act='Identity'))
|
| 46 |
+
else:
|
| 47 |
+
self.up.append(ResidualLinear(out_channels * 2, out_channels, norm=norm, act=act))
|
| 48 |
+
|
| 49 |
+
def forward(self, x):
|
| 50 |
+
down_res = []
|
| 51 |
+
for down_layer in self.down:
|
| 52 |
+
x = down_layer(x)
|
| 53 |
+
down_res.append(x)
|
| 54 |
+
|
| 55 |
+
for mid_layer in self.mid:
|
| 56 |
+
x = mid_layer(x)
|
| 57 |
+
|
| 58 |
+
down_res.reverse()
|
| 59 |
+
for up_layer, res in zip(self.up, down_res):
|
| 60 |
+
x = up_layer(torch.cat([x, res], dim=-1))
|
| 61 |
+
return x
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class VideoSSM(common.EnsembleRSSM):
|
| 65 |
+
def __init__(self, *args,
|
| 66 |
+
connector_kl={}, temporal_embeds=False, detached_post=True, n_frames=8,
|
| 67 |
+
token_dropout=0., loss_scale=1, clip_add_noise=0, clip_lafite_noise=0,
|
| 68 |
+
rescale_embeds=False, denoising_ae=False, learn_initial=True, **kwargs,):
|
| 69 |
+
super().__init__(*args, **kwargs)
|
| 70 |
+
#
|
| 71 |
+
self.n_frames = n_frames
|
| 72 |
+
# by default, adding the n_frames in actions (doesn't hurt and easier to test whether it's useful or not)
|
| 73 |
+
self.viclip_emb_dim = kwargs['action_dim'] - self.n_frames
|
| 74 |
+
#
|
| 75 |
+
self.temporal_embeds = temporal_embeds
|
| 76 |
+
self.detached_post = detached_post
|
| 77 |
+
self.connector_kl = connector_kl
|
| 78 |
+
self.token_dropout = token_dropout
|
| 79 |
+
self.loss_scale = loss_scale
|
| 80 |
+
self.rescale_embeds = rescale_embeds
|
| 81 |
+
self.clip_add_noise = clip_add_noise
|
| 82 |
+
self.clip_lafite_noise = clip_lafite_noise
|
| 83 |
+
self.clip_const = np.sqrt(self.viclip_emb_dim).item()
|
| 84 |
+
self.denoising_ae = denoising_ae
|
| 85 |
+
if self.denoising_ae:
|
| 86 |
+
self.aligner = UNetDenoiser(self.viclip_emb_dim, self.viclip_emb_dim // 2, n_layers=2, norm='layer', act='SiLU')
|
| 87 |
+
self.learn_initial = learn_initial
|
| 88 |
+
if self.learn_initial:
|
| 89 |
+
self.initial_state_pred = nn.Sequential(
|
| 90 |
+
nn.Linear(kwargs['action_dim'], kwargs['hidden']),
|
| 91 |
+
common.NormLayer(kwargs['norm'],kwargs['hidden']), common.get_act('SiLU'),
|
| 92 |
+
nn.Linear(kwargs['hidden'], kwargs['hidden']),
|
| 93 |
+
common.NormLayer(kwargs['norm'],kwargs['hidden']), common.get_act('SiLU'),
|
| 94 |
+
nn.Linear(kwargs['hidden'], kwargs['deter'])
|
| 95 |
+
)
|
| 96 |
+
# Deleting non-useful models
|
| 97 |
+
del self._obs_out
|
| 98 |
+
del self._obs_dist
|
| 99 |
+
|
| 100 |
+
def initial(self, batch_size, init_embed=None, ignore_learned=False):
|
| 101 |
+
init = super().initial(batch_size)
|
| 102 |
+
if self.learn_initial and not ignore_learned and hasattr(self, 'initial_state_pred'):
|
| 103 |
+
assert init_embed is not None
|
| 104 |
+
# patcher to avoid edge cases
|
| 105 |
+
if init_embed.shape[-1] == self.viclip_emb_dim:
|
| 106 |
+
patcher = torch.zeros((*init_embed.shape[:-1], 8), device=self.device)
|
| 107 |
+
init_embed = torch.cat([init_embed, patcher], dim=-1)
|
| 108 |
+
init['deter'] = self.initial_state_pred(init_embed)
|
| 109 |
+
stoch, stats = self.get_stoch_stats_from_deter_state(init)
|
| 110 |
+
init['stoch'] = stoch
|
| 111 |
+
init.update(stats)
|
| 112 |
+
return init
|
| 113 |
+
|
| 114 |
+
def get_action(self, video_embed):
|
| 115 |
+
n_frames = self.n_frames
|
| 116 |
+
B, T = video_embed.shape[:2]
|
| 117 |
+
|
| 118 |
+
if self.rescale_embeds:
|
| 119 |
+
video_embed = video_embed * self.clip_const
|
| 120 |
+
|
| 121 |
+
temporal_embeds = F.one_hot(torch.arange(T).to(video_embed.device) % n_frames, n_frames).reshape(1, T, n_frames,).repeat(B, 1, 1,)
|
| 122 |
+
if not self.temporal_embeds:
|
| 123 |
+
temporal_embeds *= 0
|
| 124 |
+
|
| 125 |
+
return torch.cat([video_embed, temporal_embeds],dim=-1)
|
| 126 |
+
|
| 127 |
+
def update(self, video_embed, wm_post):
|
| 128 |
+
n_frames = self.n_frames
|
| 129 |
+
B, T = video_embed.shape[:2]
|
| 130 |
+
loss = 0
|
| 131 |
+
metrics = {}
|
| 132 |
+
|
| 133 |
+
# NOVEL
|
| 134 |
+
video_embed = video_embed[:,n_frames-1::n_frames] # tested
|
| 135 |
+
video_embed = video_embed.to(self.device)
|
| 136 |
+
video_embed = video_embed.reshape(B, T // n_frames, 1, -1).repeat(1,1, n_frames, 1).reshape(B, T, -1)
|
| 137 |
+
|
| 138 |
+
orig_video_embed = video_embed
|
| 139 |
+
|
| 140 |
+
if self.clip_add_noise > 0:
|
| 141 |
+
video_embed = video_embed + torch.randn_like(video_embed, device=video_embed.device) * self.clip_add_noise
|
| 142 |
+
video_embed = nn.functional.normalize(video_embed, dim=-1)
|
| 143 |
+
if self.clip_lafite_noise > 0:
|
| 144 |
+
normed_noise = F.normalize(torch.randn_like(video_embed, device=video_embed.device), dim=-1)
|
| 145 |
+
video_embed = (1 - self.clip_lafite_noise) * video_embed + self.clip_lafite_noise * normed_noise
|
| 146 |
+
video_embed = nn.functional.normalize(video_embed, dim=-1)
|
| 147 |
+
|
| 148 |
+
if self.denoising_ae:
|
| 149 |
+
assert (self.clip_lafite_noise + self.clip_add_noise) > 0, "Nothing to denoise"
|
| 150 |
+
denoised_embed = self.aligner(video_embed)
|
| 151 |
+
denoised_embed = F.normalize(denoised_embed, dim=-1)
|
| 152 |
+
denoising_loss = 1 - F.cosine_similarity(denoised_embed, orig_video_embed, dim=-1).mean() # works same as F.mse_loss(denoised_embed, orig_video_embed).mean()
|
| 153 |
+
loss += denoising_loss
|
| 154 |
+
metrics['aligner_cosine_distance'] = denoising_loss
|
| 155 |
+
# if using a denoiser, it's the denoiser's duty to denoise the video embed
|
| 156 |
+
video_embed = orig_video_embed # could also be denoised_embed for e2e training
|
| 157 |
+
|
| 158 |
+
embed_actions = self.get_action(video_embed)
|
| 159 |
+
|
| 160 |
+
if self.detached_post:
|
| 161 |
+
wm_post = { k : v.reshape(B, T, *v.shape[2:]).detach() for k,v in wm_post.items() }
|
| 162 |
+
else:
|
| 163 |
+
wm_post = { k : v.reshape(B, T, *v.shape[2:]) for k,v in wm_post.items() }
|
| 164 |
+
|
| 165 |
+
# Get prior states
|
| 166 |
+
prior_states = defaultdict(list)
|
| 167 |
+
for t in range(T):
|
| 168 |
+
# Get video action
|
| 169 |
+
action = embed_actions[:, t]
|
| 170 |
+
|
| 171 |
+
if t == 0:
|
| 172 |
+
prev_state = self.initial(batch_size=wm_post['stoch'].shape[0], init_embed=action)
|
| 173 |
+
else:
|
| 174 |
+
# Get deter from prior, get stoch from wm_post
|
| 175 |
+
prev_state = prior
|
| 176 |
+
prev_state[self.cell_input] = wm_post[self.cell_input][:, t-1]
|
| 177 |
+
|
| 178 |
+
if self.token_dropout > 0:
|
| 179 |
+
prev_state['stoch'] = torch.einsum('b...,b->b...', prev_state['stoch'], (torch.rand(B, device=action.device) > self.token_dropout).float() )
|
| 180 |
+
|
| 181 |
+
prior = self.img_step(prev_state, action)
|
| 182 |
+
for k in prior:
|
| 183 |
+
prior_states[k].append(prior[k])
|
| 184 |
+
|
| 185 |
+
# Aggregate
|
| 186 |
+
for k in prior_states:
|
| 187 |
+
prior_states[k] = torch.stack(prior_states[k], dim=1)
|
| 188 |
+
|
| 189 |
+
# Compute loss
|
| 190 |
+
prior = prior_states
|
| 191 |
+
|
| 192 |
+
kl_loss, kl_value = self.kl_loss(wm_post, prior, **self.connector_kl)
|
| 193 |
+
video_loss = self.loss_scale * kl_loss
|
| 194 |
+
metrics['connector_kl'] = kl_value.mean()
|
| 195 |
+
loss += video_loss
|
| 196 |
+
|
| 197 |
+
# Compute initial KL
|
| 198 |
+
video_embed = video_embed.reshape(B, T // n_frames, n_frames, -1)[:,1:,0].reshape(B * (T//n_frames-1), 1, -1) # taking only one (0) and skipping first temporal step
|
| 199 |
+
embed_actions = self.get_action(video_embed)
|
| 200 |
+
wm_post = { k : v.reshape(B, T // n_frames, n_frames, *v.shape[2:])[:,1:,0].reshape(B * (T//n_frames-1), *v.shape[2:]) for k,v in wm_post.items() }
|
| 201 |
+
action = embed_actions[:, 0]
|
| 202 |
+
prev_state = self.initial(batch_size=wm_post['stoch'].shape[0], init_embed=action)
|
| 203 |
+
prior = self.img_step(prev_state, action)
|
| 204 |
+
kl_loss, kl_value = self.kl_loss(wm_post, prior, **self.connector_kl)
|
| 205 |
+
metrics['connector_initial_kl'] = kl_value.mean()
|
| 206 |
+
|
| 207 |
+
return loss, metrics
|
| 208 |
+
|
| 209 |
+
def video_imagine(self, video_embed, dreamer_init=None, sample=True, reset_every_n_frames=True, denoise=False):
|
| 210 |
+
n_frames = self.n_frames
|
| 211 |
+
B, T = video_embed.shape[:2]
|
| 212 |
+
|
| 213 |
+
if self.denoising_ae and denoise:
|
| 214 |
+
denoised_embed = self.aligner(video_embed)
|
| 215 |
+
video_embed = F.normalize(denoised_embed, dim=-1)
|
| 216 |
+
|
| 217 |
+
action = self.get_action(video_embed)
|
| 218 |
+
# Imagine
|
| 219 |
+
init = self.initial(batch_size=B, init_embed=action[:, 0]) # -> this ensures only stoch is used from the current frame
|
| 220 |
+
if dreamer_init is not None:
|
| 221 |
+
init[self.cell_input] = dreamer_init[self.cell_input]
|
| 222 |
+
|
| 223 |
+
if reset_every_n_frames:
|
| 224 |
+
prior_states = defaultdict(list)
|
| 225 |
+
for action_chunk in torch.chunk(action, T // n_frames, dim=1):
|
| 226 |
+
prior = self.imagine(action_chunk, init, sample=sample)
|
| 227 |
+
for k in prior:
|
| 228 |
+
prior_states[k].append(prior[k])
|
| 229 |
+
|
| 230 |
+
# -> this ensures only stoch is used from the current frame
|
| 231 |
+
init = self.initial(batch_size=B, ignore_learned=True)
|
| 232 |
+
init[self.cell_input] = prior[self.cell_input][:, -1]
|
| 233 |
+
|
| 234 |
+
# Agg
|
| 235 |
+
for k in prior_states:
|
| 236 |
+
prior_states[k] = torch.cat(prior_states[k], dim=1)
|
| 237 |
+
prior = prior_states
|
| 238 |
+
else:
|
| 239 |
+
prior = self.imagine(action, init, sample=sample)
|
| 240 |
+
return prior
|
app.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import gradio as gr
|
| 4 |
+
|
| 5 |
+
# prototyping
|
| 6 |
+
# from demo_test import Text2Video, Video2Video
|
| 7 |
+
|
| 8 |
+
from demo.t2v import Text2Video
|
| 9 |
+
|
| 10 |
+
t2v_examples = [
|
| 11 |
+
['walk fast clean',16,],
|
| 12 |
+
['run fast clean',16,],
|
| 13 |
+
['standing up',16],
|
| 14 |
+
['doing the splits',16],
|
| 15 |
+
['doing backflips',16],
|
| 16 |
+
['a headstand',16],
|
| 17 |
+
['karate kick',16],
|
| 18 |
+
['crunch abs',16],
|
| 19 |
+
['doing push ups',16],
|
| 20 |
+
]
|
| 21 |
+
|
| 22 |
+
def do_nothing():
|
| 23 |
+
return
|
| 24 |
+
|
| 25 |
+
def videocrafter_demo(result_dir='./tmp/'):
|
| 26 |
+
text2video = Text2Video(result_dir)
|
| 27 |
+
# video2video = Video2Video(result_dir)
|
| 28 |
+
|
| 29 |
+
# tex
|
| 30 |
+
with gr.Blocks(analytics_enabled=False) as videocrafter_iface:
|
| 31 |
+
gr.Markdown("<div align='center'> <h2> GenRL: Multimodal foundation world models for generalist embodied agents </span> </h2> \
|
| 32 |
+
<a style='font-size:18px;' href='https://github.com/mazpie/genrl'> [Github] \
|
| 33 |
+
\
|
| 34 |
+
<a style='font-size:18px;' href='https://huggingface.co/mazpie/genrl_models'> [Models] </div> \
|
| 35 |
+
\
|
| 36 |
+
<a style='font-size:18px;' href='https://huggingface.co/mazpie/genrl_models'> [Models] </div>")
|
| 37 |
+
|
| 38 |
+
gr.Markdown("<b> Notes: </b>")
|
| 39 |
+
gr.Markdown("<b> - Low quality of the videos generated is expected, as the work focuses on visual-language alignment for behavior learning, not on video generation quality.</b>")
|
| 40 |
+
gr.Markdown("<b> - The model is trained on small 64x64 images, and the videos are generated only from a small 512-dimensional embedding. </b>")
|
| 41 |
+
gr.Markdown("<b> - Some prompts require styling instructions, e.g. fast, clean, in order to work well. See some of the examples. </b>")
|
| 42 |
+
|
| 43 |
+
#######t2v#######
|
| 44 |
+
with gr.Tab(label="Text2Video"):
|
| 45 |
+
with gr.Column():
|
| 46 |
+
with gr.Row(): # .style(equal_height=False)
|
| 47 |
+
with gr.Column():
|
| 48 |
+
input_text = gr.Text(label='prompt')
|
| 49 |
+
duration = gr.Slider(minimum=8, maximum=32, elem_id=f"duration", label="duration", value=16, step=8)
|
| 50 |
+
send_btn = gr.Button("Send")
|
| 51 |
+
with gr.Column(): # label='result',
|
| 52 |
+
pass
|
| 53 |
+
with gr.Column(): # label='result',
|
| 54 |
+
output_video_1 = gr.Video(autoplay=True, width=256, height=256)
|
| 55 |
+
with gr.Row():
|
| 56 |
+
gr.Examples(examples=t2v_examples,
|
| 57 |
+
inputs=[input_text,duration],
|
| 58 |
+
outputs=[output_video_1],
|
| 59 |
+
fn=text2video.get_prompt,
|
| 60 |
+
cache_examples=False)
|
| 61 |
+
#cache_examples=os.getenv('SYSTEM') == 'spaces')
|
| 62 |
+
send_btn.click(
|
| 63 |
+
fn=text2video.get_prompt,
|
| 64 |
+
inputs=[input_text,duration],
|
| 65 |
+
outputs=[output_video_1],
|
| 66 |
+
)
|
| 67 |
+
input_text.submit(
|
| 68 |
+
fn=text2video.get_prompt,
|
| 69 |
+
inputs=[input_text,duration],
|
| 70 |
+
outputs=[output_video_1],
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
return videocrafter_iface
|
| 74 |
+
|
| 75 |
+
if __name__ == "__main__":
|
| 76 |
+
result_dir = os.path.join('./', 'results')
|
| 77 |
+
videocrafter_iface = videocrafter_demo(result_dir)
|
| 78 |
+
videocrafter_iface.queue() # concurrency_count=1, max_size=10
|
| 79 |
+
videocrafter_iface.launch()
|
| 80 |
+
# videocrafter_iface.launch(server_name='0.0.0.0', server_port=80)
|
assets/GenRL_fig1.png
ADDED
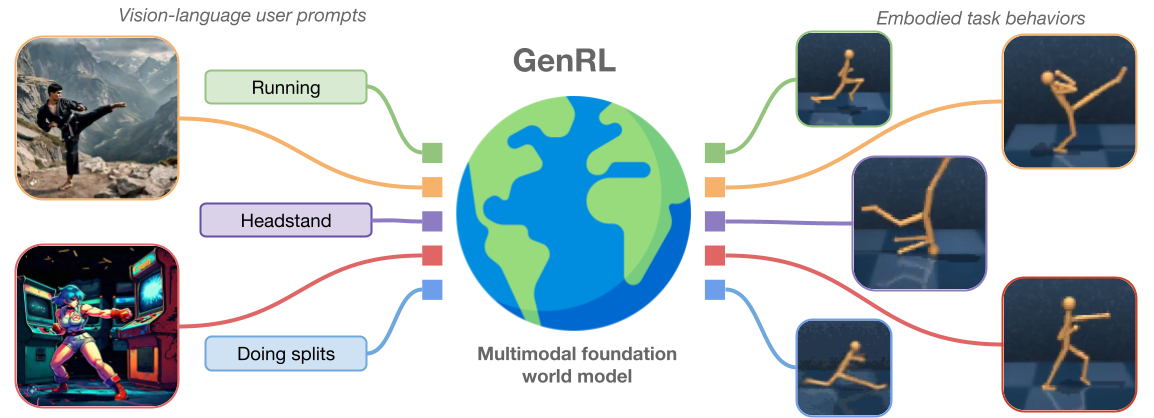
|
assets/dashboard.png
ADDED
|
assets/video_samples/a_spider_walking_on_the_floor.mp4
ADDED
|
Binary file (251 kB). View file
|
|
|
assets/video_samples/backflip.mp4
ADDED
|
Binary file (146 kB). View file
|
|
|
assets/video_samples/dancing.mp4
ADDED
|
Binary file (257 kB). View file
|
|
|
assets/video_samples/dead_spider_white.gif
ADDED

|
assets/video_samples/dog_running_seen_from_the_side.mp4
ADDED
|
Binary file (265 kB). View file
|
|
|
assets/video_samples/doing_splits.mp4
ADDED
|
Binary file (279 kB). View file
|
|
|
assets/video_samples/flex.mp4
ADDED
|
Binary file (248 kB). View file
|
|
|
assets/video_samples/headstand.mp4
ADDED
|
Binary file (162 kB). View file
|
|
|
assets/video_samples/karate_kick.mp4
ADDED
|
Binary file (293 kB). View file
|
|
|
assets/video_samples/lying_down_with_legs_up.mp4
ADDED
|
Binary file (252 kB). View file
|
|
|
assets/video_samples/person_standing_up_with_hands_up_seen_from_the_side.mp4
ADDED
|
Binary file (246 kB). View file
|
|
|
assets/video_samples/punching.mp4
ADDED
|
Binary file (310 kB). View file
|
|
|
collect_data.py
ADDED
|
@@ -0,0 +1,326 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import warnings
|
| 2 |
+
|
| 3 |
+
warnings.filterwarnings('ignore', category=DeprecationWarning)
|
| 4 |
+
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
os.environ['MKL_SERVICE_FORCE_INTEL'] = '1'
|
| 8 |
+
|
| 9 |
+
from pathlib import Path
|
| 10 |
+
|
| 11 |
+
import hydra
|
| 12 |
+
import numpy as np
|
| 13 |
+
import torch
|
| 14 |
+
import wandb
|
| 15 |
+
from dm_env import specs
|
| 16 |
+
|
| 17 |
+
import tools.utils as utils
|
| 18 |
+
from tools.logger import Logger
|
| 19 |
+
from tools.replay import ReplayBuffer, make_replay_loader
|
| 20 |
+
|
| 21 |
+
torch.backends.cudnn.benchmark = True
|
| 22 |
+
|
| 23 |
+
# os.environ['WANDB_API_KEY'] = 'local-1b6c1e2a2fd8d4c98b8c049eb2914dbceccd4b7c' # local-1b6c1e2a2fd8d4c98b8c049eb2914dbceccd4b7c
|
| 24 |
+
# os.environ['WANDB_BASE_URL'] = 'https://192.168.170.90:443'
|
| 25 |
+
# os.environ['REQUESTS_CA_BUNDLE'] = '/etc/ssl/certs/ca-certificates.crt'
|
| 26 |
+
|
| 27 |
+
def make_agent(obs_type, obs_spec, action_spec, num_expl_steps, cfg):
|
| 28 |
+
cfg.obs_type = obs_type
|
| 29 |
+
cfg.obs_shape = obs_spec.shape
|
| 30 |
+
cfg.action_shape = action_spec.shape
|
| 31 |
+
cfg.num_expl_steps = num_expl_steps
|
| 32 |
+
return hydra.utils.instantiate(cfg)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def make_dreamer_agent(obs_space, action_spec, cur_config, cfg):
|
| 36 |
+
from copy import deepcopy
|
| 37 |
+
cur_config = deepcopy(cur_config)
|
| 38 |
+
del cur_config.agent
|
| 39 |
+
return hydra.utils.instantiate(cfg, cfg=cur_config, obs_space=obs_space, act_spec=action_spec)
|
| 40 |
+
|
| 41 |
+
class Workspace:
|
| 42 |
+
def __init__(self, cfg, savedir=None, workdir=None):
|
| 43 |
+
self.workdir = Path.cwd() if workdir is None else workdir
|
| 44 |
+
print(f'workspace: {self.workdir}')
|
| 45 |
+
self.cfg = cfg
|
| 46 |
+
|
| 47 |
+
utils.set_seed_everywhere(cfg.seed)
|
| 48 |
+
self.device = torch.device(cfg.device)
|
| 49 |
+
|
| 50 |
+
# create logger
|
| 51 |
+
self.logger = Logger(self.workdir,
|
| 52 |
+
use_tb=cfg.use_tb,
|
| 53 |
+
use_wandb=cfg.use_wandb)
|
| 54 |
+
# create envs
|
| 55 |
+
self.task = task = cfg.task
|
| 56 |
+
img_size = cfg.img_size
|
| 57 |
+
|
| 58 |
+
import envs.main as envs
|
| 59 |
+
self.train_env = envs.make(task, cfg.obs_type, cfg.action_repeat, cfg.seed, img_size=img_size, viclip_encode=cfg.viclip_encode, clip_hd_rendering=cfg.clip_hd_rendering)
|
| 60 |
+
|
| 61 |
+
# # create agent
|
| 62 |
+
self.agent = make_dreamer_agent(self.train_env.obs_space, self.train_env.act_space['action'], cfg, cfg.agent)
|
| 63 |
+
|
| 64 |
+
# get meta specs
|
| 65 |
+
meta_specs = self.agent.get_meta_specs()
|
| 66 |
+
# create replay buffer
|
| 67 |
+
data_specs = (self.train_env.obs_space,
|
| 68 |
+
self.train_env.act_space,
|
| 69 |
+
specs.Array((1,), np.float32, 'reward'),
|
| 70 |
+
specs.Array((1,), np.float32, 'discount'))
|
| 71 |
+
|
| 72 |
+
# create data storage
|
| 73 |
+
self.replay_storage = ReplayBuffer(data_specs, meta_specs,
|
| 74 |
+
self.workdir / 'buffer',
|
| 75 |
+
length=cfg.batch_length, **cfg.replay,
|
| 76 |
+
device=cfg.device)
|
| 77 |
+
|
| 78 |
+
# create replay buffer
|
| 79 |
+
self.replay_loader = make_replay_loader(self.replay_storage,
|
| 80 |
+
cfg.batch_size,)
|
| 81 |
+
self._replay_iter = None
|
| 82 |
+
|
| 83 |
+
self.timer = utils.Timer()
|
| 84 |
+
self._global_step = 0
|
| 85 |
+
self._global_episode = 0
|
| 86 |
+
|
| 87 |
+
@property
|
| 88 |
+
def global_step(self):
|
| 89 |
+
return self._global_step
|
| 90 |
+
|
| 91 |
+
@property
|
| 92 |
+
def global_episode(self):
|
| 93 |
+
return self._global_episode
|
| 94 |
+
|
| 95 |
+
@property
|
| 96 |
+
def global_frame(self):
|
| 97 |
+
return self.global_step * self.cfg.action_repeat
|
| 98 |
+
|
| 99 |
+
@property
|
| 100 |
+
def replay_iter(self):
|
| 101 |
+
if self._replay_iter is None:
|
| 102 |
+
self._replay_iter = iter(self.replay_loader)
|
| 103 |
+
return self._replay_iter
|
| 104 |
+
|
| 105 |
+
def eval(self):
|
| 106 |
+
import envs.main as envs
|
| 107 |
+
eval_env = envs.make(self.task, self.cfg.obs_type, self.cfg.action_repeat, self.cfg.seed, img_size=64,)
|
| 108 |
+
step, episode, total_reward = 0, 0, 0
|
| 109 |
+
eval_until_episode = utils.Until(self.cfg.num_eval_episodes)
|
| 110 |
+
meta = self.agent.init_meta()
|
| 111 |
+
while eval_until_episode(episode):
|
| 112 |
+
time_step, dreamer_obs = eval_env.reset()
|
| 113 |
+
agent_state = None
|
| 114 |
+
while not time_step.last():
|
| 115 |
+
with torch.no_grad(), utils.eval_mode(self.agent):
|
| 116 |
+
action, agent_state = self.agent.act(dreamer_obs,
|
| 117 |
+
meta,
|
| 118 |
+
self.global_step,
|
| 119 |
+
eval_mode=True,
|
| 120 |
+
state=agent_state)
|
| 121 |
+
time_step, dreamer_obs = eval_env.step(action)
|
| 122 |
+
total_reward += time_step.reward
|
| 123 |
+
step += 1
|
| 124 |
+
|
| 125 |
+
episode += 1
|
| 126 |
+
|
| 127 |
+
with self.logger.log_and_dump_ctx(self.global_frame, ty='eval') as log:
|
| 128 |
+
log('episode_reward', total_reward / episode)
|
| 129 |
+
log('episode_length', step * self.cfg.action_repeat / episode)
|
| 130 |
+
log('episode', self.global_episode)
|
| 131 |
+
log('step', self.global_step)
|
| 132 |
+
|
| 133 |
+
def eval_imag_behavior(self,):
|
| 134 |
+
self.agent._backup_acting_behavior = self.agent._acting_behavior
|
| 135 |
+
self.agent._acting_behavior = self.agent._imag_behavior
|
| 136 |
+
self.eval()
|
| 137 |
+
self.agent._acting_behavior = self.agent._backup_acting_behavior
|
| 138 |
+
|
| 139 |
+
def train(self):
|
| 140 |
+
# predicates
|
| 141 |
+
train_until_step = utils.Until(self.cfg.num_train_frames, self.cfg.action_repeat)
|
| 142 |
+
seed_until_step = utils.Until(self.cfg.num_seed_frames, self.cfg.action_repeat)
|
| 143 |
+
eval_every_step = utils.Every(self.cfg.eval_every_frames, self.cfg.action_repeat)
|
| 144 |
+
train_every_n_steps = max(self.cfg.train_every_actions // self.cfg.action_repeat, 1)
|
| 145 |
+
should_train_step = utils.Every(train_every_n_steps * self.cfg.action_repeat, self.cfg.action_repeat)
|
| 146 |
+
should_log_scalars = utils.Every(self.cfg.log_every_frames, self.cfg.action_repeat)
|
| 147 |
+
should_log_visual = utils.Every(self.cfg.visual_every_frames, self.cfg.action_repeat)
|
| 148 |
+
should_save_model = utils.Every(self.cfg.save_every_frames, self.cfg.action_repeat)
|
| 149 |
+
|
| 150 |
+
episode_step, episode_reward = 0, 0
|
| 151 |
+
time_step, dreamer_obs = self.train_env.reset()
|
| 152 |
+
agent_state = None
|
| 153 |
+
meta = self.agent.init_meta()
|
| 154 |
+
data = dreamer_obs
|
| 155 |
+
self.replay_storage.add(data, meta)
|
| 156 |
+
metrics = None
|
| 157 |
+
while train_until_step(self.global_step):
|
| 158 |
+
if time_step.last():
|
| 159 |
+
self._global_episode += 1
|
| 160 |
+
# wait until all the metrics schema is populated
|
| 161 |
+
if metrics is not None:
|
| 162 |
+
# log stats
|
| 163 |
+
elapsed_time, total_time = self.timer.reset()
|
| 164 |
+
episode_frame = episode_step * self.cfg.action_repeat
|
| 165 |
+
with self.logger.log_and_dump_ctx(self.global_frame,
|
| 166 |
+
ty='train') as log:
|
| 167 |
+
log('fps', episode_frame / elapsed_time)
|
| 168 |
+
log('total_time', total_time)
|
| 169 |
+
log('episode_reward', episode_reward)
|
| 170 |
+
log('episode_length', episode_frame)
|
| 171 |
+
log('episode', self.global_episode)
|
| 172 |
+
log('buffer_size', len(self.replay_storage))
|
| 173 |
+
log('step', self.global_step)
|
| 174 |
+
if should_save_model(self.global_step):
|
| 175 |
+
# save last model
|
| 176 |
+
self.save_last_model()
|
| 177 |
+
|
| 178 |
+
# reset env
|
| 179 |
+
time_step, dreamer_obs = self.train_env.reset()
|
| 180 |
+
# Updating agent
|
| 181 |
+
agent_state = None # Resetting agent's latent state
|
| 182 |
+
meta = self.agent.init_meta()
|
| 183 |
+
data = dreamer_obs
|
| 184 |
+
self.replay_storage.add(data, meta)
|
| 185 |
+
episode_step = 0
|
| 186 |
+
episode_reward = 0
|
| 187 |
+
|
| 188 |
+
# try to evaluate
|
| 189 |
+
if eval_every_step(self.global_step):
|
| 190 |
+
if self.cfg.eval_modality == 'task':
|
| 191 |
+
self.eval()
|
| 192 |
+
if self.cfg.eval_modality == 'task_imag':
|
| 193 |
+
self.eval_imag_behavior()
|
| 194 |
+
if self.cfg.eval_modality == 'from_text':
|
| 195 |
+
self.logger.log('eval_total_time', self.timer.total_time(),
|
| 196 |
+
self.global_frame)
|
| 197 |
+
self.eval_from_text()
|
| 198 |
+
|
| 199 |
+
meta = self.agent.update_meta(meta, self.global_step, time_step)
|
| 200 |
+
# sample action
|
| 201 |
+
with torch.no_grad(), utils.eval_mode(self.agent):
|
| 202 |
+
if seed_until_step(self.global_step):
|
| 203 |
+
action = self.train_env.act_space['action'].sample()
|
| 204 |
+
if getattr(self.cfg, 'discrete_actions', False):
|
| 205 |
+
action = (action == np.max(action)).astype(np.float32) # one-hot
|
| 206 |
+
else:
|
| 207 |
+
action, agent_state = self.agent.act(dreamer_obs, # time_step.observation
|
| 208 |
+
meta,
|
| 209 |
+
self.global_step,
|
| 210 |
+
eval_mode=False,
|
| 211 |
+
state=agent_state)
|
| 212 |
+
|
| 213 |
+
# try to update the agent
|
| 214 |
+
if not seed_until_step(self.global_step):
|
| 215 |
+
if should_train_step(self.global_step):
|
| 216 |
+
# prof.step()
|
| 217 |
+
# Sampling data
|
| 218 |
+
batch_data = next(self.replay_iter)
|
| 219 |
+
if hasattr(self.agent, ' update_wm'):
|
| 220 |
+
state, outputs, metrics = self.agent.update_wm(batch_data, self.global_step)
|
| 221 |
+
if hasattr(self.agent, "update_acting_behavior"):
|
| 222 |
+
metrics = self.agent.update_acting_behavior(state=state, outputs=outputs, metrics=metrics, data=batch_data)[1]
|
| 223 |
+
if hasattr(self.agent, "update_imag_behavior"):
|
| 224 |
+
metrics.update(self.agent.update_imag_behavior(state=state, outputs=outputs, metrics=metrics, seq_data=batch_data,)[1])
|
| 225 |
+
else:
|
| 226 |
+
outputs, metrics = self.agent.update(batch_data, self.global_step)
|
| 227 |
+
|
| 228 |
+
if should_log_scalars(self.global_step):
|
| 229 |
+
self.logger.log_metrics(metrics, self.global_frame, ty='train')
|
| 230 |
+
if self.global_step > 0 and should_log_visual(self.global_step):
|
| 231 |
+
if hasattr(self.agent, 'report'):
|
| 232 |
+
with torch.no_grad(), utils.eval_mode(self.agent):
|
| 233 |
+
videos = self.agent.report(next(self.replay_iter))
|
| 234 |
+
self.logger.log_visual(videos, self.global_frame)
|
| 235 |
+
|
| 236 |
+
# take env step
|
| 237 |
+
time_step, dreamer_obs = self.train_env.step(action)
|
| 238 |
+
episode_reward += time_step.reward
|
| 239 |
+
data = dreamer_obs
|
| 240 |
+
if time_step.last():
|
| 241 |
+
if getattr(self.train_env, "accumulate", False):
|
| 242 |
+
assert not self.replay_storage._ongoing
|
| 243 |
+
# NOTE: this is ok as it comes right after adding to the repl
|
| 244 |
+
accumulated_data, accumulated_key = self.train_env.process_accumulate()
|
| 245 |
+
data[accumulated_key] = accumulated_data[-1]
|
| 246 |
+
self.replay_storage._ongoing_eps[0][accumulated_key][-len(accumulated_data[:-1]):] = accumulated_data[:-1]
|
| 247 |
+
self.replay_storage.add(data, meta)
|
| 248 |
+
episode_step += 1
|
| 249 |
+
self._global_step += 1
|
| 250 |
+
|
| 251 |
+
@utils.retry
|
| 252 |
+
def save_snapshot(self):
|
| 253 |
+
snapshot = self.get_snapshot_dir() / f'snapshot_{self.global_frame}.pt'
|
| 254 |
+
keys_to_save = ['agent', '_global_step', '_global_episode']
|
| 255 |
+
payload = {k: self.__dict__[k] for k in keys_to_save}
|
| 256 |
+
with snapshot.open('wb') as f:
|
| 257 |
+
torch.save(payload, f)
|
| 258 |
+
|
| 259 |
+
def setup_wandb(self):
|
| 260 |
+
cfg = self.cfg
|
| 261 |
+
exp_name = '_'.join([
|
| 262 |
+
cfg.experiment, cfg.agent.name, cfg.task, cfg.obs_type,
|
| 263 |
+
str(cfg.seed)
|
| 264 |
+
])
|
| 265 |
+
wandb.init(project=cfg.project_name, group=cfg.agent.name, name=exp_name)
|
| 266 |
+
flat_cfg = utils.flatten_dict(cfg)
|
| 267 |
+
wandb.config.update(flat_cfg)
|
| 268 |
+
self.wandb_run_id = wandb.run.id
|
| 269 |
+
|
| 270 |
+
@utils.retry
|
| 271 |
+
def save_last_model(self):
|
| 272 |
+
snapshot = self.root_dir / 'last_snapshot.pt'
|
| 273 |
+
if snapshot.is_file():
|
| 274 |
+
temp = Path(str(snapshot).replace("last_snapshot.pt", "second_last_snapshot.pt"))
|
| 275 |
+
os.replace(snapshot, temp)
|
| 276 |
+
keys_to_save = ['agent', '_global_step', '_global_episode']
|
| 277 |
+
if self.cfg.use_wandb:
|
| 278 |
+
keys_to_save.append('wandb_run_id')
|
| 279 |
+
payload = {k: self.__dict__[k] for k in keys_to_save}
|
| 280 |
+
with snapshot.open('wb') as f:
|
| 281 |
+
torch.save(payload, f)
|
| 282 |
+
|
| 283 |
+
def load_snapshot(self, snapshot_dir):
|
| 284 |
+
try:
|
| 285 |
+
snapshot = snapshot_dir / 'last_snapshot.pt'
|
| 286 |
+
with snapshot.open('rb') as f:
|
| 287 |
+
payload = torch.load(f)
|
| 288 |
+
except:
|
| 289 |
+
snapshot = snapshot_dir / 'second_last_snapshot.pt'
|
| 290 |
+
with snapshot.open('rb') as f:
|
| 291 |
+
payload = torch.load(f)
|
| 292 |
+
for k,v in payload.items():
|
| 293 |
+
setattr(self, k, v)
|
| 294 |
+
if k == 'wandb_run_id':
|
| 295 |
+
assert wandb.run is None
|
| 296 |
+
cfg = self.cfg
|
| 297 |
+
exp_name = '_'.join([
|
| 298 |
+
cfg.experiment, cfg.agent.name, cfg.task, cfg.obs_type,
|
| 299 |
+
str(cfg.seed)
|
| 300 |
+
])
|
| 301 |
+
wandb.init(project=cfg.project_name, group=cfg.agent.name, name=exp_name, id=v, resume="must")
|
| 302 |
+
|
| 303 |
+
def get_snapshot_dir(self):
|
| 304 |
+
snap_dir = self.cfg.snapshot_dir
|
| 305 |
+
snapshot_dir = self.workdir / Path(snap_dir)
|
| 306 |
+
snapshot_dir.mkdir(exist_ok=True, parents=True)
|
| 307 |
+
return snapshot_dir
|
| 308 |
+
|
| 309 |
+
@hydra.main(config_path='.', config_name='collect_data')
|
| 310 |
+
def main(cfg):
|
| 311 |
+
from collect_data import Workspace as W
|
| 312 |
+
root_dir = Path.cwd()
|
| 313 |
+
cfg.workdir = str(root_dir)
|
| 314 |
+
workspace = W(cfg)
|
| 315 |
+
workspace.root_dir = root_dir
|
| 316 |
+
snapshot = workspace.root_dir / 'last_snapshot.pt'
|
| 317 |
+
if snapshot.exists():
|
| 318 |
+
print(f'resuming: {snapshot}')
|
| 319 |
+
workspace.load_snapshot(workspace.root_dir)
|
| 320 |
+
if cfg.use_wandb and wandb.run is None:
|
| 321 |
+
# otherwise it was resumed
|
| 322 |
+
workspace.setup_wandb()
|
| 323 |
+
workspace.train()
|
| 324 |
+
|
| 325 |
+
if __name__ == '__main__':
|
| 326 |
+
main()
|
collect_data.yaml
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
defaults:
|
| 2 |
+
- agent: dreamer
|
| 3 |
+
- conf/env: dmc_pixels
|
| 4 |
+
- conf/defaults: dreamer_v3
|
| 5 |
+
- override hydra/launcher: submitit_local
|
| 6 |
+
|
| 7 |
+
# mode
|
| 8 |
+
label: default
|
| 9 |
+
# task settings
|
| 10 |
+
task: stickman_walk
|
| 11 |
+
# train settings
|
| 12 |
+
num_train_frames: 2000010
|
| 13 |
+
num_seed_frames: 4000
|
| 14 |
+
# eval
|
| 15 |
+
eval_every_frames: 100000
|
| 16 |
+
eval_modality: null
|
| 17 |
+
num_eval_episodes: 3
|
| 18 |
+
# snapshot
|
| 19 |
+
snapshot_dir: ../../../trained_models/${obs_type}/${task}/${agent.name}/${seed}
|
| 20 |
+
save_every_frames: 10_000
|
| 21 |
+
# misc
|
| 22 |
+
seed: 1
|
| 23 |
+
device: cuda:0
|
| 24 |
+
use_tb: true
|
| 25 |
+
use_wandb: true
|
| 26 |
+
|
| 27 |
+
# Clip stuff
|
| 28 |
+
viclip_encode: false
|
| 29 |
+
viclip_model: internvideo2
|
| 30 |
+
clip_hd_rendering: false
|
| 31 |
+
|
| 32 |
+
# experiment
|
| 33 |
+
experiment: data
|
| 34 |
+
project_name: genrl
|
| 35 |
+
|
| 36 |
+
# log settings
|
| 37 |
+
log_every_frames: 1000
|
| 38 |
+
visual_every_frames: 100000000 # edit for debug
|
| 39 |
+
workdir: ???
|
| 40 |
+
|
| 41 |
+
hydra:
|
| 42 |
+
run:
|
| 43 |
+
dir: ./exp_local/${now:%Y.%m.%d}/${now:%H%M%S}_${agent.name}
|
| 44 |
+
sweep:
|
| 45 |
+
dir: ./exp_sweep/${now:%Y.%m.%d}/${now:%H%M}_${agent.name}_${experiment}
|
| 46 |
+
subdir: ${hydra.job.num}
|
| 47 |
+
launcher:
|
| 48 |
+
timeout_min: 4300
|
| 49 |
+
cpus_per_task: 10
|
| 50 |
+
gpus_per_node: 1
|
| 51 |
+
tasks_per_node: 1
|
| 52 |
+
mem_gb: 160
|
| 53 |
+
nodes: 1
|
| 54 |
+
submitit_folder: ./exp_sweep/${now:%Y.%m.%d}/${now:%H%M}_${agent.name}_${experiment}/.slurm
|
conf/defaults/dreamer_v2.yaml
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
img_size: 64
|
| 3 |
+
|
| 4 |
+
# Dreamer defaults
|
| 5 |
+
rssm: {ensemble: 1, hidden: 512, deter: 512, stoch: 32, discrete: 32, norm: none, std_act: softplus, min_std: 0.1, single_obs_posterior: false, } # act: elu,
|
| 6 |
+
discount_head: {layers: 4, units: 512, norm: none, dist: binary} # act: elu
|
| 7 |
+
reward_head: {layers: 4, units: 512, norm: none, dist: mse} # act: elu
|
| 8 |
+
kl: {free: 1.0, forward: False, balance: 0.8, free_avg: False, }
|
| 9 |
+
loss_scales: {kl: 1.0, reward: 1.0, discount: 1.0, proprio: 1.0}
|
| 10 |
+
model_opt: {opt: adam, lr: 3e-4, eps: 1e-5, clip: 1000, wd: 1e-6}
|
| 11 |
+
replay: {capacity: 2e6, ongoing: False, minlen: 50, maxlen: 50, prioritize_ends: False}
|
| 12 |
+
decoder_inputs: feat
|
| 13 |
+
image_dist: normal_unit_std
|
| 14 |
+
|
| 15 |
+
actor: {layers: 4, units: 512, norm: none, dist: trunc_normal, min_std: 0.1 } # act: elu
|
| 16 |
+
critic: {layers: 4, units: 512, norm: none, dist: mse} # act: elu,
|
| 17 |
+
actor_opt: {opt: adam, lr: 8e-5, eps: 1e-5, clip: 100, wd: 1e-6}
|
| 18 |
+
critic_opt: {opt: adam, lr: 8e-5, eps: 1e-5, clip: 100, wd: 1e-6}
|
| 19 |
+
discount: 0.99
|
| 20 |
+
discount_lambda: 0.95
|
| 21 |
+
slow_target: True
|
| 22 |
+
slow_target_update: 100
|
| 23 |
+
slow_target_fraction: 1
|
| 24 |
+
slow_baseline: True
|
| 25 |
+
reward_ema: False
|
| 26 |
+
|
| 27 |
+
acting_reward_fn: env_reward
|
| 28 |
+
clip_rewards: identity
|
| 29 |
+
|
| 30 |
+
batch_size: 50
|
| 31 |
+
batch_length: 50
|
| 32 |
+
imag_horizon: 15
|
| 33 |
+
eval_state_mean: False
|
| 34 |
+
|
| 35 |
+
precision: 16
|
| 36 |
+
train_every_actions: 10
|
| 37 |
+
only_random_actions: False
|
| 38 |
+
#
|
conf/defaults/dreamer_v3.yaml
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
img_size: 64
|
| 3 |
+
|
| 4 |
+
# Dreamer defaults
|
| 5 |
+
rssm: {ensemble: 1, hidden: 512, deter: 512, stoch: 32, discrete: 32, norm: layer, std_act: softplus, min_std: 0.1, single_obs_posterior: false, } # act: elu,
|
| 6 |
+
discount_head: {layers: 4, units: 512, norm: layer, dist: binary} # act: elu
|
| 7 |
+
reward_head: {layers: 4, units: 512, norm: layer, dist: twohot} # act: elu
|
| 8 |
+
kl: { free: 1.0, forward: False, balance: 0.85, free_avg: False,}
|
| 9 |
+
loss_scales: {kl: 0.6, reward: 1.0, discount: 1.0, proprio: 1.0}
|
| 10 |
+
model_opt: {opt: adam, lr: 1e-4, eps: 1e-8, clip: 1000, wd: 1e-6}
|
| 11 |
+
replay: {capacity: 2e6, ongoing: False, minlen: 50, maxlen: 50, prioritize_ends: False}
|
| 12 |
+
decoder_inputs: feat
|
| 13 |
+
image_dist: mse
|
| 14 |
+
# Actor Critic
|
| 15 |
+
actor: {layers: 4, units: 512, norm: layer, dist: normal, min_std: 0.1 } # act: elu
|
| 16 |
+
critic: {layers: 4, units: 512, norm: layer, dist: twohot } # act: elu,
|
| 17 |
+
actor_opt: {opt: adam, lr: 3e-5, eps: 1e-5, clip: 100, wd: 1e-6}
|
| 18 |
+
critic_opt: {opt: adam, lr: 3e-5, eps: 1e-5, clip: 100, wd: 1e-6}
|
| 19 |
+
discount: 0.99
|
| 20 |
+
discount_lambda: 0.95
|
| 21 |
+
slow_target: True
|
| 22 |
+
slow_target_update: 100
|
| 23 |
+
slow_target_fraction: 1
|
| 24 |
+
slow_baseline: True
|
| 25 |
+
reward_ema: True
|
| 26 |
+
|
| 27 |
+
acting_reward_fn: env_reward
|
| 28 |
+
clip_rewards: identity
|
| 29 |
+
|
| 30 |
+
batch_size: 50
|
| 31 |
+
batch_length: 50
|
| 32 |
+
imag_horizon: 15
|
| 33 |
+
eval_state_mean: False
|
| 34 |
+
|
| 35 |
+
precision: 16
|
| 36 |
+
train_every_actions: 10
|
| 37 |
+
only_random_actions: False
|
| 38 |
+
#
|
conf/defaults/genrl.yaml
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
img_size: 64
|
| 3 |
+
|
| 4 |
+
# Dreamer defaults
|
| 5 |
+
rssm: {ensemble: 1, hidden: 1024, deter: 1024, stoch: 32, discrete: 32, norm: layer, std_act: softplus, min_std: 0.1, single_obs_posterior: true, } # act: elu,
|
| 6 |
+
discount_head: {layers: 4, units: 512, norm: none, dist: binary} # act: elu
|
| 7 |
+
reward_head: {layers: 4, units: 1024, norm: layer, dist: twohot} # act: elu
|
| 8 |
+
kl: { free: 1.0, forward: False, balance: 0.85, free_avg: False, }
|
| 9 |
+
loss_scales: {kl: 0.6, reward: 1.0, discount: 1.0, proprio: 1.0}
|
| 10 |
+
model_opt: {opt: adam, lr: 1e-4, eps: 1e-8, clip: 1000, wd: 1e-6}
|
| 11 |
+
replay: {capacity: 20e6, ongoing: False, minlen: 48, maxlen: 48, prioritize_ends: False}
|
| 12 |
+
decoder_inputs: stoch
|
| 13 |
+
image_dist: mse
|
| 14 |
+
# Actor Critic
|
| 15 |
+
actor: {layers: 4, units: 1024, norm: layer, dist: normal, min_std: 0.1 } # act: elu
|
| 16 |
+
critic: {layers: 4, units: 1024, norm: layer, dist: twohot } # act: elu,
|
| 17 |
+
actor_opt: {opt: adam, lr: 3e-5, eps: 1e-5, clip: 100, wd: 1e-6}
|
| 18 |
+
critic_opt: {opt: adam, lr: 3e-5, eps: 1e-5, clip: 100, wd: 1e-6}
|
| 19 |
+
discount: 0.99
|
| 20 |
+
discount_lambda: 0.95
|
| 21 |
+
slow_target: True
|
| 22 |
+
slow_target_update: 100
|
| 23 |
+
slow_target_fraction: 1
|
| 24 |
+
slow_baseline: True
|
| 25 |
+
reward_ema: True
|
| 26 |
+
|
| 27 |
+
acting_reward_fn: env_reward
|
| 28 |
+
clip_rewards: identity
|
| 29 |
+
|
| 30 |
+
batch_size: 48
|
| 31 |
+
batch_length: 48
|
| 32 |
+
imag_horizon: 16
|
| 33 |
+
eval_state_mean: False
|
| 34 |
+
|
| 35 |
+
precision: 16
|
| 36 |
+
train_every_actions: 10
|
| 37 |
+
only_random_actions: False
|
conf/env/dmc_pixels.yaml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
obs_type: pixels
|
| 3 |
+
action_repeat: 2
|
| 4 |
+
encoder: {mlp_keys: '$^', cnn_keys: 'observation', norm: layer, cnn_depth: 48, cnn_kernels: [4, 4, 4, 4], mlp_layers: [400, 400, 400, 400]} # act: elu
|
| 5 |
+
decoder: {mlp_keys: '$^', cnn_keys: 'observation', norm: layer, cnn_depth: 48, cnn_kernels: [5, 5, 6, 6], mlp_layers: [400, 400, 400, 400], } # act: elu
|
| 6 |
+
pred_discount: False
|
| 7 |
+
imag_actor_grad: dynamics
|
| 8 |
+
actor_grad: dynamics
|
conf/train_mode/train_behavior.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
num_train_frames: 500_010
|
| 2 |
+
batch_size: 32
|
| 3 |
+
batch_length: 32
|
| 4 |
+
agent.imag_reward_fn: video_text_reward
|
| 5 |
+
eval_modality: task_imag
|
conf/train_mode/train_model.yaml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
num_train_frames: 5_000_010
|
| 2 |
+
visual_every_frames: 250_000
|
| 3 |
+
train_world_model: True
|
| 4 |
+
train_connector: True
|
| 5 |
+
reset_world_model: True
|
| 6 |
+
reset_connector: True
|
demo/demo_test.py
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
VIDEO_PATH = Path(os.path.abspath('')) / 'assets' / 'video_samples'
|
| 4 |
+
|
| 5 |
+
class Text2Video():
|
| 6 |
+
def __init__(self, result_dir='./tmp/') -> None:
|
| 7 |
+
pass
|
| 8 |
+
|
| 9 |
+
def get_prompt(self, input_text, steps=50, cfg_scale=15.0, eta=1.0, fps=16):
|
| 10 |
+
|
| 11 |
+
return str(VIDEO_PATH / 'headstand.mp4')
|
| 12 |
+
|
| 13 |
+
class Video2Video:
|
| 14 |
+
def __init__(self, result_dir='./tmp/') -> None:
|
| 15 |
+
pass
|
| 16 |
+
|
| 17 |
+
def get_image(self, input_image, input_prompt, i2v_steps=50, i2v_cfg_scale=15.0, i2v_eta=1.0, i2v_fps=16):
|
| 18 |
+
|
| 19 |
+
return str(VIDEO_PATH / 'dancing.mp4')
|
| 20 |
+
|
| 21 |
+
if __name__ == '__main__':
|
| 22 |
+
t2v = Text2Video()
|
| 23 |
+
print(t2v.get_prompt('test'))
|
demo/t2v.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
sys.path.append(str(Path(os.path.abspath(''))))
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import numpy as np
|
| 8 |
+
from tools.genrl_utils import ViCLIPGlobalInstance
|
| 9 |
+
|
| 10 |
+
import time
|
| 11 |
+
import torchvision
|
| 12 |
+
from huggingface_hub import hf_hub_download
|
| 13 |
+
|
| 14 |
+
def save_videos(batch_tensors, savedir, filenames, fps=10):
|
| 15 |
+
# b,samples,c,t,h,w
|
| 16 |
+
n_samples = batch_tensors.shape[1]
|
| 17 |
+
for idx, vid_tensor in enumerate(batch_tensors):
|
| 18 |
+
video = vid_tensor.detach().cpu()
|
| 19 |
+
video = torch.clamp(video.float(), 0., 1.)
|
| 20 |
+
video = video.permute(1, 0, 2, 3, 4) # t,n,c,h,w
|
| 21 |
+
frame_grids = [torchvision.utils.make_grid(framesheet, nrow=int(n_samples)) for framesheet in video] #[3, 1*h, n*w]
|
| 22 |
+
grid = torch.stack(frame_grids, dim=0) # stack in temporal dim [t, 3, n*h, w]
|
| 23 |
+
grid = (grid * 255).to(torch.uint8).permute(0, 2, 3, 1)
|
| 24 |
+
savepath = os.path.join(savedir, f"{filenames[idx]}.mp4")
|
| 25 |
+
torchvision.io.write_video(savepath, grid, fps=fps, video_codec='h264', options={'crf': '10'})
|
| 26 |
+
|
| 27 |
+
class Text2Video():
|
| 28 |
+
def __init__(self,result_dir='./tmp/',gpu_num=1) -> None:
|
| 29 |
+
model_folder = str(Path(os.path.abspath('')) / 'models')
|
| 30 |
+
model_filename = 'genrl_stickman_500k_2.pt'
|
| 31 |
+
|
| 32 |
+
if not os.path.isfile(os.path.join(model_folder, model_filename)):
|
| 33 |
+
self.download_model(model_folder, model_filename)
|
| 34 |
+
if not os.path.isfile(os.path.join(model_folder, 'InternVideo2-stage2_1b-224p-f4.pt')):
|
| 35 |
+
self.download_internvideo2(model_folder)
|
| 36 |
+
self.agent = torch.load(os.path.join(model_folder, model_filename))
|
| 37 |
+
model_name = 'internvideo2'
|
| 38 |
+
|
| 39 |
+
# Get ViCLIP
|
| 40 |
+
viclip_global_instance = ViCLIPGlobalInstance(model_name)
|
| 41 |
+
if not viclip_global_instance._instantiated:
|
| 42 |
+
print("Instantiating InternVideo2")
|
| 43 |
+
viclip_global_instance.instantiate()
|
| 44 |
+
self.clip = viclip_global_instance.viclip
|
| 45 |
+
self.tokenizer = viclip_global_instance.viclip_tokenizer
|
| 46 |
+
|
| 47 |
+
self.result_dir = result_dir
|
| 48 |
+
if not os.path.exists(self.result_dir):
|
| 49 |
+
os.mkdir(self.result_dir)
|
| 50 |
+
|
| 51 |
+
def get_prompt(self, prompt, duration):
|
| 52 |
+
torch.cuda.empty_cache()
|
| 53 |
+
print('start:', prompt, time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
|
| 54 |
+
start = time.time()
|
| 55 |
+
|
| 56 |
+
prompt_str = prompt.replace("/", "_slash_") if "/" in prompt else prompt
|
| 57 |
+
prompt_str = prompt_str.replace(" ", "_") if " " in prompt else prompt_str
|
| 58 |
+
|
| 59 |
+
labels_list = [prompt_str]
|
| 60 |
+
with torch.no_grad():
|
| 61 |
+
wm = world_model = self.agent.wm
|
| 62 |
+
connector = self.agent.wm.connector
|
| 63 |
+
decoder = world_model.heads['decoder']
|
| 64 |
+
n_frames = connector.n_frames
|
| 65 |
+
|
| 66 |
+
# Get text(video) embed
|
| 67 |
+
text_feat = []
|
| 68 |
+
for text in labels_list:
|
| 69 |
+
with torch.no_grad():
|
| 70 |
+
text_feat.append(self.clip.get_txt_feat(text,))
|
| 71 |
+
text_feat = torch.stack(text_feat, dim=0).to(self.clip.device)
|
| 72 |
+
|
| 73 |
+
video_embed = text_feat
|
| 74 |
+
|
| 75 |
+
B = video_embed.shape[0]
|
| 76 |
+
T = 1
|
| 77 |
+
|
| 78 |
+
# Get actions
|
| 79 |
+
video_embed = video_embed.repeat(1, duration, 1)
|
| 80 |
+
with torch.no_grad():
|
| 81 |
+
# Imagine
|
| 82 |
+
prior = wm.connector.video_imagine(video_embed, None, sample=False, reset_every_n_frames=False, denoise=True)
|
| 83 |
+
# Decode
|
| 84 |
+
prior_recon = decoder(wm.decoder_input_fn(prior))['observation'].mean + 0.5
|
| 85 |
+
|
| 86 |
+
save_videos(prior_recon.unsqueeze(0), self.result_dir, filenames=[prompt_str], fps=15)
|
| 87 |
+
print(f"Saved in {prompt_str}.mp4. Time used: {(time.time() - start):.2f} seconds")
|
| 88 |
+
return os.path.join(self.result_dir, f"{prompt_str}.mp4")
|
| 89 |
+
|
| 90 |
+
def download_model(self, model_folder, model_filename):
|
| 91 |
+
REPO_ID = 'mazpie/genrl_models'
|
| 92 |
+
filename_list = [model_filename]
|
| 93 |
+
if not os.path.exists(model_folder):
|
| 94 |
+
os.makedirs(model_folder)
|
| 95 |
+
for filename in filename_list:
|
| 96 |
+
local_file = os.path.join(model_folder, filename)
|
| 97 |
+
|
| 98 |
+
if not os.path.exists(local_file):
|
| 99 |
+
hf_hub_download(repo_id=REPO_ID, filename=filename, local_dir=model_folder, local_dir_use_symlinks=False)
|
| 100 |
+
|
| 101 |
+
def download_internvideo2(self, model_folder):
|
| 102 |
+
REPO_ID = 'OpenGVLab/InternVideo2-Stage2_1B-224p-f4'
|
| 103 |
+
filename_list = ['InternVideo2-stage2_1b-224p-f4.pt']
|
| 104 |
+
if not os.path.exists(model_folder):
|
| 105 |
+
os.makedirs(model_folder)
|
| 106 |
+
for filename in filename_list:
|
| 107 |
+
local_file = os.path.join(model_folder, filename)
|
| 108 |
+
|
| 109 |
+
if not os.path.exists(local_file):
|
| 110 |
+
hf_hub_download(repo_id=REPO_ID, filename=filename, local_dir=model_folder, local_dir_use_symlinks=False)
|
| 111 |
+
|
| 112 |
+
if __name__ == '__main__':
|
| 113 |
+
t2v = Text2Video()
|
| 114 |
+
video_path = t2v.get_prompt('a black swan swims on the pond', 8)
|
| 115 |
+
print('done', video_path)
|
envs/__init__.py
ADDED
|
File without changes
|
envs/custom_dmc_tasks/__init__.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from . import cheetah
|
| 2 |
+
from . import walker
|
| 3 |
+
from . import quadruped
|
| 4 |
+
from . import jaco
|
| 5 |
+
from . import stickman
|
| 6 |
+
from dm_control import suite
|
| 7 |
+
|
| 8 |
+
suite._DOMAINS['stickman'] = stickman
|
| 9 |
+
suite.ALL_TASKS = suite.ALL_TASKS + suite._get_tasks('custom')
|
| 10 |
+
suite.TASKS_BY_DOMAIN = suite._get_tasks_by_domain(suite.ALL_TASKS)
|
| 11 |
+
|
| 12 |
+
def make_jaco(task, obs_type, seed, img_size, ):
|
| 13 |
+
return jaco.make(task, obs_type, seed, img_size, )
|
envs/custom_dmc_tasks/cheetah.py
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2017 The dm_control Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
# ============================================================================
|
| 15 |
+
"""Cheetah Domain."""
|
| 16 |
+
|
| 17 |
+
import collections
|
| 18 |
+
import os
|
| 19 |
+
|
| 20 |
+
from dm_control.suite import cheetah
|
| 21 |
+
from dm_control import mujoco
|
| 22 |
+
from dm_control.rl import control
|
| 23 |
+
from dm_control.suite import base
|
| 24 |
+
from dm_control.suite import common
|
| 25 |
+
from dm_control.utils import containers
|
| 26 |
+
from dm_control.utils import rewards
|
| 27 |
+
from dm_control.utils import io as resources
|
| 28 |
+
|
| 29 |
+
# How long the simulation will run, in seconds.
|
| 30 |
+
_DEFAULT_TIME_LIMIT = 10
|
| 31 |
+
|
| 32 |
+
_DOWN_HEIGHT = 0.15
|
| 33 |
+
_HIGH_HEIGHT = 1.00
|
| 34 |
+
_MID_HEIGHT = 0.45
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
# Running speed above which reward is 1.
|
| 38 |
+
_RUN_SPEED = 10
|
| 39 |
+
_SPIN_SPEED = 5
|
| 40 |
+
|
| 41 |
+
def make(task,
|
| 42 |
+
task_kwargs=None,
|
| 43 |
+
environment_kwargs=None,
|
| 44 |
+
visualize_reward=False):
|
| 45 |
+
task_kwargs = task_kwargs or {}
|
| 46 |
+
if environment_kwargs is not None:
|
| 47 |
+
task_kwargs = task_kwargs.copy()
|
| 48 |
+
task_kwargs['environment_kwargs'] = environment_kwargs
|
| 49 |
+
env = SUITE[task](**task_kwargs)
|
| 50 |
+
env.task.visualize_reward = visualize_reward
|
| 51 |
+
return env
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def get_model_and_assets():
|
| 55 |
+
"""Returns a tuple containing the model XML string and a dict of assets."""
|
| 56 |
+
root_dir = os.path.dirname(os.path.dirname(__file__))
|
| 57 |
+
xml = resources.GetResource(
|
| 58 |
+
os.path.join(root_dir, 'custom_dmc_tasks', 'cheetah.xml'))
|
| 59 |
+
return xml, common.ASSETS
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
@cheetah.SUITE.add('custom')
|
| 63 |
+
def flipping(time_limit=_DEFAULT_TIME_LIMIT,
|
| 64 |
+
random=None,
|
| 65 |
+
environment_kwargs=None):
|
| 66 |
+
"""Returns the run task."""
|
| 67 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 68 |
+
task = Cheetah(forward=False, flip=False, random=random, goal='flipping')
|
| 69 |
+
environment_kwargs = environment_kwargs or {}
|
| 70 |
+
return control.Environment(physics,
|
| 71 |
+
task,
|
| 72 |
+
time_limit=time_limit,
|
| 73 |
+
**environment_kwargs)
|
| 74 |
+
|
| 75 |
+
@cheetah.SUITE.add('custom')
|
| 76 |
+
def standing(time_limit=_DEFAULT_TIME_LIMIT,
|
| 77 |
+
random=None,
|
| 78 |
+
environment_kwargs=None):
|
| 79 |
+
"""Returns the run task."""
|
| 80 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 81 |
+
task = Cheetah(forward=False, flip=False, random=random, goal='standing')
|
| 82 |
+
environment_kwargs = environment_kwargs or {}
|
| 83 |
+
return control.Environment(physics,
|
| 84 |
+
task,
|
| 85 |
+
time_limit=time_limit,
|
| 86 |
+
**environment_kwargs)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
@cheetah.SUITE.add('custom')
|
| 90 |
+
def lying_down(time_limit=_DEFAULT_TIME_LIMIT,
|
| 91 |
+
random=None,
|
| 92 |
+
environment_kwargs=None):
|
| 93 |
+
"""Returns the run task."""
|
| 94 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 95 |
+
task = Cheetah(forward=False, flip=False, random=random, goal='lying_down')
|
| 96 |
+
environment_kwargs = environment_kwargs or {}
|
| 97 |
+
return control.Environment(physics,
|
| 98 |
+
task,
|
| 99 |
+
time_limit=time_limit,
|
| 100 |
+
**environment_kwargs)
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
@cheetah.SUITE.add('custom')
|
| 104 |
+
def run_backward(time_limit=_DEFAULT_TIME_LIMIT,
|
| 105 |
+
random=None,
|
| 106 |
+
environment_kwargs=None):
|
| 107 |
+
"""Returns the run task."""
|
| 108 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 109 |
+
task = Cheetah(forward=False, flip=False, random=random, goal='run_backward')
|
| 110 |
+
environment_kwargs = environment_kwargs or {}
|
| 111 |
+
return control.Environment(physics,
|
| 112 |
+
task,
|
| 113 |
+
time_limit=time_limit,
|
| 114 |
+
**environment_kwargs)
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
@cheetah.SUITE.add('custom')
|
| 118 |
+
def flip(time_limit=_DEFAULT_TIME_LIMIT,
|
| 119 |
+
random=None,
|
| 120 |
+
environment_kwargs=None):
|
| 121 |
+
"""Returns the run task."""
|
| 122 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 123 |
+
task = Cheetah(forward=True, flip=True, random=random, goal='flip')
|
| 124 |
+
environment_kwargs = environment_kwargs or {}
|
| 125 |
+
return control.Environment(physics,
|
| 126 |
+
task,
|
| 127 |
+
time_limit=time_limit,
|
| 128 |
+
**environment_kwargs)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
@cheetah.SUITE.add('custom')
|
| 132 |
+
def flip_backward(time_limit=_DEFAULT_TIME_LIMIT,
|
| 133 |
+
random=None,
|
| 134 |
+
environment_kwargs=None):
|
| 135 |
+
"""Returns the run task."""
|
| 136 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 137 |
+
task = Cheetah(forward=False, flip=True, random=random, goal='flip_backward')
|
| 138 |
+
environment_kwargs = environment_kwargs or {}
|
| 139 |
+
return control.Environment(physics,
|
| 140 |
+
task,
|
| 141 |
+
time_limit=time_limit,
|
| 142 |
+
**environment_kwargs)
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
class Physics(mujoco.Physics):
|
| 146 |
+
"""Physics simulation with additional features for the Cheetah domain."""
|
| 147 |
+
def speed(self):
|
| 148 |
+
"""Returns the horizontal speed of the Cheetah."""
|
| 149 |
+
return self.named.data.sensordata['torso_subtreelinvel'][0]
|
| 150 |
+
|
| 151 |
+
def angmomentum(self):
|
| 152 |
+
"""Returns the angular momentum of torso of the Cheetah about Y axis."""
|
| 153 |
+
return self.named.data.subtree_angmom['torso'][1]
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
class Cheetah(base.Task):
|
| 157 |
+
"""A `Task` to train a running Cheetah."""
|
| 158 |
+
def __init__(self, goal=None, forward=True, flip=False, random=None):
|
| 159 |
+
self._forward = 1 if forward else -1
|
| 160 |
+
self._flip = flip
|
| 161 |
+
self._goal = goal
|
| 162 |
+
super(Cheetah, self).__init__(random=random)
|
| 163 |
+
|
| 164 |
+
def initialize_episode(self, physics):
|
| 165 |
+
"""Sets the state of the environment at the start of each episode."""
|
| 166 |
+
# The indexing below assumes that all joints have a single DOF.
|
| 167 |
+
assert physics.model.nq == physics.model.njnt
|
| 168 |
+
is_limited = physics.model.jnt_limited == 1
|
| 169 |
+
lower, upper = physics.model.jnt_range[is_limited].T
|
| 170 |
+
physics.data.qpos[is_limited] = self.random.uniform(lower, upper)
|
| 171 |
+
|
| 172 |
+
# Stabilize the model before the actual simulation.
|
| 173 |
+
for _ in range(200):
|
| 174 |
+
physics.step()
|
| 175 |
+
|
| 176 |
+
physics.data.time = 0
|
| 177 |
+
self._timeout_progress = 0
|
| 178 |
+
super().initialize_episode(physics)
|
| 179 |
+
|
| 180 |
+
def _get_lying_down_reward(self, physics):
|
| 181 |
+
torso = physics.named.data.xpos['torso', 'z']
|
| 182 |
+
|
| 183 |
+
torso_down = rewards.tolerance(torso,
|
| 184 |
+
bounds=(-float('inf'), _DOWN_HEIGHT),
|
| 185 |
+
margin=_DOWN_HEIGHT * 1.5,)
|
| 186 |
+
|
| 187 |
+
feet = physics.named.data.xpos['bfoot', 'z'] + physics.named.data.xpos['ffoot', 'z']
|
| 188 |
+
|
| 189 |
+
feet_up = rewards.tolerance(feet,
|
| 190 |
+
bounds=(_MID_HEIGHT, float('inf')),
|
| 191 |
+
margin=_MID_HEIGHT / 2,)
|
| 192 |
+
return (torso_down + feet_up) / 2
|
| 193 |
+
|
| 194 |
+
def _get_standing_reward(self, physics):
|
| 195 |
+
bfoot = physics.named.data.xpos['bfoot', 'z']
|
| 196 |
+
ffoot = physics.named.data.xpos['ffoot', 'z']
|
| 197 |
+
max_foot = bfoot if bfoot > ffoot else ffoot
|
| 198 |
+
min_foot = bfoot if bfoot <= ffoot else ffoot
|
| 199 |
+
|
| 200 |
+
low_foot_low = rewards.tolerance(min_foot,
|
| 201 |
+
bounds=(-float('inf'), _DOWN_HEIGHT),
|
| 202 |
+
margin=_DOWN_HEIGHT * 1.5,)
|
| 203 |
+
|
| 204 |
+
high_foot_high = rewards.tolerance(max_foot,
|
| 205 |
+
bounds=(_HIGH_HEIGHT, float('inf')),
|
| 206 |
+
margin=_HIGH_HEIGHT / 2,)
|
| 207 |
+
return high_foot_high * low_foot_low
|
| 208 |
+
|
| 209 |
+
def _get_flip_reward(self, physics):
|
| 210 |
+
return rewards.tolerance(self._forward * physics.angmomentum(),
|
| 211 |
+
bounds=(_SPIN_SPEED, float('inf')),
|
| 212 |
+
margin=_SPIN_SPEED,
|
| 213 |
+
value_at_margin=0,
|
| 214 |
+
sigmoid='linear')
|
| 215 |
+
|
| 216 |
+
def get_observation(self, physics):
|
| 217 |
+
"""Returns an observation of the state, ignoring horizontal position."""
|
| 218 |
+
obs = collections.OrderedDict()
|
| 219 |
+
# Ignores horizontal position to maintain translational invariance.
|
| 220 |
+
obs['position'] = physics.data.qpos[1:].copy()
|
| 221 |
+
obs['velocity'] = physics.velocity()
|
| 222 |
+
return obs
|
| 223 |
+
|
| 224 |
+
def get_reward(self, physics):
|
| 225 |
+
"""Returns a reward to the agent."""
|
| 226 |
+
if self._goal in ['run', 'flip', 'run_backward', 'flip_backward']:
|
| 227 |
+
if self._flip:
|
| 228 |
+
return self._get_flip_reward(physics)
|
| 229 |
+
else:
|
| 230 |
+
reward = rewards.tolerance(self._forward * physics.speed(),
|
| 231 |
+
bounds=(_RUN_SPEED, float('inf')),
|
| 232 |
+
margin=_RUN_SPEED,
|
| 233 |
+
value_at_margin=0,
|
| 234 |
+
sigmoid='linear')
|
| 235 |
+
return reward
|
| 236 |
+
elif self._goal == 'lying_down':
|
| 237 |
+
return self._get_lying_down_reward(physics)
|
| 238 |
+
elif self._goal == 'flipping':
|
| 239 |
+
self._forward = True
|
| 240 |
+
fwd_reward = self._get_flip_reward(physics)
|
| 241 |
+
self._forward = False
|
| 242 |
+
back_reward = self._get_flip_reward(physics)
|
| 243 |
+
return max(fwd_reward, back_reward)
|
| 244 |
+
elif self._goal == 'standing':
|
| 245 |
+
return self._get_standing_reward(physics)
|
| 246 |
+
else:
|
| 247 |
+
raise NotImplementedError(self._goal)
|
envs/custom_dmc_tasks/cheetah.xml
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<mujoco model="cheetah">
|
| 2 |
+
<include file="./common/skybox.xml"/>
|
| 3 |
+
<include file="./common/visual.xml"/>
|
| 4 |
+
<include file="./common/materials.xml"/>
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
<compiler settotalmass="14"/>
|
| 8 |
+
|
| 9 |
+
<default>
|
| 10 |
+
<default class="cheetah">
|
| 11 |
+
<joint limited="true" damping=".01" armature=".1" stiffness="8" type="hinge" axis="0 1 0"/>
|
| 12 |
+
<geom contype="1" conaffinity="1" condim="3" friction=".4 .1 .1" material="self"/>
|
| 13 |
+
</default>
|
| 14 |
+
<default class="free">
|
| 15 |
+
<joint limited="false" damping="0" armature="0" stiffness="0"/>
|
| 16 |
+
</default>
|
| 17 |
+
<motor ctrllimited="true" ctrlrange="-1 1"/>
|
| 18 |
+
</default>
|
| 19 |
+
|
| 20 |
+
<statistic center="0 0 .7" extent="2"/>
|
| 21 |
+
|
| 22 |
+
<option timestep="0.01"/>
|
| 23 |
+
|
| 24 |
+
<worldbody>
|
| 25 |
+
<geom name="ground" type="plane" conaffinity="1" pos="98 0 0" size="200 .8 .5" material="grid"/>
|
| 26 |
+
<body name="torso" pos="0 0 .7" childclass="cheetah">
|
| 27 |
+
<light name="light" pos="0 0 2" mode="trackcom"/>
|
| 28 |
+
<camera name="side" pos="0 -3 0" quat="0.707 0.707 0 0" mode="trackcom"/>
|
| 29 |
+
<camera name="back" pos="-1.8 -1.3 0.8" xyaxes="0.45 -0.9 0 0.3 0.15 0.94" mode="trackcom"/>
|
| 30 |
+
<joint name="rootx" type="slide" axis="1 0 0" class="free"/>
|
| 31 |
+
<joint name="rootz" type="slide" axis="0 0 1" class="free"/>
|
| 32 |
+
<joint name="rooty" type="hinge" axis="0 1 0" class="free"/>
|
| 33 |
+
<geom name="torso" type="capsule" fromto="-.5 0 0 .5 0 0" size="0.046"/>
|
| 34 |
+
<geom name="head" type="capsule" pos=".6 0 .1" euler="0 50 0" size="0.046 .15"/>
|
| 35 |
+
<body name="bthigh" pos="-.5 0 0">
|
| 36 |
+
<joint name="bthigh" range="-30 60" stiffness="240" damping="6"/>
|
| 37 |
+
<geom name="bthigh" type="capsule" pos=".1 0 -.13" euler="0 -218 0" size="0.046 .145"/>
|
| 38 |
+
<body name="bshin" pos=".16 0 -.25">
|
| 39 |
+
<joint name="bshin" range="-50 50" stiffness="180" damping="4.5"/>
|
| 40 |
+
<geom name="bshin" type="capsule" pos="-.14 0 -.07" euler="0 -116 0" size="0.046 .15"/>
|
| 41 |
+
<body name="bfoot" pos="-.28 0 -.14">
|
| 42 |
+
<joint name="bfoot" range="-230 50" stiffness="120" damping="3"/>
|
| 43 |
+
<geom name="bfoot" type="capsule" pos=".03 0 -.097" euler="0 -15 0" size="0.046 .094"/>
|
| 44 |
+
</body>
|
| 45 |
+
</body>
|
| 46 |
+
</body>
|
| 47 |
+
<body name="fthigh" pos=".5 0 0">
|
| 48 |
+
<joint name="fthigh" range="-57 .40" stiffness="180" damping="4.5"/>
|
| 49 |
+
<geom name="fthigh" type="capsule" pos="-.07 0 -.12" euler="0 30 0" size="0.046 .133"/>
|
| 50 |
+
<body name="fshin" pos="-.14 0 -.24">
|
| 51 |
+
<joint name="fshin" range="-70 50" stiffness="120" damping="3"/>
|
| 52 |
+
<geom name="fshin" type="capsule" pos=".065 0 -.09" euler="0 -34 0" size="0.046 .106"/>
|
| 53 |
+
<body name="ffoot" pos=".13 0 -.18">
|
| 54 |
+
<joint name="ffoot" range="-28 28" stiffness="60" damping="1.5"/>
|
| 55 |
+
<geom name="ffoot" type="capsule" pos=".045 0 -.07" euler="0 -34 0" size="0.046 .07"/>
|
| 56 |
+
</body>
|
| 57 |
+
</body>
|
| 58 |
+
</body>
|
| 59 |
+
</body>
|
| 60 |
+
</worldbody>
|
| 61 |
+
|
| 62 |
+
<sensor>
|
| 63 |
+
<subtreelinvel name="torso_subtreelinvel" body="torso"/>
|
| 64 |
+
</sensor>
|
| 65 |
+
|
| 66 |
+
<actuator>
|
| 67 |
+
<motor name="bthigh" joint="bthigh" gear="120" />
|
| 68 |
+
<motor name="bshin" joint="bshin" gear="90" />
|
| 69 |
+
<motor name="bfoot" joint="bfoot" gear="60" />
|
| 70 |
+
<motor name="fthigh" joint="fthigh" gear="90" />
|
| 71 |
+
<motor name="fshin" joint="fshin" gear="60" />
|
| 72 |
+
<motor name="ffoot" joint="ffoot" gear="30" />
|
| 73 |
+
</actuator>
|
| 74 |
+
</mujoco>
|
envs/custom_dmc_tasks/jaco.py
ADDED
|
@@ -0,0 +1,222 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2019 The dm_control Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
# ============================================================================
|
| 15 |
+
|
| 16 |
+
"""A task where the goal is to move the hand close to a target prop or site."""
|
| 17 |
+
|
| 18 |
+
import collections
|
| 19 |
+
|
| 20 |
+
from dm_control import composer
|
| 21 |
+
from dm_control.composer import initializers
|
| 22 |
+
from dm_control.composer.observation import observable
|
| 23 |
+
from dm_control.composer.variation import distributions
|
| 24 |
+
from dm_control.entities import props
|
| 25 |
+
from dm_control.manipulation.shared import arenas
|
| 26 |
+
from dm_control.manipulation.shared import cameras
|
| 27 |
+
from dm_control.manipulation.shared import constants
|
| 28 |
+
from dm_control.manipulation.shared import observations
|
| 29 |
+
from dm_control.manipulation.shared import registry
|
| 30 |
+
from dm_control.manipulation.shared import robots
|
| 31 |
+
from dm_control.manipulation.shared import tags
|
| 32 |
+
from dm_control.manipulation.shared import workspaces
|
| 33 |
+
from dm_control.utils import rewards
|
| 34 |
+
import numpy as np
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
_ReachWorkspace = collections.namedtuple(
|
| 38 |
+
'_ReachWorkspace', ['target_bbox', 'tcp_bbox', 'arm_offset'])
|
| 39 |
+
|
| 40 |
+
# Ensures that the props are not touching the table before settling.
|
| 41 |
+
_PROP_Z_OFFSET = 0.001
|
| 42 |
+
|
| 43 |
+
_DUPLO_WORKSPACE = _ReachWorkspace(
|
| 44 |
+
target_bbox=workspaces.BoundingBox(
|
| 45 |
+
lower=(-0.1, -0.1, _PROP_Z_OFFSET),
|
| 46 |
+
upper=(0.1, 0.1, _PROP_Z_OFFSET)),
|
| 47 |
+
tcp_bbox=workspaces.BoundingBox(
|
| 48 |
+
lower=(-0.1, -0.1, 0.2),
|
| 49 |
+
upper=(0.1, 0.1, 0.4)),
|
| 50 |
+
arm_offset=robots.ARM_OFFSET)
|
| 51 |
+
|
| 52 |
+
_SITE_WORKSPACE = _ReachWorkspace(
|
| 53 |
+
target_bbox=workspaces.BoundingBox(
|
| 54 |
+
lower=(-0.2, -0.2, 0.02),
|
| 55 |
+
upper=(0.2, 0.2, 0.4)),
|
| 56 |
+
tcp_bbox=workspaces.BoundingBox(
|
| 57 |
+
lower=(-0.2, -0.2, 0.02),
|
| 58 |
+
upper=(0.2, 0.2, 0.4)),
|
| 59 |
+
arm_offset=robots.ARM_OFFSET)
|
| 60 |
+
|
| 61 |
+
_TARGET_RADIUS = 0.05
|
| 62 |
+
_TIME_LIMIT = 10
|
| 63 |
+
|
| 64 |
+
TASKS = {
|
| 65 |
+
'reach_top_left': workspaces.BoundingBox(
|
| 66 |
+
lower=(-0.09, 0.09, _PROP_Z_OFFSET),
|
| 67 |
+
upper=(-0.09, 0.09, _PROP_Z_OFFSET)),
|
| 68 |
+
'reach_top_right': workspaces.BoundingBox(
|
| 69 |
+
lower=(0.09, 0.09, _PROP_Z_OFFSET),
|
| 70 |
+
upper=(0.09, 0.09, _PROP_Z_OFFSET)),
|
| 71 |
+
'reach_bottom_left': workspaces.BoundingBox(
|
| 72 |
+
lower=(-0.09, -0.09, _PROP_Z_OFFSET),
|
| 73 |
+
upper=(-0.09, -0.09, _PROP_Z_OFFSET)),
|
| 74 |
+
'reach_bottom_right': workspaces.BoundingBox(
|
| 75 |
+
lower=(0.09, -0.09, _PROP_Z_OFFSET),
|
| 76 |
+
upper=(0.09, -0.09, _PROP_Z_OFFSET)),
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def make(task_id, obs_type, seed, img_size=64,):
|
| 81 |
+
obs_settings = observations.VISION if obs_type == 'pixels' else observations.PERFECT_FEATURES
|
| 82 |
+
obs_settings = obs_settings._replace(camera=obs_settings[-1]._replace(width=img_size))
|
| 83 |
+
obs_settings = obs_settings._replace(camera=obs_settings[-1]._replace(height=img_size))
|
| 84 |
+
if obs_type == 'states':
|
| 85 |
+
global _TIME_LIMIT
|
| 86 |
+
_TIME_LIMIT = 10.04
|
| 87 |
+
# Note: Adding this fixes the problem of having 249 steps with action repeat = 1
|
| 88 |
+
task = _reach(task_id, obs_settings=obs_settings, use_site=False)
|
| 89 |
+
return composer.Environment(task, time_limit=_TIME_LIMIT, random_state=seed)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class MTReach(composer.Task):
|
| 93 |
+
"""Bring the hand close to a target prop or site."""
|
| 94 |
+
|
| 95 |
+
def __init__(
|
| 96 |
+
self, task_id, arena, arm, hand, prop, obs_settings, workspace, control_timestep):
|
| 97 |
+
"""Initializes a new `Reach` task.
|
| 98 |
+
|
| 99 |
+
Args:
|
| 100 |
+
arena: `composer.Entity` instance.
|
| 101 |
+
arm: `robot_base.RobotArm` instance.
|
| 102 |
+
hand: `robot_base.RobotHand` instance.
|
| 103 |
+
prop: `composer.Entity` instance specifying the prop to reach to, or None
|
| 104 |
+
in which case the target is a fixed site whose position is specified by
|
| 105 |
+
the workspace.
|
| 106 |
+
obs_settings: `observations.ObservationSettings` instance.
|
| 107 |
+
workspace: `_ReachWorkspace` specifying the placement of the prop and TCP.
|
| 108 |
+
control_timestep: Float specifying the control timestep in seconds.
|
| 109 |
+
"""
|
| 110 |
+
self._task_id = task_id
|
| 111 |
+
self._arena = arena
|
| 112 |
+
self._arm = arm
|
| 113 |
+
self._hand = hand
|
| 114 |
+
self._arm.attach(self._hand)
|
| 115 |
+
self._arena.attach_offset(self._arm, offset=workspace.arm_offset)
|
| 116 |
+
self.control_timestep = control_timestep
|
| 117 |
+
self._tcp_initializer = initializers.ToolCenterPointInitializer(
|
| 118 |
+
self._hand, self._arm,
|
| 119 |
+
position=distributions.Uniform(*workspace.tcp_bbox),
|
| 120 |
+
quaternion=workspaces.DOWN_QUATERNION)
|
| 121 |
+
|
| 122 |
+
# Add custom camera observable.
|
| 123 |
+
self._task_observables = cameras.add_camera_observables(
|
| 124 |
+
arena, obs_settings, cameras.FRONT_CLOSE)
|
| 125 |
+
|
| 126 |
+
target_pos_distribution = distributions.Uniform(*TASKS[task_id])
|
| 127 |
+
self._prop = prop
|
| 128 |
+
if prop:
|
| 129 |
+
# The prop itself is used to visualize the target location.
|
| 130 |
+
self._make_target_site(parent_entity=prop, visible=False)
|
| 131 |
+
self._target = self._arena.add_free_entity(prop)
|
| 132 |
+
self._prop_placer = initializers.PropPlacer(
|
| 133 |
+
props=[prop],
|
| 134 |
+
position=target_pos_distribution,
|
| 135 |
+
quaternion=workspaces.uniform_z_rotation,
|
| 136 |
+
settle_physics=True)
|
| 137 |
+
else:
|
| 138 |
+
self._target = self._make_target_site(parent_entity=arena, visible=True)
|
| 139 |
+
self._target_placer = target_pos_distribution
|
| 140 |
+
|
| 141 |
+
# Commented to match EXORL
|
| 142 |
+
# obs = observable.MJCFFeature('pos', self._target)
|
| 143 |
+
# obs.configure(**obs_settings.prop_pose._asdict())
|
| 144 |
+
# self._task_observables['target_position'] = obs
|
| 145 |
+
|
| 146 |
+
# Add sites for visualizing the prop and target bounding boxes.
|
| 147 |
+
workspaces.add_bbox_site(
|
| 148 |
+
body=self.root_entity.mjcf_model.worldbody,
|
| 149 |
+
lower=workspace.tcp_bbox.lower, upper=workspace.tcp_bbox.upper,
|
| 150 |
+
rgba=constants.GREEN, name='tcp_spawn_area')
|
| 151 |
+
workspaces.add_bbox_site(
|
| 152 |
+
body=self.root_entity.mjcf_model.worldbody,
|
| 153 |
+
lower=workspace.target_bbox.lower, upper=workspace.target_bbox.upper,
|
| 154 |
+
rgba=constants.BLUE, name='target_spawn_area')
|
| 155 |
+
|
| 156 |
+
def _make_target_site(self, parent_entity, visible):
|
| 157 |
+
return workspaces.add_target_site(
|
| 158 |
+
body=parent_entity.mjcf_model.worldbody,
|
| 159 |
+
radius=_TARGET_RADIUS, visible=visible,
|
| 160 |
+
rgba=constants.RED, name='target_site')
|
| 161 |
+
|
| 162 |
+
@property
|
| 163 |
+
def root_entity(self):
|
| 164 |
+
return self._arena
|
| 165 |
+
|
| 166 |
+
@property
|
| 167 |
+
def arm(self):
|
| 168 |
+
return self._arm
|
| 169 |
+
|
| 170 |
+
@property
|
| 171 |
+
def hand(self):
|
| 172 |
+
return self._hand
|
| 173 |
+
|
| 174 |
+
@property
|
| 175 |
+
def task_observables(self):
|
| 176 |
+
return self._task_observables
|
| 177 |
+
|
| 178 |
+
def get_reward(self, physics):
|
| 179 |
+
hand_pos = physics.bind(self._hand.tool_center_point).xpos
|
| 180 |
+
target_pos = physics.bind(self._target).xpos
|
| 181 |
+
# This was used exceptionally for the PT reward predictor experiments
|
| 182 |
+
# target_pos = distributions.Uniform(*TASKS[self._task_id])()
|
| 183 |
+
distance = np.linalg.norm(hand_pos - target_pos)
|
| 184 |
+
return rewards.tolerance(
|
| 185 |
+
distance, bounds=(0, _TARGET_RADIUS), margin=_TARGET_RADIUS)
|
| 186 |
+
|
| 187 |
+
def initialize_episode(self, physics, random_state):
|
| 188 |
+
self._hand.set_grasp(physics, close_factors=random_state.uniform())
|
| 189 |
+
self._tcp_initializer(physics, random_state)
|
| 190 |
+
if self._prop:
|
| 191 |
+
self._prop_placer(physics, random_state)
|
| 192 |
+
else:
|
| 193 |
+
physics.bind(self._target).pos = (
|
| 194 |
+
self._target_placer(random_state=random_state))
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
def _reach(task_id, obs_settings, use_site):
|
| 198 |
+
"""Configure and instantiate a `Reach` task.
|
| 199 |
+
|
| 200 |
+
Args:
|
| 201 |
+
obs_settings: An `observations.ObservationSettings` instance.
|
| 202 |
+
use_site: Boolean, if True then the target will be a fixed site, otherwise
|
| 203 |
+
it will be a moveable Duplo brick.
|
| 204 |
+
|
| 205 |
+
Returns:
|
| 206 |
+
An instance of `reach.Reach`.
|
| 207 |
+
"""
|
| 208 |
+
arena = arenas.Standard()
|
| 209 |
+
arm = robots.make_arm(obs_settings=obs_settings)
|
| 210 |
+
hand = robots.make_hand(obs_settings=obs_settings)
|
| 211 |
+
if use_site:
|
| 212 |
+
workspace = _SITE_WORKSPACE
|
| 213 |
+
prop = None
|
| 214 |
+
else:
|
| 215 |
+
workspace = _DUPLO_WORKSPACE
|
| 216 |
+
prop = props.Duplo(observable_options=observations.make_options(
|
| 217 |
+
obs_settings, observations.FREEPROP_OBSERVABLES))
|
| 218 |
+
task = MTReach(task_id, arena=arena, arm=arm, hand=hand, prop=prop,
|
| 219 |
+
obs_settings=obs_settings,
|
| 220 |
+
workspace=workspace,
|
| 221 |
+
control_timestep=constants.CONTROL_TIMESTEP)
|
| 222 |
+
return task
|
envs/custom_dmc_tasks/quadruped.py
ADDED
|
@@ -0,0 +1,683 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2019 The dm_control Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
# ============================================================================
|
| 15 |
+
|
| 16 |
+
"""Quadruped Domain."""
|
| 17 |
+
|
| 18 |
+
import collections
|
| 19 |
+
|
| 20 |
+
from dm_control.suite import quadruped
|
| 21 |
+
from dm_control import mujoco
|
| 22 |
+
from dm_control.mujoco.wrapper import mjbindings
|
| 23 |
+
from dm_control.rl import control
|
| 24 |
+
from dm_control.suite import base
|
| 25 |
+
from dm_control.suite import common
|
| 26 |
+
from dm_control.utils import containers
|
| 27 |
+
from dm_control.utils import rewards
|
| 28 |
+
from dm_control.utils import xml_tools
|
| 29 |
+
from dm_control.utils import io as resources
|
| 30 |
+
from lxml import etree
|
| 31 |
+
import numpy as np
|
| 32 |
+
from scipy import ndimage
|
| 33 |
+
import os
|
| 34 |
+
|
| 35 |
+
enums = mjbindings.enums
|
| 36 |
+
mjlib = mjbindings.mjlib
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
_DEFAULT_TIME_LIMIT = 20
|
| 40 |
+
_CONTROL_TIMESTEP = .02
|
| 41 |
+
|
| 42 |
+
# Horizontal speeds above which the move reward is 1.
|
| 43 |
+
_RUN_SPEED = 5
|
| 44 |
+
_WALK_SPEED = 0.5
|
| 45 |
+
|
| 46 |
+
_JUMP_HEIGHT = 1.0 # -also good for foot up
|
| 47 |
+
_LIE_DOWN_HEIGHT = 0.2
|
| 48 |
+
_FOOT_DOWN_HEIGHT = 0.2
|
| 49 |
+
_FOOT_UP_HEIGHT = 0.8
|
| 50 |
+
|
| 51 |
+
# Constants related to terrain generation.
|
| 52 |
+
_HEIGHTFIELD_ID = 0
|
| 53 |
+
_TERRAIN_SMOOTHNESS = 0.15 # 0.0: maximally bumpy; 1.0: completely smooth.
|
| 54 |
+
_TERRAIN_BUMP_SCALE = 2 # Spatial scale of terrain bumps (in meters).
|
| 55 |
+
|
| 56 |
+
# Named model elements.
|
| 57 |
+
_TOES = ['toe_front_left', 'toe_back_left', 'toe_back_right', 'toe_front_right']
|
| 58 |
+
_WALLS = ['wall_px', 'wall_py', 'wall_nx', 'wall_ny']
|
| 59 |
+
|
| 60 |
+
def make(task,
|
| 61 |
+
task_kwargs=None,
|
| 62 |
+
environment_kwargs=None,
|
| 63 |
+
visualize_reward=False):
|
| 64 |
+
task_kwargs = task_kwargs or {}
|
| 65 |
+
if environment_kwargs is not None:
|
| 66 |
+
task_kwargs = task_kwargs.copy()
|
| 67 |
+
task_kwargs['environment_kwargs'] = environment_kwargs
|
| 68 |
+
env = SUITE[task](**task_kwargs)
|
| 69 |
+
env.task.visualize_reward = visualize_reward
|
| 70 |
+
return env
|
| 71 |
+
|
| 72 |
+
def get_model_and_assets():
|
| 73 |
+
"""Returns a tuple containing the model XML string and a dict of assets."""
|
| 74 |
+
root_dir = os.path.dirname(os.path.dirname(__file__))
|
| 75 |
+
xml = resources.GetResource(
|
| 76 |
+
os.path.join(root_dir, 'custom_dmc_tasks', 'quadruped.xml'))
|
| 77 |
+
return xml, common.ASSETS
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def make_model(floor_size=None, terrain=False, rangefinders=False,
|
| 81 |
+
walls_and_ball=False):
|
| 82 |
+
"""Returns the model XML string."""
|
| 83 |
+
root_dir = os.path.dirname(os.path.dirname(__file__))
|
| 84 |
+
xml_string = common.read_model(os.path.join(root_dir, 'custom_dmc_tasks', 'quadruped.xml'))
|
| 85 |
+
parser = etree.XMLParser(remove_blank_text=True)
|
| 86 |
+
mjcf = etree.XML(xml_string, parser)
|
| 87 |
+
|
| 88 |
+
# Set floor size.
|
| 89 |
+
if floor_size is not None:
|
| 90 |
+
floor_geom = mjcf.find('.//geom[@name=\'floor\']')
|
| 91 |
+
floor_geom.attrib['size'] = f'{floor_size} {floor_size} .5'
|
| 92 |
+
|
| 93 |
+
# Remove walls, ball and target.
|
| 94 |
+
if not walls_and_ball:
|
| 95 |
+
for wall in _WALLS:
|
| 96 |
+
wall_geom = xml_tools.find_element(mjcf, 'geom', wall)
|
| 97 |
+
wall_geom.getparent().remove(wall_geom)
|
| 98 |
+
|
| 99 |
+
# Remove ball.
|
| 100 |
+
ball_body = xml_tools.find_element(mjcf, 'body', 'ball')
|
| 101 |
+
ball_body.getparent().remove(ball_body)
|
| 102 |
+
|
| 103 |
+
# Remove target.
|
| 104 |
+
target_site = xml_tools.find_element(mjcf, 'site', 'target')
|
| 105 |
+
target_site.getparent().remove(target_site)
|
| 106 |
+
|
| 107 |
+
# Remove terrain.
|
| 108 |
+
if not terrain:
|
| 109 |
+
terrain_geom = xml_tools.find_element(mjcf, 'geom', 'terrain')
|
| 110 |
+
terrain_geom.getparent().remove(terrain_geom)
|
| 111 |
+
|
| 112 |
+
# Remove rangefinders if they're not used, as range computations can be
|
| 113 |
+
# expensive, especially in a scene with heightfields.
|
| 114 |
+
if not rangefinders:
|
| 115 |
+
rangefinder_sensors = mjcf.findall('.//rangefinder')
|
| 116 |
+
for rf in rangefinder_sensors:
|
| 117 |
+
rf.getparent().remove(rf)
|
| 118 |
+
|
| 119 |
+
return etree.tostring(mjcf, pretty_print=True)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
@quadruped.SUITE.add('custom')
|
| 123 |
+
def lie_down(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 124 |
+
"""Returns the Walk task."""
|
| 125 |
+
xml_string = make_model(floor_size=_DEFAULT_TIME_LIMIT * _WALK_SPEED)
|
| 126 |
+
physics = Physics.from_xml_string(xml_string, common.ASSETS)
|
| 127 |
+
task = Stand(goal='lie_down', random=random)
|
| 128 |
+
environment_kwargs = environment_kwargs or {}
|
| 129 |
+
return control.Environment(physics, task, time_limit=time_limit,
|
| 130 |
+
control_timestep=_CONTROL_TIMESTEP,
|
| 131 |
+
**environment_kwargs)
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
@quadruped.SUITE.add('custom')
|
| 135 |
+
def two_legs(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 136 |
+
"""Returns the Walk task."""
|
| 137 |
+
xml_string = make_model(floor_size=_DEFAULT_TIME_LIMIT * _WALK_SPEED)
|
| 138 |
+
physics = Physics.from_xml_string(xml_string, common.ASSETS)
|
| 139 |
+
task = Stand(goal='two_legs', random=random)
|
| 140 |
+
environment_kwargs = environment_kwargs or {}
|
| 141 |
+
return control.Environment(physics, task, time_limit=time_limit,
|
| 142 |
+
control_timestep=_CONTROL_TIMESTEP,
|
| 143 |
+
**environment_kwargs)
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
@quadruped.SUITE.add('custom')
|
| 147 |
+
def stand(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 148 |
+
"""Returns the Walk task."""
|
| 149 |
+
xml_string = make_model(floor_size=_DEFAULT_TIME_LIMIT * _WALK_SPEED)
|
| 150 |
+
physics = Physics.from_xml_string(xml_string, common.ASSETS)
|
| 151 |
+
task = Stand(goal='stand', random=random)
|
| 152 |
+
environment_kwargs = environment_kwargs or {}
|
| 153 |
+
return control.Environment(physics, task, time_limit=time_limit,
|
| 154 |
+
control_timestep=_CONTROL_TIMESTEP,
|
| 155 |
+
**environment_kwargs)
|
| 156 |
+
|
| 157 |
+
@quadruped.SUITE.add('custom')
|
| 158 |
+
def jump(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 159 |
+
"""Returns the Walk task."""
|
| 160 |
+
xml_string = make_model(floor_size=_DEFAULT_TIME_LIMIT * _WALK_SPEED)
|
| 161 |
+
physics = Physics.from_xml_string(xml_string, common.ASSETS)
|
| 162 |
+
task = Jump(desired_height=_JUMP_HEIGHT, random=random)
|
| 163 |
+
environment_kwargs = environment_kwargs or {}
|
| 164 |
+
return control.Environment(physics, task, time_limit=time_limit,
|
| 165 |
+
control_timestep=_CONTROL_TIMESTEP,
|
| 166 |
+
**environment_kwargs)
|
| 167 |
+
|
| 168 |
+
@quadruped.SUITE.add('custom')
|
| 169 |
+
def roll(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 170 |
+
"""Returns the Walk task."""
|
| 171 |
+
xml_string = make_model(floor_size=_DEFAULT_TIME_LIMIT * _WALK_SPEED)
|
| 172 |
+
physics = Physics.from_xml_string(xml_string, common.ASSETS)
|
| 173 |
+
task = Roll(desired_speed=_WALK_SPEED, random=random)
|
| 174 |
+
environment_kwargs = environment_kwargs or {}
|
| 175 |
+
return control.Environment(physics, task, time_limit=time_limit,
|
| 176 |
+
control_timestep=_CONTROL_TIMESTEP,
|
| 177 |
+
**environment_kwargs)
|
| 178 |
+
|
| 179 |
+
@quadruped.SUITE.add('custom')
|
| 180 |
+
def roll_fast(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 181 |
+
"""Returns the Walk task."""
|
| 182 |
+
xml_string = make_model(floor_size=_DEFAULT_TIME_LIMIT * _WALK_SPEED)
|
| 183 |
+
physics = Physics.from_xml_string(xml_string, common.ASSETS)
|
| 184 |
+
task = Roll(desired_speed=_RUN_SPEED, random=random)
|
| 185 |
+
environment_kwargs = environment_kwargs or {}
|
| 186 |
+
return control.Environment(physics, task, time_limit=time_limit,
|
| 187 |
+
control_timestep=_CONTROL_TIMESTEP,
|
| 188 |
+
**environment_kwargs)
|
| 189 |
+
|
| 190 |
+
class Physics(mujoco.Physics):
|
| 191 |
+
"""Physics simulation with additional features for the Quadruped domain."""
|
| 192 |
+
|
| 193 |
+
def _reload_from_data(self, data):
|
| 194 |
+
super()._reload_from_data(data)
|
| 195 |
+
# Clear cached sensor names when the physics is reloaded.
|
| 196 |
+
self._sensor_types_to_names = {}
|
| 197 |
+
self._hinge_names = []
|
| 198 |
+
|
| 199 |
+
def _get_sensor_names(self, *sensor_types):
|
| 200 |
+
try:
|
| 201 |
+
sensor_names = self._sensor_types_to_names[sensor_types]
|
| 202 |
+
except KeyError:
|
| 203 |
+
[sensor_ids] = np.where(np.in1d(self.model.sensor_type, sensor_types))
|
| 204 |
+
sensor_names = [self.model.id2name(s_id, 'sensor') for s_id in sensor_ids]
|
| 205 |
+
self._sensor_types_to_names[sensor_types] = sensor_names
|
| 206 |
+
return sensor_names
|
| 207 |
+
|
| 208 |
+
def torso_upright(self):
|
| 209 |
+
"""Returns the dot-product of the torso z-axis and the global z-axis."""
|
| 210 |
+
return np.asarray(self.named.data.xmat['torso', 'zz'])
|
| 211 |
+
|
| 212 |
+
def torso_velocity(self):
|
| 213 |
+
"""Returns the velocity of the torso, in the local frame."""
|
| 214 |
+
return self.named.data.sensordata['velocimeter'].copy()
|
| 215 |
+
|
| 216 |
+
def com_height(self):
|
| 217 |
+
return self.named.data.sensordata['center_of_mass'].copy()[2]
|
| 218 |
+
|
| 219 |
+
def egocentric_state(self):
|
| 220 |
+
"""Returns the state without global orientation or position."""
|
| 221 |
+
if not self._hinge_names:
|
| 222 |
+
[hinge_ids] = np.nonzero(self.model.jnt_type ==
|
| 223 |
+
enums.mjtJoint.mjJNT_HINGE)
|
| 224 |
+
self._hinge_names = [self.model.id2name(j_id, 'joint')
|
| 225 |
+
for j_id in hinge_ids]
|
| 226 |
+
return np.hstack((self.named.data.qpos[self._hinge_names],
|
| 227 |
+
self.named.data.qvel[self._hinge_names],
|
| 228 |
+
self.data.act))
|
| 229 |
+
|
| 230 |
+
def toe_positions(self):
|
| 231 |
+
"""Returns toe positions in egocentric frame."""
|
| 232 |
+
torso_frame = self.named.data.xmat['torso'].reshape(3, 3)
|
| 233 |
+
torso_pos = self.named.data.xpos['torso']
|
| 234 |
+
torso_to_toe = self.named.data.xpos[_TOES] - torso_pos
|
| 235 |
+
return torso_to_toe.dot(torso_frame)
|
| 236 |
+
|
| 237 |
+
def force_torque(self):
|
| 238 |
+
"""Returns scaled force/torque sensor readings at the toes."""
|
| 239 |
+
force_torque_sensors = self._get_sensor_names(enums.mjtSensor.mjSENS_FORCE,
|
| 240 |
+
enums.mjtSensor.mjSENS_TORQUE)
|
| 241 |
+
return np.arcsinh(self.named.data.sensordata[force_torque_sensors])
|
| 242 |
+
|
| 243 |
+
def imu(self):
|
| 244 |
+
"""Returns IMU-like sensor readings."""
|
| 245 |
+
imu_sensors = self._get_sensor_names(enums.mjtSensor.mjSENS_GYRO,
|
| 246 |
+
enums.mjtSensor.mjSENS_ACCELEROMETER)
|
| 247 |
+
return self.named.data.sensordata[imu_sensors]
|
| 248 |
+
|
| 249 |
+
def rangefinder(self):
|
| 250 |
+
"""Returns scaled rangefinder sensor readings."""
|
| 251 |
+
rf_sensors = self._get_sensor_names(enums.mjtSensor.mjSENS_RANGEFINDER)
|
| 252 |
+
rf_readings = self.named.data.sensordata[rf_sensors]
|
| 253 |
+
no_intersection = -1.0
|
| 254 |
+
return np.where(rf_readings == no_intersection, 1.0, np.tanh(rf_readings))
|
| 255 |
+
|
| 256 |
+
def origin_distance(self):
|
| 257 |
+
"""Returns the distance from the origin to the workspace."""
|
| 258 |
+
return np.asarray(np.linalg.norm(self.named.data.site_xpos['workspace']))
|
| 259 |
+
|
| 260 |
+
def origin(self):
|
| 261 |
+
"""Returns origin position in the torso frame."""
|
| 262 |
+
torso_frame = self.named.data.xmat['torso'].reshape(3, 3)
|
| 263 |
+
torso_pos = self.named.data.xpos['torso']
|
| 264 |
+
return -torso_pos.dot(torso_frame)
|
| 265 |
+
|
| 266 |
+
def ball_state(self):
|
| 267 |
+
"""Returns ball position and velocity relative to the torso frame."""
|
| 268 |
+
data = self.named.data
|
| 269 |
+
torso_frame = data.xmat['torso'].reshape(3, 3)
|
| 270 |
+
ball_rel_pos = data.xpos['ball'] - data.xpos['torso']
|
| 271 |
+
ball_rel_vel = data.qvel['ball_root'][:3] - data.qvel['root'][:3]
|
| 272 |
+
ball_rot_vel = data.qvel['ball_root'][3:]
|
| 273 |
+
ball_state = np.vstack((ball_rel_pos, ball_rel_vel, ball_rot_vel))
|
| 274 |
+
return ball_state.dot(torso_frame).ravel()
|
| 275 |
+
|
| 276 |
+
def target_position(self):
|
| 277 |
+
"""Returns target position in torso frame."""
|
| 278 |
+
torso_frame = self.named.data.xmat['torso'].reshape(3, 3)
|
| 279 |
+
torso_pos = self.named.data.xpos['torso']
|
| 280 |
+
torso_to_target = self.named.data.site_xpos['target'] - torso_pos
|
| 281 |
+
return torso_to_target.dot(torso_frame)
|
| 282 |
+
|
| 283 |
+
def ball_to_target_distance(self):
|
| 284 |
+
"""Returns horizontal distance from the ball to the target."""
|
| 285 |
+
ball_to_target = (self.named.data.site_xpos['target'] -
|
| 286 |
+
self.named.data.xpos['ball'])
|
| 287 |
+
return np.linalg.norm(ball_to_target[:2])
|
| 288 |
+
|
| 289 |
+
def self_to_ball_distance(self):
|
| 290 |
+
"""Returns horizontal distance from the quadruped workspace to the ball."""
|
| 291 |
+
self_to_ball = (self.named.data.site_xpos['workspace']
|
| 292 |
+
-self.named.data.xpos['ball'])
|
| 293 |
+
return np.linalg.norm(self_to_ball[:2])
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
def _find_non_contacting_height(physics, orientation, x_pos=0.0, y_pos=0.0):
|
| 297 |
+
"""Find a height with no contacts given a body orientation.
|
| 298 |
+
Args:
|
| 299 |
+
physics: An instance of `Physics`.
|
| 300 |
+
orientation: A quaternion.
|
| 301 |
+
x_pos: A float. Position along global x-axis.
|
| 302 |
+
y_pos: A float. Position along global y-axis.
|
| 303 |
+
Raises:
|
| 304 |
+
RuntimeError: If a non-contacting configuration has not been found after
|
| 305 |
+
10,000 attempts.
|
| 306 |
+
"""
|
| 307 |
+
z_pos = 0.0 # Start embedded in the floor.
|
| 308 |
+
num_contacts = 1
|
| 309 |
+
num_attempts = 0
|
| 310 |
+
# Move up in 1cm increments until no contacts.
|
| 311 |
+
while num_contacts > 0:
|
| 312 |
+
try:
|
| 313 |
+
with physics.reset_context():
|
| 314 |
+
physics.named.data.qpos['root'][:3] = x_pos, y_pos, z_pos
|
| 315 |
+
physics.named.data.qpos['root'][3:] = orientation
|
| 316 |
+
except control.PhysicsError:
|
| 317 |
+
# We may encounter a PhysicsError here due to filling the contact
|
| 318 |
+
# buffer, in which case we simply increment the height and continue.
|
| 319 |
+
pass
|
| 320 |
+
num_contacts = physics.data.ncon
|
| 321 |
+
z_pos += 0.01
|
| 322 |
+
num_attempts += 1
|
| 323 |
+
if num_attempts > 10000:
|
| 324 |
+
raise RuntimeError('Failed to find a non-contacting configuration.')
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
def _common_observations(physics):
|
| 328 |
+
"""Returns the observations common to all tasks."""
|
| 329 |
+
obs = collections.OrderedDict()
|
| 330 |
+
obs['egocentric_state'] = physics.egocentric_state()
|
| 331 |
+
obs['torso_velocity'] = physics.torso_velocity()
|
| 332 |
+
obs['torso_upright'] = physics.torso_upright()
|
| 333 |
+
obs['imu'] = physics.imu()
|
| 334 |
+
obs['force_torque'] = physics.force_torque()
|
| 335 |
+
return obs
|
| 336 |
+
|
| 337 |
+
def _lie_down_reward(physics, deviation_angle=0):
|
| 338 |
+
"""Returns a reward proportional to how upright the torso is.
|
| 339 |
+
Args:
|
| 340 |
+
physics: an instance of `Physics`.
|
| 341 |
+
deviation_angle: A float, in degrees. The reward is 0 when the torso is
|
| 342 |
+
exactly upside-down and 1 when the torso's z-axis is less than
|
| 343 |
+
`deviation_angle` away from the global z-axis.
|
| 344 |
+
"""
|
| 345 |
+
torso = physics.named.data.xpos['torso', 'z']
|
| 346 |
+
return rewards.tolerance(
|
| 347 |
+
torso,
|
| 348 |
+
bounds=(-float('inf'), _LIE_DOWN_HEIGHT),
|
| 349 |
+
margin=_LIE_DOWN_HEIGHT * 1.5)
|
| 350 |
+
|
| 351 |
+
|
| 352 |
+
def _two_legs_reward(physics, deviation_angle=0):
|
| 353 |
+
"""Returns a reward proportional to how upright the torso is.
|
| 354 |
+
Args:
|
| 355 |
+
physics: an instance of `Physics`.
|
| 356 |
+
deviation_angle: A float, in degrees. The reward is 0 when the torso is
|
| 357 |
+
exactly upside-down and 1 when the torso's z-axis is less than
|
| 358 |
+
`deviation_angle` away from the global z-axis.
|
| 359 |
+
"""
|
| 360 |
+
toes = []
|
| 361 |
+
for t in ['toe_front_left', 'toe_front_right', 'toe_back_left', 'toe_back_right']:
|
| 362 |
+
toe = physics.named.data.xpos[t, 'z']
|
| 363 |
+
toes.append(toe)
|
| 364 |
+
toes = sorted(toes)
|
| 365 |
+
min_toes = sum(toes[:2]) / 2
|
| 366 |
+
max_toes = sum(toes[2:]) / 2
|
| 367 |
+
toes_up = rewards.tolerance(
|
| 368 |
+
max_toes,
|
| 369 |
+
bounds=(_FOOT_UP_HEIGHT, float('inf')),
|
| 370 |
+
margin=_FOOT_UP_HEIGHT // 2)
|
| 371 |
+
toes_down = rewards.tolerance(
|
| 372 |
+
min_toes,
|
| 373 |
+
bounds=(-float('inf'), _FOOT_DOWN_HEIGHT),
|
| 374 |
+
margin=_FOOT_DOWN_HEIGHT * 1.5)
|
| 375 |
+
return toes_down * toes_up
|
| 376 |
+
|
| 377 |
+
|
| 378 |
+
def _upright_reward(physics, deviation_angle=0):
|
| 379 |
+
"""Returns a reward proportional to how upright the torso is.
|
| 380 |
+
Args:
|
| 381 |
+
physics: an instance of `Physics`.
|
| 382 |
+
deviation_angle: A float, in degrees. The reward is 0 when the torso is
|
| 383 |
+
exactly upside-down and 1 when the torso's z-axis is less than
|
| 384 |
+
`deviation_angle` away from the global z-axis.
|
| 385 |
+
"""
|
| 386 |
+
deviation = np.cos(np.deg2rad(deviation_angle))
|
| 387 |
+
return rewards.tolerance(
|
| 388 |
+
physics.torso_upright(),
|
| 389 |
+
bounds=(deviation, float('inf')),
|
| 390 |
+
sigmoid='linear',
|
| 391 |
+
margin=1 + deviation,
|
| 392 |
+
value_at_margin=0)
|
| 393 |
+
|
| 394 |
+
|
| 395 |
+
class Move(base.Task):
|
| 396 |
+
"""A quadruped task solved by moving forward at a designated speed."""
|
| 397 |
+
|
| 398 |
+
def __init__(self, desired_speed, random=None):
|
| 399 |
+
"""Initializes an instance of `Move`.
|
| 400 |
+
Args:
|
| 401 |
+
desired_speed: A float. If this value is zero, reward is given simply
|
| 402 |
+
for standing upright. Otherwise this specifies the horizontal velocity
|
| 403 |
+
at which the velocity-dependent reward component is maximized.
|
| 404 |
+
random: Optional, either a `numpy.random.RandomState` instance, an
|
| 405 |
+
integer seed for creating a new `RandomState`, or None to select a seed
|
| 406 |
+
automatically (default).
|
| 407 |
+
"""
|
| 408 |
+
self._desired_speed = desired_speed
|
| 409 |
+
super().__init__(random=random)
|
| 410 |
+
|
| 411 |
+
def initialize_episode(self, physics):
|
| 412 |
+
"""Sets the state of the environment at the start of each episode.
|
| 413 |
+
Args:
|
| 414 |
+
physics: An instance of `Physics`.
|
| 415 |
+
"""
|
| 416 |
+
# Initial configuration.
|
| 417 |
+
orientation = self.random.randn(4)
|
| 418 |
+
orientation /= np.linalg.norm(orientation)
|
| 419 |
+
_find_non_contacting_height(physics, orientation)
|
| 420 |
+
super().initialize_episode(physics)
|
| 421 |
+
|
| 422 |
+
def get_observation(self, physics):
|
| 423 |
+
"""Returns an observation to the agent."""
|
| 424 |
+
return _common_observations(physics)
|
| 425 |
+
|
| 426 |
+
def get_reward(self, physics):
|
| 427 |
+
"""Returns a reward to the agent."""
|
| 428 |
+
|
| 429 |
+
# Move reward term.
|
| 430 |
+
move_reward = rewards.tolerance(
|
| 431 |
+
physics.torso_velocity()[0],
|
| 432 |
+
bounds=(self._desired_speed, float('inf')),
|
| 433 |
+
margin=self._desired_speed,
|
| 434 |
+
value_at_margin=0.5,
|
| 435 |
+
sigmoid='linear')
|
| 436 |
+
|
| 437 |
+
return _upright_reward(physics) * move_reward
|
| 438 |
+
|
| 439 |
+
|
| 440 |
+
class Stand(base.Task):
|
| 441 |
+
"""A quadruped task solved by moving forward at a designated speed."""
|
| 442 |
+
|
| 443 |
+
def __init__(self, random=None, goal='stand'):
|
| 444 |
+
"""Initializes an instance of `Move`.
|
| 445 |
+
Args:
|
| 446 |
+
desired_speed: A float. If this value is zero, reward is given simply
|
| 447 |
+
for standing upright. Otherwise this specifies the horizontal velocity
|
| 448 |
+
at which the velocity-dependent reward component is maximized.
|
| 449 |
+
random: Optional, either a `numpy.random.RandomState` instance, an
|
| 450 |
+
integer seed for creating a new `RandomState`, or None to select a seed
|
| 451 |
+
automatically (default).
|
| 452 |
+
"""
|
| 453 |
+
super().__init__(random=random)
|
| 454 |
+
self._goal = goal
|
| 455 |
+
|
| 456 |
+
def initialize_episode(self, physics):
|
| 457 |
+
"""Sets the state of the environment at the start of each episode.
|
| 458 |
+
Args:
|
| 459 |
+
physics: An instance of `Physics`.
|
| 460 |
+
"""
|
| 461 |
+
# Initial configuration.
|
| 462 |
+
orientation = self.random.randn(4)
|
| 463 |
+
orientation /= np.linalg.norm(orientation)
|
| 464 |
+
_find_non_contacting_height(physics, orientation)
|
| 465 |
+
super().initialize_episode(physics)
|
| 466 |
+
|
| 467 |
+
def get_observation(self, physics):
|
| 468 |
+
"""Returns an observation to the agent."""
|
| 469 |
+
return _common_observations(physics)
|
| 470 |
+
|
| 471 |
+
def get_reward(self, physics):
|
| 472 |
+
"""Returns a reward to the agent."""
|
| 473 |
+
if self._goal == 'stand':
|
| 474 |
+
return _upright_reward(physics)
|
| 475 |
+
elif self._goal == 'lie_down':
|
| 476 |
+
return _lie_down_reward(physics)
|
| 477 |
+
elif self._goal == 'two_legs':
|
| 478 |
+
return _two_legs_reward(physics)
|
| 479 |
+
|
| 480 |
+
class Jump(base.Task):
|
| 481 |
+
"""A quadruped task solved by moving forward at a designated speed."""
|
| 482 |
+
|
| 483 |
+
def __init__(self, desired_height, random=None):
|
| 484 |
+
"""Initializes an instance of `Move`.
|
| 485 |
+
Args:
|
| 486 |
+
desired_speed: A float. If this value is zero, reward is given simply
|
| 487 |
+
for standing upright. Otherwise this specifies the horizontal velocity
|
| 488 |
+
at which the velocity-dependent reward component is maximized.
|
| 489 |
+
random: Optional, either a `numpy.random.RandomState` instance, an
|
| 490 |
+
integer seed for creating a new `RandomState`, or None to select a seed
|
| 491 |
+
automatically (default).
|
| 492 |
+
"""
|
| 493 |
+
self._desired_height = desired_height
|
| 494 |
+
super().__init__(random=random)
|
| 495 |
+
|
| 496 |
+
def initialize_episode(self, physics):
|
| 497 |
+
"""Sets the state of the environment at the start of each episode.
|
| 498 |
+
Args:
|
| 499 |
+
physics: An instance of `Physics`.
|
| 500 |
+
"""
|
| 501 |
+
# Initial configuration.
|
| 502 |
+
orientation = self.random.randn(4)
|
| 503 |
+
orientation /= np.linalg.norm(orientation)
|
| 504 |
+
_find_non_contacting_height(physics, orientation)
|
| 505 |
+
super().initialize_episode(physics)
|
| 506 |
+
|
| 507 |
+
def get_observation(self, physics):
|
| 508 |
+
"""Returns an observation to the agent."""
|
| 509 |
+
return _common_observations(physics)
|
| 510 |
+
|
| 511 |
+
def get_reward(self, physics):
|
| 512 |
+
"""Returns a reward to the agent."""
|
| 513 |
+
|
| 514 |
+
# Move reward term.
|
| 515 |
+
jump_up = rewards.tolerance(
|
| 516 |
+
physics.com_height(),
|
| 517 |
+
bounds=(self._desired_height, float('inf')),
|
| 518 |
+
margin=self._desired_height,
|
| 519 |
+
value_at_margin=0.5,
|
| 520 |
+
sigmoid='linear')
|
| 521 |
+
|
| 522 |
+
return _upright_reward(physics) * jump_up
|
| 523 |
+
|
| 524 |
+
|
| 525 |
+
class Roll(base.Task):
|
| 526 |
+
"""A quadruped task solved by moving forward at a designated speed."""
|
| 527 |
+
|
| 528 |
+
def __init__(self, desired_speed, random=None):
|
| 529 |
+
"""Initializes an instance of `Move`.
|
| 530 |
+
Args:
|
| 531 |
+
desired_speed: A float. If this value is zero, reward is given simply
|
| 532 |
+
for standing upright. Otherwise this specifies the horizontal velocity
|
| 533 |
+
at which the velocity-dependent reward component is maximized.
|
| 534 |
+
random: Optional, either a `numpy.random.RandomState` instance, an
|
| 535 |
+
integer seed for creating a new `RandomState`, or None to select a seed
|
| 536 |
+
automatically (default).
|
| 537 |
+
"""
|
| 538 |
+
self._desired_speed = desired_speed
|
| 539 |
+
super().__init__(random=random)
|
| 540 |
+
|
| 541 |
+
def initialize_episode(self, physics):
|
| 542 |
+
"""Sets the state of the environment at the start of each episode.
|
| 543 |
+
Args:
|
| 544 |
+
physics: An instance of `Physics`.
|
| 545 |
+
"""
|
| 546 |
+
# Initial configuration.
|
| 547 |
+
orientation = self.random.randn(4)
|
| 548 |
+
orientation /= np.linalg.norm(orientation)
|
| 549 |
+
_find_non_contacting_height(physics, orientation)
|
| 550 |
+
super().initialize_episode(physics)
|
| 551 |
+
|
| 552 |
+
def get_observation(self, physics):
|
| 553 |
+
"""Returns an observation to the agent."""
|
| 554 |
+
return _common_observations(physics)
|
| 555 |
+
|
| 556 |
+
def get_reward(self, physics):
|
| 557 |
+
"""Returns a reward to the agent."""
|
| 558 |
+
# Move reward term.
|
| 559 |
+
move_reward = rewards.tolerance(
|
| 560 |
+
np.linalg.norm(physics.torso_velocity()),
|
| 561 |
+
bounds=(self._desired_speed, float('inf')),
|
| 562 |
+
margin=self._desired_speed,
|
| 563 |
+
value_at_margin=0.5,
|
| 564 |
+
sigmoid='linear')
|
| 565 |
+
|
| 566 |
+
return _upright_reward(physics) * move_reward
|
| 567 |
+
|
| 568 |
+
|
| 569 |
+
class Escape(base.Task):
|
| 570 |
+
"""A quadruped task solved by escaping a bowl-shaped terrain."""
|
| 571 |
+
|
| 572 |
+
def initialize_episode(self, physics):
|
| 573 |
+
"""Sets the state of the environment at the start of each episode.
|
| 574 |
+
Args:
|
| 575 |
+
physics: An instance of `Physics`.
|
| 576 |
+
"""
|
| 577 |
+
# Get heightfield resolution, assert that it is square.
|
| 578 |
+
res = physics.model.hfield_nrow[_HEIGHTFIELD_ID]
|
| 579 |
+
assert res == physics.model.hfield_ncol[_HEIGHTFIELD_ID]
|
| 580 |
+
# Sinusoidal bowl shape.
|
| 581 |
+
row_grid, col_grid = np.ogrid[-1:1:res*1j, -1:1:res*1j]
|
| 582 |
+
radius = np.clip(np.sqrt(col_grid**2 + row_grid**2), .04, 1)
|
| 583 |
+
bowl_shape = .5 - np.cos(2*np.pi*radius)/2
|
| 584 |
+
# Random smooth bumps.
|
| 585 |
+
terrain_size = 2 * physics.model.hfield_size[_HEIGHTFIELD_ID, 0]
|
| 586 |
+
bump_res = int(terrain_size / _TERRAIN_BUMP_SCALE)
|
| 587 |
+
bumps = self.random.uniform(_TERRAIN_SMOOTHNESS, 1, (bump_res, bump_res))
|
| 588 |
+
smooth_bumps = ndimage.zoom(bumps, res / float(bump_res))
|
| 589 |
+
# Terrain is elementwise product.
|
| 590 |
+
terrain = bowl_shape * smooth_bumps
|
| 591 |
+
start_idx = physics.model.hfield_adr[_HEIGHTFIELD_ID]
|
| 592 |
+
physics.model.hfield_data[start_idx:start_idx+res**2] = terrain.ravel()
|
| 593 |
+
super().initialize_episode(physics)
|
| 594 |
+
|
| 595 |
+
# If we have a rendering context, we need to re-upload the modified
|
| 596 |
+
# heightfield data.
|
| 597 |
+
if physics.contexts:
|
| 598 |
+
with physics.contexts.gl.make_current() as ctx:
|
| 599 |
+
ctx.call(mjlib.mjr_uploadHField,
|
| 600 |
+
physics.model.ptr,
|
| 601 |
+
physics.contexts.mujoco.ptr,
|
| 602 |
+
_HEIGHTFIELD_ID)
|
| 603 |
+
|
| 604 |
+
# Initial configuration.
|
| 605 |
+
orientation = self.random.randn(4)
|
| 606 |
+
orientation /= np.linalg.norm(orientation)
|
| 607 |
+
_find_non_contacting_height(physics, orientation)
|
| 608 |
+
|
| 609 |
+
def get_observation(self, physics):
|
| 610 |
+
"""Returns an observation to the agent."""
|
| 611 |
+
obs = _common_observations(physics)
|
| 612 |
+
obs['origin'] = physics.origin()
|
| 613 |
+
obs['rangefinder'] = physics.rangefinder()
|
| 614 |
+
return obs
|
| 615 |
+
|
| 616 |
+
def get_reward(self, physics):
|
| 617 |
+
"""Returns a reward to the agent."""
|
| 618 |
+
|
| 619 |
+
# Escape reward term.
|
| 620 |
+
terrain_size = physics.model.hfield_size[_HEIGHTFIELD_ID, 0]
|
| 621 |
+
escape_reward = rewards.tolerance(
|
| 622 |
+
physics.origin_distance(),
|
| 623 |
+
bounds=(terrain_size, float('inf')),
|
| 624 |
+
margin=terrain_size,
|
| 625 |
+
value_at_margin=0,
|
| 626 |
+
sigmoid='linear')
|
| 627 |
+
|
| 628 |
+
return _upright_reward(physics, deviation_angle=20) * escape_reward
|
| 629 |
+
|
| 630 |
+
|
| 631 |
+
class Fetch(base.Task):
|
| 632 |
+
"""A quadruped task solved by bringing a ball to the origin."""
|
| 633 |
+
|
| 634 |
+
def initialize_episode(self, physics):
|
| 635 |
+
"""Sets the state of the environment at the start of each episode.
|
| 636 |
+
Args:
|
| 637 |
+
physics: An instance of `Physics`.
|
| 638 |
+
"""
|
| 639 |
+
# Initial configuration, random azimuth and horizontal position.
|
| 640 |
+
azimuth = self.random.uniform(0, 2*np.pi)
|
| 641 |
+
orientation = np.array((np.cos(azimuth/2), 0, 0, np.sin(azimuth/2)))
|
| 642 |
+
spawn_radius = 0.9 * physics.named.model.geom_size['floor', 0]
|
| 643 |
+
x_pos, y_pos = self.random.uniform(-spawn_radius, spawn_radius, size=(2,))
|
| 644 |
+
_find_non_contacting_height(physics, orientation, x_pos, y_pos)
|
| 645 |
+
|
| 646 |
+
# Initial ball state.
|
| 647 |
+
physics.named.data.qpos['ball_root'][:2] = self.random.uniform(
|
| 648 |
+
-spawn_radius, spawn_radius, size=(2,))
|
| 649 |
+
physics.named.data.qpos['ball_root'][2] = 2
|
| 650 |
+
physics.named.data.qvel['ball_root'][:2] = 5*self.random.randn(2)
|
| 651 |
+
super().initialize_episode(physics)
|
| 652 |
+
|
| 653 |
+
def get_observation(self, physics):
|
| 654 |
+
"""Returns an observation to the agent."""
|
| 655 |
+
obs = _common_observations(physics)
|
| 656 |
+
obs['ball_state'] = physics.ball_state()
|
| 657 |
+
obs['target_position'] = physics.target_position()
|
| 658 |
+
return obs
|
| 659 |
+
|
| 660 |
+
def get_reward(self, physics):
|
| 661 |
+
"""Returns a reward to the agent."""
|
| 662 |
+
|
| 663 |
+
# Reward for moving close to the ball.
|
| 664 |
+
arena_radius = physics.named.model.geom_size['floor', 0] * np.sqrt(2)
|
| 665 |
+
workspace_radius = physics.named.model.site_size['workspace', 0]
|
| 666 |
+
ball_radius = physics.named.model.geom_size['ball', 0]
|
| 667 |
+
reach_reward = rewards.tolerance(
|
| 668 |
+
physics.self_to_ball_distance(),
|
| 669 |
+
bounds=(0, workspace_radius+ball_radius),
|
| 670 |
+
sigmoid='linear',
|
| 671 |
+
margin=arena_radius, value_at_margin=0)
|
| 672 |
+
|
| 673 |
+
# Reward for bringing the ball to the target.
|
| 674 |
+
target_radius = physics.named.model.site_size['target', 0]
|
| 675 |
+
fetch_reward = rewards.tolerance(
|
| 676 |
+
physics.ball_to_target_distance(),
|
| 677 |
+
bounds=(0, target_radius),
|
| 678 |
+
sigmoid='linear',
|
| 679 |
+
margin=arena_radius, value_at_margin=0)
|
| 680 |
+
|
| 681 |
+
reach_then_fetch = reach_reward * (0.5 + 0.5*fetch_reward)
|
| 682 |
+
|
| 683 |
+
return _upright_reward(physics) * reach_then_fetch
|
envs/custom_dmc_tasks/quadruped.xml
ADDED
|
@@ -0,0 +1,328 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<mujoco model="quadruped">
|
| 2 |
+
|
| 3 |
+
<include file="./common/skybox.xml"/>
|
| 4 |
+
<include file="./common/visual.xml"/>
|
| 5 |
+
<include file="./common/materials.xml"/>
|
| 6 |
+
|
| 7 |
+
<visual>
|
| 8 |
+
<rgba rangefinder="1 1 0.1 0.1"/>
|
| 9 |
+
<map znear=".005" zfar="20"/>
|
| 10 |
+
</visual>
|
| 11 |
+
|
| 12 |
+
<asset>
|
| 13 |
+
<hfield name="terrain" ncol="201" nrow="201" size="30 30 5 .1"/>
|
| 14 |
+
</asset>
|
| 15 |
+
|
| 16 |
+
<option timestep=".005"/>
|
| 17 |
+
|
| 18 |
+
<default>
|
| 19 |
+
<geom solimp=".9 .99 .003" solref=".01 1"/>
|
| 20 |
+
<default class="body">
|
| 21 |
+
<geom type="capsule" size=".08" condim="1" material="self" density="500"/>
|
| 22 |
+
<joint type="hinge" damping="30" armature=".01"
|
| 23 |
+
limited="true" solimplimit="0 .99 .01"/>
|
| 24 |
+
<default class="hip">
|
| 25 |
+
<default class="yaw">
|
| 26 |
+
<joint axis="0 0 1" range="-50 50"/>
|
| 27 |
+
</default>
|
| 28 |
+
<default class="pitch">
|
| 29 |
+
<joint axis="0 1 0" range="-20 60"/>
|
| 30 |
+
</default>
|
| 31 |
+
<geom fromto="0 0 0 .3 0 .11"/>
|
| 32 |
+
</default>
|
| 33 |
+
<default class="knee">
|
| 34 |
+
<joint axis="0 1 0" range="-60 50"/>
|
| 35 |
+
<geom size=".065" fromto="0 0 0 .25 0 -.25"/>
|
| 36 |
+
</default>
|
| 37 |
+
<default class="ankle">
|
| 38 |
+
<joint axis="0 1 0" range="-45 55"/>
|
| 39 |
+
<geom size=".055" fromto="0 0 0 0 0 -.25"/>
|
| 40 |
+
</default>
|
| 41 |
+
<default class="toe">
|
| 42 |
+
<geom type="sphere" size=".08" material="effector" friction="1.5"/>
|
| 43 |
+
<site type="sphere" size=".084" material="site" group="4"/>
|
| 44 |
+
</default>
|
| 45 |
+
</default>
|
| 46 |
+
<default class="rangefinder">
|
| 47 |
+
<site type="capsule" size=".005 .1" material="site" group="4"/>
|
| 48 |
+
</default>
|
| 49 |
+
<default class="wall">
|
| 50 |
+
<geom type="plane" material="decoration"/>
|
| 51 |
+
</default>
|
| 52 |
+
|
| 53 |
+
<default class="coupling">
|
| 54 |
+
<equality solimp="0.95 0.99 0.01" solref=".005 .5"/>
|
| 55 |
+
</default>
|
| 56 |
+
|
| 57 |
+
<general ctrllimited="true" gainprm="1000" biasprm="0 -1000" biastype="affine" dyntype="filter" dynprm=".1"/>
|
| 58 |
+
<default class="yaw_act">
|
| 59 |
+
<general ctrlrange="-1 1"/>
|
| 60 |
+
</default>
|
| 61 |
+
<default class="lift_act">
|
| 62 |
+
<general ctrlrange="-1 1.1"/>
|
| 63 |
+
</default>
|
| 64 |
+
<default class="extend_act">
|
| 65 |
+
<general ctrlrange="-.8 .8"/>
|
| 66 |
+
</default>
|
| 67 |
+
</default>
|
| 68 |
+
|
| 69 |
+
<asset>
|
| 70 |
+
<texture name="ball" builtin="checker" mark="cross" width="151" height="151"
|
| 71 |
+
rgb1="0.1 0.1 0.1" rgb2="0.9 0.9 0.9" markrgb="1 1 1"/>
|
| 72 |
+
<material name="ball" texture="ball" />
|
| 73 |
+
</asset>
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
<worldbody>
|
| 77 |
+
<geom name="floor" type="plane" size="15 15 .5" material="grid"/>
|
| 78 |
+
<geom name="wall_px" class="wall" pos="-15.7 0 .7" zaxis="1 0 1" size="1 15 .5"/>
|
| 79 |
+
<geom name="wall_py" class="wall" pos="0 -15.7 .7" zaxis="0 1 1" size="15 1 .5"/>
|
| 80 |
+
<geom name="wall_nx" class="wall" pos="15.7 0 .7" zaxis="-1 0 1" size="1 15 .5"/>
|
| 81 |
+
<geom name="wall_ny" class="wall" pos="0 15.7 .7" zaxis="0 -1 1" size="15 1 .5"/>
|
| 82 |
+
<site name="target" type="cylinder" size=".4 .06" pos="0 0 .05" material="target"/>
|
| 83 |
+
|
| 84 |
+
<geom name="terrain" type="hfield" hfield="terrain" rgba=".2 .3 .4 1" pos="0 0 -.01"/>
|
| 85 |
+
|
| 86 |
+
<camera name="global" pos="-10 10 10" xyaxes="-1 -1 0 1 0 1" mode="trackcom"/>
|
| 87 |
+
<body name="torso" childclass="body" pos="0 0 .57">
|
| 88 |
+
<freejoint name="root"/>
|
| 89 |
+
|
| 90 |
+
<camera name="x" pos="-1.7 0 1" xyaxes="0 -1 0 .75 0 1" mode="trackcom"/>
|
| 91 |
+
<camera name="y" pos="0 4 2" xyaxes="-1 0 0 0 -.5 1" mode="trackcom"/>
|
| 92 |
+
<camera name="egocentric" pos=".3 0 .11" xyaxes="0 -1 0 .4 0 1" fovy="60"/>
|
| 93 |
+
<light name="light" pos="0 0 4" mode="trackcom"/>
|
| 94 |
+
|
| 95 |
+
<geom name="eye_r" type="cylinder" size=".05" fromto=".1 -.07 .12 .31 -.07 .08" mass="0"/>
|
| 96 |
+
<site name="pupil_r" type="sphere" size=".033" pos=".3 -.07 .08" zaxis="1 0 0" material="eye"/>
|
| 97 |
+
<geom name="eye_l" type="cylinder" size=".05" fromto=".1 .07 .12 .31 .07 .08" mass="0"/>
|
| 98 |
+
<site name="pupil_l" type="sphere" size=".033" pos=".3 .07 .08" zaxis="1 0 0" material="eye"/>
|
| 99 |
+
<site name="workspace" type="sphere" size=".3 .3 .3" material="site" pos=".8 0 -.2" group="3"/>
|
| 100 |
+
|
| 101 |
+
<site name="rf_00" class="rangefinder" fromto=".41 -.02 .11 .34 0 .115"/>
|
| 102 |
+
<site name="rf_01" class="rangefinder" fromto=".41 -.01 .11 .34 0 .115"/>
|
| 103 |
+
<site name="rf_02" class="rangefinder" fromto=".41 0 .11 .34 0 .115"/>
|
| 104 |
+
<site name="rf_03" class="rangefinder" fromto=".41 .01 .11 .34 0 .115"/>
|
| 105 |
+
<site name="rf_04" class="rangefinder" fromto=".41 .02 .11 .34 0 .115"/>
|
| 106 |
+
<site name="rf_10" class="rangefinder" fromto=".41 -.02 .1 .36 0 .11"/>
|
| 107 |
+
<site name="rf_11" class="rangefinder" fromto=".41 -.02 .1 .36 0 .11"/>
|
| 108 |
+
<site name="rf_12" class="rangefinder" fromto=".41 0 .1 .36 0 .11"/>
|
| 109 |
+
<site name="rf_13" class="rangefinder" fromto=".41 .01 .1 .36 0 .11"/>
|
| 110 |
+
<site name="rf_14" class="rangefinder" fromto=".41 .02 .1 .36 0 .11"/>
|
| 111 |
+
<site name="rf_20" class="rangefinder" fromto=".41 -.02 .09 .38 0 .105"/>
|
| 112 |
+
<site name="rf_21" class="rangefinder" fromto=".41 -.01 .09 .38 0 .105"/>
|
| 113 |
+
<site name="rf_22" class="rangefinder" fromto=".41 0 .09 .38 0 .105"/>
|
| 114 |
+
<site name="rf_23" class="rangefinder" fromto=".41 .01 .09 .38 0 .105"/>
|
| 115 |
+
<site name="rf_24" class="rangefinder" fromto=".41 .02 .09 .38 0 .105"/>
|
| 116 |
+
<site name="rf_30" class="rangefinder" fromto=".41 -.02 .08 .4 0 .1"/>
|
| 117 |
+
<site name="rf_31" class="rangefinder" fromto=".41 -.01 .08 .4 0 .1"/>
|
| 118 |
+
<site name="rf_32" class="rangefinder" fromto=".41 0 .08 .4 0 .1"/>
|
| 119 |
+
<site name="rf_33" class="rangefinder" fromto=".41 .01 .08 .4 0 .1"/>
|
| 120 |
+
<site name="rf_34" class="rangefinder" fromto=".41 .02 .08 .4 0 .1"/>
|
| 121 |
+
|
| 122 |
+
<geom name="torso" type="ellipsoid" size=".3 .27 .2" density="1000"/>
|
| 123 |
+
<site name="torso_touch" type="box" size=".26 .26 .26" rgba="0 0 1 0"/>
|
| 124 |
+
<site name="torso" size=".05" rgba="1 0 0 1" />
|
| 125 |
+
|
| 126 |
+
<body name="hip_front_left" pos=".2 .2 0" euler="0 0 45" childclass="hip">
|
| 127 |
+
<joint name="yaw_front_left" class="yaw"/>
|
| 128 |
+
<joint name="pitch_front_left" class="pitch"/>
|
| 129 |
+
<geom name="thigh_front_left"/>
|
| 130 |
+
<body name="knee_front_left" pos=".3 0 .11" childclass="knee">
|
| 131 |
+
<joint name="knee_front_left"/>
|
| 132 |
+
<geom name="shin_front_left"/>
|
| 133 |
+
<body name="ankle_front_left" pos=".25 0 -.25" childclass="ankle">
|
| 134 |
+
<joint name="ankle_front_left"/>
|
| 135 |
+
<geom name="foot_front_left"/>
|
| 136 |
+
<body name="toe_front_left" pos="0 0 -.3" childclass="toe">
|
| 137 |
+
<geom name="toe_front_left"/>
|
| 138 |
+
<site name="toe_front_left"/>
|
| 139 |
+
</body>
|
| 140 |
+
</body>
|
| 141 |
+
</body>
|
| 142 |
+
</body>
|
| 143 |
+
|
| 144 |
+
<body name="hip_front_right" pos=".2 -.2 0" euler="0 0 -45" childclass="hip">
|
| 145 |
+
<joint name="yaw_front_right" class="yaw"/>
|
| 146 |
+
<joint name="pitch_front_right" class="pitch"/>
|
| 147 |
+
<geom name="thigh_front_right"/>
|
| 148 |
+
<body name="knee_front_right" pos=".3 0 .11" childclass="knee">
|
| 149 |
+
<joint name="knee_front_right"/>
|
| 150 |
+
<geom name="shin_front_right"/>
|
| 151 |
+
<body name="ankle_front_right" pos=".25 0 -.25" childclass="ankle">
|
| 152 |
+
<joint name="ankle_front_right"/>
|
| 153 |
+
<geom name="foot_front_right"/>
|
| 154 |
+
<body name="toe_front_right" pos="0 0 -.3" childclass="toe">
|
| 155 |
+
<geom name="toe_front_right"/>
|
| 156 |
+
<site name="toe_front_right"/>
|
| 157 |
+
</body>
|
| 158 |
+
</body>
|
| 159 |
+
</body>
|
| 160 |
+
</body>
|
| 161 |
+
|
| 162 |
+
<body name="hip_back_right" pos="-.2 -.2 0" euler="0 0 -135" childclass="hip">
|
| 163 |
+
<joint name="yaw_back_right" class="yaw"/>
|
| 164 |
+
<joint name="pitch_back_right" class="pitch"/>
|
| 165 |
+
<geom name="thigh_back_right"/>
|
| 166 |
+
<body name="knee_back_right" pos=".3 0 .11" childclass="knee">
|
| 167 |
+
<joint name="knee_back_right"/>
|
| 168 |
+
<geom name="shin_back_right"/>
|
| 169 |
+
<body name="ankle_back_right" pos=".25 0 -.25" childclass="ankle">
|
| 170 |
+
<joint name="ankle_back_right"/>
|
| 171 |
+
<geom name="foot_back_right"/>
|
| 172 |
+
<body name="toe_back_right" pos="0 0 -.3" childclass="toe">
|
| 173 |
+
<geom name="toe_back_right"/>
|
| 174 |
+
<site name="toe_back_right"/>
|
| 175 |
+
</body>
|
| 176 |
+
</body>
|
| 177 |
+
</body>
|
| 178 |
+
</body>
|
| 179 |
+
|
| 180 |
+
<body name="hip_back_left" pos="-.2 .2 0" euler="0 0 135" childclass="hip">
|
| 181 |
+
<joint name="yaw_back_left" class="yaw"/>
|
| 182 |
+
<joint name="pitch_back_left" class="pitch"/>
|
| 183 |
+
<geom name="thigh_back_left"/>
|
| 184 |
+
<body name="knee_back_left" pos=".3 0 .11" childclass="knee">
|
| 185 |
+
<joint name="knee_back_left"/>
|
| 186 |
+
<geom name="shin_back_left"/>
|
| 187 |
+
<body name="ankle_back_left" pos=".25 0 -.25" childclass="ankle">
|
| 188 |
+
<joint name="ankle_back_left"/>
|
| 189 |
+
<geom name="foot_back_left"/>
|
| 190 |
+
<body name="toe_back_left" pos="0 0 -.3" childclass="toe">
|
| 191 |
+
<geom name="toe_back_left"/>
|
| 192 |
+
<site name="toe_back_left"/>
|
| 193 |
+
</body>
|
| 194 |
+
</body>
|
| 195 |
+
</body>
|
| 196 |
+
</body>
|
| 197 |
+
</body>
|
| 198 |
+
|
| 199 |
+
<body name="ball" pos="0 0 3">
|
| 200 |
+
<freejoint name="ball_root"/>
|
| 201 |
+
<geom name="ball" size=".15" material="ball" priority="1" condim="6" friction=".7 .005 .005"
|
| 202 |
+
solref="-10000 -30"/>
|
| 203 |
+
<light name="ball_light" pos="0 0 4" mode="trackcom"/>
|
| 204 |
+
</body>
|
| 205 |
+
|
| 206 |
+
</worldbody>
|
| 207 |
+
|
| 208 |
+
<tendon>
|
| 209 |
+
<fixed name="coupling_front_left">
|
| 210 |
+
<joint joint="pitch_front_left" coef=".333"/>
|
| 211 |
+
<joint joint="knee_front_left" coef=".333"/>
|
| 212 |
+
<joint joint="ankle_front_left" coef=".333"/>
|
| 213 |
+
</fixed>
|
| 214 |
+
<fixed name="coupling_front_right">
|
| 215 |
+
<joint joint="pitch_front_right" coef=".333"/>
|
| 216 |
+
<joint joint="knee_front_right" coef=".333"/>
|
| 217 |
+
<joint joint="ankle_front_right" coef=".333"/>
|
| 218 |
+
</fixed>
|
| 219 |
+
<fixed name="coupling_back_right">
|
| 220 |
+
<joint joint="pitch_back_right" coef=".333"/>
|
| 221 |
+
<joint joint="knee_back_right" coef=".333"/>
|
| 222 |
+
<joint joint="ankle_back_right" coef=".333"/>
|
| 223 |
+
</fixed>
|
| 224 |
+
<fixed name="coupling_back_left">
|
| 225 |
+
<joint joint="pitch_back_left" coef=".333"/>
|
| 226 |
+
<joint joint="knee_back_left" coef=".333"/>
|
| 227 |
+
<joint joint="ankle_back_left" coef=".333"/>
|
| 228 |
+
</fixed>
|
| 229 |
+
|
| 230 |
+
<fixed name="extend_front_left">
|
| 231 |
+
<joint joint="pitch_front_left" coef=".25"/>
|
| 232 |
+
<joint joint="knee_front_left" coef="-.5"/>
|
| 233 |
+
<joint joint="ankle_front_left" coef=".25"/>
|
| 234 |
+
</fixed>
|
| 235 |
+
<fixed name="lift_front_left">
|
| 236 |
+
<joint joint="pitch_front_left" coef=".5"/>
|
| 237 |
+
<joint joint="ankle_front_left" coef="-.5"/>
|
| 238 |
+
</fixed>
|
| 239 |
+
|
| 240 |
+
<fixed name="extend_front_right">
|
| 241 |
+
<joint joint="pitch_front_right" coef=".25"/>
|
| 242 |
+
<joint joint="knee_front_right" coef="-.5"/>
|
| 243 |
+
<joint joint="ankle_front_right" coef=".25"/>
|
| 244 |
+
</fixed>
|
| 245 |
+
<fixed name="lift_front_right">
|
| 246 |
+
<joint joint="pitch_front_right" coef=".5"/>
|
| 247 |
+
<joint joint="ankle_front_right" coef="-.5"/>
|
| 248 |
+
</fixed>
|
| 249 |
+
|
| 250 |
+
<fixed name="extend_back_right">
|
| 251 |
+
<joint joint="pitch_back_right" coef=".25"/>
|
| 252 |
+
<joint joint="knee_back_right" coef="-.5"/>
|
| 253 |
+
<joint joint="ankle_back_right" coef=".25"/>
|
| 254 |
+
</fixed>
|
| 255 |
+
<fixed name="lift_back_right">
|
| 256 |
+
<joint joint="pitch_back_right" coef=".5"/>
|
| 257 |
+
<joint joint="ankle_back_right" coef="-.5"/>
|
| 258 |
+
</fixed>
|
| 259 |
+
|
| 260 |
+
<fixed name="extend_back_left">
|
| 261 |
+
<joint joint="pitch_back_left" coef=".25"/>
|
| 262 |
+
<joint joint="knee_back_left" coef="-.5"/>
|
| 263 |
+
<joint joint="ankle_back_left" coef=".25"/>
|
| 264 |
+
</fixed>
|
| 265 |
+
<fixed name="lift_back_left">
|
| 266 |
+
<joint joint="pitch_back_left" coef=".5"/>
|
| 267 |
+
<joint joint="ankle_back_left" coef="-.5"/>
|
| 268 |
+
</fixed>
|
| 269 |
+
</tendon>
|
| 270 |
+
|
| 271 |
+
<equality>
|
| 272 |
+
<tendon name="coupling_front_left" tendon1="coupling_front_left" class="coupling"/>
|
| 273 |
+
<tendon name="coupling_front_right" tendon1="coupling_front_right" class="coupling"/>
|
| 274 |
+
<tendon name="coupling_back_right" tendon1="coupling_back_right" class="coupling"/>
|
| 275 |
+
<tendon name="coupling_back_left" tendon1="coupling_back_left" class="coupling"/>
|
| 276 |
+
</equality>
|
| 277 |
+
|
| 278 |
+
<actuator>
|
| 279 |
+
<general name="yaw_front_left" class="yaw_act" joint="yaw_front_left"/>
|
| 280 |
+
<general name="lift_front_left" class="lift_act" tendon="lift_front_left"/>
|
| 281 |
+
<general name="extend_front_left" class="extend_act" tendon="extend_front_left"/>
|
| 282 |
+
<general name="yaw_front_right" class="yaw_act" joint="yaw_front_right"/>
|
| 283 |
+
<general name="lift_front_right" class="lift_act" tendon="lift_front_right"/>
|
| 284 |
+
<general name="extend_front_right" class="extend_act" tendon="extend_front_right"/>
|
| 285 |
+
<general name="yaw_back_right" class="yaw_act" joint="yaw_back_right"/>
|
| 286 |
+
<general name="lift_back_right" class="lift_act" tendon="lift_back_right"/>
|
| 287 |
+
<general name="extend_back_right" class="extend_act" tendon="extend_back_right"/>
|
| 288 |
+
<general name="yaw_back_left" class="yaw_act" joint="yaw_back_left"/>
|
| 289 |
+
<general name="lift_back_left" class="lift_act" tendon="lift_back_left"/>
|
| 290 |
+
<general name="extend_back_left" class="extend_act" tendon="extend_back_left"/>
|
| 291 |
+
</actuator>
|
| 292 |
+
|
| 293 |
+
<sensor>
|
| 294 |
+
<accelerometer name="imu_accel" site="torso"/>
|
| 295 |
+
<gyro name="imu_gyro" site="torso"/>
|
| 296 |
+
<velocimeter name="velocimeter" site="torso"/>
|
| 297 |
+
<force name="force_toe_front_left" site="toe_front_left"/>
|
| 298 |
+
<force name="force_toe_front_right" site="toe_front_right"/>
|
| 299 |
+
<force name="force_toe_back_right" site="toe_back_right"/>
|
| 300 |
+
<force name="force_toe_back_left" site="toe_back_left"/>
|
| 301 |
+
<torque name="torque_toe_front_left" site="toe_front_left"/>
|
| 302 |
+
<torque name="torque_toe_front_right" site="toe_front_right"/>
|
| 303 |
+
<torque name="torque_toe_back_right" site="toe_back_right"/>
|
| 304 |
+
<torque name="torque_toe_back_left" site="toe_back_left"/>
|
| 305 |
+
<subtreecom name="center_of_mass" body="torso"/>
|
| 306 |
+
<rangefinder name="rf_00" site="rf_00"/>
|
| 307 |
+
<rangefinder name="rf_01" site="rf_01"/>
|
| 308 |
+
<rangefinder name="rf_02" site="rf_02"/>
|
| 309 |
+
<rangefinder name="rf_03" site="rf_03"/>
|
| 310 |
+
<rangefinder name="rf_04" site="rf_04"/>
|
| 311 |
+
<rangefinder name="rf_10" site="rf_10"/>
|
| 312 |
+
<rangefinder name="rf_11" site="rf_11"/>
|
| 313 |
+
<rangefinder name="rf_12" site="rf_12"/>
|
| 314 |
+
<rangefinder name="rf_13" site="rf_13"/>
|
| 315 |
+
<rangefinder name="rf_14" site="rf_14"/>
|
| 316 |
+
<rangefinder name="rf_20" site="rf_20"/>
|
| 317 |
+
<rangefinder name="rf_21" site="rf_21"/>
|
| 318 |
+
<rangefinder name="rf_22" site="rf_22"/>
|
| 319 |
+
<rangefinder name="rf_23" site="rf_23"/>
|
| 320 |
+
<rangefinder name="rf_24" site="rf_24"/>
|
| 321 |
+
<rangefinder name="rf_30" site="rf_30"/>
|
| 322 |
+
<rangefinder name="rf_31" site="rf_31"/>
|
| 323 |
+
<rangefinder name="rf_32" site="rf_32"/>
|
| 324 |
+
<rangefinder name="rf_33" site="rf_33"/>
|
| 325 |
+
<rangefinder name="rf_34" site="rf_34"/>
|
| 326 |
+
</sensor>
|
| 327 |
+
|
| 328 |
+
</mujoco>
|
envs/custom_dmc_tasks/stickman.py
ADDED
|
@@ -0,0 +1,647 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2017 The dm_control Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
# ============================================================================
|
| 15 |
+
"""Stickman Domain."""
|
| 16 |
+
|
| 17 |
+
from __future__ import absolute_import
|
| 18 |
+
from __future__ import division
|
| 19 |
+
from __future__ import print_function
|
| 20 |
+
|
| 21 |
+
import collections
|
| 22 |
+
import os
|
| 23 |
+
import numpy as np
|
| 24 |
+
import types
|
| 25 |
+
|
| 26 |
+
from dm_control import mujoco
|
| 27 |
+
from dm_control.rl import control
|
| 28 |
+
from dm_control.suite import base
|
| 29 |
+
from dm_control.suite import common
|
| 30 |
+
from dm_control.suite.utils import randomizers
|
| 31 |
+
from dm_control.utils import containers
|
| 32 |
+
from dm_control.utils import rewards
|
| 33 |
+
from dm_control.utils import io as resources
|
| 34 |
+
from dm_control import suite
|
| 35 |
+
|
| 36 |
+
class StickmanYogaPoses:
|
| 37 |
+
lie_back = [ -1.2 , 0. , -1.57, 0, 0. , 0.0, 0, -0., 0.0]
|
| 38 |
+
lie_front = [-1.2, -0, 1.57, 0, 0, 0, 0, 0., 0.]
|
| 39 |
+
legs_up = [ -1.24 , 0. , -1.57, 1.57, 0. , 0.0, 1.57, -0., 0.0]
|
| 40 |
+
|
| 41 |
+
kneel = [ -0.5 , 0. , 0, 0, -1.57, -0.8, 1.57, -1.57, 0.0]
|
| 42 |
+
side_angle = [ -0.3 , 0. , 0.9, 0, 0, -0.7, 1.87, -1.07, 0.0]
|
| 43 |
+
stand_up = [-0.15, 0., 0.34, 0.74, -1.34, -0., 1.1, -0.66, -0.1]
|
| 44 |
+
|
| 45 |
+
lean_back = [-0.27, 0., -0.45, 0.22, -1.5, 0.86, 0.6, -0.8, -0.4]
|
| 46 |
+
boat = [ -1.04 , 0. , -0.8, 1.6, 0. , 0.0, 1.6, -0., 0.0]
|
| 47 |
+
bridge = [-1.1, 0., -2.2, -0.3, -1.5, 0., -0.3, -0.8, -0.4]
|
| 48 |
+
|
| 49 |
+
head_stand = [-1, 0., -3, 0.6, -1, -0.3, 0.9, -0.5, 0.3]
|
| 50 |
+
one_feet = [-0.2, 0., 0, 0.7, -1.34, 0.5, 1.5, -0.6, 0.1]
|
| 51 |
+
arabesque = [-0.34, 0., 1.57, 1.57, 0, 0., 0, -0., 0.]
|
| 52 |
+
|
| 53 |
+
# new
|
| 54 |
+
high_kick = [-0.165, 3.3 , 5.55 , 1.35 ,-0, +0.5 , -0.7, 0. , 0.2,]
|
| 55 |
+
splits = [-0.7, 0., 0.5, -0.7, -1. , 0, 1.75, 0., -0.45 ]
|
| 56 |
+
sit_knees = [-0.6, -0.2, 0.2, 0.95, -2.5, 0 , 0.95, -2.5, 0 ]
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
_DEFAULT_TIME_LIMIT = 25
|
| 60 |
+
_CONTROL_TIMESTEP = .025
|
| 61 |
+
|
| 62 |
+
# Minimal height of torso over foot above which stand reward is 1.
|
| 63 |
+
_STAND_HEIGHT = 1.15
|
| 64 |
+
|
| 65 |
+
# Horizontal speeds (meters/second) above which move reward is 1.
|
| 66 |
+
_WALK_SPEED = 1
|
| 67 |
+
_RUN_SPEED = 8
|
| 68 |
+
|
| 69 |
+
# Copied from walker:
|
| 70 |
+
_YOGA_HANDS_UP_HEIGHT = 1.75
|
| 71 |
+
_YOGA_STAND_HEIGHT = 1.0 # lower than stan height = 1.2
|
| 72 |
+
_YOGA_LIE_DOWN_HEIGHT = 0.1
|
| 73 |
+
_YOGA_LEGS_UP_HEIGHT = 1.1
|
| 74 |
+
|
| 75 |
+
_YOGA_FEET_UP_HEIGHT = 0.5
|
| 76 |
+
_YOGA_FEET_UP_LIE_DOWN_HEIGHT = 0.35
|
| 77 |
+
|
| 78 |
+
_YOGA_KNEE_HEIGHT = 0.25
|
| 79 |
+
_YOGA_KNEESTAND_HEIGHT = 0.75
|
| 80 |
+
|
| 81 |
+
_YOGA_SITTING_HEIGHT = 0.55
|
| 82 |
+
_YOGA_SITTING_LEGS_HEIGHT = 0.15
|
| 83 |
+
|
| 84 |
+
# speed from: https://github.com/rll-research/url_benchmark/blob/710c3eb/custom_dmc_tasks/py
|
| 85 |
+
_SPIN_SPEED = 5.0
|
| 86 |
+
#
|
| 87 |
+
_PUNCH_SPEED = 5.0
|
| 88 |
+
_PUNCH_DIST = 0.29
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
SUITE = containers.TaggedTasks()
|
| 92 |
+
|
| 93 |
+
def make(task,
|
| 94 |
+
task_kwargs=None,
|
| 95 |
+
environment_kwargs=None,
|
| 96 |
+
visualize_reward=False):
|
| 97 |
+
task_kwargs = task_kwargs or {}
|
| 98 |
+
if environment_kwargs is not None:
|
| 99 |
+
task_kwargs = task_kwargs.copy()
|
| 100 |
+
task_kwargs['environment_kwargs'] = environment_kwargs
|
| 101 |
+
env = SUITE[task](**task_kwargs)
|
| 102 |
+
env.task.visualize_reward = visualize_reward
|
| 103 |
+
return env
|
| 104 |
+
|
| 105 |
+
def get_model_and_assets():
|
| 106 |
+
"""Returns a tuple containing the model XML string and a dict of assets."""
|
| 107 |
+
root_dir = os.path.dirname(os.path.dirname(__file__))
|
| 108 |
+
xml = resources.GetResource(os.path.join(root_dir, 'custom_dmc_tasks', 'stickman.xml'))
|
| 109 |
+
return xml, common.ASSETS
|
| 110 |
+
|
| 111 |
+
@SUITE.add('custom')
|
| 112 |
+
def hands_up(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 113 |
+
"""Returns the hands_up task."""
|
| 114 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 115 |
+
task = Stickman(goal='hands_up', random=random)
|
| 116 |
+
environment_kwargs = environment_kwargs or {}
|
| 117 |
+
return control.Environment(
|
| 118 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 119 |
+
**environment_kwargs)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
@SUITE.add('custom')
|
| 123 |
+
def boxing(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 124 |
+
"""Returns the boxing task."""
|
| 125 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 126 |
+
task = Stickman(goal='boxing', random=random)
|
| 127 |
+
environment_kwargs = environment_kwargs or {}
|
| 128 |
+
return control.Environment(
|
| 129 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 130 |
+
**environment_kwargs)
|
| 131 |
+
|
| 132 |
+
@SUITE.add('custom')
|
| 133 |
+
def arabesque(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 134 |
+
"""Returns the Arabesque task."""
|
| 135 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 136 |
+
task = Stickman(goal='arabesque', random=random)
|
| 137 |
+
environment_kwargs = environment_kwargs or {}
|
| 138 |
+
return control.Environment(
|
| 139 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 140 |
+
**environment_kwargs)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
@SUITE.add('custom')
|
| 144 |
+
def lying_down(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 145 |
+
"""Returns the Lie Down task."""
|
| 146 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 147 |
+
task = Stickman(goal='lying_down', random=random)
|
| 148 |
+
environment_kwargs = environment_kwargs or {}
|
| 149 |
+
return control.Environment(
|
| 150 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 151 |
+
**environment_kwargs)
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
@SUITE.add('custom')
|
| 155 |
+
def legs_up(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 156 |
+
"""Returns the Legs Up task."""
|
| 157 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 158 |
+
task = Stickman(goal='legs_up', random=random)
|
| 159 |
+
environment_kwargs = environment_kwargs or {}
|
| 160 |
+
return control.Environment(
|
| 161 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 162 |
+
**environment_kwargs)
|
| 163 |
+
|
| 164 |
+
@SUITE.add('custom')
|
| 165 |
+
def high_kick(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 166 |
+
"""Returns the High Kick task."""
|
| 167 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 168 |
+
task = Stickman(goal='high_kick', random=random)
|
| 169 |
+
environment_kwargs = environment_kwargs or {}
|
| 170 |
+
return control.Environment(
|
| 171 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 172 |
+
**environment_kwargs)
|
| 173 |
+
|
| 174 |
+
@SUITE.add('custom')
|
| 175 |
+
def one_foot(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 176 |
+
"""Returns the High Kick task."""
|
| 177 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 178 |
+
task = Stickman(goal='one_foot', random=random)
|
| 179 |
+
environment_kwargs = environment_kwargs or {}
|
| 180 |
+
return control.Environment(
|
| 181 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 182 |
+
**environment_kwargs)
|
| 183 |
+
|
| 184 |
+
@SUITE.add('custom')
|
| 185 |
+
def lunge_pose(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 186 |
+
"""Returns the High Kick task."""
|
| 187 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 188 |
+
task = Stickman(goal='lunge_pose', random=random)
|
| 189 |
+
environment_kwargs = environment_kwargs or {}
|
| 190 |
+
return control.Environment(
|
| 191 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 192 |
+
**environment_kwargs)
|
| 193 |
+
|
| 194 |
+
@SUITE.add('custom')
|
| 195 |
+
def sit_knees(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 196 |
+
"""Returns the High Kick task."""
|
| 197 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 198 |
+
task = Stickman(goal='sit_knees', random=random)
|
| 199 |
+
environment_kwargs = environment_kwargs or {}
|
| 200 |
+
return control.Environment(
|
| 201 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 202 |
+
**environment_kwargs)
|
| 203 |
+
|
| 204 |
+
@SUITE.add('custom')
|
| 205 |
+
def headstand(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 206 |
+
"""Returns the Headstand task."""
|
| 207 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 208 |
+
task = Stickman(goal='flip', move_speed=0, random=random)
|
| 209 |
+
environment_kwargs = environment_kwargs or {}
|
| 210 |
+
return control.Environment(
|
| 211 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 212 |
+
**environment_kwargs)
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
@SUITE.add('custom')
|
| 216 |
+
def urlb_flip(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 217 |
+
"""Returns the Flip task."""
|
| 218 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 219 |
+
task = Stickman(goal='urlb_flip', move_speed=_SPIN_SPEED, random=random)
|
| 220 |
+
environment_kwargs = environment_kwargs or {}
|
| 221 |
+
return control.Environment(
|
| 222 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 223 |
+
**environment_kwargs)
|
| 224 |
+
|
| 225 |
+
@SUITE.add('custom')
|
| 226 |
+
def flipping(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 227 |
+
"""Returns the Flipping task."""
|
| 228 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 229 |
+
task = Stickman(goal='flipping', move_speed=2 * _RUN_SPEED, random=random)
|
| 230 |
+
environment_kwargs = environment_kwargs or {}
|
| 231 |
+
return control.Environment(
|
| 232 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 233 |
+
**environment_kwargs)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
@SUITE.add('custom')
|
| 237 |
+
def flip(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 238 |
+
"""Returns the Flip task."""
|
| 239 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 240 |
+
task = Stickman(goal='flip', move_speed=2 * _RUN_SPEED, random=random)
|
| 241 |
+
environment_kwargs = environment_kwargs or {}
|
| 242 |
+
return control.Environment(
|
| 243 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 244 |
+
**environment_kwargs)
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
@SUITE.add('custom')
|
| 248 |
+
def backflip(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 249 |
+
"""Returns the Backflip task."""
|
| 250 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 251 |
+
task = Stickman(goal='flip', move_speed=-2 * _RUN_SPEED, random=random)
|
| 252 |
+
environment_kwargs = environment_kwargs or {}
|
| 253 |
+
return control.Environment(
|
| 254 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 255 |
+
**environment_kwargs)
|
| 256 |
+
|
| 257 |
+
@SUITE.add('custom')
|
| 258 |
+
def stand(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 259 |
+
"""Returns the Stand task."""
|
| 260 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 261 |
+
task = Stickman(move_speed=0, goal='stand', random=random)
|
| 262 |
+
environment_kwargs = environment_kwargs or {}
|
| 263 |
+
return control.Environment(
|
| 264 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 265 |
+
**environment_kwargs)
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
@SUITE.add('custom')
|
| 269 |
+
def walk(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 270 |
+
"""Returns the Walk task."""
|
| 271 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 272 |
+
task = Stickman(move_speed=_WALK_SPEED, goal='walk', random=random)
|
| 273 |
+
environment_kwargs = environment_kwargs or {}
|
| 274 |
+
return control.Environment(
|
| 275 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 276 |
+
**environment_kwargs)
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
@SUITE.add('custom')
|
| 280 |
+
def run(time_limit=_DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 281 |
+
"""Returns the Run task."""
|
| 282 |
+
physics = Physics.from_xml_string(*get_model_and_assets())
|
| 283 |
+
task = Stickman(move_speed=_RUN_SPEED, goal='run', random=random)
|
| 284 |
+
environment_kwargs = environment_kwargs or {}
|
| 285 |
+
return control.Environment(
|
| 286 |
+
physics, task, time_limit=time_limit, control_timestep=_CONTROL_TIMESTEP,
|
| 287 |
+
**environment_kwargs)
|
| 288 |
+
|
| 289 |
+
class Physics(mujoco.Physics):
|
| 290 |
+
"""Physics simulation with additional features for the stickman domain."""
|
| 291 |
+
def torso_upright(self):
|
| 292 |
+
"""Returns projection from z-axes of torso to the z-axes of world."""
|
| 293 |
+
return self.named.data.xmat['torso', 'zz']
|
| 294 |
+
|
| 295 |
+
def torso_height(self):
|
| 296 |
+
"""Returns the height of the torso."""
|
| 297 |
+
return self.named.data.xpos['torso', 'z']
|
| 298 |
+
|
| 299 |
+
def horizontal_velocity(self):
|
| 300 |
+
"""Returns the horizontal velocity of the center-of-mass."""
|
| 301 |
+
return self.named.data.sensordata['torso_subtreelinvel'][0]
|
| 302 |
+
|
| 303 |
+
def orientations(self):
|
| 304 |
+
"""Returns planar orientations of all bodies."""
|
| 305 |
+
return self.named.data.xmat[1:, ['xx', 'xz']].ravel()
|
| 306 |
+
|
| 307 |
+
def angmomentum(self):
|
| 308 |
+
"""Returns the angular momentum of torso of the stickman about Y axis."""
|
| 309 |
+
return self.named.data.subtree_angmom['torso'][1]
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
class Stickman(base.Task):
|
| 313 |
+
"""A planar stickman task."""
|
| 314 |
+
def __init__(self, move_speed=0., goal='walk', forward=True, random=None):
|
| 315 |
+
"""Initializes an instance of `Stickman`.
|
| 316 |
+
|
| 317 |
+
Args:
|
| 318 |
+
move_speed: A float. If this value is zero, reward is given simply for
|
| 319 |
+
standing up. Otherwise this specifies a target horizontal velocity for
|
| 320 |
+
the walking task.
|
| 321 |
+
random: Optional, either a `numpy.random.RandomState` instance, an
|
| 322 |
+
integer seed for creating a new `RandomState`, or None to select a seed
|
| 323 |
+
automatically (default).
|
| 324 |
+
"""
|
| 325 |
+
self._move_speed = move_speed
|
| 326 |
+
self._forward = 1 if forward else -1
|
| 327 |
+
self._goal = goal
|
| 328 |
+
super().__init__(random=random)
|
| 329 |
+
|
| 330 |
+
def _hands_up_reward(self, physics):
|
| 331 |
+
standing = self._stand_reward(physics)
|
| 332 |
+
left_hand_height = physics.named.data.xpos['left_hand', 'z']
|
| 333 |
+
right_hand_height = physics.named.data.xpos['right_hand', 'z']
|
| 334 |
+
|
| 335 |
+
hand_height = (left_hand_height + right_hand_height) / 2
|
| 336 |
+
|
| 337 |
+
hands_up = rewards.tolerance(hand_height,
|
| 338 |
+
bounds=(_YOGA_HANDS_UP_HEIGHT, float('inf')),
|
| 339 |
+
margin=_YOGA_HANDS_UP_HEIGHT/2)
|
| 340 |
+
return standing * hands_up
|
| 341 |
+
|
| 342 |
+
def _boxing_reward(self, physics):
|
| 343 |
+
# torso up, but lower than standing
|
| 344 |
+
# foot up, higher than torso
|
| 345 |
+
# foot down
|
| 346 |
+
standing = self._stand_reward(physics)
|
| 347 |
+
|
| 348 |
+
left_hand_velocity = abs(physics.named.data.subtree_linvel['left_hand'][0])
|
| 349 |
+
right_hand_velocity = abs(physics.named.data.subtree_linvel['right_hand'][0])
|
| 350 |
+
punch_reward = rewards.tolerance(
|
| 351 |
+
max(left_hand_velocity, right_hand_velocity),
|
| 352 |
+
bounds=(_PUNCH_SPEED, float('inf')),
|
| 353 |
+
margin=_PUNCH_SPEED / 2,
|
| 354 |
+
value_at_margin=0.5,
|
| 355 |
+
sigmoid='linear')
|
| 356 |
+
|
| 357 |
+
# left_hand_dist = physics.named.data.xpos['left_hand', 'x'] - physics.named.data.xpos['torso', 'x']
|
| 358 |
+
# right_hand_dist = physics.named.data.xpos['right_hand', 'x'] - physics.named.data.xpos['torso', 'x']
|
| 359 |
+
# punch_reward = rewards.tolerance(
|
| 360 |
+
# max(left_hand_dist, right_hand_dist),
|
| 361 |
+
# bounds=(_PUNCH_DIST, float('inf')),
|
| 362 |
+
# margin=_PUNCH_DIST / 2,)
|
| 363 |
+
|
| 364 |
+
return standing * punch_reward
|
| 365 |
+
|
| 366 |
+
def _arabesque_reward(self, physics):
|
| 367 |
+
# standing horizontal
|
| 368 |
+
# one foot up, same height as torso
|
| 369 |
+
# one foot down
|
| 370 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 371 |
+
bounds=(_YOGA_STAND_HEIGHT, float('inf')),
|
| 372 |
+
margin=_YOGA_STAND_HEIGHT/2)
|
| 373 |
+
|
| 374 |
+
left_foot_height = physics.named.data.xpos['left_foot', 'z']
|
| 375 |
+
right_foot_height = physics.named.data.xpos['right_foot', 'z']
|
| 376 |
+
|
| 377 |
+
max_foot = 'right_foot' if right_foot_height > left_foot_height else 'left_foot'
|
| 378 |
+
min_foot = 'right_foot' if right_foot_height <= left_foot_height else 'left_foot'
|
| 379 |
+
|
| 380 |
+
min_foot_height = physics.named.data.xpos[min_foot, 'z']
|
| 381 |
+
max_foot_height = physics.named.data.xpos[max_foot, 'z']
|
| 382 |
+
|
| 383 |
+
min_foot_down = rewards.tolerance(min_foot_height,
|
| 384 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 385 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 386 |
+
max_foot_up = rewards.tolerance(max_foot_height,
|
| 387 |
+
bounds=(_YOGA_STAND_HEIGHT, float('inf')),
|
| 388 |
+
margin=_YOGA_STAND_HEIGHT/2)
|
| 389 |
+
|
| 390 |
+
min_foot_x = physics.named.data.xpos[min_foot, 'x']
|
| 391 |
+
max_foot_x = physics.named.data.xpos[max_foot, 'x']
|
| 392 |
+
|
| 393 |
+
correct_foot_pose = 0.1 if max_foot_x > min_foot_x else 1.0
|
| 394 |
+
|
| 395 |
+
feet_pose = (min_foot_down + max_foot_up * 2) / 3
|
| 396 |
+
return standing * feet_pose * correct_foot_pose
|
| 397 |
+
|
| 398 |
+
def _lying_down_reward(self, physics):
|
| 399 |
+
# torso down and horizontal
|
| 400 |
+
# thigh and feet down
|
| 401 |
+
torso_down = rewards.tolerance(physics.torso_height(),
|
| 402 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 403 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 404 |
+
horizontal = 1 - abs(physics.torso_upright())
|
| 405 |
+
|
| 406 |
+
thigh_height = (physics.named.data.xpos['left_thigh', 'z'] + physics.named.data.xpos['right_thigh', 'z']) / 2
|
| 407 |
+
thigh_down = rewards.tolerance(thigh_height,
|
| 408 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 409 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 410 |
+
leg_height = (physics.named.data.xpos['left_leg', 'z'] + physics.named.data.xpos['right_leg', 'z']) / 2
|
| 411 |
+
leg_down = rewards.tolerance(leg_height,
|
| 412 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 413 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 414 |
+
feet_height = (physics.named.data.xpos['left_foot', 'z'] + physics.named.data.xpos['right_foot', 'z']) / 2
|
| 415 |
+
feet_down = rewards.tolerance(feet_height,
|
| 416 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 417 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 418 |
+
return (3*torso_down + horizontal + thigh_down + feet_down + leg_down) / 7
|
| 419 |
+
|
| 420 |
+
def _legs_up_reward(self, physics):
|
| 421 |
+
# torso down and horizontal
|
| 422 |
+
# legs up with thigh down
|
| 423 |
+
torso_down = rewards.tolerance(physics.torso_height(),
|
| 424 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 425 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 426 |
+
horizontal = 1 - abs(physics.torso_upright())
|
| 427 |
+
torso_down = (3*torso_down +horizontal) / 4
|
| 428 |
+
|
| 429 |
+
feet_height = (physics.named.data.xpos['left_foot', 'z'] + physics.named.data.xpos['right_foot', 'z']) / 2
|
| 430 |
+
feet_up = rewards.tolerance(feet_height,
|
| 431 |
+
bounds=(_YOGA_FEET_UP_LIE_DOWN_HEIGHT, float('inf')),
|
| 432 |
+
margin=_YOGA_FEET_UP_LIE_DOWN_HEIGHT/2)
|
| 433 |
+
|
| 434 |
+
return torso_down * feet_up
|
| 435 |
+
|
| 436 |
+
def _high_kick_reward(self, physics):
|
| 437 |
+
# torso up, but lower than standing
|
| 438 |
+
# foot up, higher than torso
|
| 439 |
+
# foot down
|
| 440 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 441 |
+
bounds=(_YOGA_STAND_HEIGHT, float('inf')),
|
| 442 |
+
margin=_YOGA_STAND_HEIGHT/2)
|
| 443 |
+
|
| 444 |
+
left_foot_height = physics.named.data.xpos['left_foot', 'z']
|
| 445 |
+
right_foot_height = physics.named.data.xpos['right_foot', 'z']
|
| 446 |
+
|
| 447 |
+
min_foot_height = min(left_foot_height, right_foot_height)
|
| 448 |
+
max_foot_height = max(left_foot_height, right_foot_height)
|
| 449 |
+
|
| 450 |
+
min_foot_down = rewards.tolerance(min_foot_height,
|
| 451 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 452 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 453 |
+
max_foot_up = rewards.tolerance(max_foot_height,
|
| 454 |
+
bounds=(_STAND_HEIGHT, float('inf')),
|
| 455 |
+
margin=_STAND_HEIGHT/2)
|
| 456 |
+
|
| 457 |
+
feet_pose = (3 * max_foot_up + min_foot_down) / 4
|
| 458 |
+
|
| 459 |
+
return standing * feet_pose
|
| 460 |
+
|
| 461 |
+
def _one_foot_reward(self, physics):
|
| 462 |
+
# torso up, standing
|
| 463 |
+
# foot up higher than foot down
|
| 464 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 465 |
+
bounds=(_YOGA_STAND_HEIGHT, float('inf')),
|
| 466 |
+
margin=_YOGA_STAND_HEIGHT/2)
|
| 467 |
+
|
| 468 |
+
left_foot_height = physics.named.data.xpos['left_foot', 'z']
|
| 469 |
+
right_foot_height = physics.named.data.xpos['right_foot', 'z']
|
| 470 |
+
|
| 471 |
+
min_foot_height = min(left_foot_height, right_foot_height)
|
| 472 |
+
max_foot_height = max(left_foot_height, right_foot_height)
|
| 473 |
+
|
| 474 |
+
min_foot_down = rewards.tolerance(min_foot_height,
|
| 475 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 476 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 477 |
+
max_foot_up = rewards.tolerance(max_foot_height,
|
| 478 |
+
bounds=(_YOGA_FEET_UP_HEIGHT, float('inf')),
|
| 479 |
+
margin=_YOGA_FEET_UP_HEIGHT/2)
|
| 480 |
+
|
| 481 |
+
return standing * max_foot_up * min_foot_down
|
| 482 |
+
|
| 483 |
+
def _lunge_pose_reward(self, physics):
|
| 484 |
+
# torso up, standing, but lower
|
| 485 |
+
# leg up higher than leg down
|
| 486 |
+
# horiontal thigh and leg
|
| 487 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 488 |
+
bounds=(_YOGA_KNEESTAND_HEIGHT, float('inf')),
|
| 489 |
+
margin=_YOGA_KNEESTAND_HEIGHT/2)
|
| 490 |
+
upright = (1 + physics.torso_upright()) / 2
|
| 491 |
+
torso = (3*standing + upright) / 4
|
| 492 |
+
|
| 493 |
+
left_leg_height = physics.named.data.xpos['left_leg', 'z']
|
| 494 |
+
right_leg_height = physics.named.data.xpos['right_leg', 'z']
|
| 495 |
+
|
| 496 |
+
min_leg_height = min(left_leg_height, right_leg_height)
|
| 497 |
+
max_leg_height = max(left_leg_height, right_leg_height)
|
| 498 |
+
|
| 499 |
+
min_leg_down = rewards.tolerance(min_leg_height,
|
| 500 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 501 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 502 |
+
max_leg_up = rewards.tolerance(max_leg_height,
|
| 503 |
+
bounds=(_YOGA_KNEE_HEIGHT, float('inf')),
|
| 504 |
+
margin=_YOGA_KNEE_HEIGHT / 2)
|
| 505 |
+
|
| 506 |
+
max_thigh = 'left_thigh' if max_leg_height == left_leg_height else 'right_thigh'
|
| 507 |
+
min_leg = 'left_leg' if min_leg_height == left_leg_height else 'right_leg'
|
| 508 |
+
|
| 509 |
+
max_thigh_horiz = 1 - abs(physics.named.data.xmat[max_thigh, 'zz'])
|
| 510 |
+
min_leg_horiz = 1 - abs(physics.named.data.xmat[min_leg, 'zz'])
|
| 511 |
+
|
| 512 |
+
legs = (min_leg_down + max_leg_up + max_thigh_horiz + min_leg_horiz) / 4
|
| 513 |
+
|
| 514 |
+
return torso * legs
|
| 515 |
+
|
| 516 |
+
def _sit_knees_reward(self, physics):
|
| 517 |
+
# torso up, standing, but lower
|
| 518 |
+
# foot up higher than foot down
|
| 519 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 520 |
+
bounds=(_YOGA_SITTING_HEIGHT, float('inf')),
|
| 521 |
+
margin=_YOGA_SITTING_HEIGHT/2)
|
| 522 |
+
upright = (1 + physics.torso_upright()) / 2
|
| 523 |
+
torso_up = (3*standing + upright) / 4
|
| 524 |
+
|
| 525 |
+
legs_height = (physics.named.data.xpos['left_leg', 'z'] + physics.named.data.xpos['right_leg', 'z']) / 2
|
| 526 |
+
legs_down = rewards.tolerance(legs_height,
|
| 527 |
+
bounds=(-float('inf'), _YOGA_SITTING_LEGS_HEIGHT),
|
| 528 |
+
margin=_YOGA_SITTING_LEGS_HEIGHT*1.5)
|
| 529 |
+
feet_height = (physics.named.data.xpos['left_foot', 'z'] + physics.named.data.xpos['right_foot', 'z']) / 2
|
| 530 |
+
feet_down = rewards.tolerance(feet_height,
|
| 531 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 532 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 533 |
+
|
| 534 |
+
l_thigh_foot_distance = max(0.1, abs(physics.named.data.xpos['left_foot', 'x'] - physics.named.data.xpos['left_thigh', 'x'])) - 0.1
|
| 535 |
+
r_thigh_foot_distance = max(0.1, abs(physics.named.data.xpos['right_foot', 'x'] - physics.named.data.xpos['right_thigh', 'x'])) - 0.1
|
| 536 |
+
close = np.exp(-(l_thigh_foot_distance + r_thigh_foot_distance)/2)
|
| 537 |
+
|
| 538 |
+
legs = (3 * legs_down + feet_down) / 4
|
| 539 |
+
return torso_up * legs * close
|
| 540 |
+
|
| 541 |
+
def _urlb_flip_reward(self, physics):
|
| 542 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 543 |
+
bounds=(_STAND_HEIGHT, float('inf')),
|
| 544 |
+
margin=_STAND_HEIGHT / 2)
|
| 545 |
+
upright = (1 + physics.torso_upright()) / 2
|
| 546 |
+
stand_reward = (3 * standing + upright) / 4
|
| 547 |
+
move_reward = rewards.tolerance(self._forward *
|
| 548 |
+
physics.named.data.subtree_angmom['torso'][1], # physics.angmomentum(),
|
| 549 |
+
bounds=(_SPIN_SPEED, float('inf')),
|
| 550 |
+
margin=_SPIN_SPEED,
|
| 551 |
+
value_at_margin=0,
|
| 552 |
+
sigmoid='linear')
|
| 553 |
+
return stand_reward * (5 * move_reward + 1) / 6
|
| 554 |
+
|
| 555 |
+
def _flip_reward(self, physics):
|
| 556 |
+
thigh_height = (physics.named.data.xpos['left_thigh', 'z'] + physics.named.data.xpos['right_thigh', 'z']) / 2
|
| 557 |
+
thigh_up = rewards.tolerance(thigh_height,
|
| 558 |
+
bounds=(_YOGA_STAND_HEIGHT, float('inf')),
|
| 559 |
+
margin=_YOGA_STAND_HEIGHT/2)
|
| 560 |
+
feet_height = (physics.named.data.xpos['left_foot', 'z'] + physics.named.data.xpos['right_foot', 'z']) / 2
|
| 561 |
+
legs_up = rewards.tolerance(feet_height,
|
| 562 |
+
bounds=(_YOGA_LEGS_UP_HEIGHT, float('inf')),
|
| 563 |
+
margin=_YOGA_LEGS_UP_HEIGHT/2)
|
| 564 |
+
upside_down_reward = (3*legs_up + 2*thigh_up) / 5
|
| 565 |
+
if self._move_speed == 0:
|
| 566 |
+
return upside_down_reward
|
| 567 |
+
move_reward = rewards.tolerance(physics.named.data.subtree_angmom['torso'][1], # physics.angmomentum(),
|
| 568 |
+
bounds=(self._move_speed, float('inf')) if self._move_speed > 0 else (-float('inf'), self._move_speed),
|
| 569 |
+
margin=abs(self._move_speed)/2,
|
| 570 |
+
value_at_margin=0.5,
|
| 571 |
+
sigmoid='linear')
|
| 572 |
+
return upside_down_reward * (5*move_reward + 1) / 6
|
| 573 |
+
|
| 574 |
+
|
| 575 |
+
def _stand_reward(self, physics):
|
| 576 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 577 |
+
bounds=(_STAND_HEIGHT, float('inf')),
|
| 578 |
+
margin=_STAND_HEIGHT / 2)
|
| 579 |
+
upright = (1 + physics.torso_upright()) / 2
|
| 580 |
+
return (3 * standing + upright) / 4
|
| 581 |
+
|
| 582 |
+
def initialize_episode(self, physics):
|
| 583 |
+
"""Sets the state of the environment at the start of each episode.
|
| 584 |
+
|
| 585 |
+
In 'standing' mode, use initial orientation and small velocities.
|
| 586 |
+
In 'random' mode, randomize joint angles and let fall to the floor.
|
| 587 |
+
|
| 588 |
+
Args:
|
| 589 |
+
physics: An instance of `Physics`.
|
| 590 |
+
|
| 591 |
+
"""
|
| 592 |
+
randomizers.randomize_limited_and_rotational_joints(physics, self.random)
|
| 593 |
+
super().initialize_episode(physics)
|
| 594 |
+
|
| 595 |
+
def get_observation(self, physics):
|
| 596 |
+
"""Returns an observation of body orientations, height and velocites."""
|
| 597 |
+
obs = collections.OrderedDict()
|
| 598 |
+
obs['orientations'] = physics.orientations()
|
| 599 |
+
obs['height'] = physics.torso_height()
|
| 600 |
+
obs['velocity'] = physics.velocity()
|
| 601 |
+
return obs
|
| 602 |
+
|
| 603 |
+
def get_reward(self, physics):
|
| 604 |
+
"""Returns a reward to the agent."""
|
| 605 |
+
if self._goal in ['stand', 'walk', 'run']:
|
| 606 |
+
stand_reward = self._stand_reward(physics)
|
| 607 |
+
move_reward = rewards.tolerance(
|
| 608 |
+
self._forward * physics.horizontal_velocity(),
|
| 609 |
+
bounds=(self._move_speed, float('inf')),
|
| 610 |
+
margin=self._move_speed / 2,
|
| 611 |
+
value_at_margin=0.5,
|
| 612 |
+
sigmoid='linear')
|
| 613 |
+
return stand_reward * (5 * move_reward + 1) / 6
|
| 614 |
+
if self._goal == 'flipping':
|
| 615 |
+
self._move_speed = abs(self._move_speed)
|
| 616 |
+
pos_rew = self._flip_reward(physics)
|
| 617 |
+
self._move_speed = -abs(self._move_speed)
|
| 618 |
+
neg_rew = self._flip_reward(physics)
|
| 619 |
+
return max(pos_rew, neg_rew)
|
| 620 |
+
try:
|
| 621 |
+
reward_fn = getattr(self, f'_{self._goal}_reward')
|
| 622 |
+
return reward_fn(physics)
|
| 623 |
+
except Exception as e:
|
| 624 |
+
print(e)
|
| 625 |
+
raise NotImplementedError(f'Goal {self._goal} or function "_{self._goal}_reward" not implemented.')
|
| 626 |
+
|
| 627 |
+
if __name__ == '__main__':
|
| 628 |
+
from dm_control import viewer
|
| 629 |
+
import numpy as np
|
| 630 |
+
|
| 631 |
+
env = boxing()
|
| 632 |
+
env.task.visualize_reward = True
|
| 633 |
+
|
| 634 |
+
action_spec = env.action_spec()
|
| 635 |
+
|
| 636 |
+
def zero_policy(time_step):
|
| 637 |
+
print(time_step.reward)
|
| 638 |
+
return np.zeros(action_spec.shape)
|
| 639 |
+
|
| 640 |
+
ts = env.reset()
|
| 641 |
+
while True:
|
| 642 |
+
ts = env.step(zero_policy(ts))
|
| 643 |
+
|
| 644 |
+
viewer.launch(env, policy=zero_policy)
|
| 645 |
+
|
| 646 |
+
# obs = env.reset()
|
| 647 |
+
# next_obs, reward, done, info = env.step(np.zeros(6))
|
envs/custom_dmc_tasks/stickman.xml
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<mujoco model="stickman">
|
| 2 |
+
<include file="./common/skybox.xml"/>
|
| 3 |
+
<include file="./common/visual.xml"/>
|
| 4 |
+
<include file="./common/materials.xml"/>
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
<option timestep="0.0025"/>
|
| 8 |
+
|
| 9 |
+
<statistic extent="2" center="0 0 1"/>
|
| 10 |
+
|
| 11 |
+
<default>
|
| 12 |
+
<joint damping=".1" armature="0.01" limited="true" solimplimit="0 .99 .01"/>
|
| 13 |
+
<geom contype="1" conaffinity="0" friction=".7 .1 .1"/>
|
| 14 |
+
<motor ctrlrange="-1 1" ctrllimited="true"/>
|
| 15 |
+
<site size="0.01"/>
|
| 16 |
+
<default class="stickman">
|
| 17 |
+
<geom material="self" type="capsule"/>
|
| 18 |
+
<joint axis="0 -1 0"/>
|
| 19 |
+
</default>
|
| 20 |
+
</default>
|
| 21 |
+
|
| 22 |
+
<worldbody>
|
| 23 |
+
<geom name="floor" type="plane" conaffinity="1" pos="248 0 0" size="250 .8 .2" material="grid" zaxis="0 0 1"/>
|
| 24 |
+
<body name="torso" pos="0 0 1.25" childclass="stickman">
|
| 25 |
+
<light name="light" pos="0 0 2" mode="trackcom"/>
|
| 26 |
+
<camera name="side" pos="0 -2.25 1.0" euler="60 0 0" mode="trackcom"/>
|
| 27 |
+
<camera name="back" pos="-2 0 .5" xyaxes="0 -1 0 1 0 3" mode="trackcom"/>
|
| 28 |
+
<joint name="rootz" axis="0 0 1" type="slide" limited="false" armature="0" damping="0"/>
|
| 29 |
+
<joint name="rootx" axis="1 0 0" type="slide" limited="false" armature="0" damping="0"/>
|
| 30 |
+
<joint name="rooty" axis="0 1 0" type="hinge" limited="false" armature="0" damping="0"/>
|
| 31 |
+
<geom name="torso" size="0.06 0.25"/>
|
| 32 |
+
|
| 33 |
+
<body name="neck" pos="0 .0 +0.35">
|
| 34 |
+
<geom name="neck" zaxis="0 0 1" size="0.045 0.045"/>
|
| 35 |
+
<body name="head" pos="0 .0 +0.1">
|
| 36 |
+
<geom name="head" type="sphere" size=".1"/>
|
| 37 |
+
</body>
|
| 38 |
+
</body>
|
| 39 |
+
|
| 40 |
+
<body name="right_thigh" pos="0 -.05 -0.25">
|
| 41 |
+
<joint name="right_hip" range="-20 100"/>
|
| 42 |
+
<geom name="right_thigh" pos="0 0 -0.225" size="0.05 0.225"/>
|
| 43 |
+
<body name="right_leg" pos="0 0 -0.7">
|
| 44 |
+
<joint name="right_knee" pos="0 0 0.25" range="-150 0"/>
|
| 45 |
+
<geom name="right_leg" size="0.04 0.25"/>
|
| 46 |
+
<body name="right_foot" pos="0.06 0 -0.25">
|
| 47 |
+
<joint name="right_ankle" pos="-0.06 0 0" range="-45 45"/>
|
| 48 |
+
<geom name="right_foot" zaxis="1 0 0" size="0.04 0.1"/>
|
| 49 |
+
</body>
|
| 50 |
+
</body>
|
| 51 |
+
</body>
|
| 52 |
+
<body name="left_thigh" pos="0 .05 -0.25" >
|
| 53 |
+
<joint name="left_hip" range="-20 100"/>
|
| 54 |
+
<geom name="left_thigh" pos="0 0 -0.225" size="0.05 0.225"/>
|
| 55 |
+
<body name="left_leg" pos="0 0 -0.7">
|
| 56 |
+
<joint name="left_knee" pos="0 0 0.25" range="-150 0"/>
|
| 57 |
+
<geom name="left_leg" size="0.04 0.25"/>
|
| 58 |
+
<body name="left_foot" pos="0.06 0 -0.25">
|
| 59 |
+
<joint name="left_ankle" pos="-0.06 0 0" range="-45 45"/>
|
| 60 |
+
<geom name="left_foot" zaxis="1 0 0" size="0.04 0.1"/>
|
| 61 |
+
</body>
|
| 62 |
+
</body>
|
| 63 |
+
</body>
|
| 64 |
+
|
| 65 |
+
<body name="left_arm" pos="0 .05 +0.2">
|
| 66 |
+
<joint name="left_shoulder" range="-20 100"/>
|
| 67 |
+
<geom name="left_arm" pos="0 0 -0.135" size="0.04 0.135"/>
|
| 68 |
+
<body name="left_forearm" pos="0 0 -0.45">
|
| 69 |
+
<joint name="left_elbow" pos="0 0 0.15" range="0 150"/>
|
| 70 |
+
<geom name="left_forearm" size="0.035 0.15"/>
|
| 71 |
+
<body name="left_hand" pos="0.0 0 -0.15">
|
| 72 |
+
<geom name="left_hand" type="sphere" size=".05"/>
|
| 73 |
+
</body>
|
| 74 |
+
</body>
|
| 75 |
+
</body>
|
| 76 |
+
|
| 77 |
+
<body name="right_arm" pos="0 -.05 +0.2">
|
| 78 |
+
<joint name="right_shoulder" range="-20 100"/>
|
| 79 |
+
<geom name="right_arm" pos="0 0 -0.135" size="0.04 0.135"/>
|
| 80 |
+
<body name="right_forearm" pos="0 0 -0.45">
|
| 81 |
+
<joint name="right_elbow" pos="0 0 0.15" range="0 150"/>
|
| 82 |
+
<geom name="right_forearm" size="0.035 0.15"/>
|
| 83 |
+
<body name="right_hand" pos="0.0 0 -0.15">
|
| 84 |
+
<geom name="right_hand" type="sphere" size=".05"/>
|
| 85 |
+
</body>
|
| 86 |
+
</body>
|
| 87 |
+
</body>
|
| 88 |
+
</body>
|
| 89 |
+
</worldbody>
|
| 90 |
+
|
| 91 |
+
<sensor>
|
| 92 |
+
<subtreelinvel name="torso_subtreelinvel" body="torso"/>
|
| 93 |
+
</sensor>
|
| 94 |
+
|
| 95 |
+
<actuator>
|
| 96 |
+
<motor name="right_hip" joint="right_hip" gear="100"/>
|
| 97 |
+
<motor name="right_knee" joint="right_knee" gear="50"/>
|
| 98 |
+
<motor name="right_ankle" joint="right_ankle" gear="20"/>
|
| 99 |
+
<motor name="left_hip" joint="left_hip" gear="100"/>
|
| 100 |
+
<motor name="left_knee" joint="left_knee" gear="50"/>
|
| 101 |
+
<motor name="left_ankle" joint="left_ankle" gear="20"/>
|
| 102 |
+
|
| 103 |
+
<motor name="left_shoulder" joint="left_shoulder" gear="100"/>
|
| 104 |
+
<motor name="left_elbow" joint="left_elbow" gear="50"/>
|
| 105 |
+
<motor name="right_shoulder" joint="right_shoulder" gear="100"/>
|
| 106 |
+
<motor name="right_elbow" joint="right_elbow" gear="50"/>
|
| 107 |
+
</actuator>
|
| 108 |
+
</mujoco>
|
envs/custom_dmc_tasks/walker.py
ADDED
|
@@ -0,0 +1,489 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
from dm_control.rl import control
|
| 5 |
+
from dm_control.suite import common
|
| 6 |
+
from dm_control.suite import walker
|
| 7 |
+
from dm_control.utils import rewards
|
| 8 |
+
from dm_control.utils import io as resources
|
| 9 |
+
|
| 10 |
+
_TASKS_DIR = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'custom_dmc_tasks')
|
| 11 |
+
|
| 12 |
+
_YOGA_STAND_HEIGHT = 1.0 # lower than stan height = 1.2
|
| 13 |
+
_YOGA_LIE_DOWN_HEIGHT = 0.1
|
| 14 |
+
_YOGA_LEGS_UP_HEIGHT = 1.1
|
| 15 |
+
|
| 16 |
+
_YOGA_FEET_UP_HEIGHT = 0.5
|
| 17 |
+
_YOGA_FEET_UP_LIE_DOWN_HEIGHT = 0.35
|
| 18 |
+
|
| 19 |
+
_YOGA_KNEE_HEIGHT = 0.25
|
| 20 |
+
_YOGA_KNEESTAND_HEIGHT = 0.75
|
| 21 |
+
|
| 22 |
+
_YOGA_SITTING_HEIGHT = 0.55
|
| 23 |
+
_YOGA_SITTING_LEGS_HEIGHT = 0.15
|
| 24 |
+
|
| 25 |
+
# speed from: https://github.com/rll-research/url_benchmark/blob/710c3eb/custom_dmc_tasks/walker.py
|
| 26 |
+
_SPIN_SPEED = 5.0
|
| 27 |
+
#
|
| 28 |
+
|
| 29 |
+
class WalkerYogaPoses:
|
| 30 |
+
"""
|
| 31 |
+
Joint positions for some yoga poses
|
| 32 |
+
"""
|
| 33 |
+
lie_back = [ -1.2 , 0. , -1.57, 0, 0. , 0.0, 0, -0., 0.0]
|
| 34 |
+
lie_front = [-1.2, -0, 1.57, 0, -0.2, 0, 0, -0.2, 0.]
|
| 35 |
+
legs_up = [ -1.24 , 0. , -1.57, 1.57, 0. , 0.0, 1.57, -0., 0.0]
|
| 36 |
+
|
| 37 |
+
kneel = [ -0.5 , 0. , 0, 0, -1.57, -0.8, 1.57, -1.57, 0.0]
|
| 38 |
+
side_angle = [ -0.3 , 0. , 0.9, 0, 0, -0.7, 1.87, -1.07, 0.0]
|
| 39 |
+
stand_up = [-0.15, 0., 0.34, 0.74, -1.34, -0., 1.1, -0.66, -0.1]
|
| 40 |
+
|
| 41 |
+
lean_back = [-0.27, 0., -0.45, 0.22, -1.5, 0.86, 0.6, -0.8, -0.4]
|
| 42 |
+
boat = [ -1.04 , 0. , -0.8, 1.6, 0. , 0.0, 1.6, -0., 0.0]
|
| 43 |
+
bridge = [-1.1, 0., -2.2, -0.3, -1.5, 0., -0.3, -0.8, -0.4]
|
| 44 |
+
|
| 45 |
+
head_stand = [-1, 0., -3, 0.6, -1, -0.3, 0.9, -0.5, 0.3]
|
| 46 |
+
one_foot = [-0.2, 0., 0, 0.7, -1.34, 0.5, 1.5, -0.6, 0.1]
|
| 47 |
+
|
| 48 |
+
arabesque = [-0.34, 0., 1.57, 1.57, 0, 0., 0, -0., 0.]
|
| 49 |
+
|
| 50 |
+
# new
|
| 51 |
+
high_kick = [-0.165, 3.3 , 5.55 , 1.35 ,-0, +0.5 , -0.7, 0. , 0.2,]
|
| 52 |
+
splits = [-0.7, 0., 0.5, -0.7, -1. , 0, 1.75, 0., -0.45 ]
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def get_model_and_assets():
|
| 56 |
+
"""Returns a tuple containing the model XML string and a dict of assets."""
|
| 57 |
+
return resources.GetResource(os.path.join(_TASKS_DIR, 'walker.xml')), common.ASSETS
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
@walker.SUITE.add('custom')
|
| 61 |
+
def walk_backwards(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 62 |
+
"""Returns the Walk Backwards task."""
|
| 63 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 64 |
+
task = BackwardsPlanarWalker(move_speed=walker._WALK_SPEED, random=random)
|
| 65 |
+
environment_kwargs = environment_kwargs or {}
|
| 66 |
+
return control.Environment(
|
| 67 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 68 |
+
**environment_kwargs)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
@walker.SUITE.add('custom')
|
| 72 |
+
def run_backwards(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 73 |
+
"""Returns the Run Backwards task."""
|
| 74 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 75 |
+
task = BackwardsPlanarWalker(move_speed=walker._RUN_SPEED, random=random)
|
| 76 |
+
environment_kwargs = environment_kwargs or {}
|
| 77 |
+
return control.Environment(
|
| 78 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 79 |
+
**environment_kwargs)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
@walker.SUITE.add('custom')
|
| 83 |
+
def arabesque(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 84 |
+
"""Returns the Arabesque task."""
|
| 85 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 86 |
+
task = YogaPlanarWalker(goal='arabesque', random=random)
|
| 87 |
+
environment_kwargs = environment_kwargs or {}
|
| 88 |
+
return control.Environment(
|
| 89 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 90 |
+
**environment_kwargs)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
@walker.SUITE.add('custom')
|
| 94 |
+
def lying_down(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 95 |
+
"""Returns the Lie Down task."""
|
| 96 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 97 |
+
task = YogaPlanarWalker(goal='lying_down', random=random)
|
| 98 |
+
environment_kwargs = environment_kwargs or {}
|
| 99 |
+
return control.Environment(
|
| 100 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 101 |
+
**environment_kwargs)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
@walker.SUITE.add('custom')
|
| 105 |
+
def legs_up(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 106 |
+
"""Returns the Legs Up task."""
|
| 107 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 108 |
+
task = YogaPlanarWalker(goal='legs_up', random=random)
|
| 109 |
+
environment_kwargs = environment_kwargs or {}
|
| 110 |
+
return control.Environment(
|
| 111 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 112 |
+
**environment_kwargs)
|
| 113 |
+
|
| 114 |
+
@walker.SUITE.add('custom')
|
| 115 |
+
def high_kick(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 116 |
+
"""Returns the High Kick task."""
|
| 117 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 118 |
+
task = YogaPlanarWalker(goal='high_kick', random=random)
|
| 119 |
+
environment_kwargs = environment_kwargs or {}
|
| 120 |
+
return control.Environment(
|
| 121 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 122 |
+
**environment_kwargs)
|
| 123 |
+
|
| 124 |
+
@walker.SUITE.add('custom')
|
| 125 |
+
def one_foot(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 126 |
+
"""Returns the High Kick task."""
|
| 127 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 128 |
+
task = YogaPlanarWalker(goal='one_foot', random=random)
|
| 129 |
+
environment_kwargs = environment_kwargs or {}
|
| 130 |
+
return control.Environment(
|
| 131 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 132 |
+
**environment_kwargs)
|
| 133 |
+
|
| 134 |
+
@walker.SUITE.add('custom')
|
| 135 |
+
def lunge_pose(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 136 |
+
"""Returns the High Kick task."""
|
| 137 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 138 |
+
task = YogaPlanarWalker(goal='lunge_pose', random=random)
|
| 139 |
+
environment_kwargs = environment_kwargs or {}
|
| 140 |
+
return control.Environment(
|
| 141 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 142 |
+
**environment_kwargs)
|
| 143 |
+
|
| 144 |
+
@walker.SUITE.add('custom')
|
| 145 |
+
def sit_knees(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 146 |
+
"""Returns the High Kick task."""
|
| 147 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 148 |
+
task = YogaPlanarWalker(goal='sit_knees', random=random)
|
| 149 |
+
environment_kwargs = environment_kwargs or {}
|
| 150 |
+
return control.Environment(
|
| 151 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 152 |
+
**environment_kwargs)
|
| 153 |
+
|
| 154 |
+
@walker.SUITE.add('custom')
|
| 155 |
+
def headstand(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 156 |
+
"""Returns the Headstand task."""
|
| 157 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 158 |
+
task = YogaPlanarWalker(goal='flip', move_speed=0, random=random)
|
| 159 |
+
environment_kwargs = environment_kwargs or {}
|
| 160 |
+
return control.Environment(
|
| 161 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 162 |
+
**environment_kwargs)
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
@walker.SUITE.add('custom')
|
| 166 |
+
def urlb_flip(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 167 |
+
"""Returns the Flip task."""
|
| 168 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 169 |
+
task = YogaPlanarWalker(goal='urlb_flip', move_speed=_SPIN_SPEED, random=random)
|
| 170 |
+
environment_kwargs = environment_kwargs or {}
|
| 171 |
+
return control.Environment(
|
| 172 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 173 |
+
**environment_kwargs)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
@walker.SUITE.add('custom')
|
| 177 |
+
def flipping(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 178 |
+
"""Returns the flipping task."""
|
| 179 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 180 |
+
task = YogaPlanarWalker(goal='flipping', move_speed=2* walker._RUN_SPEED, random=random)
|
| 181 |
+
environment_kwargs = environment_kwargs or {}
|
| 182 |
+
return control.Environment(
|
| 183 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 184 |
+
**environment_kwargs)
|
| 185 |
+
|
| 186 |
+
@walker.SUITE.add('custom')
|
| 187 |
+
def flip(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 188 |
+
"""Returns the Flip task."""
|
| 189 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 190 |
+
task = YogaPlanarWalker(goal='flip', move_speed=2* walker._RUN_SPEED, random=random)
|
| 191 |
+
environment_kwargs = environment_kwargs or {}
|
| 192 |
+
return control.Environment(
|
| 193 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 194 |
+
**environment_kwargs)
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
@walker.SUITE.add('custom')
|
| 198 |
+
def backflip(time_limit=walker._DEFAULT_TIME_LIMIT, random=None, environment_kwargs=None):
|
| 199 |
+
"""Returns the Backflip task."""
|
| 200 |
+
physics = walker.Physics.from_xml_string(*get_model_and_assets())
|
| 201 |
+
task = YogaPlanarWalker(goal='flip', move_speed=-2 * walker._RUN_SPEED, random=random)
|
| 202 |
+
environment_kwargs = environment_kwargs or {}
|
| 203 |
+
return control.Environment(
|
| 204 |
+
physics, task, time_limit=time_limit, control_timestep=walker._CONTROL_TIMESTEP,
|
| 205 |
+
**environment_kwargs)
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
class BackwardsPlanarWalker(walker.PlanarWalker):
|
| 209 |
+
"""Backwards PlanarWalker task."""
|
| 210 |
+
def __init__(self, move_speed, random=None):
|
| 211 |
+
super().__init__(move_speed, random)
|
| 212 |
+
|
| 213 |
+
def get_reward(self, physics):
|
| 214 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 215 |
+
bounds=(_YOGA_STAND_HEIGHT, float('inf')),
|
| 216 |
+
margin=_YOGA_STAND_HEIGHT/2)
|
| 217 |
+
upright = (1 + physics.torso_upright()) / 2
|
| 218 |
+
stand_reward = (3*standing + upright) / 4
|
| 219 |
+
if self._move_speed == 0:
|
| 220 |
+
return stand_reward
|
| 221 |
+
else:
|
| 222 |
+
move_reward = rewards.tolerance(physics.horizontal_velocity(),
|
| 223 |
+
bounds=(-float('inf'), -self._move_speed),
|
| 224 |
+
margin=self._move_speed/2,
|
| 225 |
+
value_at_margin=0.5,
|
| 226 |
+
sigmoid='linear')
|
| 227 |
+
return stand_reward * (5*move_reward + 1) / 6
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
class YogaPlanarWalker(walker.PlanarWalker):
|
| 231 |
+
"""Yoga PlanarWalker tasks."""
|
| 232 |
+
|
| 233 |
+
def __init__(self, goal='arabesque', move_speed=0, random=None):
|
| 234 |
+
super().__init__(0, random)
|
| 235 |
+
self._goal = goal
|
| 236 |
+
self._move_speed = move_speed
|
| 237 |
+
|
| 238 |
+
def _arabesque_reward(self, physics):
|
| 239 |
+
# standing horizontal
|
| 240 |
+
# one foot up, same height as torso
|
| 241 |
+
# one foot down
|
| 242 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 243 |
+
bounds=(_YOGA_STAND_HEIGHT, float('inf')),
|
| 244 |
+
margin=_YOGA_STAND_HEIGHT/2)
|
| 245 |
+
|
| 246 |
+
left_foot_height = physics.named.data.xpos['left_foot', 'z']
|
| 247 |
+
right_foot_height = physics.named.data.xpos['right_foot', 'z']
|
| 248 |
+
|
| 249 |
+
max_foot = 'right_foot' if right_foot_height > left_foot_height else 'left_foot'
|
| 250 |
+
min_foot = 'right_foot' if right_foot_height <= left_foot_height else 'left_foot'
|
| 251 |
+
|
| 252 |
+
min_foot_height = physics.named.data.xpos[min_foot, 'z']
|
| 253 |
+
max_foot_height = physics.named.data.xpos[max_foot, 'z']
|
| 254 |
+
|
| 255 |
+
min_foot_down = rewards.tolerance(min_foot_height,
|
| 256 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 257 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 258 |
+
max_foot_up = rewards.tolerance(max_foot_height,
|
| 259 |
+
bounds=(_YOGA_STAND_HEIGHT, float('inf')),
|
| 260 |
+
margin=_YOGA_STAND_HEIGHT/2)
|
| 261 |
+
|
| 262 |
+
min_foot_x = physics.named.data.xpos[min_foot, 'x']
|
| 263 |
+
max_foot_x = physics.named.data.xpos[max_foot, 'x']
|
| 264 |
+
|
| 265 |
+
correct_foot_pose = 0.1 if max_foot_x > min_foot_x else 1.0
|
| 266 |
+
|
| 267 |
+
feet_pose = (min_foot_down + max_foot_up * 2) / 3
|
| 268 |
+
return standing * feet_pose * correct_foot_pose
|
| 269 |
+
|
| 270 |
+
def _lying_down_reward(self, physics):
|
| 271 |
+
# torso down and horizontal
|
| 272 |
+
# thigh and feet down
|
| 273 |
+
torso_down = rewards.tolerance(physics.torso_height(),
|
| 274 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 275 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 276 |
+
horizontal = 1 - abs(physics.torso_upright())
|
| 277 |
+
|
| 278 |
+
thigh_height = (physics.named.data.xpos['left_thigh', 'z'] + physics.named.data.xpos['right_thigh', 'z']) / 2
|
| 279 |
+
thigh_down = rewards.tolerance(thigh_height,
|
| 280 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 281 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 282 |
+
leg_height = (physics.named.data.xpos['left_leg', 'z'] + physics.named.data.xpos['right_leg', 'z']) / 2
|
| 283 |
+
leg_down = rewards.tolerance(leg_height,
|
| 284 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 285 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 286 |
+
feet_height = (physics.named.data.xpos['left_foot', 'z'] + physics.named.data.xpos['right_foot', 'z']) / 2
|
| 287 |
+
feet_down = rewards.tolerance(feet_height,
|
| 288 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 289 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 290 |
+
return (3*torso_down + horizontal + thigh_down + feet_down + leg_down) / 7
|
| 291 |
+
|
| 292 |
+
def _legs_up_reward(self, physics):
|
| 293 |
+
# torso down and horizontal
|
| 294 |
+
# legs up with thigh down
|
| 295 |
+
torso_down = rewards.tolerance(physics.torso_height(),
|
| 296 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 297 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 298 |
+
horizontal = 1 - abs(physics.torso_upright())
|
| 299 |
+
torso_down = (3*torso_down +horizontal) / 4
|
| 300 |
+
|
| 301 |
+
feet_height = (physics.named.data.xpos['left_foot', 'z'] + physics.named.data.xpos['right_foot', 'z']) / 2
|
| 302 |
+
feet_up = rewards.tolerance(feet_height,
|
| 303 |
+
bounds=(_YOGA_FEET_UP_LIE_DOWN_HEIGHT, float('inf')),
|
| 304 |
+
margin=_YOGA_FEET_UP_LIE_DOWN_HEIGHT/2)
|
| 305 |
+
|
| 306 |
+
return torso_down * feet_up
|
| 307 |
+
|
| 308 |
+
def _high_kick_reward(self, physics):
|
| 309 |
+
# torso up, but lower than standing
|
| 310 |
+
# foot up, higher than torso
|
| 311 |
+
# foot down
|
| 312 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 313 |
+
bounds=(_YOGA_STAND_HEIGHT, float('inf')),
|
| 314 |
+
margin=_YOGA_STAND_HEIGHT/2)
|
| 315 |
+
|
| 316 |
+
left_foot_height = physics.named.data.xpos['left_foot', 'z']
|
| 317 |
+
right_foot_height = physics.named.data.xpos['right_foot', 'z']
|
| 318 |
+
|
| 319 |
+
min_foot_height = min(left_foot_height, right_foot_height)
|
| 320 |
+
max_foot_height = max(left_foot_height, right_foot_height)
|
| 321 |
+
|
| 322 |
+
min_foot_down = rewards.tolerance(min_foot_height,
|
| 323 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 324 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 325 |
+
max_foot_up = rewards.tolerance(max_foot_height,
|
| 326 |
+
bounds=(walker._STAND_HEIGHT, float('inf')),
|
| 327 |
+
margin=walker._STAND_HEIGHT/2)
|
| 328 |
+
|
| 329 |
+
feet_pose = (3 * max_foot_up + min_foot_down) / 4
|
| 330 |
+
|
| 331 |
+
return standing * feet_pose
|
| 332 |
+
|
| 333 |
+
def _one_foot_reward(self, physics):
|
| 334 |
+
# torso up, standing
|
| 335 |
+
# foot up higher than foot down
|
| 336 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 337 |
+
bounds=(_YOGA_STAND_HEIGHT, float('inf')),
|
| 338 |
+
margin=_YOGA_STAND_HEIGHT/2)
|
| 339 |
+
|
| 340 |
+
left_foot_height = physics.named.data.xpos['left_foot', 'z']
|
| 341 |
+
right_foot_height = physics.named.data.xpos['right_foot', 'z']
|
| 342 |
+
|
| 343 |
+
min_foot_height = min(left_foot_height, right_foot_height)
|
| 344 |
+
max_foot_height = max(left_foot_height, right_foot_height)
|
| 345 |
+
|
| 346 |
+
min_foot_down = rewards.tolerance(min_foot_height,
|
| 347 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 348 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 349 |
+
max_foot_up = rewards.tolerance(max_foot_height,
|
| 350 |
+
bounds=(_YOGA_FEET_UP_HEIGHT, float('inf')),
|
| 351 |
+
margin=_YOGA_FEET_UP_HEIGHT/2)
|
| 352 |
+
|
| 353 |
+
return standing * max_foot_up * min_foot_down
|
| 354 |
+
|
| 355 |
+
def _lunge_pose_reward(self, physics):
|
| 356 |
+
# torso up, standing, but lower
|
| 357 |
+
# leg up higher than leg down
|
| 358 |
+
# horiontal thigh and leg
|
| 359 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 360 |
+
bounds=(_YOGA_KNEESTAND_HEIGHT, float('inf')),
|
| 361 |
+
margin=_YOGA_KNEESTAND_HEIGHT/2)
|
| 362 |
+
upright = (1 + physics.torso_upright()) / 2
|
| 363 |
+
torso = (3*standing + upright) / 4
|
| 364 |
+
|
| 365 |
+
left_leg_height = physics.named.data.xpos['left_leg', 'z']
|
| 366 |
+
right_leg_height = physics.named.data.xpos['right_leg', 'z']
|
| 367 |
+
|
| 368 |
+
min_leg_height = min(left_leg_height, right_leg_height)
|
| 369 |
+
max_leg_height = max(left_leg_height, right_leg_height)
|
| 370 |
+
|
| 371 |
+
min_leg_down = rewards.tolerance(min_leg_height,
|
| 372 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 373 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 374 |
+
max_leg_up = rewards.tolerance(max_leg_height,
|
| 375 |
+
bounds=(_YOGA_KNEE_HEIGHT, float('inf')),
|
| 376 |
+
margin=_YOGA_KNEE_HEIGHT / 2)
|
| 377 |
+
|
| 378 |
+
max_thigh = 'left_thigh' if max_leg_height == left_leg_height else 'right_thigh'
|
| 379 |
+
min_leg = 'left_leg' if min_leg_height == left_leg_height else 'right_leg'
|
| 380 |
+
|
| 381 |
+
max_thigh_horiz = 1 - abs(physics.named.data.xmat[max_thigh, 'zz'])
|
| 382 |
+
min_leg_horiz = 1 - abs(physics.named.data.xmat[min_leg, 'zz'])
|
| 383 |
+
|
| 384 |
+
legs = (min_leg_down + max_leg_up + max_thigh_horiz + min_leg_horiz) / 4
|
| 385 |
+
|
| 386 |
+
return torso * legs
|
| 387 |
+
|
| 388 |
+
def _sit_knees_reward(self, physics):
|
| 389 |
+
# torso up, standing, but lower
|
| 390 |
+
# foot up higher than foot down
|
| 391 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 392 |
+
bounds=(_YOGA_SITTING_HEIGHT, float('inf')),
|
| 393 |
+
margin=_YOGA_SITTING_HEIGHT/2)
|
| 394 |
+
upright = (1 + physics.torso_upright()) / 2
|
| 395 |
+
torso_up = (3*standing + upright) / 4
|
| 396 |
+
|
| 397 |
+
legs_height = (physics.named.data.xpos['left_leg', 'z'] + physics.named.data.xpos['right_leg', 'z']) / 2
|
| 398 |
+
legs_down = rewards.tolerance(legs_height,
|
| 399 |
+
bounds=(-float('inf'), _YOGA_SITTING_LEGS_HEIGHT),
|
| 400 |
+
margin=_YOGA_SITTING_LEGS_HEIGHT*1.5)
|
| 401 |
+
feet_height = (physics.named.data.xpos['left_foot', 'z'] + physics.named.data.xpos['right_foot', 'z']) / 2
|
| 402 |
+
feet_down = rewards.tolerance(feet_height,
|
| 403 |
+
bounds=(-float('inf'), _YOGA_LIE_DOWN_HEIGHT),
|
| 404 |
+
margin=_YOGA_LIE_DOWN_HEIGHT*1.5)
|
| 405 |
+
|
| 406 |
+
l_thigh_foot_distance = max(0.1, abs(physics.named.data.xpos['left_foot', 'x'] - physics.named.data.xpos['left_thigh', 'x'])) - 0.1
|
| 407 |
+
r_thigh_foot_distance = max(0.1, abs(physics.named.data.xpos['right_foot', 'x'] - physics.named.data.xpos['right_thigh', 'x'])) - 0.1
|
| 408 |
+
close = np.exp(-(l_thigh_foot_distance + r_thigh_foot_distance)/2)
|
| 409 |
+
|
| 410 |
+
legs = (3 * legs_down + feet_down) / 4
|
| 411 |
+
return torso_up * legs * close
|
| 412 |
+
|
| 413 |
+
def _urlb_flip_reward(self, physics):
|
| 414 |
+
standing = rewards.tolerance(physics.torso_height(),
|
| 415 |
+
bounds=(walker._STAND_HEIGHT, float('inf')),
|
| 416 |
+
margin=walker._STAND_HEIGHT / 2)
|
| 417 |
+
upright = (1 + physics.torso_upright()) / 2
|
| 418 |
+
stand_reward = (3 * standing + upright) / 4
|
| 419 |
+
move_reward = rewards.tolerance(physics.named.data.subtree_angmom['torso'][1], # physics.angmomentum(),
|
| 420 |
+
bounds=(_SPIN_SPEED, float('inf')),
|
| 421 |
+
margin=_SPIN_SPEED,
|
| 422 |
+
value_at_margin=0,
|
| 423 |
+
sigmoid='linear')
|
| 424 |
+
return stand_reward * (5 * move_reward + 1) / 6
|
| 425 |
+
|
| 426 |
+
def _flip_reward(self, physics):
|
| 427 |
+
thigh_height = (physics.named.data.xpos['left_thigh', 'z'] + physics.named.data.xpos['right_thigh', 'z']) / 2
|
| 428 |
+
thigh_up = rewards.tolerance(thigh_height,
|
| 429 |
+
bounds=(_YOGA_STAND_HEIGHT, float('inf')),
|
| 430 |
+
margin=_YOGA_STAND_HEIGHT/2)
|
| 431 |
+
feet_height = (physics.named.data.xpos['left_foot', 'z'] + physics.named.data.xpos['right_foot', 'z']) / 2
|
| 432 |
+
legs_up = rewards.tolerance(feet_height,
|
| 433 |
+
bounds=(_YOGA_LEGS_UP_HEIGHT, float('inf')),
|
| 434 |
+
margin=_YOGA_LEGS_UP_HEIGHT/2)
|
| 435 |
+
upside_down_reward = (3*legs_up + 2*thigh_up) / 5
|
| 436 |
+
if self._move_speed == 0:
|
| 437 |
+
return upside_down_reward
|
| 438 |
+
move_reward = rewards.tolerance(physics.named.data.subtree_angmom['torso'][1], # physics.angmomentum(),
|
| 439 |
+
bounds=(self._move_speed, float('inf')) if self._move_speed > 0 else (-float('inf'), self._move_speed),
|
| 440 |
+
margin=abs(self._move_speed)/2,
|
| 441 |
+
value_at_margin=0.5,
|
| 442 |
+
sigmoid='linear')
|
| 443 |
+
return upside_down_reward * (5*move_reward + 1) / 6
|
| 444 |
+
|
| 445 |
+
def get_reward(self, physics):
|
| 446 |
+
if self._goal == 'arabesque':
|
| 447 |
+
return self._arabesque_reward(physics)
|
| 448 |
+
elif self._goal == 'lying_down':
|
| 449 |
+
return self._lying_down_reward(physics)
|
| 450 |
+
elif self._goal == 'legs_up':
|
| 451 |
+
return self._legs_up_reward(physics)
|
| 452 |
+
elif self._goal == 'flip':
|
| 453 |
+
return self._flip_reward(physics)
|
| 454 |
+
elif self._goal == 'flipping':
|
| 455 |
+
self._move_speed = abs(self._move_speed)
|
| 456 |
+
pos_rew = self._flip_reward(physics)
|
| 457 |
+
self._move_speed = -abs(self._move_speed)
|
| 458 |
+
neg_rew = self._flip_reward(physics)
|
| 459 |
+
return max(pos_rew, neg_rew)
|
| 460 |
+
elif self._goal == 'high_kick':
|
| 461 |
+
return self._high_kick_reward(physics)
|
| 462 |
+
elif self._goal == 'one_foot':
|
| 463 |
+
return self._one_foot_reward(physics)
|
| 464 |
+
elif self._goal == 'lunge_pose':
|
| 465 |
+
return self._lunge_pose_reward(physics)
|
| 466 |
+
elif self._goal == 'sit_knees':
|
| 467 |
+
return self._sit_knees_reward(physics)
|
| 468 |
+
elif self._goal == 'urlb_flip':
|
| 469 |
+
return self._urlb_flip_reward(physics)
|
| 470 |
+
else:
|
| 471 |
+
raise NotImplementedError(f'Goal {self._goal} is not implemented.')
|
| 472 |
+
|
| 473 |
+
|
| 474 |
+
if __name__ == '__main__':
|
| 475 |
+
from dm_control import viewer
|
| 476 |
+
import numpy as np
|
| 477 |
+
|
| 478 |
+
env = sit_knees()
|
| 479 |
+
env.task.visualize_reward = True
|
| 480 |
+
|
| 481 |
+
action_spec = env.action_spec()
|
| 482 |
+
|
| 483 |
+
def zero_policy(time_step):
|
| 484 |
+
print(time_step.reward)
|
| 485 |
+
return np.zeros(action_spec.shape)
|
| 486 |
+
viewer.launch(env, policy=zero_policy)
|
| 487 |
+
|
| 488 |
+
# obs = env.reset()
|
| 489 |
+
# next_obs, reward, done, info = env.step(np.zeros(6))
|
envs/custom_dmc_tasks/walker.xml
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<mujoco model="planar walker">
|
| 2 |
+
<include file="./common/skybox.xml"/>
|
| 3 |
+
<include file="./common/visual.xml"/>
|
| 4 |
+
<include file="./common/materials.xml"/>
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
<option timestep="0.0025"/>
|
| 8 |
+
|
| 9 |
+
<statistic extent="2" center="0 0 1"/>
|
| 10 |
+
|
| 11 |
+
<default>
|
| 12 |
+
<joint damping=".1" armature="0.01" limited="true" solimplimit="0 .99 .01"/>
|
| 13 |
+
<geom contype="1" conaffinity="0" friction=".7 .1 .1"/>
|
| 14 |
+
<motor ctrlrange="-1 1" ctrllimited="true"/>
|
| 15 |
+
<site size="0.01"/>
|
| 16 |
+
<default class="walker">
|
| 17 |
+
<geom material="self" type="capsule"/>
|
| 18 |
+
<joint axis="0 -1 0"/>
|
| 19 |
+
</default>
|
| 20 |
+
</default>
|
| 21 |
+
|
| 22 |
+
<worldbody>
|
| 23 |
+
<geom name="floor" type="plane" conaffinity="1" pos="248 0 0" size="250 .8 .2" material="grid" zaxis="0 0 1"/>
|
| 24 |
+
<body name="torso" pos="0 0 1.3" childclass="walker">
|
| 25 |
+
<light name="light" pos="0 0 2" mode="trackcom"/>
|
| 26 |
+
<camera name="side" pos="0 -2 .7" euler="60 0 0" mode="trackcom"/>
|
| 27 |
+
<camera name="back" pos="-2 0 .5" xyaxes="0 -1 0 1 0 3" mode="trackcom"/>
|
| 28 |
+
<joint name="rootz" axis="0 0 1" type="slide" limited="false" armature="0" damping="0"/>
|
| 29 |
+
<joint name="rootx" axis="1 0 0" type="slide" limited="false" armature="0" damping="0"/>
|
| 30 |
+
<joint name="rooty" axis="0 1 0" type="hinge" limited="false" armature="0" damping="0"/>
|
| 31 |
+
<geom name="torso" size="0.07 0.3"/>
|
| 32 |
+
<body name="right_thigh" pos="0 -.05 -0.3">
|
| 33 |
+
<joint name="right_hip" range="-20 100"/>
|
| 34 |
+
<geom name="right_thigh" pos="0 0 -0.225" size="0.05 0.225"/>
|
| 35 |
+
<body name="right_leg" pos="0 0 -0.7">
|
| 36 |
+
<joint name="right_knee" pos="0 0 0.25" range="-150 0"/>
|
| 37 |
+
<geom name="right_leg" size="0.04 0.25"/>
|
| 38 |
+
<body name="right_foot" pos="0.06 0 -0.25">
|
| 39 |
+
<joint name="right_ankle" pos="-0.06 0 0" range="-45 45"/>
|
| 40 |
+
<geom name="right_foot" zaxis="1 0 0" size="0.05 0.1"/>
|
| 41 |
+
</body>
|
| 42 |
+
</body>
|
| 43 |
+
</body>
|
| 44 |
+
<body name="left_thigh" pos="0 .05 -0.3" >
|
| 45 |
+
<joint name="left_hip" range="-20 100"/>
|
| 46 |
+
<geom name="left_thigh" pos="0 0 -0.225" size="0.05 0.225"/>
|
| 47 |
+
<body name="left_leg" pos="0 0 -0.7">
|
| 48 |
+
<joint name="left_knee" pos="0 0 0.25" range="-150 0"/>
|
| 49 |
+
<geom name="left_leg" size="0.04 0.25"/>
|
| 50 |
+
<body name="left_foot" pos="0.06 0 -0.25">
|
| 51 |
+
<joint name="left_ankle" pos="-0.06 0 0" range="-45 45"/>
|
| 52 |
+
<geom name="left_foot" zaxis="1 0 0" size="0.05 0.1"/>
|
| 53 |
+
</body>
|
| 54 |
+
</body>
|
| 55 |
+
</body>
|
| 56 |
+
</body>
|
| 57 |
+
</worldbody>
|
| 58 |
+
|
| 59 |
+
<sensor>
|
| 60 |
+
<subtreelinvel name="torso_subtreelinvel" body="torso"/>
|
| 61 |
+
</sensor>
|
| 62 |
+
|
| 63 |
+
<actuator>
|
| 64 |
+
<motor name="right_hip" joint="right_hip" gear="100"/>
|
| 65 |
+
<motor name="right_knee" joint="right_knee" gear="50"/>
|
| 66 |
+
<motor name="right_ankle" joint="right_ankle" gear="20"/>
|
| 67 |
+
<motor name="left_hip" joint="left_hip" gear="100"/>
|
| 68 |
+
<motor name="left_knee" joint="left_knee" gear="50"/>
|
| 69 |
+
<motor name="left_ankle" joint="left_ankle" gear="20"/>
|
| 70 |
+
</actuator>
|
| 71 |
+
</mujoco>
|
envs/kitchen_extra.py
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Environments using kitchen and Franka robot."""
|
| 2 |
+
import logging
|
| 3 |
+
import sys
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
sys.path.append((Path(__file__).parent.parent / 'third_party' / 'relay-policy-learning' / 'adept_envs').__str__())
|
| 6 |
+
import adept_envs
|
| 7 |
+
from adept_envs.franka.kitchen_multitask_v0 import KitchenTaskRelaxV1
|
| 8 |
+
import os
|
| 9 |
+
import numpy as np
|
| 10 |
+
from dm_control.mujoco import engine
|
| 11 |
+
|
| 12 |
+
OBS_ELEMENT_INDICES = {
|
| 13 |
+
"bottom burner": np.array([11, 12]),
|
| 14 |
+
"top burner": np.array([15, 16]),
|
| 15 |
+
"light switch": np.array([17, 18]),
|
| 16 |
+
"slide cabinet": np.array([19]),
|
| 17 |
+
"hinge cabinet": np.array([20, 21]),
|
| 18 |
+
"microwave": np.array([22]),
|
| 19 |
+
"kettle": np.array([23, 24, 25, 26, 27, 28, 29]),
|
| 20 |
+
}
|
| 21 |
+
OBS_ELEMENT_GOALS = {
|
| 22 |
+
"bottom burner": np.array([-0.88, -0.01]),
|
| 23 |
+
"top burner": np.array([-0.92, -0.01]),
|
| 24 |
+
"light switch": np.array([-0.69, -0.05]),
|
| 25 |
+
"slide cabinet": np.array([0.37]),
|
| 26 |
+
"hinge cabinet": np.array([0.0, 1.45]),
|
| 27 |
+
"microwave": np.array([-0.75]),
|
| 28 |
+
"kettle": np.array([-0.23, 0.75, 1.62, 0.99, 0.0, 0.0, -0.06]),
|
| 29 |
+
}
|
| 30 |
+
BONUS_THRESH = 0.3
|
| 31 |
+
|
| 32 |
+
logging.basicConfig(
|
| 33 |
+
level="INFO",
|
| 34 |
+
format="%(asctime)s [%(levelname)s] %(message)s",
|
| 35 |
+
filemode="w",
|
| 36 |
+
)
|
| 37 |
+
logger = logging.getLogger()
|
| 38 |
+
|
| 39 |
+
XPOS_NAMES = {
|
| 40 |
+
"light switch" : "lightswitchroot",
|
| 41 |
+
"slide cabinet" : "slidelink",
|
| 42 |
+
"microwave" : "microdoorroot",
|
| 43 |
+
"kettle" : "kettle",
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
class KitchenBase(KitchenTaskRelaxV1):
|
| 47 |
+
# A string of element names. The robot's task is then to modify each of
|
| 48 |
+
# these elements appropriately.
|
| 49 |
+
TASK_ELEMENTS = []
|
| 50 |
+
ALL_TASKS = [
|
| 51 |
+
"bottom burner",
|
| 52 |
+
"top burner",
|
| 53 |
+
"light switch",
|
| 54 |
+
"slide cabinet",
|
| 55 |
+
"hinge cabinet",
|
| 56 |
+
"microwave",
|
| 57 |
+
"kettle",
|
| 58 |
+
]
|
| 59 |
+
REMOVE_TASKS_WHEN_COMPLETE = True
|
| 60 |
+
TERMINATE_ON_TASK_COMPLETE = True
|
| 61 |
+
TERMINATE_ON_WRONG_COMPLETE = False
|
| 62 |
+
COMPLETE_IN_ANY_ORDER = (
|
| 63 |
+
True # This allows for the tasks to be completed in arbitrary order.
|
| 64 |
+
)
|
| 65 |
+
GRIPPER_DISTANCE_REW = False
|
| 66 |
+
|
| 67 |
+
def __init__(
|
| 68 |
+
self, dense=True, dataset_url=None, ref_max_score=None, ref_min_score=None, **kwargs
|
| 69 |
+
):
|
| 70 |
+
self.tasks_to_complete = list(self.TASK_ELEMENTS)
|
| 71 |
+
self.goal_masking = True
|
| 72 |
+
self.dense = dense
|
| 73 |
+
self.use_grasp_rewards = False
|
| 74 |
+
|
| 75 |
+
super(KitchenBase, self).__init__(**kwargs)
|
| 76 |
+
|
| 77 |
+
def set_goal_masking(self, goal_masking=True):
|
| 78 |
+
"""Sets goal masking for goal-conditioned approaches (like RPL)."""
|
| 79 |
+
self.goal_masking = goal_masking
|
| 80 |
+
|
| 81 |
+
def _get_task_goal(self, task=None, actually_return_goal=False):
|
| 82 |
+
if task is None:
|
| 83 |
+
task = ["microwave", "kettle", "bottom burner", "light switch"]
|
| 84 |
+
new_goal = np.zeros_like(self.goal)
|
| 85 |
+
if self.goal_masking and not actually_return_goal:
|
| 86 |
+
return new_goal
|
| 87 |
+
for element in task:
|
| 88 |
+
element_idx = OBS_ELEMENT_INDICES[element]
|
| 89 |
+
element_goal = OBS_ELEMENT_GOALS[element]
|
| 90 |
+
new_goal[element_idx] = element_goal
|
| 91 |
+
|
| 92 |
+
return new_goal
|
| 93 |
+
|
| 94 |
+
def reset_model(self):
|
| 95 |
+
self.tasks_to_complete = list(self.TASK_ELEMENTS)
|
| 96 |
+
return super(KitchenBase, self).reset_model()
|
| 97 |
+
|
| 98 |
+
def _get_reward_n_score(self, obs_dict):
|
| 99 |
+
reward_dict, score = super(KitchenBase, self)._get_reward_n_score(obs_dict)
|
| 100 |
+
next_q_obs = obs_dict["qp"]
|
| 101 |
+
next_obj_obs = obs_dict["obj_qp"]
|
| 102 |
+
idx_offset = len(next_q_obs)
|
| 103 |
+
completions = []
|
| 104 |
+
dense = 0
|
| 105 |
+
if self.GRIPPER_DISTANCE_REW:
|
| 106 |
+
assert len(self.tasks_to_complete) == 1
|
| 107 |
+
element = next(iter(self.tasks_to_complete))
|
| 108 |
+
gripper_pos = (self.sim.named.data.xpos['panda0_leftfinger'] + self.sim.named.data.xpos['panda0_rightfinger']) / 2
|
| 109 |
+
object_pos = self.sim.named.data.xpos[XPOS_NAMES[element]]
|
| 110 |
+
gripper_obj_dist = np.linalg.norm(object_pos - gripper_pos)
|
| 111 |
+
if self.dense:
|
| 112 |
+
reward_dict["bonus"] = -gripper_obj_dist
|
| 113 |
+
reward_dict["r_total"] = -gripper_obj_dist
|
| 114 |
+
score = -gripper_obj_dist
|
| 115 |
+
else:
|
| 116 |
+
reward_dict["bonus"] = gripper_obj_dist < 0.15
|
| 117 |
+
reward_dict["r_total"] = gripper_obj_dist < 0.15
|
| 118 |
+
score = gripper_obj_dist < 0.15
|
| 119 |
+
return reward_dict, score
|
| 120 |
+
for element in self.tasks_to_complete:
|
| 121 |
+
element_idx = OBS_ELEMENT_INDICES[element]
|
| 122 |
+
distance = np.linalg.norm(
|
| 123 |
+
next_obj_obs[..., element_idx - idx_offset] - OBS_ELEMENT_GOALS[element]
|
| 124 |
+
)
|
| 125 |
+
dense += -1 * distance # reward must be negative distance for RL
|
| 126 |
+
is_grasped = True
|
| 127 |
+
if not self.initializing and self.use_grasp_rewards:
|
| 128 |
+
if element == "slide cabinet":
|
| 129 |
+
is_grasped = False
|
| 130 |
+
for i in range(1, 6):
|
| 131 |
+
obj_pos = self.get_site_xpos("schandle{}".format(i))
|
| 132 |
+
left_pad = self.get_site_xpos("leftpad")
|
| 133 |
+
right_pad = self.get_site_xpos("rightpad")
|
| 134 |
+
within_sphere_left = np.linalg.norm(obj_pos - left_pad) < 0.07
|
| 135 |
+
within_sphere_right = np.linalg.norm(obj_pos - right_pad) < 0.07
|
| 136 |
+
right = right_pad[0] < obj_pos[0]
|
| 137 |
+
left = obj_pos[0] < left_pad[0]
|
| 138 |
+
if (
|
| 139 |
+
right
|
| 140 |
+
and left
|
| 141 |
+
and within_sphere_right
|
| 142 |
+
and within_sphere_left
|
| 143 |
+
):
|
| 144 |
+
is_grasped = True
|
| 145 |
+
if element == "top left burner":
|
| 146 |
+
is_grasped = False
|
| 147 |
+
obj_pos = self.get_site_xpos("tlbhandle")
|
| 148 |
+
left_pad = self.get_site_xpos("leftpad")
|
| 149 |
+
right_pad = self.get_site_xpos("rightpad")
|
| 150 |
+
within_sphere_left = np.linalg.norm(obj_pos - left_pad) < 0.035
|
| 151 |
+
within_sphere_right = np.linalg.norm(obj_pos - right_pad) < 0.04
|
| 152 |
+
right = right_pad[0] < obj_pos[0]
|
| 153 |
+
left = obj_pos[0] < left_pad[0]
|
| 154 |
+
if within_sphere_right and within_sphere_left and right and left:
|
| 155 |
+
is_grasped = True
|
| 156 |
+
if element == "microwave":
|
| 157 |
+
is_grasped = False
|
| 158 |
+
for i in range(1, 6):
|
| 159 |
+
obj_pos = self.get_site_xpos("mchandle{}".format(i))
|
| 160 |
+
left_pad = self.get_site_xpos("leftpad")
|
| 161 |
+
right_pad = self.get_site_xpos("rightpad")
|
| 162 |
+
within_sphere_left = np.linalg.norm(obj_pos - left_pad) < 0.05
|
| 163 |
+
within_sphere_right = np.linalg.norm(obj_pos - right_pad) < 0.05
|
| 164 |
+
if (
|
| 165 |
+
right_pad[0] < obj_pos[0]
|
| 166 |
+
and obj_pos[0] < left_pad[0]
|
| 167 |
+
and within_sphere_right
|
| 168 |
+
and within_sphere_left
|
| 169 |
+
):
|
| 170 |
+
is_grasped = True
|
| 171 |
+
if element == "hinge cabinet":
|
| 172 |
+
is_grasped = False
|
| 173 |
+
for i in range(1, 6):
|
| 174 |
+
obj_pos = self.get_site_xpos("hchandle{}".format(i))
|
| 175 |
+
left_pad = self.get_site_xpos("leftpad")
|
| 176 |
+
right_pad = self.get_site_xpos("rightpad")
|
| 177 |
+
within_sphere_left = np.linalg.norm(obj_pos - left_pad) < 0.06
|
| 178 |
+
within_sphere_right = np.linalg.norm(obj_pos - right_pad) < 0.06
|
| 179 |
+
if (
|
| 180 |
+
right_pad[0] < obj_pos[0]
|
| 181 |
+
and obj_pos[0] < left_pad[0]
|
| 182 |
+
and within_sphere_right
|
| 183 |
+
):
|
| 184 |
+
is_grasped = True
|
| 185 |
+
if element == "light switch":
|
| 186 |
+
is_grasped = False
|
| 187 |
+
for i in range(1, 4):
|
| 188 |
+
obj_pos = self.get_site_xpos("lshandle{}".format(i))
|
| 189 |
+
left_pad = self.get_site_xpos("leftpad")
|
| 190 |
+
right_pad = self.get_site_xpos("rightpad")
|
| 191 |
+
within_sphere_left = np.linalg.norm(obj_pos - left_pad) < 0.045
|
| 192 |
+
within_sphere_right = np.linalg.norm(obj_pos - right_pad) < 0.03
|
| 193 |
+
if within_sphere_right and within_sphere_left:
|
| 194 |
+
is_grasped = True
|
| 195 |
+
complete = distance < BONUS_THRESH # and is_grasped
|
| 196 |
+
if complete:
|
| 197 |
+
completions.append(element)
|
| 198 |
+
if self.REMOVE_TASKS_WHEN_COMPLETE:
|
| 199 |
+
[self.tasks_to_complete.remove(element) for element in completions]
|
| 200 |
+
bonus = float(len(completions))
|
| 201 |
+
reward_dict["bonus"] = bonus
|
| 202 |
+
reward_dict["r_total"] = bonus
|
| 203 |
+
if self.dense:
|
| 204 |
+
reward_dict["r_total"] = dense
|
| 205 |
+
score = bonus
|
| 206 |
+
return reward_dict, score
|
| 207 |
+
|
| 208 |
+
def step(self, a, b=None):
|
| 209 |
+
obs, reward, done, env_info = super(KitchenBase, self).step(a, b=b)
|
| 210 |
+
if self.TERMINATE_ON_TASK_COMPLETE:
|
| 211 |
+
done = not self.tasks_to_complete
|
| 212 |
+
if self.TERMINATE_ON_WRONG_COMPLETE:
|
| 213 |
+
all_goal = self._get_task_goal(task=self.ALL_TASKS)
|
| 214 |
+
for wrong_task in list(set(self.ALL_TASKS) - set(self.TASK_ELEMENTS)):
|
| 215 |
+
element_idx = OBS_ELEMENT_INDICES[wrong_task]
|
| 216 |
+
distance = np.linalg.norm(obs[..., element_idx] - all_goal[element_idx])
|
| 217 |
+
complete = distance < BONUS_THRESH
|
| 218 |
+
if complete:
|
| 219 |
+
done = True
|
| 220 |
+
break
|
| 221 |
+
env_info["completed_tasks"] = set(self.TASK_ELEMENTS) - set(
|
| 222 |
+
self.tasks_to_complete
|
| 223 |
+
)
|
| 224 |
+
return obs, reward, done, env_info
|
| 225 |
+
|
| 226 |
+
def get_goal(self):
|
| 227 |
+
"""Loads goal state from dataset for goal-conditioned approaches (like RPL)."""
|
| 228 |
+
raise NotImplementedError
|
| 229 |
+
|
| 230 |
+
def _split_data_into_seqs(self, data):
|
| 231 |
+
"""Splits dataset object into list of sequence dicts."""
|
| 232 |
+
seq_end_idxs = np.where(data["terminals"])[0]
|
| 233 |
+
start = 0
|
| 234 |
+
seqs = []
|
| 235 |
+
for end_idx in seq_end_idxs:
|
| 236 |
+
seqs.append(
|
| 237 |
+
dict(
|
| 238 |
+
states=data["observations"][start : end_idx + 1],
|
| 239 |
+
actions=data["actions"][start : end_idx + 1],
|
| 240 |
+
)
|
| 241 |
+
)
|
| 242 |
+
start = end_idx + 1
|
| 243 |
+
return seqs
|
| 244 |
+
|
| 245 |
+
def render(self, mode='rgb_array', resolution=(64,64)):
|
| 246 |
+
if mode =='rgb_array':
|
| 247 |
+
camera = engine.MovableCamera(self.sim, *resolution)
|
| 248 |
+
camera.set_pose(distance=2.2, lookat=[-0.2, .5, 2.], azimuth=70, elevation=-35)
|
| 249 |
+
img = camera.render()
|
| 250 |
+
return img
|
| 251 |
+
else:
|
| 252 |
+
super(KitchenTaskRelaxV1, self).render()
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
class KitchenSlideV0(KitchenBase):
|
| 256 |
+
TASK_ELEMENTS = ["slide cabinet",]
|
| 257 |
+
COMPLETE_IN_ANY_ORDER = False
|
| 258 |
+
|
| 259 |
+
class KitchenHingeV0(KitchenBase):
|
| 260 |
+
TASK_ELEMENTS = ["hinge cabinet",]
|
| 261 |
+
COMPLETE_IN_ANY_ORDER = False
|
| 262 |
+
|
| 263 |
+
class KitchenLightV0(KitchenBase):
|
| 264 |
+
TASK_ELEMENTS = ["light switch",]
|
| 265 |
+
COMPLETE_IN_ANY_ORDER = False
|
| 266 |
+
|
| 267 |
+
class KitchenKettleV0(KitchenBase):
|
| 268 |
+
TASK_ELEMENTS = ["kettle",]
|
| 269 |
+
COMPLETE_IN_ANY_ORDER = False
|
| 270 |
+
|
| 271 |
+
class KitchenMicrowaveV0(KitchenBase):
|
| 272 |
+
TASK_ELEMENTS = ["microwave",]
|
| 273 |
+
COMPLETE_IN_ANY_ORDER = False
|
| 274 |
+
|
| 275 |
+
class KitchenBurnerV0(KitchenBase):
|
| 276 |
+
TASK_ELEMENTS = ["bottom burner",]
|
| 277 |
+
COMPLETE_IN_ANY_ORDER = False
|
| 278 |
+
|
| 279 |
+
class KitchenTopBurnerV0(KitchenBase):
|
| 280 |
+
TASK_ELEMENTS = ["top burner",]
|
| 281 |
+
COMPLETE_IN_ANY_ORDER = False
|
| 282 |
+
|
| 283 |
+
class KitchenMicrowaveKettleBottomBurnerLightV0(KitchenBase):
|
| 284 |
+
TASK_ELEMENTS = ["microwave", "kettle", "bottom burner", "light switch"]
|
| 285 |
+
COMPLETE_IN_ANY_ORDER = False
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
class KitchenMicrowaveKettleLightSliderV0(KitchenBase):
|
| 289 |
+
TASK_ELEMENTS = ["microwave", "kettle", "light switch", "slide cabinet"]
|
| 290 |
+
COMPLETE_IN_ANY_ORDER = False
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
class KitchenKettleMicrowaveLightSliderV0(KitchenBase):
|
| 294 |
+
TASK_ELEMENTS = ["kettle", "microwave", "light switch", "slide cabinet"]
|
| 295 |
+
COMPLETE_IN_ANY_ORDER = False
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
class KitchenAllV0(KitchenBase):
|
| 299 |
+
TASK_ELEMENTS = KitchenBase.ALL_TASKS
|
envs/main.py
ADDED
|
@@ -0,0 +1,743 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import OrderedDict, deque
|
| 2 |
+
from typing import Any, NamedTuple
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
import dm_env
|
| 6 |
+
import numpy as np
|
| 7 |
+
from dm_env import StepType, specs
|
| 8 |
+
|
| 9 |
+
import gym
|
| 10 |
+
import torch
|
| 11 |
+
|
| 12 |
+
class ExtendedTimeStep(NamedTuple):
|
| 13 |
+
step_type: Any
|
| 14 |
+
reward: Any
|
| 15 |
+
discount: Any
|
| 16 |
+
observation: Any
|
| 17 |
+
action: Any
|
| 18 |
+
|
| 19 |
+
def first(self):
|
| 20 |
+
return self.step_type == StepType.FIRST
|
| 21 |
+
|
| 22 |
+
def mid(self):
|
| 23 |
+
return self.step_type == StepType.MID
|
| 24 |
+
|
| 25 |
+
def last(self):
|
| 26 |
+
return self.step_type == StepType.LAST
|
| 27 |
+
|
| 28 |
+
def __getitem__(self, attr):
|
| 29 |
+
return getattr(self, attr)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class FlattenJacoObservationWrapper(dm_env.Environment):
|
| 33 |
+
def __init__(self, env):
|
| 34 |
+
self._env = env
|
| 35 |
+
self._obs_spec = OrderedDict()
|
| 36 |
+
wrapped_obs_spec = env.observation_spec().copy()
|
| 37 |
+
if 'front_close' in wrapped_obs_spec:
|
| 38 |
+
spec = wrapped_obs_spec['front_close']
|
| 39 |
+
# drop batch dim
|
| 40 |
+
self._obs_spec['pixels'] = specs.BoundedArray(shape=spec.shape[1:],
|
| 41 |
+
dtype=spec.dtype,
|
| 42 |
+
minimum=spec.minimum,
|
| 43 |
+
maximum=spec.maximum,
|
| 44 |
+
name='pixels')
|
| 45 |
+
wrapped_obs_spec.pop('front_close')
|
| 46 |
+
|
| 47 |
+
for key, spec in wrapped_obs_spec.items():
|
| 48 |
+
assert spec.dtype == np.float64
|
| 49 |
+
assert type(spec) == specs.Array
|
| 50 |
+
dim = np.sum(
|
| 51 |
+
np.fromiter((int(np.prod(spec.shape))
|
| 52 |
+
for spec in wrapped_obs_spec.values()), np.int32))
|
| 53 |
+
|
| 54 |
+
self._obs_spec['observations'] = specs.Array(shape=(dim,),
|
| 55 |
+
dtype=np.float32,
|
| 56 |
+
name='observations')
|
| 57 |
+
|
| 58 |
+
def _transform_observation(self, time_step):
|
| 59 |
+
obs = OrderedDict()
|
| 60 |
+
|
| 61 |
+
if 'front_close' in time_step.observation:
|
| 62 |
+
pixels = time_step.observation['front_close']
|
| 63 |
+
time_step.observation.pop('front_close')
|
| 64 |
+
pixels = np.squeeze(pixels)
|
| 65 |
+
obs['pixels'] = pixels
|
| 66 |
+
|
| 67 |
+
features = []
|
| 68 |
+
for feature in time_step.observation.values():
|
| 69 |
+
features.append(feature.ravel())
|
| 70 |
+
obs['observations'] = np.concatenate(features, axis=0)
|
| 71 |
+
return time_step._replace(observation=obs)
|
| 72 |
+
|
| 73 |
+
def reset(self):
|
| 74 |
+
time_step = self._env.reset()
|
| 75 |
+
return self._transform_observation(time_step)
|
| 76 |
+
|
| 77 |
+
def step(self, action):
|
| 78 |
+
time_step = self._env.step(action)
|
| 79 |
+
return self._transform_observation(time_step)
|
| 80 |
+
|
| 81 |
+
def observation_spec(self):
|
| 82 |
+
return self._obs_spec
|
| 83 |
+
|
| 84 |
+
def action_spec(self):
|
| 85 |
+
return self._env.action_spec()
|
| 86 |
+
|
| 87 |
+
def __getattr__(self, name):
|
| 88 |
+
return getattr(self._env, name)
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
class ActionRepeatWrapper(dm_env.Environment):
|
| 92 |
+
def __init__(self, env, num_repeats):
|
| 93 |
+
self._env = env
|
| 94 |
+
self._num_repeats = num_repeats
|
| 95 |
+
|
| 96 |
+
def step(self, action):
|
| 97 |
+
reward = 0.0
|
| 98 |
+
discount = 1.0
|
| 99 |
+
for i in range(self._num_repeats):
|
| 100 |
+
time_step = self._env.step(action)
|
| 101 |
+
reward += (time_step.reward or 0.0) * discount
|
| 102 |
+
discount *= time_step.discount
|
| 103 |
+
if time_step.last():
|
| 104 |
+
break
|
| 105 |
+
|
| 106 |
+
return time_step._replace(reward=reward, discount=discount)
|
| 107 |
+
|
| 108 |
+
def observation_spec(self):
|
| 109 |
+
return self._env.observation_spec()
|
| 110 |
+
|
| 111 |
+
def action_spec(self):
|
| 112 |
+
return self._env.action_spec()
|
| 113 |
+
|
| 114 |
+
def reset(self):
|
| 115 |
+
return self._env.reset()
|
| 116 |
+
|
| 117 |
+
def __getattr__(self, name):
|
| 118 |
+
return getattr(self._env, name)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class FramesWrapper(dm_env.Environment):
|
| 122 |
+
def __init__(self, env, num_frames=1, pixels_key='pixels'):
|
| 123 |
+
self._env = env
|
| 124 |
+
self._num_frames = num_frames
|
| 125 |
+
self._frames = deque([], maxlen=num_frames)
|
| 126 |
+
self._pixels_key = pixels_key
|
| 127 |
+
|
| 128 |
+
wrapped_obs_spec = env.observation_spec()
|
| 129 |
+
assert pixels_key in wrapped_obs_spec
|
| 130 |
+
|
| 131 |
+
pixels_shape = wrapped_obs_spec[pixels_key].shape
|
| 132 |
+
# remove batch dim
|
| 133 |
+
if len(pixels_shape) == 4:
|
| 134 |
+
pixels_shape = pixels_shape[1:]
|
| 135 |
+
self._obs_spec = specs.BoundedArray(shape=np.concatenate(
|
| 136 |
+
[[pixels_shape[2] * num_frames], pixels_shape[:2]], axis=0),
|
| 137 |
+
dtype=np.uint8,
|
| 138 |
+
minimum=0,
|
| 139 |
+
maximum=255,
|
| 140 |
+
name='observation')
|
| 141 |
+
|
| 142 |
+
def _transform_observation(self, time_step):
|
| 143 |
+
assert len(self._frames) == self._num_frames
|
| 144 |
+
obs = np.concatenate(list(self._frames), axis=0)
|
| 145 |
+
return time_step._replace(observation=obs)
|
| 146 |
+
|
| 147 |
+
def _extract_pixels(self, time_step):
|
| 148 |
+
pixels = time_step.observation[self._pixels_key]
|
| 149 |
+
# remove batch dim
|
| 150 |
+
if len(pixels.shape) == 4:
|
| 151 |
+
pixels = pixels[0]
|
| 152 |
+
return pixels.transpose(2, 0, 1).copy()
|
| 153 |
+
|
| 154 |
+
def reset(self):
|
| 155 |
+
time_step = self._env.reset()
|
| 156 |
+
pixels = self._extract_pixels(time_step)
|
| 157 |
+
for _ in range(self._num_frames):
|
| 158 |
+
self._frames.append(pixels)
|
| 159 |
+
return self._transform_observation(time_step)
|
| 160 |
+
|
| 161 |
+
def step(self, action):
|
| 162 |
+
time_step = self._env.step(action)
|
| 163 |
+
pixels = self._extract_pixels(time_step)
|
| 164 |
+
self._frames.append(pixels)
|
| 165 |
+
return self._transform_observation(time_step)
|
| 166 |
+
|
| 167 |
+
def observation_spec(self):
|
| 168 |
+
return self._obs_spec
|
| 169 |
+
|
| 170 |
+
def action_spec(self):
|
| 171 |
+
return self._env.action_spec()
|
| 172 |
+
|
| 173 |
+
def __getattr__(self, name):
|
| 174 |
+
return getattr(self._env, name)
|
| 175 |
+
|
| 176 |
+
class OneHotAction(gym.Wrapper):
|
| 177 |
+
def __init__(self, env):
|
| 178 |
+
assert isinstance(env.action_space, gym.spaces.Discrete)
|
| 179 |
+
super().__init__(env)
|
| 180 |
+
self._random = np.random.RandomState()
|
| 181 |
+
shape = (self.env.action_space.n,)
|
| 182 |
+
space = gym.spaces.Box(low=0, high=1, shape=shape, dtype=np.float32)
|
| 183 |
+
space.discrete = True
|
| 184 |
+
self.action_space = space
|
| 185 |
+
|
| 186 |
+
def step(self, action):
|
| 187 |
+
index = np.argmax(action).astype(int)
|
| 188 |
+
reference = np.zeros_like(action)
|
| 189 |
+
reference[index] = 1
|
| 190 |
+
if not np.allclose(reference, action):
|
| 191 |
+
raise ValueError(f"Invalid one-hot action:\n{action}")
|
| 192 |
+
return self.env.step(index)
|
| 193 |
+
|
| 194 |
+
def reset(self):
|
| 195 |
+
return self.env.reset()
|
| 196 |
+
|
| 197 |
+
def _sample_action(self):
|
| 198 |
+
actions = self.env.action_space.n
|
| 199 |
+
index = self._random.randint(0, actions)
|
| 200 |
+
reference = np.zeros(actions, dtype=np.float32)
|
| 201 |
+
reference[index] = 1.0
|
| 202 |
+
return reference
|
| 203 |
+
|
| 204 |
+
class ActionDTypeWrapper(dm_env.Environment):
|
| 205 |
+
def __init__(self, env, dtype):
|
| 206 |
+
self._env = env
|
| 207 |
+
wrapped_action_spec = env.action_spec()
|
| 208 |
+
self._action_spec = specs.BoundedArray(wrapped_action_spec.shape,
|
| 209 |
+
dtype,
|
| 210 |
+
wrapped_action_spec.minimum,
|
| 211 |
+
wrapped_action_spec.maximum,
|
| 212 |
+
'action')
|
| 213 |
+
|
| 214 |
+
def step(self, action):
|
| 215 |
+
action = action.astype(self._env.action_spec().dtype)
|
| 216 |
+
return self._env.step(action)
|
| 217 |
+
|
| 218 |
+
def observation_spec(self):
|
| 219 |
+
return self._env.observation_spec()
|
| 220 |
+
|
| 221 |
+
def action_spec(self):
|
| 222 |
+
return self._action_spec
|
| 223 |
+
|
| 224 |
+
def reset(self):
|
| 225 |
+
return self._env.reset()
|
| 226 |
+
|
| 227 |
+
def __getattr__(self, name):
|
| 228 |
+
return getattr(self._env, name)
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
class ObservationDTypeWrapper(dm_env.Environment):
|
| 232 |
+
def __init__(self, env, dtype):
|
| 233 |
+
self._env = env
|
| 234 |
+
self._dtype = dtype
|
| 235 |
+
wrapped_obs_spec = env.observation_spec()['observations']
|
| 236 |
+
self._obs_spec = specs.Array(wrapped_obs_spec.shape, dtype,
|
| 237 |
+
'observation')
|
| 238 |
+
|
| 239 |
+
def _transform_observation(self, time_step):
|
| 240 |
+
obs = time_step.observation['observations'].astype(self._dtype)
|
| 241 |
+
return time_step._replace(observation=obs)
|
| 242 |
+
|
| 243 |
+
def reset(self):
|
| 244 |
+
time_step = self._env.reset()
|
| 245 |
+
return self._transform_observation(time_step)
|
| 246 |
+
|
| 247 |
+
def step(self, action):
|
| 248 |
+
time_step = self._env.step(action)
|
| 249 |
+
return self._transform_observation(time_step)
|
| 250 |
+
|
| 251 |
+
def observation_spec(self):
|
| 252 |
+
return self._obs_spec
|
| 253 |
+
|
| 254 |
+
def action_spec(self):
|
| 255 |
+
return self._env.action_spec()
|
| 256 |
+
|
| 257 |
+
def __getattr__(self, name):
|
| 258 |
+
return getattr(self._env, name)
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
class ExtendedTimeStepWrapper(dm_env.Environment):
|
| 262 |
+
def __init__(self, env):
|
| 263 |
+
self._env = env
|
| 264 |
+
|
| 265 |
+
def reset(self):
|
| 266 |
+
time_step = self._env.reset()
|
| 267 |
+
return self._augment_time_step(time_step)
|
| 268 |
+
|
| 269 |
+
def step(self, action):
|
| 270 |
+
time_step = self._env.step(action)
|
| 271 |
+
return self._augment_time_step(time_step, action)
|
| 272 |
+
|
| 273 |
+
def _augment_time_step(self, time_step, action=None):
|
| 274 |
+
if action is None:
|
| 275 |
+
action_spec = self.action_spec()
|
| 276 |
+
action = np.zeros(action_spec.shape, dtype=action_spec.dtype)
|
| 277 |
+
return ExtendedTimeStep(observation=time_step.observation,
|
| 278 |
+
step_type=time_step.step_type,
|
| 279 |
+
action=action,
|
| 280 |
+
reward=time_step.reward or 0.0,
|
| 281 |
+
discount=time_step.discount or 1.0)
|
| 282 |
+
|
| 283 |
+
def observation_spec(self):
|
| 284 |
+
return self._env.observation_spec()
|
| 285 |
+
|
| 286 |
+
def action_spec(self):
|
| 287 |
+
return self._env.action_spec()
|
| 288 |
+
|
| 289 |
+
def __getattr__(self, name):
|
| 290 |
+
return getattr(self._env, name)
|
| 291 |
+
|
| 292 |
+
class DMC:
|
| 293 |
+
def __init__(self, env):
|
| 294 |
+
self._env = env
|
| 295 |
+
self._ignored_keys = []
|
| 296 |
+
|
| 297 |
+
def step(self, action):
|
| 298 |
+
time_step = self._env.step(action)
|
| 299 |
+
assert time_step.discount in (0, 1)
|
| 300 |
+
obs = {
|
| 301 |
+
'reward': time_step.reward,
|
| 302 |
+
'is_first': False,
|
| 303 |
+
'is_last': time_step.last(),
|
| 304 |
+
'is_terminal': time_step.discount == 0,
|
| 305 |
+
'observation': time_step.observation,
|
| 306 |
+
'action' : action,
|
| 307 |
+
'discount': time_step.discount
|
| 308 |
+
}
|
| 309 |
+
return time_step, obs
|
| 310 |
+
|
| 311 |
+
def reset(self):
|
| 312 |
+
time_step = self._env.reset()
|
| 313 |
+
obs = {
|
| 314 |
+
'reward': 0.0,
|
| 315 |
+
'is_first': True,
|
| 316 |
+
'is_last': False,
|
| 317 |
+
'is_terminal': False,
|
| 318 |
+
'observation': time_step.observation,
|
| 319 |
+
'action' : np.zeros_like(self.act_space['action'].sample()),
|
| 320 |
+
'discount': time_step.discount
|
| 321 |
+
}
|
| 322 |
+
return time_step, obs
|
| 323 |
+
|
| 324 |
+
def __getattr__(self, name):
|
| 325 |
+
if name == 'obs_space':
|
| 326 |
+
obs_spaces = {
|
| 327 |
+
'observation': self._env.observation_spec(),
|
| 328 |
+
'is_first': gym.spaces.Box(0, 1, (), dtype=bool),
|
| 329 |
+
'is_last': gym.spaces.Box(0, 1, (), dtype=bool),
|
| 330 |
+
'is_terminal': gym.spaces.Box(0, 1, (), dtype=bool),
|
| 331 |
+
}
|
| 332 |
+
return obs_spaces
|
| 333 |
+
if name == 'act_space':
|
| 334 |
+
spec = self._env.action_spec()
|
| 335 |
+
action = gym.spaces.Box((spec.minimum)*spec.shape[0], (spec.maximum)*spec.shape[0], shape=spec.shape, dtype=np.float32)
|
| 336 |
+
act_space = {'action': action}
|
| 337 |
+
return act_space
|
| 338 |
+
return getattr(self._env, name)
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
class OneHotAction(gym.Wrapper):
|
| 342 |
+
def __init__(self, env):
|
| 343 |
+
assert isinstance(env.action_space, gym.spaces.Discrete)
|
| 344 |
+
super().__init__(env)
|
| 345 |
+
self._random = np.random.RandomState()
|
| 346 |
+
shape = (self.env.action_space.n,)
|
| 347 |
+
space = gym.spaces.Box(low=0, high=1, shape=shape, dtype=np.float32)
|
| 348 |
+
space.discrete = True
|
| 349 |
+
self.action_space = space
|
| 350 |
+
|
| 351 |
+
def step(self, action):
|
| 352 |
+
index = np.argmax(action).astype(int)
|
| 353 |
+
reference = np.zeros_like(action)
|
| 354 |
+
reference[index] = 1
|
| 355 |
+
if not np.allclose(reference, action):
|
| 356 |
+
raise ValueError(f"Invalid one-hot action:\n{action}")
|
| 357 |
+
return self.env.step(index)
|
| 358 |
+
|
| 359 |
+
def reset(self):
|
| 360 |
+
return self.env.reset()
|
| 361 |
+
|
| 362 |
+
def _sample_action(self):
|
| 363 |
+
actions = self.env.action_space.n
|
| 364 |
+
index = self._random.randint(0, actions)
|
| 365 |
+
reference = np.zeros(actions, dtype=np.float32)
|
| 366 |
+
reference[index] = 1.0
|
| 367 |
+
return reference
|
| 368 |
+
|
| 369 |
+
class KitchenWrapper:
|
| 370 |
+
def __init__(
|
| 371 |
+
self,
|
| 372 |
+
name,
|
| 373 |
+
seed=0,
|
| 374 |
+
action_repeat=1,
|
| 375 |
+
size=(64, 64),
|
| 376 |
+
):
|
| 377 |
+
import envs.kitchen_extra as kitchen_extra
|
| 378 |
+
self._env = {
|
| 379 |
+
'microwave' : kitchen_extra.KitchenMicrowaveV0,
|
| 380 |
+
'kettle' : kitchen_extra.KitchenKettleV0,
|
| 381 |
+
'burner' : kitchen_extra.KitchenBurnerV0,
|
| 382 |
+
'light' : kitchen_extra.KitchenLightV0,
|
| 383 |
+
'hinge' : kitchen_extra.KitchenHingeV0,
|
| 384 |
+
'slide' : kitchen_extra.KitchenSlideV0,
|
| 385 |
+
'top_burner' : kitchen_extra.KitchenTopBurnerV0,
|
| 386 |
+
}[name]()
|
| 387 |
+
|
| 388 |
+
self._size = size
|
| 389 |
+
self._action_repeat = action_repeat
|
| 390 |
+
self._seed = seed
|
| 391 |
+
self._eval = False
|
| 392 |
+
|
| 393 |
+
def eval_mode(self,):
|
| 394 |
+
self._env.dense = False
|
| 395 |
+
self._eval = True
|
| 396 |
+
|
| 397 |
+
@property
|
| 398 |
+
def obs_space(self):
|
| 399 |
+
spaces = {
|
| 400 |
+
"observation": gym.spaces.Box(0, 255, (3,) + self._size, dtype=np.uint8),
|
| 401 |
+
"is_first": gym.spaces.Box(0, 1, (), dtype=bool),
|
| 402 |
+
"is_last": gym.spaces.Box(0, 1, (), dtype=bool),
|
| 403 |
+
"is_terminal": gym.spaces.Box(0, 1, (), dtype=bool),
|
| 404 |
+
"state": self._env.observation_space,
|
| 405 |
+
}
|
| 406 |
+
return spaces
|
| 407 |
+
|
| 408 |
+
@property
|
| 409 |
+
def act_space(self):
|
| 410 |
+
action = self._env.action_space
|
| 411 |
+
return {"action": action}
|
| 412 |
+
|
| 413 |
+
def step(self, action):
|
| 414 |
+
# assert np.isfinite(action["action"]).all(), action["action"]
|
| 415 |
+
reward = 0.0
|
| 416 |
+
for _ in range(self._action_repeat):
|
| 417 |
+
state, rew, done, info = self._env.step(action.copy())
|
| 418 |
+
reward += rew
|
| 419 |
+
obs = {
|
| 420 |
+
"reward": reward,
|
| 421 |
+
"is_first": False,
|
| 422 |
+
"is_last": False, # will be handled by timelimit wrapper
|
| 423 |
+
"is_terminal": False, # will be handled by per_episode function
|
| 424 |
+
"observation": info['images'].transpose(2, 0, 1).copy(),
|
| 425 |
+
"state": state.astype(np.float32),
|
| 426 |
+
'action' : action,
|
| 427 |
+
'discount' : 1
|
| 428 |
+
}
|
| 429 |
+
if self._eval:
|
| 430 |
+
obs['reward'] = min(obs['reward'], 1)
|
| 431 |
+
if obs['reward'] > 0:
|
| 432 |
+
obs['is_last'] = True
|
| 433 |
+
return dm_env.TimeStep(
|
| 434 |
+
step_type=dm_env.StepType.MID if not obs['is_last'] else dm_env.StepType.LAST,
|
| 435 |
+
reward=obs['reward'],
|
| 436 |
+
discount=1,
|
| 437 |
+
observation=obs['observation']), obs
|
| 438 |
+
|
| 439 |
+
def reset(self,):
|
| 440 |
+
state = self._env.reset()
|
| 441 |
+
obs = {
|
| 442 |
+
"reward": 0.0,
|
| 443 |
+
"is_first": True,
|
| 444 |
+
"is_last": False,
|
| 445 |
+
"is_terminal": False,
|
| 446 |
+
"observation": self.get_visual_obs(self._size),
|
| 447 |
+
"state": state.astype(np.float32),
|
| 448 |
+
'action' : np.zeros_like(self.act_space['action'].sample()),
|
| 449 |
+
'discount' : 1
|
| 450 |
+
}
|
| 451 |
+
return dm_env.TimeStep(
|
| 452 |
+
step_type=dm_env.StepType.FIRST,
|
| 453 |
+
reward=None,
|
| 454 |
+
discount=None,
|
| 455 |
+
observation=obs['observation']), obs
|
| 456 |
+
|
| 457 |
+
def __getattr__(self, name):
|
| 458 |
+
if name == 'obs_space':
|
| 459 |
+
return self.obs_space
|
| 460 |
+
if name == 'act_space':
|
| 461 |
+
return self.act_space
|
| 462 |
+
return getattr(self._env, name)
|
| 463 |
+
|
| 464 |
+
def get_visual_obs(self, resolution):
|
| 465 |
+
img = self._env.render(resolution=resolution,).transpose(2, 0, 1).copy()
|
| 466 |
+
return img
|
| 467 |
+
|
| 468 |
+
class ViClipWrapper:
|
| 469 |
+
def __init__(self, env, hd_rendering=False, device='cuda'):
|
| 470 |
+
self._env = env
|
| 471 |
+
try:
|
| 472 |
+
from tools.genrl_utils import viclip_global_instance
|
| 473 |
+
except:
|
| 474 |
+
from tools.genrl_utils import ViCLIPGlobalInstance
|
| 475 |
+
viclip_global_instance = ViCLIPGlobalInstance()
|
| 476 |
+
|
| 477 |
+
if not viclip_global_instance._instantiated:
|
| 478 |
+
viclip_global_instance.instantiate(device)
|
| 479 |
+
self.viclip_model = viclip_global_instance.viclip
|
| 480 |
+
self.n_frames = self.viclip_model.n_frames
|
| 481 |
+
self.viclip_emb_dim = viclip_global_instance.viclip_emb_dim
|
| 482 |
+
self.n_frames = self.viclip_model.n_frames
|
| 483 |
+
self.buffer = deque(maxlen=self.n_frames)
|
| 484 |
+
# NOTE: these are hardcoded for now, as they are the best settings
|
| 485 |
+
self.accumulate = True
|
| 486 |
+
self.accumulate_buffer = []
|
| 487 |
+
self.anticipate_conv1 = False
|
| 488 |
+
self.hd_rendering = hd_rendering
|
| 489 |
+
|
| 490 |
+
def hd_render(self, obs):
|
| 491 |
+
if not self.hd_rendering:
|
| 492 |
+
return obs['observation']
|
| 493 |
+
if self._env._domain_name in ['mw', 'kitchen', 'mujoco']:
|
| 494 |
+
return self.get_visual_obs((224,224,))
|
| 495 |
+
else:
|
| 496 |
+
render_kwargs = {**getattr(self, '_render_kwargs', {})}
|
| 497 |
+
render_kwargs.update({'width' : 224, 'height' : 224})
|
| 498 |
+
return self._env.physics.render(**render_kwargs).transpose(2,0,1)
|
| 499 |
+
|
| 500 |
+
def preprocess(self, x):
|
| 501 |
+
return x
|
| 502 |
+
|
| 503 |
+
def process_accumulate(self, process_at_once=4): # NOTE: this could be varied for increasing FPS, depending on the size of the GPU
|
| 504 |
+
self.accumulate = False
|
| 505 |
+
x = np.stack(self.accumulate_buffer, axis=0)
|
| 506 |
+
# Splitting in chunks
|
| 507 |
+
chunks = []
|
| 508 |
+
chunk_idxs = list(range(0, x.shape[0] + 1, process_at_once))
|
| 509 |
+
if chunk_idxs[-1] != x.shape[0]:
|
| 510 |
+
chunk_idxs.append(x.shape[0])
|
| 511 |
+
start = 0
|
| 512 |
+
for end in chunk_idxs[1:]:
|
| 513 |
+
embeds = self.clip_process(x[start:end], bypass=True)
|
| 514 |
+
chunks.append(embeds.cpu())
|
| 515 |
+
start = end
|
| 516 |
+
embeds = torch.cat(chunks, dim=0)
|
| 517 |
+
assert embeds.shape[0] == len(self.accumulate_buffer)
|
| 518 |
+
self.accumulate = True
|
| 519 |
+
self.accumulate_buffer = []
|
| 520 |
+
return [*embeds.cpu().numpy()], 'clip_video'
|
| 521 |
+
|
| 522 |
+
def process_episode(self, obs, process_at_once=8):
|
| 523 |
+
self.accumulate = False
|
| 524 |
+
sequences = []
|
| 525 |
+
for j in range(obs.shape[0] - self.n_frames + 1):
|
| 526 |
+
sequences.append(obs[j:j+self.n_frames].copy())
|
| 527 |
+
sequences = np.stack(sequences, axis=0)
|
| 528 |
+
|
| 529 |
+
idx_start = 0
|
| 530 |
+
clip_vid = []
|
| 531 |
+
for idx_end in range(process_at_once, sequences.shape[0] + process_at_once, process_at_once):
|
| 532 |
+
x = sequences[idx_start:idx_end]
|
| 533 |
+
with torch.no_grad(): # , torch.cuda.amp.autocast():
|
| 534 |
+
x = self.clip_process(x, bypass=True)
|
| 535 |
+
clip_vid.append(x)
|
| 536 |
+
idx_start = idx_end
|
| 537 |
+
if len(clip_vid) == 1: # process all at once
|
| 538 |
+
embeds = clip_vid[0]
|
| 539 |
+
else:
|
| 540 |
+
embeds = torch.cat(clip_vid, dim=0)
|
| 541 |
+
pad = torch.zeros( (self.n_frames - 1, *embeds.shape[1:]), device=embeds.device, dtype=embeds.dtype)
|
| 542 |
+
embeds = torch.cat([pad, embeds], dim=0)
|
| 543 |
+
assert embeds.shape[0] == obs.shape[0], f"Shapes are different {embeds.shape[0]} {obs.shape[0]}"
|
| 544 |
+
return embeds.cpu().numpy()
|
| 545 |
+
|
| 546 |
+
def get_sequence(self,):
|
| 547 |
+
return np.expand_dims(np.stack(self.buffer, axis=0), axis=0)
|
| 548 |
+
|
| 549 |
+
def clip_process(self, x, bypass=False):
|
| 550 |
+
if len(self.buffer) == self.n_frames or bypass:
|
| 551 |
+
if self.accumulate:
|
| 552 |
+
self.accumulate_buffer.append(self.preprocess(x)[0])
|
| 553 |
+
return torch.zeros(self.viclip_emb_dim)
|
| 554 |
+
with torch.no_grad():
|
| 555 |
+
B, n_frames, C, H, W = x.shape
|
| 556 |
+
obs = torch.from_numpy(x.copy().reshape(B * n_frames, C, H, W)).to(self.viclip_model.device)
|
| 557 |
+
processed_obs = self.viclip_model.preprocess_transf(obs / 255)
|
| 558 |
+
reshaped_obs = processed_obs.reshape(B, n_frames, 3,processed_obs.shape[-2],processed_obs.shape[-1])
|
| 559 |
+
video_embed = self.viclip_model.get_vid_features(reshaped_obs)
|
| 560 |
+
return video_embed.detach()
|
| 561 |
+
else:
|
| 562 |
+
return torch.zeros(self.viclip_emb_dim)
|
| 563 |
+
|
| 564 |
+
def step(self, action):
|
| 565 |
+
ts, obs = self._env.step(action)
|
| 566 |
+
self.buffer.append(self.hd_render(obs))
|
| 567 |
+
obs['clip_video'] = self.clip_process(self.get_sequence()).cpu().numpy()
|
| 568 |
+
return ts, obs
|
| 569 |
+
|
| 570 |
+
def reset(self,):
|
| 571 |
+
# Important to reset the buffer
|
| 572 |
+
self.buffer = deque(maxlen=self.n_frames)
|
| 573 |
+
|
| 574 |
+
ts, obs = self._env.reset()
|
| 575 |
+
self.buffer.append(self.hd_render(obs))
|
| 576 |
+
obs['clip_video'] = self.clip_process(self.get_sequence()).cpu().numpy()
|
| 577 |
+
return ts, obs
|
| 578 |
+
|
| 579 |
+
def __getattr__(self, name):
|
| 580 |
+
if name == 'obs_space':
|
| 581 |
+
space = self._env.obs_space
|
| 582 |
+
space['clip_video'] = gym.spaces.Box(-np.inf, np.inf, (self.viclip_emb_dim,), dtype=np.float32)
|
| 583 |
+
return space
|
| 584 |
+
return getattr(self._env, name)
|
| 585 |
+
|
| 586 |
+
class TimeLimit:
|
| 587 |
+
|
| 588 |
+
def __init__(self, env, duration):
|
| 589 |
+
self._env = env
|
| 590 |
+
self._duration = duration
|
| 591 |
+
self._step = None
|
| 592 |
+
|
| 593 |
+
def __getattr__(self, name):
|
| 594 |
+
if name.startswith('__'):
|
| 595 |
+
raise AttributeError(name)
|
| 596 |
+
return getattr(self._env, name)
|
| 597 |
+
|
| 598 |
+
def step(self, action):
|
| 599 |
+
assert self._step is not None, 'Must reset environment.'
|
| 600 |
+
ts, obs = self._env.step(action)
|
| 601 |
+
self._step += 1
|
| 602 |
+
if self._duration and self._step >= self._duration:
|
| 603 |
+
ts = dm_env.TimeStep(dm_env.StepType.LAST, ts.reward, ts.discount, ts.observation)
|
| 604 |
+
obs['is_last'] = True
|
| 605 |
+
self._step = None
|
| 606 |
+
return ts, obs
|
| 607 |
+
|
| 608 |
+
def reset(self):
|
| 609 |
+
self._step = 0
|
| 610 |
+
return self._env.reset()
|
| 611 |
+
|
| 612 |
+
def reset_with_task_id(self, task_id):
|
| 613 |
+
self._step = 0
|
| 614 |
+
return self._env.reset_with_task_id(task_id)
|
| 615 |
+
|
| 616 |
+
class ClipActionWrapper:
|
| 617 |
+
|
| 618 |
+
def __init__(self, env, low=-1.0, high=1.0):
|
| 619 |
+
self._env = env
|
| 620 |
+
self._low = low
|
| 621 |
+
self._high = high
|
| 622 |
+
|
| 623 |
+
def __getattr__(self, name):
|
| 624 |
+
if name.startswith('__'):
|
| 625 |
+
raise AttributeError(name)
|
| 626 |
+
return getattr(self._env, name)
|
| 627 |
+
|
| 628 |
+
def step(self, action):
|
| 629 |
+
clipped_action = np.clip(action, self._low, self._high)
|
| 630 |
+
return self._env.step(clipped_action)
|
| 631 |
+
|
| 632 |
+
def reset(self):
|
| 633 |
+
self._step = 0
|
| 634 |
+
return self._env.reset()
|
| 635 |
+
|
| 636 |
+
def reset_with_task_id(self, task_id):
|
| 637 |
+
self._step = 0
|
| 638 |
+
return self._env.reset_with_task_id(task_id)
|
| 639 |
+
|
| 640 |
+
class NormalizeAction:
|
| 641 |
+
|
| 642 |
+
def __init__(self, env, key='action'):
|
| 643 |
+
self._env = env
|
| 644 |
+
self._key = key
|
| 645 |
+
space = env.act_space[key]
|
| 646 |
+
self._mask = np.isfinite(space.low) & np.isfinite(space.high)
|
| 647 |
+
self._low = np.where(self._mask, space.low, -1)
|
| 648 |
+
self._high = np.where(self._mask, space.high, 1)
|
| 649 |
+
|
| 650 |
+
def __getattr__(self, name):
|
| 651 |
+
if name.startswith('__'):
|
| 652 |
+
raise AttributeError(name)
|
| 653 |
+
try:
|
| 654 |
+
return getattr(self._env, name)
|
| 655 |
+
except AttributeError:
|
| 656 |
+
raise ValueError(name)
|
| 657 |
+
|
| 658 |
+
@property
|
| 659 |
+
def act_space(self):
|
| 660 |
+
low = np.where(self._mask, -np.ones_like(self._low), self._low)
|
| 661 |
+
high = np.where(self._mask, np.ones_like(self._low), self._high)
|
| 662 |
+
space = gym.spaces.Box(low, high, dtype=np.float32)
|
| 663 |
+
return {**self._env.act_space, self._key: space}
|
| 664 |
+
|
| 665 |
+
def step(self, action):
|
| 666 |
+
orig = (action[self._key] + 1) / 2 * (self._high - self._low) + self._low
|
| 667 |
+
orig = np.where(self._mask, orig, action[self._key])
|
| 668 |
+
return self._env.step({**action, self._key: orig})
|
| 669 |
+
|
| 670 |
+
def _make_jaco(obs_type, domain, task, action_repeat, seed, img_size,):
|
| 671 |
+
import envs.custom_dmc_tasks as cdmc
|
| 672 |
+
env = cdmc.make_jaco(task, obs_type, seed, img_size,)
|
| 673 |
+
env = ActionDTypeWrapper(env, np.float32)
|
| 674 |
+
env = ActionRepeatWrapper(env, action_repeat)
|
| 675 |
+
env = FlattenJacoObservationWrapper(env)
|
| 676 |
+
env._size = (img_size, img_size)
|
| 677 |
+
return env
|
| 678 |
+
|
| 679 |
+
|
| 680 |
+
def _make_dmc(obs_type, domain, task, action_repeat, seed, img_size,):
|
| 681 |
+
visualize_reward = False
|
| 682 |
+
from dm_control import manipulation, suite
|
| 683 |
+
import envs.custom_dmc_tasks as cdmc
|
| 684 |
+
|
| 685 |
+
if (domain, task) in suite.ALL_TASKS:
|
| 686 |
+
env = suite.load(domain,
|
| 687 |
+
task,
|
| 688 |
+
task_kwargs=dict(random=seed),
|
| 689 |
+
environment_kwargs=dict(flat_observation=True),
|
| 690 |
+
visualize_reward=visualize_reward)
|
| 691 |
+
else:
|
| 692 |
+
env = cdmc.make(domain,
|
| 693 |
+
task,
|
| 694 |
+
task_kwargs=dict(random=seed),
|
| 695 |
+
environment_kwargs=dict(flat_observation=True),
|
| 696 |
+
visualize_reward=visualize_reward)
|
| 697 |
+
env = ActionDTypeWrapper(env, np.float32)
|
| 698 |
+
env = ActionRepeatWrapper(env, action_repeat)
|
| 699 |
+
if obs_type == 'pixels':
|
| 700 |
+
from dm_control.suite.wrappers import pixels
|
| 701 |
+
# zoom in camera for quadruped
|
| 702 |
+
camera_id = dict(locom_rodent=1,quadruped=2).get(domain, 0)
|
| 703 |
+
render_kwargs = dict(height=img_size, width=img_size, camera_id=camera_id)
|
| 704 |
+
env = pixels.Wrapper(env,
|
| 705 |
+
pixels_only=True,
|
| 706 |
+
render_kwargs=render_kwargs)
|
| 707 |
+
env._size = (img_size, img_size)
|
| 708 |
+
env._camera = camera_id
|
| 709 |
+
return env
|
| 710 |
+
|
| 711 |
+
|
| 712 |
+
def make(name, obs_type, action_repeat, seed, img_size=64, viclip_encode=False, clip_hd_rendering=False, device='cuda'):
|
| 713 |
+
assert obs_type in ['states', 'pixels']
|
| 714 |
+
domain, task = name.split('_', 1)
|
| 715 |
+
if domain == 'kitchen':
|
| 716 |
+
env = TimeLimit(KitchenWrapper(task, seed=seed, action_repeat=action_repeat, size=(img_size,img_size)), 280 // action_repeat)
|
| 717 |
+
else:
|
| 718 |
+
os.environ['PYOPENGL_PLATFORM'] = 'egl'
|
| 719 |
+
os.environ['MUJOCO_GL'] = 'egl'
|
| 720 |
+
|
| 721 |
+
domain = dict(cup='ball_in_cup', point='point_mass').get(domain, domain)
|
| 722 |
+
|
| 723 |
+
make_fn = _make_jaco if domain == 'jaco' else _make_dmc
|
| 724 |
+
env = make_fn(obs_type, domain, task, action_repeat, seed, img_size,)
|
| 725 |
+
|
| 726 |
+
if obs_type == 'pixels':
|
| 727 |
+
env = FramesWrapper(env,)
|
| 728 |
+
else:
|
| 729 |
+
env = ObservationDTypeWrapper(env, np.float32)
|
| 730 |
+
|
| 731 |
+
from dm_control.suite.wrappers import action_scale
|
| 732 |
+
env = action_scale.Wrapper(env, minimum=-1.0, maximum=+1.0)
|
| 733 |
+
env = ExtendedTimeStepWrapper(env)
|
| 734 |
+
|
| 735 |
+
env = DMC(env)
|
| 736 |
+
env._domain_name = domain
|
| 737 |
+
|
| 738 |
+
if isinstance(env.act_space['action'], gym.spaces.Box):
|
| 739 |
+
env = ClipActionWrapper(env,)
|
| 740 |
+
|
| 741 |
+
if viclip_encode:
|
| 742 |
+
env = ViClipWrapper(env, hd_rendering=clip_hd_rendering, device=device)
|
| 743 |
+
return env
|
notebooks/demo_videoclip.ipynb
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"# InternVideo 2 demo\n",
|
| 8 |
+
"\n",
|
| 9 |
+
"It can be used to test the capabilities of InternVideo2 and to verify that the models are loaded correctly"
|
| 10 |
+
]
|
| 11 |
+
},
|
| 12 |
+
{
|
| 13 |
+
"cell_type": "code",
|
| 14 |
+
"execution_count": null,
|
| 15 |
+
"metadata": {
|
| 16 |
+
"scrolled": true
|
| 17 |
+
},
|
| 18 |
+
"outputs": [],
|
| 19 |
+
"source": [
|
| 20 |
+
"import pathlib\n",
|
| 21 |
+
"import sys\n",
|
| 22 |
+
"import os\n",
|
| 23 |
+
"sys.path.append(str(pathlib.Path(os.path.abspath('')).parent))\n",
|
| 24 |
+
"\n",
|
| 25 |
+
"from tools.genrl_utils import viclip_global_instance\n",
|
| 26 |
+
"viclip_global_instance.instantiate()"
|
| 27 |
+
]
|
| 28 |
+
},
|
| 29 |
+
{
|
| 30 |
+
"cell_type": "code",
|
| 31 |
+
"execution_count": null,
|
| 32 |
+
"metadata": {},
|
| 33 |
+
"outputs": [],
|
| 34 |
+
"source": [
|
| 35 |
+
"import cv2\n",
|
| 36 |
+
"import numpy as np\n",
|
| 37 |
+
"import torch\n",
|
| 38 |
+
"from tools.genrl_utils import INTERNVIDEO_PATH\n",
|
| 39 |
+
"\n",
|
| 40 |
+
"def _frame_from_video(video):\n",
|
| 41 |
+
" while video.isOpened():\n",
|
| 42 |
+
" success, frame = video.read()\n",
|
| 43 |
+
" if success:\n",
|
| 44 |
+
" yield frame\n",
|
| 45 |
+
" else:\n",
|
| 46 |
+
" break\n",
|
| 47 |
+
"\n",
|
| 48 |
+
"ASSET_PATH = pathlib.Path(os.path.abspath('')).parent / 'assets'\n",
|
| 49 |
+
"\n",
|
| 50 |
+
"# 83 % - A man in a gray sweater plays fetch with his dog in the snowy yard, throwing a toy and watching it run.\n",
|
| 51 |
+
"video = cv2.VideoCapture( str(INTERNVIDEO_PATH / 'InternVideo2/multi_modality/demo/example1.mp4') )\n",
|
| 52 |
+
"# # 99 % - A karate kick\n",
|
| 53 |
+
"# video = cv2.VideoCapture( str( ASSET_PATH / 'video_samples/karate_kick.mp4') ) \n",
|
| 54 |
+
"# # 99 % - A headstand\n",
|
| 55 |
+
"# video = cv2.VideoCapture( str( ASSET_PATH / 'video_samples/headstand.mp4') ) \n",
|
| 56 |
+
"\n",
|
| 57 |
+
"frames = [x for x in _frame_from_video(video)]\n",
|
| 58 |
+
"processed_frames = viclip_global_instance.viclip.preprocess_transf(torch.from_numpy(np.stack(frames[:8], axis=0)).permute(0,3,1,2) / 255)\n",
|
| 59 |
+
"frames_tensor = processed_frames.reshape(1, 8, 3, 224,224)"
|
| 60 |
+
]
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"cell_type": "code",
|
| 64 |
+
"execution_count": null,
|
| 65 |
+
"metadata": {},
|
| 66 |
+
"outputs": [],
|
| 67 |
+
"source": [
|
| 68 |
+
"text_candidates = [\"A playful dog and its owner wrestle in the snowy yard, chasing each other with joyous abandon.\",\n",
|
| 69 |
+
" \"A man in a gray coat walks through the snowy landscape, pulling a sleigh loaded with toys.\",\n",
|
| 70 |
+
" \"A person dressed in a blue jacket shovels the snow-covered pavement outside their house.\",\n",
|
| 71 |
+
" \"A pet dog excitedly runs through the snowy yard, chasing a toy thrown by its owner.\",\n",
|
| 72 |
+
" \"A person stands on the snowy floor, pushing a sled loaded with blankets, preparing for a fun-filled ride.\",\n",
|
| 73 |
+
" \"A man in a gray hat and coat walks through the snowy yard, carefully navigating around the trees.\",\n",
|
| 74 |
+
" \"A playful dog slides down a snowy hill, wagging its tail with delight.\",\n",
|
| 75 |
+
" \"A person in a blue jacket walks their pet on a leash, enjoying a peaceful winter walk among the trees.\",\n",
|
| 76 |
+
" \"A man in a gray sweater plays fetch with his dog in the snowy yard, throwing a toy and watching it run.\",\n",
|
| 77 |
+
" \"A person bundled up in a blanket walks through the snowy landscape, enjoying the serene winter scenery.\",\n",
|
| 78 |
+
" \"A person playing with a kid in the street\",\n",
|
| 79 |
+
" \"A group of friends playing bowling.\",\n",
|
| 80 |
+
" \"A japanese girl eating noodles\",\n",
|
| 81 |
+
" \"A painting by Monet\",\n",
|
| 82 |
+
" \"A karate kick\",\n",
|
| 83 |
+
" \"A headstand\"]"
|
| 84 |
+
]
|
| 85 |
+
},
|
| 86 |
+
{
|
| 87 |
+
"cell_type": "code",
|
| 88 |
+
"execution_count": null,
|
| 89 |
+
"metadata": {},
|
| 90 |
+
"outputs": [],
|
| 91 |
+
"source": [
|
| 92 |
+
"text_feat = viclip_global_instance.viclip.get_txt_feat(text_candidates)\n",
|
| 93 |
+
"video_feat = viclip_global_instance.viclip.get_vid_features(frames_tensor.to(viclip_global_instance.viclip.device))\n",
|
| 94 |
+
"\n",
|
| 95 |
+
"sorted_probs, sorted_idxs = (100.0 * video_feat @ text_feat.T).softmax(dim=-1)[0].topk(len(text_feat))\n",
|
| 96 |
+
"\n",
|
| 97 |
+
"for p, i in zip(sorted_probs, sorted_idxs):\n",
|
| 98 |
+
" if p > 0.01:\n",
|
| 99 |
+
" print(int(p * 100), '% - ', text_candidates[i])"
|
| 100 |
+
]
|
| 101 |
+
}
|
| 102 |
+
],
|
| 103 |
+
"metadata": {
|
| 104 |
+
"kernelspec": {
|
| 105 |
+
"display_name": "Python 3 (ipykernel)",
|
| 106 |
+
"language": "python",
|
| 107 |
+
"name": "python3"
|
| 108 |
+
},
|
| 109 |
+
"language_info": {
|
| 110 |
+
"codemirror_mode": {
|
| 111 |
+
"name": "ipython",
|
| 112 |
+
"version": 3
|
| 113 |
+
},
|
| 114 |
+
"file_extension": ".py",
|
| 115 |
+
"mimetype": "text/x-python",
|
| 116 |
+
"name": "python",
|
| 117 |
+
"nbconvert_exporter": "python",
|
| 118 |
+
"pygments_lexer": "ipython3",
|
| 119 |
+
"version": "3.10.14"
|
| 120 |
+
}
|
| 121 |
+
},
|
| 122 |
+
"nbformat": 4,
|
| 123 |
+
"nbformat_minor": 4
|
| 124 |
+
}
|
notebooks/text2video.ipynb
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"from pathlib import Path \n",
|
| 10 |
+
"import os\n",
|
| 11 |
+
"import sys\n",
|
| 12 |
+
"sys.path.append(str(Path(os.path.abspath('')).parent))\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"import torch\n",
|
| 15 |
+
"import numpy as np\n",
|
| 16 |
+
"\n",
|
| 17 |
+
"import matplotlib.pyplot as plt\n",
|
| 18 |
+
"import matplotlib.animation as animation\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"agent_path = Path(os.path.abspath('')).parent / 'models' / 'genrl_stickman_500k_2.pt'\n",
|
| 21 |
+
"print(\"Model path\", agent_path)\n",
|
| 22 |
+
"\n",
|
| 23 |
+
"agent = torch.load(agent_path)"
|
| 24 |
+
]
|
| 25 |
+
},
|
| 26 |
+
{
|
| 27 |
+
"cell_type": "code",
|
| 28 |
+
"execution_count": null,
|
| 29 |
+
"metadata": {},
|
| 30 |
+
"outputs": [],
|
| 31 |
+
"source": [
|
| 32 |
+
"from tools.genrl_utils import ViCLIPGlobalInstance, DOMAIN2PREDICATES\n",
|
| 33 |
+
"model_name = getattr(agent.cfg, 'viclip_model', 'viclip')\n",
|
| 34 |
+
"# Get ViCLIP\n",
|
| 35 |
+
"if 'viclip_global_instance' not in locals() or model_name != viclip_global_instance._model:\n",
|
| 36 |
+
" viclip_global_instance = ViCLIPGlobalInstance(model_name)\n",
|
| 37 |
+
" if not viclip_global_instance._instantiated:\n",
|
| 38 |
+
" print(\"Instantiating\")\n",
|
| 39 |
+
" viclip_global_instance.instantiate()\n",
|
| 40 |
+
" clip = viclip_global_instance.viclip\n",
|
| 41 |
+
" tokenizer = viclip_global_instance.viclip_tokenizer"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "code",
|
| 46 |
+
"execution_count": null,
|
| 47 |
+
"metadata": {},
|
| 48 |
+
"outputs": [],
|
| 49 |
+
"source": [
|
| 50 |
+
"SAVE = True\n",
|
| 51 |
+
"DENOISE = True\n",
|
| 52 |
+
"REVERSE = False\n",
|
| 53 |
+
"REPEAT_TIME = 2 # standard is n_frames for = 1 \n",
|
| 54 |
+
"TEXT_OVERLAY = True\n",
|
| 55 |
+
"\n",
|
| 56 |
+
"domain = agent.cfg.task.split('_')\n",
|
| 57 |
+
"\n",
|
| 58 |
+
"labels_list = ['high kick', 'stand up straight', 'doing splits']\n",
|
| 59 |
+
"\n",
|
| 60 |
+
"with torch.no_grad():\n",
|
| 61 |
+
" wm = world_model = agent.wm\n",
|
| 62 |
+
" connector = agent.wm.connector\n",
|
| 63 |
+
" decoder = world_model.heads['decoder']\n",
|
| 64 |
+
" n_frames = connector.n_frames\n",
|
| 65 |
+
" \n",
|
| 66 |
+
" # Get text(video) embed\n",
|
| 67 |
+
" text_feat = []\n",
|
| 68 |
+
" for text in labels_list:\n",
|
| 69 |
+
" with torch.no_grad():\n",
|
| 70 |
+
" text_feat.append(clip.get_txt_feat(text,))\n",
|
| 71 |
+
" text_feat = torch.stack(text_feat, dim=0).to(clip.device)\n",
|
| 72 |
+
"\n",
|
| 73 |
+
" video_embed = text_feat\n",
|
| 74 |
+
"\n",
|
| 75 |
+
" B = video_embed.shape[0]\n",
|
| 76 |
+
" T = 1\n",
|
| 77 |
+
"\n",
|
| 78 |
+
" # Get initial state\n",
|
| 79 |
+
" init = connector.initial(B, init_embed=video_embed)\n",
|
| 80 |
+
"\n",
|
| 81 |
+
" # Get actions\n",
|
| 82 |
+
" video_embed = video_embed.repeat(1,n_frames, 1)\n",
|
| 83 |
+
" action = wm.connector.get_action(video_embed)\n",
|
| 84 |
+
"\n",
|
| 85 |
+
" with torch.no_grad():\n",
|
| 86 |
+
" # Imagine\n",
|
| 87 |
+
" prior = wm.connector.video_imagine(video_embed, None, sample=False, reset_every_n_frames=False, denoise=DENOISE)\n",
|
| 88 |
+
" # Decode\n",
|
| 89 |
+
" prior_recon = decoder(wm.decoder_input_fn(prior))['observation'].mean + 0.5\n",
|
| 90 |
+
"\n",
|
| 91 |
+
" # Plotting video\n",
|
| 92 |
+
" R = int(np.sqrt(B))\n",
|
| 93 |
+
" C = min((B + (R-1)) // R, B) \n",
|
| 94 |
+
"\n",
|
| 95 |
+
" fig, axes = plt.subplots(R, C, figsize=(3.5 * C, 4 * R))\n",
|
| 96 |
+
" fig.subplots_adjust(top = 1, bottom = 0, right = 1, left = 0, hspace = 0, wspace = 0)\n",
|
| 97 |
+
" fig.set_size_inches(4,4)\n",
|
| 98 |
+
" \n",
|
| 99 |
+
" if B == 1:\n",
|
| 100 |
+
" axes = [[axes]]\n",
|
| 101 |
+
" elif R == 1:\n",
|
| 102 |
+
" axes = [axes] \n",
|
| 103 |
+
" axes = [ a for row in axes for a in row]\n",
|
| 104 |
+
"\n",
|
| 105 |
+
" file_path = f'temp_text2video.gif'\n",
|
| 106 |
+
"\n",
|
| 107 |
+
" if SAVE:\n",
|
| 108 |
+
" ims = []\n",
|
| 109 |
+
" for t in range(prior_recon.shape[1]):\n",
|
| 110 |
+
" if t == 0 :\n",
|
| 111 |
+
" continue\n",
|
| 112 |
+
" toadd = []\n",
|
| 113 |
+
" for b in range(prior_recon.shape[0]):\n",
|
| 114 |
+
" ax = axes[b]\n",
|
| 115 |
+
" ax.set_axis_off()\n",
|
| 116 |
+
" img = np.clip(prior_recon[b, t if not REVERSE else -t].cpu().permute(1,2,0), 0, 1)\n",
|
| 117 |
+
" frame = ax.imshow(img)\n",
|
| 118 |
+
" if TEXT_OVERLAY: \n",
|
| 119 |
+
" test = ax.text(0,5, labels_list[b], color='white')\n",
|
| 120 |
+
" toadd.append(frame) # add both the image and the text to the list of artists \n",
|
| 121 |
+
" ims.append(toadd)\n",
|
| 122 |
+
"\n",
|
| 123 |
+
" # Save GIFs\n",
|
| 124 |
+
" anim = animation.ArtistAnimation(fig, ims, interval=700, blit=True, repeat_delay=700)\n",
|
| 125 |
+
" writer = animation.PillowWriter(fps=15, metadata=dict(artist='Me'), bitrate=1800)\n",
|
| 126 |
+
" domain = agent.cfg.task.split('_')[0]\n",
|
| 127 |
+
" os.makedirs(f'videos/{domain}/text2video', exist_ok=True)\n",
|
| 128 |
+
" file_path = f'videos/{domain}/text2video/{\"_\".join(labels_list).replace(\" \",\"_\")}.gif'\n",
|
| 129 |
+
" print(\"GIF path: \", Path(os.path.abspath('')) / file_path)\n",
|
| 130 |
+
" anim.save(file_path, writer=writer)"
|
| 131 |
+
]
|
| 132 |
+
}
|
| 133 |
+
],
|
| 134 |
+
"metadata": {
|
| 135 |
+
"kernelspec": {
|
| 136 |
+
"display_name": "Python 3.8.10 ('base')",
|
| 137 |
+
"language": "python",
|
| 138 |
+
"name": "python3"
|
| 139 |
+
},
|
| 140 |
+
"language_info": {
|
| 141 |
+
"codemirror_mode": {
|
| 142 |
+
"name": "ipython",
|
| 143 |
+
"version": 3
|
| 144 |
+
},
|
| 145 |
+
"file_extension": ".py",
|
| 146 |
+
"mimetype": "text/x-python",
|
| 147 |
+
"name": "python",
|
| 148 |
+
"nbconvert_exporter": "python",
|
| 149 |
+
"pygments_lexer": "ipython3",
|
| 150 |
+
"version": "3.10.14"
|
| 151 |
+
},
|
| 152 |
+
"orig_nbformat": 4,
|
| 153 |
+
"vscode": {
|
| 154 |
+
"interpreter": {
|
| 155 |
+
"hash": "3d597f4c481aa0f25dceb95d2a0067e73c0966dcbd003d741d821a7208527ecf"
|
| 156 |
+
}
|
| 157 |
+
}
|
| 158 |
+
},
|
| 159 |
+
"nbformat": 4,
|
| 160 |
+
"nbformat_minor": 2
|
| 161 |
+
}
|