

Commit
•
181722d
1
Parent(s):
5f3ae13
Upload 89 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- CODEOWNERS +2 -0
- LICENSE.txt +14 -0
- MANIFEST.in +7 -0
- MiniGPT_4.pdf +3 -0
- README.md +139 -12
- app.py +146 -0
- create_align_dataset.py +134 -0
- dataset/convert_cc_sbu.py +20 -0
- dataset/convert_laion.py +20 -0
- dataset/download_cc_sbu.sh +6 -0
- dataset/download_laion.sh +6 -0
- dataset/readme.md +92 -0
- demo_dev.ipynb +0 -0
- develop.ipynb +929 -0
- environment.yml +56 -0
- eval_configs/minigpt4.yaml +30 -0
- examples/ad_1.png +0 -0
- examples/ad_2.png +0 -0
- examples/cook_1.png +0 -0
- examples/cook_2.png +0 -0
- examples/describe_1.png +0 -0
- examples/describe_2.png +0 -0
- examples/fact_1.png +0 -0
- examples/fact_2.png +0 -0
- examples/fix_1.png +0 -0
- examples/fix_2.png +0 -0
- examples/fun_1.png +0 -0
- examples/fun_2.png +0 -0
- examples/logo_1.png +0 -0
- examples/op_1.png +0 -0
- examples/op_2.png +0 -0
- examples/people_1.png +0 -0
- examples/people_2.png +0 -0
- examples/rhyme_1.png +0 -0
- examples/rhyme_2.png +0 -0
- examples/story_1.png +0 -0
- examples/story_2.png +0 -0
- examples/web_1.png +0 -0
- examples/wop_1.png +0 -0
- examples/wop_2.png +0 -0
- minigpt4/__init__.py +31 -0
- minigpt4/common/__init__.py +0 -0
- minigpt4/common/config.py +468 -0
- minigpt4/common/dist_utils.py +137 -0
- minigpt4/common/gradcam.py +24 -0
- minigpt4/common/logger.py +195 -0
- minigpt4/common/optims.py +119 -0
- minigpt4/common/registry.py +329 -0
- minigpt4/common/utils.py +424 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
MiniGPT_4.pdf filter=lfs diff=lfs merge=lfs -text
|
CODEOWNERS
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Comment line immediately above ownership line is reserved for related gus information. Please be careful while editing.
|
| 2 |
+
#ECCN:Open Source
|
LICENSE.txt
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Salesforce, Inc.
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
|
| 7 |
+
|
| 8 |
+
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
|
| 9 |
+
|
| 10 |
+
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
|
| 11 |
+
|
| 12 |
+
3. Neither the name of Salesforce.com nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
|
| 13 |
+
|
| 14 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
MANIFEST.in
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
recursive-include minigpt4/configs *.yaml *.json
|
| 2 |
+
recursive-include minigpt4/projects *.yaml *.json
|
| 3 |
+
|
| 4 |
+
recursive-exclude minigpt4/datasets/download_scripts *
|
| 5 |
+
recursive-exclude minigpt4/output *
|
| 6 |
+
|
| 7 |
+
include requirements.txt
|
MiniGPT_4.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5ef8de6eeefee0dcf33dea53e8de2a884939dc20617362052232e7a223941260
|
| 3 |
+
size 6614913
|
README.md
CHANGED
|
@@ -1,12 +1,139 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models
|
| 2 |
+
[Deyao Zhu](https://tsutikgiau.github.io/)* (On Job Market!), [Jun Chen](https://junchen14.github.io/)* (On Job Market!), Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. *Equal Contribution
|
| 3 |
+
|
| 4 |
+
**King Abdullah University of Science and Technology**
|
| 5 |
+
|
| 6 |
+
[[Project Website]](https://minigpt-4.github.io/) [[Paper]](MiniGPT_4.pdf) [Online Demo]
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
## Online Demo
|
| 10 |
+
|
| 11 |
+
Chat with MiniGPT-4 around your images
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
## Examples
|
| 15 |
+
| | |
|
| 16 |
+
:-------------------------:|:-------------------------:
|
| 17 |
+
 | 
|
| 18 |
+
 | 
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
## Abstract
|
| 25 |
+
The recent GPT-4 has demonstrated extraordinary multi-modal abilities, such as directly generating websites from handwritten text and identifying humorous elements within images. These features are rarely observed in previous vision-language models. We believe the primary reason for GPT-4's advanced multi-modal generation capabilities lies in the utilization of a more advanced large language model (LLM). To examine this phenomenon, we present MiniGPT-4, which aligns a frozen visual encoder with a frozen LLM, Vicuna, using just one projection layer.
|
| 26 |
+
Our findings reveal that MiniGPT-4 processes many capabilities similar to those exhibited by GPT-4 like detailed image description generation and website creation from hand-written drafts. Furthermore, we also observe other emerging capabilities in MiniGPT-4, including writing stories and poems inspired by given images, providing solutions to problems shown in images, teaching users how to cook based on food photos, etc.
|
| 27 |
+
These advanced capabilities can be attributed to the use of a more advanced large language model.
|
| 28 |
+
Furthermore, our method is computationally efficient, as we only train a projection layer using roughly 5 million aligned image-text pairs and an additional 3,500 carefully curated high-quality pairs.
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
## Getting Started
|
| 38 |
+
### Installation
|
| 39 |
+
|
| 40 |
+
1. Prepare the code and the environment
|
| 41 |
+
|
| 42 |
+
Git clone our repository, creating a python environment and ativate it via the following command
|
| 43 |
+
|
| 44 |
+
```bash
|
| 45 |
+
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
|
| 46 |
+
cd MiniGPT-4
|
| 47 |
+
conda env create -f environment.yml
|
| 48 |
+
conda activate minigpt4
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
2. Prepare the pretrained Vicuna weights
|
| 53 |
+
|
| 54 |
+
The current version of MiniGPT-4 is built on the v0 versoin of Vicuna-13B.
|
| 55 |
+
Please refer to their instructions [here](https://huggingface.co/lmsys/vicuna-13b-delta-v0) to obtaining the weights.
|
| 56 |
+
The final weights would be in a single folder with the following structure:
|
| 57 |
+
|
| 58 |
+
```
|
| 59 |
+
vicuna_weights
|
| 60 |
+
├── config.json
|
| 61 |
+
├── generation_config.json
|
| 62 |
+
├── pytorch_model.bin.index.json
|
| 63 |
+
├── pytorch_model-00001-of-00003.bin
|
| 64 |
+
...
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
Then, set the path to the vicuna weight in the model config file
|
| 68 |
+
[here](minigpt4/configs/models/minigpt4.yaml#L21) at Line 21.
|
| 69 |
+
|
| 70 |
+
3. Prepare the pretrained MiniGPT-4 checkpoint
|
| 71 |
+
|
| 72 |
+
To play with our pretrained model, download the pretrained checkpoint
|
| 73 |
+
[here](https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view?usp=share_link).
|
| 74 |
+
Then, set the path to the pretrained checkpoint in the evaluation config file
|
| 75 |
+
in [eval_configs/minigpt4.yaml](eval_configs/minigpt4.yaml#L15) at Line 15.
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
### Launching Demo Locally
|
| 82 |
+
|
| 83 |
+
Try out our demo [demo.py](app.py) with your images for on your local machine by running
|
| 84 |
+
|
| 85 |
+
```
|
| 86 |
+
python demo.py --cfg-path eval_configs/minigpt4.yaml
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
### Training
|
| 94 |
+
The training of MiniGPT-4 contains two-stage alignments.
|
| 95 |
+
In the first stage, the model is trained using image-text pairs from Laion and CC datasets
|
| 96 |
+
to align the vision and language model. To download and prepare the datasets, please check
|
| 97 |
+
[here](dataset/readme.md).
|
| 98 |
+
After the first stage, the visual features are mapped and can be understood by the language
|
| 99 |
+
model.
|
| 100 |
+
To launch the first stage training, run
|
| 101 |
+
|
| 102 |
+
```bash
|
| 103 |
+
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_config/minigpt4_stage1_laion.yaml
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
In the second stage, we use a small high quality image-text pair dataset created by ourselves
|
| 107 |
+
and convert it to a conversation format to further align MiniGPT-4.
|
| 108 |
+
Our second stage dataset can be download from
|
| 109 |
+
[here](https://drive.google.com/file/d/1RnS0mQJj8YU0E--sfH08scu5-ALxzLNj/view?usp=share_link).
|
| 110 |
+
After the second stage alignment, MiniGPT-4 is able to talk about the image in
|
| 111 |
+
a smooth way.
|
| 112 |
+
To launch the second stage alignment, run
|
| 113 |
+
|
| 114 |
+
```bash
|
| 115 |
+
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_config/minigpt4_stage2_align.yaml
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
## Acknowledgement
|
| 123 |
+
|
| 124 |
+
+ [BLIP2](https://huggingface.co/docs/transformers/main/model_doc/blip-2)
|
| 125 |
+
+ [Vicuna](https://github.com/lm-sys/FastChat)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
If you're using MiniGPT-4 in your research or applications, please cite using this BibTeX:
|
| 129 |
+
```bibtex
|
| 130 |
+
@misc{zhu2022minigpt4,
|
| 131 |
+
title={MiniGPT-4: Enhancing the Vision-language Understanding with Advanced Large Language Models},
|
| 132 |
+
author={Deyao Zhu and Jun Chen and Xiaoqian Shen and xiang Li and Mohamed Elhoseiny},
|
| 133 |
+
year={2023},
|
| 134 |
+
}
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
## License
|
| 138 |
+
This repository is built on [Lavis](https://github.com/salesforce/LAVIS) with BSD 3-Clause License
|
| 139 |
+
[BSD 3-Clause License](LICENSE.txt)
|
app.py
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
import torch.backends.cudnn as cudnn
|
| 8 |
+
import gradio as gr
|
| 9 |
+
|
| 10 |
+
from minigpt4.common.config import Config
|
| 11 |
+
from minigpt4.common.dist_utils import get_rank
|
| 12 |
+
from minigpt4.common.registry import registry
|
| 13 |
+
from minigpt4.conversation.conversation import Chat, CONV_VISION
|
| 14 |
+
|
| 15 |
+
# imports modules for registration
|
| 16 |
+
from minigpt4.datasets.builders import *
|
| 17 |
+
from minigpt4.models import *
|
| 18 |
+
from minigpt4.processors import *
|
| 19 |
+
from minigpt4.runners import *
|
| 20 |
+
from minigpt4.tasks import *
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def parse_args():
|
| 24 |
+
parser = argparse.ArgumentParser(description="Demo")
|
| 25 |
+
parser.add_argument("--cfg-path", type=str, default='eval_configs/minigpt4.yaml', help="path to configuration file.")
|
| 26 |
+
parser.add_argument(
|
| 27 |
+
"--options",
|
| 28 |
+
nargs="+",
|
| 29 |
+
help="override some settings in the used config, the key-value pair "
|
| 30 |
+
"in xxx=yyy format will be merged into config file (deprecate), "
|
| 31 |
+
"change to --cfg-options instead.",
|
| 32 |
+
)
|
| 33 |
+
args = parser.parse_args()
|
| 34 |
+
return args
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def setup_seeds(config):
|
| 38 |
+
seed = config.run_cfg.seed + get_rank()
|
| 39 |
+
|
| 40 |
+
random.seed(seed)
|
| 41 |
+
np.random.seed(seed)
|
| 42 |
+
torch.manual_seed(seed)
|
| 43 |
+
|
| 44 |
+
cudnn.benchmark = False
|
| 45 |
+
cudnn.deterministic = True
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
# ========================================
|
| 49 |
+
# Model Initialization
|
| 50 |
+
# ========================================
|
| 51 |
+
|
| 52 |
+
print('Initializing Chat')
|
| 53 |
+
cfg = Config(parse_args())
|
| 54 |
+
|
| 55 |
+
model_config = cfg.model_cfg
|
| 56 |
+
model_cls = registry.get_model_class(model_config.arch)
|
| 57 |
+
model = model_cls.from_config(model_config).to('cuda:0')
|
| 58 |
+
|
| 59 |
+
vis_processor_cfg = cfg.datasets_cfg.cc_align.vis_processor.train
|
| 60 |
+
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
|
| 61 |
+
chat = Chat(model, vis_processor)
|
| 62 |
+
print('Initialization Finished')
|
| 63 |
+
|
| 64 |
+
# ========================================
|
| 65 |
+
# Gradio Setting
|
| 66 |
+
# ========================================
|
| 67 |
+
|
| 68 |
+
def gradio_reset(chat_state, img_list):
|
| 69 |
+
chat_state.messages = []
|
| 70 |
+
img_list = []
|
| 71 |
+
return None, gr.update(value=None, interactive=True), gr.update(placeholder='Please upload your image first', interactive=False), gr.update(value="Upload & Start Chat", interactive=True), chat_state, img_list
|
| 72 |
+
|
| 73 |
+
def upload_img(gr_img, text_input, chat_state):
|
| 74 |
+
if gr_img is None:
|
| 75 |
+
return None, None, gr.update(interactive=True)
|
| 76 |
+
chat_state = CONV_VISION.copy()
|
| 77 |
+
img_list = []
|
| 78 |
+
llm_message = chat.upload_img(gr_img, chat_state, img_list)
|
| 79 |
+
return gr.update(interactive=False), gr.update(interactive=True, placeholder='Type and press Enter'), gr.update(value="Start Chatting", interactive=False), chat_state, img_list
|
| 80 |
+
|
| 81 |
+
def gradio_ask(user_message, chatbot, chat_state):
|
| 82 |
+
if len(user_message) == 0:
|
| 83 |
+
return gr.update(interactive=True, placeholder='Input should not be empty!'), chatbot, chat_state
|
| 84 |
+
chat.ask(user_message, chat_state)
|
| 85 |
+
chatbot = chatbot + [[user_message, None]]
|
| 86 |
+
return '', chatbot, chat_state
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def gradio_answer(chatbot, chat_state, img_list, num_beams, temperature):
|
| 90 |
+
llm_message = chat.answer(conv=chat_state, img_list=img_list, max_new_tokens=1000, num_beams=num_beams, temperature=temperature)[0]
|
| 91 |
+
chatbot[-1][1] = llm_message
|
| 92 |
+
return chatbot, chat_state, img_list
|
| 93 |
+
|
| 94 |
+
title = """<h1 align="center">Demo of MiniGPT-4</h1>"""
|
| 95 |
+
description = """<h3>This is the demo of MiniGPT-4. Upload your images and start chatting!</h3>"""
|
| 96 |
+
article = """<strong>Paper</strong>: <a href='https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf' target='_blank'>Here</a>
|
| 97 |
+
<strong>Code</strong>: <a href='https://github.com/Vision-CAIR/MiniGPT-4' target='_blank'>Here</a>
|
| 98 |
+
<strong>Project Page</strong>: <a href='https://minigpt-4.github.io/' target='_blank'>Here</a>
|
| 99 |
+
"""
|
| 100 |
+
|
| 101 |
+
#TODO show examples below
|
| 102 |
+
|
| 103 |
+
with gr.Blocks() as demo:
|
| 104 |
+
gr.Markdown(title)
|
| 105 |
+
gr.Markdown(description)
|
| 106 |
+
gr.Markdown(article)
|
| 107 |
+
|
| 108 |
+
with gr.Row():
|
| 109 |
+
with gr.Column(scale=0.5):
|
| 110 |
+
image = gr.Image(type="pil")
|
| 111 |
+
upload_button = gr.Button(value="Upload & Start Chat", interactive=True, variant="primary")
|
| 112 |
+
clear = gr.Button("Restart")
|
| 113 |
+
|
| 114 |
+
num_beams = gr.Slider(
|
| 115 |
+
minimum=1,
|
| 116 |
+
maximum=16,
|
| 117 |
+
value=5,
|
| 118 |
+
step=1,
|
| 119 |
+
interactive=True,
|
| 120 |
+
label="beam search numbers)",
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
temperature = gr.Slider(
|
| 124 |
+
minimum=0.1,
|
| 125 |
+
maximum=2.0,
|
| 126 |
+
value=1.0,
|
| 127 |
+
step=0.1,
|
| 128 |
+
interactive=True,
|
| 129 |
+
label="Temperature",
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
with gr.Column():
|
| 134 |
+
chat_state = gr.State()
|
| 135 |
+
img_list = gr.State()
|
| 136 |
+
chatbot = gr.Chatbot(label='MiniGPT-4')
|
| 137 |
+
text_input = gr.Textbox(label='User', placeholder='Please upload your image first', interactive=False)
|
| 138 |
+
|
| 139 |
+
upload_button.click(upload_img, [image, text_input, chat_state], [image, text_input, upload_button, chat_state, img_list])
|
| 140 |
+
|
| 141 |
+
text_input.submit(gradio_ask, [text_input, chatbot, chat_state], [text_input, chatbot, chat_state]).then(
|
| 142 |
+
gradio_answer, [chatbot, chat_state, img_list, num_beams, temperature], [chatbot, chat_state, img_list]
|
| 143 |
+
)
|
| 144 |
+
clear.click(gradio_reset, [chat_state, img_list], [chatbot, image, text_input, upload_button, chat_state, img_list], queue=False)
|
| 145 |
+
|
| 146 |
+
demo.launch(share=True, enable_queue=True)
|
create_align_dataset.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
import json
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
import random
|
| 6 |
+
import numpy as np
|
| 7 |
+
from PIL import Image
|
| 8 |
+
import webdataset as wds
|
| 9 |
+
import torch
|
| 10 |
+
from torchvision.datasets import ImageFolder
|
| 11 |
+
import torchvision.transforms as transforms
|
| 12 |
+
|
| 13 |
+
import openai
|
| 14 |
+
from tenacity import (
|
| 15 |
+
retry,
|
| 16 |
+
stop_after_attempt,
|
| 17 |
+
wait_random_exponential,
|
| 18 |
+
) # for exponential backoff
|
| 19 |
+
|
| 20 |
+
from minigpt4.common.config import Config
|
| 21 |
+
from minigpt4.common.registry import registry
|
| 22 |
+
from minigpt4.conversation.conversation import Chat
|
| 23 |
+
|
| 24 |
+
openai.api_key = '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'
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def prepare_chatgpt_message(task_prompt, paragraph):
|
| 28 |
+
messages = [{"role": "system", "content": task_prompt},
|
| 29 |
+
{"role": "user", "content": paragraph}]
|
| 30 |
+
return messages
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
|
| 34 |
+
def call_chatgpt(chatgpt_messages, max_tokens=200, model="gpt-3.5-turbo"):
|
| 35 |
+
response = openai.ChatCompletion.create(model=model, messages=chatgpt_messages, temperature=0.7, max_tokens=max_tokens)
|
| 36 |
+
reply = response['choices'][0]['message']['content']
|
| 37 |
+
total_tokens = response['usage']['total_tokens']
|
| 38 |
+
return reply, total_tokens
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def main(args):
|
| 42 |
+
|
| 43 |
+
print('Initializing Chat')
|
| 44 |
+
cfg = Config(args)
|
| 45 |
+
|
| 46 |
+
model_config = cfg.model_cfg
|
| 47 |
+
model_cls = registry.get_model_class(model_config.arch)
|
| 48 |
+
model = model_cls.from_config(model_config).to('cuda:{}'.format(args.device))
|
| 49 |
+
|
| 50 |
+
ckpt_path = '/ibex/project/c2133/vicuna_ckpt_test/Vicuna_pretrain_stage2_cc/20230405233_3GPU40kSTEP_MAIN/checkpoint_3.pth'
|
| 51 |
+
ckpt = torch.load(ckpt_path)
|
| 52 |
+
msg = model.load_state_dict(ckpt['model'], strict=False)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
vis_processor_cfg = cfg.datasets_cfg.cc_combine.vis_processor.train
|
| 56 |
+
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
|
| 57 |
+
|
| 58 |
+
text_processor_cfg = cfg.datasets_cfg.laion.text_processor.train
|
| 59 |
+
text_processor = registry.get_processor_class(text_processor_cfg.name).from_config(text_processor_cfg)
|
| 60 |
+
|
| 61 |
+
chat = Chat(model, vis_processor, args.device)
|
| 62 |
+
print('Initialization Finished')
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
texts = {}
|
| 67 |
+
negative_list = []
|
| 68 |
+
|
| 69 |
+
for i in tqdm(range(args.begin_id, args.end_id)):
|
| 70 |
+
image = Image.open(os.path.join(args.save_dir, 'image/{}.jpg'.format(i))).convert('RGB')
|
| 71 |
+
|
| 72 |
+
fix_prompt = \
|
| 73 |
+
"Fix the error in the given paragraph. " \
|
| 74 |
+
"Remove any repeating sentences, meanless characters, not English sentences, and so on." \
|
| 75 |
+
"Remove unnecessary repetition." \
|
| 76 |
+
"Rewrite any incomplete sentences." \
|
| 77 |
+
"Return directly the results WITHOUT explanation." \
|
| 78 |
+
"Return directly the input paragraph if it is already correct WITHOUT explanation."
|
| 79 |
+
|
| 80 |
+
answers = []
|
| 81 |
+
answer_tokens = 0
|
| 82 |
+
chat.reset()
|
| 83 |
+
chat.upload_img(image)
|
| 84 |
+
chat.ask("Describe this image in detail. Give as many details as possible. Say everything you see.")
|
| 85 |
+
answer, tokens = chat.answer()
|
| 86 |
+
answers.append(answer)
|
| 87 |
+
answer_tokens += tokens
|
| 88 |
+
if len(answer_tokens) < 80:
|
| 89 |
+
chat.ask("Continue")
|
| 90 |
+
answer, answer_token = chat.answer()
|
| 91 |
+
answers.append(answer)
|
| 92 |
+
answer_tokens += tokens
|
| 93 |
+
answer = ' '.join(answers)
|
| 94 |
+
|
| 95 |
+
chatgpt_message = prepare_chatgpt_message(fix_prompt, answer)
|
| 96 |
+
improved_answer, num_token = call_chatgpt(chatgpt_message)
|
| 97 |
+
|
| 98 |
+
if 'already correct' in improved_answer:
|
| 99 |
+
if 'repetition' in improved_answer:
|
| 100 |
+
continue
|
| 101 |
+
improved_answer = answer
|
| 102 |
+
if 'incomplete' in improved_answer or len(improved_answer) < 50:
|
| 103 |
+
negative_list.append(improved_answer)
|
| 104 |
+
else:
|
| 105 |
+
texts[i] = improved_answer
|
| 106 |
+
|
| 107 |
+
with open(os.path.join(args.save_dir, "cap_{}_{}.json".format(args.begin_id, args.end_id)), "w") as outfile:
|
| 108 |
+
# write the dictionary to the file in JSON format
|
| 109 |
+
json.dump(texts, outfile)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
if __name__ == "__main__":
|
| 113 |
+
parser = argparse.ArgumentParser(description="Create Alignment")
|
| 114 |
+
|
| 115 |
+
parser.add_argument("--cfg-path", default='train_config/minigpt4_stage2_align.yaml')
|
| 116 |
+
parser.add_argument("--save-dir", default="/ibex/project/c2133/blip_dataset/image_alignment")
|
| 117 |
+
parser.add_argument("--begin-id", type=int)
|
| 118 |
+
parser.add_argument("--end-id", type=int)
|
| 119 |
+
parser.add_argument("--device", type=int)
|
| 120 |
+
parser.add_argument(
|
| 121 |
+
"--options",
|
| 122 |
+
nargs="+",
|
| 123 |
+
help="override some settings in the used config, the key-value pair "
|
| 124 |
+
"in xxx=yyy format will be merged into config file (deprecate), "
|
| 125 |
+
"change to --cfg-options instead.",
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
args = parser.parse_args()
|
| 129 |
+
|
| 130 |
+
print("begin_id: ", args.begin_id)
|
| 131 |
+
print("end_id: ", args.end_id)
|
| 132 |
+
print("device:", args.device)
|
| 133 |
+
|
| 134 |
+
main(args)
|
dataset/convert_cc_sbu.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import csv
|
| 3 |
+
|
| 4 |
+
# specify input and output file paths
|
| 5 |
+
input_file = 'ccs_synthetic_filtered_large.json'
|
| 6 |
+
output_file = 'ccs_synthetic_filtered_large.tsv'
|
| 7 |
+
|
| 8 |
+
# load JSON data from input file
|
| 9 |
+
with open(input_file, 'r') as f:
|
| 10 |
+
data = json.load(f)
|
| 11 |
+
|
| 12 |
+
# extract header and data from JSON
|
| 13 |
+
header = data[0].keys()
|
| 14 |
+
rows = [x.values() for x in data]
|
| 15 |
+
|
| 16 |
+
# write data to TSV file
|
| 17 |
+
with open(output_file, 'w') as f:
|
| 18 |
+
writer = csv.writer(f, delimiter='\t')
|
| 19 |
+
writer.writerow(header)
|
| 20 |
+
writer.writerows(rows)
|
dataset/convert_laion.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import csv
|
| 3 |
+
|
| 4 |
+
# specify input and output file paths
|
| 5 |
+
input_file = 'laion_synthetic_filtered_large.json'
|
| 6 |
+
output_file = 'laion_synthetic_filtered_large.tsv'
|
| 7 |
+
|
| 8 |
+
# load JSON data from input file
|
| 9 |
+
with open(input_file, 'r') as f:
|
| 10 |
+
data = json.load(f)
|
| 11 |
+
|
| 12 |
+
# extract header and data from JSON
|
| 13 |
+
header = data[0].keys()
|
| 14 |
+
rows = [x.values() for x in data]
|
| 15 |
+
|
| 16 |
+
# write data to TSV file
|
| 17 |
+
with open(output_file, 'w') as f:
|
| 18 |
+
writer = csv.writer(f, delimiter='\t')
|
| 19 |
+
writer.writerow(header)
|
| 20 |
+
writer.writerows(rows)
|
dataset/download_cc_sbu.sh
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
img2dataset --url_list ccs_synthetic_filtered_large.tsv --input_format "tsv"\
|
| 4 |
+
--url_col "url" --caption_col "caption" --output_format webdataset\
|
| 5 |
+
--output_folder cc_sbu_dataset --processes_count 16 --thread_count 128 --image_size 256 \
|
| 6 |
+
--enable_wandb True
|
dataset/download_laion.sh
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
img2dataset --url_list laion_synthetic_filtered_large.tsv --input_format "tsv"\
|
| 4 |
+
--url_col "url" --caption_col "caption" --output_format webdataset\
|
| 5 |
+
--output_folder laion_dataset --processes_count 16 --thread_count 128 --image_size 256 \
|
| 6 |
+
--enable_wandb True
|
dataset/readme.md
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Download the filtered Conceptual Captions, SBU, LAION datasets
|
| 2 |
+
|
| 3 |
+
### Pre-training datasets download:
|
| 4 |
+
We use the filtered synthetic captions prepared by BLIP. For more details about the dataset, please refer to [BLIP](https://github.com/salesforce/BLIP).
|
| 5 |
+
|
| 6 |
+
It requires ~2.3T to store LAION and CC3M+CC12M+SBU datasets
|
| 7 |
+
|
| 8 |
+
Image source | Filtered synthetic caption by ViT-L
|
| 9 |
+
--- | :---:
|
| 10 |
+
CC3M+CC12M+SBU | <a href="https://storage.googleapis.com/sfr-vision-language-research/BLIP/datasets/ccs_synthetic_filtered_large.json">Download</a>
|
| 11 |
+
LAION115M | <a href="https://storage.googleapis.com/sfr-vision-language-research/BLIP/datasets/laion_synthetic_filtered_large.json">Download</a>
|
| 12 |
+
|
| 13 |
+
This will download two json files
|
| 14 |
+
```
|
| 15 |
+
ccs_synthetic_filtered_large.json
|
| 16 |
+
laion_synthetic_filtered_large.json
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
## prepare the data step-by-step
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
### setup the dataset folder and move the annotation file to the data storage folder
|
| 23 |
+
```
|
| 24 |
+
export MINIGPT4_DATASET=/YOUR/PATH/FOR/LARGE/DATASET/
|
| 25 |
+
mkdir ${MINIGPT4_DATASET}/cc_sbu
|
| 26 |
+
mkdir ${MINIGPT4_DATASET}/laion
|
| 27 |
+
mv ccs_synthetic_filtered_large.json ${MINIGPT4_DATASET}/cc_sbu
|
| 28 |
+
mv laion_synthetic_filtered_large.json ${MINIGPT4_DATASET}/laion
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
### Convert the scripts to data storate folder
|
| 32 |
+
```
|
| 33 |
+
cp convert_cc_sbu.py ${MINIGPT4_DATASET}/cc_sbu
|
| 34 |
+
cp download_cc_sbu.sh ${MINIGPT4_DATASET}/cc_sbu
|
| 35 |
+
cp convert_laion.py ${MINIGPT4_DATASET}/laion
|
| 36 |
+
cp download_laion.sh ${MINIGPT4_DATASET}/laion
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
### Convert the laion and cc_sbu annotation file format to be img2dataset format
|
| 41 |
+
```
|
| 42 |
+
cd ${MINIGPT4_DATASET}/cc_sbu
|
| 43 |
+
python convert_cc_sbu.py
|
| 44 |
+
|
| 45 |
+
cd ${MINIGPT4_DATASET}/laion
|
| 46 |
+
python convert_laion.py
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
### Download the datasets with img2dataset
|
| 50 |
+
```
|
| 51 |
+
cd ${MINIGPT4_DATASET}/cc_sbu
|
| 52 |
+
sh download_cc_sbu.sh
|
| 53 |
+
cd ${MINIGPT4_DATASET}/laion
|
| 54 |
+
sh download_laion.sh
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
The final dataset structure
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
.
|
| 62 |
+
├── ${MINIGPT4_DATASET}
|
| 63 |
+
│ ├── cc_sbu
|
| 64 |
+
│ ├── convert_cc_sbu.py
|
| 65 |
+
│ ├── download_cc_sbu.sh
|
| 66 |
+
│ ├── ccs_synthetic_filtered_large.json
|
| 67 |
+
│ ├── ccs_synthetic_filtered_large.tsv
|
| 68 |
+
│ └── cc_sbu_dataset
|
| 69 |
+
│ ├── 00000.tar
|
| 70 |
+
│ ├── 00000.parquet
|
| 71 |
+
│ ...
|
| 72 |
+
│ ├── laion
|
| 73 |
+
│ ├── convert_laion.py
|
| 74 |
+
│ ├── download_laion.sh
|
| 75 |
+
│ ├── laion_synthetic_filtered_large.json
|
| 76 |
+
│ ├── laion_synthetic_filtered_large.tsv
|
| 77 |
+
│ └── laion_dataset
|
| 78 |
+
│ ├── 00000.tar
|
| 79 |
+
│ ├── 00000.parquet
|
| 80 |
+
│ ...
|
| 81 |
+
...
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
## Set up the dataset configuration files
|
| 86 |
+
|
| 87 |
+
Then, set up the LAION dataset loading path in [here](../minigpt4/configs/datasets/laion/defaults.yaml#L13) at Line 13 as ${MINIGPT4_DATASET}/laion/laion_dataset/{00000..10488}.tar
|
| 88 |
+
|
| 89 |
+
Then, set up the Conceptual Captoin and SBU datasets loading path in [here](../minigpt4/configs/datasets/cc_sbu/defaults.yaml#L13) at Line 13 as ${MINIGPT4_DATASET}/cc_sbu/cc_sbu_dataset/{00000..01255}.tar
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
|
demo_dev.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
develop.ipynb
ADDED
|
@@ -0,0 +1,929 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"id": "d5ac353e",
|
| 7 |
+
"metadata": {
|
| 8 |
+
"pycharm": {
|
| 9 |
+
"name": "#%%\n"
|
| 10 |
+
}
|
| 11 |
+
},
|
| 12 |
+
"outputs": [],
|
| 13 |
+
"source": [
|
| 14 |
+
"import argparse\n",
|
| 15 |
+
"import os\n",
|
| 16 |
+
"import shutil\n",
|
| 17 |
+
"import random\n",
|
| 18 |
+
"from PIL import Image\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"import numpy as np\n",
|
| 21 |
+
"import torch\n",
|
| 22 |
+
"import torch.backends.cudnn as cudnn\n",
|
| 23 |
+
"from transformers import StoppingCriteria, StoppingCriteriaList\n",
|
| 24 |
+
"\n",
|
| 25 |
+
"import lavis.tasks as tasks\n",
|
| 26 |
+
"from lavis.common.config import Config\n",
|
| 27 |
+
"from lavis.common.dist_utils import get_rank, init_distributed_mode\n",
|
| 28 |
+
"from lavis.common.logger import setup_logger\n",
|
| 29 |
+
"from lavis.common.optims import (\n",
|
| 30 |
+
" LinearWarmupCosineLRScheduler,\n",
|
| 31 |
+
" LinearWarmupStepLRScheduler,\n",
|
| 32 |
+
")\n",
|
| 33 |
+
"from lavis.common.registry import registry\n",
|
| 34 |
+
"from lavis.common.utils import now\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"# imports modules for registration\n",
|
| 37 |
+
"from lavis.datasets.builders import *\n",
|
| 38 |
+
"from lavis.models import *\n",
|
| 39 |
+
"from lavis.processors import *\n",
|
| 40 |
+
"from lavis.runners import *\n",
|
| 41 |
+
"from lavis.tasks import *"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "code",
|
| 46 |
+
"execution_count": null,
|
| 47 |
+
"id": "4fdef7a6",
|
| 48 |
+
"metadata": {
|
| 49 |
+
"pycharm": {
|
| 50 |
+
"name": "#%%\n"
|
| 51 |
+
}
|
| 52 |
+
},
|
| 53 |
+
"outputs": [],
|
| 54 |
+
"source": [
|
| 55 |
+
"shutil.copytree('/ibex/project/c2133/vicuna', '/tmp/vicuna')"
|
| 56 |
+
]
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"cell_type": "code",
|
| 60 |
+
"execution_count": 2,
|
| 61 |
+
"id": "661f9e80",
|
| 62 |
+
"metadata": {
|
| 63 |
+
"pycharm": {
|
| 64 |
+
"name": "#%%\n"
|
| 65 |
+
}
|
| 66 |
+
},
|
| 67 |
+
"outputs": [],
|
| 68 |
+
"source": [
|
| 69 |
+
"class StoppingCriteriaSub(StoppingCriteria):\n",
|
| 70 |
+
"\n",
|
| 71 |
+
" def __init__(self, stops = [], encounters=1):\n",
|
| 72 |
+
" super().__init__()\n",
|
| 73 |
+
" self.stops = stops\n",
|
| 74 |
+
"\n",
|
| 75 |
+
" def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor):\n",
|
| 76 |
+
" for stop in self.stops:\n",
|
| 77 |
+
" if torch.all((stop == input_ids[0][-len(stop):])).item():\n",
|
| 78 |
+
" return True\n",
|
| 79 |
+
"\n",
|
| 80 |
+
" return False\n",
|
| 81 |
+
"\n",
|
| 82 |
+
"\n",
|
| 83 |
+
"stop_words_ids = [torch.tensor([835]).to('cuda:0'), \n",
|
| 84 |
+
" torch.tensor([2277, 29937]).to('cuda:0')] # '###' can be encoded in different ways.\n",
|
| 85 |
+
"stopping_criteria = StoppingCriteriaList([StoppingCriteriaSub(stops=stop_words_ids)])"
|
| 86 |
+
]
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"cell_type": "code",
|
| 90 |
+
"execution_count": 6,
|
| 91 |
+
"id": "1822a77a",
|
| 92 |
+
"metadata": {
|
| 93 |
+
"pycharm": {
|
| 94 |
+
"name": "#%%\n"
|
| 95 |
+
}
|
| 96 |
+
},
|
| 97 |
+
"outputs": [],
|
| 98 |
+
"source": [
|
| 99 |
+
"parser = argparse.ArgumentParser(description=\"Training\")\n",
|
| 100 |
+
"\n",
|
| 101 |
+
"parser.add_argument(\"--cfg-path\", required=True, help=\"path to configuration file.\")\n",
|
| 102 |
+
"parser.add_argument(\n",
|
| 103 |
+
" \"--options\",\n",
|
| 104 |
+
" nargs=\"+\",\n",
|
| 105 |
+
" help=\"override some settings in the used config, the key-value pair \"\n",
|
| 106 |
+
" \"in xxx=yyy format will be merged into config file (deprecate), \"\n",
|
| 107 |
+
" \"change to --cfg-options instead.\",\n",
|
| 108 |
+
")\n",
|
| 109 |
+
"\n",
|
| 110 |
+
"args = parser.parse_args([\"--cfg-path\", \"lavis/projects/blip2/train/vicuna_pretrain_stage2_cc.yaml\"])\n",
|
| 111 |
+
"\n",
|
| 112 |
+
"cfg = Config(args)\n",
|
| 113 |
+
"device = 'cuda:0'"
|
| 114 |
+
]
|
| 115 |
+
},
|
| 116 |
+
{
|
| 117 |
+
"cell_type": "code",
|
| 118 |
+
"execution_count": 4,
|
| 119 |
+
"id": "57e90f19",
|
| 120 |
+
"metadata": {
|
| 121 |
+
"pycharm": {
|
| 122 |
+
"name": "#%%\n"
|
| 123 |
+
}
|
| 124 |
+
},
|
| 125 |
+
"outputs": [],
|
| 126 |
+
"source": [
|
| 127 |
+
"vis_processor_cfg = cfg.datasets_cfg.cc_combine.vis_processor.train\n",
|
| 128 |
+
"vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)"
|
| 129 |
+
]
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"cell_type": "code",
|
| 133 |
+
"execution_count": 7,
|
| 134 |
+
"id": "4cc521da",
|
| 135 |
+
"metadata": {
|
| 136 |
+
"pycharm": {
|
| 137 |
+
"name": "#%%\n"
|
| 138 |
+
}
|
| 139 |
+
},
|
| 140 |
+
"outputs": [
|
| 141 |
+
{
|
| 142 |
+
"name": "stdout",
|
| 143 |
+
"output_type": "stream",
|
| 144 |
+
"text": [
|
| 145 |
+
"Loading LLAMA\n"
|
| 146 |
+
]
|
| 147 |
+
},
|
| 148 |
+
{
|
| 149 |
+
"data": {
|
| 150 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 151 |
+
"model_id": "abeac6970d914446adc1fb73f7e5b5f9",
|
| 152 |
+
"version_major": 2,
|
| 153 |
+
"version_minor": 0
|
| 154 |
+
},
|
| 155 |
+
"text/plain": [
|
| 156 |
+
"Loading checkpoint shards: 0%| | 0/3 [00:00<?, ?it/s]"
|
| 157 |
+
]
|
| 158 |
+
},
|
| 159 |
+
"metadata": {},
|
| 160 |
+
"output_type": "display_data"
|
| 161 |
+
},
|
| 162 |
+
{
|
| 163 |
+
"name": "stdout",
|
| 164 |
+
"output_type": "stream",
|
| 165 |
+
"text": [
|
| 166 |
+
"Loading LLAMA Done\n",
|
| 167 |
+
"Load BLIP2-LLM Checkpoint: /home/zhud/project/blip2/lavis/output/BLIP2/Vicuna_pretrain_stage2_cc/20230405233/checkpoint_3.pth\n"
|
| 168 |
+
]
|
| 169 |
+
},
|
| 170 |
+
{
|
| 171 |
+
"data": {
|
| 172 |
+
"text/html": [
|
| 173 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\"><span style=\"color: #800000; text-decoration-color: #800000\">╭─────────────────────────────── </span><span style=\"color: #800000; text-decoration-color: #800000; font-weight: bold\">Traceback </span><span style=\"color: #bf7f7f; text-decoration-color: #bf7f7f; font-weight: bold\">(most recent call last)</span><span style=\"color: #800000; text-decoration-color: #800000\"> ────────────────────────────────╮</span>\n",
|
| 174 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> in <span style=\"color: #00ff00; text-decoration-color: #00ff00\"><module></span>:<span style=\"color: #0000ff; text-decoration-color: #0000ff\">2</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 175 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 176 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">1 </span>task = tasks.setup_task(cfg) <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 177 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">❱ </span>2 model = task.build_model(cfg) <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 178 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">3 </span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 179 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 180 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #bfbf7f; text-decoration-color: #bfbf7f\">/home/zhud/project/blip2/lavis/tasks/</span><span style=\"color: #808000; text-decoration-color: #808000; font-weight: bold\">base_task.py</span>:<span style=\"color: #0000ff; text-decoration-color: #0000ff\">33</span> in <span style=\"color: #00ff00; text-decoration-color: #00ff00\">build_model</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 181 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 182 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 30 │ │ </span>model_config = cfg.model_cfg <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 183 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 31 │ │ </span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 184 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 32 │ │ </span>model_cls = registry.get_model_class(model_config.arch) <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 185 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">❱ </span> 33 <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">│ │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">return</span> model_cls.from_config(model_config) <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 186 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 34 │ </span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 187 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 35 │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">def</span> <span style=\"color: #00ff00; text-decoration-color: #00ff00\">build_datasets</span>(<span style=\"color: #00ffff; text-decoration-color: #00ffff\">self</span>, cfg): <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 188 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 36 </span><span style=\"color: #bfbfbf; text-decoration-color: #bfbfbf\">│ │ </span><span style=\"color: #808000; text-decoration-color: #808000\">\"\"\"</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 189 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 190 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #bfbf7f; text-decoration-color: #bfbf7f\">/home/zhud/project/blip2/lavis/models/blip2_models/</span><span style=\"color: #808000; text-decoration-color: #808000; font-weight: bold\">blip2_llama.py</span>:<span style=\"color: #0000ff; text-decoration-color: #0000ff\">315</span> in <span style=\"color: #00ff00; text-decoration-color: #00ff00\">from_config</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 191 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 192 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">312 │ │ </span>ckpt_path = cfg.get(<span style=\"color: #808000; text-decoration-color: #808000\">\"ckpt\"</span>, <span style=\"color: #808000; text-decoration-color: #808000\">\"\"</span>) <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 193 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">313 │ │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">if</span> ckpt_path: <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 194 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">314 │ │ │ </span><span style=\"color: #00ffff; text-decoration-color: #00ffff\">print</span>(<span style=\"color: #808000; text-decoration-color: #808000\">\"Load BLIP2-LLM Checkpoint: {}\"</span>.format(ckpt_path)) <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 195 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">❱ </span>315 <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">│ │ │ </span>ckpt = torch.load(ckpt_path, map_location=<span style=\"color: #808000; text-decoration-color: #808000\">\"cpu\"</span>) <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 196 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">316 │ │ │ </span>msg = model.load_state_dict(ckpt[<span style=\"color: #808000; text-decoration-color: #808000\">'model'</span>], strict=<span style=\"color: #0000ff; text-decoration-color: #0000ff\">False</span>) <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 197 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">317 │ │ </span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 198 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">318 │ │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">return</span> model <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 199 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 200 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #bfbf7f; text-decoration-color: #bfbf7f\">/home/zhud/anaconda3/envs/eye/lib/python3.9/site-packages/torch/</span><span style=\"color: #808000; text-decoration-color: #808000; font-weight: bold\">serialization.py</span>:<span style=\"color: #0000ff; text-decoration-color: #0000ff\">791</span> in <span style=\"color: #00ff00; text-decoration-color: #00ff00\">load</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 201 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 202 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 788 │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">if</span> <span style=\"color: #808000; text-decoration-color: #808000\">'encoding'</span> <span style=\"color: #ff00ff; text-decoration-color: #ff00ff\">not</span> <span style=\"color: #ff00ff; text-decoration-color: #ff00ff\">in</span> pickle_load_args.keys(): <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 203 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 789 │ │ </span>pickle_load_args[<span style=\"color: #808000; text-decoration-color: #808000\">'encoding'</span>] = <span style=\"color: #808000; text-decoration-color: #808000\">'utf-8'</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 204 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 790 │ </span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 205 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">❱ </span> 791 <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">│ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">with</span> _open_file_like(f, <span style=\"color: #808000; text-decoration-color: #808000\">'rb'</span>) <span style=\"color: #0000ff; text-decoration-color: #0000ff\">as</span> opened_file: <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 206 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 792 │ │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">if</span> _is_zipfile(opened_file): <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 207 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 793 │ │ │ # The zipfile reader is going to advance the current file position.</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 208 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 794 │ │ │ # If we want to actually tail call to torch.jit.load, we need to</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 209 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 210 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #bfbf7f; text-decoration-color: #bfbf7f\">/home/zhud/anaconda3/envs/eye/lib/python3.9/site-packages/torch/</span><span style=\"color: #808000; text-decoration-color: #808000; font-weight: bold\">serialization.py</span>:<span style=\"color: #0000ff; text-decoration-color: #0000ff\">271</span> in <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 211 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #00ff00; text-decoration-color: #00ff00\">_open_file_like</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 212 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 213 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 268 </span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 214 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 269 </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">def</span> <span style=\"color: #00ff00; text-decoration-color: #00ff00\">_open_file_like</span>(name_or_buffer, mode): <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 215 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 270 │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">if</span> _is_path(name_or_buffer): <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 216 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">❱ </span> 271 <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">│ │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">return</span> _open_file(name_or_buffer, mode) <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 217 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 272 │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">else</span>: <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 218 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 273 │ │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">if</span> <span style=\"color: #808000; text-decoration-color: #808000\">'w'</span> <span style=\"color: #ff00ff; text-decoration-color: #ff00ff\">in</span> mode: <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 219 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 274 │ │ │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">return</span> _open_buffer_writer(name_or_buffer) <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 220 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 221 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #bfbf7f; text-decoration-color: #bfbf7f\">/home/zhud/anaconda3/envs/eye/lib/python3.9/site-packages/torch/</span><span style=\"color: #808000; text-decoration-color: #808000; font-weight: bold\">serialization.py</span>:<span style=\"color: #0000ff; text-decoration-color: #0000ff\">252</span> in <span style=\"color: #00ff00; text-decoration-color: #00ff00\">__init__</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 222 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 223 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 249 </span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 224 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 250 </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">class</span> <span style=\"color: #00ff00; text-decoration-color: #00ff00; text-decoration: underline\">_open_file</span>(_opener): <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 225 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 251 │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">def</span> <span style=\"color: #00ff00; text-decoration-color: #00ff00\">__init__</span>(<span style=\"color: #00ffff; text-decoration-color: #00ffff\">self</span>, name, mode): <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 226 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #800000; text-decoration-color: #800000\">❱ </span> 252 <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\">│ │ </span><span style=\"color: #00ffff; text-decoration-color: #00ffff\">super</span>().<span style=\"color: #00ff00; text-decoration-color: #00ff00\">__init__</span>(<span style=\"color: #00ffff; text-decoration-color: #00ffff\">open</span>(name, mode)) <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 227 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 253 │ </span> <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 228 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 254 │ </span><span style=\"color: #0000ff; text-decoration-color: #0000ff\">def</span> <span style=\"color: #00ff00; text-decoration-color: #00ff00\">__exit__</span>(<span style=\"color: #00ffff; text-decoration-color: #00ffff\">self</span>, *args): <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 229 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">│</span> <span style=\"color: #7f7f7f; text-decoration-color: #7f7f7f\"> 255 │ │ </span><span style=\"color: #00ffff; text-decoration-color: #00ffff\">self</span>.file_like.close() <span style=\"color: #800000; text-decoration-color: #800000\">│</span>\n",
|
| 230 |
+
"<span style=\"color: #800000; text-decoration-color: #800000\">╰──────────────────────────────────────────────────────────────────────────────────────────────────╯</span>\n",
|
| 231 |
+
"<span style=\"color: #ff0000; text-decoration-color: #ff0000; font-weight: bold\">FileNotFoundError: </span><span style=\"font-weight: bold\">[</span>Errno <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">2</span><span style=\"font-weight: bold\">]</span> No such file or directory: \n",
|
| 232 |
+
"<span style=\"color: #008000; text-decoration-color: #008000\">'/home/zhud/project/blip2/lavis/output/BLIP2/Vicuna_pretrain_stage2_cc/20230405233/checkpoint_3.pth'</span>\n",
|
| 233 |
+
"</pre>\n"
|
| 234 |
+
],
|
| 235 |
+
"text/plain": [
|
| 236 |
+
"\u001B[31m╭─\u001B[0m\u001B[31m──────────────────────────────\u001B[0m\u001B[31m \u001B[0m\u001B[1;31mTraceback \u001B[0m\u001B[1;2;31m(most recent call last)\u001B[0m\u001B[31m \u001B[0m\u001B[31m───────────────────────────────\u001B[0m\u001B[31m─╮\u001B[0m\n",
|
| 237 |
+
"\u001B[31m│\u001B[0m in \u001B[92m<module>\u001B[0m:\u001B[94m2\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 238 |
+
"\u001B[31m│\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 239 |
+
"\u001B[31m│\u001B[0m \u001B[2m1 \u001B[0mtask = tasks.setup_task(cfg) \u001B[31m│\u001B[0m\n",
|
| 240 |
+
"\u001B[31m│\u001B[0m \u001B[31m❱ \u001B[0m2 model = task.build_model(cfg) \u001B[31m│\u001B[0m\n",
|
| 241 |
+
"\u001B[31m│\u001B[0m \u001B[2m3 \u001B[0m \u001B[31m│\u001B[0m\n",
|
| 242 |
+
"\u001B[31m│\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 243 |
+
"\u001B[31m│\u001B[0m \u001B[2;33m/home/zhud/project/blip2/lavis/tasks/\u001B[0m\u001B[1;33mbase_task.py\u001B[0m:\u001B[94m33\u001B[0m in \u001B[92mbuild_model\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 244 |
+
"\u001B[31m│\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 245 |
+
"\u001B[31m│\u001B[0m \u001B[2m 30 \u001B[0m\u001B[2m│ │ \u001B[0mmodel_config = cfg.model_cfg \u001B[31m│\u001B[0m\n",
|
| 246 |
+
"\u001B[31m│\u001B[0m \u001B[2m 31 \u001B[0m\u001B[2m│ │ \u001B[0m \u001B[31m│\u001B[0m\n",
|
| 247 |
+
"\u001B[31m│\u001B[0m \u001B[2m 32 \u001B[0m\u001B[2m│ │ \u001B[0mmodel_cls = registry.get_model_class(model_config.arch) \u001B[31m│\u001B[0m\n",
|
| 248 |
+
"\u001B[31m│\u001B[0m \u001B[31m❱ \u001B[0m 33 \u001B[2m│ │ \u001B[0m\u001B[94mreturn\u001B[0m model_cls.from_config(model_config) \u001B[31m│\u001B[0m\n",
|
| 249 |
+
"\u001B[31m│\u001B[0m \u001B[2m 34 \u001B[0m\u001B[2m│ \u001B[0m \u001B[31m│\u001B[0m\n",
|
| 250 |
+
"\u001B[31m│\u001B[0m \u001B[2m 35 \u001B[0m\u001B[2m│ \u001B[0m\u001B[94mdef\u001B[0m \u001B[92mbuild_datasets\u001B[0m(\u001B[96mself\u001B[0m, cfg): \u001B[31m│\u001B[0m\n",
|
| 251 |
+
"\u001B[31m│\u001B[0m \u001B[2m 36 \u001B[0m\u001B[2;90m│ │ \u001B[0m\u001B[33m\"\"\"\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 252 |
+
"\u001B[31m│\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 253 |
+
"\u001B[31m│\u001B[0m \u001B[2;33m/home/zhud/project/blip2/lavis/models/blip2_models/\u001B[0m\u001B[1;33mblip2_llama.py\u001B[0m:\u001B[94m315\u001B[0m in \u001B[92mfrom_config\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 254 |
+
"\u001B[31m│\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 255 |
+
"\u001B[31m│\u001B[0m \u001B[2m312 \u001B[0m\u001B[2m│ │ \u001B[0mckpt_path = cfg.get(\u001B[33m\"\u001B[0m\u001B[33mckpt\u001B[0m\u001B[33m\"\u001B[0m, \u001B[33m\"\u001B[0m\u001B[33m\"\u001B[0m) \u001B[31m│\u001B[0m\n",
|
| 256 |
+
"\u001B[31m│\u001B[0m \u001B[2m313 \u001B[0m\u001B[2m│ │ \u001B[0m\u001B[94mif\u001B[0m ckpt_path: \u001B[31m│\u001B[0m\n",
|
| 257 |
+
"\u001B[31m│\u001B[0m \u001B[2m314 \u001B[0m\u001B[2m│ │ │ \u001B[0m\u001B[96mprint\u001B[0m(\u001B[33m\"\u001B[0m\u001B[33mLoad BLIP2-LLM Checkpoint: \u001B[0m\u001B[33m{}\u001B[0m\u001B[33m\"\u001B[0m.format(ckpt_path)) \u001B[31m│\u001B[0m\n",
|
| 258 |
+
"\u001B[31m│\u001B[0m \u001B[31m❱ \u001B[0m315 \u001B[2m│ │ │ \u001B[0mckpt = torch.load(ckpt_path, map_location=\u001B[33m\"\u001B[0m\u001B[33mcpu\u001B[0m\u001B[33m\"\u001B[0m) \u001B[31m│\u001B[0m\n",
|
| 259 |
+
"\u001B[31m│\u001B[0m \u001B[2m316 \u001B[0m\u001B[2m│ │ │ \u001B[0mmsg = model.load_state_dict(ckpt[\u001B[33m'\u001B[0m\u001B[33mmodel\u001B[0m\u001B[33m'\u001B[0m], strict=\u001B[94mFalse\u001B[0m) \u001B[31m│\u001B[0m\n",
|
| 260 |
+
"\u001B[31m│\u001B[0m \u001B[2m317 \u001B[0m\u001B[2m│ │ \u001B[0m \u001B[31m│\u001B[0m\n",
|
| 261 |
+
"\u001B[31m│\u001B[0m \u001B[2m318 \u001B[0m\u001B[2m│ │ \u001B[0m\u001B[94mreturn\u001B[0m model \u001B[31m│\u001B[0m\n",
|
| 262 |
+
"\u001B[31m│\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 263 |
+
"\u001B[31m│\u001B[0m \u001B[2;33m/home/zhud/anaconda3/envs/eye/lib/python3.9/site-packages/torch/\u001B[0m\u001B[1;33mserialization.py\u001B[0m:\u001B[94m791\u001B[0m in \u001B[92mload\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 264 |
+
"\u001B[31m│\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 265 |
+
"\u001B[31m│\u001B[0m \u001B[2m 788 \u001B[0m\u001B[2m│ \u001B[0m\u001B[94mif\u001B[0m \u001B[33m'\u001B[0m\u001B[33mencoding\u001B[0m\u001B[33m'\u001B[0m \u001B[95mnot\u001B[0m \u001B[95min\u001B[0m pickle_load_args.keys(): \u001B[31m│\u001B[0m\n",
|
| 266 |
+
"\u001B[31m│\u001B[0m \u001B[2m 789 \u001B[0m\u001B[2m│ │ \u001B[0mpickle_load_args[\u001B[33m'\u001B[0m\u001B[33mencoding\u001B[0m\u001B[33m'\u001B[0m] = \u001B[33m'\u001B[0m\u001B[33mutf-8\u001B[0m\u001B[33m'\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 267 |
+
"\u001B[31m│\u001B[0m \u001B[2m 790 \u001B[0m\u001B[2m│ \u001B[0m \u001B[31m��\u001B[0m\n",
|
| 268 |
+
"\u001B[31m│\u001B[0m \u001B[31m❱ \u001B[0m 791 \u001B[2m│ \u001B[0m\u001B[94mwith\u001B[0m _open_file_like(f, \u001B[33m'\u001B[0m\u001B[33mrb\u001B[0m\u001B[33m'\u001B[0m) \u001B[94mas\u001B[0m opened_file: \u001B[31m│\u001B[0m\n",
|
| 269 |
+
"\u001B[31m│\u001B[0m \u001B[2m 792 \u001B[0m\u001B[2m│ │ \u001B[0m\u001B[94mif\u001B[0m _is_zipfile(opened_file): \u001B[31m│\u001B[0m\n",
|
| 270 |
+
"\u001B[31m│\u001B[0m \u001B[2m 793 \u001B[0m\u001B[2m│ │ │ \u001B[0m\u001B[2m# The zipfile reader is going to advance the current file position.\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 271 |
+
"\u001B[31m│\u001B[0m \u001B[2m 794 \u001B[0m\u001B[2m│ │ │ \u001B[0m\u001B[2m# If we want to actually tail call to torch.jit.load, we need to\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 272 |
+
"\u001B[31m│\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 273 |
+
"\u001B[31m│\u001B[0m \u001B[2;33m/home/zhud/anaconda3/envs/eye/lib/python3.9/site-packages/torch/\u001B[0m\u001B[1;33mserialization.py\u001B[0m:\u001B[94m271\u001B[0m in \u001B[31m│\u001B[0m\n",
|
| 274 |
+
"\u001B[31m│\u001B[0m \u001B[92m_open_file_like\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 275 |
+
"\u001B[31m│\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 276 |
+
"\u001B[31m│\u001B[0m \u001B[2m 268 \u001B[0m \u001B[31m│\u001B[0m\n",
|
| 277 |
+
"\u001B[31m│\u001B[0m \u001B[2m 269 \u001B[0m\u001B[94mdef\u001B[0m \u001B[92m_open_file_like\u001B[0m(name_or_buffer, mode): \u001B[31m│\u001B[0m\n",
|
| 278 |
+
"\u001B[31m│\u001B[0m \u001B[2m 270 \u001B[0m\u001B[2m│ \u001B[0m\u001B[94mif\u001B[0m _is_path(name_or_buffer): \u001B[31m│\u001B[0m\n",
|
| 279 |
+
"\u001B[31m│\u001B[0m \u001B[31m❱ \u001B[0m 271 \u001B[2m│ │ \u001B[0m\u001B[94mreturn\u001B[0m _open_file(name_or_buffer, mode) \u001B[31m│\u001B[0m\n",
|
| 280 |
+
"\u001B[31m│\u001B[0m \u001B[2m 272 \u001B[0m\u001B[2m│ \u001B[0m\u001B[94melse\u001B[0m: \u001B[31m│\u001B[0m\n",
|
| 281 |
+
"\u001B[31m│\u001B[0m \u001B[2m 273 \u001B[0m\u001B[2m│ │ \u001B[0m\u001B[94mif\u001B[0m \u001B[33m'\u001B[0m\u001B[33mw\u001B[0m\u001B[33m'\u001B[0m \u001B[95min\u001B[0m mode: \u001B[31m│\u001B[0m\n",
|
| 282 |
+
"\u001B[31m│\u001B[0m \u001B[2m 274 \u001B[0m\u001B[2m│ │ │ \u001B[0m\u001B[94mreturn\u001B[0m _open_buffer_writer(name_or_buffer) \u001B[31m│\u001B[0m\n",
|
| 283 |
+
"\u001B[31m│\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 284 |
+
"\u001B[31m│\u001B[0m \u001B[2;33m/home/zhud/anaconda3/envs/eye/lib/python3.9/site-packages/torch/\u001B[0m\u001B[1;33mserialization.py\u001B[0m:\u001B[94m252\u001B[0m in \u001B[92m__init__\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 285 |
+
"\u001B[31m│\u001B[0m \u001B[31m│\u001B[0m\n",
|
| 286 |
+
"\u001B[31m│\u001B[0m \u001B[2m 249 \u001B[0m \u001B[31m│\u001B[0m\n",
|
| 287 |
+
"\u001B[31m│\u001B[0m \u001B[2m 250 \u001B[0m\u001B[94mclass\u001B[0m \u001B[4;92m_open_file\u001B[0m(_opener): \u001B[31m│\u001B[0m\n",
|
| 288 |
+
"\u001B[31m│\u001B[0m \u001B[2m 251 \u001B[0m\u001B[2m│ \u001B[0m\u001B[94mdef\u001B[0m \u001B[92m__init__\u001B[0m(\u001B[96mself\u001B[0m, name, mode): \u001B[31m│\u001B[0m\n",
|
| 289 |
+
"\u001B[31m│\u001B[0m \u001B[31m❱ \u001B[0m 252 \u001B[2m│ │ \u001B[0m\u001B[96msuper\u001B[0m().\u001B[92m__init__\u001B[0m(\u001B[96mopen\u001B[0m(name, mode)) \u001B[31m│\u001B[0m\n",
|
| 290 |
+
"\u001B[31m│\u001B[0m \u001B[2m 253 \u001B[0m\u001B[2m│ \u001B[0m \u001B[31m│\u001B[0m\n",
|
| 291 |
+
"\u001B[31m│\u001B[0m \u001B[2m 254 \u001B[0m\u001B[2m│ \u001B[0m\u001B[94mdef\u001B[0m \u001B[92m__exit__\u001B[0m(\u001B[96mself\u001B[0m, *args): \u001B[31m│\u001B[0m\n",
|
| 292 |
+
"\u001B[31m│\u001B[0m \u001B[2m 255 \u001B[0m\u001B[2m│ │ \u001B[0m\u001B[96mself\u001B[0m.file_like.close() \u001B[31m│\u001B[0m\n",
|
| 293 |
+
"\u001B[31m╰──────────────────────────────────────────────────────────────────────────────────────────────────╯\u001B[0m\n",
|
| 294 |
+
"\u001B[1;91mFileNotFoundError: \u001B[0m\u001B[1m[\u001B[0mErrno \u001B[1;36m2\u001B[0m\u001B[1m]\u001B[0m No such file or directory: \n",
|
| 295 |
+
"\u001B[32m'/home/zhud/project/blip2/lavis/output/BLIP2/Vicuna_pretrain_stage2_cc/20230405233/checkpoint_3.pth'\u001B[0m\n"
|
| 296 |
+
]
|
| 297 |
+
},
|
| 298 |
+
"metadata": {},
|
| 299 |
+
"output_type": "display_data"
|
| 300 |
+
}
|
| 301 |
+
],
|
| 302 |
+
"source": [
|
| 303 |
+
"task = tasks.setup_task(cfg)\n",
|
| 304 |
+
"model = task.build_model(cfg)"
|
| 305 |
+
]
|
| 306 |
+
},
|
| 307 |
+
{
|
| 308 |
+
"cell_type": "code",
|
| 309 |
+
"execution_count": 9,
|
| 310 |
+
"id": "ba874036",
|
| 311 |
+
"metadata": {
|
| 312 |
+
"pycharm": {
|
| 313 |
+
"name": "#%%\n"
|
| 314 |
+
}
|
| 315 |
+
},
|
| 316 |
+
"outputs": [
|
| 317 |
+
{
|
| 318 |
+
"data": {
|
| 319 |
+
"text/plain": [
|
| 320 |
+
"'/ibex/project/c2133/vicuna'"
|
| 321 |
+
]
|
| 322 |
+
},
|
| 323 |
+
"execution_count": 9,
|
| 324 |
+
"metadata": {},
|
| 325 |
+
"output_type": "execute_result"
|
| 326 |
+
}
|
| 327 |
+
],
|
| 328 |
+
"source": []
|
| 329 |
+
},
|
| 330 |
+
{
|
| 331 |
+
"cell_type": "markdown",
|
| 332 |
+
"id": "bf1c4e1c",
|
| 333 |
+
"metadata": {
|
| 334 |
+
"pycharm": {
|
| 335 |
+
"name": "#%% md\n"
|
| 336 |
+
}
|
| 337 |
+
},
|
| 338 |
+
"source": [
|
| 339 |
+
"### Load Checkpoint"
|
| 340 |
+
]
|
| 341 |
+
},
|
| 342 |
+
{
|
| 343 |
+
"cell_type": "code",
|
| 344 |
+
"execution_count": null,
|
| 345 |
+
"id": "a2a7f2bd",
|
| 346 |
+
"metadata": {
|
| 347 |
+
"pycharm": {
|
| 348 |
+
"name": "#%%\n"
|
| 349 |
+
}
|
| 350 |
+
},
|
| 351 |
+
"outputs": [],
|
| 352 |
+
"source": [
|
| 353 |
+
"ckpt_path = '/ibex/project/c2133/vicuna_ckpt_test/Vicuna_prompt_stage2_laion/20230410145/checkpoint_4.pth'\n",
|
| 354 |
+
"ckpt = torch.load(ckpt_path, map_location=\"cpu\")\n",
|
| 355 |
+
"msg = model.load_state_dict(ckpt['model'], strict=False)\n",
|
| 356 |
+
"model = model.to(device)"
|
| 357 |
+
]
|
| 358 |
+
},
|
| 359 |
+
{
|
| 360 |
+
"cell_type": "markdown",
|
| 361 |
+
"id": "035a495f",
|
| 362 |
+
"metadata": {
|
| 363 |
+
"pycharm": {
|
| 364 |
+
"name": "#%% md\n"
|
| 365 |
+
}
|
| 366 |
+
},
|
| 367 |
+
"source": [
|
| 368 |
+
"### Example of Tokenizer"
|
| 369 |
+
]
|
| 370 |
+
},
|
| 371 |
+
{
|
| 372 |
+
"cell_type": "code",
|
| 373 |
+
"execution_count": 35,
|
| 374 |
+
"id": "3426ae10",
|
| 375 |
+
"metadata": {
|
| 376 |
+
"pycharm": {
|
| 377 |
+
"name": "#%%\n"
|
| 378 |
+
}
|
| 379 |
+
},
|
| 380 |
+
"outputs": [],
|
| 381 |
+
"source": [
|
| 382 |
+
"texts = [\"A chat\", \"The assistant gives helpful\"]\n",
|
| 383 |
+
"\n",
|
| 384 |
+
"llama_tokens = model.llama_tokenizer(\n",
|
| 385 |
+
" texts, \n",
|
| 386 |
+
" return_tensors=\"pt\", \n",
|
| 387 |
+
" padding=\"longest\",\n",
|
| 388 |
+
" truncation=True,\n",
|
| 389 |
+
" max_length=10).to(device)"
|
| 390 |
+
]
|
| 391 |
+
},
|
| 392 |
+
{
|
| 393 |
+
"cell_type": "code",
|
| 394 |
+
"execution_count": 13,
|
| 395 |
+
"id": "376400a4",
|
| 396 |
+
"metadata": {
|
| 397 |
+
"pycharm": {
|
| 398 |
+
"name": "#%%\n"
|
| 399 |
+
}
|
| 400 |
+
},
|
| 401 |
+
"outputs": [],
|
| 402 |
+
"source": [
|
| 403 |
+
"texts = \"The assistant gives helpful\"\n",
|
| 404 |
+
"\n",
|
| 405 |
+
"llama_tokens = model.llama_tokenizer(\n",
|
| 406 |
+
" texts, \n",
|
| 407 |
+
" return_tensors=\"pt\", \n",
|
| 408 |
+
" padding=\"longest\",\n",
|
| 409 |
+
" truncation=True,\n",
|
| 410 |
+
" max_length=10).to(device)"
|
| 411 |
+
]
|
| 412 |
+
},
|
| 413 |
+
{
|
| 414 |
+
"cell_type": "code",
|
| 415 |
+
"execution_count": 14,
|
| 416 |
+
"id": "6988ee66",
|
| 417 |
+
"metadata": {
|
| 418 |
+
"pycharm": {
|
| 419 |
+
"name": "#%%\n"
|
| 420 |
+
}
|
| 421 |
+
},
|
| 422 |
+
"outputs": [
|
| 423 |
+
{
|
| 424 |
+
"data": {
|
| 425 |
+
"text/plain": [
|
| 426 |
+
"torch.Size([1, 5])"
|
| 427 |
+
]
|
| 428 |
+
},
|
| 429 |
+
"execution_count": 14,
|
| 430 |
+
"metadata": {},
|
| 431 |
+
"output_type": "execute_result"
|
| 432 |
+
}
|
| 433 |
+
],
|
| 434 |
+
"source": [
|
| 435 |
+
"llama_tokens.attention_mask.shape"
|
| 436 |
+
]
|
| 437 |
+
},
|
| 438 |
+
{
|
| 439 |
+
"cell_type": "code",
|
| 440 |
+
"execution_count": 9,
|
| 441 |
+
"id": "dc9e376d",
|
| 442 |
+
"metadata": {
|
| 443 |
+
"pycharm": {
|
| 444 |
+
"name": "#%%\n"
|
| 445 |
+
}
|
| 446 |
+
},
|
| 447 |
+
"outputs": [],
|
| 448 |
+
"source": [
|
| 449 |
+
"targets = llama_tokens.input_ids.masked_fill(\n",
|
| 450 |
+
" llama_tokens.input_ids == model.llama_tokenizer.pad_token_id, -100\n",
|
| 451 |
+
" )"
|
| 452 |
+
]
|
| 453 |
+
},
|
| 454 |
+
{
|
| 455 |
+
"cell_type": "code",
|
| 456 |
+
"execution_count": 10,
|
| 457 |
+
"id": "e458fa52",
|
| 458 |
+
"metadata": {
|
| 459 |
+
"pycharm": {
|
| 460 |
+
"name": "#%%\n"
|
| 461 |
+
}
|
| 462 |
+
},
|
| 463 |
+
"outputs": [
|
| 464 |
+
{
|
| 465 |
+
"data": {
|
| 466 |
+
"text/plain": [
|
| 467 |
+
"torch.Size([2, 3])"
|
| 468 |
+
]
|
| 469 |
+
},
|
| 470 |
+
"execution_count": 10,
|
| 471 |
+
"metadata": {},
|
| 472 |
+
"output_type": "execute_result"
|
| 473 |
+
}
|
| 474 |
+
],
|
| 475 |
+
"source": [
|
| 476 |
+
"torch.ones([targets.shape[0], targets.shape[0]+1]).shape"
|
| 477 |
+
]
|
| 478 |
+
},
|
| 479 |
+
{
|
| 480 |
+
"cell_type": "code",
|
| 481 |
+
"execution_count": null,
|
| 482 |
+
"id": "24607f7a",
|
| 483 |
+
"metadata": {
|
| 484 |
+
"pycharm": {
|
| 485 |
+
"name": "#%%\n"
|
| 486 |
+
}
|
| 487 |
+
},
|
| 488 |
+
"outputs": [],
|
| 489 |
+
"source": [
|
| 490 |
+
"text = \\\n",
|
| 491 |
+
"\"### Human: What's your name?\" \\\n",
|
| 492 |
+
"\"### Assistant: \"\n",
|
| 493 |
+
"\n",
|
| 494 |
+
"\n",
|
| 495 |
+
"llama_tokens = model.llama_tokenizer(\n",
|
| 496 |
+
" text, \n",
|
| 497 |
+
" return_tensors=\"pt\", \n",
|
| 498 |
+
" ).to(device)"
|
| 499 |
+
]
|
| 500 |
+
},
|
| 501 |
+
{
|
| 502 |
+
"cell_type": "markdown",
|
| 503 |
+
"id": "5e69d3e1",
|
| 504 |
+
"metadata": {
|
| 505 |
+
"pycharm": {
|
| 506 |
+
"name": "#%% md\n"
|
| 507 |
+
}
|
| 508 |
+
},
|
| 509 |
+
"source": [
|
| 510 |
+
"### Example of Emb Input"
|
| 511 |
+
]
|
| 512 |
+
},
|
| 513 |
+
{
|
| 514 |
+
"cell_type": "code",
|
| 515 |
+
"execution_count": 188,
|
| 516 |
+
"id": "205b092f",
|
| 517 |
+
"metadata": {
|
| 518 |
+
"pycharm": {
|
| 519 |
+
"name": "#%%\n"
|
| 520 |
+
}
|
| 521 |
+
},
|
| 522 |
+
"outputs": [
|
| 523 |
+
{
|
| 524 |
+
"name": "stdout",
|
| 525 |
+
"output_type": "stream",
|
| 526 |
+
"text": [
|
| 527 |
+
"<unk>\n",
|
| 528 |
+
"\n",
|
| 529 |
+
"I'm sorry, I am an AI language model and do not have a physical form or a name. My purpose is to assist you with any questions or tasks you may have to the best of my ability. Is there anything specific you would like help with?\n",
|
| 530 |
+
"###\n"
|
| 531 |
+
]
|
| 532 |
+
}
|
| 533 |
+
],
|
| 534 |
+
"source": [
|
| 535 |
+
"inputs_embeds = model.llama_model.model.embed_tokens(llama_tokens.input_ids)\n",
|
| 536 |
+
"outputs = model.llama_model.generate(\n",
|
| 537 |
+
" inputs_embeds=inputs_embeds,\n",
|
| 538 |
+
" query_embeds=None,\n",
|
| 539 |
+
" attention_mask=llama_tokens.attention_mask,\n",
|
| 540 |
+
" max_new_tokens=500,\n",
|
| 541 |
+
" stopping_criteria=stopping_criteria,\n",
|
| 542 |
+
" )\n",
|
| 543 |
+
"output_text = model.llama_tokenizer.decode(outputs[0])\n",
|
| 544 |
+
"print(output_text)"
|
| 545 |
+
]
|
| 546 |
+
},
|
| 547 |
+
{
|
| 548 |
+
"cell_type": "code",
|
| 549 |
+
"execution_count": 189,
|
| 550 |
+
"id": "561b42f5",
|
| 551 |
+
"metadata": {
|
| 552 |
+
"pycharm": {
|
| 553 |
+
"name": "#%%\n"
|
| 554 |
+
}
|
| 555 |
+
},
|
| 556 |
+
"outputs": [
|
| 557 |
+
{
|
| 558 |
+
"data": {
|
| 559 |
+
"text/plain": [
|
| 560 |
+
"torch.Size([1, 16, 5120])"
|
| 561 |
+
]
|
| 562 |
+
},
|
| 563 |
+
"execution_count": 189,
|
| 564 |
+
"metadata": {},
|
| 565 |
+
"output_type": "execute_result"
|
| 566 |
+
}
|
| 567 |
+
],
|
| 568 |
+
"source": [
|
| 569 |
+
"inputs_embeds.shape"
|
| 570 |
+
]
|
| 571 |
+
},
|
| 572 |
+
{
|
| 573 |
+
"cell_type": "markdown",
|
| 574 |
+
"id": "a1694ad6",
|
| 575 |
+
"metadata": {
|
| 576 |
+
"pycharm": {
|
| 577 |
+
"name": "#%% md\n"
|
| 578 |
+
}
|
| 579 |
+
},
|
| 580 |
+
"source": [
|
| 581 |
+
"### Example of ID Input"
|
| 582 |
+
]
|
| 583 |
+
},
|
| 584 |
+
{
|
| 585 |
+
"cell_type": "code",
|
| 586 |
+
"execution_count": null,
|
| 587 |
+
"id": "c1dc7841",
|
| 588 |
+
"metadata": {
|
| 589 |
+
"pycharm": {
|
| 590 |
+
"name": "#%%\n"
|
| 591 |
+
}
|
| 592 |
+
},
|
| 593 |
+
"outputs": [],
|
| 594 |
+
"source": [
|
| 595 |
+
"outputs = model.llama_model.generate(\n",
|
| 596 |
+
" input_ids=llama_tokens.input_ids,\n",
|
| 597 |
+
" query_embeds=None,\n",
|
| 598 |
+
" attention_mask=llama_tokens.attention_mask,\n",
|
| 599 |
+
" max_new_tokens=500,\n",
|
| 600 |
+
" stopping_criteria=stopping_criteria,\n",
|
| 601 |
+
" )\n",
|
| 602 |
+
"output_text = model.llama_tokenizer.decode(outputs[0])\n",
|
| 603 |
+
"print(output_text)"
|
| 604 |
+
]
|
| 605 |
+
},
|
| 606 |
+
{
|
| 607 |
+
"cell_type": "markdown",
|
| 608 |
+
"id": "19dd1f9d",
|
| 609 |
+
"metadata": {
|
| 610 |
+
"pycharm": {
|
| 611 |
+
"name": "#%% md\n"
|
| 612 |
+
}
|
| 613 |
+
},
|
| 614 |
+
"source": []
|
| 615 |
+
},
|
| 616 |
+
{
|
| 617 |
+
"cell_type": "markdown",
|
| 618 |
+
"id": "468ac97e",
|
| 619 |
+
"metadata": {
|
| 620 |
+
"pycharm": {
|
| 621 |
+
"name": "#%% md\n"
|
| 622 |
+
}
|
| 623 |
+
},
|
| 624 |
+
"source": [
|
| 625 |
+
"### Example of Mixed Input"
|
| 626 |
+
]
|
| 627 |
+
},
|
| 628 |
+
{
|
| 629 |
+
"cell_type": "code",
|
| 630 |
+
"execution_count": 47,
|
| 631 |
+
"id": "4af3a9bf",
|
| 632 |
+
"metadata": {
|
| 633 |
+
"pycharm": {
|
| 634 |
+
"name": "#%%\n"
|
| 635 |
+
}
|
| 636 |
+
},
|
| 637 |
+
"outputs": [],
|
| 638 |
+
"source": [
|
| 639 |
+
"ckpt_path = '/home/zhud/project/blip2/lavis/output/BLIP2/Vicuna_pretrain_stage2_cc/20230408015/checkpoint_2.pth'\n",
|
| 640 |
+
"ckpt = torch.load(ckpt_path, map_location=\"cpu\")\n",
|
| 641 |
+
"msg = model.load_state_dict(ckpt['model'], strict=False)\n",
|
| 642 |
+
"model = model.to(device)"
|
| 643 |
+
]
|
| 644 |
+
},
|
| 645 |
+
{
|
| 646 |
+
"cell_type": "code",
|
| 647 |
+
"execution_count": 48,
|
| 648 |
+
"id": "c3148611",
|
| 649 |
+
"metadata": {
|
| 650 |
+
"pycharm": {
|
| 651 |
+
"name": "#%%\n"
|
| 652 |
+
}
|
| 653 |
+
},
|
| 654 |
+
"outputs": [],
|
| 655 |
+
"source": [
|
| 656 |
+
"# Load the image using PIL\n",
|
| 657 |
+
"image = Image.open('test_img5.jpg').convert('RGB')\n",
|
| 658 |
+
"image = vis_processor(image).unsqueeze(0).to(device)\n",
|
| 659 |
+
"inputs_llama, atts_llama = model.encode_img(image)"
|
| 660 |
+
]
|
| 661 |
+
},
|
| 662 |
+
{
|
| 663 |
+
"cell_type": "code",
|
| 664 |
+
"execution_count": 53,
|
| 665 |
+
"id": "07b82707",
|
| 666 |
+
"metadata": {
|
| 667 |
+
"pycharm": {
|
| 668 |
+
"name": "#%%\n"
|
| 669 |
+
}
|
| 670 |
+
},
|
| 671 |
+
"outputs": [],
|
| 672 |
+
"source": [
|
| 673 |
+
"text = \\\n",
|
| 674 |
+
"\"A chat between a curious human and an artificial intelligence assistant. \" \\\n",
|
| 675 |
+
"\"The assistant gives helpful, detailed, and polite answers to the human's questions. \"\\\n",
|
| 676 |
+
"\"Human may ask questions related to a given image. \" \\\n",
|
| 677 |
+
"\"The image will be wrapped as <Img> IMAGE_CONTENT </Img> \" \\\n",
|
| 678 |
+
"\"### Human: <Img>To_Split</Img> \" \\\n",
|
| 679 |
+
"\"### Assistant: Received the image. \" \\\n",
|
| 680 |
+
"\"### Human: Describe the image in detail. Say everthing you see. Describe all the things.\" \\\n",
|
| 681 |
+
"\"### Assistant: \"\n",
|
| 682 |
+
"\n",
|
| 683 |
+
"\n",
|
| 684 |
+
"text = \\\n",
|
| 685 |
+
"\"A chat between a curious human and an artificial intelligence assistant. \" \\\n",
|
| 686 |
+
"\"The assistant gives helpful, detailed, and polite answers to the human's questions. \"\\\n",
|
| 687 |
+
"\"Human may ask questions related to a given image. \" \\\n",
|
| 688 |
+
"\"The image will be wrapped as <Img> IMAGE_CONTENT </Img> \" \\\n",
|
| 689 |
+
"\"### Human: Describe the image in detail. Say everthing you see. <Img>To_Split</Img> \" \\\n",
|
| 690 |
+
"\"### Assistant: \"\n",
|
| 691 |
+
"\n",
|
| 692 |
+
"text = \\\n",
|
| 693 |
+
"\"### Human: Describe the image in detail. Say everthing you see. <Img>To_Split</Img> \" \\\n",
|
| 694 |
+
"\"### Assistant: \"\n",
|
| 695 |
+
"\n",
|
| 696 |
+
"\n",
|
| 697 |
+
"\n",
|
| 698 |
+
"# text = \\\n",
|
| 699 |
+
"# \"A chat between a curious human and an artificial intelligence assistant. \" \\\n",
|
| 700 |
+
"# \"The assistant gives helpful, detailed, and polite answers to the human's questions. \"\\\n",
|
| 701 |
+
"# \"Human may ask questions related to a given image. \" \\\n",
|
| 702 |
+
"# \"The image will be wrapped as <Img> IMAGE_CONTENT </Img> \" \\\n",
|
| 703 |
+
"# \"### Human: <Img>To_Split</Img> \" \\\n",
|
| 704 |
+
"# \"### Assistant: Received the image. \" \\\n",
|
| 705 |
+
"# \"### Human: This is a draft of a website. Give me the html code to write this website. \" \\\n",
|
| 706 |
+
"# \"Btw, you need to come up with some jokes in the website to fill the placeholders. \" \\\n",
|
| 707 |
+
"# \"Also, make the website colorful and vivid. \" \\\n",
|
| 708 |
+
"# \"### Assistant: \"\n",
|
| 709 |
+
"\n",
|
| 710 |
+
"\n",
|
| 711 |
+
"# text = \\\n",
|
| 712 |
+
"# \"Return what the human says. \" \\\n",
|
| 713 |
+
"# \"### Human: There is a big elephant in the sky. \" \\\n",
|
| 714 |
+
"# \"### Assistant: There is a big elephant in the sky. \" \\\n",
|
| 715 |
+
"# \"### Human: fdjlks klcznv_l1 \" \\\n",
|
| 716 |
+
"# \"### Assistant: fdjlks klcznv_l1 \" \\\n",
|
| 717 |
+
"# \"### Human: To_Split \" \\\n",
|
| 718 |
+
"# \"### Assistant: \"\n",
|
| 719 |
+
"\n",
|
| 720 |
+
"\n",
|
| 721 |
+
"text_1, text_2 = text.split('To_Split')\n",
|
| 722 |
+
"\n",
|
| 723 |
+
"text_1_tokens = model.llama_tokenizer(text_1, return_tensors=\"pt\").to(device)\n",
|
| 724 |
+
"text_2_tokens = model.llama_tokenizer(text_2, return_tensors=\"pt\", add_special_tokens=False).to(device)\n",
|
| 725 |
+
"text_1_emb = model.llama_model.model.embed_tokens(text_1_tokens.input_ids)\n",
|
| 726 |
+
"text_2_emb = model.llama_model.model.embed_tokens(text_2_tokens.input_ids)"
|
| 727 |
+
]
|
| 728 |
+
},
|
| 729 |
+
{
|
| 730 |
+
"cell_type": "code",
|
| 731 |
+
"execution_count": 54,
|
| 732 |
+
"id": "136b9e97",
|
| 733 |
+
"metadata": {
|
| 734 |
+
"pycharm": {
|
| 735 |
+
"name": "#%%\n"
|
| 736 |
+
}
|
| 737 |
+
},
|
| 738 |
+
"outputs": [
|
| 739 |
+
{
|
| 740 |
+
"name": "stdout",
|
| 741 |
+
"output_type": "stream",
|
| 742 |
+
"text": [
|
| 743 |
+
"<unk>\n",
|
| 744 |
+
"\n",
|
| 745 |
+
"The image shows a small bird perched on a tree stump, with a camera lens in the background\n",
|
| 746 |
+
"\n",
|
| 747 |
+
"The bird is a small bird, with a bright yellow beak and black feathers. It is perched on a tree stump, with its wings spread out and its beak open. The bird is looking to the left, as if it is about to take off.\n",
|
| 748 |
+
"\n",
|
| 749 |
+
"The camera lens in the background is a large, black lens with a silver ring around the front. The lens is attached to a camera, which is not visible in the image. The lens is pointed at the bird, with the camera's viewfinder showing the bird in the center of the frame.\n",
|
| 750 |
+
"\n",
|
| 751 |
+
"The background of the image is a forest, with trees and foliage visible in the distance. The trees are covered in leaves, and there is a thick layer of mist or fog in the air, which gives the image a dreamy, ethereal quality.\n",
|
| 752 |
+
"\n",
|
| 753 |
+
"The lighting in the image is soft and diffused, with the sun shining through the trees and casting a warm, golden light on the bird and the tree stump. The lighting creates deep shadows in the forest, which add to the sense of mystery and wonder in the image.\n",
|
| 754 |
+
"\n",
|
| 755 |
+
"The overall effect of the image is one of peacefulness and tranquility, with the bird and the forest creating a sense of calm and serenity. The image is beautifully composed, with the bird and the camera lens creating a visual balance that draws the viewer's eye to the center of the frame.\n",
|
| 756 |
+
"###\n"
|
| 757 |
+
]
|
| 758 |
+
}
|
| 759 |
+
],
|
| 760 |
+
"source": [
|
| 761 |
+
"outputs = model.llama_model.generate(\n",
|
| 762 |
+
" inputs_embeds=torch.concat([text_1_emb, inputs_llama, text_2_emb], dim=1),\n",
|
| 763 |
+
" query_embeds=None,\n",
|
| 764 |
+
" attention_mask=torch.concat([text_1_tokens.attention_mask, atts_llama, text_2_tokens.attention_mask], dim=1),\n",
|
| 765 |
+
" max_new_tokens=600,\n",
|
| 766 |
+
" stopping_criteria=stopping_criteria,\n",
|
| 767 |
+
" )\n",
|
| 768 |
+
"output_text = model.llama_tokenizer.decode(outputs[0])\n",
|
| 769 |
+
"print(output_text)"
|
| 770 |
+
]
|
| 771 |
+
},
|
| 772 |
+
{
|
| 773 |
+
"cell_type": "code",
|
| 774 |
+
"execution_count": 83,
|
| 775 |
+
"id": "54cc3d4a",
|
| 776 |
+
"metadata": {
|
| 777 |
+
"pycharm": {
|
| 778 |
+
"name": "#%%\n"
|
| 779 |
+
}
|
| 780 |
+
},
|
| 781 |
+
"outputs": [],
|
| 782 |
+
"source": [
|
| 783 |
+
"with open('lavis/prompts/image_caption.txt', 'r') as f:\n",
|
| 784 |
+
" prompts = f.read().splitlines()"
|
| 785 |
+
]
|
| 786 |
+
},
|
| 787 |
+
{
|
| 788 |
+
"cell_type": "code",
|
| 789 |
+
"execution_count": 92,
|
| 790 |
+
"id": "f52cd85c",
|
| 791 |
+
"metadata": {
|
| 792 |
+
"pycharm": {
|
| 793 |
+
"name": "#%%\n"
|
| 794 |
+
}
|
| 795 |
+
},
|
| 796 |
+
"outputs": [],
|
| 797 |
+
"source": [
|
| 798 |
+
"prompt_token = model.llama_tokenizer(prompts, return_tensors=\"pt\", padding=\"longest\",)"
|
| 799 |
+
]
|
| 800 |
+
},
|
| 801 |
+
{
|
| 802 |
+
"cell_type": "code",
|
| 803 |
+
"execution_count": 103,
|
| 804 |
+
"id": "4b0cf1d0",
|
| 805 |
+
"metadata": {
|
| 806 |
+
"pycharm": {
|
| 807 |
+
"name": "#%%\n"
|
| 808 |
+
}
|
| 809 |
+
},
|
| 810 |
+
"outputs": [
|
| 811 |
+
{
|
| 812 |
+
"name": "stdout",
|
| 813 |
+
"output_type": "stream",
|
| 814 |
+
"text": [
|
| 815 |
+
"[(15, 6), (16, 11), (17, 17), (18, 17), (19, 27), (20, 18), (21, 21), (22, 4), (23, 6), (24, 2)]\n"
|
| 816 |
+
]
|
| 817 |
+
}
|
| 818 |
+
],
|
| 819 |
+
"source": [
|
| 820 |
+
"\n",
|
| 821 |
+
"\n",
|
| 822 |
+
"my_list = prompt_token.attention_mask.sum(1).numpy()\n",
|
| 823 |
+
"counts = {}\n",
|
| 824 |
+
"\n",
|
| 825 |
+
"for element in my_list:\n",
|
| 826 |
+
" if element in counts:\n",
|
| 827 |
+
" counts[element] += 1\n",
|
| 828 |
+
" else:\n",
|
| 829 |
+
" counts[element] = 1\n",
|
| 830 |
+
"\n",
|
| 831 |
+
"print(sorted(counts.items(), key=lambda item: item[0]))"
|
| 832 |
+
]
|
| 833 |
+
},
|
| 834 |
+
{
|
| 835 |
+
"cell_type": "code",
|
| 836 |
+
"execution_count": 58,
|
| 837 |
+
"id": "f7919e93",
|
| 838 |
+
"metadata": {
|
| 839 |
+
"pycharm": {
|
| 840 |
+
"name": "#%%\n"
|
| 841 |
+
}
|
| 842 |
+
},
|
| 843 |
+
"outputs": [
|
| 844 |
+
{
|
| 845 |
+
"name": "stdout",
|
| 846 |
+
"output_type": "stream",
|
| 847 |
+
"text": [
|
| 848 |
+
"[1, 2, 1, 2, 1, 2]\n"
|
| 849 |
+
]
|
| 850 |
+
}
|
| 851 |
+
],
|
| 852 |
+
"source": [
|
| 853 |
+
"a,b = [1,1,1], [2,2,2]\n",
|
| 854 |
+
"c = [i for pair in zip(a,b) for i in pair]\n",
|
| 855 |
+
"print(c)"
|
| 856 |
+
]
|
| 857 |
+
},
|
| 858 |
+
{
|
| 859 |
+
"cell_type": "markdown",
|
| 860 |
+
"id": "3c64a037",
|
| 861 |
+
"metadata": {
|
| 862 |
+
"pycharm": {
|
| 863 |
+
"name": "#%% md\n"
|
| 864 |
+
}
|
| 865 |
+
},
|
| 866 |
+
"source": [
|
| 867 |
+
"### Example of Image Input"
|
| 868 |
+
]
|
| 869 |
+
},
|
| 870 |
+
{
|
| 871 |
+
"cell_type": "code",
|
| 872 |
+
"execution_count": 67,
|
| 873 |
+
"id": "87164578",
|
| 874 |
+
"metadata": {
|
| 875 |
+
"pycharm": {
|
| 876 |
+
"name": "#%%\n"
|
| 877 |
+
}
|
| 878 |
+
},
|
| 879 |
+
"outputs": [
|
| 880 |
+
{
|
| 881 |
+
"name": "stdout",
|
| 882 |
+
"output_type": "stream",
|
| 883 |
+
"text": [
|
| 884 |
+
"<unk>a bird eating from a bird feeder\n",
|
| 885 |
+
"\n",
|
| 886 |
+
"bird feeder, bird feeder, bird feeder, bird feeder, bird feeder, bird feeder, bird\n",
|
| 887 |
+
"bird feeder, bird feeder, bird feeder, bird feeder, bird feeder, bird feeder, bird\n",
|
| 888 |
+
"bird feeder, bird feeder, bird feeder, bird feeder, bird feeder, bird feeder, bird\n",
|
| 889 |
+
"bird feeder, bird feeder, bird feeder\n"
|
| 890 |
+
]
|
| 891 |
+
}
|
| 892 |
+
],
|
| 893 |
+
"source": [
|
| 894 |
+
"inputs_embeds = model.llama_model.model.embed_tokens(llama_tokens.input_ids)\n",
|
| 895 |
+
"bos_embeds = model.llama_model.model.embed_tokens(torch.tensor(model.llama_tokenizer.bos_token_id, device=device))[None, None]\n",
|
| 896 |
+
"outputs = model.llama_model.generate(\n",
|
| 897 |
+
" inputs_embeds=torch.concat([bos_embeds, inputs_llama], dim=1),\n",
|
| 898 |
+
" query_embeds=None,\n",
|
| 899 |
+
" attention_mask=torch.concat([atts_llama[:, :1], atts_llama], dim=1),\n",
|
| 900 |
+
" max_new_tokens=100,\n",
|
| 901 |
+
" stopping_criteria=stopping_criteria,\n",
|
| 902 |
+
" )\n",
|
| 903 |
+
"output_text = model.llama_tokenizer.decode(outputs[0])\n",
|
| 904 |
+
"print(output_text)"
|
| 905 |
+
]
|
| 906 |
+
}
|
| 907 |
+
],
|
| 908 |
+
"metadata": {
|
| 909 |
+
"kernelspec": {
|
| 910 |
+
"display_name": "eye",
|
| 911 |
+
"language": "python",
|
| 912 |
+
"name": "eye"
|
| 913 |
+
},
|
| 914 |
+
"language_info": {
|
| 915 |
+
"codemirror_mode": {
|
| 916 |
+
"name": "ipython",
|
| 917 |
+
"version": 3
|
| 918 |
+
},
|
| 919 |
+
"file_extension": ".py",
|
| 920 |
+
"mimetype": "text/x-python",
|
| 921 |
+
"name": "python",
|
| 922 |
+
"nbconvert_exporter": "python",
|
| 923 |
+
"pygments_lexer": "ipython3",
|
| 924 |
+
"version": "3.9.16"
|
| 925 |
+
}
|
| 926 |
+
},
|
| 927 |
+
"nbformat": 4,
|
| 928 |
+
"nbformat_minor": 5
|
| 929 |
+
}
|
environment.yml
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: minigpt4
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- defaults
|
| 5 |
+
dependencies:
|
| 6 |
+
- python=3.9
|
| 7 |
+
- pip
|
| 8 |
+
- pytorch=1.12.1
|
| 9 |
+
- pytorch-mutex=1.0=cuda
|
| 10 |
+
- torchaudio=0.12.1
|
| 11 |
+
- torchvision=0.13.1
|
| 12 |
+
- pip:
|
| 13 |
+
- accelerate==0.16.0
|
| 14 |
+
- aiohttp==3.8.4
|
| 15 |
+
- aiosignal==1.3.1
|
| 16 |
+
- async-timeout==4.0.2
|
| 17 |
+
- attrs==22.2.0
|
| 18 |
+
- bitsandbytes==0.37.0
|
| 19 |
+
- cchardet==2.1.7
|
| 20 |
+
- chardet==5.1.0
|
| 21 |
+
- contourpy==1.0.7
|
| 22 |
+
- cycler==0.11.0
|
| 23 |
+
- filelock==3.9.0
|
| 24 |
+
- fonttools==4.38.0
|
| 25 |
+
- frozenlist==1.3.3
|
| 26 |
+
- huggingface-hub==0.12.1
|
| 27 |
+
- importlib-resources==5.12.0
|
| 28 |
+
- kiwisolver==1.4.4
|
| 29 |
+
- matplotlib==3.7.0
|
| 30 |
+
- multidict==6.0.4
|
| 31 |
+
- openai==0.27.0
|
| 32 |
+
- packaging==23.0
|
| 33 |
+
- psutil==5.9.4
|
| 34 |
+
- pycocotools==2.0.6
|
| 35 |
+
- pyparsing==3.0.9
|
| 36 |
+
- python-dateutil==2.8.2
|
| 37 |
+
- pyyaml==6.0
|
| 38 |
+
- regex==2022.10.31
|
| 39 |
+
- tokenizers==0.13.2
|
| 40 |
+
- tqdm==4.64.1
|
| 41 |
+
- transformers==4.28.0
|
| 42 |
+
- timm==0.6.13
|
| 43 |
+
- spacy==3.5.1
|
| 44 |
+
- webdataset==0.2.48
|
| 45 |
+
- scikit-learn==1.2.2
|
| 46 |
+
- scipy==1.10.1
|
| 47 |
+
- yarl==1.8.2
|
| 48 |
+
- zipp==3.14.0
|
| 49 |
+
- tenacity==8.2.2
|
| 50 |
+
- peft
|
| 51 |
+
- pycocoevalcap
|
| 52 |
+
- sentence-transformers
|
| 53 |
+
- umap-learn
|
| 54 |
+
- notebook
|
| 55 |
+
- gradio
|
| 56 |
+
- wandb
|
eval_configs/minigpt4.yaml
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2022, salesforce.com, inc.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# SPDX-License-Identifier: BSD-3-Clause
|
| 4 |
+
# For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 5 |
+
|
| 6 |
+
model:
|
| 7 |
+
arch: mini_gpt4
|
| 8 |
+
model_type: pretrain_vicuna
|
| 9 |
+
freeze_vit: True
|
| 10 |
+
freeze_qformer: True
|
| 11 |
+
max_txt_len: 160
|
| 12 |
+
end_sym: "###"
|
| 13 |
+
prompt_path: "prompts/alignment.txt"
|
| 14 |
+
prompt_template: '###Human: {} ###Assistant: '
|
| 15 |
+
ckpt: '/ibex/project/c2133/vicuna_ckpt_test/Vicuna_stage3_align/20230412191_laion_ckpt3/checkpoint_1.pth'
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
datasets:
|
| 19 |
+
cc_align:
|
| 20 |
+
vis_processor:
|
| 21 |
+
train:
|
| 22 |
+
name: "blip2_image_eval"
|
| 23 |
+
image_size: 224
|
| 24 |
+
text_processor:
|
| 25 |
+
train:
|
| 26 |
+
name: "blip_caption"
|
| 27 |
+
|
| 28 |
+
run:
|
| 29 |
+
task: image_text_pretrain
|
| 30 |
+
|
examples/ad_1.png
ADDED
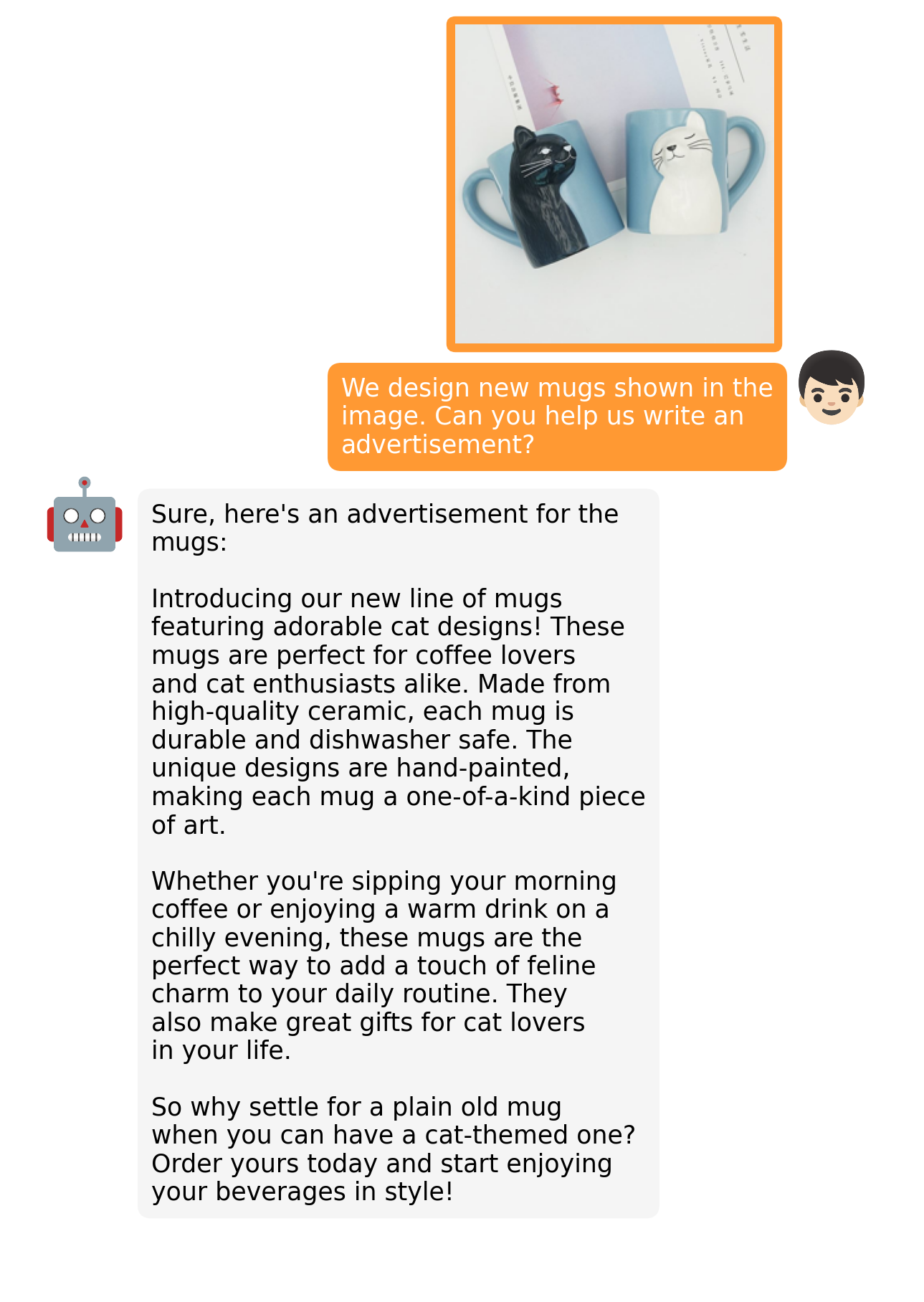
|
examples/ad_2.png
ADDED

|
examples/cook_1.png
ADDED
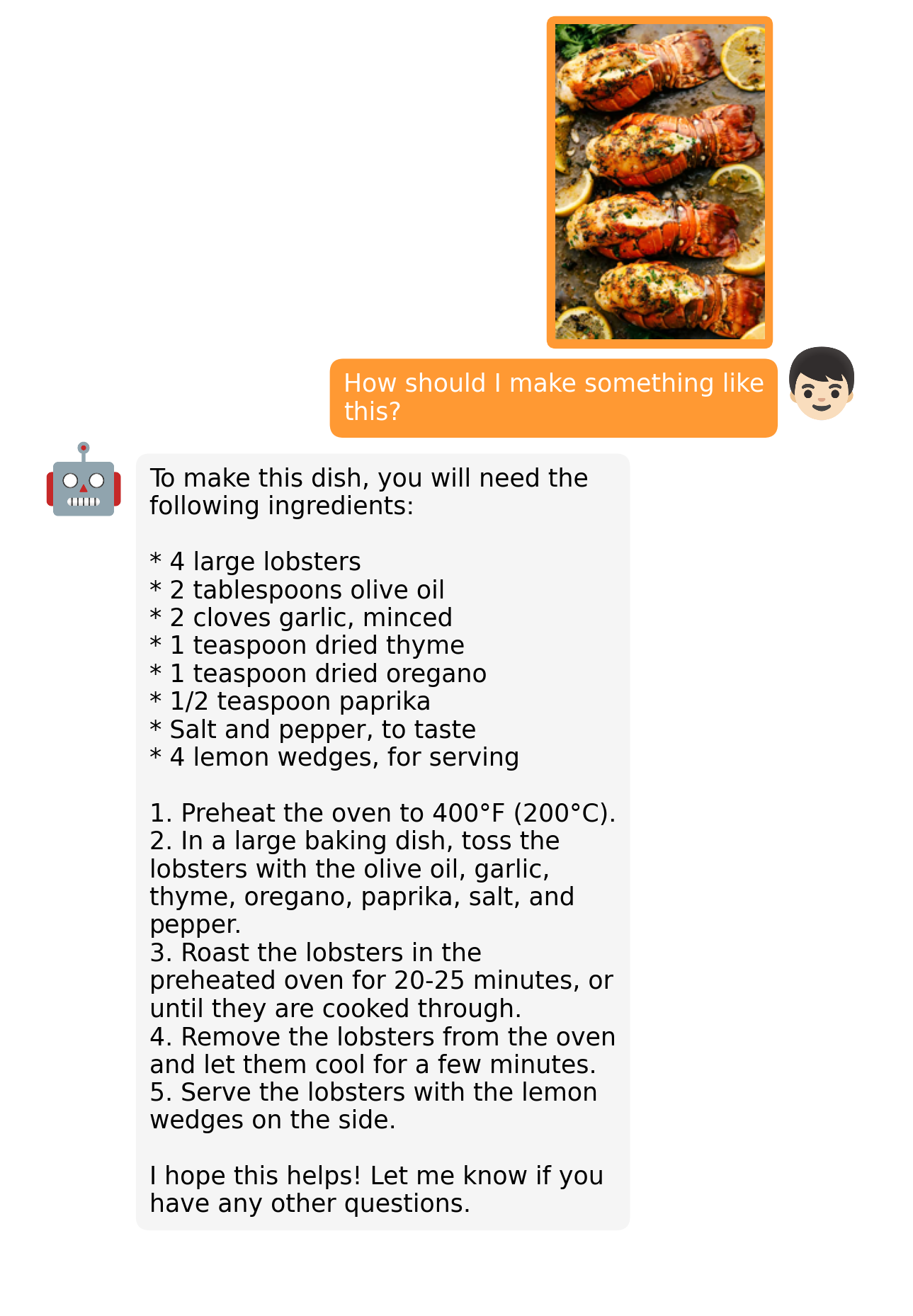
|
examples/cook_2.png
ADDED
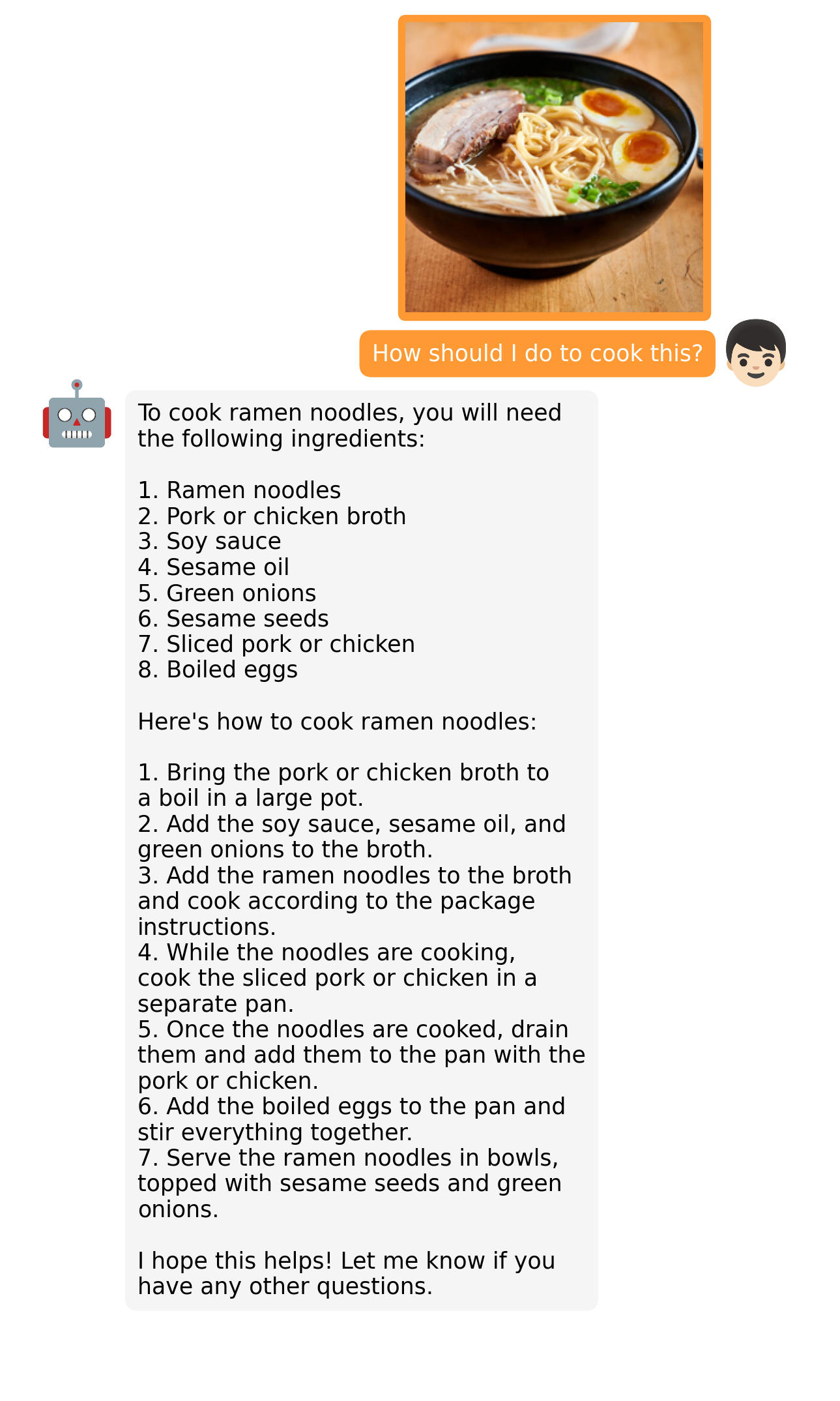
|
examples/describe_1.png
ADDED

|
examples/describe_2.png
ADDED
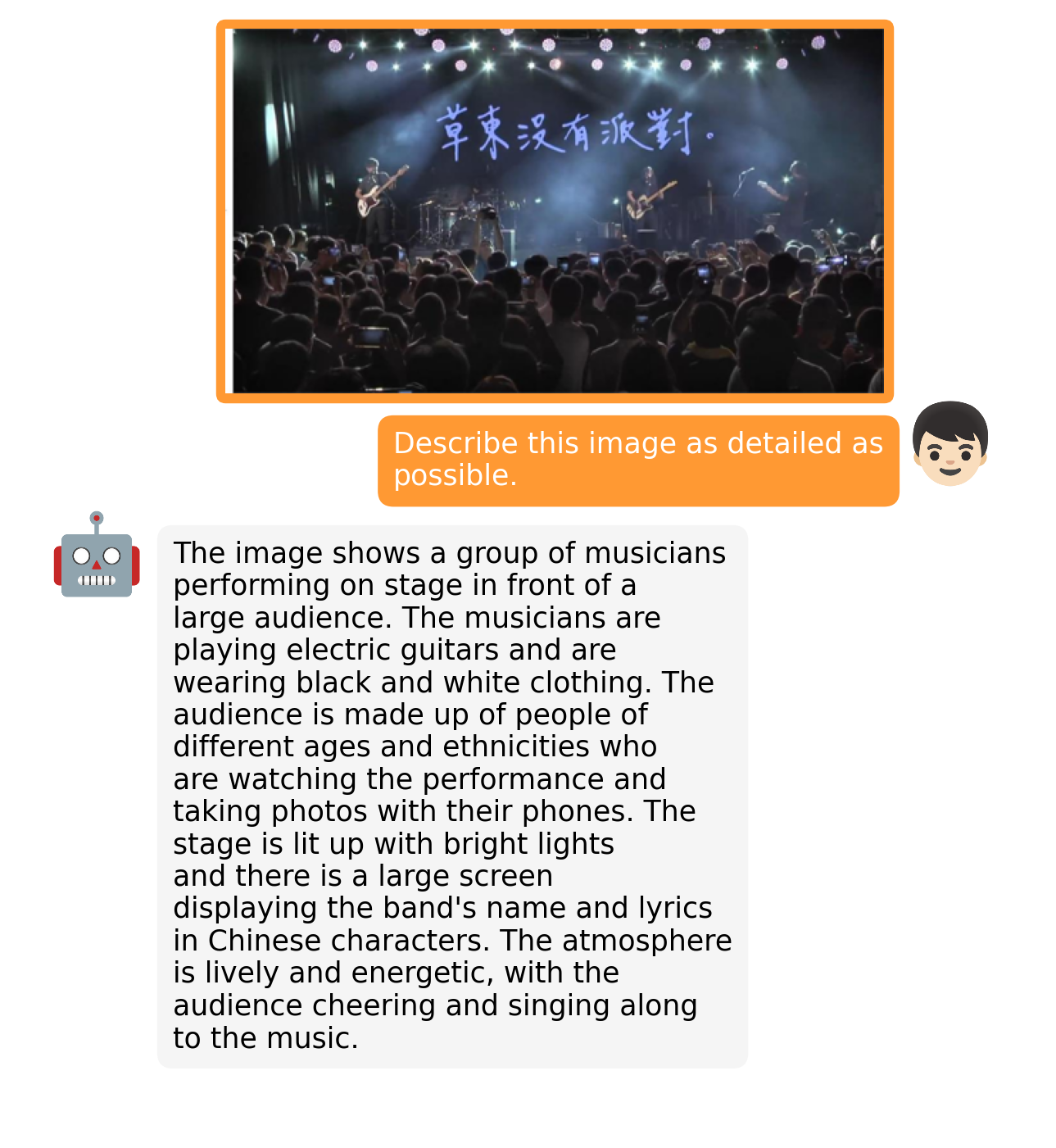
|
examples/fact_1.png
ADDED

|
examples/fact_2.png
ADDED
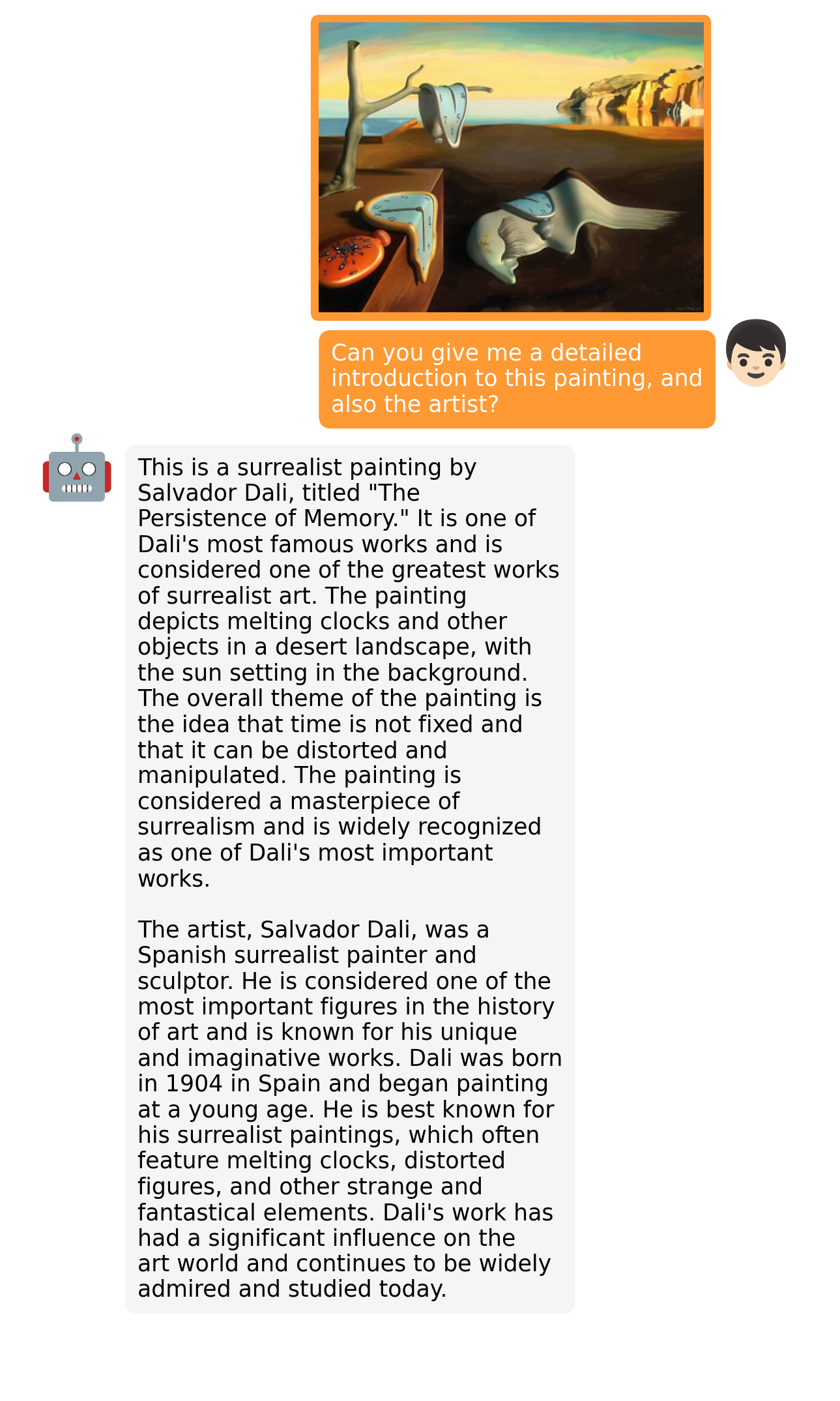
|
examples/fix_1.png
ADDED
|
examples/fix_2.png
ADDED
|
examples/fun_1.png
ADDED

|
examples/fun_2.png
ADDED
|
examples/logo_1.png
ADDED
|
|
examples/op_1.png
ADDED

|
examples/op_2.png
ADDED
|
examples/people_1.png
ADDED

|
examples/people_2.png
ADDED

|
examples/rhyme_1.png
ADDED
|
examples/rhyme_2.png
ADDED

|
examples/story_1.png
ADDED
|
examples/story_2.png
ADDED

|
examples/web_1.png
ADDED

|
examples/wop_1.png
ADDED
|
examples/wop_2.png
ADDED
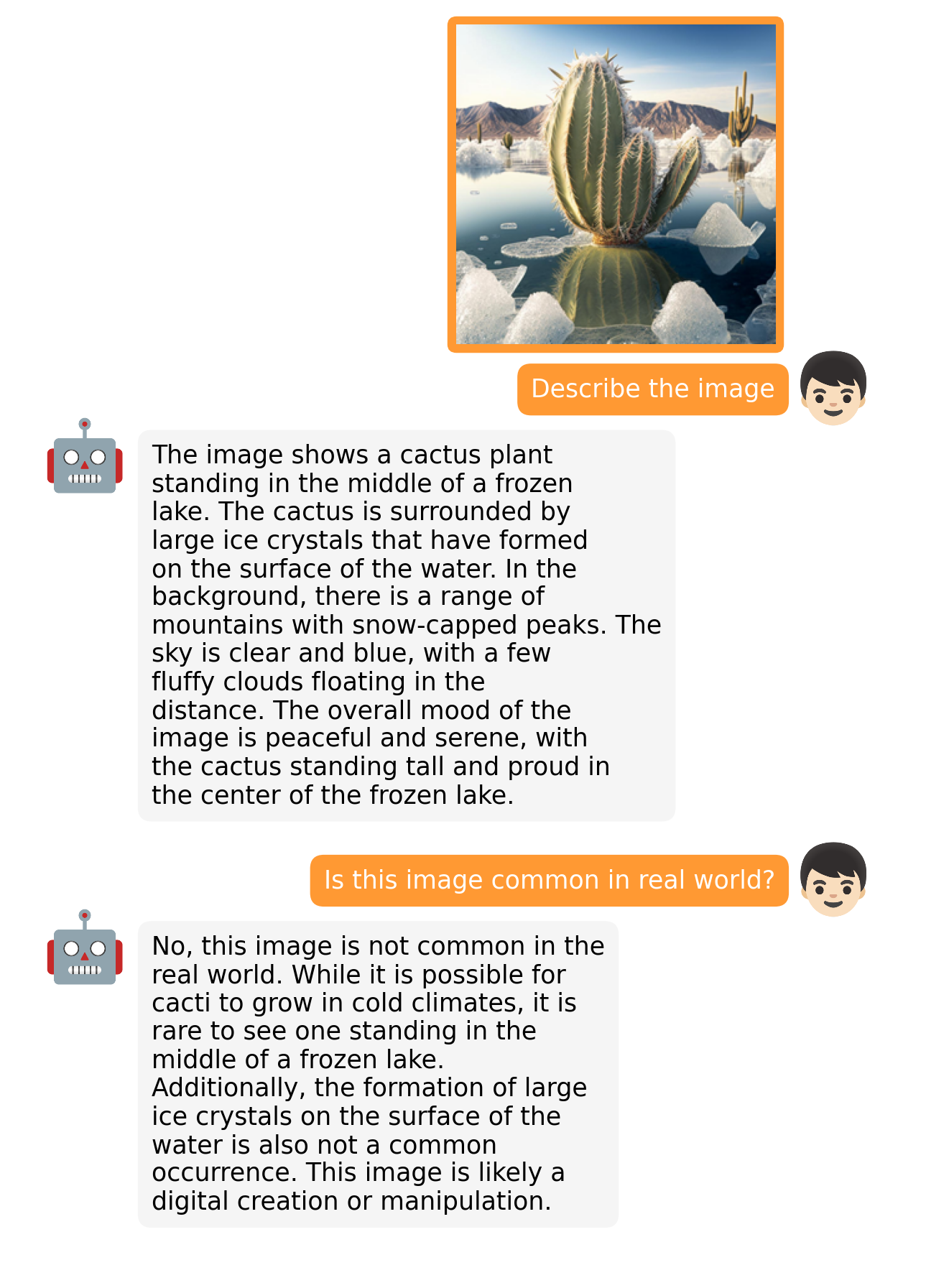
|
minigpt4/__init__.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import sys
|
| 10 |
+
|
| 11 |
+
from omegaconf import OmegaConf
|
| 12 |
+
|
| 13 |
+
from minigpt4.common.registry import registry
|
| 14 |
+
|
| 15 |
+
from minigpt4.datasets.builders import *
|
| 16 |
+
from minigpt4.models import *
|
| 17 |
+
from minigpt4.processors import *
|
| 18 |
+
from minigpt4.tasks import *
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
root_dir = os.path.dirname(os.path.abspath(__file__))
|
| 22 |
+
default_cfg = OmegaConf.load(os.path.join(root_dir, "configs/default.yaml"))
|
| 23 |
+
|
| 24 |
+
registry.register_path("library_root", root_dir)
|
| 25 |
+
repo_root = os.path.join(root_dir, "..")
|
| 26 |
+
registry.register_path("repo_root", repo_root)
|
| 27 |
+
cache_root = os.path.join(repo_root, default_cfg.env.cache_root)
|
| 28 |
+
registry.register_path("cache_root", cache_root)
|
| 29 |
+
|
| 30 |
+
registry.register("MAX_INT", sys.maxsize)
|
| 31 |
+
registry.register("SPLIT_NAMES", ["train", "val", "test"])
|
minigpt4/common/__init__.py
ADDED
|
File without changes
|
minigpt4/common/config.py
ADDED
|
@@ -0,0 +1,468 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import logging
|
| 9 |
+
import json
|
| 10 |
+
from typing import Dict
|
| 11 |
+
|
| 12 |
+
from omegaconf import OmegaConf
|
| 13 |
+
from minigpt4.common.registry import registry
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class Config:
|
| 17 |
+
def __init__(self, args):
|
| 18 |
+
self.config = {}
|
| 19 |
+
|
| 20 |
+
self.args = args
|
| 21 |
+
|
| 22 |
+
# Register the config and configuration for setup
|
| 23 |
+
registry.register("configuration", self)
|
| 24 |
+
|
| 25 |
+
user_config = self._build_opt_list(self.args.options)
|
| 26 |
+
|
| 27 |
+
config = OmegaConf.load(self.args.cfg_path)
|
| 28 |
+
|
| 29 |
+
runner_config = self.build_runner_config(config)
|
| 30 |
+
model_config = self.build_model_config(config, **user_config)
|
| 31 |
+
dataset_config = self.build_dataset_config(config)
|
| 32 |
+
|
| 33 |
+
# Validate the user-provided runner configuration
|
| 34 |
+
# model and dataset configuration are supposed to be validated by the respective classes
|
| 35 |
+
# [TODO] validate the model/dataset configuration
|
| 36 |
+
# self._validate_runner_config(runner_config)
|
| 37 |
+
|
| 38 |
+
# Override the default configuration with user options.
|
| 39 |
+
self.config = OmegaConf.merge(
|
| 40 |
+
runner_config, model_config, dataset_config, user_config
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
def _validate_runner_config(self, runner_config):
|
| 44 |
+
"""
|
| 45 |
+
This method validates the configuration, such that
|
| 46 |
+
1) all the user specified options are valid;
|
| 47 |
+
2) no type mismatches between the user specified options and the config.
|
| 48 |
+
"""
|
| 49 |
+
runner_config_validator = create_runner_config_validator()
|
| 50 |
+
runner_config_validator.validate(runner_config)
|
| 51 |
+
|
| 52 |
+
def _build_opt_list(self, opts):
|
| 53 |
+
opts_dot_list = self._convert_to_dot_list(opts)
|
| 54 |
+
return OmegaConf.from_dotlist(opts_dot_list)
|
| 55 |
+
|
| 56 |
+
@staticmethod
|
| 57 |
+
def build_model_config(config, **kwargs):
|
| 58 |
+
model = config.get("model", None)
|
| 59 |
+
assert model is not None, "Missing model configuration file."
|
| 60 |
+
|
| 61 |
+
model_cls = registry.get_model_class(model.arch)
|
| 62 |
+
assert model_cls is not None, f"Model '{model.arch}' has not been registered."
|
| 63 |
+
|
| 64 |
+
model_type = kwargs.get("model.model_type", None)
|
| 65 |
+
if not model_type:
|
| 66 |
+
model_type = model.get("model_type", None)
|
| 67 |
+
# else use the model type selected by user.
|
| 68 |
+
|
| 69 |
+
assert model_type is not None, "Missing model_type."
|
| 70 |
+
|
| 71 |
+
model_config_path = model_cls.default_config_path(model_type=model_type)
|
| 72 |
+
|
| 73 |
+
model_config = OmegaConf.create()
|
| 74 |
+
# hiararchy override, customized config > default config
|
| 75 |
+
model_config = OmegaConf.merge(
|
| 76 |
+
model_config,
|
| 77 |
+
OmegaConf.load(model_config_path),
|
| 78 |
+
{"model": config["model"]},
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
return model_config
|
| 82 |
+
|
| 83 |
+
@staticmethod
|
| 84 |
+
def build_runner_config(config):
|
| 85 |
+
return {"run": config.run}
|
| 86 |
+
|
| 87 |
+
@staticmethod
|
| 88 |
+
def build_dataset_config(config):
|
| 89 |
+
datasets = config.get("datasets", None)
|
| 90 |
+
if datasets is None:
|
| 91 |
+
raise KeyError(
|
| 92 |
+
"Expecting 'datasets' as the root key for dataset configuration."
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
dataset_config = OmegaConf.create()
|
| 96 |
+
|
| 97 |
+
for dataset_name in datasets:
|
| 98 |
+
builder_cls = registry.get_builder_class(dataset_name)
|
| 99 |
+
|
| 100 |
+
dataset_config_type = datasets[dataset_name].get("type", "default")
|
| 101 |
+
dataset_config_path = builder_cls.default_config_path(
|
| 102 |
+
type=dataset_config_type
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
# hiararchy override, customized config > default config
|
| 106 |
+
dataset_config = OmegaConf.merge(
|
| 107 |
+
dataset_config,
|
| 108 |
+
OmegaConf.load(dataset_config_path),
|
| 109 |
+
{"datasets": {dataset_name: config["datasets"][dataset_name]}},
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
return dataset_config
|
| 113 |
+
|
| 114 |
+
def _convert_to_dot_list(self, opts):
|
| 115 |
+
if opts is None:
|
| 116 |
+
opts = []
|
| 117 |
+
|
| 118 |
+
if len(opts) == 0:
|
| 119 |
+
return opts
|
| 120 |
+
|
| 121 |
+
has_equal = opts[0].find("=") != -1
|
| 122 |
+
|
| 123 |
+
if has_equal:
|
| 124 |
+
return opts
|
| 125 |
+
|
| 126 |
+
return [(opt + "=" + value) for opt, value in zip(opts[0::2], opts[1::2])]
|
| 127 |
+
|
| 128 |
+
def get_config(self):
|
| 129 |
+
return self.config
|
| 130 |
+
|
| 131 |
+
@property
|
| 132 |
+
def run_cfg(self):
|
| 133 |
+
return self.config.run
|
| 134 |
+
|
| 135 |
+
@property
|
| 136 |
+
def datasets_cfg(self):
|
| 137 |
+
return self.config.datasets
|
| 138 |
+
|
| 139 |
+
@property
|
| 140 |
+
def model_cfg(self):
|
| 141 |
+
return self.config.model
|
| 142 |
+
|
| 143 |
+
def pretty_print(self):
|
| 144 |
+
logging.info("\n===== Running Parameters =====")
|
| 145 |
+
logging.info(self._convert_node_to_json(self.config.run))
|
| 146 |
+
|
| 147 |
+
logging.info("\n====== Dataset Attributes ======")
|
| 148 |
+
datasets = self.config.datasets
|
| 149 |
+
|
| 150 |
+
for dataset in datasets:
|
| 151 |
+
if dataset in self.config.datasets:
|
| 152 |
+
logging.info(f"\n======== {dataset} =======")
|
| 153 |
+
dataset_config = self.config.datasets[dataset]
|
| 154 |
+
logging.info(self._convert_node_to_json(dataset_config))
|
| 155 |
+
else:
|
| 156 |
+
logging.warning(f"No dataset named '{dataset}' in config. Skipping")
|
| 157 |
+
|
| 158 |
+
logging.info(f"\n====== Model Attributes ======")
|
| 159 |
+
logging.info(self._convert_node_to_json(self.config.model))
|
| 160 |
+
|
| 161 |
+
def _convert_node_to_json(self, node):
|
| 162 |
+
container = OmegaConf.to_container(node, resolve=True)
|
| 163 |
+
return json.dumps(container, indent=4, sort_keys=True)
|
| 164 |
+
|
| 165 |
+
def to_dict(self):
|
| 166 |
+
return OmegaConf.to_container(self.config)
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def node_to_dict(node):
|
| 170 |
+
return OmegaConf.to_container(node)
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
class ConfigValidator:
|
| 174 |
+
"""
|
| 175 |
+
This is a preliminary implementation to centralize and validate the configuration.
|
| 176 |
+
May be altered in the future.
|
| 177 |
+
|
| 178 |
+
A helper class to validate configurations from yaml file.
|
| 179 |
+
|
| 180 |
+
This serves the following purposes:
|
| 181 |
+
1. Ensure all the options in the yaml are defined, raise error if not.
|
| 182 |
+
2. when type mismatches are found, the validator will raise an error.
|
| 183 |
+
3. a central place to store and display helpful messages for supported configurations.
|
| 184 |
+
|
| 185 |
+
"""
|
| 186 |
+
|
| 187 |
+
class _Argument:
|
| 188 |
+
def __init__(self, name, choices=None, type=None, help=None):
|
| 189 |
+
self.name = name
|
| 190 |
+
self.val = None
|
| 191 |
+
self.choices = choices
|
| 192 |
+
self.type = type
|
| 193 |
+
self.help = help
|
| 194 |
+
|
| 195 |
+
def __str__(self):
|
| 196 |
+
s = f"{self.name}={self.val}"
|
| 197 |
+
if self.type is not None:
|
| 198 |
+
s += f", ({self.type})"
|
| 199 |
+
if self.choices is not None:
|
| 200 |
+
s += f", choices: {self.choices}"
|
| 201 |
+
if self.help is not None:
|
| 202 |
+
s += f", ({self.help})"
|
| 203 |
+
return s
|
| 204 |
+
|
| 205 |
+
def __init__(self, description):
|
| 206 |
+
self.description = description
|
| 207 |
+
|
| 208 |
+
self.arguments = dict()
|
| 209 |
+
|
| 210 |
+
self.parsed_args = None
|
| 211 |
+
|
| 212 |
+
def __getitem__(self, key):
|
| 213 |
+
assert self.parsed_args is not None, "No arguments parsed yet."
|
| 214 |
+
|
| 215 |
+
return self.parsed_args[key]
|
| 216 |
+
|
| 217 |
+
def __str__(self) -> str:
|
| 218 |
+
return self.format_help()
|
| 219 |
+
|
| 220 |
+
def add_argument(self, *args, **kwargs):
|
| 221 |
+
"""
|
| 222 |
+
Assume the first argument is the name of the argument.
|
| 223 |
+
"""
|
| 224 |
+
self.arguments[args[0]] = self._Argument(*args, **kwargs)
|
| 225 |
+
|
| 226 |
+
def validate(self, config=None):
|
| 227 |
+
"""
|
| 228 |
+
Convert yaml config (dict-like) to list, required by argparse.
|
| 229 |
+
"""
|
| 230 |
+
for k, v in config.items():
|
| 231 |
+
assert (
|
| 232 |
+
k in self.arguments
|
| 233 |
+
), f"""{k} is not a valid argument. Support arguments are {self.format_arguments()}."""
|
| 234 |
+
|
| 235 |
+
if self.arguments[k].type is not None:
|
| 236 |
+
try:
|
| 237 |
+
self.arguments[k].val = self.arguments[k].type(v)
|
| 238 |
+
except ValueError:
|
| 239 |
+
raise ValueError(f"{k} is not a valid {self.arguments[k].type}.")
|
| 240 |
+
|
| 241 |
+
if self.arguments[k].choices is not None:
|
| 242 |
+
assert (
|
| 243 |
+
v in self.arguments[k].choices
|
| 244 |
+
), f"""{k} must be one of {self.arguments[k].choices}."""
|
| 245 |
+
|
| 246 |
+
return config
|
| 247 |
+
|
| 248 |
+
def format_arguments(self):
|
| 249 |
+
return str([f"{k}" for k in sorted(self.arguments.keys())])
|
| 250 |
+
|
| 251 |
+
def format_help(self):
|
| 252 |
+
# description + key-value pair string for each argument
|
| 253 |
+
help_msg = str(self.description)
|
| 254 |
+
return help_msg + ", available arguments: " + self.format_arguments()
|
| 255 |
+
|
| 256 |
+
def print_help(self):
|
| 257 |
+
# display help message
|
| 258 |
+
print(self.format_help())
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
def create_runner_config_validator():
|
| 262 |
+
validator = ConfigValidator(description="Runner configurations")
|
| 263 |
+
|
| 264 |
+
validator.add_argument(
|
| 265 |
+
"runner",
|
| 266 |
+
type=str,
|
| 267 |
+
choices=["runner_base", "runner_iter"],
|
| 268 |
+
help="""Runner to use. The "runner_base" uses epoch-based training while iter-based
|
| 269 |
+
runner runs based on iters. Default: runner_base""",
|
| 270 |
+
)
|
| 271 |
+
# add argumetns for training dataset ratios
|
| 272 |
+
validator.add_argument(
|
| 273 |
+
"train_dataset_ratios",
|
| 274 |
+
type=Dict[str, float],
|
| 275 |
+
help="""Ratios of training dataset. This is used in iteration-based runner.
|
| 276 |
+
Do not support for epoch-based runner because how to define an epoch becomes tricky.
|
| 277 |
+
Default: None""",
|
| 278 |
+
)
|
| 279 |
+
validator.add_argument(
|
| 280 |
+
"max_iters",
|
| 281 |
+
type=float,
|
| 282 |
+
help="Maximum number of iterations to run.",
|
| 283 |
+
)
|
| 284 |
+
validator.add_argument(
|
| 285 |
+
"max_epoch",
|
| 286 |
+
type=int,
|
| 287 |
+
help="Maximum number of epochs to run.",
|
| 288 |
+
)
|
| 289 |
+
# add arguments for iters_per_inner_epoch
|
| 290 |
+
validator.add_argument(
|
| 291 |
+
"iters_per_inner_epoch",
|
| 292 |
+
type=float,
|
| 293 |
+
help="Number of iterations per inner epoch. This is required when runner is runner_iter.",
|
| 294 |
+
)
|
| 295 |
+
lr_scheds_choices = registry.list_lr_schedulers()
|
| 296 |
+
validator.add_argument(
|
| 297 |
+
"lr_sched",
|
| 298 |
+
type=str,
|
| 299 |
+
choices=lr_scheds_choices,
|
| 300 |
+
help="Learning rate scheduler to use, from {}".format(lr_scheds_choices),
|
| 301 |
+
)
|
| 302 |
+
task_choices = registry.list_tasks()
|
| 303 |
+
validator.add_argument(
|
| 304 |
+
"task",
|
| 305 |
+
type=str,
|
| 306 |
+
choices=task_choices,
|
| 307 |
+
help="Task to use, from {}".format(task_choices),
|
| 308 |
+
)
|
| 309 |
+
# add arguments for init_lr
|
| 310 |
+
validator.add_argument(
|
| 311 |
+
"init_lr",
|
| 312 |
+
type=float,
|
| 313 |
+
help="Initial learning rate. This will be the learning rate after warmup and before decay.",
|
| 314 |
+
)
|
| 315 |
+
# add arguments for min_lr
|
| 316 |
+
validator.add_argument(
|
| 317 |
+
"min_lr",
|
| 318 |
+
type=float,
|
| 319 |
+
help="Minimum learning rate (after decay).",
|
| 320 |
+
)
|
| 321 |
+
# add arguments for warmup_lr
|
| 322 |
+
validator.add_argument(
|
| 323 |
+
"warmup_lr",
|
| 324 |
+
type=float,
|
| 325 |
+
help="Starting learning rate for warmup.",
|
| 326 |
+
)
|
| 327 |
+
# add arguments for learning rate decay rate
|
| 328 |
+
validator.add_argument(
|
| 329 |
+
"lr_decay_rate",
|
| 330 |
+
type=float,
|
| 331 |
+
help="Learning rate decay rate. Required if using a decaying learning rate scheduler.",
|
| 332 |
+
)
|
| 333 |
+
# add arguments for weight decay
|
| 334 |
+
validator.add_argument(
|
| 335 |
+
"weight_decay",
|
| 336 |
+
type=float,
|
| 337 |
+
help="Weight decay rate.",
|
| 338 |
+
)
|
| 339 |
+
# add arguments for training batch size
|
| 340 |
+
validator.add_argument(
|
| 341 |
+
"batch_size_train",
|
| 342 |
+
type=int,
|
| 343 |
+
help="Training batch size.",
|
| 344 |
+
)
|
| 345 |
+
# add arguments for evaluation batch size
|
| 346 |
+
validator.add_argument(
|
| 347 |
+
"batch_size_eval",
|
| 348 |
+
type=int,
|
| 349 |
+
help="Evaluation batch size, including validation and testing.",
|
| 350 |
+
)
|
| 351 |
+
# add arguments for number of workers for data loading
|
| 352 |
+
validator.add_argument(
|
| 353 |
+
"num_workers",
|
| 354 |
+
help="Number of workers for data loading.",
|
| 355 |
+
)
|
| 356 |
+
# add arguments for warm up steps
|
| 357 |
+
validator.add_argument(
|
| 358 |
+
"warmup_steps",
|
| 359 |
+
type=int,
|
| 360 |
+
help="Number of warmup steps. Required if a warmup schedule is used.",
|
| 361 |
+
)
|
| 362 |
+
# add arguments for random seed
|
| 363 |
+
validator.add_argument(
|
| 364 |
+
"seed",
|
| 365 |
+
type=int,
|
| 366 |
+
help="Random seed.",
|
| 367 |
+
)
|
| 368 |
+
# add arguments for output directory
|
| 369 |
+
validator.add_argument(
|
| 370 |
+
"output_dir",
|
| 371 |
+
type=str,
|
| 372 |
+
help="Output directory to save checkpoints and logs.",
|
| 373 |
+
)
|
| 374 |
+
# add arguments for whether only use evaluation
|
| 375 |
+
validator.add_argument(
|
| 376 |
+
"evaluate",
|
| 377 |
+
help="Whether to only evaluate the model. If true, training will not be performed.",
|
| 378 |
+
)
|
| 379 |
+
# add arguments for splits used for training, e.g. ["train", "val"]
|
| 380 |
+
validator.add_argument(
|
| 381 |
+
"train_splits",
|
| 382 |
+
type=list,
|
| 383 |
+
help="Splits to use for training.",
|
| 384 |
+
)
|
| 385 |
+
# add arguments for splits used for validation, e.g. ["val"]
|
| 386 |
+
validator.add_argument(
|
| 387 |
+
"valid_splits",
|
| 388 |
+
type=list,
|
| 389 |
+
help="Splits to use for validation. If not provided, will skip the validation.",
|
| 390 |
+
)
|
| 391 |
+
# add arguments for splits used for testing, e.g. ["test"]
|
| 392 |
+
validator.add_argument(
|
| 393 |
+
"test_splits",
|
| 394 |
+
type=list,
|
| 395 |
+
help="Splits to use for testing. If not provided, will skip the testing.",
|
| 396 |
+
)
|
| 397 |
+
# add arguments for accumulating gradient for iterations
|
| 398 |
+
validator.add_argument(
|
| 399 |
+
"accum_grad_iters",
|
| 400 |
+
type=int,
|
| 401 |
+
help="Number of iterations to accumulate gradient for.",
|
| 402 |
+
)
|
| 403 |
+
|
| 404 |
+
# ====== distributed training ======
|
| 405 |
+
validator.add_argument(
|
| 406 |
+
"device",
|
| 407 |
+
type=str,
|
| 408 |
+
choices=["cpu", "cuda"],
|
| 409 |
+
help="Device to use. Support 'cuda' or 'cpu' as for now.",
|
| 410 |
+
)
|
| 411 |
+
validator.add_argument(
|
| 412 |
+
"world_size",
|
| 413 |
+
type=int,
|
| 414 |
+
help="Number of processes participating in the job.",
|
| 415 |
+
)
|
| 416 |
+
validator.add_argument("dist_url", type=str)
|
| 417 |
+
validator.add_argument("distributed", type=bool)
|
| 418 |
+
# add arguments to opt using distributed sampler during evaluation or not
|
| 419 |
+
validator.add_argument(
|
| 420 |
+
"use_dist_eval_sampler",
|
| 421 |
+
type=bool,
|
| 422 |
+
help="Whether to use distributed sampler during evaluation or not.",
|
| 423 |
+
)
|
| 424 |
+
|
| 425 |
+
# ====== task specific ======
|
| 426 |
+
# generation task specific arguments
|
| 427 |
+
# add arguments for maximal length of text output
|
| 428 |
+
validator.add_argument(
|
| 429 |
+
"max_len",
|
| 430 |
+
type=int,
|
| 431 |
+
help="Maximal length of text output.",
|
| 432 |
+
)
|
| 433 |
+
# add arguments for minimal length of text output
|
| 434 |
+
validator.add_argument(
|
| 435 |
+
"min_len",
|
| 436 |
+
type=int,
|
| 437 |
+
help="Minimal length of text output.",
|
| 438 |
+
)
|
| 439 |
+
# add arguments number of beams
|
| 440 |
+
validator.add_argument(
|
| 441 |
+
"num_beams",
|
| 442 |
+
type=int,
|
| 443 |
+
help="Number of beams used for beam search.",
|
| 444 |
+
)
|
| 445 |
+
|
| 446 |
+
# vqa task specific arguments
|
| 447 |
+
# add arguments for number of answer candidates
|
| 448 |
+
validator.add_argument(
|
| 449 |
+
"num_ans_candidates",
|
| 450 |
+
type=int,
|
| 451 |
+
help="""For ALBEF and BLIP, these models first rank answers according to likelihood to select answer candidates.""",
|
| 452 |
+
)
|
| 453 |
+
# add arguments for inference method
|
| 454 |
+
validator.add_argument(
|
| 455 |
+
"inference_method",
|
| 456 |
+
type=str,
|
| 457 |
+
choices=["genearte", "rank"],
|
| 458 |
+
help="""Inference method to use for question answering. If rank, requires a answer list.""",
|
| 459 |
+
)
|
| 460 |
+
|
| 461 |
+
# ====== model specific ======
|
| 462 |
+
validator.add_argument(
|
| 463 |
+
"k_test",
|
| 464 |
+
type=int,
|
| 465 |
+
help="Number of top k most similar samples from ITC/VTC selection to be tested.",
|
| 466 |
+
)
|
| 467 |
+
|
| 468 |
+
return validator
|
minigpt4/common/dist_utils.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import datetime
|
| 9 |
+
import functools
|
| 10 |
+
import os
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
import torch.distributed as dist
|
| 14 |
+
import timm.models.hub as timm_hub
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def setup_for_distributed(is_master):
|
| 18 |
+
"""
|
| 19 |
+
This function disables printing when not in master process
|
| 20 |
+
"""
|
| 21 |
+
import builtins as __builtin__
|
| 22 |
+
|
| 23 |
+
builtin_print = __builtin__.print
|
| 24 |
+
|
| 25 |
+
def print(*args, **kwargs):
|
| 26 |
+
force = kwargs.pop("force", False)
|
| 27 |
+
if is_master or force:
|
| 28 |
+
builtin_print(*args, **kwargs)
|
| 29 |
+
|
| 30 |
+
__builtin__.print = print
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def is_dist_avail_and_initialized():
|
| 34 |
+
if not dist.is_available():
|
| 35 |
+
return False
|
| 36 |
+
if not dist.is_initialized():
|
| 37 |
+
return False
|
| 38 |
+
return True
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def get_world_size():
|
| 42 |
+
if not is_dist_avail_and_initialized():
|
| 43 |
+
return 1
|
| 44 |
+
return dist.get_world_size()
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_rank():
|
| 48 |
+
if not is_dist_avail_and_initialized():
|
| 49 |
+
return 0
|
| 50 |
+
return dist.get_rank()
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def is_main_process():
|
| 54 |
+
return get_rank() == 0
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def init_distributed_mode(args):
|
| 58 |
+
if "RANK" in os.environ and "WORLD_SIZE" in os.environ:
|
| 59 |
+
args.rank = int(os.environ["RANK"])
|
| 60 |
+
args.world_size = int(os.environ["WORLD_SIZE"])
|
| 61 |
+
args.gpu = int(os.environ["LOCAL_RANK"])
|
| 62 |
+
elif "SLURM_PROCID" in os.environ:
|
| 63 |
+
args.rank = int(os.environ["SLURM_PROCID"])
|
| 64 |
+
args.gpu = args.rank % torch.cuda.device_count()
|
| 65 |
+
else:
|
| 66 |
+
print("Not using distributed mode")
|
| 67 |
+
args.distributed = False
|
| 68 |
+
return
|
| 69 |
+
|
| 70 |
+
args.distributed = True
|
| 71 |
+
|
| 72 |
+
torch.cuda.set_device(args.gpu)
|
| 73 |
+
args.dist_backend = "nccl"
|
| 74 |
+
print(
|
| 75 |
+
"| distributed init (rank {}, world {}): {}".format(
|
| 76 |
+
args.rank, args.world_size, args.dist_url
|
| 77 |
+
),
|
| 78 |
+
flush=True,
|
| 79 |
+
)
|
| 80 |
+
torch.distributed.init_process_group(
|
| 81 |
+
backend=args.dist_backend,
|
| 82 |
+
init_method=args.dist_url,
|
| 83 |
+
world_size=args.world_size,
|
| 84 |
+
rank=args.rank,
|
| 85 |
+
timeout=datetime.timedelta(
|
| 86 |
+
days=365
|
| 87 |
+
), # allow auto-downloading and de-compressing
|
| 88 |
+
)
|
| 89 |
+
torch.distributed.barrier()
|
| 90 |
+
setup_for_distributed(args.rank == 0)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def get_dist_info():
|
| 94 |
+
if torch.__version__ < "1.0":
|
| 95 |
+
initialized = dist._initialized
|
| 96 |
+
else:
|
| 97 |
+
initialized = dist.is_initialized()
|
| 98 |
+
if initialized:
|
| 99 |
+
rank = dist.get_rank()
|
| 100 |
+
world_size = dist.get_world_size()
|
| 101 |
+
else: # non-distributed training
|
| 102 |
+
rank = 0
|
| 103 |
+
world_size = 1
|
| 104 |
+
return rank, world_size
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def main_process(func):
|
| 108 |
+
@functools.wraps(func)
|
| 109 |
+
def wrapper(*args, **kwargs):
|
| 110 |
+
rank, _ = get_dist_info()
|
| 111 |
+
if rank == 0:
|
| 112 |
+
return func(*args, **kwargs)
|
| 113 |
+
|
| 114 |
+
return wrapper
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def download_cached_file(url, check_hash=True, progress=False):
|
| 118 |
+
"""
|
| 119 |
+
Download a file from a URL and cache it locally. If the file already exists, it is not downloaded again.
|
| 120 |
+
If distributed, only the main process downloads the file, and the other processes wait for the file to be downloaded.
|
| 121 |
+
"""
|
| 122 |
+
|
| 123 |
+
def get_cached_file_path():
|
| 124 |
+
# a hack to sync the file path across processes
|
| 125 |
+
parts = torch.hub.urlparse(url)
|
| 126 |
+
filename = os.path.basename(parts.path)
|
| 127 |
+
cached_file = os.path.join(timm_hub.get_cache_dir(), filename)
|
| 128 |
+
|
| 129 |
+
return cached_file
|
| 130 |
+
|
| 131 |
+
if is_main_process():
|
| 132 |
+
timm_hub.download_cached_file(url, check_hash, progress)
|
| 133 |
+
|
| 134 |
+
if is_dist_avail_and_initialized():
|
| 135 |
+
dist.barrier()
|
| 136 |
+
|
| 137 |
+
return get_cached_file_path()
|
minigpt4/common/gradcam.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from matplotlib import pyplot as plt
|
| 3 |
+
from scipy.ndimage import filters
|
| 4 |
+
from skimage import transform as skimage_transform
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def getAttMap(img, attMap, blur=True, overlap=True):
|
| 8 |
+
attMap -= attMap.min()
|
| 9 |
+
if attMap.max() > 0:
|
| 10 |
+
attMap /= attMap.max()
|
| 11 |
+
attMap = skimage_transform.resize(attMap, (img.shape[:2]), order=3, mode="constant")
|
| 12 |
+
if blur:
|
| 13 |
+
attMap = filters.gaussian_filter(attMap, 0.02 * max(img.shape[:2]))
|
| 14 |
+
attMap -= attMap.min()
|
| 15 |
+
attMap /= attMap.max()
|
| 16 |
+
cmap = plt.get_cmap("jet")
|
| 17 |
+
attMapV = cmap(attMap)
|
| 18 |
+
attMapV = np.delete(attMapV, 3, 2)
|
| 19 |
+
if overlap:
|
| 20 |
+
attMap = (
|
| 21 |
+
1 * (1 - attMap**0.7).reshape(attMap.shape + (1,)) * img
|
| 22 |
+
+ (attMap**0.7).reshape(attMap.shape + (1,)) * attMapV
|
| 23 |
+
)
|
| 24 |
+
return attMap
|
minigpt4/common/logger.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import datetime
|
| 9 |
+
import logging
|
| 10 |
+
import time
|
| 11 |
+
from collections import defaultdict, deque
|
| 12 |
+
|
| 13 |
+
import torch
|
| 14 |
+
import torch.distributed as dist
|
| 15 |
+
|
| 16 |
+
from minigpt4.common import dist_utils
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class SmoothedValue(object):
|
| 20 |
+
"""Track a series of values and provide access to smoothed values over a
|
| 21 |
+
window or the global series average.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
def __init__(self, window_size=20, fmt=None):
|
| 25 |
+
if fmt is None:
|
| 26 |
+
fmt = "{median:.4f} ({global_avg:.4f})"
|
| 27 |
+
self.deque = deque(maxlen=window_size)
|
| 28 |
+
self.total = 0.0
|
| 29 |
+
self.count = 0
|
| 30 |
+
self.fmt = fmt
|
| 31 |
+
|
| 32 |
+
def update(self, value, n=1):
|
| 33 |
+
self.deque.append(value)
|
| 34 |
+
self.count += n
|
| 35 |
+
self.total += value * n
|
| 36 |
+
|
| 37 |
+
def synchronize_between_processes(self):
|
| 38 |
+
"""
|
| 39 |
+
Warning: does not synchronize the deque!
|
| 40 |
+
"""
|
| 41 |
+
if not dist_utils.is_dist_avail_and_initialized():
|
| 42 |
+
return
|
| 43 |
+
t = torch.tensor([self.count, self.total], dtype=torch.float64, device="cuda")
|
| 44 |
+
dist.barrier()
|
| 45 |
+
dist.all_reduce(t)
|
| 46 |
+
t = t.tolist()
|
| 47 |
+
self.count = int(t[0])
|
| 48 |
+
self.total = t[1]
|
| 49 |
+
|
| 50 |
+
@property
|
| 51 |
+
def median(self):
|
| 52 |
+
d = torch.tensor(list(self.deque))
|
| 53 |
+
return d.median().item()
|
| 54 |
+
|
| 55 |
+
@property
|
| 56 |
+
def avg(self):
|
| 57 |
+
d = torch.tensor(list(self.deque), dtype=torch.float32)
|
| 58 |
+
return d.mean().item()
|
| 59 |
+
|
| 60 |
+
@property
|
| 61 |
+
def global_avg(self):
|
| 62 |
+
return self.total / self.count
|
| 63 |
+
|
| 64 |
+
@property
|
| 65 |
+
def max(self):
|
| 66 |
+
return max(self.deque)
|
| 67 |
+
|
| 68 |
+
@property
|
| 69 |
+
def value(self):
|
| 70 |
+
return self.deque[-1]
|
| 71 |
+
|
| 72 |
+
def __str__(self):
|
| 73 |
+
return self.fmt.format(
|
| 74 |
+
median=self.median,
|
| 75 |
+
avg=self.avg,
|
| 76 |
+
global_avg=self.global_avg,
|
| 77 |
+
max=self.max,
|
| 78 |
+
value=self.value,
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class MetricLogger(object):
|
| 83 |
+
def __init__(self, delimiter="\t"):
|
| 84 |
+
self.meters = defaultdict(SmoothedValue)
|
| 85 |
+
self.delimiter = delimiter
|
| 86 |
+
|
| 87 |
+
def update(self, **kwargs):
|
| 88 |
+
for k, v in kwargs.items():
|
| 89 |
+
if isinstance(v, torch.Tensor):
|
| 90 |
+
v = v.item()
|
| 91 |
+
assert isinstance(v, (float, int))
|
| 92 |
+
self.meters[k].update(v)
|
| 93 |
+
|
| 94 |
+
def __getattr__(self, attr):
|
| 95 |
+
if attr in self.meters:
|
| 96 |
+
return self.meters[attr]
|
| 97 |
+
if attr in self.__dict__:
|
| 98 |
+
return self.__dict__[attr]
|
| 99 |
+
raise AttributeError(
|
| 100 |
+
"'{}' object has no attribute '{}'".format(type(self).__name__, attr)
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
def __str__(self):
|
| 104 |
+
loss_str = []
|
| 105 |
+
for name, meter in self.meters.items():
|
| 106 |
+
loss_str.append("{}: {}".format(name, str(meter)))
|
| 107 |
+
return self.delimiter.join(loss_str)
|
| 108 |
+
|
| 109 |
+
def global_avg(self):
|
| 110 |
+
loss_str = []
|
| 111 |
+
for name, meter in self.meters.items():
|
| 112 |
+
loss_str.append("{}: {:.4f}".format(name, meter.global_avg))
|
| 113 |
+
return self.delimiter.join(loss_str)
|
| 114 |
+
|
| 115 |
+
def synchronize_between_processes(self):
|
| 116 |
+
for meter in self.meters.values():
|
| 117 |
+
meter.synchronize_between_processes()
|
| 118 |
+
|
| 119 |
+
def add_meter(self, name, meter):
|
| 120 |
+
self.meters[name] = meter
|
| 121 |
+
|
| 122 |
+
def log_every(self, iterable, print_freq, header=None):
|
| 123 |
+
i = 0
|
| 124 |
+
if not header:
|
| 125 |
+
header = ""
|
| 126 |
+
start_time = time.time()
|
| 127 |
+
end = time.time()
|
| 128 |
+
iter_time = SmoothedValue(fmt="{avg:.4f}")
|
| 129 |
+
data_time = SmoothedValue(fmt="{avg:.4f}")
|
| 130 |
+
space_fmt = ":" + str(len(str(len(iterable)))) + "d"
|
| 131 |
+
log_msg = [
|
| 132 |
+
header,
|
| 133 |
+
"[{0" + space_fmt + "}/{1}]",
|
| 134 |
+
"eta: {eta}",
|
| 135 |
+
"{meters}",
|
| 136 |
+
"time: {time}",
|
| 137 |
+
"data: {data}",
|
| 138 |
+
]
|
| 139 |
+
if torch.cuda.is_available():
|
| 140 |
+
log_msg.append("max mem: {memory:.0f}")
|
| 141 |
+
log_msg = self.delimiter.join(log_msg)
|
| 142 |
+
MB = 1024.0 * 1024.0
|
| 143 |
+
for obj in iterable:
|
| 144 |
+
data_time.update(time.time() - end)
|
| 145 |
+
yield obj
|
| 146 |
+
iter_time.update(time.time() - end)
|
| 147 |
+
if i % print_freq == 0 or i == len(iterable) - 1:
|
| 148 |
+
eta_seconds = iter_time.global_avg * (len(iterable) - i)
|
| 149 |
+
eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
|
| 150 |
+
if torch.cuda.is_available():
|
| 151 |
+
print(
|
| 152 |
+
log_msg.format(
|
| 153 |
+
i,
|
| 154 |
+
len(iterable),
|
| 155 |
+
eta=eta_string,
|
| 156 |
+
meters=str(self),
|
| 157 |
+
time=str(iter_time),
|
| 158 |
+
data=str(data_time),
|
| 159 |
+
memory=torch.cuda.max_memory_allocated() / MB,
|
| 160 |
+
)
|
| 161 |
+
)
|
| 162 |
+
else:
|
| 163 |
+
print(
|
| 164 |
+
log_msg.format(
|
| 165 |
+
i,
|
| 166 |
+
len(iterable),
|
| 167 |
+
eta=eta_string,
|
| 168 |
+
meters=str(self),
|
| 169 |
+
time=str(iter_time),
|
| 170 |
+
data=str(data_time),
|
| 171 |
+
)
|
| 172 |
+
)
|
| 173 |
+
i += 1
|
| 174 |
+
end = time.time()
|
| 175 |
+
total_time = time.time() - start_time
|
| 176 |
+
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
|
| 177 |
+
print(
|
| 178 |
+
"{} Total time: {} ({:.4f} s / it)".format(
|
| 179 |
+
header, total_time_str, total_time / len(iterable)
|
| 180 |
+
)
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
class AttrDict(dict):
|
| 185 |
+
def __init__(self, *args, **kwargs):
|
| 186 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 187 |
+
self.__dict__ = self
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
def setup_logger():
|
| 191 |
+
logging.basicConfig(
|
| 192 |
+
level=logging.INFO if dist_utils.is_main_process() else logging.WARN,
|
| 193 |
+
format="%(asctime)s [%(levelname)s] %(message)s",
|
| 194 |
+
handlers=[logging.StreamHandler()],
|
| 195 |
+
)
|
minigpt4/common/optims.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import math
|
| 9 |
+
|
| 10 |
+
from minigpt4.common.registry import registry
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@registry.register_lr_scheduler("linear_warmup_step_lr")
|
| 14 |
+
class LinearWarmupStepLRScheduler:
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
optimizer,
|
| 18 |
+
max_epoch,
|
| 19 |
+
min_lr,
|
| 20 |
+
init_lr,
|
| 21 |
+
decay_rate=1,
|
| 22 |
+
warmup_start_lr=-1,
|
| 23 |
+
warmup_steps=0,
|
| 24 |
+
**kwargs
|
| 25 |
+
):
|
| 26 |
+
self.optimizer = optimizer
|
| 27 |
+
|
| 28 |
+
self.max_epoch = max_epoch
|
| 29 |
+
self.min_lr = min_lr
|
| 30 |
+
|
| 31 |
+
self.decay_rate = decay_rate
|
| 32 |
+
|
| 33 |
+
self.init_lr = init_lr
|
| 34 |
+
self.warmup_steps = warmup_steps
|
| 35 |
+
self.warmup_start_lr = warmup_start_lr if warmup_start_lr >= 0 else init_lr
|
| 36 |
+
|
| 37 |
+
def step(self, cur_epoch, cur_step):
|
| 38 |
+
if cur_epoch == 0:
|
| 39 |
+
warmup_lr_schedule(
|
| 40 |
+
step=cur_step,
|
| 41 |
+
optimizer=self.optimizer,
|
| 42 |
+
max_step=self.warmup_steps,
|
| 43 |
+
init_lr=self.warmup_start_lr,
|
| 44 |
+
max_lr=self.init_lr,
|
| 45 |
+
)
|
| 46 |
+
else:
|
| 47 |
+
step_lr_schedule(
|
| 48 |
+
epoch=cur_epoch,
|
| 49 |
+
optimizer=self.optimizer,
|
| 50 |
+
init_lr=self.init_lr,
|
| 51 |
+
min_lr=self.min_lr,
|
| 52 |
+
decay_rate=self.decay_rate,
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
@registry.register_lr_scheduler("linear_warmup_cosine_lr")
|
| 57 |
+
class LinearWarmupCosineLRScheduler:
|
| 58 |
+
def __init__(
|
| 59 |
+
self,
|
| 60 |
+
optimizer,
|
| 61 |
+
max_epoch,
|
| 62 |
+
iters_per_epoch,
|
| 63 |
+
min_lr,
|
| 64 |
+
init_lr,
|
| 65 |
+
warmup_steps=0,
|
| 66 |
+
warmup_start_lr=-1,
|
| 67 |
+
**kwargs
|
| 68 |
+
):
|
| 69 |
+
self.optimizer = optimizer
|
| 70 |
+
|
| 71 |
+
self.max_epoch = max_epoch
|
| 72 |
+
self.iters_per_epoch = iters_per_epoch
|
| 73 |
+
self.min_lr = min_lr
|
| 74 |
+
|
| 75 |
+
self.init_lr = init_lr
|
| 76 |
+
self.warmup_steps = warmup_steps
|
| 77 |
+
self.warmup_start_lr = warmup_start_lr if warmup_start_lr >= 0 else init_lr
|
| 78 |
+
|
| 79 |
+
def step(self, cur_epoch, cur_step):
|
| 80 |
+
total_cur_step = cur_epoch * self.iters_per_epoch + cur_step
|
| 81 |
+
if total_cur_step < self.warmup_steps:
|
| 82 |
+
warmup_lr_schedule(
|
| 83 |
+
step=cur_step,
|
| 84 |
+
optimizer=self.optimizer,
|
| 85 |
+
max_step=self.warmup_steps,
|
| 86 |
+
init_lr=self.warmup_start_lr,
|
| 87 |
+
max_lr=self.init_lr,
|
| 88 |
+
)
|
| 89 |
+
else:
|
| 90 |
+
cosine_lr_schedule(
|
| 91 |
+
epoch=total_cur_step,
|
| 92 |
+
optimizer=self.optimizer,
|
| 93 |
+
max_epoch=self.max_epoch * self.iters_per_epoch,
|
| 94 |
+
init_lr=self.init_lr,
|
| 95 |
+
min_lr=self.min_lr,
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def cosine_lr_schedule(optimizer, epoch, max_epoch, init_lr, min_lr):
|
| 100 |
+
"""Decay the learning rate"""
|
| 101 |
+
lr = (init_lr - min_lr) * 0.5 * (
|
| 102 |
+
1.0 + math.cos(math.pi * epoch / max_epoch)
|
| 103 |
+
) + min_lr
|
| 104 |
+
for param_group in optimizer.param_groups:
|
| 105 |
+
param_group["lr"] = lr
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def warmup_lr_schedule(optimizer, step, max_step, init_lr, max_lr):
|
| 109 |
+
"""Warmup the learning rate"""
|
| 110 |
+
lr = min(max_lr, init_lr + (max_lr - init_lr) * step / max(max_step, 1))
|
| 111 |
+
for param_group in optimizer.param_groups:
|
| 112 |
+
param_group["lr"] = lr
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def step_lr_schedule(optimizer, epoch, init_lr, min_lr, decay_rate):
|
| 116 |
+
"""Decay the learning rate"""
|
| 117 |
+
lr = max(min_lr, init_lr * (decay_rate**epoch))
|
| 118 |
+
for param_group in optimizer.param_groups:
|
| 119 |
+
param_group["lr"] = lr
|
minigpt4/common/registry.py
ADDED
|
@@ -0,0 +1,329 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Registry:
|
| 10 |
+
mapping = {
|
| 11 |
+
"builder_name_mapping": {},
|
| 12 |
+
"task_name_mapping": {},
|
| 13 |
+
"processor_name_mapping": {},
|
| 14 |
+
"model_name_mapping": {},
|
| 15 |
+
"lr_scheduler_name_mapping": {},
|
| 16 |
+
"runner_name_mapping": {},
|
| 17 |
+
"state": {},
|
| 18 |
+
"paths": {},
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
@classmethod
|
| 22 |
+
def register_builder(cls, name):
|
| 23 |
+
r"""Register a dataset builder to registry with key 'name'
|
| 24 |
+
|
| 25 |
+
Args:
|
| 26 |
+
name: Key with which the builder will be registered.
|
| 27 |
+
|
| 28 |
+
Usage:
|
| 29 |
+
|
| 30 |
+
from minigpt4.common.registry import registry
|
| 31 |
+
from minigpt4.datasets.base_dataset_builder import BaseDatasetBuilder
|
| 32 |
+
"""
|
| 33 |
+
|
| 34 |
+
def wrap(builder_cls):
|
| 35 |
+
from minigpt4.datasets.builders.base_dataset_builder import BaseDatasetBuilder
|
| 36 |
+
|
| 37 |
+
assert issubclass(
|
| 38 |
+
builder_cls, BaseDatasetBuilder
|
| 39 |
+
), "All builders must inherit BaseDatasetBuilder class, found {}".format(
|
| 40 |
+
builder_cls
|
| 41 |
+
)
|
| 42 |
+
if name in cls.mapping["builder_name_mapping"]:
|
| 43 |
+
raise KeyError(
|
| 44 |
+
"Name '{}' already registered for {}.".format(
|
| 45 |
+
name, cls.mapping["builder_name_mapping"][name]
|
| 46 |
+
)
|
| 47 |
+
)
|
| 48 |
+
cls.mapping["builder_name_mapping"][name] = builder_cls
|
| 49 |
+
return builder_cls
|
| 50 |
+
|
| 51 |
+
return wrap
|
| 52 |
+
|
| 53 |
+
@classmethod
|
| 54 |
+
def register_task(cls, name):
|
| 55 |
+
r"""Register a task to registry with key 'name'
|
| 56 |
+
|
| 57 |
+
Args:
|
| 58 |
+
name: Key with which the task will be registered.
|
| 59 |
+
|
| 60 |
+
Usage:
|
| 61 |
+
|
| 62 |
+
from minigpt4.common.registry import registry
|
| 63 |
+
"""
|
| 64 |
+
|
| 65 |
+
def wrap(task_cls):
|
| 66 |
+
from minigpt4.tasks.base_task import BaseTask
|
| 67 |
+
|
| 68 |
+
assert issubclass(
|
| 69 |
+
task_cls, BaseTask
|
| 70 |
+
), "All tasks must inherit BaseTask class"
|
| 71 |
+
if name in cls.mapping["task_name_mapping"]:
|
| 72 |
+
raise KeyError(
|
| 73 |
+
"Name '{}' already registered for {}.".format(
|
| 74 |
+
name, cls.mapping["task_name_mapping"][name]
|
| 75 |
+
)
|
| 76 |
+
)
|
| 77 |
+
cls.mapping["task_name_mapping"][name] = task_cls
|
| 78 |
+
return task_cls
|
| 79 |
+
|
| 80 |
+
return wrap
|
| 81 |
+
|
| 82 |
+
@classmethod
|
| 83 |
+
def register_model(cls, name):
|
| 84 |
+
r"""Register a task to registry with key 'name'
|
| 85 |
+
|
| 86 |
+
Args:
|
| 87 |
+
name: Key with which the task will be registered.
|
| 88 |
+
|
| 89 |
+
Usage:
|
| 90 |
+
|
| 91 |
+
from minigpt4.common.registry import registry
|
| 92 |
+
"""
|
| 93 |
+
|
| 94 |
+
def wrap(model_cls):
|
| 95 |
+
from minigpt4.models import BaseModel
|
| 96 |
+
|
| 97 |
+
assert issubclass(
|
| 98 |
+
model_cls, BaseModel
|
| 99 |
+
), "All models must inherit BaseModel class"
|
| 100 |
+
if name in cls.mapping["model_name_mapping"]:
|
| 101 |
+
raise KeyError(
|
| 102 |
+
"Name '{}' already registered for {}.".format(
|
| 103 |
+
name, cls.mapping["model_name_mapping"][name]
|
| 104 |
+
)
|
| 105 |
+
)
|
| 106 |
+
cls.mapping["model_name_mapping"][name] = model_cls
|
| 107 |
+
return model_cls
|
| 108 |
+
|
| 109 |
+
return wrap
|
| 110 |
+
|
| 111 |
+
@classmethod
|
| 112 |
+
def register_processor(cls, name):
|
| 113 |
+
r"""Register a processor to registry with key 'name'
|
| 114 |
+
|
| 115 |
+
Args:
|
| 116 |
+
name: Key with which the task will be registered.
|
| 117 |
+
|
| 118 |
+
Usage:
|
| 119 |
+
|
| 120 |
+
from minigpt4.common.registry import registry
|
| 121 |
+
"""
|
| 122 |
+
|
| 123 |
+
def wrap(processor_cls):
|
| 124 |
+
from minigpt4.processors import BaseProcessor
|
| 125 |
+
|
| 126 |
+
assert issubclass(
|
| 127 |
+
processor_cls, BaseProcessor
|
| 128 |
+
), "All processors must inherit BaseProcessor class"
|
| 129 |
+
if name in cls.mapping["processor_name_mapping"]:
|
| 130 |
+
raise KeyError(
|
| 131 |
+
"Name '{}' already registered for {}.".format(
|
| 132 |
+
name, cls.mapping["processor_name_mapping"][name]
|
| 133 |
+
)
|
| 134 |
+
)
|
| 135 |
+
cls.mapping["processor_name_mapping"][name] = processor_cls
|
| 136 |
+
return processor_cls
|
| 137 |
+
|
| 138 |
+
return wrap
|
| 139 |
+
|
| 140 |
+
@classmethod
|
| 141 |
+
def register_lr_scheduler(cls, name):
|
| 142 |
+
r"""Register a model to registry with key 'name'
|
| 143 |
+
|
| 144 |
+
Args:
|
| 145 |
+
name: Key with which the task will be registered.
|
| 146 |
+
|
| 147 |
+
Usage:
|
| 148 |
+
|
| 149 |
+
from minigpt4.common.registry import registry
|
| 150 |
+
"""
|
| 151 |
+
|
| 152 |
+
def wrap(lr_sched_cls):
|
| 153 |
+
if name in cls.mapping["lr_scheduler_name_mapping"]:
|
| 154 |
+
raise KeyError(
|
| 155 |
+
"Name '{}' already registered for {}.".format(
|
| 156 |
+
name, cls.mapping["lr_scheduler_name_mapping"][name]
|
| 157 |
+
)
|
| 158 |
+
)
|
| 159 |
+
cls.mapping["lr_scheduler_name_mapping"][name] = lr_sched_cls
|
| 160 |
+
return lr_sched_cls
|
| 161 |
+
|
| 162 |
+
return wrap
|
| 163 |
+
|
| 164 |
+
@classmethod
|
| 165 |
+
def register_runner(cls, name):
|
| 166 |
+
r"""Register a model to registry with key 'name'
|
| 167 |
+
|
| 168 |
+
Args:
|
| 169 |
+
name: Key with which the task will be registered.
|
| 170 |
+
|
| 171 |
+
Usage:
|
| 172 |
+
|
| 173 |
+
from minigpt4.common.registry import registry
|
| 174 |
+
"""
|
| 175 |
+
|
| 176 |
+
def wrap(runner_cls):
|
| 177 |
+
if name in cls.mapping["runner_name_mapping"]:
|
| 178 |
+
raise KeyError(
|
| 179 |
+
"Name '{}' already registered for {}.".format(
|
| 180 |
+
name, cls.mapping["runner_name_mapping"][name]
|
| 181 |
+
)
|
| 182 |
+
)
|
| 183 |
+
cls.mapping["runner_name_mapping"][name] = runner_cls
|
| 184 |
+
return runner_cls
|
| 185 |
+
|
| 186 |
+
return wrap
|
| 187 |
+
|
| 188 |
+
@classmethod
|
| 189 |
+
def register_path(cls, name, path):
|
| 190 |
+
r"""Register a path to registry with key 'name'
|
| 191 |
+
|
| 192 |
+
Args:
|
| 193 |
+
name: Key with which the path will be registered.
|
| 194 |
+
|
| 195 |
+
Usage:
|
| 196 |
+
|
| 197 |
+
from minigpt4.common.registry import registry
|
| 198 |
+
"""
|
| 199 |
+
assert isinstance(path, str), "All path must be str."
|
| 200 |
+
if name in cls.mapping["paths"]:
|
| 201 |
+
raise KeyError("Name '{}' already registered.".format(name))
|
| 202 |
+
cls.mapping["paths"][name] = path
|
| 203 |
+
|
| 204 |
+
@classmethod
|
| 205 |
+
def register(cls, name, obj):
|
| 206 |
+
r"""Register an item to registry with key 'name'
|
| 207 |
+
|
| 208 |
+
Args:
|
| 209 |
+
name: Key with which the item will be registered.
|
| 210 |
+
|
| 211 |
+
Usage::
|
| 212 |
+
|
| 213 |
+
from minigpt4.common.registry import registry
|
| 214 |
+
|
| 215 |
+
registry.register("config", {})
|
| 216 |
+
"""
|
| 217 |
+
path = name.split(".")
|
| 218 |
+
current = cls.mapping["state"]
|
| 219 |
+
|
| 220 |
+
for part in path[:-1]:
|
| 221 |
+
if part not in current:
|
| 222 |
+
current[part] = {}
|
| 223 |
+
current = current[part]
|
| 224 |
+
|
| 225 |
+
current[path[-1]] = obj
|
| 226 |
+
|
| 227 |
+
# @classmethod
|
| 228 |
+
# def get_trainer_class(cls, name):
|
| 229 |
+
# return cls.mapping["trainer_name_mapping"].get(name, None)
|
| 230 |
+
|
| 231 |
+
@classmethod
|
| 232 |
+
def get_builder_class(cls, name):
|
| 233 |
+
return cls.mapping["builder_name_mapping"].get(name, None)
|
| 234 |
+
|
| 235 |
+
@classmethod
|
| 236 |
+
def get_model_class(cls, name):
|
| 237 |
+
return cls.mapping["model_name_mapping"].get(name, None)
|
| 238 |
+
|
| 239 |
+
@classmethod
|
| 240 |
+
def get_task_class(cls, name):
|
| 241 |
+
return cls.mapping["task_name_mapping"].get(name, None)
|
| 242 |
+
|
| 243 |
+
@classmethod
|
| 244 |
+
def get_processor_class(cls, name):
|
| 245 |
+
return cls.mapping["processor_name_mapping"].get(name, None)
|
| 246 |
+
|
| 247 |
+
@classmethod
|
| 248 |
+
def get_lr_scheduler_class(cls, name):
|
| 249 |
+
return cls.mapping["lr_scheduler_name_mapping"].get(name, None)
|
| 250 |
+
|
| 251 |
+
@classmethod
|
| 252 |
+
def get_runner_class(cls, name):
|
| 253 |
+
return cls.mapping["runner_name_mapping"].get(name, None)
|
| 254 |
+
|
| 255 |
+
@classmethod
|
| 256 |
+
def list_runners(cls):
|
| 257 |
+
return sorted(cls.mapping["runner_name_mapping"].keys())
|
| 258 |
+
|
| 259 |
+
@classmethod
|
| 260 |
+
def list_models(cls):
|
| 261 |
+
return sorted(cls.mapping["model_name_mapping"].keys())
|
| 262 |
+
|
| 263 |
+
@classmethod
|
| 264 |
+
def list_tasks(cls):
|
| 265 |
+
return sorted(cls.mapping["task_name_mapping"].keys())
|
| 266 |
+
|
| 267 |
+
@classmethod
|
| 268 |
+
def list_processors(cls):
|
| 269 |
+
return sorted(cls.mapping["processor_name_mapping"].keys())
|
| 270 |
+
|
| 271 |
+
@classmethod
|
| 272 |
+
def list_lr_schedulers(cls):
|
| 273 |
+
return sorted(cls.mapping["lr_scheduler_name_mapping"].keys())
|
| 274 |
+
|
| 275 |
+
@classmethod
|
| 276 |
+
def list_datasets(cls):
|
| 277 |
+
return sorted(cls.mapping["builder_name_mapping"].keys())
|
| 278 |
+
|
| 279 |
+
@classmethod
|
| 280 |
+
def get_path(cls, name):
|
| 281 |
+
return cls.mapping["paths"].get(name, None)
|
| 282 |
+
|
| 283 |
+
@classmethod
|
| 284 |
+
def get(cls, name, default=None, no_warning=False):
|
| 285 |
+
r"""Get an item from registry with key 'name'
|
| 286 |
+
|
| 287 |
+
Args:
|
| 288 |
+
name (string): Key whose value needs to be retrieved.
|
| 289 |
+
default: If passed and key is not in registry, default value will
|
| 290 |
+
be returned with a warning. Default: None
|
| 291 |
+
no_warning (bool): If passed as True, warning when key doesn't exist
|
| 292 |
+
will not be generated. Useful for MMF's
|
| 293 |
+
internal operations. Default: False
|
| 294 |
+
"""
|
| 295 |
+
original_name = name
|
| 296 |
+
name = name.split(".")
|
| 297 |
+
value = cls.mapping["state"]
|
| 298 |
+
for subname in name:
|
| 299 |
+
value = value.get(subname, default)
|
| 300 |
+
if value is default:
|
| 301 |
+
break
|
| 302 |
+
|
| 303 |
+
if (
|
| 304 |
+
"writer" in cls.mapping["state"]
|
| 305 |
+
and value == default
|
| 306 |
+
and no_warning is False
|
| 307 |
+
):
|
| 308 |
+
cls.mapping["state"]["writer"].warning(
|
| 309 |
+
"Key {} is not present in registry, returning default value "
|
| 310 |
+
"of {}".format(original_name, default)
|
| 311 |
+
)
|
| 312 |
+
return value
|
| 313 |
+
|
| 314 |
+
@classmethod
|
| 315 |
+
def unregister(cls, name):
|
| 316 |
+
r"""Remove an item from registry with key 'name'
|
| 317 |
+
|
| 318 |
+
Args:
|
| 319 |
+
name: Key which needs to be removed.
|
| 320 |
+
Usage::
|
| 321 |
+
|
| 322 |
+
from mmf.common.registry import registry
|
| 323 |
+
|
| 324 |
+
config = registry.unregister("config")
|
| 325 |
+
"""
|
| 326 |
+
return cls.mapping["state"].pop(name, None)
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
registry = Registry()
|
minigpt4/common/utils.py
ADDED
|
@@ -0,0 +1,424 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import io
|
| 9 |
+
import json
|
| 10 |
+
import logging
|
| 11 |
+
import os
|
| 12 |
+
import pickle
|
| 13 |
+
import re
|
| 14 |
+
import shutil
|
| 15 |
+
import urllib
|
| 16 |
+
import urllib.error
|
| 17 |
+
import urllib.request
|
| 18 |
+
from typing import Optional
|
| 19 |
+
from urllib.parse import urlparse
|
| 20 |
+
|
| 21 |
+
import numpy as np
|
| 22 |
+
import pandas as pd
|
| 23 |
+
import yaml
|
| 24 |
+
from iopath.common.download import download
|
| 25 |
+
from iopath.common.file_io import file_lock, g_pathmgr
|
| 26 |
+
from minigpt4.common.registry import registry
|
| 27 |
+
from torch.utils.model_zoo import tqdm
|
| 28 |
+
from torchvision.datasets.utils import (
|
| 29 |
+
check_integrity,
|
| 30 |
+
download_file_from_google_drive,
|
| 31 |
+
extract_archive,
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def now():
|
| 36 |
+
from datetime import datetime
|
| 37 |
+
|
| 38 |
+
return datetime.now().strftime("%Y%m%d%H%M")[:-1]
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def is_url(url_or_filename):
|
| 42 |
+
parsed = urlparse(url_or_filename)
|
| 43 |
+
return parsed.scheme in ("http", "https")
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def get_cache_path(rel_path):
|
| 47 |
+
return os.path.expanduser(os.path.join(registry.get_path("cache_root"), rel_path))
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def get_abs_path(rel_path):
|
| 51 |
+
return os.path.join(registry.get_path("library_root"), rel_path)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def load_json(filename):
|
| 55 |
+
with open(filename, "r") as f:
|
| 56 |
+
return json.load(f)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# The following are adapted from torchvision and vissl
|
| 60 |
+
# torchvision: https://github.com/pytorch/vision
|
| 61 |
+
# vissl: https://github.com/facebookresearch/vissl/blob/main/vissl/utils/download.py
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def makedir(dir_path):
|
| 65 |
+
"""
|
| 66 |
+
Create the directory if it does not exist.
|
| 67 |
+
"""
|
| 68 |
+
is_success = False
|
| 69 |
+
try:
|
| 70 |
+
if not g_pathmgr.exists(dir_path):
|
| 71 |
+
g_pathmgr.mkdirs(dir_path)
|
| 72 |
+
is_success = True
|
| 73 |
+
except BaseException:
|
| 74 |
+
print(f"Error creating directory: {dir_path}")
|
| 75 |
+
return is_success
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def get_redirected_url(url: str):
|
| 79 |
+
"""
|
| 80 |
+
Given a URL, returns the URL it redirects to or the
|
| 81 |
+
original URL in case of no indirection
|
| 82 |
+
"""
|
| 83 |
+
import requests
|
| 84 |
+
|
| 85 |
+
with requests.Session() as session:
|
| 86 |
+
with session.get(url, stream=True, allow_redirects=True) as response:
|
| 87 |
+
if response.history:
|
| 88 |
+
return response.url
|
| 89 |
+
else:
|
| 90 |
+
return url
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def to_google_drive_download_url(view_url: str) -> str:
|
| 94 |
+
"""
|
| 95 |
+
Utility function to transform a view URL of google drive
|
| 96 |
+
to a download URL for google drive
|
| 97 |
+
Example input:
|
| 98 |
+
https://drive.google.com/file/d/137RyRjvTBkBiIfeYBNZBtViDHQ6_Ewsp/view
|
| 99 |
+
Example output:
|
| 100 |
+
https://drive.google.com/uc?export=download&id=137RyRjvTBkBiIfeYBNZBtViDHQ6_Ewsp
|
| 101 |
+
"""
|
| 102 |
+
splits = view_url.split("/")
|
| 103 |
+
assert splits[-1] == "view"
|
| 104 |
+
file_id = splits[-2]
|
| 105 |
+
return f"https://drive.google.com/uc?export=download&id={file_id}"
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def download_google_drive_url(url: str, output_path: str, output_file_name: str):
|
| 109 |
+
"""
|
| 110 |
+
Download a file from google drive
|
| 111 |
+
Downloading an URL from google drive requires confirmation when
|
| 112 |
+
the file of the size is too big (google drive notifies that
|
| 113 |
+
anti-viral checks cannot be performed on such files)
|
| 114 |
+
"""
|
| 115 |
+
import requests
|
| 116 |
+
|
| 117 |
+
with requests.Session() as session:
|
| 118 |
+
|
| 119 |
+
# First get the confirmation token and append it to the URL
|
| 120 |
+
with session.get(url, stream=True, allow_redirects=True) as response:
|
| 121 |
+
for k, v in response.cookies.items():
|
| 122 |
+
if k.startswith("download_warning"):
|
| 123 |
+
url = url + "&confirm=" + v
|
| 124 |
+
|
| 125 |
+
# Then download the content of the file
|
| 126 |
+
with session.get(url, stream=True, verify=True) as response:
|
| 127 |
+
makedir(output_path)
|
| 128 |
+
path = os.path.join(output_path, output_file_name)
|
| 129 |
+
total_size = int(response.headers.get("Content-length", 0))
|
| 130 |
+
with open(path, "wb") as file:
|
| 131 |
+
from tqdm import tqdm
|
| 132 |
+
|
| 133 |
+
with tqdm(total=total_size) as progress_bar:
|
| 134 |
+
for block in response.iter_content(
|
| 135 |
+
chunk_size=io.DEFAULT_BUFFER_SIZE
|
| 136 |
+
):
|
| 137 |
+
file.write(block)
|
| 138 |
+
progress_bar.update(len(block))
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def _get_google_drive_file_id(url: str) -> Optional[str]:
|
| 142 |
+
parts = urlparse(url)
|
| 143 |
+
|
| 144 |
+
if re.match(r"(drive|docs)[.]google[.]com", parts.netloc) is None:
|
| 145 |
+
return None
|
| 146 |
+
|
| 147 |
+
match = re.match(r"/file/d/(?P<id>[^/]*)", parts.path)
|
| 148 |
+
if match is None:
|
| 149 |
+
return None
|
| 150 |
+
|
| 151 |
+
return match.group("id")
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def _urlretrieve(url: str, filename: str, chunk_size: int = 1024) -> None:
|
| 155 |
+
with open(filename, "wb") as fh:
|
| 156 |
+
with urllib.request.urlopen(
|
| 157 |
+
urllib.request.Request(url, headers={"User-Agent": "vissl"})
|
| 158 |
+
) as response:
|
| 159 |
+
with tqdm(total=response.length) as pbar:
|
| 160 |
+
for chunk in iter(lambda: response.read(chunk_size), ""):
|
| 161 |
+
if not chunk:
|
| 162 |
+
break
|
| 163 |
+
pbar.update(chunk_size)
|
| 164 |
+
fh.write(chunk)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def download_url(
|
| 168 |
+
url: str,
|
| 169 |
+
root: str,
|
| 170 |
+
filename: Optional[str] = None,
|
| 171 |
+
md5: Optional[str] = None,
|
| 172 |
+
) -> None:
|
| 173 |
+
"""Download a file from a url and place it in root.
|
| 174 |
+
Args:
|
| 175 |
+
url (str): URL to download file from
|
| 176 |
+
root (str): Directory to place downloaded file in
|
| 177 |
+
filename (str, optional): Name to save the file under.
|
| 178 |
+
If None, use the basename of the URL.
|
| 179 |
+
md5 (str, optional): MD5 checksum of the download. If None, do not check
|
| 180 |
+
"""
|
| 181 |
+
root = os.path.expanduser(root)
|
| 182 |
+
if not filename:
|
| 183 |
+
filename = os.path.basename(url)
|
| 184 |
+
fpath = os.path.join(root, filename)
|
| 185 |
+
|
| 186 |
+
makedir(root)
|
| 187 |
+
|
| 188 |
+
# check if file is already present locally
|
| 189 |
+
if check_integrity(fpath, md5):
|
| 190 |
+
print("Using downloaded and verified file: " + fpath)
|
| 191 |
+
return
|
| 192 |
+
|
| 193 |
+
# expand redirect chain if needed
|
| 194 |
+
url = get_redirected_url(url)
|
| 195 |
+
|
| 196 |
+
# check if file is located on Google Drive
|
| 197 |
+
file_id = _get_google_drive_file_id(url)
|
| 198 |
+
if file_id is not None:
|
| 199 |
+
return download_file_from_google_drive(file_id, root, filename, md5)
|
| 200 |
+
|
| 201 |
+
# download the file
|
| 202 |
+
try:
|
| 203 |
+
print("Downloading " + url + " to " + fpath)
|
| 204 |
+
_urlretrieve(url, fpath)
|
| 205 |
+
except (urllib.error.URLError, IOError) as e: # type: ignore[attr-defined]
|
| 206 |
+
if url[:5] == "https":
|
| 207 |
+
url = url.replace("https:", "http:")
|
| 208 |
+
print(
|
| 209 |
+
"Failed download. Trying https -> http instead."
|
| 210 |
+
" Downloading " + url + " to " + fpath
|
| 211 |
+
)
|
| 212 |
+
_urlretrieve(url, fpath)
|
| 213 |
+
else:
|
| 214 |
+
raise e
|
| 215 |
+
|
| 216 |
+
# check integrity of downloaded file
|
| 217 |
+
if not check_integrity(fpath, md5):
|
| 218 |
+
raise RuntimeError("File not found or corrupted.")
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
def download_and_extract_archive(
|
| 222 |
+
url: str,
|
| 223 |
+
download_root: str,
|
| 224 |
+
extract_root: Optional[str] = None,
|
| 225 |
+
filename: Optional[str] = None,
|
| 226 |
+
md5: Optional[str] = None,
|
| 227 |
+
remove_finished: bool = False,
|
| 228 |
+
) -> None:
|
| 229 |
+
download_root = os.path.expanduser(download_root)
|
| 230 |
+
if extract_root is None:
|
| 231 |
+
extract_root = download_root
|
| 232 |
+
if not filename:
|
| 233 |
+
filename = os.path.basename(url)
|
| 234 |
+
|
| 235 |
+
download_url(url, download_root, filename, md5)
|
| 236 |
+
|
| 237 |
+
archive = os.path.join(download_root, filename)
|
| 238 |
+
print("Extracting {} to {}".format(archive, extract_root))
|
| 239 |
+
extract_archive(archive, extract_root, remove_finished)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
def cache_url(url: str, cache_dir: str) -> str:
|
| 243 |
+
"""
|
| 244 |
+
This implementation downloads the remote resource and caches it locally.
|
| 245 |
+
The resource will only be downloaded if not previously requested.
|
| 246 |
+
"""
|
| 247 |
+
parsed_url = urlparse(url)
|
| 248 |
+
dirname = os.path.join(cache_dir, os.path.dirname(parsed_url.path.lstrip("/")))
|
| 249 |
+
makedir(dirname)
|
| 250 |
+
filename = url.split("/")[-1]
|
| 251 |
+
cached = os.path.join(dirname, filename)
|
| 252 |
+
with file_lock(cached):
|
| 253 |
+
if not os.path.isfile(cached):
|
| 254 |
+
logging.info(f"Downloading {url} to {cached} ...")
|
| 255 |
+
cached = download(url, dirname, filename=filename)
|
| 256 |
+
logging.info(f"URL {url} cached in {cached}")
|
| 257 |
+
return cached
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
# TODO (prigoyal): convert this into RAII-style API
|
| 261 |
+
def create_file_symlink(file1, file2):
|
| 262 |
+
"""
|
| 263 |
+
Simply create the symlinks for a given file1 to file2.
|
| 264 |
+
Useful during model checkpointing to symlinks to the
|
| 265 |
+
latest successful checkpoint.
|
| 266 |
+
"""
|
| 267 |
+
try:
|
| 268 |
+
if g_pathmgr.exists(file2):
|
| 269 |
+
g_pathmgr.rm(file2)
|
| 270 |
+
g_pathmgr.symlink(file1, file2)
|
| 271 |
+
except Exception as e:
|
| 272 |
+
logging.info(f"Could NOT create symlink. Error: {e}")
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
def save_file(data, filename, append_to_json=True, verbose=True):
|
| 276 |
+
"""
|
| 277 |
+
Common i/o utility to handle saving data to various file formats.
|
| 278 |
+
Supported:
|
| 279 |
+
.pkl, .pickle, .npy, .json
|
| 280 |
+
Specifically for .json, users have the option to either append (default)
|
| 281 |
+
or rewrite by passing in Boolean value to append_to_json.
|
| 282 |
+
"""
|
| 283 |
+
if verbose:
|
| 284 |
+
logging.info(f"Saving data to file: {filename}")
|
| 285 |
+
file_ext = os.path.splitext(filename)[1]
|
| 286 |
+
if file_ext in [".pkl", ".pickle"]:
|
| 287 |
+
with g_pathmgr.open(filename, "wb") as fopen:
|
| 288 |
+
pickle.dump(data, fopen, pickle.HIGHEST_PROTOCOL)
|
| 289 |
+
elif file_ext == ".npy":
|
| 290 |
+
with g_pathmgr.open(filename, "wb") as fopen:
|
| 291 |
+
np.save(fopen, data)
|
| 292 |
+
elif file_ext == ".json":
|
| 293 |
+
if append_to_json:
|
| 294 |
+
with g_pathmgr.open(filename, "a") as fopen:
|
| 295 |
+
fopen.write(json.dumps(data, sort_keys=True) + "\n")
|
| 296 |
+
fopen.flush()
|
| 297 |
+
else:
|
| 298 |
+
with g_pathmgr.open(filename, "w") as fopen:
|
| 299 |
+
fopen.write(json.dumps(data, sort_keys=True) + "\n")
|
| 300 |
+
fopen.flush()
|
| 301 |
+
elif file_ext == ".yaml":
|
| 302 |
+
with g_pathmgr.open(filename, "w") as fopen:
|
| 303 |
+
dump = yaml.dump(data)
|
| 304 |
+
fopen.write(dump)
|
| 305 |
+
fopen.flush()
|
| 306 |
+
else:
|
| 307 |
+
raise Exception(f"Saving {file_ext} is not supported yet")
|
| 308 |
+
|
| 309 |
+
if verbose:
|
| 310 |
+
logging.info(f"Saved data to file: {filename}")
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
def load_file(filename, mmap_mode=None, verbose=True, allow_pickle=False):
|
| 314 |
+
"""
|
| 315 |
+
Common i/o utility to handle loading data from various file formats.
|
| 316 |
+
Supported:
|
| 317 |
+
.pkl, .pickle, .npy, .json
|
| 318 |
+
For the npy files, we support reading the files in mmap_mode.
|
| 319 |
+
If the mmap_mode of reading is not successful, we load data without the
|
| 320 |
+
mmap_mode.
|
| 321 |
+
"""
|
| 322 |
+
if verbose:
|
| 323 |
+
logging.info(f"Loading data from file: {filename}")
|
| 324 |
+
|
| 325 |
+
file_ext = os.path.splitext(filename)[1]
|
| 326 |
+
if file_ext == ".txt":
|
| 327 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 328 |
+
data = fopen.readlines()
|
| 329 |
+
elif file_ext in [".pkl", ".pickle"]:
|
| 330 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 331 |
+
data = pickle.load(fopen, encoding="latin1")
|
| 332 |
+
elif file_ext == ".npy":
|
| 333 |
+
if mmap_mode:
|
| 334 |
+
try:
|
| 335 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 336 |
+
data = np.load(
|
| 337 |
+
fopen,
|
| 338 |
+
allow_pickle=allow_pickle,
|
| 339 |
+
encoding="latin1",
|
| 340 |
+
mmap_mode=mmap_mode,
|
| 341 |
+
)
|
| 342 |
+
except ValueError as e:
|
| 343 |
+
logging.info(
|
| 344 |
+
f"Could not mmap {filename}: {e}. Trying without g_pathmgr"
|
| 345 |
+
)
|
| 346 |
+
data = np.load(
|
| 347 |
+
filename,
|
| 348 |
+
allow_pickle=allow_pickle,
|
| 349 |
+
encoding="latin1",
|
| 350 |
+
mmap_mode=mmap_mode,
|
| 351 |
+
)
|
| 352 |
+
logging.info("Successfully loaded without g_pathmgr")
|
| 353 |
+
except Exception:
|
| 354 |
+
logging.info("Could not mmap without g_pathmgr. Trying without mmap")
|
| 355 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 356 |
+
data = np.load(fopen, allow_pickle=allow_pickle, encoding="latin1")
|
| 357 |
+
else:
|
| 358 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 359 |
+
data = np.load(fopen, allow_pickle=allow_pickle, encoding="latin1")
|
| 360 |
+
elif file_ext == ".json":
|
| 361 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 362 |
+
data = json.load(fopen)
|
| 363 |
+
elif file_ext == ".yaml":
|
| 364 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 365 |
+
data = yaml.load(fopen, Loader=yaml.FullLoader)
|
| 366 |
+
elif file_ext == ".csv":
|
| 367 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 368 |
+
data = pd.read_csv(fopen)
|
| 369 |
+
else:
|
| 370 |
+
raise Exception(f"Reading from {file_ext} is not supported yet")
|
| 371 |
+
return data
|
| 372 |
+
|
| 373 |
+
|
| 374 |
+
def abspath(resource_path: str):
|
| 375 |
+
"""
|
| 376 |
+
Make a path absolute, but take into account prefixes like
|
| 377 |
+
"http://" or "manifold://"
|
| 378 |
+
"""
|
| 379 |
+
regex = re.compile(r"^\w+://")
|
| 380 |
+
if regex.match(resource_path) is None:
|
| 381 |
+
return os.path.abspath(resource_path)
|
| 382 |
+
else:
|
| 383 |
+
return resource_path
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
def makedir(dir_path):
|
| 387 |
+
"""
|
| 388 |
+
Create the directory if it does not exist.
|
| 389 |
+
"""
|
| 390 |
+
is_success = False
|
| 391 |
+
try:
|
| 392 |
+
if not g_pathmgr.exists(dir_path):
|
| 393 |
+
g_pathmgr.mkdirs(dir_path)
|
| 394 |
+
is_success = True
|
| 395 |
+
except BaseException:
|
| 396 |
+
logging.info(f"Error creating directory: {dir_path}")
|
| 397 |
+
return is_success
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
def is_url(input_url):
|
| 401 |
+
"""
|
| 402 |
+
Check if an input string is a url. look for http(s):// and ignoring the case
|
| 403 |
+
"""
|
| 404 |
+
is_url = re.match(r"^(?:http)s?://", input_url, re.IGNORECASE) is not None
|
| 405 |
+
return is_url
|
| 406 |
+
|
| 407 |
+
|
| 408 |
+
def cleanup_dir(dir):
|
| 409 |
+
"""
|
| 410 |
+
Utility for deleting a directory. Useful for cleaning the storage space
|
| 411 |
+
that contains various training artifacts like checkpoints, data etc.
|
| 412 |
+
"""
|
| 413 |
+
if os.path.exists(dir):
|
| 414 |
+
logging.info(f"Deleting directory: {dir}")
|
| 415 |
+
shutil.rmtree(dir)
|
| 416 |
+
logging.info(f"Deleted contents of directory: {dir}")
|
| 417 |
+
|
| 418 |
+
|
| 419 |
+
def get_file_size(filename):
|
| 420 |
+
"""
|
| 421 |
+
Given a file, get the size of file in MB
|
| 422 |
+
"""
|
| 423 |
+
size_in_mb = os.path.getsize(filename) / float(1024**2)
|
| 424 |
+
return size_in_mb
|