Spaces:
Running

Running

Upload 174 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +3 -0
- Home.py +16 -0
- README.md +4 -4
- pages/10_Painter.py +53 -0
- pages/11_SegGPT.py +70 -0
- pages/12_Grounding_DINO.py +92 -0
- pages/13_DocOwl_1.5.py +100 -0
- pages/14_PLLaVA.py +65 -0
- pages/15_CuMo.py +61 -0
- pages/16_DenseConnector.py +69 -0
- pages/17_Depth_Anything_V2.py +74 -0
- pages/18_Florence-2.py +78 -0
- pages/19_4M-21.py +70 -0
- pages/1_MobileSAM.py +79 -0
- pages/20_RT-DETR.py +67 -0
- pages/21_Llava-NeXT-Interleave.py +86 -0
- pages/22_Chameleon.py +88 -0
- pages/23_Video-LLaVA.py +70 -0
- pages/24_SAMv2.py +88 -0
- pages/2_Oneformer.py +62 -0
- pages/3_VITMAE.py +63 -0
- pages/4M-21/4M-21.md +32 -0
- pages/4M-21/image_1.jpg +0 -0
- pages/4M-21/image_2.jpg +0 -0
- pages/4M-21/image_3.jpg +0 -0
- pages/4M-21/video_1.mp4 +3 -0
- pages/4M-21/video_2.mp4 +0 -0
- pages/4_DINOv2.py +78 -0
- pages/5_SigLIP.py +78 -0
- pages/6_OWLv2.py +87 -0
- pages/7_Backbone.py +63 -0
- pages/8_Depth_Anything.py +100 -0
- pages/9_LLaVA-NeXT.py +74 -0
- pages/Backbone/Backbone.md +31 -0
- pages/Backbone/image_1.jpeg +0 -0
- pages/Backbone/image_2.jpeg +0 -0
- pages/Backbone/image_3.jpeg +0 -0
- pages/Backbone/image_4.jpeg +0 -0
- pages/Chameleon/Chameleon.md +43 -0
- pages/Chameleon/image_1.jpg +0 -0
- pages/Chameleon/image_2.jpg +0 -0
- pages/Chameleon/image_3.jpg +0 -0
- pages/Chameleon/image_4.jpg +0 -0
- pages/Chameleon/image_5.jpg +0 -0
- pages/Chameleon/image_6.jpg +0 -0
- pages/Chameleon/image_7.jpg +0 -0
- pages/Chameleon/video_1.mp4 +0 -0
- pages/CuMo/CuMo.md +24 -0
- pages/CuMo/image_1.jpg +0 -0
- pages/CuMo/image_2.jpg +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
pages/4M-21/video_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
pages/Depth[[:space:]]Anything/video_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
pages/RT-DETR/video_1.mp4 filter=lfs diff=lfs merge=lfs -text
|
Home.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
st.set_page_config(page_title="Home",page_icon="🏠")
|
| 4 |
+
|
| 5 |
+
# st.image("image_of_a_Turkish_lofi_girl_sitting_at_a_desk_writing_summaries_of_scientific_publications_ghibli_anime_like_hd.jpeg", use_column_width=True)
|
| 6 |
+
|
| 7 |
+
st.write("# Vision Papers 📚")
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
st.markdown(
|
| 11 |
+
"""
|
| 12 |
+
I've created a simple Streamlit App where I list summaries of papers (my browser bookmarks or Twitter bookmarks were getting messy).
|
| 13 |
+
Since you're one of my sources for bibliography, I thought you might be interested in having all your summaries grouped together somewhere
|
| 14 |
+
(average of 0.73 summaries per week, I don't know what it's your fuel but that's impressive).
|
| 15 |
+
"""
|
| 16 |
+
)
|
README.md
CHANGED
|
@@ -1,11 +1,11 @@
|
|
| 1 |
---
|
| 2 |
title: Vision Papers
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.37.0
|
| 8 |
-
app_file:
|
| 9 |
pinned: false
|
| 10 |
---
|
| 11 |
|
|
|
|
| 1 |
---
|
| 2 |
title: Vision Papers
|
| 3 |
+
emoji: 💻
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: blue
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.37.0
|
| 8 |
+
app_file: Home.py
|
| 9 |
pinned: false
|
| 10 |
---
|
| 11 |
|
pages/10_Painter.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("Painter")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1771542172946354643) (March 23, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""I read the Painter [paper](https://t.co/r3aHp29mjf) by [BAAIBeijing](https://x.com/BAAIBeijing) to convert the weights to 🤗 Transformers, and I absolutely loved the approach they took so I wanted to take time to unfold it here!
|
| 10 |
+
""")
|
| 11 |
+
st.markdown(""" """)
|
| 12 |
+
|
| 13 |
+
st.image("pages/Painter/image_1.jpeg", use_column_width=True)
|
| 14 |
+
st.markdown(""" """)
|
| 15 |
+
|
| 16 |
+
st.markdown("""So essentially this model takes inspiration from in-context learning, as in, in LLMs you give an example input output and give the actual input that you want model to complete (one-shot learning) they adapted this to images, thus the name "images speak in images".
|
| 17 |
+
|
| 18 |
+
This model doesn't have any multimodal parts, it just has an image encoder and a decoder head (linear layer, conv layer, another linear layer) so it's a single modality.
|
| 19 |
+
|
| 20 |
+
The magic sauce is the data: they input the task in the form of image and associated transformation and another image they want the transformation to take place and take smooth L2 loss over the predictions and ground truth this is like T5 of image models 😀
|
| 21 |
+
""")
|
| 22 |
+
st.markdown(""" """)
|
| 23 |
+
|
| 24 |
+
st.image("pages/Painter/image_2.jpeg", use_column_width=True)
|
| 25 |
+
st.markdown(""" """)
|
| 26 |
+
|
| 27 |
+
st.markdown("""What is so cool about it is that it can actually adapt to out of domain tasks, meaning, in below chart, it was trained on the tasks above the dashed line, and the authors found out it generalized to the tasks below the line, image tasks are well generalized 🤯
|
| 28 |
+
""")
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.image("pages/Painter/image_3.jpeg", use_column_width=True)
|
| 32 |
+
st.markdown(""" """)
|
| 33 |
+
|
| 34 |
+
st.info("""
|
| 35 |
+
Ressources:
|
| 36 |
+
[Images Speak in Images: A Generalist Painter for In-Context Visual Learning](https://arxiv.org/abs/2212.02499)
|
| 37 |
+
by Xinlong Wang, Wen Wang, Yue Cao, Chunhua Shen, Tiejun Huang (2022)
|
| 38 |
+
[GitHub](https://github.com/baaivision/Painter)""", icon="📚")
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
st.markdown(""" """)
|
| 42 |
+
st.markdown(""" """)
|
| 43 |
+
st.markdown(""" """)
|
| 44 |
+
col1, col2, col3 = st.columns(3)
|
| 45 |
+
with col1:
|
| 46 |
+
if st.button('Previous paper', use_container_width=True):
|
| 47 |
+
switch_page("LLaVA-NeXT")
|
| 48 |
+
with col2:
|
| 49 |
+
if st.button('Home', use_container_width=True):
|
| 50 |
+
switch_page("Home")
|
| 51 |
+
with col3:
|
| 52 |
+
if st.button('Next paper', use_container_width=True):
|
| 53 |
+
switch_page("SegGPT")
|
pages/11_SegGPT.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("SegGPT")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://x.com/mervenoyann/status/1773056450790666568) (March 27, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""SegGPT is a vision generalist on image segmentation, quite like GPT for computer vision ✨
|
| 10 |
+
It comes with the last release of 🤗 Transformers 🎁
|
| 11 |
+
Technical details, demo and how-to's under this!
|
| 12 |
+
""")
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.image("pages/SegGPT/image_1.jpeg", use_column_width=True)
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.markdown("""SegGPT is an extension of the <a href='Painter' target='_self'>Painter</a> where you speak to images with images: the model takes in an image prompt, transformed version of the image prompt, the actual image you want to see the same transform, and expected to output the transformed image.
|
| 19 |
+
|
| 20 |
+
SegGPT consists of a vanilla ViT with a decoder on top (linear, conv, linear). The model is trained on diverse segmentation examples, where they provide example image-mask pairs, the actual input to be segmented, and the decoder head learns to reconstruct the mask output. 👇🏻
|
| 21 |
+
""", unsafe_allow_html=True)
|
| 22 |
+
st.markdown(""" """)
|
| 23 |
+
|
| 24 |
+
st.image("pages/SegGPT/image_2.jpg", use_column_width=True)
|
| 25 |
+
st.markdown(""" """)
|
| 26 |
+
|
| 27 |
+
st.markdown("""
|
| 28 |
+
This generalizes pretty well!
|
| 29 |
+
The authors do not claim state-of-the-art results as the model is mainly used zero-shot and few-shot inference. They also do prompt tuning, where they freeze the parameters of the model and only optimize the image tensor (the input context).
|
| 30 |
+
""")
|
| 31 |
+
st.markdown(""" """)
|
| 32 |
+
|
| 33 |
+
st.image("pages/SegGPT/image_3.jpg", use_column_width=True)
|
| 34 |
+
st.markdown(""" """)
|
| 35 |
+
|
| 36 |
+
st.markdown("""Thanks to 🤗 Transformers you can use this model easily! See [here](https://t.co/U5pVpBhkfK).
|
| 37 |
+
""")
|
| 38 |
+
st.markdown(""" """)
|
| 39 |
+
|
| 40 |
+
st.image("pages/SegGPT/image_4.jpeg", use_column_width=True)
|
| 41 |
+
st.markdown(""" """)
|
| 42 |
+
|
| 43 |
+
st.markdown("""
|
| 44 |
+
I have built an app for you to try it out. I combined SegGPT with Depth Anything Model, so you don't have to upload image mask prompts in your prompt pair 🤗
|
| 45 |
+
Try it [here](https://t.co/uJIwqJeYUy). Also check out the [collection](https://t.co/HvfjWkAEzP).
|
| 46 |
+
""")
|
| 47 |
+
st.markdown(""" """)
|
| 48 |
+
|
| 49 |
+
st.image("pages/SegGPT/image_5.jpeg", use_column_width=True)
|
| 50 |
+
st.markdown(""" """)
|
| 51 |
+
|
| 52 |
+
st.info("""
|
| 53 |
+
Ressources:
|
| 54 |
+
[SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284)
|
| 55 |
+
by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang (2023)
|
| 56 |
+
[GitHub](https://github.com/baaivision/Painter)""", icon="📚")
|
| 57 |
+
|
| 58 |
+
st.markdown(""" """)
|
| 59 |
+
st.markdown(""" """)
|
| 60 |
+
st.markdown(""" """)
|
| 61 |
+
col1, col2, col3 = st.columns(3)
|
| 62 |
+
with col1:
|
| 63 |
+
if st.button('Previous paper', use_container_width=True):
|
| 64 |
+
switch_page("Painter")
|
| 65 |
+
with col2:
|
| 66 |
+
if st.button('Home', use_container_width=True):
|
| 67 |
+
switch_page("Home")
|
| 68 |
+
with col3:
|
| 69 |
+
if st.button('Next paper', use_container_width=True):
|
| 70 |
+
switch_page("Grounding DINO")
|
pages/12_Grounding_DINO.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("Grounding DINO")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1780558859221733563) (April 17, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""
|
| 10 |
+
We have merged Grounding DINO in 🤗 Transformers 🦖
|
| 11 |
+
It's an amazing zero-shot object detection model, here's why 🧶
|
| 12 |
+
""")
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.image("pages/Grounding_DINO/image_1.jpeg", use_column_width=True)
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.markdown("""There are two zero-shot object detection models as of now, one is OWL series by Google Brain and the other one is Grounding DINO 🦕
|
| 19 |
+
Grounding DINO pays immense attention to detail ⬇️
|
| 20 |
+
Also [try yourself](https://t.co/UI0CMxphE7).
|
| 21 |
+
""")
|
| 22 |
+
st.markdown(""" """)
|
| 23 |
+
|
| 24 |
+
st.image("pages/Grounding_DINO/image_2.jpeg", use_column_width=True)
|
| 25 |
+
st.image("pages/Grounding_DINO/image_3.jpeg", use_column_width=True)
|
| 26 |
+
st.markdown(""" """)
|
| 27 |
+
|
| 28 |
+
st.markdown("""I have also built another [application](https://t.co/4EHpOwEpm0) for GroundingSAM, combining GroundingDINO and Segment Anything by Meta for cutting edge zero-shot image segmentation.
|
| 29 |
+
""")
|
| 30 |
+
st.markdown(""" """)
|
| 31 |
+
|
| 32 |
+
st.image("pages/Grounding_DINO/image_4.jpeg", use_column_width=True)
|
| 33 |
+
st.markdown(""" """)
|
| 34 |
+
|
| 35 |
+
st.markdown("""Grounding DINO is essentially a model with connected image encoder (Swin transformer), text encoder (BERT) and on top of both, a decoder that outputs bounding boxes 🦖
|
| 36 |
+
This is quite similar to <a href='OWLv2' target='_self'>OWL series</a>, which uses a ViT-based detector on CLIP.
|
| 37 |
+
""", unsafe_allow_html=True)
|
| 38 |
+
st.markdown(""" """)
|
| 39 |
+
|
| 40 |
+
st.image("pages/Grounding_DINO/image_5.jpeg", use_column_width=True)
|
| 41 |
+
st.markdown(""" """)
|
| 42 |
+
|
| 43 |
+
st.markdown("""The authors train Swin-L/T with BERT contrastively (not like CLIP where they match the images to texts by means of similarity) where they try to approximate the region outputs to language phrases at the head outputs 🤩
|
| 44 |
+
""")
|
| 45 |
+
st.markdown(""" """)
|
| 46 |
+
|
| 47 |
+
st.image("pages/Grounding_DINO/image_6.jpeg", use_column_width=True)
|
| 48 |
+
st.markdown(""" """)
|
| 49 |
+
|
| 50 |
+
st.markdown("""The authors also form the text features on the sub-sentence level.
|
| 51 |
+
This means it extracts certain noun phrases from training data to remove the influence between words while removing fine-grained information.
|
| 52 |
+
""")
|
| 53 |
+
st.markdown(""" """)
|
| 54 |
+
|
| 55 |
+
st.image("pages/Grounding_DINO/image_7.jpeg", use_column_width=True)
|
| 56 |
+
st.markdown(""" """)
|
| 57 |
+
|
| 58 |
+
st.markdown("""Thanks to all of this, Grounding DINO has great performance on various REC/object detection benchmarks 🏆📈
|
| 59 |
+
""")
|
| 60 |
+
st.markdown(""" """)
|
| 61 |
+
|
| 62 |
+
st.image("pages/Grounding_DINO/image_8.jpeg", use_column_width=True)
|
| 63 |
+
st.markdown(""" """)
|
| 64 |
+
|
| 65 |
+
st.markdown("""Thanks to 🤗 Transformers, you can use Grounding DINO very easily!
|
| 66 |
+
You can also check out [NielsRogge](https://twitter.com/NielsRogge)'s [notebook here](https://t.co/8ADGFdVkta).
|
| 67 |
+
""")
|
| 68 |
+
st.markdown(""" """)
|
| 69 |
+
|
| 70 |
+
st.image("pages/Grounding_DINO/image_9.jpeg", use_column_width=True)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
st.info("""Ressources:
|
| 74 |
+
[Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499)
|
| 75 |
+
by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang (2023)
|
| 76 |
+
[GitHub](https://github.com/IDEA-Research/GroundingDINO)
|
| 77 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/grounding-dino)""", icon="📚")
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
st.markdown(""" """)
|
| 81 |
+
st.markdown(""" """)
|
| 82 |
+
st.markdown(""" """)
|
| 83 |
+
col1, col2, col3 = st.columns(3)
|
| 84 |
+
with col1:
|
| 85 |
+
if st.button('Previous paper', use_container_width=True):
|
| 86 |
+
switch_page("SegGPT")
|
| 87 |
+
with col2:
|
| 88 |
+
if st.button('Home', use_container_width=True):
|
| 89 |
+
switch_page("Home")
|
| 90 |
+
with col3:
|
| 91 |
+
if st.button('Next paper', use_container_width=True):
|
| 92 |
+
switch_page("DocOwl 1.5")
|
pages/13_DocOwl_1.5.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("DocOwl 1.5")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1782421257591357824) (April 22, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""DocOwl 1.5 is the state-of-the-art document understanding model by Alibaba with Apache 2.0 license 😍📝
|
| 10 |
+
Time to dive in and learn more 🧶
|
| 11 |
+
""")
|
| 12 |
+
st.markdown(""" """)
|
| 13 |
+
|
| 14 |
+
st.image("pages/DocOwl_1.5/image_1.jpg", use_column_width=True)
|
| 15 |
+
st.markdown(""" """)
|
| 16 |
+
|
| 17 |
+
st.markdown("""This model consists of a ViT-based visual encoder part that takes in crops of image and the original image itself.
|
| 18 |
+
Then the outputs of the encoder goes through a convolution based model, after that the outputs are merged with text and then fed to LLM.
|
| 19 |
+
""")
|
| 20 |
+
st.markdown(""" """)
|
| 21 |
+
|
| 22 |
+
st.image("pages/DocOwl_1.5/image_2.jpeg", use_column_width=True)
|
| 23 |
+
st.markdown(""" """)
|
| 24 |
+
|
| 25 |
+
st.markdown("""
|
| 26 |
+
Initially, the authors only train the convolution based part (called H-Reducer) and vision encoder while keeping LLM frozen.
|
| 27 |
+
Then for fine-tuning (on image captioning, VQA etc), they freeze vision encoder and train H-Reducer and LLM.
|
| 28 |
+
""")
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.image("pages/DocOwl_1.5/image_3.jpeg", use_column_width=True)
|
| 32 |
+
st.markdown(""" """)
|
| 33 |
+
|
| 34 |
+
st.markdown("""Also they use simple linear projection on text and documents. You can see below how they model the text prompts and outputs 🤓
|
| 35 |
+
""")
|
| 36 |
+
st.markdown(""" """)
|
| 37 |
+
|
| 38 |
+
st.image("pages/DocOwl_1.5/image_4.jpeg", use_column_width=True)
|
| 39 |
+
st.markdown(""" """)
|
| 40 |
+
|
| 41 |
+
st.markdown("""They train the model various downstream tasks including:
|
| 42 |
+
- document understanding (DUE benchmark and more)
|
| 43 |
+
- table parsing (TURL, PubTabNet)
|
| 44 |
+
- chart parsing (PlotQA and more)
|
| 45 |
+
- image parsing (OCR-CC)
|
| 46 |
+
- text localization (DocVQA and more)
|
| 47 |
+
""")
|
| 48 |
+
st.markdown(""" """)
|
| 49 |
+
|
| 50 |
+
st.image("pages/DocOwl_1.5/image_5.jpeg", use_column_width=True)
|
| 51 |
+
st.markdown(""" """)
|
| 52 |
+
|
| 53 |
+
st.markdown("""
|
| 54 |
+
They contribute a new model called DocOwl 1.5-Chat by:
|
| 55 |
+
1. creating a new document-chat dataset with questions from document VQA datasets
|
| 56 |
+
2. feeding them to ChatGPT to get long answers
|
| 57 |
+
3. fine-tune the base model with it (which IMO works very well!)
|
| 58 |
+
""")
|
| 59 |
+
st.markdown(""" """)
|
| 60 |
+
|
| 61 |
+
st.image("pages/DocOwl_1.5/image_6.jpeg", use_column_width=True)
|
| 62 |
+
st.markdown(""" """)
|
| 63 |
+
|
| 64 |
+
st.markdown("""
|
| 65 |
+
Resulting generalist model and the chat model are pretty much state-of-the-art 😍
|
| 66 |
+
Below you can see how it compares to fine-tuned models.
|
| 67 |
+
""")
|
| 68 |
+
st.markdown(""" """)
|
| 69 |
+
|
| 70 |
+
st.image("pages/DocOwl_1.5/image_7.jpeg", use_column_width=True)
|
| 71 |
+
st.markdown(""" """)
|
| 72 |
+
|
| 73 |
+
st.markdown("""All the models and the datasets (also some eval datasets on above tasks!) are in this [organization](https://t.co/sJdTw1jWTR).
|
| 74 |
+
The [Space](https://t.co/57E9DbNZXf).
|
| 75 |
+
""")
|
| 76 |
+
st.markdown(""" """)
|
| 77 |
+
|
| 78 |
+
st.image("pages/DocOwl_1.5/image_8.jpeg", use_column_width=True)
|
| 79 |
+
st.markdown(""" """)
|
| 80 |
+
|
| 81 |
+
st.info("""
|
| 82 |
+
Ressources:
|
| 83 |
+
[mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding](https://arxiv.org/abs/2403.12895)
|
| 84 |
+
by Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Chen Li, Ji Zhang, Qin Jin, Fei Huang, Jingren Zhou (2024)
|
| 85 |
+
[GitHub](https://github.com/X-PLUG/mPLUG-DocOwl)""", icon="📚")
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
st.markdown(""" """)
|
| 89 |
+
st.markdown(""" """)
|
| 90 |
+
st.markdown(""" """)
|
| 91 |
+
col1, col2, col3 = st.columns(3)
|
| 92 |
+
with col1:
|
| 93 |
+
if st.button('Previous paper', use_container_width=True):
|
| 94 |
+
switch_page("Grounding DINO")
|
| 95 |
+
with col2:
|
| 96 |
+
if st.button('Home', use_container_width=True):
|
| 97 |
+
switch_page("Home")
|
| 98 |
+
with col3:
|
| 99 |
+
if st.button('Next paper', use_container_width=True):
|
| 100 |
+
switch_page("PLLaVA")
|
pages/14_PLLaVA.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("PLLaVA")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1786336055425138939) (May 3, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""Parameter-free LLaVA for video captioning works like magic! 🤩 Let's take a look!
|
| 10 |
+
""")
|
| 11 |
+
st.markdown(""" """)
|
| 12 |
+
|
| 13 |
+
st.image("pages/PLLaVA/image_1.jpg", use_column_width=True)
|
| 14 |
+
st.markdown(""" """)
|
| 15 |
+
|
| 16 |
+
st.markdown("""Most of the video captioning models work by downsampling video frames to reduce computational complexity and memory requirements without losing a lot of information in the process.
|
| 17 |
+
PLLaVA on the other hand, uses pooling! 🤩
|
| 18 |
+
|
| 19 |
+
How? 🧐
|
| 20 |
+
It takes in frames of video, passed to ViT and then projection layer, and then output goes through average pooling where input shape is (# frames, width, height, text decoder input dim) 👇
|
| 21 |
+
""")
|
| 22 |
+
st.markdown(""" """)
|
| 23 |
+
|
| 24 |
+
st.image("pages/PLLaVA/image_2.jpeg", use_column_width=True)
|
| 25 |
+
st.markdown(""" """)
|
| 26 |
+
|
| 27 |
+
st.markdown("""Pooling operation surprisingly reduces the loss of spatial and temporal information. See below some examples on how it can capture the details 🤗
|
| 28 |
+
""")
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.image("pages/PLLaVA/image_3.jpeg", use_column_width=True)
|
| 32 |
+
st.markdown(""" """)
|
| 33 |
+
|
| 34 |
+
st.markdown("""According to authors' findings, it performs way better than many of the existing models (including proprietary VLMs) and scales very well (on text decoder).
|
| 35 |
+
""")
|
| 36 |
+
st.markdown(""" """)
|
| 37 |
+
|
| 38 |
+
st.image("pages/PLLaVA/image_4.jpeg", use_column_width=True)
|
| 39 |
+
st.markdown(""" """)
|
| 40 |
+
|
| 41 |
+
st.markdown("""
|
| 42 |
+
Model repositories 🤗 [7B](https://t.co/AeSdYsz1U7), [13B](https://t.co/GnI1niTxO7), [34B](https://t.co/HWAM0ZzvDc)
|
| 43 |
+
Spaces🤗 [7B](https://t.co/Oms2OLkf7O), [13B](https://t.co/C2RNVNA4uR)
|
| 44 |
+
""")
|
| 45 |
+
st.markdown(""" """)
|
| 46 |
+
|
| 47 |
+
st.info("""
|
| 48 |
+
Ressources:
|
| 49 |
+
[PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning](https://arxiv.org/abs/2404.16994)
|
| 50 |
+
by Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, Jiashi Feng (2024)
|
| 51 |
+
[GitHub](https://github.com/magic-research/PLLaVA)""", icon="📚")
|
| 52 |
+
|
| 53 |
+
st.markdown(""" """)
|
| 54 |
+
st.markdown(""" """)
|
| 55 |
+
st.markdown(""" """)
|
| 56 |
+
col1, col2, col3 = st.columns(3)
|
| 57 |
+
with col1:
|
| 58 |
+
if st.button('Previous paper', use_container_width=True):
|
| 59 |
+
switch_page("DocOwl 1.5")
|
| 60 |
+
with col2:
|
| 61 |
+
if st.button('Home', use_container_width=True):
|
| 62 |
+
switch_page("Home")
|
| 63 |
+
with col3:
|
| 64 |
+
if st.button('Next paper', use_container_width=True):
|
| 65 |
+
switch_page("CuMo")
|
pages/15_CuMo.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("CuMo")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1790665706205307191) (May 15, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""
|
| 10 |
+
It's raining vision language models ☔️
|
| 11 |
+
CuMo is a new vision language model that has MoE in every step of the VLM (image encoder, MLP and text decoder) and uses Mistral-7B for the decoder part 🤓
|
| 12 |
+
""")
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.image("pages/CuMo/image_1.jpg", use_column_width=True)
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.markdown("""
|
| 19 |
+
The authors firstly did pre-training of MLP with the by freezing the image encoder and text decoder, then they warmup the whole network by unfreezing and finetuning which they state to stabilize the visual instruction tuning when bringing in the experts.
|
| 20 |
+
""")
|
| 21 |
+
st.markdown(""" """)
|
| 22 |
+
|
| 23 |
+
st.image("pages/CuMo/image_2.jpg", use_column_width=True)
|
| 24 |
+
st.markdown(""" """)
|
| 25 |
+
|
| 26 |
+
st.markdown("""
|
| 27 |
+
The mixture of experts MLP blocks above are simply the same MLP blocks initialized from the single MLP that was trained during pre-training and fine-tuned in pre-finetuning 👇
|
| 28 |
+
""")
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.image("pages/CuMo/image_3.jpg", use_column_width=True)
|
| 32 |
+
st.markdown(""" """)
|
| 33 |
+
|
| 34 |
+
st.markdown("""
|
| 35 |
+
It works very well (also tested myself) that it outperforms the previous SOTA of it's size <a href='LLaVA-NeXT' target='_self'>LLaVA-NeXT</a>! 😍
|
| 36 |
+
I wonder how it would compare to IDEFICS2-8B You can try it yourself [here](https://t.co/MLIYKVh5Ee).
|
| 37 |
+
""", unsafe_allow_html=True)
|
| 38 |
+
st.markdown(""" """)
|
| 39 |
+
|
| 40 |
+
st.image("pages/CuMo/image_4.jpg", use_column_width=True)
|
| 41 |
+
st.markdown(""" """)
|
| 42 |
+
|
| 43 |
+
st.info("""
|
| 44 |
+
Ressources:
|
| 45 |
+
[CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts](https://arxiv.org/abs/2405.05949)
|
| 46 |
+
by Jiachen Li, Xinyao Wang, Sijie Zhu, Chia-Wen Kuo, Lu Xu, Fan Chen, Jitesh Jain, Humphrey Shi, Longyin Wen (2024)
|
| 47 |
+
[GitHub](https://github.com/SHI-Labs/CuMo)""", icon="📚")
|
| 48 |
+
|
| 49 |
+
st.markdown(""" """)
|
| 50 |
+
st.markdown(""" """)
|
| 51 |
+
st.markdown(""" """)
|
| 52 |
+
col1, col2, col3 = st.columns(3)
|
| 53 |
+
with col1:
|
| 54 |
+
if st.button('Previous paper', use_container_width=True):
|
| 55 |
+
switch_page("PLLaVA")
|
| 56 |
+
with col2:
|
| 57 |
+
if st.button('Home', use_container_width=True):
|
| 58 |
+
switch_page("Home")
|
| 59 |
+
with col3:
|
| 60 |
+
if st.button('Next paper', use_container_width=True):
|
| 61 |
+
switch_page("DenseConnector")
|
pages/16_DenseConnector.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("DenseConnector")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1796089181988352216) (May 30, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""Do we fully leverage image encoders in vision language models? 👀
|
| 10 |
+
A new paper built a dense connector that does it better! Let's dig in 🧶
|
| 11 |
+
""")
|
| 12 |
+
st.markdown(""" """)
|
| 13 |
+
|
| 14 |
+
st.image("pages/DenseConnector/image_1.jpg", use_column_width=True)
|
| 15 |
+
st.markdown(""" """)
|
| 16 |
+
|
| 17 |
+
st.markdown("""
|
| 18 |
+
VLMs consist of an image encoder block, a projection layer that projects image embeddings to text embedding space and then a text decoder sequentially connected 📖
|
| 19 |
+
This [paper](https://t.co/DPQzbj0eWm) explores using intermediate states of image encoder and not a single output 🤩
|
| 20 |
+
""")
|
| 21 |
+
st.markdown(""" """)
|
| 22 |
+
|
| 23 |
+
st.image("pages/DenseConnector/image_2.jpg", use_column_width=True)
|
| 24 |
+
st.markdown(""" """)
|
| 25 |
+
|
| 26 |
+
st.markdown("""
|
| 27 |
+
The authors explore three different ways of instantiating dense connector: sparse token integration, sparse channel integration and dense channel integration (each of them just take intermediate outputs and put them together in different ways, see below).
|
| 28 |
+
""")
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.image("pages/DenseConnector/image_3.jpg", use_column_width=True)
|
| 32 |
+
st.markdown(""" """)
|
| 33 |
+
|
| 34 |
+
st.markdown("""
|
| 35 |
+
They explore all three of them integrated to LLaVA 1.5 and found out each of the new models are superior to the original LLaVA 1.5.
|
| 36 |
+
""")
|
| 37 |
+
st.markdown(""" """)
|
| 38 |
+
|
| 39 |
+
st.image("pages/DenseConnector/image_4.jpg", use_column_width=True)
|
| 40 |
+
st.markdown(""" """)
|
| 41 |
+
|
| 42 |
+
st.markdown("""
|
| 43 |
+
I tried the [model](https://huggingface.co/spaces/HuanjinYao/DenseConnector-v1.5-8B) and it seems to work very well 🥹
|
| 44 |
+
The authors have released various [checkpoints](https://t.co/iF8zM2qvDa) based on different decoders (Vicuna 7/13B and Llama 3-8B).
|
| 45 |
+
""")
|
| 46 |
+
st.markdown(""" """)
|
| 47 |
+
|
| 48 |
+
st.image("pages/DenseConnector/image_5.jpg", use_column_width=True)
|
| 49 |
+
st.markdown(""" """)
|
| 50 |
+
|
| 51 |
+
st.info("""
|
| 52 |
+
Ressources:
|
| 53 |
+
[Dense Connector for MLLMs](https://arxiv.org/abs/2405.13800)
|
| 54 |
+
by Huanjin Yao, Wenhao Wu, Taojiannan Yang, YuXin Song, Mengxi Zhang, Haocheng Feng, Yifan Sun, Zhiheng Li, Wanli Ouyang, Jingdong Wang (2024)
|
| 55 |
+
[GitHub](https://github.com/HJYao00/DenseConnector)""", icon="📚")
|
| 56 |
+
|
| 57 |
+
st.markdown(""" """)
|
| 58 |
+
st.markdown(""" """)
|
| 59 |
+
st.markdown(""" """)
|
| 60 |
+
col1, col2, col3 = st.columns(3)
|
| 61 |
+
with col1:
|
| 62 |
+
if st.button('Previous paper', use_container_width=True):
|
| 63 |
+
switch_page("CuMo")
|
| 64 |
+
with col2:
|
| 65 |
+
if st.button('Home', use_container_width=True):
|
| 66 |
+
switch_page("Home")
|
| 67 |
+
with col3:
|
| 68 |
+
if st.button('Next paper', use_container_width=True):
|
| 69 |
+
switch_page("Depth Anything v2")
|
pages/17_Depth_Anything_V2.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("Depth Anything V2")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1803063120354492658) (June 18, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""
|
| 10 |
+
I love Depth Anything V2 😍
|
| 11 |
+
It’s <a href='Depth_Anything' target='_self'>Depth Anything</a>, but scaled with both larger teacher model and a gigantic dataset! Let’s unpack 🤓🧶!
|
| 12 |
+
""", unsafe_allow_html=True)
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.image("pages/Depth_Anything_v2/image_1.jpg", use_column_width=True)
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.markdown("""
|
| 19 |
+
The authors have analyzed Marigold, a diffusion based model against Depth Anything and found out what’s up with using synthetic images vs real images for MDE:
|
| 20 |
+
🔖 Real data has a lot of label noise, inaccurate depth maps (caused by depth sensors missing transparent objects etc)
|
| 21 |
+
🔖 Synthetic data have more precise and detailed depth labels and they are truly ground-truth, but there’s a distribution shift between real and synthetic images, and they have restricted scene coverage
|
| 22 |
+
""")
|
| 23 |
+
st.markdown(""" """)
|
| 24 |
+
|
| 25 |
+
st.image("pages/Depth_Anything_v2/image_2.jpg", use_column_width=True)
|
| 26 |
+
st.markdown(""" """)
|
| 27 |
+
|
| 28 |
+
st.markdown("""
|
| 29 |
+
The authors train different image encoders only on synthetic images and find out unless the encoder is very large the model can’t generalize well (but large models generalize inherently anyway) 🧐
|
| 30 |
+
But they still fail encountering real images that have wide distribution in labels 🥲
|
| 31 |
+
""")
|
| 32 |
+
st.markdown(""" """)
|
| 33 |
+
|
| 34 |
+
st.image("pages/Depth_Anything_v2/image_3.jpg", use_column_width=True)
|
| 35 |
+
st.markdown(""" """)
|
| 36 |
+
|
| 37 |
+
st.markdown("""
|
| 38 |
+
Depth Anything v2 framework is to...
|
| 39 |
+
🦖 Train a teacher model based on DINOv2-G based on 595K synthetic images
|
| 40 |
+
🏷️ Label 62M real images using teacher model
|
| 41 |
+
🦕 Train a student model using the real images labelled by teacher
|
| 42 |
+
Result: 10x faster and more accurate than Marigold!
|
| 43 |
+
""")
|
| 44 |
+
st.markdown(""" """)
|
| 45 |
+
|
| 46 |
+
st.image("pages/Depth_Anything_v2/image_4.jpg", use_column_width=True)
|
| 47 |
+
st.markdown(""" """)
|
| 48 |
+
|
| 49 |
+
st.markdown("""
|
| 50 |
+
The authors also construct a new benchmark called DA-2K that is less noisy, highly detailed and more diverse!
|
| 51 |
+
I have created a [collection](https://t.co/3fAB9b2sxi) that has the models, the dataset, the demo and CoreML converted model 😚
|
| 52 |
+
""")
|
| 53 |
+
st.markdown(""" """)
|
| 54 |
+
|
| 55 |
+
st.info("""
|
| 56 |
+
Ressources:
|
| 57 |
+
[Depth Anything V2](https://arxiv.org/abs/2406.09414)
|
| 58 |
+
by Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao (2024)
|
| 59 |
+
[GitHub](https://github.com/DepthAnything/Depth-Anything-V2)
|
| 60 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/depth_anything_v2)""", icon="📚")
|
| 61 |
+
|
| 62 |
+
st.markdown(""" """)
|
| 63 |
+
st.markdown(""" """)
|
| 64 |
+
st.markdown(""" """)
|
| 65 |
+
col1, col2, col3 = st.columns(3)
|
| 66 |
+
with col1:
|
| 67 |
+
if st.button('Previous paper', use_container_width=True):
|
| 68 |
+
switch_page("DenseConnector")
|
| 69 |
+
with col2:
|
| 70 |
+
if st.button('Home', use_container_width=True):
|
| 71 |
+
switch_page("Home")
|
| 72 |
+
with col3:
|
| 73 |
+
if st.button('Next paper', use_container_width=True):
|
| 74 |
+
switch_page("Florence-2")
|
pages/18_Florence-2.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("Florence-2")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1803769866878623819) (June 20, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""Florence-2 is a new vision foundation model by Microsoft capable of a wide variety of tasks 🤯
|
| 10 |
+
Let's unpack! 🧶
|
| 11 |
+
""")
|
| 12 |
+
st.markdown(""" """)
|
| 13 |
+
|
| 14 |
+
st.image("pages/Florence-2/image_1.jpg", use_column_width=True)
|
| 15 |
+
st.markdown(""" """)
|
| 16 |
+
|
| 17 |
+
st.markdown("""
|
| 18 |
+
This model is can handle tasks that vary from document understanding to semantic segmentation 🤩
|
| 19 |
+
[Demo](https://t.co/7YJZvjhw84) | [Collection](https://t.co/Ub7FGazDz1)
|
| 20 |
+
""")
|
| 21 |
+
st.markdown(""" """)
|
| 22 |
+
|
| 23 |
+
st.image("pages/Florence-2/image_2.jpg", use_column_width=True)
|
| 24 |
+
st.markdown(""" """)
|
| 25 |
+
|
| 26 |
+
st.markdown("""
|
| 27 |
+
The difference from previous models is that the authors have compiled a dataset that consists of 126M images with 5.4B annotations labelled with their own data engine ↓↓
|
| 28 |
+
""")
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.image("pages/Florence-2/image_3.jpg", use_column_width=True)
|
| 32 |
+
st.markdown(""" """)
|
| 33 |
+
|
| 34 |
+
st.markdown("""
|
| 35 |
+
The dataset also offers more variety in annotations compared to other datasets, it has region level and image level annotations with more variety in semantic granularity as well!
|
| 36 |
+
""")
|
| 37 |
+
st.markdown(""" """)
|
| 38 |
+
|
| 39 |
+
st.image("pages/Florence-2/image_4.jpg", use_column_width=True)
|
| 40 |
+
st.markdown(""" """)
|
| 41 |
+
|
| 42 |
+
st.markdown("""
|
| 43 |
+
The model is a similar architecture to previous models, an image encoder, a multimodality encoder with text decoder.
|
| 44 |
+
The authors have compiled the multitask dataset with prompts for each task which makes the model trainable on multiple tasks 🤗
|
| 45 |
+
""")
|
| 46 |
+
st.markdown(""" """)
|
| 47 |
+
|
| 48 |
+
st.image("pages/Florence-2/image_5.jpg", use_column_width=True)
|
| 49 |
+
st.markdown(""" """)
|
| 50 |
+
|
| 51 |
+
st.markdown("""
|
| 52 |
+
You also fine-tune this model on any task of choice, the authors also released different results on downstream tasks and report their results when un/freezing vision encoder 🤓📉
|
| 53 |
+
They have released fine-tuned models too, you can find them in the collection above 🤗
|
| 54 |
+
""")
|
| 55 |
+
st.markdown(""" """)
|
| 56 |
+
|
| 57 |
+
st.image("pages/Florence-2/image_6.jpg", use_column_width=True)
|
| 58 |
+
st.markdown(""" """)
|
| 59 |
+
|
| 60 |
+
st.info("""
|
| 61 |
+
Ressources:
|
| 62 |
+
[Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks](https://arxiv.org/abs/2311.06242)
|
| 63 |
+
by Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan (2023)
|
| 64 |
+
[Hugging Face blog post](https://huggingface.co/blog/finetune-florence2)""", icon="📚")
|
| 65 |
+
|
| 66 |
+
st.markdown(""" """)
|
| 67 |
+
st.markdown(""" """)
|
| 68 |
+
st.markdown(""" """)
|
| 69 |
+
col1, col2, col3 = st.columns(3)
|
| 70 |
+
with col1:
|
| 71 |
+
if st.button('Previous paper', use_container_width=True):
|
| 72 |
+
switch_page("Depth Anything V2")
|
| 73 |
+
with col2:
|
| 74 |
+
if st.button('Home', use_container_width=True):
|
| 75 |
+
switch_page("Home")
|
| 76 |
+
with col3:
|
| 77 |
+
if st.button('Next paper', use_container_width=True):
|
| 78 |
+
switch_page("4M-21")
|
pages/19_4M-21.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("4M-21")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1804138208814309626) (June 21, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""
|
| 10 |
+
EPFL and Apple just released 4M-21: single any-to-any model that can do anything from text-to-image generation to generating depth masks! 🙀
|
| 11 |
+
Let's unpack 🧶
|
| 12 |
+
""")
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.image("pages/4M-21/image_1.jpg", use_column_width=True)
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.markdown("""4M is a multimodal training [framework](https://t.co/jztLublfSF) introduced by Apple and EPFL.
|
| 19 |
+
Resulting model takes image and text and output image and text 🤩
|
| 20 |
+
[Models](https://t.co/1LC0rAohEl) | [Demo](https://t.co/Ra9qbKcWeY)
|
| 21 |
+
""")
|
| 22 |
+
st.markdown(""" """)
|
| 23 |
+
|
| 24 |
+
st.video("pages/4M-21/video_1.mp4", format="video/mp4")
|
| 25 |
+
st.markdown(""" """)
|
| 26 |
+
|
| 27 |
+
st.markdown("""
|
| 28 |
+
This model consists of transformer encoder and decoder, where the key to multimodality lies in input and output data:
|
| 29 |
+
input and output tokens are decoded to generate bounding boxes, generated image's pixels, captions and more!
|
| 30 |
+
""")
|
| 31 |
+
st.markdown(""" """)
|
| 32 |
+
|
| 33 |
+
st.image("pages/4M-21/image_2.jpg", use_column_width=True)
|
| 34 |
+
st.markdown(""" """)
|
| 35 |
+
|
| 36 |
+
st.markdown("""
|
| 37 |
+
This model also learnt to generate canny maps, SAM edges and other things for steerable text-to-image generation 🖼️
|
| 38 |
+
The authors only added image-to-all capabilities for the demo, but you can try to use this model for text-to-image generation as well ☺️
|
| 39 |
+
""")
|
| 40 |
+
st.markdown(""" """)
|
| 41 |
+
|
| 42 |
+
st.image("pages/4M-21/image_3.jpg", use_column_width=True)
|
| 43 |
+
st.markdown(""" """)
|
| 44 |
+
|
| 45 |
+
st.markdown("""
|
| 46 |
+
In the project page you can also see the model's text-to-image and steered generation capabilities with model's own outputs as control masks!
|
| 47 |
+
""")
|
| 48 |
+
st.markdown(""" """)
|
| 49 |
+
|
| 50 |
+
st.video("pages/4M-21/video_2.mp4", format="video/mp4")
|
| 51 |
+
st.markdown(""" """)
|
| 52 |
+
|
| 53 |
+
st.info("""
|
| 54 |
+
Ressources
|
| 55 |
+
[4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities](https://arxiv.org/abs/2406.09406) by Roman Bachmann, Oğuzhan Fatih Kar, David Mizrahi, Ali Garjani, Mingfei Gao, David Griffiths, Jiaming Hu, Afshin Dehghan, Amir Zamir (2024)
|
| 56 |
+
[GitHub](https://github.com/apple/ml-4m/)""", icon="📚")
|
| 57 |
+
|
| 58 |
+
st.markdown(""" """)
|
| 59 |
+
st.markdown(""" """)
|
| 60 |
+
st.markdown(""" """)
|
| 61 |
+
col1, col2, col3 = st.columns(3)
|
| 62 |
+
with col1:
|
| 63 |
+
if st.button('Previous paper', use_container_width=True):
|
| 64 |
+
switch_page("Florence-2")
|
| 65 |
+
with col2:
|
| 66 |
+
if st.button('Home', use_container_width=True):
|
| 67 |
+
switch_page("Home")
|
| 68 |
+
with col3:
|
| 69 |
+
if st.button('Next paper', use_container_width=True):
|
| 70 |
+
switch_page("RT-DETR")
|
pages/1_MobileSAM.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("MobileSAM")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1738959605542076863) (December 24, 2023)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""Read the MobileSAM paper this weekend 📖 Sharing some insights!
|
| 10 |
+
The idea 💡: SAM model consist of three parts, a heavy image encoder, a prompt encoder (prompt can be text, bounding box, mask or point) and a mask decoder.
|
| 11 |
+
|
| 12 |
+
To make the SAM model smaller without compromising from the performance, the authors looked into three types of distillation.
|
| 13 |
+
First one is distilling the decoder outputs directly (a more naive approach) with a completely randomly initialized small ViT and randomly initialized mask decoder.
|
| 14 |
+
However, when the ViT and the decoder are both in a bad state, this doesn't work well.
|
| 15 |
+
""")
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.image("pages/MobileSAM/image_1.jpeg", use_column_width=True)
|
| 19 |
+
st.markdown(""" """)
|
| 20 |
+
|
| 21 |
+
st.markdown("""
|
| 22 |
+
The second type of distillation is called semi-coupled, where the authors only randomly initialized the ViT image encoder and kept the mask decoder.
|
| 23 |
+
This is called semi-coupled because the image encoder distillation still depends on the mask decoder (see below 👇)
|
| 24 |
+
""")
|
| 25 |
+
st.markdown(""" """)
|
| 26 |
+
|
| 27 |
+
st.image("pages/MobileSAM/image_2.jpg", use_column_width=True)
|
| 28 |
+
st.markdown(""" """)
|
| 29 |
+
|
| 30 |
+
st.markdown("""
|
| 31 |
+
The last type of distillation, [decoupled distillation](https://openaccess.thecvf.com/content/CVPR2022/papers/Zhao_Decoupled_Knowledge_Distillation_CVPR_2022_paper.pdf), is the most intuitive IMO.
|
| 32 |
+
The authors have "decoupled" image encoder altogether and have frozen the mask decoder and didn't really distill based on generated masks.
|
| 33 |
+
This makes sense as the bottleneck here is the encoder itself and most of the time, distillation works well with encoding.
|
| 34 |
+
""")
|
| 35 |
+
st.markdown(""" """)
|
| 36 |
+
|
| 37 |
+
st.image("pages/MobileSAM/image_3.jpeg", use_column_width=True)
|
| 38 |
+
st.markdown(""" """)
|
| 39 |
+
|
| 40 |
+
st.markdown("""
|
| 41 |
+
Finally, they found out that decoupled distillation performs better than coupled distillation by means of mean IoU and requires much less compute! ♥️
|
| 42 |
+
""")
|
| 43 |
+
st.markdown(""" """)
|
| 44 |
+
|
| 45 |
+
st.image("pages/MobileSAM/image_4.jpg", use_column_width=True)
|
| 46 |
+
st.markdown(""" """)
|
| 47 |
+
|
| 48 |
+
st.markdown("""
|
| 49 |
+
Wanted to leave some links here if you'd like to try yourself 👇
|
| 50 |
+
- MobileSAM [demo](https://huggingface.co/spaces/dhkim2810/MobileSAMMobileSAM)
|
| 51 |
+
- Model [repository](https://huggingface.co/dhkim2810/MobileSAM)
|
| 52 |
+
|
| 53 |
+
If you'd like to experiment around TinyViT, [timm library](https://huggingface.co/docs/timm/index) ([Ross Wightman](https://x.com/wightmanr)) has a bunch of [checkpoints available](https://huggingface.co/models?sort=trending&search=timm%2Ftinyvit).
|
| 54 |
+
""")
|
| 55 |
+
st.markdown(""" """)
|
| 56 |
+
|
| 57 |
+
st.image("pages/MobileSAM/image_5.jpeg", use_column_width=True)
|
| 58 |
+
st.markdown(""" """)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
st.info("""
|
| 62 |
+
Ressources:
|
| 63 |
+
[Faster Segment Anything: Towards Lightweight SAM for Mobile Applications](https://arxiv.org/abs/2306.14289)
|
| 64 |
+
by Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, Choong Seon Hong (2023)
|
| 65 |
+
[GitHub](https://github.com/ChaoningZhang/MobileSAM)""", icon="📚")
|
| 66 |
+
|
| 67 |
+
st.markdown(""" """)
|
| 68 |
+
st.markdown(""" """)
|
| 69 |
+
st.markdown(""" """)
|
| 70 |
+
col1, col2, col3= st.columns(3)
|
| 71 |
+
with col1:
|
| 72 |
+
if st.button('Previous paper', use_container_width=True):
|
| 73 |
+
switch_page("Home")
|
| 74 |
+
with col2:
|
| 75 |
+
if st.button('Home', use_container_width=True):
|
| 76 |
+
switch_page("Home")
|
| 77 |
+
with col3:
|
| 78 |
+
if st.button('Next paper', use_container_width=True):
|
| 79 |
+
switch_page("OneFormer")
|
pages/20_RT-DETR.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("RT-DETR")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1807790959884665029) (July 1, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""Real-time DEtection Transformer (RT-DETR) landed in 🤗 Transformers with Apache 2.0 license 😍
|
| 10 |
+
Do DETRs Beat YOLOs on Real-time Object Detection? Keep reading 👀
|
| 11 |
+
""")
|
| 12 |
+
st.markdown(""" """)
|
| 13 |
+
|
| 14 |
+
st.video("pages/RT-DETR/video_1.mp4", format="video/mp4")
|
| 15 |
+
st.markdown(""" """)
|
| 16 |
+
|
| 17 |
+
st.markdown("""
|
| 18 |
+
Short answer, it does! 📖 [notebook](https://t.co/NNRpG9cAEa), 🔖 [models](https://t.co/ctwWQqNcEt), 🔖 [demo](https://t.co/VrmDDDjoNw)
|
| 19 |
+
|
| 20 |
+
YOLO models are known to be super fast for real-time computer vision, but they have a downside with being volatile to NMS 🥲
|
| 21 |
+
Transformer-based models on the other hand are computationally not as efficient 🥲
|
| 22 |
+
Isn't there something in between? Enter RT-DETR!
|
| 23 |
+
|
| 24 |
+
The authors combined CNN backbone, multi-stage hybrid decoder (combining convs and attn) with a transformer decoder ⇓
|
| 25 |
+
""")
|
| 26 |
+
st.markdown(""" """)
|
| 27 |
+
|
| 28 |
+
st.image("pages/RT-DETR/image_1.jpg", use_column_width=True)
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.markdown("""
|
| 32 |
+
In the paper, authors also claim one can adjust speed by changing decoder layers without retraining altogether.
|
| 33 |
+
They also conduct many ablation studies and try different decoders.
|
| 34 |
+
""")
|
| 35 |
+
st.markdown(""" """)
|
| 36 |
+
|
| 37 |
+
st.image("pages/RT-DETR/image_2.jpg", use_column_width=True)
|
| 38 |
+
st.markdown(""" """)
|
| 39 |
+
|
| 40 |
+
st.markdown("""
|
| 41 |
+
The authors find out that the model performs better in terms of speed and accuracy compared to the previous state-of-the-art 🤩
|
| 42 |
+
""")
|
| 43 |
+
st.markdown(""" """)
|
| 44 |
+
|
| 45 |
+
st.image("pages/RT-DETR/image_3.jpg", use_column_width=True)
|
| 46 |
+
st.markdown(""" """)
|
| 47 |
+
|
| 48 |
+
st.info("""
|
| 49 |
+
Ressources:
|
| 50 |
+
[DETRs Beat YOLOs on Real-time Object Detection](https://arxiv.org/abs/2304.08069)
|
| 51 |
+
by Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen (2023)
|
| 52 |
+
[GitHub](https://github.com/lyuwenyu/RT-DETR/)
|
| 53 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/main/en/model_doc/rt_detr)""", icon="📚")
|
| 54 |
+
|
| 55 |
+
st.markdown(""" """)
|
| 56 |
+
st.markdown(""" """)
|
| 57 |
+
st.markdown(""" """)
|
| 58 |
+
col1, col2, col3 = st.columns(3)
|
| 59 |
+
with col1:
|
| 60 |
+
if st.button('Previous paper', use_container_width=True):
|
| 61 |
+
switch_page("4M-21")
|
| 62 |
+
with col2:
|
| 63 |
+
if st.button('Home', use_container_width=True):
|
| 64 |
+
switch_page("Home")
|
| 65 |
+
with col3:
|
| 66 |
+
if st.button('Next paper', use_container_width=True):
|
| 67 |
+
switch_page("Llava-NeXT-Interleave")
|
pages/21_Llava-NeXT-Interleave.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("Llava-NeXT-Interleave")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1813560292397203630) (July 17, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""The vision language model in this video is 0.5B and can take in image, video and 3D! 🤯
|
| 10 |
+
Llava-NeXT-Interleave is a new vision language model trained on interleaved image, video and 3D data keep reading ⥥⥥
|
| 11 |
+
""")
|
| 12 |
+
st.markdown(""" """)
|
| 13 |
+
|
| 14 |
+
st.video("pages/Llava-NeXT-Interleave/video_1.mp4", format="video/mp4")
|
| 15 |
+
st.markdown(""" """)
|
| 16 |
+
|
| 17 |
+
st.markdown("""This model comes with 0.5B, 7B and 7B-DPO variants, all can be used with Transformers 😍
|
| 18 |
+
[Collection of models](https://t.co/sZsaglSXa3) | [Demo](https://t.co/FbpaMWJY8k)
|
| 19 |
+
See how to use below 👇🏻
|
| 20 |
+
""")
|
| 21 |
+
st.markdown(""" """)
|
| 22 |
+
|
| 23 |
+
st.image("pages/Llava-NeXT-Interleave/image_1.jpg", use_column_width=True)
|
| 24 |
+
st.markdown(""" """)
|
| 25 |
+
|
| 26 |
+
st.markdown("""
|
| 27 |
+
Authors of this paper have explored training <a href='LLaVA-NeXT' target='_self'>LLaVA-NeXT</a> on interleaved data where the data consists of multiple modalities, including image(s), video, 3D 📚
|
| 28 |
+
They have discovered that interleaved data increases results across all benchmarks!
|
| 29 |
+
""", unsafe_allow_html=True)
|
| 30 |
+
st.markdown(""" """)
|
| 31 |
+
|
| 32 |
+
st.image("pages/Llava-NeXT-Interleave/image_2.jpg", use_column_width=True)
|
| 33 |
+
st.markdown(""" """)
|
| 34 |
+
|
| 35 |
+
st.markdown("""
|
| 36 |
+
The model can do task transfer from single image tasks to multiple images 🤯
|
| 37 |
+
The authors have trained the model on single images and code yet the model can solve coding with multiple images.
|
| 38 |
+
""")
|
| 39 |
+
st.markdown(""" """)
|
| 40 |
+
|
| 41 |
+
st.image("pages/Llava-NeXT-Interleave/image_3.jpg", use_column_width=True)
|
| 42 |
+
st.markdown(""" """)
|
| 43 |
+
|
| 44 |
+
st.markdown("""
|
| 45 |
+
Same applies to other modalities, see below for video:
|
| 46 |
+
""")
|
| 47 |
+
st.markdown(""" """)
|
| 48 |
+
|
| 49 |
+
st.image("pages/Llava-NeXT-Interleave/image_4.jpg", use_column_width=True)
|
| 50 |
+
st.markdown(""" """)
|
| 51 |
+
|
| 52 |
+
st.markdown("""
|
| 53 |
+
The model also has document understanding capabilities and many real-world application areas.
|
| 54 |
+
""")
|
| 55 |
+
st.markdown(""" """)
|
| 56 |
+
|
| 57 |
+
st.image("pages/Llava-NeXT-Interleave/image_5.jpg", use_column_width=True)
|
| 58 |
+
st.markdown(""" """)
|
| 59 |
+
|
| 60 |
+
st.markdown("""
|
| 61 |
+
This release also comes with the dataset this model was fine-tuned on 📖 [M4-Instruct-Data](https://t.co/rutXMtNC0I)
|
| 62 |
+
""")
|
| 63 |
+
st.markdown(""" """)
|
| 64 |
+
|
| 65 |
+
st.image("pages/Llava-NeXT-Interleave/image_6.jpg", use_column_width=True)
|
| 66 |
+
st.markdown(""" """)
|
| 67 |
+
|
| 68 |
+
st.info("""
|
| 69 |
+
Ressources:
|
| 70 |
+
[LLaVA-NeXT: Tackling Multi-image, Video, and 3D in Large Multimodal Models](https://llava-vl.github.io/blog/2024-06-16-llava-next-interleave/)
|
| 71 |
+
by Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, Chunyuan Li (2024)
|
| 72 |
+
[GitHub](https://github.com/LLaVA-VL/LLaVA-NeXT/blob/inference/docs/LLaVA-NeXT-Interleave.md)""", icon="📚")
|
| 73 |
+
|
| 74 |
+
st.markdown(""" """)
|
| 75 |
+
st.markdown(""" """)
|
| 76 |
+
st.markdown(""" """)
|
| 77 |
+
col1, col2, col3 = st.columns(3)
|
| 78 |
+
with col1:
|
| 79 |
+
if st.button('Previous paper', use_container_width=True):
|
| 80 |
+
switch_page("RT-DETR")
|
| 81 |
+
with col2:
|
| 82 |
+
if st.button('Home', use_container_width=True):
|
| 83 |
+
switch_page("Home")
|
| 84 |
+
with col3:
|
| 85 |
+
if st.button('Next paper', use_container_width=True):
|
| 86 |
+
switch_page("Chameleon")
|
pages/22_Chameleon.py
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("Chameleon")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1814278511785312320) (July 19, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""Chameleon 🦎 by Meta is now available in 🤗 Transformers.
|
| 10 |
+
A multimodal model that comes in 7B and 34B sizes 🤩
|
| 11 |
+
But what makes this model so special? Keep reading ⇣
|
| 12 |
+
""")
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.video("pages/Chameleon/video_1.mp4", format="video/mp4")
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.markdown("""
|
| 19 |
+
[Demo](https://t.co/GsGE17fSdI) | [Models](https://t.co/cWUiVbsRz6)
|
| 20 |
+
Find below the API to load this model locally use it ⬇️
|
| 21 |
+
""")
|
| 22 |
+
st.markdown(""" """)
|
| 23 |
+
|
| 24 |
+
st.image("pages/Chameleon/image_1.jpg", use_column_width=True)
|
| 25 |
+
st.markdown(""" """)
|
| 26 |
+
|
| 27 |
+
st.markdown("""Chameleon is a unique model: it attempts to scale early fusion 🤨
|
| 28 |
+
But what is early fusion?
|
| 29 |
+
Modern vision language models use a vision encoder with a projection layer to project image embeddings so it can be promptable to text decoder.""")
|
| 30 |
+
st.markdown(""" """)
|
| 31 |
+
|
| 32 |
+
st.image("pages/Chameleon/image_2.jpg", use_column_width=True)
|
| 33 |
+
st.markdown(""" """)
|
| 34 |
+
|
| 35 |
+
st.markdown("""
|
| 36 |
+
Early fusion on the other hand attempts to fuse all features together (image patches and text) by using an image tokenizer and all tokens are projected into a shared space, which enables seamless generation 😏
|
| 37 |
+
""")
|
| 38 |
+
st.markdown(""" """)
|
| 39 |
+
|
| 40 |
+
st.image("pages/Chameleon/image_3.jpg", use_column_width=True)
|
| 41 |
+
st.markdown(""" """)
|
| 42 |
+
|
| 43 |
+
st.markdown("""
|
| 44 |
+
Authors have also introduced different architectural improvements (QK norm and revise placement of layer norms) for scalable and stable training.
|
| 45 |
+
This way they were able to increase the token count (5x tokens compared to Llama 3 which is a must with early-fusion IMO) .
|
| 46 |
+
""")
|
| 47 |
+
st.markdown(""" """)
|
| 48 |
+
|
| 49 |
+
st.image("pages/Chameleon/image_4.jpg", use_column_width=True)
|
| 50 |
+
st.markdown(""" """)
|
| 51 |
+
|
| 52 |
+
st.markdown("""
|
| 53 |
+
This model is an any-to-any model thanks to early fusion: it can take image and text input and output image and text, but image generation are disabled to prevent malicious use.
|
| 54 |
+
""")
|
| 55 |
+
st.markdown(""" """)
|
| 56 |
+
|
| 57 |
+
st.image("pages/Chameleon/image_5.jpg", use_column_width=True)
|
| 58 |
+
st.markdown(""" """)
|
| 59 |
+
|
| 60 |
+
st.markdown("""
|
| 61 |
+
One can also do text-only prompting, authors noted the model catches up with larger LLMs, and you can also see how it compares to VLMs with image-text prompting.
|
| 62 |
+
""")
|
| 63 |
+
st.markdown(""" """)
|
| 64 |
+
|
| 65 |
+
st.image("pages/Chameleon/image_6.jpg", use_column_width=True)
|
| 66 |
+
st.image("pages/Chameleon/image_6.jpg", use_column_width=True)
|
| 67 |
+
st.markdown(""" """)
|
| 68 |
+
|
| 69 |
+
st.info("""
|
| 70 |
+
Ressources:
|
| 71 |
+
[Chameleon: Mixed-Modal Early-Fusion Foundation Models](https://arxiv.org/abs/2405.09818)
|
| 72 |
+
by Chameleon Team (2024)
|
| 73 |
+
[GitHub](https://github.com/facebookresearch/chameleon)
|
| 74 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/chameleon)""", icon="📚")
|
| 75 |
+
|
| 76 |
+
st.markdown(""" """)
|
| 77 |
+
st.markdown(""" """)
|
| 78 |
+
st.markdown(""" """)
|
| 79 |
+
col1, col2, col3 = st.columns(3)
|
| 80 |
+
with col1:
|
| 81 |
+
if st.button('Previous paper', use_container_width=True):
|
| 82 |
+
switch_page("Llava-NeXT-Interleave")
|
| 83 |
+
with col2:
|
| 84 |
+
if st.button('Home', use_container_width=True):
|
| 85 |
+
switch_page("Home")
|
| 86 |
+
with col3:
|
| 87 |
+
if st.button('Next paper', use_container_width=True):
|
| 88 |
+
switch_page("Video-LLaVA")
|
pages/23_Video-LLaVA.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("Video-LLaVA")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://x.com/mervenoyann/status/1816427325073842539) (July 25, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""We have recently merged Video-LLaVA to 🤗 Transformers! 🎞️
|
| 10 |
+
What makes this model different? Keep reading ⇊
|
| 11 |
+
""")
|
| 12 |
+
st.markdown(""" """)
|
| 13 |
+
|
| 14 |
+
st.video("pages/Video-LLaVA/video_1.mp4", format="video/mp4")
|
| 15 |
+
st.markdown(""" """)
|
| 16 |
+
|
| 17 |
+
st.markdown("""[Demo](https://t.co/MVP14uEj9e) | [Model](https://t.co/oqSCMUqwJo)
|
| 18 |
+
See below how to initialize the model and processor and infer ⬇️
|
| 19 |
+
""")
|
| 20 |
+
st.markdown(""" """)
|
| 21 |
+
|
| 22 |
+
st.image("pages/Video-LLaVA/image_1.jpg", use_column_width=True)
|
| 23 |
+
st.markdown(""" """)
|
| 24 |
+
|
| 25 |
+
st.markdown("""
|
| 26 |
+
Compared to other models that take image and video input and either project them separately or downsampling video and projecting selected frames, Video-LLaVA is converting images and videos to unified representation and project them using a shared projection layer.
|
| 27 |
+
""")
|
| 28 |
+
st.markdown(""" """)
|
| 29 |
+
|
| 30 |
+
st.image("pages/Video-LLaVA/image_2.jpg", use_column_width=True)
|
| 31 |
+
st.markdown(""" """)
|
| 32 |
+
|
| 33 |
+
st.markdown("""
|
| 34 |
+
It uses Vicuna 1.5 as the language model and LanguageBind's own encoders that's based on OpenCLIP, these encoders project the modalities to an unified representation before passing to projection layer.
|
| 35 |
+
""")
|
| 36 |
+
st.markdown(""" """)
|
| 37 |
+
|
| 38 |
+
st.image("pages/Video-LLaVA/image_3.jpg", use_column_width=True)
|
| 39 |
+
st.markdown(""" """)
|
| 40 |
+
|
| 41 |
+
st.markdown("""
|
| 42 |
+
I feel like one of the coolest features of this model is the joint understanding which is also introduced recently with many models.
|
| 43 |
+
It's a relatively older model but ahead of it's time and works very well!
|
| 44 |
+
""")
|
| 45 |
+
st.markdown(""" """)
|
| 46 |
+
|
| 47 |
+
st.image("pages/Video-LLaVA/image_4.jpg", use_column_width=True)
|
| 48 |
+
st.markdown(""" """)
|
| 49 |
+
|
| 50 |
+
st.info("""
|
| 51 |
+
Ressources:
|
| 52 |
+
[Video-LLaVA: Learning United Visual Representation by Alignment Before Projection](https://arxiv.org/abs/2311.10122)
|
| 53 |
+
by Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, Li Yuan (2023)
|
| 54 |
+
[GitHub](https://github.com/PKU-YuanGroup/Video-LLaVA)
|
| 55 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/main/en/model_doc/video_llava)
|
| 56 |
+
""", icon="📚")
|
| 57 |
+
|
| 58 |
+
st.markdown(""" """)
|
| 59 |
+
st.markdown(""" """)
|
| 60 |
+
st.markdown(""" """)
|
| 61 |
+
col1, col2, col3 = st.columns(3)
|
| 62 |
+
with col1:
|
| 63 |
+
if st.button('Previous paper', use_container_width=True):
|
| 64 |
+
switch_page("Chameleon")
|
| 65 |
+
with col2:
|
| 66 |
+
if st.button('Home', use_container_width=True):
|
| 67 |
+
switch_page("Home")
|
| 68 |
+
with col3:
|
| 69 |
+
if st.button('Next paper', use_container_width=True):
|
| 70 |
+
switch_page("SAMv2")
|
pages/24_SAMv2.py
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("SAMv2")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1818675981634109701) (July 31, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""SAMv2 is just mindblowingly good 😍
|
| 10 |
+
Learn what makes this model so good at video segmentation, keep reading 🦆⇓
|
| 11 |
+
""")
|
| 12 |
+
st.markdown(""" """)
|
| 13 |
+
|
| 14 |
+
col1, col2, col3 = st.columns(3)
|
| 15 |
+
with col2:
|
| 16 |
+
st.video("pages/SAMv2/video_1.mp4", format="video/mp4")
|
| 17 |
+
st.markdown(""" """)
|
| 18 |
+
|
| 19 |
+
st.markdown("""
|
| 20 |
+
Check out the [demo](https://t.co/35ixEZgPaf) by [skalskip92](https://x.com/skalskip92) to see how to use the model locally.
|
| 21 |
+
Check out Meta's [demo](https://t.co/Bcbli9Cfim) where you can edit segmented instances too!
|
| 22 |
+
|
| 23 |
+
Segment Anything Model by Meta was released as a universal segmentation model in which you could prompt a box or point prompt to segment the object of interest
|
| 24 |
+
SAM consists of an image encoder to encode images, a prompt encoder to encode prompts, then outputs of these two are given to a mask decoder to generate masks.
|
| 25 |
+
""")
|
| 26 |
+
st.markdown(""" """)
|
| 27 |
+
|
| 28 |
+
st.image("pages/SAMv2/image_1.jpg", use_column_width=True)
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.markdown("""
|
| 32 |
+
However SAM doesn't naturally track object instances in videos, one needs to make sure to prompt the same mask or point prompt for that instance in each frame and feed each frame, which is infeasible 😔
|
| 33 |
+
But don't fret, that is where SAMv2 comes in with a memory module!
|
| 34 |
+
|
| 35 |
+
SAMv2 defines a new task called "masklet prediction" here masklet refers to the same mask instance throughout the frames 🎞️
|
| 36 |
+
Unlike SAM, SAM 2 decoder is not fed the image embedding directly from an image encoder, but attention of memories of prompted frames and object pointers.
|
| 37 |
+
""")
|
| 38 |
+
st.markdown(""" """)
|
| 39 |
+
|
| 40 |
+
st.image("pages/SAMv2/image_2.jpg", use_column_width=True)
|
| 41 |
+
st.markdown(""" """)
|
| 42 |
+
|
| 43 |
+
st.markdown("""
|
| 44 |
+
🖼️ These "memories" are essentially past predictions of object of interest up to a number of recent frames,
|
| 45 |
+
and are in form of feature maps of location info (spatial feature maps).
|
| 46 |
+
👉🏻 The object pointers are high level semantic information of the object of interest based on.
|
| 47 |
+
|
| 48 |
+
Just like SAM paper SAMv2 depends on a data engine, and the dataset it generated comes with the release: SA-V 🤯
|
| 49 |
+
This dataset is gigantic, it has 190.9K manual masklet annotations and 451.7K automatic masklets!
|
| 50 |
+
""")
|
| 51 |
+
st.markdown(""" """)
|
| 52 |
+
|
| 53 |
+
st.image("pages/SAMv2/image_3.jpg", use_column_width=True)
|
| 54 |
+
st.markdown(""" """)
|
| 55 |
+
|
| 56 |
+
st.markdown("""
|
| 57 |
+
Initially they apply SAM to each frame to assist human annotators to annotate a video at six FPS for high quality data,
|
| 58 |
+
in the second phase they add SAM and SAM2 to generate masklets across time consistently. Finally they use SAM2 to refine the masklets.
|
| 59 |
+
|
| 60 |
+
They have evaluated this model on J&F score (Jaccard Index + F-measure for contour acc) which is used to evaluate zero-shot
|
| 61 |
+
video segmentation benchmarks.
|
| 62 |
+
SAMv2 seems to outperform two previously sota models that are built on top of SAM! 🥹
|
| 63 |
+
""")
|
| 64 |
+
st.markdown(""" """)
|
| 65 |
+
|
| 66 |
+
st.image("pages/SAMv2/image_4.jpg", use_column_width=True)
|
| 67 |
+
st.markdown(""" """)
|
| 68 |
+
|
| 69 |
+
st.info("""
|
| 70 |
+
Ressources:
|
| 71 |
+
[SAM 2: Segment Anything in Images and Videos]()
|
| 72 |
+
by Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer (2024)
|
| 73 |
+
[GitHub](https://github.com/facebookresearch/segment-anything-2)
|
| 74 |
+
[Hugging Face documentation]()""", icon="📚")
|
| 75 |
+
|
| 76 |
+
st.markdown(""" """)
|
| 77 |
+
st.markdown(""" """)
|
| 78 |
+
st.markdown(""" """)
|
| 79 |
+
col1, col2, col3 = st.columns(3)
|
| 80 |
+
with col1:
|
| 81 |
+
if st.button('Previous paper', use_container_width=True):
|
| 82 |
+
switch_page("Video-LLaVA")
|
| 83 |
+
with col2:
|
| 84 |
+
if st.button('Home', use_container_width=True):
|
| 85 |
+
switch_page("Home")
|
| 86 |
+
with col3:
|
| 87 |
+
if st.button('Next paper', use_container_width=True):
|
| 88 |
+
switch_page("Home")
|
pages/2_Oneformer.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("OneFormer")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1739707076501221608) (December 26, 2023)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""
|
| 10 |
+
OneFormer: one model to segment them all? 🤯
|
| 11 |
+
I was looking into paperswithcode leaderboards when I came across OneFormer for the first time so it was time to dig in!
|
| 12 |
+
""")
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.image("pages/OneFormer/image_1.jpeg", use_column_width=True)
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.markdown("""OneFormer is a "truly universal" model for semantic, instance and panoptic segmentation tasks ⚔️
|
| 19 |
+
What makes is truly universal is that it's a single model that is trained only once and can be used across all tasks 👇
|
| 20 |
+
""")
|
| 21 |
+
st.markdown(""" """)
|
| 22 |
+
|
| 23 |
+
st.image("pages/OneFormer/image_2.jpeg", use_column_width=True)
|
| 24 |
+
st.markdown(""" """)
|
| 25 |
+
|
| 26 |
+
st.markdown("""
|
| 27 |
+
The enabler here is the text conditioning, i.e. the model is given a text query that states task type along with the appropriate input, and using contrastive loss, the model learns the difference between different task types 👇
|
| 28 |
+
""")
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.image("pages/OneFormer/image_3.jpeg", use_column_width=True)
|
| 32 |
+
st.markdown(""" """)
|
| 33 |
+
|
| 34 |
+
st.markdown("""Thanks to 🤗 Transformers, you can easily use the model!
|
| 35 |
+
I have drafted a [notebook](https://t.co/cBylk1Uv20) for you to try right away 😊
|
| 36 |
+
You can also check out the [Space](https://t.co/31GxlVo1W5) without checking out the code itself.
|
| 37 |
+
""")
|
| 38 |
+
st.markdown(""" """)
|
| 39 |
+
|
| 40 |
+
st.image("pages/OneFormer/image_4.jpeg", use_column_width=True)
|
| 41 |
+
st.markdown(""" """)
|
| 42 |
+
|
| 43 |
+
st.info("""
|
| 44 |
+
Ressources:
|
| 45 |
+
[OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220)
|
| 46 |
+
by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi (2022)
|
| 47 |
+
[GitHub](https://github.com/SHI-Labs/OneFormer)
|
| 48 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/oneformer)""", icon="📚")
|
| 49 |
+
|
| 50 |
+
st.markdown(""" """)
|
| 51 |
+
st.markdown(""" """)
|
| 52 |
+
st.markdown(""" """)
|
| 53 |
+
col1, col2, col3 = st.columns(3)
|
| 54 |
+
with col1:
|
| 55 |
+
if st.button('Previous paper', use_container_width=True):
|
| 56 |
+
switch_page("MobileSAM")
|
| 57 |
+
with col2:
|
| 58 |
+
if st.button('Home', use_container_width=True):
|
| 59 |
+
switch_page("Home")
|
| 60 |
+
with col3:
|
| 61 |
+
if st.button('Next paper', use_container_width=True):
|
| 62 |
+
switch_page("VITMAE")
|
pages/3_VITMAE.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("VITMAE")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1740688304784183664) (December 29, 2023)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""Just read VitMAE paper, sharing some highlights 🧶
|
| 10 |
+
ViTMAE is a simply yet effective self-supervised pre-training technique, where authors combined vision transformer with masked autoencoder.
|
| 11 |
+
The images are first masked (75 percent of the image!) and then the model tries to learn about the features through trying to reconstruct the original image!
|
| 12 |
+
""")
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.image("pages/VITMAE/image_1.jpeg", use_column_width=True)
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.markdown("""The image is not masked, but rather only the visible patches are fed to the encoder (and that is the only thing encoder sees!).
|
| 19 |
+
Next, a mask token is added to where the masked patches are (a bit like BERT, if you will) and the mask tokens and encoded patches are fed to decoder.
|
| 20 |
+
The decoder then tries to reconstruct the original image.
|
| 21 |
+
""")
|
| 22 |
+
st.markdown(""" """)
|
| 23 |
+
|
| 24 |
+
st.image("pages/VITMAE/image_2.jpeg", use_column_width=True)
|
| 25 |
+
st.markdown(""" """)
|
| 26 |
+
|
| 27 |
+
st.markdown("""As a result, the authors found out that high masking ratio works well in fine-tuning for downstream tasks and linear probing 🤯🤯
|
| 28 |
+
""")
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.image("pages/VITMAE/image_3.jpeg", use_column_width=True)
|
| 32 |
+
st.markdown(""" """)
|
| 33 |
+
|
| 34 |
+
st.markdown("""If you want to try the model or fine-tune, all the pre-trained VITMAE models released released by Meta are available on [Huggingface](https://t.co/didvTL9Zkm).
|
| 35 |
+
We've built a [demo](https://t.co/PkuACJiKrB) for you to see the intermediate outputs and reconstruction by VITMAE.
|
| 36 |
+
|
| 37 |
+
Also there's a nice [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb) by [@NielsRogge](https://twitter.com/NielsRogge).
|
| 38 |
+
""")
|
| 39 |
+
st.markdown(""" """)
|
| 40 |
+
|
| 41 |
+
st.image("pages/VITMAE/image_4.jpeg", use_column_width=True)
|
| 42 |
+
st.markdown(""" """)
|
| 43 |
+
|
| 44 |
+
st.info("""
|
| 45 |
+
Ressources:
|
| 46 |
+
[Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377v3)
|
| 47 |
+
by LKaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick (2021)
|
| 48 |
+
[GitHub](https://github.com/facebookresearch/mae)
|
| 49 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/vit_mae)""", icon="📚")
|
| 50 |
+
|
| 51 |
+
st.markdown(""" """)
|
| 52 |
+
st.markdown(""" """)
|
| 53 |
+
st.markdown(""" """)
|
| 54 |
+
col1, col2, col3 = st.columns(3)
|
| 55 |
+
with col1:
|
| 56 |
+
if st.button('Previous paper', use_container_width=True):
|
| 57 |
+
switch_page("OneFormer")
|
| 58 |
+
with col2:
|
| 59 |
+
if st.button('Home', use_container_width=True):
|
| 60 |
+
switch_page("Home")
|
| 61 |
+
with col3:
|
| 62 |
+
if st.button('Next paper', use_container_width=True):
|
| 63 |
+
switch_page("DINOV2")
|
pages/4M-21/4M-21.md
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
EPFL and Apple just released 4M-21: single any-to-any model that can do anything from text-to-image generation to generating depth masks! 🙀 Let's unpack 🧶
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
4M is a multimodal training [framework](https://t.co/jztLublfSF) introduced by Apple and EPFL.
|
| 6 |
+
Resulting model takes image and text and output image and text 🤩
|
| 7 |
+
[Models](https://t.co/1LC0rAohEl) | [Demo](https://t.co/Ra9qbKcWeY)
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
|
| 11 |
+
This model consists of transformer encoder and decoder, where the key to multimodality lies in input and output data: input and output tokens are decoded to generate bounding boxes, generated image's pixels, captions and more!
|
| 12 |
+
|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
This model also learnt to generate canny maps, SAM edges and other things for steerable text-to-image generation 🖼️
|
| 16 |
+
The authors only added image-to-all capabilities for the demo, but you can try to use this model for text-to-image generation as well ☺️
|
| 17 |
+
|
| 18 |
+

|
| 19 |
+
|
| 20 |
+
In the project page you can also see the model's text-to-image and steered generation capabilities with model's own outputs as control masks!
|
| 21 |
+
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
> [!TIP]
|
| 26 |
+
Ressources:
|
| 27 |
+
[4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities](https://arxiv.org/abs/2406.09406)
|
| 28 |
+
by Roman Bachmann, Oğuzhan Fatih Kar, David Mizrahi, Ali Garjani, Mingfei Gao, David Griffiths, Jiaming Hu, Afshin Dehghan, Amir Zamir (2024)
|
| 29 |
+
[GitHub](https://github.com/apple/ml-4m/)
|
| 30 |
+
|
| 31 |
+
> [!NOTE]
|
| 32 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1804138208814309626) (June 21, 2024)
|
pages/4M-21/image_1.jpg
ADDED
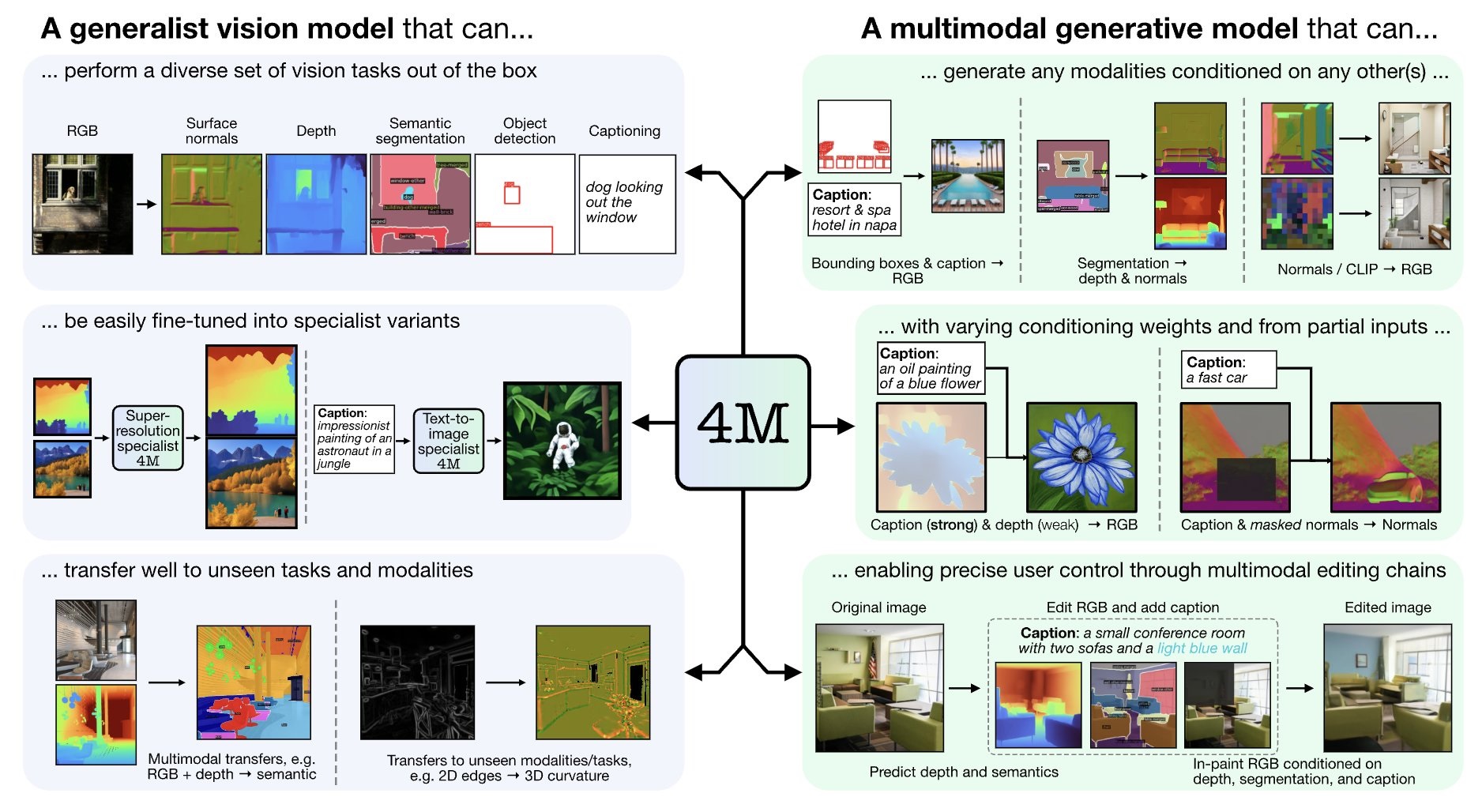
|
pages/4M-21/image_2.jpg
ADDED
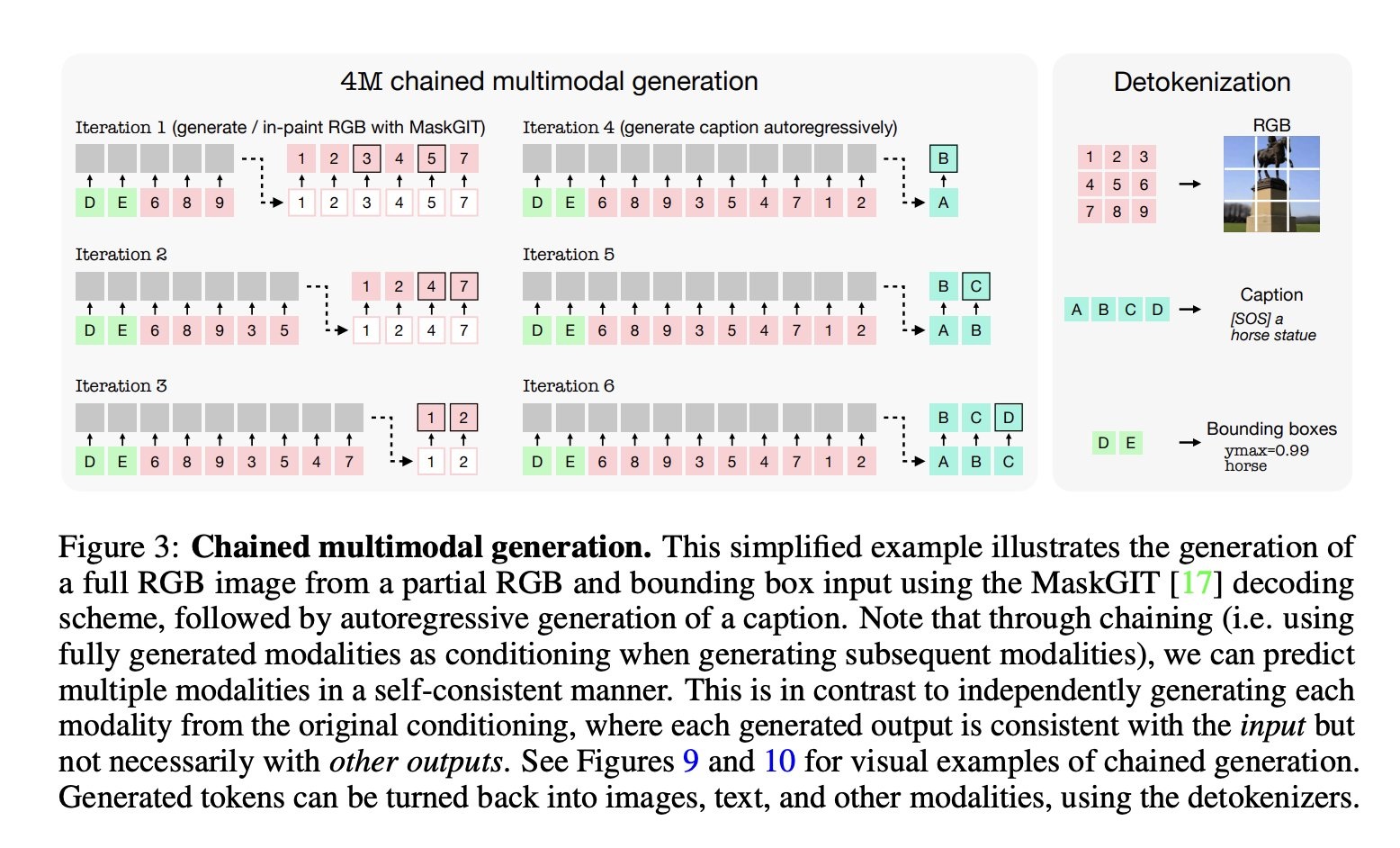
|
pages/4M-21/image_3.jpg
ADDED

|
pages/4M-21/video_1.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9cd40cb677314a9384da8e644ad3bb9eba3e23a39e776f5ce8c1437ebf3d06d8
|
| 3 |
+
size 1073547
|
pages/4M-21/video_2.mp4
ADDED
|
Binary file (461 kB). View file
|
|
|
pages/4_DINOv2.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("DINOv2")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1743290724672495827) (January 5, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""DINOv2 is the king for self-supervised learning in images 🦖🦕
|
| 10 |
+
But how does it work? I've tried to explain how it works but let's expand on it 🧶
|
| 11 |
+
""")
|
| 12 |
+
st.markdown(""" """)
|
| 13 |
+
|
| 14 |
+
st.image("pages/DINOv2/image_1.jpeg", use_column_width=True)
|
| 15 |
+
st.markdown(""" """)
|
| 16 |
+
|
| 17 |
+
st.markdown("""
|
| 18 |
+
DINOv2 is essentially DINO on steroids, so let's talk about DINOv1 first 🦕
|
| 19 |
+
It's essentially a pre-training technique to train ViTs with self-supervision, that uses an unusual way of distillation 🧟♂️👨🏻🏫.
|
| 20 |
+
Distillation is a technique where there's a large pre-trained model (teacher), and you have a smaller model (student) initialized randomly.
|
| 21 |
+
Then during training the student, you take both models'outputs, calculate divergence between them and then update the loss accordingly.
|
| 22 |
+
In this case, we have no labels! And the teacher is not pretrained!!!! 🤯
|
| 23 |
+
Well, the outputs here are the distributions, and teacher is iteratively updated according to student, which is called exponential moving average.
|
| 24 |
+
""")
|
| 25 |
+
st.markdown(""" """)
|
| 26 |
+
|
| 27 |
+
st.image("pages/DINOv2/image_2.jpg", use_column_width=True)
|
| 28 |
+
st.markdown(""" """)
|
| 29 |
+
|
| 30 |
+
st.markdown("""
|
| 31 |
+
DINO doesn't use any contrastive loss or clustering but only cross entropy loss (again, what a paper) which leads the model to collapse.
|
| 32 |
+
This can be avoided by normalizing the teacher output multiple times, but authors center (to squish logits) and sharpen (through temperature) the teacher outputs.
|
| 33 |
+
Finally, local and global crops are given to student and only global crops are given to teacher and this sort of pushes student to identify context from small parts of the image.
|
| 34 |
+
""")
|
| 35 |
+
st.markdown(""" """)
|
| 36 |
+
|
| 37 |
+
st.image("pages/DINOv2/image_3.jpeg", use_column_width=True)
|
| 38 |
+
st.markdown(""" """)
|
| 39 |
+
|
| 40 |
+
st.markdown("""How does DINOv2 improve DINO?
|
| 41 |
+
⚡️ More efficient thanks to FSDP and Flash Attention
|
| 42 |
+
🦖 Has a very efficient data augmentation technique that apparently scales to 100M+ images (put below)
|
| 43 |
+
👨🏻🏫 Uses ViT-g instead of training from scratch
|
| 44 |
+
""")
|
| 45 |
+
st.markdown(""" """)
|
| 46 |
+
|
| 47 |
+
st.image("pages/DINOv2/image_4.jpeg", use_column_width=True)
|
| 48 |
+
st.markdown(""" """)
|
| 49 |
+
|
| 50 |
+
st.markdown("""
|
| 51 |
+
The model is so powerful that you can use DINOv2 even with knn or linear classifiers without need to fine-tuning!
|
| 52 |
+
But if you'd like DINOv2 to work even better, [NielsRogge](https://twitter.com/NielsRogge) has built a [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DINOv2/Fine\_tune\_DINOv2\_for\_image\_classification\_%5Bminimal%5D.ipynb) to fine-tune it using Trainer 📖
|
| 53 |
+
He also has a [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DINOv2/Train\_a\_linear\_classifier\_on\_top\_of\_DINOv2\_for\_semantic\_segmentation.ipynb) if you feel like training a linear classifier only 📔
|
| 54 |
+
All the different DINO/v2 model checkpoints are [here](https://huggingface.co/models?search=dinoLastly).
|
| 55 |
+
Lastly, special thanks to [ykilcher](https://twitter.com/ykilcher) as I couldn't make sense of certain things in the paper and watched his awesome [tutorial](https://youtube.com/watch?v=h3ij3F) 🤩
|
| 56 |
+
""")
|
| 57 |
+
st.markdown(""" """)
|
| 58 |
+
|
| 59 |
+
st.info("""
|
| 60 |
+
Ressources:
|
| 61 |
+
[DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193)
|
| 62 |
+
by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski (2023)
|
| 63 |
+
[GitHub](https://github.com/facebookresearch/dinov2)
|
| 64 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/dinov2)""", icon="📚")
|
| 65 |
+
|
| 66 |
+
st.markdown(""" """)
|
| 67 |
+
st.markdown(""" """)
|
| 68 |
+
st.markdown(""" """)
|
| 69 |
+
col1, col2, col3 = st.columns(3)
|
| 70 |
+
with col1:
|
| 71 |
+
if st.button('Previous paper', use_container_width=True):
|
| 72 |
+
switch_page("VITMAE")
|
| 73 |
+
with col2:
|
| 74 |
+
if st.button('Home', use_container_width=True):
|
| 75 |
+
switch_page("Home")
|
| 76 |
+
with col3:
|
| 77 |
+
if st.button('Next paper', use_container_width=True):
|
| 78 |
+
switch_page("SigLIP")
|
pages/5_SigLIP.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("SigLIP")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1745476609686089800) (January 11. 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""SigLIP just got merged to 🤗 Transformers and it's super easy to use!
|
| 10 |
+
To celebrate this, I have created a repository on various SigLIP based projects!
|
| 11 |
+
But what is it and how does it work?
|
| 12 |
+
SigLIP an vision-text pre-training technique based on contrastive learning. It jointly trains an image encoder and text encoder such that the dot product of embeddings are most similar for the appropriate text-image pairs.
|
| 13 |
+
The image below is taken from CLIP, where this contrastive pre-training takes place with softmax, but SigLIP replaces softmax with sigmoid. 📎
|
| 14 |
+
""")
|
| 15 |
+
st.markdown(""" """)
|
| 16 |
+
|
| 17 |
+
st.image("pages/SigLIP/image_1.jpg", use_column_width=True)
|
| 18 |
+
st.markdown(""" """)
|
| 19 |
+
|
| 20 |
+
st.markdown("""
|
| 21 |
+
Highlights✨
|
| 22 |
+
🖼️📝 Authors used medium sized B/16 ViT for image encoder and B-sized transformer for text encoder
|
| 23 |
+
😍 More performant than CLIP on zero-shot
|
| 24 |
+
🗣️ Authors trained a multilingual model too!
|
| 25 |
+
⚡️ Super efficient, sigmoid is enabling up to 1M items per batch, but the authors chose 32k (see saturation on perf below)
|
| 26 |
+
""")
|
| 27 |
+
st.markdown(""" """)
|
| 28 |
+
|
| 29 |
+
st.image("pages/SigLIP/image_2.jpg", use_column_width=True)
|
| 30 |
+
st.markdown(""" """)
|
| 31 |
+
|
| 32 |
+
st.markdown("""
|
| 33 |
+
Below you can find prior CLIP models and SigLIP across different image encoder sizes and their performance on different datasets 👇🏻
|
| 34 |
+
""")
|
| 35 |
+
st.markdown(""" """)
|
| 36 |
+
|
| 37 |
+
st.image("pages/SigLIP/image_3.jpg", use_column_width=True)
|
| 38 |
+
st.markdown(""" """)
|
| 39 |
+
|
| 40 |
+
st.markdown("""
|
| 41 |
+
With 🤗 Transformers integration there comes zero-shot-image-classification pipeline, makes SigLIP super easy to use!
|
| 42 |
+
""")
|
| 43 |
+
st.markdown(""" """)
|
| 44 |
+
|
| 45 |
+
st.image("pages/SigLIP/image_4.jpg", use_column_width=True)
|
| 46 |
+
st.markdown(""" """)
|
| 47 |
+
|
| 48 |
+
st.markdown("""
|
| 49 |
+
What to use SigLIP for? 🧐
|
| 50 |
+
Honestly the possibilities are endless, but you can use it for image/text retrieval, zero-shot classification, training multimodal models!
|
| 51 |
+
I have made a repository with notebooks and applications that are also hosted on [Spaces](https://t.co/Ah1CrHVuPY).
|
| 52 |
+
I have built ["Draw to Search Art"](https://t.co/DcmQWMc1qd) where you can input image (upload one or draw) and search among 10k images in wikiart!
|
| 53 |
+
I've also built apps to [compare](https://t.co/m699TMvuW9) CLIP and SigLIP outputs.
|
| 54 |
+
""")
|
| 55 |
+
st.markdown(""" """)
|
| 56 |
+
|
| 57 |
+
st.image("pages/SigLIP/image_5.jpg", use_column_width=True)
|
| 58 |
+
st.markdown(""" """)
|
| 59 |
+
|
| 60 |
+
st.info("""
|
| 61 |
+
Ressources:
|
| 62 |
+
[Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343)
|
| 63 |
+
by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer (2023)
|
| 64 |
+
[GitHub](https://github.com/google-research/big_vision)
|
| 65 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/siglip)""", icon="📚")
|
| 66 |
+
st.markdown(""" """)
|
| 67 |
+
st.markdown(""" """)
|
| 68 |
+
st.markdown(""" """)
|
| 69 |
+
col1, col2, col3 = st.columns(3)
|
| 70 |
+
with col1:
|
| 71 |
+
if st.button('Previous paper', use_container_width=True):
|
| 72 |
+
switch_page("DINOv2")
|
| 73 |
+
with col2:
|
| 74 |
+
if st.button('Home', use_container_width=True):
|
| 75 |
+
switch_page("Home")
|
| 76 |
+
with col3:
|
| 77 |
+
if st.button('Next paper', use_container_width=True):
|
| 78 |
+
switch_page("OWLv2")
|
pages/6_OWLv2.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("OWLv2")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1748411972675150040) (January 19, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""Explaining the 👑 of zero-shot open-vocabulary object detection: OWLv2 🦉🧶""")
|
| 10 |
+
st.markdown(""" """)
|
| 11 |
+
|
| 12 |
+
st.image("pages/OWLv2/image_1.jpeg", use_column_width=True)
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.markdown("""
|
| 16 |
+
OWLv2 is scaled version of a model called OWL-ViT, so let's take a look at that first 📝
|
| 17 |
+
OWLViT is an open vocabulary object detector, meaning, it can detect objects it didn't explicitly see during the training 👀
|
| 18 |
+
What's cool is that it can take both image and text queries! This is thanks to how the image and text features aren't fused together.
|
| 19 |
+
""")
|
| 20 |
+
st.markdown(""" """)
|
| 21 |
+
|
| 22 |
+
st.image("pages/OWLv2/image_2.jpeg", use_column_width=True)
|
| 23 |
+
st.markdown(""" """)
|
| 24 |
+
|
| 25 |
+
st.markdown("""Taking a look at the architecture, the authors firstly do contrastive pre-training of a vision and a text encoder (just like CLIP).
|
| 26 |
+
They take that model, remove the final pooling layer and attach a lightweight classification and box detection head and fine-tune.
|
| 27 |
+
""")
|
| 28 |
+
st.markdown(""" """)
|
| 29 |
+
|
| 30 |
+
st.image("pages/OWLv2/image_3.jpeg", use_column_width=True)
|
| 31 |
+
st.markdown(""" """)
|
| 32 |
+
|
| 33 |
+
st.markdown("""During fine-tuning for object detection, they calculate the loss over bipartite matches.
|
| 34 |
+
Simply put, loss is calculated over the predicted objects against ground truth objects and the goal is to find a perfect match of these two sets where each object is matched to one object in ground truth.
|
| 35 |
+
|
| 36 |
+
OWL-ViT is very scalable.
|
| 37 |
+
One can easily scale most language models or vision-language models because they require no supervision, but this isn't the case for object detection: you still need supervision.
|
| 38 |
+
Moreover, only scaling the encoders creates a bottleneck after a while.
|
| 39 |
+
""")
|
| 40 |
+
st.markdown(""" """)
|
| 41 |
+
|
| 42 |
+
st.image("pages/OWLv2/image_1.jpeg", use_column_width=True)
|
| 43 |
+
st.markdown(""" """)
|
| 44 |
+
|
| 45 |
+
st.markdown("""
|
| 46 |
+
The authors wanted to scale OWL-ViT with more data, so they used OWL-ViT for labelling to train a better detector, "self-train" a new detector on the labels, and fine-tune the model on human-annotated data.
|
| 47 |
+
""")
|
| 48 |
+
st.markdown(""" """)
|
| 49 |
+
|
| 50 |
+
st.image("pages/OWLv2/image_4.jpeg", use_column_width=True)
|
| 51 |
+
st.markdown(""" """)
|
| 52 |
+
|
| 53 |
+
st.markdown("""
|
| 54 |
+
Thanks to this, OWLv2 scaled very well and is tops leaderboards on open vocabulary object detection 👑
|
| 55 |
+
""")
|
| 56 |
+
st.markdown(""" """)
|
| 57 |
+
|
| 58 |
+
st.image("pages/OWLv2/image_5.jpeg", use_column_width=True)
|
| 59 |
+
st.markdown(""" """)
|
| 60 |
+
|
| 61 |
+
st.markdown("""
|
| 62 |
+
Want to try OWL models?
|
| 63 |
+
I've created a [notebook](https://t.co/ick5tA6nyx) for you to see how to use it with 🤗 Transformers.
|
| 64 |
+
If you want to play with it directly, you can use this [Space](https://t.co/oghdLOtoa5).
|
| 65 |
+
All the models and the applications of OWL-series is in this [collection](https://huggingface.co/collections/merve/owl-series-65aaac3114e6582c300544df).
|
| 66 |
+
""")
|
| 67 |
+
st.markdown(""" """)
|
| 68 |
+
|
| 69 |
+
st.info("""
|
| 70 |
+
Ressources:
|
| 71 |
+
[Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683)
|
| 72 |
+
by Matthias Minderer, Alexey Gritsenko, Neil Houlsby (2023)
|
| 73 |
+
[GitHub](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit)
|
| 74 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/owlv2)""", icon="📚")
|
| 75 |
+
st.markdown(""" """)
|
| 76 |
+
st.markdown(""" """)
|
| 77 |
+
st.markdown(""" """)
|
| 78 |
+
col1, col2, col3 = st.columns(3)
|
| 79 |
+
with col1:
|
| 80 |
+
if st.button('Previous paper', use_container_width=True):
|
| 81 |
+
switch_page("SigLIP")
|
| 82 |
+
with col2:
|
| 83 |
+
if st.button('Home', use_container_width=True):
|
| 84 |
+
switch_page("Home")
|
| 85 |
+
with col3:
|
| 86 |
+
if st.button('Next paper', use_container_width=True):
|
| 87 |
+
switch_page("Backbone")
|
pages/7_Backbone.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("Backbone")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://x.com/mervenoyann/status/1749841426177810502) (January 23, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""Many cutting-edge computer vision models consist of multiple stages:
|
| 10 |
+
➰ backbone extracts the features,
|
| 11 |
+
➰ neck refines the features,
|
| 12 |
+
➰ head makes the detection for the task.
|
| 13 |
+
Implementing this is cumbersome, so 🤗 Transformers has an API for this: Backbone!
|
| 14 |
+
""")
|
| 15 |
+
st.markdown(""" """)
|
| 16 |
+
|
| 17 |
+
st.image("pages/Backbone/image_1.jpeg", use_column_width=True)
|
| 18 |
+
st.markdown(""" """)
|
| 19 |
+
|
| 20 |
+
st.markdown("""
|
| 21 |
+
Let's see an example of such model.
|
| 22 |
+
Assuming we would like to initialize a multi-stage instance segmentation model with ResNet backbone and MaskFormer neck and a head, you can use the backbone API like following (left comments for clarity) 👇
|
| 23 |
+
""")
|
| 24 |
+
st.markdown(""" """)
|
| 25 |
+
|
| 26 |
+
st.image("pages/Backbone/image_2.jpeg", use_column_width=True)
|
| 27 |
+
st.markdown(""" """)
|
| 28 |
+
|
| 29 |
+
st.markdown("""One can also use a backbone just to get features from any stage. You can initialize any backbone with `AutoBackbone` class.
|
| 30 |
+
See below how to initialize a backbone and getting the feature maps at any stage 👇
|
| 31 |
+
""")
|
| 32 |
+
st.markdown(""" """)
|
| 33 |
+
|
| 34 |
+
st.image("pages/Backbone/image_3.jpeg", use_column_width=True)
|
| 35 |
+
st.markdown(""" """)
|
| 36 |
+
|
| 37 |
+
st.markdown("""
|
| 38 |
+
Backbone API also supports any timm backbone of your choice! Check out a variation of timm backbones [here](https://t.co/Voiv0QCPB3).
|
| 39 |
+
""")
|
| 40 |
+
st.markdown(""" """)
|
| 41 |
+
|
| 42 |
+
st.image("pages/Backbone/image_4.jpeg", use_column_width=True)
|
| 43 |
+
st.markdown(""" """)
|
| 44 |
+
|
| 45 |
+
st.markdown("""
|
| 46 |
+
Leaving some links 🔗
|
| 47 |
+
📖 I've created a [notebook](https://t.co/PNfmBvdrtt) for you to play with it
|
| 48 |
+
📒 [Backbone API docs](https://t.co/Yi9F8qAigO)
|
| 49 |
+
📓 [AutoBackbone docs](https://t.co/PGo9oILHDw) (all written with love by me!💜)""")
|
| 50 |
+
|
| 51 |
+
st.markdown(""" """)
|
| 52 |
+
st.markdown(""" """)
|
| 53 |
+
st.markdown(""" """)
|
| 54 |
+
col1, col2, col3 = st.columns(3)
|
| 55 |
+
with col1:
|
| 56 |
+
if st.button('Previous paper', use_container_width=True):
|
| 57 |
+
switch_page("OWLv2")
|
| 58 |
+
with col2:
|
| 59 |
+
if st.button('Home', use_container_width=True):
|
| 60 |
+
switch_page("Home")
|
| 61 |
+
with col3:
|
| 62 |
+
if st.button('Next paper', use_container_width=True):
|
| 63 |
+
switch_page("Depth Anything")
|
pages/8_Depth_Anything.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("Depth Anything")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1750531698008498431) (January 25, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""Explaining a new state-of-the-art monocular depth estimation model: Depth Anything ✨🧶
|
| 10 |
+
It has just been integrated in transformers for super-easy use.
|
| 11 |
+
We compared it against DPTs and benchmarked it as well! You can find the usage, benchmark, demos and more below 👇
|
| 12 |
+
""")
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.video("pages/Depth_Anything/video_1.mp4", format="video/mp4")
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.markdown("""
|
| 19 |
+
The paper starts with highlighting previous depth estimation methods and the limitations regarding the data coverage. 👀
|
| 20 |
+
The model's success heavily depends on unlocking the use of unlabeled datasets, although initially the authors used self-training and failed.
|
| 21 |
+
|
| 22 |
+
What the authors have done:
|
| 23 |
+
➰ Train a teacher model on labelled dataset
|
| 24 |
+
➰ Guide the student using teacher and also use unlabelled datasets pseudolabelled by the teacher. However, this was the cause of the failure, as both architectures were similar, the outputs were the same.
|
| 25 |
+
""")
|
| 26 |
+
st.markdown(""" """)
|
| 27 |
+
|
| 28 |
+
st.image("pages/Depth_Anything/image_1.jpg", use_column_width=True)
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.markdown("""
|
| 32 |
+
So the authors have added a more difficult optimization target for student to learn additional knowledge on unlabeled images that went through color jittering, distortions, Gaussian blurring and spatial distortion, so it can learn more invariant representations from them.
|
| 33 |
+
|
| 34 |
+
The architecture consists of <a href='DINOv2' target='_self'>DINOv2</a> encoder to extract the features followed by DPT decoder. At first, they train the teacher model on labelled images, and then they jointly train the student model and add in the dataset pseudo-labelled by ViT-L.
|
| 35 |
+
""", unsafe_allow_html=True)
|
| 36 |
+
|
| 37 |
+
st.markdown(""" """)
|
| 38 |
+
|
| 39 |
+
st.image("pages/Depth_Anything/image_1.jpg", use_column_width=True)
|
| 40 |
+
st.markdown(""" """)
|
| 41 |
+
|
| 42 |
+
st.markdown("""Thanks to this, Depth Anything performs very well! I have also benchmarked the inference duration of the model against different models here. I also ran `torch.compile` benchmarks across them and got nice speed-ups 🚀
|
| 43 |
+
|
| 44 |
+
On T4 GPU, mean of 30 inferences for each. Inferred using `pipeline` (pre-processing and post-processing included with model inference).
|
| 45 |
+
|
| 46 |
+
| Model/Batch Size | 16 | 4 | 1 |
|
| 47 |
+
| ----------------------------- | --------- | -------- | ------- |
|
| 48 |
+
| intel/dpt-large | 2709.652 | 667.799 | 172.617 |
|
| 49 |
+
| facebook/dpt-dinov2-small-nyu | 2534.854 | 654.822 | 159.754 |
|
| 50 |
+
| facebook/dpt-dinov2-base-nyu | 4316.8733 | 1090.824 | 266.699 |
|
| 51 |
+
| Intel/dpt-beit-large-512 | 7961.386 | 2036.743 | 497.656 |
|
| 52 |
+
| depth-anything-small | 1692.368 | 415.915 | 143.379 |
|
| 53 |
+
|
| 54 |
+
`torch.compile`’s benchmarks with reduce-overhead mode: we have compiled the model and loaded it to the pipeline for the benchmarks to be fair.
|
| 55 |
+
|
| 56 |
+
| Model/Batch Size | 16 | 4 | 1 |
|
| 57 |
+
| ----------------------------- | -------- | -------- | ------- |
|
| 58 |
+
| intel/dpt-large | 2556.668 | 645.750 | 155.153 |
|
| 59 |
+
| facebook/dpt-dinov2-small-nyu | 2415.25 | 610.967 | 148.526 |
|
| 60 |
+
| facebook/dpt-dinov2-base-nyu | 4057.909 | 1035.672 | 245.692 |
|
| 61 |
+
| Intel/dpt-beit-large-512 | 7417.388 | 1795.882 | 426.546 |
|
| 62 |
+
| depth-anything-small | 1664.025 | 384.688 | 97.865 |
|
| 63 |
+
|
| 64 |
+
""")
|
| 65 |
+
st.markdown(""" """)
|
| 66 |
+
|
| 67 |
+
st.image("pages/Depth_Anything/image_2.jpg", use_column_width=True)
|
| 68 |
+
st.markdown(""" """)
|
| 69 |
+
|
| 70 |
+
st.markdown("""
|
| 71 |
+
You can use Depth Anything easily thanks to 🤗 Transformers with three lines of code! ✨
|
| 72 |
+
We have also built an app for you to [compare different depth estimation models](https://t.co/6uq4osdwWG) 🐝 🌸
|
| 73 |
+
See all the available Depth Anything checkpoints [here](https://t.co/Ex0IIyx7XC).
|
| 74 |
+
""")
|
| 75 |
+
st.markdown(""" """)
|
| 76 |
+
|
| 77 |
+
st.image("pages/Depth_Anything/image_3.jpg", use_column_width=True)
|
| 78 |
+
st.markdown(""" """)
|
| 79 |
+
|
| 80 |
+
st.info("""
|
| 81 |
+
Ressources:
|
| 82 |
+
[Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891)
|
| 83 |
+
by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao (2024)
|
| 84 |
+
[GitHub](https://github.com/LiheYoung/Depth-Anything)
|
| 85 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/depth_anything)""", icon="📚")
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
st.markdown(""" """)
|
| 89 |
+
st.markdown(""" """)
|
| 90 |
+
st.markdown(""" """)
|
| 91 |
+
col1, col2, col3 = st.columns(3)
|
| 92 |
+
with col1:
|
| 93 |
+
if st.button('Previous paper', use_container_width=True):
|
| 94 |
+
switch_page("Backbone")
|
| 95 |
+
with col2:
|
| 96 |
+
if st.button('Home', use_container_width=True):
|
| 97 |
+
switch_page("Home")
|
| 98 |
+
with col3:
|
| 99 |
+
if st.button('Next paper', use_container_width=True):
|
| 100 |
+
switch_page("LLaVA-NeXT")
|
pages/9_LLaVA-NeXT.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("LLaVA-NeXT")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://twitter.com/mervenoyann/status/1770832875551682563) (March 21, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""LLaVA-NeXT is recently merged to 🤗 Transformers and it outperforms many of the proprietary models like Gemini on various benchmarks!🤩
|
| 10 |
+
For those who don't know LLaVA, it's a language model that can take image 💬
|
| 11 |
+
Let's take a look, demo and more in this.
|
| 12 |
+
""")
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.image("pages/LLaVA-NeXT/image_1.jpeg", use_column_width=True)
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.markdown("""
|
| 19 |
+
LLaVA is essentially a vision-language model that consists of ViT-based CLIP encoder, a MLP projection and Vicuna as decoder ✨
|
| 20 |
+
LLaVA 1.5 was released with Vicuna, but LLaVA NeXT (1.6) is released with four different LLMs:
|
| 21 |
+
- Nous-Hermes-Yi-34B
|
| 22 |
+
- Mistral-7B
|
| 23 |
+
- Vicuna 7B & 13B
|
| 24 |
+
""")
|
| 25 |
+
st.markdown(""" """)
|
| 26 |
+
|
| 27 |
+
st.image("pages/LLaVA-NeXT/image_2.jpeg", use_column_width=True)
|
| 28 |
+
st.markdown(""" """)
|
| 29 |
+
|
| 30 |
+
st.markdown("""
|
| 31 |
+
Thanks to Transformers integration, it is very easy to use LLaVA NeXT, not only standalone but also with 4-bit loading and Flash Attention 2 💜
|
| 32 |
+
See below on standalone usage 👇
|
| 33 |
+
""")
|
| 34 |
+
st.markdown(""" """)
|
| 35 |
+
|
| 36 |
+
st.image("pages/LLaVA-NeXT/image_3.jpeg", use_column_width=True)
|
| 37 |
+
st.markdown(""" """)
|
| 38 |
+
|
| 39 |
+
st.markdown("""To fit large models and make it even faster and memory efficient, you can enable Flash Attention 2 and load model into 4-bit using bitsandbytes ⚡️ transformers makes it very easy to do this! See below 👇
|
| 40 |
+
""")
|
| 41 |
+
st.markdown(""" """)
|
| 42 |
+
|
| 43 |
+
st.image("pages/LLaVA-NeXT/image_4.jpeg", use_column_width=True)
|
| 44 |
+
st.markdown(""" """)
|
| 45 |
+
|
| 46 |
+
st.markdown("""If you want to try the code right away, here's the [notebook](https://t.co/NvoxvY9z1u).
|
| 47 |
+
Lastly, you can directly play with the LLaVA-NeXT based on Mistral-7B through the demo [here](https://t.co/JTDlqMUwEh) 🤗
|
| 48 |
+
""")
|
| 49 |
+
st.markdown(""" """)
|
| 50 |
+
|
| 51 |
+
st.video("pages/LLaVA-NeXT/video_1.mp4", format="video/mp4")
|
| 52 |
+
st.markdown(""" """)
|
| 53 |
+
|
| 54 |
+
st.info("""
|
| 55 |
+
Ressources:
|
| 56 |
+
[LLaVA-NeXT: Improved reasoning, OCR, and world knowledge](https://llava-vl.github.io/blog/2024-01-30-llava-next/)
|
| 57 |
+
by Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, Yong Jae Lee (2024)
|
| 58 |
+
[GitHub](https://github.com/haotian-liu/LLaVA/tree/main)
|
| 59 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/llava_next)""", icon="📚")
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
st.markdown(""" """)
|
| 63 |
+
st.markdown(""" """)
|
| 64 |
+
st.markdown(""" """)
|
| 65 |
+
col1, col2, col3 = st.columns(3)
|
| 66 |
+
with col1:
|
| 67 |
+
if st.button('Previous paper', use_container_width=True):
|
| 68 |
+
switch_page("Depth Anything")
|
| 69 |
+
with col2:
|
| 70 |
+
if st.button('Home', use_container_width=True):
|
| 71 |
+
switch_page("Home")
|
| 72 |
+
with col3:
|
| 73 |
+
if st.button('Next paper', use_container_width=True):
|
| 74 |
+
switch_page("Painter")
|
pages/Backbone/Backbone.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Many cutting-edge computer vision models consist of multiple stages:
|
| 2 |
+
➰ backbone extracts the features,
|
| 3 |
+
➰ neck refines the features,
|
| 4 |
+
➰ head makes the detection for the task.
|
| 5 |
+
Implementing this is cumbersome, so 🤗 transformers has an API for this: Backbone!
|
| 6 |
+
|
| 7 |
+

|
| 8 |
+
|
| 9 |
+
Let's see an example of such model.
|
| 10 |
+
Assuming we would like to initialize a multi-stage instance segmentation model with ResNet backbone and MaskFormer neck and a head, you can use the backbone API like following (left comments for clarity) 👇
|
| 11 |
+
|
| 12 |
+

|
| 13 |
+
|
| 14 |
+
One can also use a backbone just to get features from any stage. You can initialize any backbone with `AutoBackbone` class.
|
| 15 |
+
See below how to initialize a backbone and getting the feature maps at any stage 👇
|
| 16 |
+
|
| 17 |
+

|
| 18 |
+
|
| 19 |
+
Backbone API also supports any timm backbone of your choice! Check out a variation of timm backbones [here](https://t.co/Voiv0QCPB3).
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
Leaving some links 🔗:
|
| 24 |
+
📖 I've created a [notebook](https://t.co/PNfmBvdrtt) for you to play with it
|
| 25 |
+
📒 [Backbone API docs](https://t.co/Yi9F8qAigO)
|
| 26 |
+
📓 [AutoBackbone docs](https://t.co/PGo9oILHDw) 💜
|
| 27 |
+
(all written with love by me!)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
> [!NOTE]
|
| 31 |
+
[Orignial tweet](https://twitter.com/mervenoyann/status/1749841426177810502) (January 23, 2024)
|
pages/Backbone/image_1.jpeg
ADDED

|
pages/Backbone/image_2.jpeg
ADDED

|
pages/Backbone/image_3.jpeg
ADDED
|
pages/Backbone/image_4.jpeg
ADDED
|
pages/Chameleon/Chameleon.md
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Chameleon 🦎 by Meta is now available in @huggingface transformers 😍
|
| 2 |
+
A multimodal model that comes in 7B and 34B sizes 🤩
|
| 3 |
+
But what makes this model so special? keep reading ⇣
|
| 4 |
+
|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
[Demo](https://t.co/GsGE17fSdI] | [Models](https://t.co/cWUiVbsRz6)
|
| 8 |
+
Find below the API to load this model locally use it ⬇️
|
| 9 |
+
|
| 10 |
+

|
| 11 |
+
|
| 12 |
+
Chameleon is a unique model: it attempts to scale early fusion 🤨 But what is early fusion?
|
| 13 |
+
Modern vision language models use a vision encoder with a projection layer to project image embeddings so it can be promptable to text decoder.
|
| 14 |
+
|
| 15 |
+

|
| 16 |
+
|
| 17 |
+
Early fusion on the other hand attempts to fuse all features together (image patches and text) by using an image tokenizer and all tokens are projected into a shared space, which enables seamless generation 😏
|
| 18 |
+
|
| 19 |
+

|
| 20 |
+
|
| 21 |
+
Authors have also introduced different architectural improvements (QK norm and revise placement of layer norms) for scalable and stable training This way they were able to increase the token count (5x tokens compared to Llama 3 which is a must with early-fusion IMO)
|
| 22 |
+
|
| 23 |
+

|
| 24 |
+
|
| 25 |
+
This model is an any-to-any model thanks to early fusion: it can take image and text input and output image and text, but image generation are disabled to prevent malicious use.
|
| 26 |
+
|
| 27 |
+

|
| 28 |
+
|
| 29 |
+
One can also do text-only prompting, authors noted the model catches up with larger LLMs, and you can also see how it compares to VLMs with image-text prompting.
|
| 30 |
+
|
| 31 |
+

|
| 32 |
+
|
| 33 |
+

|
| 34 |
+
|
| 35 |
+
> [!TIP]
|
| 36 |
+
Ressources:
|
| 37 |
+
[Chameleon: Mixed-Modal Early-Fusion Foundation Models](https://arxiv.org/abs/2405.09818)
|
| 38 |
+
by Chameleon Team (2024)
|
| 39 |
+
[GitHub](https://github.com/facebookresearch/chameleon)
|
| 40 |
+
[Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/chameleon)
|
| 41 |
+
|
| 42 |
+
> [!NOTE]
|
| 43 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1814278511785312320) (July 19, 2024)
|
pages/Chameleon/image_1.jpg
ADDED

|
pages/Chameleon/image_2.jpg
ADDED
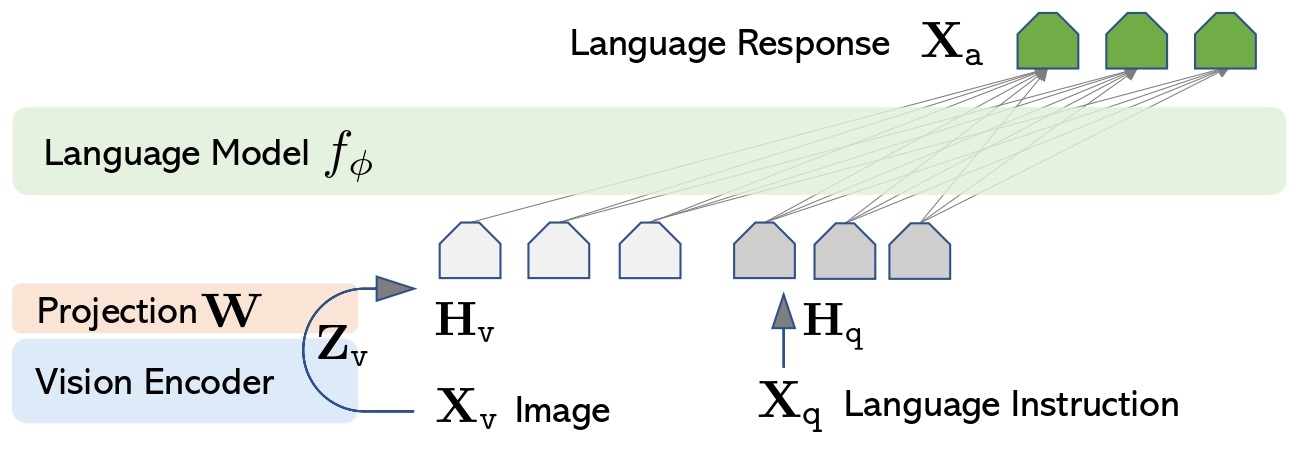
|
pages/Chameleon/image_3.jpg
ADDED
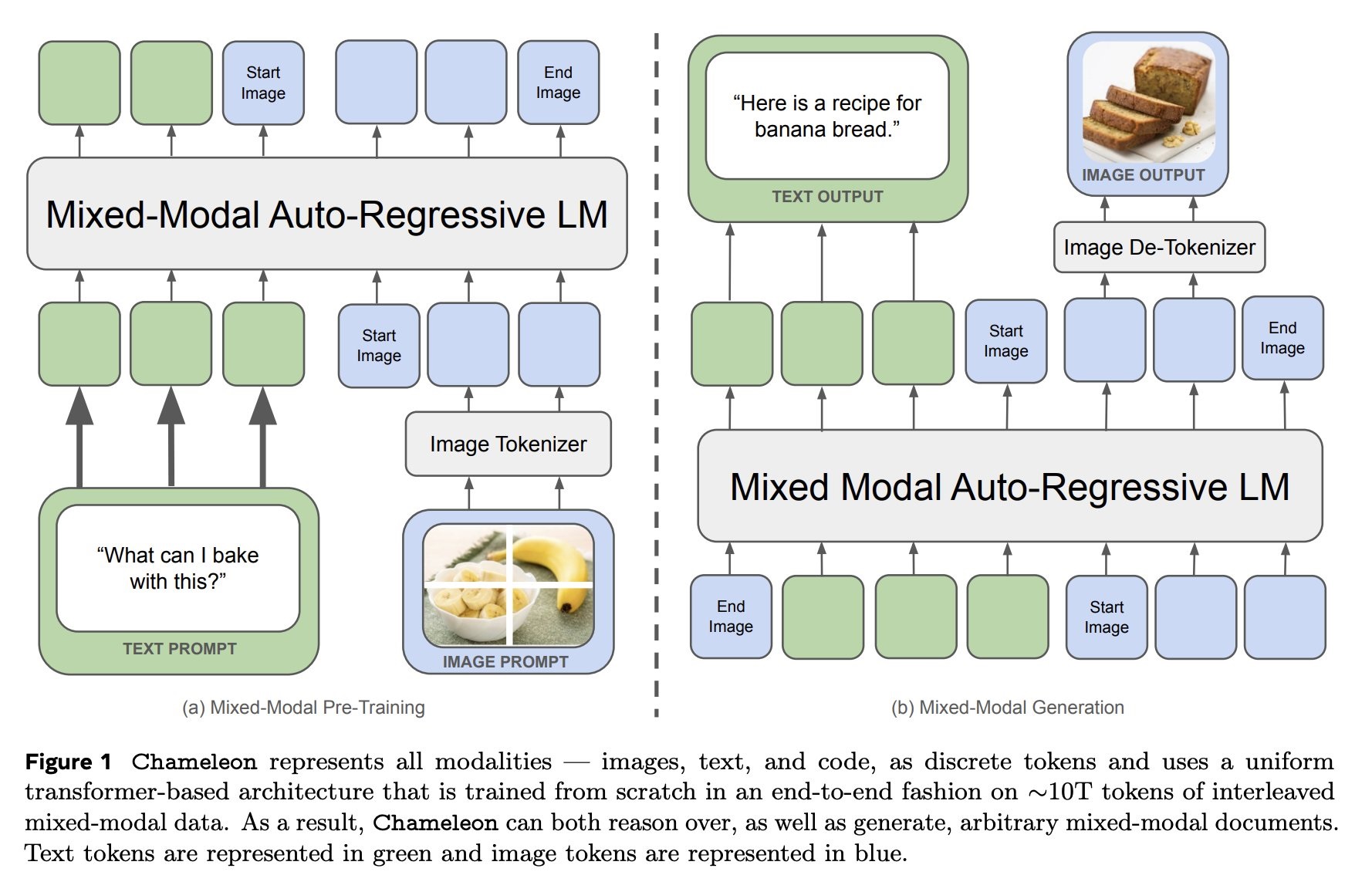
|
pages/Chameleon/image_4.jpg
ADDED
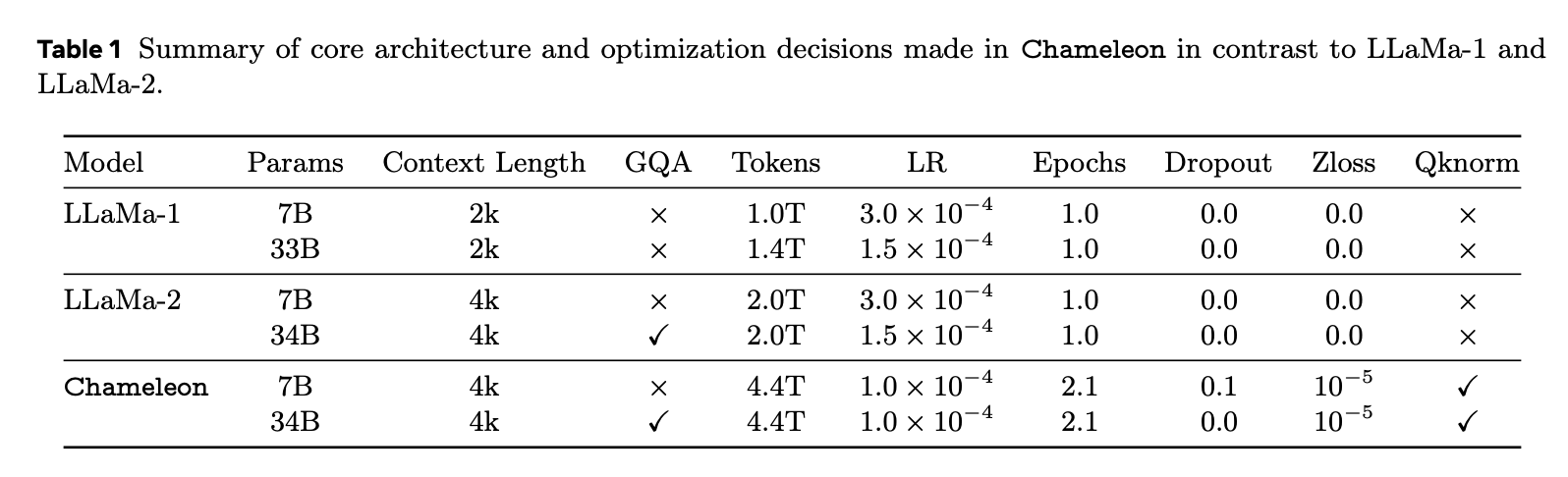
|
pages/Chameleon/image_5.jpg
ADDED

|
pages/Chameleon/image_6.jpg
ADDED
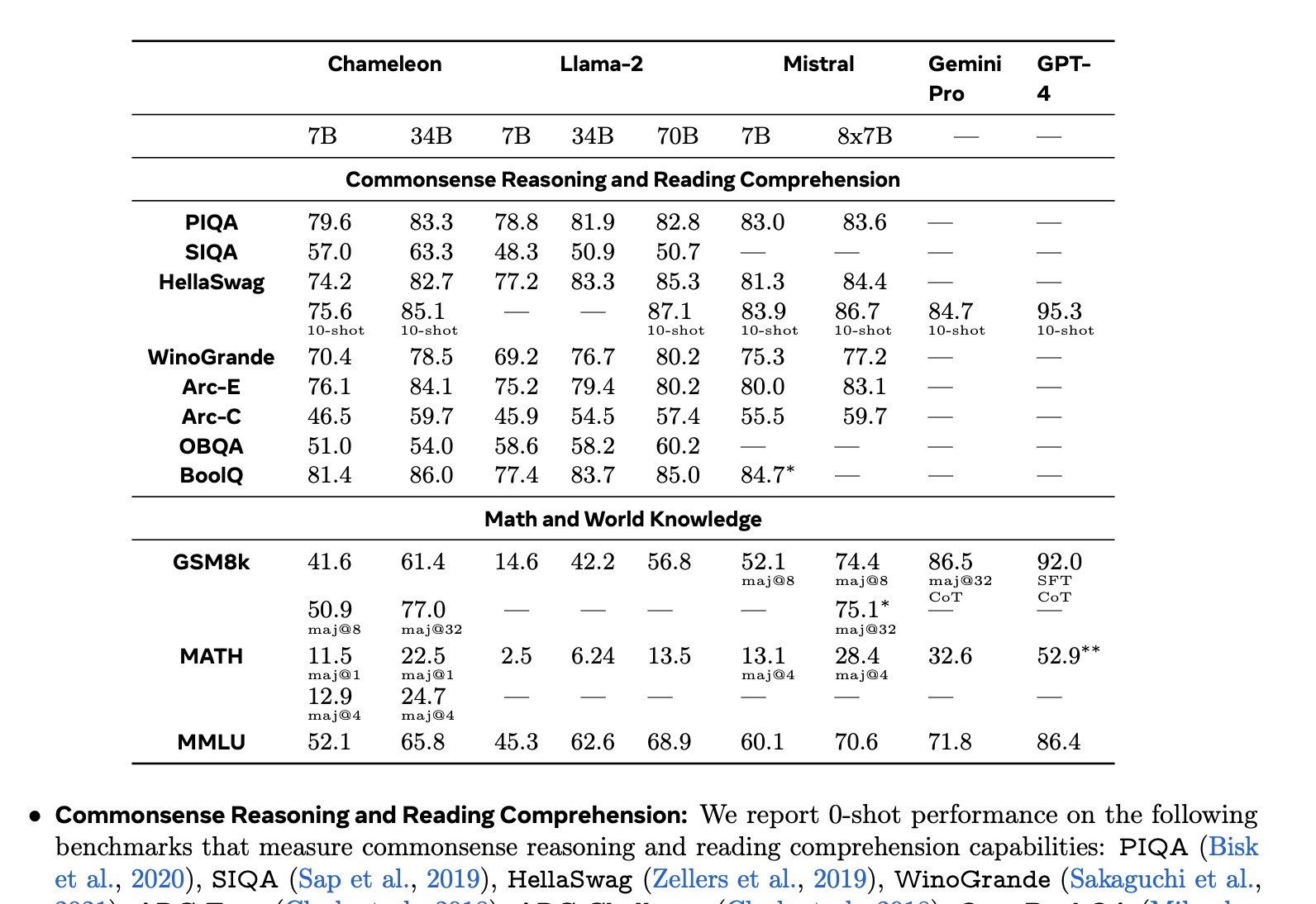
|
pages/Chameleon/image_7.jpg
ADDED
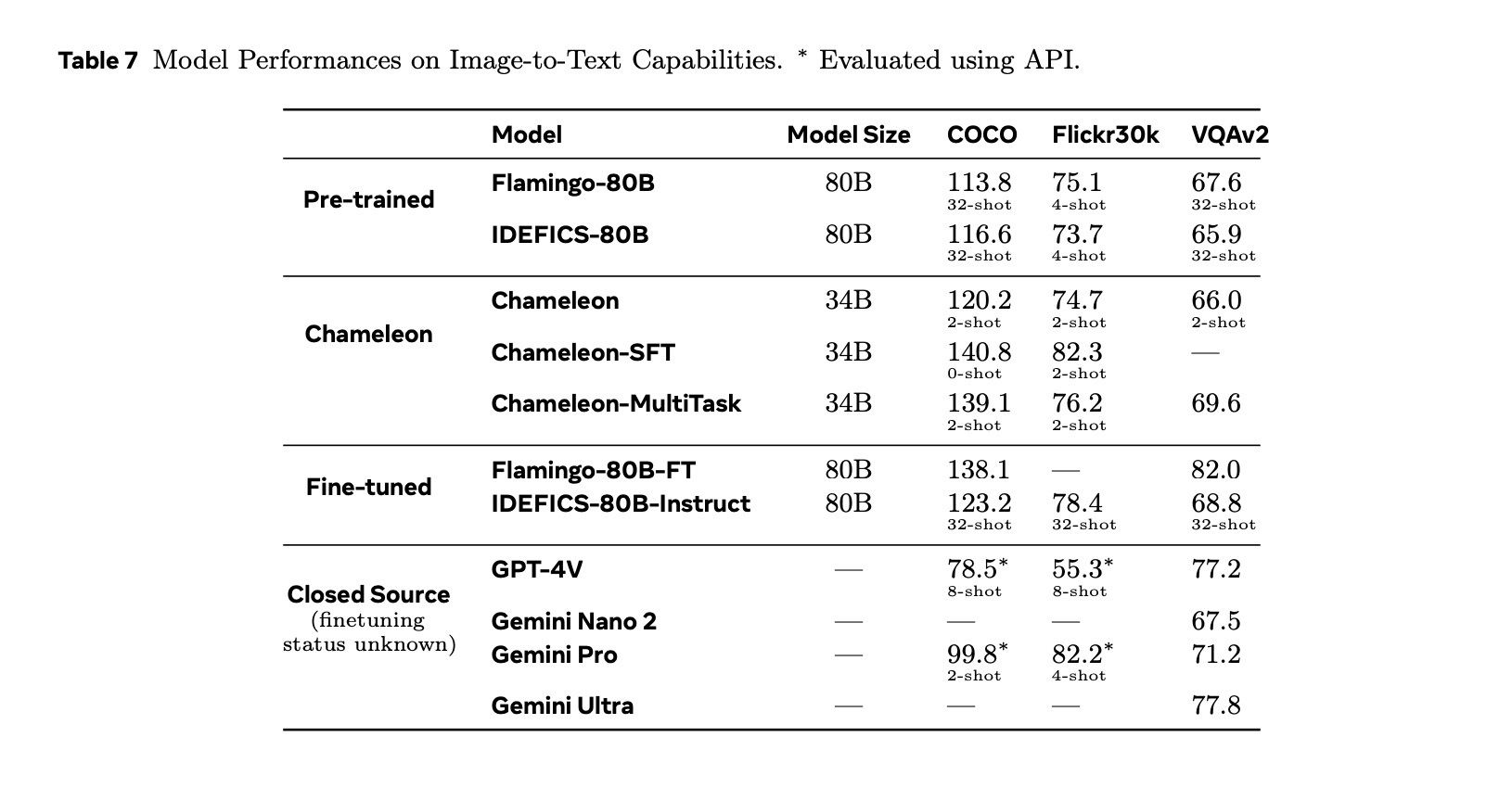
|
pages/Chameleon/video_1.mp4
ADDED
|
Binary file (866 kB). View file
|
|
|
pages/CuMo/CuMo.md
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
It's raining vision language models ☔️ CuMo is a new vision language model that has MoE in every step of the VLM (image encoder, MLP and text decoder) and uses Mistral-7B for the decoder part 🤓
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
The authors firstly did pre-training of MLP with the by freezing the image encoder and text decoder, then they warmup the whole network by unfreezing and finetuning which they state to stabilize the visual instruction tuning when bringing in the experts.
|
| 6 |
+
|
| 7 |
+

|
| 8 |
+
|
| 9 |
+
The mixture of experts MLP blocks above are simply the same MLP blocks initialized from the single MLP that was trained during pre-training and fine-tuned in pre-finetuning 👇
|
| 10 |
+
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
It works very well (also tested myself) that it outperforms the previous sota of it's size LLaVA NeXt! 😍 I wonder how it would compare to IDEFICS2-8B You can try it yourself [here](https://t.co/MLIYKVh5Ee).
|
| 14 |
+
|
| 15 |
+

|
| 16 |
+
|
| 17 |
+
> [!TIP]
|
| 18 |
+
Ressources:
|
| 19 |
+
[CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts](https://arxiv.org/abs/2405.05949)
|
| 20 |
+
by Jiachen Li, Xinyao Wang, Sijie Zhu, Chia-Wen Kuo, Lu Xu, Fan Chen, Jitesh Jain, Humphrey Shi, Longyin Wen (2024)
|
| 21 |
+
[GitHub](https://github.com/SHI-Labs/CuMo)
|
| 22 |
+
|
| 23 |
+
> [!NOTE]
|
| 24 |
+
[Original tweet](https://twitter.com/mervenoyann/status/1790665706205307191) (May 15, 2024)
|
pages/CuMo/image_1.jpg
ADDED

|
pages/CuMo/image_2.jpg
ADDED
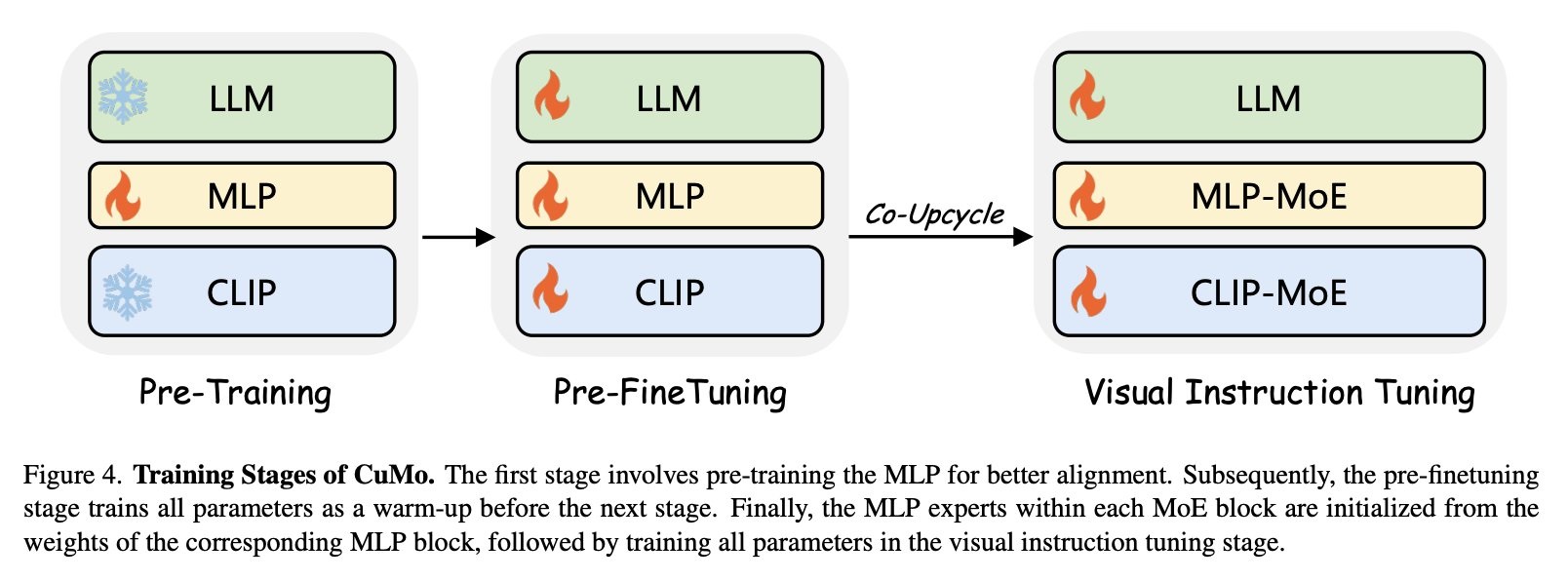
|