Spaces:
Sleeping

Sleeping
Commit
·
6f61bb9
1
Parent(s):
544aeb4
import project
Browse files- .gitignore +131 -0
- README.md +66 -13
- config/config.yaml +9 -0
- digester/chatgpt_service.py +339 -0
- digester/gradio_method_service.py +392 -0
- digester/gradio_ui_service.py +269 -0
- digester/test_chatgpt.py +106 -0
- digester/test_youtube_chain.py +102 -0
- digester/util.py +86 -0
- img/final_full_summary.png +0 -0
- img/in_process.png +0 -0
- img/multi_language.png +0 -0
- img/n_things_example.png +0 -0
- main.py +28 -0
- requirements.txt +7 -0
.gitignore
CHANGED
|
@@ -1 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
/.idea/*
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
pip-wheel-metadata/
|
| 24 |
+
share/python-wheels/
|
| 25 |
+
*.egg-info/
|
| 26 |
+
.installed.cfg
|
| 27 |
+
*.egg
|
| 28 |
+
MANIFEST
|
| 29 |
+
|
| 30 |
+
# PyInstaller
|
| 31 |
+
# Usually these files are written by a python script from a template
|
| 32 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 33 |
+
*.manifest
|
| 34 |
+
*.spec
|
| 35 |
+
|
| 36 |
+
# Installer logs
|
| 37 |
+
pip-log.txt
|
| 38 |
+
pip-delete-this-directory.txt
|
| 39 |
+
|
| 40 |
+
# Unit test / coverage reports
|
| 41 |
+
htmlcov/
|
| 42 |
+
.tox/
|
| 43 |
+
.nox/
|
| 44 |
+
.coverage
|
| 45 |
+
.coverage.*
|
| 46 |
+
.cache
|
| 47 |
+
nosetests.xml
|
| 48 |
+
coverage.xml
|
| 49 |
+
*.cover
|
| 50 |
+
*.py,cover
|
| 51 |
+
.hypothesis/
|
| 52 |
+
.pytest_cache/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
target/
|
| 76 |
+
|
| 77 |
+
# Jupyter Notebook
|
| 78 |
+
.ipynb_checkpoints
|
| 79 |
+
|
| 80 |
+
# IPython
|
| 81 |
+
profile_default/
|
| 82 |
+
ipython_config.py
|
| 83 |
+
|
| 84 |
+
# pyenv
|
| 85 |
+
.python-version
|
| 86 |
+
|
| 87 |
+
# pipenv
|
| 88 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 89 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 90 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 91 |
+
# install all needed dependencies.
|
| 92 |
+
#Pipfile.lock
|
| 93 |
+
|
| 94 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 95 |
+
__pypackages__/
|
| 96 |
+
|
| 97 |
+
# Celery stuff
|
| 98 |
+
celerybeat-schedule
|
| 99 |
+
celerybeat.pid
|
| 100 |
+
|
| 101 |
+
# SageMath parsed files
|
| 102 |
+
*.sage.py
|
| 103 |
+
|
| 104 |
+
# Environments
|
| 105 |
+
.env
|
| 106 |
+
.venv
|
| 107 |
+
env/
|
| 108 |
+
venv/
|
| 109 |
+
ENV/
|
| 110 |
+
env.bak/
|
| 111 |
+
venv.bak/
|
| 112 |
+
|
| 113 |
+
# Spyder project settings
|
| 114 |
+
.spyderproject
|
| 115 |
+
.spyproject
|
| 116 |
+
|
| 117 |
+
# Rope project settings
|
| 118 |
+
.ropeproject
|
| 119 |
+
|
| 120 |
+
# mkdocs documentation
|
| 121 |
+
/site
|
| 122 |
+
|
| 123 |
+
# mypy
|
| 124 |
+
.mypy_cache/
|
| 125 |
+
.dmypy.json
|
| 126 |
+
dmypy.json
|
| 127 |
+
|
| 128 |
+
# Pyre type checker
|
| 129 |
+
.pyre/
|
| 130 |
/.idea/*
|
| 131 |
+
config_secret.yaml
|
| 132 |
+
*report*.md
|
README.md
CHANGED
|
@@ -1,13 +1,66 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DigestEverythingGPT
|
| 2 |
+
|
| 3 |
+
DigestEverythingGPT provides world-class content summarization/query tool that leverages ChatGPT/LLMs to help users
|
| 4 |
+
quickly understand essential information from various forms of content, such as podcasts, YouTube videos, and PDF
|
| 5 |
+
documents.
|
| 6 |
+
|
| 7 |
+
The prompt engineering is **chained and tuned** so that is result is of high quality and fast. It is not a simple single
|
| 8 |
+
query and response tool.
|
| 9 |
+
|
| 10 |
+
# Showcases
|
| 11 |
+
|
| 12 |
+
**Example of summary**
|
| 13 |
+
|
| 14 |
+
- "OpenAssistant RELEASED! The world's best open-source Chat AI!" (https://www.youtube.com/watch?v=ddG2fM9i4Kk)
|
| 15 |
+
|
| 16 |
+

|
| 17 |
+
|
| 18 |
+
**DigestEverythingGPT's final output will adopt to video type.**
|
| 19 |
+
|
| 20 |
+
- For example, for the video "17 cheap purchases that save me
|
| 21 |
+
time" (https://www.youtube.com/watch?v=f7Lfukf0IKY&t=3s&ab_channel=AliAbdaal)
|
| 22 |
+
|
| 23 |
+
- it shown the summary with and specific 17 things correctly.
|
| 24 |
+
|
| 25 |
+

|
| 26 |
+
|
| 27 |
+
**LLM Loading in progress screen - chained prompt engineering, batched inference, etc.**
|
| 28 |
+
|
| 29 |
+

|
| 30 |
+
|
| 31 |
+
**Support for multiple languages** regardless of video language
|
| 32 |
+
|
| 33 |
+

|
| 34 |
+
|
| 35 |
+
# Live website
|
| 36 |
+
|
| 37 |
+
[TODO]
|
| 38 |
+
|
| 39 |
+
# Features
|
| 40 |
+
|
| 41 |
+
- **Content Summarization**:
|
| 42 |
+
- Automatically generate concise summaries of various types of content, allowing users to save time and make
|
| 43 |
+
informed decisions for in-depth engagement.
|
| 44 |
+
- Chained/Batched/Advanced prompt engineering for great quality/faster results.
|
| 45 |
+
- **Interactive "Ask" Feature** (in progress):
|
| 46 |
+
- Users can pose questions to the tool and receive answers extracted from specific sections within the full content.
|
| 47 |
+
- **Cross-Medium Support**:
|
| 48 |
+
- DigestEverythingGPT is designed to work with a wide range of content mediums.
|
| 49 |
+
- Currently, the tool supports
|
| 50 |
+
- YouTube videos [beta]
|
| 51 |
+
- podcasts (in progress)
|
| 52 |
+
- PDF documents (in progress)
|
| 53 |
+
|
| 54 |
+
# Installation
|
| 55 |
+
|
| 56 |
+
Use python 3.10+ (tested in 3.10.8). Install using requirement.txt then launch gradio UI using main.py
|
| 57 |
+
|
| 58 |
+
```
|
| 59 |
+
pip install -r requirements.txt
|
| 60 |
+
python main.py
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
# License
|
| 64 |
+
|
| 65 |
+
DigestEverything-GPT is licensed under the MIT License.
|
| 66 |
+
|
config/config.yaml
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio:
|
| 2 |
+
concurrent: 20
|
| 3 |
+
port: 7860
|
| 4 |
+
openai:
|
| 5 |
+
api_url: "https://api.openai.com/v1/chat/completions"
|
| 6 |
+
content_token: 3200 # tokens per content_main (e.g. transcript). If exceed it will be splitted and iterated
|
| 7 |
+
timeout_sec: 25
|
| 8 |
+
max_retry: 2
|
| 9 |
+
api_key: ""
|
digester/chatgpt_service.py
ADDED
|
@@ -0,0 +1,339 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
import re
|
| 4 |
+
import threading
|
| 5 |
+
import time
|
| 6 |
+
import traceback
|
| 7 |
+
|
| 8 |
+
import requests
|
| 9 |
+
|
| 10 |
+
from digester.util import get_config, Prompt, get_token, get_first_n_tokens_and_remaining, provide_text_with_css, GradioInputs
|
| 11 |
+
|
| 12 |
+
timeout_bot_msg = "Request timeout. Network error"
|
| 13 |
+
SYSTEM_PROMPT = "Be a assistant to digest youtube, podcast content to give summaries and insights"
|
| 14 |
+
|
| 15 |
+
TIMEOUT_MSG = f'{provide_text_with_css("ERROR", "red")} Request timeout.'
|
| 16 |
+
TOKEN_EXCEED_MSG = f'{provide_text_with_css("ERROR", "red")} Exceed token but it should not happen and should be splitted.'
|
| 17 |
+
|
| 18 |
+
# This piece of code heavily reference
|
| 19 |
+
# - https://github.com/GaiZhenbiao/ChuanhuChatGPT
|
| 20 |
+
# - https://github.com/binary-husky/chatgpt_academic
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
config = get_config()
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class LLMService:
|
| 27 |
+
@staticmethod
|
| 28 |
+
def report_exception(chatbot, history, chat_input, chat_output):
|
| 29 |
+
chatbot.append((chat_input, chat_output))
|
| 30 |
+
history.append(chat_input)
|
| 31 |
+
history.append(chat_output)
|
| 32 |
+
|
| 33 |
+
@staticmethod
|
| 34 |
+
def get_full_error(chunk, stream_response):
|
| 35 |
+
while True:
|
| 36 |
+
try:
|
| 37 |
+
chunk += next(stream_response)
|
| 38 |
+
except:
|
| 39 |
+
break
|
| 40 |
+
return chunk
|
| 41 |
+
|
| 42 |
+
@staticmethod
|
| 43 |
+
def generate_payload(api_key, gpt_model, inputs, history, stream):
|
| 44 |
+
headers = {
|
| 45 |
+
"Content-Type": "application/json",
|
| 46 |
+
"Authorization": f"Bearer {api_key}"
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
conversation_cnt = len(history) // 2
|
| 50 |
+
|
| 51 |
+
messages = [{"role": "system", "content": SYSTEM_PROMPT}]
|
| 52 |
+
if conversation_cnt:
|
| 53 |
+
for index in range(0, 2 * conversation_cnt, 2):
|
| 54 |
+
what_i_have_asked = {}
|
| 55 |
+
what_i_have_asked["role"] = "user"
|
| 56 |
+
what_i_have_asked["content"] = history[index]
|
| 57 |
+
what_gpt_answer = {}
|
| 58 |
+
what_gpt_answer["role"] = "assistant"
|
| 59 |
+
what_gpt_answer["content"] = history[index + 1]
|
| 60 |
+
if what_i_have_asked["content"] != "":
|
| 61 |
+
if what_gpt_answer["content"] == "": continue
|
| 62 |
+
if what_gpt_answer["content"] == timeout_bot_msg: continue
|
| 63 |
+
messages.append(what_i_have_asked)
|
| 64 |
+
messages.append(what_gpt_answer)
|
| 65 |
+
else:
|
| 66 |
+
messages[-1]['content'] = what_gpt_answer['content']
|
| 67 |
+
|
| 68 |
+
what_i_ask_now = {}
|
| 69 |
+
what_i_ask_now["role"] = "user"
|
| 70 |
+
what_i_ask_now["content"] = inputs
|
| 71 |
+
messages.append(what_i_ask_now)
|
| 72 |
+
|
| 73 |
+
payload = {
|
| 74 |
+
"model": gpt_model,
|
| 75 |
+
"messages": messages,
|
| 76 |
+
"temperature": 1.0,
|
| 77 |
+
"top_p": 1.0,
|
| 78 |
+
"n": 1,
|
| 79 |
+
"stream": stream,
|
| 80 |
+
"presence_penalty": 0,
|
| 81 |
+
"frequency_penalty": 0,
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
print(f"generate_payload() LLM: {gpt_model}, conversation_cnt: {conversation_cnt}")
|
| 85 |
+
print(f"\n[[[[[INPUT]]]]]\n{inputs}")
|
| 86 |
+
print(f"[[[[[OUTPUT]]]]]")
|
| 87 |
+
return headers, payload
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
class ChatGPTService:
|
| 91 |
+
@staticmethod
|
| 92 |
+
def say(user_say, chatbot_say, chatbot, history, status, source_md, is_append=True):
|
| 93 |
+
if is_append:
|
| 94 |
+
chatbot.append((user_say, chatbot_say))
|
| 95 |
+
else:
|
| 96 |
+
chatbot[-1] = (user_say, chatbot_say)
|
| 97 |
+
yield chatbot, history, status, source_md
|
| 98 |
+
|
| 99 |
+
@staticmethod
|
| 100 |
+
def get_reduce_token_percent(text):
|
| 101 |
+
try:
|
| 102 |
+
pattern = r"(\d+)\s+tokens\b"
|
| 103 |
+
match = re.findall(pattern, text)
|
| 104 |
+
EXCEED_ALLO = 500
|
| 105 |
+
max_limit = float(match[0]) - EXCEED_ALLO
|
| 106 |
+
current_tokens = float(match[1])
|
| 107 |
+
ratio = max_limit / current_tokens
|
| 108 |
+
assert ratio > 0 and ratio < 1
|
| 109 |
+
return ratio, str(int(current_tokens - max_limit))
|
| 110 |
+
except:
|
| 111 |
+
return 0.5, 'Unknown'
|
| 112 |
+
|
| 113 |
+
@staticmethod
|
| 114 |
+
def trigger_callgpt_pipeline(prompt_obj: Prompt, prompt_show_user: str, g_inputs: GradioInputs, is_timestamp=False):
|
| 115 |
+
chatbot, history, source_md, api_key, gpt_model = g_inputs.chatbot, g_inputs.history, f"[{g_inputs.source_textbox}] {g_inputs.source_target_textbox}", g_inputs.apikey_textbox, g_inputs.gpt_model_textbox
|
| 116 |
+
yield from ChatGPTService.say(prompt_show_user, f"{provide_text_with_css('INFO', 'blue')} waiting for ChatGPT's response.", chatbot, history, "Success", source_md)
|
| 117 |
+
|
| 118 |
+
prompts = ChatGPTService.split_prompt_content(prompt_obj, is_timestamp)
|
| 119 |
+
full_gpt_response = ""
|
| 120 |
+
for i, prompt in enumerate(prompts):
|
| 121 |
+
yield from ChatGPTService.say(None, f"{provide_text_with_css('INFO', 'blue')} Processing Batch {i + 1} / {len(prompts)}",
|
| 122 |
+
chatbot, history, "Success", source_md)
|
| 123 |
+
prompt_str = f"{prompt.prompt_prefix}{prompt.prompt_main}{prompt.prompt_suffix}"
|
| 124 |
+
|
| 125 |
+
gpt_response = yield from ChatGPTService.single_call_chatgpt_with_handling(
|
| 126 |
+
source_md, prompt_str, prompt_show_user, chatbot, api_key, gpt_model, history=[]
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
chatbot[-1] = (prompt_show_user, gpt_response)
|
| 130 |
+
# seems no need chat history now (have it later?)
|
| 131 |
+
# history.append(prompt_show_user)
|
| 132 |
+
# history.append(gpt_response)
|
| 133 |
+
full_gpt_response += gpt_response
|
| 134 |
+
yield chatbot, history, "Success", source_md # show gpt output
|
| 135 |
+
return full_gpt_response, len(prompts)
|
| 136 |
+
|
| 137 |
+
@staticmethod
|
| 138 |
+
def split_prompt_content(prompt: Prompt, is_timestamp=False) -> list:
|
| 139 |
+
"""
|
| 140 |
+
Split the prompt.prompt_main into multiple parts, each part is less than <content_token=3500> tokens
|
| 141 |
+
Then return all prompts object
|
| 142 |
+
"""
|
| 143 |
+
prompts = []
|
| 144 |
+
MAX_CONTENT_TOKEN = config.get('openai').get('content_token')
|
| 145 |
+
if not is_timestamp:
|
| 146 |
+
temp_prompt_main = prompt.prompt_main
|
| 147 |
+
while True:
|
| 148 |
+
if len(temp_prompt_main) == 0:
|
| 149 |
+
break
|
| 150 |
+
elif len(temp_prompt_main) < MAX_CONTENT_TOKEN:
|
| 151 |
+
prompts.append(Prompt(prompt_prefix=prompt.prompt_prefix,
|
| 152 |
+
prompt_main=temp_prompt_main,
|
| 153 |
+
prompt_suffix=prompt.prompt_suffix))
|
| 154 |
+
break
|
| 155 |
+
else:
|
| 156 |
+
first, last = get_first_n_tokens_and_remaining(temp_prompt_main, MAX_CONTENT_TOKEN)
|
| 157 |
+
temp_prompt_main = last
|
| 158 |
+
prompts.append(Prompt(prompt_prefix=prompt.prompt_prefix,
|
| 159 |
+
prompt_main=first,
|
| 160 |
+
prompt_suffix=prompt.prompt_suffix))
|
| 161 |
+
else:
|
| 162 |
+
# A bit ugly to handle the timestamped version and non-timestamped version in this matter.
|
| 163 |
+
# But make a working software first.
|
| 164 |
+
paragraphs_split_by_timestamp = []
|
| 165 |
+
for sentence in prompt.prompt_main.split('\n'):
|
| 166 |
+
if sentence == "":
|
| 167 |
+
continue
|
| 168 |
+
|
| 169 |
+
def is_start_with_timestamp(sentence):
|
| 170 |
+
return sentence[0].isdigit() and (sentence[1] == ":" or sentence[2] == ":")
|
| 171 |
+
|
| 172 |
+
if is_start_with_timestamp(sentence):
|
| 173 |
+
paragraphs_split_by_timestamp.append(sentence)
|
| 174 |
+
else:
|
| 175 |
+
paragraphs_split_by_timestamp[-1] += sentence
|
| 176 |
+
|
| 177 |
+
def extract_timestamp(paragraph):
|
| 178 |
+
return paragraph.split(' ')[0]
|
| 179 |
+
|
| 180 |
+
def extract_minute(timestamp):
|
| 181 |
+
return int(timestamp.split(':')[0])
|
| 182 |
+
|
| 183 |
+
def append_prompt(prompt, prompts, temp_minute, temp_paragraph, temp_timestamp):
|
| 184 |
+
prompts.append(Prompt(prompt_prefix=prompt.prompt_prefix,
|
| 185 |
+
prompt_main=temp_paragraph,
|
| 186 |
+
prompt_suffix=prompt.prompt_suffix.format(first_timestamp=temp_timestamp,
|
| 187 |
+
second_minute=temp_minute + 2,
|
| 188 |
+
third_minute=temp_minute + 4)
|
| 189 |
+
# this formatting gives better result in one-shot learning / example.
|
| 190 |
+
# ie if it is the second+ splitted prompt, don't use 0:00 as the first timestamp example
|
| 191 |
+
# use the exact first timestamp of the splitted prompt
|
| 192 |
+
))
|
| 193 |
+
|
| 194 |
+
token_num_list = list(map(get_token, paragraphs_split_by_timestamp)) # e.g. [159, 160, 158, ..]
|
| 195 |
+
timestamp_list = list(map(extract_timestamp, paragraphs_split_by_timestamp)) # e.g. ['0:00', '0:32', '1:03' ..]
|
| 196 |
+
minute_list = list(map(extract_minute, timestamp_list)) # e.g. [0, 0, 1, ..]
|
| 197 |
+
|
| 198 |
+
accumulated_token_num, temp_paragraph, temp_timestamp, temp_minute = 0, "", timestamp_list[0], minute_list[0]
|
| 199 |
+
for i, paragraph in enumerate(paragraphs_split_by_timestamp):
|
| 200 |
+
curr_token_num = token_num_list[i]
|
| 201 |
+
if accumulated_token_num + curr_token_num > MAX_CONTENT_TOKEN:
|
| 202 |
+
append_prompt(prompt, prompts, temp_minute, temp_paragraph, temp_timestamp)
|
| 203 |
+
accumulated_token_num, temp_paragraph = 0, ""
|
| 204 |
+
try:
|
| 205 |
+
temp_timestamp, temp_minute = timestamp_list[i + 1], minute_list[i + 1]
|
| 206 |
+
except IndexError:
|
| 207 |
+
temp_timestamp, temp_minute = timestamp_list[i], minute_list[i] # should be trivial. No more next part
|
| 208 |
+
else:
|
| 209 |
+
temp_paragraph += paragraph + "\n"
|
| 210 |
+
accumulated_token_num += curr_token_num
|
| 211 |
+
if accumulated_token_num > 0: # add back remaining
|
| 212 |
+
append_prompt(prompt, prompts, temp_minute, temp_paragraph, temp_timestamp)
|
| 213 |
+
return prompts
|
| 214 |
+
|
| 215 |
+
@staticmethod
|
| 216 |
+
def single_call_chatgpt_with_handling(source_md, prompt_str: str, prompt_show_user: str, chatbot, api_key, gpt_model="gpt-3.5-turbo", history=[]):
|
| 217 |
+
"""
|
| 218 |
+
Handling
|
| 219 |
+
- token exceeding -> split input
|
| 220 |
+
- timeout -> retry 2 times
|
| 221 |
+
- other error -> retry 2 times
|
| 222 |
+
"""
|
| 223 |
+
|
| 224 |
+
TIMEOUT_SECONDS, MAX_RETRY = config['openai']['timeout_sec'], config['openai']['max_retry']
|
| 225 |
+
# When multi-threaded, you need a mutable structure to pass information between different threads
|
| 226 |
+
# list is the simplest mutable structure, we put gpt output in the first position, the second position to pass the error message
|
| 227 |
+
mutable_list = [None, ''] # [gpt_output, error_message]
|
| 228 |
+
|
| 229 |
+
# multi-threading worker
|
| 230 |
+
def mt(prompt_str, history):
|
| 231 |
+
while True:
|
| 232 |
+
try:
|
| 233 |
+
mutable_list[0] = ChatGPTService.single_rest_call_chatgpt(api_key, prompt_str, gpt_model, history=history)
|
| 234 |
+
break
|
| 235 |
+
except ConnectionAbortedError as token_exceeded_error:
|
| 236 |
+
# # Try to calculate the ratio and keep as much text as possible
|
| 237 |
+
# print(f'[Local Message] Token exceeded: {token_exceeded_error}.')
|
| 238 |
+
# p_ratio, n_exceed = ChatGPTService.get_reduce_token_percent(str(token_exceeded_error))
|
| 239 |
+
# if len(history) > 0:
|
| 240 |
+
# history = [his[int(len(his) * p_ratio):] for his in history if his is not None]
|
| 241 |
+
# else:
|
| 242 |
+
# prompt_str = prompt_str[:int(len(prompt_str) * p_ratio)]
|
| 243 |
+
# mutable_list[1] = f'Warning: text too long will be truncated. Token exceeded:{n_exceed},Truncation ratio: {(1 - p_ratio):.0%}。'
|
| 244 |
+
mutable_list[0] = TOKEN_EXCEED_MSG
|
| 245 |
+
except TimeoutError as e:
|
| 246 |
+
mutable_list[0] = TIMEOUT_MSG
|
| 247 |
+
raise TimeoutError
|
| 248 |
+
except Exception as e:
|
| 249 |
+
mutable_list[0] = f'{provide_text_with_css("ERROR", "red")} Exception: {str(e)}.'
|
| 250 |
+
raise RuntimeError(f'[ERROR] Exception: {str(e)}.')
|
| 251 |
+
# TODO retry
|
| 252 |
+
|
| 253 |
+
# Create a new thread to make http requests
|
| 254 |
+
thread_name = threading.Thread(target=mt, args=(prompt_str, history))
|
| 255 |
+
thread_name.start()
|
| 256 |
+
# The original thread is responsible for continuously updating the UI, implementing a timeout countdown, and waiting for the new thread's task to complete
|
| 257 |
+
cnt = 0
|
| 258 |
+
while thread_name.is_alive():
|
| 259 |
+
cnt += 1
|
| 260 |
+
is_append = False
|
| 261 |
+
if cnt == 1:
|
| 262 |
+
is_append = True
|
| 263 |
+
yield from ChatGPTService.say(prompt_show_user, f"""
|
| 264 |
+
{provide_text_with_css("PROCESSING...", "blue")} {mutable_list[1]}waiting gpt response {cnt}/{TIMEOUT_SECONDS * 2 * (MAX_RETRY + 1)}{''.join(['.'] * (cnt % 4))}
|
| 265 |
+
{mutable_list[0]}
|
| 266 |
+
""", chatbot, history, 'Normal', source_md, is_append)
|
| 267 |
+
time.sleep(1)
|
| 268 |
+
# Get the output of gpt out of the mutable
|
| 269 |
+
gpt_response = mutable_list[0]
|
| 270 |
+
if 'ERROR' in gpt_response:
|
| 271 |
+
raise Exception
|
| 272 |
+
return gpt_response
|
| 273 |
+
|
| 274 |
+
@staticmethod
|
| 275 |
+
def single_rest_call_chatgpt(api_key, prompt_str: str, gpt_model="gpt-3.5-turbo", history=[], observe_window=None):
|
| 276 |
+
"""
|
| 277 |
+
Single call chatgpt only. No handling on multiple call (it should be in upper caller multi_call_chatgpt_with_handling())
|
| 278 |
+
- Support stream=True
|
| 279 |
+
- observe_window: used to pass the output across threads, most of the time just for the fancy visual effect, just leave it empty
|
| 280 |
+
- retry 2 times
|
| 281 |
+
"""
|
| 282 |
+
headers, payload = LLMService.generate_payload(api_key, gpt_model, prompt_str, history, stream=True)
|
| 283 |
+
|
| 284 |
+
retry = 0
|
| 285 |
+
while True:
|
| 286 |
+
try:
|
| 287 |
+
# make a POST request to the API endpoint, stream=False
|
| 288 |
+
response = requests.post(config['openai']['api_url'], headers=headers,
|
| 289 |
+
json=payload, stream=True, timeout=config['openai']['timeout_sec']
|
| 290 |
+
)
|
| 291 |
+
break
|
| 292 |
+
except requests.exceptions.ReadTimeout as e:
|
| 293 |
+
max_retry = config['openai']['max_retry']
|
| 294 |
+
retry += 1
|
| 295 |
+
traceback.print_exc()
|
| 296 |
+
if retry > max_retry:
|
| 297 |
+
raise TimeoutError
|
| 298 |
+
if max_retry != 0:
|
| 299 |
+
print(f'Request timeout. Retrying ({retry}/{max_retry}) ...')
|
| 300 |
+
|
| 301 |
+
stream_response = response.iter_lines()
|
| 302 |
+
result = ''
|
| 303 |
+
while True:
|
| 304 |
+
try:
|
| 305 |
+
chunk = next(stream_response).decode()
|
| 306 |
+
except StopIteration:
|
| 307 |
+
break
|
| 308 |
+
if len(chunk) == 0: continue
|
| 309 |
+
if not chunk.startswith('data:'):
|
| 310 |
+
error_msg = LLMService.get_full_error(chunk.encode('utf8'), stream_response).decode()
|
| 311 |
+
if "reduce the length" in error_msg:
|
| 312 |
+
raise ConnectionAbortedError("OpenAI rejected the request:" + error_msg)
|
| 313 |
+
else:
|
| 314 |
+
raise RuntimeError("OpenAI rejected the request: " + error_msg)
|
| 315 |
+
json_data = json.loads(chunk.lstrip('data:'))['choices'][0]
|
| 316 |
+
delta = json_data["delta"]
|
| 317 |
+
if len(delta) == 0: break
|
| 318 |
+
if "role" in delta: continue
|
| 319 |
+
if "content" in delta:
|
| 320 |
+
result += delta["content"]
|
| 321 |
+
print(delta["content"], end='')
|
| 322 |
+
if observe_window is not None: observe_window[0] += delta["content"]
|
| 323 |
+
else:
|
| 324 |
+
raise RuntimeError("Unexpected Json structure: " + delta)
|
| 325 |
+
if json_data['finish_reason'] == 'length':
|
| 326 |
+
raise ConnectionAbortedError("Completed normally with insufficient Tokens")
|
| 327 |
+
return result
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
if __name__ == '__main__':
|
| 331 |
+
import pickle
|
| 332 |
+
|
| 333 |
+
prompt: Prompt = pickle.load(open('prompt.pkl', 'rb'))
|
| 334 |
+
prompts = ChatGPTService.split_prompt_content(prompt, is_timestamp=True)
|
| 335 |
+
for prompt in prompts:
|
| 336 |
+
print("=====================================")
|
| 337 |
+
print(prompt.prompt_prefix)
|
| 338 |
+
print(prompt.prompt_main)
|
| 339 |
+
print(prompt.prompt_suffix)
|
digester/gradio_method_service.py
ADDED
|
@@ -0,0 +1,392 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
from everything2text4prompt.everything2text4prompt import Everything2Text4Prompt
|
| 4 |
+
from everything2text4prompt.util import BaseData, YoutubeData, PodcastData
|
| 5 |
+
|
| 6 |
+
from digester.chatgpt_service import LLMService, ChatGPTService
|
| 7 |
+
from digester.util import Prompt, provide_text_with_css, GradioInputs
|
| 8 |
+
|
| 9 |
+
WAITING_FOR_TARGET_INPUT = "Waiting for target source input"
|
| 10 |
+
RESPONSE_SUFFIX = "⚡Powered by DigestEverythingGPT in github"
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class GradioMethodService:
|
| 14 |
+
"""
|
| 15 |
+
GradioMethodService is defined as gradio functions
|
| 16 |
+
Therefore all methods here will fulfill
|
| 17 |
+
- gradio.inputs as signature
|
| 18 |
+
- gradio.outputs as return
|
| 19 |
+
Detailed-level methods called by methods in GradioMethodService will be in other classes (e.g. DigesterService)
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
@staticmethod
|
| 23 |
+
def write_results_to_file(history, file_name=None):
|
| 24 |
+
"""
|
| 25 |
+
Writes the conversation history to a file in Markdown format.
|
| 26 |
+
If no filename is specified, the filename is generated using the current time.
|
| 27 |
+
"""
|
| 28 |
+
import os, time
|
| 29 |
+
if file_name is None:
|
| 30 |
+
file_name = 'chatGPT_report' + time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) + '.md'
|
| 31 |
+
os.makedirs('./analyzer_logs/', exist_ok=True)
|
| 32 |
+
with open(f'./analyzer_logs/{file_name}', 'w', encoding='utf8') as f:
|
| 33 |
+
f.write('# chatGPT report\n')
|
| 34 |
+
for i, content in enumerate(history):
|
| 35 |
+
try:
|
| 36 |
+
if type(content) != str: content = str(content)
|
| 37 |
+
except:
|
| 38 |
+
continue
|
| 39 |
+
if i % 2 == 0:
|
| 40 |
+
f.write('## ')
|
| 41 |
+
f.write(content)
|
| 42 |
+
f.write('\n\n')
|
| 43 |
+
res = 'The above material has been written in ' + os.path.abspath(f'./analyzer_logs/{file_name}')
|
| 44 |
+
print(res)
|
| 45 |
+
return res
|
| 46 |
+
|
| 47 |
+
@staticmethod
|
| 48 |
+
def fetch_and_summarize(apikey_textbox, source_textbox, source_target_textbox, qa_textbox, gpt_model_textbox, language_textbox, chatbot, history):
|
| 49 |
+
g_inputs = GradioInputs(apikey_textbox, source_textbox, source_target_textbox, qa_textbox, gpt_model_textbox, language_textbox, chatbot, history)
|
| 50 |
+
g_inputs.history = []
|
| 51 |
+
g_inputs.chatbot = []
|
| 52 |
+
|
| 53 |
+
if g_inputs.apikey_textbox == "" or g_inputs.source_textbox == "" or g_inputs.source_target_textbox == "":
|
| 54 |
+
LLMService.report_exception(g_inputs.chatbot, g_inputs.history,
|
| 55 |
+
chat_input=f"Source target: [{g_inputs.source_textbox}] {g_inputs.source_target_textbox}",
|
| 56 |
+
chat_output=f"{provide_text_with_css('ERROR', 'red')} Please provide api key, source and target source")
|
| 57 |
+
yield g_inputs.chatbot, g_inputs.history, 'Error', WAITING_FOR_TARGET_INPUT
|
| 58 |
+
return
|
| 59 |
+
# TODO: invalid input checking
|
| 60 |
+
is_success, text_data = yield from DigesterService.fetch_text(g_inputs)
|
| 61 |
+
if not is_success:
|
| 62 |
+
return # TODO: error handling testing
|
| 63 |
+
yield from PromptEngineeringStrategy.execute_prompt_chain(g_inputs, text_data)
|
| 64 |
+
|
| 65 |
+
@staticmethod
|
| 66 |
+
def ask_question(apikey_textbox, source_textbox, target_source_textbox, qa_textbox, gpt_model_textbox, language_textbox, chatbot, history):
|
| 67 |
+
g_inputs = GradioInputs(apikey_textbox, source_textbox, target_source_textbox, qa_textbox, gpt_model_textbox, language_textbox, chatbot, history)
|
| 68 |
+
msg = f"ask_question(`{qa_textbox}`)"
|
| 69 |
+
g_inputs.chatbot.append(("test prompt query", msg))
|
| 70 |
+
yield g_inputs.chatbot, g_inputs.history, 'Normal'
|
| 71 |
+
|
| 72 |
+
@staticmethod
|
| 73 |
+
def test_formatting(apikey_textbox, source_textbox, target_source_textbox, qa_textbox, gpt_model_textbox, language_textbox, chatbot, history):
|
| 74 |
+
g_inputs = GradioInputs(apikey_textbox, source_textbox, target_source_textbox, qa_textbox, gpt_model_textbox, language_textbox, chatbot, history)
|
| 75 |
+
msg = r"""
|
| 76 |
+
# ASCII, table, code test
|
| 77 |
+
Overall, this program consists of the following files:
|
| 78 |
+
- `main.py`: This is the primary script of the program which uses NLP to analyze and summarize Python code.
|
| 79 |
+
- `model.py`: This file defines the `CodeModel` class that is used by `main.py` to model the code as graphs and performs operations on them.
|
| 80 |
+
- `parser.py`: This file contains custom parsing functions used by `model.py`.
|
| 81 |
+
- `test/`: This directory contains test scripts for `model.py` and `util.py`
|
| 82 |
+
- `util.py`: This file provides utility functions for the program such as getting the root directory of the project and reading configuration files.
|
| 83 |
+
|
| 84 |
+
`util.py` specifically has two functions:
|
| 85 |
+
|
| 86 |
+
| Function | Input | Output | Functionality |
|
| 87 |
+
|----------|-------|--------|---------------|
|
| 88 |
+
| `get_project_root()` | None | String containing the path of the parent directory of the script itself | Finds the path of the parent directory of the script itself |
|
| 89 |
+
| `get_config()` | None | Dictionary containing the contents of `config.yaml` and `config_secret.yaml`, merged together (with `config_secret.yaml` overwriting any keys with the same name in `config.yaml`) | Reads and merges two YAML configuration files (`config.yaml` and `config_secret.yaml`) located in the `config` directory in the parent directory of the script. Returns the resulting dictionary. |The above material has been written in C:\github\!CodeAnalyzerGPT\CodeAnalyzerGPT\analyzer_logs\chatGPT_report2023-04-07-14-11-55.md
|
| 90 |
+
|
| 91 |
+
The Hessian matrix is a square matrix that contains information about the second-order partial derivatives of a function. Suppose we have a function $f(x_1,x_2,...,x_n)$ which is twice continuously differentiable. Then the Hessian matrix $H(f)$ of $f$ is defined as the $n\times n$ matrix:
|
| 92 |
+
|
| 93 |
+
$$H(f) = \begin{bmatrix} \frac{\partial^2 f}{\partial x_1^2} & \frac{\partial^2 f}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_1 \partial x_n} \ \frac{\partial^2 f}{\partial x_2 \partial x_1} & \frac{\partial^2 f}{\partial x_2^2} & \cdots & \frac{\partial^2 f}{\partial x_2 \partial x_n} \ \vdots & \vdots & \ddots & \vdots \ \frac{\partial^2 f}{\partial x_n \partial x_1} & \frac{\partial^2 f}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_n^2} \ \end{bmatrix}$$
|
| 94 |
+
|
| 95 |
+
Each element in the Hessian matrix is the second-order partial derivative of the function with respect to a pair of variables, as shown in the matrix above
|
| 96 |
+
|
| 97 |
+
Here's an example Python code using SymPy module to get the derivative of a mathematical function:
|
| 98 |
+
|
| 99 |
+
```
|
| 100 |
+
import sympy as sp
|
| 101 |
+
|
| 102 |
+
x = sp.Symbol('x')
|
| 103 |
+
f = input('Enter a mathematical function in terms of x: ')
|
| 104 |
+
expr = sp.sympify(f)
|
| 105 |
+
|
| 106 |
+
dfdx = sp.diff(expr, x)
|
| 107 |
+
print('The derivative of', f, 'is:', dfdx)
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
This code will prompt the user to enter a mathematical function in terms of x and then use the `diff()` function from SymPy to calculate its derivative with respect to x. The result will be printed on the screen.
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
# Non-ASCII test
|
| 115 |
+
|
| 116 |
+
程序整体功能:CodeAnalyzerGPT工程是一个用于自动化代码分析和评审的工具。它使用了OpenAI的GPT模型对代码进行分析,然后根据一定的规则和标准来评价代码的质量和合规性。
|
| 117 |
+
|
| 118 |
+
程序的构架包含以下几个模块:
|
| 119 |
+
|
| 120 |
+
1. CodeAnalyzerGPT: 主程序模块,包含了代码分析和评审的主要逻辑。
|
| 121 |
+
|
| 122 |
+
2. analyzer: 包含了代码分析程序的具体实现。
|
| 123 |
+
|
| 124 |
+
每个文件的功能可以总结为下表:
|
| 125 |
+
|
| 126 |
+
| 文件名 | 功能描述 |
|
| 127 |
+
| --- | --- |
|
| 128 |
+
| C:\github\!CodeAnalyzerGPT\CodeAnalyzerGPT\CodeAnalyzerGPT.py | 主程序入口,调用各种处理逻辑和输出结果 |
|
| 129 |
+
| C:\github\!CodeAnalyzerGPT\CodeAnalyzerGPT\analyzer\code_analyzer.py | 代码分析器,包含了对代码文本的解析和分析逻辑 |
|
| 130 |
+
| C:\github\!CodeAnalyzerGPT\CodeAnalyzerGPT\analyzer\code_segment.py | 对代码文本进行语句和表达式的分段处理 |
|
| 131 |
+
|
| 132 |
+
"""
|
| 133 |
+
g_inputs.chatbot.append(("test prompt query", msg))
|
| 134 |
+
yield g_inputs.chatbot, g_inputs.history, 'Normal'
|
| 135 |
+
|
| 136 |
+
@staticmethod
|
| 137 |
+
def test_asking(apikey_textbox, source_textbox, target_source_textbox, qa_textbox, gpt_model_textbox, language_textbox, chatbot, history):
|
| 138 |
+
g_inputs = GradioInputs(apikey_textbox, source_textbox, target_source_textbox, qa_textbox, gpt_model_textbox, language_textbox, chatbot, history)
|
| 139 |
+
msg = f"test_ask(`{qa_textbox}`)"
|
| 140 |
+
g_inputs.chatbot.append(("test prompt query", msg))
|
| 141 |
+
g_inputs.chatbot.append(("test prompt query 2", msg))
|
| 142 |
+
g_inputs.chatbot.append(("", "test empty message"))
|
| 143 |
+
g_inputs.chatbot.append(("test empty message 2", ""))
|
| 144 |
+
g_inputs.chatbot.append((None, "output msg, test no input msg"))
|
| 145 |
+
g_inputs.chatbot.append(("input msg, , test no output msg", None))
|
| 146 |
+
g_inputs.chatbot.append((None, '<span style="background-color: yellow; color: black; padding: 3px; border-radius: 8px;">WARN</span>'))
|
| 147 |
+
yield g_inputs.chatbot, g_inputs.history, 'Normal'
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
class DigesterService:
|
| 151 |
+
@staticmethod
|
| 152 |
+
def update_ui(chatbot_input, chatbot_output, status, target_md, chatbot, history, is_append=True):
|
| 153 |
+
"""
|
| 154 |
+
For instant chatbot_input+output
|
| 155 |
+
Not suitable if chatbot_output have delay / processing time
|
| 156 |
+
"""
|
| 157 |
+
if is_append:
|
| 158 |
+
chatbot.append((chatbot_input, chatbot_output))
|
| 159 |
+
else:
|
| 160 |
+
chatbot[-1] = (chatbot_input, chatbot_output)
|
| 161 |
+
history.append(chatbot_input)
|
| 162 |
+
history.append(chatbot_output)
|
| 163 |
+
yield chatbot, history, status, target_md
|
| 164 |
+
|
| 165 |
+
@staticmethod
|
| 166 |
+
def fetch_text(g_inputs: GradioInputs) -> (bool, BaseData):
|
| 167 |
+
"""Fetch text from source using everything2text4prompt. No OpenAI call here"""
|
| 168 |
+
converter = Everything2Text4Prompt(openai_api_key=g_inputs.apikey_textbox)
|
| 169 |
+
text_data, is_success, error_msg = converter.convert_text(g_inputs.source_textbox, g_inputs.source_target_textbox)
|
| 170 |
+
text_content = text_data.full_content
|
| 171 |
+
|
| 172 |
+
chatbot_input = f"Converting source to text for [{g_inputs.source_textbox}] {g_inputs.source_target_textbox} ..."
|
| 173 |
+
target_md = f"[{g_inputs.source_textbox}] {g_inputs.source_target_textbox}"
|
| 174 |
+
if is_success:
|
| 175 |
+
chatbot_output = f"""
|
| 176 |
+
Extracted text successfully:
|
| 177 |
+
|
| 178 |
+
{text_content}
|
| 179 |
+
"""
|
| 180 |
+
yield from DigesterService.update_ui(chatbot_input, chatbot_output, "Success", target_md, g_inputs.chatbot, g_inputs.history)
|
| 181 |
+
else:
|
| 182 |
+
chatbot_output = f"""
|
| 183 |
+
{provide_text_with_css("ERROR", "red")} Text extraction failed ({error_msg})
|
| 184 |
+
"""
|
| 185 |
+
yield from DigesterService.update_ui(chatbot_input, chatbot_output, "Error", target_md, g_inputs.chatbot, g_inputs.history)
|
| 186 |
+
return is_success, text_data
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
class PromptEngineeringStrategy:
|
| 190 |
+
@staticmethod
|
| 191 |
+
def execute_prompt_chain(g_inputs: GradioInputs, text_data: BaseData):
|
| 192 |
+
if g_inputs.source_textbox == 'youtube':
|
| 193 |
+
yield from PromptEngineeringStrategy.execute_prompt_chain_youtube(g_inputs, text_data)
|
| 194 |
+
elif g_inputs.source_textbox == 'podcast':
|
| 195 |
+
yield from PromptEngineeringStrategy.execute_prompt_chain_podcast(g_inputs, text_data)
|
| 196 |
+
|
| 197 |
+
@staticmethod
|
| 198 |
+
def execute_prompt_chain_youtube(g_inputs: GradioInputs, text_data: YoutubeData):
|
| 199 |
+
yield from YoutubeChain.execute_chain(g_inputs, text_data)
|
| 200 |
+
|
| 201 |
+
@staticmethod
|
| 202 |
+
def execute_prompt_chain_podcast(g_inputs: GradioInputs, text_data: PodcastData):
|
| 203 |
+
pass
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
class Chain:
|
| 207 |
+
@staticmethod
|
| 208 |
+
def execute_chain(g_inputs: GradioInputs, text_data: YoutubeData):
|
| 209 |
+
raise NotImplementedError
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
class YoutubeChain(Chain):
|
| 213 |
+
CLASSIFIER_PROMPT = Prompt(
|
| 214 |
+
prompt_prefix="""
|
| 215 |
+
[Youtube Video types]
|
| 216 |
+
N things: The youtube will shows N items that will be described in the video. For example "17 cheap purchases that save me time", "10 AMAZING Ways AutoGPT Is Being Used RIGHT NOW". Usually the title starts with a number.
|
| 217 |
+
Tutorials: how to do or make something in order to teach a skill or how to use a product or software
|
| 218 |
+
How-to and DIY: People show how to make or do something yourself, like crafts, recipes, projects, etc
|
| 219 |
+
Interview: Interviewee shows their standpoint with a topic.
|
| 220 |
+
Others: If the video type is not listed above
|
| 221 |
+
|
| 222 |
+
[TITLE]
|
| 223 |
+
{title}
|
| 224 |
+
|
| 225 |
+
[TRANSCRIPT]
|
| 226 |
+
""",
|
| 227 |
+
prompt_main="""
|
| 228 |
+
{transcript}
|
| 229 |
+
""",
|
| 230 |
+
prompt_suffix="""
|
| 231 |
+
[TASK]
|
| 232 |
+
From the above title, transcript, classify the youtube video type listed above.
|
| 233 |
+
Give the video type with JSON format like {"type": "N things"}, and exclude other text.
|
| 234 |
+
""")
|
| 235 |
+
TIMESTAMPED_SUMMARY_PROMPT = Prompt(
|
| 236 |
+
prompt_prefix="""
|
| 237 |
+
[TITLE]
|
| 238 |
+
{title}
|
| 239 |
+
|
| 240 |
+
[Transcript with timestamp]
|
| 241 |
+
""",
|
| 242 |
+
prompt_main="""
|
| 243 |
+
{transcript_with_ts}
|
| 244 |
+
""",
|
| 245 |
+
prompt_suffix="""
|
| 246 |
+
[TASK]
|
| 247 |
+
Convert this into youtube summary.
|
| 248 |
+
Separate for 2-5minutes chunk, maximum 20 words for one line.
|
| 249 |
+
Start with the timestamp followed by the summarized text for that chunk.
|
| 250 |
+
Must use language: {language}
|
| 251 |
+
|
| 252 |
+
Example format:
|
| 253 |
+
{first_timestamp} - This is the first part
|
| 254 |
+
{second_minute}:44 - This is the second part
|
| 255 |
+
{third_minute}:02 - This is the third part
|
| 256 |
+
""")
|
| 257 |
+
|
| 258 |
+
FINAL_SUMMARY_PROMPT = Prompt(
|
| 259 |
+
prompt_prefix="""
|
| 260 |
+
[VIDEO_TYPE]
|
| 261 |
+
This is the video type
|
| 262 |
+
N things: The youtube will shows N items that will be described in the video. For example "17 cheap purchases that save me time", "10 AMAZING Ways AutoGPT Is Being Used RIGHT NOW"
|
| 263 |
+
Tutorials: how to do or make something in order to teach a skill or how to use a product or software
|
| 264 |
+
|
| 265 |
+
[TITLE]
|
| 266 |
+
{title}
|
| 267 |
+
|
| 268 |
+
[TRANSCRIPT]
|
| 269 |
+
""",
|
| 270 |
+
prompt_main="""
|
| 271 |
+
{transcript}
|
| 272 |
+
""",
|
| 273 |
+
prompt_suffix="""
|
| 274 |
+
[TASK]
|
| 275 |
+
Summarize the above transcript. Step by step showing points for the main concepts.
|
| 276 |
+
Use markdown format.
|
| 277 |
+
Must use language: {language}
|
| 278 |
+
{task_constraint}
|
| 279 |
+
|
| 280 |
+
The format is like:
|
| 281 |
+
Summary: (content of summary)
|
| 282 |
+
{format_constraint}
|
| 283 |
+
""")
|
| 284 |
+
|
| 285 |
+
FINAL_SUMMARY_TASK_CONSTRAINTS = {
|
| 286 |
+
"N things": """
|
| 287 |
+
Additionally, since it is a N things video, the summary should include the N items stated in the video.
|
| 288 |
+
""",
|
| 289 |
+
"Tutorials": """
|
| 290 |
+
Additionally, since it is a Tutorial video, provide step by step instructions for the tutorial.
|
| 291 |
+
""",
|
| 292 |
+
}
|
| 293 |
+
FINAL_SUMMARY_FORMAT_CONSTRAINTS = {
|
| 294 |
+
"N things": """
|
| 295 |
+
Items mentioned in the video: (content of N things)
|
| 296 |
+
""",
|
| 297 |
+
"Tutorials": """
|
| 298 |
+
Instructions: (step by step instructions)
|
| 299 |
+
""",
|
| 300 |
+
}
|
| 301 |
+
|
| 302 |
+
@staticmethod
|
| 303 |
+
def execute_chain(g_inputs: GradioInputs, text_data: YoutubeData):
|
| 304 |
+
text_content = text_data.full_content
|
| 305 |
+
timestamped_summary = yield from YoutubeChain.execute_timestamped_summary_chain(g_inputs, text_data)
|
| 306 |
+
video_type = yield from YoutubeChain.execute_classifer_chain(g_inputs, text_data)
|
| 307 |
+
final_summary = yield from YoutubeChain.execute_final_summary_chain(g_inputs, text_data, video_type)
|
| 308 |
+
full_summary = f"""
|
| 309 |
+
{provide_text_with_css("DONE", "green")}
|
| 310 |
+
Video: {text_data.title}
|
| 311 |
+
# Timestamped summary
|
| 312 |
+
{timestamped_summary}
|
| 313 |
+
|
| 314 |
+
# Summary
|
| 315 |
+
{final_summary}
|
| 316 |
+
|
| 317 |
+
{RESPONSE_SUFFIX}
|
| 318 |
+
"""
|
| 319 |
+
prompt_show_user = "Full summary"
|
| 320 |
+
g_inputs.chatbot[-1] = (prompt_show_user, full_summary)
|
| 321 |
+
g_inputs.history.append(prompt_show_user)
|
| 322 |
+
g_inputs.history.append(full_summary)
|
| 323 |
+
yield g_inputs.chatbot, g_inputs.history, "Success", f"[{g_inputs.source_textbox}] {g_inputs.source_target_textbox}"
|
| 324 |
+
|
| 325 |
+
@classmethod
|
| 326 |
+
def execute_classifer_chain(cls, g_inputs: GradioInputs, youtube_data: YoutubeData):
|
| 327 |
+
TRANSCRIPT_CHAR_LIMIT = 200 # Because classifer don't need to see the whole transcript
|
| 328 |
+
prompt = Prompt(cls.CLASSIFIER_PROMPT.prompt_prefix.format(title=youtube_data.title),
|
| 329 |
+
cls.CLASSIFIER_PROMPT.prompt_main.format(transcript=youtube_data.full_content[:TRANSCRIPT_CHAR_LIMIT]),
|
| 330 |
+
cls.CLASSIFIER_PROMPT.prompt_suffix
|
| 331 |
+
)
|
| 332 |
+
prompt_show_user = "Classify the video type for me"
|
| 333 |
+
response, len_prompts = yield from ChatGPTService.trigger_callgpt_pipeline(prompt, prompt_show_user, g_inputs)
|
| 334 |
+
try:
|
| 335 |
+
video_type = json.loads(response)['type']
|
| 336 |
+
except Exception as e:
|
| 337 |
+
# TODO: Exception handling, show error in UI
|
| 338 |
+
video_type = 'Others'
|
| 339 |
+
return video_type
|
| 340 |
+
|
| 341 |
+
@classmethod
|
| 342 |
+
def execute_timestamped_summary_chain(cls, g_inputs: GradioInputs, youtube_data: YoutubeData):
|
| 343 |
+
transcript_with_ts = ""
|
| 344 |
+
for entry in youtube_data.ts_transcript_list:
|
| 345 |
+
transcript_with_ts += f"{int(entry['start'] // 60)}:{int(entry['start'] % 60):02d} {entry['text']}\n"
|
| 346 |
+
prompt = Prompt(cls.TIMESTAMPED_SUMMARY_PROMPT.prompt_prefix.format(title=youtube_data.title),
|
| 347 |
+
cls.TIMESTAMPED_SUMMARY_PROMPT.prompt_main.format(transcript_with_ts=transcript_with_ts),
|
| 348 |
+
cls.TIMESTAMPED_SUMMARY_PROMPT.prompt_suffix.replace("{language}", g_inputs.language_textbox)
|
| 349 |
+
)
|
| 350 |
+
prompt_show_user = "Generate the timestamped summary"
|
| 351 |
+
response, len_prompts = yield from ChatGPTService.trigger_callgpt_pipeline(prompt, prompt_show_user, g_inputs, is_timestamp=True)
|
| 352 |
+
return response
|
| 353 |
+
|
| 354 |
+
@classmethod
|
| 355 |
+
def execute_final_summary_chain(cls, g_inputs: GradioInputs, youtube_data: YoutubeData, video_type):
|
| 356 |
+
if video_type in cls.FINAL_SUMMARY_TASK_CONSTRAINTS.keys():
|
| 357 |
+
task_constraint = cls.FINAL_SUMMARY_TASK_CONSTRAINTS[video_type]
|
| 358 |
+
format_constraint = cls.FINAL_SUMMARY_FORMAT_CONSTRAINTS[video_type]
|
| 359 |
+
else:
|
| 360 |
+
task_constraint, format_constraint = "", ""
|
| 361 |
+
prompt = Prompt(
|
| 362 |
+
cls.FINAL_SUMMARY_PROMPT.prompt_prefix.format(title=youtube_data.title),
|
| 363 |
+
cls.FINAL_SUMMARY_PROMPT.prompt_main.format(transcript=youtube_data.full_content),
|
| 364 |
+
cls.FINAL_SUMMARY_PROMPT.prompt_suffix.format(task_constraint=task_constraint, format_constraint=format_constraint, language=g_inputs.language_textbox)
|
| 365 |
+
)
|
| 366 |
+
prompt_show_user = "Generate the final summary"
|
| 367 |
+
response, len_prompts = yield from ChatGPTService.trigger_callgpt_pipeline(prompt, prompt_show_user, g_inputs)
|
| 368 |
+
if len_prompts > 1:
|
| 369 |
+
# Give summary of summaries if the video is long
|
| 370 |
+
prompt = Prompt(
|
| 371 |
+
cls.FINAL_SUMMARY_PROMPT.prompt_prefix.format(title=youtube_data.title),
|
| 372 |
+
cls.FINAL_SUMMARY_PROMPT.prompt_main.format(transcript=response),
|
| 373 |
+
cls.FINAL_SUMMARY_PROMPT.prompt_suffix.format(task_constraint=task_constraint, format_constraint=format_constraint, language=g_inputs.language_textbox)
|
| 374 |
+
)
|
| 375 |
+
prompt_show_user = "Since the video is long, generating the final summary of the summaries"
|
| 376 |
+
response, len_prompts = yield from ChatGPTService.trigger_callgpt_pipeline(prompt, prompt_show_user, g_inputs)
|
| 377 |
+
return response
|
| 378 |
+
|
| 379 |
+
|
| 380 |
+
if __name__ == '__main__':
|
| 381 |
+
GPT_MODEL = "gpt-3.5-turbo"
|
| 382 |
+
API_KEY = ""
|
| 383 |
+
input_1 = """Give me 2 ideas for the summer"""
|
| 384 |
+
# input_1 = """Explain more on the first idea"""
|
| 385 |
+
response_1 = ChatGPTService.single_rest_call_chatgpt(API_KEY, input_1, GPT_MODEL)
|
| 386 |
+
print(response_1)
|
| 387 |
+
|
| 388 |
+
input_2 = """
|
| 389 |
+
For the first idea, suggest some step by step planning for me
|
| 390 |
+
"""
|
| 391 |
+
response_2 = ChatGPTService.single_rest_call_chatgpt(API_KEY, input_2, GPT_MODEL, history=[input_1, response_1])
|
| 392 |
+
print(response_2)
|
digester/gradio_ui_service.py
ADDED
|
@@ -0,0 +1,269 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import markdown
|
| 3 |
+
|
| 4 |
+
from digester.gradio_method_service import GradioMethodService
|
| 5 |
+
|
| 6 |
+
title_html = "<h1 align=\"center\">DigestEverythingGPT</h1>"
|
| 7 |
+
|
| 8 |
+
cancel_handles = []
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class GradioUIService:
|
| 12 |
+
@staticmethod
|
| 13 |
+
def get_functions():
|
| 14 |
+
functions = {
|
| 15 |
+
"Fetch and summarize!": {
|
| 16 |
+
"function": GradioMethodService.fetch_and_summarize,
|
| 17 |
+
},
|
| 18 |
+
"Ask": {
|
| 19 |
+
"function": GradioMethodService.ask_question
|
| 20 |
+
},
|
| 21 |
+
"Test formatting": {
|
| 22 |
+
"function": GradioMethodService.test_formatting
|
| 23 |
+
},
|
| 24 |
+
"Test asking": {
|
| 25 |
+
"function": GradioMethodService.test_asking
|
| 26 |
+
},
|
| 27 |
+
}
|
| 28 |
+
return functions
|
| 29 |
+
|
| 30 |
+
@staticmethod
|
| 31 |
+
def post_define_functions(functions, folder_md):
|
| 32 |
+
"""Append extra gradio objects to functions after creating gradio objects"""
|
| 33 |
+
functions["Fetch and summarize!"]["extra_outputs"] = [folder_md]
|
| 34 |
+
return functions
|
| 35 |
+
|
| 36 |
+
@staticmethod
|
| 37 |
+
def get_gradio_ui():
|
| 38 |
+
def get_extra_outputs(functions, fn_key):
|
| 39 |
+
if functions[fn_key].get('extra_outputs'):
|
| 40 |
+
return functions[fn_key]['extra_outputs']
|
| 41 |
+
return []
|
| 42 |
+
|
| 43 |
+
# gr.Chatbot.postprocess = GradioUIService.format_io
|
| 44 |
+
functions = GradioUIService.get_functions()
|
| 45 |
+
with gr.Blocks(theme=GradioUIService.get_theme(), css=GradioUIService.get_css()) as demo:
|
| 46 |
+
gr.HTML(title_html)
|
| 47 |
+
with gr.Row().style(equal_height=True):
|
| 48 |
+
with gr.Column(scale=1):
|
| 49 |
+
with gr.Row():
|
| 50 |
+
apikey_textbox = gr.Textbox(label="OpenAI API key", placeholder="e.g. sk-xxxxx", css_class="api-key")
|
| 51 |
+
with gr.Row():
|
| 52 |
+
source_textbox = gr.Dropdown(
|
| 53 |
+
["youtube", "podcast (not support now)", "pdf (not support now)"],
|
| 54 |
+
value="youtube", label="Source", info="Choose your content provider"
|
| 55 |
+
# TODO: dynamic list from everything2text4prompt
|
| 56 |
+
)
|
| 57 |
+
with gr.Row():
|
| 58 |
+
source_target_textbox = gr.Textbox(show_label=True, label="URL / source target",
|
| 59 |
+
placeholder="For youtube video, give video id\nFor podcast, give podcast URL")
|
| 60 |
+
with gr.Accordion("Options", open=True):
|
| 61 |
+
with gr.Row():
|
| 62 |
+
gpt_model_textbox = gr.Dropdown(
|
| 63 |
+
["gpt-3.5-turbo", "gpt-4"],
|
| 64 |
+
value="gpt-3.5-turbo", label="GPT model", info="gpt-3.5 is cheaper.\nBut if you found that the result is not good, try gpt-4 \nYour API key must support gpt-4"
|
| 65 |
+
)
|
| 66 |
+
with gr.Row():
|
| 67 |
+
language_textbox = gr.Dropdown(
|
| 68 |
+
["en-US", "zh-CN", "zh-TW", "it-IT", "fr-FR", "de-DE", "es-ES", "ja-JP", "ko-KR", "ru-RU", ],
|
| 69 |
+
value="en-US", label="Language", info="Choose your language, regardless of video language"
|
| 70 |
+
)
|
| 71 |
+
with gr.Row():
|
| 72 |
+
functions["Fetch and summarize!"]["btn"] = gr.Button("Fetch and summarize!", variant="primary")
|
| 73 |
+
with gr.Row().style(equal_height=True):
|
| 74 |
+
gr.Markdown(f"Status: ")
|
| 75 |
+
status_md = gr.Markdown(f"Normal")
|
| 76 |
+
with gr.Row():
|
| 77 |
+
folder_md = gr.Markdown(f"Waiting for source target input")
|
| 78 |
+
with gr.Row():
|
| 79 |
+
qa_textbox = gr.Textbox(show_label=False, placeholder="Ask questions").style(container=False)
|
| 80 |
+
with gr.Row():
|
| 81 |
+
functions["Ask"]["btn"] = gr.Button("Ask", variant="primary")
|
| 82 |
+
with gr.Row():
|
| 83 |
+
reset_btn = gr.Button("Reset", variant="secondary")
|
| 84 |
+
reset_btn.style(size="sm")
|
| 85 |
+
stop_btn = gr.Button("Stop", variant="secondary")
|
| 86 |
+
stop_btn.style(size="sm")
|
| 87 |
+
with gr.Accordion("debug", open=True):
|
| 88 |
+
with gr.Row():
|
| 89 |
+
functions["Test formatting"]["btn"] = gr.Button("Test formatting")
|
| 90 |
+
functions["Test asking"]["btn"] = gr.Button("Test asking")
|
| 91 |
+
|
| 92 |
+
with gr.Column(scale=3):
|
| 93 |
+
chatbot = gr.Chatbot()
|
| 94 |
+
chatbot.style(height=1100)
|
| 95 |
+
history = gr.State([])
|
| 96 |
+
# after creating gradio objects, append to functions to centralize things.
|
| 97 |
+
functions = GradioUIService.post_define_functions(functions, folder_md)
|
| 98 |
+
#### handle click(=submit) and cancel behaviour
|
| 99 |
+
# Standard inputs/outputs (global for all actions)
|
| 100 |
+
inputs = [apikey_textbox, source_textbox, source_target_textbox, qa_textbox, gpt_model_textbox, language_textbox, chatbot, history]
|
| 101 |
+
outputs = [chatbot, history, status_md]
|
| 102 |
+
# fetch_and_summarize_textbox
|
| 103 |
+
fn_key = "Fetch and summarize!"
|
| 104 |
+
analyze_code_base_args = dict(fn=functions[fn_key]["function"], inputs=inputs, outputs=[*outputs, folder_md])
|
| 105 |
+
cancel_handles.append(source_target_textbox.submit(**analyze_code_base_args))
|
| 106 |
+
# qa_textbox
|
| 107 |
+
fn_key = "Ask"
|
| 108 |
+
ask_args = dict(fn=functions[fn_key]["function"], inputs=inputs, outputs=outputs)
|
| 109 |
+
cancel_handles.append(qa_textbox.submit(**ask_args))
|
| 110 |
+
# all buttons
|
| 111 |
+
for fn_key in functions:
|
| 112 |
+
click_handle = functions[fn_key]["btn"].click(fn=functions[fn_key]["function"],
|
| 113 |
+
inputs=inputs, outputs=[*outputs, *get_extra_outputs(functions, fn_key)])
|
| 114 |
+
cancel_handles.append(click_handle)
|
| 115 |
+
stop_btn.click(fn=None, inputs=None, outputs=None, cancels=cancel_handles)
|
| 116 |
+
reset_btn.click(fn=lambda: ([], [], "Already reset"), inputs=None, outputs=outputs)
|
| 117 |
+
demo.title = "DigestEverythingGPT"
|
| 118 |
+
return demo
|
| 119 |
+
|
| 120 |
+
def format_io(self, y):
|
| 121 |
+
"""
|
| 122 |
+
Convert the input and output to HTML format.
|
| 123 |
+
Paragraphize the input part of the last item in y,
|
| 124 |
+
and convert the Markdown and mathematical formula in the output part to HTML format.
|
| 125 |
+
"""
|
| 126 |
+
|
| 127 |
+
def text_divide_paragraph(text):
|
| 128 |
+
"""
|
| 129 |
+
Separate the text according to the paragraph separator and generate HTML code with paragraph tags.
|
| 130 |
+
"""
|
| 131 |
+
if '```' in text:
|
| 132 |
+
return text
|
| 133 |
+
else:
|
| 134 |
+
lines = text.split("\n")
|
| 135 |
+
for i, line in enumerate(lines):
|
| 136 |
+
lines[i] = lines[i].replace(" ", " ")
|
| 137 |
+
text = "</br>".join(lines)
|
| 138 |
+
return text
|
| 139 |
+
|
| 140 |
+
def close_up_code_segment_during_stream(gpt_reply):
|
| 141 |
+
"""
|
| 142 |
+
Handling when the GPT output is cut in half
|
| 143 |
+
Add '```' at the end of the output if the output is not complete.
|
| 144 |
+
"""
|
| 145 |
+
# guard pattern for normal cases
|
| 146 |
+
if '```' not in gpt_reply:
|
| 147 |
+
return gpt_reply
|
| 148 |
+
if gpt_reply.endswith('```'):
|
| 149 |
+
return gpt_reply
|
| 150 |
+
|
| 151 |
+
# otherwise
|
| 152 |
+
segments = gpt_reply.split('```')
|
| 153 |
+
n_mark = len(segments) - 1
|
| 154 |
+
if n_mark % 2 == 1:
|
| 155 |
+
return gpt_reply + '\n```'
|
| 156 |
+
else:
|
| 157 |
+
return gpt_reply
|
| 158 |
+
|
| 159 |
+
def markdown_convertion(txt):
|
| 160 |
+
"""
|
| 161 |
+
Convert markdown text to HTML format
|
| 162 |
+
"""
|
| 163 |
+
pre = '<div class="markdown-body">'
|
| 164 |
+
suf = '</div>'
|
| 165 |
+
# if ('$' in txt) and ('```' not in txt):
|
| 166 |
+
# return pre + markdown.markdown(txt, extensions=['fenced_code', 'tables']) + '<br><br>' + markdown.markdown(convert_math(txt, splitParagraphs=False),
|
| 167 |
+
# extensions=['fenced_code', 'tables']) + suf
|
| 168 |
+
# else:
|
| 169 |
+
# return pre + markdown.markdown(txt, extensions=['fenced_code', 'tables']) + suf
|
| 170 |
+
return pre + markdown.markdown(txt, extensions=['fenced_code', 'tables']) + suf
|
| 171 |
+
|
| 172 |
+
if y is None or y == []: return []
|
| 173 |
+
i_ask, gpt_reply = y[-1]
|
| 174 |
+
i_ask = text_divide_paragraph(i_ask)
|
| 175 |
+
gpt_reply = close_up_code_segment_during_stream(gpt_reply)
|
| 176 |
+
# y[-1] = (
|
| 177 |
+
# None if i_ask is None else markdown.markdown(i_ask, extensions=['fenced_code', 'tables']),
|
| 178 |
+
# None if gpt_reply is None else markdown_convertion(gpt_reply)
|
| 179 |
+
# )
|
| 180 |
+
return y
|
| 181 |
+
|
| 182 |
+
@staticmethod
|
| 183 |
+
def get_theme():
|
| 184 |
+
try:
|
| 185 |
+
set_theme = gr.themes.Default(
|
| 186 |
+
primary_hue=gr.themes.utils.colors.cyan,
|
| 187 |
+
neutral_hue=gr.themes.utils.colors.gray,
|
| 188 |
+
font=[gr.themes.GoogleFont("Inter"), "ui-sans-serif", "system-ui", "sans-serif", ],
|
| 189 |
+
font_mono=[gr.themes.GoogleFont("JetBrains Mono"), "Consolas", "ui-monospace", "monospace"]
|
| 190 |
+
)
|
| 191 |
+
except Exception as e:
|
| 192 |
+
set_theme = None
|
| 193 |
+
print(f'please upgrade to newer version of gradio {e}')
|
| 194 |
+
return set_theme
|
| 195 |
+
|
| 196 |
+
@staticmethod
|
| 197 |
+
def get_css():
|
| 198 |
+
css = """
|
| 199 |
+
/* Set the outer margins of the table to 1em, merge the borders between internal cells, and display empty cells. */
|
| 200 |
+
.markdown-body table {
|
| 201 |
+
margin: 1em 0;
|
| 202 |
+
border-collapse: collapse;
|
| 203 |
+
empty-cells: show;
|
| 204 |
+
}
|
| 205 |
+
|
| 206 |
+
/* Set the inner margin of the table cell to 5px, the border thickness to 1.2px, and the color to --border-color-primary. */
|
| 207 |
+
.markdown-body th, .markdown-body td {
|
| 208 |
+
border: 1.2px solid var(--border-color-primary);
|
| 209 |
+
padding: 5px;
|
| 210 |
+
}
|
| 211 |
+
|
| 212 |
+
/* Set the table header background color to rgba(175,184,193,0.2) and transparency to 0.2. */
|
| 213 |
+
.markdown-body thead {
|
| 214 |
+
background-color: rgba(175,184,193,0.2);
|
| 215 |
+
}
|
| 216 |
+
|
| 217 |
+
/* Set the padding of the table header cell to 0.5em and 0.2em. */
|
| 218 |
+
.markdown-body thead th {
|
| 219 |
+
padding: .5em .2em;
|
| 220 |
+
}
|
| 221 |
+
|
| 222 |
+
/* Remove the default padding of the list prefix to align it with the text line. */
|
| 223 |
+
.markdown-body ol, .markdown-body ul {
|
| 224 |
+
padding-inline-start: 2em !important;
|
| 225 |
+
}
|
| 226 |
+
|
| 227 |
+
/* Set the style of the chat bubble, including the radius, the maximum width, and the shadow. */
|
| 228 |
+
[class *= "message"] {
|
| 229 |
+
border-radius: var(--radius-xl) !important;
|
| 230 |
+
/* padding: var(--spacing-xl) !important; */
|
| 231 |
+
/* font-size: var(--text-md) !important; */
|
| 232 |
+
/* line-height: var(--line-md) !important; */
|
| 233 |
+
/* min-height: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl)); */
|
| 234 |
+
/* min-width: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl)); */
|
| 235 |
+
}
|
| 236 |
+
[data-testid = "bot"] {
|
| 237 |
+
max-width: 95%;
|
| 238 |
+
/* width: auto !important; */
|
| 239 |
+
border-bottom-left-radius: 0 !important;
|
| 240 |
+
}
|
| 241 |
+
[data-testid = "user"] {
|
| 242 |
+
max-width: 100%;
|
| 243 |
+
/* width: auto !important; */
|
| 244 |
+
border-bottom-right-radius: 0 !important;
|
| 245 |
+
}
|
| 246 |
+
|
| 247 |
+
/* Set the background of the inline code to light gray, set the radius and spacing. */
|
| 248 |
+
.markdown-body code {
|
| 249 |
+
font-family: 'JetBrains Mono', monospace;
|
| 250 |
+
display: inline;
|
| 251 |
+
white-space: break-spaces;
|
| 252 |
+
border-radius: 6px;
|
| 253 |
+
margin: 0 2px 0 2px;
|
| 254 |
+
padding: .2em .4em .1em .4em;
|
| 255 |
+
background-color: rgba(175,184,193,0.2);
|
| 256 |
+
}
|
| 257 |
+
/* Set the style of the code block, including the background color, the inner and outer margins, and the radius. */
|
| 258 |
+
.markdown-body pre code {
|
| 259 |
+
font-family: 'JetBrains Mono', monospace;
|
| 260 |
+
display: block;
|
| 261 |
+
overflow: auto;
|
| 262 |
+
white-space: pre;
|
| 263 |
+
background-color: rgba(175,184,193,0.2);
|
| 264 |
+
border-radius: 10px;
|
| 265 |
+
padding: 1em;
|
| 266 |
+
margin: 1em 2em 1em 0.5em;
|
| 267 |
+
}
|
| 268 |
+
"""
|
| 269 |
+
return css
|
digester/test_chatgpt.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from chatgpt_service import ChatGPTService
|
| 2 |
+
from everything2text4prompt.everything2text4prompt import Everything2Text4Prompt
|
| 3 |
+
from everything2text4prompt.util import BaseData, YoutubeData, PodcastData
|
| 4 |
+
from gradio_method_service import YoutubeChain, GradioInputs
|
| 5 |
+
from digester.util import get_config, Prompt
|
| 6 |
+
|
| 7 |
+
import json
|
| 8 |
+
|
| 9 |
+
if __name__ == '__main__':
|
| 10 |
+
config = get_config()
|
| 11 |
+
api_key = config.get("openai").get("api_key")
|
| 12 |
+
assert api_key
|
| 13 |
+
|
| 14 |
+
gradio_inputs = GradioInputs(apikey_textbox=api_key, source_textbox="", source_target_textbox="", qa_textbox="", chatbot=[], history=[])
|
| 15 |
+
prompt_str = """
|
| 16 |
+
[[[[[INPUT]]]]]
|
| 17 |
+
|
| 18 |
+
[TITLE]
|
| 19 |
+
8 Surprising Habits That Made Me A Millionaire
|
| 20 |
+
|
| 21 |
+
[Transcript with timestamp]
|
| 22 |
+
6:42 "Hey, let's do everything ourselves." That brings us on to habit number six which is to make friends
|
| 23 |
+
with people in real life and more importantly,
|
| 24 |
+
well, not more importantly, but additionally, on the internet. And the single best way I find
|
| 25 |
+
for doing this is Twitter. Twitter is an incredible,
|
| 26 |
+
incredible, incredible invention that you can use to make friends with people all around the world. And the nice thing about Twitter is that it's different to Instagram. Instagram is very sort of visual and based on posting pretty pictures, but Twitter is very much
|
| 27 |
+
based on sharing good ideas. And if you are sharing interesting ideas and you're connecting with other people who are sharing those similar ideas, that automatically leads you
|
| 28 |
+
7:13 to kind of becoming internet friends, and then they follow you, you follow them, you chat a little bit in the DMs. And over the last year, I've
|
| 29 |
+
met up with so many people who I initially met on Twitter. And I've got friends all around the world who I've never ever met in real life, but we've talked on Twitter. We know we liked the same stuff. We share the same ideas. And, A, this just makes
|
| 30 |
+
life much more fun. But if we're talking about habits to get to becoming a millionaire, I can point to lots of
|
| 31 |
+
these different connections that have really accelerated
|
| 32 |
+
the growth of my business. For example, me and my mate Thomas Frank became friends on Twitter
|
| 33 |
+
like two weeks ago. Thomas Frank then
|
| 34 |
+
introduced me to Standard
|
| 35 |
+
7:44 which is the YouTuber
|
| 36 |
+
agency that I'm now part of and that completely changed
|
| 37 |
+
the game for my business. Secondly, there's two chaps,
|
| 38 |
+
Tiago Forte and David Perell who run their own online courses. We became friends on Twitter
|
| 39 |
+
after I took their courses and started engaging with them on Twitter. And then I DMed them when I wanted help for my own Part-Time YouTuber Academy and they really helped with that. And again, that really accelerated the growth of the business to becoming a $2 million business. And when it comes to this
|
| 40 |
+
making friends thing, it's one of those things
|
| 41 |
+
that's very hard to like, if you make friends with someone,
|
| 42 |
+
then it will lead to this. It's more like you have
|
| 43 |
+
this general habit, this general attitude
|
| 44 |
+
towards making friends with whoever shares the same ideas as you
|
| 45 |
+
8:16 and just generally trying to
|
| 46 |
+
be a nice and helpful person, and you know that, eventually, that'll lead to really interesting things happening in your life
|
| 47 |
+
further down the line. On a somewhat related note, habit number seven is reading a lot. And just like we can get
|
| 48 |
+
wisdom from our real life and our internet friends via Twitter, we can get a lot more wisdom from people who have
|
| 49 |
+
written books about stuff. You know, if you speak to anyone who's successful in almost any way, they will almost always say
|
| 50 |
+
that they read a lot of books. And they will also almost always say that everyone else that
|
| 51 |
+
they know who's successful also reads a lot of books.
|
| 52 |
+
8:47 So if you're telling yourself,
|
| 53 |
+
"I don't have time to read," then you're kind of screwing yourself because (laughs) basically
|
| 54 |
+
every millionaire you ask will have spent tonnes and
|
| 55 |
+
tonnes of time reading books. And again, the great thing about books is that you've got five,
|
| 56 |
+
10, 20 years of experience that someone has boiled down to a thing that takes you
|
| 57 |
+
a few hours to read. Like Tim Ferriss was doing
|
| 58 |
+
the entrepreneurial thing for 10 years before he wrote the book. That's pretty sick. That's 10 years of wisdom that
|
| 59 |
+
you can read in a few hours. And if you read lots of books
|
| 60 |
+
of this or entrepreneurship, like business, finance,
|
| 61 |
+
9:19 basically anything you're interested in, you can just get a huge
|
| 62 |
+
amount of value from them. And it doesn't really cost very much. You can find PDFs on the internet for free if you're really averse
|
| 63 |
+
to paying for books if that's your vibe. And it's just such a great way
|
| 64 |
+
to accelerate your learning in almost anything. If you didn't know, I
|
| 65 |
+
am also writing a book, which is probably gonna
|
| 66 |
+
come out in two years' time. But I'll put a link to my
|
| 67 |
+
book mailing list newsletter, which is where I share my book journey and what it's like to
|
| 68 |
+
write and research a book and sample chapters and getting the audience's
|
| 69 |
+
opinion and stuff. So that'll be linked in
|
| 70 |
+
the video description if you wanna check it out. And finally, habit number eight
|
| 71 |
+
for becoming a millionaire is to acquire financial literacy.
|
| 72 |
+
9:51 Now, this is one of those things that no one teaches us in
|
| 73 |
+
school or university or college, but it's just one of those things that you have to learn for yourself. And you can get it through reading books, such as, for example, this book, oh crap, "The Psychology of
|
| 74 |
+
Money" by Morgan Housel, which is now a little bit dilapidated. I read this recently. It's
|
| 75 |
+
really, really, really good. 20 bite-sized lessons about money. Gonna make a video about that. But also just generally
|
| 76 |
+
taking your financial life into your own hands. I know so many people who have sort of relegated their financial
|
| 77 |
+
life to, you know, "Oh, it's just something that
|
| 78 |
+
the government will sort out."
|
| 79 |
+
10:22 Or "Oh, you know, my hospital "will figure out what taxes I need to pay "and then I'll just kind
|
| 80 |
+
of do it from there." Money is such an important part of life. It's one of the biggest sources
|
| 81 |
+
of stress in anyone's life if you don't have much of it. And so much of our life is
|
| 82 |
+
spent in the pursuit of money and financial freedom,
|
| 83 |
+
financial independence, that if we don't have financial literacy, if we don't understand the
|
| 84 |
+
basics of saving or investing or how the stock market
|
| 85 |
+
works or how taxes work, any of that kind of stuff, again, we are just screwing ourselves. Because if you wanna become a millionaire you have to have some
|
| 86 |
+
level of financial literacy to know what it takes
|
| 87 |
+
to become a millionaire and how that might actually work.
|
| 88 |
+
10:53 So recommend reading a book like "The Psychology of
|
| 89 |
+
Money by Morgan Housel. Or, if you like, you can check
|
| 90 |
+
out this video over here, which is my ultimate guide to investing in stocks and shares. That's like a half an
|
| 91 |
+
hour-long crash course on everything you need
|
| 92 |
+
to know about investing. If you don't know about investing definitely check out that video. Thank you so much for watching. Hope you found this video useful. And I will see you in
|
| 93 |
+
the next one. Bye-bye.
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
[TASK]
|
| 97 |
+
Convert this into youtube summary.
|
| 98 |
+
Separate for 2-5minutes chunk, maximum 20 words for one line.
|
| 99 |
+
Start with the timestamp followed by the summarized text for that chunk.
|
| 100 |
+
Example format:
|
| 101 |
+
6:42 - This is the first part
|
| 102 |
+
8:00 - This is the second part
|
| 103 |
+
9:22 - This is the third part
|
| 104 |
+
"""
|
| 105 |
+
GPT_MODEL = "gpt-3.5-turbo"
|
| 106 |
+
ChatGPTService.single_rest_call_chatgpt(api_key, prompt_str, GPT_MODEL)
|
digester/test_youtube_chain.py
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from chatgpt_service import ChatGPTService
|
| 2 |
+
from everything2text4prompt.everything2text4prompt import Everything2Text4Prompt
|
| 3 |
+
from everything2text4prompt.util import BaseData, YoutubeData, PodcastData
|
| 4 |
+
from gradio_method_service import YoutubeChain, GradioInputs
|
| 5 |
+
from digester.util import get_config, Prompt
|
| 6 |
+
|
| 7 |
+
import json
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class VideoExample:
|
| 11 |
+
def __init__(self, title, description, transcript):
|
| 12 |
+
self.title = title
|
| 13 |
+
self.description = description
|
| 14 |
+
self.transcript = transcript
|
| 15 |
+
|
| 16 |
+
@classmethod
|
| 17 |
+
def get_youtube_data(cls, api_key: str, video_id: str):
|
| 18 |
+
converter = Everything2Text4Prompt(openai_api_key=api_key)
|
| 19 |
+
text_data, is_success, error_msg = converter.convert_text("youtube", video_id)
|
| 20 |
+
text_data: YoutubeData
|
| 21 |
+
title = text_data.title
|
| 22 |
+
description = text_data.description
|
| 23 |
+
transcript = text_data.full_content
|
| 24 |
+
ts_transcript_list = text_data.ts_transcript_list
|
| 25 |
+
return YoutubeData(transcript, title, description, ts_transcript_list)
|
| 26 |
+
|
| 27 |
+
@staticmethod
|
| 28 |
+
def get_nthings_10_autogpt():
|
| 29 |
+
video_id = "lSTEhG021Jc"
|
| 30 |
+
return VideoExample.get_youtube_data("", video_id)
|
| 31 |
+
|
| 32 |
+
@staticmethod
|
| 33 |
+
def get_nthings_7_lifelesson():
|
| 34 |
+
video_id = "CUPe_TZECQQ"
|
| 35 |
+
return VideoExample.get_youtube_data("", video_id)
|
| 36 |
+
|
| 37 |
+
@staticmethod
|
| 38 |
+
def get_nthings_8_habits():
|
| 39 |
+
video_id = "IScN1SOcj7A"
|
| 40 |
+
return VideoExample.get_youtube_data("", video_id)
|
| 41 |
+
|
| 42 |
+
@staticmethod
|
| 43 |
+
def get_tutorial_skincare():
|
| 44 |
+
video_id = "OrElyY7MFVs"
|
| 45 |
+
return VideoExample.get_youtube_data("", video_id)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class YoutubeTestChain:
|
| 49 |
+
def __init__(self, api_key: str, gpt_model="gpt-3.5-turbo"):
|
| 50 |
+
self.api_key = api_key
|
| 51 |
+
self.gpt_model = gpt_model
|
| 52 |
+
|
| 53 |
+
def run_testing_chain(self):
|
| 54 |
+
input_1 = """Give me 2 ideas for the summer"""
|
| 55 |
+
# input_1 = """Explain more on the first idea"""
|
| 56 |
+
response_1 = ChatGPTService.single_rest_call_chatgpt(self.api_key, input_1, self.gpt_model)
|
| 57 |
+
|
| 58 |
+
input_2 = """
|
| 59 |
+
For the first idea, suggest some step by step planning for me
|
| 60 |
+
"""
|
| 61 |
+
response_2 = ChatGPTService.single_rest_call_chatgpt(self.api_key, input_2, self.gpt_model, history=[input_1, response_1])
|
| 62 |
+
|
| 63 |
+
def test_youtube_classifier(self, gradio_inputs: GradioInputs, youtube_data: YoutubeData):
|
| 64 |
+
iter = YoutubeChain.execute_classifer_chain(gradio_inputs, youtube_data)
|
| 65 |
+
while True:
|
| 66 |
+
next(iter)
|
| 67 |
+
|
| 68 |
+
def test_youtube_timestamped_summary(self, gradio_inputs: GradioInputs, youtube_data: YoutubeData):
|
| 69 |
+
iter = YoutubeChain.execute_timestamped_summary_chain(gradio_inputs, youtube_data)
|
| 70 |
+
while True:
|
| 71 |
+
next(iter)
|
| 72 |
+
|
| 73 |
+
def test_youtube_final_summary(self, gradio_inputs: GradioInputs, youtube_data: YoutubeData, video_type):
|
| 74 |
+
iter = YoutubeChain.execute_final_summary_chain(gradio_inputs, youtube_data, video_type)
|
| 75 |
+
while True:
|
| 76 |
+
next(iter)
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
if __name__ == '__main__':
|
| 80 |
+
config = get_config()
|
| 81 |
+
api_key = config.get("openai").get("api_key")
|
| 82 |
+
assert api_key
|
| 83 |
+
|
| 84 |
+
gradio_inputs = GradioInputs(apikey_textbox=api_key, source_textbox="", source_target_textbox="", qa_textbox="", chatbot=[], history=[])
|
| 85 |
+
youtube_data: YoutubeData = VideoExample.get_nthings_8_habits()
|
| 86 |
+
|
| 87 |
+
youtube_test_chain = YoutubeTestChain(api_key)
|
| 88 |
+
# youtube_test_chain.test_youtube_classifier(gradio_inputs, youtube_data)
|
| 89 |
+
youtube_test_chain.test_youtube_timestamped_summary(gradio_inputs, youtube_data)
|
| 90 |
+
# video_type = "N things"
|
| 91 |
+
# video_type = "Tutorials"
|
| 92 |
+
# video_type = "Others"
|
| 93 |
+
# youtube_test_chain.test_youtube_final_summary(gradio_inputs, youtube_data, video_type)
|
| 94 |
+
|
| 95 |
+
# converter = Everything2Text4Prompt(openai_api_key="")
|
| 96 |
+
# source_textbox = "youtube"
|
| 97 |
+
# target_source_textbox = "CUPe_TZECQQ"
|
| 98 |
+
# text_data, is_success, error_msg = converter.convert_text(source_textbox, target_source_textbox)
|
| 99 |
+
# print(text_data.title)
|
| 100 |
+
# print(text_data.description)
|
| 101 |
+
# print(text_data.full_content)
|
| 102 |
+
# print(text_data.ts_transcript_list)
|
digester/util.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
import tiktoken
|
| 5 |
+
import yaml
|
| 6 |
+
|
| 7 |
+
tokenizer = tiktoken.encoding_for_model("gpt-3.5-turbo")
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class GradioInputs:
|
| 11 |
+
"""
|
| 12 |
+
This DTO class formalized the format of "inputs" from gradio and prevent long signature
|
| 13 |
+
It will be converted in GradioMethodService.
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, apikey_textbox, source_textbox, source_target_textbox, qa_textbox, gpt_model_textbox, language_textbox, chatbot, history):
|
| 17 |
+
self.apikey_textbox = apikey_textbox
|
| 18 |
+
self.source_textbox = source_textbox
|
| 19 |
+
self.source_target_textbox = source_target_textbox
|
| 20 |
+
self.qa_textbox = qa_textbox
|
| 21 |
+
self.gpt_model_textbox = gpt_model_textbox
|
| 22 |
+
self.language_textbox = language_textbox
|
| 23 |
+
self.chatbot = chatbot
|
| 24 |
+
self.history = history
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class Prompt:
|
| 28 |
+
"""
|
| 29 |
+
Define the prompt structure
|
| 30 |
+
Prompt = "{prompt_prefix}{prompt_main}{prompt_suffix}"
|
| 31 |
+
where if the prompt is too long, {prompt_main} will be splitted into multiple parts to fulfill context length of LLM
|
| 32 |
+
|
| 33 |
+
Example: for Youtube-timestamped summary
|
| 34 |
+
prompt_prefix: Youtube Video types definitions, Title
|
| 35 |
+
prompt_main: transcript (splittable)
|
| 36 |
+
prompt_suffix: task description / constraints
|
| 37 |
+
"""
|
| 38 |
+
|
| 39 |
+
def __init__(self, prompt_prefix, prompt_main, prompt_suffix):
|
| 40 |
+
self.prompt_prefix = prompt_prefix
|
| 41 |
+
self.prompt_main = prompt_main
|
| 42 |
+
self.prompt_suffix = prompt_suffix
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def get_project_root():
|
| 46 |
+
return Path(__file__).parent.parent
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def get_config():
|
| 50 |
+
with open(os.path.join(get_project_root(), 'config/config.yaml'), encoding='utf-8') as f:
|
| 51 |
+
config = yaml.load(f, Loader=yaml.FullLoader)
|
| 52 |
+
try:
|
| 53 |
+
with open(os.path.join(get_project_root(), 'config/config_secret.yaml'), encoding='utf-8') as f:
|
| 54 |
+
config_secret = yaml.load(f, Loader=yaml.FullLoader)
|
| 55 |
+
config.update(config_secret)
|
| 56 |
+
except FileNotFoundError:
|
| 57 |
+
pass # okay to not have config_secret.yaml
|
| 58 |
+
return config
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def get_token(text: str):
|
| 62 |
+
return len(tokenizer.encode(text, disallowed_special=()))
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def get_first_n_tokens_and_remaining(text: str, n: int):
|
| 66 |
+
tokens = tokenizer.encode(text, disallowed_special=())
|
| 67 |
+
return tokenizer.decode(tokens[:n]), tokenizer.decode(tokens[n:])
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def provide_text_with_css(text, color):
|
| 71 |
+
if color == "red":
|
| 72 |
+
return f'<span style="background-color: red; color: white; padding: 3px; border-radius: 8px;">{text}</span>'
|
| 73 |
+
elif color == "green":
|
| 74 |
+
return f'<span style="background-color: #307530; color: white; padding: 3px; border-radius: 8px;">{text}</span>'
|
| 75 |
+
elif color == "blue":
|
| 76 |
+
return f'<span style="background-color: #7b7bff; color: white; padding: 3px; border-radius: 8px;">{text}</span>'
|
| 77 |
+
elif color == "yellow":
|
| 78 |
+
return f'<span style="background-color: yellow; color: black; padding: 3px; border-radius: 8px;">{text}</span>'
|
| 79 |
+
else:
|
| 80 |
+
return text
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
if __name__ == '__main__':
|
| 84 |
+
# print(get_token("def get_token(text: str)"))
|
| 85 |
+
# print(get_token("皆さんこんにちは"))
|
| 86 |
+
print(get_first_n_tokens_and_remaining("This is a string with some text to tokenize.", 30))
|
img/final_full_summary.png
ADDED
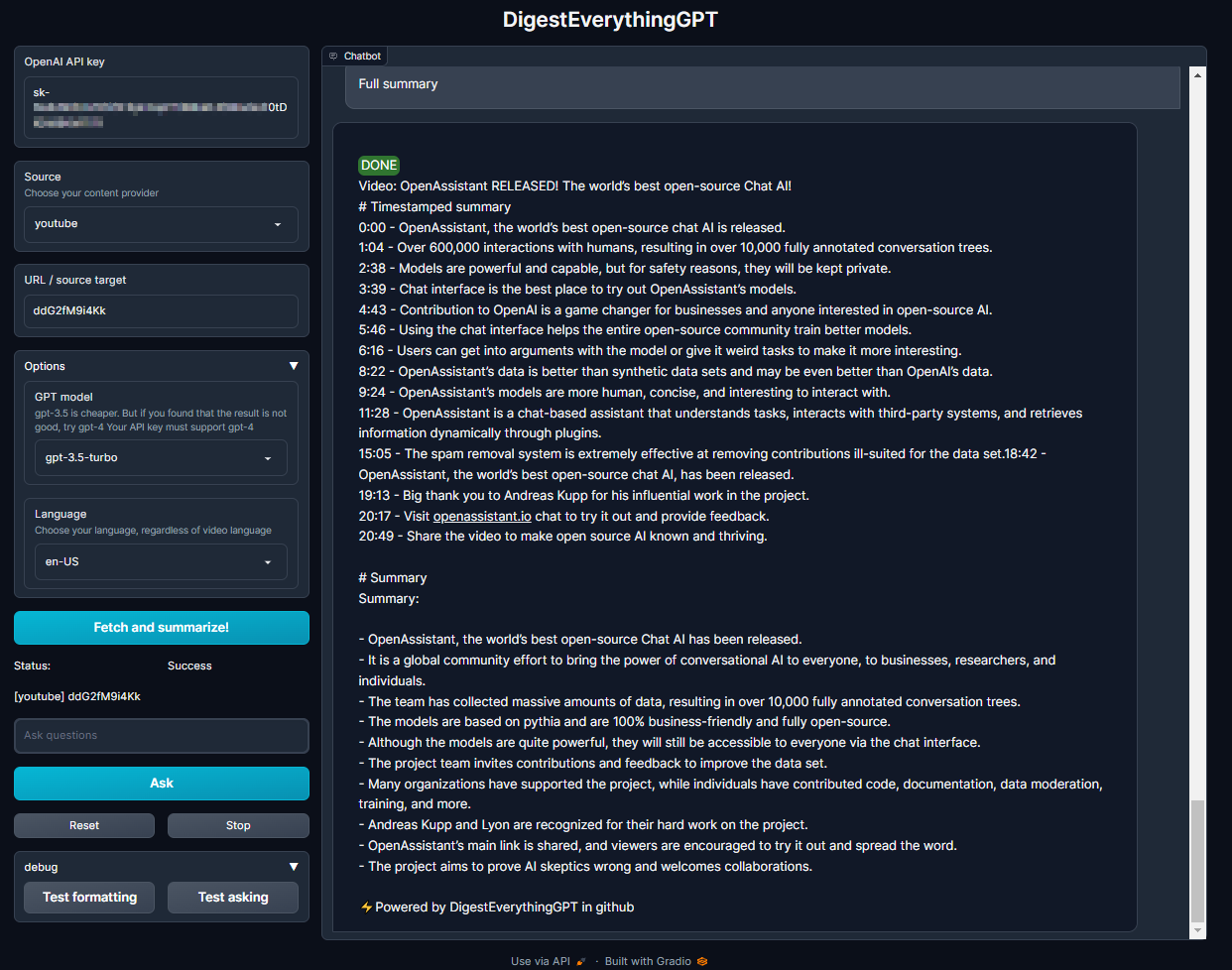
|
img/in_process.png
ADDED

|
img/multi_language.png
ADDED

|
img/n_things_example.png
ADDED

|
main.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import threading
|
| 3 |
+
import time
|
| 4 |
+
import webbrowser
|
| 5 |
+
|
| 6 |
+
from digester.gradio_ui_service import GradioUIService
|
| 7 |
+
from digester.util import get_config
|
| 8 |
+
|
| 9 |
+
os.makedirs("analyzer_logs", exist_ok=True)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def opentab_with_delay(port):
|
| 13 |
+
def open():
|
| 14 |
+
time.sleep(2)
|
| 15 |
+
webbrowser.open_new_tab(f"http://localhost:{port}/?__theme=dark")
|
| 16 |
+
|
| 17 |
+
threading.Thread(target=open, name="open-browser", daemon=True).start()
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
if __name__ == '__main__':
|
| 21 |
+
config = get_config()
|
| 22 |
+
port = config["gradio"]["port"]
|
| 23 |
+
opentab_with_delay(port)
|
| 24 |
+
demo = GradioUIService.get_gradio_ui()
|
| 25 |
+
demo.queue(concurrency_count=config['gradio']['concurrent']).launch(
|
| 26 |
+
server_name="0.0.0.0", server_port=port,
|
| 27 |
+
share=True
|
| 28 |
+
)
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio==3.24.1
|
| 2 |
+
gradio_client==0.0.7
|
| 3 |
+
tiktoken>=0.3.3
|
| 4 |
+
openai
|
| 5 |
+
Markdown
|
| 6 |
+
latex2mathml
|
| 7 |
+
everything2text4prompt
|