Spaces:
Configuration error


Configuration error
File size: 8,682 Bytes
d2a2947 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
FaceFusion
==========
> Next generation face swapper and enhancer.
[](https://github.com/facefusion/facefusion/actions?query=workflow:ci)

colab version is live and fixed but do update me in mails when google intefers or bans code, i love the cat and mouse play with google moderators and the devops guy.
im thinking about hosting somewhere for free, just have to figure out how to put limitation on process which determined by time or time of video. contact me if you are good at it. i'll handle the hosting stuff
Preview
-------
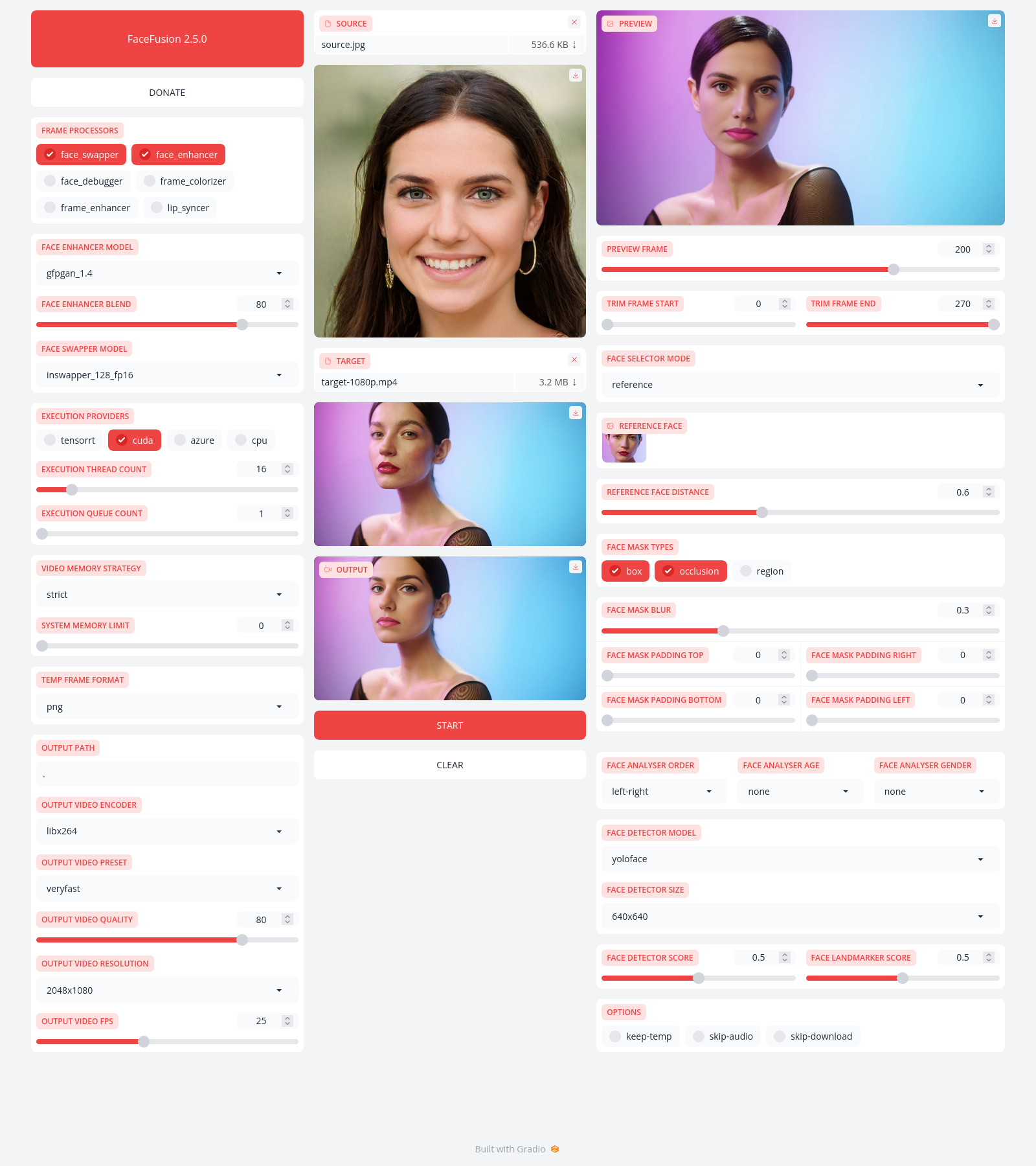
Installation
------------
Be aware, the installation needs technical skills and is not for beginners. Please do not open platform and installation related issues on GitHub. i dont care what you do.
Usage
-----
Run the command:
```
python run.py [options]
options:
-h, --help show this help message and exit
-s SOURCE_PATHS, --source SOURCE_PATHS select a source image
-t TARGET_PATH, --target TARGET_PATH select a target image or video
-o OUTPUT_PATH, --output OUTPUT_PATH specify the output file or directory
-v, --version show program's version number and exit
misc:
--skip-download omit automate downloads and lookups
--headless run the program in headless mode
--log-level {error,warn,info,debug} choose from the available log levels
execution:
--execution-providers EXECUTION_PROVIDERS [EXECUTION_PROVIDERS ...] choose from the available execution providers (choices: cpu, ...)
--execution-thread-count [1-128] specify the number of execution threads
--execution-queue-count [1-32] specify the number of execution queries
--max-memory [0-128] specify the maximum amount of ram to be used (in gb)
face analyser:
--face-analyser-order {left-right,right-left,top-bottom,bottom-top,small-large,large-small,best-worst,worst-best} specify the order used for the face analyser
--face-analyser-age {child,teen,adult,senior} specify the age used for the face analyser
--face-analyser-gender {male,female} specify the gender used for the face analyser
--face-detector-model {retinaface,yunet} specify the model used for the face detector
--face-detector-size {160x160,320x320,480x480,512x512,640x640,768x768,960x960,1024x1024} specify the size threshold used for the face detector
--face-detector-score [0.0-1.0] specify the score threshold used for the face detector
face selector:
--face-selector-mode {reference,one,many} specify the mode for the face selector
--reference-face-position REFERENCE_FACE_POSITION specify the position of the reference face
--reference-face-distance [0.0-1.5] specify the distance between the reference face and the target face
--reference-frame-number REFERENCE_FRAME_NUMBER specify the number of the reference frame
face mask:
--face-mask-types FACE_MASK_TYPES [FACE_MASK_TYPES ...] choose from the available face mask types (choices: box, occlusion, region)
--face-mask-blur [0.0-1.0] specify the blur amount for face mask
--face-mask-padding FACE_MASK_PADDING [FACE_MASK_PADDING ...] specify the face mask padding (top, right, bottom, left) in percent
--face-mask-regions FACE_MASK_REGIONS [FACE_MASK_REGIONS ...] choose from the available face mask regions (choices: skin, left-eyebrow, right-eyebrow, left-eye, right-eye, eye-glasses, nose, mouth, upper-lip, lower-lip)
frame extraction:
--trim-frame-start TRIM_FRAME_START specify the start frame for extraction
--trim-frame-end TRIM_FRAME_END specify the end frame for extraction
--temp-frame-format {jpg,png} specify the image format used for frame extraction
--temp-frame-quality [0-100] specify the image quality used for frame extraction
--keep-temp retain temporary frames after processing
output creation:
--output-image-quality [0-100] specify the quality used for the output image
--output-video-encoder {libx264,libx265,libvpx-vp9,h264_nvenc,hevc_nvenc} specify the encoder used for the output video
--output-video-quality [0-100] specify the quality used for the output video
--keep-fps preserve the frames per second (fps) of the target
--skip-audio omit audio from the target
frame processors:
--frame-processors FRAME_PROCESSORS [FRAME_PROCESSORS ...] choose from the available frame processors (choices: face_debugger, face_enhancer, face_swapper, frame_enhancer, ...)
--face-debugger-items FACE_DEBUGGER_ITEMS [FACE_DEBUGGER_ITEMS ...] specify the face debugger items (choices: bbox, kps, face-mask, score)
--face-enhancer-model {codeformer,gfpgan_1.2,gfpgan_1.3,gfpgan_1.4,gpen_bfr_256,gpen_bfr_512,restoreformer} choose the model for the frame processor
--face-enhancer-blend [0-100] specify the blend amount for the frame processor
--face-swapper-model {blendswap_256,inswapper_128,inswapper_128_fp16,simswap_256,simswap_512_unofficial} choose the model for the frame processor
--frame-enhancer-model {real_esrgan_x2plus,real_esrgan_x4plus,real_esrnet_x4plus} choose the model for the frame processor
--frame-enhancer-blend [0-100] specify the blend amount for the frame processor
uis:
--ui-layouts UI_LAYOUTS [UI_LAYOUTS ...] choose from the available ui layouts (choices: benchmark, webcam, default, ...)
```
Documentation
-------------
Read the [documentation](https://docs.facefusion.io) for a deep dive.
|