Spaces:
Runtime error


Runtime error
rromb
commited on
Commit
•
ebcf159
1
Parent(s):
49117c2
add autoencoder training details, arxiv link and figures
Browse filesFormer-commit-id: f8b4a071055f5b25421d0364770267d5fc58d79c
- README.md +45 -1
- assets/modelfigure.png +0 -0
- assets/results.gif.REMOVED.git-id +1 -0
README.md
CHANGED
|
@@ -1,4 +1,23 @@
|
|
| 1 |
# Latent Diffusion Models
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
## Requirements
|
| 4 |
A suitable [conda](https://conda.io/) environment named `ldm` can be created
|
|
@@ -31,12 +50,24 @@ conda activate ldm
|
|
| 31 |
### Get the models
|
| 32 |
|
| 33 |
Running the following script downloads und extracts all available pretrained autoencoding models.
|
| 34 |
-
|
| 35 |
```shell script
|
| 36 |
bash scripts/download_first_stages.sh
|
| 37 |
```
|
| 38 |
|
| 39 |
The first stage models can then be found in `models/first_stage_models/<model_spec>`
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 40 |
|
| 41 |
## Pretrained LDMs
|
| 42 |
| Datset | Task | Model | FID | IS | Prec | Recall | Link | Comments
|
|
@@ -102,4 +133,17 @@ Thanks for open-sourcing!
|
|
| 102 |
- The implementation of the transformer encoder is from [x-transformers](https://github.com/lucidrains/x-transformers) by [lucidrains](https://github.com/lucidrains?tab=repositories).
|
| 103 |
|
| 104 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 105 |
|
|
|
|
| 1 |
# Latent Diffusion Models
|
| 2 |
+
[arXiv](https://arxiv.org/abs/2112.10752) | [BibTeX](#bibtex)
|
| 3 |
+
|
| 4 |
+
<p align="center">
|
| 5 |
+
<img src=assets/results.gif />
|
| 6 |
+
</p>
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
[**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)<br/>
|
| 11 |
+
[Robin Rombach](https://github.com/rromb)\*,
|
| 12 |
+
[Andreas Blattmann](https://github.com/ablattmann)\*,
|
| 13 |
+
[Dominik Lorenz](https://github.com/qp-qp)\,
|
| 14 |
+
[Patrick Esser](https://github.com/pesser),
|
| 15 |
+
[Björn Ommer](https://hci.iwr.uni-heidelberg.de/Staff/bommer)<br/>
|
| 16 |
+
\* equal contribution
|
| 17 |
+
|
| 18 |
+
<p align="center">
|
| 19 |
+
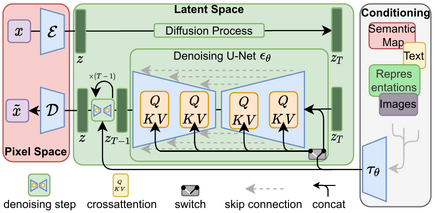
<img src=assets/modelfigure.png />
|
| 20 |
+
</p>
|
| 21 |
|
| 22 |
## Requirements
|
| 23 |
A suitable [conda](https://conda.io/) environment named `ldm` can be created
|
|
|
|
| 50 |
### Get the models
|
| 51 |
|
| 52 |
Running the following script downloads und extracts all available pretrained autoencoding models.
|
|
|
|
| 53 |
```shell script
|
| 54 |
bash scripts/download_first_stages.sh
|
| 55 |
```
|
| 56 |
|
| 57 |
The first stage models can then be found in `models/first_stage_models/<model_spec>`
|
| 58 |
+
### Training autoencoder models
|
| 59 |
+
|
| 60 |
+
Configs for training a KL-regularized autoencoder on ImageNet are provided at `configs/autoencoder`.
|
| 61 |
+
Training can be started by running
|
| 62 |
+
```
|
| 63 |
+
CUDA_VISIBLE_DEVICES=<GPU_ID> python main.py --base configs/autoencoder/<config_spec> -t --gpus 0,
|
| 64 |
+
```
|
| 65 |
+
where `config_spec` is one of {`autoencoder_kl_8x8x64.yaml`(f=32, d=64), `autoencoder_kl_16x16x16.yaml`(f=16, d=16),
|
| 66 |
+
`autoencoder_kl_32x32x4`(f=8, d=4), `autoencoder_kl_64x64x3`(f=4, d=3)}.
|
| 67 |
+
|
| 68 |
+
For training VQ-regularized models, see the [taming-transformers](https://github.com/CompVis/taming-transformers)
|
| 69 |
+
repository.
|
| 70 |
+
|
| 71 |
|
| 72 |
## Pretrained LDMs
|
| 73 |
| Datset | Task | Model | FID | IS | Prec | Recall | Link | Comments
|
|
|
|
| 133 |
- The implementation of the transformer encoder is from [x-transformers](https://github.com/lucidrains/x-transformers) by [lucidrains](https://github.com/lucidrains?tab=repositories).
|
| 134 |
|
| 135 |
|
| 136 |
+
## BibTeX
|
| 137 |
+
|
| 138 |
+
```
|
| 139 |
+
@misc{rombach2021highresolution,
|
| 140 |
+
title={High-Resolution Image Synthesis with Latent Diffusion Models},
|
| 141 |
+
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
|
| 142 |
+
year={2021},
|
| 143 |
+
eprint={2112.10752},
|
| 144 |
+
archivePrefix={arXiv},
|
| 145 |
+
primaryClass={cs.CV}
|
| 146 |
+
}
|
| 147 |
+
```
|
| 148 |
+
|
| 149 |
|
assets/modelfigure.png
ADDED
|
assets/results.gif.REMOVED.git-id
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
82b6590e670a32196093cc6333ea19e6547d07de
|