Spaces:
Runtime error

Runtime error
Feat: app.py
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- app.py +115 -0
- examples/audiogram_example01.png +0 -0
- models/audiograms/audiograms_detection.yaml +9 -0
- models/audiograms/audiograms_detection_test.yaml +8 -0
- models/audiograms/format_dataset.py +151 -0
- models/audiograms/latest/hyp.yaml +23 -0
- models/audiograms/latest/labels.png +0 -0
- models/audiograms/latest/opt.yaml +30 -0
- models/audiograms/latest/results.png +0 -0
- models/audiograms/latest/results.txt +50 -0
- models/audiograms/latest/test_batch0_gt.jpg +0 -0
- models/audiograms/latest/test_batch0_pred.jpg +0 -0
- models/audiograms/latest/train_batch0.jpg +0 -0
- models/audiograms/latest/train_batch1.jpg +0 -0
- models/audiograms/latest/train_batch2.jpg +0 -0
- models/audiograms/yolov5s.yaml +48 -0
- models/labels/format_dataset.py +183 -0
- models/labels/labels_detection.yaml +32 -0
- models/labels/labels_detection_test.yaml +32 -0
- models/labels/latest/hyp.yaml +23 -0
- models/labels/latest/labels.png +0 -0
- models/labels/latest/opt.yaml +30 -0
- models/labels/latest/results.png +0 -0
- models/labels/latest/results.txt +100 -0
- models/labels/latest/train_batch0.jpg +0 -0
- models/labels/latest/train_batch1.jpg +0 -0
- models/labels/latest/train_batch2.jpg +0 -0
- models/labels/yolov5s.yaml +48 -0
- models/symbols/format_dataset.py +208 -0
- models/symbols/latest/hyp.yaml +23 -0
- models/symbols/latest/labels.png +0 -0
- models/symbols/latest/opt.yaml +30 -0
- models/symbols/latest/results.png +0 -0
- models/symbols/latest/results.txt +50 -0
- models/symbols/latest/test_batch0_gt.jpg +0 -0
- models/symbols/latest/test_batch0_pred.jpg +0 -0
- models/symbols/latest/train_batch0.jpg +0 -0
- models/symbols/latest/train_batch1.jpg +0 -0
- models/symbols/latest/train_batch2.jpg +0 -0
- models/symbols/symbols_detection.yaml +18 -0
- models/symbols/symbols_detection_test.yaml +17 -0
- models/symbols/yolov5s.yaml +48 -0
- requirements.txt +15 -0
- src/__pycache__/interfaces.cpython-38.pyc +0 -0
- src/digitize_report.py +55 -0
- src/digitizer/__pycache__/digitization.cpython-38.pyc +0 -0
- src/digitizer/assets/fonts/arial.ttf +0 -0
- src/digitizer/assets/symbols/left_air_masked.png +0 -0
- src/digitizer/assets/symbols/left_air_masked.svg +9 -0
- src/digitizer/assets/symbols/left_air_unmasked.png +0 -0
app.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
|
| 3 |
+
Original Algorithm:
|
| 4 |
+
- https://github.com/GreenCUBIC/AudiogramDigitization
|
| 5 |
+
|
| 6 |
+
Source:
|
| 7 |
+
- huggingface app
|
| 8 |
+
- https://huggingface.co/spaces/aravinds1811/neural-style-transfer/blob/main/app.py
|
| 9 |
+
- https://huggingface.co/spaces/keras-io/ocr-for-captcha/blob/main/app.py
|
| 10 |
+
- https://huggingface.co/spaces/hugginglearners/image-style-transfer/blob/main/app.py
|
| 11 |
+
- https://tmabraham.github.io/blog/gradio_hf_spaces_tutorial
|
| 12 |
+
- huggingface push
|
| 13 |
+
- https://huggingface.co/welcome
|
| 14 |
+
"""
|
| 15 |
+
import os
|
| 16 |
+
import sys
|
| 17 |
+
from pathlib import Path
|
| 18 |
+
|
| 19 |
+
from PIL import Image
|
| 20 |
+
from matplotlib.offsetbox import OffsetImage, AnnotationBbox
|
| 21 |
+
import matplotlib.pyplot as plt
|
| 22 |
+
import pandas as pd
|
| 23 |
+
import numpy as np
|
| 24 |
+
import gradio as gr
|
| 25 |
+
|
| 26 |
+
sys.path.append(os.path.join(os.path.dirname(__file__), "src"))
|
| 27 |
+
from digitizer.digitization import generate_partial_annotation, extract_thresholds
|
| 28 |
+
|
| 29 |
+
EXAMPLES_PATH = Path('./examples')
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
max_length = 5
|
| 33 |
+
img_width = 200
|
| 34 |
+
img_height = 50
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def load_image(path, zoom=1):
|
| 38 |
+
return OffsetImage(plt.imread(path), zoom=zoom)
|
| 39 |
+
|
| 40 |
+
def plot_audiogram(digital_result):
|
| 41 |
+
thresholds = pd.DataFrame(digital_result)
|
| 42 |
+
|
| 43 |
+
# Figure
|
| 44 |
+
fig = plt.figure()
|
| 45 |
+
ax = fig.add_subplot(111)
|
| 46 |
+
|
| 47 |
+
# x axis
|
| 48 |
+
axis = [250, 500, 1000, 2000, 4000, 8000, 16000]
|
| 49 |
+
ax.set_xscale('log')
|
| 50 |
+
ax.xaxis.tick_top()
|
| 51 |
+
ax.xaxis.set_major_formatter(plt.FuncFormatter('{:.0f}'.format))
|
| 52 |
+
ax.set_xlabel('Frequency (Hz)')
|
| 53 |
+
ax.xaxis.set_label_position('top')
|
| 54 |
+
ax.set_xlim(125,16000)
|
| 55 |
+
plt.xticks(axis)
|
| 56 |
+
|
| 57 |
+
# y axis
|
| 58 |
+
ax.set_ylim(-20, 120)
|
| 59 |
+
ax.invert_yaxis()
|
| 60 |
+
ax.set_ylabel('Threshold (dB HL)')
|
| 61 |
+
|
| 62 |
+
plt.grid()
|
| 63 |
+
|
| 64 |
+
for conduction in ("air", "bone"):
|
| 65 |
+
for masking in (True, False):
|
| 66 |
+
for ear in ("left", "right"):
|
| 67 |
+
symbol_name = f"{ear}_{conduction}_{'unmasked' if not masking else 'masked'}"
|
| 68 |
+
selection = thresholds[(thresholds.conduction == conduction) & (thresholds.ear == ear) & (thresholds.masking == masking)]
|
| 69 |
+
selection = selection.sort_values("frequency")
|
| 70 |
+
|
| 71 |
+
# Plot the symbols
|
| 72 |
+
for i, threshold in selection.iterrows():
|
| 73 |
+
ab = AnnotationBbox(load_image(f"src/digitizer/assets/symbols/{symbol_name}.png", zoom=0.1), (threshold.frequency, threshold.threshold), frameon=False)
|
| 74 |
+
ax.add_artist(ab)
|
| 75 |
+
|
| 76 |
+
# Add joining line for air conduction thresholds
|
| 77 |
+
if conduction == "air":
|
| 78 |
+
plt.plot(selection.frequency, selection.threshold, color="red" if ear == "right" else "blue", linewidth=0.5)
|
| 79 |
+
|
| 80 |
+
return plt.gcf()
|
| 81 |
+
# Save audiogram plot to nparray
|
| 82 |
+
# get image as np.array
|
| 83 |
+
# canvas = plt.gca().figure.canvas
|
| 84 |
+
# canvas.draw()
|
| 85 |
+
# image = np.frombuffer(canvas.tostring_rgb(), dtype=np.uint8)
|
| 86 |
+
# return Image.fromarray(image)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
# Function for Audiogram Digit Recognition
|
| 90 |
+
def audiogram_digit_recognition(img_path):
|
| 91 |
+
digital_result = extract_thresholds(img_path, gpu=False)
|
| 92 |
+
return plot_audiogram(digital_result)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
output = gr.Plot()
|
| 96 |
+
examples = [f'{EXAMPLES_PATH}/audiogram_example01.png']
|
| 97 |
+
|
| 98 |
+
iface = gr.Interface(
|
| 99 |
+
fn=audiogram_digit_recognition,
|
| 100 |
+
inputs = gr.inputs.Image(type='filepath'),
|
| 101 |
+
outputs = output , #"image",
|
| 102 |
+
title=" AudiogramDigitization",
|
| 103 |
+
description = "facilitate the digitization of audiology reports based on pytorch",
|
| 104 |
+
article = "Algorithm Authors: <a href=\"francoischarih@sce.carleton.ca\">Francois Charih \
|
| 105 |
+
and <a href=\"jrgreen@sce.carleton.ca\"> James R. Green </a>. \
|
| 106 |
+
Based on the AudiogramDigitization <a href=\"https://github.com/GreenCUBIC/AudiogramDigitization\">github repo</a>",
|
| 107 |
+
examples = examples,
|
| 108 |
+
allow_flagging='never',
|
| 109 |
+
cache_examples=False,
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
iface.launch(
|
| 114 |
+
enable_queue=True, debug=False, inbrowser=False
|
| 115 |
+
)
|
examples/audiogram_example01.png
ADDED
|
models/audiograms/audiograms_detection.yaml
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
|
| 2 |
+
train: models/audiograms/dataset/images/train/
|
| 3 |
+
val: models/audiograms/dataset/images/validation/
|
| 4 |
+
|
| 5 |
+
# number of classes
|
| 6 |
+
nc: 1
|
| 7 |
+
|
| 8 |
+
# class names
|
| 9 |
+
names: ["AUDIOGRAM"]
|
models/audiograms/audiograms_detection_test.yaml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
|
| 2 |
+
val: data/audiograms/test/images/
|
| 3 |
+
|
| 4 |
+
# number of classes
|
| 5 |
+
nc: 1
|
| 6 |
+
|
| 7 |
+
# class names
|
| 8 |
+
names: ["AUDIOGRAM"]
|
models/audiograms/format_dataset.py
ADDED
|
@@ -0,0 +1,151 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
"""
|
| 3 |
+
Copyright (c) 2020 Carleton University Biomedical Informatics Collaboratory
|
| 4 |
+
|
| 5 |
+
This source code is licensed under the MIT license found in the
|
| 6 |
+
LICENSE file in the root directory of this source tree.
|
| 7 |
+
"""
|
| 8 |
+
from typing import List
|
| 9 |
+
from types import SimpleNamespace
|
| 10 |
+
import argparse, os, json, shutil
|
| 11 |
+
from tqdm import tqdm
|
| 12 |
+
import os.path as path
|
| 13 |
+
import numpy as np
|
| 14 |
+
from PIL import Image
|
| 15 |
+
|
| 16 |
+
def extract_audiograms(annotation: dict, image: Image) -> List[tuple]:
|
| 17 |
+
"""Extracts the bounding boxes of audiograms into a tuple compatible
|
| 18 |
+
the YOLOv5 format.
|
| 19 |
+
|
| 20 |
+
Parameters
|
| 21 |
+
----------
|
| 22 |
+
annotation : dict
|
| 23 |
+
A dictionary containing the annotations for the audiograms in a report.
|
| 24 |
+
|
| 25 |
+
image : Image
|
| 26 |
+
The image in PIL format corresponding to the annotation.
|
| 27 |
+
|
| 28 |
+
Returns
|
| 29 |
+
-------
|
| 30 |
+
tuple
|
| 31 |
+
A tuple of the form
|
| 32 |
+
(class index, x_center, y_center, width, height) where all coordinates
|
| 33 |
+
and dimensions are normalized to the width/height of the image.
|
| 34 |
+
"""
|
| 35 |
+
audiogram_label_tuples = []
|
| 36 |
+
image_width, image_height = image.size
|
| 37 |
+
for audiogram in annotation:
|
| 38 |
+
bounding_box = audiogram["boundingBox"]
|
| 39 |
+
x_center = (bounding_box["x"] + bounding_box["width"] / 2) / image_width
|
| 40 |
+
y_center = (bounding_box["y"] + bounding_box["height"] / 2) / image_height
|
| 41 |
+
box_width = bounding_box["width"] / image_width
|
| 42 |
+
box_height = bounding_box["height"] / image_width
|
| 43 |
+
audiogram_label_tuples.append((0, x_center, y_center, box_width, box_height))
|
| 44 |
+
return audiogram_label_tuples
|
| 45 |
+
|
| 46 |
+
def create_yolov5_file(bboxes: List[tuple], filename: str):
|
| 47 |
+
# Turn the bounding boxes into a string with a bounding box
|
| 48 |
+
# on each line
|
| 49 |
+
file_content = "\n".join([
|
| 50 |
+
f"{bbox[0]} {bbox[1]} {bbox[2]} {bbox[3]} {bbox[4]}"
|
| 51 |
+
for bbox in bboxes
|
| 52 |
+
])
|
| 53 |
+
|
| 54 |
+
# Save to a file
|
| 55 |
+
with open(filename, "w") as output_file:
|
| 56 |
+
output_file.write(file_content)
|
| 57 |
+
|
| 58 |
+
def create_directory_structure(data_dir: str):
|
| 59 |
+
try:
|
| 60 |
+
shutil.rmtree(path.join(data_dir))
|
| 61 |
+
except:
|
| 62 |
+
pass
|
| 63 |
+
os.mkdir(path.join(data_dir))
|
| 64 |
+
os.mkdir(path.join(data_dir, "images"))
|
| 65 |
+
os.mkdir(path.join(data_dir, "images", "train"))
|
| 66 |
+
os.mkdir(path.join(data_dir, "images", "validation"))
|
| 67 |
+
os.mkdir(path.join(data_dir, "labels"))
|
| 68 |
+
os.mkdir(path.join(data_dir, "labels", "train"))
|
| 69 |
+
os.mkdir(path.join(data_dir, "labels", "validation"))
|
| 70 |
+
|
| 71 |
+
def all_labels_valid(labels: List[tuple]):
|
| 72 |
+
for label in labels:
|
| 73 |
+
for value in label[1:]:
|
| 74 |
+
if value < 0 or value > 1:
|
| 75 |
+
return False
|
| 76 |
+
return True
|
| 77 |
+
|
| 78 |
+
def main(args: SimpleNamespace):
|
| 79 |
+
# Find all the JSON files in the input directory
|
| 80 |
+
report_ids = [
|
| 81 |
+
filename.rstrip(".json")
|
| 82 |
+
for filename in os.listdir(path.join(args.annotations_dir))
|
| 83 |
+
if filename.endswith(".json")
|
| 84 |
+
and path.exists(path.join(args.images_dir, filename.rstrip(".json") + ".jpg"))
|
| 85 |
+
]
|
| 86 |
+
|
| 87 |
+
# Shuffle
|
| 88 |
+
np.random.seed(seed=42) # for reproducibility of the shuffle
|
| 89 |
+
np.random.shuffle(report_ids)
|
| 90 |
+
|
| 91 |
+
# Create the directory structure in which the images and annotations
|
| 92 |
+
# are to be stored
|
| 93 |
+
create_directory_structure(args.data_dir)
|
| 94 |
+
|
| 95 |
+
# Iterate through the report ids, extract the annotations in YOLOv5 format
|
| 96 |
+
# and place the file in the correct directory, and the image in the correct
|
| 97 |
+
# directory.
|
| 98 |
+
for i, report_id in enumerate(tqdm(report_ids)):
|
| 99 |
+
# Decide if the image is going into the training set or validation set
|
| 100 |
+
directory = (
|
| 101 |
+
"train" if i < args.train_frac * len(report_ids) else "validation"
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
# Load the annotation`
|
| 105 |
+
annotation_content = open(
|
| 106 |
+
path.join(args.annotations_dir, f"{report_id}.json")
|
| 107 |
+
)
|
| 108 |
+
annotation = json.load(annotation_content)
|
| 109 |
+
|
| 110 |
+
# Open the corresponding image to get its dimensions
|
| 111 |
+
image = Image.open(os.path.join(args.images_dir, f"{report_id}.jpg"))
|
| 112 |
+
width, height = image.size
|
| 113 |
+
|
| 114 |
+
# Audiogram labels
|
| 115 |
+
audiogram_labels = extract_audiograms(annotation, image)
|
| 116 |
+
|
| 117 |
+
if not all_labels_valid(audiogram_labels):
|
| 118 |
+
continue
|
| 119 |
+
|
| 120 |
+
create_yolov5_file(
|
| 121 |
+
audiogram_labels,
|
| 122 |
+
path.join(args.data_dir, "labels", directory, f"{report_id}.txt")
|
| 123 |
+
)
|
| 124 |
+
image.save(
|
| 125 |
+
path.join(args.data_dir, "images", directory, f"{report_id}.jpg")
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
if __name__ == "__main__":
|
| 129 |
+
import argparse
|
| 130 |
+
|
| 131 |
+
parser = argparse.ArgumentParser(description=(
|
| 132 |
+
"Script that formats the training set for transfer learning via "
|
| 133 |
+
"the YOLOv5 model."
|
| 134 |
+
))
|
| 135 |
+
parser.add_argument("-d", "--data_dir", type=str, required=True, help=(
|
| 136 |
+
"Path to the directory containing the data. It should have 3 "
|
| 137 |
+
"subfolders named `images`, `annotations` and `labels`."
|
| 138 |
+
))
|
| 139 |
+
parser.add_argument("-a", "--annotations_dir", type=str, required=True, help=(
|
| 140 |
+
"Path to the directory containing the annotations in the JSON format."
|
| 141 |
+
))
|
| 142 |
+
parser.add_argument("-i", "--images_dir", type=str, required=True, help=(
|
| 143 |
+
"Path to the directory containing the images."
|
| 144 |
+
))
|
| 145 |
+
parser.add_argument("-f", "--train_frac", type=float, required=True, help=(
|
| 146 |
+
"Fraction of images to be used for training. (e.g. 0.8)"
|
| 147 |
+
))
|
| 148 |
+
args = parser.parse_args()
|
| 149 |
+
|
| 150 |
+
main(args)
|
| 151 |
+
|
models/audiograms/latest/hyp.yaml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
lr0: 0.01
|
| 2 |
+
lrf: 0.2
|
| 3 |
+
momentum: 0.937
|
| 4 |
+
weight_decay: 0.0005
|
| 5 |
+
giou: 0.05
|
| 6 |
+
cls: 0.5
|
| 7 |
+
cls_pw: 1.0
|
| 8 |
+
obj: 1.0
|
| 9 |
+
obj_pw: 1.0
|
| 10 |
+
iou_t: 0.2
|
| 11 |
+
anchor_t: 4.0
|
| 12 |
+
fl_gamma: 0.0
|
| 13 |
+
hsv_h: 0.015
|
| 14 |
+
hsv_s: 0.7
|
| 15 |
+
hsv_v: 0.4
|
| 16 |
+
degrees: 0.0
|
| 17 |
+
translate: 0.1
|
| 18 |
+
scale: 0.5
|
| 19 |
+
shear: 0.0
|
| 20 |
+
perspective: 0.0
|
| 21 |
+
flipud: 0.0
|
| 22 |
+
fliplr: 0.5
|
| 23 |
+
mixup: 0.0
|
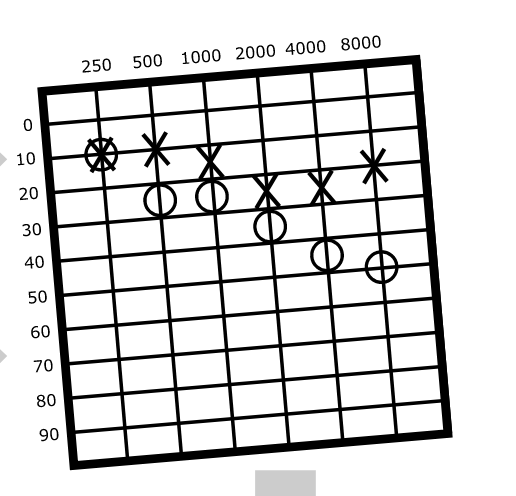
models/audiograms/latest/labels.png
ADDED
|
models/audiograms/latest/opt.yaml
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
weights: yolov5/weights/yolov5s.pt
|
| 2 |
+
cfg: yolov5/models/yolov5s.yaml
|
| 3 |
+
data: ./data/dataset.yaml
|
| 4 |
+
hyp: ./yolov5/data/hyp.scratch.yaml
|
| 5 |
+
epochs: 50
|
| 6 |
+
batch_size: 16
|
| 7 |
+
img_size:
|
| 8 |
+
- 1024
|
| 9 |
+
- 1024
|
| 10 |
+
rect: true
|
| 11 |
+
resume: false
|
| 12 |
+
nosave: false
|
| 13 |
+
notest: false
|
| 14 |
+
noautoanchor: false
|
| 15 |
+
evolve: false
|
| 16 |
+
bucket: ''
|
| 17 |
+
cache_images: false
|
| 18 |
+
image_weights: false
|
| 19 |
+
name: ''
|
| 20 |
+
device: '0'
|
| 21 |
+
multi_scale: false
|
| 22 |
+
single_cls: false
|
| 23 |
+
adam: false
|
| 24 |
+
sync_bn: false
|
| 25 |
+
local_rank: -1
|
| 26 |
+
logdir: runs/
|
| 27 |
+
workers: 8
|
| 28 |
+
total_batch_size: 16
|
| 29 |
+
world_size: 1
|
| 30 |
+
global_rank: -1
|
models/audiograms/latest/results.png
ADDED
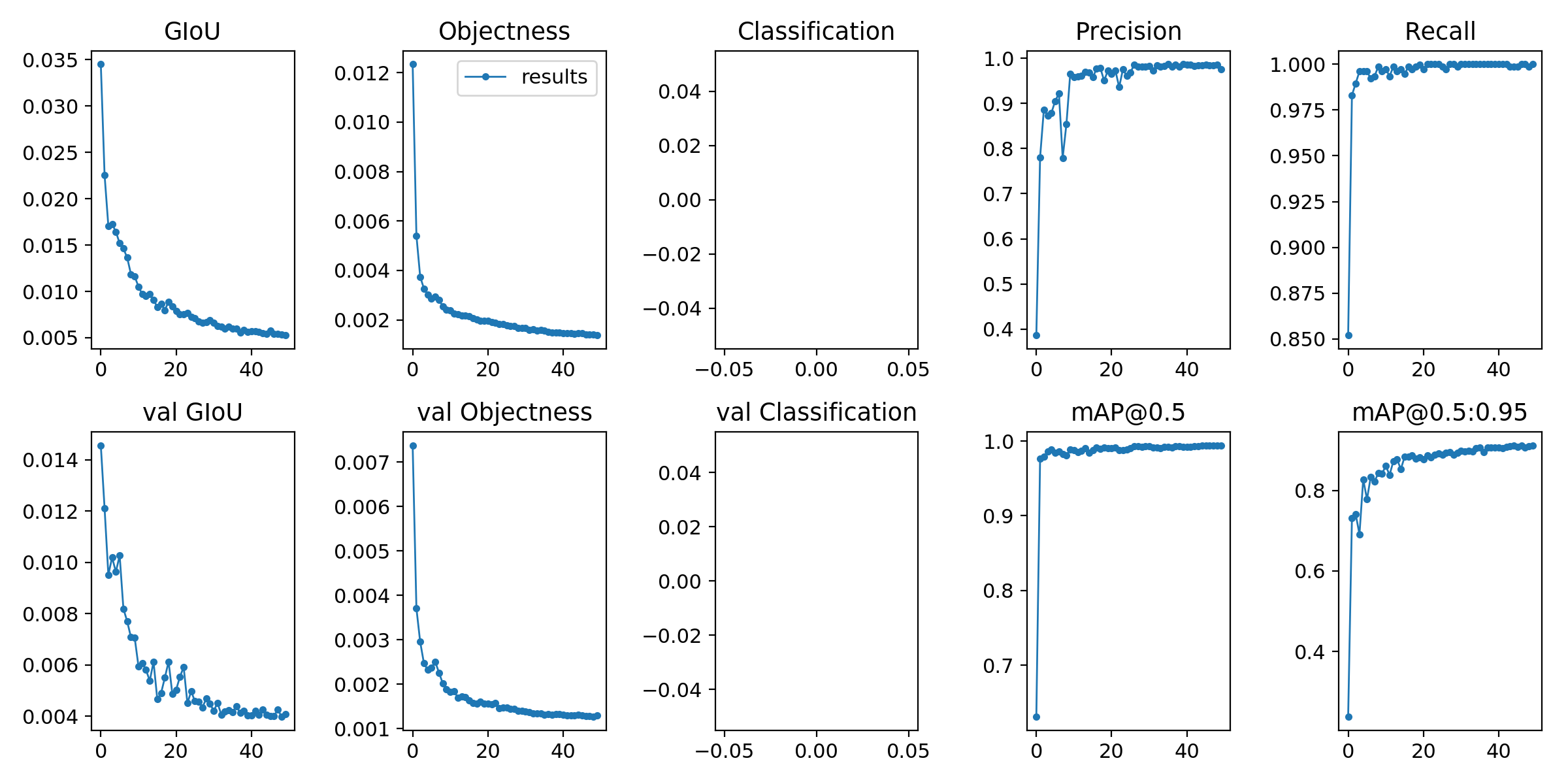
|
models/audiograms/latest/results.txt
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
0/49 7.24G 0.03451 0.01234 0 0.04685 18 768 0.386 0.8519 0.6314 0.2382 0.01455 0.007371 0
|
| 2 |
+
1/49 7.25G 0.02255 0.005412 0 0.02796 18 768 0.7806 0.9831 0.9762 0.7314 0.0121 0.003704 0
|
| 3 |
+
2/49 7.25G 0.01706 0.003746 0 0.0208 18 768 0.8866 0.9896 0.9793 0.741 0.009516 0.002951 0
|
| 4 |
+
3/49 7.25G 0.01726 0.003265 0 0.02052 18 768 0.8734 0.9961 0.9858 0.691 0.01019 0.002468 0
|
| 5 |
+
4/49 7.25G 0.01645 0.003014 0 0.01946 18 768 0.8789 0.9961 0.9885 0.8278 0.009626 0.002319 0
|
| 6 |
+
5/49 7.25G 0.01519 0.002852 0 0.01805 18 768 0.9051 0.9961 0.984 0.778 0.01027 0.002376 0
|
| 7 |
+
6/49 7.25G 0.01463 0.002948 0 0.01758 18 768 0.9223 0.9922 0.9857 0.8341 0.008192 0.002504 0
|
| 8 |
+
7/49 7.25G 0.01365 0.0028 0 0.01645 18 768 0.7791 0.9935 0.9828 0.8224 0.007701 0.002257 0
|
| 9 |
+
8/49 7.25G 0.01187 0.002558 0 0.01443 18 768 0.8548 0.9987 0.9807 0.843 0.007083 0.002018 0
|
| 10 |
+
9/49 7.25G 0.01161 0.002421 0 0.01403 18 768 0.9653 0.9961 0.9884 0.8421 0.007059 0.001885 0
|
| 11 |
+
10/49 7.25G 0.01053 0.002392 0 0.01292 18 768 0.9588 0.9974 0.9875 0.8607 0.005953 0.001821 0
|
| 12 |
+
11/49 7.25G 0.009697 0.002255 0 0.01195 18 768 0.9591 0.9935 0.9851 0.8387 0.006067 0.001839 0
|
| 13 |
+
12/49 7.25G 0.009541 0.002229 0 0.01177 18 768 0.9619 0.9987 0.9872 0.8725 0.005808 0.0017 0
|
| 14 |
+
13/49 7.25G 0.009704 0.002185 0 0.01189 18 768 0.9693 0.9961 0.9907 0.8767 0.005385 0.001728 0
|
| 15 |
+
14/49 7.25G 0.009079 0.002169 0 0.01125 18 768 0.9691 0.9974 0.9841 0.8531 0.006121 0.001715 0
|
| 16 |
+
15/49 7.25G 0.008323 0.002161 0 0.01048 18 768 0.9579 0.9948 0.9882 0.8838 0.004668 0.001631 0
|
| 17 |
+
16/49 7.25G 0.008653 0.002083 0 0.01074 18 768 0.9768 0.9987 0.9913 0.8845 0.004903 0.001578 0
|
| 18 |
+
17/49 7.25G 0.007987 0.002011 0 0.009997 18 768 0.9786 0.9974 0.9895 0.8873 0.005501 0.001565 0
|
| 19 |
+
18/49 7.25G 0.008903 0.001963 0 0.01087 18 768 0.9506 0.9987 0.9913 0.8784 0.006132 0.0016 0
|
| 20 |
+
19/49 7.25G 0.008407 0.001971 0 0.01038 18 768 0.9722 0.9999 0.9908 0.8825 0.004867 0.001558 0
|
| 21 |
+
20/49 7.25G 0.007909 0.001966 0 0.009875 18 768 0.9649 0.9974 0.9905 0.8781 0.005032 0.001563 0
|
| 22 |
+
21/49 7.25G 0.00755 0.001911 0 0.00946 18 768 0.9733 1 0.9916 0.8879 0.005532 0.001542 0
|
| 23 |
+
22/49 7.25G 0.007531 0.001892 0 0.009423 18 768 0.9359 1 0.9881 0.8821 0.005925 0.001577 0
|
| 24 |
+
23/49 7.25G 0.007707 0.001834 0 0.009541 18 768 0.9757 1 0.9881 0.8889 0.004511 0.001455 0
|
| 25 |
+
24/49 7.25G 0.00729 0.00182 0 0.00911 18 768 0.9608 1 0.9889 0.8925 0.004974 0.001477 0
|
| 26 |
+
25/49 7.25G 0.007106 0.001769 0 0.008875 18 768 0.9686 0.9987 0.9907 0.8887 0.004586 0.001471 0
|
| 27 |
+
26/49 7.25G 0.00679 0.001756 0 0.008546 18 768 0.9862 0.9974 0.993 0.8934 0.004579 0.001438 0
|
| 28 |
+
27/49 7.25G 0.006621 0.001754 0 0.008375 18 768 0.9812 1 0.993 0.8953 0.004354 0.001446 0
|
| 29 |
+
28/49 7.25G 0.006727 0.001672 0 0.008399 18 768 0.9821 1 0.9919 0.8892 0.004686 0.0014 0
|
| 30 |
+
29/49 7.25G 0.006892 0.001684 0 0.008577 18 768 0.9817 0.9987 0.993 0.8939 0.004496 0.001401 0
|
| 31 |
+
30/49 7.25G 0.006629 0.001684 0 0.008313 18 768 0.9834 1 0.9932 0.8978 0.004209 0.001381 0
|
| 32 |
+
31/49 7.25G 0.006299 0.001594 0 0.007892 18 768 0.973 1 0.9916 0.8962 0.004526 0.001369 0
|
| 33 |
+
32/49 7.25G 0.006212 0.00162 0 0.007831 18 768 0.9842 1 0.9909 0.8979 0.004059 0.001345 0
|
| 34 |
+
33/49 7.25G 0.006012 0.001572 0 0.007583 18 768 0.9817 1 0.9905 0.8964 0.004181 0.001342 0
|
| 35 |
+
34/49 7.25G 0.006232 0.001605 0 0.007837 18 768 0.9831 1 0.9922 0.9055 0.004233 0.001335 0
|
| 36 |
+
35/49 7.25G 0.005956 0.001566 0 0.007522 18 768 0.9866 1 0.9924 0.9064 0.004158 0.001314 0
|
| 37 |
+
36/49 7.25G 0.005979 0.001521 0 0.0075 18 768 0.9813 1 0.9915 0.8951 0.004402 0.00133 0
|
| 38 |
+
37/49 7.25G 0.005544 0.001476 0 0.00702 18 768 0.9859 1 0.9931 0.906 0.004128 0.001315 0
|
| 39 |
+
38/49 7.25G 0.00582 0.0015 0 0.007321 18 768 0.9808 1 0.9931 0.9066 0.004205 0.00132 0
|
| 40 |
+
39/49 7.25G 0.005607 0.001494 0 0.007101 18 768 0.9867 1 0.9926 0.9073 0.004047 0.001323 0
|
| 41 |
+
40/49 7.25G 0.005674 0.001459 0 0.007133 18 768 0.9863 1 0.9923 0.9064 0.004046 0.001307 0
|
| 42 |
+
41/49 7.25G 0.005712 0.001452 0 0.007165 18 768 0.9863 1 0.9924 0.9051 0.00421 0.001297 0
|
| 43 |
+
42/49 7.25G 0.005655 0.001459 0 0.007113 18 768 0.9823 1 0.9931 0.9089 0.004065 0.001296 0
|
| 44 |
+
43/49 7.25G 0.005481 0.001445 0 0.006926 18 768 0.9847 0.9987 0.9933 0.91 0.004256 0.001298 0
|
| 45 |
+
44/49 7.25G 0.005456 0.001474 0 0.00693 18 768 0.9844 0.9987 0.9938 0.9111 0.004057 0.001314 0
|
| 46 |
+
45/49 7.25G 0.005749 0.00145 0 0.0072 18 768 0.9863 0.9987 0.9938 0.9076 0.004 0.001296 0
|
| 47 |
+
46/49 7.25G 0.005401 0.001397 0 0.006798 18 768 0.985 1 0.9937 0.9114 0.004002 0.001283 0
|
| 48 |
+
47/49 7.25G 0.005416 0.001401 0 0.006818 18 768 0.9839 1 0.9936 0.9074 0.004271 0.001285 0
|
| 49 |
+
48/49 7.25G 0.005382 0.001397 0 0.00678 18 768 0.9857 0.9987 0.9939 0.9101 0.00399 0.00127 0
|
| 50 |
+
49/49 7.25G 0.00526 0.001375 0 0.006635 18 768 0.9754 1 0.994 0.9117 0.004094 0.001291 0
|
models/audiograms/latest/test_batch0_gt.jpg
ADDED

|
models/audiograms/latest/test_batch0_pred.jpg
ADDED

|
models/audiograms/latest/train_batch0.jpg
ADDED

|
models/audiograms/latest/train_batch1.jpg
ADDED

|
models/audiograms/latest/train_batch2.jpg
ADDED

|
models/audiograms/yolov5s.yaml
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# parameters
|
| 2 |
+
nc: 1 # number of classes
|
| 3 |
+
depth_multiple: 0.33 # model depth multiple
|
| 4 |
+
width_multiple: 0.50 # layer channel multiple
|
| 5 |
+
|
| 6 |
+
# anchors
|
| 7 |
+
anchors:
|
| 8 |
+
- [10,13, 16,30, 33,23] # P3/8
|
| 9 |
+
- [30,61, 62,45, 59,119] # P4/16
|
| 10 |
+
- [116,90, 156,198, 373,326] # P5/32
|
| 11 |
+
|
| 12 |
+
# YOLOv5 backbone
|
| 13 |
+
backbone:
|
| 14 |
+
# [from, number, module, args]
|
| 15 |
+
[[-1, 1, Focus, [64, 3]], # 0-P1/2
|
| 16 |
+
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
|
| 17 |
+
[-1, 3, BottleneckCSP, [128]],
|
| 18 |
+
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
|
| 19 |
+
[-1, 9, BottleneckCSP, [256]],
|
| 20 |
+
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
|
| 21 |
+
[-1, 9, BottleneckCSP, [512]],
|
| 22 |
+
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
|
| 23 |
+
[-1, 1, SPP, [1024, [5, 9, 13]]],
|
| 24 |
+
[-1, 3, BottleneckCSP, [1024, False]], # 9
|
| 25 |
+
]
|
| 26 |
+
|
| 27 |
+
# YOLOv5 head
|
| 28 |
+
head:
|
| 29 |
+
[[-1, 1, Conv, [512, 1, 1]],
|
| 30 |
+
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
| 31 |
+
[[-1, 6], 1, Concat, [1]], # cat backbone P4
|
| 32 |
+
[-1, 3, BottleneckCSP, [512, False]], # 13
|
| 33 |
+
|
| 34 |
+
[-1, 1, Conv, [256, 1, 1]],
|
| 35 |
+
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
| 36 |
+
[[-1, 4], 1, Concat, [1]], # cat backbone P3
|
| 37 |
+
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
|
| 38 |
+
|
| 39 |
+
[-1, 1, Conv, [256, 3, 2]],
|
| 40 |
+
[[-1, 14], 1, Concat, [1]], # cat head P4
|
| 41 |
+
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
|
| 42 |
+
|
| 43 |
+
[-1, 1, Conv, [512, 3, 2]],
|
| 44 |
+
[[-1, 10], 1, Concat, [1]], # cat head P5
|
| 45 |
+
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
|
| 46 |
+
|
| 47 |
+
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
|
| 48 |
+
]
|
models/labels/format_dataset.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
"""
|
| 3 |
+
Copyright (c) 2020 Carleton University Biomedical Informatics Collaboratory
|
| 4 |
+
|
| 5 |
+
This source code is licensed under the MIT license found in the
|
| 6 |
+
LICENSE file in the root directory of this source tree.
|
| 7 |
+
"""
|
| 8 |
+
from typing import List
|
| 9 |
+
from types import SimpleNamespace
|
| 10 |
+
import argparse, os, json, shutil
|
| 11 |
+
from tqdm import tqdm
|
| 12 |
+
import os.path as path
|
| 13 |
+
import numpy as np
|
| 14 |
+
from PIL import Image
|
| 15 |
+
|
| 16 |
+
LABEL_CLASS_INDICES = {
|
| 17 |
+
"250": 0,
|
| 18 |
+
".25": 1,
|
| 19 |
+
"500": 2,
|
| 20 |
+
".5": 3,
|
| 21 |
+
"1000": 4,
|
| 22 |
+
"1": 5,
|
| 23 |
+
"1K": 6,
|
| 24 |
+
"2000": 7,
|
| 25 |
+
"2": 8,
|
| 26 |
+
"2K": 9,
|
| 27 |
+
"4000": 10,
|
| 28 |
+
"4": 11,
|
| 29 |
+
"4K": 12,
|
| 30 |
+
"8000": 13,
|
| 31 |
+
"8": 14,
|
| 32 |
+
"8K": 15,
|
| 33 |
+
"0": 16,
|
| 34 |
+
"20": 17,
|
| 35 |
+
"40": 18,
|
| 36 |
+
"60": 19,
|
| 37 |
+
"80": 20,
|
| 38 |
+
"100": 21,
|
| 39 |
+
"120": 22
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
def extract_labels(annotation: dict, image: Image) -> List[tuple]:
|
| 43 |
+
"""Extracts the bounding boxes of labels into a tuple compatible
|
| 44 |
+
the YOLOv5 format.
|
| 45 |
+
|
| 46 |
+
Parameters
|
| 47 |
+
----------
|
| 48 |
+
annotation : dict
|
| 49 |
+
A dictionary containing the annotations for the audiograms in a report.
|
| 50 |
+
|
| 51 |
+
image : Image
|
| 52 |
+
The image in PIL format corresponding to the annotation.
|
| 53 |
+
|
| 54 |
+
Returns
|
| 55 |
+
-------
|
| 56 |
+
tuple
|
| 57 |
+
A tuple of the form
|
| 58 |
+
(class index, x_center, y_center, width, height) where all coordinates
|
| 59 |
+
and dimensions are normalized to the width/height of the image.
|
| 60 |
+
"""
|
| 61 |
+
label_label_tuples = []
|
| 62 |
+
image_width, image_height = image.size
|
| 63 |
+
for audiogram in annotation:
|
| 64 |
+
for label in audiogram["labels"]:
|
| 65 |
+
bounding_box = label["boundingBox"]
|
| 66 |
+
x_center = (bounding_box["x"] + bounding_box["width"] / 2) / image_width
|
| 67 |
+
y_center = (bounding_box["y"] + bounding_box["height"] / 2) / image_height
|
| 68 |
+
box_width = bounding_box["width"] / image_width
|
| 69 |
+
box_height = bounding_box["height"] / image_width
|
| 70 |
+
try:
|
| 71 |
+
label_label_tuples.append((LABEL_CLASS_INDICES[label["value"]], x_center, y_center, box_width, box_height))
|
| 72 |
+
except:
|
| 73 |
+
continue
|
| 74 |
+
return label_label_tuples
|
| 75 |
+
|
| 76 |
+
def create_directory_structure(data_dir: str):
|
| 77 |
+
try:
|
| 78 |
+
shutil.rmtree(path.join(data_dir))
|
| 79 |
+
except:
|
| 80 |
+
pass
|
| 81 |
+
os.mkdir(path.join(data_dir))
|
| 82 |
+
os.mkdir(path.join(data_dir, "images"))
|
| 83 |
+
os.mkdir(path.join(data_dir, "images", "train"))
|
| 84 |
+
os.mkdir(path.join(data_dir, "images", "validation"))
|
| 85 |
+
os.mkdir(path.join(data_dir, "labels"))
|
| 86 |
+
os.mkdir(path.join(data_dir, "labels", "train"))
|
| 87 |
+
os.mkdir(path.join(data_dir, "labels", "validation"))
|
| 88 |
+
|
| 89 |
+
def create_yolov5_file(bboxes: List[tuple], filename: str):
|
| 90 |
+
# Turn the bounding boxes into a string with a bounding box
|
| 91 |
+
# on each line
|
| 92 |
+
file_content = "\n".join([
|
| 93 |
+
f"{bbox[0]} {bbox[1]} {bbox[2]} {bbox[3]} {bbox[4]}"
|
| 94 |
+
for bbox in bboxes
|
| 95 |
+
])
|
| 96 |
+
|
| 97 |
+
# Save to a file
|
| 98 |
+
with open(filename, "w") as output_file:
|
| 99 |
+
output_file.write(file_content)
|
| 100 |
+
|
| 101 |
+
def all_labels_valid(labels: List[tuple]):
|
| 102 |
+
for label in labels:
|
| 103 |
+
for value in label[1:]:
|
| 104 |
+
if value < 0 or value > 1:
|
| 105 |
+
return False
|
| 106 |
+
return True
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def main(args: SimpleNamespace):
|
| 110 |
+
|
| 111 |
+
# Find all the JSON files in the input directory
|
| 112 |
+
report_ids = [
|
| 113 |
+
filename.rstrip(".json")
|
| 114 |
+
for filename in os.listdir(path.join(args.annotations_dir))
|
| 115 |
+
if filename.endswith(".json")
|
| 116 |
+
and path.exists(path.join(args.images_dir, filename.rstrip(".json") + ".jpg"))
|
| 117 |
+
]
|
| 118 |
+
|
| 119 |
+
# Shuffle
|
| 120 |
+
np.random.seed(seed=42) # for reproducibility of the shuffle
|
| 121 |
+
np.random.shuffle(report_ids)
|
| 122 |
+
|
| 123 |
+
# Create the directory structure in which the images and annotations
|
| 124 |
+
# are to be stored
|
| 125 |
+
create_directory_structure(args.data_dir)
|
| 126 |
+
|
| 127 |
+
# Iterate through the report ids, extract the annotations in YOLOv5 format
|
| 128 |
+
# and place the file in the correct directory, and the image in the correct
|
| 129 |
+
# directory.
|
| 130 |
+
for i, report_id in enumerate(tqdm(report_ids)):
|
| 131 |
+
|
| 132 |
+
# Decide if the image is going into the training set or validation set
|
| 133 |
+
directory = (
|
| 134 |
+
"train" if i < args.train_frac * len(report_ids) else "validation"
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
# Load the annotation`
|
| 138 |
+
annotation_content = open(
|
| 139 |
+
path.join(args.annotations_dir, f"{report_id}.json")
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
image = Image.open(os.path.join(args.images_dir, f"{report_id}.jpg"))
|
| 143 |
+
|
| 144 |
+
annotation = json.load(annotation_content)
|
| 145 |
+
bounding_boxes = extract_labels(annotation, image)
|
| 146 |
+
|
| 147 |
+
if not all_labels_valid(bounding_boxes):
|
| 148 |
+
continue
|
| 149 |
+
|
| 150 |
+
# Open the corresponding image to get its dimensions
|
| 151 |
+
image = Image.open(os.path.join(args.images_dir, f"{report_id}.jpg"))
|
| 152 |
+
|
| 153 |
+
create_yolov5_file(
|
| 154 |
+
bounding_boxes,
|
| 155 |
+
path.join(args.data_dir, "labels", directory, f"{report_id}.txt")
|
| 156 |
+
)
|
| 157 |
+
image.save(
|
| 158 |
+
path.join(args.data_dir, "images", directory, f"{report_id}.jpg")
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
if __name__ == "__main__":
|
| 162 |
+
import argparse
|
| 163 |
+
|
| 164 |
+
parser = argparse.ArgumentParser(description=(
|
| 165 |
+
"Script that formats the training set for transfer learning of labels detection via "
|
| 166 |
+
"the YOLOv5 model."
|
| 167 |
+
))
|
| 168 |
+
parser.add_argument("-d", "--data_dir", type=str, required=True, help=(
|
| 169 |
+
"Path to the directory where the training set should be created."
|
| 170 |
+
))
|
| 171 |
+
parser.add_argument("-a", "--annotations_dir", type=str, required=True, help=(
|
| 172 |
+
"Path to the directory containing the annotations in the JSON format."
|
| 173 |
+
))
|
| 174 |
+
parser.add_argument("-i", "--images_dir", type=str, required=True, help=(
|
| 175 |
+
"Path to the directory containing the images."
|
| 176 |
+
))
|
| 177 |
+
parser.add_argument("-f", "--train_frac", type=float, required=True, help=(
|
| 178 |
+
"Fraction of images to be used for training. (e.g. 0.8)"
|
| 179 |
+
))
|
| 180 |
+
args = parser.parse_args()
|
| 181 |
+
|
| 182 |
+
main(args)
|
| 183 |
+
|
models/labels/labels_detection.yaml
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
|
| 2 |
+
train: models/labels/dataset/images/train/
|
| 3 |
+
val: models/labels/dataset/images/validation/
|
| 4 |
+
|
| 5 |
+
# number of classes
|
| 6 |
+
nc: 21
|
| 7 |
+
|
| 8 |
+
# class names
|
| 9 |
+
names: [
|
| 10 |
+
#frequencies
|
| 11 |
+
"250",
|
| 12 |
+
".25",
|
| 13 |
+
"500",
|
| 14 |
+
".5",
|
| 15 |
+
"1000",
|
| 16 |
+
"1",
|
| 17 |
+
"1K",
|
| 18 |
+
"2000",
|
| 19 |
+
"2",
|
| 20 |
+
"2K",
|
| 21 |
+
"4000",
|
| 22 |
+
"4",
|
| 23 |
+
"4K",
|
| 24 |
+
"8000",
|
| 25 |
+
"8",
|
| 26 |
+
"8K",
|
| 27 |
+
"20",
|
| 28 |
+
"40",
|
| 29 |
+
"60",
|
| 30 |
+
"80",
|
| 31 |
+
"100",
|
| 32 |
+
]
|
models/labels/labels_detection_test.yaml
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
|
| 2 |
+
val: data/labels/test/images/
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
# number of classes
|
| 6 |
+
nc: 21
|
| 7 |
+
|
| 8 |
+
# class names
|
| 9 |
+
names: [
|
| 10 |
+
#frequencies
|
| 11 |
+
"250",
|
| 12 |
+
".25",
|
| 13 |
+
"500",
|
| 14 |
+
".5",
|
| 15 |
+
"1000",
|
| 16 |
+
"1",
|
| 17 |
+
"1K",
|
| 18 |
+
"2000",
|
| 19 |
+
"2",
|
| 20 |
+
"2K",
|
| 21 |
+
"4000",
|
| 22 |
+
"4",
|
| 23 |
+
"4K",
|
| 24 |
+
"8000",
|
| 25 |
+
"8",
|
| 26 |
+
"8K",
|
| 27 |
+
"20",
|
| 28 |
+
"40",
|
| 29 |
+
"60",
|
| 30 |
+
"80",
|
| 31 |
+
"100",
|
| 32 |
+
]
|
models/labels/latest/hyp.yaml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
lr0: 0.01
|
| 2 |
+
lrf: 0.2
|
| 3 |
+
momentum: 0.937
|
| 4 |
+
weight_decay: 0.0005
|
| 5 |
+
giou: 0.05
|
| 6 |
+
cls: 0.5
|
| 7 |
+
cls_pw: 1.0
|
| 8 |
+
obj: 1.0
|
| 9 |
+
obj_pw: 1.0
|
| 10 |
+
iou_t: 0.2
|
| 11 |
+
anchor_t: 4.0
|
| 12 |
+
fl_gamma: 0.0
|
| 13 |
+
hsv_h: 0.015
|
| 14 |
+
hsv_s: 0.7
|
| 15 |
+
hsv_v: 0.4
|
| 16 |
+
degrees: 0.0
|
| 17 |
+
translate: 0.1
|
| 18 |
+
scale: 0.5
|
| 19 |
+
shear: 0.0
|
| 20 |
+
perspective: 0.0
|
| 21 |
+
flipud: 0.0
|
| 22 |
+
fliplr: 0.5
|
| 23 |
+
mixup: 0.0
|
models/labels/latest/labels.png
ADDED
|
models/labels/latest/opt.yaml
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
weights: src/digitizer/yolov5/weights/yolov5s.pt
|
| 2 |
+
cfg: models/labels/yolov5s.yaml
|
| 3 |
+
data: models/labels/labels_detection.yaml
|
| 4 |
+
hyp: models/labels/latest/hyp.yaml
|
| 5 |
+
epochs: 100
|
| 6 |
+
batch_size: 16
|
| 7 |
+
img_size:
|
| 8 |
+
- 1024
|
| 9 |
+
- 1024
|
| 10 |
+
img_weights: false
|
| 11 |
+
rect: true
|
| 12 |
+
resume: false
|
| 13 |
+
nosave: false
|
| 14 |
+
notest: false
|
| 15 |
+
noautoanchor: false
|
| 16 |
+
evolve: false
|
| 17 |
+
bucket: ''
|
| 18 |
+
cache_images: false
|
| 19 |
+
name: ''
|
| 20 |
+
device: '0'
|
| 21 |
+
multi_scale: false
|
| 22 |
+
single_cls: false
|
| 23 |
+
adam: false
|
| 24 |
+
sync_bn: false
|
| 25 |
+
local_rank: -1
|
| 26 |
+
logdir: models/labels/model_2022-02-13T23:42:43.525128
|
| 27 |
+
workers: 8
|
| 28 |
+
total_batch_size: 16
|
| 29 |
+
world_size: 1
|
| 30 |
+
global_rank: -1
|
models/labels/latest/results.png
ADDED

|
models/labels/latest/results.txt
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
0/99 6.21G 0.1343 0.03079 0.08276 0.2479 11 768 0 0 7.281e-07 7.281e-08 0.1162 0.04079 0.07292
|
| 2 |
+
1/99 7.53G 0.1242 0.03164 0.07888 0.2347 21 768 0 0 6.771e-07 1.354e-07 0.108 0.04562 0.07046
|
| 3 |
+
2/99 7.54G 0.1144 0.03571 0.07596 0.2261 11 768 0 0 1.755e-05 3.077e-06 0.103 0.04908 0.06943
|
| 4 |
+
3/99 7.54G 0.0974 0.03939 0.07176 0.2086 21 768 0 0 0.002906 0.0006505 0.08903 0.05595 0.06616
|
| 5 |
+
4/99 7.54G 0.08186 0.04142 0.06885 0.1921 21 768 0.06358 0.04671 0.009447 0.002094 0.07272 0.05272 0.0647
|
| 6 |
+
5/99 7.54G 0.07081 0.03785 0.06656 0.1752 16 768 0.0354 0.1326 0.02577 0.007177 0.07022 0.04713 0.06211
|
| 7 |
+
6/99 7.54G 0.06693 0.03364 0.06371 0.1643 21 768 0.08782 0.1313 0.0288 0.00777 0.06502 0.04441 0.05983
|
| 8 |
+
7/99 7.54G 0.07509 0.03042 0.06239 0.1679 21 768 0.09319 0.08421 0.03582 0.009998 0.07345 0.04032 0.05778
|
| 9 |
+
8/99 7.54G 0.07271 0.03005 0.06178 0.1645 21 768 0.03703 0.08961 0.02776 0.007952 0.07044 0.03962 0.05648
|
| 10 |
+
9/99 7.54G 0.06547 0.03006 0.06104 0.1566 11 768 0.0528 0.1506 0.05014 0.01864 0.06365 0.0403 0.05501
|
| 11 |
+
10/99 7.54G 0.06298 0.02965 0.05742 0.15 21 768 0.1122 0.1863 0.04733 0.01125 0.0575 0.03968 0.05371
|
| 12 |
+
11/99 7.54G 0.06355 0.02845 0.05799 0.15 21 768 0.02575 0.2244 0.0501 0.01571 0.06196 0.03754 0.05244
|
| 13 |
+
12/99 7.54G 0.06407 0.02723 0.05621 0.1475 15 768 0.09019 0.2198 0.07907 0.02394 0.05992 0.03758 0.05161
|
| 14 |
+
13/99 7.54G 0.06065 0.02711 0.05451 0.1423 21 768 0.1057 0.2525 0.08484 0.02365 0.05797 0.03694 0.05046
|
| 15 |
+
14/99 7.54G 0.06177 0.02657 0.05381 0.1421 15 768 0.121 0.2575 0.1265 0.04451 0.04893 0.03792 0.04975
|
| 16 |
+
15/99 7.54G 0.05702 0.02646 0.05244 0.1359 21 768 0.1032 0.17 0.05749 0.0109 0.0623 0.03332 0.04756
|
| 17 |
+
16/99 7.54G 0.05945 0.0258 0.05168 0.1369 21 768 0.0545 0.3034 0.1181 0.03307 0.05174 0.03514 0.04698
|
| 18 |
+
17/99 7.54G 0.05679 0.02512 0.049 0.1309 21 768 0.07869 0.2468 0.08314 0.01848 0.06121 0.03403 0.04614
|
| 19 |
+
18/99 7.54G 0.05769 0.02475 0.04614 0.1286 21 768 0.1255 0.3201 0.1718 0.05578 0.0461 0.03457 0.04471
|
| 20 |
+
19/99 7.54G 0.05541 0.02479 0.04628 0.1265 16 768 0.0921 0.3097 0.1579 0.04787 0.05198 0.0329 0.0437
|
| 21 |
+
20/99 7.54G 0.05562 0.02399 0.04531 0.1249 21 768 0.1884 0.2838 0.2334 0.09286 0.04295 0.03469 0.04319
|
| 22 |
+
21/99 7.54G 0.05902 0.02642 0.0444 0.1298 21 768 0.08879 0.3126 0.1348 0.04382 0.05467 0.03429 0.0427
|
| 23 |
+
22/99 7.54G 0.05915 0.02351 0.04213 0.1248 21 768 0.1733 0.2864 0.1863 0.05512 0.0518 0.03256 0.04173
|
| 24 |
+
23/99 7.54G 0.05873 0.02303 0.04268 0.1244 21 768 0.1824 0.2923 0.2162 0.08527 0.04832 0.03428 0.04204
|
| 25 |
+
24/99 7.54G 0.05814 0.02323 0.04174 0.1231 21 768 0.2552 0.2882 0.2324 0.08491 0.04881 0.03281 0.04108
|
| 26 |
+
25/99 7.54G 0.0542 0.02279 0.04018 0.1172 21 768 0.1997 0.3405 0.2469 0.09714 0.04412 0.03141 0.03916
|
| 27 |
+
26/99 7.54G 0.0565 0.02218 0.03958 0.1183 21 768 0.182 0.3361 0.264 0.1002 0.04624 0.03252 0.03926
|
| 28 |
+
27/99 7.54G 0.05618 0.02221 0.03895 0.1173 21 768 0.1902 0.3454 0.2715 0.1179 0.04296 0.03168 0.0382
|
| 29 |
+
28/99 7.54G 0.05488 0.02226 0.03859 0.1157 16 768 0.2451 0.3586 0.2861 0.1166 0.04555 0.03129 0.03693
|
| 30 |
+
29/99 7.54G 0.05608 0.02212 0.0377 0.1159 21 768 0.2855 0.3915 0.3077 0.1391 0.04094 0.03167 0.03626
|
| 31 |
+
30/99 7.54G 0.05181 0.02179 0.03597 0.1096 21 768 0.1752 0.4288 0.3178 0.1396 0.04052 0.03098 0.03552
|
| 32 |
+
31/99 7.54G 0.05332 0.02198 0.03573 0.111 21 768 0.1629 0.4209 0.3078 0.142 0.04067 0.03126 0.03505
|
| 33 |
+
32/99 7.54G 0.05079 0.02127 0.03426 0.1063 16 768 0.2647 0.4019 0.3205 0.1273 0.04228 0.0313 0.03469
|
| 34 |
+
33/99 7.54G 0.0494 0.02121 0.03287 0.1035 16 768 0.2514 0.4279 0.3248 0.1422 0.04237 0.03096 0.03346
|
| 35 |
+
34/99 7.54G 0.05187 0.02088 0.03268 0.1054 21 768 0.1209 0.4301 0.1953 0.05969 0.06217 0.03133 0.03224
|
| 36 |
+
35/99 7.54G 0.05873 0.02148 0.03242 0.1126 21 768 0.2324 0.4623 0.3573 0.1543 0.04246 0.0305 0.03147
|
| 37 |
+
36/99 7.54G 0.05398 0.02115 0.031 0.1061 21 768 0.2775 0.3886 0.3195 0.1042 0.05145 0.02996 0.03089
|
| 38 |
+
37/99 7.54G 0.05629 0.02095 0.03121 0.1084 21 768 0.2928 0.4967 0.3996 0.191 0.03951 0.03025 0.03075
|
| 39 |
+
38/99 7.54G 0.05136 0.02113 0.03045 0.1029 16 768 0.2254 0.4235 0.2982 0.08752 0.05017 0.02989 0.02975
|
| 40 |
+
39/99 7.54G 0.05178 0.02102 0.03069 0.1035 18 768 0.2775 0.5149 0.4013 0.178 0.0392 0.02998 0.03019
|
| 41 |
+
40/99 7.54G 0.05023 0.02042 0.02886 0.09951 21 768 0.303 0.5104 0.4054 0.1795 0.03967 0.03003 0.03028
|
| 42 |
+
41/99 7.54G 0.05038 0.02051 0.02829 0.09918 21 768 0.3075 0.4837 0.3993 0.1842 0.03969 0.03067 0.03043
|
| 43 |
+
42/99 7.54G 0.04899 0.0214 0.02776 0.09815 21 768 0.263 0.5256 0.3875 0.1401 0.04635 0.02994 0.02939
|
| 44 |
+
43/99 7.54G 0.05134 0.02092 0.02657 0.09883 21 768 0.3034 0.5298 0.4287 0.1998 0.03948 0.02972 0.02878
|
| 45 |
+
44/99 7.54G 0.04718 0.02077 0.02645 0.0944 21 768 0.28 0.5414 0.3957 0.1446 0.04332 0.02932 0.02855
|
| 46 |
+
45/99 7.54G 0.04808 0.02024 0.0247 0.09302 21 768 0.3138 0.583 0.4504 0.2132 0.0362 0.02902 0.02797
|
| 47 |
+
46/99 7.54G 0.04708 0.01997 0.02575 0.0928 16 768 0.3195 0.5838 0.4504 0.2127 0.0376 0.02911 0.02815
|
| 48 |
+
47/99 7.54G 0.0468 0.01994 0.02458 0.09131 21 768 0.2988 0.5071 0.389 0.1299 0.04774 0.0288 0.02772
|
| 49 |
+
48/99 7.54G 0.04817 0.01988 0.02352 0.09157 21 768 0.344 0.5396 0.452 0.2008 0.03903 0.02954 0.0275
|
| 50 |
+
49/99 7.54G 0.04504 0.01988 0.02324 0.08816 21 768 0.3524 0.5616 0.4528 0.1937 0.03945 0.02953 0.02615
|
| 51 |
+
50/99 7.54G 0.04447 0.01977 0.0229 0.08714 21 768 0.331 0.5934 0.468 0.2189 0.03849 0.02878 0.0256
|
| 52 |
+
51/99 7.54G 0.04404 0.01981 0.02222 0.08607 21 768 0.3857 0.6196 0.4866 0.2108 0.03942 0.02866 0.02547
|
| 53 |
+
52/99 7.54G 0.04531 0.01942 0.02096 0.08569 21 768 0.3871 0.6105 0.4906 0.2136 0.04076 0.02887 0.02571
|
| 54 |
+
53/99 7.54G 0.04653 0.01982 0.02123 0.08759 16 768 0.4044 0.6181 0.5071 0.2409 0.03791 0.029 0.02615
|
| 55 |
+
54/99 7.54G 0.0447 0.0197 0.02206 0.08646 19 768 0.3528 0.5916 0.4848 0.1903 0.04306 0.02868 0.02565
|
| 56 |
+
55/99 7.54G 0.04564 0.01984 0.02034 0.08581 15 768 0.3561 0.6169 0.5131 0.253 0.03622 0.02889 0.02553
|
| 57 |
+
56/99 7.54G 0.04329 0.01954 0.02013 0.08295 21 768 0.3473 0.5974 0.4971 0.1924 0.0421 0.02892 0.02461
|
| 58 |
+
57/99 7.54G 0.04636 0.02079 0.02197 0.08912 21 768 0.4038 0.6035 0.5051 0.2287 0.03948 0.02927 0.02535
|
| 59 |
+
58/99 7.54G 0.04345 0.02027 0.0214 0.08512 21 768 0.3235 0.5661 0.4657 0.1647 0.04387 0.0298 0.02548
|
| 60 |
+
59/99 7.54G 0.04443 0.02014 0.02079 0.08536 16 768 0.3375 0.6146 0.5142 0.2345 0.03623 0.02925 0.02474
|
| 61 |
+
60/99 7.54G 0.03998 0.01952 0.01991 0.07941 21 768 0.3307 0.61 0.529 0.2253 0.03825 0.02906 0.02412
|
| 62 |
+
61/99 7.54G 0.04457 0.01975 0.01874 0.08306 16 768 0.4053 0.6245 0.529 0.248 0.03673 0.02878 0.02379
|
| 63 |
+
62/99 7.54G 0.04051 0.01926 0.01898 0.07875 21 768 0.3944 0.6172 0.5391 0.2481 0.03759 0.02885 0.02325
|
| 64 |
+
63/99 7.54G 0.04078 0.0187 0.02034 0.07983 15 768 0.4068 0.5992 0.542 0.2405 0.03861 0.02906 0.02271
|
| 65 |
+
64/99 7.54G 0.04194 0.01933 0.01778 0.07905 21 768 0.4722 0.6268 0.5746 0.2853 0.03541 0.02915 0.02239
|
| 66 |
+
65/99 7.54G 0.04337 0.0192 0.01906 0.08163 15 768 0.4341 0.5795 0.5289 0.1987 0.04128 0.02902 0.02316
|
| 67 |
+
66/99 7.54G 0.04128 0.01879 0.01742 0.07749 21 768 0.4445 0.6163 0.5647 0.2619 0.03696 0.02837 0.0229
|
| 68 |
+
67/99 7.54G 0.03981 0.01887 0.01654 0.07521 21 768 0.429 0.6053 0.5656 0.2208 0.04042 0.02861 0.02219
|
| 69 |
+
68/99 7.54G 0.04166 0.01899 0.01693 0.07757 21 768 0.4739 0.6238 0.5834 0.2604 0.0365 0.02828 0.02249
|
| 70 |
+
69/99 7.54G 0.03884 0.01799 0.01664 0.07348 21 768 0.4778 0.6301 0.5943 0.2901 0.03459 0.02814 0.02168
|
| 71 |
+
70/99 7.54G 0.03924 0.01881 0.01617 0.07422 16 768 0.4868 0.6183 0.5752 0.2273 0.03829 0.02862 0.02152
|
| 72 |
+
71/99 7.54G 0.04033 0.01877 0.01641 0.0755 16 768 0.5021 0.6403 0.5829 0.2733 0.03533 0.02833 0.02202
|
| 73 |
+
72/99 7.54G 0.0377 0.01832 0.01589 0.0719 21 768 0.5 0.6262 0.5632 0.2426 0.03893 0.02869 0.02321
|
| 74 |
+
73/99 7.54G 0.04055 0.01906 0.01569 0.0753 21 768 0.5057 0.634 0.587 0.2631 0.03679 0.02905 0.02234
|
| 75 |
+
74/99 7.54G 0.03823 0.01857 0.01563 0.07243 21 768 0.5011 0.628 0.593 0.2608 0.03783 0.02941 0.02249
|
| 76 |
+
75/99 7.54G 0.03925 0.01877 0.01487 0.07289 21 768 0.5047 0.6283 0.5913 0.2768 0.0361 0.02957 0.0222
|
| 77 |
+
76/99 7.54G 0.03875 0.01839 0.01479 0.07193 16 768 0.4463 0.599 0.5736 0.2188 0.0413 0.02932 0.02138
|
| 78 |
+
77/99 7.54G 0.03812 0.01841 0.01509 0.07162 21 768 0.4509 0.6188 0.6065 0.2811 0.03619 0.02859 0.02097
|
| 79 |
+
78/99 7.54G 0.03728 0.01822 0.01423 0.06973 21 768 0.4983 0.6299 0.6103 0.2777 0.0357 0.02857 0.02159
|
| 80 |
+
79/99 7.54G 0.03603 0.01836 0.01353 0.06792 21 768 0.4991 0.6373 0.6051 0.2815 0.03612 0.02848 0.02253
|
| 81 |
+
80/99 7.54G 0.03777 0.01839 0.01383 0.06999 21 768 0.513 0.6229 0.5937 0.263 0.03608 0.02879 0.02299
|
| 82 |
+
81/99 7.54G 0.03728 0.01836 0.01279 0.06842 21 768 0.514 0.6186 0.5827 0.2583 0.03696 0.02926 0.02275
|
| 83 |
+
82/99 7.54G 0.03713 0.01859 0.01255 0.06827 21 768 0.5083 0.6211 0.5856 0.2528 0.03705 0.02936 0.02303
|
| 84 |
+
83/99 7.54G 0.03855 0.0181 0.01291 0.06957 21 768 0.4544 0.6131 0.6127 0.2791 0.0352 0.02904 0.02008
|
| 85 |
+
84/99 7.54G 0.03822 0.01856 0.01275 0.06954 21 768 0.5615 0.6229 0.598 0.2552 0.0372 0.02896 0.02022
|
| 86 |
+
85/99 7.54G 0.03704 0.01768 0.01312 0.06783 11 768 0.5044 0.6311 0.6029 0.2736 0.03652 0.02857 0.01919
|
| 87 |
+
86/99 7.54G 0.03856 0.01819 0.01323 0.06998 16 768 0.5074 0.635 0.5867 0.2737 0.03738 0.0284 0.02141
|
| 88 |
+
87/99 7.54G 0.03727 0.01812 0.01262 0.06801 21 768 0.499 0.6212 0.59 0.2568 0.03755 0.02851 0.01913
|
| 89 |
+
88/99 7.54G 0.03734 0.01828 0.01226 0.06787 21 768 0.4615 0.6179 0.5588 0.2472 0.03796 0.02839 0.02268
|
| 90 |
+
89/99 7.54G 0.03812 0.01831 0.01117 0.0676 21 768 0.4669 0.614 0.5726 0.2468 0.03694 0.02835 0.02175
|
| 91 |
+
90/99 7.54G 0.0374 0.01776 0.01215 0.06732 21 768 0.4729 0.6058 0.5507 0.2349 0.03751 0.02848 0.02446
|
| 92 |
+
91/99 7.54G 0.0367 0.018 0.01198 0.06668 21 768 0.4756 0.5957 0.5559 0.2342 0.03869 0.02888 0.02457
|
| 93 |
+
92/99 7.54G 0.03697 0.01809 0.01169 0.06676 21 768 0.5018 0.5968 0.5633 0.2202 0.03954 0.02893 0.02166
|
| 94 |
+
93/99 7.54G 0.03864 0.01795 0.01148 0.06806 21 768 0.5179 0.6163 0.5839 0.2593 0.03644 0.02868 0.02088
|
| 95 |
+
94/99 7.54G 0.03675 0.01788 0.01188 0.06651 21 768 0.5553 0.6344 0.6026 0.2615 0.03735 0.02848 0.01651
|
| 96 |
+
95/99 7.54G 0.03669 0.01775 0.01129 0.06573 21 768 0.4619 0.6223 0.6031 0.2763 0.03487 0.02825 0.01765
|
| 97 |
+
96/99 7.54G 0.03597 0.01817 0.01073 0.06487 21 768 0.4948 0.6346 0.6214 0.2883 0.0345 0.02828 0.01605
|
| 98 |
+
97/99 7.54G 0.03609 0.01831 0.01066 0.06506 21 768 0.6066 0.6309 0.5749 0.246 0.03606 0.02862 0.02427
|
| 99 |
+
98/99 7.54G 0.03695 0.01775 0.01158 0.06628 21 768 0.5525 0.629 0.6034 0.2737 0.0357 0.02861 0.01991
|
| 100 |
+
99/99 7.54G 0.03731 0.01756 0.0107 0.06556 21 768 0.5626 0.6219 0.5937 0.2479 0.03711 0.02889 0.02241
|
models/labels/latest/train_batch0.jpg
ADDED

|
models/labels/latest/train_batch1.jpg
ADDED

|
models/labels/latest/train_batch2.jpg
ADDED

|
models/labels/yolov5s.yaml
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# parameters
|
| 2 |
+
nc: 23 # number of classes
|
| 3 |
+
depth_multiple: 0.33 # model depth multiple
|
| 4 |
+
width_multiple: 0.50 # layer channel multiple
|
| 5 |
+
|
| 6 |
+
# anchors
|
| 7 |
+
anchors:
|
| 8 |
+
- [10,13, 16,30, 33,23] # P3/8
|
| 9 |
+
- [30,61, 62,45, 59,119] # P4/16
|
| 10 |
+
- [116,90, 156,198, 373,326] # P5/32
|
| 11 |
+
|
| 12 |
+
# YOLOv5 backbone
|
| 13 |
+
backbone:
|
| 14 |
+
# [from, number, module, args]
|
| 15 |
+
[[-1, 1, Focus, [64, 3]], # 0-P1/2
|
| 16 |
+
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
|
| 17 |
+
[-1, 3, BottleneckCSP, [128]],
|
| 18 |
+
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
|
| 19 |
+
[-1, 9, BottleneckCSP, [256]],
|
| 20 |
+
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
|
| 21 |
+
[-1, 9, BottleneckCSP, [512]],
|
| 22 |
+
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
|
| 23 |
+
[-1, 1, SPP, [1024, [5, 9, 13]]],
|
| 24 |
+
[-1, 3, BottleneckCSP, [1024, False]], # 9
|
| 25 |
+
]
|
| 26 |
+
|
| 27 |
+
# YOLOv5 head
|
| 28 |
+
head:
|
| 29 |
+
[[-1, 1, Conv, [512, 1, 1]],
|
| 30 |
+
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
| 31 |
+
[[-1, 6], 1, Concat, [1]], # cat backbone P4
|
| 32 |
+
[-1, 3, BottleneckCSP, [512, False]], # 13
|
| 33 |
+
|
| 34 |
+
[-1, 1, Conv, [256, 1, 1]],
|
| 35 |
+
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
| 36 |
+
[[-1, 4], 1, Concat, [1]], # cat backbone P3
|
| 37 |
+
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
|
| 38 |
+
|
| 39 |
+
[-1, 1, Conv, [256, 3, 2]],
|
| 40 |
+
[[-1, 14], 1, Concat, [1]], # cat head P4
|
| 41 |
+
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
|
| 42 |
+
|
| 43 |
+
[-1, 1, Conv, [512, 3, 2]],
|
| 44 |
+
[[-1, 10], 1, Concat, [1]], # cat head P5
|
| 45 |
+
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
|
| 46 |
+
|
| 47 |
+
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
|
| 48 |
+
]
|
models/symbols/format_dataset.py
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
"""
|
| 3 |
+
Copyright (c) 2020 Carleton University Biomedical Informatics Collaboratory
|
| 4 |
+
|
| 5 |
+
This source code is licensed under the MIT license found in the
|
| 6 |
+
LICENSE file in the root directory of this source tree.
|
| 7 |
+
"""
|
| 8 |
+
from typing import List
|
| 9 |
+
from types import SimpleNamespace
|
| 10 |
+
import argparse, os, json, shutil
|
| 11 |
+
from tqdm import tqdm
|
| 12 |
+
import os.path as path
|
| 13 |
+
import numpy as np
|
| 14 |
+
from PIL import Image
|
| 15 |
+
|
| 16 |
+
# The different types of symbols that appear on audiograms
|
| 17 |
+
SYMBOL_CLASS_INDICES = {
|
| 18 |
+
"AIR_UNMASKED_LEFT": 0,
|
| 19 |
+
"AIR_UNMASKED_RIGHT": 1,
|
| 20 |
+
"AIR_MASKED_LEFT": 2,
|
| 21 |
+
"AIR_MASKED_RIGHT": 3,
|
| 22 |
+
"BONE_UNMASKED_LEFT": 4,
|
| 23 |
+
"BONE_UNMASKED_RIGHT": 5,
|
| 24 |
+
"BONE_MASKED_LEFT": 6,
|
| 25 |
+
"BONE_MASKED_RIGHT": 7,
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
def extract_audiograms(annotation: dict, image: Image) -> List[tuple]:
|
| 29 |
+
"""Extracts the bounding boxes of audiograms into a tuple compatible
|
| 30 |
+
the YOLOv5 format.
|
| 31 |
+
|
| 32 |
+
Parameters
|
| 33 |
+
----------
|
| 34 |
+
annotation : dict
|
| 35 |
+
A dictionary containing the annotations for the audiograms in a report.
|
| 36 |
+
|
| 37 |
+
image : Image
|
| 38 |
+
The image in PIL format corresponding to the annotation.
|
| 39 |
+
|
| 40 |
+
Returns
|
| 41 |
+
-------
|
| 42 |
+
tuple
|
| 43 |
+
A tuple of the form
|
| 44 |
+
(class index, x_center, y_center, width, height) where all coordinates
|
| 45 |
+
and dimensions are normalized to the width/height of the image.
|
| 46 |
+
"""
|
| 47 |
+
audiogram_label_tuples = []
|
| 48 |
+
image_width, image_height = image.size
|
| 49 |
+
for audiogram in annotation:
|
| 50 |
+
bounding_box = audiogram["boundingBox"]
|
| 51 |
+
x_center = (bounding_box["x"] + bounding_box["width"] / 2) / image_width
|
| 52 |
+
y_center = (bounding_box["y"] + bounding_box["height"] / 2) / image_height
|
| 53 |
+
box_width = bounding_box["width"] / image_width
|
| 54 |
+
box_height = bounding_box["height"] / image_width
|
| 55 |
+
audiogram_label_tuples.append((0, x_center, y_center, box_width, box_height))
|
| 56 |
+
return audiogram_label_tuples
|
| 57 |
+
|
| 58 |
+
def extract_symbols(annotation: dict, image: Image) -> List[tuple]:
|
| 59 |
+
"""Extracts the bounding boxes of the symbols into tuples
|
| 60 |
+
compatible the YOLOv5 format.
|
| 61 |
+
|
| 62 |
+
Parameters
|
| 63 |
+
----------
|
| 64 |
+
annotation : dict
|
| 65 |
+
A dictionary containing the annotations for the audiograms in a report.
|
| 66 |
+
|
| 67 |
+
image: Image
|
| 68 |
+
The corresponding image.
|
| 69 |
+
|
| 70 |
+
Returns
|
| 71 |
+
-------
|
| 72 |
+
List[List[tuple]]
|
| 73 |
+
A list of lists of tuples, where the inner lists correspond to the different
|
| 74 |
+
audiograms that may appear in the report and the tuples are the symbols.
|
| 75 |
+
"""
|
| 76 |
+
symbol_labels_tuples = []
|
| 77 |
+
for audiogram in annotation:
|
| 78 |
+
left = audiogram["boundingBox"]["x"]
|
| 79 |
+
top = audiogram["boundingBox"]["y"]
|
| 80 |
+
image_width = audiogram["boundingBox"]["width"]
|
| 81 |
+
image_height = audiogram["boundingBox"]["height"]
|
| 82 |
+
audiogram_labels = []
|
| 83 |
+
for symbol in audiogram["symbols"]:
|
| 84 |
+
bounding_box = symbol["boundingBox"]
|
| 85 |
+
x_center = (bounding_box["x"] - left + bounding_box["width"] / 2) / image_width
|
| 86 |
+
y_center = (bounding_box["y"] - top + bounding_box["height"] / 2) / image_height
|
| 87 |
+
box_width = bounding_box["width"] / image_width
|
| 88 |
+
box_height = bounding_box["height"] / image_width
|
| 89 |
+
audiogram_labels.append((SYMBOL_CLASS_INDICES[symbol["measurementType"]], x_center, y_center, box_width, box_height))
|
| 90 |
+
symbol_labels_tuples.append(audiogram_labels)
|
| 91 |
+
return symbol_labels_tuples
|
| 92 |
+
|
| 93 |
+
def create_yolov5_file(bboxes: List[tuple], filename: str):
|
| 94 |
+
# Turn the bounding boxes into a string with a bounding box
|
| 95 |
+
# on each line
|
| 96 |
+
file_content = "\n".join([
|
| 97 |
+
f"{bbox[0]} {bbox[1]} {bbox[2]} {bbox[3]} {bbox[4]}"
|
| 98 |
+
for bbox in bboxes
|
| 99 |
+
])
|
| 100 |
+
|
| 101 |
+
# Save to a file
|
| 102 |
+
with open(filename, "w") as output_file:
|
| 103 |
+
output_file.write(file_content)
|
| 104 |
+
|
| 105 |
+
def create_directory_structure(data_dir: str):
|
| 106 |
+
try:
|
| 107 |
+
shutil.rmtree(path.join(data_dir))
|
| 108 |
+
except:
|
| 109 |
+
pass
|
| 110 |
+
os.mkdir(path.join(data_dir))
|
| 111 |
+
os.mkdir(path.join(data_dir, "images"))
|
| 112 |
+
os.mkdir(path.join(data_dir, "images", "train"))
|
| 113 |
+
os.mkdir(path.join(data_dir, "images", "validation"))
|
| 114 |
+
os.mkdir(path.join(data_dir, "labels"))
|
| 115 |
+
os.mkdir(path.join(data_dir, "labels", "train"))
|
| 116 |
+
os.mkdir(path.join(data_dir, "labels", "validation"))
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def all_labels_valid(labels: List[tuple]):
|
| 120 |
+
for label in labels:
|
| 121 |
+
for value in label[1:]:
|
| 122 |
+
if value < 0 or value > 1:
|
| 123 |
+
return False
|
| 124 |
+
return True
|
| 125 |
+
|
| 126 |
+
def main(args: SimpleNamespace):
|
| 127 |
+
# Find all the JSON files in the input directory
|
| 128 |
+
report_ids = [
|
| 129 |
+
filename.rstrip(".json")
|
| 130 |
+
for filename in os.listdir(path.join(args.annotations_dir))
|
| 131 |
+
if filename.endswith(".json")
|
| 132 |
+
and path.exists(path.join(args.images_dir, filename.rstrip(".json") + ".jpg"))
|
| 133 |
+
]
|
| 134 |
+
|
| 135 |
+
# Shuffle
|
| 136 |
+
np.random.seed(seed=42) # for reproducibility of the shuffle
|
| 137 |
+
np.random.shuffle(report_ids)
|
| 138 |
+
|
| 139 |
+
# Create the directory structure in which the images and annotations
|
| 140 |
+
# are to be stored
|
| 141 |
+
create_directory_structure(args.data_dir)
|
| 142 |
+
|
| 143 |
+
# Iterate through the report ids, extract the annotations in YOLOv5 format
|
| 144 |
+
# and place the file in the correct directory, and the image in the correct
|
| 145 |
+
# directory.
|
| 146 |
+
for i, report_id in enumerate(tqdm(report_ids)):
|
| 147 |
+
# Decide if the image is going into the training set or validation set
|
| 148 |
+
directory = (
|
| 149 |
+
"train" if i < args.train_frac * len(report_ids) else "validation"
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
# Load the annotation`
|
| 153 |
+
annotation_content = open(
|
| 154 |
+
path.join(args.annotations_dir, f"{report_id}.json")
|
| 155 |
+
)
|
| 156 |
+
annotation = json.load(annotation_content)
|
| 157 |
+
|
| 158 |
+
# Open the corresponding image to get its dimensions
|
| 159 |
+
image = Image.open(os.path.join(args.images_dir, f"{report_id}.jpg"))
|
| 160 |
+
width, height = image.size
|
| 161 |
+
|
| 162 |
+
# Audiogram labels
|
| 163 |
+
audiogram_labels = extract_audiograms(annotation, image)
|
| 164 |
+
|
| 165 |
+
if not all_labels_valid(audiogram_labels):
|
| 166 |
+
continue
|
| 167 |
+
|
| 168 |
+
# Symbol labels
|
| 169 |
+
symbol_labels = extract_symbols(annotation, image)
|
| 170 |
+
for i, plot_symbols in enumerate(symbol_labels):
|
| 171 |
+
if not all_labels_valid(plot_symbols):
|
| 172 |
+
continue
|
| 173 |
+
x1 = annotation[i]["boundingBox"]["x"]
|
| 174 |
+
y1 = annotation[i]["boundingBox"]["y"]
|
| 175 |
+
x2 = annotation[i]["boundingBox"]["x"] + annotation[i]["boundingBox"]["width"]
|
| 176 |
+
y2 = annotation[i]["boundingBox"]["y"] + annotation[i]["boundingBox"]["height"]
|
| 177 |
+
create_yolov5_file(
|
| 178 |
+
plot_symbols,
|
| 179 |
+
path.join(args.data_dir, "labels", directory, f"{report_id}_{i+1}.txt")
|
| 180 |
+
)
|
| 181 |
+
image.crop((x1, y1, x2, y2)).save(
|
| 182 |
+
path.join(args.data_dir, "images", directory, f"{report_id}_{i+1}.jpg")
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
if __name__ == "__main__":
|
| 186 |
+
import argparse
|
| 187 |
+
|
| 188 |
+
parser = argparse.ArgumentParser(description=(
|
| 189 |
+
"Script that formats the training set for transfer learning via "
|
| 190 |
+
"the YOLOv5 model."
|
| 191 |
+
))
|
| 192 |
+
parser.add_argument("-d", "--data_dir", type=str, required=True, help=(
|
| 193 |
+
"Path to the directory containing the data. It should have 3 "
|
| 194 |
+
"subfolders named `images`, `annotations` and `labels`."
|
| 195 |
+
))
|
| 196 |
+
parser.add_argument("-a", "--annotations_dir", type=str, required=True, help=(
|
| 197 |
+
"Path to the directory containing the annotations in the JSON format."
|
| 198 |
+
))
|
| 199 |
+
parser.add_argument("-i", "--images_dir", type=str, required=True, help=(
|
| 200 |
+
"Path to the directory containing the images."
|
| 201 |
+
))
|
| 202 |
+
parser.add_argument("-f", "--train_frac", type=float, required=True, help=(
|
| 203 |
+
"Fraction of images to be used for training. (e.g. 0.8)"
|
| 204 |
+
))
|
| 205 |
+
args = parser.parse_args()
|
| 206 |
+
|
| 207 |
+
main(args)
|
| 208 |
+
|
models/symbols/latest/hyp.yaml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
lr0: 0.01
|
| 2 |
+
lrf: 0.2
|
| 3 |
+
momentum: 0.937
|
| 4 |
+
weight_decay: 0.0005
|
| 5 |
+
giou: 0.05
|
| 6 |
+
cls: 0.5
|
| 7 |
+
cls_pw: 1.0
|
| 8 |
+
obj: 1.0
|
| 9 |
+
obj_pw: 1.0
|
| 10 |
+
iou_t: 0.2
|
| 11 |
+
anchor_t: 4.0
|
| 12 |
+
fl_gamma: 0.0
|
| 13 |
+
hsv_h: 0.015
|
| 14 |
+
hsv_s: 0.7
|
| 15 |
+
hsv_v: 0.4
|
| 16 |
+
degrees: 0.0
|
| 17 |
+
translate: 0.1
|
| 18 |
+
scale: 0.5
|
| 19 |
+
shear: 0.0
|
| 20 |
+
perspective: 0.0
|
| 21 |
+
flipud: 0.0
|
| 22 |
+
fliplr: 0.5
|
| 23 |
+
mixup: 0.0
|
models/symbols/latest/labels.png
ADDED
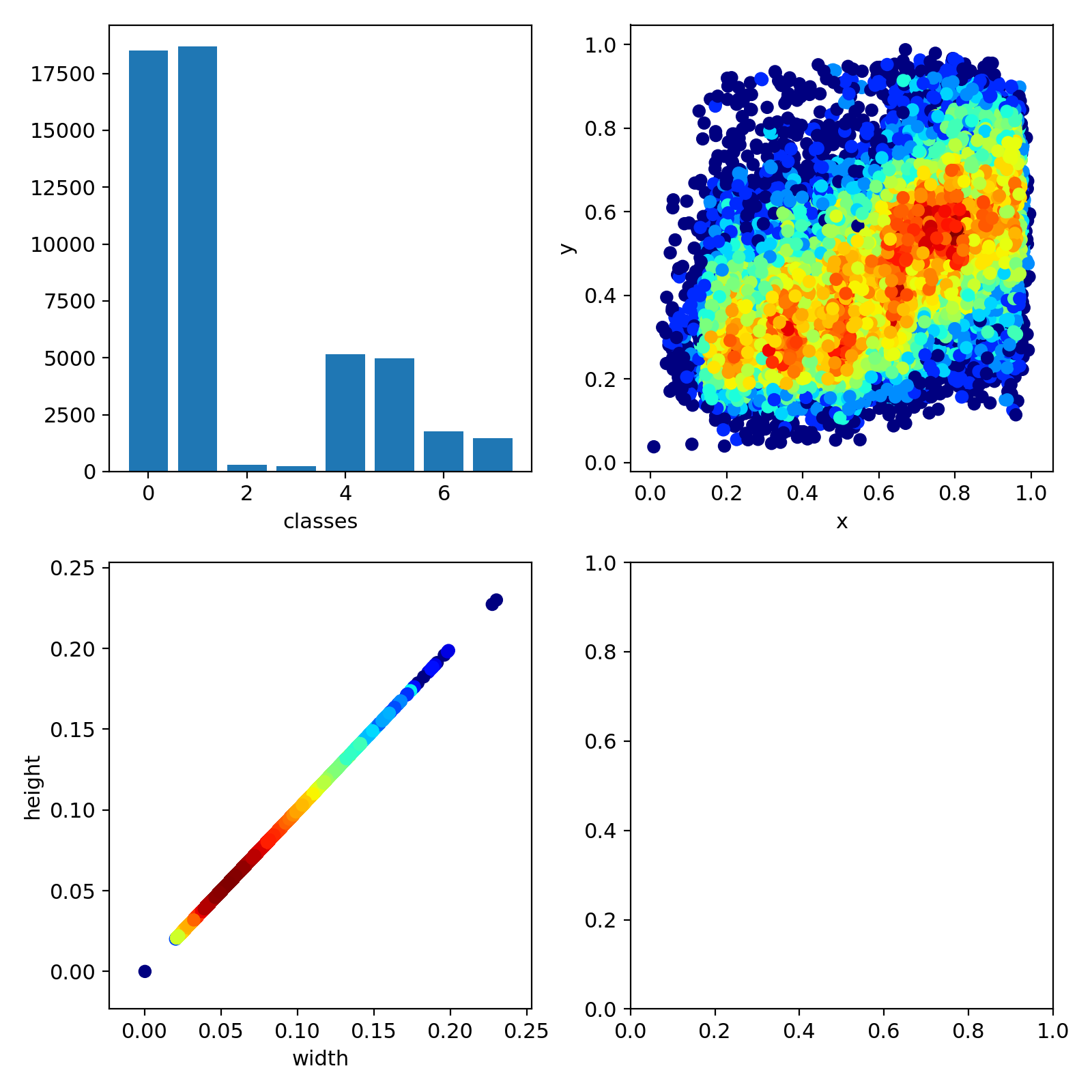
|
models/symbols/latest/opt.yaml
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
weights: yolov5/weights/yolov5s.pt
|
| 2 |
+
cfg: yolov5/models/yolov5s.yaml
|
| 3 |
+
data: symbol_detection.yaml
|
| 4 |
+
hyp: ./yolov5/data/hyp.scratch.yaml
|
| 5 |
+
epochs: 50
|
| 6 |
+
batch_size: 16
|
| 7 |
+
img_size:
|
| 8 |
+
- 1024
|
| 9 |
+
- 1024
|
| 10 |
+
rect: true
|
| 11 |
+
resume: false
|
| 12 |
+
nosave: false
|
| 13 |
+
notest: false
|
| 14 |
+
noautoanchor: false
|
| 15 |
+
evolve: false
|
| 16 |
+
bucket: ''
|
| 17 |
+
cache_images: false
|
| 18 |
+
image_weights: false
|
| 19 |
+
name: ''
|
| 20 |
+
device: '0'
|
| 21 |
+
multi_scale: false
|
| 22 |
+
single_cls: false
|
| 23 |
+
adam: false
|
| 24 |
+
sync_bn: false
|
| 25 |
+
local_rank: -1
|
| 26 |
+
logdir: runs/
|
| 27 |
+
workers: 8
|
| 28 |
+
total_batch_size: 16
|
| 29 |
+
world_size: 1
|
| 30 |
+
global_rank: -1
|
models/symbols/latest/results.png
ADDED
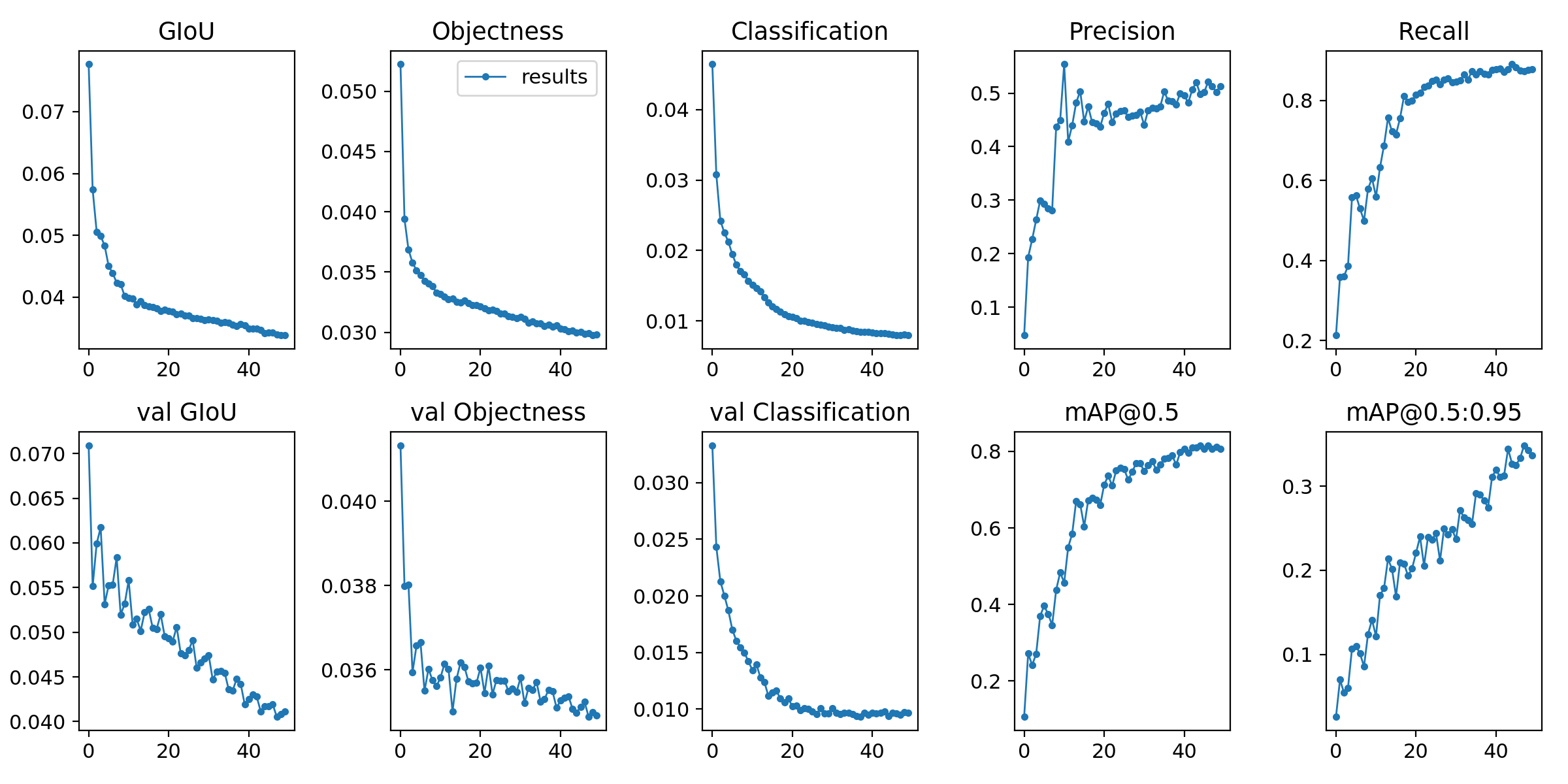
|
models/symbols/latest/results.txt
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
0/49 7.49G 0.07765 0.05224 0.04646 0.1763 7 576 0.04767 0.2132 0.1067 0.0261 0.0709 0.04132 0.03329
|
| 2 |
+
1/49 7.53G 0.0574 0.03939 0.03081 0.1276 7 576 0.1938 0.3598 0.2717 0.06994 0.05514 0.03799 0.02433
|
| 3 |
+
2/49 7.53G 0.05059 0.03685 0.02426 0.1117 7 576 0.2269 0.3609 0.2415 0.05457 0.05992 0.03802 0.0213
|
| 4 |
+
3/49 7.53G 0.04991 0.03578 0.02254 0.1082 7 576 0.2634 0.3865 0.2704 0.0603 0.06173 0.03594 0.02003
|
| 5 |
+
4/49 7.53G 0.04831 0.03514 0.02124 0.1047 6 576 0.2995 0.5582 0.3703 0.107 0.05316 0.03657 0.01871
|
| 6 |
+
5/49 7.53G 0.04502 0.03474 0.01945 0.09921 7 576 0.2936 0.5627 0.3964 0.11 0.05526 0.03665 0.01701
|
| 7 |
+
6/49 7.53G 0.04389 0.03427 0.01799 0.09615 7 576 0.2852 0.5298 0.3742 0.1009 0.0553 0.0355 0.01604
|
| 8 |
+
7/49 7.53G 0.04235 0.03403 0.01705 0.09343 7 576 0.2816 0.4995 0.3463 0.08569 0.05838 0.03602 0.01547
|
| 9 |
+
8/49 7.53G 0.0421 0.03383 0.01663 0.09256 7 576 0.4374 0.5792 0.4381 0.1241 0.05197 0.03575 0.01499
|
| 10 |
+
9/49 7.53G 0.04017 0.03327 0.01569 0.08912 7 576 0.4495 0.6056 0.4835 0.141 0.05317 0.03561 0.01422
|
| 11 |
+
10/49 7.53G 0.03991 0.0332 0.01515 0.08826 7 576 0.5538 0.5598 0.4569 0.1217 0.05581 0.03582 0.01345
|
| 12 |
+
11/49 7.53G 0.03979 0.03298 0.01464 0.08741 7 576 0.4092 0.633 0.5494 0.1704 0.05083 0.03614 0.01397
|
| 13 |
+
12/49 7.53G 0.03885 0.03274 0.01418 0.08577 7 576 0.4398 0.6878 0.5847 0.1786 0.05148 0.03602 0.01281
|
| 14 |
+
13/49 7.53G 0.03938 0.0328 0.01332 0.0855 7 576 0.4823 0.7566 0.6708 0.2135 0.05016 0.03501 0.01239
|
| 15 |
+
14/49 7.53G 0.03869 0.0325 0.0126 0.08379 7 576 0.5036 0.7224 0.6623 0.2015 0.05224 0.03578 0.01118
|
| 16 |
+
15/49 7.53G 0.03856 0.03249 0.0121 0.08314 7 576 0.4471 0.7152 0.6042 0.1691 0.05259 0.03617 0.01143
|
| 17 |
+
16/49 7.53G 0.03844 0.03263 0.01164 0.08271 7 576 0.4748 0.7556 0.6721 0.2094 0.0505 0.03606 0.01165
|
| 18 |
+
17/49 7.53G 0.03824 0.03244 0.01134 0.08202 7 576 0.4454 0.8108 0.6782 0.2079 0.05038 0.03572 0.01091
|
| 19 |
+
18/49 7.53G 0.0378 0.03225 0.01097 0.08103 7 576 0.4437 0.7971 0.6736 0.1934 0.052 0.03567 0.01057
|
| 20 |
+
19/49 7.53G 0.03797 0.03225 0.01065 0.08087 7 576 0.437 0.7995 0.6595 0.202 0.04957 0.03569 0.01094
|
| 21 |
+
20/49 7.53G 0.03772 0.03216 0.01053 0.08041 7 576 0.4631 0.8147 0.713 0.2205 0.04931 0.03605 0.01022
|
| 22 |
+
21/49 7.53G 0.03769 0.03196 0.01036 0.08001 7 576 0.4799 0.8187 0.7363 0.2399 0.04898 0.03545 0.0103
|
| 23 |
+
22/49 7.53G 0.03721 0.0318 0.01005 0.07905 7 576 0.4458 0.8343 0.7107 0.2057 0.05059 0.03609 0.009893
|
| 24 |
+
23/49 7.53G 0.0373 0.03188 0.01003 0.0792 7 576 0.462 0.8368 0.7502 0.2398 0.04766 0.03542 0.01006
|
| 25 |
+
24/49 7.53G 0.03706 0.03175 0.009794 0.07861 7 576 0.4662 0.848 0.7574 0.2366 0.04742 0.03576 0.01004
|
| 26 |
+
25/49 7.53G 0.037 0.03154 0.009702 0.07824 7 576 0.4671 0.8519 0.7534 0.2438 0.04799 0.03574 0.00978
|
| 27 |
+
26/49 7.53G 0.03664 0.03155 0.009522 0.07771 7 576 0.4553 0.8399 0.7258 0.2114 0.04911 0.03574 0.009557
|
| 28 |
+
27/49 7.53G 0.03663 0.03134 0.009434 0.07741 6 576 0.4576 0.8515 0.7464 0.2495 0.046 0.03549 0.01006
|
| 29 |
+
28/49 7.53G 0.03649 0.03125 0.009326 0.07707 7 576 0.4592 0.8557 0.7699 0.2423 0.04658 0.03556 0.009594
|
| 30 |
+
29/49 7.53G 0.03631 0.03119 0.009154 0.07665 7 576 0.4649 0.8459 0.7688 0.2489 0.04703 0.03547 0.009588
|
| 31 |
+
30/49 7.53G 0.03638 0.03128 0.009051 0.07672 7 576 0.4404 0.8472 0.7481 0.2368 0.04745 0.03581 0.01008
|
| 32 |
+
31/49 7.53G 0.03626 0.03109 0.009029 0.07638 5 576 0.4682 0.8503 0.7648 0.2715 0.0447 0.03521 0.009697
|
| 33 |
+
32/49 7.53G 0.03619 0.03078 0.008949 0.07592 7 576 0.4727 0.8656 0.7748 0.2627 0.04556 0.03557 0.009528
|
| 34 |
+
33/49 7.53G 0.03582 0.03089 0.008738 0.07544 7 576 0.4715 0.8527 0.7524 0.2595 0.04565 0.03552 0.009686
|
| 35 |
+
34/49 7.53G 0.03597 0.03074 0.008762 0.07547 6 576 0.4748 0.8733 0.7652 0.2553 0.04547 0.03571 0.009658
|
| 36 |
+
35/49 7.53G 0.03585 0.03071 0.00865 0.07521 7 576 0.5028 0.8653 0.7807 0.2915 0.04359 0.03525 0.009554
|
| 37 |
+
36/49 7.53G 0.03551 0.03053 0.008564 0.07461 6 576 0.4858 0.8738 0.7824 0.2899 0.04349 0.0353 0.009391
|
| 38 |
+
37/49 7.53G 0.03535 0.03063 0.008459 0.07443 7 576 0.4847 0.8664 0.7892 0.2833 0.04479 0.03553 0.009333
|
| 39 |
+
38/49 7.53G 0.03561 0.03047 0.008462 0.07454 7 576 0.4791 0.8654 0.7652 0.2747 0.04421 0.03549 0.009689
|
| 40 |
+
39/49 7.53G 0.03544 0.03056 0.008445 0.07445 7 576 0.4997 0.8772 0.7985 0.3108 0.04193 0.0351 0.009489
|
| 41 |
+
40/49 7.53G 0.03495 0.03029 0.008376 0.07361 7 576 0.4959 0.8783 0.8073 0.3197 0.04251 0.03527 0.009663
|
| 42 |
+
41/49 7.53G 0.03491 0.03027 0.008229 0.0734 6 576 0.4818 0.8804 0.7962 0.3107 0.043 0.03533 0.009612
|
| 43 |
+
42/49 7.53G 0.03491 0.03008 0.008287 0.07328 7 576 0.5063 0.8718 0.8105 0.3125 0.0428 0.03537 0.009683
|
| 44 |
+
43/49 7.53G 0.03472 0.03013 0.008238 0.07309 6 576 0.5203 0.8777 0.81 0.3442 0.04114 0.03507 0.009757
|
| 45 |
+
44/49 7.53G 0.03416 0.02998 0.008148 0.07229 7 576 0.4981 0.8905 0.8147 0.3268 0.04171 0.03498 0.009373
|
| 46 |
+
45/49 7.53G 0.03424 0.03003 0.008063 0.07233 7 576 0.5018 0.8824 0.8067 0.3253 0.04174 0.03512 0.009696
|
| 47 |
+
46/49 7.53G 0.03433 0.02986 0.008007 0.07219 7 576 0.5216 0.8748 0.8155 0.3331 0.04193 0.03524 0.009595
|
| 48 |
+
47/49 7.53G 0.03398 0.0299 0.00801 0.07189 7 576 0.5127 0.8726 0.8061 0.3483 0.04056 0.03489 0.009472
|
| 49 |
+
48/49 7.53G 0.03383 0.02974 0.008026 0.0716 7 576 0.5021 0.8772 0.8126 0.3428 0.04086 0.035 0.009722
|
| 50 |
+
49/49 7.53G 0.03385 0.02983 0.00794 0.07161 6 576 0.5133 0.878 0.8072 0.3366 0.04112 0.03492 0.009682
|
models/symbols/latest/test_batch0_gt.jpg
ADDED
|
models/symbols/latest/test_batch0_pred.jpg
ADDED

|
models/symbols/latest/train_batch0.jpg
ADDED
|
models/symbols/latest/train_batch1.jpg
ADDED

|
models/symbols/latest/train_batch2.jpg
ADDED

|
models/symbols/symbols_detection.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
|
| 2 |
+
train: models/symbols/dataset/images/train/
|
| 3 |
+
val: models/symbols/dataset/images/validation/
|
| 4 |
+
|
| 5 |
+
# number of classes
|
| 6 |
+
nc: 8
|
| 7 |
+
|
| 8 |
+
# class names
|
| 9 |
+
names: [
|
| 10 |
+
"AIR_UNMASKED_LEFT",
|
| 11 |
+
"AIR_UNMASKED_RIGHT",
|
| 12 |
+
"AIR_MASKED_LEFT",
|
| 13 |
+
"AIR_MASKED_RIGHT",
|
| 14 |
+
"BONE_UNMASKED_LEFT",
|
| 15 |
+
"BONE_UNMASKED_RIGHT",
|
| 16 |
+
"BONE_MASKED_LEFT",
|
| 17 |
+
"BONE_MASKED_RIGHT"
|
| 18 |
+
]
|
models/symbols/symbols_detection_test.yaml
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
|
| 2 |
+
val: data/symbols/test/images/
|
| 3 |
+
|
| 4 |
+
# number of classes
|
| 5 |
+
nc: 8
|
| 6 |
+
|
| 7 |
+
# class names
|
| 8 |
+
names: [
|
| 9 |
+
"AIR_UNMASKED_LEFT",
|
| 10 |
+
"AIR_UNMASKED_RIGHT",
|
| 11 |
+
"AIR_MASKED_LEFT",
|
| 12 |
+
"AIR_MASKED_RIGHT",
|
| 13 |
+
"BONE_UNMASKED_LEFT",
|
| 14 |
+
"BONE_UNMASKED_RIGHT",
|
| 15 |
+
"BONE_MASKED_LEFT",
|
| 16 |
+
"BONE_MASKED_RIGHT"
|
| 17 |
+
]
|
models/symbols/yolov5s.yaml
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# parameters
|
| 2 |
+
nc: 8 # number of classes
|
| 3 |
+
depth_multiple: 0.33 # model depth multiple
|
| 4 |
+
width_multiple: 0.50 # layer channel multiple
|
| 5 |
+
|
| 6 |
+
# anchors
|
| 7 |
+
anchors:
|
| 8 |
+
- [10,13, 16,30, 33,23] # P3/8
|
| 9 |
+
- [30,61, 62,45, 59,119] # P4/16
|
| 10 |
+
- [116,90, 156,198, 373,326] # P5/32
|
| 11 |
+
|
| 12 |
+
# YOLOv5 backbone
|
| 13 |
+
backbone:
|
| 14 |
+
# [from, number, module, args]
|
| 15 |
+
[[-1, 1, Focus, [64, 3]], # 0-P1/2
|
| 16 |
+
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
|
| 17 |
+
[-1, 3, BottleneckCSP, [128]],
|
| 18 |
+
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
|
| 19 |
+
[-1, 9, BottleneckCSP, [256]],
|
| 20 |
+
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
|
| 21 |
+
[-1, 9, BottleneckCSP, [512]],
|
| 22 |
+
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
|
| 23 |
+
[-1, 1, SPP, [1024, [5, 9, 13]]],
|
| 24 |
+
[-1, 3, BottleneckCSP, [1024, False]], # 9
|
| 25 |
+
]
|
| 26 |
+
|
| 27 |
+
# YOLOv5 head
|
| 28 |
+
head:
|
| 29 |
+
[[-1, 1, Conv, [512, 1, 1]],
|
| 30 |
+
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
| 31 |
+
[[-1, 6], 1, Concat, [1]], # cat backbone P4
|
| 32 |
+
[-1, 3, BottleneckCSP, [512, False]], # 13
|
| 33 |
+
|
| 34 |
+
[-1, 1, Conv, [256, 1, 1]],
|
| 35 |
+
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
| 36 |
+
[[-1, 4], 1, Concat, [1]], # cat backbone P3
|
| 37 |
+
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
|
| 38 |
+
|
| 39 |
+
[-1, 1, Conv, [256, 3, 2]],
|
| 40 |
+
[[-1, 14], 1, Concat, [1]], # cat head P4
|
| 41 |
+
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
|
| 42 |
+
|
| 43 |
+
[-1, 1, Conv, [512, 3, 2]],
|
| 44 |
+
[[-1, 10], 1, Concat, [1]], # cat head P5
|
| 45 |
+
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
|
| 46 |
+
|
| 47 |
+
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
|
| 48 |
+
]
|
requirements.txt
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
matplotlib
|
| 2 |
+
pandas
|
| 3 |
+
Pillow
|
| 4 |
+
pytesseract
|
| 5 |
+
PyYAML
|
| 6 |
+
requests
|
| 7 |
+
scipy
|
| 8 |
+
toml
|
| 9 |
+
torch==1.9.0
|
| 10 |
+
torchvision==0.10.0
|
| 11 |
+
tqdm
|
| 12 |
+
typed-ast
|
| 13 |
+
typing-extensions
|
| 14 |
+
opencv-python
|
| 15 |
+
gradio
|
src/__pycache__/interfaces.cpython-38.pyc
ADDED
|
Binary file (4.9 kB). View file
|
|
|
src/digitize_report.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
"""
|
| 3 |
+
Copyright (c) 2020, Carleton University Biomedical Informatics Collaboratory
|
| 4 |
+
|
| 5 |
+
This source code is licensed under the MIT license found in the
|
| 6 |
+
LICENSE file in the root directory of this source tree.
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
import json
|
| 10 |
+
import os
|
| 11 |
+
|
| 12 |
+
from tqdm import tqdm
|
| 13 |
+
|
| 14 |
+
from digitizer.digitization import generate_partial_annotation, extract_thresholds
|
| 15 |
+
|
| 16 |
+
if __name__ == "__main__":
|
| 17 |
+
import argparse
|
| 18 |
+
parser = argparse.ArgumentParser(description=("Digitization script "
|
| 19 |
+
"for the conversion of audiology reports to JSON documents."))
|
| 20 |
+
parser.add_argument("-i", "--input", type=str, required=True,
|
| 21 |
+
help=("Path to the audiology report (or directory) to be digitized."))
|
| 22 |
+
parser.add_argument("-o", "--output_dir", type=str, required=False,
|
| 23 |
+
help="Path to the directory in which the result is to be saved (file will have same base name as input file, but with .json extension). If not provided, result is printed to the console.")
|
| 24 |
+
parser.add_argument("-a", "--annotation_mode", action="store_true",
|
| 25 |
+
help="Whether the script should be run in `annotation mode`, i.e. return results similar in format to those of a human-made annotation. If not given, a list of thresholds is computed.")
|
| 26 |
+
parser.add_argument("-g", "--gpu", action="store_true",
|
| 27 |
+
help="Use the GPU.")
|
| 28 |
+
args = parser.parse_args()
|
| 29 |
+
|
| 30 |
+
input_files = []
|
| 31 |
+
if os.path.isfile(args.input):
|
| 32 |
+
input_files += [os.path.abspath(args.input)]
|
| 33 |
+
else:
|
| 34 |
+
input_files += [os.path.join(args.input, filename) for filename in os.listdir(args.input)]
|
| 35 |
+
|
| 36 |
+
with tqdm(total=len(input_files)) as pbar:
|
| 37 |
+
for input_file in input_files:
|
| 38 |
+
pbar.set_description(f"{os.path.basename(input_file)}")
|
| 39 |
+
|
| 40 |
+
result = None
|
| 41 |
+
if args.annotation_mode:
|
| 42 |
+
result = generate_partial_annotation(input_file, gpu=args.gpu)
|
| 43 |
+
else:
|
| 44 |
+
result = extract_thresholds(input_file, gpu=args.gpu)
|
| 45 |
+
|
| 46 |
+
result_as_string = json.dumps(result, indent=4, separators=(',', ': '))
|
| 47 |
+
|
| 48 |
+
if args.output_dir:
|
| 49 |
+
predictions_filename = os.path.basename(input_file).split(".")[0] + ".json"
|
| 50 |
+
with open(os.path.join(args.output_dir, predictions_filename), "w") as ofile:
|
| 51 |
+
ofile.write(result_as_string)
|
| 52 |
+
else:
|
| 53 |
+
print(result_as_string)
|
| 54 |
+
|
| 55 |
+
pbar.update(1) # increment the progress bar
|
src/digitizer/__pycache__/digitization.cpython-38.pyc
ADDED
|
Binary file (13.6 kB). View file
|
|
|
src/digitizer/assets/fonts/arial.ttf
ADDED
|
Binary file (773 kB). View file
|
|
|
src/digitizer/assets/symbols/left_air_masked.png
ADDED

|
src/digitizer/assets/symbols/left_air_masked.svg
ADDED

|
src/digitizer/assets/symbols/left_air_unmasked.png
ADDED

|