Spaces:
Build error

Build error
File size: 7,270 Bytes
47af768 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 |

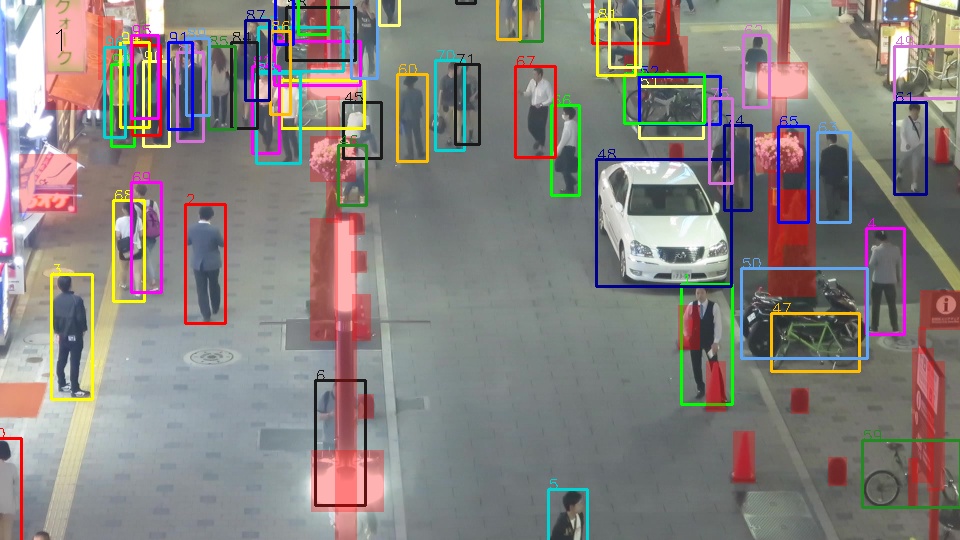
# MOTChallenge Official Evaluation Kit - Multi-Object Tracking - MOT15, MOT16, MOT17, MOT20
TrackEval is now the Official Evaluation Kit for MOTChallenge.
This repository contains the evaluation scripts for the MOT challenges available at www.MOTChallenge.net.
This codebase replaces the previous version that used to be accessible at https://github.com/dendorferpatrick/MOTChallengeEvalKit and is no longer maintained.
Challenge Name | Data url |
|----- | ----------- |
|2D MOT 15| https://motchallenge.net/data/MOT15/ |
|MOT 16| https://motchallenge.net/data/MOT16/ |
|MOT 17| https://motchallenge.net/data/MOT17/ |
|MOT 20| https://motchallenge.net/data/MOT20/ |
## Requirements
* Python (3.5 or newer)
* Numpy and Scipy
## Directories and Data
The easiest way to get started is to simply download the TrackEval example data from here: [data.zip](https://omnomnom.vision.rwth-aachen.de/data/TrackEval/data.zip) (~150mb).
This contains all the ground-truth, example trackers and meta-data that you will need.
Extract this zip into the repository root folder such that the file paths look like: TrackEval/data/gt/...
## Evaluation
To run the evaluation for your method please run the script at ```TrackEval/scripts/run_mot_challenge.py```.
Some of the basic arguments are described below. For more arguments, please see the script itself.
```BENCHMARK```: Name of the benchmark, e.g. MOT15, MO16, MOT17 or MOT20 (default : MOT17)
```SPLIT_TO_EVAL```: Data split on which to evalute e.g. train, test (default : train)
```TRACKERS_TO_EVAL```: List of tracker names for which you wish to run evaluation. e.g. MPNTrack (default: all trackers in tracker folder)
```METRICS```: List of metric families which you wish to compute. e.g. HOTA CLEAR Identity VACE (default: HOTA CLEAR Identity)
```USE_PARALLEL```: Whether to run evaluation in parallel on multiple cores. (default: False)
```NUM_PARALLEL_CORES```: Number of cores to use when running in parallel. (default: 8)
An example is below (this will work on the supplied example data above):
```
python scripts/run_mot_challenge.py --BENCHMARK MOT17 --SPLIT_TO_EVAL train --TRACKERS_TO_EVAL MPNTrack --METRICS HOTA CLEAR Identity VACE --USE_PARALLEL False --NUM_PARALLEL_CORES 1
```
## Data Format
<p>
The tracker file format should be the same as the ground truth file,
which is a CSV text-file containing one object instance per line.
Each line must contain 10 values:
</p>
</p>
<code>
<frame>,
<id>,
<bb_left>,
<bb_top>,
<bb_width>,
<bb_height>,
<conf>,
<x>,
<y>,
<z>
</code>
</p>
The world coordinates <code>x,y,z</code>
are ignored for the 2D challenge and can be filled with -1.
Similarly, the bounding boxes are ignored for the 3D challenge.
However, each line is still required to contain 10 values.
All frame numbers, target IDs and bounding boxes are 1-based. Here is an example:
<pre>
1, 3, 794.27, 247.59, 71.245, 174.88, -1, -1, -1, -1
1, 6, 1648.1, 119.61, 66.504, 163.24, -1, -1, -1, -1
1, 8, 875.49, 399.98, 95.303, 233.93, -1, -1, -1, -1
...
</pre>
## Evaluating on your own Data
The repository also allows you to include your own datasets and evaluate your method on your own challenge ```<YourChallenge>```. To do so, follow these two steps:
***1. Ground truth data preparation***
Prepare your sequences in directory ```TrackEval/data/gt/mot_challenge/<YourChallenge>``` following this structure:
```
.
|—— <SeqName01>
|—— gt
|—— gt.txt
|—— seqinfo.ini
|—— <SeqName02>
|—— ……
|—— <SeqName03>
|—— …...
```
***2. Sequence file***
Create text files containing the sequence names; ```<YourChallenge>-train.txt```, ```<YourChallenge>-test.txt```, ```<YourChallenge>-test.txt``` inside the ```seqmaps``` folder, e.g.:
```<YourChallenge>-all.txt```
```
name
<seqName1>
<seqName2>
<seqName3>
```
```<YourChallenge>-train.txt```
```
name
<seqName1>
<seqName2>
```
```<YourChallenge>-test.txt```
```
name
<seqName3>
```
To run the evaluation for your method adjust the file ```scripts/run_mot_challenge.py``` and set ```BENCHMARK = <YourChallenge>```
## Citation
If you work with the code and the benchmark, please cite:
***TrackEval***
```
@misc{luiten2020trackeval,
author = {Jonathon Luiten, Arne Hoffhues},
title = {TrackEval},
howpublished = {\url{https://github.com/JonathonLuiten/TrackEval}},
year = {2020}
}
```
***MOTChallenge Journal***
```
@article{dendorfer2020motchallenge,
title={MOTChallenge: A Benchmark for Single-camera Multiple Target Tracking},
author={Dendorfer, Patrick and Osep, Aljosa and Milan, Anton and Schindler, Konrad and Cremers, Daniel and Reid, Ian and Roth, Stefan and Leal-Taix{\'e}, Laura},
journal={International Journal of Computer Vision},
pages={1--37},
year={2020},
publisher={Springer}
}
```
***MOT 15***
```
@article{MOTChallenge2015,
title = {{MOTC}hallenge 2015: {T}owards a Benchmark for Multi-Target Tracking},
shorttitle = {MOTChallenge 2015},
url = {http://arxiv.org/abs/1504.01942},
journal = {arXiv:1504.01942 [cs]},
author = {Leal-Taix\'{e}, L. and Milan, A. and Reid, I. and Roth, S. and Schindler, K.},
month = apr,
year = {2015},
note = {arXiv: 1504.01942},
keywords = {Computer Science - Computer Vision and Pattern Recognition}
}
```
***MOT 16, MOT 17***
```
@article{MOT16,
title = {{MOT}16: {A} Benchmark for Multi-Object Tracking},
shorttitle = {MOT16},
url = {http://arxiv.org/abs/1603.00831},
journal = {arXiv:1603.00831 [cs]},
author = {Milan, A. and Leal-Taix\'{e}, L. and Reid, I. and Roth, S. and Schindler, K.},
month = mar,
year = {2016},
note = {arXiv: 1603.00831},
keywords = {Computer Science - Computer Vision and Pattern Recognition}
}
```
***MOT 20***
```
@article{MOTChallenge20,
title={MOT20: A benchmark for multi object tracking in crowded scenes},
shorttitle = {MOT20},
url = {http://arxiv.org/abs/1906.04567},
journal = {arXiv:2003.09003[cs]},
author = {Dendorfer, P. and Rezatofighi, H. and Milan, A. and Shi, J. and Cremers, D. and Reid, I. and Roth, S. and Schindler, K. and Leal-Taix\'{e}, L. },
month = mar,
year = {2020},
note = {arXiv: 2003.09003},
keywords = {Computer Science - Computer Vision and Pattern Recognition}
}
```
***HOTA metrics***
```
@article{luiten2020IJCV,
title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
journal={International Journal of Computer Vision},
pages={1--31},
year={2020},
publisher={Springer}
}
```
## Feedback and Contact
We are constantly working on improving our benchmark to provide the best performance to the community.
You can help us to make the benchmark better by open issues in the repo and reporting bugs.
For general questions, please contact one of the following:
```
Patrick Dendorfer - patrick.dendorfer@tum.de
Jonathon Luiten - luiten@vision.rwth-aachen.de
Aljosa Osep - aljosa.osep@tum.de
```
|