.py```.
+ - It's probably easiest to start by copying an existing metrics code and editing it, e.g. ```trackeval/metrics/identity.py``` is probably the simplest.
+ - Your metric should be class, and it should inherit from the ```trackeval.metrics._base_metric._BaseMetric``` class.
+ - Define an ```__init__``` function that defines the different ```fields``` (values) that your metric will calculate. See ```trackeval/metrics/_base_metric.py``` for a list of currently used field types. Feel free to add new types.
+ - Define your code to actually calculate your metric for a single sequence and single class in a function called ```eval_sequence```, which takes a data dictionary as input, and returns a results dictionary as output.
+ - Define functions for how to combine your metric field values over a) sequences ```combine_sequences```, b) over classes ```combine_classes_class_averaged```, and c) over classes weighted by the number of detections ```combine_classes_det_averaged```.
+ - We find using a function such as the ```_compute_final_fields``` function that we use in the current metrics is convienient because it is likely used for metrics calculation and for the different metric combination, however this is not required.
+ - Register your new metric by adding it to ```trackeval/metrics/init.py```
+ - Your new metric can be used by passing the metrics class to a list of metrics which is passed to the evaluator (see files in ```scripts/*```).
diff --git a/val_utils/docs/KITTI-format.txt b/val_utils/docs/KITTI-format.txt
new file mode 100644
index 0000000000000000000000000000000000000000..bfe6d6368a57cdefd6d326a3b35b8bc4e982895a
--- /dev/null
+++ b/val_utils/docs/KITTI-format.txt
@@ -0,0 +1,160 @@
+Taken from download link found at: http://www.cvlibs.net/datasets/kitti/eval_tracking.php
+
+###########################################################################
+# THE KITTI VISION BENCHMARK SUITE: TRACKING BENCHMARK #
+# Andreas Geiger Philip Lenz Raquel Urtasun #
+# Karlsruhe Institute of Technology #
+# Toyota Technological Institute at Chicago #
+# www.cvlibs.net #
+###########################################################################
+
+For recent updates see http://www.cvlibs.net/datasets/kitti/eval_tracking.php.
+
+This file describes the KITTI tracking benchmarks, consisting of 21
+training sequences and 29 test sequences.
+
+Despite the fact that we have labeled 8 different classes, only the classes
+'Car' and 'Pedestrian' are evaluated in our benchmark, as only for those
+classes enough instances for a comprehensive evaluation have been labeled.
+
+The labeling process has been performed in two steps: First we hired a set
+of annotators, to label 3D bounding boxes for tracklets in 3D Velodyne
+point clouds. Since for a pedestrian tracklet, a single 3D bounding box
+tracklet (dimensions have been fixed) often fits badly, we additionally
+labeled the left/right boundaries of each object by making use of Mechanical
+Turk. We also collected labels of the object's occlusion state, and computed
+the object's truncation via backprojecting a car/pedestrian model into the
+image plane.
+
+NOTE: WHEN SUBMITTING RESULTS, PLEASE STORE THEM IN THE SAME DATA FORMAT IN
+WHICH THE GROUND TRUTH DATA IS PROVIDED (SEE BELOW), USING THE FILE NAMES
+0000.txt 0001.txt ... CREATE A ZIP ARCHIVE OF THEM AND STORE YOUR
+RESULTS (ONLY THE RESULTS OF THE TEST SET) IN ITS ROOT FOLDER. FOR A
+RE-SUBMISSION, _ONLY_ THE RE-SUBMITTED RESULTS WILL BE SHOWN IN THE TABLE.
+
+Data Format Description
+=======================
+
+The data for training and testing can be found in the corresponding folders.
+The sub-folders are structured as follows:
+
+ - image_02/%04d/ contains the left color camera sequence images (png)
+ - image_03/%04d/ contains the right color camera sequence images (png)
+ - label_02/ contains the left color camera label files (plain text files)
+ - calib/ contains the calibration for all four cameras (plain text files)
+
+The label files contain the following information.
+All values (numerical or strings) are separated via spaces, each row
+corresponds to one object. The 17 columns represent:
+
+#Values Name Description
+----------------------------------------------------------------------------
+ 1 frame Frame within the sequence where the object appearers
+ 1 track id Unique tracking id of this object within this sequence
+ 1 type Describes the type of object: 'Car', 'Van', 'Truck',
+ 'Pedestrian', 'Person_sitting', 'Cyclist', 'Tram',
+ 'Misc' or 'DontCare'
+ 1 truncated Integer (0,1,2) indicating the level of truncation.
+ Note that this is in contrast to the object detection
+ benchmark where truncation is a float in [0,1].
+ 1 occluded Integer (0,1,2,3) indicating occlusion state:
+ 0 = fully visible, 1 = partly occluded
+ 2 = largely occluded, 3 = unknown
+ 1 alpha Observation angle of object, ranging [-pi..pi]
+ 4 bbox 2D bounding box of object in the image (0-based index):
+ contains left, top, right, bottom pixel coordinates
+ 3 dimensions 3D object dimensions: height, width, length (in meters)
+ 3 location 3D object location x,y,z in camera coordinates (in meters)
+ 1 rotation_y Rotation ry around Y-axis in camera coordinates [-pi..pi]
+ 1 score Only for results: Float, indicating confidence in
+ detection, needed for p/r curves, higher is better.
+
+
+Here, 'DontCare' labels denote regions in which objects have not been labeled,
+for example because they have been too far away from the laser scanner. To
+prevent such objects from being counted as false positives our evaluation
+script will ignore objects tracked in don't care regions of the test set.
+You can use the don't care labels in the training set to avoid that your object
+detector/tracking algorithm is harvesting hard negatives from those areas,
+in case you consider non-object regions from the training images as negative
+examples.
+
+The reference point for the 3D bounding box for each object is centered on the
+bottom face of the box. The corners of bounding box are computed as follows with
+respect to the reference point and in the object coordinate system:
+x_corners = [l/2, l/2, -l/2, -l/2, l/2, l/2, -l/2, -l/2]^T
+y_corners = [0, 0, 0, 0, -h, -h, -h, -h ]^T
+z_corners = [w/2, -w/2, -w/2, w/2, w/2, -w/2, -w/2, w/2 ]^T
+with l=length, h=height, and w=width.
+
+The coordinates in the camera coordinate system can be projected in the image
+by using the 3x4 projection matrix in the calib folder, where for the left
+color camera for which the images are provided, P2 must be used. The
+difference between rotation_y and alpha is, that rotation_y is directly
+given in camera coordinates, while alpha also considers the vector from the
+camera center to the object center, to compute the relative orientation of
+the object with respect to the camera. For example, a car which is facing
+along the X-axis of the camera coordinate system corresponds to rotation_y=0,
+no matter where it is located in the X/Z plane (bird's eye view), while
+alpha is zero only, when this object is located along the Z-axis of the
+camera. When moving the car away from the Z-axis, the observation angle
+(\alpha) will change.
+
+An overview of the coordinate systems, reference point and geometrical
+definitions is given in cs_overview.pdf.
+
+To project a point from Velodyne coordinates into the left color image,
+you can use this formula: x = P2 * R0_rect * Tr_velo_to_cam * y
+For the right color image: x = P3 * R0_rect * Tr_velo_to_cam * y
+
+Note: All matrices are stored row-major, i.e., the first values correspond
+to the first row. R0_rect contains a 3x3 matrix which you need to extend to
+a 4x4 matrix by adding a 1 as the bottom-right element and 0's elsewhere.
+Tr_xxx is a 3x4 matrix (R|t), which you need to extend to a 4x4 matrix
+in the same way!
+
+The sensors were not moved between the different days while taking footage.
+However, the full camera calibration was performed for every day separately.
+Therefore, only 'Tr_imu_velo' is constant for all sequences.
+
+Note that while all this information is available for the training data,
+only the data which is actually needed for the particular benchmark must
+be provided to the evaluation server. However, all 17 values must be provided
+at all times, with the unused ones set to their default values (=invalid).
+Additionally a 18'th value must be provided
+with a floating value of the score for a particular tracked detection, where
+higher indicates higher confidence in the detection. The range of your scores
+will be automatically determined by our evaluation server, you don't have to
+normalize it, but it should be roughly linear.
+
+Tracking Benchmark
+==================
+
+The goal in the object tracking task is to estimate object tracklets for the
+classes 'Car', 'Pedestrian', and (optional) 'Cyclist'. The tracking
+algorithm must provide as output the 2D 0-based bounding boxes in each image in
+the sequence using the format specified above, as well as a score, indicating
+the confidence in the particular frame for this track. All other values must be
+set to their default values (=invalid), see above. One text file per sequence
+must be provided in a zip archive, where each file can contain many detections,
+depending on the number of objects per sequence. In our evaluation we only
+evaluate detections/objects larger than 25 pixel (height) in the image and do
+not count Vans as false positives for cars or Sitting Persons as wrong positives
+for Pedestrians due to their similarity in appearance. (All ignored objects
+are considered as DontCare areas.) As evaluation criterion we follow the
+HOTA, CLEARMOT and Mostly-Tracked/Partly-Tracked/Mostly-Lost metrics.
+
+Raw Data
+========
+
+Raw data is mapped to the tracking benchmark sequences and available for
+download.
+
+The velodyne and positioning data for training and testing can be found in the
+corresponding folders. The sub-folders are structured as follows:
+
+ - velodyne/%04d/ contains the raw velodyne point clouds (binary file)
+ - oxts/ contains the raw position (oxts) data (plain text files)
+
+
+
diff --git a/val_utils/docs/MOTChallenge-Official/Readme.md b/val_utils/docs/MOTChallenge-Official/Readme.md
new file mode 100644
index 0000000000000000000000000000000000000000..502b504ac16e7a31c56f721675ad206d4b0e53c2
--- /dev/null
+++ b/val_utils/docs/MOTChallenge-Official/Readme.md
@@ -0,0 +1,221 @@
+
+
+# MOTChallenge Official Evaluation Kit - Multi-Object Tracking - MOT15, MOT16, MOT17, MOT20
+
+TrackEval is now the Official Evaluation Kit for MOTChallenge.
+
+This repository contains the evaluation scripts for the MOT challenges available at www.MOTChallenge.net.
+
+This codebase replaces the previous version that used to be accessible at https://github.com/dendorferpatrick/MOTChallengeEvalKit and is no longer maintained.
+
+Challenge Name | Data url |
+|----- | ----------- |
+|2D MOT 15| https://motchallenge.net/data/MOT15/ |
+|MOT 16| https://motchallenge.net/data/MOT16/ |
+|MOT 17| https://motchallenge.net/data/MOT17/ |
+|MOT 20| https://motchallenge.net/data/MOT20/ |
+
+## Requirements
+* Python (3.5 or newer)
+* Numpy and Scipy
+
+## Directories and Data
+The easiest way to get started is to simply download the TrackEval example data from here: [data.zip](https://omnomnom.vision.rwth-aachen.de/data/TrackEval/data.zip) (~150mb).
+
+This contains all the ground-truth, example trackers and meta-data that you will need.
+
+Extract this zip into the repository root folder such that the file paths look like: TrackEval/data/gt/...
+
+## Evaluation
+To run the evaluation for your method please run the script at ```TrackEval/scripts/run_mot_challenge.py```.
+
+Some of the basic arguments are described below. For more arguments, please see the script itself.
+
+```BENCHMARK```: Name of the benchmark, e.g. MOT15, MO16, MOT17 or MOT20 (default : MOT17)
+
+```SPLIT_TO_EVAL```: Data split on which to evalute e.g. train, test (default : train)
+
+```TRACKERS_TO_EVAL```: List of tracker names for which you wish to run evaluation. e.g. MPNTrack (default: all trackers in tracker folder)
+
+```METRICS```: List of metric families which you wish to compute. e.g. HOTA CLEAR Identity VACE (default: HOTA CLEAR Identity)
+
+```USE_PARALLEL```: Whether to run evaluation in parallel on multiple cores. (default: False)
+
+```NUM_PARALLEL_CORES```: Number of cores to use when running in parallel. (default: 8)
+
+An example is below (this will work on the supplied example data above):
+```
+python scripts/run_mot_challenge.py --BENCHMARK MOT17 --SPLIT_TO_EVAL train --TRACKERS_TO_EVAL MPNTrack --METRICS HOTA CLEAR Identity VACE --USE_PARALLEL False --NUM_PARALLEL_CORES 1
+```
+
+
+## Data Format
+
+The tracker file format should be the same as the ground truth file,
+which is a CSV text-file containing one object instance per line.
+Each line must contain 10 values:
+
+
+
+
+<frame>,
+<id>,
+<bb_left>,
+<bb_top>,
+<bb_width>,
+<bb_height>,
+<conf>,
+<x>,
+<y>,
+<z>
+
+
+
+The world coordinates x,y,z
+are ignored for the 2D challenge and can be filled with -1.
+Similarly, the bounding boxes are ignored for the 3D challenge.
+However, each line is still required to contain 10 values.
+
+All frame numbers, target IDs and bounding boxes are 1-based. Here is an example:
+
+
+1, 3, 794.27, 247.59, 71.245, 174.88, -1, -1, -1, -1
+1, 6, 1648.1, 119.61, 66.504, 163.24, -1, -1, -1, -1
+1, 8, 875.49, 399.98, 95.303, 233.93, -1, -1, -1, -1
+...
+
+
+
+## Evaluating on your own Data
+The repository also allows you to include your own datasets and evaluate your method on your own challenge ``````. To do so, follow these two steps:
+***1. Ground truth data preparation***
+Prepare your sequences in directory ```TrackEval/data/gt/mot_challenge/``` following this structure:
+
+```
+.
+|——
+ |—— gt
+ |—— gt.txt
+ |—— seqinfo.ini
+|——
+ |—— ……
+|——
+ |—— …...
+```
+
+***2. Sequence file***
+Create text files containing the sequence names; ```-train.txt```, ```-test.txt```, ```-test.txt``` inside the ```seqmaps``` folder, e.g.:
+```-all.txt```
+```
+name
+
+
+
+```
+
+```-train.txt```
+```
+name
+
+
+```
+
+```-test.txt```
+```
+name
+
+```
+
+
+To run the evaluation for your method adjust the file ```scripts/run_mot_challenge.py``` and set ```BENCHMARK = ```
+
+
+## Citation
+If you work with the code and the benchmark, please cite:
+
+***TrackEval***
+```
+@misc{luiten2020trackeval,
+ author = {Jonathon Luiten, Arne Hoffhues},
+ title = {TrackEval},
+ howpublished = {\url{https://github.com/JonathonLuiten/TrackEval}},
+ year = {2020}
+}
+```
+***MOTChallenge Journal***
+```
+@article{dendorfer2020motchallenge,
+ title={MOTChallenge: A Benchmark for Single-camera Multiple Target Tracking},
+ author={Dendorfer, Patrick and Osep, Aljosa and Milan, Anton and Schindler, Konrad and Cremers, Daniel and Reid, Ian and Roth, Stefan and Leal-Taix{\'e}, Laura},
+ journal={International Journal of Computer Vision},
+ pages={1--37},
+ year={2020},
+ publisher={Springer}
+}
+```
+***MOT 15***
+```
+@article{MOTChallenge2015,
+ title = {{MOTC}hallenge 2015: {T}owards a Benchmark for Multi-Target Tracking},
+ shorttitle = {MOTChallenge 2015},
+ url = {http://arxiv.org/abs/1504.01942},
+ journal = {arXiv:1504.01942 [cs]},
+ author = {Leal-Taix\'{e}, L. and Milan, A. and Reid, I. and Roth, S. and Schindler, K.},
+ month = apr,
+ year = {2015},
+ note = {arXiv: 1504.01942},
+ keywords = {Computer Science - Computer Vision and Pattern Recognition}
+}
+```
+***MOT 16, MOT 17***
+```
+@article{MOT16,
+ title = {{MOT}16: {A} Benchmark for Multi-Object Tracking},
+ shorttitle = {MOT16},
+ url = {http://arxiv.org/abs/1603.00831},
+ journal = {arXiv:1603.00831 [cs]},
+ author = {Milan, A. and Leal-Taix\'{e}, L. and Reid, I. and Roth, S. and Schindler, K.},
+ month = mar,
+ year = {2016},
+ note = {arXiv: 1603.00831},
+ keywords = {Computer Science - Computer Vision and Pattern Recognition}
+}
+```
+***MOT 20***
+```
+@article{MOTChallenge20,
+ title={MOT20: A benchmark for multi object tracking in crowded scenes},
+ shorttitle = {MOT20},
+ url = {http://arxiv.org/abs/1906.04567},
+ journal = {arXiv:2003.09003[cs]},
+ author = {Dendorfer, P. and Rezatofighi, H. and Milan, A. and Shi, J. and Cremers, D. and Reid, I. and Roth, S. and Schindler, K. and Leal-Taix\'{e}, L. },
+ month = mar,
+ year = {2020},
+ note = {arXiv: 2003.09003},
+ keywords = {Computer Science - Computer Vision and Pattern Recognition}
+}
+```
+***HOTA metrics***
+```
+@article{luiten2020IJCV,
+ title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
+ author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
+ journal={International Journal of Computer Vision},
+ pages={1--31},
+ year={2020},
+ publisher={Springer}
+}
+```
+
+## Feedback and Contact
+We are constantly working on improving our benchmark to provide the best performance to the community.
+You can help us to make the benchmark better by open issues in the repo and reporting bugs.
+
+For general questions, please contact one of the following:
+
+```
+Patrick Dendorfer - patrick.dendorfer@tum.de
+Jonathon Luiten - luiten@vision.rwth-aachen.de
+Aljosa Osep - aljosa.osep@tum.de
+```
+
diff --git a/val_utils/docs/MOTChallenge-format.txt b/val_utils/docs/MOTChallenge-format.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5a49c72aaafa242b4b900466b5ec994278671518
--- /dev/null
+++ b/val_utils/docs/MOTChallenge-format.txt
@@ -0,0 +1,37 @@
+Taken from: https://motchallenge.net/instructions/
+
+File Format
+
+Please submit your results as a single .zip file. The results for each sequence must be stored in a separate .txt file in the archive's root folder. The file name must be exactly like the sequence name (case sensitive).
+
+The file format should be the same as the ground truth file, which is a CSV text-file containing one object instance per line. Each line must contain 10 values:
+
+, , , , , , , , ,
+The conf value contains the detection confidence in the det.txt files. For the ground truth, it acts as a flag whether the entry is to be considered. A value of 0 means that this particular instance is ignored in the evaluation, while any other value can be used to mark it as active. For submitted results, all lines in the .txt file are considered. The world coordinates x,y,z are ignored for the 2D challenge and can be filled with -1. Similarly, the bounding boxes are ignored for the 3D challenge. However, each line is still required to contain 10 values.
+
+All frame numbers, target IDs and bounding boxes are 1-based. Here is an example:
+
+Tracking with bounding boxes
+(MOT15, MOT16, MOT17, MOT20)
+ 1, 3, 794.27, 247.59, 71.245, 174.88, -1, -1, -1, -1
+ 1, 6, 1648.1, 119.61, 66.504, 163.24, -1, -1, -1, -1
+ 1, 8, 875.49, 399.98, 95.303, 233.93, -1, -1, -1, -1
+ ...
+
+Multi Object Tracking & Segmentation
+(MOTS Challenge)
+Each line of an annotation txt file is structured like this (where rle means run-length encoding from COCO):
+
+time_frame id class_id img_height img_width rle
+An example line from a txt file:
+
+52 1005 1 375 1242 WSV:2d;1O10000O10000O1O100O100O1O100O1000000000000000O100O102N5K00O1O1N2O110OO2O001O1NTga3
+Meaning:
+time frame 52
+object id 1005 (meaning class id is 1, i.e. car and instance id is 5)
+class id 1
+image height 375
+image width 1242
+rle WSV:2d;1O10000O10000O1O100O100O1O100O1000000000000000O100O...1O1N
+
+image height, image width, and rle can be used together to decode a mask using cocotools(https://github.com/cocodataset/cocoapi) .
\ No newline at end of file
diff --git a/val_utils/docs/MOTS-format.txt b/val_utils/docs/MOTS-format.txt
new file mode 100644
index 0000000000000000000000000000000000000000..49244443beded2c4b62e34d8d13dd85d5e222bb3
--- /dev/null
+++ b/val_utils/docs/MOTS-format.txt
@@ -0,0 +1,45 @@
+Taken from: https://www.vision.rwth-aachen.de/page/mots
+
+
+Annotation Format
+We provide two alternative and equivalent formats, one encoded as png images, and one encoded as txt files. The txt files are smaller, and faster to be read in, but the cocotools are needed to decode the masks. For code to read the annotations also see mots_tools/blob/master/mots_common/io.py
+
+Note that in both formats an id value of 10,000 denotes an ignore region and 0 is background. The class id can be obtained by floor divison of the object id by 1000 (class_id = obj_id // 1000) and the instance id can be obtained by the object id modulo 1000 (instance_id = obj_id % 1000). The object ids are consistent over time.
+
+The class ids are the following
+
+car 1
+pedestrian 2
+png format
+The png format has a single color channel with 16 bits and can for example be read like this:
+
+import PIL.Image as Image
+img = np.array(Image.open("000005.png"))
+obj_ids = np.unique(img)
+# to correctly interpret the id of a single object
+obj_id = obj_ids[0]
+class_id = obj_id // 1000
+obj_instance_id = obj_id % 1000
+When using a TensorFlow input pipeline for reading the annotations, you can use
+
+ann_data = tf.read_file(ann_filename)
+ann = tf.image.decode_image(ann_data, dtype=tf.uint16, channels=1)
+
+
+txt format
+Each line of an annotation txt file is structured like this (where rle means run-length encoding from COCO):
+
+time_frame id class_id img_height img_width rle
+An example line from a txt file:
+
+52 1005 1 375 1242 WSV:2d;1O10000O10000O1O100O100O1O100O1000000000000000O100O102N5K00O1O1N2O110OO2O001O1NTga3
+Which means
+
+time frame 52
+object id 1005 (meaning class id is 1, i.e. car and instance id is 5)
+class id 1
+image height 375
+image width 1242
+rle WSV:2d;1O10000O10000O1O100O100O1O100O1000000000000000O100O...1O1N
+
+image height, image width, and rle can be used together to decode a mask using cocotools.
\ No newline at end of file
diff --git a/val_utils/docs/OpenWorldTracking-Official/Readme.md b/val_utils/docs/OpenWorldTracking-Official/Readme.md
new file mode 100644
index 0000000000000000000000000000000000000000..30588c28576ea02cc71b40863884ccf717243d8b
--- /dev/null
+++ b/val_utils/docs/OpenWorldTracking-Official/Readme.md
@@ -0,0 +1,49 @@
+
+# Opening Up Open-World Tracking - Official Evaluation Code
+
+TrackEval now contains the official evalution code for evaluating the task of **Open World Tracking**.
+
+This is the official code from the following paper:
+
+Opening up Open-World Tracking
+Yang Liu*, Idil Esen Zulfikar*, Jonathon Luiten*, Achal Dave*, Deva Ramanan, Bastian Leibe, Aljoša Ošep, Laura Leal-Taixé
+*Equal contribution
+CVPR 2022
+
+[Paper](https://arxiv.org/abs/2104.11221)
+
+[Website](https://openworldtracking.github.io)
+
+## Running and understanding the code
+
+The code can be run by running the following script (see script for arguments and how to run):
+[TAO-OW run script](https://github.com/JonathonLuiten/TrackEval/blob/master/scripts/run_tao_ow.py)
+
+To understand the the data is being read and used, see the TAO-OW dataset class:
+[TAO-OW dataset class](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/datasets/tao_ow.py)
+
+The implementation of the 'Open World Tracking Accuracy' (OWTA) metric proposed in the paper can be found here:
+[OWTA metric](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/metrics/hota.py)
+
+## Citation
+If you work with the code and the benchmark, please cite:
+
+***Opening Up Open-World Tracking***
+```
+@inproceedings{liu2022opening,
+ title={Opening up Open-World Tracking},
+ author={Liu, Yang and Zulfikar, Idil Esen and Luiten, Jonathon and Dave, Achal and Ramanan, Deva and Leibe, Bastian and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura},
+ journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ year={2022}
+}
+```
+
+***TrackEval***
+```
+@misc{luiten2020trackeval,
+ author = {Jonathon Luiten, Arne Hoffhues},
+ title = {TrackEval},
+ howpublished = {\url{https://github.com/JonathonLuiten/TrackEval}},
+ year = {2020}
+}
+```
diff --git a/val_utils/docs/RobMOTS-Official/Readme.md b/val_utils/docs/RobMOTS-Official/Readme.md
new file mode 100644
index 0000000000000000000000000000000000000000..4cb225604d0fad600534d833f420757034f460ad
--- /dev/null
+++ b/val_utils/docs/RobMOTS-Official/Readme.md
@@ -0,0 +1,240 @@
+[](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110)
+
+# RobMOTS Official Evaluation Code
+
+### NEWS: [RobMOTS Challenge](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110) for the [RVSU CVPR'21 Workshop](https://eval.vision.rwth-aachen.de/rvsu-workshop21/) is now live!!!! Challenge deadline June 15.
+
+### NEWS: [Call for short papers](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=74) (4 pages) on tracking and other video topics for [RVSU CVPR'21 Workshop](https://eval.vision.rwth-aachen.de/rvsu-workshop21/)!!!! Paper deadline June 4.
+
+TrackEval is now the Official Evaluation Kit for the RobMOTS Challenge.
+
+This repository contains the official evaluation code for the challenges available at the [RobMOTS Website](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110).
+
+The RobMOTS Challenge tests trackers' ability to work robustly across 8 different benchmarks, while tracking the [80 categories of objects from COCO](https://cocodataset.org/#explore).
+
+The following benchmarks are included:
+
+Benchmark | Website |
+|----- | ----------- |
+|MOTS Challenge| https://motchallenge.net/results/MOTS/ |
+|KITTI-MOTS| http://www.cvlibs.net/datasets/kitti/eval_mots.php |
+|DAVIS Challenge Unsupervised| https://davischallenge.org/challenge2020/unsupervised.html |
+|YouTube-VIS| https://youtube-vos.org/dataset/vis/ |
+|BDD100k MOTS| https://bdd-data.berkeley.edu/ |
+|TAO| https://taodataset.org/ |
+|Waymo Open Dataset| https://waymo.com/open/ |
+|OVIS| http://songbai.site/ovis/ |
+
+## Installing, obtaining the data, and running
+
+Simply follow the code snippet below to install the evaluation code, download the train groundtruth data and an example tracker, and run the evaluation code on the sample tracker.
+
+Note the code requires python 3.5 or higher.
+
+```
+# Download the TrackEval repo
+git clone https://github.com/JonathonLuiten/TrackEval.git
+
+# Move to repo folder
+cd TrackEval
+
+# Create a virtual env in the repo for evaluation
+python3 -m venv ./venv
+
+# Activate the virtual env
+source venv/bin/activate
+
+# Update pip to have the latest version of packages
+pip install --upgrade pip
+
+# Install the required packages
+pip install -r requirements.txt
+
+# Download the train gt data
+wget https://omnomnom.vision.rwth-aachen.de/data/RobMOTS/train_gt.zip
+
+# Unzip the train gt data you just downloaded.
+unzip train_gt.zip
+
+# Download the example tracker
+wget https://omnomnom.vision.rwth-aachen.de/data/RobMOTS/example_tracker.zip
+
+# Unzip the example tracker you just downloaded.
+unzip example_tracker.zip
+
+# Run the evaluation on the provided example tracker on the train split (using 4 cores in parallel)
+python scripts/run_rob_mots.py --ROBMOTS_SPLIT train --TRACKERS_TO_EVAL STP --USE_PARALLEL True --NUM_PARALLEL_CORES 4
+
+```
+
+You may further download the raw sequence images and supplied detections (as well as train GT data and example tracker) by following the ```Data Download``` link here:
+
+[RobMOTS Challenge Info](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110)
+
+## Accessing tracking evaluation results
+
+You will find the results of the evaluation (for the supplied tracker STP) in the folder ```TrackEval/data/trackers/rob_mots/train/STP/```.
+The overall summary of the results is in ```./final_results.csv```, and more detailed results per sequence and per class and results plots can be found under ```./results/*```.
+
+The ```final_results.csv``` can be most easily read by opening it in Excel or similar. The ```c```, ```d``` and ```f``` prepending the metric names refer respectively to ```class averaged```, ```detection averaged (class agnostic)``` and ```final``` (the geometric mean of class and detection averaged).
+
+## Supplied Detections
+
+To make creating your own tracker particularly easy, we supply a set of strong supplied detection.
+
+These detections are from the Detectron 2 Mask R-CNN X152 (very bottom model on this [page](https://github.com/facebookresearch/detectron2/blob/master/MODEL_ZOO.md) which achieves a COCO detection mAP score of 50.2).
+
+We then obtain segmentation masks for these detections using the Box2Seg Network (also called Refinement Net), which results in far more accurate masks than the default Mask R-CNN masks. The code for this can be found [here](https://github.com/JonathonLuiten/PReMVOS/tree/master/code/refinement_net).
+
+We supply two different supplied detections. The first is the ```raw_supplied``` detections, which is taking all 1000 detections output from the Mask R-CNN, and only removing those for which the maximum class score is less than 0.02 (here no non-maximum suppression, NMS, is run). These can be downloaded [here](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110).
+
+The second is ```non_overlap_supplied``` detections. These are the same detections as above, but with further processing steps applied to them. First we perform Non-Maximum Suppression (NMS) with a threshold of 0.5 to remove any masks which have an IoU of 0.5 or more with any other mask that has a higher score. Second we run a Non-Overlap algorithm which forces all of the masks for a single image to be non-overlapping. It does this by putting all the masks 'on top of' each other, ordered by score, such that masks with a lower score will be partially removed if a mask with a higher score partially overlaps them. Note that these detections are still only thresholded at a score of 0.02, in general we recommend further thresholding with a higher value to get a good balance of precision and recall.
+
+Code for this NMS and Non-Overlap algorithm can be found here:
+[Non-Overlap Code](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/baselines/non_overlap.py).
+
+Note that for RobMOTS evaluation the final tracking results need to be 'non-overlapping' so we recommend using the ```non_overlap_supplied``` detections, however you may use the ```raw_supplied```, or your own or any other detections as you like.
+
+Supplied detections (both raw and non-overlapping) are available for the train, val and test sets.
+
+Example code for reading in these detections and using them can be found here:
+
+[Tracker Example](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/baselines/stp.py).
+
+## Creating your own tracker
+
+We provide sample code ([Tracker Example](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/baselines/stp.py)) for our STP tracker (Simplest Tracker Possible) which walks though how to create tracking results in the required RobMOTS format.
+
+This includes code for reading in the supplied detections and writing out the tracking results in the desired format, plus many other useful functions (IoU calculation etc).
+
+## Evaluating your own tracker
+
+To evaluate your tracker, put the results in the folder ```TrackEval/data/trackers/rob_mots/train/```, in a folder alongside the supplied tracker STP with the folder labelled as your tracker name, e.g. YOUR_TRACKER.
+
+You can then run the evaluation code on your tracker like this:
+
+```
+python scripts/run_rob_mots.py --ROBMOTS_SPLIT train --TRACKERS_TO_EVAL YOUR_TRACKER --USE_PARALLEL True --NUM_PARALLEL_CORES 4
+```
+
+## Data format
+
+For RobMOTS, trackers must submit their results in the following folder format:
+
+```
+|——
+ |—— .txt
+ |—— .txt
+ |—— .txt
+|——
+ |—— .txt
+ |—— .txt
+ |—— .txt
+```
+
+See the supplied STP tracker results (in the Train Data linked above) for an example.
+
+Thus there is one .txt file for each sequence. This file has one row per detection (object mask in one frame). Each row must have 7 values and has the following format:
+
+
+
+<Timestep>(int),
+<Track ID>(int),
+<Class Number>(int),
+<Detection Confidence>(float),
+<Image Height>(int),
+<Image Width>(int),
+<Compressed RLE Mask>(string),
+
+
+
+Timesteps are the same as the frame names for the supplied images. These start at 0.
+
+Track IDs must be unique across all classes within a frame. They can be non-unique across different sequences.
+
+The mapping of class numbers to class names can be found is [this file](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/datasets/rob_mots_classmap.py). Note that this is the same as used in Detectron 2, and is the default COCO class ordering with the unused numbers removed.
+
+Detection Confidence score should be between 0 and 1. This is not used for HOTA evaluation, but is used for other eval metrics like Track mAP.
+
+Image height and width are needed to decode the compressed RLE mask representation.
+
+The Compressed RLE Mask is the same format used by coco, pycocotools and mots.
+
+An example of a tracker result file looks like this:
+
+```
+0 1 3 0.9917707443237305 1200 1920 VaTi0b0lT17F8K3M3N1O1N2O0O2M3N2N101O1O1O01O1O0100O100O01O1O100O10O1000O1000000000000000O1000001O0000000000000000O101O00000000000001O0000010O0110O0O100O1O2N1O2N0O2O2M3M2N2O1O2N5J;DgePZ1
+0 2 3 0.989478349685669 1200 1920 Ql^c05ZU12O2N001O0O10OTkNIaT17^kNKaT15^kNLbT14^kNMaT13^kNOaT11_kN0`T10_kN1`T11_kN0`T11_kN0`T1a0O00001O1O1O3M;E5K3M2N000000000O100000000000000000001O00001O2N1O1O1O000001O001O0O2O0O2M3M3M3N2O1O1O1N2O002N1O2N10O02N10000O1O101M3N2N2M7H^_g_1
+1 2 3 0.964085042476654 1200 1920 o_Uc03\U12O1O1N102N002N001O1O000O2O1O00002N6J1O001O2N1O3L3N2N4L5K2N1O000000000000001O1O2N01O01O010O01N2O0O2O1M4L3N2N101N2O001O1O100O0100000O1O1O1O2N6I4Mdm^`1
+```
+
+Note that for the evaluation to be valid, the masks must not overlap within one frame.
+
+The supplied detections have the same format (but with all the Track IDs being set to 0).
+
+The groundtruth data for most benchmarks is in the exact same format as above (usually Detection Confidence is set to 1.0). The exception is the few benchmarks for which the ground-truth is not segmentation masks but bounding boxes (Waymo and TAO). For these the last three columns are not there (height, width and mask) as these encode a mask, and instead there are 4 columns encoding the bounding box co-ordinates in the format ```x0 y0 x1 y1```, where x0 and y0 are the coordinates of the top left of the box and x1 and y0 are the coordinates for the bottom right.
+
+The groundtruth can also contain ignore regions. The are marked by being having a class number of 100 or larger. Class number 100 encodes and ignore region for all class, which class numbers higher than 100 encode ignore regions specific to each class. E.g. class number 105 are ignore regions for class 5.
+
+As well as the per sequence files described above, the groundtruth for each benchmark contains two more files ```clsmap.txt``` and ```seqmap.txt```.
+
+```clsmap.txt``` is a single row, space-separated, containing all of the valid classes that should be evaluated for each benchmark (not all benchmarks evaluate all of the coco classes).
+
+```seqmap.txt``` contains a list of the sequences to be evaluated for that benchmark. Each row has at least 4 values. These are:
+```
+
+```
+More than 4 values can be present, the remaining values are 'ignore classes for this sequence'. E.g. classes which are evaluated for the particular benchmark as a whole, but should be ignored for this sequence.
+
+## Visualizing GT and Tracker Masks
+
+We provide code for converting our .txt format with compressed RLE masks into .png format where it is easy to visualize the GT and Predicted masks.
+
+This code can be found here:
+
+[Vizualize Tracking Results](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/baselines/vizualize.py).
+
+
+## Evaluate on the validation and test server
+
+The val and test GT will NOT be provided. However we provide a live evaluation server to upload your tracking results and evaluate it on the val and test set.
+
+The val server will allow infinite uploads, while the test will limit trackers to 4 uploads total.
+
+These evaluation servers can be found here: https://eval.vision.rwth-aachen.de/vision/
+
+Ensure that your files to upload are in the correct format. Examples of the correct way to upload files can be found here: [STP val upload](https://omnomnom.vision.rwth-aachen.de/data/RobMOTS/STP_val_upload.zip), [STP test upload](https://omnomnom.vision.rwth-aachen.de/data/RobMOTS/STP_test_upload.zip).
+
+## Citation
+If you work with the code and the benchmark, please cite:
+
+***TrackEval***
+```
+@misc{luiten2020trackeval,
+ author = {Jonathon Luiten, Arne Hoffhues},
+ title = {TrackEval},
+ howpublished = {\url{https://github.com/JonathonLuiten/TrackEval}},
+ year = {2020}
+}
+```
+***HOTA metrics***
+```
+@article{luiten2020IJCV,
+ title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
+ author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
+ journal={International Journal of Computer Vision},
+ pages={1--31},
+ year={2020},
+ publisher={Springer}
+}
+```
+
+## Feedback and Contact
+We are constantly working on improving RobMOTS, and wish to provide the most useful support to the community.
+You can help us to make the benchmark better by open issues in the repo and reporting bugs.
+
+For general questions, please contact the following:
+
+```
+Jonathon Luiten - luiten@vision.rwth-aachen.de
+```
diff --git a/val_utils/docs/TAO-format.txt b/val_utils/docs/TAO-format.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a1896742f53a286b1d48b6a2ce7b47825c372011
--- /dev/null
+++ b/val_utils/docs/TAO-format.txt
@@ -0,0 +1,56 @@
+Taken from: https://github.com/TAO-Dataset/tao/blob/master/tao/toolkit/tao/tao.py
+
+Annotation file format:
+{
+ "info" : info,
+ "images" : [image],
+ "videos": [video],
+ "tracks": [track],
+ "annotations" : [annotation],
+ "categories": [category],
+ "licenses" : [license],
+}
+info: As in MS COCO
+image: {
+ "id" : int,
+ "video_id": int,
+ "file_name" : str,
+ "license" : int,
+ # Redundant fields for COCO-compatibility
+ "width": int,
+ "height": int,
+ "frame_index": int
+}
+video: {
+ "id": int,
+ "name": str,
+ "width" : int,
+ "height" : int,
+ "neg_category_ids": [int],
+ "not_exhaustive_category_ids": [int],
+ "metadata": dict, # Metadata about the video
+}
+track: {
+ "id": int,
+ "category_id": int,
+ "video_id": int
+}
+category: {
+ "id": int,
+ "name": str,
+ "synset": str, # For non-LVIS objects, this is "unknown"
+ ... [other fields copied from LVIS v0.5 and unused]
+}
+annotation: {
+ "image_id": int,
+ "track_id": int,
+ "bbox": [x,y,width,height],
+ "area": float,
+ # Redundant field for compatibility with COCO scripts
+ "category_id": int
+}
+license: {
+ "id" : int,
+ "name" : str,
+ "url" : str,
+}
diff --git a/val_utils/docs/YouTube-VIS-format.txt b/val_utils/docs/YouTube-VIS-format.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b5d542d5c8f9358dcd4d975cd7da8bbf99215256
--- /dev/null
+++ b/val_utils/docs/YouTube-VIS-format.txt
@@ -0,0 +1,44 @@
+Taken from: https://competitions.codalab.org/competitions/20128#participate-get-data
+
+The label file follows MSCOCO's style in json format. We adapt the entry name and label format for video. The definition of json file is:
+
+
+ {
+ "info" : info,
+ "videos" : [video],
+ "annotations" : [annotation],
+ "categories" : [category],
+ }
+ video{
+ "id" : int,
+ "width" : int,
+ "height" : int,
+ "length" : int,
+ "file_names" : [file_name],
+ }
+ annotation{
+ "id" : int,
+ "video_id" : int,
+ "category_id" : int,
+ "segmentations" : [RLE or [polygon] or None],
+ "areas" : [float or None],
+ "bboxes" : [[x,y,width,height] or None],
+ "iscrowd" : 0 or 1,
+ }
+ category{
+ "id" : int,
+ "name" : str,
+ "supercategory" : str,
+ }
+
+The submission file is also in json format. The file should contain a list of predictions:
+
+
+ prediction{
+ "video_id" : int,
+ "category_id" : int,
+ "segmentations" : [RLE or [polygon] or None],
+ "score" : float,
+ }
+
+The submission file should be named as "results.json", and compressed without any subfolder. There is an example "valid_submission_sample.zip" in download links above. The example is generated by our proposed MaskTrack R-CNN algorithm.
\ No newline at end of file
diff --git a/val_utils/minimum_requirements.txt b/val_utils/minimum_requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b63c322a857a3638f77c77a107f0cc4a814977e3
--- /dev/null
+++ b/val_utils/minimum_requirements.txt
@@ -0,0 +1,2 @@
+scipy==1.4.1
+numpy==1.18.1
diff --git a/val_utils/pyproject.toml b/val_utils/pyproject.toml
new file mode 100644
index 0000000000000000000000000000000000000000..374b58cbf4636f1e28bacf987ac2fe89ed27ccba
--- /dev/null
+++ b/val_utils/pyproject.toml
@@ -0,0 +1,6 @@
+[build-system]
+requires = [
+ "setuptools>=42",
+ "wheel"
+]
+build-backend = "setuptools.build_meta"
diff --git a/val_utils/requirements.txt b/val_utils/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..40d2a57c81d960e89adcb6ad7ea4d6509888a85e
--- /dev/null
+++ b/val_utils/requirements.txt
@@ -0,0 +1,10 @@
+numpy==1.18.1
+scipy==1.4.1
+pycocotools==2.0.2
+matplotlib==3.2.1
+opencv_python==4.4.0.46
+scikit_image==0.16.2
+pytest==6.0.1
+Pillow==8.1.2
+tqdm==4.64.0
+tabulate
diff --git a/val_utils/scripts/comparison_plots.py b/val_utils/scripts/comparison_plots.py
new file mode 100644
index 0000000000000000000000000000000000000000..a338f97c68a81d19fb1827085ddaffd18c825dea
--- /dev/null
+++ b/val_utils/scripts/comparison_plots.py
@@ -0,0 +1,20 @@
+import sys
+import os
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+plots_folder = os.path.abspath(os.path.join(os.path.dirname(__file__), '..', 'data', 'plots'))
+tracker_folder = os.path.abspath(os.path.join(os.path.dirname(__file__), '..', 'data', 'trackers'))
+
+# dataset = os.path.join('kitti', 'kitti_2d_box_train')
+# classes = ['cars', 'pedestrian']
+
+dataset = os.path.join('mot_challenge', 'MOT17-train')
+classes = ['pedestrian']
+
+data_fol = os.path.join(tracker_folder, dataset)
+trackers = os.listdir(data_fol)
+out_loc = os.path.join(plots_folder, dataset)
+for cls in classes:
+ trackeval.plotting.plot_compare_trackers(data_fol, trackers, cls, out_loc)
diff --git a/val_utils/scripts/run_bdd.py b/val_utils/scripts/run_bdd.py
new file mode 100644
index 0000000000000000000000000000000000000000..2043cdf085803e3954cceaabb19f3b5b2ecd8876
--- /dev/null
+++ b/val_utils/scripts/run_bdd.py
@@ -0,0 +1,89 @@
+
+""" run_bdd.py
+
+Run example:
+run_bdd.py --USE_PARALLEL False --METRICS Hota --TRACKERS_TO_EVAL qdtrack
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/bdd100k/bdd100k_val'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/bdd100k/bdd100k_val'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['pedestrian', 'rider', 'car', 'bus', 'truck', 'train', 'motorcycle', 'bicycle'],
+ # Valid: ['pedestrian', 'rider', 'car', 'bus', 'truck', 'train', 'motorcycle', 'bicycle']
+ 'SPLIT_TO_EVAL': 'val', # Valid: 'training', 'val',
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ Metric arguments:
+ 'METRICS': ['Hota','Clear', 'ID', 'Count']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ default_eval_config['PRINT_ONLY_COMBINED'] = True
+ default_dataset_config = trackeval.datasets.BDD100K.get_default_dataset_config()
+ default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity']}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.BDD100K(dataset_config)]
+ metrics_list = []
+ for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ evaluator.evaluate(dataset_list, metrics_list)
\ No newline at end of file
diff --git a/val_utils/scripts/run_burst.py b/val_utils/scripts/run_burst.py
new file mode 100644
index 0000000000000000000000000000000000000000..595526436eb12c382123cf5ce4972e4aeb44a71f
--- /dev/null
+++ b/val_utils/scripts/run_burst.py
@@ -0,0 +1,173 @@
+""" run_burst.py
+
+The example commands given below expect the following folder structure:
+
+- data
+ - gt
+ - burst
+ - {val,test}
+ - all_classes
+ - all_classes.json (filename is irrelevant)
+ - trackers
+ - burst
+ - exemplar_guided
+ - {val,test}
+ - my_tracking_method
+ - data
+ - results.json (filename is irrelevant)
+ - class_guided
+ - {val,test}
+ - my_other_tracking_method
+ - data
+ - results.json (filename is irrelevant)
+
+Run example:
+
+1) Exemplar-guided tasks (all three tasks share the same eval logic):
+run_burst.py --USE_PARALLEL True --EXEMPLAR_GUIDED True --GT_FOLDER ../data/gt/burst/{val,test}/all_classes --TRACKERS_FOLDER ../data/trackers/burst/exemplar_guided/{val,test}
+
+2) Class-guided tasks (common class and long-tail):
+run_burst.py --USE_PARALLEL FTrue --EXEMPLAR_GUIDED False --GT_FOLDER ../data/gt/burst/{val,test}/all_classes --TRACKERS_FOLDER ../data/trackers/burst/class_guided/{val,test}
+
+3) Refer to run_burst_ow.py for open world evaluation
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/burst/val'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/burst/class-guided/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
+ 'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
+ Metric arguments:
+ 'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']
+"""
+
+import sys
+import os
+import argparse
+from tabulate import tabulate
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+
+def main():
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ default_eval_config['PRINT_ONLY_COMBINED'] = True
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = True
+ default_eval_config['PLOT_CURVES'] = False
+ default_eval_config["OUTPUT_DETAILED"] = False
+ default_eval_config["PRINT_RESULTS"] = False
+ default_eval_config["OUTPUT_SUMMARY"] = False
+
+ default_dataset_config = trackeval.datasets.BURST.get_default_dataset_config()
+
+ # default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']}
+ # default_metrics_config = {'METRICS': ['HOTA']}
+ default_metrics_config = {'METRICS': ['HOTA', 'TrackMAP']}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.BURST(dataset_config)]
+ metrics_list = []
+ for metric in [trackeval.metrics.TrackMAP, trackeval.metrics.CLEAR, trackeval.metrics.Identity,
+ trackeval.metrics.HOTA]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ output_res, output_msg = evaluator.evaluate(dataset_list, metrics_list, show_progressbar=True)
+
+ class_name_to_id = {x['name']: x['id'] for x in dataset_list[0].gt_data['categories']}
+ known_list = [4, 13, 1038, 544, 1057, 34, 35, 36, 41, 45, 58, 60, 579, 1091, 1097, 1099, 78, 79, 81, 91, 1115,
+ 1117, 95, 1122, 99, 1132, 621, 1135, 625, 118, 1144, 126, 642, 1155, 133, 1162, 139, 154, 174, 185,
+ 699, 1215, 714, 717, 1229, 211, 729, 221, 229, 747, 235, 237, 779, 276, 805, 299, 829, 852, 347,
+ 371, 382, 896, 392, 926, 937, 428, 429, 961, 452, 979, 980, 982, 475, 480, 993, 1001, 502, 1018]
+
+ row_labels = ("HOTA", "DetA", "AssA", "AP")
+ trackers = list(output_res['BURST'].keys())
+ print("\n")
+
+ def average_metric(m):
+ return round(100*sum(m) / len(m), 2)
+
+ for tracker in trackers:
+ res = output_res['BURST'][tracker]['COMBINED_SEQ']
+ all_names = [x for x in res.keys() if (x != 'cls_comb_cls_av') and (x != 'cls_comb_det_av')]
+
+ class_split_names = {
+ "All": [x for x in res.keys() if (x != 'cls_comb_cls_av') and (x != 'cls_comb_det_av')],
+ "Common": [x for x in all_names if class_name_to_id[x] in known_list],
+ "Uncommon": [x for x in all_names if class_name_to_id[x] not in known_list]
+ }
+
+ # table columns: 'all', 'common', 'uncommon'
+ # table rows: HOTA, AssA, DetA, mAP
+ table_data = []
+
+ for row_label in row_labels:
+ row = [row_label]
+ for split_name in ["All", "Common", "Uncommon"]:
+ split_classes = class_split_names[split_name]
+
+ if row_label == "AP":
+ row.append(average_metric([res[c]['TrackMAP']["AP_all"].mean() for c in split_classes]))
+ else:
+ row.append(average_metric([res[c]['HOTA'][row_label].mean() for c in split_classes]))
+
+ table_data.append(row)
+
+ print(f"Results for Tracker: {tracker}\n")
+ print(tabulate(table_data, ["Metric", "All", "Common", "Uncommon"]))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/val_utils/scripts/run_burst_ow.py b/val_utils/scripts/run_burst_ow.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a941661f562046a9c7229417c3585edf6d19930
--- /dev/null
+++ b/val_utils/scripts/run_burst_ow.py
@@ -0,0 +1,117 @@
+""" run_burst_ow.py
+
+The example commands given below expect the following folder structure:
+
+- data
+ - gt
+ - burst
+ - {val,test}
+ - all_classes
+ - all_classes.json (filename is irrelevant)
+ - common_classes
+ - common_classes.json (filename is irrelevant)
+ - uncommon_classes.json
+ - uncommon_classes.json (filename is irrelevant)
+ - trackers
+ - burst
+ - open-world
+ - {val,test}
+ - my_tracking_method
+ - data
+ - results.json (filename is irrelevant)
+
+Run example:
+
+You'll need to run the eval script separately to get the OWTA metric for the three class splits. In the command below,
+replace with "common", "uncommon" and "all" to get the corresponding results.
+
+run_burst_ow.py --USE_PARALLEL True --GT_FOLDER data/gt/burst/{val,test}/_classes --TRACKERS_FOLDER data/trackers/burst/open-world/{val,test}
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, '../data/gt/burst/{val,test}/_classes'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, '../data/trackers/burst/open-world/{val,test}), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
+ 'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
+ 'SUBSET': 'unknown', # Evaluate on the following subsets ['all', 'known', 'unknown', 'distractor']
+ Metric arguments:
+ 'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ # print only combined since TrackMAP is undefined for per sequence breakdowns
+ default_eval_config['PRINT_ONLY_COMBINED'] = True
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = True
+ default_dataset_config = trackeval.datasets.BURST_OW.get_default_dataset_config()
+ # default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']}
+ default_metrics_config = {'METRICS': ['HOTA']}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.BURST_OW(dataset_config)]
+ metrics_list = []
+ # for metric in [trackeval.metrics.TrackMAP, trackeval.metrics.CLEAR, trackeval.metrics.Identity,
+ # trackeval.metrics.HOTA]:
+ for metric in [trackeval.metrics.HOTA]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ output_res, output_msg = evaluator.evaluate(dataset_list, metrics_list, show_progressbar=True)
diff --git a/val_utils/scripts/run_davis.py b/val_utils/scripts/run_davis.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e26be2463526745b378842991524e6fb086af7f
--- /dev/null
+++ b/val_utils/scripts/run_davis.py
@@ -0,0 +1,90 @@
+""" run_davis.py
+
+Run example:
+run_davis.py --USE_PARALLEL False --METRICS HOTA --TRACKERS_TO_EVAL ags
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ ' 'GT_FOLDER': os.path.join(code_path, 'data/gt/davis/'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/davis/davis_val'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'SPLIT_TO_EVAL': 'val', # Valid: 'val', 'train'
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/ImageSets/2017)
+ 'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/split-to-eval.txt)
+ 'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
+ 'GT_LOC_FORMAT': '{gt_folder}/Annotations_unsupervised/480p/{seq}',
+ # '{gt_folder}/Annotations_unsupervised/480p/{seq}'
+ 'MAX_DETECTIONS': 0 # Maximum number of allowed detections per sequence (0 for no threshold)
+ Metric arguments:
+ 'METRICS': ['HOTA', 'CLEAR', 'Identity', 'JAndF']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ default_dataset_config = trackeval.datasets.DAVIS.get_default_dataset_config()
+ default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity', 'JAndF']}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.DAVIS(dataset_config)]
+ metrics_list = []
+ for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity, trackeval.metrics.JAndF]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ evaluator.evaluate(dataset_list, metrics_list)
\ No newline at end of file
diff --git a/val_utils/scripts/run_headtracking_challenge.py b/val_utils/scripts/run_headtracking_challenge.py
new file mode 100644
index 0000000000000000000000000000000000000000..82dd597a2568ca60e956b6113f18068eea8d01c5
--- /dev/null
+++ b/val_utils/scripts/run_headtracking_challenge.py
@@ -0,0 +1,91 @@
+
+""" run_mot_challenge.py
+
+Run example:
+run_mot_challenge.py --USE_PARALLEL False --METRICS Hota --TRACKERS_TO_EVAL Lif_T
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
+ 'BENCHMARK': 'MOT17', # Valid: 'MOT17', 'MOT16', 'MOT20', 'MOT15'
+ 'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test', 'all'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'DO_PREPROC': True, # Whether to perform preprocessing (never done for 2D_MOT_2015)
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ Metric arguments:
+ 'METRICS': ['HOTA', 'CLEAR', 'Identity', 'IDEucl']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = False
+ default_dataset_config = trackeval.datasets.HeadTrackingChallenge.get_default_dataset_config()
+ default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity', 'IDEucl'], 'THRESHOLD': 0.4}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ elif setting == 'SEQ_INFO':
+ x = dict(zip(args[setting], [None]*len(args[setting])))
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.HeadTrackingChallenge(dataset_config)]
+ metrics_list = []
+ for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity, trackeval.metrics.IDEucl]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric(metrics_config))
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ evaluator.evaluate(dataset_list, metrics_list)
diff --git a/val_utils/scripts/run_kitti.py b/val_utils/scripts/run_kitti.py
new file mode 100644
index 0000000000000000000000000000000000000000..dbb63bde0a47ef51e4fe8c659c8de66ad4c8f29f
--- /dev/null
+++ b/val_utils/scripts/run_kitti.py
@@ -0,0 +1,87 @@
+
+""" run_kitti.py
+
+Run example:
+run_kitti.py --USE_PARALLEL False --METRICS Hota --TRACKERS_TO_EVAL CIWT
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/kitti/kitti_2d_box_train'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/kitti/kitti_2d_box_train/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['car', 'pedestrian'], # Valid: ['car', 'pedestrian']
+ 'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val', 'training_minus_val', 'test'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '' # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ Metric arguments:
+ 'METRICS': ['Hota','Clear', 'ID', 'Count']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = False
+ default_dataset_config = trackeval.datasets.Kitti2DBox.get_default_dataset_config()
+ default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity']}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.Kitti2DBox(dataset_config)]
+ metrics_list = []
+ for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ evaluator.evaluate(dataset_list, metrics_list)
diff --git a/val_utils/scripts/run_kitti_mots.py b/val_utils/scripts/run_kitti_mots.py
new file mode 100644
index 0000000000000000000000000000000000000000..89d6b36a123ba3dc5d6230dceff57b3793e7368c
--- /dev/null
+++ b/val_utils/scripts/run_kitti_mots.py
@@ -0,0 +1,92 @@
+
+""" run_kitti_mots.py
+
+Run example:
+run_kitti_mots.py --USE_PARALLEL False --METRICS HOTA --TRACKERS_TO_EVAL trackrcnn
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/kitti/kitti_mots'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/kitti/kitti_mots_val'), # Location of all
+ # trackers
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['car', 'pedestrian'], # Valid: ['car', 'pedestrian']
+ 'SPLIT_TO_EVAL': 'val', # Valid: 'training', 'val'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER)
+ 'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/split_to_eval.seqmap)
+ 'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
+ 'GT_LOC_FORMAT': '{gt_folder}/instances_txt/{seq}.txt', # format of gt localization
+ Metric arguments:
+ 'METRICS': ['HOTA', 'CLEAR', 'Identity']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = False
+ default_dataset_config = trackeval.datasets.KittiMOTS.get_default_dataset_config()
+ default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity']}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.KittiMOTS(dataset_config)]
+ metrics_list = []
+ for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity, trackeval.metrics.JAndF]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ evaluator.evaluate(dataset_list, metrics_list)
diff --git a/val_utils/scripts/run_mot_challenge.py b/val_utils/scripts/run_mot_challenge.py
new file mode 100644
index 0000000000000000000000000000000000000000..7b5a578a786e944e70fe1eafa6fb53d6d26f49c5
--- /dev/null
+++ b/val_utils/scripts/run_mot_challenge.py
@@ -0,0 +1,91 @@
+
+""" run_mot_challenge.py
+
+Run example:
+run_mot_challenge.py --USE_PARALLEL False --METRICS Hota --TRACKERS_TO_EVAL Lif_T
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
+ 'BENCHMARK': 'MOT17', # Valid: 'MOT17', 'MOT16', 'MOT20', 'MOT15'
+ 'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test', 'all'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'DO_PREPROC': True, # Whether to perform preprocessing (never done for 2D_MOT_2015)
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ Metric arguments:
+ 'METRICS': ['HOTA', 'CLEAR', 'Identity', 'VACE']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = False
+ default_dataset_config = trackeval.datasets.MotChallenge2DBox.get_default_dataset_config()
+ default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity'], 'THRESHOLD': 0.5}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ elif setting == 'SEQ_INFO':
+ x = dict(zip(args[setting], [None]*len(args[setting])))
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.MotChallenge2DBox(dataset_config)]
+ metrics_list = []
+ for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity, trackeval.metrics.VACE]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric(metrics_config))
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ evaluator.evaluate(dataset_list, metrics_list)
diff --git a/val_utils/scripts/run_mots_challenge.py b/val_utils/scripts/run_mots_challenge.py
new file mode 100644
index 0000000000000000000000000000000000000000..b5170660e2113d0d23dc1beb72c82830c4111b35
--- /dev/null
+++ b/val_utils/scripts/run_mots_challenge.py
@@ -0,0 +1,96 @@
+""" run_mots.py
+
+Run example:
+run_mots.py --USE_PARALLEL False --METRICS Hota --TRACKERS_TO_EVAL TrackRCNN
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
+ 'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/seqmaps)
+ 'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/MOTS-split_to_eval)
+ 'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
+ 'GT_LOC_FORMAT': '{gt_folder}/{seq}/gt/gt.txt', # '{gt_folder}/{seq}/gt/gt.txt'
+ 'SKIP_SPLIT_FOL': False, # If False, data is in GT_FOLDER/MOTS-SPLIT_TO_EVAL/ and in
+ # TRACKERS_FOLDER/MOTS-SPLIT_TO_EVAL/tracker/
+ # If True, then the middle 'MOTS-split' folder is skipped for both.
+ Metric arguments:
+ 'METRICS': ['HOTA','CLEAR', 'Identity', 'VACE', 'JAndF']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = False
+ default_dataset_config = trackeval.datasets.MOTSChallenge.get_default_dataset_config()
+ default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity']}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ elif setting == 'SEQ_INFO':
+ x = dict(zip(args[setting], [None]*len(args[setting])))
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.MOTSChallenge(dataset_config)]
+ metrics_list = []
+ for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity, trackeval.metrics.VACE,
+ trackeval.metrics.JAndF]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ evaluator.evaluate(dataset_list, metrics_list)
diff --git a/val_utils/scripts/run_person_path_22.py b/val_utils/scripts/run_person_path_22.py
new file mode 100644
index 0000000000000000000000000000000000000000..232b99c2b0d4077be7b5258c1c6b3593df93157c
--- /dev/null
+++ b/val_utils/scripts/run_person_path_22.py
@@ -0,0 +1,112 @@
+
+""" run_person_path_22.py
+
+Run example:
+python3 run_person_path_22.py \
+ --BENCHMARK person_path_22 \
+ --SPLIT_TO_EVAL test \
+ --TRACKERS_TO_EVAL custom_tracker \
+ --METRICS HOTA CLEAR Identity VACE \
+ --USE_PARALLEL True \
+ --NUM_PARALLEL_CORES 12 \
+ --TRACKERS_FOLDER $TRACKER_FOLDER
+
+where $TRACKER_FOLDER is the path of the folder containing the tracker predictions in MOTChallenge format.
+In particular, $TRACKER_FOLDER is expected to have the following structure:
+$TRACKER_FOLDER/
+ person_path_22-test/
+ custom_tracker/
+ data/
+ uid_vid_00008.mp4.txt
+ uid_vid_00009.mp4.txt
+ [...]
+ uid_vid_00235.mp4.txt
+
+Each text file contains the tracker predictions in MOTChallenge format for a given video.
+
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/person_path_22/'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/person_path_22/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
+ 'BENCHMARK': 'person_path_22', # Valid: 'person_path_22'
+ 'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test', 'all'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'DO_PREPROC': True, # Whether to perform preprocessing
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ Metric arguments:
+ 'METRICS': ['HOTA', 'CLEAR', 'Identity', 'VACE']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = False
+ default_dataset_config = trackeval.datasets.PersonPath22.get_default_dataset_config()
+ default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity'], 'THRESHOLD': 0.5}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ elif setting == 'SEQ_INFO':
+ x = dict(zip(args[setting], [None]*len(args[setting])))
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.PersonPath22(dataset_config)]
+ metrics_list = []
+ for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity, trackeval.metrics.VACE]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric(metrics_config))
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ evaluator.evaluate(dataset_list, metrics_list)
diff --git a/val_utils/scripts/run_rob_mots.py b/val_utils/scripts/run_rob_mots.py
new file mode 100644
index 0000000000000000000000000000000000000000..0fa07fedf7b9c95a12081a6ebfd8c098f277d1be
--- /dev/null
+++ b/val_utils/scripts/run_rob_mots.py
@@ -0,0 +1,142 @@
+# python3 scripts/run_rob_mots.py --ROBMOTS_SPLIT train --TRACKERS_TO_EVAL STP --USE_PARALLEL True --NUM_PARALLEL_CORES 8
+
+import sys
+import os
+import csv
+import numpy as np
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+from trackeval import utils
+
+code_path = utils.get_code_path()
+
+if __name__ == '__main__':
+ freeze_support()
+
+ script_config = {
+ 'ROBMOTS_SPLIT': 'train', # 'train', # valid: 'train', 'val', 'test', 'test_live', 'test_post', 'test_all'
+ 'BENCHMARKS': None, # If None, use all for each split.
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/rob_mots'),
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/rob_mots'),
+ }
+
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ default_eval_config['PRINT_ONLY_COMBINED'] = True
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = True
+ default_dataset_config = trackeval.datasets.RobMOTS.get_default_dataset_config()
+ config = {**default_eval_config, **default_dataset_config, **script_config}
+
+ # Command line interface:
+ config = utils.update_config(config)
+
+ if not config['BENCHMARKS']:
+ if config['ROBMOTS_SPLIT'] == 'val':
+ config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis',
+ 'tao', 'mots_challenge', 'waymo']
+ config['SPLIT_TO_EVAL'] = 'val'
+ elif config['ROBMOTS_SPLIT'] == 'test' or config['SPLIT_TO_EVAL'] == 'test_live':
+ config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'tao']
+ config['SPLIT_TO_EVAL'] = 'test'
+ elif config['ROBMOTS_SPLIT'] == 'test_post':
+ config['BENCHMARKS'] = ['mots_challenge', 'waymo', 'ovis']
+ config['SPLIT_TO_EVAL'] = 'test'
+ elif config['ROBMOTS_SPLIT'] == 'test_all':
+ config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis',
+ 'tao', 'mots_challenge', 'waymo']
+ config['SPLIT_TO_EVAL'] = 'test'
+ elif config['ROBMOTS_SPLIT'] == 'train':
+ config['BENCHMARKS'] = ['kitti_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'tao', 'bdd_mots']
+ config['SPLIT_TO_EVAL'] = 'train'
+ else:
+ config['SPLIT_TO_EVAL'] = config['ROBMOTS_SPLIT']
+
+ metrics_config = {'METRICS': ['HOTA']}
+ eval_config = {k: v for k, v in config.items() if k in config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in config.keys()}
+
+ # Run code
+ try:
+ dataset_list = []
+ for bench in config['BENCHMARKS']:
+ dataset_config['SUB_BENCHMARK'] = bench
+ dataset_list.append(trackeval.datasets.RobMOTS(dataset_config))
+ evaluator = trackeval.Evaluator(eval_config)
+ metrics_list = []
+ for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity,
+ trackeval.metrics.VACE, trackeval.metrics.JAndF]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ output_res, output_msg = evaluator.evaluate(dataset_list, metrics_list)
+ output = list(list(output_msg.values())[0].values())[0]
+
+ except Exception as err:
+ if type(err) == trackeval.utils.TrackEvalException:
+ output = str(err)
+ else:
+ output = 'Unknown error occurred.'
+
+ success = output == 'Success'
+ if not success:
+ output = 'ERROR, evaluation failed. \n\nError message: ' + output
+ print(output)
+
+ if config['TRACKERS_TO_EVAL']:
+ msg = "Thanks you for participating in the RobMOTS benchmark.\n\n"
+ msg += "The status of your evaluation is: \n" + output + '\n\n'
+ msg += "If your tracking results evaluated successfully on the evaluation server you can see your results here: \n"
+ msg += "https://eval.vision.rwth-aachen.de/vision/"
+ status_file = os.path.join(config['TRACKERS_FOLDER'], config['ROBMOTS_SPLIT'], config['TRACKERS_TO_EVAL'][0],
+ 'status.txt')
+ with open(status_file, 'w', newline='') as f:
+ f.write(msg)
+
+ if success:
+ # For each benchmark, combine the 'all' score with the 'cls_averaged' using geometric mean.
+ metrics_to_calc = ['HOTA', 'DetA', 'AssA', 'DetRe', 'DetPr', 'AssRe', 'AssPr', 'LocA']
+ trackers = list(output_res['RobMOTS.' + config['BENCHMARKS'][0]].keys())
+ for tracker in trackers:
+ # final_results[benchmark][result_type][metric]
+ final_results = {}
+ res = {bench: output_res['RobMOTS.' + bench][tracker]['COMBINED_SEQ'] for bench in config['BENCHMARKS']}
+ for bench in config['BENCHMARKS']:
+ final_results[bench] = {'cls_av': {}, 'det_av': {}, 'final': {}}
+ for metric in metrics_to_calc:
+ final_results[bench]['cls_av'][metric] = np.mean(res[bench]['cls_comb_cls_av']['HOTA'][metric])
+ final_results[bench]['det_av'][metric] = np.mean(res[bench]['all']['HOTA'][metric])
+ final_results[bench]['final'][metric] = \
+ np.sqrt(final_results[bench]['cls_av'][metric] * final_results[bench]['det_av'][metric])
+
+ # Take the arithmetic mean over all the benchmarks
+ final_results['overall'] = {'cls_av': {}, 'det_av': {}, 'final': {}}
+ for metric in metrics_to_calc:
+ final_results['overall']['cls_av'][metric] = \
+ np.mean([final_results[bench]['cls_av'][metric] for bench in config['BENCHMARKS']])
+ final_results['overall']['det_av'][metric] = \
+ np.mean([final_results[bench]['det_av'][metric] for bench in config['BENCHMARKS']])
+ final_results['overall']['final'][metric] = \
+ np.mean([final_results[bench]['final'][metric] for bench in config['BENCHMARKS']])
+
+ # Save out result
+ headers = [config['SPLIT_TO_EVAL']] + [x + '___' + metric for x in ['f', 'c', 'd'] for metric in
+ metrics_to_calc]
+
+
+ def rowify(d):
+ return [d[x][metric] for x in ['final', 'cls_av', 'det_av'] for metric in metrics_to_calc]
+
+
+ out_file = os.path.join(config['TRACKERS_FOLDER'], config['ROBMOTS_SPLIT'], tracker,
+ 'final_results.csv')
+
+ with open(out_file, 'w', newline='') as f:
+ writer = csv.writer(f, delimiter=',')
+ writer.writerow(headers)
+ writer.writerow(['overall'] + rowify(final_results['overall']))
+ for bench in config['BENCHMARKS']:
+ if bench == 'overall':
+ continue
+ writer.writerow([bench] + rowify(final_results[bench]))
diff --git a/val_utils/scripts/run_tao.py b/val_utils/scripts/run_tao.py
new file mode 100644
index 0000000000000000000000000000000000000000..c70f08d714024ac79be8b90ee19fef9ae952cca9
--- /dev/null
+++ b/val_utils/scripts/run_tao.py
@@ -0,0 +1,90 @@
+""" run_tao.py
+
+Run example:
+run_tao.py --USE_PARALLEL False --METRICS HOTA --TRACKERS_TO_EVAL Tracktor++
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/tao/tao_training'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/tao/tao_training'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
+ 'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
+ Metric arguments:
+ 'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ # print only combined since TrackMAP is undefined for per sequence breakdowns
+ default_eval_config['PRINT_ONLY_COMBINED'] = True
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = True
+ default_dataset_config = trackeval.datasets.TAO.get_default_dataset_config()
+ default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.TAO(dataset_config)]
+ metrics_list = []
+ for metric in [trackeval.metrics.TrackMAP, trackeval.metrics.CLEAR, trackeval.metrics.Identity,
+ trackeval.metrics.HOTA]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ evaluator.evaluate(dataset_list, metrics_list)
\ No newline at end of file
diff --git a/val_utils/scripts/run_tao_ow.py b/val_utils/scripts/run_tao_ow.py
new file mode 100644
index 0000000000000000000000000000000000000000..2735dd40ab8dba2caed89666cad0e5810f1854e9
--- /dev/null
+++ b/val_utils/scripts/run_tao_ow.py
@@ -0,0 +1,92 @@
+""" run_tao.py
+
+Run example:
+run_tao_ow.py --USE_PARALLEL False --METRICS HOTA --TRACKERS_TO_EVAL Tracktor++
+
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True,
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/tao/tao_training'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/tao/tao_training'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
+ 'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
+ 'SUBSET': 'unknown', # Evaluate on the following subsets ['all', 'known', 'unknown', 'distractor']
+ Metric arguments:
+ 'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ # print only combined since TrackMAP is undefined for per sequence breakdowns
+ default_eval_config['PRINT_ONLY_COMBINED'] = True
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = True
+ default_dataset_config = trackeval.datasets.TAO_OW.get_default_dataset_config()
+ default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.TAO_OW(dataset_config)]
+ metrics_list = []
+ # for metric in [trackeval.metrics.TrackMAP, trackeval.metrics.CLEAR, trackeval.metrics.Identity,
+ # trackeval.metrics.HOTA]:
+ for metric in [trackeval.metrics.HOTA]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ evaluator.evaluate(dataset_list, metrics_list)
\ No newline at end of file
diff --git a/val_utils/scripts/run_youtube_vis.py b/val_utils/scripts/run_youtube_vis.py
new file mode 100644
index 0000000000000000000000000000000000000000..d28569bc92ad9dc49e57e657bc81a2d3dccc7c51
--- /dev/null
+++ b/val_utils/scripts/run_youtube_vis.py
@@ -0,0 +1,101 @@
+
+""" run_youtube_vis.py
+Run example:
+run_youtube_vis.py --USE_PARALLEL False --METRICS HOTA --TRACKERS_TO_EVAL STEm_Seg
+Command Line Arguments: Defaults, # Comments
+ Eval arguments:
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True, # Raises exception and exits with error
+ 'RETURN_ON_ERROR': False, # if not BREAK_ON_ERROR, then returns from function on error
+ 'LOG_ON_ERROR': os.path.join(code_path, 'error_log.txt'), # if not None, save any errors into a log file.
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'DISPLAY_LESS_PROGRESS': True,
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_EMPTY_CLASSES': True, # If False, summary files are not output for classes with no detections
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ Dataset arguments:
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/youtube_vis/youtube_vis_training'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/youtube_vis/youtube_vis_training'),
+ # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
+ 'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ Metric arguments:
+ 'METRICS': ['TrackMAP', 'HOTA', 'CLEAR', 'Identity']
+"""
+
+import sys
+import os
+import argparse
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+if __name__ == '__main__':
+ freeze_support()
+
+ # Command line interface:
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ # print only combined since TrackMAP is undefined for per sequence breakdowns
+ default_eval_config['PRINT_ONLY_COMBINED'] = True
+ default_dataset_config = trackeval.datasets.YouTubeVIS.get_default_dataset_config()
+ default_metrics_config = {'METRICS': ['TrackMAP', 'HOTA', 'CLEAR', 'Identity']}
+ config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ else:
+ x = args[setting]
+ config[setting] = x
+ eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
+ metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
+
+ # Run code
+ evaluator = trackeval.Evaluator(eval_config)
+ dataset_list = [trackeval.datasets.YouTubeVIS(dataset_config)]
+ metrics_list = []
+ for metric in [trackeval.metrics.TrackMAP, trackeval.metrics.HOTA, trackeval.metrics.CLEAR,
+ trackeval.metrics.Identity]:
+ if metric.get_name() in metrics_config['METRICS']:
+ # specify TrackMAP config for YouTubeVIS
+ if metric == trackeval.metrics.TrackMAP:
+ default_track_map_config = metric.get_default_metric_config()
+ default_track_map_config['USE_TIME_RANGES'] = False
+ default_track_map_config['AREA_RANGES'] = [[0 ** 2, 128 ** 2],
+ [ 128 ** 2, 256 ** 2],
+ [256 ** 2, 1e5 ** 2]]
+ metrics_list.append(metric(default_track_map_config))
+ else:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ evaluator.evaluate(dataset_list, metrics_list)
\ No newline at end of file
diff --git a/val_utils/setup.cfg b/val_utils/setup.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..914f3de2e145992a4d55fdf294a81b7823e1f619
--- /dev/null
+++ b/val_utils/setup.cfg
@@ -0,0 +1,27 @@
+[metadata]
+name = trackeval
+version = 1.0.dev1
+author = Jonathon Luiten, Arne Hoffhues
+author_email = jonoluiten@gmail.com
+description = Code for evaluating object tracking
+long_description = file: Readme.md
+long_description_content_type = text/markdown
+url = https://github.com/JonathonLuiten/TrackEval
+project_urls =
+ Bug Tracker = https://github.com/JonathonLuiten/TrackEval/issues
+classifiers =
+ Programming Language :: Python :: 3
+ Programming Language :: Python :: 3 :: Only
+ License :: OSI Approved :: MIT License
+ Operating System :: OS Independent
+ Topic :: Scientific/Engineering
+license_files = LICENSE
+
+[options]
+install_requires =
+ numpy
+ scipy
+packages = find:
+
+[options.packages.find]
+include = trackeval*
diff --git a/val_utils/setup.py b/val_utils/setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..606849326a4002007fd42060b51e69a19c18675c
--- /dev/null
+++ b/val_utils/setup.py
@@ -0,0 +1,3 @@
+from setuptools import setup
+
+setup()
diff --git a/val_utils/tests/test_all_quick.py b/val_utils/tests/test_all_quick.py
new file mode 100644
index 0000000000000000000000000000000000000000..89cd3e8c1b2061473ef148f10e60ffd07074d3f9
--- /dev/null
+++ b/val_utils/tests/test_all_quick.py
@@ -0,0 +1,75 @@
+""" Test to ensure that the code is working correctly.
+Should test ALL metrics across all datasets and splits currently supported.
+Only tests one tracker per dataset/split to give a quick test result.
+"""
+
+import sys
+import os
+import numpy as np
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+# Fixes multiprocessing on windows, does nothing otherwise
+if __name__ == '__main__':
+ freeze_support()
+
+eval_config = {'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ }
+evaluator = trackeval.Evaluator(eval_config)
+metrics_list = [trackeval.metrics.HOTA(), trackeval.metrics.CLEAR(), trackeval.metrics.Identity()]
+
+tests = [
+ {'DATASET': 'Kitti2DBox', 'SPLIT_TO_EVAL': 'training', 'TRACKERS_TO_EVAL': ['CIWT']},
+ {'DATASET': 'MotChallenge2DBox', 'BENCHMARK': 'MOT15', 'SPLIT_TO_EVAL': 'train', 'TRACKERS_TO_EVAL': ['MPNTrack']},
+ {'DATASET': 'MotChallenge2DBox', 'BENCHMARK': 'MOT16', 'SPLIT_TO_EVAL': 'train', 'TRACKERS_TO_EVAL': ['MPNTrack']},
+ {'DATASET': 'MotChallenge2DBox', 'BENCHMARK': 'MOT17', 'SPLIT_TO_EVAL': 'train', 'TRACKERS_TO_EVAL': ['MPNTrack']},
+ {'DATASET': 'MotChallenge2DBox', 'BENCHMARK': 'MOT20', 'SPLIT_TO_EVAL': 'train', 'TRACKERS_TO_EVAL': ['MPNTrack']},
+]
+
+for dataset_config in tests:
+
+ dataset_name = dataset_config.pop('DATASET')
+ if dataset_name == 'MotChallenge2DBox':
+ dataset_list = [trackeval.datasets.MotChallenge2DBox(dataset_config)]
+ file_loc = os.path.join('mot_challenge', dataset_config['BENCHMARK'] + '-' + dataset_config['SPLIT_TO_EVAL'])
+ elif dataset_name == 'Kitti2DBox':
+ dataset_list = [trackeval.datasets.Kitti2DBox(dataset_config)]
+ file_loc = os.path.join('kitti', 'kitti_2d_box_train')
+ else:
+ raise Exception('Dataset %s does not exist.' % dataset_name)
+
+ raw_results, messages = evaluator.evaluate(dataset_list, metrics_list)
+
+ classes = dataset_list[0].config['CLASSES_TO_EVAL']
+ tracker = dataset_config['TRACKERS_TO_EVAL'][0]
+ test_data_loc = os.path.join(os.path.dirname(__file__), '..', 'data', 'tests', file_loc)
+
+ for cls in classes:
+ results = {seq: raw_results[dataset_name][tracker][seq][cls] for seq in raw_results[dataset_name][tracker].keys()}
+ current_metrics_list = metrics_list + [trackeval.metrics.Count()]
+ metric_names = trackeval.utils.validate_metrics_list(current_metrics_list)
+
+ # Load expected results:
+ test_data = trackeval.utils.load_detail(os.path.join(test_data_loc, tracker, cls + '_detailed.csv'))
+
+ # Do checks
+ for seq in test_data.keys():
+ assert len(test_data[seq].keys()) > 250, len(test_data[seq].keys())
+
+ details = []
+ for metric, metric_name in zip(current_metrics_list, metric_names):
+ table_res = {seq_key: seq_value[metric_name] for seq_key, seq_value in results.items()}
+ details.append(metric.detailed_results(table_res))
+ res_fields = sum([list(s['COMBINED_SEQ'].keys()) for s in details], [])
+ res_values = sum([list(s[seq].values()) for s in details], [])
+ res_dict = dict(zip(res_fields, res_values))
+
+ for field in test_data[seq].keys():
+ assert np.isclose(res_dict[field], test_data[seq][field]), seq + ': ' + cls + ': ' + field
+
+ print('Tracker %s tests passed' % tracker)
+print('All tests passed')
+
diff --git a/val_utils/tests/test_davis.py b/val_utils/tests/test_davis.py
new file mode 100644
index 0000000000000000000000000000000000000000..dac0a3c957939edaae2a8b910ad2f1ce30f040bd
--- /dev/null
+++ b/val_utils/tests/test_davis.py
@@ -0,0 +1,68 @@
+import sys
+import os
+import numpy as np
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+# Fixes multiprocessing on windows, does nothing otherwise
+if __name__ == '__main__':
+ freeze_support()
+
+
+eval_config = {'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'PRINT_RESULTS': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'DISPLAY_LESS_PROGRESS': True,
+ 'OUTPUT_SUMMARY': False,
+ 'OUTPUT_EMPTY_CLASSES': False,
+ 'OUTPUT_DETAILED': False,
+ 'PLOT_CURVES': False,
+ }
+evaluator = trackeval.Evaluator(eval_config)
+metrics_list = [trackeval.metrics.HOTA(), trackeval.metrics.CLEAR(), trackeval.metrics.Identity(),
+ trackeval.metrics.JAndF()]
+
+tests = [
+ {'SPLIT_TO_EVAL': 'val', 'TRACKERS_TO_EVAL': ['ags']},
+]
+
+for dataset_config in tests:
+
+ dataset_list = [trackeval.datasets.DAVIS(dataset_config)]
+ file_loc = os.path.join('davis', 'davis_unsupervised_' + dataset_config['SPLIT_TO_EVAL'])
+
+ raw_results, messages = evaluator.evaluate(dataset_list, metrics_list)
+
+ classes = dataset_list[0].config['CLASSES_TO_EVAL']
+ tracker = dataset_config['TRACKERS_TO_EVAL'][0]
+ test_data_loc = os.path.join(os.path.dirname(__file__), '..', 'data', 'tests', file_loc)
+
+ for cls in classes:
+ results = {seq: raw_results['DAVIS'][tracker][seq][cls] for seq in raw_results['DAVIS'][tracker].keys()}
+ current_metrics_list = metrics_list + [trackeval.metrics.Count()]
+ metric_names = trackeval.utils.validate_metrics_list(current_metrics_list)
+
+ # Load expected results:
+ test_data = trackeval.utils.load_detail(os.path.join(test_data_loc, tracker, cls + '_detailed.csv'))
+
+ # Do checks
+ for seq in test_data.keys():
+ assert len(test_data[seq].keys()) > 250, len(test_data[seq].keys())
+
+ details = []
+ for metric, metric_name in zip(current_metrics_list, metric_names):
+ table_res = {seq_key: seq_value[metric_name] for seq_key, seq_value in results.items()}
+ details.append(metric.detailed_results(table_res))
+ res_fields = sum([list(s['COMBINED_SEQ'].keys()) for s in details], [])
+ res_values = sum([list(s[seq].values()) for s in details], [])
+ res_dict = dict(zip(res_fields, res_values))
+
+ for field in test_data[seq].keys():
+ assert np.isclose(res_dict[field], test_data[seq][field]), seq + ': ' + cls + ': ' + field
+
+ print('Tracker %s tests passed' % tracker)
+print('All tests passed')
\ No newline at end of file
diff --git a/val_utils/tests/test_metrics.py b/val_utils/tests/test_metrics.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4738245fb69a0071486a806a6063aaf8e63773b
--- /dev/null
+++ b/val_utils/tests/test_metrics.py
@@ -0,0 +1,212 @@
+import numpy as np
+import pytest
+
+import trackeval
+
+
+def no_confusion():
+ num_timesteps = 5
+ num_gt_ids = 2
+ num_tracker_ids = 2
+
+ # No overlap between pairs (0, 0) and (1, 1).
+ similarity = np.zeros([num_timesteps, num_gt_ids, num_tracker_ids])
+ similarity[:, 0, 1] = [0, 0, 0, 1, 1]
+ similarity[:, 1, 0] = [1, 1, 0, 0, 0]
+ gt_present = np.zeros([num_timesteps, num_gt_ids])
+ gt_present[:, 0] = [1, 1, 1, 1, 1]
+ gt_present[:, 1] = [1, 1, 1, 0, 0]
+ tracker_present = np.zeros([num_timesteps, num_tracker_ids])
+ tracker_present[:, 0] = [1, 1, 1, 1, 0]
+ tracker_present[:, 1] = [1, 1, 1, 1, 1]
+
+ expected = {
+ 'clear': {
+ 'CLR_TP': 4,
+ 'CLR_FN': 4,
+ 'CLR_FP': 5,
+ 'IDSW': 0,
+ 'MOTA': 1 - 9 / 8,
+ },
+ 'identity': {
+ 'IDTP': 4,
+ 'IDFN': 4,
+ 'IDFP': 5,
+ 'IDR': 4 / 8,
+ 'IDP': 4 / 9,
+ 'IDF1': 2 * 4 / 17,
+ },
+ 'vace': {
+ 'STDA': 2 / 5 + 2 / 4,
+ 'ATA': (2 / 5 + 2 / 4) / 2,
+ },
+ }
+
+ data = _from_dense(
+ num_timesteps=num_timesteps,
+ num_gt_ids=num_gt_ids,
+ num_tracker_ids=num_tracker_ids,
+ gt_present=gt_present,
+ tracker_present=tracker_present,
+ similarity=similarity,
+ )
+ return data, expected
+
+
+def with_confusion():
+ num_timesteps = 5
+ num_gt_ids = 2
+ num_tracker_ids = 2
+
+ similarity = np.zeros([num_timesteps, num_gt_ids, num_tracker_ids])
+ similarity[:, 0, 1] = [0, 0, 0, 1, 1]
+ similarity[:, 1, 0] = [1, 1, 0, 0, 0]
+ # Add some overlap between (0, 0) and (1, 1).
+ similarity[:, 0, 0] = [0, 0, 1, 0, 0]
+ similarity[:, 1, 1] = [0, 1, 0, 0, 0]
+ gt_present = np.zeros([num_timesteps, num_gt_ids])
+ gt_present[:, 0] = [1, 1, 1, 1, 1]
+ gt_present[:, 1] = [1, 1, 1, 0, 0]
+ tracker_present = np.zeros([num_timesteps, num_tracker_ids])
+ tracker_present[:, 0] = [1, 1, 1, 1, 0]
+ tracker_present[:, 1] = [1, 1, 1, 1, 1]
+
+ expected = {
+ 'clear': {
+ 'CLR_TP': 5,
+ 'CLR_FN': 3, # 8 - 5
+ 'CLR_FP': 4, # 9 - 5
+ 'IDSW': 1,
+ 'MOTA': 1 - 8 / 8,
+ },
+ 'identity': {
+ 'IDTP': 4,
+ 'IDFN': 4,
+ 'IDFP': 5,
+ 'IDR': 4 / 8,
+ 'IDP': 4 / 9,
+ 'IDF1': 2 * 4 / 17,
+ },
+ 'vace': {
+ 'STDA': 2 / 5 + 2 / 4,
+ 'ATA': (2 / 5 + 2 / 4) / 2,
+ },
+ }
+
+ data = _from_dense(
+ num_timesteps=num_timesteps,
+ num_gt_ids=num_gt_ids,
+ num_tracker_ids=num_tracker_ids,
+ gt_present=gt_present,
+ tracker_present=tracker_present,
+ similarity=similarity,
+ )
+ return data, expected
+
+
+def split_tracks():
+ num_timesteps = 5
+ num_gt_ids = 2
+ num_tracker_ids = 5
+
+ similarity = np.zeros([num_timesteps, num_gt_ids, num_tracker_ids])
+ # Split ground-truth 0 between tracks 0, 3.
+ similarity[:, 0, 0] = [1, 1, 0, 0, 0]
+ similarity[:, 0, 3] = [0, 0, 0, 1, 1]
+ # Split ground-truth 1 between tracks 1, 2, 4.
+ similarity[:, 1, 1] = [0, 0, 1, 1, 0]
+ similarity[:, 1, 2] = [0, 0, 0, 0, 1]
+ similarity[:, 1, 4] = [1, 1, 0, 0, 0]
+ gt_present = np.zeros([num_timesteps, num_gt_ids])
+ gt_present[:, 0] = [1, 1, 0, 1, 1]
+ gt_present[:, 1] = [1, 1, 1, 1, 1]
+ tracker_present = np.zeros([num_timesteps, num_tracker_ids])
+ tracker_present[:, 0] = [1, 1, 0, 0, 0]
+ tracker_present[:, 1] = [0, 0, 1, 1, 1]
+ tracker_present[:, 2] = [0, 0, 0, 0, 1]
+ tracker_present[:, 3] = [0, 0, 1, 1, 1]
+ tracker_present[:, 4] = [1, 1, 0, 0, 0]
+
+ expected = {
+ 'clear': {
+ 'CLR_TP': 9,
+ 'CLR_FN': 0, # 9 - 9
+ 'CLR_FP': 2, # 11 - 9
+ 'IDSW': 3,
+ 'MOTA': 1 - 5 / 9,
+ },
+ 'identity': {
+ 'IDTP': 4,
+ 'IDFN': 5, # 9 - 4
+ 'IDFP': 7, # 11 - 4
+ 'IDR': 4 / 9,
+ 'IDP': 4 / 11,
+ 'IDF1': 2 * 4 / 20,
+ },
+ 'vace': {
+ 'STDA': 2 / 4 + 2 / 5,
+ 'ATA': (2 / 4 + 2 / 5) / (0.5 * (2 + 5)),
+ },
+ }
+
+ data = _from_dense(
+ num_timesteps=num_timesteps,
+ num_gt_ids=num_gt_ids,
+ num_tracker_ids=num_tracker_ids,
+ gt_present=gt_present,
+ tracker_present=tracker_present,
+ similarity=similarity,
+ )
+ return data, expected
+
+
+def _from_dense(num_timesteps, num_gt_ids, num_tracker_ids, gt_present, tracker_present, similarity):
+ gt_subset = [np.flatnonzero(gt_present[t, :]) for t in range(num_timesteps)]
+ tracker_subset = [np.flatnonzero(tracker_present[t, :]) for t in range(num_timesteps)]
+ similarity_subset = [
+ similarity[t][gt_subset[t], :][:, tracker_subset[t]]
+ for t in range(num_timesteps)
+ ]
+ data = {
+ 'num_timesteps': num_timesteps,
+ 'num_gt_ids': num_gt_ids,
+ 'num_tracker_ids': num_tracker_ids,
+ 'num_gt_dets': np.sum(gt_present),
+ 'num_tracker_dets': np.sum(tracker_present),
+ 'gt_ids': gt_subset,
+ 'tracker_ids': tracker_subset,
+ 'similarity_scores': similarity_subset,
+ }
+ return data
+
+
+METRICS_BY_NAME = {
+ 'clear': trackeval.metrics.CLEAR(),
+ 'identity': trackeval.metrics.Identity(),
+ 'vace': trackeval.metrics.VACE(),
+}
+
+SEQUENCE_BY_NAME = {
+ 'no_confusion': no_confusion(),
+ 'with_confusion': with_confusion(),
+ 'split_tracks': split_tracks(),
+}
+
+
+@pytest.mark.parametrize('sequence_name,metric_name', [
+ ('no_confusion', 'clear'),
+ ('no_confusion', 'identity'),
+ ('no_confusion', 'vace'),
+ ('with_confusion', 'clear'),
+ ('with_confusion', 'identity'),
+ ('with_confusion', 'vace'),
+ ('split_tracks', 'clear'),
+ ('split_tracks', 'identity'),
+ ('split_tracks', 'vace'),
+])
+def test_metric(sequence_name, metric_name):
+ data, expected = SEQUENCE_BY_NAME[sequence_name]
+ metric = METRICS_BY_NAME[metric_name]
+ result = metric.eval_sequence(data)
+ for key, value in expected[metric_name].items():
+ assert result[key] == pytest.approx(value), key
diff --git a/val_utils/tests/test_mot17.py b/val_utils/tests/test_mot17.py
new file mode 100644
index 0000000000000000000000000000000000000000..92b9375428a63ab9e8eb8985de3baa16f01ae1f0
--- /dev/null
+++ b/val_utils/tests/test_mot17.py
@@ -0,0 +1,76 @@
+""" Test to ensure that the code is working correctly.
+Runs all metrics on 14 trackers for the MOT Challenge MOT17 benchmark.
+"""
+
+
+import sys
+import os
+import numpy as np
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+# Fixes multiprocessing on windows, does nothing otherwise
+if __name__ == '__main__':
+ freeze_support()
+
+eval_config = {'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ }
+evaluator = trackeval.Evaluator(eval_config)
+metrics_list = [trackeval.metrics.HOTA(), trackeval.metrics.CLEAR(), trackeval.metrics.Identity()]
+test_data_loc = os.path.join(os.path.dirname(__file__), '..', 'data', 'tests', 'mot_challenge', 'MOT17-train')
+trackers = [
+ 'DPMOT',
+ 'GNNMatch',
+ 'IA',
+ 'ISE_MOT17R',
+ 'Lif_T',
+ 'Lif_TsimInt',
+ 'LPC_MOT',
+ 'MAT',
+ 'MIFTv2',
+ 'MPNTrack',
+ 'SSAT',
+ 'TracktorCorr',
+ 'Tracktorv2',
+ 'UnsupTrack',
+]
+
+for tracker in trackers:
+ # Run code on tracker
+ dataset_config = {'TRACKERS_TO_EVAL': [tracker],
+ 'BENCHMARK': 'MOT17'}
+ dataset_list = [trackeval.datasets.MotChallenge2DBox(dataset_config)]
+ raw_results, messages = evaluator.evaluate(dataset_list, metrics_list)
+
+ results = {seq: raw_results['MotChallenge2DBox'][tracker][seq]['pedestrian'] for seq in
+ raw_results['MotChallenge2DBox'][tracker].keys()}
+ current_metrics_list = metrics_list + [trackeval.metrics.Count()]
+ metric_names = trackeval.utils.validate_metrics_list(current_metrics_list)
+
+ # Load expected results:
+ test_data = trackeval.utils.load_detail(os.path.join(test_data_loc, tracker, 'pedestrian_detailed.csv'))
+ assert len(test_data.keys()) == 22, len(test_data.keys())
+
+ # Do checks
+ for seq in test_data.keys():
+ assert len(test_data[seq].keys()) > 250, len(test_data[seq].keys())
+
+ details = []
+ for metric, metric_name in zip(current_metrics_list, metric_names):
+ table_res = {seq_key: seq_value[metric_name] for seq_key, seq_value in results.items()}
+ details.append(metric.detailed_results(table_res))
+ res_fields = sum([list(s['COMBINED_SEQ'].keys()) for s in details], [])
+ res_values = sum([list(s[seq].values()) for s in details], [])
+ res_dict = dict(zip(res_fields, res_values))
+
+ for field in test_data[seq].keys():
+ if not np.isclose(res_dict[field], test_data[seq][field]):
+ print(tracker, seq, res_dict[field], test_data[seq][field], field)
+ raise AssertionError
+
+ print('Tracker %s tests passed' % tracker)
+print('All tests passed')
+
diff --git a/val_utils/tests/test_mots.py b/val_utils/tests/test_mots.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b80c83dfcbb10a20823737aeaddca9b36d4df5d
--- /dev/null
+++ b/val_utils/tests/test_mots.py
@@ -0,0 +1,66 @@
+import sys
+import os
+import numpy as np
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+
+# Fixes multiprocessing on windows, does nothing otherwise
+if __name__ == '__main__':
+ freeze_support()
+
+eval_config = {'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ }
+evaluator = trackeval.Evaluator(eval_config)
+metrics_list = [trackeval.metrics.HOTA(), trackeval.metrics.CLEAR(), trackeval.metrics.Identity()]
+
+tests = [
+ {'DATASET': 'KittiMOTS', 'SPLIT_TO_EVAL': 'val', 'TRACKERS_TO_EVAL': ['trackrcnn']},
+ {'DATASET': 'MOTSChallenge', 'SPLIT_TO_EVAL': 'train', 'TRACKERS_TO_EVAL': ['TrackRCNN']}
+]
+
+for dataset_config in tests:
+
+ dataset_name = dataset_config.pop('DATASET')
+ if dataset_name == 'MOTSChallenge':
+ dataset_list = [trackeval.datasets.MOTSChallenge(dataset_config)]
+ file_loc = os.path.join('mot_challenge', 'MOTS-' + dataset_config['SPLIT_TO_EVAL'])
+ elif dataset_name == 'KittiMOTS':
+ dataset_list = [trackeval.datasets.KittiMOTS(dataset_config)]
+ file_loc = os.path.join('kitti', 'kitti_mots_val')
+ else:
+ raise Exception('Dataset %s does not exist.' % dataset_name)
+
+ raw_results, messages = evaluator.evaluate(dataset_list, metrics_list)
+
+ classes = dataset_list[0].config['CLASSES_TO_EVAL']
+ tracker = dataset_config['TRACKERS_TO_EVAL'][0]
+ test_data_loc = os.path.join(os.path.dirname(__file__), '..', 'data', 'tests', file_loc)
+
+ for cls in classes:
+ results = {seq: raw_results[dataset_name][tracker][seq][cls] for seq in raw_results[dataset_name][tracker].keys()}
+ current_metrics_list = metrics_list + [trackeval.metrics.Count()]
+ metric_names = trackeval.utils.validate_metrics_list(current_metrics_list)
+
+ # Load expected results:
+ test_data = trackeval.utils.load_detail(os.path.join(test_data_loc, tracker, cls + '_detailed.csv'))
+
+ # Do checks
+ for seq in test_data.keys():
+ assert len(test_data[seq].keys()) > 250, len(test_data[seq].keys())
+
+ details = []
+ for metric, metric_name in zip(current_metrics_list, metric_names):
+ table_res = {seq_key: seq_value[metric_name] for seq_key, seq_value in results.items()}
+ details.append(metric.detailed_results(table_res))
+ res_fields = sum([list(s['COMBINED_SEQ'].keys()) for s in details], [])
+ res_values = sum([list(s[seq].values()) for s in details], [])
+ res_dict = dict(zip(res_fields, res_values))
+
+ for field in test_data[seq].keys():
+ assert np.isclose(res_dict[field], test_data[seq][field]), seq + ': ' + cls + ': ' + field
+
+ print('Tracker %s tests passed' % tracker)
+print('All tests passed')
\ No newline at end of file
diff --git a/val_utils/trackeval/__init__.py b/val_utils/trackeval/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..dce62dab74cda480450101fdad794a9a87485ba7
--- /dev/null
+++ b/val_utils/trackeval/__init__.py
@@ -0,0 +1,5 @@
+from .eval import Evaluator
+from . import datasets
+from . import metrics
+from . import plotting
+from . import utils
diff --git a/val_utils/trackeval/_timing.py b/val_utils/trackeval/_timing.py
new file mode 100644
index 0000000000000000000000000000000000000000..4614ba3162ad8143b4e9b3c8d9bc286e7a684f4c
--- /dev/null
+++ b/val_utils/trackeval/_timing.py
@@ -0,0 +1,65 @@
+from functools import wraps
+from time import perf_counter
+import inspect
+
+DO_TIMING = False
+DISPLAY_LESS_PROGRESS = False
+timer_dict = {}
+counter = 0
+
+
+def time(f):
+ @wraps(f)
+ def wrap(*args, **kw):
+ if DO_TIMING:
+ # Run function with timing
+ ts = perf_counter()
+ result = f(*args, **kw)
+ te = perf_counter()
+ tt = te-ts
+
+ # Get function name
+ arg_names = inspect.getfullargspec(f)[0]
+ if arg_names[0] == 'self' and DISPLAY_LESS_PROGRESS:
+ return result
+ elif arg_names[0] == 'self':
+ method_name = type(args[0]).__name__ + '.' + f.__name__
+ else:
+ method_name = f.__name__
+
+ # Record accumulative time in each function for analysis
+ if method_name in timer_dict.keys():
+ timer_dict[method_name] += tt
+ else:
+ timer_dict[method_name] = tt
+
+ # If code is finished, display timing summary
+ if method_name == "Evaluator.evaluate":
+ print("")
+ print("Timing analysis:")
+ for key, value in timer_dict.items():
+ print('%-70s %2.4f sec' % (key, value))
+ else:
+ # Get function argument values for printing special arguments of interest
+ arg_titles = ['tracker', 'seq', 'cls']
+ arg_vals = []
+ for i, a in enumerate(arg_names):
+ if a in arg_titles:
+ arg_vals.append(args[i])
+ arg_text = '(' + ', '.join(arg_vals) + ')'
+
+ # Display methods and functions with different indentation.
+ if arg_names[0] == 'self':
+ print('%-74s %2.4f sec' % (' '*4 + method_name + arg_text, tt))
+ elif arg_names[0] == 'test':
+ pass
+ else:
+ global counter
+ counter += 1
+ print('%i %-70s %2.4f sec' % (counter, method_name + arg_text, tt))
+
+ return result
+ else:
+ # If config["TIME_PROGRESS"] is false, or config["USE_PARALLEL"] is true, run functions normally without timing.
+ return f(*args, **kw)
+ return wrap
diff --git a/val_utils/trackeval/baselines/__init__.py b/val_utils/trackeval/baselines/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ddc9864ddcbcc44fcac3edd60b8a34a9879996aa
--- /dev/null
+++ b/val_utils/trackeval/baselines/__init__.py
@@ -0,0 +1,6 @@
+import baseline_utils
+import stp
+import non_overlap
+import pascal_colormap
+import thresholder
+import vizualize
\ No newline at end of file
diff --git a/val_utils/trackeval/baselines/baseline_utils.py b/val_utils/trackeval/baselines/baseline_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..b6c88fd9c9d6556d6ae1d01f421c4b15bdb0cda3
--- /dev/null
+++ b/val_utils/trackeval/baselines/baseline_utils.py
@@ -0,0 +1,321 @@
+
+import os
+import csv
+import numpy as np
+from copy import deepcopy
+from PIL import Image
+from pycocotools import mask as mask_utils
+from scipy.optimize import linear_sum_assignment
+from trackeval.baselines.pascal_colormap import pascal_colormap
+
+
+def load_seq(file_to_load):
+ """ Load input data from file in RobMOTS format (e.g. provided detections).
+ Returns: Data object with the following structure (see STP :
+ data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
+ """
+ fp = open(file_to_load)
+ dialect = csv.Sniffer().sniff(fp.readline(), delimiters=' ')
+ dialect.skipinitialspace = True
+ fp.seek(0)
+ reader = csv.reader(fp, dialect)
+ read_data = {}
+ num_timesteps = 0
+ for i, row in enumerate(reader):
+ if row[-1] in '':
+ row = row[:-1]
+ t = int(row[0])
+ cid = row[1]
+ c = int(row[2])
+ s = row[3]
+ h = row[4]
+ w = row[5]
+ rle = row[6]
+
+ if t >= num_timesteps:
+ num_timesteps = t + 1
+
+ if c in read_data.keys():
+ if t in read_data[c].keys():
+ read_data[c][t]['ids'].append(cid)
+ read_data[c][t]['scores'].append(s)
+ read_data[c][t]['im_hs'].append(h)
+ read_data[c][t]['im_ws'].append(w)
+ read_data[c][t]['mask_rles'].append(rle)
+ else:
+ read_data[c][t] = {}
+ read_data[c][t]['ids'] = [cid]
+ read_data[c][t]['scores'] = [s]
+ read_data[c][t]['im_hs'] = [h]
+ read_data[c][t]['im_ws'] = [w]
+ read_data[c][t]['mask_rles'] = [rle]
+ else:
+ read_data[c] = {t: {}}
+ read_data[c][t]['ids'] = [cid]
+ read_data[c][t]['scores'] = [s]
+ read_data[c][t]['im_hs'] = [h]
+ read_data[c][t]['im_ws'] = [w]
+ read_data[c][t]['mask_rles'] = [rle]
+ fp.close()
+
+ data = {}
+ for c in read_data.keys():
+ data[c] = [{} for _ in range(num_timesteps)]
+ for t in range(num_timesteps):
+ if t in read_data[c].keys():
+ data[c][t]['ids'] = np.atleast_1d(read_data[c][t]['ids']).astype(int)
+ data[c][t]['scores'] = np.atleast_1d(read_data[c][t]['scores']).astype(float)
+ data[c][t]['im_hs'] = np.atleast_1d(read_data[c][t]['im_hs']).astype(int)
+ data[c][t]['im_ws'] = np.atleast_1d(read_data[c][t]['im_ws']).astype(int)
+ data[c][t]['mask_rles'] = np.atleast_1d(read_data[c][t]['mask_rles']).astype(str)
+ else:
+ data[c][t]['ids'] = np.empty(0).astype(int)
+ data[c][t]['scores'] = np.empty(0).astype(float)
+ data[c][t]['im_hs'] = np.empty(0).astype(int)
+ data[c][t]['im_ws'] = np.empty(0).astype(int)
+ data[c][t]['mask_rles'] = np.empty(0).astype(str)
+ return data
+
+
+def threshold(tdata, thresh):
+ """ Removes detections below a certian threshold ('thresh') score. """
+ new_data = {}
+ to_keep = tdata['scores'] > thresh
+ for field in ['ids', 'scores', 'im_hs', 'im_ws', 'mask_rles']:
+ new_data[field] = tdata[field][to_keep]
+ return new_data
+
+
+def create_coco_mask(mask_rles, im_hs, im_ws):
+ """ Converts mask as rle text (+ height and width) to encoded version used by pycocotools. """
+ coco_masks = [{'size': [h, w], 'counts': m.encode(encoding='UTF-8')}
+ for h, w, m in zip(im_hs, im_ws, mask_rles)]
+ return coco_masks
+
+
+def mask_iou(mask_rles1, mask_rles2, im_hs, im_ws, do_ioa=0):
+ """ Calculate mask IoU between two masks.
+ Further allows 'intersection over area' instead of IoU (over the area of mask_rle1).
+ Allows either to pass in 1 boolean for do_ioa for all mask_rles2 or also one for each mask_rles2.
+ It is recommended that mask_rles1 is a detection and mask_rles2 is a groundtruth.
+ """
+ coco_masks1 = create_coco_mask(mask_rles1, im_hs, im_ws)
+ coco_masks2 = create_coco_mask(mask_rles2, im_hs, im_ws)
+
+ if not hasattr(do_ioa, "__len__"):
+ do_ioa = [do_ioa]*len(coco_masks2)
+ assert(len(coco_masks2) == len(do_ioa))
+ if len(coco_masks1) == 0 or len(coco_masks2) == 0:
+ iou = np.zeros(len(coco_masks1), len(coco_masks2))
+ else:
+ iou = mask_utils.iou(coco_masks1, coco_masks2, do_ioa)
+ return iou
+
+
+def sort_by_score(t_data):
+ """ Sorts data by score """
+ sort_index = np.argsort(t_data['scores'])[::-1]
+ for k in t_data.keys():
+ t_data[k] = t_data[k][sort_index]
+ return t_data
+
+
+def mask_NMS(t_data, nms_threshold=0.5, already_sorted=False):
+ """ Remove redundant masks by performing non-maximum suppression (NMS) """
+
+ # Sort by score
+ if not already_sorted:
+ t_data = sort_by_score(t_data)
+
+ # Calculate the mask IoU between all detections in the timestep.
+ mask_ious_all = mask_iou(t_data['mask_rles'], t_data['mask_rles'], t_data['im_hs'], t_data['im_ws'])
+
+ # Determine which masks NMS should remove
+ # (those overlapping greater than nms_threshold with another mask that has a higher score)
+ num_dets = len(t_data['mask_rles'])
+ to_remove = [False for _ in range(num_dets)]
+ for i in range(num_dets):
+ if not to_remove[i]:
+ for j in range(i + 1, num_dets):
+ if mask_ious_all[i, j] > nms_threshold:
+ to_remove[j] = True
+
+ # Remove detections which should be removed
+ to_keep = np.logical_not(to_remove)
+ for k in t_data.keys():
+ t_data[k] = t_data[k][to_keep]
+
+ return t_data
+
+
+def non_overlap(t_data, already_sorted=False):
+ """ Enforces masks to be non-overlapping in an image, does this by putting masks 'on top of one another',
+ such that higher score masks 'occlude' and thus remove parts of lower scoring masks.
+
+ Help wanted: if anyone knows a way to do this WITHOUT converting the RLE to the np.array let me know, because that
+ would be MUCH more efficient. (I have tried, but haven't yet had success).
+ """
+
+ # Sort by score
+ if not already_sorted:
+ t_data = sort_by_score(t_data)
+
+ # Get coco masks
+ coco_masks = create_coco_mask(t_data['mask_rles'], t_data['im_hs'], t_data['im_ws'])
+
+ # Create a single np.array to hold all of the non-overlapping mask
+ masks_array = np.zeros((t_data['im_hs'][0], t_data['im_ws'][0]), 'uint8')
+
+ # Decode each mask into a np.array, and place it into the overall array for the whole frame.
+ # Since masks with the lowest score are placed first, they are 'partially overridden' by masks with a higher score
+ # if they overlap.
+ for i, mask in enumerate(coco_masks[::-1]):
+ masks_array[mask_utils.decode(mask).astype('bool')] = i + 1
+
+ # Encode the resulting np.array back into a set of coco_masks which are now non-overlapping.
+ num_dets = len(coco_masks)
+ for i, j in enumerate(range(1, num_dets + 1)[::-1]):
+ coco_masks[i] = mask_utils.encode(np.asfortranarray(masks_array == j, dtype=np.uint8))
+
+ # Convert from coco_mask back into our mask_rle format.
+ t_data['mask_rles'] = [m['counts'].decode("utf-8") for m in coco_masks]
+
+ return t_data
+
+
+def masks2boxes(mask_rles, im_hs, im_ws):
+ """ Extracts bounding boxes which surround a set of masks. """
+ coco_masks = create_coco_mask(mask_rles, im_hs, im_ws)
+ boxes = np.array([mask_utils.toBbox(x) for x in coco_masks])
+ if len(boxes) == 0:
+ boxes = np.empty((0, 4))
+ return boxes
+
+
+def box_iou(bboxes1, bboxes2, box_format='xywh', do_ioa=False, do_giou=False):
+ """ Calculates the IOU (intersection over union) between two arrays of boxes.
+ Allows variable box formats ('xywh' and 'x0y0x1y1').
+ If do_ioa (intersection over area), then calculates the intersection over the area of boxes1 - this is commonly
+ used to determine if detections are within crowd ignore region.
+ If do_giou (generalized intersection over union, then calculates giou.
+ """
+ if len(bboxes1) == 0 or len(bboxes2) == 0:
+ ious = np.zeros((len(bboxes1), len(bboxes2)))
+ return ious
+ if box_format in 'xywh':
+ # layout: (x0, y0, w, h)
+ bboxes1 = deepcopy(bboxes1)
+ bboxes2 = deepcopy(bboxes2)
+
+ bboxes1[:, 2] = bboxes1[:, 0] + bboxes1[:, 2]
+ bboxes1[:, 3] = bboxes1[:, 1] + bboxes1[:, 3]
+ bboxes2[:, 2] = bboxes2[:, 0] + bboxes2[:, 2]
+ bboxes2[:, 3] = bboxes2[:, 1] + bboxes2[:, 3]
+ elif box_format not in 'x0y0x1y1':
+ raise (Exception('box_format %s is not implemented' % box_format))
+
+ # layout: (x0, y0, x1, y1)
+ min_ = np.minimum(bboxes1[:, np.newaxis, :], bboxes2[np.newaxis, :, :])
+ max_ = np.maximum(bboxes1[:, np.newaxis, :], bboxes2[np.newaxis, :, :])
+ intersection = np.maximum(min_[..., 2] - max_[..., 0], 0) * np.maximum(min_[..., 3] - max_[..., 1], 0)
+ area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * (bboxes1[..., 3] - bboxes1[..., 1])
+
+ if do_ioa:
+ ioas = np.zeros_like(intersection)
+ valid_mask = area1 > 0 + np.finfo('float').eps
+ ioas[valid_mask, :] = intersection[valid_mask, :] / area1[valid_mask][:, np.newaxis]
+
+ return ioas
+ else:
+ area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * (bboxes2[..., 3] - bboxes2[..., 1])
+ union = area1[:, np.newaxis] + area2[np.newaxis, :] - intersection
+ intersection[area1 <= 0 + np.finfo('float').eps, :] = 0
+ intersection[:, area2 <= 0 + np.finfo('float').eps] = 0
+ intersection[union <= 0 + np.finfo('float').eps] = 0
+ union[union <= 0 + np.finfo('float').eps] = 1
+ ious = intersection / union
+
+ if do_giou:
+ enclosing_area = np.maximum(max_[..., 2] - min_[..., 0], 0) * np.maximum(max_[..., 3] - min_[..., 1], 0)
+ eps = 1e-7
+ # giou
+ ious = ious - ((enclosing_area - union) / (enclosing_area + eps))
+
+ return ious
+
+
+def match(match_scores):
+ match_rows, match_cols = linear_sum_assignment(-match_scores)
+ return match_rows, match_cols
+
+
+def write_seq(output_data, out_file):
+ out_loc = os.path.dirname(out_file)
+ if not os.path.exists(out_loc):
+ os.makedirs(out_loc, exist_ok=True)
+ fp = open(out_file, 'w', newline='')
+ writer = csv.writer(fp, delimiter=' ')
+ for row in output_data:
+ writer.writerow(row)
+ fp.close()
+
+
+def combine_classes(data):
+ """ Converts data from a class-separated to a class-combined format.
+ Input format: data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
+ Output format: data[t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles', 'cls'}
+ """
+ output_data = [{} for _ in list(data.values())[0]]
+ for cls, cls_data in data.items():
+ for timestep, t_data in enumerate(cls_data):
+ for k in t_data.keys():
+ if k in output_data[timestep].keys():
+ output_data[timestep][k] += list(t_data[k])
+ else:
+ output_data[timestep][k] = list(t_data[k])
+ if 'cls' in output_data[timestep].keys():
+ output_data[timestep]['cls'] += [cls]*len(output_data[timestep]['ids'])
+ else:
+ output_data[timestep]['cls'] = [cls]*len(output_data[timestep]['ids'])
+
+ for timestep, t_data in enumerate(output_data):
+ for k in t_data.keys():
+ output_data[timestep][k] = np.array(output_data[timestep][k])
+
+ return output_data
+
+
+def save_as_png(t_data, out_file, im_h, im_w):
+ """ Save a set of segmentation masks into a PNG format, the same as used for the DAVIS dataset."""
+
+ if len(t_data['mask_rles']) > 0:
+ coco_masks = create_coco_mask(t_data['mask_rles'], t_data['im_hs'], t_data['im_ws'])
+
+ list_of_np_masks = [mask_utils.decode(mask) for mask in coco_masks]
+
+ png = np.zeros((t_data['im_hs'][0], t_data['im_ws'][0]))
+ for mask, c_id in zip(list_of_np_masks, t_data['ids']):
+ png[mask.astype("bool")] = c_id + 1
+ else:
+ png = np.zeros((im_h, im_w))
+
+ if not os.path.exists(os.path.dirname(out_file)):
+ os.makedirs(os.path.dirname(out_file))
+
+ colmap = (np.array(pascal_colormap) * 255).round().astype("uint8")
+ palimage = Image.new('P', (16, 16))
+ palimage.putpalette(colmap)
+ im = Image.fromarray(np.squeeze(png.astype("uint8")))
+ im2 = im.quantize(palette=palimage)
+ im2.save(out_file)
+
+
+def get_frame_size(data):
+ """ Gets frame height and width from data. """
+ for cls, cls_data in data.items():
+ for timestep, t_data in enumerate(cls_data):
+ if len(t_data['im_hs'] > 0):
+ im_h = t_data['im_hs'][0]
+ im_w = t_data['im_ws'][0]
+ return im_h, im_w
+ return None
diff --git a/val_utils/trackeval/baselines/non_overlap.py b/val_utils/trackeval/baselines/non_overlap.py
new file mode 100644
index 0000000000000000000000000000000000000000..43b131d01664501d9db45fbe9acf3b2d856a229f
--- /dev/null
+++ b/val_utils/trackeval/baselines/non_overlap.py
@@ -0,0 +1,92 @@
+"""
+Non-Overlap: Code to take in a set of raw detections and produce a set of non-overlapping detections from it.
+
+Author: Jonathon Luiten
+"""
+
+import os
+import sys
+from multiprocessing.pool import Pool
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
+from trackeval.baselines import baseline_utils as butils
+from trackeval.utils import get_code_path
+
+code_path = get_code_path()
+config = {
+ 'INPUT_FOL': os.path.join(code_path, 'data/detections/rob_mots/{split}/raw_supplied/data/'),
+ 'OUTPUT_FOL': os.path.join(code_path, 'data/detections/rob_mots/{split}/non_overlap_supplied/data/'),
+ 'SPLIT': 'train', # valid: 'train', 'val', 'test'.
+ 'Benchmarks': None, # If None, all benchmarks in SPLIT.
+
+ 'Num_Parallel_Cores': None, # If None, run without parallel.
+
+ 'THRESHOLD_NMS_MASK_IOU': 0.5,
+}
+
+
+def do_sequence(seq_file):
+
+ # Load input data from file (e.g. provided detections)
+ # data format: data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
+ data = butils.load_seq(seq_file)
+
+ # Converts data from a class-separated to a class-combined format.
+ # data[t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles', 'cls'}
+ data = butils.combine_classes(data)
+
+ # Where to accumulate output data for writing out
+ output_data = []
+
+ # Run for each timestep.
+ for timestep, t_data in enumerate(data):
+
+ # Remove redundant masks by performing non-maximum suppression (NMS)
+ t_data = butils.mask_NMS(t_data, nms_threshold=config['THRESHOLD_NMS_MASK_IOU'])
+
+ # Perform non-overlap, to get non_overlapping masks.
+ t_data = butils.non_overlap(t_data, already_sorted=True)
+
+ # Save result in output format to write to file later.
+ # Output Format = [timestep ID class score im_h im_w mask_RLE]
+ for i in range(len(t_data['ids'])):
+ row = [timestep, int(t_data['ids'][i]), t_data['cls'][i], t_data['scores'][i], t_data['im_hs'][i],
+ t_data['im_ws'][i], t_data['mask_rles'][i]]
+ output_data.append(row)
+
+ # Write results to file
+ out_file = seq_file.replace(config['INPUT_FOL'].format(split=config['SPLIT']),
+ config['OUTPUT_FOL'].format(split=config['SPLIT']))
+ butils.write_seq(output_data, out_file)
+
+ print('DONE:', seq_file)
+
+
+if __name__ == '__main__':
+
+ # Required to fix bug in multiprocessing on windows.
+ freeze_support()
+
+ # Obtain list of sequences to run tracker for.
+ if config['Benchmarks']:
+ benchmarks = config['Benchmarks']
+ else:
+ benchmarks = ['davis_unsupervised', 'kitti_mots', 'youtube_vis', 'ovis', 'bdd_mots', 'tao']
+ if config['SPLIT'] != 'train':
+ benchmarks += ['waymo', 'mots_challenge']
+ seqs_todo = []
+ for bench in benchmarks:
+ bench_fol = os.path.join(config['INPUT_FOL'].format(split=config['SPLIT']), bench)
+ seqs_todo += [os.path.join(bench_fol, seq) for seq in os.listdir(bench_fol)]
+
+ # Run in parallel
+ if config['Num_Parallel_Cores']:
+ with Pool(config['Num_Parallel_Cores']) as pool:
+ results = pool.map(do_sequence, seqs_todo)
+
+ # Run in series
+ else:
+ for seq_todo in seqs_todo:
+ do_sequence(seq_todo)
+
diff --git a/val_utils/trackeval/baselines/pascal_colormap.py b/val_utils/trackeval/baselines/pascal_colormap.py
new file mode 100644
index 0000000000000000000000000000000000000000..b31f348931552bf0dde374a25cc878db5614511c
--- /dev/null
+++ b/val_utils/trackeval/baselines/pascal_colormap.py
@@ -0,0 +1,257 @@
+pascal_colormap = [
+ 0 , 0, 0,
+ 0.5020, 0, 0,
+ 0, 0.5020, 0,
+ 0.5020, 0.5020, 0,
+ 0, 0, 0.5020,
+ 0.5020, 0, 0.5020,
+ 0, 0.5020, 0.5020,
+ 0.5020, 0.5020, 0.5020,
+ 0.2510, 0, 0,
+ 0.7529, 0, 0,
+ 0.2510, 0.5020, 0,
+ 0.7529, 0.5020, 0,
+ 0.2510, 0, 0.5020,
+ 0.7529, 0, 0.5020,
+ 0.2510, 0.5020, 0.5020,
+ 0.7529, 0.5020, 0.5020,
+ 0, 0.2510, 0,
+ 0.5020, 0.2510, 0,
+ 0, 0.7529, 0,
+ 0.5020, 0.7529, 0,
+ 0, 0.2510, 0.5020,
+ 0.5020, 0.2510, 0.5020,
+ 0, 0.7529, 0.5020,
+ 0.5020, 0.7529, 0.5020,
+ 0.2510, 0.2510, 0,
+ 0.7529, 0.2510, 0,
+ 0.2510, 0.7529, 0,
+ 0.7529, 0.7529, 0,
+ 0.2510, 0.2510, 0.5020,
+ 0.7529, 0.2510, 0.5020,
+ 0.2510, 0.7529, 0.5020,
+ 0.7529, 0.7529, 0.5020,
+ 0, 0, 0.2510,
+ 0.5020, 0, 0.2510,
+ 0, 0.5020, 0.2510,
+ 0.5020, 0.5020, 0.2510,
+ 0, 0, 0.7529,
+ 0.5020, 0, 0.7529,
+ 0, 0.5020, 0.7529,
+ 0.5020, 0.5020, 0.7529,
+ 0.2510, 0, 0.2510,
+ 0.7529, 0, 0.2510,
+ 0.2510, 0.5020, 0.2510,
+ 0.7529, 0.5020, 0.2510,
+ 0.2510, 0, 0.7529,
+ 0.7529, 0, 0.7529,
+ 0.2510, 0.5020, 0.7529,
+ 0.7529, 0.5020, 0.7529,
+ 0, 0.2510, 0.2510,
+ 0.5020, 0.2510, 0.2510,
+ 0, 0.7529, 0.2510,
+ 0.5020, 0.7529, 0.2510,
+ 0, 0.2510, 0.7529,
+ 0.5020, 0.2510, 0.7529,
+ 0, 0.7529, 0.7529,
+ 0.5020, 0.7529, 0.7529,
+ 0.2510, 0.2510, 0.2510,
+ 0.7529, 0.2510, 0.2510,
+ 0.2510, 0.7529, 0.2510,
+ 0.7529, 0.7529, 0.2510,
+ 0.2510, 0.2510, 0.7529,
+ 0.7529, 0.2510, 0.7529,
+ 0.2510, 0.7529, 0.7529,
+ 0.7529, 0.7529, 0.7529,
+ 0.1255, 0, 0,
+ 0.6275, 0, 0,
+ 0.1255, 0.5020, 0,
+ 0.6275, 0.5020, 0,
+ 0.1255, 0, 0.5020,
+ 0.6275, 0, 0.5020,
+ 0.1255, 0.5020, 0.5020,
+ 0.6275, 0.5020, 0.5020,
+ 0.3765, 0, 0,
+ 0.8784, 0, 0,
+ 0.3765, 0.5020, 0,
+ 0.8784, 0.5020, 0,
+ 0.3765, 0, 0.5020,
+ 0.8784, 0, 0.5020,
+ 0.3765, 0.5020, 0.5020,
+ 0.8784, 0.5020, 0.5020,
+ 0.1255, 0.2510, 0,
+ 0.6275, 0.2510, 0,
+ 0.1255, 0.7529, 0,
+ 0.6275, 0.7529, 0,
+ 0.1255, 0.2510, 0.5020,
+ 0.6275, 0.2510, 0.5020,
+ 0.1255, 0.7529, 0.5020,
+ 0.6275, 0.7529, 0.5020,
+ 0.3765, 0.2510, 0,
+ 0.8784, 0.2510, 0,
+ 0.3765, 0.7529, 0,
+ 0.8784, 0.7529, 0,
+ 0.3765, 0.2510, 0.5020,
+ 0.8784, 0.2510, 0.5020,
+ 0.3765, 0.7529, 0.5020,
+ 0.8784, 0.7529, 0.5020,
+ 0.1255, 0, 0.2510,
+ 0.6275, 0, 0.2510,
+ 0.1255, 0.5020, 0.2510,
+ 0.6275, 0.5020, 0.2510,
+ 0.1255, 0, 0.7529,
+ 0.6275, 0, 0.7529,
+ 0.1255, 0.5020, 0.7529,
+ 0.6275, 0.5020, 0.7529,
+ 0.3765, 0, 0.2510,
+ 0.8784, 0, 0.2510,
+ 0.3765, 0.5020, 0.2510,
+ 0.8784, 0.5020, 0.2510,
+ 0.3765, 0, 0.7529,
+ 0.8784, 0, 0.7529,
+ 0.3765, 0.5020, 0.7529,
+ 0.8784, 0.5020, 0.7529,
+ 0.1255, 0.2510, 0.2510,
+ 0.6275, 0.2510, 0.2510,
+ 0.1255, 0.7529, 0.2510,
+ 0.6275, 0.7529, 0.2510,
+ 0.1255, 0.2510, 0.7529,
+ 0.6275, 0.2510, 0.7529,
+ 0.1255, 0.7529, 0.7529,
+ 0.6275, 0.7529, 0.7529,
+ 0.3765, 0.2510, 0.2510,
+ 0.8784, 0.2510, 0.2510,
+ 0.3765, 0.7529, 0.2510,
+ 0.8784, 0.7529, 0.2510,
+ 0.3765, 0.2510, 0.7529,
+ 0.8784, 0.2510, 0.7529,
+ 0.3765, 0.7529, 0.7529,
+ 0.8784, 0.7529, 0.7529,
+ 0, 0.1255, 0,
+ 0.5020, 0.1255, 0,
+ 0, 0.6275, 0,
+ 0.5020, 0.6275, 0,
+ 0, 0.1255, 0.5020,
+ 0.5020, 0.1255, 0.5020,
+ 0, 0.6275, 0.5020,
+ 0.5020, 0.6275, 0.5020,
+ 0.2510, 0.1255, 0,
+ 0.7529, 0.1255, 0,
+ 0.2510, 0.6275, 0,
+ 0.7529, 0.6275, 0,
+ 0.2510, 0.1255, 0.5020,
+ 0.7529, 0.1255, 0.5020,
+ 0.2510, 0.6275, 0.5020,
+ 0.7529, 0.6275, 0.5020,
+ 0, 0.3765, 0,
+ 0.5020, 0.3765, 0,
+ 0, 0.8784, 0,
+ 0.5020, 0.8784, 0,
+ 0, 0.3765, 0.5020,
+ 0.5020, 0.3765, 0.5020,
+ 0, 0.8784, 0.5020,
+ 0.5020, 0.8784, 0.5020,
+ 0.2510, 0.3765, 0,
+ 0.7529, 0.3765, 0,
+ 0.2510, 0.8784, 0,
+ 0.7529, 0.8784, 0,
+ 0.2510, 0.3765, 0.5020,
+ 0.7529, 0.3765, 0.5020,
+ 0.2510, 0.8784, 0.5020,
+ 0.7529, 0.8784, 0.5020,
+ 0, 0.1255, 0.2510,
+ 0.5020, 0.1255, 0.2510,
+ 0, 0.6275, 0.2510,
+ 0.5020, 0.6275, 0.2510,
+ 0, 0.1255, 0.7529,
+ 0.5020, 0.1255, 0.7529,
+ 0, 0.6275, 0.7529,
+ 0.5020, 0.6275, 0.7529,
+ 0.2510, 0.1255, 0.2510,
+ 0.7529, 0.1255, 0.2510,
+ 0.2510, 0.6275, 0.2510,
+ 0.7529, 0.6275, 0.2510,
+ 0.2510, 0.1255, 0.7529,
+ 0.7529, 0.1255, 0.7529,
+ 0.2510, 0.6275, 0.7529,
+ 0.7529, 0.6275, 0.7529,
+ 0, 0.3765, 0.2510,
+ 0.5020, 0.3765, 0.2510,
+ 0, 0.8784, 0.2510,
+ 0.5020, 0.8784, 0.2510,
+ 0, 0.3765, 0.7529,
+ 0.5020, 0.3765, 0.7529,
+ 0, 0.8784, 0.7529,
+ 0.5020, 0.8784, 0.7529,
+ 0.2510, 0.3765, 0.2510,
+ 0.7529, 0.3765, 0.2510,
+ 0.2510, 0.8784, 0.2510,
+ 0.7529, 0.8784, 0.2510,
+ 0.2510, 0.3765, 0.7529,
+ 0.7529, 0.3765, 0.7529,
+ 0.2510, 0.8784, 0.7529,
+ 0.7529, 0.8784, 0.7529,
+ 0.1255, 0.1255, 0,
+ 0.6275, 0.1255, 0,
+ 0.1255, 0.6275, 0,
+ 0.6275, 0.6275, 0,
+ 0.1255, 0.1255, 0.5020,
+ 0.6275, 0.1255, 0.5020,
+ 0.1255, 0.6275, 0.5020,
+ 0.6275, 0.6275, 0.5020,
+ 0.3765, 0.1255, 0,
+ 0.8784, 0.1255, 0,
+ 0.3765, 0.6275, 0,
+ 0.8784, 0.6275, 0,
+ 0.3765, 0.1255, 0.5020,
+ 0.8784, 0.1255, 0.5020,
+ 0.3765, 0.6275, 0.5020,
+ 0.8784, 0.6275, 0.5020,
+ 0.1255, 0.3765, 0,
+ 0.6275, 0.3765, 0,
+ 0.1255, 0.8784, 0,
+ 0.6275, 0.8784, 0,
+ 0.1255, 0.3765, 0.5020,
+ 0.6275, 0.3765, 0.5020,
+ 0.1255, 0.8784, 0.5020,
+ 0.6275, 0.8784, 0.5020,
+ 0.3765, 0.3765, 0,
+ 0.8784, 0.3765, 0,
+ 0.3765, 0.8784, 0,
+ 0.8784, 0.8784, 0,
+ 0.3765, 0.3765, 0.5020,
+ 0.8784, 0.3765, 0.5020,
+ 0.3765, 0.8784, 0.5020,
+ 0.8784, 0.8784, 0.5020,
+ 0.1255, 0.1255, 0.2510,
+ 0.6275, 0.1255, 0.2510,
+ 0.1255, 0.6275, 0.2510,
+ 0.6275, 0.6275, 0.2510,
+ 0.1255, 0.1255, 0.7529,
+ 0.6275, 0.1255, 0.7529,
+ 0.1255, 0.6275, 0.7529,
+ 0.6275, 0.6275, 0.7529,
+ 0.3765, 0.1255, 0.2510,
+ 0.8784, 0.1255, 0.2510,
+ 0.3765, 0.6275, 0.2510,
+ 0.8784, 0.6275, 0.2510,
+ 0.3765, 0.1255, 0.7529,
+ 0.8784, 0.1255, 0.7529,
+ 0.3765, 0.6275, 0.7529,
+ 0.8784, 0.6275, 0.7529,
+ 0.1255, 0.3765, 0.2510,
+ 0.6275, 0.3765, 0.2510,
+ 0.1255, 0.8784, 0.2510,
+ 0.6275, 0.8784, 0.2510,
+ 0.1255, 0.3765, 0.7529,
+ 0.6275, 0.3765, 0.7529,
+ 0.1255, 0.8784, 0.7529,
+ 0.6275, 0.8784, 0.7529,
+ 0.3765, 0.3765, 0.2510,
+ 0.8784, 0.3765, 0.2510,
+ 0.3765, 0.8784, 0.2510,
+ 0.8784, 0.8784, 0.2510,
+ 0.3765, 0.3765, 0.7529,
+ 0.8784, 0.3765, 0.7529,
+ 0.3765, 0.8784, 0.7529,
+ 0.8784, 0.8784, 0.7529]
\ No newline at end of file
diff --git a/val_utils/trackeval/baselines/stp.py b/val_utils/trackeval/baselines/stp.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1c9d1e05a5958f35be9c034a623ecec047a2e6b
--- /dev/null
+++ b/val_utils/trackeval/baselines/stp.py
@@ -0,0 +1,144 @@
+"""
+STP: Simplest Tracker Possible
+
+Author: Jonathon Luiten
+
+This simple tracker, simply assigns track IDs which maximise the 'bounding box IoU' between previous tracks and current
+detections. It is also able to match detections to tracks at more than one timestep previously.
+"""
+
+import os
+import sys
+import numpy as np
+from multiprocessing.pool import Pool
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
+from trackeval.baselines import baseline_utils as butils
+from trackeval.utils import get_code_path
+
+code_path = get_code_path()
+config = {
+ 'INPUT_FOL': os.path.join(code_path, 'data/detections/rob_mots/{split}/non_overlap_supplied/data/'),
+ 'OUTPUT_FOL': os.path.join(code_path, 'data/trackers/rob_mots/{split}/STP/data/'),
+ 'SPLIT': 'train', # valid: 'train', 'val', 'test'.
+ 'Benchmarks': None, # If None, all benchmarks in SPLIT.
+
+ 'Num_Parallel_Cores': None, # If None, run without parallel.
+
+ 'DETECTION_THRESHOLD': 0.5,
+ 'ASSOCIATION_THRESHOLD': 1e-10,
+ 'MAX_FRAMES_SKIP': 7
+}
+
+
+def track_sequence(seq_file):
+
+ # Load input data from file (e.g. provided detections)
+ # data format: data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
+ data = butils.load_seq(seq_file)
+
+ # Where to accumulate output data for writing out
+ output_data = []
+
+ # To ensure IDs are unique per object across all classes.
+ curr_max_id = 0
+
+ # Run tracker for each class.
+ for cls, cls_data in data.items():
+
+ # Initialize container for holding previously tracked objects.
+ prev = {'boxes': np.empty((0, 4)),
+ 'ids': np.array([], np.int),
+ 'timesteps': np.array([])}
+
+ # Run tracker for each timestep.
+ for timestep, t_data in enumerate(cls_data):
+
+ # Threshold detections.
+ t_data = butils.threshold(t_data, config['DETECTION_THRESHOLD'])
+
+ # Convert mask dets to bounding boxes.
+ boxes = butils.masks2boxes(t_data['mask_rles'], t_data['im_hs'], t_data['im_ws'])
+
+ # Calculate IoU between previous and current frame dets.
+ ious = butils.box_iou(prev['boxes'], boxes)
+
+ # Score which decreases quickly for previous dets depending on how many timesteps before they come from.
+ prev_timestep_scores = np.power(10, -1 * prev['timesteps'])
+
+ # Matching score is such that it first tries to match 'most recent timesteps',
+ # and within each timestep maximised IoU.
+ match_scores = prev_timestep_scores[:, np.newaxis] * ious
+
+ # Find best matching between current dets and previous tracks.
+ match_rows, match_cols = butils.match(match_scores)
+
+ # Remove matches that have an IoU below a certain threshold.
+ actually_matched_mask = ious[match_rows, match_cols] > config['ASSOCIATION_THRESHOLD']
+ match_rows = match_rows[actually_matched_mask]
+ match_cols = match_cols[actually_matched_mask]
+
+ # Assign the prev track ID to the current dets if they were matched.
+ ids = np.nan * np.ones((len(boxes),), np.int)
+ ids[match_cols] = prev['ids'][match_rows]
+
+ # Create new track IDs for dets that were not matched to previous tracks.
+ num_not_matched = len(ids) - len(match_cols)
+ new_ids = np.arange(curr_max_id + 1, curr_max_id + num_not_matched + 1)
+ ids[np.isnan(ids)] = new_ids
+
+ # Update maximum ID to ensure future added tracks have a unique ID value.
+ curr_max_id += num_not_matched
+
+ # Drop tracks from 'previous tracks' if they have not been matched in the last MAX_FRAMES_SKIP frames.
+ unmatched_rows = [i for i in range(len(prev['ids'])) if
+ i not in match_rows and (prev['timesteps'][i] + 1 <= config['MAX_FRAMES_SKIP'])]
+
+ # Update the set of previous tracking results to include the newly tracked detections.
+ prev['ids'] = np.concatenate((ids, prev['ids'][unmatched_rows]), axis=0)
+ prev['boxes'] = np.concatenate((np.atleast_2d(boxes), np.atleast_2d(prev['boxes'][unmatched_rows])), axis=0)
+ prev['timesteps'] = np.concatenate((np.zeros((len(ids),)), prev['timesteps'][unmatched_rows] + 1), axis=0)
+
+ # Save result in output format to write to file later.
+ # Output Format = [timestep ID class score im_h im_w mask_RLE]
+ for i in range(len(t_data['ids'])):
+ row = [timestep, int(ids[i]), cls, t_data['scores'][i], t_data['im_hs'][i], t_data['im_ws'][i],
+ t_data['mask_rles'][i]]
+ output_data.append(row)
+
+ # Write results to file
+ out_file = seq_file.replace(config['INPUT_FOL'].format(split=config['SPLIT']),
+ config['OUTPUT_FOL'].format(split=config['SPLIT']))
+ butils.write_seq(output_data, out_file)
+
+ print('DONE:', seq_file)
+
+
+if __name__ == '__main__':
+
+ # Required to fix bug in multiprocessing on windows.
+ freeze_support()
+
+ # Obtain list of sequences to run tracker for.
+ if config['Benchmarks']:
+ benchmarks = config['Benchmarks']
+ else:
+ benchmarks = ['davis_unsupervised', 'kitti_mots', 'youtube_vis', 'ovis', 'bdd_mots', 'tao']
+ if config['SPLIT'] != 'train':
+ benchmarks += ['waymo', 'mots_challenge']
+ seqs_todo = []
+ for bench in benchmarks:
+ bench_fol = os.path.join(config['INPUT_FOL'].format(split=config['SPLIT']), bench)
+ seqs_todo += [os.path.join(bench_fol, seq) for seq in os.listdir(bench_fol)]
+
+ # Run in parallel
+ if config['Num_Parallel_Cores']:
+ with Pool(config['Num_Parallel_Cores']) as pool:
+ results = pool.map(track_sequence, seqs_todo)
+
+ # Run in series
+ else:
+ for seq_todo in seqs_todo:
+ track_sequence(seq_todo)
+
diff --git a/val_utils/trackeval/baselines/thresholder.py b/val_utils/trackeval/baselines/thresholder.py
new file mode 100644
index 0000000000000000000000000000000000000000..c589e10b95da311c03ed1045bc1d6af8f1a8c90e
--- /dev/null
+++ b/val_utils/trackeval/baselines/thresholder.py
@@ -0,0 +1,92 @@
+"""
+Thresholder
+
+Author: Jonathon Luiten
+
+Simply reads in a set of detection, thresholds them at a certain score threshold, and writes them out again.
+"""
+
+import os
+import sys
+from multiprocessing.pool import Pool
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
+from trackeval.baselines import baseline_utils as butils
+from trackeval.utils import get_code_path
+
+THRESHOLD = 0.2
+
+code_path = get_code_path()
+config = {
+ 'INPUT_FOL': os.path.join(code_path, 'data/detections/rob_mots/{split}/non_overlap_supplied/data/'),
+ 'OUTPUT_FOL': os.path.join(code_path, 'data/detections/rob_mots/{split}/threshold_' + str(100*THRESHOLD) + '/data/'),
+ 'SPLIT': 'train', # valid: 'train', 'val', 'test'.
+ 'Benchmarks': None, # If None, all benchmarks in SPLIT.
+
+ 'Num_Parallel_Cores': None, # If None, run without parallel.
+
+ 'DETECTION_THRESHOLD': THRESHOLD,
+}
+
+
+def do_sequence(seq_file):
+
+ # Load input data from file (e.g. provided detections)
+ # data format: data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
+ data = butils.load_seq(seq_file)
+
+ # Where to accumulate output data for writing out
+ output_data = []
+
+ # Run for each class.
+ for cls, cls_data in data.items():
+
+ # Run for each timestep.
+ for timestep, t_data in enumerate(cls_data):
+
+ # Threshold detections.
+ t_data = butils.threshold(t_data, config['DETECTION_THRESHOLD'])
+
+ # Save result in output format to write to file later.
+ # Output Format = [timestep ID class score im_h im_w mask_RLE]
+ for i in range(len(t_data['ids'])):
+ row = [timestep, int(t_data['ids'][i]), cls, t_data['scores'][i], t_data['im_hs'][i],
+ t_data['im_ws'][i], t_data['mask_rles'][i]]
+ output_data.append(row)
+
+ # Write results to file
+ out_file = seq_file.replace(config['INPUT_FOL'].format(split=config['SPLIT']),
+ config['OUTPUT_FOL'].format(split=config['SPLIT']))
+ butils.write_seq(output_data, out_file)
+
+ print('DONE:', seq_todo)
+
+
+if __name__ == '__main__':
+
+ # Required to fix bug in multiprocessing on windows.
+ freeze_support()
+
+ # Obtain list of sequences to run tracker for.
+ if config['Benchmarks']:
+ benchmarks = config['Benchmarks']
+ else:
+ benchmarks = ['davis_unsupervised', 'kitti_mots', 'youtube_vis', 'ovis', 'bdd_mots', 'tao']
+ if config['SPLIT'] != 'train':
+ benchmarks += ['waymo', 'mots_challenge']
+ seqs_todo = []
+ for bench in benchmarks:
+ bench_fol = os.path.join(config['INPUT_FOL'].format(split=config['SPLIT']), bench)
+ seqs_todo += [os.path.join(bench_fol, seq) for seq in os.listdir(bench_fol)]
+
+ # Run in parallel
+ if config['Num_Parallel_Cores']:
+ with Pool(config['Num_Parallel_Cores']) as pool:
+ results = pool.map(do_sequence, seqs_todo)
+
+ # Run in series
+ else:
+ for seq_todo in seqs_todo:
+ do_sequence(seq_todo)
+
diff --git a/val_utils/trackeval/baselines/vizualize.py b/val_utils/trackeval/baselines/vizualize.py
new file mode 100644
index 0000000000000000000000000000000000000000..568a30373cdb34cf122c9fd05b8496666d75f726
--- /dev/null
+++ b/val_utils/trackeval/baselines/vizualize.py
@@ -0,0 +1,94 @@
+"""
+Vizualize: Code which converts .txt rle tracking results into a visual .png format.
+
+Author: Jonathon Luiten
+"""
+
+import os
+import sys
+from multiprocessing.pool import Pool
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
+from trackeval.baselines import baseline_utils as butils
+from trackeval.utils import get_code_path
+from trackeval.datasets.rob_mots_classmap import cls_id_to_name
+
+code_path = get_code_path()
+config = {
+ # Tracker format:
+ 'INPUT_FOL': os.path.join(code_path, 'data/trackers/rob_mots/{split}/STP/data/{bench}'),
+ 'OUTPUT_FOL': os.path.join(code_path, 'data/viz/rob_mots/{split}/STP/data/{bench}'),
+ # GT format:
+ # 'INPUT_FOL': os.path.join(code_path, 'data/gt/rob_mots/{split}/{bench}/data/'),
+ # 'OUTPUT_FOL': os.path.join(code_path, 'data/gt_viz/rob_mots/{split}/{bench}/'),
+ 'SPLIT': 'train', # valid: 'train', 'val', 'test'.
+ 'Benchmarks': None, # If None, all benchmarks in SPLIT.
+ 'Num_Parallel_Cores': None, # If None, run without parallel.
+}
+
+
+def do_sequence(seq_file):
+ # Folder to save resulting visualization in
+ out_fol = seq_file.replace(config['INPUT_FOL'].format(split=config['SPLIT'], bench=bench),
+ config['OUTPUT_FOL'].format(split=config['SPLIT'], bench=bench)).replace('.txt', '')
+
+ # Load input data from file (e.g. provided detections)
+ # data format: data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
+ data = butils.load_seq(seq_file)
+
+ # Get frame size for visualizing empty frames
+ im_h, im_w = butils.get_frame_size(data)
+
+ # First run for each class.
+ for cls, cls_data in data.items():
+
+ if cls >= 100:
+ continue
+
+ # Run for each timestep.
+ for timestep, t_data in enumerate(cls_data):
+ # Save out visualization
+ out_file = os.path.join(out_fol, cls_id_to_name[cls], str(timestep).zfill(5) + '.png')
+ butils.save_as_png(t_data, out_file, im_h, im_w)
+
+
+ # Then run for all classes combined
+ # Converts data from a class-separated to a class-combined format.
+ data = butils.combine_classes(data)
+
+ # Run for each timestep.
+ for timestep, t_data in enumerate(data):
+ # Save out visualization
+ out_file = os.path.join(out_fol, 'all_classes', str(timestep).zfill(5) + '.png')
+ butils.save_as_png(t_data, out_file, im_h, im_w)
+
+ print('DONE:', seq_file)
+
+
+if __name__ == '__main__':
+
+ # Required to fix bug in multiprocessing on windows.
+ freeze_support()
+
+ # Obtain list of sequences to run tracker for.
+ if config['Benchmarks']:
+ benchmarks = config['Benchmarks']
+ else:
+ benchmarks = ['davis_unsupervised', 'kitti_mots', 'youtube_vis', 'ovis', 'bdd_mots', 'tao']
+ if config['SPLIT'] != 'train':
+ benchmarks += ['waymo', 'mots_challenge']
+ seqs_todo = []
+ for bench in benchmarks:
+ bench_fol = config['INPUT_FOL'].format(split=config['SPLIT'], bench=bench)
+ seqs_todo += [os.path.join(bench_fol, seq) for seq in os.listdir(bench_fol)]
+
+ # Run in parallel
+ if config['Num_Parallel_Cores']:
+ with Pool(config['Num_Parallel_Cores']) as pool:
+ results = pool.map(do_sequence, seqs_todo)
+
+ # Run in series
+ else:
+ for seq_todo in seqs_todo:
+ do_sequence(seq_todo)
diff --git a/val_utils/trackeval/datasets/__init__.py b/val_utils/trackeval/datasets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4fdfa9dd590c6283d56e86419b863782fa619029
--- /dev/null
+++ b/val_utils/trackeval/datasets/__init__.py
@@ -0,0 +1,17 @@
+from .kitti_2d_box import Kitti2DBox
+from .kitti_mots import KittiMOTS
+from .mot_challenge_2d_box import MotChallenge2DBox
+from .mots_challenge import MOTSChallenge
+from .bdd100k import BDD100K
+from .davis import DAVIS
+from .tao import TAO
+from .tao_ow import TAO_OW
+try:
+ from .burst import BURST
+ from .burst_ow import BURST_OW
+except ImportError as err:
+ print(f"Error importing BURST due to missing underlying dependency: {err}")
+from .youtube_vis import YouTubeVIS
+from .head_tracking_challenge import HeadTrackingChallenge
+from .rob_mots import RobMOTS
+from .person_path_22 import PersonPath22
diff --git a/val_utils/trackeval/datasets/_base_dataset.py b/val_utils/trackeval/datasets/_base_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..64bf9fc01dd3b7c45f10d1c874228aa32a062908
--- /dev/null
+++ b/val_utils/trackeval/datasets/_base_dataset.py
@@ -0,0 +1,326 @@
+import csv
+import io
+import zipfile
+import os
+import traceback
+import numpy as np
+from copy import deepcopy
+from abc import ABC, abstractmethod
+from .. import _timing
+from ..utils import TrackEvalException
+
+
+class _BaseDataset(ABC):
+ @abstractmethod
+ def __init__(self):
+ self.tracker_list = None
+ self.seq_list = None
+ self.class_list = None
+ self.output_fol = None
+ self.output_sub_fol = None
+ self.should_classes_combine = True
+ self.use_super_categories = False
+
+ # Functions to implement:
+
+ @staticmethod
+ @abstractmethod
+ def get_default_dataset_config():
+ ...
+
+ @abstractmethod
+ def _load_raw_file(self, tracker, seq, is_gt):
+ ...
+
+ @_timing.time
+ @abstractmethod
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ ...
+
+ @abstractmethod
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ ...
+
+ # Helper functions for all datasets:
+
+ @classmethod
+ def get_class_name(cls):
+ return cls.__name__
+
+ def get_name(self):
+ return self.get_class_name()
+
+ def get_output_fol(self, tracker):
+ return os.path.join(self.output_fol, tracker, self.output_sub_fol)
+
+ def get_display_name(self, tracker):
+ """ Can be overwritten if the trackers name (in files) is different to how it should be displayed.
+ By default this method just returns the trackers name as is.
+ """
+ return tracker
+
+ def get_eval_info(self):
+ """Return info about the dataset needed for the Evaluator"""
+ return self.tracker_list, self.seq_list, self.class_list
+
+ @_timing.time
+ def get_raw_seq_data(self, tracker, seq):
+ """ Loads raw data (tracker and ground-truth) for a single tracker on a single sequence.
+ Raw data includes all of the information needed for both preprocessing and evaluation, for all classes.
+ A later function (get_processed_seq_data) will perform such preprocessing and extract relevant information for
+ the evaluation of each class.
+
+ This returns a dict which contains the fields:
+ [num_timesteps]: integer
+ [gt_ids, tracker_ids, gt_classes, tracker_classes, tracker_confidences]:
+ list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ [gt_extras]: dict (for each extra) of lists (for each timestep) of 1D NDArrays (for each det).
+
+ gt_extras contains dataset specific information used for preprocessing such as occlusion and truncation levels.
+
+ Note that similarities are extracted as part of the dataset and not the metric, because almost all metrics are
+ independent of the exact method of calculating the similarity. However datasets are not (e.g. segmentation
+ masks vs 2D boxes vs 3D boxes).
+ We calculate the similarity before preprocessing because often both preprocessing and evaluation require it and
+ we don't wish to calculate this twice.
+ We calculate similarity between all gt and tracker classes (not just each class individually) to allow for
+ calculation of metrics such as class confusion matrices. Typically the impact of this on performance is low.
+ """
+ # Load raw data.
+ raw_gt_data = self._load_raw_file(tracker, seq, is_gt=True)
+ raw_tracker_data = self._load_raw_file(tracker, seq, is_gt=False)
+ raw_data = {**raw_tracker_data, **raw_gt_data} # Merges dictionaries
+
+ # Calculate similarities for each timestep.
+ similarity_scores = []
+ for t, (gt_dets_t, tracker_dets_t) in enumerate(zip(raw_data['gt_dets'], raw_data['tracker_dets'])):
+ ious = self._calculate_similarities(gt_dets_t, tracker_dets_t)
+ similarity_scores.append(ious)
+ raw_data['similarity_scores'] = similarity_scores
+ return raw_data
+
+ @staticmethod
+ def _load_simple_text_file(file, time_col=0, id_col=None, remove_negative_ids=False, valid_filter=None,
+ crowd_ignore_filter=None, convert_filter=None, is_zipped=False, zip_file=None,
+ force_delimiters=None):
+ """ Function that loads data which is in a commonly used text file format.
+ Assumes each det is given by one row of a text file.
+ There is no limit to the number or meaning of each column,
+ however one column needs to give the timestep of each det (time_col) which is default col 0.
+
+ The file dialect (deliminator, num cols, etc) is determined automatically.
+ This function automatically separates dets by timestep,
+ and is much faster than alternatives such as np.loadtext or pandas.
+
+ If remove_negative_ids is True and id_col is not None, dets with negative values in id_col are excluded.
+ These are not excluded from ignore data.
+
+ valid_filter can be used to only include certain classes.
+ It is a dict with ints as keys, and lists as values,
+ such that a row is included if "row[key].lower() is in value" for all key/value pairs in the dict.
+ If None, all classes are included.
+
+ crowd_ignore_filter can be used to read crowd_ignore regions separately. It has the same format as valid filter.
+
+ convert_filter can be used to convert value read to another format.
+ This is used most commonly to convert classes given as string to a class id.
+ This is a dict such that the key is the column to convert, and the value is another dict giving the mapping.
+
+ Optionally, input files could be a zip of multiple text files for storage efficiency.
+
+ Returns read_data and ignore_data.
+ Each is a dict (with keys as timesteps as strings) of lists (over dets) of lists (over column values).
+ Note that all data is returned as strings, and must be converted to float/int later if needed.
+ Note that timesteps will not be present in the returned dict keys if there are no dets for them
+ """
+
+ if remove_negative_ids and id_col is None:
+ raise TrackEvalException('remove_negative_ids is True, but id_col is not given.')
+ if crowd_ignore_filter is None:
+ crowd_ignore_filter = {}
+ if convert_filter is None:
+ convert_filter = {}
+ try:
+ if is_zipped: # Either open file directly or within a zip.
+ if zip_file is None:
+ raise TrackEvalException('is_zipped set to True, but no zip_file is given.')
+ archive = zipfile.ZipFile(os.path.join(zip_file), 'r')
+ fp = io.TextIOWrapper(archive.open(file, 'r'))
+ else:
+ fp = open(file)
+ read_data = {}
+ crowd_ignore_data = {}
+ fp.seek(0, os.SEEK_END)
+ # check if file is empty
+ if fp.tell():
+ fp.seek(0)
+ dialect = csv.Sniffer().sniff(fp.readline(), delimiters=force_delimiters) # Auto determine structure.
+ dialect.skipinitialspace = True # Deal with extra spaces between columns
+ fp.seek(0)
+ reader = csv.reader(fp, dialect)
+ for row in reader:
+ try:
+ # Deal with extra trailing spaces at the end of rows
+ if row[-1] in '':
+ row = row[:-1]
+ timestep = str(int(float(row[time_col])))
+ # Read ignore regions separately.
+ is_ignored = False
+ for ignore_key, ignore_value in crowd_ignore_filter.items():
+ if row[ignore_key].lower() in ignore_value:
+ # Convert values in one column (e.g. string to id)
+ for convert_key, convert_value in convert_filter.items():
+ row[convert_key] = convert_value[row[convert_key].lower()]
+ # Save data separated by timestep.
+ if timestep in crowd_ignore_data.keys():
+ crowd_ignore_data[timestep].append(row)
+ else:
+ crowd_ignore_data[timestep] = [row]
+ is_ignored = True
+ if is_ignored: # if det is an ignore region, it cannot be a normal det.
+ continue
+ # Exclude some dets if not valid.
+ if valid_filter is not None:
+ for key, value in valid_filter.items():
+ if row[key].lower() not in value:
+ continue
+ if remove_negative_ids:
+ if int(float(row[id_col])) < 0:
+ continue
+ # Convert values in one column (e.g. string to id)
+ for convert_key, convert_value in convert_filter.items():
+ row[convert_key] = convert_value[row[convert_key].lower()]
+ # Save data separated by timestep.
+ if timestep in read_data.keys():
+ read_data[timestep].append(row)
+ else:
+ read_data[timestep] = [row]
+ except Exception:
+ exc_str_init = 'In file %s the following line cannot be read correctly: \n' % os.path.basename(
+ file)
+ exc_str = ' '.join([exc_str_init]+row)
+ raise TrackEvalException(exc_str)
+ fp.close()
+ except Exception:
+ print('Error loading file: %s, printing traceback.' % file)
+ traceback.print_exc()
+ raise TrackEvalException(
+ 'File %s cannot be read because it is either not present or invalidly formatted' % os.path.basename(
+ file))
+ return read_data, crowd_ignore_data
+
+ @staticmethod
+ def _calculate_mask_ious(masks1, masks2, is_encoded=False, do_ioa=False):
+ """ Calculates the IOU (intersection over union) between two arrays of segmentation masks.
+ If is_encoded a run length encoding with pycocotools is assumed as input format, otherwise an input of numpy
+ arrays of the shape (num_masks, height, width) is assumed and the encoding is performed.
+ If do_ioa (intersection over area) , then calculates the intersection over the area of masks1 - this is commonly
+ used to determine if detections are within crowd ignore region.
+ :param masks1: first set of masks (numpy array of shape (num_masks, height, width) if not encoded,
+ else pycocotools rle encoded format)
+ :param masks2: second set of masks (numpy array of shape (num_masks, height, width) if not encoded,
+ else pycocotools rle encoded format)
+ :param is_encoded: whether the input is in pycocotools rle encoded format
+ :param do_ioa: whether to perform IoA computation
+ :return: the IoU/IoA scores
+ """
+
+ # Only loaded when run to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ # use pycocotools for run length encoding of masks
+ if not is_encoded:
+ masks1 = mask_utils.encode(np.array(np.transpose(masks1, (1, 2, 0)), order='F'))
+ masks2 = mask_utils.encode(np.array(np.transpose(masks2, (1, 2, 0)), order='F'))
+
+ # use pycocotools for iou computation of rle encoded masks
+ ious = mask_utils.iou(masks1, masks2, [do_ioa]*len(masks2))
+ if len(masks1) == 0 or len(masks2) == 0:
+ ious = np.asarray(ious).reshape(len(masks1), len(masks2))
+ assert (ious >= 0 - np.finfo('float').eps).all()
+ assert (ious <= 1 + np.finfo('float').eps).all()
+
+ return ious
+
+ @staticmethod
+ def _calculate_box_ious(bboxes1, bboxes2, box_format='xywh', do_ioa=False):
+ """ Calculates the IOU (intersection over union) between two arrays of boxes.
+ Allows variable box formats ('xywh' and 'x0y0x1y1').
+ If do_ioa (intersection over area) , then calculates the intersection over the area of boxes1 - this is commonly
+ used to determine if detections are within crowd ignore region.
+ """
+ if box_format in 'xywh':
+ # layout: (x0, y0, w, h)
+ bboxes1 = deepcopy(bboxes1)
+ bboxes2 = deepcopy(bboxes2)
+
+ bboxes1[:, 2] = bboxes1[:, 0] + bboxes1[:, 2]
+ bboxes1[:, 3] = bboxes1[:, 1] + bboxes1[:, 3]
+ bboxes2[:, 2] = bboxes2[:, 0] + bboxes2[:, 2]
+ bboxes2[:, 3] = bboxes2[:, 1] + bboxes2[:, 3]
+ elif box_format not in 'x0y0x1y1':
+ raise (TrackEvalException('box_format %s is not implemented' % box_format))
+
+ # layout: (x0, y0, x1, y1)
+ min_ = np.minimum(bboxes1[:, np.newaxis, :], bboxes2[np.newaxis, :, :])
+ max_ = np.maximum(bboxes1[:, np.newaxis, :], bboxes2[np.newaxis, :, :])
+ intersection = np.maximum(min_[..., 2] - max_[..., 0], 0) * np.maximum(min_[..., 3] - max_[..., 1], 0)
+ area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * (bboxes1[..., 3] - bboxes1[..., 1])
+
+ if do_ioa:
+ ioas = np.zeros_like(intersection)
+ valid_mask = area1 > 0 + np.finfo('float').eps
+ ioas[valid_mask, :] = intersection[valid_mask, :] / area1[valid_mask][:, np.newaxis]
+
+ return ioas
+ else:
+ area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * (bboxes2[..., 3] - bboxes2[..., 1])
+ union = area1[:, np.newaxis] + area2[np.newaxis, :] - intersection
+ intersection[area1 <= 0 + np.finfo('float').eps, :] = 0
+ intersection[:, area2 <= 0 + np.finfo('float').eps] = 0
+ intersection[union <= 0 + np.finfo('float').eps] = 0
+ union[union <= 0 + np.finfo('float').eps] = 1
+ ious = intersection / union
+ return ious
+
+ @staticmethod
+ def _calculate_euclidean_similarity(dets1, dets2, zero_distance=2.0):
+ """ Calculates the euclidean distance between two sets of detections, and then converts this into a similarity
+ measure with values between 0 and 1 using the following formula: sim = max(0, 1 - dist/zero_distance).
+ The default zero_distance of 2.0, corresponds to the default used in MOT15_3D, such that a 0.5 similarity
+ threshold corresponds to a 1m distance threshold for TPs.
+ """
+ dist = np.linalg.norm(dets1[:, np.newaxis]-dets2[np.newaxis, :], axis=2)
+ sim = np.maximum(0, 1 - dist/zero_distance)
+ return sim
+
+ @staticmethod
+ def _check_unique_ids(data, after_preproc=False):
+ """Check the requirement that the tracker_ids and gt_ids are unique per timestep"""
+ gt_ids = data['gt_ids']
+ tracker_ids = data['tracker_ids']
+ for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(gt_ids, tracker_ids)):
+ if len(tracker_ids_t) > 0:
+ unique_ids, counts = np.unique(tracker_ids_t, return_counts=True)
+ if np.max(counts) != 1:
+ duplicate_ids = unique_ids[counts > 1]
+ exc_str_init = 'Tracker predicts the same ID more than once in a single timestep ' \
+ '(seq: %s, frame: %i, ids:' % (data['seq'], t+1)
+ exc_str = ' '.join([exc_str_init] + [str(d) for d in duplicate_ids]) + ')'
+ if after_preproc:
+ exc_str_init += '\n Note that this error occurred after preprocessing (but not before), ' \
+ 'so ids may not be as in file, and something seems wrong with preproc.'
+ raise TrackEvalException(exc_str)
+ if len(gt_ids_t) > 0:
+ unique_ids, counts = np.unique(gt_ids_t, return_counts=True)
+ if np.max(counts) != 1:
+ duplicate_ids = unique_ids[counts > 1]
+ exc_str_init = 'Ground-truth has the same ID more than once in a single timestep ' \
+ '(seq: %s, frame: %i, ids:' % (data['seq'], t+1)
+ exc_str = ' '.join([exc_str_init] + [str(d) for d in duplicate_ids]) + ')'
+ if after_preproc:
+ exc_str_init += '\n Note that this error occurred after preprocessing (but not before), ' \
+ 'so ids may not be as in file, and something seems wrong with preproc.'
+ raise TrackEvalException(exc_str)
diff --git a/val_utils/trackeval/datasets/bdd100k.py b/val_utils/trackeval/datasets/bdd100k.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc4fd06ee49e520e9a8887239532816074aea41f
--- /dev/null
+++ b/val_utils/trackeval/datasets/bdd100k.py
@@ -0,0 +1,302 @@
+
+import os
+import json
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ..utils import TrackEvalException
+from ._base_dataset import _BaseDataset
+from .. import utils
+from .. import _timing
+
+
+class BDD100K(_BaseDataset):
+ """Dataset class for BDD100K tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/bdd100k/bdd100k_val'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/bdd100k/bdd100k_val'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['pedestrian', 'rider', 'car', 'bus', 'truck', 'train', 'motorcycle', 'bicycle'],
+ # Valid: ['pedestrian', 'rider', 'car', 'bus', 'truck', 'train', 'motorcycle', 'bicycle']
+ 'SPLIT_TO_EVAL': 'val', # Valid: 'training', 'val',
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+ self.gt_fol = self.config['GT_FOLDER']
+ self.tracker_fol = self.config['TRACKERS_FOLDER']
+ self.should_classes_combine = True
+ self.use_super_categories = True
+
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+
+ # Get classes to eval
+ self.valid_classes = ['pedestrian', 'rider', 'car', 'bus', 'truck', 'train', 'motorcycle', 'bicycle']
+ self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only classes [pedestrian, rider, car, '
+ 'bus, truck, train, motorcycle, bicycle] are valid.')
+ self.super_categories = {"HUMAN": [cls for cls in ["pedestrian", "rider"] if cls in self.class_list],
+ "VEHICLE": [cls for cls in ["car", "truck", "bus", "train"] if cls in self.class_list],
+ "BIKE": [cls for cls in ["motorcycle", "bicycle"] if cls in self.class_list]}
+ self.distractor_classes = ['other person', 'trailer', 'other vehicle']
+ self.class_name_to_class_id = {'pedestrian': 1, 'rider': 2, 'other person': 3, 'car': 4, 'bus': 5, 'truck': 6,
+ 'train': 7, 'trailer': 8, 'other vehicle': 9, 'motorcycle': 10, 'bicycle': 11}
+
+ # Get sequences to eval
+ self.seq_list = []
+ self.seq_lengths = {}
+
+ self.seq_list = [seq_file.replace('.json', '') for seq_file in os.listdir(self.gt_fol)]
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ for tracker in self.tracker_list:
+ for seq in self.seq_list:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.json')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException(
+ 'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
+ curr_file))
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the BDD100K format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ """
+ # File location
+ if is_gt:
+ file = os.path.join(self.gt_fol, seq + '.json')
+ else:
+ file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.json')
+
+ with open(file) as f:
+ data = json.load(f)
+
+ # sort data by frame index
+ data = sorted(data, key=lambda x: x['index'])
+
+ # check sequence length
+ if is_gt:
+ self.seq_lengths[seq] = len(data)
+ num_timesteps = len(data)
+ else:
+ num_timesteps = self.seq_lengths[seq]
+ if num_timesteps != len(data):
+ raise TrackEvalException('Number of ground truth and tracker timesteps do not match for sequence %s'
+ % seq)
+
+ # Convert data to required format
+ data_keys = ['ids', 'classes', 'dets']
+ if is_gt:
+ data_keys += ['gt_crowd_ignore_regions']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+ for t in range(num_timesteps):
+ ig_ids = []
+ keep_ids = []
+ for i in range(len(data[t]['labels'])):
+ ann = data[t]['labels'][i]
+ if is_gt and (ann['category'] in self.distractor_classes or 'attributes' in ann.keys()
+ and ann['attributes']['Crowd']):
+ ig_ids.append(i)
+ else:
+ keep_ids.append(i)
+
+ if keep_ids:
+ raw_data['dets'][t] = np.atleast_2d([[data[t]['labels'][i]['box2d']['x1'],
+ data[t]['labels'][i]['box2d']['y1'],
+ data[t]['labels'][i]['box2d']['x2'],
+ data[t]['labels'][i]['box2d']['y2']
+ ] for i in keep_ids]).astype(float)
+ raw_data['ids'][t] = np.atleast_1d([data[t]['labels'][i]['id'] for i in keep_ids]).astype(int)
+ raw_data['classes'][t] = np.atleast_1d([self.class_name_to_class_id[data[t]['labels'][i]['category']]
+ for i in keep_ids]).astype(int)
+ else:
+ raw_data['dets'][t] = np.empty((0, 4)).astype(float)
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+
+ if is_gt:
+ if ig_ids:
+ raw_data['gt_crowd_ignore_regions'][t] = np.atleast_2d([[data[t]['labels'][i]['box2d']['x1'],
+ data[t]['labels'][i]['box2d']['y1'],
+ data[t]['labels'][i]['box2d']['x2'],
+ data[t]['labels'][i]['box2d']['y2']
+ ] for i in ig_ids]).astype(float)
+ else:
+ raw_data['gt_crowd_ignore_regions'][t] = np.empty((0, 4)).astype(float)
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+ raw_data['num_timesteps'] = num_timesteps
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+
+ BDD100K:
+ In BDD100K, the 4 preproc steps are as follow:
+ 1) There are eight classes (pedestrian, rider, car, bus, truck, train, motorcycle, bicycle)
+ which are evaluated separately.
+ 2) For BDD100K there is no removal of matched tracker dets.
+ 3) Crowd ignore regions are used to remove unmatched detections.
+ 4) No removal of gt dets.
+ """
+ cls_id = self.class_name_to_class_id[cls]
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+ for t in range(raw_data['num_timesteps']):
+
+ # Only extract relevant dets for this class for preproc and eval (cls)
+ gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
+ gt_class_mask = gt_class_mask.astype(np.bool)
+ gt_ids = raw_data['gt_ids'][t][gt_class_mask]
+ gt_dets = raw_data['gt_dets'][t][gt_class_mask]
+
+ tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
+ tracker_class_mask = tracker_class_mask.astype(np.bool)
+ tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
+ tracker_dets = raw_data['tracker_dets'][t][tracker_class_mask]
+ similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
+
+ # Match tracker and gt dets (with hungarian algorithm)
+ unmatched_indices = np.arange(tracker_ids.shape[0])
+ if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
+ matching_scores = similarity_scores.copy()
+ matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_cols = match_cols[actually_matched_mask]
+ unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
+
+ # For unmatched tracker dets, remove those that are greater than 50% within a crowd ignore region.
+ unmatched_tracker_dets = tracker_dets[unmatched_indices, :]
+ crowd_ignore_regions = raw_data['gt_crowd_ignore_regions'][t]
+ intersection_with_ignore_region = self._calculate_box_ious(unmatched_tracker_dets, crowd_ignore_regions,
+ box_format='x0y0x1y1', do_ioa=True)
+ is_within_crowd_ignore_region = np.any(intersection_with_ignore_region > 0.5 + np.finfo('float').eps,
+ axis=1)
+
+ # Apply preprocessing to remove unwanted tracker dets.
+ to_remove_tracker = unmatched_indices[is_within_crowd_ignore_region]
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+
+ data['gt_ids'][t] = gt_ids
+ data['gt_dets'][t] = gt_dets
+ data['similarity_scores'][t] = similarity_scores
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+
+ # Ensure that ids are unique per timestep.
+ self._check_unique_ids(data)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t, box_format='x0y0x1y1')
+ return similarity_scores
diff --git a/val_utils/trackeval/datasets/burst.py b/val_utils/trackeval/datasets/burst.py
new file mode 100644
index 0000000000000000000000000000000000000000..475c09e874f973a3cadbf6e5df0c5053cf3c48a2
--- /dev/null
+++ b/val_utils/trackeval/datasets/burst.py
@@ -0,0 +1,49 @@
+import os
+from .burst_helpers.burst_base import BURSTBase
+from .burst_helpers.format_converter import GroundTruthBURSTFormatToTAOFormatConverter, PredictionBURSTFormatToTAOFormatConverter
+from .. import utils
+
+
+class BURST(BURSTBase):
+ """Dataset class for TAO tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ tao_config = BURSTBase.get_default_dataset_config()
+ code_path = utils.get_code_path()
+
+ # e.g. 'data/gt/tsunami/exemplar_guided/'
+ tao_config['GT_FOLDER'] = os.path.join(
+ code_path, 'data/gt/burst/val/') # Location of GT data
+ # e.g. 'data/trackers/tsunami/exemplar_guided/mask_guided/validation/'
+ tao_config['TRACKERS_FOLDER'] = os.path.join(
+ code_path, 'data/trackers/burst/class-guided/') # Trackers location
+ # set to True or False
+ tao_config['EXEMPLAR_GUIDED'] = False
+ return tao_config
+
+ def _iou_type(self):
+ return 'mask'
+
+ def _box_or_mask_from_det(self, det):
+ return det['segmentation']
+
+ def _calculate_area_for_ann(self, ann):
+ import pycocotools.mask as cocomask
+ return cocomask.area(ann["segmentation"])
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
+ return similarity_scores
+
+ def _is_exemplar_guided(self):
+ exemplar_guided = self.config['EXEMPLAR_GUIDED']
+ return exemplar_guided
+
+ def _postproc_ground_truth_data(self, data):
+ return GroundTruthBURSTFormatToTAOFormatConverter(data).convert()
+
+ def _postproc_prediction_data(self, data):
+ return PredictionBURSTFormatToTAOFormatConverter(
+ self.gt_data, data,
+ exemplar_guided=self._is_exemplar_guided()).convert()
diff --git a/val_utils/trackeval/datasets/burst_helpers/BURST_SPECIFIC_ISSUES.md b/val_utils/trackeval/datasets/burst_helpers/BURST_SPECIFIC_ISSUES.md
new file mode 100644
index 0000000000000000000000000000000000000000..184d53c26588dca01309227b90dd07a2af3da8b3
--- /dev/null
+++ b/val_utils/trackeval/datasets/burst_helpers/BURST_SPECIFIC_ISSUES.md
@@ -0,0 +1,7 @@
+The track ids in both ground truth and predictions are not globally unique, but
+start from 1 for each video. At the moment when converting from Ali format to
+TAO format, we remap the ids to be globally unique. It would be better to
+directly have this in the data though.
+
+
+Improve setting of EXEMPLAR_GUIDED flag, maybe this can be done automatically.
diff --git a/val_utils/trackeval/datasets/burst_helpers/__init__.py b/val_utils/trackeval/datasets/burst_helpers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/val_utils/trackeval/datasets/burst_helpers/burst_base.py b/val_utils/trackeval/datasets/burst_helpers/burst_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..394eda4d5c4770c18e2ad66c4816fa1860be5eb5
--- /dev/null
+++ b/val_utils/trackeval/datasets/burst_helpers/burst_base.py
@@ -0,0 +1,591 @@
+import os
+import numpy as np
+import json
+import itertools
+from collections import defaultdict
+from scipy.optimize import linear_sum_assignment
+from trackeval.utils import TrackEvalException
+from trackeval.datasets._base_dataset import _BaseDataset
+from trackeval import utils
+from trackeval import _timing
+
+
+class BURSTBase(_BaseDataset):
+ """Dataset class for TAO tracking"""
+
+ def _postproc_ground_truth_data(self, data):
+ return data
+
+ def _postproc_prediction_data(self, data):
+ return data
+
+ def _iou_type(self):
+ return 'bbox'
+
+ def _box_or_mask_from_det(self, det):
+ return np.atleast_1d(det['bbox'])
+
+ def _calculate_area_for_ann(self, ann):
+ return ann["bbox"][2] * ann["bbox"][3]
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/tao/tao_training'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/tao/tao_training'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
+ 'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
+ 'EXEMPLAR_GUIDED': False,
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+ self.gt_fol = self.config['GT_FOLDER']
+ self.tracker_fol = self.config['TRACKERS_FOLDER']
+ self.should_classes_combine = True
+ self.use_super_categories = False
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+
+ gt_dir_files = [file for file in os.listdir(self.gt_fol) if file.endswith('.json')]
+ if len(gt_dir_files) != 1:
+ raise TrackEvalException(self.gt_fol + ' does not contain exactly one json file.')
+
+ with open(os.path.join(self.gt_fol, gt_dir_files[0])) as f:
+ self.gt_data = self._postproc_ground_truth_data(json.load(f))
+
+ # merge categories marked with a merged tag in TAO dataset
+ self._merge_categories(self.gt_data['annotations'] + self.gt_data['tracks'])
+
+ # Get sequences to eval and sequence information
+ self.seq_list = [vid['name'].replace('/', '-') for vid in self.gt_data['videos']]
+ self.seq_name_to_seq_id = {vid['name'].replace('/', '-'): vid['id'] for vid in self.gt_data['videos']}
+ # compute mappings from videos to annotation data
+ self.videos_to_gt_tracks, self.videos_to_gt_images = self._compute_vid_mappings(self.gt_data['annotations'])
+ # compute sequence lengths
+ self.seq_lengths = {vid['id']: 0 for vid in self.gt_data['videos']}
+ for img in self.gt_data['images']:
+ self.seq_lengths[img['video_id']] += 1
+ self.seq_to_images_to_timestep = self._compute_image_to_timestep_mappings()
+ self.seq_to_classes = {vid['id']: {'pos_cat_ids': list({track['category_id'] for track
+ in self.videos_to_gt_tracks[vid['id']]}),
+ 'neg_cat_ids': vid['neg_category_ids'],
+ 'not_exhaustively_labeled_cat_ids': vid['not_exhaustive_category_ids']}
+ for vid in self.gt_data['videos']}
+
+ # Get classes to eval
+ considered_vid_ids = [self.seq_name_to_seq_id[vid] for vid in self.seq_list]
+ seen_cats = set([cat_id for vid_id in considered_vid_ids for cat_id
+ in self.seq_to_classes[vid_id]['pos_cat_ids']])
+ # only classes with ground truth are evaluated in TAO, also we don't evaluate distactors.
+ distractors = {20, 63, 108, 180, 188, 204, 212, 247, 303, 403, 407, 415, 490, 504, 507, 513, 529, 567,
+ 569, 588, 672, 691, 702, 708, 711, 720, 736, 737, 798, 813, 815, 827, 831, 851, 877, 883,
+ 912, 971, 976, 1130, 1133, 1134, 1169, 1184, 1220}
+ self.valid_classes = [cls['name'] for cls in self.gt_data['categories'] if (cls['id'] in seen_cats) and (cls['id'] not in distractors)]
+ cls_name_to_cls_id_map = {cls['name']: cls['id'] for cls in self.gt_data['categories']}
+
+ if self.config['CLASSES_TO_EVAL']:
+ self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only classes ' +
+ ', '.join(self.valid_classes) +
+ ' are valid (classes present in ground truth data).')
+ else:
+ self.class_list = [cls for cls in self.valid_classes]
+ self.class_name_to_class_id = {k: v for k, v in cls_name_to_cls_id_map.items() if k in self.class_list}
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ self.tracker_data = {tracker: dict() for tracker in self.tracker_list}
+
+ for tracker in self.tracker_list:
+ tr_dir_files = [file for file in os.listdir(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol))
+ if file.endswith('.json')]
+ if len(tr_dir_files) != 1:
+ raise TrackEvalException(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol)
+ + ' does not contain exactly one json file.')
+ with open(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, tr_dir_files[0])) as f:
+ curr_data = self._postproc_prediction_data(json.load(f))
+
+ # limit detections if MAX_DETECTIONS > 0
+ if self.config['MAX_DETECTIONS']:
+ curr_data = self._limit_dets_per_image(curr_data)
+
+ # fill missing video ids
+ self._fill_video_ids_inplace(curr_data)
+
+ # make track ids unique over whole evaluation set
+ self._make_track_ids_unique(curr_data)
+
+ # merge categories marked with a merged tag in TAO dataset
+ self._merge_categories(curr_data)
+
+ # get tracker sequence information
+ curr_videos_to_tracker_tracks, curr_videos_to_tracker_images = self._compute_vid_mappings(curr_data)
+ self.tracker_data[tracker]['vids_to_tracks'] = curr_videos_to_tracker_tracks
+ self.tracker_data[tracker]['vids_to_images'] = curr_videos_to_tracker_images
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the TAO format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets]: list (for each timestep) of lists of detections.
+ [classes_to_gt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
+ keys and corresponding segmentations as values) for each track
+ [classes_to_gt_track_ids, classes_to_gt_track_areas, classes_to_gt_track_lengths]: dictionary with class values
+ as keys and lists (for each track) as values
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ [classes_to_dt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
+ keys and corresponding segmentations as values) for each track
+ [classes_to_dt_track_ids, classes_to_dt_track_areas, classes_to_dt_track_lengths]: dictionary with class values
+ as keys and lists as values
+ [classes_to_dt_track_scores]: dictionary with class values as keys and 1D numpy arrays as values
+ """
+ seq_id = self.seq_name_to_seq_id[seq]
+ # File location
+ if is_gt:
+ imgs = self.videos_to_gt_images[seq_id]
+ else:
+ imgs = self.tracker_data[tracker]['vids_to_images'][seq_id]
+
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq_id]
+ img_to_timestep = self.seq_to_images_to_timestep[seq_id]
+ data_keys = ['ids', 'classes', 'dets']
+ if not is_gt:
+ data_keys += ['tracker_confidences']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+ for img in imgs:
+ # some tracker data contains images without any ground truth information, these are ignored
+ try:
+ t = img_to_timestep[img['id']]
+ except KeyError:
+ continue
+ annotations = img['annotations']
+ raw_data['dets'][t] = np.atleast_2d([ann['bbox'] for ann in annotations]).astype(float)
+ raw_data['ids'][t] = np.atleast_1d([ann['track_id'] for ann in annotations]).astype(int)
+ raw_data['classes'][t] = np.atleast_1d([ann['category_id'] for ann in annotations]).astype(int)
+ if not is_gt:
+ raw_data['tracker_confidences'][t] = np.atleast_1d([ann['score'] for ann in annotations]).astype(float)
+
+ for t, d in enumerate(raw_data['dets']):
+ if d is None:
+ raw_data['dets'][t] = np.empty((0, 4)).astype(float)
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+ if not is_gt:
+ raw_data['tracker_confidences'][t] = np.empty(0)
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+
+ all_classes = [self.class_name_to_class_id[cls] for cls in self.class_list]
+ if is_gt:
+ classes_to_consider = all_classes
+ all_tracks = self.videos_to_gt_tracks[seq_id]
+ else:
+ classes_to_consider = self.seq_to_classes[seq_id]['pos_cat_ids'] \
+ + self.seq_to_classes[seq_id]['neg_cat_ids']
+ all_tracks = self.tracker_data[tracker]['vids_to_tracks'][seq_id]
+
+ classes_to_tracks = {cls: [track for track in all_tracks if track['category_id'] == cls]
+ if cls in classes_to_consider else [] for cls in all_classes}
+
+ # mapping from classes to track information
+ raw_data['classes_to_tracks'] = {cls: [{det['image_id']: self._box_or_mask_from_det(det)
+ for det in track['annotations']} for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_ids'] = {cls: [track['id'] for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_areas'] = {cls: [track['area'] for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_lengths'] = {cls: [len(track['annotations']) for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+
+ if not is_gt:
+ raw_data['classes_to_dt_track_scores'] = {cls: np.array([np.mean([float(x['score'])
+ for x in track['annotations']])
+ for track in tracks])
+ for cls, tracks in classes_to_tracks.items()}
+
+ if is_gt:
+ key_map = {'classes_to_tracks': 'classes_to_gt_tracks',
+ 'classes_to_track_ids': 'classes_to_gt_track_ids',
+ 'classes_to_track_lengths': 'classes_to_gt_track_lengths',
+ 'classes_to_track_areas': 'classes_to_gt_track_areas'}
+ else:
+ key_map = {'classes_to_tracks': 'classes_to_dt_tracks',
+ 'classes_to_track_ids': 'classes_to_dt_track_ids',
+ 'classes_to_track_lengths': 'classes_to_dt_track_lengths',
+ 'classes_to_track_areas': 'classes_to_dt_track_areas'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+
+ raw_data['num_timesteps'] = num_timesteps
+ raw_data['neg_cat_ids'] = self.seq_to_classes[seq_id]['neg_cat_ids']
+ raw_data['not_exhaustively_labeled_cls'] = self.seq_to_classes[seq_id]['not_exhaustively_labeled_cat_ids']
+ raw_data['seq'] = seq
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+ TAO:
+ In TAO, the 4 preproc steps are as follow:
+ 1) All classes present in the ground truth data are evaluated separately.
+ 2) No matched tracker detections are removed.
+ 3) Unmatched tracker detections are removed if there is not ground truth data and the class does not
+ belong to the categories marked as negative for this sequence. Additionally, unmatched tracker
+ detections for classes which are marked as not exhaustively labeled are removed.
+ 4) No gt detections are removed.
+ Further, for TrackMAP computation track representations for the given class are accessed from a dictionary
+ and the tracks from the tracker data are sorted according to the tracker confidence.
+ """
+ cls_id = self.class_name_to_class_id[cls]
+ is_not_exhaustively_labeled = cls_id in raw_data['not_exhaustively_labeled_cls']
+ is_neg_category = cls_id in raw_data['neg_cat_ids']
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+
+ for t in range(raw_data['num_timesteps']):
+
+ # Only extract relevant dets for this class for preproc and eval (cls)
+ gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
+ gt_class_mask = gt_class_mask.astype(np.bool)
+ gt_ids = raw_data['gt_ids'][t][gt_class_mask]
+ gt_dets = raw_data['gt_dets'][t][gt_class_mask]
+
+ tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
+ tracker_class_mask = tracker_class_mask.astype(np.bool)
+ tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
+ tracker_dets = raw_data['tracker_dets'][t][tracker_class_mask]
+ tracker_confidences = raw_data['tracker_confidences'][t][tracker_class_mask]
+ similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
+
+ if not self.config['EXEMPLAR_GUIDED']:
+ # Match tracker and gt dets (with hungarian algorithm).
+ unmatched_indices = np.arange(tracker_ids.shape[0])
+ if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
+ matching_scores = similarity_scores.copy()
+ matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_cols = match_cols[actually_matched_mask]
+ unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
+
+ if gt_ids.shape[0] == 0 and not is_neg_category:
+ to_remove_tracker = unmatched_indices
+ elif is_not_exhaustively_labeled:
+ to_remove_tracker = unmatched_indices
+ else:
+ to_remove_tracker = np.array([], dtype=np.int)
+
+ # remove all unwanted unmatched tracker detections
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+ else:
+ data['tracker_ids'][t] = tracker_ids
+ data['tracker_dets'][t] = tracker_dets
+ data['tracker_confidences'][t] = tracker_confidences
+
+ data['gt_ids'][t] = gt_ids
+ data['gt_dets'][t] = gt_dets
+ data['similarity_scores'][t] = similarity_scores
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+
+ # get track representations
+ data['gt_tracks'] = raw_data['classes_to_gt_tracks'][cls_id]
+ data['gt_track_ids'] = raw_data['classes_to_gt_track_ids'][cls_id]
+ data['gt_track_lengths'] = raw_data['classes_to_gt_track_lengths'][cls_id]
+ data['gt_track_areas'] = raw_data['classes_to_gt_track_areas'][cls_id]
+ data['dt_tracks'] = raw_data['classes_to_dt_tracks'][cls_id]
+ data['dt_track_ids'] = raw_data['classes_to_dt_track_ids'][cls_id]
+ data['dt_track_lengths'] = raw_data['classes_to_dt_track_lengths'][cls_id]
+ data['dt_track_areas'] = raw_data['classes_to_dt_track_areas'][cls_id]
+ data['dt_track_scores'] = raw_data['classes_to_dt_track_scores'][cls_id]
+ data['not_exhaustively_labeled'] = is_not_exhaustively_labeled
+ data['iou_type'] = self._iou_type()
+
+ # sort tracker data tracks by tracker confidence scores
+ if data['dt_tracks']:
+ idx = np.argsort([-score for score in data['dt_track_scores']], kind="mergesort")
+ data['dt_track_scores'] = [data['dt_track_scores'][i] for i in idx]
+ data['dt_tracks'] = [data['dt_tracks'][i] for i in idx]
+ data['dt_track_ids'] = [data['dt_track_ids'][i] for i in idx]
+ data['dt_track_lengths'] = [data['dt_track_lengths'][i] for i in idx]
+ data['dt_track_areas'] = [data['dt_track_areas'][i] for i in idx]
+ # Ensure that ids are unique per timestep.
+ self._check_unique_ids(data)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t)
+ return similarity_scores
+
+ def _merge_categories(self, annotations):
+ """
+ Merges categories with a merged tag. Adapted from https://github.com/TAO-Dataset
+ :param annotations: the annotations in which the classes should be merged
+ :return: None
+ """
+ merge_map = {}
+ for category in self.gt_data['categories']:
+ if 'merged' in category:
+ for to_merge in category['merged']:
+ merge_map[to_merge['id']] = category['id']
+
+ for ann in annotations:
+ ann['category_id'] = merge_map.get(ann['category_id'], ann['category_id'])
+
+ def _compute_vid_mappings(self, annotations):
+ """
+ Computes mappings from Videos to corresponding tracks and images.
+ :param annotations: the annotations for which the mapping should be generated
+ :return: the video-to-track-mapping, the video-to-image-mapping
+ """
+ vids_to_tracks = {}
+ vids_to_imgs = {}
+ vid_ids = [vid['id'] for vid in self.gt_data['videos']]
+
+ # compute an mapping from image IDs to images
+ images = {}
+ for image in self.gt_data['images']:
+ images[image['id']] = image
+
+ for ann in annotations:
+ ann["area"] = self._calculate_area_for_ann(ann)
+
+ vid = ann["video_id"]
+ if ann["video_id"] not in vids_to_tracks.keys():
+ vids_to_tracks[ann["video_id"]] = list()
+ if ann["video_id"] not in vids_to_imgs.keys():
+ vids_to_imgs[ann["video_id"]] = list()
+
+ # Fill in vids_to_tracks
+ tid = ann["track_id"]
+ exist_tids = [track["id"] for track in vids_to_tracks[vid]]
+ try:
+ index1 = exist_tids.index(tid)
+ except ValueError:
+ index1 = -1
+ if tid not in exist_tids:
+ curr_track = {"id": tid, "category_id": ann["category_id"],
+ "video_id": vid, "annotations": [ann]}
+ vids_to_tracks[vid].append(curr_track)
+ else:
+ vids_to_tracks[vid][index1]["annotations"].append(ann)
+
+ # Fill in vids_to_imgs
+ img_id = ann['image_id']
+ exist_img_ids = [img["id"] for img in vids_to_imgs[vid]]
+ try:
+ index2 = exist_img_ids.index(img_id)
+ except ValueError:
+ index2 = -1
+ if index2 == -1:
+ curr_img = {"id": img_id, "annotations": [ann]}
+ vids_to_imgs[vid].append(curr_img)
+ else:
+ vids_to_imgs[vid][index2]["annotations"].append(ann)
+
+ # sort annotations by frame index and compute track area
+ for vid, tracks in vids_to_tracks.items():
+ for track in tracks:
+ track["annotations"] = sorted(
+ track['annotations'],
+ key=lambda x: images[x['image_id']]['frame_index'])
+ # Computer average area
+ track["area"] = (sum(x['area'] for x in track['annotations']) / len(track['annotations']))
+
+ # Ensure all videos are present
+ for vid_id in vid_ids:
+ if vid_id not in vids_to_tracks.keys():
+ vids_to_tracks[vid_id] = []
+ if vid_id not in vids_to_imgs.keys():
+ vids_to_imgs[vid_id] = []
+
+ return vids_to_tracks, vids_to_imgs
+
+ def _compute_image_to_timestep_mappings(self):
+ """
+ Computes a mapping from images to the corresponding timestep in the sequence.
+ :return: the image-to-timestep-mapping
+ """
+ images = {}
+ for image in self.gt_data['images']:
+ images[image['id']] = image
+
+ seq_to_imgs_to_timestep = {vid['id']: dict() for vid in self.gt_data['videos']}
+ for vid in seq_to_imgs_to_timestep:
+ curr_imgs = [img['id'] for img in self.videos_to_gt_images[vid]]
+ curr_imgs = sorted(curr_imgs, key=lambda x: images[x]['frame_index'])
+ seq_to_imgs_to_timestep[vid] = {curr_imgs[i]: i for i in range(len(curr_imgs))}
+
+ return seq_to_imgs_to_timestep
+
+ def _limit_dets_per_image(self, annotations):
+ """
+ Limits the number of detections for each image to config['MAX_DETECTIONS']. Adapted from
+ https://github.com/TAO-Dataset/
+ :param annotations: the annotations in which the detections should be limited
+ :return: the annotations with limited detections
+ """
+ max_dets = self.config['MAX_DETECTIONS']
+ img_ann = defaultdict(list)
+ for ann in annotations:
+ img_ann[ann["image_id"]].append(ann)
+
+ for img_id, _anns in img_ann.items():
+ if len(_anns) <= max_dets:
+ continue
+ _anns = sorted(_anns, key=lambda x: x["score"], reverse=True)
+ img_ann[img_id] = _anns[:max_dets]
+
+ return [ann for anns in img_ann.values() for ann in anns]
+
+ def _fill_video_ids_inplace(self, annotations):
+ """
+ Fills in missing video IDs inplace. Adapted from https://github.com/TAO-Dataset/
+ :param annotations: the annotations for which the videos IDs should be filled inplace
+ :return: None
+ """
+ missing_video_id = [x for x in annotations if 'video_id' not in x]
+ if missing_video_id:
+ image_id_to_video_id = {
+ x['id']: x['video_id'] for x in self.gt_data['images']
+ }
+ for x in missing_video_id:
+ x['video_id'] = image_id_to_video_id[x['image_id']]
+
+ @staticmethod
+ def _make_track_ids_unique(annotations):
+ """
+ Makes the track IDs unqiue over the whole annotation set. Adapted from https://github.com/TAO-Dataset/
+ :param annotations: the annotation set
+ :return: the number of updated IDs
+ """
+ track_id_videos = {}
+ track_ids_to_update = set()
+ max_track_id = 0
+ for ann in annotations:
+ t = ann['track_id']
+ if t not in track_id_videos:
+ track_id_videos[t] = ann['video_id']
+
+ if ann['video_id'] != track_id_videos[t]:
+ # Track id is assigned to multiple videos
+ track_ids_to_update.add(t)
+ max_track_id = max(max_track_id, t)
+
+ if track_ids_to_update:
+ #print('true')
+ next_id = itertools.count(max_track_id + 1)
+ new_track_ids = defaultdict(lambda: next(next_id))
+ for ann in annotations:
+ t = ann['track_id']
+ v = ann['video_id']
+ if t in track_ids_to_update:
+ ann['track_id'] = new_track_ids[t, v]
+ return len(track_ids_to_update)
diff --git a/val_utils/trackeval/datasets/burst_helpers/burst_ow_base.py b/val_utils/trackeval/datasets/burst_helpers/burst_ow_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..bef14d2bf6362209d01075ad6976838ef121be2e
--- /dev/null
+++ b/val_utils/trackeval/datasets/burst_helpers/burst_ow_base.py
@@ -0,0 +1,675 @@
+import os
+import numpy as np
+import json
+import itertools
+from collections import defaultdict
+from scipy.optimize import linear_sum_assignment
+from trackeval.utils import TrackEvalException
+from trackeval.datasets._base_dataset import _BaseDataset
+from trackeval import utils
+from trackeval import _timing
+
+
+class BURST_OW_Base(_BaseDataset):
+ """Dataset class for TAO tracking"""
+
+ def _postproc_ground_truth_data(self, data):
+ return data
+
+ def _postproc_prediction_data(self, data):
+ return data
+
+ def _iou_type(self):
+ return 'bbox'
+
+ def _box_or_mask_from_det(self, det):
+ return np.atleast_1d(det['bbox'])
+
+ def _calculate_area_for_ann(self, ann):
+ return ann["bbox"][2] * ann["bbox"][3]
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/tao/tao_training'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/tao/tao_training'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
+ 'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
+ 'SUBSET': 'all'
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+ self.gt_fol = self.config['GT_FOLDER']
+ self.tracker_fol = self.config['TRACKERS_FOLDER']
+ self.should_classes_combine = True
+ self.use_super_categories = False
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+
+ gt_dir_files = [file for file in os.listdir(self.gt_fol) if file.endswith('.json')]
+ if len(gt_dir_files) != 1:
+ raise TrackEvalException(self.gt_fol + ' does not contain exactly one json file.')
+
+ with open(os.path.join(self.gt_fol, gt_dir_files[0])) as f:
+ self.gt_data = self._postproc_ground_truth_data(json.load(f))
+
+ self.subset = self.config['SUBSET']
+ if self.subset != 'all':
+ # Split GT data into `known`, `unknown` or `distractor`
+ self._split_known_unknown_distractor()
+ self.gt_data = self._filter_gt_data(self.gt_data)
+
+ # merge categories marked with a merged tag in TAO dataset
+ self._merge_categories(self.gt_data['annotations'] + self.gt_data['tracks'])
+
+ # Get sequences to eval and sequence information
+ self.seq_list = [vid['name'].replace('/', '-') for vid in self.gt_data['videos']]
+ self.seq_name_to_seq_id = {vid['name'].replace('/', '-'): vid['id'] for vid in self.gt_data['videos']}
+ # compute mappings from videos to annotation data
+ self.videos_to_gt_tracks, self.videos_to_gt_images = self._compute_vid_mappings(self.gt_data['annotations'])
+ # compute sequence lengths
+ self.seq_lengths = {vid['id']: 0 for vid in self.gt_data['videos']}
+ for img in self.gt_data['images']:
+ self.seq_lengths[img['video_id']] += 1
+ self.seq_to_images_to_timestep = self._compute_image_to_timestep_mappings()
+ self.seq_to_classes = {vid['id']: {'pos_cat_ids': list({track['category_id'] for track
+ in self.videos_to_gt_tracks[vid['id']]}),
+ 'neg_cat_ids': vid['neg_category_ids'],
+ 'not_exhaustively_labeled_cat_ids': vid['not_exhaustive_category_ids']}
+ for vid in self.gt_data['videos']}
+
+ # Get classes to eval
+ considered_vid_ids = [self.seq_name_to_seq_id[vid] for vid in self.seq_list]
+ seen_cats = set([cat_id for vid_id in considered_vid_ids for cat_id
+ in self.seq_to_classes[vid_id]['pos_cat_ids']])
+ # only classes with ground truth are evaluated in TAO
+ self.valid_classes = [cls['name'] for cls in self.gt_data['categories'] if cls['id'] in seen_cats]
+ # cls_name_to_cls_id_map = {cls['name']: cls['id'] for cls in self.gt_data['categories']}
+
+ if self.config['CLASSES_TO_EVAL']:
+ # self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ # for cls in self.config['CLASSES_TO_EVAL']]
+ self.class_list = ["object"] # class-agnostic
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only classes ' +
+ ', '.join(self.valid_classes) +
+ ' are valid (classes present in ground truth data).')
+ else:
+ # self.class_list = [cls for cls in self.valid_classes]
+ self.class_list = ["object"] # class-agnostic
+ # self.class_name_to_class_id = {k: v for k, v in cls_name_to_cls_id_map.items() if k in self.class_list}
+ self.class_name_to_class_id = {"object": 1} # class-agnostic
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ self.tracker_data = {tracker: dict() for tracker in self.tracker_list}
+
+ for tracker in self.tracker_list:
+ tr_dir_files = [file for file in os.listdir(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol))
+ if file.endswith('.json')]
+ if len(tr_dir_files) != 1:
+ raise TrackEvalException(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol)
+ + ' does not contain exactly one json file.')
+ with open(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, tr_dir_files[0])) as f:
+ curr_data = self._postproc_prediction_data(json.load(f))
+
+ # limit detections if MAX_DETECTIONS > 0
+ if self.config['MAX_DETECTIONS']:
+ curr_data = self._limit_dets_per_image(curr_data)
+
+ # fill missing video ids
+ self._fill_video_ids_inplace(curr_data)
+
+ # make track ids unique over whole evaluation set
+ self._make_track_ids_unique(curr_data)
+
+ # merge categories marked with a merged tag in TAO dataset
+ self._merge_categories(curr_data)
+
+ # get tracker sequence information
+ curr_videos_to_tracker_tracks, curr_videos_to_tracker_images = self._compute_vid_mappings(curr_data)
+ self.tracker_data[tracker]['vids_to_tracks'] = curr_videos_to_tracker_tracks
+ self.tracker_data[tracker]['vids_to_images'] = curr_videos_to_tracker_images
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the TAO format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets]: list (for each timestep) of lists of detections.
+ [classes_to_gt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
+ keys and corresponding segmentations as values) for each track
+ [classes_to_gt_track_ids, classes_to_gt_track_areas, classes_to_gt_track_lengths]: dictionary with class values
+ as keys and lists (for each track) as values
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ [classes_to_dt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
+ keys and corresponding segmentations as values) for each track
+ [classes_to_dt_track_ids, classes_to_dt_track_areas, classes_to_dt_track_lengths]: dictionary with class values
+ as keys and lists as values
+ [classes_to_dt_track_scores]: dictionary with class values as keys and 1D numpy arrays as values
+ """
+ seq_id = self.seq_name_to_seq_id[seq]
+ # File location
+ if is_gt:
+ imgs = self.videos_to_gt_images[seq_id]
+ else:
+ imgs = self.tracker_data[tracker]['vids_to_images'][seq_id]
+
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq_id]
+ img_to_timestep = self.seq_to_images_to_timestep[seq_id]
+ data_keys = ['ids', 'classes', 'dets']
+ if not is_gt:
+ data_keys += ['tracker_confidences']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+ for img in imgs:
+ # some tracker data contains images without any ground truth information, these are ignored
+ try:
+ t = img_to_timestep[img['id']]
+ except KeyError:
+ continue
+ annotations = img['annotations']
+ raw_data['dets'][t] = np.atleast_2d([ann['bbox'] for ann in annotations]).astype(float)
+ raw_data['ids'][t] = np.atleast_1d([ann['track_id'] for ann in annotations]).astype(int)
+ raw_data['classes'][t] = np.atleast_1d([1 for _ in annotations]).astype(int) # class-agnostic
+ if not is_gt:
+ raw_data['tracker_confidences'][t] = np.atleast_1d([ann['score'] for ann in annotations]).astype(float)
+
+ for t, d in enumerate(raw_data['dets']):
+ if d is None:
+ raw_data['dets'][t] = np.empty((0, 4)).astype(float)
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+ if not is_gt:
+ raw_data['tracker_confidences'][t] = np.empty(0)
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+
+ # all_classes = [self.class_name_to_class_id[cls] for cls in self.class_list]
+ all_classes = [1] # class-agnostic
+
+ if is_gt:
+ classes_to_consider = all_classes
+ all_tracks = self.videos_to_gt_tracks[seq_id]
+ else:
+ # classes_to_consider = self.seq_to_classes[seq_id]['pos_cat_ids'] \
+ # + self.seq_to_classes[seq_id]['neg_cat_ids']
+ classes_to_consider = all_classes # class-agnostic
+ all_tracks = self.tracker_data[tracker]['vids_to_tracks'][seq_id]
+
+ # classes_to_tracks = {cls: [track for track in all_tracks if track['category_id'] == cls]
+ # if cls in classes_to_consider else [] for cls in all_classes}
+ classes_to_tracks = {cls: [track for track in all_tracks]
+ if cls in classes_to_consider else [] for cls in all_classes} # class-agnostic
+
+ # mapping from classes to track information
+ raw_data['classes_to_tracks'] = {cls: [{det['image_id']: self._box_or_mask_from_det(det)
+ for det in track['annotations']} for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_ids'] = {cls: [track['id'] for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_areas'] = {cls: [track['area'] for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_lengths'] = {cls: [len(track['annotations']) for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+
+ if not is_gt:
+ raw_data['classes_to_dt_track_scores'] = {cls: np.array([np.mean([float(x['score'])
+ for x in track['annotations']])
+ for track in tracks])
+ for cls, tracks in classes_to_tracks.items()}
+
+ if is_gt:
+ key_map = {'classes_to_tracks': 'classes_to_gt_tracks',
+ 'classes_to_track_ids': 'classes_to_gt_track_ids',
+ 'classes_to_track_lengths': 'classes_to_gt_track_lengths',
+ 'classes_to_track_areas': 'classes_to_gt_track_areas'}
+ else:
+ key_map = {'classes_to_tracks': 'classes_to_dt_tracks',
+ 'classes_to_track_ids': 'classes_to_dt_track_ids',
+ 'classes_to_track_lengths': 'classes_to_dt_track_lengths',
+ 'classes_to_track_areas': 'classes_to_dt_track_areas'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+
+ raw_data['num_timesteps'] = num_timesteps
+ raw_data['neg_cat_ids'] = self.seq_to_classes[seq_id]['neg_cat_ids']
+ raw_data['not_exhaustively_labeled_cls'] = self.seq_to_classes[seq_id]['not_exhaustively_labeled_cat_ids']
+ raw_data['seq'] = seq
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+ TAO:
+ In TAO, the 4 preproc steps are as follow:
+ 1) All classes present in the ground truth data are evaluated separately.
+ 2) No matched tracker detections are removed.
+ 3) Unmatched tracker detections are removed if there is not ground truth data and the class does not
+ belong to the categories marked as negative for this sequence. Additionally, unmatched tracker
+ detections for classes which are marked as not exhaustively labeled are removed.
+ 4) No gt detections are removed.
+ Further, for TrackMAP computation track representations for the given class are accessed from a dictionary
+ and the tracks from the tracker data are sorted according to the tracker confidence.
+ """
+ cls_id = self.class_name_to_class_id[cls]
+ is_not_exhaustively_labeled = cls_id in raw_data['not_exhaustively_labeled_cls']
+ is_neg_category = cls_id in raw_data['neg_cat_ids']
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+ for t in range(raw_data['num_timesteps']):
+
+ # Only extract relevant dets for this class for preproc and eval (cls)
+ gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
+ gt_class_mask = gt_class_mask.astype(np.bool)
+ gt_ids = raw_data['gt_ids'][t][gt_class_mask]
+ gt_dets = raw_data['gt_dets'][t][gt_class_mask]
+
+ tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
+ tracker_class_mask = tracker_class_mask.astype(np.bool)
+ tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
+ tracker_dets = raw_data['tracker_dets'][t][tracker_class_mask]
+ tracker_confidences = raw_data['tracker_confidences'][t][tracker_class_mask]
+ similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
+
+ # Match tracker and gt dets (with hungarian algorithm).
+ unmatched_indices = np.arange(tracker_ids.shape[0])
+ if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
+ matching_scores = similarity_scores.copy()
+ matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_cols = match_cols[actually_matched_mask]
+ unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
+
+ if gt_ids.shape[0] == 0 and not is_neg_category:
+ to_remove_tracker = unmatched_indices
+ elif is_not_exhaustively_labeled:
+ to_remove_tracker = unmatched_indices
+ else:
+ to_remove_tracker = np.array([], dtype=np.int)
+
+ # remove all unwanted unmatched tracker detections
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+
+ data['gt_ids'][t] = gt_ids
+ data['gt_dets'][t] = gt_dets
+ data['similarity_scores'][t] = similarity_scores
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+
+ # get track representations
+ data['gt_tracks'] = raw_data['classes_to_gt_tracks'][cls_id]
+ data['gt_track_ids'] = raw_data['classes_to_gt_track_ids'][cls_id]
+ data['gt_track_lengths'] = raw_data['classes_to_gt_track_lengths'][cls_id]
+ data['gt_track_areas'] = raw_data['classes_to_gt_track_areas'][cls_id]
+ data['dt_tracks'] = raw_data['classes_to_dt_tracks'][cls_id]
+ data['dt_track_ids'] = raw_data['classes_to_dt_track_ids'][cls_id]
+ data['dt_track_lengths'] = raw_data['classes_to_dt_track_lengths'][cls_id]
+ data['dt_track_areas'] = raw_data['classes_to_dt_track_areas'][cls_id]
+ data['dt_track_scores'] = raw_data['classes_to_dt_track_scores'][cls_id]
+ data['not_exhaustively_labeled'] = is_not_exhaustively_labeled
+ data['iou_type'] = self._iou_type()
+
+ # sort tracker data tracks by tracker confidence scores
+ if data['dt_tracks']:
+ idx = np.argsort([-score for score in data['dt_track_scores']], kind="mergesort")
+ data['dt_track_scores'] = [data['dt_track_scores'][i] for i in idx]
+ data['dt_tracks'] = [data['dt_tracks'][i] for i in idx]
+ data['dt_track_ids'] = [data['dt_track_ids'][i] for i in idx]
+ data['dt_track_lengths'] = [data['dt_track_lengths'][i] for i in idx]
+ data['dt_track_areas'] = [data['dt_track_areas'][i] for i in idx]
+ # Ensure that ids are unique per timestep.
+ self._check_unique_ids(data)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t)
+ return similarity_scores
+
+ def _merge_categories(self, annotations):
+ """
+ Merges categories with a merged tag. Adapted from https://github.com/TAO-Dataset
+ :param annotations: the annotations in which the classes should be merged
+ :return: None
+ """
+ merge_map = {}
+ for category in self.gt_data['categories']:
+ if 'merged' in category:
+ for to_merge in category['merged']:
+ merge_map[to_merge['id']] = category['id']
+
+ for ann in annotations:
+ ann['category_id'] = merge_map.get(ann['category_id'], ann['category_id'])
+
+ def _compute_vid_mappings(self, annotations):
+ """
+ Computes mappings from Videos to corresponding tracks and images.
+ :param annotations: the annotations for which the mapping should be generated
+ :return: the video-to-track-mapping, the video-to-image-mapping
+ """
+ vids_to_tracks = {}
+ vids_to_imgs = {}
+ vid_ids = [vid['id'] for vid in self.gt_data['videos']]
+
+ # compute an mapping from image IDs to images
+ images = {}
+ for image in self.gt_data['images']:
+ images[image['id']] = image
+
+ for ann in annotations:
+ ann["area"] = self._calculate_area_for_ann(ann)
+
+ vid = ann["video_id"]
+ if ann["video_id"] not in vids_to_tracks.keys():
+ vids_to_tracks[ann["video_id"]] = list()
+ if ann["video_id"] not in vids_to_imgs.keys():
+ vids_to_imgs[ann["video_id"]] = list()
+
+ # Fill in vids_to_tracks
+ tid = ann["track_id"]
+ exist_tids = [track["id"] for track in vids_to_tracks[vid]]
+ try:
+ index1 = exist_tids.index(tid)
+ except ValueError:
+ index1 = -1
+ if tid not in exist_tids:
+ curr_track = {"id": tid, "category_id": ann["category_id"],
+ "video_id": vid, "annotations": [ann]}
+ vids_to_tracks[vid].append(curr_track)
+ else:
+ vids_to_tracks[vid][index1]["annotations"].append(ann)
+
+ # Fill in vids_to_imgs
+ img_id = ann['image_id']
+ exist_img_ids = [img["id"] for img in vids_to_imgs[vid]]
+ try:
+ index2 = exist_img_ids.index(img_id)
+ except ValueError:
+ index2 = -1
+ if index2 == -1:
+ curr_img = {"id": img_id, "annotations": [ann]}
+ vids_to_imgs[vid].append(curr_img)
+ else:
+ vids_to_imgs[vid][index2]["annotations"].append(ann)
+
+ # sort annotations by frame index and compute track area
+ for vid, tracks in vids_to_tracks.items():
+ for track in tracks:
+ track["annotations"] = sorted(
+ track['annotations'],
+ key=lambda x: images[x['image_id']]['frame_index'])
+ # Computer average area
+ track["area"] = (sum(x['area'] for x in track['annotations']) / len(track['annotations']))
+
+ # Ensure all videos are present
+ for vid_id in vid_ids:
+ if vid_id not in vids_to_tracks.keys():
+ vids_to_tracks[vid_id] = []
+ if vid_id not in vids_to_imgs.keys():
+ vids_to_imgs[vid_id] = []
+
+ return vids_to_tracks, vids_to_imgs
+
+ def _compute_image_to_timestep_mappings(self):
+ """
+ Computes a mapping from images to the corresponding timestep in the sequence.
+ :return: the image-to-timestep-mapping
+ """
+ images = {}
+ for image in self.gt_data['images']:
+ images[image['id']] = image
+
+ seq_to_imgs_to_timestep = {vid['id']: dict() for vid in self.gt_data['videos']}
+ for vid in seq_to_imgs_to_timestep:
+ curr_imgs = [img['id'] for img in self.videos_to_gt_images[vid]]
+ curr_imgs = sorted(curr_imgs, key=lambda x: images[x]['frame_index'])
+ seq_to_imgs_to_timestep[vid] = {curr_imgs[i]: i for i in range(len(curr_imgs))}
+
+ return seq_to_imgs_to_timestep
+
+ def _limit_dets_per_image(self, annotations):
+ """
+ Limits the number of detections for each image to config['MAX_DETECTIONS']. Adapted from
+ https://github.com/TAO-Dataset/
+ :param annotations: the annotations in which the detections should be limited
+ :return: the annotations with limited detections
+ """
+ max_dets = self.config['MAX_DETECTIONS']
+ img_ann = defaultdict(list)
+ for ann in annotations:
+ img_ann[ann["image_id"]].append(ann)
+
+ for img_id, _anns in img_ann.items():
+ if len(_anns) <= max_dets:
+ continue
+ _anns = sorted(_anns, key=lambda x: x["score"], reverse=True)
+ img_ann[img_id] = _anns[:max_dets]
+
+ return [ann for anns in img_ann.values() for ann in anns]
+
+ def _fill_video_ids_inplace(self, annotations):
+ """
+ Fills in missing video IDs inplace. Adapted from https://github.com/TAO-Dataset/
+ :param annotations: the annotations for which the videos IDs should be filled inplace
+ :return: None
+ """
+ missing_video_id = [x for x in annotations if 'video_id' not in x]
+ if missing_video_id:
+ image_id_to_video_id = {
+ x['id']: x['video_id'] for x in self.gt_data['images']
+ }
+ for x in missing_video_id:
+ x['video_id'] = image_id_to_video_id[x['image_id']]
+
+ @staticmethod
+ def _make_track_ids_unique(annotations):
+ """
+ Makes the track IDs unqiue over the whole annotation set. Adapted from https://github.com/TAO-Dataset/
+ :param annotations: the annotation set
+ :return: the number of updated IDs
+ """
+ track_id_videos = {}
+ track_ids_to_update = set()
+ max_track_id = 0
+ for ann in annotations:
+ t = ann['track_id']
+ if t not in track_id_videos:
+ track_id_videos[t] = ann['video_id']
+
+ if ann['video_id'] != track_id_videos[t]:
+ # Track id is assigned to multiple videos
+ track_ids_to_update.add(t)
+ max_track_id = max(max_track_id, t)
+
+ if track_ids_to_update:
+ #print('true')
+ next_id = itertools.count(max_track_id + 1)
+ new_track_ids = defaultdict(lambda: next(next_id))
+ for ann in annotations:
+ t = ann['track_id']
+ v = ann['video_id']
+ if t in track_ids_to_update:
+ ann['track_id'] = new_track_ids[t, v]
+ return len(track_ids_to_update)
+
+ def _split_known_unknown_distractor(self):
+ all_ids = set([i for i in range(1, 2000)]) # 2000 is larger than the max category id in TAO-OW.
+ # `knowns` includes 78 TAO_category_ids that corresponds to 78 COCO classes.
+ # (The other 2 COCO classes do not have corresponding classes in TAO).
+ self.knowns = {4, 13, 1038, 544, 1057, 34, 35, 36, 41, 45, 58, 60, 579, 1091, 1097, 1099, 78, 79, 81, 91, 1115,
+ 1117, 95, 1122, 99, 1132, 621, 1135, 625, 118, 1144, 126, 642, 1155, 133, 1162, 139, 154, 174, 185,
+ 699, 1215, 714, 717, 1229, 211, 729, 221, 229, 747, 235, 237, 779, 276, 805, 299, 829, 852, 347,
+ 371, 382, 896, 392, 926, 937, 428, 429, 961, 452, 979, 980, 982, 475, 480, 993, 1001, 502, 1018}
+ # `distractors` is defined as in the paper "Opening up Open-World Tracking"
+ self.distractors = {20, 63, 108, 180, 188, 204, 212, 247, 303, 403, 407, 415, 490, 504, 507, 513, 529, 567,
+ 569, 588, 672, 691, 702, 708, 711, 720, 736, 737, 798, 813, 815, 827, 831, 851, 877, 883,
+ 912, 971, 976, 1130, 1133, 1134, 1169, 1184, 1220}
+ self.unknowns = all_ids.difference(self.knowns.union(self.distractors))
+
+ def _filter_gt_data(self, raw_gt_data):
+ """
+ Filter out irrelevant data in the raw_gt_data
+ Args:
+ raw_gt_data: directly loaded from json.
+
+ Returns:
+ filtered gt_data
+ """
+ valid_cat_ids = list()
+ if self.subset == "known":
+ valid_cat_ids = self.knowns
+ elif self.subset == "distractor":
+ valid_cat_ids = self.distractors
+ elif self.subset == "unknown":
+ valid_cat_ids = self.unknowns
+ # elif self.subset == "test_only_unknowns":
+ # valid_cat_ids = test_only_unknowns
+ else:
+ raise Exception("The parameter `SUBSET` is incorrect")
+
+ filtered = dict()
+ filtered["videos"] = raw_gt_data["videos"]
+ # filtered["videos"] = list()
+ unwanted_vid = set()
+ # for video in raw_gt_data["videos"]:
+ # datasrc = video["name"].split('/')[1]
+ # if datasrc in data_srcs:
+ # filtered["videos"].append(video)
+ # else:
+ # unwanted_vid.add(video["id"])
+
+ filtered["annotations"] = list()
+ for ann in raw_gt_data["annotations"]:
+ if (ann["video_id"] not in unwanted_vid) and (ann["category_id"] in valid_cat_ids):
+ filtered["annotations"].append(ann)
+
+ filtered["tracks"] = list()
+ for track in raw_gt_data["tracks"]:
+ if (track["video_id"] not in unwanted_vid) and (track["category_id"] in valid_cat_ids):
+ filtered["tracks"].append(track)
+
+ filtered["images"] = list()
+ for image in raw_gt_data["images"]:
+ if image["video_id"] not in unwanted_vid:
+ filtered["images"].append(image)
+
+ filtered["categories"] = list()
+ for cat in raw_gt_data["categories"]:
+ if cat["id"] in valid_cat_ids:
+ filtered["categories"].append(cat)
+
+ if "info" in raw_gt_data:
+ filtered["info"] = raw_gt_data["info"]
+ if "licenses" in raw_gt_data:
+ filtered["licenses"] = raw_gt_data["licenses"]
+
+ if "track_id_offsets" in raw_gt_data:
+ filtered["track_id_offsets"] = raw_gt_data["track_id_offsets"]
+
+ if "split" in raw_gt_data:
+ filtered["split"] = raw_gt_data["split"]
+
+ return filtered
diff --git a/val_utils/trackeval/datasets/burst_helpers/convert_burst_format_to_tao_format.py b/val_utils/trackeval/datasets/burst_helpers/convert_burst_format_to_tao_format.py
new file mode 100644
index 0000000000000000000000000000000000000000..129e42c96c835b8a67519245823b4e3f245eac60
--- /dev/null
+++ b/val_utils/trackeval/datasets/burst_helpers/convert_burst_format_to_tao_format.py
@@ -0,0 +1,39 @@
+import json
+import argparse
+from .format_converter import GroundTruthBURSTFormatToTAOFormatConverter, PredictionBURSTFormatToTAOFormatConverter
+
+
+def main(args):
+ with open(args.gt_input_file) as f:
+ ali_format_gt = json.load(f)
+ tao_format_gt = GroundTruthBURSTFormatToTAOFormatConverter(
+ ali_format_gt, args.split).convert()
+ with open(args.gt_output_file, 'w') as f:
+ json.dump(tao_format_gt, f)
+
+ if args.pred_input_file is None:
+ return
+ with open(args.pred_input_file) as f:
+ ali_format_pred = json.load(f)
+ tao_format_pred = PredictionBURSTFormatToTAOFormatConverter(
+ tao_format_gt, ali_format_pred, args.split,
+ args.exemplar_guided).convert()
+ with open(args.pred_output_file, 'w') as f:
+ json.dump(tao_format_pred, f)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--gt_input_file', type=str,
+ default='../data/gt/tsunami/exemplar_guided/validation_all_annotations.json')
+ parser.add_argument('--gt_output_file', type=str,
+ default='/tmp/val_gt.json')
+ parser.add_argument('--pred_input_file', type=str,
+ default='../data/trackers/tsunami/exemplar_guided/STCN_off_the_shelf/data/results.json')
+ parser.add_argument('--pred_output_file', type=str,
+ default='/tmp/pred.json')
+ parser.add_argument('--split', type=str, default='validation')
+ parser.add_argument('--exemplar_guided', type=bool, default=True)
+ args_ = parser.parse_args()
+ main(args_)
diff --git a/val_utils/trackeval/datasets/burst_helpers/format_converter.py b/val_utils/trackeval/datasets/burst_helpers/format_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..da43a9a3c467eef6bb4f8b1668d65ea13f9c544f
--- /dev/null
+++ b/val_utils/trackeval/datasets/burst_helpers/format_converter.py
@@ -0,0 +1,259 @@
+import os
+import json
+import pycocotools.mask as cocomask
+from tabulate import tabulate
+from typing import Union
+
+
+def _global_track_id(*, local_track_id: Union[str, int],
+ video_id: Union[str, int],
+ track_id_mapping) -> int:
+ # remap local track ids into globally unique ids
+ return track_id_mapping[str(video_id)][str(local_track_id)]
+
+
+class GroundTruthBURSTFormatToTAOFormatConverter:
+ def __init__(self, ali_format):
+ self._ali_format = ali_format
+ self._split = ali_format['split']
+ self._categories = self._make_categories()
+ self._videos = []
+ self._annotations = []
+ self._tracks = {}
+ self._images = []
+ self._next_img_id = 0
+ self._next_ann_id = 0
+
+ self._track_id_mapping = self._load_track_id_mapping()
+
+ for seq in ali_format['sequences']:
+ self._visit_seq(seq)
+
+ def _load_track_id_mapping(self):
+ id_map = {}
+ next_global_track_id = 1
+ for seq in self._ali_format['sequences']:
+ seq_id = seq['id']
+ seq_id_map = {}
+ id_map[str(seq_id)] = seq_id_map
+ for local_track_id in seq['track_category_ids']:
+ seq_id_map[str(local_track_id)] = next_global_track_id
+ next_global_track_id += 1
+ return id_map
+
+ def global_track_id(self, *, local_track_id: Union[str, int],
+ video_id: Union[str, int]) -> int:
+ return _global_track_id(local_track_id=local_track_id,
+ video_id=video_id,
+ track_id_mapping=self._track_id_mapping)
+
+ def _visit_seq(self, seq):
+ self._make_video(seq)
+ imgs = self._make_images(seq)
+ self._make_annotations_and_tracks(seq, imgs)
+
+ def _make_images(self, seq):
+ imgs = []
+ for img_path in seq['annotated_image_paths']:
+ video = self._split + '/' + seq['dataset'] + '/' + seq['seq_name']
+ file_name = video + '/' + img_path
+
+ # TODO: once python 3.9 is more common, we can use this nicer and safer code
+ #stripped = img_path.removesuffix('.jpg').removesuffix('.png').removeprefix('frame')
+ stripped = img_path.replace('.jpg', '').replace('.png', '').replace('frame', '')
+
+ last = stripped.split('_')[-1]
+ frame_idx = int(last)
+
+ img = {'id': self._next_img_id, 'video': video,
+ 'width': seq['width'], 'height': seq['height'],
+ 'file_name': file_name,
+ 'frame_index': frame_idx,
+ 'video_id': seq['id']}
+ self._next_img_id += 1
+ self._images.append(img)
+ imgs.append(img)
+ return imgs
+
+ def _make_video(self, seq):
+ video_id = seq['id']
+ dataset = seq['dataset']
+ seq_name = seq['seq_name']
+ name = f'{self._split}/' + dataset + '/' + seq_name
+ video = {
+ 'id': video_id, 'width': seq['width'], 'height': seq['height'],
+ 'neg_category_ids': seq['neg_category_ids'],
+ 'not_exhaustive_category_ids': seq['not_exhaustive_category_ids'],
+ 'name': name, 'metadata': {'dataset': dataset}}
+ self._videos.append(video)
+
+ def _make_annotations_and_tracks(self, seq, imgs):
+ video_id = seq['id']
+ segs = seq['segmentations']
+ assert len(segs) == len(imgs), (len(segs), len(imgs))
+ for frame_segs, img in zip(segs, imgs):
+ for local_track_id, seg in frame_segs.items():
+ distractors = {20, 63, 108, 180, 188, 204, 212, 247, 303, 403, 407, 415, 490, 504, 507, 513, 529, 567,
+ 569, 588, 672, 691, 702, 708, 711, 720, 736, 737, 798, 813, 815, 827, 831, 851, 877, 883,
+ 912, 971, 976, 1130, 1133, 1134, 1169, 1184, 1220}
+ global_track_id = self.global_track_id(
+ local_track_id=local_track_id, video_id=seq['id'])
+ rle = seg['rle']
+ segmentation = {'counts': rle,
+ 'size': [img['height'], img['width']]}
+ image_id = img['id']
+ category_id = int(seq['track_category_ids'][local_track_id])
+ if category_id in distractors:
+ continue
+ coco_bbox = cocomask.toBbox(segmentation)
+ bbox = [int(x) for x in coco_bbox]
+ ann = {'segmentation': segmentation, 'id': self._next_ann_id,
+ 'image_id': image_id, 'category_id': category_id,
+ 'track_id': global_track_id, 'video_id': video_id,
+ 'bbox': bbox}
+ self._next_ann_id += 1
+ self._annotations.append(ann)
+
+ if global_track_id not in self._tracks:
+ track = {'id': global_track_id, 'category_id': category_id,
+ 'video_id': video_id}
+ self._tracks[global_track_id] = track
+
+ def convert(self):
+ tracks = sorted(self._tracks.values(), key=lambda t: t['id'])
+ return {'videos': self._videos, 'annotations': self._annotations,
+ 'tracks': tracks, 'images': self._images,
+ 'categories': self._categories,
+ 'track_id_mapping': self._track_id_mapping,
+ 'split': self._split}
+
+ def _make_categories(self):
+ tao_categories_path = os.path.join(os.path.dirname(__file__), 'tao_categories.json')
+ with open(tao_categories_path) as f:
+ return json.load(f)
+
+
+class PredictionBURSTFormatToTAOFormatConverter:
+ def __init__(self, gt, ali_format, exemplar_guided):
+ self._gt = gt
+ self._ali_format = ali_format
+ if 'split' in ali_format:
+ self._split = ali_format['split']
+ gt_split = self._gt['split']
+ assert self._split == gt_split, (self._split, gt_split)
+ else:
+ self._split = self._gt['split']
+ self._exemplar_guided = exemplar_guided
+ self._result = []
+ self._next_det_id = 0
+
+ self._img_by_filename = {}
+ for img in self._gt['images']:
+ file_name = img['file_name']
+ assert file_name not in self._img_by_filename
+ self._img_by_filename[file_name] = img
+
+ self._gt_track_by_track_id = {}
+ for track in self._gt['tracks']:
+ self._gt_track_by_track_id[int(track['id'])] = track
+
+ self._filtered_out_track_ids = set()
+
+ for seq in ali_format['sequences']:
+ self._visit_seq(seq)
+
+ if exemplar_guided and len(self._filtered_out_track_ids) > 0:
+ self.print_filter_out_debug_info(ali_format)
+
+ def print_filter_out_debug_info(self, ali_format):
+ track_ids_in_pred = set()
+ a_dict_for_debugging = {}
+ for seq in ali_format['sequences']:
+ for local_track_id in seq['track_category_ids']:
+ global_track_id = _global_track_id(
+ local_track_id=local_track_id, video_id=seq['id'],
+ track_id_mapping=self._gt['track_id_mapping'])
+ track_ids_in_pred.add(global_track_id)
+ a_dict_for_debugging[global_track_id] = {'seq': seq,
+ 'local_track_id': local_track_id}
+ print('Number of Track ids in pred:', len(track_ids_in_pred))
+ print('Exemplar Guided: Filtered out',
+ len(self._filtered_out_track_ids),
+ 'tracks which were not found in the ground truth.')
+ track_ids_after_filtering = set(d['track_id'] for d in self._result)
+ print('Number of tracks after filtering:',
+ len(track_ids_after_filtering))
+ problem_tracks = list(
+ track_ids_in_pred - track_ids_after_filtering - self._filtered_out_track_ids)
+ if len(problem_tracks) > 0:
+ print("\nWARNING:", len(problem_tracks),
+ "object tracks are not present. There could be a number of reasons for this:\n"
+ "(1) If you are running evaluation for the box/point exemplar-guided task then this is to be expected"
+ " because your tracker probably didn't predict masks for every ground-truth object instance.\n"
+ "(2) If you are running evaluation for the mask exemplar-guided task, then this could indicate a "
+ "problem. Assume that you copied the given first-frame object mask to your predicted result, this "
+ "should not happen. It could be that your predictions are at the wrong frame-rate i.e. you have no "
+ "predicted masks for video frames which will be evaluated.\n")
+
+ rows = []
+ for xx in problem_tracks:
+ rows.append([a_dict_for_debugging[xx]['seq']['dataset'],
+ a_dict_for_debugging[xx]['seq']['seq_name'],
+ a_dict_for_debugging[xx]['local_track_id']])
+
+ print("For your reference, the sequence name and track IDs for these missing tracks are:")
+ print(tabulate(rows, ["Dataset", "Sequence Name", "Track ID"]))
+
+ def _visit_seq(self, seq):
+ dataset = seq['dataset']
+ seq_name = seq['seq_name']
+ assert len(seq['segmentations']) == len(seq['annotated_image_paths'])
+ for frame_segs, img_path in zip(seq['segmentations'],
+ seq['annotated_image_paths']):
+ for local_track_id_str, track_det in frame_segs.items():
+ rle = track_det['rle']
+
+ file_name = self._split + '/' + dataset + '/' + seq_name + '/' + img_path
+ # the result might have a higher frame rate than the ground truth
+ if file_name not in self._img_by_filename:
+ continue
+
+ img = self._img_by_filename[file_name]
+ img_id = img['id']
+ height = img['height']
+ width = img['width']
+ segmentation = {'counts': rle, 'size': [height, width]}
+
+ local_track_id = int(local_track_id_str)
+ if self._exemplar_guided:
+ global_track_id = _global_track_id(
+ local_track_id=local_track_id, video_id=seq['id'],
+ track_id_mapping=self._gt['track_id_mapping'])
+ else:
+ global_track_id = local_track_id
+ coco_bbox = cocomask.toBbox(segmentation)
+ bbox = [int(x) for x in coco_bbox]
+ det = {'id': self._next_det_id, 'image_id': img_id,
+ 'track_id': global_track_id, 'bbox': bbox,
+ 'segmentation': segmentation}
+ if self._exemplar_guided:
+ if global_track_id not in self._gt_track_by_track_id:
+ self._filtered_out_track_ids.add(global_track_id)
+ continue
+ gt_track = self._gt_track_by_track_id[global_track_id]
+ category_id = gt_track['category_id']
+ det['category_id'] = category_id
+ elif 'category_id' in track_det:
+ det['category_id'] = track_det['category_id']
+ else:
+ category_id = seq['track_category_ids'][local_track_id_str]
+ det['category_id'] = category_id
+ self._next_det_id += 1
+ if 'score' in track_det:
+ det['score'] = track_det['score']
+ else:
+ det['score'] = 1.0
+ self._result.append(det)
+
+ def convert(self):
+ return self._result
diff --git a/val_utils/trackeval/datasets/burst_helpers/tao_categories.json b/val_utils/trackeval/datasets/burst_helpers/tao_categories.json
new file mode 100644
index 0000000000000000000000000000000000000000..0368949f21d28c54c1b6d60afd3b4762821da5d2
--- /dev/null
+++ b/val_utils/trackeval/datasets/burst_helpers/tao_categories.json
@@ -0,0 +1 @@
+[{"id": 1, "synset": "acorn.n.01", "synonyms": ["acorn"], "def": "nut from an oak tree", "name": "acorn"}, {"id": 2, "synset": "aerosol.n.02", "synonyms": ["aerosol_can", "spray_can"], "def": "a dispenser that holds a substance under pressure", "name": "aerosol_can"}, {"id": 3, "synset": "air_conditioner.n.01", "synonyms": ["air_conditioner"], "def": "a machine that keeps air cool and dry", "name": "air_conditioner"}, {"id": 4, "synset": "airplane.n.01", "synonyms": ["airplane", "aeroplane"], "def": "an aircraft that has a fixed wing and is powered by propellers or jets", "name": "airplane"}, {"id": 5, "synset": "alarm_clock.n.01", "synonyms": ["alarm_clock"], "def": "a clock that wakes a sleeper at some preset time", "name": "alarm_clock"}, {"id": 6, "synset": "alcohol.n.01", "synonyms": ["alcohol", "alcoholic_beverage"], "def": "a liquor or brew containing alcohol as the active agent", "name": "alcohol"}, {"id": 7, "synset": "alligator.n.02", "synonyms": ["alligator", "gator"], "def": "amphibious reptiles related to crocodiles but with shorter broader snouts", "name": "alligator"}, {"id": 8, "synset": "almond.n.02", "synonyms": ["almond"], "def": "oval-shaped edible seed of the almond tree", "name": "almond"}, {"id": 9, "synset": "ambulance.n.01", "synonyms": ["ambulance"], "def": "a vehicle that takes people to and from hospitals", "name": "ambulance"}, {"id": 10, "synset": "amplifier.n.01", "synonyms": ["amplifier"], "def": "electronic equipment that increases strength of signals", "name": "amplifier"}, {"id": 11, "synset": "anklet.n.03", "synonyms": ["anklet", "ankle_bracelet"], "def": "an ornament worn around the ankle", "name": "anklet"}, {"id": 12, "synset": "antenna.n.01", "synonyms": ["antenna", "aerial", "transmitting_aerial"], "def": "an electrical device that sends or receives radio or television signals", "name": "antenna"}, {"id": 13, "synset": "apple.n.01", "synonyms": ["apple"], "def": "fruit with red or yellow or green skin and sweet to tart crisp whitish flesh", "name": "apple"}, {"id": 14, "synset": "apple_juice.n.01", "synonyms": ["apple_juice"], "def": "the juice of apples", "name": "apple_juice"}, {"id": 15, "synset": "applesauce.n.01", "synonyms": ["applesauce"], "def": "puree of stewed apples usually sweetened and spiced", "name": "applesauce"}, {"id": 16, "synset": "apricot.n.02", "synonyms": ["apricot"], "def": "downy yellow to rosy-colored fruit resembling a small peach", "name": "apricot"}, {"id": 17, "synset": "apron.n.01", "synonyms": ["apron"], "def": "a garment of cloth that is tied about the waist and worn to protect clothing", "name": "apron"}, {"id": 18, "synset": "aquarium.n.01", "synonyms": ["aquarium", "fish_tank"], "def": "a tank/pool/bowl filled with water for keeping live fish and underwater animals", "name": "aquarium"}, {"id": 19, "synset": "armband.n.02", "synonyms": ["armband"], "def": "a band worn around the upper arm", "name": "armband"}, {"id": 20, "synset": "armchair.n.01", "synonyms": ["armchair"], "def": "chair with a support on each side for arms", "name": "armchair"}, {"id": 21, "synset": "armoire.n.01", "synonyms": ["armoire"], "def": "a large wardrobe or cabinet", "name": "armoire"}, {"id": 22, "synset": "armor.n.01", "synonyms": ["armor", "armour"], "def": "protective covering made of metal and used in combat", "name": "armor"}, {"id": 23, "synset": "artichoke.n.02", "synonyms": ["artichoke"], "def": "a thistlelike flower head with edible fleshy leaves and heart", "name": "artichoke"}, {"id": 24, "synset": "ashcan.n.01", "synonyms": ["trash_can", "garbage_can", "wastebin", "dustbin", "trash_barrel", "trash_bin"], "def": "a bin that holds rubbish until it is collected", "name": "trash_can"}, {"id": 25, "synset": "ashtray.n.01", "synonyms": ["ashtray"], "def": "a receptacle for the ash from smokers' cigars or cigarettes", "name": "ashtray"}, {"id": 26, "synset": "asparagus.n.02", "synonyms": ["asparagus"], "def": "edible young shoots of the asparagus plant", "name": "asparagus"}, {"id": 27, "synset": "atomizer.n.01", "synonyms": ["atomizer", "atomiser", "spray", "sprayer", "nebulizer", "nebuliser"], "def": "a dispenser that turns a liquid (such as perfume) into a fine mist", "name": "atomizer"}, {"id": 28, "synset": "avocado.n.01", "synonyms": ["avocado"], "def": "a pear-shaped fruit with green or blackish skin and rich yellowish pulp enclosing a single large seed", "name": "avocado"}, {"id": 29, "synset": "award.n.02", "synonyms": ["award", "accolade"], "def": "a tangible symbol signifying approval or distinction", "name": "award"}, {"id": 30, "synset": "awning.n.01", "synonyms": ["awning"], "def": "a canopy made of canvas to shelter people or things from rain or sun", "name": "awning"}, {"id": 31, "synset": "ax.n.01", "synonyms": ["ax", "axe"], "def": "an edge tool with a heavy bladed head mounted across a handle", "name": "ax"}, {"id": 32, "synset": "baby_buggy.n.01", "synonyms": ["baby_buggy", "baby_carriage", "perambulator", "pram", "stroller"], "def": "a small vehicle with four wheels in which a baby or child is pushed around", "name": "baby_buggy"}, {"id": 33, "synset": "backboard.n.01", "synonyms": ["basketball_backboard"], "def": "a raised vertical board with basket attached; used to play basketball", "name": "basketball_backboard"}, {"id": 34, "synset": "backpack.n.01", "synonyms": ["backpack", "knapsack", "packsack", "rucksack", "haversack"], "def": "a bag carried by a strap on your back or shoulder", "name": "backpack"}, {"id": 35, "synset": "bag.n.04", "synonyms": ["handbag", "purse", "pocketbook"], "def": "a container used for carrying money and small personal items or accessories", "name": "handbag"}, {"id": 36, "synset": "bag.n.06", "synonyms": ["suitcase", "baggage", "luggage"], "def": "cases used to carry belongings when traveling", "name": "suitcase"}, {"id": 37, "synset": "bagel.n.01", "synonyms": ["bagel", "beigel"], "def": "glazed yeast-raised doughnut-shaped roll with hard crust", "name": "bagel"}, {"id": 38, "synset": "bagpipe.n.01", "synonyms": ["bagpipe"], "def": "a tubular wind instrument; the player blows air into a bag and squeezes it out", "name": "bagpipe"}, {"id": 39, "synset": "baguet.n.01", "synonyms": ["baguet", "baguette"], "def": "narrow French stick loaf", "name": "baguet"}, {"id": 40, "synset": "bait.n.02", "synonyms": ["bait", "lure"], "def": "something used to lure fish or other animals into danger so they can be trapped or killed", "name": "bait"}, {"id": 41, "synset": "ball.n.06", "synonyms": ["ball"], "def": "a spherical object used as a plaything", "name": "ball"}, {"id": 42, "synset": "ballet_skirt.n.01", "synonyms": ["ballet_skirt", "tutu"], "def": "very short skirt worn by ballerinas", "name": "ballet_skirt"}, {"id": 43, "synset": "balloon.n.01", "synonyms": ["balloon"], "def": "large tough nonrigid bag filled with gas or heated air", "name": "balloon"}, {"id": 44, "synset": "bamboo.n.02", "synonyms": ["bamboo"], "def": "woody tropical grass having hollow woody stems", "name": "bamboo"}, {"id": 45, "synset": "banana.n.02", "synonyms": ["banana"], "def": "elongated crescent-shaped yellow fruit with soft sweet flesh", "name": "banana"}, {"id": 46, "synset": "band_aid.n.01", "synonyms": ["Band_Aid"], "def": "trade name for an adhesive bandage to cover small cuts or blisters", "name": "Band_Aid"}, {"id": 47, "synset": "bandage.n.01", "synonyms": ["bandage"], "def": "a piece of soft material that covers and protects an injured part of the body", "name": "bandage"}, {"id": 48, "synset": "bandanna.n.01", "synonyms": ["bandanna", "bandana"], "def": "large and brightly colored handkerchief; often used as a neckerchief", "name": "bandanna"}, {"id": 49, "synset": "banjo.n.01", "synonyms": ["banjo"], "def": "a stringed instrument of the guitar family with a long neck and circular body", "name": "banjo"}, {"id": 50, "synset": "banner.n.01", "synonyms": ["banner", "streamer"], "def": "long strip of cloth or paper used for decoration or advertising", "name": "banner"}, {"id": 51, "synset": "barbell.n.01", "synonyms": ["barbell"], "def": "a bar to which heavy discs are attached at each end; used in weightlifting", "name": "barbell"}, {"id": 52, "synset": "barge.n.01", "synonyms": ["barge"], "def": "a flatbottom boat for carrying heavy loads (especially on canals)", "name": "barge"}, {"id": 53, "synset": "barrel.n.02", "synonyms": ["barrel", "cask"], "def": "a cylindrical container that holds liquids", "name": "barrel"}, {"id": 54, "synset": "barrette.n.01", "synonyms": ["barrette"], "def": "a pin for holding women's hair in place", "name": "barrette"}, {"id": 55, "synset": "barrow.n.03", "synonyms": ["barrow", "garden_cart", "lawn_cart", "wheelbarrow"], "def": "a cart for carrying small loads; has handles and one or more wheels", "name": "barrow"}, {"id": 56, "synset": "base.n.03", "synonyms": ["baseball_base"], "def": "a place that the runner must touch before scoring", "name": "baseball_base"}, {"id": 57, "synset": "baseball.n.02", "synonyms": ["baseball"], "def": "a ball used in playing baseball", "name": "baseball"}, {"id": 58, "synset": "baseball_bat.n.01", "synonyms": ["baseball_bat"], "def": "an implement used in baseball by the batter", "name": "baseball_bat"}, {"id": 59, "synset": "baseball_cap.n.01", "synonyms": ["baseball_cap", "jockey_cap", "golf_cap"], "def": "a cap with a bill", "name": "baseball_cap"}, {"id": 60, "synset": "baseball_glove.n.01", "synonyms": ["baseball_glove", "baseball_mitt"], "def": "the handwear used by fielders in playing baseball", "name": "baseball_glove"}, {"id": 61, "synset": "basket.n.01", "synonyms": ["basket", "handbasket"], "def": "a container that is usually woven and has handles", "name": "basket"}, {"id": 62, "synset": "basket.n.03", "synonyms": ["basketball_hoop"], "def": "metal hoop supporting a net through which players try to throw the basketball", "name": "basketball_hoop"}, {"id": 63, "synset": "basketball.n.02", "synonyms": ["basketball"], "def": "an inflated ball used in playing basketball", "name": "basketball"}, {"id": 64, "synset": "bass_horn.n.01", "synonyms": ["bass_horn", "sousaphone", "tuba"], "def": "the lowest brass wind instrument", "name": "bass_horn"}, {"id": 65, "synset": "bat.n.01", "synonyms": ["bat_(animal)"], "def": "nocturnal mouselike mammal with forelimbs modified to form membranous wings", "name": "bat_(animal)"}, {"id": 66, "synset": "bath_mat.n.01", "synonyms": ["bath_mat"], "def": "a heavy towel or mat to stand on while drying yourself after a bath", "name": "bath_mat"}, {"id": 67, "synset": "bath_towel.n.01", "synonyms": ["bath_towel"], "def": "a large towel; to dry yourself after a bath", "name": "bath_towel"}, {"id": 68, "synset": "bathrobe.n.01", "synonyms": ["bathrobe"], "def": "a loose-fitting robe of towelling; worn after a bath or swim", "name": "bathrobe"}, {"id": 69, "synset": "bathtub.n.01", "synonyms": ["bathtub", "bathing_tub"], "def": "a large open container that you fill with water and use to wash the body", "name": "bathtub"}, {"id": 70, "synset": "batter.n.02", "synonyms": ["batter_(food)"], "def": "a liquid or semiliquid mixture, as of flour, eggs, and milk, used in cooking", "name": "batter_(food)"}, {"id": 71, "synset": "battery.n.02", "synonyms": ["battery"], "def": "a portable device that produces electricity", "name": "battery"}, {"id": 72, "synset": "beach_ball.n.01", "synonyms": ["beachball"], "def": "large and light ball; for play at the seaside", "name": "beachball"}, {"id": 73, "synset": "bead.n.01", "synonyms": ["bead"], "def": "a small ball with a hole through the middle used for ornamentation, jewellery, etc.", "name": "bead"}, {"id": 74, "synset": "beaker.n.01", "synonyms": ["beaker"], "def": "a flatbottomed jar made of glass or plastic; used for chemistry", "name": "beaker"}, {"id": 75, "synset": "bean_curd.n.01", "synonyms": ["bean_curd", "tofu"], "def": "cheeselike food made of curdled soybean milk", "name": "bean_curd"}, {"id": 76, "synset": "beanbag.n.01", "synonyms": ["beanbag"], "def": "a bag filled with dried beans or similar items; used in games or to sit on", "name": "beanbag"}, {"id": 77, "synset": "beanie.n.01", "synonyms": ["beanie", "beany"], "def": "a small skullcap; formerly worn by schoolboys and college freshmen", "name": "beanie"}, {"id": 78, "synset": "bear.n.01", "synonyms": ["bear"], "def": "large carnivorous or omnivorous mammals with shaggy coats and claws", "name": "bear"}, {"id": 79, "synset": "bed.n.01", "synonyms": ["bed"], "def": "a piece of furniture that provides a place to sleep", "name": "bed"}, {"id": 80, "synset": "bedspread.n.01", "synonyms": ["bedspread", "bedcover", "bed_covering", "counterpane", "spread"], "def": "decorative cover for a bed", "name": "bedspread"}, {"id": 81, "synset": "beef.n.01", "synonyms": ["cow"], "def": "cattle that are reared for their meat", "name": "cow"}, {"id": 82, "synset": "beef.n.02", "synonyms": ["beef_(food)", "boeuf_(food)"], "def": "meat from an adult domestic bovine", "name": "beef_(food)"}, {"id": 83, "synset": "beeper.n.01", "synonyms": ["beeper", "pager"], "def": "an device that beeps when the person carrying it is being paged", "name": "beeper"}, {"id": 84, "synset": "beer_bottle.n.01", "synonyms": ["beer_bottle"], "def": "a bottle that holds beer", "name": "beer_bottle"}, {"id": 85, "synset": "beer_can.n.01", "synonyms": ["beer_can"], "def": "a can that holds beer", "name": "beer_can"}, {"id": 86, "synset": "beetle.n.01", "synonyms": ["beetle"], "def": "insect with hard wing covers", "name": "beetle"}, {"id": 87, "synset": "bell.n.01", "synonyms": ["bell"], "def": "a hollow device made of metal that makes a ringing sound when struck", "name": "bell"}, {"id": 88, "synset": "bell_pepper.n.02", "synonyms": ["bell_pepper", "capsicum"], "def": "large bell-shaped sweet pepper in green or red or yellow or orange or black varieties", "name": "bell_pepper"}, {"id": 89, "synset": "belt.n.02", "synonyms": ["belt"], "def": "a band to tie or buckle around the body (usually at the waist)", "name": "belt"}, {"id": 90, "synset": "belt_buckle.n.01", "synonyms": ["belt_buckle"], "def": "the buckle used to fasten a belt", "name": "belt_buckle"}, {"id": 91, "synset": "bench.n.01", "synonyms": ["bench"], "def": "a long seat for more than one person", "name": "bench"}, {"id": 92, "synset": "beret.n.01", "synonyms": ["beret"], "def": "a cap with no brim or bill; made of soft cloth", "name": "beret"}, {"id": 93, "synset": "bib.n.02", "synonyms": ["bib"], "def": "a napkin tied under the chin of a child while eating", "name": "bib"}, {"id": 94, "synset": "bible.n.01", "synonyms": ["Bible"], "def": "the sacred writings of the Christian religions", "name": "Bible"}, {"id": 95, "synset": "bicycle.n.01", "synonyms": ["bicycle", "bike_(bicycle)"], "def": "a wheeled vehicle that has two wheels and is moved by foot pedals", "name": "bicycle"}, {"id": 96, "synset": "bill.n.09", "synonyms": ["visor", "vizor"], "def": "a brim that projects to the front to shade the eyes", "name": "visor"}, {"id": 97, "synset": "binder.n.03", "synonyms": ["binder", "ring-binder"], "def": "holds loose papers or magazines", "name": "binder"}, {"id": 98, "synset": "binoculars.n.01", "synonyms": ["binoculars", "field_glasses", "opera_glasses"], "def": "an optical instrument designed for simultaneous use by both eyes", "name": "binoculars"}, {"id": 99, "synset": "bird.n.01", "synonyms": ["bird"], "def": "animal characterized by feathers and wings", "name": "bird"}, {"id": 100, "synset": "bird_feeder.n.01", "synonyms": ["birdfeeder"], "def": "an outdoor device that supplies food for wild birds", "name": "birdfeeder"}, {"id": 101, "synset": "birdbath.n.01", "synonyms": ["birdbath"], "def": "an ornamental basin (usually in a garden) for birds to bathe in", "name": "birdbath"}, {"id": 102, "synset": "birdcage.n.01", "synonyms": ["birdcage"], "def": "a cage in which a bird can be kept", "name": "birdcage"}, {"id": 103, "synset": "birdhouse.n.01", "synonyms": ["birdhouse"], "def": "a shelter for birds", "name": "birdhouse"}, {"id": 104, "synset": "birthday_cake.n.01", "synonyms": ["birthday_cake"], "def": "decorated cake served at a birthday party", "name": "birthday_cake"}, {"id": 105, "synset": "birthday_card.n.01", "synonyms": ["birthday_card"], "def": "a card expressing a birthday greeting", "name": "birthday_card"}, {"id": 106, "synset": "biscuit.n.01", "synonyms": ["biscuit_(bread)"], "def": "small round bread leavened with baking-powder or soda", "name": "biscuit_(bread)"}, {"id": 107, "synset": "black_flag.n.01", "synonyms": ["pirate_flag"], "def": "a flag usually bearing a white skull and crossbones on a black background", "name": "pirate_flag"}, {"id": 108, "synset": "black_sheep.n.02", "synonyms": ["black_sheep"], "def": "sheep with a black coat", "name": "black_sheep"}, {"id": 109, "synset": "blackboard.n.01", "synonyms": ["blackboard", "chalkboard"], "def": "sheet of slate; for writing with chalk", "name": "blackboard"}, {"id": 110, "synset": "blanket.n.01", "synonyms": ["blanket"], "def": "bedding that keeps a person warm in bed", "name": "blanket"}, {"id": 111, "synset": "blazer.n.01", "synonyms": ["blazer", "sport_jacket", "sport_coat", "sports_jacket", "sports_coat"], "def": "lightweight jacket; often striped in the colors of a club or school", "name": "blazer"}, {"id": 112, "synset": "blender.n.01", "synonyms": ["blender", "liquidizer", "liquidiser"], "def": "an electrically powered mixer that mix or chop or liquefy foods", "name": "blender"}, {"id": 113, "synset": "blimp.n.02", "synonyms": ["blimp"], "def": "a small nonrigid airship used for observation or as a barrage balloon", "name": "blimp"}, {"id": 114, "synset": "blinker.n.01", "synonyms": ["blinker", "flasher"], "def": "a light that flashes on and off; used as a signal or to send messages", "name": "blinker"}, {"id": 115, "synset": "blueberry.n.02", "synonyms": ["blueberry"], "def": "sweet edible dark-blue berries of blueberry plants", "name": "blueberry"}, {"id": 116, "synset": "boar.n.02", "synonyms": ["boar"], "def": "an uncastrated male hog", "name": "boar"}, {"id": 117, "synset": "board.n.09", "synonyms": ["gameboard"], "def": "a flat portable surface (usually rectangular) designed for board games", "name": "gameboard"}, {"id": 118, "synset": "boat.n.01", "synonyms": ["boat", "ship_(boat)"], "def": "a vessel for travel on water", "name": "boat"}, {"id": 119, "synset": "bobbin.n.01", "synonyms": ["bobbin", "spool", "reel"], "def": "a thing around which thread/tape/film or other flexible materials can be wound", "name": "bobbin"}, {"id": 120, "synset": "bobby_pin.n.01", "synonyms": ["bobby_pin", "hairgrip"], "def": "a flat wire hairpin used to hold bobbed hair in place", "name": "bobby_pin"}, {"id": 121, "synset": "boiled_egg.n.01", "synonyms": ["boiled_egg", "coddled_egg"], "def": "egg cooked briefly in the shell in gently boiling water", "name": "boiled_egg"}, {"id": 122, "synset": "bolo_tie.n.01", "synonyms": ["bolo_tie", "bolo", "bola_tie", "bola"], "def": "a cord fastened around the neck with an ornamental clasp and worn as a necktie", "name": "bolo_tie"}, {"id": 123, "synset": "bolt.n.03", "synonyms": ["deadbolt"], "def": "the part of a lock that is engaged or withdrawn with a key", "name": "deadbolt"}, {"id": 124, "synset": "bolt.n.06", "synonyms": ["bolt"], "def": "a screw that screws into a nut to form a fastener", "name": "bolt"}, {"id": 125, "synset": "bonnet.n.01", "synonyms": ["bonnet"], "def": "a hat tied under the chin", "name": "bonnet"}, {"id": 126, "synset": "book.n.01", "synonyms": ["book"], "def": "a written work or composition that has been published", "name": "book"}, {"id": 127, "synset": "book_bag.n.01", "synonyms": ["book_bag"], "def": "a bag in which students carry their books", "name": "book_bag"}, {"id": 128, "synset": "bookcase.n.01", "synonyms": ["bookcase"], "def": "a piece of furniture with shelves for storing books", "name": "bookcase"}, {"id": 129, "synset": "booklet.n.01", "synonyms": ["booklet", "brochure", "leaflet", "pamphlet"], "def": "a small book usually having a paper cover", "name": "booklet"}, {"id": 130, "synset": "bookmark.n.01", "synonyms": ["bookmark", "bookmarker"], "def": "a marker (a piece of paper or ribbon) placed between the pages of a book", "name": "bookmark"}, {"id": 131, "synset": "boom.n.04", "synonyms": ["boom_microphone", "microphone_boom"], "def": "a pole carrying an overhead microphone projected over a film or tv set", "name": "boom_microphone"}, {"id": 132, "synset": "boot.n.01", "synonyms": ["boot"], "def": "footwear that covers the whole foot and lower leg", "name": "boot"}, {"id": 133, "synset": "bottle.n.01", "synonyms": ["bottle"], "def": "a glass or plastic vessel used for storing drinks or other liquids", "name": "bottle"}, {"id": 134, "synset": "bottle_opener.n.01", "synonyms": ["bottle_opener"], "def": "an opener for removing caps or corks from bottles", "name": "bottle_opener"}, {"id": 135, "synset": "bouquet.n.01", "synonyms": ["bouquet"], "def": "an arrangement of flowers that is usually given as a present", "name": "bouquet"}, {"id": 136, "synset": "bow.n.04", "synonyms": ["bow_(weapon)"], "def": "a weapon for shooting arrows", "name": "bow_(weapon)"}, {"id": 137, "synset": "bow.n.08", "synonyms": ["bow_(decorative_ribbons)"], "def": "a decorative interlacing of ribbons", "name": "bow_(decorative_ribbons)"}, {"id": 138, "synset": "bow_tie.n.01", "synonyms": ["bow-tie", "bowtie"], "def": "a man's tie that ties in a bow", "name": "bow-tie"}, {"id": 139, "synset": "bowl.n.03", "synonyms": ["bowl"], "def": "a dish that is round and open at the top for serving foods", "name": "bowl"}, {"id": 140, "synset": "bowl.n.08", "synonyms": ["pipe_bowl"], "def": "a small round container that is open at the top for holding tobacco", "name": "pipe_bowl"}, {"id": 141, "synset": "bowler_hat.n.01", "synonyms": ["bowler_hat", "bowler", "derby_hat", "derby", "plug_hat"], "def": "a felt hat that is round and hard with a narrow brim", "name": "bowler_hat"}, {"id": 142, "synset": "bowling_ball.n.01", "synonyms": ["bowling_ball"], "def": "a large ball with finger holes used in the sport of bowling", "name": "bowling_ball"}, {"id": 143, "synset": "bowling_pin.n.01", "synonyms": ["bowling_pin"], "def": "a club-shaped wooden object used in bowling", "name": "bowling_pin"}, {"id": 144, "synset": "boxing_glove.n.01", "synonyms": ["boxing_glove"], "def": "large glove coverings the fists of a fighter worn for the sport of boxing", "name": "boxing_glove"}, {"id": 145, "synset": "brace.n.06", "synonyms": ["suspenders"], "def": "elastic straps that hold trousers up (usually used in the plural)", "name": "suspenders"}, {"id": 146, "synset": "bracelet.n.02", "synonyms": ["bracelet", "bangle"], "def": "jewelry worn around the wrist for decoration", "name": "bracelet"}, {"id": 147, "synset": "brass.n.07", "synonyms": ["brass_plaque"], "def": "a memorial made of brass", "name": "brass_plaque"}, {"id": 148, "synset": "brassiere.n.01", "synonyms": ["brassiere", "bra", "bandeau"], "def": "an undergarment worn by women to support their breasts", "name": "brassiere"}, {"id": 149, "synset": "bread-bin.n.01", "synonyms": ["bread-bin", "breadbox"], "def": "a container used to keep bread or cake in", "name": "bread-bin"}, {"id": 150, "synset": "breechcloth.n.01", "synonyms": ["breechcloth", "breechclout", "loincloth"], "def": "a garment that provides covering for the loins", "name": "breechcloth"}, {"id": 151, "synset": "bridal_gown.n.01", "synonyms": ["bridal_gown", "wedding_gown", "wedding_dress"], "def": "a gown worn by the bride at a wedding", "name": "bridal_gown"}, {"id": 152, "synset": "briefcase.n.01", "synonyms": ["briefcase"], "def": "a case with a handle; for carrying papers or files or books", "name": "briefcase"}, {"id": 153, "synset": "bristle_brush.n.01", "synonyms": ["bristle_brush"], "def": "a brush that is made with the short stiff hairs of an animal or plant", "name": "bristle_brush"}, {"id": 154, "synset": "broccoli.n.01", "synonyms": ["broccoli"], "def": "plant with dense clusters of tight green flower buds", "name": "broccoli"}, {"id": 155, "synset": "brooch.n.01", "synonyms": ["broach"], "def": "a decorative pin worn by women", "name": "broach"}, {"id": 156, "synset": "broom.n.01", "synonyms": ["broom"], "def": "bundle of straws or twigs attached to a long handle; used for cleaning", "name": "broom"}, {"id": 157, "synset": "brownie.n.03", "synonyms": ["brownie"], "def": "square or bar of very rich chocolate cake usually with nuts", "name": "brownie"}, {"id": 158, "synset": "brussels_sprouts.n.01", "synonyms": ["brussels_sprouts"], "def": "the small edible cabbage-like buds growing along a stalk", "name": "brussels_sprouts"}, {"id": 159, "synset": "bubble_gum.n.01", "synonyms": ["bubble_gum"], "def": "a kind of chewing gum that can be blown into bubbles", "name": "bubble_gum"}, {"id": 160, "synset": "bucket.n.01", "synonyms": ["bucket", "pail"], "def": "a roughly cylindrical vessel that is open at the top", "name": "bucket"}, {"id": 161, "synset": "buggy.n.01", "synonyms": ["horse_buggy"], "def": "a small lightweight carriage; drawn by a single horse", "name": "horse_buggy"}, {"id": 162, "synset": "bull.n.11", "synonyms": ["bull"], "def": "mature male cow", "name": "bull"}, {"id": 163, "synset": "bulldog.n.01", "synonyms": ["bulldog"], "def": "a thickset short-haired dog with a large head and strong undershot lower jaw", "name": "bulldog"}, {"id": 164, "synset": "bulldozer.n.01", "synonyms": ["bulldozer", "dozer"], "def": "large powerful tractor; a large blade in front flattens areas of ground", "name": "bulldozer"}, {"id": 165, "synset": "bullet_train.n.01", "synonyms": ["bullet_train"], "def": "a high-speed passenger train", "name": "bullet_train"}, {"id": 166, "synset": "bulletin_board.n.02", "synonyms": ["bulletin_board", "notice_board"], "def": "a board that hangs on a wall; displays announcements", "name": "bulletin_board"}, {"id": 167, "synset": "bulletproof_vest.n.01", "synonyms": ["bulletproof_vest"], "def": "a vest capable of resisting the impact of a bullet", "name": "bulletproof_vest"}, {"id": 168, "synset": "bullhorn.n.01", "synonyms": ["bullhorn", "megaphone"], "def": "a portable loudspeaker with built-in microphone and amplifier", "name": "bullhorn"}, {"id": 169, "synset": "bully_beef.n.01", "synonyms": ["corned_beef", "corn_beef"], "def": "beef cured or pickled in brine", "name": "corned_beef"}, {"id": 170, "synset": "bun.n.01", "synonyms": ["bun", "roll"], "def": "small rounded bread either plain or sweet", "name": "bun"}, {"id": 171, "synset": "bunk_bed.n.01", "synonyms": ["bunk_bed"], "def": "beds built one above the other", "name": "bunk_bed"}, {"id": 172, "synset": "buoy.n.01", "synonyms": ["buoy"], "def": "a float attached by rope to the seabed to mark channels in a harbor or underwater hazards", "name": "buoy"}, {"id": 173, "synset": "burrito.n.01", "synonyms": ["burrito"], "def": "a flour tortilla folded around a filling", "name": "burrito"}, {"id": 174, "synset": "bus.n.01", "synonyms": ["bus_(vehicle)", "autobus", "charabanc", "double-decker", "motorbus", "motorcoach"], "def": "a vehicle carrying many passengers; used for public transport", "name": "bus_(vehicle)"}, {"id": 175, "synset": "business_card.n.01", "synonyms": ["business_card"], "def": "a card on which are printed the person's name and business affiliation", "name": "business_card"}, {"id": 176, "synset": "butcher_knife.n.01", "synonyms": ["butcher_knife"], "def": "a large sharp knife for cutting or trimming meat", "name": "butcher_knife"}, {"id": 177, "synset": "butter.n.01", "synonyms": ["butter"], "def": "an edible emulsion of fat globules made by churning milk or cream; for cooking and table use", "name": "butter"}, {"id": 178, "synset": "butterfly.n.01", "synonyms": ["butterfly"], "def": "insect typically having a slender body with knobbed antennae and broad colorful wings", "name": "butterfly"}, {"id": 179, "synset": "button.n.01", "synonyms": ["button"], "def": "a round fastener sewn to shirts and coats etc to fit through buttonholes", "name": "button"}, {"id": 180, "synset": "cab.n.03", "synonyms": ["cab_(taxi)", "taxi", "taxicab"], "def": "a car that takes passengers where they want to go in exchange for money", "name": "cab_(taxi)"}, {"id": 181, "synset": "cabana.n.01", "synonyms": ["cabana"], "def": "a small tent used as a dressing room beside the sea or a swimming pool", "name": "cabana"}, {"id": 182, "synset": "cabin_car.n.01", "synonyms": ["cabin_car", "caboose"], "def": "a car on a freight train for use of the train crew; usually the last car on the train", "name": "cabin_car"}, {"id": 183, "synset": "cabinet.n.01", "synonyms": ["cabinet"], "def": "a piece of furniture resembling a cupboard with doors and shelves and drawers", "name": "cabinet"}, {"id": 184, "synset": "cabinet.n.03", "synonyms": ["locker", "storage_locker"], "def": "a storage compartment for clothes and valuables; usually it has a lock", "name": "locker"}, {"id": 185, "synset": "cake.n.03", "synonyms": ["cake"], "def": "baked goods made from or based on a mixture of flour, sugar, eggs, and fat", "name": "cake"}, {"id": 186, "synset": "calculator.n.02", "synonyms": ["calculator"], "def": "a small machine that is used for mathematical calculations", "name": "calculator"}, {"id": 187, "synset": "calendar.n.02", "synonyms": ["calendar"], "def": "a list or register of events (appointments/social events/court cases, etc)", "name": "calendar"}, {"id": 188, "synset": "calf.n.01", "synonyms": ["calf"], "def": "young of domestic cattle", "name": "calf"}, {"id": 189, "synset": "camcorder.n.01", "synonyms": ["camcorder"], "def": "a portable television camera and videocassette recorder", "name": "camcorder"}, {"id": 190, "synset": "camel.n.01", "synonyms": ["camel"], "def": "cud-chewing mammal used as a draft or saddle animal in desert regions", "name": "camel"}, {"id": 191, "synset": "camera.n.01", "synonyms": ["camera"], "def": "equipment for taking photographs", "name": "camera"}, {"id": 192, "synset": "camera_lens.n.01", "synonyms": ["camera_lens"], "def": "a lens that focuses the image in a camera", "name": "camera_lens"}, {"id": 193, "synset": "camper.n.02", "synonyms": ["camper_(vehicle)", "camping_bus", "motor_home"], "def": "a recreational vehicle equipped for camping out while traveling", "name": "camper_(vehicle)"}, {"id": 194, "synset": "can.n.01", "synonyms": ["can", "tin_can"], "def": "airtight sealed metal container for food or drink or paint etc.", "name": "can"}, {"id": 195, "synset": "can_opener.n.01", "synonyms": ["can_opener", "tin_opener"], "def": "a device for cutting cans open", "name": "can_opener"}, {"id": 196, "synset": "candelabrum.n.01", "synonyms": ["candelabrum", "candelabra"], "def": "branched candlestick; ornamental; has several lights", "name": "candelabrum"}, {"id": 197, "synset": "candle.n.01", "synonyms": ["candle", "candlestick"], "def": "stick of wax with a wick in the middle", "name": "candle"}, {"id": 198, "synset": "candlestick.n.01", "synonyms": ["candle_holder"], "def": "a holder with sockets for candles", "name": "candle_holder"}, {"id": 199, "synset": "candy_bar.n.01", "synonyms": ["candy_bar"], "def": "a candy shaped as a bar", "name": "candy_bar"}, {"id": 200, "synset": "candy_cane.n.01", "synonyms": ["candy_cane"], "def": "a hard candy in the shape of a rod (usually with stripes)", "name": "candy_cane"}, {"id": 201, "synset": "cane.n.01", "synonyms": ["walking_cane"], "def": "a stick that people can lean on to help them walk", "name": "walking_cane"}, {"id": 202, "synset": "canister.n.02", "synonyms": ["canister", "cannister"], "def": "metal container for storing dry foods such as tea or flour", "name": "canister"}, {"id": 203, "synset": "cannon.n.02", "synonyms": ["cannon"], "def": "heavy gun fired from a tank", "name": "cannon"}, {"id": 204, "synset": "canoe.n.01", "synonyms": ["canoe"], "def": "small and light boat; pointed at both ends; propelled with a paddle", "name": "canoe"}, {"id": 205, "synset": "cantaloup.n.02", "synonyms": ["cantaloup", "cantaloupe"], "def": "the fruit of a cantaloup vine; small to medium-sized melon with yellowish flesh", "name": "cantaloup"}, {"id": 206, "synset": "canteen.n.01", "synonyms": ["canteen"], "def": "a flask for carrying water; used by soldiers or travelers", "name": "canteen"}, {"id": 207, "synset": "cap.n.01", "synonyms": ["cap_(headwear)"], "def": "a tight-fitting headwear", "name": "cap_(headwear)"}, {"id": 208, "synset": "cap.n.02", "synonyms": ["bottle_cap", "cap_(container_lid)"], "def": "a top (as for a bottle)", "name": "bottle_cap"}, {"id": 209, "synset": "cape.n.02", "synonyms": ["cape"], "def": "a sleeveless garment like a cloak but shorter", "name": "cape"}, {"id": 210, "synset": "cappuccino.n.01", "synonyms": ["cappuccino", "coffee_cappuccino"], "def": "equal parts of espresso and steamed milk", "name": "cappuccino"}, {"id": 211, "synset": "car.n.01", "synonyms": ["car_(automobile)", "auto_(automobile)", "automobile"], "def": "a motor vehicle with four wheels", "name": "car_(automobile)"}, {"id": 212, "synset": "car.n.02", "synonyms": ["railcar_(part_of_a_train)", "railway_car_(part_of_a_train)", "railroad_car_(part_of_a_train)"], "def": "a wheeled vehicle adapted to the rails of railroad", "name": "railcar_(part_of_a_train)"}, {"id": 213, "synset": "car.n.04", "synonyms": ["elevator_car"], "def": "where passengers ride up and down", "name": "elevator_car"}, {"id": 214, "synset": "car_battery.n.01", "synonyms": ["car_battery", "automobile_battery"], "def": "a battery in a motor vehicle", "name": "car_battery"}, {"id": 215, "synset": "card.n.02", "synonyms": ["identity_card"], "def": "a card certifying the identity of the bearer", "name": "identity_card"}, {"id": 216, "synset": "card.n.03", "synonyms": ["card"], "def": "a rectangular piece of paper used to send messages (e.g. greetings or pictures)", "name": "card"}, {"id": 217, "synset": "cardigan.n.01", "synonyms": ["cardigan"], "def": "knitted jacket that is fastened up the front with buttons or a zipper", "name": "cardigan"}, {"id": 218, "synset": "cargo_ship.n.01", "synonyms": ["cargo_ship", "cargo_vessel"], "def": "a ship designed to carry cargo", "name": "cargo_ship"}, {"id": 219, "synset": "carnation.n.01", "synonyms": ["carnation"], "def": "plant with pink to purple-red spice-scented usually double flowers", "name": "carnation"}, {"id": 220, "synset": "carriage.n.02", "synonyms": ["horse_carriage"], "def": "a vehicle with wheels drawn by one or more horses", "name": "horse_carriage"}, {"id": 221, "synset": "carrot.n.01", "synonyms": ["carrot"], "def": "deep orange edible root of the cultivated carrot plant", "name": "carrot"}, {"id": 222, "synset": "carryall.n.01", "synonyms": ["tote_bag"], "def": "a capacious bag or basket", "name": "tote_bag"}, {"id": 223, "synset": "cart.n.01", "synonyms": ["cart"], "def": "a heavy open wagon usually having two wheels and drawn by an animal", "name": "cart"}, {"id": 224, "synset": "carton.n.02", "synonyms": ["carton"], "def": "a box made of cardboard; opens by flaps on top", "name": "carton"}, {"id": 225, "synset": "cash_register.n.01", "synonyms": ["cash_register", "register_(for_cash_transactions)"], "def": "a cashbox with an adding machine to register transactions", "name": "cash_register"}, {"id": 226, "synset": "casserole.n.01", "synonyms": ["casserole"], "def": "food cooked and served in a casserole", "name": "casserole"}, {"id": 227, "synset": "cassette.n.01", "synonyms": ["cassette"], "def": "a container that holds a magnetic tape used for recording or playing sound or video", "name": "cassette"}, {"id": 228, "synset": "cast.n.05", "synonyms": ["cast", "plaster_cast", "plaster_bandage"], "def": "bandage consisting of a firm covering that immobilizes broken bones while they heal", "name": "cast"}, {"id": 229, "synset": "cat.n.01", "synonyms": ["cat"], "def": "a domestic house cat", "name": "cat"}, {"id": 230, "synset": "cauliflower.n.02", "synonyms": ["cauliflower"], "def": "edible compact head of white undeveloped flowers", "name": "cauliflower"}, {"id": 231, "synset": "caviar.n.01", "synonyms": ["caviar", "caviare"], "def": "salted roe of sturgeon or other large fish; usually served as an hors d'oeuvre", "name": "caviar"}, {"id": 232, "synset": "cayenne.n.02", "synonyms": ["cayenne_(spice)", "cayenne_pepper_(spice)", "red_pepper_(spice)"], "def": "ground pods and seeds of pungent red peppers of the genus Capsicum", "name": "cayenne_(spice)"}, {"id": 233, "synset": "cd_player.n.01", "synonyms": ["CD_player"], "def": "electronic equipment for playing compact discs (CDs)", "name": "CD_player"}, {"id": 234, "synset": "celery.n.01", "synonyms": ["celery"], "def": "widely cultivated herb with aromatic leaf stalks that are eaten raw or cooked", "name": "celery"}, {"id": 235, "synset": "cellular_telephone.n.01", "synonyms": ["cellular_telephone", "cellular_phone", "cellphone", "mobile_phone", "smart_phone"], "def": "a hand-held mobile telephone", "name": "cellular_telephone"}, {"id": 236, "synset": "chain_mail.n.01", "synonyms": ["chain_mail", "ring_mail", "chain_armor", "chain_armour", "ring_armor", "ring_armour"], "def": "(Middle Ages) flexible armor made of interlinked metal rings", "name": "chain_mail"}, {"id": 237, "synset": "chair.n.01", "synonyms": ["chair"], "def": "a seat for one person, with a support for the back", "name": "chair"}, {"id": 238, "synset": "chaise_longue.n.01", "synonyms": ["chaise_longue", "chaise", "daybed"], "def": "a long chair; for reclining", "name": "chaise_longue"}, {"id": 239, "synset": "champagne.n.01", "synonyms": ["champagne"], "def": "a white sparkling wine produced in Champagne or resembling that produced there", "name": "champagne"}, {"id": 240, "synset": "chandelier.n.01", "synonyms": ["chandelier"], "def": "branched lighting fixture; often ornate; hangs from the ceiling", "name": "chandelier"}, {"id": 241, "synset": "chap.n.04", "synonyms": ["chap"], "def": "leather leggings without a seat; worn over trousers by cowboys to protect their legs", "name": "chap"}, {"id": 242, "synset": "checkbook.n.01", "synonyms": ["checkbook", "chequebook"], "def": "a book issued to holders of checking accounts", "name": "checkbook"}, {"id": 243, "synset": "checkerboard.n.01", "synonyms": ["checkerboard"], "def": "a board having 64 squares of two alternating colors", "name": "checkerboard"}, {"id": 244, "synset": "cherry.n.03", "synonyms": ["cherry"], "def": "a red fruit with a single hard stone", "name": "cherry"}, {"id": 245, "synset": "chessboard.n.01", "synonyms": ["chessboard"], "def": "a checkerboard used to play chess", "name": "chessboard"}, {"id": 246, "synset": "chest_of_drawers.n.01", "synonyms": ["chest_of_drawers_(furniture)", "bureau_(furniture)", "chest_(furniture)"], "def": "furniture with drawers for keeping clothes", "name": "chest_of_drawers_(furniture)"}, {"id": 247, "synset": "chicken.n.02", "synonyms": ["chicken_(animal)"], "def": "a domestic fowl bred for flesh or eggs", "name": "chicken_(animal)"}, {"id": 248, "synset": "chicken_wire.n.01", "synonyms": ["chicken_wire"], "def": "a galvanized wire network with a hexagonal mesh; used to build fences", "name": "chicken_wire"}, {"id": 249, "synset": "chickpea.n.01", "synonyms": ["chickpea", "garbanzo"], "def": "the seed of the chickpea plant; usually dried", "name": "chickpea"}, {"id": 250, "synset": "chihuahua.n.03", "synonyms": ["Chihuahua"], "def": "an old breed of tiny short-haired dog with protruding eyes from Mexico", "name": "Chihuahua"}, {"id": 251, "synset": "chili.n.02", "synonyms": ["chili_(vegetable)", "chili_pepper_(vegetable)", "chilli_(vegetable)", "chilly_(vegetable)", "chile_(vegetable)"], "def": "very hot and finely tapering pepper of special pungency", "name": "chili_(vegetable)"}, {"id": 252, "synset": "chime.n.01", "synonyms": ["chime", "gong"], "def": "an instrument consisting of a set of bells that are struck with a hammer", "name": "chime"}, {"id": 253, "synset": "chinaware.n.01", "synonyms": ["chinaware"], "def": "dishware made of high quality porcelain", "name": "chinaware"}, {"id": 254, "synset": "chip.n.04", "synonyms": ["crisp_(potato_chip)", "potato_chip"], "def": "a thin crisp slice of potato fried in deep fat", "name": "crisp_(potato_chip)"}, {"id": 255, "synset": "chip.n.06", "synonyms": ["poker_chip"], "def": "a small disk-shaped counter used to represent money when gambling", "name": "poker_chip"}, {"id": 256, "synset": "chocolate_bar.n.01", "synonyms": ["chocolate_bar"], "def": "a bar of chocolate candy", "name": "chocolate_bar"}, {"id": 257, "synset": "chocolate_cake.n.01", "synonyms": ["chocolate_cake"], "def": "cake containing chocolate", "name": "chocolate_cake"}, {"id": 258, "synset": "chocolate_milk.n.01", "synonyms": ["chocolate_milk"], "def": "milk flavored with chocolate syrup", "name": "chocolate_milk"}, {"id": 259, "synset": "chocolate_mousse.n.01", "synonyms": ["chocolate_mousse"], "def": "dessert mousse made with chocolate", "name": "chocolate_mousse"}, {"id": 260, "synset": "choker.n.03", "synonyms": ["choker", "collar", "neckband"], "def": "necklace that fits tightly around the neck", "name": "choker"}, {"id": 261, "synset": "chopping_board.n.01", "synonyms": ["chopping_board", "cutting_board", "chopping_block"], "def": "a wooden board where meats or vegetables can be cut", "name": "chopping_board"}, {"id": 262, "synset": "chopstick.n.01", "synonyms": ["chopstick"], "def": "one of a pair of slender sticks used as oriental tableware to eat food with", "name": "chopstick"}, {"id": 263, "synset": "christmas_tree.n.05", "synonyms": ["Christmas_tree"], "def": "an ornamented evergreen used as a Christmas decoration", "name": "Christmas_tree"}, {"id": 264, "synset": "chute.n.02", "synonyms": ["slide"], "def": "sloping channel through which things can descend", "name": "slide"}, {"id": 265, "synset": "cider.n.01", "synonyms": ["cider", "cyder"], "def": "a beverage made from juice pressed from apples", "name": "cider"}, {"id": 266, "synset": "cigar_box.n.01", "synonyms": ["cigar_box"], "def": "a box for holding cigars", "name": "cigar_box"}, {"id": 267, "synset": "cigarette.n.01", "synonyms": ["cigarette"], "def": "finely ground tobacco wrapped in paper; for smoking", "name": "cigarette"}, {"id": 268, "synset": "cigarette_case.n.01", "synonyms": ["cigarette_case", "cigarette_pack"], "def": "a small flat case for holding cigarettes", "name": "cigarette_case"}, {"id": 269, "synset": "cistern.n.02", "synonyms": ["cistern", "water_tank"], "def": "a tank that holds the water used to flush a toilet", "name": "cistern"}, {"id": 270, "synset": "clarinet.n.01", "synonyms": ["clarinet"], "def": "a single-reed instrument with a straight tube", "name": "clarinet"}, {"id": 271, "synset": "clasp.n.01", "synonyms": ["clasp"], "def": "a fastener (as a buckle or hook) that is used to hold two things together", "name": "clasp"}, {"id": 272, "synset": "cleansing_agent.n.01", "synonyms": ["cleansing_agent", "cleanser", "cleaner"], "def": "a preparation used in cleaning something", "name": "cleansing_agent"}, {"id": 273, "synset": "clementine.n.01", "synonyms": ["clementine"], "def": "a variety of mandarin orange", "name": "clementine"}, {"id": 274, "synset": "clip.n.03", "synonyms": ["clip"], "def": "any of various small fasteners used to hold loose articles together", "name": "clip"}, {"id": 275, "synset": "clipboard.n.01", "synonyms": ["clipboard"], "def": "a small writing board with a clip at the top for holding papers", "name": "clipboard"}, {"id": 276, "synset": "clock.n.01", "synonyms": ["clock", "timepiece", "timekeeper"], "def": "a timepiece that shows the time of day", "name": "clock"}, {"id": 277, "synset": "clock_tower.n.01", "synonyms": ["clock_tower"], "def": "a tower with a large clock visible high up on an outside face", "name": "clock_tower"}, {"id": 278, "synset": "clothes_hamper.n.01", "synonyms": ["clothes_hamper", "laundry_basket", "clothes_basket"], "def": "a hamper that holds dirty clothes to be washed or wet clothes to be dried", "name": "clothes_hamper"}, {"id": 279, "synset": "clothespin.n.01", "synonyms": ["clothespin", "clothes_peg"], "def": "wood or plastic fastener; for holding clothes on a clothesline", "name": "clothespin"}, {"id": 280, "synset": "clutch_bag.n.01", "synonyms": ["clutch_bag"], "def": "a woman's strapless purse that is carried in the hand", "name": "clutch_bag"}, {"id": 281, "synset": "coaster.n.03", "synonyms": ["coaster"], "def": "a covering (plate or mat) that protects the surface of a table", "name": "coaster"}, {"id": 282, "synset": "coat.n.01", "synonyms": ["coat"], "def": "an outer garment that has sleeves and covers the body from shoulder down", "name": "coat"}, {"id": 283, "synset": "coat_hanger.n.01", "synonyms": ["coat_hanger", "clothes_hanger", "dress_hanger"], "def": "a hanger that is shaped like a person's shoulders", "name": "coat_hanger"}, {"id": 284, "synset": "coatrack.n.01", "synonyms": ["coatrack", "hatrack"], "def": "a rack with hooks for temporarily holding coats and hats", "name": "coatrack"}, {"id": 285, "synset": "cock.n.04", "synonyms": ["cock", "rooster"], "def": "adult male chicken", "name": "cock"}, {"id": 286, "synset": "coconut.n.02", "synonyms": ["coconut", "cocoanut"], "def": "large hard-shelled brown oval nut with a fibrous husk", "name": "coconut"}, {"id": 287, "synset": "coffee_filter.n.01", "synonyms": ["coffee_filter"], "def": "filter (usually of paper) that passes the coffee and retains the coffee grounds", "name": "coffee_filter"}, {"id": 288, "synset": "coffee_maker.n.01", "synonyms": ["coffee_maker", "coffee_machine"], "def": "a kitchen appliance for brewing coffee automatically", "name": "coffee_maker"}, {"id": 289, "synset": "coffee_table.n.01", "synonyms": ["coffee_table", "cocktail_table"], "def": "low table where magazines can be placed and coffee or cocktails are served", "name": "coffee_table"}, {"id": 290, "synset": "coffeepot.n.01", "synonyms": ["coffeepot"], "def": "tall pot in which coffee is brewed", "name": "coffeepot"}, {"id": 291, "synset": "coil.n.05", "synonyms": ["coil"], "def": "tubing that is wound in a spiral", "name": "coil"}, {"id": 292, "synset": "coin.n.01", "synonyms": ["coin"], "def": "a flat metal piece (usually a disc) used as money", "name": "coin"}, {"id": 293, "synset": "colander.n.01", "synonyms": ["colander", "cullender"], "def": "bowl-shaped strainer; used to wash or drain foods", "name": "colander"}, {"id": 294, "synset": "coleslaw.n.01", "synonyms": ["coleslaw", "slaw"], "def": "basically shredded cabbage", "name": "coleslaw"}, {"id": 295, "synset": "coloring_material.n.01", "synonyms": ["coloring_material", "colouring_material"], "def": "any material used for its color", "name": "coloring_material"}, {"id": 296, "synset": "combination_lock.n.01", "synonyms": ["combination_lock"], "def": "lock that can be opened only by turning dials in a special sequence", "name": "combination_lock"}, {"id": 297, "synset": "comforter.n.04", "synonyms": ["pacifier", "teething_ring"], "def": "device used for an infant to suck or bite on", "name": "pacifier"}, {"id": 298, "synset": "comic_book.n.01", "synonyms": ["comic_book"], "def": "a magazine devoted to comic strips", "name": "comic_book"}, {"id": 299, "synset": "computer_keyboard.n.01", "synonyms": ["computer_keyboard", "keyboard_(computer)"], "def": "a keyboard that is a data input device for computers", "name": "computer_keyboard"}, {"id": 300, "synset": "concrete_mixer.n.01", "synonyms": ["concrete_mixer", "cement_mixer"], "def": "a machine with a large revolving drum in which cement/concrete is mixed", "name": "concrete_mixer"}, {"id": 301, "synset": "cone.n.01", "synonyms": ["cone", "traffic_cone"], "def": "a cone-shaped object used to direct traffic", "name": "cone"}, {"id": 302, "synset": "control.n.09", "synonyms": ["control", "controller"], "def": "a mechanism that controls the operation of a machine", "name": "control"}, {"id": 303, "synset": "convertible.n.01", "synonyms": ["convertible_(automobile)"], "def": "a car that has top that can be folded or removed", "name": "convertible_(automobile)"}, {"id": 304, "synset": "convertible.n.03", "synonyms": ["sofa_bed"], "def": "a sofa that can be converted into a bed", "name": "sofa_bed"}, {"id": 305, "synset": "cookie.n.01", "synonyms": ["cookie", "cooky", "biscuit_(cookie)"], "def": "any of various small flat sweet cakes (`biscuit' is the British term)", "name": "cookie"}, {"id": 306, "synset": "cookie_jar.n.01", "synonyms": ["cookie_jar", "cooky_jar"], "def": "a jar in which cookies are kept (and sometimes money is hidden)", "name": "cookie_jar"}, {"id": 307, "synset": "cooking_utensil.n.01", "synonyms": ["cooking_utensil"], "def": "a kitchen utensil made of material that does not melt easily; used for cooking", "name": "cooking_utensil"}, {"id": 308, "synset": "cooler.n.01", "synonyms": ["cooler_(for_food)", "ice_chest"], "def": "an insulated box for storing food often with ice", "name": "cooler_(for_food)"}, {"id": 309, "synset": "cork.n.04", "synonyms": ["cork_(bottle_plug)", "bottle_cork"], "def": "the plug in the mouth of a bottle (especially a wine bottle)", "name": "cork_(bottle_plug)"}, {"id": 310, "synset": "corkboard.n.01", "synonyms": ["corkboard"], "def": "a sheet consisting of cork granules", "name": "corkboard"}, {"id": 311, "synset": "corkscrew.n.01", "synonyms": ["corkscrew", "bottle_screw"], "def": "a bottle opener that pulls corks", "name": "corkscrew"}, {"id": 312, "synset": "corn.n.03", "synonyms": ["edible_corn", "corn", "maize"], "def": "ears of corn that can be prepared and served for human food", "name": "edible_corn"}, {"id": 313, "synset": "cornbread.n.01", "synonyms": ["cornbread"], "def": "bread made primarily of cornmeal", "name": "cornbread"}, {"id": 314, "synset": "cornet.n.01", "synonyms": ["cornet", "horn", "trumpet"], "def": "a brass musical instrument with a narrow tube and a flared bell and many valves", "name": "cornet"}, {"id": 315, "synset": "cornice.n.01", "synonyms": ["cornice", "valance", "valance_board", "pelmet"], "def": "a decorative framework to conceal curtain fixtures at the top of a window casing", "name": "cornice"}, {"id": 316, "synset": "cornmeal.n.01", "synonyms": ["cornmeal"], "def": "coarsely ground corn", "name": "cornmeal"}, {"id": 317, "synset": "corset.n.01", "synonyms": ["corset", "girdle"], "def": "a woman's close-fitting foundation garment", "name": "corset"}, {"id": 318, "synset": "cos.n.02", "synonyms": ["romaine_lettuce"], "def": "lettuce with long dark-green leaves in a loosely packed elongated head", "name": "romaine_lettuce"}, {"id": 319, "synset": "costume.n.04", "synonyms": ["costume"], "def": "the attire characteristic of a country or a time or a social class", "name": "costume"}, {"id": 320, "synset": "cougar.n.01", "synonyms": ["cougar", "puma", "catamount", "mountain_lion", "panther"], "def": "large American feline resembling a lion", "name": "cougar"}, {"id": 321, "synset": "coverall.n.01", "synonyms": ["coverall"], "def": "a loose-fitting protective garment that is worn over other clothing", "name": "coverall"}, {"id": 322, "synset": "cowbell.n.01", "synonyms": ["cowbell"], "def": "a bell hung around the neck of cow so that the cow can be easily located", "name": "cowbell"}, {"id": 323, "synset": "cowboy_hat.n.01", "synonyms": ["cowboy_hat", "ten-gallon_hat"], "def": "a hat with a wide brim and a soft crown; worn by American ranch hands", "name": "cowboy_hat"}, {"id": 324, "synset": "crab.n.01", "synonyms": ["crab_(animal)"], "def": "decapod having eyes on short stalks and a broad flattened shell and pincers", "name": "crab_(animal)"}, {"id": 325, "synset": "cracker.n.01", "synonyms": ["cracker"], "def": "a thin crisp wafer", "name": "cracker"}, {"id": 326, "synset": "crape.n.01", "synonyms": ["crape", "crepe", "French_pancake"], "def": "small very thin pancake", "name": "crape"}, {"id": 327, "synset": "crate.n.01", "synonyms": ["crate"], "def": "a rugged box (usually made of wood); used for shipping", "name": "crate"}, {"id": 328, "synset": "crayon.n.01", "synonyms": ["crayon", "wax_crayon"], "def": "writing or drawing implement made of a colored stick of composition wax", "name": "crayon"}, {"id": 329, "synset": "cream_pitcher.n.01", "synonyms": ["cream_pitcher"], "def": "a small pitcher for serving cream", "name": "cream_pitcher"}, {"id": 330, "synset": "credit_card.n.01", "synonyms": ["credit_card", "charge_card", "debit_card"], "def": "a card, usually plastic, used to pay for goods and services", "name": "credit_card"}, {"id": 331, "synset": "crescent_roll.n.01", "synonyms": ["crescent_roll", "croissant"], "def": "very rich flaky crescent-shaped roll", "name": "crescent_roll"}, {"id": 332, "synset": "crib.n.01", "synonyms": ["crib", "cot"], "def": "baby bed with high sides made of slats", "name": "crib"}, {"id": 333, "synset": "crock.n.03", "synonyms": ["crock_pot", "earthenware_jar"], "def": "an earthen jar (made of baked clay)", "name": "crock_pot"}, {"id": 334, "synset": "crossbar.n.01", "synonyms": ["crossbar"], "def": "a horizontal bar that goes across something", "name": "crossbar"}, {"id": 335, "synset": "crouton.n.01", "synonyms": ["crouton"], "def": "a small piece of toasted or fried bread; served in soup or salads", "name": "crouton"}, {"id": 336, "synset": "crow.n.01", "synonyms": ["crow"], "def": "black birds having a raucous call", "name": "crow"}, {"id": 337, "synset": "crown.n.04", "synonyms": ["crown"], "def": "an ornamental jeweled headdress signifying sovereignty", "name": "crown"}, {"id": 338, "synset": "crucifix.n.01", "synonyms": ["crucifix"], "def": "representation of the cross on which Jesus died", "name": "crucifix"}, {"id": 339, "synset": "cruise_ship.n.01", "synonyms": ["cruise_ship", "cruise_liner"], "def": "a passenger ship used commercially for pleasure cruises", "name": "cruise_ship"}, {"id": 340, "synset": "cruiser.n.01", "synonyms": ["police_cruiser", "patrol_car", "police_car", "squad_car"], "def": "a car in which policemen cruise the streets", "name": "police_cruiser"}, {"id": 341, "synset": "crumb.n.03", "synonyms": ["crumb"], "def": "small piece of e.g. bread or cake", "name": "crumb"}, {"id": 342, "synset": "crutch.n.01", "synonyms": ["crutch"], "def": "a wooden or metal staff that fits under the armpit and reaches to the ground", "name": "crutch"}, {"id": 343, "synset": "cub.n.03", "synonyms": ["cub_(animal)"], "def": "the young of certain carnivorous mammals such as the bear or wolf or lion", "name": "cub_(animal)"}, {"id": 344, "synset": "cube.n.05", "synonyms": ["cube", "square_block"], "def": "a block in the (approximate) shape of a cube", "name": "cube"}, {"id": 345, "synset": "cucumber.n.02", "synonyms": ["cucumber", "cuke"], "def": "cylindrical green fruit with thin green rind and white flesh eaten as a vegetable", "name": "cucumber"}, {"id": 346, "synset": "cufflink.n.01", "synonyms": ["cufflink"], "def": "jewelry consisting of linked buttons used to fasten the cuffs of a shirt", "name": "cufflink"}, {"id": 347, "synset": "cup.n.01", "synonyms": ["cup"], "def": "a small open container usually used for drinking; usually has a handle", "name": "cup", "merged": [{"frequency": "f", "id": 504, "synset": "glass.n.02", "image_count": 92, "instance_count": 313, "synonyms": ["glass_(drink_container)", "drinking_glass"], "def": "a container for holding liquids while drinking", "name": "glass_(drink_container)"}, {"frequency": "f", "id": 720, "synset": "mug.n.04", "image_count": 39, "instance_count": 93, "synonyms": ["mug"], "def": "with handle and usually cylindrical", "name": "mug"}]}, {"id": 348, "synset": "cup.n.08", "synonyms": ["trophy_cup"], "def": "a metal vessel with handles that is awarded as a trophy to a competition winner", "name": "trophy_cup"}, {"id": 349, "synset": "cupcake.n.01", "synonyms": ["cupcake"], "def": "small cake baked in a muffin tin", "name": "cupcake"}, {"id": 350, "synset": "curler.n.01", "synonyms": ["hair_curler", "hair_roller", "hair_crimper"], "def": "a cylindrical tube around which the hair is wound to curl it", "name": "hair_curler"}, {"id": 351, "synset": "curling_iron.n.01", "synonyms": ["curling_iron"], "def": "a cylindrical home appliance that heats hair that has been curled around it", "name": "curling_iron"}, {"id": 352, "synset": "curtain.n.01", "synonyms": ["curtain", "drapery"], "def": "hanging cloth used as a blind (especially for a window)", "name": "curtain"}, {"id": 353, "synset": "cushion.n.03", "synonyms": ["cushion"], "def": "a soft bag filled with air or padding such as feathers or foam rubber", "name": "cushion"}, {"id": 354, "synset": "custard.n.01", "synonyms": ["custard"], "def": "sweetened mixture of milk and eggs baked or boiled or frozen", "name": "custard"}, {"id": 355, "synset": "cutter.n.06", "synonyms": ["cutting_tool"], "def": "a cutting implement; a tool for cutting", "name": "cutting_tool"}, {"id": 356, "synset": "cylinder.n.04", "synonyms": ["cylinder"], "def": "a cylindrical container", "name": "cylinder"}, {"id": 357, "synset": "cymbal.n.01", "synonyms": ["cymbal"], "def": "a percussion instrument consisting of a concave brass disk", "name": "cymbal"}, {"id": 358, "synset": "dachshund.n.01", "synonyms": ["dachshund", "dachsie", "badger_dog"], "def": "small long-bodied short-legged breed of dog having a short sleek coat and long drooping ears", "name": "dachshund"}, {"id": 359, "synset": "dagger.n.01", "synonyms": ["dagger"], "def": "a short knife with a pointed blade used for piercing or stabbing", "name": "dagger"}, {"id": 360, "synset": "dartboard.n.01", "synonyms": ["dartboard"], "def": "a circular board of wood or cork used as the target in the game of darts", "name": "dartboard"}, {"id": 361, "synset": "date.n.08", "synonyms": ["date_(fruit)"], "def": "sweet edible fruit of the date palm with a single long woody seed", "name": "date_(fruit)"}, {"id": 362, "synset": "deck_chair.n.01", "synonyms": ["deck_chair", "beach_chair"], "def": "a folding chair for use outdoors; a wooden frame supports a length of canvas", "name": "deck_chair"}, {"id": 363, "synset": "deer.n.01", "synonyms": ["deer", "cervid"], "def": "distinguished from Bovidae by the male's having solid deciduous antlers", "name": "deer"}, {"id": 364, "synset": "dental_floss.n.01", "synonyms": ["dental_floss", "floss"], "def": "a soft thread for cleaning the spaces between the teeth", "name": "dental_floss"}, {"id": 365, "synset": "desk.n.01", "synonyms": ["desk"], "def": "a piece of furniture with a writing surface and usually drawers or other compartments", "name": "desk"}, {"id": 366, "synset": "detergent.n.01", "synonyms": ["detergent"], "def": "a surface-active chemical widely used in industry and laundering", "name": "detergent"}, {"id": 367, "synset": "diaper.n.01", "synonyms": ["diaper"], "def": "garment consisting of a folded cloth drawn up between the legs and fastened at the waist", "name": "diaper"}, {"id": 368, "synset": "diary.n.01", "synonyms": ["diary", "journal"], "def": "a daily written record of (usually personal) experiences and observations", "name": "diary"}, {"id": 369, "synset": "die.n.01", "synonyms": ["die", "dice"], "def": "a small cube with 1 to 6 spots on the six faces; used in gambling", "name": "die"}, {"id": 370, "synset": "dinghy.n.01", "synonyms": ["dinghy", "dory", "rowboat"], "def": "a small boat of shallow draft with seats and oars with which it is propelled", "name": "dinghy"}, {"id": 371, "synset": "dining_table.n.01", "synonyms": ["dining_table"], "def": "a table at which meals are served", "name": "dining_table"}, {"id": 372, "synset": "dinner_jacket.n.01", "synonyms": ["tux", "tuxedo"], "def": "semiformal evening dress for men", "name": "tux"}, {"id": 373, "synset": "dish.n.01", "synonyms": ["dish"], "def": "a piece of dishware normally used as a container for holding or serving food", "name": "dish"}, {"id": 374, "synset": "dish.n.05", "synonyms": ["dish_antenna"], "def": "directional antenna consisting of a parabolic reflector", "name": "dish_antenna"}, {"id": 375, "synset": "dishrag.n.01", "synonyms": ["dishrag", "dishcloth"], "def": "a cloth for washing dishes", "name": "dishrag"}, {"id": 376, "synset": "dishtowel.n.01", "synonyms": ["dishtowel", "tea_towel"], "def": "a towel for drying dishes", "name": "dishtowel"}, {"id": 377, "synset": "dishwasher.n.01", "synonyms": ["dishwasher", "dishwashing_machine"], "def": "a machine for washing dishes", "name": "dishwasher"}, {"id": 378, "synset": "dishwasher_detergent.n.01", "synonyms": ["dishwasher_detergent", "dishwashing_detergent", "dishwashing_liquid"], "def": "a low-sudsing detergent designed for use in dishwashers", "name": "dishwasher_detergent"}, {"id": 379, "synset": "diskette.n.01", "synonyms": ["diskette", "floppy", "floppy_disk"], "def": "a small plastic magnetic disk enclosed in a stiff envelope used to store data", "name": "diskette"}, {"id": 380, "synset": "dispenser.n.01", "synonyms": ["dispenser"], "def": "a container so designed that the contents can be used in prescribed amounts", "name": "dispenser"}, {"id": 381, "synset": "dixie_cup.n.01", "synonyms": ["Dixie_cup", "paper_cup"], "def": "a disposable cup made of paper; for holding drinks", "name": "Dixie_cup"}, {"id": 382, "synset": "dog.n.01", "synonyms": ["dog"], "def": "a common domesticated dog", "name": "dog"}, {"id": 383, "synset": "dog_collar.n.01", "synonyms": ["dog_collar"], "def": "a collar for a dog", "name": "dog_collar"}, {"id": 384, "synset": "doll.n.01", "synonyms": ["doll"], "def": "a toy replica of a HUMAN (NOT AN ANIMAL)", "name": "doll"}, {"id": 385, "synset": "dollar.n.02", "synonyms": ["dollar", "dollar_bill", "one_dollar_bill"], "def": "a piece of paper money worth one dollar", "name": "dollar"}, {"id": 386, "synset": "dolphin.n.02", "synonyms": ["dolphin"], "def": "any of various small toothed whales with a beaklike snout; larger than porpoises", "name": "dolphin"}, {"id": 387, "synset": "domestic_ass.n.01", "synonyms": ["domestic_ass", "donkey"], "def": "domestic beast of burden descended from the African wild ass; patient but stubborn", "name": "domestic_ass"}, {"id": 388, "synset": "domino.n.03", "synonyms": ["eye_mask"], "def": "a mask covering the upper part of the face but with holes for the eyes", "name": "eye_mask"}, {"id": 389, "synset": "doorbell.n.01", "synonyms": ["doorbell", "buzzer"], "def": "a button at an outer door that gives a ringing or buzzing signal when pushed", "name": "doorbell"}, {"id": 390, "synset": "doorknob.n.01", "synonyms": ["doorknob", "doorhandle"], "def": "a knob used to open a door (often called `doorhandle' in Great Britain)", "name": "doorknob"}, {"id": 391, "synset": "doormat.n.02", "synonyms": ["doormat", "welcome_mat"], "def": "a mat placed outside an exterior door for wiping the shoes before entering", "name": "doormat"}, {"id": 392, "synset": "doughnut.n.02", "synonyms": ["doughnut", "donut"], "def": "a small ring-shaped friedcake", "name": "doughnut"}, {"id": 393, "synset": "dove.n.01", "synonyms": ["dove"], "def": "any of numerous small pigeons", "name": "dove"}, {"id": 394, "synset": "dragonfly.n.01", "synonyms": ["dragonfly"], "def": "slender-bodied non-stinging insect having iridescent wings that are outspread at rest", "name": "dragonfly"}, {"id": 395, "synset": "drawer.n.01", "synonyms": ["drawer"], "def": "a boxlike container in a piece of furniture; made so as to slide in and out", "name": "drawer"}, {"id": 396, "synset": "drawers.n.01", "synonyms": ["underdrawers", "boxers", "boxershorts"], "def": "underpants worn by men", "name": "underdrawers"}, {"id": 397, "synset": "dress.n.01", "synonyms": ["dress", "frock"], "def": "a one-piece garment for a woman; has skirt and bodice", "name": "dress"}, {"id": 398, "synset": "dress_hat.n.01", "synonyms": ["dress_hat", "high_hat", "opera_hat", "silk_hat", "top_hat"], "def": "a man's hat with a tall crown; usually covered with silk or with beaver fur", "name": "dress_hat"}, {"id": 399, "synset": "dress_suit.n.01", "synonyms": ["dress_suit"], "def": "formalwear consisting of full evening dress for men", "name": "dress_suit"}, {"id": 400, "synset": "dresser.n.05", "synonyms": ["dresser"], "def": "a cabinet with shelves", "name": "dresser"}, {"id": 401, "synset": "drill.n.01", "synonyms": ["drill"], "def": "a tool with a sharp rotating point for making holes in hard materials", "name": "drill"}, {"id": 402, "synset": "drinking_fountain.n.01", "synonyms": ["drinking_fountain"], "def": "a public fountain to provide a jet of drinking water", "name": "drinking_fountain"}, {"id": 403, "synset": "drone.n.04", "synonyms": ["drone"], "def": "an aircraft without a pilot that is operated by remote control", "name": "drone"}, {"id": 404, "synset": "dropper.n.01", "synonyms": ["dropper", "eye_dropper"], "def": "pipet consisting of a small tube with a vacuum bulb at one end for drawing liquid in and releasing it a drop at a time", "name": "dropper"}, {"id": 405, "synset": "drum.n.01", "synonyms": ["drum_(musical_instrument)"], "def": "a musical percussion instrument; usually consists of a hollow cylinder with a membrane stretched across each end", "name": "drum_(musical_instrument)"}, {"id": 406, "synset": "drumstick.n.02", "synonyms": ["drumstick"], "def": "a stick used for playing a drum", "name": "drumstick"}, {"id": 407, "synset": "duck.n.01", "synonyms": ["duck"], "def": "small web-footed broad-billed swimming bird", "name": "duck"}, {"id": 408, "synset": "duckling.n.02", "synonyms": ["duckling"], "def": "young duck", "name": "duckling"}, {"id": 409, "synset": "duct_tape.n.01", "synonyms": ["duct_tape"], "def": "a wide silvery adhesive tape", "name": "duct_tape"}, {"id": 410, "synset": "duffel_bag.n.01", "synonyms": ["duffel_bag", "duffle_bag", "duffel", "duffle"], "def": "a large cylindrical bag of heavy cloth", "name": "duffel_bag"}, {"id": 411, "synset": "dumbbell.n.01", "synonyms": ["dumbbell"], "def": "an exercising weight with two ball-like ends connected by a short handle", "name": "dumbbell"}, {"id": 412, "synset": "dumpster.n.01", "synonyms": ["dumpster"], "def": "a container designed to receive and transport and dump waste", "name": "dumpster"}, {"id": 413, "synset": "dustpan.n.02", "synonyms": ["dustpan"], "def": "a short-handled receptacle into which dust can be swept", "name": "dustpan"}, {"id": 414, "synset": "dutch_oven.n.02", "synonyms": ["Dutch_oven"], "def": "iron or earthenware cooking pot; used for stews", "name": "Dutch_oven"}, {"id": 415, "synset": "eagle.n.01", "synonyms": ["eagle"], "def": "large birds of prey noted for their broad wings and strong soaring flight", "name": "eagle"}, {"id": 416, "synset": "earphone.n.01", "synonyms": ["earphone", "earpiece", "headphone"], "def": "device for listening to audio that is held over or inserted into the ear", "name": "earphone"}, {"id": 417, "synset": "earplug.n.01", "synonyms": ["earplug"], "def": "a soft plug that is inserted into the ear canal to block sound", "name": "earplug"}, {"id": 418, "synset": "earring.n.01", "synonyms": ["earring"], "def": "jewelry to ornament the ear", "name": "earring"}, {"id": 419, "synset": "easel.n.01", "synonyms": ["easel"], "def": "an upright tripod for displaying something (usually an artist's canvas)", "name": "easel"}, {"id": 420, "synset": "eclair.n.01", "synonyms": ["eclair"], "def": "oblong cream puff", "name": "eclair"}, {"id": 421, "synset": "eel.n.01", "synonyms": ["eel"], "def": "an elongate fish with fatty flesh", "name": "eel"}, {"id": 422, "synset": "egg.n.02", "synonyms": ["egg", "eggs"], "def": "oval reproductive body of a fowl (especially a hen) used as food", "name": "egg"}, {"id": 423, "synset": "egg_roll.n.01", "synonyms": ["egg_roll", "spring_roll"], "def": "minced vegetables and meat wrapped in a pancake and fried", "name": "egg_roll"}, {"id": 424, "synset": "egg_yolk.n.01", "synonyms": ["egg_yolk", "yolk_(egg)"], "def": "the yellow spherical part of an egg", "name": "egg_yolk"}, {"id": 425, "synset": "eggbeater.n.02", "synonyms": ["eggbeater", "eggwhisk"], "def": "a mixer for beating eggs or whipping cream", "name": "eggbeater"}, {"id": 426, "synset": "eggplant.n.01", "synonyms": ["eggplant", "aubergine"], "def": "egg-shaped vegetable having a shiny skin typically dark purple", "name": "eggplant"}, {"id": 427, "synset": "electric_chair.n.01", "synonyms": ["electric_chair"], "def": "a chair-shaped instrument of execution by electrocution", "name": "electric_chair"}, {"id": 428, "synset": "electric_refrigerator.n.01", "synonyms": ["refrigerator"], "def": "a refrigerator in which the coolant is pumped around by an electric motor", "name": "refrigerator"}, {"id": 429, "synset": "elephant.n.01", "synonyms": ["elephant"], "def": "a common elephant", "name": "elephant"}, {"id": 430, "synset": "elk.n.01", "synonyms": ["elk", "moose"], "def": "large northern deer with enormous flattened antlers in the male", "name": "elk"}, {"id": 431, "synset": "envelope.n.01", "synonyms": ["envelope"], "def": "a flat (usually rectangular) container for a letter, thin package, etc.", "name": "envelope"}, {"id": 432, "synset": "eraser.n.01", "synonyms": ["eraser"], "def": "an implement used to erase something", "name": "eraser"}, {"id": 433, "synset": "escargot.n.01", "synonyms": ["escargot"], "def": "edible snail usually served in the shell with a sauce of melted butter and garlic", "name": "escargot"}, {"id": 434, "synset": "eyepatch.n.01", "synonyms": ["eyepatch"], "def": "a protective cloth covering for an injured eye", "name": "eyepatch"}, {"id": 435, "synset": "falcon.n.01", "synonyms": ["falcon"], "def": "birds of prey having long pointed powerful wings adapted for swift flight", "name": "falcon"}, {"id": 436, "synset": "fan.n.01", "synonyms": ["fan"], "def": "a device for creating a current of air by movement of a surface or surfaces", "name": "fan"}, {"id": 437, "synset": "faucet.n.01", "synonyms": ["faucet", "spigot", "tap"], "def": "a regulator for controlling the flow of a liquid from a reservoir", "name": "faucet"}, {"id": 438, "synset": "fedora.n.01", "synonyms": ["fedora"], "def": "a hat made of felt with a creased crown", "name": "fedora"}, {"id": 439, "synset": "ferret.n.02", "synonyms": ["ferret"], "def": "domesticated albino variety of the European polecat bred for hunting rats and rabbits", "name": "ferret"}, {"id": 440, "synset": "ferris_wheel.n.01", "synonyms": ["Ferris_wheel"], "def": "a large wheel with suspended seats that remain upright as the wheel rotates", "name": "Ferris_wheel"}, {"id": 441, "synset": "ferry.n.01", "synonyms": ["ferry", "ferryboat"], "def": "a boat that transports people or vehicles across a body of water and operates on a regular schedule", "name": "ferry"}, {"id": 442, "synset": "fig.n.04", "synonyms": ["fig_(fruit)"], "def": "fleshy sweet pear-shaped yellowish or purple fruit eaten fresh or preserved or dried", "name": "fig_(fruit)"}, {"id": 443, "synset": "fighter.n.02", "synonyms": ["fighter_jet", "fighter_aircraft", "attack_aircraft"], "def": "a high-speed military or naval airplane designed to destroy enemy targets", "name": "fighter_jet"}, {"id": 444, "synset": "figurine.n.01", "synonyms": ["figurine"], "def": "a small carved or molded figure", "name": "figurine"}, {"id": 445, "synset": "file.n.03", "synonyms": ["file_cabinet", "filing_cabinet"], "def": "office furniture consisting of a container for keeping papers in order", "name": "file_cabinet"}, {"id": 446, "synset": "file.n.04", "synonyms": ["file_(tool)"], "def": "a steel hand tool with small sharp teeth on some or all of its surfaces; used for smoothing wood or metal", "name": "file_(tool)"}, {"id": 447, "synset": "fire_alarm.n.02", "synonyms": ["fire_alarm", "smoke_alarm"], "def": "an alarm that is tripped off by fire or smoke", "name": "fire_alarm"}, {"id": 448, "synset": "fire_engine.n.01", "synonyms": ["fire_engine", "fire_truck"], "def": "large trucks that carry firefighters and equipment to the site of a fire", "name": "fire_engine"}, {"id": 449, "synset": "fire_extinguisher.n.01", "synonyms": ["fire_extinguisher", "extinguisher"], "def": "a manually operated device for extinguishing small fires", "name": "fire_extinguisher"}, {"id": 450, "synset": "fire_hose.n.01", "synonyms": ["fire_hose"], "def": "a large hose that carries water from a fire hydrant to the site of the fire", "name": "fire_hose"}, {"id": 451, "synset": "fireplace.n.01", "synonyms": ["fireplace"], "def": "an open recess in a wall at the base of a chimney where a fire can be built", "name": "fireplace"}, {"id": 452, "synset": "fireplug.n.01", "synonyms": ["fireplug", "fire_hydrant", "hydrant"], "def": "an upright hydrant for drawing water to use in fighting a fire", "name": "fireplug"}, {"id": 453, "synset": "fish.n.01", "synonyms": ["fish"], "def": "any of various mostly cold-blooded aquatic vertebrates usually having scales and breathing through gills", "name": "fish"}, {"id": 454, "synset": "fish.n.02", "synonyms": ["fish_(food)"], "def": "the flesh of fish used as food", "name": "fish_(food)"}, {"id": 455, "synset": "fishbowl.n.02", "synonyms": ["fishbowl", "goldfish_bowl"], "def": "a transparent bowl in which small fish are kept", "name": "fishbowl"}, {"id": 456, "synset": "fishing_boat.n.01", "synonyms": ["fishing_boat", "fishing_vessel"], "def": "a vessel for fishing", "name": "fishing_boat"}, {"id": 457, "synset": "fishing_rod.n.01", "synonyms": ["fishing_rod", "fishing_pole"], "def": "a rod that is used in fishing to extend the fishing line", "name": "fishing_rod"}, {"id": 458, "synset": "flag.n.01", "synonyms": ["flag"], "def": "emblem usually consisting of a rectangular piece of cloth of distinctive design (do not include pole)", "name": "flag"}, {"id": 459, "synset": "flagpole.n.02", "synonyms": ["flagpole", "flagstaff"], "def": "a tall staff or pole on which a flag is raised", "name": "flagpole"}, {"id": 460, "synset": "flamingo.n.01", "synonyms": ["flamingo"], "def": "large pink web-footed bird with down-bent bill", "name": "flamingo"}, {"id": 461, "synset": "flannel.n.01", "synonyms": ["flannel"], "def": "a soft light woolen fabric; used for clothing", "name": "flannel"}, {"id": 462, "synset": "flash.n.10", "synonyms": ["flash", "flashbulb"], "def": "a lamp for providing momentary light to take a photograph", "name": "flash"}, {"id": 463, "synset": "flashlight.n.01", "synonyms": ["flashlight", "torch"], "def": "a small portable battery-powered electric lamp", "name": "flashlight"}, {"id": 464, "synset": "fleece.n.03", "synonyms": ["fleece"], "def": "a soft bulky fabric with deep pile; used chiefly for clothing", "name": "fleece"}, {"id": 465, "synset": "flip-flop.n.02", "synonyms": ["flip-flop_(sandal)"], "def": "a backless sandal held to the foot by a thong between two toes", "name": "flip-flop_(sandal)"}, {"id": 466, "synset": "flipper.n.01", "synonyms": ["flipper_(footwear)", "fin_(footwear)"], "def": "a shoe to aid a person in swimming", "name": "flipper_(footwear)"}, {"id": 467, "synset": "flower_arrangement.n.01", "synonyms": ["flower_arrangement", "floral_arrangement"], "def": "a decorative arrangement of flowers", "name": "flower_arrangement"}, {"id": 468, "synset": "flute.n.02", "synonyms": ["flute_glass", "champagne_flute"], "def": "a tall narrow wineglass", "name": "flute_glass"}, {"id": 469, "synset": "foal.n.01", "synonyms": ["foal"], "def": "a young horse", "name": "foal"}, {"id": 470, "synset": "folding_chair.n.01", "synonyms": ["folding_chair"], "def": "a chair that can be folded flat for storage", "name": "folding_chair"}, {"id": 471, "synset": "food_processor.n.01", "synonyms": ["food_processor"], "def": "a kitchen appliance for shredding, blending, chopping, or slicing food", "name": "food_processor"}, {"id": 472, "synset": "football.n.02", "synonyms": ["football_(American)"], "def": "the inflated oblong ball used in playing American football", "name": "football_(American)"}, {"id": 473, "synset": "football_helmet.n.01", "synonyms": ["football_helmet"], "def": "a padded helmet with a face mask to protect the head of football players", "name": "football_helmet"}, {"id": 474, "synset": "footstool.n.01", "synonyms": ["footstool", "footrest"], "def": "a low seat or a stool to rest the feet of a seated person", "name": "footstool"}, {"id": 475, "synset": "fork.n.01", "synonyms": ["fork"], "def": "cutlery used for serving and eating food", "name": "fork"}, {"id": 476, "synset": "forklift.n.01", "synonyms": ["forklift"], "def": "an industrial vehicle with a power operated fork in front that can be inserted under loads to lift and move them", "name": "forklift"}, {"id": 477, "synset": "freight_car.n.01", "synonyms": ["freight_car"], "def": "a railway car that carries freight", "name": "freight_car"}, {"id": 478, "synset": "french_toast.n.01", "synonyms": ["French_toast"], "def": "bread slice dipped in egg and milk and fried", "name": "French_toast"}, {"id": 479, "synset": "freshener.n.01", "synonyms": ["freshener", "air_freshener"], "def": "anything that freshens", "name": "freshener"}, {"id": 480, "synset": "frisbee.n.01", "synonyms": ["frisbee"], "def": "a light, plastic disk propelled with a flip of the wrist for recreation or competition", "name": "frisbee"}, {"id": 481, "synset": "frog.n.01", "synonyms": ["frog", "toad", "toad_frog"], "def": "a tailless stout-bodied amphibians with long hind limbs for leaping", "name": "frog"}, {"id": 482, "synset": "fruit_juice.n.01", "synonyms": ["fruit_juice"], "def": "drink produced by squeezing or crushing fruit", "name": "fruit_juice"}, {"id": 483, "synset": "fruit_salad.n.01", "synonyms": ["fruit_salad"], "def": "salad composed of fruits", "name": "fruit_salad"}, {"id": 484, "synset": "frying_pan.n.01", "synonyms": ["frying_pan", "frypan", "skillet"], "def": "a pan used for frying foods", "name": "frying_pan"}, {"id": 485, "synset": "fudge.n.01", "synonyms": ["fudge"], "def": "soft creamy candy", "name": "fudge"}, {"id": 486, "synset": "funnel.n.02", "synonyms": ["funnel"], "def": "a cone-shaped utensil used to channel a substance into a container with a small mouth", "name": "funnel"}, {"id": 487, "synset": "futon.n.01", "synonyms": ["futon"], "def": "a pad that is used for sleeping on the floor or on a raised frame", "name": "futon"}, {"id": 488, "synset": "gag.n.02", "synonyms": ["gag", "muzzle"], "def": "restraint put into a person's mouth to prevent speaking or shouting", "name": "gag"}, {"id": 489, "synset": "garbage.n.03", "synonyms": ["garbage"], "def": "a receptacle where waste can be discarded", "name": "garbage"}, {"id": 490, "synset": "garbage_truck.n.01", "synonyms": ["garbage_truck"], "def": "a truck for collecting domestic refuse", "name": "garbage_truck"}, {"id": 491, "synset": "garden_hose.n.01", "synonyms": ["garden_hose"], "def": "a hose used for watering a lawn or garden", "name": "garden_hose"}, {"id": 492, "synset": "gargle.n.01", "synonyms": ["gargle", "mouthwash"], "def": "a medicated solution used for gargling and rinsing the mouth", "name": "gargle"}, {"id": 493, "synset": "gargoyle.n.02", "synonyms": ["gargoyle"], "def": "an ornament consisting of a grotesquely carved figure of a person or animal", "name": "gargoyle"}, {"id": 494, "synset": "garlic.n.02", "synonyms": ["garlic", "ail"], "def": "aromatic bulb used as seasoning", "name": "garlic"}, {"id": 495, "synset": "gasmask.n.01", "synonyms": ["gasmask", "respirator", "gas_helmet"], "def": "a protective face mask with a filter", "name": "gasmask"}, {"id": 496, "synset": "gazelle.n.01", "synonyms": ["gazelle"], "def": "small swift graceful antelope of Africa and Asia having lustrous eyes", "name": "gazelle"}, {"id": 497, "synset": "gelatin.n.02", "synonyms": ["gelatin", "jelly"], "def": "an edible jelly made with gelatin and used as a dessert or salad base or a coating for foods", "name": "gelatin"}, {"id": 498, "synset": "gem.n.02", "synonyms": ["gemstone"], "def": "a crystalline rock that can be cut and polished for jewelry", "name": "gemstone"}, {"id": 499, "synset": "giant_panda.n.01", "synonyms": ["giant_panda", "panda", "panda_bear"], "def": "large black-and-white herbivorous mammal of bamboo forests of China and Tibet", "name": "giant_panda"}, {"id": 500, "synset": "gift_wrap.n.01", "synonyms": ["gift_wrap"], "def": "attractive wrapping paper suitable for wrapping gifts", "name": "gift_wrap"}, {"id": 501, "synset": "ginger.n.03", "synonyms": ["ginger", "gingerroot"], "def": "the root of the common ginger plant; used fresh as a seasoning", "name": "ginger"}, {"id": 502, "synset": "giraffe.n.01", "synonyms": ["giraffe"], "def": "tall animal having a spotted coat and small horns and very long neck and legs", "name": "giraffe"}, {"id": 503, "synset": "girdle.n.02", "synonyms": ["cincture", "sash", "waistband", "waistcloth"], "def": "a band of material around the waist that strengthens a skirt or trousers", "name": "cincture"}, {"id": 504, "synset": "glass.n.02", "synonyms": ["glass_(drink_container)", "drinking_glass"], "def": "a container for holding liquids while drinking", "name": "glass_(drink_container)"}, {"id": 505, "synset": "globe.n.03", "synonyms": ["globe"], "def": "a sphere on which a map (especially of the earth) is represented", "name": "globe"}, {"id": 506, "synset": "glove.n.02", "synonyms": ["glove"], "def": "handwear covering the hand", "name": "glove"}, {"id": 507, "synset": "goat.n.01", "synonyms": ["goat"], "def": "a common goat", "name": "goat"}, {"id": 508, "synset": "goggles.n.01", "synonyms": ["goggles"], "def": "tight-fitting spectacles worn to protect the eyes", "name": "goggles"}, {"id": 509, "synset": "goldfish.n.01", "synonyms": ["goldfish"], "def": "small golden or orange-red freshwater fishes used as pond or aquarium pets", "name": "goldfish"}, {"id": 510, "synset": "golf_club.n.02", "synonyms": ["golf_club", "golf-club"], "def": "golf equipment used by a golfer to hit a golf ball", "name": "golf_club"}, {"id": 511, "synset": "golfcart.n.01", "synonyms": ["golfcart"], "def": "a small motor vehicle in which golfers can ride between shots", "name": "golfcart"}, {"id": 512, "synset": "gondola.n.02", "synonyms": ["gondola_(boat)"], "def": "long narrow flat-bottomed boat propelled by sculling; traditionally used on canals of Venice", "name": "gondola_(boat)"}, {"id": 513, "synset": "goose.n.01", "synonyms": ["goose"], "def": "loud, web-footed long-necked aquatic birds usually larger than ducks", "name": "goose"}, {"id": 514, "synset": "gorilla.n.01", "synonyms": ["gorilla"], "def": "largest ape", "name": "gorilla"}, {"id": 515, "synset": "gourd.n.02", "synonyms": ["gourd"], "def": "any of numerous inedible fruits with hard rinds", "name": "gourd"}, {"id": 516, "synset": "gown.n.04", "synonyms": ["surgical_gown", "scrubs_(surgical_clothing)"], "def": "protective garment worn by surgeons during operations", "name": "surgical_gown"}, {"id": 517, "synset": "grape.n.01", "synonyms": ["grape"], "def": "any of various juicy fruit with green or purple skins; grow in clusters", "name": "grape"}, {"id": 518, "synset": "grasshopper.n.01", "synonyms": ["grasshopper"], "def": "plant-eating insect with hind legs adapted for leaping", "name": "grasshopper"}, {"id": 519, "synset": "grater.n.01", "synonyms": ["grater"], "def": "utensil with sharp perforations for shredding foods (as vegetables or cheese)", "name": "grater"}, {"id": 520, "synset": "gravestone.n.01", "synonyms": ["gravestone", "headstone", "tombstone"], "def": "a stone that is used to mark a grave", "name": "gravestone"}, {"id": 521, "synset": "gravy_boat.n.01", "synonyms": ["gravy_boat", "gravy_holder"], "def": "a dish (often boat-shaped) for serving gravy or sauce", "name": "gravy_boat"}, {"id": 522, "synset": "green_bean.n.02", "synonyms": ["green_bean"], "def": "a common bean plant cultivated for its slender green edible pods", "name": "green_bean"}, {"id": 523, "synset": "green_onion.n.01", "synonyms": ["green_onion", "spring_onion", "scallion"], "def": "a young onion before the bulb has enlarged", "name": "green_onion"}, {"id": 524, "synset": "griddle.n.01", "synonyms": ["griddle"], "def": "cooking utensil consisting of a flat heated surface on which food is cooked", "name": "griddle"}, {"id": 525, "synset": "grillroom.n.01", "synonyms": ["grillroom", "grill_(restaurant)"], "def": "a restaurant where food is cooked on a grill", "name": "grillroom"}, {"id": 526, "synset": "grinder.n.04", "synonyms": ["grinder_(tool)"], "def": "a machine tool that polishes metal", "name": "grinder_(tool)"}, {"id": 527, "synset": "grits.n.01", "synonyms": ["grits", "hominy_grits"], "def": "coarsely ground corn boiled as a breakfast dish", "name": "grits"}, {"id": 528, "synset": "grizzly.n.01", "synonyms": ["grizzly", "grizzly_bear"], "def": "powerful brownish-yellow bear of the uplands of western North America", "name": "grizzly"}, {"id": 529, "synset": "grocery_bag.n.01", "synonyms": ["grocery_bag"], "def": "a sack for holding customer's groceries", "name": "grocery_bag", "merged": [{"frequency": "f", "id": 912, "synset": "sack.n.01", "image_count": 37, "instance_count": 76, "synonyms": ["plastic_bag", "paper_bag"], "def": "a bag made of paper or plastic for holding customer's purchases", "name": "plastic_bag"}, {"frequency": "c", "id": 967, "synset": "shopping_bag.n.01", "image_count": 9, "instance_count": 18, "synonyms": ["shopping_bag"], "def": "a bag made of plastic or strong paper (often with handles); used to transport goods after shopping", "name": "shopping_bag"}]}, {"id": 530, "synset": "guacamole.n.01", "synonyms": ["guacamole"], "def": "a dip made of mashed avocado mixed with chopped onions and other seasonings", "name": "guacamole"}, {"id": 531, "synset": "guitar.n.01", "synonyms": ["guitar"], "def": "a stringed instrument usually having six strings; played by strumming or plucking", "name": "guitar"}, {"id": 532, "synset": "gull.n.02", "synonyms": ["gull", "seagull"], "def": "mostly white aquatic bird having long pointed wings and short legs", "name": "gull"}, {"id": 533, "synset": "gun.n.01", "synonyms": ["gun"], "def": "a weapon that discharges a bullet at high velocity from a metal tube", "name": "gun"}, {"id": 534, "synset": "hair_spray.n.01", "synonyms": ["hair_spray"], "def": "substance sprayed on the hair to hold it in place", "name": "hair_spray"}, {"id": 535, "synset": "hairbrush.n.01", "synonyms": ["hairbrush"], "def": "a brush used to groom a person's hair", "name": "hairbrush"}, {"id": 536, "synset": "hairnet.n.01", "synonyms": ["hairnet"], "def": "a small net that someone wears over their hair to keep it in place", "name": "hairnet"}, {"id": 537, "synset": "hairpin.n.01", "synonyms": ["hairpin"], "def": "a double pronged pin used to hold women's hair in place", "name": "hairpin"}, {"id": 538, "synset": "ham.n.01", "synonyms": ["ham", "jambon", "gammon"], "def": "meat cut from the thigh of a hog (usually smoked)", "name": "ham"}, {"id": 539, "synset": "hamburger.n.01", "synonyms": ["hamburger", "beefburger", "burger"], "def": "a sandwich consisting of a patty of minced beef served on a bun", "name": "hamburger"}, {"id": 540, "synset": "hammer.n.02", "synonyms": ["hammer"], "def": "a hand tool with a heavy head and a handle; used to deliver an impulsive force by striking", "name": "hammer"}, {"id": 541, "synset": "hammock.n.02", "synonyms": ["hammock"], "def": "a hanging bed of canvas or rope netting (usually suspended between two trees)", "name": "hammock"}, {"id": 542, "synset": "hamper.n.02", "synonyms": ["hamper"], "def": "a basket usually with a cover", "name": "hamper"}, {"id": 543, "synset": "hamster.n.01", "synonyms": ["hamster"], "def": "short-tailed burrowing rodent with large cheek pouches", "name": "hamster"}, {"id": 544, "synset": "hand_blower.n.01", "synonyms": ["hair_dryer"], "def": "a hand-held electric blower that can blow warm air onto the hair", "name": "hair_dryer"}, {"id": 545, "synset": "hand_glass.n.01", "synonyms": ["hand_glass", "hand_mirror"], "def": "a mirror intended to be held in the hand", "name": "hand_glass"}, {"id": 546, "synset": "hand_towel.n.01", "synonyms": ["hand_towel", "face_towel"], "def": "a small towel used to dry the hands or face", "name": "hand_towel"}, {"id": 547, "synset": "handcart.n.01", "synonyms": ["handcart", "pushcart", "hand_truck"], "def": "wheeled vehicle that can be pushed by a person", "name": "handcart"}, {"id": 548, "synset": "handcuff.n.01", "synonyms": ["handcuff"], "def": "shackle that consists of a metal loop that can be locked around the wrist", "name": "handcuff"}, {"id": 549, "synset": "handkerchief.n.01", "synonyms": ["handkerchief"], "def": "a square piece of cloth used for wiping the eyes or nose or as a costume accessory", "name": "handkerchief"}, {"id": 550, "synset": "handle.n.01", "synonyms": ["handle", "grip", "handgrip"], "def": "the appendage to an object that is designed to be held in order to use or move it", "name": "handle"}, {"id": 551, "synset": "handsaw.n.01", "synonyms": ["handsaw", "carpenter's_saw"], "def": "a saw used with one hand for cutting wood", "name": "handsaw"}, {"id": 552, "synset": "hardback.n.01", "synonyms": ["hardback_book", "hardcover_book"], "def": "a book with cardboard or cloth or leather covers", "name": "hardback_book"}, {"id": 553, "synset": "harmonium.n.01", "synonyms": ["harmonium", "organ_(musical_instrument)", "reed_organ_(musical_instrument)"], "def": "a free-reed instrument in which air is forced through the reeds by bellows", "name": "harmonium"}, {"id": 554, "synset": "hat.n.01", "synonyms": ["hat"], "def": "headwear that protects the head from bad weather, sun, or worn for fashion", "name": "hat", "merged": [{"frequency": "c", "id": 207, "synset": "cap.n.01", "image_count": 2, "instance_count": 5, "synonyms": ["cap_(headwear)"], "def": "a tight-fitting headwear", "name": "cap_(headwear)"}]}, {"id": 555, "synset": "hatbox.n.01", "synonyms": ["hatbox"], "def": "a round piece of luggage for carrying hats", "name": "hatbox"}, {"id": 556, "synset": "hatch.n.03", "synonyms": ["hatch"], "def": "a movable barrier covering a hatchway", "name": "hatch"}, {"id": 557, "synset": "head_covering.n.01", "synonyms": ["veil"], "def": "a garment that covers the head and face", "name": "veil"}, {"id": 558, "synset": "headband.n.01", "synonyms": ["headband"], "def": "a band worn around or over the head", "name": "headband"}, {"id": 559, "synset": "headboard.n.01", "synonyms": ["headboard"], "def": "a vertical board or panel forming the head of a bedstead", "name": "headboard"}, {"id": 560, "synset": "headlight.n.01", "synonyms": ["headlight", "headlamp"], "def": "a powerful light with reflector; attached to the front of an automobile or locomotive", "name": "headlight"}, {"id": 561, "synset": "headscarf.n.01", "synonyms": ["headscarf"], "def": "a kerchief worn over the head and tied under the chin", "name": "headscarf"}, {"id": 562, "synset": "headset.n.01", "synonyms": ["headset"], "def": "receiver consisting of a pair of headphones", "name": "headset"}, {"id": 563, "synset": "headstall.n.01", "synonyms": ["headstall_(for_horses)", "headpiece_(for_horses)"], "def": "the band that is the part of a bridle that fits around a horse's head", "name": "headstall_(for_horses)"}, {"id": 564, "synset": "hearing_aid.n.02", "synonyms": ["hearing_aid"], "def": "an acoustic device used to direct sound to the ear of a hearing-impaired person", "name": "hearing_aid"}, {"id": 565, "synset": "heart.n.02", "synonyms": ["heart"], "def": "a muscular organ; its contractions move the blood through the body", "name": "heart"}, {"id": 566, "synset": "heater.n.01", "synonyms": ["heater", "warmer"], "def": "device that heats water or supplies warmth to a room", "name": "heater"}, {"id": 567, "synset": "helicopter.n.01", "synonyms": ["helicopter"], "def": "an aircraft without wings that obtains its lift from the rotation of overhead blades", "name": "helicopter"}, {"id": 568, "synset": "helmet.n.02", "synonyms": ["helmet"], "def": "a protective headgear made of hard material to resist blows", "name": "helmet"}, {"id": 569, "synset": "heron.n.02", "synonyms": ["heron"], "def": "grey or white wading bird with long neck and long legs and (usually) long bill", "name": "heron"}, {"id": 570, "synset": "highchair.n.01", "synonyms": ["highchair", "feeding_chair"], "def": "a chair for feeding a very young child", "name": "highchair"}, {"id": 571, "synset": "hinge.n.01", "synonyms": ["hinge"], "def": "a joint that holds two parts together so that one can swing relative to the other", "name": "hinge"}, {"id": 572, "synset": "hippopotamus.n.01", "synonyms": ["hippopotamus"], "def": "massive thick-skinned animal living in or around rivers of tropical Africa", "name": "hippopotamus"}, {"id": 573, "synset": "hockey_stick.n.01", "synonyms": ["hockey_stick"], "def": "sports implement consisting of a stick used by hockey players to move the puck", "name": "hockey_stick"}, {"id": 574, "synset": "hog.n.03", "synonyms": ["hog", "pig"], "def": "domestic swine", "name": "hog"}, {"id": 575, "synset": "home_plate.n.01", "synonyms": ["home_plate_(baseball)", "home_base_(baseball)"], "def": "(baseball) a rubber slab where the batter stands; it must be touched by a base runner in order to score", "name": "home_plate_(baseball)"}, {"id": 576, "synset": "honey.n.01", "synonyms": ["honey"], "def": "a sweet yellow liquid produced by bees", "name": "honey"}, {"id": 577, "synset": "hood.n.06", "synonyms": ["fume_hood", "exhaust_hood"], "def": "metal covering leading to a vent that exhausts smoke or fumes", "name": "fume_hood"}, {"id": 578, "synset": "hook.n.05", "synonyms": ["hook"], "def": "a curved or bent implement for suspending or pulling something", "name": "hook"}, {"id": 579, "synset": "horse.n.01", "synonyms": ["horse"], "def": "a common horse", "name": "horse"}, {"id": 580, "synset": "hose.n.03", "synonyms": ["hose", "hosepipe"], "def": "a flexible pipe for conveying a liquid or gas", "name": "hose"}, {"id": 581, "synset": "hot-air_balloon.n.01", "synonyms": ["hot-air_balloon"], "def": "balloon for travel through the air in a basket suspended below a large bag of heated air", "name": "hot-air_balloon"}, {"id": 582, "synset": "hot_plate.n.01", "synonyms": ["hotplate"], "def": "a portable electric appliance for heating or cooking or keeping food warm", "name": "hotplate"}, {"id": 583, "synset": "hot_sauce.n.01", "synonyms": ["hot_sauce"], "def": "a pungent peppery sauce", "name": "hot_sauce"}, {"id": 584, "synset": "hourglass.n.01", "synonyms": ["hourglass"], "def": "a sandglass timer that runs for sixty minutes", "name": "hourglass"}, {"id": 585, "synset": "houseboat.n.01", "synonyms": ["houseboat"], "def": "a barge that is designed and equipped for use as a dwelling", "name": "houseboat"}, {"id": 586, "synset": "hummingbird.n.01", "synonyms": ["hummingbird"], "def": "tiny American bird having brilliant iridescent plumage and long slender bills", "name": "hummingbird"}, {"id": 587, "synset": "hummus.n.01", "synonyms": ["hummus", "humus", "hommos", "hoummos", "humous"], "def": "a thick spread made from mashed chickpeas", "name": "hummus"}, {"id": 588, "synset": "ice_bear.n.01", "synonyms": ["polar_bear"], "def": "white bear of Arctic regions", "name": "polar_bear"}, {"id": 589, "synset": "ice_cream.n.01", "synonyms": ["icecream"], "def": "frozen dessert containing cream and sugar and flavoring", "name": "icecream"}, {"id": 590, "synset": "ice_lolly.n.01", "synonyms": ["popsicle"], "def": "ice cream or water ice on a small wooden stick", "name": "popsicle"}, {"id": 591, "synset": "ice_maker.n.01", "synonyms": ["ice_maker"], "def": "an appliance included in some electric refrigerators for making ice cubes", "name": "ice_maker"}, {"id": 592, "synset": "ice_pack.n.01", "synonyms": ["ice_pack", "ice_bag"], "def": "a waterproof bag filled with ice: applied to the body (especially the head) to cool or reduce swelling", "name": "ice_pack"}, {"id": 593, "synset": "ice_skate.n.01", "synonyms": ["ice_skate"], "def": "skate consisting of a boot with a steel blade fitted to the sole", "name": "ice_skate"}, {"id": 594, "synset": "ice_tea.n.01", "synonyms": ["ice_tea", "iced_tea"], "def": "strong tea served over ice", "name": "ice_tea"}, {"id": 595, "synset": "igniter.n.01", "synonyms": ["igniter", "ignitor", "lighter"], "def": "a substance or device used to start a fire", "name": "igniter"}, {"id": 596, "synset": "incense.n.01", "synonyms": ["incense"], "def": "a substance that produces a fragrant odor when burned", "name": "incense"}, {"id": 597, "synset": "inhaler.n.01", "synonyms": ["inhaler", "inhalator"], "def": "a dispenser that produces a chemical vapor to be inhaled through mouth or nose", "name": "inhaler"}, {"id": 598, "synset": "ipod.n.01", "synonyms": ["iPod"], "def": "a pocket-sized device used to play music files", "name": "iPod"}, {"id": 599, "synset": "iron.n.04", "synonyms": ["iron_(for_clothing)", "smoothing_iron_(for_clothing)"], "def": "home appliance consisting of a flat metal base that is heated and used to smooth cloth", "name": "iron_(for_clothing)"}, {"id": 600, "synset": "ironing_board.n.01", "synonyms": ["ironing_board"], "def": "narrow padded board on collapsible supports; used for ironing clothes", "name": "ironing_board"}, {"id": 601, "synset": "jacket.n.01", "synonyms": ["jacket"], "def": "a waist-length coat", "name": "jacket"}, {"id": 602, "synset": "jam.n.01", "synonyms": ["jam"], "def": "preserve of crushed fruit", "name": "jam"}, {"id": 603, "synset": "jean.n.01", "synonyms": ["jean", "blue_jean", "denim"], "def": "(usually plural) close-fitting trousers of heavy denim for manual work or casual wear", "name": "jean"}, {"id": 604, "synset": "jeep.n.01", "synonyms": ["jeep", "landrover"], "def": "a car suitable for traveling over rough terrain", "name": "jeep"}, {"id": 605, "synset": "jelly_bean.n.01", "synonyms": ["jelly_bean", "jelly_egg"], "def": "sugar-glazed jellied candy", "name": "jelly_bean"}, {"id": 606, "synset": "jersey.n.03", "synonyms": ["jersey", "T-shirt", "tee_shirt"], "def": "a close-fitting pullover shirt", "name": "jersey"}, {"id": 607, "synset": "jet.n.01", "synonyms": ["jet_plane", "jet-propelled_plane"], "def": "an airplane powered by one or more jet engines", "name": "jet_plane"}, {"id": 608, "synset": "jewelry.n.01", "synonyms": ["jewelry", "jewellery"], "def": "an adornment (as a bracelet or ring or necklace) made of precious metals and set with gems (or imitation gems)", "name": "jewelry"}, {"id": 609, "synset": "joystick.n.02", "synonyms": ["joystick"], "def": "a control device for computers consisting of a vertical handle that can move freely in two directions", "name": "joystick"}, {"id": 610, "synset": "jump_suit.n.01", "synonyms": ["jumpsuit"], "def": "one-piece garment fashioned after a parachutist's uniform", "name": "jumpsuit"}, {"id": 611, "synset": "kayak.n.01", "synonyms": ["kayak"], "def": "a small canoe consisting of a light frame made watertight with animal skins", "name": "kayak"}, {"id": 612, "synset": "keg.n.02", "synonyms": ["keg"], "def": "small cask or barrel", "name": "keg"}, {"id": 613, "synset": "kennel.n.01", "synonyms": ["kennel", "doghouse"], "def": "outbuilding that serves as a shelter for a dog", "name": "kennel"}, {"id": 614, "synset": "kettle.n.01", "synonyms": ["kettle", "boiler"], "def": "a metal pot for stewing or boiling; usually has a lid", "name": "kettle"}, {"id": 615, "synset": "key.n.01", "synonyms": ["key"], "def": "metal instrument used to unlock a lock", "name": "key"}, {"id": 616, "synset": "keycard.n.01", "synonyms": ["keycard"], "def": "a plastic card used to gain access typically to a door", "name": "keycard"}, {"id": 617, "synset": "kilt.n.01", "synonyms": ["kilt"], "def": "a knee-length pleated tartan skirt worn by men as part of the traditional dress in the Highlands of northern Scotland", "name": "kilt"}, {"id": 618, "synset": "kimono.n.01", "synonyms": ["kimono"], "def": "a loose robe; imitated from robes originally worn by Japanese", "name": "kimono"}, {"id": 619, "synset": "kitchen_sink.n.01", "synonyms": ["kitchen_sink"], "def": "a sink in a kitchen", "name": "kitchen_sink"}, {"id": 620, "synset": "kitchen_table.n.01", "synonyms": ["kitchen_table"], "def": "a table in the kitchen", "name": "kitchen_table"}, {"id": 621, "synset": "kite.n.03", "synonyms": ["kite"], "def": "plaything consisting of a light frame covered with tissue paper; flown in wind at end of a string", "name": "kite"}, {"id": 622, "synset": "kitten.n.01", "synonyms": ["kitten", "kitty"], "def": "young domestic cat", "name": "kitten"}, {"id": 623, "synset": "kiwi.n.03", "synonyms": ["kiwi_fruit"], "def": "fuzzy brown egg-shaped fruit with slightly tart green flesh", "name": "kiwi_fruit"}, {"id": 624, "synset": "knee_pad.n.01", "synonyms": ["knee_pad"], "def": "protective garment consisting of a pad worn by football or baseball or hockey players", "name": "knee_pad"}, {"id": 625, "synset": "knife.n.01", "synonyms": ["knife"], "def": "tool with a blade and point used as a cutting instrument", "name": "knife"}, {"id": 626, "synset": "knight.n.02", "synonyms": ["knight_(chess_piece)", "horse_(chess_piece)"], "def": "a chess game piece shaped to resemble the head of a horse", "name": "knight_(chess_piece)"}, {"id": 627, "synset": "knitting_needle.n.01", "synonyms": ["knitting_needle"], "def": "needle consisting of a slender rod with pointed ends; usually used in pairs", "name": "knitting_needle"}, {"id": 628, "synset": "knob.n.02", "synonyms": ["knob"], "def": "a round handle often found on a door", "name": "knob"}, {"id": 629, "synset": "knocker.n.05", "synonyms": ["knocker_(on_a_door)", "doorknocker"], "def": "a device (usually metal and ornamental) attached by a hinge to a door", "name": "knocker_(on_a_door)"}, {"id": 630, "synset": "koala.n.01", "synonyms": ["koala", "koala_bear"], "def": "sluggish tailless Australian marsupial with grey furry ears and coat", "name": "koala"}, {"id": 631, "synset": "lab_coat.n.01", "synonyms": ["lab_coat", "laboratory_coat"], "def": "a light coat worn to protect clothing from substances used while working in a laboratory", "name": "lab_coat"}, {"id": 632, "synset": "ladder.n.01", "synonyms": ["ladder"], "def": "steps consisting of two parallel members connected by rungs", "name": "ladder"}, {"id": 633, "synset": "ladle.n.01", "synonyms": ["ladle"], "def": "a spoon-shaped vessel with a long handle frequently used to transfer liquids", "name": "ladle"}, {"id": 634, "synset": "ladybug.n.01", "synonyms": ["ladybug", "ladybeetle", "ladybird_beetle"], "def": "small round bright-colored and spotted beetle, typically red and black", "name": "ladybug"}, {"id": 635, "synset": "lamb.n.01", "synonyms": ["lamb_(animal)"], "def": "young sheep", "name": "lamb_(animal)"}, {"id": 636, "synset": "lamb_chop.n.01", "synonyms": ["lamb-chop", "lambchop"], "def": "chop cut from a lamb", "name": "lamb-chop"}, {"id": 637, "synset": "lamp.n.02", "synonyms": ["lamp"], "def": "a piece of furniture holding one or more electric light bulbs", "name": "lamp"}, {"id": 638, "synset": "lamppost.n.01", "synonyms": ["lamppost"], "def": "a metal post supporting an outdoor lamp (such as a streetlight)", "name": "lamppost"}, {"id": 639, "synset": "lampshade.n.01", "synonyms": ["lampshade"], "def": "a protective ornamental shade used to screen a light bulb from direct view", "name": "lampshade"}, {"id": 640, "synset": "lantern.n.01", "synonyms": ["lantern"], "def": "light in a transparent protective case", "name": "lantern"}, {"id": 641, "synset": "lanyard.n.02", "synonyms": ["lanyard", "laniard"], "def": "a cord worn around the neck to hold a knife or whistle, etc.", "name": "lanyard"}, {"id": 642, "synset": "laptop.n.01", "synonyms": ["laptop_computer", "notebook_computer"], "def": "a portable computer small enough to use in your lap", "name": "laptop_computer"}, {"id": 643, "synset": "lasagna.n.01", "synonyms": ["lasagna", "lasagne"], "def": "baked dish of layers of lasagna pasta with sauce and cheese and meat or vegetables", "name": "lasagna"}, {"id": 644, "synset": "latch.n.02", "synonyms": ["latch"], "def": "a bar that can be lowered or slid into a groove to fasten a door or gate", "name": "latch"}, {"id": 645, "synset": "lawn_mower.n.01", "synonyms": ["lawn_mower"], "def": "garden tool for mowing grass on lawns", "name": "lawn_mower"}, {"id": 646, "synset": "leather.n.01", "synonyms": ["leather"], "def": "an animal skin made smooth and flexible by removing the hair and then tanning", "name": "leather"}, {"id": 647, "synset": "legging.n.01", "synonyms": ["legging_(clothing)", "leging_(clothing)", "leg_covering"], "def": "a garment covering the leg (usually extending from the knee to the ankle)", "name": "legging_(clothing)"}, {"id": 648, "synset": "lego.n.01", "synonyms": ["Lego", "Lego_set"], "def": "a child's plastic construction set for making models from blocks", "name": "Lego"}, {"id": 649, "synset": "lemon.n.01", "synonyms": ["lemon"], "def": "yellow oval fruit with juicy acidic flesh", "name": "lemon"}, {"id": 650, "synset": "lemonade.n.01", "synonyms": ["lemonade"], "def": "sweetened beverage of diluted lemon juice", "name": "lemonade"}, {"id": 651, "synset": "lettuce.n.02", "synonyms": ["lettuce"], "def": "leafy plant commonly eaten in salad or on sandwiches", "name": "lettuce"}, {"id": 652, "synset": "license_plate.n.01", "synonyms": ["license_plate", "numberplate"], "def": "a plate mounted on the front and back of car and bearing the car's registration number", "name": "license_plate"}, {"id": 653, "synset": "life_buoy.n.01", "synonyms": ["life_buoy", "lifesaver", "life_belt", "life_ring"], "def": "a ring-shaped life preserver used to prevent drowning (NOT a life-jacket or vest)", "name": "life_buoy"}, {"id": 654, "synset": "life_jacket.n.01", "synonyms": ["life_jacket", "life_vest"], "def": "life preserver consisting of a sleeveless jacket of buoyant or inflatable design", "name": "life_jacket"}, {"id": 655, "synset": "light_bulb.n.01", "synonyms": ["lightbulb"], "def": "glass bulb or tube shaped electric device that emits light (DO NOT MARK LAMPS AS A WHOLE)", "name": "lightbulb"}, {"id": 656, "synset": "lightning_rod.n.02", "synonyms": ["lightning_rod", "lightning_conductor"], "def": "a metallic conductor that is attached to a high point and leads to the ground", "name": "lightning_rod"}, {"id": 657, "synset": "lime.n.06", "synonyms": ["lime"], "def": "the green acidic fruit of any of various lime trees", "name": "lime"}, {"id": 658, "synset": "limousine.n.01", "synonyms": ["limousine"], "def": "long luxurious car; usually driven by a chauffeur", "name": "limousine"}, {"id": 659, "synset": "linen.n.02", "synonyms": ["linen_paper"], "def": "a high-quality paper made of linen fibers or with a linen finish", "name": "linen_paper"}, {"id": 660, "synset": "lion.n.01", "synonyms": ["lion"], "def": "large gregarious predatory cat of Africa and India", "name": "lion"}, {"id": 661, "synset": "lip_balm.n.01", "synonyms": ["lip_balm"], "def": "a balm applied to the lips", "name": "lip_balm"}, {"id": 662, "synset": "lipstick.n.01", "synonyms": ["lipstick", "lip_rouge"], "def": "makeup that is used to color the lips", "name": "lipstick"}, {"id": 663, "synset": "liquor.n.01", "synonyms": ["liquor", "spirits", "hard_liquor", "liqueur", "cordial"], "def": "an alcoholic beverage that is distilled rather than fermented", "name": "liquor"}, {"id": 664, "synset": "lizard.n.01", "synonyms": ["lizard"], "def": "a reptile with usually two pairs of legs and a tapering tail", "name": "lizard"}, {"id": 665, "synset": "loafer.n.02", "synonyms": ["Loafer_(type_of_shoe)"], "def": "a low leather step-in shoe", "name": "Loafer_(type_of_shoe)"}, {"id": 666, "synset": "log.n.01", "synonyms": ["log"], "def": "a segment of the trunk of a tree when stripped of branches", "name": "log"}, {"id": 667, "synset": "lollipop.n.02", "synonyms": ["lollipop"], "def": "hard candy on a stick", "name": "lollipop"}, {"id": 668, "synset": "lotion.n.01", "synonyms": ["lotion"], "def": "any of various cosmetic preparations that are applied to the skin", "name": "lotion"}, {"id": 669, "synset": "loudspeaker.n.01", "synonyms": ["speaker_(stero_equipment)"], "def": "electronic device that produces sound often as part of a stereo system", "name": "speaker_(stero_equipment)"}, {"id": 670, "synset": "love_seat.n.01", "synonyms": ["loveseat"], "def": "small sofa that seats two people", "name": "loveseat"}, {"id": 671, "synset": "machine_gun.n.01", "synonyms": ["machine_gun"], "def": "a rapidly firing automatic gun", "name": "machine_gun"}, {"id": 672, "synset": "magazine.n.02", "synonyms": ["magazine"], "def": "a paperback periodic publication", "name": "magazine"}, {"id": 673, "synset": "magnet.n.01", "synonyms": ["magnet"], "def": "a device that attracts iron and produces a magnetic field", "name": "magnet"}, {"id": 674, "synset": "mail_slot.n.01", "synonyms": ["mail_slot"], "def": "a slot (usually in a door) through which mail can be delivered", "name": "mail_slot"}, {"id": 675, "synset": "mailbox.n.01", "synonyms": ["mailbox_(at_home)", "letter_box_(at_home)"], "def": "a private box for delivery of mail", "name": "mailbox_(at_home)"}, {"id": 676, "synset": "mallet.n.01", "synonyms": ["mallet"], "def": "a sports implement with a long handle and a hammer-like head used to hit a ball", "name": "mallet"}, {"id": 677, "synset": "mammoth.n.01", "synonyms": ["mammoth"], "def": "any of numerous extinct elephants widely distributed in the Pleistocene", "name": "mammoth"}, {"id": 678, "synset": "mandarin.n.05", "synonyms": ["mandarin_orange"], "def": "a somewhat flat reddish-orange loose skinned citrus of China", "name": "mandarin_orange"}, {"id": 679, "synset": "manger.n.01", "synonyms": ["manger", "trough"], "def": "a container (usually in a barn or stable) from which cattle or horses feed", "name": "manger"}, {"id": 680, "synset": "manhole.n.01", "synonyms": ["manhole"], "def": "a hole (usually with a flush cover) through which a person can gain access to an underground structure", "name": "manhole"}, {"id": 681, "synset": "map.n.01", "synonyms": ["map"], "def": "a diagrammatic representation of the earth's surface (or part of it)", "name": "map"}, {"id": 682, "synset": "marker.n.03", "synonyms": ["marker"], "def": "a writing implement for making a mark", "name": "marker"}, {"id": 683, "synset": "martini.n.01", "synonyms": ["martini"], "def": "a cocktail made of gin (or vodka) with dry vermouth", "name": "martini"}, {"id": 684, "synset": "mascot.n.01", "synonyms": ["mascot"], "def": "a person or animal that is adopted by a team or other group as a symbolic figure", "name": "mascot"}, {"id": 685, "synset": "mashed_potato.n.01", "synonyms": ["mashed_potato"], "def": "potato that has been peeled and boiled and then mashed", "name": "mashed_potato"}, {"id": 686, "synset": "masher.n.02", "synonyms": ["masher"], "def": "a kitchen utensil used for mashing (e.g. potatoes)", "name": "masher"}, {"id": 687, "synset": "mask.n.04", "synonyms": ["mask", "facemask"], "def": "a protective covering worn over the face", "name": "mask"}, {"id": 688, "synset": "mast.n.01", "synonyms": ["mast"], "def": "a vertical spar for supporting sails", "name": "mast"}, {"id": 689, "synset": "mat.n.03", "synonyms": ["mat_(gym_equipment)", "gym_mat"], "def": "sports equipment consisting of a piece of thick padding on the floor for gymnastics", "name": "mat_(gym_equipment)"}, {"id": 690, "synset": "matchbox.n.01", "synonyms": ["matchbox"], "def": "a box for holding matches", "name": "matchbox"}, {"id": 691, "synset": "mattress.n.01", "synonyms": ["mattress"], "def": "a thick pad filled with resilient material used as a bed or part of a bed", "name": "mattress"}, {"id": 692, "synset": "measuring_cup.n.01", "synonyms": ["measuring_cup"], "def": "graduated cup used to measure liquid or granular ingredients", "name": "measuring_cup"}, {"id": 693, "synset": "measuring_stick.n.01", "synonyms": ["measuring_stick", "ruler_(measuring_stick)", "measuring_rod"], "def": "measuring instrument having a sequence of marks at regular intervals", "name": "measuring_stick"}, {"id": 694, "synset": "meatball.n.01", "synonyms": ["meatball"], "def": "ground meat formed into a ball and fried or simmered in broth", "name": "meatball"}, {"id": 695, "synset": "medicine.n.02", "synonyms": ["medicine"], "def": "something that treats or prevents or alleviates the symptoms of disease", "name": "medicine"}, {"id": 696, "synset": "melon.n.01", "synonyms": ["melon"], "def": "fruit of the gourd family having a hard rind and sweet juicy flesh", "name": "melon"}, {"id": 697, "synset": "microphone.n.01", "synonyms": ["microphone"], "def": "device for converting sound waves into electrical energy", "name": "microphone"}, {"id": 698, "synset": "microscope.n.01", "synonyms": ["microscope"], "def": "magnifier of the image of small objects", "name": "microscope"}, {"id": 699, "synset": "microwave.n.02", "synonyms": ["microwave_oven"], "def": "kitchen appliance that cooks food by passing an electromagnetic wave through it", "name": "microwave_oven"}, {"id": 700, "synset": "milestone.n.01", "synonyms": ["milestone", "milepost"], "def": "stone post at side of a road to show distances", "name": "milestone"}, {"id": 701, "synset": "milk.n.01", "synonyms": ["milk"], "def": "a white nutritious liquid secreted by mammals and used as food by human beings", "name": "milk"}, {"id": 702, "synset": "minivan.n.01", "synonyms": ["minivan"], "def": "a small box-shaped passenger van", "name": "minivan"}, {"id": 703, "synset": "mint.n.05", "synonyms": ["mint_candy"], "def": "a candy that is flavored with a mint oil", "name": "mint_candy"}, {"id": 704, "synset": "mirror.n.01", "synonyms": ["mirror"], "def": "polished surface that forms images by reflecting light", "name": "mirror"}, {"id": 705, "synset": "mitten.n.01", "synonyms": ["mitten"], "def": "glove that encases the thumb separately and the other four fingers together", "name": "mitten"}, {"id": 706, "synset": "mixer.n.04", "synonyms": ["mixer_(kitchen_tool)", "stand_mixer"], "def": "a kitchen utensil that is used for mixing foods", "name": "mixer_(kitchen_tool)"}, {"id": 707, "synset": "money.n.03", "synonyms": ["money"], "def": "the official currency issued by a government or national bank", "name": "money"}, {"id": 708, "synset": "monitor.n.04", "synonyms": ["monitor_(computer_equipment) computer_monitor"], "def": "a computer monitor", "name": "monitor_(computer_equipment) computer_monitor"}, {"id": 709, "synset": "monkey.n.01", "synonyms": ["monkey"], "def": "any of various long-tailed primates", "name": "monkey"}, {"id": 710, "synset": "motor.n.01", "synonyms": ["motor"], "def": "machine that converts other forms of energy into mechanical energy and so imparts motion", "name": "motor"}, {"id": 711, "synset": "motor_scooter.n.01", "synonyms": ["motor_scooter", "scooter"], "def": "a wheeled vehicle with small wheels and a low-powered engine", "name": "motor_scooter"}, {"id": 712, "synset": "motor_vehicle.n.01", "synonyms": ["motor_vehicle", "automotive_vehicle"], "def": "a self-propelled wheeled vehicle that does not run on rails", "name": "motor_vehicle"}, {"id": 713, "synset": "motorboat.n.01", "synonyms": ["motorboat", "powerboat"], "def": "a boat propelled by an internal-combustion engine", "name": "motorboat"}, {"id": 714, "synset": "motorcycle.n.01", "synonyms": ["motorcycle"], "def": "a motor vehicle with two wheels and a strong frame", "name": "motorcycle"}, {"id": 715, "synset": "mound.n.01", "synonyms": ["mound_(baseball)", "pitcher's_mound"], "def": "(baseball) the slight elevation on which the pitcher stands", "name": "mound_(baseball)"}, {"id": 716, "synset": "mouse.n.01", "synonyms": ["mouse_(animal_rodent)"], "def": "a small rodent with pointed snouts and small ears on elongated bodies with slender usually hairless tails", "name": "mouse_(animal_rodent)"}, {"id": 717, "synset": "mouse.n.04", "synonyms": ["mouse_(computer_equipment)", "computer_mouse"], "def": "a computer input device that controls an on-screen pointer", "name": "mouse_(computer_equipment)"}, {"id": 718, "synset": "mousepad.n.01", "synonyms": ["mousepad"], "def": "a small portable pad that provides an operating surface for a computer mouse", "name": "mousepad"}, {"id": 719, "synset": "muffin.n.01", "synonyms": ["muffin"], "def": "a sweet quick bread baked in a cup-shaped pan", "name": "muffin"}, {"id": 720, "synset": "mug.n.04", "synonyms": ["mug"], "def": "with handle and usually cylindrical", "name": "mug"}, {"id": 721, "synset": "mushroom.n.02", "synonyms": ["mushroom"], "def": "a common mushroom", "name": "mushroom"}, {"id": 722, "synset": "music_stool.n.01", "synonyms": ["music_stool", "piano_stool"], "def": "a stool for piano players; usually adjustable in height", "name": "music_stool"}, {"id": 723, "synset": "musical_instrument.n.01", "synonyms": ["musical_instrument", "instrument_(musical)"], "def": "any of various devices or contrivances that can be used to produce musical tones or sounds", "name": "musical_instrument"}, {"id": 724, "synset": "nailfile.n.01", "synonyms": ["nailfile"], "def": "a small flat file for shaping the nails", "name": "nailfile"}, {"id": 725, "synset": "nameplate.n.01", "synonyms": ["nameplate"], "def": "a plate bearing a name", "name": "nameplate"}, {"id": 726, "synset": "napkin.n.01", "synonyms": ["napkin", "table_napkin", "serviette"], "def": "a small piece of table linen or paper that is used to wipe the mouth and to cover the lap in order to protect clothing", "name": "napkin"}, {"id": 727, "synset": "neckerchief.n.01", "synonyms": ["neckerchief"], "def": "a kerchief worn around the neck", "name": "neckerchief"}, {"id": 728, "synset": "necklace.n.01", "synonyms": ["necklace"], "def": "jewelry consisting of a cord or chain (often bearing gems) worn about the neck as an ornament", "name": "necklace"}, {"id": 729, "synset": "necktie.n.01", "synonyms": ["necktie", "tie_(necktie)"], "def": "neckwear consisting of a long narrow piece of material worn under a collar and tied in knot at the front", "name": "necktie"}, {"id": 730, "synset": "needle.n.03", "synonyms": ["needle"], "def": "a sharp pointed implement (usually metal)", "name": "needle"}, {"id": 731, "synset": "nest.n.01", "synonyms": ["nest"], "def": "a structure in which animals lay eggs or give birth to their young", "name": "nest"}, {"id": 732, "synset": "newsstand.n.01", "synonyms": ["newsstand"], "def": "a stall where newspapers and other periodicals are sold", "name": "newsstand"}, {"id": 733, "synset": "nightwear.n.01", "synonyms": ["nightshirt", "nightwear", "sleepwear", "nightclothes"], "def": "garments designed to be worn in bed", "name": "nightshirt"}, {"id": 734, "synset": "nosebag.n.01", "synonyms": ["nosebag_(for_animals)", "feedbag"], "def": "a canvas bag that is used to feed an animal (such as a horse); covers the muzzle and fastens at the top of the head", "name": "nosebag_(for_animals)"}, {"id": 735, "synset": "noseband.n.01", "synonyms": ["noseband_(for_animals)", "nosepiece_(for_animals)"], "def": "a strap that is the part of a bridle that goes over the animal's nose", "name": "noseband_(for_animals)"}, {"id": 736, "synset": "notebook.n.01", "synonyms": ["notebook"], "def": "a book with blank pages for recording notes or memoranda", "name": "notebook"}, {"id": 737, "synset": "notepad.n.01", "synonyms": ["notepad"], "def": "a pad of paper for keeping notes", "name": "notepad"}, {"id": 738, "synset": "nut.n.03", "synonyms": ["nut"], "def": "a small metal block (usually square or hexagonal) with internal screw thread to be fitted onto a bolt", "name": "nut"}, {"id": 739, "synset": "nutcracker.n.01", "synonyms": ["nutcracker"], "def": "a hand tool used to crack nuts open", "name": "nutcracker"}, {"id": 740, "synset": "oar.n.01", "synonyms": ["oar"], "def": "an implement used to propel or steer a boat", "name": "oar"}, {"id": 741, "synset": "octopus.n.01", "synonyms": ["octopus_(food)"], "def": "tentacles of octopus prepared as food", "name": "octopus_(food)"}, {"id": 742, "synset": "octopus.n.02", "synonyms": ["octopus_(animal)"], "def": "bottom-living cephalopod having a soft oval body with eight long tentacles", "name": "octopus_(animal)"}, {"id": 743, "synset": "oil_lamp.n.01", "synonyms": ["oil_lamp", "kerosene_lamp", "kerosine_lamp"], "def": "a lamp that burns oil (as kerosine) for light", "name": "oil_lamp"}, {"id": 744, "synset": "olive_oil.n.01", "synonyms": ["olive_oil"], "def": "oil from olives", "name": "olive_oil"}, {"id": 745, "synset": "omelet.n.01", "synonyms": ["omelet", "omelette"], "def": "beaten eggs cooked until just set; may be folded around e.g. ham or cheese or jelly", "name": "omelet"}, {"id": 746, "synset": "onion.n.01", "synonyms": ["onion"], "def": "the bulb of an onion plant", "name": "onion"}, {"id": 747, "synset": "orange.n.01", "synonyms": ["orange_(fruit)"], "def": "orange (FRUIT of an orange tree)", "name": "orange_(fruit)"}, {"id": 748, "synset": "orange_juice.n.01", "synonyms": ["orange_juice"], "def": "bottled or freshly squeezed juice of oranges", "name": "orange_juice"}, {"id": 749, "synset": "oregano.n.01", "synonyms": ["oregano", "marjoram"], "def": "aromatic Eurasian perennial herb used in cooking and baking", "name": "oregano"}, {"id": 750, "synset": "ostrich.n.02", "synonyms": ["ostrich"], "def": "fast-running African flightless bird with two-toed feet; largest living bird", "name": "ostrich"}, {"id": 751, "synset": "ottoman.n.03", "synonyms": ["ottoman", "pouf", "pouffe", "hassock"], "def": "thick cushion used as a seat", "name": "ottoman"}, {"id": 752, "synset": "overall.n.01", "synonyms": ["overalls_(clothing)"], "def": "work clothing consisting of denim trousers usually with a bib and shoulder straps", "name": "overalls_(clothing)"}, {"id": 753, "synset": "owl.n.01", "synonyms": ["owl"], "def": "nocturnal bird of prey with hawk-like beak and claws and large head with front-facing eyes", "name": "owl"}, {"id": 754, "synset": "packet.n.03", "synonyms": ["packet"], "def": "a small package or bundle", "name": "packet"}, {"id": 755, "synset": "pad.n.03", "synonyms": ["inkpad", "inking_pad", "stamp_pad"], "def": "absorbent material saturated with ink used to transfer ink evenly to a rubber stamp", "name": "inkpad"}, {"id": 756, "synset": "pad.n.04", "synonyms": ["pad"], "def": "a flat mass of soft material used for protection, stuffing, or comfort", "name": "pad"}, {"id": 757, "synset": "paddle.n.04", "synonyms": ["paddle", "boat_paddle"], "def": "a short light oar used without an oarlock to propel a canoe or small boat", "name": "paddle"}, {"id": 758, "synset": "padlock.n.01", "synonyms": ["padlock"], "def": "a detachable, portable lock", "name": "padlock"}, {"id": 759, "synset": "paintbox.n.01", "synonyms": ["paintbox"], "def": "a box containing a collection of cubes or tubes of artists' paint", "name": "paintbox"}, {"id": 760, "synset": "paintbrush.n.01", "synonyms": ["paintbrush"], "def": "a brush used as an applicator to apply paint", "name": "paintbrush"}, {"id": 761, "synset": "painting.n.01", "synonyms": ["painting"], "def": "graphic art consisting of an artistic composition made by applying paints to a surface", "name": "painting"}, {"id": 762, "synset": "pajama.n.02", "synonyms": ["pajamas", "pyjamas"], "def": "loose-fitting nightclothes worn for sleeping or lounging", "name": "pajamas"}, {"id": 763, "synset": "palette.n.02", "synonyms": ["palette", "pallet"], "def": "board that provides a flat surface on which artists mix paints and the range of colors used", "name": "palette"}, {"id": 764, "synset": "pan.n.01", "synonyms": ["pan_(for_cooking)", "cooking_pan"], "def": "cooking utensil consisting of a wide metal vessel", "name": "pan_(for_cooking)"}, {"id": 765, "synset": "pan.n.03", "synonyms": ["pan_(metal_container)"], "def": "shallow container made of metal", "name": "pan_(metal_container)"}, {"id": 766, "synset": "pancake.n.01", "synonyms": ["pancake"], "def": "a flat cake of thin batter fried on both sides on a griddle", "name": "pancake"}, {"id": 767, "synset": "pantyhose.n.01", "synonyms": ["pantyhose"], "def": "a woman's tights consisting of underpants and stockings", "name": "pantyhose"}, {"id": 768, "synset": "papaya.n.02", "synonyms": ["papaya"], "def": "large oval melon-like tropical fruit with yellowish flesh", "name": "papaya"}, {"id": 769, "synset": "paper_clip.n.01", "synonyms": ["paperclip"], "def": "a wire or plastic clip for holding sheets of paper together", "name": "paperclip"}, {"id": 770, "synset": "paper_plate.n.01", "synonyms": ["paper_plate"], "def": "a disposable plate made of cardboard", "name": "paper_plate"}, {"id": 771, "synset": "paper_towel.n.01", "synonyms": ["paper_towel"], "def": "a disposable towel made of absorbent paper", "name": "paper_towel"}, {"id": 772, "synset": "paperback_book.n.01", "synonyms": ["paperback_book", "paper-back_book", "softback_book", "soft-cover_book"], "def": "a book with paper covers", "name": "paperback_book"}, {"id": 773, "synset": "paperweight.n.01", "synonyms": ["paperweight"], "def": "a weight used to hold down a stack of papers", "name": "paperweight"}, {"id": 774, "synset": "parachute.n.01", "synonyms": ["parachute"], "def": "rescue equipment consisting of a device that fills with air and retards your fall", "name": "parachute"}, {"id": 775, "synset": "parakeet.n.01", "synonyms": ["parakeet", "parrakeet", "parroket", "paraquet", "paroquet", "parroquet"], "def": "any of numerous small slender long-tailed parrots", "name": "parakeet"}, {"id": 776, "synset": "parasail.n.01", "synonyms": ["parasail_(sports)"], "def": "parachute that will lift a person up into the air when it is towed by a motorboat or a car", "name": "parasail_(sports)"}, {"id": 777, "synset": "parchment.n.01", "synonyms": ["parchment"], "def": "a superior paper resembling sheepskin", "name": "parchment"}, {"id": 778, "synset": "parka.n.01", "synonyms": ["parka", "anorak"], "def": "a kind of heavy jacket (`windcheater' is a British term)", "name": "parka"}, {"id": 779, "synset": "parking_meter.n.01", "synonyms": ["parking_meter"], "def": "a coin-operated timer located next to a parking space", "name": "parking_meter"}, {"id": 780, "synset": "parrot.n.01", "synonyms": ["parrot"], "def": "usually brightly colored tropical birds with short hooked beaks and the ability to mimic sounds", "name": "parrot"}, {"id": 781, "synset": "passenger_car.n.01", "synonyms": ["passenger_car_(part_of_a_train)", "coach_(part_of_a_train)"], "def": "a railcar where passengers ride", "name": "passenger_car_(part_of_a_train)"}, {"id": 782, "synset": "passenger_ship.n.01", "synonyms": ["passenger_ship"], "def": "a ship built to carry passengers", "name": "passenger_ship"}, {"id": 783, "synset": "passport.n.02", "synonyms": ["passport"], "def": "a document issued by a country to a citizen allowing that person to travel abroad and re-enter the home country", "name": "passport"}, {"id": 784, "synset": "pastry.n.02", "synonyms": ["pastry"], "def": "any of various baked foods made of dough or batter", "name": "pastry"}, {"id": 785, "synset": "patty.n.01", "synonyms": ["patty_(food)"], "def": "small flat mass of chopped food", "name": "patty_(food)"}, {"id": 786, "synset": "pea.n.01", "synonyms": ["pea_(food)"], "def": "seed of a pea plant used for food", "name": "pea_(food)"}, {"id": 787, "synset": "peach.n.03", "synonyms": ["peach"], "def": "downy juicy fruit with sweet yellowish or whitish flesh", "name": "peach"}, {"id": 788, "synset": "peanut_butter.n.01", "synonyms": ["peanut_butter"], "def": "a spread made from ground peanuts", "name": "peanut_butter"}, {"id": 789, "synset": "pear.n.01", "synonyms": ["pear"], "def": "sweet juicy gritty-textured fruit available in many varieties", "name": "pear"}, {"id": 790, "synset": "peeler.n.03", "synonyms": ["peeler_(tool_for_fruit_and_vegetables)"], "def": "a device for peeling vegetables or fruits", "name": "peeler_(tool_for_fruit_and_vegetables)"}, {"id": 791, "synset": "pegboard.n.01", "synonyms": ["pegboard"], "def": "a board perforated with regularly spaced holes into which pegs can be fitted", "name": "pegboard"}, {"id": 792, "synset": "pelican.n.01", "synonyms": ["pelican"], "def": "large long-winged warm-water seabird having a large bill with a distensible pouch for fish", "name": "pelican"}, {"id": 793, "synset": "pen.n.01", "synonyms": ["pen"], "def": "a writing implement with a point from which ink flows", "name": "pen"}, {"id": 794, "synset": "pencil.n.01", "synonyms": ["pencil"], "def": "a thin cylindrical pointed writing implement made of wood and graphite", "name": "pencil"}, {"id": 795, "synset": "pencil_box.n.01", "synonyms": ["pencil_box", "pencil_case"], "def": "a box for holding pencils", "name": "pencil_box"}, {"id": 796, "synset": "pencil_sharpener.n.01", "synonyms": ["pencil_sharpener"], "def": "a rotary implement for sharpening the point on pencils", "name": "pencil_sharpener"}, {"id": 797, "synset": "pendulum.n.01", "synonyms": ["pendulum"], "def": "an apparatus consisting of an object mounted so that it swings freely under the influence of gravity", "name": "pendulum"}, {"id": 798, "synset": "penguin.n.01", "synonyms": ["penguin"], "def": "short-legged flightless birds of cold southern regions having webbed feet and wings modified as flippers", "name": "penguin"}, {"id": 799, "synset": "pennant.n.02", "synonyms": ["pennant"], "def": "a flag longer than it is wide (and often tapering)", "name": "pennant"}, {"id": 800, "synset": "penny.n.02", "synonyms": ["penny_(coin)"], "def": "a coin worth one-hundredth of the value of the basic unit", "name": "penny_(coin)"}, {"id": 801, "synset": "pepper.n.03", "synonyms": ["pepper", "peppercorn"], "def": "pungent seasoning from the berry of the common pepper plant; whole or ground", "name": "pepper"}, {"id": 802, "synset": "pepper_mill.n.01", "synonyms": ["pepper_mill", "pepper_grinder"], "def": "a mill for grinding pepper", "name": "pepper_mill"}, {"id": 803, "synset": "perfume.n.02", "synonyms": ["perfume"], "def": "a toiletry that emits and diffuses a fragrant odor", "name": "perfume"}, {"id": 804, "synset": "persimmon.n.02", "synonyms": ["persimmon"], "def": "orange fruit resembling a plum; edible when fully ripe", "name": "persimmon"}, {"id": 805, "synset": "person.n.01", "synonyms": ["baby", "child", "boy", "girl", "man", "woman", "person", "human"], "def": "a human being", "name": "baby"}, {"id": 806, "synset": "pet.n.01", "synonyms": ["pet"], "def": "a domesticated animal kept for companionship or amusement", "name": "pet"}, {"id": 807, "synset": "petfood.n.01", "synonyms": ["petfood", "pet-food"], "def": "food prepared for animal pets", "name": "petfood"}, {"id": 808, "synset": "pew.n.01", "synonyms": ["pew_(church_bench)", "church_bench"], "def": "long bench with backs; used in church by the congregation", "name": "pew_(church_bench)"}, {"id": 809, "synset": "phonebook.n.01", "synonyms": ["phonebook", "telephone_book", "telephone_directory"], "def": "a directory containing an alphabetical list of telephone subscribers and their telephone numbers", "name": "phonebook"}, {"id": 810, "synset": "phonograph_record.n.01", "synonyms": ["phonograph_record", "phonograph_recording", "record_(phonograph_recording)"], "def": "sound recording consisting of a typically black disk with a continuous groove", "name": "phonograph_record"}, {"id": 811, "synset": "piano.n.01", "synonyms": ["piano"], "def": "a keyboard instrument that is played by depressing keys that cause hammers to strike tuned strings and produce sounds", "name": "piano"}, {"id": 812, "synset": "pickle.n.01", "synonyms": ["pickle"], "def": "vegetables (especially cucumbers) preserved in brine or vinegar", "name": "pickle"}, {"id": 813, "synset": "pickup.n.01", "synonyms": ["pickup_truck"], "def": "a light truck with an open body and low sides and a tailboard", "name": "pickup_truck"}, {"id": 814, "synset": "pie.n.01", "synonyms": ["pie"], "def": "dish baked in pastry-lined pan often with a pastry top", "name": "pie"}, {"id": 815, "synset": "pigeon.n.01", "synonyms": ["pigeon"], "def": "wild and domesticated birds having a heavy body and short legs", "name": "pigeon"}, {"id": 816, "synset": "piggy_bank.n.01", "synonyms": ["piggy_bank", "penny_bank"], "def": "a child's coin bank (often shaped like a pig)", "name": "piggy_bank"}, {"id": 817, "synset": "pillow.n.01", "synonyms": ["pillow"], "def": "a cushion to support the head of a sleeping person", "name": "pillow"}, {"id": 818, "synset": "pin.n.09", "synonyms": ["pin_(non_jewelry)"], "def": "a small slender (often pointed) piece of wood or metal used to support or fasten or attach things", "name": "pin_(non_jewelry)"}, {"id": 819, "synset": "pineapple.n.02", "synonyms": ["pineapple"], "def": "large sweet fleshy tropical fruit with a tuft of stiff leaves", "name": "pineapple"}, {"id": 820, "synset": "pinecone.n.01", "synonyms": ["pinecone"], "def": "the seed-producing cone of a pine tree", "name": "pinecone"}, {"id": 821, "synset": "ping-pong_ball.n.01", "synonyms": ["ping-pong_ball"], "def": "light hollow ball used in playing table tennis", "name": "ping-pong_ball"}, {"id": 822, "synset": "pinwheel.n.03", "synonyms": ["pinwheel"], "def": "a toy consisting of vanes of colored paper or plastic that is pinned to a stick and spins when it is pointed into the wind", "name": "pinwheel"}, {"id": 823, "synset": "pipe.n.01", "synonyms": ["tobacco_pipe"], "def": "a tube with a small bowl at one end; used for smoking tobacco", "name": "tobacco_pipe"}, {"id": 824, "synset": "pipe.n.02", "synonyms": ["pipe", "piping"], "def": "a long tube made of metal or plastic that is used to carry water or oil or gas etc.", "name": "pipe"}, {"id": 825, "synset": "pistol.n.01", "synonyms": ["pistol", "handgun"], "def": "a firearm that is held and fired with one hand", "name": "pistol"}, {"id": 826, "synset": "pita.n.01", "synonyms": ["pita_(bread)", "pocket_bread"], "def": "usually small round bread that can open into a pocket for filling", "name": "pita_(bread)"}, {"id": 827, "synset": "pitcher.n.02", "synonyms": ["pitcher_(vessel_for_liquid)", "ewer"], "def": "an open vessel with a handle and a spout for pouring", "name": "pitcher_(vessel_for_liquid)"}, {"id": 828, "synset": "pitchfork.n.01", "synonyms": ["pitchfork"], "def": "a long-handled hand tool with sharp widely spaced prongs for lifting and pitching hay", "name": "pitchfork"}, {"id": 829, "synset": "pizza.n.01", "synonyms": ["pizza"], "def": "Italian open pie made of thin bread dough spread with a spiced mixture of e.g. tomato sauce and cheese", "name": "pizza"}, {"id": 830, "synset": "place_mat.n.01", "synonyms": ["place_mat"], "def": "a mat placed on a table for an individual place setting", "name": "place_mat"}, {"id": 831, "synset": "plate.n.04", "synonyms": ["plate"], "def": "dish on which food is served or from which food is eaten", "name": "plate"}, {"id": 832, "synset": "platter.n.01", "synonyms": ["platter"], "def": "a large shallow dish used for serving food", "name": "platter"}, {"id": 833, "synset": "playing_card.n.01", "synonyms": ["playing_card"], "def": "one of a pack of cards that are used to play card games", "name": "playing_card"}, {"id": 834, "synset": "playpen.n.01", "synonyms": ["playpen"], "def": "a portable enclosure in which babies may be left to play", "name": "playpen"}, {"id": 835, "synset": "pliers.n.01", "synonyms": ["pliers", "plyers"], "def": "a gripping hand tool with two hinged arms and (usually) serrated jaws", "name": "pliers"}, {"id": 836, "synset": "plow.n.01", "synonyms": ["plow_(farm_equipment)", "plough_(farm_equipment)"], "def": "a farm tool having one or more heavy blades to break the soil and cut a furrow prior to sowing", "name": "plow_(farm_equipment)"}, {"id": 837, "synset": "pocket_watch.n.01", "synonyms": ["pocket_watch"], "def": "a watch that is carried in a small watch pocket", "name": "pocket_watch"}, {"id": 838, "synset": "pocketknife.n.01", "synonyms": ["pocketknife"], "def": "a knife with a blade that folds into the handle; suitable for carrying in the pocket", "name": "pocketknife"}, {"id": 839, "synset": "poker.n.01", "synonyms": ["poker_(fire_stirring_tool)", "stove_poker", "fire_hook"], "def": "fire iron consisting of a metal rod with a handle; used to stir a fire", "name": "poker_(fire_stirring_tool)"}, {"id": 840, "synset": "pole.n.01", "synonyms": ["pole", "post"], "def": "a long (usually round) rod of wood or metal or plastic", "name": "pole"}, {"id": 841, "synset": "police_van.n.01", "synonyms": ["police_van", "police_wagon", "paddy_wagon", "patrol_wagon"], "def": "van used by police to transport prisoners", "name": "police_van"}, {"id": 842, "synset": "polo_shirt.n.01", "synonyms": ["polo_shirt", "sport_shirt"], "def": "a shirt with short sleeves designed for comfort and casual wear", "name": "polo_shirt"}, {"id": 843, "synset": "poncho.n.01", "synonyms": ["poncho"], "def": "a blanket-like cloak with a hole in the center for the head", "name": "poncho"}, {"id": 844, "synset": "pony.n.05", "synonyms": ["pony"], "def": "any of various breeds of small gentle horses usually less than five feet high at the shoulder", "name": "pony"}, {"id": 845, "synset": "pool_table.n.01", "synonyms": ["pool_table", "billiard_table", "snooker_table"], "def": "game equipment consisting of a heavy table on which pool is played", "name": "pool_table"}, {"id": 846, "synset": "pop.n.02", "synonyms": ["pop_(soda)", "soda_(pop)", "tonic", "soft_drink"], "def": "a sweet drink containing carbonated water and flavoring", "name": "pop_(soda)"}, {"id": 847, "synset": "portrait.n.02", "synonyms": ["portrait", "portrayal"], "def": "any likeness of a person, in any medium", "name": "portrait"}, {"id": 848, "synset": "postbox.n.01", "synonyms": ["postbox_(public)", "mailbox_(public)"], "def": "public box for deposit of mail", "name": "postbox_(public)"}, {"id": 849, "synset": "postcard.n.01", "synonyms": ["postcard", "postal_card", "mailing-card"], "def": "a card for sending messages by post without an envelope", "name": "postcard"}, {"id": 850, "synset": "poster.n.01", "synonyms": ["poster", "placard"], "def": "a sign posted in a public place as an advertisement", "name": "poster"}, {"id": 851, "synset": "pot.n.01", "synonyms": ["pot"], "def": "metal or earthenware cooking vessel that is usually round and deep; often has a handle and lid", "name": "pot"}, {"id": 852, "synset": "pot.n.04", "synonyms": ["flowerpot"], "def": "a container in which plants are cultivated", "name": "flowerpot"}, {"id": 853, "synset": "potato.n.01", "synonyms": ["potato"], "def": "an edible tuber native to South America", "name": "potato"}, {"id": 854, "synset": "potholder.n.01", "synonyms": ["potholder"], "def": "an insulated pad for holding hot pots", "name": "potholder"}, {"id": 855, "synset": "pottery.n.01", "synonyms": ["pottery", "clayware"], "def": "ceramic ware made from clay and baked in a kiln", "name": "pottery"}, {"id": 856, "synset": "pouch.n.01", "synonyms": ["pouch"], "def": "a small or medium size container for holding or carrying things", "name": "pouch"}, {"id": 857, "synset": "power_shovel.n.01", "synonyms": ["power_shovel", "excavator", "digger"], "def": "a machine for excavating", "name": "power_shovel"}, {"id": 858, "synset": "prawn.n.01", "synonyms": ["prawn", "shrimp"], "def": "any of various edible decapod crustaceans", "name": "prawn"}, {"id": 859, "synset": "printer.n.03", "synonyms": ["printer", "printing_machine"], "def": "a machine that prints", "name": "printer"}, {"id": 860, "synset": "projectile.n.01", "synonyms": ["projectile_(weapon)", "missile"], "def": "a weapon that is forcibly thrown or projected at a targets", "name": "projectile_(weapon)"}, {"id": 861, "synset": "projector.n.02", "synonyms": ["projector"], "def": "an optical instrument that projects an enlarged image onto a screen", "name": "projector"}, {"id": 862, "synset": "propeller.n.01", "synonyms": ["propeller", "propellor"], "def": "a mechanical device that rotates to push against air or water", "name": "propeller"}, {"id": 863, "synset": "prune.n.01", "synonyms": ["prune"], "def": "dried plum", "name": "prune"}, {"id": 864, "synset": "pudding.n.01", "synonyms": ["pudding"], "def": "any of various soft thick unsweetened baked dishes", "name": "pudding"}, {"id": 865, "synset": "puffer.n.02", "synonyms": ["puffer_(fish)", "pufferfish", "blowfish", "globefish"], "def": "fishes whose elongated spiny body can inflate itself with water or air to form a globe", "name": "puffer_(fish)"}, {"id": 866, "synset": "puffin.n.01", "synonyms": ["puffin"], "def": "seabirds having short necks and brightly colored compressed bills", "name": "puffin"}, {"id": 867, "synset": "pug.n.01", "synonyms": ["pug-dog"], "def": "small compact smooth-coated breed of Asiatic origin having a tightly curled tail and broad flat wrinkled muzzle", "name": "pug-dog"}, {"id": 868, "synset": "pumpkin.n.02", "synonyms": ["pumpkin"], "def": "usually large pulpy deep-yellow round fruit of the squash family maturing in late summer or early autumn", "name": "pumpkin"}, {"id": 869, "synset": "punch.n.03", "synonyms": ["puncher"], "def": "a tool for making holes or indentations", "name": "puncher"}, {"id": 870, "synset": "puppet.n.01", "synonyms": ["puppet", "marionette"], "def": "a small figure of a person operated from above with strings by a puppeteer", "name": "puppet"}, {"id": 871, "synset": "puppy.n.01", "synonyms": ["puppy"], "def": "a young dog", "name": "puppy"}, {"id": 872, "synset": "quesadilla.n.01", "synonyms": ["quesadilla"], "def": "a tortilla that is filled with cheese and heated", "name": "quesadilla"}, {"id": 873, "synset": "quiche.n.02", "synonyms": ["quiche"], "def": "a tart filled with rich unsweetened custard; often contains other ingredients (as cheese or ham or seafood or vegetables)", "name": "quiche"}, {"id": 874, "synset": "quilt.n.01", "synonyms": ["quilt", "comforter"], "def": "bedding made of two layers of cloth filled with stuffing and stitched together", "name": "quilt"}, {"id": 875, "synset": "rabbit.n.01", "synonyms": ["rabbit"], "def": "any of various burrowing animals of the family Leporidae having long ears and short tails", "name": "rabbit"}, {"id": 876, "synset": "racer.n.02", "synonyms": ["race_car", "racing_car"], "def": "a fast car that competes in races", "name": "race_car"}, {"id": 877, "synset": "racket.n.04", "synonyms": ["racket", "racquet"], "def": "a sports implement used to strike a ball in various games", "name": "racket"}, {"id": 878, "synset": "radar.n.01", "synonyms": ["radar"], "def": "measuring instrument in which the echo of a pulse of microwave radiation is used to detect and locate distant objects", "name": "radar"}, {"id": 879, "synset": "radiator.n.03", "synonyms": ["radiator"], "def": "a mechanism consisting of a metal honeycomb through which hot fluids circulate", "name": "radiator"}, {"id": 880, "synset": "radio_receiver.n.01", "synonyms": ["radio_receiver", "radio_set", "radio", "tuner_(radio)"], "def": "an electronic receiver that detects and demodulates and amplifies transmitted radio signals", "name": "radio_receiver"}, {"id": 881, "synset": "radish.n.03", "synonyms": ["radish", "daikon"], "def": "pungent edible root of any of various cultivated radish plants", "name": "radish"}, {"id": 882, "synset": "raft.n.01", "synonyms": ["raft"], "def": "a flat float (usually made of logs or planks) that can be used for transport or as a platform for swimmers", "name": "raft"}, {"id": 883, "synset": "rag_doll.n.01", "synonyms": ["rag_doll"], "def": "a cloth doll that is stuffed and (usually) painted", "name": "rag_doll"}, {"id": 884, "synset": "raincoat.n.01", "synonyms": ["raincoat", "waterproof_jacket"], "def": "a water-resistant coat", "name": "raincoat"}, {"id": 885, "synset": "ram.n.05", "synonyms": ["ram_(animal)"], "def": "uncastrated adult male sheep", "name": "ram_(animal)"}, {"id": 886, "synset": "raspberry.n.02", "synonyms": ["raspberry"], "def": "red or black edible aggregate berries usually smaller than the related blackberries", "name": "raspberry"}, {"id": 887, "synset": "rat.n.01", "synonyms": ["rat"], "def": "any of various long-tailed rodents similar to but larger than a mouse", "name": "rat"}, {"id": 888, "synset": "razorblade.n.01", "synonyms": ["razorblade"], "def": "a blade that has very sharp edge", "name": "razorblade"}, {"id": 889, "synset": "reamer.n.01", "synonyms": ["reamer_(juicer)", "juicer", "juice_reamer"], "def": "a squeezer with a conical ridged center that is used for squeezing juice from citrus fruit", "name": "reamer_(juicer)"}, {"id": 890, "synset": "rearview_mirror.n.01", "synonyms": ["rearview_mirror"], "def": "car mirror that reflects the view out of the rear window", "name": "rearview_mirror"}, {"id": 891, "synset": "receipt.n.02", "synonyms": ["receipt"], "def": "an acknowledgment (usually tangible) that payment has been made", "name": "receipt"}, {"id": 892, "synset": "recliner.n.01", "synonyms": ["recliner", "reclining_chair", "lounger_(chair)"], "def": "an armchair whose back can be lowered and foot can be raised to allow the sitter to recline in it", "name": "recliner"}, {"id": 893, "synset": "record_player.n.01", "synonyms": ["record_player", "phonograph_(record_player)", "turntable"], "def": "machine in which rotating records cause a stylus to vibrate and the vibrations are amplified acoustically or electronically", "name": "record_player"}, {"id": 894, "synset": "red_cabbage.n.02", "synonyms": ["red_cabbage"], "def": "compact head of purplish-red leaves", "name": "red_cabbage"}, {"id": 895, "synset": "reflector.n.01", "synonyms": ["reflector"], "def": "device that reflects light, radiation, etc.", "name": "reflector"}, {"id": 896, "synset": "remote_control.n.01", "synonyms": ["remote_control"], "def": "a device that can be used to control a machine or apparatus from a distance", "name": "remote_control"}, {"id": 897, "synset": "rhinoceros.n.01", "synonyms": ["rhinoceros"], "def": "massive powerful herbivorous odd-toed ungulate of southeast Asia and Africa having very thick skin and one or two horns on the snout", "name": "rhinoceros"}, {"id": 898, "synset": "rib.n.03", "synonyms": ["rib_(food)"], "def": "cut of meat including one or more ribs", "name": "rib_(food)"}, {"id": 899, "synset": "rifle.n.01", "synonyms": ["rifle"], "def": "a shoulder firearm with a long barrel", "name": "rifle"}, {"id": 900, "synset": "ring.n.08", "synonyms": ["ring"], "def": "jewelry consisting of a circlet of precious metal (often set with jewels) worn on the finger", "name": "ring"}, {"id": 901, "synset": "river_boat.n.01", "synonyms": ["river_boat"], "def": "a boat used on rivers or to ply a river", "name": "river_boat"}, {"id": 902, "synset": "road_map.n.02", "synonyms": ["road_map"], "def": "(NOT A ROAD) a MAP showing roads (for automobile travel)", "name": "road_map"}, {"id": 903, "synset": "robe.n.01", "synonyms": ["robe"], "def": "any loose flowing garment", "name": "robe"}, {"id": 904, "synset": "rocking_chair.n.01", "synonyms": ["rocking_chair"], "def": "a chair mounted on rockers", "name": "rocking_chair"}, {"id": 905, "synset": "roller_skate.n.01", "synonyms": ["roller_skate"], "def": "a shoe with pairs of rollers (small hard wheels) fixed to the sole", "name": "roller_skate"}, {"id": 906, "synset": "rollerblade.n.01", "synonyms": ["Rollerblade"], "def": "an in-line variant of a roller skate", "name": "Rollerblade"}, {"id": 907, "synset": "rolling_pin.n.01", "synonyms": ["rolling_pin"], "def": "utensil consisting of a cylinder (usually of wood) with a handle at each end; used to roll out dough", "name": "rolling_pin"}, {"id": 908, "synset": "root_beer.n.01", "synonyms": ["root_beer"], "def": "carbonated drink containing extracts of roots and herbs", "name": "root_beer"}, {"id": 909, "synset": "router.n.02", "synonyms": ["router_(computer_equipment)"], "def": "a device that forwards data packets between computer networks", "name": "router_(computer_equipment)"}, {"id": 910, "synset": "rubber_band.n.01", "synonyms": ["rubber_band", "elastic_band"], "def": "a narrow band of elastic rubber used to hold things (such as papers) together", "name": "rubber_band"}, {"id": 911, "synset": "runner.n.08", "synonyms": ["runner_(carpet)"], "def": "a long narrow carpet", "name": "runner_(carpet)"}, {"id": 912, "synset": "sack.n.01", "synonyms": ["plastic_bag", "paper_bag"], "def": "a bag made of paper or plastic for holding customer's purchases", "name": "plastic_bag"}, {"id": 913, "synset": "saddle.n.01", "synonyms": ["saddle_(on_an_animal)"], "def": "a seat for the rider of a horse or camel", "name": "saddle_(on_an_animal)"}, {"id": 914, "synset": "saddle_blanket.n.01", "synonyms": ["saddle_blanket", "saddlecloth", "horse_blanket"], "def": "stable gear consisting of a blanket placed under the saddle", "name": "saddle_blanket"}, {"id": 915, "synset": "saddlebag.n.01", "synonyms": ["saddlebag"], "def": "a large bag (or pair of bags) hung over a saddle", "name": "saddlebag"}, {"id": 916, "synset": "safety_pin.n.01", "synonyms": ["safety_pin"], "def": "a pin in the form of a clasp; has a guard so the point of the pin will not stick the user", "name": "safety_pin"}, {"id": 917, "synset": "sail.n.01", "synonyms": ["sail"], "def": "a large piece of fabric by means of which wind is used to propel a sailing vessel", "name": "sail"}, {"id": 918, "synset": "salad.n.01", "synonyms": ["salad"], "def": "food mixtures either arranged on a plate or tossed and served with a moist dressing; usually consisting of or including greens", "name": "salad"}, {"id": 919, "synset": "salad_plate.n.01", "synonyms": ["salad_plate", "salad_bowl"], "def": "a plate or bowl for individual servings of salad", "name": "salad_plate"}, {"id": 920, "synset": "salami.n.01", "synonyms": ["salami"], "def": "highly seasoned fatty sausage of pork and beef usually dried", "name": "salami"}, {"id": 921, "synset": "salmon.n.01", "synonyms": ["salmon_(fish)"], "def": "any of various large food and game fishes of northern waters", "name": "salmon_(fish)"}, {"id": 922, "synset": "salmon.n.03", "synonyms": ["salmon_(food)"], "def": "flesh of any of various marine or freshwater fish of the family Salmonidae", "name": "salmon_(food)"}, {"id": 923, "synset": "salsa.n.01", "synonyms": ["salsa"], "def": "spicy sauce of tomatoes and onions and chili peppers to accompany Mexican foods", "name": "salsa"}, {"id": 924, "synset": "saltshaker.n.01", "synonyms": ["saltshaker"], "def": "a shaker with a perforated top for sprinkling salt", "name": "saltshaker"}, {"id": 925, "synset": "sandal.n.01", "synonyms": ["sandal_(type_of_shoe)"], "def": "a shoe consisting of a sole fastened by straps to the foot", "name": "sandal_(type_of_shoe)"}, {"id": 926, "synset": "sandwich.n.01", "synonyms": ["sandwich"], "def": "two (or more) slices of bread with a filling between them", "name": "sandwich"}, {"id": 927, "synset": "satchel.n.01", "synonyms": ["satchel"], "def": "luggage consisting of a small case with a flat bottom and (usually) a shoulder strap", "name": "satchel"}, {"id": 928, "synset": "saucepan.n.01", "synonyms": ["saucepan"], "def": "a deep pan with a handle; used for stewing or boiling", "name": "saucepan"}, {"id": 929, "synset": "saucer.n.02", "synonyms": ["saucer"], "def": "a small shallow dish for holding a cup at the table", "name": "saucer"}, {"id": 930, "synset": "sausage.n.01", "synonyms": ["sausage"], "def": "highly seasoned minced meat stuffed in casings", "name": "sausage"}, {"id": 931, "synset": "sawhorse.n.01", "synonyms": ["sawhorse", "sawbuck"], "def": "a framework for holding wood that is being sawed", "name": "sawhorse"}, {"id": 932, "synset": "sax.n.02", "synonyms": ["saxophone"], "def": "a wind instrument with a `J'-shaped form typically made of brass", "name": "saxophone"}, {"id": 933, "synset": "scale.n.07", "synonyms": ["scale_(measuring_instrument)"], "def": "a measuring instrument for weighing; shows amount of mass", "name": "scale_(measuring_instrument)"}, {"id": 934, "synset": "scarecrow.n.01", "synonyms": ["scarecrow", "strawman"], "def": "an effigy in the shape of a man to frighten birds away from seeds", "name": "scarecrow"}, {"id": 935, "synset": "scarf.n.01", "synonyms": ["scarf"], "def": "a garment worn around the head or neck or shoulders for warmth or decoration", "name": "scarf"}, {"id": 936, "synset": "school_bus.n.01", "synonyms": ["school_bus"], "def": "a bus used to transport children to or from school", "name": "school_bus"}, {"id": 937, "synset": "scissors.n.01", "synonyms": ["scissors"], "def": "a tool having two crossed pivoting blades with looped handles", "name": "scissors"}, {"id": 938, "synset": "scoreboard.n.01", "synonyms": ["scoreboard"], "def": "a large board for displaying the score of a contest (and some other information)", "name": "scoreboard"}, {"id": 939, "synset": "scrambled_eggs.n.01", "synonyms": ["scrambled_eggs"], "def": "eggs beaten and cooked to a soft firm consistency while stirring", "name": "scrambled_eggs"}, {"id": 940, "synset": "scraper.n.01", "synonyms": ["scraper"], "def": "any of various hand tools for scraping", "name": "scraper"}, {"id": 941, "synset": "scratcher.n.03", "synonyms": ["scratcher"], "def": "a device used for scratching", "name": "scratcher"}, {"id": 942, "synset": "screwdriver.n.01", "synonyms": ["screwdriver"], "def": "a hand tool for driving screws; has a tip that fits into the head of a screw", "name": "screwdriver"}, {"id": 943, "synset": "scrub_brush.n.01", "synonyms": ["scrubbing_brush"], "def": "a brush with short stiff bristles for heavy cleaning", "name": "scrubbing_brush", "merged": [{"frequency": "c", "id": 153, "synset": "bristle_brush.n.01", "image_count": 3, "instance_count": 3, "synonyms": ["bristle_brush"], "def": "a brush that is made with the short stiff hairs of an animal or plant", "name": "bristle_brush"}]}, {"id": 944, "synset": "sculpture.n.01", "synonyms": ["sculpture"], "def": "a three-dimensional work of art", "name": "sculpture"}, {"id": 945, "synset": "seabird.n.01", "synonyms": ["seabird", "seafowl"], "def": "a bird that frequents coastal waters and the open ocean: gulls; pelicans; gannets; cormorants; albatrosses; petrels; etc.", "name": "seabird"}, {"id": 946, "synset": "seahorse.n.02", "synonyms": ["seahorse"], "def": "small fish with horse-like heads bent sharply downward and curled tails", "name": "seahorse"}, {"id": 947, "synset": "seaplane.n.01", "synonyms": ["seaplane", "hydroplane"], "def": "an airplane that can land on or take off from water", "name": "seaplane"}, {"id": 948, "synset": "seashell.n.01", "synonyms": ["seashell"], "def": "the shell of a marine organism", "name": "seashell"}, {"id": 949, "synset": "seedling.n.01", "synonyms": ["seedling"], "def": "young plant or tree grown from a seed", "name": "seedling"}, {"id": 950, "synset": "serving_dish.n.01", "synonyms": ["serving_dish"], "def": "a dish used for serving food", "name": "serving_dish"}, {"id": 951, "synset": "sewing_machine.n.01", "synonyms": ["sewing_machine"], "def": "a textile machine used as a home appliance for sewing", "name": "sewing_machine"}, {"id": 952, "synset": "shaker.n.03", "synonyms": ["shaker"], "def": "a container in which something can be shaken", "name": "shaker"}, {"id": 953, "synset": "shampoo.n.01", "synonyms": ["shampoo"], "def": "cleansing agent consisting of soaps or detergents used for washing the hair", "name": "shampoo"}, {"id": 954, "synset": "shark.n.01", "synonyms": ["shark"], "def": "typically large carnivorous fishes with sharpe teeth", "name": "shark"}, {"id": 955, "synset": "sharpener.n.01", "synonyms": ["sharpener"], "def": "any implement that is used to make something (an edge or a point) sharper", "name": "sharpener"}, {"id": 956, "synset": "sharpie.n.03", "synonyms": ["Sharpie"], "def": "a pen with indelible ink that will write on any surface", "name": "Sharpie"}, {"id": 957, "synset": "shaver.n.03", "synonyms": ["shaver_(electric)", "electric_shaver", "electric_razor"], "def": "a razor powered by an electric motor", "name": "shaver_(electric)"}, {"id": 958, "synset": "shaving_cream.n.01", "synonyms": ["shaving_cream", "shaving_soap"], "def": "toiletry consisting that forms a rich lather for softening the beard before shaving", "name": "shaving_cream"}, {"id": 959, "synset": "shawl.n.01", "synonyms": ["shawl"], "def": "cloak consisting of an oblong piece of cloth used to cover the head and shoulders", "name": "shawl"}, {"id": 960, "synset": "shears.n.01", "synonyms": ["shears"], "def": "large scissors with strong blades", "name": "shears"}, {"id": 961, "synset": "sheep.n.01", "synonyms": ["sheep"], "def": "woolly usually horned ruminant mammal related to the goat", "name": "sheep"}, {"id": 962, "synset": "shepherd_dog.n.01", "synonyms": ["shepherd_dog", "sheepdog"], "def": "any of various usually long-haired breeds of dog reared to herd and guard sheep", "name": "shepherd_dog"}, {"id": 963, "synset": "sherbert.n.01", "synonyms": ["sherbert", "sherbet"], "def": "a frozen dessert made primarily of fruit juice and sugar", "name": "sherbert"}, {"id": 964, "synset": "shield.n.02", "synonyms": ["shield"], "def": "armor carried on the arm to intercept blows", "name": "shield"}, {"id": 965, "synset": "shirt.n.01", "synonyms": ["shirt"], "def": "a garment worn on the upper half of the body", "name": "shirt"}, {"id": 966, "synset": "shoe.n.01", "synonyms": ["shoe", "sneaker_(type_of_shoe)", "tennis_shoe"], "def": "common footwear covering the foot", "name": "shoe"}, {"id": 967, "synset": "shopping_bag.n.01", "synonyms": ["shopping_bag"], "def": "a bag made of plastic or strong paper (often with handles); used to transport goods after shopping", "name": "shopping_bag"}, {"id": 968, "synset": "shopping_cart.n.01", "synonyms": ["shopping_cart"], "def": "a handcart that holds groceries or other goods while shopping", "name": "shopping_cart"}, {"id": 969, "synset": "short_pants.n.01", "synonyms": ["short_pants", "shorts_(clothing)", "trunks_(clothing)"], "def": "trousers that end at or above the knee", "name": "short_pants"}, {"id": 970, "synset": "shot_glass.n.01", "synonyms": ["shot_glass"], "def": "a small glass adequate to hold a single swallow of whiskey", "name": "shot_glass"}, {"id": 971, "synset": "shoulder_bag.n.01", "synonyms": ["shoulder_bag"], "def": "a large handbag that can be carried by a strap looped over the shoulder", "name": "shoulder_bag"}, {"id": 972, "synset": "shovel.n.01", "synonyms": ["shovel"], "def": "a hand tool for lifting loose material such as snow, dirt, etc.", "name": "shovel"}, {"id": 973, "synset": "shower.n.01", "synonyms": ["shower_head"], "def": "a plumbing fixture that sprays water over you", "name": "shower_head"}, {"id": 974, "synset": "shower_curtain.n.01", "synonyms": ["shower_curtain"], "def": "a curtain that keeps water from splashing out of the shower area", "name": "shower_curtain"}, {"id": 975, "synset": "shredder.n.01", "synonyms": ["shredder_(for_paper)"], "def": "a device that shreds documents", "name": "shredder_(for_paper)"}, {"id": 976, "synset": "sieve.n.01", "synonyms": ["sieve", "screen_(sieve)"], "def": "a strainer for separating lumps from powdered material or grading particles", "name": "sieve"}, {"id": 977, "synset": "signboard.n.01", "synonyms": ["signboard"], "def": "structure displaying a board on which advertisements can be posted", "name": "signboard"}, {"id": 978, "synset": "silo.n.01", "synonyms": ["silo"], "def": "a cylindrical tower used for storing goods", "name": "silo"}, {"id": 979, "synset": "sink.n.01", "synonyms": ["sink"], "def": "plumbing fixture consisting of a water basin fixed to a wall or floor and having a drainpipe", "name": "sink"}, {"id": 980, "synset": "skateboard.n.01", "synonyms": ["skateboard"], "def": "a board with wheels that is ridden in a standing or crouching position and propelled by foot", "name": "skateboard"}, {"id": 981, "synset": "skewer.n.01", "synonyms": ["skewer"], "def": "a long pin for holding meat in position while it is being roasted", "name": "skewer"}, {"id": 982, "synset": "ski.n.01", "synonyms": ["ski"], "def": "sports equipment for skiing on snow", "name": "ski"}, {"id": 983, "synset": "ski_boot.n.01", "synonyms": ["ski_boot"], "def": "a stiff boot that is fastened to a ski with a ski binding", "name": "ski_boot"}, {"id": 984, "synset": "ski_parka.n.01", "synonyms": ["ski_parka", "ski_jacket"], "def": "a parka to be worn while skiing", "name": "ski_parka"}, {"id": 985, "synset": "ski_pole.n.01", "synonyms": ["ski_pole"], "def": "a pole with metal points used as an aid in skiing", "name": "ski_pole"}, {"id": 986, "synset": "skirt.n.02", "synonyms": ["skirt"], "def": "a garment hanging from the waist; worn mainly by girls and women", "name": "skirt"}, {"id": 987, "synset": "sled.n.01", "synonyms": ["sled", "sledge", "sleigh"], "def": "a vehicle or flat object for transportation over snow by sliding or pulled by dogs, etc.", "name": "sled"}, {"id": 988, "synset": "sleeping_bag.n.01", "synonyms": ["sleeping_bag"], "def": "large padded bag designed to be slept in outdoors", "name": "sleeping_bag"}, {"id": 989, "synset": "sling.n.05", "synonyms": ["sling_(bandage)", "triangular_bandage"], "def": "bandage to support an injured forearm; slung over the shoulder or neck", "name": "sling_(bandage)"}, {"id": 990, "synset": "slipper.n.01", "synonyms": ["slipper_(footwear)", "carpet_slipper_(footwear)"], "def": "low footwear that can be slipped on and off easily; usually worn indoors", "name": "slipper_(footwear)"}, {"id": 991, "synset": "smoothie.n.02", "synonyms": ["smoothie"], "def": "a thick smooth drink consisting of fresh fruit pureed with ice cream or yoghurt or milk", "name": "smoothie"}, {"id": 992, "synset": "snake.n.01", "synonyms": ["snake", "serpent"], "def": "limbless scaly elongate reptile; some are venomous", "name": "snake"}, {"id": 993, "synset": "snowboard.n.01", "synonyms": ["snowboard"], "def": "a board that resembles a broad ski or a small surfboard; used in a standing position to slide down snow-covered slopes", "name": "snowboard"}, {"id": 994, "synset": "snowman.n.01", "synonyms": ["snowman"], "def": "a figure of a person made of packed snow", "name": "snowman"}, {"id": 995, "synset": "snowmobile.n.01", "synonyms": ["snowmobile"], "def": "tracked vehicle for travel on snow having skis in front", "name": "snowmobile"}, {"id": 996, "synset": "soap.n.01", "synonyms": ["soap"], "def": "a cleansing agent made from the salts of vegetable or animal fats", "name": "soap"}, {"id": 997, "synset": "soccer_ball.n.01", "synonyms": ["soccer_ball"], "def": "an inflated ball used in playing soccer (called `football' outside of the United States)", "name": "soccer_ball"}, {"id": 998, "synset": "sock.n.01", "synonyms": ["sock"], "def": "cloth covering for the foot; worn inside the shoe; reaches to between the ankle and the knee", "name": "sock"}, {"id": 999, "synset": "soda_fountain.n.02", "synonyms": ["soda_fountain"], "def": "an apparatus for dispensing soda water", "name": "soda_fountain"}, {"id": 1000, "synset": "soda_water.n.01", "synonyms": ["carbonated_water", "club_soda", "seltzer", "sparkling_water"], "def": "effervescent beverage artificially charged with carbon dioxide", "name": "carbonated_water"}, {"id": 1001, "synset": "sofa.n.01", "synonyms": ["sofa", "couch", "lounge"], "def": "an upholstered seat for more than one person", "name": "sofa"}, {"id": 1002, "synset": "softball.n.01", "synonyms": ["softball"], "def": "ball used in playing softball", "name": "softball"}, {"id": 1003, "synset": "solar_array.n.01", "synonyms": ["solar_array", "solar_battery", "solar_panel"], "def": "electrical device consisting of a large array of connected solar cells", "name": "solar_array"}, {"id": 1004, "synset": "sombrero.n.02", "synonyms": ["sombrero"], "def": "a straw hat with a tall crown and broad brim; worn in American southwest and in Mexico", "name": "sombrero"}, {"id": 1005, "synset": "soup.n.01", "synonyms": ["soup"], "def": "liquid food especially of meat or fish or vegetable stock often containing pieces of solid food", "name": "soup"}, {"id": 1006, "synset": "soup_bowl.n.01", "synonyms": ["soup_bowl"], "def": "a bowl for serving soup", "name": "soup_bowl"}, {"id": 1007, "synset": "soupspoon.n.01", "synonyms": ["soupspoon"], "def": "a spoon with a rounded bowl for eating soup", "name": "soupspoon"}, {"id": 1008, "synset": "sour_cream.n.01", "synonyms": ["sour_cream", "soured_cream"], "def": "soured light cream", "name": "sour_cream"}, {"id": 1009, "synset": "soya_milk.n.01", "synonyms": ["soya_milk", "soybean_milk", "soymilk"], "def": "a milk substitute containing soybean flour and water; used in some infant formulas and in making tofu", "name": "soya_milk"}, {"id": 1010, "synset": "space_shuttle.n.01", "synonyms": ["space_shuttle"], "def": "a reusable spacecraft with wings for a controlled descent through the Earth's atmosphere", "name": "space_shuttle"}, {"id": 1011, "synset": "sparkler.n.02", "synonyms": ["sparkler_(fireworks)"], "def": "a firework that burns slowly and throws out a shower of sparks", "name": "sparkler_(fireworks)"}, {"id": 1012, "synset": "spatula.n.02", "synonyms": ["spatula"], "def": "a hand tool with a thin flexible blade used to mix or spread soft substances", "name": "spatula"}, {"id": 1013, "synset": "spear.n.01", "synonyms": ["spear", "lance"], "def": "a long pointed rod used as a tool or weapon", "name": "spear"}, {"id": 1014, "synset": "spectacles.n.01", "synonyms": ["spectacles", "specs", "eyeglasses", "glasses"], "def": "optical instrument consisting of a frame that holds a pair of lenses for correcting defective vision", "name": "spectacles"}, {"id": 1015, "synset": "spice_rack.n.01", "synonyms": ["spice_rack"], "def": "a rack for displaying containers filled with spices", "name": "spice_rack"}, {"id": 1016, "synset": "spider.n.01", "synonyms": ["spider"], "def": "predatory arachnid with eight legs, two poison fangs, two feelers, and usually two silk-spinning organs at the back end of the body", "name": "spider"}, {"id": 1017, "synset": "sponge.n.01", "synonyms": ["sponge"], "def": "a porous mass usable to absorb water typically used for cleaning", "name": "sponge"}, {"id": 1018, "synset": "spoon.n.01", "synonyms": ["spoon"], "def": "a piece of cutlery with a shallow bowl-shaped container and a handle", "name": "spoon"}, {"id": 1019, "synset": "sportswear.n.01", "synonyms": ["sportswear", "athletic_wear", "activewear"], "def": "attire worn for sport or for casual wear", "name": "sportswear"}, {"id": 1020, "synset": "spotlight.n.02", "synonyms": ["spotlight"], "def": "a lamp that produces a strong beam of light to illuminate a restricted area; used to focus attention of a stage performer", "name": "spotlight"}, {"id": 1021, "synset": "squirrel.n.01", "synonyms": ["squirrel"], "def": "a kind of arboreal rodent having a long bushy tail", "name": "squirrel"}, {"id": 1022, "synset": "stapler.n.01", "synonyms": ["stapler_(stapling_machine)"], "def": "a machine that inserts staples into sheets of paper in order to fasten them together", "name": "stapler_(stapling_machine)"}, {"id": 1023, "synset": "starfish.n.01", "synonyms": ["starfish", "sea_star"], "def": "echinoderms characterized by five arms extending from a central disk", "name": "starfish"}, {"id": 1024, "synset": "statue.n.01", "synonyms": ["statue_(sculpture)"], "def": "a sculpture representing a human or animal", "name": "statue_(sculpture)"}, {"id": 1025, "synset": "steak.n.01", "synonyms": ["steak_(food)"], "def": "a slice of meat cut from the fleshy part of an animal or large fish", "name": "steak_(food)"}, {"id": 1026, "synset": "steak_knife.n.01", "synonyms": ["steak_knife"], "def": "a sharp table knife used in eating steak", "name": "steak_knife"}, {"id": 1027, "synset": "steamer.n.02", "synonyms": ["steamer_(kitchen_appliance)"], "def": "a cooking utensil that can be used to cook food by steaming it", "name": "steamer_(kitchen_appliance)"}, {"id": 1028, "synset": "steering_wheel.n.01", "synonyms": ["steering_wheel"], "def": "a handwheel that is used for steering", "name": "steering_wheel"}, {"id": 1029, "synset": "stencil.n.01", "synonyms": ["stencil"], "def": "a sheet of material (metal, plastic, etc.) that has been perforated with a pattern; ink or paint can pass through the perforations to create the printed pattern on the surface below", "name": "stencil"}, {"id": 1030, "synset": "step_ladder.n.01", "synonyms": ["stepladder"], "def": "a folding portable ladder hinged at the top", "name": "stepladder"}, {"id": 1031, "synset": "step_stool.n.01", "synonyms": ["step_stool"], "def": "a stool that has one or two steps that fold under the seat", "name": "step_stool"}, {"id": 1032, "synset": "stereo.n.01", "synonyms": ["stereo_(sound_system)"], "def": "electronic device for playing audio", "name": "stereo_(sound_system)"}, {"id": 1033, "synset": "stew.n.02", "synonyms": ["stew"], "def": "food prepared by stewing especially meat or fish with vegetables", "name": "stew"}, {"id": 1034, "synset": "stirrer.n.02", "synonyms": ["stirrer"], "def": "an implement used for stirring", "name": "stirrer"}, {"id": 1035, "synset": "stirrup.n.01", "synonyms": ["stirrup"], "def": "support consisting of metal loops into which rider's feet go", "name": "stirrup"}, {"id": 1036, "synset": "stocking.n.01", "synonyms": ["stockings_(leg_wear)"], "def": "close-fitting hosiery to cover the foot and leg; come in matched pairs", "name": "stockings_(leg_wear)"}, {"id": 1037, "synset": "stool.n.01", "synonyms": ["stool"], "def": "a simple seat without a back or arms", "name": "stool"}, {"id": 1038, "synset": "stop_sign.n.01", "synonyms": ["stop_sign"], "def": "a traffic sign to notify drivers that they must come to a complete stop", "name": "stop_sign"}, {"id": 1039, "synset": "stoplight.n.01", "synonyms": ["brake_light"], "def": "a red light on the rear of a motor vehicle that signals when the brakes are applied", "name": "brake_light"}, {"id": 1040, "synset": "stove.n.01", "synonyms": ["stove", "kitchen_stove", "range_(kitchen_appliance)", "kitchen_range", "cooking_stove"], "def": "a kitchen appliance used for cooking food", "name": "stove"}, {"id": 1041, "synset": "strainer.n.01", "synonyms": ["strainer"], "def": "a filter to retain larger pieces while smaller pieces and liquids pass through", "name": "strainer"}, {"id": 1042, "synset": "strap.n.01", "synonyms": ["strap"], "def": "an elongated strip of material for binding things together or holding", "name": "strap"}, {"id": 1043, "synset": "straw.n.04", "synonyms": ["straw_(for_drinking)", "drinking_straw"], "def": "a thin paper or plastic tube used to suck liquids into the mouth", "name": "straw_(for_drinking)"}, {"id": 1044, "synset": "strawberry.n.01", "synonyms": ["strawberry"], "def": "sweet fleshy red fruit", "name": "strawberry"}, {"id": 1045, "synset": "street_sign.n.01", "synonyms": ["street_sign"], "def": "a sign visible from the street", "name": "street_sign"}, {"id": 1046, "synset": "streetlight.n.01", "synonyms": ["streetlight", "street_lamp"], "def": "a lamp supported on a lamppost; for illuminating a street", "name": "streetlight"}, {"id": 1047, "synset": "string_cheese.n.01", "synonyms": ["string_cheese"], "def": "cheese formed in long strings twisted together", "name": "string_cheese"}, {"id": 1048, "synset": "stylus.n.02", "synonyms": ["stylus"], "def": "a pointed tool for writing or drawing or engraving", "name": "stylus"}, {"id": 1049, "synset": "subwoofer.n.01", "synonyms": ["subwoofer"], "def": "a loudspeaker that is designed to reproduce very low bass frequencies", "name": "subwoofer"}, {"id": 1050, "synset": "sugar_bowl.n.01", "synonyms": ["sugar_bowl"], "def": "a dish in which sugar is served", "name": "sugar_bowl"}, {"id": 1051, "synset": "sugarcane.n.01", "synonyms": ["sugarcane_(plant)"], "def": "juicy canes whose sap is a source of molasses and commercial sugar; fresh canes are sometimes chewed for the juice", "name": "sugarcane_(plant)"}, {"id": 1052, "synset": "suit.n.01", "synonyms": ["suit_(clothing)"], "def": "a set of garments (usually including a jacket and trousers or skirt) for outerwear all of the same fabric and color", "name": "suit_(clothing)"}, {"id": 1053, "synset": "sunflower.n.01", "synonyms": ["sunflower"], "def": "any plant of the genus Helianthus having large flower heads with dark disk florets and showy yellow rays", "name": "sunflower"}, {"id": 1054, "synset": "sunglasses.n.01", "synonyms": ["sunglasses"], "def": "spectacles that are darkened or polarized to protect the eyes from the glare of the sun", "name": "sunglasses"}, {"id": 1055, "synset": "sunhat.n.01", "synonyms": ["sunhat"], "def": "a hat with a broad brim that protects the face from direct exposure to the sun", "name": "sunhat"}, {"id": 1056, "synset": "sunscreen.n.01", "synonyms": ["sunscreen", "sunblock"], "def": "a cream spread on the skin; contains a chemical to filter out ultraviolet light and so protect from sunburn", "name": "sunscreen"}, {"id": 1057, "synset": "surfboard.n.01", "synonyms": ["surfboard"], "def": "a narrow buoyant board for riding surf", "name": "surfboard"}, {"id": 1058, "synset": "sushi.n.01", "synonyms": ["sushi"], "def": "rice (with raw fish) wrapped in seaweed", "name": "sushi"}, {"id": 1059, "synset": "swab.n.02", "synonyms": ["mop"], "def": "cleaning implement consisting of absorbent material fastened to a handle; for cleaning floors", "name": "mop"}, {"id": 1060, "synset": "sweat_pants.n.01", "synonyms": ["sweat_pants"], "def": "loose-fitting trousers with elastic cuffs; worn by athletes", "name": "sweat_pants"}, {"id": 1061, "synset": "sweatband.n.02", "synonyms": ["sweatband"], "def": "a band of material tied around the forehead or wrist to absorb sweat", "name": "sweatband"}, {"id": 1062, "synset": "sweater.n.01", "synonyms": ["sweater"], "def": "a crocheted or knitted garment covering the upper part of the body", "name": "sweater"}, {"id": 1063, "synset": "sweatshirt.n.01", "synonyms": ["sweatshirt"], "def": "cotton knit pullover with long sleeves worn during athletic activity", "name": "sweatshirt"}, {"id": 1064, "synset": "sweet_potato.n.02", "synonyms": ["sweet_potato"], "def": "the edible tuberous root of the sweet potato vine", "name": "sweet_potato"}, {"id": 1065, "synset": "swimsuit.n.01", "synonyms": ["swimsuit", "swimwear", "bathing_suit", "swimming_costume", "bathing_costume", "swimming_trunks", "bathing_trunks"], "def": "garment worn for swimming", "name": "swimsuit"}, {"id": 1066, "synset": "sword.n.01", "synonyms": ["sword"], "def": "a cutting or thrusting weapon that has a long metal blade", "name": "sword"}, {"id": 1067, "synset": "syringe.n.01", "synonyms": ["syringe"], "def": "a medical instrument used to inject or withdraw fluids", "name": "syringe"}, {"id": 1068, "synset": "tabasco.n.02", "synonyms": ["Tabasco_sauce"], "def": "very spicy sauce (trade name Tabasco) made from fully-aged red peppers", "name": "Tabasco_sauce"}, {"id": 1069, "synset": "table-tennis_table.n.01", "synonyms": ["table-tennis_table", "ping-pong_table"], "def": "a table used for playing table tennis", "name": "table-tennis_table"}, {"id": 1070, "synset": "table.n.02", "synonyms": ["table"], "def": "a piece of furniture having a smooth flat top that is usually supported by one or more vertical legs", "name": "table"}, {"id": 1071, "synset": "table_lamp.n.01", "synonyms": ["table_lamp"], "def": "a lamp that sits on a table", "name": "table_lamp"}, {"id": 1072, "synset": "tablecloth.n.01", "synonyms": ["tablecloth"], "def": "a covering spread over a dining table", "name": "tablecloth"}, {"id": 1073, "synset": "tachometer.n.01", "synonyms": ["tachometer"], "def": "measuring instrument for indicating speed of rotation", "name": "tachometer"}, {"id": 1074, "synset": "taco.n.02", "synonyms": ["taco"], "def": "a small tortilla cupped around a filling", "name": "taco"}, {"id": 1075, "synset": "tag.n.02", "synonyms": ["tag"], "def": "a label associated with something for the purpose of identification or information", "name": "tag"}, {"id": 1076, "synset": "taillight.n.01", "synonyms": ["taillight", "rear_light"], "def": "lamp (usually red) mounted at the rear of a motor vehicle", "name": "taillight"}, {"id": 1077, "synset": "tambourine.n.01", "synonyms": ["tambourine"], "def": "a shallow drum with a single drumhead and with metallic disks in the sides", "name": "tambourine"}, {"id": 1078, "synset": "tank.n.01", "synonyms": ["army_tank", "armored_combat_vehicle", "armoured_combat_vehicle"], "def": "an enclosed armored military vehicle; has a cannon and moves on caterpillar treads", "name": "army_tank"}, {"id": 1079, "synset": "tank.n.02", "synonyms": ["tank_(storage_vessel)", "storage_tank"], "def": "a large (usually metallic) vessel for holding gases or liquids", "name": "tank_(storage_vessel)"}, {"id": 1080, "synset": "tank_top.n.01", "synonyms": ["tank_top_(clothing)"], "def": "a tight-fitting sleeveless shirt with wide shoulder straps and low neck and no front opening", "name": "tank_top_(clothing)"}, {"id": 1081, "synset": "tape.n.01", "synonyms": ["tape_(sticky_cloth_or_paper)"], "def": "a long thin piece of cloth or paper as used for binding or fastening", "name": "tape_(sticky_cloth_or_paper)"}, {"id": 1082, "synset": "tape.n.04", "synonyms": ["tape_measure", "measuring_tape"], "def": "measuring instrument consisting of a narrow strip (cloth or metal) marked in inches or centimeters and used for measuring lengths", "name": "tape_measure"}, {"id": 1083, "synset": "tapestry.n.02", "synonyms": ["tapestry"], "def": "a heavy textile with a woven design; used for curtains and upholstery", "name": "tapestry"}, {"id": 1084, "synset": "tarpaulin.n.01", "synonyms": ["tarp"], "def": "waterproofed canvas", "name": "tarp"}, {"id": 1085, "synset": "tartan.n.01", "synonyms": ["tartan", "plaid"], "def": "a cloth having a crisscross design", "name": "tartan"}, {"id": 1086, "synset": "tassel.n.01", "synonyms": ["tassel"], "def": "adornment consisting of a bunch of cords fastened at one end", "name": "tassel"}, {"id": 1087, "synset": "tea_bag.n.01", "synonyms": ["tea_bag"], "def": "a measured amount of tea in a bag for an individual serving of tea", "name": "tea_bag"}, {"id": 1088, "synset": "teacup.n.02", "synonyms": ["teacup"], "def": "a cup from which tea is drunk", "name": "teacup"}, {"id": 1089, "synset": "teakettle.n.01", "synonyms": ["teakettle"], "def": "kettle for boiling water to make tea", "name": "teakettle"}, {"id": 1090, "synset": "teapot.n.01", "synonyms": ["teapot"], "def": "pot for brewing tea; usually has a spout and handle", "name": "teapot"}, {"id": 1091, "synset": "teddy.n.01", "synonyms": ["teddy_bear"], "def": "plaything consisting of a child's toy bear (usually plush and stuffed with soft materials)", "name": "teddy_bear"}, {"id": 1092, "synset": "telephone.n.01", "synonyms": ["telephone", "phone", "telephone_set"], "def": "electronic device for communicating by voice over long distances", "name": "telephone"}, {"id": 1093, "synset": "telephone_booth.n.01", "synonyms": ["telephone_booth", "phone_booth", "call_box", "telephone_box", "telephone_kiosk"], "def": "booth for using a telephone", "name": "telephone_booth"}, {"id": 1094, "synset": "telephone_pole.n.01", "synonyms": ["telephone_pole", "telegraph_pole", "telegraph_post"], "def": "tall pole supporting telephone wires", "name": "telephone_pole"}, {"id": 1095, "synset": "telephoto_lens.n.01", "synonyms": ["telephoto_lens", "zoom_lens"], "def": "a camera lens that magnifies the image", "name": "telephoto_lens"}, {"id": 1096, "synset": "television_camera.n.01", "synonyms": ["television_camera", "tv_camera"], "def": "television equipment for capturing and recording video", "name": "television_camera"}, {"id": 1097, "synset": "television_receiver.n.01", "synonyms": ["television_set", "tv", "tv_set"], "def": "an electronic device that receives television signals and displays them on a screen", "name": "television_set"}, {"id": 1098, "synset": "tennis_ball.n.01", "synonyms": ["tennis_ball"], "def": "ball about the size of a fist used in playing tennis", "name": "tennis_ball"}, {"id": 1099, "synset": "tennis_racket.n.01", "synonyms": ["tennis_racket"], "def": "a racket used to play tennis", "name": "tennis_racket"}, {"id": 1100, "synset": "tequila.n.01", "synonyms": ["tequila"], "def": "Mexican liquor made from fermented juices of an agave plant", "name": "tequila"}, {"id": 1101, "synset": "thermometer.n.01", "synonyms": ["thermometer"], "def": "measuring instrument for measuring temperature", "name": "thermometer"}, {"id": 1102, "synset": "thermos.n.01", "synonyms": ["thermos_bottle"], "def": "vacuum flask that preserves temperature of hot or cold drinks", "name": "thermos_bottle"}, {"id": 1103, "synset": "thermostat.n.01", "synonyms": ["thermostat"], "def": "a regulator for automatically regulating temperature by starting or stopping the supply of heat", "name": "thermostat"}, {"id": 1104, "synset": "thimble.n.02", "synonyms": ["thimble"], "def": "a small metal cap to protect the finger while sewing; can be used as a small container", "name": "thimble"}, {"id": 1105, "synset": "thread.n.01", "synonyms": ["thread", "yarn"], "def": "a fine cord of twisted fibers (of cotton or silk or wool or nylon etc.) used in sewing and weaving", "name": "thread"}, {"id": 1106, "synset": "thumbtack.n.01", "synonyms": ["thumbtack", "drawing_pin", "pushpin"], "def": "a tack for attaching papers to a bulletin board or drawing board", "name": "thumbtack"}, {"id": 1107, "synset": "tiara.n.01", "synonyms": ["tiara"], "def": "a jeweled headdress worn by women on formal occasions", "name": "tiara"}, {"id": 1108, "synset": "tiger.n.02", "synonyms": ["tiger"], "def": "large feline of forests in most of Asia having a tawny coat with black stripes", "name": "tiger"}, {"id": 1109, "synset": "tights.n.01", "synonyms": ["tights_(clothing)", "leotards"], "def": "skintight knit hose covering the body from the waist to the feet worn by acrobats and dancers and as stockings by women and girls", "name": "tights_(clothing)"}, {"id": 1110, "synset": "timer.n.01", "synonyms": ["timer", "stopwatch"], "def": "a timepiece that measures a time interval and signals its end", "name": "timer"}, {"id": 1111, "synset": "tinfoil.n.01", "synonyms": ["tinfoil"], "def": "foil made of tin or an alloy of tin and lead", "name": "tinfoil"}, {"id": 1112, "synset": "tinsel.n.01", "synonyms": ["tinsel"], "def": "a showy decoration that is basically valueless", "name": "tinsel"}, {"id": 1113, "synset": "tissue.n.02", "synonyms": ["tissue_paper"], "def": "a soft thin (usually translucent) paper", "name": "tissue_paper"}, {"id": 1114, "synset": "toast.n.01", "synonyms": ["toast_(food)"], "def": "slice of bread that has been toasted", "name": "toast_(food)"}, {"id": 1115, "synset": "toaster.n.02", "synonyms": ["toaster"], "def": "a kitchen appliance (usually electric) for toasting bread", "name": "toaster"}, {"id": 1116, "synset": "toaster_oven.n.01", "synonyms": ["toaster_oven"], "def": "kitchen appliance consisting of a small electric oven for toasting or warming food", "name": "toaster_oven"}, {"id": 1117, "synset": "toilet.n.02", "synonyms": ["toilet"], "def": "a plumbing fixture for defecation and urination", "name": "toilet"}, {"id": 1118, "synset": "toilet_tissue.n.01", "synonyms": ["toilet_tissue", "toilet_paper", "bathroom_tissue"], "def": "a soft thin absorbent paper for use in toilets", "name": "toilet_tissue"}, {"id": 1119, "synset": "tomato.n.01", "synonyms": ["tomato"], "def": "mildly acid red or yellow pulpy fruit eaten as a vegetable", "name": "tomato"}, {"id": 1120, "synset": "tongs.n.01", "synonyms": ["tongs"], "def": "any of various devices for taking hold of objects; usually have two hinged legs with handles above and pointed hooks below", "name": "tongs"}, {"id": 1121, "synset": "toolbox.n.01", "synonyms": ["toolbox"], "def": "a box or chest or cabinet for holding hand tools", "name": "toolbox"}, {"id": 1122, "synset": "toothbrush.n.01", "synonyms": ["toothbrush"], "def": "small brush; has long handle; used to clean teeth", "name": "toothbrush"}, {"id": 1123, "synset": "toothpaste.n.01", "synonyms": ["toothpaste"], "def": "a dentifrice in the form of a paste", "name": "toothpaste"}, {"id": 1124, "synset": "toothpick.n.01", "synonyms": ["toothpick"], "def": "pick consisting of a small strip of wood or plastic; used to pick food from between the teeth", "name": "toothpick"}, {"id": 1125, "synset": "top.n.09", "synonyms": ["cover"], "def": "covering for a hole (especially a hole in the top of a container)", "name": "cover"}, {"id": 1126, "synset": "tortilla.n.01", "synonyms": ["tortilla"], "def": "thin unleavened pancake made from cornmeal or wheat flour", "name": "tortilla"}, {"id": 1127, "synset": "tow_truck.n.01", "synonyms": ["tow_truck"], "def": "a truck equipped to hoist and pull wrecked cars (or to remove cars from no-parking zones)", "name": "tow_truck"}, {"id": 1128, "synset": "towel.n.01", "synonyms": ["towel"], "def": "a rectangular piece of absorbent cloth (or paper) for drying or wiping", "name": "towel"}, {"id": 1129, "synset": "towel_rack.n.01", "synonyms": ["towel_rack", "towel_rail", "towel_bar"], "def": "a rack consisting of one or more bars on which towels can be hung", "name": "towel_rack"}, {"id": 1130, "synset": "toy.n.03", "synonyms": ["toy"], "def": "a device regarded as providing amusement", "name": "toy"}, {"id": 1131, "synset": "tractor.n.01", "synonyms": ["tractor_(farm_equipment)"], "def": "a wheeled vehicle with large wheels; used in farming and other applications", "name": "tractor_(farm_equipment)"}, {"id": 1132, "synset": "traffic_light.n.01", "synonyms": ["traffic_light"], "def": "a device to control vehicle traffic often consisting of three or more lights", "name": "traffic_light"}, {"id": 1133, "synset": "trail_bike.n.01", "synonyms": ["dirt_bike"], "def": "a lightweight motorcycle equipped with rugged tires and suspension for off-road use", "name": "dirt_bike"}, {"id": 1134, "synset": "trailer_truck.n.01", "synonyms": ["trailer_truck", "tractor_trailer", "trucking_rig", "articulated_lorry", "semi_truck"], "def": "a truck consisting of a tractor and trailer together", "name": "trailer_truck"}, {"id": 1135, "synset": "train.n.01", "synonyms": ["train_(railroad_vehicle)", "railroad_train"], "def": "public or private transport provided by a line of railway cars coupled together and drawn by a locomotive", "name": "train_(railroad_vehicle)"}, {"id": 1136, "synset": "trampoline.n.01", "synonyms": ["trampoline"], "def": "gymnastic apparatus consisting of a strong canvas sheet attached with springs to a metal frame", "name": "trampoline"}, {"id": 1137, "synset": "tray.n.01", "synonyms": ["tray"], "def": "an open receptacle for holding or displaying or serving articles or food", "name": "tray"}, {"id": 1138, "synset": "tree_house.n.01", "synonyms": ["tree_house"], "def": "(NOT A TREE) a PLAYHOUSE built in the branches of a tree", "name": "tree_house"}, {"id": 1139, "synset": "trench_coat.n.01", "synonyms": ["trench_coat"], "def": "a military style raincoat; belted with deep pockets", "name": "trench_coat"}, {"id": 1140, "synset": "triangle.n.05", "synonyms": ["triangle_(musical_instrument)"], "def": "a percussion instrument consisting of a metal bar bent in the shape of an open triangle", "name": "triangle_(musical_instrument)"}, {"id": 1141, "synset": "tricycle.n.01", "synonyms": ["tricycle"], "def": "a vehicle with three wheels that is moved by foot pedals", "name": "tricycle"}, {"id": 1142, "synset": "tripod.n.01", "synonyms": ["tripod"], "def": "a three-legged rack used for support", "name": "tripod"}, {"id": 1143, "synset": "trouser.n.01", "synonyms": ["trousers", "pants_(clothing)"], "def": "a garment extending from the waist to the knee or ankle, covering each leg separately", "name": "trousers"}, {"id": 1144, "synset": "truck.n.01", "synonyms": ["truck"], "def": "an automotive vehicle suitable for hauling", "name": "truck"}, {"id": 1145, "synset": "truffle.n.03", "synonyms": ["truffle_(chocolate)", "chocolate_truffle"], "def": "creamy chocolate candy", "name": "truffle_(chocolate)"}, {"id": 1146, "synset": "trunk.n.02", "synonyms": ["trunk"], "def": "luggage consisting of a large strong case used when traveling or for storage", "name": "trunk"}, {"id": 1147, "synset": "tub.n.02", "synonyms": ["vat"], "def": "a large open vessel for holding or storing liquids", "name": "vat"}, {"id": 1148, "synset": "turban.n.01", "synonyms": ["turban"], "def": "a traditional headdress consisting of a long scarf wrapped around the head", "name": "turban"}, {"id": 1149, "synset": "turkey.n.01", "synonyms": ["turkey_(bird)"], "def": "large gallinaceous bird with fan-shaped tail; widely domesticated for food", "name": "turkey_(bird)"}, {"id": 1150, "synset": "turkey.n.04", "synonyms": ["turkey_(food)"], "def": "flesh of large domesticated fowl usually roasted", "name": "turkey_(food)"}, {"id": 1151, "synset": "turnip.n.01", "synonyms": ["turnip"], "def": "widely cultivated plant having a large fleshy edible white or yellow root", "name": "turnip"}, {"id": 1152, "synset": "turtle.n.02", "synonyms": ["turtle"], "def": "any of various aquatic and land reptiles having a bony shell and flipper-like limbs for swimming", "name": "turtle"}, {"id": 1153, "synset": "turtleneck.n.01", "synonyms": ["turtleneck_(clothing)", "polo-neck"], "def": "a sweater or jersey with a high close-fitting collar", "name": "turtleneck_(clothing)"}, {"id": 1154, "synset": "typewriter.n.01", "synonyms": ["typewriter"], "def": "hand-operated character printer for printing written messages one character at a time", "name": "typewriter"}, {"id": 1155, "synset": "umbrella.n.01", "synonyms": ["umbrella"], "def": "a lightweight handheld collapsible canopy", "name": "umbrella"}, {"id": 1156, "synset": "underwear.n.01", "synonyms": ["underwear", "underclothes", "underclothing", "underpants"], "def": "undergarment worn next to the skin and under the outer garments", "name": "underwear"}, {"id": 1157, "synset": "unicycle.n.01", "synonyms": ["unicycle"], "def": "a vehicle with a single wheel that is driven by pedals", "name": "unicycle"}, {"id": 1158, "synset": "urinal.n.01", "synonyms": ["urinal"], "def": "a plumbing fixture (usually attached to the wall) used by men to urinate", "name": "urinal"}, {"id": 1159, "synset": "urn.n.01", "synonyms": ["urn"], "def": "a large vase that usually has a pedestal or feet", "name": "urn"}, {"id": 1160, "synset": "vacuum.n.04", "synonyms": ["vacuum_cleaner"], "def": "an electrical home appliance that cleans by suction", "name": "vacuum_cleaner"}, {"id": 1161, "synset": "valve.n.03", "synonyms": ["valve"], "def": "control consisting of a mechanical device for controlling the flow of a fluid", "name": "valve"}, {"id": 1162, "synset": "vase.n.01", "synonyms": ["vase"], "def": "an open jar of glass or porcelain used as an ornament or to hold flowers", "name": "vase"}, {"id": 1163, "synset": "vending_machine.n.01", "synonyms": ["vending_machine"], "def": "a slot machine for selling goods", "name": "vending_machine"}, {"id": 1164, "synset": "vent.n.01", "synonyms": ["vent", "blowhole", "air_vent"], "def": "a hole for the escape of gas or air", "name": "vent"}, {"id": 1165, "synset": "videotape.n.01", "synonyms": ["videotape"], "def": "a video recording made on magnetic tape", "name": "videotape"}, {"id": 1166, "synset": "vinegar.n.01", "synonyms": ["vinegar"], "def": "sour-tasting liquid produced usually by oxidation of the alcohol in wine or cider and used as a condiment or food preservative", "name": "vinegar"}, {"id": 1167, "synset": "violin.n.01", "synonyms": ["violin", "fiddle"], "def": "bowed stringed instrument that is the highest member of the violin family", "name": "violin"}, {"id": 1168, "synset": "vodka.n.01", "synonyms": ["vodka"], "def": "unaged colorless liquor originating in Russia", "name": "vodka"}, {"id": 1169, "synset": "volleyball.n.02", "synonyms": ["volleyball"], "def": "an inflated ball used in playing volleyball", "name": "volleyball"}, {"id": 1170, "synset": "vulture.n.01", "synonyms": ["vulture"], "def": "any of various large birds of prey having naked heads and weak claws and feeding chiefly on carrion", "name": "vulture"}, {"id": 1171, "synset": "waffle.n.01", "synonyms": ["waffle"], "def": "pancake batter baked in a waffle iron", "name": "waffle"}, {"id": 1172, "synset": "waffle_iron.n.01", "synonyms": ["waffle_iron"], "def": "a kitchen appliance for baking waffles", "name": "waffle_iron"}, {"id": 1173, "synset": "wagon.n.01", "synonyms": ["wagon"], "def": "any of various kinds of wheeled vehicles drawn by an animal or a tractor", "name": "wagon"}, {"id": 1174, "synset": "wagon_wheel.n.01", "synonyms": ["wagon_wheel"], "def": "a wheel of a wagon", "name": "wagon_wheel"}, {"id": 1175, "synset": "walking_stick.n.01", "synonyms": ["walking_stick"], "def": "a stick carried in the hand for support in walking", "name": "walking_stick", "merged": [{"frequency": "c", "id": 201, "synset": "cane.n.01", "image_count": 5, "instance_count": 5, "synonyms": ["walking_cane"], "def": "a stick that people can lean on to help them walk", "name": "walking_cane"}]}, {"id": 1176, "synset": "wall_clock.n.01", "synonyms": ["wall_clock"], "def": "a clock mounted on a wall", "name": "wall_clock"}, {"id": 1177, "synset": "wall_socket.n.01", "synonyms": ["wall_socket", "wall_plug", "electric_outlet", "electrical_outlet", "outlet", "electric_receptacle"], "def": "receptacle providing a place in a wiring system where current can be taken to run electrical devices", "name": "wall_socket"}, {"id": 1178, "synset": "wallet.n.01", "synonyms": ["wallet", "billfold"], "def": "a pocket-size case for holding papers and paper money", "name": "wallet"}, {"id": 1179, "synset": "walrus.n.01", "synonyms": ["walrus"], "def": "either of two large northern marine mammals having ivory tusks and tough hide over thick blubber", "name": "walrus"}, {"id": 1180, "synset": "wardrobe.n.01", "synonyms": ["wardrobe"], "def": "a tall piece of furniture that provides storage space for clothes; has a door and rails or hooks for hanging clothes", "name": "wardrobe"}, {"id": 1181, "synset": "wasabi.n.02", "synonyms": ["wasabi"], "def": "the thick green root of the wasabi plant that the Japanese use in cooking and that tastes like strong horseradish", "name": "wasabi"}, {"id": 1182, "synset": "washer.n.03", "synonyms": ["automatic_washer", "washing_machine"], "def": "a home appliance for washing clothes and linens automatically", "name": "automatic_washer"}, {"id": 1183, "synset": "watch.n.01", "synonyms": ["watch", "wristwatch"], "def": "a small, portable timepiece", "name": "watch"}, {"id": 1184, "synset": "water_bottle.n.01", "synonyms": ["water_bottle"], "def": "a bottle for holding water", "name": "water_bottle"}, {"id": 1185, "synset": "water_cooler.n.01", "synonyms": ["water_cooler"], "def": "a device for cooling and dispensing drinking water", "name": "water_cooler"}, {"id": 1186, "synset": "water_faucet.n.01", "synonyms": ["water_faucet", "water_tap", "tap_(water_faucet)"], "def": "a faucet for drawing water from a pipe or cask", "name": "water_faucet"}, {"id": 1187, "synset": "water_filter.n.01", "synonyms": ["water_filter"], "def": "a filter to remove impurities from the water supply", "name": "water_filter"}, {"id": 1188, "synset": "water_heater.n.01", "synonyms": ["water_heater", "hot-water_heater"], "def": "a heater and storage tank to supply heated water", "name": "water_heater"}, {"id": 1189, "synset": "water_jug.n.01", "synonyms": ["water_jug"], "def": "a jug that holds water", "name": "water_jug"}, {"id": 1190, "synset": "water_pistol.n.01", "synonyms": ["water_gun", "squirt_gun"], "def": "plaything consisting of a toy pistol that squirts water", "name": "water_gun"}, {"id": 1191, "synset": "water_scooter.n.01", "synonyms": ["water_scooter", "sea_scooter", "jet_ski"], "def": "a motorboat resembling a motor scooter (NOT A SURFBOARD OR WATER SKI)", "name": "water_scooter"}, {"id": 1192, "synset": "water_ski.n.01", "synonyms": ["water_ski"], "def": "broad ski for skimming over water towed by a speedboat (DO NOT MARK WATER)", "name": "water_ski"}, {"id": 1193, "synset": "water_tower.n.01", "synonyms": ["water_tower"], "def": "a large reservoir for water", "name": "water_tower"}, {"id": 1194, "synset": "watering_can.n.01", "synonyms": ["watering_can"], "def": "a container with a handle and a spout with a perforated nozzle; used to sprinkle water over plants", "name": "watering_can"}, {"id": 1195, "synset": "watermelon.n.02", "synonyms": ["watermelon"], "def": "large oblong or roundish melon with a hard green rind and sweet watery red or occasionally yellowish pulp", "name": "watermelon"}, {"id": 1196, "synset": "weathervane.n.01", "synonyms": ["weathervane", "vane_(weathervane)", "wind_vane"], "def": "mechanical device attached to an elevated structure; rotates freely to show the direction of the wind", "name": "weathervane"}, {"id": 1197, "synset": "webcam.n.01", "synonyms": ["webcam"], "def": "a digital camera designed to take digital photographs and transmit them over the internet", "name": "webcam"}, {"id": 1198, "synset": "wedding_cake.n.01", "synonyms": ["wedding_cake", "bridecake"], "def": "a rich cake with two or more tiers and covered with frosting and decorations; served at a wedding reception", "name": "wedding_cake"}, {"id": 1199, "synset": "wedding_ring.n.01", "synonyms": ["wedding_ring", "wedding_band"], "def": "a ring given to the bride and/or groom at the wedding", "name": "wedding_ring"}, {"id": 1200, "synset": "wet_suit.n.01", "synonyms": ["wet_suit"], "def": "a close-fitting garment made of a permeable material; worn in cold water to retain body heat", "name": "wet_suit"}, {"id": 1201, "synset": "wheel.n.01", "synonyms": ["wheel"], "def": "a circular frame with spokes (or a solid disc) that can rotate on a shaft or axle", "name": "wheel"}, {"id": 1202, "synset": "wheelchair.n.01", "synonyms": ["wheelchair"], "def": "a movable chair mounted on large wheels", "name": "wheelchair"}, {"id": 1203, "synset": "whipped_cream.n.01", "synonyms": ["whipped_cream"], "def": "cream that has been beaten until light and fluffy", "name": "whipped_cream"}, {"id": 1204, "synset": "whiskey.n.01", "synonyms": ["whiskey"], "def": "a liquor made from fermented mash of grain", "name": "whiskey"}, {"id": 1205, "synset": "whistle.n.03", "synonyms": ["whistle"], "def": "a small wind instrument that produces a whistling sound by blowing into it", "name": "whistle"}, {"id": 1206, "synset": "wick.n.02", "synonyms": ["wick"], "def": "a loosely woven cord in a candle or oil lamp that is lit on fire", "name": "wick"}, {"id": 1207, "synset": "wig.n.01", "synonyms": ["wig"], "def": "hairpiece covering the head and made of real or synthetic hair", "name": "wig"}, {"id": 1208, "synset": "wind_chime.n.01", "synonyms": ["wind_chime"], "def": "a decorative arrangement of pieces of metal or glass or pottery that hang together loosely so the wind can cause them to tinkle", "name": "wind_chime"}, {"id": 1209, "synset": "windmill.n.01", "synonyms": ["windmill"], "def": "a mill that is powered by the wind", "name": "windmill"}, {"id": 1210, "synset": "window_box.n.01", "synonyms": ["window_box_(for_plants)"], "def": "a container for growing plants on a windowsill", "name": "window_box_(for_plants)"}, {"id": 1211, "synset": "windshield_wiper.n.01", "synonyms": ["windshield_wiper", "windscreen_wiper", "wiper_(for_windshield/screen)"], "def": "a mechanical device that cleans the windshield", "name": "windshield_wiper"}, {"id": 1212, "synset": "windsock.n.01", "synonyms": ["windsock", "air_sock", "air-sleeve", "wind_sleeve", "wind_cone"], "def": "a truncated cloth cone mounted on a mast/pole; shows wind direction", "name": "windsock"}, {"id": 1213, "synset": "wine_bottle.n.01", "synonyms": ["wine_bottle"], "def": "a bottle for holding wine", "name": "wine_bottle"}, {"id": 1214, "synset": "wine_bucket.n.01", "synonyms": ["wine_bucket", "wine_cooler"], "def": "a bucket of ice used to chill a bottle of wine", "name": "wine_bucket"}, {"id": 1215, "synset": "wineglass.n.01", "synonyms": ["wineglass"], "def": "a glass that has a stem and in which wine is served", "name": "wineglass"}, {"id": 1216, "synset": "wing_chair.n.01", "synonyms": ["wing_chair"], "def": "easy chair having wings on each side of a high back", "name": "wing_chair"}, {"id": 1217, "synset": "winker.n.02", "synonyms": ["blinder_(for_horses)"], "def": "blinds that prevent a horse from seeing something on either side", "name": "blinder_(for_horses)"}, {"id": 1218, "synset": "wok.n.01", "synonyms": ["wok"], "def": "pan with a convex bottom; used for frying in Chinese cooking", "name": "wok"}, {"id": 1219, "synset": "wolf.n.01", "synonyms": ["wolf"], "def": "a wild carnivorous mammal of the dog family, living and hunting in packs", "name": "wolf"}, {"id": 1220, "synset": "wooden_spoon.n.02", "synonyms": ["wooden_spoon"], "def": "a spoon made of wood", "name": "wooden_spoon"}, {"id": 1221, "synset": "wreath.n.01", "synonyms": ["wreath"], "def": "an arrangement of flowers, leaves, or stems fastened in a ring", "name": "wreath"}, {"id": 1222, "synset": "wrench.n.03", "synonyms": ["wrench", "spanner"], "def": "a hand tool that is used to hold or twist a nut or bolt", "name": "wrench"}, {"id": 1223, "synset": "wristband.n.01", "synonyms": ["wristband"], "def": "band consisting of a part of a sleeve that covers the wrist", "name": "wristband"}, {"id": 1224, "synset": "wristlet.n.01", "synonyms": ["wristlet", "wrist_band"], "def": "a band or bracelet worn around the wrist", "name": "wristlet"}, {"id": 1225, "synset": "yacht.n.01", "synonyms": ["yacht"], "def": "an expensive vessel propelled by sail or power and used for cruising or racing", "name": "yacht"}, {"id": 1226, "synset": "yak.n.02", "synonyms": ["yak"], "def": "large long-haired wild ox of Tibet often domesticated", "name": "yak"}, {"id": 1227, "synset": "yogurt.n.01", "synonyms": ["yogurt", "yoghurt", "yoghourt"], "def": "a custard-like food made from curdled milk", "name": "yogurt"}, {"id": 1228, "synset": "yoke.n.07", "synonyms": ["yoke_(animal_equipment)"], "def": "gear joining two animals at the neck; NOT egg yolk", "name": "yoke_(animal_equipment)"}, {"id": 1229, "synset": "zebra.n.01", "synonyms": ["zebra"], "def": "any of several fleet black-and-white striped African equines", "name": "zebra"}, {"id": 1230, "synset": "zucchini.n.02", "synonyms": ["zucchini", "courgette"], "def": "small cucumber-shaped vegetable marrow; typically dark green", "name": "zucchini"}]
\ No newline at end of file
diff --git a/val_utils/trackeval/datasets/burst_ow.py b/val_utils/trackeval/datasets/burst_ow.py
new file mode 100644
index 0000000000000000000000000000000000000000..da775456e6c539c07c85db1fc9cad5998d8baaeb
--- /dev/null
+++ b/val_utils/trackeval/datasets/burst_ow.py
@@ -0,0 +1,91 @@
+import json
+import os
+from .burst_helpers.burst_ow_base import BURST_OW_Base
+from .burst_helpers.format_converter import GroundTruthBURSTFormatToTAOFormatConverter, PredictionBURSTFormatToTAOFormatConverter
+from .. import utils
+
+
+class BURST_OW(BURST_OW_Base):
+ """Dataset class for TAO tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ tao_config = BURST_OW_Base.get_default_dataset_config()
+ code_path = utils.get_code_path()
+ tao_config['GT_FOLDER'] = os.path.join(
+ code_path, 'data/gt/burst/all_classes/val/') # Location of GT data
+ tao_config['TRACKERS_FOLDER'] = os.path.join(
+ code_path, 'data/trackers/burst/open-world/val/') # Trackers location
+ return tao_config
+
+ def _iou_type(self):
+ return 'mask'
+
+ def _box_or_mask_from_det(self, det):
+ if "segmentation" in det:
+ return det["segmentation"]
+ else:
+ return det["mask"]
+
+ def _calculate_area_for_ann(self, ann):
+ import pycocotools.mask as cocomask
+ seg = self._box_or_mask_from_det(ann)
+ return cocomask.area(seg)
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
+ return similarity_scores
+
+ def _postproc_ground_truth_data(self, data):
+ return GroundTruthBURSTFormatToTAOFormatConverter(data).convert()
+
+ def _postproc_prediction_data(self, data):
+ # if it's a list, it's already in TAO format and not in Ali format
+ # however the image ids do not match and need to be remapped
+ if isinstance(data, list):
+ _remap_image_ids(data, self.gt_data)
+ return data
+
+ return PredictionBURSTFormatToTAOFormatConverter(
+ self.gt_data, data,
+ exemplar_guided=False).convert()
+
+
+def _remap_image_ids(pred_data, ali_gt_data):
+ code_path = utils.get_code_path()
+ if 'split' in ali_gt_data:
+ split = ali_gt_data['split']
+ else:
+ split = 'val'
+
+ if split in ('val', 'validation'):
+ tao_gt_path = os.path.join(
+ code_path, 'data/gt/tao/tao_validation/gt.json')
+ else:
+ tao_gt_path = os.path.join(
+ code_path, 'data/gt/tao/tao_test/test_without_annotations.json')
+
+ with open(tao_gt_path) as f:
+ tao_gt = json.load(f)
+
+ tao_img_by_id = {}
+ for img in tao_gt['images']:
+ img_id = img['id']
+ tao_img_by_id[img_id] = img
+
+ ali_img_id_by_filename = {}
+ for ali_img in ali_gt_data['images']:
+ ali_img_id = ali_img['id']
+ file_name = ali_img['file_name'].replace("validation", "val")
+ ali_img_id_by_filename[file_name] = ali_img_id
+
+ ali_img_id_by_tao_img_id = {}
+ for tao_img_id, tao_img in tao_img_by_id.items():
+ file_name = tao_img['file_name']
+ ali_img_id = ali_img_id_by_filename[file_name]
+ ali_img_id_by_tao_img_id[tao_img_id] = ali_img_id
+
+ for det in pred_data:
+ tao_img_id = det['image_id']
+ ali_img_id = ali_img_id_by_tao_img_id[tao_img_id]
+ det['image_id'] = ali_img_id
diff --git a/val_utils/trackeval/datasets/davis.py b/val_utils/trackeval/datasets/davis.py
new file mode 100644
index 0000000000000000000000000000000000000000..9db25e933b0c4951f2ea70c5c4d806fb6b08ccd5
--- /dev/null
+++ b/val_utils/trackeval/datasets/davis.py
@@ -0,0 +1,276 @@
+import os
+import csv
+import numpy as np
+from ._base_dataset import _BaseDataset
+from ..utils import TrackEvalException
+from .. import utils
+from .. import _timing
+
+
+class DAVIS(_BaseDataset):
+ """Dataset class for DAVIS tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/davis/davis_unsupervised_val/'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/davis/davis_unsupervised_val/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'SPLIT_TO_EVAL': 'val', # Valid: 'val', 'train'
+ 'CLASSES_TO_EVAL': ['general'],
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'SEQMAP_FILE': None, # Specify seqmap file
+ 'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
+ # '{gt_folder}/Annotations_unsupervised/480p/{seq}'
+ 'MAX_DETECTIONS': 0 # Maximum number of allowed detections per sequence (0 for no threshold)
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+ # defining a default class since there are no classes in DAVIS
+ self.should_classes_combine = False
+ self.use_super_categories = False
+
+ self.gt_fol = self.config['GT_FOLDER']
+ self.tracker_fol = self.config['TRACKERS_FOLDER']
+
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.config['TRACKERS_FOLDER']
+
+ self.max_det = self.config['MAX_DETECTIONS']
+
+ # Get classes to eval
+ self.valid_classes = ['general']
+ self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only general class is valid.')
+
+ # Get sequences to eval
+ if self.config["SEQ_INFO"]:
+ self.seq_list = list(self.config["SEQ_INFO"].keys())
+ self.seq_lengths = self.config["SEQ_INFO"]
+ elif self.config["SEQMAP_FILE"]:
+ self.seq_list = []
+ seqmap_file = self.config["SEQMAP_FILE"]
+ if not os.path.isfile(seqmap_file):
+ raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
+ with open(seqmap_file) as fp:
+ reader = csv.reader(fp)
+ for i, row in enumerate(reader):
+ if row[0] == '':
+ continue
+ seq = row[0]
+ self.seq_list.append(seq)
+ else:
+ self.seq_list = os.listdir(self.gt_fol)
+
+ self.seq_lengths = {seq: len(os.listdir(os.path.join(self.gt_fol, seq))) for seq in self.seq_list}
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+ for tracker in self.tracker_list:
+ for seq in self.seq_list:
+ curr_dir = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq)
+ if not os.path.isdir(curr_dir):
+ print('Tracker directory not found: ' + curr_dir)
+ raise TrackEvalException('Tracker directory not found: ' +
+ os.path.join(tracker, self.tracker_sub_fol, seq))
+ tr_timesteps = len(os.listdir(curr_dir))
+ if self.seq_lengths[seq] != tr_timesteps:
+ raise TrackEvalException('GT folder and tracker folder have a different number'
+ 'timesteps for tracker %s and sequence %s' % (tracker, seq))
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the DAVIS format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets]: list (for each timestep) of lists of detections.
+ [masks_void]: list of masks with void pixels (pixels to be ignored during evaluation)
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ """
+
+ # Only loaded when run to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+ from PIL import Image
+
+ # File location
+ if is_gt:
+ seq_dir = os.path.join(self.gt_fol, seq)
+ else:
+ seq_dir = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq)
+
+ num_timesteps = self.seq_lengths[seq]
+ data_keys = ['ids', 'dets', 'masks_void']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+
+ # read frames
+ frames = [os.path.join(seq_dir, im_name) for im_name in sorted(os.listdir(seq_dir))]
+
+ id_list = []
+ for t in range(num_timesteps):
+ frame = np.array(Image.open(frames[t]))
+ if is_gt:
+ void = frame == 255
+ frame[void] = 0
+ raw_data['masks_void'][t] = mask_utils.encode(np.asfortranarray(void.astype(np.uint8)))
+ id_values = np.unique(frame)
+ id_values = id_values[id_values != 0]
+ id_list += list(id_values)
+ tmp = np.ones((len(id_values), *frame.shape))
+ tmp = tmp * id_values[:, None, None]
+ masks = np.array(tmp == frame[None, ...]).astype(np.uint8)
+ raw_data['dets'][t] = mask_utils.encode(np.array(np.transpose(masks, (1, 2, 0)), order='F'))
+ raw_data['ids'][t] = id_values.astype(int)
+ num_objects = len(np.unique(id_list))
+
+ if not is_gt and num_objects > self.max_det > 0:
+ raise Exception('Number of proposals (%i) for sequence %s exceeds number of maximum allowed proposals (%i).'
+ % (num_objects, seq, self.max_det))
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+ raw_data["num_timesteps"] = num_timesteps
+ raw_data['mask_shape'] = np.array(Image.open(frames[0])).shape
+ if is_gt:
+ raw_data['num_gt_ids'] = num_objects
+ else:
+ raw_data['num_tracker_ids'] = num_objects
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detection masks.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+
+ DAVIS:
+ In DAVIS, the 4 preproc steps are as follow:
+ 1) There are no classes, all detections are evaluated jointly
+ 2) No matched tracker detections are removed.
+ 3) No unmatched tracker detections are removed.
+ 4) There are no ground truth detections (e.g. those of distractor classes) to be removed.
+ Preprocessing special to DAVIS: Pixels which are marked as void in the ground truth are set to zero in the
+ tracker detections since they are not considered during evaluation.
+ """
+
+ # Only loaded when run to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ num_gt_dets = 0
+ num_tracker_dets = 0
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_timesteps = raw_data['num_timesteps']
+
+ # count detections
+ for t in range(num_timesteps):
+ num_gt_dets += len(raw_data['gt_dets'][t])
+ num_tracker_dets += len(raw_data['tracker_dets'][t])
+ unique_gt_ids += list(np.unique(raw_data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(raw_data['tracker_ids'][t]))
+
+ data['gt_ids'] = raw_data['gt_ids']
+ data['gt_dets'] = raw_data['gt_dets']
+ data['similarity_scores'] = raw_data['similarity_scores']
+ data['tracker_ids'] = raw_data['tracker_ids']
+
+ # set void pixels in tracker detections to zero
+ for t in range(num_timesteps):
+ void_mask = raw_data['masks_void'][t]
+ if mask_utils.area(void_mask) > 0:
+ void_mask_ious = np.atleast_1d(mask_utils.iou(raw_data['tracker_dets'][t], [void_mask], [False]))
+ if void_mask_ious.any():
+ rows, columns = np.where(void_mask_ious > 0)
+ for r in rows:
+ det = mask_utils.decode(raw_data['tracker_dets'][t][r])
+ void = mask_utils.decode(void_mask).astype(np.bool)
+ det[void] = 0
+ det = mask_utils.encode(np.array(det, order='F').astype(np.uint8))
+ raw_data['tracker_dets'][t][r] = det
+ data['tracker_dets'] = raw_data['tracker_dets']
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = raw_data['num_tracker_ids']
+ data['num_gt_ids'] = raw_data['num_gt_ids']
+ data['mask_shape'] = raw_data['mask_shape']
+ data['num_timesteps'] = num_timesteps
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
+ return similarity_scores
diff --git a/val_utils/trackeval/datasets/head_tracking_challenge.py b/val_utils/trackeval/datasets/head_tracking_challenge.py
new file mode 100644
index 0000000000000000000000000000000000000000..469e9a3c7701c384ce9ad9149fcdff2cc896afac
--- /dev/null
+++ b/val_utils/trackeval/datasets/head_tracking_challenge.py
@@ -0,0 +1,459 @@
+import os
+import csv
+import configparser
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_dataset import _BaseDataset
+from .. import utils
+from .. import _timing
+from ..utils import TrackEvalException
+
+
+class HeadTrackingChallenge(_BaseDataset):
+ """Dataset class for Head Tracking Challenge - 2D bounding box tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
+ 'BENCHMARK': 'HT', # Valid: 'HT'. Refers to "Head Tracking or the dataset CroHD"
+ 'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test', 'all'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'DO_PREPROC': True, # Whether to perform preprocessing (never done for MOT15)
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/seqmaps)
+ 'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/benchmark-split_to_eval)
+ 'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
+ 'GT_LOC_FORMAT': '{gt_folder}/{seq}/gt/gt.txt', # '{gt_folder}/{seq}/gt/gt.txt'
+ 'SKIP_SPLIT_FOL': False, # If False, data is in GT_FOLDER/BENCHMARK-SPLIT_TO_EVAL/ and in
+ # TRACKERS_FOLDER/BENCHMARK-SPLIT_TO_EVAL/tracker/
+ # If True, then the middle 'benchmark-split' folder is skipped for both.
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+
+ self.benchmark = self.config['BENCHMARK']
+ gt_set = self.config['BENCHMARK'] + '-' + self.config['SPLIT_TO_EVAL']
+ self.gt_set = gt_set
+ if not self.config['SKIP_SPLIT_FOL']:
+ split_fol = gt_set
+ else:
+ split_fol = ''
+ self.gt_fol = os.path.join(self.config['GT_FOLDER'], split_fol)
+ self.tracker_fol = os.path.join(self.config['TRACKERS_FOLDER'], split_fol)
+ self.should_classes_combine = False
+ self.use_super_categories = False
+ self.data_is_zipped = self.config['INPUT_AS_ZIP']
+ self.do_preproc = self.config['DO_PREPROC']
+
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+
+ # Get classes to eval
+ self.valid_classes = ['pedestrian']
+ self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only pedestrian class is valid.')
+ self.class_name_to_class_id = {'pedestrian': 1, 'static': 2, 'ignore': 3, 'person_on_vehicle': 4}
+ self.valid_class_numbers = list(self.class_name_to_class_id.values())
+
+ # Get sequences to eval and check gt files exist
+ self.seq_list, self.seq_lengths = self._get_seq_info()
+ if len(self.seq_list) < 1:
+ raise TrackEvalException('No sequences are selected to be evaluated.')
+
+ # Check gt files exist
+ for seq in self.seq_list:
+ if not self.data_is_zipped:
+ curr_file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
+ if not os.path.isfile(curr_file):
+ print('GT file not found ' + curr_file)
+ raise TrackEvalException('GT file not found for sequence: ' + seq)
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.gt_fol, 'data.zip')
+ if not os.path.isfile(curr_file):
+ print('GT file not found ' + curr_file)
+ raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ for tracker in self.tracker_list:
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException('Tracker file not found: ' + tracker + '/' + os.path.basename(curr_file))
+ else:
+ for seq in self.seq_list:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException(
+ 'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
+ curr_file))
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _get_seq_info(self):
+ seq_list = []
+ seq_lengths = {}
+ if self.config["SEQ_INFO"]:
+ seq_list = list(self.config["SEQ_INFO"].keys())
+ seq_lengths = self.config["SEQ_INFO"]
+
+ # If sequence length is 'None' tries to read sequence length from .ini files.
+ for seq, seq_length in seq_lengths.items():
+ if seq_length is None:
+ ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
+ if not os.path.isfile(ini_file):
+ raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
+ ini_data = configparser.ConfigParser()
+ ini_data.read(ini_file)
+ seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
+
+ else:
+ if self.config["SEQMAP_FILE"]:
+ seqmap_file = self.config["SEQMAP_FILE"]
+ else:
+ if self.config["SEQMAP_FOLDER"] is None:
+ seqmap_file = os.path.join(self.config['GT_FOLDER'], 'seqmaps', self.gt_set + '.txt')
+ else:
+ seqmap_file = os.path.join(self.config["SEQMAP_FOLDER"], self.gt_set + '.txt')
+ if not os.path.isfile(seqmap_file):
+ print('no seqmap found: ' + seqmap_file)
+ raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
+ with open(seqmap_file) as fp:
+ reader = csv.reader(fp)
+ for i, row in enumerate(reader):
+ if i == 0 or row[0] == '':
+ continue
+ seq = row[0]
+ seq_list.append(seq)
+ ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
+ if not os.path.isfile(ini_file):
+ raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
+ ini_data = configparser.ConfigParser()
+ ini_data.read(ini_file)
+ seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
+ return seq_list, seq_lengths
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the MOT Challenge 2D box format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
+ [gt_extras] : list (for each timestep) of dicts (for each extra) of 1D NDArrays (for each det).
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ """
+ # File location
+ if self.data_is_zipped:
+ if is_gt:
+ zip_file = os.path.join(self.gt_fol, 'data.zip')
+ else:
+ zip_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ file = seq + '.txt'
+ else:
+ zip_file = None
+ if is_gt:
+ file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
+ else:
+ file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+
+ # Load raw data from text file
+ read_data, ignore_data = self._load_simple_text_file(file, is_zipped=self.data_is_zipped, zip_file=zip_file)
+
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq]
+ data_keys = ['ids', 'classes', 'dets']
+ if is_gt:
+ data_keys += ['gt_crowd_ignore_regions', 'gt_extras']
+ else:
+ data_keys += ['tracker_confidences']
+
+ if self.benchmark == 'HT':
+ data_keys += ['visibility']
+ data_keys += ['gt_conf']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+
+ # Check for any extra time keys
+ current_time_keys = [str( t+ 1) for t in range(num_timesteps)]
+ extra_time_keys = [x for x in read_data.keys() if x not in current_time_keys]
+ if len(extra_time_keys) > 0:
+ if is_gt:
+ text = 'Ground-truth'
+ else:
+ text = 'Tracking'
+ raise TrackEvalException(
+ text + ' data contains the following invalid timesteps in seq %s: ' % seq + ', '.join(
+ [str(x) + ', ' for x in extra_time_keys]))
+
+ for t in range(num_timesteps):
+ time_key = str(t+1)
+ if time_key in read_data.keys():
+ try:
+ time_data = np.asarray(read_data[time_key], dtype=np.float)
+ except ValueError:
+ if is_gt:
+ raise TrackEvalException(
+ 'Cannot convert gt data for sequence %s to float. Is data corrupted?' % seq)
+ else:
+ raise TrackEvalException(
+ 'Cannot convert tracking data from tracker %s, sequence %s to float. Is data corrupted?' % (
+ tracker, seq))
+ try:
+ raw_data['dets'][t] = np.atleast_2d(time_data[:, 2:6])
+ raw_data['ids'][t] = np.atleast_1d(time_data[:, 1]).astype(int)
+ except IndexError:
+ if is_gt:
+ err = 'Cannot load gt data from sequence %s, because there is not enough ' \
+ 'columns in the data.' % seq
+ raise TrackEvalException(err)
+ else:
+ err = 'Cannot load tracker data from tracker %s, sequence %s, because there is not enough ' \
+ 'columns in the data.' % (tracker, seq)
+ raise TrackEvalException(err)
+ if time_data.shape[1] >= 8:
+ raw_data['gt_conf'][t] = np.atleast_1d(time_data[:, 6]).astype(float)
+ raw_data['visibility'][t] = np.atleast_1d(time_data[:, 8]).astype(float)
+ raw_data['classes'][t] = np.atleast_1d(time_data[:, 7]).astype(int)
+ else:
+ if not is_gt:
+ raw_data['classes'][t] = np.ones_like(raw_data['ids'][t])
+ else:
+ raise TrackEvalException(
+ 'GT data is not in a valid format, there is not enough rows in seq %s, timestep %i.' % (
+ seq, t))
+ if is_gt:
+ gt_extras_dict = {'zero_marked': np.atleast_1d(time_data[:, 6].astype(int))}
+ raw_data['gt_extras'][t] = gt_extras_dict
+ else:
+ raw_data['tracker_confidences'][t] = np.atleast_1d(time_data[:, 6])
+ else:
+ raw_data['dets'][t] = np.empty((0, 4))
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+ if is_gt:
+ gt_extras_dict = {'zero_marked': np.empty(0)}
+ raw_data['gt_extras'][t] = gt_extras_dict
+ else:
+ raw_data['tracker_confidences'][t] = np.empty(0)
+ if is_gt:
+ raw_data['gt_crowd_ignore_regions'][t] = np.empty((0, 4))
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+ raw_data['num_timesteps'] = num_timesteps
+ raw_data['seq'] = seq
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+
+ MOT Challenge:
+ In MOT Challenge, the 4 preproc steps are as follow:
+ 1) There is only one class (pedestrian) to be evaluated, but all other classes are used for preproc.
+ 2) Predictions are matched against all gt boxes (regardless of class), those matching with distractor
+ objects are removed.
+ 3) There is no crowd ignore regions.
+ 4) All gt dets except pedestrian are removed, also removes pedestrian gt dets marked with zero_marked.
+ """
+ # Check that input data has unique ids
+ self._check_unique_ids(raw_data)
+
+ # 'static': 2, 'ignore': 3, 'person_on_vehicle':
+
+ distractor_class_names = ['static', 'ignore', 'person_on_vehicle']
+
+ distractor_classes = [self.class_name_to_class_id[x] for x in distractor_class_names]
+ cls_id = self.class_name_to_class_id[cls]
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences',
+ 'similarity_scores', 'gt_visibility']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+ for t in range(raw_data['num_timesteps']):
+
+ # Get all data
+ gt_ids = raw_data['gt_ids'][t]
+ gt_dets = raw_data['gt_dets'][t]
+ gt_classes = raw_data['gt_classes'][t]
+ gt_visibility = raw_data['visibility'][t]
+ gt_conf = raw_data['gt_conf'][t]
+
+ gt_zero_marked = raw_data['gt_extras'][t]['zero_marked']
+
+ tracker_ids = raw_data['tracker_ids'][t]
+ tracker_dets = raw_data['tracker_dets'][t]
+ tracker_classes = raw_data['tracker_classes'][t]
+ tracker_confidences = raw_data['tracker_confidences'][t]
+ similarity_scores = raw_data['similarity_scores'][t]
+
+ # Evaluation is ONLY valid for pedestrian class
+ if len(tracker_classes) > 0 and np.max(tracker_classes) > 1:
+ raise TrackEvalException(
+ 'Evaluation is only valid for pedestrian class. Non pedestrian class (%i) found in sequence %s at '
+ 'timestep %i.' % (np.max(tracker_classes), raw_data['seq'], t))
+
+ # Match tracker and gt dets (with hungarian algorithm) and remove tracker dets which match with gt dets
+ # which are labeled as belonging to a distractor class.
+ to_remove_tracker = np.array([], np.int)
+ if self.do_preproc and self.benchmark != 'MOT15' and gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
+
+ # Check all classes are valid:
+ invalid_classes = np.setdiff1d(np.unique(gt_classes), self.valid_class_numbers)
+ if len(invalid_classes) > 0:
+ print(' '.join([str(x) for x in invalid_classes]))
+ raise(TrackEvalException('Attempting to evaluate using invalid gt classes. '
+ 'This warning only triggers if preprocessing is performed, '
+ 'e.g. not for MOT15 or where prepropressing is explicitly disabled. '
+ 'Please either check your gt data, or disable preprocessing. '
+ 'The following invalid classes were found in timestep ' + str(t) + ': ' +
+ ' '.join([str(x) for x in invalid_classes])))
+
+ matching_scores = similarity_scores.copy()
+
+ matching_scores[matching_scores < 0.4 - np.finfo('float').eps] = 0
+
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_rows = match_rows[actually_matched_mask]
+ match_cols = match_cols[actually_matched_mask]
+
+ is_distractor_class = np.logical_not(np.isin(gt_classes[match_rows], cls_id))
+ if self.benchmark == 'HT':
+ is_invisible_class = gt_visibility[match_rows] < np.finfo('float').eps
+ low_conf_class = gt_conf[match_rows] < np.finfo('float').eps
+ are_distractors = np.logical_or(is_invisible_class, is_distractor_class, low_conf_class)
+ to_remove_tracker = match_cols[are_distractors]
+ else:
+ to_remove_tracker = match_cols[is_distractor_class]
+
+ # Apply preprocessing to remove all unwanted tracker dets.
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+
+ # Remove gt detections marked as to remove (zero marked), and also remove gt detections not in pedestrian
+ if self.do_preproc and self.benchmark == 'HT':
+ gt_to_keep_mask = (np.not_equal(gt_zero_marked, 0)) & \
+ (np.equal(gt_classes, cls_id)) & \
+ (gt_visibility > 0.) & \
+ (gt_conf > 0.)
+
+ else:
+ # There are no classes for MOT15
+ gt_to_keep_mask = np.not_equal(gt_zero_marked, 0)
+ data['gt_ids'][t] = gt_ids[gt_to_keep_mask]
+ data['gt_dets'][t] = gt_dets[gt_to_keep_mask, :]
+ data['similarity_scores'][t] = similarity_scores[gt_to_keep_mask]
+ data['gt_visibility'][t] = gt_visibility # No mask!
+
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+
+ # Ensure again that ids are unique per timestep after preproc.
+ self._check_unique_ids(data, after_preproc=True)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t, box_format='xywh')
+ return similarity_scores
diff --git a/val_utils/trackeval/datasets/kitti_2d_box.py b/val_utils/trackeval/datasets/kitti_2d_box.py
new file mode 100644
index 0000000000000000000000000000000000000000..c582c4378fc347d4c3b9f264523784c2b79b76d8
--- /dev/null
+++ b/val_utils/trackeval/datasets/kitti_2d_box.py
@@ -0,0 +1,389 @@
+
+import os
+import csv
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_dataset import _BaseDataset
+from .. import utils
+from ..utils import TrackEvalException
+from .. import _timing
+
+
+class Kitti2DBox(_BaseDataset):
+ """Dataset class for KITTI 2D bounding box tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/kitti/kitti_2d_box_train'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/kitti/kitti_2d_box_train/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['car', 'pedestrian'], # Valid: ['car', 'pedestrian']
+ 'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val', 'training_minus_val', 'test'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+ self.gt_fol = self.config['GT_FOLDER']
+ self.tracker_fol = self.config['TRACKERS_FOLDER']
+ self.should_classes_combine = False
+ self.use_super_categories = False
+ self.data_is_zipped = self.config['INPUT_AS_ZIP']
+
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+
+ self.max_occlusion = 2
+ self.max_truncation = 0
+ self.min_height = 25
+
+ # Get classes to eval
+ self.valid_classes = ['car', 'pedestrian']
+ self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only classes [car, pedestrian] are valid.')
+ self.class_name_to_class_id = {'car': 1, 'van': 2, 'truck': 3, 'pedestrian': 4, 'person': 5, # person sitting
+ 'cyclist': 6, 'tram': 7, 'misc': 8, 'dontcare': 9, 'car_2': 1}
+
+ # Get sequences to eval and check gt files exist
+ self.seq_list = []
+ self.seq_lengths = {}
+ seqmap_name = 'evaluate_tracking.seqmap.' + self.config['SPLIT_TO_EVAL']
+ seqmap_file = os.path.join(self.gt_fol, seqmap_name)
+ if not os.path.isfile(seqmap_file):
+ raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
+ with open(seqmap_file) as fp:
+ dialect = csv.Sniffer().sniff(fp.read(1024))
+ fp.seek(0)
+ reader = csv.reader(fp, dialect)
+ for row in reader:
+ if len(row) >= 4:
+ seq = row[0]
+ self.seq_list.append(seq)
+ self.seq_lengths[seq] = int(row[3])
+ if not self.data_is_zipped:
+ curr_file = os.path.join(self.gt_fol, 'label_02', seq + '.txt')
+ if not os.path.isfile(curr_file):
+ raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.gt_fol, 'data.zip')
+ if not os.path.isfile(curr_file):
+ raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ for tracker in self.tracker_list:
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ if not os.path.isfile(curr_file):
+ raise TrackEvalException('Tracker file not found: ' + tracker + '/' + os.path.basename(curr_file))
+ else:
+ for seq in self.seq_list:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+ if not os.path.isfile(curr_file):
+ raise TrackEvalException(
+ 'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
+ curr_file))
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the kitti 2D box format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
+ [gt_extras] : list (for each timestep) of dicts (for each extra) of 1D NDArrays (for each det).
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ """
+ # File location
+ if self.data_is_zipped:
+ if is_gt:
+ zip_file = os.path.join(self.gt_fol, 'data.zip')
+ else:
+ zip_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ file = seq + '.txt'
+ else:
+ zip_file = None
+ if is_gt:
+ file = os.path.join(self.gt_fol, 'label_02', seq + '.txt')
+ else:
+ file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+
+ # Ignore regions
+ if is_gt:
+ crowd_ignore_filter = {2: ['dontcare']}
+ else:
+ crowd_ignore_filter = None
+
+ # Valid classes
+ valid_filter = {2: [x for x in self.class_list]}
+ if is_gt:
+ if 'car' in self.class_list:
+ valid_filter[2].append('van')
+ if 'pedestrian' in self.class_list:
+ valid_filter[2] += ['person']
+
+ # Convert kitti class strings to class ids
+ convert_filter = {2: self.class_name_to_class_id}
+
+ # Load raw data from text file
+ read_data, ignore_data = self._load_simple_text_file(file, time_col=0, id_col=1, remove_negative_ids=True,
+ valid_filter=valid_filter,
+ crowd_ignore_filter=crowd_ignore_filter,
+ convert_filter=convert_filter,
+ is_zipped=self.data_is_zipped, zip_file=zip_file)
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq]
+ data_keys = ['ids', 'classes', 'dets']
+ if is_gt:
+ data_keys += ['gt_crowd_ignore_regions', 'gt_extras']
+ else:
+ data_keys += ['tracker_confidences']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+
+ # Check for any extra time keys
+ current_time_keys = [str(t) for t in range(num_timesteps)]
+ extra_time_keys = [x for x in read_data.keys() if x not in current_time_keys]
+ if len(extra_time_keys) > 0:
+ if is_gt:
+ text = 'Ground-truth'
+ else:
+ text = 'Tracking'
+ raise TrackEvalException(
+ text + ' data contains the following invalid timesteps in seq %s: ' % seq + ', '.join(
+ [str(x) + ', ' for x in extra_time_keys]))
+
+ for t in range(num_timesteps):
+ time_key = str(t)
+ if time_key in read_data.keys():
+ time_data = np.asarray(read_data[time_key], dtype=np.float)
+ raw_data['dets'][t] = np.atleast_2d(time_data[:, 6:10])
+ raw_data['ids'][t] = np.atleast_1d(time_data[:, 1]).astype(int)
+ raw_data['classes'][t] = np.atleast_1d(time_data[:, 2]).astype(int)
+ if is_gt:
+ gt_extras_dict = {'truncation': np.atleast_1d(time_data[:, 3].astype(int)),
+ 'occlusion': np.atleast_1d(time_data[:, 4].astype(int))}
+ raw_data['gt_extras'][t] = gt_extras_dict
+ else:
+ if time_data.shape[1] > 17:
+ raw_data['tracker_confidences'][t] = np.atleast_1d(time_data[:, 17])
+ else:
+ raw_data['tracker_confidences'][t] = np.ones(time_data.shape[0])
+ else:
+ raw_data['dets'][t] = np.empty((0, 4))
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+ if is_gt:
+ gt_extras_dict = {'truncation': np.empty(0),
+ 'occlusion': np.empty(0)}
+ raw_data['gt_extras'][t] = gt_extras_dict
+ else:
+ raw_data['tracker_confidences'][t] = np.empty(0)
+ if is_gt:
+ if time_key in ignore_data.keys():
+ time_ignore = np.asarray(ignore_data[time_key], dtype=np.float)
+ raw_data['gt_crowd_ignore_regions'][t] = np.atleast_2d(time_ignore[:, 6:10])
+ else:
+ raw_data['gt_crowd_ignore_regions'][t] = np.empty((0, 4))
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+ raw_data['num_timesteps'] = num_timesteps
+ raw_data['seq'] = seq
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+
+ KITTI:
+ In KITTI, the 4 preproc steps are as follow:
+ 1) There are two classes (pedestrian and car) which are evaluated separately.
+ 2) For the pedestrian class, the 'person' class is distractor objects (people sitting).
+ For the car class, the 'van' class are distractor objects.
+ GT boxes marked as having occlusion level > 2 or truncation level > 0 are also treated as
+ distractors.
+ 3) Crowd ignore regions are used to remove unmatched detections. Also unmatched detections with
+ height <= 25 pixels are removed.
+ 4) Distractor gt dets (including truncated and occluded) are removed.
+ """
+ if cls == 'pedestrian':
+ distractor_classes = [self.class_name_to_class_id['person']]
+ elif cls == 'car':
+ distractor_classes = [self.class_name_to_class_id['van']]
+ else:
+ raise (TrackEvalException('Class %s is not evaluatable' % cls))
+ cls_id = self.class_name_to_class_id[cls]
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+ for t in range(raw_data['num_timesteps']):
+
+ # Only extract relevant dets for this class for preproc and eval (cls + distractor classes)
+ gt_class_mask = np.sum([raw_data['gt_classes'][t] == c for c in [cls_id] + distractor_classes], axis=0)
+ gt_class_mask = gt_class_mask.astype(np.bool)
+ gt_ids = raw_data['gt_ids'][t][gt_class_mask]
+ gt_dets = raw_data['gt_dets'][t][gt_class_mask]
+ gt_classes = raw_data['gt_classes'][t][gt_class_mask]
+ gt_occlusion = raw_data['gt_extras'][t]['occlusion'][gt_class_mask]
+ gt_truncation = raw_data['gt_extras'][t]['truncation'][gt_class_mask]
+
+ tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
+ tracker_class_mask = tracker_class_mask.astype(np.bool)
+ tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
+ tracker_dets = raw_data['tracker_dets'][t][tracker_class_mask]
+ tracker_confidences = raw_data['tracker_confidences'][t][tracker_class_mask]
+ similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
+
+ # Match tracker and gt dets (with hungarian algorithm) and remove tracker dets which match with gt dets
+ # which are labeled as truncated, occluded, or belonging to a distractor class.
+ to_remove_matched = np.array([], np.int)
+ unmatched_indices = np.arange(tracker_ids.shape[0])
+ if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
+ matching_scores = similarity_scores.copy()
+ matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_rows = match_rows[actually_matched_mask]
+ match_cols = match_cols[actually_matched_mask]
+
+ is_distractor_class = np.isin(gt_classes[match_rows], distractor_classes)
+ is_occluded_or_truncated = np.logical_or(
+ gt_occlusion[match_rows] > self.max_occlusion + np.finfo('float').eps,
+ gt_truncation[match_rows] > self.max_truncation + np.finfo('float').eps)
+ to_remove_matched = np.logical_or(is_distractor_class, is_occluded_or_truncated)
+ to_remove_matched = match_cols[to_remove_matched]
+ unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
+
+ # For unmatched tracker dets, also remove those smaller than a minimum height.
+ unmatched_tracker_dets = tracker_dets[unmatched_indices, :]
+ unmatched_heights = unmatched_tracker_dets[:, 3] - unmatched_tracker_dets[:, 1]
+ is_too_small = unmatched_heights <= self.min_height + np.finfo('float').eps
+
+ # For unmatched tracker dets, also remove those that are greater than 50% within a crowd ignore region.
+ crowd_ignore_regions = raw_data['gt_crowd_ignore_regions'][t]
+ intersection_with_ignore_region = self._calculate_box_ious(unmatched_tracker_dets, crowd_ignore_regions,
+ box_format='x0y0x1y1', do_ioa=True)
+ is_within_crowd_ignore_region = np.any(intersection_with_ignore_region > 0.5 + np.finfo('float').eps, axis=1)
+
+ # Apply preprocessing to remove all unwanted tracker dets.
+ to_remove_unmatched = unmatched_indices[np.logical_or(is_too_small, is_within_crowd_ignore_region)]
+ to_remove_tracker = np.concatenate((to_remove_matched, to_remove_unmatched), axis=0)
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+
+ # Also remove gt dets that were only useful for preprocessing and are not needed for evaluation.
+ # These are those that are occluded, truncated and from distractor objects.
+ gt_to_keep_mask = (np.less_equal(gt_occlusion, self.max_occlusion)) & \
+ (np.less_equal(gt_truncation, self.max_truncation)) & \
+ (np.equal(gt_classes, cls_id))
+ data['gt_ids'][t] = gt_ids[gt_to_keep_mask]
+ data['gt_dets'][t] = gt_dets[gt_to_keep_mask, :]
+ data['similarity_scores'][t] = similarity_scores[gt_to_keep_mask]
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+
+ # Ensure that ids are unique per timestep.
+ self._check_unique_ids(data)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t, box_format='x0y0x1y1')
+ return similarity_scores
diff --git a/val_utils/trackeval/datasets/kitti_mots.py b/val_utils/trackeval/datasets/kitti_mots.py
new file mode 100644
index 0000000000000000000000000000000000000000..9e04d3c2b128ce0dc80c5180a40895ef1bc8dc25
--- /dev/null
+++ b/val_utils/trackeval/datasets/kitti_mots.py
@@ -0,0 +1,426 @@
+import os
+import csv
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_dataset import _BaseDataset
+from .. import utils
+from .. import _timing
+from ..utils import TrackEvalException
+
+
+class KittiMOTS(_BaseDataset):
+ """Dataset class for KITTI MOTS tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/kitti/kitti_mots_val'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/kitti/kitti_mots_val'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['car', 'pedestrian'], # Valid: ['car', 'pedestrian']
+ 'SPLIT_TO_EVAL': 'val', # Valid: 'training', 'val'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER)
+ 'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/split_to_eval.seqmap)
+ 'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
+ 'GT_LOC_FORMAT': '{gt_folder}/label_02/{seq}.txt', # format of gt localization
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+ self.gt_fol = self.config['GT_FOLDER']
+ self.tracker_fol = self.config['TRACKERS_FOLDER']
+ self.split_to_eval = self.config['SPLIT_TO_EVAL']
+ self.should_classes_combine = False
+ self.use_super_categories = False
+ self.data_is_zipped = self.config['INPUT_AS_ZIP']
+
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+
+ # Get classes to eval
+ self.valid_classes = ['car', 'pedestrian']
+ self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. '
+ 'Only classes [car, pedestrian] are valid.')
+ self.class_name_to_class_id = {'car': '1', 'pedestrian': '2', 'ignore': '10'}
+
+ # Get sequences to eval and check gt files exist
+ self.seq_list, self.seq_lengths = self._get_seq_info()
+ if len(self.seq_list) < 1:
+ raise TrackEvalException('No sequences are selected to be evaluated.')
+
+ # Check gt files exist
+ for seq in self.seq_list:
+ if not self.data_is_zipped:
+ curr_file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
+ if not os.path.isfile(curr_file):
+ print('GT file not found ' + curr_file)
+ raise TrackEvalException('GT file not found for sequence: ' + seq)
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.gt_fol, 'data.zip')
+ if not os.path.isfile(curr_file):
+ raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ for tracker in self.tracker_list:
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException('Tracker file not found: ' + tracker + '/' + os.path.basename(curr_file))
+ else:
+ for seq in self.seq_list:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException(
+ 'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
+ curr_file))
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _get_seq_info(self):
+ seq_list = []
+ seq_lengths = {}
+ seqmap_name = 'evaluate_mots.seqmap.' + self.config['SPLIT_TO_EVAL']
+
+ if self.config["SEQ_INFO"]:
+ seq_list = list(self.config["SEQ_INFO"].keys())
+ seq_lengths = self.config["SEQ_INFO"]
+ else:
+ if self.config["SEQMAP_FILE"]:
+ seqmap_file = self.config["SEQMAP_FILE"]
+ else:
+ if self.config["SEQMAP_FOLDER"] is None:
+ seqmap_file = os.path.join(self.config['GT_FOLDER'], seqmap_name)
+ else:
+ seqmap_file = os.path.join(self.config["SEQMAP_FOLDER"], seqmap_name)
+ if not os.path.isfile(seqmap_file):
+ print('no seqmap found: ' + seqmap_file)
+ raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
+ with open(seqmap_file) as fp:
+ reader = csv.reader(fp)
+ for i, _ in enumerate(reader):
+ dialect = csv.Sniffer().sniff(fp.read(1024))
+ fp.seek(0)
+ reader = csv.reader(fp, dialect)
+ for row in reader:
+ if len(row) >= 4:
+ seq = "%04d" % int(row[0])
+ seq_list.append(seq)
+ seq_lengths[seq] = int(row[3]) + 1
+ return seq_list, seq_lengths
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the KITTI MOTS format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets]: list (for each timestep) of lists of detections.
+ [gt_ignore_region]: list (for each timestep) of masks for the ignore regions
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ """
+
+ # Only loaded when run to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ # File location
+ if self.data_is_zipped:
+ if is_gt:
+ zip_file = os.path.join(self.gt_fol, 'data.zip')
+ else:
+ zip_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ file = seq + '.txt'
+ else:
+ zip_file = None
+ if is_gt:
+ file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
+ else:
+ file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+
+ # Ignore regions
+ if is_gt:
+ crowd_ignore_filter = {2: ['10']}
+ else:
+ crowd_ignore_filter = None
+
+ # Load raw data from text file
+ read_data, ignore_data = self._load_simple_text_file(file, crowd_ignore_filter=crowd_ignore_filter,
+ is_zipped=self.data_is_zipped, zip_file=zip_file,
+ force_delimiters=' ')
+
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq]
+ data_keys = ['ids', 'classes', 'dets']
+ if is_gt:
+ data_keys += ['gt_ignore_region']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+
+ # Check for any extra time keys
+ current_time_keys = [str(t) for t in range(num_timesteps)]
+ extra_time_keys = [x for x in read_data.keys() if x not in current_time_keys]
+ if len(extra_time_keys) > 0:
+ if is_gt:
+ text = 'Ground-truth'
+ else:
+ text = 'Tracking'
+ raise TrackEvalException(
+ text + ' data contains the following invalid timesteps in seq %s: ' % seq + ', '.join(
+ [str(x) + ', ' for x in extra_time_keys]))
+
+ for t in range(num_timesteps):
+ time_key = str(t)
+ # list to collect all masks of a timestep to check for overlapping areas
+ all_masks = []
+ if time_key in read_data.keys():
+ try:
+ raw_data['dets'][t] = [{'size': [int(region[3]), int(region[4])],
+ 'counts': region[5].encode(encoding='UTF-8')}
+ for region in read_data[time_key]]
+ raw_data['ids'][t] = np.atleast_1d([region[1] for region in read_data[time_key]]).astype(int)
+ raw_data['classes'][t] = np.atleast_1d([region[2] for region in read_data[time_key]]).astype(int)
+ all_masks += raw_data['dets'][t]
+ except IndexError:
+ self._raise_index_error(is_gt, tracker, seq)
+ except ValueError:
+ self._raise_value_error(is_gt, tracker, seq)
+ else:
+ raw_data['dets'][t] = []
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+ if is_gt:
+ if time_key in ignore_data.keys():
+ try:
+ time_ignore = [{'size': [int(region[3]), int(region[4])],
+ 'counts': region[5].encode(encoding='UTF-8')}
+ for region in ignore_data[time_key]]
+ raw_data['gt_ignore_region'][t] = mask_utils.merge([mask for mask in time_ignore],
+ intersect=False)
+ all_masks += [raw_data['gt_ignore_region'][t]]
+ except IndexError:
+ self._raise_index_error(is_gt, tracker, seq)
+ except ValueError:
+ self._raise_value_error(is_gt, tracker, seq)
+ else:
+ raw_data['gt_ignore_region'][t] = mask_utils.merge([], intersect=False)
+
+ # check for overlapping masks
+ if all_masks:
+ masks_merged = all_masks[0]
+ for mask in all_masks[1:]:
+ if mask_utils.area(mask_utils.merge([masks_merged, mask], intersect=True)) != 0.0:
+ raise TrackEvalException(
+ 'Tracker has overlapping masks. Tracker: ' + tracker + ' Seq: ' + seq + ' Timestep: ' + str(
+ t))
+ masks_merged = mask_utils.merge([masks_merged, mask], intersect=False)
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+ raw_data["num_timesteps"] = num_timesteps
+ raw_data['seq'] = seq
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detection masks.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+
+ KITTI MOTS:
+ In KITTI MOTS, the 4 preproc steps are as follow:
+ 1) There are two classes (car and pedestrian) which are evaluated separately.
+ 2) There are no ground truth detections marked as to be removed/distractor classes.
+ Therefore also no matched tracker detections are removed.
+ 3) Ignore regions are used to remove unmatched detections (at least 50% overlap with ignore region).
+ 4) There are no ground truth detections (e.g. those of distractor classes) to be removed.
+ """
+ # Check that input data has unique ids
+ self._check_unique_ids(raw_data)
+
+ cls_id = int(self.class_name_to_class_id[cls])
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+ for t in range(raw_data['num_timesteps']):
+
+ # Only extract relevant dets for this class for preproc and eval (cls)
+ gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
+ gt_class_mask = gt_class_mask.astype(np.bool)
+ gt_ids = raw_data['gt_ids'][t][gt_class_mask]
+ gt_dets = [raw_data['gt_dets'][t][ind] for ind in range(len(gt_class_mask)) if gt_class_mask[ind]]
+
+ tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
+ tracker_class_mask = tracker_class_mask.astype(np.bool)
+ tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
+ tracker_dets = [raw_data['tracker_dets'][t][ind] for ind in range(len(tracker_class_mask)) if
+ tracker_class_mask[ind]]
+ similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
+
+ # Match tracker and gt dets (with hungarian algorithm)
+ unmatched_indices = np.arange(tracker_ids.shape[0])
+ if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
+ matching_scores = similarity_scores.copy()
+ matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = -10000
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_cols = match_cols[actually_matched_mask]
+
+ unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
+
+ # For unmatched tracker dets, remove those that are greater than 50% within a crowd ignore region.
+ unmatched_tracker_dets = [tracker_dets[i] for i in range(len(tracker_dets)) if i in unmatched_indices]
+ ignore_region = raw_data['gt_ignore_region'][t]
+ intersection_with_ignore_region = self._calculate_mask_ious(unmatched_tracker_dets, [ignore_region],
+ is_encoded=True, do_ioa=True)
+ is_within_ignore_region = np.any(intersection_with_ignore_region > 0.5 + np.finfo('float').eps, axis=1)
+
+ # Apply preprocessing to remove unwanted tracker dets.
+ to_remove_tracker = unmatched_indices[is_within_ignore_region]
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+
+ # Keep all ground truth detections
+ data['gt_ids'][t] = gt_ids
+ data['gt_dets'][t] = gt_dets
+ data['similarity_scores'][t] = similarity_scores
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+ data['cls'] = cls
+
+ # Ensure again that ids are unique per timestep after preproc.
+ self._check_unique_ids(data, after_preproc=True)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
+ return similarity_scores
+
+ @staticmethod
+ def _raise_index_error(is_gt, tracker, seq):
+ """
+ Auxiliary method to raise an evaluation error in case of an index error while reading files.
+ :param is_gt: whether gt or tracker data is read
+ :param tracker: the name of the tracker
+ :param seq: the name of the seq
+ :return: None
+ """
+ if is_gt:
+ err = 'Cannot load gt data from sequence %s, because there are not enough ' \
+ 'columns in the data.' % seq
+ raise TrackEvalException(err)
+ else:
+ err = 'Cannot load tracker data from tracker %s, sequence %s, because there are not enough ' \
+ 'columns in the data.' % (tracker, seq)
+ raise TrackEvalException(err)
+
+ @staticmethod
+ def _raise_value_error(is_gt, tracker, seq):
+ """
+ Auxiliary method to raise an evaluation error in case of an value error while reading files.
+ :param is_gt: whether gt or tracker data is read
+ :param tracker: the name of the tracker
+ :param seq: the name of the seq
+ :return: None
+ """
+ if is_gt:
+ raise TrackEvalException(
+ 'GT data for sequence %s cannot be converted to the right format. Is data corrupted?' % seq)
+ else:
+ raise TrackEvalException(
+ 'Tracking data from tracker %s, sequence %s cannot be converted to the right format. '
+ 'Is data corrupted?' % (tracker, seq))
diff --git a/val_utils/trackeval/datasets/mot_challenge_2d_box.py b/val_utils/trackeval/datasets/mot_challenge_2d_box.py
new file mode 100644
index 0000000000000000000000000000000000000000..68aac5127374cf8d0a6f62392e7c490e6c252b79
--- /dev/null
+++ b/val_utils/trackeval/datasets/mot_challenge_2d_box.py
@@ -0,0 +1,437 @@
+import os
+import csv
+import configparser
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_dataset import _BaseDataset
+from .. import utils
+from .. import _timing
+from ..utils import TrackEvalException
+
+
+class MotChallenge2DBox(_BaseDataset):
+ """Dataset class for MOT Challenge 2D bounding box tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
+ 'BENCHMARK': 'MOT17', # Valid: 'MOT17', 'MOT16', 'MOT20', 'MOT15'
+ 'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test', 'all'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'DO_PREPROC': True, # Whether to perform preprocessing (never done for MOT15)
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/seqmaps)
+ 'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/benchmark-split_to_eval)
+ 'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
+ 'GT_LOC_FORMAT': '{gt_folder}/{seq}/gt/gt.txt', # '{gt_folder}/{seq}/gt/gt.txt'
+ 'SKIP_SPLIT_FOL': False, # If False, data is in GT_FOLDER/BENCHMARK-SPLIT_TO_EVAL/ and in
+ # TRACKERS_FOLDER/BENCHMARK-SPLIT_TO_EVAL/tracker/
+ # If True, then the middle 'benchmark-split' folder is skipped for both.
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+
+ self.benchmark = self.config['BENCHMARK']
+ gt_set = self.config['BENCHMARK'] + '-' + self.config['SPLIT_TO_EVAL']
+ self.gt_set = gt_set
+ if not self.config['SKIP_SPLIT_FOL']:
+ split_fol = gt_set
+ else:
+ split_fol = ''
+ self.gt_fol = os.path.join(self.config['GT_FOLDER'], split_fol)
+ self.tracker_fol = os.path.join(self.config['TRACKERS_FOLDER'], split_fol)
+ self.should_classes_combine = False
+ self.use_super_categories = False
+ self.data_is_zipped = self.config['INPUT_AS_ZIP']
+ self.do_preproc = self.config['DO_PREPROC']
+
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+
+ # Get classes to eval
+ self.valid_classes = ['pedestrian']
+ self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only pedestrian class is valid.')
+ self.class_name_to_class_id = {'pedestrian': 1, 'person_on_vehicle': 2, 'car': 3, 'bicycle': 4, 'motorbike': 5,
+ 'non_mot_vehicle': 6, 'static_person': 7, 'distractor': 8, 'occluder': 9,
+ 'occluder_on_ground': 10, 'occluder_full': 11, 'reflection': 12, 'crowd': 13}
+ self.valid_class_numbers = list(self.class_name_to_class_id.values())
+
+ # Get sequences to eval and check gt files exist
+ self.seq_list, self.seq_lengths = self._get_seq_info()
+ if len(self.seq_list) < 1:
+ raise TrackEvalException('No sequences are selected to be evaluated.')
+
+ # Check gt files exist
+ for seq in self.seq_list:
+ if not self.data_is_zipped:
+ curr_file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
+ if not os.path.isfile(curr_file):
+ print('GT file not found ' + curr_file)
+ raise TrackEvalException('GT file not found for sequence: ' + seq)
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.gt_fol, 'data.zip')
+ if not os.path.isfile(curr_file):
+ print('GT file not found ' + curr_file)
+ raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ for tracker in self.tracker_list:
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException('Tracker file not found: ' + tracker + '/' + os.path.basename(curr_file))
+ else:
+ for seq in self.seq_list:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException(
+ 'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
+ curr_file))
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _get_seq_info(self):
+ seq_list = []
+ seq_lengths = {}
+ if self.config["SEQ_INFO"]:
+ seq_list = list(self.config["SEQ_INFO"].keys())
+ seq_lengths = self.config["SEQ_INFO"]
+
+ # If sequence length is 'None' tries to read sequence length from .ini files.
+ for seq, seq_length in seq_lengths.items():
+ if seq_length is None:
+ ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
+ if not os.path.isfile(ini_file):
+ raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
+ ini_data = configparser.ConfigParser()
+ ini_data.read(ini_file)
+ seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
+
+ else:
+ if self.config["SEQMAP_FILE"]:
+ seqmap_file = self.config["SEQMAP_FILE"]
+ else:
+ if self.config["SEQMAP_FOLDER"] is None:
+ seqmap_file = os.path.join(self.config['GT_FOLDER'], 'seqmaps', self.gt_set + '.txt')
+ else:
+ seqmap_file = os.path.join(self.config["SEQMAP_FOLDER"], self.gt_set + '.txt')
+ if not os.path.isfile(seqmap_file):
+ print('no seqmap found: ' + seqmap_file)
+ raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
+ with open(seqmap_file) as fp:
+ reader = csv.reader(fp)
+ for i, row in enumerate(reader):
+ if i == 0 or row[0] == '':
+ continue
+ seq = row[0]
+ seq_list.append(seq)
+ ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
+ if not os.path.isfile(ini_file):
+ raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
+ ini_data = configparser.ConfigParser()
+ ini_data.read(ini_file)
+ seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
+ return seq_list, seq_lengths
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the MOT Challenge 2D box format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
+ [gt_extras] : list (for each timestep) of dicts (for each extra) of 1D NDArrays (for each det).
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ """
+ # File location
+ if self.data_is_zipped:
+ if is_gt:
+ zip_file = os.path.join(self.gt_fol, 'data.zip')
+ else:
+ zip_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ file = seq + '.txt'
+ else:
+ zip_file = None
+ if is_gt:
+ file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
+ else:
+ file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+
+ # Load raw data from text file
+ read_data, ignore_data = self._load_simple_text_file(file, is_zipped=self.data_is_zipped, zip_file=zip_file)
+
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq]
+ data_keys = ['ids', 'classes', 'dets']
+ if is_gt:
+ data_keys += ['gt_crowd_ignore_regions', 'gt_extras']
+ else:
+ data_keys += ['tracker_confidences']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+
+ # Check for any extra time keys
+ current_time_keys = [str( t+ 1) for t in range(num_timesteps)]
+ extra_time_keys = [x for x in read_data.keys() if x not in current_time_keys]
+ if len(extra_time_keys) > 0:
+ if is_gt:
+ text = 'Ground-truth'
+ else:
+ text = 'Tracking'
+ raise TrackEvalException(
+ text + ' data contains the following invalid timesteps in seq %s: ' % seq + ', '.join(
+ [str(x) + ', ' for x in extra_time_keys]))
+
+ for t in range(num_timesteps):
+ time_key = str(t+1)
+ if time_key in read_data.keys():
+ try:
+ time_data = np.asarray(read_data[time_key], dtype=np.float)
+ except ValueError:
+ if is_gt:
+ raise TrackEvalException(
+ 'Cannot convert gt data for sequence %s to float. Is data corrupted?' % seq)
+ else:
+ raise TrackEvalException(
+ 'Cannot convert tracking data from tracker %s, sequence %s to float. Is data corrupted?' % (
+ tracker, seq))
+ try:
+ raw_data['dets'][t] = np.atleast_2d(time_data[:, 2:6])
+ raw_data['ids'][t] = np.atleast_1d(time_data[:, 1]).astype(int)
+ except IndexError:
+ if is_gt:
+ err = 'Cannot load gt data from sequence %s, because there is not enough ' \
+ 'columns in the data.' % seq
+ raise TrackEvalException(err)
+ else:
+ err = 'Cannot load tracker data from tracker %s, sequence %s, because there is not enough ' \
+ 'columns in the data.' % (tracker, seq)
+ raise TrackEvalException(err)
+ if time_data.shape[1] >= 8:
+ raw_data['classes'][t] = np.atleast_1d(time_data[:, 7]).astype(int)
+ else:
+ if not is_gt:
+ raw_data['classes'][t] = np.ones_like(raw_data['ids'][t])
+ else:
+ raise TrackEvalException(
+ 'GT data is not in a valid format, there is not enough rows in seq %s, timestep %i.' % (
+ seq, t))
+ if is_gt:
+ gt_extras_dict = {'zero_marked': np.atleast_1d(time_data[:, 6].astype(int))}
+ raw_data['gt_extras'][t] = gt_extras_dict
+ else:
+ raw_data['tracker_confidences'][t] = np.atleast_1d(time_data[:, 6])
+ else:
+ raw_data['dets'][t] = np.empty((0, 4))
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+ if is_gt:
+ gt_extras_dict = {'zero_marked': np.empty(0)}
+ raw_data['gt_extras'][t] = gt_extras_dict
+ else:
+ raw_data['tracker_confidences'][t] = np.empty(0)
+ if is_gt:
+ raw_data['gt_crowd_ignore_regions'][t] = np.empty((0, 4))
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+ raw_data['num_timesteps'] = num_timesteps
+ raw_data['seq'] = seq
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+
+ MOT Challenge:
+ In MOT Challenge, the 4 preproc steps are as follow:
+ 1) There is only one class (pedestrian) to be evaluated, but all other classes are used for preproc.
+ 2) Predictions are matched against all gt boxes (regardless of class), those matching with distractor
+ objects are removed.
+ 3) There is no crowd ignore regions.
+ 4) All gt dets except pedestrian are removed, also removes pedestrian gt dets marked with zero_marked.
+ """
+ # Check that input data has unique ids
+ self._check_unique_ids(raw_data)
+
+ distractor_class_names = ['person_on_vehicle', 'static_person', 'distractor', 'reflection']
+ if self.benchmark == 'MOT20':
+ distractor_class_names.append('non_mot_vehicle')
+ distractor_classes = [self.class_name_to_class_id[x] for x in distractor_class_names]
+ cls_id = self.class_name_to_class_id[cls]
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+ for t in range(raw_data['num_timesteps']):
+
+ # Get all data
+ gt_ids = raw_data['gt_ids'][t]
+ gt_dets = raw_data['gt_dets'][t]
+ gt_classes = raw_data['gt_classes'][t]
+ gt_zero_marked = raw_data['gt_extras'][t]['zero_marked']
+
+ tracker_ids = raw_data['tracker_ids'][t]
+ tracker_dets = raw_data['tracker_dets'][t]
+ tracker_classes = raw_data['tracker_classes'][t]
+ tracker_confidences = raw_data['tracker_confidences'][t]
+ similarity_scores = raw_data['similarity_scores'][t]
+
+ # Evaluation is ONLY valid for pedestrian class
+ if len(tracker_classes) > 0 and np.max(tracker_classes) > 1:
+ raise TrackEvalException(
+ 'Evaluation is only valid for pedestrian class. Non pedestrian class (%i) found in sequence %s at '
+ 'timestep %i.' % (np.max(tracker_classes), raw_data['seq'], t))
+
+ # Match tracker and gt dets (with hungarian algorithm) and remove tracker dets which match with gt dets
+ # which are labeled as belonging to a distractor class.
+ to_remove_tracker = np.array([], np.int)
+ if self.do_preproc and self.benchmark != 'MOT15' and gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
+
+ # Check all classes are valid:
+ invalid_classes = np.setdiff1d(np.unique(gt_classes), self.valid_class_numbers)
+ if len(invalid_classes) > 0:
+ print(' '.join([str(x) for x in invalid_classes]))
+ raise(TrackEvalException('Attempting to evaluate using invalid gt classes. '
+ 'This warning only triggers if preprocessing is performed, '
+ 'e.g. not for MOT15 or where prepropressing is explicitly disabled. '
+ 'Please either check your gt data, or disable preprocessing. '
+ 'The following invalid classes were found in timestep ' + str(t) + ': ' +
+ ' '.join([str(x) for x in invalid_classes])))
+
+ matching_scores = similarity_scores.copy()
+ matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_rows = match_rows[actually_matched_mask]
+ match_cols = match_cols[actually_matched_mask]
+
+ is_distractor_class = np.isin(gt_classes[match_rows], distractor_classes)
+ to_remove_tracker = match_cols[is_distractor_class]
+
+ # Apply preprocessing to remove all unwanted tracker dets.
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+
+ # Remove gt detections marked as to remove (zero marked), and also remove gt detections not in pedestrian
+ # class (not applicable for MOT15)
+ if self.do_preproc and self.benchmark != 'MOT15':
+ gt_to_keep_mask = (np.not_equal(gt_zero_marked, 0)) & \
+ (np.equal(gt_classes, cls_id))
+ else:
+ # There are no classes for MOT15
+ gt_to_keep_mask = np.not_equal(gt_zero_marked, 0)
+ data['gt_ids'][t] = gt_ids[gt_to_keep_mask]
+ data['gt_dets'][t] = gt_dets[gt_to_keep_mask, :]
+ data['similarity_scores'][t] = similarity_scores[gt_to_keep_mask]
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+
+ # Ensure again that ids are unique per timestep after preproc.
+ self._check_unique_ids(data, after_preproc=True)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t, box_format='xywh')
+ return similarity_scores
diff --git a/val_utils/trackeval/datasets/mots_challenge.py b/val_utils/trackeval/datasets/mots_challenge.py
new file mode 100644
index 0000000000000000000000000000000000000000..191b43842d1e5e6b358ab72fb95594279fe69aae
--- /dev/null
+++ b/val_utils/trackeval/datasets/mots_challenge.py
@@ -0,0 +1,446 @@
+import os
+import csv
+import configparser
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_dataset import _BaseDataset
+from .. import utils
+from .. import _timing
+from ..utils import TrackEvalException
+
+
+class MOTSChallenge(_BaseDataset):
+ """Dataset class for MOTS Challenge tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
+ 'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/seqmaps)
+ 'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/MOTS-split_to_eval)
+ 'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
+ 'GT_LOC_FORMAT': '{gt_folder}/{seq}/gt/gt.txt', # '{gt_folder}/{seq}/gt/gt.txt'
+ 'SKIP_SPLIT_FOL': False, # If False, data is in GT_FOLDER/MOTS-SPLIT_TO_EVAL/ and in
+ # TRACKERS_FOLDER/MOTS-SPLIT_TO_EVAL/tracker/
+ # If True, then the middle 'MOTS-split' folder is skipped for both.
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+
+ self.benchmark = 'MOTS'
+ self.gt_set = self.benchmark + '-' + self.config['SPLIT_TO_EVAL']
+ if not self.config['SKIP_SPLIT_FOL']:
+ split_fol = self.gt_set
+ else:
+ split_fol = ''
+ self.gt_fol = os.path.join(self.config['GT_FOLDER'], split_fol)
+ self.tracker_fol = os.path.join(self.config['TRACKERS_FOLDER'], split_fol)
+ self.should_classes_combine = False
+ self.use_super_categories = False
+ self.data_is_zipped = self.config['INPUT_AS_ZIP']
+
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+
+ # Get classes to eval
+ self.valid_classes = ['pedestrian']
+ self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only pedestrian class is valid.')
+ self.class_name_to_class_id = {'pedestrian': '2', 'ignore': '10'}
+
+ # Get sequences to eval and check gt files exist
+ self.seq_list, self.seq_lengths = self._get_seq_info()
+ if len(self.seq_list) < 1:
+ raise TrackEvalException('No sequences are selected to be evaluated.')
+
+ # Check gt files exist
+ for seq in self.seq_list:
+ if not self.data_is_zipped:
+ curr_file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
+ if not os.path.isfile(curr_file):
+ print('GT file not found ' + curr_file)
+ raise TrackEvalException('GT file not found for sequence: ' + seq)
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.gt_fol, 'data.zip')
+ if not os.path.isfile(curr_file):
+ print('GT file not found ' + curr_file)
+ raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ for tracker in self.tracker_list:
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException('Tracker file not found: ' + tracker + '/' + os.path.basename(curr_file))
+ else:
+ for seq in self.seq_list:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException(
+ 'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
+ curr_file))
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _get_seq_info(self):
+ seq_list = []
+ seq_lengths = {}
+ if self.config["SEQ_INFO"]:
+ seq_list = list(self.config["SEQ_INFO"].keys())
+ seq_lengths = self.config["SEQ_INFO"]
+
+ # If sequence length is 'None' tries to read sequence length from .ini files.
+ for seq, seq_length in seq_lengths.items():
+ if seq_length is None:
+ ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
+ if not os.path.isfile(ini_file):
+ raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
+ ini_data = configparser.ConfigParser()
+ ini_data.read(ini_file)
+ seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
+
+ else:
+ if self.config["SEQMAP_FILE"]:
+ seqmap_file = self.config["SEQMAP_FILE"]
+ else:
+ if self.config["SEQMAP_FOLDER"] is None:
+ seqmap_file = os.path.join(self.config['GT_FOLDER'], 'seqmaps', self.gt_set + '.txt')
+ else:
+ seqmap_file = os.path.join(self.config["SEQMAP_FOLDER"], self.gt_set + '.txt')
+ if not os.path.isfile(seqmap_file):
+ print('no seqmap found: ' + seqmap_file)
+ raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
+ with open(seqmap_file) as fp:
+ reader = csv.reader(fp)
+ for i, row in enumerate(reader):
+ if i == 0 or row[0] == '':
+ continue
+ seq = row[0]
+ seq_list.append(seq)
+ ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
+ if not os.path.isfile(ini_file):
+ raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
+ ini_data = configparser.ConfigParser()
+ ini_data.read(ini_file)
+ seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
+ return seq_list, seq_lengths
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the MOTS Challenge format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets]: list (for each timestep) of lists of detections.
+ [gt_ignore_region]: list (for each timestep) of masks for the ignore regions
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ """
+
+ # Only loaded when run to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ # File location
+ if self.data_is_zipped:
+ if is_gt:
+ zip_file = os.path.join(self.gt_fol, 'data.zip')
+ else:
+ zip_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ file = seq + '.txt'
+ else:
+ zip_file = None
+ if is_gt:
+ file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
+ else:
+ file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+
+ # Ignore regions
+ if is_gt:
+ crowd_ignore_filter = {2: ['10']}
+ else:
+ crowd_ignore_filter = None
+
+ # Load raw data from text file
+ read_data, ignore_data = self._load_simple_text_file(file, crowd_ignore_filter=crowd_ignore_filter,
+ is_zipped=self.data_is_zipped, zip_file=zip_file,
+ force_delimiters=' ')
+
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq]
+ data_keys = ['ids', 'classes', 'dets']
+ if is_gt:
+ data_keys += ['gt_ignore_region']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+
+ # Check for any extra time keys
+ current_time_keys = [str(t + 1) for t in range(num_timesteps)]
+ extra_time_keys = [x for x in read_data.keys() if x not in current_time_keys]
+ if len(extra_time_keys) > 0:
+ if is_gt:
+ text = 'Ground-truth'
+ else:
+ text = 'Tracking'
+ raise TrackEvalException(
+ text + ' data contains the following invalid timesteps in seq %s: ' % seq + ', '.join(
+ [str(x) + ', ' for x in extra_time_keys]))
+
+ for t in range(num_timesteps):
+ time_key = str(t+1)
+ # list to collect all masks of a timestep to check for overlapping areas
+ all_masks = []
+ if time_key in read_data.keys():
+ try:
+ raw_data['dets'][t] = [{'size': [int(region[3]), int(region[4])],
+ 'counts': region[5].encode(encoding='UTF-8')}
+ for region in read_data[time_key]]
+ raw_data['ids'][t] = np.atleast_1d([region[1] for region in read_data[time_key]]).astype(int)
+ raw_data['classes'][t] = np.atleast_1d([region[2] for region in read_data[time_key]]).astype(int)
+ all_masks += raw_data['dets'][t]
+ except IndexError:
+ self._raise_index_error(is_gt, tracker, seq)
+ except ValueError:
+ self._raise_value_error(is_gt, tracker, seq)
+ else:
+ raw_data['dets'][t] = []
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+ if is_gt:
+ if time_key in ignore_data.keys():
+ try:
+ time_ignore = [{'size': [int(region[3]), int(region[4])],
+ 'counts': region[5].encode(encoding='UTF-8')}
+ for region in ignore_data[time_key]]
+ raw_data['gt_ignore_region'][t] = mask_utils.merge([mask for mask in time_ignore],
+ intersect=False)
+ all_masks += [raw_data['gt_ignore_region'][t]]
+ except IndexError:
+ self._raise_index_error(is_gt, tracker, seq)
+ except ValueError:
+ self._raise_value_error(is_gt, tracker, seq)
+ else:
+ raw_data['gt_ignore_region'][t] = mask_utils.merge([], intersect=False)
+
+ # check for overlapping masks
+ if all_masks:
+ masks_merged = all_masks[0]
+ for mask in all_masks[1:]:
+ if mask_utils.area(mask_utils.merge([masks_merged, mask], intersect=True)) != 0.0:
+ raise TrackEvalException(
+ 'Tracker has overlapping masks. Tracker: ' + tracker + ' Seq: ' + seq + ' Timestep: ' + str(
+ t))
+ masks_merged = mask_utils.merge([masks_merged, mask], intersect=False)
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+ raw_data['num_timesteps'] = num_timesteps
+ raw_data['seq'] = seq
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detection masks.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+
+ MOTS Challenge:
+ In MOTS Challenge, the 4 preproc steps are as follow:
+ 1) There is only one class (pedestrians) to be evaluated.
+ 2) There are no ground truth detections marked as to be removed/distractor classes.
+ Therefore also no matched tracker detections are removed.
+ 3) Ignore regions are used to remove unmatched detections (at least 50% overlap with ignore region).
+ 4) There are no ground truth detections (e.g. those of distractor classes) to be removed.
+ """
+ # Check that input data has unique ids
+ self._check_unique_ids(raw_data)
+
+ cls_id = int(self.class_name_to_class_id[cls])
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+ for t in range(raw_data['num_timesteps']):
+
+ # Only extract relevant dets for this class for preproc and eval (cls)
+ gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
+ gt_class_mask = gt_class_mask.astype(np.bool)
+ gt_ids = raw_data['gt_ids'][t][gt_class_mask]
+ gt_dets = [raw_data['gt_dets'][t][ind] for ind in range(len(gt_class_mask)) if gt_class_mask[ind]]
+
+ tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
+ tracker_class_mask = tracker_class_mask.astype(np.bool)
+ tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
+ tracker_dets = [raw_data['tracker_dets'][t][ind] for ind in range(len(tracker_class_mask)) if
+ tracker_class_mask[ind]]
+ similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
+
+ # Match tracker and gt dets (with hungarian algorithm)
+ unmatched_indices = np.arange(tracker_ids.shape[0])
+ if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
+ matching_scores = similarity_scores.copy()
+ matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = -10000
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_cols = match_cols[actually_matched_mask]
+
+ unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
+
+ # For unmatched tracker dets, remove those that are greater than 50% within a crowd ignore region.
+ unmatched_tracker_dets = [tracker_dets[i] for i in range(len(tracker_dets)) if i in unmatched_indices]
+ ignore_region = raw_data['gt_ignore_region'][t]
+ intersection_with_ignore_region = self._calculate_mask_ious(unmatched_tracker_dets, [ignore_region],
+ is_encoded=True, do_ioa=True)
+ is_within_ignore_region = np.any(intersection_with_ignore_region > 0.5 + np.finfo('float').eps, axis=1)
+
+ # Apply preprocessing to remove unwanted tracker dets.
+ to_remove_tracker = unmatched_indices[is_within_ignore_region]
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+
+ # Keep all ground truth detections
+ data['gt_ids'][t] = gt_ids
+ data['gt_dets'][t] = gt_dets
+ data['similarity_scores'][t] = similarity_scores
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+
+ # Ensure again that ids are unique per timestep after preproc.
+ self._check_unique_ids(data, after_preproc=True)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
+ return similarity_scores
+
+ @staticmethod
+ def _raise_index_error(is_gt, tracker, seq):
+ """
+ Auxiliary method to raise an evaluation error in case of an index error while reading files.
+ :param is_gt: whether gt or tracker data is read
+ :param tracker: the name of the tracker
+ :param seq: the name of the seq
+ :return: None
+ """
+ if is_gt:
+ err = 'Cannot load gt data from sequence %s, because there are not enough ' \
+ 'columns in the data.' % seq
+ raise TrackEvalException(err)
+ else:
+ err = 'Cannot load tracker data from tracker %s, sequence %s, because there are not enough ' \
+ 'columns in the data.' % (tracker, seq)
+ raise TrackEvalException(err)
+
+ @staticmethod
+ def _raise_value_error(is_gt, tracker, seq):
+ """
+ Auxiliary method to raise an evaluation error in case of an value error while reading files.
+ :param is_gt: whether gt or tracker data is read
+ :param tracker: the name of the tracker
+ :param seq: the name of the seq
+ :return: None
+ """
+ if is_gt:
+ raise TrackEvalException(
+ 'GT data for sequence %s cannot be converted to the right format. Is data corrupted?' % seq)
+ else:
+ raise TrackEvalException(
+ 'Tracking data from tracker %s, sequence %s cannot be converted to the right format. '
+ 'Is data corrupted?' % (tracker, seq))
diff --git a/val_utils/trackeval/datasets/person_path_22.py b/val_utils/trackeval/datasets/person_path_22.py
new file mode 100644
index 0000000000000000000000000000000000000000..177954a82009d68e7e4a68a2087255fc5dcac42e
--- /dev/null
+++ b/val_utils/trackeval/datasets/person_path_22.py
@@ -0,0 +1,452 @@
+import os
+import csv
+import configparser
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_dataset import _BaseDataset
+from .. import utils
+from .. import _timing
+from ..utils import TrackEvalException
+
+class PersonPath22(_BaseDataset):
+ """Dataset class for MOT Challenge 2D bounding box tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/person_path_22/'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/person_path_22/'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
+ 'BENCHMARK': 'person_path_22', # Valid: 'person_path_22'
+ 'SPLIT_TO_EVAL': 'test', # Valid: 'train', 'test', 'all'
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'DO_PREPROC': True, # Whether to perform preprocessing
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/seqmaps)
+ 'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/benchmark-split_to_eval)
+ 'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
+ 'GT_LOC_FORMAT': '{gt_folder}/{seq}/gt/gt.txt', # '{gt_folder}/{seq}/gt/gt.txt'
+ 'SKIP_SPLIT_FOL': False, # If False, data is in GT_FOLDER/BENCHMARK-SPLIT_TO_EVAL/ and in
+ # TRACKERS_FOLDER/BENCHMARK-SPLIT_TO_EVAL/tracker/
+ # If True, then the middle 'benchmark-split' folder is skipped for both.
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+
+ self.benchmark = self.config['BENCHMARK']
+ gt_set = self.config['BENCHMARK'] + '-' + self.config['SPLIT_TO_EVAL']
+ self.gt_set = gt_set
+ if not self.config['SKIP_SPLIT_FOL']:
+ split_fol = gt_set
+ else:
+ split_fol = ''
+ self.gt_fol = os.path.join(self.config['GT_FOLDER'], split_fol)
+ self.tracker_fol = os.path.join(self.config['TRACKERS_FOLDER'], split_fol)
+ self.should_classes_combine = False
+ self.use_super_categories = False
+ self.data_is_zipped = self.config['INPUT_AS_ZIP']
+ self.do_preproc = self.config['DO_PREPROC']
+
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+
+ # Get classes to eval
+ self.valid_classes = ['pedestrian']
+ self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only pedestrian class is valid.')
+ self.class_name_to_class_id = {'pedestrian': 1, 'person_on_vehicle': 2, 'car': 3, 'bicycle': 4, 'motorbike': 5,
+ 'non_mot_vehicle': 6, 'static_person': 7, 'distractor': 8, 'occluder': 9,
+ 'occluder_on_ground': 10, 'occluder_full': 11, 'reflection': 12, 'crowd': 13}
+ self.valid_class_numbers = list(self.class_name_to_class_id.values())
+
+ # Get sequences to eval and check gt files exist
+ self.seq_list, self.seq_lengths = self._get_seq_info()
+ if len(self.seq_list) < 1:
+ raise TrackEvalException('No sequences are selected to be evaluated.')
+
+ # Check gt files exist
+ for seq in self.seq_list:
+ if not self.data_is_zipped:
+ curr_file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
+ if not os.path.isfile(curr_file):
+ print('GT file not found ' + curr_file)
+ raise TrackEvalException('GT file not found for sequence: ' + seq)
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.gt_fol, 'data.zip')
+ if not os.path.isfile(curr_file):
+ print('GT file not found ' + curr_file)
+ raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ for tracker in self.tracker_list:
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException('Tracker file not found: ' + tracker + '/' + os.path.basename(curr_file))
+ else:
+ for seq in self.seq_list:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException(
+ 'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
+ curr_file))
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _get_seq_info(self):
+ seq_list = []
+ seq_lengths = {}
+ if self.config["SEQ_INFO"]:
+ seq_list = list(self.config["SEQ_INFO"].keys())
+ seq_lengths = self.config["SEQ_INFO"]
+
+ # If sequence length is 'None' tries to read sequence length from .ini files.
+ for seq, seq_length in seq_lengths.items():
+ if seq_length is None:
+ ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
+ if not os.path.isfile(ini_file):
+ raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
+ ini_data = configparser.ConfigParser()
+ ini_data.read(ini_file)
+ seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
+
+ else:
+ if self.config["SEQMAP_FILE"]:
+ seqmap_file = self.config["SEQMAP_FILE"]
+ else:
+ if self.config["SEQMAP_FOLDER"] is None:
+ seqmap_file = os.path.join(self.config['GT_FOLDER'], 'seqmaps', self.gt_set + '.txt')
+ else:
+ seqmap_file = os.path.join(self.config["SEQMAP_FOLDER"], self.gt_set + '.txt')
+ if not os.path.isfile(seqmap_file):
+ print('no seqmap found: ' + seqmap_file)
+ raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
+ with open(seqmap_file) as fp:
+ reader = csv.reader(fp)
+ for i, row in enumerate(reader):
+ if i == 0 or row[0] == '':
+ continue
+ seq = row[0]
+ seq_list.append(seq)
+ ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
+ if not os.path.isfile(ini_file):
+ raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
+ ini_data = configparser.ConfigParser()
+ ini_data.read(ini_file)
+ seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
+ return seq_list, seq_lengths
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the MOT Challenge 2D box format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
+ [gt_extras] : list (for each timestep) of dicts (for each extra) of 1D NDArrays (for each det).
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ """
+ # File location
+ if self.data_is_zipped:
+ if is_gt:
+ zip_file = os.path.join(self.gt_fol, 'data.zip')
+ else:
+ zip_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
+ file = seq + '.txt'
+ else:
+ zip_file = None
+ if is_gt:
+ file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
+ else:
+ file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
+
+ # Ignore regions
+ if is_gt:
+ crowd_ignore_filter = {7: ['13']}
+ else:
+ crowd_ignore_filter = None
+
+ # Load raw data from text file
+ read_data, ignore_data = self._load_simple_text_file(file, is_zipped=self.data_is_zipped, zip_file=zip_file, crowd_ignore_filter=crowd_ignore_filter)
+
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq]
+ data_keys = ['ids', 'classes', 'dets']
+ if is_gt:
+ data_keys += ['gt_crowd_ignore_regions', 'gt_extras']
+ else:
+ data_keys += ['tracker_confidences']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+
+ # Check for any extra time keys
+ current_time_keys = [str( t+ 1) for t in range(num_timesteps)]
+ extra_time_keys = [x for x in read_data.keys() if x not in current_time_keys]
+ if len(extra_time_keys) > 0:
+ if is_gt:
+ text = 'Ground-truth'
+ else:
+ text = 'Tracking'
+ raise TrackEvalException(
+ text + ' data contains the following invalid timesteps in seq %s: ' % seq + ', '.join(
+ [str(x) + ', ' for x in extra_time_keys]))
+
+ for t in range(num_timesteps):
+ time_key = str(t+1)
+ if time_key in read_data.keys():
+ try:
+ time_data = np.asarray(read_data[time_key], dtype=np.float)
+ except ValueError:
+ if is_gt:
+ raise TrackEvalException(
+ 'Cannot convert gt data for sequence %s to float. Is data corrupted?' % seq)
+ else:
+ raise TrackEvalException(
+ 'Cannot convert tracking data from tracker %s, sequence %s to float. Is data corrupted?' % (
+ tracker, seq))
+ try:
+ raw_data['dets'][t] = np.atleast_2d(time_data[:, 2:6])
+ raw_data['ids'][t] = np.atleast_1d(time_data[:, 1]).astype(int)
+ except IndexError:
+ if is_gt:
+ err = 'Cannot load gt data from sequence %s, because there is not enough ' \
+ 'columns in the data.' % seq
+ raise TrackEvalException(err)
+ else:
+ err = 'Cannot load tracker data from tracker %s, sequence %s, because there is not enough ' \
+ 'columns in the data.' % (tracker, seq)
+ raise TrackEvalException(err)
+ if time_data.shape[1] >= 8:
+ raw_data['classes'][t] = np.atleast_1d(time_data[:, 7]).astype(int)
+ else:
+ if not is_gt:
+ raw_data['classes'][t] = np.ones_like(raw_data['ids'][t])
+ else:
+ raise TrackEvalException(
+ 'GT data is not in a valid format, there is not enough rows in seq %s, timestep %i.' % (
+ seq, t))
+ if is_gt:
+ gt_extras_dict = {'zero_marked': np.atleast_1d(time_data[:, 6].astype(int))}
+ raw_data['gt_extras'][t] = gt_extras_dict
+ else:
+ raw_data['tracker_confidences'][t] = np.atleast_1d(time_data[:, 6])
+ else:
+ raw_data['dets'][t] = np.empty((0, 4))
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+ if is_gt:
+ gt_extras_dict = {'zero_marked': np.empty(0)}
+ raw_data['gt_extras'][t] = gt_extras_dict
+ else:
+ raw_data['tracker_confidences'][t] = np.empty(0)
+ if is_gt:
+ if time_key in ignore_data.keys():
+ time_ignore = np.asarray(ignore_data[time_key], dtype=np.float)
+ raw_data['gt_crowd_ignore_regions'][t] = np.atleast_2d(time_ignore[:, 2:6])
+ else:
+ raw_data['gt_crowd_ignore_regions'][t] = np.empty((0, 4))
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+ raw_data['num_timesteps'] = num_timesteps
+ raw_data['seq'] = seq
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+
+ MOT Challenge:
+ In MOT Challenge, the 4 preproc steps are as follow:
+ 1) There is only one class (pedestrian) to be evaluated, but all other classes are used for preproc.
+ 2) Predictions are matched against all gt boxes (regardless of class), those matching with distractor
+ objects are removed.
+ 3) There is no crowd ignore regions.
+ 4) All gt dets except pedestrian are removed, also removes pedestrian gt dets marked with zero_marked.
+ """
+ # Check that input data has unique ids
+ self._check_unique_ids(raw_data)
+
+ distractor_class_names = ['person_on_vehicle', 'static_person', 'distractor', 'reflection']
+ if self.benchmark == 'MOT20':
+ distractor_class_names.append('non_mot_vehicle')
+ distractor_classes = [self.class_name_to_class_id[x] for x in distractor_class_names]
+ cls_id = self.class_name_to_class_id[cls]
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+ for t in range(raw_data['num_timesteps']):
+
+ # Get all data
+ gt_ids = raw_data['gt_ids'][t]
+ gt_dets = raw_data['gt_dets'][t]
+ gt_classes = raw_data['gt_classes'][t]
+ gt_zero_marked = raw_data['gt_extras'][t]['zero_marked']
+
+ tracker_ids = raw_data['tracker_ids'][t]
+ tracker_dets = raw_data['tracker_dets'][t]
+ tracker_classes = raw_data['tracker_classes'][t]
+ tracker_confidences = raw_data['tracker_confidences'][t]
+ similarity_scores = raw_data['similarity_scores'][t]
+ crowd_ignore_regions = raw_data['gt_crowd_ignore_regions'][t]
+
+ # Evaluation is ONLY valid for pedestrian class
+ if len(tracker_classes) > 0 and np.max(tracker_classes) > 1:
+ raise TrackEvalException(
+ 'Evaluation is only valid for pedestrian class. Non pedestrian class (%i) found in sequence %s at '
+ 'timestep %i.' % (np.max(tracker_classes), raw_data['seq'], t))
+
+ # Match tracker and gt dets (with hungarian algorithm) and remove tracker dets which match with gt dets
+ # which are labeled as belonging to a distractor class.
+ to_remove_tracker = np.array([], np.int)
+ if self.do_preproc and self.benchmark != 'MOT15' and (gt_ids.shape[0] > 0 or len(crowd_ignore_regions) > 0) and tracker_ids.shape[0] > 0:
+
+ # Check all classes are valid:
+ invalid_classes = np.setdiff1d(np.unique(gt_classes), self.valid_class_numbers)
+ if len(invalid_classes) > 0:
+ print(' '.join([str(x) for x in invalid_classes]))
+ raise(TrackEvalException('Attempting to evaluate using invalid gt classes. '
+ 'This warning only triggers if preprocessing is performed, '
+ 'e.g. not for MOT15 or where prepropressing is explicitly disabled. '
+ 'Please either check your gt data, or disable preprocessing. '
+ 'The following invalid classes were found in timestep ' + str(t) + ': ' +
+ ' '.join([str(x) for x in invalid_classes])))
+
+ matching_scores = similarity_scores.copy()
+ matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_rows = match_rows[actually_matched_mask]
+ match_cols = match_cols[actually_matched_mask]
+
+ is_distractor_class = np.isin(gt_classes[match_rows], distractor_classes)
+ to_remove_tracker = match_cols[is_distractor_class]
+
+ # remove bounding boxes that overlap with crowd ignore region.
+ intersection_with_ignore_region = self._calculate_box_ious(tracker_dets, crowd_ignore_regions, box_format='xywh', do_ioa=True)
+ is_within_crowd_ignore_region = np.any(intersection_with_ignore_region > 0.95 + np.finfo('float').eps, axis=1)
+ to_remove_tracker = np.unique(np.concatenate([to_remove_tracker, np.where(is_within_crowd_ignore_region)[0]]))
+
+ # Apply preprocessing to remove all unwanted tracker dets.
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+
+ # Remove gt detections marked as to remove (zero marked), and also remove gt detections not in pedestrian
+ # class (not applicable for MOT15)
+ if self.do_preproc and self.benchmark != 'MOT15':
+ gt_to_keep_mask = (np.not_equal(gt_zero_marked, 0)) & \
+ (np.equal(gt_classes, cls_id))
+ else:
+ # There are no classes for MOT15
+ gt_to_keep_mask = np.not_equal(gt_zero_marked, 0)
+ data['gt_ids'][t] = gt_ids[gt_to_keep_mask]
+ data['gt_dets'][t] = gt_dets[gt_to_keep_mask, :]
+ data['similarity_scores'][t] = similarity_scores[gt_to_keep_mask]
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+
+ # Ensure again that ids are unique per timestep after preproc.
+ self._check_unique_ids(data, after_preproc=True)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t, box_format='xywh')
+ return similarity_scores
diff --git a/val_utils/trackeval/datasets/rob_mots.py b/val_utils/trackeval/datasets/rob_mots.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6a6d1e9f47f824191b674c4f5ef9b3719907742
--- /dev/null
+++ b/val_utils/trackeval/datasets/rob_mots.py
@@ -0,0 +1,508 @@
+
+import os
+import csv
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_dataset import _BaseDataset
+from .. import utils
+from ..utils import TrackEvalException
+from .. import _timing
+from ..datasets.rob_mots_classmap import cls_id_to_name
+
+
+class RobMOTS(_BaseDataset):
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/rob_mots'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/rob_mots'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'SUB_BENCHMARK': None, # REQUIRED. Sub-benchmark to eval. If None, then error.
+ # ['mots_challenge', 'kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'waymo', 'tao']
+ 'CLASSES_TO_EVAL': None, # List of classes to eval. If None, then it does all COCO classes.
+ 'SPLIT_TO_EVAL': 'train', # valid: ['train', 'val', 'test']
+ 'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'OUTPUT_SUB_FOLDER': 'results', # Output files are saved in OUTPUT_FOLDER/DATA_LOC_FORMAT/OUTPUT_SUB_FOLDER
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/DATA_LOC_FORMAT/TRACKER_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/dataset_subfolder/seqmaps)
+ 'SEQMAP_FILE': None, # Directly specify seqmap file (if none use SEQMAP_FOLDER/BENCHMARK_SPLIT_TO_EVAL)
+ 'CLSMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/dataset_subfolder/clsmaps)
+ 'CLSMAP_FILE': None, # Directly specify seqmap file (if none use CLSMAP_FOLDER/BENCHMARK_SPLIT_TO_EVAL)
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config())
+
+ self.split = self.config['SPLIT_TO_EVAL']
+ valid_benchmarks = ['mots_challenge', 'kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'waymo', 'tao']
+ self.box_gt_benchmarks = ['waymo', 'tao']
+
+ self.sub_benchmark = self.config['SUB_BENCHMARK']
+ if not self.sub_benchmark:
+ raise TrackEvalException('SUB_BENCHMARK config input is required (there is no default value)' +
+ ', '.join(valid_benchmarks) + ' are valid.')
+ if self.sub_benchmark not in valid_benchmarks:
+ raise TrackEvalException('Attempted to evaluate an invalid benchmark: ' + self.sub_benchmark + '. Only benchmarks ' +
+ ', '.join(valid_benchmarks) + ' are valid.')
+
+ self.gt_fol = self.config['GT_FOLDER']
+ self.tracker_fol = os.path.join(self.config['TRACKERS_FOLDER'], self.config['SPLIT_TO_EVAL'])
+ self.data_is_zipped = self.config['INPUT_AS_ZIP']
+
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_sub_fol = os.path.join(self.config['OUTPUT_SUB_FOLDER'], self.sub_benchmark)
+
+ # Loops through all sub-benchmarks, and reads in seqmaps to info on all sequences to eval.
+ self._get_seq_info()
+
+ if len(self.seq_list) < 1:
+ raise TrackEvalException('No sequences are selected to be evaluated.')
+
+ valid_class_ids = np.atleast_1d(np.genfromtxt(os.path.join(self.gt_fol, self.split, self.sub_benchmark,
+ 'clsmap.txt')))
+ valid_classes = [cls_id_to_name[int(x)] for x in valid_class_ids] + ['all']
+ self.valid_class_ids = valid_class_ids
+ self.class_name_to_class_id = {cls_name: cls_id for cls_id, cls_name in cls_id_to_name.items()}
+ self.class_name_to_class_id['all'] = -1
+ if not self.config['CLASSES_TO_EVAL']:
+ self.class_list = valid_classes
+ else:
+ self.class_list = [cls if cls in valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only classes ' +
+ ', '.join(valid_classes) + ' are valid.')
+
+ # Check gt files exist
+ for seq in self.seq_list:
+ if not self.data_is_zipped:
+ curr_file = os.path.join(self.gt_fol, self.split, self.sub_benchmark, 'data', seq + '.txt')
+ if not os.path.isfile(curr_file):
+ print('GT file not found ' + curr_file)
+ raise TrackEvalException('GT file not found for sequence: ' + seq)
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.gt_fol, self.split, self.sub_benchmark, 'data.zip')
+ if not os.path.isfile(curr_file):
+ raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ for tracker in self.tracker_list:
+ if self.data_is_zipped:
+ curr_file = os.path.join(self.tracker_fol, tracker, 'data.zip')
+ if not os.path.isfile(curr_file):
+ raise TrackEvalException('Tracker file not found: ' + os.path.basename(curr_file))
+ else:
+ for seq in self.seq_list:
+ curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, self.sub_benchmark, seq
+ + '.txt')
+ if not os.path.isfile(curr_file):
+ print('Tracker file not found: ' + curr_file)
+ raise TrackEvalException(
+ 'Tracker file not found: ' + self.sub_benchmark + '/' + os.path.basename(curr_file))
+
+ def get_name(self):
+ return self.get_class_name() + '.' + self.sub_benchmark
+
+ def _get_seq_info(self):
+ self.seq_list = []
+ self.seq_lengths = {}
+ self.seq_sizes = {}
+ self.seq_ignore_class_ids = {}
+ if self.config["SEQMAP_FILE"]:
+ seqmap_file = self.config["SEQMAP_FILE"]
+ else:
+ if self.config["SEQMAP_FOLDER"] is None:
+ seqmap_file = os.path.join(self.gt_fol, self.split, self.sub_benchmark, 'seqmap.txt')
+ else:
+ seqmap_file = os.path.join(self.config["SEQMAP_FOLDER"], self.split + '.seqmap')
+ if not os.path.isfile(seqmap_file):
+ print('no seqmap found: ' + seqmap_file)
+ raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
+ with open(seqmap_file) as fp:
+ dialect = csv.Sniffer().sniff(fp.readline(), delimiters=' ')
+ fp.seek(0)
+ reader = csv.reader(fp, dialect)
+ for i, row in enumerate(reader):
+ if len(row) >= 4:
+ # first col: sequence, second col: sequence length, third and fourth col: sequence height/width
+ # The rest of the columns list the 'sequence ignore class ids' which are classes not penalized as
+ # FPs for this sequence.
+ seq = row[0]
+ self.seq_list.append(seq)
+ self.seq_lengths[seq] = int(row[1])
+ self.seq_sizes[seq] = (int(row[2]), int(row[3]))
+ self.seq_ignore_class_ids[seq] = [int(row[x]) for x in range(4, len(row))]
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the unified RobMOTS format.
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ """
+ # import to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ # File location
+ if self.data_is_zipped:
+ if is_gt:
+ zip_file = os.path.join(self.gt_fol, self.split, self.sub_benchmark, 'data.zip')
+ else:
+ zip_file = os.path.join(self.tracker_fol, tracker, 'data.zip')
+ file = seq + '.txt'
+ else:
+ zip_file = None
+ if is_gt:
+ file = os.path.join(self.gt_fol, self.split, self.sub_benchmark, 'data', seq + '.txt')
+ else:
+ file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, self.sub_benchmark, seq + '.txt')
+
+ # Load raw data from text file
+ read_data, ignore_data = self._load_simple_text_file(file, is_zipped=self.data_is_zipped, zip_file=zip_file,
+ force_delimiters=' ')
+
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq]
+ data_keys = ['ids', 'classes', 'dets']
+ if not is_gt:
+ data_keys += ['tracker_confidences']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+ for t in range(num_timesteps):
+ time_key = str(t)
+ # list to collect all masks of a timestep to check for overlapping areas (for segmentation datasets)
+ all_valid_masks = []
+ if time_key in read_data.keys():
+ try:
+ raw_data['ids'][t] = np.atleast_1d([det[1] for det in read_data[time_key]]).astype(int)
+ raw_data['classes'][t] = np.atleast_1d([det[2] for det in read_data[time_key]]).astype(int)
+ if (not is_gt) or (self.sub_benchmark not in self.box_gt_benchmarks):
+ raw_data['dets'][t] = [{'size': [int(region[4]), int(region[5])],
+ 'counts': region[6].encode(encoding='UTF-8')}
+ for region in read_data[time_key]]
+ all_valid_masks += [mask for mask, cls in zip(raw_data['dets'][t], raw_data['classes'][t]) if
+ cls < 100]
+ else:
+ raw_data['dets'][t] = np.atleast_2d([det[4:8] for det in read_data[time_key]]).astype(float)
+
+ if not is_gt:
+ raw_data['tracker_confidences'][t] = np.atleast_1d([det[3] for det
+ in read_data[time_key]]).astype(float)
+ except IndexError:
+ self._raise_index_error(is_gt, self.sub_benchmark, seq)
+ except ValueError:
+ self._raise_value_error(is_gt, self.sub_benchmark, seq)
+ # no detection in this timestep
+ else:
+ if (not is_gt) or (self.sub_benchmark not in self.box_gt_benchmarks):
+ raw_data['dets'][t] = []
+ else:
+ raw_data['dets'][t] = np.empty((0, 4)).astype(float)
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+ if not is_gt:
+ raw_data['tracker_confidences'][t] = np.empty(0).astype(float)
+
+ # check for overlapping masks
+ if all_valid_masks:
+ masks_merged = all_valid_masks[0]
+ for mask in all_valid_masks[1:]:
+ if mask_utils.area(mask_utils.merge([masks_merged, mask], intersect=True)) != 0.0:
+ err = 'Overlapping masks in frame %d' % t
+ raise TrackEvalException(err)
+ masks_merged = mask_utils.merge([masks_merged, mask], intersect=False)
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+
+ raw_data['num_timesteps'] = num_timesteps
+ raw_data['frame_size'] = self.seq_sizes[seq]
+ raw_data['seq'] = seq
+ return raw_data
+
+ @staticmethod
+ def _raise_index_error(is_gt, sub_benchmark, seq):
+ """
+ Auxiliary method to raise an evaluation error in case of an index error while reading files.
+ :param is_gt: whether gt or tracker data is read
+ :param tracker: the name of the tracker
+ :param seq: the name of the seq
+ :return: None
+ """
+ if is_gt:
+ err = 'Cannot load gt data from sequence %s, because there are not enough ' \
+ 'columns in the data.' % seq
+ raise TrackEvalException(err)
+ else:
+ err = 'Cannot load tracker data from benchmark %s, sequence %s, because there are not enough ' \
+ 'columns in the data.' % (sub_benchmark, seq)
+ raise TrackEvalException(err)
+
+ @staticmethod
+ def _raise_value_error(is_gt, sub_benchmark, seq):
+ """
+ Auxiliary method to raise an evaluation error in case of an value error while reading files.
+ :param is_gt: whether gt or tracker data is read
+ :param tracker: the name of the tracker
+ :param seq: the name of the seq
+ :return: None
+ """
+ if is_gt:
+ raise TrackEvalException(
+ 'GT data for sequence %s cannot be converted to the right format. Is data corrupted?' % seq)
+ else:
+ raise TrackEvalException(
+ 'Tracking data from benchmark %s, sequence %s cannot be converted to the right format. '
+ 'Is data corrupted?' % (sub_benchmark, seq))
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ Preprocessing (preproc) occurs in 3 steps.
+ 1) Extract only detections relevant for the class to be evaluated.
+ 2) Match gt dets and tracker dets. Tracker dets that are to a gt det (TPs) are marked as not to be
+ removed.
+ 3) Remove unmatched tracker dets if they fall within an ignore region or are too small, or if that class
+ is marked as an ignore class for that sequence.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+ Note that there is a special 'all' class, which evaluates all of the COCO classes together in a
+ 'class agnostic' fashion.
+ """
+ # import to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ # Check that input data has unique ids
+ self._check_unique_ids(raw_data)
+
+ cls_id = self.class_name_to_class_id[cls]
+ ignore_class_id = cls_id+100
+ seq = raw_data['seq']
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+
+ for t in range(raw_data['num_timesteps']):
+
+ # Only extract relevant dets for this class
+ if cls == 'all':
+ gt_class_mask = raw_data['gt_classes'][t] < 100
+ # For waymo, combine predictions for [car, truck, bus, motorcycle] into car, because they are all annotated
+ # together as one 'vehicle' class.
+ elif self.sub_benchmark == 'waymo' and cls == 'car':
+ waymo_vehicle_classes = np.array([3, 4, 6, 8])
+ gt_class_mask = np.isin(raw_data['gt_classes'][t], waymo_vehicle_classes)
+ else:
+ gt_class_mask = raw_data['gt_classes'][t] == cls_id
+ gt_class_mask = gt_class_mask.astype(np.bool)
+ gt_ids = raw_data['gt_ids'][t][gt_class_mask]
+ if cls == 'all':
+ ignore_regions_mask = raw_data['gt_classes'][t] >= 100
+ else:
+ ignore_regions_mask = raw_data['gt_classes'][t] == ignore_class_id
+ ignore_regions_mask = np.logical_or(ignore_regions_mask, raw_data['gt_classes'][t] == 100)
+ if self.sub_benchmark in self.box_gt_benchmarks:
+ gt_dets = raw_data['gt_dets'][t][gt_class_mask]
+ ignore_regions_box = raw_data['gt_dets'][t][ignore_regions_mask]
+ if len(ignore_regions_box) > 0:
+ ignore_regions_box[:, 2] = ignore_regions_box[:, 2] - ignore_regions_box[:, 0]
+ ignore_regions_box[:, 3] = ignore_regions_box[:, 3] - ignore_regions_box[:, 1]
+ ignore_regions = mask_utils.frPyObjects(ignore_regions_box, self.seq_sizes[seq][0], self.seq_sizes[seq][1])
+ else:
+ ignore_regions = []
+ else:
+ gt_dets = [raw_data['gt_dets'][t][ind] for ind in range(len(gt_class_mask)) if gt_class_mask[ind]]
+ ignore_regions = [raw_data['gt_dets'][t][ind] for ind in range(len(ignore_regions_mask)) if
+ ignore_regions_mask[ind]]
+
+ if cls == 'all':
+ tracker_class_mask = np.ones_like(raw_data['tracker_classes'][t])
+ else:
+ tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
+ tracker_class_mask = tracker_class_mask.astype(np.bool)
+ tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
+ tracker_dets = [raw_data['tracker_dets'][t][ind] for ind in range(len(tracker_class_mask)) if
+ tracker_class_mask[ind]]
+ tracker_confidences = raw_data['tracker_confidences'][t][tracker_class_mask]
+ similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
+ tracker_classes = raw_data['tracker_classes'][t][tracker_class_mask]
+
+ # Only do preproc if there are ignore regions defined to remove
+ if tracker_ids.shape[0] > 0:
+
+ # Match tracker and gt dets (with hungarian algorithm)
+ unmatched_indices = np.arange(tracker_ids.shape[0])
+ if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
+ matching_scores = similarity_scores.copy()
+ matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ # match_rows = match_rows[actually_matched_mask]
+ match_cols = match_cols[actually_matched_mask]
+ unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
+
+ # For unmatched tracker dets remove those that are greater than 50% within an ignore region.
+ # unmatched_tracker_dets = tracker_dets[unmatched_indices, :]
+ # crowd_ignore_regions = raw_data['gt_ignore_regions'][t]
+ # intersection_with_ignore_region = self. \
+ # _calculate_box_ious(unmatched_tracker_dets, crowd_ignore_regions, box_format='x0y0x1y1',
+ # do_ioa=True)
+
+
+ if cls_id in self.seq_ignore_class_ids[seq]:
+ # Remove unmatched detections for classes that are marked as 'ignore' for the whole sequence.
+ to_remove_tracker = unmatched_indices
+ else:
+ unmatched_tracker_dets = [tracker_dets[i] for i in range(len(tracker_dets)) if
+ i in unmatched_indices]
+
+ # For unmatched tracker dets remove those that are too small.
+ tracker_boxes_t = mask_utils.toBbox(unmatched_tracker_dets)
+ unmatched_widths = tracker_boxes_t[:, 2]
+ unmatched_heights = tracker_boxes_t[:, 3]
+ unmatched_size = np.maximum(unmatched_heights, unmatched_widths)
+ min_size = np.min(self.seq_sizes[seq])/8
+ is_too_small = unmatched_size <= min_size + np.finfo('float').eps
+
+ # For unmatched tracker dets remove those that are greater than 50% within an ignore region.
+ if ignore_regions:
+ ignore_region_merged = ignore_regions[0]
+ for mask in ignore_regions[1:]:
+ ignore_region_merged = mask_utils.merge([ignore_region_merged, mask], intersect=False)
+ intersection_with_ignore_region = self. \
+ _calculate_mask_ious(unmatched_tracker_dets, [ignore_region_merged], is_encoded=True, do_ioa=True)
+ is_within_ignore_region = np.any(intersection_with_ignore_region > 0.5 + np.finfo('float').eps, axis=1)
+ to_remove_tracker = unmatched_indices[np.logical_or(is_too_small, is_within_ignore_region)]
+ else:
+ to_remove_tracker = unmatched_indices[is_too_small]
+
+ # For the special 'all' class, you need to remove unmatched detections from all ignore classes and
+ # non-evaluated classes.
+ if cls == 'all':
+ unmatched_tracker_classes = [tracker_classes[i] for i in range(len(tracker_classes)) if
+ i in unmatched_indices]
+ is_ignore_class = np.isin(unmatched_tracker_classes, self.seq_ignore_class_ids[seq])
+ is_not_evaled_class = np.logical_not(np.isin(unmatched_tracker_classes, self.valid_class_ids))
+ to_remove_all = unmatched_indices[np.logical_or(is_ignore_class, is_not_evaled_class)]
+ to_remove_tracker = np.concatenate([to_remove_tracker, to_remove_all], axis=0)
+ else:
+ to_remove_tracker = np.array([], dtype=np.int)
+
+ # remove all unwanted tracker detections
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+
+ # keep all ground truth detections
+ data['gt_ids'][t] = gt_ids
+ data['gt_dets'][t] = gt_dets
+ data['similarity_scores'][t] = similarity_scores
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+ data['frame_size'] = raw_data['frame_size']
+
+ # Ensure that ids are unique per timestep.
+ self._check_unique_ids(data, after_preproc=True)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+
+ # Only loaded when run to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ if self.sub_benchmark in self.box_gt_benchmarks:
+ # Convert tracker masks to bboxes (for benchmarks with only bbox ground-truth),
+ # and then convert to x0y0x1y1 format.
+ tracker_boxes_t = mask_utils.toBbox(tracker_dets_t)
+ tracker_boxes_t[:, 2] = tracker_boxes_t[:, 0] + tracker_boxes_t[:, 2]
+ tracker_boxes_t[:, 3] = tracker_boxes_t[:, 1] + tracker_boxes_t[:, 3]
+ similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_boxes_t, box_format='x0y0x1y1')
+ else:
+ similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
+ return similarity_scores
diff --git a/val_utils/trackeval/datasets/rob_mots_classmap.py b/val_utils/trackeval/datasets/rob_mots_classmap.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b3644d0b6dc28d3a088f1cadfe71e1b1cb970f6
--- /dev/null
+++ b/val_utils/trackeval/datasets/rob_mots_classmap.py
@@ -0,0 +1,81 @@
+cls_id_to_name = {
+ 1: 'person',
+ 2: 'bicycle',
+ 3: 'car',
+ 4: 'motorcycle',
+ 5: 'airplane',
+ 6: 'bus',
+ 7: 'train',
+ 8: 'truck',
+ 9: 'boat',
+ 10: 'traffic light',
+ 11: 'fire hydrant',
+ 12: 'stop sign',
+ 13: 'parking meter',
+ 14: 'bench',
+ 15: 'bird',
+ 16: 'cat',
+ 17: 'dog',
+ 18: 'horse',
+ 19: 'sheep',
+ 20: 'cow',
+ 21: 'elephant',
+ 22: 'bear',
+ 23: 'zebra',
+ 24: 'giraffe',
+ 25: 'backpack',
+ 26: 'umbrella',
+ 27: 'handbag',
+ 28: 'tie',
+ 29: 'suitcase',
+ 30: 'frisbee',
+ 31: 'skis',
+ 32: 'snowboard',
+ 33: 'sports ball',
+ 34: 'kite',
+ 35: 'baseball bat',
+ 36: 'baseball glove',
+ 37: 'skateboard',
+ 38: 'surfboard',
+ 39: 'tennis racket',
+ 40: 'bottle',
+ 41: 'wine glass',
+ 42: 'cup',
+ 43: 'fork',
+ 44: 'knife',
+ 45: 'spoon',
+ 46: 'bowl',
+ 47: 'banana',
+ 48: 'apple',
+ 49: 'sandwich',
+ 50: 'orange',
+ 51: 'broccoli',
+ 52: 'carrot',
+ 53: 'hot dog',
+ 54: 'pizza',
+ 55: 'donut',
+ 56: 'cake',
+ 57: 'chair',
+ 58: 'couch',
+ 59: 'potted plant',
+ 60: 'bed',
+ 61: 'dining table',
+ 62: 'toilet',
+ 63: 'tv',
+ 64: 'laptop',
+ 65: 'mouse',
+ 66: 'remote',
+ 67: 'keyboard',
+ 68: 'cell phone',
+ 69: 'microwave',
+ 70: 'oven',
+ 71: 'toaster',
+ 72: 'sink',
+ 73: 'refrigerator',
+ 74: 'book',
+ 75: 'clock',
+ 76: 'vase',
+ 77: 'scissors',
+ 78: 'teddy bear',
+ 79: 'hair drier',
+ 80: 'toothbrush'}
\ No newline at end of file
diff --git a/val_utils/trackeval/datasets/run_rob_mots.py b/val_utils/trackeval/datasets/run_rob_mots.py
new file mode 100644
index 0000000000000000000000000000000000000000..87c141238d830003f40d7637819c2394bb874c38
--- /dev/null
+++ b/val_utils/trackeval/datasets/run_rob_mots.py
@@ -0,0 +1,113 @@
+
+# python3 scripts\run_rob_mots.py --ROBMOTS_SPLIT val --TRACKERS_TO_EVAL tracker_name (e.g. STP) --USE_PARALLEL True --NUM_PARALLEL_CORES 4
+
+import sys
+import os
+import csv
+import numpy as np
+from multiprocessing import freeze_support
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+import trackeval # noqa: E402
+from trackeval import utils
+code_path = utils.get_code_path()
+
+if __name__ == '__main__':
+ freeze_support()
+
+ script_config = {
+ 'ROBMOTS_SPLIT': 'train', # 'train', # valid: 'train', 'val', 'test', 'test_live', 'test_post', 'test_all'
+ 'BENCHMARKS': ['kitti_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'tao'], # 'bdd_mots' coming soon
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/rob_mots'),
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/rob_mots'),
+ }
+
+ default_eval_config = trackeval.Evaluator.get_default_eval_config()
+ default_eval_config['PRINT_ONLY_COMBINED'] = True
+ default_eval_config['DISPLAY_LESS_PROGRESS'] = True
+ default_dataset_config = trackeval.datasets.RobMOTS.get_default_dataset_config()
+ config = {**default_eval_config, **default_dataset_config, **script_config}
+
+ # Command line interface:
+ config = utils.update_config(config)
+
+ if config['ROBMOTS_SPLIT'] == 'val':
+ config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis',
+ 'tao', 'mots_challenge']
+ config['SPLIT_TO_EVAL'] = 'val'
+ elif config['ROBMOTS_SPLIT'] == 'test' or config['SPLIT_TO_EVAL'] == 'test_live':
+ config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'tao']
+ config['SPLIT_TO_EVAL'] = 'test'
+ elif config['ROBMOTS_SPLIT'] == 'test_post':
+ config['BENCHMARKS'] = ['mots_challenge', 'waymo']
+ config['SPLIT_TO_EVAL'] = 'test'
+ elif config['ROBMOTS_SPLIT'] == 'test_all':
+ config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis',
+ 'tao', 'mots_challenge', 'waymo']
+ config['SPLIT_TO_EVAL'] = 'test'
+ elif config['ROBMOTS_SPLIT'] == 'train':
+ config['BENCHMARKS'] = ['kitti_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'tao'] # 'bdd_mots' coming soon
+ config['SPLIT_TO_EVAL'] = 'train'
+
+ metrics_config = {'METRICS': ['HOTA']}
+ # metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity']}
+ eval_config = {k: v for k, v in config.items() if k in config.keys()}
+ dataset_config = {k: v for k, v in config.items() if k in config.keys()}
+
+ # Run code
+ dataset_list = []
+ for bench in config['BENCHMARKS']:
+ dataset_config['SUB_BENCHMARK'] = bench
+ dataset_list.append(trackeval.datasets.RobMOTS(dataset_config))
+ evaluator = trackeval.Evaluator(eval_config)
+ metrics_list = []
+ for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity]:
+ if metric.get_name() in metrics_config['METRICS']:
+ metrics_list.append(metric())
+ if len(metrics_list) == 0:
+ raise Exception('No metrics selected for evaluation')
+ output_res, output_msg = evaluator.evaluate(dataset_list, metrics_list)
+
+
+ # For each benchmark, combine the 'all' score with the 'cls_averaged' using geometric mean.
+ metrics_to_calc = ['HOTA', 'DetA', 'AssA', 'DetRe', 'DetPr', 'AssRe', 'AssPr', 'LocA']
+ trackers = list(output_res['RobMOTS.' + config['BENCHMARKS'][0]].keys())
+ for tracker in trackers:
+ # final_results[benchmark][result_type][metric]
+ final_results = {}
+ res = {bench: output_res['RobMOTS.' + bench][tracker]['COMBINED_SEQ'] for bench in config['BENCHMARKS']}
+ for bench in config['BENCHMARKS']:
+ final_results[bench] = {'cls_av': {}, 'det_av': {}, 'final': {}}
+ for metric in metrics_to_calc:
+ final_results[bench]['cls_av'][metric] = np.mean(res[bench]['cls_comb_cls_av']['HOTA'][metric])
+ final_results[bench]['det_av'][metric] = np.mean(res[bench]['all']['HOTA'][metric])
+ final_results[bench]['final'][metric] = \
+ np.sqrt(final_results[bench]['cls_av'][metric] * final_results[bench]['det_av'][metric])
+
+ # Take the arithmetic mean over all the benchmarks
+ final_results['overall'] = {'cls_av': {}, 'det_av': {}, 'final': {}}
+ for metric in metrics_to_calc:
+ final_results['overall']['cls_av'][metric] = \
+ np.mean([final_results[bench]['cls_av'][metric] for bench in config['BENCHMARKS']])
+ final_results['overall']['det_av'][metric] = \
+ np.mean([final_results[bench]['det_av'][metric] for bench in config['BENCHMARKS']])
+ final_results['overall']['final'][metric] = \
+ np.mean([final_results[bench]['final'][metric] for bench in config['BENCHMARKS']])
+
+ # Save out result
+ headers = [config['SPLIT_TO_EVAL']] + [x + '___' + metric for x in ['f', 'c', 'd'] for metric in metrics_to_calc]
+
+ def rowify(d):
+ return [d[x][metric] for x in ['final', 'cls_av', 'det_av'] for metric in metrics_to_calc]
+
+ out_file = os.path.join(script_config['TRACKERS_FOLDER'], script_config['ROBMOTS_SPLIT'], tracker,
+ 'final_results.csv')
+
+ with open(out_file, 'w', newline='') as f:
+ writer = csv.writer(f, delimiter=',')
+ writer.writerow(headers)
+ writer.writerow(['overall'] + rowify(final_results['overall']))
+ for bench in config['BENCHMARKS']:
+ if bench == 'overall':
+ continue
+ writer.writerow([bench] + rowify(final_results[bench]))
diff --git a/val_utils/trackeval/datasets/tao.py b/val_utils/trackeval/datasets/tao.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8461676a82d8c8aaac071ae5f9a8b5db2723049
--- /dev/null
+++ b/val_utils/trackeval/datasets/tao.py
@@ -0,0 +1,566 @@
+import os
+import numpy as np
+import json
+import itertools
+from collections import defaultdict
+from scipy.optimize import linear_sum_assignment
+from ..utils import TrackEvalException
+from ._base_dataset import _BaseDataset
+from .. import utils
+from .. import _timing
+
+
+class TAO(_BaseDataset):
+ """Dataset class for TAO tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/tao/tao_training'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/tao/tao_training'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
+ 'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+ self.gt_fol = self.config['GT_FOLDER']
+ self.tracker_fol = self.config['TRACKERS_FOLDER']
+ self.should_classes_combine = True
+ self.use_super_categories = False
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+
+ gt_dir_files = [file for file in os.listdir(self.gt_fol) if file.endswith('.json')]
+ if len(gt_dir_files) != 1:
+ raise TrackEvalException(self.gt_fol + ' does not contain exactly one json file.')
+
+ with open(os.path.join(self.gt_fol, gt_dir_files[0])) as f:
+ self.gt_data = json.load(f)
+
+ # merge categories marked with a merged tag in TAO dataset
+ self._merge_categories(self.gt_data['annotations'] + self.gt_data['tracks'])
+
+ # Get sequences to eval and sequence information
+ self.seq_list = [vid['name'].replace('/', '-') for vid in self.gt_data['videos']]
+ self.seq_name_to_seq_id = {vid['name'].replace('/', '-'): vid['id'] for vid in self.gt_data['videos']}
+ # compute mappings from videos to annotation data
+ self.videos_to_gt_tracks, self.videos_to_gt_images = self._compute_vid_mappings(self.gt_data['annotations'])
+ # compute sequence lengths
+ self.seq_lengths = {vid['id']: 0 for vid in self.gt_data['videos']}
+ for img in self.gt_data['images']:
+ self.seq_lengths[img['video_id']] += 1
+ self.seq_to_images_to_timestep = self._compute_image_to_timestep_mappings()
+ self.seq_to_classes = {vid['id']: {'pos_cat_ids': list({track['category_id'] for track
+ in self.videos_to_gt_tracks[vid['id']]}),
+ 'neg_cat_ids': vid['neg_category_ids'],
+ 'not_exhaustively_labeled_cat_ids': vid['not_exhaustive_category_ids']}
+ for vid in self.gt_data['videos']}
+
+ # Get classes to eval
+ considered_vid_ids = [self.seq_name_to_seq_id[vid] for vid in self.seq_list]
+ seen_cats = set([cat_id for vid_id in considered_vid_ids for cat_id
+ in self.seq_to_classes[vid_id]['pos_cat_ids']])
+ # only classes with ground truth are evaluated in TAO
+ self.valid_classes = [cls['name'] for cls in self.gt_data['categories'] if cls['id'] in seen_cats]
+ cls_name_to_cls_id_map = {cls['name']: cls['id'] for cls in self.gt_data['categories']}
+
+ if self.config['CLASSES_TO_EVAL']:
+ self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only classes ' +
+ ', '.join(self.valid_classes) +
+ ' are valid (classes present in ground truth data).')
+ else:
+ self.class_list = [cls for cls in self.valid_classes]
+ self.class_name_to_class_id = {k: v for k, v in cls_name_to_cls_id_map.items() if k in self.class_list}
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ self.tracker_data = {tracker: dict() for tracker in self.tracker_list}
+
+ for tracker in self.tracker_list:
+ tr_dir_files = [file for file in os.listdir(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol))
+ if file.endswith('.json')]
+ if len(tr_dir_files) != 1:
+ raise TrackEvalException(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol)
+ + ' does not contain exactly one json file.')
+ with open(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, tr_dir_files[0])) as f:
+ curr_data = json.load(f)
+
+ # limit detections if MAX_DETECTIONS > 0
+ if self.config['MAX_DETECTIONS']:
+ curr_data = self._limit_dets_per_image(curr_data)
+
+ # fill missing video ids
+ self._fill_video_ids_inplace(curr_data)
+
+ # make track ids unique over whole evaluation set
+ self._make_track_ids_unique(curr_data)
+
+ # merge categories marked with a merged tag in TAO dataset
+ self._merge_categories(curr_data)
+
+ # get tracker sequence information
+ curr_videos_to_tracker_tracks, curr_videos_to_tracker_images = self._compute_vid_mappings(curr_data)
+ self.tracker_data[tracker]['vids_to_tracks'] = curr_videos_to_tracker_tracks
+ self.tracker_data[tracker]['vids_to_images'] = curr_videos_to_tracker_images
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the TAO format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets]: list (for each timestep) of lists of detections.
+ [classes_to_gt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
+ keys and corresponding segmentations as values) for each track
+ [classes_to_gt_track_ids, classes_to_gt_track_areas, classes_to_gt_track_lengths]: dictionary with class values
+ as keys and lists (for each track) as values
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ [classes_to_dt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
+ keys and corresponding segmentations as values) for each track
+ [classes_to_dt_track_ids, classes_to_dt_track_areas, classes_to_dt_track_lengths]: dictionary with class values
+ as keys and lists as values
+ [classes_to_dt_track_scores]: dictionary with class values as keys and 1D numpy arrays as values
+ """
+ seq_id = self.seq_name_to_seq_id[seq]
+ # File location
+ if is_gt:
+ imgs = self.videos_to_gt_images[seq_id]
+ else:
+ imgs = self.tracker_data[tracker]['vids_to_images'][seq_id]
+
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq_id]
+ img_to_timestep = self.seq_to_images_to_timestep[seq_id]
+ data_keys = ['ids', 'classes', 'dets']
+ if not is_gt:
+ data_keys += ['tracker_confidences']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+ for img in imgs:
+ # some tracker data contains images without any ground truth information, these are ignored
+ try:
+ t = img_to_timestep[img['id']]
+ except KeyError:
+ continue
+ annotations = img['annotations']
+ raw_data['dets'][t] = np.atleast_2d([ann['bbox'] for ann in annotations]).astype(float)
+ raw_data['ids'][t] = np.atleast_1d([ann['track_id'] for ann in annotations]).astype(int)
+ raw_data['classes'][t] = np.atleast_1d([ann['category_id'] for ann in annotations]).astype(int)
+ if not is_gt:
+ raw_data['tracker_confidences'][t] = np.atleast_1d([ann['score'] for ann in annotations]).astype(float)
+
+ for t, d in enumerate(raw_data['dets']):
+ if d is None:
+ raw_data['dets'][t] = np.empty((0, 4)).astype(float)
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+ if not is_gt:
+ raw_data['tracker_confidences'][t] = np.empty(0)
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+
+ all_classes = [self.class_name_to_class_id[cls] for cls in self.class_list]
+ if is_gt:
+ classes_to_consider = all_classes
+ all_tracks = self.videos_to_gt_tracks[seq_id]
+ else:
+ classes_to_consider = self.seq_to_classes[seq_id]['pos_cat_ids'] \
+ + self.seq_to_classes[seq_id]['neg_cat_ids']
+ all_tracks = self.tracker_data[tracker]['vids_to_tracks'][seq_id]
+
+ classes_to_tracks = {cls: [track for track in all_tracks if track['category_id'] == cls]
+ if cls in classes_to_consider else [] for cls in all_classes}
+
+ # mapping from classes to track information
+ raw_data['classes_to_tracks'] = {cls: [{det['image_id']: np.atleast_1d(det['bbox'])
+ for det in track['annotations']} for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_ids'] = {cls: [track['id'] for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_areas'] = {cls: [track['area'] for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_lengths'] = {cls: [len(track['annotations']) for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+
+ if not is_gt:
+ raw_data['classes_to_dt_track_scores'] = {cls: np.array([np.mean([float(x['score'])
+ for x in track['annotations']])
+ for track in tracks])
+ for cls, tracks in classes_to_tracks.items()}
+
+ if is_gt:
+ key_map = {'classes_to_tracks': 'classes_to_gt_tracks',
+ 'classes_to_track_ids': 'classes_to_gt_track_ids',
+ 'classes_to_track_lengths': 'classes_to_gt_track_lengths',
+ 'classes_to_track_areas': 'classes_to_gt_track_areas'}
+ else:
+ key_map = {'classes_to_tracks': 'classes_to_dt_tracks',
+ 'classes_to_track_ids': 'classes_to_dt_track_ids',
+ 'classes_to_track_lengths': 'classes_to_dt_track_lengths',
+ 'classes_to_track_areas': 'classes_to_dt_track_areas'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+
+ raw_data['num_timesteps'] = num_timesteps
+ raw_data['neg_cat_ids'] = self.seq_to_classes[seq_id]['neg_cat_ids']
+ raw_data['not_exhaustively_labeled_cls'] = self.seq_to_classes[seq_id]['not_exhaustively_labeled_cat_ids']
+ raw_data['seq'] = seq
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+ TAO:
+ In TAO, the 4 preproc steps are as follow:
+ 1) All classes present in the ground truth data are evaluated separately.
+ 2) No matched tracker detections are removed.
+ 3) Unmatched tracker detections are removed if there is not ground truth data and the class does not
+ belong to the categories marked as negative for this sequence. Additionally, unmatched tracker
+ detections for classes which are marked as not exhaustively labeled are removed.
+ 4) No gt detections are removed.
+ Further, for TrackMAP computation track representations for the given class are accessed from a dictionary
+ and the tracks from the tracker data are sorted according to the tracker confidence.
+ """
+ cls_id = self.class_name_to_class_id[cls]
+ is_not_exhaustively_labeled = cls_id in raw_data['not_exhaustively_labeled_cls']
+ is_neg_category = cls_id in raw_data['neg_cat_ids']
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+ for t in range(raw_data['num_timesteps']):
+
+ # Only extract relevant dets for this class for preproc and eval (cls)
+ gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
+ gt_class_mask = gt_class_mask.astype(np.bool)
+ gt_ids = raw_data['gt_ids'][t][gt_class_mask]
+ gt_dets = raw_data['gt_dets'][t][gt_class_mask]
+
+ tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
+ tracker_class_mask = tracker_class_mask.astype(np.bool)
+ tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
+ tracker_dets = raw_data['tracker_dets'][t][tracker_class_mask]
+ tracker_confidences = raw_data['tracker_confidences'][t][tracker_class_mask]
+ similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
+
+ # Match tracker and gt dets (with hungarian algorithm).
+ unmatched_indices = np.arange(tracker_ids.shape[0])
+ if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
+ matching_scores = similarity_scores.copy()
+ matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_cols = match_cols[actually_matched_mask]
+ unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
+
+ if gt_ids.shape[0] == 0 and not is_neg_category:
+ to_remove_tracker = unmatched_indices
+ elif is_not_exhaustively_labeled:
+ to_remove_tracker = unmatched_indices
+ else:
+ to_remove_tracker = np.array([], dtype=np.int)
+
+ # remove all unwanted unmatched tracker detections
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+
+ data['gt_ids'][t] = gt_ids
+ data['gt_dets'][t] = gt_dets
+ data['similarity_scores'][t] = similarity_scores
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+
+ # get track representations
+ data['gt_tracks'] = raw_data['classes_to_gt_tracks'][cls_id]
+ data['gt_track_ids'] = raw_data['classes_to_gt_track_ids'][cls_id]
+ data['gt_track_lengths'] = raw_data['classes_to_gt_track_lengths'][cls_id]
+ data['gt_track_areas'] = raw_data['classes_to_gt_track_areas'][cls_id]
+ data['dt_tracks'] = raw_data['classes_to_dt_tracks'][cls_id]
+ data['dt_track_ids'] = raw_data['classes_to_dt_track_ids'][cls_id]
+ data['dt_track_lengths'] = raw_data['classes_to_dt_track_lengths'][cls_id]
+ data['dt_track_areas'] = raw_data['classes_to_dt_track_areas'][cls_id]
+ data['dt_track_scores'] = raw_data['classes_to_dt_track_scores'][cls_id]
+ data['not_exhaustively_labeled'] = is_not_exhaustively_labeled
+ data['iou_type'] = 'bbox'
+
+ # sort tracker data tracks by tracker confidence scores
+ if data['dt_tracks']:
+ idx = np.argsort([-score for score in data['dt_track_scores']], kind="mergesort")
+ data['dt_track_scores'] = [data['dt_track_scores'][i] for i in idx]
+ data['dt_tracks'] = [data['dt_tracks'][i] for i in idx]
+ data['dt_track_ids'] = [data['dt_track_ids'][i] for i in idx]
+ data['dt_track_lengths'] = [data['dt_track_lengths'][i] for i in idx]
+ data['dt_track_areas'] = [data['dt_track_areas'][i] for i in idx]
+ # Ensure that ids are unique per timestep.
+ self._check_unique_ids(data)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t)
+ return similarity_scores
+
+ def _merge_categories(self, annotations):
+ """
+ Merges categories with a merged tag. Adapted from https://github.com/TAO-Dataset
+ :param annotations: the annotations in which the classes should be merged
+ :return: None
+ """
+ merge_map = {}
+ for category in self.gt_data['categories']:
+ if 'merged' in category:
+ for to_merge in category['merged']:
+ merge_map[to_merge['id']] = category['id']
+
+ for ann in annotations:
+ ann['category_id'] = merge_map.get(ann['category_id'], ann['category_id'])
+
+ def _compute_vid_mappings(self, annotations):
+ """
+ Computes mappings from Videos to corresponding tracks and images.
+ :param annotations: the annotations for which the mapping should be generated
+ :return: the video-to-track-mapping, the video-to-image-mapping
+ """
+ vids_to_tracks = {}
+ vids_to_imgs = {}
+ vid_ids = [vid['id'] for vid in self.gt_data['videos']]
+
+ # compute an mapping from image IDs to images
+ images = {}
+ for image in self.gt_data['images']:
+ images[image['id']] = image
+
+ for ann in annotations:
+ ann["area"] = ann["bbox"][2] * ann["bbox"][3]
+
+ vid = ann["video_id"]
+ if ann["video_id"] not in vids_to_tracks.keys():
+ vids_to_tracks[ann["video_id"]] = list()
+ if ann["video_id"] not in vids_to_imgs.keys():
+ vids_to_imgs[ann["video_id"]] = list()
+
+ # Fill in vids_to_tracks
+ tid = ann["track_id"]
+ exist_tids = [track["id"] for track in vids_to_tracks[vid]]
+ try:
+ index1 = exist_tids.index(tid)
+ except ValueError:
+ index1 = -1
+ if tid not in exist_tids:
+ curr_track = {"id": tid, "category_id": ann['category_id'],
+ "video_id": vid, "annotations": [ann]}
+ vids_to_tracks[vid].append(curr_track)
+ else:
+ vids_to_tracks[vid][index1]["annotations"].append(ann)
+
+ # Fill in vids_to_imgs
+ img_id = ann['image_id']
+ exist_img_ids = [img["id"] for img in vids_to_imgs[vid]]
+ try:
+ index2 = exist_img_ids.index(img_id)
+ except ValueError:
+ index2 = -1
+ if index2 == -1:
+ curr_img = {"id": img_id, "annotations": [ann]}
+ vids_to_imgs[vid].append(curr_img)
+ else:
+ vids_to_imgs[vid][index2]["annotations"].append(ann)
+
+ # sort annotations by frame index and compute track area
+ for vid, tracks in vids_to_tracks.items():
+ for track in tracks:
+ track["annotations"] = sorted(
+ track['annotations'],
+ key=lambda x: images[x['image_id']]['frame_index'])
+ # Computer average area
+ track["area"] = (sum(x['area'] for x in track['annotations']) / len(track['annotations']))
+
+ # Ensure all videos are present
+ for vid_id in vid_ids:
+ if vid_id not in vids_to_tracks.keys():
+ vids_to_tracks[vid_id] = []
+ if vid_id not in vids_to_imgs.keys():
+ vids_to_imgs[vid_id] = []
+
+ return vids_to_tracks, vids_to_imgs
+
+ def _compute_image_to_timestep_mappings(self):
+ """
+ Computes a mapping from images to the corresponding timestep in the sequence.
+ :return: the image-to-timestep-mapping
+ """
+ images = {}
+ for image in self.gt_data['images']:
+ images[image['id']] = image
+
+ seq_to_imgs_to_timestep = {vid['id']: dict() for vid in self.gt_data['videos']}
+ for vid in seq_to_imgs_to_timestep:
+ curr_imgs = [img['id'] for img in self.videos_to_gt_images[vid]]
+ curr_imgs = sorted(curr_imgs, key=lambda x: images[x]['frame_index'])
+ seq_to_imgs_to_timestep[vid] = {curr_imgs[i]: i for i in range(len(curr_imgs))}
+
+ return seq_to_imgs_to_timestep
+
+ def _limit_dets_per_image(self, annotations):
+ """
+ Limits the number of detections for each image to config['MAX_DETECTIONS']. Adapted from
+ https://github.com/TAO-Dataset/
+ :param annotations: the annotations in which the detections should be limited
+ :return: the annotations with limited detections
+ """
+ max_dets = self.config['MAX_DETECTIONS']
+ img_ann = defaultdict(list)
+ for ann in annotations:
+ img_ann[ann["image_id"]].append(ann)
+
+ for img_id, _anns in img_ann.items():
+ if len(_anns) <= max_dets:
+ continue
+ _anns = sorted(_anns, key=lambda x: x["score"], reverse=True)
+ img_ann[img_id] = _anns[:max_dets]
+
+ return [ann for anns in img_ann.values() for ann in anns]
+
+ def _fill_video_ids_inplace(self, annotations):
+ """
+ Fills in missing video IDs inplace. Adapted from https://github.com/TAO-Dataset/
+ :param annotations: the annotations for which the videos IDs should be filled inplace
+ :return: None
+ """
+ missing_video_id = [x for x in annotations if 'video_id' not in x]
+ if missing_video_id:
+ image_id_to_video_id = {
+ x['id']: x['video_id'] for x in self.gt_data['images']
+ }
+ for x in missing_video_id:
+ x['video_id'] = image_id_to_video_id[x['image_id']]
+
+ @staticmethod
+ def _make_track_ids_unique(annotations):
+ """
+ Makes the track IDs unqiue over the whole annotation set. Adapted from https://github.com/TAO-Dataset/
+ :param annotations: the annotation set
+ :return: the number of updated IDs
+ """
+ track_id_videos = {}
+ track_ids_to_update = set()
+ max_track_id = 0
+ for ann in annotations:
+ t = ann['track_id']
+ if t not in track_id_videos:
+ track_id_videos[t] = ann['video_id']
+
+ if ann['video_id'] != track_id_videos[t]:
+ # Track id is assigned to multiple videos
+ track_ids_to_update.add(t)
+ max_track_id = max(max_track_id, t)
+
+ if track_ids_to_update:
+ print('true')
+ next_id = itertools.count(max_track_id + 1)
+ new_track_ids = defaultdict(lambda: next(next_id))
+ for ann in annotations:
+ t = ann['track_id']
+ v = ann['video_id']
+ if t in track_ids_to_update:
+ ann['track_id'] = new_track_ids[t, v]
+ return len(track_ids_to_update)
diff --git a/val_utils/trackeval/datasets/tao_ow.py b/val_utils/trackeval/datasets/tao_ow.py
new file mode 100644
index 0000000000000000000000000000000000000000..40f80d7876ed9f27fb108b732315c4f8c6fc0984
--- /dev/null
+++ b/val_utils/trackeval/datasets/tao_ow.py
@@ -0,0 +1,652 @@
+import os
+import numpy as np
+import json
+import itertools
+from collections import defaultdict
+from scipy.optimize import linear_sum_assignment
+from ..utils import TrackEvalException
+from ._base_dataset import _BaseDataset
+from .. import utils
+from .. import _timing
+
+
+class TAO_OW(_BaseDataset):
+ """Dataset class for TAO tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/tao/tao_training'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/tao/tao_training'), # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
+ 'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ 'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
+ 'SUBSET': 'all'
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+ self.gt_fol = self.config['GT_FOLDER']
+ self.tracker_fol = self.config['TRACKERS_FOLDER']
+ self.should_classes_combine = True
+ self.use_super_categories = False
+
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+
+ gt_dir_files = [file for file in os.listdir(self.gt_fol) if file.endswith('.json')]
+ if len(gt_dir_files) != 1:
+ raise TrackEvalException(self.gt_fol + ' does not contain exactly one json file.')
+
+ with open(os.path.join(self.gt_fol, gt_dir_files[0])) as f:
+ self.gt_data = json.load(f)
+
+ self.subset = self.config['SUBSET']
+ if self.subset != 'all':
+ # Split GT data into `known`, `unknown` or `distractor`
+ self._split_known_unknown_distractor()
+ self.gt_data = self._filter_gt_data(self.gt_data)
+
+ # merge categories marked with a merged tag in TAO dataset
+ self._merge_categories(self.gt_data['annotations'] + self.gt_data['tracks'])
+
+ # Get sequences to eval and sequence information
+ self.seq_list = [vid['name'].replace('/', '-') for vid in self.gt_data['videos']]
+ self.seq_name_to_seq_id = {vid['name'].replace('/', '-'): vid['id'] for vid in self.gt_data['videos']}
+ # compute mappings from videos to annotation data
+ self.videos_to_gt_tracks, self.videos_to_gt_images = self._compute_vid_mappings(self.gt_data['annotations'])
+ # compute sequence lengths
+ self.seq_lengths = {vid['id']: 0 for vid in self.gt_data['videos']}
+ for img in self.gt_data['images']:
+ self.seq_lengths[img['video_id']] += 1
+ self.seq_to_images_to_timestep = self._compute_image_to_timestep_mappings()
+ self.seq_to_classes = {vid['id']: {'pos_cat_ids': list({track['category_id'] for track
+ in self.videos_to_gt_tracks[vid['id']]}),
+ 'neg_cat_ids': vid['neg_category_ids'],
+ 'not_exhaustively_labeled_cat_ids': vid['not_exhaustive_category_ids']}
+ for vid in self.gt_data['videos']}
+
+ # Get classes to eval
+ considered_vid_ids = [self.seq_name_to_seq_id[vid] for vid in self.seq_list]
+ seen_cats = set([cat_id for vid_id in considered_vid_ids for cat_id
+ in self.seq_to_classes[vid_id]['pos_cat_ids']])
+ # only classes with ground truth are evaluated in TAO
+ self.valid_classes = [cls['name'] for cls in self.gt_data['categories'] if cls['id'] in seen_cats]
+ # cls_name_to_cls_id_map = {cls['name']: cls['id'] for cls in self.gt_data['categories']}
+
+ if self.config['CLASSES_TO_EVAL']:
+ # self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ # for cls in self.config['CLASSES_TO_EVAL']]
+ self.class_list = ["object"] # class-agnostic
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only classes ' +
+ ', '.join(self.valid_classes) +
+ ' are valid (classes present in ground truth data).')
+ else:
+ # self.class_list = [cls for cls in self.valid_classes]
+ self.class_list = ["object"] # class-agnostic
+ # self.class_name_to_class_id = {k: v for k, v in cls_name_to_cls_id_map.items() if k in self.class_list}
+ self.class_name_to_class_id = {"object": 1} # class-agnostic
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ self.tracker_data = {tracker: dict() for tracker in self.tracker_list}
+
+ for tracker in self.tracker_list:
+ tr_dir_files = [file for file in os.listdir(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol))
+ if file.endswith('.json')]
+ if len(tr_dir_files) != 1:
+ raise TrackEvalException(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol)
+ + ' does not contain exactly one json file.')
+ with open(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, tr_dir_files[0])) as f:
+ curr_data = json.load(f)
+
+ # limit detections if MAX_DETECTIONS > 0
+ if self.config['MAX_DETECTIONS']:
+ curr_data = self._limit_dets_per_image(curr_data)
+
+ # fill missing video ids
+ self._fill_video_ids_inplace(curr_data)
+
+ # make track ids unique over whole evaluation set
+ self._make_track_ids_unique(curr_data)
+
+ # merge categories marked with a merged tag in TAO dataset
+ self._merge_categories(curr_data)
+
+ # get tracker sequence information
+ curr_videos_to_tracker_tracks, curr_videos_to_tracker_images = self._compute_vid_mappings(curr_data)
+ self.tracker_data[tracker]['vids_to_tracks'] = curr_videos_to_tracker_tracks
+ self.tracker_data[tracker]['vids_to_images'] = curr_videos_to_tracker_images
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the TAO format
+
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets]: list (for each timestep) of lists of detections.
+ [classes_to_gt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
+ keys and corresponding segmentations as values) for each track
+ [classes_to_gt_track_ids, classes_to_gt_track_areas, classes_to_gt_track_lengths]: dictionary with class values
+ as keys and lists (for each track) as values
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ [classes_to_dt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
+ keys and corresponding segmentations as values) for each track
+ [classes_to_dt_track_ids, classes_to_dt_track_areas, classes_to_dt_track_lengths]: dictionary with class values
+ as keys and lists as values
+ [classes_to_dt_track_scores]: dictionary with class values as keys and 1D numpy arrays as values
+ """
+ seq_id = self.seq_name_to_seq_id[seq]
+ # File location
+ if is_gt:
+ imgs = self.videos_to_gt_images[seq_id]
+ else:
+ imgs = self.tracker_data[tracker]['vids_to_images'][seq_id]
+
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq_id]
+ img_to_timestep = self.seq_to_images_to_timestep[seq_id]
+ data_keys = ['ids', 'classes', 'dets']
+ if not is_gt:
+ data_keys += ['tracker_confidences']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+ for img in imgs:
+ # some tracker data contains images without any ground truth information, these are ignored
+ try:
+ t = img_to_timestep[img['id']]
+ except KeyError:
+ continue
+ annotations = img['annotations']
+ raw_data['dets'][t] = np.atleast_2d([ann['bbox'] for ann in annotations]).astype(float)
+ raw_data['ids'][t] = np.atleast_1d([ann['track_id'] for ann in annotations]).astype(int)
+ raw_data['classes'][t] = np.atleast_1d([1 for _ in annotations]).astype(int) # class-agnostic
+ if not is_gt:
+ raw_data['tracker_confidences'][t] = np.atleast_1d([ann['score'] for ann in annotations]).astype(float)
+
+ for t, d in enumerate(raw_data['dets']):
+ if d is None:
+ raw_data['dets'][t] = np.empty((0, 4)).astype(float)
+ raw_data['ids'][t] = np.empty(0).astype(int)
+ raw_data['classes'][t] = np.empty(0).astype(int)
+ if not is_gt:
+ raw_data['tracker_confidences'][t] = np.empty(0)
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+
+ # all_classes = [self.class_name_to_class_id[cls] for cls in self.class_list]
+ all_classes = [1] # class-agnostic
+
+ if is_gt:
+ classes_to_consider = all_classes
+ all_tracks = self.videos_to_gt_tracks[seq_id]
+ else:
+ # classes_to_consider = self.seq_to_classes[seq_id]['pos_cat_ids'] \
+ # + self.seq_to_classes[seq_id]['neg_cat_ids']
+ classes_to_consider = all_classes # class-agnostic
+ all_tracks = self.tracker_data[tracker]['vids_to_tracks'][seq_id]
+
+ # classes_to_tracks = {cls: [track for track in all_tracks if track['category_id'] == cls]
+ # if cls in classes_to_consider else [] for cls in all_classes}
+ classes_to_tracks = {cls: [track for track in all_tracks]
+ if cls in classes_to_consider else [] for cls in all_classes} # class-agnostic
+
+ # mapping from classes to track information
+ raw_data['classes_to_tracks'] = {cls: [{det['image_id']: np.atleast_1d(det['bbox'])
+ for det in track['annotations']} for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_ids'] = {cls: [track['id'] for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_areas'] = {cls: [track['area'] for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_lengths'] = {cls: [len(track['annotations']) for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+
+ if not is_gt:
+ raw_data['classes_to_dt_track_scores'] = {cls: np.array([np.mean([float(x['score'])
+ for x in track['annotations']])
+ for track in tracks])
+ for cls, tracks in classes_to_tracks.items()}
+
+ if is_gt:
+ key_map = {'classes_to_tracks': 'classes_to_gt_tracks',
+ 'classes_to_track_ids': 'classes_to_gt_track_ids',
+ 'classes_to_track_lengths': 'classes_to_gt_track_lengths',
+ 'classes_to_track_areas': 'classes_to_gt_track_areas'}
+ else:
+ key_map = {'classes_to_tracks': 'classes_to_dt_tracks',
+ 'classes_to_track_ids': 'classes_to_dt_track_ids',
+ 'classes_to_track_lengths': 'classes_to_dt_track_lengths',
+ 'classes_to_track_areas': 'classes_to_dt_track_areas'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+
+ raw_data['num_timesteps'] = num_timesteps
+ raw_data['neg_cat_ids'] = self.seq_to_classes[seq_id]['neg_cat_ids']
+ raw_data['not_exhaustively_labeled_cls'] = self.seq_to_classes[seq_id]['not_exhaustively_labeled_cat_ids']
+ raw_data['seq'] = seq
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+ TAO:
+ In TAO, the 4 preproc steps are as follow:
+ 1) All classes present in the ground truth data are evaluated separately.
+ 2) No matched tracker detections are removed.
+ 3) Unmatched tracker detections are removed if there is not ground truth data and the class does not
+ belong to the categories marked as negative for this sequence. Additionally, unmatched tracker
+ detections for classes which are marked as not exhaustively labeled are removed.
+ 4) No gt detections are removed.
+ Further, for TrackMAP computation track representations for the given class are accessed from a dictionary
+ and the tracks from the tracker data are sorted according to the tracker confidence.
+ """
+ cls_id = self.class_name_to_class_id[cls]
+ is_not_exhaustively_labeled = cls_id in raw_data['not_exhaustively_labeled_cls']
+ is_neg_category = cls_id in raw_data['neg_cat_ids']
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+ for t in range(raw_data['num_timesteps']):
+
+ # Only extract relevant dets for this class for preproc and eval (cls)
+ gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
+ gt_class_mask = gt_class_mask.astype(np.bool)
+ gt_ids = raw_data['gt_ids'][t][gt_class_mask]
+ gt_dets = raw_data['gt_dets'][t][gt_class_mask]
+
+ tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
+ tracker_class_mask = tracker_class_mask.astype(np.bool)
+ tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
+ tracker_dets = raw_data['tracker_dets'][t][tracker_class_mask]
+ tracker_confidences = raw_data['tracker_confidences'][t][tracker_class_mask]
+ similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
+
+ # Match tracker and gt dets (with hungarian algorithm).
+ unmatched_indices = np.arange(tracker_ids.shape[0])
+ if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
+ matching_scores = similarity_scores.copy()
+ matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
+ match_rows, match_cols = linear_sum_assignment(-matching_scores)
+ actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_cols = match_cols[actually_matched_mask]
+ unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
+
+ if gt_ids.shape[0] == 0 and not is_neg_category:
+ to_remove_tracker = unmatched_indices
+ elif is_not_exhaustively_labeled:
+ to_remove_tracker = unmatched_indices
+ else:
+ to_remove_tracker = np.array([], dtype=np.int)
+
+ # remove all unwanted unmatched tracker detections
+ data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
+ data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
+ data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
+ similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
+
+ data['gt_ids'][t] = gt_ids
+ data['gt_dets'][t] = gt_dets
+ data['similarity_scores'][t] = similarity_scores
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+
+ # get track representations
+ data['gt_tracks'] = raw_data['classes_to_gt_tracks'][cls_id]
+ data['gt_track_ids'] = raw_data['classes_to_gt_track_ids'][cls_id]
+ data['gt_track_lengths'] = raw_data['classes_to_gt_track_lengths'][cls_id]
+ data['gt_track_areas'] = raw_data['classes_to_gt_track_areas'][cls_id]
+ data['dt_tracks'] = raw_data['classes_to_dt_tracks'][cls_id]
+ data['dt_track_ids'] = raw_data['classes_to_dt_track_ids'][cls_id]
+ data['dt_track_lengths'] = raw_data['classes_to_dt_track_lengths'][cls_id]
+ data['dt_track_areas'] = raw_data['classes_to_dt_track_areas'][cls_id]
+ data['dt_track_scores'] = raw_data['classes_to_dt_track_scores'][cls_id]
+ data['not_exhaustively_labeled'] = is_not_exhaustively_labeled
+ data['iou_type'] = 'bbox'
+
+ # sort tracker data tracks by tracker confidence scores
+ if data['dt_tracks']:
+ idx = np.argsort([-score for score in data['dt_track_scores']], kind="mergesort")
+ data['dt_track_scores'] = [data['dt_track_scores'][i] for i in idx]
+ data['dt_tracks'] = [data['dt_tracks'][i] for i in idx]
+ data['dt_track_ids'] = [data['dt_track_ids'][i] for i in idx]
+ data['dt_track_lengths'] = [data['dt_track_lengths'][i] for i in idx]
+ data['dt_track_areas'] = [data['dt_track_areas'][i] for i in idx]
+ # Ensure that ids are unique per timestep.
+ self._check_unique_ids(data)
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t)
+ return similarity_scores
+
+ def _merge_categories(self, annotations):
+ """
+ Merges categories with a merged tag. Adapted from https://github.com/TAO-Dataset
+ :param annotations: the annotations in which the classes should be merged
+ :return: None
+ """
+ merge_map = {}
+ for category in self.gt_data['categories']:
+ if 'merged' in category:
+ for to_merge in category['merged']:
+ merge_map[to_merge['id']] = category['id']
+
+ for ann in annotations:
+ ann['category_id'] = merge_map.get(ann['category_id'], ann['category_id'])
+
+ def _compute_vid_mappings(self, annotations):
+ """
+ Computes mappings from Videos to corresponding tracks and images.
+ :param annotations: the annotations for which the mapping should be generated
+ :return: the video-to-track-mapping, the video-to-image-mapping
+ """
+ vids_to_tracks = {}
+ vids_to_imgs = {}
+ vid_ids = [vid['id'] for vid in self.gt_data['videos']]
+
+ # compute an mapping from image IDs to images
+ images = {}
+ for image in self.gt_data['images']:
+ images[image['id']] = image
+
+ for ann in annotations:
+ ann["area"] = ann["bbox"][2] * ann["bbox"][3]
+
+ vid = ann["video_id"]
+ if ann["video_id"] not in vids_to_tracks.keys():
+ vids_to_tracks[ann["video_id"]] = list()
+ if ann["video_id"] not in vids_to_imgs.keys():
+ vids_to_imgs[ann["video_id"]] = list()
+
+ # Fill in vids_to_tracks
+ tid = ann["track_id"]
+ exist_tids = [track["id"] for track in vids_to_tracks[vid]]
+ try:
+ index1 = exist_tids.index(tid)
+ except ValueError:
+ index1 = -1
+ if tid not in exist_tids:
+ curr_track = {"id": tid, "category_id": ann['category_id'],
+ "video_id": vid, "annotations": [ann]}
+ vids_to_tracks[vid].append(curr_track)
+ else:
+ vids_to_tracks[vid][index1]["annotations"].append(ann)
+
+ # Fill in vids_to_imgs
+ img_id = ann['image_id']
+ exist_img_ids = [img["id"] for img in vids_to_imgs[vid]]
+ try:
+ index2 = exist_img_ids.index(img_id)
+ except ValueError:
+ index2 = -1
+ if index2 == -1:
+ curr_img = {"id": img_id, "annotations": [ann]}
+ vids_to_imgs[vid].append(curr_img)
+ else:
+ vids_to_imgs[vid][index2]["annotations"].append(ann)
+
+ # sort annotations by frame index and compute track area
+ for vid, tracks in vids_to_tracks.items():
+ for track in tracks:
+ track["annotations"] = sorted(
+ track['annotations'],
+ key=lambda x: images[x['image_id']]['frame_index'])
+ # Computer average area
+ track["area"] = (sum(x['area'] for x in track['annotations']) / len(track['annotations']))
+
+ # Ensure all videos are present
+ for vid_id in vid_ids:
+ if vid_id not in vids_to_tracks.keys():
+ vids_to_tracks[vid_id] = []
+ if vid_id not in vids_to_imgs.keys():
+ vids_to_imgs[vid_id] = []
+
+ return vids_to_tracks, vids_to_imgs
+
+ def _compute_image_to_timestep_mappings(self):
+ """
+ Computes a mapping from images to the corresponding timestep in the sequence.
+ :return: the image-to-timestep-mapping
+ """
+ images = {}
+ for image in self.gt_data['images']:
+ images[image['id']] = image
+
+ seq_to_imgs_to_timestep = {vid['id']: dict() for vid in self.gt_data['videos']}
+ for vid in seq_to_imgs_to_timestep:
+ curr_imgs = [img['id'] for img in self.videos_to_gt_images[vid]]
+ curr_imgs = sorted(curr_imgs, key=lambda x: images[x]['frame_index'])
+ seq_to_imgs_to_timestep[vid] = {curr_imgs[i]: i for i in range(len(curr_imgs))}
+
+ return seq_to_imgs_to_timestep
+
+ def _limit_dets_per_image(self, annotations):
+ """
+ Limits the number of detections for each image to config['MAX_DETECTIONS']. Adapted from
+ https://github.com/TAO-Dataset/
+ :param annotations: the annotations in which the detections should be limited
+ :return: the annotations with limited detections
+ """
+ max_dets = self.config['MAX_DETECTIONS']
+ img_ann = defaultdict(list)
+ for ann in annotations:
+ img_ann[ann["image_id"]].append(ann)
+
+ for img_id, _anns in img_ann.items():
+ if len(_anns) <= max_dets:
+ continue
+ _anns = sorted(_anns, key=lambda x: x["score"], reverse=True)
+ img_ann[img_id] = _anns[:max_dets]
+
+ return [ann for anns in img_ann.values() for ann in anns]
+
+ def _fill_video_ids_inplace(self, annotations):
+ """
+ Fills in missing video IDs inplace. Adapted from https://github.com/TAO-Dataset/
+ :param annotations: the annotations for which the videos IDs should be filled inplace
+ :return: None
+ """
+ missing_video_id = [x for x in annotations if 'video_id' not in x]
+ if missing_video_id:
+ image_id_to_video_id = {
+ x['id']: x['video_id'] for x in self.gt_data['images']
+ }
+ for x in missing_video_id:
+ x['video_id'] = image_id_to_video_id[x['image_id']]
+
+ @staticmethod
+ def _make_track_ids_unique(annotations):
+ """
+ Makes the track IDs unqiue over the whole annotation set. Adapted from https://github.com/TAO-Dataset/
+ :param annotations: the annotation set
+ :return: the number of updated IDs
+ """
+ track_id_videos = {}
+ track_ids_to_update = set()
+ max_track_id = 0
+ for ann in annotations:
+ t = ann['track_id']
+ if t not in track_id_videos:
+ track_id_videos[t] = ann['video_id']
+
+ if ann['video_id'] != track_id_videos[t]:
+ # Track id is assigned to multiple videos
+ track_ids_to_update.add(t)
+ max_track_id = max(max_track_id, t)
+
+ if track_ids_to_update:
+ print('true')
+ next_id = itertools.count(max_track_id + 1)
+ new_track_ids = defaultdict(lambda: next(next_id))
+ for ann in annotations:
+ t = ann['track_id']
+ v = ann['video_id']
+ if t in track_ids_to_update:
+ ann['track_id'] = new_track_ids[t, v]
+ return len(track_ids_to_update)
+
+ def _split_known_unknown_distractor(self):
+ all_ids = set([i for i in range(1, 2000)]) # 2000 is larger than the max category id in TAO-OW.
+ # `knowns` includes 78 TAO_category_ids that corresponds to 78 COCO classes.
+ # (The other 2 COCO classes do not have corresponding classes in TAO).
+ self.knowns = {4, 13, 1038, 544, 1057, 34, 35, 36, 41, 45, 58, 60, 579, 1091, 1097, 1099, 78, 79, 81, 91, 1115,
+ 1117, 95, 1122, 99, 1132, 621, 1135, 625, 118, 1144, 126, 642, 1155, 133, 1162, 139, 154, 174, 185,
+ 699, 1215, 714, 717, 1229, 211, 729, 221, 229, 747, 235, 237, 779, 276, 805, 299, 829, 852, 347,
+ 371, 382, 896, 392, 926, 937, 428, 429, 961, 452, 979, 980, 982, 475, 480, 993, 1001, 502, 1018}
+ # `distractors` is defined as in the paper "Opening up Open-World Tracking"
+ self.distractors = {20, 63, 108, 180, 188, 204, 212, 247, 303, 403, 407, 415, 490, 504, 507, 513, 529, 567,
+ 569, 588, 672, 691, 702, 708, 711, 720, 736, 737, 798, 813, 815, 827, 831, 851, 877, 883,
+ 912, 971, 976, 1130, 1133, 1134, 1169, 1184, 1220}
+ self.unknowns = all_ids.difference(self.knowns.union(self.distractors))
+
+ def _filter_gt_data(self, raw_gt_data):
+ """
+ Filter out irrelevant data in the raw_gt_data
+ Args:
+ raw_gt_data: directly loaded from json.
+
+ Returns:
+ filtered gt_data
+ """
+ valid_cat_ids = list()
+ if self.subset == "known":
+ valid_cat_ids = self.knowns
+ elif self.subset == "distractor":
+ valid_cat_ids = self.distractors
+ elif self.subset == "unknown":
+ valid_cat_ids = self.unknowns
+ # elif self.subset == "test_only_unknowns":
+ # valid_cat_ids = test_only_unknowns
+ else:
+ raise Exception("The parameter `SUBSET` is incorrect")
+
+ filtered = dict()
+ filtered["videos"] = raw_gt_data["videos"]
+ # filtered["videos"] = list()
+ unwanted_vid = set()
+ # for video in raw_gt_data["videos"]:
+ # datasrc = video["name"].split('/')[1]
+ # if datasrc in data_srcs:
+ # filtered["videos"].append(video)
+ # else:
+ # unwanted_vid.add(video["id"])
+
+ filtered["annotations"] = list()
+ for ann in raw_gt_data["annotations"]:
+ if (ann["video_id"] not in unwanted_vid) and (ann["category_id"] in valid_cat_ids):
+ filtered["annotations"].append(ann)
+
+ filtered["tracks"] = list()
+ for track in raw_gt_data["tracks"]:
+ if (track["video_id"] not in unwanted_vid) and (track["category_id"] in valid_cat_ids):
+ filtered["tracks"].append(track)
+
+ filtered["images"] = list()
+ for image in raw_gt_data["images"]:
+ if image["video_id"] not in unwanted_vid:
+ filtered["images"].append(image)
+
+ filtered["categories"] = list()
+ for cat in raw_gt_data["categories"]:
+ if cat["id"] in valid_cat_ids:
+ filtered["categories"].append(cat)
+
+ filtered["info"] = raw_gt_data["info"]
+ filtered["licenses"] = raw_gt_data["licenses"]
+
+ return filtered
diff --git a/val_utils/trackeval/datasets/youtube_vis.py b/val_utils/trackeval/datasets/youtube_vis.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d5b54c9ed9045c5f4e2f25e4234f87a00f8e302
--- /dev/null
+++ b/val_utils/trackeval/datasets/youtube_vis.py
@@ -0,0 +1,364 @@
+import os
+import numpy as np
+import json
+from ._base_dataset import _BaseDataset
+from ..utils import TrackEvalException
+from .. import utils
+from .. import _timing
+
+
+class YouTubeVIS(_BaseDataset):
+ """Dataset class for YouTubeVIS tracking"""
+
+ @staticmethod
+ def get_default_dataset_config():
+ """Default class config values"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'GT_FOLDER': os.path.join(code_path, 'data/gt/youtube_vis/'), # Location of GT data
+ 'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/youtube_vis/'),
+ # Trackers location
+ 'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
+ 'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
+ 'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
+ 'SPLIT_TO_EVAL': 'train_sub_split', # Valid: 'train', 'val', 'train_sub_split'
+ 'PRINT_CONFIG': True, # Whether to print current config
+ 'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
+ 'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
+ 'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise dataset, checking that all required files are present"""
+ super().__init__()
+ # Fill non-given config values with defaults
+ self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
+ self.gt_fol = self.config['GT_FOLDER'] + 'youtube_vis_' + self.config['SPLIT_TO_EVAL']
+ self.tracker_fol = self.config['TRACKERS_FOLDER'] + 'youtube_vis_' + self.config['SPLIT_TO_EVAL']
+ self.use_super_categories = False
+ self.should_classes_combine = True
+
+ self.output_fol = self.config['OUTPUT_FOLDER']
+ if self.output_fol is None:
+ self.output_fol = self.tracker_fol
+ self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
+ self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
+
+ if not os.path.exists(self.gt_fol):
+ print("GT folder not found: " + self.gt_fol)
+ raise TrackEvalException("GT folder not found: " + os.path.basename(self.gt_fol))
+ gt_dir_files = [file for file in os.listdir(self.gt_fol) if file.endswith('.json')]
+ if len(gt_dir_files) != 1:
+ raise TrackEvalException(self.gt_fol + ' does not contain exactly one json file.')
+
+ with open(os.path.join(self.gt_fol, gt_dir_files[0])) as f:
+ self.gt_data = json.load(f)
+
+ # Get classes to eval
+ self.valid_classes = [cls['name'] for cls in self.gt_data['categories']]
+ cls_name_to_cls_id_map = {cls['name']: cls['id'] for cls in self.gt_data['categories']}
+
+ if self.config['CLASSES_TO_EVAL']:
+ self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
+ for cls in self.config['CLASSES_TO_EVAL']]
+ if not all(self.class_list):
+ raise TrackEvalException('Attempted to evaluate an invalid class. Only classes ' +
+ ', '.join(self.valid_classes) + ' are valid.')
+ else:
+ self.class_list = [cls['name'] for cls in self.gt_data['categories']]
+ self.class_name_to_class_id = {k: v for k, v in cls_name_to_cls_id_map.items() if k in self.class_list}
+
+ # Get sequences to eval and check gt files exist
+ self.seq_list = [vid['file_names'][0].split('/')[0] for vid in self.gt_data['videos']]
+ self.seq_name_to_seq_id = {vid['file_names'][0].split('/')[0]: vid['id'] for vid in self.gt_data['videos']}
+ self.seq_lengths = {vid['id']: len(vid['file_names']) for vid in self.gt_data['videos']}
+
+ # encode masks and compute track areas
+ self._prepare_gt_annotations()
+
+ # Get trackers to eval
+ if self.config['TRACKERS_TO_EVAL'] is None:
+ self.tracker_list = os.listdir(self.tracker_fol)
+ else:
+ self.tracker_list = self.config['TRACKERS_TO_EVAL']
+
+ if self.config['TRACKER_DISPLAY_NAMES'] is None:
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
+ elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
+ len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
+ self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
+ else:
+ raise TrackEvalException('List of tracker files and tracker display names do not match.')
+
+ # counter for globally unique track IDs
+ self.global_tid_counter = 0
+
+ self.tracker_data = dict()
+ for tracker in self.tracker_list:
+ tracker_dir_path = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol)
+ tr_dir_files = [file for file in os.listdir(tracker_dir_path) if file.endswith('.json')]
+ if len(tr_dir_files) != 1:
+ raise TrackEvalException(tracker_dir_path + ' does not contain exactly one json file.')
+
+ with open(os.path.join(tracker_dir_path, tr_dir_files[0])) as f:
+ curr_data = json.load(f)
+
+ self.tracker_data[tracker] = curr_data
+
+ def get_display_name(self, tracker):
+ return self.tracker_to_disp[tracker]
+
+ def _load_raw_file(self, tracker, seq, is_gt):
+ """Load a file (gt or tracker) in the YouTubeVIS format
+ If is_gt, this returns a dict which contains the fields:
+ [gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets]: list (for each timestep) of lists of detections.
+ [classes_to_gt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
+ keys and corresponding segmentations as values) for each track
+ [classes_to_gt_track_ids, classes_to_gt_track_areas, classes_to_gt_track_iscrowd]: dictionary with class values
+ as keys and lists (for each track) as values
+
+ if not is_gt, this returns a dict which contains the fields:
+ [tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
+ [tracker_dets]: list (for each timestep) of lists of detections.
+ [classes_to_dt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
+ keys and corresponding segmentations as values) for each track
+ [classes_to_dt_track_ids, classes_to_dt_track_areas]: dictionary with class values as keys and lists as values
+ [classes_to_dt_track_scores]: dictionary with class values as keys and 1D numpy arrays as values
+ """
+ # select sequence tracks
+ seq_id = self.seq_name_to_seq_id[seq]
+ if is_gt:
+ tracks = [ann for ann in self.gt_data['annotations'] if ann['video_id'] == seq_id]
+ else:
+ tracks = self._get_tracker_seq_tracks(tracker, seq_id)
+
+ # Convert data to required format
+ num_timesteps = self.seq_lengths[seq_id]
+ data_keys = ['ids', 'classes', 'dets']
+ if not is_gt:
+ data_keys += ['tracker_confidences']
+ raw_data = {key: [None] * num_timesteps for key in data_keys}
+ for t in range(num_timesteps):
+ raw_data['dets'][t] = [track['segmentations'][t] for track in tracks if track['segmentations'][t]]
+ raw_data['ids'][t] = np.atleast_1d([track['id'] for track in tracks
+ if track['segmentations'][t]]).astype(int)
+ raw_data['classes'][t] = np.atleast_1d([track['category_id'] for track in tracks
+ if track['segmentations'][t]]).astype(int)
+ if not is_gt:
+ raw_data['tracker_confidences'][t] = np.atleast_1d([track['score'] for track in tracks
+ if track['segmentations'][t]]).astype(float)
+
+ if is_gt:
+ key_map = {'ids': 'gt_ids',
+ 'classes': 'gt_classes',
+ 'dets': 'gt_dets'}
+ else:
+ key_map = {'ids': 'tracker_ids',
+ 'classes': 'tracker_classes',
+ 'dets': 'tracker_dets'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+
+ all_cls_ids = {self.class_name_to_class_id[cls] for cls in self.class_list}
+ classes_to_tracks = {cls: [track for track in tracks if track['category_id'] == cls] for cls in all_cls_ids}
+
+ # mapping from classes to track representations and track information
+ raw_data['classes_to_tracks'] = {cls: [{i: track['segmentations'][i]
+ for i in range(len(track['segmentations']))} for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_ids'] = {cls: [track['id'] for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ raw_data['classes_to_track_areas'] = {cls: [track['area'] for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+
+ if is_gt:
+ raw_data['classes_to_gt_track_iscrowd'] = {cls: [track['iscrowd'] for track in tracks]
+ for cls, tracks in classes_to_tracks.items()}
+ else:
+ raw_data['classes_to_dt_track_scores'] = {cls: np.array([track['score'] for track in tracks])
+ for cls, tracks in classes_to_tracks.items()}
+
+ if is_gt:
+ key_map = {'classes_to_tracks': 'classes_to_gt_tracks',
+ 'classes_to_track_ids': 'classes_to_gt_track_ids',
+ 'classes_to_track_areas': 'classes_to_gt_track_areas'}
+ else:
+ key_map = {'classes_to_tracks': 'classes_to_dt_tracks',
+ 'classes_to_track_ids': 'classes_to_dt_track_ids',
+ 'classes_to_track_areas': 'classes_to_dt_track_areas'}
+ for k, v in key_map.items():
+ raw_data[v] = raw_data.pop(k)
+
+ raw_data['num_timesteps'] = num_timesteps
+ raw_data['seq'] = seq
+ return raw_data
+
+ @_timing.time
+ def get_preprocessed_seq_data(self, raw_data, cls):
+ """ Preprocess data for a single sequence for a single class ready for evaluation.
+ Inputs:
+ - raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
+ - cls is the class to be evaluated.
+ Outputs:
+ - data is a dict containing all of the information that metrics need to perform evaluation.
+ It contains the following fields:
+ [num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
+ [gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
+ [gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
+ [similarity_scores]: list (for each timestep) of 2D NDArrays.
+ Notes:
+ General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
+ 1) Extract only detections relevant for the class to be evaluated (including distractor detections).
+ 2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
+ distractor class, or otherwise marked as to be removed.
+ 3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
+ other criteria (e.g. are too small).
+ 4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
+ After the above preprocessing steps, this function also calculates the number of gt and tracker detections
+ and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
+ unique within each timestep.
+ YouTubeVIS:
+ In YouTubeVIS, the 4 preproc steps are as follow:
+ 1) There are 40 classes which are evaluated separately.
+ 2) No matched tracker dets are removed.
+ 3) No unmatched tracker dets are removed.
+ 4) No gt dets are removed.
+ Further, for TrackMAP computation track representations for the given class are accessed from a dictionary
+ and the tracks from the tracker data are sorted according to the tracker confidence.
+ """
+ cls_id = self.class_name_to_class_id[cls]
+
+ data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'similarity_scores']
+ data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
+ unique_gt_ids = []
+ unique_tracker_ids = []
+ num_gt_dets = 0
+ num_tracker_dets = 0
+
+ for t in range(raw_data['num_timesteps']):
+
+ # Only extract relevant dets for this class for eval (cls)
+ gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
+ gt_class_mask = gt_class_mask.astype(np.bool)
+ gt_ids = raw_data['gt_ids'][t][gt_class_mask]
+ gt_dets = [raw_data['gt_dets'][t][ind] for ind in range(len(gt_class_mask)) if gt_class_mask[ind]]
+
+ tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
+ tracker_class_mask = tracker_class_mask.astype(np.bool)
+ tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
+ tracker_dets = [raw_data['tracker_dets'][t][ind] for ind in range(len(tracker_class_mask)) if
+ tracker_class_mask[ind]]
+ similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
+
+ data['tracker_ids'][t] = tracker_ids
+ data['tracker_dets'][t] = tracker_dets
+ data['gt_ids'][t] = gt_ids
+ data['gt_dets'][t] = gt_dets
+ data['similarity_scores'][t] = similarity_scores
+
+ unique_gt_ids += list(np.unique(data['gt_ids'][t]))
+ unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
+ num_tracker_dets += len(data['tracker_ids'][t])
+ num_gt_dets += len(data['gt_ids'][t])
+
+ # Re-label IDs such that there are no empty IDs
+ if len(unique_gt_ids) > 0:
+ unique_gt_ids = np.unique(unique_gt_ids)
+ gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
+ gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['gt_ids'][t]) > 0:
+ data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
+ if len(unique_tracker_ids) > 0:
+ unique_tracker_ids = np.unique(unique_tracker_ids)
+ tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
+ tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
+ for t in range(raw_data['num_timesteps']):
+ if len(data['tracker_ids'][t]) > 0:
+ data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
+
+ # Ensure that ids are unique per timestep.
+ self._check_unique_ids(data)
+
+ # Record overview statistics.
+ data['num_tracker_dets'] = num_tracker_dets
+ data['num_gt_dets'] = num_gt_dets
+ data['num_tracker_ids'] = len(unique_tracker_ids)
+ data['num_gt_ids'] = len(unique_gt_ids)
+ data['num_timesteps'] = raw_data['num_timesteps']
+ data['seq'] = raw_data['seq']
+
+ # get track representations
+ data['gt_tracks'] = raw_data['classes_to_gt_tracks'][cls_id]
+ data['gt_track_ids'] = raw_data['classes_to_gt_track_ids'][cls_id]
+ data['gt_track_areas'] = raw_data['classes_to_gt_track_areas'][cls_id]
+ data['gt_track_iscrowd'] = raw_data['classes_to_gt_track_iscrowd'][cls_id]
+ data['dt_tracks'] = raw_data['classes_to_dt_tracks'][cls_id]
+ data['dt_track_ids'] = raw_data['classes_to_dt_track_ids'][cls_id]
+ data['dt_track_areas'] = raw_data['classes_to_dt_track_areas'][cls_id]
+ data['dt_track_scores'] = raw_data['classes_to_dt_track_scores'][cls_id]
+ data['iou_type'] = 'mask'
+
+ # sort tracker data tracks by tracker confidence scores
+ if data['dt_tracks']:
+ idx = np.argsort([-score for score in data['dt_track_scores']], kind="mergesort")
+ data['dt_track_scores'] = [data['dt_track_scores'][i] for i in idx]
+ data['dt_tracks'] = [data['dt_tracks'][i] for i in idx]
+ data['dt_track_ids'] = [data['dt_track_ids'][i] for i in idx]
+ data['dt_track_areas'] = [data['dt_track_areas'][i] for i in idx]
+
+ return data
+
+ def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
+ similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
+ return similarity_scores
+
+ def _prepare_gt_annotations(self):
+ """
+ Prepares GT data by rle encoding segmentations and computing the average track area.
+ :return: None
+ """
+ # only loaded when needed to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ for track in self.gt_data['annotations']:
+ h = track['height']
+ w = track['width']
+ for i, seg in enumerate(track['segmentations']):
+ if seg:
+ track['segmentations'][i] = mask_utils.frPyObjects(seg, h, w)
+ areas = [a for a in track['areas'] if a]
+ if len(areas) == 0:
+ track['area'] = 0
+ else:
+ track['area'] = np.array(areas).mean()
+
+ def _get_tracker_seq_tracks(self, tracker, seq_id):
+ """
+ Prepares tracker data for a given sequence. Extracts all annotations for given sequence ID, computes
+ average track area and assigns a track ID.
+ :param tracker: the given tracker
+ :param seq_id: the sequence ID
+ :return: the extracted tracks
+ """
+ # only loaded when needed to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ tracks = [ann for ann in self.tracker_data[tracker] if ann['video_id'] == seq_id]
+ for track in tracks:
+ track['areas'] = []
+ for seg in track['segmentations']:
+ if seg:
+ track['areas'].append(mask_utils.area(seg))
+ else:
+ track['areas'].append(None)
+ areas = [a for a in track['areas'] if a]
+ if len(areas) == 0:
+ track['area'] = 0
+ else:
+ track['area'] = np.array(areas).mean()
+ track['id'] = self.global_tid_counter
+ self.global_tid_counter += 1
+ return tracks
diff --git a/val_utils/trackeval/eval.py b/val_utils/trackeval/eval.py
new file mode 100644
index 0000000000000000000000000000000000000000..82d62a016d69f1786604cf5809b639d993ea7660
--- /dev/null
+++ b/val_utils/trackeval/eval.py
@@ -0,0 +1,225 @@
+import time
+import traceback
+from multiprocessing.pool import Pool
+from functools import partial
+import os
+from . import utils
+from .utils import TrackEvalException
+from . import _timing
+from .metrics import Count
+
+try:
+ import tqdm
+ TQDM_IMPORTED = True
+except ImportError as _:
+ TQDM_IMPORTED = False
+
+
+class Evaluator:
+ """Evaluator class for evaluating different metrics for different datasets"""
+
+ @staticmethod
+ def get_default_eval_config():
+ """Returns the default config values for evaluation"""
+ code_path = utils.get_code_path()
+ default_config = {
+ 'USE_PARALLEL': False,
+ 'NUM_PARALLEL_CORES': 8,
+ 'BREAK_ON_ERROR': True, # Raises exception and exits with error
+ 'RETURN_ON_ERROR': False, # if not BREAK_ON_ERROR, then returns from function on error
+ 'LOG_ON_ERROR': os.path.join(code_path, 'error_log.txt'), # if not None, save any errors into a log file.
+
+ 'PRINT_RESULTS': True,
+ 'PRINT_ONLY_COMBINED': False,
+ 'PRINT_CONFIG': True,
+ 'TIME_PROGRESS': True,
+ 'DISPLAY_LESS_PROGRESS': True,
+
+ 'OUTPUT_SUMMARY': True,
+ 'OUTPUT_EMPTY_CLASSES': True, # If False, summary files are not output for classes with no detections
+ 'OUTPUT_DETAILED': True,
+ 'PLOT_CURVES': True,
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ """Initialise the evaluator with a config file"""
+ self.config = utils.init_config(config, self.get_default_eval_config(), 'Eval')
+ # Only run timing analysis if not run in parallel.
+ if self.config['TIME_PROGRESS'] and not self.config['USE_PARALLEL']:
+ _timing.DO_TIMING = True
+ if self.config['DISPLAY_LESS_PROGRESS']:
+ _timing.DISPLAY_LESS_PROGRESS = True
+
+ @_timing.time
+ def evaluate(self, dataset_list, metrics_list, show_progressbar=False):
+ """Evaluate a set of metrics on a set of datasets"""
+ config = self.config
+ metrics_list = metrics_list + [Count()] # Count metrics are always run
+ metric_names = utils.validate_metrics_list(metrics_list)
+ dataset_names = [dataset.get_name() for dataset in dataset_list]
+ output_res = {}
+ output_msg = {}
+
+ for dataset, dataset_name in zip(dataset_list, dataset_names):
+ # Get dataset info about what to evaluate
+ output_res[dataset_name] = {}
+ output_msg[dataset_name] = {}
+ tracker_list, seq_list, class_list = dataset.get_eval_info()
+ print('\nEvaluating %i tracker(s) on %i sequence(s) for %i class(es) on %s dataset using the following '
+ 'metrics: %s\n' % (len(tracker_list), len(seq_list), len(class_list), dataset_name,
+ ', '.join(metric_names)))
+
+ # Evaluate each tracker
+ for tracker in tracker_list:
+ # if not config['BREAK_ON_ERROR'] then go to next tracker without breaking
+ try:
+ # Evaluate each sequence in parallel or in series.
+ # returns a nested dict (res), indexed like: res[seq][class][metric_name][sub_metric field]
+ # e.g. res[seq_0001][pedestrian][hota][DetA]
+ print('\nEvaluating %s\n' % tracker)
+ time_start = time.time()
+ if config['USE_PARALLEL']:
+ if show_progressbar and TQDM_IMPORTED:
+ seq_list_sorted = sorted(seq_list)
+
+ with Pool(config['NUM_PARALLEL_CORES']) as pool, tqdm.tqdm(total=len(seq_list)) as pbar:
+ _eval_sequence = partial(eval_sequence, dataset=dataset, tracker=tracker,
+ class_list=class_list, metrics_list=metrics_list,
+ metric_names=metric_names)
+ results = []
+ for r in pool.imap(_eval_sequence, seq_list_sorted,
+ chunksize=20):
+ results.append(r)
+ pbar.update()
+ res = dict(zip(seq_list_sorted, results))
+
+ else:
+ with Pool(config['NUM_PARALLEL_CORES']) as pool:
+ _eval_sequence = partial(eval_sequence, dataset=dataset, tracker=tracker,
+ class_list=class_list, metrics_list=metrics_list,
+ metric_names=metric_names)
+ results = pool.map(_eval_sequence, seq_list)
+ res = dict(zip(seq_list, results))
+ else:
+ res = {}
+ if show_progressbar and TQDM_IMPORTED:
+ seq_list_sorted = sorted(seq_list)
+ for curr_seq in tqdm.tqdm(seq_list_sorted):
+ res[curr_seq] = eval_sequence(curr_seq, dataset, tracker, class_list, metrics_list,
+ metric_names)
+ else:
+ for curr_seq in sorted(seq_list):
+ res[curr_seq] = eval_sequence(curr_seq, dataset, tracker, class_list, metrics_list,
+ metric_names)
+
+ # Combine results over all sequences and then over all classes
+
+ # collecting combined cls keys (cls averaged, det averaged, super classes)
+ combined_cls_keys = []
+ res['COMBINED_SEQ'] = {}
+ # combine sequences for each class
+ for c_cls in class_list:
+ res['COMBINED_SEQ'][c_cls] = {}
+ for metric, metric_name in zip(metrics_list, metric_names):
+ curr_res = {seq_key: seq_value[c_cls][metric_name] for seq_key, seq_value in res.items() if
+ seq_key != 'COMBINED_SEQ'}
+ res['COMBINED_SEQ'][c_cls][metric_name] = metric.combine_sequences(curr_res)
+ # combine classes
+ if dataset.should_classes_combine:
+ combined_cls_keys += ['cls_comb_cls_av', 'cls_comb_det_av', 'all']
+ res['COMBINED_SEQ']['cls_comb_cls_av'] = {}
+ res['COMBINED_SEQ']['cls_comb_det_av'] = {}
+ for metric, metric_name in zip(metrics_list, metric_names):
+ cls_res = {cls_key: cls_value[metric_name] for cls_key, cls_value in
+ res['COMBINED_SEQ'].items() if cls_key not in combined_cls_keys}
+ res['COMBINED_SEQ']['cls_comb_cls_av'][metric_name] = \
+ metric.combine_classes_class_averaged(cls_res)
+ res['COMBINED_SEQ']['cls_comb_det_av'][metric_name] = \
+ metric.combine_classes_det_averaged(cls_res)
+ # combine classes to super classes
+ if dataset.use_super_categories:
+ for cat, sub_cats in dataset.super_categories.items():
+ combined_cls_keys.append(cat)
+ res['COMBINED_SEQ'][cat] = {}
+ for metric, metric_name in zip(metrics_list, metric_names):
+ cat_res = {cls_key: cls_value[metric_name] for cls_key, cls_value in
+ res['COMBINED_SEQ'].items() if cls_key in sub_cats}
+ res['COMBINED_SEQ'][cat][metric_name] = metric.combine_classes_det_averaged(cat_res)
+
+ # Print and output results in various formats
+ if config['TIME_PROGRESS']:
+ print('\nAll sequences for %s finished in %.2f seconds' % (tracker, time.time() - time_start))
+ output_fol = dataset.get_output_fol(tracker)
+ tracker_display_name = dataset.get_display_name(tracker)
+ for c_cls in res['COMBINED_SEQ'].keys(): # class_list + combined classes if calculated
+ summaries = []
+ details = []
+ num_dets = res['COMBINED_SEQ'][c_cls]['Count']['Dets']
+ if config['OUTPUT_EMPTY_CLASSES'] or num_dets > 0:
+ for metric, metric_name in zip(metrics_list, metric_names):
+ # for combined classes there is no per sequence evaluation
+ if c_cls in combined_cls_keys:
+ table_res = {'COMBINED_SEQ': res['COMBINED_SEQ'][c_cls][metric_name]}
+ else:
+ table_res = {seq_key: seq_value[c_cls][metric_name] for seq_key, seq_value
+ in res.items()}
+
+ if config['PRINT_RESULTS'] and config['PRINT_ONLY_COMBINED']:
+ dont_print = dataset.should_classes_combine and c_cls not in combined_cls_keys
+ if not dont_print:
+ metric.print_table({'COMBINED_SEQ': table_res['COMBINED_SEQ']},
+ tracker_display_name, c_cls)
+ elif config['PRINT_RESULTS']:
+ metric.print_table(table_res, tracker_display_name, c_cls)
+ if config['OUTPUT_SUMMARY']:
+ summaries.append(metric.summary_results(table_res))
+ if config['OUTPUT_DETAILED']:
+ details.append(metric.detailed_results(table_res))
+ if config['PLOT_CURVES']:
+ metric.plot_single_tracker_results(table_res, tracker_display_name, c_cls,
+ output_fol)
+ if config['OUTPUT_SUMMARY']:
+ utils.write_summary_results(summaries, c_cls, output_fol)
+ if config['OUTPUT_DETAILED']:
+ utils.write_detailed_results(details, c_cls, output_fol)
+
+ # Output for returning from function
+ output_res[dataset_name][tracker] = res
+ output_msg[dataset_name][tracker] = 'Success'
+
+ except Exception as err:
+ output_res[dataset_name][tracker] = None
+ if type(err) == TrackEvalException:
+ output_msg[dataset_name][tracker] = str(err)
+ else:
+ output_msg[dataset_name][tracker] = 'Unknown error occurred.'
+ print('Tracker %s was unable to be evaluated.' % tracker)
+ print(err)
+ traceback.print_exc()
+ if config['LOG_ON_ERROR'] is not None:
+ with open(config['LOG_ON_ERROR'], 'a') as f:
+ print(dataset_name, file=f)
+ print(tracker, file=f)
+ print(traceback.format_exc(), file=f)
+ print('\n\n\n', file=f)
+ if config['BREAK_ON_ERROR']:
+ raise err
+ elif config['RETURN_ON_ERROR']:
+ return output_res, output_msg
+
+ return output_res, output_msg
+
+
+@_timing.time
+def eval_sequence(seq, dataset, tracker, class_list, metrics_list, metric_names):
+ """Function for evaluating a single sequence"""
+
+ raw_data = dataset.get_raw_seq_data(tracker, seq)
+ seq_res = {}
+ for cls in class_list:
+ seq_res[cls] = {}
+ data = dataset.get_preprocessed_seq_data(raw_data, cls)
+ for metric, met_name in zip(metrics_list, metric_names):
+ seq_res[cls][met_name] = metric.eval_sequence(data)
+ return seq_res
diff --git a/val_utils/trackeval/metrics/__init__.py b/val_utils/trackeval/metrics/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1f84774682aa5ca52e98ae4424226bc3d802d3e3
--- /dev/null
+++ b/val_utils/trackeval/metrics/__init__.py
@@ -0,0 +1,8 @@
+from .hota import HOTA
+from .clear import CLEAR
+from .identity import Identity
+from .count import Count
+from .j_and_f import JAndF
+from .track_map import TrackMAP
+from .vace import VACE
+from .ideucl import IDEucl
\ No newline at end of file
diff --git a/val_utils/trackeval/metrics/_base_metric.py b/val_utils/trackeval/metrics/_base_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea488850c80bd1bfc7d37bea7456492d15b3641f
--- /dev/null
+++ b/val_utils/trackeval/metrics/_base_metric.py
@@ -0,0 +1,133 @@
+
+import numpy as np
+from abc import ABC, abstractmethod
+from .. import _timing
+from ..utils import TrackEvalException
+
+
+class _BaseMetric(ABC):
+ @abstractmethod
+ def __init__(self):
+ self.plottable = False
+ self.integer_fields = []
+ self.float_fields = []
+ self.array_labels = []
+ self.integer_array_fields = []
+ self.float_array_fields = []
+ self.fields = []
+ self.summary_fields = []
+ self.registered = False
+
+ #####################################################################
+ # Abstract functions for subclasses to implement
+
+ @_timing.time
+ @abstractmethod
+ def eval_sequence(self, data):
+ ...
+
+ @abstractmethod
+ def combine_sequences(self, all_res):
+ ...
+
+ @abstractmethod
+ def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
+ ...
+
+ @ abstractmethod
+ def combine_classes_det_averaged(self, all_res):
+ ...
+
+ def plot_single_tracker_results(self, all_res, tracker, output_folder, cls):
+ """Plot results of metrics, only valid for metrics with self.plottable"""
+ if self.plottable:
+ raise NotImplementedError('plot_results is not implemented for metric %s' % self.get_name())
+ else:
+ pass
+
+ #####################################################################
+ # Helper functions which are useful for all metrics:
+
+ @classmethod
+ def get_name(cls):
+ return cls.__name__
+
+ @staticmethod
+ def _combine_sum(all_res, field):
+ """Combine sequence results via sum"""
+ return sum([all_res[k][field] for k in all_res.keys()])
+
+ @staticmethod
+ def _combine_weighted_av(all_res, field, comb_res, weight_field):
+ """Combine sequence results via weighted average"""
+ return sum([all_res[k][field] * all_res[k][weight_field] for k in all_res.keys()]) / np.maximum(1.0, comb_res[
+ weight_field])
+
+ def print_table(self, table_res, tracker, cls):
+ """Prints table of results for all sequences"""
+ print('')
+ metric_name = self.get_name()
+ self._row_print([metric_name + ': ' + tracker + '-' + cls] + self.summary_fields)
+ for seq, results in sorted(table_res.items()):
+ if seq == 'COMBINED_SEQ':
+ continue
+ summary_res = self._summary_row(results)
+ self._row_print([seq] + summary_res)
+ summary_res = self._summary_row(table_res['COMBINED_SEQ'])
+ self._row_print(['COMBINED'] + summary_res)
+
+ def _summary_row(self, results_):
+ vals = []
+ for h in self.summary_fields:
+ if h in self.float_array_fields:
+ vals.append("{0:1.5g}".format(100 * np.mean(results_[h])))
+ elif h in self.float_fields:
+ vals.append("{0:1.5g}".format(100 * float(results_[h])))
+ elif h in self.integer_fields:
+ vals.append("{0:d}".format(int(results_[h])))
+ else:
+ raise NotImplementedError("Summary function not implemented for this field type.")
+ return vals
+
+ @staticmethod
+ def _row_print(*argv):
+ """Prints results in an evenly spaced rows, with more space in first row"""
+ if len(argv) == 1:
+ argv = argv[0]
+ to_print = '%-35s' % argv[0]
+ for v in argv[1:]:
+ to_print += '%-10s' % str(v)
+ print(to_print)
+
+ def summary_results(self, table_res):
+ """Returns a simple summary of final results for a tracker"""
+ return dict(zip(self.summary_fields, self._summary_row(table_res['COMBINED_SEQ'])))
+
+ def detailed_results(self, table_res):
+ """Returns detailed final results for a tracker"""
+ # Get detailed field information
+ detailed_fields = self.float_fields + self.integer_fields
+ for h in self.float_array_fields + self.integer_array_fields:
+ for alpha in [int(100*x) for x in self.array_labels]:
+ detailed_fields.append(h + '___' + str(alpha))
+ detailed_fields.append(h + '___AUC')
+
+ # Get detailed results
+ detailed_results = {}
+ for seq, res in table_res.items():
+ detailed_row = self._detailed_row(res)
+ if len(detailed_row) != len(detailed_fields):
+ raise TrackEvalException(
+ 'Field names and data have different sizes (%i and %i)' % (len(detailed_row), len(detailed_fields)))
+ detailed_results[seq] = dict(zip(detailed_fields, detailed_row))
+ return detailed_results
+
+ def _detailed_row(self, res):
+ detailed_row = []
+ for h in self.float_fields + self.integer_fields:
+ detailed_row.append(res[h])
+ for h in self.float_array_fields + self.integer_array_fields:
+ for i, alpha in enumerate([int(100 * x) for x in self.array_labels]):
+ detailed_row.append(res[h][i])
+ detailed_row.append(np.mean(res[h]))
+ return detailed_row
diff --git a/val_utils/trackeval/metrics/clear.py b/val_utils/trackeval/metrics/clear.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b5e291fc0c5375efa8b548c3ad81bad73865b1c
--- /dev/null
+++ b/val_utils/trackeval/metrics/clear.py
@@ -0,0 +1,186 @@
+
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_metric import _BaseMetric
+from .. import _timing
+from .. import utils
+
+class CLEAR(_BaseMetric):
+ """Class which implements the CLEAR metrics"""
+
+ @staticmethod
+ def get_default_config():
+ """Default class config values"""
+ default_config = {
+ 'THRESHOLD': 0.5, # Similarity score threshold required for a TP match. Default 0.5.
+ 'PRINT_CONFIG': True, # Whether to print the config information on init. Default: False.
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ super().__init__()
+ main_integer_fields = ['CLR_TP', 'CLR_FN', 'CLR_FP', 'IDSW', 'MT', 'PT', 'ML', 'Frag']
+ extra_integer_fields = ['CLR_Frames']
+ self.integer_fields = main_integer_fields + extra_integer_fields
+ main_float_fields = ['MOTA', 'MOTP', 'MODA', 'CLR_Re', 'CLR_Pr', 'MTR', 'PTR', 'MLR', 'sMOTA']
+ extra_float_fields = ['CLR_F1', 'FP_per_frame', 'MOTAL', 'MOTP_sum']
+ self.float_fields = main_float_fields + extra_float_fields
+ self.fields = self.float_fields + self.integer_fields
+ self.summed_fields = self.integer_fields + ['MOTP_sum']
+ self.summary_fields = main_float_fields + main_integer_fields
+
+ # Configuration options:
+ self.config = utils.init_config(config, self.get_default_config(), self.get_name())
+ self.threshold = float(self.config['THRESHOLD'])
+
+
+ @_timing.time
+ def eval_sequence(self, data):
+ """Calculates CLEAR metrics for one sequence"""
+ # Initialise results
+ res = {}
+ for field in self.fields:
+ res[field] = 0
+
+ # Return result quickly if tracker or gt sequence is empty
+ if data['num_tracker_dets'] == 0:
+ res['CLR_FN'] = data['num_gt_dets']
+ res['ML'] = data['num_gt_ids']
+ res['MLR'] = 1.0
+ return res
+ if data['num_gt_dets'] == 0:
+ res['CLR_FP'] = data['num_tracker_dets']
+ res['MLR'] = 1.0
+ return res
+
+ # Variables counting global association
+ num_gt_ids = data['num_gt_ids']
+ gt_id_count = np.zeros(num_gt_ids) # For MT/ML/PT
+ gt_matched_count = np.zeros(num_gt_ids) # For MT/ML/PT
+ gt_frag_count = np.zeros(num_gt_ids) # For Frag
+
+ # Note that IDSWs are counted based on the last time each gt_id was present (any number of frames previously),
+ # but are only used in matching to continue current tracks based on the gt_id in the single previous timestep.
+ prev_tracker_id = np.nan * np.zeros(num_gt_ids) # For scoring IDSW
+ prev_timestep_tracker_id = np.nan * np.zeros(num_gt_ids) # For matching IDSW
+
+ # Calculate scores for each timestep
+ for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
+ # Deal with the case that there are no gt_det/tracker_det in a timestep.
+ if len(gt_ids_t) == 0:
+ res['CLR_FP'] += len(tracker_ids_t)
+ continue
+ if len(tracker_ids_t) == 0:
+ res['CLR_FN'] += len(gt_ids_t)
+ gt_id_count[gt_ids_t] += 1
+ continue
+
+ # Calc score matrix to first minimise IDSWs from previous frame, and then maximise MOTP secondarily
+ similarity = data['similarity_scores'][t]
+ score_mat = (tracker_ids_t[np.newaxis, :] == prev_timestep_tracker_id[gt_ids_t[:, np.newaxis]])
+ score_mat = 1000 * score_mat + similarity
+ score_mat[similarity < self.threshold - np.finfo('float').eps] = 0
+
+ # Hungarian algorithm to find best matches
+ match_rows, match_cols = linear_sum_assignment(-score_mat)
+ actually_matched_mask = score_mat[match_rows, match_cols] > 0 + np.finfo('float').eps
+ match_rows = match_rows[actually_matched_mask]
+ match_cols = match_cols[actually_matched_mask]
+
+ matched_gt_ids = gt_ids_t[match_rows]
+ matched_tracker_ids = tracker_ids_t[match_cols]
+
+ # Calc IDSW for MOTA
+ prev_matched_tracker_ids = prev_tracker_id[matched_gt_ids]
+ is_idsw = (np.logical_not(np.isnan(prev_matched_tracker_ids))) & (
+ np.not_equal(matched_tracker_ids, prev_matched_tracker_ids))
+ res['IDSW'] += np.sum(is_idsw)
+
+ # Update counters for MT/ML/PT/Frag and record for IDSW/Frag for next timestep
+ gt_id_count[gt_ids_t] += 1
+ gt_matched_count[matched_gt_ids] += 1
+ not_previously_tracked = np.isnan(prev_timestep_tracker_id)
+ prev_tracker_id[matched_gt_ids] = matched_tracker_ids
+ prev_timestep_tracker_id[:] = np.nan
+ prev_timestep_tracker_id[matched_gt_ids] = matched_tracker_ids
+ currently_tracked = np.logical_not(np.isnan(prev_timestep_tracker_id))
+ gt_frag_count += np.logical_and(not_previously_tracked, currently_tracked)
+
+ # Calculate and accumulate basic statistics
+ num_matches = len(matched_gt_ids)
+ res['CLR_TP'] += num_matches
+ res['CLR_FN'] += len(gt_ids_t) - num_matches
+ res['CLR_FP'] += len(tracker_ids_t) - num_matches
+ if num_matches > 0:
+ res['MOTP_sum'] += sum(similarity[match_rows, match_cols])
+
+ # Calculate MT/ML/PT/Frag/MOTP
+ tracked_ratio = gt_matched_count[gt_id_count > 0] / gt_id_count[gt_id_count > 0]
+ res['MT'] = np.sum(np.greater(tracked_ratio, 0.8))
+ res['PT'] = np.sum(np.greater_equal(tracked_ratio, 0.2)) - res['MT']
+ res['ML'] = num_gt_ids - res['MT'] - res['PT']
+ res['Frag'] = np.sum(np.subtract(gt_frag_count[gt_frag_count > 0], 1))
+ res['MOTP'] = res['MOTP_sum'] / np.maximum(1.0, res['CLR_TP'])
+
+ res['CLR_Frames'] = data['num_timesteps']
+
+ # Calculate final CLEAR scores
+ res = self._compute_final_fields(res)
+ return res
+
+ def combine_sequences(self, all_res):
+ """Combines metrics across all sequences"""
+ res = {}
+ for field in self.summed_fields:
+ res[field] = self._combine_sum(all_res, field)
+ res = self._compute_final_fields(res)
+ return res
+
+ def combine_classes_det_averaged(self, all_res):
+ """Combines metrics across all classes by averaging over the detection values"""
+ res = {}
+ for field in self.summed_fields:
+ res[field] = self._combine_sum(all_res, field)
+ res = self._compute_final_fields(res)
+ return res
+
+ def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
+ """Combines metrics across all classes by averaging over the class values.
+ If 'ignore_empty_classes' is True, then it only sums over classes with at least one gt or predicted detection.
+ """
+ res = {}
+ for field in self.integer_fields:
+ if ignore_empty_classes:
+ res[field] = self._combine_sum(
+ {k: v for k, v in all_res.items() if v['CLR_TP'] + v['CLR_FN'] + v['CLR_FP'] > 0}, field)
+ else:
+ res[field] = self._combine_sum({k: v for k, v in all_res.items()}, field)
+ for field in self.float_fields:
+ if ignore_empty_classes:
+ res[field] = np.mean(
+ [v[field] for v in all_res.values() if v['CLR_TP'] + v['CLR_FN'] + v['CLR_FP'] > 0], axis=0)
+ else:
+ res[field] = np.mean([v[field] for v in all_res.values()], axis=0)
+ return res
+
+ @staticmethod
+ def _compute_final_fields(res):
+ """Calculate sub-metric ('field') values which only depend on other sub-metric values.
+ This function is used both for both per-sequence calculation, and in combining values across sequences.
+ """
+ num_gt_ids = res['MT'] + res['ML'] + res['PT']
+ res['MTR'] = res['MT'] / np.maximum(1.0, num_gt_ids)
+ res['MLR'] = res['ML'] / np.maximum(1.0, num_gt_ids)
+ res['PTR'] = res['PT'] / np.maximum(1.0, num_gt_ids)
+ res['CLR_Re'] = res['CLR_TP'] / np.maximum(1.0, res['CLR_TP'] + res['CLR_FN'])
+ res['CLR_Pr'] = res['CLR_TP'] / np.maximum(1.0, res['CLR_TP'] + res['CLR_FP'])
+ res['MODA'] = (res['CLR_TP'] - res['CLR_FP']) / np.maximum(1.0, res['CLR_TP'] + res['CLR_FN'])
+ res['MOTA'] = (res['CLR_TP'] - res['CLR_FP'] - res['IDSW']) / np.maximum(1.0, res['CLR_TP'] + res['CLR_FN'])
+ res['MOTP'] = res['MOTP_sum'] / np.maximum(1.0, res['CLR_TP'])
+ res['sMOTA'] = (res['MOTP_sum'] - res['CLR_FP'] - res['IDSW']) / np.maximum(1.0, res['CLR_TP'] + res['CLR_FN'])
+
+ res['CLR_F1'] = res['CLR_TP'] / np.maximum(1.0, res['CLR_TP'] + 0.5*res['CLR_FN'] + 0.5*res['CLR_FP'])
+ res['FP_per_frame'] = res['CLR_FP'] / np.maximum(1.0, res['CLR_Frames'])
+ safe_log_idsw = np.log10(res['IDSW']) if res['IDSW'] > 0 else res['IDSW']
+ res['MOTAL'] = (res['CLR_TP'] - res['CLR_FP'] - safe_log_idsw) / np.maximum(1.0, res['CLR_TP'] + res['CLR_FN'])
+ return res
diff --git a/val_utils/trackeval/metrics/count.py b/val_utils/trackeval/metrics/count.py
new file mode 100644
index 0000000000000000000000000000000000000000..49049b104f5eff57c661b3ff63fbc7c655cffe86
--- /dev/null
+++ b/val_utils/trackeval/metrics/count.py
@@ -0,0 +1,44 @@
+
+from ._base_metric import _BaseMetric
+from .. import _timing
+
+
+class Count(_BaseMetric):
+ """Class which simply counts the number of tracker and gt detections and ids."""
+ def __init__(self, config=None):
+ super().__init__()
+ self.integer_fields = ['Dets', 'GT_Dets', 'IDs', 'GT_IDs']
+ self.fields = self.integer_fields
+ self.summary_fields = self.fields
+
+ @_timing.time
+ def eval_sequence(self, data):
+ """Returns counts for one sequence"""
+ # Get results
+ res = {'Dets': data['num_tracker_dets'],
+ 'GT_Dets': data['num_gt_dets'],
+ 'IDs': data['num_tracker_ids'],
+ 'GT_IDs': data['num_gt_ids'],
+ 'Frames': data['num_timesteps']}
+ return res
+
+ def combine_sequences(self, all_res):
+ """Combines metrics across all sequences"""
+ res = {}
+ for field in self.integer_fields:
+ res[field] = self._combine_sum(all_res, field)
+ return res
+
+ def combine_classes_class_averaged(self, all_res, ignore_empty_classes=None):
+ """Combines metrics across all classes by averaging over the class values"""
+ res = {}
+ for field in self.integer_fields:
+ res[field] = self._combine_sum(all_res, field)
+ return res
+
+ def combine_classes_det_averaged(self, all_res):
+ """Combines metrics across all classes by averaging over the detection values"""
+ res = {}
+ for field in self.integer_fields:
+ res[field] = self._combine_sum(all_res, field)
+ return res
diff --git a/val_utils/trackeval/metrics/hota.py b/val_utils/trackeval/metrics/hota.py
new file mode 100644
index 0000000000000000000000000000000000000000..f551b766d1b4c3d4f4854bf99b04877dc1fa7c32
--- /dev/null
+++ b/val_utils/trackeval/metrics/hota.py
@@ -0,0 +1,203 @@
+
+import os
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_metric import _BaseMetric
+from .. import _timing
+
+
+class HOTA(_BaseMetric):
+ """Class which implements the HOTA metrics.
+ See: https://link.springer.com/article/10.1007/s11263-020-01375-2
+ """
+
+ def __init__(self, config=None):
+ super().__init__()
+ self.plottable = True
+ self.array_labels = np.arange(0.05, 0.99, 0.05)
+ self.integer_array_fields = ['HOTA_TP', 'HOTA_FN', 'HOTA_FP']
+ self.float_array_fields = ['HOTA', 'DetA', 'AssA', 'DetRe', 'DetPr', 'AssRe', 'AssPr', 'LocA', 'OWTA']
+ self.float_fields = ['HOTA(0)', 'LocA(0)', 'HOTALocA(0)']
+ self.fields = self.float_array_fields + self.integer_array_fields + self.float_fields
+ self.summary_fields = self.float_array_fields + self.float_fields
+
+ @_timing.time
+ def eval_sequence(self, data):
+ """Calculates the HOTA metrics for one sequence"""
+
+ # Initialise results
+ res = {}
+ for field in self.float_array_fields + self.integer_array_fields:
+ res[field] = np.zeros((len(self.array_labels)), dtype=np.float)
+ for field in self.float_fields:
+ res[field] = 0
+
+ # Return result quickly if tracker or gt sequence is empty
+ if data['num_tracker_dets'] == 0:
+ res['HOTA_FN'] = data['num_gt_dets'] * np.ones((len(self.array_labels)), dtype=np.float)
+ res['LocA'] = np.ones((len(self.array_labels)), dtype=np.float)
+ res['LocA(0)'] = 1.0
+ return res
+ if data['num_gt_dets'] == 0:
+ res['HOTA_FP'] = data['num_tracker_dets'] * np.ones((len(self.array_labels)), dtype=np.float)
+ res['LocA'] = np.ones((len(self.array_labels)), dtype=np.float)
+ res['LocA(0)'] = 1.0
+ return res
+
+ # Variables counting global association
+ potential_matches_count = np.zeros((data['num_gt_ids'], data['num_tracker_ids']))
+ gt_id_count = np.zeros((data['num_gt_ids'], 1))
+ tracker_id_count = np.zeros((1, data['num_tracker_ids']))
+
+ # First loop through each timestep and accumulate global track information.
+ for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
+ # Count the potential matches between ids in each timestep
+ # These are normalised, weighted by the match similarity.
+ similarity = data['similarity_scores'][t]
+ sim_iou_denom = similarity.sum(0)[np.newaxis, :] + similarity.sum(1)[:, np.newaxis] - similarity
+ sim_iou = np.zeros_like(similarity)
+ sim_iou_mask = sim_iou_denom > 0 + np.finfo('float').eps
+ sim_iou[sim_iou_mask] = similarity[sim_iou_mask] / sim_iou_denom[sim_iou_mask]
+ potential_matches_count[gt_ids_t[:, np.newaxis], tracker_ids_t[np.newaxis, :]] += sim_iou
+
+ # Calculate the total number of dets for each gt_id and tracker_id.
+ gt_id_count[gt_ids_t] += 1
+ tracker_id_count[0, tracker_ids_t] += 1
+
+ # Calculate overall jaccard alignment score (before unique matching) between IDs
+ global_alignment_score = potential_matches_count / (gt_id_count + tracker_id_count - potential_matches_count)
+ matches_counts = [np.zeros_like(potential_matches_count) for _ in self.array_labels]
+
+ # Calculate scores for each timestep
+ for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
+ # Deal with the case that there are no gt_det/tracker_det in a timestep.
+ if len(gt_ids_t) == 0:
+ for a, alpha in enumerate(self.array_labels):
+ res['HOTA_FP'][a] += len(tracker_ids_t)
+ continue
+ if len(tracker_ids_t) == 0:
+ for a, alpha in enumerate(self.array_labels):
+ res['HOTA_FN'][a] += len(gt_ids_t)
+ continue
+
+ # Get matching scores between pairs of dets for optimizing HOTA
+ similarity = data['similarity_scores'][t]
+ score_mat = global_alignment_score[gt_ids_t[:, np.newaxis], tracker_ids_t[np.newaxis, :]] * similarity
+
+ # Hungarian algorithm to find best matches
+ match_rows, match_cols = linear_sum_assignment(-score_mat)
+
+ # Calculate and accumulate basic statistics
+ for a, alpha in enumerate(self.array_labels):
+ actually_matched_mask = similarity[match_rows, match_cols] >= alpha - np.finfo('float').eps
+ alpha_match_rows = match_rows[actually_matched_mask]
+ alpha_match_cols = match_cols[actually_matched_mask]
+ num_matches = len(alpha_match_rows)
+ res['HOTA_TP'][a] += num_matches
+ res['HOTA_FN'][a] += len(gt_ids_t) - num_matches
+ res['HOTA_FP'][a] += len(tracker_ids_t) - num_matches
+ if num_matches > 0:
+ res['LocA'][a] += sum(similarity[alpha_match_rows, alpha_match_cols])
+ matches_counts[a][gt_ids_t[alpha_match_rows], tracker_ids_t[alpha_match_cols]] += 1
+
+ # Calculate association scores (AssA, AssRe, AssPr) for the alpha value.
+ # First calculate scores per gt_id/tracker_id combo and then average over the number of detections.
+ for a, alpha in enumerate(self.array_labels):
+ matches_count = matches_counts[a]
+ ass_a = matches_count / np.maximum(1, gt_id_count + tracker_id_count - matches_count)
+ res['AssA'][a] = np.sum(matches_count * ass_a) / np.maximum(1, res['HOTA_TP'][a])
+ ass_re = matches_count / np.maximum(1, gt_id_count)
+ res['AssRe'][a] = np.sum(matches_count * ass_re) / np.maximum(1, res['HOTA_TP'][a])
+ ass_pr = matches_count / np.maximum(1, tracker_id_count)
+ res['AssPr'][a] = np.sum(matches_count * ass_pr) / np.maximum(1, res['HOTA_TP'][a])
+
+ # Calculate final scores
+ res['LocA'] = np.maximum(1e-10, res['LocA']) / np.maximum(1e-10, res['HOTA_TP'])
+ res = self._compute_final_fields(res)
+ return res
+
+ def combine_sequences(self, all_res):
+ """Combines metrics across all sequences"""
+ res = {}
+ for field in self.integer_array_fields:
+ res[field] = self._combine_sum(all_res, field)
+ for field in ['AssRe', 'AssPr', 'AssA']:
+ res[field] = self._combine_weighted_av(all_res, field, res, weight_field='HOTA_TP')
+ loca_weighted_sum = sum([all_res[k]['LocA'] * all_res[k]['HOTA_TP'] for k in all_res.keys()])
+ res['LocA'] = np.maximum(1e-10, loca_weighted_sum) / np.maximum(1e-10, res['HOTA_TP'])
+ res = self._compute_final_fields(res)
+ return res
+
+ def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
+ """Combines metrics across all classes by averaging over the class values.
+ If 'ignore_empty_classes' is True, then it only sums over classes with at least one gt or predicted detection.
+ """
+ res = {}
+ for field in self.integer_array_fields:
+ if ignore_empty_classes:
+ res[field] = self._combine_sum(
+ {k: v for k, v in all_res.items()
+ if (v['HOTA_TP'] + v['HOTA_FN'] + v['HOTA_FP'] > 0 + np.finfo('float').eps).any()}, field)
+ else:
+ res[field] = self._combine_sum({k: v for k, v in all_res.items()}, field)
+
+ for field in self.float_fields + self.float_array_fields:
+ if ignore_empty_classes:
+ res[field] = np.mean([v[field] for v in all_res.values() if
+ (v['HOTA_TP'] + v['HOTA_FN'] + v['HOTA_FP'] > 0 + np.finfo('float').eps).any()],
+ axis=0)
+ else:
+ res[field] = np.mean([v[field] for v in all_res.values()], axis=0)
+ return res
+
+ def combine_classes_det_averaged(self, all_res):
+ """Combines metrics across all classes by averaging over the detection values"""
+ res = {}
+ for field in self.integer_array_fields:
+ res[field] = self._combine_sum(all_res, field)
+ for field in ['AssRe', 'AssPr', 'AssA']:
+ res[field] = self._combine_weighted_av(all_res, field, res, weight_field='HOTA_TP')
+ loca_weighted_sum = sum([all_res[k]['LocA'] * all_res[k]['HOTA_TP'] for k in all_res.keys()])
+ res['LocA'] = np.maximum(1e-10, loca_weighted_sum) / np.maximum(1e-10, res['HOTA_TP'])
+ res = self._compute_final_fields(res)
+ return res
+
+ @staticmethod
+ def _compute_final_fields(res):
+ """Calculate sub-metric ('field') values which only depend on other sub-metric values.
+ This function is used both for both per-sequence calculation, and in combining values across sequences.
+ """
+ res['DetRe'] = res['HOTA_TP'] / np.maximum(1, res['HOTA_TP'] + res['HOTA_FN'])
+ res['DetPr'] = res['HOTA_TP'] / np.maximum(1, res['HOTA_TP'] + res['HOTA_FP'])
+ res['DetA'] = res['HOTA_TP'] / np.maximum(1, res['HOTA_TP'] + res['HOTA_FN'] + res['HOTA_FP'])
+ res['HOTA'] = np.sqrt(res['DetA'] * res['AssA'])
+ res['OWTA'] = np.sqrt(res['DetRe'] * res['AssA'])
+
+ res['HOTA(0)'] = res['HOTA'][0]
+ res['LocA(0)'] = res['LocA'][0]
+ res['HOTALocA(0)'] = res['HOTA(0)']*res['LocA(0)']
+ return res
+
+ def plot_single_tracker_results(self, table_res, tracker, cls, output_folder):
+ """Create plot of results"""
+
+ # Only loaded when run to reduce minimum requirements
+ from matplotlib import pyplot as plt
+
+ res = table_res['COMBINED_SEQ']
+ styles_to_plot = ['r', 'b', 'g', 'b--', 'b:', 'g--', 'g:', 'm']
+ for name, style in zip(self.float_array_fields, styles_to_plot):
+ plt.plot(self.array_labels, res[name], style)
+ plt.xlabel('alpha')
+ plt.ylabel('score')
+ plt.title(tracker + ' - ' + cls)
+ plt.axis([0, 1, 0, 1])
+ legend = []
+ for name in self.float_array_fields:
+ legend += [name + ' (' + str(np.round(np.mean(res[name]), 2)) + ')']
+ plt.legend(legend, loc='lower left')
+ out_file = os.path.join(output_folder, cls + '_plot.pdf')
+ os.makedirs(os.path.dirname(out_file), exist_ok=True)
+ plt.savefig(out_file)
+ plt.savefig(out_file.replace('.pdf', '.png'))
+ plt.clf()
diff --git a/val_utils/trackeval/metrics/identity.py b/val_utils/trackeval/metrics/identity.py
new file mode 100644
index 0000000000000000000000000000000000000000..c8c6c809989e5b620ceb3822941574018e605c70
--- /dev/null
+++ b/val_utils/trackeval/metrics/identity.py
@@ -0,0 +1,135 @@
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_metric import _BaseMetric
+from .. import _timing
+from .. import utils
+
+
+class Identity(_BaseMetric):
+ """Class which implements the ID metrics"""
+
+ @staticmethod
+ def get_default_config():
+ """Default class config values"""
+ default_config = {
+ 'THRESHOLD': 0.5, # Similarity score threshold required for a IDTP match. Default 0.5.
+ 'PRINT_CONFIG': True, # Whether to print the config information on init. Default: False.
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ super().__init__()
+ self.integer_fields = ['IDTP', 'IDFN', 'IDFP']
+ self.float_fields = ['IDF1', 'IDR', 'IDP']
+ self.fields = self.float_fields + self.integer_fields
+ self.summary_fields = self.fields
+
+ # Configuration options:
+ self.config = utils.init_config(config, self.get_default_config(), self.get_name())
+ self.threshold = float(self.config['THRESHOLD'])
+
+ @_timing.time
+ def eval_sequence(self, data):
+ """Calculates ID metrics for one sequence"""
+ # Initialise results
+ res = {}
+ for field in self.fields:
+ res[field] = 0
+
+ # Return result quickly if tracker or gt sequence is empty
+ if data['num_tracker_dets'] == 0:
+ res['IDFN'] = data['num_gt_dets']
+ return res
+ if data['num_gt_dets'] == 0:
+ res['IDFP'] = data['num_tracker_dets']
+ return res
+
+ # Variables counting global association
+ potential_matches_count = np.zeros((data['num_gt_ids'], data['num_tracker_ids']))
+ gt_id_count = np.zeros(data['num_gt_ids'])
+ tracker_id_count = np.zeros(data['num_tracker_ids'])
+
+ # First loop through each timestep and accumulate global track information.
+ for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
+ # Count the potential matches between ids in each timestep
+ matches_mask = np.greater_equal(data['similarity_scores'][t], self.threshold)
+ match_idx_gt, match_idx_tracker = np.nonzero(matches_mask)
+ potential_matches_count[gt_ids_t[match_idx_gt], tracker_ids_t[match_idx_tracker]] += 1
+
+ # Calculate the total number of dets for each gt_id and tracker_id.
+ gt_id_count[gt_ids_t] += 1
+ tracker_id_count[tracker_ids_t] += 1
+
+ # Calculate optimal assignment cost matrix for ID metrics
+ num_gt_ids = data['num_gt_ids']
+ num_tracker_ids = data['num_tracker_ids']
+ fp_mat = np.zeros((num_gt_ids + num_tracker_ids, num_gt_ids + num_tracker_ids))
+ fn_mat = np.zeros((num_gt_ids + num_tracker_ids, num_gt_ids + num_tracker_ids))
+ fp_mat[num_gt_ids:, :num_tracker_ids] = 1e10
+ fn_mat[:num_gt_ids, num_tracker_ids:] = 1e10
+ for gt_id in range(num_gt_ids):
+ fn_mat[gt_id, :num_tracker_ids] = gt_id_count[gt_id]
+ fn_mat[gt_id, num_tracker_ids + gt_id] = gt_id_count[gt_id]
+ for tracker_id in range(num_tracker_ids):
+ fp_mat[:num_gt_ids, tracker_id] = tracker_id_count[tracker_id]
+ fp_mat[tracker_id + num_gt_ids, tracker_id] = tracker_id_count[tracker_id]
+ fn_mat[:num_gt_ids, :num_tracker_ids] -= potential_matches_count
+ fp_mat[:num_gt_ids, :num_tracker_ids] -= potential_matches_count
+
+ # Hungarian algorithm
+ match_rows, match_cols = linear_sum_assignment(fn_mat + fp_mat)
+
+ # Accumulate basic statistics
+ res['IDFN'] = fn_mat[match_rows, match_cols].sum().astype(np.int)
+ res['IDFP'] = fp_mat[match_rows, match_cols].sum().astype(np.int)
+ res['IDTP'] = (gt_id_count.sum() - res['IDFN']).astype(np.int)
+
+ # Calculate final ID scores
+ res = self._compute_final_fields(res)
+ return res
+
+ def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
+ """Combines metrics across all classes by averaging over the class values.
+ If 'ignore_empty_classes' is True, then it only sums over classes with at least one gt or predicted detection.
+ """
+ res = {}
+ for field in self.integer_fields:
+ if ignore_empty_classes:
+ res[field] = self._combine_sum({k: v for k, v in all_res.items()
+ if v['IDTP'] + v['IDFN'] + v['IDFP'] > 0 + np.finfo('float').eps},
+ field)
+ else:
+ res[field] = self._combine_sum({k: v for k, v in all_res.items()}, field)
+ for field in self.float_fields:
+ if ignore_empty_classes:
+ res[field] = np.mean([v[field] for v in all_res.values()
+ if v['IDTP'] + v['IDFN'] + v['IDFP'] > 0 + np.finfo('float').eps], axis=0)
+ else:
+ res[field] = np.mean([v[field] for v in all_res.values()], axis=0)
+ return res
+
+ def combine_classes_det_averaged(self, all_res):
+ """Combines metrics across all classes by averaging over the detection values"""
+ res = {}
+ for field in self.integer_fields:
+ res[field] = self._combine_sum(all_res, field)
+ res = self._compute_final_fields(res)
+ return res
+
+ def combine_sequences(self, all_res):
+ """Combines metrics across all sequences"""
+ res = {}
+ for field in self.integer_fields:
+ res[field] = self._combine_sum(all_res, field)
+ res = self._compute_final_fields(res)
+ return res
+
+ @staticmethod
+ def _compute_final_fields(res):
+ """Calculate sub-metric ('field') values which only depend on other sub-metric values.
+ This function is used both for both per-sequence calculation, and in combining values across sequences.
+ """
+ res['IDR'] = res['IDTP'] / np.maximum(1.0, res['IDTP'] + res['IDFN'])
+ res['IDP'] = res['IDTP'] / np.maximum(1.0, res['IDTP'] + res['IDFP'])
+ res['IDF1'] = res['IDTP'] / np.maximum(1.0, res['IDTP'] + 0.5 * res['IDFP'] + 0.5 * res['IDFN'])
+ return res
diff --git a/val_utils/trackeval/metrics/ideucl.py b/val_utils/trackeval/metrics/ideucl.py
new file mode 100644
index 0000000000000000000000000000000000000000..db9b57b61f603f0266c92c5c0cf6f6e2e160938a
--- /dev/null
+++ b/val_utils/trackeval/metrics/ideucl.py
@@ -0,0 +1,135 @@
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_metric import _BaseMetric
+from .. import _timing
+from collections import defaultdict
+from .. import utils
+
+
+class IDEucl(_BaseMetric):
+ """Class which implements the ID metrics"""
+
+ @staticmethod
+ def get_default_config():
+ """Default class config values"""
+ default_config = {
+ 'THRESHOLD': 0.4, # Similarity score threshold required for a IDTP match. 0.4 for IDEucl.
+ 'PRINT_CONFIG': True, # Whether to print the config information on init. Default: False.
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ super().__init__()
+ self.fields = ['IDEucl']
+ self.float_fields = self.fields
+ self.summary_fields = self.fields
+
+ # Configuration options:
+ self.config = utils.init_config(config, self.get_default_config(), self.get_name())
+ self.threshold = float(self.config['THRESHOLD'])
+
+
+ @_timing.time
+ def eval_sequence(self, data):
+ """Calculates IDEucl metrics for all frames"""
+ # Initialise results
+ res = {'IDEucl' : 0}
+
+ # Return result quickly if tracker or gt sequence is empty
+ if data['num_tracker_dets'] == 0 or data['num_gt_dets'] == 0.:
+ return res
+
+ data['centroid'] = []
+ for t, gt_det in enumerate(data['gt_dets']):
+ # import pdb;pdb.set_trace()
+ data['centroid'].append(self._compute_centroid(gt_det))
+
+ oid_hid_cent = defaultdict(list)
+ oid_cent = defaultdict(list)
+ for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
+ matches_mask = np.greater_equal(data['similarity_scores'][t], self.threshold)
+
+ # I hope the orders of ids and boxes are maintained in `data`
+ for ind, gid in enumerate(gt_ids_t):
+ oid_cent[gid].append(data['centroid'][t][ind])
+
+ match_idx_gt, match_idx_tracker = np.nonzero(matches_mask)
+ for m_gid, m_tid in zip(match_idx_gt, match_idx_tracker):
+ oid_hid_cent[gt_ids_t[m_gid], tracker_ids_t[m_tid]].append(data['centroid'][t][m_gid])
+
+ oid_hid_dist = {k : np.sum(np.linalg.norm(np.diff(np.array(v), axis=0), axis=1)) for k, v in oid_hid_cent.items()}
+ oid_dist = {int(k) : np.sum(np.linalg.norm(np.diff(np.array(v), axis=0), axis=1)) for k, v in oid_cent.items()}
+
+ unique_oid = np.unique([i[0] for i in oid_hid_dist.keys()]).tolist()
+ unique_hid = np.unique([i[1] for i in oid_hid_dist.keys()]).tolist()
+ o_len = len(unique_oid)
+ h_len = len(unique_hid)
+ dist_matrix = np.zeros((o_len, h_len))
+ for ((oid, hid), dist) in oid_hid_dist.items():
+ oid_ind = unique_oid.index(oid)
+ hid_ind = unique_hid.index(hid)
+ dist_matrix[oid_ind, hid_ind] = dist
+
+ # opt_hyp_dist contains GT ID : max dist covered by track
+ opt_hyp_dist = dict.fromkeys(oid_dist.keys(), 0.)
+ cost_matrix = np.max(dist_matrix) - dist_matrix
+ rows, cols = linear_sum_assignment(cost_matrix)
+ for (row, col) in zip(rows, cols):
+ value = dist_matrix[row, col]
+ opt_hyp_dist[int(unique_oid[row])] = value
+
+ assert len(opt_hyp_dist.keys()) == len(oid_dist.keys())
+ hyp_length = np.sum(list(opt_hyp_dist.values()))
+ gt_length = np.sum(list(oid_dist.values()))
+ id_eucl =np.mean([np.divide(a, b, out=np.zeros_like(a), where=b!=0) for a, b in zip(opt_hyp_dist.values(), oid_dist.values())])
+ res['IDEucl'] = np.divide(hyp_length, gt_length, out=np.zeros_like(hyp_length), where=gt_length!=0)
+ return res
+
+ def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
+ """Combines metrics across all classes by averaging over the class values.
+ If 'ignore_empty_classes' is True, then it only sums over classes with at least one gt or predicted detection.
+ """
+ res = {}
+
+ for field in self.float_fields:
+ if ignore_empty_classes:
+ res[field] = np.mean([v[field] for v in all_res.values()
+ if v['IDEucl'] > 0 + np.finfo('float').eps], axis=0)
+ else:
+ res[field] = np.mean([v[field] for v in all_res.values()], axis=0)
+ return res
+
+ def combine_classes_det_averaged(self, all_res):
+ """Combines metrics across all classes by averaging over the detection values"""
+ res = {}
+ for field in self.float_fields:
+ res[field] = self._combine_sum(all_res, field)
+ res = self._compute_final_fields(res, len(all_res))
+ return res
+
+ def combine_sequences(self, all_res):
+ """Combines metrics across all sequences"""
+ res = {}
+ for field in self.float_fields:
+ res[field] = self._combine_sum(all_res, field)
+ res = self._compute_final_fields(res, len(all_res))
+ return res
+
+
+ @staticmethod
+ def _compute_centroid(box):
+ box = np.array(box)
+ if len(box.shape) == 1:
+ centroid = (box[0:2] + box[2:4])/2
+ else:
+ centroid = (box[:, 0:2] + box[:, 2:4])/2
+ return np.flip(centroid, axis=1)
+
+
+ @staticmethod
+ def _compute_final_fields(res, res_len):
+ """
+ Exists only to match signature with the original Identiy class.
+
+ """
+ return {k:v/res_len for k,v in res.items()}
diff --git a/val_utils/trackeval/metrics/j_and_f.py b/val_utils/trackeval/metrics/j_and_f.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b18f046ba9aae48cc321d20a4831815c94c5933
--- /dev/null
+++ b/val_utils/trackeval/metrics/j_and_f.py
@@ -0,0 +1,310 @@
+
+import numpy as np
+import math
+from scipy.optimize import linear_sum_assignment
+from ..utils import TrackEvalException
+from ._base_metric import _BaseMetric
+from .. import _timing
+
+
+class JAndF(_BaseMetric):
+ """Class which implements the J&F metrics"""
+ def __init__(self, config=None):
+ super().__init__()
+ self.integer_fields = ['num_gt_tracks']
+ self.float_fields = ['J-Mean', 'J-Recall', 'J-Decay', 'F-Mean', 'F-Recall', 'F-Decay', 'J&F']
+ self.fields = self.float_fields + self.integer_fields
+ self.summary_fields = self.float_fields
+ self.optim_type = 'J' # possible values J, J&F
+
+ @_timing.time
+ def eval_sequence(self, data):
+ """Returns J&F metrics for one sequence"""
+
+ # Only loaded when run to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ num_timesteps = data['num_timesteps']
+ num_tracker_ids = data['num_tracker_ids']
+ num_gt_ids = data['num_gt_ids']
+ gt_dets = data['gt_dets']
+ tracker_dets = data['tracker_dets']
+ gt_ids = data['gt_ids']
+ tracker_ids = data['tracker_ids']
+
+ # get shape of frames
+ frame_shape = None
+ if num_gt_ids > 0:
+ for t in range(num_timesteps):
+ if len(gt_ids[t]) > 0:
+ frame_shape = gt_dets[t][0]['size']
+ break
+ elif num_tracker_ids > 0:
+ for t in range(num_timesteps):
+ if len(tracker_ids[t]) > 0:
+ frame_shape = tracker_dets[t][0]['size']
+ break
+
+ if frame_shape:
+ # append all zero masks for timesteps in which tracks do not have a detection
+ zero_padding = np.zeros((frame_shape), order= 'F').astype(np.uint8)
+ padding_mask = mask_utils.encode(zero_padding)
+ for t in range(num_timesteps):
+ gt_id_det_mapping = {gt_ids[t][i]: gt_dets[t][i] for i in range(len(gt_ids[t]))}
+ gt_dets[t] = [gt_id_det_mapping[index] if index in gt_ids[t] else padding_mask for index
+ in range(num_gt_ids)]
+ tracker_id_det_mapping = {tracker_ids[t][i]: tracker_dets[t][i] for i in range(len(tracker_ids[t]))}
+ tracker_dets[t] = [tracker_id_det_mapping[index] if index in tracker_ids[t] else padding_mask for index
+ in range(num_tracker_ids)]
+ # also perform zero padding if number of tracker IDs < number of ground truth IDs
+ if num_tracker_ids < num_gt_ids:
+ diff = num_gt_ids - num_tracker_ids
+ for t in range(num_timesteps):
+ tracker_dets[t] = tracker_dets[t] + [padding_mask for _ in range(diff)]
+ num_tracker_ids += diff
+
+ j = self._compute_j(gt_dets, tracker_dets, num_gt_ids, num_tracker_ids, num_timesteps)
+
+ # boundary threshold for F computation
+ bound_th = 0.008
+
+ # perform matching
+ if self.optim_type == 'J&F':
+ f = np.zeros_like(j)
+ for k in range(num_tracker_ids):
+ for i in range(num_gt_ids):
+ f[k, i, :] = self._compute_f(gt_dets, tracker_dets, k, i, bound_th)
+ optim_metrics = (np.mean(j, axis=2) + np.mean(f, axis=2)) / 2
+ row_ind, col_ind = linear_sum_assignment(- optim_metrics)
+ j_m = j[row_ind, col_ind, :]
+ f_m = f[row_ind, col_ind, :]
+ elif self.optim_type == 'J':
+ optim_metrics = np.mean(j, axis=2)
+ row_ind, col_ind = linear_sum_assignment(- optim_metrics)
+ j_m = j[row_ind, col_ind, :]
+ f_m = np.zeros_like(j_m)
+ for i, (tr_ind, gt_ind) in enumerate(zip(row_ind, col_ind)):
+ f_m[i] = self._compute_f(gt_dets, tracker_dets, tr_ind, gt_ind, bound_th)
+ else:
+ raise TrackEvalException('Unsupported optimization type %s for J&F metric.' % self.optim_type)
+
+ # append zeros for false negatives
+ if j_m.shape[0] < data['num_gt_ids']:
+ diff = data['num_gt_ids'] - j_m.shape[0]
+ j_m = np.concatenate((j_m, np.zeros((diff, j_m.shape[1]))), axis=0)
+ f_m = np.concatenate((f_m, np.zeros((diff, f_m.shape[1]))), axis=0)
+
+ # compute the metrics for each ground truth track
+ res = {
+ 'J-Mean': [np.nanmean(j_m[i, :]) for i in range(j_m.shape[0])],
+ 'J-Recall': [np.nanmean(j_m[i, :] > 0.5 + np.finfo('float').eps) for i in range(j_m.shape[0])],
+ 'F-Mean': [np.nanmean(f_m[i, :]) for i in range(f_m.shape[0])],
+ 'F-Recall': [np.nanmean(f_m[i, :] > 0.5 + np.finfo('float').eps) for i in range(f_m.shape[0])],
+ 'J-Decay': [],
+ 'F-Decay': []
+ }
+ n_bins = 4
+ ids = np.round(np.linspace(1, data['num_timesteps'], n_bins + 1) + 1e-10) - 1
+ ids = ids.astype(np.uint8)
+
+ for k in range(j_m.shape[0]):
+ d_bins_j = [j_m[k][ids[i]:ids[i + 1] + 1] for i in range(0, n_bins)]
+ res['J-Decay'].append(np.nanmean(d_bins_j[0]) - np.nanmean(d_bins_j[3]))
+ for k in range(f_m.shape[0]):
+ d_bins_f = [f_m[k][ids[i]:ids[i + 1] + 1] for i in range(0, n_bins)]
+ res['F-Decay'].append(np.nanmean(d_bins_f[0]) - np.nanmean(d_bins_f[3]))
+
+ # count number of tracks for weighting of the result
+ res['num_gt_tracks'] = len(res['J-Mean'])
+ for field in ['J-Mean', 'J-Recall', 'J-Decay', 'F-Mean', 'F-Recall', 'F-Decay']:
+ res[field] = np.mean(res[field])
+ res['J&F'] = (res['J-Mean'] + res['F-Mean']) / 2
+ return res
+
+ def combine_sequences(self, all_res):
+ """Combines metrics across all sequences"""
+ res = {'num_gt_tracks': self._combine_sum(all_res, 'num_gt_tracks')}
+ for field in self.summary_fields:
+ res[field] = self._combine_weighted_av(all_res, field, res, weight_field='num_gt_tracks')
+ return res
+
+ def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
+ """Combines metrics across all classes by averaging over the class values
+ 'ignore empty classes' is not yet implemented here.
+ """
+ res = {'num_gt_tracks': self._combine_sum(all_res, 'num_gt_tracks')}
+ for field in self.float_fields:
+ res[field] = np.mean([v[field] for v in all_res.values()])
+ return res
+
+ def combine_classes_det_averaged(self, all_res):
+ """Combines metrics across all classes by averaging over the detection values"""
+ res = {'num_gt_tracks': self._combine_sum(all_res, 'num_gt_tracks')}
+ for field in self.float_fields:
+ res[field] = np.mean([v[field] for v in all_res.values()])
+ return res
+
+ @staticmethod
+ def _seg2bmap(seg, width=None, height=None):
+ """
+ From a segmentation, compute a binary boundary map with 1 pixel wide
+ boundaries. The boundary pixels are offset by 1/2 pixel towards the
+ origin from the actual segment boundary.
+ Arguments:
+ seg : Segments labeled from 1..k.
+ width : Width of desired bmap <= seg.shape[1]
+ height : Height of desired bmap <= seg.shape[0]
+ Returns:
+ bmap (ndarray): Binary boundary map.
+ David Martin
+ January 2003
+ """
+
+ seg = seg.astype(np.bool)
+ seg[seg > 0] = 1
+
+ assert np.atleast_3d(seg).shape[2] == 1
+
+ width = seg.shape[1] if width is None else width
+ height = seg.shape[0] if height is None else height
+
+ h, w = seg.shape[:2]
+
+ ar1 = float(width) / float(height)
+ ar2 = float(w) / float(h)
+
+ assert not (
+ width > w | height > h | abs(ar1 - ar2) > 0.01
+ ), "Can" "t convert %dx%d seg to %dx%d bmap." % (w, h, width, height)
+
+ e = np.zeros_like(seg)
+ s = np.zeros_like(seg)
+ se = np.zeros_like(seg)
+
+ e[:, :-1] = seg[:, 1:]
+ s[:-1, :] = seg[1:, :]
+ se[:-1, :-1] = seg[1:, 1:]
+
+ b = seg ^ e | seg ^ s | seg ^ se
+ b[-1, :] = seg[-1, :] ^ e[-1, :]
+ b[:, -1] = seg[:, -1] ^ s[:, -1]
+ b[-1, -1] = 0
+
+ if w == width and h == height:
+ bmap = b
+ else:
+ bmap = np.zeros((height, width))
+ for x in range(w):
+ for y in range(h):
+ if b[y, x]:
+ j = 1 + math.floor((y - 1) + height / h)
+ i = 1 + math.floor((x - 1) + width / h)
+ bmap[j, i] = 1
+
+ return bmap
+
+ @staticmethod
+ def _compute_f(gt_data, tracker_data, tracker_data_id, gt_id, bound_th):
+ """
+ Perform F computation for a given gt and a given tracker ID. Adapted from
+ https://github.com/davisvideochallenge/davis2017-evaluation
+ :param gt_data: the encoded gt masks
+ :param tracker_data: the encoded tracker masks
+ :param tracker_data_id: the tracker ID
+ :param gt_id: the ground truth ID
+ :param bound_th: boundary threshold parameter
+ :return: the F value for the given tracker and gt ID
+ """
+
+ # Only loaded when run to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+ from skimage.morphology import disk
+ import cv2
+
+ f = np.zeros(len(gt_data))
+
+ for t, (gt_masks, tracker_masks) in enumerate(zip(gt_data, tracker_data)):
+ curr_tracker_mask = mask_utils.decode(tracker_masks[tracker_data_id])
+ curr_gt_mask = mask_utils.decode(gt_masks[gt_id])
+
+ bound_pix = bound_th if bound_th >= 1 - np.finfo('float').eps else \
+ np.ceil(bound_th * np.linalg.norm(curr_tracker_mask.shape))
+
+ # Get the pixel boundaries of both masks
+ fg_boundary = JAndF._seg2bmap(curr_tracker_mask)
+ gt_boundary = JAndF._seg2bmap(curr_gt_mask)
+
+ # fg_dil = binary_dilation(fg_boundary, disk(bound_pix))
+ fg_dil = cv2.dilate(fg_boundary.astype(np.uint8), disk(bound_pix).astype(np.uint8))
+ # gt_dil = binary_dilation(gt_boundary, disk(bound_pix))
+ gt_dil = cv2.dilate(gt_boundary.astype(np.uint8), disk(bound_pix).astype(np.uint8))
+
+ # Get the intersection
+ gt_match = gt_boundary * fg_dil
+ fg_match = fg_boundary * gt_dil
+
+ # Area of the intersection
+ n_fg = np.sum(fg_boundary)
+ n_gt = np.sum(gt_boundary)
+
+ # % Compute precision and recall
+ if n_fg == 0 and n_gt > 0:
+ precision = 1
+ recall = 0
+ elif n_fg > 0 and n_gt == 0:
+ precision = 0
+ recall = 1
+ elif n_fg == 0 and n_gt == 0:
+ precision = 1
+ recall = 1
+ else:
+ precision = np.sum(fg_match) / float(n_fg)
+ recall = np.sum(gt_match) / float(n_gt)
+
+ # Compute F measure
+ if precision + recall == 0:
+ f_val = 0
+ else:
+ f_val = 2 * precision * recall / (precision + recall)
+
+ f[t] = f_val
+
+ return f
+
+ @staticmethod
+ def _compute_j(gt_data, tracker_data, num_gt_ids, num_tracker_ids, num_timesteps):
+ """
+ Computation of J value for all ground truth IDs and all tracker IDs in the given sequence. Adapted from
+ https://github.com/davisvideochallenge/davis2017-evaluation
+ :param gt_data: the ground truth masks
+ :param tracker_data: the tracker masks
+ :param num_gt_ids: the number of ground truth IDs
+ :param num_tracker_ids: the number of tracker IDs
+ :param num_timesteps: the number of timesteps
+ :return: the J values
+ """
+
+ # Only loaded when run to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ j = np.zeros((num_tracker_ids, num_gt_ids, num_timesteps))
+
+ for t, (time_gt, time_data) in enumerate(zip(gt_data, tracker_data)):
+ # run length encoded masks with pycocotools
+ area_gt = mask_utils.area(time_gt)
+ time_data = list(time_data)
+ area_tr = mask_utils.area(time_data)
+
+ area_tr = np.repeat(area_tr[:, np.newaxis], len(area_gt), axis=1)
+ area_gt = np.repeat(area_gt[np.newaxis, :], len(area_tr), axis=0)
+
+ # mask iou computation with pycocotools
+ ious = np.atleast_2d(mask_utils.iou(time_data, time_gt, [0]*len(time_gt)))
+ # set iou to 1 if both masks are close to 0 (no ground truth and no predicted mask in timestep)
+ ious[np.isclose(area_tr, 0) & np.isclose(area_gt, 0)] = 1
+ assert (ious >= 0 - np.finfo('float').eps).all()
+ assert (ious <= 1 + np.finfo('float').eps).all()
+
+ j[..., t] = ious
+
+ return j
diff --git a/val_utils/trackeval/metrics/track_map.py b/val_utils/trackeval/metrics/track_map.py
new file mode 100644
index 0000000000000000000000000000000000000000..039f89084c8defd683c7f7d26cdd77834ecc2f23
--- /dev/null
+++ b/val_utils/trackeval/metrics/track_map.py
@@ -0,0 +1,462 @@
+import numpy as np
+from ._base_metric import _BaseMetric
+from .. import _timing
+from functools import partial
+from .. import utils
+from ..utils import TrackEvalException
+
+
+class TrackMAP(_BaseMetric):
+ """Class which implements the TrackMAP metrics"""
+
+ @staticmethod
+ def get_default_metric_config():
+ """Default class config values"""
+ default_config = {
+ 'USE_AREA_RANGES': True, # whether to evaluate for certain area ranges
+ 'AREA_RANGES': [[0 ** 2, 32 ** 2], # additional area range sets for which TrackMAP is evaluated
+ [32 ** 2, 96 ** 2], # (all area range always included), default values for TAO
+ [96 ** 2, 1e5 ** 2]], # evaluation
+ 'AREA_RANGE_LABELS': ["area_s", "area_m", "area_l"], # the labels for the area ranges
+ 'USE_TIME_RANGES': True, # whether to evaluate for certain time ranges (length of tracks)
+ 'TIME_RANGES': [[0, 3], [3, 10], [10, 1e5]], # additional time range sets for which TrackMAP is evaluated
+ # (all time range always included) , default values for TAO evaluation
+ 'TIME_RANGE_LABELS': ["time_s", "time_m", "time_l"], # the labels for the time ranges
+ 'IOU_THRESHOLDS': np.arange(0.5, 0.96, 0.05), # the IoU thresholds
+ 'RECALL_THRESHOLDS': np.linspace(0.0, 1.00, int(np.round((1.00 - 0.0) / 0.01) + 1), endpoint=True),
+ # recall thresholds at which precision is evaluated
+ 'MAX_DETECTIONS': 0, # limit the maximum number of considered tracks per sequence (0 for unlimited)
+ 'PRINT_CONFIG': True
+ }
+ return default_config
+
+ def __init__(self, config=None):
+ super().__init__()
+ self.config = utils.init_config(config, self.get_default_metric_config(), self.get_name())
+
+ self.num_ig_masks = 1
+ self.lbls = ['all']
+ self.use_area_rngs = self.config['USE_AREA_RANGES']
+ if self.use_area_rngs:
+ self.area_rngs = self.config['AREA_RANGES']
+ self.area_rng_lbls = self.config['AREA_RANGE_LABELS']
+ self.num_ig_masks += len(self.area_rng_lbls)
+ self.lbls += self.area_rng_lbls
+
+ self.use_time_rngs = self.config['USE_TIME_RANGES']
+ if self.use_time_rngs:
+ self.time_rngs = self.config['TIME_RANGES']
+ self.time_rng_lbls = self.config['TIME_RANGE_LABELS']
+ self.num_ig_masks += len(self.time_rng_lbls)
+ self.lbls += self.time_rng_lbls
+
+ self.array_labels = self.config['IOU_THRESHOLDS']
+ self.rec_thrs = self.config['RECALL_THRESHOLDS']
+
+ self.maxDet = self.config['MAX_DETECTIONS']
+ self.float_array_fields = ['AP_' + lbl for lbl in self.lbls] + ['AR_' + lbl for lbl in self.lbls]
+ self.fields = self.float_array_fields
+ self.summary_fields = self.float_array_fields
+
+ @_timing.time
+ def eval_sequence(self, data):
+ """Calculates GT and Tracker matches for one sequence for TrackMAP metrics. Adapted from
+ https://github.com/TAO-Dataset/"""
+
+ # Initialise results to zero for each sequence as the fields are only defined over the set of all sequences
+ res = {}
+ for field in self.fields:
+ res[field] = [0 for _ in self.array_labels]
+
+ gt_ids, dt_ids = data['gt_track_ids'], data['dt_track_ids']
+
+ if len(gt_ids) == 0 and len(dt_ids) == 0:
+ for idx in range(self.num_ig_masks):
+ res[idx] = None
+ return res
+
+ # get track data
+ gt_tr_areas = data.get('gt_track_areas', None) if self.use_area_rngs else None
+ gt_tr_lengths = data.get('gt_track_lengths', None) if self.use_time_rngs else None
+ gt_tr_iscrowd = data.get('gt_track_iscrowd', None)
+ dt_tr_areas = data.get('dt_track_areas', None) if self.use_area_rngs else None
+ dt_tr_lengths = data.get('dt_track_lengths', None) if self.use_time_rngs else None
+ is_nel = data.get('not_exhaustively_labeled', False)
+
+ # compute ignore masks for different track sets to eval
+ gt_ig_masks = self._compute_track_ig_masks(len(gt_ids), track_lengths=gt_tr_lengths, track_areas=gt_tr_areas,
+ iscrowd=gt_tr_iscrowd)
+ dt_ig_masks = self._compute_track_ig_masks(len(dt_ids), track_lengths=dt_tr_lengths, track_areas=dt_tr_areas,
+ is_not_exhaustively_labeled=is_nel, is_gt=False)
+
+ boxformat = data.get('boxformat', 'xywh')
+ ious = self._compute_track_ious(data['dt_tracks'], data['gt_tracks'], iou_function=data['iou_type'],
+ boxformat=boxformat)
+
+ for mask_idx in range(self.num_ig_masks):
+ gt_ig_mask = gt_ig_masks[mask_idx]
+
+ # Sort gt ignore last
+ gt_idx = np.argsort([g for g in gt_ig_mask], kind="mergesort")
+ gt_ids = [gt_ids[i] for i in gt_idx]
+
+ ious_sorted = ious[:, gt_idx] if len(ious) > 0 else ious
+
+ num_thrs = len(self.array_labels)
+ num_gt = len(gt_ids)
+ num_dt = len(dt_ids)
+
+ # Array to store the "id" of the matched dt/gt
+ gt_m = np.zeros((num_thrs, num_gt)) - 1
+ dt_m = np.zeros((num_thrs, num_dt)) - 1
+
+ gt_ig = np.array([gt_ig_mask[idx] for idx in gt_idx])
+ dt_ig = np.zeros((num_thrs, num_dt))
+
+ for iou_thr_idx, iou_thr in enumerate(self.array_labels):
+ if len(ious_sorted) == 0:
+ break
+
+ for dt_idx, _dt in enumerate(dt_ids):
+ iou = min([iou_thr, 1 - 1e-10])
+ # information about best match so far (m=-1 -> unmatched)
+ # store the gt_idx which matched for _dt
+ m = -1
+ for gt_idx, _ in enumerate(gt_ids):
+ # if this gt already matched continue
+ if gt_m[iou_thr_idx, gt_idx] > 0:
+ continue
+ # if _dt matched to reg gt, and on ignore gt, stop
+ if m > -1 and gt_ig[m] == 0 and gt_ig[gt_idx] == 1:
+ break
+ # continue to next gt unless better match made
+ if ious_sorted[dt_idx, gt_idx] < iou - np.finfo('float').eps:
+ continue
+ # if match successful and best so far, store appropriately
+ iou = ious_sorted[dt_idx, gt_idx]
+ m = gt_idx
+
+ # No match found for _dt, go to next _dt
+ if m == -1:
+ continue
+
+ # if gt to ignore for some reason update dt_ig.
+ # Should not be used in evaluation.
+ dt_ig[iou_thr_idx, dt_idx] = gt_ig[m]
+ # _dt match found, update gt_m, and dt_m with "id"
+ dt_m[iou_thr_idx, dt_idx] = gt_ids[m]
+ gt_m[iou_thr_idx, m] = _dt
+
+ dt_ig_mask = dt_ig_masks[mask_idx]
+
+ dt_ig_mask = np.array(dt_ig_mask).reshape((1, num_dt)) # 1 X num_dt
+ dt_ig_mask = np.repeat(dt_ig_mask, num_thrs, 0) # num_thrs X num_dt
+
+ # Based on dt_ig_mask ignore any unmatched detection by updating dt_ig
+ dt_ig = np.logical_or(dt_ig, np.logical_and(dt_m == -1, dt_ig_mask))
+ # store results for given video and category
+ res[mask_idx] = {
+ "dt_ids": dt_ids,
+ "gt_ids": gt_ids,
+ "dt_matches": dt_m,
+ "gt_matches": gt_m,
+ "dt_scores": data['dt_track_scores'],
+ "gt_ignore": gt_ig,
+ "dt_ignore": dt_ig,
+ }
+
+ return res
+
+ def combine_sequences(self, all_res):
+ """Combines metrics across all sequences. Computes precision and recall values based on track matches.
+ Adapted from https://github.com/TAO-Dataset/
+ """
+ num_thrs = len(self.array_labels)
+ num_recalls = len(self.rec_thrs)
+
+ # -1 for absent categories
+ precision = -np.ones(
+ (num_thrs, num_recalls, self.num_ig_masks)
+ )
+ recall = -np.ones((num_thrs, self.num_ig_masks))
+
+ for ig_idx in range(self.num_ig_masks):
+ ig_idx_results = [res[ig_idx] for res in all_res.values() if res[ig_idx] is not None]
+
+ # Remove elements which are None
+ if len(ig_idx_results) == 0:
+ continue
+
+ # Append all scores: shape (N,)
+ # limit considered tracks for each sequence if maxDet > 0
+ if self.maxDet == 0:
+ dt_scores = np.concatenate([res["dt_scores"] for res in ig_idx_results], axis=0)
+
+ dt_idx = np.argsort(-dt_scores, kind="mergesort")
+
+ dt_m = np.concatenate([e["dt_matches"] for e in ig_idx_results],
+ axis=1)[:, dt_idx]
+ dt_ig = np.concatenate([e["dt_ignore"] for e in ig_idx_results],
+ axis=1)[:, dt_idx]
+ elif self.maxDet > 0:
+ dt_scores = np.concatenate([res["dt_scores"][0:self.maxDet] for res in ig_idx_results], axis=0)
+
+ dt_idx = np.argsort(-dt_scores, kind="mergesort")
+
+ dt_m = np.concatenate([e["dt_matches"][:, 0:self.maxDet] for e in ig_idx_results],
+ axis=1)[:, dt_idx]
+ dt_ig = np.concatenate([e["dt_ignore"][:, 0:self.maxDet] for e in ig_idx_results],
+ axis=1)[:, dt_idx]
+ else:
+ raise Exception("Number of maximum detections must be >= 0, but is set to %i" % self.maxDet)
+
+ gt_ig = np.concatenate([res["gt_ignore"] for res in ig_idx_results])
+ # num gt anns to consider
+ num_gt = np.count_nonzero(gt_ig == 0)
+
+ if num_gt == 0:
+ continue
+
+ tps = np.logical_and(dt_m != -1, np.logical_not(dt_ig))
+ fps = np.logical_and(dt_m == -1, np.logical_not(dt_ig))
+
+ tp_sum = np.cumsum(tps, axis=1).astype(dtype=np.float)
+ fp_sum = np.cumsum(fps, axis=1).astype(dtype=np.float)
+
+ for iou_thr_idx, (tp, fp) in enumerate(zip(tp_sum, fp_sum)):
+ tp = np.array(tp)
+ fp = np.array(fp)
+ num_tp = len(tp)
+ rc = tp / num_gt
+ if num_tp:
+ recall[iou_thr_idx, ig_idx] = rc[-1]
+ else:
+ recall[iou_thr_idx, ig_idx] = 0
+
+ # np.spacing(1) ~= eps
+ pr = tp / (fp + tp + np.spacing(1))
+ pr = pr.tolist()
+
+ # Ensure precision values are monotonically decreasing
+ for i in range(num_tp - 1, 0, -1):
+ if pr[i] > pr[i - 1]:
+ pr[i - 1] = pr[i]
+
+ # find indices at the predefined recall values
+ rec_thrs_insert_idx = np.searchsorted(rc, self.rec_thrs, side="left")
+
+ pr_at_recall = [0.0] * num_recalls
+
+ try:
+ for _idx, pr_idx in enumerate(rec_thrs_insert_idx):
+ pr_at_recall[_idx] = pr[pr_idx]
+ except IndexError:
+ pass
+
+ precision[iou_thr_idx, :, ig_idx] = (np.array(pr_at_recall))
+
+ res = {'precision': precision, 'recall': recall}
+
+ # compute the precision and recall averages for the respective alpha thresholds and ignore masks
+ for lbl in self.lbls:
+ res['AP_' + lbl] = np.zeros((len(self.array_labels)), dtype=np.float)
+ res['AR_' + lbl] = np.zeros((len(self.array_labels)), dtype=np.float)
+
+ for a_id, alpha in enumerate(self.array_labels):
+ for lbl_idx, lbl in enumerate(self.lbls):
+ p = precision[a_id, :, lbl_idx]
+ if len(p[p > -1]) == 0:
+ mean_p = -1
+ else:
+ mean_p = np.mean(p[p > -1])
+ res['AP_' + lbl][a_id] = mean_p
+ res['AR_' + lbl][a_id] = recall[a_id, lbl_idx]
+
+ return res
+
+ def combine_classes_class_averaged(self, all_res, ignore_empty_classes=True):
+ """Combines metrics across all classes by averaging over the class values
+ Note mAP is not well defined for 'empty classes' so 'ignore empty classes' is always true here.
+ """
+ res = {}
+ for field in self.fields:
+ res[field] = np.zeros((len(self.array_labels)), dtype=np.float)
+ field_stacked = np.array([res[field] for res in all_res.values()])
+
+ for a_id, alpha in enumerate(self.array_labels):
+ values = field_stacked[:, a_id]
+ if len(values[values > -1]) == 0:
+ mean = -1
+ else:
+ mean = np.mean(values[values > -1])
+ res[field][a_id] = mean
+ return res
+
+ def combine_classes_det_averaged(self, all_res):
+ """Combines metrics across all classes by averaging over the detection values"""
+
+ res = {}
+ for field in self.fields:
+ res[field] = np.zeros((len(self.array_labels)), dtype=np.float)
+ field_stacked = np.array([res[field] for res in all_res.values()])
+
+ for a_id, alpha in enumerate(self.array_labels):
+ values = field_stacked[:, a_id]
+ if len(values[values > -1]) == 0:
+ mean = -1
+ else:
+ mean = np.mean(values[values > -1])
+ res[field][a_id] = mean
+ return res
+
+ def _compute_track_ig_masks(self, num_ids, track_lengths=None, track_areas=None, iscrowd=None,
+ is_not_exhaustively_labeled=False, is_gt=True):
+ """
+ Computes ignore masks for different track sets to evaluate
+ :param num_ids: the number of track IDs
+ :param track_lengths: the lengths of the tracks (number of timesteps)
+ :param track_areas: the average area of a track
+ :param iscrowd: whether a track is marked as crowd
+ :param is_not_exhaustively_labeled: whether the track category is not exhaustively labeled
+ :param is_gt: whether it is gt
+ :return: the track ignore masks
+ """
+ # for TAO tracks for classes which are not exhaustively labeled are not evaluated
+ if not is_gt and is_not_exhaustively_labeled:
+ track_ig_masks = [[1 for _ in range(num_ids)] for i in range(self.num_ig_masks)]
+ else:
+ # consider all tracks
+ track_ig_masks = [[0 for _ in range(num_ids)]]
+
+ # consider tracks with certain area
+ if self.use_area_rngs:
+ for rng in self.area_rngs:
+ track_ig_masks.append([0 if rng[0] - np.finfo('float').eps <= area <= rng[1] + np.finfo('float').eps
+ else 1 for area in track_areas])
+
+ # consider tracks with certain duration
+ if self.use_time_rngs:
+ for rng in self.time_rngs:
+ track_ig_masks.append([0 if rng[0] - np.finfo('float').eps <= length
+ <= rng[1] + np.finfo('float').eps else 1 for length in track_lengths])
+
+ # for YouTubeVIS evaluation tracks with crowd tag are not evaluated
+ if is_gt and iscrowd:
+ track_ig_masks = [np.logical_or(mask, iscrowd) for mask in track_ig_masks]
+
+ return track_ig_masks
+
+ @staticmethod
+ def _compute_bb_track_iou(dt_track, gt_track, boxformat='xywh'):
+ """
+ Calculates the track IoU for one detected track and one ground truth track for bounding boxes
+ :param dt_track: the detected track (format: dictionary with frame index as keys and
+ numpy arrays as values)
+ :param gt_track: the ground truth track (format: dictionary with frame index as keys and
+ numpy array as values)
+ :param boxformat: the format of the boxes
+ :return: the track IoU
+ """
+ intersect = 0
+ union = 0
+ image_ids = set(gt_track.keys()) | set(dt_track.keys())
+ for image in image_ids:
+ g = gt_track.get(image, None)
+ d = dt_track.get(image, None)
+ if boxformat == 'xywh':
+ if d is not None and g is not None:
+ dx, dy, dw, dh = d
+ gx, gy, gw, gh = g
+ w = max(min(dx + dw, gx + gw) - max(dx, gx), 0)
+ h = max(min(dy + dh, gy + gh) - max(dy, gy), 0)
+ i = w * h
+ u = dw * dh + gw * gh - i
+ intersect += i
+ union += u
+ elif d is None and g is not None:
+ union += g[2] * g[3]
+ elif d is not None and g is None:
+ union += d[2] * d[3]
+ elif boxformat == 'x0y0x1y1':
+ if d is not None and g is not None:
+ dx0, dy0, dx1, dy1 = d
+ gx0, gy0, gx1, gy1 = g
+ w = max(min(dx1, gx1) - max(dx0, gx0), 0)
+ h = max(min(dy1, gy1) - max(dy0, gy0), 0)
+ i = w * h
+ u = (dx1 - dx0) * (dy1 - dy0) + (gx1 - gx0) * (gy1 - gy0) - i
+ intersect += i
+ union += u
+ elif d is None and g is not None:
+ union += (g[2] - g[0]) * (g[3] - g[1])
+ elif d is not None and g is None:
+ union += (d[2] - d[0]) * (d[3] - d[1])
+ else:
+ raise TrackEvalException('BoxFormat not implemented')
+ if intersect > union:
+ raise TrackEvalException("Intersection value > union value. Are the box values corrupted?")
+ return intersect / union if union > 0 else 0
+
+ @staticmethod
+ def _compute_mask_track_iou(dt_track, gt_track):
+ """
+ Calculates the track IoU for one detected track and one ground truth track for segmentation masks
+ :param dt_track: the detected track (format: dictionary with frame index as keys and
+ pycocotools rle encoded masks as values)
+ :param gt_track: the ground truth track (format: dictionary with frame index as keys and
+ pycocotools rle encoded masks as values)
+ :return: the track IoU
+ """
+ # only loaded when needed to reduce minimum requirements
+ from pycocotools import mask as mask_utils
+
+ intersect = .0
+ union = .0
+ image_ids = set(gt_track.keys()) | set(dt_track.keys())
+ for image in image_ids:
+ g = gt_track.get(image, None)
+ d = dt_track.get(image, None)
+ if d and g:
+ intersect += mask_utils.area(mask_utils.merge([d, g], True))
+ union += mask_utils.area(mask_utils.merge([d, g], False))
+ elif not d and g:
+ union += mask_utils.area(g)
+ elif d and not g:
+ union += mask_utils.area(d)
+ if union < 0.0 - np.finfo('float').eps:
+ raise TrackEvalException("Union value < 0. Are the segmentaions corrupted?")
+ if intersect > union:
+ raise TrackEvalException("Intersection value > union value. Are the segmentations corrupted?")
+ iou = intersect / union if union > 0.0 + np.finfo('float').eps else 0.0
+ return iou
+
+ @staticmethod
+ def _compute_track_ious(dt, gt, iou_function='bbox', boxformat='xywh'):
+ """
+ Calculate track IoUs for a set of ground truth tracks and a set of detected tracks
+ """
+
+ if len(gt) == 0 and len(dt) == 0:
+ return []
+
+ if iou_function == 'bbox':
+ track_iou_function = partial(TrackMAP._compute_bb_track_iou, boxformat=boxformat)
+ elif iou_function == 'mask':
+ track_iou_function = partial(TrackMAP._compute_mask_track_iou)
+ else:
+ raise Exception('IoU function not implemented')
+
+ ious = np.zeros([len(dt), len(gt)])
+ for i, j in np.ndindex(ious.shape):
+ ious[i, j] = track_iou_function(dt[i], gt[j])
+ return ious
+
+ @staticmethod
+ def _row_print(*argv):
+ """Prints results in an evenly spaced rows, with more space in first row"""
+ if len(argv) == 1:
+ argv = argv[0]
+ to_print = '%-40s' % argv[0]
+ for v in argv[1:]:
+ to_print += '%-12s' % str(v)
+ print(to_print)
diff --git a/val_utils/trackeval/metrics/vace.py b/val_utils/trackeval/metrics/vace.py
new file mode 100644
index 0000000000000000000000000000000000000000..81858d429c6e4943ca8c168c6683517ec2907b98
--- /dev/null
+++ b/val_utils/trackeval/metrics/vace.py
@@ -0,0 +1,131 @@
+import numpy as np
+from scipy.optimize import linear_sum_assignment
+from ._base_metric import _BaseMetric
+from .. import _timing
+
+
+class VACE(_BaseMetric):
+ """Class which implements the VACE metrics.
+
+ The metrics are described in:
+ Manohar et al. (2006) "Performance Evaluation of Object Detection and Tracking in Video"
+ https://link.springer.com/chapter/10.1007/11612704_16
+
+ This implementation uses the "relaxed" variant of the metrics,
+ where an overlap threshold is applied in each frame.
+ """
+
+ def __init__(self, config=None):
+ super().__init__()
+ self.integer_fields = ['VACE_IDs', 'VACE_GT_IDs', 'num_non_empty_timesteps']
+ self.float_fields = ['STDA', 'ATA', 'FDA', 'SFDA']
+ self.fields = self.integer_fields + self.float_fields
+ self.summary_fields = ['SFDA', 'ATA']
+
+ # Fields that are accumulated over multiple videos.
+ self._additive_fields = self.integer_fields + ['STDA', 'FDA']
+
+ self.threshold = 0.5
+
+ @_timing.time
+ def eval_sequence(self, data):
+ """Calculates VACE metrics for one sequence.
+
+ Depends on the fields:
+ data['num_gt_ids']
+ data['num_tracker_ids']
+ data['gt_ids']
+ data['tracker_ids']
+ data['similarity_scores']
+ """
+ res = {}
+
+ # Obtain Average Tracking Accuracy (ATA) using track correspondence.
+ # Obtain counts necessary to compute temporal IOU.
+ # Assume that integer counts can be represented exactly as floats.
+ potential_matches_count = np.zeros((data['num_gt_ids'], data['num_tracker_ids']))
+ gt_id_count = np.zeros(data['num_gt_ids'])
+ tracker_id_count = np.zeros(data['num_tracker_ids'])
+ both_present_count = np.zeros((data['num_gt_ids'], data['num_tracker_ids']))
+ for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
+ # Count the number of frames in which two tracks satisfy the overlap criterion.
+ matches_mask = np.greater_equal(data['similarity_scores'][t], self.threshold)
+ match_idx_gt, match_idx_tracker = np.nonzero(matches_mask)
+ potential_matches_count[gt_ids_t[match_idx_gt], tracker_ids_t[match_idx_tracker]] += 1
+ # Count the number of frames in which the tracks are present.
+ gt_id_count[gt_ids_t] += 1
+ tracker_id_count[tracker_ids_t] += 1
+ both_present_count[gt_ids_t[:, np.newaxis], tracker_ids_t[np.newaxis, :]] += 1
+ # Number of frames in which either track is present (union of the two sets of frames).
+ union_count = (gt_id_count[:, np.newaxis]
+ + tracker_id_count[np.newaxis, :]
+ - both_present_count)
+ # The denominator should always be non-zero if all tracks are non-empty.
+ with np.errstate(divide='raise', invalid='raise'):
+ temporal_iou = potential_matches_count / union_count
+ # Find assignment that maximizes temporal IOU.
+ match_rows, match_cols = linear_sum_assignment(-temporal_iou)
+ res['STDA'] = temporal_iou[match_rows, match_cols].sum()
+ res['VACE_IDs'] = data['num_tracker_ids']
+ res['VACE_GT_IDs'] = data['num_gt_ids']
+
+ # Obtain Frame Detection Accuracy (FDA) using per-frame correspondence.
+ non_empty_count = 0
+ fda = 0
+ for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
+ n_g = len(gt_ids_t)
+ n_d = len(tracker_ids_t)
+ if not (n_g or n_d):
+ continue
+ # n_g > 0 or n_d > 0
+ non_empty_count += 1
+ if not (n_g and n_d):
+ continue
+ # n_g > 0 and n_d > 0
+ spatial_overlap = data['similarity_scores'][t]
+ match_rows, match_cols = linear_sum_assignment(-spatial_overlap)
+ overlap_ratio = spatial_overlap[match_rows, match_cols].sum()
+ fda += overlap_ratio / (0.5 * (n_g + n_d))
+ res['FDA'] = fda
+ res['num_non_empty_timesteps'] = non_empty_count
+
+ res.update(self._compute_final_fields(res))
+ return res
+
+ def combine_classes_class_averaged(self, all_res, ignore_empty_classes=True):
+ """Combines metrics across all classes by averaging over the class values.
+ If 'ignore_empty_classes' is True, then it only sums over classes with at least one gt or predicted detection.
+ """
+ res = {}
+ for field in self.fields:
+ if ignore_empty_classes:
+ res[field] = np.mean([v[field] for v in all_res.values()
+ if v['VACE_GT_IDs'] > 0 or v['VACE_IDs'] > 0], axis=0)
+ else:
+ res[field] = np.mean([v[field] for v in all_res.values()], axis=0)
+ return res
+
+ def combine_classes_det_averaged(self, all_res):
+ """Combines metrics across all classes by averaging over the detection values"""
+ res = {}
+ for field in self._additive_fields:
+ res[field] = _BaseMetric._combine_sum(all_res, field)
+ res = self._compute_final_fields(res)
+ return res
+
+ def combine_sequences(self, all_res):
+ """Combines metrics across all sequences"""
+ res = {}
+ for header in self._additive_fields:
+ res[header] = _BaseMetric._combine_sum(all_res, header)
+ res.update(self._compute_final_fields(res))
+ return res
+
+ @staticmethod
+ def _compute_final_fields(additive):
+ final = {}
+ with np.errstate(invalid='ignore'): # Permit nan results.
+ final['ATA'] = (additive['STDA'] /
+ (0.5 * (additive['VACE_IDs'] + additive['VACE_GT_IDs'])))
+ final['SFDA'] = additive['FDA'] / additive['num_non_empty_timesteps']
+ return final
diff --git a/val_utils/trackeval/plotting.py b/val_utils/trackeval/plotting.py
new file mode 100644
index 0000000000000000000000000000000000000000..e76fd08c2733011a043de5cde3f16cfa4055268c
--- /dev/null
+++ b/val_utils/trackeval/plotting.py
@@ -0,0 +1,230 @@
+
+import os
+import numpy as np
+from .utils import TrackEvalException
+
+
+def plot_compare_trackers(tracker_folder, tracker_list, cls, output_folder, plots_list=None):
+ """Create plots which compare metrics across different trackers."""
+ # Define what to plot
+ if plots_list is None:
+ plots_list = get_default_plots_list()
+
+ # Load data
+ data = load_multiple_tracker_summaries(tracker_folder, tracker_list, cls)
+ out_loc = os.path.join(output_folder, cls)
+
+ # Plot
+ for args in plots_list:
+ create_comparison_plot(data, out_loc, *args)
+
+
+def get_default_plots_list():
+ # y_label, x_label, sort_label, bg_label, bg_function
+ plots_list = [
+ ['AssA', 'DetA', 'HOTA', 'HOTA', 'geometric_mean'],
+ ['AssPr', 'AssRe', 'HOTA', 'AssA', 'jaccard'],
+ ['DetPr', 'DetRe', 'HOTA', 'DetA', 'jaccard'],
+ ['HOTA(0)', 'LocA(0)', 'HOTA', 'HOTALocA(0)', 'multiplication'],
+ ['HOTA', 'LocA', 'HOTA', None, None],
+
+ ['HOTA', 'MOTA', 'HOTA', None, None],
+ ['HOTA', 'IDF1', 'HOTA', None, None],
+ ['IDF1', 'MOTA', 'HOTA', None, None],
+ ]
+ return plots_list
+
+
+def load_multiple_tracker_summaries(tracker_folder, tracker_list, cls):
+ """Loads summary data for multiple trackers."""
+ data = {}
+ for tracker in tracker_list:
+ with open(os.path.join(tracker_folder, tracker, cls + '_summary.txt')) as f:
+ keys = next(f).split(' ')
+ done = False
+ while not done:
+ values = next(f).split(' ')
+ if len(values) == len(keys):
+ done = True
+ data[tracker] = dict(zip(keys, map(float, values)))
+ return data
+
+
+def create_comparison_plot(data, out_loc, y_label, x_label, sort_label, bg_label=None, bg_function=None, settings=None):
+ """ Creates a scatter plot comparing multiple trackers between two metric fields, with one on the x-axis and the
+ other on the y axis. Adds pareto optical lines and (optionally) a background contour.
+
+ Inputs:
+ data: dict of dicts such that data[tracker_name][metric_field_name] = float
+ y_label: the metric_field_name to be plotted on the y-axis
+ x_label: the metric_field_name to be plotted on the x-axis
+ sort_label: the metric_field_name by which trackers are ordered and ranked
+ bg_label: the metric_field_name by which (optional) background contours are plotted
+ bg_function: the (optional) function bg_function(x,y) which converts the x_label / y_label values into bg_label.
+ settings: dict of plot settings with keys:
+ 'gap_val': gap between axis ticks and bg curves.
+ 'num_to_plot': maximum number of trackers to plot
+ """
+
+ # Only loaded when run to reduce minimum requirements
+ from matplotlib import pyplot as plt
+
+ # Get plot settings
+ if settings is None:
+ gap_val = 2
+ num_to_plot = 20
+ else:
+ gap_val = settings['gap_val']
+ num_to_plot = settings['num_to_plot']
+
+ if (bg_label is None) != (bg_function is None):
+ raise TrackEvalException('bg_function and bg_label must either be both given or neither given.')
+
+ # Extract data
+ tracker_names = np.array(list(data.keys()))
+ sort_index = np.array([data[t][sort_label] for t in tracker_names]).argsort()[::-1]
+ x_values = np.array([data[t][x_label] for t in tracker_names])[sort_index][:num_to_plot]
+ y_values = np.array([data[t][y_label] for t in tracker_names])[sort_index][:num_to_plot]
+
+ # Print info on what is being plotted
+ tracker_names = tracker_names[sort_index][:num_to_plot]
+ print('\nPlotting %s vs %s, for the following (ordered) trackers:' % (y_label, x_label))
+ for i, name in enumerate(tracker_names):
+ print('%i: %s' % (i+1, name))
+
+ # Find best fitting boundaries for data
+ boundaries = _get_boundaries(x_values, y_values, round_val=gap_val/2)
+
+ fig = plt.figure()
+
+ # Plot background contour
+ if bg_function is not None:
+ _plot_bg_contour(bg_function, boundaries, gap_val)
+
+ # Plot pareto optimal lines
+ _plot_pareto_optimal_lines(x_values, y_values)
+
+ # Plot data points with number labels
+ labels = np.arange(len(y_values)) + 1
+ plt.plot(x_values, y_values, 'b.', markersize=15)
+ for xx, yy, l in zip(x_values, y_values, labels):
+ plt.text(xx, yy, str(l), color="red", fontsize=15)
+
+ # Add extra explanatory text to plots
+ plt.text(0, -0.11, 'label order:\nHOTA', horizontalalignment='left', verticalalignment='center',
+ transform=fig.axes[0].transAxes, color="red", fontsize=12)
+ if bg_label is not None:
+ plt.text(1, -0.11, 'curve values:\n' + bg_label, horizontalalignment='right', verticalalignment='center',
+ transform=fig.axes[0].transAxes, color="grey", fontsize=12)
+
+ plt.xlabel(x_label, fontsize=15)
+ plt.ylabel(y_label, fontsize=15)
+ title = y_label + ' vs ' + x_label
+ if bg_label is not None:
+ title += ' (' + bg_label + ')'
+ plt.title(title, fontsize=17)
+ plt.xticks(np.arange(0, 100, gap_val))
+ plt.yticks(np.arange(0, 100, gap_val))
+ min_x, max_x, min_y, max_y = boundaries
+ plt.xlim(min_x, max_x)
+ plt.ylim(min_y, max_y)
+ plt.gca().set_aspect('equal', adjustable='box')
+ plt.tight_layout()
+
+ os.makedirs(out_loc, exist_ok=True)
+ filename = os.path.join(out_loc, title.replace(' ', '_'))
+ plt.savefig(filename + '.pdf', bbox_inches='tight', pad_inches=0.05)
+ plt.savefig(filename + '.png', bbox_inches='tight', pad_inches=0.05)
+
+
+def _get_boundaries(x_values, y_values, round_val):
+ x1 = np.min(np.floor((x_values - 0.5) / round_val) * round_val)
+ x2 = np.max(np.ceil((x_values + 0.5) / round_val) * round_val)
+ y1 = np.min(np.floor((y_values - 0.5) / round_val) * round_val)
+ y2 = np.max(np.ceil((y_values + 0.5) / round_val) * round_val)
+ x_range = x2 - x1
+ y_range = y2 - y1
+ max_range = max(x_range, y_range)
+ x_center = (x1 + x2) / 2
+ y_center = (y1 + y2) / 2
+ min_x = max(x_center - max_range / 2, 0)
+ max_x = min(x_center + max_range / 2, 100)
+ min_y = max(y_center - max_range / 2, 0)
+ max_y = min(y_center + max_range / 2, 100)
+ return min_x, max_x, min_y, max_y
+
+
+def geometric_mean(x, y):
+ return np.sqrt(x * y)
+
+
+def jaccard(x, y):
+ x = x / 100
+ y = y / 100
+ return 100 * (x * y) / (x + y - x * y)
+
+
+def multiplication(x, y):
+ return x * y / 100
+
+
+bg_function_dict = {
+ "geometric_mean": geometric_mean,
+ "jaccard": jaccard,
+ "multiplication": multiplication,
+ }
+
+
+def _plot_bg_contour(bg_function, plot_boundaries, gap_val):
+ """ Plot background contour. """
+
+ # Only loaded when run to reduce minimum requirements
+ from matplotlib import pyplot as plt
+
+ # Plot background contour
+ min_x, max_x, min_y, max_y = plot_boundaries
+ x = np.arange(min_x, max_x, 0.1)
+ y = np.arange(min_y, max_y, 0.1)
+ x_grid, y_grid = np.meshgrid(x, y)
+ if bg_function in bg_function_dict.keys():
+ z_grid = bg_function_dict[bg_function](x_grid, y_grid)
+ else:
+ raise TrackEvalException("background plotting function '%s' is not defined." % bg_function)
+ levels = np.arange(0, 100, gap_val)
+ con = plt.contour(x_grid, y_grid, z_grid, levels, colors='grey')
+
+ def bg_format(val):
+ s = '{:1f}'.format(val)
+ return '{:.0f}'.format(val) if s[-1] == '0' else s
+
+ con.levels = [bg_format(val) for val in con.levels]
+ plt.clabel(con, con.levels, inline=True, fmt='%r', fontsize=8)
+
+
+def _plot_pareto_optimal_lines(x_values, y_values):
+ """ Plot pareto optimal lines """
+
+ # Only loaded when run to reduce minimum requirements
+ from matplotlib import pyplot as plt
+
+ # Plot pareto optimal lines
+ cxs = x_values
+ cys = y_values
+ best_y = np.argmax(cys)
+ x_pareto = [0, cxs[best_y]]
+ y_pareto = [cys[best_y], cys[best_y]]
+ t = 2
+ remaining = cxs > x_pareto[t - 1]
+ cys = cys[remaining]
+ cxs = cxs[remaining]
+ while len(cxs) > 0 and len(cys) > 0:
+ best_y = np.argmax(cys)
+ x_pareto += [x_pareto[t - 1], cxs[best_y]]
+ y_pareto += [cys[best_y], cys[best_y]]
+ t += 2
+ remaining = cxs > x_pareto[t - 1]
+ cys = cys[remaining]
+ cxs = cxs[remaining]
+ x_pareto.append(x_pareto[t - 1])
+ y_pareto.append(0)
+ plt.plot(np.array(x_pareto), np.array(y_pareto), '--r')
diff --git a/val_utils/trackeval/utils.py b/val_utils/trackeval/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c7c9167fe17a6d393419f14dc512c8d325b8ed2
--- /dev/null
+++ b/val_utils/trackeval/utils.py
@@ -0,0 +1,146 @@
+
+import os
+import csv
+import argparse
+from collections import OrderedDict
+
+
+def init_config(config, default_config, name=None):
+ """Initialise non-given config values with defaults"""
+ if config is None:
+ config = default_config
+ else:
+ for k in default_config.keys():
+ if k not in config.keys():
+ config[k] = default_config[k]
+ if name and config['PRINT_CONFIG']:
+ print('\n%s Config:' % name)
+ for c in config.keys():
+ print('%-20s : %-30s' % (c, config[c]))
+ return config
+
+
+def update_config(config):
+ """
+ Parse the arguments of a script and updates the config values for a given value if specified in the arguments.
+ :param config: the config to update
+ :return: the updated config
+ """
+ parser = argparse.ArgumentParser()
+ for setting in config.keys():
+ if type(config[setting]) == list or type(config[setting]) == type(None):
+ parser.add_argument("--" + setting, nargs='+')
+ else:
+ parser.add_argument("--" + setting)
+ args = parser.parse_args().__dict__
+ for setting in args.keys():
+ if args[setting] is not None:
+ if type(config[setting]) == type(True):
+ if args[setting] == 'True':
+ x = True
+ elif args[setting] == 'False':
+ x = False
+ else:
+ raise Exception('Command line parameter ' + setting + 'must be True or False')
+ elif type(config[setting]) == type(1):
+ x = int(args[setting])
+ elif type(args[setting]) == type(None):
+ x = None
+ else:
+ x = args[setting]
+ config[setting] = x
+ return config
+
+
+def get_code_path():
+ """Get base path where code is"""
+ return os.path.abspath(os.path.join(os.path.dirname(__file__), '..'))
+
+
+def validate_metrics_list(metrics_list):
+ """Get names of metric class and ensures they are unique, further checks that the fields within each metric class
+ do not have overlapping names.
+ """
+ metric_names = [metric.get_name() for metric in metrics_list]
+ # check metric names are unique
+ if len(metric_names) != len(set(metric_names)):
+ raise TrackEvalException('Code being run with multiple metrics of the same name')
+ fields = []
+ for m in metrics_list:
+ fields += m.fields
+ # check metric fields are unique
+ if len(fields) != len(set(fields)):
+ raise TrackEvalException('Code being run with multiple metrics with fields of the same name')
+ return metric_names
+
+
+def write_summary_results(summaries, cls, output_folder):
+ """Write summary results to file"""
+
+ fields = sum([list(s.keys()) for s in summaries], [])
+ values = sum([list(s.values()) for s in summaries], [])
+
+ # In order to remain consistent upon new fields being adding, for each of the following fields if they are present
+ # they will be output in the summary first in the order below. Any further fields will be output in the order each
+ # metric family is called, and within each family either in the order they were added to the dict (python >= 3.6) or
+ # randomly (python < 3.6).
+ default_order = ['HOTA', 'DetA', 'AssA', 'DetRe', 'DetPr', 'AssRe', 'AssPr', 'LocA', 'OWTA', 'HOTA(0)', 'LocA(0)',
+ 'HOTALocA(0)', 'MOTA', 'MOTP', 'MODA', 'CLR_Re', 'CLR_Pr', 'MTR', 'PTR', 'MLR', 'CLR_TP', 'CLR_FN',
+ 'CLR_FP', 'IDSW', 'MT', 'PT', 'ML', 'Frag', 'sMOTA', 'IDF1', 'IDR', 'IDP', 'IDTP', 'IDFN', 'IDFP',
+ 'Dets', 'GT_Dets', 'IDs', 'GT_IDs']
+ default_ordered_dict = OrderedDict(zip(default_order, [None for _ in default_order]))
+ for f, v in zip(fields, values):
+ default_ordered_dict[f] = v
+ for df in default_order:
+ if default_ordered_dict[df] is None:
+ del default_ordered_dict[df]
+ fields = list(default_ordered_dict.keys())
+ values = list(default_ordered_dict.values())
+
+ out_file = os.path.join(output_folder, cls + '_summary.txt')
+ os.makedirs(os.path.dirname(out_file), exist_ok=True)
+ with open(out_file, 'w', newline='') as f:
+ writer = csv.writer(f, delimiter=' ')
+ writer.writerow(fields)
+ writer.writerow(values)
+
+
+def write_detailed_results(details, cls, output_folder):
+ """Write detailed results to file"""
+ sequences = details[0].keys()
+ fields = ['seq'] + sum([list(s['COMBINED_SEQ'].keys()) for s in details], [])
+ out_file = os.path.join(output_folder, cls + '_detailed.csv')
+ os.makedirs(os.path.dirname(out_file), exist_ok=True)
+ with open(out_file, 'w', newline='') as f:
+ writer = csv.writer(f)
+ writer.writerow(fields)
+ for seq in sorted(sequences):
+ if seq == 'COMBINED_SEQ':
+ continue
+ writer.writerow([seq] + sum([list(s[seq].values()) for s in details], []))
+ writer.writerow(['COMBINED'] + sum([list(s['COMBINED_SEQ'].values()) for s in details], []))
+
+
+def load_detail(file):
+ """Loads detailed data for a tracker."""
+ data = {}
+ with open(file) as f:
+ for i, row_text in enumerate(f):
+ row = row_text.replace('\r', '').replace('\n', '').split(',')
+ if i == 0:
+ keys = row[1:]
+ continue
+ current_values = row[1:]
+ seq = row[0]
+ if seq == 'COMBINED':
+ seq = 'COMBINED_SEQ'
+ if (len(current_values) == len(keys)) and seq != '':
+ data[seq] = {}
+ for key, value in zip(keys, current_values):
+ data[seq][key] = float(value)
+ return data
+
+
+class TrackEvalException(Exception):
+ """Custom exception for catching expected errors."""
+ ...
diff --git a/video/4.mp4 b/video/4.mp4
new file mode 100644
index 0000000000000000000000000000000000000000..92274d948d7ad3794dd28efef060c393057379b3
--- /dev/null
+++ b/video/4.mp4
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:82ca0e0d5162d0024feaaf6a106974fb39927c88b8aa7c008363847f5a20376d
+size 10121349
diff --git a/video/5.mp4 b/video/5.mp4
new file mode 100644
index 0000000000000000000000000000000000000000..70739aff733b367e6d7bb0fd6dfe8a36490246ac
--- /dev/null
+++ b/video/5.mp4
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:55746f7b652b7f2f549db2ec7b2c94886f1b6f8378061acaacbd14770a44dcdf
+size 10144209
diff --git a/video/8.mp4 b/video/8.mp4
new file mode 100644
index 0000000000000000000000000000000000000000..5987cb986ccdf61ea737379e787c027efb9da031
Binary files /dev/null and b/video/8.mp4 differ
diff --git a/video/9.mp4 b/video/9.mp4
new file mode 100644
index 0000000000000000000000000000000000000000..4ef15b41d0b6a98cb61a546cf45070dbb1c2cb82
--- /dev/null
+++ b/video/9.mp4
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:6f30901e2c64c4e35ffb789b95de2692d1e319c12ba3f3e40bc53da5f21af506
+size 6177301
diff --git a/video/bicyclecity.mp4 b/video/bicyclecity.mp4
new file mode 100644
index 0000000000000000000000000000000000000000..c024bc30fed7a7a2351b9e189fd04ce56adedf65
--- /dev/null
+++ b/video/bicyclecity.mp4
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:233bd31fcaae40185e8b7e957d442c324cf9c5c8d6c864e58321f4452b57472e
+size 1099590
diff --git a/video/car.mp4 b/video/car.mp4
new file mode 100644
index 0000000000000000000000000000000000000000..c68be8e5394e247c75e9ead00f7353fcbeccf8bd
--- /dev/null
+++ b/video/car.mp4
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:69b6792e068380e5389c1aee24ec7411e6f01b541e612faf3d516018ff364591
+size 1276768
diff --git a/yolov5/.cometml-runs/074c70a5eb3b459082fea571bc2c711b.zip b/yolov5/.cometml-runs/074c70a5eb3b459082fea571bc2c711b.zip
new file mode 100644
index 0000000000000000000000000000000000000000..3f8340ee9100c72e71befa19619f05c80041899c
--- /dev/null
+++ b/yolov5/.cometml-runs/074c70a5eb3b459082fea571bc2c711b.zip
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:52b25243b18cfd3e8a7fa9c550120f9540ff70114bc01bce5f6d7e33a8eb130e
+size 35668
diff --git a/yolov5/.cometml-runs/0ae5485f8ae643bd8bb48922a165e199.zip b/yolov5/.cometml-runs/0ae5485f8ae643bd8bb48922a165e199.zip
new file mode 100644
index 0000000000000000000000000000000000000000..36f761ffd74ca50f477aefb3d86f4e71da2e7903
--- /dev/null
+++ b/yolov5/.cometml-runs/0ae5485f8ae643bd8bb48922a165e199.zip
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:20752f6449aaaf99c96c2ce104aac4c187606ddf63937d9d70827bc41a361c67
+size 28380
diff --git a/yolov5/.cometml-runs/81b2b6d464c04bba8c5860481e0293b3.zip b/yolov5/.cometml-runs/81b2b6d464c04bba8c5860481e0293b3.zip
new file mode 100644
index 0000000000000000000000000000000000000000..f56b821581615644c9e462d8e3b447cefc8f0ed3
--- /dev/null
+++ b/yolov5/.cometml-runs/81b2b6d464c04bba8c5860481e0293b3.zip
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c9127768b47e219a3eff5346700915c9a521a8b20576c91a42b50e1a3911c997
+size 28380
diff --git a/yolov5/.dockerignore b/yolov5/.dockerignore
new file mode 100644
index 0000000000000000000000000000000000000000..3b669254e7799c0460d6be8523ed15ef1d2c3ac6
--- /dev/null
+++ b/yolov5/.dockerignore
@@ -0,0 +1,222 @@
+# Repo-specific DockerIgnore -------------------------------------------------------------------------------------------
+.git
+.cache
+.idea
+runs
+output
+coco
+storage.googleapis.com
+
+data/samples/*
+**/results*.csv
+*.jpg
+
+# Neural Network weights -----------------------------------------------------------------------------------------------
+**/*.pt
+**/*.pth
+**/*.onnx
+**/*.engine
+**/*.mlmodel
+**/*.torchscript
+**/*.torchscript.pt
+**/*.tflite
+**/*.h5
+**/*.pb
+*_saved_model/
+*_web_model/
+*_openvino_model/
+
+# Below Copied From .gitignore -----------------------------------------------------------------------------------------
+# Below Copied From .gitignore -----------------------------------------------------------------------------------------
+
+
+# GitHub Python GitIgnore ----------------------------------------------------------------------------------------------
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+env/
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+wandb/
+.installed.cfg
+*.egg
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# dotenv
+.env
+
+# virtualenv
+.venv*
+venv*/
+ENV*/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+
+
+# https://github.com/github/gitignore/blob/master/Global/macOS.gitignore -----------------------------------------------
+
+# General
+.DS_Store
+.AppleDouble
+.LSOverride
+
+# Icon must end with two \r
+Icon
+Icon?
+
+# Thumbnails
+._*
+
+# Files that might appear in the root of a volume
+.DocumentRevisions-V100
+.fseventsd
+.Spotlight-V100
+.TemporaryItems
+.Trashes
+.VolumeIcon.icns
+.com.apple.timemachine.donotpresent
+
+# Directories potentially created on remote AFP share
+.AppleDB
+.AppleDesktop
+Network Trash Folder
+Temporary Items
+.apdisk
+
+
+# https://github.com/github/gitignore/blob/master/Global/JetBrains.gitignore
+# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
+# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
+
+# User-specific stuff:
+.idea/*
+.idea/**/workspace.xml
+.idea/**/tasks.xml
+.idea/dictionaries
+.html # Bokeh Plots
+.pg # TensorFlow Frozen Graphs
+.avi # videos
+
+# Sensitive or high-churn files:
+.idea/**/dataSources/
+.idea/**/dataSources.ids
+.idea/**/dataSources.local.xml
+.idea/**/sqlDataSources.xml
+.idea/**/dynamic.xml
+.idea/**/uiDesigner.xml
+
+# Gradle:
+.idea/**/gradle.xml
+.idea/**/libraries
+
+# CMake
+cmake-build-debug/
+cmake-build-release/
+
+# Mongo Explorer plugin:
+.idea/**/mongoSettings.xml
+
+## File-based project format:
+*.iws
+
+## Plugin-specific files:
+
+# IntelliJ
+out/
+
+# mpeltonen/sbt-idea plugin
+.idea_modules/
+
+# JIRA plugin
+atlassian-ide-plugin.xml
+
+# Cursive Clojure plugin
+.idea/replstate.xml
+
+# Crashlytics plugin (for Android Studio and IntelliJ)
+com_crashlytics_export_strings.xml
+crashlytics.properties
+crashlytics-build.properties
+fabric.properties
diff --git a/yolov5/.gitattributes b/yolov5/.gitattributes
new file mode 100644
index 0000000000000000000000000000000000000000..dad4239ebad5b72917cbc4bba95206c1e55d519e
--- /dev/null
+++ b/yolov5/.gitattributes
@@ -0,0 +1,2 @@
+# this drop notebooks from GitHub language stats
+*.ipynb linguist-vendored
diff --git a/yolov5/.github/ISSUE_TEMPLATE/bug-report.yml b/yolov5/.github/ISSUE_TEMPLATE/bug-report.yml
new file mode 100644
index 0000000000000000000000000000000000000000..04f9c76fde1f6b9887f3145af3b89030edba223f
--- /dev/null
+++ b/yolov5/.github/ISSUE_TEMPLATE/bug-report.yml
@@ -0,0 +1,85 @@
+name: 🐛 Bug Report
+# title: " "
+description: Problems with YOLOv5
+labels: [bug, triage]
+body:
+ - type: markdown
+ attributes:
+ value: |
+ Thank you for submitting a YOLOv5 🐛 Bug Report!
+
+ - type: checkboxes
+ attributes:
+ label: Search before asking
+ description: >
+ Please search the [issues](https://github.com/ultralytics/yolov5/issues) to see if a similar bug report already exists.
+ options:
+ - label: >
+ I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
+ required: true
+
+ - type: dropdown
+ attributes:
+ label: YOLOv5 Component
+ description: |
+ Please select the part of YOLOv5 where you found the bug.
+ multiple: true
+ options:
+ - "Training"
+ - "Validation"
+ - "Detection"
+ - "Export"
+ - "PyTorch Hub"
+ - "Multi-GPU"
+ - "Evolution"
+ - "Integrations"
+ - "Other"
+ validations:
+ required: false
+
+ - type: textarea
+ attributes:
+ label: Bug
+ description: Provide console output with error messages and/or screenshots of the bug.
+ placeholder: |
+ 💡 ProTip! Include as much information as possible (screenshots, logs, tracebacks etc.) to receive the most helpful response.
+ validations:
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Environment
+ description: Please specify the software and hardware you used to produce the bug.
+ placeholder: |
+ - YOLO: YOLOv5 🚀 v6.0-67-g60e42e1 torch 1.9.0+cu111 CUDA:0 (A100-SXM4-40GB, 40536MiB)
+ - OS: Ubuntu 20.04
+ - Python: 3.9.0
+ validations:
+ required: false
+
+ - type: textarea
+ attributes:
+ label: Minimal Reproducible Example
+ description: >
+ When asking a question, people will be better able to provide help if you provide code that they can easily understand and use to **reproduce** the problem.
+ This is referred to by community members as creating a [minimal reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/).
+ placeholder: |
+ ```
+ # Code to reproduce your issue here
+ ```
+ validations:
+ required: false
+
+ - type: textarea
+ attributes:
+ label: Additional
+ description: Anything else you would like to share?
+
+ - type: checkboxes
+ attributes:
+ label: Are you willing to submit a PR?
+ description: >
+ (Optional) We encourage you to submit a [Pull Request](https://github.com/ultralytics/yolov5/pulls) (PR) to help improve YOLOv5 for everyone, especially if you have a good understanding of how to implement a fix or feature.
+ See the YOLOv5 [Contributing Guide](https://docs.ultralytics.com/help/contributing) to get started.
+ options:
+ - label: Yes I'd like to help by submitting a PR!
diff --git a/yolov5/.github/ISSUE_TEMPLATE/config.yml b/yolov5/.github/ISSUE_TEMPLATE/config.yml
new file mode 100644
index 0000000000000000000000000000000000000000..743feb957ff1fea2c5fbf52910fa89d6de9392d3
--- /dev/null
+++ b/yolov5/.github/ISSUE_TEMPLATE/config.yml
@@ -0,0 +1,11 @@
+blank_issues_enabled: true
+contact_links:
+ - name: 📄 Docs
+ url: https://docs.ultralytics.com/yolov5
+ about: View Ultralytics YOLOv5 Docs
+ - name: 💬 Forum
+ url: https://community.ultralytics.com/
+ about: Ask on Ultralytics Community Forum
+ - name: 🎧 Discord
+ url: https://discord.gg/n6cFeSPZdD
+ about: Ask on Ultralytics Discord
diff --git a/yolov5/.github/ISSUE_TEMPLATE/feature-request.yml b/yolov5/.github/ISSUE_TEMPLATE/feature-request.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1d3d53df217e03fddd68d35bc3017586a86b37e1
--- /dev/null
+++ b/yolov5/.github/ISSUE_TEMPLATE/feature-request.yml
@@ -0,0 +1,50 @@
+name: 🚀 Feature Request
+description: Suggest a YOLOv5 idea
+# title: " "
+labels: [enhancement]
+body:
+ - type: markdown
+ attributes:
+ value: |
+ Thank you for submitting a YOLOv5 🚀 Feature Request!
+
+ - type: checkboxes
+ attributes:
+ label: Search before asking
+ description: >
+ Please search the [issues](https://github.com/ultralytics/yolov5/issues) to see if a similar feature request already exists.
+ options:
+ - label: >
+ I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar feature requests.
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Description
+ description: A short description of your feature.
+ placeholder: |
+ What new feature would you like to see in YOLOv5?
+ validations:
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Use case
+ description: |
+ Describe the use case of your feature request. It will help us understand and prioritize the feature request.
+ placeholder: |
+ How would this feature be used, and who would use it?
+
+ - type: textarea
+ attributes:
+ label: Additional
+ description: Anything else you would like to share?
+
+ - type: checkboxes
+ attributes:
+ label: Are you willing to submit a PR?
+ description: >
+ (Optional) We encourage you to submit a [Pull Request](https://github.com/ultralytics/yolov5/pulls) (PR) to help improve YOLOv5 for everyone, especially if you have a good understanding of how to implement a fix or feature.
+ See the YOLOv5 [Contributing Guide](https://docs.ultralytics.com/help/contributing) to get started.
+ options:
+ - label: Yes I'd like to help by submitting a PR!
diff --git a/yolov5/.github/ISSUE_TEMPLATE/question.yml b/yolov5/.github/ISSUE_TEMPLATE/question.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8e0993c68bab9170d972189cffeaf106c3222ae0
--- /dev/null
+++ b/yolov5/.github/ISSUE_TEMPLATE/question.yml
@@ -0,0 +1,33 @@
+name: ❓ Question
+description: Ask a YOLOv5 question
+# title: " "
+labels: [question]
+body:
+ - type: markdown
+ attributes:
+ value: |
+ Thank you for asking a YOLOv5 ❓ Question!
+
+ - type: checkboxes
+ attributes:
+ label: Search before asking
+ description: >
+ Please search the [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) to see if a similar question already exists.
+ options:
+ - label: >
+ I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Question
+ description: What is your question?
+ placeholder: |
+ 💡 ProTip! Include as much information as possible (screenshots, logs, tracebacks etc.) to receive the most helpful response.
+ validations:
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Additional
+ description: Anything else you would like to share?
diff --git a/yolov5/.github/PULL_REQUEST_TEMPLATE.md b/yolov5/.github/PULL_REQUEST_TEMPLATE.md
new file mode 100644
index 0000000000000000000000000000000000000000..d96d5afd283618f483e28c0f29c8d8886c3520ae
--- /dev/null
+++ b/yolov5/.github/PULL_REQUEST_TEMPLATE.md
@@ -0,0 +1,13 @@
+
+
+copilot:all
diff --git a/yolov5/.github/dependabot.yml b/yolov5/.github/dependabot.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c1b3d5d514c392d668238e1215e450b1d25e5ef4
--- /dev/null
+++ b/yolov5/.github/dependabot.yml
@@ -0,0 +1,23 @@
+version: 2
+updates:
+ - package-ecosystem: pip
+ directory: "/"
+ schedule:
+ interval: weekly
+ time: "04:00"
+ open-pull-requests-limit: 10
+ reviewers:
+ - glenn-jocher
+ labels:
+ - dependencies
+
+ - package-ecosystem: github-actions
+ directory: "/"
+ schedule:
+ interval: weekly
+ time: "04:00"
+ open-pull-requests-limit: 5
+ reviewers:
+ - glenn-jocher
+ labels:
+ - dependencies
diff --git a/yolov5/.github/workflows/ci-testing.yml b/yolov5/.github/workflows/ci-testing.yml
new file mode 100644
index 0000000000000000000000000000000000000000..e71a4b8f16ac124472ccf697f04212b096d29539
--- /dev/null
+++ b/yolov5/.github/workflows/ci-testing.yml
@@ -0,0 +1,167 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# YOLOv5 Continuous Integration (CI) GitHub Actions tests
+
+name: YOLOv5 CI
+
+on:
+ push:
+ branches: [ master ]
+ pull_request:
+ branches: [ master ]
+ schedule:
+ - cron: '0 0 * * *' # runs at 00:00 UTC every day
+
+jobs:
+ Benchmarks:
+ runs-on: ${{ matrix.os }}
+ strategy:
+ fail-fast: false
+ matrix:
+ os: [ ubuntu-latest ]
+ python-version: [ '3.10' ] # requires python<=3.10
+ model: [ yolov5n ]
+ steps:
+ - uses: actions/checkout@v3
+ - uses: actions/setup-python@v4
+ with:
+ python-version: ${{ matrix.python-version }}
+ cache: 'pip' # caching pip dependencies
+ - name: Install requirements
+ run: |
+ python -m pip install --upgrade pip wheel
+ pip install -r requirements.txt coremltools openvino-dev tensorflow-cpu --extra-index-url https://download.pytorch.org/whl/cpu
+ python --version
+ pip --version
+ pip list
+ - name: Benchmark DetectionModel
+ run: |
+ python benchmarks.py --data coco128.yaml --weights ${{ matrix.model }}.pt --img 320 --hard-fail 0.29
+ - name: Benchmark SegmentationModel
+ run: |
+ python benchmarks.py --data coco128-seg.yaml --weights ${{ matrix.model }}-seg.pt --img 320 --hard-fail 0.22
+ - name: Test predictions
+ run: |
+ python export.py --weights ${{ matrix.model }}-cls.pt --include onnx --img 224
+ python detect.py --weights ${{ matrix.model }}.onnx --img 320
+ python segment/predict.py --weights ${{ matrix.model }}-seg.onnx --img 320
+ python classify/predict.py --weights ${{ matrix.model }}-cls.onnx --img 224
+
+ Tests:
+ timeout-minutes: 60
+ runs-on: ${{ matrix.os }}
+ strategy:
+ fail-fast: false
+ matrix:
+ os: [ ubuntu-latest, windows-latest ] # macos-latest bug https://github.com/ultralytics/yolov5/pull/9049
+ python-version: [ '3.10' ]
+ model: [ yolov5n ]
+ include:
+ - os: ubuntu-latest
+ python-version: '3.7' # '3.6.8' min
+ model: yolov5n
+ - os: ubuntu-latest
+ python-version: '3.8'
+ model: yolov5n
+ - os: ubuntu-latest
+ python-version: '3.9'
+ model: yolov5n
+ - os: ubuntu-latest
+ python-version: '3.8' # torch 1.7.0 requires python >=3.6, <=3.8
+ model: yolov5n
+ torch: '1.7.0' # min torch version CI https://pypi.org/project/torchvision/
+ steps:
+ - uses: actions/checkout@v3
+ - uses: actions/setup-python@v4
+ with:
+ python-version: ${{ matrix.python-version }}
+ cache: 'pip' # caching pip dependencies
+ - name: Install requirements
+ run: |
+ python -m pip install --upgrade pip wheel
+ if [ "${{ matrix.torch }}" == "1.7.0" ]; then
+ pip install -r requirements.txt torch==1.7.0 torchvision==0.8.1 --extra-index-url https://download.pytorch.org/whl/cpu
+ else
+ pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cpu
+ fi
+ shell: bash # for Windows compatibility
+ - name: Check environment
+ run: |
+ python -c "import utils; utils.notebook_init()"
+ echo "RUNNER_OS is ${{ runner.os }}"
+ echo "GITHUB_EVENT_NAME is ${{ github.event_name }}"
+ echo "GITHUB_WORKFLOW is ${{ github.workflow }}"
+ echo "GITHUB_ACTOR is ${{ github.actor }}"
+ echo "GITHUB_REPOSITORY is ${{ github.repository }}"
+ echo "GITHUB_REPOSITORY_OWNER is ${{ github.repository_owner }}"
+ python --version
+ pip --version
+ pip list
+ - name: Test detection
+ shell: bash # for Windows compatibility
+ run: |
+ # export PYTHONPATH="$PWD" # to run '$ python *.py' files in subdirectories
+ m=${{ matrix.model }} # official weights
+ b=runs/train/exp/weights/best # best.pt checkpoint
+ python train.py --imgsz 64 --batch 32 --weights $m.pt --cfg $m.yaml --epochs 1 --device cpu # train
+ for d in cpu; do # devices
+ for w in $m $b; do # weights
+ python val.py --imgsz 64 --batch 32 --weights $w.pt --device $d # val
+ python detect.py --imgsz 64 --weights $w.pt --device $d # detect
+ done
+ done
+ python hubconf.py --model $m # hub
+ # python models/tf.py --weights $m.pt # build TF model
+ python models/yolo.py --cfg $m.yaml # build PyTorch model
+ python export.py --weights $m.pt --img 64 --include torchscript # export
+ python - < GitHub Actions error for ${{ github.workflow }} ❌\n\n\n*Repository:* https://github.com/${{ github.repository }}\n*Action:* https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}\n*Author:* ${{ github.actor }}\n*Event:* ${{ github.event_name }}\n"}
+ env:
+ SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_YOLO }}
diff --git a/yolov5/.github/workflows/codeql-analysis.yml b/yolov5/.github/workflows/codeql-analysis.yml
new file mode 100644
index 0000000000000000000000000000000000000000..05db12dabd1ab3eea34d088daed702b4c09509c5
--- /dev/null
+++ b/yolov5/.github/workflows/codeql-analysis.yml
@@ -0,0 +1,55 @@
+# This action runs GitHub's industry-leading static analysis engine, CodeQL, against a repository's source code to find security vulnerabilities.
+# https://github.com/github/codeql-action
+
+name: "CodeQL"
+
+on:
+ schedule:
+ - cron: '0 0 1 * *' # Runs at 00:00 UTC on the 1st of every month
+ workflow_dispatch:
+
+jobs:
+ analyze:
+ name: Analyze
+ runs-on: ubuntu-latest
+
+ strategy:
+ fail-fast: false
+ matrix:
+ language: ['python']
+ # CodeQL supports [ 'cpp', 'csharp', 'go', 'java', 'javascript', 'python' ]
+ # Learn more:
+ # https://docs.github.com/en/free-pro-team@latest/github/finding-security-vulnerabilities-and-errors-in-your-code/configuring-code-scanning#changing-the-languages-that-are-analyzed
+
+ steps:
+ - name: Checkout repository
+ uses: actions/checkout@v3
+
+ # Initializes the CodeQL tools for scanning.
+ - name: Initialize CodeQL
+ uses: github/codeql-action/init@v2
+ with:
+ languages: ${{ matrix.language }}
+ # If you wish to specify custom queries, you can do so here or in a config file.
+ # By default, queries listed here will override any specified in a config file.
+ # Prefix the list here with "+" to use these queries and those in the config file.
+ # queries: ./path/to/local/query, your-org/your-repo/queries@main
+
+ # Autobuild attempts to build any compiled languages (C/C++, C#, or Java).
+ # If this step fails, then you should remove it and run the build manually (see below)
+ - name: Autobuild
+ uses: github/codeql-action/autobuild@v2
+
+ # ℹ️ Command-line programs to run using the OS shell.
+ # 📚 https://git.io/JvXDl
+
+ # ✏️ If the Autobuild fails above, remove it and uncomment the following three lines
+ # and modify them (or add more) to build your code if your project
+ # uses a compiled language
+
+ #- run: |
+ # make bootstrap
+ # make release
+
+ - name: Perform CodeQL Analysis
+ uses: github/codeql-action/analyze@v2
diff --git a/yolov5/.github/workflows/docker.yml b/yolov5/.github/workflows/docker.yml
new file mode 100644
index 0000000000000000000000000000000000000000..13e79216fc2092b6a97ce89dc35eb53f2b3ead88
--- /dev/null
+++ b/yolov5/.github/workflows/docker.yml
@@ -0,0 +1,58 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Builds ultralytics/yolov5:latest images on DockerHub https://hub.docker.com/r/ultralytics/yolov5
+
+name: Publish Docker Images
+
+on:
+ push:
+ branches: [ master ]
+ workflow_dispatch:
+
+jobs:
+ docker:
+ if: github.repository == 'ultralytics/yolov5'
+ name: Push Docker image to Docker Hub
+ runs-on: ubuntu-latest
+ steps:
+ - name: Checkout repo
+ uses: actions/checkout@v3
+
+ - name: Set up QEMU
+ uses: docker/setup-qemu-action@v2
+
+ - name: Set up Docker Buildx
+ uses: docker/setup-buildx-action@v2
+
+ - name: Login to Docker Hub
+ uses: docker/login-action@v2
+ with:
+ username: ${{ secrets.DOCKERHUB_USERNAME }}
+ password: ${{ secrets.DOCKERHUB_TOKEN }}
+
+ - name: Build and push arm64 image
+ uses: docker/build-push-action@v4
+ continue-on-error: true
+ with:
+ context: .
+ platforms: linux/arm64
+ file: utils/docker/Dockerfile-arm64
+ push: true
+ tags: ultralytics/yolov5:latest-arm64
+
+ - name: Build and push CPU image
+ uses: docker/build-push-action@v4
+ continue-on-error: true
+ with:
+ context: .
+ file: utils/docker/Dockerfile-cpu
+ push: true
+ tags: ultralytics/yolov5:latest-cpu
+
+ - name: Build and push GPU image
+ uses: docker/build-push-action@v4
+ continue-on-error: true
+ with:
+ context: .
+ file: utils/docker/Dockerfile
+ push: true
+ tags: ultralytics/yolov5:latest
diff --git a/yolov5/.github/workflows/greetings.yml b/yolov5/.github/workflows/greetings.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8aca12d3c3705bc535cabe1bb9c7d2dcba00d368
--- /dev/null
+++ b/yolov5/.github/workflows/greetings.yml
@@ -0,0 +1,65 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+name: Greetings
+
+on:
+ pull_request_target:
+ types: [opened]
+ issues:
+ types: [opened]
+
+jobs:
+ greeting:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/first-interaction@v1
+ with:
+ repo-token: ${{ secrets.GITHUB_TOKEN }}
+ pr-message: |
+ 👋 Hello @${{ github.actor }}, thank you for submitting a YOLOv5 🚀 PR! To allow your work to be integrated as seamlessly as possible, we advise you to:
+
+ - ✅ Verify your PR is **up-to-date** with `ultralytics/yolov5` `master` branch. If your PR is behind you can update your code by clicking the 'Update branch' button or by running `git pull` and `git merge master` locally.
+ - ✅ Verify all YOLOv5 Continuous Integration (CI) **checks are passing**.
+ - ✅ Reduce changes to the absolute **minimum** required for your bug fix or feature addition. _"It is not daily increase but daily decrease, hack away the unessential. The closer to the source, the less wastage there is."_ — Bruce Lee
+
+ issue-message: |
+ 👋 Hello @${{ github.actor }}, thank you for your interest in YOLOv5 🚀! Please visit our ⭐️ [Tutorials](https://docs.ultralytics.com/yolov5/) to get started, where you can find quickstart guides for simple tasks like [Custom Data Training](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/) all the way to advanced concepts like [Hyperparameter Evolution](https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution/).
+
+ If this is a 🐛 Bug Report, please provide a **minimum reproducible example** to help us debug it.
+
+ If this is a custom training ❓ Question, please provide as much information as possible, including dataset image examples and training logs, and verify you are following our [Tips for Best Training Results](https://docs.ultralytics.com/yolov5/tutorials/tips_for_best_training_results/).
+
+ ## Requirements
+
+ [**Python>=3.7.0**](https://www.python.org/) with all [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) installed including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). To get started:
+ ```bash
+ git clone https://github.com/ultralytics/yolov5 # clone
+ cd yolov5
+ pip install -r requirements.txt # install
+ ```
+
+ ## Environments
+
+ YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+ - **Notebooks** with free GPU: 

 + - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+ - **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+ - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+ - **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)  +
+ ## Status
+
+
+
+ ## Status
+
+  +
+ If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
+
+ ## Introducing YOLOv8 🚀
+
+ We're excited to announce the launch of our latest state-of-the-art (SOTA) object detection model for 2023 - [YOLOv8](https://github.com/ultralytics/ultralytics) 🚀!
+
+ Designed to be fast, accurate, and easy to use, YOLOv8 is an ideal choice for a wide range of object detection, image segmentation and image classification tasks. With YOLOv8, you'll be able to quickly and accurately detect objects in real-time, streamline your workflows, and achieve new levels of accuracy in your projects.
+
+ Check out our [YOLOv8 Docs](https://docs.ultralytics.com/) for details and get started with:
+ ```bash
+ pip install ultralytics
+ ```
diff --git a/yolov5/.github/workflows/links.yml b/yolov5/.github/workflows/links.yml
new file mode 100644
index 0000000000000000000000000000000000000000..306689f465078ef66c82c06e612feb203a3278ef
--- /dev/null
+++ b/yolov5/.github/workflows/links.yml
@@ -0,0 +1,44 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLO Continuous Integration (CI) GitHub Actions tests broken link checker
+# Accept 429(Instagram, 'too many requests'), 999(LinkedIn, 'unknown status code'), Timeout(Twitter)
+
+name: Check Broken links
+
+on:
+ push:
+ branches: [master]
+ pull_request:
+ branches: [master]
+ workflow_dispatch:
+ schedule:
+ - cron: '0 0 * * *' # runs at 00:00 UTC every day
+
+jobs:
+ Links:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+
+ - name: Download and install lychee
+ run: |
+ LYCHEE_URL=$(curl -s https://api.github.com/repos/lycheeverse/lychee/releases/latest | grep "browser_download_url" | grep "x86_64-unknown-linux-gnu.tar.gz" | cut -d '"' -f 4)
+ curl -L $LYCHEE_URL -o lychee.tar.gz
+ tar xzf lychee.tar.gz
+ sudo mv lychee /usr/local/bin
+
+ - name: Test Markdown and HTML links with retry
+ uses: nick-invision/retry@v2
+ with:
+ timeout_minutes: 5
+ retry_wait_seconds: 60
+ max_attempts: 3
+ command: lychee --accept 429,999 --exclude-loopback --exclude twitter.com --exclude-path '**/ci.yaml' --exclude-mail --github-token ${{ secrets.GITHUB_TOKEN }} './**/*.md' './**/*.html'
+
+ - name: Test Markdown, HTML, YAML, Python and Notebook links with retry
+ if: github.event_name == 'workflow_dispatch'
+ uses: nick-invision/retry@v2
+ with:
+ timeout_minutes: 5
+ retry_wait_seconds: 60
+ max_attempts: 3
+ command: lychee --accept 429,999 --exclude-loopback --exclude twitter.com,url.com --exclude-path '**/ci.yaml' --exclude-mail --github-token ${{ secrets.GITHUB_TOKEN }} './**/*.md' './**/*.html' './**/*.yml' './**/*.yaml' './**/*.py' './**/*.ipynb'
diff --git a/yolov5/.github/workflows/stale.yml b/yolov5/.github/workflows/stale.yml
new file mode 100644
index 0000000000000000000000000000000000000000..65c8f70798f1aeaefbe4062b0e0e231c018bdd9b
--- /dev/null
+++ b/yolov5/.github/workflows/stale.yml
@@ -0,0 +1,47 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+name: Close stale issues
+on:
+ schedule:
+ - cron: '0 0 * * *' # Runs at 00:00 UTC every day
+
+jobs:
+ stale:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/stale@v8
+ with:
+ repo-token: ${{ secrets.GITHUB_TOKEN }}
+
+ stale-issue-message: |
+ 👋 Hello there! We wanted to give you a friendly reminder that this issue has not had any recent activity and may be closed soon, but don't worry - you can always reopen it if needed. If you still have any questions or concerns, please feel free to let us know how we can help.
+
+ For additional resources and information, please see the links below:
+
+ - **Docs**: https://docs.ultralytics.com
+ - **HUB**: https://hub.ultralytics.com
+ - **Community**: https://community.ultralytics.com
+
+ Feel free to inform us of any other **issues** you discover or **feature requests** that come to mind in the future. Pull Requests (PRs) are also always welcomed!
+
+ Thank you for your contributions to YOLO 🚀 and Vision AI ⭐
+
+ stale-pr-message: |
+ 👋 Hello there! We wanted to let you know that we've decided to close this pull request due to inactivity. We appreciate the effort you put into contributing to our project, but unfortunately, not all contributions are suitable or aligned with our product roadmap.
+
+ We hope you understand our decision, and please don't let it discourage you from contributing to open source projects in the future. We value all of our community members and their contributions, and we encourage you to keep exploring new projects and ways to get involved.
+
+ For additional resources and information, please see the links below:
+
+ - **Docs**: https://docs.ultralytics.com
+ - **HUB**: https://hub.ultralytics.com
+ - **Community**: https://community.ultralytics.com
+
+ Thank you for your contributions to YOLO 🚀 and Vision AI ⭐
+
+ days-before-issue-stale: 30
+ days-before-issue-close: 10
+ days-before-pr-stale: 90
+ days-before-pr-close: 30
+ exempt-issue-labels: 'documentation,tutorial,TODO'
+ operations-per-run: 300 # The maximum number of operations per run, used to control rate limiting.
diff --git a/yolov5/.github/workflows/translate-readme.yml b/yolov5/.github/workflows/translate-readme.yml
new file mode 100644
index 0000000000000000000000000000000000000000..d5e2be26f52332b2ce1f7cf2ccdac286ab5ab56e
--- /dev/null
+++ b/yolov5/.github/workflows/translate-readme.yml
@@ -0,0 +1,26 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# README translation action to translate README.md to Chinese as README.zh-CN.md on any change to README.md
+
+name: Translate README
+
+on:
+ push:
+ branches:
+ - translate_readme # replace with 'master' to enable action
+ paths:
+ - README.md
+
+jobs:
+ Translate:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+ - name: Setup Node.js
+ uses: actions/setup-node@v3
+ with:
+ node-version: 16
+ # ISO Language Codes: https://cloud.google.com/translate/docs/languages
+ - name: Adding README - Chinese Simplified
+ uses: dephraiim/translate-readme@main
+ with:
+ LANG: zh-CN
diff --git a/yolov5/.gitignore b/yolov5/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..6bcedfac610d86354e51c3719bf48bd149f644a2
--- /dev/null
+++ b/yolov5/.gitignore
@@ -0,0 +1,257 @@
+# Repo-specific GitIgnore ----------------------------------------------------------------------------------------------
+*.jpg
+*.jpeg
+*.png
+*.bmp
+*.tif
+*.tiff
+*.heic
+*.JPG
+*.JPEG
+*.PNG
+*.BMP
+*.TIF
+*.TIFF
+*.HEIC
+*.mp4
+*.mov
+*.MOV
+*.avi
+*.data
+*.json
+*.cfg
+!setup.cfg
+!cfg/yolov3*.cfg
+
+storage.googleapis.com
+runs/*
+data/*
+data/images/*
+!data/*.yaml
+!data/hyps
+!data/scripts
+!data/images
+!data/images/zidane.jpg
+!data/images/bus.jpg
+!data/*.sh
+
+results*.csv
+
+# Datasets -------------------------------------------------------------------------------------------------------------
+coco/
+coco128/
+VOC/
+
+# MATLAB GitIgnore -----------------------------------------------------------------------------------------------------
+*.m~
+*.mat
+!targets*.mat
+
+# Neural Network weights -----------------------------------------------------------------------------------------------
+*.weights
+*.pt
+*.pb
+*.onnx
+*.engine
+*.mlmodel
+*.torchscript
+*.tflite
+*.h5
+*_saved_model/
+*_web_model/
+*_openvino_model/
+*_paddle_model/
+darknet53.conv.74
+yolov3-tiny.conv.15
+
+# GitHub Python GitIgnore ----------------------------------------------------------------------------------------------
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+env/
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+/wandb/
+.installed.cfg
+*.egg
+
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# dotenv
+.env
+
+# virtualenv
+.venv*
+venv*/
+ENV*/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+
+
+# https://github.com/github/gitignore/blob/master/Global/macOS.gitignore -----------------------------------------------
+
+# General
+.DS_Store
+.AppleDouble
+.LSOverride
+
+# Icon must end with two \r
+Icon
+Icon?
+
+# Thumbnails
+._*
+
+# Files that might appear in the root of a volume
+.DocumentRevisions-V100
+.fseventsd
+.Spotlight-V100
+.TemporaryItems
+.Trashes
+.VolumeIcon.icns
+.com.apple.timemachine.donotpresent
+
+# Directories potentially created on remote AFP share
+.AppleDB
+.AppleDesktop
+Network Trash Folder
+Temporary Items
+.apdisk
+
+
+# https://github.com/github/gitignore/blob/master/Global/JetBrains.gitignore
+# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
+# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
+
+# User-specific stuff:
+.idea/*
+.idea/**/workspace.xml
+.idea/**/tasks.xml
+.idea/dictionaries
+.html # Bokeh Plots
+.pg # TensorFlow Frozen Graphs
+.avi # videos
+
+# Sensitive or high-churn files:
+.idea/**/dataSources/
+.idea/**/dataSources.ids
+.idea/**/dataSources.local.xml
+.idea/**/sqlDataSources.xml
+.idea/**/dynamic.xml
+.idea/**/uiDesigner.xml
+
+# Gradle:
+.idea/**/gradle.xml
+.idea/**/libraries
+
+# CMake
+cmake-build-debug/
+cmake-build-release/
+
+# Mongo Explorer plugin:
+.idea/**/mongoSettings.xml
+
+## File-based project format:
+*.iws
+
+## Plugin-specific files:
+
+# IntelliJ
+out/
+
+# mpeltonen/sbt-idea plugin
+.idea_modules/
+
+# JIRA plugin
+atlassian-ide-plugin.xml
+
+# Cursive Clojure plugin
+.idea/replstate.xml
+
+# Crashlytics plugin (for Android Studio and IntelliJ)
+com_crashlytics_export_strings.xml
+crashlytics.properties
+crashlytics-build.properties
+fabric.properties
diff --git a/yolov5/.idea/misc.xml b/yolov5/.idea/misc.xml
new file mode 100644
index 0000000000000000000000000000000000000000..e4c68f8253267bed823c757b5e6cc0bb39a426f9
--- /dev/null
+++ b/yolov5/.idea/misc.xml
@@ -0,0 +1,4 @@
+
+
+
+
\ No newline at end of file
diff --git a/yolov5/.idea/workspace.xml b/yolov5/.idea/workspace.xml
new file mode 100644
index 0000000000000000000000000000000000000000..df7609f168e39c0dfc7d75826fbd0a4d27dceb35
--- /dev/null
+++ b/yolov5/.idea/workspace.xml
@@ -0,0 +1,99 @@
+
+
+
+
+
+ If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
+
+ ## Introducing YOLOv8 🚀
+
+ We're excited to announce the launch of our latest state-of-the-art (SOTA) object detection model for 2023 - [YOLOv8](https://github.com/ultralytics/ultralytics) 🚀!
+
+ Designed to be fast, accurate, and easy to use, YOLOv8 is an ideal choice for a wide range of object detection, image segmentation and image classification tasks. With YOLOv8, you'll be able to quickly and accurately detect objects in real-time, streamline your workflows, and achieve new levels of accuracy in your projects.
+
+ Check out our [YOLOv8 Docs](https://docs.ultralytics.com/) for details and get started with:
+ ```bash
+ pip install ultralytics
+ ```
diff --git a/yolov5/.github/workflows/links.yml b/yolov5/.github/workflows/links.yml
new file mode 100644
index 0000000000000000000000000000000000000000..306689f465078ef66c82c06e612feb203a3278ef
--- /dev/null
+++ b/yolov5/.github/workflows/links.yml
@@ -0,0 +1,44 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLO Continuous Integration (CI) GitHub Actions tests broken link checker
+# Accept 429(Instagram, 'too many requests'), 999(LinkedIn, 'unknown status code'), Timeout(Twitter)
+
+name: Check Broken links
+
+on:
+ push:
+ branches: [master]
+ pull_request:
+ branches: [master]
+ workflow_dispatch:
+ schedule:
+ - cron: '0 0 * * *' # runs at 00:00 UTC every day
+
+jobs:
+ Links:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+
+ - name: Download and install lychee
+ run: |
+ LYCHEE_URL=$(curl -s https://api.github.com/repos/lycheeverse/lychee/releases/latest | grep "browser_download_url" | grep "x86_64-unknown-linux-gnu.tar.gz" | cut -d '"' -f 4)
+ curl -L $LYCHEE_URL -o lychee.tar.gz
+ tar xzf lychee.tar.gz
+ sudo mv lychee /usr/local/bin
+
+ - name: Test Markdown and HTML links with retry
+ uses: nick-invision/retry@v2
+ with:
+ timeout_minutes: 5
+ retry_wait_seconds: 60
+ max_attempts: 3
+ command: lychee --accept 429,999 --exclude-loopback --exclude twitter.com --exclude-path '**/ci.yaml' --exclude-mail --github-token ${{ secrets.GITHUB_TOKEN }} './**/*.md' './**/*.html'
+
+ - name: Test Markdown, HTML, YAML, Python and Notebook links with retry
+ if: github.event_name == 'workflow_dispatch'
+ uses: nick-invision/retry@v2
+ with:
+ timeout_minutes: 5
+ retry_wait_seconds: 60
+ max_attempts: 3
+ command: lychee --accept 429,999 --exclude-loopback --exclude twitter.com,url.com --exclude-path '**/ci.yaml' --exclude-mail --github-token ${{ secrets.GITHUB_TOKEN }} './**/*.md' './**/*.html' './**/*.yml' './**/*.yaml' './**/*.py' './**/*.ipynb'
diff --git a/yolov5/.github/workflows/stale.yml b/yolov5/.github/workflows/stale.yml
new file mode 100644
index 0000000000000000000000000000000000000000..65c8f70798f1aeaefbe4062b0e0e231c018bdd9b
--- /dev/null
+++ b/yolov5/.github/workflows/stale.yml
@@ -0,0 +1,47 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+name: Close stale issues
+on:
+ schedule:
+ - cron: '0 0 * * *' # Runs at 00:00 UTC every day
+
+jobs:
+ stale:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/stale@v8
+ with:
+ repo-token: ${{ secrets.GITHUB_TOKEN }}
+
+ stale-issue-message: |
+ 👋 Hello there! We wanted to give you a friendly reminder that this issue has not had any recent activity and may be closed soon, but don't worry - you can always reopen it if needed. If you still have any questions or concerns, please feel free to let us know how we can help.
+
+ For additional resources and information, please see the links below:
+
+ - **Docs**: https://docs.ultralytics.com
+ - **HUB**: https://hub.ultralytics.com
+ - **Community**: https://community.ultralytics.com
+
+ Feel free to inform us of any other **issues** you discover or **feature requests** that come to mind in the future. Pull Requests (PRs) are also always welcomed!
+
+ Thank you for your contributions to YOLO 🚀 and Vision AI ⭐
+
+ stale-pr-message: |
+ 👋 Hello there! We wanted to let you know that we've decided to close this pull request due to inactivity. We appreciate the effort you put into contributing to our project, but unfortunately, not all contributions are suitable or aligned with our product roadmap.
+
+ We hope you understand our decision, and please don't let it discourage you from contributing to open source projects in the future. We value all of our community members and their contributions, and we encourage you to keep exploring new projects and ways to get involved.
+
+ For additional resources and information, please see the links below:
+
+ - **Docs**: https://docs.ultralytics.com
+ - **HUB**: https://hub.ultralytics.com
+ - **Community**: https://community.ultralytics.com
+
+ Thank you for your contributions to YOLO 🚀 and Vision AI ⭐
+
+ days-before-issue-stale: 30
+ days-before-issue-close: 10
+ days-before-pr-stale: 90
+ days-before-pr-close: 30
+ exempt-issue-labels: 'documentation,tutorial,TODO'
+ operations-per-run: 300 # The maximum number of operations per run, used to control rate limiting.
diff --git a/yolov5/.github/workflows/translate-readme.yml b/yolov5/.github/workflows/translate-readme.yml
new file mode 100644
index 0000000000000000000000000000000000000000..d5e2be26f52332b2ce1f7cf2ccdac286ab5ab56e
--- /dev/null
+++ b/yolov5/.github/workflows/translate-readme.yml
@@ -0,0 +1,26 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# README translation action to translate README.md to Chinese as README.zh-CN.md on any change to README.md
+
+name: Translate README
+
+on:
+ push:
+ branches:
+ - translate_readme # replace with 'master' to enable action
+ paths:
+ - README.md
+
+jobs:
+ Translate:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+ - name: Setup Node.js
+ uses: actions/setup-node@v3
+ with:
+ node-version: 16
+ # ISO Language Codes: https://cloud.google.com/translate/docs/languages
+ - name: Adding README - Chinese Simplified
+ uses: dephraiim/translate-readme@main
+ with:
+ LANG: zh-CN
diff --git a/yolov5/.gitignore b/yolov5/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..6bcedfac610d86354e51c3719bf48bd149f644a2
--- /dev/null
+++ b/yolov5/.gitignore
@@ -0,0 +1,257 @@
+# Repo-specific GitIgnore ----------------------------------------------------------------------------------------------
+*.jpg
+*.jpeg
+*.png
+*.bmp
+*.tif
+*.tiff
+*.heic
+*.JPG
+*.JPEG
+*.PNG
+*.BMP
+*.TIF
+*.TIFF
+*.HEIC
+*.mp4
+*.mov
+*.MOV
+*.avi
+*.data
+*.json
+*.cfg
+!setup.cfg
+!cfg/yolov3*.cfg
+
+storage.googleapis.com
+runs/*
+data/*
+data/images/*
+!data/*.yaml
+!data/hyps
+!data/scripts
+!data/images
+!data/images/zidane.jpg
+!data/images/bus.jpg
+!data/*.sh
+
+results*.csv
+
+# Datasets -------------------------------------------------------------------------------------------------------------
+coco/
+coco128/
+VOC/
+
+# MATLAB GitIgnore -----------------------------------------------------------------------------------------------------
+*.m~
+*.mat
+!targets*.mat
+
+# Neural Network weights -----------------------------------------------------------------------------------------------
+*.weights
+*.pt
+*.pb
+*.onnx
+*.engine
+*.mlmodel
+*.torchscript
+*.tflite
+*.h5
+*_saved_model/
+*_web_model/
+*_openvino_model/
+*_paddle_model/
+darknet53.conv.74
+yolov3-tiny.conv.15
+
+# GitHub Python GitIgnore ----------------------------------------------------------------------------------------------
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+env/
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+/wandb/
+.installed.cfg
+*.egg
+
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# dotenv
+.env
+
+# virtualenv
+.venv*
+venv*/
+ENV*/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+
+
+# https://github.com/github/gitignore/blob/master/Global/macOS.gitignore -----------------------------------------------
+
+# General
+.DS_Store
+.AppleDouble
+.LSOverride
+
+# Icon must end with two \r
+Icon
+Icon?
+
+# Thumbnails
+._*
+
+# Files that might appear in the root of a volume
+.DocumentRevisions-V100
+.fseventsd
+.Spotlight-V100
+.TemporaryItems
+.Trashes
+.VolumeIcon.icns
+.com.apple.timemachine.donotpresent
+
+# Directories potentially created on remote AFP share
+.AppleDB
+.AppleDesktop
+Network Trash Folder
+Temporary Items
+.apdisk
+
+
+# https://github.com/github/gitignore/blob/master/Global/JetBrains.gitignore
+# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
+# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
+
+# User-specific stuff:
+.idea/*
+.idea/**/workspace.xml
+.idea/**/tasks.xml
+.idea/dictionaries
+.html # Bokeh Plots
+.pg # TensorFlow Frozen Graphs
+.avi # videos
+
+# Sensitive or high-churn files:
+.idea/**/dataSources/
+.idea/**/dataSources.ids
+.idea/**/dataSources.local.xml
+.idea/**/sqlDataSources.xml
+.idea/**/dynamic.xml
+.idea/**/uiDesigner.xml
+
+# Gradle:
+.idea/**/gradle.xml
+.idea/**/libraries
+
+# CMake
+cmake-build-debug/
+cmake-build-release/
+
+# Mongo Explorer plugin:
+.idea/**/mongoSettings.xml
+
+## File-based project format:
+*.iws
+
+## Plugin-specific files:
+
+# IntelliJ
+out/
+
+# mpeltonen/sbt-idea plugin
+.idea_modules/
+
+# JIRA plugin
+atlassian-ide-plugin.xml
+
+# Cursive Clojure plugin
+.idea/replstate.xml
+
+# Crashlytics plugin (for Android Studio and IntelliJ)
+com_crashlytics_export_strings.xml
+crashlytics.properties
+crashlytics-build.properties
+fabric.properties
diff --git a/yolov5/.idea/misc.xml b/yolov5/.idea/misc.xml
new file mode 100644
index 0000000000000000000000000000000000000000..e4c68f8253267bed823c757b5e6cc0bb39a426f9
--- /dev/null
+++ b/yolov5/.idea/misc.xml
@@ -0,0 +1,4 @@
+
+
+
+
\ No newline at end of file
diff --git a/yolov5/.idea/workspace.xml b/yolov5/.idea/workspace.xml
new file mode 100644
index 0000000000000000000000000000000000000000..df7609f168e39c0dfc7d75826fbd0a4d27dceb35
--- /dev/null
+++ b/yolov5/.idea/workspace.xml
@@ -0,0 +1,99 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ 1683810212049
+
+
+ 1683810212049
+
+
+
+
\ No newline at end of file
diff --git a/yolov5/.pre-commit-config.yaml b/yolov5/.pre-commit-config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..defb1372625e64855127cb7446daf8cf7536a4c3
--- /dev/null
+++ b/yolov5/.pre-commit-config.yaml
@@ -0,0 +1,69 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Pre-commit hooks. For more information see https://github.com/pre-commit/pre-commit-hooks/blob/main/README.md
+
+exclude: 'docs/'
+# Define bot property if installed via https://github.com/marketplace/pre-commit-ci
+ci:
+ autofix_prs: true
+ autoupdate_commit_msg: '[pre-commit.ci] pre-commit suggestions'
+ autoupdate_schedule: monthly
+ # submodules: true
+
+repos:
+ - repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v4.4.0
+ hooks:
+ - id: end-of-file-fixer
+ - id: trailing-whitespace
+ - id: check-case-conflict
+ - id: check-yaml
+ - id: check-docstring-first
+ - id: double-quote-string-fixer
+ - id: detect-private-key
+
+ - repo: https://github.com/asottile/pyupgrade
+ rev: v3.3.2
+ hooks:
+ - id: pyupgrade
+ name: Upgrade code
+ args: [--py37-plus]
+
+ - repo: https://github.com/PyCQA/isort
+ rev: 5.12.0
+ hooks:
+ - id: isort
+ name: Sort imports
+
+ - repo: https://github.com/google/yapf
+ rev: v0.33.0
+ hooks:
+ - id: yapf
+ name: YAPF formatting
+
+ - repo: https://github.com/executablebooks/mdformat
+ rev: 0.7.16
+ hooks:
+ - id: mdformat
+ name: MD formatting
+ additional_dependencies:
+ - mdformat-gfm
+ - mdformat-black
+ # exclude: "README.md|README.zh-CN.md|CONTRIBUTING.md"
+
+ - repo: https://github.com/PyCQA/flake8
+ rev: 6.0.0
+ hooks:
+ - id: flake8
+ name: PEP8
+
+ - repo: https://github.com/codespell-project/codespell
+ rev: v2.2.4
+ hooks:
+ - id: codespell
+ args:
+ - --ignore-words-list=crate,nd,strack,dota
+
+ #- repo: https://github.com/asottile/yesqa
+ # rev: v1.4.0
+ # hooks:
+ # - id: yesqa
diff --git a/yolov5/CITATION.cff b/yolov5/CITATION.cff
new file mode 100644
index 0000000000000000000000000000000000000000..c277230d922f869978cedaabc214d5236c6cb191
--- /dev/null
+++ b/yolov5/CITATION.cff
@@ -0,0 +1,14 @@
+cff-version: 1.2.0
+preferred-citation:
+ type: software
+ message: If you use YOLOv5, please cite it as below.
+ authors:
+ - family-names: Jocher
+ given-names: Glenn
+ orcid: "https://orcid.org/0000-0001-5950-6979"
+ title: "YOLOv5 by Ultralytics"
+ version: 7.0
+ doi: 10.5281/zenodo.3908559
+ date-released: 2020-5-29
+ license: AGPL-3.0
+ url: "https://github.com/ultralytics/yolov5"
diff --git a/yolov5/CONTRIBUTING.md b/yolov5/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..95d88b9830d68f3bdcd621144a774c32f19a700e
--- /dev/null
+++ b/yolov5/CONTRIBUTING.md
@@ -0,0 +1,93 @@
+## Contributing to YOLOv5 🚀
+
+We love your input! We want to make contributing to YOLOv5 as easy and transparent as possible, whether it's:
+
+- Reporting a bug
+- Discussing the current state of the code
+- Submitting a fix
+- Proposing a new feature
+- Becoming a maintainer
+
+YOLOv5 works so well due to our combined community effort, and for every small improvement you contribute you will be
+helping push the frontiers of what's possible in AI 😃!
+
+## Submitting a Pull Request (PR) 🛠️
+
+Submitting a PR is easy! This example shows how to submit a PR for updating `requirements.txt` in 4 steps:
+
+### 1. Select File to Update
+
+Select `requirements.txt` to update by clicking on it in GitHub.
+
+
+
+### 2. Click 'Edit this file'
+
+The button is in the top-right corner.
+
+
+
+### 3. Make Changes
+
+Change the `matplotlib` version from `3.2.2` to `3.3`.
+
+
+
+### 4. Preview Changes and Submit PR
+
+Click on the **Preview changes** tab to verify your updates. At the bottom of the screen select 'Create a **new branch**
+for this commit', assign your branch a descriptive name such as `fix/matplotlib_version` and click the green **Propose
+changes** button. All done, your PR is now submitted to YOLOv5 for review and approval 😃!
+
+
+
+### PR recommendations
+
+To allow your work to be integrated as seamlessly as possible, we advise you to:
+
+- ✅ Verify your PR is **up-to-date** with `ultralytics/yolov5` `master` branch. If your PR is behind you can update
+ your code by clicking the 'Update branch' button or by running `git pull` and `git merge master` locally.
+
+
+
+- ✅ Verify all YOLOv5 Continuous Integration (CI) **checks are passing**.
+
+
+
+- ✅ Reduce changes to the absolute **minimum** required for your bug fix or feature addition. _"It is not daily increase
+ but daily decrease, hack away the unessential. The closer to the source, the less wastage there is."_ — Bruce Lee
+
+## Submitting a Bug Report 🐛
+
+If you spot a problem with YOLOv5 please submit a Bug Report!
+
+For us to start investigating a possible problem we need to be able to reproduce it ourselves first. We've created a few
+short guidelines below to help users provide what we need to get started.
+
+When asking a question, people will be better able to provide help if you provide **code** that they can easily
+understand and use to **reproduce** the problem. This is referred to by community members as creating
+a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/). Your code that reproduces
+the problem should be:
+
+- ✅ **Minimal** – Use as little code as possible that still produces the same problem
+- ✅ **Complete** – Provide **all** parts someone else needs to reproduce your problem in the question itself
+- ✅ **Reproducible** – Test the code you're about to provide to make sure it reproduces the problem
+
+In addition to the above requirements, for [Ultralytics](https://ultralytics.com/) to provide assistance your code
+should be:
+
+- ✅ **Current** – Verify that your code is up-to-date with the current
+ GitHub [master](https://github.com/ultralytics/yolov5/tree/master), and if necessary `git pull` or `git clone` a new
+ copy to ensure your problem has not already been resolved by previous commits.
+- ✅ **Unmodified** – Your problem must be reproducible without any modifications to the codebase in this
+ repository. [Ultralytics](https://ultralytics.com/) does not provide support for custom code ⚠️.
+
+If you believe your problem meets all of the above criteria, please close this issue and raise a new one using the 🐛
+**Bug Report** [template](https://github.com/ultralytics/yolov5/issues/new/choose) and provide
+a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/) to help us better
+understand and diagnose your problem.
+
+## License
+
+By contributing, you agree that your contributions will be licensed under
+the [AGPL-3.0 license](https://choosealicense.com/licenses/agpl-3.0/)
diff --git a/yolov5/LICENSE b/yolov5/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..be3f7b28e564e7dd05eaf59d64adba1a4065ac0e
--- /dev/null
+++ b/yolov5/LICENSE
@@ -0,0 +1,661 @@
+ GNU AFFERO GENERAL PUBLIC LICENSE
+ Version 3, 19 November 2007
+
+ Copyright (C) 2007 Free Software Foundation, Inc.
+ Everyone is permitted to copy and distribute verbatim copies
+ of this license document, but changing it is not allowed.
+
+ Preamble
+
+ The GNU Affero General Public License is a free, copyleft license for
+software and other kinds of works, specifically designed to ensure
+cooperation with the community in the case of network server software.
+
+ The licenses for most software and other practical works are designed
+to take away your freedom to share and change the works. By contrast,
+our General Public Licenses are intended to guarantee your freedom to
+share and change all versions of a program--to make sure it remains free
+software for all its users.
+
+ When we speak of free software, we are referring to freedom, not
+price. Our General Public Licenses are designed to make sure that you
+have the freedom to distribute copies of free software (and charge for
+them if you wish), that you receive source code or can get it if you
+want it, that you can change the software or use pieces of it in new
+free programs, and that you know you can do these things.
+
+ Developers that use our General Public Licenses protect your rights
+with two steps: (1) assert copyright on the software, and (2) offer
+you this License which gives you legal permission to copy, distribute
+and/or modify the software.
+
+ A secondary benefit of defending all users' freedom is that
+improvements made in alternate versions of the program, if they
+receive widespread use, become available for other developers to
+incorporate. Many developers of free software are heartened and
+encouraged by the resulting cooperation. However, in the case of
+software used on network servers, this result may fail to come about.
+The GNU General Public License permits making a modified version and
+letting the public access it on a server without ever releasing its
+source code to the public.
+
+ The GNU Affero General Public License is designed specifically to
+ensure that, in such cases, the modified source code becomes available
+to the community. It requires the operator of a network server to
+provide the source code of the modified version running there to the
+users of that server. Therefore, public use of a modified version, on
+a publicly accessible server, gives the public access to the source
+code of the modified version.
+
+ An older license, called the Affero General Public License and
+published by Affero, was designed to accomplish similar goals. This is
+a different license, not a version of the Affero GPL, but Affero has
+released a new version of the Affero GPL which permits relicensing under
+this license.
+
+ The precise terms and conditions for copying, distribution and
+modification follow.
+
+ TERMS AND CONDITIONS
+
+ 0. Definitions.
+
+ "This License" refers to version 3 of the GNU Affero General Public License.
+
+ "Copyright" also means copyright-like laws that apply to other kinds of
+works, such as semiconductor masks.
+
+ "The Program" refers to any copyrightable work licensed under this
+License. Each licensee is addressed as "you". "Licensees" and
+"recipients" may be individuals or organizations.
+
+ To "modify" a work means to copy from or adapt all or part of the work
+in a fashion requiring copyright permission, other than the making of an
+exact copy. The resulting work is called a "modified version" of the
+earlier work or a work "based on" the earlier work.
+
+ A "covered work" means either the unmodified Program or a work based
+on the Program.
+
+ To "propagate" a work means to do anything with it that, without
+permission, would make you directly or secondarily liable for
+infringement under applicable copyright law, except executing it on a
+computer or modifying a private copy. Propagation includes copying,
+distribution (with or without modification), making available to the
+public, and in some countries other activities as well.
+
+ To "convey" a work means any kind of propagation that enables other
+parties to make or receive copies. Mere interaction with a user through
+a computer network, with no transfer of a copy, is not conveying.
+
+ An interactive user interface displays "Appropriate Legal Notices"
+to the extent that it includes a convenient and prominently visible
+feature that (1) displays an appropriate copyright notice, and (2)
+tells the user that there is no warranty for the work (except to the
+extent that warranties are provided), that licensees may convey the
+work under this License, and how to view a copy of this License. If
+the interface presents a list of user commands or options, such as a
+menu, a prominent item in the list meets this criterion.
+
+ 1. Source Code.
+
+ The "source code" for a work means the preferred form of the work
+for making modifications to it. "Object code" means any non-source
+form of a work.
+
+ A "Standard Interface" means an interface that either is an official
+standard defined by a recognized standards body, or, in the case of
+interfaces specified for a particular programming language, one that
+is widely used among developers working in that language.
+
+ The "System Libraries" of an executable work include anything, other
+than the work as a whole, that (a) is included in the normal form of
+packaging a Major Component, but which is not part of that Major
+Component, and (b) serves only to enable use of the work with that
+Major Component, or to implement a Standard Interface for which an
+implementation is available to the public in source code form. A
+"Major Component", in this context, means a major essential component
+(kernel, window system, and so on) of the specific operating system
+(if any) on which the executable work runs, or a compiler used to
+produce the work, or an object code interpreter used to run it.
+
+ The "Corresponding Source" for a work in object code form means all
+the source code needed to generate, install, and (for an executable
+work) run the object code and to modify the work, including scripts to
+control those activities. However, it does not include the work's
+System Libraries, or general-purpose tools or generally available free
+programs which are used unmodified in performing those activities but
+which are not part of the work. For example, Corresponding Source
+includes interface definition files associated with source files for
+the work, and the source code for shared libraries and dynamically
+linked subprograms that the work is specifically designed to require,
+such as by intimate data communication or control flow between those
+subprograms and other parts of the work.
+
+ The Corresponding Source need not include anything that users
+can regenerate automatically from other parts of the Corresponding
+Source.
+
+ The Corresponding Source for a work in source code form is that
+same work.
+
+ 2. Basic Permissions.
+
+ All rights granted under this License are granted for the term of
+copyright on the Program, and are irrevocable provided the stated
+conditions are met. This License explicitly affirms your unlimited
+permission to run the unmodified Program. The output from running a
+covered work is covered by this License only if the output, given its
+content, constitutes a covered work. This License acknowledges your
+rights of fair use or other equivalent, as provided by copyright law.
+
+ You may make, run and propagate covered works that you do not
+convey, without conditions so long as your license otherwise remains
+in force. You may convey covered works to others for the sole purpose
+of having them make modifications exclusively for you, or provide you
+with facilities for running those works, provided that you comply with
+the terms of this License in conveying all material for which you do
+not control copyright. Those thus making or running the covered works
+for you must do so exclusively on your behalf, under your direction
+and control, on terms that prohibit them from making any copies of
+your copyrighted material outside their relationship with you.
+
+ Conveying under any other circumstances is permitted solely under
+the conditions stated below. Sublicensing is not allowed; section 10
+makes it unnecessary.
+
+ 3. Protecting Users' Legal Rights From Anti-Circumvention Law.
+
+ No covered work shall be deemed part of an effective technological
+measure under any applicable law fulfilling obligations under article
+11 of the WIPO copyright treaty adopted on 20 December 1996, or
+similar laws prohibiting or restricting circumvention of such
+measures.
+
+ When you convey a covered work, you waive any legal power to forbid
+circumvention of technological measures to the extent such circumvention
+is effected by exercising rights under this License with respect to
+the covered work, and you disclaim any intention to limit operation or
+modification of the work as a means of enforcing, against the work's
+users, your or third parties' legal rights to forbid circumvention of
+technological measures.
+
+ 4. Conveying Verbatim Copies.
+
+ You may convey verbatim copies of the Program's source code as you
+receive it, in any medium, provided that you conspicuously and
+appropriately publish on each copy an appropriate copyright notice;
+keep intact all notices stating that this License and any
+non-permissive terms added in accord with section 7 apply to the code;
+keep intact all notices of the absence of any warranty; and give all
+recipients a copy of this License along with the Program.
+
+ You may charge any price or no price for each copy that you convey,
+and you may offer support or warranty protection for a fee.
+
+ 5. Conveying Modified Source Versions.
+
+ You may convey a work based on the Program, or the modifications to
+produce it from the Program, in the form of source code under the
+terms of section 4, provided that you also meet all of these conditions:
+
+ a) The work must carry prominent notices stating that you modified
+ it, and giving a relevant date.
+
+ b) The work must carry prominent notices stating that it is
+ released under this License and any conditions added under section
+ 7. This requirement modifies the requirement in section 4 to
+ "keep intact all notices".
+
+ c) You must license the entire work, as a whole, under this
+ License to anyone who comes into possession of a copy. This
+ License will therefore apply, along with any applicable section 7
+ additional terms, to the whole of the work, and all its parts,
+ regardless of how they are packaged. This License gives no
+ permission to license the work in any other way, but it does not
+ invalidate such permission if you have separately received it.
+
+ d) If the work has interactive user interfaces, each must display
+ Appropriate Legal Notices; however, if the Program has interactive
+ interfaces that do not display Appropriate Legal Notices, your
+ work need not make them do so.
+
+ A compilation of a covered work with other separate and independent
+works, which are not by their nature extensions of the covered work,
+and which are not combined with it such as to form a larger program,
+in or on a volume of a storage or distribution medium, is called an
+"aggregate" if the compilation and its resulting copyright are not
+used to limit the access or legal rights of the compilation's users
+beyond what the individual works permit. Inclusion of a covered work
+in an aggregate does not cause this License to apply to the other
+parts of the aggregate.
+
+ 6. Conveying Non-Source Forms.
+
+ You may convey a covered work in object code form under the terms
+of sections 4 and 5, provided that you also convey the
+machine-readable Corresponding Source under the terms of this License,
+in one of these ways:
+
+ a) Convey the object code in, or embodied in, a physical product
+ (including a physical distribution medium), accompanied by the
+ Corresponding Source fixed on a durable physical medium
+ customarily used for software interchange.
+
+ b) Convey the object code in, or embodied in, a physical product
+ (including a physical distribution medium), accompanied by a
+ written offer, valid for at least three years and valid for as
+ long as you offer spare parts or customer support for that product
+ model, to give anyone who possesses the object code either (1) a
+ copy of the Corresponding Source for all the software in the
+ product that is covered by this License, on a durable physical
+ medium customarily used for software interchange, for a price no
+ more than your reasonable cost of physically performing this
+ conveying of source, or (2) access to copy the
+ Corresponding Source from a network server at no charge.
+
+ c) Convey individual copies of the object code with a copy of the
+ written offer to provide the Corresponding Source. This
+ alternative is allowed only occasionally and noncommercially, and
+ only if you received the object code with such an offer, in accord
+ with subsection 6b.
+
+ d) Convey the object code by offering access from a designated
+ place (gratis or for a charge), and offer equivalent access to the
+ Corresponding Source in the same way through the same place at no
+ further charge. You need not require recipients to copy the
+ Corresponding Source along with the object code. If the place to
+ copy the object code is a network server, the Corresponding Source
+ may be on a different server (operated by you or a third party)
+ that supports equivalent copying facilities, provided you maintain
+ clear directions next to the object code saying where to find the
+ Corresponding Source. Regardless of what server hosts the
+ Corresponding Source, you remain obligated to ensure that it is
+ available for as long as needed to satisfy these requirements.
+
+ e) Convey the object code using peer-to-peer transmission, provided
+ you inform other peers where the object code and Corresponding
+ Source of the work are being offered to the general public at no
+ charge under subsection 6d.
+
+ A separable portion of the object code, whose source code is excluded
+from the Corresponding Source as a System Library, need not be
+included in conveying the object code work.
+
+ A "User Product" is either (1) a "consumer product", which means any
+tangible personal property which is normally used for personal, family,
+or household purposes, or (2) anything designed or sold for incorporation
+into a dwelling. In determining whether a product is a consumer product,
+doubtful cases shall be resolved in favor of coverage. For a particular
+product received by a particular user, "normally used" refers to a
+typical or common use of that class of product, regardless of the status
+of the particular user or of the way in which the particular user
+actually uses, or expects or is expected to use, the product. A product
+is a consumer product regardless of whether the product has substantial
+commercial, industrial or non-consumer uses, unless such uses represent
+the only significant mode of use of the product.
+
+ "Installation Information" for a User Product means any methods,
+procedures, authorization keys, or other information required to install
+and execute modified versions of a covered work in that User Product from
+a modified version of its Corresponding Source. The information must
+suffice to ensure that the continued functioning of the modified object
+code is in no case prevented or interfered with solely because
+modification has been made.
+
+ If you convey an object code work under this section in, or with, or
+specifically for use in, a User Product, and the conveying occurs as
+part of a transaction in which the right of possession and use of the
+User Product is transferred to the recipient in perpetuity or for a
+fixed term (regardless of how the transaction is characterized), the
+Corresponding Source conveyed under this section must be accompanied
+by the Installation Information. But this requirement does not apply
+if neither you nor any third party retains the ability to install
+modified object code on the User Product (for example, the work has
+been installed in ROM).
+
+ The requirement to provide Installation Information does not include a
+requirement to continue to provide support service, warranty, or updates
+for a work that has been modified or installed by the recipient, or for
+the User Product in which it has been modified or installed. Access to a
+network may be denied when the modification itself materially and
+adversely affects the operation of the network or violates the rules and
+protocols for communication across the network.
+
+ Corresponding Source conveyed, and Installation Information provided,
+in accord with this section must be in a format that is publicly
+documented (and with an implementation available to the public in
+source code form), and must require no special password or key for
+unpacking, reading or copying.
+
+ 7. Additional Terms.
+
+ "Additional permissions" are terms that supplement the terms of this
+License by making exceptions from one or more of its conditions.
+Additional permissions that are applicable to the entire Program shall
+be treated as though they were included in this License, to the extent
+that they are valid under applicable law. If additional permissions
+apply only to part of the Program, that part may be used separately
+under those permissions, but the entire Program remains governed by
+this License without regard to the additional permissions.
+
+ When you convey a copy of a covered work, you may at your option
+remove any additional permissions from that copy, or from any part of
+it. (Additional permissions may be written to require their own
+removal in certain cases when you modify the work.) You may place
+additional permissions on material, added by you to a covered work,
+for which you have or can give appropriate copyright permission.
+
+ Notwithstanding any other provision of this License, for material you
+add to a covered work, you may (if authorized by the copyright holders of
+that material) supplement the terms of this License with terms:
+
+ a) Disclaiming warranty or limiting liability differently from the
+ terms of sections 15 and 16 of this License; or
+
+ b) Requiring preservation of specified reasonable legal notices or
+ author attributions in that material or in the Appropriate Legal
+ Notices displayed by works containing it; or
+
+ c) Prohibiting misrepresentation of the origin of that material, or
+ requiring that modified versions of such material be marked in
+ reasonable ways as different from the original version; or
+
+ d) Limiting the use for publicity purposes of names of licensors or
+ authors of the material; or
+
+ e) Declining to grant rights under trademark law for use of some
+ trade names, trademarks, or service marks; or
+
+ f) Requiring indemnification of licensors and authors of that
+ material by anyone who conveys the material (or modified versions of
+ it) with contractual assumptions of liability to the recipient, for
+ any liability that these contractual assumptions directly impose on
+ those licensors and authors.
+
+ All other non-permissive additional terms are considered "further
+restrictions" within the meaning of section 10. If the Program as you
+received it, or any part of it, contains a notice stating that it is
+governed by this License along with a term that is a further
+restriction, you may remove that term. If a license document contains
+a further restriction but permits relicensing or conveying under this
+License, you may add to a covered work material governed by the terms
+of that license document, provided that the further restriction does
+not survive such relicensing or conveying.
+
+ If you add terms to a covered work in accord with this section, you
+must place, in the relevant source files, a statement of the
+additional terms that apply to those files, or a notice indicating
+where to find the applicable terms.
+
+ Additional terms, permissive or non-permissive, may be stated in the
+form of a separately written license, or stated as exceptions;
+the above requirements apply either way.
+
+ 8. Termination.
+
+ You may not propagate or modify a covered work except as expressly
+provided under this License. Any attempt otherwise to propagate or
+modify it is void, and will automatically terminate your rights under
+this License (including any patent licenses granted under the third
+paragraph of section 11).
+
+ However, if you cease all violation of this License, then your
+license from a particular copyright holder is reinstated (a)
+provisionally, unless and until the copyright holder explicitly and
+finally terminates your license, and (b) permanently, if the copyright
+holder fails to notify you of the violation by some reasonable means
+prior to 60 days after the cessation.
+
+ Moreover, your license from a particular copyright holder is
+reinstated permanently if the copyright holder notifies you of the
+violation by some reasonable means, this is the first time you have
+received notice of violation of this License (for any work) from that
+copyright holder, and you cure the violation prior to 30 days after
+your receipt of the notice.
+
+ Termination of your rights under this section does not terminate the
+licenses of parties who have received copies or rights from you under
+this License. If your rights have been terminated and not permanently
+reinstated, you do not qualify to receive new licenses for the same
+material under section 10.
+
+ 9. Acceptance Not Required for Having Copies.
+
+ You are not required to accept this License in order to receive or
+run a copy of the Program. Ancillary propagation of a covered work
+occurring solely as a consequence of using peer-to-peer transmission
+to receive a copy likewise does not require acceptance. However,
+nothing other than this License grants you permission to propagate or
+modify any covered work. These actions infringe copyright if you do
+not accept this License. Therefore, by modifying or propagating a
+covered work, you indicate your acceptance of this License to do so.
+
+ 10. Automatic Licensing of Downstream Recipients.
+
+ Each time you convey a covered work, the recipient automatically
+receives a license from the original licensors, to run, modify and
+propagate that work, subject to this License. You are not responsible
+for enforcing compliance by third parties with this License.
+
+ An "entity transaction" is a transaction transferring control of an
+organization, or substantially all assets of one, or subdividing an
+organization, or merging organizations. If propagation of a covered
+work results from an entity transaction, each party to that
+transaction who receives a copy of the work also receives whatever
+licenses to the work the party's predecessor in interest had or could
+give under the previous paragraph, plus a right to possession of the
+Corresponding Source of the work from the predecessor in interest, if
+the predecessor has it or can get it with reasonable efforts.
+
+ You may not impose any further restrictions on the exercise of the
+rights granted or affirmed under this License. For example, you may
+not impose a license fee, royalty, or other charge for exercise of
+rights granted under this License, and you may not initiate litigation
+(including a cross-claim or counterclaim in a lawsuit) alleging that
+any patent claim is infringed by making, using, selling, offering for
+sale, or importing the Program or any portion of it.
+
+ 11. Patents.
+
+ A "contributor" is a copyright holder who authorizes use under this
+License of the Program or a work on which the Program is based. The
+work thus licensed is called the contributor's "contributor version".
+
+ A contributor's "essential patent claims" are all patent claims
+owned or controlled by the contributor, whether already acquired or
+hereafter acquired, that would be infringed by some manner, permitted
+by this License, of making, using, or selling its contributor version,
+but do not include claims that would be infringed only as a
+consequence of further modification of the contributor version. For
+purposes of this definition, "control" includes the right to grant
+patent sublicenses in a manner consistent with the requirements of
+this License.
+
+ Each contributor grants you a non-exclusive, worldwide, royalty-free
+patent license under the contributor's essential patent claims, to
+make, use, sell, offer for sale, import and otherwise run, modify and
+propagate the contents of its contributor version.
+
+ In the following three paragraphs, a "patent license" is any express
+agreement or commitment, however denominated, not to enforce a patent
+(such as an express permission to practice a patent or covenant not to
+sue for patent infringement). To "grant" such a patent license to a
+party means to make such an agreement or commitment not to enforce a
+patent against the party.
+
+ If you convey a covered work, knowingly relying on a patent license,
+and the Corresponding Source of the work is not available for anyone
+to copy, free of charge and under the terms of this License, through a
+publicly available network server or other readily accessible means,
+then you must either (1) cause the Corresponding Source to be so
+available, or (2) arrange to deprive yourself of the benefit of the
+patent license for this particular work, or (3) arrange, in a manner
+consistent with the requirements of this License, to extend the patent
+license to downstream recipients. "Knowingly relying" means you have
+actual knowledge that, but for the patent license, your conveying the
+covered work in a country, or your recipient's use of the covered work
+in a country, would infringe one or more identifiable patents in that
+country that you have reason to believe are valid.
+
+ If, pursuant to or in connection with a single transaction or
+arrangement, you convey, or propagate by procuring conveyance of, a
+covered work, and grant a patent license to some of the parties
+receiving the covered work authorizing them to use, propagate, modify
+or convey a specific copy of the covered work, then the patent license
+you grant is automatically extended to all recipients of the covered
+work and works based on it.
+
+ A patent license is "discriminatory" if it does not include within
+the scope of its coverage, prohibits the exercise of, or is
+conditioned on the non-exercise of one or more of the rights that are
+specifically granted under this License. You may not convey a covered
+work if you are a party to an arrangement with a third party that is
+in the business of distributing software, under which you make payment
+to the third party based on the extent of your activity of conveying
+the work, and under which the third party grants, to any of the
+parties who would receive the covered work from you, a discriminatory
+patent license (a) in connection with copies of the covered work
+conveyed by you (or copies made from those copies), or (b) primarily
+for and in connection with specific products or compilations that
+contain the covered work, unless you entered into that arrangement,
+or that patent license was granted, prior to 28 March 2007.
+
+ Nothing in this License shall be construed as excluding or limiting
+any implied license or other defenses to infringement that may
+otherwise be available to you under applicable patent law.
+
+ 12. No Surrender of Others' Freedom.
+
+ If conditions are imposed on you (whether by court order, agreement or
+otherwise) that contradict the conditions of this License, they do not
+excuse you from the conditions of this License. If you cannot convey a
+covered work so as to satisfy simultaneously your obligations under this
+License and any other pertinent obligations, then as a consequence you may
+not convey it at all. For example, if you agree to terms that obligate you
+to collect a royalty for further conveying from those to whom you convey
+the Program, the only way you could satisfy both those terms and this
+License would be to refrain entirely from conveying the Program.
+
+ 13. Remote Network Interaction; Use with the GNU General Public License.
+
+ Notwithstanding any other provision of this License, if you modify the
+Program, your modified version must prominently offer all users
+interacting with it remotely through a computer network (if your version
+supports such interaction) an opportunity to receive the Corresponding
+Source of your version by providing access to the Corresponding Source
+from a network server at no charge, through some standard or customary
+means of facilitating copying of software. This Corresponding Source
+shall include the Corresponding Source for any work covered by version 3
+of the GNU General Public License that is incorporated pursuant to the
+following paragraph.
+
+ Notwithstanding any other provision of this License, you have
+permission to link or combine any covered work with a work licensed
+under version 3 of the GNU General Public License into a single
+combined work, and to convey the resulting work. The terms of this
+License will continue to apply to the part which is the covered work,
+but the work with which it is combined will remain governed by version
+3 of the GNU General Public License.
+
+ 14. Revised Versions of this License.
+
+ The Free Software Foundation may publish revised and/or new versions of
+the GNU Affero General Public License from time to time. Such new versions
+will be similar in spirit to the present version, but may differ in detail to
+address new problems or concerns.
+
+ Each version is given a distinguishing version number. If the
+Program specifies that a certain numbered version of the GNU Affero General
+Public License "or any later version" applies to it, you have the
+option of following the terms and conditions either of that numbered
+version or of any later version published by the Free Software
+Foundation. If the Program does not specify a version number of the
+GNU Affero General Public License, you may choose any version ever published
+by the Free Software Foundation.
+
+ If the Program specifies that a proxy can decide which future
+versions of the GNU Affero General Public License can be used, that proxy's
+public statement of acceptance of a version permanently authorizes you
+to choose that version for the Program.
+
+ Later license versions may give you additional or different
+permissions. However, no additional obligations are imposed on any
+author or copyright holder as a result of your choosing to follow a
+later version.
+
+ 15. Disclaimer of Warranty.
+
+ THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
+APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
+HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
+OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
+THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
+PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
+IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
+ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
+
+ 16. Limitation of Liability.
+
+ IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
+WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
+THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
+GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
+USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
+DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
+PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
+EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
+SUCH DAMAGES.
+
+ 17. Interpretation of Sections 15 and 16.
+
+ If the disclaimer of warranty and limitation of liability provided
+above cannot be given local legal effect according to their terms,
+reviewing courts shall apply local law that most closely approximates
+an absolute waiver of all civil liability in connection with the
+Program, unless a warranty or assumption of liability accompanies a
+copy of the Program in return for a fee.
+
+ END OF TERMS AND CONDITIONS
+
+ How to Apply These Terms to Your New Programs
+
+ If you develop a new program, and you want it to be of the greatest
+possible use to the public, the best way to achieve this is to make it
+free software which everyone can redistribute and change under these terms.
+
+ To do so, attach the following notices to the program. It is safest
+to attach them to the start of each source file to most effectively
+state the exclusion of warranty; and each file should have at least
+the "copyright" line and a pointer to where the full notice is found.
+
+
+ Copyright (C)
+
+ This program is free software: you can redistribute it and/or modify
+ it under the terms of the GNU Affero General Public License as published by
+ the Free Software Foundation, either version 3 of the License, or
+ (at your option) any later version.
+
+ This program is distributed in the hope that it will be useful,
+ but WITHOUT ANY WARRANTY; without even the implied warranty of
+ MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
+ GNU Affero General Public License for more details.
+
+ You should have received a copy of the GNU Affero General Public License
+ along with this program. If not, see .
+
+Also add information on how to contact you by electronic and paper mail.
+
+ If your software can interact with users remotely through a computer
+network, you should also make sure that it provides a way for users to
+get its source. For example, if your program is a web application, its
+interface could display a "Source" link that leads users to an archive
+of the code. There are many ways you could offer source, and different
+solutions will be better for different programs; see section 13 for the
+specific requirements.
+
+ You should also get your employer (if you work as a programmer) or school,
+if any, to sign a "copyright disclaimer" for the program, if necessary.
+For more information on this, and how to apply and follow the GNU AGPL, see
+.
diff --git a/yolov5/README.md b/yolov5/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..37f683343f53ef962472342eb856de52909a9972
--- /dev/null
+++ b/yolov5/README.md
@@ -0,0 +1,495 @@
+
+
+
+  +
+
+
+[English](README.md) | [简体中文](README.zh-CN.md)
+
+
+
+
+
+YOLOv5 🚀 is the world's most loved vision AI, representing
Ultralytics open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development.
+
+We hope that the resources here will help you get the most out of YOLOv5. Please browse the YOLOv5
Docs for details, raise an issue on
GitHub for support, and join our
Discord community for questions and discussions!
+
+To request an Enterprise License please complete the form at [Ultralytics Licensing](https://ultralytics.com/license).
+
+
+
+ 
+

+
+ 
+
+
+ 
+
+
+ 
+
+
+ 
+
+
+ 
+
+
+ 
+
+
+
+
+## YOLOv8 🚀 NEW
+
+We are thrilled to announce the launch of Ultralytics YOLOv8 🚀, our NEW cutting-edge, state-of-the-art (SOTA) model
+released at **[https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics)**.
+YOLOv8 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of
+object detection, image segmentation and image classification tasks.
+
+See the [YOLOv8 Docs](https://docs.ultralytics.com) for details and get started with:
+
+```commandline
+pip install ultralytics
+```
+
+
+
+ 
+
Documentation
+
+See the [YOLOv5 Docs](https://docs.ultralytics.com/yolov5) for full documentation on training, testing and deployment. See below for quickstart examples.
+
+
+Install
+
+Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a
+[**Python>=3.7.0**](https://www.python.org/) environment, including
+[**PyTorch>=1.7**](https://pytorch.org/get-started/locally/).
+
+```bash
+git clone https://github.com/ultralytics/yolov5 # clone
+cd yolov5
+pip install -r requirements.txt # install
+```
+
+
+
+
+Inference
+
+YOLOv5 [PyTorch Hub](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) inference. [Models](https://github.com/ultralytics/yolov5/tree/master/models) download automatically from the latest
+YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
+
+```python
+import torch
+
+# Model
+model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5n - yolov5x6, custom
+
+# Images
+img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
+
+# Inference
+results = model(img)
+
+# Results
+results.print() # or .show(), .save(), .crop(), .pandas(), etc.
+```
+
+
+
+
+Inference with detect.py
+
+`detect.py` runs inference on a variety of sources, downloading [models](https://github.com/ultralytics/yolov5/tree/master/models) automatically from
+the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases) and saving results to `runs/detect`.
+
+```bash
+python detect.py --weights yolov5s.pt --source 0 # webcam
+ img.jpg # image
+ vid.mp4 # video
+ screen # screenshot
+ path/ # directory
+ list.txt # list of images
+ list.streams # list of streams
+ 'path/*.jpg' # glob
+ 'https://youtu.be/Zgi9g1ksQHc' # YouTube
+ 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
+```
+
+
+
+
+Training
+
+The commands below reproduce YOLOv5 [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh)
+results. [Models](https://github.com/ultralytics/yolov5/tree/master/models)
+and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest
+YOLOv5 [release](https://github.com/ultralytics/yolov5/releases). Training times for YOLOv5n/s/m/l/x are
+1/2/4/6/8 days on a V100 GPU ([Multi-GPU](https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training) times faster). Use the
+largest `--batch-size` possible, or pass `--batch-size -1` for
+YOLOv5 [AutoBatch](https://github.com/ultralytics/yolov5/pull/5092). Batch sizes shown for V100-16GB.
+
+```bash
+python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128
+ yolov5s 64
+ yolov5m 40
+ yolov5l 24
+ yolov5x 16
+```
+
+ +
+
+
+
+
+
+Tutorials
+
+- [Train Custom Data](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data) 🚀 RECOMMENDED
+- [Tips for Best Training Results](https://docs.ultralytics.com/yolov5/tutorials/tips_for_best_training_results) ☘️
+- [Multi-GPU Training](https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training)
+- [PyTorch Hub](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) 🌟 NEW
+- [TFLite, ONNX, CoreML, TensorRT Export](https://docs.ultralytics.com/yolov5/tutorials/model_export) 🚀
+- [NVIDIA Jetson platform Deployment](https://docs.ultralytics.com/yolov5/tutorials/running_on_jetson_nano) 🌟 NEW
+- [Test-Time Augmentation (TTA)](https://docs.ultralytics.com/yolov5/tutorials/test_time_augmentation)
+- [Model Ensembling](https://docs.ultralytics.com/yolov5/tutorials/model_ensembling)
+- [Model Pruning/Sparsity](https://docs.ultralytics.com/yolov5/tutorials/model_pruning_and_sparsity)
+- [Hyperparameter Evolution](https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution)
+- [Transfer Learning with Frozen Layers](https://docs.ultralytics.com/yolov5/tutorials/transfer_learning_with_frozen_layers)
+- [Architecture Summary](https://docs.ultralytics.com/yolov5/tutorials/architecture_description) 🌟 NEW
+- [Roboflow for Datasets, Labeling, and Active Learning](https://docs.ultralytics.com/yolov5/tutorials/roboflow_datasets_integration)
+- [ClearML Logging](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) 🌟 NEW
+- [YOLOv5 with Neural Magic's Deepsparse](https://docs.ultralytics.com/yolov5/tutorials/neural_magic_pruning_quantization) 🌟 NEW
+- [Comet Logging](https://docs.ultralytics.com/yolov5/tutorials/comet_logging_integration) 🌟 NEW
+
+
+
+## Integrations
+
+
+
+ +
+
+
+
+
+
+| Roboflow | ClearML ⭐ NEW | Comet ⭐ NEW | Neural Magic ⭐ NEW |
+| :--------------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------: |
+| Label and export your custom datasets directly to YOLOv5 for training with [Roboflow](https://roboflow.com/?ref=ultralytics) | Automatically track, visualize and even remotely train YOLOv5 using [ClearML](https://cutt.ly/yolov5-readme-clearml) (open-source!) | Free forever, [Comet](https://bit.ly/yolov5-readme-comet2) lets you save YOLOv5 models, resume training, and interactively visualise and debug predictions | Run YOLOv5 inference up to 6x faster with [Neural Magic DeepSparse](https://bit.ly/yolov5-neuralmagic) |
+
+## Ultralytics HUB
+
+Experience seamless AI with [Ultralytics HUB](https://bit.ly/ultralytics_hub) ⭐, the all-in-one solution for data visualization, YOLOv5 and YOLOv8 🚀 model training and deployment, without any coding. Transform images into actionable insights and bring your AI visions to life with ease using our cutting-edge platform and user-friendly [Ultralytics App](https://ultralytics.com/app_install). Start your journey for **Free** now!
+
+
+ +
+##
+
+## Why YOLOv5
+
+YOLOv5 has been designed to be super easy to get started and simple to learn. We prioritize real-world results.
+
+
+
+ YOLOv5-P5 640 Figure
+
+
+
+
+ Figure Notes
+
+- **COCO AP val** denotes mAP@0.5:0.95 metric measured on the 5000-image [COCO val2017](http://cocodataset.org) dataset over various inference sizes from 256 to 1536.
+- **GPU Speed** measures average inference time per image on [COCO val2017](http://cocodataset.org) dataset using a [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) V100 instance at batch-size 32.
+- **EfficientDet** data from [google/automl](https://github.com/google/automl) at batch size 8.
+- **Reproduce** by `python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt`
+
+
+
+### Pretrained Checkpoints
+
+| Model | size
(pixels) | mAPval
50-95 | mAPval
50 | Speed
CPU b1
(ms) | Speed
V100 b1
(ms) | Speed
V100 b32
(ms) | params
(M) | FLOPs
@640 (B) |
+| ----------------------------------------------------------------------------------------------- | --------------------- | -------------------- | ----------------- | ---------------------------- | ----------------------------- | ------------------------------ | ------------------ | ---------------------- |
+| [YOLOv5n](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n.pt) | 640 | 28.0 | 45.7 | **45** | **6.3** | **0.6** | **1.9** | **4.5** |
+| [YOLOv5s](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt) | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
+| [YOLOv5m](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m.pt) | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
+| [YOLOv5l](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l.pt) | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
+| [YOLOv5x](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x.pt) | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
+| | | | | | | | | |
+| [YOLOv5n6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n6.pt) | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
+| [YOLOv5s6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s6.pt) | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
+| [YOLOv5m6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m6.pt) | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
+| [YOLOv5l6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l6.pt) | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
+| [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x6.pt)
+ [TTA] | 1280
1536 | 55.0
**55.8** | 72.7
**72.7** | 3136
- | 26.2
- | 19.4
- | 140.7
- | 209.8
- |
+
+
+ Table Notes
+
+- All checkpoints are trained to 300 epochs with default settings. Nano and Small models use [hyp.scratch-low.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml) hyps, all others use [hyp.scratch-high.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-high.yaml).
+- **mAPval** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset.
Reproduce by `python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65`
+- **Speed** averaged over COCO val images using a [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) instance. NMS times (~1 ms/img) not included.
Reproduce by `python val.py --data coco.yaml --img 640 --task speed --batch 1`
+- **TTA** [Test Time Augmentation](https://docs.ultralytics.com/yolov5/tutorials/test_time_augmentation) includes reflection and scale augmentations.
Reproduce by `python val.py --data coco.yaml --img 1536 --iou 0.7 --augment`
+
+
+
+## Segmentation
+
+Our new YOLOv5 [release v7.0](https://github.com/ultralytics/yolov5/releases/v7.0) instance segmentation models are the fastest and most accurate in the world, beating all current [SOTA benchmarks](https://paperswithcode.com/sota/real-time-instance-segmentation-on-mscoco). We've made them super simple to train, validate and deploy. See full details in our [Release Notes](https://github.com/ultralytics/yolov5/releases/v7.0) and visit our [YOLOv5 Segmentation Colab Notebook](https://github.com/ultralytics/yolov5/blob/master/segment/tutorial.ipynb) for quickstart tutorials.
+
+
+ Segmentation Checkpoints
+
+
+
+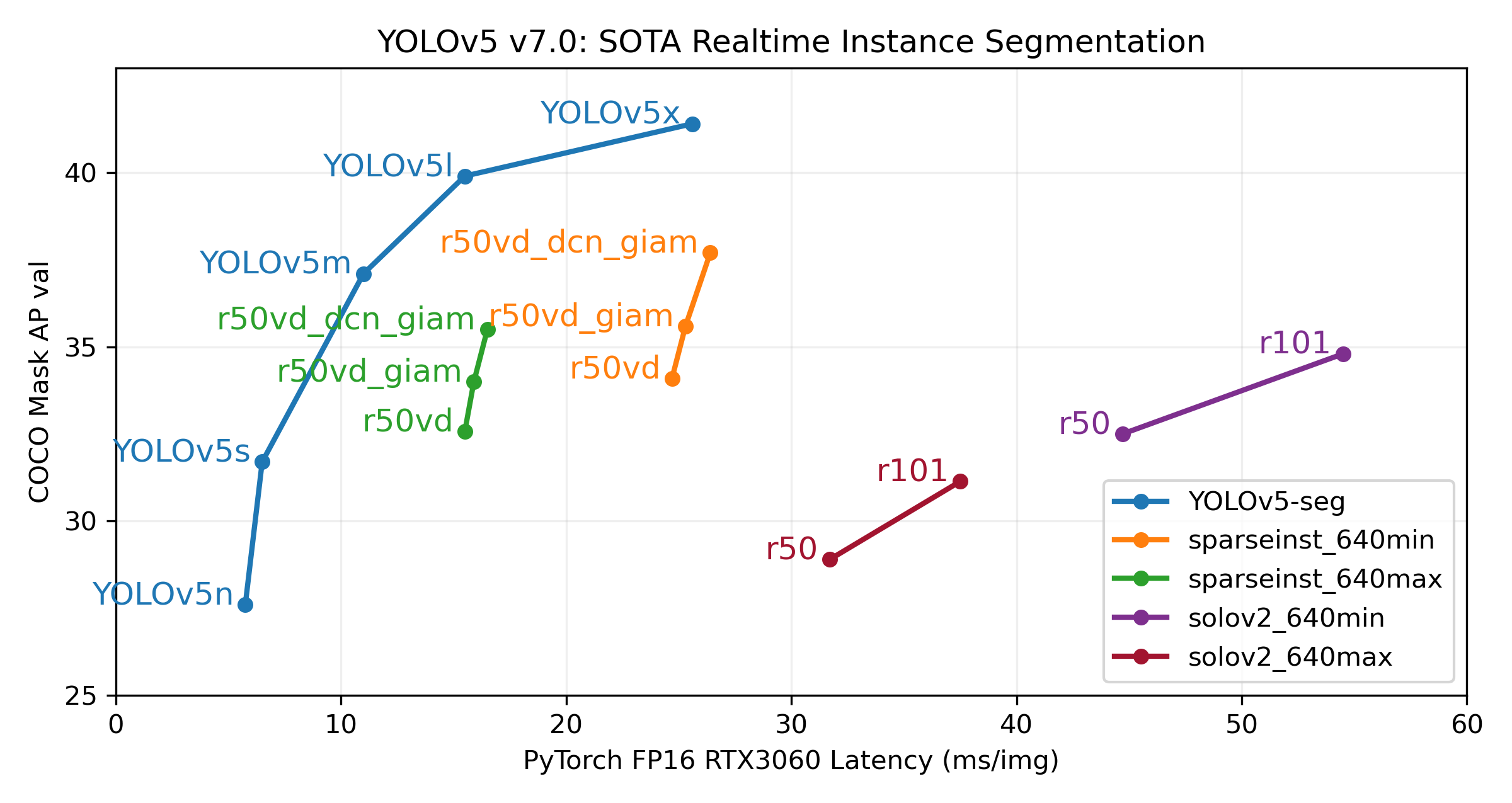
+
(pixels) | mAPbox
50-95 | mAPmask
50-95 | Train time
300 epochs
A100 (hours) | Speed
ONNX CPU
(ms) | Speed
TRT A100
(ms) | params
(M) | FLOPs
@640 (B) |
+| ------------------------------------------------------------------------------------------ | --------------------- | -------------------- | --------------------- | --------------------------------------------- | ------------------------------ | ------------------------------ | ------------------ | ---------------------- |
+| [YOLOv5n-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-seg.pt) | 640 | 27.6 | 23.4 | 80:17 | **62.7** | **1.2** | **2.0** | **7.1** |
+| [YOLOv5s-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-seg.pt) | 640 | 37.6 | 31.7 | 88:16 | 173.3 | 1.4 | 7.6 | 26.4 |
+| [YOLOv5m-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-seg.pt) | 640 | 45.0 | 37.1 | 108:36 | 427.0 | 2.2 | 22.0 | 70.8 |
+| [YOLOv5l-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-seg.pt) | 640 | 49.0 | 39.9 | 66:43 (2x) | 857.4 | 2.9 | 47.9 | 147.7 |
+| [YOLOv5x-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-seg.pt) | 640 | **50.7** | **41.4** | 62:56 (3x) | 1579.2 | 4.5 | 88.8 | 265.7 |
+
+- All checkpoints are trained to 300 epochs with SGD optimizer with `lr0=0.01` and `weight_decay=5e-5` at image size 640 and all default settings.
Runs logged to https://wandb.ai/glenn-jocher/YOLOv5_v70_official
+- **Accuracy** values are for single-model single-scale on COCO dataset.
Reproduce by `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt`
+- **Speed** averaged over 100 inference images using a [Colab Pro](https://colab.research.google.com/signup) A100 High-RAM instance. Values indicate inference speed only (NMS adds about 1ms per image).
Reproduce by `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt --batch 1`
+- **Export** to ONNX at FP32 and TensorRT at FP16 done with `export.py`.
Reproduce by `python export.py --weights yolov5s-seg.pt --include engine --device 0 --half`
+
+
+
+
+ Segmentation Usage Examples
+
+### Train
+
+YOLOv5 segmentation training supports auto-download COCO128-seg segmentation dataset with `--data coco128-seg.yaml` argument and manual download of COCO-segments dataset with `bash data/scripts/get_coco.sh --train --val --segments` and then `python train.py --data coco.yaml`.
+
+```bash
+# Single-GPU
+python segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640
+
+# Multi-GPU DDP
+python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640 --device 0,1,2,3
+```
+
+### Val
+
+Validate YOLOv5s-seg mask mAP on COCO dataset:
+
+```bash
+bash data/scripts/get_coco.sh --val --segments # download COCO val segments split (780MB, 5000 images)
+python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validate
+```
+
+### Predict
+
+Use pretrained YOLOv5m-seg.pt to predict bus.jpg:
+
+```bash
+python segment/predict.py --weights yolov5m-seg.pt --source data/images/bus.jpg
+```
+
+```python
+model = torch.hub.load(
+ "ultralytics/yolov5", "custom", "yolov5m-seg.pt"
+) # load from PyTorch Hub (WARNING: inference not yet supported)
+```
+
+| 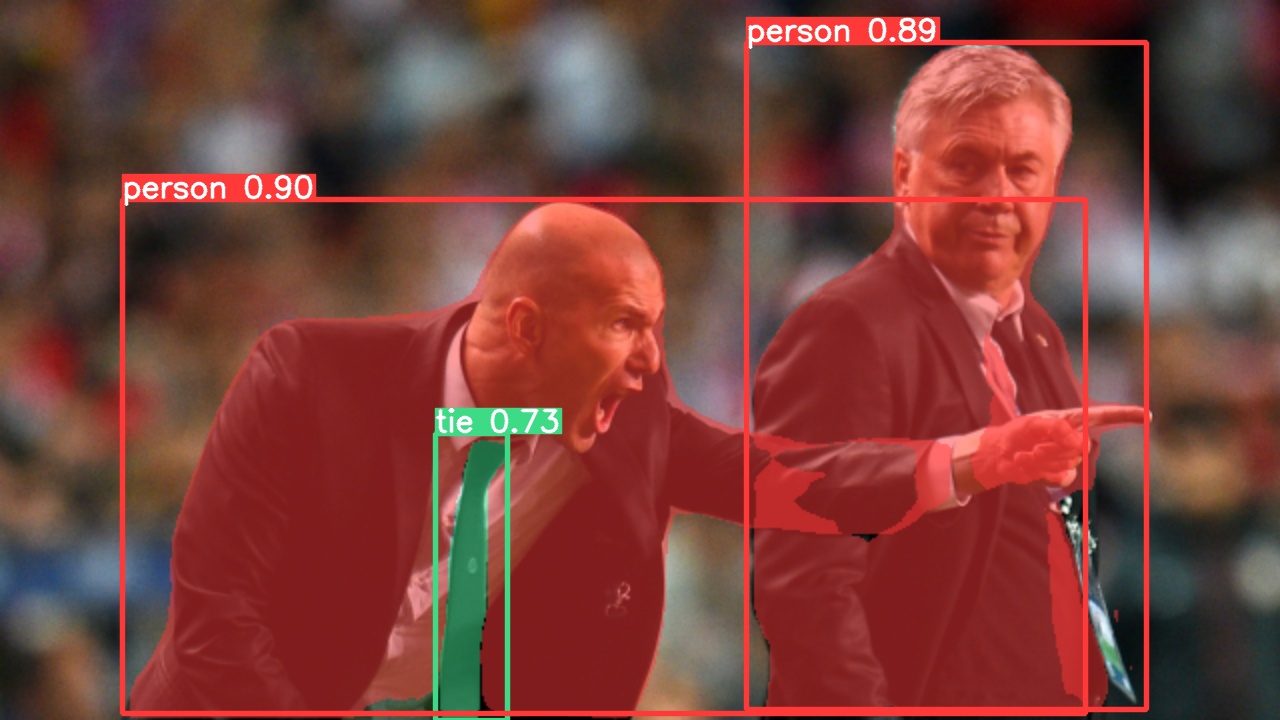 | 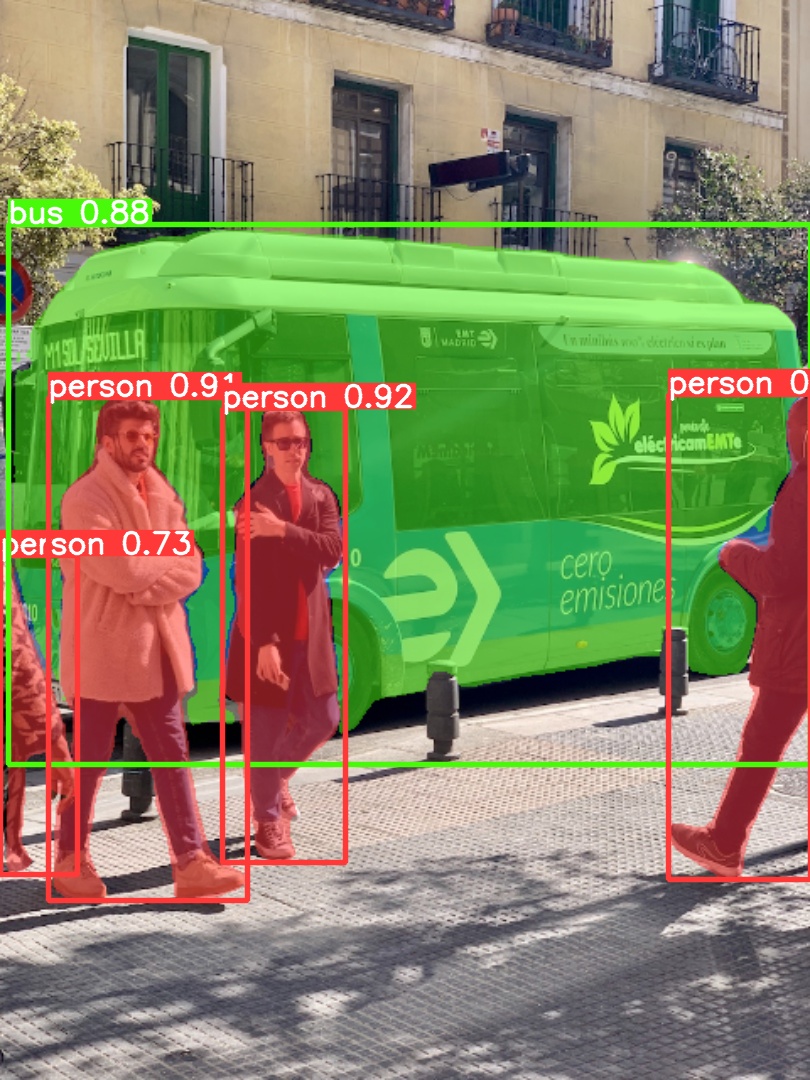 |
+| ---------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
+
+### Export
+
+Export YOLOv5s-seg model to ONNX and TensorRT:
+
+```bash
+python export.py --weights yolov5s-seg.pt --include onnx engine --img 640 --device 0
+```
+
+
+
+## Classification
+
+YOLOv5 [release v6.2](https://github.com/ultralytics/yolov5/releases) brings support for classification model training, validation and deployment! See full details in our [Release Notes](https://github.com/ultralytics/yolov5/releases/v6.2) and visit our [YOLOv5 Classification Colab Notebook](https://github.com/ultralytics/yolov5/blob/master/classify/tutorial.ipynb) for quickstart tutorials.
+
+
+ Classification Checkpoints
+
+
+
+We trained YOLOv5-cls classification models on ImageNet for 90 epochs using a 4xA100 instance, and we trained ResNet and EfficientNet models alongside with the same default training settings to compare. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google [Colab Pro](https://colab.research.google.com/signup) for easy reproducibility.
+
+| Model | size
(pixels) | acc
top1 | acc
top5 | Training
90 epochs
4xA100 (hours) | Speed
ONNX CPU
(ms) | Speed
TensorRT V100
(ms) | params
(M) | FLOPs
@224 (B) |
+| -------------------------------------------------------------------------------------------------- | --------------------- | ---------------- | ---------------- | -------------------------------------------- | ------------------------------ | ----------------------------------- | ------------------ | ---------------------- |
+| [YOLOv5n-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-cls.pt) | 224 | 64.6 | 85.4 | 7:59 | **3.3** | **0.5** | **2.5** | **0.5** |
+| [YOLOv5s-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-cls.pt) | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 |
+| [YOLOv5m-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-cls.pt) | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 |
+| [YOLOv5l-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-cls.pt) | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 |
+| [YOLOv5x-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-cls.pt) | 224 | **79.0** | **94.4** | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 |
+| | | | | | | | | |
+| [ResNet18](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet18.pt) | 224 | 70.3 | 89.5 | **6:47** | 11.2 | 0.5 | 11.7 | 3.7 |
+| [ResNet34](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet34.pt) | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 |
+| [ResNet50](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet50.pt) | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 |
+| [ResNet101](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet101.pt) | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 |
+| | | | | | | | | |
+| [EfficientNet_b0](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b0.pt) | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 |
+| [EfficientNet_b1](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b1.pt) | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 |
+| [EfficientNet_b2](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b2.pt) | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 |
+| [EfficientNet_b3](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b3.pt) | 224 | 77.7 | 94.0 | 19:19 | 18.9 | 1.9 | 12.2 | 2.4 |
+
+
+ Table Notes (click to expand)
+
+- All checkpoints are trained to 90 epochs with SGD optimizer with `lr0=0.001` and `weight_decay=5e-5` at image size 224 and all default settings.
Runs logged to https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2
+- **Accuracy** values are for single-model single-scale on [ImageNet-1k](https://www.image-net.org/index.php) dataset.
Reproduce by `python classify/val.py --data ../datasets/imagenet --img 224`
+- **Speed** averaged over 100 inference images using a Google [Colab Pro](https://colab.research.google.com/signup) V100 High-RAM instance.
Reproduce by `python classify/val.py --data ../datasets/imagenet --img 224 --batch 1`
+- **Export** to ONNX at FP32 and TensorRT at FP16 done with `export.py`.
Reproduce by `python export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224`
+
+
+
+
+
+ Classification Usage Examples
+
+### Train
+
+YOLOv5 classification training supports auto-download of MNIST, Fashion-MNIST, CIFAR10, CIFAR100, Imagenette, Imagewoof, and ImageNet datasets with the `--data` argument. To start training on MNIST for example use `--data mnist`.
+
+```bash
+# Single-GPU
+python classify/train.py --model yolov5s-cls.pt --data cifar100 --epochs 5 --img 224 --batch 128
+
+# Multi-GPU DDP
+python -m torch.distributed.run --nproc_per_node 4 --master_port 1 classify/train.py --model yolov5s-cls.pt --data imagenet --epochs 5 --img 224 --device 0,1,2,3
+```
+
+### Val
+
+Validate YOLOv5m-cls accuracy on ImageNet-1k dataset:
+
+```bash
+bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
+python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate
+```
+
+### Predict
+
+Use pretrained YOLOv5s-cls.pt to predict bus.jpg:
+
+```bash
+python classify/predict.py --weights yolov5s-cls.pt --source data/images/bus.jpg
+```
+
+```python
+model = torch.hub.load(
+ "ultralytics/yolov5", "custom", "yolov5s-cls.pt"
+) # load from PyTorch Hub
+```
+
+### Export
+
+Export a group of trained YOLOv5s-cls, ResNet and EfficientNet models to ONNX and TensorRT:
+
+```bash
+python export.py --weights yolov5s-cls.pt resnet50.pt efficientnet_b0.pt --include onnx engine --img 224
+```
+
+
+
+## Environments
+
+Get started in seconds with our verified environments. Click each icon below for details.
+
+
+
+ 
+
+
+ 
+
+
+ 
+
+
+ 
+
+
+ 
+
+
+ 
+
Contribute
+
+We love your input! We want to make contributing to YOLOv5 as easy and transparent as possible. Please see our [Contributing Guide](https://docs.ultralytics.com/help/contributing/) to get started, and fill out the [YOLOv5 Survey](https://ultralytics.com/survey?utm_source=github&utm_medium=social&utm_campaign=Survey) to send us feedback on your experiences. Thank you to all our contributors!
+
+
+
+
+ +
+##
+
+## License
+
+YOLOv5 is available under two different licenses:
+
+- **AGPL-3.0 License**: See [LICENSE](https://github.com/ultralytics/yolov5/blob/master/LICENSE) file for details.
+- **Enterprise License**: Provides greater flexibility for commercial product development without the open-source requirements of AGPL-3.0. Typical use cases are embedding Ultralytics software and AI models in commercial products and applications. Request an Enterprise License at [Ultralytics Licensing](https://ultralytics.com/license).
+
+## Contact
+
+For YOLOv5 bug reports and feature requests please visit [GitHub Issues](https://github.com/ultralytics/yolov5/issues), and join our [Discord](https://discord.gg/n6cFeSPZdD) community for questions and discussions!
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+[英文](README.md)|[简体中文](README.zh-CN.md)
+
+
+
+
+YOLOv5 🚀 是世界上最受欢迎的视觉 AI,代表
Ultralytics 对未来视觉 AI 方法的开源研究,结合在数千小时的研究和开发中积累的经验教训和最佳实践。
+
+我们希望这里的资源能帮助您充分利用 YOLOv5。请浏览 YOLOv5
文档 了解详细信息,在
GitHub 上提交问题以获得支持,并加入我们的
Discord 社区进行问题和讨论!
+
+如需申请企业许可,请在 [Ultralytics Licensing](https://ultralytics.com/license) 处填写表格
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
YOLOv8 🚀 NEW
+
+We are thrilled to announce the launch of Ultralytics YOLOv8 🚀, our NEW cutting-edge, state-of-the-art (SOTA) model
+released at **[https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics)**.
+YOLOv8 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of
+object detection, image segmentation and image classification tasks.
+
+See the [YOLOv8 Docs](https://docs.ultralytics.com) for details and get started with:
+
+```commandline
+pip install ultralytics
+```
+
+
+
+
+
文档
+
+有关训练、测试和部署的完整文档见[YOLOv5 文档](https://docs.ultralytics.com)。请参阅下面的快速入门示例。
+
+
+安装
+
+克隆 repo,并要求在 [**Python>=3.7.0**](https://www.python.org/) 环境中安装 [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) ,且要求 [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/) 。
+
+```bash
+git clone https://github.com/ultralytics/yolov5 # clone
+cd yolov5
+pip install -r requirements.txt # install
+```
+
+
+
+
+推理
+
+使用 YOLOv5 [PyTorch Hub](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) 推理。最新 [模型](https://github.com/ultralytics/yolov5/tree/master/models) 将自动的从
+YOLOv5 [release](https://github.com/ultralytics/yolov5/releases) 中下载。
+
+```python
+import torch
+
+# Model
+model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5n - yolov5x6, custom
+
+# Images
+img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
+
+# Inference
+results = model(img)
+
+# Results
+results.print() # or .show(), .save(), .crop(), .pandas(), etc.
+```
+
+
+
+
+使用 detect.py 推理
+
+`detect.py` 在各种来源上运行推理, [模型](https://github.com/ultralytics/yolov5/tree/master/models) 自动从
+最新的YOLOv5 [release](https://github.com/ultralytics/yolov5/releases) 中下载,并将结果保存到 `runs/detect` 。
+
+```bash
+python detect.py --weights yolov5s.pt --source 0 # webcam
+ img.jpg # image
+ vid.mp4 # video
+ screen # screenshot
+ path/ # directory
+ list.txt # list of images
+ list.streams # list of streams
+ 'path/*.jpg' # glob
+ 'https://youtu.be/Zgi9g1ksQHc' # YouTube
+ 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
+```
+
+
+
+
+训练
+
+下面的命令重现 YOLOv5 在 [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) 数据集上的结果。
+最新的 [模型](https://github.com/ultralytics/yolov5/tree/master/models) 和 [数据集](https://github.com/ultralytics/yolov5/tree/master/data)
+将自动的从 YOLOv5 [release](https://github.com/ultralytics/yolov5/releases) 中下载。
+YOLOv5n/s/m/l/x 在 V100 GPU 的训练时间为 1/2/4/6/8 天( [多GPU](https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training) 训练速度更快)。
+尽可能使用更大的 `--batch-size` ,或通过 `--batch-size -1` 实现
+YOLOv5 [自动批处理](https://github.com/ultralytics/yolov5/pull/5092) 。下方显示的 batchsize 适用于 V100-16GB。
+
+```bash
+python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128
+ yolov5s 64
+ yolov5m 40
+ yolov5l 24
+ yolov5x 16
+```
+
+
+
+
+
+
+教程
+
+- [训练自定义数据](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data) 🚀 推荐
+- [获得最佳训练结果的技巧](https://docs.ultralytics.com/yolov5/tutorials/tips_for_best_training_results) ☘️
+- [多GPU训练](https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training)
+- [PyTorch Hub](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) 🌟 新
+- [TFLite,ONNX,CoreML,TensorRT导出](https://docs.ultralytics.com/yolov5/tutorials/model_export) 🚀
+- [NVIDIA Jetson平台部署](https://docs.ultralytics.com/yolov5/tutorials/running_on_jetson_nano) 🌟 新
+- [测试时增强 (TTA)](https://docs.ultralytics.com/yolov5/tutorials/test_time_augmentation)
+- [模型集成](https://docs.ultralytics.com/yolov5/tutorials/model_ensembling)
+- [模型剪枝/稀疏](https://docs.ultralytics.com/yolov5/tutorials/model_pruning_and_sparsity)
+- [超参数进化](https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution)
+- [冻结层的迁移学习](https://docs.ultralytics.com/yolov5/tutorials/transfer_learning_with_frozen_layers)
+- [架构概述](https://docs.ultralytics.com/yolov5/tutorials/architecture_description) 🌟 新
+- [Roboflow用于数据集、标注和主动学习](https://docs.ultralytics.com/yolov5/tutorials/roboflow_datasets_integration)
+- [ClearML日志记录](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) 🌟 新
+- [使用Neural Magic的Deepsparse的YOLOv5](https://docs.ultralytics.com/yolov5/tutorials/neural_magic_pruning_quantization) 🌟 新
+- [Comet日志记录](https://docs.ultralytics.com/yolov5/tutorials/comet_logging_integration) 🌟 新
+
+
+
+## 模块集成
+
+
+
+
+
+
+
+
+
+| Roboflow | ClearML ⭐ 新 | Comet ⭐ 新 | Neural Magic ⭐ 新 |
+| :--------------------------------------------------------------------------------: | :-------------------------------------------------------------------------: | :--------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------: |
+| 将您的自定义数据集进行标注并直接导出到 YOLOv5 以进行训练 [Roboflow](https://roboflow.com/?ref=ultralytics) | 自动跟踪、可视化甚至远程训练 YOLOv5 [ClearML](https://cutt.ly/yolov5-readme-clearml)(开源!) | 永远免费,[Comet](https://bit.ly/yolov5-readme-comet2)可让您保存 YOLOv5 模型、恢复训练以及交互式可视化和调试预测 | 使用 [Neural Magic DeepSparse](https://bit.ly/yolov5-neuralmagic),运行 YOLOv5 推理的速度最高可提高6倍 |
+
+## Ultralytics HUB
+
+[Ultralytics HUB](https://bit.ly/ultralytics_hub) 是我们的⭐**新的**用于可视化数据集、训练 YOLOv5 🚀 模型并以无缝体验部署到现实世界的无代码解决方案。现在开始 **免费** 使用他!
+
+
+
+
+## 为什么选择 YOLOv5
+
+YOLOv5 超级容易上手,简单易学。我们优先考虑现实世界的结果。
+
+
+
+ YOLOv5-P5 640 图
+
+
+
+
+ 图表笔记
+
+- **COCO AP val** 表示 mAP@0.5:0.95 指标,在 [COCO val2017](http://cocodataset.org) 数据集的 5000 张图像上测得, 图像包含 256 到 1536 各种推理大小。
+- **显卡推理速度** 为在 [COCO val2017](http://cocodataset.org) 数据集上的平均推理时间,使用 [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) V100实例,batchsize 为 32 。
+- **EfficientDet** 数据来自 [google/automl](https://github.com/google/automl) , batchsize 为32。
+- **复现命令** 为 `python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt`
+
+
+
+### 预训练模型
+
+| 模型 | 尺寸
(像素) | mAPval
50-95 | mAPval
50 | 推理速度
CPU b1
(ms) | 推理速度
V100 b1
(ms) | 速度
V100 b32
(ms) | 参数量
(M) | FLOPs
@640 (B) |
+| ---------------------------------------------------------------------------------------------- | --------------- | -------------------- | ----------------- | --------------------------- | ---------------------------- | --------------------------- | --------------- | ---------------------- |
+| [YOLOv5n](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n.pt) | 640 | 28.0 | 45.7 | **45** | **6.3** | **0.6** | **1.9** | **4.5** |
+| [YOLOv5s](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt) | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
+| [YOLOv5m](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m.pt) | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
+| [YOLOv5l](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l.pt) | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
+| [YOLOv5x](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x.pt) | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
+| | | | | | | | | |
+| [YOLOv5n6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n6.pt) | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
+| [YOLOv5s6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s6.pt) | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
+| [YOLOv5m6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m6.pt) | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
+| [YOLOv5l6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l6.pt) | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
+| [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x6.pt)
+[TTA] | 1280
1536 | 55.0
**55.8** | 72.7
**72.7** | 3136
- | 26.2
- | 19.4
- | 140.7
- | 209.8
- |
+
+
+ 笔记
+
+- 所有模型都使用默认配置,训练 300 epochs。n和s模型使用 [hyp.scratch-low.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml) ,其他模型都使用 [hyp.scratch-high.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-high.yaml) 。
+- \*\*mAPval\*\*在单模型单尺度上计算,数据集使用 [COCO val2017](http://cocodataset.org) 。
复现命令 `python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65`
+- **推理速度**在 COCO val 图像总体时间上进行平均得到,测试环境使用[AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/)实例。 NMS 时间 (大约 1 ms/img) 不包括在内。
复现命令 `python val.py --data coco.yaml --img 640 --task speed --batch 1`
+- **TTA** [测试时数据增强](https://docs.ultralytics.com/yolov5/tutorials/test_time_augmentation) 包括反射和尺度变换。
复现命令 `python val.py --data coco.yaml --img 1536 --iou 0.7 --augment`
+
+
+
+## 实例分割模型 ⭐ 新
+
+我们新的 YOLOv5 [release v7.0](https://github.com/ultralytics/yolov5/releases/v7.0) 实例分割模型是世界上最快和最准确的模型,击败所有当前 [SOTA 基准](https://paperswithcode.com/sota/real-time-instance-segmentation-on-mscoco)。我们使它非常易于训练、验证和部署。更多细节请查看 [发行说明](https://github.com/ultralytics/yolov5/releases/v7.0) 或访问我们的 [YOLOv5 分割 Colab 笔记本](https://github.com/ultralytics/yolov5/blob/master/segment/tutorial.ipynb) 以快速入门。
+
+
+ 实例分割模型列表
+
+
+
+
+
+
+
(像素) | mAPbox
50-95 | mAPmask
50-95 | 训练时长
300 epochs
A100 GPU(小时) | 推理速度
ONNX CPU
(ms) | 推理速度
TRT A100
(ms) | 参数量
(M) | FLOPs
@640 (B) |
+| ------------------------------------------------------------------------------------------ | --------------- | -------------------- | --------------------- | --------------------------------------- | ----------------------------- | ----------------------------- | --------------- | ---------------------- |
+| [YOLOv5n-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-seg.pt) | 640 | 27.6 | 23.4 | 80:17 | **62.7** | **1.2** | **2.0** | **7.1** |
+| [YOLOv5s-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-seg.pt) | 640 | 37.6 | 31.7 | 88:16 | 173.3 | 1.4 | 7.6 | 26.4 |
+| [YOLOv5m-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-seg.pt) | 640 | 45.0 | 37.1 | 108:36 | 427.0 | 2.2 | 22.0 | 70.8 |
+| [YOLOv5l-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-seg.pt) | 640 | 49.0 | 39.9 | 66:43 (2x) | 857.4 | 2.9 | 47.9 | 147.7 |
+| [YOLOv5x-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-seg.pt) | 640 | **50.7** | **41.4** | 62:56 (3x) | 1579.2 | 4.5 | 88.8 | 265.7 |
+
+- 所有模型使用 SGD 优化器训练, 都使用 `lr0=0.01` 和 `weight_decay=5e-5` 参数, 图像大小为 640 。
训练 log 可以查看 https://wandb.ai/glenn-jocher/YOLOv5_v70_official
+- **准确性**结果都在 COCO 数据集上,使用单模型单尺度测试得到。
复现命令 `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt`
+- **推理速度**是使用 100 张图像推理时间进行平均得到,测试环境使用 [Colab Pro](https://colab.research.google.com/signup) 上 A100 高 RAM 实例。结果仅表示推理速度(NMS 每张图像增加约 1 毫秒)。
复现命令 `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt --batch 1`
+- **模型转换**到 FP32 的 ONNX 和 FP16 的 TensorRT 脚本为 `export.py`.
运行命令 `python export.py --weights yolov5s-seg.pt --include engine --device 0 --half`
+
+
+
+
+ 分割模型使用示例
+
+### 训练
+
+YOLOv5分割训练支持自动下载 COCO128-seg 分割数据集,用户仅需在启动指令中包含 `--data coco128-seg.yaml` 参数。 若要手动下载,使用命令 `bash data/scripts/get_coco.sh --train --val --segments`, 在下载完毕后,使用命令 `python train.py --data coco.yaml` 开启训练。
+
+```bash
+# 单 GPU
+python segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640
+
+# 多 GPU, DDP 模式
+python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640 --device 0,1,2,3
+```
+
+### 验证
+
+在 COCO 数据集上验证 YOLOv5s-seg mask mAP:
+
+```bash
+bash data/scripts/get_coco.sh --val --segments # 下载 COCO val segments 数据集 (780MB, 5000 images)
+python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # 验证
+```
+
+### 预测
+
+使用预训练的 YOLOv5m-seg.pt 来预测 bus.jpg:
+
+```bash
+python segment/predict.py --weights yolov5m-seg.pt --source data/images/bus.jpg
+```
+
+```python
+model = torch.hub.load(
+ "ultralytics/yolov5", "custom", "yolov5m-seg.pt"
+) # 从load from PyTorch Hub 加载模型 (WARNING: 推理暂未支持)
+```
+
+|  |  |
+| ---------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
+
+### 模型导出
+
+将 YOLOv5s-seg 模型导出到 ONNX 和 TensorRT:
+
+```bash
+python export.py --weights yolov5s-seg.pt --include onnx engine --img 640 --device 0
+```
+
+
+
+## 分类网络 ⭐ 新
+
+YOLOv5 [release v6.2](https://github.com/ultralytics/yolov5/releases) 带来对分类模型训练、验证和部署的支持!详情请查看 [发行说明](https://github.com/ultralytics/yolov5/releases/v6.2) 或访问我们的 [YOLOv5 分类 Colab 笔记本](https://github.com/ultralytics/yolov5/blob/master/classify/tutorial.ipynb) 以快速入门。
+
+
+ 分类网络模型
+
+
+
+我们使用 4xA100 实例在 ImageNet 上训练了 90 个 epochs 得到 YOLOv5-cls 分类模型,我们训练了 ResNet 和 EfficientNet 模型以及相同的默认训练设置以进行比较。我们将所有模型导出到 ONNX FP32 以进行 CPU 速度测试,并导出到 TensorRT FP16 以进行 GPU 速度测试。为了便于重现,我们在 Google 上进行了所有速度测试 [Colab Pro](https://colab.research.google.com/signup) 。
+
+| 模型 | 尺寸
(像素) | acc
top1 | acc
top5 | 训练时长
90 epochs
4xA100(小时) | 推理速度
ONNX CPU
(ms) | 推理速度
TensorRT V100
(ms) | 参数
(M) | FLOPs
@640 (B) |
+| -------------------------------------------------------------------------------------------------- | --------------- | ---------------- | ---------------- | ------------------------------------ | ----------------------------- | ---------------------------------- | -------------- | ---------------------- |
+| [YOLOv5n-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-cls.pt) | 224 | 64.6 | 85.4 | 7:59 | **3.3** | **0.5** | **2.5** | **0.5** |
+| [YOLOv5s-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-cls.pt) | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 |
+| [YOLOv5m-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-cls.pt) | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 |
+| [YOLOv5l-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-cls.pt) | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 |
+| [YOLOv5x-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-cls.pt) | 224 | **79.0** | **94.4** | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 |
+| | | | | | | | | |
+| [ResNet18](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet18.pt) | 224 | 70.3 | 89.5 | **6:47** | 11.2 | 0.5 | 11.7 | 3.7 |
+| [Resnetzch](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet34.pt) | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 |
+| [ResNet50](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet50.pt) | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 |
+| [ResNet101](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet101.pt) | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 |
+| | | | | | | | | |
+| [EfficientNet_b0](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b0.pt) | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 |
+| [EfficientNet_b1](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b1.pt) | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 |
+| [EfficientNet_b2](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b2.pt) | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 |
+| [EfficientNet_b3](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b3.pt) | 224 | 77.7 | 94.0 | 19:19 | 18.9 | 1.9 | 12.2 | 2.4 |
+
+
+ Table Notes (点击以展开)
+
+- 所有模型都使用 SGD 优化器训练 90 个 epochs,都使用 `lr0=0.001` 和 `weight_decay=5e-5` 参数, 图像大小为 224 ,且都使用默认设置。
训练 log 可以查看 https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2
+- **准确性**都在单模型单尺度上计算,数据集使用 [ImageNet-1k](https://www.image-net.org/index.php) 。
复现命令 `python classify/val.py --data ../datasets/imagenet --img 224`
+- **推理速度**是使用 100 个推理图像进行平均得到,测试环境使用谷歌 [Colab Pro](https://colab.research.google.com/signup) V100 高 RAM 实例。
复现命令 `python classify/val.py --data ../datasets/imagenet --img 224 --batch 1`
+- **模型导出**到 FP32 的 ONNX 和 FP16 的 TensorRT 使用 `export.py` 。
复现命令 `python export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224`
+
+
+
+
+ 分类训练示例
+
+### 训练
+
+YOLOv5 分类训练支持自动下载 MNIST、Fashion-MNIST、CIFAR10、CIFAR100、Imagenette、Imagewoof 和 ImageNet 数据集,命令中使用 `--data` 即可。 MNIST 示例 `--data mnist` 。
+
+```bash
+# 单 GPU
+python classify/train.py --model yolov5s-cls.pt --data cifar100 --epochs 5 --img 224 --batch 128
+
+# 多 GPU, DDP 模式
+python -m torch.distributed.run --nproc_per_node 4 --master_port 1 classify/train.py --model yolov5s-cls.pt --data imagenet --epochs 5 --img 224 --device 0,1,2,3
+```
+
+### 验证
+
+在 ImageNet-1k 数据集上验证 YOLOv5m-cls 的准确性:
+
+```bash
+bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
+python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate
+```
+
+### 预测
+
+使用预训练的 YOLOv5s-cls.pt 来预测 bus.jpg:
+
+```bash
+python classify/predict.py --weights yolov5s-cls.pt --source data/images/bus.jpg
+```
+
+```python
+model = torch.hub.load(
+ "ultralytics/yolov5", "custom", "yolov5s-cls.pt"
+) # load from PyTorch Hub
+```
+
+### 模型导出
+
+将一组经过训练的 YOLOv5s-cls、ResNet 和 EfficientNet 模型导出到 ONNX 和 TensorRT:
+
+```bash
+python export.py --weights yolov5s-cls.pt resnet50.pt efficientnet_b0.pt --include onnx engine --img 224
+```
+
+
+
+## 环境
+
+使用下面我们经过验证的环境,在几秒钟内开始使用 YOLOv5 。单击下面的图标了解详细信息。
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
贡献
+
+我们喜欢您的意见或建议!我们希望尽可能简单和透明地为 YOLOv5 做出贡献。请看我们的 [投稿指南](https://docs.ultralytics.com/help/contributing/),并填写 [YOLOv5调查](https://ultralytics.com/survey?utm_source=github&utm_medium=social&utm_campaign=Survey) 向我们发送您的体验反馈。感谢我们所有的贡献者!
+
+
+
+
+
+
+## License
+
+YOLOv5 在两种不同的 License 下可用:
+
+- **AGPL-3.0 License**: 查看 [License](https://github.com/ultralytics/yolov5/blob/master/LICENSE) 文件的详细信息。
+- **企业License**:在没有 AGPL-3.0 开源要求的情况下为商业产品开发提供更大的灵活性。典型用例是将 Ultralytics 软件和 AI 模型嵌入到商业产品和应用程序中。在以下位置申请企业许可证 [Ultralytics 许可](https://ultralytics.com/license) 。
+
+## 联系我们
+
+对于 YOLOv5 的错误报告和功能请求,请访问 [GitHub Issues](https://github.com/ultralytics/yolov5/issues),并加入我们的 [Discord](https://discord.gg/n6cFeSPZdD) 社区进行问题和讨论!
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\n",
+ "\n",
+ "
\n",
+ " 
\n",
+ "\n",
+ "\n",
+ "
\n",
+ "

\n",
+ "

\n",
+ "

\n",
+ "
\n",
+ "\n",
+ "This
YOLOv5 🚀 notebook by
Ultralytics presents simple train, validate and predict examples to help start your AI adventure.
See
GitHub for community support or
contact us for professional support.\n",
+ "\n",
+ "
 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [Imagenet](https://image-net.org/) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "WQPtK1QYVaD_",
+ "outputId": "20fc0630-141e-4a90-ea06-342cbd7ce496"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "--2022-11-22 19:53:40-- https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar\n",
+ "Resolving image-net.org (image-net.org)... 171.64.68.16\n",
+ "Connecting to image-net.org (image-net.org)|171.64.68.16|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 6744924160 (6.3G) [application/x-tar]\n",
+ "Saving to: ‘ILSVRC2012_img_val.tar’\n",
+ "\n",
+ "ILSVRC2012_img_val. 100%[===================>] 6.28G 16.1MB/s in 10m 52s \n",
+ "\n",
+ "2022-11-22 20:04:32 (9.87 MB/s) - ‘ILSVRC2012_img_val.tar’ saved [6744924160/6744924160]\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Download Imagenet val (6.3G, 50000 images)\n",
+ "!bash data/scripts/get_imagenet.sh --val"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "X58w8JLpMnjH",
+ "outputId": "41843132-98e2-4c25-d474-4cd7b246fb8e"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mclassify/val: \u001b[0mdata=../datasets/imagenet, weights=['yolov5s-cls.pt'], batch_size=128, imgsz=224, device=, workers=8, verbose=True, project=runs/val-cls, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-3-g61ebf5e Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "Model summary: 117 layers, 5447688 parameters, 0 gradients, 11.4 GFLOPs\n",
+ "validating: 100% 391/391 [04:57<00:00, 1.31it/s]\n",
+ " Class Images top1_acc top5_acc\n",
+ " all 50000 0.715 0.902\n",
+ " tench 50 0.94 0.98\n",
+ " goldfish 50 0.88 0.92\n",
+ " great white shark 50 0.78 0.96\n",
+ " tiger shark 50 0.68 0.96\n",
+ " hammerhead shark 50 0.82 0.92\n",
+ " electric ray 50 0.76 0.9\n",
+ " stingray 50 0.7 0.9\n",
+ " cock 50 0.78 0.92\n",
+ " hen 50 0.84 0.96\n",
+ " ostrich 50 0.98 1\n",
+ " brambling 50 0.9 0.96\n",
+ " goldfinch 50 0.92 0.98\n",
+ " house finch 50 0.88 0.96\n",
+ " junco 50 0.94 0.98\n",
+ " indigo bunting 50 0.86 0.88\n",
+ " American robin 50 0.9 0.96\n",
+ " bulbul 50 0.84 0.96\n",
+ " jay 50 0.9 0.96\n",
+ " magpie 50 0.84 0.96\n",
+ " chickadee 50 0.9 1\n",
+ " American dipper 50 0.82 0.92\n",
+ " kite 50 0.76 0.94\n",
+ " bald eagle 50 0.92 1\n",
+ " vulture 50 0.96 1\n",
+ " great grey owl 50 0.94 0.98\n",
+ " fire salamander 50 0.96 0.98\n",
+ " smooth newt 50 0.58 0.94\n",
+ " newt 50 0.74 0.9\n",
+ " spotted salamander 50 0.86 0.94\n",
+ " axolotl 50 0.86 0.96\n",
+ " American bullfrog 50 0.78 0.92\n",
+ " tree frog 50 0.84 0.96\n",
+ " tailed frog 50 0.48 0.8\n",
+ " loggerhead sea turtle 50 0.68 0.94\n",
+ " leatherback sea turtle 50 0.5 0.8\n",
+ " mud turtle 50 0.64 0.84\n",
+ " terrapin 50 0.52 0.98\n",
+ " box turtle 50 0.84 0.98\n",
+ " banded gecko 50 0.7 0.88\n",
+ " green iguana 50 0.76 0.94\n",
+ " Carolina anole 50 0.58 0.96\n",
+ "desert grassland whiptail lizard 50 0.82 0.94\n",
+ " agama 50 0.74 0.92\n",
+ " frilled-necked lizard 50 0.84 0.86\n",
+ " alligator lizard 50 0.58 0.78\n",
+ " Gila monster 50 0.72 0.8\n",
+ " European green lizard 50 0.42 0.9\n",
+ " chameleon 50 0.76 0.84\n",
+ " Komodo dragon 50 0.86 0.96\n",
+ " Nile crocodile 50 0.7 0.84\n",
+ " American alligator 50 0.76 0.96\n",
+ " triceratops 50 0.9 0.94\n",
+ " worm snake 50 0.76 0.88\n",
+ " ring-necked snake 50 0.8 0.92\n",
+ " eastern hog-nosed snake 50 0.58 0.88\n",
+ " smooth green snake 50 0.6 0.94\n",
+ " kingsnake 50 0.82 0.9\n",
+ " garter snake 50 0.88 0.94\n",
+ " water snake 50 0.7 0.94\n",
+ " vine snake 50 0.66 0.76\n",
+ " night snake 50 0.34 0.82\n",
+ " boa constrictor 50 0.8 0.96\n",
+ " African rock python 50 0.48 0.76\n",
+ " Indian cobra 50 0.82 0.94\n",
+ " green mamba 50 0.54 0.86\n",
+ " sea snake 50 0.62 0.9\n",
+ " Saharan horned viper 50 0.56 0.86\n",
+ "eastern diamondback rattlesnake 50 0.6 0.86\n",
+ " sidewinder 50 0.28 0.86\n",
+ " trilobite 50 0.98 0.98\n",
+ " harvestman 50 0.86 0.94\n",
+ " scorpion 50 0.86 0.94\n",
+ " yellow garden spider 50 0.92 0.96\n",
+ " barn spider 50 0.38 0.98\n",
+ " European garden spider 50 0.62 0.98\n",
+ " southern black widow 50 0.88 0.94\n",
+ " tarantula 50 0.94 1\n",
+ " wolf spider 50 0.82 0.92\n",
+ " tick 50 0.74 0.84\n",
+ " centipede 50 0.68 0.82\n",
+ " black grouse 50 0.88 0.98\n",
+ " ptarmigan 50 0.78 0.94\n",
+ " ruffed grouse 50 0.88 1\n",
+ " prairie grouse 50 0.92 1\n",
+ " peacock 50 0.88 0.9\n",
+ " quail 50 0.9 0.94\n",
+ " partridge 50 0.74 0.96\n",
+ " grey parrot 50 0.9 0.96\n",
+ " macaw 50 0.88 0.98\n",
+ "sulphur-crested cockatoo 50 0.86 0.92\n",
+ " lorikeet 50 0.96 1\n",
+ " coucal 50 0.82 0.88\n",
+ " bee eater 50 0.96 0.98\n",
+ " hornbill 50 0.9 0.96\n",
+ " hummingbird 50 0.88 0.96\n",
+ " jacamar 50 0.92 0.94\n",
+ " toucan 50 0.84 0.94\n",
+ " duck 50 0.76 0.94\n",
+ " red-breasted merganser 50 0.86 0.96\n",
+ " goose 50 0.74 0.96\n",
+ " black swan 50 0.94 0.98\n",
+ " tusker 50 0.54 0.92\n",
+ " echidna 50 0.98 1\n",
+ " platypus 50 0.72 0.84\n",
+ " wallaby 50 0.78 0.88\n",
+ " koala 50 0.84 0.92\n",
+ " wombat 50 0.78 0.84\n",
+ " jellyfish 50 0.88 0.96\n",
+ " sea anemone 50 0.72 0.9\n",
+ " brain coral 50 0.88 0.96\n",
+ " flatworm 50 0.8 0.98\n",
+ " nematode 50 0.86 0.9\n",
+ " conch 50 0.74 0.88\n",
+ " snail 50 0.78 0.88\n",
+ " slug 50 0.74 0.82\n",
+ " sea slug 50 0.88 0.98\n",
+ " chiton 50 0.88 0.98\n",
+ " chambered nautilus 50 0.88 0.92\n",
+ " Dungeness crab 50 0.78 0.94\n",
+ " rock crab 50 0.68 0.86\n",
+ " fiddler crab 50 0.64 0.86\n",
+ " red king crab 50 0.76 0.96\n",
+ " American lobster 50 0.78 0.96\n",
+ " spiny lobster 50 0.74 0.88\n",
+ " crayfish 50 0.56 0.86\n",
+ " hermit crab 50 0.78 0.96\n",
+ " isopod 50 0.66 0.78\n",
+ " white stork 50 0.88 0.96\n",
+ " black stork 50 0.84 0.98\n",
+ " spoonbill 50 0.96 1\n",
+ " flamingo 50 0.94 1\n",
+ " little blue heron 50 0.92 0.98\n",
+ " great egret 50 0.9 0.96\n",
+ " bittern 50 0.86 0.94\n",
+ " crane (bird) 50 0.62 0.9\n",
+ " limpkin 50 0.98 1\n",
+ " common gallinule 50 0.92 0.96\n",
+ " American coot 50 0.9 0.98\n",
+ " bustard 50 0.92 0.96\n",
+ " ruddy turnstone 50 0.94 1\n",
+ " dunlin 50 0.86 0.94\n",
+ " common redshank 50 0.9 0.96\n",
+ " dowitcher 50 0.84 0.96\n",
+ " oystercatcher 50 0.86 0.94\n",
+ " pelican 50 0.92 0.96\n",
+ " king penguin 50 0.88 0.96\n",
+ " albatross 50 0.9 1\n",
+ " grey whale 50 0.84 0.92\n",
+ " killer whale 50 0.92 1\n",
+ " dugong 50 0.84 0.96\n",
+ " sea lion 50 0.82 0.92\n",
+ " Chihuahua 50 0.66 0.84\n",
+ " Japanese Chin 50 0.72 0.98\n",
+ " Maltese 50 0.76 0.94\n",
+ " Pekingese 50 0.84 0.94\n",
+ " Shih Tzu 50 0.74 0.96\n",
+ " King Charles Spaniel 50 0.88 0.98\n",
+ " Papillon 50 0.86 0.94\n",
+ " toy terrier 50 0.48 0.94\n",
+ " Rhodesian Ridgeback 50 0.76 0.98\n",
+ " Afghan Hound 50 0.84 1\n",
+ " Basset Hound 50 0.8 0.92\n",
+ " Beagle 50 0.82 0.96\n",
+ " Bloodhound 50 0.48 0.72\n",
+ " Bluetick Coonhound 50 0.86 0.94\n",
+ " Black and Tan Coonhound 50 0.54 0.8\n",
+ "Treeing Walker Coonhound 50 0.66 0.98\n",
+ " English foxhound 50 0.32 0.84\n",
+ " Redbone Coonhound 50 0.62 0.94\n",
+ " borzoi 50 0.92 1\n",
+ " Irish Wolfhound 50 0.48 0.88\n",
+ " Italian Greyhound 50 0.76 0.98\n",
+ " Whippet 50 0.74 0.92\n",
+ " Ibizan Hound 50 0.6 0.86\n",
+ " Norwegian Elkhound 50 0.88 0.98\n",
+ " Otterhound 50 0.62 0.9\n",
+ " Saluki 50 0.72 0.92\n",
+ " Scottish Deerhound 50 0.86 0.98\n",
+ " Weimaraner 50 0.88 0.94\n",
+ "Staffordshire Bull Terrier 50 0.66 0.98\n",
+ "American Staffordshire Terrier 50 0.64 0.92\n",
+ " Bedlington Terrier 50 0.9 0.92\n",
+ " Border Terrier 50 0.86 0.92\n",
+ " Kerry Blue Terrier 50 0.78 0.98\n",
+ " Irish Terrier 50 0.7 0.96\n",
+ " Norfolk Terrier 50 0.68 0.9\n",
+ " Norwich Terrier 50 0.72 1\n",
+ " Yorkshire Terrier 50 0.66 0.9\n",
+ " Wire Fox Terrier 50 0.64 0.98\n",
+ " Lakeland Terrier 50 0.74 0.92\n",
+ " Sealyham Terrier 50 0.76 0.9\n",
+ " Airedale Terrier 50 0.82 0.92\n",
+ " Cairn Terrier 50 0.76 0.9\n",
+ " Australian Terrier 50 0.48 0.84\n",
+ " Dandie Dinmont Terrier 50 0.82 0.92\n",
+ " Boston Terrier 50 0.92 1\n",
+ " Miniature Schnauzer 50 0.68 0.9\n",
+ " Giant Schnauzer 50 0.72 0.98\n",
+ " Standard Schnauzer 50 0.74 1\n",
+ " Scottish Terrier 50 0.76 0.96\n",
+ " Tibetan Terrier 50 0.48 1\n",
+ "Australian Silky Terrier 50 0.66 0.96\n",
+ "Soft-coated Wheaten Terrier 50 0.74 0.96\n",
+ "West Highland White Terrier 50 0.88 0.96\n",
+ " Lhasa Apso 50 0.68 0.96\n",
+ " Flat-Coated Retriever 50 0.72 0.94\n",
+ " Curly-coated Retriever 50 0.82 0.94\n",
+ " Golden Retriever 50 0.86 0.94\n",
+ " Labrador Retriever 50 0.82 0.94\n",
+ "Chesapeake Bay Retriever 50 0.76 0.96\n",
+ "German Shorthaired Pointer 50 0.8 0.96\n",
+ " Vizsla 50 0.68 0.96\n",
+ " English Setter 50 0.7 1\n",
+ " Irish Setter 50 0.8 0.9\n",
+ " Gordon Setter 50 0.84 0.92\n",
+ " Brittany 50 0.84 0.96\n",
+ " Clumber Spaniel 50 0.92 0.96\n",
+ "English Springer Spaniel 50 0.88 1\n",
+ " Welsh Springer Spaniel 50 0.92 1\n",
+ " Cocker Spaniels 50 0.7 0.94\n",
+ " Sussex Spaniel 50 0.72 0.92\n",
+ " Irish Water Spaniel 50 0.88 0.98\n",
+ " Kuvasz 50 0.66 0.9\n",
+ " Schipperke 50 0.9 0.98\n",
+ " Groenendael 50 0.8 0.94\n",
+ " Malinois 50 0.86 0.98\n",
+ " Briard 50 0.52 0.8\n",
+ " Australian Kelpie 50 0.6 0.88\n",
+ " Komondor 50 0.88 0.94\n",
+ " Old English Sheepdog 50 0.94 0.98\n",
+ " Shetland Sheepdog 50 0.74 0.9\n",
+ " collie 50 0.6 0.96\n",
+ " Border Collie 50 0.74 0.96\n",
+ " Bouvier des Flandres 50 0.78 0.94\n",
+ " Rottweiler 50 0.88 0.96\n",
+ " German Shepherd Dog 50 0.8 0.98\n",
+ " Dobermann 50 0.68 0.96\n",
+ " Miniature Pinscher 50 0.76 0.88\n",
+ "Greater Swiss Mountain Dog 50 0.68 0.94\n",
+ " Bernese Mountain Dog 50 0.96 1\n",
+ " Appenzeller Sennenhund 50 0.22 1\n",
+ " Entlebucher Sennenhund 50 0.64 0.98\n",
+ " Boxer 50 0.7 0.92\n",
+ " Bullmastiff 50 0.78 0.98\n",
+ " Tibetan Mastiff 50 0.88 0.96\n",
+ " French Bulldog 50 0.84 0.94\n",
+ " Great Dane 50 0.54 0.9\n",
+ " St. Bernard 50 0.92 1\n",
+ " husky 50 0.46 0.98\n",
+ " Alaskan Malamute 50 0.76 0.96\n",
+ " Siberian Husky 50 0.46 0.98\n",
+ " Dalmatian 50 0.94 0.98\n",
+ " Affenpinscher 50 0.78 0.9\n",
+ " Basenji 50 0.92 0.94\n",
+ " pug 50 0.94 0.98\n",
+ " Leonberger 50 1 1\n",
+ " Newfoundland 50 0.78 0.96\n",
+ " Pyrenean Mountain Dog 50 0.78 0.96\n",
+ " Samoyed 50 0.96 1\n",
+ " Pomeranian 50 0.98 1\n",
+ " Chow Chow 50 0.9 0.96\n",
+ " Keeshond 50 0.88 0.94\n",
+ " Griffon Bruxellois 50 0.84 0.98\n",
+ " Pembroke Welsh Corgi 50 0.82 0.94\n",
+ " Cardigan Welsh Corgi 50 0.66 0.98\n",
+ " Toy Poodle 50 0.52 0.88\n",
+ " Miniature Poodle 50 0.52 0.92\n",
+ " Standard Poodle 50 0.8 1\n",
+ " Mexican hairless dog 50 0.88 0.98\n",
+ " grey wolf 50 0.82 0.92\n",
+ " Alaskan tundra wolf 50 0.78 0.98\n",
+ " red wolf 50 0.48 0.9\n",
+ " coyote 50 0.64 0.86\n",
+ " dingo 50 0.76 0.88\n",
+ " dhole 50 0.9 0.98\n",
+ " African wild dog 50 0.98 1\n",
+ " hyena 50 0.88 0.96\n",
+ " red fox 50 0.54 0.92\n",
+ " kit fox 50 0.72 0.98\n",
+ " Arctic fox 50 0.94 1\n",
+ " grey fox 50 0.7 0.94\n",
+ " tabby cat 50 0.54 0.92\n",
+ " tiger cat 50 0.22 0.94\n",
+ " Persian cat 50 0.9 0.98\n",
+ " Siamese cat 50 0.96 1\n",
+ " Egyptian Mau 50 0.54 0.8\n",
+ " cougar 50 0.9 1\n",
+ " lynx 50 0.72 0.88\n",
+ " leopard 50 0.78 0.98\n",
+ " snow leopard 50 0.9 0.98\n",
+ " jaguar 50 0.7 0.94\n",
+ " lion 50 0.9 0.98\n",
+ " tiger 50 0.92 0.98\n",
+ " cheetah 50 0.94 0.98\n",
+ " brown bear 50 0.94 0.98\n",
+ " American black bear 50 0.8 1\n",
+ " polar bear 50 0.84 0.96\n",
+ " sloth bear 50 0.72 0.92\n",
+ " mongoose 50 0.7 0.92\n",
+ " meerkat 50 0.82 0.92\n",
+ " tiger beetle 50 0.92 0.94\n",
+ " ladybug 50 0.86 0.94\n",
+ " ground beetle 50 0.64 0.94\n",
+ " longhorn beetle 50 0.62 0.88\n",
+ " leaf beetle 50 0.64 0.98\n",
+ " dung beetle 50 0.86 0.98\n",
+ " rhinoceros beetle 50 0.86 0.94\n",
+ " weevil 50 0.9 1\n",
+ " fly 50 0.78 0.94\n",
+ " bee 50 0.68 0.94\n",
+ " ant 50 0.68 0.78\n",
+ " grasshopper 50 0.5 0.92\n",
+ " cricket 50 0.64 0.92\n",
+ " stick insect 50 0.64 0.92\n",
+ " cockroach 50 0.72 0.8\n",
+ " mantis 50 0.64 0.86\n",
+ " cicada 50 0.9 0.96\n",
+ " leafhopper 50 0.88 0.94\n",
+ " lacewing 50 0.78 0.92\n",
+ " dragonfly 50 0.82 0.98\n",
+ " damselfly 50 0.82 1\n",
+ " red admiral 50 0.94 0.96\n",
+ " ringlet 50 0.86 0.98\n",
+ " monarch butterfly 50 0.9 0.92\n",
+ " small white 50 0.9 1\n",
+ " sulphur butterfly 50 0.92 1\n",
+ "gossamer-winged butterfly 50 0.88 1\n",
+ " starfish 50 0.88 0.92\n",
+ " sea urchin 50 0.84 0.94\n",
+ " sea cucumber 50 0.66 0.84\n",
+ " cottontail rabbit 50 0.72 0.94\n",
+ " hare 50 0.84 0.96\n",
+ " Angora rabbit 50 0.94 0.98\n",
+ " hamster 50 0.96 1\n",
+ " porcupine 50 0.88 0.98\n",
+ " fox squirrel 50 0.76 0.94\n",
+ " marmot 50 0.92 0.96\n",
+ " beaver 50 0.78 0.94\n",
+ " guinea pig 50 0.78 0.94\n",
+ " common sorrel 50 0.96 0.98\n",
+ " zebra 50 0.94 0.96\n",
+ " pig 50 0.5 0.76\n",
+ " wild boar 50 0.84 0.96\n",
+ " warthog 50 0.84 0.96\n",
+ " hippopotamus 50 0.88 0.96\n",
+ " ox 50 0.48 0.94\n",
+ " water buffalo 50 0.78 0.94\n",
+ " bison 50 0.88 0.96\n",
+ " ram 50 0.58 0.92\n",
+ " bighorn sheep 50 0.66 1\n",
+ " Alpine ibex 50 0.92 0.98\n",
+ " hartebeest 50 0.94 1\n",
+ " impala 50 0.82 0.96\n",
+ " gazelle 50 0.7 0.96\n",
+ " dromedary 50 0.9 1\n",
+ " llama 50 0.82 0.94\n",
+ " weasel 50 0.44 0.92\n",
+ " mink 50 0.78 0.96\n",
+ " European polecat 50 0.46 0.9\n",
+ " black-footed ferret 50 0.68 0.96\n",
+ " otter 50 0.66 0.88\n",
+ " skunk 50 0.96 0.96\n",
+ " badger 50 0.86 0.92\n",
+ " armadillo 50 0.88 0.9\n",
+ " three-toed sloth 50 0.96 1\n",
+ " orangutan 50 0.78 0.92\n",
+ " gorilla 50 0.82 0.94\n",
+ " chimpanzee 50 0.84 0.94\n",
+ " gibbon 50 0.76 0.86\n",
+ " siamang 50 0.68 0.94\n",
+ " guenon 50 0.8 0.94\n",
+ " patas monkey 50 0.62 0.82\n",
+ " baboon 50 0.9 0.98\n",
+ " macaque 50 0.8 0.86\n",
+ " langur 50 0.6 0.82\n",
+ " black-and-white colobus 50 0.86 0.9\n",
+ " proboscis monkey 50 1 1\n",
+ " marmoset 50 0.74 0.98\n",
+ " white-headed capuchin 50 0.72 0.9\n",
+ " howler monkey 50 0.86 0.94\n",
+ " titi 50 0.5 0.9\n",
+ "Geoffroy's spider monkey 50 0.42 0.8\n",
+ " common squirrel monkey 50 0.76 0.92\n",
+ " ring-tailed lemur 50 0.72 0.94\n",
+ " indri 50 0.9 0.96\n",
+ " Asian elephant 50 0.58 0.92\n",
+ " African bush elephant 50 0.7 0.98\n",
+ " red panda 50 0.94 0.94\n",
+ " giant panda 50 0.94 0.98\n",
+ " snoek 50 0.74 0.9\n",
+ " eel 50 0.6 0.84\n",
+ " coho salmon 50 0.84 0.96\n",
+ " rock beauty 50 0.88 0.98\n",
+ " clownfish 50 0.78 0.98\n",
+ " sturgeon 50 0.68 0.94\n",
+ " garfish 50 0.62 0.8\n",
+ " lionfish 50 0.96 0.96\n",
+ " pufferfish 50 0.88 0.96\n",
+ " abacus 50 0.74 0.88\n",
+ " abaya 50 0.84 0.92\n",
+ " academic gown 50 0.42 0.86\n",
+ " accordion 50 0.8 0.9\n",
+ " acoustic guitar 50 0.5 0.76\n",
+ " aircraft carrier 50 0.8 0.96\n",
+ " airliner 50 0.92 1\n",
+ " airship 50 0.76 0.82\n",
+ " altar 50 0.64 0.98\n",
+ " ambulance 50 0.88 0.98\n",
+ " amphibious vehicle 50 0.64 0.94\n",
+ " analog clock 50 0.52 0.92\n",
+ " apiary 50 0.82 0.96\n",
+ " apron 50 0.7 0.84\n",
+ " waste container 50 0.4 0.8\n",
+ " assault rifle 50 0.42 0.84\n",
+ " backpack 50 0.34 0.64\n",
+ " bakery 50 0.4 0.68\n",
+ " balance beam 50 0.8 0.98\n",
+ " balloon 50 0.86 0.96\n",
+ " ballpoint pen 50 0.52 0.96\n",
+ " Band-Aid 50 0.7 0.9\n",
+ " banjo 50 0.84 1\n",
+ " baluster 50 0.68 0.94\n",
+ " barbell 50 0.56 0.9\n",
+ " barber chair 50 0.7 0.92\n",
+ " barbershop 50 0.54 0.86\n",
+ " barn 50 0.96 0.96\n",
+ " barometer 50 0.84 0.98\n",
+ " barrel 50 0.56 0.88\n",
+ " wheelbarrow 50 0.66 0.88\n",
+ " baseball 50 0.74 0.98\n",
+ " basketball 50 0.88 0.98\n",
+ " bassinet 50 0.66 0.92\n",
+ " bassoon 50 0.74 0.98\n",
+ " swimming cap 50 0.62 0.88\n",
+ " bath towel 50 0.54 0.78\n",
+ " bathtub 50 0.4 0.88\n",
+ " station wagon 50 0.66 0.84\n",
+ " lighthouse 50 0.78 0.94\n",
+ " beaker 50 0.52 0.68\n",
+ " military cap 50 0.84 0.96\n",
+ " beer bottle 50 0.66 0.88\n",
+ " beer glass 50 0.6 0.84\n",
+ " bell-cot 50 0.56 0.96\n",
+ " bib 50 0.58 0.82\n",
+ " tandem bicycle 50 0.86 0.96\n",
+ " bikini 50 0.56 0.88\n",
+ " ring binder 50 0.64 0.84\n",
+ " binoculars 50 0.54 0.78\n",
+ " birdhouse 50 0.86 0.94\n",
+ " boathouse 50 0.74 0.92\n",
+ " bobsleigh 50 0.92 0.96\n",
+ " bolo tie 50 0.8 0.94\n",
+ " poke bonnet 50 0.64 0.86\n",
+ " bookcase 50 0.66 0.92\n",
+ " bookstore 50 0.62 0.88\n",
+ " bottle cap 50 0.58 0.7\n",
+ " bow 50 0.72 0.86\n",
+ " bow tie 50 0.7 0.9\n",
+ " brass 50 0.92 0.96\n",
+ " bra 50 0.5 0.7\n",
+ " breakwater 50 0.62 0.86\n",
+ " breastplate 50 0.4 0.9\n",
+ " broom 50 0.6 0.86\n",
+ " bucket 50 0.66 0.8\n",
+ " buckle 50 0.5 0.68\n",
+ " bulletproof vest 50 0.5 0.78\n",
+ " high-speed train 50 0.94 0.96\n",
+ " butcher shop 50 0.74 0.94\n",
+ " taxicab 50 0.64 0.86\n",
+ " cauldron 50 0.44 0.66\n",
+ " candle 50 0.48 0.74\n",
+ " cannon 50 0.88 0.94\n",
+ " canoe 50 0.94 1\n",
+ " can opener 50 0.66 0.86\n",
+ " cardigan 50 0.68 0.8\n",
+ " car mirror 50 0.94 0.96\n",
+ " carousel 50 0.94 0.98\n",
+ " tool kit 50 0.56 0.78\n",
+ " carton 50 0.42 0.7\n",
+ " car wheel 50 0.38 0.74\n",
+ "automated teller machine 50 0.76 0.94\n",
+ " cassette 50 0.52 0.8\n",
+ " cassette player 50 0.28 0.9\n",
+ " castle 50 0.78 0.88\n",
+ " catamaran 50 0.78 1\n",
+ " CD player 50 0.52 0.82\n",
+ " cello 50 0.82 1\n",
+ " mobile phone 50 0.68 0.86\n",
+ " chain 50 0.38 0.66\n",
+ " chain-link fence 50 0.7 0.84\n",
+ " chain mail 50 0.64 0.9\n",
+ " chainsaw 50 0.84 0.92\n",
+ " chest 50 0.68 0.92\n",
+ " chiffonier 50 0.26 0.64\n",
+ " chime 50 0.62 0.84\n",
+ " china cabinet 50 0.82 0.96\n",
+ " Christmas stocking 50 0.92 0.94\n",
+ " church 50 0.62 0.9\n",
+ " movie theater 50 0.58 0.88\n",
+ " cleaver 50 0.32 0.62\n",
+ " cliff dwelling 50 0.88 1\n",
+ " cloak 50 0.32 0.64\n",
+ " clogs 50 0.58 0.88\n",
+ " cocktail shaker 50 0.62 0.7\n",
+ " coffee mug 50 0.44 0.72\n",
+ " coffeemaker 50 0.64 0.92\n",
+ " coil 50 0.66 0.84\n",
+ " combination lock 50 0.64 0.84\n",
+ " computer keyboard 50 0.7 0.82\n",
+ " confectionery store 50 0.54 0.86\n",
+ " container ship 50 0.82 0.98\n",
+ " convertible 50 0.78 0.98\n",
+ " corkscrew 50 0.82 0.92\n",
+ " cornet 50 0.46 0.88\n",
+ " cowboy boot 50 0.64 0.8\n",
+ " cowboy hat 50 0.64 0.82\n",
+ " cradle 50 0.38 0.8\n",
+ " crane (machine) 50 0.78 0.94\n",
+ " crash helmet 50 0.92 0.96\n",
+ " crate 50 0.52 0.82\n",
+ " infant bed 50 0.74 1\n",
+ " Crock Pot 50 0.78 0.9\n",
+ " croquet ball 50 0.9 0.96\n",
+ " crutch 50 0.46 0.7\n",
+ " cuirass 50 0.54 0.86\n",
+ " dam 50 0.74 0.92\n",
+ " desk 50 0.6 0.86\n",
+ " desktop computer 50 0.54 0.94\n",
+ " rotary dial telephone 50 0.88 0.94\n",
+ " diaper 50 0.68 0.84\n",
+ " digital clock 50 0.54 0.76\n",
+ " digital watch 50 0.58 0.86\n",
+ " dining table 50 0.76 0.9\n",
+ " dishcloth 50 0.94 1\n",
+ " dishwasher 50 0.44 0.78\n",
+ " disc brake 50 0.98 1\n",
+ " dock 50 0.54 0.94\n",
+ " dog sled 50 0.84 1\n",
+ " dome 50 0.72 0.92\n",
+ " doormat 50 0.56 0.82\n",
+ " drilling rig 50 0.84 0.96\n",
+ " drum 50 0.38 0.68\n",
+ " drumstick 50 0.56 0.72\n",
+ " dumbbell 50 0.62 0.9\n",
+ " Dutch oven 50 0.7 0.84\n",
+ " electric fan 50 0.82 0.86\n",
+ " electric guitar 50 0.62 0.84\n",
+ " electric locomotive 50 0.92 0.98\n",
+ " entertainment center 50 0.9 0.98\n",
+ " envelope 50 0.44 0.86\n",
+ " espresso machine 50 0.72 0.94\n",
+ " face powder 50 0.7 0.92\n",
+ " feather boa 50 0.7 0.84\n",
+ " filing cabinet 50 0.88 0.98\n",
+ " fireboat 50 0.94 0.98\n",
+ " fire engine 50 0.84 0.9\n",
+ " fire screen sheet 50 0.62 0.76\n",
+ " flagpole 50 0.74 0.88\n",
+ " flute 50 0.36 0.72\n",
+ " folding chair 50 0.62 0.84\n",
+ " football helmet 50 0.86 0.94\n",
+ " forklift 50 0.8 0.92\n",
+ " fountain 50 0.84 0.94\n",
+ " fountain pen 50 0.76 0.92\n",
+ " four-poster bed 50 0.78 0.94\n",
+ " freight car 50 0.96 1\n",
+ " French horn 50 0.76 0.92\n",
+ " frying pan 50 0.36 0.78\n",
+ " fur coat 50 0.84 0.96\n",
+ " garbage truck 50 0.9 0.98\n",
+ " gas mask 50 0.84 0.92\n",
+ " gas pump 50 0.9 0.98\n",
+ " goblet 50 0.68 0.82\n",
+ " go-kart 50 0.9 1\n",
+ " golf ball 50 0.84 0.9\n",
+ " golf cart 50 0.78 0.86\n",
+ " gondola 50 0.98 0.98\n",
+ " gong 50 0.74 0.92\n",
+ " gown 50 0.62 0.96\n",
+ " grand piano 50 0.7 0.96\n",
+ " greenhouse 50 0.8 0.98\n",
+ " grille 50 0.72 0.9\n",
+ " grocery store 50 0.66 0.94\n",
+ " guillotine 50 0.86 0.92\n",
+ " barrette 50 0.52 0.66\n",
+ " hair spray 50 0.5 0.74\n",
+ " half-track 50 0.78 0.9\n",
+ " hammer 50 0.56 0.76\n",
+ " hamper 50 0.64 0.84\n",
+ " hair dryer 50 0.56 0.74\n",
+ " hand-held computer 50 0.42 0.86\n",
+ " handkerchief 50 0.78 0.94\n",
+ " hard disk drive 50 0.76 0.84\n",
+ " harmonica 50 0.7 0.88\n",
+ " harp 50 0.88 0.96\n",
+ " harvester 50 0.78 1\n",
+ " hatchet 50 0.54 0.74\n",
+ " holster 50 0.66 0.84\n",
+ " home theater 50 0.64 0.94\n",
+ " honeycomb 50 0.56 0.88\n",
+ " hook 50 0.3 0.6\n",
+ " hoop skirt 50 0.64 0.86\n",
+ " horizontal bar 50 0.68 0.98\n",
+ " horse-drawn vehicle 50 0.88 0.94\n",
+ " hourglass 50 0.88 0.96\n",
+ " iPod 50 0.76 0.94\n",
+ " clothes iron 50 0.82 0.88\n",
+ " jack-o'-lantern 50 0.98 0.98\n",
+ " jeans 50 0.68 0.84\n",
+ " jeep 50 0.72 0.9\n",
+ " T-shirt 50 0.72 0.96\n",
+ " jigsaw puzzle 50 0.84 0.94\n",
+ " pulled rickshaw 50 0.86 0.94\n",
+ " joystick 50 0.8 0.9\n",
+ " kimono 50 0.84 0.96\n",
+ " knee pad 50 0.62 0.88\n",
+ " knot 50 0.66 0.8\n",
+ " lab coat 50 0.8 0.96\n",
+ " ladle 50 0.36 0.64\n",
+ " lampshade 50 0.48 0.84\n",
+ " laptop computer 50 0.26 0.88\n",
+ " lawn mower 50 0.78 0.96\n",
+ " lens cap 50 0.46 0.72\n",
+ " paper knife 50 0.26 0.5\n",
+ " library 50 0.54 0.9\n",
+ " lifeboat 50 0.92 0.98\n",
+ " lighter 50 0.56 0.78\n",
+ " limousine 50 0.76 0.92\n",
+ " ocean liner 50 0.88 0.94\n",
+ " lipstick 50 0.74 0.9\n",
+ " slip-on shoe 50 0.74 0.92\n",
+ " lotion 50 0.5 0.86\n",
+ " speaker 50 0.52 0.68\n",
+ " loupe 50 0.32 0.52\n",
+ " sawmill 50 0.72 0.9\n",
+ " magnetic compass 50 0.52 0.82\n",
+ " mail bag 50 0.68 0.92\n",
+ " mailbox 50 0.82 0.92\n",
+ " tights 50 0.22 0.94\n",
+ " tank suit 50 0.24 0.9\n",
+ " manhole cover 50 0.96 0.98\n",
+ " maraca 50 0.74 0.9\n",
+ " marimba 50 0.84 0.94\n",
+ " mask 50 0.44 0.82\n",
+ " match 50 0.66 0.9\n",
+ " maypole 50 0.96 1\n",
+ " maze 50 0.8 0.96\n",
+ " measuring cup 50 0.54 0.76\n",
+ " medicine chest 50 0.6 0.84\n",
+ " megalith 50 0.8 0.92\n",
+ " microphone 50 0.52 0.7\n",
+ " microwave oven 50 0.48 0.72\n",
+ " military uniform 50 0.62 0.84\n",
+ " milk can 50 0.68 0.82\n",
+ " minibus 50 0.7 1\n",
+ " miniskirt 50 0.46 0.76\n",
+ " minivan 50 0.38 0.8\n",
+ " missile 50 0.4 0.84\n",
+ " mitten 50 0.76 0.88\n",
+ " mixing bowl 50 0.8 0.92\n",
+ " mobile home 50 0.54 0.78\n",
+ " Model T 50 0.92 0.96\n",
+ " modem 50 0.58 0.86\n",
+ " monastery 50 0.44 0.9\n",
+ " monitor 50 0.4 0.86\n",
+ " moped 50 0.56 0.94\n",
+ " mortar 50 0.68 0.94\n",
+ " square academic cap 50 0.5 0.84\n",
+ " mosque 50 0.9 1\n",
+ " mosquito net 50 0.9 0.98\n",
+ " scooter 50 0.9 0.98\n",
+ " mountain bike 50 0.78 0.96\n",
+ " tent 50 0.88 0.96\n",
+ " computer mouse 50 0.42 0.82\n",
+ " mousetrap 50 0.76 0.88\n",
+ " moving van 50 0.4 0.72\n",
+ " muzzle 50 0.5 0.72\n",
+ " nail 50 0.68 0.74\n",
+ " neck brace 50 0.56 0.68\n",
+ " necklace 50 0.86 1\n",
+ " nipple 50 0.7 0.88\n",
+ " notebook computer 50 0.34 0.84\n",
+ " obelisk 50 0.8 0.92\n",
+ " oboe 50 0.6 0.84\n",
+ " ocarina 50 0.8 0.86\n",
+ " odometer 50 0.96 1\n",
+ " oil filter 50 0.58 0.82\n",
+ " organ 50 0.82 0.9\n",
+ " oscilloscope 50 0.9 0.96\n",
+ " overskirt 50 0.2 0.7\n",
+ " bullock cart 50 0.7 0.94\n",
+ " oxygen mask 50 0.46 0.84\n",
+ " packet 50 0.5 0.78\n",
+ " paddle 50 0.56 0.94\n",
+ " paddle wheel 50 0.86 0.96\n",
+ " padlock 50 0.74 0.78\n",
+ " paintbrush 50 0.62 0.8\n",
+ " pajamas 50 0.56 0.92\n",
+ " palace 50 0.64 0.96\n",
+ " pan flute 50 0.84 0.86\n",
+ " paper towel 50 0.66 0.84\n",
+ " parachute 50 0.92 0.94\n",
+ " parallel bars 50 0.62 0.96\n",
+ " park bench 50 0.74 0.9\n",
+ " parking meter 50 0.84 0.92\n",
+ " passenger car 50 0.5 0.82\n",
+ " patio 50 0.58 0.84\n",
+ " payphone 50 0.74 0.92\n",
+ " pedestal 50 0.52 0.9\n",
+ " pencil case 50 0.64 0.92\n",
+ " pencil sharpener 50 0.52 0.78\n",
+ " perfume 50 0.7 0.9\n",
+ " Petri dish 50 0.6 0.8\n",
+ " photocopier 50 0.88 0.98\n",
+ " plectrum 50 0.7 0.84\n",
+ " Pickelhaube 50 0.72 0.86\n",
+ " picket fence 50 0.84 0.94\n",
+ " pickup truck 50 0.64 0.92\n",
+ " pier 50 0.52 0.82\n",
+ " piggy bank 50 0.82 0.94\n",
+ " pill bottle 50 0.76 0.86\n",
+ " pillow 50 0.76 0.9\n",
+ " ping-pong ball 50 0.84 0.88\n",
+ " pinwheel 50 0.76 0.88\n",
+ " pirate ship 50 0.76 0.94\n",
+ " pitcher 50 0.46 0.84\n",
+ " hand plane 50 0.84 0.94\n",
+ " planetarium 50 0.88 0.98\n",
+ " plastic bag 50 0.36 0.62\n",
+ " plate rack 50 0.52 0.78\n",
+ " plow 50 0.78 0.88\n",
+ " plunger 50 0.42 0.7\n",
+ " Polaroid camera 50 0.84 0.92\n",
+ " pole 50 0.38 0.74\n",
+ " police van 50 0.76 0.94\n",
+ " poncho 50 0.58 0.86\n",
+ " billiard table 50 0.8 0.88\n",
+ " soda bottle 50 0.56 0.94\n",
+ " pot 50 0.78 0.92\n",
+ " potter's wheel 50 0.9 0.94\n",
+ " power drill 50 0.42 0.72\n",
+ " prayer rug 50 0.7 0.86\n",
+ " printer 50 0.54 0.86\n",
+ " prison 50 0.7 0.9\n",
+ " projectile 50 0.28 0.9\n",
+ " projector 50 0.62 0.84\n",
+ " hockey puck 50 0.92 0.96\n",
+ " punching bag 50 0.6 0.68\n",
+ " purse 50 0.42 0.78\n",
+ " quill 50 0.68 0.84\n",
+ " quilt 50 0.64 0.9\n",
+ " race car 50 0.72 0.92\n",
+ " racket 50 0.72 0.9\n",
+ " radiator 50 0.66 0.76\n",
+ " radio 50 0.64 0.92\n",
+ " radio telescope 50 0.9 0.96\n",
+ " rain barrel 50 0.8 0.98\n",
+ " recreational vehicle 50 0.84 0.94\n",
+ " reel 50 0.72 0.82\n",
+ " reflex camera 50 0.72 0.92\n",
+ " refrigerator 50 0.7 0.9\n",
+ " remote control 50 0.7 0.88\n",
+ " restaurant 50 0.5 0.66\n",
+ " revolver 50 0.82 1\n",
+ " rifle 50 0.38 0.7\n",
+ " rocking chair 50 0.62 0.84\n",
+ " rotisserie 50 0.88 0.92\n",
+ " eraser 50 0.54 0.76\n",
+ " rugby ball 50 0.86 0.94\n",
+ " ruler 50 0.68 0.86\n",
+ " running shoe 50 0.78 0.94\n",
+ " safe 50 0.82 0.92\n",
+ " safety pin 50 0.4 0.62\n",
+ " salt shaker 50 0.66 0.9\n",
+ " sandal 50 0.66 0.86\n",
+ " sarong 50 0.64 0.86\n",
+ " saxophone 50 0.66 0.88\n",
+ " scabbard 50 0.76 0.92\n",
+ " weighing scale 50 0.58 0.78\n",
+ " school bus 50 0.92 1\n",
+ " schooner 50 0.84 1\n",
+ " scoreboard 50 0.9 0.96\n",
+ " CRT screen 50 0.14 0.7\n",
+ " screw 50 0.9 0.98\n",
+ " screwdriver 50 0.3 0.58\n",
+ " seat belt 50 0.88 0.94\n",
+ " sewing machine 50 0.76 0.9\n",
+ " shield 50 0.56 0.82\n",
+ " shoe store 50 0.78 0.96\n",
+ " shoji 50 0.8 0.92\n",
+ " shopping basket 50 0.52 0.88\n",
+ " shopping cart 50 0.76 0.92\n",
+ " shovel 50 0.62 0.84\n",
+ " shower cap 50 0.7 0.84\n",
+ " shower curtain 50 0.64 0.82\n",
+ " ski 50 0.74 0.92\n",
+ " ski mask 50 0.72 0.88\n",
+ " sleeping bag 50 0.68 0.8\n",
+ " slide rule 50 0.72 0.88\n",
+ " sliding door 50 0.44 0.78\n",
+ " slot machine 50 0.94 0.98\n",
+ " snorkel 50 0.86 0.98\n",
+ " snowmobile 50 0.88 1\n",
+ " snowplow 50 0.84 0.98\n",
+ " soap dispenser 50 0.56 0.86\n",
+ " soccer ball 50 0.86 0.96\n",
+ " sock 50 0.62 0.76\n",
+ " solar thermal collector 50 0.72 0.96\n",
+ " sombrero 50 0.6 0.84\n",
+ " soup bowl 50 0.56 0.94\n",
+ " space bar 50 0.34 0.88\n",
+ " space heater 50 0.52 0.74\n",
+ " space shuttle 50 0.82 0.96\n",
+ " spatula 50 0.3 0.6\n",
+ " motorboat 50 0.86 1\n",
+ " spider web 50 0.7 0.9\n",
+ " spindle 50 0.86 0.98\n",
+ " sports car 50 0.6 0.94\n",
+ " spotlight 50 0.26 0.6\n",
+ " stage 50 0.68 0.86\n",
+ " steam locomotive 50 0.94 1\n",
+ " through arch bridge 50 0.84 0.96\n",
+ " steel drum 50 0.82 0.9\n",
+ " stethoscope 50 0.6 0.82\n",
+ " scarf 50 0.5 0.92\n",
+ " stone wall 50 0.76 0.9\n",
+ " stopwatch 50 0.58 0.9\n",
+ " stove 50 0.46 0.74\n",
+ " strainer 50 0.64 0.84\n",
+ " tram 50 0.88 0.96\n",
+ " stretcher 50 0.6 0.8\n",
+ " couch 50 0.8 0.96\n",
+ " stupa 50 0.88 0.88\n",
+ " submarine 50 0.72 0.92\n",
+ " suit 50 0.4 0.78\n",
+ " sundial 50 0.58 0.74\n",
+ " sunglass 50 0.14 0.58\n",
+ " sunglasses 50 0.28 0.58\n",
+ " sunscreen 50 0.32 0.7\n",
+ " suspension bridge 50 0.6 0.94\n",
+ " mop 50 0.74 0.92\n",
+ " sweatshirt 50 0.28 0.66\n",
+ " swimsuit 50 0.52 0.82\n",
+ " swing 50 0.76 0.84\n",
+ " switch 50 0.56 0.76\n",
+ " syringe 50 0.62 0.82\n",
+ " table lamp 50 0.6 0.88\n",
+ " tank 50 0.8 0.96\n",
+ " tape player 50 0.46 0.76\n",
+ " teapot 50 0.84 1\n",
+ " teddy bear 50 0.82 0.94\n",
+ " television 50 0.6 0.9\n",
+ " tennis ball 50 0.7 0.94\n",
+ " thatched roof 50 0.88 0.9\n",
+ " front curtain 50 0.8 0.92\n",
+ " thimble 50 0.6 0.8\n",
+ " threshing machine 50 0.56 0.88\n",
+ " throne 50 0.72 0.82\n",
+ " tile roof 50 0.72 0.94\n",
+ " toaster 50 0.66 0.84\n",
+ " tobacco shop 50 0.42 0.7\n",
+ " toilet seat 50 0.62 0.88\n",
+ " torch 50 0.64 0.84\n",
+ " totem pole 50 0.92 0.98\n",
+ " tow truck 50 0.62 0.88\n",
+ " toy store 50 0.6 0.94\n",
+ " tractor 50 0.76 0.98\n",
+ " semi-trailer truck 50 0.78 0.92\n",
+ " tray 50 0.46 0.64\n",
+ " trench coat 50 0.54 0.72\n",
+ " tricycle 50 0.72 0.94\n",
+ " trimaran 50 0.7 0.98\n",
+ " tripod 50 0.58 0.86\n",
+ " triumphal arch 50 0.92 0.98\n",
+ " trolleybus 50 0.9 1\n",
+ " trombone 50 0.54 0.88\n",
+ " tub 50 0.24 0.82\n",
+ " turnstile 50 0.84 0.94\n",
+ " typewriter keyboard 50 0.68 0.98\n",
+ " umbrella 50 0.52 0.7\n",
+ " unicycle 50 0.74 0.96\n",
+ " upright piano 50 0.76 0.9\n",
+ " vacuum cleaner 50 0.62 0.9\n",
+ " vase 50 0.5 0.78\n",
+ " vault 50 0.76 0.92\n",
+ " velvet 50 0.2 0.42\n",
+ " vending machine 50 0.9 1\n",
+ " vestment 50 0.54 0.82\n",
+ " viaduct 50 0.78 0.86\n",
+ " violin 50 0.68 0.78\n",
+ " volleyball 50 0.86 1\n",
+ " waffle iron 50 0.72 0.88\n",
+ " wall clock 50 0.54 0.88\n",
+ " wallet 50 0.52 0.9\n",
+ " wardrobe 50 0.68 0.88\n",
+ " military aircraft 50 0.9 0.98\n",
+ " sink 50 0.72 0.96\n",
+ " washing machine 50 0.78 0.94\n",
+ " water bottle 50 0.54 0.74\n",
+ " water jug 50 0.22 0.74\n",
+ " water tower 50 0.9 0.96\n",
+ " whiskey jug 50 0.64 0.74\n",
+ " whistle 50 0.72 0.84\n",
+ " wig 50 0.84 0.9\n",
+ " window screen 50 0.68 0.8\n",
+ " window shade 50 0.52 0.76\n",
+ " Windsor tie 50 0.22 0.66\n",
+ " wine bottle 50 0.42 0.82\n",
+ " wing 50 0.54 0.96\n",
+ " wok 50 0.46 0.82\n",
+ " wooden spoon 50 0.58 0.8\n",
+ " wool 50 0.32 0.82\n",
+ " split-rail fence 50 0.74 0.9\n",
+ " shipwreck 50 0.84 0.96\n",
+ " yawl 50 0.78 0.96\n",
+ " yurt 50 0.84 1\n",
+ " website 50 0.98 1\n",
+ " comic book 50 0.62 0.9\n",
+ " crossword 50 0.84 0.88\n",
+ " traffic sign 50 0.78 0.9\n",
+ " traffic light 50 0.8 0.94\n",
+ " dust jacket 50 0.72 0.94\n",
+ " menu 50 0.82 0.96\n",
+ " plate 50 0.44 0.88\n",
+ " guacamole 50 0.8 0.92\n",
+ " consomme 50 0.54 0.88\n",
+ " hot pot 50 0.86 0.98\n",
+ " trifle 50 0.92 0.98\n",
+ " ice cream 50 0.68 0.94\n",
+ " ice pop 50 0.62 0.84\n",
+ " baguette 50 0.62 0.88\n",
+ " bagel 50 0.64 0.92\n",
+ " pretzel 50 0.72 0.88\n",
+ " cheeseburger 50 0.9 1\n",
+ " hot dog 50 0.74 0.94\n",
+ " mashed potato 50 0.74 0.9\n",
+ " cabbage 50 0.84 0.96\n",
+ " broccoli 50 0.9 0.96\n",
+ " cauliflower 50 0.82 1\n",
+ " zucchini 50 0.74 0.9\n",
+ " spaghetti squash 50 0.8 0.96\n",
+ " acorn squash 50 0.82 0.96\n",
+ " butternut squash 50 0.7 0.94\n",
+ " cucumber 50 0.6 0.96\n",
+ " artichoke 50 0.84 0.94\n",
+ " bell pepper 50 0.84 0.98\n",
+ " cardoon 50 0.88 0.94\n",
+ " mushroom 50 0.38 0.92\n",
+ " Granny Smith 50 0.9 0.96\n",
+ " strawberry 50 0.6 0.88\n",
+ " orange 50 0.7 0.92\n",
+ " lemon 50 0.78 0.98\n",
+ " fig 50 0.82 0.96\n",
+ " pineapple 50 0.86 0.96\n",
+ " banana 50 0.84 0.96\n",
+ " jackfruit 50 0.9 0.98\n",
+ " custard apple 50 0.86 0.96\n",
+ " pomegranate 50 0.82 0.98\n",
+ " hay 50 0.8 0.92\n",
+ " carbonara 50 0.88 0.94\n",
+ " chocolate syrup 50 0.46 0.84\n",
+ " dough 50 0.4 0.6\n",
+ " meatloaf 50 0.58 0.84\n",
+ " pizza 50 0.84 0.96\n",
+ " pot pie 50 0.68 0.9\n",
+ " burrito 50 0.8 0.98\n",
+ " red wine 50 0.54 0.82\n",
+ " espresso 50 0.64 0.88\n",
+ " cup 50 0.38 0.7\n",
+ " eggnog 50 0.38 0.7\n",
+ " alp 50 0.54 0.88\n",
+ " bubble 50 0.8 0.96\n",
+ " cliff 50 0.64 1\n",
+ " coral reef 50 0.72 0.96\n",
+ " geyser 50 0.94 1\n",
+ " lakeshore 50 0.54 0.88\n",
+ " promontory 50 0.58 0.94\n",
+ " shoal 50 0.6 0.96\n",
+ " seashore 50 0.44 0.78\n",
+ " valley 50 0.72 0.94\n",
+ " volcano 50 0.78 0.96\n",
+ " baseball player 50 0.72 0.94\n",
+ " bridegroom 50 0.72 0.88\n",
+ " scuba diver 50 0.8 1\n",
+ " rapeseed 50 0.94 0.98\n",
+ " daisy 50 0.96 0.98\n",
+ " yellow lady's slipper 50 1 1\n",
+ " corn 50 0.4 0.88\n",
+ " acorn 50 0.92 0.98\n",
+ " rose hip 50 0.92 0.98\n",
+ " horse chestnut seed 50 0.94 0.98\n",
+ " coral fungus 50 0.96 0.96\n",
+ " agaric 50 0.82 0.94\n",
+ " gyromitra 50 0.98 1\n",
+ " stinkhorn mushroom 50 0.8 0.94\n",
+ " earth star 50 0.98 1\n",
+ " hen-of-the-woods 50 0.8 0.96\n",
+ " bolete 50 0.74 0.94\n",
+ " ear 50 0.48 0.94\n",
+ " toilet paper 50 0.36 0.68\n",
+ "Speed: 0.1ms pre-process, 0.3ms inference, 0.0ms post-process per image at shape (1, 3, 224, 224)\n",
+ "Results saved to \u001b[1mruns/val-cls/exp\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Validate YOLOv5s on Imagenet val\n",
+ "!python classify/val.py --weights yolov5s-cls.pt --data ../datasets/imagenet --img 224 --half"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [Imagenet](https://image-net.org/) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "WQPtK1QYVaD_",
+ "outputId": "20fc0630-141e-4a90-ea06-342cbd7ce496"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "--2022-11-22 19:53:40-- https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar\n",
+ "Resolving image-net.org (image-net.org)... 171.64.68.16\n",
+ "Connecting to image-net.org (image-net.org)|171.64.68.16|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 6744924160 (6.3G) [application/x-tar]\n",
+ "Saving to: ‘ILSVRC2012_img_val.tar’\n",
+ "\n",
+ "ILSVRC2012_img_val. 100%[===================>] 6.28G 16.1MB/s in 10m 52s \n",
+ "\n",
+ "2022-11-22 20:04:32 (9.87 MB/s) - ‘ILSVRC2012_img_val.tar’ saved [6744924160/6744924160]\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Download Imagenet val (6.3G, 50000 images)\n",
+ "!bash data/scripts/get_imagenet.sh --val"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "X58w8JLpMnjH",
+ "outputId": "41843132-98e2-4c25-d474-4cd7b246fb8e"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mclassify/val: \u001b[0mdata=../datasets/imagenet, weights=['yolov5s-cls.pt'], batch_size=128, imgsz=224, device=, workers=8, verbose=True, project=runs/val-cls, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-3-g61ebf5e Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "Model summary: 117 layers, 5447688 parameters, 0 gradients, 11.4 GFLOPs\n",
+ "validating: 100% 391/391 [04:57<00:00, 1.31it/s]\n",
+ " Class Images top1_acc top5_acc\n",
+ " all 50000 0.715 0.902\n",
+ " tench 50 0.94 0.98\n",
+ " goldfish 50 0.88 0.92\n",
+ " great white shark 50 0.78 0.96\n",
+ " tiger shark 50 0.68 0.96\n",
+ " hammerhead shark 50 0.82 0.92\n",
+ " electric ray 50 0.76 0.9\n",
+ " stingray 50 0.7 0.9\n",
+ " cock 50 0.78 0.92\n",
+ " hen 50 0.84 0.96\n",
+ " ostrich 50 0.98 1\n",
+ " brambling 50 0.9 0.96\n",
+ " goldfinch 50 0.92 0.98\n",
+ " house finch 50 0.88 0.96\n",
+ " junco 50 0.94 0.98\n",
+ " indigo bunting 50 0.86 0.88\n",
+ " American robin 50 0.9 0.96\n",
+ " bulbul 50 0.84 0.96\n",
+ " jay 50 0.9 0.96\n",
+ " magpie 50 0.84 0.96\n",
+ " chickadee 50 0.9 1\n",
+ " American dipper 50 0.82 0.92\n",
+ " kite 50 0.76 0.94\n",
+ " bald eagle 50 0.92 1\n",
+ " vulture 50 0.96 1\n",
+ " great grey owl 50 0.94 0.98\n",
+ " fire salamander 50 0.96 0.98\n",
+ " smooth newt 50 0.58 0.94\n",
+ " newt 50 0.74 0.9\n",
+ " spotted salamander 50 0.86 0.94\n",
+ " axolotl 50 0.86 0.96\n",
+ " American bullfrog 50 0.78 0.92\n",
+ " tree frog 50 0.84 0.96\n",
+ " tailed frog 50 0.48 0.8\n",
+ " loggerhead sea turtle 50 0.68 0.94\n",
+ " leatherback sea turtle 50 0.5 0.8\n",
+ " mud turtle 50 0.64 0.84\n",
+ " terrapin 50 0.52 0.98\n",
+ " box turtle 50 0.84 0.98\n",
+ " banded gecko 50 0.7 0.88\n",
+ " green iguana 50 0.76 0.94\n",
+ " Carolina anole 50 0.58 0.96\n",
+ "desert grassland whiptail lizard 50 0.82 0.94\n",
+ " agama 50 0.74 0.92\n",
+ " frilled-necked lizard 50 0.84 0.86\n",
+ " alligator lizard 50 0.58 0.78\n",
+ " Gila monster 50 0.72 0.8\n",
+ " European green lizard 50 0.42 0.9\n",
+ " chameleon 50 0.76 0.84\n",
+ " Komodo dragon 50 0.86 0.96\n",
+ " Nile crocodile 50 0.7 0.84\n",
+ " American alligator 50 0.76 0.96\n",
+ " triceratops 50 0.9 0.94\n",
+ " worm snake 50 0.76 0.88\n",
+ " ring-necked snake 50 0.8 0.92\n",
+ " eastern hog-nosed snake 50 0.58 0.88\n",
+ " smooth green snake 50 0.6 0.94\n",
+ " kingsnake 50 0.82 0.9\n",
+ " garter snake 50 0.88 0.94\n",
+ " water snake 50 0.7 0.94\n",
+ " vine snake 50 0.66 0.76\n",
+ " night snake 50 0.34 0.82\n",
+ " boa constrictor 50 0.8 0.96\n",
+ " African rock python 50 0.48 0.76\n",
+ " Indian cobra 50 0.82 0.94\n",
+ " green mamba 50 0.54 0.86\n",
+ " sea snake 50 0.62 0.9\n",
+ " Saharan horned viper 50 0.56 0.86\n",
+ "eastern diamondback rattlesnake 50 0.6 0.86\n",
+ " sidewinder 50 0.28 0.86\n",
+ " trilobite 50 0.98 0.98\n",
+ " harvestman 50 0.86 0.94\n",
+ " scorpion 50 0.86 0.94\n",
+ " yellow garden spider 50 0.92 0.96\n",
+ " barn spider 50 0.38 0.98\n",
+ " European garden spider 50 0.62 0.98\n",
+ " southern black widow 50 0.88 0.94\n",
+ " tarantula 50 0.94 1\n",
+ " wolf spider 50 0.82 0.92\n",
+ " tick 50 0.74 0.84\n",
+ " centipede 50 0.68 0.82\n",
+ " black grouse 50 0.88 0.98\n",
+ " ptarmigan 50 0.78 0.94\n",
+ " ruffed grouse 50 0.88 1\n",
+ " prairie grouse 50 0.92 1\n",
+ " peacock 50 0.88 0.9\n",
+ " quail 50 0.9 0.94\n",
+ " partridge 50 0.74 0.96\n",
+ " grey parrot 50 0.9 0.96\n",
+ " macaw 50 0.88 0.98\n",
+ "sulphur-crested cockatoo 50 0.86 0.92\n",
+ " lorikeet 50 0.96 1\n",
+ " coucal 50 0.82 0.88\n",
+ " bee eater 50 0.96 0.98\n",
+ " hornbill 50 0.9 0.96\n",
+ " hummingbird 50 0.88 0.96\n",
+ " jacamar 50 0.92 0.94\n",
+ " toucan 50 0.84 0.94\n",
+ " duck 50 0.76 0.94\n",
+ " red-breasted merganser 50 0.86 0.96\n",
+ " goose 50 0.74 0.96\n",
+ " black swan 50 0.94 0.98\n",
+ " tusker 50 0.54 0.92\n",
+ " echidna 50 0.98 1\n",
+ " platypus 50 0.72 0.84\n",
+ " wallaby 50 0.78 0.88\n",
+ " koala 50 0.84 0.92\n",
+ " wombat 50 0.78 0.84\n",
+ " jellyfish 50 0.88 0.96\n",
+ " sea anemone 50 0.72 0.9\n",
+ " brain coral 50 0.88 0.96\n",
+ " flatworm 50 0.8 0.98\n",
+ " nematode 50 0.86 0.9\n",
+ " conch 50 0.74 0.88\n",
+ " snail 50 0.78 0.88\n",
+ " slug 50 0.74 0.82\n",
+ " sea slug 50 0.88 0.98\n",
+ " chiton 50 0.88 0.98\n",
+ " chambered nautilus 50 0.88 0.92\n",
+ " Dungeness crab 50 0.78 0.94\n",
+ " rock crab 50 0.68 0.86\n",
+ " fiddler crab 50 0.64 0.86\n",
+ " red king crab 50 0.76 0.96\n",
+ " American lobster 50 0.78 0.96\n",
+ " spiny lobster 50 0.74 0.88\n",
+ " crayfish 50 0.56 0.86\n",
+ " hermit crab 50 0.78 0.96\n",
+ " isopod 50 0.66 0.78\n",
+ " white stork 50 0.88 0.96\n",
+ " black stork 50 0.84 0.98\n",
+ " spoonbill 50 0.96 1\n",
+ " flamingo 50 0.94 1\n",
+ " little blue heron 50 0.92 0.98\n",
+ " great egret 50 0.9 0.96\n",
+ " bittern 50 0.86 0.94\n",
+ " crane (bird) 50 0.62 0.9\n",
+ " limpkin 50 0.98 1\n",
+ " common gallinule 50 0.92 0.96\n",
+ " American coot 50 0.9 0.98\n",
+ " bustard 50 0.92 0.96\n",
+ " ruddy turnstone 50 0.94 1\n",
+ " dunlin 50 0.86 0.94\n",
+ " common redshank 50 0.9 0.96\n",
+ " dowitcher 50 0.84 0.96\n",
+ " oystercatcher 50 0.86 0.94\n",
+ " pelican 50 0.92 0.96\n",
+ " king penguin 50 0.88 0.96\n",
+ " albatross 50 0.9 1\n",
+ " grey whale 50 0.84 0.92\n",
+ " killer whale 50 0.92 1\n",
+ " dugong 50 0.84 0.96\n",
+ " sea lion 50 0.82 0.92\n",
+ " Chihuahua 50 0.66 0.84\n",
+ " Japanese Chin 50 0.72 0.98\n",
+ " Maltese 50 0.76 0.94\n",
+ " Pekingese 50 0.84 0.94\n",
+ " Shih Tzu 50 0.74 0.96\n",
+ " King Charles Spaniel 50 0.88 0.98\n",
+ " Papillon 50 0.86 0.94\n",
+ " toy terrier 50 0.48 0.94\n",
+ " Rhodesian Ridgeback 50 0.76 0.98\n",
+ " Afghan Hound 50 0.84 1\n",
+ " Basset Hound 50 0.8 0.92\n",
+ " Beagle 50 0.82 0.96\n",
+ " Bloodhound 50 0.48 0.72\n",
+ " Bluetick Coonhound 50 0.86 0.94\n",
+ " Black and Tan Coonhound 50 0.54 0.8\n",
+ "Treeing Walker Coonhound 50 0.66 0.98\n",
+ " English foxhound 50 0.32 0.84\n",
+ " Redbone Coonhound 50 0.62 0.94\n",
+ " borzoi 50 0.92 1\n",
+ " Irish Wolfhound 50 0.48 0.88\n",
+ " Italian Greyhound 50 0.76 0.98\n",
+ " Whippet 50 0.74 0.92\n",
+ " Ibizan Hound 50 0.6 0.86\n",
+ " Norwegian Elkhound 50 0.88 0.98\n",
+ " Otterhound 50 0.62 0.9\n",
+ " Saluki 50 0.72 0.92\n",
+ " Scottish Deerhound 50 0.86 0.98\n",
+ " Weimaraner 50 0.88 0.94\n",
+ "Staffordshire Bull Terrier 50 0.66 0.98\n",
+ "American Staffordshire Terrier 50 0.64 0.92\n",
+ " Bedlington Terrier 50 0.9 0.92\n",
+ " Border Terrier 50 0.86 0.92\n",
+ " Kerry Blue Terrier 50 0.78 0.98\n",
+ " Irish Terrier 50 0.7 0.96\n",
+ " Norfolk Terrier 50 0.68 0.9\n",
+ " Norwich Terrier 50 0.72 1\n",
+ " Yorkshire Terrier 50 0.66 0.9\n",
+ " Wire Fox Terrier 50 0.64 0.98\n",
+ " Lakeland Terrier 50 0.74 0.92\n",
+ " Sealyham Terrier 50 0.76 0.9\n",
+ " Airedale Terrier 50 0.82 0.92\n",
+ " Cairn Terrier 50 0.76 0.9\n",
+ " Australian Terrier 50 0.48 0.84\n",
+ " Dandie Dinmont Terrier 50 0.82 0.92\n",
+ " Boston Terrier 50 0.92 1\n",
+ " Miniature Schnauzer 50 0.68 0.9\n",
+ " Giant Schnauzer 50 0.72 0.98\n",
+ " Standard Schnauzer 50 0.74 1\n",
+ " Scottish Terrier 50 0.76 0.96\n",
+ " Tibetan Terrier 50 0.48 1\n",
+ "Australian Silky Terrier 50 0.66 0.96\n",
+ "Soft-coated Wheaten Terrier 50 0.74 0.96\n",
+ "West Highland White Terrier 50 0.88 0.96\n",
+ " Lhasa Apso 50 0.68 0.96\n",
+ " Flat-Coated Retriever 50 0.72 0.94\n",
+ " Curly-coated Retriever 50 0.82 0.94\n",
+ " Golden Retriever 50 0.86 0.94\n",
+ " Labrador Retriever 50 0.82 0.94\n",
+ "Chesapeake Bay Retriever 50 0.76 0.96\n",
+ "German Shorthaired Pointer 50 0.8 0.96\n",
+ " Vizsla 50 0.68 0.96\n",
+ " English Setter 50 0.7 1\n",
+ " Irish Setter 50 0.8 0.9\n",
+ " Gordon Setter 50 0.84 0.92\n",
+ " Brittany 50 0.84 0.96\n",
+ " Clumber Spaniel 50 0.92 0.96\n",
+ "English Springer Spaniel 50 0.88 1\n",
+ " Welsh Springer Spaniel 50 0.92 1\n",
+ " Cocker Spaniels 50 0.7 0.94\n",
+ " Sussex Spaniel 50 0.72 0.92\n",
+ " Irish Water Spaniel 50 0.88 0.98\n",
+ " Kuvasz 50 0.66 0.9\n",
+ " Schipperke 50 0.9 0.98\n",
+ " Groenendael 50 0.8 0.94\n",
+ " Malinois 50 0.86 0.98\n",
+ " Briard 50 0.52 0.8\n",
+ " Australian Kelpie 50 0.6 0.88\n",
+ " Komondor 50 0.88 0.94\n",
+ " Old English Sheepdog 50 0.94 0.98\n",
+ " Shetland Sheepdog 50 0.74 0.9\n",
+ " collie 50 0.6 0.96\n",
+ " Border Collie 50 0.74 0.96\n",
+ " Bouvier des Flandres 50 0.78 0.94\n",
+ " Rottweiler 50 0.88 0.96\n",
+ " German Shepherd Dog 50 0.8 0.98\n",
+ " Dobermann 50 0.68 0.96\n",
+ " Miniature Pinscher 50 0.76 0.88\n",
+ "Greater Swiss Mountain Dog 50 0.68 0.94\n",
+ " Bernese Mountain Dog 50 0.96 1\n",
+ " Appenzeller Sennenhund 50 0.22 1\n",
+ " Entlebucher Sennenhund 50 0.64 0.98\n",
+ " Boxer 50 0.7 0.92\n",
+ " Bullmastiff 50 0.78 0.98\n",
+ " Tibetan Mastiff 50 0.88 0.96\n",
+ " French Bulldog 50 0.84 0.94\n",
+ " Great Dane 50 0.54 0.9\n",
+ " St. Bernard 50 0.92 1\n",
+ " husky 50 0.46 0.98\n",
+ " Alaskan Malamute 50 0.76 0.96\n",
+ " Siberian Husky 50 0.46 0.98\n",
+ " Dalmatian 50 0.94 0.98\n",
+ " Affenpinscher 50 0.78 0.9\n",
+ " Basenji 50 0.92 0.94\n",
+ " pug 50 0.94 0.98\n",
+ " Leonberger 50 1 1\n",
+ " Newfoundland 50 0.78 0.96\n",
+ " Pyrenean Mountain Dog 50 0.78 0.96\n",
+ " Samoyed 50 0.96 1\n",
+ " Pomeranian 50 0.98 1\n",
+ " Chow Chow 50 0.9 0.96\n",
+ " Keeshond 50 0.88 0.94\n",
+ " Griffon Bruxellois 50 0.84 0.98\n",
+ " Pembroke Welsh Corgi 50 0.82 0.94\n",
+ " Cardigan Welsh Corgi 50 0.66 0.98\n",
+ " Toy Poodle 50 0.52 0.88\n",
+ " Miniature Poodle 50 0.52 0.92\n",
+ " Standard Poodle 50 0.8 1\n",
+ " Mexican hairless dog 50 0.88 0.98\n",
+ " grey wolf 50 0.82 0.92\n",
+ " Alaskan tundra wolf 50 0.78 0.98\n",
+ " red wolf 50 0.48 0.9\n",
+ " coyote 50 0.64 0.86\n",
+ " dingo 50 0.76 0.88\n",
+ " dhole 50 0.9 0.98\n",
+ " African wild dog 50 0.98 1\n",
+ " hyena 50 0.88 0.96\n",
+ " red fox 50 0.54 0.92\n",
+ " kit fox 50 0.72 0.98\n",
+ " Arctic fox 50 0.94 1\n",
+ " grey fox 50 0.7 0.94\n",
+ " tabby cat 50 0.54 0.92\n",
+ " tiger cat 50 0.22 0.94\n",
+ " Persian cat 50 0.9 0.98\n",
+ " Siamese cat 50 0.96 1\n",
+ " Egyptian Mau 50 0.54 0.8\n",
+ " cougar 50 0.9 1\n",
+ " lynx 50 0.72 0.88\n",
+ " leopard 50 0.78 0.98\n",
+ " snow leopard 50 0.9 0.98\n",
+ " jaguar 50 0.7 0.94\n",
+ " lion 50 0.9 0.98\n",
+ " tiger 50 0.92 0.98\n",
+ " cheetah 50 0.94 0.98\n",
+ " brown bear 50 0.94 0.98\n",
+ " American black bear 50 0.8 1\n",
+ " polar bear 50 0.84 0.96\n",
+ " sloth bear 50 0.72 0.92\n",
+ " mongoose 50 0.7 0.92\n",
+ " meerkat 50 0.82 0.92\n",
+ " tiger beetle 50 0.92 0.94\n",
+ " ladybug 50 0.86 0.94\n",
+ " ground beetle 50 0.64 0.94\n",
+ " longhorn beetle 50 0.62 0.88\n",
+ " leaf beetle 50 0.64 0.98\n",
+ " dung beetle 50 0.86 0.98\n",
+ " rhinoceros beetle 50 0.86 0.94\n",
+ " weevil 50 0.9 1\n",
+ " fly 50 0.78 0.94\n",
+ " bee 50 0.68 0.94\n",
+ " ant 50 0.68 0.78\n",
+ " grasshopper 50 0.5 0.92\n",
+ " cricket 50 0.64 0.92\n",
+ " stick insect 50 0.64 0.92\n",
+ " cockroach 50 0.72 0.8\n",
+ " mantis 50 0.64 0.86\n",
+ " cicada 50 0.9 0.96\n",
+ " leafhopper 50 0.88 0.94\n",
+ " lacewing 50 0.78 0.92\n",
+ " dragonfly 50 0.82 0.98\n",
+ " damselfly 50 0.82 1\n",
+ " red admiral 50 0.94 0.96\n",
+ " ringlet 50 0.86 0.98\n",
+ " monarch butterfly 50 0.9 0.92\n",
+ " small white 50 0.9 1\n",
+ " sulphur butterfly 50 0.92 1\n",
+ "gossamer-winged butterfly 50 0.88 1\n",
+ " starfish 50 0.88 0.92\n",
+ " sea urchin 50 0.84 0.94\n",
+ " sea cucumber 50 0.66 0.84\n",
+ " cottontail rabbit 50 0.72 0.94\n",
+ " hare 50 0.84 0.96\n",
+ " Angora rabbit 50 0.94 0.98\n",
+ " hamster 50 0.96 1\n",
+ " porcupine 50 0.88 0.98\n",
+ " fox squirrel 50 0.76 0.94\n",
+ " marmot 50 0.92 0.96\n",
+ " beaver 50 0.78 0.94\n",
+ " guinea pig 50 0.78 0.94\n",
+ " common sorrel 50 0.96 0.98\n",
+ " zebra 50 0.94 0.96\n",
+ " pig 50 0.5 0.76\n",
+ " wild boar 50 0.84 0.96\n",
+ " warthog 50 0.84 0.96\n",
+ " hippopotamus 50 0.88 0.96\n",
+ " ox 50 0.48 0.94\n",
+ " water buffalo 50 0.78 0.94\n",
+ " bison 50 0.88 0.96\n",
+ " ram 50 0.58 0.92\n",
+ " bighorn sheep 50 0.66 1\n",
+ " Alpine ibex 50 0.92 0.98\n",
+ " hartebeest 50 0.94 1\n",
+ " impala 50 0.82 0.96\n",
+ " gazelle 50 0.7 0.96\n",
+ " dromedary 50 0.9 1\n",
+ " llama 50 0.82 0.94\n",
+ " weasel 50 0.44 0.92\n",
+ " mink 50 0.78 0.96\n",
+ " European polecat 50 0.46 0.9\n",
+ " black-footed ferret 50 0.68 0.96\n",
+ " otter 50 0.66 0.88\n",
+ " skunk 50 0.96 0.96\n",
+ " badger 50 0.86 0.92\n",
+ " armadillo 50 0.88 0.9\n",
+ " three-toed sloth 50 0.96 1\n",
+ " orangutan 50 0.78 0.92\n",
+ " gorilla 50 0.82 0.94\n",
+ " chimpanzee 50 0.84 0.94\n",
+ " gibbon 50 0.76 0.86\n",
+ " siamang 50 0.68 0.94\n",
+ " guenon 50 0.8 0.94\n",
+ " patas monkey 50 0.62 0.82\n",
+ " baboon 50 0.9 0.98\n",
+ " macaque 50 0.8 0.86\n",
+ " langur 50 0.6 0.82\n",
+ " black-and-white colobus 50 0.86 0.9\n",
+ " proboscis monkey 50 1 1\n",
+ " marmoset 50 0.74 0.98\n",
+ " white-headed capuchin 50 0.72 0.9\n",
+ " howler monkey 50 0.86 0.94\n",
+ " titi 50 0.5 0.9\n",
+ "Geoffroy's spider monkey 50 0.42 0.8\n",
+ " common squirrel monkey 50 0.76 0.92\n",
+ " ring-tailed lemur 50 0.72 0.94\n",
+ " indri 50 0.9 0.96\n",
+ " Asian elephant 50 0.58 0.92\n",
+ " African bush elephant 50 0.7 0.98\n",
+ " red panda 50 0.94 0.94\n",
+ " giant panda 50 0.94 0.98\n",
+ " snoek 50 0.74 0.9\n",
+ " eel 50 0.6 0.84\n",
+ " coho salmon 50 0.84 0.96\n",
+ " rock beauty 50 0.88 0.98\n",
+ " clownfish 50 0.78 0.98\n",
+ " sturgeon 50 0.68 0.94\n",
+ " garfish 50 0.62 0.8\n",
+ " lionfish 50 0.96 0.96\n",
+ " pufferfish 50 0.88 0.96\n",
+ " abacus 50 0.74 0.88\n",
+ " abaya 50 0.84 0.92\n",
+ " academic gown 50 0.42 0.86\n",
+ " accordion 50 0.8 0.9\n",
+ " acoustic guitar 50 0.5 0.76\n",
+ " aircraft carrier 50 0.8 0.96\n",
+ " airliner 50 0.92 1\n",
+ " airship 50 0.76 0.82\n",
+ " altar 50 0.64 0.98\n",
+ " ambulance 50 0.88 0.98\n",
+ " amphibious vehicle 50 0.64 0.94\n",
+ " analog clock 50 0.52 0.92\n",
+ " apiary 50 0.82 0.96\n",
+ " apron 50 0.7 0.84\n",
+ " waste container 50 0.4 0.8\n",
+ " assault rifle 50 0.42 0.84\n",
+ " backpack 50 0.34 0.64\n",
+ " bakery 50 0.4 0.68\n",
+ " balance beam 50 0.8 0.98\n",
+ " balloon 50 0.86 0.96\n",
+ " ballpoint pen 50 0.52 0.96\n",
+ " Band-Aid 50 0.7 0.9\n",
+ " banjo 50 0.84 1\n",
+ " baluster 50 0.68 0.94\n",
+ " barbell 50 0.56 0.9\n",
+ " barber chair 50 0.7 0.92\n",
+ " barbershop 50 0.54 0.86\n",
+ " barn 50 0.96 0.96\n",
+ " barometer 50 0.84 0.98\n",
+ " barrel 50 0.56 0.88\n",
+ " wheelbarrow 50 0.66 0.88\n",
+ " baseball 50 0.74 0.98\n",
+ " basketball 50 0.88 0.98\n",
+ " bassinet 50 0.66 0.92\n",
+ " bassoon 50 0.74 0.98\n",
+ " swimming cap 50 0.62 0.88\n",
+ " bath towel 50 0.54 0.78\n",
+ " bathtub 50 0.4 0.88\n",
+ " station wagon 50 0.66 0.84\n",
+ " lighthouse 50 0.78 0.94\n",
+ " beaker 50 0.52 0.68\n",
+ " military cap 50 0.84 0.96\n",
+ " beer bottle 50 0.66 0.88\n",
+ " beer glass 50 0.6 0.84\n",
+ " bell-cot 50 0.56 0.96\n",
+ " bib 50 0.58 0.82\n",
+ " tandem bicycle 50 0.86 0.96\n",
+ " bikini 50 0.56 0.88\n",
+ " ring binder 50 0.64 0.84\n",
+ " binoculars 50 0.54 0.78\n",
+ " birdhouse 50 0.86 0.94\n",
+ " boathouse 50 0.74 0.92\n",
+ " bobsleigh 50 0.92 0.96\n",
+ " bolo tie 50 0.8 0.94\n",
+ " poke bonnet 50 0.64 0.86\n",
+ " bookcase 50 0.66 0.92\n",
+ " bookstore 50 0.62 0.88\n",
+ " bottle cap 50 0.58 0.7\n",
+ " bow 50 0.72 0.86\n",
+ " bow tie 50 0.7 0.9\n",
+ " brass 50 0.92 0.96\n",
+ " bra 50 0.5 0.7\n",
+ " breakwater 50 0.62 0.86\n",
+ " breastplate 50 0.4 0.9\n",
+ " broom 50 0.6 0.86\n",
+ " bucket 50 0.66 0.8\n",
+ " buckle 50 0.5 0.68\n",
+ " bulletproof vest 50 0.5 0.78\n",
+ " high-speed train 50 0.94 0.96\n",
+ " butcher shop 50 0.74 0.94\n",
+ " taxicab 50 0.64 0.86\n",
+ " cauldron 50 0.44 0.66\n",
+ " candle 50 0.48 0.74\n",
+ " cannon 50 0.88 0.94\n",
+ " canoe 50 0.94 1\n",
+ " can opener 50 0.66 0.86\n",
+ " cardigan 50 0.68 0.8\n",
+ " car mirror 50 0.94 0.96\n",
+ " carousel 50 0.94 0.98\n",
+ " tool kit 50 0.56 0.78\n",
+ " carton 50 0.42 0.7\n",
+ " car wheel 50 0.38 0.74\n",
+ "automated teller machine 50 0.76 0.94\n",
+ " cassette 50 0.52 0.8\n",
+ " cassette player 50 0.28 0.9\n",
+ " castle 50 0.78 0.88\n",
+ " catamaran 50 0.78 1\n",
+ " CD player 50 0.52 0.82\n",
+ " cello 50 0.82 1\n",
+ " mobile phone 50 0.68 0.86\n",
+ " chain 50 0.38 0.66\n",
+ " chain-link fence 50 0.7 0.84\n",
+ " chain mail 50 0.64 0.9\n",
+ " chainsaw 50 0.84 0.92\n",
+ " chest 50 0.68 0.92\n",
+ " chiffonier 50 0.26 0.64\n",
+ " chime 50 0.62 0.84\n",
+ " china cabinet 50 0.82 0.96\n",
+ " Christmas stocking 50 0.92 0.94\n",
+ " church 50 0.62 0.9\n",
+ " movie theater 50 0.58 0.88\n",
+ " cleaver 50 0.32 0.62\n",
+ " cliff dwelling 50 0.88 1\n",
+ " cloak 50 0.32 0.64\n",
+ " clogs 50 0.58 0.88\n",
+ " cocktail shaker 50 0.62 0.7\n",
+ " coffee mug 50 0.44 0.72\n",
+ " coffeemaker 50 0.64 0.92\n",
+ " coil 50 0.66 0.84\n",
+ " combination lock 50 0.64 0.84\n",
+ " computer keyboard 50 0.7 0.82\n",
+ " confectionery store 50 0.54 0.86\n",
+ " container ship 50 0.82 0.98\n",
+ " convertible 50 0.78 0.98\n",
+ " corkscrew 50 0.82 0.92\n",
+ " cornet 50 0.46 0.88\n",
+ " cowboy boot 50 0.64 0.8\n",
+ " cowboy hat 50 0.64 0.82\n",
+ " cradle 50 0.38 0.8\n",
+ " crane (machine) 50 0.78 0.94\n",
+ " crash helmet 50 0.92 0.96\n",
+ " crate 50 0.52 0.82\n",
+ " infant bed 50 0.74 1\n",
+ " Crock Pot 50 0.78 0.9\n",
+ " croquet ball 50 0.9 0.96\n",
+ " crutch 50 0.46 0.7\n",
+ " cuirass 50 0.54 0.86\n",
+ " dam 50 0.74 0.92\n",
+ " desk 50 0.6 0.86\n",
+ " desktop computer 50 0.54 0.94\n",
+ " rotary dial telephone 50 0.88 0.94\n",
+ " diaper 50 0.68 0.84\n",
+ " digital clock 50 0.54 0.76\n",
+ " digital watch 50 0.58 0.86\n",
+ " dining table 50 0.76 0.9\n",
+ " dishcloth 50 0.94 1\n",
+ " dishwasher 50 0.44 0.78\n",
+ " disc brake 50 0.98 1\n",
+ " dock 50 0.54 0.94\n",
+ " dog sled 50 0.84 1\n",
+ " dome 50 0.72 0.92\n",
+ " doormat 50 0.56 0.82\n",
+ " drilling rig 50 0.84 0.96\n",
+ " drum 50 0.38 0.68\n",
+ " drumstick 50 0.56 0.72\n",
+ " dumbbell 50 0.62 0.9\n",
+ " Dutch oven 50 0.7 0.84\n",
+ " electric fan 50 0.82 0.86\n",
+ " electric guitar 50 0.62 0.84\n",
+ " electric locomotive 50 0.92 0.98\n",
+ " entertainment center 50 0.9 0.98\n",
+ " envelope 50 0.44 0.86\n",
+ " espresso machine 50 0.72 0.94\n",
+ " face powder 50 0.7 0.92\n",
+ " feather boa 50 0.7 0.84\n",
+ " filing cabinet 50 0.88 0.98\n",
+ " fireboat 50 0.94 0.98\n",
+ " fire engine 50 0.84 0.9\n",
+ " fire screen sheet 50 0.62 0.76\n",
+ " flagpole 50 0.74 0.88\n",
+ " flute 50 0.36 0.72\n",
+ " folding chair 50 0.62 0.84\n",
+ " football helmet 50 0.86 0.94\n",
+ " forklift 50 0.8 0.92\n",
+ " fountain 50 0.84 0.94\n",
+ " fountain pen 50 0.76 0.92\n",
+ " four-poster bed 50 0.78 0.94\n",
+ " freight car 50 0.96 1\n",
+ " French horn 50 0.76 0.92\n",
+ " frying pan 50 0.36 0.78\n",
+ " fur coat 50 0.84 0.96\n",
+ " garbage truck 50 0.9 0.98\n",
+ " gas mask 50 0.84 0.92\n",
+ " gas pump 50 0.9 0.98\n",
+ " goblet 50 0.68 0.82\n",
+ " go-kart 50 0.9 1\n",
+ " golf ball 50 0.84 0.9\n",
+ " golf cart 50 0.78 0.86\n",
+ " gondola 50 0.98 0.98\n",
+ " gong 50 0.74 0.92\n",
+ " gown 50 0.62 0.96\n",
+ " grand piano 50 0.7 0.96\n",
+ " greenhouse 50 0.8 0.98\n",
+ " grille 50 0.72 0.9\n",
+ " grocery store 50 0.66 0.94\n",
+ " guillotine 50 0.86 0.92\n",
+ " barrette 50 0.52 0.66\n",
+ " hair spray 50 0.5 0.74\n",
+ " half-track 50 0.78 0.9\n",
+ " hammer 50 0.56 0.76\n",
+ " hamper 50 0.64 0.84\n",
+ " hair dryer 50 0.56 0.74\n",
+ " hand-held computer 50 0.42 0.86\n",
+ " handkerchief 50 0.78 0.94\n",
+ " hard disk drive 50 0.76 0.84\n",
+ " harmonica 50 0.7 0.88\n",
+ " harp 50 0.88 0.96\n",
+ " harvester 50 0.78 1\n",
+ " hatchet 50 0.54 0.74\n",
+ " holster 50 0.66 0.84\n",
+ " home theater 50 0.64 0.94\n",
+ " honeycomb 50 0.56 0.88\n",
+ " hook 50 0.3 0.6\n",
+ " hoop skirt 50 0.64 0.86\n",
+ " horizontal bar 50 0.68 0.98\n",
+ " horse-drawn vehicle 50 0.88 0.94\n",
+ " hourglass 50 0.88 0.96\n",
+ " iPod 50 0.76 0.94\n",
+ " clothes iron 50 0.82 0.88\n",
+ " jack-o'-lantern 50 0.98 0.98\n",
+ " jeans 50 0.68 0.84\n",
+ " jeep 50 0.72 0.9\n",
+ " T-shirt 50 0.72 0.96\n",
+ " jigsaw puzzle 50 0.84 0.94\n",
+ " pulled rickshaw 50 0.86 0.94\n",
+ " joystick 50 0.8 0.9\n",
+ " kimono 50 0.84 0.96\n",
+ " knee pad 50 0.62 0.88\n",
+ " knot 50 0.66 0.8\n",
+ " lab coat 50 0.8 0.96\n",
+ " ladle 50 0.36 0.64\n",
+ " lampshade 50 0.48 0.84\n",
+ " laptop computer 50 0.26 0.88\n",
+ " lawn mower 50 0.78 0.96\n",
+ " lens cap 50 0.46 0.72\n",
+ " paper knife 50 0.26 0.5\n",
+ " library 50 0.54 0.9\n",
+ " lifeboat 50 0.92 0.98\n",
+ " lighter 50 0.56 0.78\n",
+ " limousine 50 0.76 0.92\n",
+ " ocean liner 50 0.88 0.94\n",
+ " lipstick 50 0.74 0.9\n",
+ " slip-on shoe 50 0.74 0.92\n",
+ " lotion 50 0.5 0.86\n",
+ " speaker 50 0.52 0.68\n",
+ " loupe 50 0.32 0.52\n",
+ " sawmill 50 0.72 0.9\n",
+ " magnetic compass 50 0.52 0.82\n",
+ " mail bag 50 0.68 0.92\n",
+ " mailbox 50 0.82 0.92\n",
+ " tights 50 0.22 0.94\n",
+ " tank suit 50 0.24 0.9\n",
+ " manhole cover 50 0.96 0.98\n",
+ " maraca 50 0.74 0.9\n",
+ " marimba 50 0.84 0.94\n",
+ " mask 50 0.44 0.82\n",
+ " match 50 0.66 0.9\n",
+ " maypole 50 0.96 1\n",
+ " maze 50 0.8 0.96\n",
+ " measuring cup 50 0.54 0.76\n",
+ " medicine chest 50 0.6 0.84\n",
+ " megalith 50 0.8 0.92\n",
+ " microphone 50 0.52 0.7\n",
+ " microwave oven 50 0.48 0.72\n",
+ " military uniform 50 0.62 0.84\n",
+ " milk can 50 0.68 0.82\n",
+ " minibus 50 0.7 1\n",
+ " miniskirt 50 0.46 0.76\n",
+ " minivan 50 0.38 0.8\n",
+ " missile 50 0.4 0.84\n",
+ " mitten 50 0.76 0.88\n",
+ " mixing bowl 50 0.8 0.92\n",
+ " mobile home 50 0.54 0.78\n",
+ " Model T 50 0.92 0.96\n",
+ " modem 50 0.58 0.86\n",
+ " monastery 50 0.44 0.9\n",
+ " monitor 50 0.4 0.86\n",
+ " moped 50 0.56 0.94\n",
+ " mortar 50 0.68 0.94\n",
+ " square academic cap 50 0.5 0.84\n",
+ " mosque 50 0.9 1\n",
+ " mosquito net 50 0.9 0.98\n",
+ " scooter 50 0.9 0.98\n",
+ " mountain bike 50 0.78 0.96\n",
+ " tent 50 0.88 0.96\n",
+ " computer mouse 50 0.42 0.82\n",
+ " mousetrap 50 0.76 0.88\n",
+ " moving van 50 0.4 0.72\n",
+ " muzzle 50 0.5 0.72\n",
+ " nail 50 0.68 0.74\n",
+ " neck brace 50 0.56 0.68\n",
+ " necklace 50 0.86 1\n",
+ " nipple 50 0.7 0.88\n",
+ " notebook computer 50 0.34 0.84\n",
+ " obelisk 50 0.8 0.92\n",
+ " oboe 50 0.6 0.84\n",
+ " ocarina 50 0.8 0.86\n",
+ " odometer 50 0.96 1\n",
+ " oil filter 50 0.58 0.82\n",
+ " organ 50 0.82 0.9\n",
+ " oscilloscope 50 0.9 0.96\n",
+ " overskirt 50 0.2 0.7\n",
+ " bullock cart 50 0.7 0.94\n",
+ " oxygen mask 50 0.46 0.84\n",
+ " packet 50 0.5 0.78\n",
+ " paddle 50 0.56 0.94\n",
+ " paddle wheel 50 0.86 0.96\n",
+ " padlock 50 0.74 0.78\n",
+ " paintbrush 50 0.62 0.8\n",
+ " pajamas 50 0.56 0.92\n",
+ " palace 50 0.64 0.96\n",
+ " pan flute 50 0.84 0.86\n",
+ " paper towel 50 0.66 0.84\n",
+ " parachute 50 0.92 0.94\n",
+ " parallel bars 50 0.62 0.96\n",
+ " park bench 50 0.74 0.9\n",
+ " parking meter 50 0.84 0.92\n",
+ " passenger car 50 0.5 0.82\n",
+ " patio 50 0.58 0.84\n",
+ " payphone 50 0.74 0.92\n",
+ " pedestal 50 0.52 0.9\n",
+ " pencil case 50 0.64 0.92\n",
+ " pencil sharpener 50 0.52 0.78\n",
+ " perfume 50 0.7 0.9\n",
+ " Petri dish 50 0.6 0.8\n",
+ " photocopier 50 0.88 0.98\n",
+ " plectrum 50 0.7 0.84\n",
+ " Pickelhaube 50 0.72 0.86\n",
+ " picket fence 50 0.84 0.94\n",
+ " pickup truck 50 0.64 0.92\n",
+ " pier 50 0.52 0.82\n",
+ " piggy bank 50 0.82 0.94\n",
+ " pill bottle 50 0.76 0.86\n",
+ " pillow 50 0.76 0.9\n",
+ " ping-pong ball 50 0.84 0.88\n",
+ " pinwheel 50 0.76 0.88\n",
+ " pirate ship 50 0.76 0.94\n",
+ " pitcher 50 0.46 0.84\n",
+ " hand plane 50 0.84 0.94\n",
+ " planetarium 50 0.88 0.98\n",
+ " plastic bag 50 0.36 0.62\n",
+ " plate rack 50 0.52 0.78\n",
+ " plow 50 0.78 0.88\n",
+ " plunger 50 0.42 0.7\n",
+ " Polaroid camera 50 0.84 0.92\n",
+ " pole 50 0.38 0.74\n",
+ " police van 50 0.76 0.94\n",
+ " poncho 50 0.58 0.86\n",
+ " billiard table 50 0.8 0.88\n",
+ " soda bottle 50 0.56 0.94\n",
+ " pot 50 0.78 0.92\n",
+ " potter's wheel 50 0.9 0.94\n",
+ " power drill 50 0.42 0.72\n",
+ " prayer rug 50 0.7 0.86\n",
+ " printer 50 0.54 0.86\n",
+ " prison 50 0.7 0.9\n",
+ " projectile 50 0.28 0.9\n",
+ " projector 50 0.62 0.84\n",
+ " hockey puck 50 0.92 0.96\n",
+ " punching bag 50 0.6 0.68\n",
+ " purse 50 0.42 0.78\n",
+ " quill 50 0.68 0.84\n",
+ " quilt 50 0.64 0.9\n",
+ " race car 50 0.72 0.92\n",
+ " racket 50 0.72 0.9\n",
+ " radiator 50 0.66 0.76\n",
+ " radio 50 0.64 0.92\n",
+ " radio telescope 50 0.9 0.96\n",
+ " rain barrel 50 0.8 0.98\n",
+ " recreational vehicle 50 0.84 0.94\n",
+ " reel 50 0.72 0.82\n",
+ " reflex camera 50 0.72 0.92\n",
+ " refrigerator 50 0.7 0.9\n",
+ " remote control 50 0.7 0.88\n",
+ " restaurant 50 0.5 0.66\n",
+ " revolver 50 0.82 1\n",
+ " rifle 50 0.38 0.7\n",
+ " rocking chair 50 0.62 0.84\n",
+ " rotisserie 50 0.88 0.92\n",
+ " eraser 50 0.54 0.76\n",
+ " rugby ball 50 0.86 0.94\n",
+ " ruler 50 0.68 0.86\n",
+ " running shoe 50 0.78 0.94\n",
+ " safe 50 0.82 0.92\n",
+ " safety pin 50 0.4 0.62\n",
+ " salt shaker 50 0.66 0.9\n",
+ " sandal 50 0.66 0.86\n",
+ " sarong 50 0.64 0.86\n",
+ " saxophone 50 0.66 0.88\n",
+ " scabbard 50 0.76 0.92\n",
+ " weighing scale 50 0.58 0.78\n",
+ " school bus 50 0.92 1\n",
+ " schooner 50 0.84 1\n",
+ " scoreboard 50 0.9 0.96\n",
+ " CRT screen 50 0.14 0.7\n",
+ " screw 50 0.9 0.98\n",
+ " screwdriver 50 0.3 0.58\n",
+ " seat belt 50 0.88 0.94\n",
+ " sewing machine 50 0.76 0.9\n",
+ " shield 50 0.56 0.82\n",
+ " shoe store 50 0.78 0.96\n",
+ " shoji 50 0.8 0.92\n",
+ " shopping basket 50 0.52 0.88\n",
+ " shopping cart 50 0.76 0.92\n",
+ " shovel 50 0.62 0.84\n",
+ " shower cap 50 0.7 0.84\n",
+ " shower curtain 50 0.64 0.82\n",
+ " ski 50 0.74 0.92\n",
+ " ski mask 50 0.72 0.88\n",
+ " sleeping bag 50 0.68 0.8\n",
+ " slide rule 50 0.72 0.88\n",
+ " sliding door 50 0.44 0.78\n",
+ " slot machine 50 0.94 0.98\n",
+ " snorkel 50 0.86 0.98\n",
+ " snowmobile 50 0.88 1\n",
+ " snowplow 50 0.84 0.98\n",
+ " soap dispenser 50 0.56 0.86\n",
+ " soccer ball 50 0.86 0.96\n",
+ " sock 50 0.62 0.76\n",
+ " solar thermal collector 50 0.72 0.96\n",
+ " sombrero 50 0.6 0.84\n",
+ " soup bowl 50 0.56 0.94\n",
+ " space bar 50 0.34 0.88\n",
+ " space heater 50 0.52 0.74\n",
+ " space shuttle 50 0.82 0.96\n",
+ " spatula 50 0.3 0.6\n",
+ " motorboat 50 0.86 1\n",
+ " spider web 50 0.7 0.9\n",
+ " spindle 50 0.86 0.98\n",
+ " sports car 50 0.6 0.94\n",
+ " spotlight 50 0.26 0.6\n",
+ " stage 50 0.68 0.86\n",
+ " steam locomotive 50 0.94 1\n",
+ " through arch bridge 50 0.84 0.96\n",
+ " steel drum 50 0.82 0.9\n",
+ " stethoscope 50 0.6 0.82\n",
+ " scarf 50 0.5 0.92\n",
+ " stone wall 50 0.76 0.9\n",
+ " stopwatch 50 0.58 0.9\n",
+ " stove 50 0.46 0.74\n",
+ " strainer 50 0.64 0.84\n",
+ " tram 50 0.88 0.96\n",
+ " stretcher 50 0.6 0.8\n",
+ " couch 50 0.8 0.96\n",
+ " stupa 50 0.88 0.88\n",
+ " submarine 50 0.72 0.92\n",
+ " suit 50 0.4 0.78\n",
+ " sundial 50 0.58 0.74\n",
+ " sunglass 50 0.14 0.58\n",
+ " sunglasses 50 0.28 0.58\n",
+ " sunscreen 50 0.32 0.7\n",
+ " suspension bridge 50 0.6 0.94\n",
+ " mop 50 0.74 0.92\n",
+ " sweatshirt 50 0.28 0.66\n",
+ " swimsuit 50 0.52 0.82\n",
+ " swing 50 0.76 0.84\n",
+ " switch 50 0.56 0.76\n",
+ " syringe 50 0.62 0.82\n",
+ " table lamp 50 0.6 0.88\n",
+ " tank 50 0.8 0.96\n",
+ " tape player 50 0.46 0.76\n",
+ " teapot 50 0.84 1\n",
+ " teddy bear 50 0.82 0.94\n",
+ " television 50 0.6 0.9\n",
+ " tennis ball 50 0.7 0.94\n",
+ " thatched roof 50 0.88 0.9\n",
+ " front curtain 50 0.8 0.92\n",
+ " thimble 50 0.6 0.8\n",
+ " threshing machine 50 0.56 0.88\n",
+ " throne 50 0.72 0.82\n",
+ " tile roof 50 0.72 0.94\n",
+ " toaster 50 0.66 0.84\n",
+ " tobacco shop 50 0.42 0.7\n",
+ " toilet seat 50 0.62 0.88\n",
+ " torch 50 0.64 0.84\n",
+ " totem pole 50 0.92 0.98\n",
+ " tow truck 50 0.62 0.88\n",
+ " toy store 50 0.6 0.94\n",
+ " tractor 50 0.76 0.98\n",
+ " semi-trailer truck 50 0.78 0.92\n",
+ " tray 50 0.46 0.64\n",
+ " trench coat 50 0.54 0.72\n",
+ " tricycle 50 0.72 0.94\n",
+ " trimaran 50 0.7 0.98\n",
+ " tripod 50 0.58 0.86\n",
+ " triumphal arch 50 0.92 0.98\n",
+ " trolleybus 50 0.9 1\n",
+ " trombone 50 0.54 0.88\n",
+ " tub 50 0.24 0.82\n",
+ " turnstile 50 0.84 0.94\n",
+ " typewriter keyboard 50 0.68 0.98\n",
+ " umbrella 50 0.52 0.7\n",
+ " unicycle 50 0.74 0.96\n",
+ " upright piano 50 0.76 0.9\n",
+ " vacuum cleaner 50 0.62 0.9\n",
+ " vase 50 0.5 0.78\n",
+ " vault 50 0.76 0.92\n",
+ " velvet 50 0.2 0.42\n",
+ " vending machine 50 0.9 1\n",
+ " vestment 50 0.54 0.82\n",
+ " viaduct 50 0.78 0.86\n",
+ " violin 50 0.68 0.78\n",
+ " volleyball 50 0.86 1\n",
+ " waffle iron 50 0.72 0.88\n",
+ " wall clock 50 0.54 0.88\n",
+ " wallet 50 0.52 0.9\n",
+ " wardrobe 50 0.68 0.88\n",
+ " military aircraft 50 0.9 0.98\n",
+ " sink 50 0.72 0.96\n",
+ " washing machine 50 0.78 0.94\n",
+ " water bottle 50 0.54 0.74\n",
+ " water jug 50 0.22 0.74\n",
+ " water tower 50 0.9 0.96\n",
+ " whiskey jug 50 0.64 0.74\n",
+ " whistle 50 0.72 0.84\n",
+ " wig 50 0.84 0.9\n",
+ " window screen 50 0.68 0.8\n",
+ " window shade 50 0.52 0.76\n",
+ " Windsor tie 50 0.22 0.66\n",
+ " wine bottle 50 0.42 0.82\n",
+ " wing 50 0.54 0.96\n",
+ " wok 50 0.46 0.82\n",
+ " wooden spoon 50 0.58 0.8\n",
+ " wool 50 0.32 0.82\n",
+ " split-rail fence 50 0.74 0.9\n",
+ " shipwreck 50 0.84 0.96\n",
+ " yawl 50 0.78 0.96\n",
+ " yurt 50 0.84 1\n",
+ " website 50 0.98 1\n",
+ " comic book 50 0.62 0.9\n",
+ " crossword 50 0.84 0.88\n",
+ " traffic sign 50 0.78 0.9\n",
+ " traffic light 50 0.8 0.94\n",
+ " dust jacket 50 0.72 0.94\n",
+ " menu 50 0.82 0.96\n",
+ " plate 50 0.44 0.88\n",
+ " guacamole 50 0.8 0.92\n",
+ " consomme 50 0.54 0.88\n",
+ " hot pot 50 0.86 0.98\n",
+ " trifle 50 0.92 0.98\n",
+ " ice cream 50 0.68 0.94\n",
+ " ice pop 50 0.62 0.84\n",
+ " baguette 50 0.62 0.88\n",
+ " bagel 50 0.64 0.92\n",
+ " pretzel 50 0.72 0.88\n",
+ " cheeseburger 50 0.9 1\n",
+ " hot dog 50 0.74 0.94\n",
+ " mashed potato 50 0.74 0.9\n",
+ " cabbage 50 0.84 0.96\n",
+ " broccoli 50 0.9 0.96\n",
+ " cauliflower 50 0.82 1\n",
+ " zucchini 50 0.74 0.9\n",
+ " spaghetti squash 50 0.8 0.96\n",
+ " acorn squash 50 0.82 0.96\n",
+ " butternut squash 50 0.7 0.94\n",
+ " cucumber 50 0.6 0.96\n",
+ " artichoke 50 0.84 0.94\n",
+ " bell pepper 50 0.84 0.98\n",
+ " cardoon 50 0.88 0.94\n",
+ " mushroom 50 0.38 0.92\n",
+ " Granny Smith 50 0.9 0.96\n",
+ " strawberry 50 0.6 0.88\n",
+ " orange 50 0.7 0.92\n",
+ " lemon 50 0.78 0.98\n",
+ " fig 50 0.82 0.96\n",
+ " pineapple 50 0.86 0.96\n",
+ " banana 50 0.84 0.96\n",
+ " jackfruit 50 0.9 0.98\n",
+ " custard apple 50 0.86 0.96\n",
+ " pomegranate 50 0.82 0.98\n",
+ " hay 50 0.8 0.92\n",
+ " carbonara 50 0.88 0.94\n",
+ " chocolate syrup 50 0.46 0.84\n",
+ " dough 50 0.4 0.6\n",
+ " meatloaf 50 0.58 0.84\n",
+ " pizza 50 0.84 0.96\n",
+ " pot pie 50 0.68 0.9\n",
+ " burrito 50 0.8 0.98\n",
+ " red wine 50 0.54 0.82\n",
+ " espresso 50 0.64 0.88\n",
+ " cup 50 0.38 0.7\n",
+ " eggnog 50 0.38 0.7\n",
+ " alp 50 0.54 0.88\n",
+ " bubble 50 0.8 0.96\n",
+ " cliff 50 0.64 1\n",
+ " coral reef 50 0.72 0.96\n",
+ " geyser 50 0.94 1\n",
+ " lakeshore 50 0.54 0.88\n",
+ " promontory 50 0.58 0.94\n",
+ " shoal 50 0.6 0.96\n",
+ " seashore 50 0.44 0.78\n",
+ " valley 50 0.72 0.94\n",
+ " volcano 50 0.78 0.96\n",
+ " baseball player 50 0.72 0.94\n",
+ " bridegroom 50 0.72 0.88\n",
+ " scuba diver 50 0.8 1\n",
+ " rapeseed 50 0.94 0.98\n",
+ " daisy 50 0.96 0.98\n",
+ " yellow lady's slipper 50 1 1\n",
+ " corn 50 0.4 0.88\n",
+ " acorn 50 0.92 0.98\n",
+ " rose hip 50 0.92 0.98\n",
+ " horse chestnut seed 50 0.94 0.98\n",
+ " coral fungus 50 0.96 0.96\n",
+ " agaric 50 0.82 0.94\n",
+ " gyromitra 50 0.98 1\n",
+ " stinkhorn mushroom 50 0.8 0.94\n",
+ " earth star 50 0.98 1\n",
+ " hen-of-the-woods 50 0.8 0.96\n",
+ " bolete 50 0.74 0.94\n",
+ " ear 50 0.48 0.94\n",
+ " toilet paper 50 0.36 0.68\n",
+ "Speed: 0.1ms pre-process, 0.3ms inference, 0.0ms post-process per image at shape (1, 3, 224, 224)\n",
+ "Results saved to \u001b[1mruns/val-cls/exp\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Validate YOLOv5s on Imagenet val\n",
+ "!python classify/val.py --weights yolov5s-cls.pt --data ../datasets/imagenet --img 224 --half"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
\n",
+ "Close the active learning loop by sampling images from your inference conditions with the `roboflow` pip package\n",
+ "
\n",
+ "\n",
+ "Train a YOLOv5s Classification model on the [Imagenette](https://image-net.org/) dataset with `--data imagenet`, starting from pretrained `--pretrained yolov5s-cls.pt`.\n",
+ "\n",
+ "- **Pretrained [Models](https://github.com/ultralytics/yolov5/tree/master/models)** are downloaded\n",
+ "automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases)\n",
+ "- **Training Results** are saved to `runs/train-cls/` with incrementing run directories, i.e. `runs/train-cls/exp2`, `runs/train-cls/exp3` etc.\n",
+ "
\n",
+ "\n",
+ "A **Mosaic Dataloader** is used for training which combines 4 images into 1 mosaic.\n",
+ "\n",
+ "## Train on Custom Data with Roboflow 🌟 NEW\n",
+ "\n",
+ "[Roboflow](https://roboflow.com/?ref=ultralytics) enables you to easily **organize, label, and prepare** a high quality dataset with your own custom data. Roboflow also makes it easy to establish an active learning pipeline, collaborate with your team on dataset improvement, and integrate directly into your model building workflow with the `roboflow` pip package.\n",
+ "\n",
+ "- Custom Training Example: [https://blog.roboflow.com/train-yolov5-classification-custom-data/](https://blog.roboflow.com/train-yolov5-classification-custom-data/?ref=ultralytics)\n",
+ "- Custom Training Notebook: [](https://colab.research.google.com/drive/1KZiKUAjtARHAfZCXbJRv14-pOnIsBLPV?usp=sharing)\n",
+ "
\n",
+ "\n",
+ "
Label images lightning fast (including with model-assisted labeling)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "i3oKtE4g-aNn"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Select YOLOv5 🚀 logger {run: 'auto'}\n",
+ "logger = 'Comet' #@param ['Comet', 'ClearML', 'TensorBoard']\n",
+ "\n",
+ "if logger == 'Comet':\n",
+ " %pip install -q comet_ml\n",
+ " import comet_ml; comet_ml.init()\n",
+ "elif logger == 'ClearML':\n",
+ " %pip install -q clearml\n",
+ " import clearml; clearml.browser_login()\n",
+ "elif logger == 'TensorBoard':\n",
+ " %load_ext tensorboard\n",
+ " %tensorboard --logdir runs/train"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "1NcFxRcFdJ_O",
+ "outputId": "77c8d487-16db-4073-b3ea-06cabf2e7766"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mclassify/train: \u001b[0mmodel=yolov5s-cls.pt, data=imagenette160, epochs=5, batch_size=64, imgsz=224, nosave=False, cache=ram, device=, workers=8, project=runs/train-cls, name=exp, exist_ok=False, pretrained=True, optimizer=Adam, lr0=0.001, decay=5e-05, label_smoothing=0.1, cutoff=None, dropout=None, verbose=False, seed=0, local_rank=-1\n",
+ "\u001b[34m\u001b[1mgithub: \u001b[0mup to date with https://github.com/ultralytics/yolov5 ✅\n",
+ "YOLOv5 🚀 v7.0-3-g61ebf5e Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)\n",
+ "\n",
+ "\u001b[34m\u001b[1mTensorBoard: \u001b[0mStart with 'tensorboard --logdir runs/train-cls', view at http://localhost:6006/\n",
+ "\n",
+ "Dataset not found ⚠️, missing path /content/datasets/imagenette160, attempting download...\n",
+ "Downloading https://github.com/ultralytics/yolov5/releases/download/v1.0/imagenette160.zip to /content/datasets/imagenette160.zip...\n",
+ "100% 103M/103M [00:00<00:00, 347MB/s] \n",
+ "Unzipping /content/datasets/imagenette160.zip...\n",
+ "Dataset download success ✅ (3.3s), saved to \u001b[1m/content/datasets/imagenette160\u001b[0m\n",
+ "\n",
+ "\u001b[34m\u001b[1malbumentations: \u001b[0mRandomResizedCrop(p=1.0, height=224, width=224, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=1), HorizontalFlip(p=0.5), ColorJitter(p=0.5, brightness=[0.6, 1.4], contrast=[0.6, 1.4], saturation=[0.6, 1.4], hue=[0, 0]), Normalize(p=1.0, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0), ToTensorV2(always_apply=True, p=1.0, transpose_mask=False)\n",
+ "Model summary: 149 layers, 4185290 parameters, 4185290 gradients, 10.5 GFLOPs\n",
+ "\u001b[34m\u001b[1moptimizer:\u001b[0m Adam(lr=0.001) with parameter groups 32 weight(decay=0.0), 33 weight(decay=5e-05), 33 bias\n",
+ "Image sizes 224 train, 224 test\n",
+ "Using 1 dataloader workers\n",
+ "Logging results to \u001b[1mruns/train-cls/exp\u001b[0m\n",
+ "Starting yolov5s-cls.pt training on imagenette160 dataset with 10 classes for 5 epochs...\n",
+ "\n",
+ " Epoch GPU_mem train_loss val_loss top1_acc top5_acc\n",
+ " 1/5 1.47G 1.05 0.974 0.828 0.975: 100% 148/148 [00:38<00:00, 3.82it/s]\n",
+ " 2/5 1.73G 0.895 0.766 0.911 0.994: 100% 148/148 [00:36<00:00, 4.03it/s]\n",
+ " 3/5 1.73G 0.82 0.704 0.934 0.996: 100% 148/148 [00:35<00:00, 4.20it/s]\n",
+ " 4/5 1.73G 0.766 0.664 0.951 0.998: 100% 148/148 [00:36<00:00, 4.05it/s]\n",
+ " 5/5 1.73G 0.724 0.634 0.959 0.997: 100% 148/148 [00:37<00:00, 3.94it/s]\n",
+ "\n",
+ "Training complete (0.052 hours)\n",
+ "Results saved to \u001b[1mruns/train-cls/exp\u001b[0m\n",
+ "Predict: python classify/predict.py --weights runs/train-cls/exp/weights/best.pt --source im.jpg\n",
+ "Validate: python classify/val.py --weights runs/train-cls/exp/weights/best.pt --data /content/datasets/imagenette160\n",
+ "Export: python export.py --weights runs/train-cls/exp/weights/best.pt --include onnx\n",
+ "PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'runs/train-cls/exp/weights/best.pt')\n",
+ "Visualize: https://netron.app\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Train YOLOv5s Classification on Imagenette160 for 3 epochs\n",
+ "!python classify/train.py --model yolov5s-cls.pt --data imagenette160 --epochs 5 --img 224 --cache"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "15glLzbQx5u0"
+ },
+ "source": [
+ "# 4. Visualize"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nWOsI5wJR1o3"
+ },
+ "source": [
+ "## Comet Logging and Visualization 🌟 NEW\n",
+ "\n",
+ "[Comet](https://www.comet.com/site/lp/yolov5-with-comet/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=yolov5_colab) is now fully integrated with YOLOv5. Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://www.comet.com/docs/v2/guides/comet-dashboard/code-panels/about-panels/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=yolov5_colab)! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!\n",
+ "\n",
+ "Getting started is easy:\n",
+ "```shell\n",
+ "pip install comet_ml # 1. install\n",
+ "export COMET_API_KEY= # 2. paste API key\n",
+ "python train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt # 3. train\n",
+ "```\n",
+ "To learn more about all of the supported Comet features for this integration, check out the [Comet Tutorial](https://docs.ultralytics.com/yolov5/tutorials/comet_logging_integration). If you'd like to learn more about Comet, head over to our [documentation](https://www.comet.com/docs/v2/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=yolov5_colab). Get started by trying out the Comet Colab Notebook:\n",
+ "[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Lay2WsTjNJzP"
+ },
+ "source": [
+ "## ClearML Logging and Automation 🌟 NEW\n",
+ "\n",
+ "[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML (check cells above):\n",
+ "\n",
+ "- `pip install clearml`\n",
+ "- run `clearml-init` to connect to a ClearML server (**deploy your own [open-source server](https://github.com/allegroai/clearml-server)**, or use our [free hosted server](https://cutt.ly/yolov5-notebook-clearml))\n",
+ "\n",
+ "You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).\n",
+ "\n",
+ "You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) for details!\n",
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Lay2WsTjNJzP"
+ },
+ "source": [
+ "## ClearML Logging and Automation 🌟 NEW\n",
+ "\n",
+ "[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML (check cells above):\n",
+ "\n",
+ "- `pip install clearml`\n",
+ "- run `clearml-init` to connect to a ClearML server (**deploy your own [open-source server](https://github.com/allegroai/clearml-server)**, or use our [free hosted server](https://cutt.ly/yolov5-notebook-clearml))\n",
+ "\n",
+ "You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).\n",
+ "\n",
+ "You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) for details!\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n",
+ "\n",
+ "This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices. \n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n",
+ "\n",
+ "This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices. \n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Notebooks** with free GPU: \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Notebooks** with free GPU: \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)  \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "outputs": [],
+ "source": [
+ "# YOLOv5 PyTorch HUB Inference (DetectionModels only)\n",
+ "import torch\n",
+ "\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # yolov5n - yolov5x6 or custom\n",
+ "im = 'https://ultralytics.com/images/zidane.jpg' # file, Path, PIL.Image, OpenCV, nparray, list\n",
+ "results = model(im) # inference\n",
+ "results.print() # or .show(), .save(), .crop(), .pandas(), etc."
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "name": "YOLOv5 Classification Tutorial",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.12"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/yolov5/classify/val.py b/yolov5/classify/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..643489d64d36cb4d445d3a74c04eed747619b933
--- /dev/null
+++ b/yolov5/classify/val.py
@@ -0,0 +1,170 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Validate a trained YOLOv5 classification model on a classification dataset
+
+Usage:
+ $ bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
+ $ python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate ImageNet
+
+Usage - formats:
+ $ python classify/val.py --weights yolov5s-cls.pt # PyTorch
+ yolov5s-cls.torchscript # TorchScript
+ yolov5s-cls.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s-cls_openvino_model # OpenVINO
+ yolov5s-cls.engine # TensorRT
+ yolov5s-cls.mlmodel # CoreML (macOS-only)
+ yolov5s-cls_saved_model # TensorFlow SavedModel
+ yolov5s-cls.pb # TensorFlow GraphDef
+ yolov5s-cls.tflite # TensorFlow Lite
+ yolov5s-cls_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s-cls_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import os
+import sys
+from pathlib import Path
+
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.dataloaders import create_classification_dataloader
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, Profile, check_img_size, check_requirements, colorstr,
+ increment_path, print_args)
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+@smart_inference_mode()
+def run(
+ data=ROOT / '../datasets/mnist', # dataset dir
+ weights=ROOT / 'yolov5s-cls.pt', # model.pt path(s)
+ batch_size=128, # batch size
+ imgsz=224, # inference size (pixels)
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ verbose=False, # verbose output
+ project=ROOT / 'runs/val-cls', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=False, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ criterion=None,
+ pbar=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ save_dir.mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Dataloader
+ data = Path(data)
+ test_dir = data / 'test' if (data / 'test').exists() else data / 'val' # data/test or data/val
+ dataloader = create_classification_dataloader(path=test_dir,
+ imgsz=imgsz,
+ batch_size=batch_size,
+ augment=False,
+ rank=-1,
+ workers=workers)
+
+ model.eval()
+ pred, targets, loss, dt = [], [], 0, (Profile(), Profile(), Profile())
+ n = len(dataloader) # number of batches
+ action = 'validating' if dataloader.dataset.root.stem == 'val' else 'testing'
+ desc = f'{pbar.desc[:-36]}{action:>36}' if pbar else f'{action}'
+ bar = tqdm(dataloader, desc, n, not training, bar_format=TQDM_BAR_FORMAT, position=0)
+ with torch.cuda.amp.autocast(enabled=device.type != 'cpu'):
+ for images, labels in bar:
+ with dt[0]:
+ images, labels = images.to(device, non_blocking=True), labels.to(device)
+
+ with dt[1]:
+ y = model(images)
+
+ with dt[2]:
+ pred.append(y.argsort(1, descending=True)[:, :5])
+ targets.append(labels)
+ if criterion:
+ loss += criterion(y, labels)
+
+ loss /= n
+ pred, targets = torch.cat(pred), torch.cat(targets)
+ correct = (targets[:, None] == pred).float()
+ acc = torch.stack((correct[:, 0], correct.max(1).values), dim=1) # (top1, top5) accuracy
+ top1, top5 = acc.mean(0).tolist()
+
+ if pbar:
+ pbar.desc = f'{pbar.desc[:-36]}{loss:>12.3g}{top1:>12.3g}{top5:>12.3g}'
+ if verbose: # all classes
+ LOGGER.info(f"{'Class':>24}{'Images':>12}{'top1_acc':>12}{'top5_acc':>12}")
+ LOGGER.info(f"{'all':>24}{targets.shape[0]:>12}{top1:>12.3g}{top5:>12.3g}")
+ for i, c in model.names.items():
+ acc_i = acc[targets == i]
+ top1i, top5i = acc_i.mean(0).tolist()
+ LOGGER.info(f'{c:>24}{acc_i.shape[0]:>12}{top1i:>12.3g}{top5i:>12.3g}')
+
+ # Print results
+ t = tuple(x.t / len(dataloader.dataset.samples) * 1E3 for x in dt) # speeds per image
+ shape = (1, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms post-process per image at shape {shape}' % t)
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
+
+ return top1, top5, loss
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / '../datasets/mnist', help='dataset path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s-cls.pt', help='model.pt path(s)')
+ parser.add_argument('--batch-size', type=int, default=128, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=224, help='inference size (pixels)')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--verbose', nargs='?', const=True, default=True, help='verbose output')
+ parser.add_argument('--project', default=ROOT / 'runs/val-cls', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/data/Argoverse.yaml b/yolov5/data/Argoverse.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..8a65407a633371210feed2779f1476186b9185bc
--- /dev/null
+++ b/yolov5/data/Argoverse.yaml
@@ -0,0 +1,74 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Argoverse-HD dataset (ring-front-center camera) http://www.cs.cmu.edu/~mengtial/proj/streaming/ by Argo AI
+# Example usage: python train.py --data Argoverse.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── Argoverse ← downloads here (31.3 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Argoverse # dataset root dir
+train: Argoverse-1.1/images/train/ # train images (relative to 'path') 39384 images
+val: Argoverse-1.1/images/val/ # val images (relative to 'path') 15062 images
+test: Argoverse-1.1/images/test/ # test images (optional) https://eval.ai/web/challenges/challenge-page/800/overview
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: bus
+ 5: truck
+ 6: traffic_light
+ 7: stop_sign
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import json
+
+ from tqdm import tqdm
+ from utils.general import download, Path
+
+
+ def argoverse2yolo(set):
+ labels = {}
+ a = json.load(open(set, "rb"))
+ for annot in tqdm(a['annotations'], desc=f"Converting {set} to YOLOv5 format..."):
+ img_id = annot['image_id']
+ img_name = a['images'][img_id]['name']
+ img_label_name = f'{img_name[:-3]}txt'
+
+ cls = annot['category_id'] # instance class id
+ x_center, y_center, width, height = annot['bbox']
+ x_center = (x_center + width / 2) / 1920.0 # offset and scale
+ y_center = (y_center + height / 2) / 1200.0 # offset and scale
+ width /= 1920.0 # scale
+ height /= 1200.0 # scale
+
+ img_dir = set.parents[2] / 'Argoverse-1.1' / 'labels' / a['seq_dirs'][a['images'][annot['image_id']]['sid']]
+ if not img_dir.exists():
+ img_dir.mkdir(parents=True, exist_ok=True)
+
+ k = str(img_dir / img_label_name)
+ if k not in labels:
+ labels[k] = []
+ labels[k].append(f"{cls} {x_center} {y_center} {width} {height}\n")
+
+ for k in labels:
+ with open(k, "w") as f:
+ f.writelines(labels[k])
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://argoverse-hd.s3.us-east-2.amazonaws.com/Argoverse-HD-Full.zip']
+ download(urls, dir=dir, delete=False)
+
+ # Convert
+ annotations_dir = 'Argoverse-HD/annotations/'
+ (dir / 'Argoverse-1.1' / 'tracking').rename(dir / 'Argoverse-1.1' / 'images') # rename 'tracking' to 'images'
+ for d in "train.json", "val.json":
+ argoverse2yolo(dir / annotations_dir / d) # convert VisDrone annotations to YOLO labels
diff --git a/yolov5/data/FLIR.yaml b/yolov5/data/FLIR.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..89da77a742da141897bc21b26d31e2a368912de4
--- /dev/null
+++ b/yolov5/data/FLIR.yaml
@@ -0,0 +1,28 @@
+train: ../VOCdevkit/images/train/ # 8493 images 训练集
+val: ../VOCdevkit/images/val/ # 2249 images 验证集
+
+
+# number of classes 类别数
+nc: 15
+
+
+# Classes
+names:
+ 0: person
+ 1: bike
+ 2: car
+ 3: motor
+ 4: bus
+ 5: train
+ 6: truck
+ 7: light
+ 8: hydrant
+ 9: sign
+ 10: dog
+ 11: skateboard
+ 12: stroller
+ 13: scooter
+ 14: other vehicle
+
+
+
diff --git a/yolov5/data/GlobalWheat2020.yaml b/yolov5/data/GlobalWheat2020.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..7b02ac95dd95d1b8fc466b268775f33b5f60ce88
--- /dev/null
+++ b/yolov5/data/GlobalWheat2020.yaml
@@ -0,0 +1,54 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Global Wheat 2020 dataset http://www.global-wheat.com/ by University of Saskatchewan
+# Example usage: python train.py --data GlobalWheat2020.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── GlobalWheat2020 ← downloads here (7.0 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/GlobalWheat2020 # dataset root dir
+train: # train images (relative to 'path') 3422 images
+ - images/arvalis_1
+ - images/arvalis_2
+ - images/arvalis_3
+ - images/ethz_1
+ - images/rres_1
+ - images/inrae_1
+ - images/usask_1
+val: # val images (relative to 'path') 748 images (WARNING: train set contains ethz_1)
+ - images/ethz_1
+test: # test images (optional) 1276 images
+ - images/utokyo_1
+ - images/utokyo_2
+ - images/nau_1
+ - images/uq_1
+
+# Classes
+names:
+ 0: wheat_head
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from utils.general import download, Path
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://zenodo.org/record/4298502/files/global-wheat-codalab-official.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/GlobalWheat2020_labels.zip']
+ download(urls, dir=dir)
+
+ # Make Directories
+ for p in 'annotations', 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+
+ # Move
+ for p in 'arvalis_1', 'arvalis_2', 'arvalis_3', 'ethz_1', 'rres_1', 'inrae_1', 'usask_1', \
+ 'utokyo_1', 'utokyo_2', 'nau_1', 'uq_1':
+ (dir / p).rename(dir / 'images' / p) # move to /images
+ f = (dir / p).with_suffix('.json') # json file
+ if f.exists():
+ f.rename((dir / 'annotations' / p).with_suffix('.json')) # move to /annotations
diff --git a/yolov5/data/ImageNet.yaml b/yolov5/data/ImageNet.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5fdcb63f89a5c4a0e4a579fc0b3bf995e8777e87
--- /dev/null
+++ b/yolov5/data/ImageNet.yaml
@@ -0,0 +1,1022 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# ImageNet-1k dataset https://www.image-net.org/index.php by Stanford University
+# Simplified class names from https://github.com/anishathalye/imagenet-simple-labels
+# Example usage: python classify/train.py --data imagenet
+# parent
+# ├── yolov5
+# └── datasets
+# └── imagenet ← downloads here (144 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/imagenet # dataset root dir
+train: train # train images (relative to 'path') 1281167 images
+val: val # val images (relative to 'path') 50000 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: tench
+ 1: goldfish
+ 2: great white shark
+ 3: tiger shark
+ 4: hammerhead shark
+ 5: electric ray
+ 6: stingray
+ 7: cock
+ 8: hen
+ 9: ostrich
+ 10: brambling
+ 11: goldfinch
+ 12: house finch
+ 13: junco
+ 14: indigo bunting
+ 15: American robin
+ 16: bulbul
+ 17: jay
+ 18: magpie
+ 19: chickadee
+ 20: American dipper
+ 21: kite
+ 22: bald eagle
+ 23: vulture
+ 24: great grey owl
+ 25: fire salamander
+ 26: smooth newt
+ 27: newt
+ 28: spotted salamander
+ 29: axolotl
+ 30: American bullfrog
+ 31: tree frog
+ 32: tailed frog
+ 33: loggerhead sea turtle
+ 34: leatherback sea turtle
+ 35: mud turtle
+ 36: terrapin
+ 37: box turtle
+ 38: banded gecko
+ 39: green iguana
+ 40: Carolina anole
+ 41: desert grassland whiptail lizard
+ 42: agama
+ 43: frilled-necked lizard
+ 44: alligator lizard
+ 45: Gila monster
+ 46: European green lizard
+ 47: chameleon
+ 48: Komodo dragon
+ 49: Nile crocodile
+ 50: American alligator
+ 51: triceratops
+ 52: worm snake
+ 53: ring-necked snake
+ 54: eastern hog-nosed snake
+ 55: smooth green snake
+ 56: kingsnake
+ 57: garter snake
+ 58: water snake
+ 59: vine snake
+ 60: night snake
+ 61: boa constrictor
+ 62: African rock python
+ 63: Indian cobra
+ 64: green mamba
+ 65: sea snake
+ 66: Saharan horned viper
+ 67: eastern diamondback rattlesnake
+ 68: sidewinder
+ 69: trilobite
+ 70: harvestman
+ 71: scorpion
+ 72: yellow garden spider
+ 73: barn spider
+ 74: European garden spider
+ 75: southern black widow
+ 76: tarantula
+ 77: wolf spider
+ 78: tick
+ 79: centipede
+ 80: black grouse
+ 81: ptarmigan
+ 82: ruffed grouse
+ 83: prairie grouse
+ 84: peacock
+ 85: quail
+ 86: partridge
+ 87: grey parrot
+ 88: macaw
+ 89: sulphur-crested cockatoo
+ 90: lorikeet
+ 91: coucal
+ 92: bee eater
+ 93: hornbill
+ 94: hummingbird
+ 95: jacamar
+ 96: toucan
+ 97: duck
+ 98: red-breasted merganser
+ 99: goose
+ 100: black swan
+ 101: tusker
+ 102: echidna
+ 103: platypus
+ 104: wallaby
+ 105: koala
+ 106: wombat
+ 107: jellyfish
+ 108: sea anemone
+ 109: brain coral
+ 110: flatworm
+ 111: nematode
+ 112: conch
+ 113: snail
+ 114: slug
+ 115: sea slug
+ 116: chiton
+ 117: chambered nautilus
+ 118: Dungeness crab
+ 119: rock crab
+ 120: fiddler crab
+ 121: red king crab
+ 122: American lobster
+ 123: spiny lobster
+ 124: crayfish
+ 125: hermit crab
+ 126: isopod
+ 127: white stork
+ 128: black stork
+ 129: spoonbill
+ 130: flamingo
+ 131: little blue heron
+ 132: great egret
+ 133: bittern
+ 134: crane (bird)
+ 135: limpkin
+ 136: common gallinule
+ 137: American coot
+ 138: bustard
+ 139: ruddy turnstone
+ 140: dunlin
+ 141: common redshank
+ 142: dowitcher
+ 143: oystercatcher
+ 144: pelican
+ 145: king penguin
+ 146: albatross
+ 147: grey whale
+ 148: killer whale
+ 149: dugong
+ 150: sea lion
+ 151: Chihuahua
+ 152: Japanese Chin
+ 153: Maltese
+ 154: Pekingese
+ 155: Shih Tzu
+ 156: King Charles Spaniel
+ 157: Papillon
+ 158: toy terrier
+ 159: Rhodesian Ridgeback
+ 160: Afghan Hound
+ 161: Basset Hound
+ 162: Beagle
+ 163: Bloodhound
+ 164: Bluetick Coonhound
+ 165: Black and Tan Coonhound
+ 166: Treeing Walker Coonhound
+ 167: English foxhound
+ 168: Redbone Coonhound
+ 169: borzoi
+ 170: Irish Wolfhound
+ 171: Italian Greyhound
+ 172: Whippet
+ 173: Ibizan Hound
+ 174: Norwegian Elkhound
+ 175: Otterhound
+ 176: Saluki
+ 177: Scottish Deerhound
+ 178: Weimaraner
+ 179: Staffordshire Bull Terrier
+ 180: American Staffordshire Terrier
+ 181: Bedlington Terrier
+ 182: Border Terrier
+ 183: Kerry Blue Terrier
+ 184: Irish Terrier
+ 185: Norfolk Terrier
+ 186: Norwich Terrier
+ 187: Yorkshire Terrier
+ 188: Wire Fox Terrier
+ 189: Lakeland Terrier
+ 190: Sealyham Terrier
+ 191: Airedale Terrier
+ 192: Cairn Terrier
+ 193: Australian Terrier
+ 194: Dandie Dinmont Terrier
+ 195: Boston Terrier
+ 196: Miniature Schnauzer
+ 197: Giant Schnauzer
+ 198: Standard Schnauzer
+ 199: Scottish Terrier
+ 200: Tibetan Terrier
+ 201: Australian Silky Terrier
+ 202: Soft-coated Wheaten Terrier
+ 203: West Highland White Terrier
+ 204: Lhasa Apso
+ 205: Flat-Coated Retriever
+ 206: Curly-coated Retriever
+ 207: Golden Retriever
+ 208: Labrador Retriever
+ 209: Chesapeake Bay Retriever
+ 210: German Shorthaired Pointer
+ 211: Vizsla
+ 212: English Setter
+ 213: Irish Setter
+ 214: Gordon Setter
+ 215: Brittany
+ 216: Clumber Spaniel
+ 217: English Springer Spaniel
+ 218: Welsh Springer Spaniel
+ 219: Cocker Spaniels
+ 220: Sussex Spaniel
+ 221: Irish Water Spaniel
+ 222: Kuvasz
+ 223: Schipperke
+ 224: Groenendael
+ 225: Malinois
+ 226: Briard
+ 227: Australian Kelpie
+ 228: Komondor
+ 229: Old English Sheepdog
+ 230: Shetland Sheepdog
+ 231: collie
+ 232: Border Collie
+ 233: Bouvier des Flandres
+ 234: Rottweiler
+ 235: German Shepherd Dog
+ 236: Dobermann
+ 237: Miniature Pinscher
+ 238: Greater Swiss Mountain Dog
+ 239: Bernese Mountain Dog
+ 240: Appenzeller Sennenhund
+ 241: Entlebucher Sennenhund
+ 242: Boxer
+ 243: Bullmastiff
+ 244: Tibetan Mastiff
+ 245: French Bulldog
+ 246: Great Dane
+ 247: St. Bernard
+ 248: husky
+ 249: Alaskan Malamute
+ 250: Siberian Husky
+ 251: Dalmatian
+ 252: Affenpinscher
+ 253: Basenji
+ 254: pug
+ 255: Leonberger
+ 256: Newfoundland
+ 257: Pyrenean Mountain Dog
+ 258: Samoyed
+ 259: Pomeranian
+ 260: Chow Chow
+ 261: Keeshond
+ 262: Griffon Bruxellois
+ 263: Pembroke Welsh Corgi
+ 264: Cardigan Welsh Corgi
+ 265: Toy Poodle
+ 266: Miniature Poodle
+ 267: Standard Poodle
+ 268: Mexican hairless dog
+ 269: grey wolf
+ 270: Alaskan tundra wolf
+ 271: red wolf
+ 272: coyote
+ 273: dingo
+ 274: dhole
+ 275: African wild dog
+ 276: hyena
+ 277: red fox
+ 278: kit fox
+ 279: Arctic fox
+ 280: grey fox
+ 281: tabby cat
+ 282: tiger cat
+ 283: Persian cat
+ 284: Siamese cat
+ 285: Egyptian Mau
+ 286: cougar
+ 287: lynx
+ 288: leopard
+ 289: snow leopard
+ 290: jaguar
+ 291: lion
+ 292: tiger
+ 293: cheetah
+ 294: brown bear
+ 295: American black bear
+ 296: polar bear
+ 297: sloth bear
+ 298: mongoose
+ 299: meerkat
+ 300: tiger beetle
+ 301: ladybug
+ 302: ground beetle
+ 303: longhorn beetle
+ 304: leaf beetle
+ 305: dung beetle
+ 306: rhinoceros beetle
+ 307: weevil
+ 308: fly
+ 309: bee
+ 310: ant
+ 311: grasshopper
+ 312: cricket
+ 313: stick insect
+ 314: cockroach
+ 315: mantis
+ 316: cicada
+ 317: leafhopper
+ 318: lacewing
+ 319: dragonfly
+ 320: damselfly
+ 321: red admiral
+ 322: ringlet
+ 323: monarch butterfly
+ 324: small white
+ 325: sulphur butterfly
+ 326: gossamer-winged butterfly
+ 327: starfish
+ 328: sea urchin
+ 329: sea cucumber
+ 330: cottontail rabbit
+ 331: hare
+ 332: Angora rabbit
+ 333: hamster
+ 334: porcupine
+ 335: fox squirrel
+ 336: marmot
+ 337: beaver
+ 338: guinea pig
+ 339: common sorrel
+ 340: zebra
+ 341: pig
+ 342: wild boar
+ 343: warthog
+ 344: hippopotamus
+ 345: ox
+ 346: water buffalo
+ 347: bison
+ 348: ram
+ 349: bighorn sheep
+ 350: Alpine ibex
+ 351: hartebeest
+ 352: impala
+ 353: gazelle
+ 354: dromedary
+ 355: llama
+ 356: weasel
+ 357: mink
+ 358: European polecat
+ 359: black-footed ferret
+ 360: otter
+ 361: skunk
+ 362: badger
+ 363: armadillo
+ 364: three-toed sloth
+ 365: orangutan
+ 366: gorilla
+ 367: chimpanzee
+ 368: gibbon
+ 369: siamang
+ 370: guenon
+ 371: patas monkey
+ 372: baboon
+ 373: macaque
+ 374: langur
+ 375: black-and-white colobus
+ 376: proboscis monkey
+ 377: marmoset
+ 378: white-headed capuchin
+ 379: howler monkey
+ 380: titi
+ 381: Geoffroy's spider monkey
+ 382: common squirrel monkey
+ 383: ring-tailed lemur
+ 384: indri
+ 385: Asian elephant
+ 386: African bush elephant
+ 387: red panda
+ 388: giant panda
+ 389: snoek
+ 390: eel
+ 391: coho salmon
+ 392: rock beauty
+ 393: clownfish
+ 394: sturgeon
+ 395: garfish
+ 396: lionfish
+ 397: pufferfish
+ 398: abacus
+ 399: abaya
+ 400: academic gown
+ 401: accordion
+ 402: acoustic guitar
+ 403: aircraft carrier
+ 404: airliner
+ 405: airship
+ 406: altar
+ 407: ambulance
+ 408: amphibious vehicle
+ 409: analog clock
+ 410: apiary
+ 411: apron
+ 412: waste container
+ 413: assault rifle
+ 414: backpack
+ 415: bakery
+ 416: balance beam
+ 417: balloon
+ 418: ballpoint pen
+ 419: Band-Aid
+ 420: banjo
+ 421: baluster
+ 422: barbell
+ 423: barber chair
+ 424: barbershop
+ 425: barn
+ 426: barometer
+ 427: barrel
+ 428: wheelbarrow
+ 429: baseball
+ 430: basketball
+ 431: bassinet
+ 432: bassoon
+ 433: swimming cap
+ 434: bath towel
+ 435: bathtub
+ 436: station wagon
+ 437: lighthouse
+ 438: beaker
+ 439: military cap
+ 440: beer bottle
+ 441: beer glass
+ 442: bell-cot
+ 443: bib
+ 444: tandem bicycle
+ 445: bikini
+ 446: ring binder
+ 447: binoculars
+ 448: birdhouse
+ 449: boathouse
+ 450: bobsleigh
+ 451: bolo tie
+ 452: poke bonnet
+ 453: bookcase
+ 454: bookstore
+ 455: bottle cap
+ 456: bow
+ 457: bow tie
+ 458: brass
+ 459: bra
+ 460: breakwater
+ 461: breastplate
+ 462: broom
+ 463: bucket
+ 464: buckle
+ 465: bulletproof vest
+ 466: high-speed train
+ 467: butcher shop
+ 468: taxicab
+ 469: cauldron
+ 470: candle
+ 471: cannon
+ 472: canoe
+ 473: can opener
+ 474: cardigan
+ 475: car mirror
+ 476: carousel
+ 477: tool kit
+ 478: carton
+ 479: car wheel
+ 480: automated teller machine
+ 481: cassette
+ 482: cassette player
+ 483: castle
+ 484: catamaran
+ 485: CD player
+ 486: cello
+ 487: mobile phone
+ 488: chain
+ 489: chain-link fence
+ 490: chain mail
+ 491: chainsaw
+ 492: chest
+ 493: chiffonier
+ 494: chime
+ 495: china cabinet
+ 496: Christmas stocking
+ 497: church
+ 498: movie theater
+ 499: cleaver
+ 500: cliff dwelling
+ 501: cloak
+ 502: clogs
+ 503: cocktail shaker
+ 504: coffee mug
+ 505: coffeemaker
+ 506: coil
+ 507: combination lock
+ 508: computer keyboard
+ 509: confectionery store
+ 510: container ship
+ 511: convertible
+ 512: corkscrew
+ 513: cornet
+ 514: cowboy boot
+ 515: cowboy hat
+ 516: cradle
+ 517: crane (machine)
+ 518: crash helmet
+ 519: crate
+ 520: infant bed
+ 521: Crock Pot
+ 522: croquet ball
+ 523: crutch
+ 524: cuirass
+ 525: dam
+ 526: desk
+ 527: desktop computer
+ 528: rotary dial telephone
+ 529: diaper
+ 530: digital clock
+ 531: digital watch
+ 532: dining table
+ 533: dishcloth
+ 534: dishwasher
+ 535: disc brake
+ 536: dock
+ 537: dog sled
+ 538: dome
+ 539: doormat
+ 540: drilling rig
+ 541: drum
+ 542: drumstick
+ 543: dumbbell
+ 544: Dutch oven
+ 545: electric fan
+ 546: electric guitar
+ 547: electric locomotive
+ 548: entertainment center
+ 549: envelope
+ 550: espresso machine
+ 551: face powder
+ 552: feather boa
+ 553: filing cabinet
+ 554: fireboat
+ 555: fire engine
+ 556: fire screen sheet
+ 557: flagpole
+ 558: flute
+ 559: folding chair
+ 560: football helmet
+ 561: forklift
+ 562: fountain
+ 563: fountain pen
+ 564: four-poster bed
+ 565: freight car
+ 566: French horn
+ 567: frying pan
+ 568: fur coat
+ 569: garbage truck
+ 570: gas mask
+ 571: gas pump
+ 572: goblet
+ 573: go-kart
+ 574: golf ball
+ 575: golf cart
+ 576: gondola
+ 577: gong
+ 578: gown
+ 579: grand piano
+ 580: greenhouse
+ 581: grille
+ 582: grocery store
+ 583: guillotine
+ 584: barrette
+ 585: hair spray
+ 586: half-track
+ 587: hammer
+ 588: hamper
+ 589: hair dryer
+ 590: hand-held computer
+ 591: handkerchief
+ 592: hard disk drive
+ 593: harmonica
+ 594: harp
+ 595: harvester
+ 596: hatchet
+ 597: holster
+ 598: home theater
+ 599: honeycomb
+ 600: hook
+ 601: hoop skirt
+ 602: horizontal bar
+ 603: horse-drawn vehicle
+ 604: hourglass
+ 605: iPod
+ 606: clothes iron
+ 607: jack-o'-lantern
+ 608: jeans
+ 609: jeep
+ 610: T-shirt
+ 611: jigsaw puzzle
+ 612: pulled rickshaw
+ 613: joystick
+ 614: kimono
+ 615: knee pad
+ 616: knot
+ 617: lab coat
+ 618: ladle
+ 619: lampshade
+ 620: laptop computer
+ 621: lawn mower
+ 622: lens cap
+ 623: paper knife
+ 624: library
+ 625: lifeboat
+ 626: lighter
+ 627: limousine
+ 628: ocean liner
+ 629: lipstick
+ 630: slip-on shoe
+ 631: lotion
+ 632: speaker
+ 633: loupe
+ 634: sawmill
+ 635: magnetic compass
+ 636: mail bag
+ 637: mailbox
+ 638: tights
+ 639: tank suit
+ 640: manhole cover
+ 641: maraca
+ 642: marimba
+ 643: mask
+ 644: match
+ 645: maypole
+ 646: maze
+ 647: measuring cup
+ 648: medicine chest
+ 649: megalith
+ 650: microphone
+ 651: microwave oven
+ 652: military uniform
+ 653: milk can
+ 654: minibus
+ 655: miniskirt
+ 656: minivan
+ 657: missile
+ 658: mitten
+ 659: mixing bowl
+ 660: mobile home
+ 661: Model T
+ 662: modem
+ 663: monastery
+ 664: monitor
+ 665: moped
+ 666: mortar
+ 667: square academic cap
+ 668: mosque
+ 669: mosquito net
+ 670: scooter
+ 671: mountain bike
+ 672: tent
+ 673: computer mouse
+ 674: mousetrap
+ 675: moving van
+ 676: muzzle
+ 677: nail
+ 678: neck brace
+ 679: necklace
+ 680: nipple
+ 681: notebook computer
+ 682: obelisk
+ 683: oboe
+ 684: ocarina
+ 685: odometer
+ 686: oil filter
+ 687: organ
+ 688: oscilloscope
+ 689: overskirt
+ 690: bullock cart
+ 691: oxygen mask
+ 692: packet
+ 693: paddle
+ 694: paddle wheel
+ 695: padlock
+ 696: paintbrush
+ 697: pajamas
+ 698: palace
+ 699: pan flute
+ 700: paper towel
+ 701: parachute
+ 702: parallel bars
+ 703: park bench
+ 704: parking meter
+ 705: passenger car
+ 706: patio
+ 707: payphone
+ 708: pedestal
+ 709: pencil case
+ 710: pencil sharpener
+ 711: perfume
+ 712: Petri dish
+ 713: photocopier
+ 714: plectrum
+ 715: Pickelhaube
+ 716: picket fence
+ 717: pickup truck
+ 718: pier
+ 719: piggy bank
+ 720: pill bottle
+ 721: pillow
+ 722: ping-pong ball
+ 723: pinwheel
+ 724: pirate ship
+ 725: pitcher
+ 726: hand plane
+ 727: planetarium
+ 728: plastic bag
+ 729: plate rack
+ 730: plow
+ 731: plunger
+ 732: Polaroid camera
+ 733: pole
+ 734: police van
+ 735: poncho
+ 736: billiard table
+ 737: soda bottle
+ 738: pot
+ 739: potter's wheel
+ 740: power drill
+ 741: prayer rug
+ 742: printer
+ 743: prison
+ 744: projectile
+ 745: projector
+ 746: hockey puck
+ 747: punching bag
+ 748: purse
+ 749: quill
+ 750: quilt
+ 751: race car
+ 752: racket
+ 753: radiator
+ 754: radio
+ 755: radio telescope
+ 756: rain barrel
+ 757: recreational vehicle
+ 758: reel
+ 759: reflex camera
+ 760: refrigerator
+ 761: remote control
+ 762: restaurant
+ 763: revolver
+ 764: rifle
+ 765: rocking chair
+ 766: rotisserie
+ 767: eraser
+ 768: rugby ball
+ 769: ruler
+ 770: running shoe
+ 771: safe
+ 772: safety pin
+ 773: salt shaker
+ 774: sandal
+ 775: sarong
+ 776: saxophone
+ 777: scabbard
+ 778: weighing scale
+ 779: school bus
+ 780: schooner
+ 781: scoreboard
+ 782: CRT screen
+ 783: screw
+ 784: screwdriver
+ 785: seat belt
+ 786: sewing machine
+ 787: shield
+ 788: shoe store
+ 789: shoji
+ 790: shopping basket
+ 791: shopping cart
+ 792: shovel
+ 793: shower cap
+ 794: shower curtain
+ 795: ski
+ 796: ski mask
+ 797: sleeping bag
+ 798: slide rule
+ 799: sliding door
+ 800: slot machine
+ 801: snorkel
+ 802: snowmobile
+ 803: snowplow
+ 804: soap dispenser
+ 805: soccer ball
+ 806: sock
+ 807: solar thermal collector
+ 808: sombrero
+ 809: soup bowl
+ 810: space bar
+ 811: space heater
+ 812: space shuttle
+ 813: spatula
+ 814: motorboat
+ 815: spider web
+ 816: spindle
+ 817: sports car
+ 818: spotlight
+ 819: stage
+ 820: steam locomotive
+ 821: through arch bridge
+ 822: steel drum
+ 823: stethoscope
+ 824: scarf
+ 825: stone wall
+ 826: stopwatch
+ 827: stove
+ 828: strainer
+ 829: tram
+ 830: stretcher
+ 831: couch
+ 832: stupa
+ 833: submarine
+ 834: suit
+ 835: sundial
+ 836: sunglass
+ 837: sunglasses
+ 838: sunscreen
+ 839: suspension bridge
+ 840: mop
+ 841: sweatshirt
+ 842: swimsuit
+ 843: swing
+ 844: switch
+ 845: syringe
+ 846: table lamp
+ 847: tank
+ 848: tape player
+ 849: teapot
+ 850: teddy bear
+ 851: television
+ 852: tennis ball
+ 853: thatched roof
+ 854: front curtain
+ 855: thimble
+ 856: threshing machine
+ 857: throne
+ 858: tile roof
+ 859: toaster
+ 860: tobacco shop
+ 861: toilet seat
+ 862: torch
+ 863: totem pole
+ 864: tow truck
+ 865: toy store
+ 866: tractor
+ 867: semi-trailer truck
+ 868: tray
+ 869: trench coat
+ 870: tricycle
+ 871: trimaran
+ 872: tripod
+ 873: triumphal arch
+ 874: trolleybus
+ 875: trombone
+ 876: tub
+ 877: turnstile
+ 878: typewriter keyboard
+ 879: umbrella
+ 880: unicycle
+ 881: upright piano
+ 882: vacuum cleaner
+ 883: vase
+ 884: vault
+ 885: velvet
+ 886: vending machine
+ 887: vestment
+ 888: viaduct
+ 889: violin
+ 890: volleyball
+ 891: waffle iron
+ 892: wall clock
+ 893: wallet
+ 894: wardrobe
+ 895: military aircraft
+ 896: sink
+ 897: washing machine
+ 898: water bottle
+ 899: water jug
+ 900: water tower
+ 901: whiskey jug
+ 902: whistle
+ 903: wig
+ 904: window screen
+ 905: window shade
+ 906: Windsor tie
+ 907: wine bottle
+ 908: wing
+ 909: wok
+ 910: wooden spoon
+ 911: wool
+ 912: split-rail fence
+ 913: shipwreck
+ 914: yawl
+ 915: yurt
+ 916: website
+ 917: comic book
+ 918: crossword
+ 919: traffic sign
+ 920: traffic light
+ 921: dust jacket
+ 922: menu
+ 923: plate
+ 924: guacamole
+ 925: consomme
+ 926: hot pot
+ 927: trifle
+ 928: ice cream
+ 929: ice pop
+ 930: baguette
+ 931: bagel
+ 932: pretzel
+ 933: cheeseburger
+ 934: hot dog
+ 935: mashed potato
+ 936: cabbage
+ 937: broccoli
+ 938: cauliflower
+ 939: zucchini
+ 940: spaghetti squash
+ 941: acorn squash
+ 942: butternut squash
+ 943: cucumber
+ 944: artichoke
+ 945: bell pepper
+ 946: cardoon
+ 947: mushroom
+ 948: Granny Smith
+ 949: strawberry
+ 950: orange
+ 951: lemon
+ 952: fig
+ 953: pineapple
+ 954: banana
+ 955: jackfruit
+ 956: custard apple
+ 957: pomegranate
+ 958: hay
+ 959: carbonara
+ 960: chocolate syrup
+ 961: dough
+ 962: meatloaf
+ 963: pizza
+ 964: pot pie
+ 965: burrito
+ 966: red wine
+ 967: espresso
+ 968: cup
+ 969: eggnog
+ 970: alp
+ 971: bubble
+ 972: cliff
+ 973: coral reef
+ 974: geyser
+ 975: lakeshore
+ 976: promontory
+ 977: shoal
+ 978: seashore
+ 979: valley
+ 980: volcano
+ 981: baseball player
+ 982: bridegroom
+ 983: scuba diver
+ 984: rapeseed
+ 985: daisy
+ 986: yellow lady's slipper
+ 987: corn
+ 988: acorn
+ 989: rose hip
+ 990: horse chestnut seed
+ 991: coral fungus
+ 992: agaric
+ 993: gyromitra
+ 994: stinkhorn mushroom
+ 995: earth star
+ 996: hen-of-the-woods
+ 997: bolete
+ 998: ear
+ 999: toilet paper
+
+
+# Download script/URL (optional)
+download: data/scripts/get_imagenet.sh
diff --git a/yolov5/data/Objects365.yaml b/yolov5/data/Objects365.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..bb2aa34cd4a4f85870747039485695893b3e4c2b
--- /dev/null
+++ b/yolov5/data/Objects365.yaml
@@ -0,0 +1,438 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Objects365 dataset https://www.objects365.org/ by Megvii
+# Example usage: python train.py --data Objects365.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── Objects365 ← downloads here (712 GB = 367G data + 345G zips)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Objects365 # dataset root dir
+train: images/train # train images (relative to 'path') 1742289 images
+val: images/val # val images (relative to 'path') 80000 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: Person
+ 1: Sneakers
+ 2: Chair
+ 3: Other Shoes
+ 4: Hat
+ 5: Car
+ 6: Lamp
+ 7: Glasses
+ 8: Bottle
+ 9: Desk
+ 10: Cup
+ 11: Street Lights
+ 12: Cabinet/shelf
+ 13: Handbag/Satchel
+ 14: Bracelet
+ 15: Plate
+ 16: Picture/Frame
+ 17: Helmet
+ 18: Book
+ 19: Gloves
+ 20: Storage box
+ 21: Boat
+ 22: Leather Shoes
+ 23: Flower
+ 24: Bench
+ 25: Potted Plant
+ 26: Bowl/Basin
+ 27: Flag
+ 28: Pillow
+ 29: Boots
+ 30: Vase
+ 31: Microphone
+ 32: Necklace
+ 33: Ring
+ 34: SUV
+ 35: Wine Glass
+ 36: Belt
+ 37: Monitor/TV
+ 38: Backpack
+ 39: Umbrella
+ 40: Traffic Light
+ 41: Speaker
+ 42: Watch
+ 43: Tie
+ 44: Trash bin Can
+ 45: Slippers
+ 46: Bicycle
+ 47: Stool
+ 48: Barrel/bucket
+ 49: Van
+ 50: Couch
+ 51: Sandals
+ 52: Basket
+ 53: Drum
+ 54: Pen/Pencil
+ 55: Bus
+ 56: Wild Bird
+ 57: High Heels
+ 58: Motorcycle
+ 59: Guitar
+ 60: Carpet
+ 61: Cell Phone
+ 62: Bread
+ 63: Camera
+ 64: Canned
+ 65: Truck
+ 66: Traffic cone
+ 67: Cymbal
+ 68: Lifesaver
+ 69: Towel
+ 70: Stuffed Toy
+ 71: Candle
+ 72: Sailboat
+ 73: Laptop
+ 74: Awning
+ 75: Bed
+ 76: Faucet
+ 77: Tent
+ 78: Horse
+ 79: Mirror
+ 80: Power outlet
+ 81: Sink
+ 82: Apple
+ 83: Air Conditioner
+ 84: Knife
+ 85: Hockey Stick
+ 86: Paddle
+ 87: Pickup Truck
+ 88: Fork
+ 89: Traffic Sign
+ 90: Balloon
+ 91: Tripod
+ 92: Dog
+ 93: Spoon
+ 94: Clock
+ 95: Pot
+ 96: Cow
+ 97: Cake
+ 98: Dinning Table
+ 99: Sheep
+ 100: Hanger
+ 101: Blackboard/Whiteboard
+ 102: Napkin
+ 103: Other Fish
+ 104: Orange/Tangerine
+ 105: Toiletry
+ 106: Keyboard
+ 107: Tomato
+ 108: Lantern
+ 109: Machinery Vehicle
+ 110: Fan
+ 111: Green Vegetables
+ 112: Banana
+ 113: Baseball Glove
+ 114: Airplane
+ 115: Mouse
+ 116: Train
+ 117: Pumpkin
+ 118: Soccer
+ 119: Skiboard
+ 120: Luggage
+ 121: Nightstand
+ 122: Tea pot
+ 123: Telephone
+ 124: Trolley
+ 125: Head Phone
+ 126: Sports Car
+ 127: Stop Sign
+ 128: Dessert
+ 129: Scooter
+ 130: Stroller
+ 131: Crane
+ 132: Remote
+ 133: Refrigerator
+ 134: Oven
+ 135: Lemon
+ 136: Duck
+ 137: Baseball Bat
+ 138: Surveillance Camera
+ 139: Cat
+ 140: Jug
+ 141: Broccoli
+ 142: Piano
+ 143: Pizza
+ 144: Elephant
+ 145: Skateboard
+ 146: Surfboard
+ 147: Gun
+ 148: Skating and Skiing shoes
+ 149: Gas stove
+ 150: Donut
+ 151: Bow Tie
+ 152: Carrot
+ 153: Toilet
+ 154: Kite
+ 155: Strawberry
+ 156: Other Balls
+ 157: Shovel
+ 158: Pepper
+ 159: Computer Box
+ 160: Toilet Paper
+ 161: Cleaning Products
+ 162: Chopsticks
+ 163: Microwave
+ 164: Pigeon
+ 165: Baseball
+ 166: Cutting/chopping Board
+ 167: Coffee Table
+ 168: Side Table
+ 169: Scissors
+ 170: Marker
+ 171: Pie
+ 172: Ladder
+ 173: Snowboard
+ 174: Cookies
+ 175: Radiator
+ 176: Fire Hydrant
+ 177: Basketball
+ 178: Zebra
+ 179: Grape
+ 180: Giraffe
+ 181: Potato
+ 182: Sausage
+ 183: Tricycle
+ 184: Violin
+ 185: Egg
+ 186: Fire Extinguisher
+ 187: Candy
+ 188: Fire Truck
+ 189: Billiards
+ 190: Converter
+ 191: Bathtub
+ 192: Wheelchair
+ 193: Golf Club
+ 194: Briefcase
+ 195: Cucumber
+ 196: Cigar/Cigarette
+ 197: Paint Brush
+ 198: Pear
+ 199: Heavy Truck
+ 200: Hamburger
+ 201: Extractor
+ 202: Extension Cord
+ 203: Tong
+ 204: Tennis Racket
+ 205: Folder
+ 206: American Football
+ 207: earphone
+ 208: Mask
+ 209: Kettle
+ 210: Tennis
+ 211: Ship
+ 212: Swing
+ 213: Coffee Machine
+ 214: Slide
+ 215: Carriage
+ 216: Onion
+ 217: Green beans
+ 218: Projector
+ 219: Frisbee
+ 220: Washing Machine/Drying Machine
+ 221: Chicken
+ 222: Printer
+ 223: Watermelon
+ 224: Saxophone
+ 225: Tissue
+ 226: Toothbrush
+ 227: Ice cream
+ 228: Hot-air balloon
+ 229: Cello
+ 230: French Fries
+ 231: Scale
+ 232: Trophy
+ 233: Cabbage
+ 234: Hot dog
+ 235: Blender
+ 236: Peach
+ 237: Rice
+ 238: Wallet/Purse
+ 239: Volleyball
+ 240: Deer
+ 241: Goose
+ 242: Tape
+ 243: Tablet
+ 244: Cosmetics
+ 245: Trumpet
+ 246: Pineapple
+ 247: Golf Ball
+ 248: Ambulance
+ 249: Parking meter
+ 250: Mango
+ 251: Key
+ 252: Hurdle
+ 253: Fishing Rod
+ 254: Medal
+ 255: Flute
+ 256: Brush
+ 257: Penguin
+ 258: Megaphone
+ 259: Corn
+ 260: Lettuce
+ 261: Garlic
+ 262: Swan
+ 263: Helicopter
+ 264: Green Onion
+ 265: Sandwich
+ 266: Nuts
+ 267: Speed Limit Sign
+ 268: Induction Cooker
+ 269: Broom
+ 270: Trombone
+ 271: Plum
+ 272: Rickshaw
+ 273: Goldfish
+ 274: Kiwi fruit
+ 275: Router/modem
+ 276: Poker Card
+ 277: Toaster
+ 278: Shrimp
+ 279: Sushi
+ 280: Cheese
+ 281: Notepaper
+ 282: Cherry
+ 283: Pliers
+ 284: CD
+ 285: Pasta
+ 286: Hammer
+ 287: Cue
+ 288: Avocado
+ 289: Hamimelon
+ 290: Flask
+ 291: Mushroom
+ 292: Screwdriver
+ 293: Soap
+ 294: Recorder
+ 295: Bear
+ 296: Eggplant
+ 297: Board Eraser
+ 298: Coconut
+ 299: Tape Measure/Ruler
+ 300: Pig
+ 301: Showerhead
+ 302: Globe
+ 303: Chips
+ 304: Steak
+ 305: Crosswalk Sign
+ 306: Stapler
+ 307: Camel
+ 308: Formula 1
+ 309: Pomegranate
+ 310: Dishwasher
+ 311: Crab
+ 312: Hoverboard
+ 313: Meat ball
+ 314: Rice Cooker
+ 315: Tuba
+ 316: Calculator
+ 317: Papaya
+ 318: Antelope
+ 319: Parrot
+ 320: Seal
+ 321: Butterfly
+ 322: Dumbbell
+ 323: Donkey
+ 324: Lion
+ 325: Urinal
+ 326: Dolphin
+ 327: Electric Drill
+ 328: Hair Dryer
+ 329: Egg tart
+ 330: Jellyfish
+ 331: Treadmill
+ 332: Lighter
+ 333: Grapefruit
+ 334: Game board
+ 335: Mop
+ 336: Radish
+ 337: Baozi
+ 338: Target
+ 339: French
+ 340: Spring Rolls
+ 341: Monkey
+ 342: Rabbit
+ 343: Pencil Case
+ 344: Yak
+ 345: Red Cabbage
+ 346: Binoculars
+ 347: Asparagus
+ 348: Barbell
+ 349: Scallop
+ 350: Noddles
+ 351: Comb
+ 352: Dumpling
+ 353: Oyster
+ 354: Table Tennis paddle
+ 355: Cosmetics Brush/Eyeliner Pencil
+ 356: Chainsaw
+ 357: Eraser
+ 358: Lobster
+ 359: Durian
+ 360: Okra
+ 361: Lipstick
+ 362: Cosmetics Mirror
+ 363: Curling
+ 364: Table Tennis
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from tqdm import tqdm
+
+ from utils.general import Path, check_requirements, download, np, xyxy2xywhn
+
+ check_requirements(('pycocotools>=2.0',))
+ from pycocotools.coco import COCO
+
+ # Make Directories
+ dir = Path(yaml['path']) # dataset root dir
+ for p in 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+ for q in 'train', 'val':
+ (dir / p / q).mkdir(parents=True, exist_ok=True)
+
+ # Train, Val Splits
+ for split, patches in [('train', 50 + 1), ('val', 43 + 1)]:
+ print(f"Processing {split} in {patches} patches ...")
+ images, labels = dir / 'images' / split, dir / 'labels' / split
+
+ # Download
+ url = f"https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/{split}/"
+ if split == 'train':
+ download([f'{url}zhiyuan_objv2_{split}.tar.gz'], dir=dir, delete=False) # annotations json
+ download([f'{url}patch{i}.tar.gz' for i in range(patches)], dir=images, curl=True, delete=False, threads=8)
+ elif split == 'val':
+ download([f'{url}zhiyuan_objv2_{split}.json'], dir=dir, delete=False) # annotations json
+ download([f'{url}images/v1/patch{i}.tar.gz' for i in range(15 + 1)], dir=images, curl=True, delete=False, threads=8)
+ download([f'{url}images/v2/patch{i}.tar.gz' for i in range(16, patches)], dir=images, curl=True, delete=False, threads=8)
+
+ # Move
+ for f in tqdm(images.rglob('*.jpg'), desc=f'Moving {split} images'):
+ f.rename(images / f.name) # move to /images/{split}
+
+ # Labels
+ coco = COCO(dir / f'zhiyuan_objv2_{split}.json')
+ names = [x["name"] for x in coco.loadCats(coco.getCatIds())]
+ for cid, cat in enumerate(names):
+ catIds = coco.getCatIds(catNms=[cat])
+ imgIds = coco.getImgIds(catIds=catIds)
+ for im in tqdm(coco.loadImgs(imgIds), desc=f'Class {cid + 1}/{len(names)} {cat}'):
+ width, height = im["width"], im["height"]
+ path = Path(im["file_name"]) # image filename
+ try:
+ with open(labels / path.with_suffix('.txt').name, 'a') as file:
+ annIds = coco.getAnnIds(imgIds=im["id"], catIds=catIds, iscrowd=None)
+ for a in coco.loadAnns(annIds):
+ x, y, w, h = a['bbox'] # bounding box in xywh (xy top-left corner)
+ xyxy = np.array([x, y, x + w, y + h])[None] # pixels(1,4)
+ x, y, w, h = xyxy2xywhn(xyxy, w=width, h=height, clip=True)[0] # normalized and clipped
+ file.write(f"{cid} {x:.5f} {y:.5f} {w:.5f} {h:.5f}\n")
+ except Exception as e:
+ print(e)
diff --git a/yolov5/data/SKU-110K.yaml b/yolov5/data/SKU-110K.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a943eecdeee699c6f85d08311b925b2ededc8836
--- /dev/null
+++ b/yolov5/data/SKU-110K.yaml
@@ -0,0 +1,53 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# SKU-110K retail items dataset https://github.com/eg4000/SKU110K_CVPR19 by Trax Retail
+# Example usage: python train.py --data SKU-110K.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── SKU-110K ← downloads here (13.6 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/SKU-110K # dataset root dir
+train: train.txt # train images (relative to 'path') 8219 images
+val: val.txt # val images (relative to 'path') 588 images
+test: test.txt # test images (optional) 2936 images
+
+# Classes
+names:
+ 0: object
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import shutil
+ from tqdm import tqdm
+ from utils.general import np, pd, Path, download, xyxy2xywh
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ parent = Path(dir.parent) # download dir
+ urls = ['http://trax-geometry.s3.amazonaws.com/cvpr_challenge/SKU110K_fixed.tar.gz']
+ download(urls, dir=parent, delete=False)
+
+ # Rename directories
+ if dir.exists():
+ shutil.rmtree(dir)
+ (parent / 'SKU110K_fixed').rename(dir) # rename dir
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # create labels dir
+
+ # Convert labels
+ names = 'image', 'x1', 'y1', 'x2', 'y2', 'class', 'image_width', 'image_height' # column names
+ for d in 'annotations_train.csv', 'annotations_val.csv', 'annotations_test.csv':
+ x = pd.read_csv(dir / 'annotations' / d, names=names).values # annotations
+ images, unique_images = x[:, 0], np.unique(x[:, 0])
+ with open((dir / d).with_suffix('.txt').__str__().replace('annotations_', ''), 'w') as f:
+ f.writelines(f'./images/{s}\n' for s in unique_images)
+ for im in tqdm(unique_images, desc=f'Converting {dir / d}'):
+ cls = 0 # single-class dataset
+ with open((dir / 'labels' / im).with_suffix('.txt'), 'a') as f:
+ for r in x[images == im]:
+ w, h = r[6], r[7] # image width, height
+ xywh = xyxy2xywh(np.array([[r[1] / w, r[2] / h, r[3] / w, r[4] / h]]))[0] # instance
+ f.write(f"{cls} {xywh[0]:.5f} {xywh[1]:.5f} {xywh[2]:.5f} {xywh[3]:.5f}\n") # write label
diff --git a/yolov5/data/VOC.yaml b/yolov5/data/VOC.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..104856f0c9c77dbcccff866d0d0677be5c08c2a0
--- /dev/null
+++ b/yolov5/data/VOC.yaml
@@ -0,0 +1,100 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
+# Example usage: python train.py --data VOC.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── VOC ← downloads here (2.8 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/VOC
+train: # train images (relative to 'path') 16551 images
+ - images/train2012
+ - images/train2007
+ - images/val2012
+ - images/val2007
+val: # val images (relative to 'path') 4952 images
+ - images/test2007
+test: # test images (optional)
+ - images/test2007
+
+# Classes
+names:
+ 0: aeroplane
+ 1: bicycle
+ 2: bird
+ 3: boat
+ 4: bottle
+ 5: bus
+ 6: car
+ 7: cat
+ 8: chair
+ 9: cow
+ 10: diningtable
+ 11: dog
+ 12: horse
+ 13: motorbike
+ 14: person
+ 15: pottedplant
+ 16: sheep
+ 17: sofa
+ 18: train
+ 19: tvmonitor
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import xml.etree.ElementTree as ET
+
+ from tqdm import tqdm
+ from utils.general import download, Path
+
+
+ def convert_label(path, lb_path, year, image_id):
+ def convert_box(size, box):
+ dw, dh = 1. / size[0], 1. / size[1]
+ x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
+ return x * dw, y * dh, w * dw, h * dh
+
+ in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
+ out_file = open(lb_path, 'w')
+ tree = ET.parse(in_file)
+ root = tree.getroot()
+ size = root.find('size')
+ w = int(size.find('width').text)
+ h = int(size.find('height').text)
+
+ names = list(yaml['names'].values()) # names list
+ for obj in root.iter('object'):
+ cls = obj.find('name').text
+ if cls in names and int(obj.find('difficult').text) != 1:
+ xmlbox = obj.find('bndbox')
+ bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
+ cls_id = names.index(cls) # class id
+ out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [f'{url}VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
+ f'{url}VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
+ f'{url}VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
+ download(urls, dir=dir / 'images', delete=False, curl=True, threads=3)
+
+ # Convert
+ path = dir / 'images/VOCdevkit'
+ for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
+ imgs_path = dir / 'images' / f'{image_set}{year}'
+ lbs_path = dir / 'labels' / f'{image_set}{year}'
+ imgs_path.mkdir(exist_ok=True, parents=True)
+ lbs_path.mkdir(exist_ok=True, parents=True)
+
+ with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
+ image_ids = f.read().strip().split()
+ for id in tqdm(image_ids, desc=f'{image_set}{year}'):
+ f = path / f'VOC{year}/JPEGImages/{id}.jpg' # old img path
+ lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
+ f.rename(imgs_path / f.name) # move image
+ convert_label(path, lb_path, year, id) # convert labels to YOLO format
diff --git a/yolov5/data/VisDrone.yaml b/yolov5/data/VisDrone.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2a13904dc8dd50c3906b18cc414a6975b2c28dd6
--- /dev/null
+++ b/yolov5/data/VisDrone.yaml
@@ -0,0 +1,70 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# VisDrone2019-DET dataset https://github.com/VisDrone/VisDrone-Dataset by Tianjin University
+# Example usage: python train.py --data VisDrone.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── VisDrone ← downloads here (2.3 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/VisDrone # dataset root dir
+train: VisDrone2019-DET-train/images # train images (relative to 'path') 6471 images
+val: VisDrone2019-DET-val/images # val images (relative to 'path') 548 images
+test: VisDrone2019-DET-test-dev/images # test images (optional) 1610 images
+
+# Classes
+names:
+ 0: pedestrian
+ 1: people
+ 2: bicycle
+ 3: car
+ 4: van
+ 5: truck
+ 6: tricycle
+ 7: awning-tricycle
+ 8: bus
+ 9: motor
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from utils.general import download, os, Path
+
+ def visdrone2yolo(dir):
+ from PIL import Image
+ from tqdm import tqdm
+
+ def convert_box(size, box):
+ # Convert VisDrone box to YOLO xywh box
+ dw = 1. / size[0]
+ dh = 1. / size[1]
+ return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
+
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
+ pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
+ for f in pbar:
+ img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
+ lines = []
+ with open(f, 'r') as file: # read annotation.txt
+ for row in [x.split(',') for x in file.read().strip().splitlines()]:
+ if row[4] == '0': # VisDrone 'ignored regions' class 0
+ continue
+ cls = int(row[5]) - 1
+ box = convert_box(img_size, tuple(map(int, row[:4])))
+ lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
+ with open(str(f).replace(os.sep + 'annotations' + os.sep, os.sep + 'labels' + os.sep), 'w') as fl:
+ fl.writelines(lines) # write label.txt
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-train.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-val.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-dev.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-challenge.zip']
+ download(urls, dir=dir, curl=True, threads=4)
+
+ # Convert
+ for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
+ visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
diff --git a/yolov5/data/coco.yaml b/yolov5/data/coco.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ea32cb6269a362886c7283e4a3d543115891eec8
--- /dev/null
+++ b/yolov5/data/coco.yaml
@@ -0,0 +1,116 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# COCO 2017 dataset http://cocodataset.org by Microsoft
+# Example usage: python train.py --data coco.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco ← downloads here (20.1 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco # dataset root dir
+train: train2017.txt # train images (relative to 'path') 118287 images
+val: val2017.txt # val images (relative to 'path') 5000 images
+test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: |
+ from utils.general import download, Path
+
+
+ # Download labels
+ segments = False # segment or box labels
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
+ download(urls, dir=dir.parent)
+
+ # Download data
+ urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
+ 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
+ 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
+ download(urls, dir=dir / 'images', threads=3)
diff --git a/yolov5/data/coco128-seg.yaml b/yolov5/data/coco128-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..0a2499c00a1aa012b0d1a031714977843874b29d
--- /dev/null
+++ b/yolov5/data/coco128-seg.yaml
@@ -0,0 +1,101 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
+# Example usage: python train.py --data coco128.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco128-seg ← downloads here (7 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco128-seg # dataset root dir
+train: images/train2017 # train images (relative to 'path') 128 images
+val: images/train2017 # val images (relative to 'path') 128 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco128-seg.zip
diff --git a/yolov5/data/coco128.yaml b/yolov5/data/coco128.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..0cb53120be2c88db1543e9600576d200c4775a41
--- /dev/null
+++ b/yolov5/data/coco128.yaml
@@ -0,0 +1,101 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
+# Example usage: python train.py --data coco128.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco128 ← downloads here (7 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco128 # dataset root dir
+train: images/train2017 # train images (relative to 'path') 128 images
+val: images/train2017 # val images (relative to 'path') 128 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco128.zip
diff --git a/yolov5/data/hyps/hyp.Objects365.yaml b/yolov5/data/hyps/hyp.Objects365.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c4b6e8051d7bafd93155c8e03e1b264b468f68a7
--- /dev/null
+++ b/yolov5/data/hyps/hyp.Objects365.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for Objects365 training
+# python train.py --weights yolov5m.pt --data Objects365.yaml --evolve
+# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.00258
+lrf: 0.17
+momentum: 0.779
+weight_decay: 0.00058
+warmup_epochs: 1.33
+warmup_momentum: 0.86
+warmup_bias_lr: 0.0711
+box: 0.0539
+cls: 0.299
+cls_pw: 0.825
+obj: 0.632
+obj_pw: 1.0
+iou_t: 0.2
+anchor_t: 3.44
+anchors: 3.2
+fl_gamma: 0.0
+hsv_h: 0.0188
+hsv_s: 0.704
+hsv_v: 0.36
+degrees: 0.0
+translate: 0.0902
+scale: 0.491
+shear: 0.0
+perspective: 0.0
+flipud: 0.0
+fliplr: 0.5
+mosaic: 1.0
+mixup: 0.0
+copy_paste: 0.0
diff --git a/yolov5/data/hyps/hyp.VOC.yaml b/yolov5/data/hyps/hyp.VOC.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ce20dbbddbdbdb7228ca3262fade10b64b798087
--- /dev/null
+++ b/yolov5/data/hyps/hyp.VOC.yaml
@@ -0,0 +1,40 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for VOC training
+# python train.py --batch 128 --weights yolov5m6.pt --data VOC.yaml --epochs 50 --img 512 --hyp hyp.scratch-med.yaml --evolve
+# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
+
+# YOLOv5 Hyperparameter Evolution Results
+# Best generation: 467
+# Last generation: 996
+# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
+# 0.87729, 0.85125, 0.91286, 0.72664, 0.0076739, 0.0042529, 0.0013865
+
+lr0: 0.00334
+lrf: 0.15135
+momentum: 0.74832
+weight_decay: 0.00025
+warmup_epochs: 3.3835
+warmup_momentum: 0.59462
+warmup_bias_lr: 0.18657
+box: 0.02
+cls: 0.21638
+cls_pw: 0.5
+obj: 0.51728
+obj_pw: 0.67198
+iou_t: 0.2
+anchor_t: 3.3744
+fl_gamma: 0.0
+hsv_h: 0.01041
+hsv_s: 0.54703
+hsv_v: 0.27739
+degrees: 0.0
+translate: 0.04591
+scale: 0.75544
+shear: 0.0
+perspective: 0.0
+flipud: 0.0
+fliplr: 0.5
+mosaic: 0.85834
+mixup: 0.04266
+copy_paste: 0.0
+anchors: 3.412
diff --git a/yolov5/data/hyps/hyp.no-augmentation.yaml b/yolov5/data/hyps/hyp.no-augmentation.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..8da18150538b9918e6140f12ed0740bbc8e95955
--- /dev/null
+++ b/yolov5/data/hyps/hyp.no-augmentation.yaml
@@ -0,0 +1,35 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters when using Albumentations frameworks
+# python train.py --hyp hyp.no-augmentation.yaml
+# See https://github.com/ultralytics/yolov5/pull/3882 for YOLOv5 + Albumentations Usage examples
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+# this parameters are all zero since we want to use albumentation framework
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0 # image HSV-Hue augmentation (fraction)
+hsv_s: 0 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0 # image translation (+/- fraction)
+scale: 0 # image scale (+/- gain)
+shear: 0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.0 # image flip left-right (probability)
+mosaic: 0.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/yolov5/data/hyps/hyp.scratch-high.yaml b/yolov5/data/hyps/hyp.scratch-high.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..0a0f4ec216219890f93f457ce7bc31036490d96d
--- /dev/null
+++ b/yolov5/data/hyps/hyp.scratch-high.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for high-augmentation COCO training from scratch
+# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.9 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.1 # image mixup (probability)
+copy_paste: 0.1 # segment copy-paste (probability)
diff --git a/yolov5/data/hyps/hyp.scratch-low.yaml b/yolov5/data/hyps/hyp.scratch-low.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..9d722568f5266f60b6fc4a6cd1d126be6fd0c146
--- /dev/null
+++ b/yolov5/data/hyps/hyp.scratch-low.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for low-augmentation COCO training from scratch
+# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.5 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 1.0 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.5 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/yolov5/data/hyps/hyp.scratch-med.yaml b/yolov5/data/hyps/hyp.scratch-med.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..f6abb090bb0420a92e571e6d83c12d37f206a8fc
--- /dev/null
+++ b/yolov5/data/hyps/hyp.scratch-med.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for medium-augmentation COCO training from scratch
+# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.9 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.1 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/yolov5/data/images/bus.jpg b/yolov5/data/images/bus.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..b43e311165c785f000eb7493ff8fb662d06a3f83
Binary files /dev/null and b/yolov5/data/images/bus.jpg differ
diff --git a/yolov5/data/images/video-4FRnNpmSmwktFJKjg-frame-000850-4EXx8Fi3iE4nWNcCn.jpg b/yolov5/data/images/video-4FRnNpmSmwktFJKjg-frame-000850-4EXx8Fi3iE4nWNcCn.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..d6d21400d9112ce5239d1ae597d6b161bc437d27
Binary files /dev/null and b/yolov5/data/images/video-4FRnNpmSmwktFJKjg-frame-000850-4EXx8Fi3iE4nWNcCn.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000010-KRtKNoxRWwwgfz62F.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000010-KRtKNoxRWwwgfz62F.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..a4faea6dec2aadf2eb17f3b7cb7c6ce8083848c6
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000010-KRtKNoxRWwwgfz62F.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000043-Qo8ZHanDJ7p8epxpX.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000043-Qo8ZHanDJ7p8epxpX.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..2bde486d59af93ec7f7628250522c89686d674f6
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000043-Qo8ZHanDJ7p8epxpX.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000044-Z5MfsCQMgR3mMAeYX.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000044-Z5MfsCQMgR3mMAeYX.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..32cb2ab81db52309c0a9bf352e740a0539e7c891
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000044-Z5MfsCQMgR3mMAeYX.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000045-yQ8azA2FYFFJpscM8.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000045-yQ8azA2FYFFJpscM8.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..645dff8e07602bd13d431bcd23c2ed474be4f2ec
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000045-yQ8azA2FYFFJpscM8.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000046-mz6XiyZJZeRtyFQvu.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000046-mz6XiyZJZeRtyFQvu.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..fec2fd90e78d7a96bb5fcc4190f0b3d9379938dd
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000046-mz6XiyZJZeRtyFQvu.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000047-yiafE6z9N5PtfHnSH.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000047-yiafE6z9N5PtfHnSH.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6603af4b505874c8b841dd259a77cb7d8578a76c
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000047-yiafE6z9N5PtfHnSH.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000048-uZnkEjQhZvpj9wqS7.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000048-uZnkEjQhZvpj9wqS7.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..afd7465346b77555e627ccf1f34f1766077e7a7b
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000048-uZnkEjQhZvpj9wqS7.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000049-ZXap8fc92GtrTZPbW.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000049-ZXap8fc92GtrTZPbW.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..9e4940aeba10608dbdae4ca828c68fd6a0f8c761
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000049-ZXap8fc92GtrTZPbW.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000050-hSZ786SKo3GhdfPcA.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000050-hSZ786SKo3GhdfPcA.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..12ecfad9645be49be6f51efc5ce43042680edf3d
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000050-hSZ786SKo3GhdfPcA.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000051-p6qknbBumgWvxToxT.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000051-p6qknbBumgWvxToxT.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..71ccd6c35792b9e44e4ef768f108f57cabfd1646
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000051-p6qknbBumgWvxToxT.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000052-afEMvoJQLzkgehnax.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000052-afEMvoJQLzkgehnax.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6b8b9198ecb27448827a8ef10464b1c69a8fadcd
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000052-afEMvoJQLzkgehnax.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000053-3DtD28HJ4uGDaEcAS.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000053-3DtD28HJ4uGDaEcAS.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..57bdc3d7703982b0907d349b64e6f8315a9c7984
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000053-3DtD28HJ4uGDaEcAS.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000054-j7JbDL2yDt4KNHGDZ.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000054-j7JbDL2yDt4KNHGDZ.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..f0b27a8d03622e8eba57b78db29bab780774a5df
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000054-j7JbDL2yDt4KNHGDZ.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000055-n3vz85ez27B8BX9Qd.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000055-n3vz85ez27B8BX9Qd.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..632fe9fd1bd18809fe91740aac504175892b124f
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000055-n3vz85ez27B8BX9Qd.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000056-XxAJfrE3rBn6ETSTS.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000056-XxAJfrE3rBn6ETSTS.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..b8f95d5c57d574b29238d7129eb1a968165e559c
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000056-XxAJfrE3rBn6ETSTS.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000057-ba65sSn2Gm3zqr3GD.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000057-ba65sSn2Gm3zqr3GD.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..531a371c744235e9274dc2332d6712f5d964cfd6
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000057-ba65sSn2Gm3zqr3GD.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000058-XnbHMehqXsxpNdcRi.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000058-XnbHMehqXsxpNdcRi.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..d2aba55f7e86257ff49240ce4fe58216c2a4ad53
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000058-XnbHMehqXsxpNdcRi.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000059-hY7B5y9Frdi5FauHJ.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000059-hY7B5y9Frdi5FauHJ.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e2978e9f1fc440780a55c67aebe2ccc4d3d98c33
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000059-hY7B5y9Frdi5FauHJ.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000060-HxavCNELiqedirhFo.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000060-HxavCNELiqedirhFo.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..79df7fafe7f0530f5d284ad90e6965b9cb06551d
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000060-HxavCNELiqedirhFo.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000191-HnXJKowwSKf9AtA9K.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000191-HnXJKowwSKf9AtA9K.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..5fd1bf7366dd4db5ac562ee582d7e52610f65d79
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000191-HnXJKowwSKf9AtA9K.jpg differ
diff --git a/yolov5/data/images/video-ePoikf5LyTTfqchga-frame-000397-wvZieNFhvhBzzzJuT.jpg b/yolov5/data/images/video-ePoikf5LyTTfqchga-frame-000397-wvZieNFhvhBzzzJuT.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..5c5ef29c7fdca555b5a05c44f3e98ba5f66e0a73
Binary files /dev/null and b/yolov5/data/images/video-ePoikf5LyTTfqchga-frame-000397-wvZieNFhvhBzzzJuT.jpg differ
diff --git a/yolov5/data/images/zidane.jpg b/yolov5/data/images/zidane.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..92d72ea124760ce5dbf9425e3aa8f371e7481328
Binary files /dev/null and b/yolov5/data/images/zidane.jpg differ
diff --git a/yolov5/data/scripts/download_weights.sh b/yolov5/data/scripts/download_weights.sh
new file mode 100644
index 0000000000000000000000000000000000000000..e408959b32b245f5a6bb1291db16afd138c56a37
--- /dev/null
+++ b/yolov5/data/scripts/download_weights.sh
@@ -0,0 +1,22 @@
+#!/bin/bash
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Download latest models from https://github.com/ultralytics/yolov5/releases
+# Example usage: bash data/scripts/download_weights.sh
+# parent
+# └── yolov5
+# ├── yolov5s.pt ← downloads here
+# ├── yolov5m.pt
+# └── ...
+
+python - <= cls >= 0, f'incorrect class index {cls}'
+
+ # Write YOLO label
+ if id not in shapes:
+ shapes[id] = Image.open(file).size
+ box = xyxy2xywhn(box[None].astype(np.float), w=shapes[id][0], h=shapes[id][1], clip=True)
+ with open((labels / id).with_suffix('.txt'), 'a') as f:
+ f.write(f"{cls} {' '.join(f'{x:.6f}' for x in box[0])}\n") # write label.txt
+ except Exception as e:
+ print(f'WARNING: skipping one label for {file}: {e}')
+
+
+ # Download manually from https://challenge.xviewdataset.org
+ dir = Path(yaml['path']) # dataset root dir
+ # urls = ['https://d307kc0mrhucc3.cloudfront.net/train_labels.zip', # train labels
+ # 'https://d307kc0mrhucc3.cloudfront.net/train_images.zip', # 15G, 847 train images
+ # 'https://d307kc0mrhucc3.cloudfront.net/val_images.zip'] # 5G, 282 val images (no labels)
+ # download(urls, dir=dir, delete=False)
+
+ # Convert labels
+ convert_labels(dir / 'xView_train.geojson')
+
+ # Move images
+ images = Path(dir / 'images')
+ images.mkdir(parents=True, exist_ok=True)
+ Path(dir / 'train_images').rename(dir / 'images' / 'train')
+ Path(dir / 'val_images').rename(dir / 'images' / 'val')
+
+ # Split
+ autosplit(dir / 'images' / 'train')
diff --git a/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_arctanx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.3 b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_arctanx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.3
new file mode 100644
index 0000000000000000000000000000000000000000..38e90391fd651b3ec4a87f9b5e9e6af0618a78eb
--- /dev/null
+++ b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_arctanx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.3
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:76c711e70801814eb48f287989d6077d1a0f3008ca25f06ca80be7ca6d775def
+size 4586
diff --git a/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xcosx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.2 b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xcosx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.2
new file mode 100644
index 0000000000000000000000000000000000000000..46e58ae67b28171ad7f80231c52e8fd6b1f4a6be
--- /dev/null
+++ b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xcosx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.2
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:52d31bebe5cdaef5644eb8188e5d1bebf868077e2d167be31104fd36cc193676
+size 4586
diff --git a/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xsinx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.1 b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xsinx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.1
new file mode 100644
index 0000000000000000000000000000000000000000..9029f9bb0922c5efb6e3b07fae4b58ec24be7dfb
--- /dev/null
+++ b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xsinx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.1
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:255d8dccc227f37333e6c61f37e41b6e2cf0664a6ee8be046a75b7a7cb485803
+size 4586
diff --git a/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.0 b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.0
new file mode 100644
index 0000000000000000000000000000000000000000..74f3d315128d1daf70ef5387376d91965b3a6b52
--- /dev/null
+++ b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.0
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ebb31737cfc931f7b31ae1ad2dfe62f59e1f226ce62ab3df94728cc316d5dfaf
+size 9184
diff --git a/yolov5/datasets/test.py b/yolov5/datasets/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..fab959aa99ace4169bb37e36fc47efccaa335e79
--- /dev/null
+++ b/yolov5/datasets/test.py
@@ -0,0 +1,12 @@
+from torch.utils.tensorboard import SummaryWriter
+import numpy as np
+writer = SummaryWriter(comment='test_tensorboard')
+for x in range(100):
+ writer.add_scalar('y=2x', x * 2, x)
+ writer.add_scalar('y=pow(2, x)', 2 ** x, x)
+
+ writer.add_scalars('/images', {"xsinx": x * np.sin(x),
+ "xcosx": x * np.cos(x),
+ "arctanx": np.arctan(x)}, x)
+writer.close()
+
diff --git a/yolov5/detect.py b/yolov5/detect.py
new file mode 100644
index 0000000000000000000000000000000000000000..792e12473d6ee06da4f9706957d3f992d98b9e2e
--- /dev/null
+++ b/yolov5/detect.py
@@ -0,0 +1,261 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Run YOLOv5 detection inference on images, videos, directories, globs, YouTube, webcam, streams, etc.
+
+Usage - sources:
+ $ python detect.py --weights yolov5s.pt --source 0 # webcam
+ img.jpg # image
+ vid.mp4 # video
+ screen # screenshot
+ path/ # directory
+ list.txt # list of images
+ list.streams # list of streams
+ 'path/*.jpg' # glob
+ 'https://youtu.be/Zgi9g1ksQHc' # YouTube
+ 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
+
+Usage - formats:
+ $ python detect.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s_openvino_model # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import os
+import platform
+import sys
+from pathlib import Path
+
+import torch
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
+from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
+ increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
+from utils.plots import Annotator, colors, save_one_box
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+@smart_inference_mode()
+def run(
+ weights=ROOT / 'yolov5s.pt', # model path or triton URL
+ source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
+ data=ROOT / 'data/coco128.yaml', # dataset.yaml path
+ imgsz=(640, 640), # inference size (height, width)
+ conf_thres=0.25, # confidence threshold
+ iou_thres=0.45, # NMS IOU threshold
+ max_det=1000, # maximum detections per image
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ view_img=False, # show results
+ save_txt=False, # save results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_crop=False, # save cropped prediction boxes
+ nosave=False, # do not save images/videos
+ classes=None, # filter by class: --class 0, or --class 0 2 3
+ agnostic_nms=False, # class-agnostic NMS
+ augment=False, # augmented inference
+ visualize=False, # visualize features
+ update=False, # update all models
+ project=ROOT / 'runs/detect', # save results to project/name
+ name='exp', # save results to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ line_thickness=1, # bounding box thickness (pixels)
+ hide_labels=False, # hide labels
+ hide_conf=False, # hide confidences
+ half=False, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ vid_stride=1, # video frame-rate stride
+):
+ source = str(source)
+ save_img = not nosave and not source.endswith('.txt') # save inference images
+ is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
+ is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
+ webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
+ screenshot = source.lower().startswith('screen')
+ if is_url and is_file:
+ source = check_file(source) # download
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ device = select_device(device)
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, names, pt = model.stride, model.names, model.pt
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+
+ # Dataloader
+ bs = 1 # batch_size
+ if webcam:
+ view_img = check_imshow(warn=True)
+ dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
+ bs = len(dataset)
+ elif screenshot:
+ dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
+ else:
+ dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
+ vid_path, vid_writer = [None] * bs, [None] * bs
+
+ # Run inference
+ model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # warmup
+ seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
+ for path, im, im0s, vid_cap, s in dataset:
+ with dt[0]:
+ im = torch.from_numpy(im).to(model.device)
+ im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+
+ # Inference
+ with dt[1]:
+ visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
+ pred = model(im, augment=augment, visualize=visualize)
+
+ # NMS
+ with dt[2]:
+ pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
+
+ # Second-stage classifier (optional)
+ # pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
+
+ # Process predictions
+ for i, det in enumerate(pred): # per image
+ seen += 1
+ if webcam: # batch_size >= 1
+ p, im0, frame = path[i], im0s[i].copy(), dataset.count
+ s += f'{i}: '
+ else:
+ p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
+
+ p = Path(p) # to Path
+ save_path = str(save_dir / p.name) # im.jpg
+ txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
+ s += '%gx%g ' % im.shape[2:] # print string
+ gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
+ imc = im0.copy() if save_crop else im0 # for save_crop
+ annotator = Annotator(im0, line_width=line_thickness, example=str(names))
+ if len(det):
+ # Rescale boxes from img_size to im0 size
+ det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
+
+ # Print results
+ for c in det[:, 5].unique():
+ n = (det[:, 5] == c).sum() # detections per class
+ s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
+
+ # Write results
+ for *xyxy, conf, cls in reversed(det):
+ if save_txt: # Write to file
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(f'{txt_path}.txt', 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+ if save_img or save_crop or view_img: # Add bbox to image
+ c = int(cls) # integer class
+ label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
+ annotator.box_label(xyxy, label, color=colors(c, True))
+ if save_crop:
+ save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
+
+ # Stream results
+ im0 = annotator.result()
+ if view_img:
+ if platform.system() == 'Linux' and p not in windows:
+ windows.append(p)
+ cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
+ cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
+ cv2.imshow(str(p), im0)
+ cv2.waitKey(1) # 1 millisecond
+
+ # Save results (image with detections)
+ if save_img:
+ if dataset.mode == 'image':
+ cv2.imwrite(save_path, im0)
+ else: # 'video' or 'stream'
+ if vid_path[i] != save_path: # new video
+ vid_path[i] = save_path
+ if isinstance(vid_writer[i], cv2.VideoWriter):
+ vid_writer[i].release() # release previous video writer
+ if vid_cap: # video
+ fps = vid_cap.get(cv2.CAP_PROP_FPS)
+ w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ else: # stream
+ fps, w, h = 30, im0.shape[1], im0.shape[0]
+ save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
+ vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ vid_writer[i].write(im0)
+
+ # Print time (inference-only)
+ LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms")
+
+ # Print results
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
+ if save_txt or save_img:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ if update:
+ strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning)
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
+ parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
+ parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--view-img', action='store_true', help='show results')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
+ parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
+ parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
+ parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--visualize', action='store_true', help='visualize features')
+ parser.add_argument('--update', action='store_true', help='update all models')
+ parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
+ parser.add_argument('--name', default='exp', help='save results to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
+ parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
+ parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
+ opt = parser.parse_args()
+ opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/export.py b/yolov5/export.py
new file mode 100644
index 0000000000000000000000000000000000000000..067d9a22f292bf53004f9470f0198977a6880fab
--- /dev/null
+++ b/yolov5/export.py
@@ -0,0 +1,818 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Export a YOLOv5 PyTorch model to other formats. TensorFlow exports authored by https://github.com/zldrobit
+
+Format | `export.py --include` | Model
+--- | --- | ---
+PyTorch | - | yolov5s.pt
+TorchScript | `torchscript` | yolov5s.torchscript
+ONNX | `onnx` | yolov5s.onnx
+OpenVINO | `openvino` | yolov5s_openvino_model/
+TensorRT | `engine` | yolov5s.engine
+CoreML | `coreml` | yolov5s.mlmodel
+TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
+TensorFlow GraphDef | `pb` | yolov5s.pb
+TensorFlow Lite | `tflite` | yolov5s.tflite
+TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
+TensorFlow.js | `tfjs` | yolov5s_web_model/
+PaddlePaddle | `paddle` | yolov5s_paddle_model/
+
+Requirements:
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
+
+Usage:
+ $ python export.py --weights yolov5s.pt --include torchscript onnx openvino engine coreml tflite ...
+
+Inference:
+ $ python detect.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s_openvino_model # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s_paddle_model # PaddlePaddle
+
+TensorFlow.js:
+ $ cd .. && git clone https://github.com/zldrobit/tfjs-yolov5-example.git && cd tfjs-yolov5-example
+ $ npm install
+ $ ln -s ../../yolov5/yolov5s_web_model public/yolov5s_web_model
+ $ npm start
+"""
+
+import argparse
+import contextlib
+import json
+import os
+import platform
+import re
+import subprocess
+import sys
+import time
+import warnings
+from pathlib import Path
+
+import pandas as pd
+import torch
+from torch.utils.mobile_optimizer import optimize_for_mobile
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+if platform.system() != 'Windows':
+ ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from yolov5.models.experimental import attempt_load
+from yolov5.models.yolo import ClassificationModel, Detect, DetectionModel, SegmentationModel
+from yolov5.utils.dataloaders import LoadImages
+from yolov5.utils.general import (LOGGER, Profile, check_dataset, check_img_size, check_requirements, check_version,
+ check_yaml, colorstr, file_size, get_default_args, print_args, url2file, yaml_save)
+from yolov5.utils.torch_utils import select_device, smart_inference_mode
+
+MACOS = platform.system() == 'Darwin' # macOS environment
+
+
+class iOSModel(torch.nn.Module):
+
+ def __init__(self, model, im):
+ super().__init__()
+ b, c, h, w = im.shape # batch, channel, height, width
+ self.model = model
+ self.nc = model.nc # number of classes
+ if w == h:
+ self.normalize = 1. / w
+ else:
+ self.normalize = torch.tensor([1. / w, 1. / h, 1. / w, 1. / h]) # broadcast (slower, smaller)
+ # np = model(im)[0].shape[1] # number of points
+ # self.normalize = torch.tensor([1. / w, 1. / h, 1. / w, 1. / h]).expand(np, 4) # explicit (faster, larger)
+
+ def forward(self, x):
+ xywh, conf, cls = self.model(x)[0].squeeze().split((4, 1, self.nc), 1)
+ return cls * conf, xywh * self.normalize # confidence (3780, 80), coordinates (3780, 4)
+
+
+def export_formats():
+ # YOLOv5 export formats
+ x = [
+ ['PyTorch', '-', '.pt', True, True],
+ ['TorchScript', 'torchscript', '.torchscript', True, True],
+ ['ONNX', 'onnx', '.onnx', True, True],
+ ['OpenVINO', 'openvino', '_openvino_model', True, False],
+ ['TensorRT', 'engine', '.engine', False, True],
+ ['CoreML', 'coreml', '.mlmodel', True, False],
+ ['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
+ ['TensorFlow GraphDef', 'pb', '.pb', True, True],
+ ['TensorFlow Lite', 'tflite', '.tflite', True, False],
+ ['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
+ ['TensorFlow.js', 'tfjs', '_web_model', False, False],
+ ['PaddlePaddle', 'paddle', '_paddle_model', True, True],]
+ return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
+
+
+def try_export(inner_func):
+ # YOLOv5 export decorator, i..e @try_export
+ inner_args = get_default_args(inner_func)
+
+ def outer_func(*args, **kwargs):
+ prefix = inner_args['prefix']
+ try:
+ with Profile() as dt:
+ f, model = inner_func(*args, **kwargs)
+ LOGGER.info(f'{prefix} export success ✅ {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)')
+ return f, model
+ except Exception as e:
+ LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}')
+ return None, None
+
+ return outer_func
+
+
+@try_export
+def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
+ # YOLOv5 TorchScript model export
+ LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
+ f = file.with_suffix('.torchscript')
+
+ ts = torch.jit.trace(model, im, strict=False)
+ d = {'shape': im.shape, 'stride': int(max(model.stride)), 'names': model.names}
+ extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
+ if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
+ optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
+ else:
+ ts.save(str(f), _extra_files=extra_files)
+ return f, None
+
+
+@try_export
+def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')):
+ # YOLOv5 ONNX export
+ check_requirements('onnx>=1.12.0')
+ import onnx
+
+ LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
+ f = file.with_suffix('.onnx')
+
+ output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']
+ if dynamic:
+ dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
+ if isinstance(model, SegmentationModel):
+ dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
+ dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
+ elif isinstance(model, DetectionModel):
+ dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
+
+ torch.onnx.export(
+ model.cpu() if dynamic else model, # --dynamic only compatible with cpu
+ im.cpu() if dynamic else im,
+ f,
+ verbose=False,
+ opset_version=opset,
+ do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
+ input_names=['images'],
+ output_names=output_names,
+ dynamic_axes=dynamic or None)
+
+ # Checks
+ model_onnx = onnx.load(f) # load onnx model
+ onnx.checker.check_model(model_onnx) # check onnx model
+
+ # Metadata
+ d = {'stride': int(max(model.stride)), 'names': model.names}
+ for k, v in d.items():
+ meta = model_onnx.metadata_props.add()
+ meta.key, meta.value = k, str(v)
+ onnx.save(model_onnx, f)
+
+ # Simplify
+ if simplify:
+ try:
+ cuda = torch.cuda.is_available()
+ check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
+ import onnxsim
+
+ LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
+ model_onnx, check = onnxsim.simplify(model_onnx)
+ assert check, 'assert check failed'
+ onnx.save(model_onnx, f)
+ except Exception as e:
+ LOGGER.info(f'{prefix} simplifier failure: {e}')
+ return f, model_onnx
+
+
+@try_export
+def export_openvino(file, metadata, half, prefix=colorstr('OpenVINO:')):
+ # YOLOv5 OpenVINO export
+ check_requirements('openvino-dev') # requires openvino-dev: https://pypi.org/project/openvino-dev/
+ import openvino.inference_engine as ie
+
+ LOGGER.info(f'\n{prefix} starting export with openvino {ie.__version__}...')
+ f = str(file).replace('.pt', f'_openvino_model{os.sep}')
+
+ args = [
+ 'mo',
+ '--input_model',
+ str(file.with_suffix('.onnx')),
+ '--output_dir',
+ f,
+ '--data_type',
+ ('FP16' if half else 'FP32'),]
+ subprocess.run(args, check=True, env=os.environ) # export
+ yaml_save(Path(f) / file.with_suffix('.yaml').name, metadata) # add metadata.yaml
+ return f, None
+
+
+@try_export
+def export_paddle(model, im, file, metadata, prefix=colorstr('PaddlePaddle:')):
+ # YOLOv5 Paddle export
+ check_requirements(('paddlepaddle', 'x2paddle'))
+ import x2paddle
+ from x2paddle.convert import pytorch2paddle
+
+ LOGGER.info(f'\n{prefix} starting export with X2Paddle {x2paddle.__version__}...')
+ f = str(file).replace('.pt', f'_paddle_model{os.sep}')
+
+ pytorch2paddle(module=model, save_dir=f, jit_type='trace', input_examples=[im]) # export
+ yaml_save(Path(f) / file.with_suffix('.yaml').name, metadata) # add metadata.yaml
+ return f, None
+
+
+@try_export
+def export_coreml(model, im, file, int8, half, nms, prefix=colorstr('CoreML:')):
+ # YOLOv5 CoreML export
+ check_requirements('coremltools')
+ import coremltools as ct
+
+ LOGGER.info(f'\n{prefix} starting export with coremltools {ct.__version__}...')
+ f = file.with_suffix('.mlmodel')
+
+ if nms:
+ model = iOSModel(model, im)
+ ts = torch.jit.trace(model, im, strict=False) # TorchScript model
+ ct_model = ct.convert(ts, inputs=[ct.ImageType('image', shape=im.shape, scale=1 / 255, bias=[0, 0, 0])])
+ bits, mode = (8, 'kmeans_lut') if int8 else (16, 'linear') if half else (32, None)
+ if bits < 32:
+ if MACOS: # quantization only supported on macOS
+ with warnings.catch_warnings():
+ warnings.filterwarnings('ignore', category=DeprecationWarning) # suppress numpy==1.20 float warning
+ ct_model = ct.models.neural_network.quantization_utils.quantize_weights(ct_model, bits, mode)
+ else:
+ print(f'{prefix} quantization only supported on macOS, skipping...')
+ ct_model.save(f)
+ return f, ct_model
+
+
+@try_export
+def export_engine(model, im, file, half, dynamic, simplify, workspace=4, verbose=False, prefix=colorstr('TensorRT:')):
+ # YOLOv5 TensorRT export https://developer.nvidia.com/tensorrt
+ assert im.device.type != 'cpu', 'export running on CPU but must be on GPU, i.e. `python export.py --device 0`'
+ try:
+ import tensorrt as trt
+ except Exception:
+ if platform.system() == 'Linux':
+ check_requirements('nvidia-tensorrt', cmds='-U --index-url https://pypi.ngc.nvidia.com')
+ import tensorrt as trt
+
+ if trt.__version__[0] == '7': # TensorRT 7 handling https://github.com/ultralytics/yolov5/issues/6012
+ grid = model.model[-1].anchor_grid
+ model.model[-1].anchor_grid = [a[..., :1, :1, :] for a in grid]
+ export_onnx(model, im, file, 12, dynamic, simplify) # opset 12
+ model.model[-1].anchor_grid = grid
+ else: # TensorRT >= 8
+ check_version(trt.__version__, '8.0.0', hard=True) # require tensorrt>=8.0.0
+ export_onnx(model, im, file, 12, dynamic, simplify) # opset 12
+ onnx = file.with_suffix('.onnx')
+
+ LOGGER.info(f'\n{prefix} starting export with TensorRT {trt.__version__}...')
+ assert onnx.exists(), f'failed to export ONNX file: {onnx}'
+ f = file.with_suffix('.engine') # TensorRT engine file
+ logger = trt.Logger(trt.Logger.INFO)
+ if verbose:
+ logger.min_severity = trt.Logger.Severity.VERBOSE
+
+ builder = trt.Builder(logger)
+ config = builder.create_builder_config()
+ config.max_workspace_size = workspace * 1 << 30
+ # config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, workspace << 30) # fix TRT 8.4 deprecation notice
+
+ flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
+ network = builder.create_network(flag)
+ parser = trt.OnnxParser(network, logger)
+ if not parser.parse_from_file(str(onnx)):
+ raise RuntimeError(f'failed to load ONNX file: {onnx}')
+
+ inputs = [network.get_input(i) for i in range(network.num_inputs)]
+ outputs = [network.get_output(i) for i in range(network.num_outputs)]
+ for inp in inputs:
+ LOGGER.info(f'{prefix} input "{inp.name}" with shape{inp.shape} {inp.dtype}')
+ for out in outputs:
+ LOGGER.info(f'{prefix} output "{out.name}" with shape{out.shape} {out.dtype}')
+
+ if dynamic:
+ if im.shape[0] <= 1:
+ LOGGER.warning(f'{prefix} WARNING ⚠️ --dynamic model requires maximum --batch-size argument')
+ profile = builder.create_optimization_profile()
+ for inp in inputs:
+ profile.set_shape(inp.name, (1, *im.shape[1:]), (max(1, im.shape[0] // 2), *im.shape[1:]), im.shape)
+ config.add_optimization_profile(profile)
+
+ LOGGER.info(f'{prefix} building FP{16 if builder.platform_has_fast_fp16 and half else 32} engine as {f}')
+ if builder.platform_has_fast_fp16 and half:
+ config.set_flag(trt.BuilderFlag.FP16)
+ with builder.build_engine(network, config) as engine, open(f, 'wb') as t:
+ t.write(engine.serialize())
+ return f, None
+
+
+@try_export
+def export_saved_model(model,
+ im,
+ file,
+ dynamic,
+ tf_nms=False,
+ agnostic_nms=False,
+ topk_per_class=100,
+ topk_all=100,
+ iou_thres=0.45,
+ conf_thres=0.25,
+ keras=False,
+ prefix=colorstr('TensorFlow SavedModel:')):
+ # YOLOv5 TensorFlow SavedModel export
+ try:
+ import tensorflow as tf
+ except Exception:
+ check_requirements(f"tensorflow{'' if torch.cuda.is_available() else '-macos' if MACOS else '-cpu'}")
+ import tensorflow as tf
+ from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
+
+ from models.tf import TFModel
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = str(file).replace('.pt', '_saved_model')
+ batch_size, ch, *imgsz = list(im.shape) # BCHW
+
+ tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
+ im = tf.zeros((batch_size, *imgsz, ch)) # BHWC order for TensorFlow
+ _ = tf_model.predict(im, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
+ inputs = tf.keras.Input(shape=(*imgsz, ch), batch_size=None if dynamic else batch_size)
+ outputs = tf_model.predict(inputs, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
+ keras_model = tf.keras.Model(inputs=inputs, outputs=outputs)
+ keras_model.trainable = False
+ keras_model.summary()
+ if keras:
+ keras_model.save(f, save_format='tf')
+ else:
+ spec = tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype)
+ m = tf.function(lambda x: keras_model(x)) # full model
+ m = m.get_concrete_function(spec)
+ frozen_func = convert_variables_to_constants_v2(m)
+ tfm = tf.Module()
+ tfm.__call__ = tf.function(lambda x: frozen_func(x)[:4] if tf_nms else frozen_func(x), [spec])
+ tfm.__call__(im)
+ tf.saved_model.save(tfm,
+ f,
+ options=tf.saved_model.SaveOptions(experimental_custom_gradients=False) if check_version(
+ tf.__version__, '2.6') else tf.saved_model.SaveOptions())
+ return f, keras_model
+
+
+@try_export
+def export_pb(keras_model, file, prefix=colorstr('TensorFlow GraphDef:')):
+ # YOLOv5 TensorFlow GraphDef *.pb export https://github.com/leimao/Frozen_Graph_TensorFlow
+ import tensorflow as tf
+ from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = file.with_suffix('.pb')
+
+ m = tf.function(lambda x: keras_model(x)) # full model
+ m = m.get_concrete_function(tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype))
+ frozen_func = convert_variables_to_constants_v2(m)
+ frozen_func.graph.as_graph_def()
+ tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=str(f.parent), name=f.name, as_text=False)
+ return f, None
+
+
+@try_export
+def export_tflite(keras_model, im, file, int8, data, nms, agnostic_nms, prefix=colorstr('TensorFlow Lite:')):
+ # YOLOv5 TensorFlow Lite export
+ import tensorflow as tf
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ batch_size, ch, *imgsz = list(im.shape) # BCHW
+ f = str(file).replace('.pt', '-fp16.tflite')
+
+ converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
+ converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
+ converter.target_spec.supported_types = [tf.float16]
+ converter.optimizations = [tf.lite.Optimize.DEFAULT]
+ if int8:
+ from models.tf import representative_dataset_gen
+ dataset = LoadImages(check_dataset(check_yaml(data))['train'], img_size=imgsz, auto=False)
+ converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib=100)
+ converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
+ converter.target_spec.supported_types = []
+ converter.inference_input_type = tf.uint8 # or tf.int8
+ converter.inference_output_type = tf.uint8 # or tf.int8
+ converter.experimental_new_quantizer = True
+ f = str(file).replace('.pt', '-int8.tflite')
+ if nms or agnostic_nms:
+ converter.target_spec.supported_ops.append(tf.lite.OpsSet.SELECT_TF_OPS)
+
+ tflite_model = converter.convert()
+ open(f, 'wb').write(tflite_model)
+ return f, None
+
+
+@try_export
+def export_edgetpu(file, prefix=colorstr('Edge TPU:')):
+ # YOLOv5 Edge TPU export https://coral.ai/docs/edgetpu/models-intro/
+ cmd = 'edgetpu_compiler --version'
+ help_url = 'https://coral.ai/docs/edgetpu/compiler/'
+ assert platform.system() == 'Linux', f'export only supported on Linux. See {help_url}'
+ if subprocess.run(f'{cmd} > /dev/null 2>&1', shell=True).returncode != 0:
+ LOGGER.info(f'\n{prefix} export requires Edge TPU compiler. Attempting install from {help_url}')
+ sudo = subprocess.run('sudo --version >/dev/null', shell=True).returncode == 0 # sudo installed on system
+ for c in (
+ 'curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -',
+ 'echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list',
+ 'sudo apt-get update', 'sudo apt-get install edgetpu-compiler'):
+ subprocess.run(c if sudo else c.replace('sudo ', ''), shell=True, check=True)
+ ver = subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1]
+
+ LOGGER.info(f'\n{prefix} starting export with Edge TPU compiler {ver}...')
+ f = str(file).replace('.pt', '-int8_edgetpu.tflite') # Edge TPU model
+ f_tfl = str(file).replace('.pt', '-int8.tflite') # TFLite model
+
+ subprocess.run([
+ 'edgetpu_compiler',
+ '-s',
+ '-d',
+ '-k',
+ '10',
+ '--out_dir',
+ str(file.parent),
+ f_tfl,], check=True)
+ return f, None
+
+
+@try_export
+def export_tfjs(file, int8, prefix=colorstr('TensorFlow.js:')):
+ # YOLOv5 TensorFlow.js export
+ check_requirements('tensorflowjs')
+ import tensorflowjs as tfjs
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflowjs {tfjs.__version__}...')
+ f = str(file).replace('.pt', '_web_model') # js dir
+ f_pb = file.with_suffix('.pb') # *.pb path
+ f_json = f'{f}/model.json' # *.json path
+
+ args = [
+ 'tensorflowjs_converter',
+ '--input_format=tf_frozen_model',
+ '--quantize_uint8' if int8 else '',
+ '--output_node_names=Identity,Identity_1,Identity_2,Identity_3',
+ str(f_pb),
+ str(f),]
+ subprocess.run([arg for arg in args if arg], check=True)
+
+ json = Path(f_json).read_text()
+ with open(f_json, 'w') as j: # sort JSON Identity_* in ascending order
+ subst = re.sub(
+ r'{"outputs": {"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}}}', r'{"outputs": {"Identity": {"name": "Identity"}, '
+ r'"Identity_1": {"name": "Identity_1"}, '
+ r'"Identity_2": {"name": "Identity_2"}, '
+ r'"Identity_3": {"name": "Identity_3"}}}', json)
+ j.write(subst)
+ return f, None
+
+
+def add_tflite_metadata(file, metadata, num_outputs):
+ # Add metadata to *.tflite models per https://www.tensorflow.org/lite/models/convert/metadata
+ with contextlib.suppress(ImportError):
+ # check_requirements('tflite_support')
+ from tflite_support import flatbuffers
+ from tflite_support import metadata as _metadata
+ from tflite_support import metadata_schema_py_generated as _metadata_fb
+
+ tmp_file = Path('/tmp/meta.txt')
+ with open(tmp_file, 'w') as meta_f:
+ meta_f.write(str(metadata))
+
+ model_meta = _metadata_fb.ModelMetadataT()
+ label_file = _metadata_fb.AssociatedFileT()
+ label_file.name = tmp_file.name
+ model_meta.associatedFiles = [label_file]
+
+ subgraph = _metadata_fb.SubGraphMetadataT()
+ subgraph.inputTensorMetadata = [_metadata_fb.TensorMetadataT()]
+ subgraph.outputTensorMetadata = [_metadata_fb.TensorMetadataT()] * num_outputs
+ model_meta.subgraphMetadata = [subgraph]
+
+ b = flatbuffers.Builder(0)
+ b.Finish(model_meta.Pack(b), _metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
+ metadata_buf = b.Output()
+
+ populator = _metadata.MetadataPopulator.with_model_file(file)
+ populator.load_metadata_buffer(metadata_buf)
+ populator.load_associated_files([str(tmp_file)])
+ populator.populate()
+ tmp_file.unlink()
+
+
+def pipeline_coreml(model, im, file, names, y, prefix=colorstr('CoreML Pipeline:')):
+ # YOLOv5 CoreML pipeline
+ import coremltools as ct
+ from PIL import Image
+
+ print(f'{prefix} starting pipeline with coremltools {ct.__version__}...')
+ batch_size, ch, h, w = list(im.shape) # BCHW
+ t = time.time()
+
+ # Output shapes
+ spec = model.get_spec()
+ out0, out1 = iter(spec.description.output)
+ if platform.system() == 'Darwin':
+ img = Image.new('RGB', (w, h)) # img(192 width, 320 height)
+ # img = torch.zeros((*opt.img_size, 3)).numpy() # img size(320,192,3) iDetection
+ out = model.predict({'image': img})
+ out0_shape, out1_shape = out[out0.name].shape, out[out1.name].shape
+ else: # linux and windows can not run model.predict(), get sizes from pytorch output y
+ s = tuple(y[0].shape)
+ out0_shape, out1_shape = (s[1], s[2] - 5), (s[1], 4) # (3780, 80), (3780, 4)
+
+ # Checks
+ nx, ny = spec.description.input[0].type.imageType.width, spec.description.input[0].type.imageType.height
+ na, nc = out0_shape
+ # na, nc = out0.type.multiArrayType.shape # number anchors, classes
+ assert len(names) == nc, f'{len(names)} names found for nc={nc}' # check
+
+ # Define output shapes (missing)
+ out0.type.multiArrayType.shape[:] = out0_shape # (3780, 80)
+ out1.type.multiArrayType.shape[:] = out1_shape # (3780, 4)
+ # spec.neuralNetwork.preprocessing[0].featureName = '0'
+
+ # Flexible input shapes
+ # from coremltools.models.neural_network import flexible_shape_utils
+ # s = [] # shapes
+ # s.append(flexible_shape_utils.NeuralNetworkImageSize(320, 192))
+ # s.append(flexible_shape_utils.NeuralNetworkImageSize(640, 384)) # (height, width)
+ # flexible_shape_utils.add_enumerated_image_sizes(spec, feature_name='image', sizes=s)
+ # r = flexible_shape_utils.NeuralNetworkImageSizeRange() # shape ranges
+ # r.add_height_range((192, 640))
+ # r.add_width_range((192, 640))
+ # flexible_shape_utils.update_image_size_range(spec, feature_name='image', size_range=r)
+
+ # Print
+ print(spec.description)
+
+ # Model from spec
+ model = ct.models.MLModel(spec)
+
+ # 3. Create NMS protobuf
+ nms_spec = ct.proto.Model_pb2.Model()
+ nms_spec.specificationVersion = 5
+ for i in range(2):
+ decoder_output = model._spec.description.output[i].SerializeToString()
+ nms_spec.description.input.add()
+ nms_spec.description.input[i].ParseFromString(decoder_output)
+ nms_spec.description.output.add()
+ nms_spec.description.output[i].ParseFromString(decoder_output)
+
+ nms_spec.description.output[0].name = 'confidence'
+ nms_spec.description.output[1].name = 'coordinates'
+
+ output_sizes = [nc, 4]
+ for i in range(2):
+ ma_type = nms_spec.description.output[i].type.multiArrayType
+ ma_type.shapeRange.sizeRanges.add()
+ ma_type.shapeRange.sizeRanges[0].lowerBound = 0
+ ma_type.shapeRange.sizeRanges[0].upperBound = -1
+ ma_type.shapeRange.sizeRanges.add()
+ ma_type.shapeRange.sizeRanges[1].lowerBound = output_sizes[i]
+ ma_type.shapeRange.sizeRanges[1].upperBound = output_sizes[i]
+ del ma_type.shape[:]
+
+ nms = nms_spec.nonMaximumSuppression
+ nms.confidenceInputFeatureName = out0.name # 1x507x80
+ nms.coordinatesInputFeatureName = out1.name # 1x507x4
+ nms.confidenceOutputFeatureName = 'confidence'
+ nms.coordinatesOutputFeatureName = 'coordinates'
+ nms.iouThresholdInputFeatureName = 'iouThreshold'
+ nms.confidenceThresholdInputFeatureName = 'confidenceThreshold'
+ nms.iouThreshold = 0.45
+ nms.confidenceThreshold = 0.25
+ nms.pickTop.perClass = True
+ nms.stringClassLabels.vector.extend(names.values())
+ nms_model = ct.models.MLModel(nms_spec)
+
+ # 4. Pipeline models together
+ pipeline = ct.models.pipeline.Pipeline(input_features=[('image', ct.models.datatypes.Array(3, ny, nx)),
+ ('iouThreshold', ct.models.datatypes.Double()),
+ ('confidenceThreshold', ct.models.datatypes.Double())],
+ output_features=['confidence', 'coordinates'])
+ pipeline.add_model(model)
+ pipeline.add_model(nms_model)
+
+ # Correct datatypes
+ pipeline.spec.description.input[0].ParseFromString(model._spec.description.input[0].SerializeToString())
+ pipeline.spec.description.output[0].ParseFromString(nms_model._spec.description.output[0].SerializeToString())
+ pipeline.spec.description.output[1].ParseFromString(nms_model._spec.description.output[1].SerializeToString())
+
+ # Update metadata
+ pipeline.spec.specificationVersion = 5
+ pipeline.spec.description.metadata.versionString = 'https://github.com/ultralytics/yolov5'
+ pipeline.spec.description.metadata.shortDescription = 'https://github.com/ultralytics/yolov5'
+ pipeline.spec.description.metadata.author = 'glenn.jocher@ultralytics.com'
+ pipeline.spec.description.metadata.license = 'https://github.com/ultralytics/yolov5/blob/master/LICENSE'
+ pipeline.spec.description.metadata.userDefined.update({
+ 'classes': ','.join(names.values()),
+ 'iou_threshold': str(nms.iouThreshold),
+ 'confidence_threshold': str(nms.confidenceThreshold)})
+
+ # Save the model
+ f = file.with_suffix('.mlmodel') # filename
+ model = ct.models.MLModel(pipeline.spec)
+ model.input_description['image'] = 'Input image'
+ model.input_description['iouThreshold'] = f'(optional) IOU Threshold override (default: {nms.iouThreshold})'
+ model.input_description['confidenceThreshold'] = \
+ f'(optional) Confidence Threshold override (default: {nms.confidenceThreshold})'
+ model.output_description['confidence'] = 'Boxes × Class confidence (see user-defined metadata "classes")'
+ model.output_description['coordinates'] = 'Boxes × [x, y, width, height] (relative to image size)'
+ model.save(f) # pipelined
+ print(f'{prefix} pipeline success ({time.time() - t:.2f}s), saved as {f} ({file_size(f):.1f} MB)')
+
+
+@smart_inference_mode()
+def run(
+ data=ROOT / 'data/coco128.yaml', # 'dataset.yaml path'
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=(640, 640), # image (height, width)
+ batch_size=1, # batch size
+ device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ include=('torchscript', 'onnx'), # include formats
+ half=False, # FP16 half-precision export
+ inplace=False, # set YOLOv5 Detect() inplace=True
+ keras=False, # use Keras
+ optimize=False, # TorchScript: optimize for mobile
+ int8=False, # CoreML/TF INT8 quantization
+ dynamic=False, # ONNX/TF/TensorRT: dynamic axes
+ simplify=False, # ONNX: simplify model
+ opset=12, # ONNX: opset version
+ verbose=False, # TensorRT: verbose log
+ workspace=4, # TensorRT: workspace size (GB)
+ nms=False, # TF: add NMS to model
+ agnostic_nms=False, # TF: add agnostic NMS to model
+ topk_per_class=100, # TF.js NMS: topk per class to keep
+ topk_all=100, # TF.js NMS: topk for all classes to keep
+ iou_thres=0.45, # TF.js NMS: IoU threshold
+ conf_thres=0.25, # TF.js NMS: confidence threshold
+):
+ t = time.time()
+ include = [x.lower() for x in include] # to lowercase
+ fmts = tuple(export_formats()['Argument'][1:]) # --include arguments
+ flags = [x in include for x in fmts]
+ assert sum(flags) == len(include), f'ERROR: Invalid --include {include}, valid --include arguments are {fmts}'
+ jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle = flags # export booleans
+ file = Path(url2file(weights) if str(weights).startswith(('http:/', 'https:/')) else weights) # PyTorch weights
+
+ # Load PyTorch model
+ device = select_device(device)
+ if half:
+ assert device.type != 'cpu' or coreml, '--half only compatible with GPU export, i.e. use --device 0'
+ assert not dynamic, '--half not compatible with --dynamic, i.e. use either --half or --dynamic but not both'
+ model = attempt_load(weights, device=device, inplace=True, fuse=True) # load FP32 model
+
+ # Checks
+ imgsz *= 2 if len(imgsz) == 1 else 1 # expand
+ if optimize:
+ assert device.type == 'cpu', '--optimize not compatible with cuda devices, i.e. use --device cpu'
+
+ # Input
+ gs = int(max(model.stride)) # grid size (max stride)
+ imgsz = [check_img_size(x, gs) for x in imgsz] # verify img_size are gs-multiples
+ im = torch.zeros(batch_size, 3, *imgsz).to(device) # image size(1,3,320,192) BCHW iDetection
+
+ # Update model
+ model.eval()
+ for k, m in model.named_modules():
+ if isinstance(m, Detect):
+ m.inplace = inplace
+ m.dynamic = dynamic
+ m.export = True
+
+ for _ in range(2):
+ y = model(im) # dry runs
+ if half and not coreml:
+ im, model = im.half(), model.half() # to FP16
+ shape = tuple((y[0] if isinstance(y, tuple) else y).shape) # model output shape
+ metadata = {'stride': int(max(model.stride)), 'names': model.names} # model metadata
+ LOGGER.info(f"\n{colorstr('PyTorch:')} starting from {file} with output shape {shape} ({file_size(file):.1f} MB)")
+
+ # Exports
+ f = [''] * len(fmts) # exported filenames
+ warnings.filterwarnings(action='ignore', category=torch.jit.TracerWarning) # suppress TracerWarning
+ if jit: # TorchScript
+ f[0], _ = export_torchscript(model, im, file, optimize)
+ if engine: # TensorRT required before ONNX
+ f[1], _ = export_engine(model, im, file, half, dynamic, simplify, workspace, verbose)
+ if onnx or xml: # OpenVINO requires ONNX
+ f[2], _ = export_onnx(model, im, file, opset, dynamic, simplify)
+ if xml: # OpenVINO
+ f[3], _ = export_openvino(file, metadata, half)
+ if coreml: # CoreML
+ f[4], ct_model = export_coreml(model, im, file, int8, half, nms)
+ if nms:
+ pipeline_coreml(ct_model, im, file, model.names, y)
+ if any((saved_model, pb, tflite, edgetpu, tfjs)): # TensorFlow formats
+ assert not tflite or not tfjs, 'TFLite and TF.js models must be exported separately, please pass only one type.'
+ assert not isinstance(model, ClassificationModel), 'ClassificationModel export to TF formats not yet supported.'
+ f[5], s_model = export_saved_model(model.cpu(),
+ im,
+ file,
+ dynamic,
+ tf_nms=nms or agnostic_nms or tfjs,
+ agnostic_nms=agnostic_nms or tfjs,
+ topk_per_class=topk_per_class,
+ topk_all=topk_all,
+ iou_thres=iou_thres,
+ conf_thres=conf_thres,
+ keras=keras)
+ if pb or tfjs: # pb prerequisite to tfjs
+ f[6], _ = export_pb(s_model, file)
+ if tflite or edgetpu:
+ f[7], _ = export_tflite(s_model, im, file, int8 or edgetpu, data=data, nms=nms, agnostic_nms=agnostic_nms)
+ if edgetpu:
+ f[8], _ = export_edgetpu(file)
+ add_tflite_metadata(f[8] or f[7], metadata, num_outputs=len(s_model.outputs))
+ if tfjs:
+ f[9], _ = export_tfjs(file, int8)
+ if paddle: # PaddlePaddle
+ f[10], _ = export_paddle(model, im, file, metadata)
+
+ # Finish
+ f = [str(x) for x in f if x] # filter out '' and None
+ if any(f):
+ cls, det, seg = (isinstance(model, x) for x in (ClassificationModel, DetectionModel, SegmentationModel)) # type
+ det &= not seg # segmentation models inherit from SegmentationModel(DetectionModel)
+ dir = Path('segment' if seg else 'classify' if cls else '')
+ h = '--half' if half else '' # --half FP16 inference arg
+ s = '# WARNING ⚠️ ClassificationModel not yet supported for PyTorch Hub AutoShape inference' if cls else \
+ '# WARNING ⚠️ SegmentationModel not yet supported for PyTorch Hub AutoShape inference' if seg else ''
+ LOGGER.info(f'\nExport complete ({time.time() - t:.1f}s)'
+ f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
+ f"\nDetect: python {dir / ('detect.py' if det else 'predict.py')} --weights {f[-1]} {h}"
+ f"\nValidate: python {dir / 'val.py'} --weights {f[-1]} {h}"
+ f"\nPyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', '{f[-1]}') {s}"
+ f'\nVisualize: https://netron.app')
+ return f # return list of exported files/dirs
+
+
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
+ parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
+ parser.add_argument('--keras', action='store_true', help='TF: use Keras')
+ parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
+ parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
+ parser.add_argument('--dynamic', action='store_true', help='ONNX/TF/TensorRT: dynamic axes')
+ parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
+ parser.add_argument('--opset', type=int, default=17, help='ONNX: opset version')
+ parser.add_argument('--verbose', action='store_true', help='TensorRT: verbose log')
+ parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')
+ parser.add_argument('--nms', action='store_true', help='TF: add NMS to model')
+ parser.add_argument('--agnostic-nms', action='store_true', help='TF: add agnostic NMS to model')
+ parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
+ parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
+ parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
+ parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
+ parser.add_argument(
+ '--include',
+ nargs='+',
+ default=['torchscript'],
+ help='torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle')
+ opt = parser.parse_known_args()[0] if known else parser.parse_args()
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ for opt.weights in (opt.weights if isinstance(opt.weights, list) else [opt.weights]):
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/hubconf.py b/yolov5/hubconf.py
new file mode 100644
index 0000000000000000000000000000000000000000..73caf06685da77db0c63cd4e392d86b949c00a97
--- /dev/null
+++ b/yolov5/hubconf.py
@@ -0,0 +1,169 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+PyTorch Hub models https://pytorch.org/hub/ultralytics_yolov5
+
+Usage:
+ import torch
+ model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # official model
+ model = torch.hub.load('ultralytics/yolov5:master', 'yolov5s') # from branch
+ model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.pt') # custom/local model
+ model = torch.hub.load('.', 'custom', 'yolov5s.pt', source='local') # local repo
+"""
+
+import torch
+
+
+def _create(name, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ """Creates or loads a YOLOv5 model
+
+ Arguments:
+ name (str): model name 'yolov5s' or path 'path/to/best.pt'
+ pretrained (bool): load pretrained weights into the model
+ channels (int): number of input channels
+ classes (int): number of model classes
+ autoshape (bool): apply YOLOv5 .autoshape() wrapper to model
+ verbose (bool): print all information to screen
+ device (str, torch.device, None): device to use for model parameters
+
+ Returns:
+ YOLOv5 model
+ """
+ from pathlib import Path
+
+ from models.common import AutoShape, DetectMultiBackend
+ from models.experimental import attempt_load
+ from models.yolo import ClassificationModel, DetectionModel, SegmentationModel
+ from utils.downloads import attempt_download
+ from utils.general import LOGGER, check_requirements, intersect_dicts, logging
+ from utils.torch_utils import select_device
+
+ if not verbose:
+ LOGGER.setLevel(logging.WARNING)
+ check_requirements(exclude=('opencv-python', 'tensorboard', 'thop'))
+ name = Path(name)
+ path = name.with_suffix('.pt') if name.suffix == '' and not name.is_dir() else name # checkpoint path
+ try:
+ device = select_device(device)
+ if pretrained and channels == 3 and classes == 80:
+ try:
+ model = DetectMultiBackend(path, device=device, fuse=autoshape) # detection model
+ if autoshape:
+ if model.pt and isinstance(model.model, ClassificationModel):
+ LOGGER.warning('WARNING ⚠️ YOLOv5 ClassificationModel is not yet AutoShape compatible. '
+ 'You must pass torch tensors in BCHW to this model, i.e. shape(1,3,224,224).')
+ elif model.pt and isinstance(model.model, SegmentationModel):
+ LOGGER.warning('WARNING ⚠️ YOLOv5 SegmentationModel is not yet AutoShape compatible. '
+ 'You will not be able to run inference with this model.')
+ else:
+ model = AutoShape(model) # for file/URI/PIL/cv2/np inputs and NMS
+ except Exception:
+ model = attempt_load(path, device=device, fuse=False) # arbitrary model
+ else:
+ cfg = list((Path(__file__).parent / 'models').rglob(f'{path.stem}.yaml'))[0] # model.yaml path
+ model = DetectionModel(cfg, channels, classes) # create model
+ if pretrained:
+ ckpt = torch.load(attempt_download(path), map_location=device) # load
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=['anchors']) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ if len(ckpt['model'].names) == classes:
+ model.names = ckpt['model'].names # set class names attribute
+ if not verbose:
+ LOGGER.setLevel(logging.INFO) # reset to default
+ return model.to(device)
+
+ except Exception as e:
+ help_url = 'https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading'
+ s = f'{e}. Cache may be out of date, try `force_reload=True` or see {help_url} for help.'
+ raise Exception(s) from e
+
+
+def custom(path='path/to/model.pt', autoshape=True, _verbose=True, device=None):
+ # YOLOv5 custom or local model
+ return _create(path, autoshape=autoshape, verbose=_verbose, device=device)
+
+
+def yolov5n(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-nano model https://github.com/ultralytics/yolov5
+ return _create('yolov5n', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5s(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-small model https://github.com/ultralytics/yolov5
+ return _create('yolov5s', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5m(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-medium model https://github.com/ultralytics/yolov5
+ return _create('yolov5m', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5l(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-large model https://github.com/ultralytics/yolov5
+ return _create('yolov5l', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5x(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-xlarge model https://github.com/ultralytics/yolov5
+ return _create('yolov5x', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5n6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-nano-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5n6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5s6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-small-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5s6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5m6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-medium-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5m6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5l6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-large-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5l6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5x6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-xlarge-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5x6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+if __name__ == '__main__':
+ import argparse
+ from pathlib import Path
+
+ import numpy as np
+ from PIL import Image
+
+ from utils.general import cv2, print_args
+
+ # Argparser
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model', type=str, default='yolov5s', help='model name')
+ opt = parser.parse_args()
+ print_args(vars(opt))
+
+ # Model
+ model = _create(name=opt.model, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True)
+ # model = custom(path='path/to/model.pt') # custom
+
+ # Images
+ imgs = [
+ 'data/images/zidane.jpg', # filename
+ Path('data/images/zidane.jpg'), # Path
+ 'https://ultralytics.com/images/zidane.jpg', # URI
+ cv2.imread('data/images/bus.jpg')[:, :, ::-1], # OpenCV
+ Image.open('data/images/bus.jpg'), # PIL
+ np.zeros((320, 640, 3))] # numpy
+
+ # Inference
+ results = model(imgs, size=320) # batched inference
+
+ # Results
+ results.print()
+ results.save()
diff --git a/yolov5/models/__init__.py b/yolov5/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/yolov5/models/__pycache__/__init__.cpython-38.pyc b/yolov5/models/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..201b0be1e7b16b0da38c04b7821c4270d8660afa
Binary files /dev/null and b/yolov5/models/__pycache__/__init__.cpython-38.pyc differ
diff --git a/yolov5/models/__pycache__/__init__.cpython-39.pyc b/yolov5/models/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1e2934992bf072ae51810e1a233430da994a619a
Binary files /dev/null and b/yolov5/models/__pycache__/__init__.cpython-39.pyc differ
diff --git a/yolov5/models/__pycache__/common.cpython-38.pyc b/yolov5/models/__pycache__/common.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..70840eab1adda4358a1bb42aa122c01be5ab2deb
Binary files /dev/null and b/yolov5/models/__pycache__/common.cpython-38.pyc differ
diff --git a/yolov5/models/__pycache__/common.cpython-39.pyc b/yolov5/models/__pycache__/common.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cc4d87ba7fc3585e43ebcc5d59e4322bec3dfa70
Binary files /dev/null and b/yolov5/models/__pycache__/common.cpython-39.pyc differ
diff --git a/yolov5/models/__pycache__/experimental.cpython-38.pyc b/yolov5/models/__pycache__/experimental.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..04ea5916faadc4be3af14ff694036a616b004a63
Binary files /dev/null and b/yolov5/models/__pycache__/experimental.cpython-38.pyc differ
diff --git a/yolov5/models/__pycache__/experimental.cpython-39.pyc b/yolov5/models/__pycache__/experimental.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4a6ecb9e6caff1ec001af5bc33211aa7789d30dd
Binary files /dev/null and b/yolov5/models/__pycache__/experimental.cpython-39.pyc differ
diff --git a/yolov5/models/__pycache__/yolo.cpython-38.pyc b/yolov5/models/__pycache__/yolo.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..86681e5c39429e7bcefebc8749870dd9b7fe69ea
Binary files /dev/null and b/yolov5/models/__pycache__/yolo.cpython-38.pyc differ
diff --git a/yolov5/models/__pycache__/yolo.cpython-39.pyc b/yolov5/models/__pycache__/yolo.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3d54a1a671e81b0cf71b257ab3ae9c74c93a20f8
Binary files /dev/null and b/yolov5/models/__pycache__/yolo.cpython-39.pyc differ
diff --git a/yolov5/models/common.py b/yolov5/models/common.py
new file mode 100644
index 0000000000000000000000000000000000000000..195ccd63a10c64de45de57fc2fe1653d3e745a0e
--- /dev/null
+++ b/yolov5/models/common.py
@@ -0,0 +1,871 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Common modules
+"""
+
+import ast
+import contextlib
+import json
+import math
+import platform
+import warnings
+import zipfile
+from collections import OrderedDict, namedtuple
+from copy import copy
+from pathlib import Path
+from urllib.parse import urlparse
+
+import cv2
+import numpy as np
+import pandas as pd
+import requests
+import torch
+import torch.nn as nn
+from PIL import Image
+from torch.cuda import amp
+
+from yolov5.utils import TryExcept
+from yolov5.utils.dataloaders import exif_transpose, letterbox
+from yolov5.utils.general import (LOGGER, ROOT, Profile, check_requirements, check_suffix, check_version, colorstr,
+ increment_path, is_jupyter, make_divisible, non_max_suppression, scale_boxes, xywh2xyxy,
+ xyxy2xywh, yaml_load)
+from yolov5.utils.plots import Annotator, colors, save_one_box
+from yolov5.utils.torch_utils import copy_attr, smart_inference_mode
+
+
+def autopad(k, p=None, d=1): # kernel, padding, dilation
+ # Pad to 'same' shape outputs
+ if d > 1:
+ k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
+ if p is None:
+ p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
+ return p
+
+
+class Conv(nn.Module):
+ # Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
+ default_act = nn.SiLU() # default activation
+
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
+ self.bn = nn.BatchNorm2d(c2)
+ self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
+
+ def forward(self, x):
+ return self.act(self.bn(self.conv(x)))
+
+ def forward_fuse(self, x):
+ return self.act(self.conv(x))
+
+
+class DWConv(Conv):
+ # Depth-wise convolution
+ def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation
+ super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
+
+
+class DWConvTranspose2d(nn.ConvTranspose2d):
+ # Depth-wise transpose convolution
+ def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # ch_in, ch_out, kernel, stride, padding, padding_out
+ super().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))
+
+
+class TransformerLayer(nn.Module):
+ # Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
+ def __init__(self, c, num_heads):
+ super().__init__()
+ self.q = nn.Linear(c, c, bias=False)
+ self.k = nn.Linear(c, c, bias=False)
+ self.v = nn.Linear(c, c, bias=False)
+ self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
+ self.fc1 = nn.Linear(c, c, bias=False)
+ self.fc2 = nn.Linear(c, c, bias=False)
+
+ def forward(self, x):
+ x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
+ x = self.fc2(self.fc1(x)) + x
+ return x
+
+
+class TransformerBlock(nn.Module):
+ # Vision Transformer https://arxiv.org/abs/2010.11929
+ def __init__(self, c1, c2, num_heads, num_layers):
+ super().__init__()
+ self.conv = None
+ if c1 != c2:
+ self.conv = Conv(c1, c2)
+ self.linear = nn.Linear(c2, c2) # learnable position embedding
+ self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
+ self.c2 = c2
+
+ def forward(self, x):
+ if self.conv is not None:
+ x = self.conv(x)
+ b, _, w, h = x.shape
+ p = x.flatten(2).permute(2, 0, 1)
+ return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
+
+
+class Bottleneck(nn.Module):
+ # Standard bottleneck
+ def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_, c2, 3, 1, g=g)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class BottleneckCSP(nn.Module):
+ # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
+ self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
+ self.cv4 = Conv(2 * c_, c2, 1, 1)
+ self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
+ self.act = nn.SiLU()
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
+
+ def forward(self, x):
+ y1 = self.cv3(self.m(self.cv1(x)))
+ y2 = self.cv2(x)
+ return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))
+
+
+class CrossConv(nn.Module):
+ # Cross Convolution Downsample
+ def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
+ # ch_in, ch_out, kernel, stride, groups, expansion, shortcut
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, (1, k), (1, s))
+ self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class C3(nn.Module):
+ # CSP Bottleneck with 3 convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c1, c_, 1, 1)
+ self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
+
+ def forward(self, x):
+ return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
+
+
+class C3x(C3):
+ # C3 module with cross-convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = nn.Sequential(*(CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)))
+
+
+class C3TR(C3):
+ # C3 module with TransformerBlock()
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = TransformerBlock(c_, c_, 4, n)
+
+
+class C3SPP(C3):
+ # C3 module with SPP()
+ def __init__(self, c1, c2, k=(5, 9, 13), n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = SPP(c_, c_, k)
+
+
+class C3Ghost(C3):
+ # C3 module with GhostBottleneck()
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e) # hidden channels
+ self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
+
+
+class SPP(nn.Module):
+ # Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
+ def __init__(self, c1, c2, k=(5, 9, 13)):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
+ self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
+
+ def forward(self, x):
+ x = self.cv1(x)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
+ return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
+
+
+class SPPF(nn.Module):
+ # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
+ def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * 4, c2, 1, 1)
+ self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
+
+ def forward(self, x):
+ x = self.cv1(x)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
+
+
+class Focus(nn.Module):
+ # Focus wh information into c-space
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
+ # self.contract = Contract(gain=2)
+
+ def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
+ return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
+ # return self.conv(self.contract(x))
+
+
+class GhostConv(nn.Module):
+ # Ghost Convolution https://github.com/huawei-noah/ghostnet
+ def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
+ super().__init__()
+ c_ = c2 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, k, s, None, g, act=act)
+ self.cv2 = Conv(c_, c_, 5, 1, None, c_, act=act)
+
+ def forward(self, x):
+ y = self.cv1(x)
+ return torch.cat((y, self.cv2(y)), 1)
+
+
+class GhostBottleneck(nn.Module):
+ # Ghost Bottleneck https://github.com/huawei-noah/ghostnet
+ def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
+ super().__init__()
+ c_ = c2 // 2
+ self.conv = nn.Sequential(
+ GhostConv(c1, c_, 1, 1), # pw
+ DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dw
+ GhostConv(c_, c2, 1, 1, act=False)) # pw-linear
+ self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False), Conv(c1, c2, 1, 1,
+ act=False)) if s == 2 else nn.Identity()
+
+ def forward(self, x):
+ return self.conv(x) + self.shortcut(x)
+
+
+class Contract(nn.Module):
+ # Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
+ def __init__(self, gain=2):
+ super().__init__()
+ self.gain = gain
+
+ def forward(self, x):
+ b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain'
+ s = self.gain
+ x = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)
+ x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
+ return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)
+
+
+class Expand(nn.Module):
+ # Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
+ def __init__(self, gain=2):
+ super().__init__()
+ self.gain = gain
+
+ def forward(self, x):
+ b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
+ s = self.gain
+ x = x.view(b, s, s, c // s ** 2, h, w) # x(1,2,2,16,80,80)
+ x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
+ return x.view(b, c // s ** 2, h * s, w * s) # x(1,16,160,160)
+
+
+class Concat(nn.Module):
+ # Concatenate a list of tensors along dimension
+ def __init__(self, dimension=1):
+ super().__init__()
+ self.d = dimension
+
+ def forward(self, x):
+ return torch.cat(x, self.d)
+
+
+class DetectMultiBackend(nn.Module):
+ # YOLOv5 MultiBackend class for python inference on various backends
+ def __init__(self, weights='yolov5s.pt', device=torch.device('cpu'), dnn=False, data=None, fp16=False, fuse=True):
+ # Usage:
+ # PyTorch: weights = *.pt
+ # TorchScript: *.torchscript
+ # ONNX Runtime: *.onnx
+ # ONNX OpenCV DNN: *.onnx --dnn
+ # OpenVINO: *_openvino_model
+ # CoreML: *.mlmodel
+ # TensorRT: *.engine
+ # TensorFlow SavedModel: *_saved_model
+ # TensorFlow GraphDef: *.pb
+ # TensorFlow Lite: *.tflite
+ # TensorFlow Edge TPU: *_edgetpu.tflite
+ # PaddlePaddle: *_paddle_model
+ from models.experimental import attempt_download, attempt_load # scoped to avoid circular import
+
+ super().__init__()
+ w = str(weights[0] if isinstance(weights, list) else weights)
+ pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle, triton = self._model_type(w)
+ fp16 &= pt or jit or onnx or engine # FP16
+ nhwc = coreml or saved_model or pb or tflite or edgetpu # BHWC formats (vs torch BCWH)
+ stride = 32 # default stride
+ cuda = torch.cuda.is_available() and device.type != 'cpu' # use CUDA
+ if not (pt or triton):
+ w = attempt_download(w) # download if not local
+
+ if pt: # PyTorch
+ model = attempt_load(weights if isinstance(weights, list) else w, device=device, inplace=True, fuse=fuse)
+ stride = max(int(model.stride.max()), 32) # model stride
+ names = model.module.names if hasattr(model, 'module') else model.names # get class names
+ model.half() if fp16 else model.float()
+ self.model = model # explicitly assign for to(), cpu(), cuda(), half()
+ elif jit: # TorchScript
+ LOGGER.info(f'Loading {w} for TorchScript inference...')
+ extra_files = {'config.txt': ''} # model metadata
+ model = torch.jit.load(w, _extra_files=extra_files, map_location=device)
+ model.half() if fp16 else model.float()
+ if extra_files['config.txt']: # load metadata dict
+ d = json.loads(extra_files['config.txt'],
+ object_hook=lambda d: {
+ int(k) if k.isdigit() else k: v
+ for k, v in d.items()})
+ stride, names = int(d['stride']), d['names']
+ elif dnn: # ONNX OpenCV DNN
+ LOGGER.info(f'Loading {w} for ONNX OpenCV DNN inference...')
+ check_requirements('opencv-python>=4.5.4')
+ net = cv2.dnn.readNetFromONNX(w)
+ elif onnx: # ONNX Runtime
+ LOGGER.info(f'Loading {w} for ONNX Runtime inference...')
+ check_requirements(('onnx', 'onnxruntime-gpu' if cuda else 'onnxruntime'))
+ import onnxruntime
+ providers = ['CUDAExecutionProvider', 'CPUExecutionProvider'] if cuda else ['CPUExecutionProvider']
+ session = onnxruntime.InferenceSession(w, providers=providers)
+ output_names = [x.name for x in session.get_outputs()]
+ meta = session.get_modelmeta().custom_metadata_map # metadata
+ if 'stride' in meta:
+ stride, names = int(meta['stride']), eval(meta['names'])
+ elif xml: # OpenVINO
+ LOGGER.info(f'Loading {w} for OpenVINO inference...')
+ check_requirements('openvino') # requires openvino-dev: https://pypi.org/project/openvino-dev/
+ from openvino.runtime import Core, Layout, get_batch
+ ie = Core()
+ if not Path(w).is_file(): # if not *.xml
+ w = next(Path(w).glob('*.xml')) # get *.xml file from *_openvino_model dir
+ network = ie.read_model(model=w, weights=Path(w).with_suffix('.bin'))
+ if network.get_parameters()[0].get_layout().empty:
+ network.get_parameters()[0].set_layout(Layout('NCHW'))
+ batch_dim = get_batch(network)
+ if batch_dim.is_static:
+ batch_size = batch_dim.get_length()
+ executable_network = ie.compile_model(network, device_name='CPU') # device_name="MYRIAD" for Intel NCS2
+ stride, names = self._load_metadata(Path(w).with_suffix('.yaml')) # load metadata
+ elif engine: # TensorRT
+ LOGGER.info(f'Loading {w} for TensorRT inference...')
+ import tensorrt as trt # https://developer.nvidia.com/nvidia-tensorrt-download
+ check_version(trt.__version__, '7.0.0', hard=True) # require tensorrt>=7.0.0
+ if device.type == 'cpu':
+ device = torch.device('cuda:0')
+ Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))
+ logger = trt.Logger(trt.Logger.INFO)
+ with open(w, 'rb') as f, trt.Runtime(logger) as runtime:
+ model = runtime.deserialize_cuda_engine(f.read())
+ context = model.create_execution_context()
+ bindings = OrderedDict()
+ output_names = []
+ fp16 = False # default updated below
+ dynamic = False
+ for i in range(model.num_bindings):
+ name = model.get_binding_name(i)
+ dtype = trt.nptype(model.get_binding_dtype(i))
+ if model.binding_is_input(i):
+ if -1 in tuple(model.get_binding_shape(i)): # dynamic
+ dynamic = True
+ context.set_binding_shape(i, tuple(model.get_profile_shape(0, i)[2]))
+ if dtype == np.float16:
+ fp16 = True
+ else: # output
+ output_names.append(name)
+ shape = tuple(context.get_binding_shape(i))
+ im = torch.from_numpy(np.empty(shape, dtype=dtype)).to(device)
+ bindings[name] = Binding(name, dtype, shape, im, int(im.data_ptr()))
+ binding_addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())
+ batch_size = bindings['images'].shape[0] # if dynamic, this is instead max batch size
+ elif coreml: # CoreML
+ LOGGER.info(f'Loading {w} for CoreML inference...')
+ import coremltools as ct
+ model = ct.models.MLModel(w)
+ elif saved_model: # TF SavedModel
+ LOGGER.info(f'Loading {w} for TensorFlow SavedModel inference...')
+ import tensorflow as tf
+ keras = False # assume TF1 saved_model
+ model = tf.keras.models.load_model(w) if keras else tf.saved_model.load(w)
+ elif pb: # GraphDef https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
+ LOGGER.info(f'Loading {w} for TensorFlow GraphDef inference...')
+ import tensorflow as tf
+
+ def wrap_frozen_graph(gd, inputs, outputs):
+ x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=''), []) # wrapped
+ ge = x.graph.as_graph_element
+ return x.prune(tf.nest.map_structure(ge, inputs), tf.nest.map_structure(ge, outputs))
+
+ def gd_outputs(gd):
+ name_list, input_list = [], []
+ for node in gd.node: # tensorflow.core.framework.node_def_pb2.NodeDef
+ name_list.append(node.name)
+ input_list.extend(node.input)
+ return sorted(f'{x}:0' for x in list(set(name_list) - set(input_list)) if not x.startswith('NoOp'))
+
+ gd = tf.Graph().as_graph_def() # TF GraphDef
+ with open(w, 'rb') as f:
+ gd.ParseFromString(f.read())
+ frozen_func = wrap_frozen_graph(gd, inputs='x:0', outputs=gd_outputs(gd))
+ elif tflite or edgetpu: # https://www.tensorflow.org/lite/guide/python#install_tensorflow_lite_for_python
+ try: # https://coral.ai/docs/edgetpu/tflite-python/#update-existing-tf-lite-code-for-the-edge-tpu
+ from tflite_runtime.interpreter import Interpreter, load_delegate
+ except ImportError:
+ import tensorflow as tf
+ Interpreter, load_delegate = tf.lite.Interpreter, tf.lite.experimental.load_delegate,
+ if edgetpu: # TF Edge TPU https://coral.ai/software/#edgetpu-runtime
+ LOGGER.info(f'Loading {w} for TensorFlow Lite Edge TPU inference...')
+ delegate = {
+ 'Linux': 'libedgetpu.so.1',
+ 'Darwin': 'libedgetpu.1.dylib',
+ 'Windows': 'edgetpu.dll'}[platform.system()]
+ interpreter = Interpreter(model_path=w, experimental_delegates=[load_delegate(delegate)])
+ else: # TFLite
+ LOGGER.info(f'Loading {w} for TensorFlow Lite inference...')
+ interpreter = Interpreter(model_path=w) # load TFLite model
+ interpreter.allocate_tensors() # allocate
+ input_details = interpreter.get_input_details() # inputs
+ output_details = interpreter.get_output_details() # outputs
+ # load metadata
+ with contextlib.suppress(zipfile.BadZipFile):
+ with zipfile.ZipFile(w, 'r') as model:
+ meta_file = model.namelist()[0]
+ meta = ast.literal_eval(model.read(meta_file).decode('utf-8'))
+ stride, names = int(meta['stride']), meta['names']
+ elif tfjs: # TF.js
+ raise NotImplementedError('ERROR: YOLOv5 TF.js inference is not supported')
+ elif paddle: # PaddlePaddle
+ LOGGER.info(f'Loading {w} for PaddlePaddle inference...')
+ check_requirements('paddlepaddle-gpu' if cuda else 'paddlepaddle')
+ import paddle.inference as pdi
+ if not Path(w).is_file(): # if not *.pdmodel
+ w = next(Path(w).rglob('*.pdmodel')) # get *.pdmodel file from *_paddle_model dir
+ weights = Path(w).with_suffix('.pdiparams')
+ config = pdi.Config(str(w), str(weights))
+ if cuda:
+ config.enable_use_gpu(memory_pool_init_size_mb=2048, device_id=0)
+ predictor = pdi.create_predictor(config)
+ input_handle = predictor.get_input_handle(predictor.get_input_names()[0])
+ output_names = predictor.get_output_names()
+ elif triton: # NVIDIA Triton Inference Server
+ LOGGER.info(f'Using {w} as Triton Inference Server...')
+ check_requirements('tritonclient[all]')
+ from utils.triton import TritonRemoteModel
+ model = TritonRemoteModel(url=w)
+ nhwc = model.runtime.startswith('tensorflow')
+ else:
+ raise NotImplementedError(f'ERROR: {w} is not a supported format')
+
+ # class names
+ if 'names' not in locals():
+ names = yaml_load(data)['names'] if data else {i: f'class{i}' for i in range(999)}
+ if names[0] == 'n01440764' and len(names) == 1000: # ImageNet
+ names = yaml_load(ROOT / 'data/ImageNet.yaml')['names'] # human-readable names
+
+ self.__dict__.update(locals()) # assign all variables to self
+
+ def forward(self, im, augment=False, visualize=False):
+ # YOLOv5 MultiBackend inference
+ b, ch, h, w = im.shape # batch, channel, height, width
+ if self.fp16 and im.dtype != torch.float16:
+ im = im.half() # to FP16
+ if self.nhwc:
+ im = im.permute(0, 2, 3, 1) # torch BCHW to numpy BHWC shape(1,320,192,3)
+
+ if self.pt: # PyTorch
+ y = self.model(im, augment=augment, visualize=visualize) if augment or visualize else self.model(im)
+ elif self.jit: # TorchScript
+ y = self.model(im)
+ elif self.dnn: # ONNX OpenCV DNN
+ im = im.cpu().numpy() # torch to numpy
+ self.net.setInput(im)
+ y = self.net.forward()
+ elif self.onnx: # ONNX Runtime
+ im = im.cpu().numpy() # torch to numpy
+ y = self.session.run(self.output_names, {self.session.get_inputs()[0].name: im})
+ elif self.xml: # OpenVINO
+ im = im.cpu().numpy() # FP32
+ y = list(self.executable_network([im]).values())
+ elif self.engine: # TensorRT
+ if self.dynamic and im.shape != self.bindings['images'].shape:
+ i = self.model.get_binding_index('images')
+ self.context.set_binding_shape(i, im.shape) # reshape if dynamic
+ self.bindings['images'] = self.bindings['images']._replace(shape=im.shape)
+ for name in self.output_names:
+ i = self.model.get_binding_index(name)
+ self.bindings[name].data.resize_(tuple(self.context.get_binding_shape(i)))
+ s = self.bindings['images'].shape
+ assert im.shape == s, f"input size {im.shape} {'>' if self.dynamic else 'not equal to'} max model size {s}"
+ self.binding_addrs['images'] = int(im.data_ptr())
+ self.context.execute_v2(list(self.binding_addrs.values()))
+ y = [self.bindings[x].data for x in sorted(self.output_names)]
+ elif self.coreml: # CoreML
+ im = im.cpu().numpy()
+ im = Image.fromarray((im[0] * 255).astype('uint8'))
+ # im = im.resize((192, 320), Image.ANTIALIAS)
+ y = self.model.predict({'image': im}) # coordinates are xywh normalized
+ if 'confidence' in y:
+ box = xywh2xyxy(y['coordinates'] * [[w, h, w, h]]) # xyxy pixels
+ conf, cls = y['confidence'].max(1), y['confidence'].argmax(1).astype(np.float)
+ y = np.concatenate((box, conf.reshape(-1, 1), cls.reshape(-1, 1)), 1)
+ else:
+ y = list(reversed(y.values())) # reversed for segmentation models (pred, proto)
+ elif self.paddle: # PaddlePaddle
+ im = im.cpu().numpy().astype(np.float32)
+ self.input_handle.copy_from_cpu(im)
+ self.predictor.run()
+ y = [self.predictor.get_output_handle(x).copy_to_cpu() for x in self.output_names]
+ elif self.triton: # NVIDIA Triton Inference Server
+ y = self.model(im)
+ else: # TensorFlow (SavedModel, GraphDef, Lite, Edge TPU)
+ im = im.cpu().numpy()
+ if self.saved_model: # SavedModel
+ y = self.model(im, training=False) if self.keras else self.model(im)
+ elif self.pb: # GraphDef
+ y = self.frozen_func(x=self.tf.constant(im))
+ else: # Lite or Edge TPU
+ input = self.input_details[0]
+ int8 = input['dtype'] == np.uint8 # is TFLite quantized uint8 model
+ if int8:
+ scale, zero_point = input['quantization']
+ im = (im / scale + zero_point).astype(np.uint8) # de-scale
+ self.interpreter.set_tensor(input['index'], im)
+ self.interpreter.invoke()
+ y = []
+ for output in self.output_details:
+ x = self.interpreter.get_tensor(output['index'])
+ if int8:
+ scale, zero_point = output['quantization']
+ x = (x.astype(np.float32) - zero_point) * scale # re-scale
+ y.append(x)
+ y = [x if isinstance(x, np.ndarray) else x.numpy() for x in y]
+ y[0][..., :4] *= [w, h, w, h] # xywh normalized to pixels
+
+ if isinstance(y, (list, tuple)):
+ return self.from_numpy(y[0]) if len(y) == 1 else [self.from_numpy(x) for x in y]
+ else:
+ return self.from_numpy(y)
+
+ def from_numpy(self, x):
+ return torch.from_numpy(x).to(self.device) if isinstance(x, np.ndarray) else x
+
+ def warmup(self, imgsz=(1, 3, 640, 640)):
+ # Warmup model by running inference once
+ warmup_types = self.pt, self.jit, self.onnx, self.engine, self.saved_model, self.pb, self.triton
+ if any(warmup_types) and (self.device.type != 'cpu' or self.triton):
+ im = torch.empty(*imgsz, dtype=torch.half if self.fp16 else torch.float, device=self.device) # input
+ for _ in range(2 if self.jit else 1): #
+ self.forward(im) # warmup
+
+ @staticmethod
+ def _model_type(p='path/to/model.pt'):
+ # Return model type from model path, i.e. path='path/to/model.onnx' -> type=onnx
+ # types = [pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle]
+ from yolov5.export import export_formats
+ from yolov5.utils.downloads import is_url
+ sf = list(export_formats().Suffix) # export suffixes
+ if not is_url(p, check=False):
+ check_suffix(p, sf) # checks
+ url = urlparse(p) # if url may be Triton inference server
+ types = [s in Path(p).name for s in sf]
+ types[8] &= not types[9] # tflite &= not edgetpu
+ triton = not any(types) and all([any(s in url.scheme for s in ['http', 'grpc']), url.netloc])
+ return types + [triton]
+
+ @staticmethod
+ def _load_metadata(f=Path('path/to/meta.yaml')):
+ # Load metadata from meta.yaml if it exists
+ if f.exists():
+ d = yaml_load(f)
+ return d['stride'], d['names'] # assign stride, names
+ return None, None
+
+
+class AutoShape(nn.Module):
+ # YOLOv5 input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMS
+ conf = 0.25 # NMS confidence threshold
+ iou = 0.45 # NMS IoU threshold
+ agnostic = False # NMS class-agnostic
+ multi_label = False # NMS multiple labels per box
+ classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
+ max_det = 1000 # maximum number of detections per image
+ amp = False # Automatic Mixed Precision (AMP) inference
+
+ def __init__(self, model, verbose=True):
+ super().__init__()
+ if verbose:
+ LOGGER.info('Adding AutoShape... ')
+ copy_attr(self, model, include=('yaml', 'nc', 'hyp', 'names', 'stride', 'abc'), exclude=()) # copy attributes
+ self.dmb = isinstance(model, DetectMultiBackend) # DetectMultiBackend() instance
+ self.pt = not self.dmb or model.pt # PyTorch model
+ self.model = model.eval()
+ if self.pt:
+ m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()
+ m.inplace = False # Detect.inplace=False for safe multithread inference
+ m.export = True # do not output loss values
+
+ def _apply(self, fn):
+ # Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
+ self = super()._apply(fn)
+ if self.pt:
+ m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()
+ m.stride = fn(m.stride)
+ m.grid = list(map(fn, m.grid))
+ if isinstance(m.anchor_grid, list):
+ m.anchor_grid = list(map(fn, m.anchor_grid))
+ return self
+
+ @smart_inference_mode()
+ def forward(self, ims, size=640, augment=False, profile=False):
+ # Inference from various sources. For size(height=640, width=1280), RGB images example inputs are:
+ # file: ims = 'data/images/zidane.jpg' # str or PosixPath
+ # URI: = 'https://ultralytics.com/images/zidane.jpg'
+ # OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)
+ # PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)
+ # numpy: = np.zeros((640,1280,3)) # HWC
+ # torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)
+ # multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
+
+ dt = (Profile(), Profile(), Profile())
+ with dt[0]:
+ if isinstance(size, int): # expand
+ size = (size, size)
+ p = next(self.model.parameters()) if self.pt else torch.empty(1, device=self.model.device) # param
+ autocast = self.amp and (p.device.type != 'cpu') # Automatic Mixed Precision (AMP) inference
+ if isinstance(ims, torch.Tensor): # torch
+ with amp.autocast(autocast):
+ return self.model(ims.to(p.device).type_as(p), augment=augment) # inference
+
+ # Pre-process
+ n, ims = (len(ims), list(ims)) if isinstance(ims, (list, tuple)) else (1, [ims]) # number, list of images
+ shape0, shape1, files = [], [], [] # image and inference shapes, filenames
+ for i, im in enumerate(ims):
+ f = f'image{i}' # filename
+ if isinstance(im, (str, Path)): # filename or uri
+ im, f = Image.open(requests.get(im, stream=True).raw if str(im).startswith('http') else im), im
+ im = np.asarray(exif_transpose(im))
+ elif isinstance(im, Image.Image): # PIL Image
+ im, f = np.asarray(exif_transpose(im)), getattr(im, 'filename', f) or f
+ files.append(Path(f).with_suffix('.jpg').name)
+ if im.shape[0] < 5: # image in CHW
+ im = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)
+ im = im[..., :3] if im.ndim == 3 else cv2.cvtColor(im, cv2.COLOR_GRAY2BGR) # enforce 3ch input
+ s = im.shape[:2] # HWC
+ shape0.append(s) # image shape
+ g = max(size) / max(s) # gain
+ shape1.append([int(y * g) for y in s])
+ ims[i] = im if im.data.contiguous else np.ascontiguousarray(im) # update
+ shape1 = [make_divisible(x, self.stride) for x in np.array(shape1).max(0)] # inf shape
+ x = [letterbox(im, shape1, auto=False)[0] for im in ims] # pad
+ x = np.ascontiguousarray(np.array(x).transpose((0, 3, 1, 2))) # stack and BHWC to BCHW
+ x = torch.from_numpy(x).to(p.device).type_as(p) / 255 # uint8 to fp16/32
+
+ with amp.autocast(autocast):
+ # Inference
+ with dt[1]:
+ y = self.model(x, augment=augment) # forward
+
+ # Post-process
+ with dt[2]:
+ y = non_max_suppression(y if self.dmb else y[0],
+ self.conf,
+ self.iou,
+ self.classes,
+ self.agnostic,
+ self.multi_label,
+ max_det=self.max_det) # NMS
+ for i in range(n):
+ scale_boxes(shape1, y[i][:, :4], shape0[i])
+
+ return Detections(ims, y, files, dt, self.names, x.shape)
+
+
+class Detections:
+ # YOLOv5 detections class for inference results
+ def __init__(self, ims, pred, files, times=(0, 0, 0), names=None, shape=None):
+ super().__init__()
+ d = pred[0].device # device
+ gn = [torch.tensor([*(im.shape[i] for i in [1, 0, 1, 0]), 1, 1], device=d) for im in ims] # normalizations
+ self.ims = ims # list of images as numpy arrays
+ self.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)
+ self.names = names # class names
+ self.files = files # image filenames
+ self.times = times # profiling times
+ self.xyxy = pred # xyxy pixels
+ self.xywh = [xyxy2xywh(x) for x in pred] # xywh pixels
+ self.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalized
+ self.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalized
+ self.n = len(self.pred) # number of images (batch size)
+ self.t = tuple(x.t / self.n * 1E3 for x in times) # timestamps (ms)
+ self.s = tuple(shape) # inference BCHW shape
+
+ def _run(self, pprint=False, show=False, save=False, crop=False, render=False, labels=True, save_dir=Path('')):
+ s, crops = '', []
+ for i, (im, pred) in enumerate(zip(self.ims, self.pred)):
+ s += f'\nimage {i + 1}/{len(self.pred)}: {im.shape[0]}x{im.shape[1]} ' # string
+ if pred.shape[0]:
+ for c in pred[:, -1].unique():
+ n = (pred[:, -1] == c).sum() # detections per class
+ s += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, " # add to string
+ s = s.rstrip(', ')
+ if show or save or render or crop:
+ annotator = Annotator(im, example=str(self.names))
+ for *box, conf, cls in reversed(pred): # xyxy, confidence, class
+ label = f'{self.names[int(cls)]} {conf:.2f}'
+ if crop:
+ file = save_dir / 'crops' / self.names[int(cls)] / self.files[i] if save else None
+ crops.append({
+ 'box': box,
+ 'conf': conf,
+ 'cls': cls,
+ 'label': label,
+ 'im': save_one_box(box, im, file=file, save=save)})
+ else: # all others
+ annotator.box_label(box, label if labels else '', color=colors(cls))
+ im = annotator.im
+ else:
+ s += '(no detections)'
+
+ im = Image.fromarray(im.astype(np.uint8)) if isinstance(im, np.ndarray) else im # from np
+ if show:
+ if is_jupyter():
+ from IPython.display import display
+ display(im)
+ else:
+ im.show(self.files[i])
+ if save:
+ f = self.files[i]
+ im.save(save_dir / f) # save
+ if i == self.n - 1:
+ LOGGER.info(f"Saved {self.n} image{'s' * (self.n > 1)} to {colorstr('bold', save_dir)}")
+ if render:
+ self.ims[i] = np.asarray(im)
+ if pprint:
+ s = s.lstrip('\n')
+ return f'{s}\nSpeed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {self.s}' % self.t
+ if crop:
+ if save:
+ LOGGER.info(f'Saved results to {save_dir}\n')
+ return crops
+
+ @TryExcept('Showing images is not supported in this environment')
+ def show(self, labels=True):
+ self._run(show=True, labels=labels) # show results
+
+ def save(self, labels=True, save_dir='runs/detect/exp', exist_ok=False):
+ save_dir = increment_path(save_dir, exist_ok, mkdir=True) # increment save_dir
+ self._run(save=True, labels=labels, save_dir=save_dir) # save results
+
+ def crop(self, save=True, save_dir='runs/detect/exp', exist_ok=False):
+ save_dir = increment_path(save_dir, exist_ok, mkdir=True) if save else None
+ return self._run(crop=True, save=save, save_dir=save_dir) # crop results
+
+ def render(self, labels=True):
+ self._run(render=True, labels=labels) # render results
+ return self.ims
+
+ def pandas(self):
+ # return detections as pandas DataFrames, i.e. print(results.pandas().xyxy[0])
+ new = copy(self) # return copy
+ ca = 'xmin', 'ymin', 'xmax', 'ymax', 'confidence', 'class', 'name' # xyxy columns
+ cb = 'xcenter', 'ycenter', 'width', 'height', 'confidence', 'class', 'name' # xywh columns
+ for k, c in zip(['xyxy', 'xyxyn', 'xywh', 'xywhn'], [ca, ca, cb, cb]):
+ a = [[x[:5] + [int(x[5]), self.names[int(x[5])]] for x in x.tolist()] for x in getattr(self, k)] # update
+ setattr(new, k, [pd.DataFrame(x, columns=c) for x in a])
+ return new
+
+ def tolist(self):
+ # return a list of Detections objects, i.e. 'for result in results.tolist():'
+ r = range(self.n) # iterable
+ x = [Detections([self.ims[i]], [self.pred[i]], [self.files[i]], self.times, self.names, self.s) for i in r]
+ # for d in x:
+ # for k in ['ims', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:
+ # setattr(d, k, getattr(d, k)[0]) # pop out of list
+ return x
+
+ def print(self):
+ LOGGER.info(self.__str__())
+
+ def __len__(self): # override len(results)
+ return self.n
+
+ def __str__(self): # override print(results)
+ return self._run(pprint=True) # print results
+
+ def __repr__(self):
+ return f'YOLOv5 {self.__class__} instance\n' + self.__str__()
+
+
+class Proto(nn.Module):
+ # YOLOv5 mask Proto module for segmentation models
+ def __init__(self, c1, c_=256, c2=32): # ch_in, number of protos, number of masks
+ super().__init__()
+ self.cv1 = Conv(c1, c_, k=3)
+ self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
+ self.cv2 = Conv(c_, c_, k=3)
+ self.cv3 = Conv(c_, c2)
+
+ def forward(self, x):
+ return self.cv3(self.cv2(self.upsample(self.cv1(x))))
+
+
+class Classify(nn.Module):
+ # YOLOv5 classification head, i.e. x(b,c1,20,20) to x(b,c2)
+ def __init__(self,
+ c1,
+ c2,
+ k=1,
+ s=1,
+ p=None,
+ g=1,
+ dropout_p=0.0): # ch_in, ch_out, kernel, stride, padding, groups, dropout probability
+ super().__init__()
+ c_ = 1280 # efficientnet_b0 size
+ self.conv = Conv(c1, c_, k, s, autopad(k, p), g)
+ self.pool = nn.AdaptiveAvgPool2d(1) # to x(b,c_,1,1)
+ self.drop = nn.Dropout(p=dropout_p, inplace=True)
+ self.linear = nn.Linear(c_, c2) # to x(b,c2)
+
+ def forward(self, x):
+ if isinstance(x, list):
+ x = torch.cat(x, 1)
+ return self.linear(self.drop(self.pool(self.conv(x)).flatten(1)))
diff --git a/yolov5/models/experimental.py b/yolov5/models/experimental.py
new file mode 100644
index 0000000000000000000000000000000000000000..b554401b133438a7d38a927c6fdd263503e78c35
--- /dev/null
+++ b/yolov5/models/experimental.py
@@ -0,0 +1,111 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Experimental modules
+"""
+import math
+
+import numpy as np
+import torch
+import torch.nn as nn
+
+from yolov5.utils.downloads import attempt_download
+
+
+class Sum(nn.Module):
+ # Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
+ def __init__(self, n, weight=False): # n: number of inputs
+ super().__init__()
+ self.weight = weight # apply weights boolean
+ self.iter = range(n - 1) # iter object
+ if weight:
+ self.w = nn.Parameter(-torch.arange(1.0, n) / 2, requires_grad=True) # layer weights
+
+ def forward(self, x):
+ y = x[0] # no weight
+ if self.weight:
+ w = torch.sigmoid(self.w) * 2
+ for i in self.iter:
+ y = y + x[i + 1] * w[i]
+ else:
+ for i in self.iter:
+ y = y + x[i + 1]
+ return y
+
+
+class MixConv2d(nn.Module):
+ # Mixed Depth-wise Conv https://arxiv.org/abs/1907.09595
+ def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True): # ch_in, ch_out, kernel, stride, ch_strategy
+ super().__init__()
+ n = len(k) # number of convolutions
+ if equal_ch: # equal c_ per group
+ i = torch.linspace(0, n - 1E-6, c2).floor() # c2 indices
+ c_ = [(i == g).sum() for g in range(n)] # intermediate channels
+ else: # equal weight.numel() per group
+ b = [c2] + [0] * n
+ a = np.eye(n + 1, n, k=-1)
+ a -= np.roll(a, 1, axis=1)
+ a *= np.array(k) ** 2
+ a[0] = 1
+ c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = b
+
+ self.m = nn.ModuleList([
+ nn.Conv2d(c1, int(c_), k, s, k // 2, groups=math.gcd(c1, int(c_)), bias=False) for k, c_ in zip(k, c_)])
+ self.bn = nn.BatchNorm2d(c2)
+ self.act = nn.SiLU()
+
+ def forward(self, x):
+ return self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
+
+
+class Ensemble(nn.ModuleList):
+ # Ensemble of models
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x, augment=False, profile=False, visualize=False):
+ y = [module(x, augment, profile, visualize)[0] for module in self]
+ # y = torch.stack(y).max(0)[0] # max ensemble
+ # y = torch.stack(y).mean(0) # mean ensemble
+ y = torch.cat(y, 1) # nms ensemble
+ return y, None # inference, train output
+
+
+def attempt_load(weights, device=None, inplace=True, fuse=True):
+ # Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a
+ from models.yolo import Detect, Model
+
+ model = Ensemble()
+ for w in weights if isinstance(weights, list) else [weights]:
+ ckpt = torch.load(attempt_download(w), map_location='cpu') # load
+ ckpt = (ckpt.get('ema') or ckpt['model']).to(device).float() # FP32 model
+
+ # Model compatibility updates
+ if not hasattr(ckpt, 'stride'):
+ ckpt.stride = torch.tensor([32.])
+ if hasattr(ckpt, 'names') and isinstance(ckpt.names, (list, tuple)):
+ ckpt.names = dict(enumerate(ckpt.names)) # convert to dict
+
+ model.append(ckpt.fuse().eval() if fuse and hasattr(ckpt, 'fuse') else ckpt.eval()) # model in eval mode
+
+ # Module compatibility updates
+ for m in model.modules():
+ t = type(m)
+ if t in (nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model):
+ m.inplace = inplace # torch 1.7.0 compatibility
+ if t is Detect and not isinstance(m.anchor_grid, list):
+ delattr(m, 'anchor_grid')
+ setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)
+ elif t is nn.Upsample and not hasattr(m, 'recompute_scale_factor'):
+ m.recompute_scale_factor = None # torch 1.11.0 compatibility
+
+ # Return model
+ if len(model) == 1:
+ return model[-1]
+
+ # Return detection ensemble
+ print(f'Ensemble created with {weights}\n')
+ for k in 'names', 'nc', 'yaml':
+ setattr(model, k, getattr(model[0], k))
+ model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride # max stride
+ assert all(model[0].nc == m.nc for m in model), f'Models have different class counts: {[m.nc for m in model]}'
+ return model
diff --git a/yolov5/models/hub/anchors.yaml b/yolov5/models/hub/anchors.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..df2f668b022ca363b47e62ef95bdf20d418fe0e3
--- /dev/null
+++ b/yolov5/models/hub/anchors.yaml
@@ -0,0 +1,59 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Default anchors for COCO data
+
+
+# P5 -------------------------------------------------------------------------------------------------------------------
+# P5-640:
+anchors_p5_640:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+
+# P6 -------------------------------------------------------------------------------------------------------------------
+# P6-640: thr=0.25: 0.9964 BPR, 5.54 anchors past thr, n=12, img_size=640, metric_all=0.281/0.716-mean/best, past_thr=0.469-mean: 9,11, 21,19, 17,41, 43,32, 39,70, 86,64, 65,131, 134,130, 120,265, 282,180, 247,354, 512,387
+anchors_p6_640:
+ - [9,11, 21,19, 17,41] # P3/8
+ - [43,32, 39,70, 86,64] # P4/16
+ - [65,131, 134,130, 120,265] # P5/32
+ - [282,180, 247,354, 512,387] # P6/64
+
+# P6-1280: thr=0.25: 0.9950 BPR, 5.55 anchors past thr, n=12, img_size=1280, metric_all=0.281/0.714-mean/best, past_thr=0.468-mean: 19,27, 44,40, 38,94, 96,68, 86,152, 180,137, 140,301, 303,264, 238,542, 436,615, 739,380, 925,792
+anchors_p6_1280:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# P6-1920: thr=0.25: 0.9950 BPR, 5.55 anchors past thr, n=12, img_size=1920, metric_all=0.281/0.714-mean/best, past_thr=0.468-mean: 28,41, 67,59, 57,141, 144,103, 129,227, 270,205, 209,452, 455,396, 358,812, 653,922, 1109,570, 1387,1187
+anchors_p6_1920:
+ - [28,41, 67,59, 57,141] # P3/8
+ - [144,103, 129,227, 270,205] # P4/16
+ - [209,452, 455,396, 358,812] # P5/32
+ - [653,922, 1109,570, 1387,1187] # P6/64
+
+
+# P7 -------------------------------------------------------------------------------------------------------------------
+# P7-640: thr=0.25: 0.9962 BPR, 6.76 anchors past thr, n=15, img_size=640, metric_all=0.275/0.733-mean/best, past_thr=0.466-mean: 11,11, 13,30, 29,20, 30,46, 61,38, 39,92, 78,80, 146,66, 79,163, 149,150, 321,143, 157,303, 257,402, 359,290, 524,372
+anchors_p7_640:
+ - [11,11, 13,30, 29,20] # P3/8
+ - [30,46, 61,38, 39,92] # P4/16
+ - [78,80, 146,66, 79,163] # P5/32
+ - [149,150, 321,143, 157,303] # P6/64
+ - [257,402, 359,290, 524,372] # P7/128
+
+# P7-1280: thr=0.25: 0.9968 BPR, 6.71 anchors past thr, n=15, img_size=1280, metric_all=0.273/0.732-mean/best, past_thr=0.463-mean: 19,22, 54,36, 32,77, 70,83, 138,71, 75,173, 165,159, 148,334, 375,151, 334,317, 251,626, 499,474, 750,326, 534,814, 1079,818
+anchors_p7_1280:
+ - [19,22, 54,36, 32,77] # P3/8
+ - [70,83, 138,71, 75,173] # P4/16
+ - [165,159, 148,334, 375,151] # P5/32
+ - [334,317, 251,626, 499,474] # P6/64
+ - [750,326, 534,814, 1079,818] # P7/128
+
+# P7-1920: thr=0.25: 0.9968 BPR, 6.71 anchors past thr, n=15, img_size=1920, metric_all=0.273/0.732-mean/best, past_thr=0.463-mean: 29,34, 81,55, 47,115, 105,124, 207,107, 113,259, 247,238, 222,500, 563,227, 501,476, 376,939, 749,711, 1126,489, 801,1222, 1618,1227
+anchors_p7_1920:
+ - [29,34, 81,55, 47,115] # P3/8
+ - [105,124, 207,107, 113,259] # P4/16
+ - [247,238, 222,500, 563,227] # P5/32
+ - [501,476, 376,939, 749,711] # P6/64
+ - [1126,489, 801,1222, 1618,1227] # P7/128
diff --git a/yolov5/models/hub/yolov3-spp.yaml b/yolov5/models/hub/yolov3-spp.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..4a71ed405277ce10a3c3f386834764ff0a82d53c
--- /dev/null
+++ b/yolov5/models/hub/yolov3-spp.yaml
@@ -0,0 +1,51 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3-SPP head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, SPP, [512, [5, 9, 13]]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov3-tiny.yaml b/yolov5/models/hub/yolov3-tiny.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..50b47e282df482b6f4f8dfb485c914ab1cbf6274
--- /dev/null
+++ b/yolov5/models/hub/yolov3-tiny.yaml
@@ -0,0 +1,41 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,14, 23,27, 37,58] # P4/16
+ - [81,82, 135,169, 344,319] # P5/32
+
+# YOLOv3-tiny backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [16, 3, 1]], # 0
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2
+ [-1, 1, Conv, [32, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4
+ [-1, 1, Conv, [64, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8
+ [-1, 1, Conv, [128, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16
+ [-1, 1, Conv, [256, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32
+ [-1, 1, Conv, [512, 3, 1]],
+ [-1, 1, nn.ZeroPad2d, [[0, 1, 0, 1]]], # 11
+ [-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12
+ ]
+
+# YOLOv3-tiny head
+head:
+ [[-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium)
+
+ [[19, 15], 1, Detect, [nc, anchors]], # Detect(P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov3.yaml b/yolov5/models/hub/yolov3.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c5e21098f89379487dde6f236b78667fad0ad57f
--- /dev/null
+++ b/yolov5/models/hub/yolov3.yaml
@@ -0,0 +1,51 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3 head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5-bifpn.yaml b/yolov5/models/hub/yolov5-bifpn.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..9dbdd4ee0580c4a5613548607b6970aefda8c03e
--- /dev/null
+++ b/yolov5/models/hub/yolov5-bifpn.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 BiFPN head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14, 6], 1, Concat, [1]], # cat P4 <--- BiFPN change
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5-fpn.yaml b/yolov5/models/hub/yolov5-fpn.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2292eb1185a0d4c14985c3039d01fcffa26b32fd
--- /dev/null
+++ b/yolov5/models/hub/yolov5-fpn.yaml
@@ -0,0 +1,42 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 FPN head
+head:
+ [[-1, 3, C3, [1024, False]], # 10 (P5/32-large)
+
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 3, C3, [512, False]], # 14 (P4/16-medium)
+
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 3, C3, [256, False]], # 18 (P3/8-small)
+
+ [[18, 14, 10], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5-p2.yaml b/yolov5/models/hub/yolov5-p2.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2c0ae44841cc967bceee310c3b5606c7d191c6f7
--- /dev/null
+++ b/yolov5/models/hub/yolov5-p2.yaml
@@ -0,0 +1,54 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head with (P2, P3, P4, P5) outputs
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 2], 1, Concat, [1]], # cat backbone P2
+ [-1, 1, C3, [128, False]], # 21 (P2/4-xsmall)
+
+ [-1, 1, Conv, [128, 3, 2]],
+ [[-1, 18], 1, Concat, [1]], # cat head P3
+ [-1, 3, C3, [256, False]], # 24 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 27 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 30 (P5/32-large)
+
+ [[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5-p34.yaml b/yolov5/models/hub/yolov5-p34.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..60ae3b4b6f30d0b1a5ba901d021de77d14953161
--- /dev/null
+++ b/yolov5/models/hub/yolov5-p34.yaml
@@ -0,0 +1,41 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [ [ -1, 1, Conv, [ 64, 6, 2, 2 ] ], # 0-P1/2
+ [ -1, 1, Conv, [ 128, 3, 2 ] ], # 1-P2/4
+ [ -1, 3, C3, [ 128 ] ],
+ [ -1, 1, Conv, [ 256, 3, 2 ] ], # 3-P3/8
+ [ -1, 6, C3, [ 256 ] ],
+ [ -1, 1, Conv, [ 512, 3, 2 ] ], # 5-P4/16
+ [ -1, 9, C3, [ 512 ] ],
+ [ -1, 1, Conv, [ 1024, 3, 2 ] ], # 7-P5/32
+ [ -1, 3, C3, [ 1024 ] ],
+ [ -1, 1, SPPF, [ 1024, 5 ] ], # 9
+ ]
+
+# YOLOv5 v6.0 head with (P3, P4) outputs
+head:
+ [ [ -1, 1, Conv, [ 512, 1, 1 ] ],
+ [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
+ [ [ -1, 6 ], 1, Concat, [ 1 ] ], # cat backbone P4
+ [ -1, 3, C3, [ 512, False ] ], # 13
+
+ [ -1, 1, Conv, [ 256, 1, 1 ] ],
+ [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
+ [ [ -1, 4 ], 1, Concat, [ 1 ] ], # cat backbone P3
+ [ -1, 3, C3, [ 256, False ] ], # 17 (P3/8-small)
+
+ [ -1, 1, Conv, [ 256, 3, 2 ] ],
+ [ [ -1, 14 ], 1, Concat, [ 1 ] ], # cat head P4
+ [ -1, 3, C3, [ 512, False ] ], # 20 (P4/16-medium)
+
+ [ [ 17, 20 ], 1, Detect, [ nc, anchors ] ], # Detect(P3, P4)
+ ]
diff --git a/yolov5/models/hub/yolov5-p6.yaml b/yolov5/models/hub/yolov5-p6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a9e1b5f90c72dbe0c7257001761da7190c7b235b
--- /dev/null
+++ b/yolov5/models/hub/yolov5-p6.yaml
@@ -0,0 +1,56 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head with (P3, P4, P5, P6) outputs
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/hub/yolov5-p7.yaml b/yolov5/models/hub/yolov5-p7.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a502412f08877bd233580bf048558758f8d0c1c4
--- /dev/null
+++ b/yolov5/models/hub/yolov5-p7.yaml
@@ -0,0 +1,67 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, Conv, [1280, 3, 2]], # 11-P7/128
+ [-1, 3, C3, [1280]],
+ [-1, 1, SPPF, [1280, 5]], # 13
+ ]
+
+# YOLOv5 v6.0 head with (P3, P4, P5, P6, P7) outputs
+head:
+ [[-1, 1, Conv, [1024, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 10], 1, Concat, [1]], # cat backbone P6
+ [-1, 3, C3, [1024, False]], # 17
+
+ [-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 21
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 25
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 29 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 26], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 32 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 22], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 35 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 18], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 38 (P6/64-xlarge)
+
+ [-1, 1, Conv, [1024, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P7
+ [-1, 3, C3, [1280, False]], # 41 (P7/128-xxlarge)
+
+ [[29, 32, 35, 38, 41], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6, P7)
+ ]
diff --git a/yolov5/models/hub/yolov5-panet.yaml b/yolov5/models/hub/yolov5-panet.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5595e25738235718d5b4eb8672fc50301f0c043d
--- /dev/null
+++ b/yolov5/models/hub/yolov5-panet.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 PANet head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5l6.yaml b/yolov5/models/hub/yolov5l6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..651dbb0251ae89817e6292e215e57ab7ddc9a92a
--- /dev/null
+++ b/yolov5/models/hub/yolov5l6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/hub/yolov5m6.yaml b/yolov5/models/hub/yolov5m6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..059b12b46929cc481a014298a5ab5ae2b2bdaf68
--- /dev/null
+++ b/yolov5/models/hub/yolov5m6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/hub/yolov5n6.yaml b/yolov5/models/hub/yolov5n6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5052e7cbfc8b972a577af8c1668e0d475728268c
--- /dev/null
+++ b/yolov5/models/hub/yolov5n6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/hub/yolov5s-LeakyReLU.yaml b/yolov5/models/hub/yolov5s-LeakyReLU.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..0368a78dcbb42c690a2ee81789c248d41009d665
--- /dev/null
+++ b/yolov5/models/hub/yolov5s-LeakyReLU.yaml
@@ -0,0 +1,49 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+activation: nn.LeakyReLU(0.1) # <----- Conv() activation used throughout entire YOLOv5 model
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5s-ghost.yaml b/yolov5/models/hub/yolov5s-ghost.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ce5238fa5dfcd629b01d5a4a29388d6a7646d6ec
--- /dev/null
+++ b/yolov5/models/hub/yolov5s-ghost.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, GhostConv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3Ghost, [128]],
+ [-1, 1, GhostConv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3Ghost, [256]],
+ [-1, 1, GhostConv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3Ghost, [512]],
+ [-1, 1, GhostConv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3Ghost, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, GhostConv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3Ghost, [512, False]], # 13
+
+ [-1, 1, GhostConv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3Ghost, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, GhostConv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3Ghost, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, GhostConv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3Ghost, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5s-transformer.yaml b/yolov5/models/hub/yolov5s-transformer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..f5267163453c059a6b948567ec1fe5a9af18f7e5
--- /dev/null
+++ b/yolov5/models/hub/yolov5s-transformer.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3TR, [1024]], # 9 <--- C3TR() Transformer module
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5s6.yaml b/yolov5/models/hub/yolov5s6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2f39b0379e74dbfdd584896561337572d47ee580
--- /dev/null
+++ b/yolov5/models/hub/yolov5s6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/hub/yolov5x6.yaml b/yolov5/models/hub/yolov5x6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..e1edbcb8634c7c8abc68fa99bf53a2106700129c
--- /dev/null
+++ b/yolov5/models/hub/yolov5x6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/segment/yolov5l-seg.yaml b/yolov5/models/segment/yolov5l-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..71f80cc0805490c21adbb27bc093a04c4bc7b882
--- /dev/null
+++ b/yolov5/models/segment/yolov5l-seg.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/segment/yolov5m-seg.yaml b/yolov5/models/segment/yolov5m-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2b8e1db2818acbbcd6d2b340c2d950fc3108d4d4
--- /dev/null
+++ b/yolov5/models/segment/yolov5m-seg.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/segment/yolov5n-seg.yaml b/yolov5/models/segment/yolov5n-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..1f67f8e3dfb05af091943100d7578e5f30770455
--- /dev/null
+++ b/yolov5/models/segment/yolov5n-seg.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/segment/yolov5s-seg.yaml b/yolov5/models/segment/yolov5s-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2ff2524ca9b559fa416854dba8af9d3e16eb8323
--- /dev/null
+++ b/yolov5/models/segment/yolov5s-seg.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.5 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/segment/yolov5x-seg.yaml b/yolov5/models/segment/yolov5x-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..589f65c76f954c4db6bc88e4fb0a6d26be70556e
--- /dev/null
+++ b/yolov5/models/segment/yolov5x-seg.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/tf.py b/yolov5/models/tf.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc0a465d7edd094231bd7d2230eb9fe9270ed27e
--- /dev/null
+++ b/yolov5/models/tf.py
@@ -0,0 +1,608 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+TensorFlow, Keras and TFLite versions of YOLOv5
+Authored by https://github.com/zldrobit in PR https://github.com/ultralytics/yolov5/pull/1127
+
+Usage:
+ $ python models/tf.py --weights yolov5s.pt
+
+Export:
+ $ python export.py --weights yolov5s.pt --include saved_model pb tflite tfjs
+"""
+
+import argparse
+import sys
+from copy import deepcopy
+from pathlib import Path
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+# ROOT = ROOT.relative_to(Path.cwd()) # relative
+
+import numpy as np
+import tensorflow as tf
+import torch
+import torch.nn as nn
+from tensorflow import keras
+
+from models.common import (C3, SPP, SPPF, Bottleneck, BottleneckCSP, C3x, Concat, Conv, CrossConv, DWConv,
+ DWConvTranspose2d, Focus, autopad)
+from models.experimental import MixConv2d, attempt_load
+from models.yolo import Detect, Segment
+from utils.activations import SiLU
+from utils.general import LOGGER, make_divisible, print_args
+
+
+class TFBN(keras.layers.Layer):
+ # TensorFlow BatchNormalization wrapper
+ def __init__(self, w=None):
+ super().__init__()
+ self.bn = keras.layers.BatchNormalization(
+ beta_initializer=keras.initializers.Constant(w.bias.numpy()),
+ gamma_initializer=keras.initializers.Constant(w.weight.numpy()),
+ moving_mean_initializer=keras.initializers.Constant(w.running_mean.numpy()),
+ moving_variance_initializer=keras.initializers.Constant(w.running_var.numpy()),
+ epsilon=w.eps)
+
+ def call(self, inputs):
+ return self.bn(inputs)
+
+
+class TFPad(keras.layers.Layer):
+ # Pad inputs in spatial dimensions 1 and 2
+ def __init__(self, pad):
+ super().__init__()
+ if isinstance(pad, int):
+ self.pad = tf.constant([[0, 0], [pad, pad], [pad, pad], [0, 0]])
+ else: # tuple/list
+ self.pad = tf.constant([[0, 0], [pad[0], pad[0]], [pad[1], pad[1]], [0, 0]])
+
+ def call(self, inputs):
+ return tf.pad(inputs, self.pad, mode='constant', constant_values=0)
+
+
+class TFConv(keras.layers.Layer):
+ # Standard convolution
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
+ # ch_in, ch_out, weights, kernel, stride, padding, groups
+ super().__init__()
+ assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
+ # TensorFlow convolution padding is inconsistent with PyTorch (e.g. k=3 s=2 'SAME' padding)
+ # see https://stackoverflow.com/questions/52975843/comparing-conv2d-with-padding-between-tensorflow-and-pytorch
+ conv = keras.layers.Conv2D(
+ filters=c2,
+ kernel_size=k,
+ strides=s,
+ padding='SAME' if s == 1 else 'VALID',
+ use_bias=not hasattr(w, 'bn'),
+ kernel_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy()))
+ self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv])
+ self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity
+ self.act = activations(w.act) if act else tf.identity
+
+ def call(self, inputs):
+ return self.act(self.bn(self.conv(inputs)))
+
+
+class TFDWConv(keras.layers.Layer):
+ # Depthwise convolution
+ def __init__(self, c1, c2, k=1, s=1, p=None, act=True, w=None):
+ # ch_in, ch_out, weights, kernel, stride, padding, groups
+ super().__init__()
+ assert c2 % c1 == 0, f'TFDWConv() output={c2} must be a multiple of input={c1} channels'
+ conv = keras.layers.DepthwiseConv2D(
+ kernel_size=k,
+ depth_multiplier=c2 // c1,
+ strides=s,
+ padding='SAME' if s == 1 else 'VALID',
+ use_bias=not hasattr(w, 'bn'),
+ depthwise_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy()))
+ self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv])
+ self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity
+ self.act = activations(w.act) if act else tf.identity
+
+ def call(self, inputs):
+ return self.act(self.bn(self.conv(inputs)))
+
+
+class TFDWConvTranspose2d(keras.layers.Layer):
+ # Depthwise ConvTranspose2d
+ def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0, w=None):
+ # ch_in, ch_out, weights, kernel, stride, padding, groups
+ super().__init__()
+ assert c1 == c2, f'TFDWConv() output={c2} must be equal to input={c1} channels'
+ assert k == 4 and p1 == 1, 'TFDWConv() only valid for k=4 and p1=1'
+ weight, bias = w.weight.permute(2, 3, 1, 0).numpy(), w.bias.numpy()
+ self.c1 = c1
+ self.conv = [
+ keras.layers.Conv2DTranspose(filters=1,
+ kernel_size=k,
+ strides=s,
+ padding='VALID',
+ output_padding=p2,
+ use_bias=True,
+ kernel_initializer=keras.initializers.Constant(weight[..., i:i + 1]),
+ bias_initializer=keras.initializers.Constant(bias[i])) for i in range(c1)]
+
+ def call(self, inputs):
+ return tf.concat([m(x) for m, x in zip(self.conv, tf.split(inputs, self.c1, 3))], 3)[:, 1:-1, 1:-1]
+
+
+class TFFocus(keras.layers.Layer):
+ # Focus wh information into c-space
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
+ # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = TFConv(c1 * 4, c2, k, s, p, g, act, w.conv)
+
+ def call(self, inputs): # x(b,w,h,c) -> y(b,w/2,h/2,4c)
+ # inputs = inputs / 255 # normalize 0-255 to 0-1
+ inputs = [inputs[:, ::2, ::2, :], inputs[:, 1::2, ::2, :], inputs[:, ::2, 1::2, :], inputs[:, 1::2, 1::2, :]]
+ return self.conv(tf.concat(inputs, 3))
+
+
+class TFBottleneck(keras.layers.Layer):
+ # Standard bottleneck
+ def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, w=None): # ch_in, ch_out, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_, c2, 3, 1, g=g, w=w.cv2)
+ self.add = shortcut and c1 == c2
+
+ def call(self, inputs):
+ return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs))
+
+
+class TFCrossConv(keras.layers.Layer):
+ # Cross Convolution
+ def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False, w=None):
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, (1, k), (1, s), w=w.cv1)
+ self.cv2 = TFConv(c_, c2, (k, 1), (s, 1), g=g, w=w.cv2)
+ self.add = shortcut and c1 == c2
+
+ def call(self, inputs):
+ return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs))
+
+
+class TFConv2d(keras.layers.Layer):
+ # Substitution for PyTorch nn.Conv2D
+ def __init__(self, c1, c2, k, s=1, g=1, bias=True, w=None):
+ super().__init__()
+ assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
+ self.conv = keras.layers.Conv2D(filters=c2,
+ kernel_size=k,
+ strides=s,
+ padding='VALID',
+ use_bias=bias,
+ kernel_initializer=keras.initializers.Constant(
+ w.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer=keras.initializers.Constant(w.bias.numpy()) if bias else None)
+
+ def call(self, inputs):
+ return self.conv(inputs)
+
+
+class TFBottleneckCSP(keras.layers.Layer):
+ # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv2d(c1, c_, 1, 1, bias=False, w=w.cv2)
+ self.cv3 = TFConv2d(c_, c_, 1, 1, bias=False, w=w.cv3)
+ self.cv4 = TFConv(2 * c_, c2, 1, 1, w=w.cv4)
+ self.bn = TFBN(w.bn)
+ self.act = lambda x: keras.activations.swish(x)
+ self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ y1 = self.cv3(self.m(self.cv1(inputs)))
+ y2 = self.cv2(inputs)
+ return self.cv4(self.act(self.bn(tf.concat((y1, y2), axis=3))))
+
+
+class TFC3(keras.layers.Layer):
+ # CSP Bottleneck with 3 convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2)
+ self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3)
+ self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3))
+
+
+class TFC3x(keras.layers.Layer):
+ # 3 module with cross-convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2)
+ self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3)
+ self.m = keras.Sequential([
+ TFCrossConv(c_, c_, k=3, s=1, g=g, e=1.0, shortcut=shortcut, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3))
+
+
+class TFSPP(keras.layers.Layer):
+ # Spatial pyramid pooling layer used in YOLOv3-SPP
+ def __init__(self, c1, c2, k=(5, 9, 13), w=None):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_ * (len(k) + 1), c2, 1, 1, w=w.cv2)
+ self.m = [keras.layers.MaxPool2D(pool_size=x, strides=1, padding='SAME') for x in k]
+
+ def call(self, inputs):
+ x = self.cv1(inputs)
+ return self.cv2(tf.concat([x] + [m(x) for m in self.m], 3))
+
+
+class TFSPPF(keras.layers.Layer):
+ # Spatial pyramid pooling-Fast layer
+ def __init__(self, c1, c2, k=5, w=None):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_ * 4, c2, 1, 1, w=w.cv2)
+ self.m = keras.layers.MaxPool2D(pool_size=k, strides=1, padding='SAME')
+
+ def call(self, inputs):
+ x = self.cv1(inputs)
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(tf.concat([x, y1, y2, self.m(y2)], 3))
+
+
+class TFDetect(keras.layers.Layer):
+ # TF YOLOv5 Detect layer
+ def __init__(self, nc=80, anchors=(), ch=(), imgsz=(640, 640), w=None): # detection layer
+ super().__init__()
+ self.stride = tf.convert_to_tensor(w.stride.numpy(), dtype=tf.float32)
+ self.nc = nc # number of classes
+ self.no = nc + 5 # number of outputs per anchor
+ self.nl = len(anchors) # number of detection layers
+ self.na = len(anchors[0]) // 2 # number of anchors
+ self.grid = [tf.zeros(1)] * self.nl # init grid
+ self.anchors = tf.convert_to_tensor(w.anchors.numpy(), dtype=tf.float32)
+ self.anchor_grid = tf.reshape(self.anchors * tf.reshape(self.stride, [self.nl, 1, 1]), [self.nl, 1, -1, 1, 2])
+ self.m = [TFConv2d(x, self.no * self.na, 1, w=w.m[i]) for i, x in enumerate(ch)]
+ self.training = False # set to False after building model
+ self.imgsz = imgsz
+ for i in range(self.nl):
+ ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
+ self.grid[i] = self._make_grid(nx, ny)
+
+ def call(self, inputs):
+ z = [] # inference output
+ x = []
+ for i in range(self.nl):
+ x.append(self.m[i](inputs[i]))
+ # x(bs,20,20,255) to x(bs,3,20,20,85)
+ ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
+ x[i] = tf.reshape(x[i], [-1, ny * nx, self.na, self.no])
+
+ if not self.training: # inference
+ y = x[i]
+ grid = tf.transpose(self.grid[i], [0, 2, 1, 3]) - 0.5
+ anchor_grid = tf.transpose(self.anchor_grid[i], [0, 2, 1, 3]) * 4
+ xy = (tf.sigmoid(y[..., 0:2]) * 2 + grid) * self.stride[i] # xy
+ wh = tf.sigmoid(y[..., 2:4]) ** 2 * anchor_grid
+ # Normalize xywh to 0-1 to reduce calibration error
+ xy /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
+ wh /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
+ y = tf.concat([xy, wh, tf.sigmoid(y[..., 4:5 + self.nc]), y[..., 5 + self.nc:]], -1)
+ z.append(tf.reshape(y, [-1, self.na * ny * nx, self.no]))
+
+ return tf.transpose(x, [0, 2, 1, 3]) if self.training else (tf.concat(z, 1),)
+
+ @staticmethod
+ def _make_grid(nx=20, ny=20):
+ # yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
+ # return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
+ xv, yv = tf.meshgrid(tf.range(nx), tf.range(ny))
+ return tf.cast(tf.reshape(tf.stack([xv, yv], 2), [1, 1, ny * nx, 2]), dtype=tf.float32)
+
+
+class TFSegment(TFDetect):
+ # YOLOv5 Segment head for segmentation models
+ def __init__(self, nc=80, anchors=(), nm=32, npr=256, ch=(), imgsz=(640, 640), w=None):
+ super().__init__(nc, anchors, ch, imgsz, w)
+ self.nm = nm # number of masks
+ self.npr = npr # number of protos
+ self.no = 5 + nc + self.nm # number of outputs per anchor
+ self.m = [TFConv2d(x, self.no * self.na, 1, w=w.m[i]) for i, x in enumerate(ch)] # output conv
+ self.proto = TFProto(ch[0], self.npr, self.nm, w=w.proto) # protos
+ self.detect = TFDetect.call
+
+ def call(self, x):
+ p = self.proto(x[0])
+ # p = TFUpsample(None, scale_factor=4, mode='nearest')(self.proto(x[0])) # (optional) full-size protos
+ p = tf.transpose(p, [0, 3, 1, 2]) # from shape(1,160,160,32) to shape(1,32,160,160)
+ x = self.detect(self, x)
+ return (x, p) if self.training else (x[0], p)
+
+
+class TFProto(keras.layers.Layer):
+
+ def __init__(self, c1, c_=256, c2=32, w=None):
+ super().__init__()
+ self.cv1 = TFConv(c1, c_, k=3, w=w.cv1)
+ self.upsample = TFUpsample(None, scale_factor=2, mode='nearest')
+ self.cv2 = TFConv(c_, c_, k=3, w=w.cv2)
+ self.cv3 = TFConv(c_, c2, w=w.cv3)
+
+ def call(self, inputs):
+ return self.cv3(self.cv2(self.upsample(self.cv1(inputs))))
+
+
+class TFUpsample(keras.layers.Layer):
+ # TF version of torch.nn.Upsample()
+ def __init__(self, size, scale_factor, mode, w=None): # warning: all arguments needed including 'w'
+ super().__init__()
+ assert scale_factor % 2 == 0, 'scale_factor must be multiple of 2'
+ self.upsample = lambda x: tf.image.resize(x, (x.shape[1] * scale_factor, x.shape[2] * scale_factor), mode)
+ # self.upsample = keras.layers.UpSampling2D(size=scale_factor, interpolation=mode)
+ # with default arguments: align_corners=False, half_pixel_centers=False
+ # self.upsample = lambda x: tf.raw_ops.ResizeNearestNeighbor(images=x,
+ # size=(x.shape[1] * 2, x.shape[2] * 2))
+
+ def call(self, inputs):
+ return self.upsample(inputs)
+
+
+class TFConcat(keras.layers.Layer):
+ # TF version of torch.concat()
+ def __init__(self, dimension=1, w=None):
+ super().__init__()
+ assert dimension == 1, 'convert only NCHW to NHWC concat'
+ self.d = 3
+
+ def call(self, inputs):
+ return tf.concat(inputs, self.d)
+
+
+def parse_model(d, ch, model, imgsz): # model_dict, input_channels(3)
+ LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
+ anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
+ na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
+ no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
+
+ layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
+ for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
+ m_str = m
+ m = eval(m) if isinstance(m, str) else m # eval strings
+ for j, a in enumerate(args):
+ try:
+ args[j] = eval(a) if isinstance(a, str) else a # eval strings
+ except NameError:
+ pass
+
+ n = max(round(n * gd), 1) if n > 1 else n # depth gain
+ if m in [
+ nn.Conv2d, Conv, DWConv, DWConvTranspose2d, Bottleneck, SPP, SPPF, MixConv2d, Focus, CrossConv,
+ BottleneckCSP, C3, C3x]:
+ c1, c2 = ch[f], args[0]
+ c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
+
+ args = [c1, c2, *args[1:]]
+ if m in [BottleneckCSP, C3, C3x]:
+ args.insert(2, n)
+ n = 1
+ elif m is nn.BatchNorm2d:
+ args = [ch[f]]
+ elif m is Concat:
+ c2 = sum(ch[-1 if x == -1 else x + 1] for x in f)
+ elif m in [Detect, Segment]:
+ args.append([ch[x + 1] for x in f])
+ if isinstance(args[1], int): # number of anchors
+ args[1] = [list(range(args[1] * 2))] * len(f)
+ if m is Segment:
+ args[3] = make_divisible(args[3] * gw, 8)
+ args.append(imgsz)
+ else:
+ c2 = ch[f]
+
+ tf_m = eval('TF' + m_str.replace('nn.', ''))
+ m_ = keras.Sequential([tf_m(*args, w=model.model[i][j]) for j in range(n)]) if n > 1 \
+ else tf_m(*args, w=model.model[i]) # module
+
+ torch_m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
+ t = str(m)[8:-2].replace('__main__.', '') # module type
+ np = sum(x.numel() for x in torch_m_.parameters()) # number params
+ m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
+ LOGGER.info(f'{i:>3}{str(f):>18}{str(n):>3}{np:>10} {t:<40}{str(args):<30}') # print
+ save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
+ layers.append(m_)
+ ch.append(c2)
+ return keras.Sequential(layers), sorted(save)
+
+
+class TFModel:
+ # TF YOLOv5 model
+ def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, model=None, imgsz=(640, 640)): # model, channels, classes
+ super().__init__()
+ if isinstance(cfg, dict):
+ self.yaml = cfg # model dict
+ else: # is *.yaml
+ import yaml # for torch hub
+ self.yaml_file = Path(cfg).name
+ with open(cfg) as f:
+ self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
+
+ # Define model
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding {cfg} nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override yaml value
+ self.model, self.savelist = parse_model(deepcopy(self.yaml), ch=[ch], model=model, imgsz=imgsz)
+
+ def predict(self,
+ inputs,
+ tf_nms=False,
+ agnostic_nms=False,
+ topk_per_class=100,
+ topk_all=100,
+ iou_thres=0.45,
+ conf_thres=0.25):
+ y = [] # outputs
+ x = inputs
+ for m in self.model.layers:
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+
+ x = m(x) # run
+ y.append(x if m.i in self.savelist else None) # save output
+
+ # Add TensorFlow NMS
+ if tf_nms:
+ boxes = self._xywh2xyxy(x[0][..., :4])
+ probs = x[0][:, :, 4:5]
+ classes = x[0][:, :, 5:]
+ scores = probs * classes
+ if agnostic_nms:
+ nms = AgnosticNMS()((boxes, classes, scores), topk_all, iou_thres, conf_thres)
+ else:
+ boxes = tf.expand_dims(boxes, 2)
+ nms = tf.image.combined_non_max_suppression(boxes,
+ scores,
+ topk_per_class,
+ topk_all,
+ iou_thres,
+ conf_thres,
+ clip_boxes=False)
+ return (nms,)
+ return x # output [1,6300,85] = [xywh, conf, class0, class1, ...]
+ # x = x[0] # [x(1,6300,85), ...] to x(6300,85)
+ # xywh = x[..., :4] # x(6300,4) boxes
+ # conf = x[..., 4:5] # x(6300,1) confidences
+ # cls = tf.reshape(tf.cast(tf.argmax(x[..., 5:], axis=1), tf.float32), (-1, 1)) # x(6300,1) classes
+ # return tf.concat([conf, cls, xywh], 1)
+
+ @staticmethod
+ def _xywh2xyxy(xywh):
+ # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+ x, y, w, h = tf.split(xywh, num_or_size_splits=4, axis=-1)
+ return tf.concat([x - w / 2, y - h / 2, x + w / 2, y + h / 2], axis=-1)
+
+
+class AgnosticNMS(keras.layers.Layer):
+ # TF Agnostic NMS
+ def call(self, input, topk_all, iou_thres, conf_thres):
+ # wrap map_fn to avoid TypeSpec related error https://stackoverflow.com/a/65809989/3036450
+ return tf.map_fn(lambda x: self._nms(x, topk_all, iou_thres, conf_thres),
+ input,
+ fn_output_signature=(tf.float32, tf.float32, tf.float32, tf.int32),
+ name='agnostic_nms')
+
+ @staticmethod
+ def _nms(x, topk_all=100, iou_thres=0.45, conf_thres=0.25): # agnostic NMS
+ boxes, classes, scores = x
+ class_inds = tf.cast(tf.argmax(classes, axis=-1), tf.float32)
+ scores_inp = tf.reduce_max(scores, -1)
+ selected_inds = tf.image.non_max_suppression(boxes,
+ scores_inp,
+ max_output_size=topk_all,
+ iou_threshold=iou_thres,
+ score_threshold=conf_thres)
+ selected_boxes = tf.gather(boxes, selected_inds)
+ padded_boxes = tf.pad(selected_boxes,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]], [0, 0]],
+ mode='CONSTANT',
+ constant_values=0.0)
+ selected_scores = tf.gather(scores_inp, selected_inds)
+ padded_scores = tf.pad(selected_scores,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
+ mode='CONSTANT',
+ constant_values=-1.0)
+ selected_classes = tf.gather(class_inds, selected_inds)
+ padded_classes = tf.pad(selected_classes,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
+ mode='CONSTANT',
+ constant_values=-1.0)
+ valid_detections = tf.shape(selected_inds)[0]
+ return padded_boxes, padded_scores, padded_classes, valid_detections
+
+
+def activations(act=nn.SiLU):
+ # Returns TF activation from input PyTorch activation
+ if isinstance(act, nn.LeakyReLU):
+ return lambda x: keras.activations.relu(x, alpha=0.1)
+ elif isinstance(act, nn.Hardswish):
+ return lambda x: x * tf.nn.relu6(x + 3) * 0.166666667
+ elif isinstance(act, (nn.SiLU, SiLU)):
+ return lambda x: keras.activations.swish(x)
+ else:
+ raise Exception(f'no matching TensorFlow activation found for PyTorch activation {act}')
+
+
+def representative_dataset_gen(dataset, ncalib=100):
+ # Representative dataset generator for use with converter.representative_dataset, returns a generator of np arrays
+ for n, (path, img, im0s, vid_cap, string) in enumerate(dataset):
+ im = np.transpose(img, [1, 2, 0])
+ im = np.expand_dims(im, axis=0).astype(np.float32)
+ im /= 255
+ yield [im]
+ if n >= ncalib:
+ break
+
+
+def run(
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=(640, 640), # inference size h,w
+ batch_size=1, # batch size
+ dynamic=False, # dynamic batch size
+):
+ # PyTorch model
+ im = torch.zeros((batch_size, 3, *imgsz)) # BCHW image
+ model = attempt_load(weights, device=torch.device('cpu'), inplace=True, fuse=False)
+ _ = model(im) # inference
+ model.info()
+
+ # TensorFlow model
+ im = tf.zeros((batch_size, *imgsz, 3)) # BHWC image
+ tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
+ _ = tf_model.predict(im) # inference
+
+ # Keras model
+ im = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size)
+ keras_model = keras.Model(inputs=im, outputs=tf_model.predict(im))
+ keras_model.summary()
+
+ LOGGER.info('PyTorch, TensorFlow and Keras models successfully verified.\nUse export.py for TF model export.')
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--dynamic', action='store_true', help='dynamic batch size')
+ opt = parser.parse_args()
+ opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/models/yolo.py b/yolov5/models/yolo.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf4ac8c8da0ad90df26413852c519b031559f8c6
--- /dev/null
+++ b/yolov5/models/yolo.py
@@ -0,0 +1,391 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+YOLO-specific modules
+
+Usage:
+ $ python models/yolo.py --cfg yolov5s.yaml
+"""
+
+import argparse
+import contextlib
+import os
+import platform
+import sys
+from copy import deepcopy
+from pathlib import Path
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+if platform.system() != 'Windows':
+ ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from yolov5.models.common import *
+from yolov5.models.experimental import *
+from yolov5.utils.autoanchor import check_anchor_order
+from yolov5.utils.general import LOGGER, check_version, check_yaml, make_divisible, print_args
+from yolov5.utils.plots import feature_visualization
+from yolov5.utils.torch_utils import (fuse_conv_and_bn, initialize_weights, model_info, profile, scale_img, select_device,
+ time_sync)
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+
+class Detect(nn.Module):
+ # YOLOv5 Detect head for detection models
+ stride = None # strides computed during build
+ dynamic = False # force grid reconstruction
+ export = False # export mode
+
+ def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
+ super().__init__()
+ self.nc = nc # number of classes
+ self.no = nc + 5 # number of outputs per anchor
+ self.nl = len(anchors) # number of detection layers
+ self.na = len(anchors[0]) // 2 # number of anchors
+ self.grid = [torch.empty(0) for _ in range(self.nl)] # init grid
+ self.anchor_grid = [torch.empty(0) for _ in range(self.nl)] # init anchor grid
+ self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
+ self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
+ self.inplace = inplace # use inplace ops (e.g. slice assignment)
+
+ def forward(self, x):
+ z = [] # inference output
+ for i in range(self.nl):
+ x[i] = self.m[i](x[i]) # conv
+ bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
+ x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
+
+ if not self.training: # inference
+ if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
+ self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
+
+ if isinstance(self, Segment): # (boxes + masks)
+ xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)
+ xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xy
+ wh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # wh
+ y = torch.cat((xy, wh, conf.sigmoid(), mask), 4)
+ else: # Detect (boxes only)
+ xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)
+ xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
+ wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
+ y = torch.cat((xy, wh, conf), 4)
+ z.append(y.view(bs, self.na * nx * ny, self.no))
+
+ return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
+
+ def _make_grid(self, nx=20, ny=20, i=0, torch_1_10=check_version(torch.__version__, '1.10.0')):
+ d = self.anchors[i].device
+ t = self.anchors[i].dtype
+ shape = 1, self.na, ny, nx, 2 # grid shape
+ y, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)
+ yv, xv = torch.meshgrid(y, x, indexing='ij') if torch_1_10 else torch.meshgrid(y, x) # torch>=0.7 compatibility
+ grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5
+ anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)
+ return grid, anchor_grid
+
+
+class Segment(Detect):
+ # YOLOv5 Segment head for segmentation models
+ def __init__(self, nc=80, anchors=(), nm=32, npr=256, ch=(), inplace=True):
+ super().__init__(nc, anchors, ch, inplace)
+ self.nm = nm # number of masks
+ self.npr = npr # number of protos
+ self.no = 5 + nc + self.nm # number of outputs per anchor
+ self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
+ self.proto = Proto(ch[0], self.npr, self.nm) # protos
+ self.detect = Detect.forward
+
+ def forward(self, x):
+ p = self.proto(x[0])
+ x = self.detect(self, x)
+ return (x, p) if self.training else (x[0], p) if self.export else (x[0], p, x[1])
+
+
+class BaseModel(nn.Module):
+ # YOLOv5 base model
+ def forward(self, x, profile=False, visualize=False):
+ return self._forward_once(x, profile, visualize) # single-scale inference, train
+
+ def _forward_once(self, x, profile=False, visualize=False):
+ y, dt = [], [] # outputs
+ for m in self.model:
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+ if profile:
+ self._profile_one_layer(m, x, dt)
+ x = m(x) # run
+ y.append(x if m.i in self.save else None) # save output
+ if visualize:
+ feature_visualization(x, m.type, m.i, save_dir=visualize)
+ return x
+
+ def _profile_one_layer(self, m, x, dt):
+ c = m == self.model[-1] # is final layer, copy input as inplace fix
+ o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
+ t = time_sync()
+ for _ in range(10):
+ m(x.copy() if c else x)
+ dt.append((time_sync() - t) * 100)
+ if m == self.model[0]:
+ LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} module")
+ LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
+ if c:
+ LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
+
+ def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
+ LOGGER.info('Fusing layers... ')
+ for m in self.model.modules():
+ if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
+ m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
+ delattr(m, 'bn') # remove batchnorm
+ m.forward = m.forward_fuse # update forward
+ self.info()
+ return self
+
+ def info(self, verbose=False, img_size=640): # print model information
+ model_info(self, verbose, img_size)
+
+ def _apply(self, fn):
+ # Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
+ self = super()._apply(fn)
+ m = self.model[-1] # Detect()
+ if isinstance(m, (Detect, Segment)):
+ m.stride = fn(m.stride)
+ m.grid = list(map(fn, m.grid))
+ if isinstance(m.anchor_grid, list):
+ m.anchor_grid = list(map(fn, m.anchor_grid))
+ return self
+
+
+class DetectionModel(BaseModel):
+ # YOLOv5 detection model
+ def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
+ super().__init__()
+ if isinstance(cfg, dict):
+ self.yaml = cfg # model dict
+ else: # is *.yaml
+ import yaml # for torch hub
+ self.yaml_file = Path(cfg).name
+ with open(cfg, encoding='ascii', errors='ignore') as f:
+ self.yaml = yaml.safe_load(f) # model dict
+
+ # Define model
+ ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override yaml value
+ if anchors:
+ LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
+ self.yaml['anchors'] = round(anchors) # override yaml value
+ self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
+ self.names = [str(i) for i in range(self.yaml['nc'])] # default names
+ self.inplace = self.yaml.get('inplace', True)
+
+ # Build strides, anchors
+ m = self.model[-1] # Detect()
+ if isinstance(m, (Detect, Segment)):
+ s = 256 # 2x min stride
+ m.inplace = self.inplace
+ forward = lambda x: self.forward(x)[0] if isinstance(m, Segment) else self.forward(x)
+ m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forward
+ check_anchor_order(m)
+ m.anchors /= m.stride.view(-1, 1, 1)
+ self.stride = m.stride
+ self._initialize_biases() # only run once
+
+ # Init weights, biases
+ initialize_weights(self)
+ self.info()
+ LOGGER.info('')
+
+ def forward(self, x, augment=False, profile=False, visualize=False):
+ if augment:
+ return self._forward_augment(x) # augmented inference, None
+ return self._forward_once(x, profile, visualize) # single-scale inference, train
+
+ def _forward_augment(self, x):
+ img_size = x.shape[-2:] # height, width
+ s = [1, 0.83, 0.67] # scales
+ f = [None, 3, None] # flips (2-ud, 3-lr)
+ y = [] # outputs
+ for si, fi in zip(s, f):
+ xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
+ yi = self._forward_once(xi)[0] # forward
+ # cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
+ yi = self._descale_pred(yi, fi, si, img_size)
+ y.append(yi)
+ y = self._clip_augmented(y) # clip augmented tails
+ return torch.cat(y, 1), None # augmented inference, train
+
+ def _descale_pred(self, p, flips, scale, img_size):
+ # de-scale predictions following augmented inference (inverse operation)
+ if self.inplace:
+ p[..., :4] /= scale # de-scale
+ if flips == 2:
+ p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
+ elif flips == 3:
+ p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
+ else:
+ x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
+ if flips == 2:
+ y = img_size[0] - y # de-flip ud
+ elif flips == 3:
+ x = img_size[1] - x # de-flip lr
+ p = torch.cat((x, y, wh, p[..., 4:]), -1)
+ return p
+
+ def _clip_augmented(self, y):
+ # Clip YOLOv5 augmented inference tails
+ nl = self.model[-1].nl # number of detection layers (P3-P5)
+ g = sum(4 ** x for x in range(nl)) # grid points
+ e = 1 # exclude layer count
+ i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indices
+ y[0] = y[0][:, :-i] # large
+ i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
+ y[-1] = y[-1][:, i:] # small
+ return y
+
+ def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
+ # https://arxiv.org/abs/1708.02002 section 3.3
+ # cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
+ m = self.model[-1] # Detect() module
+ for mi, s in zip(m.m, m.stride): # from
+ b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
+ b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
+ b.data[:, 5:5 + m.nc] += math.log(0.6 / (m.nc - 0.99999)) if cf is None else torch.log(cf / cf.sum()) # cls
+ mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
+
+
+Model = DetectionModel # retain YOLOv5 'Model' class for backwards compatibility
+
+
+class SegmentationModel(DetectionModel):
+ # YOLOv5 segmentation model
+ def __init__(self, cfg='yolov5s-seg.yaml', ch=3, nc=None, anchors=None):
+ super().__init__(cfg, ch, nc, anchors)
+
+
+class ClassificationModel(BaseModel):
+ # YOLOv5 classification model
+ def __init__(self, cfg=None, model=None, nc=1000, cutoff=10): # yaml, model, number of classes, cutoff index
+ super().__init__()
+ self._from_detection_model(model, nc, cutoff) if model is not None else self._from_yaml(cfg)
+
+ def _from_detection_model(self, model, nc=1000, cutoff=10):
+ # Create a YOLOv5 classification model from a YOLOv5 detection model
+ if isinstance(model, DetectMultiBackend):
+ model = model.model # unwrap DetectMultiBackend
+ model.model = model.model[:cutoff] # backbone
+ m = model.model[-1] # last layer
+ ch = m.conv.in_channels if hasattr(m, 'conv') else m.cv1.conv.in_channels # ch into module
+ c = Classify(ch, nc) # Classify()
+ c.i, c.f, c.type = m.i, m.f, 'models.common.Classify' # index, from, type
+ model.model[-1] = c # replace
+ self.model = model.model
+ self.stride = model.stride
+ self.save = []
+ self.nc = nc
+
+ def _from_yaml(self, cfg):
+ # Create a YOLOv5 classification model from a *.yaml file
+ self.model = None
+
+
+def parse_model(d, ch): # model_dict, input_channels(3)
+ # Parse a YOLOv5 model.yaml dictionary
+ LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
+ anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
+ if act:
+ Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
+ LOGGER.info(f"{colorstr('activation:')} {act}") # print
+ na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
+ no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
+
+ layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
+ for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
+ m = eval(m) if isinstance(m, str) else m # eval strings
+ for j, a in enumerate(args):
+ with contextlib.suppress(NameError):
+ args[j] = eval(a) if isinstance(a, str) else a # eval strings
+
+ n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
+ if m in {
+ Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
+ BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
+ c1, c2 = ch[f], args[0]
+ if c2 != no: # if not output
+ c2 = make_divisible(c2 * gw, 8)
+
+ args = [c1, c2, *args[1:]]
+ if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
+ args.insert(2, n) # number of repeats
+ n = 1
+ elif m is nn.BatchNorm2d:
+ args = [ch[f]]
+ elif m is Concat:
+ c2 = sum(ch[x] for x in f)
+ # TODO: channel, gw, gd
+ elif m in {Detect, Segment}:
+ args.append([ch[x] for x in f])
+ if isinstance(args[1], int): # number of anchors
+ args[1] = [list(range(args[1] * 2))] * len(f)
+ if m is Segment:
+ args[3] = make_divisible(args[3] * gw, 8)
+ elif m is Contract:
+ c2 = ch[f] * args[0] ** 2
+ elif m is Expand:
+ c2 = ch[f] // args[0] ** 2
+ else:
+ c2 = ch[f]
+
+ m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
+ t = str(m)[8:-2].replace('__main__.', '') # module type
+ np = sum(x.numel() for x in m_.parameters()) # number params
+ m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
+ LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
+ save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
+ layers.append(m_)
+ if i == 0:
+ ch = []
+ ch.append(c2)
+ return nn.Sequential(*layers), sorted(save)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
+ parser.add_argument('--batch-size', type=int, default=1, help='total batch size for all GPUs')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--profile', action='store_true', help='profile model speed')
+ parser.add_argument('--line-profile', action='store_true', help='profile model speed layer by layer')
+ parser.add_argument('--test', action='store_true', help='test all yolo*.yaml')
+ opt = parser.parse_args()
+ opt.cfg = check_yaml(opt.cfg) # check YAML
+ print_args(vars(opt))
+ device = select_device(opt.device)
+
+ # Create model
+ im = torch.rand(opt.batch_size, 3, 640, 640).to(device)
+ model = Model(opt.cfg).to(device)
+
+ # Options
+ if opt.line_profile: # profile layer by layer
+ model(im, profile=True)
+
+ elif opt.profile: # profile forward-backward
+ results = profile(input=im, ops=[model], n=3)
+
+ elif opt.test: # test all models
+ for cfg in Path(ROOT / 'models').rglob('yolo*.yaml'):
+ try:
+ _ = Model(cfg)
+ except Exception as e:
+ print(f'Error in {cfg}: {e}')
+
+ else: # report fused model summary
+ model.fuse()
diff --git a/yolov5/models/yolov5l.yaml b/yolov5/models/yolov5l.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..31362f8769327bad3afdb65d39a3b940397ecfae
--- /dev/null
+++ b/yolov5/models/yolov5l.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/yolov5m.yaml b/yolov5/models/yolov5m.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a76900c5a2e2602d59ece8645bbd67e0dc454311
--- /dev/null
+++ b/yolov5/models/yolov5m.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/yolov5n.yaml b/yolov5/models/yolov5n.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..aba96cfc54f48c2cb2fe16aae2b0b94e38826c9d
--- /dev/null
+++ b/yolov5/models/yolov5n.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/yolov5s.yaml b/yolov5/models/yolov5s.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5d05364c49363adb2b863ecf163e45516679dc03
--- /dev/null
+++ b/yolov5/models/yolov5s.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/yolov5x.yaml b/yolov5/models/yolov5x.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..4bdd93915da550d62c4ada3684c5660ff5034404
--- /dev/null
+++ b/yolov5/models/yolov5x.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/requirements.txt b/yolov5/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..65924c9feec41273a8a4d2bb238e5622ac928a96
--- /dev/null
+++ b/yolov5/requirements.txt
@@ -0,0 +1,49 @@
+# YOLOv5 requirements
+# Usage: pip install -r requirements.txt
+
+# Base ------------------------------------------------------------------------
+gitpython>=3.1.30
+matplotlib>=3.3
+numpy>=1.18.5
+opencv-python>=4.1.1
+Pillow>=7.1.2
+psutil # system resources
+PyYAML>=5.3.1
+requests>=2.23.0
+scipy>=1.4.1
+thop>=0.1.1 # FLOPs computation
+torch>=1.7.0 # see https://pytorch.org/get-started/locally (recommended)
+torchvision>=0.8.1
+tqdm>=4.64.0
+# protobuf<=3.20.1 # https://github.com/ultralytics/yolov5/issues/8012
+
+# Logging ---------------------------------------------------------------------
+# tensorboard>=2.4.1
+# clearml>=1.2.0
+# comet
+
+# Plotting --------------------------------------------------------------------
+pandas>=1.1.4
+seaborn>=0.11.0
+
+# Export ----------------------------------------------------------------------
+# coremltools>=6.0 # CoreML export
+# onnx>=1.10.0 # ONNX export
+# onnx-simplifier>=0.4.1 # ONNX simplifier
+# nvidia-pyindex # TensorRT export
+# nvidia-tensorrt # TensorRT export
+# scikit-learn<=1.1.2 # CoreML quantization
+# tensorflow>=2.4.0 # TF exports (-cpu, -aarch64, -macos)
+# tensorflowjs>=3.9.0 # TF.js export
+# openvino-dev # OpenVINO export
+
+# Deploy ----------------------------------------------------------------------
+setuptools>=65.5.1 # Snyk vulnerability fix
+# tritonclient[all]~=2.24.0
+
+# Extras ----------------------------------------------------------------------
+# ipython # interactive notebook
+# mss # screenshots
+# albumentations>=1.0.3
+# pycocotools>=2.0.6 # COCO mAP
+# ultralytics # HUB https://hub.ultralytics.com
diff --git a/yolov5/segment/predict.py b/yolov5/segment/predict.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d4d6036358a755e297cbc83e2579242712b128a
--- /dev/null
+++ b/yolov5/segment/predict.py
@@ -0,0 +1,284 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Run YOLOv5 segmentation inference on images, videos, directories, streams, etc.
+
+Usage - sources:
+ $ python segment/predict.py --weights yolov5s-seg.pt --source 0 # webcam
+ img.jpg # image
+ vid.mp4 # video
+ screen # screenshot
+ path/ # directory
+ list.txt # list of images
+ list.streams # list of streams
+ 'path/*.jpg' # glob
+ 'https://youtu.be/Zgi9g1ksQHc' # YouTube
+ 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
+
+Usage - formats:
+ $ python segment/predict.py --weights yolov5s-seg.pt # PyTorch
+ yolov5s-seg.torchscript # TorchScript
+ yolov5s-seg.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s-seg_openvino_model # OpenVINO
+ yolov5s-seg.engine # TensorRT
+ yolov5s-seg.mlmodel # CoreML (macOS-only)
+ yolov5s-seg_saved_model # TensorFlow SavedModel
+ yolov5s-seg.pb # TensorFlow GraphDef
+ yolov5s-seg.tflite # TensorFlow Lite
+ yolov5s-seg_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s-seg_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import os
+import platform
+import sys
+from pathlib import Path
+
+import torch
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
+from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
+ increment_path, non_max_suppression, print_args, scale_boxes, scale_segments,
+ strip_optimizer)
+from utils.plots import Annotator, colors, save_one_box
+from utils.segment.general import masks2segments, process_mask, process_mask_native
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+@smart_inference_mode()
+def run(
+ weights=ROOT / 'yolov5s-seg.pt', # model.pt path(s)
+ source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
+ data=ROOT / 'data/coco128.yaml', # dataset.yaml path
+ imgsz=(640, 640), # inference size (height, width)
+ conf_thres=0.25, # confidence threshold
+ iou_thres=0.45, # NMS IOU threshold
+ max_det=1000, # maximum detections per image
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ view_img=False, # show results
+ save_txt=False, # save results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_crop=False, # save cropped prediction boxes
+ nosave=False, # do not save images/videos
+ classes=None, # filter by class: --class 0, or --class 0 2 3
+ agnostic_nms=False, # class-agnostic NMS
+ augment=False, # augmented inference
+ visualize=False, # visualize features
+ update=False, # update all models
+ project=ROOT / 'runs/predict-seg', # save results to project/name
+ name='exp', # save results to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ line_thickness=3, # bounding box thickness (pixels)
+ hide_labels=False, # hide labels
+ hide_conf=False, # hide confidences
+ half=False, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ vid_stride=1, # video frame-rate stride
+ retina_masks=False,
+):
+ source = str(source)
+ save_img = not nosave and not source.endswith('.txt') # save inference images
+ is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
+ is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
+ webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
+ screenshot = source.lower().startswith('screen')
+ if is_url and is_file:
+ source = check_file(source) # download
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ device = select_device(device)
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, names, pt = model.stride, model.names, model.pt
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+
+ # Dataloader
+ bs = 1 # batch_size
+ if webcam:
+ view_img = check_imshow(warn=True)
+ dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
+ bs = len(dataset)
+ elif screenshot:
+ dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
+ else:
+ dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
+ vid_path, vid_writer = [None] * bs, [None] * bs
+
+ # Run inference
+ model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
+ seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
+ for path, im, im0s, vid_cap, s in dataset:
+ with dt[0]:
+ im = torch.from_numpy(im).to(model.device)
+ im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+
+ # Inference
+ with dt[1]:
+ visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
+ pred, proto = model(im, augment=augment, visualize=visualize)[:2]
+
+ # NMS
+ with dt[2]:
+ pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det, nm=32)
+
+ # Second-stage classifier (optional)
+ # pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
+
+ # Process predictions
+ for i, det in enumerate(pred): # per image
+ seen += 1
+ if webcam: # batch_size >= 1
+ p, im0, frame = path[i], im0s[i].copy(), dataset.count
+ s += f'{i}: '
+ else:
+ p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
+
+ p = Path(p) # to Path
+ save_path = str(save_dir / p.name) # im.jpg
+ txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
+ s += '%gx%g ' % im.shape[2:] # print string
+ imc = im0.copy() if save_crop else im0 # for save_crop
+ annotator = Annotator(im0, line_width=line_thickness, example=str(names))
+ if len(det):
+ if retina_masks:
+ # scale bbox first the crop masks
+ det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round() # rescale boxes to im0 size
+ masks = process_mask_native(proto[i], det[:, 6:], det[:, :4], im0.shape[:2]) # HWC
+ else:
+ masks = process_mask(proto[i], det[:, 6:], det[:, :4], im.shape[2:], upsample=True) # HWC
+ det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round() # rescale boxes to im0 size
+
+ # Segments
+ if save_txt:
+ segments = [
+ scale_segments(im0.shape if retina_masks else im.shape[2:], x, im0.shape, normalize=True)
+ for x in reversed(masks2segments(masks))]
+
+ # Print results
+ for c in det[:, 5].unique():
+ n = (det[:, 5] == c).sum() # detections per class
+ s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
+
+ # Mask plotting
+ annotator.masks(
+ masks,
+ colors=[colors(x, True) for x in det[:, 5]],
+ im_gpu=torch.as_tensor(im0, dtype=torch.float16).to(device).permute(2, 0, 1).flip(0).contiguous() /
+ 255 if retina_masks else im[i])
+
+ # Write results
+ for j, (*xyxy, conf, cls) in enumerate(reversed(det[:, :6])):
+ if save_txt: # Write to file
+ seg = segments[j].reshape(-1) # (n,2) to (n*2)
+ line = (cls, *seg, conf) if save_conf else (cls, *seg) # label format
+ with open(f'{txt_path}.txt', 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+ if save_img or save_crop or view_img: # Add bbox to image
+ c = int(cls) # integer class
+ label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
+ annotator.box_label(xyxy, label, color=colors(c, True))
+ # annotator.draw.polygon(segments[j], outline=colors(c, True), width=3)
+ if save_crop:
+ save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
+
+ # Stream results
+ im0 = annotator.result()
+ if view_img:
+ if platform.system() == 'Linux' and p not in windows:
+ windows.append(p)
+ cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
+ cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
+ cv2.imshow(str(p), im0)
+ if cv2.waitKey(1) == ord('q'): # 1 millisecond
+ exit()
+
+ # Save results (image with detections)
+ if save_img:
+ if dataset.mode == 'image':
+ cv2.imwrite(save_path, im0)
+ else: # 'video' or 'stream'
+ if vid_path[i] != save_path: # new video
+ vid_path[i] = save_path
+ if isinstance(vid_writer[i], cv2.VideoWriter):
+ vid_writer[i].release() # release previous video writer
+ if vid_cap: # video
+ fps = vid_cap.get(cv2.CAP_PROP_FPS)
+ w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ else: # stream
+ fps, w, h = 30, im0.shape[1], im0.shape[0]
+ save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
+ vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ vid_writer[i].write(im0)
+
+ # Print time (inference-only)
+ LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms")
+
+ # Print results
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
+ if save_txt or save_img:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ if update:
+ strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning)
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s-seg.pt', help='model path(s)')
+ parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
+ parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--view-img', action='store_true', help='show results')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
+ parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
+ parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
+ parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--visualize', action='store_true', help='visualize features')
+ parser.add_argument('--update', action='store_true', help='update all models')
+ parser.add_argument('--project', default=ROOT / 'runs/predict-seg', help='save results to project/name')
+ parser.add_argument('--name', default='exp', help='save results to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
+ parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
+ parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
+ parser.add_argument('--retina-masks', action='store_true', help='whether to plot masks in native resolution')
+ opt = parser.parse_args()
+ opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/segment/train.py b/yolov5/segment/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..073fc742005b856992f853af2a54093c638d79b6
--- /dev/null
+++ b/yolov5/segment/train.py
@@ -0,0 +1,666 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Train a YOLOv5 segment model on a segment dataset
+Models and datasets download automatically from the latest YOLOv5 release.
+
+Usage - Single-GPU training:
+ $ python segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640 # from pretrained (recommended)
+ $ python segment/train.py --data coco128-seg.yaml --weights '' --cfg yolov5s-seg.yaml --img 640 # from scratch
+
+Usage - Multi-GPU DDP training:
+ $ python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640 --device 0,1,2,3
+
+Models: https://github.com/ultralytics/yolov5/tree/master/models
+Datasets: https://github.com/ultralytics/yolov5/tree/master/data
+Tutorial: https://docs.ultralytics.com/yolov5/tutorials/train_custom_data
+"""
+
+import argparse
+import math
+import os
+import random
+import subprocess
+import sys
+import time
+from copy import deepcopy
+from datetime import datetime
+from pathlib import Path
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import yaml
+from torch.optim import lr_scheduler
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import segment.val as validate # for end-of-epoch mAP
+from models.experimental import attempt_load
+from models.yolo import SegmentationModel
+from utils.autoanchor import check_anchors
+from utils.autobatch import check_train_batch_size
+from utils.callbacks import Callbacks
+from utils.downloads import attempt_download, is_url
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, check_amp, check_dataset, check_file, check_git_info,
+ check_git_status, check_img_size, check_requirements, check_suffix, check_yaml, colorstr,
+ get_latest_run, increment_path, init_seeds, intersect_dicts, labels_to_class_weights,
+ labels_to_image_weights, one_cycle, print_args, print_mutation, strip_optimizer, yaml_save)
+from utils.loggers import GenericLogger
+from utils.plots import plot_evolve, plot_labels
+from utils.segment.dataloaders import create_dataloader
+from utils.segment.loss import ComputeLoss
+from utils.segment.metrics import KEYS, fitness
+from utils.segment.plots import plot_images_and_masks, plot_results_with_masks
+from utils.torch_utils import (EarlyStopping, ModelEMA, de_parallel, select_device, smart_DDP, smart_optimizer,
+ smart_resume, torch_distributed_zero_first)
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+GIT_INFO = check_git_info()
+
+
+def train(hyp, opt, device, callbacks): # hyp is path/to/hyp.yaml or hyp dictionary
+ save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze, mask_ratio = \
+ Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
+ opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze, opt.mask_ratio
+ # callbacks.run('on_pretrain_routine_start')
+
+ # Directories
+ w = save_dir / 'weights' # weights dir
+ (w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
+ last, best = w / 'last.pt', w / 'best.pt'
+
+ # Hyperparameters
+ if isinstance(hyp, str):
+ with open(hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
+ opt.hyp = hyp.copy() # for saving hyps to checkpoints
+
+ # Save run settings
+ if not evolve:
+ yaml_save(save_dir / 'hyp.yaml', hyp)
+ yaml_save(save_dir / 'opt.yaml', vars(opt))
+
+ # Loggers
+ data_dict = None
+ if RANK in {-1, 0}:
+ logger = GenericLogger(opt=opt, console_logger=LOGGER)
+
+ # Config
+ plots = not evolve and not opt.noplots # create plots
+ overlap = not opt.no_overlap
+ cuda = device.type != 'cpu'
+ init_seeds(opt.seed + 1 + RANK, deterministic=True)
+ with torch_distributed_zero_first(LOCAL_RANK):
+ data_dict = data_dict or check_dataset(data) # check if None
+ train_path, val_path = data_dict['train'], data_dict['val']
+ nc = 1 if single_cls else int(data_dict['nc']) # number of classes
+ names = {0: 'item'} if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
+ is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
+
+ # Model
+ check_suffix(weights, '.pt') # check weights
+ pretrained = weights.endswith('.pt')
+ if pretrained:
+ with torch_distributed_zero_first(LOCAL_RANK):
+ weights = attempt_download(weights) # download if not found locally
+ ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
+ model = SegmentationModel(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device)
+ exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
+ else:
+ model = SegmentationModel(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ amp = check_amp(model) # check AMP
+
+ # Freeze
+ freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze
+ for k, v in model.named_parameters():
+ v.requires_grad = True # train all layers
+ # v.register_hook(lambda x: torch.nan_to_num(x)) # NaN to 0 (commented for erratic training results)
+ if any(x in k for x in freeze):
+ LOGGER.info(f'freezing {k}')
+ v.requires_grad = False
+
+ # Image size
+ gs = max(int(model.stride.max()), 32) # grid size (max stride)
+ imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
+
+ # Batch size
+ if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
+ batch_size = check_train_batch_size(model, imgsz, amp)
+ logger.update_params({'batch_size': batch_size})
+ # loggers.on_params_update({"batch_size": batch_size})
+
+ # Optimizer
+ nbs = 64 # nominal batch size
+ accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
+ hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
+ optimizer = smart_optimizer(model, opt.optimizer, hyp['lr0'], hyp['momentum'], hyp['weight_decay'])
+
+ # Scheduler
+ if opt.cos_lr:
+ lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
+ else:
+ lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
+ scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
+
+ # EMA
+ ema = ModelEMA(model) if RANK in {-1, 0} else None
+
+ # Resume
+ best_fitness, start_epoch = 0.0, 0
+ if pretrained:
+ if resume:
+ best_fitness, start_epoch, epochs = smart_resume(ckpt, optimizer, ema, weights, epochs, resume)
+ del ckpt, csd
+
+ # DP mode
+ if cuda and RANK == -1 and torch.cuda.device_count() > 1:
+ LOGGER.warning(
+ 'WARNING ⚠️ DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
+ 'See Multi-GPU Tutorial at https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training to get started.'
+ )
+ model = torch.nn.DataParallel(model)
+
+ # SyncBatchNorm
+ if opt.sync_bn and cuda and RANK != -1:
+ model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
+ LOGGER.info('Using SyncBatchNorm()')
+
+ # Trainloader
+ train_loader, dataset = create_dataloader(
+ train_path,
+ imgsz,
+ batch_size // WORLD_SIZE,
+ gs,
+ single_cls,
+ hyp=hyp,
+ augment=True,
+ cache=None if opt.cache == 'val' else opt.cache,
+ rect=opt.rect,
+ rank=LOCAL_RANK,
+ workers=workers,
+ image_weights=opt.image_weights,
+ quad=opt.quad,
+ prefix=colorstr('train: '),
+ shuffle=True,
+ mask_downsample_ratio=mask_ratio,
+ overlap_mask=overlap,
+ )
+ labels = np.concatenate(dataset.labels, 0)
+ mlc = int(labels[:, 0].max()) # max label class
+ assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
+
+ # Process 0
+ if RANK in {-1, 0}:
+ val_loader = create_dataloader(val_path,
+ imgsz,
+ batch_size // WORLD_SIZE * 2,
+ gs,
+ single_cls,
+ hyp=hyp,
+ cache=None if noval else opt.cache,
+ rect=True,
+ rank=-1,
+ workers=workers * 2,
+ pad=0.5,
+ mask_downsample_ratio=mask_ratio,
+ overlap_mask=overlap,
+ prefix=colorstr('val: '))[0]
+
+ if not resume:
+ if not opt.noautoanchor:
+ check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz) # run AutoAnchor
+ model.half().float() # pre-reduce anchor precision
+
+ if plots:
+ plot_labels(labels, names, save_dir)
+ # callbacks.run('on_pretrain_routine_end', labels, names)
+
+ # DDP mode
+ if cuda and RANK != -1:
+ model = smart_DDP(model)
+
+ # Model attributes
+ nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
+ hyp['box'] *= 3 / nl # scale to layers
+ hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
+ hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
+ hyp['label_smoothing'] = opt.label_smoothing
+ model.nc = nc # attach number of classes to model
+ model.hyp = hyp # attach hyperparameters to model
+ model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
+ model.names = names
+
+ # Start training
+ t0 = time.time()
+ nb = len(train_loader) # number of batches
+ nw = max(round(hyp['warmup_epochs'] * nb), 100) # number of warmup iterations, max(3 epochs, 100 iterations)
+ # nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
+ last_opt_step = -1
+ maps = np.zeros(nc) # mAP per class
+ results = (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
+ scheduler.last_epoch = start_epoch - 1 # do not move
+ scaler = torch.cuda.amp.GradScaler(enabled=amp)
+ stopper, stop = EarlyStopping(patience=opt.patience), False
+ compute_loss = ComputeLoss(model, overlap=overlap) # init loss class
+ # callbacks.run('on_train_start')
+ LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
+ f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
+ f"Logging results to {colorstr('bold', save_dir)}\n"
+ f'Starting training for {epochs} epochs...')
+ for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
+ # callbacks.run('on_train_epoch_start')
+ model.train()
+
+ # Update image weights (optional, single-GPU only)
+ if opt.image_weights:
+ cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
+ iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
+ dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
+
+ # Update mosaic border (optional)
+ # b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
+ # dataset.mosaic_border = [b - imgsz, -b] # height, width borders
+
+ mloss = torch.zeros(4, device=device) # mean losses
+ if RANK != -1:
+ train_loader.sampler.set_epoch(epoch)
+ pbar = enumerate(train_loader)
+ LOGGER.info(('\n' + '%11s' * 8) %
+ ('Epoch', 'GPU_mem', 'box_loss', 'seg_loss', 'obj_loss', 'cls_loss', 'Instances', 'Size'))
+ if RANK in {-1, 0}:
+ pbar = tqdm(pbar, total=nb, bar_format=TQDM_BAR_FORMAT) # progress bar
+ optimizer.zero_grad()
+ for i, (imgs, targets, paths, _, masks) in pbar: # batch ------------------------------------------------------
+ # callbacks.run('on_train_batch_start')
+ ni = i + nb * epoch # number integrated batches (since train start)
+ imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
+
+ # Warmup
+ if ni <= nw:
+ xi = [0, nw] # x interp
+ # compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
+ accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
+ for j, x in enumerate(optimizer.param_groups):
+ # bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
+ x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 0 else 0.0, x['initial_lr'] * lf(epoch)])
+ if 'momentum' in x:
+ x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
+
+ # Multi-scale
+ if opt.multi_scale:
+ sz = random.randrange(int(imgsz * 0.5), int(imgsz * 1.5) + gs) // gs * gs # size
+ sf = sz / max(imgs.shape[2:]) # scale factor
+ if sf != 1:
+ ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
+ imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
+
+ # Forward
+ with torch.cuda.amp.autocast(amp):
+ pred = model(imgs) # forward
+ loss, loss_items = compute_loss(pred, targets.to(device), masks=masks.to(device).float())
+ if RANK != -1:
+ loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
+ if opt.quad:
+ loss *= 4.
+
+ # Backward
+ scaler.scale(loss).backward()
+
+ # Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
+ if ni - last_opt_step >= accumulate:
+ scaler.unscale_(optimizer) # unscale gradients
+ torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0) # clip gradients
+ scaler.step(optimizer) # optimizer.step
+ scaler.update()
+ optimizer.zero_grad()
+ if ema:
+ ema.update(model)
+ last_opt_step = ni
+
+ # Log
+ if RANK in {-1, 0}:
+ mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
+ mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
+ pbar.set_description(('%11s' * 2 + '%11.4g' * 6) %
+ (f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
+ # callbacks.run('on_train_batch_end', model, ni, imgs, targets, paths)
+ # if callbacks.stop_training:
+ # return
+
+ # Mosaic plots
+ if plots:
+ if ni < 3:
+ plot_images_and_masks(imgs, targets, masks, paths, save_dir / f'train_batch{ni}.jpg')
+ if ni == 10:
+ files = sorted(save_dir.glob('train*.jpg'))
+ logger.log_images(files, 'Mosaics', epoch)
+ # end batch ------------------------------------------------------------------------------------------------
+
+ # Scheduler
+ lr = [x['lr'] for x in optimizer.param_groups] # for loggers
+ scheduler.step()
+
+ if RANK in {-1, 0}:
+ # mAP
+ # callbacks.run('on_train_epoch_end', epoch=epoch)
+ ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
+ final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
+ if not noval or final_epoch: # Calculate mAP
+ results, maps, _ = validate.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ half=amp,
+ model=ema.ema,
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ callbacks=callbacks,
+ compute_loss=compute_loss,
+ mask_downsample_ratio=mask_ratio,
+ overlap=overlap)
+
+ # Update best mAP
+ fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
+ stop = stopper(epoch=epoch, fitness=fi) # early stop check
+ if fi > best_fitness:
+ best_fitness = fi
+ log_vals = list(mloss) + list(results) + lr
+ # callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
+ # Log val metrics and media
+ metrics_dict = dict(zip(KEYS, log_vals))
+ logger.log_metrics(metrics_dict, epoch)
+
+ # Save model
+ if (not nosave) or (final_epoch and not evolve): # if save
+ ckpt = {
+ 'epoch': epoch,
+ 'best_fitness': best_fitness,
+ 'model': deepcopy(de_parallel(model)).half(),
+ 'ema': deepcopy(ema.ema).half(),
+ 'updates': ema.updates,
+ 'optimizer': optimizer.state_dict(),
+ 'opt': vars(opt),
+ 'git': GIT_INFO, # {remote, branch, commit} if a git repo
+ 'date': datetime.now().isoformat()}
+
+ # Save last, best and delete
+ torch.save(ckpt, last)
+ if best_fitness == fi:
+ torch.save(ckpt, best)
+ if opt.save_period > 0 and epoch % opt.save_period == 0:
+ torch.save(ckpt, w / f'epoch{epoch}.pt')
+ logger.log_model(w / f'epoch{epoch}.pt')
+ del ckpt
+ # callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
+
+ # EarlyStopping
+ if RANK != -1: # if DDP training
+ broadcast_list = [stop if RANK == 0 else None]
+ dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks
+ if RANK != 0:
+ stop = broadcast_list[0]
+ if stop:
+ break # must break all DDP ranks
+
+ # end epoch ----------------------------------------------------------------------------------------------------
+ # end training -----------------------------------------------------------------------------------------------------
+ if RANK in {-1, 0}:
+ LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
+ for f in last, best:
+ if f.exists():
+ strip_optimizer(f) # strip optimizers
+ if f is best:
+ LOGGER.info(f'\nValidating {f}...')
+ results, _, _ = validate.run(
+ data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=attempt_load(f, device).half(),
+ iou_thres=0.65 if is_coco else 0.60, # best pycocotools at iou 0.65
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ save_json=is_coco,
+ verbose=True,
+ plots=plots,
+ callbacks=callbacks,
+ compute_loss=compute_loss,
+ mask_downsample_ratio=mask_ratio,
+ overlap=overlap) # val best model with plots
+ if is_coco:
+ # callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
+ metrics_dict = dict(zip(KEYS, list(mloss) + list(results) + lr))
+ logger.log_metrics(metrics_dict, epoch)
+
+ # callbacks.run('on_train_end', last, best, epoch, results)
+ # on train end callback using genericLogger
+ logger.log_metrics(dict(zip(KEYS[4:16], results)), epochs)
+ if not opt.evolve:
+ logger.log_model(best, epoch)
+ if plots:
+ plot_results_with_masks(file=save_dir / 'results.csv') # save results.png
+ files = ['results.png', 'confusion_matrix.png', *(f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R'))]
+ files = [(save_dir / f) for f in files if (save_dir / f).exists()] # filter
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
+ logger.log_images(files, 'Results', epoch + 1)
+ logger.log_images(sorted(save_dir.glob('val*.jpg')), 'Validation', epoch + 1)
+ torch.cuda.empty_cache()
+ return results
+
+
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s-seg.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128-seg.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
+ parser.add_argument('--noplots', action='store_true', help='save no plot files')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train-seg', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--seed', type=int, default=0, help='Global training seed')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+
+ # Instance Segmentation Args
+ parser.add_argument('--mask-ratio', type=int, default=4, help='Downsample the truth masks to saving memory')
+ parser.add_argument('--no-overlap', action='store_true', help='Overlap masks train faster at slightly less mAP')
+
+ return parser.parse_known_args()[0] if known else parser.parse_args()
+
+
+def main(opt, callbacks=Callbacks()):
+ # Checks
+ if RANK in {-1, 0}:
+ print_args(vars(opt))
+ check_git_status()
+ check_requirements()
+
+ # Resume
+ if opt.resume and not opt.evolve: # resume from specified or most recent last.pt
+ last = Path(check_file(opt.resume) if isinstance(opt.resume, str) else get_latest_run())
+ opt_yaml = last.parent.parent / 'opt.yaml' # train options yaml
+ opt_data = opt.data # original dataset
+ if opt_yaml.is_file():
+ with open(opt_yaml, errors='ignore') as f:
+ d = yaml.safe_load(f)
+ else:
+ d = torch.load(last, map_location='cpu')['opt']
+ opt = argparse.Namespace(**d) # replace
+ opt.cfg, opt.weights, opt.resume = '', str(last), True # reinstate
+ if is_url(opt_data):
+ opt.data = check_file(opt_data) # avoid HUB resume auth timeout
+ else:
+ opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
+ check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
+ assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
+ if opt.evolve:
+ if opt.project == str(ROOT / 'runs/train-seg'): # if default project name, rename to runs/evolve-seg
+ opt.project = str(ROOT / 'runs/evolve-seg')
+ opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
+ if opt.name == 'cfg':
+ opt.name = Path(opt.cfg).stem # use model.yaml as name
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
+
+ # DDP mode
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ if LOCAL_RANK != -1:
+ msg = 'is not compatible with YOLOv5 Multi-GPU DDP training'
+ assert not opt.image_weights, f'--image-weights {msg}'
+ assert not opt.evolve, f'--evolve {msg}'
+ assert opt.batch_size != -1, f'AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size'
+ assert opt.batch_size % WORLD_SIZE == 0, f'--batch-size {opt.batch_size} must be multiple of WORLD_SIZE'
+ assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
+ torch.cuda.set_device(LOCAL_RANK)
+ device = torch.device('cuda', LOCAL_RANK)
+ dist.init_process_group(backend='nccl' if dist.is_nccl_available() else 'gloo')
+
+ # Train
+ if not opt.evolve:
+ train(opt.hyp, opt, device, callbacks)
+
+ # Evolve hyperparameters (optional)
+ else:
+ # Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
+ meta = {
+ 'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
+ 'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
+ 'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
+ 'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
+ 'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
+ 'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
+ 'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
+ 'box': (1, 0.02, 0.2), # box loss gain
+ 'cls': (1, 0.2, 4.0), # cls loss gain
+ 'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
+ 'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
+ 'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
+ 'iou_t': (0, 0.1, 0.7), # IoU training threshold
+ 'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
+ 'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
+ 'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
+ 'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
+ 'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
+ 'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
+ 'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
+ 'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
+ 'scale': (1, 0.0, 0.9), # image scale (+/- gain)
+ 'shear': (1, 0.0, 10.0), # image shear (+/- deg)
+ 'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
+ 'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
+ 'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
+ 'mosaic': (1, 0.0, 1.0), # image mixup (probability)
+ 'mixup': (1, 0.0, 1.0), # image mixup (probability)
+ 'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
+
+ with open(opt.hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ if 'anchors' not in hyp: # anchors commented in hyp.yaml
+ hyp['anchors'] = 3
+ if opt.noautoanchor:
+ del hyp['anchors'], meta['anchors']
+ opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
+ # ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
+ evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
+ if opt.bucket:
+ # download evolve.csv if exists
+ subprocess.run([
+ 'gsutil',
+ 'cp',
+ f'gs://{opt.bucket}/evolve.csv',
+ str(evolve_csv),])
+
+ for _ in range(opt.evolve): # generations to evolve
+ if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
+ # Select parent(s)
+ parent = 'single' # parent selection method: 'single' or 'weighted'
+ x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
+ n = min(5, len(x)) # number of previous results to consider
+ x = x[np.argsort(-fitness(x))][:n] # top n mutations
+ w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
+ if parent == 'single' or len(x) == 1:
+ # x = x[random.randint(0, n - 1)] # random selection
+ x = x[random.choices(range(n), weights=w)[0]] # weighted selection
+ elif parent == 'weighted':
+ x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
+
+ # Mutate
+ mp, s = 0.8, 0.2 # mutation probability, sigma
+ npr = np.random
+ npr.seed(int(time.time()))
+ g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
+ ng = len(meta)
+ v = np.ones(ng)
+ while all(v == 1): # mutate until a change occurs (prevent duplicates)
+ v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
+ for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
+ hyp[k] = float(x[i + 12] * v[i]) # mutate
+
+ # Constrain to limits
+ for k, v in meta.items():
+ hyp[k] = max(hyp[k], v[1]) # lower limit
+ hyp[k] = min(hyp[k], v[2]) # upper limit
+ hyp[k] = round(hyp[k], 5) # significant digits
+
+ # Train mutation
+ results = train(hyp.copy(), opt, device, callbacks)
+ callbacks = Callbacks()
+ # Write mutation results
+ print_mutation(KEYS[4:16], results, hyp.copy(), save_dir, opt.bucket)
+
+ # Plot results
+ plot_evolve(evolve_csv)
+ LOGGER.info(f'Hyperparameter evolution finished {opt.evolve} generations\n'
+ f"Results saved to {colorstr('bold', save_dir)}\n"
+ f'Usage example: $ python train.py --hyp {evolve_yaml}')
+
+
+def run(**kwargs):
+ # Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
+ opt = parse_opt(True)
+ for k, v in kwargs.items():
+ setattr(opt, k, v)
+ main(opt)
+ return opt
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/segment/tutorial.ipynb b/yolov5/segment/tutorial.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..f2aee9e26b336a66cc0b5f6d3c30006fdedc4b82
--- /dev/null
+++ b/yolov5/segment/tutorial.ipynb
@@ -0,0 +1,595 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "t6MPjfT5NrKQ"
+ },
+ "source": [
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "outputs": [],
+ "source": [
+ "# YOLOv5 PyTorch HUB Inference (DetectionModels only)\n",
+ "import torch\n",
+ "\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # yolov5n - yolov5x6 or custom\n",
+ "im = 'https://ultralytics.com/images/zidane.jpg' # file, Path, PIL.Image, OpenCV, nparray, list\n",
+ "results = model(im) # inference\n",
+ "results.print() # or .show(), .save(), .crop(), .pandas(), etc."
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "name": "YOLOv5 Classification Tutorial",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.12"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/yolov5/classify/val.py b/yolov5/classify/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..643489d64d36cb4d445d3a74c04eed747619b933
--- /dev/null
+++ b/yolov5/classify/val.py
@@ -0,0 +1,170 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Validate a trained YOLOv5 classification model on a classification dataset
+
+Usage:
+ $ bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
+ $ python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate ImageNet
+
+Usage - formats:
+ $ python classify/val.py --weights yolov5s-cls.pt # PyTorch
+ yolov5s-cls.torchscript # TorchScript
+ yolov5s-cls.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s-cls_openvino_model # OpenVINO
+ yolov5s-cls.engine # TensorRT
+ yolov5s-cls.mlmodel # CoreML (macOS-only)
+ yolov5s-cls_saved_model # TensorFlow SavedModel
+ yolov5s-cls.pb # TensorFlow GraphDef
+ yolov5s-cls.tflite # TensorFlow Lite
+ yolov5s-cls_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s-cls_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import os
+import sys
+from pathlib import Path
+
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.dataloaders import create_classification_dataloader
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, Profile, check_img_size, check_requirements, colorstr,
+ increment_path, print_args)
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+@smart_inference_mode()
+def run(
+ data=ROOT / '../datasets/mnist', # dataset dir
+ weights=ROOT / 'yolov5s-cls.pt', # model.pt path(s)
+ batch_size=128, # batch size
+ imgsz=224, # inference size (pixels)
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ verbose=False, # verbose output
+ project=ROOT / 'runs/val-cls', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=False, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ criterion=None,
+ pbar=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ save_dir.mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Dataloader
+ data = Path(data)
+ test_dir = data / 'test' if (data / 'test').exists() else data / 'val' # data/test or data/val
+ dataloader = create_classification_dataloader(path=test_dir,
+ imgsz=imgsz,
+ batch_size=batch_size,
+ augment=False,
+ rank=-1,
+ workers=workers)
+
+ model.eval()
+ pred, targets, loss, dt = [], [], 0, (Profile(), Profile(), Profile())
+ n = len(dataloader) # number of batches
+ action = 'validating' if dataloader.dataset.root.stem == 'val' else 'testing'
+ desc = f'{pbar.desc[:-36]}{action:>36}' if pbar else f'{action}'
+ bar = tqdm(dataloader, desc, n, not training, bar_format=TQDM_BAR_FORMAT, position=0)
+ with torch.cuda.amp.autocast(enabled=device.type != 'cpu'):
+ for images, labels in bar:
+ with dt[0]:
+ images, labels = images.to(device, non_blocking=True), labels.to(device)
+
+ with dt[1]:
+ y = model(images)
+
+ with dt[2]:
+ pred.append(y.argsort(1, descending=True)[:, :5])
+ targets.append(labels)
+ if criterion:
+ loss += criterion(y, labels)
+
+ loss /= n
+ pred, targets = torch.cat(pred), torch.cat(targets)
+ correct = (targets[:, None] == pred).float()
+ acc = torch.stack((correct[:, 0], correct.max(1).values), dim=1) # (top1, top5) accuracy
+ top1, top5 = acc.mean(0).tolist()
+
+ if pbar:
+ pbar.desc = f'{pbar.desc[:-36]}{loss:>12.3g}{top1:>12.3g}{top5:>12.3g}'
+ if verbose: # all classes
+ LOGGER.info(f"{'Class':>24}{'Images':>12}{'top1_acc':>12}{'top5_acc':>12}")
+ LOGGER.info(f"{'all':>24}{targets.shape[0]:>12}{top1:>12.3g}{top5:>12.3g}")
+ for i, c in model.names.items():
+ acc_i = acc[targets == i]
+ top1i, top5i = acc_i.mean(0).tolist()
+ LOGGER.info(f'{c:>24}{acc_i.shape[0]:>12}{top1i:>12.3g}{top5i:>12.3g}')
+
+ # Print results
+ t = tuple(x.t / len(dataloader.dataset.samples) * 1E3 for x in dt) # speeds per image
+ shape = (1, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms post-process per image at shape {shape}' % t)
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
+
+ return top1, top5, loss
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / '../datasets/mnist', help='dataset path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s-cls.pt', help='model.pt path(s)')
+ parser.add_argument('--batch-size', type=int, default=128, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=224, help='inference size (pixels)')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--verbose', nargs='?', const=True, default=True, help='verbose output')
+ parser.add_argument('--project', default=ROOT / 'runs/val-cls', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/data/Argoverse.yaml b/yolov5/data/Argoverse.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..8a65407a633371210feed2779f1476186b9185bc
--- /dev/null
+++ b/yolov5/data/Argoverse.yaml
@@ -0,0 +1,74 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Argoverse-HD dataset (ring-front-center camera) http://www.cs.cmu.edu/~mengtial/proj/streaming/ by Argo AI
+# Example usage: python train.py --data Argoverse.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── Argoverse ← downloads here (31.3 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Argoverse # dataset root dir
+train: Argoverse-1.1/images/train/ # train images (relative to 'path') 39384 images
+val: Argoverse-1.1/images/val/ # val images (relative to 'path') 15062 images
+test: Argoverse-1.1/images/test/ # test images (optional) https://eval.ai/web/challenges/challenge-page/800/overview
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: bus
+ 5: truck
+ 6: traffic_light
+ 7: stop_sign
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import json
+
+ from tqdm import tqdm
+ from utils.general import download, Path
+
+
+ def argoverse2yolo(set):
+ labels = {}
+ a = json.load(open(set, "rb"))
+ for annot in tqdm(a['annotations'], desc=f"Converting {set} to YOLOv5 format..."):
+ img_id = annot['image_id']
+ img_name = a['images'][img_id]['name']
+ img_label_name = f'{img_name[:-3]}txt'
+
+ cls = annot['category_id'] # instance class id
+ x_center, y_center, width, height = annot['bbox']
+ x_center = (x_center + width / 2) / 1920.0 # offset and scale
+ y_center = (y_center + height / 2) / 1200.0 # offset and scale
+ width /= 1920.0 # scale
+ height /= 1200.0 # scale
+
+ img_dir = set.parents[2] / 'Argoverse-1.1' / 'labels' / a['seq_dirs'][a['images'][annot['image_id']]['sid']]
+ if not img_dir.exists():
+ img_dir.mkdir(parents=True, exist_ok=True)
+
+ k = str(img_dir / img_label_name)
+ if k not in labels:
+ labels[k] = []
+ labels[k].append(f"{cls} {x_center} {y_center} {width} {height}\n")
+
+ for k in labels:
+ with open(k, "w") as f:
+ f.writelines(labels[k])
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://argoverse-hd.s3.us-east-2.amazonaws.com/Argoverse-HD-Full.zip']
+ download(urls, dir=dir, delete=False)
+
+ # Convert
+ annotations_dir = 'Argoverse-HD/annotations/'
+ (dir / 'Argoverse-1.1' / 'tracking').rename(dir / 'Argoverse-1.1' / 'images') # rename 'tracking' to 'images'
+ for d in "train.json", "val.json":
+ argoverse2yolo(dir / annotations_dir / d) # convert VisDrone annotations to YOLO labels
diff --git a/yolov5/data/FLIR.yaml b/yolov5/data/FLIR.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..89da77a742da141897bc21b26d31e2a368912de4
--- /dev/null
+++ b/yolov5/data/FLIR.yaml
@@ -0,0 +1,28 @@
+train: ../VOCdevkit/images/train/ # 8493 images 训练集
+val: ../VOCdevkit/images/val/ # 2249 images 验证集
+
+
+# number of classes 类别数
+nc: 15
+
+
+# Classes
+names:
+ 0: person
+ 1: bike
+ 2: car
+ 3: motor
+ 4: bus
+ 5: train
+ 6: truck
+ 7: light
+ 8: hydrant
+ 9: sign
+ 10: dog
+ 11: skateboard
+ 12: stroller
+ 13: scooter
+ 14: other vehicle
+
+
+
diff --git a/yolov5/data/GlobalWheat2020.yaml b/yolov5/data/GlobalWheat2020.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..7b02ac95dd95d1b8fc466b268775f33b5f60ce88
--- /dev/null
+++ b/yolov5/data/GlobalWheat2020.yaml
@@ -0,0 +1,54 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Global Wheat 2020 dataset http://www.global-wheat.com/ by University of Saskatchewan
+# Example usage: python train.py --data GlobalWheat2020.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── GlobalWheat2020 ← downloads here (7.0 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/GlobalWheat2020 # dataset root dir
+train: # train images (relative to 'path') 3422 images
+ - images/arvalis_1
+ - images/arvalis_2
+ - images/arvalis_3
+ - images/ethz_1
+ - images/rres_1
+ - images/inrae_1
+ - images/usask_1
+val: # val images (relative to 'path') 748 images (WARNING: train set contains ethz_1)
+ - images/ethz_1
+test: # test images (optional) 1276 images
+ - images/utokyo_1
+ - images/utokyo_2
+ - images/nau_1
+ - images/uq_1
+
+# Classes
+names:
+ 0: wheat_head
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from utils.general import download, Path
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://zenodo.org/record/4298502/files/global-wheat-codalab-official.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/GlobalWheat2020_labels.zip']
+ download(urls, dir=dir)
+
+ # Make Directories
+ for p in 'annotations', 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+
+ # Move
+ for p in 'arvalis_1', 'arvalis_2', 'arvalis_3', 'ethz_1', 'rres_1', 'inrae_1', 'usask_1', \
+ 'utokyo_1', 'utokyo_2', 'nau_1', 'uq_1':
+ (dir / p).rename(dir / 'images' / p) # move to /images
+ f = (dir / p).with_suffix('.json') # json file
+ if f.exists():
+ f.rename((dir / 'annotations' / p).with_suffix('.json')) # move to /annotations
diff --git a/yolov5/data/ImageNet.yaml b/yolov5/data/ImageNet.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5fdcb63f89a5c4a0e4a579fc0b3bf995e8777e87
--- /dev/null
+++ b/yolov5/data/ImageNet.yaml
@@ -0,0 +1,1022 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# ImageNet-1k dataset https://www.image-net.org/index.php by Stanford University
+# Simplified class names from https://github.com/anishathalye/imagenet-simple-labels
+# Example usage: python classify/train.py --data imagenet
+# parent
+# ├── yolov5
+# └── datasets
+# └── imagenet ← downloads here (144 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/imagenet # dataset root dir
+train: train # train images (relative to 'path') 1281167 images
+val: val # val images (relative to 'path') 50000 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: tench
+ 1: goldfish
+ 2: great white shark
+ 3: tiger shark
+ 4: hammerhead shark
+ 5: electric ray
+ 6: stingray
+ 7: cock
+ 8: hen
+ 9: ostrich
+ 10: brambling
+ 11: goldfinch
+ 12: house finch
+ 13: junco
+ 14: indigo bunting
+ 15: American robin
+ 16: bulbul
+ 17: jay
+ 18: magpie
+ 19: chickadee
+ 20: American dipper
+ 21: kite
+ 22: bald eagle
+ 23: vulture
+ 24: great grey owl
+ 25: fire salamander
+ 26: smooth newt
+ 27: newt
+ 28: spotted salamander
+ 29: axolotl
+ 30: American bullfrog
+ 31: tree frog
+ 32: tailed frog
+ 33: loggerhead sea turtle
+ 34: leatherback sea turtle
+ 35: mud turtle
+ 36: terrapin
+ 37: box turtle
+ 38: banded gecko
+ 39: green iguana
+ 40: Carolina anole
+ 41: desert grassland whiptail lizard
+ 42: agama
+ 43: frilled-necked lizard
+ 44: alligator lizard
+ 45: Gila monster
+ 46: European green lizard
+ 47: chameleon
+ 48: Komodo dragon
+ 49: Nile crocodile
+ 50: American alligator
+ 51: triceratops
+ 52: worm snake
+ 53: ring-necked snake
+ 54: eastern hog-nosed snake
+ 55: smooth green snake
+ 56: kingsnake
+ 57: garter snake
+ 58: water snake
+ 59: vine snake
+ 60: night snake
+ 61: boa constrictor
+ 62: African rock python
+ 63: Indian cobra
+ 64: green mamba
+ 65: sea snake
+ 66: Saharan horned viper
+ 67: eastern diamondback rattlesnake
+ 68: sidewinder
+ 69: trilobite
+ 70: harvestman
+ 71: scorpion
+ 72: yellow garden spider
+ 73: barn spider
+ 74: European garden spider
+ 75: southern black widow
+ 76: tarantula
+ 77: wolf spider
+ 78: tick
+ 79: centipede
+ 80: black grouse
+ 81: ptarmigan
+ 82: ruffed grouse
+ 83: prairie grouse
+ 84: peacock
+ 85: quail
+ 86: partridge
+ 87: grey parrot
+ 88: macaw
+ 89: sulphur-crested cockatoo
+ 90: lorikeet
+ 91: coucal
+ 92: bee eater
+ 93: hornbill
+ 94: hummingbird
+ 95: jacamar
+ 96: toucan
+ 97: duck
+ 98: red-breasted merganser
+ 99: goose
+ 100: black swan
+ 101: tusker
+ 102: echidna
+ 103: platypus
+ 104: wallaby
+ 105: koala
+ 106: wombat
+ 107: jellyfish
+ 108: sea anemone
+ 109: brain coral
+ 110: flatworm
+ 111: nematode
+ 112: conch
+ 113: snail
+ 114: slug
+ 115: sea slug
+ 116: chiton
+ 117: chambered nautilus
+ 118: Dungeness crab
+ 119: rock crab
+ 120: fiddler crab
+ 121: red king crab
+ 122: American lobster
+ 123: spiny lobster
+ 124: crayfish
+ 125: hermit crab
+ 126: isopod
+ 127: white stork
+ 128: black stork
+ 129: spoonbill
+ 130: flamingo
+ 131: little blue heron
+ 132: great egret
+ 133: bittern
+ 134: crane (bird)
+ 135: limpkin
+ 136: common gallinule
+ 137: American coot
+ 138: bustard
+ 139: ruddy turnstone
+ 140: dunlin
+ 141: common redshank
+ 142: dowitcher
+ 143: oystercatcher
+ 144: pelican
+ 145: king penguin
+ 146: albatross
+ 147: grey whale
+ 148: killer whale
+ 149: dugong
+ 150: sea lion
+ 151: Chihuahua
+ 152: Japanese Chin
+ 153: Maltese
+ 154: Pekingese
+ 155: Shih Tzu
+ 156: King Charles Spaniel
+ 157: Papillon
+ 158: toy terrier
+ 159: Rhodesian Ridgeback
+ 160: Afghan Hound
+ 161: Basset Hound
+ 162: Beagle
+ 163: Bloodhound
+ 164: Bluetick Coonhound
+ 165: Black and Tan Coonhound
+ 166: Treeing Walker Coonhound
+ 167: English foxhound
+ 168: Redbone Coonhound
+ 169: borzoi
+ 170: Irish Wolfhound
+ 171: Italian Greyhound
+ 172: Whippet
+ 173: Ibizan Hound
+ 174: Norwegian Elkhound
+ 175: Otterhound
+ 176: Saluki
+ 177: Scottish Deerhound
+ 178: Weimaraner
+ 179: Staffordshire Bull Terrier
+ 180: American Staffordshire Terrier
+ 181: Bedlington Terrier
+ 182: Border Terrier
+ 183: Kerry Blue Terrier
+ 184: Irish Terrier
+ 185: Norfolk Terrier
+ 186: Norwich Terrier
+ 187: Yorkshire Terrier
+ 188: Wire Fox Terrier
+ 189: Lakeland Terrier
+ 190: Sealyham Terrier
+ 191: Airedale Terrier
+ 192: Cairn Terrier
+ 193: Australian Terrier
+ 194: Dandie Dinmont Terrier
+ 195: Boston Terrier
+ 196: Miniature Schnauzer
+ 197: Giant Schnauzer
+ 198: Standard Schnauzer
+ 199: Scottish Terrier
+ 200: Tibetan Terrier
+ 201: Australian Silky Terrier
+ 202: Soft-coated Wheaten Terrier
+ 203: West Highland White Terrier
+ 204: Lhasa Apso
+ 205: Flat-Coated Retriever
+ 206: Curly-coated Retriever
+ 207: Golden Retriever
+ 208: Labrador Retriever
+ 209: Chesapeake Bay Retriever
+ 210: German Shorthaired Pointer
+ 211: Vizsla
+ 212: English Setter
+ 213: Irish Setter
+ 214: Gordon Setter
+ 215: Brittany
+ 216: Clumber Spaniel
+ 217: English Springer Spaniel
+ 218: Welsh Springer Spaniel
+ 219: Cocker Spaniels
+ 220: Sussex Spaniel
+ 221: Irish Water Spaniel
+ 222: Kuvasz
+ 223: Schipperke
+ 224: Groenendael
+ 225: Malinois
+ 226: Briard
+ 227: Australian Kelpie
+ 228: Komondor
+ 229: Old English Sheepdog
+ 230: Shetland Sheepdog
+ 231: collie
+ 232: Border Collie
+ 233: Bouvier des Flandres
+ 234: Rottweiler
+ 235: German Shepherd Dog
+ 236: Dobermann
+ 237: Miniature Pinscher
+ 238: Greater Swiss Mountain Dog
+ 239: Bernese Mountain Dog
+ 240: Appenzeller Sennenhund
+ 241: Entlebucher Sennenhund
+ 242: Boxer
+ 243: Bullmastiff
+ 244: Tibetan Mastiff
+ 245: French Bulldog
+ 246: Great Dane
+ 247: St. Bernard
+ 248: husky
+ 249: Alaskan Malamute
+ 250: Siberian Husky
+ 251: Dalmatian
+ 252: Affenpinscher
+ 253: Basenji
+ 254: pug
+ 255: Leonberger
+ 256: Newfoundland
+ 257: Pyrenean Mountain Dog
+ 258: Samoyed
+ 259: Pomeranian
+ 260: Chow Chow
+ 261: Keeshond
+ 262: Griffon Bruxellois
+ 263: Pembroke Welsh Corgi
+ 264: Cardigan Welsh Corgi
+ 265: Toy Poodle
+ 266: Miniature Poodle
+ 267: Standard Poodle
+ 268: Mexican hairless dog
+ 269: grey wolf
+ 270: Alaskan tundra wolf
+ 271: red wolf
+ 272: coyote
+ 273: dingo
+ 274: dhole
+ 275: African wild dog
+ 276: hyena
+ 277: red fox
+ 278: kit fox
+ 279: Arctic fox
+ 280: grey fox
+ 281: tabby cat
+ 282: tiger cat
+ 283: Persian cat
+ 284: Siamese cat
+ 285: Egyptian Mau
+ 286: cougar
+ 287: lynx
+ 288: leopard
+ 289: snow leopard
+ 290: jaguar
+ 291: lion
+ 292: tiger
+ 293: cheetah
+ 294: brown bear
+ 295: American black bear
+ 296: polar bear
+ 297: sloth bear
+ 298: mongoose
+ 299: meerkat
+ 300: tiger beetle
+ 301: ladybug
+ 302: ground beetle
+ 303: longhorn beetle
+ 304: leaf beetle
+ 305: dung beetle
+ 306: rhinoceros beetle
+ 307: weevil
+ 308: fly
+ 309: bee
+ 310: ant
+ 311: grasshopper
+ 312: cricket
+ 313: stick insect
+ 314: cockroach
+ 315: mantis
+ 316: cicada
+ 317: leafhopper
+ 318: lacewing
+ 319: dragonfly
+ 320: damselfly
+ 321: red admiral
+ 322: ringlet
+ 323: monarch butterfly
+ 324: small white
+ 325: sulphur butterfly
+ 326: gossamer-winged butterfly
+ 327: starfish
+ 328: sea urchin
+ 329: sea cucumber
+ 330: cottontail rabbit
+ 331: hare
+ 332: Angora rabbit
+ 333: hamster
+ 334: porcupine
+ 335: fox squirrel
+ 336: marmot
+ 337: beaver
+ 338: guinea pig
+ 339: common sorrel
+ 340: zebra
+ 341: pig
+ 342: wild boar
+ 343: warthog
+ 344: hippopotamus
+ 345: ox
+ 346: water buffalo
+ 347: bison
+ 348: ram
+ 349: bighorn sheep
+ 350: Alpine ibex
+ 351: hartebeest
+ 352: impala
+ 353: gazelle
+ 354: dromedary
+ 355: llama
+ 356: weasel
+ 357: mink
+ 358: European polecat
+ 359: black-footed ferret
+ 360: otter
+ 361: skunk
+ 362: badger
+ 363: armadillo
+ 364: three-toed sloth
+ 365: orangutan
+ 366: gorilla
+ 367: chimpanzee
+ 368: gibbon
+ 369: siamang
+ 370: guenon
+ 371: patas monkey
+ 372: baboon
+ 373: macaque
+ 374: langur
+ 375: black-and-white colobus
+ 376: proboscis monkey
+ 377: marmoset
+ 378: white-headed capuchin
+ 379: howler monkey
+ 380: titi
+ 381: Geoffroy's spider monkey
+ 382: common squirrel monkey
+ 383: ring-tailed lemur
+ 384: indri
+ 385: Asian elephant
+ 386: African bush elephant
+ 387: red panda
+ 388: giant panda
+ 389: snoek
+ 390: eel
+ 391: coho salmon
+ 392: rock beauty
+ 393: clownfish
+ 394: sturgeon
+ 395: garfish
+ 396: lionfish
+ 397: pufferfish
+ 398: abacus
+ 399: abaya
+ 400: academic gown
+ 401: accordion
+ 402: acoustic guitar
+ 403: aircraft carrier
+ 404: airliner
+ 405: airship
+ 406: altar
+ 407: ambulance
+ 408: amphibious vehicle
+ 409: analog clock
+ 410: apiary
+ 411: apron
+ 412: waste container
+ 413: assault rifle
+ 414: backpack
+ 415: bakery
+ 416: balance beam
+ 417: balloon
+ 418: ballpoint pen
+ 419: Band-Aid
+ 420: banjo
+ 421: baluster
+ 422: barbell
+ 423: barber chair
+ 424: barbershop
+ 425: barn
+ 426: barometer
+ 427: barrel
+ 428: wheelbarrow
+ 429: baseball
+ 430: basketball
+ 431: bassinet
+ 432: bassoon
+ 433: swimming cap
+ 434: bath towel
+ 435: bathtub
+ 436: station wagon
+ 437: lighthouse
+ 438: beaker
+ 439: military cap
+ 440: beer bottle
+ 441: beer glass
+ 442: bell-cot
+ 443: bib
+ 444: tandem bicycle
+ 445: bikini
+ 446: ring binder
+ 447: binoculars
+ 448: birdhouse
+ 449: boathouse
+ 450: bobsleigh
+ 451: bolo tie
+ 452: poke bonnet
+ 453: bookcase
+ 454: bookstore
+ 455: bottle cap
+ 456: bow
+ 457: bow tie
+ 458: brass
+ 459: bra
+ 460: breakwater
+ 461: breastplate
+ 462: broom
+ 463: bucket
+ 464: buckle
+ 465: bulletproof vest
+ 466: high-speed train
+ 467: butcher shop
+ 468: taxicab
+ 469: cauldron
+ 470: candle
+ 471: cannon
+ 472: canoe
+ 473: can opener
+ 474: cardigan
+ 475: car mirror
+ 476: carousel
+ 477: tool kit
+ 478: carton
+ 479: car wheel
+ 480: automated teller machine
+ 481: cassette
+ 482: cassette player
+ 483: castle
+ 484: catamaran
+ 485: CD player
+ 486: cello
+ 487: mobile phone
+ 488: chain
+ 489: chain-link fence
+ 490: chain mail
+ 491: chainsaw
+ 492: chest
+ 493: chiffonier
+ 494: chime
+ 495: china cabinet
+ 496: Christmas stocking
+ 497: church
+ 498: movie theater
+ 499: cleaver
+ 500: cliff dwelling
+ 501: cloak
+ 502: clogs
+ 503: cocktail shaker
+ 504: coffee mug
+ 505: coffeemaker
+ 506: coil
+ 507: combination lock
+ 508: computer keyboard
+ 509: confectionery store
+ 510: container ship
+ 511: convertible
+ 512: corkscrew
+ 513: cornet
+ 514: cowboy boot
+ 515: cowboy hat
+ 516: cradle
+ 517: crane (machine)
+ 518: crash helmet
+ 519: crate
+ 520: infant bed
+ 521: Crock Pot
+ 522: croquet ball
+ 523: crutch
+ 524: cuirass
+ 525: dam
+ 526: desk
+ 527: desktop computer
+ 528: rotary dial telephone
+ 529: diaper
+ 530: digital clock
+ 531: digital watch
+ 532: dining table
+ 533: dishcloth
+ 534: dishwasher
+ 535: disc brake
+ 536: dock
+ 537: dog sled
+ 538: dome
+ 539: doormat
+ 540: drilling rig
+ 541: drum
+ 542: drumstick
+ 543: dumbbell
+ 544: Dutch oven
+ 545: electric fan
+ 546: electric guitar
+ 547: electric locomotive
+ 548: entertainment center
+ 549: envelope
+ 550: espresso machine
+ 551: face powder
+ 552: feather boa
+ 553: filing cabinet
+ 554: fireboat
+ 555: fire engine
+ 556: fire screen sheet
+ 557: flagpole
+ 558: flute
+ 559: folding chair
+ 560: football helmet
+ 561: forklift
+ 562: fountain
+ 563: fountain pen
+ 564: four-poster bed
+ 565: freight car
+ 566: French horn
+ 567: frying pan
+ 568: fur coat
+ 569: garbage truck
+ 570: gas mask
+ 571: gas pump
+ 572: goblet
+ 573: go-kart
+ 574: golf ball
+ 575: golf cart
+ 576: gondola
+ 577: gong
+ 578: gown
+ 579: grand piano
+ 580: greenhouse
+ 581: grille
+ 582: grocery store
+ 583: guillotine
+ 584: barrette
+ 585: hair spray
+ 586: half-track
+ 587: hammer
+ 588: hamper
+ 589: hair dryer
+ 590: hand-held computer
+ 591: handkerchief
+ 592: hard disk drive
+ 593: harmonica
+ 594: harp
+ 595: harvester
+ 596: hatchet
+ 597: holster
+ 598: home theater
+ 599: honeycomb
+ 600: hook
+ 601: hoop skirt
+ 602: horizontal bar
+ 603: horse-drawn vehicle
+ 604: hourglass
+ 605: iPod
+ 606: clothes iron
+ 607: jack-o'-lantern
+ 608: jeans
+ 609: jeep
+ 610: T-shirt
+ 611: jigsaw puzzle
+ 612: pulled rickshaw
+ 613: joystick
+ 614: kimono
+ 615: knee pad
+ 616: knot
+ 617: lab coat
+ 618: ladle
+ 619: lampshade
+ 620: laptop computer
+ 621: lawn mower
+ 622: lens cap
+ 623: paper knife
+ 624: library
+ 625: lifeboat
+ 626: lighter
+ 627: limousine
+ 628: ocean liner
+ 629: lipstick
+ 630: slip-on shoe
+ 631: lotion
+ 632: speaker
+ 633: loupe
+ 634: sawmill
+ 635: magnetic compass
+ 636: mail bag
+ 637: mailbox
+ 638: tights
+ 639: tank suit
+ 640: manhole cover
+ 641: maraca
+ 642: marimba
+ 643: mask
+ 644: match
+ 645: maypole
+ 646: maze
+ 647: measuring cup
+ 648: medicine chest
+ 649: megalith
+ 650: microphone
+ 651: microwave oven
+ 652: military uniform
+ 653: milk can
+ 654: minibus
+ 655: miniskirt
+ 656: minivan
+ 657: missile
+ 658: mitten
+ 659: mixing bowl
+ 660: mobile home
+ 661: Model T
+ 662: modem
+ 663: monastery
+ 664: monitor
+ 665: moped
+ 666: mortar
+ 667: square academic cap
+ 668: mosque
+ 669: mosquito net
+ 670: scooter
+ 671: mountain bike
+ 672: tent
+ 673: computer mouse
+ 674: mousetrap
+ 675: moving van
+ 676: muzzle
+ 677: nail
+ 678: neck brace
+ 679: necklace
+ 680: nipple
+ 681: notebook computer
+ 682: obelisk
+ 683: oboe
+ 684: ocarina
+ 685: odometer
+ 686: oil filter
+ 687: organ
+ 688: oscilloscope
+ 689: overskirt
+ 690: bullock cart
+ 691: oxygen mask
+ 692: packet
+ 693: paddle
+ 694: paddle wheel
+ 695: padlock
+ 696: paintbrush
+ 697: pajamas
+ 698: palace
+ 699: pan flute
+ 700: paper towel
+ 701: parachute
+ 702: parallel bars
+ 703: park bench
+ 704: parking meter
+ 705: passenger car
+ 706: patio
+ 707: payphone
+ 708: pedestal
+ 709: pencil case
+ 710: pencil sharpener
+ 711: perfume
+ 712: Petri dish
+ 713: photocopier
+ 714: plectrum
+ 715: Pickelhaube
+ 716: picket fence
+ 717: pickup truck
+ 718: pier
+ 719: piggy bank
+ 720: pill bottle
+ 721: pillow
+ 722: ping-pong ball
+ 723: pinwheel
+ 724: pirate ship
+ 725: pitcher
+ 726: hand plane
+ 727: planetarium
+ 728: plastic bag
+ 729: plate rack
+ 730: plow
+ 731: plunger
+ 732: Polaroid camera
+ 733: pole
+ 734: police van
+ 735: poncho
+ 736: billiard table
+ 737: soda bottle
+ 738: pot
+ 739: potter's wheel
+ 740: power drill
+ 741: prayer rug
+ 742: printer
+ 743: prison
+ 744: projectile
+ 745: projector
+ 746: hockey puck
+ 747: punching bag
+ 748: purse
+ 749: quill
+ 750: quilt
+ 751: race car
+ 752: racket
+ 753: radiator
+ 754: radio
+ 755: radio telescope
+ 756: rain barrel
+ 757: recreational vehicle
+ 758: reel
+ 759: reflex camera
+ 760: refrigerator
+ 761: remote control
+ 762: restaurant
+ 763: revolver
+ 764: rifle
+ 765: rocking chair
+ 766: rotisserie
+ 767: eraser
+ 768: rugby ball
+ 769: ruler
+ 770: running shoe
+ 771: safe
+ 772: safety pin
+ 773: salt shaker
+ 774: sandal
+ 775: sarong
+ 776: saxophone
+ 777: scabbard
+ 778: weighing scale
+ 779: school bus
+ 780: schooner
+ 781: scoreboard
+ 782: CRT screen
+ 783: screw
+ 784: screwdriver
+ 785: seat belt
+ 786: sewing machine
+ 787: shield
+ 788: shoe store
+ 789: shoji
+ 790: shopping basket
+ 791: shopping cart
+ 792: shovel
+ 793: shower cap
+ 794: shower curtain
+ 795: ski
+ 796: ski mask
+ 797: sleeping bag
+ 798: slide rule
+ 799: sliding door
+ 800: slot machine
+ 801: snorkel
+ 802: snowmobile
+ 803: snowplow
+ 804: soap dispenser
+ 805: soccer ball
+ 806: sock
+ 807: solar thermal collector
+ 808: sombrero
+ 809: soup bowl
+ 810: space bar
+ 811: space heater
+ 812: space shuttle
+ 813: spatula
+ 814: motorboat
+ 815: spider web
+ 816: spindle
+ 817: sports car
+ 818: spotlight
+ 819: stage
+ 820: steam locomotive
+ 821: through arch bridge
+ 822: steel drum
+ 823: stethoscope
+ 824: scarf
+ 825: stone wall
+ 826: stopwatch
+ 827: stove
+ 828: strainer
+ 829: tram
+ 830: stretcher
+ 831: couch
+ 832: stupa
+ 833: submarine
+ 834: suit
+ 835: sundial
+ 836: sunglass
+ 837: sunglasses
+ 838: sunscreen
+ 839: suspension bridge
+ 840: mop
+ 841: sweatshirt
+ 842: swimsuit
+ 843: swing
+ 844: switch
+ 845: syringe
+ 846: table lamp
+ 847: tank
+ 848: tape player
+ 849: teapot
+ 850: teddy bear
+ 851: television
+ 852: tennis ball
+ 853: thatched roof
+ 854: front curtain
+ 855: thimble
+ 856: threshing machine
+ 857: throne
+ 858: tile roof
+ 859: toaster
+ 860: tobacco shop
+ 861: toilet seat
+ 862: torch
+ 863: totem pole
+ 864: tow truck
+ 865: toy store
+ 866: tractor
+ 867: semi-trailer truck
+ 868: tray
+ 869: trench coat
+ 870: tricycle
+ 871: trimaran
+ 872: tripod
+ 873: triumphal arch
+ 874: trolleybus
+ 875: trombone
+ 876: tub
+ 877: turnstile
+ 878: typewriter keyboard
+ 879: umbrella
+ 880: unicycle
+ 881: upright piano
+ 882: vacuum cleaner
+ 883: vase
+ 884: vault
+ 885: velvet
+ 886: vending machine
+ 887: vestment
+ 888: viaduct
+ 889: violin
+ 890: volleyball
+ 891: waffle iron
+ 892: wall clock
+ 893: wallet
+ 894: wardrobe
+ 895: military aircraft
+ 896: sink
+ 897: washing machine
+ 898: water bottle
+ 899: water jug
+ 900: water tower
+ 901: whiskey jug
+ 902: whistle
+ 903: wig
+ 904: window screen
+ 905: window shade
+ 906: Windsor tie
+ 907: wine bottle
+ 908: wing
+ 909: wok
+ 910: wooden spoon
+ 911: wool
+ 912: split-rail fence
+ 913: shipwreck
+ 914: yawl
+ 915: yurt
+ 916: website
+ 917: comic book
+ 918: crossword
+ 919: traffic sign
+ 920: traffic light
+ 921: dust jacket
+ 922: menu
+ 923: plate
+ 924: guacamole
+ 925: consomme
+ 926: hot pot
+ 927: trifle
+ 928: ice cream
+ 929: ice pop
+ 930: baguette
+ 931: bagel
+ 932: pretzel
+ 933: cheeseburger
+ 934: hot dog
+ 935: mashed potato
+ 936: cabbage
+ 937: broccoli
+ 938: cauliflower
+ 939: zucchini
+ 940: spaghetti squash
+ 941: acorn squash
+ 942: butternut squash
+ 943: cucumber
+ 944: artichoke
+ 945: bell pepper
+ 946: cardoon
+ 947: mushroom
+ 948: Granny Smith
+ 949: strawberry
+ 950: orange
+ 951: lemon
+ 952: fig
+ 953: pineapple
+ 954: banana
+ 955: jackfruit
+ 956: custard apple
+ 957: pomegranate
+ 958: hay
+ 959: carbonara
+ 960: chocolate syrup
+ 961: dough
+ 962: meatloaf
+ 963: pizza
+ 964: pot pie
+ 965: burrito
+ 966: red wine
+ 967: espresso
+ 968: cup
+ 969: eggnog
+ 970: alp
+ 971: bubble
+ 972: cliff
+ 973: coral reef
+ 974: geyser
+ 975: lakeshore
+ 976: promontory
+ 977: shoal
+ 978: seashore
+ 979: valley
+ 980: volcano
+ 981: baseball player
+ 982: bridegroom
+ 983: scuba diver
+ 984: rapeseed
+ 985: daisy
+ 986: yellow lady's slipper
+ 987: corn
+ 988: acorn
+ 989: rose hip
+ 990: horse chestnut seed
+ 991: coral fungus
+ 992: agaric
+ 993: gyromitra
+ 994: stinkhorn mushroom
+ 995: earth star
+ 996: hen-of-the-woods
+ 997: bolete
+ 998: ear
+ 999: toilet paper
+
+
+# Download script/URL (optional)
+download: data/scripts/get_imagenet.sh
diff --git a/yolov5/data/Objects365.yaml b/yolov5/data/Objects365.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..bb2aa34cd4a4f85870747039485695893b3e4c2b
--- /dev/null
+++ b/yolov5/data/Objects365.yaml
@@ -0,0 +1,438 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Objects365 dataset https://www.objects365.org/ by Megvii
+# Example usage: python train.py --data Objects365.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── Objects365 ← downloads here (712 GB = 367G data + 345G zips)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Objects365 # dataset root dir
+train: images/train # train images (relative to 'path') 1742289 images
+val: images/val # val images (relative to 'path') 80000 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: Person
+ 1: Sneakers
+ 2: Chair
+ 3: Other Shoes
+ 4: Hat
+ 5: Car
+ 6: Lamp
+ 7: Glasses
+ 8: Bottle
+ 9: Desk
+ 10: Cup
+ 11: Street Lights
+ 12: Cabinet/shelf
+ 13: Handbag/Satchel
+ 14: Bracelet
+ 15: Plate
+ 16: Picture/Frame
+ 17: Helmet
+ 18: Book
+ 19: Gloves
+ 20: Storage box
+ 21: Boat
+ 22: Leather Shoes
+ 23: Flower
+ 24: Bench
+ 25: Potted Plant
+ 26: Bowl/Basin
+ 27: Flag
+ 28: Pillow
+ 29: Boots
+ 30: Vase
+ 31: Microphone
+ 32: Necklace
+ 33: Ring
+ 34: SUV
+ 35: Wine Glass
+ 36: Belt
+ 37: Monitor/TV
+ 38: Backpack
+ 39: Umbrella
+ 40: Traffic Light
+ 41: Speaker
+ 42: Watch
+ 43: Tie
+ 44: Trash bin Can
+ 45: Slippers
+ 46: Bicycle
+ 47: Stool
+ 48: Barrel/bucket
+ 49: Van
+ 50: Couch
+ 51: Sandals
+ 52: Basket
+ 53: Drum
+ 54: Pen/Pencil
+ 55: Bus
+ 56: Wild Bird
+ 57: High Heels
+ 58: Motorcycle
+ 59: Guitar
+ 60: Carpet
+ 61: Cell Phone
+ 62: Bread
+ 63: Camera
+ 64: Canned
+ 65: Truck
+ 66: Traffic cone
+ 67: Cymbal
+ 68: Lifesaver
+ 69: Towel
+ 70: Stuffed Toy
+ 71: Candle
+ 72: Sailboat
+ 73: Laptop
+ 74: Awning
+ 75: Bed
+ 76: Faucet
+ 77: Tent
+ 78: Horse
+ 79: Mirror
+ 80: Power outlet
+ 81: Sink
+ 82: Apple
+ 83: Air Conditioner
+ 84: Knife
+ 85: Hockey Stick
+ 86: Paddle
+ 87: Pickup Truck
+ 88: Fork
+ 89: Traffic Sign
+ 90: Balloon
+ 91: Tripod
+ 92: Dog
+ 93: Spoon
+ 94: Clock
+ 95: Pot
+ 96: Cow
+ 97: Cake
+ 98: Dinning Table
+ 99: Sheep
+ 100: Hanger
+ 101: Blackboard/Whiteboard
+ 102: Napkin
+ 103: Other Fish
+ 104: Orange/Tangerine
+ 105: Toiletry
+ 106: Keyboard
+ 107: Tomato
+ 108: Lantern
+ 109: Machinery Vehicle
+ 110: Fan
+ 111: Green Vegetables
+ 112: Banana
+ 113: Baseball Glove
+ 114: Airplane
+ 115: Mouse
+ 116: Train
+ 117: Pumpkin
+ 118: Soccer
+ 119: Skiboard
+ 120: Luggage
+ 121: Nightstand
+ 122: Tea pot
+ 123: Telephone
+ 124: Trolley
+ 125: Head Phone
+ 126: Sports Car
+ 127: Stop Sign
+ 128: Dessert
+ 129: Scooter
+ 130: Stroller
+ 131: Crane
+ 132: Remote
+ 133: Refrigerator
+ 134: Oven
+ 135: Lemon
+ 136: Duck
+ 137: Baseball Bat
+ 138: Surveillance Camera
+ 139: Cat
+ 140: Jug
+ 141: Broccoli
+ 142: Piano
+ 143: Pizza
+ 144: Elephant
+ 145: Skateboard
+ 146: Surfboard
+ 147: Gun
+ 148: Skating and Skiing shoes
+ 149: Gas stove
+ 150: Donut
+ 151: Bow Tie
+ 152: Carrot
+ 153: Toilet
+ 154: Kite
+ 155: Strawberry
+ 156: Other Balls
+ 157: Shovel
+ 158: Pepper
+ 159: Computer Box
+ 160: Toilet Paper
+ 161: Cleaning Products
+ 162: Chopsticks
+ 163: Microwave
+ 164: Pigeon
+ 165: Baseball
+ 166: Cutting/chopping Board
+ 167: Coffee Table
+ 168: Side Table
+ 169: Scissors
+ 170: Marker
+ 171: Pie
+ 172: Ladder
+ 173: Snowboard
+ 174: Cookies
+ 175: Radiator
+ 176: Fire Hydrant
+ 177: Basketball
+ 178: Zebra
+ 179: Grape
+ 180: Giraffe
+ 181: Potato
+ 182: Sausage
+ 183: Tricycle
+ 184: Violin
+ 185: Egg
+ 186: Fire Extinguisher
+ 187: Candy
+ 188: Fire Truck
+ 189: Billiards
+ 190: Converter
+ 191: Bathtub
+ 192: Wheelchair
+ 193: Golf Club
+ 194: Briefcase
+ 195: Cucumber
+ 196: Cigar/Cigarette
+ 197: Paint Brush
+ 198: Pear
+ 199: Heavy Truck
+ 200: Hamburger
+ 201: Extractor
+ 202: Extension Cord
+ 203: Tong
+ 204: Tennis Racket
+ 205: Folder
+ 206: American Football
+ 207: earphone
+ 208: Mask
+ 209: Kettle
+ 210: Tennis
+ 211: Ship
+ 212: Swing
+ 213: Coffee Machine
+ 214: Slide
+ 215: Carriage
+ 216: Onion
+ 217: Green beans
+ 218: Projector
+ 219: Frisbee
+ 220: Washing Machine/Drying Machine
+ 221: Chicken
+ 222: Printer
+ 223: Watermelon
+ 224: Saxophone
+ 225: Tissue
+ 226: Toothbrush
+ 227: Ice cream
+ 228: Hot-air balloon
+ 229: Cello
+ 230: French Fries
+ 231: Scale
+ 232: Trophy
+ 233: Cabbage
+ 234: Hot dog
+ 235: Blender
+ 236: Peach
+ 237: Rice
+ 238: Wallet/Purse
+ 239: Volleyball
+ 240: Deer
+ 241: Goose
+ 242: Tape
+ 243: Tablet
+ 244: Cosmetics
+ 245: Trumpet
+ 246: Pineapple
+ 247: Golf Ball
+ 248: Ambulance
+ 249: Parking meter
+ 250: Mango
+ 251: Key
+ 252: Hurdle
+ 253: Fishing Rod
+ 254: Medal
+ 255: Flute
+ 256: Brush
+ 257: Penguin
+ 258: Megaphone
+ 259: Corn
+ 260: Lettuce
+ 261: Garlic
+ 262: Swan
+ 263: Helicopter
+ 264: Green Onion
+ 265: Sandwich
+ 266: Nuts
+ 267: Speed Limit Sign
+ 268: Induction Cooker
+ 269: Broom
+ 270: Trombone
+ 271: Plum
+ 272: Rickshaw
+ 273: Goldfish
+ 274: Kiwi fruit
+ 275: Router/modem
+ 276: Poker Card
+ 277: Toaster
+ 278: Shrimp
+ 279: Sushi
+ 280: Cheese
+ 281: Notepaper
+ 282: Cherry
+ 283: Pliers
+ 284: CD
+ 285: Pasta
+ 286: Hammer
+ 287: Cue
+ 288: Avocado
+ 289: Hamimelon
+ 290: Flask
+ 291: Mushroom
+ 292: Screwdriver
+ 293: Soap
+ 294: Recorder
+ 295: Bear
+ 296: Eggplant
+ 297: Board Eraser
+ 298: Coconut
+ 299: Tape Measure/Ruler
+ 300: Pig
+ 301: Showerhead
+ 302: Globe
+ 303: Chips
+ 304: Steak
+ 305: Crosswalk Sign
+ 306: Stapler
+ 307: Camel
+ 308: Formula 1
+ 309: Pomegranate
+ 310: Dishwasher
+ 311: Crab
+ 312: Hoverboard
+ 313: Meat ball
+ 314: Rice Cooker
+ 315: Tuba
+ 316: Calculator
+ 317: Papaya
+ 318: Antelope
+ 319: Parrot
+ 320: Seal
+ 321: Butterfly
+ 322: Dumbbell
+ 323: Donkey
+ 324: Lion
+ 325: Urinal
+ 326: Dolphin
+ 327: Electric Drill
+ 328: Hair Dryer
+ 329: Egg tart
+ 330: Jellyfish
+ 331: Treadmill
+ 332: Lighter
+ 333: Grapefruit
+ 334: Game board
+ 335: Mop
+ 336: Radish
+ 337: Baozi
+ 338: Target
+ 339: French
+ 340: Spring Rolls
+ 341: Monkey
+ 342: Rabbit
+ 343: Pencil Case
+ 344: Yak
+ 345: Red Cabbage
+ 346: Binoculars
+ 347: Asparagus
+ 348: Barbell
+ 349: Scallop
+ 350: Noddles
+ 351: Comb
+ 352: Dumpling
+ 353: Oyster
+ 354: Table Tennis paddle
+ 355: Cosmetics Brush/Eyeliner Pencil
+ 356: Chainsaw
+ 357: Eraser
+ 358: Lobster
+ 359: Durian
+ 360: Okra
+ 361: Lipstick
+ 362: Cosmetics Mirror
+ 363: Curling
+ 364: Table Tennis
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from tqdm import tqdm
+
+ from utils.general import Path, check_requirements, download, np, xyxy2xywhn
+
+ check_requirements(('pycocotools>=2.0',))
+ from pycocotools.coco import COCO
+
+ # Make Directories
+ dir = Path(yaml['path']) # dataset root dir
+ for p in 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+ for q in 'train', 'val':
+ (dir / p / q).mkdir(parents=True, exist_ok=True)
+
+ # Train, Val Splits
+ for split, patches in [('train', 50 + 1), ('val', 43 + 1)]:
+ print(f"Processing {split} in {patches} patches ...")
+ images, labels = dir / 'images' / split, dir / 'labels' / split
+
+ # Download
+ url = f"https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/{split}/"
+ if split == 'train':
+ download([f'{url}zhiyuan_objv2_{split}.tar.gz'], dir=dir, delete=False) # annotations json
+ download([f'{url}patch{i}.tar.gz' for i in range(patches)], dir=images, curl=True, delete=False, threads=8)
+ elif split == 'val':
+ download([f'{url}zhiyuan_objv2_{split}.json'], dir=dir, delete=False) # annotations json
+ download([f'{url}images/v1/patch{i}.tar.gz' for i in range(15 + 1)], dir=images, curl=True, delete=False, threads=8)
+ download([f'{url}images/v2/patch{i}.tar.gz' for i in range(16, patches)], dir=images, curl=True, delete=False, threads=8)
+
+ # Move
+ for f in tqdm(images.rglob('*.jpg'), desc=f'Moving {split} images'):
+ f.rename(images / f.name) # move to /images/{split}
+
+ # Labels
+ coco = COCO(dir / f'zhiyuan_objv2_{split}.json')
+ names = [x["name"] for x in coco.loadCats(coco.getCatIds())]
+ for cid, cat in enumerate(names):
+ catIds = coco.getCatIds(catNms=[cat])
+ imgIds = coco.getImgIds(catIds=catIds)
+ for im in tqdm(coco.loadImgs(imgIds), desc=f'Class {cid + 1}/{len(names)} {cat}'):
+ width, height = im["width"], im["height"]
+ path = Path(im["file_name"]) # image filename
+ try:
+ with open(labels / path.with_suffix('.txt').name, 'a') as file:
+ annIds = coco.getAnnIds(imgIds=im["id"], catIds=catIds, iscrowd=None)
+ for a in coco.loadAnns(annIds):
+ x, y, w, h = a['bbox'] # bounding box in xywh (xy top-left corner)
+ xyxy = np.array([x, y, x + w, y + h])[None] # pixels(1,4)
+ x, y, w, h = xyxy2xywhn(xyxy, w=width, h=height, clip=True)[0] # normalized and clipped
+ file.write(f"{cid} {x:.5f} {y:.5f} {w:.5f} {h:.5f}\n")
+ except Exception as e:
+ print(e)
diff --git a/yolov5/data/SKU-110K.yaml b/yolov5/data/SKU-110K.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a943eecdeee699c6f85d08311b925b2ededc8836
--- /dev/null
+++ b/yolov5/data/SKU-110K.yaml
@@ -0,0 +1,53 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# SKU-110K retail items dataset https://github.com/eg4000/SKU110K_CVPR19 by Trax Retail
+# Example usage: python train.py --data SKU-110K.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── SKU-110K ← downloads here (13.6 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/SKU-110K # dataset root dir
+train: train.txt # train images (relative to 'path') 8219 images
+val: val.txt # val images (relative to 'path') 588 images
+test: test.txt # test images (optional) 2936 images
+
+# Classes
+names:
+ 0: object
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import shutil
+ from tqdm import tqdm
+ from utils.general import np, pd, Path, download, xyxy2xywh
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ parent = Path(dir.parent) # download dir
+ urls = ['http://trax-geometry.s3.amazonaws.com/cvpr_challenge/SKU110K_fixed.tar.gz']
+ download(urls, dir=parent, delete=False)
+
+ # Rename directories
+ if dir.exists():
+ shutil.rmtree(dir)
+ (parent / 'SKU110K_fixed').rename(dir) # rename dir
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # create labels dir
+
+ # Convert labels
+ names = 'image', 'x1', 'y1', 'x2', 'y2', 'class', 'image_width', 'image_height' # column names
+ for d in 'annotations_train.csv', 'annotations_val.csv', 'annotations_test.csv':
+ x = pd.read_csv(dir / 'annotations' / d, names=names).values # annotations
+ images, unique_images = x[:, 0], np.unique(x[:, 0])
+ with open((dir / d).with_suffix('.txt').__str__().replace('annotations_', ''), 'w') as f:
+ f.writelines(f'./images/{s}\n' for s in unique_images)
+ for im in tqdm(unique_images, desc=f'Converting {dir / d}'):
+ cls = 0 # single-class dataset
+ with open((dir / 'labels' / im).with_suffix('.txt'), 'a') as f:
+ for r in x[images == im]:
+ w, h = r[6], r[7] # image width, height
+ xywh = xyxy2xywh(np.array([[r[1] / w, r[2] / h, r[3] / w, r[4] / h]]))[0] # instance
+ f.write(f"{cls} {xywh[0]:.5f} {xywh[1]:.5f} {xywh[2]:.5f} {xywh[3]:.5f}\n") # write label
diff --git a/yolov5/data/VOC.yaml b/yolov5/data/VOC.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..104856f0c9c77dbcccff866d0d0677be5c08c2a0
--- /dev/null
+++ b/yolov5/data/VOC.yaml
@@ -0,0 +1,100 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
+# Example usage: python train.py --data VOC.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── VOC ← downloads here (2.8 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/VOC
+train: # train images (relative to 'path') 16551 images
+ - images/train2012
+ - images/train2007
+ - images/val2012
+ - images/val2007
+val: # val images (relative to 'path') 4952 images
+ - images/test2007
+test: # test images (optional)
+ - images/test2007
+
+# Classes
+names:
+ 0: aeroplane
+ 1: bicycle
+ 2: bird
+ 3: boat
+ 4: bottle
+ 5: bus
+ 6: car
+ 7: cat
+ 8: chair
+ 9: cow
+ 10: diningtable
+ 11: dog
+ 12: horse
+ 13: motorbike
+ 14: person
+ 15: pottedplant
+ 16: sheep
+ 17: sofa
+ 18: train
+ 19: tvmonitor
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import xml.etree.ElementTree as ET
+
+ from tqdm import tqdm
+ from utils.general import download, Path
+
+
+ def convert_label(path, lb_path, year, image_id):
+ def convert_box(size, box):
+ dw, dh = 1. / size[0], 1. / size[1]
+ x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
+ return x * dw, y * dh, w * dw, h * dh
+
+ in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
+ out_file = open(lb_path, 'w')
+ tree = ET.parse(in_file)
+ root = tree.getroot()
+ size = root.find('size')
+ w = int(size.find('width').text)
+ h = int(size.find('height').text)
+
+ names = list(yaml['names'].values()) # names list
+ for obj in root.iter('object'):
+ cls = obj.find('name').text
+ if cls in names and int(obj.find('difficult').text) != 1:
+ xmlbox = obj.find('bndbox')
+ bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
+ cls_id = names.index(cls) # class id
+ out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [f'{url}VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
+ f'{url}VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
+ f'{url}VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
+ download(urls, dir=dir / 'images', delete=False, curl=True, threads=3)
+
+ # Convert
+ path = dir / 'images/VOCdevkit'
+ for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
+ imgs_path = dir / 'images' / f'{image_set}{year}'
+ lbs_path = dir / 'labels' / f'{image_set}{year}'
+ imgs_path.mkdir(exist_ok=True, parents=True)
+ lbs_path.mkdir(exist_ok=True, parents=True)
+
+ with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
+ image_ids = f.read().strip().split()
+ for id in tqdm(image_ids, desc=f'{image_set}{year}'):
+ f = path / f'VOC{year}/JPEGImages/{id}.jpg' # old img path
+ lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
+ f.rename(imgs_path / f.name) # move image
+ convert_label(path, lb_path, year, id) # convert labels to YOLO format
diff --git a/yolov5/data/VisDrone.yaml b/yolov5/data/VisDrone.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2a13904dc8dd50c3906b18cc414a6975b2c28dd6
--- /dev/null
+++ b/yolov5/data/VisDrone.yaml
@@ -0,0 +1,70 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# VisDrone2019-DET dataset https://github.com/VisDrone/VisDrone-Dataset by Tianjin University
+# Example usage: python train.py --data VisDrone.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── VisDrone ← downloads here (2.3 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/VisDrone # dataset root dir
+train: VisDrone2019-DET-train/images # train images (relative to 'path') 6471 images
+val: VisDrone2019-DET-val/images # val images (relative to 'path') 548 images
+test: VisDrone2019-DET-test-dev/images # test images (optional) 1610 images
+
+# Classes
+names:
+ 0: pedestrian
+ 1: people
+ 2: bicycle
+ 3: car
+ 4: van
+ 5: truck
+ 6: tricycle
+ 7: awning-tricycle
+ 8: bus
+ 9: motor
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from utils.general import download, os, Path
+
+ def visdrone2yolo(dir):
+ from PIL import Image
+ from tqdm import tqdm
+
+ def convert_box(size, box):
+ # Convert VisDrone box to YOLO xywh box
+ dw = 1. / size[0]
+ dh = 1. / size[1]
+ return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
+
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
+ pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
+ for f in pbar:
+ img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
+ lines = []
+ with open(f, 'r') as file: # read annotation.txt
+ for row in [x.split(',') for x in file.read().strip().splitlines()]:
+ if row[4] == '0': # VisDrone 'ignored regions' class 0
+ continue
+ cls = int(row[5]) - 1
+ box = convert_box(img_size, tuple(map(int, row[:4])))
+ lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
+ with open(str(f).replace(os.sep + 'annotations' + os.sep, os.sep + 'labels' + os.sep), 'w') as fl:
+ fl.writelines(lines) # write label.txt
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-train.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-val.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-dev.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-challenge.zip']
+ download(urls, dir=dir, curl=True, threads=4)
+
+ # Convert
+ for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
+ visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
diff --git a/yolov5/data/coco.yaml b/yolov5/data/coco.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ea32cb6269a362886c7283e4a3d543115891eec8
--- /dev/null
+++ b/yolov5/data/coco.yaml
@@ -0,0 +1,116 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# COCO 2017 dataset http://cocodataset.org by Microsoft
+# Example usage: python train.py --data coco.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco ← downloads here (20.1 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco # dataset root dir
+train: train2017.txt # train images (relative to 'path') 118287 images
+val: val2017.txt # val images (relative to 'path') 5000 images
+test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: |
+ from utils.general import download, Path
+
+
+ # Download labels
+ segments = False # segment or box labels
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
+ download(urls, dir=dir.parent)
+
+ # Download data
+ urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
+ 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
+ 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
+ download(urls, dir=dir / 'images', threads=3)
diff --git a/yolov5/data/coco128-seg.yaml b/yolov5/data/coco128-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..0a2499c00a1aa012b0d1a031714977843874b29d
--- /dev/null
+++ b/yolov5/data/coco128-seg.yaml
@@ -0,0 +1,101 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
+# Example usage: python train.py --data coco128.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco128-seg ← downloads here (7 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco128-seg # dataset root dir
+train: images/train2017 # train images (relative to 'path') 128 images
+val: images/train2017 # val images (relative to 'path') 128 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco128-seg.zip
diff --git a/yolov5/data/coco128.yaml b/yolov5/data/coco128.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..0cb53120be2c88db1543e9600576d200c4775a41
--- /dev/null
+++ b/yolov5/data/coco128.yaml
@@ -0,0 +1,101 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
+# Example usage: python train.py --data coco128.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco128 ← downloads here (7 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco128 # dataset root dir
+train: images/train2017 # train images (relative to 'path') 128 images
+val: images/train2017 # val images (relative to 'path') 128 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco128.zip
diff --git a/yolov5/data/hyps/hyp.Objects365.yaml b/yolov5/data/hyps/hyp.Objects365.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c4b6e8051d7bafd93155c8e03e1b264b468f68a7
--- /dev/null
+++ b/yolov5/data/hyps/hyp.Objects365.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for Objects365 training
+# python train.py --weights yolov5m.pt --data Objects365.yaml --evolve
+# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.00258
+lrf: 0.17
+momentum: 0.779
+weight_decay: 0.00058
+warmup_epochs: 1.33
+warmup_momentum: 0.86
+warmup_bias_lr: 0.0711
+box: 0.0539
+cls: 0.299
+cls_pw: 0.825
+obj: 0.632
+obj_pw: 1.0
+iou_t: 0.2
+anchor_t: 3.44
+anchors: 3.2
+fl_gamma: 0.0
+hsv_h: 0.0188
+hsv_s: 0.704
+hsv_v: 0.36
+degrees: 0.0
+translate: 0.0902
+scale: 0.491
+shear: 0.0
+perspective: 0.0
+flipud: 0.0
+fliplr: 0.5
+mosaic: 1.0
+mixup: 0.0
+copy_paste: 0.0
diff --git a/yolov5/data/hyps/hyp.VOC.yaml b/yolov5/data/hyps/hyp.VOC.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ce20dbbddbdbdb7228ca3262fade10b64b798087
--- /dev/null
+++ b/yolov5/data/hyps/hyp.VOC.yaml
@@ -0,0 +1,40 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for VOC training
+# python train.py --batch 128 --weights yolov5m6.pt --data VOC.yaml --epochs 50 --img 512 --hyp hyp.scratch-med.yaml --evolve
+# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
+
+# YOLOv5 Hyperparameter Evolution Results
+# Best generation: 467
+# Last generation: 996
+# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
+# 0.87729, 0.85125, 0.91286, 0.72664, 0.0076739, 0.0042529, 0.0013865
+
+lr0: 0.00334
+lrf: 0.15135
+momentum: 0.74832
+weight_decay: 0.00025
+warmup_epochs: 3.3835
+warmup_momentum: 0.59462
+warmup_bias_lr: 0.18657
+box: 0.02
+cls: 0.21638
+cls_pw: 0.5
+obj: 0.51728
+obj_pw: 0.67198
+iou_t: 0.2
+anchor_t: 3.3744
+fl_gamma: 0.0
+hsv_h: 0.01041
+hsv_s: 0.54703
+hsv_v: 0.27739
+degrees: 0.0
+translate: 0.04591
+scale: 0.75544
+shear: 0.0
+perspective: 0.0
+flipud: 0.0
+fliplr: 0.5
+mosaic: 0.85834
+mixup: 0.04266
+copy_paste: 0.0
+anchors: 3.412
diff --git a/yolov5/data/hyps/hyp.no-augmentation.yaml b/yolov5/data/hyps/hyp.no-augmentation.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..8da18150538b9918e6140f12ed0740bbc8e95955
--- /dev/null
+++ b/yolov5/data/hyps/hyp.no-augmentation.yaml
@@ -0,0 +1,35 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters when using Albumentations frameworks
+# python train.py --hyp hyp.no-augmentation.yaml
+# See https://github.com/ultralytics/yolov5/pull/3882 for YOLOv5 + Albumentations Usage examples
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+# this parameters are all zero since we want to use albumentation framework
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0 # image HSV-Hue augmentation (fraction)
+hsv_s: 0 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0 # image translation (+/- fraction)
+scale: 0 # image scale (+/- gain)
+shear: 0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.0 # image flip left-right (probability)
+mosaic: 0.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/yolov5/data/hyps/hyp.scratch-high.yaml b/yolov5/data/hyps/hyp.scratch-high.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..0a0f4ec216219890f93f457ce7bc31036490d96d
--- /dev/null
+++ b/yolov5/data/hyps/hyp.scratch-high.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for high-augmentation COCO training from scratch
+# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.9 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.1 # image mixup (probability)
+copy_paste: 0.1 # segment copy-paste (probability)
diff --git a/yolov5/data/hyps/hyp.scratch-low.yaml b/yolov5/data/hyps/hyp.scratch-low.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..9d722568f5266f60b6fc4a6cd1d126be6fd0c146
--- /dev/null
+++ b/yolov5/data/hyps/hyp.scratch-low.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for low-augmentation COCO training from scratch
+# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.5 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 1.0 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.5 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/yolov5/data/hyps/hyp.scratch-med.yaml b/yolov5/data/hyps/hyp.scratch-med.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..f6abb090bb0420a92e571e6d83c12d37f206a8fc
--- /dev/null
+++ b/yolov5/data/hyps/hyp.scratch-med.yaml
@@ -0,0 +1,34 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Hyperparameters for medium-augmentation COCO training from scratch
+# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.9 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.1 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
diff --git a/yolov5/data/images/bus.jpg b/yolov5/data/images/bus.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..b43e311165c785f000eb7493ff8fb662d06a3f83
Binary files /dev/null and b/yolov5/data/images/bus.jpg differ
diff --git a/yolov5/data/images/video-4FRnNpmSmwktFJKjg-frame-000850-4EXx8Fi3iE4nWNcCn.jpg b/yolov5/data/images/video-4FRnNpmSmwktFJKjg-frame-000850-4EXx8Fi3iE4nWNcCn.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..d6d21400d9112ce5239d1ae597d6b161bc437d27
Binary files /dev/null and b/yolov5/data/images/video-4FRnNpmSmwktFJKjg-frame-000850-4EXx8Fi3iE4nWNcCn.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000010-KRtKNoxRWwwgfz62F.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000010-KRtKNoxRWwwgfz62F.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..a4faea6dec2aadf2eb17f3b7cb7c6ce8083848c6
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000010-KRtKNoxRWwwgfz62F.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000043-Qo8ZHanDJ7p8epxpX.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000043-Qo8ZHanDJ7p8epxpX.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..2bde486d59af93ec7f7628250522c89686d674f6
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000043-Qo8ZHanDJ7p8epxpX.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000044-Z5MfsCQMgR3mMAeYX.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000044-Z5MfsCQMgR3mMAeYX.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..32cb2ab81db52309c0a9bf352e740a0539e7c891
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000044-Z5MfsCQMgR3mMAeYX.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000045-yQ8azA2FYFFJpscM8.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000045-yQ8azA2FYFFJpscM8.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..645dff8e07602bd13d431bcd23c2ed474be4f2ec
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000045-yQ8azA2FYFFJpscM8.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000046-mz6XiyZJZeRtyFQvu.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000046-mz6XiyZJZeRtyFQvu.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..fec2fd90e78d7a96bb5fcc4190f0b3d9379938dd
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000046-mz6XiyZJZeRtyFQvu.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000047-yiafE6z9N5PtfHnSH.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000047-yiafE6z9N5PtfHnSH.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6603af4b505874c8b841dd259a77cb7d8578a76c
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000047-yiafE6z9N5PtfHnSH.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000048-uZnkEjQhZvpj9wqS7.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000048-uZnkEjQhZvpj9wqS7.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..afd7465346b77555e627ccf1f34f1766077e7a7b
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000048-uZnkEjQhZvpj9wqS7.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000049-ZXap8fc92GtrTZPbW.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000049-ZXap8fc92GtrTZPbW.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..9e4940aeba10608dbdae4ca828c68fd6a0f8c761
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000049-ZXap8fc92GtrTZPbW.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000050-hSZ786SKo3GhdfPcA.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000050-hSZ786SKo3GhdfPcA.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..12ecfad9645be49be6f51efc5ce43042680edf3d
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000050-hSZ786SKo3GhdfPcA.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000051-p6qknbBumgWvxToxT.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000051-p6qknbBumgWvxToxT.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..71ccd6c35792b9e44e4ef768f108f57cabfd1646
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000051-p6qknbBumgWvxToxT.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000052-afEMvoJQLzkgehnax.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000052-afEMvoJQLzkgehnax.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6b8b9198ecb27448827a8ef10464b1c69a8fadcd
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000052-afEMvoJQLzkgehnax.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000053-3DtD28HJ4uGDaEcAS.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000053-3DtD28HJ4uGDaEcAS.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..57bdc3d7703982b0907d349b64e6f8315a9c7984
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000053-3DtD28HJ4uGDaEcAS.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000054-j7JbDL2yDt4KNHGDZ.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000054-j7JbDL2yDt4KNHGDZ.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..f0b27a8d03622e8eba57b78db29bab780774a5df
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000054-j7JbDL2yDt4KNHGDZ.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000055-n3vz85ez27B8BX9Qd.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000055-n3vz85ez27B8BX9Qd.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..632fe9fd1bd18809fe91740aac504175892b124f
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000055-n3vz85ez27B8BX9Qd.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000056-XxAJfrE3rBn6ETSTS.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000056-XxAJfrE3rBn6ETSTS.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..b8f95d5c57d574b29238d7129eb1a968165e559c
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000056-XxAJfrE3rBn6ETSTS.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000057-ba65sSn2Gm3zqr3GD.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000057-ba65sSn2Gm3zqr3GD.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..531a371c744235e9274dc2332d6712f5d964cfd6
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000057-ba65sSn2Gm3zqr3GD.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000058-XnbHMehqXsxpNdcRi.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000058-XnbHMehqXsxpNdcRi.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..d2aba55f7e86257ff49240ce4fe58216c2a4ad53
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000058-XnbHMehqXsxpNdcRi.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000059-hY7B5y9Frdi5FauHJ.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000059-hY7B5y9Frdi5FauHJ.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e2978e9f1fc440780a55c67aebe2ccc4d3d98c33
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000059-hY7B5y9Frdi5FauHJ.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000060-HxavCNELiqedirhFo.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000060-HxavCNELiqedirhFo.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..79df7fafe7f0530f5d284ad90e6965b9cb06551d
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000060-HxavCNELiqedirhFo.jpg differ
diff --git a/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000191-HnXJKowwSKf9AtA9K.jpg b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000191-HnXJKowwSKf9AtA9K.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..5fd1bf7366dd4db5ac562ee582d7e52610f65d79
Binary files /dev/null and b/yolov5/data/images/video-6tLtjdkv5K5BuhB37-frame-000191-HnXJKowwSKf9AtA9K.jpg differ
diff --git a/yolov5/data/images/video-ePoikf5LyTTfqchga-frame-000397-wvZieNFhvhBzzzJuT.jpg b/yolov5/data/images/video-ePoikf5LyTTfqchga-frame-000397-wvZieNFhvhBzzzJuT.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..5c5ef29c7fdca555b5a05c44f3e98ba5f66e0a73
Binary files /dev/null and b/yolov5/data/images/video-ePoikf5LyTTfqchga-frame-000397-wvZieNFhvhBzzzJuT.jpg differ
diff --git a/yolov5/data/images/zidane.jpg b/yolov5/data/images/zidane.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..92d72ea124760ce5dbf9425e3aa8f371e7481328
Binary files /dev/null and b/yolov5/data/images/zidane.jpg differ
diff --git a/yolov5/data/scripts/download_weights.sh b/yolov5/data/scripts/download_weights.sh
new file mode 100644
index 0000000000000000000000000000000000000000..e408959b32b245f5a6bb1291db16afd138c56a37
--- /dev/null
+++ b/yolov5/data/scripts/download_weights.sh
@@ -0,0 +1,22 @@
+#!/bin/bash
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Download latest models from https://github.com/ultralytics/yolov5/releases
+# Example usage: bash data/scripts/download_weights.sh
+# parent
+# └── yolov5
+# ├── yolov5s.pt ← downloads here
+# ├── yolov5m.pt
+# └── ...
+
+python - <= cls >= 0, f'incorrect class index {cls}'
+
+ # Write YOLO label
+ if id not in shapes:
+ shapes[id] = Image.open(file).size
+ box = xyxy2xywhn(box[None].astype(np.float), w=shapes[id][0], h=shapes[id][1], clip=True)
+ with open((labels / id).with_suffix('.txt'), 'a') as f:
+ f.write(f"{cls} {' '.join(f'{x:.6f}' for x in box[0])}\n") # write label.txt
+ except Exception as e:
+ print(f'WARNING: skipping one label for {file}: {e}')
+
+
+ # Download manually from https://challenge.xviewdataset.org
+ dir = Path(yaml['path']) # dataset root dir
+ # urls = ['https://d307kc0mrhucc3.cloudfront.net/train_labels.zip', # train labels
+ # 'https://d307kc0mrhucc3.cloudfront.net/train_images.zip', # 15G, 847 train images
+ # 'https://d307kc0mrhucc3.cloudfront.net/val_images.zip'] # 5G, 282 val images (no labels)
+ # download(urls, dir=dir, delete=False)
+
+ # Convert labels
+ convert_labels(dir / 'xView_train.geojson')
+
+ # Move images
+ images = Path(dir / 'images')
+ images.mkdir(parents=True, exist_ok=True)
+ Path(dir / 'train_images').rename(dir / 'images' / 'train')
+ Path(dir / 'val_images').rename(dir / 'images' / 'val')
+
+ # Split
+ autosplit(dir / 'images' / 'train')
diff --git a/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_arctanx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.3 b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_arctanx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.3
new file mode 100644
index 0000000000000000000000000000000000000000..38e90391fd651b3ec4a87f9b5e9e6af0618a78eb
--- /dev/null
+++ b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_arctanx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.3
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:76c711e70801814eb48f287989d6077d1a0f3008ca25f06ca80be7ca6d775def
+size 4586
diff --git a/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xcosx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.2 b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xcosx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.2
new file mode 100644
index 0000000000000000000000000000000000000000..46e58ae67b28171ad7f80231c52e8fd6b1f4a6be
--- /dev/null
+++ b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xcosx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.2
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:52d31bebe5cdaef5644eb8188e5d1bebf868077e2d167be31104fd36cc193676
+size 4586
diff --git a/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xsinx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.1 b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xsinx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.1
new file mode 100644
index 0000000000000000000000000000000000000000..9029f9bb0922c5efb6e3b07fae4b58ec24be7dfb
--- /dev/null
+++ b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/_images_xsinx/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.1
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:255d8dccc227f37333e6c61f37e41b6e2cf0664a6ee8be046a75b7a7cb485803
+size 4586
diff --git a/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.0 b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.0
new file mode 100644
index 0000000000000000000000000000000000000000..74f3d315128d1daf70ef5387376d91965b3a6b52
--- /dev/null
+++ b/yolov5/datasets/runs/May17_09-16-11_DESKTOP-NGLUKKBtest_tensorboard/events.out.tfevents.1684286171.DESKTOP-NGLUKKB.8816.0
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ebb31737cfc931f7b31ae1ad2dfe62f59e1f226ce62ab3df94728cc316d5dfaf
+size 9184
diff --git a/yolov5/datasets/test.py b/yolov5/datasets/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..fab959aa99ace4169bb37e36fc47efccaa335e79
--- /dev/null
+++ b/yolov5/datasets/test.py
@@ -0,0 +1,12 @@
+from torch.utils.tensorboard import SummaryWriter
+import numpy as np
+writer = SummaryWriter(comment='test_tensorboard')
+for x in range(100):
+ writer.add_scalar('y=2x', x * 2, x)
+ writer.add_scalar('y=pow(2, x)', 2 ** x, x)
+
+ writer.add_scalars('/images', {"xsinx": x * np.sin(x),
+ "xcosx": x * np.cos(x),
+ "arctanx": np.arctan(x)}, x)
+writer.close()
+
diff --git a/yolov5/detect.py b/yolov5/detect.py
new file mode 100644
index 0000000000000000000000000000000000000000..792e12473d6ee06da4f9706957d3f992d98b9e2e
--- /dev/null
+++ b/yolov5/detect.py
@@ -0,0 +1,261 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Run YOLOv5 detection inference on images, videos, directories, globs, YouTube, webcam, streams, etc.
+
+Usage - sources:
+ $ python detect.py --weights yolov5s.pt --source 0 # webcam
+ img.jpg # image
+ vid.mp4 # video
+ screen # screenshot
+ path/ # directory
+ list.txt # list of images
+ list.streams # list of streams
+ 'path/*.jpg' # glob
+ 'https://youtu.be/Zgi9g1ksQHc' # YouTube
+ 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
+
+Usage - formats:
+ $ python detect.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s_openvino_model # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import os
+import platform
+import sys
+from pathlib import Path
+
+import torch
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
+from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
+ increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
+from utils.plots import Annotator, colors, save_one_box
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+@smart_inference_mode()
+def run(
+ weights=ROOT / 'yolov5s.pt', # model path or triton URL
+ source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
+ data=ROOT / 'data/coco128.yaml', # dataset.yaml path
+ imgsz=(640, 640), # inference size (height, width)
+ conf_thres=0.25, # confidence threshold
+ iou_thres=0.45, # NMS IOU threshold
+ max_det=1000, # maximum detections per image
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ view_img=False, # show results
+ save_txt=False, # save results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_crop=False, # save cropped prediction boxes
+ nosave=False, # do not save images/videos
+ classes=None, # filter by class: --class 0, or --class 0 2 3
+ agnostic_nms=False, # class-agnostic NMS
+ augment=False, # augmented inference
+ visualize=False, # visualize features
+ update=False, # update all models
+ project=ROOT / 'runs/detect', # save results to project/name
+ name='exp', # save results to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ line_thickness=1, # bounding box thickness (pixels)
+ hide_labels=False, # hide labels
+ hide_conf=False, # hide confidences
+ half=False, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ vid_stride=1, # video frame-rate stride
+):
+ source = str(source)
+ save_img = not nosave and not source.endswith('.txt') # save inference images
+ is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
+ is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
+ webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
+ screenshot = source.lower().startswith('screen')
+ if is_url and is_file:
+ source = check_file(source) # download
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ device = select_device(device)
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, names, pt = model.stride, model.names, model.pt
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+
+ # Dataloader
+ bs = 1 # batch_size
+ if webcam:
+ view_img = check_imshow(warn=True)
+ dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
+ bs = len(dataset)
+ elif screenshot:
+ dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
+ else:
+ dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
+ vid_path, vid_writer = [None] * bs, [None] * bs
+
+ # Run inference
+ model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # warmup
+ seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
+ for path, im, im0s, vid_cap, s in dataset:
+ with dt[0]:
+ im = torch.from_numpy(im).to(model.device)
+ im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+
+ # Inference
+ with dt[1]:
+ visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
+ pred = model(im, augment=augment, visualize=visualize)
+
+ # NMS
+ with dt[2]:
+ pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
+
+ # Second-stage classifier (optional)
+ # pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
+
+ # Process predictions
+ for i, det in enumerate(pred): # per image
+ seen += 1
+ if webcam: # batch_size >= 1
+ p, im0, frame = path[i], im0s[i].copy(), dataset.count
+ s += f'{i}: '
+ else:
+ p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
+
+ p = Path(p) # to Path
+ save_path = str(save_dir / p.name) # im.jpg
+ txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
+ s += '%gx%g ' % im.shape[2:] # print string
+ gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
+ imc = im0.copy() if save_crop else im0 # for save_crop
+ annotator = Annotator(im0, line_width=line_thickness, example=str(names))
+ if len(det):
+ # Rescale boxes from img_size to im0 size
+ det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
+
+ # Print results
+ for c in det[:, 5].unique():
+ n = (det[:, 5] == c).sum() # detections per class
+ s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
+
+ # Write results
+ for *xyxy, conf, cls in reversed(det):
+ if save_txt: # Write to file
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(f'{txt_path}.txt', 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+ if save_img or save_crop or view_img: # Add bbox to image
+ c = int(cls) # integer class
+ label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
+ annotator.box_label(xyxy, label, color=colors(c, True))
+ if save_crop:
+ save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
+
+ # Stream results
+ im0 = annotator.result()
+ if view_img:
+ if platform.system() == 'Linux' and p not in windows:
+ windows.append(p)
+ cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
+ cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
+ cv2.imshow(str(p), im0)
+ cv2.waitKey(1) # 1 millisecond
+
+ # Save results (image with detections)
+ if save_img:
+ if dataset.mode == 'image':
+ cv2.imwrite(save_path, im0)
+ else: # 'video' or 'stream'
+ if vid_path[i] != save_path: # new video
+ vid_path[i] = save_path
+ if isinstance(vid_writer[i], cv2.VideoWriter):
+ vid_writer[i].release() # release previous video writer
+ if vid_cap: # video
+ fps = vid_cap.get(cv2.CAP_PROP_FPS)
+ w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ else: # stream
+ fps, w, h = 30, im0.shape[1], im0.shape[0]
+ save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
+ vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ vid_writer[i].write(im0)
+
+ # Print time (inference-only)
+ LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms")
+
+ # Print results
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
+ if save_txt or save_img:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ if update:
+ strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning)
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
+ parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
+ parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--view-img', action='store_true', help='show results')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
+ parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
+ parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
+ parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--visualize', action='store_true', help='visualize features')
+ parser.add_argument('--update', action='store_true', help='update all models')
+ parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
+ parser.add_argument('--name', default='exp', help='save results to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
+ parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
+ parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
+ opt = parser.parse_args()
+ opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/export.py b/yolov5/export.py
new file mode 100644
index 0000000000000000000000000000000000000000..067d9a22f292bf53004f9470f0198977a6880fab
--- /dev/null
+++ b/yolov5/export.py
@@ -0,0 +1,818 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Export a YOLOv5 PyTorch model to other formats. TensorFlow exports authored by https://github.com/zldrobit
+
+Format | `export.py --include` | Model
+--- | --- | ---
+PyTorch | - | yolov5s.pt
+TorchScript | `torchscript` | yolov5s.torchscript
+ONNX | `onnx` | yolov5s.onnx
+OpenVINO | `openvino` | yolov5s_openvino_model/
+TensorRT | `engine` | yolov5s.engine
+CoreML | `coreml` | yolov5s.mlmodel
+TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
+TensorFlow GraphDef | `pb` | yolov5s.pb
+TensorFlow Lite | `tflite` | yolov5s.tflite
+TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
+TensorFlow.js | `tfjs` | yolov5s_web_model/
+PaddlePaddle | `paddle` | yolov5s_paddle_model/
+
+Requirements:
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
+
+Usage:
+ $ python export.py --weights yolov5s.pt --include torchscript onnx openvino engine coreml tflite ...
+
+Inference:
+ $ python detect.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s_openvino_model # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s_paddle_model # PaddlePaddle
+
+TensorFlow.js:
+ $ cd .. && git clone https://github.com/zldrobit/tfjs-yolov5-example.git && cd tfjs-yolov5-example
+ $ npm install
+ $ ln -s ../../yolov5/yolov5s_web_model public/yolov5s_web_model
+ $ npm start
+"""
+
+import argparse
+import contextlib
+import json
+import os
+import platform
+import re
+import subprocess
+import sys
+import time
+import warnings
+from pathlib import Path
+
+import pandas as pd
+import torch
+from torch.utils.mobile_optimizer import optimize_for_mobile
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+if platform.system() != 'Windows':
+ ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from yolov5.models.experimental import attempt_load
+from yolov5.models.yolo import ClassificationModel, Detect, DetectionModel, SegmentationModel
+from yolov5.utils.dataloaders import LoadImages
+from yolov5.utils.general import (LOGGER, Profile, check_dataset, check_img_size, check_requirements, check_version,
+ check_yaml, colorstr, file_size, get_default_args, print_args, url2file, yaml_save)
+from yolov5.utils.torch_utils import select_device, smart_inference_mode
+
+MACOS = platform.system() == 'Darwin' # macOS environment
+
+
+class iOSModel(torch.nn.Module):
+
+ def __init__(self, model, im):
+ super().__init__()
+ b, c, h, w = im.shape # batch, channel, height, width
+ self.model = model
+ self.nc = model.nc # number of classes
+ if w == h:
+ self.normalize = 1. / w
+ else:
+ self.normalize = torch.tensor([1. / w, 1. / h, 1. / w, 1. / h]) # broadcast (slower, smaller)
+ # np = model(im)[0].shape[1] # number of points
+ # self.normalize = torch.tensor([1. / w, 1. / h, 1. / w, 1. / h]).expand(np, 4) # explicit (faster, larger)
+
+ def forward(self, x):
+ xywh, conf, cls = self.model(x)[0].squeeze().split((4, 1, self.nc), 1)
+ return cls * conf, xywh * self.normalize # confidence (3780, 80), coordinates (3780, 4)
+
+
+def export_formats():
+ # YOLOv5 export formats
+ x = [
+ ['PyTorch', '-', '.pt', True, True],
+ ['TorchScript', 'torchscript', '.torchscript', True, True],
+ ['ONNX', 'onnx', '.onnx', True, True],
+ ['OpenVINO', 'openvino', '_openvino_model', True, False],
+ ['TensorRT', 'engine', '.engine', False, True],
+ ['CoreML', 'coreml', '.mlmodel', True, False],
+ ['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
+ ['TensorFlow GraphDef', 'pb', '.pb', True, True],
+ ['TensorFlow Lite', 'tflite', '.tflite', True, False],
+ ['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
+ ['TensorFlow.js', 'tfjs', '_web_model', False, False],
+ ['PaddlePaddle', 'paddle', '_paddle_model', True, True],]
+ return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
+
+
+def try_export(inner_func):
+ # YOLOv5 export decorator, i..e @try_export
+ inner_args = get_default_args(inner_func)
+
+ def outer_func(*args, **kwargs):
+ prefix = inner_args['prefix']
+ try:
+ with Profile() as dt:
+ f, model = inner_func(*args, **kwargs)
+ LOGGER.info(f'{prefix} export success ✅ {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)')
+ return f, model
+ except Exception as e:
+ LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}')
+ return None, None
+
+ return outer_func
+
+
+@try_export
+def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
+ # YOLOv5 TorchScript model export
+ LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
+ f = file.with_suffix('.torchscript')
+
+ ts = torch.jit.trace(model, im, strict=False)
+ d = {'shape': im.shape, 'stride': int(max(model.stride)), 'names': model.names}
+ extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
+ if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
+ optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
+ else:
+ ts.save(str(f), _extra_files=extra_files)
+ return f, None
+
+
+@try_export
+def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')):
+ # YOLOv5 ONNX export
+ check_requirements('onnx>=1.12.0')
+ import onnx
+
+ LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
+ f = file.with_suffix('.onnx')
+
+ output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']
+ if dynamic:
+ dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
+ if isinstance(model, SegmentationModel):
+ dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
+ dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
+ elif isinstance(model, DetectionModel):
+ dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
+
+ torch.onnx.export(
+ model.cpu() if dynamic else model, # --dynamic only compatible with cpu
+ im.cpu() if dynamic else im,
+ f,
+ verbose=False,
+ opset_version=opset,
+ do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
+ input_names=['images'],
+ output_names=output_names,
+ dynamic_axes=dynamic or None)
+
+ # Checks
+ model_onnx = onnx.load(f) # load onnx model
+ onnx.checker.check_model(model_onnx) # check onnx model
+
+ # Metadata
+ d = {'stride': int(max(model.stride)), 'names': model.names}
+ for k, v in d.items():
+ meta = model_onnx.metadata_props.add()
+ meta.key, meta.value = k, str(v)
+ onnx.save(model_onnx, f)
+
+ # Simplify
+ if simplify:
+ try:
+ cuda = torch.cuda.is_available()
+ check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
+ import onnxsim
+
+ LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
+ model_onnx, check = onnxsim.simplify(model_onnx)
+ assert check, 'assert check failed'
+ onnx.save(model_onnx, f)
+ except Exception as e:
+ LOGGER.info(f'{prefix} simplifier failure: {e}')
+ return f, model_onnx
+
+
+@try_export
+def export_openvino(file, metadata, half, prefix=colorstr('OpenVINO:')):
+ # YOLOv5 OpenVINO export
+ check_requirements('openvino-dev') # requires openvino-dev: https://pypi.org/project/openvino-dev/
+ import openvino.inference_engine as ie
+
+ LOGGER.info(f'\n{prefix} starting export with openvino {ie.__version__}...')
+ f = str(file).replace('.pt', f'_openvino_model{os.sep}')
+
+ args = [
+ 'mo',
+ '--input_model',
+ str(file.with_suffix('.onnx')),
+ '--output_dir',
+ f,
+ '--data_type',
+ ('FP16' if half else 'FP32'),]
+ subprocess.run(args, check=True, env=os.environ) # export
+ yaml_save(Path(f) / file.with_suffix('.yaml').name, metadata) # add metadata.yaml
+ return f, None
+
+
+@try_export
+def export_paddle(model, im, file, metadata, prefix=colorstr('PaddlePaddle:')):
+ # YOLOv5 Paddle export
+ check_requirements(('paddlepaddle', 'x2paddle'))
+ import x2paddle
+ from x2paddle.convert import pytorch2paddle
+
+ LOGGER.info(f'\n{prefix} starting export with X2Paddle {x2paddle.__version__}...')
+ f = str(file).replace('.pt', f'_paddle_model{os.sep}')
+
+ pytorch2paddle(module=model, save_dir=f, jit_type='trace', input_examples=[im]) # export
+ yaml_save(Path(f) / file.with_suffix('.yaml').name, metadata) # add metadata.yaml
+ return f, None
+
+
+@try_export
+def export_coreml(model, im, file, int8, half, nms, prefix=colorstr('CoreML:')):
+ # YOLOv5 CoreML export
+ check_requirements('coremltools')
+ import coremltools as ct
+
+ LOGGER.info(f'\n{prefix} starting export with coremltools {ct.__version__}...')
+ f = file.with_suffix('.mlmodel')
+
+ if nms:
+ model = iOSModel(model, im)
+ ts = torch.jit.trace(model, im, strict=False) # TorchScript model
+ ct_model = ct.convert(ts, inputs=[ct.ImageType('image', shape=im.shape, scale=1 / 255, bias=[0, 0, 0])])
+ bits, mode = (8, 'kmeans_lut') if int8 else (16, 'linear') if half else (32, None)
+ if bits < 32:
+ if MACOS: # quantization only supported on macOS
+ with warnings.catch_warnings():
+ warnings.filterwarnings('ignore', category=DeprecationWarning) # suppress numpy==1.20 float warning
+ ct_model = ct.models.neural_network.quantization_utils.quantize_weights(ct_model, bits, mode)
+ else:
+ print(f'{prefix} quantization only supported on macOS, skipping...')
+ ct_model.save(f)
+ return f, ct_model
+
+
+@try_export
+def export_engine(model, im, file, half, dynamic, simplify, workspace=4, verbose=False, prefix=colorstr('TensorRT:')):
+ # YOLOv5 TensorRT export https://developer.nvidia.com/tensorrt
+ assert im.device.type != 'cpu', 'export running on CPU but must be on GPU, i.e. `python export.py --device 0`'
+ try:
+ import tensorrt as trt
+ except Exception:
+ if platform.system() == 'Linux':
+ check_requirements('nvidia-tensorrt', cmds='-U --index-url https://pypi.ngc.nvidia.com')
+ import tensorrt as trt
+
+ if trt.__version__[0] == '7': # TensorRT 7 handling https://github.com/ultralytics/yolov5/issues/6012
+ grid = model.model[-1].anchor_grid
+ model.model[-1].anchor_grid = [a[..., :1, :1, :] for a in grid]
+ export_onnx(model, im, file, 12, dynamic, simplify) # opset 12
+ model.model[-1].anchor_grid = grid
+ else: # TensorRT >= 8
+ check_version(trt.__version__, '8.0.0', hard=True) # require tensorrt>=8.0.0
+ export_onnx(model, im, file, 12, dynamic, simplify) # opset 12
+ onnx = file.with_suffix('.onnx')
+
+ LOGGER.info(f'\n{prefix} starting export with TensorRT {trt.__version__}...')
+ assert onnx.exists(), f'failed to export ONNX file: {onnx}'
+ f = file.with_suffix('.engine') # TensorRT engine file
+ logger = trt.Logger(trt.Logger.INFO)
+ if verbose:
+ logger.min_severity = trt.Logger.Severity.VERBOSE
+
+ builder = trt.Builder(logger)
+ config = builder.create_builder_config()
+ config.max_workspace_size = workspace * 1 << 30
+ # config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, workspace << 30) # fix TRT 8.4 deprecation notice
+
+ flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
+ network = builder.create_network(flag)
+ parser = trt.OnnxParser(network, logger)
+ if not parser.parse_from_file(str(onnx)):
+ raise RuntimeError(f'failed to load ONNX file: {onnx}')
+
+ inputs = [network.get_input(i) for i in range(network.num_inputs)]
+ outputs = [network.get_output(i) for i in range(network.num_outputs)]
+ for inp in inputs:
+ LOGGER.info(f'{prefix} input "{inp.name}" with shape{inp.shape} {inp.dtype}')
+ for out in outputs:
+ LOGGER.info(f'{prefix} output "{out.name}" with shape{out.shape} {out.dtype}')
+
+ if dynamic:
+ if im.shape[0] <= 1:
+ LOGGER.warning(f'{prefix} WARNING ⚠️ --dynamic model requires maximum --batch-size argument')
+ profile = builder.create_optimization_profile()
+ for inp in inputs:
+ profile.set_shape(inp.name, (1, *im.shape[1:]), (max(1, im.shape[0] // 2), *im.shape[1:]), im.shape)
+ config.add_optimization_profile(profile)
+
+ LOGGER.info(f'{prefix} building FP{16 if builder.platform_has_fast_fp16 and half else 32} engine as {f}')
+ if builder.platform_has_fast_fp16 and half:
+ config.set_flag(trt.BuilderFlag.FP16)
+ with builder.build_engine(network, config) as engine, open(f, 'wb') as t:
+ t.write(engine.serialize())
+ return f, None
+
+
+@try_export
+def export_saved_model(model,
+ im,
+ file,
+ dynamic,
+ tf_nms=False,
+ agnostic_nms=False,
+ topk_per_class=100,
+ topk_all=100,
+ iou_thres=0.45,
+ conf_thres=0.25,
+ keras=False,
+ prefix=colorstr('TensorFlow SavedModel:')):
+ # YOLOv5 TensorFlow SavedModel export
+ try:
+ import tensorflow as tf
+ except Exception:
+ check_requirements(f"tensorflow{'' if torch.cuda.is_available() else '-macos' if MACOS else '-cpu'}")
+ import tensorflow as tf
+ from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
+
+ from models.tf import TFModel
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = str(file).replace('.pt', '_saved_model')
+ batch_size, ch, *imgsz = list(im.shape) # BCHW
+
+ tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
+ im = tf.zeros((batch_size, *imgsz, ch)) # BHWC order for TensorFlow
+ _ = tf_model.predict(im, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
+ inputs = tf.keras.Input(shape=(*imgsz, ch), batch_size=None if dynamic else batch_size)
+ outputs = tf_model.predict(inputs, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
+ keras_model = tf.keras.Model(inputs=inputs, outputs=outputs)
+ keras_model.trainable = False
+ keras_model.summary()
+ if keras:
+ keras_model.save(f, save_format='tf')
+ else:
+ spec = tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype)
+ m = tf.function(lambda x: keras_model(x)) # full model
+ m = m.get_concrete_function(spec)
+ frozen_func = convert_variables_to_constants_v2(m)
+ tfm = tf.Module()
+ tfm.__call__ = tf.function(lambda x: frozen_func(x)[:4] if tf_nms else frozen_func(x), [spec])
+ tfm.__call__(im)
+ tf.saved_model.save(tfm,
+ f,
+ options=tf.saved_model.SaveOptions(experimental_custom_gradients=False) if check_version(
+ tf.__version__, '2.6') else tf.saved_model.SaveOptions())
+ return f, keras_model
+
+
+@try_export
+def export_pb(keras_model, file, prefix=colorstr('TensorFlow GraphDef:')):
+ # YOLOv5 TensorFlow GraphDef *.pb export https://github.com/leimao/Frozen_Graph_TensorFlow
+ import tensorflow as tf
+ from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = file.with_suffix('.pb')
+
+ m = tf.function(lambda x: keras_model(x)) # full model
+ m = m.get_concrete_function(tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype))
+ frozen_func = convert_variables_to_constants_v2(m)
+ frozen_func.graph.as_graph_def()
+ tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=str(f.parent), name=f.name, as_text=False)
+ return f, None
+
+
+@try_export
+def export_tflite(keras_model, im, file, int8, data, nms, agnostic_nms, prefix=colorstr('TensorFlow Lite:')):
+ # YOLOv5 TensorFlow Lite export
+ import tensorflow as tf
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ batch_size, ch, *imgsz = list(im.shape) # BCHW
+ f = str(file).replace('.pt', '-fp16.tflite')
+
+ converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
+ converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
+ converter.target_spec.supported_types = [tf.float16]
+ converter.optimizations = [tf.lite.Optimize.DEFAULT]
+ if int8:
+ from models.tf import representative_dataset_gen
+ dataset = LoadImages(check_dataset(check_yaml(data))['train'], img_size=imgsz, auto=False)
+ converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib=100)
+ converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
+ converter.target_spec.supported_types = []
+ converter.inference_input_type = tf.uint8 # or tf.int8
+ converter.inference_output_type = tf.uint8 # or tf.int8
+ converter.experimental_new_quantizer = True
+ f = str(file).replace('.pt', '-int8.tflite')
+ if nms or agnostic_nms:
+ converter.target_spec.supported_ops.append(tf.lite.OpsSet.SELECT_TF_OPS)
+
+ tflite_model = converter.convert()
+ open(f, 'wb').write(tflite_model)
+ return f, None
+
+
+@try_export
+def export_edgetpu(file, prefix=colorstr('Edge TPU:')):
+ # YOLOv5 Edge TPU export https://coral.ai/docs/edgetpu/models-intro/
+ cmd = 'edgetpu_compiler --version'
+ help_url = 'https://coral.ai/docs/edgetpu/compiler/'
+ assert platform.system() == 'Linux', f'export only supported on Linux. See {help_url}'
+ if subprocess.run(f'{cmd} > /dev/null 2>&1', shell=True).returncode != 0:
+ LOGGER.info(f'\n{prefix} export requires Edge TPU compiler. Attempting install from {help_url}')
+ sudo = subprocess.run('sudo --version >/dev/null', shell=True).returncode == 0 # sudo installed on system
+ for c in (
+ 'curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -',
+ 'echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list',
+ 'sudo apt-get update', 'sudo apt-get install edgetpu-compiler'):
+ subprocess.run(c if sudo else c.replace('sudo ', ''), shell=True, check=True)
+ ver = subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1]
+
+ LOGGER.info(f'\n{prefix} starting export with Edge TPU compiler {ver}...')
+ f = str(file).replace('.pt', '-int8_edgetpu.tflite') # Edge TPU model
+ f_tfl = str(file).replace('.pt', '-int8.tflite') # TFLite model
+
+ subprocess.run([
+ 'edgetpu_compiler',
+ '-s',
+ '-d',
+ '-k',
+ '10',
+ '--out_dir',
+ str(file.parent),
+ f_tfl,], check=True)
+ return f, None
+
+
+@try_export
+def export_tfjs(file, int8, prefix=colorstr('TensorFlow.js:')):
+ # YOLOv5 TensorFlow.js export
+ check_requirements('tensorflowjs')
+ import tensorflowjs as tfjs
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflowjs {tfjs.__version__}...')
+ f = str(file).replace('.pt', '_web_model') # js dir
+ f_pb = file.with_suffix('.pb') # *.pb path
+ f_json = f'{f}/model.json' # *.json path
+
+ args = [
+ 'tensorflowjs_converter',
+ '--input_format=tf_frozen_model',
+ '--quantize_uint8' if int8 else '',
+ '--output_node_names=Identity,Identity_1,Identity_2,Identity_3',
+ str(f_pb),
+ str(f),]
+ subprocess.run([arg for arg in args if arg], check=True)
+
+ json = Path(f_json).read_text()
+ with open(f_json, 'w') as j: # sort JSON Identity_* in ascending order
+ subst = re.sub(
+ r'{"outputs": {"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}}}', r'{"outputs": {"Identity": {"name": "Identity"}, '
+ r'"Identity_1": {"name": "Identity_1"}, '
+ r'"Identity_2": {"name": "Identity_2"}, '
+ r'"Identity_3": {"name": "Identity_3"}}}', json)
+ j.write(subst)
+ return f, None
+
+
+def add_tflite_metadata(file, metadata, num_outputs):
+ # Add metadata to *.tflite models per https://www.tensorflow.org/lite/models/convert/metadata
+ with contextlib.suppress(ImportError):
+ # check_requirements('tflite_support')
+ from tflite_support import flatbuffers
+ from tflite_support import metadata as _metadata
+ from tflite_support import metadata_schema_py_generated as _metadata_fb
+
+ tmp_file = Path('/tmp/meta.txt')
+ with open(tmp_file, 'w') as meta_f:
+ meta_f.write(str(metadata))
+
+ model_meta = _metadata_fb.ModelMetadataT()
+ label_file = _metadata_fb.AssociatedFileT()
+ label_file.name = tmp_file.name
+ model_meta.associatedFiles = [label_file]
+
+ subgraph = _metadata_fb.SubGraphMetadataT()
+ subgraph.inputTensorMetadata = [_metadata_fb.TensorMetadataT()]
+ subgraph.outputTensorMetadata = [_metadata_fb.TensorMetadataT()] * num_outputs
+ model_meta.subgraphMetadata = [subgraph]
+
+ b = flatbuffers.Builder(0)
+ b.Finish(model_meta.Pack(b), _metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
+ metadata_buf = b.Output()
+
+ populator = _metadata.MetadataPopulator.with_model_file(file)
+ populator.load_metadata_buffer(metadata_buf)
+ populator.load_associated_files([str(tmp_file)])
+ populator.populate()
+ tmp_file.unlink()
+
+
+def pipeline_coreml(model, im, file, names, y, prefix=colorstr('CoreML Pipeline:')):
+ # YOLOv5 CoreML pipeline
+ import coremltools as ct
+ from PIL import Image
+
+ print(f'{prefix} starting pipeline with coremltools {ct.__version__}...')
+ batch_size, ch, h, w = list(im.shape) # BCHW
+ t = time.time()
+
+ # Output shapes
+ spec = model.get_spec()
+ out0, out1 = iter(spec.description.output)
+ if platform.system() == 'Darwin':
+ img = Image.new('RGB', (w, h)) # img(192 width, 320 height)
+ # img = torch.zeros((*opt.img_size, 3)).numpy() # img size(320,192,3) iDetection
+ out = model.predict({'image': img})
+ out0_shape, out1_shape = out[out0.name].shape, out[out1.name].shape
+ else: # linux and windows can not run model.predict(), get sizes from pytorch output y
+ s = tuple(y[0].shape)
+ out0_shape, out1_shape = (s[1], s[2] - 5), (s[1], 4) # (3780, 80), (3780, 4)
+
+ # Checks
+ nx, ny = spec.description.input[0].type.imageType.width, spec.description.input[0].type.imageType.height
+ na, nc = out0_shape
+ # na, nc = out0.type.multiArrayType.shape # number anchors, classes
+ assert len(names) == nc, f'{len(names)} names found for nc={nc}' # check
+
+ # Define output shapes (missing)
+ out0.type.multiArrayType.shape[:] = out0_shape # (3780, 80)
+ out1.type.multiArrayType.shape[:] = out1_shape # (3780, 4)
+ # spec.neuralNetwork.preprocessing[0].featureName = '0'
+
+ # Flexible input shapes
+ # from coremltools.models.neural_network import flexible_shape_utils
+ # s = [] # shapes
+ # s.append(flexible_shape_utils.NeuralNetworkImageSize(320, 192))
+ # s.append(flexible_shape_utils.NeuralNetworkImageSize(640, 384)) # (height, width)
+ # flexible_shape_utils.add_enumerated_image_sizes(spec, feature_name='image', sizes=s)
+ # r = flexible_shape_utils.NeuralNetworkImageSizeRange() # shape ranges
+ # r.add_height_range((192, 640))
+ # r.add_width_range((192, 640))
+ # flexible_shape_utils.update_image_size_range(spec, feature_name='image', size_range=r)
+
+ # Print
+ print(spec.description)
+
+ # Model from spec
+ model = ct.models.MLModel(spec)
+
+ # 3. Create NMS protobuf
+ nms_spec = ct.proto.Model_pb2.Model()
+ nms_spec.specificationVersion = 5
+ for i in range(2):
+ decoder_output = model._spec.description.output[i].SerializeToString()
+ nms_spec.description.input.add()
+ nms_spec.description.input[i].ParseFromString(decoder_output)
+ nms_spec.description.output.add()
+ nms_spec.description.output[i].ParseFromString(decoder_output)
+
+ nms_spec.description.output[0].name = 'confidence'
+ nms_spec.description.output[1].name = 'coordinates'
+
+ output_sizes = [nc, 4]
+ for i in range(2):
+ ma_type = nms_spec.description.output[i].type.multiArrayType
+ ma_type.shapeRange.sizeRanges.add()
+ ma_type.shapeRange.sizeRanges[0].lowerBound = 0
+ ma_type.shapeRange.sizeRanges[0].upperBound = -1
+ ma_type.shapeRange.sizeRanges.add()
+ ma_type.shapeRange.sizeRanges[1].lowerBound = output_sizes[i]
+ ma_type.shapeRange.sizeRanges[1].upperBound = output_sizes[i]
+ del ma_type.shape[:]
+
+ nms = nms_spec.nonMaximumSuppression
+ nms.confidenceInputFeatureName = out0.name # 1x507x80
+ nms.coordinatesInputFeatureName = out1.name # 1x507x4
+ nms.confidenceOutputFeatureName = 'confidence'
+ nms.coordinatesOutputFeatureName = 'coordinates'
+ nms.iouThresholdInputFeatureName = 'iouThreshold'
+ nms.confidenceThresholdInputFeatureName = 'confidenceThreshold'
+ nms.iouThreshold = 0.45
+ nms.confidenceThreshold = 0.25
+ nms.pickTop.perClass = True
+ nms.stringClassLabels.vector.extend(names.values())
+ nms_model = ct.models.MLModel(nms_spec)
+
+ # 4. Pipeline models together
+ pipeline = ct.models.pipeline.Pipeline(input_features=[('image', ct.models.datatypes.Array(3, ny, nx)),
+ ('iouThreshold', ct.models.datatypes.Double()),
+ ('confidenceThreshold', ct.models.datatypes.Double())],
+ output_features=['confidence', 'coordinates'])
+ pipeline.add_model(model)
+ pipeline.add_model(nms_model)
+
+ # Correct datatypes
+ pipeline.spec.description.input[0].ParseFromString(model._spec.description.input[0].SerializeToString())
+ pipeline.spec.description.output[0].ParseFromString(nms_model._spec.description.output[0].SerializeToString())
+ pipeline.spec.description.output[1].ParseFromString(nms_model._spec.description.output[1].SerializeToString())
+
+ # Update metadata
+ pipeline.spec.specificationVersion = 5
+ pipeline.spec.description.metadata.versionString = 'https://github.com/ultralytics/yolov5'
+ pipeline.spec.description.metadata.shortDescription = 'https://github.com/ultralytics/yolov5'
+ pipeline.spec.description.metadata.author = 'glenn.jocher@ultralytics.com'
+ pipeline.spec.description.metadata.license = 'https://github.com/ultralytics/yolov5/blob/master/LICENSE'
+ pipeline.spec.description.metadata.userDefined.update({
+ 'classes': ','.join(names.values()),
+ 'iou_threshold': str(nms.iouThreshold),
+ 'confidence_threshold': str(nms.confidenceThreshold)})
+
+ # Save the model
+ f = file.with_suffix('.mlmodel') # filename
+ model = ct.models.MLModel(pipeline.spec)
+ model.input_description['image'] = 'Input image'
+ model.input_description['iouThreshold'] = f'(optional) IOU Threshold override (default: {nms.iouThreshold})'
+ model.input_description['confidenceThreshold'] = \
+ f'(optional) Confidence Threshold override (default: {nms.confidenceThreshold})'
+ model.output_description['confidence'] = 'Boxes × Class confidence (see user-defined metadata "classes")'
+ model.output_description['coordinates'] = 'Boxes × [x, y, width, height] (relative to image size)'
+ model.save(f) # pipelined
+ print(f'{prefix} pipeline success ({time.time() - t:.2f}s), saved as {f} ({file_size(f):.1f} MB)')
+
+
+@smart_inference_mode()
+def run(
+ data=ROOT / 'data/coco128.yaml', # 'dataset.yaml path'
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=(640, 640), # image (height, width)
+ batch_size=1, # batch size
+ device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ include=('torchscript', 'onnx'), # include formats
+ half=False, # FP16 half-precision export
+ inplace=False, # set YOLOv5 Detect() inplace=True
+ keras=False, # use Keras
+ optimize=False, # TorchScript: optimize for mobile
+ int8=False, # CoreML/TF INT8 quantization
+ dynamic=False, # ONNX/TF/TensorRT: dynamic axes
+ simplify=False, # ONNX: simplify model
+ opset=12, # ONNX: opset version
+ verbose=False, # TensorRT: verbose log
+ workspace=4, # TensorRT: workspace size (GB)
+ nms=False, # TF: add NMS to model
+ agnostic_nms=False, # TF: add agnostic NMS to model
+ topk_per_class=100, # TF.js NMS: topk per class to keep
+ topk_all=100, # TF.js NMS: topk for all classes to keep
+ iou_thres=0.45, # TF.js NMS: IoU threshold
+ conf_thres=0.25, # TF.js NMS: confidence threshold
+):
+ t = time.time()
+ include = [x.lower() for x in include] # to lowercase
+ fmts = tuple(export_formats()['Argument'][1:]) # --include arguments
+ flags = [x in include for x in fmts]
+ assert sum(flags) == len(include), f'ERROR: Invalid --include {include}, valid --include arguments are {fmts}'
+ jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle = flags # export booleans
+ file = Path(url2file(weights) if str(weights).startswith(('http:/', 'https:/')) else weights) # PyTorch weights
+
+ # Load PyTorch model
+ device = select_device(device)
+ if half:
+ assert device.type != 'cpu' or coreml, '--half only compatible with GPU export, i.e. use --device 0'
+ assert not dynamic, '--half not compatible with --dynamic, i.e. use either --half or --dynamic but not both'
+ model = attempt_load(weights, device=device, inplace=True, fuse=True) # load FP32 model
+
+ # Checks
+ imgsz *= 2 if len(imgsz) == 1 else 1 # expand
+ if optimize:
+ assert device.type == 'cpu', '--optimize not compatible with cuda devices, i.e. use --device cpu'
+
+ # Input
+ gs = int(max(model.stride)) # grid size (max stride)
+ imgsz = [check_img_size(x, gs) for x in imgsz] # verify img_size are gs-multiples
+ im = torch.zeros(batch_size, 3, *imgsz).to(device) # image size(1,3,320,192) BCHW iDetection
+
+ # Update model
+ model.eval()
+ for k, m in model.named_modules():
+ if isinstance(m, Detect):
+ m.inplace = inplace
+ m.dynamic = dynamic
+ m.export = True
+
+ for _ in range(2):
+ y = model(im) # dry runs
+ if half and not coreml:
+ im, model = im.half(), model.half() # to FP16
+ shape = tuple((y[0] if isinstance(y, tuple) else y).shape) # model output shape
+ metadata = {'stride': int(max(model.stride)), 'names': model.names} # model metadata
+ LOGGER.info(f"\n{colorstr('PyTorch:')} starting from {file} with output shape {shape} ({file_size(file):.1f} MB)")
+
+ # Exports
+ f = [''] * len(fmts) # exported filenames
+ warnings.filterwarnings(action='ignore', category=torch.jit.TracerWarning) # suppress TracerWarning
+ if jit: # TorchScript
+ f[0], _ = export_torchscript(model, im, file, optimize)
+ if engine: # TensorRT required before ONNX
+ f[1], _ = export_engine(model, im, file, half, dynamic, simplify, workspace, verbose)
+ if onnx or xml: # OpenVINO requires ONNX
+ f[2], _ = export_onnx(model, im, file, opset, dynamic, simplify)
+ if xml: # OpenVINO
+ f[3], _ = export_openvino(file, metadata, half)
+ if coreml: # CoreML
+ f[4], ct_model = export_coreml(model, im, file, int8, half, nms)
+ if nms:
+ pipeline_coreml(ct_model, im, file, model.names, y)
+ if any((saved_model, pb, tflite, edgetpu, tfjs)): # TensorFlow formats
+ assert not tflite or not tfjs, 'TFLite and TF.js models must be exported separately, please pass only one type.'
+ assert not isinstance(model, ClassificationModel), 'ClassificationModel export to TF formats not yet supported.'
+ f[5], s_model = export_saved_model(model.cpu(),
+ im,
+ file,
+ dynamic,
+ tf_nms=nms or agnostic_nms or tfjs,
+ agnostic_nms=agnostic_nms or tfjs,
+ topk_per_class=topk_per_class,
+ topk_all=topk_all,
+ iou_thres=iou_thres,
+ conf_thres=conf_thres,
+ keras=keras)
+ if pb or tfjs: # pb prerequisite to tfjs
+ f[6], _ = export_pb(s_model, file)
+ if tflite or edgetpu:
+ f[7], _ = export_tflite(s_model, im, file, int8 or edgetpu, data=data, nms=nms, agnostic_nms=agnostic_nms)
+ if edgetpu:
+ f[8], _ = export_edgetpu(file)
+ add_tflite_metadata(f[8] or f[7], metadata, num_outputs=len(s_model.outputs))
+ if tfjs:
+ f[9], _ = export_tfjs(file, int8)
+ if paddle: # PaddlePaddle
+ f[10], _ = export_paddle(model, im, file, metadata)
+
+ # Finish
+ f = [str(x) for x in f if x] # filter out '' and None
+ if any(f):
+ cls, det, seg = (isinstance(model, x) for x in (ClassificationModel, DetectionModel, SegmentationModel)) # type
+ det &= not seg # segmentation models inherit from SegmentationModel(DetectionModel)
+ dir = Path('segment' if seg else 'classify' if cls else '')
+ h = '--half' if half else '' # --half FP16 inference arg
+ s = '# WARNING ⚠️ ClassificationModel not yet supported for PyTorch Hub AutoShape inference' if cls else \
+ '# WARNING ⚠️ SegmentationModel not yet supported for PyTorch Hub AutoShape inference' if seg else ''
+ LOGGER.info(f'\nExport complete ({time.time() - t:.1f}s)'
+ f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
+ f"\nDetect: python {dir / ('detect.py' if det else 'predict.py')} --weights {f[-1]} {h}"
+ f"\nValidate: python {dir / 'val.py'} --weights {f[-1]} {h}"
+ f"\nPyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', '{f[-1]}') {s}"
+ f'\nVisualize: https://netron.app')
+ return f # return list of exported files/dirs
+
+
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
+ parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
+ parser.add_argument('--keras', action='store_true', help='TF: use Keras')
+ parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
+ parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
+ parser.add_argument('--dynamic', action='store_true', help='ONNX/TF/TensorRT: dynamic axes')
+ parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
+ parser.add_argument('--opset', type=int, default=17, help='ONNX: opset version')
+ parser.add_argument('--verbose', action='store_true', help='TensorRT: verbose log')
+ parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')
+ parser.add_argument('--nms', action='store_true', help='TF: add NMS to model')
+ parser.add_argument('--agnostic-nms', action='store_true', help='TF: add agnostic NMS to model')
+ parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
+ parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
+ parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
+ parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
+ parser.add_argument(
+ '--include',
+ nargs='+',
+ default=['torchscript'],
+ help='torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle')
+ opt = parser.parse_known_args()[0] if known else parser.parse_args()
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ for opt.weights in (opt.weights if isinstance(opt.weights, list) else [opt.weights]):
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/hubconf.py b/yolov5/hubconf.py
new file mode 100644
index 0000000000000000000000000000000000000000..73caf06685da77db0c63cd4e392d86b949c00a97
--- /dev/null
+++ b/yolov5/hubconf.py
@@ -0,0 +1,169 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+PyTorch Hub models https://pytorch.org/hub/ultralytics_yolov5
+
+Usage:
+ import torch
+ model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # official model
+ model = torch.hub.load('ultralytics/yolov5:master', 'yolov5s') # from branch
+ model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.pt') # custom/local model
+ model = torch.hub.load('.', 'custom', 'yolov5s.pt', source='local') # local repo
+"""
+
+import torch
+
+
+def _create(name, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ """Creates or loads a YOLOv5 model
+
+ Arguments:
+ name (str): model name 'yolov5s' or path 'path/to/best.pt'
+ pretrained (bool): load pretrained weights into the model
+ channels (int): number of input channels
+ classes (int): number of model classes
+ autoshape (bool): apply YOLOv5 .autoshape() wrapper to model
+ verbose (bool): print all information to screen
+ device (str, torch.device, None): device to use for model parameters
+
+ Returns:
+ YOLOv5 model
+ """
+ from pathlib import Path
+
+ from models.common import AutoShape, DetectMultiBackend
+ from models.experimental import attempt_load
+ from models.yolo import ClassificationModel, DetectionModel, SegmentationModel
+ from utils.downloads import attempt_download
+ from utils.general import LOGGER, check_requirements, intersect_dicts, logging
+ from utils.torch_utils import select_device
+
+ if not verbose:
+ LOGGER.setLevel(logging.WARNING)
+ check_requirements(exclude=('opencv-python', 'tensorboard', 'thop'))
+ name = Path(name)
+ path = name.with_suffix('.pt') if name.suffix == '' and not name.is_dir() else name # checkpoint path
+ try:
+ device = select_device(device)
+ if pretrained and channels == 3 and classes == 80:
+ try:
+ model = DetectMultiBackend(path, device=device, fuse=autoshape) # detection model
+ if autoshape:
+ if model.pt and isinstance(model.model, ClassificationModel):
+ LOGGER.warning('WARNING ⚠️ YOLOv5 ClassificationModel is not yet AutoShape compatible. '
+ 'You must pass torch tensors in BCHW to this model, i.e. shape(1,3,224,224).')
+ elif model.pt and isinstance(model.model, SegmentationModel):
+ LOGGER.warning('WARNING ⚠️ YOLOv5 SegmentationModel is not yet AutoShape compatible. '
+ 'You will not be able to run inference with this model.')
+ else:
+ model = AutoShape(model) # for file/URI/PIL/cv2/np inputs and NMS
+ except Exception:
+ model = attempt_load(path, device=device, fuse=False) # arbitrary model
+ else:
+ cfg = list((Path(__file__).parent / 'models').rglob(f'{path.stem}.yaml'))[0] # model.yaml path
+ model = DetectionModel(cfg, channels, classes) # create model
+ if pretrained:
+ ckpt = torch.load(attempt_download(path), map_location=device) # load
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=['anchors']) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ if len(ckpt['model'].names) == classes:
+ model.names = ckpt['model'].names # set class names attribute
+ if not verbose:
+ LOGGER.setLevel(logging.INFO) # reset to default
+ return model.to(device)
+
+ except Exception as e:
+ help_url = 'https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading'
+ s = f'{e}. Cache may be out of date, try `force_reload=True` or see {help_url} for help.'
+ raise Exception(s) from e
+
+
+def custom(path='path/to/model.pt', autoshape=True, _verbose=True, device=None):
+ # YOLOv5 custom or local model
+ return _create(path, autoshape=autoshape, verbose=_verbose, device=device)
+
+
+def yolov5n(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-nano model https://github.com/ultralytics/yolov5
+ return _create('yolov5n', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5s(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-small model https://github.com/ultralytics/yolov5
+ return _create('yolov5s', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5m(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-medium model https://github.com/ultralytics/yolov5
+ return _create('yolov5m', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5l(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-large model https://github.com/ultralytics/yolov5
+ return _create('yolov5l', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5x(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-xlarge model https://github.com/ultralytics/yolov5
+ return _create('yolov5x', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5n6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-nano-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5n6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5s6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-small-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5s6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5m6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-medium-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5m6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5l6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-large-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5l6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5x6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-xlarge-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5x6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+if __name__ == '__main__':
+ import argparse
+ from pathlib import Path
+
+ import numpy as np
+ from PIL import Image
+
+ from utils.general import cv2, print_args
+
+ # Argparser
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model', type=str, default='yolov5s', help='model name')
+ opt = parser.parse_args()
+ print_args(vars(opt))
+
+ # Model
+ model = _create(name=opt.model, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True)
+ # model = custom(path='path/to/model.pt') # custom
+
+ # Images
+ imgs = [
+ 'data/images/zidane.jpg', # filename
+ Path('data/images/zidane.jpg'), # Path
+ 'https://ultralytics.com/images/zidane.jpg', # URI
+ cv2.imread('data/images/bus.jpg')[:, :, ::-1], # OpenCV
+ Image.open('data/images/bus.jpg'), # PIL
+ np.zeros((320, 640, 3))] # numpy
+
+ # Inference
+ results = model(imgs, size=320) # batched inference
+
+ # Results
+ results.print()
+ results.save()
diff --git a/yolov5/models/__init__.py b/yolov5/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/yolov5/models/__pycache__/__init__.cpython-38.pyc b/yolov5/models/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..201b0be1e7b16b0da38c04b7821c4270d8660afa
Binary files /dev/null and b/yolov5/models/__pycache__/__init__.cpython-38.pyc differ
diff --git a/yolov5/models/__pycache__/__init__.cpython-39.pyc b/yolov5/models/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1e2934992bf072ae51810e1a233430da994a619a
Binary files /dev/null and b/yolov5/models/__pycache__/__init__.cpython-39.pyc differ
diff --git a/yolov5/models/__pycache__/common.cpython-38.pyc b/yolov5/models/__pycache__/common.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..70840eab1adda4358a1bb42aa122c01be5ab2deb
Binary files /dev/null and b/yolov5/models/__pycache__/common.cpython-38.pyc differ
diff --git a/yolov5/models/__pycache__/common.cpython-39.pyc b/yolov5/models/__pycache__/common.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cc4d87ba7fc3585e43ebcc5d59e4322bec3dfa70
Binary files /dev/null and b/yolov5/models/__pycache__/common.cpython-39.pyc differ
diff --git a/yolov5/models/__pycache__/experimental.cpython-38.pyc b/yolov5/models/__pycache__/experimental.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..04ea5916faadc4be3af14ff694036a616b004a63
Binary files /dev/null and b/yolov5/models/__pycache__/experimental.cpython-38.pyc differ
diff --git a/yolov5/models/__pycache__/experimental.cpython-39.pyc b/yolov5/models/__pycache__/experimental.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4a6ecb9e6caff1ec001af5bc33211aa7789d30dd
Binary files /dev/null and b/yolov5/models/__pycache__/experimental.cpython-39.pyc differ
diff --git a/yolov5/models/__pycache__/yolo.cpython-38.pyc b/yolov5/models/__pycache__/yolo.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..86681e5c39429e7bcefebc8749870dd9b7fe69ea
Binary files /dev/null and b/yolov5/models/__pycache__/yolo.cpython-38.pyc differ
diff --git a/yolov5/models/__pycache__/yolo.cpython-39.pyc b/yolov5/models/__pycache__/yolo.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3d54a1a671e81b0cf71b257ab3ae9c74c93a20f8
Binary files /dev/null and b/yolov5/models/__pycache__/yolo.cpython-39.pyc differ
diff --git a/yolov5/models/common.py b/yolov5/models/common.py
new file mode 100644
index 0000000000000000000000000000000000000000..195ccd63a10c64de45de57fc2fe1653d3e745a0e
--- /dev/null
+++ b/yolov5/models/common.py
@@ -0,0 +1,871 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Common modules
+"""
+
+import ast
+import contextlib
+import json
+import math
+import platform
+import warnings
+import zipfile
+from collections import OrderedDict, namedtuple
+from copy import copy
+from pathlib import Path
+from urllib.parse import urlparse
+
+import cv2
+import numpy as np
+import pandas as pd
+import requests
+import torch
+import torch.nn as nn
+from PIL import Image
+from torch.cuda import amp
+
+from yolov5.utils import TryExcept
+from yolov5.utils.dataloaders import exif_transpose, letterbox
+from yolov5.utils.general import (LOGGER, ROOT, Profile, check_requirements, check_suffix, check_version, colorstr,
+ increment_path, is_jupyter, make_divisible, non_max_suppression, scale_boxes, xywh2xyxy,
+ xyxy2xywh, yaml_load)
+from yolov5.utils.plots import Annotator, colors, save_one_box
+from yolov5.utils.torch_utils import copy_attr, smart_inference_mode
+
+
+def autopad(k, p=None, d=1): # kernel, padding, dilation
+ # Pad to 'same' shape outputs
+ if d > 1:
+ k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
+ if p is None:
+ p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
+ return p
+
+
+class Conv(nn.Module):
+ # Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
+ default_act = nn.SiLU() # default activation
+
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
+ self.bn = nn.BatchNorm2d(c2)
+ self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
+
+ def forward(self, x):
+ return self.act(self.bn(self.conv(x)))
+
+ def forward_fuse(self, x):
+ return self.act(self.conv(x))
+
+
+class DWConv(Conv):
+ # Depth-wise convolution
+ def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation
+ super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
+
+
+class DWConvTranspose2d(nn.ConvTranspose2d):
+ # Depth-wise transpose convolution
+ def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # ch_in, ch_out, kernel, stride, padding, padding_out
+ super().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))
+
+
+class TransformerLayer(nn.Module):
+ # Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
+ def __init__(self, c, num_heads):
+ super().__init__()
+ self.q = nn.Linear(c, c, bias=False)
+ self.k = nn.Linear(c, c, bias=False)
+ self.v = nn.Linear(c, c, bias=False)
+ self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
+ self.fc1 = nn.Linear(c, c, bias=False)
+ self.fc2 = nn.Linear(c, c, bias=False)
+
+ def forward(self, x):
+ x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
+ x = self.fc2(self.fc1(x)) + x
+ return x
+
+
+class TransformerBlock(nn.Module):
+ # Vision Transformer https://arxiv.org/abs/2010.11929
+ def __init__(self, c1, c2, num_heads, num_layers):
+ super().__init__()
+ self.conv = None
+ if c1 != c2:
+ self.conv = Conv(c1, c2)
+ self.linear = nn.Linear(c2, c2) # learnable position embedding
+ self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
+ self.c2 = c2
+
+ def forward(self, x):
+ if self.conv is not None:
+ x = self.conv(x)
+ b, _, w, h = x.shape
+ p = x.flatten(2).permute(2, 0, 1)
+ return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
+
+
+class Bottleneck(nn.Module):
+ # Standard bottleneck
+ def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_, c2, 3, 1, g=g)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class BottleneckCSP(nn.Module):
+ # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
+ self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
+ self.cv4 = Conv(2 * c_, c2, 1, 1)
+ self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
+ self.act = nn.SiLU()
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
+
+ def forward(self, x):
+ y1 = self.cv3(self.m(self.cv1(x)))
+ y2 = self.cv2(x)
+ return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))
+
+
+class CrossConv(nn.Module):
+ # Cross Convolution Downsample
+ def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
+ # ch_in, ch_out, kernel, stride, groups, expansion, shortcut
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, (1, k), (1, s))
+ self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class C3(nn.Module):
+ # CSP Bottleneck with 3 convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c1, c_, 1, 1)
+ self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
+
+ def forward(self, x):
+ return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
+
+
+class C3x(C3):
+ # C3 module with cross-convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = nn.Sequential(*(CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)))
+
+
+class C3TR(C3):
+ # C3 module with TransformerBlock()
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = TransformerBlock(c_, c_, 4, n)
+
+
+class C3SPP(C3):
+ # C3 module with SPP()
+ def __init__(self, c1, c2, k=(5, 9, 13), n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = SPP(c_, c_, k)
+
+
+class C3Ghost(C3):
+ # C3 module with GhostBottleneck()
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e) # hidden channels
+ self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
+
+
+class SPP(nn.Module):
+ # Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
+ def __init__(self, c1, c2, k=(5, 9, 13)):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
+ self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
+
+ def forward(self, x):
+ x = self.cv1(x)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
+ return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
+
+
+class SPPF(nn.Module):
+ # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
+ def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * 4, c2, 1, 1)
+ self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
+
+ def forward(self, x):
+ x = self.cv1(x)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
+
+
+class Focus(nn.Module):
+ # Focus wh information into c-space
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
+ # self.contract = Contract(gain=2)
+
+ def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
+ return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
+ # return self.conv(self.contract(x))
+
+
+class GhostConv(nn.Module):
+ # Ghost Convolution https://github.com/huawei-noah/ghostnet
+ def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
+ super().__init__()
+ c_ = c2 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, k, s, None, g, act=act)
+ self.cv2 = Conv(c_, c_, 5, 1, None, c_, act=act)
+
+ def forward(self, x):
+ y = self.cv1(x)
+ return torch.cat((y, self.cv2(y)), 1)
+
+
+class GhostBottleneck(nn.Module):
+ # Ghost Bottleneck https://github.com/huawei-noah/ghostnet
+ def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
+ super().__init__()
+ c_ = c2 // 2
+ self.conv = nn.Sequential(
+ GhostConv(c1, c_, 1, 1), # pw
+ DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dw
+ GhostConv(c_, c2, 1, 1, act=False)) # pw-linear
+ self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False), Conv(c1, c2, 1, 1,
+ act=False)) if s == 2 else nn.Identity()
+
+ def forward(self, x):
+ return self.conv(x) + self.shortcut(x)
+
+
+class Contract(nn.Module):
+ # Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
+ def __init__(self, gain=2):
+ super().__init__()
+ self.gain = gain
+
+ def forward(self, x):
+ b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain'
+ s = self.gain
+ x = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)
+ x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
+ return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)
+
+
+class Expand(nn.Module):
+ # Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
+ def __init__(self, gain=2):
+ super().__init__()
+ self.gain = gain
+
+ def forward(self, x):
+ b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
+ s = self.gain
+ x = x.view(b, s, s, c // s ** 2, h, w) # x(1,2,2,16,80,80)
+ x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
+ return x.view(b, c // s ** 2, h * s, w * s) # x(1,16,160,160)
+
+
+class Concat(nn.Module):
+ # Concatenate a list of tensors along dimension
+ def __init__(self, dimension=1):
+ super().__init__()
+ self.d = dimension
+
+ def forward(self, x):
+ return torch.cat(x, self.d)
+
+
+class DetectMultiBackend(nn.Module):
+ # YOLOv5 MultiBackend class for python inference on various backends
+ def __init__(self, weights='yolov5s.pt', device=torch.device('cpu'), dnn=False, data=None, fp16=False, fuse=True):
+ # Usage:
+ # PyTorch: weights = *.pt
+ # TorchScript: *.torchscript
+ # ONNX Runtime: *.onnx
+ # ONNX OpenCV DNN: *.onnx --dnn
+ # OpenVINO: *_openvino_model
+ # CoreML: *.mlmodel
+ # TensorRT: *.engine
+ # TensorFlow SavedModel: *_saved_model
+ # TensorFlow GraphDef: *.pb
+ # TensorFlow Lite: *.tflite
+ # TensorFlow Edge TPU: *_edgetpu.tflite
+ # PaddlePaddle: *_paddle_model
+ from models.experimental import attempt_download, attempt_load # scoped to avoid circular import
+
+ super().__init__()
+ w = str(weights[0] if isinstance(weights, list) else weights)
+ pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle, triton = self._model_type(w)
+ fp16 &= pt or jit or onnx or engine # FP16
+ nhwc = coreml or saved_model or pb or tflite or edgetpu # BHWC formats (vs torch BCWH)
+ stride = 32 # default stride
+ cuda = torch.cuda.is_available() and device.type != 'cpu' # use CUDA
+ if not (pt or triton):
+ w = attempt_download(w) # download if not local
+
+ if pt: # PyTorch
+ model = attempt_load(weights if isinstance(weights, list) else w, device=device, inplace=True, fuse=fuse)
+ stride = max(int(model.stride.max()), 32) # model stride
+ names = model.module.names if hasattr(model, 'module') else model.names # get class names
+ model.half() if fp16 else model.float()
+ self.model = model # explicitly assign for to(), cpu(), cuda(), half()
+ elif jit: # TorchScript
+ LOGGER.info(f'Loading {w} for TorchScript inference...')
+ extra_files = {'config.txt': ''} # model metadata
+ model = torch.jit.load(w, _extra_files=extra_files, map_location=device)
+ model.half() if fp16 else model.float()
+ if extra_files['config.txt']: # load metadata dict
+ d = json.loads(extra_files['config.txt'],
+ object_hook=lambda d: {
+ int(k) if k.isdigit() else k: v
+ for k, v in d.items()})
+ stride, names = int(d['stride']), d['names']
+ elif dnn: # ONNX OpenCV DNN
+ LOGGER.info(f'Loading {w} for ONNX OpenCV DNN inference...')
+ check_requirements('opencv-python>=4.5.4')
+ net = cv2.dnn.readNetFromONNX(w)
+ elif onnx: # ONNX Runtime
+ LOGGER.info(f'Loading {w} for ONNX Runtime inference...')
+ check_requirements(('onnx', 'onnxruntime-gpu' if cuda else 'onnxruntime'))
+ import onnxruntime
+ providers = ['CUDAExecutionProvider', 'CPUExecutionProvider'] if cuda else ['CPUExecutionProvider']
+ session = onnxruntime.InferenceSession(w, providers=providers)
+ output_names = [x.name for x in session.get_outputs()]
+ meta = session.get_modelmeta().custom_metadata_map # metadata
+ if 'stride' in meta:
+ stride, names = int(meta['stride']), eval(meta['names'])
+ elif xml: # OpenVINO
+ LOGGER.info(f'Loading {w} for OpenVINO inference...')
+ check_requirements('openvino') # requires openvino-dev: https://pypi.org/project/openvino-dev/
+ from openvino.runtime import Core, Layout, get_batch
+ ie = Core()
+ if not Path(w).is_file(): # if not *.xml
+ w = next(Path(w).glob('*.xml')) # get *.xml file from *_openvino_model dir
+ network = ie.read_model(model=w, weights=Path(w).with_suffix('.bin'))
+ if network.get_parameters()[0].get_layout().empty:
+ network.get_parameters()[0].set_layout(Layout('NCHW'))
+ batch_dim = get_batch(network)
+ if batch_dim.is_static:
+ batch_size = batch_dim.get_length()
+ executable_network = ie.compile_model(network, device_name='CPU') # device_name="MYRIAD" for Intel NCS2
+ stride, names = self._load_metadata(Path(w).with_suffix('.yaml')) # load metadata
+ elif engine: # TensorRT
+ LOGGER.info(f'Loading {w} for TensorRT inference...')
+ import tensorrt as trt # https://developer.nvidia.com/nvidia-tensorrt-download
+ check_version(trt.__version__, '7.0.0', hard=True) # require tensorrt>=7.0.0
+ if device.type == 'cpu':
+ device = torch.device('cuda:0')
+ Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))
+ logger = trt.Logger(trt.Logger.INFO)
+ with open(w, 'rb') as f, trt.Runtime(logger) as runtime:
+ model = runtime.deserialize_cuda_engine(f.read())
+ context = model.create_execution_context()
+ bindings = OrderedDict()
+ output_names = []
+ fp16 = False # default updated below
+ dynamic = False
+ for i in range(model.num_bindings):
+ name = model.get_binding_name(i)
+ dtype = trt.nptype(model.get_binding_dtype(i))
+ if model.binding_is_input(i):
+ if -1 in tuple(model.get_binding_shape(i)): # dynamic
+ dynamic = True
+ context.set_binding_shape(i, tuple(model.get_profile_shape(0, i)[2]))
+ if dtype == np.float16:
+ fp16 = True
+ else: # output
+ output_names.append(name)
+ shape = tuple(context.get_binding_shape(i))
+ im = torch.from_numpy(np.empty(shape, dtype=dtype)).to(device)
+ bindings[name] = Binding(name, dtype, shape, im, int(im.data_ptr()))
+ binding_addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())
+ batch_size = bindings['images'].shape[0] # if dynamic, this is instead max batch size
+ elif coreml: # CoreML
+ LOGGER.info(f'Loading {w} for CoreML inference...')
+ import coremltools as ct
+ model = ct.models.MLModel(w)
+ elif saved_model: # TF SavedModel
+ LOGGER.info(f'Loading {w} for TensorFlow SavedModel inference...')
+ import tensorflow as tf
+ keras = False # assume TF1 saved_model
+ model = tf.keras.models.load_model(w) if keras else tf.saved_model.load(w)
+ elif pb: # GraphDef https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
+ LOGGER.info(f'Loading {w} for TensorFlow GraphDef inference...')
+ import tensorflow as tf
+
+ def wrap_frozen_graph(gd, inputs, outputs):
+ x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=''), []) # wrapped
+ ge = x.graph.as_graph_element
+ return x.prune(tf.nest.map_structure(ge, inputs), tf.nest.map_structure(ge, outputs))
+
+ def gd_outputs(gd):
+ name_list, input_list = [], []
+ for node in gd.node: # tensorflow.core.framework.node_def_pb2.NodeDef
+ name_list.append(node.name)
+ input_list.extend(node.input)
+ return sorted(f'{x}:0' for x in list(set(name_list) - set(input_list)) if not x.startswith('NoOp'))
+
+ gd = tf.Graph().as_graph_def() # TF GraphDef
+ with open(w, 'rb') as f:
+ gd.ParseFromString(f.read())
+ frozen_func = wrap_frozen_graph(gd, inputs='x:0', outputs=gd_outputs(gd))
+ elif tflite or edgetpu: # https://www.tensorflow.org/lite/guide/python#install_tensorflow_lite_for_python
+ try: # https://coral.ai/docs/edgetpu/tflite-python/#update-existing-tf-lite-code-for-the-edge-tpu
+ from tflite_runtime.interpreter import Interpreter, load_delegate
+ except ImportError:
+ import tensorflow as tf
+ Interpreter, load_delegate = tf.lite.Interpreter, tf.lite.experimental.load_delegate,
+ if edgetpu: # TF Edge TPU https://coral.ai/software/#edgetpu-runtime
+ LOGGER.info(f'Loading {w} for TensorFlow Lite Edge TPU inference...')
+ delegate = {
+ 'Linux': 'libedgetpu.so.1',
+ 'Darwin': 'libedgetpu.1.dylib',
+ 'Windows': 'edgetpu.dll'}[platform.system()]
+ interpreter = Interpreter(model_path=w, experimental_delegates=[load_delegate(delegate)])
+ else: # TFLite
+ LOGGER.info(f'Loading {w} for TensorFlow Lite inference...')
+ interpreter = Interpreter(model_path=w) # load TFLite model
+ interpreter.allocate_tensors() # allocate
+ input_details = interpreter.get_input_details() # inputs
+ output_details = interpreter.get_output_details() # outputs
+ # load metadata
+ with contextlib.suppress(zipfile.BadZipFile):
+ with zipfile.ZipFile(w, 'r') as model:
+ meta_file = model.namelist()[0]
+ meta = ast.literal_eval(model.read(meta_file).decode('utf-8'))
+ stride, names = int(meta['stride']), meta['names']
+ elif tfjs: # TF.js
+ raise NotImplementedError('ERROR: YOLOv5 TF.js inference is not supported')
+ elif paddle: # PaddlePaddle
+ LOGGER.info(f'Loading {w} for PaddlePaddle inference...')
+ check_requirements('paddlepaddle-gpu' if cuda else 'paddlepaddle')
+ import paddle.inference as pdi
+ if not Path(w).is_file(): # if not *.pdmodel
+ w = next(Path(w).rglob('*.pdmodel')) # get *.pdmodel file from *_paddle_model dir
+ weights = Path(w).with_suffix('.pdiparams')
+ config = pdi.Config(str(w), str(weights))
+ if cuda:
+ config.enable_use_gpu(memory_pool_init_size_mb=2048, device_id=0)
+ predictor = pdi.create_predictor(config)
+ input_handle = predictor.get_input_handle(predictor.get_input_names()[0])
+ output_names = predictor.get_output_names()
+ elif triton: # NVIDIA Triton Inference Server
+ LOGGER.info(f'Using {w} as Triton Inference Server...')
+ check_requirements('tritonclient[all]')
+ from utils.triton import TritonRemoteModel
+ model = TritonRemoteModel(url=w)
+ nhwc = model.runtime.startswith('tensorflow')
+ else:
+ raise NotImplementedError(f'ERROR: {w} is not a supported format')
+
+ # class names
+ if 'names' not in locals():
+ names = yaml_load(data)['names'] if data else {i: f'class{i}' for i in range(999)}
+ if names[0] == 'n01440764' and len(names) == 1000: # ImageNet
+ names = yaml_load(ROOT / 'data/ImageNet.yaml')['names'] # human-readable names
+
+ self.__dict__.update(locals()) # assign all variables to self
+
+ def forward(self, im, augment=False, visualize=False):
+ # YOLOv5 MultiBackend inference
+ b, ch, h, w = im.shape # batch, channel, height, width
+ if self.fp16 and im.dtype != torch.float16:
+ im = im.half() # to FP16
+ if self.nhwc:
+ im = im.permute(0, 2, 3, 1) # torch BCHW to numpy BHWC shape(1,320,192,3)
+
+ if self.pt: # PyTorch
+ y = self.model(im, augment=augment, visualize=visualize) if augment or visualize else self.model(im)
+ elif self.jit: # TorchScript
+ y = self.model(im)
+ elif self.dnn: # ONNX OpenCV DNN
+ im = im.cpu().numpy() # torch to numpy
+ self.net.setInput(im)
+ y = self.net.forward()
+ elif self.onnx: # ONNX Runtime
+ im = im.cpu().numpy() # torch to numpy
+ y = self.session.run(self.output_names, {self.session.get_inputs()[0].name: im})
+ elif self.xml: # OpenVINO
+ im = im.cpu().numpy() # FP32
+ y = list(self.executable_network([im]).values())
+ elif self.engine: # TensorRT
+ if self.dynamic and im.shape != self.bindings['images'].shape:
+ i = self.model.get_binding_index('images')
+ self.context.set_binding_shape(i, im.shape) # reshape if dynamic
+ self.bindings['images'] = self.bindings['images']._replace(shape=im.shape)
+ for name in self.output_names:
+ i = self.model.get_binding_index(name)
+ self.bindings[name].data.resize_(tuple(self.context.get_binding_shape(i)))
+ s = self.bindings['images'].shape
+ assert im.shape == s, f"input size {im.shape} {'>' if self.dynamic else 'not equal to'} max model size {s}"
+ self.binding_addrs['images'] = int(im.data_ptr())
+ self.context.execute_v2(list(self.binding_addrs.values()))
+ y = [self.bindings[x].data for x in sorted(self.output_names)]
+ elif self.coreml: # CoreML
+ im = im.cpu().numpy()
+ im = Image.fromarray((im[0] * 255).astype('uint8'))
+ # im = im.resize((192, 320), Image.ANTIALIAS)
+ y = self.model.predict({'image': im}) # coordinates are xywh normalized
+ if 'confidence' in y:
+ box = xywh2xyxy(y['coordinates'] * [[w, h, w, h]]) # xyxy pixels
+ conf, cls = y['confidence'].max(1), y['confidence'].argmax(1).astype(np.float)
+ y = np.concatenate((box, conf.reshape(-1, 1), cls.reshape(-1, 1)), 1)
+ else:
+ y = list(reversed(y.values())) # reversed for segmentation models (pred, proto)
+ elif self.paddle: # PaddlePaddle
+ im = im.cpu().numpy().astype(np.float32)
+ self.input_handle.copy_from_cpu(im)
+ self.predictor.run()
+ y = [self.predictor.get_output_handle(x).copy_to_cpu() for x in self.output_names]
+ elif self.triton: # NVIDIA Triton Inference Server
+ y = self.model(im)
+ else: # TensorFlow (SavedModel, GraphDef, Lite, Edge TPU)
+ im = im.cpu().numpy()
+ if self.saved_model: # SavedModel
+ y = self.model(im, training=False) if self.keras else self.model(im)
+ elif self.pb: # GraphDef
+ y = self.frozen_func(x=self.tf.constant(im))
+ else: # Lite or Edge TPU
+ input = self.input_details[0]
+ int8 = input['dtype'] == np.uint8 # is TFLite quantized uint8 model
+ if int8:
+ scale, zero_point = input['quantization']
+ im = (im / scale + zero_point).astype(np.uint8) # de-scale
+ self.interpreter.set_tensor(input['index'], im)
+ self.interpreter.invoke()
+ y = []
+ for output in self.output_details:
+ x = self.interpreter.get_tensor(output['index'])
+ if int8:
+ scale, zero_point = output['quantization']
+ x = (x.astype(np.float32) - zero_point) * scale # re-scale
+ y.append(x)
+ y = [x if isinstance(x, np.ndarray) else x.numpy() for x in y]
+ y[0][..., :4] *= [w, h, w, h] # xywh normalized to pixels
+
+ if isinstance(y, (list, tuple)):
+ return self.from_numpy(y[0]) if len(y) == 1 else [self.from_numpy(x) for x in y]
+ else:
+ return self.from_numpy(y)
+
+ def from_numpy(self, x):
+ return torch.from_numpy(x).to(self.device) if isinstance(x, np.ndarray) else x
+
+ def warmup(self, imgsz=(1, 3, 640, 640)):
+ # Warmup model by running inference once
+ warmup_types = self.pt, self.jit, self.onnx, self.engine, self.saved_model, self.pb, self.triton
+ if any(warmup_types) and (self.device.type != 'cpu' or self.triton):
+ im = torch.empty(*imgsz, dtype=torch.half if self.fp16 else torch.float, device=self.device) # input
+ for _ in range(2 if self.jit else 1): #
+ self.forward(im) # warmup
+
+ @staticmethod
+ def _model_type(p='path/to/model.pt'):
+ # Return model type from model path, i.e. path='path/to/model.onnx' -> type=onnx
+ # types = [pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle]
+ from yolov5.export import export_formats
+ from yolov5.utils.downloads import is_url
+ sf = list(export_formats().Suffix) # export suffixes
+ if not is_url(p, check=False):
+ check_suffix(p, sf) # checks
+ url = urlparse(p) # if url may be Triton inference server
+ types = [s in Path(p).name for s in sf]
+ types[8] &= not types[9] # tflite &= not edgetpu
+ triton = not any(types) and all([any(s in url.scheme for s in ['http', 'grpc']), url.netloc])
+ return types + [triton]
+
+ @staticmethod
+ def _load_metadata(f=Path('path/to/meta.yaml')):
+ # Load metadata from meta.yaml if it exists
+ if f.exists():
+ d = yaml_load(f)
+ return d['stride'], d['names'] # assign stride, names
+ return None, None
+
+
+class AutoShape(nn.Module):
+ # YOLOv5 input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMS
+ conf = 0.25 # NMS confidence threshold
+ iou = 0.45 # NMS IoU threshold
+ agnostic = False # NMS class-agnostic
+ multi_label = False # NMS multiple labels per box
+ classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
+ max_det = 1000 # maximum number of detections per image
+ amp = False # Automatic Mixed Precision (AMP) inference
+
+ def __init__(self, model, verbose=True):
+ super().__init__()
+ if verbose:
+ LOGGER.info('Adding AutoShape... ')
+ copy_attr(self, model, include=('yaml', 'nc', 'hyp', 'names', 'stride', 'abc'), exclude=()) # copy attributes
+ self.dmb = isinstance(model, DetectMultiBackend) # DetectMultiBackend() instance
+ self.pt = not self.dmb or model.pt # PyTorch model
+ self.model = model.eval()
+ if self.pt:
+ m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()
+ m.inplace = False # Detect.inplace=False for safe multithread inference
+ m.export = True # do not output loss values
+
+ def _apply(self, fn):
+ # Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
+ self = super()._apply(fn)
+ if self.pt:
+ m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()
+ m.stride = fn(m.stride)
+ m.grid = list(map(fn, m.grid))
+ if isinstance(m.anchor_grid, list):
+ m.anchor_grid = list(map(fn, m.anchor_grid))
+ return self
+
+ @smart_inference_mode()
+ def forward(self, ims, size=640, augment=False, profile=False):
+ # Inference from various sources. For size(height=640, width=1280), RGB images example inputs are:
+ # file: ims = 'data/images/zidane.jpg' # str or PosixPath
+ # URI: = 'https://ultralytics.com/images/zidane.jpg'
+ # OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)
+ # PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)
+ # numpy: = np.zeros((640,1280,3)) # HWC
+ # torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)
+ # multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
+
+ dt = (Profile(), Profile(), Profile())
+ with dt[0]:
+ if isinstance(size, int): # expand
+ size = (size, size)
+ p = next(self.model.parameters()) if self.pt else torch.empty(1, device=self.model.device) # param
+ autocast = self.amp and (p.device.type != 'cpu') # Automatic Mixed Precision (AMP) inference
+ if isinstance(ims, torch.Tensor): # torch
+ with amp.autocast(autocast):
+ return self.model(ims.to(p.device).type_as(p), augment=augment) # inference
+
+ # Pre-process
+ n, ims = (len(ims), list(ims)) if isinstance(ims, (list, tuple)) else (1, [ims]) # number, list of images
+ shape0, shape1, files = [], [], [] # image and inference shapes, filenames
+ for i, im in enumerate(ims):
+ f = f'image{i}' # filename
+ if isinstance(im, (str, Path)): # filename or uri
+ im, f = Image.open(requests.get(im, stream=True).raw if str(im).startswith('http') else im), im
+ im = np.asarray(exif_transpose(im))
+ elif isinstance(im, Image.Image): # PIL Image
+ im, f = np.asarray(exif_transpose(im)), getattr(im, 'filename', f) or f
+ files.append(Path(f).with_suffix('.jpg').name)
+ if im.shape[0] < 5: # image in CHW
+ im = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)
+ im = im[..., :3] if im.ndim == 3 else cv2.cvtColor(im, cv2.COLOR_GRAY2BGR) # enforce 3ch input
+ s = im.shape[:2] # HWC
+ shape0.append(s) # image shape
+ g = max(size) / max(s) # gain
+ shape1.append([int(y * g) for y in s])
+ ims[i] = im if im.data.contiguous else np.ascontiguousarray(im) # update
+ shape1 = [make_divisible(x, self.stride) for x in np.array(shape1).max(0)] # inf shape
+ x = [letterbox(im, shape1, auto=False)[0] for im in ims] # pad
+ x = np.ascontiguousarray(np.array(x).transpose((0, 3, 1, 2))) # stack and BHWC to BCHW
+ x = torch.from_numpy(x).to(p.device).type_as(p) / 255 # uint8 to fp16/32
+
+ with amp.autocast(autocast):
+ # Inference
+ with dt[1]:
+ y = self.model(x, augment=augment) # forward
+
+ # Post-process
+ with dt[2]:
+ y = non_max_suppression(y if self.dmb else y[0],
+ self.conf,
+ self.iou,
+ self.classes,
+ self.agnostic,
+ self.multi_label,
+ max_det=self.max_det) # NMS
+ for i in range(n):
+ scale_boxes(shape1, y[i][:, :4], shape0[i])
+
+ return Detections(ims, y, files, dt, self.names, x.shape)
+
+
+class Detections:
+ # YOLOv5 detections class for inference results
+ def __init__(self, ims, pred, files, times=(0, 0, 0), names=None, shape=None):
+ super().__init__()
+ d = pred[0].device # device
+ gn = [torch.tensor([*(im.shape[i] for i in [1, 0, 1, 0]), 1, 1], device=d) for im in ims] # normalizations
+ self.ims = ims # list of images as numpy arrays
+ self.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)
+ self.names = names # class names
+ self.files = files # image filenames
+ self.times = times # profiling times
+ self.xyxy = pred # xyxy pixels
+ self.xywh = [xyxy2xywh(x) for x in pred] # xywh pixels
+ self.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalized
+ self.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalized
+ self.n = len(self.pred) # number of images (batch size)
+ self.t = tuple(x.t / self.n * 1E3 for x in times) # timestamps (ms)
+ self.s = tuple(shape) # inference BCHW shape
+
+ def _run(self, pprint=False, show=False, save=False, crop=False, render=False, labels=True, save_dir=Path('')):
+ s, crops = '', []
+ for i, (im, pred) in enumerate(zip(self.ims, self.pred)):
+ s += f'\nimage {i + 1}/{len(self.pred)}: {im.shape[0]}x{im.shape[1]} ' # string
+ if pred.shape[0]:
+ for c in pred[:, -1].unique():
+ n = (pred[:, -1] == c).sum() # detections per class
+ s += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, " # add to string
+ s = s.rstrip(', ')
+ if show or save or render or crop:
+ annotator = Annotator(im, example=str(self.names))
+ for *box, conf, cls in reversed(pred): # xyxy, confidence, class
+ label = f'{self.names[int(cls)]} {conf:.2f}'
+ if crop:
+ file = save_dir / 'crops' / self.names[int(cls)] / self.files[i] if save else None
+ crops.append({
+ 'box': box,
+ 'conf': conf,
+ 'cls': cls,
+ 'label': label,
+ 'im': save_one_box(box, im, file=file, save=save)})
+ else: # all others
+ annotator.box_label(box, label if labels else '', color=colors(cls))
+ im = annotator.im
+ else:
+ s += '(no detections)'
+
+ im = Image.fromarray(im.astype(np.uint8)) if isinstance(im, np.ndarray) else im # from np
+ if show:
+ if is_jupyter():
+ from IPython.display import display
+ display(im)
+ else:
+ im.show(self.files[i])
+ if save:
+ f = self.files[i]
+ im.save(save_dir / f) # save
+ if i == self.n - 1:
+ LOGGER.info(f"Saved {self.n} image{'s' * (self.n > 1)} to {colorstr('bold', save_dir)}")
+ if render:
+ self.ims[i] = np.asarray(im)
+ if pprint:
+ s = s.lstrip('\n')
+ return f'{s}\nSpeed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {self.s}' % self.t
+ if crop:
+ if save:
+ LOGGER.info(f'Saved results to {save_dir}\n')
+ return crops
+
+ @TryExcept('Showing images is not supported in this environment')
+ def show(self, labels=True):
+ self._run(show=True, labels=labels) # show results
+
+ def save(self, labels=True, save_dir='runs/detect/exp', exist_ok=False):
+ save_dir = increment_path(save_dir, exist_ok, mkdir=True) # increment save_dir
+ self._run(save=True, labels=labels, save_dir=save_dir) # save results
+
+ def crop(self, save=True, save_dir='runs/detect/exp', exist_ok=False):
+ save_dir = increment_path(save_dir, exist_ok, mkdir=True) if save else None
+ return self._run(crop=True, save=save, save_dir=save_dir) # crop results
+
+ def render(self, labels=True):
+ self._run(render=True, labels=labels) # render results
+ return self.ims
+
+ def pandas(self):
+ # return detections as pandas DataFrames, i.e. print(results.pandas().xyxy[0])
+ new = copy(self) # return copy
+ ca = 'xmin', 'ymin', 'xmax', 'ymax', 'confidence', 'class', 'name' # xyxy columns
+ cb = 'xcenter', 'ycenter', 'width', 'height', 'confidence', 'class', 'name' # xywh columns
+ for k, c in zip(['xyxy', 'xyxyn', 'xywh', 'xywhn'], [ca, ca, cb, cb]):
+ a = [[x[:5] + [int(x[5]), self.names[int(x[5])]] for x in x.tolist()] for x in getattr(self, k)] # update
+ setattr(new, k, [pd.DataFrame(x, columns=c) for x in a])
+ return new
+
+ def tolist(self):
+ # return a list of Detections objects, i.e. 'for result in results.tolist():'
+ r = range(self.n) # iterable
+ x = [Detections([self.ims[i]], [self.pred[i]], [self.files[i]], self.times, self.names, self.s) for i in r]
+ # for d in x:
+ # for k in ['ims', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:
+ # setattr(d, k, getattr(d, k)[0]) # pop out of list
+ return x
+
+ def print(self):
+ LOGGER.info(self.__str__())
+
+ def __len__(self): # override len(results)
+ return self.n
+
+ def __str__(self): # override print(results)
+ return self._run(pprint=True) # print results
+
+ def __repr__(self):
+ return f'YOLOv5 {self.__class__} instance\n' + self.__str__()
+
+
+class Proto(nn.Module):
+ # YOLOv5 mask Proto module for segmentation models
+ def __init__(self, c1, c_=256, c2=32): # ch_in, number of protos, number of masks
+ super().__init__()
+ self.cv1 = Conv(c1, c_, k=3)
+ self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
+ self.cv2 = Conv(c_, c_, k=3)
+ self.cv3 = Conv(c_, c2)
+
+ def forward(self, x):
+ return self.cv3(self.cv2(self.upsample(self.cv1(x))))
+
+
+class Classify(nn.Module):
+ # YOLOv5 classification head, i.e. x(b,c1,20,20) to x(b,c2)
+ def __init__(self,
+ c1,
+ c2,
+ k=1,
+ s=1,
+ p=None,
+ g=1,
+ dropout_p=0.0): # ch_in, ch_out, kernel, stride, padding, groups, dropout probability
+ super().__init__()
+ c_ = 1280 # efficientnet_b0 size
+ self.conv = Conv(c1, c_, k, s, autopad(k, p), g)
+ self.pool = nn.AdaptiveAvgPool2d(1) # to x(b,c_,1,1)
+ self.drop = nn.Dropout(p=dropout_p, inplace=True)
+ self.linear = nn.Linear(c_, c2) # to x(b,c2)
+
+ def forward(self, x):
+ if isinstance(x, list):
+ x = torch.cat(x, 1)
+ return self.linear(self.drop(self.pool(self.conv(x)).flatten(1)))
diff --git a/yolov5/models/experimental.py b/yolov5/models/experimental.py
new file mode 100644
index 0000000000000000000000000000000000000000..b554401b133438a7d38a927c6fdd263503e78c35
--- /dev/null
+++ b/yolov5/models/experimental.py
@@ -0,0 +1,111 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Experimental modules
+"""
+import math
+
+import numpy as np
+import torch
+import torch.nn as nn
+
+from yolov5.utils.downloads import attempt_download
+
+
+class Sum(nn.Module):
+ # Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
+ def __init__(self, n, weight=False): # n: number of inputs
+ super().__init__()
+ self.weight = weight # apply weights boolean
+ self.iter = range(n - 1) # iter object
+ if weight:
+ self.w = nn.Parameter(-torch.arange(1.0, n) / 2, requires_grad=True) # layer weights
+
+ def forward(self, x):
+ y = x[0] # no weight
+ if self.weight:
+ w = torch.sigmoid(self.w) * 2
+ for i in self.iter:
+ y = y + x[i + 1] * w[i]
+ else:
+ for i in self.iter:
+ y = y + x[i + 1]
+ return y
+
+
+class MixConv2d(nn.Module):
+ # Mixed Depth-wise Conv https://arxiv.org/abs/1907.09595
+ def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True): # ch_in, ch_out, kernel, stride, ch_strategy
+ super().__init__()
+ n = len(k) # number of convolutions
+ if equal_ch: # equal c_ per group
+ i = torch.linspace(0, n - 1E-6, c2).floor() # c2 indices
+ c_ = [(i == g).sum() for g in range(n)] # intermediate channels
+ else: # equal weight.numel() per group
+ b = [c2] + [0] * n
+ a = np.eye(n + 1, n, k=-1)
+ a -= np.roll(a, 1, axis=1)
+ a *= np.array(k) ** 2
+ a[0] = 1
+ c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = b
+
+ self.m = nn.ModuleList([
+ nn.Conv2d(c1, int(c_), k, s, k // 2, groups=math.gcd(c1, int(c_)), bias=False) for k, c_ in zip(k, c_)])
+ self.bn = nn.BatchNorm2d(c2)
+ self.act = nn.SiLU()
+
+ def forward(self, x):
+ return self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
+
+
+class Ensemble(nn.ModuleList):
+ # Ensemble of models
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x, augment=False, profile=False, visualize=False):
+ y = [module(x, augment, profile, visualize)[0] for module in self]
+ # y = torch.stack(y).max(0)[0] # max ensemble
+ # y = torch.stack(y).mean(0) # mean ensemble
+ y = torch.cat(y, 1) # nms ensemble
+ return y, None # inference, train output
+
+
+def attempt_load(weights, device=None, inplace=True, fuse=True):
+ # Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a
+ from models.yolo import Detect, Model
+
+ model = Ensemble()
+ for w in weights if isinstance(weights, list) else [weights]:
+ ckpt = torch.load(attempt_download(w), map_location='cpu') # load
+ ckpt = (ckpt.get('ema') or ckpt['model']).to(device).float() # FP32 model
+
+ # Model compatibility updates
+ if not hasattr(ckpt, 'stride'):
+ ckpt.stride = torch.tensor([32.])
+ if hasattr(ckpt, 'names') and isinstance(ckpt.names, (list, tuple)):
+ ckpt.names = dict(enumerate(ckpt.names)) # convert to dict
+
+ model.append(ckpt.fuse().eval() if fuse and hasattr(ckpt, 'fuse') else ckpt.eval()) # model in eval mode
+
+ # Module compatibility updates
+ for m in model.modules():
+ t = type(m)
+ if t in (nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model):
+ m.inplace = inplace # torch 1.7.0 compatibility
+ if t is Detect and not isinstance(m.anchor_grid, list):
+ delattr(m, 'anchor_grid')
+ setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)
+ elif t is nn.Upsample and not hasattr(m, 'recompute_scale_factor'):
+ m.recompute_scale_factor = None # torch 1.11.0 compatibility
+
+ # Return model
+ if len(model) == 1:
+ return model[-1]
+
+ # Return detection ensemble
+ print(f'Ensemble created with {weights}\n')
+ for k in 'names', 'nc', 'yaml':
+ setattr(model, k, getattr(model[0], k))
+ model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride # max stride
+ assert all(model[0].nc == m.nc for m in model), f'Models have different class counts: {[m.nc for m in model]}'
+ return model
diff --git a/yolov5/models/hub/anchors.yaml b/yolov5/models/hub/anchors.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..df2f668b022ca363b47e62ef95bdf20d418fe0e3
--- /dev/null
+++ b/yolov5/models/hub/anchors.yaml
@@ -0,0 +1,59 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Default anchors for COCO data
+
+
+# P5 -------------------------------------------------------------------------------------------------------------------
+# P5-640:
+anchors_p5_640:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+
+# P6 -------------------------------------------------------------------------------------------------------------------
+# P6-640: thr=0.25: 0.9964 BPR, 5.54 anchors past thr, n=12, img_size=640, metric_all=0.281/0.716-mean/best, past_thr=0.469-mean: 9,11, 21,19, 17,41, 43,32, 39,70, 86,64, 65,131, 134,130, 120,265, 282,180, 247,354, 512,387
+anchors_p6_640:
+ - [9,11, 21,19, 17,41] # P3/8
+ - [43,32, 39,70, 86,64] # P4/16
+ - [65,131, 134,130, 120,265] # P5/32
+ - [282,180, 247,354, 512,387] # P6/64
+
+# P6-1280: thr=0.25: 0.9950 BPR, 5.55 anchors past thr, n=12, img_size=1280, metric_all=0.281/0.714-mean/best, past_thr=0.468-mean: 19,27, 44,40, 38,94, 96,68, 86,152, 180,137, 140,301, 303,264, 238,542, 436,615, 739,380, 925,792
+anchors_p6_1280:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# P6-1920: thr=0.25: 0.9950 BPR, 5.55 anchors past thr, n=12, img_size=1920, metric_all=0.281/0.714-mean/best, past_thr=0.468-mean: 28,41, 67,59, 57,141, 144,103, 129,227, 270,205, 209,452, 455,396, 358,812, 653,922, 1109,570, 1387,1187
+anchors_p6_1920:
+ - [28,41, 67,59, 57,141] # P3/8
+ - [144,103, 129,227, 270,205] # P4/16
+ - [209,452, 455,396, 358,812] # P5/32
+ - [653,922, 1109,570, 1387,1187] # P6/64
+
+
+# P7 -------------------------------------------------------------------------------------------------------------------
+# P7-640: thr=0.25: 0.9962 BPR, 6.76 anchors past thr, n=15, img_size=640, metric_all=0.275/0.733-mean/best, past_thr=0.466-mean: 11,11, 13,30, 29,20, 30,46, 61,38, 39,92, 78,80, 146,66, 79,163, 149,150, 321,143, 157,303, 257,402, 359,290, 524,372
+anchors_p7_640:
+ - [11,11, 13,30, 29,20] # P3/8
+ - [30,46, 61,38, 39,92] # P4/16
+ - [78,80, 146,66, 79,163] # P5/32
+ - [149,150, 321,143, 157,303] # P6/64
+ - [257,402, 359,290, 524,372] # P7/128
+
+# P7-1280: thr=0.25: 0.9968 BPR, 6.71 anchors past thr, n=15, img_size=1280, metric_all=0.273/0.732-mean/best, past_thr=0.463-mean: 19,22, 54,36, 32,77, 70,83, 138,71, 75,173, 165,159, 148,334, 375,151, 334,317, 251,626, 499,474, 750,326, 534,814, 1079,818
+anchors_p7_1280:
+ - [19,22, 54,36, 32,77] # P3/8
+ - [70,83, 138,71, 75,173] # P4/16
+ - [165,159, 148,334, 375,151] # P5/32
+ - [334,317, 251,626, 499,474] # P6/64
+ - [750,326, 534,814, 1079,818] # P7/128
+
+# P7-1920: thr=0.25: 0.9968 BPR, 6.71 anchors past thr, n=15, img_size=1920, metric_all=0.273/0.732-mean/best, past_thr=0.463-mean: 29,34, 81,55, 47,115, 105,124, 207,107, 113,259, 247,238, 222,500, 563,227, 501,476, 376,939, 749,711, 1126,489, 801,1222, 1618,1227
+anchors_p7_1920:
+ - [29,34, 81,55, 47,115] # P3/8
+ - [105,124, 207,107, 113,259] # P4/16
+ - [247,238, 222,500, 563,227] # P5/32
+ - [501,476, 376,939, 749,711] # P6/64
+ - [1126,489, 801,1222, 1618,1227] # P7/128
diff --git a/yolov5/models/hub/yolov3-spp.yaml b/yolov5/models/hub/yolov3-spp.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..4a71ed405277ce10a3c3f386834764ff0a82d53c
--- /dev/null
+++ b/yolov5/models/hub/yolov3-spp.yaml
@@ -0,0 +1,51 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3-SPP head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, SPP, [512, [5, 9, 13]]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov3-tiny.yaml b/yolov5/models/hub/yolov3-tiny.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..50b47e282df482b6f4f8dfb485c914ab1cbf6274
--- /dev/null
+++ b/yolov5/models/hub/yolov3-tiny.yaml
@@ -0,0 +1,41 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,14, 23,27, 37,58] # P4/16
+ - [81,82, 135,169, 344,319] # P5/32
+
+# YOLOv3-tiny backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [16, 3, 1]], # 0
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2
+ [-1, 1, Conv, [32, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4
+ [-1, 1, Conv, [64, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8
+ [-1, 1, Conv, [128, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16
+ [-1, 1, Conv, [256, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32
+ [-1, 1, Conv, [512, 3, 1]],
+ [-1, 1, nn.ZeroPad2d, [[0, 1, 0, 1]]], # 11
+ [-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12
+ ]
+
+# YOLOv3-tiny head
+head:
+ [[-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium)
+
+ [[19, 15], 1, Detect, [nc, anchors]], # Detect(P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov3.yaml b/yolov5/models/hub/yolov3.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c5e21098f89379487dde6f236b78667fad0ad57f
--- /dev/null
+++ b/yolov5/models/hub/yolov3.yaml
@@ -0,0 +1,51 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3 head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5-bifpn.yaml b/yolov5/models/hub/yolov5-bifpn.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..9dbdd4ee0580c4a5613548607b6970aefda8c03e
--- /dev/null
+++ b/yolov5/models/hub/yolov5-bifpn.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 BiFPN head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14, 6], 1, Concat, [1]], # cat P4 <--- BiFPN change
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5-fpn.yaml b/yolov5/models/hub/yolov5-fpn.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2292eb1185a0d4c14985c3039d01fcffa26b32fd
--- /dev/null
+++ b/yolov5/models/hub/yolov5-fpn.yaml
@@ -0,0 +1,42 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 FPN head
+head:
+ [[-1, 3, C3, [1024, False]], # 10 (P5/32-large)
+
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 3, C3, [512, False]], # 14 (P4/16-medium)
+
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 3, C3, [256, False]], # 18 (P3/8-small)
+
+ [[18, 14, 10], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5-p2.yaml b/yolov5/models/hub/yolov5-p2.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2c0ae44841cc967bceee310c3b5606c7d191c6f7
--- /dev/null
+++ b/yolov5/models/hub/yolov5-p2.yaml
@@ -0,0 +1,54 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head with (P2, P3, P4, P5) outputs
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 2], 1, Concat, [1]], # cat backbone P2
+ [-1, 1, C3, [128, False]], # 21 (P2/4-xsmall)
+
+ [-1, 1, Conv, [128, 3, 2]],
+ [[-1, 18], 1, Concat, [1]], # cat head P3
+ [-1, 3, C3, [256, False]], # 24 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 27 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 30 (P5/32-large)
+
+ [[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5-p34.yaml b/yolov5/models/hub/yolov5-p34.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..60ae3b4b6f30d0b1a5ba901d021de77d14953161
--- /dev/null
+++ b/yolov5/models/hub/yolov5-p34.yaml
@@ -0,0 +1,41 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [ [ -1, 1, Conv, [ 64, 6, 2, 2 ] ], # 0-P1/2
+ [ -1, 1, Conv, [ 128, 3, 2 ] ], # 1-P2/4
+ [ -1, 3, C3, [ 128 ] ],
+ [ -1, 1, Conv, [ 256, 3, 2 ] ], # 3-P3/8
+ [ -1, 6, C3, [ 256 ] ],
+ [ -1, 1, Conv, [ 512, 3, 2 ] ], # 5-P4/16
+ [ -1, 9, C3, [ 512 ] ],
+ [ -1, 1, Conv, [ 1024, 3, 2 ] ], # 7-P5/32
+ [ -1, 3, C3, [ 1024 ] ],
+ [ -1, 1, SPPF, [ 1024, 5 ] ], # 9
+ ]
+
+# YOLOv5 v6.0 head with (P3, P4) outputs
+head:
+ [ [ -1, 1, Conv, [ 512, 1, 1 ] ],
+ [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
+ [ [ -1, 6 ], 1, Concat, [ 1 ] ], # cat backbone P4
+ [ -1, 3, C3, [ 512, False ] ], # 13
+
+ [ -1, 1, Conv, [ 256, 1, 1 ] ],
+ [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
+ [ [ -1, 4 ], 1, Concat, [ 1 ] ], # cat backbone P3
+ [ -1, 3, C3, [ 256, False ] ], # 17 (P3/8-small)
+
+ [ -1, 1, Conv, [ 256, 3, 2 ] ],
+ [ [ -1, 14 ], 1, Concat, [ 1 ] ], # cat head P4
+ [ -1, 3, C3, [ 512, False ] ], # 20 (P4/16-medium)
+
+ [ [ 17, 20 ], 1, Detect, [ nc, anchors ] ], # Detect(P3, P4)
+ ]
diff --git a/yolov5/models/hub/yolov5-p6.yaml b/yolov5/models/hub/yolov5-p6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a9e1b5f90c72dbe0c7257001761da7190c7b235b
--- /dev/null
+++ b/yolov5/models/hub/yolov5-p6.yaml
@@ -0,0 +1,56 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head with (P3, P4, P5, P6) outputs
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/hub/yolov5-p7.yaml b/yolov5/models/hub/yolov5-p7.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a502412f08877bd233580bf048558758f8d0c1c4
--- /dev/null
+++ b/yolov5/models/hub/yolov5-p7.yaml
@@ -0,0 +1,67 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, Conv, [1280, 3, 2]], # 11-P7/128
+ [-1, 3, C3, [1280]],
+ [-1, 1, SPPF, [1280, 5]], # 13
+ ]
+
+# YOLOv5 v6.0 head with (P3, P4, P5, P6, P7) outputs
+head:
+ [[-1, 1, Conv, [1024, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 10], 1, Concat, [1]], # cat backbone P6
+ [-1, 3, C3, [1024, False]], # 17
+
+ [-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 21
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 25
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 29 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 26], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 32 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 22], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 35 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 18], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 38 (P6/64-xlarge)
+
+ [-1, 1, Conv, [1024, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P7
+ [-1, 3, C3, [1280, False]], # 41 (P7/128-xxlarge)
+
+ [[29, 32, 35, 38, 41], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6, P7)
+ ]
diff --git a/yolov5/models/hub/yolov5-panet.yaml b/yolov5/models/hub/yolov5-panet.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5595e25738235718d5b4eb8672fc50301f0c043d
--- /dev/null
+++ b/yolov5/models/hub/yolov5-panet.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 PANet head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5l6.yaml b/yolov5/models/hub/yolov5l6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..651dbb0251ae89817e6292e215e57ab7ddc9a92a
--- /dev/null
+++ b/yolov5/models/hub/yolov5l6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/hub/yolov5m6.yaml b/yolov5/models/hub/yolov5m6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..059b12b46929cc481a014298a5ab5ae2b2bdaf68
--- /dev/null
+++ b/yolov5/models/hub/yolov5m6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/hub/yolov5n6.yaml b/yolov5/models/hub/yolov5n6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5052e7cbfc8b972a577af8c1668e0d475728268c
--- /dev/null
+++ b/yolov5/models/hub/yolov5n6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/hub/yolov5s-LeakyReLU.yaml b/yolov5/models/hub/yolov5s-LeakyReLU.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..0368a78dcbb42c690a2ee81789c248d41009d665
--- /dev/null
+++ b/yolov5/models/hub/yolov5s-LeakyReLU.yaml
@@ -0,0 +1,49 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+activation: nn.LeakyReLU(0.1) # <----- Conv() activation used throughout entire YOLOv5 model
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5s-ghost.yaml b/yolov5/models/hub/yolov5s-ghost.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ce5238fa5dfcd629b01d5a4a29388d6a7646d6ec
--- /dev/null
+++ b/yolov5/models/hub/yolov5s-ghost.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, GhostConv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3Ghost, [128]],
+ [-1, 1, GhostConv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3Ghost, [256]],
+ [-1, 1, GhostConv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3Ghost, [512]],
+ [-1, 1, GhostConv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3Ghost, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, GhostConv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3Ghost, [512, False]], # 13
+
+ [-1, 1, GhostConv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3Ghost, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, GhostConv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3Ghost, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, GhostConv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3Ghost, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5s-transformer.yaml b/yolov5/models/hub/yolov5s-transformer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..f5267163453c059a6b948567ec1fe5a9af18f7e5
--- /dev/null
+++ b/yolov5/models/hub/yolov5s-transformer.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3TR, [1024]], # 9 <--- C3TR() Transformer module
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/hub/yolov5s6.yaml b/yolov5/models/hub/yolov5s6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2f39b0379e74dbfdd584896561337572d47ee580
--- /dev/null
+++ b/yolov5/models/hub/yolov5s6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/hub/yolov5x6.yaml b/yolov5/models/hub/yolov5x6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..e1edbcb8634c7c8abc68fa99bf53a2106700129c
--- /dev/null
+++ b/yolov5/models/hub/yolov5x6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/yolov5/models/segment/yolov5l-seg.yaml b/yolov5/models/segment/yolov5l-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..71f80cc0805490c21adbb27bc093a04c4bc7b882
--- /dev/null
+++ b/yolov5/models/segment/yolov5l-seg.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/segment/yolov5m-seg.yaml b/yolov5/models/segment/yolov5m-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2b8e1db2818acbbcd6d2b340c2d950fc3108d4d4
--- /dev/null
+++ b/yolov5/models/segment/yolov5m-seg.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/segment/yolov5n-seg.yaml b/yolov5/models/segment/yolov5n-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..1f67f8e3dfb05af091943100d7578e5f30770455
--- /dev/null
+++ b/yolov5/models/segment/yolov5n-seg.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/segment/yolov5s-seg.yaml b/yolov5/models/segment/yolov5s-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2ff2524ca9b559fa416854dba8af9d3e16eb8323
--- /dev/null
+++ b/yolov5/models/segment/yolov5s-seg.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.5 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/segment/yolov5x-seg.yaml b/yolov5/models/segment/yolov5x-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..589f65c76f954c4db6bc88e4fb0a6d26be70556e
--- /dev/null
+++ b/yolov5/models/segment/yolov5x-seg.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/tf.py b/yolov5/models/tf.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc0a465d7edd094231bd7d2230eb9fe9270ed27e
--- /dev/null
+++ b/yolov5/models/tf.py
@@ -0,0 +1,608 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+TensorFlow, Keras and TFLite versions of YOLOv5
+Authored by https://github.com/zldrobit in PR https://github.com/ultralytics/yolov5/pull/1127
+
+Usage:
+ $ python models/tf.py --weights yolov5s.pt
+
+Export:
+ $ python export.py --weights yolov5s.pt --include saved_model pb tflite tfjs
+"""
+
+import argparse
+import sys
+from copy import deepcopy
+from pathlib import Path
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+# ROOT = ROOT.relative_to(Path.cwd()) # relative
+
+import numpy as np
+import tensorflow as tf
+import torch
+import torch.nn as nn
+from tensorflow import keras
+
+from models.common import (C3, SPP, SPPF, Bottleneck, BottleneckCSP, C3x, Concat, Conv, CrossConv, DWConv,
+ DWConvTranspose2d, Focus, autopad)
+from models.experimental import MixConv2d, attempt_load
+from models.yolo import Detect, Segment
+from utils.activations import SiLU
+from utils.general import LOGGER, make_divisible, print_args
+
+
+class TFBN(keras.layers.Layer):
+ # TensorFlow BatchNormalization wrapper
+ def __init__(self, w=None):
+ super().__init__()
+ self.bn = keras.layers.BatchNormalization(
+ beta_initializer=keras.initializers.Constant(w.bias.numpy()),
+ gamma_initializer=keras.initializers.Constant(w.weight.numpy()),
+ moving_mean_initializer=keras.initializers.Constant(w.running_mean.numpy()),
+ moving_variance_initializer=keras.initializers.Constant(w.running_var.numpy()),
+ epsilon=w.eps)
+
+ def call(self, inputs):
+ return self.bn(inputs)
+
+
+class TFPad(keras.layers.Layer):
+ # Pad inputs in spatial dimensions 1 and 2
+ def __init__(self, pad):
+ super().__init__()
+ if isinstance(pad, int):
+ self.pad = tf.constant([[0, 0], [pad, pad], [pad, pad], [0, 0]])
+ else: # tuple/list
+ self.pad = tf.constant([[0, 0], [pad[0], pad[0]], [pad[1], pad[1]], [0, 0]])
+
+ def call(self, inputs):
+ return tf.pad(inputs, self.pad, mode='constant', constant_values=0)
+
+
+class TFConv(keras.layers.Layer):
+ # Standard convolution
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
+ # ch_in, ch_out, weights, kernel, stride, padding, groups
+ super().__init__()
+ assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
+ # TensorFlow convolution padding is inconsistent with PyTorch (e.g. k=3 s=2 'SAME' padding)
+ # see https://stackoverflow.com/questions/52975843/comparing-conv2d-with-padding-between-tensorflow-and-pytorch
+ conv = keras.layers.Conv2D(
+ filters=c2,
+ kernel_size=k,
+ strides=s,
+ padding='SAME' if s == 1 else 'VALID',
+ use_bias=not hasattr(w, 'bn'),
+ kernel_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy()))
+ self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv])
+ self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity
+ self.act = activations(w.act) if act else tf.identity
+
+ def call(self, inputs):
+ return self.act(self.bn(self.conv(inputs)))
+
+
+class TFDWConv(keras.layers.Layer):
+ # Depthwise convolution
+ def __init__(self, c1, c2, k=1, s=1, p=None, act=True, w=None):
+ # ch_in, ch_out, weights, kernel, stride, padding, groups
+ super().__init__()
+ assert c2 % c1 == 0, f'TFDWConv() output={c2} must be a multiple of input={c1} channels'
+ conv = keras.layers.DepthwiseConv2D(
+ kernel_size=k,
+ depth_multiplier=c2 // c1,
+ strides=s,
+ padding='SAME' if s == 1 else 'VALID',
+ use_bias=not hasattr(w, 'bn'),
+ depthwise_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy()))
+ self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv])
+ self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity
+ self.act = activations(w.act) if act else tf.identity
+
+ def call(self, inputs):
+ return self.act(self.bn(self.conv(inputs)))
+
+
+class TFDWConvTranspose2d(keras.layers.Layer):
+ # Depthwise ConvTranspose2d
+ def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0, w=None):
+ # ch_in, ch_out, weights, kernel, stride, padding, groups
+ super().__init__()
+ assert c1 == c2, f'TFDWConv() output={c2} must be equal to input={c1} channels'
+ assert k == 4 and p1 == 1, 'TFDWConv() only valid for k=4 and p1=1'
+ weight, bias = w.weight.permute(2, 3, 1, 0).numpy(), w.bias.numpy()
+ self.c1 = c1
+ self.conv = [
+ keras.layers.Conv2DTranspose(filters=1,
+ kernel_size=k,
+ strides=s,
+ padding='VALID',
+ output_padding=p2,
+ use_bias=True,
+ kernel_initializer=keras.initializers.Constant(weight[..., i:i + 1]),
+ bias_initializer=keras.initializers.Constant(bias[i])) for i in range(c1)]
+
+ def call(self, inputs):
+ return tf.concat([m(x) for m, x in zip(self.conv, tf.split(inputs, self.c1, 3))], 3)[:, 1:-1, 1:-1]
+
+
+class TFFocus(keras.layers.Layer):
+ # Focus wh information into c-space
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
+ # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = TFConv(c1 * 4, c2, k, s, p, g, act, w.conv)
+
+ def call(self, inputs): # x(b,w,h,c) -> y(b,w/2,h/2,4c)
+ # inputs = inputs / 255 # normalize 0-255 to 0-1
+ inputs = [inputs[:, ::2, ::2, :], inputs[:, 1::2, ::2, :], inputs[:, ::2, 1::2, :], inputs[:, 1::2, 1::2, :]]
+ return self.conv(tf.concat(inputs, 3))
+
+
+class TFBottleneck(keras.layers.Layer):
+ # Standard bottleneck
+ def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, w=None): # ch_in, ch_out, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_, c2, 3, 1, g=g, w=w.cv2)
+ self.add = shortcut and c1 == c2
+
+ def call(self, inputs):
+ return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs))
+
+
+class TFCrossConv(keras.layers.Layer):
+ # Cross Convolution
+ def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False, w=None):
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, (1, k), (1, s), w=w.cv1)
+ self.cv2 = TFConv(c_, c2, (k, 1), (s, 1), g=g, w=w.cv2)
+ self.add = shortcut and c1 == c2
+
+ def call(self, inputs):
+ return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs))
+
+
+class TFConv2d(keras.layers.Layer):
+ # Substitution for PyTorch nn.Conv2D
+ def __init__(self, c1, c2, k, s=1, g=1, bias=True, w=None):
+ super().__init__()
+ assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
+ self.conv = keras.layers.Conv2D(filters=c2,
+ kernel_size=k,
+ strides=s,
+ padding='VALID',
+ use_bias=bias,
+ kernel_initializer=keras.initializers.Constant(
+ w.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer=keras.initializers.Constant(w.bias.numpy()) if bias else None)
+
+ def call(self, inputs):
+ return self.conv(inputs)
+
+
+class TFBottleneckCSP(keras.layers.Layer):
+ # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv2d(c1, c_, 1, 1, bias=False, w=w.cv2)
+ self.cv3 = TFConv2d(c_, c_, 1, 1, bias=False, w=w.cv3)
+ self.cv4 = TFConv(2 * c_, c2, 1, 1, w=w.cv4)
+ self.bn = TFBN(w.bn)
+ self.act = lambda x: keras.activations.swish(x)
+ self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ y1 = self.cv3(self.m(self.cv1(inputs)))
+ y2 = self.cv2(inputs)
+ return self.cv4(self.act(self.bn(tf.concat((y1, y2), axis=3))))
+
+
+class TFC3(keras.layers.Layer):
+ # CSP Bottleneck with 3 convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2)
+ self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3)
+ self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3))
+
+
+class TFC3x(keras.layers.Layer):
+ # 3 module with cross-convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2)
+ self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3)
+ self.m = keras.Sequential([
+ TFCrossConv(c_, c_, k=3, s=1, g=g, e=1.0, shortcut=shortcut, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3))
+
+
+class TFSPP(keras.layers.Layer):
+ # Spatial pyramid pooling layer used in YOLOv3-SPP
+ def __init__(self, c1, c2, k=(5, 9, 13), w=None):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_ * (len(k) + 1), c2, 1, 1, w=w.cv2)
+ self.m = [keras.layers.MaxPool2D(pool_size=x, strides=1, padding='SAME') for x in k]
+
+ def call(self, inputs):
+ x = self.cv1(inputs)
+ return self.cv2(tf.concat([x] + [m(x) for m in self.m], 3))
+
+
+class TFSPPF(keras.layers.Layer):
+ # Spatial pyramid pooling-Fast layer
+ def __init__(self, c1, c2, k=5, w=None):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_ * 4, c2, 1, 1, w=w.cv2)
+ self.m = keras.layers.MaxPool2D(pool_size=k, strides=1, padding='SAME')
+
+ def call(self, inputs):
+ x = self.cv1(inputs)
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(tf.concat([x, y1, y2, self.m(y2)], 3))
+
+
+class TFDetect(keras.layers.Layer):
+ # TF YOLOv5 Detect layer
+ def __init__(self, nc=80, anchors=(), ch=(), imgsz=(640, 640), w=None): # detection layer
+ super().__init__()
+ self.stride = tf.convert_to_tensor(w.stride.numpy(), dtype=tf.float32)
+ self.nc = nc # number of classes
+ self.no = nc + 5 # number of outputs per anchor
+ self.nl = len(anchors) # number of detection layers
+ self.na = len(anchors[0]) // 2 # number of anchors
+ self.grid = [tf.zeros(1)] * self.nl # init grid
+ self.anchors = tf.convert_to_tensor(w.anchors.numpy(), dtype=tf.float32)
+ self.anchor_grid = tf.reshape(self.anchors * tf.reshape(self.stride, [self.nl, 1, 1]), [self.nl, 1, -1, 1, 2])
+ self.m = [TFConv2d(x, self.no * self.na, 1, w=w.m[i]) for i, x in enumerate(ch)]
+ self.training = False # set to False after building model
+ self.imgsz = imgsz
+ for i in range(self.nl):
+ ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
+ self.grid[i] = self._make_grid(nx, ny)
+
+ def call(self, inputs):
+ z = [] # inference output
+ x = []
+ for i in range(self.nl):
+ x.append(self.m[i](inputs[i]))
+ # x(bs,20,20,255) to x(bs,3,20,20,85)
+ ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
+ x[i] = tf.reshape(x[i], [-1, ny * nx, self.na, self.no])
+
+ if not self.training: # inference
+ y = x[i]
+ grid = tf.transpose(self.grid[i], [0, 2, 1, 3]) - 0.5
+ anchor_grid = tf.transpose(self.anchor_grid[i], [0, 2, 1, 3]) * 4
+ xy = (tf.sigmoid(y[..., 0:2]) * 2 + grid) * self.stride[i] # xy
+ wh = tf.sigmoid(y[..., 2:4]) ** 2 * anchor_grid
+ # Normalize xywh to 0-1 to reduce calibration error
+ xy /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
+ wh /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
+ y = tf.concat([xy, wh, tf.sigmoid(y[..., 4:5 + self.nc]), y[..., 5 + self.nc:]], -1)
+ z.append(tf.reshape(y, [-1, self.na * ny * nx, self.no]))
+
+ return tf.transpose(x, [0, 2, 1, 3]) if self.training else (tf.concat(z, 1),)
+
+ @staticmethod
+ def _make_grid(nx=20, ny=20):
+ # yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
+ # return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
+ xv, yv = tf.meshgrid(tf.range(nx), tf.range(ny))
+ return tf.cast(tf.reshape(tf.stack([xv, yv], 2), [1, 1, ny * nx, 2]), dtype=tf.float32)
+
+
+class TFSegment(TFDetect):
+ # YOLOv5 Segment head for segmentation models
+ def __init__(self, nc=80, anchors=(), nm=32, npr=256, ch=(), imgsz=(640, 640), w=None):
+ super().__init__(nc, anchors, ch, imgsz, w)
+ self.nm = nm # number of masks
+ self.npr = npr # number of protos
+ self.no = 5 + nc + self.nm # number of outputs per anchor
+ self.m = [TFConv2d(x, self.no * self.na, 1, w=w.m[i]) for i, x in enumerate(ch)] # output conv
+ self.proto = TFProto(ch[0], self.npr, self.nm, w=w.proto) # protos
+ self.detect = TFDetect.call
+
+ def call(self, x):
+ p = self.proto(x[0])
+ # p = TFUpsample(None, scale_factor=4, mode='nearest')(self.proto(x[0])) # (optional) full-size protos
+ p = tf.transpose(p, [0, 3, 1, 2]) # from shape(1,160,160,32) to shape(1,32,160,160)
+ x = self.detect(self, x)
+ return (x, p) if self.training else (x[0], p)
+
+
+class TFProto(keras.layers.Layer):
+
+ def __init__(self, c1, c_=256, c2=32, w=None):
+ super().__init__()
+ self.cv1 = TFConv(c1, c_, k=3, w=w.cv1)
+ self.upsample = TFUpsample(None, scale_factor=2, mode='nearest')
+ self.cv2 = TFConv(c_, c_, k=3, w=w.cv2)
+ self.cv3 = TFConv(c_, c2, w=w.cv3)
+
+ def call(self, inputs):
+ return self.cv3(self.cv2(self.upsample(self.cv1(inputs))))
+
+
+class TFUpsample(keras.layers.Layer):
+ # TF version of torch.nn.Upsample()
+ def __init__(self, size, scale_factor, mode, w=None): # warning: all arguments needed including 'w'
+ super().__init__()
+ assert scale_factor % 2 == 0, 'scale_factor must be multiple of 2'
+ self.upsample = lambda x: tf.image.resize(x, (x.shape[1] * scale_factor, x.shape[2] * scale_factor), mode)
+ # self.upsample = keras.layers.UpSampling2D(size=scale_factor, interpolation=mode)
+ # with default arguments: align_corners=False, half_pixel_centers=False
+ # self.upsample = lambda x: tf.raw_ops.ResizeNearestNeighbor(images=x,
+ # size=(x.shape[1] * 2, x.shape[2] * 2))
+
+ def call(self, inputs):
+ return self.upsample(inputs)
+
+
+class TFConcat(keras.layers.Layer):
+ # TF version of torch.concat()
+ def __init__(self, dimension=1, w=None):
+ super().__init__()
+ assert dimension == 1, 'convert only NCHW to NHWC concat'
+ self.d = 3
+
+ def call(self, inputs):
+ return tf.concat(inputs, self.d)
+
+
+def parse_model(d, ch, model, imgsz): # model_dict, input_channels(3)
+ LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
+ anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
+ na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
+ no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
+
+ layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
+ for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
+ m_str = m
+ m = eval(m) if isinstance(m, str) else m # eval strings
+ for j, a in enumerate(args):
+ try:
+ args[j] = eval(a) if isinstance(a, str) else a # eval strings
+ except NameError:
+ pass
+
+ n = max(round(n * gd), 1) if n > 1 else n # depth gain
+ if m in [
+ nn.Conv2d, Conv, DWConv, DWConvTranspose2d, Bottleneck, SPP, SPPF, MixConv2d, Focus, CrossConv,
+ BottleneckCSP, C3, C3x]:
+ c1, c2 = ch[f], args[0]
+ c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
+
+ args = [c1, c2, *args[1:]]
+ if m in [BottleneckCSP, C3, C3x]:
+ args.insert(2, n)
+ n = 1
+ elif m is nn.BatchNorm2d:
+ args = [ch[f]]
+ elif m is Concat:
+ c2 = sum(ch[-1 if x == -1 else x + 1] for x in f)
+ elif m in [Detect, Segment]:
+ args.append([ch[x + 1] for x in f])
+ if isinstance(args[1], int): # number of anchors
+ args[1] = [list(range(args[1] * 2))] * len(f)
+ if m is Segment:
+ args[3] = make_divisible(args[3] * gw, 8)
+ args.append(imgsz)
+ else:
+ c2 = ch[f]
+
+ tf_m = eval('TF' + m_str.replace('nn.', ''))
+ m_ = keras.Sequential([tf_m(*args, w=model.model[i][j]) for j in range(n)]) if n > 1 \
+ else tf_m(*args, w=model.model[i]) # module
+
+ torch_m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
+ t = str(m)[8:-2].replace('__main__.', '') # module type
+ np = sum(x.numel() for x in torch_m_.parameters()) # number params
+ m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
+ LOGGER.info(f'{i:>3}{str(f):>18}{str(n):>3}{np:>10} {t:<40}{str(args):<30}') # print
+ save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
+ layers.append(m_)
+ ch.append(c2)
+ return keras.Sequential(layers), sorted(save)
+
+
+class TFModel:
+ # TF YOLOv5 model
+ def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, model=None, imgsz=(640, 640)): # model, channels, classes
+ super().__init__()
+ if isinstance(cfg, dict):
+ self.yaml = cfg # model dict
+ else: # is *.yaml
+ import yaml # for torch hub
+ self.yaml_file = Path(cfg).name
+ with open(cfg) as f:
+ self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
+
+ # Define model
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding {cfg} nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override yaml value
+ self.model, self.savelist = parse_model(deepcopy(self.yaml), ch=[ch], model=model, imgsz=imgsz)
+
+ def predict(self,
+ inputs,
+ tf_nms=False,
+ agnostic_nms=False,
+ topk_per_class=100,
+ topk_all=100,
+ iou_thres=0.45,
+ conf_thres=0.25):
+ y = [] # outputs
+ x = inputs
+ for m in self.model.layers:
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+
+ x = m(x) # run
+ y.append(x if m.i in self.savelist else None) # save output
+
+ # Add TensorFlow NMS
+ if tf_nms:
+ boxes = self._xywh2xyxy(x[0][..., :4])
+ probs = x[0][:, :, 4:5]
+ classes = x[0][:, :, 5:]
+ scores = probs * classes
+ if agnostic_nms:
+ nms = AgnosticNMS()((boxes, classes, scores), topk_all, iou_thres, conf_thres)
+ else:
+ boxes = tf.expand_dims(boxes, 2)
+ nms = tf.image.combined_non_max_suppression(boxes,
+ scores,
+ topk_per_class,
+ topk_all,
+ iou_thres,
+ conf_thres,
+ clip_boxes=False)
+ return (nms,)
+ return x # output [1,6300,85] = [xywh, conf, class0, class1, ...]
+ # x = x[0] # [x(1,6300,85), ...] to x(6300,85)
+ # xywh = x[..., :4] # x(6300,4) boxes
+ # conf = x[..., 4:5] # x(6300,1) confidences
+ # cls = tf.reshape(tf.cast(tf.argmax(x[..., 5:], axis=1), tf.float32), (-1, 1)) # x(6300,1) classes
+ # return tf.concat([conf, cls, xywh], 1)
+
+ @staticmethod
+ def _xywh2xyxy(xywh):
+ # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+ x, y, w, h = tf.split(xywh, num_or_size_splits=4, axis=-1)
+ return tf.concat([x - w / 2, y - h / 2, x + w / 2, y + h / 2], axis=-1)
+
+
+class AgnosticNMS(keras.layers.Layer):
+ # TF Agnostic NMS
+ def call(self, input, topk_all, iou_thres, conf_thres):
+ # wrap map_fn to avoid TypeSpec related error https://stackoverflow.com/a/65809989/3036450
+ return tf.map_fn(lambda x: self._nms(x, topk_all, iou_thres, conf_thres),
+ input,
+ fn_output_signature=(tf.float32, tf.float32, tf.float32, tf.int32),
+ name='agnostic_nms')
+
+ @staticmethod
+ def _nms(x, topk_all=100, iou_thres=0.45, conf_thres=0.25): # agnostic NMS
+ boxes, classes, scores = x
+ class_inds = tf.cast(tf.argmax(classes, axis=-1), tf.float32)
+ scores_inp = tf.reduce_max(scores, -1)
+ selected_inds = tf.image.non_max_suppression(boxes,
+ scores_inp,
+ max_output_size=topk_all,
+ iou_threshold=iou_thres,
+ score_threshold=conf_thres)
+ selected_boxes = tf.gather(boxes, selected_inds)
+ padded_boxes = tf.pad(selected_boxes,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]], [0, 0]],
+ mode='CONSTANT',
+ constant_values=0.0)
+ selected_scores = tf.gather(scores_inp, selected_inds)
+ padded_scores = tf.pad(selected_scores,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
+ mode='CONSTANT',
+ constant_values=-1.0)
+ selected_classes = tf.gather(class_inds, selected_inds)
+ padded_classes = tf.pad(selected_classes,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
+ mode='CONSTANT',
+ constant_values=-1.0)
+ valid_detections = tf.shape(selected_inds)[0]
+ return padded_boxes, padded_scores, padded_classes, valid_detections
+
+
+def activations(act=nn.SiLU):
+ # Returns TF activation from input PyTorch activation
+ if isinstance(act, nn.LeakyReLU):
+ return lambda x: keras.activations.relu(x, alpha=0.1)
+ elif isinstance(act, nn.Hardswish):
+ return lambda x: x * tf.nn.relu6(x + 3) * 0.166666667
+ elif isinstance(act, (nn.SiLU, SiLU)):
+ return lambda x: keras.activations.swish(x)
+ else:
+ raise Exception(f'no matching TensorFlow activation found for PyTorch activation {act}')
+
+
+def representative_dataset_gen(dataset, ncalib=100):
+ # Representative dataset generator for use with converter.representative_dataset, returns a generator of np arrays
+ for n, (path, img, im0s, vid_cap, string) in enumerate(dataset):
+ im = np.transpose(img, [1, 2, 0])
+ im = np.expand_dims(im, axis=0).astype(np.float32)
+ im /= 255
+ yield [im]
+ if n >= ncalib:
+ break
+
+
+def run(
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=(640, 640), # inference size h,w
+ batch_size=1, # batch size
+ dynamic=False, # dynamic batch size
+):
+ # PyTorch model
+ im = torch.zeros((batch_size, 3, *imgsz)) # BCHW image
+ model = attempt_load(weights, device=torch.device('cpu'), inplace=True, fuse=False)
+ _ = model(im) # inference
+ model.info()
+
+ # TensorFlow model
+ im = tf.zeros((batch_size, *imgsz, 3)) # BHWC image
+ tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
+ _ = tf_model.predict(im) # inference
+
+ # Keras model
+ im = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size)
+ keras_model = keras.Model(inputs=im, outputs=tf_model.predict(im))
+ keras_model.summary()
+
+ LOGGER.info('PyTorch, TensorFlow and Keras models successfully verified.\nUse export.py for TF model export.')
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--dynamic', action='store_true', help='dynamic batch size')
+ opt = parser.parse_args()
+ opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/models/yolo.py b/yolov5/models/yolo.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf4ac8c8da0ad90df26413852c519b031559f8c6
--- /dev/null
+++ b/yolov5/models/yolo.py
@@ -0,0 +1,391 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+YOLO-specific modules
+
+Usage:
+ $ python models/yolo.py --cfg yolov5s.yaml
+"""
+
+import argparse
+import contextlib
+import os
+import platform
+import sys
+from copy import deepcopy
+from pathlib import Path
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+if platform.system() != 'Windows':
+ ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from yolov5.models.common import *
+from yolov5.models.experimental import *
+from yolov5.utils.autoanchor import check_anchor_order
+from yolov5.utils.general import LOGGER, check_version, check_yaml, make_divisible, print_args
+from yolov5.utils.plots import feature_visualization
+from yolov5.utils.torch_utils import (fuse_conv_and_bn, initialize_weights, model_info, profile, scale_img, select_device,
+ time_sync)
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+
+class Detect(nn.Module):
+ # YOLOv5 Detect head for detection models
+ stride = None # strides computed during build
+ dynamic = False # force grid reconstruction
+ export = False # export mode
+
+ def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
+ super().__init__()
+ self.nc = nc # number of classes
+ self.no = nc + 5 # number of outputs per anchor
+ self.nl = len(anchors) # number of detection layers
+ self.na = len(anchors[0]) // 2 # number of anchors
+ self.grid = [torch.empty(0) for _ in range(self.nl)] # init grid
+ self.anchor_grid = [torch.empty(0) for _ in range(self.nl)] # init anchor grid
+ self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
+ self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
+ self.inplace = inplace # use inplace ops (e.g. slice assignment)
+
+ def forward(self, x):
+ z = [] # inference output
+ for i in range(self.nl):
+ x[i] = self.m[i](x[i]) # conv
+ bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
+ x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
+
+ if not self.training: # inference
+ if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
+ self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
+
+ if isinstance(self, Segment): # (boxes + masks)
+ xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)
+ xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xy
+ wh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # wh
+ y = torch.cat((xy, wh, conf.sigmoid(), mask), 4)
+ else: # Detect (boxes only)
+ xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)
+ xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
+ wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
+ y = torch.cat((xy, wh, conf), 4)
+ z.append(y.view(bs, self.na * nx * ny, self.no))
+
+ return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
+
+ def _make_grid(self, nx=20, ny=20, i=0, torch_1_10=check_version(torch.__version__, '1.10.0')):
+ d = self.anchors[i].device
+ t = self.anchors[i].dtype
+ shape = 1, self.na, ny, nx, 2 # grid shape
+ y, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)
+ yv, xv = torch.meshgrid(y, x, indexing='ij') if torch_1_10 else torch.meshgrid(y, x) # torch>=0.7 compatibility
+ grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5
+ anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)
+ return grid, anchor_grid
+
+
+class Segment(Detect):
+ # YOLOv5 Segment head for segmentation models
+ def __init__(self, nc=80, anchors=(), nm=32, npr=256, ch=(), inplace=True):
+ super().__init__(nc, anchors, ch, inplace)
+ self.nm = nm # number of masks
+ self.npr = npr # number of protos
+ self.no = 5 + nc + self.nm # number of outputs per anchor
+ self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
+ self.proto = Proto(ch[0], self.npr, self.nm) # protos
+ self.detect = Detect.forward
+
+ def forward(self, x):
+ p = self.proto(x[0])
+ x = self.detect(self, x)
+ return (x, p) if self.training else (x[0], p) if self.export else (x[0], p, x[1])
+
+
+class BaseModel(nn.Module):
+ # YOLOv5 base model
+ def forward(self, x, profile=False, visualize=False):
+ return self._forward_once(x, profile, visualize) # single-scale inference, train
+
+ def _forward_once(self, x, profile=False, visualize=False):
+ y, dt = [], [] # outputs
+ for m in self.model:
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+ if profile:
+ self._profile_one_layer(m, x, dt)
+ x = m(x) # run
+ y.append(x if m.i in self.save else None) # save output
+ if visualize:
+ feature_visualization(x, m.type, m.i, save_dir=visualize)
+ return x
+
+ def _profile_one_layer(self, m, x, dt):
+ c = m == self.model[-1] # is final layer, copy input as inplace fix
+ o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
+ t = time_sync()
+ for _ in range(10):
+ m(x.copy() if c else x)
+ dt.append((time_sync() - t) * 100)
+ if m == self.model[0]:
+ LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} module")
+ LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
+ if c:
+ LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
+
+ def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
+ LOGGER.info('Fusing layers... ')
+ for m in self.model.modules():
+ if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
+ m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
+ delattr(m, 'bn') # remove batchnorm
+ m.forward = m.forward_fuse # update forward
+ self.info()
+ return self
+
+ def info(self, verbose=False, img_size=640): # print model information
+ model_info(self, verbose, img_size)
+
+ def _apply(self, fn):
+ # Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
+ self = super()._apply(fn)
+ m = self.model[-1] # Detect()
+ if isinstance(m, (Detect, Segment)):
+ m.stride = fn(m.stride)
+ m.grid = list(map(fn, m.grid))
+ if isinstance(m.anchor_grid, list):
+ m.anchor_grid = list(map(fn, m.anchor_grid))
+ return self
+
+
+class DetectionModel(BaseModel):
+ # YOLOv5 detection model
+ def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
+ super().__init__()
+ if isinstance(cfg, dict):
+ self.yaml = cfg # model dict
+ else: # is *.yaml
+ import yaml # for torch hub
+ self.yaml_file = Path(cfg).name
+ with open(cfg, encoding='ascii', errors='ignore') as f:
+ self.yaml = yaml.safe_load(f) # model dict
+
+ # Define model
+ ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override yaml value
+ if anchors:
+ LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
+ self.yaml['anchors'] = round(anchors) # override yaml value
+ self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
+ self.names = [str(i) for i in range(self.yaml['nc'])] # default names
+ self.inplace = self.yaml.get('inplace', True)
+
+ # Build strides, anchors
+ m = self.model[-1] # Detect()
+ if isinstance(m, (Detect, Segment)):
+ s = 256 # 2x min stride
+ m.inplace = self.inplace
+ forward = lambda x: self.forward(x)[0] if isinstance(m, Segment) else self.forward(x)
+ m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forward
+ check_anchor_order(m)
+ m.anchors /= m.stride.view(-1, 1, 1)
+ self.stride = m.stride
+ self._initialize_biases() # only run once
+
+ # Init weights, biases
+ initialize_weights(self)
+ self.info()
+ LOGGER.info('')
+
+ def forward(self, x, augment=False, profile=False, visualize=False):
+ if augment:
+ return self._forward_augment(x) # augmented inference, None
+ return self._forward_once(x, profile, visualize) # single-scale inference, train
+
+ def _forward_augment(self, x):
+ img_size = x.shape[-2:] # height, width
+ s = [1, 0.83, 0.67] # scales
+ f = [None, 3, None] # flips (2-ud, 3-lr)
+ y = [] # outputs
+ for si, fi in zip(s, f):
+ xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
+ yi = self._forward_once(xi)[0] # forward
+ # cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
+ yi = self._descale_pred(yi, fi, si, img_size)
+ y.append(yi)
+ y = self._clip_augmented(y) # clip augmented tails
+ return torch.cat(y, 1), None # augmented inference, train
+
+ def _descale_pred(self, p, flips, scale, img_size):
+ # de-scale predictions following augmented inference (inverse operation)
+ if self.inplace:
+ p[..., :4] /= scale # de-scale
+ if flips == 2:
+ p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
+ elif flips == 3:
+ p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
+ else:
+ x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
+ if flips == 2:
+ y = img_size[0] - y # de-flip ud
+ elif flips == 3:
+ x = img_size[1] - x # de-flip lr
+ p = torch.cat((x, y, wh, p[..., 4:]), -1)
+ return p
+
+ def _clip_augmented(self, y):
+ # Clip YOLOv5 augmented inference tails
+ nl = self.model[-1].nl # number of detection layers (P3-P5)
+ g = sum(4 ** x for x in range(nl)) # grid points
+ e = 1 # exclude layer count
+ i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indices
+ y[0] = y[0][:, :-i] # large
+ i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
+ y[-1] = y[-1][:, i:] # small
+ return y
+
+ def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
+ # https://arxiv.org/abs/1708.02002 section 3.3
+ # cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
+ m = self.model[-1] # Detect() module
+ for mi, s in zip(m.m, m.stride): # from
+ b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
+ b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
+ b.data[:, 5:5 + m.nc] += math.log(0.6 / (m.nc - 0.99999)) if cf is None else torch.log(cf / cf.sum()) # cls
+ mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
+
+
+Model = DetectionModel # retain YOLOv5 'Model' class for backwards compatibility
+
+
+class SegmentationModel(DetectionModel):
+ # YOLOv5 segmentation model
+ def __init__(self, cfg='yolov5s-seg.yaml', ch=3, nc=None, anchors=None):
+ super().__init__(cfg, ch, nc, anchors)
+
+
+class ClassificationModel(BaseModel):
+ # YOLOv5 classification model
+ def __init__(self, cfg=None, model=None, nc=1000, cutoff=10): # yaml, model, number of classes, cutoff index
+ super().__init__()
+ self._from_detection_model(model, nc, cutoff) if model is not None else self._from_yaml(cfg)
+
+ def _from_detection_model(self, model, nc=1000, cutoff=10):
+ # Create a YOLOv5 classification model from a YOLOv5 detection model
+ if isinstance(model, DetectMultiBackend):
+ model = model.model # unwrap DetectMultiBackend
+ model.model = model.model[:cutoff] # backbone
+ m = model.model[-1] # last layer
+ ch = m.conv.in_channels if hasattr(m, 'conv') else m.cv1.conv.in_channels # ch into module
+ c = Classify(ch, nc) # Classify()
+ c.i, c.f, c.type = m.i, m.f, 'models.common.Classify' # index, from, type
+ model.model[-1] = c # replace
+ self.model = model.model
+ self.stride = model.stride
+ self.save = []
+ self.nc = nc
+
+ def _from_yaml(self, cfg):
+ # Create a YOLOv5 classification model from a *.yaml file
+ self.model = None
+
+
+def parse_model(d, ch): # model_dict, input_channels(3)
+ # Parse a YOLOv5 model.yaml dictionary
+ LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
+ anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
+ if act:
+ Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
+ LOGGER.info(f"{colorstr('activation:')} {act}") # print
+ na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
+ no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
+
+ layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
+ for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
+ m = eval(m) if isinstance(m, str) else m # eval strings
+ for j, a in enumerate(args):
+ with contextlib.suppress(NameError):
+ args[j] = eval(a) if isinstance(a, str) else a # eval strings
+
+ n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
+ if m in {
+ Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
+ BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
+ c1, c2 = ch[f], args[0]
+ if c2 != no: # if not output
+ c2 = make_divisible(c2 * gw, 8)
+
+ args = [c1, c2, *args[1:]]
+ if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
+ args.insert(2, n) # number of repeats
+ n = 1
+ elif m is nn.BatchNorm2d:
+ args = [ch[f]]
+ elif m is Concat:
+ c2 = sum(ch[x] for x in f)
+ # TODO: channel, gw, gd
+ elif m in {Detect, Segment}:
+ args.append([ch[x] for x in f])
+ if isinstance(args[1], int): # number of anchors
+ args[1] = [list(range(args[1] * 2))] * len(f)
+ if m is Segment:
+ args[3] = make_divisible(args[3] * gw, 8)
+ elif m is Contract:
+ c2 = ch[f] * args[0] ** 2
+ elif m is Expand:
+ c2 = ch[f] // args[0] ** 2
+ else:
+ c2 = ch[f]
+
+ m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
+ t = str(m)[8:-2].replace('__main__.', '') # module type
+ np = sum(x.numel() for x in m_.parameters()) # number params
+ m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
+ LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
+ save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
+ layers.append(m_)
+ if i == 0:
+ ch = []
+ ch.append(c2)
+ return nn.Sequential(*layers), sorted(save)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
+ parser.add_argument('--batch-size', type=int, default=1, help='total batch size for all GPUs')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--profile', action='store_true', help='profile model speed')
+ parser.add_argument('--line-profile', action='store_true', help='profile model speed layer by layer')
+ parser.add_argument('--test', action='store_true', help='test all yolo*.yaml')
+ opt = parser.parse_args()
+ opt.cfg = check_yaml(opt.cfg) # check YAML
+ print_args(vars(opt))
+ device = select_device(opt.device)
+
+ # Create model
+ im = torch.rand(opt.batch_size, 3, 640, 640).to(device)
+ model = Model(opt.cfg).to(device)
+
+ # Options
+ if opt.line_profile: # profile layer by layer
+ model(im, profile=True)
+
+ elif opt.profile: # profile forward-backward
+ results = profile(input=im, ops=[model], n=3)
+
+ elif opt.test: # test all models
+ for cfg in Path(ROOT / 'models').rglob('yolo*.yaml'):
+ try:
+ _ = Model(cfg)
+ except Exception as e:
+ print(f'Error in {cfg}: {e}')
+
+ else: # report fused model summary
+ model.fuse()
diff --git a/yolov5/models/yolov5l.yaml b/yolov5/models/yolov5l.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..31362f8769327bad3afdb65d39a3b940397ecfae
--- /dev/null
+++ b/yolov5/models/yolov5l.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/yolov5m.yaml b/yolov5/models/yolov5m.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a76900c5a2e2602d59ece8645bbd67e0dc454311
--- /dev/null
+++ b/yolov5/models/yolov5m.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/yolov5n.yaml b/yolov5/models/yolov5n.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..aba96cfc54f48c2cb2fe16aae2b0b94e38826c9d
--- /dev/null
+++ b/yolov5/models/yolov5n.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/yolov5s.yaml b/yolov5/models/yolov5s.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5d05364c49363adb2b863ecf163e45516679dc03
--- /dev/null
+++ b/yolov5/models/yolov5s.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/models/yolov5x.yaml b/yolov5/models/yolov5x.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..4bdd93915da550d62c4ada3684c5660ff5034404
--- /dev/null
+++ b/yolov5/models/yolov5x.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/yolov5/requirements.txt b/yolov5/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..65924c9feec41273a8a4d2bb238e5622ac928a96
--- /dev/null
+++ b/yolov5/requirements.txt
@@ -0,0 +1,49 @@
+# YOLOv5 requirements
+# Usage: pip install -r requirements.txt
+
+# Base ------------------------------------------------------------------------
+gitpython>=3.1.30
+matplotlib>=3.3
+numpy>=1.18.5
+opencv-python>=4.1.1
+Pillow>=7.1.2
+psutil # system resources
+PyYAML>=5.3.1
+requests>=2.23.0
+scipy>=1.4.1
+thop>=0.1.1 # FLOPs computation
+torch>=1.7.0 # see https://pytorch.org/get-started/locally (recommended)
+torchvision>=0.8.1
+tqdm>=4.64.0
+# protobuf<=3.20.1 # https://github.com/ultralytics/yolov5/issues/8012
+
+# Logging ---------------------------------------------------------------------
+# tensorboard>=2.4.1
+# clearml>=1.2.0
+# comet
+
+# Plotting --------------------------------------------------------------------
+pandas>=1.1.4
+seaborn>=0.11.0
+
+# Export ----------------------------------------------------------------------
+# coremltools>=6.0 # CoreML export
+# onnx>=1.10.0 # ONNX export
+# onnx-simplifier>=0.4.1 # ONNX simplifier
+# nvidia-pyindex # TensorRT export
+# nvidia-tensorrt # TensorRT export
+# scikit-learn<=1.1.2 # CoreML quantization
+# tensorflow>=2.4.0 # TF exports (-cpu, -aarch64, -macos)
+# tensorflowjs>=3.9.0 # TF.js export
+# openvino-dev # OpenVINO export
+
+# Deploy ----------------------------------------------------------------------
+setuptools>=65.5.1 # Snyk vulnerability fix
+# tritonclient[all]~=2.24.0
+
+# Extras ----------------------------------------------------------------------
+# ipython # interactive notebook
+# mss # screenshots
+# albumentations>=1.0.3
+# pycocotools>=2.0.6 # COCO mAP
+# ultralytics # HUB https://hub.ultralytics.com
diff --git a/yolov5/segment/predict.py b/yolov5/segment/predict.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d4d6036358a755e297cbc83e2579242712b128a
--- /dev/null
+++ b/yolov5/segment/predict.py
@@ -0,0 +1,284 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Run YOLOv5 segmentation inference on images, videos, directories, streams, etc.
+
+Usage - sources:
+ $ python segment/predict.py --weights yolov5s-seg.pt --source 0 # webcam
+ img.jpg # image
+ vid.mp4 # video
+ screen # screenshot
+ path/ # directory
+ list.txt # list of images
+ list.streams # list of streams
+ 'path/*.jpg' # glob
+ 'https://youtu.be/Zgi9g1ksQHc' # YouTube
+ 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
+
+Usage - formats:
+ $ python segment/predict.py --weights yolov5s-seg.pt # PyTorch
+ yolov5s-seg.torchscript # TorchScript
+ yolov5s-seg.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s-seg_openvino_model # OpenVINO
+ yolov5s-seg.engine # TensorRT
+ yolov5s-seg.mlmodel # CoreML (macOS-only)
+ yolov5s-seg_saved_model # TensorFlow SavedModel
+ yolov5s-seg.pb # TensorFlow GraphDef
+ yolov5s-seg.tflite # TensorFlow Lite
+ yolov5s-seg_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s-seg_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import os
+import platform
+import sys
+from pathlib import Path
+
+import torch
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
+from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
+ increment_path, non_max_suppression, print_args, scale_boxes, scale_segments,
+ strip_optimizer)
+from utils.plots import Annotator, colors, save_one_box
+from utils.segment.general import masks2segments, process_mask, process_mask_native
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+@smart_inference_mode()
+def run(
+ weights=ROOT / 'yolov5s-seg.pt', # model.pt path(s)
+ source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
+ data=ROOT / 'data/coco128.yaml', # dataset.yaml path
+ imgsz=(640, 640), # inference size (height, width)
+ conf_thres=0.25, # confidence threshold
+ iou_thres=0.45, # NMS IOU threshold
+ max_det=1000, # maximum detections per image
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ view_img=False, # show results
+ save_txt=False, # save results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_crop=False, # save cropped prediction boxes
+ nosave=False, # do not save images/videos
+ classes=None, # filter by class: --class 0, or --class 0 2 3
+ agnostic_nms=False, # class-agnostic NMS
+ augment=False, # augmented inference
+ visualize=False, # visualize features
+ update=False, # update all models
+ project=ROOT / 'runs/predict-seg', # save results to project/name
+ name='exp', # save results to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ line_thickness=3, # bounding box thickness (pixels)
+ hide_labels=False, # hide labels
+ hide_conf=False, # hide confidences
+ half=False, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ vid_stride=1, # video frame-rate stride
+ retina_masks=False,
+):
+ source = str(source)
+ save_img = not nosave and not source.endswith('.txt') # save inference images
+ is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
+ is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
+ webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
+ screenshot = source.lower().startswith('screen')
+ if is_url and is_file:
+ source = check_file(source) # download
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ device = select_device(device)
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, names, pt = model.stride, model.names, model.pt
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+
+ # Dataloader
+ bs = 1 # batch_size
+ if webcam:
+ view_img = check_imshow(warn=True)
+ dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
+ bs = len(dataset)
+ elif screenshot:
+ dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
+ else:
+ dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
+ vid_path, vid_writer = [None] * bs, [None] * bs
+
+ # Run inference
+ model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
+ seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
+ for path, im, im0s, vid_cap, s in dataset:
+ with dt[0]:
+ im = torch.from_numpy(im).to(model.device)
+ im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+
+ # Inference
+ with dt[1]:
+ visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
+ pred, proto = model(im, augment=augment, visualize=visualize)[:2]
+
+ # NMS
+ with dt[2]:
+ pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det, nm=32)
+
+ # Second-stage classifier (optional)
+ # pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
+
+ # Process predictions
+ for i, det in enumerate(pred): # per image
+ seen += 1
+ if webcam: # batch_size >= 1
+ p, im0, frame = path[i], im0s[i].copy(), dataset.count
+ s += f'{i}: '
+ else:
+ p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
+
+ p = Path(p) # to Path
+ save_path = str(save_dir / p.name) # im.jpg
+ txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
+ s += '%gx%g ' % im.shape[2:] # print string
+ imc = im0.copy() if save_crop else im0 # for save_crop
+ annotator = Annotator(im0, line_width=line_thickness, example=str(names))
+ if len(det):
+ if retina_masks:
+ # scale bbox first the crop masks
+ det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round() # rescale boxes to im0 size
+ masks = process_mask_native(proto[i], det[:, 6:], det[:, :4], im0.shape[:2]) # HWC
+ else:
+ masks = process_mask(proto[i], det[:, 6:], det[:, :4], im.shape[2:], upsample=True) # HWC
+ det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round() # rescale boxes to im0 size
+
+ # Segments
+ if save_txt:
+ segments = [
+ scale_segments(im0.shape if retina_masks else im.shape[2:], x, im0.shape, normalize=True)
+ for x in reversed(masks2segments(masks))]
+
+ # Print results
+ for c in det[:, 5].unique():
+ n = (det[:, 5] == c).sum() # detections per class
+ s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
+
+ # Mask plotting
+ annotator.masks(
+ masks,
+ colors=[colors(x, True) for x in det[:, 5]],
+ im_gpu=torch.as_tensor(im0, dtype=torch.float16).to(device).permute(2, 0, 1).flip(0).contiguous() /
+ 255 if retina_masks else im[i])
+
+ # Write results
+ for j, (*xyxy, conf, cls) in enumerate(reversed(det[:, :6])):
+ if save_txt: # Write to file
+ seg = segments[j].reshape(-1) # (n,2) to (n*2)
+ line = (cls, *seg, conf) if save_conf else (cls, *seg) # label format
+ with open(f'{txt_path}.txt', 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+ if save_img or save_crop or view_img: # Add bbox to image
+ c = int(cls) # integer class
+ label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
+ annotator.box_label(xyxy, label, color=colors(c, True))
+ # annotator.draw.polygon(segments[j], outline=colors(c, True), width=3)
+ if save_crop:
+ save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
+
+ # Stream results
+ im0 = annotator.result()
+ if view_img:
+ if platform.system() == 'Linux' and p not in windows:
+ windows.append(p)
+ cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
+ cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
+ cv2.imshow(str(p), im0)
+ if cv2.waitKey(1) == ord('q'): # 1 millisecond
+ exit()
+
+ # Save results (image with detections)
+ if save_img:
+ if dataset.mode == 'image':
+ cv2.imwrite(save_path, im0)
+ else: # 'video' or 'stream'
+ if vid_path[i] != save_path: # new video
+ vid_path[i] = save_path
+ if isinstance(vid_writer[i], cv2.VideoWriter):
+ vid_writer[i].release() # release previous video writer
+ if vid_cap: # video
+ fps = vid_cap.get(cv2.CAP_PROP_FPS)
+ w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ else: # stream
+ fps, w, h = 30, im0.shape[1], im0.shape[0]
+ save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
+ vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ vid_writer[i].write(im0)
+
+ # Print time (inference-only)
+ LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms")
+
+ # Print results
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
+ if save_txt or save_img:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ if update:
+ strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning)
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s-seg.pt', help='model path(s)')
+ parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
+ parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--view-img', action='store_true', help='show results')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
+ parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
+ parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
+ parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--visualize', action='store_true', help='visualize features')
+ parser.add_argument('--update', action='store_true', help='update all models')
+ parser.add_argument('--project', default=ROOT / 'runs/predict-seg', help='save results to project/name')
+ parser.add_argument('--name', default='exp', help='save results to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
+ parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
+ parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
+ parser.add_argument('--retina-masks', action='store_true', help='whether to plot masks in native resolution')
+ opt = parser.parse_args()
+ opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+ run(**vars(opt))
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/segment/train.py b/yolov5/segment/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..073fc742005b856992f853af2a54093c638d79b6
--- /dev/null
+++ b/yolov5/segment/train.py
@@ -0,0 +1,666 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Train a YOLOv5 segment model on a segment dataset
+Models and datasets download automatically from the latest YOLOv5 release.
+
+Usage - Single-GPU training:
+ $ python segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640 # from pretrained (recommended)
+ $ python segment/train.py --data coco128-seg.yaml --weights '' --cfg yolov5s-seg.yaml --img 640 # from scratch
+
+Usage - Multi-GPU DDP training:
+ $ python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640 --device 0,1,2,3
+
+Models: https://github.com/ultralytics/yolov5/tree/master/models
+Datasets: https://github.com/ultralytics/yolov5/tree/master/data
+Tutorial: https://docs.ultralytics.com/yolov5/tutorials/train_custom_data
+"""
+
+import argparse
+import math
+import os
+import random
+import subprocess
+import sys
+import time
+from copy import deepcopy
+from datetime import datetime
+from pathlib import Path
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import yaml
+from torch.optim import lr_scheduler
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import segment.val as validate # for end-of-epoch mAP
+from models.experimental import attempt_load
+from models.yolo import SegmentationModel
+from utils.autoanchor import check_anchors
+from utils.autobatch import check_train_batch_size
+from utils.callbacks import Callbacks
+from utils.downloads import attempt_download, is_url
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, check_amp, check_dataset, check_file, check_git_info,
+ check_git_status, check_img_size, check_requirements, check_suffix, check_yaml, colorstr,
+ get_latest_run, increment_path, init_seeds, intersect_dicts, labels_to_class_weights,
+ labels_to_image_weights, one_cycle, print_args, print_mutation, strip_optimizer, yaml_save)
+from utils.loggers import GenericLogger
+from utils.plots import plot_evolve, plot_labels
+from utils.segment.dataloaders import create_dataloader
+from utils.segment.loss import ComputeLoss
+from utils.segment.metrics import KEYS, fitness
+from utils.segment.plots import plot_images_and_masks, plot_results_with_masks
+from utils.torch_utils import (EarlyStopping, ModelEMA, de_parallel, select_device, smart_DDP, smart_optimizer,
+ smart_resume, torch_distributed_zero_first)
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+GIT_INFO = check_git_info()
+
+
+def train(hyp, opt, device, callbacks): # hyp is path/to/hyp.yaml or hyp dictionary
+ save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze, mask_ratio = \
+ Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
+ opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze, opt.mask_ratio
+ # callbacks.run('on_pretrain_routine_start')
+
+ # Directories
+ w = save_dir / 'weights' # weights dir
+ (w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
+ last, best = w / 'last.pt', w / 'best.pt'
+
+ # Hyperparameters
+ if isinstance(hyp, str):
+ with open(hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
+ opt.hyp = hyp.copy() # for saving hyps to checkpoints
+
+ # Save run settings
+ if not evolve:
+ yaml_save(save_dir / 'hyp.yaml', hyp)
+ yaml_save(save_dir / 'opt.yaml', vars(opt))
+
+ # Loggers
+ data_dict = None
+ if RANK in {-1, 0}:
+ logger = GenericLogger(opt=opt, console_logger=LOGGER)
+
+ # Config
+ plots = not evolve and not opt.noplots # create plots
+ overlap = not opt.no_overlap
+ cuda = device.type != 'cpu'
+ init_seeds(opt.seed + 1 + RANK, deterministic=True)
+ with torch_distributed_zero_first(LOCAL_RANK):
+ data_dict = data_dict or check_dataset(data) # check if None
+ train_path, val_path = data_dict['train'], data_dict['val']
+ nc = 1 if single_cls else int(data_dict['nc']) # number of classes
+ names = {0: 'item'} if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
+ is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
+
+ # Model
+ check_suffix(weights, '.pt') # check weights
+ pretrained = weights.endswith('.pt')
+ if pretrained:
+ with torch_distributed_zero_first(LOCAL_RANK):
+ weights = attempt_download(weights) # download if not found locally
+ ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
+ model = SegmentationModel(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device)
+ exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
+ else:
+ model = SegmentationModel(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ amp = check_amp(model) # check AMP
+
+ # Freeze
+ freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze
+ for k, v in model.named_parameters():
+ v.requires_grad = True # train all layers
+ # v.register_hook(lambda x: torch.nan_to_num(x)) # NaN to 0 (commented for erratic training results)
+ if any(x in k for x in freeze):
+ LOGGER.info(f'freezing {k}')
+ v.requires_grad = False
+
+ # Image size
+ gs = max(int(model.stride.max()), 32) # grid size (max stride)
+ imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
+
+ # Batch size
+ if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
+ batch_size = check_train_batch_size(model, imgsz, amp)
+ logger.update_params({'batch_size': batch_size})
+ # loggers.on_params_update({"batch_size": batch_size})
+
+ # Optimizer
+ nbs = 64 # nominal batch size
+ accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
+ hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
+ optimizer = smart_optimizer(model, opt.optimizer, hyp['lr0'], hyp['momentum'], hyp['weight_decay'])
+
+ # Scheduler
+ if opt.cos_lr:
+ lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
+ else:
+ lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
+ scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
+
+ # EMA
+ ema = ModelEMA(model) if RANK in {-1, 0} else None
+
+ # Resume
+ best_fitness, start_epoch = 0.0, 0
+ if pretrained:
+ if resume:
+ best_fitness, start_epoch, epochs = smart_resume(ckpt, optimizer, ema, weights, epochs, resume)
+ del ckpt, csd
+
+ # DP mode
+ if cuda and RANK == -1 and torch.cuda.device_count() > 1:
+ LOGGER.warning(
+ 'WARNING ⚠️ DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
+ 'See Multi-GPU Tutorial at https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training to get started.'
+ )
+ model = torch.nn.DataParallel(model)
+
+ # SyncBatchNorm
+ if opt.sync_bn and cuda and RANK != -1:
+ model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
+ LOGGER.info('Using SyncBatchNorm()')
+
+ # Trainloader
+ train_loader, dataset = create_dataloader(
+ train_path,
+ imgsz,
+ batch_size // WORLD_SIZE,
+ gs,
+ single_cls,
+ hyp=hyp,
+ augment=True,
+ cache=None if opt.cache == 'val' else opt.cache,
+ rect=opt.rect,
+ rank=LOCAL_RANK,
+ workers=workers,
+ image_weights=opt.image_weights,
+ quad=opt.quad,
+ prefix=colorstr('train: '),
+ shuffle=True,
+ mask_downsample_ratio=mask_ratio,
+ overlap_mask=overlap,
+ )
+ labels = np.concatenate(dataset.labels, 0)
+ mlc = int(labels[:, 0].max()) # max label class
+ assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
+
+ # Process 0
+ if RANK in {-1, 0}:
+ val_loader = create_dataloader(val_path,
+ imgsz,
+ batch_size // WORLD_SIZE * 2,
+ gs,
+ single_cls,
+ hyp=hyp,
+ cache=None if noval else opt.cache,
+ rect=True,
+ rank=-1,
+ workers=workers * 2,
+ pad=0.5,
+ mask_downsample_ratio=mask_ratio,
+ overlap_mask=overlap,
+ prefix=colorstr('val: '))[0]
+
+ if not resume:
+ if not opt.noautoanchor:
+ check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz) # run AutoAnchor
+ model.half().float() # pre-reduce anchor precision
+
+ if plots:
+ plot_labels(labels, names, save_dir)
+ # callbacks.run('on_pretrain_routine_end', labels, names)
+
+ # DDP mode
+ if cuda and RANK != -1:
+ model = smart_DDP(model)
+
+ # Model attributes
+ nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
+ hyp['box'] *= 3 / nl # scale to layers
+ hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
+ hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
+ hyp['label_smoothing'] = opt.label_smoothing
+ model.nc = nc # attach number of classes to model
+ model.hyp = hyp # attach hyperparameters to model
+ model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
+ model.names = names
+
+ # Start training
+ t0 = time.time()
+ nb = len(train_loader) # number of batches
+ nw = max(round(hyp['warmup_epochs'] * nb), 100) # number of warmup iterations, max(3 epochs, 100 iterations)
+ # nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
+ last_opt_step = -1
+ maps = np.zeros(nc) # mAP per class
+ results = (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
+ scheduler.last_epoch = start_epoch - 1 # do not move
+ scaler = torch.cuda.amp.GradScaler(enabled=amp)
+ stopper, stop = EarlyStopping(patience=opt.patience), False
+ compute_loss = ComputeLoss(model, overlap=overlap) # init loss class
+ # callbacks.run('on_train_start')
+ LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
+ f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
+ f"Logging results to {colorstr('bold', save_dir)}\n"
+ f'Starting training for {epochs} epochs...')
+ for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
+ # callbacks.run('on_train_epoch_start')
+ model.train()
+
+ # Update image weights (optional, single-GPU only)
+ if opt.image_weights:
+ cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
+ iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
+ dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
+
+ # Update mosaic border (optional)
+ # b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
+ # dataset.mosaic_border = [b - imgsz, -b] # height, width borders
+
+ mloss = torch.zeros(4, device=device) # mean losses
+ if RANK != -1:
+ train_loader.sampler.set_epoch(epoch)
+ pbar = enumerate(train_loader)
+ LOGGER.info(('\n' + '%11s' * 8) %
+ ('Epoch', 'GPU_mem', 'box_loss', 'seg_loss', 'obj_loss', 'cls_loss', 'Instances', 'Size'))
+ if RANK in {-1, 0}:
+ pbar = tqdm(pbar, total=nb, bar_format=TQDM_BAR_FORMAT) # progress bar
+ optimizer.zero_grad()
+ for i, (imgs, targets, paths, _, masks) in pbar: # batch ------------------------------------------------------
+ # callbacks.run('on_train_batch_start')
+ ni = i + nb * epoch # number integrated batches (since train start)
+ imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
+
+ # Warmup
+ if ni <= nw:
+ xi = [0, nw] # x interp
+ # compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
+ accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
+ for j, x in enumerate(optimizer.param_groups):
+ # bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
+ x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 0 else 0.0, x['initial_lr'] * lf(epoch)])
+ if 'momentum' in x:
+ x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
+
+ # Multi-scale
+ if opt.multi_scale:
+ sz = random.randrange(int(imgsz * 0.5), int(imgsz * 1.5) + gs) // gs * gs # size
+ sf = sz / max(imgs.shape[2:]) # scale factor
+ if sf != 1:
+ ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
+ imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
+
+ # Forward
+ with torch.cuda.amp.autocast(amp):
+ pred = model(imgs) # forward
+ loss, loss_items = compute_loss(pred, targets.to(device), masks=masks.to(device).float())
+ if RANK != -1:
+ loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
+ if opt.quad:
+ loss *= 4.
+
+ # Backward
+ scaler.scale(loss).backward()
+
+ # Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
+ if ni - last_opt_step >= accumulate:
+ scaler.unscale_(optimizer) # unscale gradients
+ torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0) # clip gradients
+ scaler.step(optimizer) # optimizer.step
+ scaler.update()
+ optimizer.zero_grad()
+ if ema:
+ ema.update(model)
+ last_opt_step = ni
+
+ # Log
+ if RANK in {-1, 0}:
+ mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
+ mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
+ pbar.set_description(('%11s' * 2 + '%11.4g' * 6) %
+ (f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
+ # callbacks.run('on_train_batch_end', model, ni, imgs, targets, paths)
+ # if callbacks.stop_training:
+ # return
+
+ # Mosaic plots
+ if plots:
+ if ni < 3:
+ plot_images_and_masks(imgs, targets, masks, paths, save_dir / f'train_batch{ni}.jpg')
+ if ni == 10:
+ files = sorted(save_dir.glob('train*.jpg'))
+ logger.log_images(files, 'Mosaics', epoch)
+ # end batch ------------------------------------------------------------------------------------------------
+
+ # Scheduler
+ lr = [x['lr'] for x in optimizer.param_groups] # for loggers
+ scheduler.step()
+
+ if RANK in {-1, 0}:
+ # mAP
+ # callbacks.run('on_train_epoch_end', epoch=epoch)
+ ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
+ final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
+ if not noval or final_epoch: # Calculate mAP
+ results, maps, _ = validate.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ half=amp,
+ model=ema.ema,
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ callbacks=callbacks,
+ compute_loss=compute_loss,
+ mask_downsample_ratio=mask_ratio,
+ overlap=overlap)
+
+ # Update best mAP
+ fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
+ stop = stopper(epoch=epoch, fitness=fi) # early stop check
+ if fi > best_fitness:
+ best_fitness = fi
+ log_vals = list(mloss) + list(results) + lr
+ # callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
+ # Log val metrics and media
+ metrics_dict = dict(zip(KEYS, log_vals))
+ logger.log_metrics(metrics_dict, epoch)
+
+ # Save model
+ if (not nosave) or (final_epoch and not evolve): # if save
+ ckpt = {
+ 'epoch': epoch,
+ 'best_fitness': best_fitness,
+ 'model': deepcopy(de_parallel(model)).half(),
+ 'ema': deepcopy(ema.ema).half(),
+ 'updates': ema.updates,
+ 'optimizer': optimizer.state_dict(),
+ 'opt': vars(opt),
+ 'git': GIT_INFO, # {remote, branch, commit} if a git repo
+ 'date': datetime.now().isoformat()}
+
+ # Save last, best and delete
+ torch.save(ckpt, last)
+ if best_fitness == fi:
+ torch.save(ckpt, best)
+ if opt.save_period > 0 and epoch % opt.save_period == 0:
+ torch.save(ckpt, w / f'epoch{epoch}.pt')
+ logger.log_model(w / f'epoch{epoch}.pt')
+ del ckpt
+ # callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
+
+ # EarlyStopping
+ if RANK != -1: # if DDP training
+ broadcast_list = [stop if RANK == 0 else None]
+ dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks
+ if RANK != 0:
+ stop = broadcast_list[0]
+ if stop:
+ break # must break all DDP ranks
+
+ # end epoch ----------------------------------------------------------------------------------------------------
+ # end training -----------------------------------------------------------------------------------------------------
+ if RANK in {-1, 0}:
+ LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
+ for f in last, best:
+ if f.exists():
+ strip_optimizer(f) # strip optimizers
+ if f is best:
+ LOGGER.info(f'\nValidating {f}...')
+ results, _, _ = validate.run(
+ data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=attempt_load(f, device).half(),
+ iou_thres=0.65 if is_coco else 0.60, # best pycocotools at iou 0.65
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ save_json=is_coco,
+ verbose=True,
+ plots=plots,
+ callbacks=callbacks,
+ compute_loss=compute_loss,
+ mask_downsample_ratio=mask_ratio,
+ overlap=overlap) # val best model with plots
+ if is_coco:
+ # callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
+ metrics_dict = dict(zip(KEYS, list(mloss) + list(results) + lr))
+ logger.log_metrics(metrics_dict, epoch)
+
+ # callbacks.run('on_train_end', last, best, epoch, results)
+ # on train end callback using genericLogger
+ logger.log_metrics(dict(zip(KEYS[4:16], results)), epochs)
+ if not opt.evolve:
+ logger.log_model(best, epoch)
+ if plots:
+ plot_results_with_masks(file=save_dir / 'results.csv') # save results.png
+ files = ['results.png', 'confusion_matrix.png', *(f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R'))]
+ files = [(save_dir / f) for f in files if (save_dir / f).exists()] # filter
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
+ logger.log_images(files, 'Results', epoch + 1)
+ logger.log_images(sorted(save_dir.glob('val*.jpg')), 'Validation', epoch + 1)
+ torch.cuda.empty_cache()
+ return results
+
+
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s-seg.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128-seg.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
+ parser.add_argument('--noplots', action='store_true', help='save no plot files')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train-seg', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--seed', type=int, default=0, help='Global training seed')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+
+ # Instance Segmentation Args
+ parser.add_argument('--mask-ratio', type=int, default=4, help='Downsample the truth masks to saving memory')
+ parser.add_argument('--no-overlap', action='store_true', help='Overlap masks train faster at slightly less mAP')
+
+ return parser.parse_known_args()[0] if known else parser.parse_args()
+
+
+def main(opt, callbacks=Callbacks()):
+ # Checks
+ if RANK in {-1, 0}:
+ print_args(vars(opt))
+ check_git_status()
+ check_requirements()
+
+ # Resume
+ if opt.resume and not opt.evolve: # resume from specified or most recent last.pt
+ last = Path(check_file(opt.resume) if isinstance(opt.resume, str) else get_latest_run())
+ opt_yaml = last.parent.parent / 'opt.yaml' # train options yaml
+ opt_data = opt.data # original dataset
+ if opt_yaml.is_file():
+ with open(opt_yaml, errors='ignore') as f:
+ d = yaml.safe_load(f)
+ else:
+ d = torch.load(last, map_location='cpu')['opt']
+ opt = argparse.Namespace(**d) # replace
+ opt.cfg, opt.weights, opt.resume = '', str(last), True # reinstate
+ if is_url(opt_data):
+ opt.data = check_file(opt_data) # avoid HUB resume auth timeout
+ else:
+ opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
+ check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
+ assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
+ if opt.evolve:
+ if opt.project == str(ROOT / 'runs/train-seg'): # if default project name, rename to runs/evolve-seg
+ opt.project = str(ROOT / 'runs/evolve-seg')
+ opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
+ if opt.name == 'cfg':
+ opt.name = Path(opt.cfg).stem # use model.yaml as name
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
+
+ # DDP mode
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ if LOCAL_RANK != -1:
+ msg = 'is not compatible with YOLOv5 Multi-GPU DDP training'
+ assert not opt.image_weights, f'--image-weights {msg}'
+ assert not opt.evolve, f'--evolve {msg}'
+ assert opt.batch_size != -1, f'AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size'
+ assert opt.batch_size % WORLD_SIZE == 0, f'--batch-size {opt.batch_size} must be multiple of WORLD_SIZE'
+ assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
+ torch.cuda.set_device(LOCAL_RANK)
+ device = torch.device('cuda', LOCAL_RANK)
+ dist.init_process_group(backend='nccl' if dist.is_nccl_available() else 'gloo')
+
+ # Train
+ if not opt.evolve:
+ train(opt.hyp, opt, device, callbacks)
+
+ # Evolve hyperparameters (optional)
+ else:
+ # Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
+ meta = {
+ 'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
+ 'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
+ 'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
+ 'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
+ 'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
+ 'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
+ 'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
+ 'box': (1, 0.02, 0.2), # box loss gain
+ 'cls': (1, 0.2, 4.0), # cls loss gain
+ 'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
+ 'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
+ 'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
+ 'iou_t': (0, 0.1, 0.7), # IoU training threshold
+ 'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
+ 'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
+ 'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
+ 'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
+ 'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
+ 'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
+ 'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
+ 'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
+ 'scale': (1, 0.0, 0.9), # image scale (+/- gain)
+ 'shear': (1, 0.0, 10.0), # image shear (+/- deg)
+ 'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
+ 'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
+ 'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
+ 'mosaic': (1, 0.0, 1.0), # image mixup (probability)
+ 'mixup': (1, 0.0, 1.0), # image mixup (probability)
+ 'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
+
+ with open(opt.hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ if 'anchors' not in hyp: # anchors commented in hyp.yaml
+ hyp['anchors'] = 3
+ if opt.noautoanchor:
+ del hyp['anchors'], meta['anchors']
+ opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
+ # ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
+ evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
+ if opt.bucket:
+ # download evolve.csv if exists
+ subprocess.run([
+ 'gsutil',
+ 'cp',
+ f'gs://{opt.bucket}/evolve.csv',
+ str(evolve_csv),])
+
+ for _ in range(opt.evolve): # generations to evolve
+ if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
+ # Select parent(s)
+ parent = 'single' # parent selection method: 'single' or 'weighted'
+ x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
+ n = min(5, len(x)) # number of previous results to consider
+ x = x[np.argsort(-fitness(x))][:n] # top n mutations
+ w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
+ if parent == 'single' or len(x) == 1:
+ # x = x[random.randint(0, n - 1)] # random selection
+ x = x[random.choices(range(n), weights=w)[0]] # weighted selection
+ elif parent == 'weighted':
+ x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
+
+ # Mutate
+ mp, s = 0.8, 0.2 # mutation probability, sigma
+ npr = np.random
+ npr.seed(int(time.time()))
+ g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
+ ng = len(meta)
+ v = np.ones(ng)
+ while all(v == 1): # mutate until a change occurs (prevent duplicates)
+ v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
+ for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
+ hyp[k] = float(x[i + 12] * v[i]) # mutate
+
+ # Constrain to limits
+ for k, v in meta.items():
+ hyp[k] = max(hyp[k], v[1]) # lower limit
+ hyp[k] = min(hyp[k], v[2]) # upper limit
+ hyp[k] = round(hyp[k], 5) # significant digits
+
+ # Train mutation
+ results = train(hyp.copy(), opt, device, callbacks)
+ callbacks = Callbacks()
+ # Write mutation results
+ print_mutation(KEYS[4:16], results, hyp.copy(), save_dir, opt.bucket)
+
+ # Plot results
+ plot_evolve(evolve_csv)
+ LOGGER.info(f'Hyperparameter evolution finished {opt.evolve} generations\n'
+ f"Results saved to {colorstr('bold', save_dir)}\n"
+ f'Usage example: $ python train.py --hyp {evolve_yaml}')
+
+
+def run(**kwargs):
+ # Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
+ opt = parse_opt(True)
+ for k, v in kwargs.items():
+ setattr(opt, k, v)
+ main(opt)
+ return opt
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/segment/tutorial.ipynb b/yolov5/segment/tutorial.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..f2aee9e26b336a66cc0b5f6d3c30006fdedc4b82
--- /dev/null
+++ b/yolov5/segment/tutorial.ipynb
@@ -0,0 +1,595 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "t6MPjfT5NrKQ"
+ },
+ "source": [
+ "\n",
+ "\n",
+ "
\n",
+ " \n",
+ "\n",
+ "\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "\n",
+ "This
YOLOv5 🚀 notebook by
Ultralytics presents simple train, validate and predict examples to help start your AI adventure.
See
GitHub for community support or
contact us for professional support.\n",
+ "\n",
+ "
 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "WQPtK1QYVaD_",
+ "outputId": "9d751d8c-bee8-4339-cf30-9854ca530449"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Downloading https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels-segments.zip ...\n",
+ "Downloading http://images.cocodataset.org/zips/val2017.zip ...\n",
+ "######################################################################## 100.0%\n",
+ "######################################################################## 100.0%\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Download COCO val\n",
+ "!bash data/scripts/get_coco.sh --val --segments # download (780M - 5000 images)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "X58w8JLpMnjH",
+ "outputId": "a140d67a-02da-479e-9ddb-7d54bf9e407a"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1msegment/val: \u001b[0mdata=/content/yolov5/data/coco.yaml, weights=['yolov5s-seg.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=False, project=runs/val-seg, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-2-gc9d47ae Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "YOLOv5s-seg summary: 224 layers, 7611485 parameters, 0 gradients, 26.4 GFLOPs\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco/val2017... 4952 images, 48 backgrounds, 0 corrupt: 100% 5000/5000 [00:03<00:00, 1361.31it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mNew cache created: /content/datasets/coco/val2017.cache\n",
+ " Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100% 157/157 [01:54<00:00, 1.37it/s]\n",
+ " all 5000 36335 0.673 0.517 0.566 0.373 0.672 0.49 0.532 0.319\n",
+ "Speed: 0.6ms pre-process, 4.4ms inference, 2.9ms NMS per image at shape (32, 3, 640, 640)\n",
+ "Results saved to \u001b[1mruns/val-seg/exp\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Validate YOLOv5s-seg on COCO val\n",
+ "!python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 --half"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "WQPtK1QYVaD_",
+ "outputId": "9d751d8c-bee8-4339-cf30-9854ca530449"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Downloading https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels-segments.zip ...\n",
+ "Downloading http://images.cocodataset.org/zips/val2017.zip ...\n",
+ "######################################################################## 100.0%\n",
+ "######################################################################## 100.0%\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Download COCO val\n",
+ "!bash data/scripts/get_coco.sh --val --segments # download (780M - 5000 images)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "X58w8JLpMnjH",
+ "outputId": "a140d67a-02da-479e-9ddb-7d54bf9e407a"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1msegment/val: \u001b[0mdata=/content/yolov5/data/coco.yaml, weights=['yolov5s-seg.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=False, project=runs/val-seg, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-2-gc9d47ae Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "YOLOv5s-seg summary: 224 layers, 7611485 parameters, 0 gradients, 26.4 GFLOPs\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco/val2017... 4952 images, 48 backgrounds, 0 corrupt: 100% 5000/5000 [00:03<00:00, 1361.31it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mNew cache created: /content/datasets/coco/val2017.cache\n",
+ " Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100% 157/157 [01:54<00:00, 1.37it/s]\n",
+ " all 5000 36335 0.673 0.517 0.566 0.373 0.672 0.49 0.532 0.319\n",
+ "Speed: 0.6ms pre-process, 4.4ms inference, 2.9ms NMS per image at shape (32, 3, 640, 640)\n",
+ "Results saved to \u001b[1mruns/val-seg/exp\u001b[0m\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Validate YOLOv5s-seg on COCO val\n",
+ "!python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 --half"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
\n",
+ "Close the active learning loop by sampling images from your inference conditions with the `roboflow` pip package\n",
+ "
\n",
+ "\n",
+ "Train a YOLOv5s-seg model on the [COCO128](https://www.kaggle.com/ultralytics/coco128) dataset with `--data coco128-seg.yaml`, starting from pretrained `--weights yolov5s-seg.pt`, or from randomly initialized `--weights '' --cfg yolov5s-seg.yaml`.\n",
+ "\n",
+ "- **Pretrained [Models](https://github.com/ultralytics/yolov5/tree/master/models)** are downloaded\n",
+ "automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases)\n",
+ "- **[Datasets](https://github.com/ultralytics/yolov5/tree/master/data)** available for autodownload include: [COCO](https://github.com/ultralytics/yolov5/blob/master/data/coco.yaml), [COCO128](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml), [Argoverse](https://github.com/ultralytics/yolov5/blob/master/data/Argoverse.yaml), [VisDrone](https://github.com/ultralytics/yolov5/blob/master/data/VisDrone.yaml), [GlobalWheat](https://github.com/ultralytics/yolov5/blob/master/data/GlobalWheat2020.yaml), [xView](https://github.com/ultralytics/yolov5/blob/master/data/xView.yaml), [Objects365](https://github.com/ultralytics/yolov5/blob/master/data/Objects365.yaml), [SKU-110K](https://github.com/ultralytics/yolov5/blob/master/data/SKU-110K.yaml).\n",
+ "- **Training Results** are saved to `runs/train-seg/` with incrementing run directories, i.e. `runs/train-seg/exp2`, `runs/train-seg/exp3` etc.\n",
+ "
\n",
+ "\n",
+ "A **Mosaic Dataloader** is used for training which combines 4 images into 1 mosaic.\n",
+ "\n",
+ "## Train on Custom Data with Roboflow 🌟 NEW\n",
+ "\n",
+ "[Roboflow](https://roboflow.com/?ref=ultralytics) enables you to easily **organize, label, and prepare** a high quality dataset with your own custom data. Roboflow also makes it easy to establish an active learning pipeline, collaborate with your team on dataset improvement, and integrate directly into your model building workflow with the `roboflow` pip package.\n",
+ "\n",
+ "- Custom Training Example: [https://blog.roboflow.com/train-yolov5-instance-segmentation-custom-dataset/](https://blog.roboflow.com/train-yolov5-instance-segmentation-custom-dataset/?ref=ultralytics)\n",
+ "- Custom Training Notebook: [](https://colab.research.google.com/drive/1JTz7kpmHsg-5qwVz2d2IH3AaenI1tv0N?usp=sharing)\n",
+ "
\n",
+ "\n",
+ "
Label images lightning fast (including with model-assisted labeling)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "i3oKtE4g-aNn"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Select YOLOv5 🚀 logger {run: 'auto'}\n",
+ "logger = 'Comet' #@param ['Comet', 'ClearML', 'TensorBoard']\n",
+ "\n",
+ "if logger == 'Comet':\n",
+ " %pip install -q comet_ml\n",
+ " import comet_ml; comet_ml.init()\n",
+ "elif logger == 'ClearML':\n",
+ " %pip install -q clearml\n",
+ " import clearml; clearml.browser_login()\n",
+ "elif logger == 'TensorBoard':\n",
+ " %load_ext tensorboard\n",
+ " %tensorboard --logdir runs/train"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "1NcFxRcFdJ_O",
+ "outputId": "3a3e0cf7-e79c-47a5-c8e7-2d26eeeab988"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1msegment/train: \u001b[0mweights=yolov5s-seg.pt, cfg=, data=coco128-seg.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=3, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=ram, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train-seg, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, mask_ratio=4, no_overlap=False\n",
+ "\u001b[34m\u001b[1mgithub: \u001b[0mup to date with https://github.com/ultralytics/yolov5 ✅\n",
+ "YOLOv5 🚀 v7.0-2-gc9d47ae Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)\n",
+ "\n",
+ "\u001b[34m\u001b[1mhyperparameters: \u001b[0mlr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0\n",
+ "\u001b[34m\u001b[1mTensorBoard: \u001b[0mStart with 'tensorboard --logdir runs/train-seg', view at http://localhost:6006/\n",
+ "\n",
+ "Dataset not found ⚠️, missing paths ['/content/datasets/coco128-seg/images/train2017']\n",
+ "Downloading https://ultralytics.com/assets/coco128-seg.zip to coco128-seg.zip...\n",
+ "100% 6.79M/6.79M [00:01<00:00, 6.73MB/s]\n",
+ "Dataset download success ✅ (1.9s), saved to \u001b[1m/content/datasets\u001b[0m\n",
+ "\n",
+ " from n params module arguments \n",
+ " 0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2] \n",
+ " 1 -1 1 18560 models.common.Conv [32, 64, 3, 2] \n",
+ " 2 -1 1 18816 models.common.C3 [64, 64, 1] \n",
+ " 3 -1 1 73984 models.common.Conv [64, 128, 3, 2] \n",
+ " 4 -1 2 115712 models.common.C3 [128, 128, 2] \n",
+ " 5 -1 1 295424 models.common.Conv [128, 256, 3, 2] \n",
+ " 6 -1 3 625152 models.common.C3 [256, 256, 3] \n",
+ " 7 -1 1 1180672 models.common.Conv [256, 512, 3, 2] \n",
+ " 8 -1 1 1182720 models.common.C3 [512, 512, 1] \n",
+ " 9 -1 1 656896 models.common.SPPF [512, 512, 5] \n",
+ " 10 -1 1 131584 models.common.Conv [512, 256, 1, 1] \n",
+ " 11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] \n",
+ " 12 [-1, 6] 1 0 models.common.Concat [1] \n",
+ " 13 -1 1 361984 models.common.C3 [512, 256, 1, False] \n",
+ " 14 -1 1 33024 models.common.Conv [256, 128, 1, 1] \n",
+ " 15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] \n",
+ " 16 [-1, 4] 1 0 models.common.Concat [1] \n",
+ " 17 -1 1 90880 models.common.C3 [256, 128, 1, False] \n",
+ " 18 -1 1 147712 models.common.Conv [128, 128, 3, 2] \n",
+ " 19 [-1, 14] 1 0 models.common.Concat [1] \n",
+ " 20 -1 1 296448 models.common.C3 [256, 256, 1, False] \n",
+ " 21 -1 1 590336 models.common.Conv [256, 256, 3, 2] \n",
+ " 22 [-1, 10] 1 0 models.common.Concat [1] \n",
+ " 23 -1 1 1182720 models.common.C3 [512, 512, 1, False] \n",
+ " 24 [17, 20, 23] 1 615133 models.yolo.Segment [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], 32, 128, [128, 256, 512]]\n",
+ "Model summary: 225 layers, 7621277 parameters, 7621277 gradients, 26.6 GFLOPs\n",
+ "\n",
+ "Transferred 367/367 items from yolov5s-seg.pt\n",
+ "\u001b[34m\u001b[1mAMP: \u001b[0mchecks passed ✅\n",
+ "\u001b[34m\u001b[1moptimizer:\u001b[0m SGD(lr=0.01) with parameter groups 60 weight(decay=0.0), 63 weight(decay=0.0005), 63 bias\n",
+ "\u001b[34m\u001b[1malbumentations: \u001b[0mBlur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01), CLAHE(p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))\n",
+ "\u001b[34m\u001b[1mtrain: \u001b[0mScanning /content/datasets/coco128-seg/labels/train2017... 126 images, 2 backgrounds, 0 corrupt: 100% 128/128 [00:00<00:00, 1389.59it/s]\n",
+ "\u001b[34m\u001b[1mtrain: \u001b[0mNew cache created: /content/datasets/coco128-seg/labels/train2017.cache\n",
+ "\u001b[34m\u001b[1mtrain: \u001b[0mCaching images (0.1GB ram): 100% 128/128 [00:00<00:00, 238.86it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco128-seg/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100% 128/128 [00:00 # 2. paste API key\n",
+ "python train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt # 3. train\n",
+ "```\n",
+ "To learn more about all of the supported Comet features for this integration, check out the [Comet Tutorial](https://docs.ultralytics.com/yolov5/tutorials/comet_logging_integration). If you'd like to learn more about Comet, head over to our [documentation](https://www.comet.com/docs/v2/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=yolov5_colab). Get started by trying out the Comet Colab Notebook:\n",
+ "[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)\n",
+ "\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Lay2WsTjNJzP"
+ },
+ "source": [
+ "## ClearML Logging and Automation 🌟 NEW\n",
+ "\n",
+ "[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML (check cells above):\n",
+ "\n",
+ "- `pip install clearml`\n",
+ "- run `clearml-init` to connect to a ClearML server (**deploy your own [open-source server](https://github.com/allegroai/clearml-server)**, or use our [free hosted server](https://cutt.ly/yolov5-notebook-clearml))\n",
+ "\n",
+ "You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).\n",
+ "\n",
+ "You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) for details!\n",
+ "\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n",
+ "\n",
+ "This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices. \n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Notebooks** with free GPU: \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "outputs": [],
+ "source": [
+ "# YOLOv5 PyTorch HUB Inference (DetectionModels only)\n",
+ "import torch\n",
+ "\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s-seg') # yolov5n - yolov5x6 or custom\n",
+ "im = 'https://ultralytics.com/images/zidane.jpg' # file, Path, PIL.Image, OpenCV, nparray, list\n",
+ "results = model(im) # inference\n",
+ "results.print() # or .show(), .save(), .crop(), .pandas(), etc."
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "name": "YOLOv5 Segmentation Tutorial",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.12"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/yolov5/segment/val.py b/yolov5/segment/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0575fd59a91632af67082bd561d9b4171df50e5
--- /dev/null
+++ b/yolov5/segment/val.py
@@ -0,0 +1,473 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Validate a trained YOLOv5 segment model on a segment dataset
+
+Usage:
+ $ bash data/scripts/get_coco.sh --val --segments # download COCO-segments val split (1G, 5000 images)
+ $ python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validate COCO-segments
+
+Usage - formats:
+ $ python segment/val.py --weights yolov5s-seg.pt # PyTorch
+ yolov5s-seg.torchscript # TorchScript
+ yolov5s-seg.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s-seg_openvino_label # OpenVINO
+ yolov5s-seg.engine # TensorRT
+ yolov5s-seg.mlmodel # CoreML (macOS-only)
+ yolov5s-seg_saved_model # TensorFlow SavedModel
+ yolov5s-seg.pb # TensorFlow GraphDef
+ yolov5s-seg.tflite # TensorFlow Lite
+ yolov5s-seg_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s-seg_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import json
+import os
+import subprocess
+import sys
+from multiprocessing.pool import ThreadPool
+from pathlib import Path
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import torch.nn.functional as F
+
+from models.common import DetectMultiBackend
+from models.yolo import SegmentationModel
+from utils.callbacks import Callbacks
+from utils.general import (LOGGER, NUM_THREADS, TQDM_BAR_FORMAT, Profile, check_dataset, check_img_size,
+ check_requirements, check_yaml, coco80_to_coco91_class, colorstr, increment_path,
+ non_max_suppression, print_args, scale_boxes, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, box_iou
+from utils.plots import output_to_target, plot_val_study
+from utils.segment.dataloaders import create_dataloader
+from utils.segment.general import mask_iou, process_mask, process_mask_native, scale_image
+from utils.segment.metrics import Metrics, ap_per_class_box_and_mask
+from utils.segment.plots import plot_images_and_masks
+from utils.torch_utils import de_parallel, select_device, smart_inference_mode
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map, pred_masks):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ from pycocotools.mask import encode
+
+ def single_encode(x):
+ rle = encode(np.asarray(x[:, :, None], order='F', dtype='uint8'))[0]
+ rle['counts'] = rle['counts'].decode('utf-8')
+ return rle
+
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ pred_masks = np.transpose(pred_masks, (2, 0, 1))
+ with ThreadPool(NUM_THREADS) as pool:
+ rles = pool.map(single_encode, pred_masks)
+ for i, (p, b) in enumerate(zip(predn.tolist(), box.tolist())):
+ jdict.append({
+ 'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5),
+ 'segmentation': rles[i]})
+
+
+def process_batch(detections, labels, iouv, pred_masks=None, gt_masks=None, overlap=False, masks=False):
+ """
+ Return correct prediction matrix
+ Arguments:
+ detections (array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (array[N, 10]), for 10 IoU levels
+ """
+ if masks:
+ if overlap:
+ nl = len(labels)
+ index = torch.arange(nl, device=gt_masks.device).view(nl, 1, 1) + 1
+ gt_masks = gt_masks.repeat(nl, 1, 1) # shape(1,640,640) -> (n,640,640)
+ gt_masks = torch.where(gt_masks == index, 1.0, 0.0)
+ if gt_masks.shape[1:] != pred_masks.shape[1:]:
+ gt_masks = F.interpolate(gt_masks[None], pred_masks.shape[1:], mode='bilinear', align_corners=False)[0]
+ gt_masks = gt_masks.gt_(0.5)
+ iou = mask_iou(gt_masks.view(gt_masks.shape[0], -1), pred_masks.view(pred_masks.shape[0], -1))
+ else: # boxes
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
+ correct_class = labels[:, 0:1] == detections[:, 5]
+ for i in range(len(iouv)):
+ x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ correct[matches[:, 1].astype(int), i] = True
+ return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
+
+
+@smart_inference_mode()
+def run(
+ data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ max_det=300, # maximum detections per image
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val-seg', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ overlap=False,
+ mask_downsample_ratio=1,
+ compute_loss=None,
+ callbacks=Callbacks(),
+):
+ if save_json:
+ check_requirements('pycocotools>=2.0.6')
+ process = process_mask_native # more accurate
+ else:
+ process = process_mask # faster
+
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ nm = de_parallel(model).model[-1].nm # number of masks
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ nm = de_parallel(model).model.model[-1].nm if isinstance(model, SegmentationModel) else 32 # number of masks
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ cuda = device.type != 'cpu'
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith(f'coco{os.sep}val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10, device=device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and not single_cls: # check --weights are trained on --data
+ ncm = model.model.nc
+ assert ncm == nc, f'{weights} ({ncm} classes) trained on different --data than what you passed ({nc} ' \
+ f'classes). Pass correct combination of --weights and --data that are trained together.'
+ model.warmup(imgsz=(1 if pt else batch_size, 3, imgsz, imgsz)) # warmup
+ pad, rect = (0.0, False) if task == 'speed' else (0.5, pt) # square inference for benchmarks
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task],
+ imgsz,
+ batch_size,
+ stride,
+ single_cls,
+ pad=pad,
+ rect=rect,
+ workers=workers,
+ prefix=colorstr(f'{task}: '),
+ overlap_mask=overlap,
+ mask_downsample_ratio=mask_downsample_ratio)[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = model.names if hasattr(model, 'names') else model.module.names # get class names
+ if isinstance(names, (list, tuple)): # old format
+ names = dict(enumerate(names))
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%22s' + '%11s' * 10) % ('Class', 'Images', 'Instances', 'Box(P', 'R', 'mAP50', 'mAP50-95)', 'Mask(P', 'R',
+ 'mAP50', 'mAP50-95)')
+ dt = Profile(), Profile(), Profile()
+ metrics = Metrics()
+ loss = torch.zeros(4, device=device)
+ jdict, stats = [], []
+ # callbacks.run('on_val_start')
+ pbar = tqdm(dataloader, desc=s, bar_format=TQDM_BAR_FORMAT) # progress bar
+ for batch_i, (im, targets, paths, shapes, masks) in enumerate(pbar):
+ # callbacks.run('on_val_batch_start')
+ with dt[0]:
+ if cuda:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ masks = masks.to(device)
+ masks = masks.float()
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+
+ # Inference
+ with dt[1]:
+ preds, protos, train_out = model(im) if compute_loss else (*model(im, augment=augment)[:2], None)
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss((train_out, protos), targets, masks)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.tensor((width, height, width, height), device=device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ with dt[2]:
+ preds = non_max_suppression(preds,
+ conf_thres,
+ iou_thres,
+ labels=lb,
+ multi_label=True,
+ agnostic=single_cls,
+ max_det=max_det,
+ nm=nm)
+
+ # Metrics
+ plot_masks = [] # masks for plotting
+ for si, (pred, proto) in enumerate(zip(preds, protos)):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl, npr = labels.shape[0], pred.shape[0] # number of labels, predictions
+ path, shape = Path(paths[si]), shapes[si][0]
+ correct_masks = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ correct_bboxes = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ seen += 1
+
+ if npr == 0:
+ if nl:
+ stats.append((correct_masks, correct_bboxes, *torch.zeros((2, 0), device=device), labels[:, 0]))
+ if plots:
+ confusion_matrix.process_batch(detections=None, labels=labels[:, 0])
+ continue
+
+ # Masks
+ midx = [si] if overlap else targets[:, 0] == si
+ gt_masks = masks[midx]
+ pred_masks = process(proto, pred[:, 6:], pred[:, :4], shape=im[si].shape[1:])
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_boxes(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct_bboxes = process_batch(predn, labelsn, iouv)
+ correct_masks = process_batch(predn, labelsn, iouv, pred_masks, gt_masks, overlap=overlap, masks=True)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ stats.append((correct_masks, correct_bboxes, pred[:, 4], pred[:, 5], labels[:, 0])) # (conf, pcls, tcls)
+
+ pred_masks = torch.as_tensor(pred_masks, dtype=torch.uint8)
+ if plots and batch_i < 3:
+ plot_masks.append(pred_masks[:15]) # filter top 15 to plot
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+ if save_json:
+ pred_masks = scale_image(im[si].shape[1:],
+ pred_masks.permute(1, 2, 0).contiguous().cpu().numpy(), shape, shapes[si][1])
+ save_one_json(predn, jdict, path, class_map, pred_masks) # append to COCO-JSON dictionary
+ # callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ if len(plot_masks):
+ plot_masks = torch.cat(plot_masks, dim=0)
+ plot_images_and_masks(im, targets, masks, paths, save_dir / f'val_batch{batch_i}_labels.jpg', names)
+ plot_images_and_masks(im, output_to_target(preds, max_det=15), plot_masks, paths,
+ save_dir / f'val_batch{batch_i}_pred.jpg', names) # pred
+
+ # callbacks.run('on_val_batch_end')
+
+ # Compute metrics
+ stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ results = ap_per_class_box_and_mask(*stats, plot=plots, save_dir=save_dir, names=names)
+ metrics.update(results)
+ nt = np.bincount(stats[4].astype(int), minlength=nc) # number of targets per class
+
+ # Print results
+ pf = '%22s' + '%11i' * 2 + '%11.3g' * 8 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), *metrics.mean_results()))
+ if nt.sum() == 0:
+ LOGGER.warning(f'WARNING ⚠️ no labels found in {task} set, can not compute metrics without labels')
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(metrics.ap_class_index):
+ LOGGER.info(pf % (names[c], seen, nt[c], *metrics.class_result(i)))
+
+ # Print speeds
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ # callbacks.run('on_val_end')
+
+ mp_bbox, mr_bbox, map50_bbox, map_bbox, mp_mask, mr_mask, map50_mask, map_mask = metrics.mean_results()
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path('../datasets/coco/annotations/instances_val2017.json')) # annotations
+ pred_json = str(save_dir / f'{w}_predictions.json') # predictions
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ results = []
+ for eval in COCOeval(anno, pred, 'bbox'), COCOeval(anno, pred, 'segm'):
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.im_files] # img ID to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ results.extend(eval.stats[:2]) # update results (mAP@0.5:0.95, mAP@0.5)
+ map_bbox, map50_bbox, map_mask, map50_mask = results
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ final_metric = mp_bbox, mr_bbox, map50_bbox, map_bbox, mp_mask, mr_mask, map50_mask, map_mask
+ return (*final_metric, *(loss.cpu() / len(dataloader)).tolist()), metrics.get_maps(nc), t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128-seg.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s-seg.pt', help='model path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=300, help='maximum detections per image')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val-seg', help='save results to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ # opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(requirements=ROOT / 'requirements.txt', exclude=('tensorboard', 'thop'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.warning(f'WARNING ⚠️ confidence threshold {opt.conf_thres} > 0.001 produces invalid results')
+ if opt.save_hybrid:
+ LOGGER.warning('WARNING ⚠️ --save-hybrid returns high mAP from hybrid labels, not from predictions alone')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ opt.half = torch.cuda.is_available() and opt.device != 'cpu' # FP16 for fastest results
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ subprocess.run(['zip', '-r', 'study.zip', 'study_*.txt'])
+ plot_val_study(x=x) # plot
+ else:
+ raise NotImplementedError(f'--task {opt.task} not in ("train", "val", "test", "speed", "study")')
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/setup.cfg b/yolov5/setup.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..d7c4cb3e1a4d34291816835b071ba0d75243d79b
--- /dev/null
+++ b/yolov5/setup.cfg
@@ -0,0 +1,54 @@
+# Project-wide configuration file, can be used for package metadata and other toll configurations
+# Example usage: global configuration for PEP8 (via flake8) setting or default pytest arguments
+# Local usage: pip install pre-commit, pre-commit run --all-files
+
+[metadata]
+license_file = LICENSE
+description_file = README.md
+
+[tool:pytest]
+norecursedirs =
+ .git
+ dist
+ build
+addopts =
+ --doctest-modules
+ --durations=25
+ --color=yes
+
+[flake8]
+max-line-length = 120
+exclude = .tox,*.egg,build,temp
+select = E,W,F
+doctests = True
+verbose = 2
+# https://pep8.readthedocs.io/en/latest/intro.html#error-codes
+format = pylint
+# see: https://www.flake8rules.com/
+ignore = E731,F405,E402,F401,W504,E127,E231,E501,F403
+ # E731: Do not assign a lambda expression, use a def
+ # F405: name may be undefined, or defined from star imports: module
+ # E402: module level import not at top of file
+ # F401: module imported but unused
+ # W504: line break after binary operator
+ # E127: continuation line over-indented for visual indent
+ # E231: missing whitespace after ‘,’, ‘;’, or ‘:’
+ # E501: line too long
+ # F403: ‘from module import *’ used; unable to detect undefined names
+
+[isort]
+# https://pycqa.github.io/isort/docs/configuration/options.html
+line_length = 120
+# see: https://pycqa.github.io/isort/docs/configuration/multi_line_output_modes.html
+multi_line_output = 0
+
+[yapf]
+based_on_style = pep8
+spaces_before_comment = 2
+COLUMN_LIMIT = 120
+COALESCE_BRACKETS = True
+SPACES_AROUND_POWER_OPERATOR = True
+SPACE_BETWEEN_ENDING_COMMA_AND_CLOSING_BRACKET = False
+SPLIT_BEFORE_CLOSING_BRACKET = False
+SPLIT_BEFORE_FIRST_ARGUMENT = False
+# EACH_DICT_ENTRY_ON_SEPARATE_LINE = False
diff --git a/yolov5/train.py b/yolov5/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..216da6399028bd3f6ed399bfdd377d25e3356a6e
--- /dev/null
+++ b/yolov5/train.py
@@ -0,0 +1,642 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Train a YOLOv5 model on a custom dataset.
+Models and datasets download automatically from the latest YOLOv5 release.
+
+Usage - Single-GPU training:
+ $ python train.py --data coco128.yaml --weights yolov5s.pt --img 640 # from pretrained (recommended)
+ $ python train.py --data coco128.yaml --weights '' --cfg yolov5s.yaml --img 640 # from scratch
+
+Usage - Multi-GPU DDP training:
+ $ python -m torch.distributed.run --nproc_per_node 4 --master_port 1 train.py --data coco128.yaml --weights yolov5s.pt --img 640 --device 0,1,2,3
+
+Models: https://github.com/ultralytics/yolov5/tree/master/models
+Datasets: https://github.com/ultralytics/yolov5/tree/master/data
+Tutorial: https://docs.ultralytics.com/yolov5/tutorials/train_custom_data
+"""
+
+import argparse
+import math
+import os
+import random
+import subprocess
+import sys
+import time
+from copy import deepcopy
+from datetime import datetime
+from pathlib import Path
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import yaml
+from torch.optim import lr_scheduler
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import val as validate # for end-of-epoch mAP
+from models.experimental import attempt_load
+from models.yolo import Model
+from utils.autoanchor import check_anchors
+from utils.autobatch import check_train_batch_size
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.downloads import attempt_download, is_url
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, check_amp, check_dataset, check_file, check_git_info,
+ check_git_status, check_img_size, check_requirements, check_suffix, check_yaml, colorstr,
+ get_latest_run, increment_path, init_seeds, intersect_dicts, labels_to_class_weights,
+ labels_to_image_weights, methods, one_cycle, print_args, print_mutation, strip_optimizer,
+ yaml_save)
+from utils.loggers import Loggers
+from utils.loggers.comet.comet_utils import check_comet_resume
+from utils.loss import ComputeLoss
+from utils.metrics import fitness
+from utils.plots import plot_evolve
+from utils.torch_utils import (EarlyStopping, ModelEMA, de_parallel, select_device, smart_DDP, smart_optimizer,
+ smart_resume, torch_distributed_zero_first)
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+GIT_INFO = check_git_info()
+
+
+def train(hyp, opt, device, callbacks): # hyp is path/to/hyp.yaml or hyp dictionary
+ save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze = \
+ Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
+ opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
+ callbacks.run('on_pretrain_routine_start')
+
+ # Directories
+ w = save_dir / 'weights' # weights dir
+ (w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
+ last, best = w / 'last.pt', w / 'best.pt'
+
+ # Hyperparameters
+ if isinstance(hyp, str):
+ with open(hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
+ opt.hyp = hyp.copy() # for saving hyps to checkpoints
+
+ # Save run settings
+ if not evolve:
+ yaml_save(save_dir / 'hyp.yaml', hyp)
+ yaml_save(save_dir / 'opt.yaml', vars(opt))
+
+ # Loggers
+ data_dict = None
+ if RANK in {-1, 0}:
+ loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
+
+ # Register actions
+ for k in methods(loggers):
+ callbacks.register_action(k, callback=getattr(loggers, k))
+
+ # Process custom dataset artifact link
+ data_dict = loggers.remote_dataset
+ if resume: # If resuming runs from remote artifact
+ weights, epochs, hyp, batch_size = opt.weights, opt.epochs, opt.hyp, opt.batch_size
+
+ # Config
+ plots = not evolve and not opt.noplots # create plots
+ cuda = device.type != 'cpu'
+ init_seeds(opt.seed + 1 + RANK, deterministic=True)
+ with torch_distributed_zero_first(LOCAL_RANK):
+ data_dict = data_dict or check_dataset(data) # check if None
+ train_path, val_path = data_dict['train'], data_dict['val']
+ nc = 1 if single_cls else int(data_dict['nc']) # number of classes
+ names = {0: 'item'} if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
+ is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
+
+ # Model
+ check_suffix(weights, '.pt') # check weights
+ pretrained = weights.endswith('.pt')
+ if pretrained:
+ with torch_distributed_zero_first(LOCAL_RANK):
+ weights = attempt_download(weights) # download if not found locally
+ ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
+ model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
+ else:
+ model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ amp = check_amp(model) # check AMP
+
+ # Freeze
+ freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze
+ for k, v in model.named_parameters():
+ v.requires_grad = True # train all layers
+ # v.register_hook(lambda x: torch.nan_to_num(x)) # NaN to 0 (commented for erratic training results)
+ if any(x in k for x in freeze):
+ LOGGER.info(f'freezing {k}')
+ v.requires_grad = False
+
+ # Image size
+ gs = max(int(model.stride.max()), 32) # grid size (max stride)
+ imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
+
+ # Batch size
+ if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
+ batch_size = check_train_batch_size(model, imgsz, amp)
+ loggers.on_params_update({'batch_size': batch_size})
+
+ # Optimizer
+ nbs = 64 # nominal batch size
+ accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
+ hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
+ optimizer = smart_optimizer(model, opt.optimizer, hyp['lr0'], hyp['momentum'], hyp['weight_decay'])
+
+ # Scheduler
+ if opt.cos_lr:
+ lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
+ else:
+ lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
+ scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
+
+ # EMA
+ ema = ModelEMA(model) if RANK in {-1, 0} else None
+
+ # Resume
+ best_fitness, start_epoch = 0.0, 0
+ if pretrained:
+ if resume:
+ best_fitness, start_epoch, epochs = smart_resume(ckpt, optimizer, ema, weights, epochs, resume)
+ del ckpt, csd
+
+ # DP mode
+ if cuda and RANK == -1 and torch.cuda.device_count() > 1:
+ LOGGER.warning(
+ 'WARNING ⚠️ DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
+ 'See Multi-GPU Tutorial at https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training to get started.'
+ )
+ model = torch.nn.DataParallel(model)
+
+ # SyncBatchNorm
+ if opt.sync_bn and cuda and RANK != -1:
+ model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
+ LOGGER.info('Using SyncBatchNorm()')
+
+ # Trainloader
+ train_loader, dataset = create_dataloader(train_path,
+ imgsz,
+ batch_size // WORLD_SIZE,
+ gs,
+ single_cls,
+ hyp=hyp,
+ augment=True,
+ cache=None if opt.cache == 'val' else opt.cache,
+ rect=opt.rect,
+ rank=LOCAL_RANK,
+ workers=workers,
+ image_weights=opt.image_weights,
+ quad=opt.quad,
+ prefix=colorstr('train: '),
+ shuffle=True,
+ seed=opt.seed)
+ labels = np.concatenate(dataset.labels, 0)
+ mlc = int(labels[:, 0].max()) # max label class
+ assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
+
+ # Process 0
+ if RANK in {-1, 0}:
+ val_loader = create_dataloader(val_path,
+ imgsz,
+ batch_size // WORLD_SIZE * 2,
+ gs,
+ single_cls,
+ hyp=hyp,
+ cache=None if noval else opt.cache,
+ rect=True,
+ rank=-1,
+ workers=workers * 2,
+ pad=0.5,
+ prefix=colorstr('val: '))[0]
+
+ if not resume:
+ if not opt.noautoanchor:
+ check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz) # run AutoAnchor
+ model.half().float() # pre-reduce anchor precision
+
+ callbacks.run('on_pretrain_routine_end', labels, names)
+
+ # DDP mode
+ if cuda and RANK != -1:
+ model = smart_DDP(model)
+
+ # Model attributes
+ nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
+ hyp['box'] *= 3 / nl # scale to layers
+ hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
+ hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
+ hyp['label_smoothing'] = opt.label_smoothing
+ model.nc = nc # attach number of classes to model
+ model.hyp = hyp # attach hyperparameters to model
+ model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
+ model.names = names
+
+ # Start training
+ t0 = time.time()
+ nb = len(train_loader) # number of batches
+ nw = max(round(hyp['warmup_epochs'] * nb), 100) # number of warmup iterations, max(3 epochs, 100 iterations)
+ # nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
+ last_opt_step = -1
+ maps = np.zeros(nc) # mAP per class
+ results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
+ scheduler.last_epoch = start_epoch - 1 # do not move
+ scaler = torch.cuda.amp.GradScaler(enabled=amp)
+ stopper, stop = EarlyStopping(patience=opt.patience), False
+ compute_loss = ComputeLoss(model) # init loss class
+ callbacks.run('on_train_start')
+ LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
+ f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
+ f"Logging results to {colorstr('bold', save_dir)}\n"
+ f'Starting training for {epochs} epochs...')
+ for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
+ callbacks.run('on_train_epoch_start')
+ model.train()
+
+ # Update image weights (optional, single-GPU only)
+ if opt.image_weights:
+ cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
+ iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
+ dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
+
+ # Update mosaic border (optional)
+ # b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
+ # dataset.mosaic_border = [b - imgsz, -b] # height, width borders
+
+ mloss = torch.zeros(3, device=device) # mean losses
+ if RANK != -1:
+ train_loader.sampler.set_epoch(epoch)
+ pbar = enumerate(train_loader)
+ LOGGER.info(('\n' + '%11s' * 7) % ('Epoch', 'GPU_mem', 'box_loss', 'obj_loss', 'cls_loss', 'Instances', 'Size'))
+ if RANK in {-1, 0}:
+ pbar = tqdm(pbar, total=nb, bar_format=TQDM_BAR_FORMAT) # progress bar
+ optimizer.zero_grad()
+ for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
+ callbacks.run('on_train_batch_start')
+ ni = i + nb * epoch # number integrated batches (since train start)
+ imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
+
+ # Warmup
+ if ni <= nw:
+ xi = [0, nw] # x interp
+ # compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
+ accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
+ for j, x in enumerate(optimizer.param_groups):
+ # bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
+ x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 0 else 0.0, x['initial_lr'] * lf(epoch)])
+ if 'momentum' in x:
+ x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
+
+ # Multi-scale
+ if opt.multi_scale:
+ sz = random.randrange(int(imgsz * 0.5), int(imgsz * 1.5) + gs) // gs * gs # size
+ sf = sz / max(imgs.shape[2:]) # scale factor
+ if sf != 1:
+ ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
+ imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
+
+ # Forward
+ with torch.cuda.amp.autocast(amp):
+ pred = model(imgs) # forward
+ loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
+ if RANK != -1:
+ loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
+ if opt.quad:
+ loss *= 4.
+
+ # Backward
+ scaler.scale(loss).backward()
+
+ # Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
+ if ni - last_opt_step >= accumulate:
+ scaler.unscale_(optimizer) # unscale gradients
+ torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0) # clip gradients
+ scaler.step(optimizer) # optimizer.step
+ scaler.update()
+ optimizer.zero_grad()
+ if ema:
+ ema.update(model)
+ last_opt_step = ni
+
+ # Log
+ if RANK in {-1, 0}:
+ mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
+ mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
+ pbar.set_description(('%11s' * 2 + '%11.4g' * 5) %
+ (f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
+ callbacks.run('on_train_batch_end', model, ni, imgs, targets, paths, list(mloss))
+ if callbacks.stop_training:
+ return
+ # end batch ------------------------------------------------------------------------------------------------
+
+ # Scheduler
+ lr = [x['lr'] for x in optimizer.param_groups] # for loggers
+ scheduler.step()
+
+ if RANK in {-1, 0}:
+ # mAP
+ callbacks.run('on_train_epoch_end', epoch=epoch)
+ ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
+ final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
+ if not noval or final_epoch: # Calculate mAP
+ results, maps, _ = validate.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ half=amp,
+ model=ema.ema,
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ callbacks=callbacks,
+ compute_loss=compute_loss)
+
+ # Update best mAP
+ fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
+ stop = stopper(epoch=epoch, fitness=fi) # early stop check
+ if fi > best_fitness:
+ best_fitness = fi
+ log_vals = list(mloss) + list(results) + lr
+ callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
+
+ # Save model
+ if (not nosave) or (final_epoch and not evolve): # if save
+ ckpt = {
+ 'epoch': epoch,
+ 'best_fitness': best_fitness,
+ 'model': deepcopy(de_parallel(model)).half(),
+ 'ema': deepcopy(ema.ema).half(),
+ 'updates': ema.updates,
+ 'optimizer': optimizer.state_dict(),
+ 'opt': vars(opt),
+ 'git': GIT_INFO, # {remote, branch, commit} if a git repo
+ 'date': datetime.now().isoformat()}
+
+ # Save last, best and delete
+ torch.save(ckpt, last)
+ if best_fitness == fi:
+ torch.save(ckpt, best)
+ if opt.save_period > 0 and epoch % opt.save_period == 0:
+ torch.save(ckpt, w / f'epoch{epoch}.pt')
+ del ckpt
+ callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
+
+ # EarlyStopping
+ if RANK != -1: # if DDP training
+ broadcast_list = [stop if RANK == 0 else None]
+ dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks
+ if RANK != 0:
+ stop = broadcast_list[0]
+ if stop:
+ break # must break all DDP ranks
+
+ # end epoch ----------------------------------------------------------------------------------------------------
+ # end training -----------------------------------------------------------------------------------------------------
+ if RANK in {-1, 0}:
+ LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
+ for f in last, best:
+ if f.exists():
+ strip_optimizer(f) # strip optimizers
+ if f is best:
+ LOGGER.info(f'\nValidating {f}...')
+ results, _, _ = validate.run(
+ data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=attempt_load(f, device).half(),
+ iou_thres=0.65 if is_coco else 0.60, # best pycocotools at iou 0.65
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ save_json=is_coco,
+ verbose=True,
+ plots=plots,
+ callbacks=callbacks,
+ compute_loss=compute_loss) # val best model with plots
+ if is_coco:
+ callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
+
+ callbacks.run('on_train_end', last, best, epoch, results)
+
+ torch.cuda.empty_cache()
+ return results
+
+
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
+ parser.add_argument('--noplots', action='store_true', help='save no plot files')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--seed', type=int, default=0, help='Global training seed')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+
+ # Logger arguments
+ parser.add_argument('--entity', default=None, help='Entity')
+ parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='Upload data, "val" option')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='Version of dataset artifact to use')
+
+ return parser.parse_known_args()[0] if known else parser.parse_args()
+
+
+def main(opt, callbacks=Callbacks()):
+ # Checks
+ if RANK in {-1, 0}:
+ print_args(vars(opt))
+ check_git_status()
+ check_requirements()
+
+ # Resume (from specified or most recent last.pt)
+ if opt.resume and not check_comet_resume(opt) and not opt.evolve:
+ last = Path(check_file(opt.resume) if isinstance(opt.resume, str) else get_latest_run())
+ opt_yaml = last.parent.parent / 'opt.yaml' # train options yaml
+ opt_data = opt.data # original dataset
+ if opt_yaml.is_file():
+ with open(opt_yaml, errors='ignore') as f:
+ d = yaml.safe_load(f)
+ else:
+ d = torch.load(last, map_location='cpu')['opt']
+ opt = argparse.Namespace(**d) # replace
+ opt.cfg, opt.weights, opt.resume = '', str(last), True # reinstate
+ if is_url(opt_data):
+ opt.data = check_file(opt_data) # avoid HUB resume auth timeout
+ else:
+ opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
+ check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
+ assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
+ if opt.evolve:
+ if opt.project == str(ROOT / 'runs/train'): # if default project name, rename to runs/evolve
+ opt.project = str(ROOT / 'runs/evolve')
+ opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
+ if opt.name == 'cfg':
+ opt.name = Path(opt.cfg).stem # use model.yaml as name
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
+
+ # DDP mode
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ if LOCAL_RANK != -1:
+ msg = 'is not compatible with YOLOv5 Multi-GPU DDP training'
+ assert not opt.image_weights, f'--image-weights {msg}'
+ assert not opt.evolve, f'--evolve {msg}'
+ assert opt.batch_size != -1, f'AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size'
+ assert opt.batch_size % WORLD_SIZE == 0, f'--batch-size {opt.batch_size} must be multiple of WORLD_SIZE'
+ assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
+ torch.cuda.set_device(LOCAL_RANK)
+ device = torch.device('cuda', LOCAL_RANK)
+ dist.init_process_group(backend='nccl' if dist.is_nccl_available() else 'gloo')
+
+ # Train
+ if not opt.evolve:
+ train(opt.hyp, opt, device, callbacks)
+
+ # Evolve hyperparameters (optional)
+ else:
+ # Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
+ meta = {
+ 'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
+ 'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
+ 'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
+ 'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
+ 'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
+ 'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
+ 'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
+ 'box': (1, 0.02, 0.2), # box loss gain
+ 'cls': (1, 0.2, 4.0), # cls loss gain
+ 'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
+ 'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
+ 'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
+ 'iou_t': (0, 0.1, 0.7), # IoU training threshold
+ 'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
+ 'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
+ 'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
+ 'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
+ 'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
+ 'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
+ 'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
+ 'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
+ 'scale': (1, 0.0, 0.9), # image scale (+/- gain)
+ 'shear': (1, 0.0, 10.0), # image shear (+/- deg)
+ 'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
+ 'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
+ 'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
+ 'mosaic': (1, 0.0, 1.0), # image mixup (probability)
+ 'mixup': (1, 0.0, 1.0), # image mixup (probability)
+ 'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
+
+ with open(opt.hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ if 'anchors' not in hyp: # anchors commented in hyp.yaml
+ hyp['anchors'] = 3
+ if opt.noautoanchor:
+ del hyp['anchors'], meta['anchors']
+ opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
+ # ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
+ evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
+ if opt.bucket:
+ # download evolve.csv if exists
+ subprocess.run([
+ 'gsutil',
+ 'cp',
+ f'gs://{opt.bucket}/evolve.csv',
+ str(evolve_csv),])
+
+ for _ in range(opt.evolve): # generations to evolve
+ if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
+ # Select parent(s)
+ parent = 'single' # parent selection method: 'single' or 'weighted'
+ x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
+ n = min(5, len(x)) # number of previous results to consider
+ x = x[np.argsort(-fitness(x))][:n] # top n mutations
+ w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
+ if parent == 'single' or len(x) == 1:
+ # x = x[random.randint(0, n - 1)] # random selection
+ x = x[random.choices(range(n), weights=w)[0]] # weighted selection
+ elif parent == 'weighted':
+ x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
+
+ # Mutate
+ mp, s = 0.8, 0.2 # mutation probability, sigma
+ npr = np.random
+ npr.seed(int(time.time()))
+ g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
+ ng = len(meta)
+ v = np.ones(ng)
+ while all(v == 1): # mutate until a change occurs (prevent duplicates)
+ v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
+ for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
+ hyp[k] = float(x[i + 7] * v[i]) # mutate
+
+ # Constrain to limits
+ for k, v in meta.items():
+ hyp[k] = max(hyp[k], v[1]) # lower limit
+ hyp[k] = min(hyp[k], v[2]) # upper limit
+ hyp[k] = round(hyp[k], 5) # significant digits
+
+ # Train mutation
+ results = train(hyp.copy(), opt, device, callbacks)
+ callbacks = Callbacks()
+ # Write mutation results
+ keys = ('metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95', 'val/box_loss',
+ 'val/obj_loss', 'val/cls_loss')
+ print_mutation(keys, results, hyp.copy(), save_dir, opt.bucket)
+
+ # Plot results
+ plot_evolve(evolve_csv)
+ LOGGER.info(f'Hyperparameter evolution finished {opt.evolve} generations\n'
+ f"Results saved to {colorstr('bold', save_dir)}\n"
+ f'Usage example: $ python train.py --hyp {evolve_yaml}')
+
+
+def run(**kwargs):
+ # Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
+ opt = parse_opt(True)
+ for k, v in kwargs.items():
+ setattr(opt, k, v)
+ main(opt)
+ return opt
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/tutorial.ipynb b/yolov5/tutorial.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..be87068822af223ba8383b6912b55e9f79181b0b
--- /dev/null
+++ b/yolov5/tutorial.ipynb
@@ -0,0 +1,605 @@
+{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "name": "YOLOv5 Tutorial",
+ "provenance": []
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ },
+ "accelerator": "GPU"
+ },
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "t6MPjfT5NrKQ"
+ },
+ "source": [
+ "\n",
+ "\n",
+ "
\n",
+ " \n",
+ "\n",
+ "\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "\n",
+ "This
YOLOv5 🚀 notebook by
Ultralytics presents simple train, validate and predict examples to help start your AI adventure.
We hope that the resources in this notebook will help you get the most out of YOLOv5. Please browse the YOLOv5
Docs for details, raise an issue on
GitHub for support, and join our
Discord community for questions and discussions!\n",
+ "\n",
+ "
 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "cf7d52f0-281c-4c96-a488-79f5908f8426"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip') # download (780M - 5000 images)\n",
+ "!unzip -q tmp.zip -d ../datasets && rm tmp.zip # unzip"
+ ],
+ "execution_count": 3,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stderr",
+ "text": [
+ "100%|██████████| 780M/780M [00:12<00:00, 66.6MB/s]\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "X58w8JLpMnjH",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "3e234e05-ee8b-4ad1-b1a4-f6a55d5e4f3d"
+ },
+ "source": [
+ "# Validate YOLOv5s on COCO val\n",
+ "!python val.py --weights yolov5s.pt --data coco.yaml --img 640 --half"
+ ],
+ "execution_count": 4,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mval: \u001b[0mdata=/content/yolov5/data/coco.yaml, weights=['yolov5s.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-136-g71244ae Python-3.9.16 torch-2.0.0+cu118 CUDA:0 (Tesla T4, 15102MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco/val2017... 4952 images, 48 backgrounds, 0 corrupt: 100% 5000/5000 [00:02<00:00, 2024.59it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mNew cache created: /content/datasets/coco/val2017.cache\n",
+ " Class Images Instances P R mAP50 mAP50-95: 100% 157/157 [01:25<00:00, 1.84it/s]\n",
+ " all 5000 36335 0.671 0.519 0.566 0.371\n",
+ "Speed: 0.1ms pre-process, 3.1ms inference, 2.3ms NMS per image at shape (32, 3, 640, 640)\n",
+ "\n",
+ "Evaluating pycocotools mAP... saving runs/val/exp/yolov5s_predictions.json...\n",
+ "loading annotations into memory...\n",
+ "Done (t=0.43s)\n",
+ "creating index...\n",
+ "index created!\n",
+ "Loading and preparing results...\n",
+ "DONE (t=5.32s)\n",
+ "creating index...\n",
+ "index created!\n",
+ "Running per image evaluation...\n",
+ "Evaluate annotation type *bbox*\n",
+ "DONE (t=78.89s).\n",
+ "Accumulating evaluation results...\n",
+ "DONE (t=14.51s).\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.374\n",
+ " Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.572\n",
+ " Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.402\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.211\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.423\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.489\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.311\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.516\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.566\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.378\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.625\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.722\n",
+ "Results saved to \u001b[1mruns/val/exp\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "cf7d52f0-281c-4c96-a488-79f5908f8426"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip') # download (780M - 5000 images)\n",
+ "!unzip -q tmp.zip -d ../datasets && rm tmp.zip # unzip"
+ ],
+ "execution_count": 3,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stderr",
+ "text": [
+ "100%|██████████| 780M/780M [00:12<00:00, 66.6MB/s]\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "X58w8JLpMnjH",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "3e234e05-ee8b-4ad1-b1a4-f6a55d5e4f3d"
+ },
+ "source": [
+ "# Validate YOLOv5s on COCO val\n",
+ "!python val.py --weights yolov5s.pt --data coco.yaml --img 640 --half"
+ ],
+ "execution_count": 4,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mval: \u001b[0mdata=/content/yolov5/data/coco.yaml, weights=['yolov5s.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-136-g71244ae Python-3.9.16 torch-2.0.0+cu118 CUDA:0 (Tesla T4, 15102MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco/val2017... 4952 images, 48 backgrounds, 0 corrupt: 100% 5000/5000 [00:02<00:00, 2024.59it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mNew cache created: /content/datasets/coco/val2017.cache\n",
+ " Class Images Instances P R mAP50 mAP50-95: 100% 157/157 [01:25<00:00, 1.84it/s]\n",
+ " all 5000 36335 0.671 0.519 0.566 0.371\n",
+ "Speed: 0.1ms pre-process, 3.1ms inference, 2.3ms NMS per image at shape (32, 3, 640, 640)\n",
+ "\n",
+ "Evaluating pycocotools mAP... saving runs/val/exp/yolov5s_predictions.json...\n",
+ "loading annotations into memory...\n",
+ "Done (t=0.43s)\n",
+ "creating index...\n",
+ "index created!\n",
+ "Loading and preparing results...\n",
+ "DONE (t=5.32s)\n",
+ "creating index...\n",
+ "index created!\n",
+ "Running per image evaluation...\n",
+ "Evaluate annotation type *bbox*\n",
+ "DONE (t=78.89s).\n",
+ "Accumulating evaluation results...\n",
+ "DONE (t=14.51s).\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.374\n",
+ " Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.572\n",
+ " Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.402\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.211\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.423\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.489\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.311\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.516\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.566\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.378\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.625\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.722\n",
+ "Results saved to \u001b[1mruns/val/exp\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
\n",
+ "Close the active learning loop by sampling images from your inference conditions with the `roboflow` pip package\n",
+ "
\n",
+ "\n",
+ "Train a YOLOv5s model on the [COCO128](https://www.kaggle.com/ultralytics/coco128) dataset with `--data coco128.yaml`, starting from pretrained `--weights yolov5s.pt`, or from randomly initialized `--weights '' --cfg yolov5s.yaml`.\n",
+ "\n",
+ "- **Pretrained [Models](https://github.com/ultralytics/yolov5/tree/master/models)** are downloaded\n",
+ "automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases)\n",
+ "- **[Datasets](https://github.com/ultralytics/yolov5/tree/master/data)** available for autodownload include: [COCO](https://github.com/ultralytics/yolov5/blob/master/data/coco.yaml), [COCO128](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml), [Argoverse](https://github.com/ultralytics/yolov5/blob/master/data/Argoverse.yaml), [VisDrone](https://github.com/ultralytics/yolov5/blob/master/data/VisDrone.yaml), [GlobalWheat](https://github.com/ultralytics/yolov5/blob/master/data/GlobalWheat2020.yaml), [xView](https://github.com/ultralytics/yolov5/blob/master/data/xView.yaml), [Objects365](https://github.com/ultralytics/yolov5/blob/master/data/Objects365.yaml), [SKU-110K](https://github.com/ultralytics/yolov5/blob/master/data/SKU-110K.yaml).\n",
+ "- **Training Results** are saved to `runs/train/` with incrementing run directories, i.e. `runs/train/exp2`, `runs/train/exp3` etc.\n",
+ "
\n",
+ "\n",
+ "A **Mosaic Dataloader** is used for training which combines 4 images into 1 mosaic.\n",
+ "\n",
+ "## Label a dataset on Roboflow (optional)\n",
+ "\n",
+ "[Roboflow](https://roboflow.com/?ref=ultralytics) enables you to easily **organize, label, and prepare** a high quality dataset with your own custom data. Roboflow also makes it easy to establish an active learning pipeline, collaborate with your team on dataset improvement, and integrate directly into your model building workflow with the `roboflow` pip package."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "#@title Select YOLOv5 🚀 logger {run: 'auto'}\n",
+ "logger = 'Comet' #@param ['Comet', 'ClearML', 'TensorBoard']\n",
+ "\n",
+ "if logger == 'Comet':\n",
+ " %pip install -q comet_ml\n",
+ " import comet_ml; comet_ml.init()\n",
+ "elif logger == 'ClearML':\n",
+ " %pip install -q clearml\n",
+ " import clearml; clearml.browser_login()\n",
+ "elif logger == 'TensorBoard':\n",
+ " %load_ext tensorboard\n",
+ " %tensorboard --logdir runs/train"
+ ],
+ "metadata": {
+ "id": "i3oKtE4g-aNn"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "1NcFxRcFdJ_O",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "bbeeea2b-04fc-4185-aa64-258690495b5a"
+ },
+ "source": [
+ "# Train YOLOv5s on COCO128 for 3 epochs\n",
+ "!python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache"
+ ],
+ "execution_count": 5,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "2023-04-09 14:11:38.063605: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.\n",
+ "To enable the following instructions: AVX2 AVX512F FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.\n",
+ "2023-04-09 14:11:39.026661: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT\n",
+ "\u001b[34m\u001b[1mtrain: \u001b[0mweights=yolov5s.pt, cfg=, data=coco128.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=3, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=ram, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest\n",
+ "\u001b[34m\u001b[1mgithub: \u001b[0mup to date with https://github.com/ultralytics/yolov5 ✅\n",
+ "YOLOv5 🚀 v7.0-136-g71244ae Python-3.9.16 torch-2.0.0+cu118 CUDA:0 (Tesla T4, 15102MiB)\n",
+ "\n",
+ "\u001b[34m\u001b[1mhyperparameters: \u001b[0mlr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0\n",
+ "\u001b[34m\u001b[1mClearML: \u001b[0mrun 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 in ClearML\n",
+ "\u001b[34m\u001b[1mComet: \u001b[0mrun 'pip install comet_ml' to automatically track and visualize YOLOv5 🚀 runs in Comet\n",
+ "\u001b[34m\u001b[1mTensorBoard: \u001b[0mStart with 'tensorboard --logdir runs/train', view at http://localhost:6006/\n",
+ "\n",
+ "Dataset not found ⚠️, missing paths ['/content/datasets/coco128/images/train2017']\n",
+ "Downloading https://ultralytics.com/assets/coco128.zip to coco128.zip...\n",
+ "100% 6.66M/6.66M [00:00<00:00, 75.6MB/s]\n",
+ "Dataset download success ✅ (0.6s), saved to \u001b[1m/content/datasets\u001b[0m\n",
+ "\n",
+ " from n params module arguments \n",
+ " 0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2] \n",
+ " 1 -1 1 18560 models.common.Conv [32, 64, 3, 2] \n",
+ " 2 -1 1 18816 models.common.C3 [64, 64, 1] \n",
+ " 3 -1 1 73984 models.common.Conv [64, 128, 3, 2] \n",
+ " 4 -1 2 115712 models.common.C3 [128, 128, 2] \n",
+ " 5 -1 1 295424 models.common.Conv [128, 256, 3, 2] \n",
+ " 6 -1 3 625152 models.common.C3 [256, 256, 3] \n",
+ " 7 -1 1 1180672 models.common.Conv [256, 512, 3, 2] \n",
+ " 8 -1 1 1182720 models.common.C3 [512, 512, 1] \n",
+ " 9 -1 1 656896 models.common.SPPF [512, 512, 5] \n",
+ " 10 -1 1 131584 models.common.Conv [512, 256, 1, 1] \n",
+ " 11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] \n",
+ " 12 [-1, 6] 1 0 models.common.Concat [1] \n",
+ " 13 -1 1 361984 models.common.C3 [512, 256, 1, False] \n",
+ " 14 -1 1 33024 models.common.Conv [256, 128, 1, 1] \n",
+ " 15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] \n",
+ " 16 [-1, 4] 1 0 models.common.Concat [1] \n",
+ " 17 -1 1 90880 models.common.C3 [256, 128, 1, False] \n",
+ " 18 -1 1 147712 models.common.Conv [128, 128, 3, 2] \n",
+ " 19 [-1, 14] 1 0 models.common.Concat [1] \n",
+ " 20 -1 1 296448 models.common.C3 [256, 256, 1, False] \n",
+ " 21 -1 1 590336 models.common.Conv [256, 256, 3, 2] \n",
+ " 22 [-1, 10] 1 0 models.common.Concat [1] \n",
+ " 23 -1 1 1182720 models.common.C3 [512, 512, 1, False] \n",
+ " 24 [17, 20, 23] 1 229245 models.yolo.Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]\n",
+ "Model summary: 214 layers, 7235389 parameters, 7235389 gradients, 16.6 GFLOPs\n",
+ "\n",
+ "Transferred 349/349 items from yolov5s.pt\n",
+ "\u001b[34m\u001b[1mAMP: \u001b[0mchecks passed ✅\n",
+ "\u001b[34m\u001b[1moptimizer:\u001b[0m SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005), 60 bias\n",
+ "\u001b[34m\u001b[1malbumentations: \u001b[0mBlur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01), CLAHE(p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))\n",
+ "\u001b[34m\u001b[1mtrain: \u001b[0mScanning /content/datasets/coco128/labels/train2017... 126 images, 2 backgrounds, 0 corrupt: 100% 128/128 [00:00<00:00, 1709.36it/s]\n",
+ "\u001b[34m\u001b[1mtrain: \u001b[0mNew cache created: /content/datasets/coco128/labels/train2017.cache\n",
+ "\u001b[34m\u001b[1mtrain: \u001b[0mCaching images (0.1GB ram): 100% 128/128 [00:00<00:00, 264.35it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco128/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100% 128/128 [00:00 # 2. paste API key\n",
+ "python train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt # 3. train\n",
+ "```\n",
+ "To learn more about all of the supported Comet features for this integration, check out the [Comet Tutorial](https://docs.ultralytics.com/yolov5/tutorials/comet_logging_integration). If you'd like to learn more about Comet, head over to our [documentation](https://www.comet.com/docs/v2/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=yolov5_colab). Get started by trying out the Comet Colab Notebook:\n",
+ "[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)\n",
+ "\n",
+ "\n",
+ ""
+ ],
+ "metadata": {
+ "id": "nWOsI5wJR1o3"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## ClearML Logging and Automation 🌟 NEW\n",
+ "\n",
+ "[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML (check cells above):\n",
+ "\n",
+ "- `pip install clearml`\n",
+ "- run `clearml-init` to connect to a ClearML server (**deploy your own [open-source server](https://github.com/allegroai/clearml-server)**, or use our [free hosted server](https://cutt.ly/yolov5-notebook-clearml))\n",
+ "\n",
+ "You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).\n",
+ "\n",
+ "You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) for details!\n",
+ "\n",
+ "\n",
+ ""
+ ],
+ "metadata": {
+ "id": "Lay2WsTjNJzP"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n",
+ "\n",
+ "This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices. \n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Notebooks** with free GPU: \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "source": [
+ "# YOLOv5 PyTorch HUB Inference (DetectionModels only)\n",
+ "import torch\n",
+ "\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # yolov5n - yolov5x6 or custom\n",
+ "im = 'https://ultralytics.com/images/zidane.jpg' # file, Path, PIL.Image, OpenCV, nparray, list\n",
+ "results = model(im) # inference\n",
+ "results.print() # or .show(), .save(), .crop(), .pandas(), etc."
+ ],
+ "execution_count": null,
+ "outputs": []
+ }
+ ]
+}
diff --git a/yolov5/utils/__init__.py b/yolov5/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..916b06f5b69b5a8dd7139716ab6d95e3185fa385
--- /dev/null
+++ b/yolov5/utils/__init__.py
@@ -0,0 +1,82 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+utils/initialization
+"""
+
+import contextlib
+import platform
+import threading
+
+
+def emojis(str=''):
+ # Return platform-dependent emoji-safe version of string
+ return str.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else str
+
+
+class TryExcept(contextlib.ContextDecorator):
+ # YOLOv5 TryExcept class. Usage: @TryExcept() decorator or 'with TryExcept():' context manager
+ def __init__(self, msg=''):
+ self.msg = msg
+
+ def __enter__(self):
+ pass
+
+ def __exit__(self, exc_type, value, traceback):
+ if value:
+ print(emojis(f"{self.msg}{': ' if self.msg else ''}{value}"))
+ return True
+
+
+def threaded(func):
+ # Multi-threads a target function and returns thread. Usage: @threaded decorator
+ def wrapper(*args, **kwargs):
+ thread = threading.Thread(target=func, args=args, kwargs=kwargs, daemon=True)
+ thread.start()
+ return thread
+
+ return wrapper
+
+
+def join_threads(verbose=False):
+ # Join all daemon threads, i.e. atexit.register(lambda: join_threads())
+ main_thread = threading.current_thread()
+ for t in threading.enumerate():
+ if t is not main_thread:
+ if verbose:
+ print(f'Joining thread {t.name}')
+ t.join()
+
+
+def notebook_init(verbose=True):
+ # Check system software and hardware
+ print('Checking setup...')
+
+ import os
+ import shutil
+
+ from utils.general import check_font, check_requirements, is_colab
+ from utils.torch_utils import select_device # imports
+
+ check_font()
+
+ import psutil
+
+ if is_colab():
+ shutil.rmtree('/content/sample_data', ignore_errors=True) # remove colab /sample_data directory
+
+ # System info
+ display = None
+ if verbose:
+ gb = 1 << 30 # bytes to GiB (1024 ** 3)
+ ram = psutil.virtual_memory().total
+ total, used, free = shutil.disk_usage('/')
+ with contextlib.suppress(Exception): # clear display if ipython is installed
+ from IPython import display
+ display.clear_output()
+ s = f'({os.cpu_count()} CPUs, {ram / gb:.1f} GB RAM, {(total - free) / gb:.1f}/{total / gb:.1f} GB disk)'
+ else:
+ s = ''
+
+ select_device(newline=False)
+ print(emojis(f'Setup complete ✅ {s}'))
+ return display
diff --git a/yolov5/utils/__pycache__/__init__.cpython-38.pyc b/yolov5/utils/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9ff310ef4a9e0f1b14b7236ee81a9d1080a439ca
Binary files /dev/null and b/yolov5/utils/__pycache__/__init__.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/__init__.cpython-39.pyc b/yolov5/utils/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5006e980776c2142a2a2c4be293d77b646b26548
Binary files /dev/null and b/yolov5/utils/__pycache__/__init__.cpython-39.pyc differ
diff --git a/yolov5/utils/__pycache__/augmentations.cpython-38.pyc b/yolov5/utils/__pycache__/augmentations.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e2e817bb45e269e4b8950d677db0cab7e81e258f
Binary files /dev/null and b/yolov5/utils/__pycache__/augmentations.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/augmentations.cpython-39.pyc b/yolov5/utils/__pycache__/augmentations.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..44b51b3cbfbb95e97856c81219c18c501ab25215
Binary files /dev/null and b/yolov5/utils/__pycache__/augmentations.cpython-39.pyc differ
diff --git a/yolov5/utils/__pycache__/autoanchor.cpython-38.pyc b/yolov5/utils/__pycache__/autoanchor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c569c6a776971470b52025431203b26033096b6d
Binary files /dev/null and b/yolov5/utils/__pycache__/autoanchor.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/autoanchor.cpython-39.pyc b/yolov5/utils/__pycache__/autoanchor.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f50ef9e21144806e4358f035f3226152c235181b
Binary files /dev/null and b/yolov5/utils/__pycache__/autoanchor.cpython-39.pyc differ
diff --git a/yolov5/utils/__pycache__/autobatch.cpython-38.pyc b/yolov5/utils/__pycache__/autobatch.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..78fbe2ff6f4a176a123669d2d94099df11227857
Binary files /dev/null and b/yolov5/utils/__pycache__/autobatch.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/callbacks.cpython-38.pyc b/yolov5/utils/__pycache__/callbacks.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d6cde69f0eda30efda15c18d6c9f58d84127a5e1
Binary files /dev/null and b/yolov5/utils/__pycache__/callbacks.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/dataloaders.cpython-38.pyc b/yolov5/utils/__pycache__/dataloaders.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..89160366d34a2b8c16c75b957cdf81966f6336c3
Binary files /dev/null and b/yolov5/utils/__pycache__/dataloaders.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/dataloaders.cpython-39.pyc b/yolov5/utils/__pycache__/dataloaders.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..65c3f9bc5d841a3d3d66da960e4ec4ffea75f341
Binary files /dev/null and b/yolov5/utils/__pycache__/dataloaders.cpython-39.pyc differ
diff --git a/yolov5/utils/__pycache__/downloads.cpython-38.pyc b/yolov5/utils/__pycache__/downloads.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..22ec09e4808e58b27f1289ad0f724f74fef77b4e
Binary files /dev/null and b/yolov5/utils/__pycache__/downloads.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/downloads.cpython-39.pyc b/yolov5/utils/__pycache__/downloads.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e495bed9fd2dfffd40bb52ff8537b85e00b7d63e
Binary files /dev/null and b/yolov5/utils/__pycache__/downloads.cpython-39.pyc differ
diff --git a/yolov5/utils/__pycache__/general.cpython-38.pyc b/yolov5/utils/__pycache__/general.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..636293a85ec68a6eef959f138a9f61a4d148b474
Binary files /dev/null and b/yolov5/utils/__pycache__/general.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/general.cpython-39.pyc b/yolov5/utils/__pycache__/general.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..80c11cb89df111ccf0ff4e9e911fe096202b371f
Binary files /dev/null and b/yolov5/utils/__pycache__/general.cpython-39.pyc differ
diff --git a/yolov5/utils/__pycache__/loss.cpython-38.pyc b/yolov5/utils/__pycache__/loss.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..87253677273dcf2791aea1040b568ffe6c3678d1
Binary files /dev/null and b/yolov5/utils/__pycache__/loss.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/metrics.cpython-38.pyc b/yolov5/utils/__pycache__/metrics.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e1ea4fafde9a2eff6751c97eeff4659b29c2c8db
Binary files /dev/null and b/yolov5/utils/__pycache__/metrics.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/metrics.cpython-39.pyc b/yolov5/utils/__pycache__/metrics.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c195755412b6be602e15519da99430eac6de174e
Binary files /dev/null and b/yolov5/utils/__pycache__/metrics.cpython-39.pyc differ
diff --git a/yolov5/utils/__pycache__/plots.cpython-38.pyc b/yolov5/utils/__pycache__/plots.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..26026fa6f5081e861a994c499300fae7f44eb821
Binary files /dev/null and b/yolov5/utils/__pycache__/plots.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/plots.cpython-39.pyc b/yolov5/utils/__pycache__/plots.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b638aa9b18e60ba3af0fae7052a0721fb72b5ca2
Binary files /dev/null and b/yolov5/utils/__pycache__/plots.cpython-39.pyc differ
diff --git a/yolov5/utils/__pycache__/torch_utils.cpython-38.pyc b/yolov5/utils/__pycache__/torch_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..751c641eb5d52b1b859a6014171d5285802ba32c
Binary files /dev/null and b/yolov5/utils/__pycache__/torch_utils.cpython-38.pyc differ
diff --git a/yolov5/utils/__pycache__/torch_utils.cpython-39.pyc b/yolov5/utils/__pycache__/torch_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9768be9a0a937510ea68832b0d9d85779734a498
Binary files /dev/null and b/yolov5/utils/__pycache__/torch_utils.cpython-39.pyc differ
diff --git a/yolov5/utils/activations.py b/yolov5/utils/activations.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4d4bbde5ec8610a5ff13fe2ef2281721c14ca1a
--- /dev/null
+++ b/yolov5/utils/activations.py
@@ -0,0 +1,103 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Activation functions
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class SiLU(nn.Module):
+ # SiLU activation https://arxiv.org/pdf/1606.08415.pdf
+ @staticmethod
+ def forward(x):
+ return x * torch.sigmoid(x)
+
+
+class Hardswish(nn.Module):
+ # Hard-SiLU activation
+ @staticmethod
+ def forward(x):
+ # return x * F.hardsigmoid(x) # for TorchScript and CoreML
+ return x * F.hardtanh(x + 3, 0.0, 6.0) / 6.0 # for TorchScript, CoreML and ONNX
+
+
+class Mish(nn.Module):
+ # Mish activation https://github.com/digantamisra98/Mish
+ @staticmethod
+ def forward(x):
+ return x * F.softplus(x).tanh()
+
+
+class MemoryEfficientMish(nn.Module):
+ # Mish activation memory-efficient
+ class F(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, x):
+ ctx.save_for_backward(x)
+ return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ x = ctx.saved_tensors[0]
+ sx = torch.sigmoid(x)
+ fx = F.softplus(x).tanh()
+ return grad_output * (fx + x * sx * (1 - fx * fx))
+
+ def forward(self, x):
+ return self.F.apply(x)
+
+
+class FReLU(nn.Module):
+ # FReLU activation https://arxiv.org/abs/2007.11824
+ def __init__(self, c1, k=3): # ch_in, kernel
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
+ self.bn = nn.BatchNorm2d(c1)
+
+ def forward(self, x):
+ return torch.max(x, self.bn(self.conv(x)))
+
+
+class AconC(nn.Module):
+ r""" ACON activation (activate or not)
+ AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
+ according to "Activate or Not: Learning Customized Activation" .
+ """
+
+ def __init__(self, c1):
+ super().__init__()
+ self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.beta = nn.Parameter(torch.ones(1, c1, 1, 1))
+
+ def forward(self, x):
+ dpx = (self.p1 - self.p2) * x
+ return dpx * torch.sigmoid(self.beta * dpx) + self.p2 * x
+
+
+class MetaAconC(nn.Module):
+ r""" ACON activation (activate or not)
+ MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network
+ according to "Activate or Not: Learning Customized Activation" .
+ """
+
+ def __init__(self, c1, k=1, s=1, r=16): # ch_in, kernel, stride, r
+ super().__init__()
+ c2 = max(r, c1 // r)
+ self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.fc1 = nn.Conv2d(c1, c2, k, s, bias=True)
+ self.fc2 = nn.Conv2d(c2, c1, k, s, bias=True)
+ # self.bn1 = nn.BatchNorm2d(c2)
+ # self.bn2 = nn.BatchNorm2d(c1)
+
+ def forward(self, x):
+ y = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
+ # batch-size 1 bug/instabilities https://github.com/ultralytics/yolov5/issues/2891
+ # beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(y))))) # bug/unstable
+ beta = torch.sigmoid(self.fc2(self.fc1(y))) # bug patch BN layers removed
+ dpx = (self.p1 - self.p2) * x
+ return dpx * torch.sigmoid(beta * dpx) + self.p2 * x
diff --git a/yolov5/utils/augmentations.py b/yolov5/utils/augmentations.py
new file mode 100644
index 0000000000000000000000000000000000000000..6cbbc990501d8aa902117369aa6f5c4ee0a244be
--- /dev/null
+++ b/yolov5/utils/augmentations.py
@@ -0,0 +1,397 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Image augmentation functions
+"""
+
+import math
+import random
+
+import cv2
+import numpy as np
+import torch
+import torchvision.transforms as T
+import torchvision.transforms.functional as TF
+
+from yolov5.utils.general import LOGGER, check_version, colorstr, resample_segments, segment2box, xywhn2xyxy
+from yolov5.utils.metrics import bbox_ioa
+
+IMAGENET_MEAN = 0.485, 0.456, 0.406 # RGB mean
+IMAGENET_STD = 0.229, 0.224, 0.225 # RGB standard deviation
+
+
+class Albumentations:
+ # YOLOv5 Albumentations class (optional, only used if package is installed)
+ def __init__(self, size=640):
+ self.transform = None
+ prefix = colorstr('albumentations: ')
+ try:
+ import albumentations as A
+ check_version(A.__version__, '1.0.3', hard=True) # version requirement
+
+ T = [
+ A.RandomResizedCrop(height=size, width=size, scale=(0.8, 1.0), ratio=(0.9, 1.11), p=0.0),
+ A.Blur(p=0.01),
+ A.MedianBlur(p=0.01),
+ A.ToGray(p=0.01),
+ A.CLAHE(p=0.01),
+ A.RandomBrightnessContrast(p=0.0),
+ A.RandomGamma(p=0.0),
+ A.ImageCompression(quality_lower=75, p=0.0)] # transforms
+ self.transform = A.Compose(T, bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels']))
+
+ LOGGER.info(prefix + ', '.join(f'{x}'.replace('always_apply=False, ', '') for x in T if x.p))
+ except ImportError: # package not installed, skip
+ pass
+ except Exception as e:
+ LOGGER.info(f'{prefix}{e}')
+
+ def __call__(self, im, labels, p=1.0):
+ if self.transform and random.random() < p:
+ new = self.transform(image=im, bboxes=labels[:, 1:], class_labels=labels[:, 0]) # transformed
+ im, labels = new['image'], np.array([[c, *b] for c, b in zip(new['class_labels'], new['bboxes'])])
+ return im, labels
+
+
+def normalize(x, mean=IMAGENET_MEAN, std=IMAGENET_STD, inplace=False):
+ # Denormalize RGB images x per ImageNet stats in BCHW format, i.e. = (x - mean) / std
+ return TF.normalize(x, mean, std, inplace=inplace)
+
+
+def denormalize(x, mean=IMAGENET_MEAN, std=IMAGENET_STD):
+ # Denormalize RGB images x per ImageNet stats in BCHW format, i.e. = x * std + mean
+ for i in range(3):
+ x[:, i] = x[:, i] * std[i] + mean[i]
+ return x
+
+
+def augment_hsv(im, hgain=0.5, sgain=0.5, vgain=0.5):
+ # HSV color-space augmentation
+ if hgain or sgain or vgain:
+ r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains
+ hue, sat, val = cv2.split(cv2.cvtColor(im, cv2.COLOR_BGR2HSV))
+ dtype = im.dtype # uint8
+
+ x = np.arange(0, 256, dtype=r.dtype)
+ lut_hue = ((x * r[0]) % 180).astype(dtype)
+ lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
+ lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
+
+ im_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
+ cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR, dst=im) # no return needed
+
+
+def hist_equalize(im, clahe=True, bgr=False):
+ # Equalize histogram on BGR image 'im' with im.shape(n,m,3) and range 0-255
+ yuv = cv2.cvtColor(im, cv2.COLOR_BGR2YUV if bgr else cv2.COLOR_RGB2YUV)
+ if clahe:
+ c = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
+ yuv[:, :, 0] = c.apply(yuv[:, :, 0])
+ else:
+ yuv[:, :, 0] = cv2.equalizeHist(yuv[:, :, 0]) # equalize Y channel histogram
+ return cv2.cvtColor(yuv, cv2.COLOR_YUV2BGR if bgr else cv2.COLOR_YUV2RGB) # convert YUV image to RGB
+
+
+def replicate(im, labels):
+ # Replicate labels
+ h, w = im.shape[:2]
+ boxes = labels[:, 1:].astype(int)
+ x1, y1, x2, y2 = boxes.T
+ s = ((x2 - x1) + (y2 - y1)) / 2 # side length (pixels)
+ for i in s.argsort()[:round(s.size * 0.5)]: # smallest indices
+ x1b, y1b, x2b, y2b = boxes[i]
+ bh, bw = y2b - y1b, x2b - x1b
+ yc, xc = int(random.uniform(0, h - bh)), int(random.uniform(0, w - bw)) # offset x, y
+ x1a, y1a, x2a, y2a = [xc, yc, xc + bw, yc + bh]
+ im[y1a:y2a, x1a:x2a] = im[y1b:y2b, x1b:x2b] # im4[ymin:ymax, xmin:xmax]
+ labels = np.append(labels, [[labels[i, 0], x1a, y1a, x2a, y2a]], axis=0)
+
+ return im, labels
+
+
+def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
+ # Resize and pad image while meeting stride-multiple constraints
+ shape = im.shape[:2] # current shape [height, width]
+ if isinstance(new_shape, int):
+ new_shape = (new_shape, new_shape)
+
+ # Scale ratio (new / old)
+ r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
+ if not scaleup: # only scale down, do not scale up (for better val mAP)
+ r = min(r, 1.0)
+
+ # Compute padding
+ ratio = r, r # width, height ratios
+ new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
+ dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
+ if auto: # minimum rectangle
+ dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
+ elif scaleFill: # stretch
+ dw, dh = 0.0, 0.0
+ new_unpad = (new_shape[1], new_shape[0])
+ ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
+
+ dw /= 2 # divide padding into 2 sides
+ dh /= 2
+
+ if shape[::-1] != new_unpad: # resize
+ im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
+ top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
+ left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
+ im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
+ return im, ratio, (dw, dh)
+
+
+def random_perspective(im,
+ targets=(),
+ segments=(),
+ degrees=10,
+ translate=.1,
+ scale=.1,
+ shear=10,
+ perspective=0.0,
+ border=(0, 0)):
+ # torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(0.1, 0.1), scale=(0.9, 1.1), shear=(-10, 10))
+ # targets = [cls, xyxy]
+
+ height = im.shape[0] + border[0] * 2 # shape(h,w,c)
+ width = im.shape[1] + border[1] * 2
+
+ # Center
+ C = np.eye(3)
+ C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
+ C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
+
+ # Perspective
+ P = np.eye(3)
+ P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
+ P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
+
+ # Rotation and Scale
+ R = np.eye(3)
+ a = random.uniform(-degrees, degrees)
+ # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
+ s = random.uniform(1 - scale, 1 + scale)
+ # s = 2 ** random.uniform(-scale, scale)
+ R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
+
+ # Shear
+ S = np.eye(3)
+ S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
+ S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
+
+ # Translation
+ T = np.eye(3)
+ T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation (pixels)
+ T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation (pixels)
+
+ # Combined rotation matrix
+ M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
+ if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
+ if perspective:
+ im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
+ else: # affine
+ im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
+
+ # Visualize
+ # import matplotlib.pyplot as plt
+ # ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
+ # ax[0].imshow(im[:, :, ::-1]) # base
+ # ax[1].imshow(im2[:, :, ::-1]) # warped
+
+ # Transform label coordinates
+ n = len(targets)
+ if n:
+ use_segments = any(x.any() for x in segments) and len(segments) == n
+ new = np.zeros((n, 4))
+ if use_segments: # warp segments
+ segments = resample_segments(segments) # upsample
+ for i, segment in enumerate(segments):
+ xy = np.ones((len(segment), 3))
+ xy[:, :2] = segment
+ xy = xy @ M.T # transform
+ xy = xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2] # perspective rescale or affine
+
+ # clip
+ new[i] = segment2box(xy, width, height)
+
+ else: # warp boxes
+ xy = np.ones((n * 4, 3))
+ xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
+ xy = xy @ M.T # transform
+ xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
+
+ # create new boxes
+ x = xy[:, [0, 2, 4, 6]]
+ y = xy[:, [1, 3, 5, 7]]
+ new = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
+
+ # clip
+ new[:, [0, 2]] = new[:, [0, 2]].clip(0, width)
+ new[:, [1, 3]] = new[:, [1, 3]].clip(0, height)
+
+ # filter candidates
+ i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01 if use_segments else 0.10)
+ targets = targets[i]
+ targets[:, 1:5] = new[i]
+
+ return im, targets
+
+
+def copy_paste(im, labels, segments, p=0.5):
+ # Implement Copy-Paste augmentation https://arxiv.org/abs/2012.07177, labels as nx5 np.array(cls, xyxy)
+ n = len(segments)
+ if p and n:
+ h, w, c = im.shape # height, width, channels
+ im_new = np.zeros(im.shape, np.uint8)
+ for j in random.sample(range(n), k=round(p * n)):
+ l, s = labels[j], segments[j]
+ box = w - l[3], l[2], w - l[1], l[4]
+ ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
+ if (ioa < 0.30).all(): # allow 30% obscuration of existing labels
+ labels = np.concatenate((labels, [[l[0], *box]]), 0)
+ segments.append(np.concatenate((w - s[:, 0:1], s[:, 1:2]), 1))
+ cv2.drawContours(im_new, [segments[j].astype(np.int32)], -1, (1, 1, 1), cv2.FILLED)
+
+ result = cv2.flip(im, 1) # augment segments (flip left-right)
+ i = cv2.flip(im_new, 1).astype(bool)
+ im[i] = result[i] # cv2.imwrite('debug.jpg', im) # debug
+
+ return im, labels, segments
+
+
+def cutout(im, labels, p=0.5):
+ # Applies image cutout augmentation https://arxiv.org/abs/1708.04552
+ if random.random() < p:
+ h, w = im.shape[:2]
+ scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction
+ for s in scales:
+ mask_h = random.randint(1, int(h * s)) # create random masks
+ mask_w = random.randint(1, int(w * s))
+
+ # box
+ xmin = max(0, random.randint(0, w) - mask_w // 2)
+ ymin = max(0, random.randint(0, h) - mask_h // 2)
+ xmax = min(w, xmin + mask_w)
+ ymax = min(h, ymin + mask_h)
+
+ # apply random color mask
+ im[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)]
+
+ # return unobscured labels
+ if len(labels) and s > 0.03:
+ box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32)
+ ioa = bbox_ioa(box, xywhn2xyxy(labels[:, 1:5], w, h)) # intersection over area
+ labels = labels[ioa < 0.60] # remove >60% obscured labels
+
+ return labels
+
+
+def mixup(im, labels, im2, labels2):
+ # Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
+ r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
+ im = (im * r + im2 * (1 - r)).astype(np.uint8)
+ labels = np.concatenate((labels, labels2), 0)
+ return im, labels
+
+
+def box_candidates(box1, box2, wh_thr=2, ar_thr=100, area_thr=0.1, eps=1e-16): # box1(4,n), box2(4,n)
+ # Compute candidate boxes: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
+ w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
+ w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
+ ar = np.maximum(w2 / (h2 + eps), h2 / (w2 + eps)) # aspect ratio
+ return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + eps) > area_thr) & (ar < ar_thr) # candidates
+
+
+def classify_albumentations(
+ augment=True,
+ size=224,
+ scale=(0.08, 1.0),
+ ratio=(0.75, 1.0 / 0.75), # 0.75, 1.33
+ hflip=0.5,
+ vflip=0.0,
+ jitter=0.4,
+ mean=IMAGENET_MEAN,
+ std=IMAGENET_STD,
+ auto_aug=False):
+ # YOLOv5 classification Albumentations (optional, only used if package is installed)
+ prefix = colorstr('albumentations: ')
+ try:
+ import albumentations as A
+ from albumentations.pytorch import ToTensorV2
+ check_version(A.__version__, '1.0.3', hard=True) # version requirement
+ if augment: # Resize and crop
+ T = [A.RandomResizedCrop(height=size, width=size, scale=scale, ratio=ratio)]
+ if auto_aug:
+ # TODO: implement AugMix, AutoAug & RandAug in albumentation
+ LOGGER.info(f'{prefix}auto augmentations are currently not supported')
+ else:
+ if hflip > 0:
+ T += [A.HorizontalFlip(p=hflip)]
+ if vflip > 0:
+ T += [A.VerticalFlip(p=vflip)]
+ if jitter > 0:
+ color_jitter = (float(jitter),) * 3 # repeat value for brightness, contrast, satuaration, 0 hue
+ T += [A.ColorJitter(*color_jitter, 0)]
+ else: # Use fixed crop for eval set (reproducibility)
+ T = [A.SmallestMaxSize(max_size=size), A.CenterCrop(height=size, width=size)]
+ T += [A.Normalize(mean=mean, std=std), ToTensorV2()] # Normalize and convert to Tensor
+ LOGGER.info(prefix + ', '.join(f'{x}'.replace('always_apply=False, ', '') for x in T if x.p))
+ return A.Compose(T)
+
+ except ImportError: # package not installed, skip
+ LOGGER.warning(f'{prefix}⚠️ not found, install with `pip install albumentations` (recommended)')
+ except Exception as e:
+ LOGGER.info(f'{prefix}{e}')
+
+
+def classify_transforms(size=224):
+ # Transforms to apply if albumentations not installed
+ assert isinstance(size, int), f'ERROR: classify_transforms size {size} must be integer, not (list, tuple)'
+ # T.Compose([T.ToTensor(), T.Resize(size), T.CenterCrop(size), T.Normalize(IMAGENET_MEAN, IMAGENET_STD)])
+ return T.Compose([CenterCrop(size), ToTensor(), T.Normalize(IMAGENET_MEAN, IMAGENET_STD)])
+
+
+class LetterBox:
+ # YOLOv5 LetterBox class for image preprocessing, i.e. T.Compose([LetterBox(size), ToTensor()])
+ def __init__(self, size=(640, 640), auto=False, stride=32):
+ super().__init__()
+ self.h, self.w = (size, size) if isinstance(size, int) else size
+ self.auto = auto # pass max size integer, automatically solve for short side using stride
+ self.stride = stride # used with auto
+
+ def __call__(self, im): # im = np.array HWC
+ imh, imw = im.shape[:2]
+ r = min(self.h / imh, self.w / imw) # ratio of new/old
+ h, w = round(imh * r), round(imw * r) # resized image
+ hs, ws = (math.ceil(x / self.stride) * self.stride for x in (h, w)) if self.auto else self.h, self.w
+ top, left = round((hs - h) / 2 - 0.1), round((ws - w) / 2 - 0.1)
+ im_out = np.full((self.h, self.w, 3), 114, dtype=im.dtype)
+ im_out[top:top + h, left:left + w] = cv2.resize(im, (w, h), interpolation=cv2.INTER_LINEAR)
+ return im_out
+
+
+class CenterCrop:
+ # YOLOv5 CenterCrop class for image preprocessing, i.e. T.Compose([CenterCrop(size), ToTensor()])
+ def __init__(self, size=640):
+ super().__init__()
+ self.h, self.w = (size, size) if isinstance(size, int) else size
+
+ def __call__(self, im): # im = np.array HWC
+ imh, imw = im.shape[:2]
+ m = min(imh, imw) # min dimension
+ top, left = (imh - m) // 2, (imw - m) // 2
+ return cv2.resize(im[top:top + m, left:left + m], (self.w, self.h), interpolation=cv2.INTER_LINEAR)
+
+
+class ToTensor:
+ # YOLOv5 ToTensor class for image preprocessing, i.e. T.Compose([LetterBox(size), ToTensor()])
+ def __init__(self, half=False):
+ super().__init__()
+ self.half = half
+
+ def __call__(self, im): # im = np.array HWC in BGR order
+ im = np.ascontiguousarray(im.transpose((2, 0, 1))[::-1]) # HWC to CHW -> BGR to RGB -> contiguous
+ im = torch.from_numpy(im) # to torch
+ im = im.half() if self.half else im.float() # uint8 to fp16/32
+ im /= 255.0 # 0-255 to 0.0-1.0
+ return im
diff --git a/yolov5/utils/autoanchor.py b/yolov5/utils/autoanchor.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb7e3a0aa68c3dc48c692804c2aff4e81cacc26a
--- /dev/null
+++ b/yolov5/utils/autoanchor.py
@@ -0,0 +1,169 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+AutoAnchor utils
+"""
+
+import random
+
+import numpy as np
+import torch
+import yaml
+from tqdm import tqdm
+
+from yolov5.utils import TryExcept
+from yolov5.utils.general import LOGGER, TQDM_BAR_FORMAT, colorstr
+
+PREFIX = colorstr('AutoAnchor: ')
+
+
+def check_anchor_order(m):
+ # Check anchor order against stride order for YOLOv5 Detect() module m, and correct if necessary
+ a = m.anchors.prod(-1).mean(-1).view(-1) # mean anchor area per output layer
+ da = a[-1] - a[0] # delta a
+ ds = m.stride[-1] - m.stride[0] # delta s
+ if da and (da.sign() != ds.sign()): # same order
+ LOGGER.info(f'{PREFIX}Reversing anchor order')
+ m.anchors[:] = m.anchors.flip(0)
+
+
+@TryExcept(f'{PREFIX}ERROR')
+def check_anchors(dataset, model, thr=4.0, imgsz=640):
+ # Check anchor fit to data, recompute if necessary
+ m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
+ shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
+ scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
+ wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # wh
+
+ def metric(k): # compute metric
+ r = wh[:, None] / k[None]
+ x = torch.min(r, 1 / r).min(2)[0] # ratio metric
+ best = x.max(1)[0] # best_x
+ aat = (x > 1 / thr).float().sum(1).mean() # anchors above threshold
+ bpr = (best > 1 / thr).float().mean() # best possible recall
+ return bpr, aat
+
+ stride = m.stride.to(m.anchors.device).view(-1, 1, 1) # model strides
+ anchors = m.anchors.clone() * stride # current anchors
+ bpr, aat = metric(anchors.cpu().view(-1, 2))
+ s = f'\n{PREFIX}{aat:.2f} anchors/target, {bpr:.3f} Best Possible Recall (BPR). '
+ if bpr > 0.98: # threshold to recompute
+ LOGGER.info(f'{s}Current anchors are a good fit to dataset ✅')
+ else:
+ LOGGER.info(f'{s}Anchors are a poor fit to dataset ⚠️, attempting to improve...')
+ na = m.anchors.numel() // 2 # number of anchors
+ anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)
+ new_bpr = metric(anchors)[0]
+ if new_bpr > bpr: # replace anchors
+ anchors = torch.tensor(anchors, device=m.anchors.device).type_as(m.anchors)
+ m.anchors[:] = anchors.clone().view_as(m.anchors)
+ check_anchor_order(m) # must be in pixel-space (not grid-space)
+ m.anchors /= stride
+ s = f'{PREFIX}Done ✅ (optional: update model *.yaml to use these anchors in the future)'
+ else:
+ s = f'{PREFIX}Done ⚠️ (original anchors better than new anchors, proceeding with original anchors)'
+ LOGGER.info(s)
+
+
+def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
+ """ Creates kmeans-evolved anchors from training dataset
+
+ Arguments:
+ dataset: path to data.yaml, or a loaded dataset
+ n: number of anchors
+ img_size: image size used for training
+ thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
+ gen: generations to evolve anchors using genetic algorithm
+ verbose: print all results
+
+ Return:
+ k: kmeans evolved anchors
+
+ Usage:
+ from utils.autoanchor import *; _ = kmean_anchors()
+ """
+ from scipy.cluster.vq import kmeans
+
+ npr = np.random
+ thr = 1 / thr
+
+ def metric(k, wh): # compute metrics
+ r = wh[:, None] / k[None]
+ x = torch.min(r, 1 / r).min(2)[0] # ratio metric
+ # x = wh_iou(wh, torch.tensor(k)) # iou metric
+ return x, x.max(1)[0] # x, best_x
+
+ def anchor_fitness(k): # mutation fitness
+ _, best = metric(torch.tensor(k, dtype=torch.float32), wh)
+ return (best * (best > thr).float()).mean() # fitness
+
+ def print_results(k, verbose=True):
+ k = k[np.argsort(k.prod(1))] # sort small to large
+ x, best = metric(k, wh0)
+ bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
+ s = f'{PREFIX}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr\n' \
+ f'{PREFIX}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, ' \
+ f'past_thr={x[x > thr].mean():.3f}-mean: '
+ for x in k:
+ s += '%i,%i, ' % (round(x[0]), round(x[1]))
+ if verbose:
+ LOGGER.info(s[:-2])
+ return k
+
+ if isinstance(dataset, str): # *.yaml file
+ with open(dataset, errors='ignore') as f:
+ data_dict = yaml.safe_load(f) # model dict
+ from utils.dataloaders import LoadImagesAndLabels
+ dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
+
+ # Get label wh
+ shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
+ wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
+
+ # Filter
+ i = (wh0 < 3.0).any(1).sum()
+ if i:
+ LOGGER.info(f'{PREFIX}WARNING ⚠️ Extremely small objects found: {i} of {len(wh0)} labels are <3 pixels in size')
+ wh = wh0[(wh0 >= 2.0).any(1)].astype(np.float32) # filter > 2 pixels
+ # wh = wh * (npr.rand(wh.shape[0], 1) * 0.9 + 0.1) # multiply by random scale 0-1
+
+ # Kmeans init
+ try:
+ LOGGER.info(f'{PREFIX}Running kmeans for {n} anchors on {len(wh)} points...')
+ assert n <= len(wh) # apply overdetermined constraint
+ s = wh.std(0) # sigmas for whitening
+ k = kmeans(wh / s, n, iter=30)[0] * s # points
+ assert n == len(k) # kmeans may return fewer points than requested if wh is insufficient or too similar
+ except Exception:
+ LOGGER.warning(f'{PREFIX}WARNING ⚠️ switching strategies from kmeans to random init')
+ k = np.sort(npr.rand(n * 2)).reshape(n, 2) * img_size # random init
+ wh, wh0 = (torch.tensor(x, dtype=torch.float32) for x in (wh, wh0))
+ k = print_results(k, verbose=False)
+
+ # Plot
+ # k, d = [None] * 20, [None] * 20
+ # for i in tqdm(range(1, 21)):
+ # k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
+ # fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
+ # ax = ax.ravel()
+ # ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
+ # fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
+ # ax[0].hist(wh[wh[:, 0]<100, 0],400)
+ # ax[1].hist(wh[wh[:, 1]<100, 1],400)
+ # fig.savefig('wh.png', dpi=200)
+
+ # Evolve
+ f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
+ pbar = tqdm(range(gen), bar_format=TQDM_BAR_FORMAT) # progress bar
+ for _ in pbar:
+ v = np.ones(sh)
+ while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
+ v = ((npr.random(sh) < mp) * random.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
+ kg = (k.copy() * v).clip(min=2.0)
+ fg = anchor_fitness(kg)
+ if fg > f:
+ f, k = fg, kg.copy()
+ pbar.desc = f'{PREFIX}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
+ if verbose:
+ print_results(k, verbose)
+
+ return print_results(k).astype(np.float32)
diff --git a/yolov5/utils/autobatch.py b/yolov5/utils/autobatch.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa763b888462a3dabf7ae161c24d9599fcfd8d9a
--- /dev/null
+++ b/yolov5/utils/autobatch.py
@@ -0,0 +1,72 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Auto-batch utils
+"""
+
+from copy import deepcopy
+
+import numpy as np
+import torch
+
+from utils.general import LOGGER, colorstr
+from utils.torch_utils import profile
+
+
+def check_train_batch_size(model, imgsz=640, amp=True):
+ # Check YOLOv5 training batch size
+ with torch.cuda.amp.autocast(amp):
+ return autobatch(deepcopy(model).train(), imgsz) # compute optimal batch size
+
+
+def autobatch(model, imgsz=640, fraction=0.8, batch_size=16):
+ # Automatically estimate best YOLOv5 batch size to use `fraction` of available CUDA memory
+ # Usage:
+ # import torch
+ # from utils.autobatch import autobatch
+ # model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False)
+ # print(autobatch(model))
+
+ # Check device
+ prefix = colorstr('AutoBatch: ')
+ LOGGER.info(f'{prefix}Computing optimal batch size for --imgsz {imgsz}')
+ device = next(model.parameters()).device # get model device
+ if device.type == 'cpu':
+ LOGGER.info(f'{prefix}CUDA not detected, using default CPU batch-size {batch_size}')
+ return batch_size
+ if torch.backends.cudnn.benchmark:
+ LOGGER.info(f'{prefix} ⚠️ Requires torch.backends.cudnn.benchmark=False, using default batch-size {batch_size}')
+ return batch_size
+
+ # Inspect CUDA memory
+ gb = 1 << 30 # bytes to GiB (1024 ** 3)
+ d = str(device).upper() # 'CUDA:0'
+ properties = torch.cuda.get_device_properties(device) # device properties
+ t = properties.total_memory / gb # GiB total
+ r = torch.cuda.memory_reserved(device) / gb # GiB reserved
+ a = torch.cuda.memory_allocated(device) / gb # GiB allocated
+ f = t - (r + a) # GiB free
+ LOGGER.info(f'{prefix}{d} ({properties.name}) {t:.2f}G total, {r:.2f}G reserved, {a:.2f}G allocated, {f:.2f}G free')
+
+ # Profile batch sizes
+ batch_sizes = [1, 2, 4, 8, 16]
+ try:
+ img = [torch.empty(b, 3, imgsz, imgsz) for b in batch_sizes]
+ results = profile(img, model, n=3, device=device)
+ except Exception as e:
+ LOGGER.warning(f'{prefix}{e}')
+
+ # Fit a solution
+ y = [x[2] for x in results if x] # memory [2]
+ p = np.polyfit(batch_sizes[:len(y)], y, deg=1) # first degree polynomial fit
+ b = int((f * fraction - p[1]) / p[0]) # y intercept (optimal batch size)
+ if None in results: # some sizes failed
+ i = results.index(None) # first fail index
+ if b >= batch_sizes[i]: # y intercept above failure point
+ b = batch_sizes[max(i - 1, 0)] # select prior safe point
+ if b < 1 or b > 1024: # b outside of safe range
+ b = batch_size
+ LOGGER.warning(f'{prefix}WARNING ⚠️ CUDA anomaly detected, recommend restart environment and retry command.')
+
+ fraction = (np.polyval(p, b) + r + a) / t # actual fraction predicted
+ LOGGER.info(f'{prefix}Using batch-size {b} for {d} {t * fraction:.2f}G/{t:.2f}G ({fraction * 100:.0f}%) ✅')
+ return b
diff --git a/yolov5/utils/aws/__init__.py b/yolov5/utils/aws/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/yolov5/utils/aws/mime.sh b/yolov5/utils/aws/mime.sh
new file mode 100644
index 0000000000000000000000000000000000000000..c319a83cfbdf09bea634c3bd9fca737c0b1dd505
--- /dev/null
+++ b/yolov5/utils/aws/mime.sh
@@ -0,0 +1,26 @@
+# AWS EC2 instance startup 'MIME' script https://aws.amazon.com/premiumsupport/knowledge-center/execute-user-data-ec2/
+# This script will run on every instance restart, not only on first start
+# --- DO NOT COPY ABOVE COMMENTS WHEN PASTING INTO USERDATA ---
+
+Content-Type: multipart/mixed; boundary="//"
+MIME-Version: 1.0
+
+--//
+Content-Type: text/cloud-config; charset="us-ascii"
+MIME-Version: 1.0
+Content-Transfer-Encoding: 7bit
+Content-Disposition: attachment; filename="cloud-config.txt"
+
+#cloud-config
+cloud_final_modules:
+- [scripts-user, always]
+
+--//
+Content-Type: text/x-shellscript; charset="us-ascii"
+MIME-Version: 1.0
+Content-Transfer-Encoding: 7bit
+Content-Disposition: attachment; filename="userdata.txt"
+
+#!/bin/bash
+# --- paste contents of userdata.sh here ---
+--//
diff --git a/yolov5/utils/aws/resume.py b/yolov5/utils/aws/resume.py
new file mode 100644
index 0000000000000000000000000000000000000000..b21731c979a121ab8227280351b70d6062efd983
--- /dev/null
+++ b/yolov5/utils/aws/resume.py
@@ -0,0 +1,40 @@
+# Resume all interrupted trainings in yolov5/ dir including DDP trainings
+# Usage: $ python utils/aws/resume.py
+
+import os
+import sys
+from pathlib import Path
+
+import torch
+import yaml
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[2] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+port = 0 # --master_port
+path = Path('').resolve()
+for last in path.rglob('*/**/last.pt'):
+ ckpt = torch.load(last)
+ if ckpt['optimizer'] is None:
+ continue
+
+ # Load opt.yaml
+ with open(last.parent.parent / 'opt.yaml', errors='ignore') as f:
+ opt = yaml.safe_load(f)
+
+ # Get device count
+ d = opt['device'].split(',') # devices
+ nd = len(d) # number of devices
+ ddp = nd > 1 or (nd == 0 and torch.cuda.device_count() > 1) # distributed data parallel
+
+ if ddp: # multi-GPU
+ port += 1
+ cmd = f'python -m torch.distributed.run --nproc_per_node {nd} --master_port {port} train.py --resume {last}'
+ else: # single-GPU
+ cmd = f'python train.py --resume {last}'
+
+ cmd += ' > /dev/null 2>&1 &' # redirect output to dev/null and run in daemon thread
+ print(cmd)
+ os.system(cmd)
diff --git a/yolov5/utils/aws/userdata.sh b/yolov5/utils/aws/userdata.sh
new file mode 100644
index 0000000000000000000000000000000000000000..5fc1332ac1b0d1794cf8f8c5f6918059ae5dc381
--- /dev/null
+++ b/yolov5/utils/aws/userdata.sh
@@ -0,0 +1,27 @@
+#!/bin/bash
+# AWS EC2 instance startup script https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/user-data.html
+# This script will run only once on first instance start (for a re-start script see mime.sh)
+# /home/ubuntu (ubuntu) or /home/ec2-user (amazon-linux) is working dir
+# Use >300 GB SSD
+
+cd home/ubuntu
+if [ ! -d yolov5 ]; then
+ echo "Running first-time script." # install dependencies, download COCO, pull Docker
+ git clone https://github.com/ultralytics/yolov5 -b master && sudo chmod -R 777 yolov5
+ cd yolov5
+ bash data/scripts/get_coco.sh && echo "COCO done." &
+ sudo docker pull ultralytics/yolov5:latest && echo "Docker done." &
+ python -m pip install --upgrade pip && pip install -r requirements.txt && python detect.py && echo "Requirements done." &
+ wait && echo "All tasks done." # finish background tasks
+else
+ echo "Running re-start script." # resume interrupted runs
+ i=0
+ list=$(sudo docker ps -qa) # container list i.e. $'one\ntwo\nthree\nfour'
+ while IFS= read -r id; do
+ ((i++))
+ echo "restarting container $i: $id"
+ sudo docker start $id
+ # sudo docker exec -it $id python train.py --resume # single-GPU
+ sudo docker exec -d $id python utils/aws/resume.py # multi-scenario
+ done <<<"$list"
+fi
diff --git a/yolov5/utils/callbacks.py b/yolov5/utils/callbacks.py
new file mode 100644
index 0000000000000000000000000000000000000000..ccebba02bcaa9d27e3f74e18014f3c9fa0385685
--- /dev/null
+++ b/yolov5/utils/callbacks.py
@@ -0,0 +1,76 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Callback utils
+"""
+
+import threading
+
+
+class Callbacks:
+ """"
+ Handles all registered callbacks for YOLOv5 Hooks
+ """
+
+ def __init__(self):
+ # Define the available callbacks
+ self._callbacks = {
+ 'on_pretrain_routine_start': [],
+ 'on_pretrain_routine_end': [],
+ 'on_train_start': [],
+ 'on_train_epoch_start': [],
+ 'on_train_batch_start': [],
+ 'optimizer_step': [],
+ 'on_before_zero_grad': [],
+ 'on_train_batch_end': [],
+ 'on_train_epoch_end': [],
+ 'on_val_start': [],
+ 'on_val_batch_start': [],
+ 'on_val_image_end': [],
+ 'on_val_batch_end': [],
+ 'on_val_end': [],
+ 'on_fit_epoch_end': [], # fit = train + val
+ 'on_model_save': [],
+ 'on_train_end': [],
+ 'on_params_update': [],
+ 'teardown': [],}
+ self.stop_training = False # set True to interrupt training
+
+ def register_action(self, hook, name='', callback=None):
+ """
+ Register a new action to a callback hook
+
+ Args:
+ hook: The callback hook name to register the action to
+ name: The name of the action for later reference
+ callback: The callback to fire
+ """
+ assert hook in self._callbacks, f"hook '{hook}' not found in callbacks {self._callbacks}"
+ assert callable(callback), f"callback '{callback}' is not callable"
+ self._callbacks[hook].append({'name': name, 'callback': callback})
+
+ def get_registered_actions(self, hook=None):
+ """"
+ Returns all the registered actions by callback hook
+
+ Args:
+ hook: The name of the hook to check, defaults to all
+ """
+ return self._callbacks[hook] if hook else self._callbacks
+
+ def run(self, hook, *args, thread=False, **kwargs):
+ """
+ Loop through the registered actions and fire all callbacks on main thread
+
+ Args:
+ hook: The name of the hook to check, defaults to all
+ args: Arguments to receive from YOLOv5
+ thread: (boolean) Run callbacks in daemon thread
+ kwargs: Keyword Arguments to receive from YOLOv5
+ """
+
+ assert hook in self._callbacks, f"hook '{hook}' not found in callbacks {self._callbacks}"
+ for logger in self._callbacks[hook]:
+ if thread:
+ threading.Thread(target=logger['callback'], args=args, kwargs=kwargs, daemon=True).start()
+ else:
+ logger['callback'](*args, **kwargs)
diff --git a/yolov5/utils/dataloaders.py b/yolov5/utils/dataloaders.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cbd70bdc647e00adb39bd20d180f0617df8e9b6
--- /dev/null
+++ b/yolov5/utils/dataloaders.py
@@ -0,0 +1,1222 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Dataloaders and dataset utils
+"""
+
+import contextlib
+import glob
+import hashlib
+import json
+import math
+import os
+import random
+import shutil
+import time
+from itertools import repeat
+from multiprocessing.pool import Pool, ThreadPool
+from pathlib import Path
+from threading import Thread
+from urllib.parse import urlparse
+
+import numpy as np
+import psutil
+import torch
+import torch.nn.functional as F
+import torchvision
+import yaml
+from PIL import ExifTags, Image, ImageOps
+from torch.utils.data import DataLoader, Dataset, dataloader, distributed
+from tqdm import tqdm
+
+from yolov5.utils.augmentations import (Albumentations, augment_hsv, classify_albumentations, classify_transforms, copy_paste,
+ letterbox, mixup, random_perspective)
+from yolov5.utils.general import (DATASETS_DIR, LOGGER, NUM_THREADS, TQDM_BAR_FORMAT, check_dataset, check_requirements,
+ check_yaml, clean_str, cv2, is_colab, is_kaggle, segments2boxes, unzip_file, xyn2xy,
+ xywh2xyxy, xywhn2xyxy, xyxy2xywhn)
+from yolov5.utils.torch_utils import torch_distributed_zero_first
+
+# Parameters
+HELP_URL = 'See https://docs.ultralytics.com/yolov5/tutorials/train_custom_data'
+IMG_FORMATS = 'bmp', 'dng', 'jpeg', 'jpg', 'mpo', 'png', 'tif', 'tiff', 'webp', 'pfm' # include image suffixes
+VID_FORMATS = 'asf', 'avi', 'gif', 'm4v', 'mkv', 'mov', 'mp4', 'mpeg', 'mpg', 'ts', 'wmv' # include video suffixes
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+PIN_MEMORY = str(os.getenv('PIN_MEMORY', True)).lower() == 'true' # global pin_memory for dataloaders
+
+# Get orientation exif tag
+for orientation in ExifTags.TAGS.keys():
+ if ExifTags.TAGS[orientation] == 'Orientation':
+ break
+
+
+def get_hash(paths):
+ # Returns a single hash value of a list of paths (files or dirs)
+ size = sum(os.path.getsize(p) for p in paths if os.path.exists(p)) # sizes
+ h = hashlib.sha256(str(size).encode()) # hash sizes
+ h.update(''.join(paths).encode()) # hash paths
+ return h.hexdigest() # return hash
+
+
+def exif_size(img):
+ # Returns exif-corrected PIL size
+ s = img.size # (width, height)
+ with contextlib.suppress(Exception):
+ rotation = dict(img._getexif().items())[orientation]
+ if rotation in [6, 8]: # rotation 270 or 90
+ s = (s[1], s[0])
+ return s
+
+
+def exif_transpose(image):
+ """
+ Transpose a PIL image accordingly if it has an EXIF Orientation tag.
+ Inplace version of https://github.com/python-pillow/Pillow/blob/master/src/PIL/ImageOps.py exif_transpose()
+
+ :param image: The image to transpose.
+ :return: An image.
+ """
+ exif = image.getexif()
+ orientation = exif.get(0x0112, 1) # default 1
+ if orientation > 1:
+ method = {
+ 2: Image.FLIP_LEFT_RIGHT,
+ 3: Image.ROTATE_180,
+ 4: Image.FLIP_TOP_BOTTOM,
+ 5: Image.TRANSPOSE,
+ 6: Image.ROTATE_270,
+ 7: Image.TRANSVERSE,
+ 8: Image.ROTATE_90}.get(orientation)
+ if method is not None:
+ image = image.transpose(method)
+ del exif[0x0112]
+ image.info['exif'] = exif.tobytes()
+ return image
+
+
+def seed_worker(worker_id):
+ # Set dataloader worker seed https://pytorch.org/docs/stable/notes/randomness.html#dataloader
+ worker_seed = torch.initial_seed() % 2 ** 32
+ np.random.seed(worker_seed)
+ random.seed(worker_seed)
+
+
+def create_dataloader(path,
+ imgsz,
+ batch_size,
+ stride,
+ single_cls=False,
+ hyp=None,
+ augment=False,
+ cache=False,
+ pad=0.0,
+ rect=False,
+ rank=-1,
+ workers=8,
+ image_weights=False,
+ quad=False,
+ prefix='',
+ shuffle=False,
+ seed=0):
+ if rect and shuffle:
+ LOGGER.warning('WARNING ⚠️ --rect is incompatible with DataLoader shuffle, setting shuffle=False')
+ shuffle = False
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = LoadImagesAndLabels(
+ path,
+ imgsz,
+ batch_size,
+ augment=augment, # augmentation
+ hyp=hyp, # hyperparameters
+ rect=rect, # rectangular batches
+ cache_images=cache,
+ single_cls=single_cls,
+ stride=int(stride),
+ pad=pad,
+ image_weights=image_weights,
+ prefix=prefix)
+
+ batch_size = min(batch_size, len(dataset))
+ nd = torch.cuda.device_count() # number of CUDA devices
+ nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
+ sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
+ loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
+ generator = torch.Generator()
+ generator.manual_seed(6148914691236517205 + seed + RANK)
+ return loader(dataset,
+ batch_size=batch_size,
+ shuffle=shuffle and sampler is None,
+ num_workers=nw,
+ sampler=sampler,
+ pin_memory=PIN_MEMORY,
+ collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn,
+ worker_init_fn=seed_worker,
+ generator=generator), dataset
+
+
+class InfiniteDataLoader(dataloader.DataLoader):
+ """ Dataloader that reuses workers
+
+ Uses same syntax as vanilla DataLoader
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
+ self.iterator = super().__iter__()
+
+ def __len__(self):
+ return len(self.batch_sampler.sampler)
+
+ def __iter__(self):
+ for _ in range(len(self)):
+ yield next(self.iterator)
+
+
+class _RepeatSampler:
+ """ Sampler that repeats forever
+
+ Args:
+ sampler (Sampler)
+ """
+
+ def __init__(self, sampler):
+ self.sampler = sampler
+
+ def __iter__(self):
+ while True:
+ yield from iter(self.sampler)
+
+
+class LoadScreenshots:
+ # YOLOv5 screenshot dataloader, i.e. `python detect.py --source "screen 0 100 100 512 256"`
+ def __init__(self, source, img_size=640, stride=32, auto=True, transforms=None):
+ # source = [screen_number left top width height] (pixels)
+ check_requirements('mss')
+ import mss
+
+ source, *params = source.split()
+ self.screen, left, top, width, height = 0, None, None, None, None # default to full screen 0
+ if len(params) == 1:
+ self.screen = int(params[0])
+ elif len(params) == 4:
+ left, top, width, height = (int(x) for x in params)
+ elif len(params) == 5:
+ self.screen, left, top, width, height = (int(x) for x in params)
+ self.img_size = img_size
+ self.stride = stride
+ self.transforms = transforms
+ self.auto = auto
+ self.mode = 'stream'
+ self.frame = 0
+ self.sct = mss.mss()
+
+ # Parse monitor shape
+ monitor = self.sct.monitors[self.screen]
+ self.top = monitor['top'] if top is None else (monitor['top'] + top)
+ self.left = monitor['left'] if left is None else (monitor['left'] + left)
+ self.width = width or monitor['width']
+ self.height = height or monitor['height']
+ self.monitor = {'left': self.left, 'top': self.top, 'width': self.width, 'height': self.height}
+
+ def __iter__(self):
+ return self
+
+ def __next__(self):
+ # mss screen capture: get raw pixels from the screen as np array
+ im0 = np.array(self.sct.grab(self.monitor))[:, :, :3] # [:, :, :3] BGRA to BGR
+ s = f'screen {self.screen} (LTWH): {self.left},{self.top},{self.width},{self.height}: '
+
+ if self.transforms:
+ im = self.transforms(im0) # transforms
+ else:
+ im = letterbox(im0, self.img_size, stride=self.stride, auto=self.auto)[0] # padded resize
+ im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ im = np.ascontiguousarray(im) # contiguous
+ self.frame += 1
+ return str(self.screen), im, im0, None, s # screen, img, original img, im0s, s
+
+
+class LoadImages:
+ # YOLOv5 image/video dataloader, i.e. `python detect.py --source image.jpg/vid.mp4`
+ def __init__(self, path, img_size=640, stride=32, auto=True, transforms=None, vid_stride=1):
+ if isinstance(path, str) and Path(path).suffix == '.txt': # *.txt file with img/vid/dir on each line
+ path = Path(path).read_text().rsplit()
+ files = []
+ for p in sorted(path) if isinstance(path, (list, tuple)) else [path]:
+ p = str(Path(p).resolve())
+ if '*' in p:
+ files.extend(sorted(glob.glob(p, recursive=True))) # glob
+ elif os.path.isdir(p):
+ files.extend(sorted(glob.glob(os.path.join(p, '*.*')))) # dir
+ elif os.path.isfile(p):
+ files.append(p) # files
+ else:
+ raise FileNotFoundError(f'{p} does not exist')
+
+ images = [x for x in files if x.split('.')[-1].lower() in IMG_FORMATS]
+ videos = [x for x in files if x.split('.')[-1].lower() in VID_FORMATS]
+ ni, nv = len(images), len(videos)
+
+ self.img_size = img_size
+ self.stride = stride
+ self.files = images + videos
+ self.nf = ni + nv # number of files
+ self.video_flag = [False] * ni + [True] * nv
+ self.mode = 'image'
+ self.auto = auto
+ self.transforms = transforms # optional
+ self.vid_stride = vid_stride # video frame-rate stride
+ if any(videos):
+ self._new_video(videos[0]) # new video
+ else:
+ self.cap = None
+ assert self.nf > 0, f'No images or videos found in {p}. ' \
+ f'Supported formats are:\nimages: {IMG_FORMATS}\nvideos: {VID_FORMATS}'
+
+ def __iter__(self):
+ self.count = 0
+ return self
+
+ def __next__(self):
+ if self.count == self.nf:
+ raise StopIteration
+ path = self.files[self.count]
+
+ if self.video_flag[self.count]:
+ # Read video
+ self.mode = 'video'
+ for _ in range(self.vid_stride):
+ self.cap.grab()
+ ret_val, im0 = self.cap.retrieve()
+ while not ret_val:
+ self.count += 1
+ self.cap.release()
+ if self.count == self.nf: # last video
+ raise StopIteration
+ path = self.files[self.count]
+ self._new_video(path)
+ ret_val, im0 = self.cap.read()
+
+ self.frame += 1
+ # im0 = self._cv2_rotate(im0) # for use if cv2 autorotation is False
+ s = f'video {self.count + 1}/{self.nf} ({self.frame}/{self.frames}) {path}: '
+
+ else:
+ # Read image
+ self.count += 1
+ im0 = cv2.imread(path) # BGR
+ assert im0 is not None, f'Image Not Found {path}'
+ s = f'image {self.count}/{self.nf} {path}: '
+
+ if self.transforms:
+ im = self.transforms(im0) # transforms
+ else:
+ im = letterbox(im0, self.img_size, stride=self.stride, auto=self.auto)[0] # padded resize
+ im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ im = np.ascontiguousarray(im) # contiguous
+
+ return path, im, im0, self.cap, s
+
+ def _new_video(self, path):
+ # Create a new video capture object
+ self.frame = 0
+ self.cap = cv2.VideoCapture(path)
+ self.frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT) / self.vid_stride)
+ self.orientation = int(self.cap.get(cv2.CAP_PROP_ORIENTATION_META)) # rotation degrees
+ # self.cap.set(cv2.CAP_PROP_ORIENTATION_AUTO, 0) # disable https://github.com/ultralytics/yolov5/issues/8493
+
+ def _cv2_rotate(self, im):
+ # Rotate a cv2 video manually
+ if self.orientation == 0:
+ return cv2.rotate(im, cv2.ROTATE_90_CLOCKWISE)
+ elif self.orientation == 180:
+ return cv2.rotate(im, cv2.ROTATE_90_COUNTERCLOCKWISE)
+ elif self.orientation == 90:
+ return cv2.rotate(im, cv2.ROTATE_180)
+ return im
+
+ def __len__(self):
+ return self.nf # number of files
+
+
+class LoadStreams:
+ # YOLOv5 streamloader, i.e. `python detect.py --source 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streams`
+ def __init__(self, sources='file.streams', img_size=640, stride=32, auto=True, transforms=None, vid_stride=1):
+ torch.backends.cudnn.benchmark = True # faster for fixed-size inference
+ self.mode = 'stream'
+ self.img_size = img_size
+ self.stride = stride
+ self.vid_stride = vid_stride # video frame-rate stride
+ sources = Path(sources).read_text().rsplit() if os.path.isfile(sources) else [sources]
+ n = len(sources)
+ self.sources = [clean_str(x) for x in sources] # clean source names for later
+ self.imgs, self.fps, self.frames, self.threads = [None] * n, [0] * n, [0] * n, [None] * n
+ for i, s in enumerate(sources): # index, source
+ # Start thread to read frames from video stream
+ st = f'{i + 1}/{n}: {s}... '
+ if urlparse(s).hostname in ('www.youtube.com', 'youtube.com', 'youtu.be'): # if source is YouTube video
+ # YouTube format i.e. 'https://www.youtube.com/watch?v=Zgi9g1ksQHc' or 'https://youtu.be/Zgi9g1ksQHc'
+ check_requirements(('pafy', 'youtube_dl==2020.12.2'))
+ import pafy
+ s = pafy.new(s).getbest(preftype='mp4').url # YouTube URL
+ s = eval(s) if s.isnumeric() else s # i.e. s = '0' local webcam
+ if s == 0:
+ assert not is_colab(), '--source 0 webcam unsupported on Colab. Rerun command in a local environment.'
+ assert not is_kaggle(), '--source 0 webcam unsupported on Kaggle. Rerun command in a local environment.'
+ cap = cv2.VideoCapture(s)
+ assert cap.isOpened(), f'{st}Failed to open {s}'
+ w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ fps = cap.get(cv2.CAP_PROP_FPS) # warning: may return 0 or nan
+ self.frames[i] = max(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)), 0) or float('inf') # infinite stream fallback
+ self.fps[i] = max((fps if math.isfinite(fps) else 0) % 100, 0) or 30 # 30 FPS fallback
+
+ _, self.imgs[i] = cap.read() # guarantee first frame
+ self.threads[i] = Thread(target=self.update, args=([i, cap, s]), daemon=True)
+ LOGGER.info(f'{st} Success ({self.frames[i]} frames {w}x{h} at {self.fps[i]:.2f} FPS)')
+ self.threads[i].start()
+ LOGGER.info('') # newline
+
+ # check for common shapes
+ s = np.stack([letterbox(x, img_size, stride=stride, auto=auto)[0].shape for x in self.imgs])
+ self.rect = np.unique(s, axis=0).shape[0] == 1 # rect inference if all shapes equal
+ self.auto = auto and self.rect
+ self.transforms = transforms # optional
+ if not self.rect:
+ LOGGER.warning('WARNING ⚠️ Stream shapes differ. For optimal performance supply similarly-shaped streams.')
+
+ def update(self, i, cap, stream):
+ # Read stream `i` frames in daemon thread
+ n, f = 0, self.frames[i] # frame number, frame array
+ while cap.isOpened() and n < f:
+ n += 1
+ cap.grab() # .read() = .grab() followed by .retrieve()
+ if n % self.vid_stride == 0:
+ success, im = cap.retrieve()
+ if success:
+ self.imgs[i] = im
+ else:
+ LOGGER.warning('WARNING ⚠️ Video stream unresponsive, please check your IP camera connection.')
+ self.imgs[i] = np.zeros_like(self.imgs[i])
+ cap.open(stream) # re-open stream if signal was lost
+ time.sleep(0.0) # wait time
+
+ def __iter__(self):
+ self.count = -1
+ return self
+
+ def __next__(self):
+ self.count += 1
+ if not all(x.is_alive() for x in self.threads) or cv2.waitKey(1) == ord('q'): # q to quit
+ cv2.destroyAllWindows()
+ raise StopIteration
+
+ im0 = self.imgs.copy()
+ if self.transforms:
+ im = np.stack([self.transforms(x) for x in im0]) # transforms
+ else:
+ im = np.stack([letterbox(x, self.img_size, stride=self.stride, auto=self.auto)[0] for x in im0]) # resize
+ im = im[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW
+ im = np.ascontiguousarray(im) # contiguous
+
+ return self.sources, im, im0, None, ''
+
+ def __len__(self):
+ return len(self.sources) # 1E12 frames = 32 streams at 30 FPS for 30 years
+
+
+def img2label_paths(img_paths):
+ # Define label paths as a function of image paths
+ sa, sb = f'{os.sep}images{os.sep}', f'{os.sep}labels{os.sep}' # /images/, /labels/ substrings
+ return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
+
+
+class LoadImagesAndLabels(Dataset):
+ # YOLOv5 train_loader/val_loader, loads images and labels for training and validation
+ cache_version = 0.6 # dataset labels *.cache version
+ rand_interp_methods = [cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4]
+
+ def __init__(self,
+ path,
+ img_size=640,
+ batch_size=16,
+ augment=False,
+ hyp=None,
+ rect=False,
+ image_weights=False,
+ cache_images=False,
+ single_cls=False,
+ stride=32,
+ pad=0.0,
+ min_items=0,
+ prefix=''):
+ self.img_size = img_size
+ self.augment = augment
+ self.hyp = hyp
+ self.image_weights = image_weights
+ self.rect = False if image_weights else rect
+ self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
+ self.mosaic_border = [-img_size // 2, -img_size // 2]
+ self.stride = stride
+ self.path = path
+ self.albumentations = Albumentations(size=img_size) if augment else None
+
+ try:
+ f = [] # image files
+ for p in path if isinstance(path, list) else [path]:
+ p = Path(p) # os-agnostic
+ if p.is_dir(): # dir
+ f += glob.glob(str(p / '**' / '*.*'), recursive=True)
+ # f = list(p.rglob('*.*')) # pathlib
+ elif p.is_file(): # file
+ with open(p) as t:
+ t = t.read().strip().splitlines()
+ parent = str(p.parent) + os.sep
+ f += [x.replace('./', parent, 1) if x.startswith('./') else x for x in t] # to global path
+ # f += [p.parent / x.lstrip(os.sep) for x in t] # to global path (pathlib)
+ else:
+ raise FileNotFoundError(f'{prefix}{p} does not exist')
+ self.im_files = sorted(x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS)
+ # self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
+ assert self.im_files, f'{prefix}No images found'
+ except Exception as e:
+ raise Exception(f'{prefix}Error loading data from {path}: {e}\n{HELP_URL}') from e
+
+ # Check cache
+ self.label_files = img2label_paths(self.im_files) # labels
+ cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache')
+ try:
+ cache, exists = np.load(cache_path, allow_pickle=True).item(), True # load dict
+ assert cache['version'] == self.cache_version # matches current version
+ assert cache['hash'] == get_hash(self.label_files + self.im_files) # identical hash
+ except Exception:
+ cache, exists = self.cache_labels(cache_path, prefix), False # run cache ops
+
+ # Display cache
+ nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupt, total
+ if exists and LOCAL_RANK in {-1, 0}:
+ d = f'Scanning {cache_path}... {nf} images, {nm + ne} backgrounds, {nc} corrupt'
+ tqdm(None, desc=prefix + d, total=n, initial=n, bar_format=TQDM_BAR_FORMAT) # display cache results
+ if cache['msgs']:
+ LOGGER.info('\n'.join(cache['msgs'])) # display warnings
+ assert nf > 0 or not augment, f'{prefix}No labels found in {cache_path}, can not start training. {HELP_URL}'
+
+ # Read cache
+ [cache.pop(k) for k in ('hash', 'version', 'msgs')] # remove items
+ labels, shapes, self.segments = zip(*cache.values())
+ nl = len(np.concatenate(labels, 0)) # number of labels
+ assert nl > 0 or not augment, f'{prefix}All labels empty in {cache_path}, can not start training. {HELP_URL}'
+ self.labels = list(labels)
+ self.shapes = np.array(shapes)
+ self.im_files = list(cache.keys()) # update
+ self.label_files = img2label_paths(cache.keys()) # update
+
+ # Filter images
+ if min_items:
+ include = np.array([len(x) >= min_items for x in self.labels]).nonzero()[0].astype(int)
+ LOGGER.info(f'{prefix}{n - len(include)}/{n} images filtered from dataset')
+ self.im_files = [self.im_files[i] for i in include]
+ self.label_files = [self.label_files[i] for i in include]
+ self.labels = [self.labels[i] for i in include]
+ self.segments = [self.segments[i] for i in include]
+ self.shapes = self.shapes[include] # wh
+
+ # Create indices
+ n = len(self.shapes) # number of images
+ bi = np.floor(np.arange(n) / batch_size).astype(int) # batch index
+ nb = bi[-1] + 1 # number of batches
+ self.batch = bi # batch index of image
+ self.n = n
+ self.indices = range(n)
+
+ # Update labels
+ include_class = [] # filter labels to include only these classes (optional)
+ self.segments = list(self.segments)
+ include_class_array = np.array(include_class).reshape(1, -1)
+ for i, (label, segment) in enumerate(zip(self.labels, self.segments)):
+ if include_class:
+ j = (label[:, 0:1] == include_class_array).any(1)
+ self.labels[i] = label[j]
+ if segment:
+ self.segments[i] = [segment[idx] for idx, elem in enumerate(j) if elem]
+ if single_cls: # single-class training, merge all classes into 0
+ self.labels[i][:, 0] = 0
+
+ # Rectangular Training
+ if self.rect:
+ # Sort by aspect ratio
+ s = self.shapes # wh
+ ar = s[:, 1] / s[:, 0] # aspect ratio
+ irect = ar.argsort()
+ self.im_files = [self.im_files[i] for i in irect]
+ self.label_files = [self.label_files[i] for i in irect]
+ self.labels = [self.labels[i] for i in irect]
+ self.segments = [self.segments[i] for i in irect]
+ self.shapes = s[irect] # wh
+ ar = ar[irect]
+
+ # Set training image shapes
+ shapes = [[1, 1]] * nb
+ for i in range(nb):
+ ari = ar[bi == i]
+ mini, maxi = ari.min(), ari.max()
+ if maxi < 1:
+ shapes[i] = [maxi, 1]
+ elif mini > 1:
+ shapes[i] = [1, 1 / mini]
+
+ self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(int) * stride
+
+ # Cache images into RAM/disk for faster training
+ if cache_images == 'ram' and not self.check_cache_ram(prefix=prefix):
+ cache_images = False
+ self.ims = [None] * n
+ self.npy_files = [Path(f).with_suffix('.npy') for f in self.im_files]
+ if cache_images:
+ b, gb = 0, 1 << 30 # bytes of cached images, bytes per gigabytes
+ self.im_hw0, self.im_hw = [None] * n, [None] * n
+ fcn = self.cache_images_to_disk if cache_images == 'disk' else self.load_image
+ results = ThreadPool(NUM_THREADS).imap(fcn, range(n))
+ pbar = tqdm(enumerate(results), total=n, bar_format=TQDM_BAR_FORMAT, disable=LOCAL_RANK > 0)
+ for i, x in pbar:
+ if cache_images == 'disk':
+ b += self.npy_files[i].stat().st_size
+ else: # 'ram'
+ self.ims[i], self.im_hw0[i], self.im_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
+ b += self.ims[i].nbytes
+ pbar.desc = f'{prefix}Caching images ({b / gb:.1f}GB {cache_images})'
+ pbar.close()
+
+ def check_cache_ram(self, safety_margin=0.1, prefix=''):
+ # Check image caching requirements vs available memory
+ b, gb = 0, 1 << 30 # bytes of cached images, bytes per gigabytes
+ n = min(self.n, 30) # extrapolate from 30 random images
+ for _ in range(n):
+ im = cv2.imread(random.choice(self.im_files)) # sample image
+ ratio = self.img_size / max(im.shape[0], im.shape[1]) # max(h, w) # ratio
+ b += im.nbytes * ratio ** 2
+ mem_required = b * self.n / n # GB required to cache dataset into RAM
+ mem = psutil.virtual_memory()
+ cache = mem_required * (1 + safety_margin) < mem.available # to cache or not to cache, that is the question
+ if not cache:
+ LOGGER.info(f'{prefix}{mem_required / gb:.1f}GB RAM required, '
+ f'{mem.available / gb:.1f}/{mem.total / gb:.1f}GB available, '
+ f"{'caching images ✅' if cache else 'not caching images ⚠️'}")
+ return cache
+
+ def cache_labels(self, path=Path('./labels.cache'), prefix=''):
+ # Cache dataset labels, check images and read shapes
+ x = {} # dict
+ nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
+ desc = f'{prefix}Scanning {path.parent / path.stem}...'
+ with Pool(NUM_THREADS) as pool:
+ pbar = tqdm(pool.imap(verify_image_label, zip(self.im_files, self.label_files, repeat(prefix))),
+ desc=desc,
+ total=len(self.im_files),
+ bar_format=TQDM_BAR_FORMAT)
+ for im_file, lb, shape, segments, nm_f, nf_f, ne_f, nc_f, msg in pbar:
+ nm += nm_f
+ nf += nf_f
+ ne += ne_f
+ nc += nc_f
+ if im_file:
+ x[im_file] = [lb, shape, segments]
+ if msg:
+ msgs.append(msg)
+ pbar.desc = f'{desc} {nf} images, {nm + ne} backgrounds, {nc} corrupt'
+
+ pbar.close()
+ if msgs:
+ LOGGER.info('\n'.join(msgs))
+ if nf == 0:
+ LOGGER.warning(f'{prefix}WARNING ⚠️ No labels found in {path}. {HELP_URL}')
+ x['hash'] = get_hash(self.label_files + self.im_files)
+ x['results'] = nf, nm, ne, nc, len(self.im_files)
+ x['msgs'] = msgs # warnings
+ x['version'] = self.cache_version # cache version
+ try:
+ np.save(path, x) # save cache for next time
+ path.with_suffix('.cache.npy').rename(path) # remove .npy suffix
+ LOGGER.info(f'{prefix}New cache created: {path}')
+ except Exception as e:
+ LOGGER.warning(f'{prefix}WARNING ⚠️ Cache directory {path.parent} is not writeable: {e}') # not writeable
+ return x
+
+ def __len__(self):
+ return len(self.im_files)
+
+ # def __iter__(self):
+ # self.count = -1
+ # print('ran dataset iter')
+ # #self.shuffled_vector = np.random.permutation(self.nF) if self.augment else np.arange(self.nF)
+ # return self
+
+ def __getitem__(self, index):
+ index = self.indices[index] # linear, shuffled, or image_weights
+
+ hyp = self.hyp
+ mosaic = self.mosaic and random.random() < hyp['mosaic']
+ if mosaic:
+ # Load mosaic
+ img, labels = self.load_mosaic(index)
+ shapes = None
+
+ # MixUp augmentation
+ if random.random() < hyp['mixup']:
+ img, labels = mixup(img, labels, *self.load_mosaic(random.randint(0, self.n - 1)))
+
+ else:
+ # Load image
+ img, (h0, w0), (h, w) = self.load_image(index)
+
+ # Letterbox
+ shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
+ img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
+ shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
+
+ labels = self.labels[index].copy()
+ if labels.size: # normalized xywh to pixel xyxy format
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
+
+ if self.augment:
+ img, labels = random_perspective(img,
+ labels,
+ degrees=hyp['degrees'],
+ translate=hyp['translate'],
+ scale=hyp['scale'],
+ shear=hyp['shear'],
+ perspective=hyp['perspective'])
+
+ nl = len(labels) # number of labels
+ if nl:
+ labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1E-3)
+
+ if self.augment:
+ # Albumentations
+ img, labels = self.albumentations(img, labels)
+ nl = len(labels) # update after albumentations
+
+ # HSV color-space
+ augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
+
+ # Flip up-down
+ if random.random() < hyp['flipud']:
+ img = np.flipud(img)
+ if nl:
+ labels[:, 2] = 1 - labels[:, 2]
+
+ # Flip left-right
+ if random.random() < hyp['fliplr']:
+ img = np.fliplr(img)
+ if nl:
+ labels[:, 1] = 1 - labels[:, 1]
+
+ # Cutouts
+ # labels = cutout(img, labels, p=0.5)
+ # nl = len(labels) # update after cutout
+
+ labels_out = torch.zeros((nl, 6))
+ if nl:
+ labels_out[:, 1:] = torch.from_numpy(labels)
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return torch.from_numpy(img), labels_out, self.im_files[index], shapes
+
+ def load_image(self, i):
+ # Loads 1 image from dataset index 'i', returns (im, original hw, resized hw)
+ im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i],
+ if im is None: # not cached in RAM
+ if fn.exists(): # load npy
+ im = np.load(fn)
+ else: # read image
+ im = cv2.imread(f) # BGR
+ assert im is not None, f'Image Not Found {f}'
+ h0, w0 = im.shape[:2] # orig hw
+ r = self.img_size / max(h0, w0) # ratio
+ if r != 1: # if sizes are not equal
+ interp = cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREA
+ im = cv2.resize(im, (math.ceil(w0 * r), math.ceil(h0 * r)), interpolation=interp)
+ return im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
+ return self.ims[i], self.im_hw0[i], self.im_hw[i] # im, hw_original, hw_resized
+
+ def cache_images_to_disk(self, i):
+ # Saves an image as an *.npy file for faster loading
+ f = self.npy_files[i]
+ if not f.exists():
+ np.save(f.as_posix(), cv2.imread(self.im_files[i]))
+
+ def load_mosaic(self, index):
+ # YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
+ labels4, segments4 = [], []
+ s = self.img_size
+ yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
+ indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
+ random.shuffle(indices)
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img4
+ if i == 0: # top left
+ img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
+ elif i == 1: # top right
+ x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
+ x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
+ elif i == 2: # bottom left
+ x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
+ elif i == 3: # bottom right
+ x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
+
+ img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
+ padw = x1a - x1b
+ padh = y1a - y1b
+
+ # Labels
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
+ labels4.append(labels)
+ segments4.extend(segments)
+
+ # Concat/clip labels
+ labels4 = np.concatenate(labels4, 0)
+ for x in (labels4[:, 1:], *segments4):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img4, labels4 = replicate(img4, labels4) # replicate
+
+ # Augment
+ img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
+ img4, labels4 = random_perspective(img4,
+ labels4,
+ segments4,
+ degrees=self.hyp['degrees'],
+ translate=self.hyp['translate'],
+ scale=self.hyp['scale'],
+ shear=self.hyp['shear'],
+ perspective=self.hyp['perspective'],
+ border=self.mosaic_border) # border to remove
+
+ return img4, labels4
+
+ def load_mosaic9(self, index):
+ # YOLOv5 9-mosaic loader. Loads 1 image + 8 random images into a 9-image mosaic
+ labels9, segments9 = [], []
+ s = self.img_size
+ indices = [index] + random.choices(self.indices, k=8) # 8 additional image indices
+ random.shuffle(indices)
+ hp, wp = -1, -1 # height, width previous
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img9
+ if i == 0: # center
+ img9 = np.full((s * 3, s * 3, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ h0, w0 = h, w
+ c = s, s, s + w, s + h # xmin, ymin, xmax, ymax (base) coordinates
+ elif i == 1: # top
+ c = s, s - h, s + w, s
+ elif i == 2: # top right
+ c = s + wp, s - h, s + wp + w, s
+ elif i == 3: # right
+ c = s + w0, s, s + w0 + w, s + h
+ elif i == 4: # bottom right
+ c = s + w0, s + hp, s + w0 + w, s + hp + h
+ elif i == 5: # bottom
+ c = s + w0 - w, s + h0, s + w0, s + h0 + h
+ elif i == 6: # bottom left
+ c = s + w0 - wp - w, s + h0, s + w0 - wp, s + h0 + h
+ elif i == 7: # left
+ c = s - w, s + h0 - h, s, s + h0
+ elif i == 8: # top left
+ c = s - w, s + h0 - hp - h, s, s + h0 - hp
+
+ padx, pady = c[:2]
+ x1, y1, x2, y2 = (max(x, 0) for x in c) # allocate coords
+
+ # Labels
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padx, pady) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padx, pady) for x in segments]
+ labels9.append(labels)
+ segments9.extend(segments)
+
+ # Image
+ img9[y1:y2, x1:x2] = img[y1 - pady:, x1 - padx:] # img9[ymin:ymax, xmin:xmax]
+ hp, wp = h, w # height, width previous
+
+ # Offset
+ yc, xc = (int(random.uniform(0, s)) for _ in self.mosaic_border) # mosaic center x, y
+ img9 = img9[yc:yc + 2 * s, xc:xc + 2 * s]
+
+ # Concat/clip labels
+ labels9 = np.concatenate(labels9, 0)
+ labels9[:, [1, 3]] -= xc
+ labels9[:, [2, 4]] -= yc
+ c = np.array([xc, yc]) # centers
+ segments9 = [x - c for x in segments9]
+
+ for x in (labels9[:, 1:], *segments9):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img9, labels9 = replicate(img9, labels9) # replicate
+
+ # Augment
+ img9, labels9, segments9 = copy_paste(img9, labels9, segments9, p=self.hyp['copy_paste'])
+ img9, labels9 = random_perspective(img9,
+ labels9,
+ segments9,
+ degrees=self.hyp['degrees'],
+ translate=self.hyp['translate'],
+ scale=self.hyp['scale'],
+ shear=self.hyp['shear'],
+ perspective=self.hyp['perspective'],
+ border=self.mosaic_border) # border to remove
+
+ return img9, labels9
+
+ @staticmethod
+ def collate_fn(batch):
+ im, label, path, shapes = zip(*batch) # transposed
+ for i, lb in enumerate(label):
+ lb[:, 0] = i # add target image index for build_targets()
+ return torch.stack(im, 0), torch.cat(label, 0), path, shapes
+
+ @staticmethod
+ def collate_fn4(batch):
+ im, label, path, shapes = zip(*batch) # transposed
+ n = len(shapes) // 4
+ im4, label4, path4, shapes4 = [], [], path[:n], shapes[:n]
+
+ ho = torch.tensor([[0.0, 0, 0, 1, 0, 0]])
+ wo = torch.tensor([[0.0, 0, 1, 0, 0, 0]])
+ s = torch.tensor([[1, 1, 0.5, 0.5, 0.5, 0.5]]) # scale
+ for i in range(n): # zidane torch.zeros(16,3,720,1280) # BCHW
+ i *= 4
+ if random.random() < 0.5:
+ im1 = F.interpolate(im[i].unsqueeze(0).float(), scale_factor=2.0, mode='bilinear',
+ align_corners=False)[0].type(im[i].type())
+ lb = label[i]
+ else:
+ im1 = torch.cat((torch.cat((im[i], im[i + 1]), 1), torch.cat((im[i + 2], im[i + 3]), 1)), 2)
+ lb = torch.cat((label[i], label[i + 1] + ho, label[i + 2] + wo, label[i + 3] + ho + wo), 0) * s
+ im4.append(im1)
+ label4.append(lb)
+
+ for i, lb in enumerate(label4):
+ lb[:, 0] = i # add target image index for build_targets()
+
+ return torch.stack(im4, 0), torch.cat(label4, 0), path4, shapes4
+
+
+# Ancillary functions --------------------------------------------------------------------------------------------------
+def flatten_recursive(path=DATASETS_DIR / 'coco128'):
+ # Flatten a recursive directory by bringing all files to top level
+ new_path = Path(f'{str(path)}_flat')
+ if os.path.exists(new_path):
+ shutil.rmtree(new_path) # delete output folder
+ os.makedirs(new_path) # make new output folder
+ for file in tqdm(glob.glob(f'{str(Path(path))}/**/*.*', recursive=True)):
+ shutil.copyfile(file, new_path / Path(file).name)
+
+
+def extract_boxes(path=DATASETS_DIR / 'coco128'): # from utils.dataloaders import *; extract_boxes()
+ # Convert detection dataset into classification dataset, with one directory per class
+ path = Path(path) # images dir
+ shutil.rmtree(path / 'classification') if (path / 'classification').is_dir() else None # remove existing
+ files = list(path.rglob('*.*'))
+ n = len(files) # number of files
+ for im_file in tqdm(files, total=n):
+ if im_file.suffix[1:] in IMG_FORMATS:
+ # image
+ im = cv2.imread(str(im_file))[..., ::-1] # BGR to RGB
+ h, w = im.shape[:2]
+
+ # labels
+ lb_file = Path(img2label_paths([str(im_file)])[0])
+ if Path(lb_file).exists():
+ with open(lb_file) as f:
+ lb = np.array([x.split() for x in f.read().strip().splitlines()], dtype=np.float32) # labels
+
+ for j, x in enumerate(lb):
+ c = int(x[0]) # class
+ f = (path / 'classifier') / f'{c}' / f'{path.stem}_{im_file.stem}_{j}.jpg' # new filename
+ if not f.parent.is_dir():
+ f.parent.mkdir(parents=True)
+
+ b = x[1:] * [w, h, w, h] # box
+ # b[2:] = b[2:].max() # rectangle to square
+ b[2:] = b[2:] * 1.2 + 3 # pad
+ b = xywh2xyxy(b.reshape(-1, 4)).ravel().astype(int)
+
+ b[[0, 2]] = np.clip(b[[0, 2]], 0, w) # clip boxes outside of image
+ b[[1, 3]] = np.clip(b[[1, 3]], 0, h)
+ assert cv2.imwrite(str(f), im[b[1]:b[3], b[0]:b[2]]), f'box failure in {f}'
+
+
+def autosplit(path=DATASETS_DIR / 'coco128/images', weights=(0.9, 0.1, 0.0), annotated_only=False):
+ """ Autosplit a dataset into train/val/test splits and save path/autosplit_*.txt files
+ Usage: from utils.dataloaders import *; autosplit()
+ Arguments
+ path: Path to images directory
+ weights: Train, val, test weights (list, tuple)
+ annotated_only: Only use images with an annotated txt file
+ """
+ path = Path(path) # images dir
+ files = sorted(x for x in path.rglob('*.*') if x.suffix[1:].lower() in IMG_FORMATS) # image files only
+ n = len(files) # number of files
+ random.seed(0) # for reproducibility
+ indices = random.choices([0, 1, 2], weights=weights, k=n) # assign each image to a split
+
+ txt = ['autosplit_train.txt', 'autosplit_val.txt', 'autosplit_test.txt'] # 3 txt files
+ for x in txt:
+ if (path.parent / x).exists():
+ (path.parent / x).unlink() # remove existing
+
+ print(f'Autosplitting images from {path}' + ', using *.txt labeled images only' * annotated_only)
+ for i, img in tqdm(zip(indices, files), total=n):
+ if not annotated_only or Path(img2label_paths([str(img)])[0]).exists(): # check label
+ with open(path.parent / txt[i], 'a') as f:
+ f.write(f'./{img.relative_to(path.parent).as_posix()}' + '\n') # add image to txt file
+
+
+def verify_image_label(args):
+ # Verify one image-label pair
+ im_file, lb_file, prefix = args
+ nm, nf, ne, nc, msg, segments = 0, 0, 0, 0, '', [] # number (missing, found, empty, corrupt), message, segments
+ try:
+ # verify images
+ im = Image.open(im_file)
+ im.verify() # PIL verify
+ shape = exif_size(im) # image size
+ assert (shape[0] > 9) & (shape[1] > 9), f'image size {shape} <10 pixels'
+ assert im.format.lower() in IMG_FORMATS, f'invalid image format {im.format}'
+ if im.format.lower() in ('jpg', 'jpeg'):
+ with open(im_file, 'rb') as f:
+ f.seek(-2, 2)
+ if f.read() != b'\xff\xd9': # corrupt JPEG
+ ImageOps.exif_transpose(Image.open(im_file)).save(im_file, 'JPEG', subsampling=0, quality=100)
+ msg = f'{prefix}WARNING ⚠️ {im_file}: corrupt JPEG restored and saved'
+
+ # verify labels
+ if os.path.isfile(lb_file):
+ nf = 1 # label found
+ with open(lb_file) as f:
+ lb = [x.split() for x in f.read().strip().splitlines() if len(x)]
+ if any(len(x) > 6 for x in lb): # is segment
+ classes = np.array([x[0] for x in lb], dtype=np.float32)
+ segments = [np.array(x[1:], dtype=np.float32).reshape(-1, 2) for x in lb] # (cls, xy1...)
+ lb = np.concatenate((classes.reshape(-1, 1), segments2boxes(segments)), 1) # (cls, xywh)
+ lb = np.array(lb, dtype=np.float32)
+ nl = len(lb)
+ if nl:
+ assert lb.shape[1] == 5, f'labels require 5 columns, {lb.shape[1]} columns detected'
+ assert (lb >= 0).all(), f'negative label values {lb[lb < 0]}'
+ assert (lb[:, 1:] <= 1).all(), f'non-normalized or out of bounds coordinates {lb[:, 1:][lb[:, 1:] > 1]}'
+ _, i = np.unique(lb, axis=0, return_index=True)
+ if len(i) < nl: # duplicate row check
+ lb = lb[i] # remove duplicates
+ if segments:
+ segments = [segments[x] for x in i]
+ msg = f'{prefix}WARNING ⚠️ {im_file}: {nl - len(i)} duplicate labels removed'
+ else:
+ ne = 1 # label empty
+ lb = np.zeros((0, 5), dtype=np.float32)
+ else:
+ nm = 1 # label missing
+ lb = np.zeros((0, 5), dtype=np.float32)
+ return im_file, lb, shape, segments, nm, nf, ne, nc, msg
+ except Exception as e:
+ nc = 1
+ msg = f'{prefix}WARNING ⚠️ {im_file}: ignoring corrupt image/label: {e}'
+ return [None, None, None, None, nm, nf, ne, nc, msg]
+
+
+class HUBDatasetStats():
+ """ Class for generating HUB dataset JSON and `-hub` dataset directory
+
+ Arguments
+ path: Path to data.yaml or data.zip (with data.yaml inside data.zip)
+ autodownload: Attempt to download dataset if not found locally
+
+ Usage
+ from utils.dataloaders import HUBDatasetStats
+ stats = HUBDatasetStats('coco128.yaml', autodownload=True) # usage 1
+ stats = HUBDatasetStats('path/to/coco128.zip') # usage 2
+ stats.get_json(save=False)
+ stats.process_images()
+ """
+
+ def __init__(self, path='coco128.yaml', autodownload=False):
+ # Initialize class
+ zipped, data_dir, yaml_path = self._unzip(Path(path))
+ try:
+ with open(check_yaml(yaml_path), errors='ignore') as f:
+ data = yaml.safe_load(f) # data dict
+ if zipped:
+ data['path'] = data_dir
+ except Exception as e:
+ raise Exception('error/HUB/dataset_stats/yaml_load') from e
+
+ check_dataset(data, autodownload) # download dataset if missing
+ self.hub_dir = Path(data['path'] + '-hub')
+ self.im_dir = self.hub_dir / 'images'
+ self.im_dir.mkdir(parents=True, exist_ok=True) # makes /images
+ self.stats = {'nc': data['nc'], 'names': list(data['names'].values())} # statistics dictionary
+ self.data = data
+
+ @staticmethod
+ def _find_yaml(dir):
+ # Return data.yaml file
+ files = list(dir.glob('*.yaml')) or list(dir.rglob('*.yaml')) # try root level first and then recursive
+ assert files, f'No *.yaml file found in {dir}'
+ if len(files) > 1:
+ files = [f for f in files if f.stem == dir.stem] # prefer *.yaml files that match dir name
+ assert files, f'Multiple *.yaml files found in {dir}, only 1 *.yaml file allowed'
+ assert len(files) == 1, f'Multiple *.yaml files found: {files}, only 1 *.yaml file allowed in {dir}'
+ return files[0]
+
+ def _unzip(self, path):
+ # Unzip data.zip
+ if not str(path).endswith('.zip'): # path is data.yaml
+ return False, None, path
+ assert Path(path).is_file(), f'Error unzipping {path}, file not found'
+ unzip_file(path, path=path.parent)
+ dir = path.with_suffix('') # dataset directory == zip name
+ assert dir.is_dir(), f'Error unzipping {path}, {dir} not found. path/to/abc.zip MUST unzip to path/to/abc/'
+ return True, str(dir), self._find_yaml(dir) # zipped, data_dir, yaml_path
+
+ def _hub_ops(self, f, max_dim=1920):
+ # HUB ops for 1 image 'f': resize and save at reduced quality in /dataset-hub for web/app viewing
+ f_new = self.im_dir / Path(f).name # dataset-hub image filename
+ try: # use PIL
+ im = Image.open(f)
+ r = max_dim / max(im.height, im.width) # ratio
+ if r < 1.0: # image too large
+ im = im.resize((int(im.width * r), int(im.height * r)))
+ im.save(f_new, 'JPEG', quality=50, optimize=True) # save
+ except Exception as e: # use OpenCV
+ LOGGER.info(f'WARNING ⚠️ HUB ops PIL failure {f}: {e}')
+ im = cv2.imread(f)
+ im_height, im_width = im.shape[:2]
+ r = max_dim / max(im_height, im_width) # ratio
+ if r < 1.0: # image too large
+ im = cv2.resize(im, (int(im_width * r), int(im_height * r)), interpolation=cv2.INTER_AREA)
+ cv2.imwrite(str(f_new), im)
+
+ def get_json(self, save=False, verbose=False):
+ # Return dataset JSON for Ultralytics HUB
+ def _round(labels):
+ # Update labels to integer class and 6 decimal place floats
+ return [[int(c), *(round(x, 4) for x in points)] for c, *points in labels]
+
+ for split in 'train', 'val', 'test':
+ if self.data.get(split) is None:
+ self.stats[split] = None # i.e. no test set
+ continue
+ dataset = LoadImagesAndLabels(self.data[split]) # load dataset
+ x = np.array([
+ np.bincount(label[:, 0].astype(int), minlength=self.data['nc'])
+ for label in tqdm(dataset.labels, total=dataset.n, desc='Statistics')]) # shape(128x80)
+ self.stats[split] = {
+ 'instance_stats': {
+ 'total': int(x.sum()),
+ 'per_class': x.sum(0).tolist()},
+ 'image_stats': {
+ 'total': dataset.n,
+ 'unlabelled': int(np.all(x == 0, 1).sum()),
+ 'per_class': (x > 0).sum(0).tolist()},
+ 'labels': [{
+ str(Path(k).name): _round(v.tolist())} for k, v in zip(dataset.im_files, dataset.labels)]}
+
+ # Save, print and return
+ if save:
+ stats_path = self.hub_dir / 'stats.json'
+ print(f'Saving {stats_path.resolve()}...')
+ with open(stats_path, 'w') as f:
+ json.dump(self.stats, f) # save stats.json
+ if verbose:
+ print(json.dumps(self.stats, indent=2, sort_keys=False))
+ return self.stats
+
+ def process_images(self):
+ # Compress images for Ultralytics HUB
+ for split in 'train', 'val', 'test':
+ if self.data.get(split) is None:
+ continue
+ dataset = LoadImagesAndLabels(self.data[split]) # load dataset
+ desc = f'{split} images'
+ for _ in tqdm(ThreadPool(NUM_THREADS).imap(self._hub_ops, dataset.im_files), total=dataset.n, desc=desc):
+ pass
+ print(f'Done. All images saved to {self.im_dir}')
+ return self.im_dir
+
+
+# Classification dataloaders -------------------------------------------------------------------------------------------
+class ClassificationDataset(torchvision.datasets.ImageFolder):
+ """
+ YOLOv5 Classification Dataset.
+ Arguments
+ root: Dataset path
+ transform: torchvision transforms, used by default
+ album_transform: Albumentations transforms, used if installed
+ """
+
+ def __init__(self, root, augment, imgsz, cache=False):
+ super().__init__(root=root)
+ self.torch_transforms = classify_transforms(imgsz)
+ self.album_transforms = classify_albumentations(augment, imgsz) if augment else None
+ self.cache_ram = cache is True or cache == 'ram'
+ self.cache_disk = cache == 'disk'
+ self.samples = [list(x) + [Path(x[0]).with_suffix('.npy'), None] for x in self.samples] # file, index, npy, im
+
+ def __getitem__(self, i):
+ f, j, fn, im = self.samples[i] # filename, index, filename.with_suffix('.npy'), image
+ if self.cache_ram and im is None:
+ im = self.samples[i][3] = cv2.imread(f)
+ elif self.cache_disk:
+ if not fn.exists(): # load npy
+ np.save(fn.as_posix(), cv2.imread(f))
+ im = np.load(fn)
+ else: # read image
+ im = cv2.imread(f) # BGR
+ if self.album_transforms:
+ sample = self.album_transforms(image=cv2.cvtColor(im, cv2.COLOR_BGR2RGB))['image']
+ else:
+ sample = self.torch_transforms(im)
+ return sample, j
+
+
+def create_classification_dataloader(path,
+ imgsz=224,
+ batch_size=16,
+ augment=True,
+ cache=False,
+ rank=-1,
+ workers=8,
+ shuffle=True):
+ # Returns Dataloader object to be used with YOLOv5 Classifier
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = ClassificationDataset(root=path, imgsz=imgsz, augment=augment, cache=cache)
+ batch_size = min(batch_size, len(dataset))
+ nd = torch.cuda.device_count()
+ nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers])
+ sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
+ generator = torch.Generator()
+ generator.manual_seed(6148914691236517205 + RANK)
+ return InfiniteDataLoader(dataset,
+ batch_size=batch_size,
+ shuffle=shuffle and sampler is None,
+ num_workers=nw,
+ sampler=sampler,
+ pin_memory=PIN_MEMORY,
+ worker_init_fn=seed_worker,
+ generator=generator) # or DataLoader(persistent_workers=True)
diff --git a/yolov5/utils/docker/Dockerfile b/yolov5/utils/docker/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..ff657dea2bf23ae4221f31a2c52453c4ee966f34
--- /dev/null
+++ b/yolov5/utils/docker/Dockerfile
@@ -0,0 +1,74 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Builds ultralytics/yolov5:latest image on DockerHub https://hub.docker.com/r/ultralytics/yolov5
+# Image is CUDA-optimized for YOLOv5 single/multi-GPU training and inference
+
+# Start FROM PyTorch image https://hub.docker.com/r/pytorch/pytorch
+FROM pytorch/pytorch:2.0.0-cuda11.7-cudnn8-runtime
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+ENV DEBIAN_FRONTEND noninteractive
+RUN apt update
+RUN TZ=Etc/UTC apt install -y tzdata
+RUN apt install --no-install-recommends -y gcc git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg
+# RUN alias python=python3
+
+# Security updates
+# https://security.snyk.io/vuln/SNYK-UBUNTU1804-OPENSSL-3314796
+RUN apt upgrade --no-install-recommends -y openssl
+
+# Create working directory
+RUN rm -rf /usr/src/app && mkdir -p /usr/src/app
+WORKDIR /usr/src/app
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
+
+# Install pip packages
+COPY requirements.txt .
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache -r requirements.txt albumentations comet gsutil notebook \
+ coremltools onnx onnx-simplifier onnxruntime 'openvino-dev>=2022.3'
+ # tensorflow tensorflowjs \
+
+# Set environment variables
+ENV OMP_NUM_THREADS=1
+
+# Cleanup
+ENV DEBIAN_FRONTEND teletype
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/yolov5:latest && sudo docker build -f utils/docker/Dockerfile -t $t . && sudo docker push $t
+
+# Pull and Run
+# t=ultralytics/yolov5:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all $t
+
+# Pull and Run with local directory access
+# t=ultralytics/yolov5:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v "$(pwd)"/datasets:/usr/src/datasets $t
+
+# Kill all
+# sudo docker kill $(sudo docker ps -q)
+
+# Kill all image-based
+# sudo docker kill $(sudo docker ps -qa --filter ancestor=ultralytics/yolov5:latest)
+
+# DockerHub tag update
+# t=ultralytics/yolov5:latest tnew=ultralytics/yolov5:v6.2 && sudo docker pull $t && sudo docker tag $t $tnew && sudo docker push $tnew
+
+# Clean up
+# sudo docker system prune -a --volumes
+
+# Update Ubuntu drivers
+# https://www.maketecheasier.com/install-nvidia-drivers-ubuntu/
+
+# DDP test
+# python -m torch.distributed.run --nproc_per_node 2 --master_port 1 train.py --epochs 3
+
+# GCP VM from Image
+# docker.io/ultralytics/yolov5:latest
diff --git a/yolov5/utils/docker/Dockerfile-arm64 b/yolov5/utils/docker/Dockerfile-arm64
new file mode 100644
index 0000000000000000000000000000000000000000..7b5c610e5071b2aa712b7e521c39145c11016773
--- /dev/null
+++ b/yolov5/utils/docker/Dockerfile-arm64
@@ -0,0 +1,41 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Builds ultralytics/yolov5:latest-arm64 image on DockerHub https://hub.docker.com/r/ultralytics/yolov5
+# Image is aarch64-compatible for Apple M1 and other ARM architectures i.e. Jetson Nano and Raspberry Pi
+
+# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
+FROM arm64v8/ubuntu:22.10
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+ENV DEBIAN_FRONTEND noninteractive
+RUN apt update
+RUN TZ=Etc/UTC apt install -y tzdata
+RUN apt install --no-install-recommends -y python3-pip git zip curl htop gcc libgl1-mesa-glx libglib2.0-0 libpython3-dev
+# RUN alias python=python3
+
+# Install pip packages
+COPY requirements.txt .
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache -r requirements.txt albumentations gsutil notebook \
+ coremltools onnx onnxruntime
+ # tensorflow-aarch64 tensorflowjs \
+
+# Create working directory
+RUN mkdir -p /usr/src/app
+WORKDIR /usr/src/app
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
+ENV DEBIAN_FRONTEND teletype
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/yolov5:latest-arm64 && sudo docker build --platform linux/arm64 -f utils/docker/Dockerfile-arm64 -t $t . && sudo docker push $t
+
+# Pull and Run
+# t=ultralytics/yolov5:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
diff --git a/yolov5/utils/docker/Dockerfile-cpu b/yolov5/utils/docker/Dockerfile-cpu
new file mode 100644
index 0000000000000000000000000000000000000000..613bdffa47685c19428f92fe33c1c9958ff917aa
--- /dev/null
+++ b/yolov5/utils/docker/Dockerfile-cpu
@@ -0,0 +1,42 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+# Builds ultralytics/yolov5:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/yolov5
+# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv5 deployments
+
+# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
+FROM ubuntu:22.10
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+ENV DEBIAN_FRONTEND noninteractive
+RUN apt update
+RUN TZ=Etc/UTC apt install -y tzdata
+RUN apt install --no-install-recommends -y python3-pip git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg
+# RUN alias python=python3
+
+# Install pip packages
+COPY requirements.txt .
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache -r requirements.txt albumentations gsutil notebook \
+ coremltools onnx onnx-simplifier onnxruntime 'openvino-dev>=2022.3' \
+ # tensorflow tensorflowjs \
+ --extra-index-url https://download.pytorch.org/whl/cpu
+
+# Create working directory
+RUN mkdir -p /usr/src/app
+WORKDIR /usr/src/app
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
+ENV DEBIAN_FRONTEND teletype
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/yolov5:latest-cpu && sudo docker build -f utils/docker/Dockerfile-cpu -t $t . && sudo docker push $t
+
+# Pull and Run
+# t=ultralytics/yolov5:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
diff --git a/yolov5/utils/downloads.py b/yolov5/utils/downloads.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef51853f3f13c5497707d501d65a6b5c5ab8699d
--- /dev/null
+++ b/yolov5/utils/downloads.py
@@ -0,0 +1,128 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Download utils
+"""
+
+import logging
+import os
+import subprocess
+import urllib
+from pathlib import Path
+
+import requests
+import torch
+
+
+def is_url(url, check=True):
+ # Check if string is URL and check if URL exists
+ try:
+ url = str(url)
+ result = urllib.parse.urlparse(url)
+ assert all([result.scheme, result.netloc]) # check if is url
+ return (urllib.request.urlopen(url).getcode() == 200) if check else True # check if exists online
+ except (AssertionError, urllib.request.HTTPError):
+ return False
+
+
+def gsutil_getsize(url=''):
+ # gs://bucket/file size https://cloud.google.com/storage/docs/gsutil/commands/du
+ output = subprocess.check_output(['gsutil', 'du', url], shell=True, encoding='utf-8')
+ if output:
+ return int(output.split()[0])
+ return 0
+
+
+def url_getsize(url='https://ultralytics.com/images/bus.jpg'):
+ # Return downloadable file size in bytes
+ response = requests.head(url, allow_redirects=True)
+ return int(response.headers.get('content-length', -1))
+
+
+def curl_download(url, filename, *, silent: bool = False) -> bool:
+ """
+ Download a file from a url to a filename using curl.
+ """
+ silent_option = 'sS' if silent else '' # silent
+ proc = subprocess.run([
+ 'curl',
+ '-#',
+ f'-{silent_option}L',
+ url,
+ '--output',
+ filename,
+ '--retry',
+ '9',
+ '-C',
+ '-',])
+ return proc.returncode == 0
+
+
+def safe_download(file, url, url2=None, min_bytes=1E0, error_msg=''):
+ # Attempts to download file from url or url2, checks and removes incomplete downloads < min_bytes
+ from yolov5.utils.general import LOGGER
+
+ file = Path(file)
+ assert_msg = f"Downloaded file '{file}' does not exist or size is < min_bytes={min_bytes}"
+ try: # url1
+ LOGGER.info(f'Downloading {url} to {file}...')
+ torch.hub.download_url_to_file(url, str(file), progress=LOGGER.level <= logging.INFO)
+ assert file.exists() and file.stat().st_size > min_bytes, assert_msg # check
+ except Exception as e: # url2
+ if file.exists():
+ file.unlink() # remove partial downloads
+ LOGGER.info(f'ERROR: {e}\nRe-attempting {url2 or url} to {file}...')
+ # curl download, retry and resume on fail
+ curl_download(url2 or url, file)
+ finally:
+ if not file.exists() or file.stat().st_size < min_bytes: # check
+ if file.exists():
+ file.unlink() # remove partial downloads
+ LOGGER.info(f'ERROR: {assert_msg}\n{error_msg}')
+ LOGGER.info('')
+
+
+def attempt_download(file, repo='ultralytics/yolov5', release='v7.0'):
+ # Attempt file download from GitHub release assets if not found locally. release = 'latest', 'v7.0', etc.
+ from yolov5.utils.general import LOGGER
+
+ def github_assets(repository, version='latest'):
+ # Return GitHub repo tag (i.e. 'v7.0') and assets (i.e. ['yolov5s.pt', 'yolov5m.pt', ...])
+ if version != 'latest':
+ version = f'tags/{version}' # i.e. tags/v7.0
+ response = requests.get(f'https://api.github.com/repos/{repository}/releases/{version}').json() # github api
+ return response['tag_name'], [x['name'] for x in response['assets']] # tag, assets
+
+ file = Path(str(file).strip().replace("'", ''))
+ if not file.exists():
+ # URL specified
+ name = Path(urllib.parse.unquote(str(file))).name # decode '%2F' to '/' etc.
+ if str(file).startswith(('http:/', 'https:/')): # download
+ url = str(file).replace(':/', '://') # Pathlib turns :// -> :/
+ file = name.split('?')[0] # parse authentication https://url.com/file.txt?auth...
+ if Path(file).is_file():
+ LOGGER.info(f'Found {url} locally at {file}') # file already exists
+ else:
+ safe_download(file=file, url=url, min_bytes=1E5)
+ return file
+
+ # GitHub assets
+ assets = [f'yolov5{size}{suffix}.pt' for size in 'nsmlx' for suffix in ('', '6', '-cls', '-seg')] # default
+ try:
+ tag, assets = github_assets(repo, release)
+ except Exception:
+ try:
+ tag, assets = github_assets(repo) # latest release
+ except Exception:
+ try:
+ tag = subprocess.check_output('git tag', shell=True, stderr=subprocess.STDOUT).decode().split()[-1]
+ except Exception:
+ tag = release
+
+ if name in assets:
+ file.parent.mkdir(parents=True, exist_ok=True) # make parent dir (if required)
+ safe_download(file,
+ url=f'https://github.com/{repo}/releases/download/{tag}/{name}',
+ min_bytes=1E5,
+ error_msg=f'{file} missing, try downloading from https://github.com/{repo}/releases/{tag}')
+
+ return str(file)
diff --git a/yolov5/utils/flask_rest_api/README.md b/yolov5/utils/flask_rest_api/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a726acbd92043458311dd949cc09c0195cd35400
--- /dev/null
+++ b/yolov5/utils/flask_rest_api/README.md
@@ -0,0 +1,73 @@
+# Flask REST API
+
+[REST](https://en.wikipedia.org/wiki/Representational_state_transfer) [API](https://en.wikipedia.org/wiki/API)s are
+commonly used to expose Machine Learning (ML) models to other services. This folder contains an example REST API
+created using Flask to expose the YOLOv5s model from [PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5/).
+
+## Requirements
+
+[Flask](https://palletsprojects.com/p/flask/) is required. Install with:
+
+```shell
+$ pip install Flask
+```
+
+## Run
+
+After Flask installation run:
+
+```shell
+$ python3 restapi.py --port 5000
+```
+
+Then use [curl](https://curl.se/) to perform a request:
+
+```shell
+$ curl -X POST -F image=@zidane.jpg 'http://localhost:5000/v1/object-detection/yolov5s'
+```
+
+The model inference results are returned as a JSON response:
+
+```json
+[
+ {
+ "class": 0,
+ "confidence": 0.8900438547,
+ "height": 0.9318675399,
+ "name": "person",
+ "width": 0.3264600933,
+ "xcenter": 0.7438579798,
+ "ycenter": 0.5207948685
+ },
+ {
+ "class": 0,
+ "confidence": 0.8440024257,
+ "height": 0.7155083418,
+ "name": "person",
+ "width": 0.6546785235,
+ "xcenter": 0.427829951,
+ "ycenter": 0.6334488392
+ },
+ {
+ "class": 27,
+ "confidence": 0.3771208823,
+ "height": 0.3902671337,
+ "name": "tie",
+ "width": 0.0696444362,
+ "xcenter": 0.3675483763,
+ "ycenter": 0.7991207838
+ },
+ {
+ "class": 27,
+ "confidence": 0.3527112305,
+ "height": 0.1540903747,
+ "name": "tie",
+ "width": 0.0336618312,
+ "xcenter": 0.7814827561,
+ "ycenter": 0.5065554976
+ }
+]
+```
+
+An example python script to perform inference using [requests](https://docs.python-requests.org/en/master/) is given
+in `example_request.py`
diff --git a/yolov5/utils/flask_rest_api/example_request.py b/yolov5/utils/flask_rest_api/example_request.py
new file mode 100644
index 0000000000000000000000000000000000000000..256ad1319c82abf941a50f2d690a4ec1244616bd
--- /dev/null
+++ b/yolov5/utils/flask_rest_api/example_request.py
@@ -0,0 +1,19 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Perform test request
+"""
+
+import pprint
+
+import requests
+
+DETECTION_URL = 'http://localhost:5000/v1/object-detection/yolov5s'
+IMAGE = 'zidane.jpg'
+
+# Read image
+with open(IMAGE, 'rb') as f:
+ image_data = f.read()
+
+response = requests.post(DETECTION_URL, files={'image': image_data}).json()
+
+pprint.pprint(response)
diff --git a/yolov5/utils/flask_rest_api/restapi.py b/yolov5/utils/flask_rest_api/restapi.py
new file mode 100644
index 0000000000000000000000000000000000000000..ae4756b276e4b5d4215d29ee1761e520adc05f54
--- /dev/null
+++ b/yolov5/utils/flask_rest_api/restapi.py
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Run a Flask REST API exposing one or more YOLOv5s models
+"""
+
+import argparse
+import io
+
+import torch
+from flask import Flask, request
+from PIL import Image
+
+app = Flask(__name__)
+models = {}
+
+DETECTION_URL = '/v1/object-detection/'
+
+
+@app.route(DETECTION_URL, methods=['POST'])
+def predict(model):
+ if request.method != 'POST':
+ return
+
+ if request.files.get('image'):
+ # Method 1
+ # with request.files["image"] as f:
+ # im = Image.open(io.BytesIO(f.read()))
+
+ # Method 2
+ im_file = request.files['image']
+ im_bytes = im_file.read()
+ im = Image.open(io.BytesIO(im_bytes))
+
+ if model in models:
+ results = models[model](im, size=640) # reduce size=320 for faster inference
+ return results.pandas().xyxy[0].to_json(orient='records')
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Flask API exposing YOLOv5 model')
+ parser.add_argument('--port', default=5000, type=int, help='port number')
+ parser.add_argument('--model', nargs='+', default=['yolov5s'], help='model(s) to run, i.e. --model yolov5n yolov5s')
+ opt = parser.parse_args()
+
+ for m in opt.model:
+ models[m] = torch.hub.load('ultralytics/yolov5', m, force_reload=True, skip_validation=True)
+
+ app.run(host='0.0.0.0', port=opt.port) # debug=True causes Restarting with stat
diff --git a/yolov5/utils/general.py b/yolov5/utils/general.py
new file mode 100644
index 0000000000000000000000000000000000000000..6315b211bb607242a38f66624d5cc3692a68d71b
--- /dev/null
+++ b/yolov5/utils/general.py
@@ -0,0 +1,1158 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+General utils
+"""
+
+import contextlib
+import glob
+import inspect
+import logging
+import logging.config
+import math
+import os
+import platform
+import random
+import re
+import signal
+import subprocess
+import sys
+import time
+import urllib
+from copy import deepcopy
+from datetime import datetime
+from itertools import repeat
+from multiprocessing.pool import ThreadPool
+from pathlib import Path
+from subprocess import check_output
+from tarfile import is_tarfile
+from typing import Optional
+from zipfile import ZipFile, is_zipfile
+
+import cv2
+import numpy as np
+import pandas as pd
+import pkg_resources as pkg
+import torch
+import torchvision
+import yaml
+
+from yolov5.utils import TryExcept, emojis
+from yolov5.utils.downloads import curl_download, gsutil_getsize
+from yolov5.utils.metrics import box_iou, fitness
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+RANK = int(os.getenv('RANK', -1))
+
+# Settings
+NUM_THREADS = min(8, max(1, os.cpu_count() - 1)) # number of YOLOv5 multiprocessing threads
+DATASETS_DIR = Path(os.getenv('YOLOv5_DATASETS_DIR', ROOT.parent / 'datasets')) # global datasets directory
+AUTOINSTALL = str(os.getenv('YOLOv5_AUTOINSTALL', True)).lower() == 'true' # global auto-install mode
+VERBOSE = str(os.getenv('YOLOv5_VERBOSE', True)).lower() == 'true' # global verbose mode
+TQDM_BAR_FORMAT = '{l_bar}{bar:10}{r_bar}' # tqdm bar format
+FONT = 'Arial.ttf' # https://ultralytics.com/assets/Arial.ttf
+
+torch.set_printoptions(linewidth=320, precision=5, profile='long')
+np.set_printoptions(linewidth=320, formatter={'float_kind': '{:11.5g}'.format}) # format short g, %precision=5
+pd.options.display.max_columns = 10
+cv2.setNumThreads(0) # prevent OpenCV from multithreading (incompatible with PyTorch DataLoader)
+os.environ['NUMEXPR_MAX_THREADS'] = str(NUM_THREADS) # NumExpr max threads
+os.environ['OMP_NUM_THREADS'] = '1' if platform.system() == 'darwin' else str(NUM_THREADS) # OpenMP (PyTorch and SciPy)
+os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # suppress verbose TF compiler warnings in Colab
+
+
+def is_ascii(s=''):
+ # Is string composed of all ASCII (no UTF) characters? (note str().isascii() introduced in python 3.7)
+ s = str(s) # convert list, tuple, None, etc. to str
+ return len(s.encode().decode('ascii', 'ignore')) == len(s)
+
+
+def is_chinese(s='人工智能'):
+ # Is string composed of any Chinese characters?
+ return bool(re.search('[\u4e00-\u9fff]', str(s)))
+
+
+def is_colab():
+ # Is environment a Google Colab instance?
+ return 'google.colab' in sys.modules
+
+
+def is_jupyter():
+ """
+ Check if the current script is running inside a Jupyter Notebook.
+ Verified on Colab, Jupyterlab, Kaggle, Paperspace.
+
+ Returns:
+ bool: True if running inside a Jupyter Notebook, False otherwise.
+ """
+ with contextlib.suppress(Exception):
+ from IPython import get_ipython
+ return get_ipython() is not None
+ return False
+
+
+def is_kaggle():
+ # Is environment a Kaggle Notebook?
+ return os.environ.get('PWD') == '/kaggle/working' and os.environ.get('KAGGLE_URL_BASE') == 'https://www.kaggle.com'
+
+
+def is_docker() -> bool:
+ """Check if the process runs inside a docker container."""
+ if Path('/.dockerenv').exists():
+ return True
+ try: # check if docker is in control groups
+ with open('/proc/self/cgroup') as file:
+ return any('docker' in line for line in file)
+ except OSError:
+ return False
+
+
+def is_writeable(dir, test=False):
+ # Return True if directory has write permissions, test opening a file with write permissions if test=True
+ if not test:
+ return os.access(dir, os.W_OK) # possible issues on Windows
+ file = Path(dir) / 'tmp.txt'
+ try:
+ with open(file, 'w'): # open file with write permissions
+ pass
+ file.unlink() # remove file
+ return True
+ except OSError:
+ return False
+
+
+LOGGING_NAME = 'yolov5'
+
+
+def set_logging(name=LOGGING_NAME, verbose=True):
+ # sets up logging for the given name
+ rank = int(os.getenv('RANK', -1)) # rank in world for Multi-GPU trainings
+ level = logging.INFO if verbose and rank in {-1, 0} else logging.ERROR
+ logging.config.dictConfig({
+ 'version': 1,
+ 'disable_existing_loggers': False,
+ 'formatters': {
+ name: {
+ 'format': '%(message)s'}},
+ 'handlers': {
+ name: {
+ 'class': 'logging.StreamHandler',
+ 'formatter': name,
+ 'level': level,}},
+ 'loggers': {
+ name: {
+ 'level': level,
+ 'handlers': [name],
+ 'propagate': False,}}})
+
+
+set_logging(LOGGING_NAME) # run before defining LOGGER
+LOGGER = logging.getLogger(LOGGING_NAME) # define globally (used in train.py, val.py, detect.py, etc.)
+if platform.system() == 'Windows':
+ for fn in LOGGER.info, LOGGER.warning:
+ setattr(LOGGER, fn.__name__, lambda x: fn(emojis(x))) # emoji safe logging
+
+
+def user_config_dir(dir='Ultralytics', env_var='YOLOV5_CONFIG_DIR'):
+ # Return path of user configuration directory. Prefer environment variable if exists. Make dir if required.
+ env = os.getenv(env_var)
+ if env:
+ path = Path(env) # use environment variable
+ else:
+ cfg = {'Windows': 'AppData/Roaming', 'Linux': '.config', 'Darwin': 'Library/Application Support'} # 3 OS dirs
+ path = Path.home() / cfg.get(platform.system(), '') # OS-specific config dir
+ path = (path if is_writeable(path) else Path('/tmp')) / dir # GCP and AWS lambda fix, only /tmp is writeable
+ path.mkdir(exist_ok=True) # make if required
+ return path
+
+
+CONFIG_DIR = user_config_dir() # Ultralytics settings dir
+
+
+class Profile(contextlib.ContextDecorator):
+ # YOLOv5 Profile class. Usage: @Profile() decorator or 'with Profile():' context manager
+ def __init__(self, t=0.0):
+ self.t = t
+ self.cuda = torch.cuda.is_available()
+
+ def __enter__(self):
+ self.start = self.time()
+ return self
+
+ def __exit__(self, type, value, traceback):
+ self.dt = self.time() - self.start # delta-time
+ self.t += self.dt # accumulate dt
+
+ def time(self):
+ if self.cuda:
+ torch.cuda.synchronize()
+ return time.time()
+
+
+class Timeout(contextlib.ContextDecorator):
+ # YOLOv5 Timeout class. Usage: @Timeout(seconds) decorator or 'with Timeout(seconds):' context manager
+ def __init__(self, seconds, *, timeout_msg='', suppress_timeout_errors=True):
+ self.seconds = int(seconds)
+ self.timeout_message = timeout_msg
+ self.suppress = bool(suppress_timeout_errors)
+
+ def _timeout_handler(self, signum, frame):
+ raise TimeoutError(self.timeout_message)
+
+ def __enter__(self):
+ if platform.system() != 'Windows': # not supported on Windows
+ signal.signal(signal.SIGALRM, self._timeout_handler) # Set handler for SIGALRM
+ signal.alarm(self.seconds) # start countdown for SIGALRM to be raised
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ if platform.system() != 'Windows':
+ signal.alarm(0) # Cancel SIGALRM if it's scheduled
+ if self.suppress and exc_type is TimeoutError: # Suppress TimeoutError
+ return True
+
+
+class WorkingDirectory(contextlib.ContextDecorator):
+ # Usage: @WorkingDirectory(dir) decorator or 'with WorkingDirectory(dir):' context manager
+ def __init__(self, new_dir):
+ self.dir = new_dir # new dir
+ self.cwd = Path.cwd().resolve() # current dir
+
+ def __enter__(self):
+ os.chdir(self.dir)
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ os.chdir(self.cwd)
+
+
+def methods(instance):
+ # Get class/instance methods
+ return [f for f in dir(instance) if callable(getattr(instance, f)) and not f.startswith('__')]
+
+
+def print_args(args: Optional[dict] = None, show_file=True, show_func=False):
+ # Print function arguments (optional args dict)
+ x = inspect.currentframe().f_back # previous frame
+ file, _, func, _, _ = inspect.getframeinfo(x)
+ if args is None: # get args automatically
+ args, _, _, frm = inspect.getargvalues(x)
+ args = {k: v for k, v in frm.items() if k in args}
+ try:
+ file = Path(file).resolve().relative_to(ROOT).with_suffix('')
+ except ValueError:
+ file = Path(file).stem
+ s = (f'{file}: ' if show_file else '') + (f'{func}: ' if show_func else '')
+ LOGGER.info(colorstr(s) + ', '.join(f'{k}={v}' for k, v in args.items()))
+
+
+def init_seeds(seed=0, deterministic=False):
+ # Initialize random number generator (RNG) seeds https://pytorch.org/docs/stable/notes/randomness.html
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed) # for Multi-GPU, exception safe
+ # torch.backends.cudnn.benchmark = True # AutoBatch problem https://github.com/ultralytics/yolov5/issues/9287
+ if deterministic and check_version(torch.__version__, '1.12.0'): # https://github.com/ultralytics/yolov5/pull/8213
+ torch.use_deterministic_algorithms(True)
+ torch.backends.cudnn.deterministic = True
+ os.environ['CUBLAS_WORKSPACE_CONFIG'] = ':4096:8'
+ os.environ['PYTHONHASHSEED'] = str(seed)
+
+
+def intersect_dicts(da, db, exclude=()):
+ # Dictionary intersection of matching keys and shapes, omitting 'exclude' keys, using da values
+ return {k: v for k, v in da.items() if k in db and all(x not in k for x in exclude) and v.shape == db[k].shape}
+
+
+def get_default_args(func):
+ # Get func() default arguments
+ signature = inspect.signature(func)
+ return {k: v.default for k, v in signature.parameters.items() if v.default is not inspect.Parameter.empty}
+
+
+def get_latest_run(search_dir='.'):
+ # Return path to most recent 'last.pt' in /runs (i.e. to --resume from)
+ last_list = glob.glob(f'{search_dir}/**/last*.pt', recursive=True)
+ return max(last_list, key=os.path.getctime) if last_list else ''
+
+
+def file_age(path=__file__):
+ # Return days since last file update
+ dt = (datetime.now() - datetime.fromtimestamp(Path(path).stat().st_mtime)) # delta
+ return dt.days # + dt.seconds / 86400 # fractional days
+
+
+def file_date(path=__file__):
+ # Return human-readable file modification date, i.e. '2021-3-26'
+ t = datetime.fromtimestamp(Path(path).stat().st_mtime)
+ return f'{t.year}-{t.month}-{t.day}'
+
+
+def file_size(path):
+ # Return file/dir size (MB)
+ mb = 1 << 20 # bytes to MiB (1024 ** 2)
+ path = Path(path)
+ if path.is_file():
+ return path.stat().st_size / mb
+ elif path.is_dir():
+ return sum(f.stat().st_size for f in path.glob('**/*') if f.is_file()) / mb
+ else:
+ return 0.0
+
+
+def check_online():
+ # Check internet connectivity
+ import socket
+
+ def run_once():
+ # Check once
+ try:
+ socket.create_connection(('1.1.1.1', 443), 5) # check host accessibility
+ return True
+ except OSError:
+ return False
+
+ return run_once() or run_once() # check twice to increase robustness to intermittent connectivity issues
+
+
+def git_describe(path=ROOT): # path must be a directory
+ # Return human-readable git description, i.e. v5.0-5-g3e25f1e https://git-scm.com/docs/git-describe
+ try:
+ assert (Path(path) / '.git').is_dir()
+ return check_output(f'git -C {path} describe --tags --long --always', shell=True).decode()[:-1]
+ except Exception:
+ return ''
+
+
+@TryExcept()
+@WorkingDirectory(ROOT)
+def check_git_status(repo='ultralytics/yolov5', branch='master'):
+ # YOLOv5 status check, recommend 'git pull' if code is out of date
+ url = f'https://github.com/{repo}'
+ msg = f', for updates see {url}'
+ s = colorstr('github: ') # string
+ assert Path('.git').exists(), s + 'skipping check (not a git repository)' + msg
+ assert check_online(), s + 'skipping check (offline)' + msg
+
+ splits = re.split(pattern=r'\s', string=check_output('git remote -v', shell=True).decode())
+ matches = [repo in s for s in splits]
+ if any(matches):
+ remote = splits[matches.index(True) - 1]
+ else:
+ remote = 'ultralytics'
+ check_output(f'git remote add {remote} {url}', shell=True)
+ check_output(f'git fetch {remote}', shell=True, timeout=5) # git fetch
+ local_branch = check_output('git rev-parse --abbrev-ref HEAD', shell=True).decode().strip() # checked out
+ n = int(check_output(f'git rev-list {local_branch}..{remote}/{branch} --count', shell=True)) # commits behind
+ if n > 0:
+ pull = 'git pull' if remote == 'origin' else f'git pull {remote} {branch}'
+ s += f"⚠️ YOLOv5 is out of date by {n} commit{'s' * (n > 1)}. Use '{pull}' or 'git clone {url}' to update."
+ else:
+ s += f'up to date with {url} ✅'
+ LOGGER.info(s)
+
+
+@WorkingDirectory(ROOT)
+def check_git_info(path='.'):
+ # YOLOv5 git info check, return {remote, branch, commit}
+ check_requirements('gitpython')
+ import git
+ try:
+ repo = git.Repo(path)
+ remote = repo.remotes.origin.url.replace('.git', '') # i.e. 'https://github.com/ultralytics/yolov5'
+ commit = repo.head.commit.hexsha # i.e. '3134699c73af83aac2a481435550b968d5792c0d'
+ try:
+ branch = repo.active_branch.name # i.e. 'main'
+ except TypeError: # not on any branch
+ branch = None # i.e. 'detached HEAD' state
+ return {'remote': remote, 'branch': branch, 'commit': commit}
+ except git.exc.InvalidGitRepositoryError: # path is not a git dir
+ return {'remote': None, 'branch': None, 'commit': None}
+
+
+def check_python(minimum='3.7.0'):
+ # Check current python version vs. required python version
+ check_version(platform.python_version(), minimum, name='Python ', hard=True)
+
+
+def check_version(current='0.0.0', minimum='0.0.0', name='version ', pinned=False, hard=False, verbose=False):
+ # Check version vs. required version
+ current, minimum = (pkg.parse_version(x) for x in (current, minimum))
+ result = (current == minimum) if pinned else (current >= minimum) # bool
+ s = f'WARNING ⚠️ {name}{minimum} is required by YOLOv5, but {name}{current} is currently installed' # string
+ if hard:
+ assert result, emojis(s) # assert min requirements met
+ if verbose and not result:
+ LOGGER.warning(s)
+ return result
+
+
+@TryExcept()
+def check_requirements(requirements=ROOT.parent / 'requirements.txt', exclude=(), install=True, cmds=''):
+ """
+ Check if installed dependencies meet YOLOv5 requirements and attempt to auto-update if needed.
+
+ Args:
+ requirements (Union[Path, str, List[str]]): Path to a requirements.txt file, a single package requirement as a
+ string, or a list of package requirements as strings.
+ exclude (Tuple[str]): Tuple of package names to exclude from checking.
+ install (bool): If True, attempt to auto-update packages that don't meet requirements.
+ cmds (str): Additional commands to pass to the pip install command when auto-updating.
+
+ Returns:
+ None
+ """
+ prefix = colorstr('red', 'bold', 'requirements:')
+ check_python() # check python version
+ file = None
+ if isinstance(requirements, Path): # requirements.txt file
+ file = requirements.resolve()
+ assert file.exists(), f'{prefix} {file} not found, check failed.'
+ with file.open() as f:
+ requirements = [f'{x.name}{x.specifier}' for x in pkg.parse_requirements(f) if x.name not in exclude]
+ elif isinstance(requirements, str):
+ requirements = [requirements]
+
+ s = '' # console string
+ n = 0 # number of packages updates
+ for r in requirements:
+ try:
+ pkg.require(r)
+ except (pkg.VersionConflict, pkg.DistributionNotFound): # exception if requirements not met
+ try: # attempt to import (slower but more accurate)
+ import importlib
+ importlib.import_module(next(pkg.parse_requirements(r)).name)
+ except ImportError:
+ s += f'"{r}" '
+ n += 1
+
+ if s and install and AUTOINSTALL: # check environment variable
+ LOGGER.info(f"{prefix} YOLOv5 requirement{'s' * (n > 1)} {s}not found, attempting AutoUpdate...")
+ try:
+ assert check_online(), 'AutoUpdate skipped (offline)'
+ LOGGER.info(subprocess.check_output(f'pip install {s} {cmds}', shell=True).decode())
+ s = f"{prefix} {n} package{'s' * (n > 1)} updated per {file or requirements}\n" \
+ f"{prefix} ⚠️ {colorstr('bold', 'Restart runtime or rerun command for updates to take effect')}\n"
+ LOGGER.info(s)
+ except Exception as e:
+ LOGGER.warning(f'{prefix} ❌ {e}')
+
+
+def check_img_size(imgsz, s=32, floor=0):
+ # Verify image size is a multiple of stride s in each dimension
+ if isinstance(imgsz, int): # integer i.e. img_size=640
+ new_size = max(make_divisible(imgsz, int(s)), floor)
+ else: # list i.e. img_size=[640, 480]
+ imgsz = list(imgsz) # convert to list if tuple
+ new_size = [max(make_divisible(x, int(s)), floor) for x in imgsz]
+ if new_size != imgsz:
+ LOGGER.warning(f'WARNING ⚠️ --img-size {imgsz} must be multiple of max stride {s}, updating to {new_size}')
+ return new_size
+
+
+def check_imshow(warn=False):
+ # Check if environment supports image displays
+ try:
+ assert not is_jupyter()
+ assert not is_docker()
+ cv2.imshow('test', np.zeros((1, 1, 3)))
+ cv2.waitKey(1)
+ cv2.destroyAllWindows()
+ cv2.waitKey(1)
+ return True
+ except Exception as e:
+ if warn:
+ LOGGER.warning(f'WARNING ⚠️ Environment does not support cv2.imshow() or PIL Image.show()\n{e}')
+ return False
+
+
+def check_suffix(file='yolov5s.pt', suffix=('.pt',), msg=''):
+ # Check file(s) for acceptable suffix
+ if file and suffix:
+ if isinstance(suffix, str):
+ suffix = [suffix]
+ for f in file if isinstance(file, (list, tuple)) else [file]:
+ s = Path(f).suffix.lower() # file suffix
+ if len(s):
+ assert s in suffix, f'{msg}{f} acceptable suffix is {suffix}'
+
+
+def check_yaml(file, suffix=('.yaml', '.yml')):
+ # Search/download YAML file (if necessary) and return path, checking suffix
+ return check_file(file, suffix)
+
+
+def check_file(file, suffix=''):
+ # Search/download file (if necessary) and return path
+ check_suffix(file, suffix) # optional
+ file = str(file) # convert to str()
+ if os.path.isfile(file) or not file: # exists
+ return file
+ elif file.startswith(('http:/', 'https:/')): # download
+ url = file # warning: Pathlib turns :// -> :/
+ file = Path(urllib.parse.unquote(file).split('?')[0]).name # '%2F' to '/', split https://url.com/file.txt?auth
+ if os.path.isfile(file):
+ LOGGER.info(f'Found {url} locally at {file}') # file already exists
+ else:
+ LOGGER.info(f'Downloading {url} to {file}...')
+ torch.hub.download_url_to_file(url, file)
+ assert Path(file).exists() and Path(file).stat().st_size > 0, f'File download failed: {url}' # check
+ return file
+ elif file.startswith('clearml://'): # ClearML Dataset ID
+ assert 'clearml' in sys.modules, "ClearML is not installed, so cannot use ClearML dataset. Try running 'pip install clearml'."
+ return file
+ else: # search
+ files = []
+ for d in 'data', 'models', 'utils': # search directories
+ files.extend(glob.glob(str(ROOT / d / '**' / file), recursive=True)) # find file
+ assert len(files), f'File not found: {file}' # assert file was found
+ assert len(files) == 1, f"Multiple files match '{file}', specify exact path: {files}" # assert unique
+ return files[0] # return file
+
+
+def check_font(font=FONT, progress=False):
+ # Download font to CONFIG_DIR if necessary
+ font = Path(font)
+ file = CONFIG_DIR / font.name
+ if not font.exists() and not file.exists():
+ url = f'https://ultralytics.com/assets/{font.name}'
+ LOGGER.info(f'Downloading {url} to {file}...')
+ torch.hub.download_url_to_file(url, str(file), progress=progress)
+
+
+def check_dataset(data, autodownload=True):
+ # Download, check and/or unzip dataset if not found locally
+
+ # Download (optional)
+ extract_dir = ''
+ if isinstance(data, (str, Path)) and (is_zipfile(data) or is_tarfile(data)):
+ download(data, dir=f'{DATASETS_DIR}/{Path(data).stem}', unzip=True, delete=False, curl=False, threads=1)
+ data = next((DATASETS_DIR / Path(data).stem).rglob('*.yaml'))
+ extract_dir, autodownload = data.parent, False
+
+ # Read yaml (optional)
+ if isinstance(data, (str, Path)):
+ data = yaml_load(data) # dictionary
+
+ # Checks
+ for k in 'train', 'val', 'names':
+ assert k in data, emojis(f"data.yaml '{k}:' field missing ❌")
+ if isinstance(data['names'], (list, tuple)): # old array format
+ data['names'] = dict(enumerate(data['names'])) # convert to dict
+ assert all(isinstance(k, int) for k in data['names'].keys()), 'data.yaml names keys must be integers, i.e. 2: car'
+ data['nc'] = len(data['names'])
+
+ # Resolve paths
+ path = Path(extract_dir or data.get('path') or '') # optional 'path' default to '.'
+ if not path.is_absolute():
+ path = (ROOT / path).resolve()
+ data['path'] = path # download scripts
+ for k in 'train', 'val', 'test':
+ if data.get(k): # prepend path
+ if isinstance(data[k], str):
+ x = (path / data[k]).resolve()
+ if not x.exists() and data[k].startswith('../'):
+ x = (path / data[k][3:]).resolve()
+ data[k] = str(x)
+ else:
+ data[k] = [str((path / x).resolve()) for x in data[k]]
+
+ # Parse yaml
+ train, val, test, s = (data.get(x) for x in ('train', 'val', 'test', 'download'))
+ if val:
+ val = [Path(x).resolve() for x in (val if isinstance(val, list) else [val])] # val path
+ if not all(x.exists() for x in val):
+ LOGGER.info('\nDataset not found ⚠️, missing paths %s' % [str(x) for x in val if not x.exists()])
+ if not s or not autodownload:
+ raise Exception('Dataset not found ❌')
+ t = time.time()
+ if s.startswith('http') and s.endswith('.zip'): # URL
+ f = Path(s).name # filename
+ LOGGER.info(f'Downloading {s} to {f}...')
+ torch.hub.download_url_to_file(s, f)
+ Path(DATASETS_DIR).mkdir(parents=True, exist_ok=True) # create root
+ unzip_file(f, path=DATASETS_DIR) # unzip
+ Path(f).unlink() # remove zip
+ r = None # success
+ elif s.startswith('bash '): # bash script
+ LOGGER.info(f'Running {s} ...')
+ r = subprocess.run(s, shell=True)
+ else: # python script
+ r = exec(s, {'yaml': data}) # return None
+ dt = f'({round(time.time() - t, 1)}s)'
+ s = f"success ✅ {dt}, saved to {colorstr('bold', DATASETS_DIR)}" if r in (0, None) else f'failure {dt} ❌'
+ LOGGER.info(f'Dataset download {s}')
+ check_font('Arial.ttf' if is_ascii(data['names']) else 'Arial.Unicode.ttf', progress=True) # download fonts
+ return data # dictionary
+
+
+def check_amp(model):
+ # Check PyTorch Automatic Mixed Precision (AMP) functionality. Return True on correct operation
+ from models.common import AutoShape, DetectMultiBackend
+
+ def amp_allclose(model, im):
+ # All close FP32 vs AMP results
+ m = AutoShape(model, verbose=False) # model
+ a = m(im).xywhn[0] # FP32 inference
+ m.amp = True
+ b = m(im).xywhn[0] # AMP inference
+ return a.shape == b.shape and torch.allclose(a, b, atol=0.1) # close to 10% absolute tolerance
+
+ prefix = colorstr('AMP: ')
+ device = next(model.parameters()).device # get model device
+ if device.type in ('cpu', 'mps'):
+ return False # AMP only used on CUDA devices
+ f = ROOT / 'data' / 'images' / 'bus.jpg' # image to check
+ im = f if f.exists() else 'https://ultralytics.com/images/bus.jpg' if check_online() else np.ones((640, 640, 3))
+ try:
+ assert amp_allclose(deepcopy(model), im) or amp_allclose(DetectMultiBackend('yolov5n.pt', device), im)
+ LOGGER.info(f'{prefix}checks passed ✅')
+ return True
+ except Exception:
+ help_url = 'https://github.com/ultralytics/yolov5/issues/7908'
+ LOGGER.warning(f'{prefix}checks failed ❌, disabling Automatic Mixed Precision. See {help_url}')
+ return False
+
+
+def yaml_load(file='data.yaml'):
+ # Single-line safe yaml loading
+ with open(file, errors='ignore') as f:
+ return yaml.safe_load(f)
+
+
+def yaml_save(file='data.yaml', data={}):
+ # Single-line safe yaml saving
+ with open(file, 'w') as f:
+ yaml.safe_dump({k: str(v) if isinstance(v, Path) else v for k, v in data.items()}, f, sort_keys=False)
+
+
+def unzip_file(file, path=None, exclude=('.DS_Store', '__MACOSX')):
+ # Unzip a *.zip file to path/, excluding files containing strings in exclude list
+ if path is None:
+ path = Path(file).parent # default path
+ with ZipFile(file) as zipObj:
+ for f in zipObj.namelist(): # list all archived filenames in the zip
+ if all(x not in f for x in exclude):
+ zipObj.extract(f, path=path)
+
+
+def url2file(url):
+ # Convert URL to filename, i.e. https://url.com/file.txt?auth -> file.txt
+ url = str(Path(url)).replace(':/', '://') # Pathlib turns :// -> :/
+ return Path(urllib.parse.unquote(url)).name.split('?')[0] # '%2F' to '/', split https://url.com/file.txt?auth
+
+
+def download(url, dir='.', unzip=True, delete=True, curl=False, threads=1, retry=3):
+ # Multithreaded file download and unzip function, used in data.yaml for autodownload
+ def download_one(url, dir):
+ # Download 1 file
+ success = True
+ if os.path.isfile(url):
+ f = Path(url) # filename
+ else: # does not exist
+ f = dir / Path(url).name
+ LOGGER.info(f'Downloading {url} to {f}...')
+ for i in range(retry + 1):
+ if curl:
+ success = curl_download(url, f, silent=(threads > 1))
+ else:
+ torch.hub.download_url_to_file(url, f, progress=threads == 1) # torch download
+ success = f.is_file()
+ if success:
+ break
+ elif i < retry:
+ LOGGER.warning(f'⚠️ Download failure, retrying {i + 1}/{retry} {url}...')
+ else:
+ LOGGER.warning(f'❌ Failed to download {url}...')
+
+ if unzip and success and (f.suffix == '.gz' or is_zipfile(f) or is_tarfile(f)):
+ LOGGER.info(f'Unzipping {f}...')
+ if is_zipfile(f):
+ unzip_file(f, dir) # unzip
+ elif is_tarfile(f):
+ subprocess.run(['tar', 'xf', f, '--directory', f.parent], check=True) # unzip
+ elif f.suffix == '.gz':
+ subprocess.run(['tar', 'xfz', f, '--directory', f.parent], check=True) # unzip
+ if delete:
+ f.unlink() # remove zip
+
+ dir = Path(dir)
+ dir.mkdir(parents=True, exist_ok=True) # make directory
+ if threads > 1:
+ pool = ThreadPool(threads)
+ pool.imap(lambda x: download_one(*x), zip(url, repeat(dir))) # multithreaded
+ pool.close()
+ pool.join()
+ else:
+ for u in [url] if isinstance(url, (str, Path)) else url:
+ download_one(u, dir)
+
+
+def make_divisible(x, divisor):
+ # Returns nearest x divisible by divisor
+ if isinstance(divisor, torch.Tensor):
+ divisor = int(divisor.max()) # to int
+ return math.ceil(x / divisor) * divisor
+
+
+def clean_str(s):
+ # Cleans a string by replacing special characters with underscore _
+ return re.sub(pattern='[|@#!¡·$€%&()=?¿^*;:,¨´><+]', repl='_', string=s)
+
+
+def one_cycle(y1=0.0, y2=1.0, steps=100):
+ # lambda function for sinusoidal ramp from y1 to y2 https://arxiv.org/pdf/1812.01187.pdf
+ return lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
+
+
+def colorstr(*input):
+ # Colors a string https://en.wikipedia.org/wiki/ANSI_escape_code, i.e. colorstr('blue', 'hello world')
+ *args, string = input if len(input) > 1 else ('blue', 'bold', input[0]) # color arguments, string
+ colors = {
+ 'black': '\033[30m', # basic colors
+ 'red': '\033[31m',
+ 'green': '\033[32m',
+ 'yellow': '\033[33m',
+ 'blue': '\033[34m',
+ 'magenta': '\033[35m',
+ 'cyan': '\033[36m',
+ 'white': '\033[37m',
+ 'bright_black': '\033[90m', # bright colors
+ 'bright_red': '\033[91m',
+ 'bright_green': '\033[92m',
+ 'bright_yellow': '\033[93m',
+ 'bright_blue': '\033[94m',
+ 'bright_magenta': '\033[95m',
+ 'bright_cyan': '\033[96m',
+ 'bright_white': '\033[97m',
+ 'end': '\033[0m', # misc
+ 'bold': '\033[1m',
+ 'underline': '\033[4m'}
+ return ''.join(colors[x] for x in args) + f'{string}' + colors['end']
+
+
+def labels_to_class_weights(labels, nc=80):
+ # Get class weights (inverse frequency) from training labels
+ if labels[0] is None: # no labels loaded
+ return torch.Tensor()
+
+ labels = np.concatenate(labels, 0) # labels.shape = (866643, 5) for COCO
+ classes = labels[:, 0].astype(int) # labels = [class xywh]
+ weights = np.bincount(classes, minlength=nc) # occurrences per class
+
+ # Prepend gridpoint count (for uCE training)
+ # gpi = ((320 / 32 * np.array([1, 2, 4])) ** 2 * 3).sum() # gridpoints per image
+ # weights = np.hstack([gpi * len(labels) - weights.sum() * 9, weights * 9]) ** 0.5 # prepend gridpoints to start
+
+ weights[weights == 0] = 1 # replace empty bins with 1
+ weights = 1 / weights # number of targets per class
+ weights /= weights.sum() # normalize
+ return torch.from_numpy(weights).float()
+
+
+def labels_to_image_weights(labels, nc=80, class_weights=np.ones(80)):
+ # Produces image weights based on class_weights and image contents
+ # Usage: index = random.choices(range(n), weights=image_weights, k=1) # weighted image sample
+ class_counts = np.array([np.bincount(x[:, 0].astype(int), minlength=nc) for x in labels])
+ return (class_weights.reshape(1, nc) * class_counts).sum(1)
+
+
+def coco80_to_coco91_class(): # converts 80-index (val2014) to 91-index (paper)
+ # https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
+ # a = np.loadtxt('data/coco.names', dtype='str', delimiter='\n')
+ # b = np.loadtxt('data/coco_paper.names', dtype='str', delimiter='\n')
+ # x1 = [list(a[i] == b).index(True) + 1 for i in range(80)] # darknet to coco
+ # x2 = [list(b[i] == a).index(True) if any(b[i] == a) else None for i in range(91)] # coco to darknet
+ return [
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34,
+ 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63,
+ 64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88, 89, 90]
+
+
+def xyxy2xywh(x):
+ # Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[..., 0] = (x[..., 0] + x[..., 2]) / 2 # x center
+ y[..., 1] = (x[..., 1] + x[..., 3]) / 2 # y center
+ y[..., 2] = x[..., 2] - x[..., 0] # width
+ y[..., 3] = x[..., 3] - x[..., 1] # height
+ return y
+
+
+def xywh2xyxy(x):
+ # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[..., 0] = x[..., 0] - x[..., 2] / 2 # top left x
+ y[..., 1] = x[..., 1] - x[..., 3] / 2 # top left y
+ y[..., 2] = x[..., 0] + x[..., 2] / 2 # bottom right x
+ y[..., 3] = x[..., 1] + x[..., 3] / 2 # bottom right y
+ return y
+
+
+def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):
+ # Convert nx4 boxes from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[..., 0] = w * (x[..., 0] - x[..., 2] / 2) + padw # top left x
+ y[..., 1] = h * (x[..., 1] - x[..., 3] / 2) + padh # top left y
+ y[..., 2] = w * (x[..., 0] + x[..., 2] / 2) + padw # bottom right x
+ y[..., 3] = h * (x[..., 1] + x[..., 3] / 2) + padh # bottom right y
+ return y
+
+
+def xyxy2xywhn(x, w=640, h=640, clip=False, eps=0.0):
+ # Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] normalized where xy1=top-left, xy2=bottom-right
+ if clip:
+ clip_boxes(x, (h - eps, w - eps)) # warning: inplace clip
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[..., 0] = ((x[..., 0] + x[..., 2]) / 2) / w # x center
+ y[..., 1] = ((x[..., 1] + x[..., 3]) / 2) / h # y center
+ y[..., 2] = (x[..., 2] - x[..., 0]) / w # width
+ y[..., 3] = (x[..., 3] - x[..., 1]) / h # height
+ return y
+
+
+def xyn2xy(x, w=640, h=640, padw=0, padh=0):
+ # Convert normalized segments into pixel segments, shape (n,2)
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[..., 0] = w * x[..., 0] + padw # top left x
+ y[..., 1] = h * x[..., 1] + padh # top left y
+ return y
+
+
+def segment2box(segment, width=640, height=640):
+ # Convert 1 segment label to 1 box label, applying inside-image constraint, i.e. (xy1, xy2, ...) to (xyxy)
+ x, y = segment.T # segment xy
+ inside = (x >= 0) & (y >= 0) & (x <= width) & (y <= height)
+ x, y, = x[inside], y[inside]
+ return np.array([x.min(), y.min(), x.max(), y.max()]) if any(x) else np.zeros((1, 4)) # xyxy
+
+
+def segments2boxes(segments):
+ # Convert segment labels to box labels, i.e. (cls, xy1, xy2, ...) to (cls, xywh)
+ boxes = []
+ for s in segments:
+ x, y = s.T # segment xy
+ boxes.append([x.min(), y.min(), x.max(), y.max()]) # cls, xyxy
+ return xyxy2xywh(np.array(boxes)) # cls, xywh
+
+
+def resample_segments(segments, n=1000):
+ # Up-sample an (n,2) segment
+ for i, s in enumerate(segments):
+ s = np.concatenate((s, s[0:1, :]), axis=0)
+ x = np.linspace(0, len(s) - 1, n)
+ xp = np.arange(len(s))
+ segments[i] = np.concatenate([np.interp(x, xp, s[:, i]) for i in range(2)]).reshape(2, -1).T # segment xy
+ return segments
+
+
+def scale_boxes(img1_shape, boxes, img0_shape, ratio_pad=None):
+ # Rescale boxes (xyxy) from img1_shape to img0_shape
+ if ratio_pad is None: # calculate from img0_shape
+ gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
+ pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
+ else:
+ gain = ratio_pad[0][0]
+ pad = ratio_pad[1]
+
+ boxes[..., [0, 2]] -= pad[0] # x padding
+ boxes[..., [1, 3]] -= pad[1] # y padding
+ boxes[..., :4] /= gain
+ clip_boxes(boxes, img0_shape)
+ return boxes
+
+
+def scale_segments(img1_shape, segments, img0_shape, ratio_pad=None, normalize=False):
+ # Rescale coords (xyxy) from img1_shape to img0_shape
+ if ratio_pad is None: # calculate from img0_shape
+ gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
+ pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
+ else:
+ gain = ratio_pad[0][0]
+ pad = ratio_pad[1]
+
+ segments[:, 0] -= pad[0] # x padding
+ segments[:, 1] -= pad[1] # y padding
+ segments /= gain
+ clip_segments(segments, img0_shape)
+ if normalize:
+ segments[:, 0] /= img0_shape[1] # width
+ segments[:, 1] /= img0_shape[0] # height
+ return segments
+
+
+def clip_boxes(boxes, shape):
+ # Clip boxes (xyxy) to image shape (height, width)
+ if isinstance(boxes, torch.Tensor): # faster individually
+ boxes[..., 0].clamp_(0, shape[1]) # x1
+ boxes[..., 1].clamp_(0, shape[0]) # y1
+ boxes[..., 2].clamp_(0, shape[1]) # x2
+ boxes[..., 3].clamp_(0, shape[0]) # y2
+ else: # np.array (faster grouped)
+ boxes[..., [0, 2]] = boxes[..., [0, 2]].clip(0, shape[1]) # x1, x2
+ boxes[..., [1, 3]] = boxes[..., [1, 3]].clip(0, shape[0]) # y1, y2
+
+
+def clip_segments(segments, shape):
+ # Clip segments (xy1,xy2,...) to image shape (height, width)
+ if isinstance(segments, torch.Tensor): # faster individually
+ segments[:, 0].clamp_(0, shape[1]) # x
+ segments[:, 1].clamp_(0, shape[0]) # y
+ else: # np.array (faster grouped)
+ segments[:, 0] = segments[:, 0].clip(0, shape[1]) # x
+ segments[:, 1] = segments[:, 1].clip(0, shape[0]) # y
+
+
+def non_max_suppression(
+ prediction,
+ conf_thres=0.25,
+ iou_thres=0.45,
+ classes=None,
+ agnostic=False,
+ multi_label=False,
+ labels=(),
+ max_det=300,
+ nm=0, # number of masks
+):
+ """Non-Maximum Suppression (NMS) on inference results to reject overlapping detections
+
+ Returns:
+ list of detections, on (n,6) tensor per image [xyxy, conf, cls]
+ """
+
+ # Checks
+ assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
+ assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
+ if isinstance(prediction, (list, tuple)): # YOLOv5 model in validation model, output = (inference_out, loss_out)
+ prediction = prediction[0] # select only inference output
+
+ device = prediction.device
+ mps = 'mps' in device.type # Apple MPS
+ if mps: # MPS not fully supported yet, convert tensors to CPU before NMS
+ prediction = prediction.cpu()
+ bs = prediction.shape[0] # batch size
+ nc = prediction.shape[2] - nm - 5 # number of classes
+ xc = prediction[..., 4] > conf_thres # candidates
+
+ # Settings
+ # min_wh = 2 # (pixels) minimum box width and height
+ max_wh = 7680 # (pixels) maximum box width and height
+ max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
+ time_limit = 0.5 + 0.05 * bs # seconds to quit after
+ redundant = True # require redundant detections
+ multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
+ merge = False # use merge-NMS
+
+ t = time.time()
+ mi = 5 + nc # mask start index
+ output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
+ for xi, x in enumerate(prediction): # image index, image inference
+ # Apply constraints
+ # x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
+ x = x[xc[xi]] # confidence
+
+ # Cat apriori labels if autolabelling
+ if labels and len(labels[xi]):
+ lb = labels[xi]
+ v = torch.zeros((len(lb), nc + nm + 5), device=x.device)
+ v[:, :4] = lb[:, 1:5] # box
+ v[:, 4] = 1.0 # conf
+ v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
+ x = torch.cat((x, v), 0)
+
+ # If none remain process next image
+ if not x.shape[0]:
+ continue
+
+ # Compute conf
+ x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
+
+ # Box/Mask
+ box = xywh2xyxy(x[:, :4]) # center_x, center_y, width, height) to (x1, y1, x2, y2)
+ mask = x[:, mi:] # zero columns if no masks
+
+ # Detections matrix nx6 (xyxy, conf, cls)
+ if multi_label:
+ i, j = (x[:, 5:mi] > conf_thres).nonzero(as_tuple=False).T
+ x = torch.cat((box[i], x[i, 5 + j, None], j[:, None].float(), mask[i]), 1)
+ else: # best class only
+ conf, j = x[:, 5:mi].max(1, keepdim=True)
+ x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]
+
+ # Filter by class
+ if classes is not None:
+ x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
+
+ # Apply finite constraint
+ # if not torch.isfinite(x).all():
+ # x = x[torch.isfinite(x).all(1)]
+
+ # Check shape
+ n = x.shape[0] # number of boxes
+ if not n: # no boxes
+ continue
+ x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence and remove excess boxes
+
+ # Batched NMS
+ c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
+ boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
+ i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
+ i = i[:max_det] # limit detections
+ if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
+ # update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
+ iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
+ weights = iou * scores[None] # box weights
+ x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
+ if redundant:
+ i = i[iou.sum(1) > 1] # require redundancy
+
+ output[xi] = x[i]
+ if mps:
+ output[xi] = output[xi].to(device)
+ if (time.time() - t) > time_limit:
+ LOGGER.warning(f'WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded')
+ break # time limit exceeded
+
+ return output
+
+
+def strip_optimizer(f='best.pt', s=''): # from utils.general import *; strip_optimizer()
+ # Strip optimizer from 'f' to finalize training, optionally save as 's'
+ x = torch.load(f, map_location=torch.device('cpu'))
+ if x.get('ema'):
+ x['model'] = x['ema'] # replace model with ema
+ for k in 'optimizer', 'best_fitness', 'ema', 'updates': # keys
+ x[k] = None
+ x['epoch'] = -1
+ x['model'].half() # to FP16
+ for p in x['model'].parameters():
+ p.requires_grad = False
+ torch.save(x, s or f)
+ mb = os.path.getsize(s or f) / 1E6 # filesize
+ LOGGER.info(f"Optimizer stripped from {f},{f' saved as {s},' if s else ''} {mb:.1f}MB")
+
+
+def print_mutation(keys, results, hyp, save_dir, bucket, prefix=colorstr('evolve: ')):
+ evolve_csv = save_dir / 'evolve.csv'
+ evolve_yaml = save_dir / 'hyp_evolve.yaml'
+ keys = tuple(keys) + tuple(hyp.keys()) # [results + hyps]
+ keys = tuple(x.strip() for x in keys)
+ vals = results + tuple(hyp.values())
+ n = len(keys)
+
+ # Download (optional)
+ if bucket:
+ url = f'gs://{bucket}/evolve.csv'
+ if gsutil_getsize(url) > (evolve_csv.stat().st_size if evolve_csv.exists() else 0):
+ subprocess.run(['gsutil', 'cp', f'{url}', f'{save_dir}']) # download evolve.csv if larger than local
+
+ # Log to evolve.csv
+ s = '' if evolve_csv.exists() else (('%20s,' * n % keys).rstrip(',') + '\n') # add header
+ with open(evolve_csv, 'a') as f:
+ f.write(s + ('%20.5g,' * n % vals).rstrip(',') + '\n')
+
+ # Save yaml
+ with open(evolve_yaml, 'w') as f:
+ data = pd.read_csv(evolve_csv, skipinitialspace=True)
+ data = data.rename(columns=lambda x: x.strip()) # strip keys
+ i = np.argmax(fitness(data.values[:, :4])) #
+ generations = len(data)
+ f.write('# YOLOv5 Hyperparameter Evolution Results\n' + f'# Best generation: {i}\n' +
+ f'# Last generation: {generations - 1}\n' + '# ' + ', '.join(f'{x.strip():>20s}' for x in keys[:7]) +
+ '\n' + '# ' + ', '.join(f'{x:>20.5g}' for x in data.values[i, :7]) + '\n\n')
+ yaml.safe_dump(data.loc[i][7:].to_dict(), f, sort_keys=False)
+
+ # Print to screen
+ LOGGER.info(prefix + f'{generations} generations finished, current result:\n' + prefix +
+ ', '.join(f'{x.strip():>20s}' for x in keys) + '\n' + prefix + ', '.join(f'{x:20.5g}'
+ for x in vals) + '\n\n')
+
+ if bucket:
+ subprocess.run(['gsutil', 'cp', f'{evolve_csv}', f'{evolve_yaml}', f'gs://{bucket}']) # upload
+
+
+def apply_classifier(x, model, img, im0):
+ # Apply a second stage classifier to YOLO outputs
+ # Example model = torchvision.models.__dict__['efficientnet_b0'](pretrained=True).to(device).eval()
+ im0 = [im0] if isinstance(im0, np.ndarray) else im0
+ for i, d in enumerate(x): # per image
+ if d is not None and len(d):
+ d = d.clone()
+
+ # Reshape and pad cutouts
+ b = xyxy2xywh(d[:, :4]) # boxes
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # rectangle to square
+ b[:, 2:] = b[:, 2:] * 1.3 + 30 # pad
+ d[:, :4] = xywh2xyxy(b).long()
+
+ # Rescale boxes from img_size to im0 size
+ scale_boxes(img.shape[2:], d[:, :4], im0[i].shape)
+
+ # Classes
+ pred_cls1 = d[:, 5].long()
+ ims = []
+ for a in d:
+ cutout = im0[i][int(a[1]):int(a[3]), int(a[0]):int(a[2])]
+ im = cv2.resize(cutout, (224, 224)) # BGR
+
+ im = im[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
+ im = np.ascontiguousarray(im, dtype=np.float32) # uint8 to float32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ ims.append(im)
+
+ pred_cls2 = model(torch.Tensor(ims).to(d.device)).argmax(1) # classifier prediction
+ x[i] = x[i][pred_cls1 == pred_cls2] # retain matching class detections
+
+ return x
+
+
+def increment_path(path, exist_ok=False, sep='', mkdir=False):
+ # Increment file or directory path, i.e. runs/exp --> runs/exp{sep}2, runs/exp{sep}3, ... etc.
+ path = Path(path) # os-agnostic
+ if path.exists() and not exist_ok:
+ path, suffix = (path.with_suffix(''), path.suffix) if path.is_file() else (path, '')
+
+ # Method 1
+ for n in range(2, 9999):
+ p = f'{path}{sep}{n}{suffix}' # increment path
+ if not os.path.exists(p): #
+ break
+ path = Path(p)
+
+ # Method 2 (deprecated)
+ # dirs = glob.glob(f"{path}{sep}*") # similar paths
+ # matches = [re.search(rf"{path.stem}{sep}(\d+)", d) for d in dirs]
+ # i = [int(m.groups()[0]) for m in matches if m] # indices
+ # n = max(i) + 1 if i else 2 # increment number
+ # path = Path(f"{path}{sep}{n}{suffix}") # increment path
+
+ if mkdir:
+ path.mkdir(parents=True, exist_ok=True) # make directory
+
+ return path
+
+
+# OpenCV Multilanguage-friendly functions ------------------------------------------------------------------------------------
+imshow_ = cv2.imshow # copy to avoid recursion errors
+
+
+def imread(filename, flags=cv2.IMREAD_COLOR):
+ return cv2.imdecode(np.fromfile(filename, np.uint8), flags)
+
+
+def imwrite(filename, img):
+ try:
+ cv2.imencode(Path(filename).suffix, img)[1].tofile(filename)
+ return True
+ except Exception:
+ return False
+
+
+def imshow(path, im):
+ imshow_(path.encode('unicode_escape').decode(), im)
+
+
+if Path(inspect.stack()[0].filename).parent.parent.as_posix() in inspect.stack()[-1].filename:
+ cv2.imread, cv2.imwrite, cv2.imshow = imread, imwrite, imshow # redefine
+
+# Variables ------------------------------------------------------------------------------------------------------------
diff --git a/yolov5/utils/google_app_engine/Dockerfile b/yolov5/utils/google_app_engine/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..0155618f475104e9858b81470339558156c94e13
--- /dev/null
+++ b/yolov5/utils/google_app_engine/Dockerfile
@@ -0,0 +1,25 @@
+FROM gcr.io/google-appengine/python
+
+# Create a virtualenv for dependencies. This isolates these packages from
+# system-level packages.
+# Use -p python3 or -p python3.7 to select python version. Default is version 2.
+RUN virtualenv /env -p python3
+
+# Setting these environment variables are the same as running
+# source /env/bin/activate.
+ENV VIRTUAL_ENV /env
+ENV PATH /env/bin:$PATH
+
+RUN apt-get update && apt-get install -y python-opencv
+
+# Copy the application's requirements.txt and run pip to install all
+# dependencies into the virtualenv.
+ADD requirements.txt /app/requirements.txt
+RUN pip install -r /app/requirements.txt
+
+# Add the application source code.
+ADD . /app
+
+# Run a WSGI server to serve the application. gunicorn must be declared as
+# a dependency in requirements.txt.
+CMD gunicorn -b :$PORT main:app
diff --git a/yolov5/utils/google_app_engine/additional_requirements.txt b/yolov5/utils/google_app_engine/additional_requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..fce1511588e3f09711e4b2d8f0490a5effc7dc0f
--- /dev/null
+++ b/yolov5/utils/google_app_engine/additional_requirements.txt
@@ -0,0 +1,5 @@
+# add these requirements in your app on top of the existing ones
+pip==21.1
+Flask==2.3.2
+gunicorn==19.10.0
+werkzeug>=2.2.3 # not directly required, pinned by Snyk to avoid a vulnerability
diff --git a/yolov5/utils/google_app_engine/app.yaml b/yolov5/utils/google_app_engine/app.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5056b7c1186d6ad278957bbd6e976c3a0f169a30
--- /dev/null
+++ b/yolov5/utils/google_app_engine/app.yaml
@@ -0,0 +1,14 @@
+runtime: custom
+env: flex
+
+service: yolov5app
+
+liveness_check:
+ initial_delay_sec: 600
+
+manual_scaling:
+ instances: 1
+resources:
+ cpu: 1
+ memory_gb: 4
+ disk_size_gb: 20
diff --git a/yolov5/utils/loggers/__init__.py b/yolov5/utils/loggers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c7c283b728ac0ffa758fbea70cacbe433299e3b0
--- /dev/null
+++ b/yolov5/utils/loggers/__init__.py
@@ -0,0 +1,405 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Logging utils
+"""
+
+import os
+import warnings
+from pathlib import Path
+
+import pkg_resources as pkg
+import torch
+
+from utils.general import LOGGER, colorstr, cv2
+from utils.loggers.clearml.clearml_utils import ClearmlLogger
+from utils.loggers.wandb.wandb_utils import WandbLogger
+from utils.plots import plot_images, plot_labels, plot_results
+from utils.torch_utils import de_parallel
+
+LOGGERS = ('csv', 'tb', 'wandb', 'clearml', 'comet') # *.csv, TensorBoard, Weights & Biases, ClearML
+RANK = int(os.getenv('RANK', -1))
+
+try:
+ from torch.utils.tensorboard import SummaryWriter
+except ImportError:
+ SummaryWriter = lambda *args: None # None = SummaryWriter(str)
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+ if pkg.parse_version(wandb.__version__) >= pkg.parse_version('0.12.2') and RANK in {0, -1}:
+ try:
+ wandb_login_success = wandb.login(timeout=30)
+ except wandb.errors.UsageError: # known non-TTY terminal issue
+ wandb_login_success = False
+ if not wandb_login_success:
+ wandb = None
+except (ImportError, AssertionError):
+ wandb = None
+
+try:
+ import clearml
+
+ assert hasattr(clearml, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ clearml = None
+
+try:
+ if RANK not in [0, -1]:
+ comet_ml = None
+ else:
+ import comet_ml
+
+ assert hasattr(comet_ml, '__version__') # verify package import not local dir
+ from utils.loggers.comet import CometLogger
+
+except (ModuleNotFoundError, ImportError, AssertionError):
+ comet_ml = None
+
+
+class Loggers():
+ # YOLOv5 Loggers class
+ def __init__(self, save_dir=None, weights=None, opt=None, hyp=None, logger=None, include=LOGGERS):
+ self.save_dir = save_dir
+ self.weights = weights
+ self.opt = opt
+ self.hyp = hyp
+ self.plots = not opt.noplots # plot results
+ self.logger = logger # for printing results to console
+ self.include = include
+ self.keys = [
+ 'train/box_loss',
+ 'train/obj_loss',
+ 'train/cls_loss', # train loss
+ 'metrics/precision',
+ 'metrics/recall',
+ 'metrics/mAP_0.5',
+ 'metrics/mAP_0.5:0.95', # metrics
+ 'val/box_loss',
+ 'val/obj_loss',
+ 'val/cls_loss', # val loss
+ 'x/lr0',
+ 'x/lr1',
+ 'x/lr2'] # params
+ self.best_keys = ['best/epoch', 'best/precision', 'best/recall', 'best/mAP_0.5', 'best/mAP_0.5:0.95']
+ for k in LOGGERS:
+ setattr(self, k, None) # init empty logger dictionary
+ self.csv = True # always log to csv
+
+ # Messages
+ if not clearml:
+ prefix = colorstr('ClearML: ')
+ s = f"{prefix}run 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 in ClearML"
+ self.logger.info(s)
+ if not comet_ml:
+ prefix = colorstr('Comet: ')
+ s = f"{prefix}run 'pip install comet_ml' to automatically track and visualize YOLOv5 🚀 runs in Comet"
+ self.logger.info(s)
+ # TensorBoard
+ s = self.save_dir
+ if 'tb' in self.include and not self.opt.evolve:
+ prefix = colorstr('TensorBoard: ')
+ self.logger.info(f"{prefix}Start with 'tensorboard --logdir {s.parent}', view at http://localhost:6006/")
+ self.tb = SummaryWriter(str(s))
+
+ # W&B
+ if wandb and 'wandb' in self.include:
+ self.opt.hyp = self.hyp # add hyperparameters
+ self.wandb = WandbLogger(self.opt)
+ else:
+ self.wandb = None
+
+ # ClearML
+ if clearml and 'clearml' in self.include:
+ try:
+ self.clearml = ClearmlLogger(self.opt, self.hyp)
+ except Exception:
+ self.clearml = None
+ prefix = colorstr('ClearML: ')
+ LOGGER.warning(f'{prefix}WARNING ⚠️ ClearML is installed but not configured, skipping ClearML logging.'
+ f' See https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration#readme')
+
+ else:
+ self.clearml = None
+
+ # Comet
+ if comet_ml and 'comet' in self.include:
+ if isinstance(self.opt.resume, str) and self.opt.resume.startswith('comet://'):
+ run_id = self.opt.resume.split('/')[-1]
+ self.comet_logger = CometLogger(self.opt, self.hyp, run_id=run_id)
+
+ else:
+ self.comet_logger = CometLogger(self.opt, self.hyp)
+
+ else:
+ self.comet_logger = None
+
+ @property
+ def remote_dataset(self):
+ # Get data_dict if custom dataset artifact link is provided
+ data_dict = None
+ if self.clearml:
+ data_dict = self.clearml.data_dict
+ if self.wandb:
+ data_dict = self.wandb.data_dict
+ if self.comet_logger:
+ data_dict = self.comet_logger.data_dict
+
+ return data_dict
+
+ def on_train_start(self):
+ if self.comet_logger:
+ self.comet_logger.on_train_start()
+
+ def on_pretrain_routine_start(self):
+ if self.comet_logger:
+ self.comet_logger.on_pretrain_routine_start()
+
+ def on_pretrain_routine_end(self, labels, names):
+ # Callback runs on pre-train routine end
+ if self.plots:
+ plot_labels(labels, names, self.save_dir)
+ paths = self.save_dir.glob('*labels*.jpg') # training labels
+ if self.wandb:
+ self.wandb.log({'Labels': [wandb.Image(str(x), caption=x.name) for x in paths]})
+ # if self.clearml:
+ # pass # ClearML saves these images automatically using hooks
+ if self.comet_logger:
+ self.comet_logger.on_pretrain_routine_end(paths)
+
+ def on_train_batch_end(self, model, ni, imgs, targets, paths, vals):
+ log_dict = dict(zip(self.keys[:3], vals))
+ # Callback runs on train batch end
+ # ni: number integrated batches (since train start)
+ if self.plots:
+ if ni < 3:
+ f = self.save_dir / f'train_batch{ni}.jpg' # filename
+ plot_images(imgs, targets, paths, f)
+ if ni == 0 and self.tb and not self.opt.sync_bn:
+ log_tensorboard_graph(self.tb, model, imgsz=(self.opt.imgsz, self.opt.imgsz))
+ if ni == 10 and (self.wandb or self.clearml):
+ files = sorted(self.save_dir.glob('train*.jpg'))
+ if self.wandb:
+ self.wandb.log({'Mosaics': [wandb.Image(str(f), caption=f.name) for f in files if f.exists()]})
+ if self.clearml:
+ self.clearml.log_debug_samples(files, title='Mosaics')
+
+ if self.comet_logger:
+ self.comet_logger.on_train_batch_end(log_dict, step=ni)
+
+ def on_train_epoch_end(self, epoch):
+ # Callback runs on train epoch end
+ if self.wandb:
+ self.wandb.current_epoch = epoch + 1
+
+ if self.comet_logger:
+ self.comet_logger.on_train_epoch_end(epoch)
+
+ def on_val_start(self):
+ if self.comet_logger:
+ self.comet_logger.on_val_start()
+
+ def on_val_image_end(self, pred, predn, path, names, im):
+ # Callback runs on val image end
+ if self.wandb:
+ self.wandb.val_one_image(pred, predn, path, names, im)
+ if self.clearml:
+ self.clearml.log_image_with_boxes(path, pred, names, im)
+
+ def on_val_batch_end(self, batch_i, im, targets, paths, shapes, out):
+ if self.comet_logger:
+ self.comet_logger.on_val_batch_end(batch_i, im, targets, paths, shapes, out)
+
+ def on_val_end(self, nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix):
+ # Callback runs on val end
+ if self.wandb or self.clearml:
+ files = sorted(self.save_dir.glob('val*.jpg'))
+ if self.wandb:
+ self.wandb.log({'Validation': [wandb.Image(str(f), caption=f.name) for f in files]})
+ if self.clearml:
+ self.clearml.log_debug_samples(files, title='Validation')
+
+ if self.comet_logger:
+ self.comet_logger.on_val_end(nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix)
+
+ def on_fit_epoch_end(self, vals, epoch, best_fitness, fi):
+ # Callback runs at the end of each fit (train+val) epoch
+ x = dict(zip(self.keys, vals))
+ if self.csv:
+ file = self.save_dir / 'results.csv'
+ n = len(x) + 1 # number of cols
+ s = '' if file.exists() else (('%20s,' * n % tuple(['epoch'] + self.keys)).rstrip(',') + '\n') # add header
+ with open(file, 'a') as f:
+ f.write(s + ('%20.5g,' * n % tuple([epoch] + vals)).rstrip(',') + '\n')
+
+ if self.tb:
+ for k, v in x.items():
+ self.tb.add_scalar(k, v, epoch)
+ elif self.clearml: # log to ClearML if TensorBoard not used
+ for k, v in x.items():
+ title, series = k.split('/')
+ self.clearml.task.get_logger().report_scalar(title, series, v, epoch)
+
+ if self.wandb:
+ if best_fitness == fi:
+ best_results = [epoch] + vals[3:7]
+ for i, name in enumerate(self.best_keys):
+ self.wandb.wandb_run.summary[name] = best_results[i] # log best results in the summary
+ self.wandb.log(x)
+ self.wandb.end_epoch()
+
+ if self.clearml:
+ self.clearml.current_epoch_logged_images = set() # reset epoch image limit
+ self.clearml.current_epoch += 1
+
+ if self.comet_logger:
+ self.comet_logger.on_fit_epoch_end(x, epoch=epoch)
+
+ def on_model_save(self, last, epoch, final_epoch, best_fitness, fi):
+ # Callback runs on model save event
+ if (epoch + 1) % self.opt.save_period == 0 and not final_epoch and self.opt.save_period != -1:
+ if self.wandb:
+ self.wandb.log_model(last.parent, self.opt, epoch, fi, best_model=best_fitness == fi)
+ if self.clearml:
+ self.clearml.task.update_output_model(model_path=str(last),
+ model_name='Latest Model',
+ auto_delete_file=False)
+
+ if self.comet_logger:
+ self.comet_logger.on_model_save(last, epoch, final_epoch, best_fitness, fi)
+
+ def on_train_end(self, last, best, epoch, results):
+ # Callback runs on training end, i.e. saving best model
+ if self.plots:
+ plot_results(file=self.save_dir / 'results.csv') # save results.png
+ files = ['results.png', 'confusion_matrix.png', *(f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R'))]
+ files = [(self.save_dir / f) for f in files if (self.save_dir / f).exists()] # filter
+ self.logger.info(f"Results saved to {colorstr('bold', self.save_dir)}")
+
+ if self.tb and not self.clearml: # These images are already captured by ClearML by now, we don't want doubles
+ for f in files:
+ self.tb.add_image(f.stem, cv2.imread(str(f))[..., ::-1], epoch, dataformats='HWC')
+
+ if self.wandb:
+ self.wandb.log(dict(zip(self.keys[3:10], results)))
+ self.wandb.log({'Results': [wandb.Image(str(f), caption=f.name) for f in files]})
+ # Calling wandb.log. TODO: Refactor this into WandbLogger.log_model
+ if not self.opt.evolve:
+ wandb.log_artifact(str(best if best.exists() else last),
+ type='model',
+ name=f'run_{self.wandb.wandb_run.id}_model',
+ aliases=['latest', 'best', 'stripped'])
+ self.wandb.finish_run()
+
+ if self.clearml and not self.opt.evolve:
+ self.clearml.task.update_output_model(model_path=str(best if best.exists() else last),
+ name='Best Model',
+ auto_delete_file=False)
+
+ if self.comet_logger:
+ final_results = dict(zip(self.keys[3:10], results))
+ self.comet_logger.on_train_end(files, self.save_dir, last, best, epoch, final_results)
+
+ def on_params_update(self, params: dict):
+ # Update hyperparams or configs of the experiment
+ if self.wandb:
+ self.wandb.wandb_run.config.update(params, allow_val_change=True)
+ if self.comet_logger:
+ self.comet_logger.on_params_update(params)
+
+
+class GenericLogger:
+ """
+ YOLOv5 General purpose logger for non-task specific logging
+ Usage: from utils.loggers import GenericLogger; logger = GenericLogger(...)
+ Arguments
+ opt: Run arguments
+ console_logger: Console logger
+ include: loggers to include
+ """
+
+ def __init__(self, opt, console_logger, include=('tb', 'wandb')):
+ # init default loggers
+ self.save_dir = Path(opt.save_dir)
+ self.include = include
+ self.console_logger = console_logger
+ self.csv = self.save_dir / 'results.csv' # CSV logger
+ if 'tb' in self.include:
+ prefix = colorstr('TensorBoard: ')
+ self.console_logger.info(
+ f"{prefix}Start with 'tensorboard --logdir {self.save_dir.parent}', view at http://localhost:6006/")
+ self.tb = SummaryWriter(str(self.save_dir))
+
+ if wandb and 'wandb' in self.include:
+ self.wandb = wandb.init(project=web_project_name(str(opt.project)),
+ name=None if opt.name == 'exp' else opt.name,
+ config=opt)
+ else:
+ self.wandb = None
+
+ def log_metrics(self, metrics, epoch):
+ # Log metrics dictionary to all loggers
+ if self.csv:
+ keys, vals = list(metrics.keys()), list(metrics.values())
+ n = len(metrics) + 1 # number of cols
+ s = '' if self.csv.exists() else (('%23s,' * n % tuple(['epoch'] + keys)).rstrip(',') + '\n') # header
+ with open(self.csv, 'a') as f:
+ f.write(s + ('%23.5g,' * n % tuple([epoch] + vals)).rstrip(',') + '\n')
+
+ if self.tb:
+ for k, v in metrics.items():
+ self.tb.add_scalar(k, v, epoch)
+
+ if self.wandb:
+ self.wandb.log(metrics, step=epoch)
+
+ def log_images(self, files, name='Images', epoch=0):
+ # Log images to all loggers
+ files = [Path(f) for f in (files if isinstance(files, (tuple, list)) else [files])] # to Path
+ files = [f for f in files if f.exists()] # filter by exists
+
+ if self.tb:
+ for f in files:
+ self.tb.add_image(f.stem, cv2.imread(str(f))[..., ::-1], epoch, dataformats='HWC')
+
+ if self.wandb:
+ self.wandb.log({name: [wandb.Image(str(f), caption=f.name) for f in files]}, step=epoch)
+
+ def log_graph(self, model, imgsz=(640, 640)):
+ # Log model graph to all loggers
+ if self.tb:
+ log_tensorboard_graph(self.tb, model, imgsz)
+
+ def log_model(self, model_path, epoch=0, metadata={}):
+ # Log model to all loggers
+ if self.wandb:
+ art = wandb.Artifact(name=f'run_{wandb.run.id}_model', type='model', metadata=metadata)
+ art.add_file(str(model_path))
+ wandb.log_artifact(art)
+
+ def update_params(self, params):
+ # Update the parameters logged
+ if self.wandb:
+ wandb.run.config.update(params, allow_val_change=True)
+
+
+def log_tensorboard_graph(tb, model, imgsz=(640, 640)):
+ # Log model graph to TensorBoard
+ try:
+ p = next(model.parameters()) # for device, type
+ imgsz = (imgsz, imgsz) if isinstance(imgsz, int) else imgsz # expand
+ im = torch.zeros((1, 3, *imgsz)).to(p.device).type_as(p) # input image (WARNING: must be zeros, not empty)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress jit trace warning
+ tb.add_graph(torch.jit.trace(de_parallel(model), im, strict=False), [])
+ except Exception as e:
+ LOGGER.warning(f'WARNING ⚠️ TensorBoard graph visualization failure {e}')
+
+
+def web_project_name(project):
+ # Convert local project name to web project name
+ if not project.startswith('runs/train'):
+ return project
+ suffix = '-Classify' if project.endswith('-cls') else '-Segment' if project.endswith('-seg') else ''
+ return f'YOLOv5{suffix}'
diff --git a/yolov5/utils/loggers/__pycache__/__init__.cpython-38.pyc b/yolov5/utils/loggers/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7d5420503e97dc978775ec173f9b0f3aa5c37084
Binary files /dev/null and b/yolov5/utils/loggers/__pycache__/__init__.cpython-38.pyc differ
diff --git a/yolov5/utils/loggers/clearml/README.md b/yolov5/utils/loggers/clearml/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca41c040193c1d8817a870404af09871b511f7ed
--- /dev/null
+++ b/yolov5/utils/loggers/clearml/README.md
@@ -0,0 +1,237 @@
+# ClearML Integration
+
+
 +
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+
+
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+
+And so much more. It's up to you how many of these tools you want to use, you can stick to the experiment manager, or chain them all together into an impressive pipeline!
+
+
+
+
+
+
+
+
+## 🦾 Setting Things Up
+
+To keep track of your experiments and/or data, ClearML needs to communicate to a server. You have 2 options to get one:
+
+Either sign up for free to the [ClearML Hosted Service](https://cutt.ly/yolov5-tutorial-clearml) or you can set up your own server, see [here](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server). Even the server is open-source, so even if you're dealing with sensitive data, you should be good to go!
+
+1. Install the `clearml` python package:
+
+ ```bash
+ pip install clearml
+ ```
+
+1. Connect the ClearML SDK to the server by [creating credentials](https://app.clear.ml/settings/workspace-configuration) (go right top to Settings -> Workspace -> Create new credentials), then execute the command below and follow the instructions:
+
+ ```bash
+ clearml-init
+ ```
+
+That's it! You're done 😎
+
+
+
+## 🚀 Training YOLOv5 With ClearML
+
+To enable ClearML experiment tracking, simply install the ClearML pip package.
+
+```bash
+pip install clearml>=1.2.0
+```
+
+This will enable integration with the YOLOv5 training script. Every training run from now on, will be captured and stored by the ClearML experiment manager.
+
+If you want to change the `project_name` or `task_name`, use the `--project` and `--name` arguments of the `train.py` script, by default the project will be called `YOLOv5` and the task `Training`.
+PLEASE NOTE: ClearML uses `/` as a delimiter for subprojects, so be careful when using `/` in your project name!
+
+```bash
+python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
+```
+
+or with custom project and task name:
+
+```bash
+python train.py --project my_project --name my_training --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
+```
+
+This will capture:
+
+- Source code + uncommitted changes
+- Installed packages
+- (Hyper)parameters
+- Model files (use `--save-period n` to save a checkpoint every n epochs)
+- Console output
+- Scalars (mAP_0.5, mAP_0.5:0.95, precision, recall, losses, learning rates, ...)
+- General info such as machine details, runtime, creation date etc.
+- All produced plots such as label correlogram and confusion matrix
+- Images with bounding boxes per epoch
+- Mosaic per epoch
+- Validation images per epoch
+- ...
+
+That's a lot right? 🤯
+Now, we can visualize all of this information in the ClearML UI to get an overview of our training progress. Add custom columns to the table view (such as e.g. mAP_0.5) so you can easily sort on the best performing model. Or select multiple experiments and directly compare them!
+
+There even more we can do with all of this information, like hyperparameter optimization and remote execution, so keep reading if you want to see how that works!
+
+
+
+## 🔗 Dataset Version Management
+
+Versioning your data separately from your code is generally a good idea and makes it easy to acquire the latest version too. This repository supports supplying a dataset version ID, and it will make sure to get the data if it's not there yet. Next to that, this workflow also saves the used dataset ID as part of the task parameters, so you will always know for sure which data was used in which experiment!
+
+
+
+### Prepare Your Dataset
+
+The YOLOv5 repository supports a number of different datasets by using yaml files containing their information. By default datasets are downloaded to the `../datasets` folder in relation to the repository root folder. So if you downloaded the `coco128` dataset using the link in the yaml or with the scripts provided by yolov5, you get this folder structure:
+
+```
+..
+|_ yolov5
+|_ datasets
+ |_ coco128
+ |_ images
+ |_ labels
+ |_ LICENSE
+ |_ README.txt
+```
+
+But this can be any dataset you wish. Feel free to use your own, as long as you keep to this folder structure.
+
+Next, ⚠️**copy the corresponding yaml file to the root of the dataset folder**⚠️. This yaml files contains the information ClearML will need to properly use the dataset. You can make this yourself too, of course, just follow the structure of the example yamls.
+
+Basically we need the following keys: `path`, `train`, `test`, `val`, `nc`, `names`.
+
+```
+..
+|_ yolov5
+|_ datasets
+ |_ coco128
+ |_ images
+ |_ labels
+ |_ coco128.yaml # <---- HERE!
+ |_ LICENSE
+ |_ README.txt
+```
+
+### Upload Your Dataset
+
+To get this dataset into ClearML as a versioned dataset, go to the dataset root folder and run the following command:
+
+```bash
+cd coco128
+clearml-data sync --project YOLOv5 --name coco128 --folder .
+```
+
+The command `clearml-data sync` is actually a shorthand command. You could also run these commands one after the other:
+
+```bash
+# Optionally add --parent if you want to base
+# this version on another dataset version, so no duplicate files are uploaded!
+clearml-data create --name coco128 --project YOLOv5
+clearml-data add --files .
+clearml-data close
+```
+
+### Run Training Using A ClearML Dataset
+
+Now that you have a ClearML dataset, you can very simply use it to train custom YOLOv5 🚀 models!
+
+```bash
+python train.py --img 640 --batch 16 --epochs 3 --data clearml:// --weights yolov5s.pt --cache
+```
+
+
+
+## 👀 Hyperparameter Optimization
+
+Now that we have our experiments and data versioned, it's time to take a look at what we can build on top!
+
+Using the code information, installed packages and environment details, the experiment itself is now **completely reproducible**. In fact, ClearML allows you to clone an experiment and even change its parameters. We can then just rerun it with these new parameters automatically, this is basically what HPO does!
+
+To **run hyperparameter optimization locally**, we've included a pre-made script for you. Just make sure a training task has been run at least once, so it is in the ClearML experiment manager, we will essentially clone it and change its hyperparameters.
+
+You'll need to fill in the ID of this `template task` in the script found at `utils/loggers/clearml/hpo.py` and then just run it :) You can change `task.execute_locally()` to `task.execute()` to put it in a ClearML queue and have a remote agent work on it instead.
+
+```bash
+# To use optuna, install it first, otherwise you can change the optimizer to just be RandomSearch
+pip install optuna
+python utils/loggers/clearml/hpo.py
+```
+
+
+
+## 🤯 Remote Execution (advanced)
+
+Running HPO locally is really handy, but what if we want to run our experiments on a remote machine instead? Maybe you have access to a very powerful GPU machine on-site, or you have some budget to use cloud GPUs.
+This is where the ClearML Agent comes into play. Check out what the agent can do here:
+
+- [YouTube video](https://youtu.be/MX3BrXnaULs)
+- [Documentation](https://clear.ml/docs/latest/docs/clearml_agent)
+
+In short: every experiment tracked by the experiment manager contains enough information to reproduce it on a different machine (installed packages, uncommitted changes etc.). So a ClearML agent does just that: it listens to a queue for incoming tasks and when it finds one, it recreates the environment and runs it while still reporting scalars, plots etc. to the experiment manager.
+
+You can turn any machine (a cloud VM, a local GPU machine, your own laptop ... ) into a ClearML agent by simply running:
+
+```bash
+clearml-agent daemon --queue [--docker]
+```
+
+### Cloning, Editing And Enqueuing
+
+With our agent running, we can give it some work. Remember from the HPO section that we can clone a task and edit the hyperparameters? We can do that from the interface too!
+
+🪄 Clone the experiment by right-clicking it
+
+🎯 Edit the hyperparameters to what you wish them to be
+
+⏳ Enqueue the task to any of the queues by right-clicking it
+
+
+
+### Executing A Task Remotely
+
+Now you can clone a task like we explained above, or simply mark your current script by adding `task.execute_remotely()` and on execution it will be put into a queue, for the agent to start working on!
+
+To run the YOLOv5 training script remotely, all you have to do is add this line to the training.py script after the clearml logger has been instantiated:
+
+```python
+# ...
+# Loggers
+data_dict = None
+if RANK in {-1, 0}:
+ loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
+ if loggers.clearml:
+ loggers.clearml.task.execute_remotely(queue="my_queue") # <------ ADD THIS LINE
+ # Data_dict is either None is user did not choose for ClearML dataset or is filled in by ClearML
+ data_dict = loggers.clearml.data_dict
+# ...
+```
+
+When running the training script after this change, python will run the script up until that line, after which it will package the code and send it to the queue instead!
+
+### Autoscaling workers
+
+ClearML comes with autoscalers too! This tool will automatically spin up new remote machines in the cloud of your choice (AWS, GCP, Azure) and turn them into ClearML agents for you whenever there are experiments detected in the queue. Once the tasks are processed, the autoscaler will automatically shut down the remote machines, and you stop paying!
+
+Check out the autoscalers getting started video below.
+
+[](https://youtu.be/j4XVMAaUt3E)
diff --git a/yolov5/utils/loggers/clearml/__init__.py b/yolov5/utils/loggers/clearml/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/yolov5/utils/loggers/clearml/__pycache__/__init__.cpython-38.pyc b/yolov5/utils/loggers/clearml/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ff31ea920b3519ce737dea9067632528404f3f3e
Binary files /dev/null and b/yolov5/utils/loggers/clearml/__pycache__/__init__.cpython-38.pyc differ
diff --git a/yolov5/utils/loggers/clearml/__pycache__/clearml_utils.cpython-38.pyc b/yolov5/utils/loggers/clearml/__pycache__/clearml_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..61bf8081cb2b7c54cc093ea349e9bceee3b22805
Binary files /dev/null and b/yolov5/utils/loggers/clearml/__pycache__/clearml_utils.cpython-38.pyc differ
diff --git a/yolov5/utils/loggers/clearml/clearml_utils.py b/yolov5/utils/loggers/clearml/clearml_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..2764abe90da80a7b270bca9c0fd89b99ec25af3b
--- /dev/null
+++ b/yolov5/utils/loggers/clearml/clearml_utils.py
@@ -0,0 +1,164 @@
+"""Main Logger class for ClearML experiment tracking."""
+import glob
+import re
+from pathlib import Path
+
+import numpy as np
+import yaml
+
+from utils.plots import Annotator, colors
+
+try:
+ import clearml
+ from clearml import Dataset, Task
+
+ assert hasattr(clearml, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ clearml = None
+
+
+def construct_dataset(clearml_info_string):
+ """Load in a clearml dataset and fill the internal data_dict with its contents.
+ """
+ dataset_id = clearml_info_string.replace('clearml://', '')
+ dataset = Dataset.get(dataset_id=dataset_id)
+ dataset_root_path = Path(dataset.get_local_copy())
+
+ # We'll search for the yaml file definition in the dataset
+ yaml_filenames = list(glob.glob(str(dataset_root_path / '*.yaml')) + glob.glob(str(dataset_root_path / '*.yml')))
+ if len(yaml_filenames) > 1:
+ raise ValueError('More than one yaml file was found in the dataset root, cannot determine which one contains '
+ 'the dataset definition this way.')
+ elif len(yaml_filenames) == 0:
+ raise ValueError('No yaml definition found in dataset root path, check that there is a correct yaml file '
+ 'inside the dataset root path.')
+ with open(yaml_filenames[0]) as f:
+ dataset_definition = yaml.safe_load(f)
+
+ assert set(dataset_definition.keys()).issuperset(
+ {'train', 'test', 'val', 'nc', 'names'}
+ ), "The right keys were not found in the yaml file, make sure it at least has the following keys: ('train', 'test', 'val', 'nc', 'names')"
+
+ data_dict = dict()
+ data_dict['train'] = str(
+ (dataset_root_path / dataset_definition['train']).resolve()) if dataset_definition['train'] else None
+ data_dict['test'] = str(
+ (dataset_root_path / dataset_definition['test']).resolve()) if dataset_definition['test'] else None
+ data_dict['val'] = str(
+ (dataset_root_path / dataset_definition['val']).resolve()) if dataset_definition['val'] else None
+ data_dict['nc'] = dataset_definition['nc']
+ data_dict['names'] = dataset_definition['names']
+
+ return data_dict
+
+
+class ClearmlLogger:
+ """Log training runs, datasets, models, and predictions to ClearML.
+
+ This logger sends information to ClearML at app.clear.ml or to your own hosted server. By default,
+ this information includes hyperparameters, system configuration and metrics, model metrics, code information and
+ basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+ """
+
+ def __init__(self, opt, hyp):
+ """
+ - Initialize ClearML Task, this object will capture the experiment
+ - Upload dataset version to ClearML Data if opt.upload_dataset is True
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ hyp (dict) -- Hyperparameters for this run
+
+ """
+ self.current_epoch = 0
+ # Keep tracked of amount of logged images to enforce a limit
+ self.current_epoch_logged_images = set()
+ # Maximum number of images to log to clearML per epoch
+ self.max_imgs_to_log_per_epoch = 16
+ # Get the interval of epochs when bounding box images should be logged
+ self.bbox_interval = opt.bbox_interval
+ self.clearml = clearml
+ self.task = None
+ self.data_dict = None
+ if self.clearml:
+ self.task = Task.init(
+ project_name=opt.project if opt.project != 'runs/train' else 'YOLOv5',
+ task_name=opt.name if opt.name != 'exp' else 'Training',
+ tags=['YOLOv5'],
+ output_uri=True,
+ reuse_last_task_id=opt.exist_ok,
+ auto_connect_frameworks={'pytorch': False}
+ # We disconnect pytorch auto-detection, because we added manual model save points in the code
+ )
+ # ClearML's hooks will already grab all general parameters
+ # Only the hyperparameters coming from the yaml config file
+ # will have to be added manually!
+ self.task.connect(hyp, name='Hyperparameters')
+ self.task.connect(opt, name='Args')
+
+ # Make sure the code is easily remotely runnable by setting the docker image to use by the remote agent
+ self.task.set_base_docker('ultralytics/yolov5:latest',
+ docker_arguments='--ipc=host -e="CLEARML_AGENT_SKIP_PYTHON_ENV_INSTALL=1"',
+ docker_setup_bash_script='pip install clearml')
+
+ # Get ClearML Dataset Version if requested
+ if opt.data.startswith('clearml://'):
+ # data_dict should have the following keys:
+ # names, nc (number of classes), test, train, val (all three relative paths to ../datasets)
+ self.data_dict = construct_dataset(opt.data)
+ # Set data to data_dict because wandb will crash without this information and opt is the best way
+ # to give it to them
+ opt.data = self.data_dict
+
+ def log_debug_samples(self, files, title='Debug Samples'):
+ """
+ Log files (images) as debug samples in the ClearML task.
+
+ arguments:
+ files (List(PosixPath)) a list of file paths in PosixPath format
+ title (str) A title that groups together images with the same values
+ """
+ for f in files:
+ if f.exists():
+ it = re.search(r'_batch(\d+)', f.name)
+ iteration = int(it.groups()[0]) if it else 0
+ self.task.get_logger().report_image(title=title,
+ series=f.name.replace(it.group(), ''),
+ local_path=str(f),
+ iteration=iteration)
+
+ def log_image_with_boxes(self, image_path, boxes, class_names, image, conf_threshold=0.25):
+ """
+ Draw the bounding boxes on a single image and report the result as a ClearML debug sample.
+
+ arguments:
+ image_path (PosixPath) the path the original image file
+ boxes (list): list of scaled predictions in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ class_names (dict): dict containing mapping of class int to class name
+ image (Tensor): A torch tensor containing the actual image data
+ """
+ if len(self.current_epoch_logged_images) < self.max_imgs_to_log_per_epoch and self.current_epoch >= 0:
+ # Log every bbox_interval times and deduplicate for any intermittend extra eval runs
+ if self.current_epoch % self.bbox_interval == 0 and image_path not in self.current_epoch_logged_images:
+ im = np.ascontiguousarray(np.moveaxis(image.mul(255).clamp(0, 255).byte().cpu().numpy(), 0, 2))
+ annotator = Annotator(im=im, pil=True)
+ for i, (conf, class_nr, box) in enumerate(zip(boxes[:, 4], boxes[:, 5], boxes[:, :4])):
+ color = colors(i)
+
+ class_name = class_names[int(class_nr)]
+ confidence_percentage = round(float(conf) * 100, 2)
+ label = f'{class_name}: {confidence_percentage}%'
+
+ if conf > conf_threshold:
+ annotator.rectangle(box.cpu().numpy(), outline=color)
+ annotator.box_label(box.cpu().numpy(), label=label, color=color)
+
+ annotated_image = annotator.result()
+ self.task.get_logger().report_image(title='Bounding Boxes',
+ series=image_path.name,
+ iteration=self.current_epoch,
+ image=annotated_image)
+ self.current_epoch_logged_images.add(image_path)
diff --git a/yolov5/utils/loggers/clearml/hpo.py b/yolov5/utils/loggers/clearml/hpo.py
new file mode 100644
index 0000000000000000000000000000000000000000..ee518b0fbfc89ee811b51bbf85341eee4f685be1
--- /dev/null
+++ b/yolov5/utils/loggers/clearml/hpo.py
@@ -0,0 +1,84 @@
+from clearml import Task
+# Connecting ClearML with the current process,
+# from here on everything is logged automatically
+from clearml.automation import HyperParameterOptimizer, UniformParameterRange
+from clearml.automation.optuna import OptimizerOptuna
+
+task = Task.init(project_name='Hyper-Parameter Optimization',
+ task_name='YOLOv5',
+ task_type=Task.TaskTypes.optimizer,
+ reuse_last_task_id=False)
+
+# Example use case:
+optimizer = HyperParameterOptimizer(
+ # This is the experiment we want to optimize
+ base_task_id='',
+ # here we define the hyper-parameters to optimize
+ # Notice: The parameter name should exactly match what you see in the UI: /
+ # For Example, here we see in the base experiment a section Named: "General"
+ # under it a parameter named "batch_size", this becomes "General/batch_size"
+ # If you have `argparse` for example, then arguments will appear under the "Args" section,
+ # and you should instead pass "Args/batch_size"
+ hyper_parameters=[
+ UniformParameterRange('Hyperparameters/lr0', min_value=1e-5, max_value=1e-1),
+ UniformParameterRange('Hyperparameters/lrf', min_value=0.01, max_value=1.0),
+ UniformParameterRange('Hyperparameters/momentum', min_value=0.6, max_value=0.98),
+ UniformParameterRange('Hyperparameters/weight_decay', min_value=0.0, max_value=0.001),
+ UniformParameterRange('Hyperparameters/warmup_epochs', min_value=0.0, max_value=5.0),
+ UniformParameterRange('Hyperparameters/warmup_momentum', min_value=0.0, max_value=0.95),
+ UniformParameterRange('Hyperparameters/warmup_bias_lr', min_value=0.0, max_value=0.2),
+ UniformParameterRange('Hyperparameters/box', min_value=0.02, max_value=0.2),
+ UniformParameterRange('Hyperparameters/cls', min_value=0.2, max_value=4.0),
+ UniformParameterRange('Hyperparameters/cls_pw', min_value=0.5, max_value=2.0),
+ UniformParameterRange('Hyperparameters/obj', min_value=0.2, max_value=4.0),
+ UniformParameterRange('Hyperparameters/obj_pw', min_value=0.5, max_value=2.0),
+ UniformParameterRange('Hyperparameters/iou_t', min_value=0.1, max_value=0.7),
+ UniformParameterRange('Hyperparameters/anchor_t', min_value=2.0, max_value=8.0),
+ UniformParameterRange('Hyperparameters/fl_gamma', min_value=0.0, max_value=4.0),
+ UniformParameterRange('Hyperparameters/hsv_h', min_value=0.0, max_value=0.1),
+ UniformParameterRange('Hyperparameters/hsv_s', min_value=0.0, max_value=0.9),
+ UniformParameterRange('Hyperparameters/hsv_v', min_value=0.0, max_value=0.9),
+ UniformParameterRange('Hyperparameters/degrees', min_value=0.0, max_value=45.0),
+ UniformParameterRange('Hyperparameters/translate', min_value=0.0, max_value=0.9),
+ UniformParameterRange('Hyperparameters/scale', min_value=0.0, max_value=0.9),
+ UniformParameterRange('Hyperparameters/shear', min_value=0.0, max_value=10.0),
+ UniformParameterRange('Hyperparameters/perspective', min_value=0.0, max_value=0.001),
+ UniformParameterRange('Hyperparameters/flipud', min_value=0.0, max_value=1.0),
+ UniformParameterRange('Hyperparameters/fliplr', min_value=0.0, max_value=1.0),
+ UniformParameterRange('Hyperparameters/mosaic', min_value=0.0, max_value=1.0),
+ UniformParameterRange('Hyperparameters/mixup', min_value=0.0, max_value=1.0),
+ UniformParameterRange('Hyperparameters/copy_paste', min_value=0.0, max_value=1.0)],
+ # this is the objective metric we want to maximize/minimize
+ objective_metric_title='metrics',
+ objective_metric_series='mAP_0.5',
+ # now we decide if we want to maximize it or minimize it (accuracy we maximize)
+ objective_metric_sign='max',
+ # let us limit the number of concurrent experiments,
+ # this in turn will make sure we do dont bombard the scheduler with experiments.
+ # if we have an auto-scaler connected, this, by proxy, will limit the number of machine
+ max_number_of_concurrent_tasks=1,
+ # this is the optimizer class (actually doing the optimization)
+ # Currently, we can choose from GridSearch, RandomSearch or OptimizerBOHB (Bayesian optimization Hyper-Band)
+ optimizer_class=OptimizerOptuna,
+ # If specified only the top K performing Tasks will be kept, the others will be automatically archived
+ save_top_k_tasks_only=5, # 5,
+ compute_time_limit=None,
+ total_max_jobs=20,
+ min_iteration_per_job=None,
+ max_iteration_per_job=None,
+)
+
+# report every 10 seconds, this is way too often, but we are testing here
+optimizer.set_report_period(10 / 60)
+# You can also use the line below instead to run all the optimizer tasks locally, without using queues or agent
+# an_optimizer.start_locally(job_complete_callback=job_complete_callback)
+# set the time limit for the optimization process (2 hours)
+optimizer.set_time_limit(in_minutes=120.0)
+# Start the optimization process in the local environment
+optimizer.start_locally()
+# wait until process is done (notice we are controlling the optimization process in the background)
+optimizer.wait()
+# make sure background optimization stopped
+optimizer.stop()
+
+print('We are done, good bye')
diff --git a/yolov5/utils/loggers/comet/README.md b/yolov5/utils/loggers/comet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..aee8d16a336c1bff89bfc0c1679dcb6ee8751a48
--- /dev/null
+++ b/yolov5/utils/loggers/comet/README.md
@@ -0,0 +1,258 @@
+ +
+# YOLOv5 with Comet
+
+This guide will cover how to use YOLOv5 with [Comet](https://bit.ly/yolov5-readme-comet2)
+
+# About Comet
+
+Comet builds tools that help data scientists, engineers, and team leaders accelerate and optimize machine learning and deep learning models.
+
+Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://www.comet.com/docs/v2/guides/comet-dashboard/code-panels/about-panels/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)!
+Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
+
+# Getting Started
+
+## Install Comet
+
+```shell
+pip install comet_ml
+```
+
+## Configure Comet Credentials
+
+There are two ways to configure Comet with YOLOv5.
+
+You can either set your credentials through environment variables
+
+**Environment Variables**
+
+```shell
+export COMET_API_KEY=
+export COMET_PROJECT_NAME= # This will default to 'yolov5'
+```
+
+Or create a `.comet.config` file in your working directory and set your credentials there.
+
+**Comet Configuration File**
+
+```
+[comet]
+api_key=
+project_name= # This will default to 'yolov5'
+```
+
+## Run the Training Script
+
+```shell
+# Train YOLOv5s on COCO128 for 5 epochs
+python train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov5s.pt
+```
+
+That's it! Comet will automatically log your hyperparameters, command line arguments, training and validation metrics. You can visualize and analyze your runs in the Comet UI
+
+
+
+# YOLOv5 with Comet
+
+This guide will cover how to use YOLOv5 with [Comet](https://bit.ly/yolov5-readme-comet2)
+
+# About Comet
+
+Comet builds tools that help data scientists, engineers, and team leaders accelerate and optimize machine learning and deep learning models.
+
+Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://www.comet.com/docs/v2/guides/comet-dashboard/code-panels/about-panels/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)!
+Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
+
+# Getting Started
+
+## Install Comet
+
+```shell
+pip install comet_ml
+```
+
+## Configure Comet Credentials
+
+There are two ways to configure Comet with YOLOv5.
+
+You can either set your credentials through environment variables
+
+**Environment Variables**
+
+```shell
+export COMET_API_KEY=
+export COMET_PROJECT_NAME= # This will default to 'yolov5'
+```
+
+Or create a `.comet.config` file in your working directory and set your credentials there.
+
+**Comet Configuration File**
+
+```
+[comet]
+api_key=
+project_name= # This will default to 'yolov5'
+```
+
+## Run the Training Script
+
+```shell
+# Train YOLOv5s on COCO128 for 5 epochs
+python train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov5s.pt
+```
+
+That's it! Comet will automatically log your hyperparameters, command line arguments, training and validation metrics. You can visualize and analyze your runs in the Comet UI
+
+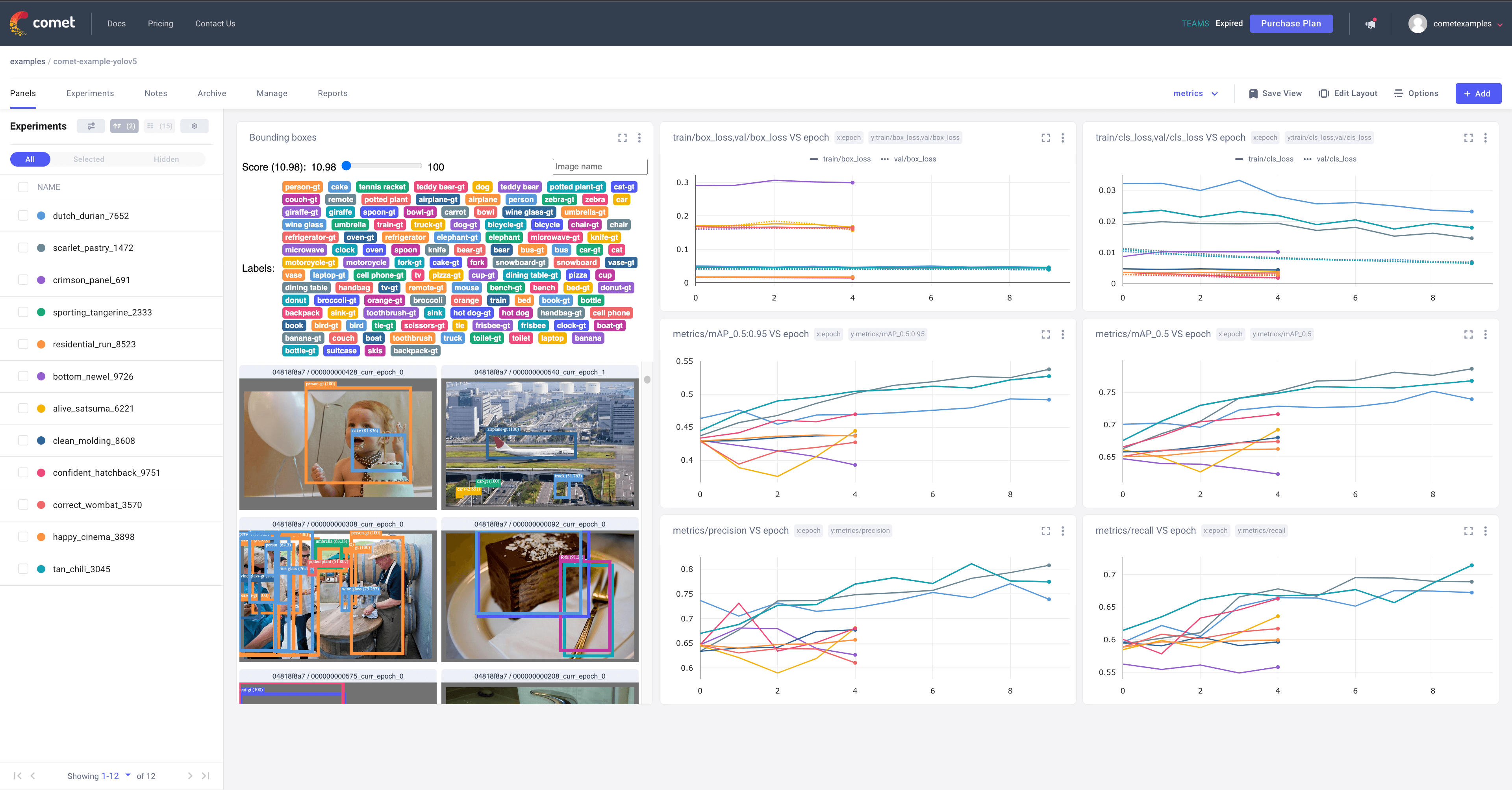 +
+# Try out an Example!
+
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+Or better yet, try it out yourself in this Colab Notebook
+
+[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
+
+# Log automatically
+
+By default, Comet will log the following items
+
+## Metrics
+
+- Box Loss, Object Loss, Classification Loss for the training and validation data
+- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
+- Precision and Recall for the validation data
+
+## Parameters
+
+- Model Hyperparameters
+- All parameters passed through the command line options
+
+## Visualizations
+
+- Confusion Matrix of the model predictions on the validation data
+- Plots for the PR and F1 curves across all classes
+- Correlogram of the Class Labels
+
+# Configure Comet Logging
+
+Comet can be configured to log additional data either through command line flags passed to the training script
+or through environment variables.
+
+```shell
+export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
+export COMET_MODEL_NAME= #Set the name for the saved model. Defaults to yolov5
+export COMET_LOG_CONFUSION_MATRIX=false # Set to disable logging a Comet Confusion Matrix. Defaults to true
+export COMET_MAX_IMAGE_UPLOADS= # Controls how many total image predictions to log to Comet. Defaults to 100.
+export COMET_LOG_PER_CLASS_METRICS=true # Set to log evaluation metrics for each detected class at the end of training. Defaults to false
+export COMET_DEFAULT_CHECKPOINT_FILENAME= # Set this if you would like to resume training from a different checkpoint. Defaults to 'last.pt'
+export COMET_LOG_BATCH_LEVEL_METRICS=true # Set this if you would like to log training metrics at the batch level. Defaults to false.
+export COMET_LOG_PREDICTIONS=true # Set this to false to disable logging model predictions
+```
+
+## Logging Checkpoints with Comet
+
+Logging Models to Comet is disabled by default. To enable it, pass the `save-period` argument to the training script. This will save the
+logged checkpoints to Comet based on the interval value provided by `save-period`
+
+```shell
+python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data coco128.yaml \
+--weights yolov5s.pt \
+--save-period 1
+```
+
+## Logging Model Predictions
+
+By default, model predictions (images, ground truth labels and bounding boxes) will be logged to Comet.
+
+You can control the frequency of logged predictions and the associated images by passing the `bbox_interval` command line argument. Predictions can be visualized using Comet's Object Detection Custom Panel. This frequency corresponds to every Nth batch of data per epoch. In the example below, we are logging every 2nd batch of data for each epoch.
+
+**Note:** The YOLOv5 validation dataloader will default to a batch size of 32, so you will have to set the logging frequency accordingly.
+
+Here is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+```shell
+python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data coco128.yaml \
+--weights yolov5s.pt \
+--bbox_interval 2
+```
+
+### Controlling the number of Prediction Images logged to Comet
+
+When logging predictions from YOLOv5, Comet will log the images associated with each set of predictions. By default a maximum of 100 validation images are logged. You can increase or decrease this number using the `COMET_MAX_IMAGE_UPLOADS` environment variable.
+
+```shell
+env COMET_MAX_IMAGE_UPLOADS=200 python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data coco128.yaml \
+--weights yolov5s.pt \
+--bbox_interval 1
+```
+
+### Logging Class Level Metrics
+
+Use the `COMET_LOG_PER_CLASS_METRICS` environment variable to log mAP, precision, recall, f1 for each class.
+
+```shell
+env COMET_LOG_PER_CLASS_METRICS=true python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data coco128.yaml \
+--weights yolov5s.pt
+```
+
+## Uploading a Dataset to Comet Artifacts
+
+If you would like to store your data using [Comet Artifacts](https://www.comet.com/docs/v2/guides/data-management/using-artifacts/#learn-more?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github), you can do so using the `upload_dataset` flag.
+
+The dataset be organized in the way described in the [YOLOv5 documentation](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/). The dataset config `yaml` file must follow the same format as that of the `coco128.yaml` file.
+
+```shell
+python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data coco128.yaml \
+--weights yolov5s.pt \
+--upload_dataset
+```
+
+You can find the uploaded dataset in the Artifacts tab in your Comet Workspace
+
+
+# Try out an Example!
+
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+Or better yet, try it out yourself in this Colab Notebook
+
+[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
+
+# Log automatically
+
+By default, Comet will log the following items
+
+## Metrics
+
+- Box Loss, Object Loss, Classification Loss for the training and validation data
+- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
+- Precision and Recall for the validation data
+
+## Parameters
+
+- Model Hyperparameters
+- All parameters passed through the command line options
+
+## Visualizations
+
+- Confusion Matrix of the model predictions on the validation data
+- Plots for the PR and F1 curves across all classes
+- Correlogram of the Class Labels
+
+# Configure Comet Logging
+
+Comet can be configured to log additional data either through command line flags passed to the training script
+or through environment variables.
+
+```shell
+export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
+export COMET_MODEL_NAME= #Set the name for the saved model. Defaults to yolov5
+export COMET_LOG_CONFUSION_MATRIX=false # Set to disable logging a Comet Confusion Matrix. Defaults to true
+export COMET_MAX_IMAGE_UPLOADS= # Controls how many total image predictions to log to Comet. Defaults to 100.
+export COMET_LOG_PER_CLASS_METRICS=true # Set to log evaluation metrics for each detected class at the end of training. Defaults to false
+export COMET_DEFAULT_CHECKPOINT_FILENAME= # Set this if you would like to resume training from a different checkpoint. Defaults to 'last.pt'
+export COMET_LOG_BATCH_LEVEL_METRICS=true # Set this if you would like to log training metrics at the batch level. Defaults to false.
+export COMET_LOG_PREDICTIONS=true # Set this to false to disable logging model predictions
+```
+
+## Logging Checkpoints with Comet
+
+Logging Models to Comet is disabled by default. To enable it, pass the `save-period` argument to the training script. This will save the
+logged checkpoints to Comet based on the interval value provided by `save-period`
+
+```shell
+python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data coco128.yaml \
+--weights yolov5s.pt \
+--save-period 1
+```
+
+## Logging Model Predictions
+
+By default, model predictions (images, ground truth labels and bounding boxes) will be logged to Comet.
+
+You can control the frequency of logged predictions and the associated images by passing the `bbox_interval` command line argument. Predictions can be visualized using Comet's Object Detection Custom Panel. This frequency corresponds to every Nth batch of data per epoch. In the example below, we are logging every 2nd batch of data for each epoch.
+
+**Note:** The YOLOv5 validation dataloader will default to a batch size of 32, so you will have to set the logging frequency accordingly.
+
+Here is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+```shell
+python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data coco128.yaml \
+--weights yolov5s.pt \
+--bbox_interval 2
+```
+
+### Controlling the number of Prediction Images logged to Comet
+
+When logging predictions from YOLOv5, Comet will log the images associated with each set of predictions. By default a maximum of 100 validation images are logged. You can increase or decrease this number using the `COMET_MAX_IMAGE_UPLOADS` environment variable.
+
+```shell
+env COMET_MAX_IMAGE_UPLOADS=200 python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data coco128.yaml \
+--weights yolov5s.pt \
+--bbox_interval 1
+```
+
+### Logging Class Level Metrics
+
+Use the `COMET_LOG_PER_CLASS_METRICS` environment variable to log mAP, precision, recall, f1 for each class.
+
+```shell
+env COMET_LOG_PER_CLASS_METRICS=true python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data coco128.yaml \
+--weights yolov5s.pt
+```
+
+## Uploading a Dataset to Comet Artifacts
+
+If you would like to store your data using [Comet Artifacts](https://www.comet.com/docs/v2/guides/data-management/using-artifacts/#learn-more?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github), you can do so using the `upload_dataset` flag.
+
+The dataset be organized in the way described in the [YOLOv5 documentation](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/). The dataset config `yaml` file must follow the same format as that of the `coco128.yaml` file.
+
+```shell
+python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data coco128.yaml \
+--weights yolov5s.pt \
+--upload_dataset
+```
+
+You can find the uploaded dataset in the Artifacts tab in your Comet Workspace
+ +
+You can preview the data directly in the Comet UI.
+
+
+You can preview the data directly in the Comet UI.
+ +
+Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
+
+
+Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
+ +
+### Using a saved Artifact
+
+If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
+
+```
+# contents of artifact.yaml file
+path: "comet:///:"
+```
+
+Then pass this file to your training script in the following way
+
+```shell
+python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data artifact.yaml \
+--weights yolov5s.pt
+```
+
+Artifacts also allow you to track the lineage of data as it flows through your Experimentation workflow. Here you can see a graph that shows you all the experiments that have used your uploaded dataset.
+
+
+### Using a saved Artifact
+
+If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
+
+```
+# contents of artifact.yaml file
+path: "comet:///:"
+```
+
+Then pass this file to your training script in the following way
+
+```shell
+python train.py \
+--img 640 \
+--batch 16 \
+--epochs 5 \
+--data artifact.yaml \
+--weights yolov5s.pt
+```
+
+Artifacts also allow you to track the lineage of data as it flows through your Experimentation workflow. Here you can see a graph that shows you all the experiments that have used your uploaded dataset.
+ +
+## Resuming a Training Run
+
+If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
+
+The Run Path has the following format `comet:////`.
+
+This will restore the run to its state before the interruption, which includes restoring the model from a checkpoint, restoring all hyperparameters and training arguments and downloading Comet dataset Artifacts if they were used in the original run. The resumed run will continue logging to the existing Experiment in the Comet UI
+
+```shell
+python train.py \
+--resume "comet://"
+```
+
+## Hyperparameter Search with the Comet Optimizer
+
+YOLOv5 is also integrated with Comet's Optimizer, making is simple to visualize hyperparameter sweeps in the Comet UI.
+
+### Configuring an Optimizer Sweep
+
+To configure the Comet Optimizer, you will have to create a JSON file with the information about the sweep. An example file has been provided in `utils/loggers/comet/optimizer_config.json`
+
+```shell
+python utils/loggers/comet/hpo.py \
+ --comet_optimizer_config "utils/loggers/comet/optimizer_config.json"
+```
+
+The `hpo.py` script accepts the same arguments as `train.py`. If you wish to pass additional arguments to your sweep simply add them after
+the script.
+
+```shell
+python utils/loggers/comet/hpo.py \
+ --comet_optimizer_config "utils/loggers/comet/optimizer_config.json" \
+ --save-period 1 \
+ --bbox_interval 1
+```
+
+### Running a Sweep in Parallel
+
+```shell
+comet optimizer -j utils/loggers/comet/hpo.py \
+ utils/loggers/comet/optimizer_config.json"
+```
+
+### Visualizing Results
+
+Comet provides a number of ways to visualize the results of your sweep. Take a look at a [project with a completed sweep here](https://www.comet.com/examples/comet-example-yolov5/view/PrlArHGuuhDTKC1UuBmTtOSXD/panels?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+
+
+## Resuming a Training Run
+
+If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
+
+The Run Path has the following format `comet:////`.
+
+This will restore the run to its state before the interruption, which includes restoring the model from a checkpoint, restoring all hyperparameters and training arguments and downloading Comet dataset Artifacts if they were used in the original run. The resumed run will continue logging to the existing Experiment in the Comet UI
+
+```shell
+python train.py \
+--resume "comet://"
+```
+
+## Hyperparameter Search with the Comet Optimizer
+
+YOLOv5 is also integrated with Comet's Optimizer, making is simple to visualize hyperparameter sweeps in the Comet UI.
+
+### Configuring an Optimizer Sweep
+
+To configure the Comet Optimizer, you will have to create a JSON file with the information about the sweep. An example file has been provided in `utils/loggers/comet/optimizer_config.json`
+
+```shell
+python utils/loggers/comet/hpo.py \
+ --comet_optimizer_config "utils/loggers/comet/optimizer_config.json"
+```
+
+The `hpo.py` script accepts the same arguments as `train.py`. If you wish to pass additional arguments to your sweep simply add them after
+the script.
+
+```shell
+python utils/loggers/comet/hpo.py \
+ --comet_optimizer_config "utils/loggers/comet/optimizer_config.json" \
+ --save-period 1 \
+ --bbox_interval 1
+```
+
+### Running a Sweep in Parallel
+
+```shell
+comet optimizer -j utils/loggers/comet/hpo.py \
+ utils/loggers/comet/optimizer_config.json"
+```
+
+### Visualizing Results
+
+Comet provides a number of ways to visualize the results of your sweep. Take a look at a [project with a completed sweep here](https://www.comet.com/examples/comet-example-yolov5/view/PrlArHGuuhDTKC1UuBmTtOSXD/panels?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+ diff --git a/yolov5/utils/loggers/comet/__init__.py b/yolov5/utils/loggers/comet/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d4599841c9fc4df3e9ad4bf847f8bd13c3a9175d
--- /dev/null
+++ b/yolov5/utils/loggers/comet/__init__.py
@@ -0,0 +1,508 @@
+import glob
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+try:
+ import comet_ml
+
+ # Project Configuration
+ config = comet_ml.config.get_config()
+ COMET_PROJECT_NAME = config.get_string(os.getenv('COMET_PROJECT_NAME'), 'comet.project_name', default='yolov5')
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+ COMET_PROJECT_NAME = None
+
+import PIL
+import torch
+import torchvision.transforms as T
+import yaml
+
+from utils.dataloaders import img2label_paths
+from utils.general import check_dataset, scale_boxes, xywh2xyxy
+from utils.metrics import box_iou
+
+COMET_PREFIX = 'comet://'
+
+COMET_MODE = os.getenv('COMET_MODE', 'online')
+
+# Model Saving Settings
+COMET_MODEL_NAME = os.getenv('COMET_MODEL_NAME', 'yolov5')
+
+# Dataset Artifact Settings
+COMET_UPLOAD_DATASET = os.getenv('COMET_UPLOAD_DATASET', 'false').lower() == 'true'
+
+# Evaluation Settings
+COMET_LOG_CONFUSION_MATRIX = os.getenv('COMET_LOG_CONFUSION_MATRIX', 'true').lower() == 'true'
+COMET_LOG_PREDICTIONS = os.getenv('COMET_LOG_PREDICTIONS', 'true').lower() == 'true'
+COMET_MAX_IMAGE_UPLOADS = int(os.getenv('COMET_MAX_IMAGE_UPLOADS', 100))
+
+# Confusion Matrix Settings
+CONF_THRES = float(os.getenv('CONF_THRES', 0.001))
+IOU_THRES = float(os.getenv('IOU_THRES', 0.6))
+
+# Batch Logging Settings
+COMET_LOG_BATCH_METRICS = os.getenv('COMET_LOG_BATCH_METRICS', 'false').lower() == 'true'
+COMET_BATCH_LOGGING_INTERVAL = os.getenv('COMET_BATCH_LOGGING_INTERVAL', 1)
+COMET_PREDICTION_LOGGING_INTERVAL = os.getenv('COMET_PREDICTION_LOGGING_INTERVAL', 1)
+COMET_LOG_PER_CLASS_METRICS = os.getenv('COMET_LOG_PER_CLASS_METRICS', 'false').lower() == 'true'
+
+RANK = int(os.getenv('RANK', -1))
+
+to_pil = T.ToPILImage()
+
+
+class CometLogger:
+ """Log metrics, parameters, source code, models and much more
+ with Comet
+ """
+
+ def __init__(self, opt, hyp, run_id=None, job_type='Training', **experiment_kwargs) -> None:
+ self.job_type = job_type
+ self.opt = opt
+ self.hyp = hyp
+
+ # Comet Flags
+ self.comet_mode = COMET_MODE
+
+ self.save_model = opt.save_period > -1
+ self.model_name = COMET_MODEL_NAME
+
+ # Batch Logging Settings
+ self.log_batch_metrics = COMET_LOG_BATCH_METRICS
+ self.comet_log_batch_interval = COMET_BATCH_LOGGING_INTERVAL
+
+ # Dataset Artifact Settings
+ self.upload_dataset = self.opt.upload_dataset if self.opt.upload_dataset else COMET_UPLOAD_DATASET
+ self.resume = self.opt.resume
+
+ # Default parameters to pass to Experiment objects
+ self.default_experiment_kwargs = {
+ 'log_code': False,
+ 'log_env_gpu': True,
+ 'log_env_cpu': True,
+ 'project_name': COMET_PROJECT_NAME,}
+ self.default_experiment_kwargs.update(experiment_kwargs)
+ self.experiment = self._get_experiment(self.comet_mode, run_id)
+
+ self.data_dict = self.check_dataset(self.opt.data)
+ self.class_names = self.data_dict['names']
+ self.num_classes = self.data_dict['nc']
+
+ self.logged_images_count = 0
+ self.max_images = COMET_MAX_IMAGE_UPLOADS
+
+ if run_id is None:
+ self.experiment.log_other('Created from', 'YOLOv5')
+ if not isinstance(self.experiment, comet_ml.OfflineExperiment):
+ workspace, project_name, experiment_id = self.experiment.url.split('/')[-3:]
+ self.experiment.log_other(
+ 'Run Path',
+ f'{workspace}/{project_name}/{experiment_id}',
+ )
+ self.log_parameters(vars(opt))
+ self.log_parameters(self.opt.hyp)
+ self.log_asset_data(
+ self.opt.hyp,
+ name='hyperparameters.json',
+ metadata={'type': 'hyp-config-file'},
+ )
+ self.log_asset(
+ f'{self.opt.save_dir}/opt.yaml',
+ metadata={'type': 'opt-config-file'},
+ )
+
+ self.comet_log_confusion_matrix = COMET_LOG_CONFUSION_MATRIX
+
+ if hasattr(self.opt, 'conf_thres'):
+ self.conf_thres = self.opt.conf_thres
+ else:
+ self.conf_thres = CONF_THRES
+ if hasattr(self.opt, 'iou_thres'):
+ self.iou_thres = self.opt.iou_thres
+ else:
+ self.iou_thres = IOU_THRES
+
+ self.log_parameters({'val_iou_threshold': self.iou_thres, 'val_conf_threshold': self.conf_thres})
+
+ self.comet_log_predictions = COMET_LOG_PREDICTIONS
+ if self.opt.bbox_interval == -1:
+ self.comet_log_prediction_interval = 1 if self.opt.epochs < 10 else self.opt.epochs // 10
+ else:
+ self.comet_log_prediction_interval = self.opt.bbox_interval
+
+ if self.comet_log_predictions:
+ self.metadata_dict = {}
+ self.logged_image_names = []
+
+ self.comet_log_per_class_metrics = COMET_LOG_PER_CLASS_METRICS
+
+ self.experiment.log_others({
+ 'comet_mode': COMET_MODE,
+ 'comet_max_image_uploads': COMET_MAX_IMAGE_UPLOADS,
+ 'comet_log_per_class_metrics': COMET_LOG_PER_CLASS_METRICS,
+ 'comet_log_batch_metrics': COMET_LOG_BATCH_METRICS,
+ 'comet_log_confusion_matrix': COMET_LOG_CONFUSION_MATRIX,
+ 'comet_model_name': COMET_MODEL_NAME,})
+
+ # Check if running the Experiment with the Comet Optimizer
+ if hasattr(self.opt, 'comet_optimizer_id'):
+ self.experiment.log_other('optimizer_id', self.opt.comet_optimizer_id)
+ self.experiment.log_other('optimizer_objective', self.opt.comet_optimizer_objective)
+ self.experiment.log_other('optimizer_metric', self.opt.comet_optimizer_metric)
+ self.experiment.log_other('optimizer_parameters', json.dumps(self.hyp))
+
+ def _get_experiment(self, mode, experiment_id=None):
+ if mode == 'offline':
+ if experiment_id is not None:
+ return comet_ml.ExistingOfflineExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.OfflineExperiment(**self.default_experiment_kwargs,)
+
+ else:
+ try:
+ if experiment_id is not None:
+ return comet_ml.ExistingExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.Experiment(**self.default_experiment_kwargs)
+
+ except ValueError:
+ logger.warning('COMET WARNING: '
+ 'Comet credentials have not been set. '
+ 'Comet will default to offline logging. '
+ 'Please set your credentials to enable online logging.')
+ return self._get_experiment('offline', experiment_id)
+
+ return
+
+ def log_metrics(self, log_dict, **kwargs):
+ self.experiment.log_metrics(log_dict, **kwargs)
+
+ def log_parameters(self, log_dict, **kwargs):
+ self.experiment.log_parameters(log_dict, **kwargs)
+
+ def log_asset(self, asset_path, **kwargs):
+ self.experiment.log_asset(asset_path, **kwargs)
+
+ def log_asset_data(self, asset, **kwargs):
+ self.experiment.log_asset_data(asset, **kwargs)
+
+ def log_image(self, img, **kwargs):
+ self.experiment.log_image(img, **kwargs)
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ if not self.save_model:
+ return
+
+ model_metadata = {
+ 'fitness_score': fitness_score[-1],
+ 'epochs_trained': epoch + 1,
+ 'save_period': opt.save_period,
+ 'total_epochs': opt.epochs,}
+
+ model_files = glob.glob(f'{path}/*.pt')
+ for model_path in model_files:
+ name = Path(model_path).name
+
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ metadata=model_metadata,
+ overwrite=True,
+ )
+
+ def check_dataset(self, data_file):
+ with open(data_file) as f:
+ data_config = yaml.safe_load(f)
+
+ if data_config['path'].startswith(COMET_PREFIX):
+ path = data_config['path'].replace(COMET_PREFIX, '')
+ data_dict = self.download_dataset_artifact(path)
+
+ return data_dict
+
+ self.log_asset(self.opt.data, metadata={'type': 'data-config-file'})
+
+ return check_dataset(data_file)
+
+ def log_predictions(self, image, labelsn, path, shape, predn):
+ if self.logged_images_count >= self.max_images:
+ return
+ detections = predn[predn[:, 4] > self.conf_thres]
+ iou = box_iou(labelsn[:, 1:], detections[:, :4])
+ mask, _ = torch.where(iou > self.iou_thres)
+ if len(mask) == 0:
+ return
+
+ filtered_detections = detections[mask]
+ filtered_labels = labelsn[mask]
+
+ image_id = path.split('/')[-1].split('.')[0]
+ image_name = f'{image_id}_curr_epoch_{self.experiment.curr_epoch}'
+ if image_name not in self.logged_image_names:
+ native_scale_image = PIL.Image.open(path)
+ self.log_image(native_scale_image, name=image_name)
+ self.logged_image_names.append(image_name)
+
+ metadata = []
+ for cls, *xyxy in filtered_labels.tolist():
+ metadata.append({
+ 'label': f'{self.class_names[int(cls)]}-gt',
+ 'score': 100,
+ 'box': {
+ 'x': xyxy[0],
+ 'y': xyxy[1],
+ 'x2': xyxy[2],
+ 'y2': xyxy[3]},})
+ for *xyxy, conf, cls in filtered_detections.tolist():
+ metadata.append({
+ 'label': f'{self.class_names[int(cls)]}',
+ 'score': conf * 100,
+ 'box': {
+ 'x': xyxy[0],
+ 'y': xyxy[1],
+ 'x2': xyxy[2],
+ 'y2': xyxy[3]},})
+
+ self.metadata_dict[image_name] = metadata
+ self.logged_images_count += 1
+
+ return
+
+ def preprocess_prediction(self, image, labels, shape, pred):
+ nl, _ = labels.shape[0], pred.shape[0]
+
+ # Predictions
+ if self.opt.single_cls:
+ pred[:, 5] = 0
+
+ predn = pred.clone()
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1])
+
+ labelsn = None
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(image.shape[1:], tbox, shape[0], shape[1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1]) # native-space pred
+
+ return predn, labelsn
+
+ def add_assets_to_artifact(self, artifact, path, asset_path, split):
+ img_paths = sorted(glob.glob(f'{asset_path}/*'))
+ label_paths = img2label_paths(img_paths)
+
+ for image_file, label_file in zip(img_paths, label_paths):
+ image_logical_path, label_logical_path = map(lambda x: os.path.relpath(x, path), [image_file, label_file])
+
+ try:
+ artifact.add(image_file, logical_path=image_logical_path, metadata={'split': split})
+ artifact.add(label_file, logical_path=label_logical_path, metadata={'split': split})
+ except ValueError as e:
+ logger.error('COMET ERROR: Error adding file to Artifact. Skipping file.')
+ logger.error(f'COMET ERROR: {e}')
+ continue
+
+ return artifact
+
+ def upload_dataset_artifact(self):
+ dataset_name = self.data_dict.get('dataset_name', 'yolov5-dataset')
+ path = str((ROOT / Path(self.data_dict['path'])).resolve())
+
+ metadata = self.data_dict.copy()
+ for key in ['train', 'val', 'test']:
+ split_path = metadata.get(key)
+ if split_path is not None:
+ metadata[key] = split_path.replace(path, '')
+
+ artifact = comet_ml.Artifact(name=dataset_name, artifact_type='dataset', metadata=metadata)
+ for key in metadata.keys():
+ if key in ['train', 'val', 'test']:
+ if isinstance(self.upload_dataset, str) and (key != self.upload_dataset):
+ continue
+
+ asset_path = self.data_dict.get(key)
+ if asset_path is not None:
+ artifact = self.add_assets_to_artifact(artifact, path, asset_path, key)
+
+ self.experiment.log_artifact(artifact)
+
+ return
+
+ def download_dataset_artifact(self, artifact_path):
+ logged_artifact = self.experiment.get_artifact(artifact_path)
+ artifact_save_dir = str(Path(self.opt.save_dir) / logged_artifact.name)
+ logged_artifact.download(artifact_save_dir)
+
+ metadata = logged_artifact.metadata
+ data_dict = metadata.copy()
+ data_dict['path'] = artifact_save_dir
+
+ metadata_names = metadata.get('names')
+ if type(metadata_names) == dict:
+ data_dict['names'] = {int(k): v for k, v in metadata.get('names').items()}
+ elif type(metadata_names) == list:
+ data_dict['names'] = {int(k): v for k, v in zip(range(len(metadata_names)), metadata_names)}
+ else:
+ raise "Invalid 'names' field in dataset yaml file. Please use a list or dictionary"
+
+ data_dict = self.update_data_paths(data_dict)
+ return data_dict
+
+ def update_data_paths(self, data_dict):
+ path = data_dict.get('path', '')
+
+ for split in ['train', 'val', 'test']:
+ if data_dict.get(split):
+ split_path = data_dict.get(split)
+ data_dict[split] = (f'{path}/{split_path}' if isinstance(split, str) else [
+ f'{path}/{x}' for x in split_path])
+
+ return data_dict
+
+ def on_pretrain_routine_end(self, paths):
+ if self.opt.resume:
+ return
+
+ for path in paths:
+ self.log_asset(str(path))
+
+ if self.upload_dataset:
+ if not self.resume:
+ self.upload_dataset_artifact()
+
+ return
+
+ def on_train_start(self):
+ self.log_parameters(self.hyp)
+
+ def on_train_epoch_start(self):
+ return
+
+ def on_train_epoch_end(self, epoch):
+ self.experiment.curr_epoch = epoch
+
+ return
+
+ def on_train_batch_start(self):
+ return
+
+ def on_train_batch_end(self, log_dict, step):
+ self.experiment.curr_step = step
+ if self.log_batch_metrics and (step % self.comet_log_batch_interval == 0):
+ self.log_metrics(log_dict, step=step)
+
+ return
+
+ def on_train_end(self, files, save_dir, last, best, epoch, results):
+ if self.comet_log_predictions:
+ curr_epoch = self.experiment.curr_epoch
+ self.experiment.log_asset_data(self.metadata_dict, 'image-metadata.json', epoch=curr_epoch)
+
+ for f in files:
+ self.log_asset(f, metadata={'epoch': epoch})
+ self.log_asset(f'{save_dir}/results.csv', metadata={'epoch': epoch})
+
+ if not self.opt.evolve:
+ model_path = str(best if best.exists() else last)
+ name = Path(model_path).name
+ if self.save_model:
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ overwrite=True,
+ )
+
+ # Check if running Experiment with Comet Optimizer
+ if hasattr(self.opt, 'comet_optimizer_id'):
+ metric = results.get(self.opt.comet_optimizer_metric)
+ self.experiment.log_other('optimizer_metric_value', metric)
+
+ self.finish_run()
+
+ def on_val_start(self):
+ return
+
+ def on_val_batch_start(self):
+ return
+
+ def on_val_batch_end(self, batch_i, images, targets, paths, shapes, outputs):
+ if not (self.comet_log_predictions and ((batch_i + 1) % self.comet_log_prediction_interval == 0)):
+ return
+
+ for si, pred in enumerate(outputs):
+ if len(pred) == 0:
+ continue
+
+ image = images[si]
+ labels = targets[targets[:, 0] == si, 1:]
+ shape = shapes[si]
+ path = paths[si]
+ predn, labelsn = self.preprocess_prediction(image, labels, shape, pred)
+ if labelsn is not None:
+ self.log_predictions(image, labelsn, path, shape, predn)
+
+ return
+
+ def on_val_end(self, nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix):
+ if self.comet_log_per_class_metrics:
+ if self.num_classes > 1:
+ for i, c in enumerate(ap_class):
+ class_name = self.class_names[c]
+ self.experiment.log_metrics(
+ {
+ 'mAP@.5': ap50[i],
+ 'mAP@.5:.95': ap[i],
+ 'precision': p[i],
+ 'recall': r[i],
+ 'f1': f1[i],
+ 'true_positives': tp[i],
+ 'false_positives': fp[i],
+ 'support': nt[c]},
+ prefix=class_name)
+
+ if self.comet_log_confusion_matrix:
+ epoch = self.experiment.curr_epoch
+ class_names = list(self.class_names.values())
+ class_names.append('background')
+ num_classes = len(class_names)
+
+ self.experiment.log_confusion_matrix(
+ matrix=confusion_matrix.matrix,
+ max_categories=num_classes,
+ labels=class_names,
+ epoch=epoch,
+ column_label='Actual Category',
+ row_label='Predicted Category',
+ file_name=f'confusion-matrix-epoch-{epoch}.json',
+ )
+
+ def on_fit_epoch_end(self, result, epoch):
+ self.log_metrics(result, epoch=epoch)
+
+ def on_model_save(self, last, epoch, final_epoch, best_fitness, fi):
+ if ((epoch + 1) % self.opt.save_period == 0 and not final_epoch) and self.opt.save_period != -1:
+ self.log_model(last.parent, self.opt, epoch, fi, best_model=best_fitness == fi)
+
+ def on_params_update(self, params):
+ self.log_parameters(params)
+
+ def finish_run(self):
+ self.experiment.end()
diff --git a/yolov5/utils/loggers/comet/__pycache__/__init__.cpython-38.pyc b/yolov5/utils/loggers/comet/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c2a91a150ef754d368a606081e4b483b8c095092
Binary files /dev/null and b/yolov5/utils/loggers/comet/__pycache__/__init__.cpython-38.pyc differ
diff --git a/yolov5/utils/loggers/comet/__pycache__/comet_utils.cpython-38.pyc b/yolov5/utils/loggers/comet/__pycache__/comet_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a89697990874cfa09d0612ec84421b553dd66316
Binary files /dev/null and b/yolov5/utils/loggers/comet/__pycache__/comet_utils.cpython-38.pyc differ
diff --git a/yolov5/utils/loggers/comet/comet_utils.py b/yolov5/utils/loggers/comet/comet_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..27600761ad2843a6ab66aa22ad06782bb4b7eea7
--- /dev/null
+++ b/yolov5/utils/loggers/comet/comet_utils.py
@@ -0,0 +1,150 @@
+import logging
+import os
+from urllib.parse import urlparse
+
+try:
+ import comet_ml
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+
+import yaml
+
+logger = logging.getLogger(__name__)
+
+COMET_PREFIX = 'comet://'
+COMET_MODEL_NAME = os.getenv('COMET_MODEL_NAME', 'yolov5')
+COMET_DEFAULT_CHECKPOINT_FILENAME = os.getenv('COMET_DEFAULT_CHECKPOINT_FILENAME', 'last.pt')
+
+
+def download_model_checkpoint(opt, experiment):
+ model_dir = f'{opt.project}/{experiment.name}'
+ os.makedirs(model_dir, exist_ok=True)
+
+ model_name = COMET_MODEL_NAME
+ model_asset_list = experiment.get_model_asset_list(model_name)
+
+ if len(model_asset_list) == 0:
+ logger.error(f'COMET ERROR: No checkpoints found for model name : {model_name}')
+ return
+
+ model_asset_list = sorted(
+ model_asset_list,
+ key=lambda x: x['step'],
+ reverse=True,
+ )
+ logged_checkpoint_map = {asset['fileName']: asset['assetId'] for asset in model_asset_list}
+
+ resource_url = urlparse(opt.weights)
+ checkpoint_filename = resource_url.query
+
+ if checkpoint_filename:
+ asset_id = logged_checkpoint_map.get(checkpoint_filename)
+ else:
+ asset_id = logged_checkpoint_map.get(COMET_DEFAULT_CHECKPOINT_FILENAME)
+ checkpoint_filename = COMET_DEFAULT_CHECKPOINT_FILENAME
+
+ if asset_id is None:
+ logger.error(f'COMET ERROR: Checkpoint {checkpoint_filename} not found in the given Experiment')
+ return
+
+ try:
+ logger.info(f'COMET INFO: Downloading checkpoint {checkpoint_filename}')
+ asset_filename = checkpoint_filename
+
+ model_binary = experiment.get_asset(asset_id, return_type='binary', stream=False)
+ model_download_path = f'{model_dir}/{asset_filename}'
+ with open(model_download_path, 'wb') as f:
+ f.write(model_binary)
+
+ opt.weights = model_download_path
+
+ except Exception as e:
+ logger.warning('COMET WARNING: Unable to download checkpoint from Comet')
+ logger.exception(e)
+
+
+def set_opt_parameters(opt, experiment):
+ """Update the opts Namespace with parameters
+ from Comet's ExistingExperiment when resuming a run
+
+ Args:
+ opt (argparse.Namespace): Namespace of command line options
+ experiment (comet_ml.APIExperiment): Comet API Experiment object
+ """
+ asset_list = experiment.get_asset_list()
+ resume_string = opt.resume
+
+ for asset in asset_list:
+ if asset['fileName'] == 'opt.yaml':
+ asset_id = asset['assetId']
+ asset_binary = experiment.get_asset(asset_id, return_type='binary', stream=False)
+ opt_dict = yaml.safe_load(asset_binary)
+ for key, value in opt_dict.items():
+ setattr(opt, key, value)
+ opt.resume = resume_string
+
+ # Save hyperparameters to YAML file
+ # Necessary to pass checks in training script
+ save_dir = f'{opt.project}/{experiment.name}'
+ os.makedirs(save_dir, exist_ok=True)
+
+ hyp_yaml_path = f'{save_dir}/hyp.yaml'
+ with open(hyp_yaml_path, 'w') as f:
+ yaml.dump(opt.hyp, f)
+ opt.hyp = hyp_yaml_path
+
+
+def check_comet_weights(opt):
+ """Downloads model weights from Comet and updates the
+ weights path to point to saved weights location
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if weights are successfully downloaded
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.weights, str):
+ if opt.weights.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.weights)
+ experiment_path = f'{resource.netloc}{resource.path}'
+ experiment = api.get(experiment_path)
+ download_model_checkpoint(opt, experiment)
+ return True
+
+ return None
+
+
+def check_comet_resume(opt):
+ """Restores run parameters to its original state based on the model checkpoint
+ and logged Experiment parameters.
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if the run is restored successfully
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.resume)
+ experiment_path = f'{resource.netloc}{resource.path}'
+ experiment = api.get(experiment_path)
+ set_opt_parameters(opt, experiment)
+ download_model_checkpoint(opt, experiment)
+
+ return True
+
+ return None
diff --git a/yolov5/utils/loggers/comet/hpo.py b/yolov5/utils/loggers/comet/hpo.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc49115c13581554bebe1ddddaf3d5e10caaae07
--- /dev/null
+++ b/yolov5/utils/loggers/comet/hpo.py
@@ -0,0 +1,118 @@
+import argparse
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+import comet_ml
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+# Project Configuration
+config = comet_ml.config.get_config()
+COMET_PROJECT_NAME = config.get_string(os.getenv('COMET_PROJECT_NAME'), 'comet.project_name', default='yolov5')
+
+
+def get_args(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=300, help='total training epochs')
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
+ parser.add_argument('--noplots', action='store_true', help='save no plot files')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--seed', type=int, default=0, help='Global training seed')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ # Comet Arguments
+ parser.add_argument('--comet_optimizer_config', type=str, help='Comet: Path to a Comet Optimizer Config File.')
+ parser.add_argument('--comet_optimizer_id', type=str, help='Comet: ID of the Comet Optimizer sweep.')
+ parser.add_argument('--comet_optimizer_objective', type=str, help="Comet: Set to 'minimize' or 'maximize'.")
+ parser.add_argument('--comet_optimizer_metric', type=str, help='Comet: Metric to Optimize.')
+ parser.add_argument('--comet_optimizer_workers',
+ type=int,
+ default=1,
+ help='Comet: Number of Parallel Workers to use with the Comet Optimizer.')
+
+ return parser.parse_known_args()[0] if known else parser.parse_args()
+
+
+def run(parameters, opt):
+ hyp_dict = {k: v for k, v in parameters.items() if k not in ['epochs', 'batch_size']}
+
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.batch_size = parameters.get('batch_size')
+ opt.epochs = parameters.get('epochs')
+
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == '__main__':
+ opt = get_args(known=True)
+
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.project = str(opt.project)
+
+ optimizer_id = os.getenv('COMET_OPTIMIZER_ID')
+ if optimizer_id is None:
+ with open(opt.comet_optimizer_config) as f:
+ optimizer_config = json.load(f)
+ optimizer = comet_ml.Optimizer(optimizer_config)
+ else:
+ optimizer = comet_ml.Optimizer(optimizer_id)
+
+ opt.comet_optimizer_id = optimizer.id
+ status = optimizer.status()
+
+ opt.comet_optimizer_objective = status['spec']['objective']
+ opt.comet_optimizer_metric = status['spec']['metric']
+
+ logger.info('COMET INFO: Starting Hyperparameter Sweep')
+ for parameter in optimizer.get_parameters():
+ run(parameter['parameters'], opt)
diff --git a/yolov5/utils/loggers/comet/optimizer_config.json b/yolov5/utils/loggers/comet/optimizer_config.json
new file mode 100644
index 0000000000000000000000000000000000000000..83ddddab6f2084b4bdf84dca1e61696de200d1b8
--- /dev/null
+++ b/yolov5/utils/loggers/comet/optimizer_config.json
@@ -0,0 +1,209 @@
+{
+ "algorithm": "random",
+ "parameters": {
+ "anchor_t": {
+ "type": "discrete",
+ "values": [
+ 2,
+ 8
+ ]
+ },
+ "batch_size": {
+ "type": "discrete",
+ "values": [
+ 16,
+ 32,
+ 64
+ ]
+ },
+ "box": {
+ "type": "discrete",
+ "values": [
+ 0.02,
+ 0.2
+ ]
+ },
+ "cls": {
+ "type": "discrete",
+ "values": [
+ 0.2
+ ]
+ },
+ "cls_pw": {
+ "type": "discrete",
+ "values": [
+ 0.5
+ ]
+ },
+ "copy_paste": {
+ "type": "discrete",
+ "values": [
+ 1
+ ]
+ },
+ "degrees": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 45
+ ]
+ },
+ "epochs": {
+ "type": "discrete",
+ "values": [
+ 5
+ ]
+ },
+ "fl_gamma": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "fliplr": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "flipud": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_h": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_s": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_v": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "iou_t": {
+ "type": "discrete",
+ "values": [
+ 0.7
+ ]
+ },
+ "lr0": {
+ "type": "discrete",
+ "values": [
+ 1e-05,
+ 0.1
+ ]
+ },
+ "lrf": {
+ "type": "discrete",
+ "values": [
+ 0.01,
+ 1
+ ]
+ },
+ "mixup": {
+ "type": "discrete",
+ "values": [
+ 1
+ ]
+ },
+ "momentum": {
+ "type": "discrete",
+ "values": [
+ 0.6
+ ]
+ },
+ "mosaic": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "obj": {
+ "type": "discrete",
+ "values": [
+ 0.2
+ ]
+ },
+ "obj_pw": {
+ "type": "discrete",
+ "values": [
+ 0.5
+ ]
+ },
+ "optimizer": {
+ "type": "categorical",
+ "values": [
+ "SGD",
+ "Adam",
+ "AdamW"
+ ]
+ },
+ "perspective": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "scale": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "shear": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "translate": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "warmup_bias_lr": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.2
+ ]
+ },
+ "warmup_epochs": {
+ "type": "discrete",
+ "values": [
+ 5
+ ]
+ },
+ "warmup_momentum": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.95
+ ]
+ },
+ "weight_decay": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.001
+ ]
+ }
+ },
+ "spec": {
+ "maxCombo": 0,
+ "metric": "metrics/mAP_0.5",
+ "objective": "maximize"
+ },
+ "trials": 1
+}
diff --git a/yolov5/utils/loggers/wandb/__init__.py b/yolov5/utils/loggers/wandb/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/yolov5/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc b/yolov5/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..05a9a272bf599235bcc48b918c27a89f730a7b6f
Binary files /dev/null and b/yolov5/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc differ
diff --git a/yolov5/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc b/yolov5/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c7a21b4b4600b95824858c54a00b28ee54c92855
Binary files /dev/null and b/yolov5/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc differ
diff --git a/yolov5/utils/loggers/wandb/wandb_utils.py b/yolov5/utils/loggers/wandb/wandb_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ea32b1d4c6ec62920a9e90af085346d0f7a5f2c
--- /dev/null
+++ b/yolov5/utils/loggers/wandb/wandb_utils.py
@@ -0,0 +1,193 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# WARNING ⚠️ wandb is deprecated and will be removed in future release.
+# See supported integrations at https://github.com/ultralytics/yolov5#integrations
+
+import logging
+import os
+import sys
+from contextlib import contextmanager
+from pathlib import Path
+
+from utils.general import LOGGER, colorstr
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+RANK = int(os.getenv('RANK', -1))
+DEPRECATION_WARNING = f"{colorstr('wandb')}: WARNING ⚠️ wandb is deprecated and will be removed in a future release. " \
+ f'See supported integrations at https://github.com/ultralytics/yolov5#integrations.'
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+ LOGGER.warning(DEPRECATION_WARNING)
+except (ImportError, AssertionError):
+ wandb = None
+
+
+class WandbLogger():
+ """Log training runs, datasets, models, and predictions to Weights & Biases.
+
+ This logger sends information to W&B at wandb.ai. By default, this information
+ includes hyperparameters, system configuration and metrics, model metrics,
+ and basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+
+ For more on how this logger is used, see the Weights & Biases documentation:
+ https://docs.wandb.com/guides/integrations/yolov5
+ """
+
+ def __init__(self, opt, run_id=None, job_type='Training'):
+ """
+ - Initialize WandbLogger instance
+ - Upload dataset if opt.upload_dataset is True
+ - Setup training processes if job_type is 'Training'
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ run_id (str) -- Run ID of W&B run to be resumed
+ job_type (str) -- To set the job_type for this run
+
+ """
+ # Pre-training routine --
+ self.job_type = job_type
+ self.wandb, self.wandb_run = wandb, wandb.run if wandb else None
+ self.val_artifact, self.train_artifact = None, None
+ self.train_artifact_path, self.val_artifact_path = None, None
+ self.result_artifact = None
+ self.val_table, self.result_table = None, None
+ self.max_imgs_to_log = 16
+ self.data_dict = None
+ if self.wandb:
+ self.wandb_run = wandb.init(config=opt,
+ resume='allow',
+ project='YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem,
+ entity=opt.entity,
+ name=opt.name if opt.name != 'exp' else None,
+ job_type=job_type,
+ id=run_id,
+ allow_val_change=True) if not wandb.run else wandb.run
+
+ if self.wandb_run:
+ if self.job_type == 'Training':
+ if isinstance(opt.data, dict):
+ # This means another dataset manager has already processed the dataset info (e.g. ClearML)
+ # and they will have stored the already processed dict in opt.data
+ self.data_dict = opt.data
+ self.setup_training(opt)
+
+ def setup_training(self, opt):
+ """
+ Setup the necessary processes for training YOLO models:
+ - Attempt to download model checkpoint and dataset artifacts if opt.resume stats with WANDB_ARTIFACT_PREFIX
+ - Update data_dict, to contain info of previous run if resumed and the paths of dataset artifact if downloaded
+ - Setup log_dict, initialize bbox_interval
+
+ arguments:
+ opt (namespace) -- commandline arguments for this run
+
+ """
+ self.log_dict, self.current_epoch = {}, 0
+ self.bbox_interval = opt.bbox_interval
+ if isinstance(opt.resume, str):
+ model_dir, _ = self.download_model_artifact(opt)
+ if model_dir:
+ self.weights = Path(model_dir) / 'last.pt'
+ config = self.wandb_run.config
+ opt.weights, opt.save_period, opt.batch_size, opt.bbox_interval, opt.epochs, opt.hyp, opt.imgsz = str(
+ self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs, \
+ config.hyp, config.imgsz
+
+ if opt.bbox_interval == -1:
+ self.bbox_interval = opt.bbox_interval = (opt.epochs // 10) if opt.epochs > 10 else 1
+ if opt.evolve or opt.noplots:
+ self.bbox_interval = opt.bbox_interval = opt.epochs + 1 # disable bbox_interval
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ """
+ Log the model checkpoint as W&B artifact
+
+ arguments:
+ path (Path) -- Path of directory containing the checkpoints
+ opt (namespace) -- Command line arguments for this run
+ epoch (int) -- Current epoch number
+ fitness_score (float) -- fitness score for current epoch
+ best_model (boolean) -- Boolean representing if the current checkpoint is the best yet.
+ """
+ model_artifact = wandb.Artifact('run_' + wandb.run.id + '_model',
+ type='model',
+ metadata={
+ 'original_url': str(path),
+ 'epochs_trained': epoch + 1,
+ 'save period': opt.save_period,
+ 'project': opt.project,
+ 'total_epochs': opt.epochs,
+ 'fitness_score': fitness_score})
+ model_artifact.add_file(str(path / 'last.pt'), name='last.pt')
+ wandb.log_artifact(model_artifact,
+ aliases=['latest', 'last', 'epoch ' + str(self.current_epoch), 'best' if best_model else ''])
+ LOGGER.info(f'Saving model artifact on epoch {epoch + 1}')
+
+ def val_one_image(self, pred, predn, path, names, im):
+ pass
+
+ def log(self, log_dict):
+ """
+ save the metrics to the logging dictionary
+
+ arguments:
+ log_dict (Dict) -- metrics/media to be logged in current step
+ """
+ if self.wandb_run:
+ for key, value in log_dict.items():
+ self.log_dict[key] = value
+
+ def end_epoch(self):
+ """
+ commit the log_dict, model artifacts and Tables to W&B and flush the log_dict.
+
+ arguments:
+ best_result (boolean): Boolean representing if the result of this evaluation is best or not
+ """
+ if self.wandb_run:
+ with all_logging_disabled():
+ try:
+ wandb.log(self.log_dict)
+ except BaseException as e:
+ LOGGER.info(
+ f'An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}'
+ )
+ self.wandb_run.finish()
+ self.wandb_run = None
+ self.log_dict = {}
+
+ def finish_run(self):
+ """
+ Log metrics if any and finish the current W&B run
+ """
+ if self.wandb_run:
+ if self.log_dict:
+ with all_logging_disabled():
+ wandb.log(self.log_dict)
+ wandb.run.finish()
+ LOGGER.warning(DEPRECATION_WARNING)
+
+
+@contextmanager
+def all_logging_disabled(highest_level=logging.CRITICAL):
+ """ source - https://gist.github.com/simon-weber/7853144
+ A context manager that will prevent any logging messages triggered during the body from being processed.
+ :param highest_level: the maximum logging level in use.
+ This would only need to be changed if a custom level greater than CRITICAL is defined.
+ """
+ previous_level = logging.root.manager.disable
+ logging.disable(highest_level)
+ try:
+ yield
+ finally:
+ logging.disable(previous_level)
diff --git a/yolov5/utils/loss.py b/yolov5/utils/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..26cca8797315a425b26d1c8c083bd321d7b52fff
--- /dev/null
+++ b/yolov5/utils/loss.py
@@ -0,0 +1,234 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import de_parallel
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ sort_obj_iou = False
+
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, p, targets): # predictions, targets
+ lcls = torch.zeros(1, device=self.device) # class loss
+ lbox = torch.zeros(1, device=self.device) # box loss
+ lobj = torch.zeros(1, device=self.device) # object loss
+ tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ # pxy, pwh, _, pcls = pi[b, a, gj, gi].tensor_split((2, 4, 5), dim=1) # faster, requires torch 1.8.0
+ pxy, pwh, _, pcls = pi[b, a, gj, gi].split((2, 2, 1, self.nc), 1) # target-subset of predictions
+
+ # Regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ bs = tobj.shape[0] # batch size
+
+ return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ gain = torch.ones(7, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+
+ return tcls, tbox, indices, anch
diff --git a/yolov5/utils/metrics.py b/yolov5/utils/metrics.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6305ed384443282352eb44600344f9397d793e1
--- /dev/null
+++ b/yolov5/utils/metrics.py
@@ -0,0 +1,360 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+from yolov5.utils import TryExcept, threaded
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def smooth(y, f=0.05):
+ # Box filter of fraction f
+ nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)
+ p = np.ones(nf // 2) # ones padding
+ yp = np.concatenate((p * y[0], y, p * y[-1]), 0) # y padded
+ return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothed
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16, prefix=''):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes, nt = np.unique(target_cls, return_counts=True)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = nt[ci] # number of labels
+ n_p = i.sum() # number of predictions
+ if n_p == 0 or n_l == 0:
+ continue
+
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + eps) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + eps)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = dict(enumerate(names)) # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / f'{prefix}PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / f'{prefix}F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / f'{prefix}P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / f'{prefix}R_curve.png', names, ylabel='Recall')
+
+ i = smooth(f1.mean(0), 0.1).argmax() # max F1 index
+ p, r, f1 = p[:, i], r[:, i], f1[:, i]
+ tp = (r * nt).round() # true positives
+ fp = (tp / (p + eps) - tp).round() # false positives
+ return tp, fp, p, r, f1, ap, unique_classes.astype(int)
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ if detections is None:
+ gt_classes = labels.int()
+ for gc in gt_classes:
+ self.matrix[self.nc, gc] += 1 # background FN
+ return
+
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(int)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # true background
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # predicted background
+
+ def tp_fp(self):
+ tp = self.matrix.diagonal() # true positives
+ fp = self.matrix.sum(1) - tp # false positives
+ # fn = self.matrix.sum(0) - tp # false negatives (missed detections)
+ return tp[:-1], fp[:-1] # remove background class
+
+ @TryExcept('WARNING ⚠️ ConfusionMatrix plot failure')
+ def plot(self, normalize=True, save_dir='', names=()):
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig, ax = plt.subplots(1, 1, figsize=(12, 9), tight_layout=True)
+ nc, nn = self.nc, len(names) # number of classes, names
+ sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
+ labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
+ ticklabels = (names + ['background']) if labels else 'auto'
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array,
+ ax=ax,
+ annot=nc < 30,
+ annot_kws={
+ 'size': 8},
+ cmap='Blues',
+ fmt='.2f',
+ square=True,
+ vmin=0.0,
+ xticklabels=ticklabels,
+ yticklabels=ticklabels).set_facecolor((1, 1, 1))
+ ax.set_xlabel('True')
+ ax.set_ylabel('Predicted')
+ ax.set_title('Confusion Matrix')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close(fig)
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
+
+ # Get the coordinates of bounding boxes
+ if xywh: # transform from xywh to xyxy
+ (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
+ w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
+ b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
+ b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
+ else: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
+ w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
+ w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
+
+ # Intersection area
+ inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
+ (b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
+
+ # Union Area
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ # IoU
+ iou = inter / union
+ if CIoU or DIoU or GIoU:
+ cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
+ ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
+ if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ return iou - rho2 / c2 # DIoU
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ return iou # IoU
+
+
+def box_iou(box1, box2, eps=1e-7):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ (a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
+ inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
+
+ # IoU = inter / (area1 + area2 - inter)
+ return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
+
+
+def bbox_ioa(box1, box2, eps=1e-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.T
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2, eps=1e-7):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter + eps) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+
+@threaded
+def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
+ ax.set_title('Precision-Recall Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
+
+
+@threaded
+def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = smooth(py.mean(0), 0.05)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
+ ax.set_title(f'{ylabel}-Confidence Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
diff --git a/yolov5/utils/plots.py b/yolov5/utils/plots.py
new file mode 100644
index 0000000000000000000000000000000000000000..37c544b3bff1054b619b19a396aa0fe7725a84a8
--- /dev/null
+++ b/yolov5/utils/plots.py
@@ -0,0 +1,560 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Plotting utils
+"""
+
+import contextlib
+import math
+import os
+from copy import copy
+from pathlib import Path
+from urllib.error import URLError
+
+import cv2
+import matplotlib
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import seaborn as sn
+import torch
+from PIL import Image, ImageDraw, ImageFont
+
+from yolov5.utils import TryExcept, threaded
+from yolov5.utils.general import (CONFIG_DIR, FONT, LOGGER, check_font, check_requirements, clip_boxes, increment_path,
+ is_ascii, xywh2xyxy, xyxy2xywh)
+from yolov5.utils.metrics import fitness
+from yolov5.utils.segment.general import scale_image
+
+# Settings
+RANK = int(os.getenv('RANK', -1))
+matplotlib.rc('font', **{'size': 11})
+matplotlib.use('Agg') # for writing to files only
+
+
+class Colors:
+ # Ultralytics color palette https://ultralytics.com/
+ def __init__(self):
+ # hex = matplotlib.colors.TABLEAU_COLORS.values()
+ hexs = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
+ '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
+ self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
+ self.n = len(self.palette)
+
+ def __call__(self, i, bgr=False):
+ c = self.palette[int(i) % self.n]
+ return (c[2], c[1], c[0]) if bgr else c
+
+ @staticmethod
+ def hex2rgb(h): # rgb order (PIL)
+ return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
+
+
+colors = Colors() # create instance for 'from utils.plots import colors'
+
+
+def check_pil_font(font=FONT, size=10):
+ # Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
+ font = Path(font)
+ font = font if font.exists() else (CONFIG_DIR / font.name)
+ try:
+ return ImageFont.truetype(str(font) if font.exists() else font.name, size)
+ except Exception: # download if missing
+ try:
+ check_font(font)
+ return ImageFont.truetype(str(font), size)
+ except TypeError:
+ check_requirements('Pillow>=8.4.0') # known issue https://github.com/ultralytics/yolov5/issues/5374
+ except URLError: # not online
+ return ImageFont.load_default()
+
+
+class Annotator:
+ # YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
+ def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
+ assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
+ non_ascii = not is_ascii(example) # non-latin labels, i.e. asian, arabic, cyrillic
+ self.pil = pil or non_ascii
+ if self.pil: # use PIL
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+ self.font = check_pil_font(font='Arial.Unicode.ttf' if non_ascii else font,
+ size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
+ else: # use cv2
+ self.im = im
+ self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
+
+ def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
+ # Add one xyxy box to image with label
+ if self.pil or not is_ascii(label):
+ self.draw.rectangle(box, width=self.lw, outline=color) # box
+ if label:
+ w, h = self.font.getsize(label) # text width, height (WARNING: deprecated) in 9.2.0
+ # _, _, w, h = self.font.getbbox(label) # text width, height (New)
+ outside = box[1] - h >= 0 # label fits outside box
+ self.draw.rectangle(
+ (box[0], box[1] - h if outside else box[1], box[0] + w + 1,
+ box[1] + 1 if outside else box[1] + h + 1),
+ fill=color,
+ )
+ # self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
+ self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
+ else: # cv2
+ p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
+ cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
+ if label:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = p1[1] - h >= 3
+ p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
+ cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
+ cv2.putText(self.im,
+ label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
+ 0,
+ self.lw / 3,
+ txt_color,
+ thickness=tf,
+ lineType=cv2.LINE_AA)
+
+ def masks(self, masks, colors, im_gpu, alpha=0.5, retina_masks=False):
+ """Plot masks at once.
+ Args:
+ masks (tensor): predicted masks on cuda, shape: [n, h, w]
+ colors (List[List[Int]]): colors for predicted masks, [[r, g, b] * n]
+ im_gpu (tensor): img is in cuda, shape: [3, h, w], range: [0, 1]
+ alpha (float): mask transparency: 0.0 fully transparent, 1.0 opaque
+ """
+ if self.pil:
+ # convert to numpy first
+ self.im = np.asarray(self.im).copy()
+ if len(masks) == 0:
+ self.im[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
+ colors = torch.tensor(colors, device=im_gpu.device, dtype=torch.float32) / 255.0
+ colors = colors[:, None, None] # shape(n,1,1,3)
+ masks = masks.unsqueeze(3) # shape(n,h,w,1)
+ masks_color = masks * (colors * alpha) # shape(n,h,w,3)
+
+ inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
+ mcs = (masks_color * inv_alph_masks).sum(0) * 2 # mask color summand shape(n,h,w,3)
+
+ im_gpu = im_gpu.flip(dims=[0]) # flip channel
+ im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
+ im_gpu = im_gpu * inv_alph_masks[-1] + mcs
+ im_mask = (im_gpu * 255).byte().cpu().numpy()
+ self.im[:] = im_mask if retina_masks else scale_image(im_gpu.shape, im_mask, self.im.shape)
+ if self.pil:
+ # convert im back to PIL and update draw
+ self.fromarray(self.im)
+
+ def rectangle(self, xy, fill=None, outline=None, width=1):
+ # Add rectangle to image (PIL-only)
+ self.draw.rectangle(xy, fill, outline, width)
+
+ def text(self, xy, text, txt_color=(255, 255, 255), anchor='top'):
+ # Add text to image (PIL-only)
+ if anchor == 'bottom': # start y from font bottom
+ w, h = self.font.getsize(text) # text width, height
+ xy[1] += 1 - h
+ self.draw.text(xy, text, fill=txt_color, font=self.font)
+
+ def fromarray(self, im):
+ # Update self.im from a numpy array
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+
+ def result(self):
+ # Return annotated image as array
+ return np.asarray(self.im)
+
+
+def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
+ """
+ x: Features to be visualized
+ module_type: Module type
+ stage: Module stage within model
+ n: Maximum number of feature maps to plot
+ save_dir: Directory to save results
+ """
+ if 'Detect' not in module_type:
+ batch, channels, height, width = x.shape # batch, channels, height, width
+ if height > 1 and width > 1:
+ f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
+
+ blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
+ n = min(n, channels) # number of plots
+ fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
+ ax = ax.ravel()
+ plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
+ ax[i].axis('off')
+
+ LOGGER.info(f'Saving {f}... ({n}/{channels})')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ np.save(str(f.with_suffix('.npy')), x[0].cpu().numpy()) # npy save
+
+
+def hist2d(x, y, n=100):
+ # 2d histogram used in labels.png and evolve.png
+ xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
+ hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
+ xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1)
+ yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1)
+ return np.log(hist[xidx, yidx])
+
+
+def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
+ from scipy.signal import butter, filtfilt
+
+ # https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
+ def butter_lowpass(cutoff, fs, order):
+ nyq = 0.5 * fs
+ normal_cutoff = cutoff / nyq
+ return butter(order, normal_cutoff, btype='low', analog=False)
+
+ b, a = butter_lowpass(cutoff, fs, order=order)
+ return filtfilt(b, a, data) # forward-backward filter
+
+
+def output_to_target(output, max_det=300):
+ # Convert model output to target format [batch_id, class_id, x, y, w, h, conf] for plotting
+ targets = []
+ for i, o in enumerate(output):
+ box, conf, cls = o[:max_det, :6].cpu().split((4, 1, 1), 1)
+ j = torch.full((conf.shape[0], 1), i)
+ targets.append(torch.cat((j, cls, xyxy2xywh(box), conf), 1))
+ return torch.cat(targets, 0).numpy()
+
+
+@threaded
+def plot_images(images, targets, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ ti = targets[targets[:, 0] == i] # image targets
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+ annotator.im.save(fname) # save
+
+
+def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
+ # Plot LR simulating training for full epochs
+ optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
+ y = []
+ for _ in range(epochs):
+ scheduler.step()
+ y.append(optimizer.param_groups[0]['lr'])
+ plt.plot(y, '.-', label='LR')
+ plt.xlabel('epoch')
+ plt.ylabel('LR')
+ plt.grid()
+ plt.xlim(0, epochs)
+ plt.ylim(0)
+ plt.savefig(Path(save_dir) / 'LR.png', dpi=200)
+ plt.close()
+
+
+def plot_val_txt(): # from utils.plots import *; plot_val()
+ # Plot val.txt histograms
+ x = np.loadtxt('val.txt', dtype=np.float32)
+ box = xyxy2xywh(x[:, :4])
+ cx, cy = box[:, 0], box[:, 1]
+
+ fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
+ ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
+ ax.set_aspect('equal')
+ plt.savefig('hist2d.png', dpi=300)
+
+ fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
+ ax[0].hist(cx, bins=600)
+ ax[1].hist(cy, bins=600)
+ plt.savefig('hist1d.png', dpi=200)
+
+
+def plot_targets_txt(): # from utils.plots import *; plot_targets_txt()
+ # Plot targets.txt histograms
+ x = np.loadtxt('targets.txt', dtype=np.float32).T
+ s = ['x targets', 'y targets', 'width targets', 'height targets']
+ fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
+ ax = ax.ravel()
+ for i in range(4):
+ ax[i].hist(x[i], bins=100, label=f'{x[i].mean():.3g} +/- {x[i].std():.3g}')
+ ax[i].legend()
+ ax[i].set_title(s[i])
+ plt.savefig('targets.jpg', dpi=200)
+
+
+def plot_val_study(file='', dir='', x=None): # from utils.plots import *; plot_val_study()
+ # Plot file=study.txt generated by val.py (or plot all study*.txt in dir)
+ save_dir = Path(file).parent if file else Path(dir)
+ plot2 = False # plot additional results
+ if plot2:
+ ax = plt.subplots(2, 4, figsize=(10, 6), tight_layout=True)[1].ravel()
+
+ fig2, ax2 = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
+ # for f in [save_dir / f'study_coco_{x}.txt' for x in ['yolov5n6', 'yolov5s6', 'yolov5m6', 'yolov5l6', 'yolov5x6']]:
+ for f in sorted(save_dir.glob('study*.txt')):
+ y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
+ x = np.arange(y.shape[1]) if x is None else np.array(x)
+ if plot2:
+ s = ['P', 'R', 'mAP@.5', 'mAP@.5:.95', 't_preprocess (ms/img)', 't_inference (ms/img)', 't_NMS (ms/img)']
+ for i in range(7):
+ ax[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
+ ax[i].set_title(s[i])
+
+ j = y[3].argmax() + 1
+ ax2.plot(y[5, 1:j],
+ y[3, 1:j] * 1E2,
+ '.-',
+ linewidth=2,
+ markersize=8,
+ label=f.stem.replace('study_coco_', '').replace('yolo', 'YOLO'))
+
+ ax2.plot(1E3 / np.array([209, 140, 97, 58, 35, 18]), [34.6, 40.5, 43.0, 47.5, 49.7, 51.5],
+ 'k.-',
+ linewidth=2,
+ markersize=8,
+ alpha=.25,
+ label='EfficientDet')
+
+ ax2.grid(alpha=0.2)
+ ax2.set_yticks(np.arange(20, 60, 5))
+ ax2.set_xlim(0, 57)
+ ax2.set_ylim(25, 55)
+ ax2.set_xlabel('GPU Speed (ms/img)')
+ ax2.set_ylabel('COCO AP val')
+ ax2.legend(loc='lower right')
+ f = save_dir / 'study.png'
+ print(f'Saving {f}...')
+ plt.savefig(f, dpi=300)
+
+
+@TryExcept() # known issue https://github.com/ultralytics/yolov5/issues/5395
+def plot_labels(labels, names=(), save_dir=Path('')):
+ # plot dataset labels
+ LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
+ c, b = labels[:, 0], labels[:, 1:].transpose() # classes, boxes
+ nc = int(c.max() + 1) # number of classes
+ x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
+
+ # seaborn correlogram
+ sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
+ plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
+ plt.close()
+
+ # matplotlib labels
+ matplotlib.use('svg') # faster
+ ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
+ y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
+ with contextlib.suppress(Exception): # color histogram bars by class
+ [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # known issue #3195
+ ax[0].set_ylabel('instances')
+ if 0 < len(names) < 30:
+ ax[0].set_xticks(range(len(names)))
+ ax[0].set_xticklabels(list(names.values()), rotation=90, fontsize=10)
+ else:
+ ax[0].set_xlabel('classes')
+ sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
+ sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
+
+ # rectangles
+ labels[:, 1:3] = 0.5 # center
+ labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
+ img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
+ for cls, *box in labels[:1000]:
+ ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
+ ax[1].imshow(img)
+ ax[1].axis('off')
+
+ for a in [0, 1, 2, 3]:
+ for s in ['top', 'right', 'left', 'bottom']:
+ ax[a].spines[s].set_visible(False)
+
+ plt.savefig(save_dir / 'labels.jpg', dpi=200)
+ matplotlib.use('Agg')
+ plt.close()
+
+
+def imshow_cls(im, labels=None, pred=None, names=None, nmax=25, verbose=False, f=Path('images.jpg')):
+ # Show classification image grid with labels (optional) and predictions (optional)
+ from utils.augmentations import denormalize
+
+ names = names or [f'class{i}' for i in range(1000)]
+ blocks = torch.chunk(denormalize(im.clone()).cpu().float(), len(im),
+ dim=0) # select batch index 0, block by channels
+ n = min(len(blocks), nmax) # number of plots
+ m = min(8, round(n ** 0.5)) # 8 x 8 default
+ fig, ax = plt.subplots(math.ceil(n / m), m) # 8 rows x n/8 cols
+ ax = ax.ravel() if m > 1 else [ax]
+ # plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze().permute((1, 2, 0)).numpy().clip(0.0, 1.0))
+ ax[i].axis('off')
+ if labels is not None:
+ s = names[labels[i]] + (f'—{names[pred[i]]}' if pred is not None else '')
+ ax[i].set_title(s, fontsize=8, verticalalignment='top')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ if verbose:
+ LOGGER.info(f'Saving {f}')
+ if labels is not None:
+ LOGGER.info('True: ' + ' '.join(f'{names[i]:3s}' for i in labels[:nmax]))
+ if pred is not None:
+ LOGGER.info('Predicted:' + ' '.join(f'{names[i]:3s}' for i in pred[:nmax]))
+ return f
+
+
+def plot_evolve(evolve_csv='path/to/evolve.csv'): # from utils.plots import *; plot_evolve()
+ # Plot evolve.csv hyp evolution results
+ evolve_csv = Path(evolve_csv)
+ data = pd.read_csv(evolve_csv)
+ keys = [x.strip() for x in data.columns]
+ x = data.values
+ f = fitness(x)
+ j = np.argmax(f) # max fitness index
+ plt.figure(figsize=(10, 12), tight_layout=True)
+ matplotlib.rc('font', **{'size': 8})
+ print(f'Best results from row {j} of {evolve_csv}:')
+ for i, k in enumerate(keys[7:]):
+ v = x[:, 7 + i]
+ mu = v[j] # best single result
+ plt.subplot(6, 5, i + 1)
+ plt.scatter(v, f, c=hist2d(v, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
+ plt.plot(mu, f.max(), 'k+', markersize=15)
+ plt.title(f'{k} = {mu:.3g}', fontdict={'size': 9}) # limit to 40 characters
+ if i % 5 != 0:
+ plt.yticks([])
+ print(f'{k:>15}: {mu:.3g}')
+ f = evolve_csv.with_suffix('.png') # filename
+ plt.savefig(f, dpi=200)
+ plt.close()
+ print(f'Saved {f}')
+
+
+def plot_results(file='path/to/results.csv', dir=''):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):
+ y = data.values[:, j].astype('float')
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)
+ ax[i].set_title(s[j], fontsize=12)
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ LOGGER.info(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
+
+
+def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
+ # Plot iDetection '*.txt' per-image logs. from utils.plots import *; profile_idetection()
+ ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
+ s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
+ files = list(Path(save_dir).glob('frames*.txt'))
+ for fi, f in enumerate(files):
+ try:
+ results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
+ n = results.shape[1] # number of rows
+ x = np.arange(start, min(stop, n) if stop else n)
+ results = results[:, x]
+ t = (results[0] - results[0].min()) # set t0=0s
+ results[0] = x
+ for i, a in enumerate(ax):
+ if i < len(results):
+ label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
+ a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
+ a.set_title(s[i])
+ a.set_xlabel('time (s)')
+ # if fi == len(files) - 1:
+ # a.set_ylim(bottom=0)
+ for side in ['top', 'right']:
+ a.spines[side].set_visible(False)
+ else:
+ a.remove()
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}; {e}')
+ ax[1].legend()
+ plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
+
+
+def save_one_box(xyxy, im, file=Path('im.jpg'), gain=1.02, pad=10, square=False, BGR=False, save=True):
+ # Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
+ xyxy = torch.tensor(xyxy).view(-1, 4)
+ b = xyxy2xywh(xyxy) # boxes
+ if square:
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
+ b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
+ xyxy = xywh2xyxy(b).long()
+ clip_boxes(xyxy, im.shape)
+ crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
+ if save:
+ file.parent.mkdir(parents=True, exist_ok=True) # make directory
+ f = str(increment_path(file).with_suffix('.jpg'))
+ # cv2.imwrite(f, crop) # save BGR, https://github.com/ultralytics/yolov5/issues/7007 chroma subsampling issue
+ Image.fromarray(crop[..., ::-1]).save(f, quality=95, subsampling=0) # save RGB
+ return crop
diff --git a/yolov5/utils/segment/__init__.py b/yolov5/utils/segment/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/yolov5/utils/segment/__pycache__/__init__.cpython-38.pyc b/yolov5/utils/segment/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..aa3349ac3836ffe7067e5fde6688707192021992
Binary files /dev/null and b/yolov5/utils/segment/__pycache__/__init__.cpython-38.pyc differ
diff --git a/yolov5/utils/segment/__pycache__/__init__.cpython-39.pyc b/yolov5/utils/segment/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..635eae3a9aafc734fe0c21f597f4722a5aafaeba
Binary files /dev/null and b/yolov5/utils/segment/__pycache__/__init__.cpython-39.pyc differ
diff --git a/yolov5/utils/segment/__pycache__/general.cpython-38.pyc b/yolov5/utils/segment/__pycache__/general.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a659cef28bdb8b0d0c6c353e8bce8a5e358102aa
Binary files /dev/null and b/yolov5/utils/segment/__pycache__/general.cpython-38.pyc differ
diff --git a/yolov5/utils/segment/__pycache__/general.cpython-39.pyc b/yolov5/utils/segment/__pycache__/general.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0a1a728e0a62f99bfe4db5a49c92b317ad19366e
Binary files /dev/null and b/yolov5/utils/segment/__pycache__/general.cpython-39.pyc differ
diff --git a/yolov5/utils/segment/augmentations.py b/yolov5/utils/segment/augmentations.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8154b834869acd87f80c0152c870b7631a918ba
--- /dev/null
+++ b/yolov5/utils/segment/augmentations.py
@@ -0,0 +1,104 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Image augmentation functions
+"""
+
+import math
+import random
+
+import cv2
+import numpy as np
+
+from ..augmentations import box_candidates
+from ..general import resample_segments, segment2box
+
+
+def mixup(im, labels, segments, im2, labels2, segments2):
+ # Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
+ r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
+ im = (im * r + im2 * (1 - r)).astype(np.uint8)
+ labels = np.concatenate((labels, labels2), 0)
+ segments = np.concatenate((segments, segments2), 0)
+ return im, labels, segments
+
+
+def random_perspective(im,
+ targets=(),
+ segments=(),
+ degrees=10,
+ translate=.1,
+ scale=.1,
+ shear=10,
+ perspective=0.0,
+ border=(0, 0)):
+ # torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
+ # targets = [cls, xyxy]
+
+ height = im.shape[0] + border[0] * 2 # shape(h,w,c)
+ width = im.shape[1] + border[1] * 2
+
+ # Center
+ C = np.eye(3)
+ C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
+ C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
+
+ # Perspective
+ P = np.eye(3)
+ P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
+ P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
+
+ # Rotation and Scale
+ R = np.eye(3)
+ a = random.uniform(-degrees, degrees)
+ # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
+ s = random.uniform(1 - scale, 1 + scale)
+ # s = 2 ** random.uniform(-scale, scale)
+ R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
+
+ # Shear
+ S = np.eye(3)
+ S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
+ S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
+
+ # Translation
+ T = np.eye(3)
+ T[0, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * width) # x translation (pixels)
+ T[1, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * height) # y translation (pixels)
+
+ # Combined rotation matrix
+ M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
+ if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
+ if perspective:
+ im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
+ else: # affine
+ im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
+
+ # Visualize
+ # import matplotlib.pyplot as plt
+ # ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
+ # ax[0].imshow(im[:, :, ::-1]) # base
+ # ax[1].imshow(im2[:, :, ::-1]) # warped
+
+ # Transform label coordinates
+ n = len(targets)
+ new_segments = []
+ if n:
+ new = np.zeros((n, 4))
+ segments = resample_segments(segments) # upsample
+ for i, segment in enumerate(segments):
+ xy = np.ones((len(segment), 3))
+ xy[:, :2] = segment
+ xy = xy @ M.T # transform
+ xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]) # perspective rescale or affine
+
+ # clip
+ new[i] = segment2box(xy, width, height)
+ new_segments.append(xy)
+
+ # filter candidates
+ i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01)
+ targets = targets[i]
+ targets[:, 1:5] = new[i]
+ new_segments = np.array(new_segments)[i]
+
+ return im, targets, new_segments
diff --git a/yolov5/utils/segment/dataloaders.py b/yolov5/utils/segment/dataloaders.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ee826dba69cb0cda00c48b82710784cd39c5a81
--- /dev/null
+++ b/yolov5/utils/segment/dataloaders.py
@@ -0,0 +1,332 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Dataloaders
+"""
+
+import os
+import random
+
+import cv2
+import numpy as np
+import torch
+from torch.utils.data import DataLoader, distributed
+
+from ..augmentations import augment_hsv, copy_paste, letterbox
+from ..dataloaders import InfiniteDataLoader, LoadImagesAndLabels, seed_worker
+from ..general import LOGGER, xyn2xy, xywhn2xyxy, xyxy2xywhn
+from ..torch_utils import torch_distributed_zero_first
+from .augmentations import mixup, random_perspective
+
+RANK = int(os.getenv('RANK', -1))
+
+
+def create_dataloader(path,
+ imgsz,
+ batch_size,
+ stride,
+ single_cls=False,
+ hyp=None,
+ augment=False,
+ cache=False,
+ pad=0.0,
+ rect=False,
+ rank=-1,
+ workers=8,
+ image_weights=False,
+ quad=False,
+ prefix='',
+ shuffle=False,
+ mask_downsample_ratio=1,
+ overlap_mask=False,
+ seed=0):
+ if rect and shuffle:
+ LOGGER.warning('WARNING ⚠️ --rect is incompatible with DataLoader shuffle, setting shuffle=False')
+ shuffle = False
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = LoadImagesAndLabelsAndMasks(
+ path,
+ imgsz,
+ batch_size,
+ augment=augment, # augmentation
+ hyp=hyp, # hyperparameters
+ rect=rect, # rectangular batches
+ cache_images=cache,
+ single_cls=single_cls,
+ stride=int(stride),
+ pad=pad,
+ image_weights=image_weights,
+ prefix=prefix,
+ downsample_ratio=mask_downsample_ratio,
+ overlap=overlap_mask)
+
+ batch_size = min(batch_size, len(dataset))
+ nd = torch.cuda.device_count() # number of CUDA devices
+ nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
+ sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
+ loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
+ generator = torch.Generator()
+ generator.manual_seed(6148914691236517205 + seed + RANK)
+ return loader(
+ dataset,
+ batch_size=batch_size,
+ shuffle=shuffle and sampler is None,
+ num_workers=nw,
+ sampler=sampler,
+ pin_memory=True,
+ collate_fn=LoadImagesAndLabelsAndMasks.collate_fn4 if quad else LoadImagesAndLabelsAndMasks.collate_fn,
+ worker_init_fn=seed_worker,
+ generator=generator,
+ ), dataset
+
+
+class LoadImagesAndLabelsAndMasks(LoadImagesAndLabels): # for training/testing
+
+ def __init__(
+ self,
+ path,
+ img_size=640,
+ batch_size=16,
+ augment=False,
+ hyp=None,
+ rect=False,
+ image_weights=False,
+ cache_images=False,
+ single_cls=False,
+ stride=32,
+ pad=0,
+ min_items=0,
+ prefix='',
+ downsample_ratio=1,
+ overlap=False,
+ ):
+ super().__init__(path, img_size, batch_size, augment, hyp, rect, image_weights, cache_images, single_cls,
+ stride, pad, min_items, prefix)
+ self.downsample_ratio = downsample_ratio
+ self.overlap = overlap
+
+ def __getitem__(self, index):
+ index = self.indices[index] # linear, shuffled, or image_weights
+
+ hyp = self.hyp
+ mosaic = self.mosaic and random.random() < hyp['mosaic']
+ masks = []
+ if mosaic:
+ # Load mosaic
+ img, labels, segments = self.load_mosaic(index)
+ shapes = None
+
+ # MixUp augmentation
+ if random.random() < hyp['mixup']:
+ img, labels, segments = mixup(img, labels, segments, *self.load_mosaic(random.randint(0, self.n - 1)))
+
+ else:
+ # Load image
+ img, (h0, w0), (h, w) = self.load_image(index)
+
+ # Letterbox
+ shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
+ img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
+ shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
+
+ labels = self.labels[index].copy()
+ # [array, array, ....], array.shape=(num_points, 2), xyxyxyxy
+ segments = self.segments[index].copy()
+ if len(segments):
+ for i_s in range(len(segments)):
+ segments[i_s] = xyn2xy(
+ segments[i_s],
+ ratio[0] * w,
+ ratio[1] * h,
+ padw=pad[0],
+ padh=pad[1],
+ )
+ if labels.size: # normalized xywh to pixel xyxy format
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
+
+ if self.augment:
+ img, labels, segments = random_perspective(img,
+ labels,
+ segments=segments,
+ degrees=hyp['degrees'],
+ translate=hyp['translate'],
+ scale=hyp['scale'],
+ shear=hyp['shear'],
+ perspective=hyp['perspective'])
+
+ nl = len(labels) # number of labels
+ if nl:
+ labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1e-3)
+ if self.overlap:
+ masks, sorted_idx = polygons2masks_overlap(img.shape[:2],
+ segments,
+ downsample_ratio=self.downsample_ratio)
+ masks = masks[None] # (640, 640) -> (1, 640, 640)
+ labels = labels[sorted_idx]
+ else:
+ masks = polygons2masks(img.shape[:2], segments, color=1, downsample_ratio=self.downsample_ratio)
+
+ masks = (torch.from_numpy(masks) if len(masks) else torch.zeros(1 if self.overlap else nl, img.shape[0] //
+ self.downsample_ratio, img.shape[1] //
+ self.downsample_ratio))
+ # TODO: albumentations support
+ if self.augment:
+ # Albumentations
+ # there are some augmentation that won't change boxes and masks,
+ # so just be it for now.
+ img, labels = self.albumentations(img, labels)
+ nl = len(labels) # update after albumentations
+
+ # HSV color-space
+ augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
+
+ # Flip up-down
+ if random.random() < hyp['flipud']:
+ img = np.flipud(img)
+ if nl:
+ labels[:, 2] = 1 - labels[:, 2]
+ masks = torch.flip(masks, dims=[1])
+
+ # Flip left-right
+ if random.random() < hyp['fliplr']:
+ img = np.fliplr(img)
+ if nl:
+ labels[:, 1] = 1 - labels[:, 1]
+ masks = torch.flip(masks, dims=[2])
+
+ # Cutouts # labels = cutout(img, labels, p=0.5)
+
+ labels_out = torch.zeros((nl, 6))
+ if nl:
+ labels_out[:, 1:] = torch.from_numpy(labels)
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return (torch.from_numpy(img), labels_out, self.im_files[index], shapes, masks)
+
+ def load_mosaic(self, index):
+ # YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
+ labels4, segments4 = [], []
+ s = self.img_size
+ yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
+
+ # 3 additional image indices
+ indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img4
+ if i == 0: # top left
+ img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
+ elif i == 1: # top right
+ x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
+ x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
+ elif i == 2: # bottom left
+ x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
+ elif i == 3: # bottom right
+ x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
+
+ img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
+ padw = x1a - x1b
+ padh = y1a - y1b
+
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
+ labels4.append(labels)
+ segments4.extend(segments)
+
+ # Concat/clip labels
+ labels4 = np.concatenate(labels4, 0)
+ for x in (labels4[:, 1:], *segments4):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img4, labels4 = replicate(img4, labels4) # replicate
+
+ # Augment
+ img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
+ img4, labels4, segments4 = random_perspective(img4,
+ labels4,
+ segments4,
+ degrees=self.hyp['degrees'],
+ translate=self.hyp['translate'],
+ scale=self.hyp['scale'],
+ shear=self.hyp['shear'],
+ perspective=self.hyp['perspective'],
+ border=self.mosaic_border) # border to remove
+ return img4, labels4, segments4
+
+ @staticmethod
+ def collate_fn(batch):
+ img, label, path, shapes, masks = zip(*batch) # transposed
+ batched_masks = torch.cat(masks, 0)
+ for i, l in enumerate(label):
+ l[:, 0] = i # add target image index for build_targets()
+ return torch.stack(img, 0), torch.cat(label, 0), path, shapes, batched_masks
+
+
+def polygon2mask(img_size, polygons, color=1, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (np.ndarray): [N, M], N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ mask = np.zeros(img_size, dtype=np.uint8)
+ polygons = np.asarray(polygons)
+ polygons = polygons.astype(np.int32)
+ shape = polygons.shape
+ polygons = polygons.reshape(shape[0], -1, 2)
+ cv2.fillPoly(mask, polygons, color=color)
+ nh, nw = (img_size[0] // downsample_ratio, img_size[1] // downsample_ratio)
+ # NOTE: fillPoly firstly then resize is trying the keep the same way
+ # of loss calculation when mask-ratio=1.
+ mask = cv2.resize(mask, (nw, nh))
+ return mask
+
+
+def polygons2masks(img_size, polygons, color, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (list[np.ndarray]): each polygon is [N, M],
+ N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ masks = []
+ for si in range(len(polygons)):
+ mask = polygon2mask(img_size, [polygons[si].reshape(-1)], color, downsample_ratio)
+ masks.append(mask)
+ return np.array(masks)
+
+
+def polygons2masks_overlap(img_size, segments, downsample_ratio=1):
+ """Return a (640, 640) overlap mask."""
+ masks = np.zeros((img_size[0] // downsample_ratio, img_size[1] // downsample_ratio),
+ dtype=np.int32 if len(segments) > 255 else np.uint8)
+ areas = []
+ ms = []
+ for si in range(len(segments)):
+ mask = polygon2mask(
+ img_size,
+ [segments[si].reshape(-1)],
+ downsample_ratio=downsample_ratio,
+ color=1,
+ )
+ ms.append(mask)
+ areas.append(mask.sum())
+ areas = np.asarray(areas)
+ index = np.argsort(-areas)
+ ms = np.array(ms)[index]
+ for i in range(len(segments)):
+ mask = ms[i] * (i + 1)
+ masks = masks + mask
+ masks = np.clip(masks, a_min=0, a_max=i + 1)
+ return masks, index
diff --git a/yolov5/utils/segment/general.py b/yolov5/utils/segment/general.py
new file mode 100644
index 0000000000000000000000000000000000000000..f1b2f1dd120ff47eec618e0c25239c28c4d88475
--- /dev/null
+++ b/yolov5/utils/segment/general.py
@@ -0,0 +1,160 @@
+import cv2
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+
+def crop_mask(masks, boxes):
+ """
+ "Crop" predicted masks by zeroing out everything not in the predicted bbox.
+ Vectorized by Chong (thanks Chong).
+
+ Args:
+ - masks should be a size [n, h, w] tensor of masks
+ - boxes should be a size [n, 4] tensor of bbox coords in relative point form
+ """
+
+ n, h, w = masks.shape
+ x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1) # x1 shape(1,1,n)
+ r = torch.arange(w, device=masks.device, dtype=x1.dtype)[None, None, :] # rows shape(1,w,1)
+ c = torch.arange(h, device=masks.device, dtype=x1.dtype)[None, :, None] # cols shape(h,1,1)
+
+ return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
+
+
+def process_mask_upsample(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape: input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask(protos, masks_in, bboxes, shape, upsample=False):
+ """
+ Crop before upsample.
+ proto_out: [mask_dim, mask_h, mask_w]
+ out_masks: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape:input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ ih, iw = shape
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw) # CHW
+
+ downsampled_bboxes = bboxes.clone()
+ downsampled_bboxes[:, 0] *= mw / iw
+ downsampled_bboxes[:, 2] *= mw / iw
+ downsampled_bboxes[:, 3] *= mh / ih
+ downsampled_bboxes[:, 1] *= mh / ih
+
+ masks = crop_mask(masks, downsampled_bboxes) # CHW
+ if upsample:
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask_native(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape: input_image_size, (h, w)
+
+ return: h, w, n
+ """
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ gain = min(mh / shape[0], mw / shape[1]) # gain = old / new
+ pad = (mw - shape[1] * gain) / 2, (mh - shape[0] * gain) / 2 # wh padding
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(mh - pad[1]), int(mw - pad[0])
+ masks = masks[:, top:bottom, left:right]
+
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def scale_image(im1_shape, masks, im0_shape, ratio_pad=None):
+ """
+ img1_shape: model input shape, [h, w]
+ img0_shape: origin pic shape, [h, w, 3]
+ masks: [h, w, num]
+ """
+ # Rescale coordinates (xyxy) from im1_shape to im0_shape
+ if ratio_pad is None: # calculate from im0_shape
+ gain = min(im1_shape[0] / im0_shape[0], im1_shape[1] / im0_shape[1]) # gain = old / new
+ pad = (im1_shape[1] - im0_shape[1] * gain) / 2, (im1_shape[0] - im0_shape[0] * gain) / 2 # wh padding
+ else:
+ pad = ratio_pad[1]
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(im1_shape[0] - pad[1]), int(im1_shape[1] - pad[0])
+
+ if len(masks.shape) < 2:
+ raise ValueError(f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}')
+ masks = masks[top:bottom, left:right]
+ # masks = masks.permute(2, 0, 1).contiguous()
+ # masks = F.interpolate(masks[None], im0_shape[:2], mode='bilinear', align_corners=False)[0]
+ # masks = masks.permute(1, 2, 0).contiguous()
+ masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]))
+
+ if len(masks.shape) == 2:
+ masks = masks[:, :, None]
+ return masks
+
+
+def mask_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [M, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, [N, M]
+ """
+ intersection = torch.matmul(mask1, mask2.t()).clamp(0)
+ union = (mask1.sum(1)[:, None] + mask2.sum(1)[None]) - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [N, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, (N, )
+ """
+ intersection = (mask1 * mask2).sum(1).clamp(0) # (N, )
+ union = (mask1.sum(1) + mask2.sum(1))[None] - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks2segments(masks, strategy='largest'):
+ # Convert masks(n,160,160) into segments(n,xy)
+ segments = []
+ for x in masks.int().cpu().numpy().astype('uint8'):
+ c = cv2.findContours(x, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
+ if c:
+ if strategy == 'concat': # concatenate all segments
+ c = np.concatenate([x.reshape(-1, 2) for x in c])
+ elif strategy == 'largest': # select largest segment
+ c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
+ else:
+ c = np.zeros((0, 2)) # no segments found
+ segments.append(c.astype('float32'))
+ return segments
diff --git a/yolov5/utils/segment/loss.py b/yolov5/utils/segment/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..caeff3cad586b4367990aa4626ed6c326b04baf3
--- /dev/null
+++ b/yolov5/utils/segment/loss.py
@@ -0,0 +1,185 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..general import xywh2xyxy
+from ..loss import FocalLoss, smooth_BCE
+from ..metrics import bbox_iou
+from ..torch_utils import de_parallel
+from .general import crop_mask
+
+
+class ComputeLoss:
+ # Compute losses
+ def __init__(self, model, autobalance=False, overlap=False):
+ self.sort_obj_iou = False
+ self.overlap = overlap
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.nm = m.nm # number of masks
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, preds, targets, masks): # predictions, targets, model
+ p, proto = preds
+ bs, nm, mask_h, mask_w = proto.shape # batch size, number of masks, mask height, mask width
+ lcls = torch.zeros(1, device=self.device)
+ lbox = torch.zeros(1, device=self.device)
+ lobj = torch.zeros(1, device=self.device)
+ lseg = torch.zeros(1, device=self.device)
+ tcls, tbox, indices, anchors, tidxs, xywhn = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ pxy, pwh, _, pcls, pmask = pi[b, a, gj, gi].split((2, 2, 1, self.nc, nm), 1) # subset of predictions
+
+ # Box regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Mask regression
+ if tuple(masks.shape[-2:]) != (mask_h, mask_w): # downsample
+ masks = F.interpolate(masks[None], (mask_h, mask_w), mode='nearest')[0]
+ marea = xywhn[i][:, 2:].prod(1) # mask width, height normalized
+ mxyxy = xywh2xyxy(xywhn[i] * torch.tensor([mask_w, mask_h, mask_w, mask_h], device=self.device))
+ for bi in b.unique():
+ j = b == bi # matching index
+ if self.overlap:
+ mask_gti = torch.where(masks[bi][None] == tidxs[i][j].view(-1, 1, 1), 1.0, 0.0)
+ else:
+ mask_gti = masks[tidxs[i]][j]
+ lseg += self.single_mask_loss(mask_gti, pmask[j], proto[bi], mxyxy[j], marea[j])
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ lseg *= self.hyp['box'] / bs
+
+ loss = lbox + lobj + lcls + lseg
+ return loss * bs, torch.cat((lbox, lseg, lobj, lcls)).detach()
+
+ def single_mask_loss(self, gt_mask, pred, proto, xyxy, area):
+ # Mask loss for one image
+ pred_mask = (pred @ proto.view(self.nm, -1)).view(-1, *proto.shape[1:]) # (n,32) @ (32,80,80) -> (n,80,80)
+ loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction='none')
+ return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).mean()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch, tidxs, xywhn = [], [], [], [], [], []
+ gain = torch.ones(8, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ if self.overlap:
+ batch = p[0].shape[0]
+ ti = []
+ for i in range(batch):
+ num = (targets[:, 0] == i).sum() # find number of targets of each image
+ ti.append(torch.arange(num, device=self.device).float().view(1, num).repeat(na, 1) + 1) # (na, num)
+ ti = torch.cat(ti, 1) # (na, nt)
+ else:
+ ti = torch.arange(nt, device=self.device).float().view(1, nt).repeat(na, 1)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None], ti[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, at = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ (a, tidx), (b, c) = at.long().T, bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+ tidxs.append(tidx)
+ xywhn.append(torch.cat((gxy, gwh), 1) / gain[2:6]) # xywh normalized
+
+ return tcls, tbox, indices, anch, tidxs, xywhn
diff --git a/yolov5/utils/segment/metrics.py b/yolov5/utils/segment/metrics.py
new file mode 100644
index 0000000000000000000000000000000000000000..6020fa062ba562c770a3a6dd17daf7fa30e1dfc2
--- /dev/null
+++ b/yolov5/utils/segment/metrics.py
@@ -0,0 +1,210 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import numpy as np
+
+from ..metrics import ap_per_class
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9, 0.0, 0.0, 0.1, 0.9]
+ return (x[:, :8] * w).sum(1)
+
+
+def ap_per_class_box_and_mask(
+ tp_m,
+ tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=False,
+ save_dir='.',
+ names=(),
+):
+ """
+ Args:
+ tp_b: tp of boxes.
+ tp_m: tp of masks.
+ other arguments see `func: ap_per_class`.
+ """
+ results_boxes = ap_per_class(tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix='Box')[2:]
+ results_masks = ap_per_class(tp_m,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix='Mask')[2:]
+
+ results = {
+ 'boxes': {
+ 'p': results_boxes[0],
+ 'r': results_boxes[1],
+ 'ap': results_boxes[3],
+ 'f1': results_boxes[2],
+ 'ap_class': results_boxes[4]},
+ 'masks': {
+ 'p': results_masks[0],
+ 'r': results_masks[1],
+ 'ap': results_masks[3],
+ 'f1': results_masks[2],
+ 'ap_class': results_masks[4]}}
+ return results
+
+
+class Metric:
+
+ def __init__(self) -> None:
+ self.p = [] # (nc, )
+ self.r = [] # (nc, )
+ self.f1 = [] # (nc, )
+ self.all_ap = [] # (nc, 10)
+ self.ap_class_index = [] # (nc, )
+
+ @property
+ def ap50(self):
+ """AP@0.5 of all classes.
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap[:, 0] if len(self.all_ap) else []
+
+ @property
+ def ap(self):
+ """AP@0.5:0.95
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap.mean(1) if len(self.all_ap) else []
+
+ @property
+ def mp(self):
+ """mean precision of all classes.
+ Return:
+ float.
+ """
+ return self.p.mean() if len(self.p) else 0.0
+
+ @property
+ def mr(self):
+ """mean recall of all classes.
+ Return:
+ float.
+ """
+ return self.r.mean() if len(self.r) else 0.0
+
+ @property
+ def map50(self):
+ """Mean AP@0.5 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap[:, 0].mean() if len(self.all_ap) else 0.0
+
+ @property
+ def map(self):
+ """Mean AP@0.5:0.95 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap.mean() if len(self.all_ap) else 0.0
+
+ def mean_results(self):
+ """Mean of results, return mp, mr, map50, map"""
+ return (self.mp, self.mr, self.map50, self.map)
+
+ def class_result(self, i):
+ """class-aware result, return p[i], r[i], ap50[i], ap[i]"""
+ return (self.p[i], self.r[i], self.ap50[i], self.ap[i])
+
+ def get_maps(self, nc):
+ maps = np.zeros(nc) + self.map
+ for i, c in enumerate(self.ap_class_index):
+ maps[c] = self.ap[i]
+ return maps
+
+ def update(self, results):
+ """
+ Args:
+ results: tuple(p, r, ap, f1, ap_class)
+ """
+ p, r, all_ap, f1, ap_class_index = results
+ self.p = p
+ self.r = r
+ self.all_ap = all_ap
+ self.f1 = f1
+ self.ap_class_index = ap_class_index
+
+
+class Metrics:
+ """Metric for boxes and masks."""
+
+ def __init__(self) -> None:
+ self.metric_box = Metric()
+ self.metric_mask = Metric()
+
+ def update(self, results):
+ """
+ Args:
+ results: Dict{'boxes': Dict{}, 'masks': Dict{}}
+ """
+ self.metric_box.update(list(results['boxes'].values()))
+ self.metric_mask.update(list(results['masks'].values()))
+
+ def mean_results(self):
+ return self.metric_box.mean_results() + self.metric_mask.mean_results()
+
+ def class_result(self, i):
+ return self.metric_box.class_result(i) + self.metric_mask.class_result(i)
+
+ def get_maps(self, nc):
+ return self.metric_box.get_maps(nc) + self.metric_mask.get_maps(nc)
+
+ @property
+ def ap_class_index(self):
+ # boxes and masks have the same ap_class_index
+ return self.metric_box.ap_class_index
+
+
+KEYS = [
+ 'train/box_loss',
+ 'train/seg_loss', # train loss
+ 'train/obj_loss',
+ 'train/cls_loss',
+ 'metrics/precision(B)',
+ 'metrics/recall(B)',
+ 'metrics/mAP_0.5(B)',
+ 'metrics/mAP_0.5:0.95(B)', # metrics
+ 'metrics/precision(M)',
+ 'metrics/recall(M)',
+ 'metrics/mAP_0.5(M)',
+ 'metrics/mAP_0.5:0.95(M)', # metrics
+ 'val/box_loss',
+ 'val/seg_loss', # val loss
+ 'val/obj_loss',
+ 'val/cls_loss',
+ 'x/lr0',
+ 'x/lr1',
+ 'x/lr2',]
+
+BEST_KEYS = [
+ 'best/epoch',
+ 'best/precision(B)',
+ 'best/recall(B)',
+ 'best/mAP_0.5(B)',
+ 'best/mAP_0.5:0.95(B)',
+ 'best/precision(M)',
+ 'best/recall(M)',
+ 'best/mAP_0.5(M)',
+ 'best/mAP_0.5:0.95(M)',]
diff --git a/yolov5/utils/segment/plots.py b/yolov5/utils/segment/plots.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b22ec838ac93220187b60f5bdaf50eae19d7397
--- /dev/null
+++ b/yolov5/utils/segment/plots.py
@@ -0,0 +1,143 @@
+import contextlib
+import math
+from pathlib import Path
+
+import cv2
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import torch
+
+from .. import threaded
+from ..general import xywh2xyxy
+from ..plots import Annotator, colors
+
+
+@threaded
+def plot_images_and_masks(images, targets, masks, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+ if isinstance(masks, torch.Tensor):
+ masks = masks.cpu().numpy().astype(int)
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ idx = targets[:, 0] == i
+ ti = targets[idx] # image targets
+
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+
+ # Plot masks
+ if len(masks):
+ if masks.max() > 1.0: # mean that masks are overlap
+ image_masks = masks[[i]] # (1, 640, 640)
+ nl = len(ti)
+ index = np.arange(nl).reshape(nl, 1, 1) + 1
+ image_masks = np.repeat(image_masks, nl, axis=0)
+ image_masks = np.where(image_masks == index, 1.0, 0.0)
+ else:
+ image_masks = masks[idx]
+
+ im = np.asarray(annotator.im).copy()
+ for j, box in enumerate(boxes.T.tolist()):
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ color = colors(classes[j])
+ mh, mw = image_masks[j].shape
+ if mh != h or mw != w:
+ mask = image_masks[j].astype(np.uint8)
+ mask = cv2.resize(mask, (w, h))
+ mask = mask.astype(bool)
+ else:
+ mask = image_masks[j].astype(bool)
+ with contextlib.suppress(Exception):
+ im[y:y + h, x:x + w, :][mask] = im[y:y + h, x:x + w, :][mask] * 0.4 + np.array(color) * 0.6
+ annotator.fromarray(im)
+ annotator.im.save(fname) # save
+
+
+def plot_results_with_masks(file='path/to/results.csv', dir='', best=True):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 8, figsize=(18, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ index = np.argmax(0.9 * data.values[:, 8] + 0.1 * data.values[:, 7] + 0.9 * data.values[:, 12] +
+ 0.1 * data.values[:, 11])
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 6, 9, 10, 13, 14, 15, 16, 7, 8, 11, 12]):
+ y = data.values[:, j]
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=2)
+ if best:
+ # best
+ ax[i].scatter(index, y[index], color='r', label=f'best:{index}', marker='*', linewidth=3)
+ ax[i].set_title(s[j] + f'\n{round(y[index], 5)}')
+ else:
+ # last
+ ax[i].scatter(x[-1], y[-1], color='r', label='last', marker='*', linewidth=3)
+ ax[i].set_title(s[j] + f'\n{round(y[-1], 5)}')
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
diff --git a/yolov5/utils/torch_utils.py b/yolov5/utils/torch_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b42be027414a24a4ad7bf39a8476871c51158da
--- /dev/null
+++ b/yolov5/utils/torch_utils.py
@@ -0,0 +1,432 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+PyTorch utils
+"""
+
+import math
+import os
+import platform
+import subprocess
+import time
+import warnings
+from contextlib import contextmanager
+from copy import deepcopy
+from pathlib import Path
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn.parallel import DistributedDataParallel as DDP
+
+from yolov5.utils.general import LOGGER, check_version, colorstr, file_date, git_describe
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+# Suppress PyTorch warnings
+warnings.filterwarnings('ignore', message='User provided device_type of \'cuda\', but CUDA is not available. Disabling')
+warnings.filterwarnings('ignore', category=UserWarning)
+
+
+def smart_inference_mode(torch_1_9=check_version(torch.__version__, '1.9.0')):
+ # Applies torch.inference_mode() decorator if torch>=1.9.0 else torch.no_grad() decorator
+ def decorate(fn):
+ return (torch.inference_mode if torch_1_9 else torch.no_grad)()(fn)
+
+ return decorate
+
+
+def smartCrossEntropyLoss(label_smoothing=0.0):
+ # Returns nn.CrossEntropyLoss with label smoothing enabled for torch>=1.10.0
+ if check_version(torch.__version__, '1.10.0'):
+ return nn.CrossEntropyLoss(label_smoothing=label_smoothing)
+ if label_smoothing > 0:
+ LOGGER.warning(f'WARNING ⚠️ label smoothing {label_smoothing} requires torch>=1.10.0')
+ return nn.CrossEntropyLoss()
+
+
+def smart_DDP(model):
+ # Model DDP creation with checks
+ assert not check_version(torch.__version__, '1.12.0', pinned=True), \
+ 'torch==1.12.0 torchvision==0.13.0 DDP training is not supported due to a known issue. ' \
+ 'Please upgrade or downgrade torch to use DDP. See https://github.com/ultralytics/yolov5/issues/8395'
+ if check_version(torch.__version__, '1.11.0'):
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK, static_graph=True)
+ else:
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+
+def reshape_classifier_output(model, n=1000):
+ # Update a TorchVision classification model to class count 'n' if required
+ from models.common import Classify
+ name, m = list((model.model if hasattr(model, 'model') else model).named_children())[-1] # last module
+ if isinstance(m, Classify): # YOLOv5 Classify() head
+ if m.linear.out_features != n:
+ m.linear = nn.Linear(m.linear.in_features, n)
+ elif isinstance(m, nn.Linear): # ResNet, EfficientNet
+ if m.out_features != n:
+ setattr(model, name, nn.Linear(m.in_features, n))
+ elif isinstance(m, nn.Sequential):
+ types = [type(x) for x in m]
+ if nn.Linear in types:
+ i = types.index(nn.Linear) # nn.Linear index
+ if m[i].out_features != n:
+ m[i] = nn.Linear(m[i].in_features, n)
+ elif nn.Conv2d in types:
+ i = types.index(nn.Conv2d) # nn.Conv2d index
+ if m[i].out_channels != n:
+ m[i] = nn.Conv2d(m[i].in_channels, n, m[i].kernel_size, m[i].stride, bias=m[i].bias is not None)
+
+
+@contextmanager
+def torch_distributed_zero_first(local_rank: int):
+ # Decorator to make all processes in distributed training wait for each local_master to do something
+ if local_rank not in [-1, 0]:
+ dist.barrier(device_ids=[local_rank])
+ yield
+ if local_rank == 0:
+ dist.barrier(device_ids=[0])
+
+
+def device_count():
+ # Returns number of CUDA devices available. Safe version of torch.cuda.device_count(). Supports Linux and Windows
+ assert platform.system() in ('Linux', 'Windows'), 'device_count() only supported on Linux or Windows'
+ try:
+ cmd = 'nvidia-smi -L | wc -l' if platform.system() == 'Linux' else 'nvidia-smi -L | find /c /v ""' # Windows
+ return int(subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1])
+ except Exception:
+ return 0
+
+
+def select_device(device='', batch_size=0, newline=True):
+ # device = None or 'cpu' or 0 or '0' or '0,1,2,3'
+ s = f'YOLOv5 🚀 {git_describe() or file_date()} Python-{platform.python_version()} torch-{torch.__version__} '
+ device = str(device).strip().lower().replace('cuda:', '').replace('none', '') # to string, 'cuda:0' to '0'
+ cpu = device == 'cpu'
+ mps = device == 'mps' # Apple Metal Performance Shaders (MPS)
+ if cpu or mps:
+ os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
+ elif device: # non-cpu device requested
+ os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable - must be before assert is_available()
+ assert torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(',', '')), \
+ f"Invalid CUDA '--device {device}' requested, use '--device cpu' or pass valid CUDA device(s)"
+
+ if not cpu and not mps and torch.cuda.is_available(): # prefer GPU if available
+ devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
+ n = len(devices) # device count
+ if n > 1 and batch_size > 0: # check batch_size is divisible by device_count
+ assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
+ space = ' ' * (len(s) + 1)
+ for i, d in enumerate(devices):
+ p = torch.cuda.get_device_properties(i)
+ s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / (1 << 20):.0f}MiB)\n" # bytes to MB
+ arg = 'cuda:0'
+ elif mps and getattr(torch, 'has_mps', False) and torch.backends.mps.is_available(): # prefer MPS if available
+ s += 'MPS\n'
+ arg = 'mps'
+ else: # revert to CPU
+ s += 'CPU\n'
+ arg = 'cpu'
+
+ if not newline:
+ s = s.rstrip()
+ LOGGER.info(s)
+ return torch.device(arg)
+
+
+def time_sync():
+ # PyTorch-accurate time
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def profile(input, ops, n=10, device=None):
+ """ YOLOv5 speed/memory/FLOPs profiler
+ Usage:
+ input = torch.randn(16, 3, 640, 640)
+ m1 = lambda x: x * torch.sigmoid(x)
+ m2 = nn.SiLU()
+ profile(input, [m1, m2], n=100) # profile over 100 iterations
+ """
+ results = []
+ if not isinstance(device, torch.device):
+ device = select_device(device)
+ print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
+ try:
+ flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
+ except Exception:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ _ = (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception: # no backward method
+ # print(e) # for debug
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in, s_out = (tuple(x.shape) if isinstance(x, torch.Tensor) else 'list' for x in (x, y)) # shapes
+ p = sum(x.numel() for x in m.parameters()) if isinstance(m, nn.Module) else 0 # parameters
+ print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ print(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
+
+
+def is_parallel(model):
+ # Returns True if model is of type DP or DDP
+ return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
+
+
+def de_parallel(model):
+ # De-parallelize a model: returns single-GPU model if model is of type DP or DDP
+ return model.module if is_parallel(model) else model
+
+
+def initialize_weights(model):
+ for m in model.modules():
+ t = type(m)
+ if t is nn.Conv2d:
+ pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif t is nn.BatchNorm2d:
+ m.eps = 1e-3
+ m.momentum = 0.03
+ elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
+ m.inplace = True
+
+
+def find_modules(model, mclass=nn.Conv2d):
+ # Finds layer indices matching module class 'mclass'
+ return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
+
+
+def sparsity(model):
+ # Return global model sparsity
+ a, b = 0, 0
+ for p in model.parameters():
+ a += p.numel()
+ b += (p == 0).sum()
+ return b / a
+
+
+def prune(model, amount=0.3):
+ # Prune model to requested global sparsity
+ import torch.nn.utils.prune as prune
+ for name, m in model.named_modules():
+ if isinstance(m, nn.Conv2d):
+ prune.l1_unstructured(m, name='weight', amount=amount) # prune
+ prune.remove(m, 'weight') # make permanent
+ LOGGER.info(f'Model pruned to {sparsity(model):.3g} global sparsity')
+
+
+def fuse_conv_and_bn(conv, bn):
+ # Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
+ fusedconv = nn.Conv2d(conv.in_channels,
+ conv.out_channels,
+ kernel_size=conv.kernel_size,
+ stride=conv.stride,
+ padding=conv.padding,
+ dilation=conv.dilation,
+ groups=conv.groups,
+ bias=True).requires_grad_(False).to(conv.weight.device)
+
+ # Prepare filters
+ w_conv = conv.weight.clone().view(conv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
+
+ # Prepare spatial bias
+ b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fusedconv
+
+
+def model_info(model, verbose=False, imgsz=640):
+ # Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
+ n_p = sum(x.numel() for x in model.parameters()) # number parameters
+ n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
+ if verbose:
+ print(f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
+ for i, (name, p) in enumerate(model.named_parameters()):
+ name = name.replace('module_list.', '')
+ print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
+ (i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
+
+ try: # FLOPs
+ p = next(model.parameters())
+ stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32 # max stride
+ im = torch.empty((1, p.shape[1], stride, stride), device=p.device) # input image in BCHW format
+ flops = thop.profile(deepcopy(model), inputs=(im,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
+ imgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/float
+ fs = f', {flops * imgsz[0] / stride * imgsz[1] / stride:.1f} GFLOPs' # 640x640 GFLOPs
+ except Exception:
+ fs = ''
+
+ name = Path(model.yaml_file).stem.replace('yolov5', 'YOLOv5') if hasattr(model, 'yaml_file') else 'Model'
+ LOGGER.info(f'{name} summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}')
+
+
+def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
+ # Scales img(bs,3,y,x) by ratio constrained to gs-multiple
+ if ratio == 1.0:
+ return img
+ h, w = img.shape[2:]
+ s = (int(h * ratio), int(w * ratio)) # new size
+ img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
+ if not same_shape: # pad/crop img
+ h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
+ return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
+
+
+def copy_attr(a, b, include=(), exclude=()):
+ # Copy attributes from b to a, options to only include [...] and to exclude [...]
+ for k, v in b.__dict__.items():
+ if (len(include) and k not in include) or k.startswith('_') or k in exclude:
+ continue
+ else:
+ setattr(a, k, v)
+
+
+def smart_optimizer(model, name='Adam', lr=0.001, momentum=0.9, decay=1e-5):
+ # YOLOv5 3-param group optimizer: 0) weights with decay, 1) weights no decay, 2) biases no decay
+ g = [], [], [] # optimizer parameter groups
+ bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
+ for v in model.modules():
+ for p_name, p in v.named_parameters(recurse=0):
+ if p_name == 'bias': # bias (no decay)
+ g[2].append(p)
+ elif p_name == 'weight' and isinstance(v, bn): # weight (no decay)
+ g[1].append(p)
+ else:
+ g[0].append(p) # weight (with decay)
+
+ if name == 'Adam':
+ optimizer = torch.optim.Adam(g[2], lr=lr, betas=(momentum, 0.999)) # adjust beta1 to momentum
+ elif name == 'AdamW':
+ optimizer = torch.optim.AdamW(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
+ elif name == 'RMSProp':
+ optimizer = torch.optim.RMSprop(g[2], lr=lr, momentum=momentum)
+ elif name == 'SGD':
+ optimizer = torch.optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
+ else:
+ raise NotImplementedError(f'Optimizer {name} not implemented.')
+
+ optimizer.add_param_group({'params': g[0], 'weight_decay': decay}) # add g0 with weight_decay
+ optimizer.add_param_group({'params': g[1], 'weight_decay': 0.0}) # add g1 (BatchNorm2d weights)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}) with parameter groups "
+ f'{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias')
+ return optimizer
+
+
+def smart_hub_load(repo='ultralytics/yolov5', model='yolov5s', **kwargs):
+ # YOLOv5 torch.hub.load() wrapper with smart error/issue handling
+ if check_version(torch.__version__, '1.9.1'):
+ kwargs['skip_validation'] = True # validation causes GitHub API rate limit errors
+ if check_version(torch.__version__, '1.12.0'):
+ kwargs['trust_repo'] = True # argument required starting in torch 0.12
+ try:
+ return torch.hub.load(repo, model, **kwargs)
+ except Exception:
+ return torch.hub.load(repo, model, force_reload=True, **kwargs)
+
+
+def smart_resume(ckpt, optimizer, ema=None, weights='yolov5s.pt', epochs=300, resume=True):
+ # Resume training from a partially trained checkpoint
+ best_fitness = 0.0
+ start_epoch = ckpt['epoch'] + 1
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer']) # optimizer
+ best_fitness = ckpt['best_fitness']
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict()) # EMA
+ ema.updates = ckpt['updates']
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.\n' \
+ f"Start a new training without --resume, i.e. 'python train.py --weights {weights}'"
+ LOGGER.info(f'Resuming training from {weights} from epoch {start_epoch} to {epochs} total epochs')
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+ return best_fitness, start_epoch, epochs
+
+
+class EarlyStopping:
+ # YOLOv5 simple early stopper
+ def __init__(self, patience=30):
+ self.best_fitness = 0.0 # i.e. mAP
+ self.best_epoch = 0
+ self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
+ self.possible_stop = False # possible stop may occur next epoch
+
+ def __call__(self, epoch, fitness):
+ if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
+ self.best_epoch = epoch
+ self.best_fitness = fitness
+ delta = epoch - self.best_epoch # epochs without improvement
+ self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
+ stop = delta >= self.patience # stop training if patience exceeded
+ if stop:
+ LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
+ f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
+ f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
+ f'i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.')
+ return stop
+
+
+class ModelEMA:
+ """ Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
+ Keeps a moving average of everything in the model state_dict (parameters and buffers)
+ For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ """
+
+ def __init__(self, model, decay=0.9999, tau=2000, updates=0):
+ # Create EMA
+ self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
+ self.updates = updates # number of EMA updates
+ self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
+ for p in self.ema.parameters():
+ p.requires_grad_(False)
+
+ def update(self, model):
+ # Update EMA parameters
+ self.updates += 1
+ d = self.decay(self.updates)
+
+ msd = de_parallel(model).state_dict() # model state_dict
+ for k, v in self.ema.state_dict().items():
+ if v.dtype.is_floating_point: # true for FP16 and FP32
+ v *= d
+ v += (1 - d) * msd[k].detach()
+ # assert v.dtype == msd[k].dtype == torch.float32, f'{k}: EMA {v.dtype} and model {msd[k].dtype} must be FP32'
+
+ def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
+ # Update EMA attributes
+ copy_attr(self.ema, model, include, exclude)
diff --git a/yolov5/utils/triton.py b/yolov5/utils/triton.py
new file mode 100644
index 0000000000000000000000000000000000000000..b5153dad940ddeceda4d8e39ac3d90e3efa66448
--- /dev/null
+++ b/yolov5/utils/triton.py
@@ -0,0 +1,85 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+""" Utils to interact with the Triton Inference Server
+"""
+
+import typing
+from urllib.parse import urlparse
+
+import torch
+
+
+class TritonRemoteModel:
+ """ A wrapper over a model served by the Triton Inference Server. It can
+ be configured to communicate over GRPC or HTTP. It accepts Torch Tensors
+ as input and returns them as outputs.
+ """
+
+ def __init__(self, url: str):
+ """
+ Keyword arguments:
+ url: Fully qualified address of the Triton server - for e.g. grpc://localhost:8000
+ """
+
+ parsed_url = urlparse(url)
+ if parsed_url.scheme == 'grpc':
+ from tritonclient.grpc import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton GRPC client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository.models[0].name
+ self.metadata = self.client.get_model_metadata(self.model_name, as_json=True)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i['shape']], i['datatype']) for i in self.metadata['inputs']]
+
+ else:
+ from tritonclient.http import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton HTTP client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository[0]['name']
+ self.metadata = self.client.get_model_metadata(self.model_name)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i['shape']], i['datatype']) for i in self.metadata['inputs']]
+
+ self._create_input_placeholders_fn = create_input_placeholders
+
+ @property
+ def runtime(self):
+ """Returns the model runtime"""
+ return self.metadata.get('backend', self.metadata.get('platform'))
+
+ def __call__(self, *args, **kwargs) -> typing.Union[torch.Tensor, typing.Tuple[torch.Tensor, ...]]:
+ """ Invokes the model. Parameters can be provided via args or kwargs.
+ args, if provided, are assumed to match the order of inputs of the model.
+ kwargs are matched with the model input names.
+ """
+ inputs = self._create_inputs(*args, **kwargs)
+ response = self.client.infer(model_name=self.model_name, inputs=inputs)
+ result = []
+ for output in self.metadata['outputs']:
+ tensor = torch.as_tensor(response.as_numpy(output['name']))
+ result.append(tensor)
+ return result[0] if len(result) == 1 else result
+
+ def _create_inputs(self, *args, **kwargs):
+ args_len, kwargs_len = len(args), len(kwargs)
+ if not args_len and not kwargs_len:
+ raise RuntimeError('No inputs provided.')
+ if args_len and kwargs_len:
+ raise RuntimeError('Cannot specify args and kwargs at the same time')
+
+ placeholders = self._create_input_placeholders_fn()
+ if args_len:
+ if args_len != len(placeholders):
+ raise RuntimeError(f'Expected {len(placeholders)} inputs, got {args_len}.')
+ for input, value in zip(placeholders, args):
+ input.set_data_from_numpy(value.cpu().numpy())
+ else:
+ for input in placeholders:
+ value = kwargs[input.name]
+ input.set_data_from_numpy(value.cpu().numpy())
+ return placeholders
diff --git a/yolov5/val.py b/yolov5/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d01f1a5996d7cd93e27f4a57b85f8fbdbc3fce6
--- /dev/null
+++ b/yolov5/val.py
@@ -0,0 +1,409 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Validate a trained YOLOv5 detection model on a detection dataset
+
+Usage:
+ $ python val.py --weights yolov5s.pt --data coco128.yaml --img 640
+
+Usage - formats:
+ $ python val.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s_openvino_model # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import json
+import os
+import subprocess
+import sys
+from pathlib import Path
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, Profile, check_dataset, check_img_size, check_requirements,
+ check_yaml, coco80_to_coco91_class, colorstr, increment_path, non_max_suppression,
+ print_args, scale_boxes, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, ap_per_class, box_iou
+from utils.plots import output_to_target, plot_images, plot_val_study
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ jdict.append({
+ 'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5)})
+
+
+def process_batch(detections, labels, iouv):
+ """
+ Return correct prediction matrix
+ Arguments:
+ detections (array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (array[N, 10]), for 10 IoU levels
+ """
+ correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+ correct_class = labels[:, 0:1] == detections[:, 5]
+ for i in range(len(iouv)):
+ x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ correct[matches[:, 1].astype(int), i] = True
+ return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
+
+
+@smart_inference_mode()
+def run(
+ data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ max_det=300, # maximum detections per image
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ callbacks=Callbacks(),
+ compute_loss=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ cuda = device.type != 'cpu'
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith(f'coco{os.sep}val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10, device=device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and not single_cls: # check --weights are trained on --data
+ ncm = model.model.nc
+ assert ncm == nc, f'{weights} ({ncm} classes) trained on different --data than what you passed ({nc} ' \
+ f'classes). Pass correct combination of --weights and --data that are trained together.'
+ model.warmup(imgsz=(1 if pt else batch_size, 3, imgsz, imgsz)) # warmup
+ pad, rect = (0.0, False) if task == 'speed' else (0.5, pt) # square inference for benchmarks
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task],
+ imgsz,
+ batch_size,
+ stride,
+ single_cls,
+ pad=pad,
+ rect=rect,
+ workers=workers,
+ prefix=colorstr(f'{task}: '))[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = model.names if hasattr(model, 'names') else model.module.names # get class names
+ if isinstance(names, (list, tuple)): # old format
+ names = dict(enumerate(names))
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%22s' + '%11s' * 6) % ('Class', 'Images', 'Instances', 'P', 'R', 'mAP50', 'mAP50-95')
+ tp, fp, p, r, f1, mp, mr, map50, ap50, map = 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
+ dt = Profile(), Profile(), Profile() # profiling times
+ loss = torch.zeros(3, device=device)
+ jdict, stats, ap, ap_class = [], [], [], []
+ callbacks.run('on_val_start')
+ pbar = tqdm(dataloader, desc=s, bar_format=TQDM_BAR_FORMAT) # progress bar
+ for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
+ callbacks.run('on_val_batch_start')
+ with dt[0]:
+ if cuda:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+
+ # Inference
+ with dt[1]:
+ preds, train_out = model(im) if compute_loss else (model(im, augment=augment), None)
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss(train_out, targets)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.tensor((width, height, width, height), device=device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ with dt[2]:
+ preds = non_max_suppression(preds,
+ conf_thres,
+ iou_thres,
+ labels=lb,
+ multi_label=True,
+ agnostic=single_cls,
+ max_det=max_det)
+
+ # Metrics
+ for si, pred in enumerate(preds):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl, npr = labels.shape[0], pred.shape[0] # number of labels, predictions
+ path, shape = Path(paths[si]), shapes[si][0]
+ correct = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ seen += 1
+
+ if npr == 0:
+ if nl:
+ stats.append((correct, *torch.zeros((2, 0), device=device), labels[:, 0]))
+ if plots:
+ confusion_matrix.process_batch(detections=None, labels=labels[:, 0])
+ continue
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_boxes(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct = process_batch(predn, labelsn, iouv)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ stats.append((correct, pred[:, 4], pred[:, 5], labels[:, 0])) # (correct, conf, pcls, tcls)
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+ if save_json:
+ save_one_json(predn, jdict, path, class_map) # append to COCO-JSON dictionary
+ callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ plot_images(im, targets, paths, save_dir / f'val_batch{batch_i}_labels.jpg', names) # labels
+ plot_images(im, output_to_target(preds), paths, save_dir / f'val_batch{batch_i}_pred.jpg', names) # pred
+
+ callbacks.run('on_val_batch_end', batch_i, im, targets, paths, shapes, preds)
+
+ # Compute metrics
+ stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
+ ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
+ mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
+ nt = np.bincount(stats[3].astype(int), minlength=nc) # number of targets per class
+
+ # Print results
+ pf = '%22s' + '%11i' * 2 + '%11.3g' * 4 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
+ if nt.sum() == 0:
+ LOGGER.warning(f'WARNING ⚠️ no labels found in {task} set, can not compute metrics without labels')
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(ap_class):
+ LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
+
+ # Print speeds
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ callbacks.run('on_val_end', nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix)
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path('../datasets/coco/annotations/instances_val2017.json')) # annotations
+ pred_json = str(save_dir / f'{w}_predictions.json') # predictions
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements('pycocotools>=2.0.6')
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ eval = COCOeval(anno, pred, 'bbox')
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.im_files] # image IDs to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ maps = np.zeros(nc) + map
+ for i, c in enumerate(ap_class):
+ maps[c] = ap[i]
+ return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=300, help='maximum detections per image')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.info(f'WARNING ⚠️ confidence threshold {opt.conf_thres} > 0.001 produces invalid results')
+ if opt.save_hybrid:
+ LOGGER.info('WARNING ⚠️ --save-hybrid will return high mAP from hybrid labels, not from predictions alone')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ opt.half = torch.cuda.is_available() and opt.device != 'cpu' # FP16 for fastest results
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ subprocess.run(['zip', '-r', 'study.zip', 'study_*.txt'])
+ plot_val_study(x=x) # plot
+ else:
+ raise NotImplementedError(f'--task {opt.task} not in ("train", "val", "test", "speed", "study")')
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/yolov5s.pt b/yolov5/yolov5s.pt
new file mode 100644
index 0000000000000000000000000000000000000000..cd69a5e14d396322319b06304274238c0188a522
--- /dev/null
+++ b/yolov5/yolov5s.pt
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8b3b748c1e592ddd8868022e8732fde20025197328490623cc16c6f24d0782ee
+size 14808437
diff --git a/yolov5/utils/loggers/comet/__init__.py b/yolov5/utils/loggers/comet/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d4599841c9fc4df3e9ad4bf847f8bd13c3a9175d
--- /dev/null
+++ b/yolov5/utils/loggers/comet/__init__.py
@@ -0,0 +1,508 @@
+import glob
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+try:
+ import comet_ml
+
+ # Project Configuration
+ config = comet_ml.config.get_config()
+ COMET_PROJECT_NAME = config.get_string(os.getenv('COMET_PROJECT_NAME'), 'comet.project_name', default='yolov5')
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+ COMET_PROJECT_NAME = None
+
+import PIL
+import torch
+import torchvision.transforms as T
+import yaml
+
+from utils.dataloaders import img2label_paths
+from utils.general import check_dataset, scale_boxes, xywh2xyxy
+from utils.metrics import box_iou
+
+COMET_PREFIX = 'comet://'
+
+COMET_MODE = os.getenv('COMET_MODE', 'online')
+
+# Model Saving Settings
+COMET_MODEL_NAME = os.getenv('COMET_MODEL_NAME', 'yolov5')
+
+# Dataset Artifact Settings
+COMET_UPLOAD_DATASET = os.getenv('COMET_UPLOAD_DATASET', 'false').lower() == 'true'
+
+# Evaluation Settings
+COMET_LOG_CONFUSION_MATRIX = os.getenv('COMET_LOG_CONFUSION_MATRIX', 'true').lower() == 'true'
+COMET_LOG_PREDICTIONS = os.getenv('COMET_LOG_PREDICTIONS', 'true').lower() == 'true'
+COMET_MAX_IMAGE_UPLOADS = int(os.getenv('COMET_MAX_IMAGE_UPLOADS', 100))
+
+# Confusion Matrix Settings
+CONF_THRES = float(os.getenv('CONF_THRES', 0.001))
+IOU_THRES = float(os.getenv('IOU_THRES', 0.6))
+
+# Batch Logging Settings
+COMET_LOG_BATCH_METRICS = os.getenv('COMET_LOG_BATCH_METRICS', 'false').lower() == 'true'
+COMET_BATCH_LOGGING_INTERVAL = os.getenv('COMET_BATCH_LOGGING_INTERVAL', 1)
+COMET_PREDICTION_LOGGING_INTERVAL = os.getenv('COMET_PREDICTION_LOGGING_INTERVAL', 1)
+COMET_LOG_PER_CLASS_METRICS = os.getenv('COMET_LOG_PER_CLASS_METRICS', 'false').lower() == 'true'
+
+RANK = int(os.getenv('RANK', -1))
+
+to_pil = T.ToPILImage()
+
+
+class CometLogger:
+ """Log metrics, parameters, source code, models and much more
+ with Comet
+ """
+
+ def __init__(self, opt, hyp, run_id=None, job_type='Training', **experiment_kwargs) -> None:
+ self.job_type = job_type
+ self.opt = opt
+ self.hyp = hyp
+
+ # Comet Flags
+ self.comet_mode = COMET_MODE
+
+ self.save_model = opt.save_period > -1
+ self.model_name = COMET_MODEL_NAME
+
+ # Batch Logging Settings
+ self.log_batch_metrics = COMET_LOG_BATCH_METRICS
+ self.comet_log_batch_interval = COMET_BATCH_LOGGING_INTERVAL
+
+ # Dataset Artifact Settings
+ self.upload_dataset = self.opt.upload_dataset if self.opt.upload_dataset else COMET_UPLOAD_DATASET
+ self.resume = self.opt.resume
+
+ # Default parameters to pass to Experiment objects
+ self.default_experiment_kwargs = {
+ 'log_code': False,
+ 'log_env_gpu': True,
+ 'log_env_cpu': True,
+ 'project_name': COMET_PROJECT_NAME,}
+ self.default_experiment_kwargs.update(experiment_kwargs)
+ self.experiment = self._get_experiment(self.comet_mode, run_id)
+
+ self.data_dict = self.check_dataset(self.opt.data)
+ self.class_names = self.data_dict['names']
+ self.num_classes = self.data_dict['nc']
+
+ self.logged_images_count = 0
+ self.max_images = COMET_MAX_IMAGE_UPLOADS
+
+ if run_id is None:
+ self.experiment.log_other('Created from', 'YOLOv5')
+ if not isinstance(self.experiment, comet_ml.OfflineExperiment):
+ workspace, project_name, experiment_id = self.experiment.url.split('/')[-3:]
+ self.experiment.log_other(
+ 'Run Path',
+ f'{workspace}/{project_name}/{experiment_id}',
+ )
+ self.log_parameters(vars(opt))
+ self.log_parameters(self.opt.hyp)
+ self.log_asset_data(
+ self.opt.hyp,
+ name='hyperparameters.json',
+ metadata={'type': 'hyp-config-file'},
+ )
+ self.log_asset(
+ f'{self.opt.save_dir}/opt.yaml',
+ metadata={'type': 'opt-config-file'},
+ )
+
+ self.comet_log_confusion_matrix = COMET_LOG_CONFUSION_MATRIX
+
+ if hasattr(self.opt, 'conf_thres'):
+ self.conf_thres = self.opt.conf_thres
+ else:
+ self.conf_thres = CONF_THRES
+ if hasattr(self.opt, 'iou_thres'):
+ self.iou_thres = self.opt.iou_thres
+ else:
+ self.iou_thres = IOU_THRES
+
+ self.log_parameters({'val_iou_threshold': self.iou_thres, 'val_conf_threshold': self.conf_thres})
+
+ self.comet_log_predictions = COMET_LOG_PREDICTIONS
+ if self.opt.bbox_interval == -1:
+ self.comet_log_prediction_interval = 1 if self.opt.epochs < 10 else self.opt.epochs // 10
+ else:
+ self.comet_log_prediction_interval = self.opt.bbox_interval
+
+ if self.comet_log_predictions:
+ self.metadata_dict = {}
+ self.logged_image_names = []
+
+ self.comet_log_per_class_metrics = COMET_LOG_PER_CLASS_METRICS
+
+ self.experiment.log_others({
+ 'comet_mode': COMET_MODE,
+ 'comet_max_image_uploads': COMET_MAX_IMAGE_UPLOADS,
+ 'comet_log_per_class_metrics': COMET_LOG_PER_CLASS_METRICS,
+ 'comet_log_batch_metrics': COMET_LOG_BATCH_METRICS,
+ 'comet_log_confusion_matrix': COMET_LOG_CONFUSION_MATRIX,
+ 'comet_model_name': COMET_MODEL_NAME,})
+
+ # Check if running the Experiment with the Comet Optimizer
+ if hasattr(self.opt, 'comet_optimizer_id'):
+ self.experiment.log_other('optimizer_id', self.opt.comet_optimizer_id)
+ self.experiment.log_other('optimizer_objective', self.opt.comet_optimizer_objective)
+ self.experiment.log_other('optimizer_metric', self.opt.comet_optimizer_metric)
+ self.experiment.log_other('optimizer_parameters', json.dumps(self.hyp))
+
+ def _get_experiment(self, mode, experiment_id=None):
+ if mode == 'offline':
+ if experiment_id is not None:
+ return comet_ml.ExistingOfflineExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.OfflineExperiment(**self.default_experiment_kwargs,)
+
+ else:
+ try:
+ if experiment_id is not None:
+ return comet_ml.ExistingExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.Experiment(**self.default_experiment_kwargs)
+
+ except ValueError:
+ logger.warning('COMET WARNING: '
+ 'Comet credentials have not been set. '
+ 'Comet will default to offline logging. '
+ 'Please set your credentials to enable online logging.')
+ return self._get_experiment('offline', experiment_id)
+
+ return
+
+ def log_metrics(self, log_dict, **kwargs):
+ self.experiment.log_metrics(log_dict, **kwargs)
+
+ def log_parameters(self, log_dict, **kwargs):
+ self.experiment.log_parameters(log_dict, **kwargs)
+
+ def log_asset(self, asset_path, **kwargs):
+ self.experiment.log_asset(asset_path, **kwargs)
+
+ def log_asset_data(self, asset, **kwargs):
+ self.experiment.log_asset_data(asset, **kwargs)
+
+ def log_image(self, img, **kwargs):
+ self.experiment.log_image(img, **kwargs)
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ if not self.save_model:
+ return
+
+ model_metadata = {
+ 'fitness_score': fitness_score[-1],
+ 'epochs_trained': epoch + 1,
+ 'save_period': opt.save_period,
+ 'total_epochs': opt.epochs,}
+
+ model_files = glob.glob(f'{path}/*.pt')
+ for model_path in model_files:
+ name = Path(model_path).name
+
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ metadata=model_metadata,
+ overwrite=True,
+ )
+
+ def check_dataset(self, data_file):
+ with open(data_file) as f:
+ data_config = yaml.safe_load(f)
+
+ if data_config['path'].startswith(COMET_PREFIX):
+ path = data_config['path'].replace(COMET_PREFIX, '')
+ data_dict = self.download_dataset_artifact(path)
+
+ return data_dict
+
+ self.log_asset(self.opt.data, metadata={'type': 'data-config-file'})
+
+ return check_dataset(data_file)
+
+ def log_predictions(self, image, labelsn, path, shape, predn):
+ if self.logged_images_count >= self.max_images:
+ return
+ detections = predn[predn[:, 4] > self.conf_thres]
+ iou = box_iou(labelsn[:, 1:], detections[:, :4])
+ mask, _ = torch.where(iou > self.iou_thres)
+ if len(mask) == 0:
+ return
+
+ filtered_detections = detections[mask]
+ filtered_labels = labelsn[mask]
+
+ image_id = path.split('/')[-1].split('.')[0]
+ image_name = f'{image_id}_curr_epoch_{self.experiment.curr_epoch}'
+ if image_name not in self.logged_image_names:
+ native_scale_image = PIL.Image.open(path)
+ self.log_image(native_scale_image, name=image_name)
+ self.logged_image_names.append(image_name)
+
+ metadata = []
+ for cls, *xyxy in filtered_labels.tolist():
+ metadata.append({
+ 'label': f'{self.class_names[int(cls)]}-gt',
+ 'score': 100,
+ 'box': {
+ 'x': xyxy[0],
+ 'y': xyxy[1],
+ 'x2': xyxy[2],
+ 'y2': xyxy[3]},})
+ for *xyxy, conf, cls in filtered_detections.tolist():
+ metadata.append({
+ 'label': f'{self.class_names[int(cls)]}',
+ 'score': conf * 100,
+ 'box': {
+ 'x': xyxy[0],
+ 'y': xyxy[1],
+ 'x2': xyxy[2],
+ 'y2': xyxy[3]},})
+
+ self.metadata_dict[image_name] = metadata
+ self.logged_images_count += 1
+
+ return
+
+ def preprocess_prediction(self, image, labels, shape, pred):
+ nl, _ = labels.shape[0], pred.shape[0]
+
+ # Predictions
+ if self.opt.single_cls:
+ pred[:, 5] = 0
+
+ predn = pred.clone()
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1])
+
+ labelsn = None
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(image.shape[1:], tbox, shape[0], shape[1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1]) # native-space pred
+
+ return predn, labelsn
+
+ def add_assets_to_artifact(self, artifact, path, asset_path, split):
+ img_paths = sorted(glob.glob(f'{asset_path}/*'))
+ label_paths = img2label_paths(img_paths)
+
+ for image_file, label_file in zip(img_paths, label_paths):
+ image_logical_path, label_logical_path = map(lambda x: os.path.relpath(x, path), [image_file, label_file])
+
+ try:
+ artifact.add(image_file, logical_path=image_logical_path, metadata={'split': split})
+ artifact.add(label_file, logical_path=label_logical_path, metadata={'split': split})
+ except ValueError as e:
+ logger.error('COMET ERROR: Error adding file to Artifact. Skipping file.')
+ logger.error(f'COMET ERROR: {e}')
+ continue
+
+ return artifact
+
+ def upload_dataset_artifact(self):
+ dataset_name = self.data_dict.get('dataset_name', 'yolov5-dataset')
+ path = str((ROOT / Path(self.data_dict['path'])).resolve())
+
+ metadata = self.data_dict.copy()
+ for key in ['train', 'val', 'test']:
+ split_path = metadata.get(key)
+ if split_path is not None:
+ metadata[key] = split_path.replace(path, '')
+
+ artifact = comet_ml.Artifact(name=dataset_name, artifact_type='dataset', metadata=metadata)
+ for key in metadata.keys():
+ if key in ['train', 'val', 'test']:
+ if isinstance(self.upload_dataset, str) and (key != self.upload_dataset):
+ continue
+
+ asset_path = self.data_dict.get(key)
+ if asset_path is not None:
+ artifact = self.add_assets_to_artifact(artifact, path, asset_path, key)
+
+ self.experiment.log_artifact(artifact)
+
+ return
+
+ def download_dataset_artifact(self, artifact_path):
+ logged_artifact = self.experiment.get_artifact(artifact_path)
+ artifact_save_dir = str(Path(self.opt.save_dir) / logged_artifact.name)
+ logged_artifact.download(artifact_save_dir)
+
+ metadata = logged_artifact.metadata
+ data_dict = metadata.copy()
+ data_dict['path'] = artifact_save_dir
+
+ metadata_names = metadata.get('names')
+ if type(metadata_names) == dict:
+ data_dict['names'] = {int(k): v for k, v in metadata.get('names').items()}
+ elif type(metadata_names) == list:
+ data_dict['names'] = {int(k): v for k, v in zip(range(len(metadata_names)), metadata_names)}
+ else:
+ raise "Invalid 'names' field in dataset yaml file. Please use a list or dictionary"
+
+ data_dict = self.update_data_paths(data_dict)
+ return data_dict
+
+ def update_data_paths(self, data_dict):
+ path = data_dict.get('path', '')
+
+ for split in ['train', 'val', 'test']:
+ if data_dict.get(split):
+ split_path = data_dict.get(split)
+ data_dict[split] = (f'{path}/{split_path}' if isinstance(split, str) else [
+ f'{path}/{x}' for x in split_path])
+
+ return data_dict
+
+ def on_pretrain_routine_end(self, paths):
+ if self.opt.resume:
+ return
+
+ for path in paths:
+ self.log_asset(str(path))
+
+ if self.upload_dataset:
+ if not self.resume:
+ self.upload_dataset_artifact()
+
+ return
+
+ def on_train_start(self):
+ self.log_parameters(self.hyp)
+
+ def on_train_epoch_start(self):
+ return
+
+ def on_train_epoch_end(self, epoch):
+ self.experiment.curr_epoch = epoch
+
+ return
+
+ def on_train_batch_start(self):
+ return
+
+ def on_train_batch_end(self, log_dict, step):
+ self.experiment.curr_step = step
+ if self.log_batch_metrics and (step % self.comet_log_batch_interval == 0):
+ self.log_metrics(log_dict, step=step)
+
+ return
+
+ def on_train_end(self, files, save_dir, last, best, epoch, results):
+ if self.comet_log_predictions:
+ curr_epoch = self.experiment.curr_epoch
+ self.experiment.log_asset_data(self.metadata_dict, 'image-metadata.json', epoch=curr_epoch)
+
+ for f in files:
+ self.log_asset(f, metadata={'epoch': epoch})
+ self.log_asset(f'{save_dir}/results.csv', metadata={'epoch': epoch})
+
+ if not self.opt.evolve:
+ model_path = str(best if best.exists() else last)
+ name = Path(model_path).name
+ if self.save_model:
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ overwrite=True,
+ )
+
+ # Check if running Experiment with Comet Optimizer
+ if hasattr(self.opt, 'comet_optimizer_id'):
+ metric = results.get(self.opt.comet_optimizer_metric)
+ self.experiment.log_other('optimizer_metric_value', metric)
+
+ self.finish_run()
+
+ def on_val_start(self):
+ return
+
+ def on_val_batch_start(self):
+ return
+
+ def on_val_batch_end(self, batch_i, images, targets, paths, shapes, outputs):
+ if not (self.comet_log_predictions and ((batch_i + 1) % self.comet_log_prediction_interval == 0)):
+ return
+
+ for si, pred in enumerate(outputs):
+ if len(pred) == 0:
+ continue
+
+ image = images[si]
+ labels = targets[targets[:, 0] == si, 1:]
+ shape = shapes[si]
+ path = paths[si]
+ predn, labelsn = self.preprocess_prediction(image, labels, shape, pred)
+ if labelsn is not None:
+ self.log_predictions(image, labelsn, path, shape, predn)
+
+ return
+
+ def on_val_end(self, nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix):
+ if self.comet_log_per_class_metrics:
+ if self.num_classes > 1:
+ for i, c in enumerate(ap_class):
+ class_name = self.class_names[c]
+ self.experiment.log_metrics(
+ {
+ 'mAP@.5': ap50[i],
+ 'mAP@.5:.95': ap[i],
+ 'precision': p[i],
+ 'recall': r[i],
+ 'f1': f1[i],
+ 'true_positives': tp[i],
+ 'false_positives': fp[i],
+ 'support': nt[c]},
+ prefix=class_name)
+
+ if self.comet_log_confusion_matrix:
+ epoch = self.experiment.curr_epoch
+ class_names = list(self.class_names.values())
+ class_names.append('background')
+ num_classes = len(class_names)
+
+ self.experiment.log_confusion_matrix(
+ matrix=confusion_matrix.matrix,
+ max_categories=num_classes,
+ labels=class_names,
+ epoch=epoch,
+ column_label='Actual Category',
+ row_label='Predicted Category',
+ file_name=f'confusion-matrix-epoch-{epoch}.json',
+ )
+
+ def on_fit_epoch_end(self, result, epoch):
+ self.log_metrics(result, epoch=epoch)
+
+ def on_model_save(self, last, epoch, final_epoch, best_fitness, fi):
+ if ((epoch + 1) % self.opt.save_period == 0 and not final_epoch) and self.opt.save_period != -1:
+ self.log_model(last.parent, self.opt, epoch, fi, best_model=best_fitness == fi)
+
+ def on_params_update(self, params):
+ self.log_parameters(params)
+
+ def finish_run(self):
+ self.experiment.end()
diff --git a/yolov5/utils/loggers/comet/__pycache__/__init__.cpython-38.pyc b/yolov5/utils/loggers/comet/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c2a91a150ef754d368a606081e4b483b8c095092
Binary files /dev/null and b/yolov5/utils/loggers/comet/__pycache__/__init__.cpython-38.pyc differ
diff --git a/yolov5/utils/loggers/comet/__pycache__/comet_utils.cpython-38.pyc b/yolov5/utils/loggers/comet/__pycache__/comet_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a89697990874cfa09d0612ec84421b553dd66316
Binary files /dev/null and b/yolov5/utils/loggers/comet/__pycache__/comet_utils.cpython-38.pyc differ
diff --git a/yolov5/utils/loggers/comet/comet_utils.py b/yolov5/utils/loggers/comet/comet_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..27600761ad2843a6ab66aa22ad06782bb4b7eea7
--- /dev/null
+++ b/yolov5/utils/loggers/comet/comet_utils.py
@@ -0,0 +1,150 @@
+import logging
+import os
+from urllib.parse import urlparse
+
+try:
+ import comet_ml
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+
+import yaml
+
+logger = logging.getLogger(__name__)
+
+COMET_PREFIX = 'comet://'
+COMET_MODEL_NAME = os.getenv('COMET_MODEL_NAME', 'yolov5')
+COMET_DEFAULT_CHECKPOINT_FILENAME = os.getenv('COMET_DEFAULT_CHECKPOINT_FILENAME', 'last.pt')
+
+
+def download_model_checkpoint(opt, experiment):
+ model_dir = f'{opt.project}/{experiment.name}'
+ os.makedirs(model_dir, exist_ok=True)
+
+ model_name = COMET_MODEL_NAME
+ model_asset_list = experiment.get_model_asset_list(model_name)
+
+ if len(model_asset_list) == 0:
+ logger.error(f'COMET ERROR: No checkpoints found for model name : {model_name}')
+ return
+
+ model_asset_list = sorted(
+ model_asset_list,
+ key=lambda x: x['step'],
+ reverse=True,
+ )
+ logged_checkpoint_map = {asset['fileName']: asset['assetId'] for asset in model_asset_list}
+
+ resource_url = urlparse(opt.weights)
+ checkpoint_filename = resource_url.query
+
+ if checkpoint_filename:
+ asset_id = logged_checkpoint_map.get(checkpoint_filename)
+ else:
+ asset_id = logged_checkpoint_map.get(COMET_DEFAULT_CHECKPOINT_FILENAME)
+ checkpoint_filename = COMET_DEFAULT_CHECKPOINT_FILENAME
+
+ if asset_id is None:
+ logger.error(f'COMET ERROR: Checkpoint {checkpoint_filename} not found in the given Experiment')
+ return
+
+ try:
+ logger.info(f'COMET INFO: Downloading checkpoint {checkpoint_filename}')
+ asset_filename = checkpoint_filename
+
+ model_binary = experiment.get_asset(asset_id, return_type='binary', stream=False)
+ model_download_path = f'{model_dir}/{asset_filename}'
+ with open(model_download_path, 'wb') as f:
+ f.write(model_binary)
+
+ opt.weights = model_download_path
+
+ except Exception as e:
+ logger.warning('COMET WARNING: Unable to download checkpoint from Comet')
+ logger.exception(e)
+
+
+def set_opt_parameters(opt, experiment):
+ """Update the opts Namespace with parameters
+ from Comet's ExistingExperiment when resuming a run
+
+ Args:
+ opt (argparse.Namespace): Namespace of command line options
+ experiment (comet_ml.APIExperiment): Comet API Experiment object
+ """
+ asset_list = experiment.get_asset_list()
+ resume_string = opt.resume
+
+ for asset in asset_list:
+ if asset['fileName'] == 'opt.yaml':
+ asset_id = asset['assetId']
+ asset_binary = experiment.get_asset(asset_id, return_type='binary', stream=False)
+ opt_dict = yaml.safe_load(asset_binary)
+ for key, value in opt_dict.items():
+ setattr(opt, key, value)
+ opt.resume = resume_string
+
+ # Save hyperparameters to YAML file
+ # Necessary to pass checks in training script
+ save_dir = f'{opt.project}/{experiment.name}'
+ os.makedirs(save_dir, exist_ok=True)
+
+ hyp_yaml_path = f'{save_dir}/hyp.yaml'
+ with open(hyp_yaml_path, 'w') as f:
+ yaml.dump(opt.hyp, f)
+ opt.hyp = hyp_yaml_path
+
+
+def check_comet_weights(opt):
+ """Downloads model weights from Comet and updates the
+ weights path to point to saved weights location
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if weights are successfully downloaded
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.weights, str):
+ if opt.weights.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.weights)
+ experiment_path = f'{resource.netloc}{resource.path}'
+ experiment = api.get(experiment_path)
+ download_model_checkpoint(opt, experiment)
+ return True
+
+ return None
+
+
+def check_comet_resume(opt):
+ """Restores run parameters to its original state based on the model checkpoint
+ and logged Experiment parameters.
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if the run is restored successfully
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.resume)
+ experiment_path = f'{resource.netloc}{resource.path}'
+ experiment = api.get(experiment_path)
+ set_opt_parameters(opt, experiment)
+ download_model_checkpoint(opt, experiment)
+
+ return True
+
+ return None
diff --git a/yolov5/utils/loggers/comet/hpo.py b/yolov5/utils/loggers/comet/hpo.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc49115c13581554bebe1ddddaf3d5e10caaae07
--- /dev/null
+++ b/yolov5/utils/loggers/comet/hpo.py
@@ -0,0 +1,118 @@
+import argparse
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+import comet_ml
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+# Project Configuration
+config = comet_ml.config.get_config()
+COMET_PROJECT_NAME = config.get_string(os.getenv('COMET_PROJECT_NAME'), 'comet.project_name', default='yolov5')
+
+
+def get_args(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=300, help='total training epochs')
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
+ parser.add_argument('--noplots', action='store_true', help='save no plot files')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--seed', type=int, default=0, help='Global training seed')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ # Comet Arguments
+ parser.add_argument('--comet_optimizer_config', type=str, help='Comet: Path to a Comet Optimizer Config File.')
+ parser.add_argument('--comet_optimizer_id', type=str, help='Comet: ID of the Comet Optimizer sweep.')
+ parser.add_argument('--comet_optimizer_objective', type=str, help="Comet: Set to 'minimize' or 'maximize'.")
+ parser.add_argument('--comet_optimizer_metric', type=str, help='Comet: Metric to Optimize.')
+ parser.add_argument('--comet_optimizer_workers',
+ type=int,
+ default=1,
+ help='Comet: Number of Parallel Workers to use with the Comet Optimizer.')
+
+ return parser.parse_known_args()[0] if known else parser.parse_args()
+
+
+def run(parameters, opt):
+ hyp_dict = {k: v for k, v in parameters.items() if k not in ['epochs', 'batch_size']}
+
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.batch_size = parameters.get('batch_size')
+ opt.epochs = parameters.get('epochs')
+
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == '__main__':
+ opt = get_args(known=True)
+
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.project = str(opt.project)
+
+ optimizer_id = os.getenv('COMET_OPTIMIZER_ID')
+ if optimizer_id is None:
+ with open(opt.comet_optimizer_config) as f:
+ optimizer_config = json.load(f)
+ optimizer = comet_ml.Optimizer(optimizer_config)
+ else:
+ optimizer = comet_ml.Optimizer(optimizer_id)
+
+ opt.comet_optimizer_id = optimizer.id
+ status = optimizer.status()
+
+ opt.comet_optimizer_objective = status['spec']['objective']
+ opt.comet_optimizer_metric = status['spec']['metric']
+
+ logger.info('COMET INFO: Starting Hyperparameter Sweep')
+ for parameter in optimizer.get_parameters():
+ run(parameter['parameters'], opt)
diff --git a/yolov5/utils/loggers/comet/optimizer_config.json b/yolov5/utils/loggers/comet/optimizer_config.json
new file mode 100644
index 0000000000000000000000000000000000000000..83ddddab6f2084b4bdf84dca1e61696de200d1b8
--- /dev/null
+++ b/yolov5/utils/loggers/comet/optimizer_config.json
@@ -0,0 +1,209 @@
+{
+ "algorithm": "random",
+ "parameters": {
+ "anchor_t": {
+ "type": "discrete",
+ "values": [
+ 2,
+ 8
+ ]
+ },
+ "batch_size": {
+ "type": "discrete",
+ "values": [
+ 16,
+ 32,
+ 64
+ ]
+ },
+ "box": {
+ "type": "discrete",
+ "values": [
+ 0.02,
+ 0.2
+ ]
+ },
+ "cls": {
+ "type": "discrete",
+ "values": [
+ 0.2
+ ]
+ },
+ "cls_pw": {
+ "type": "discrete",
+ "values": [
+ 0.5
+ ]
+ },
+ "copy_paste": {
+ "type": "discrete",
+ "values": [
+ 1
+ ]
+ },
+ "degrees": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 45
+ ]
+ },
+ "epochs": {
+ "type": "discrete",
+ "values": [
+ 5
+ ]
+ },
+ "fl_gamma": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "fliplr": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "flipud": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_h": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_s": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_v": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "iou_t": {
+ "type": "discrete",
+ "values": [
+ 0.7
+ ]
+ },
+ "lr0": {
+ "type": "discrete",
+ "values": [
+ 1e-05,
+ 0.1
+ ]
+ },
+ "lrf": {
+ "type": "discrete",
+ "values": [
+ 0.01,
+ 1
+ ]
+ },
+ "mixup": {
+ "type": "discrete",
+ "values": [
+ 1
+ ]
+ },
+ "momentum": {
+ "type": "discrete",
+ "values": [
+ 0.6
+ ]
+ },
+ "mosaic": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "obj": {
+ "type": "discrete",
+ "values": [
+ 0.2
+ ]
+ },
+ "obj_pw": {
+ "type": "discrete",
+ "values": [
+ 0.5
+ ]
+ },
+ "optimizer": {
+ "type": "categorical",
+ "values": [
+ "SGD",
+ "Adam",
+ "AdamW"
+ ]
+ },
+ "perspective": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "scale": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "shear": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "translate": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "warmup_bias_lr": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.2
+ ]
+ },
+ "warmup_epochs": {
+ "type": "discrete",
+ "values": [
+ 5
+ ]
+ },
+ "warmup_momentum": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.95
+ ]
+ },
+ "weight_decay": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.001
+ ]
+ }
+ },
+ "spec": {
+ "maxCombo": 0,
+ "metric": "metrics/mAP_0.5",
+ "objective": "maximize"
+ },
+ "trials": 1
+}
diff --git a/yolov5/utils/loggers/wandb/__init__.py b/yolov5/utils/loggers/wandb/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/yolov5/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc b/yolov5/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..05a9a272bf599235bcc48b918c27a89f730a7b6f
Binary files /dev/null and b/yolov5/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc differ
diff --git a/yolov5/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc b/yolov5/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c7a21b4b4600b95824858c54a00b28ee54c92855
Binary files /dev/null and b/yolov5/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc differ
diff --git a/yolov5/utils/loggers/wandb/wandb_utils.py b/yolov5/utils/loggers/wandb/wandb_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ea32b1d4c6ec62920a9e90af085346d0f7a5f2c
--- /dev/null
+++ b/yolov5/utils/loggers/wandb/wandb_utils.py
@@ -0,0 +1,193 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+
+# WARNING ⚠️ wandb is deprecated and will be removed in future release.
+# See supported integrations at https://github.com/ultralytics/yolov5#integrations
+
+import logging
+import os
+import sys
+from contextlib import contextmanager
+from pathlib import Path
+
+from utils.general import LOGGER, colorstr
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+RANK = int(os.getenv('RANK', -1))
+DEPRECATION_WARNING = f"{colorstr('wandb')}: WARNING ⚠️ wandb is deprecated and will be removed in a future release. " \
+ f'See supported integrations at https://github.com/ultralytics/yolov5#integrations.'
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+ LOGGER.warning(DEPRECATION_WARNING)
+except (ImportError, AssertionError):
+ wandb = None
+
+
+class WandbLogger():
+ """Log training runs, datasets, models, and predictions to Weights & Biases.
+
+ This logger sends information to W&B at wandb.ai. By default, this information
+ includes hyperparameters, system configuration and metrics, model metrics,
+ and basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+
+ For more on how this logger is used, see the Weights & Biases documentation:
+ https://docs.wandb.com/guides/integrations/yolov5
+ """
+
+ def __init__(self, opt, run_id=None, job_type='Training'):
+ """
+ - Initialize WandbLogger instance
+ - Upload dataset if opt.upload_dataset is True
+ - Setup training processes if job_type is 'Training'
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ run_id (str) -- Run ID of W&B run to be resumed
+ job_type (str) -- To set the job_type for this run
+
+ """
+ # Pre-training routine --
+ self.job_type = job_type
+ self.wandb, self.wandb_run = wandb, wandb.run if wandb else None
+ self.val_artifact, self.train_artifact = None, None
+ self.train_artifact_path, self.val_artifact_path = None, None
+ self.result_artifact = None
+ self.val_table, self.result_table = None, None
+ self.max_imgs_to_log = 16
+ self.data_dict = None
+ if self.wandb:
+ self.wandb_run = wandb.init(config=opt,
+ resume='allow',
+ project='YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem,
+ entity=opt.entity,
+ name=opt.name if opt.name != 'exp' else None,
+ job_type=job_type,
+ id=run_id,
+ allow_val_change=True) if not wandb.run else wandb.run
+
+ if self.wandb_run:
+ if self.job_type == 'Training':
+ if isinstance(opt.data, dict):
+ # This means another dataset manager has already processed the dataset info (e.g. ClearML)
+ # and they will have stored the already processed dict in opt.data
+ self.data_dict = opt.data
+ self.setup_training(opt)
+
+ def setup_training(self, opt):
+ """
+ Setup the necessary processes for training YOLO models:
+ - Attempt to download model checkpoint and dataset artifacts if opt.resume stats with WANDB_ARTIFACT_PREFIX
+ - Update data_dict, to contain info of previous run if resumed and the paths of dataset artifact if downloaded
+ - Setup log_dict, initialize bbox_interval
+
+ arguments:
+ opt (namespace) -- commandline arguments for this run
+
+ """
+ self.log_dict, self.current_epoch = {}, 0
+ self.bbox_interval = opt.bbox_interval
+ if isinstance(opt.resume, str):
+ model_dir, _ = self.download_model_artifact(opt)
+ if model_dir:
+ self.weights = Path(model_dir) / 'last.pt'
+ config = self.wandb_run.config
+ opt.weights, opt.save_period, opt.batch_size, opt.bbox_interval, opt.epochs, opt.hyp, opt.imgsz = str(
+ self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs, \
+ config.hyp, config.imgsz
+
+ if opt.bbox_interval == -1:
+ self.bbox_interval = opt.bbox_interval = (opt.epochs // 10) if opt.epochs > 10 else 1
+ if opt.evolve or opt.noplots:
+ self.bbox_interval = opt.bbox_interval = opt.epochs + 1 # disable bbox_interval
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ """
+ Log the model checkpoint as W&B artifact
+
+ arguments:
+ path (Path) -- Path of directory containing the checkpoints
+ opt (namespace) -- Command line arguments for this run
+ epoch (int) -- Current epoch number
+ fitness_score (float) -- fitness score for current epoch
+ best_model (boolean) -- Boolean representing if the current checkpoint is the best yet.
+ """
+ model_artifact = wandb.Artifact('run_' + wandb.run.id + '_model',
+ type='model',
+ metadata={
+ 'original_url': str(path),
+ 'epochs_trained': epoch + 1,
+ 'save period': opt.save_period,
+ 'project': opt.project,
+ 'total_epochs': opt.epochs,
+ 'fitness_score': fitness_score})
+ model_artifact.add_file(str(path / 'last.pt'), name='last.pt')
+ wandb.log_artifact(model_artifact,
+ aliases=['latest', 'last', 'epoch ' + str(self.current_epoch), 'best' if best_model else ''])
+ LOGGER.info(f'Saving model artifact on epoch {epoch + 1}')
+
+ def val_one_image(self, pred, predn, path, names, im):
+ pass
+
+ def log(self, log_dict):
+ """
+ save the metrics to the logging dictionary
+
+ arguments:
+ log_dict (Dict) -- metrics/media to be logged in current step
+ """
+ if self.wandb_run:
+ for key, value in log_dict.items():
+ self.log_dict[key] = value
+
+ def end_epoch(self):
+ """
+ commit the log_dict, model artifacts and Tables to W&B and flush the log_dict.
+
+ arguments:
+ best_result (boolean): Boolean representing if the result of this evaluation is best or not
+ """
+ if self.wandb_run:
+ with all_logging_disabled():
+ try:
+ wandb.log(self.log_dict)
+ except BaseException as e:
+ LOGGER.info(
+ f'An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}'
+ )
+ self.wandb_run.finish()
+ self.wandb_run = None
+ self.log_dict = {}
+
+ def finish_run(self):
+ """
+ Log metrics if any and finish the current W&B run
+ """
+ if self.wandb_run:
+ if self.log_dict:
+ with all_logging_disabled():
+ wandb.log(self.log_dict)
+ wandb.run.finish()
+ LOGGER.warning(DEPRECATION_WARNING)
+
+
+@contextmanager
+def all_logging_disabled(highest_level=logging.CRITICAL):
+ """ source - https://gist.github.com/simon-weber/7853144
+ A context manager that will prevent any logging messages triggered during the body from being processed.
+ :param highest_level: the maximum logging level in use.
+ This would only need to be changed if a custom level greater than CRITICAL is defined.
+ """
+ previous_level = logging.root.manager.disable
+ logging.disable(highest_level)
+ try:
+ yield
+ finally:
+ logging.disable(previous_level)
diff --git a/yolov5/utils/loss.py b/yolov5/utils/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..26cca8797315a425b26d1c8c083bd321d7b52fff
--- /dev/null
+++ b/yolov5/utils/loss.py
@@ -0,0 +1,234 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import de_parallel
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ sort_obj_iou = False
+
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, p, targets): # predictions, targets
+ lcls = torch.zeros(1, device=self.device) # class loss
+ lbox = torch.zeros(1, device=self.device) # box loss
+ lobj = torch.zeros(1, device=self.device) # object loss
+ tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ # pxy, pwh, _, pcls = pi[b, a, gj, gi].tensor_split((2, 4, 5), dim=1) # faster, requires torch 1.8.0
+ pxy, pwh, _, pcls = pi[b, a, gj, gi].split((2, 2, 1, self.nc), 1) # target-subset of predictions
+
+ # Regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ bs = tobj.shape[0] # batch size
+
+ return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ gain = torch.ones(7, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+
+ return tcls, tbox, indices, anch
diff --git a/yolov5/utils/metrics.py b/yolov5/utils/metrics.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6305ed384443282352eb44600344f9397d793e1
--- /dev/null
+++ b/yolov5/utils/metrics.py
@@ -0,0 +1,360 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+from yolov5.utils import TryExcept, threaded
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def smooth(y, f=0.05):
+ # Box filter of fraction f
+ nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)
+ p = np.ones(nf // 2) # ones padding
+ yp = np.concatenate((p * y[0], y, p * y[-1]), 0) # y padded
+ return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothed
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16, prefix=''):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes, nt = np.unique(target_cls, return_counts=True)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = nt[ci] # number of labels
+ n_p = i.sum() # number of predictions
+ if n_p == 0 or n_l == 0:
+ continue
+
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + eps) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + eps)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = dict(enumerate(names)) # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / f'{prefix}PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / f'{prefix}F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / f'{prefix}P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / f'{prefix}R_curve.png', names, ylabel='Recall')
+
+ i = smooth(f1.mean(0), 0.1).argmax() # max F1 index
+ p, r, f1 = p[:, i], r[:, i], f1[:, i]
+ tp = (r * nt).round() # true positives
+ fp = (tp / (p + eps) - tp).round() # false positives
+ return tp, fp, p, r, f1, ap, unique_classes.astype(int)
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ if detections is None:
+ gt_classes = labels.int()
+ for gc in gt_classes:
+ self.matrix[self.nc, gc] += 1 # background FN
+ return
+
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(int)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # true background
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # predicted background
+
+ def tp_fp(self):
+ tp = self.matrix.diagonal() # true positives
+ fp = self.matrix.sum(1) - tp # false positives
+ # fn = self.matrix.sum(0) - tp # false negatives (missed detections)
+ return tp[:-1], fp[:-1] # remove background class
+
+ @TryExcept('WARNING ⚠️ ConfusionMatrix plot failure')
+ def plot(self, normalize=True, save_dir='', names=()):
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig, ax = plt.subplots(1, 1, figsize=(12, 9), tight_layout=True)
+ nc, nn = self.nc, len(names) # number of classes, names
+ sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
+ labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
+ ticklabels = (names + ['background']) if labels else 'auto'
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array,
+ ax=ax,
+ annot=nc < 30,
+ annot_kws={
+ 'size': 8},
+ cmap='Blues',
+ fmt='.2f',
+ square=True,
+ vmin=0.0,
+ xticklabels=ticklabels,
+ yticklabels=ticklabels).set_facecolor((1, 1, 1))
+ ax.set_xlabel('True')
+ ax.set_ylabel('Predicted')
+ ax.set_title('Confusion Matrix')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close(fig)
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
+
+ # Get the coordinates of bounding boxes
+ if xywh: # transform from xywh to xyxy
+ (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
+ w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
+ b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
+ b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
+ else: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
+ w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
+ w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
+
+ # Intersection area
+ inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
+ (b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
+
+ # Union Area
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ # IoU
+ iou = inter / union
+ if CIoU or DIoU or GIoU:
+ cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
+ ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
+ if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ return iou - rho2 / c2 # DIoU
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ return iou # IoU
+
+
+def box_iou(box1, box2, eps=1e-7):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ (a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
+ inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
+
+ # IoU = inter / (area1 + area2 - inter)
+ return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
+
+
+def bbox_ioa(box1, box2, eps=1e-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.T
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2, eps=1e-7):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter + eps) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+
+@threaded
+def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
+ ax.set_title('Precision-Recall Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
+
+
+@threaded
+def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = smooth(py.mean(0), 0.05)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
+ ax.set_title(f'{ylabel}-Confidence Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
diff --git a/yolov5/utils/plots.py b/yolov5/utils/plots.py
new file mode 100644
index 0000000000000000000000000000000000000000..37c544b3bff1054b619b19a396aa0fe7725a84a8
--- /dev/null
+++ b/yolov5/utils/plots.py
@@ -0,0 +1,560 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Plotting utils
+"""
+
+import contextlib
+import math
+import os
+from copy import copy
+from pathlib import Path
+from urllib.error import URLError
+
+import cv2
+import matplotlib
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import seaborn as sn
+import torch
+from PIL import Image, ImageDraw, ImageFont
+
+from yolov5.utils import TryExcept, threaded
+from yolov5.utils.general import (CONFIG_DIR, FONT, LOGGER, check_font, check_requirements, clip_boxes, increment_path,
+ is_ascii, xywh2xyxy, xyxy2xywh)
+from yolov5.utils.metrics import fitness
+from yolov5.utils.segment.general import scale_image
+
+# Settings
+RANK = int(os.getenv('RANK', -1))
+matplotlib.rc('font', **{'size': 11})
+matplotlib.use('Agg') # for writing to files only
+
+
+class Colors:
+ # Ultralytics color palette https://ultralytics.com/
+ def __init__(self):
+ # hex = matplotlib.colors.TABLEAU_COLORS.values()
+ hexs = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
+ '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
+ self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
+ self.n = len(self.palette)
+
+ def __call__(self, i, bgr=False):
+ c = self.palette[int(i) % self.n]
+ return (c[2], c[1], c[0]) if bgr else c
+
+ @staticmethod
+ def hex2rgb(h): # rgb order (PIL)
+ return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
+
+
+colors = Colors() # create instance for 'from utils.plots import colors'
+
+
+def check_pil_font(font=FONT, size=10):
+ # Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
+ font = Path(font)
+ font = font if font.exists() else (CONFIG_DIR / font.name)
+ try:
+ return ImageFont.truetype(str(font) if font.exists() else font.name, size)
+ except Exception: # download if missing
+ try:
+ check_font(font)
+ return ImageFont.truetype(str(font), size)
+ except TypeError:
+ check_requirements('Pillow>=8.4.0') # known issue https://github.com/ultralytics/yolov5/issues/5374
+ except URLError: # not online
+ return ImageFont.load_default()
+
+
+class Annotator:
+ # YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
+ def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
+ assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
+ non_ascii = not is_ascii(example) # non-latin labels, i.e. asian, arabic, cyrillic
+ self.pil = pil or non_ascii
+ if self.pil: # use PIL
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+ self.font = check_pil_font(font='Arial.Unicode.ttf' if non_ascii else font,
+ size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
+ else: # use cv2
+ self.im = im
+ self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
+
+ def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
+ # Add one xyxy box to image with label
+ if self.pil or not is_ascii(label):
+ self.draw.rectangle(box, width=self.lw, outline=color) # box
+ if label:
+ w, h = self.font.getsize(label) # text width, height (WARNING: deprecated) in 9.2.0
+ # _, _, w, h = self.font.getbbox(label) # text width, height (New)
+ outside = box[1] - h >= 0 # label fits outside box
+ self.draw.rectangle(
+ (box[0], box[1] - h if outside else box[1], box[0] + w + 1,
+ box[1] + 1 if outside else box[1] + h + 1),
+ fill=color,
+ )
+ # self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
+ self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
+ else: # cv2
+ p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
+ cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
+ if label:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = p1[1] - h >= 3
+ p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
+ cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
+ cv2.putText(self.im,
+ label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
+ 0,
+ self.lw / 3,
+ txt_color,
+ thickness=tf,
+ lineType=cv2.LINE_AA)
+
+ def masks(self, masks, colors, im_gpu, alpha=0.5, retina_masks=False):
+ """Plot masks at once.
+ Args:
+ masks (tensor): predicted masks on cuda, shape: [n, h, w]
+ colors (List[List[Int]]): colors for predicted masks, [[r, g, b] * n]
+ im_gpu (tensor): img is in cuda, shape: [3, h, w], range: [0, 1]
+ alpha (float): mask transparency: 0.0 fully transparent, 1.0 opaque
+ """
+ if self.pil:
+ # convert to numpy first
+ self.im = np.asarray(self.im).copy()
+ if len(masks) == 0:
+ self.im[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
+ colors = torch.tensor(colors, device=im_gpu.device, dtype=torch.float32) / 255.0
+ colors = colors[:, None, None] # shape(n,1,1,3)
+ masks = masks.unsqueeze(3) # shape(n,h,w,1)
+ masks_color = masks * (colors * alpha) # shape(n,h,w,3)
+
+ inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
+ mcs = (masks_color * inv_alph_masks).sum(0) * 2 # mask color summand shape(n,h,w,3)
+
+ im_gpu = im_gpu.flip(dims=[0]) # flip channel
+ im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
+ im_gpu = im_gpu * inv_alph_masks[-1] + mcs
+ im_mask = (im_gpu * 255).byte().cpu().numpy()
+ self.im[:] = im_mask if retina_masks else scale_image(im_gpu.shape, im_mask, self.im.shape)
+ if self.pil:
+ # convert im back to PIL and update draw
+ self.fromarray(self.im)
+
+ def rectangle(self, xy, fill=None, outline=None, width=1):
+ # Add rectangle to image (PIL-only)
+ self.draw.rectangle(xy, fill, outline, width)
+
+ def text(self, xy, text, txt_color=(255, 255, 255), anchor='top'):
+ # Add text to image (PIL-only)
+ if anchor == 'bottom': # start y from font bottom
+ w, h = self.font.getsize(text) # text width, height
+ xy[1] += 1 - h
+ self.draw.text(xy, text, fill=txt_color, font=self.font)
+
+ def fromarray(self, im):
+ # Update self.im from a numpy array
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+
+ def result(self):
+ # Return annotated image as array
+ return np.asarray(self.im)
+
+
+def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
+ """
+ x: Features to be visualized
+ module_type: Module type
+ stage: Module stage within model
+ n: Maximum number of feature maps to plot
+ save_dir: Directory to save results
+ """
+ if 'Detect' not in module_type:
+ batch, channels, height, width = x.shape # batch, channels, height, width
+ if height > 1 and width > 1:
+ f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
+
+ blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
+ n = min(n, channels) # number of plots
+ fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
+ ax = ax.ravel()
+ plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
+ ax[i].axis('off')
+
+ LOGGER.info(f'Saving {f}... ({n}/{channels})')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ np.save(str(f.with_suffix('.npy')), x[0].cpu().numpy()) # npy save
+
+
+def hist2d(x, y, n=100):
+ # 2d histogram used in labels.png and evolve.png
+ xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
+ hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
+ xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1)
+ yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1)
+ return np.log(hist[xidx, yidx])
+
+
+def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
+ from scipy.signal import butter, filtfilt
+
+ # https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
+ def butter_lowpass(cutoff, fs, order):
+ nyq = 0.5 * fs
+ normal_cutoff = cutoff / nyq
+ return butter(order, normal_cutoff, btype='low', analog=False)
+
+ b, a = butter_lowpass(cutoff, fs, order=order)
+ return filtfilt(b, a, data) # forward-backward filter
+
+
+def output_to_target(output, max_det=300):
+ # Convert model output to target format [batch_id, class_id, x, y, w, h, conf] for plotting
+ targets = []
+ for i, o in enumerate(output):
+ box, conf, cls = o[:max_det, :6].cpu().split((4, 1, 1), 1)
+ j = torch.full((conf.shape[0], 1), i)
+ targets.append(torch.cat((j, cls, xyxy2xywh(box), conf), 1))
+ return torch.cat(targets, 0).numpy()
+
+
+@threaded
+def plot_images(images, targets, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ ti = targets[targets[:, 0] == i] # image targets
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+ annotator.im.save(fname) # save
+
+
+def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
+ # Plot LR simulating training for full epochs
+ optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
+ y = []
+ for _ in range(epochs):
+ scheduler.step()
+ y.append(optimizer.param_groups[0]['lr'])
+ plt.plot(y, '.-', label='LR')
+ plt.xlabel('epoch')
+ plt.ylabel('LR')
+ plt.grid()
+ plt.xlim(0, epochs)
+ plt.ylim(0)
+ plt.savefig(Path(save_dir) / 'LR.png', dpi=200)
+ plt.close()
+
+
+def plot_val_txt(): # from utils.plots import *; plot_val()
+ # Plot val.txt histograms
+ x = np.loadtxt('val.txt', dtype=np.float32)
+ box = xyxy2xywh(x[:, :4])
+ cx, cy = box[:, 0], box[:, 1]
+
+ fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
+ ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
+ ax.set_aspect('equal')
+ plt.savefig('hist2d.png', dpi=300)
+
+ fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
+ ax[0].hist(cx, bins=600)
+ ax[1].hist(cy, bins=600)
+ plt.savefig('hist1d.png', dpi=200)
+
+
+def plot_targets_txt(): # from utils.plots import *; plot_targets_txt()
+ # Plot targets.txt histograms
+ x = np.loadtxt('targets.txt', dtype=np.float32).T
+ s = ['x targets', 'y targets', 'width targets', 'height targets']
+ fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
+ ax = ax.ravel()
+ for i in range(4):
+ ax[i].hist(x[i], bins=100, label=f'{x[i].mean():.3g} +/- {x[i].std():.3g}')
+ ax[i].legend()
+ ax[i].set_title(s[i])
+ plt.savefig('targets.jpg', dpi=200)
+
+
+def plot_val_study(file='', dir='', x=None): # from utils.plots import *; plot_val_study()
+ # Plot file=study.txt generated by val.py (or plot all study*.txt in dir)
+ save_dir = Path(file).parent if file else Path(dir)
+ plot2 = False # plot additional results
+ if plot2:
+ ax = plt.subplots(2, 4, figsize=(10, 6), tight_layout=True)[1].ravel()
+
+ fig2, ax2 = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
+ # for f in [save_dir / f'study_coco_{x}.txt' for x in ['yolov5n6', 'yolov5s6', 'yolov5m6', 'yolov5l6', 'yolov5x6']]:
+ for f in sorted(save_dir.glob('study*.txt')):
+ y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
+ x = np.arange(y.shape[1]) if x is None else np.array(x)
+ if plot2:
+ s = ['P', 'R', 'mAP@.5', 'mAP@.5:.95', 't_preprocess (ms/img)', 't_inference (ms/img)', 't_NMS (ms/img)']
+ for i in range(7):
+ ax[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
+ ax[i].set_title(s[i])
+
+ j = y[3].argmax() + 1
+ ax2.plot(y[5, 1:j],
+ y[3, 1:j] * 1E2,
+ '.-',
+ linewidth=2,
+ markersize=8,
+ label=f.stem.replace('study_coco_', '').replace('yolo', 'YOLO'))
+
+ ax2.plot(1E3 / np.array([209, 140, 97, 58, 35, 18]), [34.6, 40.5, 43.0, 47.5, 49.7, 51.5],
+ 'k.-',
+ linewidth=2,
+ markersize=8,
+ alpha=.25,
+ label='EfficientDet')
+
+ ax2.grid(alpha=0.2)
+ ax2.set_yticks(np.arange(20, 60, 5))
+ ax2.set_xlim(0, 57)
+ ax2.set_ylim(25, 55)
+ ax2.set_xlabel('GPU Speed (ms/img)')
+ ax2.set_ylabel('COCO AP val')
+ ax2.legend(loc='lower right')
+ f = save_dir / 'study.png'
+ print(f'Saving {f}...')
+ plt.savefig(f, dpi=300)
+
+
+@TryExcept() # known issue https://github.com/ultralytics/yolov5/issues/5395
+def plot_labels(labels, names=(), save_dir=Path('')):
+ # plot dataset labels
+ LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
+ c, b = labels[:, 0], labels[:, 1:].transpose() # classes, boxes
+ nc = int(c.max() + 1) # number of classes
+ x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
+
+ # seaborn correlogram
+ sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
+ plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
+ plt.close()
+
+ # matplotlib labels
+ matplotlib.use('svg') # faster
+ ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
+ y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
+ with contextlib.suppress(Exception): # color histogram bars by class
+ [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # known issue #3195
+ ax[0].set_ylabel('instances')
+ if 0 < len(names) < 30:
+ ax[0].set_xticks(range(len(names)))
+ ax[0].set_xticklabels(list(names.values()), rotation=90, fontsize=10)
+ else:
+ ax[0].set_xlabel('classes')
+ sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
+ sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
+
+ # rectangles
+ labels[:, 1:3] = 0.5 # center
+ labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
+ img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
+ for cls, *box in labels[:1000]:
+ ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
+ ax[1].imshow(img)
+ ax[1].axis('off')
+
+ for a in [0, 1, 2, 3]:
+ for s in ['top', 'right', 'left', 'bottom']:
+ ax[a].spines[s].set_visible(False)
+
+ plt.savefig(save_dir / 'labels.jpg', dpi=200)
+ matplotlib.use('Agg')
+ plt.close()
+
+
+def imshow_cls(im, labels=None, pred=None, names=None, nmax=25, verbose=False, f=Path('images.jpg')):
+ # Show classification image grid with labels (optional) and predictions (optional)
+ from utils.augmentations import denormalize
+
+ names = names or [f'class{i}' for i in range(1000)]
+ blocks = torch.chunk(denormalize(im.clone()).cpu().float(), len(im),
+ dim=0) # select batch index 0, block by channels
+ n = min(len(blocks), nmax) # number of plots
+ m = min(8, round(n ** 0.5)) # 8 x 8 default
+ fig, ax = plt.subplots(math.ceil(n / m), m) # 8 rows x n/8 cols
+ ax = ax.ravel() if m > 1 else [ax]
+ # plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze().permute((1, 2, 0)).numpy().clip(0.0, 1.0))
+ ax[i].axis('off')
+ if labels is not None:
+ s = names[labels[i]] + (f'—{names[pred[i]]}' if pred is not None else '')
+ ax[i].set_title(s, fontsize=8, verticalalignment='top')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ if verbose:
+ LOGGER.info(f'Saving {f}')
+ if labels is not None:
+ LOGGER.info('True: ' + ' '.join(f'{names[i]:3s}' for i in labels[:nmax]))
+ if pred is not None:
+ LOGGER.info('Predicted:' + ' '.join(f'{names[i]:3s}' for i in pred[:nmax]))
+ return f
+
+
+def plot_evolve(evolve_csv='path/to/evolve.csv'): # from utils.plots import *; plot_evolve()
+ # Plot evolve.csv hyp evolution results
+ evolve_csv = Path(evolve_csv)
+ data = pd.read_csv(evolve_csv)
+ keys = [x.strip() for x in data.columns]
+ x = data.values
+ f = fitness(x)
+ j = np.argmax(f) # max fitness index
+ plt.figure(figsize=(10, 12), tight_layout=True)
+ matplotlib.rc('font', **{'size': 8})
+ print(f'Best results from row {j} of {evolve_csv}:')
+ for i, k in enumerate(keys[7:]):
+ v = x[:, 7 + i]
+ mu = v[j] # best single result
+ plt.subplot(6, 5, i + 1)
+ plt.scatter(v, f, c=hist2d(v, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
+ plt.plot(mu, f.max(), 'k+', markersize=15)
+ plt.title(f'{k} = {mu:.3g}', fontdict={'size': 9}) # limit to 40 characters
+ if i % 5 != 0:
+ plt.yticks([])
+ print(f'{k:>15}: {mu:.3g}')
+ f = evolve_csv.with_suffix('.png') # filename
+ plt.savefig(f, dpi=200)
+ plt.close()
+ print(f'Saved {f}')
+
+
+def plot_results(file='path/to/results.csv', dir=''):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):
+ y = data.values[:, j].astype('float')
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)
+ ax[i].set_title(s[j], fontsize=12)
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ LOGGER.info(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
+
+
+def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
+ # Plot iDetection '*.txt' per-image logs. from utils.plots import *; profile_idetection()
+ ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
+ s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
+ files = list(Path(save_dir).glob('frames*.txt'))
+ for fi, f in enumerate(files):
+ try:
+ results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
+ n = results.shape[1] # number of rows
+ x = np.arange(start, min(stop, n) if stop else n)
+ results = results[:, x]
+ t = (results[0] - results[0].min()) # set t0=0s
+ results[0] = x
+ for i, a in enumerate(ax):
+ if i < len(results):
+ label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
+ a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
+ a.set_title(s[i])
+ a.set_xlabel('time (s)')
+ # if fi == len(files) - 1:
+ # a.set_ylim(bottom=0)
+ for side in ['top', 'right']:
+ a.spines[side].set_visible(False)
+ else:
+ a.remove()
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}; {e}')
+ ax[1].legend()
+ plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
+
+
+def save_one_box(xyxy, im, file=Path('im.jpg'), gain=1.02, pad=10, square=False, BGR=False, save=True):
+ # Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
+ xyxy = torch.tensor(xyxy).view(-1, 4)
+ b = xyxy2xywh(xyxy) # boxes
+ if square:
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
+ b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
+ xyxy = xywh2xyxy(b).long()
+ clip_boxes(xyxy, im.shape)
+ crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
+ if save:
+ file.parent.mkdir(parents=True, exist_ok=True) # make directory
+ f = str(increment_path(file).with_suffix('.jpg'))
+ # cv2.imwrite(f, crop) # save BGR, https://github.com/ultralytics/yolov5/issues/7007 chroma subsampling issue
+ Image.fromarray(crop[..., ::-1]).save(f, quality=95, subsampling=0) # save RGB
+ return crop
diff --git a/yolov5/utils/segment/__init__.py b/yolov5/utils/segment/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/yolov5/utils/segment/__pycache__/__init__.cpython-38.pyc b/yolov5/utils/segment/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..aa3349ac3836ffe7067e5fde6688707192021992
Binary files /dev/null and b/yolov5/utils/segment/__pycache__/__init__.cpython-38.pyc differ
diff --git a/yolov5/utils/segment/__pycache__/__init__.cpython-39.pyc b/yolov5/utils/segment/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..635eae3a9aafc734fe0c21f597f4722a5aafaeba
Binary files /dev/null and b/yolov5/utils/segment/__pycache__/__init__.cpython-39.pyc differ
diff --git a/yolov5/utils/segment/__pycache__/general.cpython-38.pyc b/yolov5/utils/segment/__pycache__/general.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a659cef28bdb8b0d0c6c353e8bce8a5e358102aa
Binary files /dev/null and b/yolov5/utils/segment/__pycache__/general.cpython-38.pyc differ
diff --git a/yolov5/utils/segment/__pycache__/general.cpython-39.pyc b/yolov5/utils/segment/__pycache__/general.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0a1a728e0a62f99bfe4db5a49c92b317ad19366e
Binary files /dev/null and b/yolov5/utils/segment/__pycache__/general.cpython-39.pyc differ
diff --git a/yolov5/utils/segment/augmentations.py b/yolov5/utils/segment/augmentations.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8154b834869acd87f80c0152c870b7631a918ba
--- /dev/null
+++ b/yolov5/utils/segment/augmentations.py
@@ -0,0 +1,104 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Image augmentation functions
+"""
+
+import math
+import random
+
+import cv2
+import numpy as np
+
+from ..augmentations import box_candidates
+from ..general import resample_segments, segment2box
+
+
+def mixup(im, labels, segments, im2, labels2, segments2):
+ # Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
+ r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
+ im = (im * r + im2 * (1 - r)).astype(np.uint8)
+ labels = np.concatenate((labels, labels2), 0)
+ segments = np.concatenate((segments, segments2), 0)
+ return im, labels, segments
+
+
+def random_perspective(im,
+ targets=(),
+ segments=(),
+ degrees=10,
+ translate=.1,
+ scale=.1,
+ shear=10,
+ perspective=0.0,
+ border=(0, 0)):
+ # torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
+ # targets = [cls, xyxy]
+
+ height = im.shape[0] + border[0] * 2 # shape(h,w,c)
+ width = im.shape[1] + border[1] * 2
+
+ # Center
+ C = np.eye(3)
+ C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
+ C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
+
+ # Perspective
+ P = np.eye(3)
+ P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
+ P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
+
+ # Rotation and Scale
+ R = np.eye(3)
+ a = random.uniform(-degrees, degrees)
+ # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
+ s = random.uniform(1 - scale, 1 + scale)
+ # s = 2 ** random.uniform(-scale, scale)
+ R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
+
+ # Shear
+ S = np.eye(3)
+ S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
+ S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
+
+ # Translation
+ T = np.eye(3)
+ T[0, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * width) # x translation (pixels)
+ T[1, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * height) # y translation (pixels)
+
+ # Combined rotation matrix
+ M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
+ if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
+ if perspective:
+ im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
+ else: # affine
+ im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
+
+ # Visualize
+ # import matplotlib.pyplot as plt
+ # ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
+ # ax[0].imshow(im[:, :, ::-1]) # base
+ # ax[1].imshow(im2[:, :, ::-1]) # warped
+
+ # Transform label coordinates
+ n = len(targets)
+ new_segments = []
+ if n:
+ new = np.zeros((n, 4))
+ segments = resample_segments(segments) # upsample
+ for i, segment in enumerate(segments):
+ xy = np.ones((len(segment), 3))
+ xy[:, :2] = segment
+ xy = xy @ M.T # transform
+ xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]) # perspective rescale or affine
+
+ # clip
+ new[i] = segment2box(xy, width, height)
+ new_segments.append(xy)
+
+ # filter candidates
+ i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01)
+ targets = targets[i]
+ targets[:, 1:5] = new[i]
+ new_segments = np.array(new_segments)[i]
+
+ return im, targets, new_segments
diff --git a/yolov5/utils/segment/dataloaders.py b/yolov5/utils/segment/dataloaders.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ee826dba69cb0cda00c48b82710784cd39c5a81
--- /dev/null
+++ b/yolov5/utils/segment/dataloaders.py
@@ -0,0 +1,332 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Dataloaders
+"""
+
+import os
+import random
+
+import cv2
+import numpy as np
+import torch
+from torch.utils.data import DataLoader, distributed
+
+from ..augmentations import augment_hsv, copy_paste, letterbox
+from ..dataloaders import InfiniteDataLoader, LoadImagesAndLabels, seed_worker
+from ..general import LOGGER, xyn2xy, xywhn2xyxy, xyxy2xywhn
+from ..torch_utils import torch_distributed_zero_first
+from .augmentations import mixup, random_perspective
+
+RANK = int(os.getenv('RANK', -1))
+
+
+def create_dataloader(path,
+ imgsz,
+ batch_size,
+ stride,
+ single_cls=False,
+ hyp=None,
+ augment=False,
+ cache=False,
+ pad=0.0,
+ rect=False,
+ rank=-1,
+ workers=8,
+ image_weights=False,
+ quad=False,
+ prefix='',
+ shuffle=False,
+ mask_downsample_ratio=1,
+ overlap_mask=False,
+ seed=0):
+ if rect and shuffle:
+ LOGGER.warning('WARNING ⚠️ --rect is incompatible with DataLoader shuffle, setting shuffle=False')
+ shuffle = False
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = LoadImagesAndLabelsAndMasks(
+ path,
+ imgsz,
+ batch_size,
+ augment=augment, # augmentation
+ hyp=hyp, # hyperparameters
+ rect=rect, # rectangular batches
+ cache_images=cache,
+ single_cls=single_cls,
+ stride=int(stride),
+ pad=pad,
+ image_weights=image_weights,
+ prefix=prefix,
+ downsample_ratio=mask_downsample_ratio,
+ overlap=overlap_mask)
+
+ batch_size = min(batch_size, len(dataset))
+ nd = torch.cuda.device_count() # number of CUDA devices
+ nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
+ sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
+ loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
+ generator = torch.Generator()
+ generator.manual_seed(6148914691236517205 + seed + RANK)
+ return loader(
+ dataset,
+ batch_size=batch_size,
+ shuffle=shuffle and sampler is None,
+ num_workers=nw,
+ sampler=sampler,
+ pin_memory=True,
+ collate_fn=LoadImagesAndLabelsAndMasks.collate_fn4 if quad else LoadImagesAndLabelsAndMasks.collate_fn,
+ worker_init_fn=seed_worker,
+ generator=generator,
+ ), dataset
+
+
+class LoadImagesAndLabelsAndMasks(LoadImagesAndLabels): # for training/testing
+
+ def __init__(
+ self,
+ path,
+ img_size=640,
+ batch_size=16,
+ augment=False,
+ hyp=None,
+ rect=False,
+ image_weights=False,
+ cache_images=False,
+ single_cls=False,
+ stride=32,
+ pad=0,
+ min_items=0,
+ prefix='',
+ downsample_ratio=1,
+ overlap=False,
+ ):
+ super().__init__(path, img_size, batch_size, augment, hyp, rect, image_weights, cache_images, single_cls,
+ stride, pad, min_items, prefix)
+ self.downsample_ratio = downsample_ratio
+ self.overlap = overlap
+
+ def __getitem__(self, index):
+ index = self.indices[index] # linear, shuffled, or image_weights
+
+ hyp = self.hyp
+ mosaic = self.mosaic and random.random() < hyp['mosaic']
+ masks = []
+ if mosaic:
+ # Load mosaic
+ img, labels, segments = self.load_mosaic(index)
+ shapes = None
+
+ # MixUp augmentation
+ if random.random() < hyp['mixup']:
+ img, labels, segments = mixup(img, labels, segments, *self.load_mosaic(random.randint(0, self.n - 1)))
+
+ else:
+ # Load image
+ img, (h0, w0), (h, w) = self.load_image(index)
+
+ # Letterbox
+ shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
+ img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
+ shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
+
+ labels = self.labels[index].copy()
+ # [array, array, ....], array.shape=(num_points, 2), xyxyxyxy
+ segments = self.segments[index].copy()
+ if len(segments):
+ for i_s in range(len(segments)):
+ segments[i_s] = xyn2xy(
+ segments[i_s],
+ ratio[0] * w,
+ ratio[1] * h,
+ padw=pad[0],
+ padh=pad[1],
+ )
+ if labels.size: # normalized xywh to pixel xyxy format
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
+
+ if self.augment:
+ img, labels, segments = random_perspective(img,
+ labels,
+ segments=segments,
+ degrees=hyp['degrees'],
+ translate=hyp['translate'],
+ scale=hyp['scale'],
+ shear=hyp['shear'],
+ perspective=hyp['perspective'])
+
+ nl = len(labels) # number of labels
+ if nl:
+ labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1e-3)
+ if self.overlap:
+ masks, sorted_idx = polygons2masks_overlap(img.shape[:2],
+ segments,
+ downsample_ratio=self.downsample_ratio)
+ masks = masks[None] # (640, 640) -> (1, 640, 640)
+ labels = labels[sorted_idx]
+ else:
+ masks = polygons2masks(img.shape[:2], segments, color=1, downsample_ratio=self.downsample_ratio)
+
+ masks = (torch.from_numpy(masks) if len(masks) else torch.zeros(1 if self.overlap else nl, img.shape[0] //
+ self.downsample_ratio, img.shape[1] //
+ self.downsample_ratio))
+ # TODO: albumentations support
+ if self.augment:
+ # Albumentations
+ # there are some augmentation that won't change boxes and masks,
+ # so just be it for now.
+ img, labels = self.albumentations(img, labels)
+ nl = len(labels) # update after albumentations
+
+ # HSV color-space
+ augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
+
+ # Flip up-down
+ if random.random() < hyp['flipud']:
+ img = np.flipud(img)
+ if nl:
+ labels[:, 2] = 1 - labels[:, 2]
+ masks = torch.flip(masks, dims=[1])
+
+ # Flip left-right
+ if random.random() < hyp['fliplr']:
+ img = np.fliplr(img)
+ if nl:
+ labels[:, 1] = 1 - labels[:, 1]
+ masks = torch.flip(masks, dims=[2])
+
+ # Cutouts # labels = cutout(img, labels, p=0.5)
+
+ labels_out = torch.zeros((nl, 6))
+ if nl:
+ labels_out[:, 1:] = torch.from_numpy(labels)
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return (torch.from_numpy(img), labels_out, self.im_files[index], shapes, masks)
+
+ def load_mosaic(self, index):
+ # YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
+ labels4, segments4 = [], []
+ s = self.img_size
+ yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
+
+ # 3 additional image indices
+ indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img4
+ if i == 0: # top left
+ img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
+ elif i == 1: # top right
+ x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
+ x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
+ elif i == 2: # bottom left
+ x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
+ elif i == 3: # bottom right
+ x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
+
+ img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
+ padw = x1a - x1b
+ padh = y1a - y1b
+
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
+ labels4.append(labels)
+ segments4.extend(segments)
+
+ # Concat/clip labels
+ labels4 = np.concatenate(labels4, 0)
+ for x in (labels4[:, 1:], *segments4):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img4, labels4 = replicate(img4, labels4) # replicate
+
+ # Augment
+ img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
+ img4, labels4, segments4 = random_perspective(img4,
+ labels4,
+ segments4,
+ degrees=self.hyp['degrees'],
+ translate=self.hyp['translate'],
+ scale=self.hyp['scale'],
+ shear=self.hyp['shear'],
+ perspective=self.hyp['perspective'],
+ border=self.mosaic_border) # border to remove
+ return img4, labels4, segments4
+
+ @staticmethod
+ def collate_fn(batch):
+ img, label, path, shapes, masks = zip(*batch) # transposed
+ batched_masks = torch.cat(masks, 0)
+ for i, l in enumerate(label):
+ l[:, 0] = i # add target image index for build_targets()
+ return torch.stack(img, 0), torch.cat(label, 0), path, shapes, batched_masks
+
+
+def polygon2mask(img_size, polygons, color=1, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (np.ndarray): [N, M], N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ mask = np.zeros(img_size, dtype=np.uint8)
+ polygons = np.asarray(polygons)
+ polygons = polygons.astype(np.int32)
+ shape = polygons.shape
+ polygons = polygons.reshape(shape[0], -1, 2)
+ cv2.fillPoly(mask, polygons, color=color)
+ nh, nw = (img_size[0] // downsample_ratio, img_size[1] // downsample_ratio)
+ # NOTE: fillPoly firstly then resize is trying the keep the same way
+ # of loss calculation when mask-ratio=1.
+ mask = cv2.resize(mask, (nw, nh))
+ return mask
+
+
+def polygons2masks(img_size, polygons, color, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (list[np.ndarray]): each polygon is [N, M],
+ N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ masks = []
+ for si in range(len(polygons)):
+ mask = polygon2mask(img_size, [polygons[si].reshape(-1)], color, downsample_ratio)
+ masks.append(mask)
+ return np.array(masks)
+
+
+def polygons2masks_overlap(img_size, segments, downsample_ratio=1):
+ """Return a (640, 640) overlap mask."""
+ masks = np.zeros((img_size[0] // downsample_ratio, img_size[1] // downsample_ratio),
+ dtype=np.int32 if len(segments) > 255 else np.uint8)
+ areas = []
+ ms = []
+ for si in range(len(segments)):
+ mask = polygon2mask(
+ img_size,
+ [segments[si].reshape(-1)],
+ downsample_ratio=downsample_ratio,
+ color=1,
+ )
+ ms.append(mask)
+ areas.append(mask.sum())
+ areas = np.asarray(areas)
+ index = np.argsort(-areas)
+ ms = np.array(ms)[index]
+ for i in range(len(segments)):
+ mask = ms[i] * (i + 1)
+ masks = masks + mask
+ masks = np.clip(masks, a_min=0, a_max=i + 1)
+ return masks, index
diff --git a/yolov5/utils/segment/general.py b/yolov5/utils/segment/general.py
new file mode 100644
index 0000000000000000000000000000000000000000..f1b2f1dd120ff47eec618e0c25239c28c4d88475
--- /dev/null
+++ b/yolov5/utils/segment/general.py
@@ -0,0 +1,160 @@
+import cv2
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+
+def crop_mask(masks, boxes):
+ """
+ "Crop" predicted masks by zeroing out everything not in the predicted bbox.
+ Vectorized by Chong (thanks Chong).
+
+ Args:
+ - masks should be a size [n, h, w] tensor of masks
+ - boxes should be a size [n, 4] tensor of bbox coords in relative point form
+ """
+
+ n, h, w = masks.shape
+ x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1) # x1 shape(1,1,n)
+ r = torch.arange(w, device=masks.device, dtype=x1.dtype)[None, None, :] # rows shape(1,w,1)
+ c = torch.arange(h, device=masks.device, dtype=x1.dtype)[None, :, None] # cols shape(h,1,1)
+
+ return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
+
+
+def process_mask_upsample(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape: input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask(protos, masks_in, bboxes, shape, upsample=False):
+ """
+ Crop before upsample.
+ proto_out: [mask_dim, mask_h, mask_w]
+ out_masks: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape:input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ ih, iw = shape
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw) # CHW
+
+ downsampled_bboxes = bboxes.clone()
+ downsampled_bboxes[:, 0] *= mw / iw
+ downsampled_bboxes[:, 2] *= mw / iw
+ downsampled_bboxes[:, 3] *= mh / ih
+ downsampled_bboxes[:, 1] *= mh / ih
+
+ masks = crop_mask(masks, downsampled_bboxes) # CHW
+ if upsample:
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask_native(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ protos: [mask_dim, mask_h, mask_w]
+ masks_in: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape: input_image_size, (h, w)
+
+ return: h, w, n
+ """
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ gain = min(mh / shape[0], mw / shape[1]) # gain = old / new
+ pad = (mw - shape[1] * gain) / 2, (mh - shape[0] * gain) / 2 # wh padding
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(mh - pad[1]), int(mw - pad[0])
+ masks = masks[:, top:bottom, left:right]
+
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def scale_image(im1_shape, masks, im0_shape, ratio_pad=None):
+ """
+ img1_shape: model input shape, [h, w]
+ img0_shape: origin pic shape, [h, w, 3]
+ masks: [h, w, num]
+ """
+ # Rescale coordinates (xyxy) from im1_shape to im0_shape
+ if ratio_pad is None: # calculate from im0_shape
+ gain = min(im1_shape[0] / im0_shape[0], im1_shape[1] / im0_shape[1]) # gain = old / new
+ pad = (im1_shape[1] - im0_shape[1] * gain) / 2, (im1_shape[0] - im0_shape[0] * gain) / 2 # wh padding
+ else:
+ pad = ratio_pad[1]
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(im1_shape[0] - pad[1]), int(im1_shape[1] - pad[0])
+
+ if len(masks.shape) < 2:
+ raise ValueError(f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}')
+ masks = masks[top:bottom, left:right]
+ # masks = masks.permute(2, 0, 1).contiguous()
+ # masks = F.interpolate(masks[None], im0_shape[:2], mode='bilinear', align_corners=False)[0]
+ # masks = masks.permute(1, 2, 0).contiguous()
+ masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]))
+
+ if len(masks.shape) == 2:
+ masks = masks[:, :, None]
+ return masks
+
+
+def mask_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [M, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, [N, M]
+ """
+ intersection = torch.matmul(mask1, mask2.t()).clamp(0)
+ union = (mask1.sum(1)[:, None] + mask2.sum(1)[None]) - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [N, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, (N, )
+ """
+ intersection = (mask1 * mask2).sum(1).clamp(0) # (N, )
+ union = (mask1.sum(1) + mask2.sum(1))[None] - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks2segments(masks, strategy='largest'):
+ # Convert masks(n,160,160) into segments(n,xy)
+ segments = []
+ for x in masks.int().cpu().numpy().astype('uint8'):
+ c = cv2.findContours(x, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
+ if c:
+ if strategy == 'concat': # concatenate all segments
+ c = np.concatenate([x.reshape(-1, 2) for x in c])
+ elif strategy == 'largest': # select largest segment
+ c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
+ else:
+ c = np.zeros((0, 2)) # no segments found
+ segments.append(c.astype('float32'))
+ return segments
diff --git a/yolov5/utils/segment/loss.py b/yolov5/utils/segment/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..caeff3cad586b4367990aa4626ed6c326b04baf3
--- /dev/null
+++ b/yolov5/utils/segment/loss.py
@@ -0,0 +1,185 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..general import xywh2xyxy
+from ..loss import FocalLoss, smooth_BCE
+from ..metrics import bbox_iou
+from ..torch_utils import de_parallel
+from .general import crop_mask
+
+
+class ComputeLoss:
+ # Compute losses
+ def __init__(self, model, autobalance=False, overlap=False):
+ self.sort_obj_iou = False
+ self.overlap = overlap
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.nm = m.nm # number of masks
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, preds, targets, masks): # predictions, targets, model
+ p, proto = preds
+ bs, nm, mask_h, mask_w = proto.shape # batch size, number of masks, mask height, mask width
+ lcls = torch.zeros(1, device=self.device)
+ lbox = torch.zeros(1, device=self.device)
+ lobj = torch.zeros(1, device=self.device)
+ lseg = torch.zeros(1, device=self.device)
+ tcls, tbox, indices, anchors, tidxs, xywhn = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ pxy, pwh, _, pcls, pmask = pi[b, a, gj, gi].split((2, 2, 1, self.nc, nm), 1) # subset of predictions
+
+ # Box regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Mask regression
+ if tuple(masks.shape[-2:]) != (mask_h, mask_w): # downsample
+ masks = F.interpolate(masks[None], (mask_h, mask_w), mode='nearest')[0]
+ marea = xywhn[i][:, 2:].prod(1) # mask width, height normalized
+ mxyxy = xywh2xyxy(xywhn[i] * torch.tensor([mask_w, mask_h, mask_w, mask_h], device=self.device))
+ for bi in b.unique():
+ j = b == bi # matching index
+ if self.overlap:
+ mask_gti = torch.where(masks[bi][None] == tidxs[i][j].view(-1, 1, 1), 1.0, 0.0)
+ else:
+ mask_gti = masks[tidxs[i]][j]
+ lseg += self.single_mask_loss(mask_gti, pmask[j], proto[bi], mxyxy[j], marea[j])
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ lseg *= self.hyp['box'] / bs
+
+ loss = lbox + lobj + lcls + lseg
+ return loss * bs, torch.cat((lbox, lseg, lobj, lcls)).detach()
+
+ def single_mask_loss(self, gt_mask, pred, proto, xyxy, area):
+ # Mask loss for one image
+ pred_mask = (pred @ proto.view(self.nm, -1)).view(-1, *proto.shape[1:]) # (n,32) @ (32,80,80) -> (n,80,80)
+ loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction='none')
+ return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).mean()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch, tidxs, xywhn = [], [], [], [], [], []
+ gain = torch.ones(8, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ if self.overlap:
+ batch = p[0].shape[0]
+ ti = []
+ for i in range(batch):
+ num = (targets[:, 0] == i).sum() # find number of targets of each image
+ ti.append(torch.arange(num, device=self.device).float().view(1, num).repeat(na, 1) + 1) # (na, num)
+ ti = torch.cat(ti, 1) # (na, nt)
+ else:
+ ti = torch.arange(nt, device=self.device).float().view(1, nt).repeat(na, 1)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None], ti[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, at = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ (a, tidx), (b, c) = at.long().T, bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+ tidxs.append(tidx)
+ xywhn.append(torch.cat((gxy, gwh), 1) / gain[2:6]) # xywh normalized
+
+ return tcls, tbox, indices, anch, tidxs, xywhn
diff --git a/yolov5/utils/segment/metrics.py b/yolov5/utils/segment/metrics.py
new file mode 100644
index 0000000000000000000000000000000000000000..6020fa062ba562c770a3a6dd17daf7fa30e1dfc2
--- /dev/null
+++ b/yolov5/utils/segment/metrics.py
@@ -0,0 +1,210 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import numpy as np
+
+from ..metrics import ap_per_class
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9, 0.0, 0.0, 0.1, 0.9]
+ return (x[:, :8] * w).sum(1)
+
+
+def ap_per_class_box_and_mask(
+ tp_m,
+ tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=False,
+ save_dir='.',
+ names=(),
+):
+ """
+ Args:
+ tp_b: tp of boxes.
+ tp_m: tp of masks.
+ other arguments see `func: ap_per_class`.
+ """
+ results_boxes = ap_per_class(tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix='Box')[2:]
+ results_masks = ap_per_class(tp_m,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix='Mask')[2:]
+
+ results = {
+ 'boxes': {
+ 'p': results_boxes[0],
+ 'r': results_boxes[1],
+ 'ap': results_boxes[3],
+ 'f1': results_boxes[2],
+ 'ap_class': results_boxes[4]},
+ 'masks': {
+ 'p': results_masks[0],
+ 'r': results_masks[1],
+ 'ap': results_masks[3],
+ 'f1': results_masks[2],
+ 'ap_class': results_masks[4]}}
+ return results
+
+
+class Metric:
+
+ def __init__(self) -> None:
+ self.p = [] # (nc, )
+ self.r = [] # (nc, )
+ self.f1 = [] # (nc, )
+ self.all_ap = [] # (nc, 10)
+ self.ap_class_index = [] # (nc, )
+
+ @property
+ def ap50(self):
+ """AP@0.5 of all classes.
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap[:, 0] if len(self.all_ap) else []
+
+ @property
+ def ap(self):
+ """AP@0.5:0.95
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap.mean(1) if len(self.all_ap) else []
+
+ @property
+ def mp(self):
+ """mean precision of all classes.
+ Return:
+ float.
+ """
+ return self.p.mean() if len(self.p) else 0.0
+
+ @property
+ def mr(self):
+ """mean recall of all classes.
+ Return:
+ float.
+ """
+ return self.r.mean() if len(self.r) else 0.0
+
+ @property
+ def map50(self):
+ """Mean AP@0.5 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap[:, 0].mean() if len(self.all_ap) else 0.0
+
+ @property
+ def map(self):
+ """Mean AP@0.5:0.95 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap.mean() if len(self.all_ap) else 0.0
+
+ def mean_results(self):
+ """Mean of results, return mp, mr, map50, map"""
+ return (self.mp, self.mr, self.map50, self.map)
+
+ def class_result(self, i):
+ """class-aware result, return p[i], r[i], ap50[i], ap[i]"""
+ return (self.p[i], self.r[i], self.ap50[i], self.ap[i])
+
+ def get_maps(self, nc):
+ maps = np.zeros(nc) + self.map
+ for i, c in enumerate(self.ap_class_index):
+ maps[c] = self.ap[i]
+ return maps
+
+ def update(self, results):
+ """
+ Args:
+ results: tuple(p, r, ap, f1, ap_class)
+ """
+ p, r, all_ap, f1, ap_class_index = results
+ self.p = p
+ self.r = r
+ self.all_ap = all_ap
+ self.f1 = f1
+ self.ap_class_index = ap_class_index
+
+
+class Metrics:
+ """Metric for boxes and masks."""
+
+ def __init__(self) -> None:
+ self.metric_box = Metric()
+ self.metric_mask = Metric()
+
+ def update(self, results):
+ """
+ Args:
+ results: Dict{'boxes': Dict{}, 'masks': Dict{}}
+ """
+ self.metric_box.update(list(results['boxes'].values()))
+ self.metric_mask.update(list(results['masks'].values()))
+
+ def mean_results(self):
+ return self.metric_box.mean_results() + self.metric_mask.mean_results()
+
+ def class_result(self, i):
+ return self.metric_box.class_result(i) + self.metric_mask.class_result(i)
+
+ def get_maps(self, nc):
+ return self.metric_box.get_maps(nc) + self.metric_mask.get_maps(nc)
+
+ @property
+ def ap_class_index(self):
+ # boxes and masks have the same ap_class_index
+ return self.metric_box.ap_class_index
+
+
+KEYS = [
+ 'train/box_loss',
+ 'train/seg_loss', # train loss
+ 'train/obj_loss',
+ 'train/cls_loss',
+ 'metrics/precision(B)',
+ 'metrics/recall(B)',
+ 'metrics/mAP_0.5(B)',
+ 'metrics/mAP_0.5:0.95(B)', # metrics
+ 'metrics/precision(M)',
+ 'metrics/recall(M)',
+ 'metrics/mAP_0.5(M)',
+ 'metrics/mAP_0.5:0.95(M)', # metrics
+ 'val/box_loss',
+ 'val/seg_loss', # val loss
+ 'val/obj_loss',
+ 'val/cls_loss',
+ 'x/lr0',
+ 'x/lr1',
+ 'x/lr2',]
+
+BEST_KEYS = [
+ 'best/epoch',
+ 'best/precision(B)',
+ 'best/recall(B)',
+ 'best/mAP_0.5(B)',
+ 'best/mAP_0.5:0.95(B)',
+ 'best/precision(M)',
+ 'best/recall(M)',
+ 'best/mAP_0.5(M)',
+ 'best/mAP_0.5:0.95(M)',]
diff --git a/yolov5/utils/segment/plots.py b/yolov5/utils/segment/plots.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b22ec838ac93220187b60f5bdaf50eae19d7397
--- /dev/null
+++ b/yolov5/utils/segment/plots.py
@@ -0,0 +1,143 @@
+import contextlib
+import math
+from pathlib import Path
+
+import cv2
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import torch
+
+from .. import threaded
+from ..general import xywh2xyxy
+from ..plots import Annotator, colors
+
+
+@threaded
+def plot_images_and_masks(images, targets, masks, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+ if isinstance(masks, torch.Tensor):
+ masks = masks.cpu().numpy().astype(int)
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ idx = targets[:, 0] == i
+ ti = targets[idx] # image targets
+
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+
+ # Plot masks
+ if len(masks):
+ if masks.max() > 1.0: # mean that masks are overlap
+ image_masks = masks[[i]] # (1, 640, 640)
+ nl = len(ti)
+ index = np.arange(nl).reshape(nl, 1, 1) + 1
+ image_masks = np.repeat(image_masks, nl, axis=0)
+ image_masks = np.where(image_masks == index, 1.0, 0.0)
+ else:
+ image_masks = masks[idx]
+
+ im = np.asarray(annotator.im).copy()
+ for j, box in enumerate(boxes.T.tolist()):
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ color = colors(classes[j])
+ mh, mw = image_masks[j].shape
+ if mh != h or mw != w:
+ mask = image_masks[j].astype(np.uint8)
+ mask = cv2.resize(mask, (w, h))
+ mask = mask.astype(bool)
+ else:
+ mask = image_masks[j].astype(bool)
+ with contextlib.suppress(Exception):
+ im[y:y + h, x:x + w, :][mask] = im[y:y + h, x:x + w, :][mask] * 0.4 + np.array(color) * 0.6
+ annotator.fromarray(im)
+ annotator.im.save(fname) # save
+
+
+def plot_results_with_masks(file='path/to/results.csv', dir='', best=True):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 8, figsize=(18, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ index = np.argmax(0.9 * data.values[:, 8] + 0.1 * data.values[:, 7] + 0.9 * data.values[:, 12] +
+ 0.1 * data.values[:, 11])
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 6, 9, 10, 13, 14, 15, 16, 7, 8, 11, 12]):
+ y = data.values[:, j]
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=2)
+ if best:
+ # best
+ ax[i].scatter(index, y[index], color='r', label=f'best:{index}', marker='*', linewidth=3)
+ ax[i].set_title(s[j] + f'\n{round(y[index], 5)}')
+ else:
+ # last
+ ax[i].scatter(x[-1], y[-1], color='r', label='last', marker='*', linewidth=3)
+ ax[i].set_title(s[j] + f'\n{round(y[-1], 5)}')
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
diff --git a/yolov5/utils/torch_utils.py b/yolov5/utils/torch_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b42be027414a24a4ad7bf39a8476871c51158da
--- /dev/null
+++ b/yolov5/utils/torch_utils.py
@@ -0,0 +1,432 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+PyTorch utils
+"""
+
+import math
+import os
+import platform
+import subprocess
+import time
+import warnings
+from contextlib import contextmanager
+from copy import deepcopy
+from pathlib import Path
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn.parallel import DistributedDataParallel as DDP
+
+from yolov5.utils.general import LOGGER, check_version, colorstr, file_date, git_describe
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+# Suppress PyTorch warnings
+warnings.filterwarnings('ignore', message='User provided device_type of \'cuda\', but CUDA is not available. Disabling')
+warnings.filterwarnings('ignore', category=UserWarning)
+
+
+def smart_inference_mode(torch_1_9=check_version(torch.__version__, '1.9.0')):
+ # Applies torch.inference_mode() decorator if torch>=1.9.0 else torch.no_grad() decorator
+ def decorate(fn):
+ return (torch.inference_mode if torch_1_9 else torch.no_grad)()(fn)
+
+ return decorate
+
+
+def smartCrossEntropyLoss(label_smoothing=0.0):
+ # Returns nn.CrossEntropyLoss with label smoothing enabled for torch>=1.10.0
+ if check_version(torch.__version__, '1.10.0'):
+ return nn.CrossEntropyLoss(label_smoothing=label_smoothing)
+ if label_smoothing > 0:
+ LOGGER.warning(f'WARNING ⚠️ label smoothing {label_smoothing} requires torch>=1.10.0')
+ return nn.CrossEntropyLoss()
+
+
+def smart_DDP(model):
+ # Model DDP creation with checks
+ assert not check_version(torch.__version__, '1.12.0', pinned=True), \
+ 'torch==1.12.0 torchvision==0.13.0 DDP training is not supported due to a known issue. ' \
+ 'Please upgrade or downgrade torch to use DDP. See https://github.com/ultralytics/yolov5/issues/8395'
+ if check_version(torch.__version__, '1.11.0'):
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK, static_graph=True)
+ else:
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+
+def reshape_classifier_output(model, n=1000):
+ # Update a TorchVision classification model to class count 'n' if required
+ from models.common import Classify
+ name, m = list((model.model if hasattr(model, 'model') else model).named_children())[-1] # last module
+ if isinstance(m, Classify): # YOLOv5 Classify() head
+ if m.linear.out_features != n:
+ m.linear = nn.Linear(m.linear.in_features, n)
+ elif isinstance(m, nn.Linear): # ResNet, EfficientNet
+ if m.out_features != n:
+ setattr(model, name, nn.Linear(m.in_features, n))
+ elif isinstance(m, nn.Sequential):
+ types = [type(x) for x in m]
+ if nn.Linear in types:
+ i = types.index(nn.Linear) # nn.Linear index
+ if m[i].out_features != n:
+ m[i] = nn.Linear(m[i].in_features, n)
+ elif nn.Conv2d in types:
+ i = types.index(nn.Conv2d) # nn.Conv2d index
+ if m[i].out_channels != n:
+ m[i] = nn.Conv2d(m[i].in_channels, n, m[i].kernel_size, m[i].stride, bias=m[i].bias is not None)
+
+
+@contextmanager
+def torch_distributed_zero_first(local_rank: int):
+ # Decorator to make all processes in distributed training wait for each local_master to do something
+ if local_rank not in [-1, 0]:
+ dist.barrier(device_ids=[local_rank])
+ yield
+ if local_rank == 0:
+ dist.barrier(device_ids=[0])
+
+
+def device_count():
+ # Returns number of CUDA devices available. Safe version of torch.cuda.device_count(). Supports Linux and Windows
+ assert platform.system() in ('Linux', 'Windows'), 'device_count() only supported on Linux or Windows'
+ try:
+ cmd = 'nvidia-smi -L | wc -l' if platform.system() == 'Linux' else 'nvidia-smi -L | find /c /v ""' # Windows
+ return int(subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1])
+ except Exception:
+ return 0
+
+
+def select_device(device='', batch_size=0, newline=True):
+ # device = None or 'cpu' or 0 or '0' or '0,1,2,3'
+ s = f'YOLOv5 🚀 {git_describe() or file_date()} Python-{platform.python_version()} torch-{torch.__version__} '
+ device = str(device).strip().lower().replace('cuda:', '').replace('none', '') # to string, 'cuda:0' to '0'
+ cpu = device == 'cpu'
+ mps = device == 'mps' # Apple Metal Performance Shaders (MPS)
+ if cpu or mps:
+ os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
+ elif device: # non-cpu device requested
+ os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable - must be before assert is_available()
+ assert torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(',', '')), \
+ f"Invalid CUDA '--device {device}' requested, use '--device cpu' or pass valid CUDA device(s)"
+
+ if not cpu and not mps and torch.cuda.is_available(): # prefer GPU if available
+ devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
+ n = len(devices) # device count
+ if n > 1 and batch_size > 0: # check batch_size is divisible by device_count
+ assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
+ space = ' ' * (len(s) + 1)
+ for i, d in enumerate(devices):
+ p = torch.cuda.get_device_properties(i)
+ s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / (1 << 20):.0f}MiB)\n" # bytes to MB
+ arg = 'cuda:0'
+ elif mps and getattr(torch, 'has_mps', False) and torch.backends.mps.is_available(): # prefer MPS if available
+ s += 'MPS\n'
+ arg = 'mps'
+ else: # revert to CPU
+ s += 'CPU\n'
+ arg = 'cpu'
+
+ if not newline:
+ s = s.rstrip()
+ LOGGER.info(s)
+ return torch.device(arg)
+
+
+def time_sync():
+ # PyTorch-accurate time
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def profile(input, ops, n=10, device=None):
+ """ YOLOv5 speed/memory/FLOPs profiler
+ Usage:
+ input = torch.randn(16, 3, 640, 640)
+ m1 = lambda x: x * torch.sigmoid(x)
+ m2 = nn.SiLU()
+ profile(input, [m1, m2], n=100) # profile over 100 iterations
+ """
+ results = []
+ if not isinstance(device, torch.device):
+ device = select_device(device)
+ print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
+ try:
+ flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
+ except Exception:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ _ = (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception: # no backward method
+ # print(e) # for debug
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in, s_out = (tuple(x.shape) if isinstance(x, torch.Tensor) else 'list' for x in (x, y)) # shapes
+ p = sum(x.numel() for x in m.parameters()) if isinstance(m, nn.Module) else 0 # parameters
+ print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ print(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
+
+
+def is_parallel(model):
+ # Returns True if model is of type DP or DDP
+ return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
+
+
+def de_parallel(model):
+ # De-parallelize a model: returns single-GPU model if model is of type DP or DDP
+ return model.module if is_parallel(model) else model
+
+
+def initialize_weights(model):
+ for m in model.modules():
+ t = type(m)
+ if t is nn.Conv2d:
+ pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif t is nn.BatchNorm2d:
+ m.eps = 1e-3
+ m.momentum = 0.03
+ elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
+ m.inplace = True
+
+
+def find_modules(model, mclass=nn.Conv2d):
+ # Finds layer indices matching module class 'mclass'
+ return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
+
+
+def sparsity(model):
+ # Return global model sparsity
+ a, b = 0, 0
+ for p in model.parameters():
+ a += p.numel()
+ b += (p == 0).sum()
+ return b / a
+
+
+def prune(model, amount=0.3):
+ # Prune model to requested global sparsity
+ import torch.nn.utils.prune as prune
+ for name, m in model.named_modules():
+ if isinstance(m, nn.Conv2d):
+ prune.l1_unstructured(m, name='weight', amount=amount) # prune
+ prune.remove(m, 'weight') # make permanent
+ LOGGER.info(f'Model pruned to {sparsity(model):.3g} global sparsity')
+
+
+def fuse_conv_and_bn(conv, bn):
+ # Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
+ fusedconv = nn.Conv2d(conv.in_channels,
+ conv.out_channels,
+ kernel_size=conv.kernel_size,
+ stride=conv.stride,
+ padding=conv.padding,
+ dilation=conv.dilation,
+ groups=conv.groups,
+ bias=True).requires_grad_(False).to(conv.weight.device)
+
+ # Prepare filters
+ w_conv = conv.weight.clone().view(conv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
+
+ # Prepare spatial bias
+ b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fusedconv
+
+
+def model_info(model, verbose=False, imgsz=640):
+ # Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
+ n_p = sum(x.numel() for x in model.parameters()) # number parameters
+ n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
+ if verbose:
+ print(f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
+ for i, (name, p) in enumerate(model.named_parameters()):
+ name = name.replace('module_list.', '')
+ print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
+ (i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
+
+ try: # FLOPs
+ p = next(model.parameters())
+ stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32 # max stride
+ im = torch.empty((1, p.shape[1], stride, stride), device=p.device) # input image in BCHW format
+ flops = thop.profile(deepcopy(model), inputs=(im,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
+ imgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/float
+ fs = f', {flops * imgsz[0] / stride * imgsz[1] / stride:.1f} GFLOPs' # 640x640 GFLOPs
+ except Exception:
+ fs = ''
+
+ name = Path(model.yaml_file).stem.replace('yolov5', 'YOLOv5') if hasattr(model, 'yaml_file') else 'Model'
+ LOGGER.info(f'{name} summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}')
+
+
+def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
+ # Scales img(bs,3,y,x) by ratio constrained to gs-multiple
+ if ratio == 1.0:
+ return img
+ h, w = img.shape[2:]
+ s = (int(h * ratio), int(w * ratio)) # new size
+ img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
+ if not same_shape: # pad/crop img
+ h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
+ return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
+
+
+def copy_attr(a, b, include=(), exclude=()):
+ # Copy attributes from b to a, options to only include [...] and to exclude [...]
+ for k, v in b.__dict__.items():
+ if (len(include) and k not in include) or k.startswith('_') or k in exclude:
+ continue
+ else:
+ setattr(a, k, v)
+
+
+def smart_optimizer(model, name='Adam', lr=0.001, momentum=0.9, decay=1e-5):
+ # YOLOv5 3-param group optimizer: 0) weights with decay, 1) weights no decay, 2) biases no decay
+ g = [], [], [] # optimizer parameter groups
+ bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
+ for v in model.modules():
+ for p_name, p in v.named_parameters(recurse=0):
+ if p_name == 'bias': # bias (no decay)
+ g[2].append(p)
+ elif p_name == 'weight' and isinstance(v, bn): # weight (no decay)
+ g[1].append(p)
+ else:
+ g[0].append(p) # weight (with decay)
+
+ if name == 'Adam':
+ optimizer = torch.optim.Adam(g[2], lr=lr, betas=(momentum, 0.999)) # adjust beta1 to momentum
+ elif name == 'AdamW':
+ optimizer = torch.optim.AdamW(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
+ elif name == 'RMSProp':
+ optimizer = torch.optim.RMSprop(g[2], lr=lr, momentum=momentum)
+ elif name == 'SGD':
+ optimizer = torch.optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
+ else:
+ raise NotImplementedError(f'Optimizer {name} not implemented.')
+
+ optimizer.add_param_group({'params': g[0], 'weight_decay': decay}) # add g0 with weight_decay
+ optimizer.add_param_group({'params': g[1], 'weight_decay': 0.0}) # add g1 (BatchNorm2d weights)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}) with parameter groups "
+ f'{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias')
+ return optimizer
+
+
+def smart_hub_load(repo='ultralytics/yolov5', model='yolov5s', **kwargs):
+ # YOLOv5 torch.hub.load() wrapper with smart error/issue handling
+ if check_version(torch.__version__, '1.9.1'):
+ kwargs['skip_validation'] = True # validation causes GitHub API rate limit errors
+ if check_version(torch.__version__, '1.12.0'):
+ kwargs['trust_repo'] = True # argument required starting in torch 0.12
+ try:
+ return torch.hub.load(repo, model, **kwargs)
+ except Exception:
+ return torch.hub.load(repo, model, force_reload=True, **kwargs)
+
+
+def smart_resume(ckpt, optimizer, ema=None, weights='yolov5s.pt', epochs=300, resume=True):
+ # Resume training from a partially trained checkpoint
+ best_fitness = 0.0
+ start_epoch = ckpt['epoch'] + 1
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer']) # optimizer
+ best_fitness = ckpt['best_fitness']
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict()) # EMA
+ ema.updates = ckpt['updates']
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.\n' \
+ f"Start a new training without --resume, i.e. 'python train.py --weights {weights}'"
+ LOGGER.info(f'Resuming training from {weights} from epoch {start_epoch} to {epochs} total epochs')
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+ return best_fitness, start_epoch, epochs
+
+
+class EarlyStopping:
+ # YOLOv5 simple early stopper
+ def __init__(self, patience=30):
+ self.best_fitness = 0.0 # i.e. mAP
+ self.best_epoch = 0
+ self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
+ self.possible_stop = False # possible stop may occur next epoch
+
+ def __call__(self, epoch, fitness):
+ if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
+ self.best_epoch = epoch
+ self.best_fitness = fitness
+ delta = epoch - self.best_epoch # epochs without improvement
+ self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
+ stop = delta >= self.patience # stop training if patience exceeded
+ if stop:
+ LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
+ f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
+ f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
+ f'i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.')
+ return stop
+
+
+class ModelEMA:
+ """ Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
+ Keeps a moving average of everything in the model state_dict (parameters and buffers)
+ For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ """
+
+ def __init__(self, model, decay=0.9999, tau=2000, updates=0):
+ # Create EMA
+ self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
+ self.updates = updates # number of EMA updates
+ self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
+ for p in self.ema.parameters():
+ p.requires_grad_(False)
+
+ def update(self, model):
+ # Update EMA parameters
+ self.updates += 1
+ d = self.decay(self.updates)
+
+ msd = de_parallel(model).state_dict() # model state_dict
+ for k, v in self.ema.state_dict().items():
+ if v.dtype.is_floating_point: # true for FP16 and FP32
+ v *= d
+ v += (1 - d) * msd[k].detach()
+ # assert v.dtype == msd[k].dtype == torch.float32, f'{k}: EMA {v.dtype} and model {msd[k].dtype} must be FP32'
+
+ def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
+ # Update EMA attributes
+ copy_attr(self.ema, model, include, exclude)
diff --git a/yolov5/utils/triton.py b/yolov5/utils/triton.py
new file mode 100644
index 0000000000000000000000000000000000000000..b5153dad940ddeceda4d8e39ac3d90e3efa66448
--- /dev/null
+++ b/yolov5/utils/triton.py
@@ -0,0 +1,85 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+""" Utils to interact with the Triton Inference Server
+"""
+
+import typing
+from urllib.parse import urlparse
+
+import torch
+
+
+class TritonRemoteModel:
+ """ A wrapper over a model served by the Triton Inference Server. It can
+ be configured to communicate over GRPC or HTTP. It accepts Torch Tensors
+ as input and returns them as outputs.
+ """
+
+ def __init__(self, url: str):
+ """
+ Keyword arguments:
+ url: Fully qualified address of the Triton server - for e.g. grpc://localhost:8000
+ """
+
+ parsed_url = urlparse(url)
+ if parsed_url.scheme == 'grpc':
+ from tritonclient.grpc import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton GRPC client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository.models[0].name
+ self.metadata = self.client.get_model_metadata(self.model_name, as_json=True)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i['shape']], i['datatype']) for i in self.metadata['inputs']]
+
+ else:
+ from tritonclient.http import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton HTTP client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository[0]['name']
+ self.metadata = self.client.get_model_metadata(self.model_name)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i['shape']], i['datatype']) for i in self.metadata['inputs']]
+
+ self._create_input_placeholders_fn = create_input_placeholders
+
+ @property
+ def runtime(self):
+ """Returns the model runtime"""
+ return self.metadata.get('backend', self.metadata.get('platform'))
+
+ def __call__(self, *args, **kwargs) -> typing.Union[torch.Tensor, typing.Tuple[torch.Tensor, ...]]:
+ """ Invokes the model. Parameters can be provided via args or kwargs.
+ args, if provided, are assumed to match the order of inputs of the model.
+ kwargs are matched with the model input names.
+ """
+ inputs = self._create_inputs(*args, **kwargs)
+ response = self.client.infer(model_name=self.model_name, inputs=inputs)
+ result = []
+ for output in self.metadata['outputs']:
+ tensor = torch.as_tensor(response.as_numpy(output['name']))
+ result.append(tensor)
+ return result[0] if len(result) == 1 else result
+
+ def _create_inputs(self, *args, **kwargs):
+ args_len, kwargs_len = len(args), len(kwargs)
+ if not args_len and not kwargs_len:
+ raise RuntimeError('No inputs provided.')
+ if args_len and kwargs_len:
+ raise RuntimeError('Cannot specify args and kwargs at the same time')
+
+ placeholders = self._create_input_placeholders_fn()
+ if args_len:
+ if args_len != len(placeholders):
+ raise RuntimeError(f'Expected {len(placeholders)} inputs, got {args_len}.')
+ for input, value in zip(placeholders, args):
+ input.set_data_from_numpy(value.cpu().numpy())
+ else:
+ for input in placeholders:
+ value = kwargs[input.name]
+ input.set_data_from_numpy(value.cpu().numpy())
+ return placeholders
diff --git a/yolov5/val.py b/yolov5/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d01f1a5996d7cd93e27f4a57b85f8fbdbc3fce6
--- /dev/null
+++ b/yolov5/val.py
@@ -0,0 +1,409 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Validate a trained YOLOv5 detection model on a detection dataset
+
+Usage:
+ $ python val.py --weights yolov5s.pt --data coco128.yaml --img 640
+
+Usage - formats:
+ $ python val.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s_openvino_model # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import json
+import os
+import subprocess
+import sys
+from pathlib import Path
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, Profile, check_dataset, check_img_size, check_requirements,
+ check_yaml, coco80_to_coco91_class, colorstr, increment_path, non_max_suppression,
+ print_args, scale_boxes, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, ap_per_class, box_iou
+from utils.plots import output_to_target, plot_images, plot_val_study
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ jdict.append({
+ 'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5)})
+
+
+def process_batch(detections, labels, iouv):
+ """
+ Return correct prediction matrix
+ Arguments:
+ detections (array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (array[N, 10]), for 10 IoU levels
+ """
+ correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+ correct_class = labels[:, 0:1] == detections[:, 5]
+ for i in range(len(iouv)):
+ x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ correct[matches[:, 1].astype(int), i] = True
+ return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
+
+
+@smart_inference_mode()
+def run(
+ data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ max_det=300, # maximum detections per image
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ callbacks=Callbacks(),
+ compute_loss=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ cuda = device.type != 'cpu'
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith(f'coco{os.sep}val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10, device=device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and not single_cls: # check --weights are trained on --data
+ ncm = model.model.nc
+ assert ncm == nc, f'{weights} ({ncm} classes) trained on different --data than what you passed ({nc} ' \
+ f'classes). Pass correct combination of --weights and --data that are trained together.'
+ model.warmup(imgsz=(1 if pt else batch_size, 3, imgsz, imgsz)) # warmup
+ pad, rect = (0.0, False) if task == 'speed' else (0.5, pt) # square inference for benchmarks
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task],
+ imgsz,
+ batch_size,
+ stride,
+ single_cls,
+ pad=pad,
+ rect=rect,
+ workers=workers,
+ prefix=colorstr(f'{task}: '))[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = model.names if hasattr(model, 'names') else model.module.names # get class names
+ if isinstance(names, (list, tuple)): # old format
+ names = dict(enumerate(names))
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%22s' + '%11s' * 6) % ('Class', 'Images', 'Instances', 'P', 'R', 'mAP50', 'mAP50-95')
+ tp, fp, p, r, f1, mp, mr, map50, ap50, map = 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
+ dt = Profile(), Profile(), Profile() # profiling times
+ loss = torch.zeros(3, device=device)
+ jdict, stats, ap, ap_class = [], [], [], []
+ callbacks.run('on_val_start')
+ pbar = tqdm(dataloader, desc=s, bar_format=TQDM_BAR_FORMAT) # progress bar
+ for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
+ callbacks.run('on_val_batch_start')
+ with dt[0]:
+ if cuda:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+
+ # Inference
+ with dt[1]:
+ preds, train_out = model(im) if compute_loss else (model(im, augment=augment), None)
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss(train_out, targets)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.tensor((width, height, width, height), device=device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ with dt[2]:
+ preds = non_max_suppression(preds,
+ conf_thres,
+ iou_thres,
+ labels=lb,
+ multi_label=True,
+ agnostic=single_cls,
+ max_det=max_det)
+
+ # Metrics
+ for si, pred in enumerate(preds):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl, npr = labels.shape[0], pred.shape[0] # number of labels, predictions
+ path, shape = Path(paths[si]), shapes[si][0]
+ correct = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ seen += 1
+
+ if npr == 0:
+ if nl:
+ stats.append((correct, *torch.zeros((2, 0), device=device), labels[:, 0]))
+ if plots:
+ confusion_matrix.process_batch(detections=None, labels=labels[:, 0])
+ continue
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_boxes(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct = process_batch(predn, labelsn, iouv)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ stats.append((correct, pred[:, 4], pred[:, 5], labels[:, 0])) # (correct, conf, pcls, tcls)
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+ if save_json:
+ save_one_json(predn, jdict, path, class_map) # append to COCO-JSON dictionary
+ callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ plot_images(im, targets, paths, save_dir / f'val_batch{batch_i}_labels.jpg', names) # labels
+ plot_images(im, output_to_target(preds), paths, save_dir / f'val_batch{batch_i}_pred.jpg', names) # pred
+
+ callbacks.run('on_val_batch_end', batch_i, im, targets, paths, shapes, preds)
+
+ # Compute metrics
+ stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
+ ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
+ mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
+ nt = np.bincount(stats[3].astype(int), minlength=nc) # number of targets per class
+
+ # Print results
+ pf = '%22s' + '%11i' * 2 + '%11.3g' * 4 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
+ if nt.sum() == 0:
+ LOGGER.warning(f'WARNING ⚠️ no labels found in {task} set, can not compute metrics without labels')
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(ap_class):
+ LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
+
+ # Print speeds
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ callbacks.run('on_val_end', nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix)
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path('../datasets/coco/annotations/instances_val2017.json')) # annotations
+ pred_json = str(save_dir / f'{w}_predictions.json') # predictions
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements('pycocotools>=2.0.6')
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ eval = COCOeval(anno, pred, 'bbox')
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.im_files] # image IDs to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ maps = np.zeros(nc) + map
+ for i, c in enumerate(ap_class):
+ maps[c] = ap[i]
+ return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=300, help='maximum detections per image')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.info(f'WARNING ⚠️ confidence threshold {opt.conf_thres} > 0.001 produces invalid results')
+ if opt.save_hybrid:
+ LOGGER.info('WARNING ⚠️ --save-hybrid will return high mAP from hybrid labels, not from predictions alone')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ opt.half = torch.cuda.is_available() and opt.device != 'cpu' # FP16 for fastest results
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ subprocess.run(['zip', '-r', 'study.zip', 'study_*.txt'])
+ plot_val_study(x=x) # plot
+ else:
+ raise NotImplementedError(f'--task {opt.task} not in ("train", "val", "test", "speed", "study")')
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/yolov5/yolov5s.pt b/yolov5/yolov5s.pt
new file mode 100644
index 0000000000000000000000000000000000000000..cd69a5e14d396322319b06304274238c0188a522
--- /dev/null
+++ b/yolov5/yolov5s.pt
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8b3b748c1e592ddd8868022e8732fde20025197328490623cc16c6f24d0782ee
+size 14808437
 +
+ +
+