
impira/layoutlm-document-qa
Document Question Answering • 0.1B • Updated
• 14k • 1.17k
Document Question Answering (also known as Document Visual Question Answering) is the task of answering questions on document images. Document question answering models take a (document, question) pair as input and return an answer in natural language. Models usually rely on multi-modal features, combining text, position of words (bounding-boxes) and image.
What is the idea behind the consumer relations efficiency team?
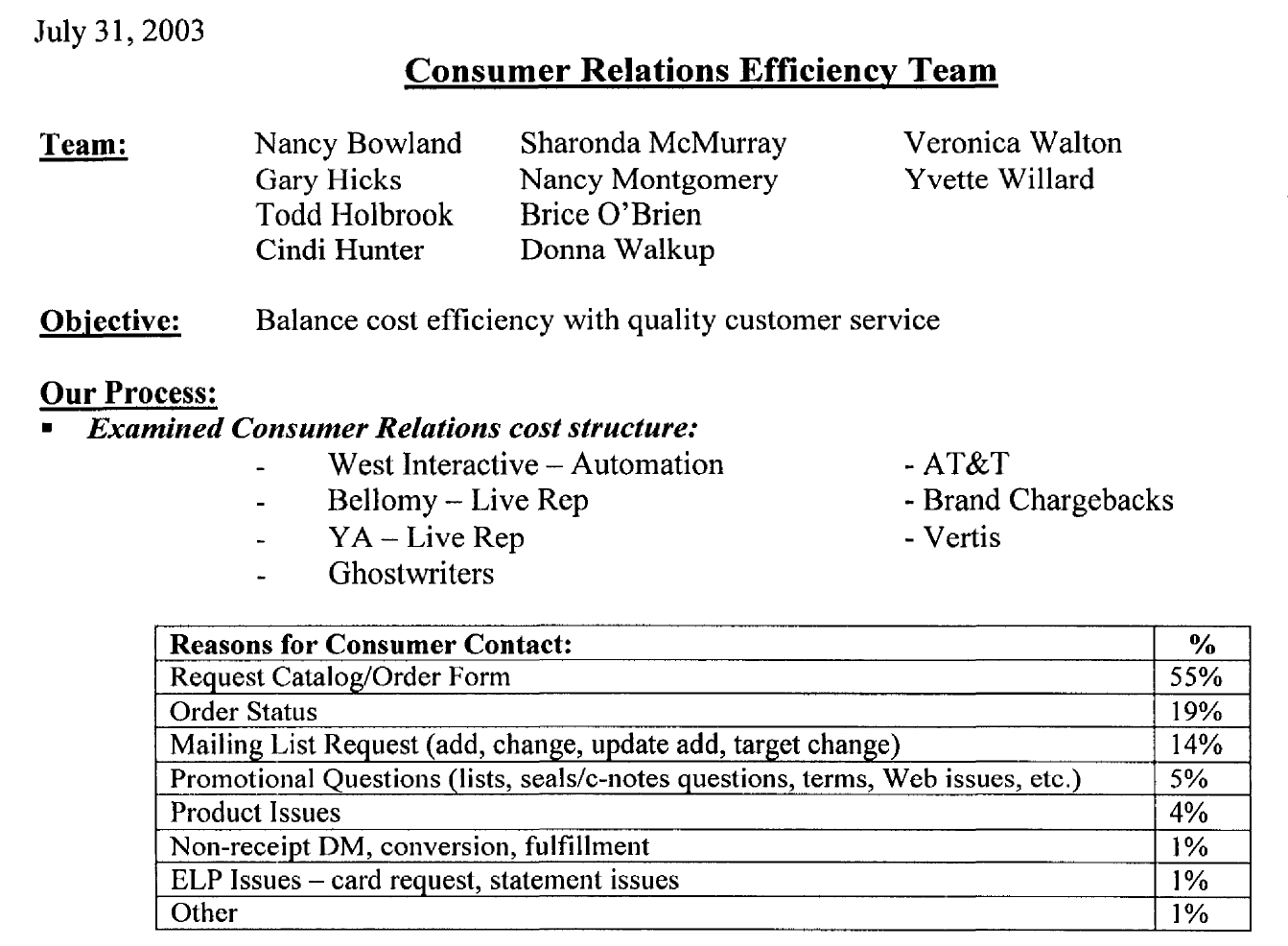
Balance cost efficiency with quality customer service
Document Question Answering models can be used to answer natural language questions about documents. Typically, document QA models consider textual, layout and potentially visual information. This is useful when the question requires some understanding of the visual aspects of the document. Nevertheless, certain document QA models can work without document images. Hence the task is not limited to visually-rich documents and allows users to ask questions based on spreadsheets, text PDFs, etc!
One of the most popular use cases of document question answering models is the parsing of structured documents. For example, you can extract the name, address, and other information from a form. You can also use the model to extract information from a table, or even a resume.
Another very popular use case is invoice information extraction. For example, you can extract the invoice number, the invoice date, the total amount, the VAT number, and the invoice recipient.
You can infer with Document QA models with the 🤗 Transformers library using the document-question-answering pipeline. If no model checkpoint is given, the pipeline will be initialized with impira/layoutlm-document-qa. This pipeline takes question(s) and document(s) as input, and returns the answer.
👉 Note that the question answering task solved here is extractive: the model extracts the answer from a context (the document).
from transformers import pipeline
from PIL import Image
pipe = pipeline("document-question-answering", model="naver-clova-ix/donut-base-finetuned-docvqa")
question = "What is the purchase amount?"
image = Image.open("your-document.png")
pipe(image=image, question=question)
## [{'answer': '20,000$'}]
Would you like to learn more about Document QA? Awesome! Here are some curated resources that you may find helpful!
The contents of this page are contributed by Eliott Zemour and reviewed by Kwadwo Agyapon-Ntra and Ankur Goyal.
No example widget is defined for this task.
Note Contribute by proposing a widget for this task !
Note A robust document question answering model.
Note A document question answering model specialized in invoices.
Note A special model for OCR-free document question answering.
Note A powerful model for document question answering.
Note Largest document understanding dataset.
Note Dataset from the 2020 DocVQA challenge. The documents are taken from the UCSF Industry Documents Library.
Note A robust document question answering application.
Note An application that can answer questions from invoices.
Note An application to compare different document question answering models.

