
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,22 +1,14 @@
|
|
| 1 |
---
|
| 2 |
-
|
| 3 |
-
-
|
| 4 |
language:
|
| 5 |
- en
|
| 6 |
-
size_categories:
|
| 7 |
-
- 1K<n<10K
|
| 8 |
---
|
| 9 |
-
|
| 10 |
-
- 1000 LIMA (Zero-Shot Instruction)
|
| 11 |
-
- 30 LIMA (Multi-Shot Instruction)
|
| 12 |
-
- 37 OASST1 (Handpicked Multi-Shot Instruction)
|
| 13 |
-
- 1 Simpsons Episode (Zero-Shot Instruction-to-Chat)
|
| 14 |
-
- 1 Futruama Episdoe (Zero-Shot Instruction-to-Chat)
|
| 15 |
-
- 1 MF DOOM Lyrics (Multi-Shot Instruction)
|
| 16 |
-
- 1 MF DOOM Lyrics (Zero-Shot Instruction)
|
| 17 |
|
|
|
|
| 18 |
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
-
|
| 22 |
-
|
|
|
|
| 1 |
---
|
| 2 |
+
datasets:
|
| 3 |
+
- xzuyn/lima-multiturn-alpaca
|
| 4 |
language:
|
| 5 |
- en
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
|
| 9 |
+
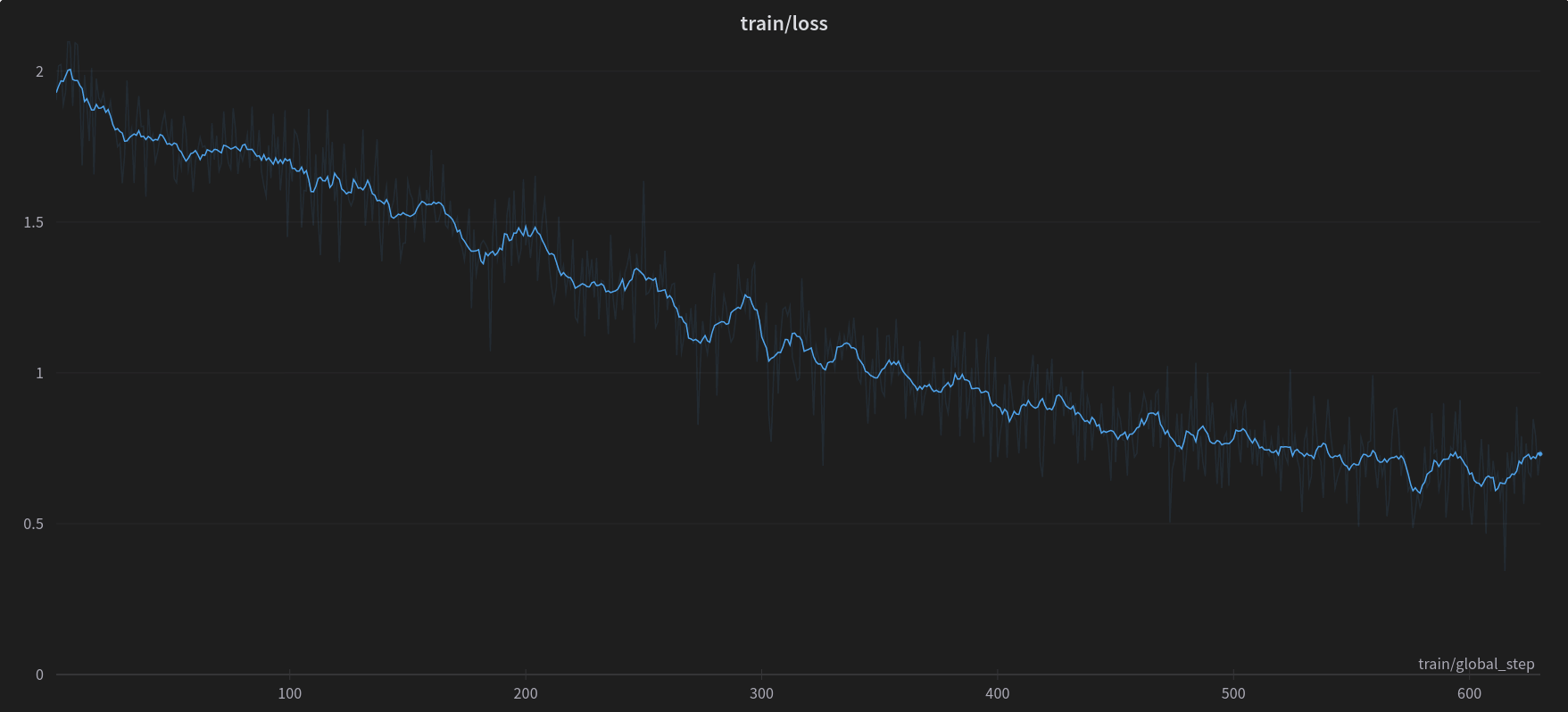
Trained on a 7900XTX.
|
| 10 |
|
| 11 |
+
[Zeus-LLM-Trainer](https://github.com/official-elinas/zeus-llm-trainer) command to recreate:
|
| 12 |
+
```
|
| 13 |
+
python finetune.py --data_path "xzuyn/lima-multiturn-alpaca" --learning_rate 0.0001 --optim "paged_adamw_8bit" --train_4bit --lora_r 32 --lora_alpha 32 --prompt_template_name "alpaca_short" --num_train_epochs 15 --gradient_accumulation_steps 24 --per_device_train_batch_size 1 --logging_steps 1 --save_total_limit 20 --use_gradient_checkpointing True --save_and_eval_steps 1 --group_by_length True --cutoff_len 4096 --val_set_size 0 --use_flash_attn True --base_model "meta-llama/Llama-2-7b-hf"
|
| 14 |
+
```
|