
Commit
•
29381e2
1
Parent(s):
0735385
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
datasets:
|
| 3 |
+
- Open-Orca/OpenOrca
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
library_name: transformers
|
| 7 |
+
pipeline_tag: text-generation
|
| 8 |
+
license: apache-2.0
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
## This repo contains a SHARDED version of: https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca
|
| 13 |
+
|
| 14 |
+
### Huge thanks to the publishers for their amazing work, all credits go to them: https://huggingface.co/Open-Orca
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
<p><h1>🐋 Mistral-7B-OpenOrca 🐋</h1></p>
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+

|
| 21 |
+
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
# OpenOrca - Mistral - 7B - 8k
|
| 25 |
+
|
| 26 |
+
We have used our own [OpenOrca dataset](https://huggingface.co/datasets/Open-Orca/OpenOrca) to fine-tune on top of [Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1).
|
| 27 |
+
This dataset is our attempt to reproduce the dataset generated for Microsoft Research's [Orca Paper](https://arxiv.org/abs/2306.02707).
|
| 28 |
+
We use [OpenChat](https://huggingface.co/openchat) packing, trained with [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
|
| 29 |
+
|
| 30 |
+
This release is trained on a curated filtered subset of most of our GPT-4 augmented data.
|
| 31 |
+
It is the same subset of our data as was used in our [OpenOrcaxOpenChat-Preview2-13B model](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B).
|
| 32 |
+
|
| 33 |
+
**HF Leaderboard evals place this model as #1 for all models smaller than 30B at release time, outperforming all other 7B and 13B models!**
|
| 34 |
+
|
| 35 |
+
This release provides a first: a fully open model with class-breaking performance, capable of running fully accelerated on even moderate consumer GPUs.
|
| 36 |
+
Our thanks to the Mistral team for leading the way here.
|
| 37 |
+
|
| 38 |
+
We affectionately codename this model: "*MistralOrca*"
|
| 39 |
+
|
| 40 |
+
If you'd like to try the model now, we have it running on fast GPUs unquantized: https://huggingface.co/spaces/Open-Orca/Mistral-7B-OpenOrca
|
| 41 |
+
|
| 42 |
+
Want to visualize our full (pre-filtering) dataset? Check out our [Nomic Atlas Map](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2).
|
| 43 |
+
|
| 44 |
+
[<img src="https://huggingface.co/Open-Orca/OpenOrca-Preview1-13B/resolve/main/OpenOrca%20Nomic%20Atlas.png" alt="Atlas Nomic Dataset Map" width="400" height="400" />](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
We are in-process with training more models, so keep a look out on our org for releases coming soon with exciting partners.
|
| 48 |
+
|
| 49 |
+
We will also give sneak-peak announcements on our Discord, which you can find here:
|
| 50 |
+
|
| 51 |
+
https://AlignmentLab.ai
|
| 52 |
+
|
| 53 |
+
or check the OpenAccess AI Collective Discord for more information about Axolotl trainer here:
|
| 54 |
+
|
| 55 |
+
https://discord.gg/5y8STgB3P3
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
# Quantized Models
|
| 59 |
+
|
| 60 |
+
Quantized versions of this model are generously made available by [TheBloke](https://huggingface.co/TheBloke).
|
| 61 |
+
|
| 62 |
+
- AWQ: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ
|
| 63 |
+
- GPTQ: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GPTQ
|
| 64 |
+
- GGUF: https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
# Prompt Template
|
| 68 |
+
|
| 69 |
+
We used [OpenAI's Chat Markup Language (ChatML)](https://github.com/openai/openai-python/blob/main/chatml.md) format, with `<|im_start|>` and `<|im_end|>` tokens added to support this.
|
| 70 |
+
|
| 71 |
+
This means that, e.g., in [oobabooga](https://github.com/oobabooga/text-generation-webui/) the "`MPT-Chat`" instruction template should work, as it also uses ChatML.
|
| 72 |
+
|
| 73 |
+
This formatting is also available via a pre-defined [Transformers chat template](https://huggingface.co/docs/transformers/main/chat_templating),
|
| 74 |
+
which means that lists of messages can be formatted for you with the `apply_chat_template()` method:
|
| 75 |
+
|
| 76 |
+
```python
|
| 77 |
+
chat = [
|
| 78 |
+
{"role": "system", "content": "You are MistralOrca, a large language model trained by Alignment Lab AI. Write out your reasoning step-by-step to be sure you get the right answers!"}
|
| 79 |
+
{"role": "user", "content": "How are you?"},
|
| 80 |
+
{"role": "assistant", "content": "I am doing well!"},
|
| 81 |
+
{"role": "user", "content": "Please tell me about how mistral winds have attracted super-orcas."},
|
| 82 |
+
]
|
| 83 |
+
tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
which will yield:
|
| 87 |
+
|
| 88 |
+
```
|
| 89 |
+
<|im_start|>system
|
| 90 |
+
You are MistralOrca, a large language model trained by Alignment Lab AI. Write out your reasoning step-by-step to be sure you get the right answers!
|
| 91 |
+
<|im_end|>
|
| 92 |
+
<|im_start|>user
|
| 93 |
+
How are you?<|im_end|>
|
| 94 |
+
<|im_start|>assistant
|
| 95 |
+
I am doing well!<|im_end|>
|
| 96 |
+
<|im_start|>user
|
| 97 |
+
Please tell me about how mistral winds have attracted super-orcas.<|im_end|>
|
| 98 |
+
<|im_start|>assistant
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
If you use `tokenize=True` and `return_tensors="pt"` instead, then you will get a tokenized
|
| 102 |
+
and formatted conversation ready to pass to `model.generate()`.
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
# Inference
|
| 106 |
+
|
| 107 |
+
See [this notebook](https://colab.research.google.com/drive/1yZlLSifCGELAX5GN582kZypHCv0uJuNX?usp=sharing) for inference details.
|
| 108 |
+
|
| 109 |
+
Note that you need the development snapshot of Transformers currently, as support for Mistral hasn't been released into PyPI yet:
|
| 110 |
+
|
| 111 |
+
```
|
| 112 |
+
pip install git+https://github.com/huggingface/transformers
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
# Evaluation
|
| 117 |
+
|
| 118 |
+
## HuggingFace Leaderboard Performance
|
| 119 |
+
|
| 120 |
+
We have evaluated using the methodology and tools for the HuggingFace Leaderboard, and find that we have dramatically improved upon the base model.
|
| 121 |
+
We find **106%** of the base model's performance on HF Leaderboard evals, averaging **65.84**.
|
| 122 |
+
|
| 123 |
+
At release time, this beats all 7B and 13B models!
|
| 124 |
+
|
| 125 |
+
This is also **98.6%** of *`Llama2-70b-chat`*'s performance!
|
| 126 |
+
|
| 127 |
+
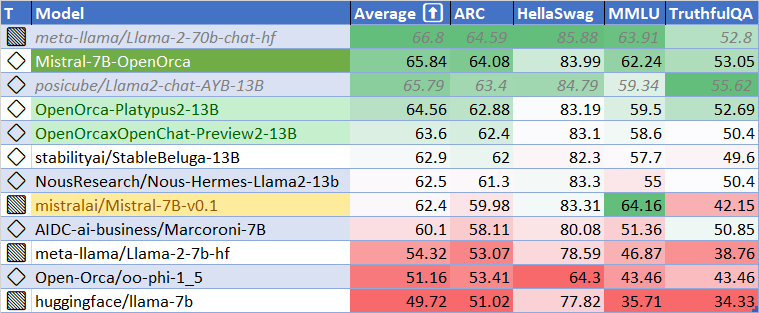
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
| Metric | Value |
|
| 131 |
+
|-----------------------|-------|
|
| 132 |
+
| MMLU (5-shot) | 62.24 |
|
| 133 |
+
| ARC (25-shot) | 64.08 |
|
| 134 |
+
| HellaSwag (10-shot) | 83.99 |
|
| 135 |
+
| TruthfulQA (0-shot) | 53.05 |
|
| 136 |
+
| Avg. | 65.84 |
|
| 137 |
+
|
| 138 |
+
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
## AGIEval Performance
|
| 142 |
+
|
| 143 |
+
We compare our results to the base Mistral-7B model (using LM Evaluation Harness).
|
| 144 |
+
|
| 145 |
+
We find **129%** of the base model's performance on AGI Eval, averaging **0.397**.
|
| 146 |
+
As well, we significantly improve upon the official `mistralai/Mistral-7B-Instruct-v0.1` finetuning, achieving **119%** of their performance.
|
| 147 |
+
|
| 148 |
+

|
| 149 |
+
|
| 150 |
+
## BigBench-Hard Performance
|
| 151 |
+
|
| 152 |
+
We find **119%** of the base model's performance on BigBench-Hard, averaging **0.416**.
|
| 153 |
+
|
| 154 |
+

|
| 155 |
+
|
| 156 |
+
## GPT4ALL Leaderboard Performance
|
| 157 |
+
|
| 158 |
+
We gain a slight edge over our previous releases, again topping the leaderboard, averaging **72.38**.
|
| 159 |
+
|
| 160 |
+

|
| 161 |
+
|
| 162 |
+
## MT-Bench Performance
|
| 163 |
+
|
| 164 |
+
MT-Bench uses GPT-4 as a judge of model response quality, across a wide range of challenges.
|
| 165 |
+
We find our performance is *on-par with `Llama2-70b-chat`*, averaging **6.86**.
|
| 166 |
+
|
| 167 |
+

|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
# Dataset
|
| 171 |
+
|
| 172 |
+
We used a curated, filtered selection of most of the GPT-4 augmented data from our OpenOrca dataset, which aims to reproduce the Orca Research Paper dataset.
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
# Training
|
| 176 |
+
|
| 177 |
+
We trained with 8x A6000 GPUs for 62 hours, completing 4 epochs of full fine tuning on our dataset in one training run.
|
| 178 |
+
Commodity cost was ~$400.
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
# Citation
|
| 182 |
+
|
| 183 |
+
```bibtex
|
| 184 |
+
@software{lian2023mistralorca1
|
| 185 |
+
title = {MistralOrca: Mistral-7B Model Instruct-tuned on Filtered OpenOrcaV1 GPT-4 Dataset},
|
| 186 |
+
author = {Wing Lian and Bleys Goodson and Guan Wang and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
|
| 187 |
+
year = {2023},
|
| 188 |
+
publisher = {HuggingFace},
|
| 189 |
+
journal = {HuggingFace repository},
|
| 190 |
+
howpublished = {\url{https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca},
|
| 191 |
+
}
|
| 192 |
+
@misc{mukherjee2023orca,
|
| 193 |
+
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
|
| 194 |
+
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
|
| 195 |
+
year={2023},
|
| 196 |
+
eprint={2306.02707},
|
| 197 |
+
archivePrefix={arXiv},
|
| 198 |
+
primaryClass={cs.CL}
|
| 199 |
+
}
|
| 200 |
+
@misc{longpre2023flan,
|
| 201 |
+
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
|
| 202 |
+
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
|
| 203 |
+
year={2023},
|
| 204 |
+
eprint={2301.13688},
|
| 205 |
+
archivePrefix={arXiv},
|
| 206 |
+
primaryClass={cs.AI}
|
| 207 |
+
}
|
| 208 |
+
```
|