
Commit
·
6c60ccc
1
Parent(s):
79e67d7
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +2 -0
- .gitignore +131 -0
- LICENSE +35 -0
- README.md +167 -0
- assets/CodeFormer_logo.png +0 -0
- assets/color_enhancement_result1.png +0 -0
- assets/color_enhancement_result2.png +0 -0
- assets/imgsli_1.jpg +0 -0
- assets/imgsli_2.jpg +0 -0
- assets/imgsli_3.jpg +0 -0
- assets/inpainting_result1.png +0 -0
- assets/inpainting_result2.png +0 -0
- assets/network.jpg +0 -0
- assets/restoration_result1.png +0 -0
- assets/restoration_result2.png +0 -0
- assets/restoration_result3.png +0 -0
- assets/restoration_result4.png +0 -0
- basicsr/VERSION +1 -0
- basicsr/__init__.py +11 -0
- basicsr/__pycache__/__init__.cpython-310.pyc +0 -0
- basicsr/__pycache__/train.cpython-310.pyc +0 -0
- basicsr/__pycache__/version.cpython-310.pyc +0 -0
- basicsr/archs/__init__.py +25 -0
- basicsr/archs/__pycache__/__init__.cpython-310.pyc +0 -0
- basicsr/archs/__pycache__/arcface_arch.cpython-310.pyc +0 -0
- basicsr/archs/__pycache__/arch_util.cpython-310.pyc +0 -0
- basicsr/archs/__pycache__/codeformer_arch.cpython-310.pyc +0 -0
- basicsr/archs/__pycache__/rrdbnet_arch.cpython-310.pyc +0 -0
- basicsr/archs/__pycache__/vgg_arch.cpython-310.pyc +0 -0
- basicsr/archs/__pycache__/vqgan_arch.cpython-310.pyc +0 -0
- basicsr/archs/arcface_arch.py +245 -0
- basicsr/archs/arch_util.py +318 -0
- basicsr/archs/codeformer_arch.py +280 -0
- basicsr/archs/rrdbnet_arch.py +119 -0
- basicsr/archs/vgg_arch.py +161 -0
- basicsr/archs/vqgan_arch.py +434 -0
- basicsr/data/__init__.py +100 -0
- basicsr/data/__pycache__/__init__.cpython-310.pyc +0 -0
- basicsr/data/__pycache__/data_sampler.cpython-310.pyc +0 -0
- basicsr/data/__pycache__/data_util.cpython-310.pyc +0 -0
- basicsr/data/__pycache__/ffhq_blind_dataset.cpython-310.pyc +0 -0
- basicsr/data/__pycache__/ffhq_blind_joint_dataset.cpython-310.pyc +0 -0
- basicsr/data/__pycache__/gaussian_kernels.cpython-310.pyc +0 -0
- basicsr/data/__pycache__/paired_image_dataset.cpython-310.pyc +0 -0
- basicsr/data/__pycache__/prefetch_dataloader.cpython-310.pyc +0 -0
- basicsr/data/__pycache__/transforms.cpython-310.pyc +0 -0
- basicsr/data/data_sampler.py +48 -0
- basicsr/data/data_util.py +392 -0
- basicsr/data/ffhq_blind_dataset.py +299 -0
- basicsr/data/ffhq_blind_joint_dataset.py +324 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
results/test_img_0.7/final_results/color_enhancement_result1.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
weights/dlib/shape_predictor_5_face_landmarks-c4b1e980.dat filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.vscode
|
| 2 |
+
|
| 3 |
+
# ignored files
|
| 4 |
+
version.py
|
| 5 |
+
|
| 6 |
+
# ignored files with suffix
|
| 7 |
+
*.html
|
| 8 |
+
# *.png
|
| 9 |
+
# *.jpeg
|
| 10 |
+
# *.jpg
|
| 11 |
+
*.pt
|
| 12 |
+
*.gif
|
| 13 |
+
*.pth
|
| 14 |
+
*.dat
|
| 15 |
+
*.zip
|
| 16 |
+
|
| 17 |
+
# template
|
| 18 |
+
|
| 19 |
+
# Byte-compiled / optimized / DLL files
|
| 20 |
+
__pycache__/
|
| 21 |
+
*.py[cod]
|
| 22 |
+
*$py.class
|
| 23 |
+
|
| 24 |
+
# C extensions
|
| 25 |
+
*.so
|
| 26 |
+
|
| 27 |
+
# Distribution / packaging
|
| 28 |
+
.Python
|
| 29 |
+
build/
|
| 30 |
+
develop-eggs/
|
| 31 |
+
dist/
|
| 32 |
+
downloads/
|
| 33 |
+
eggs/
|
| 34 |
+
.eggs/
|
| 35 |
+
lib/
|
| 36 |
+
lib64/
|
| 37 |
+
parts/
|
| 38 |
+
sdist/
|
| 39 |
+
var/
|
| 40 |
+
wheels/
|
| 41 |
+
*.egg-info/
|
| 42 |
+
.installed.cfg
|
| 43 |
+
*.egg
|
| 44 |
+
MANIFEST
|
| 45 |
+
|
| 46 |
+
# PyInstaller
|
| 47 |
+
# Usually these files are written by a python script from a template
|
| 48 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 49 |
+
*.manifest
|
| 50 |
+
*.spec
|
| 51 |
+
|
| 52 |
+
# Installer logs
|
| 53 |
+
pip-log.txt
|
| 54 |
+
pip-delete-this-directory.txt
|
| 55 |
+
|
| 56 |
+
# Unit test / coverage reports
|
| 57 |
+
htmlcov/
|
| 58 |
+
.tox/
|
| 59 |
+
.coverage
|
| 60 |
+
.coverage.*
|
| 61 |
+
.cache
|
| 62 |
+
nosetests.xml
|
| 63 |
+
coverage.xml
|
| 64 |
+
*.cover
|
| 65 |
+
.hypothesis/
|
| 66 |
+
.pytest_cache/
|
| 67 |
+
|
| 68 |
+
# Translations
|
| 69 |
+
*.mo
|
| 70 |
+
*.pot
|
| 71 |
+
|
| 72 |
+
# Django stuff:
|
| 73 |
+
*.log
|
| 74 |
+
local_settings.py
|
| 75 |
+
db.sqlite3
|
| 76 |
+
|
| 77 |
+
# Flask stuff:
|
| 78 |
+
instance/
|
| 79 |
+
.webassets-cache
|
| 80 |
+
|
| 81 |
+
# Scrapy stuff:
|
| 82 |
+
.scrapy
|
| 83 |
+
|
| 84 |
+
# Sphinx documentation
|
| 85 |
+
docs/_build/
|
| 86 |
+
|
| 87 |
+
# PyBuilder
|
| 88 |
+
target/
|
| 89 |
+
|
| 90 |
+
# Jupyter Notebook
|
| 91 |
+
.ipynb_checkpoints
|
| 92 |
+
|
| 93 |
+
# pyenv
|
| 94 |
+
.python-version
|
| 95 |
+
|
| 96 |
+
# celery beat schedule file
|
| 97 |
+
celerybeat-schedule
|
| 98 |
+
|
| 99 |
+
# SageMath parsed files
|
| 100 |
+
*.sage.py
|
| 101 |
+
|
| 102 |
+
# Environments
|
| 103 |
+
.env
|
| 104 |
+
.venv
|
| 105 |
+
env/
|
| 106 |
+
venv/
|
| 107 |
+
ENV/
|
| 108 |
+
env.bak/
|
| 109 |
+
venv.bak/
|
| 110 |
+
|
| 111 |
+
# Spyder project settings
|
| 112 |
+
.spyderproject
|
| 113 |
+
.spyproject
|
| 114 |
+
|
| 115 |
+
# Rope project settings
|
| 116 |
+
.ropeproject
|
| 117 |
+
|
| 118 |
+
# mkdocs documentation
|
| 119 |
+
/site
|
| 120 |
+
|
| 121 |
+
# mypy
|
| 122 |
+
.mypy_cache/
|
| 123 |
+
|
| 124 |
+
# project
|
| 125 |
+
results/
|
| 126 |
+
experiments/
|
| 127 |
+
tb_logger/
|
| 128 |
+
run.sh
|
| 129 |
+
*debug*
|
| 130 |
+
*_old*
|
| 131 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
S-Lab License 1.0
|
| 2 |
+
|
| 3 |
+
Copyright 2022 S-Lab
|
| 4 |
+
|
| 5 |
+
Redistribution and use for non-commercial purpose in source and
|
| 6 |
+
binary forms, with or without modification, are permitted provided
|
| 7 |
+
that the following conditions are met:
|
| 8 |
+
|
| 9 |
+
1. Redistributions of source code must retain the above copyright
|
| 10 |
+
notice, this list of conditions and the following disclaimer.
|
| 11 |
+
|
| 12 |
+
2. Redistributions in binary form must reproduce the above copyright
|
| 13 |
+
notice, this list of conditions and the following disclaimer in
|
| 14 |
+
the documentation and/or other materials provided with the
|
| 15 |
+
distribution.
|
| 16 |
+
|
| 17 |
+
3. Neither the name of the copyright holder nor the names of its
|
| 18 |
+
contributors may be used to endorse or promote products derived
|
| 19 |
+
from this software without specific prior written permission.
|
| 20 |
+
|
| 21 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
| 22 |
+
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
| 23 |
+
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
| 24 |
+
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
| 25 |
+
HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
| 26 |
+
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
| 27 |
+
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
| 28 |
+
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
| 29 |
+
THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
| 30 |
+
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 31 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 32 |
+
|
| 33 |
+
In the event that redistribution and/or use for commercial purpose in
|
| 34 |
+
source or binary forms, with or without modification is required,
|
| 35 |
+
please contact the contributor(s) of the work.
|
README.md
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="center">
|
| 2 |
+
<img src="assets/CodeFormer_logo.png" height=110>
|
| 3 |
+
</p>
|
| 4 |
+
|
| 5 |
+
## Towards Robust Blind Face Restoration with Codebook Lookup Transformer (NeurIPS 2022)
|
| 6 |
+
|
| 7 |
+
[Paper](https://arxiv.org/abs/2206.11253) | [Project Page](https://shangchenzhou.com/projects/CodeFormer/) | [Video](https://youtu.be/d3VDpkXlueI)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
<a href="https://colab.research.google.com/drive/1m52PNveE4PBhYrecj34cnpEeiHcC5LTb?usp=sharing"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="google colab logo"></a> [](https://huggingface.co/spaces/sczhou/CodeFormer) [](https://replicate.com/sczhou/codeformer) [](https://openxlab.org.cn/apps/detail/ShangchenZhou/CodeFormer) 
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
[Shangchen Zhou](https://shangchenzhou.com/), [Kelvin C.K. Chan](https://ckkelvinchan.github.io/), [Chongyi Li](https://li-chongyi.github.io/), [Chen Change Loy](https://www.mmlab-ntu.com/person/ccloy/)
|
| 14 |
+
|
| 15 |
+
S-Lab, Nanyang Technological University
|
| 16 |
+
|
| 17 |
+
<img src="assets/network.jpg" width="800px"/>
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
:star: If CodeFormer is helpful to your images or projects, please help star this repo. Thanks! :hugs:
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
### Update
|
| 24 |
+
- **2023.07.20**: Integrated to :panda_face: [OpenXLab](https://openxlab.org.cn/apps). Try out online demo! [](https://openxlab.org.cn/apps/detail/ShangchenZhou/CodeFormer)
|
| 25 |
+
- **2023.04.19**: :whale: Training codes and config files are public available now.
|
| 26 |
+
- **2023.04.09**: Add features of inpainting and colorization for cropped and aligned face images.
|
| 27 |
+
- **2023.02.10**: Include `dlib` as a new face detector option, it produces more accurate face identity.
|
| 28 |
+
- **2022.10.05**: Support video input `--input_path [YOUR_VIDEO.mp4]`. Try it to enhance your videos! :clapper:
|
| 29 |
+
- **2022.09.14**: Integrated to :hugs: [Hugging Face](https://huggingface.co/spaces). Try out online demo! [](https://huggingface.co/spaces/sczhou/CodeFormer)
|
| 30 |
+
- **2022.09.09**: Integrated to :rocket: [Replicate](https://replicate.com/explore). Try out online demo! [](https://replicate.com/sczhou/codeformer)
|
| 31 |
+
- [**More**](docs/history_changelog.md)
|
| 32 |
+
|
| 33 |
+
### TODO
|
| 34 |
+
- [x] Add training code and config files
|
| 35 |
+
- [x] Add checkpoint and script for face inpainting
|
| 36 |
+
- [x] Add checkpoint and script for face colorization
|
| 37 |
+
- [x] ~~Add background image enhancement~~
|
| 38 |
+
|
| 39 |
+
#### :panda_face: Try Enhancing Old Photos / Fixing AI-arts
|
| 40 |
+
[<img src="assets/imgsli_1.jpg" height="226px"/>](https://imgsli.com/MTI3NTE2) [<img src="assets/imgsli_2.jpg" height="226px"/>](https://imgsli.com/MTI3NTE1) [<img src="assets/imgsli_3.jpg" height="226px"/>](https://imgsli.com/MTI3NTIw)
|
| 41 |
+
|
| 42 |
+
#### Face Restoration
|
| 43 |
+
|
| 44 |
+
<img src="assets/restoration_result1.png" width="400px"/> <img src="assets/restoration_result2.png" width="400px"/>
|
| 45 |
+
<img src="assets/restoration_result3.png" width="400px"/> <img src="assets/restoration_result4.png" width="400px"/>
|
| 46 |
+
|
| 47 |
+
#### Face Color Enhancement and Restoration
|
| 48 |
+
|
| 49 |
+
<img src="assets/color_enhancement_result1.png" width="400px"/> <img src="assets/color_enhancement_result2.png" width="400px"/>
|
| 50 |
+
|
| 51 |
+
#### Face Inpainting
|
| 52 |
+
|
| 53 |
+
<img src="assets/inpainting_result1.png" width="400px"/> <img src="assets/inpainting_result2.png" width="400px"/>
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
### Dependencies and Installation
|
| 58 |
+
|
| 59 |
+
- Pytorch >= 1.7.1
|
| 60 |
+
- CUDA >= 10.1
|
| 61 |
+
- Other required packages in `requirements.txt`
|
| 62 |
+
```
|
| 63 |
+
# git clone this repository
|
| 64 |
+
git clone https://github.com/sczhou/CodeFormer
|
| 65 |
+
cd CodeFormer
|
| 66 |
+
|
| 67 |
+
# create new anaconda env
|
| 68 |
+
conda create -n codeformer python=3.8 -y
|
| 69 |
+
conda activate codeformer
|
| 70 |
+
|
| 71 |
+
# install python dependencies
|
| 72 |
+
pip3 install -r requirements.txt
|
| 73 |
+
python basicsr/setup.py develop
|
| 74 |
+
conda install -c conda-forge dlib (only for face detection or cropping with dlib)
|
| 75 |
+
```
|
| 76 |
+
<!-- conda install -c conda-forge dlib -->
|
| 77 |
+
|
| 78 |
+
### Quick Inference
|
| 79 |
+
|
| 80 |
+
#### Download Pre-trained Models:
|
| 81 |
+
Download the facelib and dlib pretrained models from [[Releases](https://github.com/sczhou/CodeFormer/releases/tag/v0.1.0) | [Google Drive](https://drive.google.com/drive/folders/1b_3qwrzY_kTQh0-SnBoGBgOrJ_PLZSKm?usp=sharing) | [OneDrive](https://entuedu-my.sharepoint.com/:f:/g/personal/s200094_e_ntu_edu_sg/EvDxR7FcAbZMp_MA9ouq7aQB8XTppMb3-T0uGZ_2anI2mg?e=DXsJFo)] to the `weights/facelib` folder. You can manually download the pretrained models OR download by running the following command:
|
| 82 |
+
```
|
| 83 |
+
python scripts/download_pretrained_models.py facelib
|
| 84 |
+
python scripts/download_pretrained_models.py dlib (only for dlib face detector)
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
Download the CodeFormer pretrained models from [[Releases](https://github.com/sczhou/CodeFormer/releases/tag/v0.1.0) | [Google Drive](https://drive.google.com/drive/folders/1CNNByjHDFt0b95q54yMVp6Ifo5iuU6QS?usp=sharing) | [OneDrive](https://entuedu-my.sharepoint.com/:f:/g/personal/s200094_e_ntu_edu_sg/EoKFj4wo8cdIn2-TY2IV6CYBhZ0pIG4kUOeHdPR_A5nlbg?e=AO8UN9)] to the `weights/CodeFormer` folder. You can manually download the pretrained models OR download by running the following command:
|
| 88 |
+
```
|
| 89 |
+
python scripts/download_pretrained_models.py CodeFormer
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
#### Prepare Testing Data:
|
| 93 |
+
You can put the testing images in the `inputs/TestWhole` folder. If you would like to test on cropped and aligned faces, you can put them in the `inputs/cropped_faces` folder. You can get the cropped and aligned faces by running the following command:
|
| 94 |
+
```
|
| 95 |
+
# you may need to install dlib via: conda install -c conda-forge dlib
|
| 96 |
+
python scripts/crop_align_face.py -i [input folder] -o [output folder]
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
#### Testing:
|
| 101 |
+
[Note] If you want to compare CodeFormer in your paper, please run the following command indicating `--has_aligned` (for cropped and aligned face), as the command for the whole image will involve a process of face-background fusion that may damage hair texture on the boundary, which leads to unfair comparison.
|
| 102 |
+
|
| 103 |
+
Fidelity weight *w* lays in [0, 1]. Generally, smaller *w* tends to produce a higher-quality result, while larger *w* yields a higher-fidelity result. The results will be saved in the `results` folder.
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
🧑🏻 Face Restoration (cropped and aligned face)
|
| 107 |
+
```
|
| 108 |
+
# For cropped and aligned faces (512x512)
|
| 109 |
+
python inference_codeformer.py -w 0.5 --has_aligned --input_path [image folder]|[image path]
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
:framed_picture: Whole Image Enhancement
|
| 113 |
+
```
|
| 114 |
+
# For whole image
|
| 115 |
+
# Add '--bg_upsampler realesrgan' to enhance the background regions with Real-ESRGAN
|
| 116 |
+
# Add '--face_upsample' to further upsample restorated face with Real-ESRGAN
|
| 117 |
+
python inference_codeformer.py -w 0.7 --input_path [image folder]|[image path]
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
:clapper: Video Enhancement
|
| 121 |
+
```
|
| 122 |
+
# For Windows/Mac users, please install ffmpeg first
|
| 123 |
+
conda install -c conda-forge ffmpeg
|
| 124 |
+
```
|
| 125 |
+
```
|
| 126 |
+
# For video clips
|
| 127 |
+
# Video path should end with '.mp4'|'.mov'|'.avi'
|
| 128 |
+
python inference_codeformer.py --bg_upsampler realesrgan --face_upsample -w 1.0 --input_path [video path]
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
🌈 Face Colorization (cropped and aligned face)
|
| 132 |
+
```
|
| 133 |
+
# For cropped and aligned faces (512x512)
|
| 134 |
+
# Colorize black and white or faded photo
|
| 135 |
+
python inference_colorization.py --input_path [image folder]|[image path]
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
🎨 Face Inpainting (cropped and aligned face)
|
| 139 |
+
```
|
| 140 |
+
# For cropped and aligned faces (512x512)
|
| 141 |
+
# Inputs could be masked by white brush using an image editing app (e.g., Photoshop)
|
| 142 |
+
# (check out the examples in inputs/masked_faces)
|
| 143 |
+
python inference_inpainting.py --input_path [image folder]|[image path]
|
| 144 |
+
```
|
| 145 |
+
### Training:
|
| 146 |
+
The training commands can be found in the documents: [English](docs/train.md) **|** [简体中文](docs/train_CN.md).
|
| 147 |
+
|
| 148 |
+
### Citation
|
| 149 |
+
If our work is useful for your research, please consider citing:
|
| 150 |
+
|
| 151 |
+
@inproceedings{zhou2022codeformer,
|
| 152 |
+
author = {Zhou, Shangchen and Chan, Kelvin C.K. and Li, Chongyi and Loy, Chen Change},
|
| 153 |
+
title = {Towards Robust Blind Face Restoration with Codebook Lookup TransFormer},
|
| 154 |
+
booktitle = {NeurIPS},
|
| 155 |
+
year = {2022}
|
| 156 |
+
}
|
| 157 |
+
|
| 158 |
+
### License
|
| 159 |
+
|
| 160 |
+
This project is licensed under <a rel="license" href="https://github.com/sczhou/CodeFormer/blob/master/LICENSE">NTU S-Lab License 1.0</a>. Redistribution and use should follow this license.
|
| 161 |
+
|
| 162 |
+
### Acknowledgement
|
| 163 |
+
|
| 164 |
+
This project is based on [BasicSR](https://github.com/XPixelGroup/BasicSR). Some codes are brought from [Unleashing Transformers](https://github.com/samb-t/unleashing-transformers), [YOLOv5-face](https://github.com/deepcam-cn/yolov5-face), and [FaceXLib](https://github.com/xinntao/facexlib). We also adopt [Real-ESRGAN](https://github.com/xinntao/Real-ESRGAN) to support background image enhancement. Thanks for their awesome works.
|
| 165 |
+
|
| 166 |
+
### Contact
|
| 167 |
+
If you have any questions, please feel free to reach me out at `shangchenzhou@gmail.com`.
|
assets/CodeFormer_logo.png
ADDED
|
|
assets/color_enhancement_result1.png
ADDED

|
assets/color_enhancement_result2.png
ADDED

|
assets/imgsli_1.jpg
ADDED

|
assets/imgsli_2.jpg
ADDED

|
assets/imgsli_3.jpg
ADDED

|
assets/inpainting_result1.png
ADDED

|
assets/inpainting_result2.png
ADDED

|
assets/network.jpg
ADDED
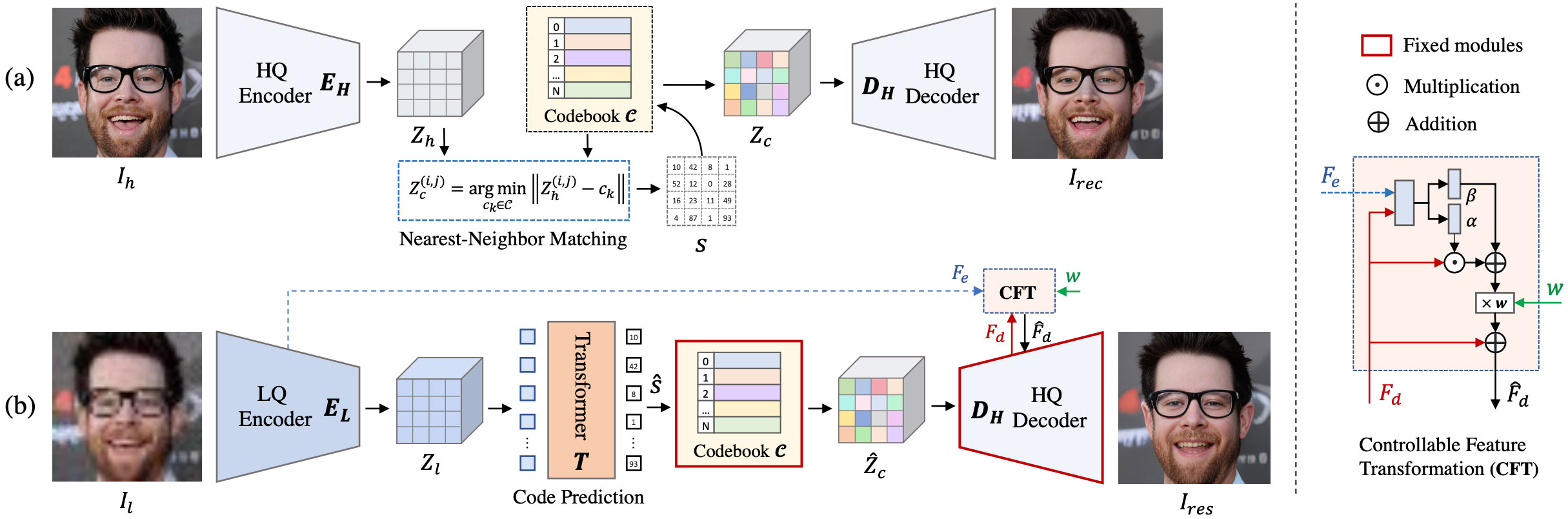
|
assets/restoration_result1.png
ADDED

|
assets/restoration_result2.png
ADDED

|
assets/restoration_result3.png
ADDED

|
assets/restoration_result4.png
ADDED

|
basicsr/VERSION
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
1.3.2
|
basicsr/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# https://github.com/xinntao/BasicSR
|
| 2 |
+
# flake8: noqa
|
| 3 |
+
from .archs import *
|
| 4 |
+
from .data import *
|
| 5 |
+
from .losses import *
|
| 6 |
+
from .metrics import *
|
| 7 |
+
from .models import *
|
| 8 |
+
from .ops import *
|
| 9 |
+
from .train import *
|
| 10 |
+
from .utils import *
|
| 11 |
+
from .version import __gitsha__, __version__
|
basicsr/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (345 Bytes). View file
|
|
|
basicsr/__pycache__/train.cpython-310.pyc
ADDED
|
Binary file (6.31 kB). View file
|
|
|
basicsr/__pycache__/version.cpython-310.pyc
ADDED
|
Binary file (223 Bytes). View file
|
|
|
basicsr/archs/__init__.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import importlib
|
| 2 |
+
from copy import deepcopy
|
| 3 |
+
from os import path as osp
|
| 4 |
+
|
| 5 |
+
from basicsr.utils import get_root_logger, scandir
|
| 6 |
+
from basicsr.utils.registry import ARCH_REGISTRY
|
| 7 |
+
|
| 8 |
+
__all__ = ['build_network']
|
| 9 |
+
|
| 10 |
+
# automatically scan and import arch modules for registry
|
| 11 |
+
# scan all the files under the 'archs' folder and collect files ending with
|
| 12 |
+
# '_arch.py'
|
| 13 |
+
arch_folder = osp.dirname(osp.abspath(__file__))
|
| 14 |
+
arch_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(arch_folder) if v.endswith('_arch.py')]
|
| 15 |
+
# import all the arch modules
|
| 16 |
+
_arch_modules = [importlib.import_module(f'basicsr.archs.{file_name}') for file_name in arch_filenames]
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def build_network(opt):
|
| 20 |
+
opt = deepcopy(opt)
|
| 21 |
+
network_type = opt.pop('type')
|
| 22 |
+
net = ARCH_REGISTRY.get(network_type)(**opt)
|
| 23 |
+
logger = get_root_logger()
|
| 24 |
+
logger.info(f'Network [{net.__class__.__name__}] is created.')
|
| 25 |
+
return net
|
basicsr/archs/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (1.14 kB). View file
|
|
|
basicsr/archs/__pycache__/arcface_arch.cpython-310.pyc
ADDED
|
Binary file (7.35 kB). View file
|
|
|
basicsr/archs/__pycache__/arch_util.cpython-310.pyc
ADDED
|
Binary file (10.8 kB). View file
|
|
|
basicsr/archs/__pycache__/codeformer_arch.cpython-310.pyc
ADDED
|
Binary file (9.3 kB). View file
|
|
|
basicsr/archs/__pycache__/rrdbnet_arch.cpython-310.pyc
ADDED
|
Binary file (4.43 kB). View file
|
|
|
basicsr/archs/__pycache__/vgg_arch.cpython-310.pyc
ADDED
|
Binary file (4.83 kB). View file
|
|
|
basicsr/archs/__pycache__/vqgan_arch.cpython-310.pyc
ADDED
|
Binary file (11.1 kB). View file
|
|
|
basicsr/archs/arcface_arch.py
ADDED
|
@@ -0,0 +1,245 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
from basicsr.utils.registry import ARCH_REGISTRY
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def conv3x3(inplanes, outplanes, stride=1):
|
| 6 |
+
"""A simple wrapper for 3x3 convolution with padding.
|
| 7 |
+
|
| 8 |
+
Args:
|
| 9 |
+
inplanes (int): Channel number of inputs.
|
| 10 |
+
outplanes (int): Channel number of outputs.
|
| 11 |
+
stride (int): Stride in convolution. Default: 1.
|
| 12 |
+
"""
|
| 13 |
+
return nn.Conv2d(inplanes, outplanes, kernel_size=3, stride=stride, padding=1, bias=False)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class BasicBlock(nn.Module):
|
| 17 |
+
"""Basic residual block used in the ResNetArcFace architecture.
|
| 18 |
+
|
| 19 |
+
Args:
|
| 20 |
+
inplanes (int): Channel number of inputs.
|
| 21 |
+
planes (int): Channel number of outputs.
|
| 22 |
+
stride (int): Stride in convolution. Default: 1.
|
| 23 |
+
downsample (nn.Module): The downsample module. Default: None.
|
| 24 |
+
"""
|
| 25 |
+
expansion = 1 # output channel expansion ratio
|
| 26 |
+
|
| 27 |
+
def __init__(self, inplanes, planes, stride=1, downsample=None):
|
| 28 |
+
super(BasicBlock, self).__init__()
|
| 29 |
+
self.conv1 = conv3x3(inplanes, planes, stride)
|
| 30 |
+
self.bn1 = nn.BatchNorm2d(planes)
|
| 31 |
+
self.relu = nn.ReLU(inplace=True)
|
| 32 |
+
self.conv2 = conv3x3(planes, planes)
|
| 33 |
+
self.bn2 = nn.BatchNorm2d(planes)
|
| 34 |
+
self.downsample = downsample
|
| 35 |
+
self.stride = stride
|
| 36 |
+
|
| 37 |
+
def forward(self, x):
|
| 38 |
+
residual = x
|
| 39 |
+
|
| 40 |
+
out = self.conv1(x)
|
| 41 |
+
out = self.bn1(out)
|
| 42 |
+
out = self.relu(out)
|
| 43 |
+
|
| 44 |
+
out = self.conv2(out)
|
| 45 |
+
out = self.bn2(out)
|
| 46 |
+
|
| 47 |
+
if self.downsample is not None:
|
| 48 |
+
residual = self.downsample(x)
|
| 49 |
+
|
| 50 |
+
out += residual
|
| 51 |
+
out = self.relu(out)
|
| 52 |
+
|
| 53 |
+
return out
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class IRBlock(nn.Module):
|
| 57 |
+
"""Improved residual block (IR Block) used in the ResNetArcFace architecture.
|
| 58 |
+
|
| 59 |
+
Args:
|
| 60 |
+
inplanes (int): Channel number of inputs.
|
| 61 |
+
planes (int): Channel number of outputs.
|
| 62 |
+
stride (int): Stride in convolution. Default: 1.
|
| 63 |
+
downsample (nn.Module): The downsample module. Default: None.
|
| 64 |
+
use_se (bool): Whether use the SEBlock (squeeze and excitation block). Default: True.
|
| 65 |
+
"""
|
| 66 |
+
expansion = 1 # output channel expansion ratio
|
| 67 |
+
|
| 68 |
+
def __init__(self, inplanes, planes, stride=1, downsample=None, use_se=True):
|
| 69 |
+
super(IRBlock, self).__init__()
|
| 70 |
+
self.bn0 = nn.BatchNorm2d(inplanes)
|
| 71 |
+
self.conv1 = conv3x3(inplanes, inplanes)
|
| 72 |
+
self.bn1 = nn.BatchNorm2d(inplanes)
|
| 73 |
+
self.prelu = nn.PReLU()
|
| 74 |
+
self.conv2 = conv3x3(inplanes, planes, stride)
|
| 75 |
+
self.bn2 = nn.BatchNorm2d(planes)
|
| 76 |
+
self.downsample = downsample
|
| 77 |
+
self.stride = stride
|
| 78 |
+
self.use_se = use_se
|
| 79 |
+
if self.use_se:
|
| 80 |
+
self.se = SEBlock(planes)
|
| 81 |
+
|
| 82 |
+
def forward(self, x):
|
| 83 |
+
residual = x
|
| 84 |
+
out = self.bn0(x)
|
| 85 |
+
out = self.conv1(out)
|
| 86 |
+
out = self.bn1(out)
|
| 87 |
+
out = self.prelu(out)
|
| 88 |
+
|
| 89 |
+
out = self.conv2(out)
|
| 90 |
+
out = self.bn2(out)
|
| 91 |
+
if self.use_se:
|
| 92 |
+
out = self.se(out)
|
| 93 |
+
|
| 94 |
+
if self.downsample is not None:
|
| 95 |
+
residual = self.downsample(x)
|
| 96 |
+
|
| 97 |
+
out += residual
|
| 98 |
+
out = self.prelu(out)
|
| 99 |
+
|
| 100 |
+
return out
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
class Bottleneck(nn.Module):
|
| 104 |
+
"""Bottleneck block used in the ResNetArcFace architecture.
|
| 105 |
+
|
| 106 |
+
Args:
|
| 107 |
+
inplanes (int): Channel number of inputs.
|
| 108 |
+
planes (int): Channel number of outputs.
|
| 109 |
+
stride (int): Stride in convolution. Default: 1.
|
| 110 |
+
downsample (nn.Module): The downsample module. Default: None.
|
| 111 |
+
"""
|
| 112 |
+
expansion = 4 # output channel expansion ratio
|
| 113 |
+
|
| 114 |
+
def __init__(self, inplanes, planes, stride=1, downsample=None):
|
| 115 |
+
super(Bottleneck, self).__init__()
|
| 116 |
+
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
|
| 117 |
+
self.bn1 = nn.BatchNorm2d(planes)
|
| 118 |
+
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
|
| 119 |
+
self.bn2 = nn.BatchNorm2d(planes)
|
| 120 |
+
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
|
| 121 |
+
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
|
| 122 |
+
self.relu = nn.ReLU(inplace=True)
|
| 123 |
+
self.downsample = downsample
|
| 124 |
+
self.stride = stride
|
| 125 |
+
|
| 126 |
+
def forward(self, x):
|
| 127 |
+
residual = x
|
| 128 |
+
|
| 129 |
+
out = self.conv1(x)
|
| 130 |
+
out = self.bn1(out)
|
| 131 |
+
out = self.relu(out)
|
| 132 |
+
|
| 133 |
+
out = self.conv2(out)
|
| 134 |
+
out = self.bn2(out)
|
| 135 |
+
out = self.relu(out)
|
| 136 |
+
|
| 137 |
+
out = self.conv3(out)
|
| 138 |
+
out = self.bn3(out)
|
| 139 |
+
|
| 140 |
+
if self.downsample is not None:
|
| 141 |
+
residual = self.downsample(x)
|
| 142 |
+
|
| 143 |
+
out += residual
|
| 144 |
+
out = self.relu(out)
|
| 145 |
+
|
| 146 |
+
return out
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
class SEBlock(nn.Module):
|
| 150 |
+
"""The squeeze-and-excitation block (SEBlock) used in the IRBlock.
|
| 151 |
+
|
| 152 |
+
Args:
|
| 153 |
+
channel (int): Channel number of inputs.
|
| 154 |
+
reduction (int): Channel reduction ration. Default: 16.
|
| 155 |
+
"""
|
| 156 |
+
|
| 157 |
+
def __init__(self, channel, reduction=16):
|
| 158 |
+
super(SEBlock, self).__init__()
|
| 159 |
+
self.avg_pool = nn.AdaptiveAvgPool2d(1) # pool to 1x1 without spatial information
|
| 160 |
+
self.fc = nn.Sequential(
|
| 161 |
+
nn.Linear(channel, channel // reduction), nn.PReLU(), nn.Linear(channel // reduction, channel),
|
| 162 |
+
nn.Sigmoid())
|
| 163 |
+
|
| 164 |
+
def forward(self, x):
|
| 165 |
+
b, c, _, _ = x.size()
|
| 166 |
+
y = self.avg_pool(x).view(b, c)
|
| 167 |
+
y = self.fc(y).view(b, c, 1, 1)
|
| 168 |
+
return x * y
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
@ARCH_REGISTRY.register()
|
| 172 |
+
class ResNetArcFace(nn.Module):
|
| 173 |
+
"""ArcFace with ResNet architectures.
|
| 174 |
+
|
| 175 |
+
Ref: ArcFace: Additive Angular Margin Loss for Deep Face Recognition.
|
| 176 |
+
|
| 177 |
+
Args:
|
| 178 |
+
block (str): Block used in the ArcFace architecture.
|
| 179 |
+
layers (tuple(int)): Block numbers in each layer.
|
| 180 |
+
use_se (bool): Whether use the SEBlock (squeeze and excitation block). Default: True.
|
| 181 |
+
"""
|
| 182 |
+
|
| 183 |
+
def __init__(self, block, layers, use_se=True):
|
| 184 |
+
if block == 'IRBlock':
|
| 185 |
+
block = IRBlock
|
| 186 |
+
self.inplanes = 64
|
| 187 |
+
self.use_se = use_se
|
| 188 |
+
super(ResNetArcFace, self).__init__()
|
| 189 |
+
|
| 190 |
+
self.conv1 = nn.Conv2d(1, 64, kernel_size=3, padding=1, bias=False)
|
| 191 |
+
self.bn1 = nn.BatchNorm2d(64)
|
| 192 |
+
self.prelu = nn.PReLU()
|
| 193 |
+
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
|
| 194 |
+
self.layer1 = self._make_layer(block, 64, layers[0])
|
| 195 |
+
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
|
| 196 |
+
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
|
| 197 |
+
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
|
| 198 |
+
self.bn4 = nn.BatchNorm2d(512)
|
| 199 |
+
self.dropout = nn.Dropout()
|
| 200 |
+
self.fc5 = nn.Linear(512 * 8 * 8, 512)
|
| 201 |
+
self.bn5 = nn.BatchNorm1d(512)
|
| 202 |
+
|
| 203 |
+
# initialization
|
| 204 |
+
for m in self.modules():
|
| 205 |
+
if isinstance(m, nn.Conv2d):
|
| 206 |
+
nn.init.xavier_normal_(m.weight)
|
| 207 |
+
elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.BatchNorm1d):
|
| 208 |
+
nn.init.constant_(m.weight, 1)
|
| 209 |
+
nn.init.constant_(m.bias, 0)
|
| 210 |
+
elif isinstance(m, nn.Linear):
|
| 211 |
+
nn.init.xavier_normal_(m.weight)
|
| 212 |
+
nn.init.constant_(m.bias, 0)
|
| 213 |
+
|
| 214 |
+
def _make_layer(self, block, planes, num_blocks, stride=1):
|
| 215 |
+
downsample = None
|
| 216 |
+
if stride != 1 or self.inplanes != planes * block.expansion:
|
| 217 |
+
downsample = nn.Sequential(
|
| 218 |
+
nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False),
|
| 219 |
+
nn.BatchNorm2d(planes * block.expansion),
|
| 220 |
+
)
|
| 221 |
+
layers = []
|
| 222 |
+
layers.append(block(self.inplanes, planes, stride, downsample, use_se=self.use_se))
|
| 223 |
+
self.inplanes = planes
|
| 224 |
+
for _ in range(1, num_blocks):
|
| 225 |
+
layers.append(block(self.inplanes, planes, use_se=self.use_se))
|
| 226 |
+
|
| 227 |
+
return nn.Sequential(*layers)
|
| 228 |
+
|
| 229 |
+
def forward(self, x):
|
| 230 |
+
x = self.conv1(x)
|
| 231 |
+
x = self.bn1(x)
|
| 232 |
+
x = self.prelu(x)
|
| 233 |
+
x = self.maxpool(x)
|
| 234 |
+
|
| 235 |
+
x = self.layer1(x)
|
| 236 |
+
x = self.layer2(x)
|
| 237 |
+
x = self.layer3(x)
|
| 238 |
+
x = self.layer4(x)
|
| 239 |
+
x = self.bn4(x)
|
| 240 |
+
x = self.dropout(x)
|
| 241 |
+
x = x.view(x.size(0), -1)
|
| 242 |
+
x = self.fc5(x)
|
| 243 |
+
x = self.bn5(x)
|
| 244 |
+
|
| 245 |
+
return x
|
basicsr/archs/arch_util.py
ADDED
|
@@ -0,0 +1,318 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import collections.abc
|
| 2 |
+
import math
|
| 3 |
+
import torch
|
| 4 |
+
import torchvision
|
| 5 |
+
import warnings
|
| 6 |
+
from distutils.version import LooseVersion
|
| 7 |
+
from itertools import repeat
|
| 8 |
+
from torch import nn as nn
|
| 9 |
+
from torch.nn import functional as F
|
| 10 |
+
from torch.nn import init as init
|
| 11 |
+
from torch.nn.modules.batchnorm import _BatchNorm
|
| 12 |
+
|
| 13 |
+
from basicsr.ops.dcn import ModulatedDeformConvPack, modulated_deform_conv
|
| 14 |
+
from basicsr.utils import get_root_logger
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
@torch.no_grad()
|
| 18 |
+
def default_init_weights(module_list, scale=1, bias_fill=0, **kwargs):
|
| 19 |
+
"""Initialize network weights.
|
| 20 |
+
|
| 21 |
+
Args:
|
| 22 |
+
module_list (list[nn.Module] | nn.Module): Modules to be initialized.
|
| 23 |
+
scale (float): Scale initialized weights, especially for residual
|
| 24 |
+
blocks. Default: 1.
|
| 25 |
+
bias_fill (float): The value to fill bias. Default: 0
|
| 26 |
+
kwargs (dict): Other arguments for initialization function.
|
| 27 |
+
"""
|
| 28 |
+
if not isinstance(module_list, list):
|
| 29 |
+
module_list = [module_list]
|
| 30 |
+
for module in module_list:
|
| 31 |
+
for m in module.modules():
|
| 32 |
+
if isinstance(m, nn.Conv2d):
|
| 33 |
+
init.kaiming_normal_(m.weight, **kwargs)
|
| 34 |
+
m.weight.data *= scale
|
| 35 |
+
if m.bias is not None:
|
| 36 |
+
m.bias.data.fill_(bias_fill)
|
| 37 |
+
elif isinstance(m, nn.Linear):
|
| 38 |
+
init.kaiming_normal_(m.weight, **kwargs)
|
| 39 |
+
m.weight.data *= scale
|
| 40 |
+
if m.bias is not None:
|
| 41 |
+
m.bias.data.fill_(bias_fill)
|
| 42 |
+
elif isinstance(m, _BatchNorm):
|
| 43 |
+
init.constant_(m.weight, 1)
|
| 44 |
+
if m.bias is not None:
|
| 45 |
+
m.bias.data.fill_(bias_fill)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def make_layer(basic_block, num_basic_block, **kwarg):
|
| 49 |
+
"""Make layers by stacking the same blocks.
|
| 50 |
+
|
| 51 |
+
Args:
|
| 52 |
+
basic_block (nn.module): nn.module class for basic block.
|
| 53 |
+
num_basic_block (int): number of blocks.
|
| 54 |
+
|
| 55 |
+
Returns:
|
| 56 |
+
nn.Sequential: Stacked blocks in nn.Sequential.
|
| 57 |
+
"""
|
| 58 |
+
layers = []
|
| 59 |
+
for _ in range(num_basic_block):
|
| 60 |
+
layers.append(basic_block(**kwarg))
|
| 61 |
+
return nn.Sequential(*layers)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class ResidualBlockNoBN(nn.Module):
|
| 65 |
+
"""Residual block without BN.
|
| 66 |
+
|
| 67 |
+
It has a style of:
|
| 68 |
+
---Conv-ReLU-Conv-+-
|
| 69 |
+
|________________|
|
| 70 |
+
|
| 71 |
+
Args:
|
| 72 |
+
num_feat (int): Channel number of intermediate features.
|
| 73 |
+
Default: 64.
|
| 74 |
+
res_scale (float): Residual scale. Default: 1.
|
| 75 |
+
pytorch_init (bool): If set to True, use pytorch default init,
|
| 76 |
+
otherwise, use default_init_weights. Default: False.
|
| 77 |
+
"""
|
| 78 |
+
|
| 79 |
+
def __init__(self, num_feat=64, res_scale=1, pytorch_init=False):
|
| 80 |
+
super(ResidualBlockNoBN, self).__init__()
|
| 81 |
+
self.res_scale = res_scale
|
| 82 |
+
self.conv1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=True)
|
| 83 |
+
self.conv2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=True)
|
| 84 |
+
self.relu = nn.ReLU(inplace=True)
|
| 85 |
+
|
| 86 |
+
if not pytorch_init:
|
| 87 |
+
default_init_weights([self.conv1, self.conv2], 0.1)
|
| 88 |
+
|
| 89 |
+
def forward(self, x):
|
| 90 |
+
identity = x
|
| 91 |
+
out = self.conv2(self.relu(self.conv1(x)))
|
| 92 |
+
return identity + out * self.res_scale
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
class Upsample(nn.Sequential):
|
| 96 |
+
"""Upsample module.
|
| 97 |
+
|
| 98 |
+
Args:
|
| 99 |
+
scale (int): Scale factor. Supported scales: 2^n and 3.
|
| 100 |
+
num_feat (int): Channel number of intermediate features.
|
| 101 |
+
"""
|
| 102 |
+
|
| 103 |
+
def __init__(self, scale, num_feat):
|
| 104 |
+
m = []
|
| 105 |
+
if (scale & (scale - 1)) == 0: # scale = 2^n
|
| 106 |
+
for _ in range(int(math.log(scale, 2))):
|
| 107 |
+
m.append(nn.Conv2d(num_feat, 4 * num_feat, 3, 1, 1))
|
| 108 |
+
m.append(nn.PixelShuffle(2))
|
| 109 |
+
elif scale == 3:
|
| 110 |
+
m.append(nn.Conv2d(num_feat, 9 * num_feat, 3, 1, 1))
|
| 111 |
+
m.append(nn.PixelShuffle(3))
|
| 112 |
+
else:
|
| 113 |
+
raise ValueError(f'scale {scale} is not supported. Supported scales: 2^n and 3.')
|
| 114 |
+
super(Upsample, self).__init__(*m)
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def flow_warp(x, flow, interp_mode='bilinear', padding_mode='zeros', align_corners=True):
|
| 118 |
+
"""Warp an image or feature map with optical flow.
|
| 119 |
+
|
| 120 |
+
Args:
|
| 121 |
+
x (Tensor): Tensor with size (n, c, h, w).
|
| 122 |
+
flow (Tensor): Tensor with size (n, h, w, 2), normal value.
|
| 123 |
+
interp_mode (str): 'nearest' or 'bilinear'. Default: 'bilinear'.
|
| 124 |
+
padding_mode (str): 'zeros' or 'border' or 'reflection'.
|
| 125 |
+
Default: 'zeros'.
|
| 126 |
+
align_corners (bool): Before pytorch 1.3, the default value is
|
| 127 |
+
align_corners=True. After pytorch 1.3, the default value is
|
| 128 |
+
align_corners=False. Here, we use the True as default.
|
| 129 |
+
|
| 130 |
+
Returns:
|
| 131 |
+
Tensor: Warped image or feature map.
|
| 132 |
+
"""
|
| 133 |
+
assert x.size()[-2:] == flow.size()[1:3]
|
| 134 |
+
_, _, h, w = x.size()
|
| 135 |
+
# create mesh grid
|
| 136 |
+
grid_y, grid_x = torch.meshgrid(torch.arange(0, h).type_as(x), torch.arange(0, w).type_as(x))
|
| 137 |
+
grid = torch.stack((grid_x, grid_y), 2).float() # W(x), H(y), 2
|
| 138 |
+
grid.requires_grad = False
|
| 139 |
+
|
| 140 |
+
vgrid = grid + flow
|
| 141 |
+
# scale grid to [-1,1]
|
| 142 |
+
vgrid_x = 2.0 * vgrid[:, :, :, 0] / max(w - 1, 1) - 1.0
|
| 143 |
+
vgrid_y = 2.0 * vgrid[:, :, :, 1] / max(h - 1, 1) - 1.0
|
| 144 |
+
vgrid_scaled = torch.stack((vgrid_x, vgrid_y), dim=3)
|
| 145 |
+
output = F.grid_sample(x, vgrid_scaled, mode=interp_mode, padding_mode=padding_mode, align_corners=align_corners)
|
| 146 |
+
|
| 147 |
+
# TODO, what if align_corners=False
|
| 148 |
+
return output
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def resize_flow(flow, size_type, sizes, interp_mode='bilinear', align_corners=False):
|
| 152 |
+
"""Resize a flow according to ratio or shape.
|
| 153 |
+
|
| 154 |
+
Args:
|
| 155 |
+
flow (Tensor): Precomputed flow. shape [N, 2, H, W].
|
| 156 |
+
size_type (str): 'ratio' or 'shape'.
|
| 157 |
+
sizes (list[int | float]): the ratio for resizing or the final output
|
| 158 |
+
shape.
|
| 159 |
+
1) The order of ratio should be [ratio_h, ratio_w]. For
|
| 160 |
+
downsampling, the ratio should be smaller than 1.0 (i.e., ratio
|
| 161 |
+
< 1.0). For upsampling, the ratio should be larger than 1.0 (i.e.,
|
| 162 |
+
ratio > 1.0).
|
| 163 |
+
2) The order of output_size should be [out_h, out_w].
|
| 164 |
+
interp_mode (str): The mode of interpolation for resizing.
|
| 165 |
+
Default: 'bilinear'.
|
| 166 |
+
align_corners (bool): Whether align corners. Default: False.
|
| 167 |
+
|
| 168 |
+
Returns:
|
| 169 |
+
Tensor: Resized flow.
|
| 170 |
+
"""
|
| 171 |
+
_, _, flow_h, flow_w = flow.size()
|
| 172 |
+
if size_type == 'ratio':
|
| 173 |
+
output_h, output_w = int(flow_h * sizes[0]), int(flow_w * sizes[1])
|
| 174 |
+
elif size_type == 'shape':
|
| 175 |
+
output_h, output_w = sizes[0], sizes[1]
|
| 176 |
+
else:
|
| 177 |
+
raise ValueError(f'Size type should be ratio or shape, but got type {size_type}.')
|
| 178 |
+
|
| 179 |
+
input_flow = flow.clone()
|
| 180 |
+
ratio_h = output_h / flow_h
|
| 181 |
+
ratio_w = output_w / flow_w
|
| 182 |
+
input_flow[:, 0, :, :] *= ratio_w
|
| 183 |
+
input_flow[:, 1, :, :] *= ratio_h
|
| 184 |
+
resized_flow = F.interpolate(
|
| 185 |
+
input=input_flow, size=(output_h, output_w), mode=interp_mode, align_corners=align_corners)
|
| 186 |
+
return resized_flow
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
# TODO: may write a cpp file
|
| 190 |
+
def pixel_unshuffle(x, scale):
|
| 191 |
+
""" Pixel unshuffle.
|
| 192 |
+
|
| 193 |
+
Args:
|
| 194 |
+
x (Tensor): Input feature with shape (b, c, hh, hw).
|
| 195 |
+
scale (int): Downsample ratio.
|
| 196 |
+
|
| 197 |
+
Returns:
|
| 198 |
+
Tensor: the pixel unshuffled feature.
|
| 199 |
+
"""
|
| 200 |
+
b, c, hh, hw = x.size()
|
| 201 |
+
out_channel = c * (scale**2)
|
| 202 |
+
assert hh % scale == 0 and hw % scale == 0
|
| 203 |
+
h = hh // scale
|
| 204 |
+
w = hw // scale
|
| 205 |
+
x_view = x.view(b, c, h, scale, w, scale)
|
| 206 |
+
return x_view.permute(0, 1, 3, 5, 2, 4).reshape(b, out_channel, h, w)
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
class DCNv2Pack(ModulatedDeformConvPack):
|
| 210 |
+
"""Modulated deformable conv for deformable alignment.
|
| 211 |
+
|
| 212 |
+
Different from the official DCNv2Pack, which generates offsets and masks
|
| 213 |
+
from the preceding features, this DCNv2Pack takes another different
|
| 214 |
+
features to generate offsets and masks.
|
| 215 |
+
|
| 216 |
+
Ref:
|
| 217 |
+
Delving Deep into Deformable Alignment in Video Super-Resolution.
|
| 218 |
+
"""
|
| 219 |
+
|
| 220 |
+
def forward(self, x, feat):
|
| 221 |
+
out = self.conv_offset(feat)
|
| 222 |
+
o1, o2, mask = torch.chunk(out, 3, dim=1)
|
| 223 |
+
offset = torch.cat((o1, o2), dim=1)
|
| 224 |
+
mask = torch.sigmoid(mask)
|
| 225 |
+
|
| 226 |
+
offset_absmean = torch.mean(torch.abs(offset))
|
| 227 |
+
if offset_absmean > 50:
|
| 228 |
+
logger = get_root_logger()
|
| 229 |
+
logger.warning(f'Offset abs mean is {offset_absmean}, larger than 50.')
|
| 230 |
+
|
| 231 |
+
if LooseVersion(torchvision.__version__) >= LooseVersion('0.9.0'):
|
| 232 |
+
return torchvision.ops.deform_conv2d(x, offset, self.weight, self.bias, self.stride, self.padding,
|
| 233 |
+
self.dilation, mask)
|
| 234 |
+
else:
|
| 235 |
+
return modulated_deform_conv(x, offset, mask, self.weight, self.bias, self.stride, self.padding,
|
| 236 |
+
self.dilation, self.groups, self.deformable_groups)
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
def _no_grad_trunc_normal_(tensor, mean, std, a, b):
|
| 240 |
+
# From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/weight_init.py
|
| 241 |
+
# Cut & paste from PyTorch official master until it's in a few official releases - RW
|
| 242 |
+
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
|
| 243 |
+
def norm_cdf(x):
|
| 244 |
+
# Computes standard normal cumulative distribution function
|
| 245 |
+
return (1. + math.erf(x / math.sqrt(2.))) / 2.
|
| 246 |
+
|
| 247 |
+
if (mean < a - 2 * std) or (mean > b + 2 * std):
|
| 248 |
+
warnings.warn(
|
| 249 |
+
'mean is more than 2 std from [a, b] in nn.init.trunc_normal_. '
|
| 250 |
+
'The distribution of values may be incorrect.',
|
| 251 |
+
stacklevel=2)
|
| 252 |
+
|
| 253 |
+
with torch.no_grad():
|
| 254 |
+
# Values are generated by using a truncated uniform distribution and
|
| 255 |
+
# then using the inverse CDF for the normal distribution.
|
| 256 |
+
# Get upper and lower cdf values
|
| 257 |
+
low = norm_cdf((a - mean) / std)
|
| 258 |
+
up = norm_cdf((b - mean) / std)
|
| 259 |
+
|
| 260 |
+
# Uniformly fill tensor with values from [low, up], then translate to
|
| 261 |
+
# [2l-1, 2u-1].
|
| 262 |
+
tensor.uniform_(2 * low - 1, 2 * up - 1)
|
| 263 |
+
|
| 264 |
+
# Use inverse cdf transform for normal distribution to get truncated
|
| 265 |
+
# standard normal
|
| 266 |
+
tensor.erfinv_()
|
| 267 |
+
|
| 268 |
+
# Transform to proper mean, std
|
| 269 |
+
tensor.mul_(std * math.sqrt(2.))
|
| 270 |
+
tensor.add_(mean)
|
| 271 |
+
|
| 272 |
+
# Clamp to ensure it's in the proper range
|
| 273 |
+
tensor.clamp_(min=a, max=b)
|
| 274 |
+
return tensor
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
|
| 278 |
+
r"""Fills the input Tensor with values drawn from a truncated
|
| 279 |
+
normal distribution.
|
| 280 |
+
|
| 281 |
+
From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/weight_init.py
|
| 282 |
+
|
| 283 |
+
The values are effectively drawn from the
|
| 284 |
+
normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
|
| 285 |
+
with values outside :math:`[a, b]` redrawn until they are within
|
| 286 |
+
the bounds. The method used for generating the random values works
|
| 287 |
+
best when :math:`a \leq \text{mean} \leq b`.
|
| 288 |
+
|
| 289 |
+
Args:
|
| 290 |
+
tensor: an n-dimensional `torch.Tensor`
|
| 291 |
+
mean: the mean of the normal distribution
|
| 292 |
+
std: the standard deviation of the normal distribution
|
| 293 |
+
a: the minimum cutoff value
|
| 294 |
+
b: the maximum cutoff value
|
| 295 |
+
|
| 296 |
+
Examples:
|
| 297 |
+
>>> w = torch.empty(3, 5)
|
| 298 |
+
>>> nn.init.trunc_normal_(w)
|
| 299 |
+
"""
|
| 300 |
+
return _no_grad_trunc_normal_(tensor, mean, std, a, b)
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
# From PyTorch
|
| 304 |
+
def _ntuple(n):
|
| 305 |
+
|
| 306 |
+
def parse(x):
|
| 307 |
+
if isinstance(x, collections.abc.Iterable):
|
| 308 |
+
return x
|
| 309 |
+
return tuple(repeat(x, n))
|
| 310 |
+
|
| 311 |
+
return parse
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
to_1tuple = _ntuple(1)
|
| 315 |
+
to_2tuple = _ntuple(2)
|
| 316 |
+
to_3tuple = _ntuple(3)
|
| 317 |
+
to_4tuple = _ntuple(4)
|
| 318 |
+
to_ntuple = _ntuple
|
basicsr/archs/codeformer_arch.py
ADDED
|
@@ -0,0 +1,280 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn, Tensor
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
from typing import Optional, List
|
| 7 |
+
|
| 8 |
+
from basicsr.archs.vqgan_arch import *
|
| 9 |
+
from basicsr.utils import get_root_logger
|
| 10 |
+
from basicsr.utils.registry import ARCH_REGISTRY
|
| 11 |
+
|
| 12 |
+
def calc_mean_std(feat, eps=1e-5):
|
| 13 |
+
"""Calculate mean and std for adaptive_instance_normalization.
|
| 14 |
+
|
| 15 |
+
Args:
|
| 16 |
+
feat (Tensor): 4D tensor.
|
| 17 |
+
eps (float): A small value added to the variance to avoid
|
| 18 |
+
divide-by-zero. Default: 1e-5.
|
| 19 |
+
"""
|
| 20 |
+
size = feat.size()
|
| 21 |
+
assert len(size) == 4, 'The input feature should be 4D tensor.'
|
| 22 |
+
b, c = size[:2]
|
| 23 |
+
feat_var = feat.view(b, c, -1).var(dim=2) + eps
|
| 24 |
+
feat_std = feat_var.sqrt().view(b, c, 1, 1)
|
| 25 |
+
feat_mean = feat.view(b, c, -1).mean(dim=2).view(b, c, 1, 1)
|
| 26 |
+
return feat_mean, feat_std
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def adaptive_instance_normalization(content_feat, style_feat):
|
| 30 |
+
"""Adaptive instance normalization.
|
| 31 |
+
|
| 32 |
+
Adjust the reference features to have the similar color and illuminations
|
| 33 |
+
as those in the degradate features.
|
| 34 |
+
|
| 35 |
+
Args:
|
| 36 |
+
content_feat (Tensor): The reference feature.
|
| 37 |
+
style_feat (Tensor): The degradate features.
|
| 38 |
+
"""
|
| 39 |
+
size = content_feat.size()
|
| 40 |
+
style_mean, style_std = calc_mean_std(style_feat)
|
| 41 |
+
content_mean, content_std = calc_mean_std(content_feat)
|
| 42 |
+
normalized_feat = (content_feat - content_mean.expand(size)) / content_std.expand(size)
|
| 43 |
+
return normalized_feat * style_std.expand(size) + style_mean.expand(size)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class PositionEmbeddingSine(nn.Module):
|
| 47 |
+
"""
|
| 48 |
+
This is a more standard version of the position embedding, very similar to the one
|
| 49 |
+
used by the Attention is all you need paper, generalized to work on images.
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
|
| 53 |
+
super().__init__()
|
| 54 |
+
self.num_pos_feats = num_pos_feats
|
| 55 |
+
self.temperature = temperature
|
| 56 |
+
self.normalize = normalize
|
| 57 |
+
if scale is not None and normalize is False:
|
| 58 |
+
raise ValueError("normalize should be True if scale is passed")
|
| 59 |
+
if scale is None:
|
| 60 |
+
scale = 2 * math.pi
|
| 61 |
+
self.scale = scale
|
| 62 |
+
|
| 63 |
+
def forward(self, x, mask=None):
|
| 64 |
+
if mask is None:
|
| 65 |
+
mask = torch.zeros((x.size(0), x.size(2), x.size(3)), device=x.device, dtype=torch.bool)
|
| 66 |
+
not_mask = ~mask
|
| 67 |
+
y_embed = not_mask.cumsum(1, dtype=torch.float32)
|
| 68 |
+
x_embed = not_mask.cumsum(2, dtype=torch.float32)
|
| 69 |
+
if self.normalize:
|
| 70 |
+
eps = 1e-6
|
| 71 |
+
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
|
| 72 |
+
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
|
| 73 |
+
|
| 74 |
+
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
|
| 75 |
+
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
|
| 76 |
+
|
| 77 |
+
pos_x = x_embed[:, :, :, None] / dim_t
|
| 78 |
+
pos_y = y_embed[:, :, :, None] / dim_t
|
| 79 |
+
pos_x = torch.stack(
|
| 80 |
+
(pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4
|
| 81 |
+
).flatten(3)
|
| 82 |
+
pos_y = torch.stack(
|
| 83 |
+
(pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4
|
| 84 |
+
).flatten(3)
|
| 85 |
+
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
|
| 86 |
+
return pos
|
| 87 |
+
|
| 88 |
+
def _get_activation_fn(activation):
|
| 89 |
+
"""Return an activation function given a string"""
|
| 90 |
+
if activation == "relu":
|
| 91 |
+
return F.relu
|
| 92 |
+
if activation == "gelu":
|
| 93 |
+
return F.gelu
|
| 94 |
+
if activation == "glu":
|
| 95 |
+
return F.glu
|
| 96 |
+
raise RuntimeError(F"activation should be relu/gelu, not {activation}.")
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class TransformerSALayer(nn.Module):
|
| 100 |
+
def __init__(self, embed_dim, nhead=8, dim_mlp=2048, dropout=0.0, activation="gelu"):
|
| 101 |
+
super().__init__()
|
| 102 |
+
self.self_attn = nn.MultiheadAttention(embed_dim, nhead, dropout=dropout)
|
| 103 |
+
# Implementation of Feedforward model - MLP
|
| 104 |
+
self.linear1 = nn.Linear(embed_dim, dim_mlp)
|
| 105 |
+
self.dropout = nn.Dropout(dropout)
|
| 106 |
+
self.linear2 = nn.Linear(dim_mlp, embed_dim)
|
| 107 |
+
|
| 108 |
+
self.norm1 = nn.LayerNorm(embed_dim)
|
| 109 |
+
self.norm2 = nn.LayerNorm(embed_dim)
|
| 110 |
+
self.dropout1 = nn.Dropout(dropout)
|
| 111 |
+
self.dropout2 = nn.Dropout(dropout)
|
| 112 |
+
|
| 113 |
+
self.activation = _get_activation_fn(activation)
|
| 114 |
+
|
| 115 |
+
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
|
| 116 |
+
return tensor if pos is None else tensor + pos
|
| 117 |
+
|
| 118 |
+
def forward(self, tgt,
|
| 119 |
+
tgt_mask: Optional[Tensor] = None,
|
| 120 |
+
tgt_key_padding_mask: Optional[Tensor] = None,
|
| 121 |
+
query_pos: Optional[Tensor] = None):
|
| 122 |
+
|
| 123 |
+
# self attention
|
| 124 |
+
tgt2 = self.norm1(tgt)
|
| 125 |
+
q = k = self.with_pos_embed(tgt2, query_pos)
|
| 126 |
+
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
|
| 127 |
+
key_padding_mask=tgt_key_padding_mask)[0]
|
| 128 |
+
tgt = tgt + self.dropout1(tgt2)
|
| 129 |
+
|
| 130 |
+
# ffn
|
| 131 |
+
tgt2 = self.norm2(tgt)
|
| 132 |
+
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
|
| 133 |
+
tgt = tgt + self.dropout2(tgt2)
|
| 134 |
+
return tgt
|
| 135 |
+
|
| 136 |
+
class Fuse_sft_block(nn.Module):
|
| 137 |
+
def __init__(self, in_ch, out_ch):
|
| 138 |
+
super().__init__()
|
| 139 |
+
self.encode_enc = ResBlock(2*in_ch, out_ch)
|
| 140 |
+
|
| 141 |
+
self.scale = nn.Sequential(
|
| 142 |
+
nn.Conv2d(in_ch, out_ch, kernel_size=3, padding=1),
|
| 143 |
+
nn.LeakyReLU(0.2, True),
|
| 144 |
+
nn.Conv2d(out_ch, out_ch, kernel_size=3, padding=1))
|
| 145 |
+
|
| 146 |
+
self.shift = nn.Sequential(
|
| 147 |
+
nn.Conv2d(in_ch, out_ch, kernel_size=3, padding=1),
|
| 148 |
+
nn.LeakyReLU(0.2, True),
|
| 149 |
+
nn.Conv2d(out_ch, out_ch, kernel_size=3, padding=1))
|
| 150 |
+
|
| 151 |
+
def forward(self, enc_feat, dec_feat, w=1):
|
| 152 |
+
enc_feat = self.encode_enc(torch.cat([enc_feat, dec_feat], dim=1))
|
| 153 |
+
scale = self.scale(enc_feat)
|
| 154 |
+
shift = self.shift(enc_feat)
|
| 155 |
+
residual = w * (dec_feat * scale + shift)
|
| 156 |
+
out = dec_feat + residual
|
| 157 |
+
return out
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
@ARCH_REGISTRY.register()
|
| 161 |
+
class CodeFormer(VQAutoEncoder):
|
| 162 |
+
def __init__(self, dim_embd=512, n_head=8, n_layers=9,
|
| 163 |
+
codebook_size=1024, latent_size=256,
|
| 164 |
+
connect_list=['32', '64', '128', '256'],
|
| 165 |
+
fix_modules=['quantize','generator'], vqgan_path=None):
|
| 166 |
+
super(CodeFormer, self).__init__(512, 64, [1, 2, 2, 4, 4, 8], 'nearest',2, [16], codebook_size)
|
| 167 |
+
|
| 168 |
+
if vqgan_path is not None:
|
| 169 |
+
self.load_state_dict(
|
| 170 |
+
torch.load(vqgan_path, map_location='cpu')['params_ema'])
|
| 171 |
+
|
| 172 |
+
if fix_modules is not None:
|
| 173 |
+
for module in fix_modules:
|
| 174 |
+
for param in getattr(self, module).parameters():
|
| 175 |
+
param.requires_grad = False
|
| 176 |
+
|
| 177 |
+
self.connect_list = connect_list
|
| 178 |
+
self.n_layers = n_layers
|
| 179 |
+
self.dim_embd = dim_embd
|
| 180 |
+
self.dim_mlp = dim_embd*2
|
| 181 |
+
|
| 182 |
+
self.position_emb = nn.Parameter(torch.zeros(latent_size, self.dim_embd))
|
| 183 |
+
self.feat_emb = nn.Linear(256, self.dim_embd)
|
| 184 |
+
|
| 185 |
+
# transformer
|
| 186 |
+
self.ft_layers = nn.Sequential(*[TransformerSALayer(embed_dim=dim_embd, nhead=n_head, dim_mlp=self.dim_mlp, dropout=0.0)
|
| 187 |
+
for _ in range(self.n_layers)])
|
| 188 |
+
|
| 189 |
+
# logits_predict head
|
| 190 |
+
self.idx_pred_layer = nn.Sequential(
|
| 191 |
+
nn.LayerNorm(dim_embd),
|
| 192 |
+
nn.Linear(dim_embd, codebook_size, bias=False))
|
| 193 |
+
|
| 194 |
+
self.channels = {
|
| 195 |
+
'16': 512,
|
| 196 |
+
'32': 256,
|
| 197 |
+
'64': 256,
|
| 198 |
+
'128': 128,
|
| 199 |
+
'256': 128,
|
| 200 |
+
'512': 64,
|
| 201 |
+
}
|
| 202 |
+
|
| 203 |
+
# after second residual block for > 16, before attn layer for ==16
|
| 204 |
+
self.fuse_encoder_block = {'512':2, '256':5, '128':8, '64':11, '32':14, '16':18}
|
| 205 |
+
# after first residual block for > 16, before attn layer for ==16
|
| 206 |
+
self.fuse_generator_block = {'16':6, '32': 9, '64':12, '128':15, '256':18, '512':21}
|
| 207 |
+
|
| 208 |
+
# fuse_convs_dict
|
| 209 |
+
self.fuse_convs_dict = nn.ModuleDict()
|
| 210 |
+
for f_size in self.connect_list:
|
| 211 |
+
in_ch = self.channels[f_size]
|
| 212 |
+
self.fuse_convs_dict[f_size] = Fuse_sft_block(in_ch, in_ch)
|
| 213 |
+
|
| 214 |
+
def _init_weights(self, module):
|
| 215 |
+
if isinstance(module, (nn.Linear, nn.Embedding)):
|
| 216 |
+
module.weight.data.normal_(mean=0.0, std=0.02)
|
| 217 |
+
if isinstance(module, nn.Linear) and module.bias is not None:
|
| 218 |
+
module.bias.data.zero_()
|
| 219 |
+
elif isinstance(module, nn.LayerNorm):
|
| 220 |
+
module.bias.data.zero_()
|
| 221 |
+
module.weight.data.fill_(1.0)
|
| 222 |
+
|
| 223 |
+
def forward(self, x, w=0, detach_16=True, code_only=False, adain=False):
|
| 224 |
+
# ################### Encoder #####################
|
| 225 |
+
enc_feat_dict = {}
|
| 226 |
+
out_list = [self.fuse_encoder_block[f_size] for f_size in self.connect_list]
|
| 227 |
+
for i, block in enumerate(self.encoder.blocks):
|
| 228 |
+
x = block(x)
|
| 229 |
+
if i in out_list:
|
| 230 |
+
enc_feat_dict[str(x.shape[-1])] = x.clone()
|
| 231 |
+
|
| 232 |
+
lq_feat = x
|
| 233 |
+
# ################# Transformer ###################
|
| 234 |
+
# quant_feat, codebook_loss, quant_stats = self.quantize(lq_feat)
|
| 235 |
+
pos_emb = self.position_emb.unsqueeze(1).repeat(1,x.shape[0],1)
|
| 236 |
+
# BCHW -> BC(HW) -> (HW)BC
|
| 237 |
+
feat_emb = self.feat_emb(lq_feat.flatten(2).permute(2,0,1))
|
| 238 |
+
query_emb = feat_emb
|
| 239 |
+
# Transformer encoder
|
| 240 |
+
for layer in self.ft_layers:
|
| 241 |
+
query_emb = layer(query_emb, query_pos=pos_emb)
|
| 242 |
+
|
| 243 |
+
# output logits
|
| 244 |
+
logits = self.idx_pred_layer(query_emb) # (hw)bn
|
| 245 |
+
logits = logits.permute(1,0,2) # (hw)bn -> b(hw)n
|
| 246 |
+
|
| 247 |
+
if code_only: # for training stage II
|
| 248 |
+
# logits doesn't need softmax before cross_entropy loss
|
| 249 |
+
return logits, lq_feat
|
| 250 |
+
|
| 251 |
+
# ################# Quantization ###################
|
| 252 |
+
# if self.training:
|
| 253 |
+
# quant_feat = torch.einsum('btn,nc->btc', [soft_one_hot, self.quantize.embedding.weight])
|
| 254 |
+
# # b(hw)c -> bc(hw) -> bchw
|
| 255 |
+
# quant_feat = quant_feat.permute(0,2,1).view(lq_feat.shape)
|
| 256 |
+
# ------------
|
| 257 |
+
soft_one_hot = F.softmax(logits, dim=2)
|
| 258 |
+
_, top_idx = torch.topk(soft_one_hot, 1, dim=2)
|
| 259 |
+
quant_feat = self.quantize.get_codebook_feat(top_idx, shape=[x.shape[0],16,16,256])
|
| 260 |
+
# preserve gradients
|
| 261 |
+
# quant_feat = lq_feat + (quant_feat - lq_feat).detach()
|
| 262 |
+
|
| 263 |
+
if detach_16:
|
| 264 |
+
quant_feat = quant_feat.detach() # for training stage III
|
| 265 |
+
if adain:
|
| 266 |
+
quant_feat = adaptive_instance_normalization(quant_feat, lq_feat)
|
| 267 |
+
|
| 268 |
+
# ################## Generator ####################
|
| 269 |
+
x = quant_feat
|
| 270 |
+
fuse_list = [self.fuse_generator_block[f_size] for f_size in self.connect_list]
|
| 271 |
+
|
| 272 |
+
for i, block in enumerate(self.generator.blocks):
|
| 273 |
+
x = block(x)
|
| 274 |
+
if i in fuse_list: # fuse after i-th block
|
| 275 |
+
f_size = str(x.shape[-1])
|
| 276 |
+
if w>0:
|
| 277 |
+
x = self.fuse_convs_dict[f_size](enc_feat_dict[f_size].detach(), x, w)
|
| 278 |
+
out = x
|
| 279 |
+
# logits doesn't need softmax before cross_entropy loss
|
| 280 |
+
return out, logits, lq_feat
|
basicsr/archs/rrdbnet_arch.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn as nn
|
| 3 |
+
from torch.nn import functional as F
|
| 4 |
+
|
| 5 |
+
from basicsr.utils.registry import ARCH_REGISTRY
|
| 6 |
+
from .arch_util import default_init_weights, make_layer, pixel_unshuffle
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class ResidualDenseBlock(nn.Module):
|
| 10 |
+
"""Residual Dense Block.
|
| 11 |
+
|
| 12 |
+
Used in RRDB block in ESRGAN.
|
| 13 |
+
|
| 14 |
+
Args:
|
| 15 |
+
num_feat (int): Channel number of intermediate features.
|
| 16 |
+
num_grow_ch (int): Channels for each growth.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
def __init__(self, num_feat=64, num_grow_ch=32):
|
| 20 |
+
super(ResidualDenseBlock, self).__init__()
|
| 21 |
+
self.conv1 = nn.Conv2d(num_feat, num_grow_ch, 3, 1, 1)
|
| 22 |
+
self.conv2 = nn.Conv2d(num_feat + num_grow_ch, num_grow_ch, 3, 1, 1)
|
| 23 |
+
self.conv3 = nn.Conv2d(num_feat + 2 * num_grow_ch, num_grow_ch, 3, 1, 1)
|
| 24 |
+
self.conv4 = nn.Conv2d(num_feat + 3 * num_grow_ch, num_grow_ch, 3, 1, 1)
|
| 25 |
+
self.conv5 = nn.Conv2d(num_feat + 4 * num_grow_ch, num_feat, 3, 1, 1)
|
| 26 |
+
|
| 27 |
+
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
|
| 28 |
+
|
| 29 |
+
# initialization
|
| 30 |
+
default_init_weights([self.conv1, self.conv2, self.conv3, self.conv4, self.conv5], 0.1)
|
| 31 |
+
|
| 32 |
+
def forward(self, x):
|
| 33 |
+
x1 = self.lrelu(self.conv1(x))
|
| 34 |
+
x2 = self.lrelu(self.conv2(torch.cat((x, x1), 1)))
|
| 35 |
+
x3 = self.lrelu(self.conv3(torch.cat((x, x1, x2), 1)))
|
| 36 |
+
x4 = self.lrelu(self.conv4(torch.cat((x, x1, x2, x3), 1)))
|
| 37 |
+
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
|
| 38 |
+
# Emperically, we use 0.2 to scale the residual for better performance
|
| 39 |
+
return x5 * 0.2 + x
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class RRDB(nn.Module):
|
| 43 |
+
"""Residual in Residual Dense Block.
|
| 44 |
+
|
| 45 |
+
Used in RRDB-Net in ESRGAN.
|
| 46 |
+
|
| 47 |
+
Args:
|
| 48 |
+
num_feat (int): Channel number of intermediate features.
|
| 49 |
+
num_grow_ch (int): Channels for each growth.
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
def __init__(self, num_feat, num_grow_ch=32):
|
| 53 |
+
super(RRDB, self).__init__()
|
| 54 |
+
self.rdb1 = ResidualDenseBlock(num_feat, num_grow_ch)
|
| 55 |
+
self.rdb2 = ResidualDenseBlock(num_feat, num_grow_ch)
|
| 56 |
+
self.rdb3 = ResidualDenseBlock(num_feat, num_grow_ch)
|
| 57 |
+
|
| 58 |
+
def forward(self, x):
|
| 59 |
+
out = self.rdb1(x)
|
| 60 |
+
out = self.rdb2(out)
|
| 61 |
+
out = self.rdb3(out)
|
| 62 |
+
# Emperically, we use 0.2 to scale the residual for better performance
|
| 63 |
+
return out * 0.2 + x
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
@ARCH_REGISTRY.register()
|
| 67 |
+
class RRDBNet(nn.Module):
|
| 68 |
+
"""Networks consisting of Residual in Residual Dense Block, which is used
|
| 69 |
+
in ESRGAN.
|
| 70 |
+
|
| 71 |
+
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks.
|
| 72 |
+
|
| 73 |
+
We extend ESRGAN for scale x2 and scale x1.
|
| 74 |
+
Note: This is one option for scale 1, scale 2 in RRDBNet.
|
| 75 |
+
We first employ the pixel-unshuffle (an inverse operation of pixelshuffle to reduce the spatial size
|
| 76 |
+
and enlarge the channel size before feeding inputs into the main ESRGAN architecture.
|
| 77 |
+
|
| 78 |
+
Args:
|
| 79 |
+
num_in_ch (int): Channel number of inputs.
|
| 80 |
+
num_out_ch (int): Channel number of outputs.
|
| 81 |
+
num_feat (int): Channel number of intermediate features.
|
| 82 |
+
Default: 64
|
| 83 |
+
num_block (int): Block number in the trunk network. Defaults: 23
|
| 84 |
+
num_grow_ch (int): Channels for each growth. Default: 32.
|
| 85 |
+
"""
|
| 86 |
+
|
| 87 |
+
def __init__(self, num_in_ch, num_out_ch, scale=4, num_feat=64, num_block=23, num_grow_ch=32):
|
| 88 |
+
super(RRDBNet, self).__init__()
|
| 89 |
+
self.scale = scale
|
| 90 |
+
if scale == 2:
|
| 91 |
+
num_in_ch = num_in_ch * 4
|
| 92 |
+
elif scale == 1:
|
| 93 |
+
num_in_ch = num_in_ch * 16
|
| 94 |
+
self.conv_first = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1)
|
| 95 |
+
self.body = make_layer(RRDB, num_block, num_feat=num_feat, num_grow_ch=num_grow_ch)
|
| 96 |
+
self.conv_body = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
|
| 97 |
+
# upsample
|
| 98 |
+
self.conv_up1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
|
| 99 |
+
self.conv_up2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
|
| 100 |
+
self.conv_hr = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
|
| 101 |
+
self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
|
| 102 |
+
|
| 103 |
+
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
|
| 104 |
+
|
| 105 |
+
def forward(self, x):
|
| 106 |
+
if self.scale == 2:
|
| 107 |
+
feat = pixel_unshuffle(x, scale=2)
|
| 108 |
+
elif self.scale == 1:
|
| 109 |
+
feat = pixel_unshuffle(x, scale=4)
|
| 110 |
+
else:
|
| 111 |
+
feat = x
|
| 112 |
+
feat = self.conv_first(feat)
|
| 113 |
+
body_feat = self.conv_body(self.body(feat))
|
| 114 |
+
feat = feat + body_feat
|
| 115 |
+
# upsample
|
| 116 |
+
feat = self.lrelu(self.conv_up1(F.interpolate(feat, scale_factor=2, mode='nearest')))
|
| 117 |
+
feat = self.lrelu(self.conv_up2(F.interpolate(feat, scale_factor=2, mode='nearest')))
|
| 118 |
+
out = self.conv_last(self.lrelu(self.conv_hr(feat)))
|
| 119 |
+
return out
|
basicsr/archs/vgg_arch.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
from collections import OrderedDict
|
| 4 |
+
from torch import nn as nn
|
| 5 |
+
from torchvision.models import vgg as vgg
|
| 6 |
+
|
| 7 |
+
from basicsr.utils.registry import ARCH_REGISTRY
|
| 8 |
+
|
| 9 |
+
VGG_PRETRAIN_PATH = 'experiments/pretrained_models/vgg19-dcbb9e9d.pth'
|
| 10 |
+
NAMES = {
|
| 11 |
+
'vgg11': [
|
| 12 |
+
'conv1_1', 'relu1_1', 'pool1', 'conv2_1', 'relu2_1', 'pool2', 'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2',
|
| 13 |
+
'pool3', 'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'pool4', 'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2',
|
| 14 |
+
'pool5'
|
| 15 |
+
],
|
| 16 |
+
'vgg13': [
|
| 17 |
+
'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1', 'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
|
| 18 |
+
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'pool3', 'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'pool4',
|
| 19 |
+
'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'pool5'
|
| 20 |
+
],
|
| 21 |
+
'vgg16': [
|
| 22 |
+
'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1', 'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
|
| 23 |
+
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3', 'relu3_3', 'pool3', 'conv4_1', 'relu4_1', 'conv4_2',
|
| 24 |
+
'relu4_2', 'conv4_3', 'relu4_3', 'pool4', 'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3', 'relu5_3',
|
| 25 |
+
'pool5'
|
| 26 |
+
],
|
| 27 |
+
'vgg19': [
|
| 28 |
+
'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1', 'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
|
| 29 |
+
'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3', 'relu3_3', 'conv3_4', 'relu3_4', 'pool3', 'conv4_1',
|
| 30 |
+
'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3', 'relu4_3', 'conv4_4', 'relu4_4', 'pool4', 'conv5_1', 'relu5_1',
|
| 31 |
+
'conv5_2', 'relu5_2', 'conv5_3', 'relu5_3', 'conv5_4', 'relu5_4', 'pool5'
|
| 32 |
+
]
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def insert_bn(names):
|
| 37 |
+
"""Insert bn layer after each conv.
|
| 38 |
+
|
| 39 |
+
Args:
|
| 40 |
+
names (list): The list of layer names.
|
| 41 |
+
|
| 42 |
+
Returns:
|
| 43 |
+
list: The list of layer names with bn layers.
|
| 44 |
+
"""
|
| 45 |
+
names_bn = []
|
| 46 |
+
for name in names:
|
| 47 |
+
names_bn.append(name)
|
| 48 |
+
if 'conv' in name:
|
| 49 |
+
position = name.replace('conv', '')
|
| 50 |
+
names_bn.append('bn' + position)
|
| 51 |
+
return names_bn
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
@ARCH_REGISTRY.register()
|
| 55 |
+
class VGGFeatureExtractor(nn.Module):
|
| 56 |
+
"""VGG network for feature extraction.
|
| 57 |
+
|
| 58 |
+
In this implementation, we allow users to choose whether use normalization
|
| 59 |
+
in the input feature and the type of vgg network. Note that the pretrained
|
| 60 |
+
path must fit the vgg type.
|
| 61 |
+
|
| 62 |
+
Args:
|
| 63 |
+
layer_name_list (list[str]): Forward function returns the corresponding
|
| 64 |
+
features according to the layer_name_list.
|
| 65 |
+
Example: {'relu1_1', 'relu2_1', 'relu3_1'}.
|
| 66 |
+
vgg_type (str): Set the type of vgg network. Default: 'vgg19'.
|
| 67 |
+
use_input_norm (bool): If True, normalize the input image. Importantly,
|
| 68 |
+
the input feature must in the range [0, 1]. Default: True.
|
| 69 |
+
range_norm (bool): If True, norm images with range [-1, 1] to [0, 1].
|
| 70 |
+
Default: False.
|
| 71 |
+
requires_grad (bool): If true, the parameters of VGG network will be
|
| 72 |
+
optimized. Default: False.
|
| 73 |
+
remove_pooling (bool): If true, the max pooling operations in VGG net
|
| 74 |
+
will be removed. Default: False.
|
| 75 |
+
pooling_stride (int): The stride of max pooling operation. Default: 2.
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
def __init__(self,
|
| 79 |
+
layer_name_list,
|
| 80 |
+
vgg_type='vgg19',
|
| 81 |
+
use_input_norm=True,
|
| 82 |
+
range_norm=False,
|
| 83 |
+
requires_grad=False,
|
| 84 |
+
remove_pooling=False,
|
| 85 |
+
pooling_stride=2):
|
| 86 |
+
super(VGGFeatureExtractor, self).__init__()
|
| 87 |
+
|
| 88 |
+
self.layer_name_list = layer_name_list
|
| 89 |
+
self.use_input_norm = use_input_norm
|
| 90 |
+
self.range_norm = range_norm
|
| 91 |
+
|
| 92 |
+
self.names = NAMES[vgg_type.replace('_bn', '')]
|
| 93 |
+
if 'bn' in vgg_type:
|
| 94 |
+
self.names = insert_bn(self.names)
|
| 95 |
+
|
| 96 |
+
# only borrow layers that will be used to avoid unused params
|
| 97 |
+
max_idx = 0
|
| 98 |
+
for v in layer_name_list:
|
| 99 |
+
idx = self.names.index(v)
|
| 100 |
+
if idx > max_idx:
|
| 101 |
+
max_idx = idx
|
| 102 |
+
|
| 103 |
+
if os.path.exists(VGG_PRETRAIN_PATH):
|
| 104 |
+
vgg_net = getattr(vgg, vgg_type)(pretrained=False)
|
| 105 |
+
state_dict = torch.load(VGG_PRETRAIN_PATH, map_location=lambda storage, loc: storage)
|
| 106 |
+
vgg_net.load_state_dict(state_dict)
|
| 107 |
+
else:
|
| 108 |
+
vgg_net = getattr(vgg, vgg_type)(pretrained=True)
|
| 109 |
+
|
| 110 |
+
features = vgg_net.features[:max_idx + 1]
|
| 111 |
+
|
| 112 |
+
modified_net = OrderedDict()
|
| 113 |
+
for k, v in zip(self.names, features):
|
| 114 |
+
if 'pool' in k:
|
| 115 |
+
# if remove_pooling is true, pooling operation will be removed
|
| 116 |
+
if remove_pooling:
|
| 117 |
+
continue
|
| 118 |
+
else:
|
| 119 |
+
# in some cases, we may want to change the default stride
|
| 120 |
+
modified_net[k] = nn.MaxPool2d(kernel_size=2, stride=pooling_stride)
|
| 121 |
+
else:
|
| 122 |
+
modified_net[k] = v
|
| 123 |
+
|
| 124 |
+
self.vgg_net = nn.Sequential(modified_net)
|
| 125 |
+
|
| 126 |
+
if not requires_grad:
|
| 127 |
+
self.vgg_net.eval()
|
| 128 |
+
for param in self.parameters():
|
| 129 |
+
param.requires_grad = False
|
| 130 |
+
else:
|
| 131 |
+
self.vgg_net.train()
|
| 132 |
+
for param in self.parameters():
|
| 133 |
+
param.requires_grad = True
|
| 134 |
+
|
| 135 |
+
if self.use_input_norm:
|
| 136 |
+
# the mean is for image with range [0, 1]
|
| 137 |
+
self.register_buffer('mean', torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1))
|
| 138 |
+
# the std is for image with range [0, 1]
|
| 139 |
+
self.register_buffer('std', torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1))
|
| 140 |
+
|
| 141 |
+
def forward(self, x):
|
| 142 |
+
"""Forward function.
|
| 143 |
+
|
| 144 |
+
Args:
|
| 145 |
+
x (Tensor): Input tensor with shape (n, c, h, w).
|
| 146 |
+
|
| 147 |
+
Returns:
|
| 148 |
+
Tensor: Forward results.
|
| 149 |
+
"""
|
| 150 |
+
if self.range_norm:
|
| 151 |
+
x = (x + 1) / 2
|
| 152 |
+
if self.use_input_norm:
|
| 153 |
+
x = (x - self.mean) / self.std
|
| 154 |
+
output = {}
|
| 155 |
+
|
| 156 |
+
for key, layer in self.vgg_net._modules.items():
|
| 157 |
+
x = layer(x)
|
| 158 |
+
if key in self.layer_name_list:
|
| 159 |
+
output[key] = x.clone()
|
| 160 |
+
|
| 161 |
+
return output
|
basicsr/archs/vqgan_arch.py
ADDED
|
@@ -0,0 +1,434 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
VQGAN code, adapted from the original created by the Unleashing Transformers authors:
|
| 3 |
+
https://github.com/samb-t/unleashing-transformers/blob/master/models/vqgan.py
|
| 4 |
+
|
| 5 |
+
'''
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import copy
|
| 11 |
+
from basicsr.utils import get_root_logger
|
| 12 |
+
from basicsr.utils.registry import ARCH_REGISTRY
|
| 13 |
+
|
| 14 |
+
def normalize(in_channels):
|
| 15 |
+
return torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
@torch.jit.script
|
| 19 |
+
def swish(x):
|
| 20 |
+
return x*torch.sigmoid(x)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
# Define VQVAE classes
|
| 24 |
+
class VectorQuantizer(nn.Module):
|
| 25 |
+
def __init__(self, codebook_size, emb_dim, beta):
|
| 26 |
+
super(VectorQuantizer, self).__init__()
|
| 27 |
+
self.codebook_size = codebook_size # number of embeddings
|
| 28 |
+
self.emb_dim = emb_dim # dimension of embedding
|
| 29 |
+
self.beta = beta # commitment cost used in loss term, beta * ||z_e(x)-sg[e]||^2
|
| 30 |
+
self.embedding = nn.Embedding(self.codebook_size, self.emb_dim)
|
| 31 |
+
self.embedding.weight.data.uniform_(-1.0 / self.codebook_size, 1.0 / self.codebook_size)
|
| 32 |
+
|
| 33 |
+
def forward(self, z):
|
| 34 |
+
# reshape z -> (batch, height, width, channel) and flatten
|
| 35 |
+
z = z.permute(0, 2, 3, 1).contiguous()
|
| 36 |
+
z_flattened = z.view(-1, self.emb_dim)
|
| 37 |
+
|
| 38 |
+
# distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
|
| 39 |
+
d = (z_flattened ** 2).sum(dim=1, keepdim=True) + (self.embedding.weight**2).sum(1) - \
|
| 40 |
+
2 * torch.matmul(z_flattened, self.embedding.weight.t())
|
| 41 |
+
|
| 42 |
+
mean_distance = torch.mean(d)
|
| 43 |
+
# find closest encodings
|
| 44 |
+
min_encoding_indices = torch.argmin(d, dim=1).unsqueeze(1)
|
| 45 |
+
# min_encoding_scores, min_encoding_indices = torch.topk(d, 1, dim=1, largest=False)
|
| 46 |
+
# [0-1], higher score, higher confidence
|
| 47 |
+
# min_encoding_scores = torch.exp(-min_encoding_scores/10)
|
| 48 |
+
|
| 49 |
+
min_encodings = torch.zeros(min_encoding_indices.shape[0], self.codebook_size).to(z)
|
| 50 |
+
min_encodings.scatter_(1, min_encoding_indices, 1)
|
| 51 |
+
|
| 52 |
+
# get quantized latent vectors
|
| 53 |
+
z_q = torch.matmul(min_encodings, self.embedding.weight).view(z.shape)
|
| 54 |
+
# compute loss for embedding
|
| 55 |
+
loss = torch.mean((z_q.detach()-z)**2) + self.beta * torch.mean((z_q - z.detach()) ** 2)
|
| 56 |
+
# preserve gradients
|
| 57 |
+
z_q = z + (z_q - z).detach()
|
| 58 |
+
|
| 59 |
+
# perplexity
|
| 60 |
+
e_mean = torch.mean(min_encodings, dim=0)
|
| 61 |
+
perplexity = torch.exp(-torch.sum(e_mean * torch.log(e_mean + 1e-10)))
|
| 62 |
+
# reshape back to match original input shape
|
| 63 |
+
z_q = z_q.permute(0, 3, 1, 2).contiguous()
|
| 64 |
+
|
| 65 |
+
return z_q, loss, {
|
| 66 |
+
"perplexity": perplexity,
|
| 67 |
+
"min_encodings": min_encodings,
|
| 68 |
+
"min_encoding_indices": min_encoding_indices,
|
| 69 |
+
"mean_distance": mean_distance
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
def get_codebook_feat(self, indices, shape):
|
| 73 |
+
# input indices: batch*token_num -> (batch*token_num)*1
|
| 74 |
+
# shape: batch, height, width, channel
|
| 75 |
+
indices = indices.view(-1,1)
|
| 76 |
+
min_encodings = torch.zeros(indices.shape[0], self.codebook_size).to(indices)
|
| 77 |
+
min_encodings.scatter_(1, indices, 1)
|
| 78 |
+
# get quantized latent vectors
|
| 79 |
+
z_q = torch.matmul(min_encodings.float(), self.embedding.weight)
|
| 80 |
+
|
| 81 |
+
if shape is not None: # reshape back to match original input shape
|
| 82 |
+
z_q = z_q.view(shape).permute(0, 3, 1, 2).contiguous()
|
| 83 |
+
|
| 84 |
+
return z_q
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class GumbelQuantizer(nn.Module):
|
| 88 |
+
def __init__(self, codebook_size, emb_dim, num_hiddens, straight_through=False, kl_weight=5e-4, temp_init=1.0):
|
| 89 |
+
super().__init__()
|
| 90 |
+
self.codebook_size = codebook_size # number of embeddings
|
| 91 |
+
self.emb_dim = emb_dim # dimension of embedding
|
| 92 |
+
self.straight_through = straight_through
|
| 93 |
+
self.temperature = temp_init
|
| 94 |
+
self.kl_weight = kl_weight
|
| 95 |
+
self.proj = nn.Conv2d(num_hiddens, codebook_size, 1) # projects last encoder layer to quantized logits
|
| 96 |
+
self.embed = nn.Embedding(codebook_size, emb_dim)
|
| 97 |
+
|
| 98 |
+
def forward(self, z):
|
| 99 |
+
hard = self.straight_through if self.training else True
|
| 100 |
+
|
| 101 |
+
logits = self.proj(z)
|
| 102 |
+
|
| 103 |
+
soft_one_hot = F.gumbel_softmax(logits, tau=self.temperature, dim=1, hard=hard)
|
| 104 |
+
|
| 105 |
+
z_q = torch.einsum("b n h w, n d -> b d h w", soft_one_hot, self.embed.weight)
|
| 106 |
+
|
| 107 |
+
# + kl divergence to the prior loss
|
| 108 |
+
qy = F.softmax(logits, dim=1)
|
| 109 |
+
diff = self.kl_weight * torch.sum(qy * torch.log(qy * self.codebook_size + 1e-10), dim=1).mean()
|
| 110 |
+
min_encoding_indices = soft_one_hot.argmax(dim=1)
|
| 111 |
+
|
| 112 |
+
return z_q, diff, {
|
| 113 |
+
"min_encoding_indices": min_encoding_indices
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
class Downsample(nn.Module):
|
| 118 |
+
def __init__(self, in_channels):
|
| 119 |
+
super().__init__()
|
| 120 |
+
self.conv = torch.nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=2, padding=0)
|
| 121 |
+
|
| 122 |
+
def forward(self, x):
|
| 123 |
+
pad = (0, 1, 0, 1)
|
| 124 |
+
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
|
| 125 |
+
x = self.conv(x)
|
| 126 |
+
return x
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
class Upsample(nn.Module):
|
| 130 |
+
def __init__(self, in_channels):
|
| 131 |
+
super().__init__()
|
| 132 |
+
self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1)
|
| 133 |
+
|
| 134 |
+
def forward(self, x):
|
| 135 |
+
x = F.interpolate(x, scale_factor=2.0, mode="nearest")
|
| 136 |
+
x = self.conv(x)
|
| 137 |
+
|
| 138 |
+
return x
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
class ResBlock(nn.Module):
|
| 142 |
+
def __init__(self, in_channels, out_channels=None):
|
| 143 |
+
super(ResBlock, self).__init__()
|
| 144 |
+
self.in_channels = in_channels
|
| 145 |
+
self.out_channels = in_channels if out_channels is None else out_channels
|
| 146 |
+
self.norm1 = normalize(in_channels)
|
| 147 |
+
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
| 148 |
+
self.norm2 = normalize(out_channels)
|
| 149 |
+
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
| 150 |
+
if self.in_channels != self.out_channels:
|
| 151 |
+
self.conv_out = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
|
| 152 |
+
|
| 153 |
+
def forward(self, x_in):
|
| 154 |
+
x = x_in
|
| 155 |
+
x = self.norm1(x)
|
| 156 |
+
x = swish(x)
|
| 157 |
+
x = self.conv1(x)
|
| 158 |
+
x = self.norm2(x)
|
| 159 |
+
x = swish(x)
|
| 160 |
+
x = self.conv2(x)
|
| 161 |
+
if self.in_channels != self.out_channels:
|
| 162 |
+
x_in = self.conv_out(x_in)
|
| 163 |
+
|
| 164 |
+
return x + x_in
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
class AttnBlock(nn.Module):
|
| 168 |
+
def __init__(self, in_channels):
|
| 169 |
+
super().__init__()
|
| 170 |
+
self.in_channels = in_channels
|
| 171 |
+
|
| 172 |
+
self.norm = normalize(in_channels)
|
| 173 |
+
self.q = torch.nn.Conv2d(
|
| 174 |
+
in_channels,
|
| 175 |
+
in_channels,
|
| 176 |
+
kernel_size=1,
|
| 177 |
+
stride=1,
|
| 178 |
+
padding=0
|
| 179 |
+
)
|
| 180 |
+
self.k = torch.nn.Conv2d(
|
| 181 |
+
in_channels,
|
| 182 |
+
in_channels,
|
| 183 |
+
kernel_size=1,
|
| 184 |
+
stride=1,
|
| 185 |
+
padding=0
|
| 186 |
+
)
|
| 187 |
+
self.v = torch.nn.Conv2d(
|
| 188 |
+
in_channels,
|
| 189 |
+
in_channels,
|
| 190 |
+
kernel_size=1,
|
| 191 |
+
stride=1,
|
| 192 |
+
padding=0
|
| 193 |
+
)
|
| 194 |
+
self.proj_out = torch.nn.Conv2d(
|
| 195 |
+
in_channels,
|
| 196 |
+
in_channels,
|
| 197 |
+
kernel_size=1,
|
| 198 |
+
stride=1,
|
| 199 |
+
padding=0
|
| 200 |
+
)
|
| 201 |
+
|
| 202 |
+
def forward(self, x):
|
| 203 |
+
h_ = x
|
| 204 |
+
h_ = self.norm(h_)
|
| 205 |
+
q = self.q(h_)
|
| 206 |
+
k = self.k(h_)
|
| 207 |
+
v = self.v(h_)
|
| 208 |
+
|
| 209 |
+
# compute attention
|
| 210 |
+
b, c, h, w = q.shape
|
| 211 |
+
q = q.reshape(b, c, h*w)
|
| 212 |
+
q = q.permute(0, 2, 1)
|
| 213 |
+
k = k.reshape(b, c, h*w)
|
| 214 |
+
w_ = torch.bmm(q, k)
|
| 215 |
+
w_ = w_ * (int(c)**(-0.5))
|
| 216 |
+
w_ = F.softmax(w_, dim=2)
|
| 217 |
+
|
| 218 |
+
# attend to values
|
| 219 |
+
v = v.reshape(b, c, h*w)
|
| 220 |
+
w_ = w_.permute(0, 2, 1)
|
| 221 |
+
h_ = torch.bmm(v, w_)
|
| 222 |
+
h_ = h_.reshape(b, c, h, w)
|
| 223 |
+
|
| 224 |
+
h_ = self.proj_out(h_)
|
| 225 |
+
|
| 226 |
+
return x+h_
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
class Encoder(nn.Module):
|
| 230 |
+
def __init__(self, in_channels, nf, emb_dim, ch_mult, num_res_blocks, resolution, attn_resolutions):
|
| 231 |
+
super().__init__()
|
| 232 |
+
self.nf = nf
|
| 233 |
+
self.num_resolutions = len(ch_mult)
|
| 234 |
+
self.num_res_blocks = num_res_blocks
|
| 235 |
+
self.resolution = resolution
|
| 236 |
+
self.attn_resolutions = attn_resolutions
|
| 237 |
+
|
| 238 |
+
curr_res = self.resolution
|
| 239 |
+
in_ch_mult = (1,)+tuple(ch_mult)
|
| 240 |
+
|
| 241 |
+
blocks = []
|
| 242 |
+
# initial convultion
|
| 243 |
+
blocks.append(nn.Conv2d(in_channels, nf, kernel_size=3, stride=1, padding=1))
|
| 244 |
+
|
| 245 |
+
# residual and downsampling blocks, with attention on smaller res (16x16)
|
| 246 |
+
for i in range(self.num_resolutions):
|
| 247 |
+
block_in_ch = nf * in_ch_mult[i]
|
| 248 |
+
block_out_ch = nf * ch_mult[i]
|
| 249 |
+
for _ in range(self.num_res_blocks):
|
| 250 |
+
blocks.append(ResBlock(block_in_ch, block_out_ch))
|
| 251 |
+
block_in_ch = block_out_ch
|
| 252 |
+
if curr_res in attn_resolutions:
|
| 253 |
+
blocks.append(AttnBlock(block_in_ch))
|
| 254 |
+
|
| 255 |
+
if i != self.num_resolutions - 1:
|
| 256 |
+
blocks.append(Downsample(block_in_ch))
|
| 257 |
+
curr_res = curr_res // 2
|
| 258 |
+
|
| 259 |
+
# non-local attention block
|
| 260 |
+
blocks.append(ResBlock(block_in_ch, block_in_ch))
|
| 261 |
+
blocks.append(AttnBlock(block_in_ch))
|
| 262 |
+
blocks.append(ResBlock(block_in_ch, block_in_ch))
|
| 263 |
+
|
| 264 |
+
# normalise and convert to latent size
|
| 265 |
+
blocks.append(normalize(block_in_ch))
|
| 266 |
+
blocks.append(nn.Conv2d(block_in_ch, emb_dim, kernel_size=3, stride=1, padding=1))
|
| 267 |
+
self.blocks = nn.ModuleList(blocks)
|
| 268 |
+
|
| 269 |
+
def forward(self, x):
|
| 270 |
+
for block in self.blocks:
|
| 271 |
+
x = block(x)
|
| 272 |
+
|
| 273 |
+
return x
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
class Generator(nn.Module):
|
| 277 |
+
def __init__(self, nf, emb_dim, ch_mult, res_blocks, img_size, attn_resolutions):
|
| 278 |
+
super().__init__()
|
| 279 |
+
self.nf = nf
|
| 280 |
+
self.ch_mult = ch_mult
|
| 281 |
+
self.num_resolutions = len(self.ch_mult)
|
| 282 |
+
self.num_res_blocks = res_blocks
|
| 283 |
+
self.resolution = img_size
|
| 284 |
+
self.attn_resolutions = attn_resolutions
|
| 285 |
+
self.in_channels = emb_dim
|
| 286 |
+
self.out_channels = 3
|
| 287 |
+
block_in_ch = self.nf * self.ch_mult[-1]
|
| 288 |
+
curr_res = self.resolution // 2 ** (self.num_resolutions-1)
|
| 289 |
+
|
| 290 |
+
blocks = []
|
| 291 |
+
# initial conv
|
| 292 |
+
blocks.append(nn.Conv2d(self.in_channels, block_in_ch, kernel_size=3, stride=1, padding=1))
|
| 293 |
+
|
| 294 |
+
# non-local attention block
|
| 295 |
+
blocks.append(ResBlock(block_in_ch, block_in_ch))
|
| 296 |
+
blocks.append(AttnBlock(block_in_ch))
|
| 297 |
+
blocks.append(ResBlock(block_in_ch, block_in_ch))
|
| 298 |
+
|
| 299 |
+
for i in reversed(range(self.num_resolutions)):
|
| 300 |
+
block_out_ch = self.nf * self.ch_mult[i]
|
| 301 |
+
|
| 302 |
+
for _ in range(self.num_res_blocks):
|
| 303 |
+
blocks.append(ResBlock(block_in_ch, block_out_ch))
|
| 304 |
+
block_in_ch = block_out_ch
|
| 305 |
+
|
| 306 |
+
if curr_res in self.attn_resolutions:
|
| 307 |
+
blocks.append(AttnBlock(block_in_ch))
|
| 308 |
+
|
| 309 |
+
if i != 0:
|
| 310 |
+
blocks.append(Upsample(block_in_ch))
|
| 311 |
+
curr_res = curr_res * 2
|
| 312 |
+
|
| 313 |
+
blocks.append(normalize(block_in_ch))
|
| 314 |
+
blocks.append(nn.Conv2d(block_in_ch, self.out_channels, kernel_size=3, stride=1, padding=1))
|
| 315 |
+
|
| 316 |
+
self.blocks = nn.ModuleList(blocks)
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
def forward(self, x):
|
| 320 |
+
for block in self.blocks:
|
| 321 |
+
x = block(x)
|
| 322 |
+
|
| 323 |
+
return x
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
@ARCH_REGISTRY.register()
|
| 327 |
+
class VQAutoEncoder(nn.Module):
|
| 328 |
+
def __init__(self, img_size, nf, ch_mult, quantizer="nearest", res_blocks=2, attn_resolutions=[16], codebook_size=1024, emb_dim=256,
|
| 329 |
+
beta=0.25, gumbel_straight_through=False, gumbel_kl_weight=1e-8, model_path=None):
|
| 330 |
+
super().__init__()
|
| 331 |
+
logger = get_root_logger()
|
| 332 |
+
self.in_channels = 3
|
| 333 |
+
self.nf = nf
|
| 334 |
+
self.n_blocks = res_blocks
|
| 335 |
+
self.codebook_size = codebook_size
|
| 336 |
+
self.embed_dim = emb_dim
|
| 337 |
+
self.ch_mult = ch_mult
|
| 338 |
+
self.resolution = img_size
|
| 339 |
+
self.attn_resolutions = attn_resolutions
|
| 340 |
+
self.quantizer_type = quantizer
|
| 341 |
+
self.encoder = Encoder(
|
| 342 |
+
self.in_channels,
|
| 343 |
+
self.nf,
|
| 344 |
+
self.embed_dim,
|
| 345 |
+
self.ch_mult,
|
| 346 |
+
self.n_blocks,
|
| 347 |
+
self.resolution,
|
| 348 |
+
self.attn_resolutions
|
| 349 |
+
)
|
| 350 |
+
if self.quantizer_type == "nearest":
|
| 351 |
+
self.beta = beta #0.25
|
| 352 |
+
self.quantize = VectorQuantizer(self.codebook_size, self.embed_dim, self.beta)
|
| 353 |
+
elif self.quantizer_type == "gumbel":
|
| 354 |
+
self.gumbel_num_hiddens = emb_dim
|
| 355 |
+
self.straight_through = gumbel_straight_through
|
| 356 |
+
self.kl_weight = gumbel_kl_weight
|
| 357 |
+
self.quantize = GumbelQuantizer(
|
| 358 |
+
self.codebook_size,
|
| 359 |
+
self.embed_dim,
|
| 360 |
+
self.gumbel_num_hiddens,
|
| 361 |
+
self.straight_through,
|
| 362 |
+
self.kl_weight
|
| 363 |
+
)
|
| 364 |
+
self.generator = Generator(
|
| 365 |
+
self.nf,
|
| 366 |
+
self.embed_dim,
|
| 367 |
+
self.ch_mult,
|
| 368 |
+
self.n_blocks,
|
| 369 |
+
self.resolution,
|
| 370 |
+
self.attn_resolutions
|
| 371 |
+
)
|
| 372 |
+
|
| 373 |
+
if model_path is not None:
|
| 374 |
+
chkpt = torch.load(model_path, map_location='cpu')
|
| 375 |
+
if 'params_ema' in chkpt:
|
| 376 |
+
self.load_state_dict(torch.load(model_path, map_location='cpu')['params_ema'])
|
| 377 |
+
logger.info(f'vqgan is loaded from: {model_path} [params_ema]')
|
| 378 |
+
elif 'params' in chkpt:
|
| 379 |
+
self.load_state_dict(torch.load(model_path, map_location='cpu')['params'])
|
| 380 |
+
logger.info(f'vqgan is loaded from: {model_path} [params]')
|
| 381 |
+
else:
|
| 382 |
+
raise ValueError(f'Wrong params!')
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
def forward(self, x):
|
| 386 |
+
x = self.encoder(x)
|
| 387 |
+
quant, codebook_loss, quant_stats = self.quantize(x)
|
| 388 |
+
x = self.generator(quant)
|
| 389 |
+
return x, codebook_loss, quant_stats
|
| 390 |
+
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+
# patch based discriminator
|
| 394 |
+
@ARCH_REGISTRY.register()
|
| 395 |
+
class VQGANDiscriminator(nn.Module):
|
| 396 |
+
def __init__(self, nc=3, ndf=64, n_layers=4, model_path=None):
|
| 397 |
+
super().__init__()
|
| 398 |
+
|
| 399 |
+
layers = [nn.Conv2d(nc, ndf, kernel_size=4, stride=2, padding=1), nn.LeakyReLU(0.2, True)]
|
| 400 |
+
ndf_mult = 1
|
| 401 |
+
ndf_mult_prev = 1
|
| 402 |
+
for n in range(1, n_layers): # gradually increase the number of filters
|
| 403 |
+
ndf_mult_prev = ndf_mult
|
| 404 |
+
ndf_mult = min(2 ** n, 8)
|
| 405 |
+
layers += [
|
| 406 |
+
nn.Conv2d(ndf * ndf_mult_prev, ndf * ndf_mult, kernel_size=4, stride=2, padding=1, bias=False),
|
| 407 |
+
nn.BatchNorm2d(ndf * ndf_mult),
|
| 408 |
+
nn.LeakyReLU(0.2, True)
|
| 409 |
+
]
|
| 410 |
+
|
| 411 |
+
ndf_mult_prev = ndf_mult
|
| 412 |
+
ndf_mult = min(2 ** n_layers, 8)
|
| 413 |
+
|
| 414 |
+
layers += [
|
| 415 |
+
nn.Conv2d(ndf * ndf_mult_prev, ndf * ndf_mult, kernel_size=4, stride=1, padding=1, bias=False),
|
| 416 |
+
nn.BatchNorm2d(ndf * ndf_mult),
|
| 417 |
+
nn.LeakyReLU(0.2, True)
|
| 418 |
+
]
|
| 419 |
+
|
| 420 |
+
layers += [
|
| 421 |
+
nn.Conv2d(ndf * ndf_mult, 1, kernel_size=4, stride=1, padding=1)] # output 1 channel prediction map
|
| 422 |
+
self.main = nn.Sequential(*layers)
|
| 423 |
+
|
| 424 |
+
if model_path is not None:
|
| 425 |
+
chkpt = torch.load(model_path, map_location='cpu')
|
| 426 |
+
if 'params_d' in chkpt:
|
| 427 |
+
self.load_state_dict(torch.load(model_path, map_location='cpu')['params_d'])
|
| 428 |
+
elif 'params' in chkpt:
|
| 429 |
+
self.load_state_dict(torch.load(model_path, map_location='cpu')['params'])
|
| 430 |
+
else:
|
| 431 |
+
raise ValueError(f'Wrong params!')
|
| 432 |
+
|
| 433 |
+
def forward(self, x):
|
| 434 |
+
return self.main(x)
|
basicsr/data/__init__.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import importlib
|
| 2 |
+
import numpy as np
|
| 3 |
+
import random
|
| 4 |
+
import torch
|
| 5 |
+
import torch.utils.data
|
| 6 |
+
from copy import deepcopy
|
| 7 |
+
from functools import partial
|
| 8 |
+
from os import path as osp
|
| 9 |
+
|
| 10 |
+
from basicsr.data.prefetch_dataloader import PrefetchDataLoader
|
| 11 |
+
from basicsr.utils import get_root_logger, scandir
|
| 12 |
+
from basicsr.utils.dist_util import get_dist_info
|
| 13 |
+
from basicsr.utils.registry import DATASET_REGISTRY
|
| 14 |
+
|
| 15 |
+
__all__ = ['build_dataset', 'build_dataloader']
|
| 16 |
+
|
| 17 |
+
# automatically scan and import dataset modules for registry
|
| 18 |
+
# scan all the files under the data folder with '_dataset' in file names
|
| 19 |
+
data_folder = osp.dirname(osp.abspath(__file__))
|
| 20 |
+
dataset_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(data_folder) if v.endswith('_dataset.py')]
|
| 21 |
+
# import all the dataset modules
|
| 22 |
+
_dataset_modules = [importlib.import_module(f'basicsr.data.{file_name}') for file_name in dataset_filenames]
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def build_dataset(dataset_opt):
|
| 26 |
+
"""Build dataset from options.
|
| 27 |
+
|
| 28 |
+
Args:
|
| 29 |
+
dataset_opt (dict): Configuration for dataset. It must constain:
|
| 30 |
+
name (str): Dataset name.
|
| 31 |
+
type (str): Dataset type.
|
| 32 |
+
"""
|
| 33 |
+
dataset_opt = deepcopy(dataset_opt)
|
| 34 |
+
dataset = DATASET_REGISTRY.get(dataset_opt['type'])(dataset_opt)
|
| 35 |
+
logger = get_root_logger()
|
| 36 |
+
logger.info(f'Dataset [{dataset.__class__.__name__}] - {dataset_opt["name"]} ' 'is built.')
|
| 37 |
+
return dataset
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def build_dataloader(dataset, dataset_opt, num_gpu=1, dist=False, sampler=None, seed=None):
|
| 41 |
+
"""Build dataloader.
|
| 42 |
+
|
| 43 |
+
Args:
|
| 44 |
+
dataset (torch.utils.data.Dataset): Dataset.
|
| 45 |
+
dataset_opt (dict): Dataset options. It contains the following keys:
|
| 46 |
+
phase (str): 'train' or 'val'.
|
| 47 |
+
num_worker_per_gpu (int): Number of workers for each GPU.
|
| 48 |
+
batch_size_per_gpu (int): Training batch size for each GPU.
|
| 49 |
+
num_gpu (int): Number of GPUs. Used only in the train phase.
|
| 50 |
+
Default: 1.
|
| 51 |
+
dist (bool): Whether in distributed training. Used only in the train
|
| 52 |
+
phase. Default: False.
|
| 53 |
+
sampler (torch.utils.data.sampler): Data sampler. Default: None.
|
| 54 |
+
seed (int | None): Seed. Default: None
|
| 55 |
+
"""
|
| 56 |
+
phase = dataset_opt['phase']
|
| 57 |
+
rank, _ = get_dist_info()
|
| 58 |
+
if phase == 'train':
|
| 59 |
+
if dist: # distributed training
|
| 60 |
+
batch_size = dataset_opt['batch_size_per_gpu']
|
| 61 |
+
num_workers = dataset_opt['num_worker_per_gpu']
|
| 62 |
+
else: # non-distributed training
|
| 63 |
+
multiplier = 1 if num_gpu == 0 else num_gpu
|
| 64 |
+
batch_size = dataset_opt['batch_size_per_gpu'] * multiplier
|
| 65 |
+
num_workers = dataset_opt['num_worker_per_gpu'] * multiplier
|
| 66 |
+
dataloader_args = dict(
|
| 67 |
+
dataset=dataset,
|
| 68 |
+
batch_size=batch_size,
|
| 69 |
+
shuffle=False,
|
| 70 |
+
num_workers=num_workers,
|
| 71 |
+
sampler=sampler,
|
| 72 |
+
drop_last=True)
|
| 73 |
+
if sampler is None:
|
| 74 |
+
dataloader_args['shuffle'] = True
|
| 75 |
+
dataloader_args['worker_init_fn'] = partial(
|
| 76 |
+
worker_init_fn, num_workers=num_workers, rank=rank, seed=seed) if seed is not None else None
|
| 77 |
+
elif phase in ['val', 'test']: # validation
|
| 78 |
+
dataloader_args = dict(dataset=dataset, batch_size=1, shuffle=False, num_workers=0)
|
| 79 |
+
else:
|
| 80 |
+
raise ValueError(f'Wrong dataset phase: {phase}. ' "Supported ones are 'train', 'val' and 'test'.")
|
| 81 |
+
|
| 82 |
+
dataloader_args['pin_memory'] = dataset_opt.get('pin_memory', False)
|
| 83 |
+
|
| 84 |
+
prefetch_mode = dataset_opt.get('prefetch_mode')
|
| 85 |
+
if prefetch_mode == 'cpu': # CPUPrefetcher
|
| 86 |
+
num_prefetch_queue = dataset_opt.get('num_prefetch_queue', 1)
|
| 87 |
+
logger = get_root_logger()
|
| 88 |
+
logger.info(f'Use {prefetch_mode} prefetch dataloader: ' f'num_prefetch_queue = {num_prefetch_queue}')
|
| 89 |
+
return PrefetchDataLoader(num_prefetch_queue=num_prefetch_queue, **dataloader_args)
|
| 90 |
+
else:
|
| 91 |
+
# prefetch_mode=None: Normal dataloader
|
| 92 |
+
# prefetch_mode='cuda': dataloader for CUDAPrefetcher
|
| 93 |
+
return torch.utils.data.DataLoader(**dataloader_args)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def worker_init_fn(worker_id, num_workers, rank, seed):
|
| 97 |
+
# Set the worker seed to num_workers * rank + worker_id + seed
|
| 98 |
+
worker_seed = num_workers * rank + worker_id + seed
|
| 99 |
+
np.random.seed(worker_seed)
|
| 100 |
+
random.seed(worker_seed)
|
basicsr/data/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (3.53 kB). View file
|
|
|
basicsr/data/__pycache__/data_sampler.cpython-310.pyc
ADDED
|
Binary file (2.13 kB). View file
|
|
|
basicsr/data/__pycache__/data_util.cpython-310.pyc
ADDED
|
Binary file (13.4 kB). View file
|
|
|
basicsr/data/__pycache__/ffhq_blind_dataset.cpython-310.pyc
ADDED
|
Binary file (7.89 kB). View file
|
|
|
basicsr/data/__pycache__/ffhq_blind_joint_dataset.cpython-310.pyc
ADDED
|
Binary file (8.48 kB). View file
|
|
|
basicsr/data/__pycache__/gaussian_kernels.cpython-310.pyc
ADDED
|
Binary file (17.4 kB). View file
|
|
|
basicsr/data/__pycache__/paired_image_dataset.cpython-310.pyc
ADDED
|
Binary file (3.74 kB). View file
|
|
|
basicsr/data/__pycache__/prefetch_dataloader.cpython-310.pyc
ADDED
|
Binary file (4.34 kB). View file
|
|
|
basicsr/data/__pycache__/transforms.cpython-310.pyc
ADDED
|
Binary file (5.4 kB). View file
|
|
|
basicsr/data/data_sampler.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
from torch.utils.data.sampler import Sampler
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class EnlargedSampler(Sampler):
|
| 7 |
+
"""Sampler that restricts data loading to a subset of the dataset.
|
| 8 |
+
|
| 9 |
+
Modified from torch.utils.data.distributed.DistributedSampler
|
| 10 |
+
Support enlarging the dataset for iteration-based training, for saving
|
| 11 |
+
time when restart the dataloader after each epoch
|
| 12 |
+
|
| 13 |
+
Args:
|
| 14 |
+
dataset (torch.utils.data.Dataset): Dataset used for sampling.
|
| 15 |
+
num_replicas (int | None): Number of processes participating in
|
| 16 |
+
the training. It is usually the world_size.
|
| 17 |
+
rank (int | None): Rank of the current process within num_replicas.
|
| 18 |
+
ratio (int): Enlarging ratio. Default: 1.
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
def __init__(self, dataset, num_replicas, rank, ratio=1):
|
| 22 |
+
self.dataset = dataset
|
| 23 |
+
self.num_replicas = num_replicas
|
| 24 |
+
self.rank = rank
|
| 25 |
+
self.epoch = 0
|
| 26 |
+
self.num_samples = math.ceil(len(self.dataset) * ratio / self.num_replicas)
|
| 27 |
+
self.total_size = self.num_samples * self.num_replicas
|
| 28 |
+
|
| 29 |
+
def __iter__(self):
|
| 30 |
+
# deterministically shuffle based on epoch
|
| 31 |
+
g = torch.Generator()
|
| 32 |
+
g.manual_seed(self.epoch)
|
| 33 |
+
indices = torch.randperm(self.total_size, generator=g).tolist()
|
| 34 |
+
|
| 35 |
+
dataset_size = len(self.dataset)
|
| 36 |
+
indices = [v % dataset_size for v in indices]
|
| 37 |
+
|
| 38 |
+
# subsample
|
| 39 |
+
indices = indices[self.rank:self.total_size:self.num_replicas]
|
| 40 |
+
assert len(indices) == self.num_samples
|
| 41 |
+
|
| 42 |
+
return iter(indices)
|
| 43 |
+
|
| 44 |
+
def __len__(self):
|
| 45 |
+
return self.num_samples
|
| 46 |
+
|
| 47 |
+
def set_epoch(self, epoch):
|
| 48 |
+
self.epoch = epoch
|
basicsr/data/data_util.py
ADDED
|
@@ -0,0 +1,392 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import math
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
from os import path as osp
|
| 6 |
+
from PIL import Image, ImageDraw
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
|
| 9 |
+
from basicsr.data.transforms import mod_crop
|
| 10 |
+
from basicsr.utils import img2tensor, scandir
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def read_img_seq(path, require_mod_crop=False, scale=1):
|
| 14 |
+
"""Read a sequence of images from a given folder path.
|
| 15 |
+
|
| 16 |
+
Args:
|
| 17 |
+
path (list[str] | str): List of image paths or image folder path.
|
| 18 |
+
require_mod_crop (bool): Require mod crop for each image.
|
| 19 |
+
Default: False.
|
| 20 |
+
scale (int): Scale factor for mod_crop. Default: 1.
|
| 21 |
+
|
| 22 |
+
Returns:
|
| 23 |
+
Tensor: size (t, c, h, w), RGB, [0, 1].
|
| 24 |
+
"""
|
| 25 |
+
if isinstance(path, list):
|
| 26 |
+
img_paths = path
|
| 27 |
+
else:
|
| 28 |
+
img_paths = sorted(list(scandir(path, full_path=True)))
|
| 29 |
+
imgs = [cv2.imread(v).astype(np.float32) / 255. for v in img_paths]
|
| 30 |
+
if require_mod_crop:
|
| 31 |
+
imgs = [mod_crop(img, scale) for img in imgs]
|
| 32 |
+
imgs = img2tensor(imgs, bgr2rgb=True, float32=True)
|
| 33 |
+
imgs = torch.stack(imgs, dim=0)
|
| 34 |
+
return imgs
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def generate_frame_indices(crt_idx, max_frame_num, num_frames, padding='reflection'):
|
| 38 |
+
"""Generate an index list for reading `num_frames` frames from a sequence
|
| 39 |
+
of images.
|
| 40 |
+
|
| 41 |
+
Args:
|
| 42 |
+
crt_idx (int): Current center index.
|
| 43 |
+
max_frame_num (int): Max number of the sequence of images (from 1).
|
| 44 |
+
num_frames (int): Reading num_frames frames.
|
| 45 |
+
padding (str): Padding mode, one of
|
| 46 |
+
'replicate' | 'reflection' | 'reflection_circle' | 'circle'
|
| 47 |
+
Examples: current_idx = 0, num_frames = 5
|
| 48 |
+
The generated frame indices under different padding mode:
|
| 49 |
+
replicate: [0, 0, 0, 1, 2]
|
| 50 |
+
reflection: [2, 1, 0, 1, 2]
|
| 51 |
+
reflection_circle: [4, 3, 0, 1, 2]
|
| 52 |
+
circle: [3, 4, 0, 1, 2]
|
| 53 |
+
|
| 54 |
+
Returns:
|
| 55 |
+
list[int]: A list of indices.
|
| 56 |
+
"""
|
| 57 |
+
assert num_frames % 2 == 1, 'num_frames should be an odd number.'
|
| 58 |
+
assert padding in ('replicate', 'reflection', 'reflection_circle', 'circle'), f'Wrong padding mode: {padding}.'
|
| 59 |
+
|
| 60 |
+
max_frame_num = max_frame_num - 1 # start from 0
|
| 61 |
+
num_pad = num_frames // 2
|
| 62 |
+
|
| 63 |
+
indices = []
|
| 64 |
+
for i in range(crt_idx - num_pad, crt_idx + num_pad + 1):
|
| 65 |
+
if i < 0:
|
| 66 |
+
if padding == 'replicate':
|
| 67 |
+
pad_idx = 0
|
| 68 |
+
elif padding == 'reflection':
|
| 69 |
+
pad_idx = -i
|
| 70 |
+
elif padding == 'reflection_circle':
|
| 71 |
+
pad_idx = crt_idx + num_pad - i
|
| 72 |
+
else:
|
| 73 |
+
pad_idx = num_frames + i
|
| 74 |
+
elif i > max_frame_num:
|
| 75 |
+
if padding == 'replicate':
|
| 76 |
+
pad_idx = max_frame_num
|
| 77 |
+
elif padding == 'reflection':
|
| 78 |
+
pad_idx = max_frame_num * 2 - i
|
| 79 |
+
elif padding == 'reflection_circle':
|
| 80 |
+
pad_idx = (crt_idx - num_pad) - (i - max_frame_num)
|
| 81 |
+
else:
|
| 82 |
+
pad_idx = i - num_frames
|
| 83 |
+
else:
|
| 84 |
+
pad_idx = i
|
| 85 |
+
indices.append(pad_idx)
|
| 86 |
+
return indices
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def paired_paths_from_lmdb(folders, keys):
|
| 90 |
+
"""Generate paired paths from lmdb files.
|
| 91 |
+
|
| 92 |
+
Contents of lmdb. Taking the `lq.lmdb` for example, the file structure is:
|
| 93 |
+
|
| 94 |
+
lq.lmdb
|
| 95 |
+
├── data.mdb
|
| 96 |
+
├── lock.mdb
|
| 97 |
+
├── meta_info.txt
|
| 98 |
+
|
| 99 |
+
The data.mdb and lock.mdb are standard lmdb files and you can refer to
|
| 100 |
+
https://lmdb.readthedocs.io/en/release/ for more details.
|
| 101 |
+
|
| 102 |
+
The meta_info.txt is a specified txt file to record the meta information
|
| 103 |
+
of our datasets. It will be automatically created when preparing
|
| 104 |
+
datasets by our provided dataset tools.
|
| 105 |
+
Each line in the txt file records
|
| 106 |
+
1)image name (with extension),
|
| 107 |
+
2)image shape,
|
| 108 |
+
3)compression level, separated by a white space.
|
| 109 |
+
Example: `baboon.png (120,125,3) 1`
|
| 110 |
+
|
| 111 |
+
We use the image name without extension as the lmdb key.
|
| 112 |
+
Note that we use the same key for the corresponding lq and gt images.
|
| 113 |
+
|
| 114 |
+
Args:
|
| 115 |
+
folders (list[str]): A list of folder path. The order of list should
|
| 116 |
+
be [input_folder, gt_folder].
|
| 117 |
+
keys (list[str]): A list of keys identifying folders. The order should
|
| 118 |
+
be in consistent with folders, e.g., ['lq', 'gt'].
|
| 119 |
+
Note that this key is different from lmdb keys.
|
| 120 |
+
|
| 121 |
+
Returns:
|
| 122 |
+
list[str]: Returned path list.
|
| 123 |
+
"""
|
| 124 |
+
assert len(folders) == 2, ('The len of folders should be 2 with [input_folder, gt_folder]. '
|
| 125 |
+
f'But got {len(folders)}')
|
| 126 |
+
assert len(keys) == 2, ('The len of keys should be 2 with [input_key, gt_key]. ' f'But got {len(keys)}')
|
| 127 |
+
input_folder, gt_folder = folders
|
| 128 |
+
input_key, gt_key = keys
|
| 129 |
+
|
| 130 |
+
if not (input_folder.endswith('.lmdb') and gt_folder.endswith('.lmdb')):
|
| 131 |
+
raise ValueError(f'{input_key} folder and {gt_key} folder should both in lmdb '
|
| 132 |
+
f'formats. But received {input_key}: {input_folder}; '
|
| 133 |
+
f'{gt_key}: {gt_folder}')
|
| 134 |
+
# ensure that the two meta_info files are the same
|
| 135 |
+
with open(osp.join(input_folder, 'meta_info.txt')) as fin:
|
| 136 |
+
input_lmdb_keys = [line.split('.')[0] for line in fin]
|
| 137 |
+
with open(osp.join(gt_folder, 'meta_info.txt')) as fin:
|
| 138 |
+
gt_lmdb_keys = [line.split('.')[0] for line in fin]
|
| 139 |
+
if set(input_lmdb_keys) != set(gt_lmdb_keys):
|
| 140 |
+
raise ValueError(f'Keys in {input_key}_folder and {gt_key}_folder are different.')
|
| 141 |
+
else:
|
| 142 |
+
paths = []
|
| 143 |
+
for lmdb_key in sorted(input_lmdb_keys):
|
| 144 |
+
paths.append(dict([(f'{input_key}_path', lmdb_key), (f'{gt_key}_path', lmdb_key)]))
|
| 145 |
+
return paths
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def paired_paths_from_meta_info_file(folders, keys, meta_info_file, filename_tmpl):
|
| 149 |
+
"""Generate paired paths from an meta information file.
|
| 150 |
+
|
| 151 |
+
Each line in the meta information file contains the image names and
|
| 152 |
+
image shape (usually for gt), separated by a white space.
|
| 153 |
+
|
| 154 |
+
Example of an meta information file:
|
| 155 |
+
```
|
| 156 |
+
0001_s001.png (480,480,3)
|
| 157 |
+
0001_s002.png (480,480,3)
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
Args:
|
| 161 |
+
folders (list[str]): A list of folder path. The order of list should
|
| 162 |
+
be [input_folder, gt_folder].
|
| 163 |
+
keys (list[str]): A list of keys identifying folders. The order should
|
| 164 |
+
be in consistent with folders, e.g., ['lq', 'gt'].
|
| 165 |
+
meta_info_file (str): Path to the meta information file.
|
| 166 |
+
filename_tmpl (str): Template for each filename. Note that the
|
| 167 |
+
template excludes the file extension. Usually the filename_tmpl is
|
| 168 |
+
for files in the input folder.
|
| 169 |
+
|
| 170 |
+
Returns:
|
| 171 |
+
list[str]: Returned path list.
|
| 172 |
+
"""
|
| 173 |
+
assert len(folders) == 2, ('The len of folders should be 2 with [input_folder, gt_folder]. '
|
| 174 |
+
f'But got {len(folders)}')
|
| 175 |
+
assert len(keys) == 2, ('The len of keys should be 2 with [input_key, gt_key]. ' f'But got {len(keys)}')
|
| 176 |
+
input_folder, gt_folder = folders
|
| 177 |
+
input_key, gt_key = keys
|
| 178 |
+
|
| 179 |
+
with open(meta_info_file, 'r') as fin:
|
| 180 |
+
gt_names = [line.split(' ')[0] for line in fin]
|
| 181 |
+
|
| 182 |
+
paths = []
|
| 183 |
+
for gt_name in gt_names:
|
| 184 |
+
basename, ext = osp.splitext(osp.basename(gt_name))
|
| 185 |
+
input_name = f'{filename_tmpl.format(basename)}{ext}'
|
| 186 |
+
input_path = osp.join(input_folder, input_name)
|
| 187 |
+
gt_path = osp.join(gt_folder, gt_name)
|
| 188 |
+
paths.append(dict([(f'{input_key}_path', input_path), (f'{gt_key}_path', gt_path)]))
|
| 189 |
+
return paths
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
def paired_paths_from_folder(folders, keys, filename_tmpl):
|
| 193 |
+
"""Generate paired paths from folders.
|
| 194 |
+
|
| 195 |
+
Args:
|
| 196 |
+
folders (list[str]): A list of folder path. The order of list should
|
| 197 |
+
be [input_folder, gt_folder].
|
| 198 |
+
keys (list[str]): A list of keys identifying folders. The order should
|
| 199 |
+
be in consistent with folders, e.g., ['lq', 'gt'].
|
| 200 |
+
filename_tmpl (str): Template for each filename. Note that the
|
| 201 |
+
template excludes the file extension. Usually the filename_tmpl is
|
| 202 |
+
for files in the input folder.
|
| 203 |
+
|
| 204 |
+
Returns:
|
| 205 |
+
list[str]: Returned path list.
|
| 206 |
+
"""
|
| 207 |
+
assert len(folders) == 2, ('The len of folders should be 2 with [input_folder, gt_folder]. '
|
| 208 |
+
f'But got {len(folders)}')
|
| 209 |
+
assert len(keys) == 2, ('The len of keys should be 2 with [input_key, gt_key]. ' f'But got {len(keys)}')
|
| 210 |
+
input_folder, gt_folder = folders
|
| 211 |
+
input_key, gt_key = keys
|
| 212 |
+
|
| 213 |
+
input_paths = list(scandir(input_folder))
|
| 214 |
+
gt_paths = list(scandir(gt_folder))
|
| 215 |
+
assert len(input_paths) == len(gt_paths), (f'{input_key} and {gt_key} datasets have different number of images: '
|
| 216 |
+
f'{len(input_paths)}, {len(gt_paths)}.')
|
| 217 |
+
paths = []
|
| 218 |
+
for gt_path in gt_paths:
|
| 219 |
+
basename, ext = osp.splitext(osp.basename(gt_path))
|
| 220 |
+
input_name = f'{filename_tmpl.format(basename)}{ext}'
|
| 221 |
+
input_path = osp.join(input_folder, input_name)
|
| 222 |
+
assert input_name in input_paths, (f'{input_name} is not in ' f'{input_key}_paths.')
|
| 223 |
+
gt_path = osp.join(gt_folder, gt_path)
|
| 224 |
+
paths.append(dict([(f'{input_key}_path', input_path), (f'{gt_key}_path', gt_path)]))
|
| 225 |
+
return paths
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
def paths_from_folder(folder):
|
| 229 |
+
"""Generate paths from folder.
|
| 230 |
+
|
| 231 |
+
Args:
|
| 232 |
+
folder (str): Folder path.
|
| 233 |
+
|
| 234 |
+
Returns:
|
| 235 |
+
list[str]: Returned path list.
|
| 236 |
+
"""
|
| 237 |
+
|
| 238 |
+
paths = list(scandir(folder))
|
| 239 |
+
paths = [osp.join(folder, path) for path in paths]
|
| 240 |
+
return paths
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
def paths_from_lmdb(folder):
|
| 244 |
+
"""Generate paths from lmdb.
|
| 245 |
+
|
| 246 |
+
Args:
|
| 247 |
+
folder (str): Folder path.
|
| 248 |
+
|
| 249 |
+
Returns:
|
| 250 |
+
list[str]: Returned path list.
|
| 251 |
+
"""
|
| 252 |
+
if not folder.endswith('.lmdb'):
|
| 253 |
+
raise ValueError(f'Folder {folder}folder should in lmdb format.')
|
| 254 |
+
with open(osp.join(folder, 'meta_info.txt')) as fin:
|
| 255 |
+
paths = [line.split('.')[0] for line in fin]
|
| 256 |
+
return paths
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
def generate_gaussian_kernel(kernel_size=13, sigma=1.6):
|
| 260 |
+
"""Generate Gaussian kernel used in `duf_downsample`.
|
| 261 |
+
|
| 262 |
+
Args:
|
| 263 |
+
kernel_size (int): Kernel size. Default: 13.
|
| 264 |
+
sigma (float): Sigma of the Gaussian kernel. Default: 1.6.
|
| 265 |
+
|
| 266 |
+
Returns:
|
| 267 |
+
np.array: The Gaussian kernel.
|
| 268 |
+
"""
|
| 269 |
+
from scipy.ndimage import filters as filters
|
| 270 |
+
kernel = np.zeros((kernel_size, kernel_size))
|
| 271 |
+
# set element at the middle to one, a dirac delta
|
| 272 |
+
kernel[kernel_size // 2, kernel_size // 2] = 1
|
| 273 |
+
# gaussian-smooth the dirac, resulting in a gaussian filter
|
| 274 |
+
return filters.gaussian_filter(kernel, sigma)
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
def duf_downsample(x, kernel_size=13, scale=4):
|
| 278 |
+
"""Downsamping with Gaussian kernel used in the DUF official code.
|
| 279 |
+
|
| 280 |
+
Args:
|
| 281 |
+
x (Tensor): Frames to be downsampled, with shape (b, t, c, h, w).
|
| 282 |
+
kernel_size (int): Kernel size. Default: 13.
|
| 283 |
+
scale (int): Downsampling factor. Supported scale: (2, 3, 4).
|
| 284 |
+
Default: 4.
|
| 285 |
+
|
| 286 |
+
Returns:
|
| 287 |
+
Tensor: DUF downsampled frames.
|
| 288 |
+
"""
|
| 289 |
+
assert scale in (2, 3, 4), f'Only support scale (2, 3, 4), but got {scale}.'
|
| 290 |
+
|
| 291 |
+
squeeze_flag = False
|
| 292 |
+
if x.ndim == 4:
|
| 293 |
+
squeeze_flag = True
|
| 294 |
+
x = x.unsqueeze(0)
|
| 295 |
+
b, t, c, h, w = x.size()
|
| 296 |
+
x = x.view(-1, 1, h, w)
|
| 297 |
+
pad_w, pad_h = kernel_size // 2 + scale * 2, kernel_size // 2 + scale * 2
|
| 298 |
+
x = F.pad(x, (pad_w, pad_w, pad_h, pad_h), 'reflect')
|
| 299 |
+
|
| 300 |
+
gaussian_filter = generate_gaussian_kernel(kernel_size, 0.4 * scale)
|
| 301 |
+
gaussian_filter = torch.from_numpy(gaussian_filter).type_as(x).unsqueeze(0).unsqueeze(0)
|
| 302 |
+
x = F.conv2d(x, gaussian_filter, stride=scale)
|
| 303 |
+
x = x[:, :, 2:-2, 2:-2]
|
| 304 |
+
x = x.view(b, t, c, x.size(2), x.size(3))
|
| 305 |
+
if squeeze_flag:
|
| 306 |
+
x = x.squeeze(0)
|
| 307 |
+
return x
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
def brush_stroke_mask(img, color=(255,255,255)):
|
| 311 |
+
min_num_vertex = 8
|
| 312 |
+
max_num_vertex = 28
|
| 313 |
+
mean_angle = 2*math.pi / 5
|
| 314 |
+
angle_range = 2*math.pi / 12
|
| 315 |
+
# training large mask ratio (training setting)
|
| 316 |
+
min_width = 30
|
| 317 |
+
max_width = 70
|
| 318 |
+
# very large mask ratio (test setting and refine after 200k)
|
| 319 |
+
# min_width = 80
|
| 320 |
+
# max_width = 120
|
| 321 |
+
def generate_mask(H, W, img=None):
|
| 322 |
+
average_radius = math.sqrt(H*H+W*W) / 8
|
| 323 |
+
mask = Image.new('RGB', (W, H), 0)
|
| 324 |
+
if img is not None: mask = img # Image.fromarray(img)
|
| 325 |
+
|
| 326 |
+
for _ in range(np.random.randint(1, 4)):
|
| 327 |
+
num_vertex = np.random.randint(min_num_vertex, max_num_vertex)
|
| 328 |
+
angle_min = mean_angle - np.random.uniform(0, angle_range)
|
| 329 |
+
angle_max = mean_angle + np.random.uniform(0, angle_range)
|
| 330 |
+
angles = []
|
| 331 |
+
vertex = []
|
| 332 |
+
for i in range(num_vertex):
|
| 333 |
+
if i % 2 == 0:
|
| 334 |
+
angles.append(2*math.pi - np.random.uniform(angle_min, angle_max))
|
| 335 |
+
else:
|
| 336 |
+
angles.append(np.random.uniform(angle_min, angle_max))
|
| 337 |
+
|
| 338 |
+
h, w = mask.size
|
| 339 |
+
vertex.append((int(np.random.randint(0, w)), int(np.random.randint(0, h))))
|
| 340 |
+
for i in range(num_vertex):
|
| 341 |
+
r = np.clip(
|
| 342 |
+
np.random.normal(loc=average_radius, scale=average_radius//2),
|
| 343 |
+
0, 2*average_radius)
|
| 344 |
+
new_x = np.clip(vertex[-1][0] + r * math.cos(angles[i]), 0, w)
|
| 345 |
+
new_y = np.clip(vertex[-1][1] + r * math.sin(angles[i]), 0, h)
|
| 346 |
+
vertex.append((int(new_x), int(new_y)))
|
| 347 |
+
|
| 348 |
+
draw = ImageDraw.Draw(mask)
|
| 349 |
+
width = int(np.random.uniform(min_width, max_width))
|
| 350 |
+
draw.line(vertex, fill=color, width=width)
|
| 351 |
+
for v in vertex:
|
| 352 |
+
draw.ellipse((v[0] - width//2,
|
| 353 |
+
v[1] - width//2,
|
| 354 |
+
v[0] + width//2,
|
| 355 |
+
v[1] + width//2),
|
| 356 |
+
fill=color)
|
| 357 |
+
|
| 358 |
+
return mask
|
| 359 |
+
|
| 360 |
+
width, height = img.size
|
| 361 |
+
mask = generate_mask(height, width, img)
|
| 362 |
+
return mask
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
def random_ff_mask(shape, max_angle = 10, max_len = 100, max_width = 70, times = 10):
|
| 366 |
+
"""Generate a random free form mask with configuration.
|
| 367 |
+
Args:
|
| 368 |
+
config: Config should have configuration including IMG_SHAPES,
|
| 369 |
+
VERTICAL_MARGIN, HEIGHT, HORIZONTAL_MARGIN, WIDTH.
|
| 370 |
+
Returns:
|
| 371 |
+
tuple: (top, left, height, width)
|
| 372 |
+
Link:
|
| 373 |
+
https://github.com/csqiangwen/DeepFillv2_Pytorch/blob/master/train_dataset.py
|
| 374 |
+
"""
|
| 375 |
+
height = shape[0]
|
| 376 |
+
width = shape[1]
|
| 377 |
+
mask = np.zeros((height, width), np.float32)
|
| 378 |
+
times = np.random.randint(times-5, times)
|
| 379 |
+
for i in range(times):
|
| 380 |
+
start_x = np.random.randint(width)
|
| 381 |
+
start_y = np.random.randint(height)
|
| 382 |
+
for j in range(1 + np.random.randint(5)):
|
| 383 |
+
angle = 0.01 + np.random.randint(max_angle)
|
| 384 |
+
if i % 2 == 0:
|
| 385 |
+
angle = 2 * 3.1415926 - angle
|
| 386 |
+
length = 10 + np.random.randint(max_len-20, max_len)
|
| 387 |
+
brush_w = 5 + np.random.randint(max_width-30, max_width)
|
| 388 |
+
end_x = (start_x + length * np.sin(angle)).astype(np.int32)
|
| 389 |
+
end_y = (start_y + length * np.cos(angle)).astype(np.int32)
|
| 390 |
+
cv2.line(mask, (start_y, start_x), (end_y, end_x), 1.0, brush_w)
|
| 391 |
+
start_x, start_y = end_x, end_y
|
| 392 |
+
return mask.astype(np.float32)
|
basicsr/data/ffhq_blind_dataset.py
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import math
|
| 3 |
+
import random
|
| 4 |
+
import numpy as np
|
| 5 |
+
import os.path as osp
|
| 6 |
+
from scipy.io import loadmat
|
| 7 |
+
from PIL import Image
|
| 8 |
+
import torch
|
| 9 |
+
import torch.utils.data as data
|
| 10 |
+
from torchvision.transforms.functional import (adjust_brightness, adjust_contrast,
|
| 11 |
+
adjust_hue, adjust_saturation, normalize)
|
| 12 |
+
from basicsr.data import gaussian_kernels as gaussian_kernels
|
| 13 |
+
from basicsr.data.transforms import augment
|
| 14 |
+
from basicsr.data.data_util import paths_from_folder, brush_stroke_mask, random_ff_mask
|
| 15 |
+
from basicsr.utils import FileClient, get_root_logger, imfrombytes, img2tensor
|
| 16 |
+
from basicsr.utils.registry import DATASET_REGISTRY
|
| 17 |
+
|
| 18 |
+
@DATASET_REGISTRY.register()
|
| 19 |
+
class FFHQBlindDataset(data.Dataset):
|
| 20 |
+
|
| 21 |
+
def __init__(self, opt):
|
| 22 |
+
super(FFHQBlindDataset, self).__init__()
|
| 23 |
+
logger = get_root_logger()
|
| 24 |
+
self.opt = opt
|
| 25 |
+
# file client (io backend)
|
| 26 |
+
self.file_client = None
|
| 27 |
+
self.io_backend_opt = opt['io_backend']
|
| 28 |
+
|
| 29 |
+
self.gt_folder = opt['dataroot_gt']
|
| 30 |
+
self.gt_size = opt.get('gt_size', 512)
|
| 31 |
+
self.in_size = opt.get('in_size', 512)
|
| 32 |
+
assert self.gt_size >= self.in_size, 'Wrong setting.'
|
| 33 |
+
|
| 34 |
+
self.mean = opt.get('mean', [0.5, 0.5, 0.5])
|
| 35 |
+
self.std = opt.get('std', [0.5, 0.5, 0.5])
|
| 36 |
+
|
| 37 |
+
self.component_path = opt.get('component_path', None)
|
| 38 |
+
self.latent_gt_path = opt.get('latent_gt_path', None)
|
| 39 |
+
|
| 40 |
+
if self.component_path is not None:
|
| 41 |
+
self.crop_components = True
|
| 42 |
+
self.components_dict = torch.load(self.component_path)
|
| 43 |
+
self.eye_enlarge_ratio = opt.get('eye_enlarge_ratio', 1.4)
|
| 44 |
+
self.nose_enlarge_ratio = opt.get('nose_enlarge_ratio', 1.1)
|
| 45 |
+
self.mouth_enlarge_ratio = opt.get('mouth_enlarge_ratio', 1.3)
|
| 46 |
+
else:
|
| 47 |
+
self.crop_components = False
|
| 48 |
+
|
| 49 |
+
if self.latent_gt_path is not None:
|
| 50 |
+
self.load_latent_gt = True
|
| 51 |
+
self.latent_gt_dict = torch.load(self.latent_gt_path)
|
| 52 |
+
else:
|
| 53 |
+
self.load_latent_gt = False
|
| 54 |
+
|
| 55 |
+
if self.io_backend_opt['type'] == 'lmdb':
|
| 56 |
+
self.io_backend_opt['db_paths'] = self.gt_folder
|
| 57 |
+
if not self.gt_folder.endswith('.lmdb'):
|
| 58 |
+
raise ValueError("'dataroot_gt' should end with '.lmdb', "f'but received {self.gt_folder}')
|
| 59 |
+
with open(osp.join(self.gt_folder, 'meta_info.txt')) as fin:
|
| 60 |
+
self.paths = [line.split('.')[0] for line in fin]
|
| 61 |
+
else:
|
| 62 |
+
self.paths = paths_from_folder(self.gt_folder)
|
| 63 |
+
|
| 64 |
+
# inpainting mask
|
| 65 |
+
self.gen_inpaint_mask = opt.get('gen_inpaint_mask', False)
|
| 66 |
+
if self.gen_inpaint_mask:
|
| 67 |
+
logger.info(f'generate mask ...')
|
| 68 |
+
# self.mask_max_angle = opt.get('mask_max_angle', 10)
|
| 69 |
+
# self.mask_max_len = opt.get('mask_max_len', 150)
|
| 70 |
+
# self.mask_max_width = opt.get('mask_max_width', 50)
|
| 71 |
+
# self.mask_draw_times = opt.get('mask_draw_times', 10)
|
| 72 |
+
# # print
|
| 73 |
+
# logger.info(f'mask_max_angle: {self.mask_max_angle}')
|
| 74 |
+
# logger.info(f'mask_max_len: {self.mask_max_len}')
|
| 75 |
+
# logger.info(f'mask_max_width: {self.mask_max_width}')
|
| 76 |
+
# logger.info(f'mask_draw_times: {self.mask_draw_times}')
|
| 77 |
+
|
| 78 |
+
# perform corrupt
|
| 79 |
+
self.use_corrupt = opt.get('use_corrupt', True)
|
| 80 |
+
self.use_motion_kernel = False
|
| 81 |
+
# self.use_motion_kernel = opt.get('use_motion_kernel', True)
|
| 82 |
+
|
| 83 |
+
if self.use_motion_kernel:
|
| 84 |
+
self.motion_kernel_prob = opt.get('motion_kernel_prob', 0.001)
|
| 85 |
+
motion_kernel_path = opt.get('motion_kernel_path', 'basicsr/data/motion-blur-kernels-32.pth')
|
| 86 |
+
self.motion_kernels = torch.load(motion_kernel_path)
|
| 87 |
+
|
| 88 |
+
if self.use_corrupt and not self.gen_inpaint_mask:
|
| 89 |
+
# degradation configurations
|
| 90 |
+
self.blur_kernel_size = opt['blur_kernel_size']
|
| 91 |
+
self.blur_sigma = opt['blur_sigma']
|
| 92 |
+
self.kernel_list = opt['kernel_list']
|
| 93 |
+
self.kernel_prob = opt['kernel_prob']
|
| 94 |
+
self.downsample_range = opt['downsample_range']
|
| 95 |
+
self.noise_range = opt['noise_range']
|
| 96 |
+
self.jpeg_range = opt['jpeg_range']
|
| 97 |
+
# print
|
| 98 |
+
logger.info(f'Blur: blur_kernel_size {self.blur_kernel_size}, sigma: [{", ".join(map(str, self.blur_sigma))}]')
|
| 99 |
+
logger.info(f'Downsample: downsample_range [{", ".join(map(str, self.downsample_range))}]')
|
| 100 |
+
logger.info(f'Noise: [{", ".join(map(str, self.noise_range))}]')
|
| 101 |
+
logger.info(f'JPEG compression: [{", ".join(map(str, self.jpeg_range))}]')
|
| 102 |
+
|
| 103 |
+
# color jitter
|
| 104 |
+
self.color_jitter_prob = opt.get('color_jitter_prob', None)
|
| 105 |
+
self.color_jitter_pt_prob = opt.get('color_jitter_pt_prob', None)
|
| 106 |
+
self.color_jitter_shift = opt.get('color_jitter_shift', 20)
|
| 107 |
+
if self.color_jitter_prob is not None:
|
| 108 |
+
logger.info(f'Use random color jitter. Prob: {self.color_jitter_prob}, shift: {self.color_jitter_shift}')
|
| 109 |
+
|
| 110 |
+
# to gray
|
| 111 |
+
self.gray_prob = opt.get('gray_prob', 0.0)
|
| 112 |
+
if self.gray_prob is not None:
|
| 113 |
+
logger.info(f'Use random gray. Prob: {self.gray_prob}')
|
| 114 |
+
self.color_jitter_shift /= 255.
|
| 115 |
+
|
| 116 |
+
@staticmethod
|
| 117 |
+
def color_jitter(img, shift):
|
| 118 |
+
"""jitter color: randomly jitter the RGB values, in numpy formats"""
|
| 119 |
+
jitter_val = np.random.uniform(-shift, shift, 3).astype(np.float32)
|
| 120 |
+
img = img + jitter_val
|
| 121 |
+
img = np.clip(img, 0, 1)
|
| 122 |
+
return img
|
| 123 |
+
|
| 124 |
+
@staticmethod
|
| 125 |
+
def color_jitter_pt(img, brightness, contrast, saturation, hue):
|
| 126 |
+
"""jitter color: randomly jitter the brightness, contrast, saturation, and hue, in torch Tensor formats"""
|
| 127 |
+
fn_idx = torch.randperm(4)
|
| 128 |
+
for fn_id in fn_idx:
|
| 129 |
+
if fn_id == 0 and brightness is not None:
|
| 130 |
+
brightness_factor = torch.tensor(1.0).uniform_(brightness[0], brightness[1]).item()
|
| 131 |
+
img = adjust_brightness(img, brightness_factor)
|
| 132 |
+
|
| 133 |
+
if fn_id == 1 and contrast is not None:
|
| 134 |
+
contrast_factor = torch.tensor(1.0).uniform_(contrast[0], contrast[1]).item()
|
| 135 |
+
img = adjust_contrast(img, contrast_factor)
|
| 136 |
+
|
| 137 |
+
if fn_id == 2 and saturation is not None:
|
| 138 |
+
saturation_factor = torch.tensor(1.0).uniform_(saturation[0], saturation[1]).item()
|
| 139 |
+
img = adjust_saturation(img, saturation_factor)
|
| 140 |
+
|
| 141 |
+
if fn_id == 3 and hue is not None:
|
| 142 |
+
hue_factor = torch.tensor(1.0).uniform_(hue[0], hue[1]).item()
|
| 143 |
+
img = adjust_hue(img, hue_factor)
|
| 144 |
+
return img
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
def get_component_locations(self, name, status):
|
| 148 |
+
components_bbox = self.components_dict[name]
|
| 149 |
+
if status[0]: # hflip
|
| 150 |
+
# exchange right and left eye
|
| 151 |
+
tmp = components_bbox['left_eye']
|
| 152 |
+
components_bbox['left_eye'] = components_bbox['right_eye']
|
| 153 |
+
components_bbox['right_eye'] = tmp
|
| 154 |
+
# modify the width coordinate
|
| 155 |
+
components_bbox['left_eye'][0] = self.gt_size - components_bbox['left_eye'][0]
|
| 156 |
+
components_bbox['right_eye'][0] = self.gt_size - components_bbox['right_eye'][0]
|
| 157 |
+
components_bbox['nose'][0] = self.gt_size - components_bbox['nose'][0]
|
| 158 |
+
components_bbox['mouth'][0] = self.gt_size - components_bbox['mouth'][0]
|
| 159 |
+
|
| 160 |
+
locations_gt = {}
|
| 161 |
+
locations_in = {}
|
| 162 |
+
for part in ['left_eye', 'right_eye', 'nose', 'mouth']:
|
| 163 |
+
mean = components_bbox[part][0:2]
|
| 164 |
+
half_len = components_bbox[part][2]
|
| 165 |
+
if 'eye' in part:
|
| 166 |
+
half_len *= self.eye_enlarge_ratio
|
| 167 |
+
elif part == 'nose':
|
| 168 |
+
half_len *= self.nose_enlarge_ratio
|
| 169 |
+
elif part == 'mouth':
|
| 170 |
+
half_len *= self.mouth_enlarge_ratio
|
| 171 |
+
loc = np.hstack((mean - half_len + 1, mean + half_len))
|
| 172 |
+
loc = torch.from_numpy(loc).float()
|
| 173 |
+
locations_gt[part] = loc
|
| 174 |
+
loc_in = loc/(self.gt_size//self.in_size)
|
| 175 |
+
locations_in[part] = loc_in
|
| 176 |
+
return locations_gt, locations_in
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
def __getitem__(self, index):
|
| 180 |
+
if self.file_client is None:
|
| 181 |
+
self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
|
| 182 |
+
|
| 183 |
+
# load gt image
|
| 184 |
+
gt_path = self.paths[index]
|
| 185 |
+
name = osp.basename(gt_path)[:-4]
|
| 186 |
+
img_bytes = self.file_client.get(gt_path)
|
| 187 |
+
img_gt = imfrombytes(img_bytes, float32=True)
|
| 188 |
+
|
| 189 |
+
# random horizontal flip
|
| 190 |
+
img_gt, status = augment(img_gt, hflip=self.opt['use_hflip'], rotation=False, return_status=True)
|
| 191 |
+
|
| 192 |
+
if self.load_latent_gt:
|
| 193 |
+
if status[0]:
|
| 194 |
+
latent_gt = self.latent_gt_dict['hflip'][name]
|
| 195 |
+
else:
|
| 196 |
+
latent_gt = self.latent_gt_dict['orig'][name]
|
| 197 |
+
|
| 198 |
+
if self.crop_components:
|
| 199 |
+
locations_gt, locations_in = self.get_component_locations(name, status)
|
| 200 |
+
|
| 201 |
+
# generate in image
|
| 202 |
+
img_in = img_gt
|
| 203 |
+
if self.use_corrupt and not self.gen_inpaint_mask:
|
| 204 |
+
# motion blur
|
| 205 |
+
if self.use_motion_kernel and random.random() < self.motion_kernel_prob:
|
| 206 |
+
m_i = random.randint(0,31)
|
| 207 |
+
k = self.motion_kernels[f'{m_i:02d}']
|
| 208 |
+
img_in = cv2.filter2D(img_in,-1,k)
|
| 209 |
+
|
| 210 |
+
# gaussian blur
|
| 211 |
+
kernel = gaussian_kernels.random_mixed_kernels(
|
| 212 |
+
self.kernel_list,
|
| 213 |
+
self.kernel_prob,
|
| 214 |
+
self.blur_kernel_size,
|
| 215 |
+
self.blur_sigma,
|
| 216 |
+
self.blur_sigma,
|
| 217 |
+
[-math.pi, math.pi],
|
| 218 |
+
noise_range=None)
|
| 219 |
+
img_in = cv2.filter2D(img_in, -1, kernel)
|
| 220 |
+
|
| 221 |
+
# downsample
|
| 222 |
+
scale = np.random.uniform(self.downsample_range[0], self.downsample_range[1])
|
| 223 |
+
img_in = cv2.resize(img_in, (int(self.gt_size // scale), int(self.gt_size // scale)), interpolation=cv2.INTER_LINEAR)
|
| 224 |
+
|
| 225 |
+
# noise
|
| 226 |
+
if self.noise_range is not None:
|
| 227 |
+
noise_sigma = np.random.uniform(self.noise_range[0] / 255., self.noise_range[1] / 255.)
|
| 228 |
+
noise = np.float32(np.random.randn(*(img_in.shape))) * noise_sigma
|
| 229 |
+
img_in = img_in + noise
|
| 230 |
+
img_in = np.clip(img_in, 0, 1)
|
| 231 |
+
|
| 232 |
+
# jpeg
|
| 233 |
+
if self.jpeg_range is not None:
|
| 234 |
+
jpeg_p = np.random.uniform(self.jpeg_range[0], self.jpeg_range[1])
|
| 235 |
+
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), jpeg_p]
|
| 236 |
+
_, encimg = cv2.imencode('.jpg', img_in * 255., encode_param)
|
| 237 |
+
img_in = np.float32(cv2.imdecode(encimg, 1)) / 255.
|
| 238 |
+
|
| 239 |
+
# resize to in_size
|
| 240 |
+
img_in = cv2.resize(img_in, (self.in_size, self.in_size), interpolation=cv2.INTER_LINEAR)
|
| 241 |
+
|
| 242 |
+
# if self.gen_inpaint_mask:
|
| 243 |
+
# inpaint_mask = random_ff_mask(shape=(self.gt_size,self.gt_size),
|
| 244 |
+
# max_angle = self.mask_max_angle, max_len = self.mask_max_len,
|
| 245 |
+
# max_width = self.mask_max_width, times = self.mask_draw_times)
|
| 246 |
+
# img_in = img_in * (1 - inpaint_mask.reshape(self.gt_size,self.gt_size,1)) + \
|
| 247 |
+
# 1.0 * inpaint_mask.reshape(self.gt_size,self.gt_size,1)
|
| 248 |
+
|
| 249 |
+
# inpaint_mask = torch.from_numpy(inpaint_mask).view(1,self.gt_size,self.gt_size)
|
| 250 |
+
|
| 251 |
+
if self.gen_inpaint_mask:
|
| 252 |
+
img_in = (img_in*255).astype('uint8')
|
| 253 |
+
img_in = brush_stroke_mask(Image.fromarray(img_in))
|
| 254 |
+
img_in = np.array(img_in) / 255.
|
| 255 |
+
|
| 256 |
+
# random color jitter (only for lq)
|
| 257 |
+
if self.color_jitter_prob is not None and (np.random.uniform() < self.color_jitter_prob):
|
| 258 |
+
img_in = self.color_jitter(img_in, self.color_jitter_shift)
|
| 259 |
+
# random to gray (only for lq)
|
| 260 |
+
if self.gray_prob and np.random.uniform() < self.gray_prob:
|
| 261 |
+
img_in = cv2.cvtColor(img_in, cv2.COLOR_BGR2GRAY)
|
| 262 |
+
img_in = np.tile(img_in[:, :, None], [1, 1, 3])
|
| 263 |
+
|
| 264 |
+
# BGR to RGB, HWC to CHW, numpy to tensor
|
| 265 |
+
img_in, img_gt = img2tensor([img_in, img_gt], bgr2rgb=True, float32=True)
|
| 266 |
+
|
| 267 |
+
# random color jitter (pytorch version) (only for lq)
|
| 268 |
+
if self.color_jitter_pt_prob is not None and (np.random.uniform() < self.color_jitter_pt_prob):
|
| 269 |
+
brightness = self.opt.get('brightness', (0.5, 1.5))
|
| 270 |
+
contrast = self.opt.get('contrast', (0.5, 1.5))
|
| 271 |
+
saturation = self.opt.get('saturation', (0, 1.5))
|
| 272 |
+
hue = self.opt.get('hue', (-0.1, 0.1))
|
| 273 |
+
img_in = self.color_jitter_pt(img_in, brightness, contrast, saturation, hue)
|
| 274 |
+
|
| 275 |
+
# round and clip
|
| 276 |
+
img_in = np.clip((img_in * 255.0).round(), 0, 255) / 255.
|
| 277 |
+
|
| 278 |
+
# Set vgg range_norm=True if use the normalization here
|
| 279 |
+
# normalize
|
| 280 |
+
normalize(img_in, self.mean, self.std, inplace=True)
|
| 281 |
+
normalize(img_gt, self.mean, self.std, inplace=True)
|
| 282 |
+
|
| 283 |
+
return_dict = {'in': img_in, 'gt': img_gt, 'gt_path': gt_path}
|
| 284 |
+
|
| 285 |
+
if self.crop_components:
|
| 286 |
+
return_dict['locations_in'] = locations_in
|
| 287 |
+
return_dict['locations_gt'] = locations_gt
|
| 288 |
+
|
| 289 |
+
if self.load_latent_gt:
|
| 290 |
+
return_dict['latent_gt'] = latent_gt
|
| 291 |
+
|
| 292 |
+
# if self.gen_inpaint_mask:
|
| 293 |
+
# return_dict['inpaint_mask'] = inpaint_mask
|
| 294 |
+
|
| 295 |
+
return return_dict
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
def __len__(self):
|
| 299 |
+
return len(self.paths)
|
basicsr/data/ffhq_blind_joint_dataset.py
ADDED
|
@@ -0,0 +1,324 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import math
|
| 3 |
+
import random
|
| 4 |
+
import numpy as np
|
| 5 |
+
import os.path as osp
|
| 6 |
+
from scipy.io import loadmat
|
| 7 |
+
import torch
|
| 8 |
+
import torch.utils.data as data
|
| 9 |
+
from torchvision.transforms.functional import (adjust_brightness, adjust_contrast,
|
| 10 |
+
adjust_hue, adjust_saturation, normalize)
|
| 11 |
+
from basicsr.data import gaussian_kernels as gaussian_kernels
|
| 12 |
+
from basicsr.data.transforms import augment
|
| 13 |
+
from basicsr.data.data_util import paths_from_folder
|
| 14 |
+
from basicsr.utils import FileClient, get_root_logger, imfrombytes, img2tensor
|
| 15 |
+
from basicsr.utils.registry import DATASET_REGISTRY
|
| 16 |
+
|
| 17 |
+
@DATASET_REGISTRY.register()
|
| 18 |
+
class FFHQBlindJointDataset(data.Dataset):
|
| 19 |
+
|
| 20 |
+
def __init__(self, opt):
|
| 21 |
+
super(FFHQBlindJointDataset, self).__init__()
|
| 22 |
+
logger = get_root_logger()
|
| 23 |
+
self.opt = opt
|
| 24 |
+
# file client (io backend)
|
| 25 |
+
self.file_client = None
|
| 26 |
+
self.io_backend_opt = opt['io_backend']
|
| 27 |
+
|
| 28 |
+
self.gt_folder = opt['dataroot_gt']
|
| 29 |
+
self.gt_size = opt.get('gt_size', 512)
|
| 30 |
+
self.in_size = opt.get('in_size', 512)
|
| 31 |
+
assert self.gt_size >= self.in_size, 'Wrong setting.'
|
| 32 |
+
|
| 33 |
+
self.mean = opt.get('mean', [0.5, 0.5, 0.5])
|
| 34 |
+
self.std = opt.get('std', [0.5, 0.5, 0.5])
|
| 35 |
+
|
| 36 |
+
self.component_path = opt.get('component_path', None)
|
| 37 |
+
self.latent_gt_path = opt.get('latent_gt_path', None)
|
| 38 |
+
|
| 39 |
+
if self.component_path is not None:
|
| 40 |
+
self.crop_components = True
|
| 41 |
+
self.components_dict = torch.load(self.component_path)
|
| 42 |
+
self.eye_enlarge_ratio = opt.get('eye_enlarge_ratio', 1.4)
|
| 43 |
+
self.nose_enlarge_ratio = opt.get('nose_enlarge_ratio', 1.1)
|
| 44 |
+
self.mouth_enlarge_ratio = opt.get('mouth_enlarge_ratio', 1.3)
|
| 45 |
+
else:
|
| 46 |
+
self.crop_components = False
|
| 47 |
+
|
| 48 |
+
if self.latent_gt_path is not None:
|
| 49 |
+
self.load_latent_gt = True
|
| 50 |
+
self.latent_gt_dict = torch.load(self.latent_gt_path)
|
| 51 |
+
else:
|
| 52 |
+
self.load_latent_gt = False
|
| 53 |
+
|
| 54 |
+
if self.io_backend_opt['type'] == 'lmdb':
|
| 55 |
+
self.io_backend_opt['db_paths'] = self.gt_folder
|
| 56 |
+
if not self.gt_folder.endswith('.lmdb'):
|
| 57 |
+
raise ValueError("'dataroot_gt' should end with '.lmdb', "f'but received {self.gt_folder}')
|
| 58 |
+
with open(osp.join(self.gt_folder, 'meta_info.txt')) as fin:
|
| 59 |
+
self.paths = [line.split('.')[0] for line in fin]
|
| 60 |
+
else:
|
| 61 |
+
self.paths = paths_from_folder(self.gt_folder)
|
| 62 |
+
|
| 63 |
+
# perform corrupt
|
| 64 |
+
self.use_corrupt = opt.get('use_corrupt', True)
|
| 65 |
+
self.use_motion_kernel = False
|
| 66 |
+
# self.use_motion_kernel = opt.get('use_motion_kernel', True)
|
| 67 |
+
|
| 68 |
+
if self.use_motion_kernel:
|
| 69 |
+
self.motion_kernel_prob = opt.get('motion_kernel_prob', 0.001)
|
| 70 |
+
motion_kernel_path = opt.get('motion_kernel_path', 'basicsr/data/motion-blur-kernels-32.pth')
|
| 71 |
+
self.motion_kernels = torch.load(motion_kernel_path)
|
| 72 |
+
|
| 73 |
+
if self.use_corrupt:
|
| 74 |
+
# degradation configurations
|
| 75 |
+
self.blur_kernel_size = self.opt['blur_kernel_size']
|
| 76 |
+
self.kernel_list = self.opt['kernel_list']
|
| 77 |
+
self.kernel_prob = self.opt['kernel_prob']
|
| 78 |
+
# Small degradation
|
| 79 |
+
self.blur_sigma = self.opt['blur_sigma']
|
| 80 |
+
self.downsample_range = self.opt['downsample_range']
|
| 81 |
+
self.noise_range = self.opt['noise_range']
|
| 82 |
+
self.jpeg_range = self.opt['jpeg_range']
|
| 83 |
+
# Large degradation
|
| 84 |
+
self.blur_sigma_large = self.opt['blur_sigma_large']
|
| 85 |
+
self.downsample_range_large = self.opt['downsample_range_large']
|
| 86 |
+
self.noise_range_large = self.opt['noise_range_large']
|
| 87 |
+
self.jpeg_range_large = self.opt['jpeg_range_large']
|
| 88 |
+
|
| 89 |
+
# print
|
| 90 |
+
logger.info(f'Blur: blur_kernel_size {self.blur_kernel_size}, sigma: [{", ".join(map(str, self.blur_sigma))}]')
|
| 91 |
+
logger.info(f'Downsample: downsample_range [{", ".join(map(str, self.downsample_range))}]')
|
| 92 |
+
logger.info(f'Noise: [{", ".join(map(str, self.noise_range))}]')
|
| 93 |
+
logger.info(f'JPEG compression: [{", ".join(map(str, self.jpeg_range))}]')
|
| 94 |
+
|
| 95 |
+
# color jitter
|
| 96 |
+
self.color_jitter_prob = opt.get('color_jitter_prob', None)
|
| 97 |
+
self.color_jitter_pt_prob = opt.get('color_jitter_pt_prob', None)
|
| 98 |
+
self.color_jitter_shift = opt.get('color_jitter_shift', 20)
|
| 99 |
+
if self.color_jitter_prob is not None:
|
| 100 |
+
logger.info(f'Use random color jitter. Prob: {self.color_jitter_prob}, shift: {self.color_jitter_shift}')
|
| 101 |
+
|
| 102 |
+
# to gray
|
| 103 |
+
self.gray_prob = opt.get('gray_prob', 0.0)
|
| 104 |
+
if self.gray_prob is not None:
|
| 105 |
+
logger.info(f'Use random gray. Prob: {self.gray_prob}')
|
| 106 |
+
self.color_jitter_shift /= 255.
|
| 107 |
+
|
| 108 |
+
@staticmethod
|
| 109 |
+
def color_jitter(img, shift):
|
| 110 |
+
"""jitter color: randomly jitter the RGB values, in numpy formats"""
|
| 111 |
+
jitter_val = np.random.uniform(-shift, shift, 3).astype(np.float32)
|
| 112 |
+
img = img + jitter_val
|
| 113 |
+
img = np.clip(img, 0, 1)
|
| 114 |
+
return img
|
| 115 |
+
|
| 116 |
+
@staticmethod
|
| 117 |
+
def color_jitter_pt(img, brightness, contrast, saturation, hue):
|
| 118 |
+
"""jitter color: randomly jitter the brightness, contrast, saturation, and hue, in torch Tensor formats"""
|
| 119 |
+
fn_idx = torch.randperm(4)
|
| 120 |
+
for fn_id in fn_idx:
|
| 121 |
+
if fn_id == 0 and brightness is not None:
|
| 122 |
+
brightness_factor = torch.tensor(1.0).uniform_(brightness[0], brightness[1]).item()
|
| 123 |
+
img = adjust_brightness(img, brightness_factor)
|
| 124 |
+
|
| 125 |
+
if fn_id == 1 and contrast is not None:
|
| 126 |
+
contrast_factor = torch.tensor(1.0).uniform_(contrast[0], contrast[1]).item()
|
| 127 |
+
img = adjust_contrast(img, contrast_factor)
|
| 128 |
+
|
| 129 |
+
if fn_id == 2 and saturation is not None:
|
| 130 |
+
saturation_factor = torch.tensor(1.0).uniform_(saturation[0], saturation[1]).item()
|
| 131 |
+
img = adjust_saturation(img, saturation_factor)
|
| 132 |
+
|
| 133 |
+
if fn_id == 3 and hue is not None:
|
| 134 |
+
hue_factor = torch.tensor(1.0).uniform_(hue[0], hue[1]).item()
|
| 135 |
+
img = adjust_hue(img, hue_factor)
|
| 136 |
+
return img
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def get_component_locations(self, name, status):
|
| 140 |
+
components_bbox = self.components_dict[name]
|
| 141 |
+
if status[0]: # hflip
|
| 142 |
+
# exchange right and left eye
|
| 143 |
+
tmp = components_bbox['left_eye']
|
| 144 |
+
components_bbox['left_eye'] = components_bbox['right_eye']
|
| 145 |
+
components_bbox['right_eye'] = tmp
|
| 146 |
+
# modify the width coordinate
|
| 147 |
+
components_bbox['left_eye'][0] = self.gt_size - components_bbox['left_eye'][0]
|
| 148 |
+
components_bbox['right_eye'][0] = self.gt_size - components_bbox['right_eye'][0]
|
| 149 |
+
components_bbox['nose'][0] = self.gt_size - components_bbox['nose'][0]
|
| 150 |
+
components_bbox['mouth'][0] = self.gt_size - components_bbox['mouth'][0]
|
| 151 |
+
|
| 152 |
+
locations_gt = {}
|
| 153 |
+
locations_in = {}
|
| 154 |
+
for part in ['left_eye', 'right_eye', 'nose', 'mouth']:
|
| 155 |
+
mean = components_bbox[part][0:2]
|
| 156 |
+
half_len = components_bbox[part][2]
|
| 157 |
+
if 'eye' in part:
|
| 158 |
+
half_len *= self.eye_enlarge_ratio
|
| 159 |
+
elif part == 'nose':
|
| 160 |
+
half_len *= self.nose_enlarge_ratio
|
| 161 |
+
elif part == 'mouth':
|
| 162 |
+
half_len *= self.mouth_enlarge_ratio
|
| 163 |
+
loc = np.hstack((mean - half_len + 1, mean + half_len))
|
| 164 |
+
loc = torch.from_numpy(loc).float()
|
| 165 |
+
locations_gt[part] = loc
|
| 166 |
+
loc_in = loc/(self.gt_size//self.in_size)
|
| 167 |
+
locations_in[part] = loc_in
|
| 168 |
+
return locations_gt, locations_in
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def __getitem__(self, index):
|
| 172 |
+
if self.file_client is None:
|
| 173 |
+
self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
|
| 174 |
+
|
| 175 |
+
# load gt image
|
| 176 |
+
gt_path = self.paths[index]
|
| 177 |
+
name = osp.basename(gt_path)[:-4]
|
| 178 |
+
img_bytes = self.file_client.get(gt_path)
|
| 179 |
+
img_gt = imfrombytes(img_bytes, float32=True)
|
| 180 |
+
|
| 181 |
+
# random horizontal flip
|
| 182 |
+
img_gt, status = augment(img_gt, hflip=self.opt['use_hflip'], rotation=False, return_status=True)
|
| 183 |
+
|
| 184 |
+
if self.load_latent_gt:
|
| 185 |
+
if status[0]:
|
| 186 |
+
latent_gt = self.latent_gt_dict['hflip'][name]
|
| 187 |
+
else:
|
| 188 |
+
latent_gt = self.latent_gt_dict['orig'][name]
|
| 189 |
+
|
| 190 |
+
if self.crop_components:
|
| 191 |
+
locations_gt, locations_in = self.get_component_locations(name, status)
|
| 192 |
+
|
| 193 |
+
# generate in image
|
| 194 |
+
img_in = img_gt
|
| 195 |
+
if self.use_corrupt:
|
| 196 |
+
# motion blur
|
| 197 |
+
if self.use_motion_kernel and random.random() < self.motion_kernel_prob:
|
| 198 |
+
m_i = random.randint(0,31)
|
| 199 |
+
k = self.motion_kernels[f'{m_i:02d}']
|
| 200 |
+
img_in = cv2.filter2D(img_in,-1,k)
|
| 201 |
+
|
| 202 |
+
# gaussian blur
|
| 203 |
+
kernel = gaussian_kernels.random_mixed_kernels(
|
| 204 |
+
self.kernel_list,
|
| 205 |
+
self.kernel_prob,
|
| 206 |
+
self.blur_kernel_size,
|
| 207 |
+
self.blur_sigma,
|
| 208 |
+
self.blur_sigma,
|
| 209 |
+
[-math.pi, math.pi],
|
| 210 |
+
noise_range=None)
|
| 211 |
+
img_in = cv2.filter2D(img_in, -1, kernel)
|
| 212 |
+
|
| 213 |
+
# downsample
|
| 214 |
+
scale = np.random.uniform(self.downsample_range[0], self.downsample_range[1])
|
| 215 |
+
img_in = cv2.resize(img_in, (int(self.gt_size // scale), int(self.gt_size // scale)), interpolation=cv2.INTER_LINEAR)
|
| 216 |
+
|
| 217 |
+
# noise
|
| 218 |
+
if self.noise_range is not None:
|
| 219 |
+
noise_sigma = np.random.uniform(self.noise_range[0] / 255., self.noise_range[1] / 255.)
|
| 220 |
+
noise = np.float32(np.random.randn(*(img_in.shape))) * noise_sigma
|
| 221 |
+
img_in = img_in + noise
|
| 222 |
+
img_in = np.clip(img_in, 0, 1)
|
| 223 |
+
|
| 224 |
+
# jpeg
|
| 225 |
+
if self.jpeg_range is not None:
|
| 226 |
+
jpeg_p = np.random.uniform(self.jpeg_range[0], self.jpeg_range[1])
|
| 227 |
+
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), jpeg_p]
|
| 228 |
+
_, encimg = cv2.imencode('.jpg', img_in * 255., encode_param)
|
| 229 |
+
img_in = np.float32(cv2.imdecode(encimg, 1)) / 255.
|
| 230 |
+
|
| 231 |
+
# resize to in_size
|
| 232 |
+
img_in = cv2.resize(img_in, (self.in_size, self.in_size), interpolation=cv2.INTER_LINEAR)
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
# generate in_large with large degradation
|
| 236 |
+
img_in_large = img_gt
|
| 237 |
+
|
| 238 |
+
if self.use_corrupt:
|
| 239 |
+
# motion blur
|
| 240 |
+
if self.use_motion_kernel and random.random() < self.motion_kernel_prob:
|
| 241 |
+
m_i = random.randint(0,31)
|
| 242 |
+
k = self.motion_kernels[f'{m_i:02d}']
|
| 243 |
+
img_in_large = cv2.filter2D(img_in_large,-1,k)
|
| 244 |
+
|
| 245 |
+
# gaussian blur
|
| 246 |
+
kernel = gaussian_kernels.random_mixed_kernels(
|
| 247 |
+
self.kernel_list,
|
| 248 |
+
self.kernel_prob,
|
| 249 |
+
self.blur_kernel_size,
|
| 250 |
+
self.blur_sigma_large,
|
| 251 |
+
self.blur_sigma_large,
|
| 252 |
+
[-math.pi, math.pi],
|
| 253 |
+
noise_range=None)
|
| 254 |
+
img_in_large = cv2.filter2D(img_in_large, -1, kernel)
|
| 255 |
+
|
| 256 |
+
# downsample
|
| 257 |
+
scale = np.random.uniform(self.downsample_range_large[0], self.downsample_range_large[1])
|
| 258 |
+
img_in_large = cv2.resize(img_in_large, (int(self.gt_size // scale), int(self.gt_size // scale)), interpolation=cv2.INTER_LINEAR)
|
| 259 |
+
|
| 260 |
+
# noise
|
| 261 |
+
if self.noise_range_large is not None:
|
| 262 |
+
noise_sigma = np.random.uniform(self.noise_range_large[0] / 255., self.noise_range_large[1] / 255.)
|
| 263 |
+
noise = np.float32(np.random.randn(*(img_in_large.shape))) * noise_sigma
|
| 264 |
+
img_in_large = img_in_large + noise
|
| 265 |
+
img_in_large = np.clip(img_in_large, 0, 1)
|
| 266 |
+
|
| 267 |
+
# jpeg
|
| 268 |
+
if self.jpeg_range_large is not None:
|
| 269 |
+
jpeg_p = np.random.uniform(self.jpeg_range_large[0], self.jpeg_range_large[1])
|
| 270 |
+
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), jpeg_p]
|
| 271 |
+
_, encimg = cv2.imencode('.jpg', img_in_large * 255., encode_param)
|
| 272 |
+
img_in_large = np.float32(cv2.imdecode(encimg, 1)) / 255.
|
| 273 |
+
|
| 274 |
+
# resize to in_size
|
| 275 |
+
img_in_large = cv2.resize(img_in_large, (self.in_size, self.in_size), interpolation=cv2.INTER_LINEAR)
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
# random color jitter (only for lq)
|
| 279 |
+
if self.color_jitter_prob is not None and (np.random.uniform() < self.color_jitter_prob):
|
| 280 |
+
img_in = self.color_jitter(img_in, self.color_jitter_shift)
|
| 281 |
+
img_in_large = self.color_jitter(img_in_large, self.color_jitter_shift)
|
| 282 |
+
# random to gray (only for lq)
|
| 283 |
+
if self.gray_prob and np.random.uniform() < self.gray_prob:
|
| 284 |
+
img_in = cv2.cvtColor(img_in, cv2.COLOR_BGR2GRAY)
|
| 285 |
+
img_in = np.tile(img_in[:, :, None], [1, 1, 3])
|
| 286 |
+
img_in_large = cv2.cvtColor(img_in_large, cv2.COLOR_BGR2GRAY)
|
| 287 |
+
img_in_large = np.tile(img_in_large[:, :, None], [1, 1, 3])
|
| 288 |
+
|
| 289 |
+
# BGR to RGB, HWC to CHW, numpy to tensor
|
| 290 |
+
img_in, img_in_large, img_gt = img2tensor([img_in, img_in_large, img_gt], bgr2rgb=True, float32=True)
|
| 291 |
+
|
| 292 |
+
# random color jitter (pytorch version) (only for lq)
|
| 293 |
+
if self.color_jitter_pt_prob is not None and (np.random.uniform() < self.color_jitter_pt_prob):
|
| 294 |
+
brightness = self.opt.get('brightness', (0.5, 1.5))
|
| 295 |
+
contrast = self.opt.get('contrast', (0.5, 1.5))
|
| 296 |
+
saturation = self.opt.get('saturation', (0, 1.5))
|
| 297 |
+
hue = self.opt.get('hue', (-0.1, 0.1))
|
| 298 |
+
img_in = self.color_jitter_pt(img_in, brightness, contrast, saturation, hue)
|
| 299 |
+
img_in_large = self.color_jitter_pt(img_in_large, brightness, contrast, saturation, hue)
|
| 300 |
+
|
| 301 |
+
# round and clip
|
| 302 |
+
img_in = np.clip((img_in * 255.0).round(), 0, 255) / 255.
|
| 303 |
+
img_in_large = np.clip((img_in_large * 255.0).round(), 0, 255) / 255.
|
| 304 |
+
|
| 305 |
+
# Set vgg range_norm=True if use the normalization here
|
| 306 |
+
# normalize
|
| 307 |
+
normalize(img_in, self.mean, self.std, inplace=True)
|
| 308 |
+
normalize(img_in_large, self.mean, self.std, inplace=True)
|
| 309 |
+
normalize(img_gt, self.mean, self.std, inplace=True)
|
| 310 |
+
|
| 311 |
+
return_dict = {'in': img_in, 'in_large_de': img_in_large, 'gt': img_gt, 'gt_path': gt_path}
|
| 312 |
+
|
| 313 |
+
if self.crop_components:
|
| 314 |
+
return_dict['locations_in'] = locations_in
|
| 315 |
+
return_dict['locations_gt'] = locations_gt
|
| 316 |
+
|
| 317 |
+
if self.load_latent_gt:
|
| 318 |
+
return_dict['latent_gt'] = latent_gt
|
| 319 |
+
|
| 320 |
+
return return_dict
|
| 321 |
+
|
| 322 |
+
|
| 323 |
+
def __len__(self):
|
| 324 |
+
return len(self.paths)
|