

本模型在数据集BAAI/IndustryCorpus2中用来进行质量评估
为什么要筛选低质量的数据
下面是从数据中抽取的低质量数据,可以看到这种数据对模型的学习是有害无益的
{"text": "\\_\\__\n\nTranslated from *Chinese Journal of Biochemistry and Molecular Biology*, 2007, 23(2): 154--159 \\[译自:中国生物化学与分子生物学报\\]\n"} {"text": "#ifndef _IMGBMP_H_\n#define _IMGBMP_H_\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\nconst uint8_t bmp[]={\n\\/\\/-- 调入了一幅图像:D:\\我的文档\\My Pictures\\12864-555.bmp --*\\/\n\\/\\/-- 宽度x高度=128x64 --\n0x00,0x06,0x0A,0xFE,0x0A,0xC6,0x00,0xE0,0x00,0xF0,0x00,0xF8,0x00,0x00,0x00,0x00,\n0x00,0x00,0xFE,0x7D,0xBB,0xC7,0xEF,0xEF,0xEF,0xEF,0xEF,0xEF,0xEF,0xC7,0xBB,0x7D,\n0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x08,\n0x0C,0xFE,0xFE,0x0C,0x08,0x20,0x60,0xFE,0xFE,0x60,0x20,0x00,0x00,0x00,0x78,0x48,\n0xFE,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xBA,0xBA,0x82,0xFE,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,0x01,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFE,0xFF,\n0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,0xFF,0x00,0x00,0xFE,0xFF,0x03,\n0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,0xFE,0x00,0x00,0x00,0x00,0xC0,0xC0,\n0xC0,0x00,0x00,0x00,0x00,0xFE,0xFF,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,\n0xFF,0xFE,0x00,0x00,0xFE,0xFF,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0x03,0xFF,\n0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0xFF,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0xFF,0x00,0x00,0xFF,0xFF,0x0C,\n0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0xFF,0xFF,0x00,0x00,0x00,0x00,0xE1,0xE1,\n0xE1,0x00,0x00,0x00,0x00,0xFF,0xFF,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0xFF,0xFF,0x00,0x00,0xFF,0xFF,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0x0C,0xFF,\n0xFF,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x0F,0x1F,\n0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,0x0F,0x00,0x00,0x0F,0x1F,0x18,\n0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,0x0F,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x0F,0x1F,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,\n0x1F,0x0F,0x00,0x00,0x0F,0x1F,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x1F,\n0x0F,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0xE2,0x92,0x8A,0x86,0x00,0x00,0x7C,0x82,0x82,0x82,0x7C,\n0x00,0xFE,0x00,0x82,0x92,0xAA,0xC6,0x00,0x00,0xC0,0xC0,0x00,0x7C,0x82,0x82,0x82,\n0x7C,0x00,0x00,0x02,0x02,0x02,0xFE,0x00,0x00,0xC0,0xC0,0x00,0x7C,0x82,0x82,0x82,\n0x7C,0x00,0x00,0xFE,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x24,0xA4,0x2E,0x24,0xE4,0x24,0x2E,0xA4,0x24,0x00,0x00,0x00,0xF8,0x4A,0x4C,\n0x48,0xF8,0x48,0x4C,0x4A,0xF8,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xC0,0x20,0x10,0x10,\n0x10,0x10,0x20,0xC0,0x00,0x00,0xC0,0x20,0x10,0x10,0x10,0x10,0x20,0xC0,0x00,0x00,\n0x00,0x12,0x0A,0x07,0x02,0x7F,0x02,0x07,0x0A,0x12,0x00,0x00,0x00,0x0B,0x0A,0x0A,\n0x0A,0x7F,0x0A,0x0A,0x0A,0x0B,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\n0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x1F,0x20,0x40,0x40,\n0x40,0x50,0x20,0x5F,0x80,0x00,0x1F,0x20,0x40,0x40,0x40,0x50,0x20,0x5F,0x80,0x00,\n}; \n\n\n#ifdef __cplusplus\n}\n#endif\n\n#endif \\/\\/ _IMGBMP_H_ _SSD1306_16BIT_H_\n"}数据构建
数据来源:随机采样预训练语料
标签构建:设计数据打分细则,借助LLM模型进行多轮打分,筛选多轮打分分差小于2的数据
数据规模:20k打分数据,中英文比例1:1
数据打分prompt
quality_prompt = """Below is an extract from a web page. Evaluate whether the page has a high natural language value and could be useful in an naturanl language task to train a good language model using the additive 5-point scoring system described below. Points are accumulated based on the satisfaction of each criterion: - Zero score if the content contains only some meaningless content or private content, such as some random code, http url or copyright information, personally identifiable information, binary encoding of images. - Add 1 point if the extract provides some basic information, even if it includes some useless contents like advertisements and promotional material. - Add another point if the extract is written in good style, semantically fluent, and free of repetitive content and grammatical errors. - Award a third point tf the extract has relatively complete semantic content, and is written in a good and fluent style, the entire content expresses something related to the same topic, rather than a patchwork of several unrelated items. - A fourth point is awarded if the extract has obvious educational or literary value, or provides a meaningful point or content, contributes to the learning of the topic, and is written in a clear and consistent style. It may be similar to a chapter in a textbook or tutorial, providing a lot of educational content, including exercises and solutions, with little to no superfluous information. The content is coherent and focused, which is valuable for structured learning. - A fifth point is awarded if the extract has outstanding educational value or is of very high information density, provides very high value and meaningful content, does not contain useless information, and is well suited for teaching or knowledge transfer. It contains detailed reasoning, has an easy-to-follow writing style, and can provide deep and thorough insights. The extract: <{EXAMPLE}>. After examining the extract: - Briefly justify your total score, up to 50 words. - Conclude with the score using the format: "Quality score: <total points>" ... """模型训练
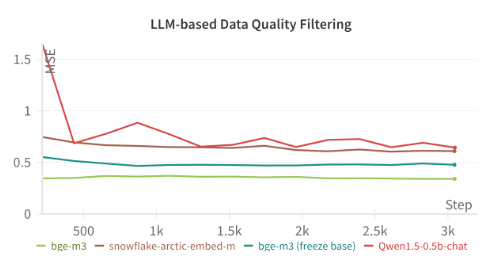
模型选型:与分类模型类似,我们同样使用的是0.5b规模的模型,并对比试验了beg-m3和qwen-0.5b,最终实验显示bge-m3综合表现最优
模型超参:基座bge-m3,全参数训练,lr=1e-5,batch_size=64, max_length = 2048
模型评估:在验证集上模型与GPT4对样本质量判定一致率为90%
高质量数据带来的训练收益
我们为了验证高质量的数据是否能带来更高效的训练效率,在同一基座模型下,使用从未筛选之前的50b数据中抽取出高质量数据,可以认为两个数据的分布大体是一致的,进行自回归训练.
曲线中可以看到,经过高质量数据训练的模型14B的tokens可以达到普通数据50B的模型表现,高质量的数据可以极大的提升训练效率。
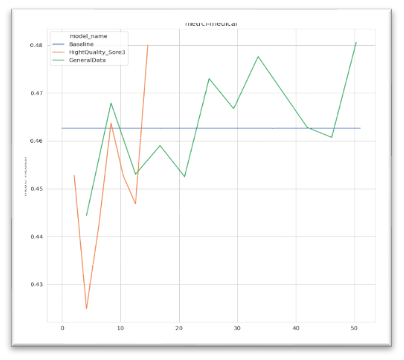


此外,高质量的数据可以作为预训练的退火阶段的数据加入到模型中,进一步拉升模型效果,为了验证这个猜测,我们在训练行业模型时候,在模型的退火阶段加入了筛选之后高质量数据和部分指令数据转成的预训练数据,可以看到极大提高了模型的表现。

最后,高质量的预训练语料中包含着丰富的高价值知识性内容,可以从中提取出指令数据进一步提升指令数据的丰富度和知识性,这也催发了Industry-Instruction项目的诞生,我们会在那里进行详细的说明。