
Evaluation Results | Model Download | Setup Environment | Quick Start | Questions and Bugs | License | Citation | Contact
Goedel-Prover: A New Frontier in Open-source Automated Theorem Proving
1. Introduction
We introduce Goedel-Prover, an open-source language model that achieves state-of-the-art performance in automated formal proof generation for mathematical problems. A key challenge in this field is the scarcity of formalized mathematical statements and proofs, which we address through the following approaches. First, we train statement formalizers to translate natural language math problems from Numina into the formal language Lean 4, and use an LLM to verify that the formal statements accurately preserve the content of the original problems. This results in a dataset of 1.64 million formal statements. We then iteratively build a large dataset of formal proofs by training a series of provers: each prover is able to prove many statements that the previous ones could not, and these new proofs are added to the training set for the next prover. Despite using only supervised fine-tuning, our final prover (fine-tuned on DeepSeek-Prover-V1.5-Base) significantly outperforms the previous best open-source model, DeepSeek-Prover-V1.5-RL, which uses reinforcement learning (RL). On the miniF2F benchmark, our model achieves a success rate of 57.6% (Pass@32), surpassing DeepSeek-Prover-V1.5-RL by 7.6%. On PutnamBench, Goedel-Prover successfully solves 7 problems (Pass@512), ranking first on the leaderboard. Furthermore, it generates 29.7K formal proofs for Lean Workbook problems, nearly doubling the 15.7K produced by prior work. We provide extensive discussion of our training methodology, highlighting the key design choices that contribute to Goedel-Prover's strong performance. We then explore direct preference optimization (DPO) and other forms of reinforcement learning on top of Goedel-Prover-SFT, improving success to over 60% (Pass@32) on miniF2F. Additionally, we fully open source our code, model, and formalized statements to facilitate future research.
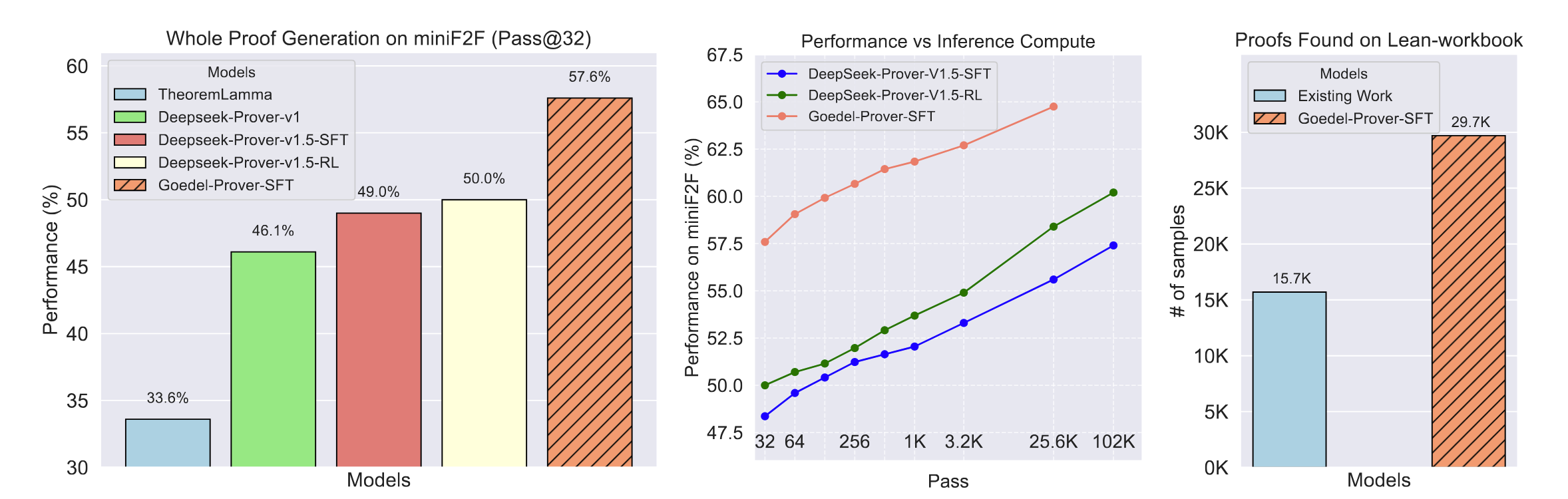
Caption: The Pass@N metric indicates that we generate N proofs for a single problem; if any one of these N proofs successfully solves the problem, it is considered solved. (Left): The performance of Pass@32 for full proof generation on miniF2F. Due to limited compute, we compare with DeepSeek-Prover-v1.5 on the Pass@32 metric. (Middle): This sub-figure presents a comparison of Goedel-Prover and Deepseek-Prover-v1.5 in terms of miniF2F performance across different inference budgets, ranging from Pass@32, 64, 128, ..., 4 * 6400, to 16 * 6400. The performance numbers of Deepseek-Prover-v1.5 are directly taken from Table 1 of Xin et al. (2024b). Due to computational resource constraints, we tested Goedel-Prover-SFT only up to Pass@4 × 6400. Notably, Goedel-Prover-SFT's Pass@256 already exceeds the Pass@16 * 6400 performance of Deepseek-Prover-v1.5-RL (without inference time tree search). (Right): The number of problems solved in Lean-workbook by Goedel-Prover-SFT compared to prior works. InternLM2.5-Step-Prover and InternLM-Math-Plus collectively solve and open-source 15.7K samples, while we solve and open-source 29.7K samples.
2. Evaluation Results
| Model | Compute (Pass) | miniF2F-test |
|---|---|---|
| TheoremLamma | 128 | 33.6% |
| DeepSeek-Prover-V1 | 32 | 46.1% |
| DeepSeek-Prover-V1.5-SFT | 32 | 48.2% |
| DeepSeek-Prover-V1.5-RL | 32 | 50.0% |
| Goedel-Prover-SFT | 32 | 57.6% |
| Goedel-Prover-DPO | 32 | 60.2% |
| Goedel-Prover-RL | 32 | 60.5% |
| ------------------------ | ------------------ | ------------------ |
| DeepSeek-Prover-V1.5-SFT | 3200 | 53.3% |
| DeepSeek-Prover-V1.5-RL | 3200 | 54.9% |
| Goedel-Prover-SFT | 3200 | 62.7% |
| Goedel-Prover-DPO | 3200 | 65.0% |
| Goedel-Prover-RL | 3200 | 63.2% |
| ------------------------ | ------------------ | ------------------ |
| DeepSeek-Prover-V1.5-SFT | 25600 | 55.8% |
| DeepSeek-Prover-V1.5-RL | 25600 | 58.5% |
| Goedel-Prover-SFT | 25600 | 64.7% |
Caption: Comparison of Goedel-Prover-SFT with existing methods for whole proof generation on miniF2F, assessing performance across various inference time computations.
| miniF2F | ProofNet | FormalNumina | Lean-workbook | |
|---|---|---|---|---|
| Deepseek-Prover-v1.5-RL | 50.0% | 16.0% | 54.0% | 14.7% |
| Goedel-Prover-SFT | 57.6% | 15.2% | 61.2% | 21.2% |
Caption: Comparison of Goedel-Prover-SFT with Deepseek-Prover-v1.5-RL for whole proof generation on miniF2F, ProofNet,FormalNumina,Lean-workbook. We report the Pass@32 performance for miniF2F, ProofNet, and FormalNumina datasets. For the Lean-workbook, we evaluate performance using Pass@16 due to the large number of problems (140K) it contains, allowing us to save on computational costs. FormalNumina is a private test set created by formalizing a randomly sampled collection of 250 problems from Numina.
| Ranking | Model | Type | Num-solved | Compute |
|---|---|---|---|---|
| 1 | Goedel-Prover-SFT 🟩 | Whole Proof Generation | 7 | 512 |
| 1 | ABEL | Tree Search Method | 7 | 596 |
| 3 | Goedel-Prover-SFT 🟩 | Whole Proof Generation | 6 | 32 |
| 3 | InternLM2.5-StepProver 🟩 | Tree Search Method | 6 | 2×32×600 |
| 5 | InternLM 7B | Whole Proof Generation | 4 | 4096 |
| 6 | GPT-4o | Whole Proof Generation | 1 | 10 |
| 7 | COPRA (GPT-4o) 🟩 | Whole Proof Generation | 1 | 1 |
| 8 | ReProver w/ retrieval 🟩 | Whole Proof Generation | 0 | 1 |
| 9 | ReProver w/o retrieval 🟩 | Whole Proof Generation | 0 | 1 |
Caption: Our model rank the 1st on Putnam Leaderboard. The performance numbers for existing works are taken from the leaderboard. 🟩 indicates open sourced models.
3. Dataset Downloads
We are also releasing the largest lean problem set Goedel-Pset-v1 and the proofs of the problems in Lean-workbook found by our Goedel-Prover-SFT, .
| Datasets | Download |
|---|---|
| Goedel-Pset-v1 | 🤗 HuggingFace |
| Lean-workbook-proofs | 🤗 HuggingFace |
4. Citation
@misc{lin2025goedelproverfrontiermodelopensource,
title={Goedel-Prover: A Frontier Model for Open-Source Automated Theorem Proving},
author={Yong Lin and Shange Tang and Bohan Lyu and Jiayun Wu and Hongzhou Lin and Kaiyu Yang and Jia Li and Mengzhou Xia and Danqi Chen and Sanjeev Arora and Chi Jin},
year={2025},
eprint={2502.07640},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2502.07640},
}
- Downloads last month
- 762