
Antidote Project
Collection
Data and models generated within the Antidote Project (https://univ-cotedazur.eu/antidote)
•
20 items
•
Updated
•
5

We present Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Medical mT5 is an encoder-decoder model developed by continuing the training of publicly available mT5 checkpoints on medical domain data for English, Spanish, French, and Italian.
| Medical mT5-Large (HiTZ/Medical-mT5-large) | Medical mT5-XL (HiTZ/Medical-mT5-xl) | |
|---|---|---|
| Param. no. | 738M | 3B |
| Sequence Length | 1024 | 480 |
| Token/step | 65536 | 30720 |
| Epochs | 1 | 1 |
| Total Tokens | 4.5B | 4.5B |
| Optimizer | Adafactor | Adafactor |
| LR | 0.001 | 0.001 |
| Scheduler | Constant | Constant |
| Hardware | 4xA100 | 4xA100 |
| Time (h) | 10.5 | 20.5 |
| CO2eq (kg) | 2.9 | 5.6 |
You can load the model using
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("HiTZ/Medical-mT5-large")
model = AutoModelForSeq2SeqLM.from_pretrained("HiTZ/Medical-mT5-large")
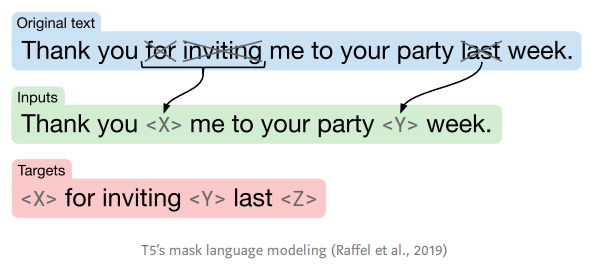
The model has been trained using the T5 masked language modelling tasks. You need to finetune the model for your task.
| Language | Source | Words |
|---|---|---|
| English | ClinicalTrials | 127.4M |
| EMEA | 12M | |
| PubMed | 968.4M | |
| Spanish | EMEA | 13.6M |
| PubMed | 8.4M | |
| Medical Crawler | 918M | |
| SPACC | 350K | |
| UFAL | 10.5M | |
| WikiMed | 5.2M | |
| French | PubMed | 1.4M |
| Science Direct | 15.2M | |
| Wikipedia - Médecine | 5M | |
| EDP | 48K | |
| Google Patents | 654M | |
| Italian | Medical Commoncrawl - IT | 67M |
| Drug instructions | 30.5M | |
| Wikipedia - Medicina | 13.3M | |
| E3C Corpus - IT | 11.6M | |
| Medicine descriptions | 6.3M | |
| Medical theses | 5.8M | |
| Medical websites | 4M | |
| PubMed | 2.3M | |
| Supplement description | 1.3M | |
| Medical notes | 975K | |
| Pathologies | 157K | |
| Medical test simulations | 26K | |
| Clinical cases | 20K |
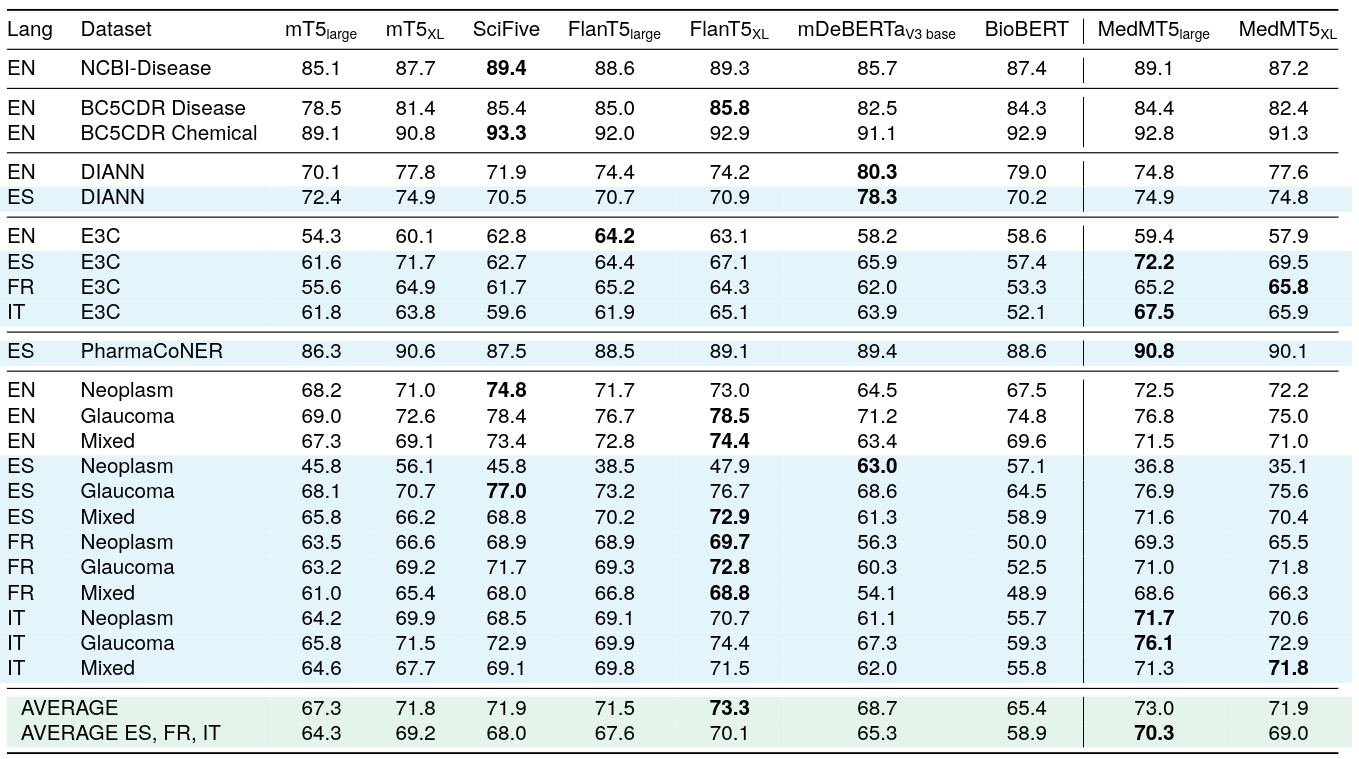
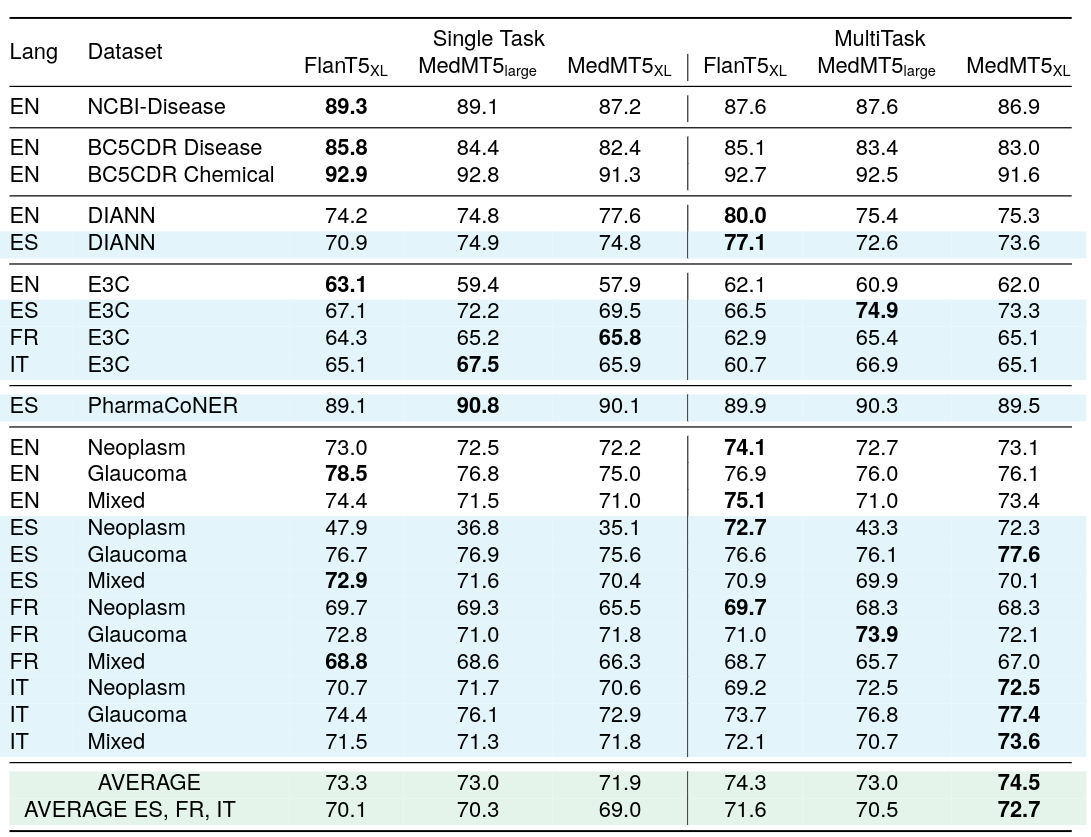
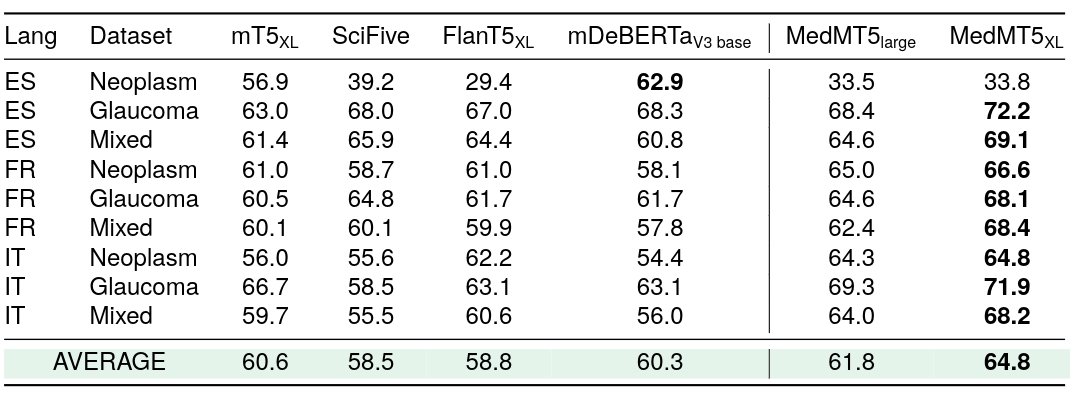
We have released two Medical mT5 models finetuned for multilingual sequence labelling.
| HiTZ/Medical-mT5-large | HiTZ/Medical-mT5-xl | HiTZ/Medical-mT5-large-multitask | HiTZ/Medical-mT5-xl-multitask | |
|---|---|---|---|---|
| Param. no. | 738M | 3B | 738M | 3B |
| Task | Language Modeling | Language Modeling | Multitask Sequence Labeling | Multitask Sequence Labeling |
Our research in developing Medical mT5, a multilingual text-to-text model for the medical domain, has ethical implications that we acknowledge. Firstly, the broader impact of this work lies in its potential to improve medical communication and understanding across languages, which can enhance healthcare access and quality for diverse linguistic communities. However, it also raises ethical considerations related to privacy and data security. To create our multilingual corpus, we have taken measures to anonymize and protect sensitive patient information, adhering to data protection regulations in each language's jurisdiction or deriving our data from sources that explicitly address this issue in line with privacy and safety regulations and guidelines. Furthermore, we are committed to transparency and fairness in our model's development and evaluation. We have worked to ensure that our benchmarks are representative and unbiased, and we will continue to monitor and address any potential biases in the future. Finally, we emphasize our commitment to open source by making our data, code, and models publicly available, with the aim of promoting collaboration within the research community.
@misc{garcíaferrero2024medical,
title={Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain},
author={Iker García-Ferrero and Rodrigo Agerri and Aitziber Atutxa Salazar and Elena Cabrio and Iker de la Iglesia and Alberto Lavelli and Bernardo Magnini and Benjamin Molinet and Johana Ramirez-Romero and German Rigau and Jose Maria Villa-Gonzalez and Serena Villata and Andrea Zaninello},
year={2024},
eprint={2404.07613},
archivePrefix={arXiv},
primaryClass={cs.CL}
}