

metadata
license: apache-2.0
base_model: bert-base-multilingual-cased
datasets:
- HiTZ/multilingual-abstrct
language:
- en
- es
- fr
- it
metrics:
- f1
pipeline_tag: token-classification
library_name: transformers
widget:
- text: >-
The dysuria resolved faster in patients implanted with 103Pd but was
unaffected by the use of supplemental radiotherapy and/or androgen
deprivation therapy.
- text: >-
La disuria se resolvió más rápidamente en los pacientes implantados con
103Pd, pero no se vio afectada por el uso de radioterapia suplementaria
y/o terapia de privación de andrógenos.
- text: >-
La dysurie s'est résorbée plus rapidement chez les patients implantés avec
du 103Pd, mais n'a pas été affectée par l'utilisation d'une radiothérapie
complémentaire et/ou d'une thérapie de privation d'androgènes.
- text: >-
La disuria si è risolta più rapidamente nei pazienti impiantati con 103Pd,
ma non è stata influenzata dall'uso della radioterapia supplementare e/o
della terapia di deprivazione androgenica.

mBERT for multilingual Argument Detection in the Medical Domain
This model is a fine-tuned version of bert-base-multilingual-cased for the argument component detection task on AbstRCT data in English, Spanish, French and Italian (https://huggingface.co/datasets/HiTZ/multilingual-abstrct).
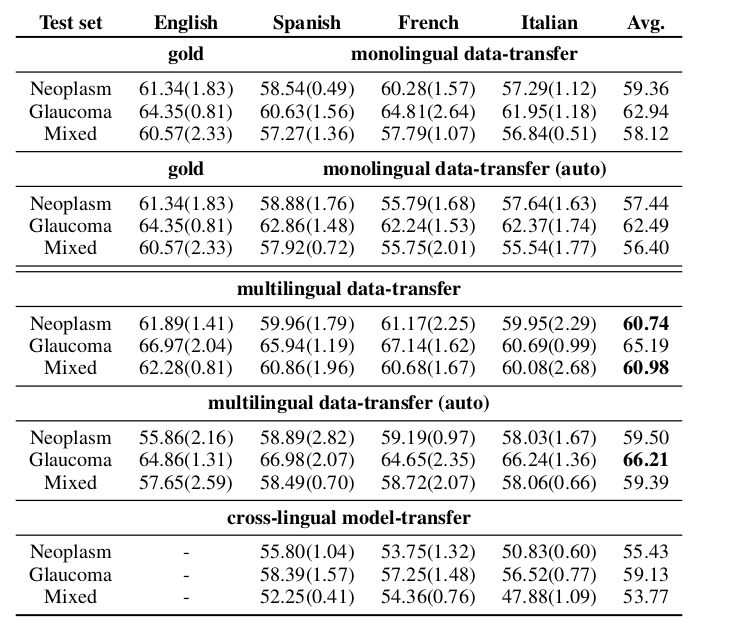
Performance
F1-macro scores (at sequence level) and their averages per test set from the argument component detection results of monolingual, monolingual automatically post-processed, multilingual, multilingual automatically post-processed, and crosslingual experiments.
Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
Framework versions
- Transformers 4.40.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.2
Contact: Anar Yeginbergen and Rodrigo Agerri HiTZ Center - Ixa, University of the Basque Country UPV/EHU