
zhoudong
commited on
Commit
·
c571390
1
Parent(s):
de100d2
init
Browse files- README.md +214 -3
- README_EN.md +231 -0
- README_SPEED.md +23 -0
- assets/chat_en.png +0 -0
- assets/github-mark.png +0 -0
- assets/megrez_logo.png +0 -0
- assets/mmlu.jpg +0 -0
- assets/mmlu_en.png +0 -0
- assets/mtbench.jpg +0 -0
- assets/needle_test.png +0 -0
- assets/websearch.gif +0 -0
- assets/wechat-group.jpg +0 -0
- assets/wechat-official.jpg +0 -0
- config.json +31 -0
- generation_config.json +6 -0
README.md
CHANGED
|
@@ -1,3 +1,214 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- zh
|
| 6 |
+
pipeline_tag: text-generation
|
| 7 |
+
---
|
| 8 |
+
# Megrez-3B: 软硬协同释放无穹端侧智能
|
| 9 |
+
<p align="center">
|
| 10 |
+
<img src="assets/megrez_logo.png" width="400"/>
|
| 11 |
+
<p>
|
| 12 |
+
|
| 13 |
+
<p align="center">
|
| 14 |
+
🔗 <a href="https://github.com/infinigence/Infini-Megrez">GitHub</a>   |   🏠 <a href="https://cloud.infini-ai.com/genstudio/model/mo-c73owqiotql7lozr">Infini-AI mass</a>   |   📖 <a href="https://huggingface.co/Infinigence/Megrez-3B-Instruct/blob/main/assets/wechat-official.jpg">WeChat Official</a>   |   💬 <a href="https://huggingface.co/Infinigence/Megrez-3B-Instruct/blob/main/assets/wechat-group.jpg">WeChat Groups</a>  
|
| 15 |
+
</p>
|
| 16 |
+
<h4 align="center">
|
| 17 |
+
<p>
|
| 18 |
+
<b>中文</b> | <a href="https://huggingface.co/Infinigence/Megrez-3B-Instruct/blob/main/README_EN.md">English</a>
|
| 19 |
+
<p>
|
| 20 |
+
</h4>
|
| 21 |
+
|
| 22 |
+
## 模型简介
|
| 23 |
+
Megrez-3B-Instruct是由无问芯穹([Infinigence AI](https://cloud.infini-ai.com/platform/ai))完全自主训练的大语言模型。Megrez-3B旨在通过软硬协同理念,打造一款极速推理、小巧精悍、极易上手的端侧智能解决方案。Megrez-3B具有以下优点:
|
| 24 |
+
1. 高精度:Megrez-3B虽然参数规模只有3B,但通过提升数据质量,成功弥合模型能力代差,将上一代14B模型的能力成功压缩进3B大小的模型,在主流榜单上取得了优秀的性能表现。
|
| 25 |
+
2. 高速度:模型小≠速度快。Megrez-3B通过软硬协同优化,确保了各结构参数与主流硬件高度适配,推理速度领先同精度模型最大300%。
|
| 26 |
+
3. 简单易用:模型设计之初我们进行了激烈的讨论:应该在结构设计上留出更多软硬协同的空间(如ReLU、稀疏化、更精简的结构等),还是使用经典结构便于开发者直接用起来?我们选择了后者,即采用最原始的LLaMA结构,开发者无需任何修改便可将模型部署于各种平台,最小化二次开发复杂度。
|
| 27 |
+
4. 丰富应用:我们提供了完整的WebSearch方案。我们对模型进行了针对性训练,使模型可以自动决策搜索调用时机,在搜索和对话中自动切换,并提供更好的总结效果。我们提供了完整的部署工程代码 [github](https://github.com/infinigence/InfiniWebSearch),用户可以基于该功能构建属于自己的Kimi或Perplexity,克服小模型常见的幻觉问题和知识储备不足的局限。
|
| 28 |
+
|
| 29 |
+
## 基础信息
|
| 30 |
+
* Architecture: Llama-2 with GQA
|
| 31 |
+
* Context length: 32K tokens
|
| 32 |
+
* Params (Total): 2.92B
|
| 33 |
+
* Params (Backbone only, w/o Emb or Softmax): 2.29B
|
| 34 |
+
* Vocab Size: 122880
|
| 35 |
+
* Training data: 3T tokens
|
| 36 |
+
* Supported languages: Chinese & English
|
| 37 |
+
|
| 38 |
+
在文本生成等具备生成多样性的任务上,我们推荐推理参数temperature=0.7;在数学、推理等任务上,我们推荐推理参数temperature=0.2
|
| 39 |
+
|
| 40 |
+
## 性能
|
| 41 |
+
我们使用开源评测工具 [OpenCompass](https://github.com/open-compass/opencompass) 对 Megrez-3B-Instruct 进行了评测。部分评测结果如下表所示。
|
| 42 |
+
|
| 43 |
+
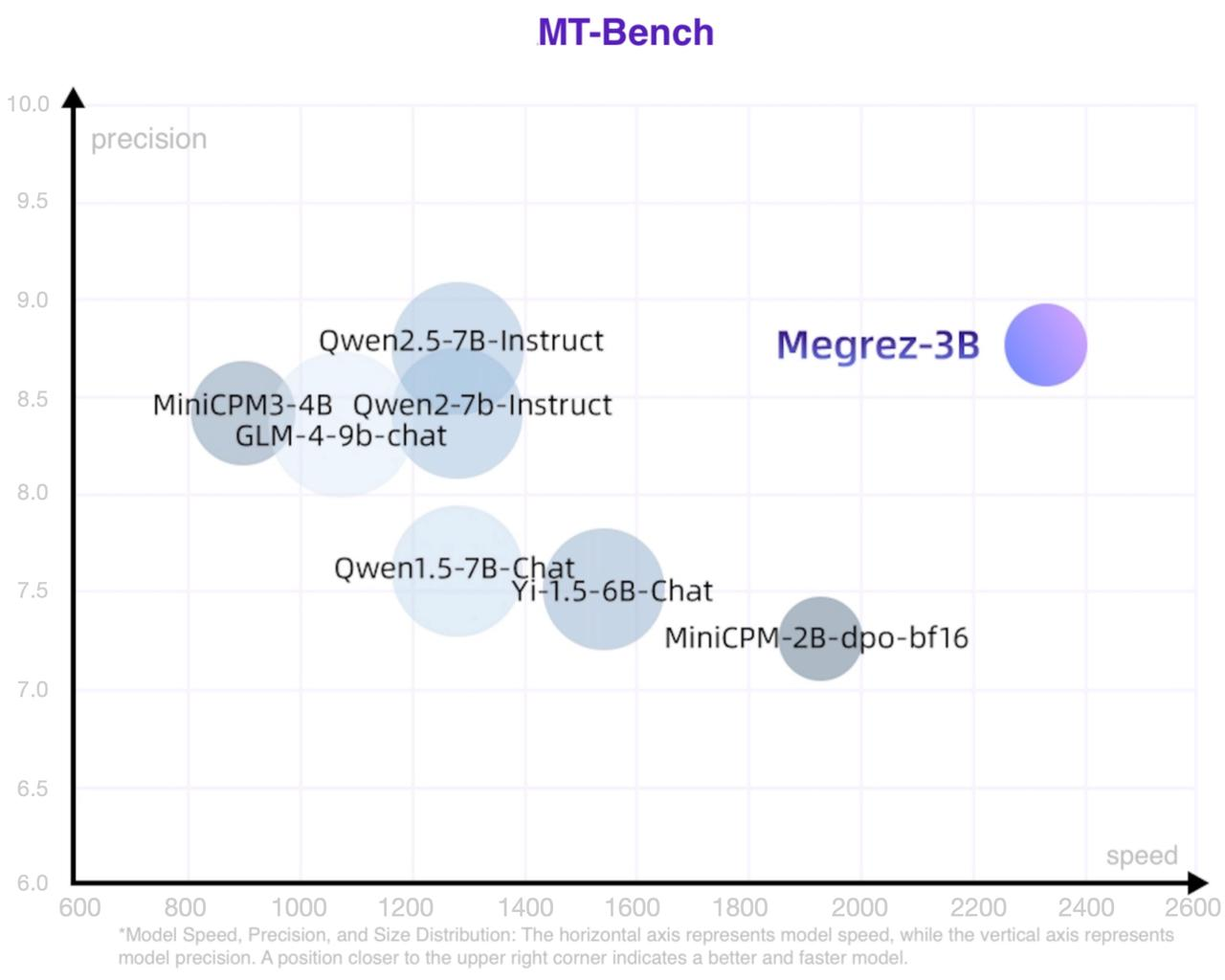
速度精度模型大小散点图如下,位置越靠近右上表明模型越好越快
|
| 44 |
+
 
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
### 综合能力
|
| 48 |
+
|
| 49 |
+
| 模型 | 指令模型 | # Non-Emb Params | 推理速度 (tokens/s) | C-EVAL | CMMLU | MMLU | MMLU-Pro | HumanEval | MBPP | GSM8K | MATH |
|
| 50 |
+
|:---------------------:|:--------:|:---------------:|:-------------------:|:------:|:-----:|:-----:|:--------:|:---------:|:-----:|:-----:|:-----:|
|
| 51 |
+
| Megrez-3B-Instruct | Y | 2.3 | 2329.4 | 84.8 | 74.7 | 72.8 | 46.1 | 78.7 | 71.0 | 65.5 | 28.3 |
|
| 52 |
+
| Qwen2-1.5B | | 1.3 | 3299.5 | 70.6 | 70.3 | 56.5 | 21.8 | 31.1 | 37.4 | 58.5 | 21.7 |
|
| 53 |
+
| Qwen2.5-1.5B | | 1.3 | 3318.8 | - | - | 60.9 | 28.5 | 37.2 | 60.2 | 68.5 | 35.0 |
|
| 54 |
+
| MiniCPM-2B | | 2.4 | 1930.8 | 51.1 | 51.1 | 53.5 | - | 50.0 | 47.3 | 53.8 | 10.2 |
|
| 55 |
+
| Qwen2.5-3B | | 2.8 | 2248.3 | - | - | 65.6 | 34.6 | 42.1 | 57.1 | 79.1 | 42.6 |
|
| 56 |
+
| Qwen2.5-3B-Instruct | Y | 2.8 | 2248.3 | - | - | - | 43.7 | 74.4 | 72.7 | 86.7 | 65.9 |
|
| 57 |
+
| Qwen1.5-4B | | 3.2 | 1837.9 | 67.6 | 66.7 | 56.1 | - | 25.6 | 29.2 | 57.0 | 10.0 |
|
| 58 |
+
| Phi-3.5-mini-instruct | Y | 3.6 | 1559.1 | 46.1 | 46.9 | 69.0 | - | 62.8 | 69.6 | 86.2 | 48.5 |
|
| 59 |
+
| MiniCPM3-4B | Y | 3.9 | 901.1 | 73.6 | 73.3 | 67.2 | - | 74.4 | 72.5 | 81.1 | 46.6 |
|
| 60 |
+
| Yi-1.5-6B | | 5.5 | 1542.7 | - | 70.8 | 63.5 | - | 36.5 | 56.8 | 62.2 | 28.4 |
|
| 61 |
+
| Qwen1.5-7B | | 6.5 | 1282.3 | 74.1 | 73.1 | 61.0 | 29.9 | 36.0 | 51.6 | 62.5 | 20.3 |
|
| 62 |
+
| Qwen2-7B | | 6.5 | 1279.4 | 83.2 | 83.9 | 70.3 | 40.0 | 51.2 | 65.9 | 79.9 | 44.2 |
|
| 63 |
+
| Qwen2.5-7B | | 6.5 | 1283.4 | - | - | 74.2 | 45.0 | 57.9 | 74.9 | 85.4 | 49.8 |
|
| 64 |
+
| Meta-Llama-3.1-8B | | 7.0 | 1255.9 | - | - | 66.7 | 37.1 | - | - | - | - |
|
| 65 |
+
| GLM-4-9B-chat | Y | 8.2 | 1076.1 | 75.6 | 71.5 | 72.4 | - | 71.8 | - | 79.6 | 50.6 |
|
| 66 |
+
| Baichuan2-13B-Base | | 12.6 | 756.7 | 58.1 | 62.0 | 59.2 | - | 17.1 | 30.2 | 52.8 | 10.1 |
|
| 67 |
+
| Qwen1.5-14B | | 12.6 | 735.6 | 78.7 | 77.6 | 67.6 | - | 37.8 | 44.0 | 70.1 | 29.2 |
|
| 68 |
+
|
| 69 |
+
- Qwen2-1.5B模型的指标在其论文和Qwen2.5报告中点数不一致,当前采用原始论文中的精度
|
| 70 |
+
- 测速配置详见 <a href="https://huggingface.co/Infinigence/Megrez-3B-Instruct/blob/main/README_SPEED.md">README_SPEED.md</a>
|
| 71 |
+
|
| 72 |
+
### 对话能力
|
| 73 |
+
本表只摘出有官方MT-Bench或AlignBench点数的模型
|
| 74 |
+
|
| 75 |
+
| 模型 | # Non-Emb Params | 推理速度 (tokens/s) | MT-Bench | AlignBench (ZH) |
|
| 76 |
+
|---------------------|--------------------------------------|:--------------------------:|:--------:|:---------------:|
|
| 77 |
+
| Megrez-3B-Instruct | 2.3 | 2329.4 | 8.64 | 7.06 |
|
| 78 |
+
| MiniCPM-2B-sft-bf16 | 2.4 | 1930.8 | - | 4.64 |
|
| 79 |
+
| MiniCPM-2B-dpo-bf16 | 2.4 | 1930.8 | 7.25 | - |
|
| 80 |
+
| Qwen2.5-3B-Instruct | 2.8 | 2248.3 | - | - |
|
| 81 |
+
| MiniCPM3-4B | 3.9 | 901.1 | 8.41 | 6.74 |
|
| 82 |
+
| Yi-1.5-6B-Chat | 5.5 | 1542.7 | 7.50 | 6.20 |
|
| 83 |
+
| Qwen1.5-7B-Chat | 6.5 | 1282.3 | 7.60 | 6.20 |
|
| 84 |
+
| Qwen2-7b-Instruct | 6.5 | 1279.4 | 8.41 | 7.21 |
|
| 85 |
+
| Qwen2.5-7B-Instruct | 6.5 | 1283.4 | 8.75 | - |
|
| 86 |
+
| glm-4-9b-chat | 8.2 | 1076.1 | 8.35 | 7.01 |
|
| 87 |
+
| Baichuan2-13B-Chat | 12.6 | 756.7 | - | 5.25 |
|
| 88 |
+
|
| 89 |
+
### LLM Leaderboard
|
| 90 |
+
|
| 91 |
+
| 模型 | # Non-Emb Params | 推理速度 (tokens/s) | IFeval strict-prompt | BBH | ARC_C | HellaSwag | WinoGrande | TriviaQA |
|
| 92 |
+
|-----------------------|--------------------------------------|:--------------------------:|:--------------------:|:----:|:-----:|:---------:|:----------:|:--------:|
|
| 93 |
+
| Megrez-3B-Instruct | 2.3 | 2329.4 | 68.6 | 72.6 | 95.6 | 83.9 | 78.8 | 81.6 |
|
| 94 |
+
| MiniCPM-2B | 2.4 | 1930.8 | - | 36.9 | 68.0 | 68.3 | - | 32.5 |
|
| 95 |
+
| Qwen2.5-3B | 2.8 | 2248.3 | - | 56.3 | 56.5 | 74.6 | 71.1 | - |
|
| 96 |
+
| Qwen2.5-3B-Instruct | 2.8 | 2248.3 | 58.2 | - | - | - | - | - |
|
| 97 |
+
| Phi-3.5-mini-instruct | 3.6 | 1559.1 | - | 69.0 | 84.6 | 69.4 | 68.5 | - |
|
| 98 |
+
| MiniCPM3-4B | 3.9 | 901.1 | 68.4 | 70.2 | - | - | - | - |
|
| 99 |
+
| Qwen2-7B-Instruct | 6.5 | 1279.4 | - | 62.6 | 60.6 | 80.7 | 77.0 | - |
|
| 100 |
+
| Meta-Llama-3.1-8B | 7.0 | 1255.9 | 71.5 | 28.9 | 83.4 | - | - | - |
|
| 101 |
+
|
| 102 |
+
### 长文本能力
|
| 103 |
+
#### Longbench
|
| 104 |
+
|
| 105 |
+
| | 单文档问答 | 多文档问答 | 概要任务 | 少样本学习 | 人工合成任务 | 代码任务 | 平均 |
|
| 106 |
+
|-----------------------|:------------------:|:-----------------:|:-------------:|:-----------------:|:---------------:|:----------------:|:-------:|
|
| 107 |
+
| Megrez-3B-Instruct | 39.67 | 55.53 | 24.51 | 62.52 | 68.5 | 66.73 | 52.91 |
|
| 108 |
+
| GPT-3.5-Turbo-16k | 50.5 | 33.7 | 21.25 | 48.15 | 54.1 | 54.1 | 43.63 |
|
| 109 |
+
| ChatGLM3-6B-32k | 51.3 | 45.7 | 23.65 | 55.05 | 56.2 | 56.2 | 48.02 |
|
| 110 |
+
| InternLM2-Chat-7B-SFT | 47.3 | 45.2 | 25.3 | 59.9 | 67.2 | 43.5 | 48.07 |
|
| 111 |
+
|
| 112 |
+
#### 长文本对话能力
|
| 113 |
+
|
| 114 |
+
| | Longbench-Chat |
|
| 115 |
+
|--------------------------|----------------|
|
| 116 |
+
| Megrez-3B-Instruct | 4.98 |
|
| 117 |
+
| Vicuna-7b-v1.5-16k | 3.51 |
|
| 118 |
+
| Mistral-7B-Instruct-v0.2 | 5.84 |
|
| 119 |
+
| ChatGLM3-6B-128k | 6.52 |
|
| 120 |
+
| GLM-4-9B-Chat | 7.72 |
|
| 121 |
+
|
| 122 |
+
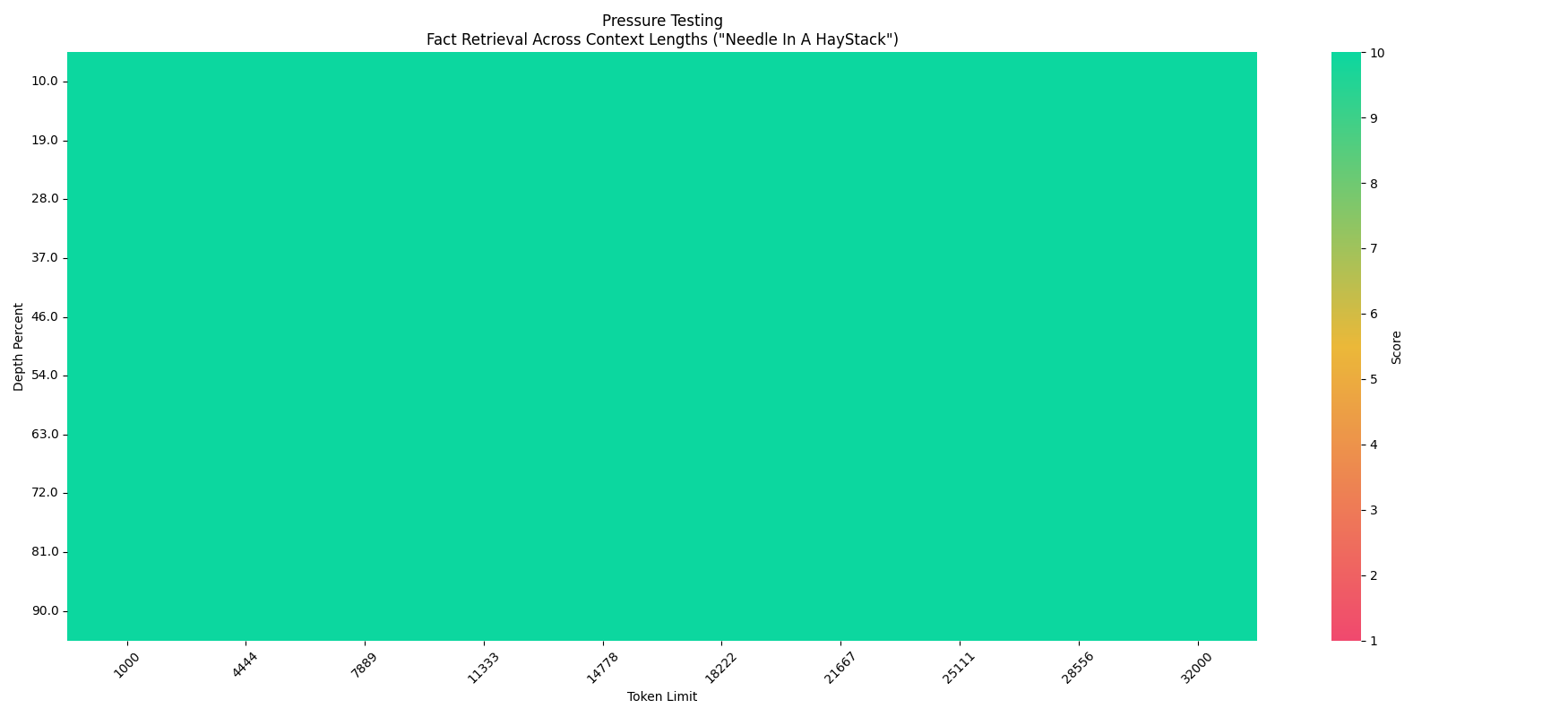
#### 大海捞针实验 (Needle In A Haystack - Pressure Test)
|
| 123 |
+
关于Megrez-3B-Instruct在32K文本下的大海捞针压力测试结果
|
| 124 |
+

|
| 125 |
+
|
| 126 |
+
## WebSearch
|
| 127 |
+
我们模型进行了针对性训练,并提供了完整的工程部署方案。[InfiniWebSearch](https://github.com/infinigence/InfiniWebSearch) 具有以下优势:
|
| 128 |
+
1. 自动决定调用时机:自动决策搜索调用时机,在搜索和对话中自动切换,避免一直调用或一直不调用
|
| 129 |
+
2. 上下文理解:根据多轮对话生成合理的搜索query或处理搜索结果,更好的理解用户意图
|
| 130 |
+
3. 带参考信息的结构化输出:每个结论注明出处,便于查验
|
| 131 |
+
4. 一个模型两种用法:通过sys prompt区分WebSearch功能开启与否,兼顾LLM的高精度与WebSearch的用户体验,两种能力不乱窜
|
| 132 |
+
|
| 133 |
+
我们对模型进行了针对性训练,使模型可以自动决策搜索调用时机,在搜索和对话中自动切换,并提供更好的总结效果。我们提供了完整的部署工程代码 ,用户可以基于该功能构建属于自己的Kimi或Perplexity,克服小模型常见的幻觉问题和知识储备不足的局限。
|
| 134 |
+
|
| 135 |
+

|
| 136 |
+
|
| 137 |
+
## 快速上手
|
| 138 |
+
### 在线体验
|
| 139 |
+
[MaaS (推荐)](https://cloud.infini-ai.com/genstudio/model/mo-c73owqiotql7lozr)
|
| 140 |
+
|
| 141 |
+
### 推理参数
|
| 142 |
+
- 对于对话、文章撰写等具有一定随机性或发散性的输出,可以采用 temperature=0.7等参数进行推理
|
| 143 |
+
- 对于数学、逻辑推理等确定性较高的输出,建议使用 **temperature=0.2** 的参数进行推理,以减少采样带来的幻觉影响,获得更好的推理能力
|
| 144 |
+
|
| 145 |
+
### Huggingface 推理
|
| 146 |
+
安装transformers后,运行以下代码。
|
| 147 |
+
``` python
|
| 148 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 149 |
+
import torch
|
| 150 |
+
|
| 151 |
+
path = "Infinigence/Megrez-3B-Instruct"
|
| 152 |
+
device = "cuda"
|
| 153 |
+
|
| 154 |
+
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True)
|
| 155 |
+
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
|
| 156 |
+
|
| 157 |
+
messages = [
|
| 158 |
+
{"role": "user", "content": "讲讲黄焖鸡的做法。"},
|
| 159 |
+
]
|
| 160 |
+
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True).to(device)
|
| 161 |
+
|
| 162 |
+
model_outputs = model.generate(
|
| 163 |
+
model_inputs,
|
| 164 |
+
do_sample=True,
|
| 165 |
+
max_new_tokens=1024,
|
| 166 |
+
top_p=0.9,
|
| 167 |
+
temperature=0.2
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
output_token_ids = [
|
| 171 |
+
model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs))
|
| 172 |
+
]
|
| 173 |
+
|
| 174 |
+
responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0]
|
| 175 |
+
print(responses)
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
### vLLM 推理
|
| 179 |
+
|
| 180 |
+
- 安装vLLM
|
| 181 |
+
```bash
|
| 182 |
+
# Install vLLM with CUDA 12.1.
|
| 183 |
+
pip install vllm
|
| 184 |
+
```
|
| 185 |
+
- 测试样例
|
| 186 |
+
```python
|
| 187 |
+
from transformers import AutoTokenizer
|
| 188 |
+
from vllm import LLM, SamplingParams
|
| 189 |
+
|
| 190 |
+
model_name = "Infinigence/Megrez-3B-Instruct"
|
| 191 |
+
prompt = [{"role": "user", "content": "讲讲黄焖鸡的做法。"}]
|
| 192 |
+
|
| 193 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 194 |
+
input_text = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
|
| 195 |
+
|
| 196 |
+
llm = LLM(
|
| 197 |
+
model=model_name,
|
| 198 |
+
trust_remote_code=True,
|
| 199 |
+
tensor_parallel_size=1
|
| 200 |
+
)
|
| 201 |
+
sampling_params = SamplingParams(top_p=0.9, temperature=0.2, max_tokens=1024)
|
| 202 |
+
|
| 203 |
+
outputs = llm.generate(prompts=input_text, sampling_params=sampling_params)
|
| 204 |
+
|
| 205 |
+
print(outputs[0].outputs[0].text)
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
## 开源协议及使用声明
|
| 210 |
+
- 协议:本仓库中代码依照 [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0) 协议开源
|
| 211 |
+
- 幻觉:大模型天然存在幻觉问题,用户使用过程中请勿完全相信模型生成的内容。若用户想获取更符合事实的生成内容,推荐利用我们的WebSearch功能,详见 [InfiniWebSearch](https://github.com/paxionfull/InfiniWebSearch)。
|
| 212 |
+
- 数学&推理:小模型在数学和推理任务上更容易出错误的计算过程或推理链条,从而导致最终结果错误。特别的,小模型的输出softmax分布相比大模型明显不够sharp,在较高temperature下更容易出现多次推理结果不一致的问题,在数学/推理等确定性问题上更为明显。我们推荐在这类问题��,调低temperature,或尝试多次推理验证。
|
| 213 |
+
- System Prompt:和绝大多数模型一样,我们推荐使用配置文件中chat_template默认的system prompt,以获得稳定和平衡的体验。本次模型发布弱化了角色扮演等涉及特定领域应用方面的能力,用户若有特定领域的应用需求,我们推荐在本模型基础上按需进行适当微调。
|
| 214 |
+
- 价值观及安全性:本模型已尽全力确保训练过程中使用的数据的合规性,但由于数据的大体量及复杂性,仍有可能存在一些无法预见的问题。如果出现使用本开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
|
README_EN.md
ADDED
|
@@ -0,0 +1,231 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- zh
|
| 6 |
+
pipeline_tag: text-generation
|
| 7 |
+
---
|
| 8 |
+
# Megrez-3B: The integration of software and hardware unleashes the potential of edge intelligence
|
| 9 |
+
|
| 10 |
+
<p align="center">
|
| 11 |
+
<img src="assets/megrez_logo.png" width="400"/>
|
| 12 |
+
<p>
|
| 13 |
+
<p align="center">
|
| 14 |
+
🔗 <a href="https://github.com/infinigence/Infini-Megrez">GitHub</a>   |   
|
| 15 |
+
🏠 <a href="https://cloud.infini-ai.com/genstudio/model/mo-c73owqiotql7lozr">Infini-AI mass</a>   |   
|
| 16 |
+
📖 <a href="https://huggingface.co/Infinigence/Megrez-3B-Instruct/blob/main/assets/wechat-official.jpg">WeChat Official</a>   |   
|
| 17 |
+
💬 <a href="https://huggingface.co/Infinigence/Megrez-3B-Instruct/blob/main/assets/wechat-group.jpg">WeChat Groups</a>  
|
| 18 |
+
</p>
|
| 19 |
+
<h4 align="center">
|
| 20 |
+
<p>
|
| 21 |
+
<a href="https://huggingface.co/Infinigence/Megrez-3B-Instruct/blob/main/README.md">中文</a> | <b>English</b>
|
| 22 |
+
<p>
|
| 23 |
+
</h4>
|
| 24 |
+
|
| 25 |
+
## Introduction
|
| 26 |
+
|
| 27 |
+
Megrez-3B is a large language model trained by [Infinigence AI](https://cloud.infini-ai.com/platform/ai). Megrez-3B aims to provide a fast inference, compact, and powerful edge-side intelligent solution through software-hardware co-design. Megrez-3B has the following advantages:
|
| 28 |
+
|
| 29 |
+
1. High Accuracy: Megrez-3B successfully compresses the capabilities of the previous 14 billion model into a 3 billion size, and achieves excellent performance on mainstream benchmarks.
|
| 30 |
+
2. High Speed: A smaller model does not necessarily bring faster speed. Megrez-3B ensures a high degree of compatibility with mainstream hardware through software-hardware co-design, leading an inference speedup up to 300% compared to previous models of the same accuracy.
|
| 31 |
+
3. Easy to Use: In the beginning, we had a debate about model design: should we design a unique but efficient model structure, or use a classic structure for ease of use? We chose the latter and adopt the most primitive LLaMA structure, which allows developers to deploy the model on various platforms without any modifications and minimize the complexity of future development.
|
| 32 |
+
4. Rich Applications: We have provided a fullstack WebSearch solution. Our model is functionally trained on web search tasks, enabling it to automatically determine the timing of search invocations and provide better summarization results. The complete deployment code is released on [github](https://github.com/infinigence/InfiniWebSearch).
|
| 33 |
+
|
| 34 |
+
## Model Card
|
| 35 |
+
|
| 36 |
+
* Model name: Megrez-3B-Instruct
|
| 37 |
+
* Architecture: Llama-2 with GQA
|
| 38 |
+
* Context length: 32K tokens
|
| 39 |
+
* Params (Total): 2.92B
|
| 40 |
+
* Params (Backbone only, w/o Emb or Softmax): 2.29B
|
| 41 |
+
* Vocab Size: 122880
|
| 42 |
+
* Training data: 3T tokens
|
| 43 |
+
* Supported languages: Chinese & English
|
| 44 |
+
|
| 45 |
+
For text generation and other tasks that benefit from diversity, we recommend using the inference parameter temperature=0.7. For mathematical and reasoning tasks, we recommend using the inference parameter temperature=0.2.
|
| 46 |
+
|
| 47 |
+
## Performance
|
| 48 |
+
|
| 49 |
+
We have evaluated Megrez-3B-Instruct using the open-source evaluation tool [OpenCompass](https://github.com/open-compass/opencompass) on several important benchmarks. Some of the evaluation results are shown in the table below.
|
| 50 |
+
|
| 51 |
+
### General Benchmarks
|
| 52 |
+
|
| 53 |
+
| Models | chat model | # Non-Emb Params | Inference Speed (tokens/s) | C-EVAL | CMMLU | MMLU | MMLU-Pro | HumanEval | MBPP | GSM8K | MATH |
|
| 54 |
+
|:---------------------:|:--------:|:---------------:|:-------------------:|:------:|:-----:|:-----:|:--------:|:---------:|:-----:|:-----:|:-----:|
|
| 55 |
+
| Megrez-3B-Instruct | Y | 2.3 | 2329.4 | 84.8 | 74.7 | 72.8 | 46.1 | 78.7 | 71.0 | 65.5 | 28.3 |
|
| 56 |
+
| Qwen2-1.5B | | 1.3 | 3299.5 | 70.6 | 70.3 | 56.5 | 21.8 | 31.1 | 37.4 | 58.5 | 21.7 |
|
| 57 |
+
| Qwen2.5-1.5B | | 1.3 | 3318.8 | - | - | 60.9 | 28.5 | 37.2 | 60.2 | 68.5 | 35.0 |
|
| 58 |
+
| MiniCPM-2B | | 2.4 | 1930.8 | 51.1 | 51.1 | 53.5 | - | 50.0 | 47.3 | 53.8 | 10.2 |
|
| 59 |
+
| Qwen2.5-3B | | 2.8 | 2248.3 | - | - | 65.6 | 34.6 | 42.1 | 57.1 | 79.1 | 42.6 |
|
| 60 |
+
| Qwen2.5-3B-Instruct | Y | 2.8 | 2248.3 | - | - | - | 43.7 | 74.4 | 72.7 | 86.7 | 65.9 |
|
| 61 |
+
| Qwen1.5-4B | | 3.2 | 1837.9 | 67.6 | 66.7 | 56.1 | - | 25.6 | 29.2 | 57.0 | 10.0 |
|
| 62 |
+
| Phi-3.5-mini-instruct | Y | 3.6 | 1559.1 | 46.1 | 46.9 | 69.0 | - | 62.8 | 69.6 | 86.2 | 48.5 |
|
| 63 |
+
| MiniCPM3-4B | Y | 3.9 | 901.1 | 73.6 | 73.3 | 67.2 | - | 74.4 | 72.5 | 81.1 | 46.6 |
|
| 64 |
+
| Yi-1.5-6B | | 5.5 | 1542.7 | - | 70.8 | 63.5 | - | 36.5 | 56.8 | 62.2 | 28.4 |
|
| 65 |
+
| Qwen1.5-7B | | 6.5 | 1282.3 | 74.1 | 73.1 | 61.0 | 29.9 | 36.0 | 51.6 | 62.5 | 20.3 |
|
| 66 |
+
| Qwen2-7B | | 6.5 | 1279.4 | 83.2 | 83.9 | 70.3 | 40.0 | 51.2 | 65.9 | 79.9 | 44.2 |
|
| 67 |
+
| Qwen2.5-7B | | 6.5 | 1283.4 | - | - | 74.2 | 45.0 | 57.9 | 74.9 | 85.4 | 49.8 |
|
| 68 |
+
| Meta-Llama-3.1-8B | | 7.0 | 1255.9 | - | - | 66.7 | 37.1 | - | - | - | - |
|
| 69 |
+
| GLM-4-9B-chat | Y | 8.2 | 1076.1 | 75.6 | 71.5 | 72.4 | - | 71.8 | - | 79.6 | 50.6 |
|
| 70 |
+
| Baichuan2-13B-Base | | 12.6 | 756.7 | 58.1 | 62.0 | 59.2 | - | 17.1 | 30.2 | 52.8 | 10.1 |
|
| 71 |
+
| Qwen1.5-14B | | 12.6 | 735.6 | 78.7 | 77.6 | 67.6 | - | 37.8 | 44.0 | 70.1 | 29.2 |
|
| 72 |
+
|
| 73 |
+
- The metrics of the Qwen2-1.5B model are inconsistent between its paper and the latest report; the table adopts the metrics from the original paper.
|
| 74 |
+
- For details on the configuration for measuring speed, please refer to <a href="https://huggingface.co/Infinigence/Megrez-3B-Instruct/blob/main/README_SPEED.md">README_SPEED.md</a>
|
| 75 |
+
|
| 76 |
+
### Chat Benchmarks
|
| 77 |
+
|
| 78 |
+
This table only includes models with official MT-Bench or AlignBench benchmarks.
|
| 79 |
+
|
| 80 |
+
| Models | # Non-Emb Params | Inference Speed (tokens/s) | MT-Bench | AlignBench (ZH) |
|
| 81 |
+
|---------------------|--------------------------------------|:--------------------------:|:--------:|:---------------:|
|
| 82 |
+
| Megrez-3B-Instruct | 2.3 | 2329.4 | 8.64 | 7.06 |
|
| 83 |
+
| MiniCPM-2B-sft-bf16 | 2.4 | 1930.8 | - | 4.64 |
|
| 84 |
+
| MiniCPM-2B-dpo-bf16 | 2.4 | 1930.8 | 7.25 | - |
|
| 85 |
+
| Qwen2.5-3B-Instruct | 2.8 | 2248.3 | - | - |
|
| 86 |
+
| MiniCPM3-4B | 3.9 | 901.1 | 8.41 | 6.74 |
|
| 87 |
+
| Yi-1.5-6B-Chat | 5.5 | 1542.7 | 7.50 | 6.20 |
|
| 88 |
+
| Qwen1.5-7B-Chat | 6.5 | 1282.3 | 7.60 | 6.20 |
|
| 89 |
+
| Qwen2-7b-Instruct | 6.5 | 1279.4 | 8.41 | 7.21 |
|
| 90 |
+
| Qwen2.5-7B-Instruct | 6.5 | 1283.4 | 8.75 | - |
|
| 91 |
+
| glm-4-9b-chat | 8.2 | 1076.1 | 8.35 | 7.01 |
|
| 92 |
+
| Baichuan2-13B-Chat | 12.6 | 756.7 | - | 5.25 |
|
| 93 |
+
|
| 94 |
+
### LLM Leaderboard
|
| 95 |
+
|
| 96 |
+
| Models | # Non-Emb Params | Inference Speed (tokens/s) | IFEval | BBH | ARC_C | HellaSwag | WinoGrande | TriviaQA |
|
| 97 |
+
|-----------------------|--------------------------------------|:--------------------------:|:--------------------:|:----:|:-----:|:---------:|:----------:|:--------:|
|
| 98 |
+
| Megrez-3B-Instruct | 2.3 | 2329.4 | 68.6 | 72.6 | 95.6 | 83.9 | 78.8 | 81.6 |
|
| 99 |
+
| MiniCPM-2B | 2.4 | 1930.8 | - | 36.9 | 68.0 | 68.3 | - | 32.5 |
|
| 100 |
+
| Qwen2.5-3B | 2.8 | 2248.3 | - | 56.3 | 56.5 | 74.6 | 71.1 | - |
|
| 101 |
+
| Qwen2.5-3B-Instruct | 2.8 | 2248.3 | 58.2 | - | - | - | - | - |
|
| 102 |
+
| Phi-3.5-mini-instruct | 3.6 | 1559.1 | - | 69.0 | 84.6 | 69.4 | 68.5 | - |
|
| 103 |
+
| MiniCPM3-4B | 3.9 | 901.1 | 68.4 | 70.2 | - | - | - | - |
|
| 104 |
+
| Qwen2-7B-Instruct | 6.5 | 1279.4 | - | 62.6 | 60.6 | 80.7 | 77.0 | - |
|
| 105 |
+
| Meta-Llama-3.1-8B | 7.0 | 1255.9 | 71.5 | 28.9 | 83.4 | - | - | - |
|
| 106 |
+
|
| 107 |
+
### Long text Capability
|
| 108 |
+
#### Longbench
|
| 109 |
+
|
| 110 |
+
| | single-document-qa | multi-document-qa | summarization | few-shot-learning | synthetic-tasks | code-completion | Average |
|
| 111 |
+
|------------------------|:------------------:|:-----------------:|:-------------:|:-----------------:|:---------------:|:----------------:|:-------:|
|
| 112 |
+
| Megrez-3B-Instruct-32K | 39.67 | 55.53 | 24.51 | 62.52 | 68.5 | 66.73 | 52.91 |
|
| 113 |
+
| GPT-3.5-Turbo-16k | 50.5 | 33.7 | 21.25 | 48.15 | 54.1 | 54.1 | 43.63 |
|
| 114 |
+
| ChatGLM3-6B-32k | 51.3 | 45.7 | 23.65 | 55.05 | 56.2 | 56.2 | 48.02 |
|
| 115 |
+
| InternLM2-Chat-7B-SFT | 47.3 | 45.2 | 25.3 | 59.9 | 67.2 | 43.5 | 48.07 |
|
| 116 |
+
|
| 117 |
+
#### Longbench-Chat
|
| 118 |
+
|
| 119 |
+
| | Longbench-Chat |
|
| 120 |
+
|--------------------------|----------------|
|
| 121 |
+
| Megrez-3B-Instruct(32K) | 4.98 |
|
| 122 |
+
| Vicuna-7b-v1.5-16k | 3.51 |
|
| 123 |
+
| Mistral-7B-Instruct-v0.2 | 5.84 |
|
| 124 |
+
| ChatGLM3-6B-128k | 6.52 |
|
| 125 |
+
| GLM-4-9B-Chat | 7.72 |
|
| 126 |
+
|
| 127 |
+
#### Needle In A Haystack - Pressure Test
|
| 128 |
+
Regarding the Megrez-3B-Instruct model's performance under the 32K text retrieval stress test.
|
| 129 |
+

|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
### Inference Speed
|
| 133 |
+
|
| 134 |
+
The scatter plot of speed, accuracy and model size is roughly as follows:
|
| 135 |
+

|
| 136 |
+

|
| 137 |
+
|
| 138 |
+
## WebSearch
|
| 139 |
+
|
| 140 |
+
We have provided a fullstack WebSearch solution which has the following advantages:
|
| 141 |
+
|
| 142 |
+
1. Automatically determine the timing of search invocations: Switch between search and conversation automatically without tendency.
|
| 143 |
+
2. In-Context understanding: Generate reasonable search queries or process search results based on multi-turn conversations.
|
| 144 |
+
3. Structured output: Each conclusion is attributed to its source for easy verification.
|
| 145 |
+
4. One model with two usages: Enable the WebSearch ability by changing system prompt. Or you can use it as a classic LLM.
|
| 146 |
+
|
| 147 |
+
Our model is functionally trained on web search tasks. Users can build their own Kimi or Perplexity based on this feature, which overcomes the hallucination issues and gets update knowledge.
|
| 148 |
+

|
| 149 |
+
|
| 150 |
+
## Quick Start
|
| 151 |
+
|
| 152 |
+
### Online Experience
|
| 153 |
+
|
| 154 |
+
[MaaS](https://cloud.infini-ai.com/genstudio/model/mo-c73owqiotql7lozr)(recommend)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
### Huggingface
|
| 158 |
+
|
| 159 |
+
It is recommended to use the **temperature=0.2** parameter for inference to achieve better reasoning capabilities.
|
| 160 |
+
``` python
|
| 161 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 162 |
+
import torch
|
| 163 |
+
|
| 164 |
+
path = "Infinigence/Megrez-3B-Instruct"
|
| 165 |
+
device = "cuda"
|
| 166 |
+
|
| 167 |
+
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True)
|
| 168 |
+
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
|
| 169 |
+
|
| 170 |
+
messages = [
|
| 171 |
+
{"role": "user", "content": "How to make braised chicken in brown sauce?"},
|
| 172 |
+
]
|
| 173 |
+
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True).to(device)
|
| 174 |
+
|
| 175 |
+
model_outputs = model.generate(
|
| 176 |
+
model_inputs,
|
| 177 |
+
do_sample=True,
|
| 178 |
+
max_new_tokens=1024,
|
| 179 |
+
top_p=0.9,
|
| 180 |
+
temperature=0.2
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
output_token_ids = [
|
| 184 |
+
model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs))
|
| 185 |
+
]
|
| 186 |
+
|
| 187 |
+
responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0]
|
| 188 |
+
print(responses)
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
### vLLM 推理
|
| 192 |
+
|
| 193 |
+
- Installation
|
| 194 |
+
|
| 195 |
+
```bash
|
| 196 |
+
# Install vLLM with CUDA 12.1.
|
| 197 |
+
pip install vllm
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
- Example code
|
| 201 |
+
|
| 202 |
+
```python
|
| 203 |
+
python inference/inference_vllm.py --model_path <hf_repo_path> --prompt_path prompts/prompt_demo.txt
|
| 204 |
+
from transformers import AutoTokenizer
|
| 205 |
+
from vllm import LLM, SamplingParams
|
| 206 |
+
|
| 207 |
+
model_name = "Infinigence/Megrez-3B-Instruct"
|
| 208 |
+
prompt = [{"role": "user", "content": "How to make braised chicken in brown sauce?"}]
|
| 209 |
+
|
| 210 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 211 |
+
input_text = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
|
| 212 |
+
|
| 213 |
+
llm = LLM(
|
| 214 |
+
model=model_name,
|
| 215 |
+
trust_remote_code=True,
|
| 216 |
+
tensor_parallel_size=1
|
| 217 |
+
)
|
| 218 |
+
sampling_params = SamplingParams(top_p=0.9, temperature=0.2, max_tokens=1024, repetition_penalty=1.02)
|
| 219 |
+
|
| 220 |
+
outputs = llm.generate(prompts=input_text, sampling_params=sampling_params)
|
| 221 |
+
|
| 222 |
+
print(outputs[0].outputs[0].text)
|
| 223 |
+
```
|
| 224 |
+
|
| 225 |
+
## License and Statement
|
| 226 |
+
|
| 227 |
+
- License: Our models are released under [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0).
|
| 228 |
+
- Hallucination: LLMs inherently suffer from hallucination issues. Users are advised not to fully trust the content generated by the model. If accurate outputs are required, we recommend utilizing our WebSearch framework as detailed in [InfiniWebSearch](https://github.com/paxionfull/InfiniWebSearch).
|
| 229 |
+
- Mathematics & Reasoning: Small LLMs tend to produce more incorrect calculations or flawed reasoning chains in tasks like mathematics and reasoning. Notably, the softmax distribution of Small LLMs is less sharp compared to LLMs, making them more sensitive to inconsistent reasoning results, especially under higher temperature settings. We recommend lowering the temperature or verifying through multiple inference attempts in deterministic tasks such as mathematics and logical reasoning.
|
| 230 |
+
- System Prompt: Like other models, we recommend to use the default system prompt in the configuration file's chat_template for a stable and balanced experience. If users have specific domain needs, we recommend making appropriate fine-tuning based on this model as needed.
|
| 231 |
+
- Values & Safety: We have made great effort to ensure the compliance of the training data. However, unforeseen issues may still arise. Users should take full responsibility for evaluating and verifying it on their own when using content generated by our model.
|
README_SPEED.md
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 测速结果的补充说明
|
| 2 |
+
- GPU测速
|
| 3 |
+
- 我们采用业界广泛使用的推理部署开源框架[vllm](https://github.com/vllm-project/vllm)进行推理速度测试
|
| 4 |
+
- 实验配置为:max_num_seqs=8, prefill_tokens=128 and decode_tokens=128,测试设备为NVIDIA A100
|
| 5 |
+
- vLLM的serving工作流并不存在batch_size的概念,这里采用max_num_seqs(每次迭代的最大序列数)来近似此概念。
|
| 6 |
+
- 测试脚本详见 [throughput-benchmarking](https://github.com/infinigence/Infini-Megrez/tree/main?tab=readme-ov-file#throughput-benchmarking)
|
| 7 |
+
- CPU测速
|
| 8 |
+
- 与GPU不同,CPU上存在llama.cpp、Ollama、厂商自研等多种推理框架
|
| 9 |
+
- 我们选择Intel [ipex-llm](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/CPU/vLLM-Serving)作为CPU推理引擎
|
| 10 |
+
- 实验配置为:max_num_seqs=1 prefill_tokens=128 and decode_tokens=128,测试设备为Intel(R) Xeon(R) Platinum 8358P
|
| 11 |
+
- 注意:Intel的ipex-llm方案仅支持qwen, baichuan, llama等结构,暂不支持MiniCPM系列
|
| 12 |
+
- 手机平台测试
|
| 13 |
+
- TBD
|
| 14 |
+
- 嵌入式平台测试
|
| 15 |
+
- 我们在瑞星微RK3576上进行了速度测试,选用厂商提供的[rknn-llm](https://github.com/airockchip/rknn-llm)框架
|
| 16 |
+
|
| 17 |
+
## 测速结果汇总
|
| 18 |
+
|
| 19 |
+
| | Megrez-3B | Qwen2.5-3B | MiniCPM3 | MiniCPM-2B |
|
| 20 |
+
|-----------------------|-----------|------------|--------|--------|
|
| 21 |
+
| A100 (BF16) | 1159.93 | 1123.38 | 455.44 | 978.96 |
|
| 22 |
+
| Intel(R) Xeon(R) Platinum 8358P (IPEX INT4) | 27.49 | 25.99 | X | 22.84 |
|
| 23 |
+
| RK3576 (INT4) | 8.79 | 7.73 | X | 6.45 |
|
assets/chat_en.png
ADDED
|
assets/github-mark.png
ADDED

|
assets/megrez_logo.png
ADDED
|
|
assets/mmlu.jpg
ADDED
|
assets/mmlu_en.png
ADDED
|
assets/mtbench.jpg
ADDED
|
assets/needle_test.png
ADDED
|
assets/websearch.gif
ADDED

|
assets/wechat-group.jpg
ADDED

|
assets/wechat-official.jpg
ADDED

|
config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "Megrez-3B-Instruct",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"LlamaForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_bias": false,
|
| 7 |
+
"attention_dropout": 0.0,
|
| 8 |
+
"bos_token_id": null,
|
| 9 |
+
"eos_token_id": 120005,
|
| 10 |
+
"hidden_act": "silu",
|
| 11 |
+
"hidden_size": 2560,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 7168,
|
| 14 |
+
"max_position_embeddings": 4096,
|
| 15 |
+
"max_sequence_length": 4096,
|
| 16 |
+
"mlp_bias": false,
|
| 17 |
+
"model_type": "llama",
|
| 18 |
+
"num_attention_heads": 40,
|
| 19 |
+
"num_hidden_layers": 32,
|
| 20 |
+
"num_key_value_heads": 10,
|
| 21 |
+
"pad_token_id": 0,
|
| 22 |
+
"pretraining_tp": 1,
|
| 23 |
+
"rms_norm_eps": 1e-05,
|
| 24 |
+
"rope_scaling": null,
|
| 25 |
+
"rope_theta": 5000000.0,
|
| 26 |
+
"tie_word_embeddings": false,
|
| 27 |
+
"torch_dtype": "bfloat16",
|
| 28 |
+
"transformers_version": "4.44.2",
|
| 29 |
+
"use_cache": false,
|
| 30 |
+
"vocab_size": 122880
|
| 31 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"eos_token_id": 120005,
|
| 4 |
+
"pad_token_id": 0,
|
| 5 |
+
"transformers_version": "4.44.2"
|
| 6 |
+
}
|