
![]()
Kai Li1,2, Yi Luo2
1Tsinghua University, Beijing, China
2Tencent AI Lab, Shenzhen, China
ArXiv | Demo

Apollo: Band-sequence Modeling for High-Quality Music Restoration in Compressed Audio
📖 Abstract
Apollo is a novel music restoration method designed to address distortions and artefacts caused by audio codecs, especially at low bitrates. Operating in the frequency domain, Apollo uses a frequency band-split module, band-sequence modeling, and frequency band reconstruction to restore the audio quality of MP3-compressed music. It divides the spectrogram into sub-bands, extracts gain-shape representations, and models both sub-band and temporal information for high-quality audio recovery. Trained with a Generative Adversarial Network (GAN), Apollo outperforms existing SR-GAN models on the MUSDB18-HQ and MoisesDB datasets, excelling in complex multi-instrument and vocal scenarios, while maintaining efficiency.
🔥 News
- [2024.09.10] Apollo is now available on ArXiv and Demo.
- [2024.09.106] Apollo checkpoints and pre-trained models are available for download.
⚡️ Installation
clone the repository
git clone https://github.com/JusperLee/Apollo.git && cd Apollo
conda create --name look2hear --file look2hear.yml
conda activate look2hear
🖥️ Usage
🗂️ Datasets
Apollo is trained on the MUSDB18-HQ and MoisesDB datasets. To download the datasets, run the following commands:
wget https://zenodo.org/records/3338373/files/musdb18hq.zip?download=1
wget https://ds-website-downloads.55c2710389d9da776875002a7d018e59.r2.cloudflarestorage.com/moisesdb.zip
During data preprocessing, we drew inspiration from music separation techniques and implemented the following steps:
Source Activity Detection (SAD):
We used a Source Activity Detector (SAD) to remove silent regions from the audio tracks, retaining only the significant portions for training.Data Augmentation:
We performed real-time data augmentation by mixing tracks from different songs. For each mix, we randomly selected between 1 and 8 stems from the 11 available tracks, extracting 3-second clips from each selected stem. These clips were scaled in energy by a random factor within the range of [-10, 10] dB relative to their original levels. The selected clips were then summed together to create simulated mixed music.Simulating Dynamic Bitrate Compression:
We simulated various bitrate scenarios by applying MP3 codecs with bitrates of [24000, 32000, 48000, 64000, 96000, 128000].Rescaling:
To ensure consistency across all samples, we rescaled both the target and the encoded audio based on their maximum absolute values.Saving as HDF5:
After preprocessing, all data (including the source stems, mixed tracks, and compressed audio) was saved in HDF5 format, making it easy to load for training and evaluation purposes.
🚀 Training
To train the Apollo model, run the following command:
python train.py --conf_dir=configs/apollo.yml
🎨 Evaluation
To evaluate the Apollo model, run the following command:
python inference.py --in_wav=assets/input.wav --out_wav=assets/output.wav
📊 Results
Here, you can include a brief overview of the performance metrics or results that Apollo achieves using different bitrates
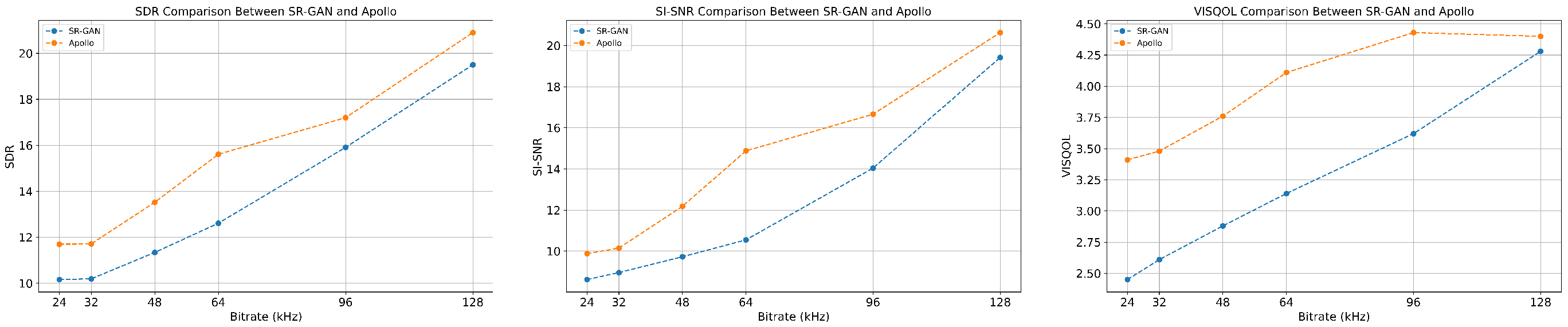
Different methods' SDR/SI-SNR/VISQOL scores for various types of music, as well as the number of model parameters and GPU inference time. For the GPU inference time test, a music signal with a sampling rate of 44.1 kHz and a length of 1 second was used.

License

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Acknowledgements
Apollo is developed by the Look2Hear at Tsinghua University.
Citation
If you use Apollo in your research or project, please cite the following paper:
@article{li2024apollo,
title={Apollo: Band-sequence Modeling for High-Quality Music Restoration in Compressed Audio},
author={Li, Kai and Luo, Yi},
journal={xxxxxx},
year={2024}
}
Contact
For any questions or feedback regarding Apollo, feel free to reach out to us via email: tsinghua.kaili@gmail.com