
FBI-LLM: Scaling Up Fully Binarized LLMs from Scratch via Autoregressive Distillation
Paper
•
2407.07093
•
Published
•
1
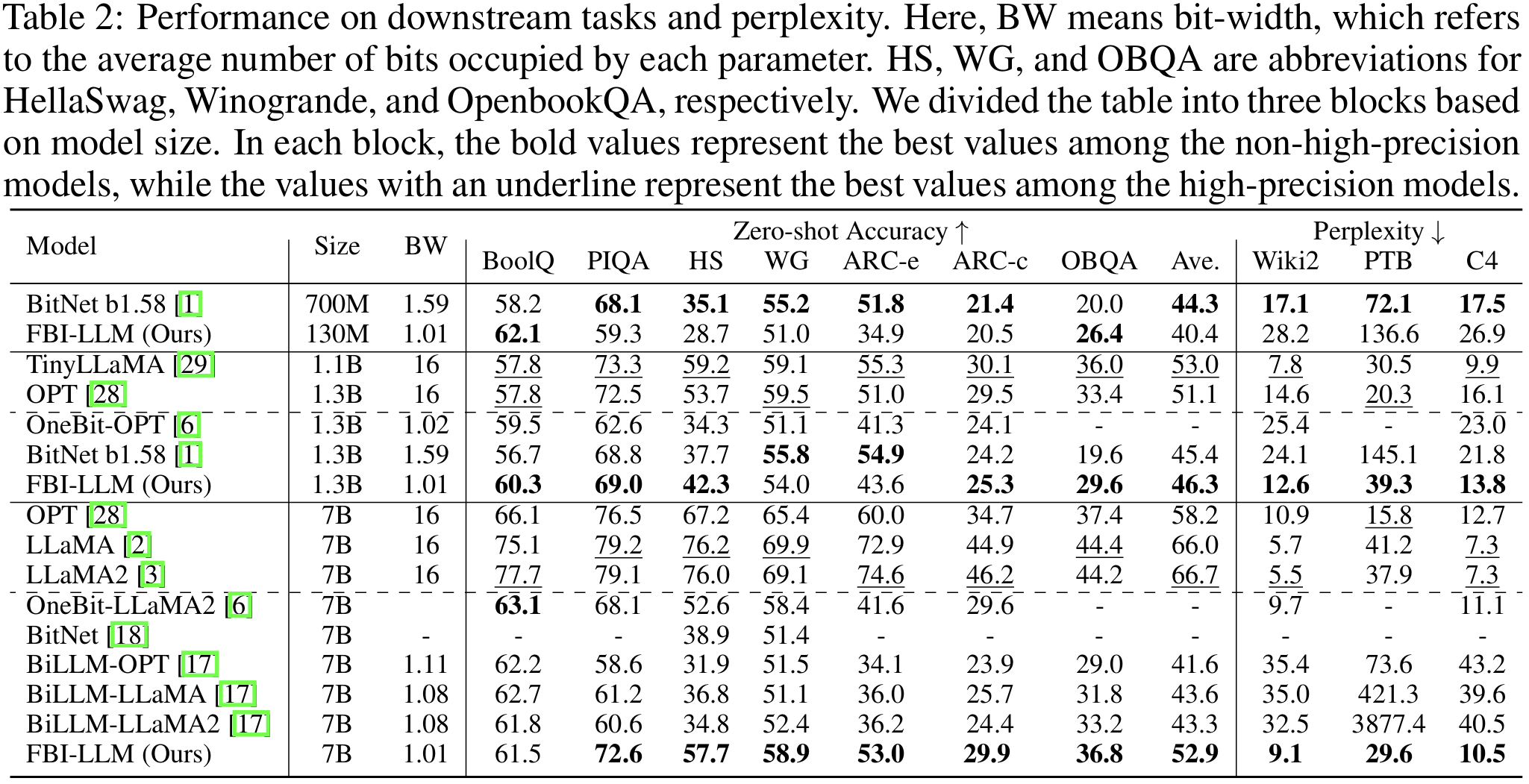
This work presents a Fully BInarized Large Language Model (FBI-LLM), demonstrating for the first time how to train a large-scale binary language model (not the ternary LLM like BitNet b1.58 from scratch to match the performance of its full-precision counterparts (e.g., FP16 or BF16) in transformer-based LLMs. It achieves this by employing an autoregressive distillation (AD) loss with maintaining equivalent model dimensions (130M, 1.3B, 7B) and training data volume as regular LLM pretraining, while delivering competitive results in terms of perplexity and task-specific effectiveness. Intriguingly, by analyzing the training trajectory, we find that the pretrained weight is not necessary for training binarized LLMs from scratch. This research encourages a new computational framework and may facilitate the future design of specialized hardware tailored for fully 1-bit LLMs. We make all models, code, and training dataset fully accessible and transparent to support further research.
Input: Models input text only.
Output: Models generate text only.
We use the same tokenizer as meta-llama/Llama-2-7b-hf
We use AmberDateset to train our models.
Please download the code from LiqunMa/FBI-LLM firstly
from pathlib import Path
from transformers import AutoTokenizer,LlamaConfig,LlamaForCausalLM, AutoModelForCausalLM
from qat.replace_module import replace_with_learnable_binarylinear
def load_model(model_size, model_dir):
assert model_size in ["130M", "1.3B", "7B"]
model_dir = Path(model_dir)
with Path(f'FBI-LLM_configs/FBI-LLM_llama2_{model_size}.json').open('r') as r_f:
config = json.load(r_f)
llama_config = LlamaConfig(**config)
model = LlamaForCausalLM(llama_config).to('cuda')
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf', padding_side="right", use_fast=False)
model = replace_with_learnable_binarylinear(model, scaling_pattern = "column", keep_parts = ["lm_head"])
weight_dict = {}
ckpt_plist = [p for p in model_dir.iterdir() if p.suffix == '.bin']
for p in ckpt_plist:
weight_dict = torch.load(p)
for k,v in _weight_dict.items():
if 'self_attn.rotary_emb.inv_freq' not in k:
weight_dict[k] = v
model.load_state_dict(weight_dict)
for param in model.parameters():
param.data = param.data.to(torch.float16)
return model, tokenizer
@misc{ma2024fbillmscalingfullybinarized,
title={FBI-LLM: Scaling Up Fully Binarized LLMs from Scratch via Autoregressive Distillation},
author={Liqun Ma and Mingjie Sun and Zhiqiang Shen},
year={2024},
eprint={2407.07093},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.07093},
}