

license: apache-2.0
language:
- ar
pipeline_tag: text-classification
library_name: transformers
base_model:
- Omartificial-Intelligence-Space/Arabic-Triplet-Matryoshka-V2
tags:
- reranking
- sentence-transformers
datasets:
- unicamp-dl/mmarco
Namaa-Reranker-v1 🚀✨
NAMAA-space releases Namaa-Reranker-v1, a high-performance model fine-tuned on unicamp-dl/mmarco to elevate Arabic document retrieval and ranking to new heights! 📚🇸🇦
This model is designed to improve search relevance of arabic documents by accurately ranking documents based on their contextual fit for a given query.
Key Features 🔑
- Optimized for Arabic: Built on the highly performant Omartificial-Intelligence-Space/Arabic-Triplet-Matryoshka-V2 with exclusivly rich Arabic data.
- Advanced Document Ranking: Ranks results with precision, perfect for search engines, recommendation systems, and question-answering applications.
- State-of-the-Art Performance: Achieves excellent performance compared to famous rerankers(See Evaluation), ensuring reliable relevance and precision.
Example Use Cases 💼
- Retrieval Augmented Generation: Improve search result relevance for Arabic content.
- Content Recommendation: Deliver top-tier Arabic content suggestions.
- Question Answering: Boost answer retrieval quality in Arabic-focused systems.
Usage
Within sentence-transformers
The usage becomes easier when you have SentenceTransformers installed. Then, you can use the pre-trained models like this:
from sentence_transformers import CrossEncoder
model = CrossEncoder('NAMAA-Space/Namaa-Reranker-v1', max_length=512)
Query = 'كيف يمكن استخدام التعلم العميق في معالجة الصور الطبية؟'
Paragraph1 = 'التعلم العميق يساعد في تحليل الصور الطبية وتشخيص الأمراض'
Paragraph2 = 'الذكاء الاصطناعي يستخدم في تحسين الإنتاجية في الصناعات'
scores = model.predict([(Query, Paragraph1), (Query, Paragraph2)])
Evaluation
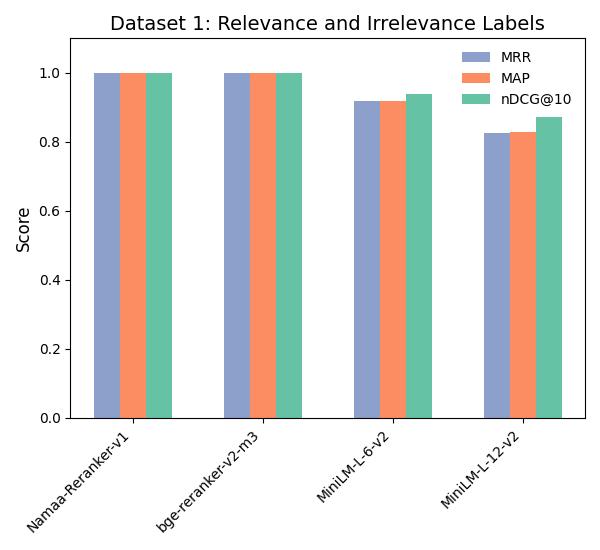
We evaluate our model on two different datasets using the metrics MAP, MRR and NDCG@10:
The purpose of this evaluation is to highlight the performance of our model with regards to: Relevant/Irrelevant labels and positive/multiple negatives documents:
Dataset 1: NAMAA-Space/Ar-Reranking-Eval
Dataset 2: NAMAA-Space/Arabic-Reranking-Triplet-5-Eval
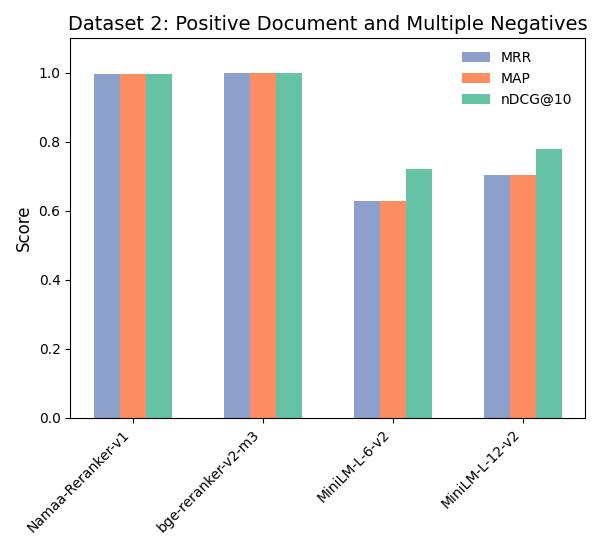
As seen, The model performs extremly well in comparison to other famous rerankers.
WIP: More comparisons and evaluation on arabic datasets.