

license: llama2
base_model: codellama/CodeLlama-13b-Instruct-hf
model-index:
- name: NexusRaven-13B
results: []
NexusRaven-13B: Surpassing the state-of-the-art in open-source function calling LLMs.
Nexusflow HF - NexusRaven blog post - NexusRaven-13B - NexusRaven-13B Twitter Thread - NexusRaven-13B Github - NexusRaven API evaluation dataset

Table of contents
This model is a fine-tuned version of codellama/CodeLlama-13b-Instruct-hf.
Introducing NexusRaven-13B
NexusRaven is an open-source and commercially viable function calling LLM that surpasses the state-of-the-art in function calling capabilities.
📊 Performance Highlights: With our demonstration retrieval system, NexusRaven-13B achieves a 95% success rate in using cybersecurity tools such as CVE/CPE Search and VirusTotal, while prompting GPT-4 achieves 64%. It has significantly lower cost and faster inference speed compared to GPT-4.
🔧 Generalization to the Unseen: NexusRaven-13B generalizes to tools never seen during model training, achieving a success rate comparable with GPT-3.5 in zero-shot setting, significantly outperforming all other open-source LLMs of similar sizes.
🔥 Commercially Permissive: The training of NexusRaven-13B does not involve any data generated by proprietary LLMs such as GPT-4. You have full control of the model when deployed in commercial applications.
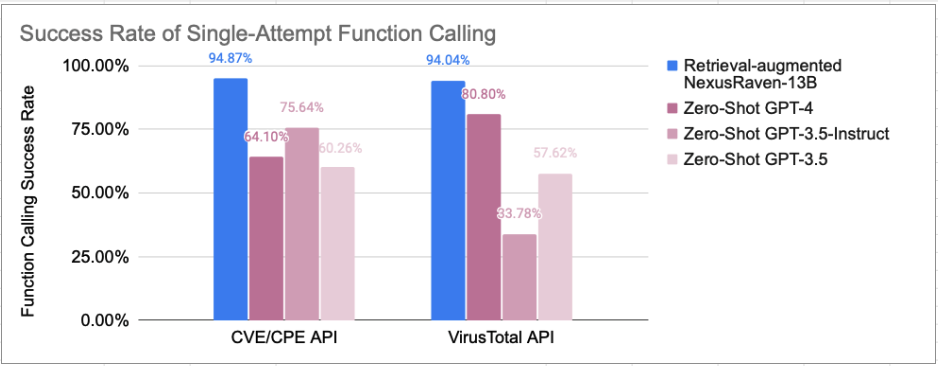
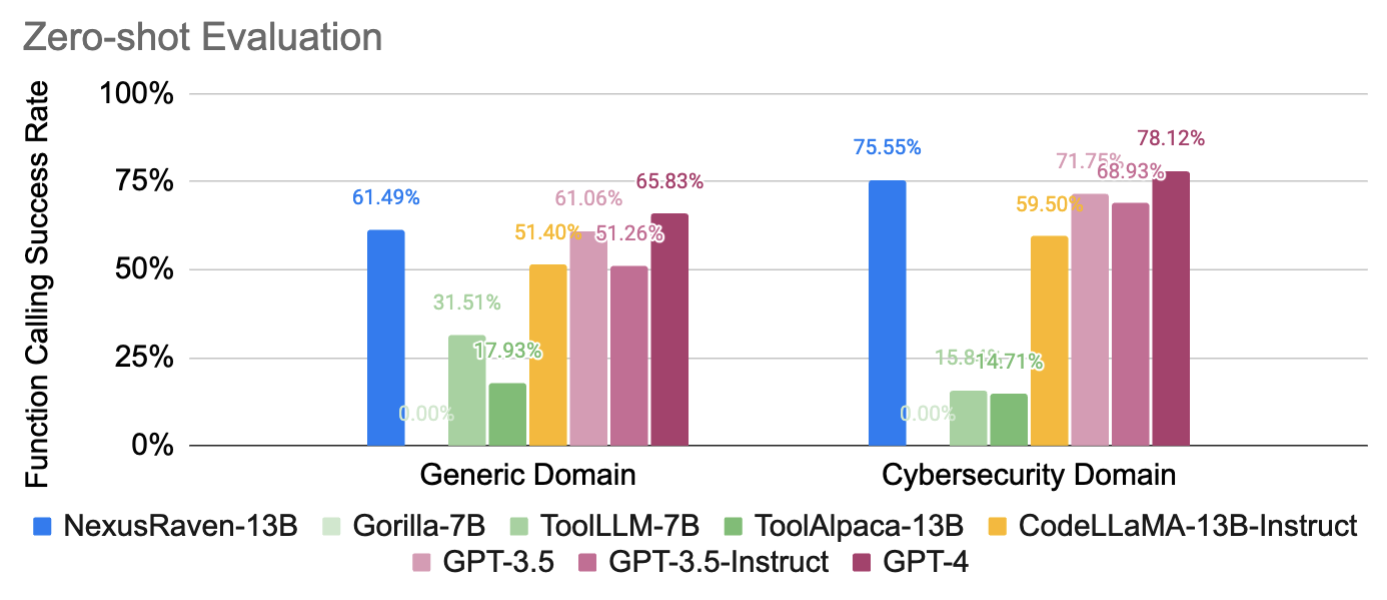
NexusRaven model usage
NexusRaven accepts a list of python functions. These python functions can do anything (including sending GET/POST requests to external APIs!). The two requirements include the python function signature and the appropriate docstring to generate the function call.
NexusRaven is highly compatible with langchain. See langchain_example.py. An example without langchain can be found in non_langchain_example.py.
Please note that the model will reflect on the answer sometimes, so we highly recommend stopping the model generation at a stopping criteria of ["\nReflection:"], to avoid spending unnecessary tokens during inference, but the reflection might help in some rare cases. This is reflected in our langchain example.
More information about how to prompt the model can be found in prompting_readme.md.
The "Initial Answer" can be executed to run the function.
Quickstart
You can run the model on a GPU using the following code.
# Please `pip install transformers accelerate`
from transformers import pipeline
pipeline = pipeline(
"text-generation",
model="Nexusflow/NexusRaven-13B",
torch_dtype="auto",
device_map="auto",
)
prompt_template = """
<human>:
OPTION:
<func_start>def hello_world(n : int)<func_end>
<docstring_start>
\"\"\"
Prints hello world to the user.
Args:
n (int) : Number of times to print hello world.
\"\"\"
<docstring_end>
OPTION:
<func_start>def hello_universe(n : int)<func_end>
<docstring_start>
\"\"\"
Prints hello universe to the user.
Args:
n (int) : Number of times to print hello universe.
\"\"\"
<docstring_end>
User Query: Question: {question}
Please pick a function from the above options that best answers the user query and fill in the appropriate arguments.<human_end>
"""
prompt = prompt_template.format(question="Please print hello world 10 times.")
result = pipeline(prompt, max_new_tokens=100, return_full_text=False, do_sample=False)[0]["generated_text"]
# Get the "Initial Call" only
start_str = "Initial Answer: "
end_str = "\nReflection: "
start_idx = result.find(start_str) + len(start_str)
end_idx = result.find(end_str)
function_call = result[start_idx: end_idx]
print (f"Generated Call: {function_call}")
This will output:
Generated Call: hello_world(10)
Which can be executed.
Training procedure
Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.95) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 2.0
Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
Limitations
- We highly recommend using a stop criteria of
["\nReflection:"]. The model was trained to first generate an answer and then reflect on its answer to either improve the answer or keep the answer the same. However, this "chain of thought" is often not helpful, and the final answer is seldom better than the initial call. Therefore, we strongly recommend using the Initial Call as the main call to execute. - The model works best when it is connected with a retriever when there are a multitude of functions, as a large number of functions will saturate the context window of this model.
- The model can be prone to generate incorrect calls. Please ensure proper guardrails to capture errant behavior is in place.
License
This model was trained on commercially viable data and is licensed under the Llama 2 community license following the original CodeLlama-13b-hf model.
References
We thank the CodeLlama team for their amazing models!
@misc{rozière2023code,
title={Code Llama: Open Foundation Models for Code},
author={Baptiste Rozière and Jonas Gehring and Fabian Gloeckle and Sten Sootla and Itai Gat and Xiaoqing Ellen Tan and Yossi Adi and Jingyu Liu and Tal Remez and Jérémy Rapin and Artyom Kozhevnikov and Ivan Evtimov and Joanna Bitton and Manish Bhatt and Cristian Canton Ferrer and Aaron Grattafiori and Wenhan Xiong and Alexandre Défossez and Jade Copet and Faisal Azhar and Hugo Touvron and Louis Martin and Nicolas Usunier and Thomas Scialom and Gabriel Synnaeve},
year={2023},
eprint={2308.12950},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Citation
@misc{nexusraven,
title={NexusRaven: Surpassing the state-of-the-art in open-source function calling LLMs},
author={Nexusflow.ai team},
year={2023},
url={http://nexusflow.ai/blog}
}
Contact
Please reach out to info@nexusflow.ai for any questions!