
Update README.md
#5
by
qubvel-hf
HF staff
- opened
README.md
CHANGED
|
@@ -22,17 +22,25 @@ widget:
|
|
| 22 |
---
|
| 23 |
|
| 24 |
|
| 25 |
-
# Model Card for
|
| 26 |
|
| 27 |
-
<!-- Provide a quick summary of what the model is/does. -->
|
| 28 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 29 |
|
| 30 |
|
| 31 |
## Model Details
|
| 32 |
|
| 33 |
-
|
| 34 |
|
| 35 |
-
The YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy.
|
| 36 |
However, we observe that the speed and accuracy of YOLOs are negatively affected by the NMS.
|
| 37 |
Recently, end-to-end Transformer-based detectors (DETRs) have provided an alternative to eliminating NMS.
|
| 38 |
Nevertheless, the high computational cost limits their practicality and hinders them from fully exploiting the advantage of excluding NMS.
|
|
@@ -47,61 +55,32 @@ We also develop scaled RT-DETRs that outperform the lighter YOLO detectors (S an
|
|
| 47 |
Furthermore, RT-DETR-R50 outperforms DINO-R50 by 2.2% AP in accuracy and about 21 times in FPS.
|
| 48 |
After pre-training with Objects365, RT-DETR-R50 / R101 achieves 55.3% / 56.2% AP. The project page: this [https URL](https://zhao-yian.github.io/RTDETR/).
|
| 49 |
|
| 50 |
-

|
| 51 |
|
| 52 |
-
|
|
|
|
| 53 |
|
| 54 |
- **Developed by:** Yian Zhao and Sangbum Choi
|
| 55 |
-
- **Funded by
|
| 56 |
and the Shenzhen Medical Research Funds in China (No.
|
| 57 |
B2302037).
|
| 58 |
-
- **Shared by
|
| 59 |
-
- **Model type:**
|
| 60 |
-
- **Language(s) (NLP):**
|
| 61 |
- **License:** Apache-2.0
|
| 62 |
-
- **Finetuned from model [optional]:**
|
| 63 |
|
| 64 |
-
### Model Sources
|
| 65 |
|
| 66 |
<!-- Provide the basic links for the model. -->
|
| 67 |
|
|
|
|
| 68 |
- **Repository:** https://github.com/lyuwenyu/RT-DETR
|
| 69 |
-
- **Paper
|
| 70 |
-
- **Demo
|
| 71 |
-
|
| 72 |
-
## Uses
|
| 73 |
-
|
| 74 |
-
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 75 |
-
|
| 76 |
-
### Direct Use
|
| 77 |
-
|
| 78 |
-
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
|
| 79 |
-
|
| 80 |
-
You can use the raw model for object detection. See the [model hub](https://huggingface.co/models?search=rtdetr) to look for all available RTDETR models.
|
| 81 |
-
|
| 82 |
-
### Downstream Use [optional]
|
| 83 |
-
|
| 84 |
-
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
|
| 85 |
-
|
| 86 |
-
### Out-of-Scope Use
|
| 87 |
-
|
| 88 |
-
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
|
| 89 |
-
|
| 90 |
-
## Bias, Risks, and Limitations
|
| 91 |
-
|
| 92 |
-
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 93 |
-
|
| 94 |
-
### Recommendations
|
| 95 |
-
|
| 96 |
-
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
|
| 97 |
-
|
| 98 |
-
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
|
| 99 |
|
| 100 |
## How to Get Started with the Model
|
| 101 |
|
| 102 |
Use the code below to get started with the model.
|
| 103 |
|
| 104 |
-
```
|
| 105 |
import torch
|
| 106 |
import requests
|
| 107 |
|
|
@@ -148,77 +127,48 @@ The RTDETR model was trained on [COCO 2017 object detection](https://cocodataset
|
|
| 148 |
|
| 149 |
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 150 |
|
| 151 |
-
We conduct experiments on
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
dataset. We report the standard COCO metrics, including
|
| 155 |
-
AP (averaged over uniformly sampled IoU thresholds ranging from 0.50-0.95 with a step size of 0.05), AP50, AP75, as
|
| 156 |
-
well as AP at different scales: APS, APM, APL.
|
| 157 |
|
| 158 |
-
|
| 159 |
|
| 160 |
-
Images are resized
|
| 161 |
|
| 162 |
-
|
| 163 |
|
| 164 |
- **Training regime:** <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 165 |
|
| 166 |

|
| 167 |
|
| 168 |
-
#### Speeds, Sizes, Times [optional]
|
| 169 |
-
|
| 170 |
-
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
|
| 171 |
|
| 172 |
## Evaluation
|
| 173 |
|
| 174 |
-
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 175 |
-
|
| 176 |
-
This model achieves an AP (average precision) of 53.1 on COCO 2017 validation. For more details regarding evaluation results, we refer to table 2 of the original paper.
|
| 177 |
|
| 178 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 179 |
|
| 180 |
-
#### Testing Data
|
| 181 |
|
| 182 |
-
<!-- This should link to a Dataset Card if possible. -->
|
| 183 |
-
|
| 184 |
-
#### Factors
|
| 185 |
-
|
| 186 |
-
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 187 |
-
|
| 188 |
-
#### Metrics
|
| 189 |
-
|
| 190 |
-
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 191 |
-
|
| 192 |
-
### Results
|
| 193 |
-
|
| 194 |
-
#### Summary
|
| 195 |
-
|
| 196 |
-
|
| 197 |
-
|
| 198 |
-
## Model Examination [optional]
|
| 199 |
-
|
| 200 |
-
<!-- Relevant interpretability work for the model goes here -->
|
| 201 |
-
|
| 202 |
-
## Environmental Impact
|
| 203 |
-
|
| 204 |
-
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 205 |
-
|
| 206 |
-
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 207 |
-
|
| 208 |
-
|
| 209 |
-
## Technical Specifications [optional]
|
| 210 |
|
| 211 |
### Model Architecture and Objective
|
| 212 |
|
| 213 |
|
| 214 |
|
| 215 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 216 |
|
| 217 |
-
#### Hardware
|
| 218 |
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
## Citation [optional]
|
| 222 |
|
| 223 |
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 224 |
|
|
@@ -235,16 +185,8 @@ Carbon emissions can be estimated using the [Machine Learning Impact calculator]
|
|
| 235 |
}
|
| 236 |
```
|
| 237 |
|
| 238 |
-
|
| 239 |
-
|
| 240 |
-
## Glossary [optional]
|
| 241 |
-
|
| 242 |
-
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
|
| 243 |
-
|
| 244 |
-
## More Information [optional]
|
| 245 |
-
|
| 246 |
-
## Model Card Authors [optional]
|
| 247 |
|
| 248 |
-
[Sangbum Choi](https://huggingface.co/danelcsb)
|
|
|
|
| 249 |
|
| 250 |
-
## Model Card Contact
|
|
|
|
| 22 |
---
|
| 23 |
|
| 24 |
|
| 25 |
+
# Model Card for RT-DETR
|
| 26 |
|
|
|
|
| 27 |
|
| 28 |
+
## Table of Contents
|
| 29 |
+
|
| 30 |
+
1. [Model Details](#model-details)
|
| 31 |
+
2. [Model Sources](#model-sources)
|
| 32 |
+
3. [How to Get Started with the Model](#how-to-get-started-with-the-model)
|
| 33 |
+
4. [Training Details](#training-details)
|
| 34 |
+
5. [Evaluation](#evaluation)
|
| 35 |
+
6. [Model Architecture and Objective](#model-architecture-and-objective)
|
| 36 |
+
7. [Citation](#citation)
|
| 37 |
|
| 38 |
|
| 39 |
## Model Details
|
| 40 |
|
| 41 |
+

|
| 42 |
|
| 43 |
+
> The YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy.
|
| 44 |
However, we observe that the speed and accuracy of YOLOs are negatively affected by the NMS.
|
| 45 |
Recently, end-to-end Transformer-based detectors (DETRs) have provided an alternative to eliminating NMS.
|
| 46 |
Nevertheless, the high computational cost limits their practicality and hinders them from fully exploiting the advantage of excluding NMS.
|
|
|
|
| 55 |
Furthermore, RT-DETR-R50 outperforms DINO-R50 by 2.2% AP in accuracy and about 21 times in FPS.
|
| 56 |
After pre-training with Objects365, RT-DETR-R50 / R101 achieves 55.3% / 56.2% AP. The project page: this [https URL](https://zhao-yian.github.io/RTDETR/).
|
| 57 |
|
|
|
|
| 58 |
|
| 59 |
+
|
| 60 |
+
This is the model card of a 🤗 [transformers](https://huggingface.co/docs/transformers/index) model that has been pushed on the Hub.
|
| 61 |
|
| 62 |
- **Developed by:** Yian Zhao and Sangbum Choi
|
| 63 |
+
- **Funded by:** National Key R&D Program of China (No.2022ZD0118201), Natural Science Foundation of China (No.61972217, 32071459, 62176249, 62006133, 62271465),
|
| 64 |
and the Shenzhen Medical Research Funds in China (No.
|
| 65 |
B2302037).
|
| 66 |
+
- **Shared by:** Sangbum Choi
|
| 67 |
+
- **Model type:** [RT-DETR](https://huggingface.co/docs/transformers/main/en/model_doc/rt_detr)
|
|
|
|
| 68 |
- **License:** Apache-2.0
|
|
|
|
| 69 |
|
| 70 |
+
### Model Sources
|
| 71 |
|
| 72 |
<!-- Provide the basic links for the model. -->
|
| 73 |
|
| 74 |
+
- **HF Docs:** [RT-DETR](https://huggingface.co/docs/transformers/main/en/model_doc/rt_detr)
|
| 75 |
- **Repository:** https://github.com/lyuwenyu/RT-DETR
|
| 76 |
+
- **Paper:** https://arxiv.org/abs/2304.08069
|
| 77 |
+
- **Demo:** [RT-DETR Tracking](https://huggingface.co/spaces/merve/RT-DETR-tracking-coco)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 78 |
|
| 79 |
## How to Get Started with the Model
|
| 80 |
|
| 81 |
Use the code below to get started with the model.
|
| 82 |
|
| 83 |
+
```python
|
| 84 |
import torch
|
| 85 |
import requests
|
| 86 |
|
|
|
|
| 127 |
|
| 128 |
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 129 |
|
| 130 |
+
We conduct experiments on COCO and Objects365 datasets, where RT-DETR is trained on COCO train2017 and validated on COCO val2017 dataset.
|
| 131 |
+
We report the standard COCO metrics, including AP (averaged over uniformly sampled IoU thresholds ranging from 0.50-0.95 with a step size of 0.05),
|
| 132 |
+
AP50, AP75, as well as AP at different scales: APS, APM, APL.
|
|
|
|
|
|
|
|
|
|
| 133 |
|
| 134 |
+
### Preprocessing
|
| 135 |
|
| 136 |
+
Images are resized to 640x640 pixels and rescaled with `image_mean=[0.485, 0.456, 0.406]` and `image_std=[0.229, 0.224, 0.225]`.
|
| 137 |
|
| 138 |
+
### Training Hyperparameters
|
| 139 |
|
| 140 |
- **Training regime:** <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 141 |
|
| 142 |

|
| 143 |
|
|
|
|
|
|
|
|
|
|
| 144 |
|
| 145 |
## Evaluation
|
| 146 |
|
|
|
|
|
|
|
|
|
|
| 147 |
|
| 148 |
+
| Model | #Epochs | #Params (M) | GFLOPs | FPS_bs=1 | AP (val) | AP50 (val) | AP75 (val) | AP-s (val) | AP-m (val) | AP-l (val) |
|
| 149 |
+
|----------------------------|---------|-------------|--------|----------|--------|-----------|-----------|----------|----------|----------|
|
| 150 |
+
| RT-DETR-R18 | 72 | 20 | 60.7 | 217 | 46.5 | 63.8 | 50.4 | 28.4 | 49.8 | 63.0 |
|
| 151 |
+
| RT-DETR-R34 | 72 | 31 | 91.0 | 172 | 48.5 | 66.2 | 52.3 | 30.2 | 51.9 | 66.2 |
|
| 152 |
+
| RT-DETR R50 | 72 | 42 | 136 | 108 | 53.1 | 71.3 | 57.7 | 34.8 | 58.0 | 70.0 |
|
| 153 |
+
| RT-DETR R101| 72 | 76 | 259 | 74 | 54.3 | 72.7 | 58.6 | 36.0 | 58.8 | 72.1 |
|
| 154 |
+
| RT-DETR-R18 (Objects 365 pretrained) | 60 | 20 | 61 | 217 | 49.2 | 66.6 | 53.5 | 33.2 | 52.3 | 64.8 |
|
| 155 |
+
| RT-DETR-R50 (Objects 365 pretrained) | 24 | 42 | 136 | 108 | 55.3 | 73.4 | 60.1 | 37.9 | 59.9 | 71.8 |
|
| 156 |
+
| RT-DETR-R101 (Objects 365 pretrained) | 24 | 76 | 259 | 74 | 56.2 | 74.6 | 61.3 | 38.3 | 60.5 | 73.5 |
|
| 157 |
|
|
|
|
| 158 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 159 |
|
| 160 |
### Model Architecture and Objective
|
| 161 |
|
| 162 |

|
| 163 |
|
| 164 |
+
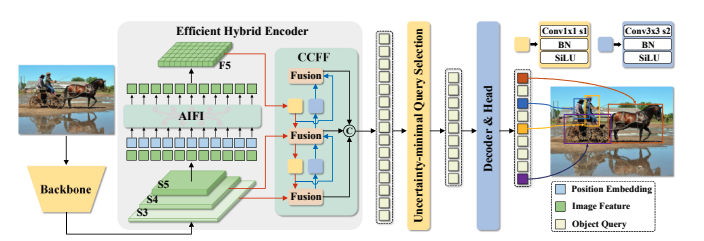
Overview of RT-DETR. We feed the features from the last three stages of the backbone into the encoder. The efficient hybrid
|
| 165 |
+
encoder transforms multi-scale features into a sequence of image features through the Attention-based Intra-scale Feature Interaction (AIFI)
|
| 166 |
+
and the CNN-based Cross-scale Feature Fusion (CCFF). Then, the uncertainty-minimal query selection selects a fixed number of encoder
|
| 167 |
+
features to serve as initial object queries for the decoder. Finally, the decoder with auxiliary prediction heads iteratively optimizes object
|
| 168 |
+
queries to generate categories and boxes.
|
| 169 |
|
|
|
|
| 170 |
|
| 171 |
+
## Citation
|
|
|
|
|
|
|
| 172 |
|
| 173 |
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 174 |
|
|
|
|
| 185 |
}
|
| 186 |
```
|
| 187 |
|
| 188 |
+
## Model Card Authors
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 189 |
|
| 190 |
+
[Sangbum Choi](https://huggingface.co/danelcsb)
|
| 191 |
+
[Pavel Iakubovskii](https://huggingface.co/qubvel-hf)
|
| 192 |
|
|
|