
Embedding Dimension: Up to 1024, supports user-defined output dimensions ranging from 32 to 1024
#3
by chaochaoli - opened

[32, 1024]的任何整数都行吗?
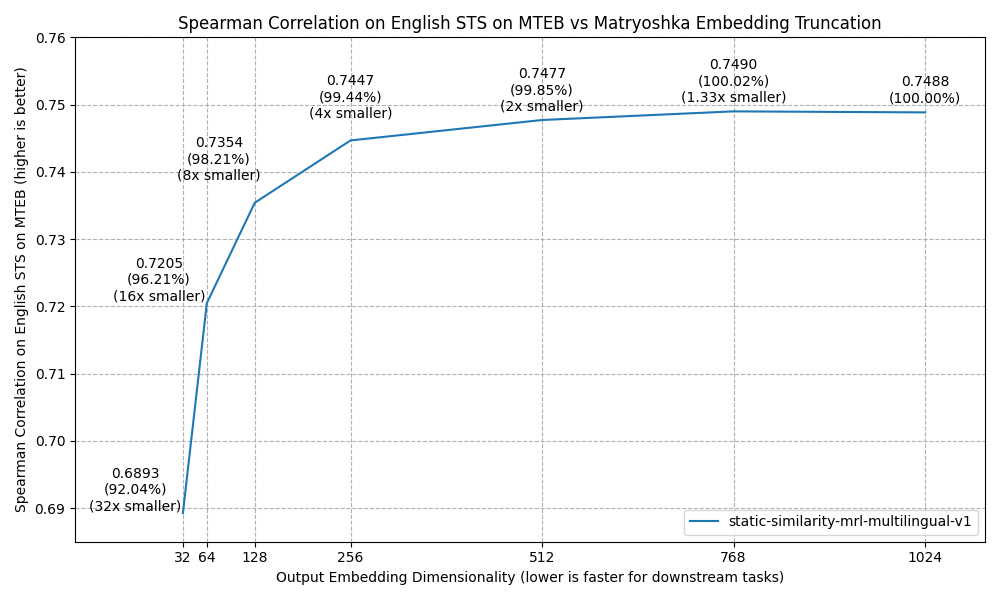
我看别人都是32的倍数
有截断dim的demo示例吗?

有截断dim的demo示例吗?
这是我试的 看着没啥问题
batch_dict = tokenize(tokenizer, batch_texts, eod_id, max_length)
batch_dict.to(model.device)
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = embeddings[:, :dimension]
embeddings = F.normalize(embeddings, p=2, dim=1).detach().cpu().numpy()
chaochaoli changed discussion status to closed