
LightingRL Series
Collection
Diffusion Large Language Models with a SOTA Accuracy–Parallelism Trade-off • 7 items • Updated
• 2
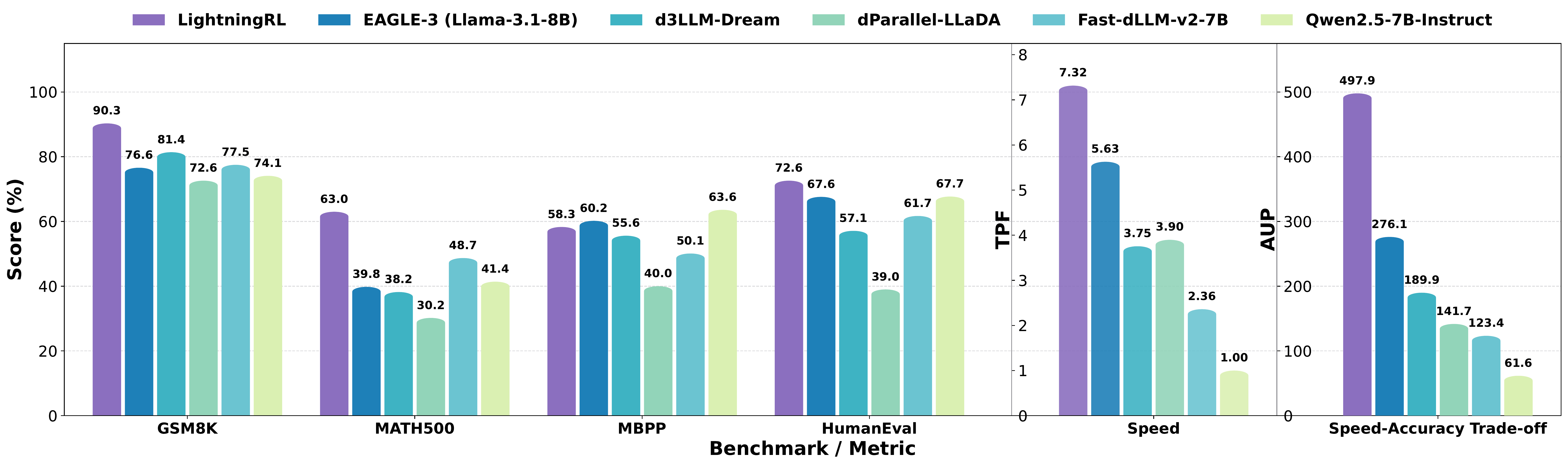
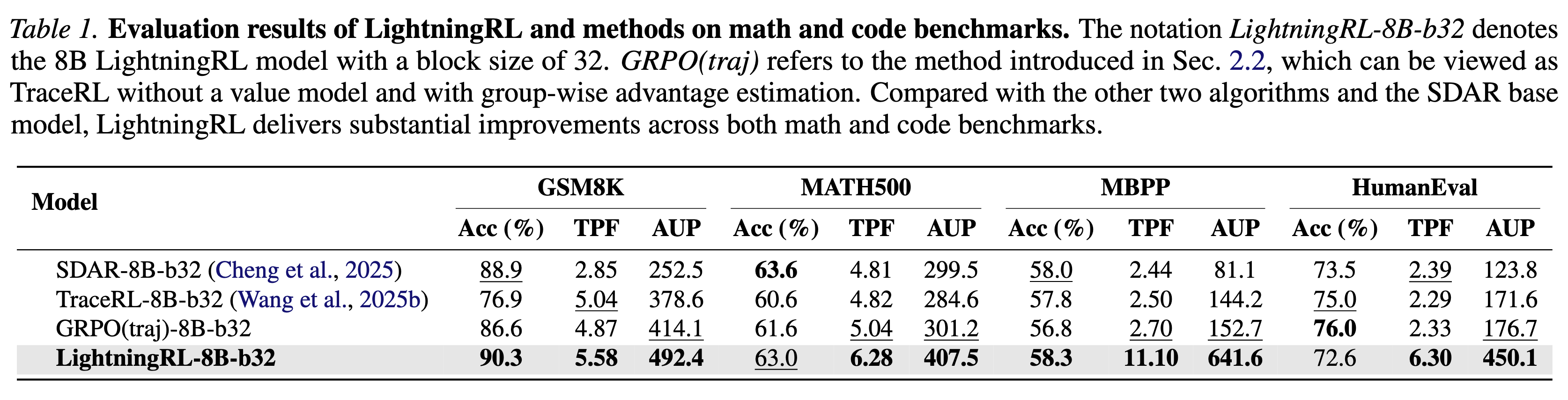
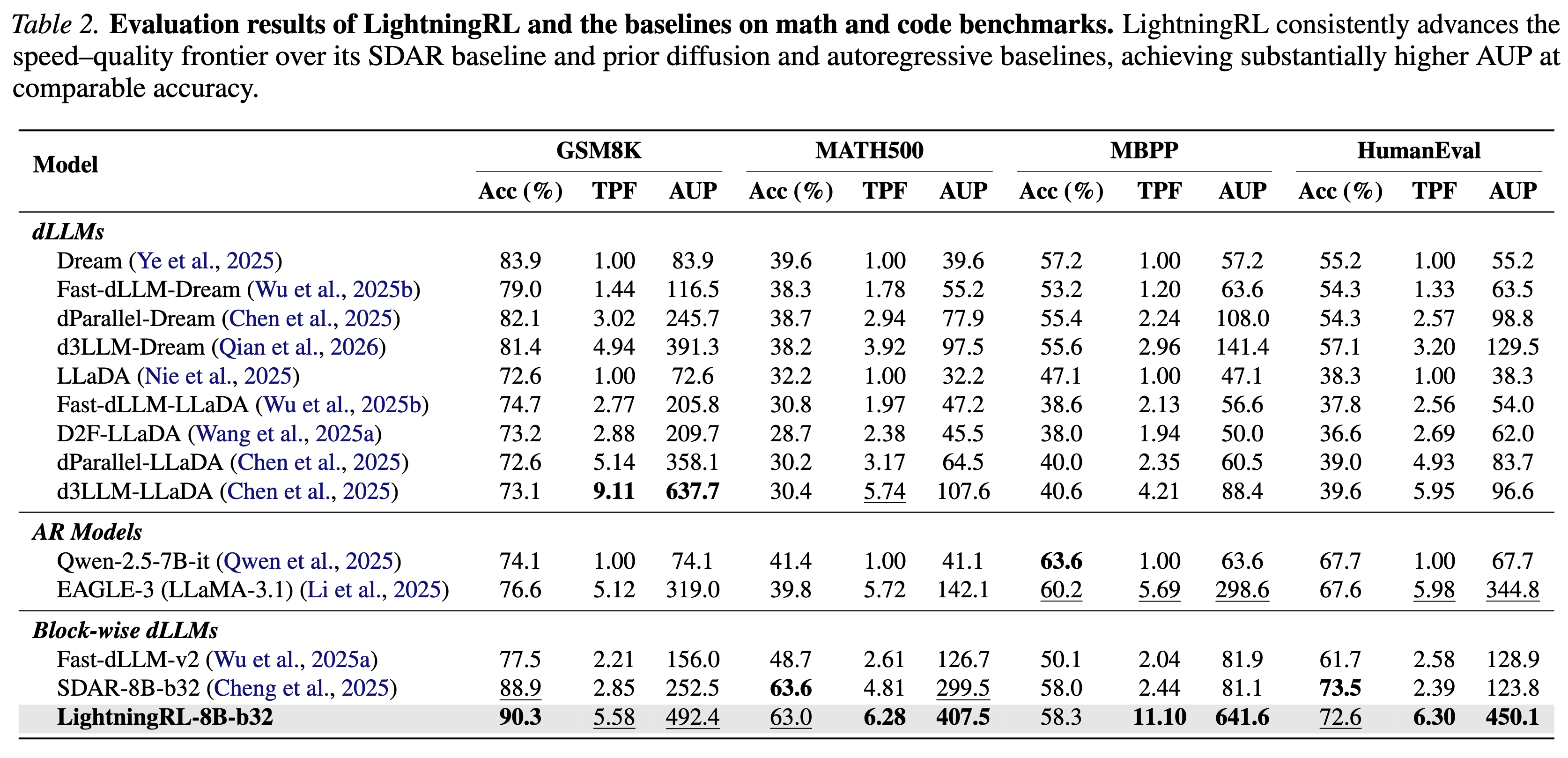
We introduce LightningRL, a reinforcement learning post-training framework for block-wise diffusion Large Language Models (dLLMs) that breaks the accuracy–parallelism trade-off. Applied to SDAR-8B, LightningRL achieves 7.32 average TPF and 497.9 AUP — simultaneously improving both generation quality and inference speed.
@article{hu2026lightningrl,
title={LightningRL: Breaking the Accuracy--Parallelism Trade-off of Block-wise dLLMs via Reinforcement Learning},
author={Hu, Yanzhe and Jin, Yijie and Liu, Pengfei and Yu, Kai and Deng, Zhijie},
journal={arXiv preprint},
year={2026},
note={Coming soon}
}