
library_name: transformers
datasets:
- Svngoku/french-multilingual-reward-bench-dpo
language:
- fr
base_model:
- CohereForAI/aya-expanse-8b
metrics:
- bleu
- accuracy
pipeline_tag: text-generation
Model Card for French Aya Expanse 8B

Aya Expanse 8B is an open-weight research release of a model with highly advanced multilingual capabilities. It focuses on pairing a highly performant pre-trained Command family of models with the result of a year’s dedicated research from Cohere For AI, including data arbitrage, multilingual preference training, safety tuning, and model merging. The result is a powerful multilingual large language model.
This model card corresponds to the 8-billion version of the Aya Expanse model. We also released an 32-billion version which you can find here.
- Developed by: Cohere For AI
- Point of Contact: Cohere For AI: cohere.for.ai
- License: CC-BY-NC, requires also adhering to C4AI's Acceptable Use Policy
- Model: Aya Expanse 8B
- Model Size: 8 billion parameters
Supported Languages
The model cover 23 languages: Arabic, Chinese (simplified & traditional), Czech, Dutch, English, French, German, Greek, Hebrew, Hebrew, Hindi, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Spanish, Turkish, Ukrainian, and Vietnamese.
But the fine-tuned version is focus on French
How to Use Aya Expanse
Install the transformers library and load Aya Expanse 8B as follows:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "Svngoku/French-Aya-Expanse-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
# Format the message with the chat template
messages = [{"role": "user", "content": "Quels est la superficie de Paris"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Anneme onu ne kadar sevdiğimi anlatan bir mektup yaz<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
gen_tokens = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)
Example Notebooks
Fine-Tuning:
Community-Contributed Use Cases::
The following notebooks contributed by Cohere For AI Community members show how Aya Expanse can be used for different use cases:
Model Details
Input: Models input text only.
Output: Models generate text only.
Model Architecture: Aya Expanse 8B is an auto-regressive language model that uses an optimized transformer architecture. Post-training includes supervised finetuning, preference training, and model merging.
Languages covered: The model is particularly optimized for multilinguality and supports the following languages: Arabic, Chinese (simplified & traditional), Czech, Dutch, English, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Spanish, Turkish, Ukrainian, and Vietnamese
Context length: 8K
For more details about how the model was trained, check out our blogpost.
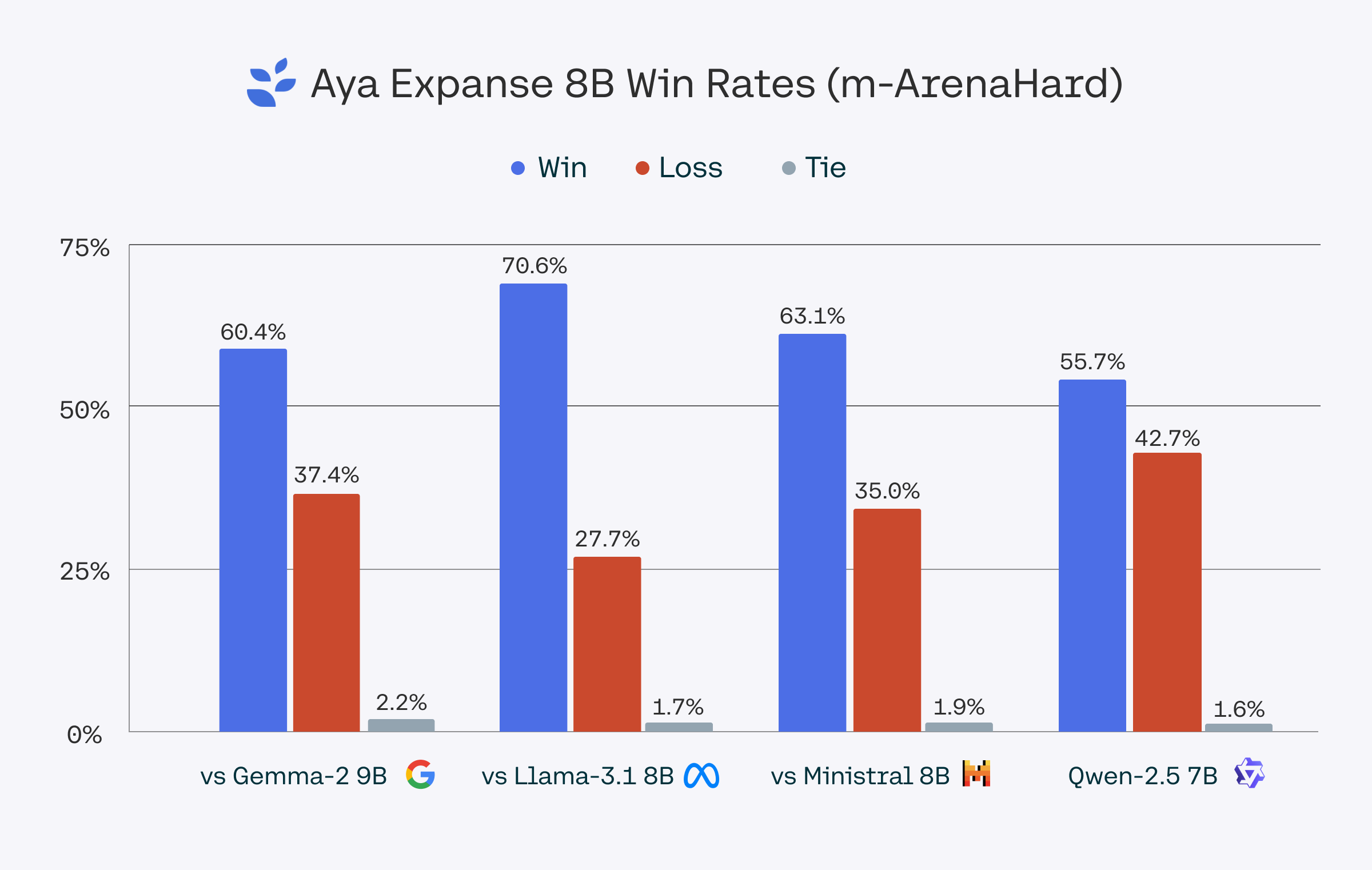
Evaluation
They evaluated Aya Expanse 8B against Gemma 2 9B, Llama 3.1 8B, Ministral 8B, and Qwen 2.5 7B using the dolly_human_edited subset from the Aya Evaluation Suite dataset and m-ArenaHard, a dataset based on the Arena-Hard-Auto dataset and translated to the 23 languages we support in Aya Expanse 8B. Win-rates were determined using gpt-4o-2024-08-06 as a judge. For a conservative benchmark, we report results from gpt-4o-2024-08-06, though gpt-4o-mini scores showed even stronger performance.
The m-ArenaHard dataset, used to evaluate Aya Expanse’s capabilities, is publicly available here.



Model Card Contact
For errors or additional questions about details in this model card, contact info@for.ai.
Terms of Use
They hope that the release of this model will make community-based research efforts more accessible, by releasing the weights of a highly performant multilingual model to researchers all over the world. This model is governed by a CC-BY-NC License with an acceptable use addendum, and also requires adhering to C4AI's Acceptable Use Policy.