
Divot: Diffusion Powers Video Tokenizer for Comprehension and Generation
Paper • 2412.04432 • Published • 16
![]()
We introduce Divot, a Diffusion-Powered Video Tokenizer, which leverages the diffusion process for self-supervised video representation learning. We posit that if a video diffusion model can effectively de-noise video clips by taking the features of a video tokenizer as the condition, then the tokenizer has successfully captured robust spatial and temporal information. Additionally, the video diffusion model inherently functions as a de-tokenizer, decoding videos from their representations. Building upon the Divot tokenizer, we present Divot-LLM through video-to-text autoregression and text-to-video generation by modeling the distributions of continuous-valued Divot features with a Gaussian Mixture Model.
All models, training code and inference code are released!
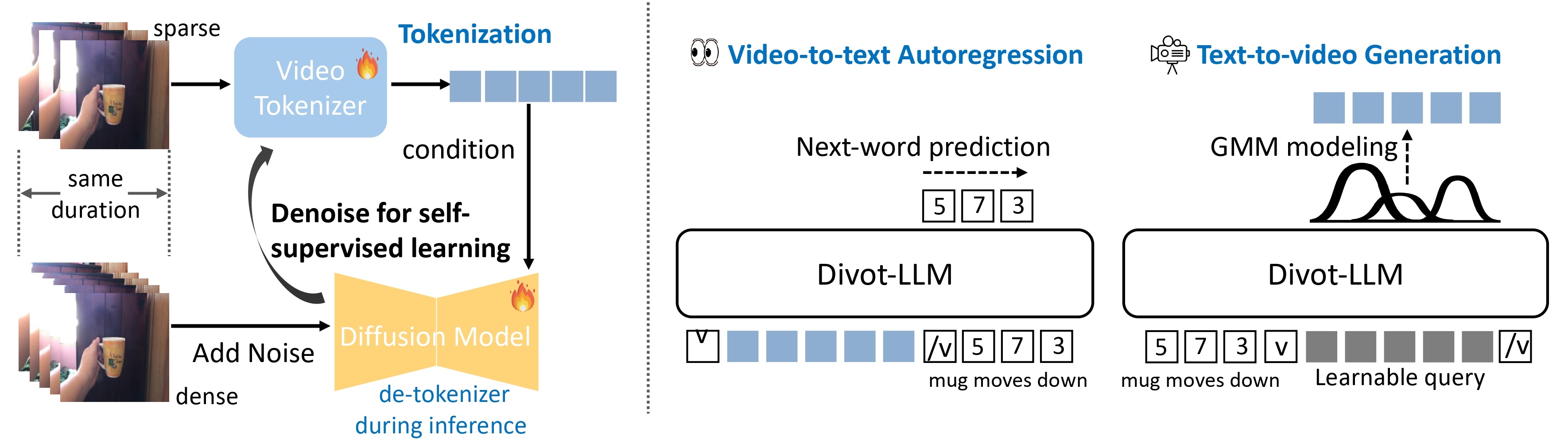
We utilize the diffusion procedure to learn a video tokenizer in a self-supervised manner for unified comprehension and generation, where the spatiotemporal representations serve as the condition of a diffusion model to de-noise video clips. Additionally, the proxy diffusion model functions as a de-tokenizer to decode realistic video clips from the video representations.
After training the the Divot tokenizer, video features from the Divot tokenizer are fed into the LLM to perform next-word prediction for video comprehension, while learnable queries are input into the LLM to model the distributions of Divot features using a Gaussian Mixture Model (GMM) for video generation. During inference, video features are sampled from the predicted GMM distribution to decode videos using the de-tokenizer.
Clone the repo and install dependent packages
git clone https://github.com/TencentARC/Divot.git
cd Divot
pip install -r requirements.txt
We release the pretrained tokenizer and de-tokenizer, pre-trained and instruction-tuned Divot-LLM. Please download the checkpoints and save them under the folder ./pretrained. For example, ./pretrained/Divot_tokenizer_detokenizer.
You also need to download Mistral-7B-Instruct-v0.1 and CLIP-ViT-H-14-laion2B-s32B-b79K, and save them under the folder ./pretrained.
python3 src/tools/eval_Divot_video_recon.py
python3 src/tools/eval_Divot_video_comp.py
python3 src/tools/eval_Divot_video_gen.py
./pretrained.sh scripts/train_Divot_pretrain_comp_gen.sh
./pretrained.### For video comprehension
sh scripts/train_Divot_sft_comp.sh
### For video generation
sh scripts/train_Divot_sft_gen.sh
cd train_output/sft_comp/checkpoint-xxxx
python3 zero_to_fp32.py . pytorch_model.bin
python3 src/tools/merge_agent_lora_weight.py
llm_cfg_path = 'configs/clm_models/mistral7b_merged_sft_comp.yaml'
agent_cfg_path = 'configs/clm_models/agent_7b_in64_out64_video_gmm_sft_comp.yaml'
Divot is licensed under the Apache License Version 2.0 for academic purpose only except for the third-party components listed in License.
If you find the work helpful, please consider citing:
@article{ge2024divot,
title={Divot: Diffusion Powers Video Tokenizer for Comprehension and Generation},
author={Ge, Yuying and Li, Yizhuo and Ge, Yixiao and Shan, Ying},
journal={arXiv preprint arXiv:2412.04432},
year={2024}
}
Our code for Divot tokenizer and de-tokenizer is built upon DynamiCrafter. Thanks for their excellent work!