
Model Details
We introduce a suite of neural language model tools for pre-training, fine-tuning SMILES-based molecular language models. Furthermore, we also provide recipes for semi-supervised recipes for fine-tuning these languages in low-data settings using Semi-supervised learning.
Enumeration-aware Molecular Transformers
Introduces contrastive learning alongside multi-task regression, and masked language modelling as pre-training objectives to inject enumeration knowledge into pre-trained language models.
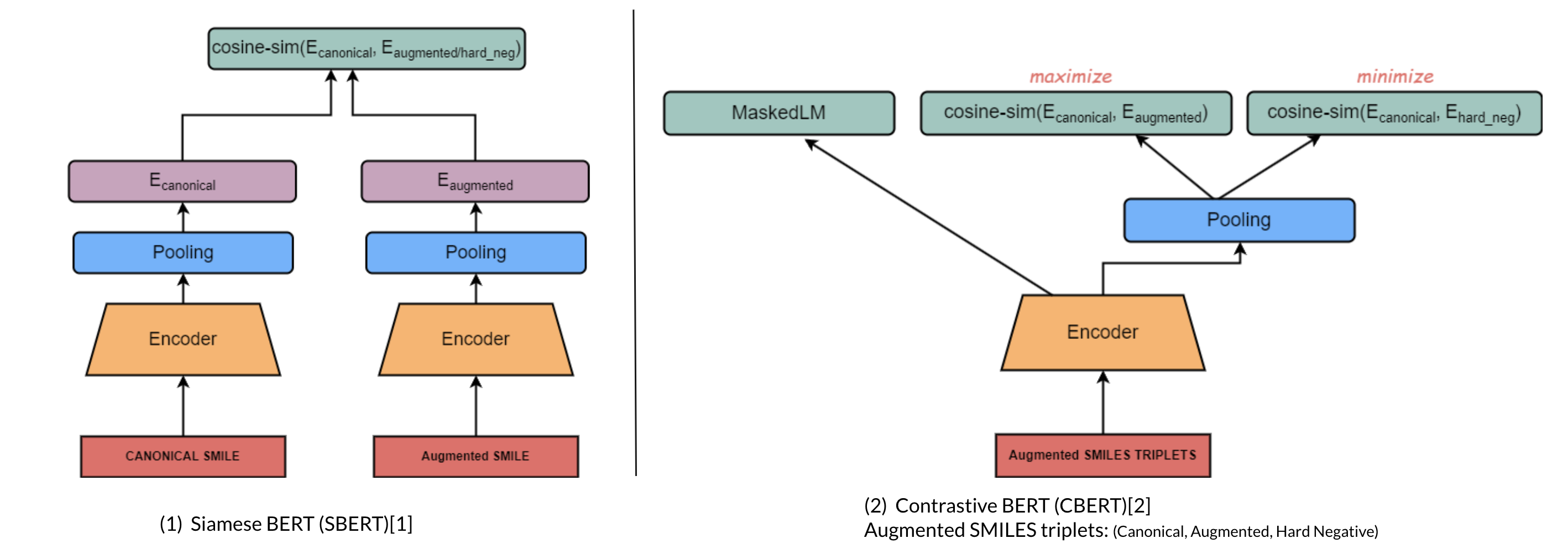
a. Molecular Domain Adaptation (Contrastive Encoder-based)
i. Architecture

ii. Contrastive Learning
b. Canonicalization Encoder-decoder (Denoising Encoder-decoder)
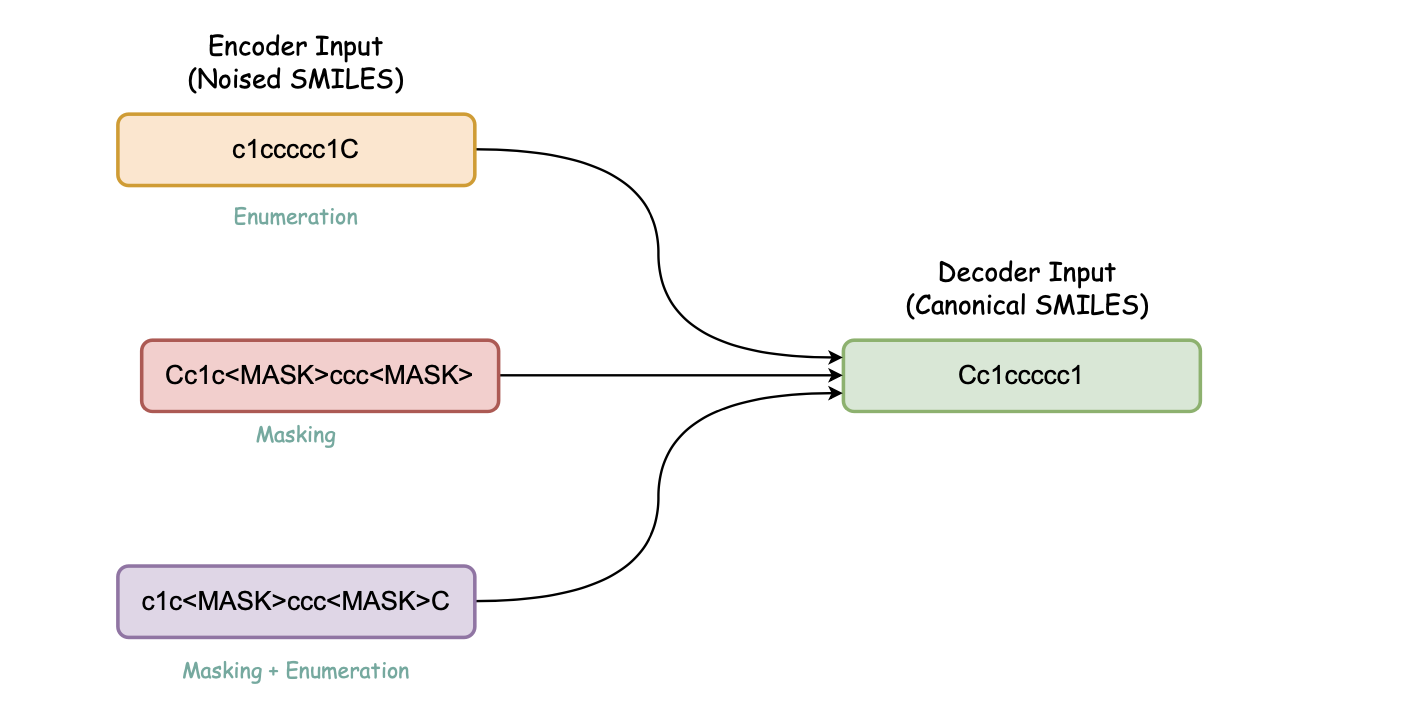
Pretraining steps for this model:
- Pretrain BERT model with Multi task regression on physicochemical properties on Guacamol dataset
- Domain adaptation on MUV dataset with Constrastive Learning, Masked Language Modeling
Fore more details please see our github repository.
- Downloads last month
- 5
Inference Providers NEW
This model isn't deployed by any Inference Provider. 🙋 Ask for provider support